mirror of
https://github.com/kohya-ss/sd-scripts.git
synced 2026-04-06 13:47:06 +00:00
Compare commits
1885 Commits
v0.6.2
...
6c5c307f94
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
6c5c307f94 | ||
|
|
fa53f71ec0 | ||
|
|
1dae34b0af | ||
|
|
dd7a666727 | ||
|
|
b2c330407b | ||
|
|
c018765583 | ||
|
|
3cb9025b4b | ||
|
|
adf4b7b9c0 | ||
|
|
b637c31365 | ||
|
|
7cbae516c1 | ||
|
|
5fb3172baf | ||
|
|
5cdad10de5 | ||
|
|
89b246f3f6 | ||
|
|
4be0e94fad | ||
|
|
0e168dd1eb | ||
|
|
2723a75f91 | ||
|
|
5f793fb0f4 | ||
|
|
feb38356ea | ||
|
|
cdb49f9fe7 | ||
|
|
bd19e4c15d | ||
|
|
343c929e39 | ||
|
|
b2abe873a5 | ||
|
|
7c159291e9 | ||
|
|
1cd95b2d8b | ||
|
|
1bd0b0faf1 | ||
|
|
d633b51126 | ||
|
|
1a3ec9ea74 | ||
|
|
e1aedceffa | ||
|
|
2217704ce1 | ||
|
|
f90fa1a89a | ||
|
|
98a42e4cd6 | ||
|
|
892f8be78f | ||
|
|
50694df3cf | ||
|
|
609d1292f6 | ||
|
|
48d368fa55 | ||
|
|
3265f2edfb | ||
|
|
ef051427df | ||
|
|
573a7fa06c | ||
|
|
ae72efb92b | ||
|
|
449e70b4cf | ||
|
|
b237b8deb3 | ||
|
|
34e7138b6a | ||
|
|
9144463f7b | ||
|
|
1640e53392 | ||
|
|
e21a7736f8 | ||
|
|
8b5ce3e641 | ||
|
|
da07e4c617 | ||
|
|
966e9d7f6b | ||
|
|
2a2760e702 | ||
|
|
b996440c5f | ||
|
|
a9af52692a | ||
|
|
c6bc632ec6 | ||
|
|
f7f971f50d | ||
|
|
c4be615f69 | ||
|
|
e06e063970 | ||
|
|
94e3dbebea | ||
|
|
95a65b89a5 | ||
|
|
872124c5e1 | ||
|
|
a5a162044c | ||
|
|
a33cad714e | ||
|
|
f7fc7ddda2 | ||
|
|
5e366acda4 | ||
|
|
5462a6bb24 | ||
|
|
63711390a0 | ||
|
|
206adb6438 | ||
|
|
60bfa97b19 | ||
|
|
f0c767e0f2 | ||
|
|
a0c26a0efa | ||
|
|
67d0621313 | ||
|
|
6a826d21b1 | ||
|
|
4c197a538b | ||
|
|
4b79d73504 | ||
|
|
121853ca2a | ||
|
|
58df9dffa4 | ||
|
|
31f7df3b3a | ||
|
|
753c794549 | ||
|
|
e7b89826c5 | ||
|
|
806d535ef1 | ||
|
|
3876343fad | ||
|
|
040d976597 | ||
|
|
9621d9d637 | ||
|
|
e7b8e9a778 | ||
|
|
f41e9e2b58 | ||
|
|
8f20c37949 | ||
|
|
b090d15f7d | ||
|
|
f834b2e0d4 | ||
|
|
f6b4bdc83f | ||
|
|
2ce506e187 | ||
|
|
f5b004009e | ||
|
|
cbe2a9da45 | ||
|
|
f318ddaeea | ||
|
|
39458ec0e3 | ||
|
|
2732be0b29 | ||
|
|
1a73b5e8a5 | ||
|
|
e04b9f0497 | ||
|
|
29b0500e70 | ||
|
|
4e2a80a6ca | ||
|
|
d831c88832 | ||
|
|
bae7fa74eb | ||
|
|
f5d44fd487 | ||
|
|
4568631b43 | ||
|
|
e1c666e97f | ||
|
|
8783f8aed3 | ||
|
|
9a61d61b22 | ||
|
|
7a651efd4d | ||
|
|
aa0af24d01 | ||
|
|
209c02dbb6 | ||
|
|
419a9c4af4 | ||
|
|
cbc9e1a3b1 | ||
|
|
a0f0afbb46 | ||
|
|
7f983c558d | ||
|
|
5149be5a87 | ||
|
|
ee8e670765 | ||
|
|
f8337726cf | ||
|
|
fe4c18934c | ||
|
|
78685b9c5f | ||
|
|
ef4397963b | ||
|
|
0bb0d91615 | ||
|
|
952f9ce7be | ||
|
|
884fc8c7f5 | ||
|
|
ddfb38e501 | ||
|
|
6c82327dc8 | ||
|
|
9984868154 | ||
|
|
142d0be180 | ||
|
|
c38b07d0da | ||
|
|
80710134d5 | ||
|
|
fe81d40202 | ||
|
|
989448afdd | ||
|
|
884e07d73e | ||
|
|
e836b7f66d | ||
|
|
8cadec68bb | ||
|
|
5a5138d0ab | ||
|
|
c52c45cd7a | ||
|
|
ac72cf88a7 | ||
|
|
f7acd2f7a3 | ||
|
|
4b12746d39 | ||
|
|
28cce2271b | ||
|
|
1470cb8508 | ||
|
|
69a85a0a11 | ||
|
|
14ee64823f | ||
|
|
acba279b0b | ||
|
|
0e7f7808b0 | ||
|
|
f61c442f0b | ||
|
|
6f24bce7cc | ||
|
|
6edbe00547 | ||
|
|
18e62515c4 | ||
|
|
1273af0cdc | ||
|
|
2857f21abf | ||
|
|
3ad71e1acf | ||
|
|
c6fab554f4 | ||
|
|
3ce0c6e71f | ||
|
|
63ec59fc0b | ||
|
|
f25c265836 | ||
|
|
351bed965c | ||
|
|
dcce057609 | ||
|
|
a125c10852 | ||
|
|
c149cf283b | ||
|
|
9bb50c26c4 | ||
|
|
10bfcb9ac5 | ||
|
|
bf0f86e797 | ||
|
|
056472c2fc | ||
|
|
d24d733892 | ||
|
|
0ad2cb854d | ||
|
|
24c605ee3b | ||
|
|
b9c091eafc | ||
|
|
5249732a0f | ||
|
|
75dd8c872b | ||
|
|
aebfea255f | ||
|
|
bd6418a940 | ||
|
|
5dff02a65d | ||
|
|
250f0eb9b0 | ||
|
|
96feb61c0a | ||
|
|
450630c6bd | ||
|
|
10de781806 | ||
|
|
6c8973c2da | ||
|
|
af14eab6d7 | ||
|
|
c28e7a47c3 | ||
|
|
32f06012a7 | ||
|
|
eef05504de | ||
|
|
4987057701 | ||
|
|
c84a163b32 | ||
|
|
7de68c1eb1 | ||
|
|
9eda938876 | ||
|
|
d98400b06e | ||
|
|
518545bffb | ||
|
|
d300f19045 | ||
|
|
aec7e16094 | ||
|
|
77a160d886 | ||
|
|
0b763ef1f1 | ||
|
|
b4e862626a | ||
|
|
c4958b5dca | ||
|
|
8fd0b12d1f | ||
|
|
404ddb060d | ||
|
|
24d2ea86c7 | ||
|
|
d53a532a82 | ||
|
|
3adbbb6e33 | ||
|
|
a7b33f3204 | ||
|
|
c0c36a4e2f | ||
|
|
25771a5180 | ||
|
|
e0fcb5152a | ||
|
|
a96d684ffa | ||
|
|
13ccfc39f8 | ||
|
|
30295c9668 | ||
|
|
999df5ec15 | ||
|
|
88960e6309 | ||
|
|
88dc3213a9 | ||
|
|
1a9bf2ab56 | ||
|
|
8a72f56c9f | ||
|
|
d0b335d8cf | ||
|
|
2a53524588 | ||
|
|
4e7dfc0b1b | ||
|
|
2e0fcc50cb | ||
|
|
0b90555916 | ||
|
|
9a50c96a68 | ||
|
|
7bd9a6b19e | ||
|
|
3f9eab4946 | ||
|
|
7fb0d30feb | ||
|
|
b4d1152293 | ||
|
|
2fffcb605c | ||
|
|
a87e999786 | ||
|
|
05f392fa27 | ||
|
|
6731d8a57f | ||
|
|
078ee28a94 | ||
|
|
5034c6f813 | ||
|
|
884c1f37c4 | ||
|
|
935e0037dc | ||
|
|
52d13373c0 | ||
|
|
8e4dc1f441 | ||
|
|
0e929f97b9 | ||
|
|
1db78559a6 | ||
|
|
3e6935a07e | ||
|
|
fc40a279fa | ||
|
|
cadcd3169b | ||
|
|
bcd3a5a60a | ||
|
|
77dbabe849 | ||
|
|
d94bed645a | ||
|
|
0145efc2f2 | ||
|
|
bb47f1ea89 | ||
|
|
61eda76278 | ||
|
|
e4d6923409 | ||
|
|
a376fec79c | ||
|
|
5753b8ff6b | ||
|
|
2bfda1271b | ||
|
|
e7e371c9ce | ||
|
|
08aed008eb | ||
|
|
c5fb5ec48f | ||
|
|
19a180ff90 | ||
|
|
2982197cd4 | ||
|
|
5b38d07f03 | ||
|
|
f344df01e2 | ||
|
|
e2ed265104 | ||
|
|
e85813200a | ||
|
|
a27ace74d9 | ||
|
|
865c8d55e2 | ||
|
|
7c075a9c8d | ||
|
|
b4a89c3cdf | ||
|
|
f62c68df3c | ||
|
|
a4fae93dce | ||
|
|
1684ababcd | ||
|
|
64430eb9b2 | ||
|
|
d8717a3d1c | ||
|
|
a21b6a917e | ||
|
|
4625b34f4e | ||
|
|
80320d21fe | ||
|
|
29523c9b68 | ||
|
|
fd3a445769 | ||
|
|
13296ae93b | ||
|
|
0e8ac43760 | ||
|
|
bc9252cc1b | ||
|
|
3b25de1f17 | ||
|
|
f0b07c52ab | ||
|
|
309c44bdf2 | ||
|
|
8387e0b95c | ||
|
|
5c50cdbb44 | ||
|
|
46ad3be059 | ||
|
|
abf2c44bc5 | ||
|
|
adb775c616 | ||
|
|
4fc917821a | ||
|
|
899f3454b6 | ||
|
|
b11c053b8f | ||
|
|
c46f08a87a | ||
|
|
0d9da0ea71 | ||
|
|
f501209c37 | ||
|
|
c8af252a44 | ||
|
|
7f984f4775 | ||
|
|
d33d5eccd1 | ||
|
|
7c61c0dfe0 | ||
|
|
26db64be17 | ||
|
|
629073cd9d | ||
|
|
06df0377f9 | ||
|
|
176baa6b95 | ||
|
|
b1bbd4576c | ||
|
|
ceb19bebf8 | ||
|
|
8f5a2eba3d | ||
|
|
5a18a03ffc | ||
|
|
572cc3efb8 | ||
|
|
52c8dec953 | ||
|
|
4589262f8f | ||
|
|
c56dc90b26 | ||
|
|
7f93e21f30 | ||
|
|
9f1892cc8e | ||
|
|
1a4f1ff0f1 | ||
|
|
00e12eed65 | ||
|
|
ee0f754b08 | ||
|
|
606e6875d2 | ||
|
|
fd36fd1aa9 | ||
|
|
92845e8806 | ||
|
|
f1423a7229 | ||
|
|
b822b7e60b | ||
|
|
ede3470260 | ||
|
|
b3c56b22bd | ||
|
|
583ab27b3c | ||
|
|
aa5978dffd | ||
|
|
aaa26bb882 | ||
|
|
d0b5c0e5cf | ||
|
|
59d98e45a9 | ||
|
|
3149b2771f | ||
|
|
96a133c998 | ||
|
|
1f432e2c0e | ||
|
|
9e9a13aa8a | ||
|
|
93a4efabb5 | ||
|
|
381303d64f | ||
|
|
0181b7a042 | ||
|
|
182544dcce | ||
|
|
e64dc05c2a | ||
|
|
8ebe858f89 | ||
|
|
a0f11730f7 | ||
|
|
30008168e3 | ||
|
|
1481217eb2 | ||
|
|
61f7283167 | ||
|
|
2ba1cc7791 | ||
|
|
6364379f17 | ||
|
|
5253a38783 | ||
|
|
8f4ee8fc34 | ||
|
|
367f348430 | ||
|
|
89f0d27a59 | ||
|
|
d40f5b1e4e | ||
|
|
8aa126582e | ||
|
|
e8b3254858 | ||
|
|
16cef81aea | ||
|
|
d151833526 | ||
|
|
936d333ff4 | ||
|
|
f974c6b257 | ||
|
|
5d5a7d2acf | ||
|
|
1eddac26b0 | ||
|
|
8e6817b0c2 | ||
|
|
d93ad90a71 | ||
|
|
7197266703 | ||
|
|
5b210ad717 | ||
|
|
b81bcd0b01 | ||
|
|
6f4d365775 | ||
|
|
a4f3a9fc1a | ||
|
|
b425466e7b | ||
|
|
c8be141ae0 | ||
|
|
0b25a05e3c | ||
|
|
3647d065b5 | ||
|
|
620a06f517 | ||
|
|
564ec5fb7f | ||
|
|
7e90cdd47a | ||
|
|
e5b5c7e1db | ||
|
|
7482784f74 | ||
|
|
ea53290f62 | ||
|
|
75933d70a1 | ||
|
|
aa2bde7ece | ||
|
|
e8c15c7167 | ||
|
|
9fe8a47080 | ||
|
|
1f22a94cfe | ||
|
|
5e45df722d | ||
|
|
09c4710d1e | ||
|
|
3f49053c90 | ||
|
|
dfe1ab6c50 | ||
|
|
b6e4194ea5 | ||
|
|
b5d1f1caea | ||
|
|
d6c3e6346e | ||
|
|
800d068e37 | ||
|
|
3817b65b45 | ||
|
|
a69884a209 | ||
|
|
acdca2abb7 | ||
|
|
ba5251168a | ||
|
|
cad182d29a | ||
|
|
a2daa87007 | ||
|
|
1bba7acd9a | ||
|
|
d6f7e2e20c | ||
|
|
272f4c3775 | ||
|
|
734333d0c9 | ||
|
|
9647f1e324 | ||
|
|
42fe22f5a2 | ||
|
|
ce2610d29b | ||
|
|
0886d976f1 | ||
|
|
542f980443 | ||
|
|
70403f6977 | ||
|
|
7b83d50dc0 | ||
|
|
2f69f4dbdb | ||
|
|
9a415ba965 | ||
|
|
3d79239be4 | ||
|
|
ec350c83eb | ||
|
|
49651892ce | ||
|
|
1fcac98280 | ||
|
|
b286304e5f | ||
|
|
ae409e83c9 | ||
|
|
5228db1548 | ||
|
|
f4a0047865 | ||
|
|
a1a5627b13 | ||
|
|
ce37c08b9a | ||
|
|
f68702f71c | ||
|
|
5f9047c8cf | ||
|
|
6e90c0f86c | ||
|
|
67fde015f7 | ||
|
|
386b7332c6 | ||
|
|
905f081798 | ||
|
|
59ae9ea20c | ||
|
|
fc772affbe | ||
|
|
653621de57 | ||
|
|
2c94d17f05 | ||
|
|
48e7da2d4a | ||
|
|
ba725a84e9 | ||
|
|
42a801514c | ||
|
|
6d7bec8a37 | ||
|
|
025cca699b | ||
|
|
efb2a128cd | ||
|
|
13df47516d | ||
|
|
7f2747176b | ||
|
|
ca1c129ffd | ||
|
|
545425c13e | ||
|
|
7729c4c8f9 | ||
|
|
d0128d18be | ||
|
|
58e9e146a3 | ||
|
|
6597631b90 | ||
|
|
4a36996134 | ||
|
|
dc7d5fb459 | ||
|
|
894037f2c6 | ||
|
|
bd16bd13ae | ||
|
|
98efbc3bb7 | ||
|
|
9436b41061 | ||
|
|
1aa2f00e85 | ||
|
|
3ed7606f88 | ||
|
|
3365cfadd7 | ||
|
|
44782dd790 | ||
|
|
7c22e12a39 | ||
|
|
6051fa8217 | ||
|
|
aa36c48685 | ||
|
|
bb7bae5dff | ||
|
|
3ce23b7f16 | ||
|
|
733fdc09c6 | ||
|
|
f3a010978c | ||
|
|
3c7496ae3f | ||
|
|
6965a0178a | ||
|
|
4671e23778 | ||
|
|
16015635d2 | ||
|
|
60a76ebb72 | ||
|
|
a00b06bc97 | ||
|
|
63337d9fe4 | ||
|
|
ee295c7d9f | ||
|
|
7323ee1b9d | ||
|
|
c0caf33e3f | ||
|
|
ab88b431b0 | ||
|
|
d154e76c45 | ||
|
|
76b761943b | ||
|
|
cd80752175 | ||
|
|
177203818a | ||
|
|
344845b429 | ||
|
|
0911683717 | ||
|
|
a24db1d532 | ||
|
|
c5b803ce94 | ||
|
|
4a71687d20 | ||
|
|
de830b8941 | ||
|
|
45ec02b2a8 | ||
|
|
42c0a9e1fc | ||
|
|
0778dd9b1d | ||
|
|
0750859133 | ||
|
|
29f31d005f | ||
|
|
b6a3093216 | ||
|
|
86a2f3fd26 | ||
|
|
532f5c58a6 | ||
|
|
59b3b94faf | ||
|
|
f1ac81e07a | ||
|
|
e8529613d8 | ||
|
|
58b82a576e | ||
|
|
b833d47afe | ||
|
|
23ce75cf95 | ||
|
|
6acdbed967 | ||
|
|
ca6b68ef7d | ||
|
|
9c1168a088 | ||
|
|
c04e5dfe92 | ||
|
|
6e3c1d0b58 | ||
|
|
345daaa986 | ||
|
|
b489082495 | ||
|
|
25929dd0d7 | ||
|
|
ee9265cf26 | ||
|
|
0456858992 | ||
|
|
2bbb40ce51 | ||
|
|
4c61adc996 | ||
|
|
264167fa16 | ||
|
|
d6f158ddf6 | ||
|
|
1e61392cf2 | ||
|
|
9fde0d7972 | ||
|
|
556f3f1696 | ||
|
|
1231f5114c | ||
|
|
742bee9738 | ||
|
|
fcb2ff010c | ||
|
|
f8850296c8 | ||
|
|
c64d1a22fc | ||
|
|
1c63e7cc49 | ||
|
|
f4840ef29e | ||
|
|
bbf6bbd5ea | ||
|
|
a9c5aa1f93 | ||
|
|
1c0ae306e5 | ||
|
|
1f9ba40b8b | ||
|
|
695f38962c | ||
|
|
0522070d19 | ||
|
|
6604b36044 | ||
|
|
58bfa36d02 | ||
|
|
fbfc2753eb | ||
|
|
c8c3569df2 | ||
|
|
534059dea5 | ||
|
|
7470173044 | ||
|
|
d23c7322ee | ||
|
|
7f6e124c7c | ||
|
|
449c1c5c50 | ||
|
|
8743532963 | ||
|
|
cb89e0284e | ||
|
|
64bd5317dc | ||
|
|
62164e5792 | ||
|
|
05bb9183fa | ||
|
|
e89653975d | ||
|
|
f2d38e6cda | ||
|
|
d3305f975e | ||
|
|
8e378cf03d | ||
|
|
3cb8cb2d4f | ||
|
|
e425996a59 | ||
|
|
abff4b0ec7 | ||
|
|
2be336688d | ||
|
|
6bee18db4f | ||
|
|
8b36d907d8 | ||
|
|
3e5d89c76c | ||
|
|
2610e96e9e | ||
|
|
63738ecb07 | ||
|
|
5ab00f9b49 | ||
|
|
e369b9a252 | ||
|
|
09a3740f6c | ||
|
|
e3fd6c52a0 | ||
|
|
1dc873d9b4 | ||
|
|
14c9ba925f | ||
|
|
34e7f509c4 | ||
|
|
bdf9a8cc29 | ||
|
|
1476040787 | ||
|
|
cc11989755 | ||
|
|
0fe6320f09 | ||
|
|
14f642f88b | ||
|
|
a5a27fe4c3 | ||
|
|
7b61e9eb58 | ||
|
|
9c885e549d | ||
|
|
4f7f248071 | ||
|
|
89825d6898 | ||
|
|
dd3b846b54 | ||
|
|
e59e276fb9 | ||
|
|
2dd063a679 | ||
|
|
c7cadbc8c7 | ||
|
|
6593cfbec1 | ||
|
|
87f5224e2d | ||
|
|
928b9393da | ||
|
|
f40632bac6 | ||
|
|
be5860f8e2 | ||
|
|
575f583fd9 | ||
|
|
9dff44d785 | ||
|
|
740ec1d526 | ||
|
|
420a180d93 | ||
|
|
0b5229a955 | ||
|
|
2a61fc0784 | ||
|
|
31ca899b6b | ||
|
|
4dd4cd6ec8 | ||
|
|
35778f0218 | ||
|
|
b2660bbe74 | ||
|
|
2a188f07e6 | ||
|
|
e358b118af | ||
|
|
42f6edf3a8 | ||
|
|
ccfaa001e7 | ||
|
|
0047bb1fc3 | ||
|
|
fd2d879ac8 | ||
|
|
5c5b544b91 | ||
|
|
2bb0f547d7 | ||
|
|
2cb7a6db02 | ||
|
|
17cf249d76 | ||
|
|
cde90b8903 | ||
|
|
3fe94b058a | ||
|
|
92482c7a07 | ||
|
|
7feaae5f06 | ||
|
|
02bd76e6c7 | ||
|
|
26bd4540a6 | ||
|
|
8fac3c3b08 | ||
|
|
2a2042a762 | ||
|
|
b3248a8eef | ||
|
|
186aa5b97d | ||
|
|
b8d3feca77 | ||
|
|
123474d784 | ||
|
|
e877b306c8 | ||
|
|
6adb69be63 | ||
|
|
387b40ea37 | ||
|
|
e5ac095749 | ||
|
|
5eb6d209d5 | ||
|
|
f264f4091f | ||
|
|
5e86323f12 | ||
|
|
588ea9e123 | ||
|
|
bafd10d558 | ||
|
|
e54462a4a9 | ||
|
|
40ed54bfc0 | ||
|
|
43849030cf | ||
|
|
aab943cea3 | ||
|
|
81c0c965a2 | ||
|
|
5e32ee26a1 | ||
|
|
e0db59695f | ||
|
|
264328d117 | ||
|
|
82daa98fe8 | ||
|
|
9aa6f52ac3 | ||
|
|
830df4abcc | ||
|
|
9e23368e3d | ||
|
|
1434d8506f | ||
|
|
70a179e446 | ||
|
|
8c3c825b5f | ||
|
|
bdddc20d68 | ||
|
|
b502f58488 | ||
|
|
c9a1417157 | ||
|
|
ce5b532582 | ||
|
|
1e2f7b0e44 | ||
|
|
80bb3f4ecf | ||
|
|
d4e19fbd5e | ||
|
|
0af4edd8a6 | ||
|
|
75554867ce | ||
|
|
af8e216035 | ||
|
|
1065dd1b56 | ||
|
|
d4f7849592 | ||
|
|
a1255d637f | ||
|
|
db2b4d41b9 | ||
|
|
b649bbf2b6 | ||
|
|
731664b8c3 | ||
|
|
e070bd9973 | ||
|
|
ca44e3e447 | ||
|
|
150579db32 | ||
|
|
8549669f89 | ||
|
|
900d551a6a | ||
|
|
56b4ea963e | ||
|
|
014064fd81 | ||
|
|
56bf761164 | ||
|
|
0031d916f0 | ||
|
|
d2c549d7b2 | ||
|
|
f52fb66e8f | ||
|
|
5fba6f514a | ||
|
|
b1e6504007 | ||
|
|
b8ae745d0c | ||
|
|
c632af860e | ||
|
|
f8c5146d71 | ||
|
|
0286114bd2 | ||
|
|
e3c43bda49 | ||
|
|
623017f716 | ||
|
|
be14c06267 | ||
|
|
0e7c592933 | ||
|
|
e1b63c2249 | ||
|
|
8fc30f8205 | ||
|
|
138dac4aea | ||
|
|
7fe8e162cb | ||
|
|
aa932429d1 | ||
|
|
09b4d1e9b6 | ||
|
|
2c45d979e6 | ||
|
|
ef70aa7b42 | ||
|
|
d8d7142665 | ||
|
|
3cc5b8db99 | ||
|
|
2500f5a798 | ||
|
|
1275e148df | ||
|
|
2d5f7fa709 | ||
|
|
886ffb4d65 | ||
|
|
d02a6ef7c4 | ||
|
|
bfc3a65acd | ||
|
|
2244cf5b83 | ||
|
|
c65cf3812d | ||
|
|
74228c9953 | ||
|
|
5bb9f7fb1a | ||
|
|
e277b5789e | ||
|
|
ecaea909b1 | ||
|
|
c80c304779 | ||
|
|
ff4083b910 | ||
|
|
0d3058b65a | ||
|
|
d005652d03 | ||
|
|
43bfeea600 | ||
|
|
035c4a8552 | ||
|
|
f2bc820133 | ||
|
|
9f4dac5731 | ||
|
|
3de42b6edb | ||
|
|
886f75345c | ||
|
|
126159f7c4 | ||
|
|
83e3048cb0 | ||
|
|
ba08a89894 | ||
|
|
dece2c388f | ||
|
|
3028027e07 | ||
|
|
c2440f9e53 | ||
|
|
33e942e36e | ||
|
|
793999d116 | ||
|
|
d78f6a775c | ||
|
|
8bea039a8d | ||
|
|
012e7e63a5 | ||
|
|
0243c65877 | ||
|
|
8919b31145 | ||
|
|
56a63f01ae | ||
|
|
e0c3630203 | ||
|
|
d050638571 | ||
|
|
1567549220 | ||
|
|
fe2aa32484 | ||
|
|
1a0f5b0c38 | ||
|
|
822fe57859 | ||
|
|
a9aa52658a | ||
|
|
24b1fdb664 | ||
|
|
9249d00311 | ||
|
|
3ebb65f945 | ||
|
|
ce49ced699 | ||
|
|
a94bc84dec | ||
|
|
4296e286b8 | ||
|
|
392e8dedd8 | ||
|
|
2cd6aa281c | ||
|
|
bf91bea2e4 | ||
|
|
da94fd934e | ||
|
|
56a7bc171d | ||
|
|
1beddd84e5 | ||
|
|
65fb69f808 | ||
|
|
e74f58148c | ||
|
|
c1d16a76d6 | ||
|
|
ab7b231870 | ||
|
|
fba769222b | ||
|
|
29177d2f03 | ||
|
|
e1f23af1bc | ||
|
|
95ff9dba0c | ||
|
|
583d4a436c | ||
|
|
24f8975fb7 | ||
|
|
0535cd29b9 | ||
|
|
de4bb657b0 | ||
|
|
3957372ded | ||
|
|
b844c70d14 | ||
|
|
0b7927e50b | ||
|
|
706a48d50e | ||
|
|
d7e14721e2 | ||
|
|
9c757c2fba | ||
|
|
e7040669bc | ||
|
|
1286e00bb0 | ||
|
|
e74502117b | ||
|
|
bbd160b4ca | ||
|
|
a2ad7e5644 | ||
|
|
0cbe95bcc7 | ||
|
|
d8d15f1a7e | ||
|
|
96c677b459 | ||
|
|
be078bdaca | ||
|
|
9f44ef1330 | ||
|
|
6445bb2bc9 | ||
|
|
c9ff4de905 | ||
|
|
2d8ee3c280 | ||
|
|
0485f236a0 | ||
|
|
93d9fbf607 | ||
|
|
c15a3a1a65 | ||
|
|
43ad73860d | ||
|
|
b755ebd0a4 | ||
|
|
f4a0bea6dc | ||
|
|
734d2e5b2b | ||
|
|
f3ce80ef8f | ||
|
|
9d2860760d | ||
|
|
3387dc7306 | ||
|
|
57ae44eb61 | ||
|
|
1d7118a622 | ||
|
|
cefe52629e | ||
|
|
237317fffd | ||
|
|
a823fd9fb8 | ||
|
|
c7c666b182 | ||
|
|
d83f2e92da | ||
|
|
8311e88225 | ||
|
|
eaafa5c9da | ||
|
|
6dbfd47a59 | ||
|
|
fd68703f37 | ||
|
|
65b8a064f6 | ||
|
|
d10ff62a78 | ||
|
|
d29af146b8 | ||
|
|
ce144476cf | ||
|
|
62ec3e6424 | ||
|
|
de25945a93 | ||
|
|
0005867ba5 | ||
|
|
16bb5699ac | ||
|
|
319e4d9831 | ||
|
|
2889108d85 | ||
|
|
d9129522a6 | ||
|
|
90ed2dfb52 | ||
|
|
56cb2fc885 | ||
|
|
b7cff0a754 | ||
|
|
b65ae9b439 | ||
|
|
6abacf04da | ||
|
|
4f6d915d15 | ||
|
|
1e30aa83b4 | ||
|
|
92e7600cc2 | ||
|
|
ef510b3cb9 | ||
|
|
928e0fc096 | ||
|
|
1bcf8d600b | ||
|
|
f8f5b16958 | ||
|
|
826ab5ce2e | ||
|
|
25c9040f4f | ||
|
|
3a6154b7b0 | ||
|
|
2a3aefb4e4 | ||
|
|
35882f8d5b | ||
|
|
34f2315047 | ||
|
|
8fdfd8c857 | ||
|
|
8ecf0fc4bf | ||
|
|
930d709e3d | ||
|
|
daa6ad5165 | ||
|
|
a0cfb0894c | ||
|
|
6c0e8a5a17 | ||
|
|
a61cf73a5c | ||
|
|
3be712e3e0 | ||
|
|
0087a46e14 | ||
|
|
72287d39c7 | ||
|
|
ea9242653c | ||
|
|
d5c076cf90 | ||
|
|
4ca29edbff | ||
|
|
5639c2adc0 | ||
|
|
cf689e7aa6 | ||
|
|
2e89cd2cc6 | ||
|
|
1e8108fec9 | ||
|
|
81411a398e | ||
|
|
99744af53a | ||
|
|
afb971f9c3 | ||
|
|
bf9f798985 | ||
|
|
b0a980844a | ||
|
|
2d8fa3387a | ||
|
|
a4d27a232b | ||
|
|
98c91a7625 | ||
|
|
e1cd19c0c0 | ||
|
|
2b07a92c8d | ||
|
|
e17c42cb0d | ||
|
|
7e459c00b2 | ||
|
|
6ab48b09d8 | ||
|
|
388b3b4b74 | ||
|
|
dbed5126bd | ||
|
|
9381332020 | ||
|
|
6f6faf9b5a | ||
|
|
92b1f6d968 | ||
|
|
c62c95e862 | ||
|
|
9e72be0a13 | ||
|
|
486fe8f70a | ||
|
|
6e72a799c8 | ||
|
|
d034032a5d | ||
|
|
a450488928 | ||
|
|
ef535ec6bb | ||
|
|
7e688913ae | ||
|
|
25f77f6ef0 | ||
|
|
400955d3ea | ||
|
|
7367584e67 | ||
|
|
e45d3f8634 | ||
|
|
3921a4efda | ||
|
|
739a8969bc | ||
|
|
08ef886bfe | ||
|
|
35b6cb0cd1 | ||
|
|
8aaa1967bd | ||
|
|
e2d822cad7 | ||
|
|
7db4222119 | ||
|
|
9760d097b0 | ||
|
|
56d7651f08 | ||
|
|
9711c96f96 | ||
|
|
f5ce754bc2 | ||
|
|
4cf42cc5d4 | ||
|
|
0415d200f5 | ||
|
|
a7d5dabde3 | ||
|
|
4af36f9632 | ||
|
|
9e09a69df1 | ||
|
|
74f91c2ff7 | ||
|
|
d25ae361d0 | ||
|
|
82314ac2e7 | ||
|
|
8a0f12dde8 | ||
|
|
358f13f2c9 | ||
|
|
808d2d1f48 | ||
|
|
36b2e6fc28 | ||
|
|
da4d0fe016 | ||
|
|
231df197dd | ||
|
|
cdb2d9c516 | ||
|
|
aa850aa531 | ||
|
|
f6dbf7c419 | ||
|
|
a593e837f3 | ||
|
|
3d68754def | ||
|
|
b9bdd10129 | ||
|
|
96eb74f0cb | ||
|
|
68162172eb | ||
|
|
1db495127f | ||
|
|
31507b9901 | ||
|
|
002d75179a | ||
|
|
1a977e847a | ||
|
|
41dee60383 | ||
|
|
9ca7a5b6cc | ||
|
|
1f16b80e88 | ||
|
|
2e67978ee2 | ||
|
|
87526942a6 | ||
|
|
082f13658b | ||
|
|
b8896aad40 | ||
|
|
6f0e235f2c | ||
|
|
3d402927ef | ||
|
|
9dc7997803 | ||
|
|
3ea4fce5e0 | ||
|
|
c9de7c4e9a | ||
|
|
50e3d62474 | ||
|
|
ea18d5ba6d | ||
|
|
19086465e8 | ||
|
|
66cf435479 | ||
|
|
381598c8bb | ||
|
|
828a581e29 | ||
|
|
8f2ba27869 | ||
|
|
0b3e4f7ab6 | ||
|
|
4802e4aaec | ||
|
|
0fe4eafac9 | ||
|
|
d53ea22b2a | ||
|
|
a518e3c819 | ||
|
|
9dd1ee458c | ||
|
|
25f961bc77 | ||
|
|
e5268286bf | ||
|
|
56bb81c9e6 | ||
|
|
22413a5247 | ||
|
|
18d7597b0b | ||
|
|
4a441889d4 | ||
|
|
3259928ce4 | ||
|
|
1a104dc75e | ||
|
|
58fb64819a | ||
|
|
5bfe5e411b | ||
|
|
4ecbac131a | ||
|
|
4dbcef429b | ||
|
|
321e24d83b | ||
|
|
e5bab69e3a | ||
|
|
3eb27ced52 | ||
|
|
b2363f1021 | ||
|
|
0d96e10b3e | ||
|
|
fc85496f7e | ||
|
|
2870be9b52 | ||
|
|
71ad3c0f45 | ||
|
|
ffce3b5098 | ||
|
|
a4c3155148 | ||
|
|
58cadf476b | ||
|
|
d50c1b3c5c | ||
|
|
e8cfd4ba1d | ||
|
|
fb12b6d8e5 | ||
|
|
00513b9b70 | ||
|
|
da6fea3d97 | ||
|
|
f2dd43e198 | ||
|
|
db6752901f | ||
|
|
febc5c59fa | ||
|
|
4c798129b0 | ||
|
|
38e4c602b1 | ||
|
|
e4d9e3c843 | ||
|
|
de0e0b9468 | ||
|
|
c68baae480 | ||
|
|
47187f7079 | ||
|
|
e3ddd1fbbe | ||
|
|
0640f017ab | ||
|
|
2f19175dfe | ||
|
|
146edce693 | ||
|
|
153764a687 | ||
|
|
589c2aa025 | ||
|
|
16677da0d9 | ||
|
|
a384bf2187 | ||
|
|
1c296f7229 | ||
|
|
e96a5217c3 | ||
|
|
39b82f26e5 | ||
|
|
3701507874 | ||
|
|
78020936d2 | ||
|
|
9ddb4d7a01 | ||
|
|
8d1b1acd33 | ||
|
|
02298e3c4a | ||
|
|
44190416c6 | ||
|
|
3c8193f642 | ||
|
|
c6a437054a | ||
|
|
1ffc0b330a | ||
|
|
e01e148705 | ||
|
|
e9f3a622f4 | ||
|
|
7983d3db5f | ||
|
|
bee8cee7e8 | ||
|
|
f3d2cf22ff | ||
|
|
6dbc23cf63 | ||
|
|
c1ba0b4356 | ||
|
|
607e041f3d | ||
|
|
793aeb94da | ||
|
|
b56d5f7801 | ||
|
|
017b82ebe3 | ||
|
|
2a359e0a41 | ||
|
|
3fd8cdc55d | ||
|
|
7fe81502d0 | ||
|
|
52e64c69cf | ||
|
|
58c2d856ae | ||
|
|
8db0cadcee | ||
|
|
dbb7bb288e | ||
|
|
969f82ab47 | ||
|
|
834445a1d6 | ||
|
|
fdbb03c360 | ||
|
|
040e26ff1d | ||
|
|
0540c33aca | ||
|
|
52652cba1a | ||
|
|
5cb145d13b | ||
|
|
b886d0a359 | ||
|
|
4477116a64 | ||
|
|
2c9db5d9f2 | ||
|
|
fc374375de | ||
|
|
feefcf256e | ||
|
|
64916a35b2 | ||
|
|
4f203ce40d | ||
|
|
68467bdf4d | ||
|
|
fde8026c2d | ||
|
|
89ad69b6a0 | ||
|
|
459b12539b | ||
|
|
3b251b758d | ||
|
|
229c5a38ef | ||
|
|
36d4023431 | ||
|
|
086f6000f2 | ||
|
|
75833e84a1 | ||
|
|
71e2c91330 | ||
|
|
bfb352bc43 | ||
|
|
c973b29da4 | ||
|
|
683f3d6ab3 | ||
|
|
dfa30790a9 | ||
|
|
d30ebb205c | ||
|
|
90b18795fc | ||
|
|
089727b5ee | ||
|
|
921036dd91 | ||
|
|
cd587ce62c | ||
|
|
1933ab4b48 | ||
|
|
b748b48dbb | ||
|
|
c7691607ea | ||
|
|
f99fe281cb | ||
|
|
80e9f72234 | ||
|
|
2258a1b753 | ||
|
|
059ee047f3 | ||
|
|
2c2ca9d726 | ||
|
|
f5323e3c4b | ||
|
|
cae5aa0a56 | ||
|
|
6ba84288d9 | ||
|
|
434dc408f9 | ||
|
|
ae3f625739 | ||
|
|
f1f30ab418 | ||
|
|
bc586ce190 | ||
|
|
4012fd24f6 | ||
|
|
954731d564 | ||
|
|
dd9763be31 | ||
|
|
b86af6798d | ||
|
|
6f7e93d5cc | ||
|
|
6c08e97e1f | ||
|
|
78e0a7630c | ||
|
|
c86e356013 | ||
|
|
5a2afb3588 | ||
|
|
ab1e389347 | ||
|
|
ea05e3fd5b | ||
|
|
a2b8531627 | ||
|
|
c24422fb9d | ||
|
|
9c4492b58a | ||
|
|
9bbb28c361 | ||
|
|
1648ade6da | ||
|
|
993b2ab4c1 | ||
|
|
8d5858826f | ||
|
|
025347214d | ||
|
|
ae97c8bfd1 | ||
|
|
381c44955e | ||
|
|
ad97410ba5 | ||
|
|
691f04322a | ||
|
|
79d1c12ab0 | ||
|
|
0c7baea88c | ||
|
|
f4a4c11cd3 | ||
|
|
594c7f7050 | ||
|
|
d17c0f5084 | ||
|
|
a35e7bd595 | ||
|
|
d9456020d7 | ||
|
|
fbb98f144e | ||
|
|
9b6b39f204 | ||
|
|
855add067b | ||
|
|
bf6cd4b9da | ||
|
|
3b0db0f17f | ||
|
|
119cc99fb0 | ||
|
|
5f6196e4c7 | ||
|
|
46331a9e8e | ||
|
|
cf09c6aa9f | ||
|
|
80dbbf5e48 | ||
|
|
7da41be281 | ||
|
|
e281e867e6 | ||
|
|
6c51c971d1 | ||
|
|
a71c35ccd9 | ||
|
|
5410a8c79b | ||
|
|
a7dff592d3 | ||
|
|
f9317052ed | ||
|
|
86e40fabbc | ||
|
|
3419c3de0d | ||
|
|
7081a0cf0f | ||
|
|
0ef4fe70f0 | ||
|
|
b5e8045df4 | ||
|
|
443f02942c | ||
|
|
0a8ec5224e | ||
|
|
6b1520a46b | ||
|
|
f811b115ba | ||
|
|
d05965dbad | ||
|
|
53954a1e2e | ||
|
|
86399407b2 | ||
|
|
948029fe61 | ||
|
|
5d7ed0dff0 | ||
|
|
bd7e2295b7 | ||
|
|
97524f1bda | ||
|
|
74c266a597 | ||
|
|
d282c45002 | ||
|
|
a6c41c6bea | ||
|
|
63e58f78e3 | ||
|
|
befbec5335 | ||
|
|
7d84ac2177 | ||
|
|
a51723cc2a | ||
|
|
095b8035e6 | ||
|
|
124ec45876 | ||
|
|
47359b8fac | ||
|
|
923b761ce3 | ||
|
|
78cfb01922 | ||
|
|
b558a5b73d | ||
|
|
14c9372a38 | ||
|
|
a9b64ffba8 | ||
|
|
e3ccf8fbf7 | ||
|
|
0e4a5738df | ||
|
|
eefb3cc1e7 | ||
|
|
074d32af20 | ||
|
|
2d7389185c | ||
|
|
4a5546d40e | ||
|
|
175193623b | ||
|
|
f2c727fc8c | ||
|
|
577e9913ca | ||
|
|
fccbee2727 | ||
|
|
e0acb10f31 | ||
|
|
5d5f39b6e6 | ||
|
|
e69d34103b | ||
|
|
a21218bdd5 | ||
|
|
81e8af6519 | ||
|
|
8b7c14246a | ||
|
|
52b3799989 | ||
|
|
738c397e1a | ||
|
|
0e703608f9 | ||
|
|
fb9110bac1 | ||
|
|
24092e6f21 | ||
|
|
f4132018c5 | ||
|
|
488d1870ab | ||
|
|
86279c8855 | ||
|
|
4d5186d1cf | ||
|
|
a6f1ed2e14 | ||
|
|
d1fb480887 | ||
|
|
75e4a951d0 | ||
|
|
42f3318e17 | ||
|
|
baa0e97ced | ||
|
|
71ebcc5e25 | ||
|
|
93bed60762 | ||
|
|
41d32c0be4 | ||
|
|
cbe9c5dc06 | ||
|
|
d3745db764 | ||
|
|
358ca205a3 | ||
|
|
c748719115 | ||
|
|
98f42d3a0b | ||
|
|
35c6053de3 | ||
|
|
20ae603221 | ||
|
|
672851e805 | ||
|
|
e579648ce9 | ||
|
|
e24d9606a2 | ||
|
|
75ecb047e2 | ||
|
|
f897d55781 | ||
|
|
7202596393 | ||
|
|
03f0816f86 | ||
|
|
5d9e2873f6 | ||
|
|
055f02e1e1 | ||
|
|
9b8ea12d34 | ||
|
|
74fe0453b2 | ||
|
|
a98fecaeb1 | ||
|
|
2445a5b74e | ||
|
|
62556619bd | ||
|
|
7d2a9268b9 | ||
|
|
3970bf4080 | ||
|
|
4295f91dcd | ||
|
|
2824312d5e | ||
|
|
64873c1b43 | ||
|
|
efd3b58973 | ||
|
|
6279b33736 | ||
|
|
5f6bf29e52 | ||
|
|
e793d7780d | ||
|
|
1492bcbfa2 | ||
|
|
bf2de5620c | ||
|
|
dfe08f395f | ||
|
|
6269682c56 | ||
|
|
2f9a344297 | ||
|
|
11aced3500 | ||
|
|
1567ce1e17 | ||
|
|
5cca1fdc40 | ||
|
|
9f0f0d573d | ||
|
|
716a92cbed | ||
|
|
a6a2b5a867 | ||
|
|
2ca4d0c831 | ||
|
|
7f948db158 | ||
|
|
9d7729c00d | ||
|
|
988dee02b9 | ||
|
|
d4b9568269 | ||
|
|
ccc3a481e7 | ||
|
|
8f6f734a6f | ||
|
|
cd19df49cd | ||
|
|
736365bdd5 | ||
|
|
6ceedb9448 | ||
|
|
930a3912a7 | ||
|
|
cf790d87c4 | ||
|
|
4e67fb8444 | ||
|
|
50f631c768 | ||
|
|
85bc371ebc | ||
|
|
322ee52c77 | ||
|
|
c576f80639 | ||
|
|
478156b4f7 | ||
|
|
afc38707d5 | ||
|
|
2e4bee6f24 | ||
|
|
d5ab97b69b | ||
|
|
7cb44e4502 | ||
|
|
7a20df5ad5 | ||
|
|
bea4362e21 | ||
|
|
6805cafa9b | ||
|
|
711b40ccda | ||
|
|
696dd7f668 | ||
|
|
e0a3c69223 | ||
|
|
c59249a664 | ||
|
|
fef172966f | ||
|
|
5a1ebc4c7c | ||
|
|
2a0f45aea9 | ||
|
|
1f77bb6e73 | ||
|
|
a7ef6422b6 | ||
|
|
9cfa68c92f | ||
|
|
6f3f701d3d | ||
|
|
d2a99a19d4 | ||
|
|
0395a35543 | ||
|
|
987d4a969d | ||
|
|
976d092c68 | ||
|
|
e6b15c7e4a | ||
|
|
ef50436464 | ||
|
|
26d35794e3 | ||
|
|
dcf0eeb5b6 | ||
|
|
32b759a328 | ||
|
|
09ef3ffa8b | ||
|
|
aab265e431 | ||
|
|
da9b34fa26 | ||
|
|
716bad188b | ||
|
|
4f93bf10f0 | ||
|
|
07bf2a21ac | ||
|
|
8ac2d2a92f | ||
|
|
76aee71257 | ||
|
|
1db5d790ed | ||
|
|
663b481029 | ||
|
|
1ab6493268 | ||
|
|
ab716302e4 | ||
|
|
b9d2181192 | ||
|
|
49148eb36e | ||
|
|
479bac447e | ||
|
|
15d5e78ac2 | ||
|
|
fd7f27f044 | ||
|
|
62e7516537 | ||
|
|
20296b4f0e | ||
|
|
5cae6db804 | ||
|
|
1a36f9dc65 | ||
|
|
c2497877ca | ||
|
|
3b5c1a1d4b | ||
|
|
9a2e385f12 | ||
|
|
7080e1a11c | ||
|
|
0a52b83c6a | ||
|
|
11ed8e2a6d | ||
|
|
bb20c09a9a | ||
|
|
04ef8d395f | ||
|
|
0676f1a86f | ||
|
|
6b7823df07 | ||
|
|
2186e417ba | ||
|
|
1519e3067c | ||
|
|
35e5424255 | ||
|
|
8c7d05afd2 | ||
|
|
f8360a4831 | ||
|
|
8556b9d7f5 | ||
|
|
3efd90b2ad | ||
|
|
7adcd9cd1a | ||
|
|
aff05e043f | ||
|
|
ff2c0c192e | ||
|
|
d309a27a51 | ||
|
|
471d274803 | ||
|
|
35f4c9b5c7 | ||
|
|
034a49c69d | ||
|
|
3b6825d7e2 | ||
|
|
bb5ae389f7 | ||
|
|
d61ecb26fd | ||
|
|
07ef03d340 | ||
|
|
9278031e60 | ||
|
|
4a2cef887c | ||
|
|
42750f7846 | ||
|
|
e8c3a02830 | ||
|
|
d31aa143f4 | ||
|
|
710e777a92 | ||
|
|
912dca8f65 | ||
|
|
db84530074 | ||
|
|
72bbaac96d | ||
|
|
5713d63dc5 | ||
|
|
d653e594c2 | ||
|
|
dd7bb33ab6 | ||
|
|
a9c6182b3f | ||
|
|
3d70137d31 | ||
|
|
bce9a081db | ||
|
|
46cf41cc93 | ||
|
|
81a440c8e8 | ||
|
|
f24a3b5282 | ||
|
|
383b4a2c3e | ||
|
|
df59822a27 | ||
|
|
0908c5414d | ||
|
|
ee46134fa7 | ||
|
|
7a4e50705c | ||
|
|
2952bca520 | ||
|
|
39bb319d4c | ||
|
|
29b6fa6212 | ||
|
|
1bdd83a85f | ||
|
|
1624c239c2 | ||
|
|
4a913ce61e | ||
|
|
2c50ea0403 | ||
|
|
298c6c2343 | ||
|
|
2897a89dfd | ||
|
|
764e333fa2 | ||
|
|
c61e3bf4c9 | ||
|
|
fc8649d80f | ||
|
|
0fb9ecf1f3 | ||
|
|
97958400fb | ||
|
|
610566fbb9 | ||
|
|
684954695d | ||
|
|
6d6d86260b | ||
|
|
c856ea4249 | ||
|
|
d0923d6710 | ||
|
|
f312522cef | ||
|
|
da5a144589 | ||
|
|
2c1e669bd8 | ||
|
|
e20e9f61ac | ||
|
|
6b3148fd3f | ||
|
|
569ca72fc4 | ||
|
|
9c591bdb12 | ||
|
|
e545fdfd9a | ||
|
|
c89252101e | ||
|
|
a93c524b3a | ||
|
|
3de9e6c443 | ||
|
|
33c311ed19 | ||
|
|
5b19bda85c | ||
|
|
95ae56bd22 | ||
|
|
990192d077 | ||
|
|
f3e69531c3 | ||
|
|
0cb3272bda | ||
|
|
6231aa91e2 | ||
|
|
489b728dbc | ||
|
|
583e2b2d01 | ||
|
|
5dc2a0d3fd | ||
|
|
2c731418ad | ||
|
|
5c150675bf | ||
|
|
fea810b437 | ||
|
|
96d877be90 | ||
|
|
40d917b0fe | ||
|
|
e72020ae01 | ||
|
|
01d929ee2a | ||
|
|
cf876fcdb4 | ||
|
|
291c29caaf | ||
|
|
01e00ac1b0 | ||
|
|
a9ed4ed8a8 | ||
|
|
9d6a5a0c79 | ||
|
|
fb97a7aab1 | ||
|
|
1cefb2a753 | ||
|
|
63992b81c8 | ||
|
|
d8f68674fb | ||
|
|
9d00c8eea2 | ||
|
|
0d21925bdf | ||
|
|
efef5c8ead | ||
|
|
3d2bb1a8f1 | ||
|
|
837a4dddb8 | ||
|
|
b2626bc7a9 | ||
|
|
202f2c3292 | ||
|
|
2a23713f71 | ||
|
|
681034d001 | ||
|
|
17813ff5b4 | ||
|
|
3e81bd6b67 | ||
|
|
23ae358e0f | ||
|
|
f611726364 | ||
|
|
33ee0acd35 | ||
|
|
8b79e3b06c | ||
|
|
cf49e912fc | ||
|
|
66741c035c | ||
|
|
406511c333 | ||
|
|
8a2d68d63e | ||
|
|
07d297fdbe | ||
|
|
0d4e8b50d0 | ||
|
|
1d7c5c2a98 | ||
|
|
0faa350175 | ||
|
|
8a7509db75 | ||
|
|
025368f51c | ||
|
|
5fe52ed322 | ||
|
|
8b247a330b | ||
|
|
d6f458fcb3 | ||
|
|
b8b84021e5 | ||
|
|
70fe7e18be | ||
|
|
9378da3c82 | ||
|
|
a4857fa764 | ||
|
|
592014923f | ||
|
|
6d06b215bf | ||
|
|
2d87bb648f | ||
|
|
56ebef35b0 | ||
|
|
13d8b22d25 | ||
|
|
27f9b6ffeb | ||
|
|
c8fcfd4581 | ||
|
|
49c24285c7 | ||
|
|
c918489259 | ||
|
|
93155242fa | ||
|
|
4cc919607a | ||
|
|
81419f7f32 | ||
|
|
6bd6cd9c51 | ||
|
|
35a1d68eb6 | ||
|
|
365a06bdb6 | ||
|
|
8e117f9f92 | ||
|
|
209eafb631 | ||
|
|
14aa2923cf | ||
|
|
1e395ed285 | ||
|
|
98615166b0 | ||
|
|
28272de97a | ||
|
|
7e736da30c | ||
|
|
20e929e27e | ||
|
|
477b5260aa | ||
|
|
d39f1a3427 | ||
|
|
3757855231 | ||
|
|
d846431015 | ||
|
|
624edf428f | ||
|
|
54500b861d | ||
|
|
f2491ee0ac | ||
|
|
1f169ee7fb | ||
|
|
66817992c1 | ||
|
|
8052bcd5cd | ||
|
|
55886a0116 | ||
|
|
33e90cc6a0 | ||
|
|
d5be8125b0 | ||
|
|
b99cd2a920 | ||
|
|
b64389c8a9 | ||
|
|
db7a28ac25 | ||
|
|
d337bbf8a0 | ||
|
|
90c47140b8 | ||
|
|
0ecfd91a20 | ||
|
|
a0e05fa291 | ||
|
|
e33c007cd0 | ||
|
|
80aca1ccc7 | ||
|
|
6b3a580ee5 | ||
|
|
207fc8b256 | ||
|
|
74561dbdac | ||
|
|
867e7d3238 | ||
|
|
5f08a21d12 | ||
|
|
95bc6e8749 | ||
|
|
4530b96c67 | ||
|
|
360af27749 | ||
|
|
0ee75fd75d | ||
|
|
2eae9b66d0 | ||
|
|
f6d417e26d | ||
|
|
903825af6f | ||
|
|
948cf17499 | ||
|
|
cd59003003 | ||
|
|
f19a48a28c | ||
|
|
4c6f3125fc | ||
|
|
497051c14b | ||
|
|
6400116715 | ||
|
|
f77bdf96d8 | ||
|
|
c06a86706a | ||
|
|
e0beb6a999 | ||
|
|
633bb8d339 | ||
|
|
7e850f3b7e | ||
|
|
59c9a8e7ae | ||
|
|
c2419ddabf | ||
|
|
2e0942d5c8 | ||
|
|
6155f9c171 | ||
|
|
f64c78b777 | ||
|
|
3d12cdc643 | ||
|
|
526488feaa | ||
|
|
5d88351bb5 | ||
|
|
a46a4781e8 | ||
|
|
b44644bcec | ||
|
|
1f4a495e16 | ||
|
|
d97a1638d3 | ||
|
|
ef28a919d2 | ||
|
|
71369ac98b | ||
|
|
85f1114c4a | ||
|
|
927c687628 | ||
|
|
6d5cffaee9 | ||
|
|
fbc550d02e | ||
|
|
014c4b47c9 | ||
|
|
9be19ad777 | ||
|
|
1161a5c6da | ||
|
|
9947197a84 | ||
|
|
50c6aaae62 | ||
|
|
edd314cc8a | ||
|
|
8b2a11fd5e | ||
|
|
15b463d18d | ||
|
|
0c1975501c | ||
|
|
98f8785a4f | ||
|
|
b74dfba215 | ||
|
|
bee5c3f1b8 | ||
|
|
e191892824 | ||
|
|
2841927dba | ||
|
|
0646112010 | ||
|
|
782b11b844 | ||
|
|
5a86bbc0a0 | ||
|
|
fef7eb73ad | ||
|
|
62fa4734fe | ||
|
|
b5db90c8a8 | ||
|
|
3e1591661e | ||
|
|
1e52fe6e09 | ||
|
|
809fca0be9 | ||
|
|
5fa473d5f3 | ||
|
|
784a90c3a6 | ||
|
|
6111151f50 | ||
|
|
afc03af3ca | ||
|
|
306ee24c90 | ||
|
|
3f7235c36f | ||
|
|
9d678a6f41 | ||
|
|
983698dd1b | ||
|
|
9a60b8a0ba | ||
|
|
adf99a332e | ||
|
|
d713e4c757 | ||
|
|
a90c9c2776 | ||
|
|
d43fcd638e | ||
|
|
e32e24adf5 | ||
|
|
e2c2689f5c | ||
|
|
8415014de6 | ||
|
|
3307ccb2dc | ||
|
|
6889ee2b85 | ||
|
|
bf31f18c46 | ||
|
|
e73d103eca | ||
|
|
12e58ab37f | ||
|
|
daad50e384 | ||
|
|
4e339bb101 | ||
|
|
b83ce0c352 | ||
|
|
6f80fe17fc | ||
|
|
7ea38f90d7 | ||
|
|
f4a2bc6cf8 | ||
|
|
78226f8574 | ||
|
|
04b1defaf9 | ||
|
|
3cdbbb43be | ||
|
|
92f41f1051 | ||
|
|
c142dadb46 | ||
|
|
cd54af019a | ||
|
|
e5f9772a35 | ||
|
|
a02056c566 | ||
|
|
2dfa26cca0 | ||
|
|
25d8cd473e | ||
|
|
f4935dd6be | ||
|
|
9d855091bf | ||
|
|
f3be995c28 | ||
|
|
9d7619d1eb | ||
|
|
c6d52fdea4 | ||
|
|
cf6832896f | ||
|
|
6b1cf6c4fd | ||
|
|
db80c5a2e7 | ||
|
|
89aae3e04f | ||
|
|
0636399c8c | ||
|
|
7e474d21ca | ||
|
|
f61996b425 | ||
|
|
496c3f2732 | ||
|
|
8856c19c76 | ||
|
|
0eacadfa99 | ||
|
|
2a4ae88f18 | ||
|
|
a296654c1b | ||
|
|
b62185b821 | ||
|
|
e6034b7eb6 | ||
|
|
54a4aa22ed | ||
|
|
9ec70252d0 | ||
|
|
e20b6acfe9 | ||
|
|
d9180c03f6 | ||
|
|
4072f723c1 | ||
|
|
cf8021020f | ||
|
|
fb1054b5e3 | ||
|
|
1e4512b2c8 | ||
|
|
3a7326ae46 | ||
|
|
38b59a93de | ||
|
|
1199eacb72 | ||
|
|
fdb58b0b62 | ||
|
|
315fbc11e5 | ||
|
|
4a1b92d309 | ||
|
|
272dd993e6 | ||
|
|
96a52d9810 | ||
|
|
50544b7805 | ||
|
|
b78c0e2a69 | ||
|
|
2b969e9c42 | ||
|
|
e83ee217d3 | ||
|
|
b1e44e96bc | ||
|
|
7ae0cde754 | ||
|
|
c1d5c24bc7 | ||
|
|
eec6aaddda | ||
|
|
bb167f94ca | ||
|
|
2e4783bcdf | ||
|
|
7b31c0830f | ||
|
|
8f645d354e | ||
|
|
7ec9a7af79 | ||
|
|
50b53e183e | ||
|
|
d131bde183 | ||
|
|
d1864e2430 | ||
|
|
8ba02ac829 | ||
|
|
73a08c0be0 | ||
|
|
c45d2f214b | ||
|
|
9a67e0df39 | ||
|
|
acf16c063a | ||
|
|
86a8cbd002 | ||
|
|
fc276a51fb | ||
|
|
771f33d17d | ||
|
|
e6d1f509a0 | ||
|
|
225e871819 | ||
|
|
7875ca8fb5 | ||
|
|
6d2d8dfd2f | ||
|
|
0ec7166098 | ||
|
|
3d66a234b0 | ||
|
|
8a073ee49f | ||
|
|
7e20c6d1a1 | ||
|
|
1d4672d747 | ||
|
|
39e62b948e | ||
|
|
41d195715d | ||
|
|
3db97f8897 | ||
|
|
516f64f4d9 | ||
|
|
62dd99bee5 | ||
|
|
94c151aea3 | ||
|
|
81fa54837f | ||
|
|
9de357e373 | ||
|
|
b4a3824ce4 | ||
|
|
3bb80ebf20 | ||
|
|
cdffd19f61 | ||
|
|
a7ce2633f3 | ||
|
|
8fa5fb2816 | ||
|
|
8df948565a | ||
|
|
3c67e595b8 | ||
|
|
814996b14f | ||
|
|
2e67d74df4 | ||
|
|
b841dd78fe | ||
|
|
68ca0ea995 | ||
|
|
f54b784d88 | ||
|
|
b6e328ea8f | ||
|
|
5c80117fbd | ||
|
|
c2ceb6de5f | ||
|
|
77ec70d145 | ||
|
|
a380502c01 | ||
|
|
0416f26a76 | ||
|
|
3579b4570f | ||
|
|
256ff5b56c | ||
|
|
7502f662ab | ||
|
|
d974959738 | ||
|
|
5f348579d1 | ||
|
|
8371a7a3aa | ||
|
|
1d25703ac3 | ||
|
|
fe7ede5af3 | ||
|
|
d599394f60 | ||
|
|
66c03be45f | ||
|
|
c1d62383c6 | ||
|
|
73ab110260 | ||
|
|
cc3d40ca44 | ||
|
|
288efddf2f | ||
|
|
4a34e5804e | ||
|
|
3d0375daa6 | ||
|
|
3060eb5baf | ||
|
|
ce46aa0c3b | ||
|
|
3b35547da0 | ||
|
|
6aa62b9b66 | ||
|
|
2febbfe4b0 | ||
|
|
ea182461d3 | ||
|
|
5863676ccb | ||
|
|
97611e89ca | ||
|
|
64cf922841 | ||
|
|
227a62e4c4 | ||
|
|
38e21f5c1a | ||
|
|
d395bc0647 | ||
|
|
afce13d101 | ||
|
|
8521ab7990 | ||
|
|
71a6d49d06 | ||
|
|
07d5c71090 | ||
|
|
a751dc25d6 | ||
|
|
753c63e11b | ||
|
|
b0dfbe7086 | ||
|
|
31018d57b6 | ||
|
|
9ebebb22db | ||
|
|
2c461e4ad3 | ||
|
|
56ca5dfa15 | ||
|
|
747af145ed | ||
|
|
7981ee186f | ||
|
|
9e9df2b501 | ||
|
|
f7f762c676 | ||
|
|
0b730d904f | ||
|
|
11e8c7d8ff | ||
|
|
663f953a78 | ||
|
|
bfd909ab79 | ||
|
|
0cfcb5a49c | ||
|
|
6a86de1927 | ||
|
|
5114e8daf1 | ||
|
|
1c09867b3e | ||
|
|
2b4229fa51 | ||
|
|
92e50133f8 | ||
|
|
c4269b5efa | ||
|
|
19dfa24abb | ||
|
|
c7fd336c5d | ||
|
|
ed30af8343 | ||
|
|
1e0b059982 | ||
|
|
038c09f552 | ||
|
|
5d1b54de45 | ||
|
|
18156bf2a1 | ||
|
|
5845de7d7c | ||
|
|
e97d67a681 | ||
|
|
f0bb3ae825 | ||
|
|
9806b00f74 | ||
|
|
f2989b36c2 | ||
|
|
624fbadea2 | ||
|
|
d4ba37f543 | ||
|
|
449ad7502c | ||
|
|
44404fcd6d | ||
|
|
1da6d43109 | ||
|
|
9aee793078 | ||
|
|
89c3033401 | ||
|
|
67f09b7d7e | ||
|
|
0dfffcd88a | ||
|
|
9e1683cf2b | ||
|
|
4d0c06e397 | ||
|
|
0315611b11 | ||
|
|
33a6234b52 | ||
|
|
4b7b3bc04a | ||
|
|
035dd3a900 | ||
|
|
4e25c8f78e | ||
|
|
7f6b581ef8 | ||
|
|
cc274fb7fb | ||
|
|
334d07bf96 | ||
|
|
6417f5d7c1 | ||
|
|
8088c04a71 | ||
|
|
f7b1911f1b | ||
|
|
045cd38b6e | ||
|
|
dccdb8771c | ||
|
|
d4b5cab7f7 | ||
|
|
363f1dfab9 | ||
|
|
4e24733f1c | ||
|
|
bb91a10b5f | ||
|
|
98635ebde2 | ||
|
|
24823b061d | ||
|
|
0fe1afd4ef | ||
|
|
c0a7df9ee1 | ||
|
|
5907bbd9de | ||
|
|
5db792b10b | ||
|
|
7c38c33ed6 | ||
|
|
5bec05e045 | ||
|
|
6084611508 | ||
|
|
71a7a27319 | ||
|
|
ec2efe52e4 | ||
|
|
0f0158ddaa | ||
|
|
dde7807b00 | ||
|
|
1e3daa247b | ||
|
|
3bd00b88c2 | ||
|
|
62d00b4520 | ||
|
|
4f8ce00477 | ||
|
|
1214f35985 | ||
|
|
e743ee5d5c | ||
|
|
23c4e5cb01 | ||
|
|
1f1cae6c5a | ||
|
|
c8d209d36c | ||
|
|
f8e8df5a04 | ||
|
|
f4c9276336 | ||
|
|
a5c38e5d5b | ||
|
|
9c7237157d | ||
|
|
5931948adb | ||
|
|
8a5e3904a0 | ||
|
|
d679dc4de1 | ||
|
|
a002d10a4d | ||
|
|
3a06968332 | ||
|
|
6fbd526931 | ||
|
|
c437dce056 | ||
|
|
fc00691898 | ||
|
|
990ceddd14 | ||
|
|
226db64736 | ||
|
|
2429ac73b2 | ||
|
|
dd8e17cb37 | ||
|
|
db756e9a34 | ||
|
|
16e5981d31 | ||
|
|
575c51fd3b | ||
|
|
5b2447f71d | ||
|
|
0ccb4d4a3a | ||
|
|
b5bb8bec67 | ||
|
|
5cdf4e34a1 | ||
|
|
061e157191 | ||
|
|
d859a3a925 | ||
|
|
5a1a14f9fc | ||
|
|
b6ba4cac83 | ||
|
|
99b607c60c | ||
|
|
289298b17d | ||
|
|
f7a1868fc2 | ||
|
|
02bb8e0ac3 | ||
|
|
bc909e8359 | ||
|
|
c971d9319c | ||
|
|
0c942106bf | ||
|
|
c0c4d4ddc6 | ||
|
|
c924c47f37 | ||
|
|
5b54086663 | ||
|
|
9e797cc151 | ||
|
|
cc10a62e16 | ||
|
|
7e5b6154d0 | ||
|
|
6d6df18387 | ||
|
|
ca36f47dfc | ||
|
|
45f9cc9e0e | ||
|
|
3699a90645 | ||
|
|
714846e1e1 | ||
|
|
08d85d4013 | ||
|
|
0ec7743436 | ||
|
|
a72d80aa85 | ||
|
|
b556fc43bc | ||
|
|
dbb9c19669 | ||
|
|
bca6a44974 | ||
|
|
8ab5c8cb28 | ||
|
|
774c4059fb | ||
|
|
5f1d07d62f | ||
|
|
cd984992cf | ||
|
|
99f4940eb7 | ||
|
|
41dd835a89 | ||
|
|
ee42c5cd42 | ||
|
|
47b6101465 | ||
|
|
7889a52f95 | ||
|
|
8d562ecf48 | ||
|
|
2767a0f9f2 | ||
|
|
af08c56ce0 | ||
|
|
dfc56e9227 | ||
|
|
84d157995e | ||
|
|
ed5bfda372 | ||
|
|
a59822540f | ||
|
|
968bbd2f47 | ||
|
|
1b4bdff331 | ||
|
|
678fe003e3 | ||
|
|
3b1af3f1a6 | ||
|
|
437501cde3 | ||
|
|
8bd2072e19 | ||
|
|
85df289190 | ||
|
|
8856496aac | ||
|
|
a7df7db464 | ||
|
|
59507c7c02 | ||
|
|
09c719c926 | ||
|
|
e54b6311ef | ||
|
|
fdbdb4748a | ||
|
|
76a2b14cdb | ||
|
|
b08154dc36 | ||
|
|
165fc43655 | ||
|
|
42cbf75cfa | ||
|
|
e6ad3cbc66 | ||
|
|
2127907dd3 | ||
|
|
164a1978de | ||
|
|
cb1076ed23 | ||
|
|
ad5f318d06 | ||
|
|
60bbe64489 | ||
|
|
b9085fc80a | ||
|
|
2fad5b88bc | ||
|
|
b271a6bd89 | ||
|
|
758a1e7f66 | ||
|
|
1cba447102 | ||
|
|
e25164cfed | ||
|
|
f6556f7972 | ||
|
|
69579668bb | ||
|
|
2e688b7cd3 | ||
|
|
2fcbfec178 | ||
|
|
e1143caf38 | ||
|
|
a7485e4d9e | ||
|
|
335b2f960e | ||
|
|
b18d099291 | ||
|
|
bc803e01c7 | ||
|
|
eaa2460701 | ||
|
|
c7dbcc6483 | ||
|
|
ad8a5934e1 | ||
|
|
7078e6477e | ||
|
|
69475f5bf1 | ||
|
|
ddeeb9428c | ||
|
|
780c60630c | ||
|
|
40c37b1219 | ||
|
|
c14b09376a | ||
|
|
fbcf56b2ba | ||
|
|
2d369b32f9 | ||
|
|
d52c524fc2 | ||
|
|
c2b51fbe98 | ||
|
|
7f2ac589f9 | ||
|
|
dff3872897 | ||
|
|
4f4b92da7d | ||
|
|
18f171d885 | ||
|
|
c72f8acea1 | ||
|
|
abedbc726f | ||
|
|
3e8d389e3e | ||
|
|
8810f8a728 | ||
|
|
5de91b9d81 | ||
|
|
57bc2abf41 | ||
|
|
dd50514d17 | ||
|
|
ac4935bf79 | ||
|
|
c817862cf7 | ||
|
|
c3768aaa46 | ||
|
|
a85fcfe05f | ||
|
|
1890535d1b | ||
|
|
9bb52acc14 | ||
|
|
551fdf32c3 | ||
|
|
74008ce487 | ||
|
|
852481e14d |
9
.ai/claude.prompt.md
Normal file
9
.ai/claude.prompt.md
Normal file
@@ -0,0 +1,9 @@
|
||||
## About This File
|
||||
|
||||
This file provides guidance to Claude Code (claude.ai/code) when working with code in this repository.
|
||||
|
||||
## 1. Project Context
|
||||
Here is the essential context for our project. Please read and understand it thoroughly.
|
||||
|
||||
### Project Overview
|
||||
@./context/01-overview.md
|
||||
104
.ai/context/01-overview.md
Normal file
104
.ai/context/01-overview.md
Normal file
@@ -0,0 +1,104 @@
|
||||
This file provides the overview and guidance for developers working with the codebase, including setup instructions, architecture details, and common commands.
|
||||
|
||||
## Project Architecture
|
||||
|
||||
### Core Training Framework
|
||||
The codebase is built around a **strategy pattern architecture** that supports multiple diffusion model families:
|
||||
|
||||
- **`library/strategy_base.py`**: Base classes for tokenization, text encoding, latent caching, and training strategies
|
||||
- **`library/strategy_*.py`**: Model-specific implementations for SD, SDXL, SD3, FLUX, etc.
|
||||
- **`library/train_util.py`**: Core training utilities shared across all model types
|
||||
- **`library/config_util.py`**: Configuration management with TOML support
|
||||
|
||||
### Model Support Structure
|
||||
Each supported model family has a consistent structure:
|
||||
- **Training script**: `{model}_train.py` (full fine-tuning), `{model}_train_network.py` (LoRA/network training)
|
||||
- **Model utilities**: `library/{model}_models.py`, `library/{model}_train_utils.py`, `library/{model}_utils.py`
|
||||
- **Networks**: `networks/lora_{model}.py`, `networks/oft_{model}.py` for adapter training
|
||||
|
||||
### Supported Models
|
||||
- **Stable Diffusion 1.x**: `train*.py`, `library/train_util.py`, `train_db.py` (for DreamBooth)
|
||||
- **SDXL**: `sdxl_train*.py`, `library/sdxl_*`
|
||||
- **SD3**: `sd3_train*.py`, `library/sd3_*`
|
||||
- **FLUX.1**: `flux_train*.py`, `library/flux_*`
|
||||
- **Lumina Image 2.0**: `lumina_train*.py`, `library/lumina_*`
|
||||
- **HunyuanImage-2.1**: `hunyuan_image_train*.py`, `library/hunyuan_image_*`
|
||||
- **Anima-Preview**: `anima_train*.py`, `library/anima_*`
|
||||
|
||||
### Key Components
|
||||
|
||||
#### Memory Management
|
||||
- **Block swapping**: CPU-GPU memory optimization via `--blocks_to_swap` parameter, works with custom offloading. Only available for models with transformer architectures like SD3 and FLUX.1.
|
||||
- **Custom offloading**: `library/custom_offloading_utils.py` for advanced memory management
|
||||
- **Gradient checkpointing**: Memory reduction during training
|
||||
|
||||
#### Training Features
|
||||
- **LoRA training**: Low-rank adaptation networks in `networks/lora*.py`
|
||||
- **ControlNet training**: Conditional generation control
|
||||
- **Textual Inversion**: Custom embedding training
|
||||
- **Multi-resolution training**: Bucket-based aspect ratio handling
|
||||
- **Validation loss**: Real-time training monitoring, only for LoRA training
|
||||
|
||||
#### Configuration System
|
||||
Dataset configuration uses TOML files with structured validation:
|
||||
```toml
|
||||
[datasets.sample_dataset]
|
||||
resolution = 1024
|
||||
batch_size = 2
|
||||
|
||||
[[datasets.sample_dataset.subsets]]
|
||||
image_dir = "path/to/images"
|
||||
caption_extension = ".txt"
|
||||
```
|
||||
|
||||
## Common Development Commands
|
||||
|
||||
### Training Commands Pattern
|
||||
All training scripts follow this general pattern:
|
||||
```bash
|
||||
accelerate launch --mixed_precision bf16 {script_name}.py \
|
||||
--pretrained_model_name_or_path model.safetensors \
|
||||
--dataset_config config.toml \
|
||||
--output_dir output \
|
||||
--output_name model_name \
|
||||
[model-specific options]
|
||||
```
|
||||
|
||||
### Memory Optimization
|
||||
For low VRAM environments, use block swapping:
|
||||
```bash
|
||||
# Add to any training command for memory reduction
|
||||
--blocks_to_swap 10 # Swap 10 blocks to CPU (adjust number as needed)
|
||||
```
|
||||
|
||||
### Utility Scripts
|
||||
Located in `tools/` directory:
|
||||
- `tools/merge_lora.py`: Merge LoRA weights into base models
|
||||
- `tools/cache_latents.py`: Pre-cache VAE latents for faster training
|
||||
- `tools/cache_text_encoder_outputs.py`: Pre-cache text encoder outputs
|
||||
|
||||
## Development Notes
|
||||
|
||||
### Strategy Pattern Implementation
|
||||
When adding support for new models, implement the four core strategies:
|
||||
1. `TokenizeStrategy`: Text tokenization handling
|
||||
2. `TextEncodingStrategy`: Text encoder forward pass
|
||||
3. `LatentsCachingStrategy`: VAE encoding/caching
|
||||
4. `TextEncoderOutputsCachingStrategy`: Text encoder output caching
|
||||
|
||||
### Testing Approach
|
||||
- Unit tests focus on utility functions and model loading
|
||||
- Integration tests validate training script syntax and basic execution
|
||||
- Most tests use mocks to avoid requiring actual model files
|
||||
- Add tests for new model support in `tests/test_{model}_*.py`
|
||||
|
||||
### Configuration System
|
||||
- Use `config_util.py` dataclasses for type-safe configuration
|
||||
- Support both command-line arguments and TOML file configuration
|
||||
- Validate configuration early in training scripts to prevent runtime errors
|
||||
|
||||
### Memory Management
|
||||
- Always consider VRAM limitations when implementing features
|
||||
- Use gradient checkpointing for large models
|
||||
- Implement block swapping for models with transformer architectures
|
||||
- Cache intermediate results (latents, text embeddings) when possible
|
||||
9
.ai/gemini.prompt.md
Normal file
9
.ai/gemini.prompt.md
Normal file
@@ -0,0 +1,9 @@
|
||||
## About This File
|
||||
|
||||
This file provides guidance to Gemini CLI (https://github.com/google-gemini/gemini-cli) when working with code in this repository.
|
||||
|
||||
## 1. Project Context
|
||||
Here is the essential context for our project. Please read and understand it thoroughly.
|
||||
|
||||
### Project Overview
|
||||
@./context/01-overview.md
|
||||
3
.github/FUNDING.yml
vendored
Normal file
3
.github/FUNDING.yml
vendored
Normal file
@@ -0,0 +1,3 @@
|
||||
# These are supported funding model platforms
|
||||
|
||||
github: kohya-ss
|
||||
7
.github/dependabot.yml
vendored
Normal file
7
.github/dependabot.yml
vendored
Normal file
@@ -0,0 +1,7 @@
|
||||
---
|
||||
version: 2
|
||||
updates:
|
||||
- package-ecosystem: "github-actions"
|
||||
directory: "/"
|
||||
schedule:
|
||||
interval: "monthly"
|
||||
51
.github/workflows/tests.yml
vendored
Normal file
51
.github/workflows/tests.yml
vendored
Normal file
@@ -0,0 +1,51 @@
|
||||
name: Test with pytest
|
||||
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
- dev
|
||||
- sd3
|
||||
pull_request:
|
||||
branches:
|
||||
- main
|
||||
- dev
|
||||
- sd3
|
||||
|
||||
# CKV2_GHA_1: "Ensure top-level permissions are not set to write-all"
|
||||
permissions: read-all
|
||||
|
||||
jobs:
|
||||
build:
|
||||
runs-on: ${{ matrix.os }}
|
||||
strategy:
|
||||
matrix:
|
||||
os: [ubuntu-latest]
|
||||
python-version: ["3.10"] # Python versions to test
|
||||
pytorch-version: ["2.4.0", "2.6.0"] # PyTorch versions to test
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
with:
|
||||
# https://woodruffw.github.io/zizmor/audits/#artipacked
|
||||
persist-credentials: false
|
||||
|
||||
- uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
cache: 'pip'
|
||||
|
||||
- name: Install and update pip, setuptools, wheel
|
||||
run: |
|
||||
# Setuptools, wheel for compiling some packages
|
||||
python -m pip install --upgrade pip setuptools wheel
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
# Pre-install torch to pin version (requirements.txt has dependencies like transformers which requires pytorch)
|
||||
pip install dadaptation==3.2 torch==${{ matrix.pytorch-version }} torchvision pytest==8.3.4
|
||||
pip install -r requirements.txt
|
||||
|
||||
- name: Test with pytest
|
||||
run: pytest # See pytest.ini for configuration
|
||||
|
||||
16
.github/workflows/typos.yml
vendored
16
.github/workflows/typos.yml
vendored
@@ -1,21 +1,29 @@
|
||||
---
|
||||
# yamllint disable rule:line-length
|
||||
name: Typos
|
||||
|
||||
on: # yamllint disable-line rule:truthy
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
- dev
|
||||
pull_request:
|
||||
types:
|
||||
- opened
|
||||
- synchronize
|
||||
- reopened
|
||||
|
||||
# CKV2_GHA_1: "Ensure top-level permissions are not set to write-all"
|
||||
permissions: read-all
|
||||
|
||||
jobs:
|
||||
build:
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- uses: actions/checkout@v4
|
||||
with:
|
||||
# https://woodruffw.github.io/zizmor/audits/#artipacked
|
||||
persist-credentials: false
|
||||
|
||||
- name: typos-action
|
||||
uses: crate-ci/typos@v1.13.10
|
||||
uses: crate-ci/typos@v1.28.1
|
||||
|
||||
7
.gitignore
vendored
7
.gitignore
vendored
@@ -6,3 +6,10 @@ venv
|
||||
build
|
||||
.vscode
|
||||
wandb
|
||||
CLAUDE.md
|
||||
GEMINI.md
|
||||
.claude
|
||||
.gemini
|
||||
MagicMock
|
||||
.codex-tmp
|
||||
references
|
||||
|
||||
277
README-ja.md
277
README-ja.md
@@ -1,36 +1,185 @@
|
||||
## リポジトリについて
|
||||
Stable Diffusionの学習、画像生成、その他のスクリプトを入れたリポジトリです。
|
||||
# sd-scripts
|
||||
|
||||
[README in English](./README.md) ←更新情報はこちらにあります
|
||||
[English](./README.md) / [日本語](./README-ja.md)
|
||||
|
||||
GUIやPowerShellスクリプトなど、より使いやすくする機能が[bmaltais氏のリポジトリ](https://github.com/bmaltais/kohya_ss)で提供されています(英語です)のであわせてご覧ください。bmaltais氏に感謝します。
|
||||
## 目次
|
||||
|
||||
以下のスクリプトがあります。
|
||||
<details>
|
||||
<summary>クリックすると展開します</summary>
|
||||
|
||||
* DreamBooth、U-NetおよびText Encoderの学習をサポート
|
||||
* fine-tuning、同上
|
||||
- [はじめに](#はじめに)
|
||||
- [スポンサー](#スポンサー)
|
||||
- [スポンサー募集のお知らせ](#スポンサー募集のお知らせ)
|
||||
- [更新履歴](#更新履歴)
|
||||
- [サポートモデル](#サポートモデル)
|
||||
- [機能](#機能)
|
||||
- [ドキュメント](#ドキュメント)
|
||||
- [学習ドキュメント(英語および日本語)](#学習ドキュメント英語および日本語)
|
||||
- [その他のドキュメント](#その他のドキュメント)
|
||||
- [旧ドキュメント(日本語)](#旧ドキュメント日本語)
|
||||
- [AIコーディングエージェントを使う開発者の方へ](#aiコーディングエージェントを使う開発者の方へ)
|
||||
- [Windows環境でのインストール](#windows環境でのインストール)
|
||||
- [Windowsでの動作に必要なプログラム](#windowsでの動作に必要なプログラム)
|
||||
- [インストール手順](#インストール手順)
|
||||
- [requirements.txtとPyTorchについて](#requirementstxtとpytorchについて)
|
||||
- [xformersのインストール(オプション)](#xformersのインストールオプション)
|
||||
- [Linux/WSL2環境でのインストール](#linuxwsl2環境でのインストール)
|
||||
- [DeepSpeedのインストール(実験的、LinuxまたはWSL2のみ)](#deepspeedのインストール実験的linuxまたはwsl2のみ)
|
||||
- [アップグレード](#アップグレード)
|
||||
- [PyTorchのアップグレード](#pytorchのアップグレード)
|
||||
- [謝意](#謝意)
|
||||
- [ライセンス](#ライセンス)
|
||||
|
||||
</details>
|
||||
|
||||
## はじめに
|
||||
|
||||
Stable Diffusion等の画像生成モデルの学習、モデルによる画像生成、その他のスクリプトを入れたリポジトリです。
|
||||
|
||||
### スポンサー
|
||||
|
||||
このプロジェクトを支援してくださる企業・団体の皆様に深く感謝いたします。
|
||||
|
||||
<a href="https://aihub.co.jp/">
|
||||
<img src="./images/logo_aihub.png" alt="AiHUB株式会社" title="AiHUB株式会社" height="100px">
|
||||
</a>
|
||||
|
||||
### スポンサー募集のお知らせ
|
||||
|
||||
このプロジェクトがお役に立ったなら、ご支援いただけると嬉しく思います。 [GitHub Sponsors](https://github.com/sponsors/kohya-ss/)で受け付けています。
|
||||
|
||||
### 更新履歴
|
||||
|
||||
- **Version 0.10.3 (2026-04-02):**
|
||||
- Animaでfp16で学習する際の安定性をさらに改善しました。[PR #2302](https://github.com/kohya-ss/sd-scripts/pull/2302) 問題をご報告いただいた方々に深く感謝します。
|
||||
|
||||
- **Version 0.10.2 (2026-03-30):**
|
||||
- SD/SDXLのLECO学習に対応しました。[PR #2285](https://github.com/kohya-ss/sd-scripts/pull/2285) および [PR #2294](https://github.com/kohya-ss/sd-scripts/pull/2294) umisetokikaze氏に深く感謝します。
|
||||
- 詳細は[ドキュメント](./docs/train_leco.md)をご覧ください。
|
||||
- `networks/resize_lora.py`が`torch.svd_lowrank`に対応し、大幅に高速化されました。[PR #2240](https://github.com/kohya-ss/sd-scripts/pull/2240) および [PR #2296](https://github.com/kohya-ss/sd-scripts/pull/2296) woct0rdho氏に深く感謝します。
|
||||
- デフォルトは有効になっています。`--svd_lowrank_niter`オプションで反復回数を指定できます(デフォルトは2、多いほど精度が向上します)。0にすると従来の方法になります。詳細は `--help` でご確認ください。
|
||||
- LoKr/LoHaをSDXL/Animaでサポートしました。[PR #2275](https://github.com/kohya-ss/sd-scripts/pull/2275)
|
||||
- 詳細は[ドキュメント](./docs/loha_lokr.md)をご覧ください。
|
||||
- マルチ解像度データセット(同じ画像を複数のbucketサイズにリサイズして使用)がSD/SDXLの学習でサポートされました。[PR #2269](https://github.com/kohya-ss/sd-scripts/pull/2269) また、マルチ解像度データセットで同じ解像度の画像が重複して使用される事象への対応を行いました。[PR #2273](https://github.com/kohya-ss/sd-scripts/pull/2273)
|
||||
- woct0rdho氏に感謝します。
|
||||
- [ドキュメント英語版](./docs/config_README-en.md#behavior-when-there-are-duplicate-subsets) / [ドキュメント日本語版](./docs/config_README-ja.md#重複したサブセットが存在する時の挙動) をご覧ください。
|
||||
- Animaでfp16で学習する際の安定性が向上しました。[PR #2297](https://github.com/kohya-ss/sd-scripts/pull/2297) ただし、依然として不安定な場合があるようです。問題が発生する場合は、詳細をIssueでお知らせください。
|
||||
- その他、細かいバグ修正や改善を行いました。
|
||||
|
||||
- **Version 0.10.1 (2026-02-13):**
|
||||
- [Anima Preview](https://huggingface.co/circlestone-labs/Anima)モデルのLoRA学習およびfine-tuningをサポートしました。[PR #2260](https://github.com/kohya-ss/sd-scripts/pull/2260) および[PR #2261](https://github.com/kohya-ss/sd-scripts/pull/2261)
|
||||
- 素晴らしいモデルを公開された CircleStone Labs、および PR #2260を提出していただいたduongve13112002氏に深く感謝します。
|
||||
- 詳細は[ドキュメント](./docs/anima_train_network.md)をご覧ください。
|
||||
|
||||
- **Version 0.10.0 (2026-01-19):**
|
||||
- `sd3`ブランチを`main`ブランチにマージしました。このバージョンからFLUX.1およびSD3/SD3.5等のモデルが`main`ブランチでサポートされます。
|
||||
- ドキュメントにはまだ不備があるため、お気づきの点はIssue等でお知らせください。
|
||||
- `sd3`ブランチは当面、`dev`ブランチと同期して開発ブランチとして維持します。
|
||||
|
||||
### サポートモデル
|
||||
|
||||
* **Stable Diffusion 1.x/2.x**
|
||||
* **SDXL**
|
||||
* **SD3/SD3.5**
|
||||
* **FLUX.1**
|
||||
* **LUMINA**
|
||||
* **HunyuanImage-2.1**
|
||||
|
||||
### 機能
|
||||
|
||||
* LoRA学習
|
||||
* fine-tuning(DreamBooth):HunyuanImage-2.1以外のモデル
|
||||
* Textual Inversion学習:SD/SDXL
|
||||
* 画像生成
|
||||
* モデル変換(Stable Diffision ckpt/safetensorsとDiffusersの相互変換)
|
||||
* その他、モデル変換やタグ付け、LoRAマージなどのユーティリティ
|
||||
|
||||
## 使用法について
|
||||
## ドキュメント
|
||||
|
||||
当リポジトリ内およびnote.comに記事がありますのでそちらをご覧ください(将来的にはすべてこちらへ移すかもしれません)。
|
||||
### 学習ドキュメント(英語および日本語)
|
||||
|
||||
* [学習について、共通編](./train_README-ja.md) : データ整備やオプションなど
|
||||
* [データセット設定](./config_README-ja.md)
|
||||
* [DreamBoothの学習について](./train_db_README-ja.md)
|
||||
* [fine-tuningのガイド](./fine_tune_README_ja.md):
|
||||
* [LoRAの学習について](./train_network_README-ja.md)
|
||||
* [Textual Inversionの学習について](./train_ti_README-ja.md)
|
||||
* note.com [画像生成スクリプト](https://note.com/kohya_ss/n/n2693183a798e)
|
||||
* note.com [モデル変換スクリプト](https://note.com/kohya_ss/n/n374f316fe4ad)
|
||||
日本語は折りたたまれているか、別のドキュメントにあります。
|
||||
|
||||
## Windowsでの動作に必要なプログラム
|
||||
* [LoRA学習の概要](./docs/train_network.md)
|
||||
* [データセット設定](./docs/config_README-ja.md) / [英語版](./docs/config_README-en.md)
|
||||
* [高度な学習オプション](./docs/train_network_advanced.md)
|
||||
* [SDXL学習](./docs/sdxl_train_network.md)
|
||||
* [SD3学習](./docs/sd3_train_network.md)
|
||||
* [FLUX.1学習](./docs/flux_train_network.md)
|
||||
* [LUMINA学習](./docs/lumina_train_network.md)
|
||||
* [HunyuanImage-2.1学習](./docs/hunyuan_image_train_network.md)
|
||||
* [Fine-tuning](./docs/fine_tune.md)
|
||||
* [Textual Inversion学習](./docs/train_textual_inversion.md)
|
||||
* [ControlNet-LLLite学習](./docs/train_lllite_README-ja.md) / [英語版](./docs/train_lllite_README.md)
|
||||
* [Validation](./docs/validation.md)
|
||||
* [マスク損失学習](./docs/masked_loss_README-ja.md) / [英語版](./docs/masked_loss_README.md)
|
||||
|
||||
Python 3.10.6およびGitが必要です。
|
||||
### その他のドキュメント
|
||||
|
||||
- Python 3.10.6: https://www.python.org/ftp/python/3.10.6/python-3.10.6-amd64.exe
|
||||
- git: https://git-scm.com/download/win
|
||||
* [画像生成スクリプト](./docs/gen_img_README-ja.md) / [英語版](./docs/gen_img_README.md)
|
||||
* [WD14 Taggerによる画像タグ付け](./docs/wd14_tagger_README-ja.md) / [英語版](./docs/wd14_tagger_README-en.md)
|
||||
|
||||
### 旧ドキュメント(日本語)
|
||||
|
||||
* [学習について、共通編](./docs/train_README-ja.md) : データ整備やオプションなど
|
||||
* [DreamBoothの学習について](./docs/train_db_README-ja.md)
|
||||
|
||||
## AIコーディングエージェントを使う開発者の方へ
|
||||
|
||||
This repository provides recommended instructions to help AI agents like Claude and Gemini understand our project context and coding standards.
|
||||
|
||||
To use them, you need to opt-in by creating your own configuration file in the project root.
|
||||
|
||||
**Quick Setup:**
|
||||
|
||||
1. Create a `CLAUDE.md` and/or `GEMINI.md` file in the project root.
|
||||
2. Add the following line to your `CLAUDE.md` to import the repository's recommended prompt:
|
||||
|
||||
```markdown
|
||||
@./.ai/claude.prompt.md
|
||||
```
|
||||
|
||||
or for Gemini:
|
||||
|
||||
```markdown
|
||||
@./.ai/gemini.prompt.md
|
||||
```
|
||||
|
||||
3. You can now add your own personal instructions below the import line (e.g., `Always respond in Japanese.`).
|
||||
|
||||
This approach ensures that you have full control over the instructions given to your agent while benefiting from the shared project context. Your `CLAUDE.md` and `GEMINI.md` are already listed in `.gitignore`, so they won't be committed to the repository.
|
||||
|
||||
このリポジトリでは、AIコーディングエージェント(例:Claude、Geminiなど)がプロジェクトのコンテキストやコーディング標準を理解できるようにするための推奨プロンプトを提供しています。
|
||||
|
||||
それらを使用するには、プロジェクトディレクトリに設定ファイルを作成して明示的に有効にする必要があります。
|
||||
|
||||
**簡単なセットアップ手順:**
|
||||
|
||||
1. プロジェクトルートに `CLAUDE.md` や `GEMINI.md` ファイルを作成します。
|
||||
2. `CLAUDE.md` に以下の行を追加して、リポジトリの推奨プロンプトをインポートします。
|
||||
|
||||
```markdown
|
||||
@./.ai/claude.prompt.md
|
||||
```
|
||||
|
||||
またはGeminiの場合:
|
||||
|
||||
```markdown
|
||||
@./.ai/gemini.prompt.md
|
||||
```
|
||||
3. インポート行の下に、独自の指示を追加できます(例:`常に日本語で応答してください。`)。
|
||||
|
||||
この方法により、エージェントに与える指示を各開発者が管理しつつ、リポジトリの推奨コンテキストを活用できます。`CLAUDE.md` および `GEMINI.md` は `.gitignore` に登録されているため、リポジトリにコミットされることはありません。
|
||||
|
||||
## Windows環境でのインストール
|
||||
|
||||
### Windowsでの動作に必要なプログラム
|
||||
|
||||
Python 3.10.xおよびGitが必要です。
|
||||
|
||||
- Python 3.10.x: https://www.python.org/downloads/windows/ からWindows installer (64-bit)をダウンロード
|
||||
- git: https://git-scm.com/download/win から最新版をダウンロード
|
||||
|
||||
Python 3.11.x、3.12.xでも恐らく動作します(未テスト)。
|
||||
|
||||
PowerShellを使う場合、venvを使えるようにするためには以下の手順でセキュリティ設定を変更してください。
|
||||
(venvに限らずスクリプトの実行が可能になりますので注意してください。)
|
||||
@@ -39,13 +188,9 @@ PowerShellを使う場合、venvを使えるようにするためには以下の
|
||||
- 「Set-ExecutionPolicy Unrestricted」と入力し、Yと答えます。
|
||||
- 管理者のPowerShellを閉じます。
|
||||
|
||||
## Windows環境でのインストール
|
||||
### インストール手順
|
||||
|
||||
以下の例ではPyTorchは1.12.1/CUDA 11.6版をインストールします。CUDA 11.3版やPyTorch 1.13を使う場合は適宜書き換えください。
|
||||
|
||||
(なお、python -m venv~の行で「python」とだけ表示された場合、py -m venv~のようにpythonをpyに変更してください。)
|
||||
|
||||
通常の(管理者ではない)PowerShellを開き以下を順に実行します。
|
||||
PowerShellを使う場合、通常の(管理者ではない)PowerShellを開き以下を順に実行します。
|
||||
|
||||
```powershell
|
||||
git clone https://github.com/kohya-ss/sd-scripts.git
|
||||
@@ -54,50 +199,22 @@ cd sd-scripts
|
||||
python -m venv venv
|
||||
.\venv\Scripts\activate
|
||||
|
||||
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
|
||||
pip install torch==2.6.0 torchvision==0.21.0 --index-url https://download.pytorch.org/whl/cu124
|
||||
pip install --upgrade -r requirements.txt
|
||||
pip install -U -I --no-deps https://github.com/C43H66N12O12S2/stable-diffusion-webui/releases/download/f/xformers-0.0.14.dev0-cp310-cp310-win_amd64.whl
|
||||
|
||||
cp .\bitsandbytes_windows\*.dll .\venv\Lib\site-packages\bitsandbytes\
|
||||
cp .\bitsandbytes_windows\cextension.py .\venv\Lib\site-packages\bitsandbytes\cextension.py
|
||||
cp .\bitsandbytes_windows\main.py .\venv\Lib\site-packages\bitsandbytes\cuda_setup\main.py
|
||||
|
||||
accelerate config
|
||||
```
|
||||
|
||||
<!--
|
||||
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117
|
||||
pip install --use-pep517 --upgrade -r requirements.txt
|
||||
pip install -U -I --no-deps xformers==0.0.16
|
||||
-->
|
||||
コマンドプロンプトでも同一です。
|
||||
|
||||
コマンドプロンプトでは以下になります。
|
||||
(なお、python -m venv~の行で「python」とだけ表示された場合、py -m venv~のようにpythonをpyに変更してください。)
|
||||
|
||||
注:`bitsandbytes`、`prodigyopt`、`lion-pytorch` は `requirements.txt` に含まれています。
|
||||
|
||||
```bat
|
||||
git clone https://github.com/kohya-ss/sd-scripts.git
|
||||
cd sd-scripts
|
||||
|
||||
python -m venv venv
|
||||
.\venv\Scripts\activate
|
||||
|
||||
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
|
||||
pip install --upgrade -r requirements.txt
|
||||
pip install -U -I --no-deps https://github.com/C43H66N12O12S2/stable-diffusion-webui/releases/download/f/xformers-0.0.14.dev0-cp310-cp310-win_amd64.whl
|
||||
|
||||
copy /y .\bitsandbytes_windows\*.dll .\venv\Lib\site-packages\bitsandbytes\
|
||||
copy /y .\bitsandbytes_windows\cextension.py .\venv\Lib\site-packages\bitsandbytes\cextension.py
|
||||
copy /y .\bitsandbytes_windows\main.py .\venv\Lib\site-packages\bitsandbytes\cuda_setup\main.py
|
||||
|
||||
accelerate config
|
||||
```
|
||||
|
||||
(注:``python -m venv venv`` のほうが ``python -m venv --system-site-packages venv`` より安全そうなため書き換えました。globalなpythonにパッケージがインストールしてあると、後者だといろいろと問題が起きます。)
|
||||
この例ではCUDA 12.4版をインストールします。異なるバージョンのCUDAを使用する場合は、適切なバージョンのPyTorchをインストールしてください。たとえばCUDA 12.1版の場合は `pip install torch==2.6.0 torchvision==0.21.0 --index-url https://download.pytorch.org/whl/cu121` としてください。
|
||||
|
||||
accelerate configの質問には以下のように答えてください。(bf16で学習する場合、最後の質問にはbf16と答えてください。)
|
||||
|
||||
※0.15.0から日本語環境では選択のためにカーソルキーを押すと落ちます(……)。数字キーの0、1、2……で選択できますので、そちらを使ってください。
|
||||
|
||||
```txt
|
||||
- This machine
|
||||
- No distributed training
|
||||
@@ -111,9 +228,37 @@ accelerate configの質問には以下のように答えてください。(bf1
|
||||
※場合によって ``ValueError: fp16 mixed precision requires a GPU`` というエラーが出ることがあるようです。この場合、6番目の質問(
|
||||
``What GPU(s) (by id) should be used for training on this machine as a comma-separated list? [all]:``)に「0」と答えてください。(id `0`のGPUが使われます。)
|
||||
|
||||
### PyTorchとxformersのバージョンについて
|
||||
### requirements.txtとPyTorchについて
|
||||
|
||||
他のバージョンでは学習がうまくいかない場合があるようです。特に他の理由がなければ指定のバージョンをお使いください。
|
||||
PyTorchは環境によってバージョンが異なるため、requirements.txtには含まれていません。前述のインストール手順を参考に、環境に合わせてPyTorchをインストールしてください。
|
||||
|
||||
スクリプトはPyTorch 2.6.0でテストしています。PyTorch 2.6.0以降が必要です。
|
||||
|
||||
RTX 50シリーズGPUの場合、PyTorch 2.8.0とCUDA 12.8/12.9を使用してください。`requirements.txt`はこのバージョンでも動作します。
|
||||
|
||||
### xformersのインストール(オプション)
|
||||
|
||||
xformersをインストールするには、仮想環境を有効にした状態で以下のコマンドを実行してください。
|
||||
|
||||
```bash
|
||||
pip install xformers --index-url https://download.pytorch.org/whl/cu124
|
||||
```
|
||||
|
||||
必要に応じてCUDAバージョンを変更してください。一部のGPUアーキテクチャではxformersが利用できない場合があります。
|
||||
|
||||
## Linux/WSL2環境でのインストール
|
||||
|
||||
LinuxまたはWSL2環境でのインストール手順はWindows環境とほぼ同じです。`venv\Scripts\activate` の部分を `source venv/bin/activate` に変更してください。
|
||||
|
||||
※NVIDIAドライバやCUDAツールキットなどは事前にインストールしておいてください。
|
||||
|
||||
### DeepSpeedのインストール(実験的、LinuxまたはWSL2のみ)
|
||||
|
||||
DeepSpeedをインストールするには、仮想環境を有効にした状態で以下のコマンドを実行してください。
|
||||
|
||||
```bash
|
||||
pip install deepspeed==0.16.7
|
||||
```
|
||||
|
||||
## アップグレード
|
||||
|
||||
@@ -128,6 +273,10 @@ pip install --use-pep517 --upgrade -r requirements.txt
|
||||
|
||||
コマンドが成功すれば新しいバージョンが使用できます。
|
||||
|
||||
### PyTorchのアップグレード
|
||||
|
||||
PyTorchをアップグレードする場合は、[Windows環境でのインストール](#windows環境でのインストール)のセクションの`pip install`コマンドを参考にしてください。
|
||||
|
||||
## 謝意
|
||||
|
||||
LoRAの実装は[cloneofsimo氏のリポジトリ](https://github.com/cloneofsimo/lora)を基にしたものです。感謝申し上げます。
|
||||
@@ -143,5 +292,3 @@ Conv2d 3x3への拡大は [cloneofsimo氏](https://github.com/cloneofsimo/lora)
|
||||
[bitsandbytes](https://github.com/TimDettmers/bitsandbytes): MIT
|
||||
|
||||
[BLIP](https://github.com/salesforce/BLIP): BSD-3-Clause
|
||||
|
||||
|
||||
|
||||
354
README.md
354
README.md
@@ -1,48 +1,153 @@
|
||||
This repository contains training, generation and utility scripts for Stable Diffusion.
|
||||
# sd-scripts
|
||||
|
||||
[__Change History__](#change-history) is moved to the bottom of the page.
|
||||
更新履歴は[ページ末尾](#change-history)に移しました。
|
||||
[English](./README.md) / [日本語](./README-ja.md)
|
||||
|
||||
[日本語版README](./README-ja.md)
|
||||
## Table of Contents
|
||||
<details>
|
||||
<summary>Click to expand</summary>
|
||||
|
||||
For easier use (GUI and PowerShell scripts etc...), please visit [the repository maintained by bmaltais](https://github.com/bmaltais/kohya_ss). Thanks to @bmaltais!
|
||||
- [Introduction](#introduction)
|
||||
- [Supported Models](#supported-models)
|
||||
- [Features](#features)
|
||||
- [Sponsors](#sponsors)
|
||||
- [Support the Project](#support-the-project)
|
||||
- [Documentation](#documentation)
|
||||
- [Training Documentation (English and Japanese)](#training-documentation-english-and-japanese)
|
||||
- [Other Documentation (English and Japanese)](#other-documentation-english-and-japanese)
|
||||
- [For Developers Using AI Coding Agents](#for-developers-using-ai-coding-agents)
|
||||
- [Windows Installation](#windows-installation)
|
||||
- [Windows Required Dependencies](#windows-required-dependencies)
|
||||
- [Installation Steps](#installation-steps)
|
||||
- [About requirements.txt and PyTorch](#about-requirementstxt-and-pytorch)
|
||||
- [xformers installation (optional)](#xformers-installation-optional)
|
||||
- [Linux/WSL2 Installation](#linuxwsl2-installation)
|
||||
- [DeepSpeed installation (experimental, Linux or WSL2 only)](#deepspeed-installation-experimental-linux-or-wsl2-only)
|
||||
- [Upgrade](#upgrade)
|
||||
- [Upgrade PyTorch](#upgrade-pytorch)
|
||||
- [Credits](#credits)
|
||||
- [License](#license)
|
||||
|
||||
This repository contains the scripts for:
|
||||
</details>
|
||||
|
||||
## Introduction
|
||||
|
||||
This repository contains training, generation and utility scripts for Stable Diffusion and other image generation models.
|
||||
|
||||
### Sponsors
|
||||
|
||||
We are grateful to the following companies for their generous sponsorship:
|
||||
|
||||
<a href="https://aihub.co.jp/top-en">
|
||||
<img src="./images/logo_aihub.png" alt="AiHUB Inc." title="AiHUB Inc." height="100px">
|
||||
</a>
|
||||
|
||||
### Support the Project
|
||||
|
||||
If you find this project helpful, please consider supporting its development via [GitHub Sponsors](https://github.com/sponsors/kohya-ss/). Your support is greatly appreciated!
|
||||
|
||||
### Change History
|
||||
|
||||
- **Version 0.10.3 (2026-04-02):**
|
||||
- Stability when training with fp16 on Anima has been further improved. See [PR #2302](https://github.com/kohya-ss/sd-scripts/pull/2302) for details. We deeply appreciate those who reported the issue.
|
||||
|
||||
- **Version 0.10.2 (2026-03-30):**
|
||||
- LECO training for SD/SDXL is now supported. Many thanks to umisetokikaze for [PR #2285](https://github.com/kohya-ss/sd-scripts/pull/2285) and [PR #2294](https://github.com/kohya-ss/sd-scripts/pull/2294).
|
||||
- Please refer to the [documentation](./docs/train_leco.md) for details.
|
||||
- `networks/resize_lora.py` has been updated to use `torch.svd_lowrank`, resulting in a significant speedup. Many thanks to woct0rdho for [PR #2240](https://github.com/kohya-ss/sd-scripts/pull/2240) and [PR #2296](https://github.com/kohya-ss/sd-scripts/pull/2296).
|
||||
- It is enabled by default. You can specify the number of iterations with the `--svd_lowrank_niter` option (default is 2, more iterations will improve accuracy). Setting it to 0 will revert to the previous method. Please check `--help` for details.
|
||||
- LoKr/LoHa is now supported for SDXL/Anima. See [PR #2275](https://github.com/kohya-ss/sd-scripts/pull/2275) for details.
|
||||
- Please refer to the [documentation](./docs/loha_lokr.md) for details.
|
||||
- Multi-resolution datasets (using the same image resized to multiple bucket sizes) are now supported in SD/SDXL training. We also addressed the issue of duplicate images with the same resolution being used in multi-resolution datasets. See [PR #2269](https://github.com/kohya-ss/sd-scripts/pull/2269) and [PR #2273](https://github.com/kohya-ss/sd-scripts/pull/2273) for details.
|
||||
- Thanks to woct0rdho for the contribution.
|
||||
- Please refer to the [English documentation](./docs/config_README-en.md#behavior-when-there-are-duplicate-subsets) / [Japanese documentation](./docs/config_README-ja.md#重複したサブセットが存在する時の挙動) for details.
|
||||
- Stability when training with fp16 on Anima has been improved. See [PR #2297](https://github.com/kohya-ss/sd-scripts/pull/2297) for details. However, it still seems to be unstable in some cases. If you encounter any issues, please let us know the details via Issues.
|
||||
- Other minor bug fixes and improvements were made.
|
||||
|
||||
- **Version 0.10.1 (2026-02-13):**
|
||||
- [Anima Preview](https://huggingface.co/circlestone-labs/Anima) model LoRA training and fine-tuning are now supported. See [PR #2260](https://github.com/kohya-ss/sd-scripts/pull/2260) and [PR #2261](https://github.com/kohya-ss/sd-scripts/pull/2261).
|
||||
- Many thanks to CircleStone Labs for releasing this amazing model, and to duongve13112002 for submitting great PR #2260.
|
||||
- For details, please refer to the [documentation](./docs/anima_train_network.md).
|
||||
|
||||
- **Version 0.10.0 (2026-01-19):**
|
||||
- `sd3` branch is merged to `main` branch. From this version, FLUX.1 and SD3/SD3.5 etc. are supported in the `main` branch.
|
||||
- There are still some missing parts in the documentation, so please let us know if you find any issues via Issues etc.
|
||||
- The `sd3` branch will be maintained as a development branch synchronized with `dev` for the time being.
|
||||
|
||||
### Supported Models
|
||||
|
||||
* **Stable Diffusion 1.x/2.x**
|
||||
* **SDXL**
|
||||
* **SD3/SD3.5**
|
||||
* **FLUX.1**
|
||||
* **LUMINA**
|
||||
* **HunyuanImage-2.1**
|
||||
|
||||
### Features
|
||||
|
||||
* DreamBooth training, including U-Net and Text Encoder
|
||||
* Fine-tuning (native training), including U-Net and Text Encoder
|
||||
* LoRA training
|
||||
* Texutl Inversion training
|
||||
* Fine-tuning (native training, DreamBooth): except for HunyuanImage-2.1
|
||||
* Textual Inversion training: SD/SDXL
|
||||
* Image generation
|
||||
* Model conversion (supports 1.x and 2.x, Stable Diffision ckpt/safetensors and Diffusers)
|
||||
* Other utilities such as model conversion, image tagging, LoRA merging, etc.
|
||||
|
||||
__Stable Diffusion web UI now seems to support LoRA trained by ``sd-scripts``.__ (SD 1.x based only) Thank you for great work!!!
|
||||
## Documentation
|
||||
|
||||
## About requirements.txt
|
||||
### Training Documentation (English and Japanese)
|
||||
|
||||
These files do not contain requirements for PyTorch. Because the versions of them depend on your environment. Please install PyTorch at first (see installation guide below.)
|
||||
* [LoRA Training Overview](./docs/train_network.md)
|
||||
* [Dataset config](./docs/config_README-en.md) / [Japanese version](./docs/config_README-ja.md)
|
||||
* [Advanced Training](./docs/train_network_advanced.md)
|
||||
* [SDXL Training](./docs/sdxl_train_network.md)
|
||||
* [SD3 Training](./docs/sd3_train_network.md)
|
||||
* [FLUX.1 Training](./docs/flux_train_network.md)
|
||||
* [LUMINA Training](./docs/lumina_train_network.md)
|
||||
* [HunyuanImage-2.1 Training](./docs/hunyuan_image_train_network.md)
|
||||
* [Fine-tuning](./docs/fine_tune.md)
|
||||
* [Textual Inversion Training](./docs/train_textual_inversion.md)
|
||||
* [ControlNet-LLLite Training](./docs/train_lllite_README.md) / [Japanese version](./docs/train_lllite_README-ja.md)
|
||||
* [Validation](./docs/validation.md)
|
||||
* [Masked Loss Training](./docs/masked_loss_README.md) / [Japanese version](./docs/masked_loss_README-ja.md)
|
||||
|
||||
The scripts are tested with PyTorch 1.12.1 and 1.13.0, Diffusers 0.10.2.
|
||||
### Other Documentation (English and Japanese)
|
||||
|
||||
## Links to how-to-use documents
|
||||
* [Image generation](./docs/gen_img_README.md) / [Japanese version](./docs/gen_img_README-ja.md)
|
||||
* [Tagging images with WD14 Tagger](./docs/wd14_tagger_README-en.md) / [Japanese version](./docs/wd14_tagger_README-ja.md)
|
||||
|
||||
All documents are in Japanese currently.
|
||||
## For Developers Using AI Coding Agents
|
||||
|
||||
* [Training guide - common](./train_README-ja.md) : data preparation, options etc...
|
||||
* [Dataset config](./config_README-ja.md)
|
||||
* [DreamBooth training guide](./train_db_README-ja.md)
|
||||
* [Step by Step fine-tuning guide](./fine_tune_README_ja.md):
|
||||
* [training LoRA](./train_network_README-ja.md)
|
||||
* [training Textual Inversion](./train_ti_README-ja.md)
|
||||
* note.com [Image generation](https://note.com/kohya_ss/n/n2693183a798e)
|
||||
* note.com [Model conversion](https://note.com/kohya_ss/n/n374f316fe4ad)
|
||||
This repository provides recommended instructions to help AI agents like Claude and Gemini understand our project context and coding standards.
|
||||
|
||||
## Windows Required Dependencies
|
||||
To use them, you need to opt-in by creating your own configuration file in the project root.
|
||||
|
||||
Python 3.10.6 and Git:
|
||||
**Quick Setup:**
|
||||
|
||||
- Python 3.10.6: https://www.python.org/ftp/python/3.10.6/python-3.10.6-amd64.exe
|
||||
- git: https://git-scm.com/download/win
|
||||
1. Create a `CLAUDE.md` and/or `GEMINI.md` file in the project root.
|
||||
2. Add the following line to your `CLAUDE.md` to import the repository's recommended prompt:
|
||||
|
||||
```markdown
|
||||
@./.ai/claude.prompt.md
|
||||
```
|
||||
|
||||
or for Gemini:
|
||||
|
||||
```markdown
|
||||
@./.ai/gemini.prompt.md
|
||||
```
|
||||
|
||||
3. You can now add your own personal instructions below the import line (e.g., `Always respond in Japanese.`).
|
||||
|
||||
This approach ensures that you have full control over the instructions given to your agent while benefiting from the shared project context. Your `CLAUDE.md` and `GEMINI.md` are already listed in `.gitignore`, so they won't be committed to the repository.
|
||||
|
||||
## Windows Installation
|
||||
|
||||
### Windows Required Dependencies
|
||||
|
||||
Python 3.10.x and Git:
|
||||
|
||||
- Python 3.10.x: Download Windows installer (64-bit) from https://www.python.org/downloads/windows/
|
||||
- git: Download latest installer from https://git-scm.com/download/win
|
||||
|
||||
Python 3.11.x, and 3.12.x will work but not tested.
|
||||
|
||||
Give unrestricted script access to powershell so venv can work:
|
||||
|
||||
@@ -50,7 +155,7 @@ Give unrestricted script access to powershell so venv can work:
|
||||
- Type `Set-ExecutionPolicy Unrestricted` and answer A
|
||||
- Close admin powershell window
|
||||
|
||||
## Windows Installation
|
||||
### Installation Steps
|
||||
|
||||
Open a regular Powershell terminal and type the following inside:
|
||||
|
||||
@@ -61,18 +166,17 @@ cd sd-scripts
|
||||
python -m venv venv
|
||||
.\venv\Scripts\activate
|
||||
|
||||
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
|
||||
pip install torch==2.6.0 torchvision==0.21.0 --index-url https://download.pytorch.org/whl/cu124
|
||||
pip install --upgrade -r requirements.txt
|
||||
pip install -U -I --no-deps https://github.com/C43H66N12O12S2/stable-diffusion-webui/releases/download/f/xformers-0.0.14.dev0-cp310-cp310-win_amd64.whl
|
||||
|
||||
cp .\bitsandbytes_windows\*.dll .\venv\Lib\site-packages\bitsandbytes\
|
||||
cp .\bitsandbytes_windows\cextension.py .\venv\Lib\site-packages\bitsandbytes\cextension.py
|
||||
cp .\bitsandbytes_windows\main.py .\venv\Lib\site-packages\bitsandbytes\cuda_setup\main.py
|
||||
|
||||
accelerate config
|
||||
```
|
||||
|
||||
update: ``python -m venv venv`` is seemed to be safer than ``python -m venv --system-site-packages venv`` (some user have packages in global python).
|
||||
If `python -m venv` shows only `python`, change `python` to `py`.
|
||||
|
||||
Note: `bitsandbytes`, `prodigyopt` and `lion-pytorch` are included in the requirements.txt. If you'd like to use another version, please install it manually.
|
||||
|
||||
This installation is for CUDA 12.4. If you use a different version of CUDA, please install the appropriate version of PyTorch. For example, if you use CUDA 12.1, please install `pip install torch==2.6.0 torchvision==0.21.0 --index-url https://download.pytorch.org/whl/cu121`.
|
||||
|
||||
Answers to accelerate config:
|
||||
|
||||
@@ -86,15 +190,44 @@ Answers to accelerate config:
|
||||
- fp16
|
||||
```
|
||||
|
||||
note: Some user reports ``ValueError: fp16 mixed precision requires a GPU`` is occurred in training. In this case, answer `0` for the 6th question:
|
||||
If you'd like to use bf16, please answer `bf16` to the last question.
|
||||
|
||||
Note: Some user reports ``ValueError: fp16 mixed precision requires a GPU`` is occurred in training. In this case, answer `0` for the 6th question:
|
||||
``What GPU(s) (by id) should be used for training on this machine as a comma-separated list? [all]:``
|
||||
|
||||
(Single GPU with id `0` will be used.)
|
||||
|
||||
### about PyTorch and xformers
|
||||
## About requirements.txt and PyTorch
|
||||
|
||||
Other versions of PyTorch and xformers seem to have problems with training.
|
||||
If there is no other reason, please install the specified version.
|
||||
The file does not contain requirements for PyTorch. Because the version of PyTorch depends on the environment, it is not included in the file. Please install PyTorch first according to the environment. See installation instructions below.
|
||||
|
||||
The scripts are tested with PyTorch 2.6.0. PyTorch 2.6.0 or later is required.
|
||||
|
||||
For RTX 50 series GPUs, PyTorch 2.8.0 with CUDA 12.8/12.9 should be used. `requirements.txt` will work with this version.
|
||||
|
||||
### xformers installation (optional)
|
||||
|
||||
To install xformers, run the following command in your activated virtual environment:
|
||||
|
||||
```bash
|
||||
pip install xformers --index-url https://download.pytorch.org/whl/cu124
|
||||
```
|
||||
|
||||
Please change the CUDA version in the URL according to your environment if necessary. xformers may not be available for some GPU architectures.
|
||||
|
||||
## Linux/WSL2 Installation
|
||||
|
||||
Linux or WSL2 installation steps are almost the same as Windows. Just change `venv\Scripts\activate` to `source venv/bin/activate`.
|
||||
|
||||
Note: Please make sure that NVIDIA driver and CUDA toolkit are installed in advance.
|
||||
|
||||
### DeepSpeed installation (experimental, Linux or WSL2 only)
|
||||
|
||||
To install DeepSpeed, run the following command in your activated virtual environment:
|
||||
|
||||
```bash
|
||||
pip install deepspeed==0.16.7
|
||||
```
|
||||
|
||||
## Upgrade
|
||||
|
||||
@@ -109,6 +242,10 @@ pip install --use-pep517 --upgrade -r requirements.txt
|
||||
|
||||
Once the commands have completed successfully you should be ready to use the new version.
|
||||
|
||||
### Upgrade PyTorch
|
||||
|
||||
If you want to upgrade PyTorch, you can upgrade it with `pip install` command in [Windows Installation](#windows-installation) section.
|
||||
|
||||
## Credits
|
||||
|
||||
The implementation for LoRA is based on [cloneofsimo's repo](https://github.com/cloneofsimo/lora). Thank you for great work!
|
||||
@@ -124,140 +261,3 @@ The majority of scripts is licensed under ASL 2.0 (including codes from Diffuser
|
||||
[bitsandbytes](https://github.com/TimDettmers/bitsandbytes): MIT
|
||||
|
||||
[BLIP](https://github.com/salesforce/BLIP): BSD-3-Clause
|
||||
|
||||
## Change History
|
||||
|
||||
### 23 Apr. 2023, 2023/4/23:
|
||||
|
||||
- Fixed to log to TensorBoard when `--logging_dir` is specified and `--log_with` is not specified.
|
||||
- `--logging_dir`を指定し`--log_with`を指定しない場合に、以前と同様にTensorBoardへログ出力するよう修正しました。
|
||||
|
||||
### 22 Apr. 2023, 2023/4/22:
|
||||
|
||||
- Added support for logging to wandb. Please refer to [PR #428](https://github.com/kohya-ss/sd-scripts/pull/428). Thank you p1atdev!
|
||||
- `wandb` installation is required. Please install it with `pip install wandb`. Login to wandb with `wandb login` command, or set `--wandb_api_key` option for automatic login.
|
||||
- Please let me know if you find any bugs as the test is not complete.
|
||||
- You can automatically login to wandb by setting the `--wandb_api_key` option. Please be careful with the handling of API Key. [PR #435](https://github.com/kohya-ss/sd-scripts/pull/435) Thank you Linaqruf!
|
||||
|
||||
- Improved the behavior of `--debug_dataset` on non-Windows environments. [PR #429](https://github.com/kohya-ss/sd-scripts/pull/429) Thank you tsukimiya!
|
||||
- Fixed `--face_crop_aug` option not working in Fine tuning method.
|
||||
- Prepared code to use any upscaler in `gen_img_diffusers.py`.
|
||||
|
||||
- wandbへのロギングをサポートしました。詳細は [PR #428](https://github.com/kohya-ss/sd-scripts/pull/428)をご覧ください。p1atdev氏に感謝します。
|
||||
- `wandb` のインストールが別途必要です。`pip install wandb` でインストールしてください。また `wandb login` でログインしてください(学習スクリプト内でログインする場合は `--wandb_api_key` オプションを設定してください)。
|
||||
- テスト未了のため不具合等ありましたらご連絡ください。
|
||||
- wandbへのロギング時に `--wandb_api_key` オプションを設定することで自動ログインできます。API Keyの扱いにご注意ください。 [PR #435](https://github.com/kohya-ss/sd-scripts/pull/435) Linaqruf氏に感謝します。
|
||||
|
||||
- Windows以外の環境での`--debug_dataset` の動作を改善しました。[PR #429](https://github.com/kohya-ss/sd-scripts/pull/429) tsukimiya氏に感謝します。
|
||||
- `--face_crop_aug`オプションがFine tuning方式で動作しなかったのを修正しました。
|
||||
- `gen_img_diffusers.py`に任意のupscalerを利用するためのコード準備を行いました。
|
||||
|
||||
### 19 Apr. 2023, 2023/4/19:
|
||||
- Fixed `lora_interrogator.py` not working. Please refer to [PR #392](https://github.com/kohya-ss/sd-scripts/pull/392) for details. Thank you A2va and heyalexchoi!
|
||||
- Fixed the handling of tags containing `_` in `tag_images_by_wd14_tagger.py`.
|
||||
- `lora_interrogator.py`が動作しなくなっていたのを修正しました。詳細は [PR #392](https://github.com/kohya-ss/sd-scripts/pull/392) をご参照ください。A2va氏およびheyalexchoi氏に感謝します。
|
||||
- `tag_images_by_wd14_tagger.py`で`_`を含むタグの取り扱いを修正しました。
|
||||
|
||||
### Naming of LoRA
|
||||
|
||||
The LoRA supported by `train_network.py` has been named to avoid confusion. The documentation has been updated. The following are the names of LoRA types in this repository.
|
||||
|
||||
1. __LoRA-LierLa__ : (LoRA for __Li__ n __e__ a __r__ __La__ yers)
|
||||
|
||||
LoRA for Linear layers and Conv2d layers with 1x1 kernel
|
||||
|
||||
2. __LoRA-C3Lier__ : (LoRA for __C__ olutional layers with __3__ x3 Kernel and __Li__ n __e__ a __r__ layers)
|
||||
|
||||
In addition to 1., LoRA for Conv2d layers with 3x3 kernel
|
||||
|
||||
LoRA-LierLa is the default LoRA type for `train_network.py` (without `conv_dim` network arg). LoRA-LierLa can be used with [our extension](https://github.com/kohya-ss/sd-webui-additional-networks) for AUTOMATIC1111's Web UI, or with the built-in LoRA feature of the Web UI.
|
||||
|
||||
To use LoRA-C3Liar with Web UI, please use our extension.
|
||||
|
||||
### LoRAの名称について
|
||||
|
||||
`train_network.py` がサポートするLoRAについて、混乱を避けるため名前を付けました。ドキュメントは更新済みです。以下は当リポジトリ内の独自の名称です。
|
||||
|
||||
1. __LoRA-LierLa__ : (LoRA for __Li__ n __e__ a __r__ __La__ yers、リエラと読みます)
|
||||
|
||||
Linear 層およびカーネルサイズ 1x1 の Conv2d 層に適用されるLoRA
|
||||
|
||||
2. __LoRA-C3Lier__ : (LoRA for __C__ olutional layers with __3__ x3 Kernel and __Li__ n __e__ a __r__ layers、セリアと読みます)
|
||||
|
||||
1.に加え、カーネルサイズ 3x3 の Conv2d 層に適用されるLoRA
|
||||
|
||||
LoRA-LierLa は[Web UI向け拡張](https://github.com/kohya-ss/sd-webui-additional-networks)、またはAUTOMATIC1111氏のWeb UIのLoRA機能で使用することができます。
|
||||
|
||||
LoRA-C3Liarを使いWeb UIで生成するには拡張を使用してください。
|
||||
|
||||
### 17 Apr. 2023, 2023/4/17:
|
||||
|
||||
- Added the `--recursive` option to each script in the `finetune` folder to process folders recursively. Please refer to [PR #400](https://github.com/kohya-ss/sd-scripts/pull/400/) for details. Thanks to Linaqruf!
|
||||
- `finetune`フォルダ内の各スクリプトに再起的にフォルダを処理するオプション`--recursive`を追加しました。詳細は [PR #400](https://github.com/kohya-ss/sd-scripts/pull/400/) を参照してください。Linaqruf 氏に感謝します。
|
||||
|
||||
### 14 Apr. 2023, 2023/4/14:
|
||||
- Fixed a bug that caused an error when loading DyLoRA with the `--network_weight` option in `train_network.py`.
|
||||
- `train_network.py`で、DyLoRAを`--network_weight`オプションで読み込むとエラーになる不具合を修正しました。
|
||||
|
||||
### 13 Apr. 2023, 2023/4/13:
|
||||
|
||||
- Added support for DyLoRA in `train_network.py`. Please refer to [here](./train_network_README-ja.md#dylora) for details (currently only in Japanese).
|
||||
- Added support for caching latents to disk in each training script. Please specify __both__ `--cache_latents` and `--cache_latents_to_disk` options.
|
||||
- The files are saved in the same folder as the images with the extension `.npz`. If you specify the `--flip_aug` option, the files with `_flip.npz` will also be saved.
|
||||
- Multi-GPU training has not been tested.
|
||||
- This feature is not tested with all combinations of datasets and training scripts, so there may be bugs.
|
||||
- Added workaround for an error that occurs when training with `fp16` or `bf16` in `fine_tune.py`.
|
||||
|
||||
- `train_network.py`でDyLoRAをサポートしました。詳細は[こちら](./train_network_README-ja.md#dylora)をご覧ください。
|
||||
- 各学習スクリプトでlatentのディスクへのキャッシュをサポートしました。`--cache_latents`オプションに __加えて__、`--cache_latents_to_disk`オプションを指定してください。
|
||||
- 画像と同じフォルダに、拡張子 `.npz` で保存されます。`--flip_aug`オプションを指定した場合、`_flip.npz`が付いたファイルにも保存されます。
|
||||
- マルチGPUでの学習は未テストです。
|
||||
- すべてのDataset、学習スクリプトの組み合わせでテストしたわけではないため、不具合があるかもしれません。
|
||||
- `fine_tune.py`で、`fp16`および`bf16`の学習時にエラーが出る不具合に対して対策を行いました。
|
||||
|
||||
## Sample image generation during training
|
||||
A prompt file might look like this, for example
|
||||
|
||||
```
|
||||
# prompt 1
|
||||
masterpiece, best quality, (1girl), in white shirts, upper body, looking at viewer, simple background --n low quality, worst quality, bad anatomy,bad composition, poor, low effort --w 768 --h 768 --d 1 --l 7.5 --s 28
|
||||
|
||||
# prompt 2
|
||||
masterpiece, best quality, 1boy, in business suit, standing at street, looking back --n (low quality, worst quality), bad anatomy,bad composition, poor, low effort --w 576 --h 832 --d 2 --l 5.5 --s 40
|
||||
```
|
||||
|
||||
Lines beginning with `#` are comments. You can specify options for the generated image with options like `--n` after the prompt. The following can be used.
|
||||
|
||||
* `--n` Negative prompt up to the next option.
|
||||
* `--w` Specifies the width of the generated image.
|
||||
* `--h` Specifies the height of the generated image.
|
||||
* `--d` Specifies the seed of the generated image.
|
||||
* `--l` Specifies the CFG scale of the generated image.
|
||||
* `--s` Specifies the number of steps in the generation.
|
||||
|
||||
The prompt weighting such as `( )` and `[ ]` are working.
|
||||
|
||||
## サンプル画像生成
|
||||
プロンプトファイルは例えば以下のようになります。
|
||||
|
||||
```
|
||||
# prompt 1
|
||||
masterpiece, best quality, (1girl), in white shirts, upper body, looking at viewer, simple background --n low quality, worst quality, bad anatomy,bad composition, poor, low effort --w 768 --h 768 --d 1 --l 7.5 --s 28
|
||||
|
||||
# prompt 2
|
||||
masterpiece, best quality, 1boy, in business suit, standing at street, looking back --n (low quality, worst quality), bad anatomy,bad composition, poor, low effort --w 576 --h 832 --d 2 --l 5.5 --s 40
|
||||
```
|
||||
|
||||
`#` で始まる行はコメントになります。`--n` のように「ハイフン二個+英小文字」の形でオプションを指定できます。以下が使用可能できます。
|
||||
|
||||
* `--n` Negative prompt up to the next option.
|
||||
* `--w` Specifies the width of the generated image.
|
||||
* `--h` Specifies the height of the generated image.
|
||||
* `--d` Specifies the seed of the generated image.
|
||||
* `--l` Specifies the CFG scale of the generated image.
|
||||
* `--s` Specifies the number of steps in the generation.
|
||||
|
||||
`( )` や `[ ]` などの重みづけも動作します。
|
||||
|
||||
Please read [Releases](https://github.com/kohya-ss/sd-scripts/releases) for recent updates.
|
||||
最近の更新情報は [Release](https://github.com/kohya-ss/sd-scripts/releases) をご覧ください。
|
||||
|
||||
213
XTI_hijack.py
213
XTI_hijack.py
@@ -1,133 +1,127 @@
|
||||
import torch
|
||||
from library.device_utils import init_ipex
|
||||
init_ipex()
|
||||
|
||||
from typing import Union, List, Optional, Dict, Any, Tuple
|
||||
from diffusers.models.unet_2d_condition import UNet2DConditionOutput
|
||||
|
||||
def unet_forward_XTI(self,
|
||||
sample: torch.FloatTensor,
|
||||
timestep: Union[torch.Tensor, float, int],
|
||||
encoder_hidden_states: torch.Tensor,
|
||||
class_labels: Optional[torch.Tensor] = None,
|
||||
return_dict: bool = True,
|
||||
) -> Union[UNet2DConditionOutput, Tuple]:
|
||||
r"""
|
||||
Args:
|
||||
sample (`torch.FloatTensor`): (batch, channel, height, width) noisy inputs tensor
|
||||
timestep (`torch.FloatTensor` or `float` or `int`): (batch) timesteps
|
||||
encoder_hidden_states (`torch.FloatTensor`): (batch, sequence_length, feature_dim) encoder hidden states
|
||||
return_dict (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not to return a [`models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain tuple.
|
||||
from library.original_unet import SampleOutput
|
||||
|
||||
Returns:
|
||||
[`~models.unet_2d_condition.UNet2DConditionOutput`] or `tuple`:
|
||||
[`~models.unet_2d_condition.UNet2DConditionOutput`] if `return_dict` is True, otherwise a `tuple`. When
|
||||
returning a tuple, the first element is the sample tensor.
|
||||
"""
|
||||
# By default samples have to be AT least a multiple of the overall upsampling factor.
|
||||
# The overall upsampling factor is equal to 2 ** (# num of upsampling layears).
|
||||
# However, the upsampling interpolation output size can be forced to fit any upsampling size
|
||||
# on the fly if necessary.
|
||||
default_overall_up_factor = 2**self.num_upsamplers
|
||||
|
||||
# upsample size should be forwarded when sample is not a multiple of `default_overall_up_factor`
|
||||
forward_upsample_size = False
|
||||
upsample_size = None
|
||||
def unet_forward_XTI(
|
||||
self,
|
||||
sample: torch.FloatTensor,
|
||||
timestep: Union[torch.Tensor, float, int],
|
||||
encoder_hidden_states: torch.Tensor,
|
||||
class_labels: Optional[torch.Tensor] = None,
|
||||
return_dict: bool = True,
|
||||
) -> Union[Dict, Tuple]:
|
||||
r"""
|
||||
Args:
|
||||
sample (`torch.FloatTensor`): (batch, channel, height, width) noisy inputs tensor
|
||||
timestep (`torch.FloatTensor` or `float` or `int`): (batch) timesteps
|
||||
encoder_hidden_states (`torch.FloatTensor`): (batch, sequence_length, feature_dim) encoder hidden states
|
||||
return_dict (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not to return a dict instead of a plain tuple.
|
||||
|
||||
if any(s % default_overall_up_factor != 0 for s in sample.shape[-2:]):
|
||||
logger.info("Forward upsample size to force interpolation output size.")
|
||||
forward_upsample_size = True
|
||||
Returns:
|
||||
`SampleOutput` or `tuple`:
|
||||
`SampleOutput` if `return_dict` is True, otherwise a `tuple`. When returning a tuple, the first element is the sample tensor.
|
||||
"""
|
||||
# By default samples have to be AT least a multiple of the overall upsampling factor.
|
||||
# The overall upsampling factor is equal to 2 ** (# num of upsampling layears).
|
||||
# However, the upsampling interpolation output size can be forced to fit any upsampling size
|
||||
# on the fly if necessary.
|
||||
# デフォルトではサンプルは「2^アップサンプルの数」、つまり64の倍数である必要がある
|
||||
# ただそれ以外のサイズにも対応できるように、必要ならアップサンプルのサイズを変更する
|
||||
# 多分画質が悪くなるので、64で割り切れるようにしておくのが良い
|
||||
default_overall_up_factor = 2**self.num_upsamplers
|
||||
|
||||
# 0. center input if necessary
|
||||
if self.config.center_input_sample:
|
||||
sample = 2 * sample - 1.0
|
||||
# upsample size should be forwarded when sample is not a multiple of `default_overall_up_factor`
|
||||
# 64で割り切れないときはupsamplerにサイズを伝える
|
||||
forward_upsample_size = False
|
||||
upsample_size = None
|
||||
|
||||
# 1. time
|
||||
timesteps = timestep
|
||||
if not torch.is_tensor(timesteps):
|
||||
# TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
|
||||
# This would be a good case for the `match` statement (Python 3.10+)
|
||||
is_mps = sample.device.type == "mps"
|
||||
if isinstance(timestep, float):
|
||||
dtype = torch.float32 if is_mps else torch.float64
|
||||
else:
|
||||
dtype = torch.int32 if is_mps else torch.int64
|
||||
timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
|
||||
elif len(timesteps.shape) == 0:
|
||||
timesteps = timesteps[None].to(sample.device)
|
||||
if any(s % default_overall_up_factor != 0 for s in sample.shape[-2:]):
|
||||
# logger.info("Forward upsample size to force interpolation output size.")
|
||||
forward_upsample_size = True
|
||||
|
||||
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
|
||||
timesteps = timesteps.expand(sample.shape[0])
|
||||
# 1. time
|
||||
timesteps = timestep
|
||||
timesteps = self.handle_unusual_timesteps(sample, timesteps) # 変な時だけ処理
|
||||
|
||||
t_emb = self.time_proj(timesteps)
|
||||
t_emb = self.time_proj(timesteps)
|
||||
|
||||
# timesteps does not contain any weights and will always return f32 tensors
|
||||
# but time_embedding might actually be running in fp16. so we need to cast here.
|
||||
# there might be better ways to encapsulate this.
|
||||
t_emb = t_emb.to(dtype=self.dtype)
|
||||
emb = self.time_embedding(t_emb)
|
||||
# timesteps does not contain any weights and will always return f32 tensors
|
||||
# but time_embedding might actually be running in fp16. so we need to cast here.
|
||||
# there might be better ways to encapsulate this.
|
||||
# timestepsは重みを含まないので常にfloat32のテンソルを返す
|
||||
# しかしtime_embeddingはfp16で動いているかもしれないので、ここでキャストする必要がある
|
||||
# time_projでキャストしておけばいいんじゃね?
|
||||
t_emb = t_emb.to(dtype=self.dtype)
|
||||
emb = self.time_embedding(t_emb)
|
||||
|
||||
if self.config.num_class_embeds is not None:
|
||||
if class_labels is None:
|
||||
raise ValueError("class_labels should be provided when num_class_embeds > 0")
|
||||
class_emb = self.class_embedding(class_labels).to(dtype=self.dtype)
|
||||
emb = emb + class_emb
|
||||
# 2. pre-process
|
||||
sample = self.conv_in(sample)
|
||||
|
||||
# 2. pre-process
|
||||
sample = self.conv_in(sample)
|
||||
# 3. down
|
||||
down_block_res_samples = (sample,)
|
||||
down_i = 0
|
||||
for downsample_block in self.down_blocks:
|
||||
# downblockはforwardで必ずencoder_hidden_statesを受け取るようにしても良さそうだけど、
|
||||
# まあこちらのほうがわかりやすいかもしれない
|
||||
if downsample_block.has_cross_attention:
|
||||
sample, res_samples = downsample_block(
|
||||
hidden_states=sample,
|
||||
temb=emb,
|
||||
encoder_hidden_states=encoder_hidden_states[down_i : down_i + 2],
|
||||
)
|
||||
down_i += 2
|
||||
else:
|
||||
sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
|
||||
|
||||
# 3. down
|
||||
down_block_res_samples = (sample,)
|
||||
down_i = 0
|
||||
for downsample_block in self.down_blocks:
|
||||
if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
|
||||
sample, res_samples = downsample_block(
|
||||
hidden_states=sample,
|
||||
temb=emb,
|
||||
encoder_hidden_states=encoder_hidden_states[down_i:down_i+2],
|
||||
)
|
||||
down_i += 2
|
||||
else:
|
||||
sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
|
||||
down_block_res_samples += res_samples
|
||||
|
||||
down_block_res_samples += res_samples
|
||||
# 4. mid
|
||||
sample = self.mid_block(sample, emb, encoder_hidden_states=encoder_hidden_states[6])
|
||||
|
||||
# 4. mid
|
||||
sample = self.mid_block(sample, emb, encoder_hidden_states=encoder_hidden_states[6])
|
||||
# 5. up
|
||||
up_i = 7
|
||||
for i, upsample_block in enumerate(self.up_blocks):
|
||||
is_final_block = i == len(self.up_blocks) - 1
|
||||
|
||||
# 5. up
|
||||
up_i = 7
|
||||
for i, upsample_block in enumerate(self.up_blocks):
|
||||
is_final_block = i == len(self.up_blocks) - 1
|
||||
res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
|
||||
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)] # skip connection
|
||||
|
||||
res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
|
||||
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
|
||||
# if we have not reached the final block and need to forward the upsample size, we do it here
|
||||
# 前述のように最後のブロック以外ではupsample_sizeを伝える
|
||||
if not is_final_block and forward_upsample_size:
|
||||
upsample_size = down_block_res_samples[-1].shape[2:]
|
||||
|
||||
# if we have not reached the final block and need to forward the
|
||||
# upsample size, we do it here
|
||||
if not is_final_block and forward_upsample_size:
|
||||
upsample_size = down_block_res_samples[-1].shape[2:]
|
||||
if upsample_block.has_cross_attention:
|
||||
sample = upsample_block(
|
||||
hidden_states=sample,
|
||||
temb=emb,
|
||||
res_hidden_states_tuple=res_samples,
|
||||
encoder_hidden_states=encoder_hidden_states[up_i : up_i + 3],
|
||||
upsample_size=upsample_size,
|
||||
)
|
||||
up_i += 3
|
||||
else:
|
||||
sample = upsample_block(
|
||||
hidden_states=sample, temb=emb, res_hidden_states_tuple=res_samples, upsample_size=upsample_size
|
||||
)
|
||||
|
||||
if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
|
||||
sample = upsample_block(
|
||||
hidden_states=sample,
|
||||
temb=emb,
|
||||
res_hidden_states_tuple=res_samples,
|
||||
encoder_hidden_states=encoder_hidden_states[up_i:up_i+3],
|
||||
upsample_size=upsample_size,
|
||||
)
|
||||
up_i += 3
|
||||
else:
|
||||
sample = upsample_block(
|
||||
hidden_states=sample, temb=emb, res_hidden_states_tuple=res_samples, upsample_size=upsample_size
|
||||
)
|
||||
# 6. post-process
|
||||
sample = self.conv_norm_out(sample)
|
||||
sample = self.conv_act(sample)
|
||||
sample = self.conv_out(sample)
|
||||
# 6. post-process
|
||||
sample = self.conv_norm_out(sample)
|
||||
sample = self.conv_act(sample)
|
||||
sample = self.conv_out(sample)
|
||||
|
||||
if not return_dict:
|
||||
return (sample,)
|
||||
if not return_dict:
|
||||
return (sample,)
|
||||
|
||||
return SampleOutput(sample=sample)
|
||||
|
||||
return UNet2DConditionOutput(sample=sample)
|
||||
|
||||
def downblock_forward_XTI(
|
||||
self, hidden_states, temb=None, encoder_hidden_states=None, attention_mask=None, cross_attention_kwargs=None
|
||||
@@ -166,6 +160,7 @@ def downblock_forward_XTI(
|
||||
|
||||
return hidden_states, output_states
|
||||
|
||||
|
||||
def upblock_forward_XTI(
|
||||
self,
|
||||
hidden_states,
|
||||
@@ -199,11 +194,11 @@ def upblock_forward_XTI(
|
||||
else:
|
||||
hidden_states = resnet(hidden_states, temb)
|
||||
hidden_states = attn(hidden_states, encoder_hidden_states=encoder_hidden_states[i]).sample
|
||||
|
||||
|
||||
i += 1
|
||||
|
||||
if self.upsamplers is not None:
|
||||
for upsampler in self.upsamplers:
|
||||
hidden_states = upsampler(hidden_states, upsample_size)
|
||||
|
||||
return hidden_states
|
||||
return hidden_states
|
||||
|
||||
27
_typos.toml
27
_typos.toml
@@ -2,6 +2,7 @@
|
||||
# Instruction: https://github.com/marketplace/actions/typos-action#getting-started
|
||||
|
||||
[default.extend-identifiers]
|
||||
ddPn08="ddPn08"
|
||||
|
||||
[default.extend-words]
|
||||
NIN="NIN"
|
||||
@@ -9,7 +10,29 @@ parms="parms"
|
||||
nin="nin"
|
||||
extention="extention" # Intentionally left
|
||||
nd="nd"
|
||||
|
||||
shs="shs"
|
||||
sts="sts"
|
||||
scs="scs"
|
||||
cpc="cpc"
|
||||
coc="coc"
|
||||
cic="cic"
|
||||
msm="msm"
|
||||
usu="usu"
|
||||
ici="ici"
|
||||
lvl="lvl"
|
||||
dii="dii"
|
||||
muk="muk"
|
||||
ori="ori"
|
||||
hru="hru"
|
||||
rik="rik"
|
||||
koo="koo"
|
||||
yos="yos"
|
||||
wn="wn"
|
||||
hime="hime"
|
||||
OT="OT"
|
||||
byt="byt"
|
||||
tak="tak"
|
||||
temperal="temperal"
|
||||
|
||||
[files]
|
||||
extend-exclude = ["_typos.toml"]
|
||||
extend-exclude = ["_typos.toml", "venv", "configs"]
|
||||
|
||||
1082
anima_minimal_inference.py
Normal file
1082
anima_minimal_inference.py
Normal file
File diff suppressed because it is too large
Load Diff
759
anima_train.py
Normal file
759
anima_train.py
Normal file
@@ -0,0 +1,759 @@
|
||||
# Anima full finetune training script
|
||||
|
||||
import argparse
|
||||
from concurrent.futures import ThreadPoolExecutor
|
||||
import copy
|
||||
import gc
|
||||
import math
|
||||
import os
|
||||
from multiprocessing import Value
|
||||
from typing import List
|
||||
import toml
|
||||
|
||||
from tqdm import tqdm
|
||||
|
||||
import torch
|
||||
from library import flux_train_utils, qwen_image_autoencoder_kl
|
||||
from library.device_utils import init_ipex, clean_memory_on_device
|
||||
from library.sd3_train_utils import FlowMatchEulerDiscreteScheduler
|
||||
|
||||
init_ipex()
|
||||
|
||||
from accelerate.utils import set_seed
|
||||
from library import deepspeed_utils, anima_models, anima_train_utils, anima_utils, strategy_base, strategy_anima, sai_model_spec
|
||||
|
||||
import library.train_util as train_util
|
||||
|
||||
from library.utils import setup_logging, add_logging_arguments
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
import library.config_util as config_util
|
||||
|
||||
from library.config_util import (
|
||||
ConfigSanitizer,
|
||||
BlueprintGenerator,
|
||||
)
|
||||
from library.custom_train_functions import apply_masked_loss, add_custom_train_arguments
|
||||
|
||||
|
||||
def train(args):
|
||||
train_util.verify_training_args(args)
|
||||
train_util.prepare_dataset_args(args, True)
|
||||
deepspeed_utils.prepare_deepspeed_args(args)
|
||||
setup_logging(args, reset=True)
|
||||
|
||||
# backward compatibility
|
||||
if not args.skip_cache_check:
|
||||
args.skip_cache_check = args.skip_latents_validity_check
|
||||
|
||||
if args.cache_text_encoder_outputs_to_disk and not args.cache_text_encoder_outputs:
|
||||
logger.warning("cache_text_encoder_outputs_to_disk is enabled, so cache_text_encoder_outputs is also enabled")
|
||||
args.cache_text_encoder_outputs = True
|
||||
|
||||
if args.cpu_offload_checkpointing and not args.gradient_checkpointing:
|
||||
logger.warning("cpu_offload_checkpointing is enabled, so gradient_checkpointing is also enabled")
|
||||
args.gradient_checkpointing = True
|
||||
|
||||
if args.unsloth_offload_checkpointing:
|
||||
if not args.gradient_checkpointing:
|
||||
logger.warning("unsloth_offload_checkpointing is enabled, so gradient_checkpointing is also enabled")
|
||||
args.gradient_checkpointing = True
|
||||
assert not args.cpu_offload_checkpointing, "Cannot use both --unsloth_offload_checkpointing and --cpu_offload_checkpointing"
|
||||
|
||||
assert (
|
||||
args.blocks_to_swap is None or args.blocks_to_swap == 0
|
||||
) or not args.cpu_offload_checkpointing, "blocks_to_swap is not supported with cpu_offload_checkpointing"
|
||||
|
||||
assert (
|
||||
args.blocks_to_swap is None or args.blocks_to_swap == 0
|
||||
) or not args.unsloth_offload_checkpointing, "blocks_to_swap is not supported with unsloth_offload_checkpointing"
|
||||
|
||||
cache_latents = args.cache_latents
|
||||
use_dreambooth_method = args.in_json is None
|
||||
|
||||
if args.seed is not None:
|
||||
set_seed(args.seed)
|
||||
|
||||
# prepare caching strategy: must be set before preparing dataset
|
||||
if args.cache_latents:
|
||||
latents_caching_strategy = strategy_anima.AnimaLatentsCachingStrategy(
|
||||
args.cache_latents_to_disk, args.vae_batch_size, args.skip_cache_check
|
||||
)
|
||||
strategy_base.LatentsCachingStrategy.set_strategy(latents_caching_strategy)
|
||||
|
||||
# prepare dataset
|
||||
if args.dataset_class is None:
|
||||
blueprint_generator = BlueprintGenerator(ConfigSanitizer(True, True, args.masked_loss, True))
|
||||
if args.dataset_config is not None:
|
||||
logger.info(f"Load dataset config from {args.dataset_config}")
|
||||
user_config = config_util.load_user_config(args.dataset_config)
|
||||
ignored = ["train_data_dir", "in_json"]
|
||||
if any(getattr(args, attr) is not None for attr in ignored):
|
||||
logger.warning("ignore following options because config file is found: {0}".format(", ".join(ignored)))
|
||||
else:
|
||||
if use_dreambooth_method:
|
||||
logger.info("Using DreamBooth method.")
|
||||
user_config = {
|
||||
"datasets": [
|
||||
{
|
||||
"subsets": config_util.generate_dreambooth_subsets_config_by_subdirs(
|
||||
args.train_data_dir, args.reg_data_dir
|
||||
)
|
||||
}
|
||||
]
|
||||
}
|
||||
else:
|
||||
logger.info("Training with captions.")
|
||||
user_config = {
|
||||
"datasets": [
|
||||
{
|
||||
"subsets": [
|
||||
{
|
||||
"image_dir": args.train_data_dir,
|
||||
"metadata_file": args.in_json,
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
blueprint = blueprint_generator.generate(user_config, args)
|
||||
train_dataset_group, val_dataset_group = config_util.generate_dataset_group_by_blueprint(blueprint.dataset_group)
|
||||
else:
|
||||
train_dataset_group = train_util.load_arbitrary_dataset(args)
|
||||
val_dataset_group = None
|
||||
|
||||
current_epoch = Value("i", 0)
|
||||
current_step = Value("i", 0)
|
||||
ds_for_collator = train_dataset_group if args.max_data_loader_n_workers == 0 else None
|
||||
collator = train_util.collator_class(current_epoch, current_step, ds_for_collator)
|
||||
|
||||
train_dataset_group.verify_bucket_reso_steps(16) # Qwen-Image VAE spatial downscale = 8 * patch size = 2
|
||||
|
||||
if args.debug_dataset:
|
||||
if args.cache_text_encoder_outputs:
|
||||
strategy_base.TextEncoderOutputsCachingStrategy.set_strategy(
|
||||
strategy_anima.AnimaTextEncoderOutputsCachingStrategy(
|
||||
args.cache_text_encoder_outputs_to_disk, args.text_encoder_batch_size, False, False
|
||||
)
|
||||
)
|
||||
train_dataset_group.set_current_strategies()
|
||||
train_util.debug_dataset(train_dataset_group, True)
|
||||
return
|
||||
if len(train_dataset_group) == 0:
|
||||
logger.error("No data found. Please verify the metadata file and train_data_dir option.")
|
||||
return
|
||||
|
||||
if cache_latents:
|
||||
assert train_dataset_group.is_latent_cacheable(), "when caching latents, either color_aug or random_crop cannot be used"
|
||||
|
||||
if args.cache_text_encoder_outputs:
|
||||
assert train_dataset_group.is_text_encoder_output_cacheable(
|
||||
cache_supports_dropout=True
|
||||
), "when caching text encoder output, shuffle_caption, token_warmup_step or caption_tag_dropout_rate cannot be used"
|
||||
|
||||
# prepare accelerator
|
||||
logger.info("prepare accelerator")
|
||||
accelerator = train_util.prepare_accelerator(args)
|
||||
|
||||
# mixed precision dtype
|
||||
weight_dtype, save_dtype = train_util.prepare_dtype(args)
|
||||
|
||||
# Load tokenizers and set strategies
|
||||
logger.info("Loading tokenizers...")
|
||||
qwen3_text_encoder, qwen3_tokenizer = anima_utils.load_qwen3_text_encoder(args.qwen3, dtype=weight_dtype, device="cpu")
|
||||
t5_tokenizer = anima_utils.load_t5_tokenizer(args.t5_tokenizer_path)
|
||||
|
||||
# Set tokenize strategy
|
||||
tokenize_strategy = strategy_anima.AnimaTokenizeStrategy(
|
||||
qwen3_tokenizer=qwen3_tokenizer,
|
||||
t5_tokenizer=t5_tokenizer,
|
||||
qwen3_max_length=args.qwen3_max_token_length,
|
||||
t5_max_length=args.t5_max_token_length,
|
||||
)
|
||||
strategy_base.TokenizeStrategy.set_strategy(tokenize_strategy)
|
||||
|
||||
text_encoding_strategy = strategy_anima.AnimaTextEncodingStrategy()
|
||||
strategy_base.TextEncodingStrategy.set_strategy(text_encoding_strategy)
|
||||
|
||||
# Prepare text encoder (always frozen for Anima)
|
||||
qwen3_text_encoder.to(weight_dtype)
|
||||
qwen3_text_encoder.requires_grad_(False)
|
||||
|
||||
# Cache text encoder outputs
|
||||
sample_prompts_te_outputs = None
|
||||
if args.cache_text_encoder_outputs:
|
||||
qwen3_text_encoder.to(accelerator.device)
|
||||
qwen3_text_encoder.eval()
|
||||
|
||||
text_encoder_caching_strategy = strategy_anima.AnimaTextEncoderOutputsCachingStrategy(
|
||||
args.cache_text_encoder_outputs_to_disk, args.text_encoder_batch_size, args.skip_cache_check, is_partial=False
|
||||
)
|
||||
strategy_base.TextEncoderOutputsCachingStrategy.set_strategy(text_encoder_caching_strategy)
|
||||
|
||||
with accelerator.autocast():
|
||||
train_dataset_group.new_cache_text_encoder_outputs([qwen3_text_encoder], accelerator)
|
||||
|
||||
# cache sample prompt embeddings
|
||||
if args.sample_prompts is not None:
|
||||
logger.info(f"Cache Text Encoder outputs for sample prompts: {args.sample_prompts}")
|
||||
prompts = train_util.load_prompts(args.sample_prompts)
|
||||
sample_prompts_te_outputs = {}
|
||||
with accelerator.autocast(), torch.no_grad():
|
||||
for prompt_dict in prompts:
|
||||
for p in [prompt_dict.get("prompt", ""), prompt_dict.get("negative_prompt", "")]:
|
||||
if p not in sample_prompts_te_outputs:
|
||||
logger.info(f" cache TE outputs for: {p}")
|
||||
tokens_and_masks = tokenize_strategy.tokenize(p)
|
||||
sample_prompts_te_outputs[p] = text_encoding_strategy.encode_tokens(
|
||||
tokenize_strategy, [qwen3_text_encoder], tokens_and_masks
|
||||
)
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
# free text encoder memory
|
||||
qwen3_text_encoder = None
|
||||
gc.collect() # Force garbage collection to free memory
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
# Load VAE and cache latents
|
||||
logger.info("Loading Anima VAE...")
|
||||
vae = qwen_image_autoencoder_kl.load_vae(
|
||||
args.vae, device="cpu", disable_mmap=True, spatial_chunk_size=args.vae_chunk_size, disable_cache=args.vae_disable_cache
|
||||
)
|
||||
|
||||
if cache_latents:
|
||||
vae.to(accelerator.device, dtype=weight_dtype)
|
||||
vae.requires_grad_(False)
|
||||
vae.eval()
|
||||
|
||||
train_dataset_group.new_cache_latents(vae, accelerator)
|
||||
|
||||
vae.to("cpu")
|
||||
clean_memory_on_device(accelerator.device)
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
# Load DiT (MiniTrainDIT + optional LLM Adapter)
|
||||
logger.info("Loading Anima DiT...")
|
||||
dit = anima_utils.load_anima_model(
|
||||
"cpu", args.pretrained_model_name_or_path, args.attn_mode, args.split_attn, "cpu", dit_weight_dtype=None
|
||||
)
|
||||
|
||||
if args.gradient_checkpointing:
|
||||
dit.enable_gradient_checkpointing(
|
||||
cpu_offload=args.cpu_offload_checkpointing,
|
||||
unsloth_offload=args.unsloth_offload_checkpointing,
|
||||
)
|
||||
|
||||
train_dit = args.learning_rate != 0
|
||||
dit.requires_grad_(train_dit)
|
||||
if not train_dit:
|
||||
dit.to(accelerator.device, dtype=weight_dtype)
|
||||
|
||||
# Block swap
|
||||
is_swapping_blocks = args.blocks_to_swap is not None and args.blocks_to_swap > 0
|
||||
if is_swapping_blocks:
|
||||
logger.info(f"Enable block swap: blocks_to_swap={args.blocks_to_swap}")
|
||||
dit.enable_block_swap(args.blocks_to_swap, accelerator.device)
|
||||
|
||||
if not cache_latents:
|
||||
vae.requires_grad_(False)
|
||||
vae.eval()
|
||||
vae.to(accelerator.device, dtype=weight_dtype)
|
||||
|
||||
# Setup optimizer with parameter groups
|
||||
if train_dit:
|
||||
param_groups = anima_train_utils.get_anima_param_groups(
|
||||
dit,
|
||||
base_lr=args.learning_rate,
|
||||
self_attn_lr=args.self_attn_lr,
|
||||
cross_attn_lr=args.cross_attn_lr,
|
||||
mlp_lr=args.mlp_lr,
|
||||
mod_lr=args.mod_lr,
|
||||
llm_adapter_lr=args.llm_adapter_lr,
|
||||
)
|
||||
else:
|
||||
param_groups = []
|
||||
|
||||
training_models = []
|
||||
if train_dit:
|
||||
training_models.append(dit)
|
||||
|
||||
# calculate trainable parameters
|
||||
n_params = 0
|
||||
for group in param_groups:
|
||||
for p in group["params"]:
|
||||
n_params += p.numel()
|
||||
|
||||
accelerator.print(f"train dit: {train_dit}")
|
||||
accelerator.print(f"number of training models: {len(training_models)}")
|
||||
accelerator.print(f"number of trainable parameters: {n_params:,}")
|
||||
|
||||
# prepare optimizer
|
||||
accelerator.print("prepare optimizer, data loader etc.")
|
||||
|
||||
if args.fused_backward_pass:
|
||||
# Pass per-component param_groups directly to preserve per-component LRs
|
||||
_, _, optimizer = train_util.get_optimizer(args, trainable_params=param_groups)
|
||||
optimizer_train_fn, optimizer_eval_fn = train_util.get_optimizer_train_eval_fn(optimizer, args)
|
||||
else:
|
||||
_, _, optimizer = train_util.get_optimizer(args, trainable_params=param_groups)
|
||||
optimizer_train_fn, optimizer_eval_fn = train_util.get_optimizer_train_eval_fn(optimizer, args)
|
||||
|
||||
# prepare dataloader
|
||||
train_dataset_group.set_current_strategies()
|
||||
|
||||
n_workers = min(args.max_data_loader_n_workers, os.cpu_count())
|
||||
train_dataloader = torch.utils.data.DataLoader(
|
||||
train_dataset_group,
|
||||
batch_size=1,
|
||||
shuffle=True,
|
||||
collate_fn=collator,
|
||||
num_workers=n_workers,
|
||||
persistent_workers=args.persistent_data_loader_workers,
|
||||
)
|
||||
|
||||
# calculate training steps
|
||||
if args.max_train_epochs is not None:
|
||||
args.max_train_steps = args.max_train_epochs * math.ceil(
|
||||
len(train_dataloader) / accelerator.num_processes / args.gradient_accumulation_steps
|
||||
)
|
||||
accelerator.print(f"override steps. steps for {args.max_train_epochs} epochs: {args.max_train_steps}")
|
||||
|
||||
train_dataset_group.set_max_train_steps(args.max_train_steps)
|
||||
|
||||
# lr scheduler
|
||||
lr_scheduler = train_util.get_scheduler_fix(args, optimizer, accelerator.num_processes)
|
||||
|
||||
# full fp16/bf16 training
|
||||
dit_weight_dtype = weight_dtype
|
||||
if args.full_fp16:
|
||||
assert args.mixed_precision == "fp16", "full_fp16 requires mixed_precision='fp16'"
|
||||
accelerator.print("enable full fp16 training.")
|
||||
elif args.full_bf16:
|
||||
assert args.mixed_precision == "bf16", "full_bf16 requires mixed_precision='bf16'"
|
||||
accelerator.print("enable full bf16 training.")
|
||||
else:
|
||||
dit_weight_dtype = torch.float32 # If neither full_fp16 nor full_bf16, the model weights should be in float32
|
||||
dit.to(dit_weight_dtype) # convert dit to target weight dtype
|
||||
|
||||
# move text encoder to GPU if not cached
|
||||
if not args.cache_text_encoder_outputs and qwen3_text_encoder is not None:
|
||||
qwen3_text_encoder.to(accelerator.device)
|
||||
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
# Prepare with accelerator
|
||||
# Temporarily move non-training models off GPU to reduce memory during DDP init
|
||||
# if not args.cache_text_encoder_outputs and qwen3_text_encoder is not None:
|
||||
# qwen3_text_encoder.to("cpu")
|
||||
# if not cache_latents and vae is not None:
|
||||
# vae.to("cpu")
|
||||
# clean_memory_on_device(accelerator.device)
|
||||
|
||||
if args.deepspeed:
|
||||
ds_model = deepspeed_utils.prepare_deepspeed_model(args, mmdit=dit)
|
||||
ds_model, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
|
||||
ds_model, optimizer, train_dataloader, lr_scheduler
|
||||
)
|
||||
training_models = [ds_model]
|
||||
else:
|
||||
if train_dit:
|
||||
dit = accelerator.prepare(dit, device_placement=[not is_swapping_blocks])
|
||||
if is_swapping_blocks:
|
||||
accelerator.unwrap_model(dit).move_to_device_except_swap_blocks(accelerator.device)
|
||||
optimizer, train_dataloader, lr_scheduler = accelerator.prepare(optimizer, train_dataloader, lr_scheduler)
|
||||
|
||||
# Move non-training models back to GPU
|
||||
if not args.cache_text_encoder_outputs and qwen3_text_encoder is not None:
|
||||
qwen3_text_encoder.to(accelerator.device)
|
||||
if not cache_latents and vae is not None:
|
||||
vae.to(accelerator.device, dtype=weight_dtype)
|
||||
|
||||
if args.full_fp16:
|
||||
train_util.patch_accelerator_for_fp16_training(accelerator)
|
||||
|
||||
# resume
|
||||
train_util.resume_from_local_or_hf_if_specified(accelerator, args)
|
||||
|
||||
if args.fused_backward_pass:
|
||||
# use fused optimizer for backward pass: other optimizers will be supported in the future
|
||||
import library.adafactor_fused
|
||||
|
||||
library.adafactor_fused.patch_adafactor_fused(optimizer)
|
||||
|
||||
for param_group in optimizer.param_groups:
|
||||
for parameter in param_group["params"]:
|
||||
if parameter.requires_grad:
|
||||
|
||||
def create_grad_hook(p_group):
|
||||
def grad_hook(tensor: torch.Tensor):
|
||||
if accelerator.sync_gradients and args.max_grad_norm != 0.0:
|
||||
accelerator.clip_grad_norm_(tensor, args.max_grad_norm)
|
||||
optimizer.step_param(tensor, p_group)
|
||||
tensor.grad = None
|
||||
|
||||
return grad_hook
|
||||
|
||||
parameter.register_post_accumulate_grad_hook(create_grad_hook(param_group))
|
||||
|
||||
# Training loop
|
||||
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
|
||||
num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
|
||||
if (args.save_n_epoch_ratio is not None) and (args.save_n_epoch_ratio > 0):
|
||||
args.save_every_n_epochs = math.floor(num_train_epochs / args.save_n_epoch_ratio) or 1
|
||||
|
||||
accelerator.print("running training / 学習開始")
|
||||
accelerator.print(f" num examples / サンプル数: {train_dataset_group.num_train_images}")
|
||||
accelerator.print(f" num batches per epoch / 1epochのバッチ数: {len(train_dataloader)}")
|
||||
accelerator.print(f" num epochs / epoch数: {num_train_epochs}")
|
||||
accelerator.print(
|
||||
f" batch size per device / バッチサイズ: {', '.join([str(d.batch_size) for d in train_dataset_group.datasets])}"
|
||||
)
|
||||
accelerator.print(f" gradient accumulation steps / 勾配を合計するステップ数 = {args.gradient_accumulation_steps}")
|
||||
accelerator.print(f" total optimization steps / 学習ステップ数: {args.max_train_steps}")
|
||||
|
||||
progress_bar = tqdm(range(args.max_train_steps), smoothing=0, disable=not accelerator.is_local_main_process, desc="steps")
|
||||
global_step = 0
|
||||
|
||||
noise_scheduler = FlowMatchEulerDiscreteScheduler(num_train_timesteps=1000, shift=args.discrete_flow_shift)
|
||||
# Copy for noise and timestep generation, because noise_scheduler may be changed during training in future
|
||||
noise_scheduler_copy = copy.deepcopy(noise_scheduler)
|
||||
|
||||
if accelerator.is_main_process:
|
||||
init_kwargs = {}
|
||||
if args.wandb_run_name:
|
||||
init_kwargs["wandb"] = {"name": args.wandb_run_name}
|
||||
if args.log_tracker_config is not None:
|
||||
init_kwargs = toml.load(args.log_tracker_config)
|
||||
accelerator.init_trackers(
|
||||
"finetuning" if args.log_tracker_name is None else args.log_tracker_name,
|
||||
config=train_util.get_sanitized_config_or_none(args),
|
||||
init_kwargs=init_kwargs,
|
||||
)
|
||||
|
||||
if "wandb" in [tracker.name for tracker in accelerator.trackers]:
|
||||
import wandb
|
||||
|
||||
wandb.define_metric("epoch")
|
||||
wandb.define_metric("loss/epoch", step_metric="epoch")
|
||||
|
||||
if is_swapping_blocks:
|
||||
accelerator.unwrap_model(dit).prepare_block_swap_before_forward()
|
||||
|
||||
# For --sample_at_first
|
||||
optimizer_eval_fn()
|
||||
anima_train_utils.sample_images(
|
||||
accelerator,
|
||||
args,
|
||||
0,
|
||||
global_step,
|
||||
dit,
|
||||
vae,
|
||||
qwen3_text_encoder,
|
||||
tokenize_strategy,
|
||||
text_encoding_strategy,
|
||||
sample_prompts_te_outputs,
|
||||
)
|
||||
optimizer_train_fn()
|
||||
if len(accelerator.trackers) > 0:
|
||||
accelerator.log({}, step=0)
|
||||
|
||||
# Show model info
|
||||
unwrapped_dit = accelerator.unwrap_model(dit) if dit is not None else None
|
||||
if unwrapped_dit is not None:
|
||||
logger.info(f"dit device: {unwrapped_dit.device}, dtype: {unwrapped_dit.dtype}")
|
||||
if qwen3_text_encoder is not None:
|
||||
logger.info(f"qwen3 device: {qwen3_text_encoder.device}")
|
||||
if vae is not None:
|
||||
logger.info(f"vae device: {vae.device}")
|
||||
|
||||
loss_recorder = train_util.LossRecorder()
|
||||
epoch = 0
|
||||
for epoch in range(num_train_epochs):
|
||||
accelerator.print(f"\nepoch {epoch+1}/{num_train_epochs}")
|
||||
current_epoch.value = epoch + 1
|
||||
|
||||
for m in training_models:
|
||||
m.train()
|
||||
|
||||
for step, batch in enumerate(train_dataloader):
|
||||
current_step.value = global_step
|
||||
|
||||
with accelerator.accumulate(*training_models):
|
||||
# Get latents
|
||||
if "latents" in batch and batch["latents"] is not None:
|
||||
latents = batch["latents"].to(accelerator.device, dtype=dit_weight_dtype)
|
||||
if latents.ndim == 5: # Fallback for 5D latents (old cache)
|
||||
latents = latents.squeeze(2) # (B, C, 1, H, W) -> (B, C, H, W)
|
||||
else:
|
||||
with torch.no_grad():
|
||||
# images are already [-1, 1] from IMAGE_TRANSFORMS, add temporal dim
|
||||
images = batch["images"].to(accelerator.device, dtype=weight_dtype)
|
||||
latents = vae.encode_pixels_to_latents(images).to(accelerator.device, dtype=dit_weight_dtype)
|
||||
|
||||
if torch.any(torch.isnan(latents)):
|
||||
accelerator.print("NaN found in latents, replacing with zeros")
|
||||
latents = torch.nan_to_num(latents, 0, out=latents)
|
||||
|
||||
# Get text encoder outputs
|
||||
text_encoder_outputs_list = batch.get("text_encoder_outputs_list", None)
|
||||
if text_encoder_outputs_list is not None:
|
||||
# Cached outputs
|
||||
caption_dropout_rates = text_encoder_outputs_list[-1]
|
||||
text_encoder_outputs_list = text_encoder_outputs_list[:-1]
|
||||
|
||||
# Apply caption dropout to cached outputs
|
||||
text_encoder_outputs_list = text_encoding_strategy.drop_cached_text_encoder_outputs(
|
||||
*text_encoder_outputs_list, caption_dropout_rates=caption_dropout_rates
|
||||
)
|
||||
prompt_embeds, attn_mask, t5_input_ids, t5_attn_mask = text_encoder_outputs_list
|
||||
else:
|
||||
# Encode on-the-fly
|
||||
input_ids_list = batch["input_ids_list"]
|
||||
with torch.no_grad():
|
||||
prompt_embeds, attn_mask, t5_input_ids, t5_attn_mask = text_encoding_strategy.encode_tokens(
|
||||
tokenize_strategy, [qwen3_text_encoder], input_ids_list
|
||||
)
|
||||
|
||||
# Move to device
|
||||
prompt_embeds = prompt_embeds.to(accelerator.device, dtype=dit_weight_dtype)
|
||||
attn_mask = attn_mask.to(accelerator.device)
|
||||
t5_input_ids = t5_input_ids.to(accelerator.device, dtype=torch.long)
|
||||
t5_attn_mask = t5_attn_mask.to(accelerator.device)
|
||||
|
||||
# Noise and timesteps
|
||||
noise = torch.randn_like(latents)
|
||||
|
||||
# Get noisy model input and timesteps
|
||||
noisy_model_input, timesteps, sigmas = flux_train_utils.get_noisy_model_input_and_timesteps(
|
||||
args, noise_scheduler_copy, latents, noise, accelerator.device, dit_weight_dtype
|
||||
)
|
||||
timesteps = timesteps / 1000.0 # scale to [0, 1] range. timesteps is float32
|
||||
|
||||
# NaN checks
|
||||
if torch.any(torch.isnan(noisy_model_input)):
|
||||
accelerator.print("NaN found in noisy_model_input, replacing with zeros")
|
||||
noisy_model_input = torch.nan_to_num(noisy_model_input, 0, out=noisy_model_input)
|
||||
|
||||
# Create padding mask
|
||||
# padding_mask: (B, 1, H_latent, W_latent)
|
||||
bs = latents.shape[0]
|
||||
h_latent = latents.shape[-2]
|
||||
w_latent = latents.shape[-1]
|
||||
padding_mask = torch.zeros(bs, 1, h_latent, w_latent, dtype=dit_weight_dtype, device=accelerator.device)
|
||||
|
||||
# DiT forward (LLM adapter runs inside forward for DDP gradient sync)
|
||||
noisy_model_input = noisy_model_input.unsqueeze(2) # 4D to 5D, (B, C, 1, H, W)
|
||||
with accelerator.autocast():
|
||||
model_pred = dit(
|
||||
noisy_model_input,
|
||||
timesteps,
|
||||
prompt_embeds,
|
||||
padding_mask=padding_mask,
|
||||
source_attention_mask=attn_mask,
|
||||
t5_input_ids=t5_input_ids,
|
||||
t5_attn_mask=t5_attn_mask,
|
||||
)
|
||||
model_pred = model_pred.squeeze(2) # 5D to 4D, (B, C, H, W)
|
||||
|
||||
# Compute loss (rectified flow: target = noise - latents)
|
||||
target = noise - latents
|
||||
|
||||
# Weighting
|
||||
weighting = anima_train_utils.compute_loss_weighting_for_anima(
|
||||
weighting_scheme=args.weighting_scheme, sigmas=sigmas
|
||||
)
|
||||
|
||||
# Loss
|
||||
huber_c = train_util.get_huber_threshold_if_needed(args, timesteps, None)
|
||||
loss = train_util.conditional_loss(model_pred.float(), target.float(), args.loss_type, "none", huber_c)
|
||||
if args.masked_loss or ("alpha_masks" in batch and batch["alpha_masks"] is not None):
|
||||
loss = apply_masked_loss(loss, batch)
|
||||
loss = loss.mean([1, 2, 3]) # (B, C, H, W) -> (B,)
|
||||
|
||||
if weighting is not None:
|
||||
loss = loss * weighting
|
||||
|
||||
loss_weights = batch["loss_weights"]
|
||||
loss = loss * loss_weights
|
||||
loss = loss.mean()
|
||||
|
||||
accelerator.backward(loss)
|
||||
|
||||
if not args.fused_backward_pass:
|
||||
if accelerator.sync_gradients and args.max_grad_norm != 0.0:
|
||||
params_to_clip = []
|
||||
for m in training_models:
|
||||
params_to_clip.extend(m.parameters())
|
||||
accelerator.clip_grad_norm_(params_to_clip, args.max_grad_norm)
|
||||
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
optimizer.zero_grad(set_to_none=True)
|
||||
else:
|
||||
# optimizer.step() and optimizer.zero_grad() are called in the optimizer hook
|
||||
lr_scheduler.step()
|
||||
|
||||
# Checks if the accelerator has performed an optimization step
|
||||
if accelerator.sync_gradients:
|
||||
progress_bar.update(1)
|
||||
global_step += 1
|
||||
|
||||
optimizer_eval_fn()
|
||||
anima_train_utils.sample_images(
|
||||
accelerator,
|
||||
args,
|
||||
None,
|
||||
global_step,
|
||||
dit,
|
||||
vae,
|
||||
qwen3_text_encoder,
|
||||
tokenize_strategy,
|
||||
text_encoding_strategy,
|
||||
sample_prompts_te_outputs,
|
||||
)
|
||||
|
||||
# Save at specific steps
|
||||
if args.save_every_n_steps is not None and global_step % args.save_every_n_steps == 0:
|
||||
accelerator.wait_for_everyone()
|
||||
if accelerator.is_main_process:
|
||||
anima_train_utils.save_anima_model_on_epoch_end_or_stepwise(
|
||||
args,
|
||||
False,
|
||||
accelerator,
|
||||
save_dtype,
|
||||
epoch,
|
||||
num_train_epochs,
|
||||
global_step,
|
||||
accelerator.unwrap_model(dit) if train_dit else None,
|
||||
)
|
||||
optimizer_train_fn()
|
||||
|
||||
current_loss = loss.detach().item()
|
||||
if len(accelerator.trackers) > 0:
|
||||
logs = {"loss": current_loss}
|
||||
train_util.append_lr_to_logs_with_names(
|
||||
logs,
|
||||
lr_scheduler,
|
||||
args.optimizer_type,
|
||||
["base", "self_attn", "cross_attn", "mlp", "mod", "llm_adapter"] if train_dit else [],
|
||||
)
|
||||
accelerator.log(logs, step=global_step)
|
||||
|
||||
loss_recorder.add(epoch=epoch, step=step, loss=current_loss)
|
||||
avr_loss: float = loss_recorder.moving_average
|
||||
logs = {"avr_loss": avr_loss}
|
||||
progress_bar.set_postfix(**logs)
|
||||
|
||||
if global_step >= args.max_train_steps:
|
||||
break
|
||||
|
||||
if len(accelerator.trackers) > 0:
|
||||
logs = {"loss/epoch": loss_recorder.moving_average, "epoch": epoch + 1}
|
||||
accelerator.log(logs, step=global_step)
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
optimizer_eval_fn()
|
||||
if args.save_every_n_epochs is not None:
|
||||
if accelerator.is_main_process:
|
||||
anima_train_utils.save_anima_model_on_epoch_end_or_stepwise(
|
||||
args,
|
||||
True,
|
||||
accelerator,
|
||||
save_dtype,
|
||||
epoch,
|
||||
num_train_epochs,
|
||||
global_step,
|
||||
accelerator.unwrap_model(dit) if train_dit else None,
|
||||
)
|
||||
|
||||
anima_train_utils.sample_images(
|
||||
accelerator,
|
||||
args,
|
||||
epoch + 1,
|
||||
global_step,
|
||||
dit,
|
||||
vae,
|
||||
qwen3_text_encoder,
|
||||
tokenize_strategy,
|
||||
text_encoding_strategy,
|
||||
sample_prompts_te_outputs,
|
||||
)
|
||||
|
||||
# End training
|
||||
is_main_process = accelerator.is_main_process
|
||||
dit = accelerator.unwrap_model(dit)
|
||||
|
||||
accelerator.end_training()
|
||||
optimizer_eval_fn()
|
||||
|
||||
if args.save_state or args.save_state_on_train_end:
|
||||
train_util.save_state_on_train_end(args, accelerator)
|
||||
|
||||
del accelerator
|
||||
|
||||
if is_main_process and train_dit:
|
||||
anima_train_utils.save_anima_model_on_train_end(
|
||||
args,
|
||||
save_dtype,
|
||||
epoch,
|
||||
global_step,
|
||||
dit,
|
||||
)
|
||||
logger.info("model saved.")
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
add_logging_arguments(parser)
|
||||
train_util.add_sd_models_arguments(parser)
|
||||
train_util.add_dataset_arguments(parser, True, True, True)
|
||||
train_util.add_training_arguments(parser, False)
|
||||
train_util.add_masked_loss_arguments(parser)
|
||||
deepspeed_utils.add_deepspeed_arguments(parser)
|
||||
train_util.add_sd_saving_arguments(parser)
|
||||
train_util.add_optimizer_arguments(parser)
|
||||
config_util.add_config_arguments(parser)
|
||||
add_custom_train_arguments(parser)
|
||||
train_util.add_dit_training_arguments(parser)
|
||||
anima_train_utils.add_anima_training_arguments(parser)
|
||||
sai_model_spec.add_model_spec_arguments(parser)
|
||||
|
||||
parser.add_argument(
|
||||
"--cpu_offload_checkpointing",
|
||||
action="store_true",
|
||||
help="offload gradient checkpointing to CPU (reduces VRAM at cost of speed)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--unsloth_offload_checkpointing",
|
||||
action="store_true",
|
||||
help="offload activations to CPU RAM using async non-blocking transfers (faster than --cpu_offload_checkpointing). "
|
||||
"Cannot be used with --cpu_offload_checkpointing or --blocks_to_swap.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--skip_latents_validity_check",
|
||||
action="store_true",
|
||||
help="[Deprecated] use 'skip_cache_check' instead",
|
||||
)
|
||||
|
||||
return parser
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
train_util.verify_command_line_training_args(args)
|
||||
args = train_util.read_config_from_file(args, parser)
|
||||
|
||||
if args.attn_mode == "sdpa":
|
||||
args.attn_mode = "torch" # backward compatibility
|
||||
|
||||
train(args)
|
||||
451
anima_train_network.py
Normal file
451
anima_train_network.py
Normal file
@@ -0,0 +1,451 @@
|
||||
# Anima LoRA training script
|
||||
|
||||
import argparse
|
||||
from typing import Any, Optional, Union
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from accelerate import Accelerator
|
||||
from library.device_utils import init_ipex, clean_memory_on_device
|
||||
|
||||
init_ipex()
|
||||
|
||||
from library import (
|
||||
anima_models,
|
||||
anima_train_utils,
|
||||
anima_utils,
|
||||
flux_train_utils,
|
||||
qwen_image_autoencoder_kl,
|
||||
sd3_train_utils,
|
||||
strategy_anima,
|
||||
strategy_base,
|
||||
train_util,
|
||||
)
|
||||
import train_network
|
||||
from library.utils import setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
class AnimaNetworkTrainer(train_network.NetworkTrainer):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.sample_prompts_te_outputs = None
|
||||
|
||||
def assert_extra_args(
|
||||
self,
|
||||
args,
|
||||
train_dataset_group: Union[train_util.DatasetGroup, train_util.MinimalDataset],
|
||||
val_dataset_group: Optional[train_util.DatasetGroup],
|
||||
):
|
||||
if args.fp8_base or args.fp8_base_unet:
|
||||
logger.warning("fp8_base and fp8_base_unet are not supported. / fp8_baseとfp8_base_unetはサポートされていません。")
|
||||
args.fp8_base = False
|
||||
args.fp8_base_unet = False
|
||||
args.fp8_scaled = False # Anima DiT does not support fp8_scaled
|
||||
|
||||
if args.cache_text_encoder_outputs_to_disk and not args.cache_text_encoder_outputs:
|
||||
logger.warning("cache_text_encoder_outputs_to_disk is enabled, so cache_text_encoder_outputs is also enabled")
|
||||
args.cache_text_encoder_outputs = True
|
||||
|
||||
if args.cache_text_encoder_outputs:
|
||||
assert train_dataset_group.is_text_encoder_output_cacheable(
|
||||
cache_supports_dropout=True
|
||||
), "when caching Text Encoder output, shuffle_caption, token_warmup_step or caption_tag_dropout_rate cannot be used"
|
||||
|
||||
assert (
|
||||
args.network_train_unet_only or not args.cache_text_encoder_outputs
|
||||
), "network for Text Encoder cannot be trained with caching Text Encoder outputs / Text Encoderの出力をキャッシュしながらText Encoderのネットワークを学習することはできません"
|
||||
|
||||
assert (
|
||||
args.blocks_to_swap is None or args.blocks_to_swap == 0
|
||||
) or not args.cpu_offload_checkpointing, "blocks_to_swap is not supported with cpu_offload_checkpointing"
|
||||
|
||||
if args.unsloth_offload_checkpointing:
|
||||
if not args.gradient_checkpointing:
|
||||
logger.warning("unsloth_offload_checkpointing is enabled, so gradient_checkpointing is also enabled")
|
||||
args.gradient_checkpointing = True
|
||||
assert (
|
||||
not args.cpu_offload_checkpointing
|
||||
), "Cannot use both --unsloth_offload_checkpointing and --cpu_offload_checkpointing"
|
||||
assert (
|
||||
args.blocks_to_swap is None or args.blocks_to_swap == 0
|
||||
), "blocks_to_swap is not supported with unsloth_offload_checkpointing"
|
||||
|
||||
train_dataset_group.verify_bucket_reso_steps(16) # WanVAE spatial downscale = 8 and patch size = 2
|
||||
if val_dataset_group is not None:
|
||||
val_dataset_group.verify_bucket_reso_steps(16)
|
||||
|
||||
def load_target_model(self, args, weight_dtype, accelerator):
|
||||
self.is_swapping_blocks = args.blocks_to_swap is not None and args.blocks_to_swap > 0
|
||||
|
||||
# Load Qwen3 text encoder (tokenizers already loaded in get_tokenize_strategy)
|
||||
logger.info("Loading Qwen3 text encoder...")
|
||||
qwen3_text_encoder, _ = anima_utils.load_qwen3_text_encoder(args.qwen3, dtype=weight_dtype, device="cpu")
|
||||
qwen3_text_encoder.eval()
|
||||
|
||||
# Load VAE
|
||||
logger.info("Loading Anima VAE...")
|
||||
vae = qwen_image_autoencoder_kl.load_vae(
|
||||
args.vae, device="cpu", disable_mmap=True, spatial_chunk_size=args.vae_chunk_size, disable_cache=args.vae_disable_cache
|
||||
)
|
||||
vae.to(weight_dtype)
|
||||
vae.eval()
|
||||
|
||||
# Return format: (model_type, text_encoders, vae, unet)
|
||||
return "anima", [qwen3_text_encoder], vae, None # unet loaded lazily
|
||||
|
||||
def load_unet_lazily(self, args, weight_dtype, accelerator, text_encoders) -> tuple[nn.Module, list[nn.Module]]:
|
||||
loading_dtype = None if args.fp8_scaled else weight_dtype
|
||||
loading_device = "cpu" if self.is_swapping_blocks else accelerator.device
|
||||
|
||||
attn_mode = "torch"
|
||||
if args.xformers:
|
||||
attn_mode = "xformers"
|
||||
if args.attn_mode is not None:
|
||||
attn_mode = args.attn_mode
|
||||
|
||||
# Load DiT
|
||||
logger.info(f"Loading Anima DiT model with attn_mode={attn_mode}, split_attn: {args.split_attn}...")
|
||||
model = anima_utils.load_anima_model(
|
||||
accelerator.device,
|
||||
args.pretrained_model_name_or_path,
|
||||
attn_mode,
|
||||
args.split_attn,
|
||||
loading_device,
|
||||
loading_dtype,
|
||||
args.fp8_scaled,
|
||||
)
|
||||
|
||||
# Store unsloth preference so that when the base NetworkTrainer calls
|
||||
# dit.enable_gradient_checkpointing(cpu_offload=...), we can override to use unsloth.
|
||||
# The base trainer only passes cpu_offload, so we store the flag on the model.
|
||||
self._use_unsloth_offload_checkpointing = args.unsloth_offload_checkpointing
|
||||
|
||||
# Block swap
|
||||
self.is_swapping_blocks = args.blocks_to_swap is not None and args.blocks_to_swap > 0
|
||||
if self.is_swapping_blocks:
|
||||
logger.info(f"enable block swap: blocks_to_swap={args.blocks_to_swap}")
|
||||
model.enable_block_swap(args.blocks_to_swap, accelerator.device)
|
||||
|
||||
return model, text_encoders
|
||||
|
||||
def get_tokenize_strategy(self, args):
|
||||
# Load tokenizers from paths (called before load_target_model, so self.qwen3_tokenizer isn't set yet)
|
||||
tokenize_strategy = strategy_anima.AnimaTokenizeStrategy(
|
||||
qwen3_path=args.qwen3,
|
||||
t5_tokenizer_path=args.t5_tokenizer_path,
|
||||
qwen3_max_length=args.qwen3_max_token_length,
|
||||
t5_max_length=args.t5_max_token_length,
|
||||
)
|
||||
return tokenize_strategy
|
||||
|
||||
def get_tokenizers(self, tokenize_strategy: strategy_anima.AnimaTokenizeStrategy):
|
||||
return [tokenize_strategy.qwen3_tokenizer]
|
||||
|
||||
def get_latents_caching_strategy(self, args):
|
||||
return strategy_anima.AnimaLatentsCachingStrategy(args.cache_latents_to_disk, args.vae_batch_size, args.skip_cache_check)
|
||||
|
||||
def get_text_encoding_strategy(self, args):
|
||||
return strategy_anima.AnimaTextEncodingStrategy()
|
||||
|
||||
def post_process_network(self, args, accelerator, network, text_encoders, unet):
|
||||
pass
|
||||
|
||||
def get_models_for_text_encoding(self, args, accelerator, text_encoders):
|
||||
if args.cache_text_encoder_outputs:
|
||||
return None # no text encoders needed for encoding
|
||||
return text_encoders
|
||||
|
||||
def get_text_encoder_outputs_caching_strategy(self, args):
|
||||
if args.cache_text_encoder_outputs:
|
||||
return strategy_anima.AnimaTextEncoderOutputsCachingStrategy(
|
||||
args.cache_text_encoder_outputs_to_disk, args.text_encoder_batch_size, args.skip_cache_check, False
|
||||
)
|
||||
return None
|
||||
|
||||
def cache_text_encoder_outputs_if_needed(
|
||||
self, args, accelerator: Accelerator, unet, vae, text_encoders, dataset: train_util.DatasetGroup, weight_dtype
|
||||
):
|
||||
if args.cache_text_encoder_outputs:
|
||||
if not args.lowram:
|
||||
# We cannot move DiT to CPU because of block swap, so only move VAE
|
||||
logger.info("move vae to cpu to save memory")
|
||||
org_vae_device = vae.device
|
||||
vae.to("cpu")
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
logger.info("move text encoder to gpu")
|
||||
text_encoders[0].to(accelerator.device)
|
||||
|
||||
with accelerator.autocast():
|
||||
dataset.new_cache_text_encoder_outputs(text_encoders, accelerator)
|
||||
|
||||
# cache sample prompts
|
||||
if args.sample_prompts is not None:
|
||||
logger.info(f"cache Text Encoder outputs for sample prompts: {args.sample_prompts}")
|
||||
|
||||
tokenize_strategy = strategy_base.TokenizeStrategy.get_strategy()
|
||||
text_encoding_strategy = strategy_base.TextEncodingStrategy.get_strategy()
|
||||
|
||||
prompts = train_util.load_prompts(args.sample_prompts)
|
||||
sample_prompts_te_outputs = {}
|
||||
with accelerator.autocast(), torch.no_grad():
|
||||
for prompt_dict in prompts:
|
||||
for p in [prompt_dict.get("prompt", ""), prompt_dict.get("negative_prompt", "")]:
|
||||
if p not in sample_prompts_te_outputs:
|
||||
logger.info(f" cache TE outputs for: {p}")
|
||||
tokens_and_masks = tokenize_strategy.tokenize(p)
|
||||
sample_prompts_te_outputs[p] = text_encoding_strategy.encode_tokens(
|
||||
tokenize_strategy, text_encoders, tokens_and_masks
|
||||
)
|
||||
self.sample_prompts_te_outputs = sample_prompts_te_outputs
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
# move text encoder back to cpu
|
||||
logger.info("move text encoder back to cpu")
|
||||
text_encoders[0].to("cpu")
|
||||
|
||||
if not args.lowram:
|
||||
logger.info("move vae back to original device")
|
||||
vae.to(org_vae_device)
|
||||
|
||||
clean_memory_on_device(accelerator.device)
|
||||
else:
|
||||
# move text encoder to device for encoding during training/validation
|
||||
text_encoders[0].to(accelerator.device)
|
||||
|
||||
def sample_images(self, accelerator, args, epoch, global_step, device, vae, tokenizer, text_encoder, unet):
|
||||
text_encoders = text_encoder if isinstance(text_encoder, list) else [text_encoder] # compatibility
|
||||
te = self.get_models_for_text_encoding(args, accelerator, text_encoders)
|
||||
qwen3_te = te[0] if te is not None else None
|
||||
|
||||
text_encoding_strategy = strategy_base.TextEncodingStrategy.get_strategy()
|
||||
tokenize_strategy = strategy_base.TokenizeStrategy.get_strategy()
|
||||
anima_train_utils.sample_images(
|
||||
accelerator,
|
||||
args,
|
||||
epoch,
|
||||
global_step,
|
||||
unet,
|
||||
vae,
|
||||
qwen3_te,
|
||||
tokenize_strategy,
|
||||
text_encoding_strategy,
|
||||
self.sample_prompts_te_outputs,
|
||||
)
|
||||
|
||||
def get_noise_scheduler(self, args: argparse.Namespace, device: torch.device) -> Any:
|
||||
noise_scheduler = sd3_train_utils.FlowMatchEulerDiscreteScheduler(num_train_timesteps=1000, shift=args.discrete_flow_shift)
|
||||
return noise_scheduler
|
||||
|
||||
def encode_images_to_latents(self, args, vae, images):
|
||||
vae: qwen_image_autoencoder_kl.AutoencoderKLQwenImage
|
||||
return vae.encode_pixels_to_latents(images) # Keep 4D for input/output
|
||||
|
||||
def shift_scale_latents(self, args, latents):
|
||||
# Latents already normalized by vae.encode with scale
|
||||
return latents
|
||||
|
||||
def get_noise_pred_and_target(
|
||||
self,
|
||||
args,
|
||||
accelerator,
|
||||
noise_scheduler,
|
||||
latents,
|
||||
batch,
|
||||
text_encoder_conds,
|
||||
unet,
|
||||
network,
|
||||
weight_dtype,
|
||||
train_unet,
|
||||
is_train=True,
|
||||
):
|
||||
anima: anima_models.Anima = unet
|
||||
|
||||
# Sample noise
|
||||
if latents.ndim == 5: # Fallback for 5D latents (old cache)
|
||||
latents = latents.squeeze(2) # [B, C, 1, H, W] -> [B, C, H, W]
|
||||
noise = torch.randn_like(latents)
|
||||
|
||||
# Get noisy model input and timesteps
|
||||
noisy_model_input, timesteps, sigmas = flux_train_utils.get_noisy_model_input_and_timesteps(
|
||||
args, noise_scheduler, latents, noise, accelerator.device, weight_dtype
|
||||
)
|
||||
timesteps = timesteps / 1000.0 # scale to [0, 1] range. timesteps is float32
|
||||
|
||||
# Gradient checkpointing support
|
||||
if args.gradient_checkpointing:
|
||||
noisy_model_input.requires_grad_(True)
|
||||
for t in text_encoder_conds:
|
||||
if t is not None and t.dtype.is_floating_point:
|
||||
t.requires_grad_(True)
|
||||
|
||||
# Unpack text encoder conditions
|
||||
prompt_embeds, attn_mask, t5_input_ids, t5_attn_mask = text_encoder_conds[
|
||||
:4
|
||||
] # ignore caption_dropout_rate which is not needed for training step
|
||||
|
||||
# Move to device
|
||||
prompt_embeds = prompt_embeds.to(accelerator.device, dtype=weight_dtype)
|
||||
attn_mask = attn_mask.to(accelerator.device)
|
||||
t5_input_ids = t5_input_ids.to(accelerator.device, dtype=torch.long)
|
||||
t5_attn_mask = t5_attn_mask.to(accelerator.device)
|
||||
|
||||
# Create padding mask
|
||||
bs = latents.shape[0]
|
||||
h_latent = latents.shape[-2]
|
||||
w_latent = latents.shape[-1]
|
||||
padding_mask = torch.zeros(bs, 1, h_latent, w_latent, dtype=weight_dtype, device=accelerator.device)
|
||||
|
||||
# Call model
|
||||
noisy_model_input = noisy_model_input.unsqueeze(2) # 4D to 5D, [B, C, H, W] -> [B, C, 1, H, W]
|
||||
with torch.set_grad_enabled(is_train), accelerator.autocast():
|
||||
model_pred = anima(
|
||||
noisy_model_input,
|
||||
timesteps,
|
||||
prompt_embeds,
|
||||
padding_mask=padding_mask,
|
||||
target_input_ids=t5_input_ids,
|
||||
target_attention_mask=t5_attn_mask,
|
||||
source_attention_mask=attn_mask,
|
||||
)
|
||||
model_pred = model_pred.squeeze(2) # 5D to 4D, [B, C, 1, H, W] -> [B, C, H, W]
|
||||
|
||||
# Rectified flow target: noise - latents
|
||||
target = noise - latents
|
||||
|
||||
# Loss weighting
|
||||
weighting = anima_train_utils.compute_loss_weighting_for_anima(weighting_scheme=args.weighting_scheme, sigmas=sigmas)
|
||||
|
||||
return model_pred, target, timesteps, weighting
|
||||
|
||||
def process_batch(
|
||||
self,
|
||||
batch,
|
||||
text_encoders,
|
||||
unet,
|
||||
network,
|
||||
vae,
|
||||
noise_scheduler,
|
||||
vae_dtype,
|
||||
weight_dtype,
|
||||
accelerator,
|
||||
args,
|
||||
text_encoding_strategy,
|
||||
tokenize_strategy,
|
||||
is_train=True,
|
||||
train_text_encoder=True,
|
||||
train_unet=True,
|
||||
) -> torch.Tensor:
|
||||
"""Override base process_batch for caption dropout with cached text encoder outputs."""
|
||||
|
||||
# Text encoder conditions
|
||||
text_encoder_outputs_list = batch.get("text_encoder_outputs_list", None)
|
||||
anima_text_encoding_strategy: strategy_anima.AnimaTextEncodingStrategy = text_encoding_strategy
|
||||
if text_encoder_outputs_list is not None:
|
||||
caption_dropout_rates = text_encoder_outputs_list[-1]
|
||||
text_encoder_outputs_list = text_encoder_outputs_list[:-1]
|
||||
|
||||
# Apply caption dropout to cached outputs
|
||||
text_encoder_outputs_list = anima_text_encoding_strategy.drop_cached_text_encoder_outputs(
|
||||
*text_encoder_outputs_list, caption_dropout_rates=caption_dropout_rates
|
||||
)
|
||||
# Add the caption dropout rates back to the list for validation dataset (which is re-used batch items)
|
||||
batch["text_encoder_outputs_list"] = text_encoder_outputs_list + [caption_dropout_rates]
|
||||
|
||||
return super().process_batch(
|
||||
batch,
|
||||
text_encoders,
|
||||
unet,
|
||||
network,
|
||||
vae,
|
||||
noise_scheduler,
|
||||
vae_dtype,
|
||||
weight_dtype,
|
||||
accelerator,
|
||||
args,
|
||||
text_encoding_strategy,
|
||||
tokenize_strategy,
|
||||
is_train,
|
||||
train_text_encoder,
|
||||
train_unet,
|
||||
)
|
||||
|
||||
def post_process_loss(self, loss, args, timesteps, noise_scheduler):
|
||||
return loss
|
||||
|
||||
def get_sai_model_spec(self, args):
|
||||
return train_util.get_sai_model_spec_dataclass(None, args, False, True, False, anima="preview").to_metadata_dict()
|
||||
|
||||
def update_metadata(self, metadata, args):
|
||||
metadata["ss_weighting_scheme"] = args.weighting_scheme
|
||||
metadata["ss_logit_mean"] = args.logit_mean
|
||||
metadata["ss_logit_std"] = args.logit_std
|
||||
metadata["ss_mode_scale"] = args.mode_scale
|
||||
metadata["ss_timestep_sampling"] = args.timestep_sampling
|
||||
metadata["ss_sigmoid_scale"] = args.sigmoid_scale
|
||||
metadata["ss_discrete_flow_shift"] = args.discrete_flow_shift
|
||||
|
||||
def is_text_encoder_not_needed_for_training(self, args):
|
||||
return args.cache_text_encoder_outputs and not self.is_train_text_encoder(args)
|
||||
|
||||
def prepare_text_encoder_grad_ckpt_workaround(self, index, text_encoder):
|
||||
# Set first parameter's requires_grad to True to workaround Accelerate gradient checkpointing bug
|
||||
first_param = next(text_encoder.parameters())
|
||||
first_param.requires_grad_(True)
|
||||
|
||||
def prepare_unet_with_accelerator(
|
||||
self, args: argparse.Namespace, accelerator: Accelerator, unet: torch.nn.Module
|
||||
) -> torch.nn.Module:
|
||||
# The base NetworkTrainer only calls enable_gradient_checkpointing(cpu_offload=True/False),
|
||||
# so we re-apply with unsloth_offload if needed (after base has already enabled it).
|
||||
if self._use_unsloth_offload_checkpointing and args.gradient_checkpointing:
|
||||
unet.enable_gradient_checkpointing(unsloth_offload=True)
|
||||
|
||||
if not self.is_swapping_blocks:
|
||||
return super().prepare_unet_with_accelerator(args, accelerator, unet)
|
||||
|
||||
model = unet
|
||||
model = accelerator.prepare(model, device_placement=[not self.is_swapping_blocks])
|
||||
accelerator.unwrap_model(model).move_to_device_except_swap_blocks(accelerator.device)
|
||||
accelerator.unwrap_model(model).prepare_block_swap_before_forward()
|
||||
|
||||
return model
|
||||
|
||||
def on_validation_step_end(self, args, accelerator, network, text_encoders, unet, batch, weight_dtype):
|
||||
if self.is_swapping_blocks:
|
||||
# prepare for next forward: because backward pass is not called, we need to prepare it here
|
||||
accelerator.unwrap_model(unet).prepare_block_swap_before_forward()
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = train_network.setup_parser()
|
||||
train_util.add_dit_training_arguments(parser)
|
||||
anima_train_utils.add_anima_training_arguments(parser)
|
||||
# parser.add_argument("--fp8_scaled", action="store_true", help="Use scaled fp8 for DiT / DiTにスケーリングされたfp8を使う")
|
||||
parser.add_argument(
|
||||
"--unsloth_offload_checkpointing",
|
||||
action="store_true",
|
||||
help="offload activations to CPU RAM using async non-blocking transfers (faster than --cpu_offload_checkpointing). "
|
||||
"Cannot be used with --cpu_offload_checkpointing or --blocks_to_swap.",
|
||||
)
|
||||
return parser
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
train_util.verify_command_line_training_args(args)
|
||||
args = train_util.read_config_from_file(args, parser)
|
||||
|
||||
if args.attn_mode == "sdpa":
|
||||
args.attn_mode = "torch" # backward compatibility
|
||||
|
||||
trainer = AnimaNetworkTrainer()
|
||||
trainer.train(args)
|
||||
BIN
bitsandbytes_windows/libbitsandbytes_cuda118.dll
Normal file
BIN
bitsandbytes_windows/libbitsandbytes_cuda118.dll
Normal file
Binary file not shown.
@@ -1,166 +1,166 @@
|
||||
"""
|
||||
extract factors the build is dependent on:
|
||||
[X] compute capability
|
||||
[ ] TODO: Q - What if we have multiple GPUs of different makes?
|
||||
- CUDA version
|
||||
- Software:
|
||||
- CPU-only: only CPU quantization functions (no optimizer, no matrix multiple)
|
||||
- CuBLAS-LT: full-build 8-bit optimizer
|
||||
- no CuBLAS-LT: no 8-bit matrix multiplication (`nomatmul`)
|
||||
|
||||
evaluation:
|
||||
- if paths faulty, return meaningful error
|
||||
- else:
|
||||
- determine CUDA version
|
||||
- determine capabilities
|
||||
- based on that set the default path
|
||||
"""
|
||||
|
||||
import ctypes
|
||||
|
||||
from .paths import determine_cuda_runtime_lib_path
|
||||
|
||||
|
||||
def check_cuda_result(cuda, result_val):
|
||||
# 3. Check for CUDA errors
|
||||
if result_val != 0:
|
||||
error_str = ctypes.c_char_p()
|
||||
cuda.cuGetErrorString(result_val, ctypes.byref(error_str))
|
||||
print(f"CUDA exception! Error code: {error_str.value.decode()}")
|
||||
|
||||
def get_cuda_version(cuda, cudart_path):
|
||||
# https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART____VERSION.html#group__CUDART____VERSION
|
||||
try:
|
||||
cudart = ctypes.CDLL(cudart_path)
|
||||
except OSError:
|
||||
# TODO: shouldn't we error or at least warn here?
|
||||
print(f'ERROR: libcudart.so could not be read from path: {cudart_path}!')
|
||||
return None
|
||||
|
||||
version = ctypes.c_int()
|
||||
check_cuda_result(cuda, cudart.cudaRuntimeGetVersion(ctypes.byref(version)))
|
||||
version = int(version.value)
|
||||
major = version//1000
|
||||
minor = (version-(major*1000))//10
|
||||
|
||||
if major < 11:
|
||||
print('CUDA SETUP: CUDA version lower than 11 are currently not supported for LLM.int8(). You will be only to use 8-bit optimizers and quantization routines!!')
|
||||
|
||||
return f'{major}{minor}'
|
||||
|
||||
|
||||
def get_cuda_lib_handle():
|
||||
# 1. find libcuda.so library (GPU driver) (/usr/lib)
|
||||
try:
|
||||
cuda = ctypes.CDLL("libcuda.so")
|
||||
except OSError:
|
||||
# TODO: shouldn't we error or at least warn here?
|
||||
print('CUDA SETUP: WARNING! libcuda.so not found! Do you have a CUDA driver installed? If you are on a cluster, make sure you are on a CUDA machine!')
|
||||
return None
|
||||
check_cuda_result(cuda, cuda.cuInit(0))
|
||||
|
||||
return cuda
|
||||
|
||||
|
||||
def get_compute_capabilities(cuda):
|
||||
"""
|
||||
1. find libcuda.so library (GPU driver) (/usr/lib)
|
||||
init_device -> init variables -> call function by reference
|
||||
2. call extern C function to determine CC
|
||||
(https://docs.nvidia.com/cuda/cuda-driver-api/group__CUDA__DEVICE__DEPRECATED.html)
|
||||
3. Check for CUDA errors
|
||||
https://stackoverflow.com/questions/14038589/what-is-the-canonical-way-to-check-for-errors-using-the-cuda-runtime-api
|
||||
# bits taken from https://gist.github.com/f0k/63a664160d016a491b2cbea15913d549
|
||||
"""
|
||||
|
||||
|
||||
nGpus = ctypes.c_int()
|
||||
cc_major = ctypes.c_int()
|
||||
cc_minor = ctypes.c_int()
|
||||
|
||||
device = ctypes.c_int()
|
||||
|
||||
check_cuda_result(cuda, cuda.cuDeviceGetCount(ctypes.byref(nGpus)))
|
||||
ccs = []
|
||||
for i in range(nGpus.value):
|
||||
check_cuda_result(cuda, cuda.cuDeviceGet(ctypes.byref(device), i))
|
||||
ref_major = ctypes.byref(cc_major)
|
||||
ref_minor = ctypes.byref(cc_minor)
|
||||
# 2. call extern C function to determine CC
|
||||
check_cuda_result(
|
||||
cuda, cuda.cuDeviceComputeCapability(ref_major, ref_minor, device)
|
||||
)
|
||||
ccs.append(f"{cc_major.value}.{cc_minor.value}")
|
||||
|
||||
return ccs
|
||||
|
||||
|
||||
# def get_compute_capability()-> Union[List[str, ...], None]: # FIXME: error
|
||||
def get_compute_capability(cuda):
|
||||
"""
|
||||
Extracts the highest compute capbility from all available GPUs, as compute
|
||||
capabilities are downwards compatible. If no GPUs are detected, it returns
|
||||
None.
|
||||
"""
|
||||
ccs = get_compute_capabilities(cuda)
|
||||
if ccs is not None:
|
||||
# TODO: handle different compute capabilities; for now, take the max
|
||||
return ccs[-1]
|
||||
return None
|
||||
|
||||
|
||||
def evaluate_cuda_setup():
|
||||
print('')
|
||||
print('='*35 + 'BUG REPORT' + '='*35)
|
||||
print('Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issues')
|
||||
print('For effortless bug reporting copy-paste your error into this form: https://docs.google.com/forms/d/e/1FAIpQLScPB8emS3Thkp66nvqwmjTEgxp8Y9ufuWTzFyr9kJ5AoI47dQ/viewform?usp=sf_link')
|
||||
print('='*80)
|
||||
return "libbitsandbytes_cuda116.dll" # $$$
|
||||
|
||||
binary_name = "libbitsandbytes_cpu.so"
|
||||
#if not torch.cuda.is_available():
|
||||
#print('No GPU detected. Loading CPU library...')
|
||||
#return binary_name
|
||||
|
||||
cudart_path = determine_cuda_runtime_lib_path()
|
||||
if cudart_path is None:
|
||||
print(
|
||||
"WARNING: No libcudart.so found! Install CUDA or the cudatoolkit package (anaconda)!"
|
||||
)
|
||||
return binary_name
|
||||
|
||||
print(f"CUDA SETUP: CUDA runtime path found: {cudart_path}")
|
||||
cuda = get_cuda_lib_handle()
|
||||
cc = get_compute_capability(cuda)
|
||||
print(f"CUDA SETUP: Highest compute capability among GPUs detected: {cc}")
|
||||
cuda_version_string = get_cuda_version(cuda, cudart_path)
|
||||
|
||||
|
||||
if cc == '':
|
||||
print(
|
||||
"WARNING: No GPU detected! Check your CUDA paths. Processing to load CPU-only library..."
|
||||
)
|
||||
return binary_name
|
||||
|
||||
# 7.5 is the minimum CC vor cublaslt
|
||||
has_cublaslt = cc in ["7.5", "8.0", "8.6"]
|
||||
|
||||
# TODO:
|
||||
# (1) CUDA missing cases (no CUDA installed by CUDA driver (nvidia-smi accessible)
|
||||
# (2) Multiple CUDA versions installed
|
||||
|
||||
# we use ls -l instead of nvcc to determine the cuda version
|
||||
# since most installations will have the libcudart.so installed, but not the compiler
|
||||
print(f'CUDA SETUP: Detected CUDA version {cuda_version_string}')
|
||||
|
||||
def get_binary_name():
|
||||
"if not has_cublaslt (CC < 7.5), then we have to choose _nocublaslt.so"
|
||||
bin_base_name = "libbitsandbytes_cuda"
|
||||
if has_cublaslt:
|
||||
return f"{bin_base_name}{cuda_version_string}.so"
|
||||
else:
|
||||
return f"{bin_base_name}{cuda_version_string}_nocublaslt.so"
|
||||
|
||||
binary_name = get_binary_name()
|
||||
|
||||
return binary_name
|
||||
"""
|
||||
extract factors the build is dependent on:
|
||||
[X] compute capability
|
||||
[ ] TODO: Q - What if we have multiple GPUs of different makes?
|
||||
- CUDA version
|
||||
- Software:
|
||||
- CPU-only: only CPU quantization functions (no optimizer, no matrix multiple)
|
||||
- CuBLAS-LT: full-build 8-bit optimizer
|
||||
- no CuBLAS-LT: no 8-bit matrix multiplication (`nomatmul`)
|
||||
|
||||
evaluation:
|
||||
- if paths faulty, return meaningful error
|
||||
- else:
|
||||
- determine CUDA version
|
||||
- determine capabilities
|
||||
- based on that set the default path
|
||||
"""
|
||||
|
||||
import ctypes
|
||||
|
||||
from .paths import determine_cuda_runtime_lib_path
|
||||
|
||||
|
||||
def check_cuda_result(cuda, result_val):
|
||||
# 3. Check for CUDA errors
|
||||
if result_val != 0:
|
||||
error_str = ctypes.c_char_p()
|
||||
cuda.cuGetErrorString(result_val, ctypes.byref(error_str))
|
||||
print(f"CUDA exception! Error code: {error_str.value.decode()}")
|
||||
|
||||
def get_cuda_version(cuda, cudart_path):
|
||||
# https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART____VERSION.html#group__CUDART____VERSION
|
||||
try:
|
||||
cudart = ctypes.CDLL(cudart_path)
|
||||
except OSError:
|
||||
# TODO: shouldn't we error or at least warn here?
|
||||
print(f'ERROR: libcudart.so could not be read from path: {cudart_path}!')
|
||||
return None
|
||||
|
||||
version = ctypes.c_int()
|
||||
check_cuda_result(cuda, cudart.cudaRuntimeGetVersion(ctypes.byref(version)))
|
||||
version = int(version.value)
|
||||
major = version//1000
|
||||
minor = (version-(major*1000))//10
|
||||
|
||||
if major < 11:
|
||||
print('CUDA SETUP: CUDA version lower than 11 are currently not supported for LLM.int8(). You will be only to use 8-bit optimizers and quantization routines!!')
|
||||
|
||||
return f'{major}{minor}'
|
||||
|
||||
|
||||
def get_cuda_lib_handle():
|
||||
# 1. find libcuda.so library (GPU driver) (/usr/lib)
|
||||
try:
|
||||
cuda = ctypes.CDLL("libcuda.so")
|
||||
except OSError:
|
||||
# TODO: shouldn't we error or at least warn here?
|
||||
print('CUDA SETUP: WARNING! libcuda.so not found! Do you have a CUDA driver installed? If you are on a cluster, make sure you are on a CUDA machine!')
|
||||
return None
|
||||
check_cuda_result(cuda, cuda.cuInit(0))
|
||||
|
||||
return cuda
|
||||
|
||||
|
||||
def get_compute_capabilities(cuda):
|
||||
"""
|
||||
1. find libcuda.so library (GPU driver) (/usr/lib)
|
||||
init_device -> init variables -> call function by reference
|
||||
2. call extern C function to determine CC
|
||||
(https://docs.nvidia.com/cuda/cuda-driver-api/group__CUDA__DEVICE__DEPRECATED.html)
|
||||
3. Check for CUDA errors
|
||||
https://stackoverflow.com/questions/14038589/what-is-the-canonical-way-to-check-for-errors-using-the-cuda-runtime-api
|
||||
# bits taken from https://gist.github.com/f0k/63a664160d016a491b2cbea15913d549
|
||||
"""
|
||||
|
||||
|
||||
nGpus = ctypes.c_int()
|
||||
cc_major = ctypes.c_int()
|
||||
cc_minor = ctypes.c_int()
|
||||
|
||||
device = ctypes.c_int()
|
||||
|
||||
check_cuda_result(cuda, cuda.cuDeviceGetCount(ctypes.byref(nGpus)))
|
||||
ccs = []
|
||||
for i in range(nGpus.value):
|
||||
check_cuda_result(cuda, cuda.cuDeviceGet(ctypes.byref(device), i))
|
||||
ref_major = ctypes.byref(cc_major)
|
||||
ref_minor = ctypes.byref(cc_minor)
|
||||
# 2. call extern C function to determine CC
|
||||
check_cuda_result(
|
||||
cuda, cuda.cuDeviceComputeCapability(ref_major, ref_minor, device)
|
||||
)
|
||||
ccs.append(f"{cc_major.value}.{cc_minor.value}")
|
||||
|
||||
return ccs
|
||||
|
||||
|
||||
# def get_compute_capability()-> Union[List[str, ...], None]: # FIXME: error
|
||||
def get_compute_capability(cuda):
|
||||
"""
|
||||
Extracts the highest compute capbility from all available GPUs, as compute
|
||||
capabilities are downwards compatible. If no GPUs are detected, it returns
|
||||
None.
|
||||
"""
|
||||
ccs = get_compute_capabilities(cuda)
|
||||
if ccs is not None:
|
||||
# TODO: handle different compute capabilities; for now, take the max
|
||||
return ccs[-1]
|
||||
return None
|
||||
|
||||
|
||||
def evaluate_cuda_setup():
|
||||
print('')
|
||||
print('='*35 + 'BUG REPORT' + '='*35)
|
||||
print('Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issues')
|
||||
print('For effortless bug reporting copy-paste your error into this form: https://docs.google.com/forms/d/e/1FAIpQLScPB8emS3Thkp66nvqwmjTEgxp8Y9ufuWTzFyr9kJ5AoI47dQ/viewform?usp=sf_link')
|
||||
print('='*80)
|
||||
return "libbitsandbytes_cuda116.dll" # $$$
|
||||
|
||||
binary_name = "libbitsandbytes_cpu.so"
|
||||
#if not torch.cuda.is_available():
|
||||
#print('No GPU detected. Loading CPU library...')
|
||||
#return binary_name
|
||||
|
||||
cudart_path = determine_cuda_runtime_lib_path()
|
||||
if cudart_path is None:
|
||||
print(
|
||||
"WARNING: No libcudart.so found! Install CUDA or the cudatoolkit package (anaconda)!"
|
||||
)
|
||||
return binary_name
|
||||
|
||||
print(f"CUDA SETUP: CUDA runtime path found: {cudart_path}")
|
||||
cuda = get_cuda_lib_handle()
|
||||
cc = get_compute_capability(cuda)
|
||||
print(f"CUDA SETUP: Highest compute capability among GPUs detected: {cc}")
|
||||
cuda_version_string = get_cuda_version(cuda, cudart_path)
|
||||
|
||||
|
||||
if cc == '':
|
||||
print(
|
||||
"WARNING: No GPU detected! Check your CUDA paths. Processing to load CPU-only library..."
|
||||
)
|
||||
return binary_name
|
||||
|
||||
# 7.5 is the minimum CC vor cublaslt
|
||||
has_cublaslt = cc in ["7.5", "8.0", "8.6"]
|
||||
|
||||
# TODO:
|
||||
# (1) CUDA missing cases (no CUDA installed by CUDA driver (nvidia-smi accessible)
|
||||
# (2) Multiple CUDA versions installed
|
||||
|
||||
# we use ls -l instead of nvcc to determine the cuda version
|
||||
# since most installations will have the libcudart.so installed, but not the compiler
|
||||
print(f'CUDA SETUP: Detected CUDA version {cuda_version_string}')
|
||||
|
||||
def get_binary_name():
|
||||
"if not has_cublaslt (CC < 7.5), then we have to choose _nocublaslt.so"
|
||||
bin_base_name = "libbitsandbytes_cuda"
|
||||
if has_cublaslt:
|
||||
return f"{bin_base_name}{cuda_version_string}.so"
|
||||
else:
|
||||
return f"{bin_base_name}{cuda_version_string}_nocublaslt.so"
|
||||
|
||||
binary_name = get_binary_name()
|
||||
|
||||
return binary_name
|
||||
|
||||
30
configs/qwen3_06b/config.json
Normal file
30
configs/qwen3_06b/config.json
Normal file
@@ -0,0 +1,30 @@
|
||||
{
|
||||
"architectures": [
|
||||
"Qwen3ForCausalLM"
|
||||
],
|
||||
"attention_bias": false,
|
||||
"attention_dropout": 0.0,
|
||||
"bos_token_id": 151643,
|
||||
"eos_token_id": 151643,
|
||||
"head_dim": 128,
|
||||
"hidden_act": "silu",
|
||||
"hidden_size": 1024,
|
||||
"initializer_range": 0.02,
|
||||
"intermediate_size": 3072,
|
||||
"max_position_embeddings": 32768,
|
||||
"max_window_layers": 28,
|
||||
"model_type": "qwen3",
|
||||
"num_attention_heads": 16,
|
||||
"num_hidden_layers": 28,
|
||||
"num_key_value_heads": 8,
|
||||
"rms_norm_eps": 1e-06,
|
||||
"rope_scaling": null,
|
||||
"rope_theta": 1000000,
|
||||
"sliding_window": null,
|
||||
"tie_word_embeddings": true,
|
||||
"torch_dtype": "bfloat16",
|
||||
"transformers_version": "4.51.0",
|
||||
"use_cache": true,
|
||||
"use_sliding_window": false,
|
||||
"vocab_size": 151936
|
||||
}
|
||||
151388
configs/qwen3_06b/merges.txt
Normal file
151388
configs/qwen3_06b/merges.txt
Normal file
File diff suppressed because it is too large
Load Diff
303282
configs/qwen3_06b/tokenizer.json
Normal file
303282
configs/qwen3_06b/tokenizer.json
Normal file
File diff suppressed because it is too large
Load Diff
239
configs/qwen3_06b/tokenizer_config.json
Normal file
239
configs/qwen3_06b/tokenizer_config.json
Normal file
@@ -0,0 +1,239 @@
|
||||
{
|
||||
"add_bos_token": false,
|
||||
"add_prefix_space": false,
|
||||
"added_tokens_decoder": {
|
||||
"151643": {
|
||||
"content": "<|endoftext|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"151644": {
|
||||
"content": "<|im_start|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"151645": {
|
||||
"content": "<|im_end|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"151646": {
|
||||
"content": "<|object_ref_start|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"151647": {
|
||||
"content": "<|object_ref_end|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"151648": {
|
||||
"content": "<|box_start|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"151649": {
|
||||
"content": "<|box_end|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"151650": {
|
||||
"content": "<|quad_start|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"151651": {
|
||||
"content": "<|quad_end|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"151652": {
|
||||
"content": "<|vision_start|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"151653": {
|
||||
"content": "<|vision_end|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"151654": {
|
||||
"content": "<|vision_pad|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"151655": {
|
||||
"content": "<|image_pad|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"151656": {
|
||||
"content": "<|video_pad|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": true
|
||||
},
|
||||
"151657": {
|
||||
"content": "<tool_call>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"151658": {
|
||||
"content": "</tool_call>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"151659": {
|
||||
"content": "<|fim_prefix|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"151660": {
|
||||
"content": "<|fim_middle|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"151661": {
|
||||
"content": "<|fim_suffix|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"151662": {
|
||||
"content": "<|fim_pad|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"151663": {
|
||||
"content": "<|repo_name|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"151664": {
|
||||
"content": "<|file_sep|>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"151665": {
|
||||
"content": "<tool_response>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"151666": {
|
||||
"content": "</tool_response>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"151667": {
|
||||
"content": "<think>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
},
|
||||
"151668": {
|
||||
"content": "</think>",
|
||||
"lstrip": false,
|
||||
"normalized": false,
|
||||
"rstrip": false,
|
||||
"single_word": false,
|
||||
"special": false
|
||||
}
|
||||
},
|
||||
"additional_special_tokens": [
|
||||
"<|im_start|>",
|
||||
"<|im_end|>",
|
||||
"<|object_ref_start|>",
|
||||
"<|object_ref_end|>",
|
||||
"<|box_start|>",
|
||||
"<|box_end|>",
|
||||
"<|quad_start|>",
|
||||
"<|quad_end|>",
|
||||
"<|vision_start|>",
|
||||
"<|vision_end|>",
|
||||
"<|vision_pad|>",
|
||||
"<|image_pad|>",
|
||||
"<|video_pad|>"
|
||||
],
|
||||
"bos_token": null,
|
||||
"chat_template": "{%- if tools %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0].role == 'system' %}\n {{- messages[0].content + '\\n\\n' }}\n {%- endif %}\n {{- \"# Tools\\n\\nYou may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within <tools></tools> XML tags:\\n<tools>\" }}\n {%- for tool in tools %}\n {{- \"\\n\" }}\n {{- tool | tojson }}\n {%- endfor %}\n {{- \"\\n</tools>\\n\\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\\n<tool_call>\\n{\\\"name\\\": <function-name>, \\\"arguments\\\": <args-json-object>}\\n</tool_call><|im_end|>\\n\" }}\n{%- else %}\n {%- if messages[0].role == 'system' %}\n {{- '<|im_start|>system\\n' + messages[0].content + '<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- set ns = namespace(multi_step_tool=true, last_query_index=messages|length - 1) %}\n{%- for message in messages[::-1] %}\n {%- set index = (messages|length - 1) - loop.index0 %}\n {%- if ns.multi_step_tool and message.role == \"user\" and not(message.content.startswith('<tool_response>') and message.content.endswith('</tool_response>')) %}\n {%- set ns.multi_step_tool = false %}\n {%- set ns.last_query_index = index %}\n {%- endif %}\n{%- endfor %}\n{%- for message in messages %}\n {%- if (message.role == \"user\") or (message.role == \"system\" and not loop.first) %}\n {{- '<|im_start|>' + message.role + '\\n' + message.content + '<|im_end|>' + '\\n' }}\n {%- elif message.role == \"assistant\" %}\n {%- set content = message.content %}\n {%- set reasoning_content = '' %}\n {%- if message.reasoning_content is defined and message.reasoning_content is not none %}\n {%- set reasoning_content = message.reasoning_content %}\n {%- else %}\n {%- if '</think>' in message.content %}\n {%- set content = message.content.split('</think>')[-1].lstrip('\\n') %}\n {%- set reasoning_content = message.content.split('</think>')[0].rstrip('\\n').split('<think>')[-1].lstrip('\\n') %}\n {%- endif %}\n {%- endif %}\n {%- if loop.index0 > ns.last_query_index %}\n {%- if loop.last or (not loop.last and reasoning_content) %}\n {{- '<|im_start|>' + message.role + '\\n<think>\\n' + reasoning_content.strip('\\n') + '\\n</think>\\n\\n' + content.lstrip('\\n') }}\n {%- else %}\n {{- '<|im_start|>' + message.role + '\\n' + content }}\n {%- endif %}\n {%- else %}\n {{- '<|im_start|>' + message.role + '\\n' + content }}\n {%- endif %}\n {%- if message.tool_calls %}\n {%- for tool_call in message.tool_calls %}\n {%- if (loop.first and content) or (not loop.first) %}\n {{- '\\n' }}\n {%- endif %}\n {%- if tool_call.function %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '<tool_call>\\n{\"name\": \"' }}\n {{- tool_call.name }}\n {{- '\", \"arguments\": ' }}\n {%- if tool_call.arguments is string %}\n {{- tool_call.arguments }}\n {%- else %}\n {{- tool_call.arguments | tojson }}\n {%- endif %}\n {{- '}\\n</tool_call>' }}\n {%- endfor %}\n {%- endif %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"tool\" %}\n {%- if loop.first or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|im_start|>user' }}\n {%- endif %}\n {{- '\\n<tool_response>\\n' }}\n {{- message.content }}\n {{- '\\n</tool_response>' }}\n {%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n' }}\n {%- if enable_thinking is defined and enable_thinking is false %}\n {{- '<think>\\n\\n</think>\\n\\n' }}\n {%- endif %}\n{%- endif %}",
|
||||
"clean_up_tokenization_spaces": false,
|
||||
"eos_token": "<|endoftext|>",
|
||||
"errors": "replace",
|
||||
"model_max_length": 131072,
|
||||
"pad_token": "<|endoftext|>",
|
||||
"split_special_tokens": false,
|
||||
"tokenizer_class": "Qwen2Tokenizer",
|
||||
"unk_token": null
|
||||
}
|
||||
1
configs/qwen3_06b/vocab.json
Normal file
1
configs/qwen3_06b/vocab.json
Normal file
File diff suppressed because one or more lines are too long
51
configs/t5_old/config.json
Normal file
51
configs/t5_old/config.json
Normal file
@@ -0,0 +1,51 @@
|
||||
{
|
||||
"architectures": [
|
||||
"T5WithLMHeadModel"
|
||||
],
|
||||
"d_ff": 65536,
|
||||
"d_kv": 128,
|
||||
"d_model": 1024,
|
||||
"decoder_start_token_id": 0,
|
||||
"dropout_rate": 0.1,
|
||||
"eos_token_id": 1,
|
||||
"initializer_factor": 1.0,
|
||||
"is_encoder_decoder": true,
|
||||
"layer_norm_epsilon": 1e-06,
|
||||
"model_type": "t5",
|
||||
"n_positions": 512,
|
||||
"num_heads": 128,
|
||||
"num_layers": 24,
|
||||
"output_past": true,
|
||||
"pad_token_id": 0,
|
||||
"relative_attention_num_buckets": 32,
|
||||
"task_specific_params": {
|
||||
"summarization": {
|
||||
"early_stopping": true,
|
||||
"length_penalty": 2.0,
|
||||
"max_length": 200,
|
||||
"min_length": 30,
|
||||
"no_repeat_ngram_size": 3,
|
||||
"num_beams": 4,
|
||||
"prefix": "summarize: "
|
||||
},
|
||||
"translation_en_to_de": {
|
||||
"early_stopping": true,
|
||||
"max_length": 300,
|
||||
"num_beams": 4,
|
||||
"prefix": "translate English to German: "
|
||||
},
|
||||
"translation_en_to_fr": {
|
||||
"early_stopping": true,
|
||||
"max_length": 300,
|
||||
"num_beams": 4,
|
||||
"prefix": "translate English to French: "
|
||||
},
|
||||
"translation_en_to_ro": {
|
||||
"early_stopping": true,
|
||||
"max_length": 300,
|
||||
"num_beams": 4,
|
||||
"prefix": "translate English to Romanian: "
|
||||
}
|
||||
},
|
||||
"vocab_size": 32128
|
||||
}
|
||||
BIN
configs/t5_old/spiece.model
Normal file
BIN
configs/t5_old/spiece.model
Normal file
Binary file not shown.
1
configs/t5_old/tokenizer.json
Normal file
1
configs/t5_old/tokenizer.json
Normal file
File diff suppressed because one or more lines are too long
655
docs/anima_train_network.md
Normal file
655
docs/anima_train_network.md
Normal file
@@ -0,0 +1,655 @@
|
||||
# LoRA Training Guide for Anima using `anima_train_network.py` / `anima_train_network.py` を用いたAnima モデルのLoRA学習ガイド
|
||||
|
||||
This document explains how to train LoRA (Low-Rank Adaptation) models for Anima using `anima_train_network.py` in the `sd-scripts` repository.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
このドキュメントでは、`sd-scripts`リポジトリに含まれる`anima_train_network.py`を使用して、Anima モデルに対するLoRA (Low-Rank Adaptation) モデルを学習する基本的な手順について解説します。
|
||||
|
||||
</details>
|
||||
|
||||
## 1. Introduction / はじめに
|
||||
|
||||
`anima_train_network.py` trains additional networks such as LoRA for Anima models. Anima adopts a DiT (Diffusion Transformer) architecture based on the MiniTrainDIT design with Rectified Flow training. It uses a Qwen3-0.6B text encoder, an LLM Adapter (6-layer transformer bridge from Qwen3 to T5-compatible space), and a Qwen-Image VAE (16-channel, 8x spatial downscale).
|
||||
|
||||
Qwen-Image VAE and Qwen-Image VAE have same architecture, but [official Anima weight is named for Qwen-Image VAE](https://huggingface.co/circlestone-labs/Anima/tree/main/split_files/vae).
|
||||
|
||||
This guide assumes you already understand the basics of LoRA training. For common usage and options, see the [train_network.py guide](train_network.md). Some parameters are similar to those in [`sd3_train_network.py`](sd3_train_network.md) and [`flux_train_network.py`](flux_train_network.md).
|
||||
|
||||
**Prerequisites:**
|
||||
|
||||
* The `sd-scripts` repository has been cloned and the Python environment is ready.
|
||||
* A training dataset has been prepared. See the [Dataset Configuration Guide](./config_README-en.md).
|
||||
* Anima model files for training are available.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
`anima_train_network.py`は、Anima モデルに対してLoRAなどの追加ネットワークを学習させるためのスクリプトです。AnimaはMiniTrainDIT設計に基づくDiT (Diffusion Transformer) アーキテクチャを採用しており、Rectified Flow学習を使用します。テキストエンコーダーとしてQwen3-0.6B、LLM Adapter (Qwen3からT5互換空間への6層Transformerブリッジ)、およびQwen-Image VAE (16チャンネル、8倍空間ダウンスケール) を使用します。
|
||||
|
||||
Qwen-Image VAEとQwen-Image VAEは同じアーキテクチャですが、[Anima公式の重みはQwen-Image VAE用](https://huggingface.co/circlestone-labs/Anima/tree/main/split_files/vae)のようです。
|
||||
|
||||
このガイドは、基本的なLoRA学習の手順を理解しているユーザーを対象としています。基本的な使い方や共通のオプションについては、[`train_network.py`のガイド](train_network.md)を参照してください。また一部のパラメータは [`sd3_train_network.py`](sd3_train_network.md) や [`flux_train_network.py`](flux_train_network.md) と同様のものがあるため、そちらも参考にしてください。
|
||||
|
||||
**前提条件:**
|
||||
|
||||
* `sd-scripts`リポジトリのクローンとPython環境のセットアップが完了していること。
|
||||
* 学習用データセットの準備が完了していること。(データセットの準備については[データセット設定ガイド](./config_README-en.md)を参照してください)
|
||||
* 学習対象のAnimaモデルファイルが準備できていること。
|
||||
</details>
|
||||
|
||||
## 2. Differences from `train_network.py` / `train_network.py` との違い
|
||||
|
||||
`anima_train_network.py` is based on `train_network.py` but modified for Anima. Main differences are:
|
||||
|
||||
* **Target models:** Anima DiT models.
|
||||
* **Model structure:** Uses a MiniTrainDIT (Transformer based) instead of U-Net. Employs a single text encoder (Qwen3-0.6B), an LLM Adapter that bridges Qwen3 embeddings to T5-compatible cross-attention space, and a Qwen-Image VAE (16-channel latent space with 8x spatial downscale).
|
||||
* **Arguments:** Uses the common `--pretrained_model_name_or_path` for the DiT model path, `--qwen3` for the Qwen3 text encoder, and `--vae` for the Qwen-Image VAE. The LLM adapter and T5 tokenizer can be specified separately with `--llm_adapter_path` and `--t5_tokenizer_path`.
|
||||
* **Incompatible arguments:** Stable Diffusion v1/v2 options such as `--v2`, `--v_parameterization` and `--clip_skip` are not used. `--fp8_base` is not supported.
|
||||
* **Timestep sampling:** Uses the same `--timestep_sampling` options as FLUX training (`sigma`, `uniform`, `sigmoid`, `shift`, `flux_shift`).
|
||||
* **LoRA:** Uses regex-based module selection and per-module rank/learning rate control (`network_reg_dims`, `network_reg_lrs`) instead of per-component arguments. Module exclusion/inclusion is controlled by `exclude_patterns` and `include_patterns`.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
`anima_train_network.py`は`train_network.py`をベースに、Anima モデルに対応するための変更が加えられています。主な違いは以下の通りです。
|
||||
|
||||
* **対象モデル:** Anima DiTモデルを対象とします。
|
||||
* **モデル構造:** U-Netの代わりにMiniTrainDIT (Transformerベース) を使用します。テキストエンコーダーとしてQwen3-0.6B、Qwen3埋め込みをT5互換のクロスアテンション空間に変換するLLM Adapter、およびQwen-Image VAE (16チャンネル潜在空間、8倍空間ダウンスケール) を使用します。
|
||||
* **引数:** DiTモデルのパスには共通引数`--pretrained_model_name_or_path`を、Qwen3テキストエンコーダーには`--qwen3`を、Qwen-Image VAEには`--vae`を使用します。LLM AdapterとT5トークナイザーはそれぞれ`--llm_adapter_path`、`--t5_tokenizer_path`で個別に指定できます。
|
||||
* **一部引数の非互換性:** Stable Diffusion v1/v2向けの引数(例: `--v2`, `--v_parameterization`, `--clip_skip`)は使用されません。`--fp8_base`はサポートされていません。
|
||||
* **タイムステップサンプリング:** FLUX学習と同じ`--timestep_sampling`オプション(`sigma`、`uniform`、`sigmoid`、`shift`、`flux_shift`)を使用します。
|
||||
* **LoRA:** コンポーネント別の引数の代わりに、正規表現ベースのモジュール選択とモジュール単位のランク/学習率制御(`network_reg_dims`、`network_reg_lrs`)を使用します。モジュールの除外/包含は`exclude_patterns`と`include_patterns`で制御します。
|
||||
</details>
|
||||
|
||||
## 3. Preparation / 準備
|
||||
|
||||
The following files are required before starting training:
|
||||
|
||||
1. **Training script:** `anima_train_network.py`
|
||||
2. **Anima DiT model file:** `.safetensors` file for the base DiT model.
|
||||
3. **Qwen3-0.6B text encoder:** Either a HuggingFace model directory, or a single `.safetensors` file (uses the bundled config files in `configs/qwen3_06b/`).
|
||||
4. **Qwen-Image VAE model file:** `.safetensors` or `.pth` file for the VAE.
|
||||
5. **LLM Adapter model file (optional):** `.safetensors` file. If not provided separately, the adapter is loaded from the DiT file if the key `llm_adapter.out_proj.weight` exists.
|
||||
6. **T5 Tokenizer (optional):** If not specified, uses the bundled tokenizer at `configs/t5_old/`.
|
||||
7. **Dataset definition file (.toml):** Dataset settings in TOML format. (See the [Dataset Configuration Guide](./config_README-en.md).) In this document we use `my_anima_dataset_config.toml` as an example.
|
||||
|
||||
Model files can be obtained from the [Anima HuggingFace repository](https://huggingface.co/circlestone-labs/Anima).
|
||||
|
||||
**Notes:**
|
||||
* The T5 tokenizer only needs the tokenizer files (not the T5 model weights). It uses the vocabulary from `google/t5-v1_1-xxl`.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
学習を開始する前に、以下のファイルが必要です。
|
||||
|
||||
1. **学習スクリプト:** `anima_train_network.py`
|
||||
2. **Anima DiTモデルファイル:** ベースとなるDiTモデルの`.safetensors`ファイル。
|
||||
3. **Qwen3-0.6Bテキストエンコーダー:** HuggingFaceモデルディレクトリまたは単体の`.safetensors`ファイル(バンドル版の`configs/qwen3_06b/`の設定ファイルが使用されます)。
|
||||
4. **Qwen-Image VAEモデルファイル:** VAEの`.safetensors`または`.pth`ファイル。
|
||||
5. **LLM Adapterモデルファイル(オプション):** `.safetensors`ファイル。個別に指定しない場合、DiTファイル内に`llm_adapter.out_proj.weight`キーが存在すればそこから読み込まれます。
|
||||
6. **T5トークナイザー(オプション):** 指定しない場合、`configs/t5_old/`のバンドル版トークナイザーを使用します。
|
||||
7. **データセット定義ファイル (.toml):** 学習データセットの設定を記述したTOML形式のファイル。(詳細は[データセット設定ガイド](./config_README-en.md)を参照してください)。例として`my_anima_dataset_config.toml`を使用します。
|
||||
|
||||
モデルファイルは[HuggingFaceのAnimaリポジトリ](https://huggingface.co/circlestone-labs/Anima)から入手できます。
|
||||
|
||||
**注意:**
|
||||
* T5トークナイザーを別途指定する場合、トークナイザーファイルのみ必要です(T5モデルの重みは不要)。`google/t5-v1_1-xxl`の語彙を使用します。
|
||||
</details>
|
||||
|
||||
## 4. Running the Training / 学習の実行
|
||||
|
||||
Execute `anima_train_network.py` from the terminal to start training. The overall command-line format is the same as `train_network.py`, but Anima specific options must be supplied.
|
||||
|
||||
Example command:
|
||||
|
||||
```bash
|
||||
accelerate launch --num_cpu_threads_per_process 1 anima_train_network.py \
|
||||
--pretrained_model_name_or_path="<path to Anima DiT model>" \
|
||||
--qwen3="<path to Qwen3-0.6B model or directory>" \
|
||||
--vae="<path to Qwen-Image VAE model>" \
|
||||
--dataset_config="my_anima_dataset_config.toml" \
|
||||
--output_dir="<output directory>" \
|
||||
--output_name="my_anima_lora" \
|
||||
--save_model_as=safetensors \
|
||||
--network_module=networks.lora_anima \
|
||||
--network_dim=8 \
|
||||
--learning_rate=1e-4 \
|
||||
--optimizer_type="AdamW8bit" \
|
||||
--lr_scheduler="constant" \
|
||||
--timestep_sampling="sigmoid" \
|
||||
--discrete_flow_shift=1.0 \
|
||||
--max_train_epochs=10 \
|
||||
--save_every_n_epochs=1 \
|
||||
--mixed_precision="bf16" \
|
||||
--gradient_checkpointing \
|
||||
--cache_latents \
|
||||
--cache_text_encoder_outputs \
|
||||
--vae_chunk_size=64 \
|
||||
--vae_disable_cache
|
||||
```
|
||||
|
||||
*(Write the command on one line or use `\` or `^` for line breaks.)*
|
||||
|
||||
The learning rate of `1e-4` is just an example. Adjust it according to your dataset and objectives. This value is for `alpha=1.0` (default). If increasing `--network_alpha`, consider lowering the learning rate.
|
||||
|
||||
If loss becomes NaN, ensure you are using PyTorch version 2.5 or higher.
|
||||
|
||||
**Note:** `--vae_chunk_size` and `--vae_disable_cache` are custom options in this repository to reduce memory usage of the Qwen-Image VAE.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
学習は、ターミナルから`anima_train_network.py`を実行することで開始します。基本的なコマンドラインの構造は`train_network.py`と同様ですが、Anima特有の引数を指定する必要があります。
|
||||
|
||||
コマンドラインの例は英語のドキュメントを参照してください。
|
||||
|
||||
※実際には1行で書くか、適切な改行文字(`\` または `^`)を使用してください。
|
||||
|
||||
学習率1e-4はあくまで一例です。データセットや目的に応じて適切に調整してください。またこの値はalpha=1.0(デフォルト)での値です。`--network_alpha`を増やす場合は学習率を下げることを検討してください。
|
||||
|
||||
lossがNaNになる場合は、PyTorchのバージョンが2.5以上であることを確認してください。
|
||||
|
||||
注意: `--vae_chunk_size`および`--vae_disable_cache`は当リポジトリ独自のオプションで、Qwen-Image VAEのメモリ使用量を削減するために使用します。
|
||||
|
||||
</details>
|
||||
|
||||
### 4.1. Explanation of Key Options / 主要なコマンドライン引数の解説
|
||||
|
||||
Besides the arguments explained in the [train_network.py guide](train_network.md), specify the following Anima specific options. For shared options (`--output_dir`, `--output_name`, `--network_module`, etc.), see that guide.
|
||||
|
||||
#### Model Options [Required] / モデル関連 [必須]
|
||||
|
||||
* `--pretrained_model_name_or_path="<path to Anima DiT model>"` **[Required]**
|
||||
- Path to the Anima DiT model `.safetensors` file. The model config (channels, blocks, heads) is auto-detected from the state dict. ComfyUI format with `net.` prefix is supported.
|
||||
* `--qwen3="<path to Qwen3-0.6B model>"` **[Required]**
|
||||
- Path to the Qwen3-0.6B text encoder. Can be a HuggingFace model directory or a single `.safetensors` file. The text encoder is always frozen during training.
|
||||
* `--vae="<path to Qwen-Image VAE model>"` **[Required]**
|
||||
- Path to the Qwen-Image VAE model `.safetensors` or `.pth` file. Fixed config: `dim=96, z_dim=16`.
|
||||
|
||||
#### Model Options [Optional] / モデル関連 [オプション]
|
||||
|
||||
* `--llm_adapter_path="<path to LLM adapter>"` *[Optional]*
|
||||
- Path to a separate LLM adapter weights file. If omitted, the adapter is loaded from the DiT file when the key `llm_adapter.out_proj.weight` exists.
|
||||
* `--t5_tokenizer_path="<path to T5 tokenizer>"` *[Optional]*
|
||||
- Path to the T5 tokenizer directory. If omitted, uses the bundled config at `configs/t5_old/`.
|
||||
|
||||
#### Anima Training Parameters / Anima 学習パラメータ
|
||||
|
||||
* `--timestep_sampling=<choice>`
|
||||
- Timestep sampling method. Choose from `sigma`, `uniform`, `sigmoid` (default), `shift`, `flux_shift`. Same options as FLUX training. See the [flux_train_network.py guide](flux_train_network.md) for details on each method.
|
||||
* `--discrete_flow_shift=<float>`
|
||||
- Shift for the timestep distribution in Rectified Flow training. Default `1.0`. This value is used when `--timestep_sampling` is set to **`shift`**. The shift formula is `t_shifted = (t * shift) / (1 + (shift - 1) * t)`.
|
||||
* `--sigmoid_scale=<float>`
|
||||
- Scale factor when `--timestep_sampling` is set to `sigmoid`, `shift`, or `flux_shift`. Default `1.0`.
|
||||
* `--qwen3_max_token_length=<integer>`
|
||||
- Maximum token length for the Qwen3 tokenizer. Default `512`.
|
||||
* `--t5_max_token_length=<integer>`
|
||||
- Maximum token length for the T5 tokenizer. Default `512`.
|
||||
* `--attn_mode=<choice>`
|
||||
- Attention implementation to use. Choose from `torch` (default), `xformers`, `flash`, `sageattn`. `xformers` requires `--split_attn`. `sageattn` does not support training (inference only). This option overrides `--xformers`.
|
||||
* `--split_attn`
|
||||
- Split attention computation to reduce memory usage. Required when using `--attn_mode xformers`.
|
||||
|
||||
#### Component-wise Learning Rates / コンポーネント別学習率
|
||||
|
||||
These options set separate learning rates for each component of the Anima model. They are primarily used for full fine-tuning. Set to `0` to freeze a component:
|
||||
|
||||
* `--self_attn_lr=<float>` - Learning rate for self-attention layers. Default: same as `--learning_rate`.
|
||||
* `--cross_attn_lr=<float>` - Learning rate for cross-attention layers. Default: same as `--learning_rate`.
|
||||
* `--mlp_lr=<float>` - Learning rate for MLP layers. Default: same as `--learning_rate`.
|
||||
* `--mod_lr=<float>` - Learning rate for AdaLN modulation layers. Default: same as `--learning_rate`. Note: modulation layers are not included in LoRA by default.
|
||||
* `--llm_adapter_lr=<float>` - Learning rate for LLM adapter layers. Default: same as `--learning_rate`.
|
||||
|
||||
For LoRA training, use `network_reg_lrs` in `--network_args` instead. See [Section 5.2](#52-regex-based-rank-and-learning-rate-control--正規表現によるランク学習率の制御).
|
||||
|
||||
#### Memory and Speed / メモリ・速度関連
|
||||
|
||||
* `--blocks_to_swap=<integer>`
|
||||
- Number of Transformer blocks to swap between CPU and GPU. More blocks reduce VRAM but slow training. Maximum values depend on model size:
|
||||
- 28-block model: max **26** (Anima-Preview)
|
||||
- 36-block model: max **34**
|
||||
- 20-block model: max **18**
|
||||
- Cannot be used with `--cpu_offload_checkpointing` or `--unsloth_offload_checkpointing`.
|
||||
* `--unsloth_offload_checkpointing`
|
||||
- Offload activations to CPU RAM using async non-blocking transfers (faster than `--cpu_offload_checkpointing`). Cannot be combined with `--cpu_offload_checkpointing` or `--blocks_to_swap`.
|
||||
* `--cache_text_encoder_outputs`
|
||||
- Cache Qwen3 text encoder outputs to reduce VRAM usage. Recommended when not training text encoder LoRA.
|
||||
* `--cache_text_encoder_outputs_to_disk`
|
||||
- Cache text encoder outputs to disk. Auto-enables `--cache_text_encoder_outputs`.
|
||||
* `--cache_latents`, `--cache_latents_to_disk`
|
||||
- Cache Qwen-Image VAE latent outputs.
|
||||
* `--vae_chunk_size=<integer>`
|
||||
- Chunk size for Qwen-Image VAE processing. Reduces VRAM usage at the cost of speed. Default is no chunking.
|
||||
* `--vae_disable_cache`
|
||||
- Disable internal caching in Qwen-Image VAE to reduce VRAM usage.
|
||||
|
||||
#### Incompatible or Unsupported Options / 非互換・非サポートの引数
|
||||
|
||||
* `--v2`, `--v_parameterization`, `--clip_skip` - Options for Stable Diffusion v1/v2 that are not used for Anima training.
|
||||
* `--fp8_base` - Not supported for Anima. If specified, it will be disabled with a warning.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
[`train_network.py`のガイド](train_network.md)で説明されている引数に加え、以下のAnima特有の引数を指定します。共通の引数については、上記ガイドを参照してください。
|
||||
|
||||
#### モデル関連 [必須]
|
||||
|
||||
* `--pretrained_model_name_or_path="<path to Anima DiT model>"` **[必須]** - Anima DiTモデルの`.safetensors`ファイルのパスを指定します。モデルの設定はstate dictから自動検出されます。`net.`プレフィックス付きのComfyUIフォーマットもサポートしています。
|
||||
* `--qwen3="<path to Qwen3-0.6B model>"` **[必須]** - Qwen3-0.6Bテキストエンコーダーのパスを指定します。HuggingFaceモデルディレクトリまたは単体の`.safetensors`ファイルが使用できます。
|
||||
* `--vae="<path to Qwen-Image VAE model>"` **[必須]** - Qwen-Image VAEモデルのパスを指定します。
|
||||
|
||||
#### モデル関連 [オプション]
|
||||
|
||||
* `--llm_adapter_path="<path to LLM adapter>"` *[オプション]* - 個別のLLM Adapterの重みファイルのパス。
|
||||
* `--t5_tokenizer_path="<path to T5 tokenizer>"` *[オプション]* - T5トークナイザーディレクトリのパス。
|
||||
|
||||
#### Anima 学習パラメータ
|
||||
|
||||
* `--timestep_sampling` - タイムステップのサンプリング方法。`sigma`、`uniform`、`sigmoid`(デフォルト)、`shift`、`flux_shift`から選択。FLUX学習と同じオプションです。各方法の詳細は[flux_train_network.pyのガイド](flux_train_network.md)を参照してください。
|
||||
* `--discrete_flow_shift` - Rectified Flow学習のタイムステップ分布シフト。デフォルト`1.0`。`--timestep_sampling`が`shift`の場合に使用されます。
|
||||
* `--sigmoid_scale` - `sigmoid`、`shift`、`flux_shift`タイムステップサンプリングのスケール係数。デフォルト`1.0`。
|
||||
* `--qwen3_max_token_length` - Qwen3トークナイザーの最大トークン長。デフォルト`512`。
|
||||
* `--t5_max_token_length` - T5トークナイザーの最大トークン長。デフォルト`512`。
|
||||
* `--attn_mode` - 使用するAttentionの実装。`torch`(デフォルト)、`xformers`、`flash`、`sageattn`から選択。`xformers`は`--split_attn`の指定が必要です。`sageattn`はトレーニングをサポートしていません(推論のみ)。
|
||||
* `--split_attn` - メモリ使用量を減らすためにattention時にバッチを分割します。`--attn_mode xformers`使用時に必要です。
|
||||
|
||||
#### コンポーネント別学習率
|
||||
|
||||
これらのオプションは、Animaモデルの各コンポーネントに個別の学習率を設定します。主にフルファインチューニング用です。`0`に設定するとそのコンポーネントをフリーズします:
|
||||
|
||||
* `--self_attn_lr` - Self-attention層の学習率。
|
||||
* `--cross_attn_lr` - Cross-attention層の学習率。
|
||||
* `--mlp_lr` - MLP層の学習率。
|
||||
* `--mod_lr` - AdaLNモジュレーション層の学習率。モジュレーション層はデフォルトではLoRAに含まれません。
|
||||
* `--llm_adapter_lr` - LLM Adapter層の学習率。
|
||||
|
||||
LoRA学習の場合は、`--network_args`の`network_reg_lrs`を使用してください。[セクション5.2](#52-regex-based-rank-and-learning-rate-control--正規表現によるランク学習率の制御)を参照。
|
||||
|
||||
#### メモリ・速度関連
|
||||
|
||||
* `--blocks_to_swap` - TransformerブロックをCPUとGPUでスワップしてVRAMを節約。`--cpu_offload_checkpointing`および`--unsloth_offload_checkpointing`とは併用できません。
|
||||
* `--unsloth_offload_checkpointing` - 非同期転送でアクティベーションをCPU RAMにオフロード。`--cpu_offload_checkpointing`および`--blocks_to_swap`とは併用できません。
|
||||
* `--cache_text_encoder_outputs` - Qwen3の出力をキャッシュしてメモリ使用量を削減。
|
||||
* `--cache_latents`, `--cache_latents_to_disk` - Qwen-Image VAEの出力をキャッシュ。
|
||||
* `--vae_chunk_size` - Qwen-Image VAEのチャンク処理サイズ。メモリ使用量を削減しますが速度が低下します。デフォルトはチャンク処理なし。
|
||||
* `--vae_disable_cache` - Qwen-Image VAEの内部キャッシュを無効化してメモリ使用量を削減します。
|
||||
|
||||
#### 非互換・非サポートの引数
|
||||
|
||||
* `--v2`, `--v_parameterization`, `--clip_skip` - Stable Diffusion v1/v2向けの引数。Animaの学習では使用されません。
|
||||
* `--fp8_base` - Animaではサポートされていません。指定した場合、警告とともに無効化されます。
|
||||
</details>
|
||||
|
||||
### 4.2. Starting Training / 学習の開始
|
||||
|
||||
After setting the required arguments, run the command to begin training. The overall flow and how to check logs are the same as in the [train_network.py guide](train_network.md#32-starting-the-training--学習の開始).
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
必要な引数を設定したら、コマンドを実行して学習を開始します。全体の流れやログの確認方法は、[train_network.pyのガイド](train_network.md#32-starting-the-training--学習の開始)と同様です。
|
||||
|
||||
</details>
|
||||
|
||||
## 5. LoRA Target Modules / LoRAの学習対象モジュール
|
||||
|
||||
When training LoRA with `anima_train_network.py`, the following modules are targeted by default:
|
||||
|
||||
* **DiT Blocks (`Block`)**: Self-attention (`self_attn`), cross-attention (`cross_attn`), and MLP (`mlp`) layers within each transformer block. Modulation (`adaln_modulation`), norm, embedder, and final layers are excluded by default.
|
||||
* **Embedding layers (`PatchEmbed`, `TimestepEmbedding`) and Final layer (`FinalLayer`)**: Excluded by default but can be included using `include_patterns`.
|
||||
* **LLM Adapter Blocks (`LLMAdapterTransformerBlock`)**: Only when `--network_args "train_llm_adapter=True"` is specified.
|
||||
* **Text Encoder (Qwen3)**: Only when `--network_train_unet_only` is NOT specified and `--cache_text_encoder_outputs` is NOT used.
|
||||
|
||||
The LoRA network module is `networks.lora_anima`.
|
||||
|
||||
### 5.1. Module Selection with Patterns / パターンによるモジュール選択
|
||||
|
||||
By default, the following modules are excluded from LoRA via the built-in exclude pattern:
|
||||
```
|
||||
.*(_modulation|_norm|_embedder|final_layer).*
|
||||
```
|
||||
|
||||
You can customize which modules are included or excluded using regex patterns in `--network_args`:
|
||||
|
||||
* `exclude_patterns` - Exclude modules matching these patterns (in addition to the default exclusion).
|
||||
* `include_patterns` - Force-include modules matching these patterns, overriding exclusion.
|
||||
|
||||
Patterns are matched against the full module name using `re.fullmatch()`.
|
||||
|
||||
Example to include the final layer:
|
||||
```
|
||||
--network_args "include_patterns=['.*final_layer.*']"
|
||||
```
|
||||
|
||||
Example to additionally exclude MLP layers:
|
||||
```
|
||||
--network_args "exclude_patterns=['.*mlp.*']"
|
||||
```
|
||||
|
||||
### 5.2. Regex-based Rank and Learning Rate Control / 正規表現によるランク・学習率の制御
|
||||
|
||||
You can specify different ranks (network_dim) and learning rates for modules matching specific regex patterns:
|
||||
|
||||
* `network_reg_dims`: Specify ranks for modules matching a regular expression. The format is a comma-separated string of `pattern=rank`.
|
||||
* Example: `--network_args "network_reg_dims=.*self_attn.*=8,.*cross_attn.*=4,.*mlp.*=8"`
|
||||
* This sets the rank to 8 for self-attention modules, 4 for cross-attention modules, and 8 for MLP modules.
|
||||
* `network_reg_lrs`: Specify learning rates for modules matching a regular expression. The format is a comma-separated string of `pattern=lr`.
|
||||
* Example: `--network_args "network_reg_lrs=.*self_attn.*=1e-4,.*cross_attn.*=5e-5"`
|
||||
* This sets the learning rate to `1e-4` for self-attention modules and `5e-5` for cross-attention modules.
|
||||
|
||||
**Notes:**
|
||||
|
||||
* Settings via `network_reg_dims` and `network_reg_lrs` take precedence over the global `--network_dim` and `--learning_rate` settings.
|
||||
* Patterns are matched using `re.fullmatch()` against the module's original name (e.g., `blocks.0.self_attn.q_proj`).
|
||||
|
||||
### 5.3. LLM Adapter LoRA / LLM Adapter LoRA
|
||||
|
||||
To apply LoRA to the LLM Adapter blocks:
|
||||
|
||||
```
|
||||
--network_args "train_llm_adapter=True"
|
||||
```
|
||||
|
||||
In preliminary tests, lowering the learning rate for the LLM Adapter seems to improve stability. Adjust it using something like: `"network_reg_lrs=.*llm_adapter.*=5e-5"`.
|
||||
|
||||
### 5.4. Other Network Args / その他のネットワーク引数
|
||||
|
||||
* `--network_args "verbose=True"` - Print all LoRA module names and their dimensions.
|
||||
* `--network_args "rank_dropout=0.1"` - Rank dropout rate.
|
||||
* `--network_args "module_dropout=0.1"` - Module dropout rate.
|
||||
* `--network_args "loraplus_lr_ratio=2.0"` - LoRA+ learning rate ratio.
|
||||
* `--network_args "loraplus_unet_lr_ratio=2.0"` - LoRA+ learning rate ratio for DiT only.
|
||||
* `--network_args "loraplus_text_encoder_lr_ratio=2.0"` - LoRA+ learning rate ratio for text encoder only.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
`anima_train_network.py`でLoRAを学習させる場合、デフォルトでは以下のモジュールが対象となります。
|
||||
|
||||
* **DiTブロック (`Block`)**: 各Transformerブロック内のSelf-attention(`self_attn`)、Cross-attention(`cross_attn`)、MLP(`mlp`)層。モジュレーション(`adaln_modulation`)、norm、embedder、final layerはデフォルトで除外されます。
|
||||
* **埋め込み層 (`PatchEmbed`, `TimestepEmbedding`) と最終層 (`FinalLayer`)**: デフォルトで除外されますが、`include_patterns`で含めることができます。
|
||||
* **LLM Adapterブロック (`LLMAdapterTransformerBlock`)**: `--network_args "train_llm_adapter=True"`を指定した場合のみ。
|
||||
* **テキストエンコーダー (Qwen3)**: `--network_train_unet_only`を指定せず、かつ`--cache_text_encoder_outputs`を使用しない場合のみ。
|
||||
|
||||
### 5.1. パターンによるモジュール選択
|
||||
|
||||
デフォルトでは以下のモジュールが組み込みの除外パターンによりLoRAから除外されます:
|
||||
```
|
||||
.*(_modulation|_norm|_embedder|final_layer).*
|
||||
```
|
||||
|
||||
`--network_args`で正規表現パターンを使用して、含めるモジュールと除外するモジュールをカスタマイズできます:
|
||||
|
||||
* `exclude_patterns` - これらのパターンにマッチするモジュールを除外(デフォルトの除外に追加)。
|
||||
* `include_patterns` - これらのパターンにマッチするモジュールを強制的に含める(除外を上書き)。
|
||||
|
||||
パターンは`re.fullmatch()`を使用して完全なモジュール名に対してマッチングされます。
|
||||
|
||||
### 5.2. 正規表現によるランク・学習率の制御
|
||||
|
||||
正規表現にマッチするモジュールに対して、異なるランクや学習率を指定できます:
|
||||
|
||||
* `network_reg_dims`: 正規表現にマッチするモジュールに対してランクを指定します。`pattern=rank`形式の文字列をカンマで区切って指定します。
|
||||
* 例: `--network_args "network_reg_dims=.*self_attn.*=8,.*cross_attn.*=4,.*mlp.*=8"`
|
||||
* `network_reg_lrs`: 正規表現にマッチするモジュールに対して学習率を指定します。`pattern=lr`形式の文字列をカンマで区切って指定します。
|
||||
* 例: `--network_args "network_reg_lrs=.*self_attn.*=1e-4,.*cross_attn.*=5e-5"`
|
||||
|
||||
**注意点:**
|
||||
* `network_reg_dims`および`network_reg_lrs`での設定は、全体設定である`--network_dim`や`--learning_rate`よりも優先されます。
|
||||
* パターンはモジュールのオリジナル名(例: `blocks.0.self_attn.q_proj`)に対して`re.fullmatch()`でマッチングされます。
|
||||
|
||||
### 5.3. LLM Adapter LoRA
|
||||
|
||||
LLM AdapterブロックにLoRAを適用するには:`--network_args "train_llm_adapter=True"`
|
||||
|
||||
簡易な検証ではLLM Adapterの学習率はある程度下げた方が安定するようです。`"network_reg_lrs=.*llm_adapter.*=5e-5"`などで調整してください。
|
||||
|
||||
### 5.4. その他のネットワーク引数
|
||||
|
||||
* `verbose=True` - 全LoRAモジュール名とdimを表示
|
||||
* `rank_dropout` - ランクドロップアウト率
|
||||
* `module_dropout` - モジュールドロップアウト率
|
||||
* `loraplus_lr_ratio` - LoRA+学習率比率
|
||||
* `loraplus_unet_lr_ratio` - DiT専用のLoRA+学習率比率
|
||||
* `loraplus_text_encoder_lr_ratio` - テキストエンコーダー専用のLoRA+学習率比率
|
||||
|
||||
</details>
|
||||
|
||||
## 6. Using the Trained Model / 学習済みモデルの利用
|
||||
|
||||
When training finishes, a LoRA model file (e.g. `my_anima_lora.safetensors`) is saved in the directory specified by `output_dir`. Use this file with inference environments that support Anima, such as ComfyUI with appropriate nodes.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
学習が完了すると、指定した`output_dir`にLoRAモデルファイル(例: `my_anima_lora.safetensors`)が保存されます。このファイルは、Anima モデルに対応した推論環境(例: ComfyUI + 適切なノード)で使用できます。
|
||||
|
||||
</details>
|
||||
|
||||
## 7. Advanced Settings / 高度な設定
|
||||
|
||||
### 7.1. VRAM Usage Optimization / VRAM使用量の最適化
|
||||
|
||||
Anima models can be large, so GPUs with limited VRAM may require optimization:
|
||||
|
||||
#### Key VRAM Reduction Options
|
||||
|
||||
- **`--blocks_to_swap <number>`**: Swaps blocks between CPU and GPU to reduce VRAM usage. Higher numbers save more VRAM but reduce training speed. See model-specific max values in section 4.1.
|
||||
|
||||
- **`--unsloth_offload_checkpointing`**: Offloads gradient checkpoints to CPU using async non-blocking transfers. Faster than `--cpu_offload_checkpointing`. Cannot be combined with `--blocks_to_swap`.
|
||||
|
||||
- **`--gradient_checkpointing`**: Standard gradient checkpointing to reduce VRAM at the cost of compute.
|
||||
|
||||
- **`--cache_text_encoder_outputs`**: Caches Qwen3 outputs so the text encoder can be freed from VRAM during training.
|
||||
|
||||
- **`--cache_latents`**: Caches Qwen-Image VAE outputs so the VAE can be freed from VRAM during training.
|
||||
|
||||
- **Using Adafactor optimizer**: Can reduce VRAM usage:
|
||||
```
|
||||
--optimizer_type adafactor --optimizer_args "relative_step=False" "scale_parameter=False" "warmup_init=False" --lr_scheduler constant_with_warmup --max_grad_norm 0.0
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
Animaモデルは大きい場合があるため、VRAMが限られたGPUでは最適化が必要です。
|
||||
|
||||
主要なVRAM削減オプション:
|
||||
- `--blocks_to_swap`: CPUとGPU間でブロックをスワップ
|
||||
- `--unsloth_offload_checkpointing`: 非同期転送でアクティベーションをCPUにオフロード
|
||||
- `--gradient_checkpointing`: 標準的な勾配チェックポイント
|
||||
- `--cache_text_encoder_outputs`: Qwen3の出力をキャッシュ
|
||||
- `--cache_latents`: Qwen-Image VAEの出力をキャッシュ
|
||||
- Adafactorオプティマイザの使用
|
||||
|
||||
</details>
|
||||
|
||||
### 7.2. Training Settings / 学習設定
|
||||
|
||||
#### Timestep Sampling
|
||||
|
||||
The `--timestep_sampling` option specifies how timesteps are sampled. The available methods are the same as FLUX training:
|
||||
|
||||
- `sigma`: Sigma-based sampling like SD3.
|
||||
- `uniform`: Uniform random sampling from [0, 1].
|
||||
- `sigmoid` (default): Sample from Normal(0,1), multiply by `sigmoid_scale`, apply sigmoid. Good general-purpose option.
|
||||
- `shift`: Like `sigmoid`, but applies the discrete flow shift formula: `t_shifted = (t * shift) / (1 + (shift - 1) * t)`.
|
||||
- `flux_shift`: Resolution-dependent shift used in FLUX training.
|
||||
|
||||
See the [flux_train_network.py guide](flux_train_network.md) for detailed descriptions.
|
||||
|
||||
#### Discrete Flow Shift
|
||||
|
||||
The `--discrete_flow_shift` option (default `1.0`) only applies when `--timestep_sampling` is set to `shift`. The formula is:
|
||||
|
||||
```
|
||||
t_shifted = (t * shift) / (1 + (shift - 1) * t)
|
||||
```
|
||||
|
||||
#### Loss Weighting
|
||||
|
||||
The `--weighting_scheme` option specifies loss weighting by timestep:
|
||||
|
||||
- `uniform` (default): Equal weight for all timesteps.
|
||||
- `sigma_sqrt`: Weight by `sigma^(-2)`.
|
||||
- `cosmap`: Weight by `2 / (pi * (1 - 2*sigma + 2*sigma^2))`.
|
||||
- `none`: Same as uniform.
|
||||
- `logit_normal`, `mode`: Additional schemes from SD3 training. See the [`sd3_train_network.md` guide](sd3_train_network.md) for details.
|
||||
|
||||
#### Caption Dropout
|
||||
|
||||
Caption dropout uses the `caption_dropout_rate` setting from the dataset configuration (per-subset in TOML). When using `--cache_text_encoder_outputs`, the dropout rate is stored with each cached entry and applied during training, so caption dropout is compatible with text encoder output caching.
|
||||
|
||||
**If you change the `caption_dropout_rate` setting, you must delete and regenerate the cache.**
|
||||
|
||||
Note: Currently, only Anima supports combining `caption_dropout_rate` with text encoder output caching.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
#### タイムステップサンプリング
|
||||
|
||||
`--timestep_sampling`でタイムステップのサンプリング方法を指定します。FLUX学習と同じ方法が利用できます:
|
||||
|
||||
- `sigma`: SD3と同様のシグマベースサンプリング。
|
||||
- `uniform`: [0, 1]の一様分布からサンプリング。
|
||||
- `sigmoid`(デフォルト): 正規分布からサンプリングし、sigmoidを適用。汎用的なオプション。
|
||||
- `shift`: `sigmoid`と同様だが、離散フローシフトの式を適用。
|
||||
- `flux_shift`: FLUX学習で使用される解像度依存のシフト。
|
||||
|
||||
詳細は[flux_train_network.pyのガイド](flux_train_network.md)を参照してください。
|
||||
|
||||
#### 離散フローシフト
|
||||
|
||||
`--discrete_flow_shift`(デフォルト`1.0`)は`--timestep_sampling`が`shift`の場合のみ適用されます。
|
||||
|
||||
#### 損失の重み付け
|
||||
|
||||
`--weighting_scheme`でタイムステップごとの損失の重み付けを指定します。
|
||||
|
||||
#### キャプションドロップアウト
|
||||
|
||||
キャプションドロップアウトにはデータセット設定(TOMLでのサブセット単位)の`caption_dropout_rate`を使用します。`--cache_text_encoder_outputs`使用時は、ドロップアウト率が各キャッシュエントリとともに保存され、学習中に適用されるため、テキストエンコーダー出力キャッシュと同時に使用できます。
|
||||
|
||||
**`caption_dropout_rate`の設定を変えた場合、キャッシュを削除し、再生成する必要があります。**
|
||||
|
||||
※`caption_dropout_rate`をテキストエンコーダー出力キャッシュと組み合わせられるのは、今のところAnimaのみです。
|
||||
|
||||
</details>
|
||||
|
||||
### 7.3. Text Encoder LoRA Support / Text Encoder LoRAのサポート
|
||||
|
||||
Anima LoRA training supports training Qwen3 text encoder LoRA:
|
||||
|
||||
- To train only DiT: specify `--network_train_unet_only`
|
||||
- To train DiT and Qwen3: omit `--network_train_unet_only` and do NOT use `--cache_text_encoder_outputs`
|
||||
|
||||
You can specify a separate learning rate for Qwen3 with `--text_encoder_lr`. If not specified, the default `--learning_rate` is used.
|
||||
|
||||
Note: When `--cache_text_encoder_outputs` is used, text encoder outputs are pre-computed and the text encoder is removed from GPU, so text encoder LoRA cannot be trained.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
Anima LoRA学習では、Qwen3テキストエンコーダーのLoRAもトレーニングできます。
|
||||
|
||||
- DiTのみ学習: `--network_train_unet_only`を指定
|
||||
- DiTとQwen3を学習: `--network_train_unet_only`を省略し、`--cache_text_encoder_outputs`を使用しない
|
||||
|
||||
Qwen3に個別の学習率を指定するには`--text_encoder_lr`を使用します。未指定の場合は`--learning_rate`が使われます。
|
||||
|
||||
注意: `--cache_text_encoder_outputs`を使用する場合、テキストエンコーダーの出力が事前に計算されGPUから解放されるため、テキストエンコーダーLoRAは学習できません。
|
||||
|
||||
</details>
|
||||
|
||||
## 8. Other Training Options / その他の学習オプション
|
||||
|
||||
- **`--loss_type`**: Loss function for training. Default `l2`.
|
||||
- `l1`: L1 loss.
|
||||
- `l2`: L2 loss (mean squared error).
|
||||
- `huber`: Huber loss.
|
||||
- `smooth_l1`: Smooth L1 loss.
|
||||
|
||||
- **`--huber_schedule`**, **`--huber_c`**, **`--huber_scale`**: Parameters for Huber loss when `--loss_type` is `huber` or `smooth_l1`.
|
||||
|
||||
- **`--ip_noise_gamma`**, **`--ip_noise_gamma_random_strength`**: Input Perturbation noise gamma values.
|
||||
|
||||
- **`--fused_backward_pass`**: Fuses the backward pass and optimizer step to reduce VRAM usage. Only works with Adafactor. For details, see the [`sdxl_train_network.py` guide](sdxl_train_network.md).
|
||||
|
||||
- **`--weighting_scheme`**, **`--logit_mean`**, **`--logit_std`**, **`--mode_scale`**: Timestep loss weighting options. For details, refer to the [`sd3_train_network.md` guide](sd3_train_network.md).
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
- **`--loss_type`**: 学習に用いる損失関数。デフォルト`l2`。`l1`, `l2`, `huber`, `smooth_l1`から選択。
|
||||
- **`--huber_schedule`**, **`--huber_c`**, **`--huber_scale`**: Huber損失のパラメータ。
|
||||
- **`--ip_noise_gamma`**: Input Perturbationノイズガンマ値。
|
||||
- **`--fused_backward_pass`**: バックワードパスとオプティマイザステップの融合。
|
||||
- **`--weighting_scheme`** 等: タイムステップ損失の重み付け。詳細は[`sd3_train_network.md`](sd3_train_network.md)を参照。
|
||||
|
||||
</details>
|
||||
|
||||
## 9. Related Tools / 関連ツール
|
||||
|
||||
### `networks/anima_convert_lora_to_comfy.py`
|
||||
|
||||
A script to convert LoRA models to ComfyUI-compatible format. ComfyUI does not directly support sd-scripts format Qwen3 LoRA, so conversion is necessary (conversion may not be needed for DiT-only LoRA). You can convert from the sd-scripts format to ComfyUI format with:
|
||||
|
||||
```bash
|
||||
python networks/convert_anima_lora_to_comfy.py path/to/source.safetensors path/to/destination.safetensors
|
||||
```
|
||||
|
||||
Using the `--reverse` option allows conversion in the opposite direction (ComfyUI format to sd-scripts format). However, reverse conversion is only possible for LoRAs converted by this script. LoRAs created with other training tools cannot be converted.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
**`networks/convert_anima_lora_to_comfy.py`**
|
||||
|
||||
LoRAモデルをComfyUI互換形式に変換するスクリプト。ComfyUIがsd-scripts形式のQwen3 LoRAを直接サポートしていないため、変換が必要です(DiTのみのLoRAの場合は変換不要のようです)。sd-scripts形式からComfyUI形式への変換は以下のコマンドで行います:
|
||||
|
||||
```bash
|
||||
python networks/convert_anima_lora_to_comfy.py path/to/source.safetensors path/to/destination.safetensors
|
||||
```
|
||||
|
||||
`--reverse`オプションを付けると、逆変換(ComfyUI形式からsd-scripts形式)も可能です。ただし、逆変換ができるのはこのスクリプトで変換したLoRAに限ります。他の学習ツールで作成したLoRAは変換できません。
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
## 10. Others / その他
|
||||
|
||||
### Metadata Saved in LoRA Models
|
||||
|
||||
The following metadata is saved in the LoRA model file:
|
||||
|
||||
* `ss_weighting_scheme`
|
||||
* `ss_logit_mean`
|
||||
* `ss_logit_std`
|
||||
* `ss_mode_scale`
|
||||
* `ss_timestep_sampling`
|
||||
* `ss_sigmoid_scale`
|
||||
* `ss_discrete_flow_shift`
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
`anima_train_network.py`には、サンプル画像の生成 (`--sample_prompts`など) や詳細なオプティマイザ設定など、`train_network.py`と共通の機能も多く存在します。これらについては、[`train_network.py`のガイド](train_network.md#5-other-features--その他の機能)やスクリプトのヘルプ (`python anima_train_network.py --help`) を参照してください。
|
||||
|
||||
### LoRAモデルに保存されるメタデータ
|
||||
|
||||
以下のメタデータがLoRAモデルファイルに保存されます:
|
||||
|
||||
* `ss_weighting_scheme`
|
||||
* `ss_logit_mean`
|
||||
* `ss_logit_std`
|
||||
* `ss_mode_scale`
|
||||
* `ss_timestep_sampling`
|
||||
* `ss_sigmoid_scale`
|
||||
* `ss_discrete_flow_shift`
|
||||
|
||||
</details>
|
||||
419
docs/config_README-en.md
Normal file
419
docs/config_README-en.md
Normal file
@@ -0,0 +1,419 @@
|
||||
First version: A.I Translation by Model: NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO, editing by Darkstorm2150
|
||||
|
||||
Document is updated and maintained manually.
|
||||
|
||||
# Config Readme
|
||||
|
||||
This README is about the configuration files that can be passed with the `--dataset_config` option.
|
||||
|
||||
## Overview
|
||||
|
||||
By passing a configuration file, users can make detailed settings.
|
||||
|
||||
* Multiple datasets can be configured
|
||||
* For example, by setting `resolution` for each dataset, they can be mixed and trained.
|
||||
* In training methods that support both the DreamBooth approach and the fine-tuning approach, datasets of the DreamBooth method and the fine-tuning method can be mixed.
|
||||
* Settings can be changed for each subset
|
||||
* A subset is a partition of the dataset by image directory or metadata. Several subsets make up a dataset.
|
||||
* Options such as `keep_tokens` and `flip_aug` can be set for each subset. On the other hand, options such as `resolution` and `batch_size` can be set for each dataset, and their values are common among subsets belonging to the same dataset. More details will be provided later.
|
||||
|
||||
The configuration file format can be JSON or TOML. Considering the ease of writing, it is recommended to use [TOML](https://toml.io/ja/v1.0.0-rc.2). The following explanation assumes the use of TOML.
|
||||
|
||||
|
||||
Here is an example of a configuration file written in TOML.
|
||||
|
||||
```toml
|
||||
[general]
|
||||
shuffle_caption = true
|
||||
caption_extension = '.txt'
|
||||
keep_tokens = 1
|
||||
|
||||
# This is a DreamBooth-style dataset
|
||||
[[datasets]]
|
||||
resolution = 512
|
||||
batch_size = 4
|
||||
keep_tokens = 2
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\hoge'
|
||||
class_tokens = 'hoge girl'
|
||||
# This subset uses keep_tokens = 2 (the value of the parent datasets)
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\fuga'
|
||||
class_tokens = 'fuga boy'
|
||||
keep_tokens = 3
|
||||
|
||||
[[datasets.subsets]]
|
||||
is_reg = true
|
||||
image_dir = 'C:\reg'
|
||||
class_tokens = 'human'
|
||||
keep_tokens = 1
|
||||
|
||||
# This is a fine-tuning dataset
|
||||
[[datasets]]
|
||||
resolution = [768, 768]
|
||||
batch_size = 2
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\piyo'
|
||||
metadata_file = 'C:\piyo\piyo_md.json'
|
||||
# This subset uses keep_tokens = 1 (the value of [general])
|
||||
```
|
||||
|
||||
In this example, three directories are trained as a DreamBooth-style dataset at 512x512 (batch size 4), and one directory is trained as a fine-tuning dataset at 768x768 (batch size 2).
|
||||
|
||||
## Settings for datasets and subsets
|
||||
|
||||
Settings for datasets and subsets are divided into several registration locations.
|
||||
|
||||
* `[general]`
|
||||
* This is where options that apply to all datasets or all subsets are specified.
|
||||
* If there are options with the same name in the dataset-specific or subset-specific settings, the dataset-specific or subset-specific settings take precedence.
|
||||
* `[[datasets]]`
|
||||
* `datasets` is where settings for datasets are registered. This is where options that apply individually to each dataset are specified.
|
||||
* If there are subset-specific settings, the subset-specific settings take precedence.
|
||||
* `[[datasets.subsets]]`
|
||||
* `datasets.subsets` is where settings for subsets are registered. This is where options that apply individually to each subset are specified.
|
||||
|
||||
Here is an image showing the correspondence between image directories and registration locations in the previous example.
|
||||
|
||||
```
|
||||
C:\
|
||||
├─ hoge -> [[datasets.subsets]] No.1 ┐ ┐
|
||||
├─ fuga -> [[datasets.subsets]] No.2 |-> [[datasets]] No.1 |-> [general]
|
||||
├─ reg -> [[datasets.subsets]] No.3 ┘ |
|
||||
└─ piyo -> [[datasets.subsets]] No.4 --> [[datasets]] No.2 ┘
|
||||
```
|
||||
|
||||
The image directory corresponds to each `[[datasets.subsets]]`. Then, multiple `[[datasets.subsets]]` are combined to form one `[[datasets]]`. All `[[datasets]]` and `[[datasets.subsets]]` belong to `[general]`.
|
||||
|
||||
The available options for each registration location may differ, but if the same option is specified, the value in the lower registration location will take precedence. You can check how the `keep_tokens` option is handled in the previous example for better understanding.
|
||||
|
||||
Additionally, the available options may vary depending on the method that the learning approach supports.
|
||||
|
||||
* Options specific to the DreamBooth method
|
||||
* Options specific to the fine-tuning method
|
||||
* Options available when using the caption dropout technique
|
||||
|
||||
When using both the DreamBooth method and the fine-tuning method, they can be used together with a learning approach that supports both.
|
||||
When using them together, a point to note is that the method is determined based on the dataset, so it is not possible to mix DreamBooth method subsets and fine-tuning method subsets within the same dataset.
|
||||
In other words, if you want to use both methods together, you need to set up subsets of different methods belonging to different datasets.
|
||||
|
||||
In terms of program behavior, if the `metadata_file` option exists, it is determined to be a subset of fine-tuning. Therefore, for subsets belonging to the same dataset, as long as they are either "all have the `metadata_file` option" or "all have no `metadata_file` option," there is no problem.
|
||||
|
||||
Below, the available options will be explained. For options with the same name as the command-line argument, the explanation will be omitted in principle. Please refer to other READMEs.
|
||||
|
||||
### Common options for all learning methods
|
||||
|
||||
These are options that can be specified regardless of the learning method.
|
||||
|
||||
#### Data set specific options
|
||||
|
||||
These are options related to the configuration of the data set. They cannot be described in `datasets.subsets`.
|
||||
|
||||
|
||||
| Option Name | Example Setting | `[general]` | `[[datasets]]` |
|
||||
| ---- | ---- | ---- | ---- |
|
||||
| `batch_size` | `1` | o | o |
|
||||
| `bucket_no_upscale` | `true` | o | o |
|
||||
| `bucket_reso_steps` | `64` | o | o |
|
||||
| `enable_bucket` | `true` | o | o |
|
||||
| `max_bucket_reso` | `1024` | o | o |
|
||||
| `min_bucket_reso` | `128` | o | o |
|
||||
| `resolution` | `256`, `[512, 512]` | o | o |
|
||||
| `skip_image_resolution` | `768`, `[512, 768]` | o | o |
|
||||
|
||||
* `batch_size`
|
||||
* This corresponds to the command-line argument `--train_batch_size`.
|
||||
* `max_bucket_reso`, `min_bucket_reso`
|
||||
* Specify the maximum and minimum resolutions of the bucket. It must be divisible by `bucket_reso_steps`.
|
||||
* `skip_image_resolution`
|
||||
* Images whose original resolution (area) is equal to or smaller than the specified resolution will be skipped. Specify as `'size'` or `[width, height]`. This corresponds to the command-line argument `--skip_image_resolution`.
|
||||
* Useful when sharing the same image directory across multiple datasets with different resolutions, to exclude low-resolution source images from higher-resolution datasets.
|
||||
|
||||
These settings are fixed per dataset. That means that subsets belonging to the same dataset will share these settings. For example, if you want to prepare datasets with different resolutions, you can define them as separate datasets as shown in the example above, and set different resolutions for each.
|
||||
|
||||
#### Options for Subsets
|
||||
|
||||
These options are related to subset configuration.
|
||||
|
||||
| Option Name | Example | `[general]` | `[[datasets]]` | `[[dataset.subsets]]` |
|
||||
| ---- | ---- | ---- | ---- | ---- |
|
||||
| `color_aug` | `false` | o | o | o |
|
||||
| `face_crop_aug_range` | `[1.0, 3.0]` | o | o | o |
|
||||
| `flip_aug` | `true` | o | o | o |
|
||||
| `keep_tokens` | `2` | o | o | o |
|
||||
| `num_repeats` | `10` | o | o | o |
|
||||
| `random_crop` | `false` | o | o | o |
|
||||
| `shuffle_caption` | `true` | o | o | o |
|
||||
| `caption_prefix` | `"masterpiece, best quality, "` | o | o | o |
|
||||
| `caption_suffix` | `", from side"` | o | o | o |
|
||||
| `caption_separator` | (not specified) | o | o | o |
|
||||
| `keep_tokens_separator` | `“|||”` | o | o | o |
|
||||
| `secondary_separator` | `“;;;”` | o | o | o |
|
||||
| `enable_wildcard` | `true` | o | o | o |
|
||||
| `resize_interpolation` | (not specified) | o | o | o |
|
||||
|
||||
* `num_repeats`
|
||||
* Specifies the number of repeats for images in a subset. This is equivalent to `--dataset_repeats` in fine-tuning but can be specified for any training method.
|
||||
* `caption_prefix`, `caption_suffix`
|
||||
* Specifies the prefix and suffix strings to be appended to the captions. Shuffling is performed with these strings included. Be cautious when using `keep_tokens`.
|
||||
* `caption_separator`
|
||||
* Specifies the string to separate the tags. The default is `,`. This option is usually not necessary to set.
|
||||
* `keep_tokens_separator`
|
||||
* Specifies the string to separate the parts to be fixed in the caption. For example, if you specify `aaa, bbb ||| ccc, ddd, eee, fff ||| ggg, hhh`, the parts `aaa, bbb` and `ggg, hhh` will remain, and the rest will be shuffled and dropped. The comma in between is not necessary. As a result, the prompt will be `aaa, bbb, eee, ccc, fff, ggg, hhh` or `aaa, bbb, fff, ccc, eee, ggg, hhh`, etc.
|
||||
* `secondary_separator`
|
||||
* Specifies an additional separator. The part separated by this separator is treated as one tag and is shuffled and dropped. It is then replaced by `caption_separator`. For example, if you specify `aaa;;;bbb;;;ccc`, it will be replaced by `aaa,bbb,ccc` or dropped together.
|
||||
* `enable_wildcard`
|
||||
* Enables wildcard notation. This will be explained later.
|
||||
* `resize_interpolation`
|
||||
* Specifies the interpolation method used when resizing images. Normally, there is no need to specify this. The following options can be specified: `lanczos`, `nearest`, `bilinear`, `linear`, `bicubic`, `cubic`, `area`, `box`. By default (when not specified), `area` is used for downscaling, and `lanczos` is used for upscaling. If this option is specified, the same interpolation method will be used for both upscaling and downscaling. When `lanczos` or `box` is specified, PIL is used; for other options, OpenCV is used.
|
||||
|
||||
### DreamBooth-specific options
|
||||
|
||||
DreamBooth-specific options only exist as subsets-specific options.
|
||||
|
||||
#### Subset-specific options
|
||||
|
||||
Options related to the configuration of DreamBooth subsets.
|
||||
|
||||
| Option Name | Example Setting | `[general]` | `[[datasets]]` | `[[dataset.subsets]]` |
|
||||
| ---- | ---- | ---- | ---- | ---- |
|
||||
| `image_dir` | `'C:\hoge'` | - | - | o (required) |
|
||||
| `caption_extension` | `".txt"` | o | o | o |
|
||||
| `class_tokens` | `"sks girl"` | - | - | o |
|
||||
| `cache_info` | `false` | o | o | o |
|
||||
| `is_reg` | `false` | - | - | o |
|
||||
|
||||
Firstly, note that for `image_dir`, the path to the image files must be specified as being directly in the directory. Unlike the previous DreamBooth method, where images had to be placed in subdirectories, this is not compatible with that specification. Also, even if you name the folder something like "5_cat", the number of repeats of the image and the class name will not be reflected. If you want to set these individually, you will need to explicitly specify them using `num_repeats` and `class_tokens`.
|
||||
|
||||
* `image_dir`
|
||||
* Specifies the path to the image directory. This is a required option.
|
||||
* Images must be placed directly under the directory.
|
||||
* `class_tokens`
|
||||
* Sets the class tokens.
|
||||
* Only used during training when a corresponding caption file does not exist. The determination of whether or not to use it is made on a per-image basis. If `class_tokens` is not specified and a caption file is not found, an error will occur.
|
||||
* `cache_info`
|
||||
* Specifies whether to cache the image size and caption. If not specified, it is set to `false`. The cache is saved in `metadata_cache.json` in `image_dir`.
|
||||
* Caching speeds up the loading of the dataset after the first time. It is effective when dealing with thousands of images or more.
|
||||
* `is_reg`
|
||||
* Specifies whether the subset images are for normalization. If not specified, it is set to `false`, meaning that the images are not for normalization.
|
||||
|
||||
### Fine-tuning method specific options
|
||||
|
||||
The options for the fine-tuning method only exist for subset-specific options.
|
||||
|
||||
#### Subset-specific options
|
||||
|
||||
These options are related to the configuration of the fine-tuning method's subsets.
|
||||
|
||||
| Option name | Example setting | `[general]` | `[[datasets]]` | `[[dataset.subsets]]` |
|
||||
| ---- | ---- | ---- | ---- | ---- |
|
||||
| `image_dir` | `'C:\hoge'` | - | - | o |
|
||||
| `metadata_file` | `'C:\piyo\piyo_md.json'` | - | - | o (required) |
|
||||
|
||||
* `image_dir`
|
||||
* Specify the path to the image directory. Unlike the DreamBooth method, specifying it is not mandatory, but it is recommended to do so.
|
||||
* The case where it is not necessary to specify is when the `--full_path` is added to the command line when generating the metadata file.
|
||||
* The images must be placed directly under the directory.
|
||||
* `metadata_file`
|
||||
* Specify the path to the metadata file used for the subset. This is a required option.
|
||||
* It is equivalent to the command-line argument `--in_json`.
|
||||
* Due to the specification that a metadata file must be specified for each subset, it is recommended to avoid creating a metadata file with images from different directories as a single metadata file. It is strongly recommended to prepare a separate metadata file for each image directory and register them as separate subsets.
|
||||
|
||||
### Options available when caption dropout method can be used
|
||||
|
||||
The options available when the caption dropout method can be used exist only for subsets. Regardless of whether it's the DreamBooth method or fine-tuning method, if it supports caption dropout, it can be specified.
|
||||
|
||||
#### Subset-specific options
|
||||
|
||||
Options related to the setting of subsets that caption dropout can be used for.
|
||||
|
||||
| Option Name | `[general]` | `[[datasets]]` | `[[dataset.subsets]]` |
|
||||
| ---- | ---- | ---- | ---- |
|
||||
| `caption_dropout_every_n_epochs` | o | o | o |
|
||||
| `caption_dropout_rate` | o | o | o |
|
||||
| `caption_tag_dropout_rate` | o | o | o |
|
||||
|
||||
## Behavior when there are duplicate subsets
|
||||
|
||||
In the case of the DreamBooth dataset, if there are multiple `image_dir` directories with the same content, they are considered to be duplicate subsets. For the fine-tuning dataset, if there are multiple `metadata_file` files with the same content, they are considered to be duplicate subsets. If duplicate subsets exist in the dataset, subsequent subsets will be ignored.
|
||||
|
||||
However, if they belong to different datasets, they are not considered duplicates. For example, if you have subsets with the same `image_dir` in different datasets, they will not be considered duplicates. This is useful when you want to train with the same image but with different resolutions.
|
||||
|
||||
```toml
|
||||
# If data sets exist separately, they are not considered duplicates and are both used for training.
|
||||
|
||||
[[datasets]]
|
||||
resolution = 512
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\hoge'
|
||||
|
||||
[[datasets]]
|
||||
resolution = 768
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\hoge'
|
||||
```
|
||||
|
||||
When using multi-resolution datasets, you can use `skip_image_resolution` to exclude images whose original size is too small for higher-resolution datasets. This prevents overlapping of low-resolution images across datasets and improves training quality. This option can also be used to simply exclude low-resolution source images from datasets.
|
||||
|
||||
```toml
|
||||
[general]
|
||||
enable_bucket = true
|
||||
bucket_no_upscale = true
|
||||
max_bucket_reso = 1536
|
||||
|
||||
[[datasets]]
|
||||
resolution = 768
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\hoge'
|
||||
|
||||
[[datasets]]
|
||||
resolution = 1024
|
||||
skip_image_resolution = 768
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\hoge'
|
||||
|
||||
[[datasets]]
|
||||
resolution = 1280
|
||||
skip_image_resolution = 1024
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\hoge'
|
||||
```
|
||||
|
||||
In this example, the 1024-resolution dataset skips images whose original size is 768x768 or smaller, and the 1280-resolution dataset skips images whose original size is 1024x1024 or smaller.
|
||||
|
||||
## Command Line Argument and Configuration File
|
||||
|
||||
There are options in the configuration file that have overlapping roles with command line argument options.
|
||||
|
||||
The following command line argument options are ignored if a configuration file is passed:
|
||||
|
||||
* `--train_data_dir`
|
||||
* `--reg_data_dir`
|
||||
* `--in_json`
|
||||
|
||||
For the command line options listed below, if an option is specified in both the command line arguments and the configuration file, the value from the configuration file will be given priority. Unless otherwise noted, the option names are the same.
|
||||
|
||||
| Command Line Argument Option | Corresponding Configuration File Option |
|
||||
| ------------------------------- | --------------------------------------- |
|
||||
| `--bucket_no_upscale` | |
|
||||
| `--bucket_reso_steps` | |
|
||||
| `--caption_dropout_every_n_epochs` | |
|
||||
| `--caption_dropout_rate` | |
|
||||
| `--caption_extension` | |
|
||||
| `--caption_tag_dropout_rate` | |
|
||||
| `--color_aug` | |
|
||||
| `--dataset_repeats` | `num_repeats` |
|
||||
| `--enable_bucket` | |
|
||||
| `--face_crop_aug_range` | |
|
||||
| `--flip_aug` | |
|
||||
| `--keep_tokens` | |
|
||||
| `--min_bucket_reso` | |
|
||||
| `--random_crop` | |
|
||||
| `--resolution` | |
|
||||
| `--shuffle_caption` | |
|
||||
| `--skip_image_resolution` | |
|
||||
| `--train_batch_size` | `batch_size` |
|
||||
|
||||
## Error Guide
|
||||
|
||||
Currently, we are using an external library to check if the configuration file is written correctly, but the development has not been completed, and there is a problem that the error message is not clear. In the future, we plan to improve this problem.
|
||||
|
||||
As a temporary measure, we will list common errors and their solutions. If you encounter an error even though it should be correct or if the error content is not understandable, please contact us as it may be a bug.
|
||||
|
||||
* `voluptuous.error.MultipleInvalid: required key not provided @ ...`: This error occurs when a required option is not provided. It is highly likely that you forgot to specify the option or misspelled the option name.
|
||||
* The error location is indicated by `...` in the error message. For example, if you encounter an error like `voluptuous.error.MultipleInvalid: required key not provided @ data['datasets'][0]['subsets'][0]['image_dir']`, it means that the `image_dir` option does not exist in the 0th `subsets` of the 0th `datasets` setting.
|
||||
* `voluptuous.error.MultipleInvalid: expected int for dictionary value @ ...`: This error occurs when the specified value format is incorrect. It is highly likely that the value format is incorrect. The `int` part changes depending on the target option. The example configurations in this README may be helpful.
|
||||
* `voluptuous.error.MultipleInvalid: extra keys not allowed @ ...`: This error occurs when there is an option name that is not supported. It is highly likely that you misspelled the option name or mistakenly included it.
|
||||
|
||||
## Miscellaneous
|
||||
|
||||
### Multi-line captions
|
||||
|
||||
By setting `enable_wildcard = true`, multiple-line captions are also enabled. If the caption file consists of multiple lines, one line is randomly selected as the caption.
|
||||
|
||||
```txt
|
||||
1girl, hatsune miku, vocaloid, upper body, looking at viewer, microphone, stage
|
||||
a girl with a microphone standing on a stage
|
||||
detailed digital art of a girl with a microphone on a stage
|
||||
```
|
||||
|
||||
It can be combined with wildcard notation.
|
||||
|
||||
In metadata files, you can also specify multiple-line captions. In the `.json` metadata file, use `\n` to represent a line break. If the caption file consists of multiple lines, `merge_captions_to_metadata.py` will create a metadata file in this format.
|
||||
|
||||
The tags in the metadata (`tags`) are added to each line of the caption.
|
||||
|
||||
```json
|
||||
{
|
||||
"/path/to/image.png": {
|
||||
"caption": "a cartoon of a frog with the word frog on it\ntest multiline caption1\ntest multiline caption2",
|
||||
"tags": "open mouth, simple background, standing, no humans, animal, black background, frog, animal costume, animal focus"
|
||||
},
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
In this case, the actual caption will be `a cartoon of a frog with the word frog on it, open mouth, simple background ...`, `test multiline caption1, open mouth, simple background ...`, `test multiline caption2, open mouth, simple background ...`, etc.
|
||||
|
||||
### Example of configuration file : `secondary_separator`, wildcard notation, `keep_tokens_separator`, etc.
|
||||
|
||||
```toml
|
||||
[general]
|
||||
flip_aug = true
|
||||
color_aug = false
|
||||
resolution = [1024, 1024]
|
||||
|
||||
[[datasets]]
|
||||
batch_size = 6
|
||||
enable_bucket = true
|
||||
bucket_no_upscale = true
|
||||
caption_extension = ".txt"
|
||||
keep_tokens_separator= "|||"
|
||||
shuffle_caption = true
|
||||
caption_tag_dropout_rate = 0.1
|
||||
secondary_separator = ";;;" # subset 側に書くこともできます / can be written in the subset side
|
||||
enable_wildcard = true # 同上 / same as above
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = "/path/to/image_dir"
|
||||
num_repeats = 1
|
||||
|
||||
# ||| の前後はカンマは不要です(自動的に追加されます) / No comma is required before and after ||| (it is added automatically)
|
||||
caption_prefix = "1girl, hatsune miku, vocaloid |||"
|
||||
|
||||
# ||| の後はシャッフル、drop されず残ります / After |||, it is not shuffled or dropped and remains
|
||||
# 単純に文字列として連結されるので、カンマなどは自分で入れる必要があります / It is simply concatenated as a string, so you need to put commas yourself
|
||||
caption_suffix = ", anime screencap ||| masterpiece, rating: general"
|
||||
```
|
||||
|
||||
### Example of caption, secondary_separator notation: `secondary_separator = ";;;"`
|
||||
|
||||
```txt
|
||||
1girl, hatsune miku, vocaloid, upper body, looking at viewer, sky;;;cloud;;;day, outdoors
|
||||
```
|
||||
The part `sky;;;cloud;;;day` is replaced with `sky,cloud,day` without shuffling or dropping. When shuffling and dropping are enabled, it is processed as a whole (as one tag). For example, it becomes `vocaloid, 1girl, upper body, sky,cloud,day, outdoors, hatsune miku` (shuffled) or `vocaloid, 1girl, outdoors, looking at viewer, upper body, hatsune miku` (dropped).
|
||||
|
||||
### Example of caption, enable_wildcard notation: `enable_wildcard = true`
|
||||
|
||||
```txt
|
||||
1girl, hatsune miku, vocaloid, upper body, looking at viewer, {simple|white} background
|
||||
```
|
||||
`simple` or `white` is randomly selected, and it becomes `simple background` or `white background`.
|
||||
|
||||
```txt
|
||||
1girl, hatsune miku, vocaloid, {{retro style}}
|
||||
```
|
||||
If you want to include `{` or `}` in the tag string, double them like `{{` or `}}` (in this example, the actual caption used for training is `{retro style}`).
|
||||
|
||||
### Example of caption, `keep_tokens_separator` notation: `keep_tokens_separator = "|||"`
|
||||
|
||||
```txt
|
||||
1girl, hatsune miku, vocaloid ||| stage, microphone, white shirt, smile ||| best quality, rating: general
|
||||
```
|
||||
It becomes `1girl, hatsune miku, vocaloid, microphone, stage, white shirt, best quality, rating: general` or `1girl, hatsune miku, vocaloid, white shirt, smile, stage, microphone, best quality, rating: general` etc.
|
||||
|
||||
@@ -1,5 +1,3 @@
|
||||
For non-Japanese speakers: this README is provided only in Japanese in the current state. Sorry for inconvenience. We will provide English version in the near future.
|
||||
|
||||
`--dataset_config` で渡すことができる設定ファイルに関する説明です。
|
||||
|
||||
## 概要
|
||||
@@ -117,9 +115,15 @@ DreamBooth の手法と fine tuning の手法の両方とも利用可能な学
|
||||
| `max_bucket_reso` | `1024` | o | o |
|
||||
| `min_bucket_reso` | `128` | o | o |
|
||||
| `resolution` | `256`, `[512, 512]` | o | o |
|
||||
| `skip_image_resolution` | `768`, `[512, 768]` | o | o |
|
||||
|
||||
* `batch_size`
|
||||
* コマンドライン引数の `--train_batch_size` と同等です。
|
||||
* `max_bucket_reso`, `min_bucket_reso`
|
||||
* bucketの最大、最小解像度を指定します。`bucket_reso_steps` で割り切れる必要があります。
|
||||
* `skip_image_resolution`
|
||||
* 指定した解像度(面積)以下の画像をスキップします。`'サイズ'` または `[幅, 高さ]` で指定します。コマンドライン引数の `--skip_image_resolution` と同等です。
|
||||
* 同じ画像ディレクトリを異なる解像度の複数のデータセットで使い回す場合に、低解像度の元画像を高解像度のデータセットから除外するために使用します。
|
||||
|
||||
これらの設定はデータセットごとに固定です。
|
||||
つまり、データセットに所属するサブセットはこれらの設定を共有することになります。
|
||||
@@ -138,9 +142,33 @@ DreamBooth の手法と fine tuning の手法の両方とも利用可能な学
|
||||
| `num_repeats` | `10` | o | o | o |
|
||||
| `random_crop` | `false` | o | o | o |
|
||||
| `shuffle_caption` | `true` | o | o | o |
|
||||
| `caption_prefix` | `“masterpiece, best quality, ”` | o | o | o |
|
||||
| `caption_suffix` | `“, from side”` | o | o | o |
|
||||
| `caption_separator` | (通常は設定しません) | o | o | o |
|
||||
| `keep_tokens_separator` | `“|||”` | o | o | o |
|
||||
| `secondary_separator` | `“;;;”` | o | o | o |
|
||||
| `enable_wildcard` | `true` | o | o | o |
|
||||
| `resize_interpolation` |(通常は設定しません) | o | o | o |
|
||||
|
||||
* `num_repeats`
|
||||
* サブセットの画像の繰り返し回数を指定します。fine tuning における `--dataset_repeats` に相当しますが、`num_repeats` はどの学習方法でも指定可能です。
|
||||
* `caption_prefix`, `caption_suffix`
|
||||
* キャプションの前、後に付与する文字列を指定します。シャッフルはこれらの文字列を含めた状態で行われます。`keep_tokens` を指定する場合には注意してください。
|
||||
|
||||
* `caption_separator`
|
||||
* タグを区切る文字列を指定します。デフォルトは `,` です。このオプションは通常は設定する必要はありません。
|
||||
|
||||
* `keep_tokens_separator`
|
||||
* キャプションで固定したい部分を区切る文字列を指定します。たとえば `aaa, bbb ||| ccc, ddd, eee, fff ||| ggg, hhh` のように指定すると、`aaa, bbb` と `ggg, hhh` の部分はシャッフル、drop されず残ります。間のカンマは不要です。結果としてプロンプトは `aaa, bbb, eee, ccc, fff, ggg, hhh` や `aaa, bbb, fff, ccc, eee, ggg, hhh` などになります。
|
||||
|
||||
* `secondary_separator`
|
||||
* 追加の区切り文字を指定します。この区切り文字で区切られた部分は一つのタグとして扱われ、シャッフル、drop されます。その後、`caption_separator` に置き換えられます。たとえば `aaa;;;bbb;;;ccc` のように指定すると、`aaa,bbb,ccc` に置き換えられるか、まとめて drop されます。
|
||||
|
||||
* `enable_wildcard`
|
||||
* ワイルドカード記法および複数行キャプションを有効にします。ワイルドカード記法、複数行キャプションについては後述します。
|
||||
|
||||
* `resize_interpolation`
|
||||
* 画像のリサイズ時に使用する補間方法を指定します。通常は指定しなくて構いません。`lanczos`, `nearest`, `bilinear`, `linear`, `bicubic`, `cubic`, `area`, `box` が指定可能です。デフォルト(未指定時)は、縮小時は `area`、拡大時は `lanczos` になります。このオプションを指定すると、拡大時・縮小時とも同じ補間方法が使用されます。`lanczos`、`box`を指定するとPILが、それ以外を指定するとOpenCVが使用されます。
|
||||
|
||||
### DreamBooth 方式専用のオプション
|
||||
|
||||
@@ -155,6 +183,7 @@ DreamBooth 方式のサブセットの設定に関わるオプションです。
|
||||
| `image_dir` | `‘C:\hoge’` | - | - | o(必須) |
|
||||
| `caption_extension` | `".txt"` | o | o | o |
|
||||
| `class_tokens` | `“sks girl”` | - | - | o |
|
||||
| `cache_info` | `false` | o | o | o |
|
||||
| `is_reg` | `false` | - | - | o |
|
||||
|
||||
まず注意点として、 `image_dir` には画像ファイルが直下に置かれているパスを指定する必要があります。従来の DreamBooth の手法ではサブディレクトリに画像を置く必要がありましたが、そちらとは仕様に互換性がありません。また、`5_cat` のようなフォルダ名にしても、画像の繰り返し回数とクラス名は反映されません。これらを個別に設定したい場合、`num_repeats` と `class_tokens` で明示的に指定する必要があることに注意してください。
|
||||
@@ -165,6 +194,9 @@ DreamBooth 方式のサブセットの設定に関わるオプションです。
|
||||
* `class_tokens`
|
||||
* クラストークンを設定します。
|
||||
* 画像に対応する caption ファイルが存在しない場合にのみ学習時に利用されます。利用するかどうかの判定は画像ごとに行います。`class_tokens` を指定しなかった場合に caption ファイルも見つからなかった場合にはエラーになります。
|
||||
* `cache_info`
|
||||
* 画像サイズ、キャプションをキャッシュするかどうかを指定します。指定しなかった場合は `false` になります。キャッシュは `image_dir` に `metadata_cache.json` というファイル名で保存されます。
|
||||
* キャッシュを行うと、二回目以降のデータセット読み込みが高速化されます。数千枚以上の画像を扱う場合には有効です。
|
||||
* `is_reg`
|
||||
* サブセットの画像が正規化用かどうかを指定します。指定しなかった場合は `false` として、つまり正規化画像ではないとして扱います。
|
||||
|
||||
@@ -231,6 +263,34 @@ resolution = 768
|
||||
image_dir = 'C:\hoge'
|
||||
```
|
||||
|
||||
なお、マルチ解像度データセットでは `skip_image_resolution` を使用して、元の画像サイズが小さい画像を高解像度データセットから除外できます。これにより、低解像度画像のデータセット間での重複を防ぎ、学習品質を向上させることができます。また、小さい画像を除外するフィルターとしても機能します。
|
||||
|
||||
```toml
|
||||
[general]
|
||||
enable_bucket = true
|
||||
bucket_no_upscale = true
|
||||
max_bucket_reso = 1536
|
||||
|
||||
[[datasets]]
|
||||
resolution = 768
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\hoge'
|
||||
|
||||
[[datasets]]
|
||||
resolution = 1024
|
||||
skip_image_resolution = 768
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\hoge'
|
||||
|
||||
[[datasets]]
|
||||
resolution = 1280
|
||||
skip_image_resolution = 1024
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\hoge'
|
||||
```
|
||||
|
||||
この例では、1024 解像度のデータセットでは元の画像サイズが 768x768 以下の画像がスキップされ、1280 解像度のデータセットでは 1024x1024 以下の画像がスキップされます。
|
||||
|
||||
## コマンドライン引数との併用
|
||||
|
||||
設定ファイルのオプションの中には、コマンドライン引数のオプションと役割が重複しているものがあります。
|
||||
@@ -261,6 +321,7 @@ resolution = 768
|
||||
| `--random_crop` | |
|
||||
| `--resolution` | |
|
||||
| `--shuffle_caption` | |
|
||||
| `--skip_image_resolution` | |
|
||||
| `--train_batch_size` | `batch_size` |
|
||||
|
||||
## エラーの手引き
|
||||
@@ -276,4 +337,89 @@ resolution = 768
|
||||
* `voluptuous.error.MultipleInvalid: expected int for dictionary value @ ...`: 指定する値の形式が不正というエラーです。値の形式が間違っている可能性が高いです。`int` の部分は対象となるオプションによって変わります。この README に載っているオプションの「設定例」が役立つかもしれません。
|
||||
* `voluptuous.error.MultipleInvalid: extra keys not allowed @ ...`: 対応していないオプション名が存在している場合に発生するエラーです。オプション名を間違って記述しているか、誤って紛れ込んでいる可能性が高いです。
|
||||
|
||||
## その他
|
||||
|
||||
### 複数行キャプション
|
||||
|
||||
`enable_wildcard = true` を設定することで、複数行キャプションも同時に有効になります。キャプションファイルが複数の行からなる場合、ランダムに一つの行が選ばれてキャプションとして利用されます。
|
||||
|
||||
```txt
|
||||
1girl, hatsune miku, vocaloid, upper body, looking at viewer, microphone, stage
|
||||
a girl with a microphone standing on a stage
|
||||
detailed digital art of a girl with a microphone on a stage
|
||||
```
|
||||
|
||||
ワイルドカード記法と組み合わせることも可能です。
|
||||
|
||||
メタデータファイルでも同様に複数行キャプションを指定することができます。メタデータの .json 内には、`\n` を使って改行を表現してください。キャプションファイルが複数行からなる場合、`merge_captions_to_metadata.py` を使うと、この形式でメタデータファイルが作成されます。
|
||||
|
||||
メタデータのタグ (`tags`) は、キャプションの各行に追加されます。
|
||||
|
||||
```json
|
||||
{
|
||||
"/path/to/image.png": {
|
||||
"caption": "a cartoon of a frog with the word frog on it\ntest multiline caption1\ntest multiline caption2",
|
||||
"tags": "open mouth, simple background, standing, no humans, animal, black background, frog, animal costume, animal focus"
|
||||
},
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
この場合、実際のキャプションは `a cartoon of a frog with the word frog on it, open mouth, simple background ...` または `test multiline caption1, open mouth, simple background ...`、 `test multiline caption2, open mouth, simple background ...` 等になります。
|
||||
|
||||
### 設定ファイルの記述例:追加の区切り文字、ワイルドカード記法、`keep_tokens_separator` 等
|
||||
|
||||
```toml
|
||||
[general]
|
||||
flip_aug = true
|
||||
color_aug = false
|
||||
resolution = [1024, 1024]
|
||||
|
||||
[[datasets]]
|
||||
batch_size = 6
|
||||
enable_bucket = true
|
||||
bucket_no_upscale = true
|
||||
caption_extension = ".txt"
|
||||
keep_tokens_separator= "|||"
|
||||
shuffle_caption = true
|
||||
caption_tag_dropout_rate = 0.1
|
||||
secondary_separator = ";;;" # subset 側に書くこともできます / can be written in the subset side
|
||||
enable_wildcard = true # 同上 / same as above
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = "/path/to/image_dir"
|
||||
num_repeats = 1
|
||||
|
||||
# ||| の前後はカンマは不要です(自動的に追加されます) / No comma is required before and after ||| (it is added automatically)
|
||||
caption_prefix = "1girl, hatsune miku, vocaloid |||"
|
||||
|
||||
# ||| の後はシャッフル、drop されず残ります / After |||, it is not shuffled or dropped and remains
|
||||
# 単純に文字列として連結されるので、カンマなどは自分で入れる必要があります / It is simply concatenated as a string, so you need to put commas yourself
|
||||
caption_suffix = ", anime screencap ||| masterpiece, rating: general"
|
||||
```
|
||||
|
||||
### キャプション記述例、secondary_separator 記法:`secondary_separator = ";;;"` の場合
|
||||
|
||||
```txt
|
||||
1girl, hatsune miku, vocaloid, upper body, looking at viewer, sky;;;cloud;;;day, outdoors
|
||||
```
|
||||
`sky;;;cloud;;;day` の部分はシャッフル、drop されず `sky,cloud,day` に置換されます。シャッフル、drop が有効な場合、まとめて(一つのタグとして)処理されます。つまり `vocaloid, 1girl, upper body, sky,cloud,day, outdoors, hatsune miku` (シャッフル)や `vocaloid, 1girl, outdoors, looking at viewer, upper body, hatsune miku` (drop されたケース)などになります。
|
||||
|
||||
### キャプション記述例、ワイルドカード記法: `enable_wildcard = true` の場合
|
||||
|
||||
```txt
|
||||
1girl, hatsune miku, vocaloid, upper body, looking at viewer, {simple|white} background
|
||||
```
|
||||
ランダムに `simple` または `white` が選ばれ、`simple background` または `white background` になります。
|
||||
|
||||
```txt
|
||||
1girl, hatsune miku, vocaloid, {{retro style}}
|
||||
```
|
||||
タグ文字列に `{` や `}` そのものを含めたい場合は `{{` や `}}` のように二つ重ねてください(この例では実際に学習に用いられるキャプションは `{retro style}` になります)。
|
||||
|
||||
### キャプション記述例、`keep_tokens_separator` 記法: `keep_tokens_separator = "|||"` の場合
|
||||
|
||||
```txt
|
||||
1girl, hatsune miku, vocaloid ||| stage, microphone, white shirt, smile ||| best quality, rating: general
|
||||
```
|
||||
`1girl, hatsune miku, vocaloid, microphone, stage, white shirt, best quality, rating: general` や `1girl, hatsune miku, vocaloid, white shirt, smile, stage, microphone, best quality, rating: general` などになります。
|
||||
347
docs/fine_tune.md
Normal file
347
docs/fine_tune.md
Normal file
@@ -0,0 +1,347 @@
|
||||
# Fine-tuning Guide
|
||||
|
||||
This document explains how to perform fine-tuning on various model architectures using the `*_train.py` scripts.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
# Fine-tuning ガイド
|
||||
|
||||
このドキュメントでは、`*_train.py` スクリプトを用いた、各種モデルアーキテクチャのFine-tuningの方法について解説します。
|
||||
|
||||
</details>
|
||||
|
||||
### Difference between Fine-tuning and LoRA tuning
|
||||
|
||||
This repository supports two methods for additional model training: **Fine-tuning** and **LoRA (Low-Rank Adaptation)**. Each method has distinct features and advantages.
|
||||
|
||||
**Fine-tuning** is a method that retrains all (or most) of the weights of a pre-trained model.
|
||||
- **Pros**: It can improve the overall expressive power of the model and is suitable for learning styles or concepts that differ significantly from the original model.
|
||||
- **Cons**:
|
||||
- It requires a large amount of VRAM and computational cost.
|
||||
- The saved file size is large (same as the original model).
|
||||
- It is prone to "overfitting," where the model loses the diversity of the original model if over-trained.
|
||||
- **Corresponding scripts**: Scripts named `*_train.py`, such as `sdxl_train.py`, `sd3_train.py`, `flux_train.py`, and `lumina_train.py`.
|
||||
|
||||
**LoRA tuning** is a method that freezes the model's weights and only trains a small additional network called an "adapter."
|
||||
- **Pros**:
|
||||
- It allows for fast training with low VRAM and computational cost.
|
||||
- It is considered resistant to overfitting because it trains fewer weights.
|
||||
- The saved file (LoRA network) is very small, ranging from tens to hundreds of MB, making it easy to manage.
|
||||
- Multiple LoRAs can be used in combination.
|
||||
- **Cons**: Since it does not train the entire model, it may not achieve changes as significant as fine-tuning.
|
||||
- **Corresponding scripts**: Scripts named `*_train_network.py`, such as `sdxl_train_network.py`, `sd3_train_network.py`, and `flux_train_network.py`.
|
||||
|
||||
| Feature | Fine-tuning | LoRA tuning |
|
||||
|:---|:---|:---|
|
||||
| **Training Target** | All model weights | Additional network (adapter) only |
|
||||
| **VRAM/Compute Cost**| High | Low |
|
||||
| **Training Time** | Long | Short |
|
||||
| **File Size** | Large (several GB) | Small (few MB to hundreds of MB) |
|
||||
| **Overfitting Risk** | High | Low |
|
||||
| **Suitable Use Case** | Major style changes, concept learning | Adding specific characters or styles |
|
||||
|
||||
Generally, it is recommended to start with **LoRA tuning** if you want to add a specific character or style. **Fine-tuning** is a valid option for more fundamental style changes or aiming for a high-quality model.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
### Fine-tuningとLoRA学習の違い
|
||||
|
||||
このリポジトリでは、モデルの追加学習手法として**Fine-tuning**と**LoRA (Low-Rank Adaptation)**学習の2種類をサポートしています。それぞれの手法には異なる特徴と利点があります。
|
||||
|
||||
**Fine-tuning**は、事前学習済みモデルの重み全体(または大部分)を再学習する手法です。
|
||||
- **利点**: モデル全体の表現力を向上させることができ、元のモデルから大きく変化した画風やコンセプトの学習に適しています。
|
||||
- **欠点**:
|
||||
- 学習には多くのVRAMと計算コストが必要です。
|
||||
- 保存されるファイルサイズが大きくなります(元のモデルと同じサイズ)。
|
||||
- 学習させすぎると、元のモデルが持っていた多様性が失われる「過学習(overfitting)」に陥りやすい傾向があります。
|
||||
- **対応スクリプト**: `sdxl_train.py`, `sd3_train.py`, `flux_train.py`, `lumina_train.py` など、`*_train.py` という命名規則のスクリプトが対応します。
|
||||
|
||||
**LoRA学習**は、モデルの重みは凍結(固定)したまま、「アダプター」と呼ばれる小さな追加ネットワークのみを学習する手法です。
|
||||
- **利点**:
|
||||
- 少ないVRAMと計算コストで高速に学習できます。
|
||||
- 学習する重みが少ないため、過学習に強いとされています。
|
||||
- 保存されるファイル(LoRAネットワーク)は数十〜数百MBと非常に小さく、管理が容易です。
|
||||
- 複数のLoRAを組み合わせて使用することも可能です。
|
||||
- **欠点**: モデル全体を学習するわけではないため、Fine-tuningほどの大きな変化は期待できない場合があります。
|
||||
- **対応スクリプト**: `sdxl_train_network.py`, `sd3_train_network.py`, `flux_train_network.py` など、`*_train_network.py` という命名規則のスクリプトが対応します。
|
||||
|
||||
| 特徴 | Fine-tuning | LoRA学習 |
|
||||
|:---|:---|:---|
|
||||
| **学習対象** | モデルの全重み | 追加ネットワーク(アダプター)のみ |
|
||||
| **VRAM/計算コスト**| 大 | 小 |
|
||||
| **学習時間** | 長 | 短 |
|
||||
| **ファイルサイズ** | 大(数GB) | 小(数MB〜数百MB) |
|
||||
| **過学習リスク** | 高 | 低 |
|
||||
| **適した用途** | 大規模な画風変更、コンセプト学習 | 特定のキャラ、画風の追加学習 |
|
||||
|
||||
一般的に、特定のキャラクターや画風を追加したい場合は**LoRA学習**から試すことが推奨されます。より根本的な画風の変更や、高品質なモデルを目指す場合は**Fine-tuning**が有効な選択肢となります。
|
||||
|
||||
</details>
|
||||
|
||||
---
|
||||
|
||||
### Fine-tuning for each architecture
|
||||
|
||||
Fine-tuning updates the entire weights of the model, so it has different options and considerations than LoRA tuning. This section describes the fine-tuning scripts for major architectures.
|
||||
|
||||
The basic command structure is common to all architectures.
|
||||
|
||||
```bash
|
||||
accelerate launch --mixed_precision bf16 {script_name}.py \
|
||||
--pretrained_model_name_or_path <path_to_model> \
|
||||
--dataset_config <path_to_config.toml> \
|
||||
--output_dir <output_directory> \
|
||||
--output_name <model_output_name> \
|
||||
--save_model_as safetensors \
|
||||
--max_train_steps 10000 \
|
||||
--learning_rate 1e-5 \
|
||||
--optimizer_type AdamW8bit
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
### 各アーキテクチャのFine-tuning
|
||||
|
||||
Fine-tuningはモデルの重み全体を更新するため、LoRA学習とは異なるオプションや考慮事項があります。ここでは主要なアーキテクチャごとのFine-tuningスクリプトについて説明します。
|
||||
|
||||
基本的なコマンドの構造は、どのアーキテクチャでも共通です。
|
||||
|
||||
```bash
|
||||
accelerate launch --mixed_precision bf16 {script_name}.py \
|
||||
--pretrained_model_name_or_path <path_to_model> \
|
||||
--dataset_config <path_to_config.toml> \
|
||||
--output_dir <output_directory> \
|
||||
--output_name <model_output_name> \
|
||||
--save_model_as safetensors \
|
||||
--max_train_steps 10000 \
|
||||
--learning_rate 1e-5 \
|
||||
--optimizer_type AdamW8bit
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
#### SDXL (`sdxl_train.py`)
|
||||
|
||||
Performs fine-tuning for SDXL models. It is possible to train both the U-Net and the Text Encoders.
|
||||
|
||||
**Key Options:**
|
||||
|
||||
- `--train_text_encoder`: Includes the weights of the Text Encoders (CLIP ViT-L and OpenCLIP ViT-bigG) in the training. Effective for significant style changes or strongly learning specific concepts.
|
||||
- `--learning_rate_te1`, `--learning_rate_te2`: Set individual learning rates for each Text Encoder.
|
||||
- `--block_lr`: Divides the U-Net into 23 blocks and sets a different learning rate for each block. This allows for advanced adjustments, such as strengthening or weakening the learning of specific layers. (Not available in LoRA tuning).
|
||||
|
||||
**Command Example:**
|
||||
|
||||
```bash
|
||||
accelerate launch --mixed_precision bf16 sdxl_train.py \
|
||||
--pretrained_model_name_or_path "sd_xl_base_1.0.safetensors" \
|
||||
--dataset_config "dataset_config.toml" \
|
||||
--output_dir "output" \
|
||||
--output_name "sdxl_finetuned" \
|
||||
--train_text_encoder \
|
||||
--learning_rate 1e-5 \
|
||||
--learning_rate_te1 5e-6 \
|
||||
--learning_rate_te2 2e-6
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
#### SDXL (`sdxl_train.py`)
|
||||
|
||||
SDXLモデルのFine-tuningを行います。U-NetとText Encoderの両方を学習させることが可能です。
|
||||
|
||||
**主要なオプション:**
|
||||
|
||||
- `--train_text_encoder`: Text Encoder(CLIP ViT-LとOpenCLIP ViT-bigG)の重みを学習対象に含めます。画風を大きく変えたい場合や、特定の概念を強く学習させたい場合に有効です。
|
||||
- `--learning_rate_te1`, `--learning_rate_te2`: それぞれのText Encoderに個別の学習率を設定します。
|
||||
- `--block_lr`: U-Netを23個のブロックに分割し、ブロックごとに異なる学習率を設定できます。特定の層の学習を強めたり弱めたりする高度な調整が可能です。(LoRA学習では利用できません)
|
||||
|
||||
**コマンド例:**
|
||||
|
||||
```bash
|
||||
accelerate launch --mixed_precision bf16 sdxl_train.py \
|
||||
--pretrained_model_name_or_path "sd_xl_base_1.0.safetensors" \
|
||||
--dataset_config "dataset_config.toml" \
|
||||
--output_dir "output" \
|
||||
--output_name "sdxl_finetuned" \
|
||||
--train_text_encoder \
|
||||
--learning_rate 1e-5 \
|
||||
--learning_rate_te1 5e-6 \
|
||||
--learning_rate_te2 2e-6
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
#### SD3 (`sd3_train.py`)
|
||||
|
||||
Performs fine-tuning for Stable Diffusion 3 Medium models. SD3 consists of three Text Encoders (CLIP-L, CLIP-G, T5-XXL) and a MMDiT (equivalent to U-Net), which can be targeted for training.
|
||||
|
||||
**Key Options:**
|
||||
|
||||
- `--train_text_encoder`: Enables training for CLIP-L and CLIP-G.
|
||||
- `--train_t5xxl`: Enables training for T5-XXL. T5-XXL is a very large model and requires a lot of VRAM for training.
|
||||
- `--blocks_to_swap`: A memory optimization feature to reduce VRAM usage. It swaps some blocks of the MMDiT to CPU memory during training. Useful for using larger batch sizes in low VRAM environments. (Also available in LoRA tuning).
|
||||
- `--num_last_block_to_freeze`: Freezes the weights of the last N blocks of the MMDiT, excluding them from training. Useful for maintaining model stability while focusing on learning in the lower layers.
|
||||
|
||||
**Command Example:**
|
||||
|
||||
```bash
|
||||
accelerate launch --mixed_precision bf16 sd3_train.py \
|
||||
--pretrained_model_name_or_path "sd3_medium.safetensors" \
|
||||
--dataset_config "dataset_config.toml" \
|
||||
--output_dir "output" \
|
||||
--output_name "sd3_finetuned" \
|
||||
--train_text_encoder \
|
||||
--learning_rate 4e-6 \
|
||||
--blocks_to_swap 10
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
#### SD3 (`sd3_train.py`)
|
||||
|
||||
Stable Diffusion 3 MediumモデルのFine-tuningを行います。SD3は3つのText Encoder(CLIP-L, CLIP-G, T5-XXL)とMMDiT(U-Netに相当)で構成されており、これらを学習対象にできます。
|
||||
|
||||
**主要なオプション:**
|
||||
|
||||
- `--train_text_encoder`: CLIP-LとCLIP-Gの学習を有効にします。
|
||||
- `--train_t5xxl`: T5-XXLの学習を有効にします。T5-XXLは非常に大きなモデルのため、学習には多くのVRAMが必要です。
|
||||
- `--blocks_to_swap`: VRAM使用量を削減するためのメモリ最適化機能です。MMDiTの一部のブロックを学習中にCPUメモリに退避(スワップ)させます。VRAMが少ない環境で大きなバッチサイズを使いたい場合に有効です。(LoRA学習でも利用可能)
|
||||
- `--num_last_block_to_freeze`: MMDiTの最後のNブロックの重みを凍結し、学習対象から除外します。モデルの安定性を保ちつつ、下位層を中心に学習させたい場合に有効です。
|
||||
|
||||
**コマンド例:**
|
||||
|
||||
```bash
|
||||
accelerate launch --mixed_precision bf16 sd3_train.py \
|
||||
--pretrained_model_name_or_path "sd3_medium.safetensors" \
|
||||
--dataset_config "dataset_config.toml" \
|
||||
--output_dir "output" \
|
||||
--output_name "sd3_finetuned" \
|
||||
--train_text_encoder \
|
||||
--learning_rate 4e-6 \
|
||||
--blocks_to_swap 10
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
#### FLUX.1 (`flux_train.py`)
|
||||
|
||||
Performs fine-tuning for FLUX.1 models. FLUX.1 is internally composed of two Transformer blocks (Double Blocks, Single Blocks).
|
||||
|
||||
**Key Options:**
|
||||
|
||||
- `--blocks_to_swap`: Similar to SD3, this feature swaps Transformer blocks to the CPU for memory optimization.
|
||||
- `--blockwise_fused_optimizers`: An experimental feature that aims to streamline training by applying individual optimizers to each block.
|
||||
|
||||
**Command Example:**
|
||||
|
||||
```bash
|
||||
accelerate launch --mixed_precision bf16 flux_train.py \
|
||||
--pretrained_model_name_or_path "FLUX.1-dev.safetensors" \
|
||||
--dataset_config "dataset_config.toml" \
|
||||
--output_dir "output" \
|
||||
--output_name "flux1_finetuned" \
|
||||
--learning_rate 1e-5 \
|
||||
--blocks_to_swap 18
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
#### FLUX.1 (`flux_train.py`)
|
||||
|
||||
FLUX.1モデルのFine-tuningを行います。FLUX.1は内部的に2つのTransformerブロック(Double Blocks, Single Blocks)で構成されています。
|
||||
|
||||
**主要なオプション:**
|
||||
|
||||
- `--blocks_to_swap`: SD3と同様に、メモリ最適化のためにTransformerブロックをCPUにスワップする機能です。
|
||||
- `--blockwise_fused_optimizers`: 実験的な機能で、各ブロックに個別のオプティマイザを適用し、学習を効率化することを目指します。
|
||||
|
||||
**コマンド例:**
|
||||
|
||||
```bash
|
||||
accelerate launch --mixed_precision bf16 flux_train.py \
|
||||
--pretrained_model_name_or_path "FLUX.1-dev.safetensors" \
|
||||
--dataset_config "dataset_config.toml" \
|
||||
--output_dir "output" \
|
||||
--output_name "flux1_finetuned" \
|
||||
--learning_rate 1e-5 \
|
||||
--blocks_to_swap 18
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
#### Lumina (`lumina_train.py`)
|
||||
|
||||
Performs fine-tuning for Lumina-Next DiT models.
|
||||
|
||||
**Key Options:**
|
||||
|
||||
- `--use_flash_attn`: Enables Flash Attention to speed up computation.
|
||||
- `lumina_train.py` is relatively new, and many of its options are shared with other scripts. Training can be performed following the basic command pattern.
|
||||
|
||||
**Command Example:**
|
||||
|
||||
```bash
|
||||
accelerate launch --mixed_precision bf16 lumina_train.py \
|
||||
--pretrained_model_name_or_path "Lumina-Next-DiT-B.safetensors" \
|
||||
--dataset_config "dataset_config.toml" \
|
||||
--output_dir "output" \
|
||||
--output_name "lumina_finetuned" \
|
||||
--learning_rate 1e-5
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
#### Lumina (`lumina_train.py`)
|
||||
|
||||
Lumina-Next DiTモデルのFine-tuningを行います。
|
||||
|
||||
**主要なオプション:**
|
||||
|
||||
- `--use_flash_attn`: Flash Attentionを有効にし、計算を高速化します。
|
||||
- `lumina_train.py`は比較的新しく、オプションは他のスクリプトと共通化されている部分が多いです。基本的なコマンドパターンに従って学習を行えます。
|
||||
|
||||
**コマンド例:**
|
||||
|
||||
```bash
|
||||
accelerate launch --mixed_precision bf16 lumina_train.py \
|
||||
--pretrained_model_name_or_path "Lumina-Next-DiT-B.safetensors" \
|
||||
--dataset_config "dataset_config.toml" \
|
||||
--output_dir "output" \
|
||||
--output_name "lumina_finetuned" \
|
||||
--learning_rate 1e-5
|
||||
```
|
||||
|
||||
</details>
|
||||
|
||||
---
|
||||
|
||||
### Differences between Fine-tuning and LoRA tuning per architecture
|
||||
|
||||
| Architecture | Key Features/Options Specific to Fine-tuning | Main Differences from LoRA tuning |
|
||||
|:---|:---|:---|
|
||||
| **SDXL** | `--block_lr` | Only fine-tuning allows for granular control over the learning rate for each U-Net block. |
|
||||
| **SD3** | `--train_text_encoder`, `--train_t5xxl`, `--num_last_block_to_freeze` | Only fine-tuning can train the entire Text Encoders. LoRA only trains the adapter parts. |
|
||||
| **FLUX.1** | `--blockwise_fused_optimizers` | Since fine-tuning updates the entire model's weights, more experimental optimizer options are available. |
|
||||
| **Lumina** | (Few specific options) | Basic training options are common, but fine-tuning differs in that it updates the entire model's foundation. |
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
### アーキテクチャごとのFine-tuningとLoRA学習の違い
|
||||
|
||||
| アーキテクチャ | Fine-tuning特有の主要機能・オプション | LoRA学習との主な違い |
|
||||
|:---|:---|:---|
|
||||
| **SDXL** | `--block_lr` | U-Netのブロックごとに学習率を細かく制御できるのはFine-tuningのみです。 |
|
||||
| **SD3** | `--train_text_encoder`, `--train_t5xxl`, `--num_last_block_to_freeze` | Text Encoder全体を学習対象にできるのはFine-tuningです。LoRAではアダプター部分のみ学習します。 |
|
||||
| **FLUX.1** | `--blockwise_fused_optimizers` | Fine-tuningではモデル全体の重みを更新するため、より実験的なオプティマイザの選択肢が用意されています。 |
|
||||
| **Lumina** | (特有のオプションは少ない) | 基本的な学習オプションは共通ですが、Fine-tuningはモデルの基盤全体を更新する点で異なります。 |
|
||||
|
||||
</details>
|
||||
709
docs/flux_train_network.md
Normal file
709
docs/flux_train_network.md
Normal file
@@ -0,0 +1,709 @@
|
||||
Status: reviewed
|
||||
|
||||
# LoRA Training Guide for FLUX.1 using `flux_train_network.py` / `flux_train_network.py` を用いたFLUX.1モデルのLoRA学習ガイド
|
||||
|
||||
This document explains how to train LoRA models for the FLUX.1 model using `flux_train_network.py` included in the `sd-scripts` repository.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
このドキュメントでは、`sd-scripts`リポジトリに含まれる`flux_train_network.py`を使用して、FLUX.1モデルに対するLoRA (Low-Rank Adaptation) モデルを学習する基本的な手順について解説します。
|
||||
|
||||
</details>
|
||||
|
||||
## 1. Introduction / はじめに
|
||||
|
||||
`flux_train_network.py` trains additional networks such as LoRA on the FLUX.1 model, which uses a transformer-based architecture different from Stable Diffusion. Two text encoders, CLIP-L and T5-XXL, and a dedicated AutoEncoder are used.
|
||||
|
||||
This guide assumes you know the basics of LoRA training. For common options see [train_network.py](train_network.md) and [sdxl_train_network.py](sdxl_train_network.md).
|
||||
|
||||
**Prerequisites:**
|
||||
|
||||
* The repository is cloned and the Python environment is ready.
|
||||
* A training dataset is prepared. See the dataset configuration guide.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
`flux_train_network.py`は、FLUX.1モデルに対してLoRAなどの追加ネットワークを学習させるためのスクリプトです。FLUX.1はStable Diffusionとは異なるアーキテクチャを持つ画像生成モデルであり、このスクリプトを使用することで、特定のキャラクターや画風を再現するLoRAモデルを作成できます。
|
||||
|
||||
このガイドは、基本的なLoRA学習の手順を理解しているユーザーを対象としています。基本的な使い方や共通のオプションについては、[`train_network.py`のガイド](train_network.md)を参照してください。また一部のパラメータは [`sdxl_train_network.py`](sdxl_train_network.md) と同様のものがあるため、そちらも参考にしてください。
|
||||
|
||||
**前提条件:**
|
||||
|
||||
* `sd-scripts`リポジトリのクローンとPython環境のセットアップが完了していること。
|
||||
* 学習用データセットの準備が完了していること。(データセットの準備については[データセット設定ガイド](link/to/dataset/config/doc)を参照してください)
|
||||
|
||||
</details>
|
||||
|
||||
## 2. Differences from `train_network.py` / `train_network.py` との違い
|
||||
|
||||
`flux_train_network.py` is based on `train_network.py` but adapted for FLUX.1. Main differences include:
|
||||
|
||||
* **Target model:** FLUX.1 model (dev or schnell version).
|
||||
* **Model structure:** Unlike Stable Diffusion, FLUX.1 uses a Transformer-based architecture with two text encoders (CLIP-L and T5-XXL) and a dedicated AutoEncoder (AE) instead of VAE.
|
||||
* **Required arguments:** Additional arguments for FLUX.1 model, CLIP-L, T5-XXL, and AE model files.
|
||||
* **Incompatible options:** Some Stable Diffusion-specific arguments (e.g., `--v2`, `--clip_skip`, `--max_token_length`) are not used in FLUX.1 training.
|
||||
* **FLUX.1-specific arguments:** Additional arguments for FLUX.1-specific training parameters like timestep sampling and guidance scale.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
`flux_train_network.py`は`train_network.py`をベースに、FLUX.1モデルに対応するための変更が加えられています。主な違いは以下の通りです。
|
||||
|
||||
* **対象モデル:** FLUX.1モデル(dev版またはschnell版)を対象とします。
|
||||
* **モデル構造:** Stable Diffusionとは異なり、FLUX.1はTransformerベースのアーキテクチャを持ちます。Text EncoderとしてCLIP-LとT5-XXLの二つを使用し、VAEの代わりに専用のAutoEncoder (AE) を使用します。
|
||||
* **必須の引数:** FLUX.1モデル、CLIP-L、T5-XXL、AEの各モデルファイルを指定する引数が追加されています。
|
||||
* **一部引数の非互換性:** Stable Diffusion向けの引数の一部(例: `--v2`, `--clip_skip`, `--max_token_length`)はFLUX.1の学習では使用されません。
|
||||
* **FLUX.1特有の引数:** タイムステップのサンプリング方法やガイダンススケールなど、FLUX.1特有の学習パラメータを指定する引数が追加されています。
|
||||
|
||||
</details>
|
||||
|
||||
## 3. Preparation / 準備
|
||||
|
||||
Before starting training you need:
|
||||
|
||||
1. **Training script:** `flux_train_network.py`
|
||||
2. **FLUX.1 model file:** Base FLUX.1 model `.safetensors` file (e.g., `flux1-dev.safetensors`).
|
||||
3. **Text Encoder model files:**
|
||||
- CLIP-L model `.safetensors` file (e.g., `clip_l.safetensors`)
|
||||
- T5-XXL model `.safetensors` file (e.g., `t5xxl.safetensors`)
|
||||
4. **AutoEncoder model file:** FLUX.1-compatible AE model `.safetensors` file (e.g., `ae.safetensors`).
|
||||
5. **Dataset definition file (.toml):** TOML format file describing training dataset configuration (e.g., `my_flux_dataset_config.toml`).
|
||||
|
||||
### Downloading Required Models
|
||||
|
||||
To train FLUX.1 models, you need to download the following model files:
|
||||
|
||||
- **DiT, AE**: Download from the [black-forest-labs/FLUX.1 dev](https://huggingface.co/black-forest-labs/FLUX.1-dev) repository. Use `flux1-dev.safetensors` and `ae.safetensors`. The weights in the subfolder are in Diffusers format and cannot be used.
|
||||
- **Text Encoder 1 (T5-XXL), Text Encoder 2 (CLIP-L)**: Download from the [ComfyUI FLUX Text Encoders](https://huggingface.co/comfyanonymous/flux_text_encoders) repository. Please use `t5xxl_fp16.safetensors` for T5-XXL. Thanks to ComfyUI for providing these models.
|
||||
|
||||
To train Chroma models, you need to download the Chroma model file from the following repository:
|
||||
|
||||
- **Chroma Base**: Download from the [lodestones/Chroma1-Base](https://huggingface.co/lodestones/Chroma1-Base) repository. Use `Chroma.safetensors`.
|
||||
|
||||
We have tested Chroma training with the weights from the [lodestones/Chroma](https://huggingface.co/lodestones/Chroma) repository.
|
||||
|
||||
AE and T5-XXL models are same as FLUX.1, so you can use the same files. CLIP-L model is not used for Chroma training, so you can omit the `--clip_l` argument.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
学習を開始する前に、以下のファイルが必要です。
|
||||
|
||||
1. **学習スクリプト:** `flux_train_network.py`
|
||||
2. **FLUX.1モデルファイル:** 学習のベースとなるFLUX.1モデルの`.safetensors`ファイル(例: `flux1-dev.safetensors`)。
|
||||
3. **Text Encoderモデルファイル:**
|
||||
- CLIP-Lモデルの`.safetensors`ファイル。例として`clip_l.safetensors`を使用します。
|
||||
- T5-XXLモデルの`.safetensors`ファイル。例として`t5xxl.safetensors`を使用します。
|
||||
4. **AutoEncoderモデルファイル:** FLUX.1に対応するAEモデルの`.safetensors`ファイル。例として`ae.safetensors`を使用します。
|
||||
5. **データセット定義ファイル (.toml):** 学習データセットの設定を記述したTOML形式のファイル。(詳細は[データセット設定ガイド](link/to/dataset/config/doc)を参照してください)。例として`my_flux_dataset_config.toml`を使用します。
|
||||
|
||||
**必要なモデルのダウンロード**
|
||||
|
||||
FLUX.1モデルを学習するためには、以下のモデルファイルをダウンロードする必要があります。
|
||||
|
||||
- **DiT, AE**: [black-forest-labs/FLUX.1 dev](https://huggingface.co/black-forest-labs/FLUX.1-dev) リポジトリからダウンロードします。`flux1-dev.safetensors`と`ae.safetensors`を使用してください。サブフォルダ内の重みはDiffusers形式であり、使用できません。
|
||||
- **Text Encoder 1 (T5-XXL), Text Encoder 2 (CLIP-L)**: [ComfyUI FLUX Text Encoders](https://huggingface.co/comfyanonymous/flux_text_encoders) リポジトリからダウンロードします。T5-XXLには`t5xxl_fp16.safetensors`を使用してください。これらのモデルを提供いただいたComfyUIに感謝します。
|
||||
|
||||
Chromaモデルを学習する場合は、以下のリポジトリからChromaモデルファイルをダウンロードする必要があります。
|
||||
|
||||
- **Chroma Base**: [lodestones/Chroma1-Base](https://huggingface.co/lodestones/Chroma1-Base) リポジトリからダウンロードします。`Chroma.safetensors`を使用してください。
|
||||
|
||||
Chromaの学習のテストは [lodestones/Chroma](https://huggingface.co/lodestones/Chroma) リポジトリの重みを使用して行いました。
|
||||
|
||||
AEとT5-XXLモデルはFLUX.1と同じものを使用できるため、同じファイルを使用します。CLIP-LモデルはChroma学習では使用されないため、`--clip_l`引数は省略できます。
|
||||
|
||||
</details>
|
||||
|
||||
## 4. Running the Training / 学習の実行
|
||||
|
||||
Run `flux_train_network.py` from the terminal with FLUX.1 specific arguments. Here's a basic command example:
|
||||
|
||||
```bash
|
||||
accelerate launch --num_cpu_threads_per_process 1 flux_train_network.py \
|
||||
--pretrained_model_name_or_path="<path to FLUX.1 model>" \
|
||||
--clip_l="<path to CLIP-L model>" \
|
||||
--t5xxl="<path to T5-XXL model>" \
|
||||
--ae="<path to AE model>" \
|
||||
--dataset_config="my_flux_dataset_config.toml" \
|
||||
--output_dir="<output directory>" \
|
||||
--output_name="my_flux_lora" \
|
||||
--save_model_as=safetensors \
|
||||
--network_module=networks.lora_flux \
|
||||
--network_dim=16 \
|
||||
--network_alpha=1 \
|
||||
--learning_rate=1e-4 \
|
||||
--optimizer_type="AdamW8bit" \
|
||||
--lr_scheduler="constant" \
|
||||
--sdpa \
|
||||
--max_train_epochs=10 \
|
||||
--save_every_n_epochs=1 \
|
||||
--mixed_precision="fp16" \
|
||||
--gradient_checkpointing \
|
||||
--guidance_scale=1.0 \
|
||||
--timestep_sampling="flux_shift" \
|
||||
--model_prediction_type="raw" \
|
||||
--blocks_to_swap=18 \
|
||||
--cache_text_encoder_outputs \
|
||||
--cache_latents
|
||||
```
|
||||
|
||||
### Training Chroma Models
|
||||
|
||||
If you want to train a Chroma model, specify `--model_type=chroma`. Chroma does not use CLIP-L, so the `--clip_l` argument is not needed. T5XXL and AE are same as FLUX.1. The command would look like this:
|
||||
|
||||
```bash
|
||||
accelerate launch --num_cpu_threads_per_process 1 flux_train_network.py \
|
||||
--pretrained_model_name_or_path="<path to Chroma model>" \
|
||||
--model_type=chroma \
|
||||
--t5xxl="<path to T5-XXL model>" \
|
||||
--ae="<path to AE model>" \
|
||||
--dataset_config="my_flux_dataset_config.toml" \
|
||||
--output_dir="<output directory>" \
|
||||
--output_name="my_chroma_lora" \
|
||||
--guidance_scale=0.0 \
|
||||
--timestep_sampling="sigmoid" \
|
||||
--apply_t5_attn_mask \
|
||||
...
|
||||
```
|
||||
|
||||
Note that for Chroma models, `--guidance_scale=0.0` is required to disable guidance scale, and `--apply_t5_attn_mask` is needed to apply attention masks for T5XXL Text Encoder.
|
||||
|
||||
The sample image generation during training requires specifying a negative prompt. Also, set `--g 0` to disable embedded guidance scale and `--l 4.0` to set the CFG scale. For example:
|
||||
|
||||
```
|
||||
Japanese shrine in the summer forest. --n low quality, ugly, unfinished, out of focus, deformed, disfigure, blurry, smudged, restricted palette, flat colors --w 512 --h 512 --d 1 --l 4.0 --g 0.0 --s 20
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
学習は、ターミナルから`flux_train_network.py`を実行することで開始します。基本的なコマンドラインの構造は`train_network.py`と同様ですが、FLUX.1特有の引数を指定する必要があります。
|
||||
|
||||
コマンドラインの例は英語のドキュメントを参照してください。
|
||||
|
||||
#### Chromaモデルの学習
|
||||
|
||||
Chromaモデルを学習したい場合は、`--model_type=chroma`を指定します。ChromaはCLIP-Lを使用しないため、`--clip_l`引数は不要です。T5XXLとAEはFLUX.1と同様です。
|
||||
|
||||
コマンドラインの例は英語のドキュメントを参照してください。
|
||||
|
||||
学習中のサンプル画像生成には、ネガティブプロンプトを指定してください。また `--g 0` を指定して埋め込みガイダンススケールを無効化し、`--l 4.0` を指定してCFGスケールを設定します。
|
||||
|
||||
</details>
|
||||
|
||||
### 4.1. Explanation of Key Options / 主要なコマンドライン引数の解説
|
||||
|
||||
The script adds FLUX.1 specific arguments. For common arguments (like `--output_dir`, `--output_name`, `--network_module`, etc.), see the [`train_network.py` guide](train_network.md).
|
||||
|
||||
#### Model-related [Required]
|
||||
|
||||
* `--pretrained_model_name_or_path="<path to FLUX.1/Chroma model>"` **[Required]**
|
||||
- Specifies the path to the base FLUX.1 or Chroma model `.safetensors` file. Diffusers format directories are not currently supported.
|
||||
* `--model_type=<model type>`
|
||||
- Specifies the type of base model for training. Choose from `flux` or `chroma`. Default is `flux`.
|
||||
* `--clip_l="<path to CLIP-L model>"` **[Required when flux is selected]**
|
||||
- Specifies the path to the CLIP-L Text Encoder model `.safetensors` file. Not needed when `--model_type=chroma`.
|
||||
* `--t5xxl="<path to T5-XXL model>"` **[Required]**
|
||||
- Specifies the path to the T5-XXL Text Encoder model `.safetensors` file.
|
||||
* `--ae="<path to AE model>"` **[Required]**
|
||||
- Specifies the path to the FLUX.1-compatible AutoEncoder model `.safetensors` file.
|
||||
|
||||
#### FLUX.1 Training Parameters
|
||||
|
||||
* `--guidance_scale=<float>`
|
||||
- FLUX.1 dev version is distilled with specific guidance scale values, but for training, specify `1.0` to disable guidance scale. Default is `3.5`, so be sure to specify this. Usually ignored for schnell version.
|
||||
- Chroma requires `--guidance_scale=0.0` to disable guidance scale.
|
||||
* `--timestep_sampling=<choice>`
|
||||
- Specifies the sampling method for timesteps (noise levels) during training. Choose from `sigma`, `uniform`, `sigmoid`, `shift`, `flux_shift`. Default is `sigma`. Recommended is `flux_shift`. For Chroma models, `sigmoid` is recommended.
|
||||
* `--sigmoid_scale=<float>`
|
||||
- Scale factor when `timestep_sampling` is set to `sigmoid`, `shift`, or `flux_shift`. Default and recommended value is `1.0`.
|
||||
* `--model_prediction_type=<choice>`
|
||||
- Specifies what the model predicts. Choose from `raw` (use prediction as-is), `additive` (add to noise input), `sigma_scaled` (apply sigma scaling). Default is `sigma_scaled`. Recommended is `raw`.
|
||||
* `--discrete_flow_shift=<float>`
|
||||
- Specifies the shift value for the scheduler used in Flow Matching. Default is `3.0`. This value is ignored when `timestep_sampling` is set to other than `shift`.
|
||||
|
||||
#### Memory/Speed Related
|
||||
|
||||
* `--fp8_base`
|
||||
- Enables training in FP8 format for FLUX.1, CLIP-L, and T5-XXL. This can significantly reduce VRAM usage, but the training results may vary.
|
||||
* `--blocks_to_swap=<integer>` **[Experimental Feature]**
|
||||
- Setting to reduce VRAM usage by swapping parts of the model (Transformer blocks) between CPU and GPU. Specify the number of blocks to swap as an integer (e.g., `18`). Larger values reduce VRAM usage but decrease training speed. Adjust according to your GPU's VRAM capacity. Can be used with `gradient_checkpointing`.
|
||||
- Cannot be used with `--cpu_offload_checkpointing`.
|
||||
* `--cache_text_encoder_outputs`
|
||||
- Caches the outputs of CLIP-L and T5-XXL. This reduces memory usage.
|
||||
* `--cache_latents`, `--cache_latents_to_disk`
|
||||
- Caches the outputs of AE. Similar functionality to [sdxl_train_network.py](sdxl_train_network.md).
|
||||
|
||||
#### Incompatible/Deprecated Arguments
|
||||
|
||||
* `--v2`, `--v_parameterization`, `--clip_skip`: These are Stable Diffusion-specific arguments and are not used in FLUX.1 training.
|
||||
* `--max_token_length`: This is an argument for Stable Diffusion v1/v2. For FLUX.1, use `--t5xxl_max_token_length`.
|
||||
* `--split_mode`: Deprecated argument. Use `--blocks_to_swap` instead.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
[`train_network.py`のガイド](train_network.md)で説明されている引数に加え、以下のFLUX.1特有の引数を指定します。共通の引数(`--output_dir`, `--output_name`, `--network_module`, `--network_dim`, `--network_alpha`, `--learning_rate`など)については、上記ガイドを参照してください。
|
||||
|
||||
コマンドラインの例と詳細な引数の説明は英語のドキュメントを参照してください。
|
||||
|
||||
</details>
|
||||
|
||||
### 4.2. Starting Training / 学習の開始
|
||||
|
||||
Training begins once you run the command with the required options. Log checking is the same as in [`train_network.py`](train_network.md#32-starting-the-training--学習の開始).
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
必要な引数を設定し、コマンドを実行すると学習が開始されます。基本的な流れやログの確認方法は[`train_network.py`のガイド](train_network.md#32-starting-the-training--学習の開始)と同様です。
|
||||
|
||||
</details>
|
||||
|
||||
## 5. Using the Trained Model / 学習済みモデルの利用
|
||||
|
||||
After training, a LoRA model file is saved in `output_dir` and can be used in inference environments supporting FLUX.1 (e.g. ComfyUI + Flux nodes).
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
学習が完了すると、指定した`output_dir`にLoRAモデルファイル(例: `my_flux_lora.safetensors`)が保存されます。このファイルは、FLUX.1モデルに対応した推論環境(例: ComfyUI + ComfyUI-FluxNodes)で使用できます。
|
||||
|
||||
</details>
|
||||
|
||||
## 6. Advanced Settings / 高度な設定
|
||||
|
||||
### 6.1. VRAM Usage Optimization / VRAM使用量の最適化
|
||||
|
||||
FLUX.1 is a relatively large model, so GPUs without sufficient VRAM require optimization. Here are settings to reduce VRAM usage (with `--fp8_base`):
|
||||
|
||||
#### Recommended Settings by GPU Memory
|
||||
|
||||
| GPU Memory | Recommended Settings |
|
||||
|------------|---------------------|
|
||||
| 24GB VRAM | Basic settings work fine (batch size 2) |
|
||||
| 16GB VRAM | Set batch size to 1 and use `--blocks_to_swap` |
|
||||
| 12GB VRAM | Use `--blocks_to_swap 16` and 8bit AdamW |
|
||||
| 10GB VRAM | Use `--blocks_to_swap 22`, recommend fp8 format for T5XXL |
|
||||
| 8GB VRAM | Use `--blocks_to_swap 28`, recommend fp8 format for T5XXL |
|
||||
|
||||
#### Key VRAM Reduction Options
|
||||
|
||||
- **`--fp8_base`**: Enables training in FP8 format.
|
||||
|
||||
- **`--blocks_to_swap <number>`**: Swaps blocks between CPU and GPU to reduce VRAM usage. Higher numbers save more VRAM but reduce training speed. FLUX.1 supports up to 35 blocks for swapping.
|
||||
|
||||
- **`--cpu_offload_checkpointing`**: Offloads gradient checkpoints to CPU. Can reduce VRAM usage by up to 1GB but decreases training speed by about 15%. Cannot be used with `--blocks_to_swap`. Chroma models do not support this option.
|
||||
|
||||
- **Using Adafactor optimizer**: Can reduce VRAM usage more than 8bit AdamW:
|
||||
```
|
||||
--optimizer_type adafactor --optimizer_args "relative_step=False" "scale_parameter=False" "warmup_init=False" --lr_scheduler constant_with_warmup --max_grad_norm 0.0
|
||||
```
|
||||
|
||||
- **Using T5XXL fp8 format**: For GPUs with less than 10GB VRAM, using fp8 format T5XXL checkpoints is recommended. Download `t5xxl_fp8_e4m3fn.safetensors` from [comfyanonymous/flux_text_encoders](https://huggingface.co/comfyanonymous/flux_text_encoders) (use without `scaled`).
|
||||
|
||||
- **FP8/FP16 Mixed Training [Experimental]**: Specify `--fp8_base_unet` to train the FLUX.1 model in FP8 format while training Text Encoders (CLIP-L/T5XXL) in BF16/FP16 format. This can further reduce VRAM usage.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
FLUX.1モデルは比較的大きなモデルであるため、十分なVRAMを持たないGPUでは工夫が必要です。VRAM使用量を削減するための設定の詳細は英語のドキュメントを参照してください。
|
||||
|
||||
主要なVRAM削減オプション:
|
||||
- `--fp8_base`: FP8形式での学習を有効化
|
||||
- `--blocks_to_swap`: CPUとGPU間でブロックをスワップ
|
||||
- `--cpu_offload_checkpointing`: 勾配チェックポイントをCPUにオフロード
|
||||
- Adafactorオプティマイザの使用
|
||||
- T5XXLのfp8形式の使用
|
||||
- FP8/FP16混合学習(実験的機能)
|
||||
|
||||
</details>
|
||||
|
||||
### 6.2. Important FLUX.1 LoRA Training Settings / FLUX.1 LoRA学習の重要な設定
|
||||
|
||||
FLUX.1 training has many unknowns, and several settings can be specified with arguments:
|
||||
|
||||
#### Timestep Sampling Methods
|
||||
|
||||
The `--timestep_sampling` option specifies how timesteps (0-1) are sampled:
|
||||
|
||||
- `sigma`: Sigma-based like SD3
|
||||
- `uniform`: Uniform random
|
||||
- `sigmoid`: Sigmoid of normal distribution random (similar to x-flux, AI-toolkit)
|
||||
- `shift`: Sigmoid value of normal distribution random with shift. The `--discrete_flow_shift` setting is used to shift the sigmoid value.
|
||||
- `flux_shift`: Shift sigmoid value of normal distribution random according to resolution (similar to FLUX.1 dev inference).
|
||||
|
||||
`--discrete_flow_shift` only applies when `--timestep_sampling` is set to `shift`.
|
||||
|
||||
#### Model Prediction Processing
|
||||
|
||||
The `--model_prediction_type` option specifies how to interpret and process model predictions:
|
||||
|
||||
- `raw`: Use as-is (similar to x-flux) **[Recommended]**
|
||||
- `additive`: Add to noise input
|
||||
- `sigma_scaled`: Apply sigma scaling (similar to SD3)
|
||||
|
||||
#### Recommended Settings
|
||||
|
||||
Based on experiments, the following settings work well:
|
||||
```
|
||||
--timestep_sampling shift --discrete_flow_shift 3.1582 --model_prediction_type raw --guidance_scale 1.0
|
||||
```
|
||||
|
||||
For Chroma models, the following settings are recommended:
|
||||
```
|
||||
--timestep_sampling sigmoid --model_prediction_type raw --guidance_scale 0.0
|
||||
```
|
||||
|
||||
**About Guidance Scale**: FLUX.1 dev version is distilled with specific guidance scale values, but for training, specify `--guidance_scale 1.0` to disable guidance scale. Chroma requires `--guidance_scale 0.0` to disable guidance scale because it is not distilled.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
FLUX.1の学習には多くの未知の点があり、いくつかの設定は引数で指定できます。詳細な説明とコマンドラインの例は英語のドキュメントを参照してください。
|
||||
|
||||
主要な設定オプション:
|
||||
- タイムステップのサンプリング方法(`--timestep_sampling`)
|
||||
- モデル予測の処理方法(`--model_prediction_type`)
|
||||
- 推奨設定の組み合わせ
|
||||
|
||||
</details>
|
||||
|
||||
### 6.3. Layer-specific Rank Configuration / 各層に対するランク指定
|
||||
|
||||
You can specify different ranks (network_dim) for each layer of FLUX.1. This allows you to emphasize or disable LoRA effects for specific layers.
|
||||
|
||||
Specify the following network_args to set ranks for each layer. Setting 0 disables LoRA for that layer:
|
||||
|
||||
| network_args | Target Layer |
|
||||
|--------------|--------------|
|
||||
| img_attn_dim | DoubleStreamBlock img_attn |
|
||||
| txt_attn_dim | DoubleStreamBlock txt_attn |
|
||||
| img_mlp_dim | DoubleStreamBlock img_mlp |
|
||||
| txt_mlp_dim | DoubleStreamBlock txt_mlp |
|
||||
| img_mod_dim | DoubleStreamBlock img_mod |
|
||||
| txt_mod_dim | DoubleStreamBlock txt_mod |
|
||||
| single_dim | SingleStreamBlock linear1 and linear2 |
|
||||
| single_mod_dim | SingleStreamBlock modulation |
|
||||
|
||||
Example usage:
|
||||
```
|
||||
--network_args "img_attn_dim=4" "img_mlp_dim=8" "txt_attn_dim=2" "txt_mlp_dim=2" "img_mod_dim=2" "txt_mod_dim=2" "single_dim=4" "single_mod_dim=2"
|
||||
```
|
||||
|
||||
To apply LoRA to FLUX conditioning layers, specify `in_dims` in network_args as a comma-separated list of 5 numbers:
|
||||
|
||||
```
|
||||
--network_args "in_dims=[4,2,2,2,4]"
|
||||
```
|
||||
|
||||
Each number corresponds to `img_in`, `time_in`, `vector_in`, `guidance_in`, `txt_in`. The example above applies LoRA to all conditioning layers with ranks of 4 for `img_in` and `txt_in`, and ranks of 2 for others.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
FLUX.1の各層に対して異なるランク(network_dim)を指定できます。これにより、特定の層に対してLoRAの効果を強調したり、無効化したりできます。
|
||||
|
||||
詳細な設定方法とコマンドラインの例は英語のドキュメントを参照してください。
|
||||
|
||||
</details>
|
||||
|
||||
### 6.4. Block Selection for Training / 学習するブロックの指定
|
||||
|
||||
You can specify which blocks to train using `train_double_block_indices` and `train_single_block_indices` in network_args. Indices are 0-based. Default is to train all blocks if omitted.
|
||||
|
||||
Specify indices as integer lists like `0,1,5,8` or integer ranges like `0,1,4-5,7`:
|
||||
- Double blocks: 19 blocks, valid range 0-18
|
||||
- Single blocks: 38 blocks, valid range 0-37
|
||||
- Specify `all` to train all blocks
|
||||
- Specify `none` to skip training blocks
|
||||
|
||||
Example usage:
|
||||
```
|
||||
--network_args "train_double_block_indices=0,1,8-12,18" "train_single_block_indices=3,10,20-25,37"
|
||||
```
|
||||
|
||||
Or:
|
||||
```
|
||||
--network_args "train_double_block_indices=none" "train_single_block_indices=10-15"
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
FLUX.1 LoRA学習では、network_argsの`train_double_block_indices`と`train_single_block_indices`を指定することで、学習するブロックを指定できます。
|
||||
|
||||
詳細な設定方法とコマンドラインの例は英語のドキュメントを参照してください。
|
||||
|
||||
</details>
|
||||
|
||||
### 6.5. Regular Expression-based Rank/LR Configuration / 正規表現によるランク・学習率の指定
|
||||
|
||||
You can specify ranks (dims) and learning rates for LoRA modules using regular expressions. This allows for more flexible and fine-grained control than specifying by layer.
|
||||
|
||||
These settings are specified via the `network_args` argument.
|
||||
|
||||
* `network_reg_dims`: Specify ranks for modules matching a regular expression. The format is a comma-separated string of `pattern=rank`.
|
||||
* Example: `--network_args "network_reg_dims=single.*_modulation.*=4,img_attn=8"`
|
||||
* This sets the rank to 4 for modules whose names contain `single` and contain `_modulation`, and to 8 for modules containing `img_attn`.
|
||||
* `network_reg_lrs`: Specify learning rates for modules matching a regular expression. The format is a comma-separated string of `pattern=lr`.
|
||||
* Example: `--network_args "network_reg_lrs=single_blocks_(\d|10)_=1e-3,double_blocks=2e-3"`
|
||||
* This sets the learning rate to `1e-3` for modules whose names contain `single_blocks` followed by a digit (`0` to `9`) or `10`, and to `2e-3` for modules whose names contain `double_blocks`.
|
||||
|
||||
**Notes:**
|
||||
|
||||
* Settings via `network_reg_dims` and `network_reg_lrs` take precedence over the global `--network_dim` and `--learning_rate` settings.
|
||||
* If a module name matches multiple patterns, the setting from the last matching pattern in the string will be applied.
|
||||
* These settings are applied after the block-specific training settings (`train_double_block_indices`, `train_single_block_indices`).
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
正規表現を用いて、LoRAのモジュールごとにランク(dim)や学習率を指定することができます。これにより、層ごとの指定よりも柔軟できめ細やかな制御が可能になります。
|
||||
|
||||
これらの設定は `network_args` 引数で指定します。
|
||||
|
||||
* `network_reg_dims`: 正規表現にマッチするモジュールに対してランクを指定します。`pattern=rank` という形式の文字列をカンマで区切って指定します。
|
||||
* 例: `--network_args "network_reg_dims=single.*_modulation.*=4,img_attn=8"`
|
||||
* この例では、名前に `single` で始まり `_modulation` を含むモジュールのランクを4に、`img_attn` を含むモジュールのランクを8に設定します。
|
||||
* `network_reg_lrs`: 正規表現にマッチするモジュールに対して学習率を指定します。`pattern=lr` という形式の文字列をカンマで区切って指定します。
|
||||
* 例: `--network_args "network_reg_lrs=single_blocks_(\d|10)_=1e-3,double_blocks=2e-3"`
|
||||
* この例では、名前が `single_blocks` で始まり、後に数字(`0`から`9`)または`10`が続くモジュールの学習率を `1e-3` に、`double_blocks` を含むモジュールの学習率を `2e-3` に設定します。
|
||||
**注意点:**
|
||||
|
||||
* `network_reg_dims` および `network_reg_lrs` での設定は、全体設定である `--network_dim` や `--learning_rate` よりも優先されます。
|
||||
* あるモジュール名が複数のパターンにマッチした場合、文字列の中で後方にあるパターンの設定が適用されます。
|
||||
* これらの設定は、ブロック指定(`train_double_block_indices`, `train_single_block_indices`)が適用された後に行われます。
|
||||
|
||||
</details>
|
||||
|
||||
### 6.6. Text Encoder LoRA Support / Text Encoder LoRAのサポート
|
||||
|
||||
FLUX.1 LoRA training supports training CLIP-L and T5XXL LoRA:
|
||||
|
||||
- To train only FLUX.1: specify `--network_train_unet_only`
|
||||
- To train FLUX.1 and CLIP-L: omit `--network_train_unet_only`
|
||||
- To train FLUX.1, CLIP-L, and T5XXL: omit `--network_train_unet_only` and add `--network_args "train_t5xxl=True"`
|
||||
|
||||
You can specify individual learning rates for CLIP-L and T5XXL with `--text_encoder_lr`. For example, `--text_encoder_lr 1e-4 1e-5` sets the first value for CLIP-L and the second for T5XXL. Specifying one value uses the same learning rate for both. If `--text_encoder_lr` is not specified, the default `--learning_rate` is used for both.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
FLUX.1 LoRA学習は、CLIP-LとT5XXL LoRAのトレーニングもサポートしています。
|
||||
|
||||
詳細な設定方法とコマンドラインの例は英語のドキュメントを参照してください。
|
||||
|
||||
</details>
|
||||
|
||||
### 6.7. Multi-Resolution Training / マルチ解像度トレーニング
|
||||
|
||||
You can define multiple resolutions in the dataset configuration file, with different batch sizes for each resolution.
|
||||
|
||||
Configuration file example:
|
||||
```toml
|
||||
[general]
|
||||
# Common settings
|
||||
flip_aug = true
|
||||
color_aug = false
|
||||
keep_tokens_separator= "|||"
|
||||
shuffle_caption = false
|
||||
caption_tag_dropout_rate = 0
|
||||
caption_extension = ".txt"
|
||||
|
||||
[[datasets]]
|
||||
# First resolution settings
|
||||
batch_size = 2
|
||||
enable_bucket = true
|
||||
resolution = [1024, 1024]
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = "path/to/image/directory"
|
||||
num_repeats = 1
|
||||
|
||||
[[datasets]]
|
||||
# Second resolution settings
|
||||
batch_size = 3
|
||||
enable_bucket = true
|
||||
resolution = [768, 768]
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = "path/to/image/directory"
|
||||
num_repeats = 1
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
データセット設定ファイルで複数の解像度を定義できます。各解像度に対して異なるバッチサイズを指定することができます。
|
||||
|
||||
設定ファイルの例は英語のドキュメントを参照してください。
|
||||
|
||||
</details>
|
||||
|
||||
### 6.8. Validation / 検証
|
||||
|
||||
You can calculate validation loss during training using a validation dataset to evaluate model generalization performance.
|
||||
|
||||
To set up validation, add a `validation_split` and optionally `validation_seed` to your dataset configuration TOML file.
|
||||
|
||||
```toml
|
||||
validation_seed = 42 # [Optional] Validation seed, otherwise uses training seed for validation split .
|
||||
enable_bucket = true
|
||||
resolution = [1024, 1024]
|
||||
|
||||
[[datasets]]
|
||||
[[datasets.subsets]]
|
||||
# This directory will use 100% of the images for training
|
||||
image_dir = "path/to/image/directory"
|
||||
|
||||
[[datasets]]
|
||||
validation_split = 0.1 # Split between 0.0 and 1.0 where 1.0 will use the full subset as a validation dataset
|
||||
|
||||
[[datasets.subsets]]
|
||||
# This directory will split 10% to validation and 90% to training
|
||||
image_dir = "path/to/image/second-directory"
|
||||
|
||||
[[datasets]]
|
||||
validation_split = 1.0 # Will use this full subset as a validation subset.
|
||||
|
||||
[[datasets.subsets]]
|
||||
# This directory will use the 100% to validation and 0% to training
|
||||
image_dir = "path/to/image/full_validation"
|
||||
```
|
||||
|
||||
**Notes:**
|
||||
|
||||
* Validation loss calculation uses fixed timestep sampling and random seeds to reduce loss variation due to randomness for more stable evaluation.
|
||||
* Currently, validation loss is not supported when using Schedule-Free optimizers (`AdamWScheduleFree`, `RAdamScheduleFree`, `ProdigyScheduleFree`).
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
学習中に検証データセットを使用して損失 (Validation Loss) を計算し、モデルの汎化性能を評価できます。
|
||||
|
||||
詳細な設定方法とコマンドラインの例は英語のドキュメントを参照してください。
|
||||
|
||||
</details>
|
||||
|
||||
## 7. Additional Options / 追加オプション
|
||||
|
||||
### 7.1. Other FLUX.1-specific Options / その他のFLUX.1特有のオプション
|
||||
|
||||
- **T5 Attention Mask Application**: Specify `--apply_t5_attn_mask` to apply attention masks during T5XXL Text Encoder training and inference. Not recommended due to limited inference environment support. **For Chroma models, this option is required.**
|
||||
|
||||
- **IP Noise Gamma**: Use `--ip_noise_gamma` and `--ip_noise_gamma_random_strength` to adjust Input Perturbation noise gamma values during training. See Stable Diffusion 3 training options for details.
|
||||
|
||||
- **LoRA-GGPO Support**: Use LoRA-GGPO (Gradient Group Proportion Optimizer) to stabilize LoRA training:
|
||||
```bash
|
||||
--network_args "ggpo_sigma=0.03" "ggpo_beta=0.01"
|
||||
```
|
||||
|
||||
- **Q/K/V Projection Layer Splitting [Experimental]**: Specify `--network_args "split_qkv=True"` to individually split and apply LoRA to Q/K/V (and SingleStreamBlock Text) projection layers within Attention layers.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
その他のFLUX.1特有のオプション:
|
||||
- T5 Attention Maskの適用(Chromaモデルでは必須)
|
||||
- IPノイズガンマ
|
||||
- LoRA-GGPOサポート
|
||||
- Q/K/V射影層の分割(実験的機能)
|
||||
|
||||
詳細な設定方法とコマンドラインの例は英語のドキュメントを参照してください。
|
||||
|
||||
</details>
|
||||
|
||||
### 7.2. Dataset-related Additional Options / データセット関連の追加オプション
|
||||
|
||||
#### Interpolation Method for Resizing
|
||||
|
||||
You can specify the interpolation method when resizing dataset images to training resolution. Specify `interpolation_type` in the `[[datasets]]` or `[general]` section of the dataset configuration TOML file.
|
||||
|
||||
Available values: `bicubic` (default), `bilinear`, `lanczos`, `nearest`, `area`
|
||||
|
||||
```toml
|
||||
[[datasets]]
|
||||
resolution = [1024, 1024]
|
||||
enable_bucket = true
|
||||
interpolation_type = "lanczos" # Example: Use Lanczos interpolation
|
||||
# ...
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
データセットの画像を学習解像度にリサイズする際の補間方法を指定できます。
|
||||
|
||||
設定方法とオプションの詳細は英語のドキュメントを参照してください。
|
||||
|
||||
</details>
|
||||
|
||||
### 7.3. Other Training Options / その他の学習オプション
|
||||
|
||||
- **`--controlnet_model_name_or_path`**: Specifies the path to a ControlNet model compatible with FLUX.1. This allows for training a LoRA that works in conjunction with ControlNet. This is an advanced feature and requires a compatible ControlNet model.
|
||||
|
||||
- **`--loss_type`**: Specifies the loss function for training. The default is `l2`.
|
||||
- `l1`: L1 loss.
|
||||
- `l2`: L2 loss (mean squared error).
|
||||
- `huber`: Huber loss.
|
||||
- `smooth_l1`: Smooth L1 loss.
|
||||
|
||||
- **`--huber_schedule`**, **`--huber_c`**, **`--huber_scale`**: These are parameters for Huber loss. They are used when `--loss_type` is set to `huber` or `smooth_l1`.
|
||||
|
||||
- **`--t5xxl_max_token_length`**: Specifies the maximum token length for the T5-XXL text encoder. For details, refer to the [`sd3_train_network.md` guide](sd3_train_network.md).
|
||||
|
||||
- **`--weighting_scheme`**, **`--logit_mean`**, **`--logit_std`**, **`--mode_scale`**: These options allow you to adjust the loss weighting for each timestep. For details, refer to the [`sd3_train_network.md` guide](sd3_train_network.md).
|
||||
|
||||
- **`--fused_backward_pass`**: Fuses the backward pass and optimizer step to reduce VRAM usage. For details, refer to the [`sdxl_train_network.md` guide](sdxl_train_network.md).
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
- **`--controlnet_model_name_or_path`**: FLUX.1互換のControlNetモデルへのパスを指定します。これにより、ControlNetと連携して動作するLoRAを学習できます。これは高度な機能であり、互換性のあるControlNetモデルが必要です。
|
||||
- **`--loss_type`**: 学習に用いる損失関数を指定します。デフォルトは `l2` です。
|
||||
- `l1`: L1損失。
|
||||
- `l2`: L2損失(平均二乗誤差)。
|
||||
- `huber`: Huber損失。
|
||||
- `smooth_l1`: Smooth L1損失。
|
||||
- **`--huber_schedule`**, **`--huber_c`**, **`--huber_scale`**: これらはHuber損失のパラメータです。`--loss_type` が `huber` または `smooth_l1` の場合に使用されます。
|
||||
- **`--t5xxl_max_token_length`**: T5-XXLテキストエンコーダの最大トークン長を指定します。詳細は [`sd3_train_network.md` ガイド](sd3_train_network.md) を参照してください。
|
||||
- **`--weighting_scheme`**, **`--logit_mean`**, **`--logit_std`**, **`--mode_scale`**: これらのオプションは、各タイムステップの損失の重み付けを調整するために使用されます。詳細は [`sd3_train_network.md` ガイド](sd3_train_network.md) を参照してください。
|
||||
- **`--fused_backward_pass`**: バックワードパスとオプティマイザステップを融合してVRAM使用量を削減します。詳細は [`sdxl_train_network.md` ガイド](sdxl_train_network.md) を参照してください。
|
||||
|
||||
</details>
|
||||
|
||||
## 8. Related Tools / 関連ツール
|
||||
|
||||
Several related scripts are provided for models trained with `flux_train_network.py` and to assist with the training process:
|
||||
|
||||
* **`networks/flux_extract_lora.py`**: Extracts LoRA models from the difference between trained and base models.
|
||||
* **`convert_flux_lora.py`**: Converts trained LoRA models to other formats like Diffusers (AI-Toolkit) format. When trained with Q/K/V split option, converting with this script can reduce model size.
|
||||
* **`networks/flux_merge_lora.py`**: Merges trained LoRA models into FLUX.1 base models.
|
||||
* **`flux_minimal_inference.py`**: Simple inference script for generating images with trained LoRA models. You can specify `flux` or `chroma` with the `--model_type` argument.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
`flux_train_network.py` で学習したモデルや、学習プロセスに役立つ関連スクリプトが提供されています:
|
||||
|
||||
* **`networks/flux_extract_lora.py`**: 学習済みモデルとベースモデルの差分から LoRA モデルを抽出。
|
||||
* **`convert_flux_lora.py`**: 学習した LoRA モデルを Diffusers (AI-Toolkit) 形式など他の形式に変換。
|
||||
* **`networks/flux_merge_lora.py`**: 学習した LoRA モデルを FLUX.1 ベースモデルにマージ。
|
||||
* **`flux_minimal_inference.py`**: 学習した LoRA モデルを適用して画像を生成するシンプルな推論スクリプト。
|
||||
`--model_type` 引数で `flux` または `chroma` を指定できます。
|
||||
|
||||
</details>
|
||||
|
||||
## 9. Others / その他
|
||||
|
||||
`flux_train_network.py` includes many features common with `train_network.py`, such as sample image generation (`--sample_prompts`, etc.) and detailed optimizer settings. For these features, refer to the [`train_network.py` guide](train_network.md#5-other-features--その他の機能) or the script help (`python flux_train_network.py --help`).
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
`flux_train_network.py`には、サンプル画像の生成 (`--sample_prompts`など) や詳細なオプティマイザ設定など、`train_network.py`と共通の機能も多く存在します。これらについては、[`train_network.py`のガイド](train_network.md#5-other-features--その他の機能)やスクリプトのヘルプ (`python flux_train_network.py --help`) を参照してください。
|
||||
|
||||
</details>
|
||||
537
docs/gen_img_README-ja.md
Normal file
537
docs/gen_img_README-ja.md
Normal file
@@ -0,0 +1,537 @@
|
||||
SD 1.x、2.x、およびSDXLのモデル、当リポジトリで学習したLoRA、ControlNet、ControlNet-LLLiteなどに対応した、独自の推論(画像生成)スクリプトです。コマンドラインから用います。
|
||||
|
||||
# 概要
|
||||
|
||||
* 独自の推論(画像生成)スクリプト。
|
||||
* SD 1.x、2.x (base/v-parameterization)、およびSDXLモデルに対応。
|
||||
* txt2img、img2img、inpaintingに対応。
|
||||
* 対話モード、およびファイルからのプロンプト読み込み、連続生成に対応。
|
||||
* プロンプト1行あたりの生成枚数を指定可能。
|
||||
* 全体の繰り返し回数を指定可能。
|
||||
* `fp16`だけでなく`bf16`にも対応。
|
||||
* xformers、SDPA(Scaled Dot-Product Attention)に対応。
|
||||
* プロンプトの225トークンへの拡張。ネガティブプロンプト、重みづけに対応。
|
||||
* Diffusersの各種samplerに対応。
|
||||
* Text Encoderのclip skip(最後からn番目の層の出力を用いる)に対応。
|
||||
* VAEの別途読み込み、VAEのバッチ処理やスライスによる省メモリ化に対応。
|
||||
* Highres. fix(独自実装およびGradual Latent)、upscale対応。
|
||||
* LoRA、DyLoRA対応。適用率指定、複数LoRA同時利用、重みのマージに対応。
|
||||
* Attention Couple、Regional LoRAに対応。
|
||||
* ControlNet (v1.0/v1.1)、ControlNet-LLLiteに対応。
|
||||
* 途中でモデルを切り替えることはできませんが、バッチファイルを組むことで対応できます。
|
||||
|
||||
# 基本的な使い方
|
||||
|
||||
## 対話モードでの画像生成
|
||||
|
||||
以下のように入力してください。
|
||||
|
||||
```batchfile
|
||||
python gen_img.py --ckpt <モデル名> --outdir <画像出力先> --xformers --fp16 --interactive
|
||||
```
|
||||
|
||||
`--ckpt`オプションにモデル(Stable Diffusionのcheckpointファイル、またはDiffusersのモデルフォルダ)、`--outdir`オプションに画像の出力先フォルダを指定します。
|
||||
|
||||
`--xformers`オプションでxformersの使用を指定します。`--fp16`オプションでfp16(半精度)での推論を行います。RTX 30系以降のGPUでは `--bf16`オプションでbf16(bfloat16)での推論を行うこともできます。
|
||||
|
||||
`--interactive`オプションで対話モードを指定しています。
|
||||
|
||||
Stable Diffusion 2.0(またはそこからの追加学習モデル)を使う場合は`--v2`オプションを追加してください。v-parameterizationを使うモデル(`768-v-ema.ckpt`およびそこからの追加学習モデル)を使う場合はさらに`--v_parameterization`を追加してください。
|
||||
|
||||
SDXLモデルを使う場合は`--sdxl`オプションを追加してください。
|
||||
|
||||
`--v2`や`--sdxl`の指定有無が間違っているとモデル読み込み時にエラーになります。`--v_parameterization`の指定有無が間違っていると茶色い画像が表示されます。
|
||||
|
||||
`Type prompt:`と表示されたらプロンプトを入力してください。
|
||||
|
||||

|
||||
|
||||
※画像が表示されずエラーになる場合、headless(画面表示機能なし)のOpenCVがインストールされているかもしれません。`pip install opencv-python`として通常のOpenCVを入れてください。または`--no_preview`オプションで画像表示を止めてください。
|
||||
|
||||
画像ウィンドウを選択してから何らかのキーを押すとウィンドウが閉じ、次のプロンプトが入力できます。プロンプトでCtrl+Z、エンターの順に打鍵するとスクリプトを閉じます。
|
||||
|
||||
## 単一のプロンプトで画像を一括生成
|
||||
|
||||
以下のように入力します(実際には1行で入力します)。
|
||||
|
||||
```batchfile
|
||||
python gen_img.py --ckpt <モデル名> --outdir <画像出力先>
|
||||
--xformers --fp16 --images_per_prompt <生成枚数> --prompt "<プロンプト>"
|
||||
```
|
||||
|
||||
`--images_per_prompt`オプションで、プロンプト1件当たりの生成枚数を指定します。`--prompt`オプションでプロンプトを指定します。スペースを含む場合はダブルクォーテーションで囲んでください。
|
||||
|
||||
`--batch_size`オプションでバッチサイズを指定できます(後述)。
|
||||
|
||||
## ファイルからプロンプトを読み込み一括生成
|
||||
|
||||
以下のように入力します。
|
||||
|
||||
```batchfile
|
||||
python gen_img.py --ckpt <モデル名> --outdir <画像出力先>
|
||||
--xformers --fp16 --from_file <プロンプトファイル名>
|
||||
```
|
||||
|
||||
`--from_file`オプションで、プロンプトが記述されたファイルを指定します。1行1プロンプトで記述してください。`--images_per_prompt`オプションを指定して1行あたり生成枚数を指定できます。
|
||||
|
||||
## ネガティブプロンプト、重みづけの使用
|
||||
|
||||
プロンプトオプション(プロンプト内で`--x`のように指定、後述)で`--n`を書くと、以降がネガティブプロンプトとなります。
|
||||
|
||||
またAUTOMATIC1111氏のWeb UIと同様の `()` や` []` 、`(xxx:1.3)` などによる重みづけが可能です(実装はDiffusersの[Long Prompt Weighting Stable Diffusion](https://github.com/huggingface/diffusers/blob/main/examples/community/README.md#long-prompt-weighting-stable-diffusion)からコピーしたものです)。
|
||||
|
||||
コマンドラインからのプロンプト指定、ファイルからのプロンプト読み込みでも同様に指定できます。
|
||||
|
||||

|
||||
|
||||
# 主なオプション
|
||||
|
||||
コマンドラインから指定してください。
|
||||
|
||||
## モデルの指定
|
||||
|
||||
- `--ckpt <モデル名>`:モデル名を指定します。`--ckpt`オプションは必須です。Stable Diffusionのcheckpointファイル、またはDiffusersのモデルフォルダ、Hugging FaceのモデルIDを指定できます。
|
||||
|
||||
- `--v1`:Stable Diffusion 1.x系のモデルを使う場合に指定します。これがデフォルトの動作です。
|
||||
|
||||
- `--v2`:Stable Diffusion 2.x系のモデルを使う場合に指定します。1.x系の場合には指定不要です。
|
||||
|
||||
- `--sdxl`:Stable Diffusion XLモデルを使う場合に指定します。
|
||||
|
||||
- `--v_parameterization`:v-parameterizationを使うモデルを使う場合に指定します(`768-v-ema.ckpt`およびそこからの追加学習モデル、Waifu Diffusion v1.5など)。
|
||||
|
||||
`--v2`や`--sdxl`の指定有無が間違っているとモデル読み込み時にエラーになります。`--v_parameterization`の指定有無が間違っていると茶色い画像が表示されます。
|
||||
|
||||
- `--zero_terminal_snr`:noise schedulerのbetasを修正して、zero terminal SNRを強制します。
|
||||
|
||||
- `--pyramid_noise_prob`:ピラミッドノイズを適用する確率を指定します。
|
||||
|
||||
- `--pyramid_noise_discount_range`:ピラミッドノイズの割引率の範囲を指定します。
|
||||
|
||||
- `--noise_offset_prob`:ノイズオフセットを適用する確率を指定します。
|
||||
|
||||
- `--noise_offset_range`:ノイズオフセットの範囲を指定します。
|
||||
|
||||
- `--vae`:使用する VAE を指定します。未指定時はモデル内の VAE を使用します。
|
||||
|
||||
- `--tokenizer_cache_dir`:トークナイザーのキャッシュディレクトリを指定します(オフライン利用のため)。
|
||||
|
||||
## 画像生成と出力
|
||||
|
||||
- `--interactive`:インタラクティブモードで動作します。プロンプトを入力すると画像が生成されます。
|
||||
|
||||
- `--prompt <プロンプト>`:プロンプトを指定します。スペースを含む場合はダブルクォーテーションで囲んでください。
|
||||
|
||||
- `--from_file <プロンプトファイル名>`:プロンプトが記述されたファイルを指定します。1行1プロンプトで記述してください。なお画像サイズやguidance scaleはプロンプトオプション(後述)で指定できます。
|
||||
|
||||
- `--from_module <モジュールファイル>`:Pythonモジュールからプロンプトを読み込みます。モジュールは`get_prompter(args, pipe, networks)`関数を実装している必要があります。
|
||||
|
||||
- `--prompter_module_args`:prompterモジュールに渡す追加の引数を指定します。
|
||||
|
||||
- `--W <画像幅>`:画像の幅を指定します。デフォルトは`512`です。
|
||||
|
||||
- `--H <画像高さ>`:画像の高さを指定します。デフォルトは`512`です。
|
||||
|
||||
- `--steps <ステップ数>`:サンプリングステップ数を指定します。デフォルトは`50`です。
|
||||
|
||||
- `--scale <ガイダンススケール>`:unconditionalガイダンススケールを指定します。デフォルトは`7.5`です。
|
||||
|
||||
- `--sampler <サンプラー名>`:サンプラーを指定します。デフォルトは`ddim`です。
|
||||
`ddim`, `pndm`, `lms`, `euler`, `euler_a`, `heun`, `dpm_2`, `dpm_2_a`, `dpmsolver`, `dpmsolver++`, `dpmsingle`, `k_lms`, `k_euler`, `k_euler_a`, `k_dpm_2`, `k_dpm_2_a` が指定可能です。
|
||||
|
||||
- `--outdir <画像出力先フォルダ>`:画像の出力先を指定します。
|
||||
|
||||
- `--images_per_prompt <生成枚数>`:プロンプト1件当たりの生成枚数を指定します。デフォルトは`1`です。
|
||||
|
||||
- `--clip_skip <スキップ数>`:CLIPの後ろから何番目の層を使うかを指定します。デフォルトはSD1/2の場合1、SDXLの場合2です。
|
||||
|
||||
- `--max_embeddings_multiples <倍数>`:CLIPの入出力長をデフォルト(75)の何倍にするかを指定します。未指定時は75のままです。たとえば3を指定すると入出力長が225になります。
|
||||
|
||||
- `--negative_scale` : uncoditioningのguidance scaleを個別に指定します。[gcem156氏のこちらの記事](https://note.com/gcem156/n/ne9a53e4a6f43)を参考に実装したものです。
|
||||
|
||||
- `--emb_normalize_mode`:embedding正規化モードを指定します。"original"(デフォルト)、"abs"、"none"から選択できます。プロンプトの重みの正規化方法に影響します。
|
||||
|
||||
- `--force_scheduler_zero_steps_offset`:スケジューラのステップオフセットを、スケジューラ設定の `steps_offset` の値に関わらず強制的にゼロにします。
|
||||
|
||||
## SDXL固有のオプション
|
||||
|
||||
SDXL モデル(`--sdxl`フラグ付き)を使用する場合、追加のコンディショニングオプションが利用できます:
|
||||
|
||||
- `--original_height`:SDXL コンディショニング用の元の高さを指定します。これはモデルの対象解像度の理解に影響します。
|
||||
|
||||
- `--original_width`:SDXL コンディショニング用の元の幅を指定します。これはモデルの対象解像度の理解に影響します。
|
||||
|
||||
- `--original_height_negative`:SDXL ネガティブコンディショニング用の元の高さを指定します。
|
||||
|
||||
- `--original_width_negative`:SDXL ネガティブコンディショニング用の元の幅を指定します。
|
||||
|
||||
- `--crop_top`:SDXL コンディショニング用のクロップ上オフセットを指定します。
|
||||
|
||||
- `--crop_left`:SDXL コンディショニング用のクロップ左オフセットを指定します。
|
||||
|
||||
## メモリ使用量や生成速度の調整
|
||||
|
||||
- `--batch_size <バッチサイズ>`:バッチサイズを指定します。デフォルトは`1`です。バッチサイズが大きいとメモリを多く消費しますが、生成速度が速くなります。
|
||||
|
||||
- `--vae_batch_size <VAEのバッチサイズ>`:VAEのバッチサイズを指定します。デフォルトはバッチサイズと同じです。1未満の値を指定すると、バッチサイズに対する比率として扱われます。
|
||||
VAEのほうがメモリを多く消費するため、デノイジング後(stepが100%になった後)でメモリ不足になる場合があります。このような場合にはVAEのバッチサイズを小さくしてください。
|
||||
|
||||
- `--vae_slices <スライス数>`:VAE処理時に画像をスライスに分割してVRAM使用量を削減します。None(デフォルト)で分割なし。16や32のような値が推奨されます。有効にすると処理が遅くなりますが、VRAM使用量が少なくなります。
|
||||
|
||||
- `--no_half_vae`:VAE処理でfp16/bf16精度の使用を防ぎます。代わりにfp32を使用します。VAE関連の問題やアーティファクトが発生した場合に使用してください。
|
||||
|
||||
- `--xformers`:xformersを使う場合に指定します。
|
||||
|
||||
- `--sdpa`:最適化のためにPyTorch 2のscaled dot-product attentionを使用します。
|
||||
|
||||
- `--diffusers_xformers`:Diffusers経由でxformersを使用します(注:Hypernetworksと互換性がありません)。
|
||||
|
||||
- `--fp16`:fp16(半精度)での推論を行います。`fp16`と`bf16`をどちらも指定しない場合はfp32(単精度)での推論を行います。
|
||||
|
||||
- `--bf16`:bf16(bfloat16)での推論を行います。RTX 30系以降のGPUでのみ指定可能です。`--bf16`オプションはRTX 30系以外のGPUではエラーになります。SDXLでは`fp16`よりも`bf16`のほうが推論結果がNaNになる(真っ黒の画像になる)可能性が低いようです。
|
||||
|
||||
## 追加ネットワーク(LoRA等)の使用
|
||||
|
||||
- `--network_module`:使用する追加ネットワークを指定します。LoRAの場合は`--network_module networks.lora`と指定します。複数のLoRAを使用する場合は`--network_module networks.lora networks.lora networks.lora`のように指定します。
|
||||
|
||||
- `--network_weights`:使用する追加ネットワークの重みファイルを指定します。`--network_weights model.safetensors`のように指定します。複数のLoRAを使用する場合は`--network_weights model1.safetensors model2.safetensors model3.safetensors`のように指定します。引数の数は`--network_module`で指定した数と同じにしてください。
|
||||
|
||||
- `--network_mul`:使用する追加ネットワークの重みを何倍にするかを指定します。デフォルトは`1`です。`--network_mul 0.8`のように指定します。複数のLoRAを使用する場合は`--network_mul 0.4 0.5 0.7`のように指定します。引数の数は`--network_module`で指定した数と同じにしてください。
|
||||
|
||||
- `--network_merge`:使用する追加ネットワークの重みを`--network_mul`に指定した重みであらかじめマージします。`--network_pre_calc` と同時に使用できません。プロンプトオプションの`--am`、およびRegional LoRAは使用できなくなりますが、LoRA未使用時と同じ程度まで生成が高速化されます。
|
||||
|
||||
- `--network_pre_calc`:使用する追加ネットワークの重みを生成ごとにあらかじめ計算します。プロンプトオプションの`--am`が使用できます。LoRA未使用時と同じ程度まで生成は高速化されますが、生成前に重みを計算する時間が必要で、またメモリ使用量も若干増加します。Regional LoRA使用時は無効になります 。
|
||||
|
||||
- `--network_regional_mask_max_color_codes`:リージョナルマスクに使用する色コードの最大数を指定します。指定されていない場合、マスクはチャンネルごとに適用されます。Regional LoRAと組み合わせて、マスク内の色で定義できるリージョン数を制御するために使用されます。
|
||||
|
||||
- `--network_args`:key=value形式でネットワークモジュールに渡す追加引数を指定します。例: `--network_args "alpha=1.0,dropout=0.1"`。
|
||||
|
||||
- `--network_merge_n_models`:ネットワークマージを使用する場合、マージするモデル数を指定します(全ての読み込み済みネットワークをマージする代わりに)。
|
||||
|
||||
# 主なオプションの指定例
|
||||
|
||||
次は同一プロンプトで64枚をバッチサイズ4で一括生成する例です。
|
||||
|
||||
```batchfile
|
||||
python gen_img.py --ckpt model.ckpt --outdir outputs
|
||||
--xformers --fp16 --W 512 --H 704 --scale 12.5 --sampler k_euler_a
|
||||
--steps 32 --batch_size 4 --images_per_prompt 64
|
||||
--prompt "beautiful flowers --n monochrome"
|
||||
```
|
||||
|
||||
次はファイルに書かれたプロンプトを、それぞれ10枚ずつ、バッチサイズ4で一括生成する例です。
|
||||
|
||||
```batchfile
|
||||
python gen_img.py --ckpt model.ckpt --outdir outputs
|
||||
--xformers --fp16 --W 512 --H 704 --scale 12.5 --sampler k_euler_a
|
||||
--steps 32 --batch_size 4 --images_per_prompt 10
|
||||
--from_file prompts.txt
|
||||
```
|
||||
|
||||
Textual Inversion(後述)およびLoRAの使用例です。
|
||||
|
||||
```batchfile
|
||||
python gen_img.py --ckpt model.safetensors
|
||||
--scale 8 --steps 48 --outdir txt2img --xformers
|
||||
--W 512 --H 768 --fp16 --sampler k_euler_a
|
||||
--textual_inversion_embeddings goodembed.safetensors negprompt.pt
|
||||
--network_module networks.lora networks.lora
|
||||
--network_weights model1.safetensors model2.safetensors
|
||||
--network_mul 0.4 0.8
|
||||
--clip_skip 2 --max_embeddings_multiples 1
|
||||
--batch_size 8 --images_per_prompt 1 --interactive
|
||||
```
|
||||
|
||||
# プロンプトオプション
|
||||
|
||||
プロンプト内で、`--n`のように「ハイフンふたつ+アルファベットn文字」でプロンプトから各種オプションの指定が可能です。対話モード、コマンドライン、ファイル、いずれからプロンプトを指定する場合でも有効です。
|
||||
|
||||
プロンプトのオプション指定`--n`の前後にはスペースを入れてください。
|
||||
|
||||
- `--n`:ネガティブプロンプトを指定します。
|
||||
|
||||
- `--w`:画像幅を指定します。コマンドラインからの指定を上書きします。
|
||||
|
||||
- `--h`:画像高さを指定します。コマンドラインからの指定を上書きします。
|
||||
|
||||
- `--s`:ステップ数を指定します。コマンドラインからの指定を上書きします。
|
||||
|
||||
- `--d`:この画像の乱数seedを指定します。`--images_per_prompt`を指定している場合は「--d 1,2,3,4」のようにカンマ区切りで複数指定してください。
|
||||
※様々な理由により、Web UIとは同じ乱数seedでも生成される画像が異なる場合があります。
|
||||
|
||||
- `--l`:guidance scaleを指定します。コマンドラインからの指定を上書きします。
|
||||
|
||||
- `--t`:img2img(後述)のstrengthを指定します。コマンドラインからの指定を上書きします。
|
||||
|
||||
- `--nl`:ネガティブプロンプトのguidance scaleを指定します(後述)。コマンドラインからの指定を上書きします。
|
||||
|
||||
- `--am`:追加ネットワークの重みを指定します。コマンドラインからの指定を上書きします。複数の追加ネットワークを使用する場合は`--am 0.8,0.5,0.3`のように __カンマ区切りで__ 指定します。
|
||||
|
||||
- `--ow`:SDXLのoriginal_widthを指定します。
|
||||
|
||||
- `--oh`:SDXLのoriginal_heightを指定します。
|
||||
|
||||
- `--nw`:SDXLのoriginal_width_negativeを指定します。
|
||||
|
||||
- `--nh`:SDXLのoriginal_height_negativeを指定します。
|
||||
|
||||
- `--ct`:SDXLのcrop_topを指定します。
|
||||
|
||||
- `--cl`:SDXLのcrop_leftを指定します。
|
||||
|
||||
- `--c`:CLIPプロンプトを指定します。
|
||||
|
||||
- `--f`:生成ファイル名を指定します。
|
||||
|
||||
※これらのオプションを指定すると、バッチサイズよりも小さいサイズでバッチが実行される場合があります(これらの値が異なると一括生成できないため)。(あまり気にしなくて大丈夫ですが、ファイルからプロンプトを読み込み生成する場合は、これらの値が同一のプロンプトを並べておくと効率が良くなります。)
|
||||
|
||||
例:
|
||||
```
|
||||
(masterpiece, best quality), 1girl, in shirt and plated skirt, standing at street under cherry blossoms, upper body, [from below], kind smile, looking at another, [goodembed] --n realistic, real life, (negprompt), (lowres:1.1), (worst quality:1.2), (low quality:1.1), bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, normal quality, jpeg artifacts, signature, watermark, username, blurry --w 960 --h 640 --s 28 --d 1
|
||||
```
|
||||
|
||||

|
||||
|
||||
# プロンプトのワイルドカード (Dynamic Prompts)
|
||||
|
||||
Dynamic Prompts (Wildcard) 記法に対応しています。Web UIの拡張機能等と完全に同じではありませんが、以下の機能が利用可能です。
|
||||
|
||||
- `{A|B|C}` : A, B, C の中からランダムに1つを選択します。
|
||||
- `{e$$A|B|C}` : A, B, C のすべてを順に利用します(全列挙)。プロンプト内に複数の `{e$$...}` がある場合、すべての組み合わせが生成されます。
|
||||
- 例:`{e$$red|blue} flower, {e$$1girl|2girls}` → `red flower, 1girl`, `red flower, 2girls`, `blue flower, 1girl`, `blue flower, 2girls` の4枚が生成されます。
|
||||
- `{n$$A|B|C}` : A, B, C の中から n 個をランダムに選択して結合します。
|
||||
- 例:`{2$$A|B|C}` → `A, B` や `B, C` など。
|
||||
- `{n-m$$A|B|C}` : A, B, C の中から n 個から m 個をランダムに選択して結合します。
|
||||
- `{$$sep$$A|B|C}` : 選択された項目を sep で結合します(デフォルトは `, `)。
|
||||
- 例:`{2$$ and $$A|B|C}` → `A and B` など。
|
||||
|
||||
これらは組み合わせて利用可能です。
|
||||
|
||||
# img2img
|
||||
|
||||
## オプション
|
||||
|
||||
- `--image_path`:img2imgに利用する画像を指定します。`--image_path template.png`のように指定します。フォルダを指定すると、そのフォルダの画像を順次利用します。
|
||||
|
||||
- `--strength`:img2imgのstrengthを指定します。`--strength 0.8`のように指定します。デフォルトは`0.8`です。
|
||||
|
||||
- `--sequential_file_name`:ファイル名を連番にするかどうかを指定します。指定すると生成されるファイル名が`im_000001.png`からの連番になります。
|
||||
|
||||
- `--use_original_file_name`:指定すると生成ファイル名がオリジナルのファイル名の前に追加されます(img2imgモード用)。
|
||||
|
||||
- `--clip_vision_strength`:指定した強度でimg2img用のCLIP Vision Conditioningを有効にします。CLIP Visionモデルを使用して入力画像からのコンディショニングを強化します。
|
||||
|
||||
## コマンドラインからの実行例
|
||||
|
||||
```batchfile
|
||||
python gen_img.py --ckpt trinart_characters_it4_v1_vae_merged.ckpt
|
||||
--outdir outputs --xformers --fp16 --scale 12.5 --sampler k_euler --steps 32
|
||||
--image_path template.png --strength 0.8
|
||||
--prompt "1girl, cowboy shot, brown hair, pony tail, brown eyes,
|
||||
sailor school uniform, outdoors
|
||||
--n lowres, bad anatomy, bad hands, error, missing fingers, cropped,
|
||||
worst quality, low quality, normal quality, jpeg artifacts, (blurry),
|
||||
hair ornament, glasses"
|
||||
--batch_size 8 --images_per_prompt 32
|
||||
```
|
||||
|
||||
`--image_path`オプションにフォルダを指定すると、そのフォルダの画像を順次読み込みます。生成される枚数は画像枚数ではなく、プロンプト数になりますので、`--images_per_promptPPオプションを指定してimg2imgする画像の枚数とプロンプト数を合わせてください。
|
||||
|
||||
ファイルはファイル名でソートして読み込みます。なおソート順は文字列順となりますので(`1.jpg→2.jpg→10.jpg`ではなく`1.jpg→10.jpg→2.jpg`の順)、頭を0埋めするなどしてご対応ください(`01.jpg→02.jpg→10.jpg`)。
|
||||
|
||||
## img2imgを利用したupscale
|
||||
|
||||
img2img時にコマンドラインオプションの`--W`と`--H`で生成画像サイズを指定すると、元画像をそのサイズにリサイズしてからimg2imgを行います。
|
||||
|
||||
またimg2imgの元画像がこのスクリプトで生成した画像の場合、プロンプトを省略すると、元画像のメタデータからプロンプトを取得しそのまま用います。これによりHighres. fixの2nd stageの動作だけを行うことができます。
|
||||
|
||||
## img2img時のinpainting
|
||||
|
||||
画像およびマスク画像を指定してinpaintingできます(inpaintingモデルには対応しておらず、単にマスク領域を対象にimg2imgするだけです)。
|
||||
|
||||
オプションは以下の通りです。
|
||||
|
||||
- `--mask_image`:マスク画像を指定します。`--img_path`と同様にフォルダを指定すると、そのフォルダの画像を順次利用します。
|
||||
|
||||
マスク画像はグレースケール画像で、白の部分がinpaintingされます。境界をグラデーションしておくとなんとなく滑らかになりますのでお勧めです。
|
||||
|
||||

|
||||
|
||||
# その他の機能
|
||||
|
||||
## Textual Inversion
|
||||
|
||||
`--textual_inversion_embeddings`オプションで使用するembeddingsを指定します(複数指定可)。拡張子を除いたファイル名をプロンプト内で使用することで、そのembeddingsを利用します(Web UIと同様の使用法です)。ネガティブプロンプト内でも使用できます。
|
||||
|
||||
モデルとして、当リポジトリで学習したTextual Inversionモデル、およびWeb UIで学習したTextual Inversionモデル(画像埋め込みは非対応)を利用できます
|
||||
|
||||
## Highres. fix
|
||||
|
||||
AUTOMATIC1111氏のWeb UIにある機能の類似機能です(独自実装のためもしかしたらいろいろ異なるかもしれません)。最初に小さめの画像を生成し、その画像を元にimg2imgすることで、画像全体の破綻を防ぎつつ大きな解像度の画像を生成します。
|
||||
|
||||
2nd stageのstep数は`--steps` と`--strength`オプションの値から計算されます(`steps*strength`)。
|
||||
|
||||
img2imgと併用できません。
|
||||
|
||||
以下のオプションがあります。
|
||||
|
||||
- `--highres_fix_scale`:Highres. fixを有効にして、1st stageで生成する画像のサイズを、倍率で指定します。最終出力が1024x1024で、最初に512x512の画像を生成する場合は`--highres_fix_scale 0.5`のように指定します。Web UI出の指定の逆数になっていますのでご注意ください。
|
||||
|
||||
- `--highres_fix_steps`:1st stageの画像のステップ数を指定します。デフォルトは`28`です。
|
||||
|
||||
- `--highres_fix_strength`:1st stageのimg2img時のstrengthを指定します。省略時は`--strength`と同じ値になります。
|
||||
|
||||
- `--highres_fix_save_1st`:1st stageの画像を保存するかどうかを指定します。
|
||||
|
||||
- `--highres_fix_latents_upscaling`:指定すると2nd stageの画像生成時に1st stageの画像をlatentベースでupscalingします(bilinearのみ対応)。未指定時は画像をLANCZOS4でupscalingします。
|
||||
|
||||
- `--highres_fix_upscaler`:2nd stageに任意のupscalerを利用します。現在は`--highres_fix_upscaler tools.latent_upscaler` のみ対応しています。
|
||||
|
||||
- `--highres_fix_upscaler_args`:`--highres_fix_upscaler`で指定したupscalerに渡す引数を指定します。
|
||||
`tools.latent_upscaler`の場合は、`--highres_fix_upscaler_args "weights=D:\Work\SD\Models\others\etc\upscaler-v1-e100-220.safetensors"`のように重みファイルを指定します。
|
||||
|
||||
- `--highres_fix_disable_control_net`:Highres fixの2nd stageでControlNetを無効にします。デフォルトでは、ControlNetは両ステージで使用されます。
|
||||
|
||||
コマンドラインの例です。
|
||||
|
||||
```batchfile
|
||||
python gen_img.py --ckpt trinart_characters_it4_v1_vae_merged.ckpt
|
||||
--n_iter 1 --scale 7.5 --W 1024 --H 1024 --batch_size 1 --outdir ../txt2img
|
||||
--steps 48 --sampler ddim --fp16
|
||||
--xformers
|
||||
--images_per_prompt 1 --interactive
|
||||
--highres_fix_scale 0.5 --highres_fix_steps 28 --strength 0.5
|
||||
```
|
||||
|
||||
## Deep Shrink
|
||||
|
||||
Deep Shrinkは、異なるタイムステップで異なる深度のUNetを使用して生成プロセスを最適化する技術です。生成品質と効率を向上させることができます。
|
||||
|
||||
以下のオプションがあります:
|
||||
|
||||
- `--ds_depth_1`:第1フェーズでこの深度のDeep Shrinkを有効にします。有効な値は0から8です。
|
||||
|
||||
- `--ds_timesteps_1`:このタイムステップまでDeep Shrink深度1を適用します。デフォルトは650です。
|
||||
|
||||
- `--ds_depth_2`:Deep Shrinkの第2フェーズの深度を指定します。
|
||||
|
||||
- `--ds_timesteps_2`:このタイムステップまでDeep Shrink深度2を適用します。デフォルトは650です。
|
||||
|
||||
- `--ds_ratio`:Deep Shrinkでのダウンサンプリングの比率を指定します。デフォルトは0.5です。
|
||||
|
||||
これらのパラメータはプロンプトオプションでも指定できます:
|
||||
|
||||
- `--dsd1`:プロンプトからDeep Shrink深度1を指定します。
|
||||
|
||||
- `--dst1`:プロンプトからDeep Shrinkタイムステップ1を指定します。
|
||||
|
||||
- `--dsd2`:プロンプトからDeep Shrink深度2を指定します。
|
||||
|
||||
- `--dst2`:プロンプトからDeep Shrinkタイムステップ2を指定します。
|
||||
|
||||
- `--dsr`:プロンプトからDeep Shrink比率を指定します。
|
||||
|
||||
## ControlNet
|
||||
|
||||
現在はControlNet 1.0のみ動作確認しています。プリプロセスはCannyのみサポートしています。
|
||||
|
||||
以下のオプションがあります。
|
||||
|
||||
- `--control_net_models`:ControlNetのモデルファイルを指定します。
|
||||
複数指定すると、それらをstepごとに切り替えて利用します(Web UIのControlNet拡張の実装と異なります)。diffと通常の両方をサポートします。
|
||||
|
||||
- `--guide_image_path`:ControlNetに使うヒント画像を指定します。`--img_path`と同様にフォルダを指定すると、そのフォルダの画像を順次利用します。Canny以外のモデルの場合には、あらかじめプリプロセスを行っておいてください。
|
||||
|
||||
- `--control_net_preps`:ControlNetのプリプロセスを指定します。`--control_net_models`と同様に複数指定可能です。現在はcannyのみ対応しています。対象モデルでプリプロセスを使用しない場合は `none` を指定します。
|
||||
cannyの場合 `--control_net_preps canny_63_191`のように、閾値1と2を'_'で区切って指定できます。
|
||||
|
||||
- `--control_net_multipliers`:ControlNetの適用時の重みを指定します(`1.0`で通常、`0.5`なら半分の影響力で適用)。`--control_net_models`と同様に複数指定可能です。
|
||||
|
||||
- `--control_net_ratios`:ControlNetを適用するstepの範囲を指定します。`0.5`の場合は、step数の半分までControlNetを適用します。`--control_net_models`と同様に複数指定可能です。
|
||||
|
||||
コマンドラインの例です。
|
||||
|
||||
```batchfile
|
||||
python gen_img.py --ckpt model_ckpt --scale 8 --steps 48 --outdir txt2img --xformers
|
||||
--W 512 --H 768 --bf16 --sampler k_euler_a
|
||||
--control_net_models diff_control_sd15_canny.safetensors --control_net_multipliers 1.0
|
||||
--guide_image_path guide.png --control_net_ratios 1.0 --interactive
|
||||
```
|
||||
|
||||
## ControlNet-LLLite
|
||||
|
||||
ControlNet-LLLiteは、類似の誘導目的に使用できるControlNetの軽量な代替手段です。
|
||||
|
||||
以下のオプションがあります:
|
||||
|
||||
- `--control_net_lllite_models`:ControlNet-LLLiteモデルファイルを指定します。
|
||||
|
||||
- `--control_net_multipliers`:ControlNet-LLLiteの倍率を指定します(重みに類似)。
|
||||
|
||||
- `--control_net_ratios`:ControlNet-LLLiteを適用するステップの比率を指定します。
|
||||
|
||||
注意:ControlNetとControlNet-LLLiteは同時に使用できません。
|
||||
|
||||
## Attention Couple + Reginal LoRA
|
||||
|
||||
プロンプトをいくつかの部分に分割し、それぞれのプロンプトを画像内のどの領域に適用するかを指定できる機能です。個別のオプションはありませんが、`mask_path`とプロンプトで指定します。
|
||||
|
||||
まず、プロンプトで` AND `を利用して、複数部分を定義します。最初の3つに対して領域指定ができ、以降の部分は画像全体へ適用されます。ネガティブプロンプトは画像全体に適用されます。
|
||||
|
||||
以下ではANDで3つの部分を定義しています。
|
||||
|
||||
```
|
||||
shs 2girls, looking at viewer, smile AND bsb 2girls, looking back AND 2girls --n bad quality, worst quality
|
||||
```
|
||||
|
||||
次にマスク画像を用意します。マスク画像はカラーの画像で、RGBの各チャネルがプロンプトのANDで区切られた部分に対応します。またあるチャネルの値がすべて0の場合、画像全体に適用されます。
|
||||
|
||||
上記の例では、Rチャネルが`shs 2girls, looking at viewer, smile`、Gチャネルが`bsb 2girls, looking back`に、Bチャネルが`2girls`に対応します。次のようなマスク画像を使用すると、Bチャネルに指定がありませんので、`2girls`は画像全体に適用されます。
|
||||
|
||||

|
||||
|
||||
マスク画像は`--mask_path`で指定します。現在は1枚のみ対応しています。指定した画像サイズに自動的にリサイズされ適用されます。
|
||||
|
||||
ControlNetと組み合わせることも可能です(細かい位置指定にはControlNetとの組み合わせを推奨します)。
|
||||
|
||||
LoRAを指定すると、`--network_weights`で指定した複数のLoRAがそれぞれANDの各部分に対応します。現在の制約として、LoRAの数はANDの部分の数と同じである必要があります。
|
||||
|
||||
# その他のオプション
|
||||
|
||||
- `--no_preview` : 対話モードでプレビュー画像を表示しません。OpenCVがインストールされていない場合や、出力されたファイルを直接確認する場合に指定してください。
|
||||
|
||||
- `--n_iter` : 生成を繰り返す回数を指定します。デフォルトは1です。プロンプトをファイルから読み込むとき、複数回の生成を行いたい場合に指定します。
|
||||
|
||||
- `--tokenizer_cache_dir` : トークナイザーのキャッシュディレクトリを指定します。(作業中)
|
||||
|
||||
- `--seed` : 乱数seedを指定します。1枚生成時はその画像のseed、複数枚生成時は各画像のseedを生成するための乱数のseedになります(`--from_file`で複数画像生成するとき、`--seed`オプションを指定すると複数回実行したときに各画像が同じseedになります)。
|
||||
|
||||
- `--iter_same_seed` : プロンプトに乱数seedの指定がないとき、`--n_iter`の繰り返し内ではすべて同じseedを使います。`--from_file`で指定した複数のプロンプト間でseedを統一して比較するときに使います。
|
||||
|
||||
- `--diffusers_xformers` : Diffuserのxformersを使用します。
|
||||
|
||||
- `--opt_channels_last` : 推論時にテンソルのチャンネルを最後に配置します。場合によっては高速化されることがあります。
|
||||
|
||||
- `--shuffle_prompts`:繰り返し時にプロンプトの順序をシャッフルします。`--from_file`で複数のプロンプトを使用する場合に便利です。
|
||||
|
||||
- `--network_show_meta`:追加ネットワークのメタデータを表示します。
|
||||
|
||||
---
|
||||
|
||||
# Gradual Latent について
|
||||
|
||||
latentのサイズを徐々に大きくしていくHires fixです。
|
||||
|
||||
- `--gradual_latent_timesteps` : latentのサイズを大きくし始めるタイムステップを指定します。デフォルトは None で、Gradual Latentを使用しません。750 くらいから始めてみてください。
|
||||
- `--gradual_latent_ratio` : latentの初期サイズを指定します。デフォルトは 0.5 で、デフォルトの latent サイズの半分のサイズから始めます。
|
||||
- `--gradual_latent_ratio_step`: latentのサイズを大きくする割合を指定します。デフォルトは 0.125 で、latentのサイズを 0.625, 0.75, 0.875, 1.0 と徐々に大きくします。
|
||||
- `--gradual_latent_ratio_every_n_steps`: latentのサイズを大きくする間隔を指定します。デフォルトは 3 で、3ステップごとに latent のサイズを大きくします。
|
||||
- `--gradual_latent_s_noise`:Gradual LatentのS_noiseパラメータを指定します。デフォルトは1.0です。
|
||||
- `--gradual_latent_unsharp_params`:Gradual Latentのアンシャープマスクパラメータをksize,sigma,strength,target-x形式で指定します(target-x: 1=True, 0=False)。推奨値:`3,0.5,0.5,1`または`3,1.0,1.0,0`。
|
||||
|
||||
それぞれのオプションは、プロンプトオプション、`--glt`、`--glr`、`--gls`、`--gle` でも指定できます。
|
||||
|
||||
サンプラーに手を加えているため、__サンプラーに `euler_a` を指定してください。__ 他のサンプラーでは動作しません。
|
||||
|
||||
SD 1.5 のほうが効果があります。SDXL ではかなり微妙です。
|
||||
|
||||
552
docs/gen_img_README.md
Normal file
552
docs/gen_img_README.md
Normal file
@@ -0,0 +1,552 @@
|
||||
<!-- filepath: d:\\Work\\SD\\dev\\sd-scripts\\docs\\gen_img_README-en.md -->
|
||||
This is an inference (image generation) script that supports SD 1.x and 2.x models, LoRA trained with this repository, ControlNet (only v1.0 has been confirmed to work), etc. It is used from the command line.
|
||||
|
||||
# Overview
|
||||
|
||||
* Inference (image generation) script.
|
||||
* Supports SD 1.x, 2.x (base/v-parameterization), and SDXL models.
|
||||
* Supports txt2img, img2img, and inpainting.
|
||||
* Supports interactive mode, prompt reading from files, and continuous generation.
|
||||
* The number of images generated per prompt line can be specified.
|
||||
* The total number of repetitions can be specified.
|
||||
* Supports not only `fp16` but also `bf16`.
|
||||
* Supports xformers and SDPA (Scaled Dot-Product Attention).
|
||||
* Extension of prompts to 225 tokens. Supports negative prompts and weighting.
|
||||
* Supports various samplers from Diffusers.
|
||||
* Supports clip skip (uses the output of the nth layer from the end) of Text Encoder.
|
||||
* Separate loading of VAE, supports VAE batch processing and slicing for memory saving.
|
||||
* Highres. fix (original implementation and Gradual Latent), upscale support.
|
||||
* LoRA, DyLoRA support. Supports application rate specification, simultaneous use of multiple LoRAs, and weight merging.
|
||||
* Supports Attention Couple, Regional LoRA.
|
||||
* Supports ControlNet (v1.0/v1.1), ControlNet-LLLite.
|
||||
* It is not possible to switch models midway, but it can be handled by creating a batch file.
|
||||
|
||||
# Basic Usage
|
||||
|
||||
## Image Generation in Interactive Mode
|
||||
|
||||
Enter as follows:
|
||||
|
||||
```batchfile
|
||||
python gen_img.py --ckpt <model_name> --outdir <image_output_destination> --xformers --fp16 --interactive
|
||||
```
|
||||
|
||||
Specify the model (Stable Diffusion checkpoint file or Diffusers model folder) in the `--ckpt` option and the image output destination folder in the `--outdir` option.
|
||||
|
||||
Specify the use of xformers with the `--xformers` option (remove it if you do not use xformers). The `--fp16` option performs inference in fp16 (single precision). For RTX 30 series GPUs, you can also perform inference in bf16 (bfloat16) with the `--bf16` option.
|
||||
|
||||
The `--interactive` option specifies interactive mode.
|
||||
|
||||
If you are using Stable Diffusion 2.0 (or a model with additional training from it), add the `--v2` option. If you are using a model that uses v-parameterization (`768-v-ema.ckpt` and models with additional training from it), add `--v_parameterization` as well.
|
||||
|
||||
If the `--v2` specification is incorrect, an error will occur when loading the model. If the `--v_parameterization` specification is incorrect, a brown image will be displayed.
|
||||
|
||||
When `Type prompt:` is displayed, enter the prompt.
|
||||
|
||||

|
||||
|
||||
*If the image is not displayed and an error occurs, headless (no screen display function) OpenCV may be installed. Install normal OpenCV with `pip install opencv-python`. Alternatively, stop image display with the `--no_preview` option.
|
||||
|
||||
Select the image window and press any key to close the window and enter the next prompt. Press Ctrl+Z and then Enter in the prompt to close the script.
|
||||
|
||||
## Batch Generation of Images with a Single Prompt
|
||||
|
||||
Enter as follows (actually entered on one line):
|
||||
|
||||
```batchfile
|
||||
python gen_img.py --ckpt <model_name> --outdir <image_output_destination> \
|
||||
--xformers --fp16 --images_per_prompt <number_of_images_to_generate> --prompt "<prompt>"
|
||||
```
|
||||
|
||||
Specify the number of images to generate per prompt with the `--images_per_prompt` option. Specify the prompt with the `--prompt` option. If it contains spaces, enclose it in double quotes.
|
||||
|
||||
You can specify the batch size with the `--batch_size` option (described later).
|
||||
|
||||
## Batch Generation by Reading Prompts from a File
|
||||
|
||||
Enter as follows:
|
||||
|
||||
```batchfile
|
||||
python gen_img.py --ckpt <model_name> --outdir <image_output_destination> \
|
||||
--xformers --fp16 --from_file <prompt_file_name>
|
||||
```
|
||||
|
||||
Specify the file containing the prompts with the `--from_file` option. Write one prompt per line. You can specify the number of images to generate per line with the `--images_per_prompt` option.
|
||||
|
||||
## Using Negative Prompts and Weighting
|
||||
|
||||
If you write `--n` in the prompt options (specified like `--x` in the prompt, described later), the following will be a negative prompt.
|
||||
|
||||
Also, weighting with `()` and `[]`, `(xxx:1.3)`, etc., similar to AUTOMATIC1111's Web UI, is possible (the implementation is copied from Diffusers' [Long Prompt Weighting Stable Diffusion](https://github.com/huggingface/diffusers/blob/main/examples/community/README.md#long-prompt-weighting-stable-diffusion)).
|
||||
|
||||
It can be specified similarly for prompt specification from the command line and prompt reading from files.
|
||||
|
||||

|
||||
|
||||
# Main Options
|
||||
|
||||
Specify from the command line.
|
||||
|
||||
## Model Specification
|
||||
|
||||
- `--ckpt <model_name>`: Specifies the model name. The `--ckpt` option is mandatory. You can specify a Stable Diffusion checkpoint file, a Diffusers model folder, or a Hugging Face model ID.
|
||||
|
||||
- `--v1`: Specify when using Stable Diffusion 1.x series models. This is the default behavior.
|
||||
|
||||
- `--v2`: Specify when using Stable Diffusion 2.x series models. Not required for 1.x series.
|
||||
|
||||
- `--sdxl`: Specify when using Stable Diffusion XL models.
|
||||
|
||||
- `--v_parameterization`: Specify when using models that use v-parameterization (`768-v-ema.ckpt` and models with additional training from it, Waifu Diffusion v1.5, etc.).
|
||||
|
||||
If the `--v2` or `--sdxl` specification is incorrect, an error will occur when loading the model. If the `--v_parameterization` specification is incorrect, a brown image will be displayed.
|
||||
|
||||
- `--zero_terminal_snr`: Modifies the noise scheduler betas to enforce zero terminal SNR.
|
||||
|
||||
- `--pyramid_noise_prob`: Specifies the probability of applying pyramid noise.
|
||||
|
||||
- `--pyramid_noise_discount_range`: Specifies the discount range for pyramid noise.
|
||||
|
||||
- `--noise_offset_prob`: Specifies the probability of applying noise offset.
|
||||
|
||||
- `--noise_offset_range`: Specifies the range of noise offset.
|
||||
|
||||
- `--vae`: Specifies the VAE to use. If not specified, the VAE in the model will be used.
|
||||
|
||||
- `--tokenizer_cache_dir`: Specifies the cache directory for the tokenizer (for offline usage).
|
||||
|
||||
## Image Generation and Output
|
||||
|
||||
- `--interactive`: Operates in interactive mode. Images are generated when prompts are entered.
|
||||
|
||||
- `--prompt <prompt>`: Specifies the prompt. If it contains spaces, enclose it in double quotes.
|
||||
|
||||
- `--from_file <prompt_file_name>`: Specifies the file containing the prompts. Write one prompt per line. Image size and guidance scale can be specified with prompt options (described later).
|
||||
|
||||
- `--from_module <module_file>`: Loads prompts from a Python module. The module should implement a `get_prompter(args, pipe, networks)` function.
|
||||
|
||||
- `--prompter_module_args`: Specifies additional arguments to pass to the prompter module.
|
||||
|
||||
- `--W <image_width>`: Specifies the width of the image. The default is `512`.
|
||||
|
||||
- `--H <image_height>`: Specifies the height of the image. The default is `512`.
|
||||
|
||||
- `--steps <number_of_steps>`: Specifies the number of sampling steps. The default is `50`.
|
||||
|
||||
- `--scale <guidance_scale>`: Specifies the unconditional guidance scale. The default is `7.5`.
|
||||
|
||||
- `--sampler <sampler_name>`: Specifies the sampler. The default is `ddim`.
|
||||
`ddim`, `pndm`, `lms`, `euler`, `euler_a`, `heun`, `dpm_2`, `dpm_2_a`, `dpmsolver`, `dpmsolver++`, `dpmsingle`, `k_lms`, `k_euler`, `k_euler_a`, `k_dpm_2`, `k_dpm_2_a` can be specified.
|
||||
|
||||
- `--outdir <image_output_destination_folder>`: Specifies the output destination for images.
|
||||
|
||||
- `--images_per_prompt <number_of_images_to_generate>`: Specifies the number of images to generate per prompt. The default is `1`.
|
||||
|
||||
- `--clip_skip <number_of_skips>`: Specifies which layer from the end of CLIP to use. Default is 1 for SD1/2, 2 for SDXL.
|
||||
|
||||
- `--max_embeddings_multiples <multiplier>`: Specifies how many times the CLIP input/output length should be multiplied by the default (75). If not specified, it remains 75. For example, specifying 3 makes the input/output length 225.
|
||||
|
||||
- `--negative_scale`: Specifies the guidance scale for unconditioning individually. Implemented with reference to [this article by gcem156](https://note.com/gcem156/n/ne9a53e4a6f43).
|
||||
|
||||
- `--emb_normalize_mode`: Specifies the embedding normalization mode. Options are "original" (default), "abs", and "none". This affects how prompt weights are normalized.
|
||||
|
||||
- `--force_scheduler_zero_steps_offset`: Forces the scheduler step offset to zero regardless of the `steps_offset` value in the scheduler configuration.
|
||||
|
||||
## SDXL-Specific Options
|
||||
|
||||
When using SDXL models (with `--sdxl` flag), additional conditioning options are available:
|
||||
|
||||
- `--original_height`: Specifies the original height for SDXL conditioning. This affects the model's understanding of the target resolution.
|
||||
|
||||
- `--original_width`: Specifies the original width for SDXL conditioning. This affects the model's understanding of the target resolution.
|
||||
|
||||
- `--original_height_negative`: Specifies the original height for SDXL negative conditioning.
|
||||
|
||||
- `--original_width_negative`: Specifies the original width for SDXL negative conditioning.
|
||||
|
||||
- `--crop_top`: Specifies the crop top offset for SDXL conditioning.
|
||||
|
||||
- `--crop_left`: Specifies the crop left offset for SDXL conditioning.
|
||||
|
||||
## Adjusting Memory Usage and Generation Speed
|
||||
|
||||
- `--batch_size <batch_size>`: Specifies the batch size. The default is `1`. A larger batch size consumes more memory but speeds up generation.
|
||||
|
||||
- `--vae_batch_size <VAE_batch_size>`: Specifies the VAE batch size. The default is the same as the batch size.
|
||||
Since VAE consumes more memory, memory shortages may occur after denoising (after the step reaches 100%). In such cases, reduce the VAE batch size.
|
||||
|
||||
- `--vae_slices <number_of_slices>`: Splits the image into slices for VAE processing to reduce VRAM usage. None (default) for no splitting. Values like 16 or 32 are recommended. Enabling this is slower but uses less VRAM.
|
||||
|
||||
- `--no_half_vae`: Prevents using fp16/bf16 precision for VAE processing. Uses fp32 instead. Use this if you encounter VAE-related issues or artifacts.
|
||||
|
||||
- `--xformers`: Specify when using xformers.
|
||||
|
||||
- `--sdpa`: Use scaled dot-product attention in PyTorch 2 for optimization.
|
||||
|
||||
- `--diffusers_xformers`: Use xformers via Diffusers (note: incompatible with Hypernetworks).
|
||||
|
||||
- `--fp16`: Performs inference in fp16 (single precision). If neither `fp16` nor `bf16` is specified, inference is performed in fp32 (single precision).
|
||||
|
||||
- `--bf16`: Performs inference in bf16 (bfloat16). Can only be specified for RTX 30 series GPUs. The `--bf16` option will cause an error on GPUs other than the RTX 30 series. It seems that `bf16` is less likely to result in NaN (black image) inference results than `fp16`.
|
||||
|
||||
## Using Additional Networks (LoRA, etc.)
|
||||
|
||||
- `--network_module`: Specifies the additional network to use. For LoRA, specify `--network_module networks.lora`. To use multiple LoRAs, specify like `--network_module networks.lora networks.lora networks.lora`.
|
||||
|
||||
- `--network_weights`: Specifies the weight file of the additional network to use. Specify like `--network_weights model.safetensors`. To use multiple LoRAs, specify like `--network_weights model1.safetensors model2.safetensors model3.safetensors`. The number of arguments should be the same as the number specified in `--network_module`.
|
||||
|
||||
- `--network_mul`: Specifies how many times to multiply the weight of the additional network to use. The default is `1`. Specify like `--network_mul 0.8`. To use multiple LoRAs, specify like `--network_mul 0.4 0.5 0.7`. The number of arguments should be the same as the number specified in `--network_module`.
|
||||
|
||||
- `--network_merge`: Merges the weights of the additional networks to be used in advance with the weights specified in `--network_mul`. Cannot be used simultaneously with `--network_pre_calc`. The prompt option `--am` and Regional LoRA can no longer be used, but generation will be accelerated to the same extent as when LoRA is not used.
|
||||
|
||||
- `--network_pre_calc`: Calculates the weights of the additional network to be used in advance for each generation. The prompt option `--am` can be used. Generation is accelerated to the same extent as when LoRA is not used, but time is required to calculate the weights before generation, and memory usage also increases slightly. It is disabled when Regional LoRA is used.
|
||||
|
||||
- `--network_regional_mask_max_color_codes`: Specifies the maximum number of color codes to use for regional masks. If not specified, masks are applied by channel. Used with Regional LoRA to control the number of regions that can be defined by colors in the mask.
|
||||
|
||||
- `--network_args`: Specifies additional arguments to pass to the network module in key=value format. For example: `--network_args "alpha=1.0,dropout=0.1"`.
|
||||
|
||||
- `--network_merge_n_models`: When using network merging, specifies the number of models to merge (instead of merging all loaded networks).
|
||||
|
||||
# Examples of Main Option Specifications
|
||||
|
||||
The following is an example of batch generating 64 images with the same prompt and a batch size of 4.
|
||||
|
||||
```batchfile
|
||||
python gen_img.py --ckpt model.ckpt --outdir outputs \
|
||||
--xformers --fp16 --W 512 --H 704 --scale 12.5 --sampler k_euler_a \
|
||||
--steps 32 --batch_size 4 --images_per_prompt 64 \
|
||||
--prompt "beautiful flowers --n monochrome"
|
||||
```
|
||||
|
||||
The following is an example of batch generating 10 images each for prompts written in a file, with a batch size of 4.
|
||||
|
||||
```batchfile
|
||||
python gen_img.py --ckpt model.ckpt --outdir outputs \
|
||||
--xformers --fp16 --W 512 --H 704 --scale 12.5 --sampler k_euler_a \
|
||||
--steps 32 --batch_size 4 --images_per_prompt 10 \
|
||||
--from_file prompts.txt
|
||||
```
|
||||
|
||||
Example of using Textual Inversion (described later) and LoRA.
|
||||
|
||||
```batchfile
|
||||
python gen_img.py --ckpt model.safetensors \
|
||||
--scale 8 --steps 48 --outdir txt2img --xformers \
|
||||
--W 512 --H 768 --fp16 --sampler k_euler_a \
|
||||
--textual_inversion_embeddings goodembed.safetensors negprompt.pt \
|
||||
--network_module networks.lora networks.lora \
|
||||
--network_weights model1.safetensors model2.safetensors \
|
||||
--network_mul 0.4 0.8 \
|
||||
--clip_skip 2 --max_embeddings_multiples 1 \
|
||||
--batch_size 8 --images_per_prompt 1 --interactive
|
||||
```
|
||||
|
||||
# Prompt Options
|
||||
|
||||
In the prompt, you can specify various options from the prompt with "two hyphens + n alphabetic characters" like `--n`. It is valid whether specifying the prompt from interactive mode, command line, or file.
|
||||
|
||||
Please put spaces before and after the prompt option specification `--n`.
|
||||
|
||||
- `--n`: Specifies a negative prompt.
|
||||
|
||||
- `--w`: Specifies the image width. Overrides the command line specification.
|
||||
|
||||
- `--h`: Specifies the image height. Overrides the command line specification.
|
||||
|
||||
- `--s`: Specifies the number of steps. Overrides the command line specification.
|
||||
|
||||
- `--d`: Specifies the random seed for this image. If `--images_per_prompt` is specified, specify multiple seeds separated by commas, like "--d 1,2,3,4".
|
||||
*For various reasons, the generated image may differ from the Web UI even with the same random seed.
|
||||
|
||||
- `--l`: Specifies the guidance scale. Overrides the command line specification.
|
||||
|
||||
- `--t`: Specifies the strength of img2img (described later). Overrides the command line specification.
|
||||
|
||||
- `--nl`: Specifies the guidance scale for negative prompts (described later). Overrides the command line specification.
|
||||
|
||||
- `--am`: Specifies the weight of the additional network. Overrides the command line specification. If using multiple additional networks, specify them separated by __commas__, like `--am 0.8,0.5,0.3`.
|
||||
|
||||
- `--ow`: Specifies original_width for SDXL.
|
||||
|
||||
- `--oh`: Specifies original_height for SDXL.
|
||||
|
||||
- `--nw`: Specifies original_width_negative for SDXL.
|
||||
|
||||
- `--nh`: Specifies original_height_negative for SDXL.
|
||||
|
||||
- `--ct`: Specifies crop_top for SDXL.
|
||||
|
||||
- `--cl`: Specifies crop_left for SDXL.
|
||||
|
||||
- `--c`: Specifies the CLIP prompt.
|
||||
|
||||
- `--f`: Specifies the generated file name.
|
||||
|
||||
- `--glt`: Specifies the timestep to start increasing the size of the latent for Gradual Latent. Overrides the command line specification.
|
||||
|
||||
- `--glr`: Specifies the initial size of the latent for Gradual Latent as a ratio. Overrides the command line specification.
|
||||
|
||||
- `--gls`: Specifies the ratio to increase the size of the latent for Gradual Latent. Overrides the command line specification.
|
||||
|
||||
- `--gle`: Specifies the interval to increase the size of the latent for Gradual Latent. Overrides the command line specification.
|
||||
|
||||
*Specifying these options may cause the batch to be executed with a size smaller than the batch size (because they cannot be generated collectively if these values are different). (You don't have to worry too much, but when reading prompts from a file and generating, arranging prompts with the same values for these options will improve efficiency.)
|
||||
|
||||
Example:
|
||||
```
|
||||
(masterpiece, best quality), 1girl, in shirt and plated skirt, standing at street under cherry blossoms, upper body, [from below], kind smile, looking at another, [goodembed] --n realistic, real life, (negprompt), (lowres:1.1), (worst quality:1.2), (low quality:1.1), bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, normal quality, jpeg artifacts, signature, watermark, username, blurry --w 960 --h 640 --s 28 --d 1
|
||||
```
|
||||
|
||||

|
||||
|
||||
# Wildcards in Prompts (Dynamic Prompts)
|
||||
|
||||
Dynamic Prompts (Wildcard) notation is supported. While not exactly the same as the Web UI extension, the following features are available.
|
||||
|
||||
- `{A|B|C}` : Randomly selects one from A, B, or C.
|
||||
- `{e$$A|B|C}` : Uses all of A, B, and C in order (enumeration). If there are multiple `{e$$...}` in the prompt, all combinations will be generated.
|
||||
- Example: `{e$$red|blue} flower, {e$$1girl|2girls}` -> Generates 4 images: `red flower, 1girl`, `red flower, 2girls`, `blue flower, 1girl`, `blue flower, 2girls`.
|
||||
- `{n$$A|B|C}` : Randomly selects n items from A, B, C and combines them.
|
||||
- Example: `{2$$A|B|C}` -> `A, B` or `B, C`, etc.
|
||||
- `{n-m$$A|B|C}` : Randomly selects between n and m items from A, B, C and combines them.
|
||||
- `{$$sep$$A|B|C}` : Combines selected items with `sep` (default is `, `).
|
||||
- Example: `{2$$ and $$A|B|C}` -> `A and B`, etc.
|
||||
|
||||
These can be used in combination.
|
||||
|
||||
# img2img
|
||||
|
||||
## Options
|
||||
|
||||
- `--image_path`: Specifies the image to use for img2img. Specify like `--image_path template.png`. If a folder is specified, images in that folder will be used sequentially.
|
||||
|
||||
- `--strength`: Specifies the strength of img2img. Specify like `--strength 0.8`. The default is `0.8`.
|
||||
|
||||
- `--sequential_file_name`: Specifies whether to make file names sequential. If specified, the generated file names will be sequential starting from `im_000001.png`.
|
||||
|
||||
- `--use_original_file_name`: If specified, the generated file name will be prepended with the original file name (for img2img mode).
|
||||
|
||||
- `--clip_vision_strength`: Enables CLIP Vision Conditioning for img2img with the specified strength. Uses the CLIP Vision model to enhance conditioning from the input image.
|
||||
|
||||
## Command Line Execution Example
|
||||
|
||||
```batchfile
|
||||
python gen_img.py --ckpt trinart_characters_it4_v1_vae_merged.ckpt \
|
||||
--outdir outputs --xformers --fp16 --scale 12.5 --sampler k_euler --steps 32 \
|
||||
--image_path template.png --strength 0.8 \
|
||||
--prompt "1girl, cowboy shot, brown hair, pony tail, brown eyes, \
|
||||
sailor school uniform, outdoors \
|
||||
--n lowres, bad anatomy, bad hands, error, missing fingers, cropped, \
|
||||
worst quality, low quality, normal quality, jpeg artifacts, (blurry), \
|
||||
hair ornament, glasses" \
|
||||
--batch_size 8 --images_per_prompt 32
|
||||
```
|
||||
|
||||
If a folder is specified in the `--image_path` option, images in that folder will be read sequentially. The number of images generated will be the number of prompts, not the number of images, so please match the number of images to img2img and the number of prompts by specifying the `--images_per_prompt` option.
|
||||
|
||||
Files are read sorted by file name. Note that the sort order is string order (not `1.jpg -> 2.jpg -> 10.jpg` but `1.jpg -> 10.jpg -> 2.jpg`), so please pad the beginning with zeros (e.g., `01.jpg -> 02.jpg -> 10.jpg`).
|
||||
|
||||
## Upscale using img2img
|
||||
|
||||
If you specify the generated image size with the `--W` and `--H` command line options during img2img, the original image will be resized to that size before img2img.
|
||||
|
||||
Also, if the original image for img2img was generated by this script, omitting the prompt will retrieve the prompt from the original image's metadata and use it as is. This allows you to perform only the 2nd stage operation of Highres. fix.
|
||||
|
||||
## Inpainting during img2img
|
||||
|
||||
You can specify an image and a mask image for inpainting (inpainting models are not supported, it simply performs img2img on the mask area).
|
||||
|
||||
The options are as follows:
|
||||
|
||||
- `--mask_image`: Specifies the mask image. Similar to `--img_path`, if a folder is specified, images in that folder will be used sequentially.
|
||||
|
||||
The mask image is a grayscale image, and the white parts will be inpainted. It is recommended to gradient the boundaries to make it somewhat smooth.
|
||||
|
||||

|
||||
|
||||
# Other Features
|
||||
|
||||
## Textual Inversion
|
||||
|
||||
Specify the embeddings to use with the `--textual_inversion_embeddings` option (multiple specifications possible). By using the file name without the extension in the prompt, that embedding will be used (same usage as Web UI). It can also be used in negative prompts.
|
||||
|
||||
As models, you can use Textual Inversion models trained with this repository and Textual Inversion models trained with Web UI (image embedding is not supported).
|
||||
|
||||
## Highres. fix
|
||||
|
||||
This is a similar feature to the one in AUTOMATIC1111's Web UI (it may differ in various ways as it is an original implementation). It first generates a smaller image and then uses that image as a base for img2img to generate a large resolution image while preventing the entire image from collapsing.
|
||||
|
||||
The number of steps for the 2nd stage is calculated from the values of the `--steps` and `--strength` options (`steps*strength`).
|
||||
|
||||
Cannot be used with img2img.
|
||||
|
||||
The following options are available:
|
||||
|
||||
- `--highres_fix_scale`: Enables Highres. fix and specifies the size of the image generated in the 1st stage as a magnification. If the final output is 1024x1024 and you want to generate a 512x512 image first, specify like `--highres_fix_scale 0.5`. Please note that this is the reciprocal of the specification in Web UI.
|
||||
|
||||
- `--highres_fix_steps`: Specifies the number of steps for the 1st stage image. The default is `28`.
|
||||
|
||||
- `--highres_fix_save_1st`: Specifies whether to save the 1st stage image.
|
||||
|
||||
- `--highres_fix_latents_upscaling`: If specified, the 1st stage image will be upscaled on a latent basis during 2nd stage image generation (only bilinear is supported). If not specified, the image will be upscaled with LANCZOS4.
|
||||
|
||||
- `--highres_fix_upscaler`: Uses an arbitrary upscaler for the 2nd stage. Currently, only `--highres_fix_upscaler tools.latent_upscaler` is supported.
|
||||
|
||||
- `--highres_fix_upscaler_args`: Specifies the arguments to pass to the upscaler specified with `--highres_fix_upscaler`.
|
||||
For `tools.latent_upscaler`, specify the weight file like `--highres_fix_upscaler_args "weights=D:\\Work\\SD\\Models\\others\\etc\\upscaler-v1-e100-220.safetensors"`.
|
||||
|
||||
- `--highres_fix_disable_control_net`: Disables ControlNet for the 2nd stage of Highres fix. By default, ControlNet is used in both stages.
|
||||
|
||||
Command line example:
|
||||
|
||||
```batchfile
|
||||
python gen_img.py --ckpt trinart_characters_it4_v1_vae_merged.ckpt\
|
||||
--n_iter 1 --scale 7.5 --W 1024 --H 1024 --batch_size 1 --outdir ../txt2img \
|
||||
--steps 48 --sampler ddim --fp16 \
|
||||
--xformers \
|
||||
--images_per_prompt 1 --interactive \
|
||||
--highres_fix_scale 0.5 --highres_fix_steps 28 --strength 0.5
|
||||
```
|
||||
|
||||
## Deep Shrink
|
||||
|
||||
Deep Shrink is a technique that optimizes the generation process by using different depths of the UNet at different timesteps. It can improve generation quality and efficiency.
|
||||
|
||||
The following options are available:
|
||||
|
||||
- `--ds_depth_1`: Enables Deep Shrink with this depth for the first phase. Valid values are 0 to 8.
|
||||
|
||||
- `--ds_timesteps_1`: Applies Deep Shrink depth 1 until this timestep. Default is 650.
|
||||
|
||||
- `--ds_depth_2`: Specifies the depth for the second phase of Deep Shrink.
|
||||
|
||||
- `--ds_timesteps_2`: Applies Deep Shrink depth 2 until this timestep. Default is 650.
|
||||
|
||||
- `--ds_ratio`: Specifies the ratio for downsampling in Deep Shrink. Default is 0.5.
|
||||
|
||||
These parameters can also be specified through prompt options:
|
||||
|
||||
- `--dsd1`: Specifies Deep Shrink depth 1 from the prompt.
|
||||
|
||||
- `--dst1`: Specifies Deep Shrink timestep 1 from the prompt.
|
||||
|
||||
- `--dsd2`: Specifies Deep Shrink depth 2 from the prompt.
|
||||
|
||||
- `--dst2`: Specifies Deep Shrink timestep 2 from the prompt.
|
||||
|
||||
- `--dsr`: Specifies Deep Shrink ratio from the prompt.
|
||||
|
||||
*Additional prompt options for Gradual Latent (requires `euler_a` sampler):*
|
||||
|
||||
- `--glt`: Specifies the timestep to start increasing the size of the latent for Gradual Latent. Overrides the command line specification.
|
||||
|
||||
- `--glr`: Specifies the initial size of the latent for Gradual Latent as a ratio. Overrides the command line specification.
|
||||
|
||||
- `--gls`: Specifies the ratio to increase the size of the latent for Gradual Latent. Overrides the command line specification.
|
||||
|
||||
- `--gle`: Specifies the interval to increase the size of the latent for Gradual Latent. Overrides the command line specification.
|
||||
|
||||
## ControlNet
|
||||
|
||||
Currently, only ControlNet 1.0 has been confirmed to work. Only Canny is supported for preprocessing.
|
||||
|
||||
The following options are available:
|
||||
|
||||
- `--control_net_models`: Specifies the ControlNet model file.
|
||||
If multiple are specified, they will be switched and used for each step (differs from the implementation of the ControlNet extension in Web UI). Supports both diff and normal.
|
||||
|
||||
- `--guide_image_path`: Specifies the hint image to use for ControlNet. Similar to `--img_path`, if a folder is specified, images in that folder will be used sequentially. For models other than Canny, please perform preprocessing beforehand.
|
||||
|
||||
- `--control_net_preps`: Specifies the preprocessing for ControlNet. Multiple specifications are possible, similar to `--control_net_models`. Currently, only canny is supported. If preprocessing is not used for the target model, specify `none`.
|
||||
For canny, you can specify thresholds 1 and 2 separated by `_`, like `--control_net_preps canny_63_191`.
|
||||
|
||||
- `--control_net_weights`: Specifies the weight when applying ControlNet (`1.0` for normal, `0.5` for half influence). Multiple specifications are possible, similar to `--control_net_models`.
|
||||
|
||||
- `--control_net_ratios`: Specifies the range of steps to apply ControlNet. If `0.5`, ControlNet is applied up to half the number of steps. Multiple specifications are possible, similar to `--control_net_models`.
|
||||
|
||||
Command line example:
|
||||
|
||||
```batchfile
|
||||
python gen_img.py --ckpt model_ckpt --scale 8 --steps 48 --outdir txt2img --xformers \
|
||||
--W 512 --H 768 --bf16 --sampler k_euler_a \
|
||||
--control_net_models diff_control_sd15_canny.safetensors --control_net_weights 1.0 \
|
||||
--guide_image_path guide.png --control_net_ratios 1.0 --interactive
|
||||
```
|
||||
|
||||
## ControlNet-LLLite
|
||||
|
||||
ControlNet-LLLite is a lightweight alternative to ControlNet that can be used for similar guidance purposes.
|
||||
|
||||
The following options are available:
|
||||
|
||||
- `--control_net_lllite_models`: Specifies the ControlNet-LLLite model files.
|
||||
|
||||
- `--control_net_multipliers`: Specifies the multiplier for ControlNet-LLLite (similar to weights).
|
||||
|
||||
- `--control_net_ratios`: Specifies the ratio of steps to apply ControlNet-LLLite.
|
||||
|
||||
Note that ControlNet and ControlNet-LLLite cannot be used at the same time.
|
||||
|
||||
## Attention Couple + Regional LoRA
|
||||
|
||||
This is a feature that allows you to divide the prompt into several parts and specify which region in the image each prompt should be applied to. There are no individual options, but it is specified with `mask_path` and the prompt.
|
||||
|
||||
First, define multiple parts using ` AND ` in the prompt. Region specification can be done for the first three parts, and subsequent parts are applied to the entire image. Negative prompts are applied to the entire image.
|
||||
|
||||
In the following, three parts are defined with AND.
|
||||
|
||||
```
|
||||
shs 2girls, looking at viewer, smile AND bsb 2girls, looking back AND 2girls --n bad quality, worst quality
|
||||
```
|
||||
|
||||
Next, prepare a mask image. The mask image is a color image, and each RGB channel corresponds to the part separated by AND in the prompt. Also, if the value of a certain channel is all 0, it is applied to the entire image.
|
||||
|
||||
In the example above, the R channel corresponds to `shs 2girls, looking at viewer, smile`, the G channel to `bsb 2girls, looking back`, and the B channel to `2girls`. If you use a mask image like the following, since there is no specification for the B channel, `2girls` will be applied to the entire image.
|
||||
|
||||

|
||||
|
||||
The mask image is specified with `--mask_path`. Currently, only one image is supported. It is automatically resized and applied to the specified image size.
|
||||
|
||||
It can also be combined with ControlNet (combination with ControlNet is recommended for detailed position specification).
|
||||
|
||||
If LoRA is specified, multiple LoRAs specified with `--network_weights` will correspond to each part of AND. As a current constraint, the number of LoRAs must be the same as the number of AND parts.
|
||||
|
||||
# Other Options
|
||||
|
||||
- `--no_preview`: Does not display preview images in interactive mode. Specify this if OpenCV is not installed or if you want to check the output files directly.
|
||||
|
||||
- `--n_iter`: Specifies the number of times to repeat generation. The default is 1. Specify this when you want to perform generation multiple times when reading prompts from a file.
|
||||
|
||||
- `--tokenizer_cache_dir`: Specifies the cache directory for the tokenizer. (Work in progress)
|
||||
|
||||
- `--seed`: Specifies the random seed. When generating one image, it is the seed for that image. When generating multiple images, it is the seed for the random numbers used to generate the seeds for each image (when generating multiple images with `--from_file`, specifying the `--seed` option will make each image have the same seed when executed multiple times).
|
||||
|
||||
- `--iter_same_seed`: When there is no random seed specification in the prompt, the same seed is used for all repetitions of `--n_iter`. Used to unify and compare seeds between multiple prompts specified with `--from_file`.
|
||||
|
||||
- `--shuffle_prompts`: Shuffles the order of prompts in iteration. Useful when using `--from_file` with multiple prompts.
|
||||
|
||||
- `--diffusers_xformers`: Uses Diffuser's xformers.
|
||||
|
||||
- `--opt_channels_last`: Arranges tensor channels last during inference. May speed up in some cases.
|
||||
|
||||
- `--network_show_meta`: Displays the metadata of the additional network.
|
||||
|
||||
|
||||
---
|
||||
|
||||
# About Gradual Latent
|
||||
|
||||
Gradual Latent is a Hires fix that gradually increases the size of the latent. `gen_img.py`, `sdxl_gen_img.py`, and `gen_img.py` have the following options.
|
||||
|
||||
- `--gradual_latent_timesteps`: Specifies the timestep to start increasing the size of the latent. The default is None, which means Gradual Latent is not used. Please try around 750 at first.
|
||||
- `--gradual_latent_ratio`: Specifies the initial size of the latent. The default is 0.5, which means it starts with half the default latent size.
|
||||
- `--gradual_latent_ratio_step`: Specifies the ratio to increase the size of the latent. The default is 0.125, which means the latent size is gradually increased to 0.625, 0.75, 0.875, 1.0.
|
||||
- `--gradual_latent_ratio_every_n_steps`: Specifies the interval to increase the size of the latent. The default is 3, which means the latent size is increased every 3 steps.
|
||||
- `--gradual_latent_s_noise`: Specifies the s_noise parameter for Gradual Latent. Default is 1.0.
|
||||
- `--gradual_latent_unsharp_params`: Specifies unsharp mask parameters for Gradual Latent in the format: ksize,sigma,strength,target-x (target-x: 1=True, 0=False). Recommended values: `3,0.5,0.5,1` or `3,1.0,1.0,0`.
|
||||
|
||||
Each option can also be specified with prompt options, `--glt`, `--glr`, `--gls`, `--gle`.
|
||||
|
||||
__Please specify `euler_a` for the sampler.__ Because the source code of the sampler is modified. It will not work with other samplers.
|
||||
|
||||
It is more effective with SD 1.5. It is quite subtle with SDXL.
|
||||
525
docs/hunyuan_image_train_network.md
Normal file
525
docs/hunyuan_image_train_network.md
Normal file
@@ -0,0 +1,525 @@
|
||||
Status: reviewed
|
||||
|
||||
# LoRA Training Guide for HunyuanImage-2.1 using `hunyuan_image_train_network.py` / `hunyuan_image_train_network.py` を用いたHunyuanImage-2.1モデルのLoRA学習ガイド
|
||||
|
||||
This document explains how to train LoRA models for the HunyuanImage-2.1 model using `hunyuan_image_train_network.py` included in the `sd-scripts` repository.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
このドキュメントでは、`sd-scripts`リポジトリに含まれる`hunyuan_image_train_network.py`を使用して、HunyuanImage-2.1モデルに対するLoRA (Low-Rank Adaptation) モデルを学習する基本的な手順について解説します。
|
||||
|
||||
</details>
|
||||
|
||||
## 1. Introduction / はじめに
|
||||
|
||||
`hunyuan_image_train_network.py` trains additional networks such as LoRA on the HunyuanImage-2.1 model, which uses a transformer-based architecture (DiT) different from Stable Diffusion. Two text encoders, Qwen2.5-VL and byT5, and a dedicated VAE are used.
|
||||
|
||||
This guide assumes you know the basics of LoRA training. For common options see [train_network.py](train_network.md) and [sdxl_train_network.py](sdxl_train_network.md).
|
||||
|
||||
**Prerequisites:**
|
||||
|
||||
* The repository is cloned and the Python environment is ready.
|
||||
* A training dataset is prepared. See the dataset configuration guide.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
`hunyuan_image_train_network.py`はHunyuanImage-2.1モデルに対してLoRAなどの追加ネットワークを学習させるためのスクリプトです。HunyuanImage-2.1はStable Diffusionとは異なるDiT (Diffusion Transformer) アーキテクチャを持つ画像生成モデルであり、このスクリプトを使用することで、特定のキャラクターや画風を再現するLoRAモデルを作成できます。
|
||||
|
||||
このガイドは、基本的なLoRA学習の手順を理解しているユーザーを対象としています。基本的な使い方や共通のオプションについては、[`train_network.py`のガイド](train_network.md)を参照してください。また一部のパラメータは [`sdxl_train_network.py`](sdxl_train_network.md) や [`flux_train_network.py`](flux_train_network.md) と同様のものがあるため、そちらも参考にしてください。
|
||||
|
||||
**前提条件:**
|
||||
|
||||
* `sd-scripts`リポジトリのクローンとPython環境のセットアップが完了していること。
|
||||
* 学習用データセットの準備が完了していること。(データセットの準備については[データセット設定ガイド](config_README-ja.md)を参照してください)
|
||||
|
||||
</details>
|
||||
|
||||
## 2. Differences from `train_network.py` / `train_network.py` との違い
|
||||
|
||||
`hunyuan_image_train_network.py` is based on `train_network.py` but adapted for HunyuanImage-2.1. Main differences include:
|
||||
|
||||
* **Target model:** HunyuanImage-2.1 model.
|
||||
* **Model structure:** HunyuanImage-2.1 uses a Transformer-based architecture (DiT). It uses two text encoders (Qwen2.5-VL and byT5) and a dedicated VAE.
|
||||
* **Required arguments:** Additional arguments for the DiT model, Qwen2.5-VL, byT5, and VAE model files.
|
||||
* **Incompatible options:** Some Stable Diffusion-specific arguments (e.g., `--v2`, `--clip_skip`, `--max_token_length`) are not used.
|
||||
* **HunyuanImage-2.1-specific arguments:** Additional arguments for specific training parameters like flow matching.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
`hunyuan_image_train_network.py`は`train_network.py`をベースに、HunyuanImage-2.1モデルに対応するための変更が加えられています。主な違いは以下の通りです。
|
||||
|
||||
* **対象モデル:** HunyuanImage-2.1モデルを対象とします。
|
||||
* **モデル構造:** HunyuanImage-2.1はDiTベースのアーキテクチャを持ちます。Text EncoderとしてQwen2.5-VLとbyT5の二つを使用し、専用のVAEを使用します。
|
||||
* **必須の引数:** DiTモデル、Qwen2.5-VL、byT5、VAEの各モデルファイルを指定する引数が追加されています。
|
||||
* **一部引数の非互換性:** Stable Diffusion向けの引数の一部(例: `--v2`, `--clip_skip`, `--max_token_length`)は使用されません。
|
||||
* **HunyuanImage-2.1特有の引数:** Flow Matchingなど、特有の学習パラメータを指定する引数が追加されています。
|
||||
|
||||
</details>
|
||||
|
||||
## 3. Preparation / 準備
|
||||
|
||||
Before starting training you need:
|
||||
|
||||
1. **Training script:** `hunyuan_image_train_network.py`
|
||||
2. **HunyuanImage-2.1 DiT model file:** Base DiT model `.safetensors` file.
|
||||
3. **Text Encoder model files:**
|
||||
- Qwen2.5-VL model file (`--text_encoder`).
|
||||
- byT5 model file (`--byt5`).
|
||||
4. **VAE model file:** HunyuanImage-2.1-compatible VAE model `.safetensors` file (`--vae`).
|
||||
5. **Dataset definition file (.toml):** TOML format file describing training dataset configuration.
|
||||
|
||||
### Downloading Required Models
|
||||
|
||||
To train HunyuanImage-2.1 models, you need to download the following model files:
|
||||
|
||||
- **DiT Model**: Download from the [Tencent HunyuanImage-2.1](https://huggingface.co/tencent/HunyuanImage-2.1/) repository. Use `dit/hunyuanimage2.1.safetensors`.
|
||||
- **Text Encoders and VAE**: Download from the [Comfy-Org/HunyuanImage_2.1_ComfyUI](https://huggingface.co/Comfy-Org/HunyuanImage_2.1_ComfyUI) repository:
|
||||
- Qwen2.5-VL: `split_files/text_encoders/qwen_2.5_vl_7b.safetensors`
|
||||
- byT5: `split_files/text_encoders/byt5_small_glyphxl_fp16.safetensors`
|
||||
- VAE: `split_files/vae/hunyuan_image_2.1_vae_fp16.safetensors`
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
学習を開始する前に、以下のファイルが必要です。
|
||||
|
||||
1. **学習スクリプト:** `hunyuan_image_train_network.py`
|
||||
2. **HunyuanImage-2.1 DiTモデルファイル:** 学習のベースとなるDiTモデルの`.safetensors`ファイル。
|
||||
3. **Text Encoderモデルファイル:**
|
||||
- Qwen2.5-VLモデルファイル (`--text_encoder`)。
|
||||
- byT5モデルファイル (`--byt5`)。
|
||||
4. **VAEモデルファイル:** HunyuanImage-2.1に対応するVAEモデルの`.safetensors`ファイル (`--vae`)。
|
||||
5. **データセット定義ファイル (.toml):** 学習データセットの設定を記述したTOML形式のファイル。(詳細は[データセット設定ガイド](config_README-ja.md)を参照してください)。
|
||||
|
||||
**必要なモデルのダウンロード**
|
||||
|
||||
HunyuanImage-2.1モデルを学習するためには、以下のモデルファイルをダウンロードする必要があります:
|
||||
|
||||
- **DiTモデル**: [Tencent HunyuanImage-2.1](https://huggingface.co/tencent/HunyuanImage-2.1/) リポジトリから `dit/hunyuanimage2.1.safetensors` をダウンロードします。
|
||||
- **Text EncoderとVAE**: [Comfy-Org/HunyuanImage_2.1_ComfyUI](https://huggingface.co/Comfy-Org/HunyuanImage_2.1_ComfyUI) リポジトリから以下をダウンロードします:
|
||||
- Qwen2.5-VL: `split_files/text_encoders/qwen_2.5_vl_7b.safetensors`
|
||||
- byT5: `split_files/text_encoders/byt5_small_glyphxl_fp16.safetensors`
|
||||
- VAE: `split_files/vae/hunyuan_image_2.1_vae_fp16.safetensors`
|
||||
|
||||
</details>
|
||||
|
||||
## 4. Running the Training / 学習の実行
|
||||
|
||||
Run `hunyuan_image_train_network.py` from the terminal with HunyuanImage-2.1 specific arguments. Here's a basic command example:
|
||||
|
||||
```bash
|
||||
accelerate launch --num_cpu_threads_per_process 1 hunyuan_image_train_network.py \
|
||||
--pretrained_model_name_or_path="<path to HunyuanDiT model>" \
|
||||
--text_encoder="<path to Qwen2.5-VL model>" \
|
||||
--byt5="<path to byT5 model>" \
|
||||
--vae="<path to VAE model>" \
|
||||
--dataset_config="my_hunyuan_dataset_config.toml" \
|
||||
--output_dir="<output directory>" \
|
||||
--output_name="my_hunyuan_lora" \
|
||||
--save_model_as=safetensors \
|
||||
--network_module=networks.lora_hunyuan_image \
|
||||
--network_dim=16 \
|
||||
--network_alpha=1 \
|
||||
--network_train_unet_only \
|
||||
--learning_rate=1e-4 \
|
||||
--optimizer_type="AdamW8bit" \
|
||||
--lr_scheduler="constant" \
|
||||
--attn_mode="torch" \
|
||||
--split_attn \
|
||||
--max_train_epochs=10 \
|
||||
--save_every_n_epochs=1 \
|
||||
--mixed_precision="bf16" \
|
||||
--gradient_checkpointing \
|
||||
--model_prediction_type="raw" \
|
||||
--discrete_flow_shift=5.0 \
|
||||
--blocks_to_swap=18 \
|
||||
--cache_text_encoder_outputs \
|
||||
--cache_latents
|
||||
```
|
||||
|
||||
**HunyuanImage-2.1 training does not support LoRA modules for Text Encoders, so `--network_train_unet_only` is required.**
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
学習は、ターミナルから`hunyuan_image_train_network.py`を実行することで開始します。基本的なコマンドラインの構造は`train_network.py`と同様ですが、HunyuanImage-2.1特有の引数を指定する必要があります。
|
||||
|
||||
コマンドラインの例は英語のドキュメントを参照してください。
|
||||
|
||||
</details>
|
||||
|
||||
### 4.1. Explanation of Key Options / 主要なコマンドライン引数の解説
|
||||
|
||||
The script adds HunyuanImage-2.1 specific arguments. For common arguments (like `--output_dir`, `--output_name`, `--network_module`, etc.), see the [`train_network.py` guide](train_network.md).
|
||||
|
||||
#### Model-related [Required]
|
||||
|
||||
* `--pretrained_model_name_or_path="<path to HunyuanDiT model>"` **[Required]**
|
||||
- Specifies the path to the base DiT model `.safetensors` file.
|
||||
* `--text_encoder="<path to Qwen2.5-VL model>"` **[Required]**
|
||||
- Specifies the path to the Qwen2.5-VL Text Encoder model file. Should be `bfloat16`.
|
||||
* `--byt5="<path to byT5 model>"` **[Required]**
|
||||
- Specifies the path to the byT5 Text Encoder model file. Should be `float16`.
|
||||
* `--vae="<path to VAE model>"` **[Required]**
|
||||
- Specifies the path to the HunyuanImage-2.1-compatible VAE model `.safetensors` file.
|
||||
|
||||
#### HunyuanImage-2.1 Training Parameters
|
||||
|
||||
* `--network_train_unet_only` **[Required]**
|
||||
- Specifies that only the DiT model will be trained. LoRA modules for Text Encoders are not supported.
|
||||
* `--discrete_flow_shift=<float>`
|
||||
- Specifies the shift value for the scheduler used in Flow Matching. Default is `5.0`.
|
||||
* `--model_prediction_type=<choice>`
|
||||
- Specifies what the model predicts. Choose from `raw`, `additive`, `sigma_scaled`. Default and recommended is `raw`.
|
||||
* `--timestep_sampling=<choice>`
|
||||
- Specifies the sampling method for timesteps (noise levels) during training. Choose from `sigma`, `uniform`, `sigmoid`, `shift`, `flux_shift`. Default is `sigma`.
|
||||
* `--sigmoid_scale=<float>`
|
||||
- Scale factor when `timestep_sampling` is set to `sigmoid`, `shift`, or `flux_shift`. Default is `1.0`.
|
||||
|
||||
#### Memory/Speed Related
|
||||
|
||||
* `--attn_mode=<choice>`
|
||||
- Specifies the attention implementation to use. Options are `torch`, `xformers`, `flash`, `sageattn`. Default is `torch` (use scaled dot product attention). Each library must be installed separately other than `torch`. If using `xformers`, also specify `--split_attn` if the batch size is more than 1.
|
||||
* `--split_attn`
|
||||
- Splits the batch during attention computation to process one item at a time, reducing VRAM usage by avoiding attention mask computation. Can improve speed when using `torch`. Required when using `xformers` with batch size greater than 1.
|
||||
* `--fp8_scaled`
|
||||
- Enables training the DiT model in scaled FP8 format. This can significantly reduce VRAM usage (can run with as little as 8GB VRAM when combined with `--blocks_to_swap`), but the training results may vary. This is a newer alternative to the unsupported `--fp8_base` option. See [Musubi Tuner's documentation](https://github.com/kohya-ss/musubi-tuner/blob/main/docs/advanced_config.md#fp8-weight-optimization-for-models--%E3%83%A2%E3%83%87%E3%83%AB%E3%81%AE%E9%87%8D%E3%81%BF%E3%81%AEfp8%E3%81%B8%E3%81%AE%E6%9C%80%E9%81%A9%E5%8C%96) for details.
|
||||
* `--fp8_vl`
|
||||
- Use FP8 for the VLM (Qwen2.5-VL) text encoder.
|
||||
* `--text_encoder_cpu`
|
||||
- Runs the text encoders on CPU to reduce VRAM usage. This is useful when VRAM is insufficient (less than 12GB). Encoding one text may take a few minutes (depending on CPU). It is highly recommended to use this option with `--cache_text_encoder_outputs_to_disk` to avoid repeated encoding every time training starts. **In addition, increasing `--num_cpu_threads_per_process` in the `accelerate launch` command, like `--num_cpu_threads_per_process=8` or `16`, can speed up encoding in some environments.**
|
||||
* `--blocks_to_swap=<integer>` **[Experimental Feature]**
|
||||
- Setting to reduce VRAM usage by swapping parts of the model (Transformer blocks) between CPU and GPU. Specify the number of blocks to swap as an integer (e.g., `18`). Larger values reduce VRAM usage but decrease training speed. Adjust according to your GPU's VRAM capacity. Can be used with `gradient_checkpointing`.
|
||||
* `--cache_text_encoder_outputs`
|
||||
- Caches the outputs of Qwen2.5-VL and byT5. This reduces memory usage.
|
||||
* `--cache_latents`, `--cache_latents_to_disk`
|
||||
- Caches the outputs of VAE. Similar functionality to [sdxl_train_network.py](sdxl_train_network.md).
|
||||
* `--vae_chunk_size=<integer>`
|
||||
- Enables chunked processing in the VAE to reduce VRAM usage during encoding and decoding. Specify the chunk size as an integer (e.g., `16`). Larger values use more VRAM but are faster. Default is `None` (no chunking). This option is useful when VRAM is limited (e.g., 8GB or 12GB).
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
[`train_network.py`のガイド](train_network.md)で説明されている引数に加え、以下のHunyuanImage-2.1特有の引数を指定します。共通の引数(`--output_dir`, `--output_name`, `--network_module`, `--network_dim`, `--network_alpha`, `--learning_rate`など)については、上記ガイドを参照してください。
|
||||
|
||||
コマンドラインの例と詳細な引数の説明は英語のドキュメントを参照してください。
|
||||
|
||||
</details>
|
||||
|
||||
## 5. Using the Trained Model / 学習済みモデルの利用
|
||||
|
||||
After training, a LoRA model file is saved in `output_dir` and can be used in inference environments supporting HunyuanImage-2.1.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
学習が完了すると、指定した`output_dir`にLoRAモデルファイル(例: `my_hunyuan_lora.safetensors`)が保存されます。このファイルは、HunyuanImage-2.1モデルに対応した推論環境で使用できます。
|
||||
|
||||
</details>
|
||||
|
||||
## 6. Advanced Settings / 高度な設定
|
||||
|
||||
### 6.1. VRAM Usage Optimization / VRAM使用量の最適化
|
||||
|
||||
HunyuanImage-2.1 is a large model, so GPUs without sufficient VRAM require optimization.
|
||||
|
||||
#### Recommended Settings by GPU Memory
|
||||
|
||||
Based on testing with the pull request, here are recommended VRAM optimization settings:
|
||||
|
||||
| GPU Memory | Recommended Settings |
|
||||
|------------|---------------------|
|
||||
| 40GB+ VRAM | Standard settings (no special optimization needed) |
|
||||
| 24GB VRAM | `--fp8_scaled --blocks_to_swap 9` |
|
||||
| 12GB VRAM | `--fp8_scaled --blocks_to_swap 32` |
|
||||
| 8GB VRAM | `--fp8_scaled --blocks_to_swap 37` |
|
||||
|
||||
#### Key VRAM Reduction Options
|
||||
|
||||
- **`--fp8_scaled`**: Enables training the DiT in scaled FP8 format. This is the recommended FP8 option for HunyuanImage-2.1, replacing the unsupported `--fp8_base` option. Essential for <40GB VRAM environments.
|
||||
- **`--fp8_vl`**: Use FP8 for the VLM (Qwen2.5-VL) text encoder.
|
||||
- **`--blocks_to_swap <number>`**: Swaps blocks between CPU and GPU to reduce VRAM usage. Higher numbers save more VRAM but reduce training speed. Up to 37 blocks can be swapped for HunyuanImage-2.1.
|
||||
- **`--cpu_offload_checkpointing`**: Offloads gradient checkpoints to CPU. Can reduce VRAM usage but decreases training speed. Cannot be used with `--blocks_to_swap`.
|
||||
- **Using Adafactor optimizer**: Can reduce VRAM usage more than 8bit AdamW:
|
||||
```
|
||||
--optimizer_type adafactor --optimizer_args "relative_step=False" "scale_parameter=False" "warmup_init=False" --lr_scheduler constant_with_warmup --max_grad_norm 0.0
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
HunyuanImage-2.1は大きなモデルであるため、十分なVRAMを持たないGPUでは工夫が必要です。
|
||||
|
||||
#### GPU別推奨設定
|
||||
|
||||
Pull Requestのテスト結果に基づく推奨VRAM最適化設定:
|
||||
|
||||
| GPU Memory | 推奨設定 |
|
||||
|------------|---------|
|
||||
| 40GB+ VRAM | 標準設定(特別な最適化不要) |
|
||||
| 24GB VRAM | `--fp8_scaled --blocks_to_swap 9` |
|
||||
| 12GB VRAM | `--fp8_scaled --blocks_to_swap 32` |
|
||||
| 8GB VRAM | `--fp8_scaled --blocks_to_swap 37` |
|
||||
|
||||
主要なVRAM削減オプション:
|
||||
- `--fp8_scaled`: DiTをスケールされたFP8形式で学習(推奨されるFP8オプション、40GB VRAM未満の環境では必須)
|
||||
- `--fp8_vl`: VLMテキストエンコーダにFP8を使用
|
||||
- `--blocks_to_swap`: CPUとGPU間でブロックをスワップ(最大37ブロック)
|
||||
- `--cpu_offload_checkpointing`: 勾配チェックポイントをCPUにオフロード
|
||||
- Adafactorオプティマイザの使用
|
||||
|
||||
</details>
|
||||
|
||||
### 6.2. Important HunyuanImage-2.1 LoRA Training Settings / HunyuanImage-2.1 LoRA学習の重要な設定
|
||||
|
||||
HunyuanImage-2.1 training has several settings that can be specified with arguments:
|
||||
|
||||
#### Timestep Sampling Methods
|
||||
|
||||
The `--timestep_sampling` option specifies how timesteps (0-1) are sampled:
|
||||
|
||||
- `sigma`: Sigma-based like SD3 (Default)
|
||||
- `uniform`: Uniform random
|
||||
- `sigmoid`: Sigmoid of normal distribution random
|
||||
- `shift`: Sigmoid value of normal distribution random with shift.
|
||||
- `flux_shift`: Shift sigmoid value of normal distribution random according to resolution.
|
||||
|
||||
#### Model Prediction Processing
|
||||
|
||||
The `--model_prediction_type` option specifies how to interpret and process model predictions:
|
||||
|
||||
- `raw`: Use as-is **[Recommended, Default]**
|
||||
- `additive`: Add to noise input
|
||||
- `sigma_scaled`: Apply sigma scaling
|
||||
|
||||
#### Recommended Settings
|
||||
|
||||
Based on experiments, the default settings work well:
|
||||
```
|
||||
--model_prediction_type raw --discrete_flow_shift 5.0
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
HunyuanImage-2.1の学習には、引数で指定できるいくつかの設定があります。詳細な説明とコマンドラインの例は英語のドキュメントを参照してください。
|
||||
|
||||
主要な設定オプション:
|
||||
- タイムステップのサンプリング方法(`--timestep_sampling`)
|
||||
- モデル予測の処理方法(`--model_prediction_type`)
|
||||
- 推奨設定の組み合わせ
|
||||
|
||||
</details>
|
||||
|
||||
### 6.3. Regular Expression-based Rank/LR Configuration / 正規表現によるランク・学習率の指定
|
||||
|
||||
You can specify ranks (dims) and learning rates for LoRA modules using regular expressions. This allows for more flexible and fine-grained control.
|
||||
|
||||
These settings are specified via the `network_args` argument.
|
||||
|
||||
* `network_reg_dims`: Specify ranks for modules matching a regular expression. The format is a comma-separated string of `pattern=rank`.
|
||||
* Example: `--network_args "network_reg_dims=attn.*.q_proj=4,attn.*.k_proj=4"`
|
||||
* `network_reg_lrs`: Specify learning rates for modules matching a regular expression. The format is a comma-separated string of `pattern=lr`.
|
||||
* Example: `--network_args "network_reg_lrs=down_blocks.1=1e-4,up_blocks.2=2e-4"`
|
||||
|
||||
**Notes:**
|
||||
|
||||
* To find the correct module names for the patterns, you may need to inspect the model structure.
|
||||
* Settings via `network_reg_dims` and `network_reg_lrs` take precedence over the global `--network_dim` and `--learning_rate` settings.
|
||||
* If a module name matches multiple patterns, the setting from the last matching pattern in the string will be applied.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
正規表現を用いて、LoRAのモジュールごとにランク(dim)や学習率を指定することができます。これにより、柔軟できめ細やかな制御が可能になります。
|
||||
|
||||
これらの設定は `network_args` 引数で指定します。
|
||||
|
||||
* `network_reg_dims`: 正規表現にマッチするモジュールに対してランクを指定します。
|
||||
* `network_reg_lrs`: 正規表現にマッチするモジュールに対して学習率を指定します。
|
||||
|
||||
**注意点:**
|
||||
|
||||
* パターンのための正確なモジュール名を見つけるには、モデルの構造を調べる必要があるかもしれません。
|
||||
* `network_reg_dims` および `network_reg_lrs` での設定は、全体設定である `--network_dim` や `--learning_rate` よりも優先されます。
|
||||
* あるモジュール名が複数のパターンにマッチした場合、文字列の中で後方にあるパターンの設定が適用されます。
|
||||
|
||||
</details>
|
||||
|
||||
### 6.4. Multi-Resolution Training / マルチ解像度トレーニング
|
||||
|
||||
You can define multiple resolutions in the dataset configuration file, with different batch sizes for each resolution.
|
||||
|
||||
**Note:** This feature is available, but it is **not recommended** as the HunyuanImage-2.1 base model was not trained with multi-resolution capabilities. Using it may lead to unexpected results.
|
||||
|
||||
Configuration file example:
|
||||
```toml
|
||||
[general]
|
||||
shuffle_caption = true
|
||||
caption_extension = ".txt"
|
||||
|
||||
[[datasets]]
|
||||
batch_size = 2
|
||||
enable_bucket = true
|
||||
resolution = [1024, 1024]
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = "path/to/image/directory"
|
||||
num_repeats = 1
|
||||
|
||||
[[datasets]]
|
||||
batch_size = 1
|
||||
enable_bucket = true
|
||||
resolution = [1280, 768]
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = "path/to/another/directory"
|
||||
num_repeats = 1
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
データセット設定ファイルで複数の解像度を定義できます。各解像度に対して異なるバッチサイズを指定することができます。
|
||||
|
||||
**注意:** この機能は利用可能ですが、HunyuanImage-2.1のベースモデルはマルチ解像度で学習されていないため、**非推奨**です。使用すると予期しない結果になる可能性があります。
|
||||
|
||||
設定ファイルの例は英語のドキュメントを参照してください。
|
||||
|
||||
</details>
|
||||
|
||||
### 6.5. Validation / 検証
|
||||
|
||||
You can calculate validation loss during training using a validation dataset to evaluate model generalization performance. This feature works the same as in other training scripts. For details, please refer to the [Validation Guide](validation.md).
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
学習中に検証データセットを使用して損失 (Validation Loss) を計算し、モデルの汎化性能を評価できます。この機能は他の学習スクリプトと同様に動作します。詳細は[検証ガイド](validation.md)を参照してください。
|
||||
|
||||
</details>
|
||||
|
||||
## 7. Other Training Options / その他の学習オプション
|
||||
|
||||
- **`--ip_noise_gamma`**: Use `--ip_noise_gamma` and `--ip_noise_gamma_random_strength` to adjust Input Perturbation noise gamma values during training. See Stable Diffusion 3 training options for details.
|
||||
|
||||
- **`--loss_type`**: Specifies the loss function for training. The default is `l2`.
|
||||
- `l1`: L1 loss.
|
||||
- `l2`: L2 loss (mean squared error).
|
||||
- `huber`: Huber loss.
|
||||
- `smooth_l1`: Smooth L1 loss.
|
||||
|
||||
- **`--huber_schedule`**, **`--huber_c`**, **`--huber_scale`**: These are parameters for Huber loss. They are used when `--loss_type` is `huber` or `smooth_l1`.
|
||||
|
||||
- **`--weighting_scheme`**, **`--logit_mean`**, **`--logit_std`**, **`--mode_scale`**: These options allow you to adjust the loss weighting for each timestep. For details, refer to the [`sd3_train_network.md` guide](sd3_train_network.md).
|
||||
|
||||
- **`--fused_backward_pass`**: Fuses the backward pass and optimizer step to reduce VRAM usage.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
- **`--ip_noise_gamma`**: Input Perturbationノイズのガンマ値を調整します。
|
||||
- **`--loss_type`**: 学習に用いる損失関数を指定します。
|
||||
- **`--huber_schedule`**, **`--huber_c`**, **`--huber_scale`**: Huber損失のパラメータです。
|
||||
- **`--weighting_scheme`**, **`--logit_mean`**, **`--logit_std`**, **`--mode_scale`**: 各タイムステップの損失の重み付けを調整します。
|
||||
- **`--fused_backward_pass`**: バックワードパスとオプティマイザステップを融合してVRAM使用量を削減します。
|
||||
|
||||
</details>
|
||||
|
||||
## 8. Using the Inference Script / 推論スクリプトの使用法
|
||||
|
||||
The `hunyuan_image_minimal_inference.py` script allows you to generate images using trained LoRA models. Here's a basic usage example:
|
||||
|
||||
```bash
|
||||
python hunyuan_image_minimal_inference.py \
|
||||
--dit "<path to hunyuanimage2.1.safetensors>" \
|
||||
--text_encoder "<path to qwen_2.5_vl_7b.safetensors>" \
|
||||
--byt5 "<path to byt5_small_glyphxl_fp16.safetensors>" \
|
||||
--vae "<path to hunyuan_image_2.1_vae_fp16.safetensors>" \
|
||||
--lora_weight "<path to your trained LoRA>" \
|
||||
--lora_multiplier 1.0 \
|
||||
--attn_mode "torch" \
|
||||
--prompt "A cute cartoon penguin in a snowy landscape" \
|
||||
--image_size 2048 2048 \
|
||||
--infer_steps 50 \
|
||||
--guidance_scale 3.5 \
|
||||
--flow_shift 5.0 \
|
||||
--seed 542017 \
|
||||
--save_path "output_image.png"
|
||||
```
|
||||
|
||||
**Key Options:**
|
||||
- `--fp8_scaled`: Use scaled FP8 format for reduced VRAM usage during inference
|
||||
- `--blocks_to_swap`: Swap blocks to CPU to reduce VRAM usage
|
||||
- `--image_size`: Resolution in **height width** (inference is most stable at 2560x1536, 2304x1792, 2048x2048, 1792x2304, 1536x2560 according to the official repo)
|
||||
- `--guidance_scale`: CFG scale (default: 3.5)
|
||||
- `--flow_shift`: Flow matching shift parameter (default: 5.0)
|
||||
- `--text_encoder_cpu`: Run the text encoders on CPU to reduce VRAM usage
|
||||
- `--vae_chunk_size`: Chunk size for VAE decoding to reduce memory usage (default: None, no chunking). 16 is recommended if enabled.
|
||||
- `--apg_start_step_general` and `--apg_start_step_ocr`: Start steps for APG (Adaptive Projected Guidance) if using APG during inference. `5` and `38` are the official recommended values for 50 steps. If this value exceeds `--infer_steps`, APG will not be applied.
|
||||
- `--guidance_rescale`: Rescales the guidance for steps before APG starts. Default is `0.0` (no rescaling). If you use this option, a value around `0.5` might be good starting point.
|
||||
- `--guidance_rescale_apg`: Rescales the guidance for APG. Default is `0.0` (no rescaling). This option doesn't seem to have a large effect, but if you use it, a value around `0.5` might be a good starting point.
|
||||
|
||||
`--split_attn` is not supported (since inference is done one at a time). `--fp8_vl` is not supported, please use CPU for the text encoder if VRAM is insufficient.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
`hunyuan_image_minimal_inference.py`スクリプトを使用して、学習したLoRAモデルで画像を生成できます。基本的な使用例は英語のドキュメントを参照してください。
|
||||
|
||||
**主要なオプション:**
|
||||
- `--fp8_scaled`: VRAM使用量削減のためのスケールFP8形式
|
||||
- `--blocks_to_swap`: VRAM使用量削減のためのブロックスワップ
|
||||
- `--image_size`: 解像度(2048x2048で最も安定)
|
||||
- `--guidance_scale`: CFGスケール(推奨: 3.5)
|
||||
- `--flow_shift`: Flow Matchingシフトパラメータ(デフォルト: 5.0)
|
||||
- `--text_encoder_cpu`: テキストエンコーダをCPUで実行してVRAM使用量削減
|
||||
- `--vae_chunk_size`: VAEデコーディングのチャンクサイズ(デフォルト: None、チャンク処理なし)。有効にする場合は16を推奨。
|
||||
- `--apg_start_step_general` と `--apg_start_step_ocr`: 推論中にAPGを使用する場合の開始ステップ。50ステップの場合、公式推奨値はそれぞれ5と38です。この値が`--infer_steps`を超えると、APGは適用されません。
|
||||
- `--guidance_rescale`: APG開始前のステップに対するガイダンスのリスケーリング。デフォルトは0.0(リスケーリングなし)。使用する場合、0.5程度から始めて調整してください。
|
||||
- `--guidance_rescale_apg`: APGに対するガイダンスのリスケーリング。デフォルトは0.0(リスケーリングなし)。このオプションは大きな効果はないようですが、使用する場合は0.5程度から始めて調整してください。
|
||||
|
||||
`--split_attn`はサポートされていません(1件ずつ推論するため)。`--fp8_vl`もサポートされていません。VRAMが不足する場合はテキストエンコーダをCPUで実行してください。
|
||||
|
||||
</details>
|
||||
|
||||
## 9. Related Tools / 関連ツール
|
||||
|
||||
### `networks/convert_hunyuan_image_lora_to_comfy.py`
|
||||
|
||||
A script to convert LoRA models to ComfyUI-compatible format. The formats differ slightly, so conversion is necessary. You can convert from the sd-scripts format to ComfyUI format with:
|
||||
|
||||
```bash
|
||||
python networks/convert_hunyuan_image_lora_to_comfy.py path/to/source.safetensors path/to/destination.safetensors
|
||||
```
|
||||
|
||||
Using the `--reverse` option allows conversion in the opposite direction (ComfyUI format to sd-scripts format). However, reverse conversion is only possible for LoRAs converted by this script. LoRAs created with other training tools cannot be converted.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
**`networks/convert_hunyuan_image_lora_to_comfy.py`**
|
||||
|
||||
LoRAモデルをComfyUI互換形式に変換するスクリプト。わずかに形式が異なるため、変換が必要です。以下の指定で、sd-scriptsの形式からComfyUI形式に変換できます。
|
||||
|
||||
```bash
|
||||
python networks/convert_hunyuan_image_lora_to_comfy.py path/to/source.safetensors path/to/destination.safetensors
|
||||
```
|
||||
|
||||
`--reverse`オプションを付けると、逆変換(ComfyUI形式からsd-scripts形式)も可能です。ただし、逆変換ができるのはこのスクリプトで変換したLoRAに限ります。他の学習ツールで作成したLoRAは変換できません。
|
||||
|
||||
</details>
|
||||
|
||||
## 10. Others / その他
|
||||
|
||||
`hunyuan_image_train_network.py` includes many features common with `train_network.py`, such as sample image generation (`--sample_prompts`, etc.) and detailed optimizer settings. For these features, refer to the [`train_network.py` guide](train_network.md#5-other-features--その他の機能) or the script help (`python hunyuan_image_train_network.py --help`).
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
`hunyuan_image_train_network.py`には、サンプル画像の生成 (`--sample_prompts`など) や詳細なオプティマイザ設定など、`train_network.py`と共通の機能も多く存在します。これらについては、[`train_network.py`のガイド](train_network.md#5-other-features--その他の機能)やスクリプトのヘルプ (`python hunyuan_image_train_network.py --help`) を参照してください。
|
||||
|
||||
</details>
|
||||
359
docs/loha_lokr.md
Normal file
359
docs/loha_lokr.md
Normal file
@@ -0,0 +1,359 @@
|
||||
> 📝 Click on the language section to expand / 言語をクリックして展開
|
||||
|
||||
# LoHa / LoKr (LyCORIS)
|
||||
|
||||
## Overview / 概要
|
||||
|
||||
In addition to standard LoRA, sd-scripts supports **LoHa** (Low-rank Hadamard Product) and **LoKr** (Low-rank Kronecker Product) as alternative parameter-efficient fine-tuning methods. These are based on techniques from the [LyCORIS](https://github.com/KohakuBlueleaf/LyCORIS) project.
|
||||
|
||||
- **LoHa**: Represents weight updates as a Hadamard (element-wise) product of two low-rank matrices. Reference: [FedPara (arXiv:2108.06098)](https://arxiv.org/abs/2108.06098)
|
||||
- **LoKr**: Represents weight updates as a Kronecker product with optional low-rank decomposition. Reference: [LoKr (arXiv:2309.14859)](https://arxiv.org/abs/2309.14859)
|
||||
|
||||
The algorithms and recommended settings are described in the [LyCORIS documentation](https://github.com/KohakuBlueleaf/LyCORIS/blob/main/docs/Algo-List.md) and [guidelines](https://github.com/KohakuBlueleaf/LyCORIS/blob/main/docs/Guidelines.md).
|
||||
|
||||
Both methods target Linear and Conv2d layers. Conv2d 1x1 layers are treated similarly to Linear layers. For Conv2d 3x3+ layers, optional Tucker decomposition or flat (kernel-flattened) mode is available.
|
||||
|
||||
This feature is experimental.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
sd-scriptsでは、標準的なLoRAに加え、代替のパラメータ効率の良いファインチューニング手法として **LoHa**(Low-rank Hadamard Product)と **LoKr**(Low-rank Kronecker Product)をサポートしています。これらは [LyCORIS](https://github.com/KohakuBlueleaf/LyCORIS) プロジェクトの手法に基づいています。
|
||||
|
||||
- **LoHa**: 重みの更新を2つの低ランク行列のHadamard積(要素ごとの積)で表現します。参考文献: [FedPara (arXiv:2108.06098)](https://arxiv.org/abs/2108.06098)
|
||||
- **LoKr**: 重みの更新をKronecker積と、オプションの低ランク分解で表現します。参考文献: [LoKr (arXiv:2309.14859)](https://arxiv.org/abs/2309.14859)
|
||||
|
||||
アルゴリズムと推奨設定は[LyCORISのアルゴリズム解説](https://github.com/KohakuBlueleaf/LyCORIS/blob/main/docs/Algo-List.md)と[ガイドライン](https://github.com/KohakuBlueleaf/LyCORIS/blob/main/docs/Guidelines.md)を参照してください。
|
||||
|
||||
LinearおよびConv2d層の両方を対象としています。Conv2d 1x1層はLinear層と同様に扱われます。Conv2d 3x3+層については、オプションのTucker分解またはflat(カーネル平坦化)モードが利用可能です。
|
||||
|
||||
この機能は実験的なものです。
|
||||
|
||||
</details>
|
||||
|
||||
## Acknowledgments / 謝辞
|
||||
|
||||
The LoHa and LoKr implementations in sd-scripts are based on the [LyCORIS](https://github.com/KohakuBlueleaf/LyCORIS) project by [KohakuBlueleaf](https://github.com/KohakuBlueleaf). We would like to express our sincere gratitude for the excellent research and open-source contributions that made this implementation possible.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
sd-scriptsのLoHaおよびLoKrの実装は、[KohakuBlueleaf](https://github.com/KohakuBlueleaf)氏による[LyCORIS](https://github.com/KohakuBlueleaf/LyCORIS)プロジェクトに基づいています。この実装を可能にしてくださった素晴らしい研究とオープンソースへの貢献に心から感謝いたします。
|
||||
|
||||
</details>
|
||||
|
||||
## Supported architectures / 対応アーキテクチャ
|
||||
|
||||
LoHa and LoKr automatically detect the model architecture and apply appropriate default settings. The following architectures are currently supported:
|
||||
|
||||
- **SDXL**: Targets `Transformer2DModel` for UNet and `CLIPAttention`/`CLIPMLP` for text encoders. Conv2d layers in `ResnetBlock2D`, `Downsample2D`, and `Upsample2D` are also supported when `conv_dim` is specified. No default `exclude_patterns`.
|
||||
- **Anima**: Targets `Block`, `PatchEmbed`, `TimestepEmbedding`, and `FinalLayer` for DiT, and `Qwen3Attention`/`Qwen3MLP` for the text encoder. Default `exclude_patterns` automatically skips modulation, normalization, embedder, and final_layer modules.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
LoHaとLoKrは、モデルのアーキテクチャを自動で検出し、適切なデフォルト設定を適用します。現在、以下のアーキテクチャに対応しています:
|
||||
|
||||
- **SDXL**: UNetの`Transformer2DModel`、テキストエンコーダの`CLIPAttention`/`CLIPMLP`を対象とします。`conv_dim`を指定した場合、`ResnetBlock2D`、`Downsample2D`、`Upsample2D`のConv2d層も対象になります。デフォルトの`exclude_patterns`はありません。
|
||||
- **Anima**: DiTの`Block`、`PatchEmbed`、`TimestepEmbedding`、`FinalLayer`、テキストエンコーダの`Qwen3Attention`/`Qwen3MLP`を対象とします。デフォルトの`exclude_patterns`により、modulation、normalization、embedder、final_layerモジュールは自動的にスキップされます。
|
||||
|
||||
</details>
|
||||
|
||||
## Training / 学習
|
||||
|
||||
To use LoHa or LoKr, change the `--network_module` argument in your training command. All other training options (dataset config, optimizer, etc.) remain the same as LoRA.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
LoHaまたはLoKrを使用するには、学習コマンドの `--network_module` 引数を変更します。その他の学習オプション(データセット設定、オプティマイザなど)はLoRAと同じです。
|
||||
|
||||
</details>
|
||||
|
||||
### LoHa (SDXL)
|
||||
|
||||
```bash
|
||||
accelerate launch --num_cpu_threads_per_process 1 --mixed_precision bf16 sdxl_train_network.py \
|
||||
--pretrained_model_name_or_path path/to/sdxl.safetensors \
|
||||
--dataset_config path/to/toml \
|
||||
--mixed_precision bf16 --fp8_base \
|
||||
--optimizer_type adamw8bit --learning_rate 2e-4 --gradient_checkpointing \
|
||||
--network_module networks.loha --network_dim 32 --network_alpha 16 \
|
||||
--max_train_epochs 16 --save_every_n_epochs 1 \
|
||||
--output_dir path/to/output --output_name my-loha
|
||||
```
|
||||
|
||||
### LoKr (SDXL)
|
||||
|
||||
```bash
|
||||
accelerate launch --num_cpu_threads_per_process 1 --mixed_precision bf16 sdxl_train_network.py \
|
||||
--pretrained_model_name_or_path path/to/sdxl.safetensors \
|
||||
--dataset_config path/to/toml \
|
||||
--mixed_precision bf16 --fp8_base \
|
||||
--optimizer_type adamw8bit --learning_rate 2e-4 --gradient_checkpointing \
|
||||
--network_module networks.lokr --network_dim 32 --network_alpha 16 \
|
||||
--max_train_epochs 16 --save_every_n_epochs 1 \
|
||||
--output_dir path/to/output --output_name my-lokr
|
||||
```
|
||||
|
||||
For Anima, replace `sdxl_train_network.py` with `anima_train_network.py` and use the appropriate model path and options.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
Animaの場合は、`sdxl_train_network.py` を `anima_train_network.py` に置き換え、適切なモデルパスとオプションを使用してください。
|
||||
|
||||
</details>
|
||||
|
||||
### Common training options / 共通の学習オプション
|
||||
|
||||
The following `--network_args` options are available for both LoHa and LoKr, same as LoRA:
|
||||
|
||||
| Option | Description |
|
||||
|---|---|
|
||||
| `verbose=True` | Display detailed information about the network modules |
|
||||
| `rank_dropout=0.1` | Apply dropout to the rank dimension during training |
|
||||
| `module_dropout=0.1` | Randomly skip entire modules during training |
|
||||
| `exclude_patterns=[r'...']` | Exclude modules matching the regex patterns (in addition to architecture defaults) |
|
||||
| `include_patterns=[r'...']` | Override excludes: modules matching these regex patterns will be included even if they match `exclude_patterns` |
|
||||
| `network_reg_lrs=regex1=lr1,regex2=lr2` | Set per-module learning rates using regex patterns |
|
||||
| `network_reg_dims=regex1=dim1,regex2=dim2` | Set per-module dimensions (rank) using regex patterns |
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
以下の `--network_args` オプションは、LoRAと同様にLoHaとLoKrの両方で使用できます:
|
||||
|
||||
| オプション | 説明 |
|
||||
|---|---|
|
||||
| `verbose=True` | ネットワークモジュールの詳細情報を表示 |
|
||||
| `rank_dropout=0.1` | 学習時にランク次元にドロップアウトを適用 |
|
||||
| `module_dropout=0.1` | 学習時にモジュール全体をランダムにスキップ |
|
||||
| `exclude_patterns=[r'...']` | 正規表現パターンに一致するモジュールを除外(アーキテクチャのデフォルトに追加) |
|
||||
| `include_patterns=[r'...']` | 正規表現パターンに一致するモジュールのみを対象とする |
|
||||
| `network_reg_lrs=regex1=lr1,regex2=lr2` | 正規表現パターンでモジュールごとの学習率を設定 |
|
||||
| `network_reg_dims=regex1=dim1,regex2=dim2` | 正規表現パターンでモジュールごとの次元(ランク)を設定 |
|
||||
|
||||
</details>
|
||||
|
||||
### Conv2d support / Conv2dサポート
|
||||
|
||||
By default, LoHa and LoKr target Linear and Conv2d 1x1 layers. To also train Conv2d 3x3+ layers (e.g., in SDXL's ResNet blocks), use the `conv_dim` and `conv_alpha` options:
|
||||
|
||||
```bash
|
||||
--network_args "conv_dim=16" "conv_alpha=8"
|
||||
```
|
||||
|
||||
For Conv2d 3x3+ layers, you can enable Tucker decomposition for more efficient parameter representation:
|
||||
|
||||
```bash
|
||||
--network_args "conv_dim=16" "conv_alpha=8" "use_tucker=True"
|
||||
```
|
||||
|
||||
- Without `use_tucker`: The kernel dimensions are flattened into the input dimension (flat mode).
|
||||
- With `use_tucker=True`: A separate Tucker tensor is used to handle the kernel dimensions, which can be more parameter-efficient.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
デフォルトでは、LoHaとLoKrはLinearおよびConv2d 1x1層を対象とします。Conv2d 3x3+層(SDXLのResNetブロックなど)も学習するには、`conv_dim`と`conv_alpha`オプションを使用します:
|
||||
|
||||
```bash
|
||||
--network_args "conv_dim=16" "conv_alpha=8"
|
||||
```
|
||||
|
||||
Conv2d 3x3+層に対して、Tucker分解を有効にすることで、より効率的なパラメータ表現が可能です:
|
||||
|
||||
```bash
|
||||
--network_args "conv_dim=16" "conv_alpha=8" "use_tucker=True"
|
||||
```
|
||||
|
||||
- `use_tucker`なし: カーネル次元が入力次元に平坦化されます(flatモード)。
|
||||
- `use_tucker=True`: カーネル次元を扱う別のTuckerテンソルが使用され、よりパラメータ効率が良くなる場合があります。
|
||||
|
||||
</details>
|
||||
|
||||
### LoKr-specific option: `factor` / LoKr固有のオプション: `factor`
|
||||
|
||||
LoKr decomposes weight dimensions using factorization. The `factor` option controls how dimensions are split:
|
||||
|
||||
- `factor=-1` (default): Automatically find balanced factors. For example, dimension 512 is split into (16, 32).
|
||||
- `factor=N` (positive integer): Force factorization using the specified value. For example, `factor=4` splits dimension 512 into (4, 128).
|
||||
|
||||
```bash
|
||||
--network_args "factor=4"
|
||||
```
|
||||
|
||||
When `network_dim` (rank) is large enough relative to the factorized dimensions, LoKr uses a full matrix instead of a low-rank decomposition for the second factor. A warning will be logged in this case.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
LoKrは重みの次元を因数分解して分割します。`factor` オプションでその分割方法を制御します:
|
||||
|
||||
- `factor=-1`(デフォルト): バランスの良い因数を自動的に見つけます。例えば、次元512は(16, 32)に分割されます。
|
||||
- `factor=N`(正の整数): 指定した値で因数分解します。例えば、`factor=4` は次元512を(4, 128)に分割します。
|
||||
|
||||
```bash
|
||||
--network_args "factor=4"
|
||||
```
|
||||
|
||||
`network_dim`(ランク)が因数分解された次元に対して十分に大きい場合、LoKrは第2因子に低ランク分解ではなくフル行列を使用します。その場合、警告がログに出力されます。
|
||||
|
||||
</details>
|
||||
|
||||
### Anima-specific option: `train_llm_adapter` / Anima固有のオプション: `train_llm_adapter`
|
||||
|
||||
For Anima, you can additionally train the LLM adapter modules by specifying:
|
||||
|
||||
```bash
|
||||
--network_args "train_llm_adapter=True"
|
||||
```
|
||||
|
||||
This includes `LLMAdapterTransformerBlock` modules as training targets.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
Animaでは、以下を指定することでLLMアダプターモジュールも追加で学習できます:
|
||||
|
||||
```bash
|
||||
--network_args "train_llm_adapter=True"
|
||||
```
|
||||
|
||||
これにより、`LLMAdapterTransformerBlock` モジュールが学習対象に含まれます。
|
||||
|
||||
</details>
|
||||
|
||||
### LoRA+ / LoRA+
|
||||
|
||||
LoRA+ (`loraplus_lr_ratio` etc. in `--network_args`) is supported with LoHa/LoKr. For LoHa, the second pair of matrices (`hada_w2_a`) is treated as the "plus" (higher learning rate) parameter group. For LoKr, the scale factor (`lokr_w1`) is treated as the "plus" parameter group.
|
||||
|
||||
```bash
|
||||
--network_args "loraplus_lr_ratio=4"
|
||||
```
|
||||
|
||||
This feature has been confirmed to work in basic testing, but feedback is welcome. If you encounter any issues, please report them.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
LoRA+(`--network_args` の `loraplus_lr_ratio` 等)はLoHa/LoKrでもサポートされています。LoHaでは第2ペアの行列(`hada_w2_a`)が「plus」(より高い学習率)パラメータグループとして扱われます。LoKrではスケール係数(`lokr_w1`)が「plus」パラメータグループとして扱われます。
|
||||
|
||||
```bash
|
||||
--network_args "loraplus_lr_ratio=4"
|
||||
```
|
||||
|
||||
この機能は基本的なテストでは動作確認されていますが、フィードバックをお待ちしています。問題が発生した場合はご報告ください。
|
||||
|
||||
</details>
|
||||
|
||||
## How LoHa and LoKr work / LoHaとLoKrの仕組み
|
||||
|
||||
### LoHa
|
||||
|
||||
LoHa represents the weight update as a Hadamard (element-wise) product of two low-rank matrices:
|
||||
|
||||
```
|
||||
ΔW = (W1a × W1b) ⊙ (W2a × W2b)
|
||||
```
|
||||
|
||||
where `W1a`, `W1b`, `W2a`, `W2b` are low-rank matrices with rank `network_dim`. This means LoHa has roughly **twice the number of trainable parameters** compared to LoRA at the same rank, but can capture more complex weight structures due to the element-wise product.
|
||||
|
||||
For Conv2d 3x3+ layers with Tucker decomposition, each pair additionally has a Tucker tensor `T` and the reconstruction becomes: `einsum("i j ..., j r, i p -> p r ...", T, Wb, Wa)`.
|
||||
|
||||
### LoKr
|
||||
|
||||
LoKr represents the weight update using a Kronecker product:
|
||||
|
||||
```
|
||||
ΔW = W1 ⊗ W2 (where W2 = W2a × W2b in low-rank mode)
|
||||
```
|
||||
|
||||
The original weight dimensions are factorized (e.g., a 512×512 weight might be split so that W1 is 16×16 and W2 is 32×32). W1 is always a full matrix (small), while W2 can be either low-rank decomposed or a full matrix depending on the rank setting. LoKr tends to produce **smaller models** compared to LoRA at the same rank.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
### LoHa
|
||||
|
||||
LoHaは重みの更新を2つの低ランク行列のHadamard積(要素ごとの積)で表現します:
|
||||
|
||||
```
|
||||
ΔW = (W1a × W1b) ⊙ (W2a × W2b)
|
||||
```
|
||||
|
||||
ここで `W1a`, `W1b`, `W2a`, `W2b` はランク `network_dim` の低ランク行列です。LoHaは同じランクのLoRAと比較して学習可能なパラメータ数が **約2倍** になりますが、要素ごとの積により、より複雑な重み構造を捉えることができます。
|
||||
|
||||
Conv2d 3x3+層でTucker分解を使用する場合、各ペアにはさらにTuckerテンソル `T` があり、再構成は `einsum("i j ..., j r, i p -> p r ...", T, Wb, Wa)` となります。
|
||||
|
||||
### LoKr
|
||||
|
||||
LoKrはKronecker積を使って重みの更新を表現します:
|
||||
|
||||
```
|
||||
ΔW = W1 ⊗ W2 (低ランクモードでは W2 = W2a × W2b)
|
||||
```
|
||||
|
||||
元の重みの次元が因数分解されます(例: 512×512の重みが、W1が16×16、W2が32×32に分割されます)。W1は常にフル行列(小さい)で、W2はランク設定に応じて低ランク分解またはフル行列になります。LoKrは同じランクのLoRAと比較して **より小さいモデル** を生成する傾向があります。
|
||||
|
||||
</details>
|
||||
|
||||
## Inference / 推論
|
||||
|
||||
Trained LoHa/LoKr weights are saved in safetensors format, just like LoRA.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
学習済みのLoHa/LoKrの重みは、LoRAと同様にsafetensors形式で保存されます。
|
||||
|
||||
</details>
|
||||
|
||||
### SDXL
|
||||
|
||||
For SDXL, use `gen_img.py` with `--network_module` and `--network_weights`, the same way as LoRA:
|
||||
|
||||
```bash
|
||||
python gen_img.py --ckpt path/to/sdxl.safetensors \
|
||||
--network_module networks.loha --network_weights path/to/loha.safetensors \
|
||||
--prompt "your prompt" ...
|
||||
```
|
||||
|
||||
Replace `networks.loha` with `networks.lokr` for LoKr weights.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
SDXLでは、LoRAと同様に `gen_img.py` で `--network_module` と `--network_weights` を指定します:
|
||||
|
||||
```bash
|
||||
python gen_img.py --ckpt path/to/sdxl.safetensors \
|
||||
--network_module networks.loha --network_weights path/to/loha.safetensors \
|
||||
--prompt "your prompt" ...
|
||||
```
|
||||
|
||||
LoKrの重みを使用する場合は `networks.loha` を `networks.lokr` に置き換えてください。
|
||||
|
||||
</details>
|
||||
|
||||
### Anima
|
||||
|
||||
For Anima, use `anima_minimal_inference.py` with the `--lora_weight` argument. LoRA, LoHa, and LoKr weights are automatically detected and merged:
|
||||
|
||||
```bash
|
||||
python anima_minimal_inference.py --dit path/to/dit --prompt "your prompt" \
|
||||
--lora_weight path/to/loha_or_lokr.safetensors ...
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
Animaでは、`anima_minimal_inference.py` に `--lora_weight` 引数を指定します。LoRA、LoHa、LoKrの重みは自動的に判定されてマージされます:
|
||||
|
||||
```bash
|
||||
python anima_minimal_inference.py --dit path/to/dit --prompt "your prompt" \
|
||||
--lora_weight path/to/loha_or_lokr.safetensors ...
|
||||
```
|
||||
|
||||
</details>
|
||||
319
docs/lumina_train_network.md
Normal file
319
docs/lumina_train_network.md
Normal file
@@ -0,0 +1,319 @@
|
||||
# LoRA Training Guide for Lumina Image 2.0 using `lumina_train_network.py` / `lumina_train_network.py` を用いたLumina Image 2.0モデルのLoRA学習ガイド
|
||||
|
||||
This document explains how to train LoRA (Low-Rank Adaptation) models for Lumina Image 2.0 using `lumina_train_network.py` in the `sd-scripts` repository.
|
||||
|
||||
## 1. Introduction / はじめに
|
||||
|
||||
`lumina_train_network.py` trains additional networks such as LoRA for Lumina Image 2.0 models. Lumina Image 2.0 adopts a Next-DiT (Next-generation Diffusion Transformer) architecture, which differs from previous Stable Diffusion models. It uses a single text encoder (Gemma2) and a dedicated AutoEncoder (AE).
|
||||
|
||||
This guide assumes you already understand the basics of LoRA training. For common usage and options, see [the train_network.py guide](./train_network.md). Some parameters are similar to those in [`sd3_train_network.py`](sd3_train_network.md) and [`flux_train_network.py`](flux_train_network.md).
|
||||
|
||||
**Prerequisites:**
|
||||
|
||||
* The `sd-scripts` repository has been cloned and the Python environment is ready.
|
||||
* A training dataset has been prepared. See the [Dataset Configuration Guide](./config_README-en.md).
|
||||
* Lumina Image 2.0 model files for training are available.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
`lumina_train_network.py`は、Lumina Image 2.0モデルに対してLoRAなどの追加ネットワークを学習させるためのスクリプトです。Lumina Image 2.0は、Next-DiT (Next-generation Diffusion Transformer) と呼ばれる新しいアーキテクチャを採用しており、従来のStable Diffusionモデルとは構造が異なります。テキストエンコーダーとしてGemma2を単体で使用し、専用のAutoEncoder (AE) を使用します。
|
||||
|
||||
このガイドは、基本的なLoRA学習の手順を理解しているユーザーを対象としています。基本的な使い方や共通のオプションについては、`train_network.py`のガイド(作成中)を参照してください。また一部のパラメータは [`sd3_train_network.py`](sd3_train_network.md) や [`flux_train_network.py`](flux_train_network.md) と同様のものがあるため、そちらも参考にしてください。
|
||||
|
||||
**前提条件:**
|
||||
|
||||
* `sd-scripts`リポジトリのクローンとPython環境のセットアップが完了していること。
|
||||
* 学習用データセットの準備が完了していること。(データセットの準備については[データセット設定ガイド](./config_README-en.md)を参照してください)
|
||||
* 学習対象のLumina Image 2.0モデルファイルが準備できていること。
|
||||
</details>
|
||||
|
||||
## 2. Differences from `train_network.py` / `train_network.py` との違い
|
||||
|
||||
`lumina_train_network.py` is based on `train_network.py` but modified for Lumina Image 2.0. Main differences are:
|
||||
|
||||
* **Target models:** Lumina Image 2.0 models.
|
||||
* **Model structure:** Uses Next-DiT (Transformer based) instead of U-Net and employs a single text encoder (Gemma2). The AutoEncoder (AE) is not compatible with SDXL/SD3/FLUX.
|
||||
* **Arguments:** Options exist to specify the Lumina Image 2.0 model, Gemma2 text encoder and AE. With a single `.safetensors` file, these components are typically provided separately.
|
||||
* **Incompatible arguments:** Stable Diffusion v1/v2 options such as `--v2`, `--v_parameterization` and `--clip_skip` are not used.
|
||||
* **Lumina specific options:** Additional parameters for timestep sampling, model prediction type, discrete flow shift, and system prompt.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
`lumina_train_network.py`は`train_network.py`をベースに、Lumina Image 2.0モデルに対応するための変更が加えられています。主な違いは以下の通りです。
|
||||
|
||||
* **対象モデル:** Lumina Image 2.0モデルを対象とします。
|
||||
* **モデル構造:** U-Netの代わりにNext-DiT (Transformerベース) を使用します。Text EncoderとしてGemma2を単体で使用し、専用のAutoEncoder (AE) を使用します。
|
||||
* **引数:** Lumina Image 2.0モデル、Gemma2 Text Encoder、AEを指定する引数があります。通常、これらのコンポーネントは個別に提供されます。
|
||||
* **一部引数の非互換性:** Stable Diffusion v1/v2向けの引数(例: `--v2`, `--v_parameterization`, `--clip_skip`)はLumina Image 2.0の学習では使用されません。
|
||||
* **Lumina特有の引数:** タイムステップのサンプリング、モデル予測タイプ、離散フローシフト、システムプロンプトに関する引数が追加されています。
|
||||
</details>
|
||||
|
||||
## 3. Preparation / 準備
|
||||
|
||||
The following files are required before starting training:
|
||||
|
||||
1. **Training script:** `lumina_train_network.py`
|
||||
2. **Lumina Image 2.0 model file:** `.safetensors` file for the base model.
|
||||
3. **Gemma2 text encoder file:** `.safetensors` file for the text encoder.
|
||||
4. **AutoEncoder (AE) file:** `.safetensors` file for the AE.
|
||||
5. **Dataset definition file (.toml):** Dataset settings in TOML format. (See the [Dataset Configuration Guide](./config_README-en.md). In this document we use `my_lumina_dataset_config.toml` as an example.
|
||||
|
||||
|
||||
**Model Files:**
|
||||
* Lumina Image 2.0: `lumina-image-2.safetensors` ([full precision link](https://huggingface.co/rockerBOO/lumina-image-2/blob/main/lumina-image-2.safetensors)) or `lumina_2_model_bf16.safetensors` ([bf16 link](https://huggingface.co/Comfy-Org/Lumina_Image_2.0_Repackaged/blob/main/split_files/diffusion_models/lumina_2_model_bf16.safetensors))
|
||||
* Gemma2 2B (fp16): `gemma-2-2b.safetensors` ([link](https://huggingface.co/Comfy-Org/Lumina_Image_2.0_Repackaged/blob/main/split_files/text_encoders/gemma_2_2b_fp16.safetensors))
|
||||
* AutoEncoder: `ae.safetensors` ([link](https://huggingface.co/Comfy-Org/Lumina_Image_2.0_Repackaged/blob/main/split_files/vae/ae.safetensors)) (same as FLUX)
|
||||
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
学習を開始する前に、以下のファイルが必要です。
|
||||
|
||||
1. **学習スクリプト:** `lumina_train_network.py`
|
||||
2. **Lumina Image 2.0モデルファイル:** 学習のベースとなるLumina Image 2.0モデルの`.safetensors`ファイル。
|
||||
3. **Gemma2テキストエンコーダーファイル:** Gemma2テキストエンコーダーの`.safetensors`ファイル。
|
||||
4. **AutoEncoder (AE) ファイル:** AEの`.safetensors`ファイル。
|
||||
5. **データセット定義ファイル (.toml):** 学習データセットの設定を記述したTOML形式のファイル。(詳細は[データセット設定ガイド](./config_README-en.md)を参照してください)。
|
||||
* 例として`my_lumina_dataset_config.toml`を使用します。
|
||||
|
||||
**モデルファイル** は英語ドキュメントの通りです。
|
||||
|
||||
</details>
|
||||
|
||||
## 4. Running the Training / 学習の実行
|
||||
|
||||
Execute `lumina_train_network.py` from the terminal to start training. The overall command-line format is the same as `train_network.py`, but Lumina Image 2.0 specific options must be supplied.
|
||||
|
||||
Example command:
|
||||
|
||||
```bash
|
||||
accelerate launch --num_cpu_threads_per_process 1 lumina_train_network.py \
|
||||
--pretrained_model_name_or_path="lumina-image-2.safetensors" \
|
||||
--gemma2="gemma-2-2b.safetensors" \
|
||||
--ae="ae.safetensors" \
|
||||
--dataset_config="my_lumina_dataset_config.toml" \
|
||||
--output_dir="./output" \
|
||||
--output_name="my_lumina_lora" \
|
||||
--save_model_as=safetensors \
|
||||
--network_module=networks.lora_lumina \
|
||||
--network_dim=8 \
|
||||
--network_alpha=8 \
|
||||
--learning_rate=1e-4 \
|
||||
--optimizer_type="AdamW" \
|
||||
--lr_scheduler="constant" \
|
||||
--timestep_sampling="nextdit_shift" \
|
||||
--discrete_flow_shift=6.0 \
|
||||
--model_prediction_type="raw" \
|
||||
--system_prompt="You are an assistant designed to generate high-quality images based on user prompts." \
|
||||
--max_train_epochs=10 \
|
||||
--save_every_n_epochs=1 \
|
||||
--mixed_precision="bf16" \
|
||||
--gradient_checkpointing \
|
||||
--cache_latents \
|
||||
--cache_text_encoder_outputs
|
||||
```
|
||||
|
||||
*(Write the command on one line or use `\` or `^` for line breaks.)*
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
学習は、ターミナルから`lumina_train_network.py`を実行することで開始します。基本的なコマンドラインの構造は`train_network.py`と同様ですが、Lumina Image 2.0特有の引数を指定する必要があります。
|
||||
|
||||
以下に、基本的なコマンドライン実行例を示します。
|
||||
|
||||
```bash
|
||||
accelerate launch --num_cpu_threads_per_process 1 lumina_train_network.py \
|
||||
--pretrained_model_name_or_path="lumina-image-2.safetensors" \
|
||||
--gemma2="gemma-2-2b.safetensors" \
|
||||
--ae="ae.safetensors" \
|
||||
--dataset_config="my_lumina_dataset_config.toml" \
|
||||
--output_dir="./output" \
|
||||
--output_name="my_lumina_lora" \
|
||||
--save_model_as=safetensors \
|
||||
--network_module=networks.lora_lumina \
|
||||
--network_dim=8 \
|
||||
--network_alpha=8 \
|
||||
--learning_rate=1e-4 \
|
||||
--optimizer_type="AdamW" \
|
||||
--lr_scheduler="constant" \
|
||||
--timestep_sampling="nextdit_shift" \
|
||||
--discrete_flow_shift=6.0 \
|
||||
--model_prediction_type="raw" \
|
||||
--system_prompt="You are an assistant designed to generate high-quality images based on user prompts." \
|
||||
--max_train_epochs=10 \
|
||||
--save_every_n_epochs=1 \
|
||||
--mixed_precision="bf16" \
|
||||
--gradient_checkpointing \
|
||||
--cache_latents \
|
||||
--cache_text_encoder_outputs
|
||||
```
|
||||
|
||||
※実際には1行で書くか、適切な改行文字(`\` または `^`)を使用してください。
|
||||
</details>
|
||||
|
||||
### 4.1. Explanation of Key Options / 主要なコマンドライン引数の解説
|
||||
|
||||
Besides the arguments explained in the [train_network.py guide](train_network.md), specify the following Lumina Image 2.0 options. For shared options (`--output_dir`, `--output_name`, etc.), see that guide.
|
||||
|
||||
#### Model Options / モデル関連
|
||||
|
||||
* `--pretrained_model_name_or_path="<path to Lumina model>"` **required** – Path to the Lumina Image 2.0 model.
|
||||
* `--gemma2="<path to Gemma2 model>"` **required** – Path to the Gemma2 text encoder `.safetensors` file.
|
||||
* `--ae="<path to AE model>"` **required** – Path to the AutoEncoder `.safetensors` file.
|
||||
|
||||
#### Lumina Image 2.0 Training Parameters / Lumina Image 2.0 学習パラメータ
|
||||
|
||||
* `--gemma2_max_token_length=<integer>` – Max token length for Gemma2. Default is 256.
|
||||
* `--timestep_sampling=<choice>` – Timestep sampling method. Options: `sigma`, `uniform`, `sigmoid`, `shift`, `nextdit_shift`. Default `shift`. **Recommended: `nextdit_shift`**
|
||||
* `--discrete_flow_shift=<float>` – Discrete flow shift for the Euler Discrete Scheduler. Default `6.0`.
|
||||
* `--model_prediction_type=<choice>` – Model prediction processing method. Options: `raw`, `additive`, `sigma_scaled`. Default `raw`. **Recommended: `raw`**
|
||||
* `--system_prompt=<string>` – System prompt to prepend to all prompts. Recommended: `"You are an assistant designed to generate high-quality images based on user prompts."` or `"You are an assistant designed to generate high-quality images with the highest degree of image-text alignment based on textual prompts."`
|
||||
* `--use_flash_attn` – Use Flash Attention. Requires `pip install flash-attn` (may not be supported in all environments). If installed correctly, it speeds up training.
|
||||
* `--use_sage_attn` – Use Sage Attention for the model.
|
||||
* `--sample_batch_size=<integer>` – Batch size to use for sampling, defaults to `--training_batch_size` value. Sample batches are bucketed by width, height, guidance scale, and seed.
|
||||
* `--sigmoid_scale=<float>` – Scale factor for sigmoid timestep sampling. Default `1.0`.
|
||||
|
||||
#### Memory and Speed / メモリ・速度関連
|
||||
|
||||
* `--blocks_to_swap=<integer>` **[experimental]** – Swap a number of Transformer blocks between CPU and GPU. More blocks reduce VRAM but slow training. Cannot be used with `--cpu_offload_checkpointing`.
|
||||
* `--cache_text_encoder_outputs` – Cache Gemma2 outputs to reduce memory usage.
|
||||
* `--cache_latents`, `--cache_latents_to_disk` – Cache AE outputs.
|
||||
* `--fp8_base` – Use FP8 precision for the base model.
|
||||
|
||||
#### Network Arguments / ネットワーク引数
|
||||
|
||||
For Lumina Image 2.0, you can specify different dimensions for various components:
|
||||
|
||||
* `--network_args` can include:
|
||||
* `"attn_dim=4"` – Attention dimension
|
||||
* `"mlp_dim=4"` – MLP dimension
|
||||
* `"mod_dim=4"` – Modulation dimension
|
||||
* `"refiner_dim=4"` – Refiner blocks dimension
|
||||
* `"embedder_dims=[4,4,4]"` – Embedder dimensions for x, t, and caption embedders
|
||||
|
||||
#### Incompatible or Deprecated Options / 非互換・非推奨の引数
|
||||
|
||||
* `--v2`, `--v_parameterization`, `--clip_skip` – Options for Stable Diffusion v1/v2 that are not used for Lumina Image 2.0.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
[`train_network.py`のガイド](train_network.md)で説明されている引数に加え、以下のLumina Image 2.0特有の引数を指定します。共通の引数については、上記ガイドを参照してください。
|
||||
|
||||
#### モデル関連
|
||||
|
||||
* `--pretrained_model_name_or_path="<path to Lumina model>"` **[必須]**
|
||||
* 学習のベースとなるLumina Image 2.0モデルの`.safetensors`ファイルのパスを指定します。
|
||||
* `--gemma2="<path to Gemma2 model>"` **[必須]**
|
||||
* Gemma2テキストエンコーダーの`.safetensors`ファイルのパスを指定します。
|
||||
* `--ae="<path to AE model>"` **[必須]**
|
||||
* AutoEncoderの`.safetensors`ファイルのパスを指定します。
|
||||
|
||||
#### Lumina Image 2.0 学習パラメータ
|
||||
|
||||
* `--gemma2_max_token_length=<integer>` – Gemma2で使用するトークンの最大長を指定します。デフォルトは256です。
|
||||
* `--timestep_sampling=<choice>` – タイムステップのサンプリング方法を指定します。`sigma`, `uniform`, `sigmoid`, `shift`, `nextdit_shift`から選択します。デフォルトは`shift`です。**推奨: `nextdit_shift`**
|
||||
* `--discrete_flow_shift=<float>` – Euler Discrete Schedulerの離散フローシフトを指定します。デフォルトは`6.0`です。
|
||||
* `--model_prediction_type=<choice>` – モデル予測の処理方法を指定します。`raw`, `additive`, `sigma_scaled`から選択します。デフォルトは`raw`です。**推奨: `raw`**
|
||||
* `--system_prompt=<string>` – 全てのプロンプトに前置するシステムプロンプトを指定します。推奨: `"You are an assistant designed to generate high-quality images based on user prompts."` または `"You are an assistant designed to generate high-quality images with the highest degree of image-text alignment based on textual prompts."`
|
||||
* `--use_flash_attn` – Flash Attentionを使用します。`pip install flash-attn`でインストールが必要です(環境によってはサポートされていません)。正しくインストールされている場合は、指定すると学習が高速化されます。
|
||||
* `--use_sage_attn` – Sage Attentionを使用します。
|
||||
* `--sample_batch_size=<integer>` – サンプリングに使用するバッチサイズ。デフォルトは `--training_batch_size` の値です。サンプルバッチは、幅、高さ、ガイダンススケール、シードによってバケット化されます。
|
||||
* `--sigmoid_scale=<float>` – sigmoidタイムステップサンプリングのスケール係数を指定します。デフォルトは`1.0`です。
|
||||
|
||||
#### メモリ・速度関連
|
||||
|
||||
* `--blocks_to_swap=<integer>` **[実験的機能]** – TransformerブロックをCPUとGPUでスワップしてVRAMを節約します。`--cpu_offload_checkpointing`とは併用できません。
|
||||
* `--cache_text_encoder_outputs` – Gemma2の出力をキャッシュしてメモリ使用量を削減します。
|
||||
* `--cache_latents`, `--cache_latents_to_disk` – AEの出力をキャッシュします。
|
||||
* `--fp8_base` – ベースモデルにFP8精度を使用します。
|
||||
|
||||
#### ネットワーク引数
|
||||
|
||||
Lumina Image 2.0では、各コンポーネントに対して異なる次元を指定できます:
|
||||
|
||||
* `--network_args` には以下を含めることができます:
|
||||
* `"attn_dim=4"` – アテンション次元
|
||||
* `"mlp_dim=4"` – MLP次元
|
||||
* `"mod_dim=4"` – モジュレーション次元
|
||||
* `"refiner_dim=4"` – リファイナーブロック次元
|
||||
* `"embedder_dims=[4,4,4]"` – x、t、キャプションエンベッダーのエンベッダー次元
|
||||
|
||||
#### 非互換・非推奨の引数
|
||||
|
||||
* `--v2`, `--v_parameterization`, `--clip_skip` – Stable Diffusion v1/v2向けの引数のため、Lumina Image 2.0学習では使用されません。
|
||||
</details>
|
||||
|
||||
### 4.2. Starting Training / 学習の開始
|
||||
|
||||
After setting the required arguments, run the command to begin training. The overall flow and how to check logs are the same as in the [train_network.py guide](train_network.md#32-starting-the-training--学習の開始).
|
||||
|
||||
## 5. Using the Trained Model / 学習済みモデルの利用
|
||||
|
||||
When training finishes, a LoRA model file (e.g. `my_lumina_lora.safetensors`) is saved in the directory specified by `output_dir`. Use this file with inference environments that support Lumina Image 2.0, such as ComfyUI with appropriate nodes.
|
||||
|
||||
### Inference with scripts in this repository / このリポジトリのスクリプトを使用した推論
|
||||
|
||||
The inference script is also available. The script is `lumina_minimal_inference.py`. See `--help` for options.
|
||||
|
||||
```
|
||||
python lumina_minimal_inference.py --pretrained_model_name_or_path path/to/lumina.safetensors --gemma2_path path/to/gemma.safetensors" --ae_path path/to/flux_ae.safetensors --output_dir path/to/output_dir --offload --seed 1234 --prompt "Positive prompt" --system_prompt "You are an assistant designed to generate high-quality images based on user prompts." --negative_prompt "negative prompt"
|
||||
```
|
||||
|
||||
`--add_system_prompt_to_negative_prompt` option can be used to add the system prompt to the negative prompt.
|
||||
|
||||
`--lora_weights` option can be used to specify the LoRA weights file, and optional multiplier (like `path;1.0`).
|
||||
|
||||
## 6. Others / その他
|
||||
|
||||
`lumina_train_network.py` shares many features with `train_network.py`, such as sample image generation (`--sample_prompts`, etc.) and detailed optimizer settings. For these, see the [train_network.py guide](train_network.md#5-other-features--その他の機能) or run `python lumina_train_network.py --help`.
|
||||
|
||||
### 6.1. Recommended Settings / 推奨設定
|
||||
|
||||
Based on the contributor's recommendations, here are the suggested settings for optimal training:
|
||||
|
||||
**Key Parameters:**
|
||||
* `--timestep_sampling="nextdit_shift"`
|
||||
* `--discrete_flow_shift=6.0`
|
||||
* `--model_prediction_type="raw"`
|
||||
* `--mixed_precision="bf16"`
|
||||
|
||||
**System Prompts:**
|
||||
* General purpose: `"You are an assistant designed to generate high-quality images based on user prompts."`
|
||||
* High image-text alignment: `"You are an assistant designed to generate high-quality images with the highest degree of image-text alignment based on textual prompts."`
|
||||
|
||||
**Sample Prompts:**
|
||||
Sample prompts can include CFG truncate (`--ctr`) and Renorm CFG (`-rcfg`) parameters:
|
||||
* `--ctr 0.25 --rcfg 1.0` (default values)
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
必要な引数を設定し、コマンドを実行すると学習が開始されます。基本的な流れやログの確認方法は[`train_network.py`のガイド](train_network.md#32-starting-the-training--学習の開始)と同様です。
|
||||
|
||||
学習が完了すると、指定した`output_dir`にLoRAモデルファイル(例: `my_lumina_lora.safetensors`)が保存されます。このファイルは、Lumina Image 2.0モデルに対応した推論環境(例: ComfyUI + 適切なノード)で使用できます。
|
||||
|
||||
当リポジトリ内の推論スクリプトを用いて推論することも可能です。スクリプトは`lumina_minimal_inference.py`です。オプションは`--help`で確認できます。記述例は英語版のドキュメントをご確認ください。
|
||||
|
||||
`lumina_train_network.py`には、サンプル画像の生成 (`--sample_prompts`など) や詳細なオプティマイザ設定など、`train_network.py`と共通の機能も多く存在します。これらについては、[`train_network.py`のガイド](train_network.md#5-other-features--その他の機能)やスクリプトのヘルプ (`python lumina_train_network.py --help`) を参照してください。
|
||||
|
||||
### 6.1. 推奨設定
|
||||
|
||||
コントリビューターの推奨に基づく、最適な学習のための推奨設定:
|
||||
|
||||
**主要パラメータ:**
|
||||
* `--timestep_sampling="nextdit_shift"`
|
||||
* `--discrete_flow_shift=6.0`
|
||||
* `--model_prediction_type="raw"`
|
||||
* `--mixed_precision="bf16"`
|
||||
|
||||
**システムプロンプト:**
|
||||
* 汎用目的: `"You are an assistant designed to generate high-quality images based on user prompts."`
|
||||
* 高い画像-テキスト整合性: `"You are an assistant designed to generate high-quality images with the highest degree of image-text alignment based on textual prompts."`
|
||||
|
||||
**サンプルプロンプト:**
|
||||
サンプルプロンプトには CFG truncate (`--ctr`) と Renorm CFG (`--rcfg`) パラメータを含めることができます:
|
||||
* `--ctr 0.25 --rcfg 1.0` (デフォルト値)
|
||||
|
||||
</details>
|
||||
57
docs/masked_loss_README-ja.md
Normal file
57
docs/masked_loss_README-ja.md
Normal file
@@ -0,0 +1,57 @@
|
||||
## マスクロスについて
|
||||
|
||||
マスクロスは、入力画像のマスクで指定された部分だけ損失計算することで、画像の一部分だけを学習することができる機能です。
|
||||
たとえばキャラクタを学習したい場合、キャラクタ部分だけをマスクして学習することで、背景を無視して学習することができます。
|
||||
|
||||
マスクロスのマスクには、二種類の指定方法があります。
|
||||
|
||||
- マスク画像を用いる方法
|
||||
- 透明度(アルファチャネル)を使用する方法
|
||||
|
||||
なお、サンプルは [ずんずんPJイラスト/3Dデータ](https://zunko.jp/con_illust.html) の「AI画像モデル用学習データ」を使用しています。
|
||||
|
||||
### マスク画像を用いる方法
|
||||
|
||||
学習画像それぞれに対応するマスク画像を用意する方法です。学習画像と同じファイル名のマスク画像を用意し、それを学習画像と別のディレクトリに保存します。
|
||||
|
||||
- 学習画像
|
||||

|
||||
- マスク画像
|
||||

|
||||
|
||||
```.toml
|
||||
[[datasets.subsets]]
|
||||
image_dir = "/path/to/a_zundamon"
|
||||
caption_extension = ".txt"
|
||||
conditioning_data_dir = "/path/to/a_zundamon_mask"
|
||||
num_repeats = 8
|
||||
```
|
||||
|
||||
マスク画像は、学習画像と同じサイズで、学習する部分を白、無視する部分を黒で描画します。グレースケールにも対応しています(127 ならロス重みが 0.5 になります)。なお、正確にはマスク画像の R チャネルが用いられます。
|
||||
|
||||
DreamBooth 方式の dataset で、`conditioning_data_dir` で指定したディレクトリにマスク画像を保存してください。ControlNet のデータセットと同じですので、詳細は [ControlNet-LLLite](train_lllite_README-ja.md#データセットの準備) を参照してください。
|
||||
|
||||
### 透明度(アルファチャネル)を使用する方法
|
||||
|
||||
学習画像の透明度(アルファチャネル)がマスクとして使用されます。透明度が 0 の部分は無視され、255 の部分は学習されます。半透明の場合は、その透明度に応じてロス重みが変化します(127 ならおおむね 0.5)。
|
||||
|
||||

|
||||
|
||||
※それぞれの画像は透過PNG
|
||||
|
||||
学習時のスクリプトのオプションに `--alpha_mask` を指定するか、dataset の設定ファイルの subset で、`alpha_mask` を指定してください。たとえば、以下のようになります。
|
||||
|
||||
```toml
|
||||
[[datasets.subsets]]
|
||||
image_dir = "/path/to/image/dir"
|
||||
caption_extension = ".txt"
|
||||
num_repeats = 8
|
||||
alpha_mask = true
|
||||
```
|
||||
|
||||
## 学習時の注意事項
|
||||
|
||||
- 現時点では DreamBooth 方式の dataset のみ対応しています。
|
||||
- マスクは latents のサイズ、つまり 1/8 に縮小されてから適用されます。そのため、細かい部分(たとえばアホ毛やイヤリングなど)はうまく学習できない可能性があります。マスクをわずかに拡張するなどの工夫が必要かもしれません。
|
||||
- マスクロスを用いる場合、学習対象外の部分をキャプションに含める必要はないかもしれません。(要検証)
|
||||
- `alpha_mask` の場合、マスクの有無を切り替えると latents キャッシュが自動的に再生成されます。
|
||||
56
docs/masked_loss_README.md
Normal file
56
docs/masked_loss_README.md
Normal file
@@ -0,0 +1,56 @@
|
||||
## Masked Loss
|
||||
|
||||
Masked loss is a feature that allows you to train only part of an image by calculating the loss only for the part specified by the mask of the input image. For example, if you want to train a character, you can train only the character part by masking it, ignoring the background.
|
||||
|
||||
There are two ways to specify the mask for masked loss.
|
||||
|
||||
- Using a mask image
|
||||
- Using transparency (alpha channel) of the image
|
||||
|
||||
The sample uses the "AI image model training data" from [ZunZunPJ Illustration/3D Data](https://zunko.jp/con_illust.html).
|
||||
|
||||
### Using a mask image
|
||||
|
||||
This is a method of preparing a mask image corresponding to each training image. Prepare a mask image with the same file name as the training image and save it in a different directory from the training image.
|
||||
|
||||
- Training image
|
||||

|
||||
- Mask image
|
||||

|
||||
|
||||
```.toml
|
||||
[[datasets.subsets]]
|
||||
image_dir = "/path/to/a_zundamon"
|
||||
caption_extension = ".txt"
|
||||
conditioning_data_dir = "/path/to/a_zundamon_mask"
|
||||
num_repeats = 8
|
||||
```
|
||||
|
||||
The mask image is the same size as the training image, with the part to be trained drawn in white and the part to be ignored in black. It also supports grayscale (127 gives a loss weight of 0.5). The R channel of the mask image is used currently.
|
||||
|
||||
Use the dataset in the DreamBooth method, and save the mask image in the directory specified by `conditioning_data_dir`. It is the same as the ControlNet dataset, so please refer to [ControlNet-LLLite](train_lllite_README.md#Preparing-the-dataset) for details.
|
||||
|
||||
### Using transparency (alpha channel) of the image
|
||||
|
||||
The transparency (alpha channel) of the training image is used as a mask. The part with transparency 0 is ignored, the part with transparency 255 is trained. For semi-transparent parts, the loss weight changes according to the transparency (127 gives a weight of about 0.5).
|
||||
|
||||

|
||||
|
||||
※Each image is a transparent PNG
|
||||
|
||||
Specify `--alpha_mask` in the training script options or specify `alpha_mask` in the subset of the dataset configuration file. For example, it will look like this.
|
||||
|
||||
```toml
|
||||
[[datasets.subsets]]
|
||||
image_dir = "/path/to/image/dir"
|
||||
caption_extension = ".txt"
|
||||
num_repeats = 8
|
||||
alpha_mask = true
|
||||
```
|
||||
|
||||
## Notes on training
|
||||
|
||||
- At the moment, only the dataset in the DreamBooth method is supported.
|
||||
- The mask is applied after the size is reduced to 1/8, which is the size of the latents. Therefore, fine details (such as ahoge or earrings) may not be learned well. Some dilations of the mask may be necessary.
|
||||
- If using masked loss, it may not be necessary to include parts that are not to be trained in the caption. (To be verified)
|
||||
- In the case of `alpha_mask`, the latents cache is automatically regenerated when the enable/disable state of the mask is switched.
|
||||
355
docs/sd3_train_network.md
Normal file
355
docs/sd3_train_network.md
Normal file
@@ -0,0 +1,355 @@
|
||||
# LoRA Training Guide for Stable Diffusion 3/3.5 using `sd3_train_network.py` / `sd3_train_network.py` を用いたStable Diffusion 3/3.5モデルのLoRA学習ガイド
|
||||
|
||||
This document explains how to train LoRA (Low-Rank Adaptation) models for Stable Diffusion 3 (SD3) and Stable Diffusion 3.5 (SD3.5) using `sd3_train_network.py` in the `sd-scripts` repository.
|
||||
|
||||
## 1. Introduction / はじめに
|
||||
|
||||
`sd3_train_network.py` trains additional networks such as LoRA for SD3/3.5 models. SD3 adopts a new architecture called MMDiT (Multi-Modal Diffusion Transformer), so its structure differs from previous Stable Diffusion models. With this script you can create LoRA models specialized for SD3/3.5.
|
||||
|
||||
This guide assumes you already understand the basics of LoRA training. For common usage and options, see the [train_network.py guide](train_network.md). Some parameters are the same as those in [`sdxl_train_network.py`](sdxl_train_network.md).
|
||||
|
||||
**Prerequisites:**
|
||||
|
||||
* The `sd-scripts` repository has been cloned and the Python environment is ready.
|
||||
* A training dataset has been prepared. See the [Dataset Configuration Guide](link/to/dataset/config/doc).
|
||||
* SD3/3.5 model files for training are available.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
`sd3_train_network.py`は、Stable Diffusion 3/3.5モデルに対してLoRAなどの追加ネットワークを学習させるためのスクリプトです。SD3は、MMDiT (Multi-Modal Diffusion Transformer) と呼ばれる新しいアーキテクチャを採用しており、従来のStable Diffusionモデルとは構造が異なります。このスクリプトを使用することで、SD3/3.5モデルに特化したLoRAモデルを作成できます。
|
||||
|
||||
このガイドは、基本的なLoRA学習の手順を理解しているユーザーを対象としています。基本的な使い方や共通のオプションについては、[`train_network.py`のガイド](train_network.md)を参照してください。また一部のパラメータは [`sdxl_train_network.py`](sdxl_train_network.md) と同様のものがあるため、そちらも参考にしてください。
|
||||
|
||||
**前提条件:**
|
||||
|
||||
* `sd-scripts`リポジトリのクローンとPython環境のセットアップが完了していること。
|
||||
* 学習用データセットの準備が完了していること。(データセットの準備については[データセット設定ガイド](link/to/dataset/config/doc)を参照してください)
|
||||
* 学習対象のSD3/3.5モデルファイルが準備できていること。
|
||||
</details>
|
||||
|
||||
## 2. Differences from `train_network.py` / `train_network.py` との違い
|
||||
|
||||
`sd3_train_network.py` is based on `train_network.py` but modified for SD3/3.5. Main differences are:
|
||||
|
||||
* **Target models:** Stable Diffusion 3 and 3.5 Medium/Large.
|
||||
* **Model structure:** Uses MMDiT (Transformer based) instead of U-Net and employs three text encoders: CLIP-L, CLIP-G and T5-XXL. The VAE is not compatible with SDXL.
|
||||
* **Arguments:** Options exist to specify the SD3/3.5 model, text encoders and VAE. With a single `.safetensors` file, these paths are detected automatically, so separate paths are optional.
|
||||
* **Incompatible arguments:** Stable Diffusion v1/v2 options such as `--v2`, `--v_parameterization` and `--clip_skip` are not used.
|
||||
* **SD3 specific options:** Additional parameters for attention masks, dropout rates, positional embedding adjustments (for SD3.5), timestep sampling and loss weighting.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
`sd3_train_network.py`は`train_network.py`をベースに、SD3/3.5モデルに対応するための変更が加えられています。主な違いは以下の通りです。
|
||||
|
||||
* **対象モデル:** Stable Diffusion 3, 3.5 Medium / Large モデルを対象とします。
|
||||
* **モデル構造:** U-Netの代わりにMMDiT (Transformerベース) を使用します。Text EncoderとしてCLIP-L, CLIP-G, T5-XXLの三つを使用します。VAEはSDXLと互換性がありません。
|
||||
* **引数:** SD3/3.5モデル、Text Encoder群、VAEを指定する引数があります。ただし、単一ファイルの`.safetensors`形式であれば、内部で自動的に分離されるため、個別のパス指定は必須ではありません。
|
||||
* **一部引数の非互換性:** Stable Diffusion v1/v2向けの引数(例: `--v2`, `--v_parameterization`, `--clip_skip`)はSD3/3.5の学習では使用されません。
|
||||
* **SD3特有の引数:** Text Encoderのアテンションマスクやドロップアウト率、Positional Embeddingの調整(SD3.5向け)、タイムステップのサンプリングや損失の重み付けに関する引数が追加されています。
|
||||
</details>
|
||||
|
||||
## 3. Preparation / 準備
|
||||
|
||||
The following files are required before starting training:
|
||||
|
||||
1. **Training script:** `sd3_train_network.py`
|
||||
2. **SD3/3.5 model file:** `.safetensors` file for the base model and paths to each text encoder. Single-file format can also be used.
|
||||
3. **Dataset definition file (.toml):** Dataset settings in TOML format. (See the [Dataset Configuration Guide](link/to/dataset/config/doc).) In this document we use `my_sd3_dataset_config.toml` as an example.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
学習を開始する前に、以下のファイルが必要です。
|
||||
|
||||
1. **学習スクリプト:** `sd3_train_network.py`
|
||||
2. **SD3/3.5モデルファイル:** 学習のベースとなるSD3/3.5モデルの`.safetensors`ファイル。またText Encoderをそれぞれ対応する引数でパスを指定します。
|
||||
* 単一ファイル形式も使用可能です。
|
||||
3. **データセット定義ファイル (.toml):** 学習データセットの設定を記述したTOML形式のファイル。(詳細は[データセット設定ガイド](link/to/dataset/config/doc)を参照してください)。
|
||||
* 例として`my_sd3_dataset_config.toml`を使用します。
|
||||
</details>
|
||||
|
||||
## 4. Running the Training / 学習の実行
|
||||
|
||||
Execute `sd3_train_network.py` from the terminal to start training. The overall command-line format is the same as `train_network.py`, but SD3/3.5 specific options must be supplied.
|
||||
|
||||
Example command:
|
||||
|
||||
```bash
|
||||
accelerate launch --num_cpu_threads_per_process 1 sd3_train_network.py \
|
||||
--pretrained_model_name_or_path="<path to SD3 model>" \
|
||||
--clip_l="<path to CLIP-L model>" \
|
||||
--clip_g="<path to CLIP-G model>" \
|
||||
--t5xxl="<path to T5-XXL model>" \
|
||||
--dataset_config="my_sd3_dataset_config.toml" \
|
||||
--output_dir="<output directory for training results>" \
|
||||
--output_name="my_sd3_lora" \
|
||||
--save_model_as=safetensors \
|
||||
--network_module=networks.lora \
|
||||
--network_dim=16 \
|
||||
--network_alpha=1 \
|
||||
--learning_rate=1e-4 \
|
||||
--optimizer_type="AdamW8bit" \
|
||||
--lr_scheduler="constant" \
|
||||
--sdpa \
|
||||
--max_train_epochs=10 \
|
||||
--save_every_n_epochs=1 \
|
||||
--mixed_precision="fp16" \
|
||||
--gradient_checkpointing \
|
||||
--weighting_scheme="uniform" \
|
||||
--blocks_to_swap=32
|
||||
```
|
||||
|
||||
*(Write the command on one line or use `\` or `^` for line breaks.)*
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
学習は、ターミナルから`sd3_train_network.py`を実行することで開始します。基本的なコマンドラインの構造は`train_network.py`と同様ですが、SD3/3.5特有の引数を指定する必要があります。
|
||||
|
||||
以下に、基本的なコマンドライン実行例を示します。
|
||||
|
||||
```bash
|
||||
accelerate launch --num_cpu_threads_per_process 1 sd3_train_network.py
|
||||
--pretrained_model_name_or_path="<path to SD3 model>"
|
||||
--clip_l="<path to CLIP-L model>"
|
||||
--clip_g="<path to CLIP-G model>"
|
||||
--t5xxl="<path to T5-XXL model>"
|
||||
--dataset_config="my_sd3_dataset_config.toml"
|
||||
--output_dir="<output directory for training results>"
|
||||
--output_name="my_sd3_lora"
|
||||
--save_model_as=safetensors
|
||||
--network_module=networks.lora
|
||||
--network_dim=16
|
||||
--network_alpha=1
|
||||
--learning_rate=1e-4
|
||||
--optimizer_type="AdamW8bit"
|
||||
--lr_scheduler="constant"
|
||||
--sdpa
|
||||
--max_train_epochs=10
|
||||
--save_every_n_epochs=1
|
||||
--mixed_precision="fp16"
|
||||
--gradient_checkpointing
|
||||
--weighting_scheme="uniform"
|
||||
--blocks_to_swap=32
|
||||
```
|
||||
|
||||
※実際には1行で書くか、適切な改行文字(`\` または `^`)を使用してください。
|
||||
|
||||
</details>
|
||||
|
||||
### 4.1. Explanation of Key Options / 主要なコマンドライン引数の解説
|
||||
|
||||
Besides the arguments explained in the [train_network.py guide](train_network.md), specify the following SD3/3.5 options. For shared options (`--output_dir`, `--output_name`, etc.), see that guide.
|
||||
|
||||
#### Model Options / モデル関連
|
||||
|
||||
* `--pretrained_model_name_or_path="<path to SD3 model>"` **required** – Path to the SD3/3.5 model.
|
||||
* `--clip_l`, `--clip_g`, `--t5xxl`, `--vae` – Skip these if the base model is a single file; otherwise specify each `.safetensors` path. `--vae` is usually unnecessary unless you use a different VAE.
|
||||
|
||||
#### SD3/3.5 Training Parameters / SD3/3.5 学習パラメータ
|
||||
|
||||
* `--t5xxl_max_token_length=<integer>` – Max token length for T5-XXL. Default `256`.
|
||||
* `--apply_lg_attn_mask` – Apply an attention mask to CLIP-L/CLIP-G outputs.
|
||||
* `--apply_t5_attn_mask` – Apply an attention mask to T5-XXL outputs.
|
||||
* `--clip_l_dropout_rate`, `--clip_g_dropout_rate`, `--t5_dropout_rate` – Dropout rates for the text encoders. Default `0.0`.
|
||||
* `--pos_emb_random_crop_rate=<float>` **[SD3.5]** – Probability of randomly cropping the positional embedding.
|
||||
* `--enable_scaled_pos_embed` **[SD3.5][experimental]** – Scale positional embeddings when training with multiple resolutions.
|
||||
* `--training_shift=<float>` – Shift applied to the timestep distribution. Default `1.0`.
|
||||
* `--weighting_scheme=<choice>` – Weighting method for loss by timestep. Default `uniform`.
|
||||
* `--logit_mean=<float>` – Mean value for `logit_normal` weighting scheme. Default `0.0`.
|
||||
* `--logit_std=<float>` – Standard deviation for `logit_normal` weighting scheme. Default `1.0`.
|
||||
* `--mode_scale=<float>` – Scale factor for `mode` weighting scheme. Default `1.29`.
|
||||
|
||||
#### Memory and Speed / メモリ・速度関連
|
||||
|
||||
* `--blocks_to_swap=<integer>` **[experimental]** – Swap a number of Transformer blocks between CPU and GPU. More blocks reduce VRAM but slow training. Cannot be used with `--cpu_offload_checkpointing`.
|
||||
* `--cache_text_encoder_outputs` – Caches the outputs of the text encoders to reduce VRAM usage and speed up training. This is particularly effective for SD3, which uses three text encoders. Recommended when not training the text encoder LoRA. For more details, see the [`sdxl_train_network.py` guide](sdxl_train_network.md).
|
||||
* `--cache_text_encoder_outputs_to_disk` – Caches the text encoder outputs to disk when the above option is enabled.
|
||||
* `--t5xxl_device=<device>` **[not supported yet]** – Specifies the device for T5-XXL model. If not specified, uses accelerator's device.
|
||||
* `--t5xxl_dtype=<dtype>` **[not supported yet]** – Specifies the dtype for T5-XXL model. If not specified, uses default dtype from mixed precision.
|
||||
* `--save_clip` **[not supported yet]** – Saves CLIP models to checkpoint (unified checkpoint format not yet supported).
|
||||
* `--save_t5xxl` **[not supported yet]** – Saves T5-XXL model to checkpoint (unified checkpoint format not yet supported).
|
||||
|
||||
#### Incompatible or Deprecated Options / 非互換・非推奨の引数
|
||||
|
||||
* `--v2`, `--v_parameterization`, `--clip_skip` – Options for Stable Diffusion v1/v2 that are not used for SD3/3.5.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
[`train_network.py`のガイド](train_network.md)で説明されている引数に加え、以下のSD3/3.5特有の引数を指定します。共通の引数については、上記ガイドを参照してください。
|
||||
|
||||
#### モデル関連
|
||||
|
||||
* `--pretrained_model_name_or_path="<path to SD3 model>"` **[必須]**
|
||||
* 学習のベースとなるSD3/3.5モデルの`.safetensors`ファイルのパスを指定します。
|
||||
* `--clip_l`, `--clip_g`, `--t5xxl`, `--vae`:
|
||||
* ベースモデルが単一ファイル形式の場合、これらの指定は不要です(自動的にモデル内部から読み込まれます)。
|
||||
* Text Encoderが別ファイルとして提供されている場合は、それぞれの`.safetensors`ファイルのパスを指定します。`--vae` はベースモデルに含まれているため、通常は指定する必要はありません(明示的に異なるVAEを使用する場合のみ指定)。
|
||||
|
||||
#### SD3/3.5 学習パラメータ
|
||||
|
||||
* `--t5xxl_max_token_length=<integer>` – T5-XXLで使用するトークンの最大長を指定します。デフォルトは`256`です。
|
||||
* `--apply_lg_attn_mask` – CLIP-L/CLIP-Gの出力にパディング用のマスクを適用します。
|
||||
* `--apply_t5_attn_mask` – T5-XXLの出力にパディング用のマスクを適用します。
|
||||
* `--clip_l_dropout_rate`, `--clip_g_dropout_rate`, `--t5_dropout_rate` – 各Text Encoderのドロップアウト率を指定します。デフォルトは`0.0`です。
|
||||
* `--pos_emb_random_crop_rate=<float>` **[SD3.5向け]** – Positional Embeddingにランダムクロップを適用する確率を指定します。
|
||||
* `--enable_scaled_pos_embed` **[SD3.5向け][実験的機能]** – マルチ解像度学習時に解像度に応じてPositional Embeddingをスケーリングします。
|
||||
* `--training_shift=<float>` – タイムステップ分布を調整するためのシフト値です。デフォルトは`1.0`です。
|
||||
* `--weighting_scheme=<choice>` – タイムステップに応じた損失の重み付け方法を指定します。デフォルトは`uniform`です。
|
||||
* `--logit_mean=<float>` – `logit_normal`重み付けスキームの平均値です。デフォルトは`0.0`です。
|
||||
* `--logit_std=<float>` – `logit_normal`重み付けスキームの標準偏差です。デフォルトは`1.0`です。
|
||||
* `--mode_scale=<float>` – `mode`重み付けスキームのスケール係数です。デフォルトは`1.29`です。
|
||||
|
||||
#### メモリ・速度関連
|
||||
|
||||
* `--blocks_to_swap=<integer>` **[実験的機能]** – TransformerブロックをCPUとGPUでスワップしてVRAMを節約します。`--cpu_offload_checkpointing`とは併用できません。
|
||||
* `--cache_text_encoder_outputs` – Text Encoderの出力をキャッシュし、VRAM使用量削減と学習高速化を図ります。SD3は3つのText Encoderを持つため特に効果的です。Text EncoderのLoRAを学習しない場合に推奨されます。詳細は[`sdxl_train_network.py`のガイド](sdxl_train_network.md)を参照してください。
|
||||
* `--cache_text_encoder_outputs_to_disk` – 上記オプションと併用し、Text Encoderの出力をディスクにキャッシュします。
|
||||
* `--t5xxl_device=<device>` **[未サポート]** – T5-XXLモデルのデバイスを指定します。指定しない場合はacceleratorのデバイスを使用します。
|
||||
* `--t5xxl_dtype=<dtype>` **[未サポート]** – T5-XXLモデルのdtypeを指定します。指定しない場合はデフォルトのdtype(mixed precisionから)を使用します。
|
||||
* `--save_clip` **[未サポート]** – CLIPモデルをチェックポイントに保存します(統合チェックポイント形式は未サポート)。
|
||||
* `--save_t5xxl` **[未サポート]** – T5-XXLモデルをチェックポイントに保存します(統合チェックポイント形式は未サポート)。
|
||||
|
||||
#### 非互換・非推奨の引数
|
||||
|
||||
* `--v2`, `--v_parameterization`, `--clip_skip` – Stable Diffusion v1/v2向けの引数のため、SD3/3.5学習では使用されません。
|
||||
|
||||
</details>
|
||||
|
||||
### 4.2. Starting Training / 学習の開始
|
||||
|
||||
After setting the required arguments, run the command to begin training. The overall flow and how to check logs are the same as in the [train_network.py guide](train_network.md#32-starting-the-training--学習の開始).
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
必要な引数を設定したら、コマンドを実行して学習を開始します。全体の流れやログの確認方法は、[train_network.pyのガイド](train_network.md#32-starting-the-training--学習の開始)と同様です。
|
||||
|
||||
</details>
|
||||
|
||||
## 5. LoRA Target Modules / LoRAの学習対象モジュール
|
||||
|
||||
When training LoRA with `sd3_train_network.py`, the following modules are targeted by default:
|
||||
|
||||
* **MMDiT (replaces U-Net)**:
|
||||
* `qkv` (Query, Key, Value) matrices and `proj_out` (output projection) in the attention blocks.
|
||||
* **final_layer**:
|
||||
* The output layer at the end of MMDiT.
|
||||
|
||||
By using `--network_args`, you can apply more detailed controls, such as setting different ranks (dimensions) for each module.
|
||||
|
||||
### Specify rank for each layer in SD3 LoRA / 各層のランクを指定する
|
||||
|
||||
You can specify the rank for each layer in SD3 by specifying the following network_args. If you specify `0`, LoRA will not be applied to that layer.
|
||||
|
||||
When network_args is not specified, the default value (`network_dim`) is applied, same as before.
|
||||
|
||||
|network_args|target layer|
|
||||
|---|---|
|
||||
|context_attn_dim|attn in context_block|
|
||||
|context_mlp_dim|mlp in context_block|
|
||||
|context_mod_dim|adaLN_modulation in context_block|
|
||||
|x_attn_dim|attn in x_block|
|
||||
|x_mlp_dim|mlp in x_block|
|
||||
|x_mod_dim|adaLN_modulation in x_block|
|
||||
|
||||
`"verbose=True"` is also available for debugging. It shows the rank of each layer.
|
||||
|
||||
example:
|
||||
```
|
||||
--network_args "context_attn_dim=2" "context_mlp_dim=3" "context_mod_dim=4" "x_attn_dim=5" "x_mlp_dim=6" "x_mod_dim=7" "verbose=True"
|
||||
```
|
||||
|
||||
You can apply LoRA to the conditioning layers of SD3 by specifying `emb_dims` in network_args. When specifying, be sure to specify 6 numbers in `[]` as a comma-separated list.
|
||||
|
||||
example:
|
||||
```
|
||||
--network_args "emb_dims=[2,3,4,5,6,7]"
|
||||
```
|
||||
|
||||
Each number corresponds to `context_embedder`, `t_embedder`, `x_embedder`, `y_embedder`, `final_layer_adaLN_modulation`, `final_layer_linear`. The above example applies LoRA to all conditioning layers, with rank 2 for `context_embedder`, 3 for `t_embedder`, 4 for `context_embedder`, 5 for `y_embedder`, 6 for `final_layer_adaLN_modulation`, and 7 for `final_layer_linear`.
|
||||
|
||||
If you specify `0`, LoRA will not be applied to that layer. For example, `[4,0,0,4,0,0]` applies LoRA only to `context_embedder` and `y_embedder`.
|
||||
|
||||
### Specify blocks to train in SD3 LoRA training
|
||||
|
||||
You can specify the blocks to train in SD3 LoRA training by specifying `train_block_indices` in network_args. The indices are 0-based. The default (when omitted) is to train all blocks. The indices are specified as a list of integers or a range of integers, like `0,1,5,8` or `0,1,4-5,7`.
|
||||
|
||||
The number of blocks depends on the model. The valid range is 0-(the number of blocks - 1). `all` is also available to train all blocks, `none` is also available to train no blocks.
|
||||
|
||||
example:
|
||||
```
|
||||
--network_args "train_block_indices=1,2,6-8"
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
`sd3_train_network.py`でLoRAを学習させる場合、デフォルトでは以下のモジュールが対象となります。
|
||||
|
||||
* **MMDiT (U-Netの代替)**:
|
||||
* Attentionブロック内の`qkv`(Query, Key, Value)行列と、`proj_out`(出力Projection)。
|
||||
* **final_layer**:
|
||||
* MMDiTの最後にある出力層。
|
||||
|
||||
`--network_args` を使用することで、モジュールごとに異なるランク(次元数)を設定するなど、より詳細な制御が可能です。
|
||||
|
||||
### SD3 LoRAで各層のランクを指定する
|
||||
|
||||
各層のランクを指定するには、`--network_args`オプションを使用します。`0`を指定すると、その層にはLoRAが適用されません。
|
||||
|
||||
network_argsが指定されない場合、デフォルト値(`network_dim`)が適用されます。
|
||||
|
||||
|network_args|target layer|
|
||||
|---|---|
|
||||
|context_attn_dim|attn in context_block|
|
||||
|context_mlp_dim|mlp in context_block|
|
||||
|context_mod_dim|adaLN_modulation in context_block|
|
||||
|x_attn_dim|attn in x_block|
|
||||
|x_mlp_dim|mlp in x_block|
|
||||
|x_mod_dim|adaLN_modulation in x_block|
|
||||
|
||||
`"verbose=True"`を指定すると、各層のランクが表示されます。
|
||||
|
||||
例:
|
||||
|
||||
```bash
|
||||
--network_args "context_attn_dim=2" "context_mlp_dim=3" "context_mod_dim=4" "x_attn_dim=5" "x_mlp_dim=6" "x_mod_dim=7" "verbose=True"
|
||||
```
|
||||
|
||||
また、`emb_dims`を指定することで、SD3の条件付け層にLoRAを適用することもできます。指定する際は、必ず`[]`内にカンマ区切りで6つの数字を指定してください。
|
||||
|
||||
```bash
|
||||
--network_args "emb_dims=[2,3,4,5,6,7]"
|
||||
```
|
||||
|
||||
各数字は、`context_embedder`、`t_embedder`、`x_embedder`、`y_embedder`、`final_layer_adaLN_modulation`、`final_layer_linear`に対応しています。上記の例では、すべての条件付け層にLoRAを適用し、`context_embedder`に2、`t_embedder`に3、`x_embedder`に4、`y_embedder`に5、`final_layer_adaLN_modulation`に6、`final_layer_linear`に7のランクを設定しています。
|
||||
|
||||
`0`を指定すると、その層にはLoRAが適用されません。例えば、`[4,0,0,4,0,0]`と指定すると、`context_embedder`と`y_embedder`のみにLoRAが適用されます。
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
## 6. Using the Trained Model / 学習済みモデルの利用
|
||||
|
||||
When training finishes, a LoRA model file (e.g. `my_sd3_lora.safetensors`) is saved in the directory specified by `output_dir`. Use this file with inference environments that support SD3/3.5, such as ComfyUI.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
学習が完了すると、指定した`output_dir`にLoRAモデルファイル(例: `my_sd3_lora.safetensors`)が保存されます。このファイルは、SD3/3.5モデルに対応した推論環境(例: ComfyUIなど)で使用できます。
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
## 7. Others / その他
|
||||
|
||||
`sd3_train_network.py` shares many features with `train_network.py`, such as sample image generation (`--sample_prompts`, etc.) and detailed optimizer settings. For these, see the [train_network.py guide](train_network.md#5-other-features--その他の機能) or run `python sd3_train_network.py --help`.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
`sd3_train_network.py`には、サンプル画像の生成 (`--sample_prompts`など) や詳細なオプティマイザ設定など、`train_network.py`と共通の機能も多く存在します。これらについては、[`train_network.py`のガイド](train_network.md#5-other-features--その他の機能)やスクリプトのヘルプ (`python sd3_train_network.py --help`) を参照してください。
|
||||
|
||||
</details>
|
||||
321
docs/sdxl_train_network.md
Normal file
321
docs/sdxl_train_network.md
Normal file
@@ -0,0 +1,321 @@
|
||||
# How to Use the SDXL LoRA Training Script `sdxl_train_network.py` / SDXL LoRA学習スクリプト `sdxl_train_network.py` の使い方
|
||||
|
||||
This document explains the basic procedure for training a LoRA (Low-Rank Adaptation) model for SDXL (Stable Diffusion XL) using `sdxl_train_network.py` included in the `sd-scripts` repository.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
このドキュメントでは、`sd-scripts` リポジトリに含まれる `sdxl_train_network.py` を使用して、SDXL (Stable Diffusion XL) モデルに対する LoRA (Low-Rank Adaptation) モデルを学習する基本的な手順について解説します。
|
||||
</details>
|
||||
|
||||
## 1. Introduction / はじめに
|
||||
|
||||
`sdxl_train_network.py` is a script for training additional networks such as LoRA for SDXL models. The basic usage is common with `train_network.py` (see [How to Use the LoRA Training Script `train_network.py`](train_network.md)), but SDXL model-specific settings are required.
|
||||
|
||||
This guide focuses on SDXL LoRA training, explaining the main differences from `train_network.py` and SDXL-specific configuration items.
|
||||
|
||||
**Prerequisites:**
|
||||
|
||||
* You have cloned the `sd-scripts` repository and set up the Python environment.
|
||||
* Your training dataset is ready. (Please refer to the [Dataset Preparation Guide](link/to/dataset/doc) for dataset preparation)
|
||||
* You have read [How to Use the LoRA Training Script `train_network.py`](train_network.md).
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
`sdxl_train_network.py` は、SDXL モデルに対して LoRA などの追加ネットワークを学習させるためのスクリプトです。基本的な使い方は `train_network.py` ([LoRA学習スクリプト `train_network.py` の使い方](train_network.md) 参照) と共通ですが、SDXL モデル特有の設定が必要となります。
|
||||
|
||||
このガイドでは、SDXL LoRA 学習に焦点を当て、`train_network.py` との主な違いや SDXL 特有の設定項目を中心に説明します。
|
||||
|
||||
**前提条件:**
|
||||
|
||||
* `sd-scripts` リポジトリのクローンと Python 環境のセットアップが完了していること。
|
||||
* 学習用データセットの準備が完了していること。(データセットの準備については[データセット準備ガイド](link/to/dataset/doc)を参照してください)
|
||||
* [LoRA学習スクリプト `train_network.py` の使い方](train_network.md) を一読していること。
|
||||
</details>
|
||||
|
||||
## 2. Preparation / 準備
|
||||
|
||||
Before starting training, you need the following files:
|
||||
|
||||
1. **Training Script:** `sdxl_train_network.py`
|
||||
2. **Dataset Definition File (.toml):** A TOML format file describing the training dataset configuration.
|
||||
|
||||
### About the Dataset Definition File
|
||||
|
||||
The basic format of the dataset definition file (`.toml`) is the same as for `train_network.py`. Please refer to the [Dataset Configuration Guide](link/to/dataset/config/doc) and [How to Use the LoRA Training Script `train_network.py`](train_network.md#about-the-dataset-definition-file).
|
||||
|
||||
For SDXL, it is common to use high-resolution datasets and the aspect ratio bucketing feature (`enable_bucket = true`).
|
||||
|
||||
In this example, we'll use a file named `my_sdxl_dataset_config.toml`.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
学習を開始する前に、以下のファイルが必要です。
|
||||
|
||||
1. **学習スクリプト:** `sdxl_train_network.py`
|
||||
2. **データセット定義ファイル (.toml):** 学習データセットの設定を記述した TOML 形式のファイル。
|
||||
|
||||
### データセット定義ファイルについて
|
||||
|
||||
データセット定義ファイル (`.toml`) の基本的な書き方は `train_network.py` と共通です。[データセット設定ガイド](link/to/dataset/config/doc) および [LoRA学習スクリプト `train_network.py` の使い方](train_network.md#データセット定義ファイルについて) を参照してください。
|
||||
|
||||
SDXL では、高解像度のデータセットや、アスペクト比バケツ機能 (`enable_bucket = true`) の利用が一般的です。
|
||||
|
||||
ここでは、例として `my_sdxl_dataset_config.toml` という名前のファイルを使用することにします。
|
||||
</details>
|
||||
|
||||
## 3. Running the Training / 学習の実行
|
||||
|
||||
Training starts by running `sdxl_train_network.py` from the terminal.
|
||||
|
||||
Here's a basic command line execution example for SDXL LoRA training:
|
||||
|
||||
```bash
|
||||
accelerate launch --num_cpu_threads_per_process 1 sdxl_train_network.py
|
||||
--pretrained_model_name_or_path="<SDXL base model path>"
|
||||
--dataset_config="my_sdxl_dataset_config.toml"
|
||||
--output_dir="<output directory for training results>"
|
||||
--output_name="my_sdxl_lora"
|
||||
--save_model_as=safetensors
|
||||
--network_module=networks.lora
|
||||
--network_dim=32
|
||||
--network_alpha=16
|
||||
--learning_rate=1e-4
|
||||
--unet_lr=1e-4
|
||||
--text_encoder_lr1=1e-5
|
||||
--text_encoder_lr2=1e-5
|
||||
--optimizer_type="AdamW8bit"
|
||||
--lr_scheduler="constant"
|
||||
--max_train_epochs=10
|
||||
--save_every_n_epochs=1
|
||||
--mixed_precision="bf16"
|
||||
--gradient_checkpointing
|
||||
--cache_text_encoder_outputs
|
||||
--cache_latents
|
||||
```
|
||||
|
||||
Comparing with the execution example of `train_network.py`, the following points are different:
|
||||
|
||||
* The script to execute is `sdxl_train_network.py`.
|
||||
* You specify an SDXL base model for `--pretrained_model_name_or_path`.
|
||||
* `--text_encoder_lr` is split into `--text_encoder_lr1` and `--text_encoder_lr2` (since SDXL has two Text Encoders).
|
||||
* `--mixed_precision` is recommended to be `bf16` or `fp16`.
|
||||
* `--cache_text_encoder_outputs` and `--cache_latents` are recommended to reduce VRAM usage.
|
||||
|
||||
Next, we'll explain the main command line arguments that differ from `train_network.py`. For common arguments, please refer to [How to Use the LoRA Training Script `train_network.py`](train_network.md#31-main-command-line-arguments).
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
学習は、ターミナルから `sdxl_train_network.py` を実行することで開始します。
|
||||
|
||||
以下に、SDXL LoRA 学習における基本的なコマンドライン実行例を示します。
|
||||
|
||||
```bash
|
||||
accelerate launch --num_cpu_threads_per_process 1 sdxl_train_network.py
|
||||
--pretrained_model_name_or_path="<SDXLベースモデルのパス>"
|
||||
--dataset_config="my_sdxl_dataset_config.toml"
|
||||
--output_dir="<学習結果の出力先ディレクトリ>"
|
||||
--output_name="my_sdxl_lora"
|
||||
--save_model_as=safetensors
|
||||
--network_module=networks.lora
|
||||
--network_dim=32
|
||||
--network_alpha=16
|
||||
--learning_rate=1e-4
|
||||
--unet_lr=1e-4
|
||||
--text_encoder_lr1=1e-5
|
||||
--text_encoder_lr2=1e-5
|
||||
--optimizer_type="AdamW8bit"
|
||||
--lr_scheduler="constant"
|
||||
--max_train_epochs=10
|
||||
--save_every_n_epochs=1
|
||||
--mixed_precision="bf16"
|
||||
--gradient_checkpointing
|
||||
--cache_text_encoder_outputs
|
||||
--cache_latents
|
||||
```
|
||||
|
||||
`train_network.py` の実行例と比較すると、以下の点が異なります。
|
||||
|
||||
* 実行するスクリプトが `sdxl_train_network.py` になります。
|
||||
* `--pretrained_model_name_or_path` には SDXL のベースモデルを指定します。
|
||||
* `--text_encoder_lr` が `--text_encoder_lr1` と `--text_encoder_lr2` に分かれています(SDXL は2つの Text Encoder を持つため)。
|
||||
* `--mixed_precision` は `bf16` または `fp16` が推奨されます。
|
||||
* `--cache_text_encoder_outputs` や `--cache_latents` は VRAM 使用量を削減するために推奨されます。
|
||||
|
||||
次に、`train_network.py` との差分となる主要なコマンドライン引数について解説します。共通の引数については、[LoRA学習スクリプト `train_network.py` の使い方](train_network.md#31-主要なコマンドライン引数) を参照してください。
|
||||
</details>
|
||||
|
||||
### 3.1. Main Command Line Arguments (Differences) / 主要なコマンドライン引数(差分)
|
||||
|
||||
#### Model Related / モデル関連
|
||||
|
||||
* `--pretrained_model_name_or_path="<model path>"` **[Required]**
|
||||
* Specifies the **SDXL model** to be used as the base for training. You can specify a Hugging Face Hub model ID (e.g., `"stabilityai/stable-diffusion-xl-base-1.0"`), a local Diffusers format model directory, or a path to a `.safetensors` file.
|
||||
* `--v2`, `--v_parameterization`
|
||||
* These arguments are for SD1.x/2.x. When using `sdxl_train_network.py`, since an SDXL model is assumed, these **typically do not need to be specified**.
|
||||
|
||||
#### Dataset Related / データセット関連
|
||||
|
||||
* `--dataset_config="<config file path>"`
|
||||
* This is common with `train_network.py`.
|
||||
* For SDXL, it is common to use high-resolution data and the bucketing feature (specify `enable_bucket = true` in the `.toml` file).
|
||||
|
||||
#### Output & Save Related / 出力・保存関連
|
||||
|
||||
* These are common with `train_network.py`.
|
||||
|
||||
#### LoRA Parameters / LoRA パラメータ
|
||||
|
||||
* These are common with `train_network.py`.
|
||||
|
||||
#### Training Parameters / 学習パラメータ
|
||||
|
||||
* `--learning_rate=1e-4`
|
||||
* Overall learning rate. This becomes the default value if `unet_lr`, `text_encoder_lr1`, and `text_encoder_lr2` are not specified.
|
||||
* `--unet_lr=1e-4`
|
||||
* Learning rate for LoRA modules in the U-Net part. If not specified, the value of `--learning_rate` is used.
|
||||
* `--text_encoder_lr1=1e-5`
|
||||
* Learning rate for LoRA modules in **Text Encoder 1 (OpenCLIP ViT-G/14)**. If not specified, the value of `--learning_rate` is used. A smaller value than U-Net is recommended.
|
||||
* `--text_encoder_lr2=1e-5`
|
||||
* Learning rate for LoRA modules in **Text Encoder 2 (CLIP ViT-L/14)**. If not specified, the value of `--learning_rate` is used. A smaller value than U-Net is recommended.
|
||||
* `--optimizer_type="AdamW8bit"`
|
||||
* Common with `train_network.py`.
|
||||
* `--lr_scheduler="constant"`
|
||||
* Common with `train_network.py`.
|
||||
* `--lr_warmup_steps`
|
||||
* Common with `train_network.py`.
|
||||
* `--max_train_steps`, `--max_train_epochs`
|
||||
* Common with `train_network.py`.
|
||||
* `--mixed_precision="bf16"`
|
||||
* Mixed precision training setting. For SDXL, `bf16` or `fp16` is recommended. Choose the one supported by your GPU. This reduces VRAM usage and improves training speed.
|
||||
* `--gradient_accumulation_steps=1`
|
||||
* Common with `train_network.py`.
|
||||
* `--gradient_checkpointing`
|
||||
* Common with `train_network.py`. Recommended to enable for SDXL due to its high memory consumption.
|
||||
* `--cache_latents`
|
||||
* Caches VAE outputs in memory (or on disk when `--cache_latents_to_disk` is specified). By skipping VAE computation, this reduces VRAM usage and speeds up training. Image augmentations (`--color_aug`, `--flip_aug`, `--random_crop`, etc.) are disabled. This option is recommended for SDXL training.
|
||||
* `--cache_latents_to_disk`
|
||||
* Used with `--cache_latents`, caches to disk. When loading the dataset for the first time, VAE outputs are cached to disk. This is recommended when you have a large number of training images, as it allows you to skip VAE computation on subsequent training runs.
|
||||
* `--cache_text_encoder_outputs`
|
||||
* Caches Text Encoder outputs in memory (or on disk when `--cache_text_encoder_outputs_to_disk` is specified). By skipping Text Encoder computation, this reduces VRAM usage and speeds up training. Caption augmentations (`--shuffle_caption`, `--caption_dropout_rate`, etc.) are disabled.
|
||||
* **Note:** When using this option, LoRA modules for Text Encoder cannot be trained (`--network_train_unet_only` must be specified).
|
||||
* `--cache_text_encoder_outputs_to_disk`
|
||||
* Used with `--cache_text_encoder_outputs`, caches to disk.
|
||||
* `--no_half_vae`
|
||||
* Runs VAE in `float32` even when using mixed precision (`fp16`/`bf16`). Since SDXL's VAE can be unstable in `float16`, enable this when using `fp16`.
|
||||
* `--clip_skip`
|
||||
* Not normally used for SDXL. No need to specify.
|
||||
* `--fused_backward_pass`
|
||||
* Fuses gradient computation and optimizer steps to reduce VRAM usage. Available for SDXL. (Currently only supports the `Adafactor` optimizer)
|
||||
|
||||
#### Others / その他
|
||||
|
||||
* `--seed`, `--logging_dir`, `--log_prefix`, etc. are common with `train_network.py`.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
#### モデル関連
|
||||
|
||||
* `--pretrained_model_name_or_path="<モデルのパス>"` **[必須]**
|
||||
* 学習のベースとなる **SDXL モデル**を指定します。Hugging Face Hub のモデル ID (例: `"stabilityai/stable-diffusion-xl-base-1.0"`) や、ローカルの Diffusers 形式モデルのディレクトリ、`.safetensors` ファイルのパスを指定できます。
|
||||
* `--v2`, `--v_parameterization`
|
||||
* これらの引数は SD1.x/2.x 用です。`sdxl_train_network.py` を使用する場合、SDXL モデルであることが前提となるため、通常は**指定する必要はありません**。
|
||||
|
||||
#### データセット関連
|
||||
|
||||
* `--dataset_config="<設定ファイルのパス>"`
|
||||
* `train_network.py` と共通です。
|
||||
* SDXL では高解像度データやバケツ機能 (`.toml` で `enable_bucket = true` を指定) の利用が一般的です。
|
||||
|
||||
#### 出力・保存関連
|
||||
|
||||
* `train_network.py` と共通です。
|
||||
|
||||
#### LoRA パラメータ
|
||||
|
||||
* `train_network.py` と共通です。
|
||||
|
||||
#### 学習パラメータ
|
||||
|
||||
* `--learning_rate=1e-4`
|
||||
* 全体の学習率。`unet_lr`, `text_encoder_lr1`, `text_encoder_lr2` が指定されない場合のデフォルト値となります。
|
||||
* `--unet_lr=1e-4`
|
||||
* U-Net 部分の LoRA モジュールに対する学習率。指定しない場合は `--learning_rate` の値が使用されます。
|
||||
* `--text_encoder_lr1=1e-5`
|
||||
* **Text Encoder 1 (OpenCLIP ViT-G/14) の LoRA モジュール**に対する学習率。指定しない場合は `--learning_rate` の値が使用されます。U-Net より小さめの値が推奨されます。
|
||||
* `--text_encoder_lr2=1e-5`
|
||||
* **Text Encoder 2 (CLIP ViT-L/14) の LoRA モジュール**に対する学習率。指定しない場合は `--learning_rate` の値が使用されます。U-Net より小さめの値が推奨されます。
|
||||
* `--optimizer_type="AdamW8bit"`
|
||||
* `train_network.py` と共通です。
|
||||
* `--lr_scheduler="constant"`
|
||||
* `train_network.py` と共通です。
|
||||
* `--lr_warmup_steps`
|
||||
* `train_network.py` と共通です。
|
||||
* `--max_train_steps`, `--max_train_epochs`
|
||||
* `train_network.py` と共通です。
|
||||
* `--mixed_precision="bf16"`
|
||||
* 混合精度学習の設定。SDXL では `bf16` または `fp16` の使用が推奨されます。GPU が対応している方を選択してください。VRAM 使用量を削減し、学習速度を向上させます。
|
||||
* `--gradient_accumulation_steps=1`
|
||||
* `train_network.py` と共通です。
|
||||
* `--gradient_checkpointing`
|
||||
* `train_network.py` と共通です。SDXL はメモリ消費が大きいため、有効にすることが推奨されます。
|
||||
* `--cache_latents`
|
||||
* VAE の出力をメモリ(または `--cache_latents_to_disk` 指定時はディスク)にキャッシュします。VAE の計算を省略できるため、VRAM 使用量を削減し、学習を高速化できます。画像に対する Augmentation (`--color_aug`, `--flip_aug`, `--random_crop` 等) が無効になります。SDXL 学習では推奨されるオプションです。
|
||||
* `--cache_latents_to_disk`
|
||||
* `--cache_latents` と併用し、キャッシュ先をディスクにします。データセットを最初に読み込む際に、VAE の出力をディスクにキャッシュします。二回目以降の学習で VAE の計算を省略できるため、学習データの枚数が多い場合に推奨されます。
|
||||
* `--cache_text_encoder_outputs`
|
||||
* Text Encoder の出力をメモリ(または `--cache_text_encoder_outputs_to_disk` 指定時はディスク)にキャッシュします。Text Encoder の計算を省略できるため、VRAM 使用量を削減し、学習を高速化できます。キャプションに対する Augmentation (`--shuffle_caption`, `--caption_dropout_rate` 等) が無効になります。
|
||||
* **注意:** このオプションを使用する場合、Text Encoder の LoRA モジュールは学習できません (`--network_train_unet_only` の指定が必須です)。
|
||||
* `--cache_text_encoder_outputs_to_disk`
|
||||
* `--cache_text_encoder_outputs` と併用し、キャッシュ先をディスクにします。
|
||||
* `--no_half_vae`
|
||||
* 混合精度 (`fp16`/`bf16`) 使用時でも VAE を `float32` で動作させます。SDXL の VAE は `float16` で不安定になることがあるため、`fp16` 指定時には有効にしてください。
|
||||
* `--clip_skip`
|
||||
* SDXL では通常使用しません。指定は不要です。
|
||||
* `--fused_backward_pass`
|
||||
* 勾配計算とオプティマイザのステップを融合し、VRAM使用量を削減します。SDXLで利用可能です。(現在 `Adafactor` オプティマイザのみ対応)
|
||||
|
||||
#### その他
|
||||
|
||||
* `--seed`, `--logging_dir`, `--log_prefix` などは `train_network.py` と共通です。
|
||||
</details>
|
||||
|
||||
### 3.2. Starting the Training / 学習の開始
|
||||
|
||||
After setting the necessary arguments, execute the command to start training. The training progress will be displayed on the console. The basic flow is the same as with `train_network.py`.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
必要な引数を設定し、コマンドを実行すると学習が開始されます。学習の進行状況はコンソールに出力されます。基本的な流れは `train_network.py` と同じです。
|
||||
</details>
|
||||
|
||||
## 4. Using the Trained Model / 学習済みモデルの利用
|
||||
|
||||
When training is complete, a LoRA model file (`.safetensors`, etc.) with the name specified by `output_name` will be saved in the directory specified by `output_dir`.
|
||||
|
||||
This file can be used with GUI tools that support SDXL, such as AUTOMATIC1111/stable-diffusion-webui and ComfyUI.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
学習が完了すると、`output_dir` で指定したディレクトリに、`output_name` で指定した名前の LoRA モデルファイル (`.safetensors` など) が保存されます。
|
||||
|
||||
このファイルは、AUTOMATIC1111/stable-diffusion-webui 、ComfyUI などの SDXL に対応した GUI ツールで利用できます。
|
||||
</details>
|
||||
|
||||
## 5. Supplement: Main Differences from `train_network.py` / 補足: `train_network.py` との主な違い
|
||||
|
||||
* **Target Model:** `sdxl_train_network.py` is exclusively for SDXL models.
|
||||
* **Text Encoder:** Since SDXL has two Text Encoders, there are differences in learning rate specifications (`--text_encoder_lr1`, `--text_encoder_lr2`), etc.
|
||||
* **Caching Features:** `--cache_text_encoder_outputs` is particularly effective for SDXL and is recommended.
|
||||
* **Recommended Settings:** Due to high VRAM usage, mixed precision (`bf16` or `fp16`), `gradient_checkpointing`, and caching features (`--cache_latents`, `--cache_text_encoder_outputs`) are recommended. When using `fp16`, it is recommended to run the VAE in `float32` with `--no_half_vae`.
|
||||
|
||||
For other detailed options, please refer to the script's help (`python sdxl_train_network.py --help`) and other documents in the repository.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
* **対象モデル:** `sdxl_train_network.py` は SDXL モデル専用です。
|
||||
* **Text Encoder:** SDXL は 2 つの Text Encoder を持つため、学習率の指定 (`--text_encoder_lr1`, `--text_encoder_lr2`) などが異なります。
|
||||
* **キャッシュ機能:** `--cache_text_encoder_outputs` は SDXL で特に効果が高く、推奨されます。
|
||||
* **推奨設定:** VRAM 使用量が大きいため、`bf16` または `fp16` の混合精度、`gradient_checkpointing`、キャッシュ機能 (`--cache_latents`, `--cache_text_encoder_outputs`) の利用が推奨されます。`fp16` 指定時は、VAE は `--no_half_vae` で `float32` 動作を推奨します。
|
||||
|
||||
その他の詳細なオプションについては、スクリプトのヘルプ (`python sdxl_train_network.py --help`) やリポジトリ内の他のドキュメントを参照してください。
|
||||
</details>
|
||||
@@ -295,7 +295,7 @@ Stable Diffusion のv1は512\*512で学習されていますが、それに加
|
||||
|
||||
また任意の解像度で学習するため、事前に画像データの縦横比を統一しておく必要がなくなります。
|
||||
|
||||
設定で有効、向こうが切り替えられますが、ここまでの設定ファイルの記述例では有効になっています(`true` が設定されています)。
|
||||
設定で有効、無効が切り替えられますが、ここまでの設定ファイルの記述例では有効になっています(`true` が設定されています)。
|
||||
|
||||
学習解像度はパラメータとして与えられた解像度の面積(=メモリ使用量)を超えない範囲で、64ピクセル単位(デフォルト、変更可)で縦横に調整、作成されます。
|
||||
|
||||
@@ -374,6 +374,10 @@ classがひとつで対象が複数の場合、正則化画像フォルダはひ
|
||||
|
||||
サンプル出力するステップ数またはエポック数を指定します。この数ごとにサンプル出力します。両方指定するとエポック数が優先されます。
|
||||
|
||||
- `--sample_at_first`
|
||||
|
||||
学習開始前にサンプル出力します。学習前との比較ができます。
|
||||
|
||||
- `--sample_prompts`
|
||||
|
||||
サンプル出力用プロンプトのファイルを指定します。
|
||||
@@ -463,27 +467,6 @@ masterpiece, best quality, 1boy, in business suit, standing at street, looking b
|
||||
|
||||
xformersオプションを指定するとxformersのCrossAttentionを用います。xformersをインストールしていない場合やエラーとなる場合(環境にもよりますが `mixed_precision="no"` の場合など)、代わりに `mem_eff_attn` オプションを指定すると省メモリ版CrossAttentionを使用します(xformersよりも速度は遅くなります)。
|
||||
|
||||
- `--save_precision`
|
||||
|
||||
保存時のデータ精度を指定します。save_precisionオプションにfloat、fp16、bf16のいずれかを指定すると、その形式でモデルを保存します(DreamBooth、fine tuningでDiffusers形式でモデルを保存する場合は無効です)。モデルのサイズを削減したい場合などにお使いください。
|
||||
|
||||
- `--save_every_n_epochs` / `--save_state` / `--resume`
|
||||
save_every_n_epochsオプションに数値を指定すると、そのエポックごとに学習途中のモデルを保存します。
|
||||
|
||||
save_stateオプションを同時に指定すると、optimizer等の状態も含めた学習状態を合わせて保存します(保存したモデルからも学習再開できますが、それに比べると精度の向上、学習時間の短縮が期待できます)。保存先はフォルダになります。
|
||||
|
||||
学習状態は保存先フォルダに `<output_name>-??????-state`(??????はエポック数)という名前のフォルダで出力されます。長時間にわたる学習時にご利用ください。
|
||||
|
||||
保存された学習状態から学習を再開するにはresumeオプションを使います。学習状態のフォルダ(`output_dir` ではなくその中のstateのフォルダ)を指定してください。
|
||||
|
||||
なおAcceleratorの仕様により、エポック数、global stepは保存されておらず、resumeしたときにも1からになりますがご容赦ください。
|
||||
|
||||
- `--save_model_as` (DreamBooth, fine tuning のみ)
|
||||
|
||||
モデルの保存形式を`ckpt, safetensors, diffusers, diffusers_safetensors` から選べます。
|
||||
|
||||
`--save_model_as=safetensors` のように指定します。Stable Diffusion形式(ckptまたはsafetensors)を読み込み、Diffusers形式で保存する場合、不足する情報はHugging Faceからv1.5またはv2.1の情報を落としてきて補完します。
|
||||
|
||||
- `--clip_skip`
|
||||
|
||||
`2` を指定すると、Text Encoder (CLIP) の後ろから二番目の層の出力を用います。1またはオプション省略時は最後の層を用います。
|
||||
@@ -502,6 +485,12 @@ masterpiece, best quality, 1boy, in business suit, standing at street, looking b
|
||||
|
||||
clip_skipと同様に、モデルの学習状態と異なる長さで学習するには、ある程度の教師データ枚数、長めの学習時間が必要になると思われます。
|
||||
|
||||
- `--weighted_captions`
|
||||
|
||||
指定するとAutomatic1111氏のWeb UIと同様の重み付きキャプションが有効になります。「Textual Inversion と XTI」以外の学習に使用できます。キャプションだけでなく DreamBooth 手法の token string でも有効です。
|
||||
|
||||
重みづけキャプションの記法はWeb UIとほぼ同じで、(abc)や[abc]、(abc:1.23)などが使用できます。入れ子も可能です。括弧内にカンマを含めるとプロンプトのshuffle/dropoutで括弧の対応付けがおかしくなるため、括弧内にはカンマを含めないでください。
|
||||
|
||||
- `--persistent_data_loader_workers`
|
||||
|
||||
Windows環境で指定するとエポック間の待ち時間が大幅に短縮されます。
|
||||
@@ -527,12 +516,28 @@ masterpiece, best quality, 1boy, in business suit, standing at street, looking b
|
||||
|
||||
その後ブラウザを開き、http://localhost:6006/ へアクセスすると表示されます。
|
||||
|
||||
- `--log_with` / `--log_tracker_name`
|
||||
|
||||
学習ログの保存に関するオプションです。`tensorboard` だけでなく `wandb`への保存が可能です。詳細は [PR#428](https://github.com/kohya-ss/sd-scripts/pull/428)をご覧ください。
|
||||
|
||||
- `--noise_offset`
|
||||
|
||||
こちらの記事の実装になります: https://www.crosslabs.org//blog/diffusion-with-offset-noise
|
||||
|
||||
全体的に暗い、明るい画像の生成結果が良くなる可能性があるようです。LoRA学習でも有効なようです。`0.1` 程度の値を指定するとよいようです。
|
||||
|
||||
- `--adaptive_noise_scale` (実験的オプション)
|
||||
|
||||
Noise offsetの値を、latentsの各チャネルの平均値の絶対値に応じて自動調整するオプションです。`--noise_offset` と同時に指定することで有効になります。Noise offsetの値は `noise_offset + abs(mean(latents, dim=(2,3))) * adaptive_noise_scale` で計算されます。latentは正規分布に近いためnoise_offsetの1/10~同程度の値を指定するとよいかもしれません。
|
||||
|
||||
負の値も指定でき、その場合はnoise offsetは0以上にclipされます。
|
||||
|
||||
- `--multires_noise_iterations` / `--multires_noise_discount`
|
||||
|
||||
Multi resolution noise (pyramid noise)の設定です。詳細は [PR#471](https://github.com/kohya-ss/sd-scripts/pull/471) およびこちらのページ [Multi-Resolution Noise for Diffusion Model Training](https://wandb.ai/johnowhitaker/multires_noise/reports/Multi-Resolution-Noise-for-Diffusion-Model-Training--VmlldzozNjYyOTU2) を参照してください。
|
||||
|
||||
`--multires_noise_iterations` に数値を指定すると有効になります。6~10程度の値が良いようです。`--multires_noise_discount` に0.1~0.3 程度の値(LoRA学習等比較的データセットが小さい場合のPR作者の推奨)、ないしは0.8程度の値(元記事の推奨)を指定してください(デフォルトは 0.3)。
|
||||
|
||||
- `--debug_dataset`
|
||||
|
||||
このオプションを付けることで学習を行う前に事前にどのような画像データ、キャプションで学習されるかを確認できます。Escキーを押すと終了してコマンドラインに戻ります。`S`キーで次のステップ(バッチ)、`E`キーで次のエポックに進みます。
|
||||
@@ -545,14 +550,62 @@ masterpiece, best quality, 1boy, in business suit, standing at street, looking b
|
||||
|
||||
DreamBoothおよびfine tuningでは、保存されるモデルはこのVAEを組み込んだものになります。
|
||||
|
||||
- `--cache_latents`
|
||||
- `--cache_latents` / `--cache_latents_to_disk`
|
||||
|
||||
使用VRAMを減らすためVAEの出力をメインメモリにキャッシュします。`flip_aug` 以外のaugmentationは使えなくなります。また全体の学習速度が若干速くなります。
|
||||
|
||||
cache_latents_to_diskを指定するとキャッシュをディスクに保存します。スクリプトを終了し、再度起動した場合もキャッシュが有効になります。
|
||||
|
||||
- `--min_snr_gamma`
|
||||
|
||||
Min-SNR Weighting strategyを指定します。詳細は[こちら](https://github.com/kohya-ss/sd-scripts/pull/308)を参照してください。論文では`5`が推奨されています。
|
||||
|
||||
## モデルの保存に関する設定
|
||||
|
||||
- `--save_precision`
|
||||
|
||||
保存時のデータ精度を指定します。save_precisionオプションにfloat、fp16、bf16のいずれかを指定すると、その形式でモデルを保存します(DreamBooth、fine tuningでDiffusers形式でモデルを保存する場合は無効です)。モデルのサイズを削減したい場合などにお使いください。
|
||||
|
||||
- `--save_every_n_epochs` / `--save_state` / `--resume`
|
||||
|
||||
save_every_n_epochsオプションに数値を指定すると、そのエポックごとに学習途中のモデルを保存します。
|
||||
|
||||
save_stateオプションを同時に指定すると、optimizer等の状態も含めた学習状態を合わせて保存します(保存したモデルからも学習再開できますが、それに比べると精度の向上、学習時間の短縮が期待できます)。保存先はフォルダになります。
|
||||
|
||||
学習状態は保存先フォルダに `<output_name>-??????-state`(??????はエポック数)という名前のフォルダで出力されます。長時間にわたる学習時にご利用ください。
|
||||
|
||||
保存された学習状態から学習を再開するにはresumeオプションを使います。学習状態のフォルダ(`output_dir` ではなくその中のstateのフォルダ)を指定してください。
|
||||
|
||||
なおAcceleratorの仕様により、エポック数、global stepは保存されておらず、resumeしたときにも1からになりますがご容赦ください。
|
||||
|
||||
- `--save_every_n_steps`
|
||||
|
||||
save_every_n_stepsオプションに数値を指定すると、そのステップごとに学習途中のモデルを保存します。save_every_n_epochsと同時に指定できます。
|
||||
|
||||
- `--save_model_as` (DreamBooth, fine tuning のみ)
|
||||
|
||||
モデルの保存形式を`ckpt, safetensors, diffusers, diffusers_safetensors` から選べます。
|
||||
|
||||
`--save_model_as=safetensors` のように指定します。Stable Diffusion形式(ckptまたはsafetensors)を読み込み、Diffusers形式で保存する場合、不足する情報はHugging Faceからv1.5またはv2.1の情報を落としてきて補完します。
|
||||
|
||||
- `--huggingface_repo_id` 等
|
||||
|
||||
huggingface_repo_idが指定されているとモデル保存時に同時にHuggingFaceにアップロードします。アクセストークンの取り扱いに注意してください(HuggingFaceのドキュメントを参照してください)。
|
||||
|
||||
他の引数をたとえば以下のように指定してください。
|
||||
|
||||
- `--huggingface_repo_id "your-hf-name/your-model" --huggingface_path_in_repo "path" --huggingface_repo_type model --huggingface_repo_visibility private --huggingface_token hf_YourAccessTokenHere`
|
||||
|
||||
huggingface_repo_visibilityに`public`を指定するとリポジトリが公開されます。省略時または`private`(などpublic以外)を指定すると非公開になります。
|
||||
|
||||
`--save_state`オプション指定時に`--save_state_to_huggingface`を指定するとstateもアップロードします。
|
||||
|
||||
`--resume`オプション指定時に`--resume_from_huggingface`を指定するとHuggingFaceからstateをダウンロードして再開します。その時の --resumeオプションは `--resume {repo_id}/{path_in_repo}:{revision}:{repo_type}`になります。
|
||||
|
||||
例: `--resume_from_huggingface --resume your-hf-name/your-model/path/test-000002-state:main:model`
|
||||
|
||||
`--async_upload`オプションを指定するとアップロードを非同期で行います。
|
||||
|
||||
## オプティマイザ関係
|
||||
|
||||
- `--optimizer_type`
|
||||
@@ -560,12 +613,22 @@ masterpiece, best quality, 1boy, in business suit, standing at street, looking b
|
||||
- AdamW : [torch.optim.AdamW](https://pytorch.org/docs/stable/generated/torch.optim.AdamW.html)
|
||||
- 過去のバージョンのオプション未指定時と同じ
|
||||
- AdamW8bit : 引数は同上
|
||||
- PagedAdamW8bit : 引数は同上
|
||||
- 過去のバージョンの--use_8bit_adam指定時と同じ
|
||||
- Lion : https://github.com/lucidrains/lion-pytorch
|
||||
- 過去のバージョンの--use_lion_optimizer指定時と同じ
|
||||
- Lion8bit : 引数は同上
|
||||
- PagedLion8bit : 引数は同上
|
||||
- SGDNesterov : [torch.optim.SGD](https://pytorch.org/docs/stable/generated/torch.optim.SGD.html), nesterov=True
|
||||
- SGDNesterov8bit : 引数は同上
|
||||
- DAdaptation : https://github.com/facebookresearch/dadaptation
|
||||
- DAdaptation(DAdaptAdamPreprint) : https://github.com/facebookresearch/dadaptation
|
||||
- DAdaptAdam : 引数は同上
|
||||
- DAdaptAdaGrad : 引数は同上
|
||||
- DAdaptAdan : 引数は同上
|
||||
- DAdaptAdanIP : 引数は同上
|
||||
- DAdaptLion : 引数は同上
|
||||
- DAdaptSGD : 引数は同上
|
||||
- Prodigy : https://github.com/konstmish/prodigy
|
||||
- AdaFactor : [Transformers AdaFactor](https://huggingface.co/docs/transformers/main_classes/optimizer_schedules)
|
||||
- 任意のオプティマイザ
|
||||
|
||||
@@ -585,7 +648,7 @@ masterpiece, best quality, 1boy, in business suit, standing at street, looking b
|
||||
|
||||
詳細については各自お調べください。
|
||||
|
||||
任意のスケジューラを使う場合、任意のオプティマイザと同様に、`--scheduler_args`でオプション引数を指定してください。
|
||||
任意のスケジューラを使う場合、任意のオプティマイザと同様に、`--lr_scheduler_args`でオプション引数を指定してください。
|
||||
|
||||
### オプティマイザの指定について
|
||||
|
||||
912
docs/train_README-zh.md
Normal file
912
docs/train_README-zh.md
Normal file
@@ -0,0 +1,912 @@
|
||||
__由于文档正在更新中,描述可能有错误。__
|
||||
|
||||
# 关于训练,通用描述
|
||||
本库支持模型微调(fine tuning)、DreamBooth、训练LoRA和文本反转(Textual Inversion)(包括[XTI:P+](https://github.com/kohya-ss/sd-scripts/pull/327)
|
||||
)
|
||||
本文档将说明它们通用的训练数据准备方法和选项等。
|
||||
|
||||
# 概要
|
||||
|
||||
请提前参考本仓库的README,准备好环境。
|
||||
|
||||
|
||||
以下本节说明。
|
||||
|
||||
1. 准备训练数据(使用设置文件的新格式)
|
||||
1. 训练中使用的术语的简要解释
|
||||
1. 先前的指定格式(不使用设置文件,而是从命令行指定)
|
||||
1. 生成训练过程中的示例图像
|
||||
1. 各脚本中常用的共同选项
|
||||
1. 准备 fine tuning 方法的元数据:如说明文字(打标签)等
|
||||
|
||||
|
||||
1. 如果只执行一次,训练就可以进行(相关内容,请参阅各个脚本的文档)。如果需要,以后可以随时参考。
|
||||
|
||||
|
||||
|
||||
# 关于准备训练数据
|
||||
|
||||
在任意文件夹(也可以是多个文件夹)中准备好训练数据的图像文件。支持 `.png`, `.jpg`, `.jpeg`, `.webp`, `.bmp` 格式的文件。通常不需要进行任何预处理,如调整大小等。
|
||||
|
||||
但是请勿使用极小的图像,若其尺寸比训练分辨率(稍后将提到)还小,建议事先使用超分辨率AI等进行放大。另外,请注意不要使用过大的图像(约为3000 x 3000像素以上),因为这可能会导致错误,建议事先缩小。
|
||||
|
||||
在训练时,需要整理要用于训练模型的图像数据,并将其指定给脚本。根据训练数据的数量、训练目标和说明(图像描述)是否可用等因素,可以使用几种方法指定训练数据。以下是其中的一些方法(每个名称都不是通用的,而是该存储库自定义的定义)。有关正则化图像的信息将在稍后提供。
|
||||
|
||||
1. DreamBooth、class + identifier方式(可使用正则化图像)
|
||||
|
||||
将训练目标与特定单词(identifier)相关联进行训练。无需准备说明。例如,当要学习特定角色时,由于无需准备说明,因此比较方便,但由于训练数据的所有元素都与identifier相关联,例如发型、服装、背景等,因此在生成时可能会出现无法更换服装的情况。
|
||||
|
||||
2. DreamBooth、说明方式(可使用正则化图像)
|
||||
|
||||
事先给每个图片写说明(caption),存放到文本文件中,然后进行训练。例如,通过将图像详细信息(如穿着白色衣服的角色A、穿着红色衣服的角色A等)记录在caption中,可以将角色和其他元素分离,并期望模型更准确地学习角色。
|
||||
|
||||
3. 微调方式(不可使用正则化图像)
|
||||
|
||||
先将说明收集到元数据文件中。支持分离标签和说明以及预先缓存latents等功能,以加速训练(这些将在另一篇文档中介绍)。(虽然名为fine tuning方式,但不仅限于fine tuning。)
|
||||
|
||||
训练对象和你可以使用的规范方法的组合如下。
|
||||
|
||||
| 训练对象或方法 | 脚本 | DB/class+identifier | DB/caption | fine tuning |
|
||||
|----------------| ----- | ----- | ----- | ----- |
|
||||
| fine tuning微调模型 | `fine_tune.py`| x | x | o |
|
||||
| DreamBooth训练模型 | `train_db.py`| o | o | x |
|
||||
| LoRA | `train_network.py`| o | o | o |
|
||||
| Textual Invesion | `train_textual_inversion.py`| o | o | o |
|
||||
|
||||
## 选择哪一个
|
||||
|
||||
如果您想要训练LoRA、Textual Inversion而不需要准备说明(caption)文件,则建议使用DreamBooth class+identifier。如果您能够准备caption文件,则DreamBooth Captions方法更好。如果您有大量的训练数据并且不使用正则化图像,则请考虑使用fine-tuning方法。
|
||||
|
||||
对于DreamBooth也是一样的,但不能使用fine-tuning方法。若要进行微调,只能使用fine-tuning方式。
|
||||
|
||||
# 每种方法的指定方式
|
||||
|
||||
在这里,我们只介绍每种指定方法的典型模式。有关更详细的指定方法,请参见[数据集设置](./config_README-ja.md)。
|
||||
|
||||
# DreamBooth,class+identifier方法(可使用正则化图像)
|
||||
|
||||
在该方法中,每个图像将被视为使用与 `class identifier` 相同的标题进行训练(例如 `shs dog`)。
|
||||
|
||||
这样一来,每张图片都相当于使用标题“分类标识”(例如“shs dog”)进行训练。
|
||||
|
||||
## step 1.确定identifier和class
|
||||
|
||||
要将训练的目标与identifier和属于该目标的class相关联。
|
||||
|
||||
(虽然有很多称呼,但暂时按照原始论文的说法。)
|
||||
|
||||
以下是简要说明(请查阅详细信息)。
|
||||
|
||||
class是训练目标的一般类别。例如,如果要学习特定品种的狗,则class将是“dog”。对于动漫角色,根据模型不同,可能是“boy”或“girl”,也可能是“1boy”或“1girl”。
|
||||
|
||||
identifier是用于识别训练目标并进行学习的单词。可以使用任何单词,但是根据原始论文,“Tokenizer生成的3个或更少字符的罕见单词”是最好的选择。
|
||||
|
||||
使用identifier和class,例如,“shs dog”可以将模型训练为从class中识别并学习所需的目标。
|
||||
|
||||
在图像生成时,使用“shs dog”将生成所学习狗种的图像。
|
||||
|
||||
(作为identifier,我最近使用的一些参考是“shs sts scs cpc coc cic msm usu ici lvl cic dii muk ori hru rik koo yos wny”等。最好是不包含在Danbooru标签中的单词。)
|
||||
|
||||
## step 2. 决定是否使用正则化图像,并在使用时生成正则化图像
|
||||
|
||||
正则化图像是为防止前面提到的语言漂移,即整个类别被拉扯成为训练目标而生成的图像。如果不使用正则化图像,例如在 `shs 1girl` 中学习特定角色时,即使在简单的 `1girl` 提示下生成,也会越来越像该角色。这是因为 `1girl` 在训练时的标题中包含了该角色的信息。
|
||||
|
||||
通过同时学习目标图像和正则化图像,类别仍然保持不变,仅在将标识符附加到提示中时才生成目标图像。
|
||||
|
||||
如果您只想在LoRA或DreamBooth中使用特定的角色,则可以不使用正则化图像。
|
||||
|
||||
在Textual Inversion中也不需要使用(如果要学习的token string不包含在标题中,则不会学习任何内容)。
|
||||
|
||||
一般情况下,使用在训练目标模型时只使用类别名称生成的图像作为正则化图像是常见的做法(例如 `1girl`)。但是,如果生成的图像质量不佳,可以尝试修改提示或使用从网络上另外下载的图像。
|
||||
|
||||
(由于正则化图像也被训练,因此其质量会影响模型。)
|
||||
|
||||
通常,准备数百张图像是理想的(图像数量太少会导致类别图像无法被归纳,特征也不会被学习)。
|
||||
|
||||
如果要使用生成的图像,生成图像的大小通常应与训练分辨率(更准确地说,是bucket的分辨率,见下文)相匹配。
|
||||
|
||||
|
||||
|
||||
## step 2. 设置文件的描述
|
||||
|
||||
创建一个文本文件,并将其扩展名更改为`.toml`。例如,您可以按以下方式进行描述:
|
||||
|
||||
(以`#`开头的部分是注释,因此您可以直接复制粘贴,或者将其删除。)
|
||||
|
||||
```toml
|
||||
[general]
|
||||
enable_bucket = true # 是否使用Aspect Ratio Bucketing
|
||||
|
||||
[[datasets]]
|
||||
resolution = 512 # 训练分辨率
|
||||
batch_size = 4 # 批次大小
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\hoge' # 指定包含训练图像的文件夹
|
||||
class_tokens = 'hoge girl' # 指定标识符类
|
||||
num_repeats = 10 # 训练图像的重复次数
|
||||
|
||||
# 以下仅在使用正则化图像时进行描述。不使用则删除
|
||||
[[datasets.subsets]]
|
||||
is_reg = true
|
||||
image_dir = 'C:\reg' # 指定包含正则化图像的文件夹
|
||||
class_tokens = 'girl' # 指定class
|
||||
num_repeats = 1 # 正则化图像的重复次数,基本上1就可以了
|
||||
```
|
||||
|
||||
基本上只需更改以下几个地方即可进行训练。
|
||||
|
||||
1. 训练分辨率
|
||||
|
||||
指定一个数字表示正方形(如果是 `512`,则为 512x512),如果使用方括号和逗号分隔的两个数字,则表示横向×纵向(如果是`[512,768]`,则为 512x768)。在SD1.x系列中,原始训练分辨率为512。指定较大的分辨率,如 `[512,768]` 可能会减少纵向和横向图像生成时的错误。在SD2.x 768系列中,分辨率为 `768`。
|
||||
|
||||
1. 批次大小
|
||||
|
||||
指定同时训练多少个数据。这取决于GPU的VRAM大小和训练分辨率。详细信息将在后面说明。此外,fine tuning/DreamBooth/LoRA等也会影响批次大小,请查看各个脚本的说明。
|
||||
|
||||
1. 文件夹指定
|
||||
|
||||
指定用于学习的图像和正则化图像(仅在使用时)的文件夹。指定包含图像数据的文件夹。
|
||||
|
||||
1. identifier 和 class 的指定
|
||||
|
||||
如前所述,与示例相同。
|
||||
|
||||
1. 重复次数
|
||||
|
||||
将在后面说明。
|
||||
|
||||
### 关于重复次数
|
||||
|
||||
重复次数用于调整正则化图像和训练用图像的数量。由于正则化图像的数量多于训练用图像,因此需要重复使用训练用图像来达到一对一的比例,从而实现训练。
|
||||
|
||||
请将重复次数指定为“ __训练用图像的重复次数×训练用图像的数量≥正则化图像的重复次数×正则化图像的数量__ ”。
|
||||
|
||||
(1个epoch(指训练数据过完一遍)的数据量为“训练用图像的重复次数×训练用图像的数量”。如果正则化图像的数量多于这个值,则剩余的正则化图像将不会被使用。)
|
||||
|
||||
## 步骤 3. 训练
|
||||
|
||||
详情请参考相关文档进行训练。
|
||||
|
||||
# DreamBooth,文本说明(caption)方式(可使用正则化图像)
|
||||
|
||||
在此方式中,每个图像都将通过caption进行训练。
|
||||
|
||||
## 步骤 1. 准备文本说明文件
|
||||
|
||||
请将与图像具有相同文件名且扩展名为 `.caption`(可以在设置中更改)的文件放置在用于训练图像的文件夹中。每个文件应该只有一行。编码为 `UTF-8`。
|
||||
|
||||
## 步骤 2. 决定是否使用正则化图像,并在使用时生成正则化图像
|
||||
|
||||
与class+identifier格式相同。可以在规范化图像上附加caption,但通常不需要。
|
||||
|
||||
## 步骤 2. 编写设置文件
|
||||
|
||||
创建一个文本文件并将扩展名更改为 `.toml`。例如,您可以按以下方式进行描述:
|
||||
|
||||
```toml
|
||||
[general]
|
||||
enable_bucket = true # 是否使用Aspect Ratio Bucketing
|
||||
|
||||
[[datasets]]
|
||||
resolution = 512 # 训练分辨率
|
||||
batch_size = 4 # 批次大小
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\hoge' # 指定包含训练图像的文件夹
|
||||
caption_extension = '.caption' # 若使用txt文件,更改此项
|
||||
num_repeats = 10 # 训练图像的重复次数
|
||||
|
||||
# 以下仅在使用正则化图像时进行描述。不使用则删除
|
||||
[[datasets.subsets]]
|
||||
is_reg = true
|
||||
image_dir = 'C:\reg' # 指定包含正则化图像的文件夹
|
||||
class_tokens = 'girl' # 指定class
|
||||
num_repeats = 1 # 正则化图像的重复次数,基本上1就可以了
|
||||
```
|
||||
|
||||
基本上只需更改以下几个地方来训练。除非另有说明,否则与class+identifier方法相同。
|
||||
|
||||
1. 训练分辨率
|
||||
2. 批次大小
|
||||
3. 文件夹指定
|
||||
4. caption文件的扩展名
|
||||
|
||||
可以指定任意的扩展名。
|
||||
5. 重复次数
|
||||
|
||||
## 步骤 3. 训练
|
||||
|
||||
详情请参考相关文档进行训练。
|
||||
|
||||
# 微调方法(fine tuning)
|
||||
|
||||
## 步骤 1. 准备元数据
|
||||
|
||||
将caption和标签整合到管理文件中称为元数据。它的扩展名为 `.json`,格式为json。由于创建方法较长,因此在本文档的末尾进行描述。
|
||||
|
||||
## 步骤 2. 编写设置文件
|
||||
|
||||
创建一个文本文件,将扩展名设置为 `.toml`。例如,可以按以下方式编写:
|
||||
```toml
|
||||
[general]
|
||||
shuffle_caption = true
|
||||
keep_tokens = 1
|
||||
|
||||
[[datasets]]
|
||||
resolution = 512 # 图像分辨率
|
||||
batch_size = 4 # 批次大小
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\piyo' # 指定包含训练图像的文件夹
|
||||
metadata_file = 'C:\piyo\piyo_md.json' # 元数据文件名
|
||||
```
|
||||
|
||||
基本上只需更改以下几个地方来训练。除非另有说明,否则与DreamBooth, class+identifier方法相同。
|
||||
|
||||
1. 训练分辨率
|
||||
2. 批次大小
|
||||
3. 指定文件夹
|
||||
4. 元数据文件名
|
||||
|
||||
指定使用后面所述方法创建的元数据文件。
|
||||
|
||||
|
||||
## 第三步:训练
|
||||
|
||||
详情请参考相关文档进行训练。
|
||||
|
||||
# 训练中使用的术语简单解释
|
||||
|
||||
由于省略了细节并且我自己也没有完全理解,因此请自行查阅详细信息。
|
||||
|
||||
## 微调(fine tuning)
|
||||
|
||||
指训练模型并微调其性能。具体含义因用法而异,但在 Stable Diffusion 中,狭义的微调是指使用图像和caption进行训练模型。DreamBooth 可视为狭义微调的一种特殊方法。广义的微调包括 LoRA、Textual Inversion、Hypernetworks 等,包括训练模型的所有内容。
|
||||
|
||||
## 步骤(step)
|
||||
|
||||
粗略地说,每次在训练数据上进行一次计算即为一步。具体来说,“将训练数据的caption传递给当前模型,将生成的图像与训练数据的图像进行比较,稍微更改模型,以使其更接近训练数据”即为一步。
|
||||
|
||||
## 批次大小(batch size)
|
||||
|
||||
批次大小指定每个步骤要计算多少数据。批次计算可以提高速度。一般来说,批次大小越大,精度也越高。
|
||||
|
||||
“批次大小×步数”是用于训练的数据数量。因此,建议减少步数以增加批次大小。
|
||||
|
||||
(但是,例如,“批次大小为 1,步数为 1600”和“批次大小为 4,步数为 400”将不会产生相同的结果。如果使用相同的学习速率,通常后者会导致模型欠拟合。请尝试增加学习率(例如 `2e-6`),将步数设置为 500 等。)
|
||||
|
||||
批次大小越大,GPU 内存消耗就越大。如果内存不足,将导致错误,或者在边缘时将导致训练速度降低。建议在任务管理器或 `nvidia-smi` 命令中检查使用的内存量进行调整。
|
||||
|
||||
注意,一个批次是指“一个数据单位”。
|
||||
|
||||
## 学习率
|
||||
|
||||
学习率指的是每个步骤中改变的程度。如果指定一个大的值,学习速度就会加快,但是可能会出现变化太大导致模型崩溃或无法达到最佳状态的情况。如果指定一个小的值,学习速度会变慢,同时可能无法达到最佳状态。
|
||||
|
||||
在fine tuning、DreamBooth、LoRA等过程中,学习率会有很大的差异,并且也会受到训练数据、所需训练的模型、批次大小和步骤数等因素的影响。建议从通常值开始,观察训练状态并逐渐调整。
|
||||
|
||||
默认情况下,整个训练过程中学习率是固定的。但是可以通过调度程序指定学习率如何变化,因此结果也会有所不同。
|
||||
|
||||
## Epoch
|
||||
|
||||
Epoch指的是训练数据被完整训练一遍(即数据已经迭代一轮)。如果指定了重复次数,则在重复后的数据迭代一轮后,为1个epoch。
|
||||
|
||||
1个epoch的步骤数通常为“数据量÷批次大小”,但如果使用Aspect Ratio Bucketing,则略微增加(由于不同bucket的数据不能在同一个批次中,因此步骤数会增加)。
|
||||
|
||||
## 长宽比分桶(Aspect Ratio Bucketing)
|
||||
|
||||
Stable Diffusion 的 v1 是以 512\*512 的分辨率进行训练的,但同时也可以在其他分辨率下进行训练,例如 256\*1024 和 384\*640。这样可以减少裁剪的部分,希望更准确地学习图像和标题之间的关系。
|
||||
|
||||
此外,由于可以在任意分辨率下进行训练,因此不再需要事先统一图像数据的长宽比。
|
||||
|
||||
此值可以被设定,其在此之前的配置文件示例中已被启用(设置为 `true`)。
|
||||
|
||||
只要不超过作为参数给出的分辨率区域(= 内存使用量),就可以按 64 像素的增量(默认值,可更改)在垂直和水平方向上调整和创建训练分辨率。
|
||||
|
||||
在机器学习中,通常需要将所有输入大小统一,但实际上只要在同一批次中统一即可。 NovelAI 所说的分桶(bucketing) 指的是,预先将训练数据按照长宽比分类到每个学习分辨率下,并通过使用每个 bucket 内的图像创建批次来统一批次图像大小。
|
||||
|
||||
# 以前的指定格式(不使用 .toml 文件,而是使用命令行选项指定)
|
||||
|
||||
这是一种通过命令行选项而不是指定 .toml 文件的方法。有 DreamBooth 类+标识符方法、DreamBooth caption方法、微调方法三种方式。
|
||||
|
||||
## DreamBooth、类+标识符方式
|
||||
|
||||
指定文件夹名称以指定迭代次数。还要使用 `train_data_dir` 和 `reg_data_dir` 选项。
|
||||
|
||||
### 第1步。准备用于训练的图像
|
||||
|
||||
创建一个用于存储训练图像的文件夹。__此外__,按以下名称创建目录。
|
||||
|
||||
```
|
||||
<迭代次数>_<标识符> <类别>
|
||||
```
|
||||
|
||||
不要忘记下划线``_``。
|
||||
|
||||
例如,如果在名为“sls frog”的提示下重复数据 20 次,则为“20_sls frog”。如下所示:
|
||||
|
||||

|
||||
|
||||
### 多个类别、多个标识符的训练
|
||||
|
||||
该方法很简单,在用于训练的图像文件夹中,需要准备多个文件夹,每个文件夹都是以“重复次数_<标识符> <类别>”命名的,同样,在正则化图像文件夹中,也需要准备多个文件夹,每个文件夹都是以“重复次数_<类别>”命名的。
|
||||
|
||||
例如,如果要同时训练“sls青蛙”和“cpc兔子”,则应按以下方式准备文件夹。
|
||||
|
||||
|
||||
|
||||
如果一个类别包含多个对象,可以只使用一个正则化图像文件夹。例如,如果在1girl类别中有角色A和角色B,则可以按照以下方式处理:
|
||||
|
||||
- train_girls
|
||||
- 10_sls 1girl
|
||||
- 10_cpc 1girl
|
||||
- reg_girls
|
||||
- 1_1girl
|
||||
|
||||
### step 2. 准备正规化图像
|
||||
|
||||
这是使用正则化图像时的过程。
|
||||
|
||||
创建一个文件夹来存储正则化的图像。 __此外,__ 创建一个名为``<repeat count>_<class>`` 的目录。
|
||||
|
||||
例如,使用提示“frog”并且不重复数据(仅一次):
|
||||
|
||||
|
||||
|
||||
步骤3. 执行训练
|
||||
|
||||
执行每个训练脚本。使用 `--train_data_dir` 选项指定包含训练数据文件夹的父文件夹(不是包含图像的文件夹),使用 `--reg_data_dir` 选项指定包含正则化图像的父文件夹(不是包含图像的文件夹)。
|
||||
|
||||
## DreamBooth,带文本说明(caption)的方式
|
||||
|
||||
在包含训练图像和正则化图像的文件夹中,将与图像具有相同文件名的文件.caption(可以使用选项进行更改)放置在该文件夹中,然后从该文件中加载caption所作为提示进行训练。
|
||||
|
||||
※文件夹名称(标识符类)不再用于这些图像的训练。
|
||||
|
||||
默认的caption文件扩展名为.caption。可以使用训练脚本的 `--caption_extension` 选项进行更改。 使用 `--shuffle_caption` 选项,同时对每个逗号分隔的部分进行训练时会对训练时的caption进行混洗。
|
||||
|
||||
## 微调方式
|
||||
|
||||
创建元数据的方式与使用配置文件相同。 使用 `in_json` 选项指定元数据文件。
|
||||
|
||||
# 训练过程中的样本输出
|
||||
|
||||
通过在训练中使用模型生成图像,可以检查训练进度。将以下选项指定为训练脚本。
|
||||
|
||||
- `--sample_every_n_steps` / `--sample_every_n_epochs`
|
||||
|
||||
指定要采样的步数或epoch数。为这些数字中的每一个输出样本。如果两者都指定,则 epoch 数优先。
|
||||
- `--sample_prompts`
|
||||
|
||||
指定示例输出的提示文件。
|
||||
|
||||
- `--sample_sampler`
|
||||
|
||||
指定用于采样输出的采样器。
|
||||
`'ddim', 'pndm', 'heun', 'dpmsolver', 'dpmsolver++', 'dpmsingle', 'k_lms', 'k_euler', 'k_euler_a', 'k_dpm_2', 'k_dpm_2_a'`が選べます。
|
||||
|
||||
要输出样本,您需要提前准备一个包含提示的文本文件。每行输入一个提示。
|
||||
|
||||
```txt
|
||||
# prompt 1
|
||||
masterpiece, best quality, 1girl, in white shirts, upper body, looking at viewer, simple background --n low quality, worst quality, bad anatomy,bad composition, poor, low effort --w 768 --h 768 --d 1 --l 7.5 --s 28
|
||||
|
||||
# prompt 2
|
||||
masterpiece, best quality, 1boy, in business suit, standing at street, looking back --n low quality, worst quality, bad anatomy,bad composition, poor, low effort --w 576 --h 832 --d 2 --l 5.5 --s 40
|
||||
```
|
||||
|
||||
以“#”开头的行是注释。您可以使用“`--` + 小写字母”为生成的图像指定选项,例如 `--n`。您可以使用:
|
||||
|
||||
- `--n` 否定提示到下一个选项。
|
||||
- `--w` 指定生成图像的宽度。
|
||||
- `--h` 指定生成图像的高度。
|
||||
- `--d` 指定生成图像的种子。
|
||||
- `--l` 指定生成图像的 CFG 比例。
|
||||
- `--s` 指定生成过程中的步骤数。
|
||||
|
||||
|
||||
# 每个脚本通用的常用选项
|
||||
|
||||
文档更新可能跟不上脚本更新。在这种情况下,请使用 `--help` 选项检查可用选项。
|
||||
## 学习模型规范
|
||||
|
||||
- `--v2` / `--v_parameterization`
|
||||
|
||||
如果使用 Hugging Face 的 stable-diffusion-2-base 或来自它的微调模型作为学习目标模型(对于在推理时指示使用 `v2-inference.yaml` 的模型),`- 当使用-v2` 选项与 stable-diffusion-2、768-v-ema.ckpt 及其微调模型(对于在推理过程中使用 `v2-inference-v.yaml` 的模型),`- 指定两个 -v2`和 `--v_parameterization` 选项。
|
||||
|
||||
以下几点在 Stable Diffusion 2.0 中发生了显着变化。
|
||||
|
||||
1. 使用分词器
|
||||
2. 使用哪个Text Encoder,使用哪个输出层(2.0使用倒数第二层)
|
||||
3. Text Encoder的输出维度(768->1024)
|
||||
4. U-Net的结构(CrossAttention的头数等)
|
||||
5. v-parameterization(采样方式好像变了)
|
||||
|
||||
其中base使用1-4,非base使用1-5(768-v)。使用 1-4 进行 v2 选择,使用 5 进行 v_parameterization 选择。
|
||||
- `--pretrained_model_name_or_path`
|
||||
|
||||
指定要从中执行额外训练的模型。您可以指定Stable Diffusion检查点文件(.ckpt 或 .safetensors)、diffusers本地磁盘上的模型目录或diffusers模型 ID(例如“stabilityai/stable-diffusion-2”)。
|
||||
## 训练设置
|
||||
|
||||
- `--output_dir`
|
||||
|
||||
指定训练后保存模型的文件夹。
|
||||
|
||||
- `--output_name`
|
||||
|
||||
指定不带扩展名的模型文件名。
|
||||
|
||||
- `--dataset_config`
|
||||
|
||||
指定描述数据集配置的 .toml 文件。
|
||||
|
||||
- `--max_train_steps` / `--max_train_epochs`
|
||||
|
||||
指定要训练的步数或epoch数。如果两者都指定,则 epoch 数优先。
|
||||
-
|
||||
- `--mixed_precision`
|
||||
|
||||
训练混合精度以节省内存。指定像`--mixed_precision = "fp16"`。与无混合精度(默认)相比,精度可能较低,但训练所需的 GPU 内存明显较少。
|
||||
|
||||
(在RTX30系列以后也可以指定`bf16`,请配合您在搭建环境时做的加速设置)。
|
||||
- `--gradient_checkpointing`
|
||||
|
||||
通过逐步计算权重而不是在训练期间一次计算所有权重来减少训练所需的 GPU 内存量。关闭它不会影响准确性,但打开它允许更大的批次大小,所以那里有影响。
|
||||
|
||||
另外,打开它通常会减慢速度,但可以增加批次大小,因此总的训练时间实际上可能会更快。
|
||||
|
||||
- `--xformers` / `--mem_eff_attn`
|
||||
|
||||
当指定 xformers 选项时,使用 xformers 的 CrossAttention。如果未安装 xformers 或发生错误(取决于环境,例如 `mixed_precision="no"`),请指定 `mem_eff_attn` 选项而不是使用 CrossAttention 的内存节省版本(xformers 比 慢)。
|
||||
- `--save_precision`
|
||||
|
||||
指定保存时的数据精度。为 save_precision 选项指定 float、fp16 或 bf16 将以该格式保存模型(在 DreamBooth 中保存 Diffusers 格式时无效,微调)。当您想缩小模型的尺寸时请使用它。
|
||||
- `--save_every_n_epochs` / `--save_state` / `--resume`
|
||||
为 save_every_n_epochs 选项指定一个数字可以在每个时期的训练期间保存模型。
|
||||
|
||||
如果同时指定save_state选项,训练状态包括优化器的状态等都会一起保存。。保存目的地将是一个文件夹。
|
||||
|
||||
训练状态输出到目标文件夹中名为“<output_name>-??????-state”(??????是epoch数)的文件夹中。长时间训练时请使用。
|
||||
|
||||
使用 resume 选项从保存的训练状态恢复训练。指定训练状态文件夹(其中的状态文件夹,而不是 `output_dir`)。
|
||||
|
||||
请注意,由于 Accelerator 规范,epoch 数和全局步数不会保存,即使恢复时它们也从 1 开始。
|
||||
- `--save_model_as` (DreamBooth, fine tuning 仅有的)
|
||||
|
||||
您可以从 `ckpt, safetensors, diffusers, diffusers_safetensors` 中选择模型保存格式。
|
||||
|
||||
- `--save_model_as=safetensors` 指定喜欢当读取Stable Diffusion格式(ckpt 或safetensors)并以diffusers格式保存时,缺少的信息通过从 Hugging Face 中删除 v1.5 或 v2.1 信息来补充。
|
||||
|
||||
- `--clip_skip`
|
||||
|
||||
`2` 如果指定,则使用文本编码器 (CLIP) 的倒数第二层的输出。如果省略 1 或选项,则使用最后一层。
|
||||
|
||||
*SD2.0默认使用倒数第二层,训练SD2.0时请不要指定。
|
||||
|
||||
如果被训练的模型最初被训练为使用第二层,则 2 是一个很好的值。
|
||||
|
||||
如果您使用的是最后一层,那么整个模型都会根据该假设进行训练。因此,如果再次使用第二层进行训练,可能需要一定数量的teacher数据和更长时间的训练才能得到想要的训练结果。
|
||||
- `--max_token_length`
|
||||
|
||||
默认值为 75。您可以通过指定“150”或“225”来扩展令牌长度来训练。使用长字幕训练时指定。
|
||||
|
||||
但由于训练时token展开的规范与Automatic1111的web UI(除法等规范)略有不同,如非必要建议用75训练。
|
||||
|
||||
与clip_skip一样,训练与模型训练状态不同的长度可能需要一定量的teacher数据和更长的学习时间。
|
||||
|
||||
- `--persistent_data_loader_workers`
|
||||
|
||||
在 Windows 环境中指定它可以显着减少时期之间的延迟。
|
||||
|
||||
- `--max_data_loader_n_workers`
|
||||
|
||||
指定数据加载的进程数。大量的进程会更快地加载数据并更有效地使用 GPU,但会消耗更多的主内存。默认是"`8`或者`CPU并发执行线程数 - 1`,取小者",所以如果主存没有空间或者GPU使用率大概在90%以上,就看那些数字和 `2` 或将其降低到大约 `1`。
|
||||
- `--logging_dir` / `--log_prefix`
|
||||
|
||||
保存训练日志的选项。在 logging_dir 选项中指定日志保存目标文件夹。以 TensorBoard 格式保存日志。
|
||||
|
||||
例如,如果您指定 --logging_dir=logs,将在您的工作文件夹中创建一个日志文件夹,并将日志保存在日期/时间文件夹中。
|
||||
此外,如果您指定 --log_prefix 选项,则指定的字符串将添加到日期和时间之前。使用“--logging_dir=logs --log_prefix=db_style1_”进行识别。
|
||||
|
||||
要检查 TensorBoard 中的日志,请打开另一个命令提示符并在您的工作文件夹中键入:
|
||||
```
|
||||
tensorboard --logdir=logs
|
||||
```
|
||||
|
||||
我觉得tensorboard会在环境搭建的时候安装,如果没有安装,请用`pip install tensorboard`安装。)
|
||||
|
||||
然后打开浏览器到http://localhost:6006/就可以看到了。
|
||||
- `--noise_offset`
|
||||
本文的实现:https://www.crosslabs.org//blog/diffusion-with-offset-noise
|
||||
|
||||
看起来它可能会为整体更暗和更亮的图像产生更好的结果。它似乎对 LoRA 训练也有效。指定一个大约 0.1 的值似乎很好。
|
||||
|
||||
- `--debug_dataset`
|
||||
|
||||
通过添加此选项,您可以在训练之前检查将训练什么样的图像数据和标题。按 Esc 退出并返回命令行。按 `S` 进入下一步(批次),按 `E` 进入下一个epoch。
|
||||
|
||||
*图片在 Linux 环境(包括 Colab)下不显示。
|
||||
|
||||
- `--vae`
|
||||
|
||||
如果您在 vae 选项中指定Stable Diffusion检查点、VAE 检查点文件、扩散模型或 VAE(两者都可以指定本地或拥抱面模型 ID),则该 VAE 用于训练(缓存时的潜伏)或在训练过程中获得潜伏)。
|
||||
|
||||
对于 DreamBooth 和微调,保存的模型将包含此 VAE
|
||||
|
||||
- `--cache_latents`
|
||||
|
||||
在主内存中缓存 VAE 输出以减少 VRAM 使用。除 flip_aug 之外的任何增强都将不可用。此外,整体训练速度略快。
|
||||
- `--min_snr_gamma`
|
||||
|
||||
指定最小 SNR 加权策略。细节是[这里](https://github.com/kohya-ss/sd-scripts/pull/308)请参阅。论文中推荐`5`。
|
||||
|
||||
## 优化器相关
|
||||
|
||||
- `--optimizer_type`
|
||||
-- 指定优化器类型。您可以指定
|
||||
- AdamW : [torch.optim.AdamW](https://pytorch.org/docs/stable/generated/torch.optim.AdamW.html)
|
||||
- 与过去版本中未指定选项时相同
|
||||
- AdamW8bit : 参数同上
|
||||
- PagedAdamW8bit : 参数同上
|
||||
- 与过去版本中指定的 --use_8bit_adam 相同
|
||||
- Lion : https://github.com/lucidrains/lion-pytorch
|
||||
- Lion8bit : 参数同上
|
||||
- PagedLion8bit : 参数同上
|
||||
- 与过去版本中指定的 --use_lion_optimizer 相同
|
||||
- SGDNesterov : [torch.optim.SGD](https://pytorch.org/docs/stable/generated/torch.optim.SGD.html), nesterov=True
|
||||
- SGDNesterov8bit : 参数同上
|
||||
- DAdaptation(DAdaptAdamPreprint) : https://github.com/facebookresearch/dadaptation
|
||||
- DAdaptAdam : 参数同上
|
||||
- DAdaptAdaGrad : 参数同上
|
||||
- DAdaptAdan : 参数同上
|
||||
- DAdaptAdanIP : 参数同上
|
||||
- DAdaptLion : 参数同上
|
||||
- DAdaptSGD : 参数同上
|
||||
- Prodigy : https://github.com/konstmish/prodigy
|
||||
- AdaFactor : [Transformers AdaFactor](https://huggingface.co/docs/transformers/main_classes/optimizer_schedules)
|
||||
- 任何优化器
|
||||
|
||||
- `--learning_rate`
|
||||
|
||||
指定学习率。合适的学习率取决于训练脚本,所以请参考每个解释。
|
||||
- `--lr_scheduler` / `--lr_warmup_steps` / `--lr_scheduler_num_cycles` / `--lr_scheduler_power`
|
||||
|
||||
学习率的调度程序相关规范。
|
||||
|
||||
使用 lr_scheduler 选项,您可以从线性、余弦、cosine_with_restarts、多项式、常数、constant_with_warmup 或任何调度程序中选择学习率调度程序。默认值是常量。
|
||||
|
||||
使用 lr_warmup_steps,您可以指定预热调度程序的步数(逐渐改变学习率)。
|
||||
|
||||
lr_scheduler_num_cycles 是 cosine with restarts 调度器中的重启次数,lr_scheduler_power 是多项式调度器中的多项式幂。
|
||||
|
||||
有关详细信息,请自行研究。
|
||||
|
||||
要使用任何调度程序,请像使用任何优化器一样使用“--lr_scheduler_args”指定可选参数。
|
||||
### 关于指定优化器
|
||||
|
||||
使用 --optimizer_args 选项指定优化器选项参数。可以以key=value的格式指定多个值。此外,您可以指定多个值,以逗号分隔。例如,要指定 AdamW 优化器的参数,``--optimizer_args weight_decay=0.01 betas=.9,.999``。
|
||||
|
||||
指定可选参数时,请检查每个优化器的规格。
|
||||
一些优化器有一个必需的参数,如果省略它会自动添加(例如 SGDNesterov 的动量)。检查控制台输出。
|
||||
|
||||
D-Adaptation 优化器自动调整学习率。学习率选项指定的值不是学习率本身,而是D-Adaptation决定的学习率的应用率,所以通常指定1.0。如果您希望 Text Encoder 的学习率是 U-Net 的一半,请指定 ``--text_encoder_lr=0.5 --unet_lr=1.0``。
|
||||
如果指定 relative_step=True,AdaFactor 优化器可以自动调整学习率(如果省略,将默认添加)。自动调整时,学习率调度器被迫使用 adafactor_scheduler。此外,指定 scale_parameter 和 warmup_init 似乎也不错。
|
||||
|
||||
自动调整的选项类似于``--optimizer_args "relative_step=True" "scale_parameter=True" "warmup_init=True"``。
|
||||
|
||||
如果您不想自动调整学习率,请添加可选参数 ``relative_step=False``。在那种情况下,似乎建议将 constant_with_warmup 用于学习率调度程序,而不要为梯度剪裁范数。所以参数就像``--optimizer_type=adafactor --optimizer_args "relative_step=False" --lr_scheduler="constant_with_warmup" --max_grad_norm=0.0``。
|
||||
|
||||
### 使用任何优化器
|
||||
|
||||
使用 ``torch.optim`` 优化器时,仅指定类名(例如 ``--optimizer_type=RMSprop``),使用其他模块的优化器时,指定“模块名.类名”。(例如``--optimizer_type=bitsandbytes.optim.lamb.LAMB``)。
|
||||
|
||||
(内部仅通过 importlib 未确认操作。如果需要,请安装包。)
|
||||
<!--
|
||||
## 使用任意大小的图像进行训练 --resolution
|
||||
你可以在广场外训练。请在分辨率中指定“宽度、高度”,如“448,640”。宽度和高度必须能被 64 整除。匹配训练图像和正则化图像的大小。
|
||||
|
||||
就我个人而言,我经常生成垂直长的图像,所以我有时会用“448、640”来训练。
|
||||
|
||||
## 纵横比分桶 --enable_bucket / --min_bucket_reso / --max_bucket_reso
|
||||
它通过指定 enable_bucket 选项来启用。 Stable Diffusion 在 512x512 分辨率下训练,但也在 256x768 和 384x640 等分辨率下训练。
|
||||
|
||||
如果指定此选项,则不需要将训练图像和正则化图像统一为特定分辨率。从多种分辨率(纵横比)中进行选择,并在该分辨率下训练。
|
||||
由于分辨率为 64 像素,纵横比可能与原始图像不完全相同。
|
||||
|
||||
您可以使用 min_bucket_reso 选项指定分辨率的最小大小,使用 max_bucket_reso 指定最大大小。默认值分别为 256 和 1024。
|
||||
例如,将最小尺寸指定为 384 将不会使用 256x1024 或 320x768 等分辨率。
|
||||
如果将分辨率增加到 768x768,您可能需要将 1280 指定为最大尺寸。
|
||||
|
||||
启用 Aspect Ratio Ratio Bucketing 时,最好准备具有与训练图像相似的各种分辨率的正则化图像。
|
||||
|
||||
(因为一批中的图像不偏向于训练图像和正则化图像。
|
||||
|
||||
## 扩充 --color_aug / --flip_aug
|
||||
增强是一种通过在训练过程中动态改变数据来提高模型性能的方法。在使用 color_aug 巧妙地改变色调并使用 flip_aug 左右翻转的同时训练。
|
||||
|
||||
由于数据是动态变化的,因此不能与 cache_latents 选项一起指定。
|
||||
|
||||
## 使用 fp16 梯度训练(实验特征)--full_fp16
|
||||
如果指定 full_fp16 选项,梯度从普通 float32 变为 float16 (fp16) 并训练(它似乎是 full fp16 训练而不是混合精度)。
|
||||
结果,似乎 SD1.x 512x512 大小可以在 VRAM 使用量小于 8GB 的情况下训练,而 SD2.x 512x512 大小可以在 VRAM 使用量小于 12GB 的情况下训练。
|
||||
|
||||
预先在加速配置中指定 fp16,并可选择设置 ``mixed_precision="fp16"``(bf16 不起作用)。
|
||||
|
||||
为了最大限度地减少内存使用,请使用 xformers、use_8bit_adam、cache_latents、gradient_checkpointing 选项并将 train_batch_size 设置为 1。
|
||||
|
||||
(如果你负担得起,逐步增加 train_batch_size 应该会提高一点精度。)
|
||||
|
||||
它是通过修补 PyTorch 源代码实现的(已通过 PyTorch 1.12.1 和 1.13.0 确认)。准确率会大幅下降,途中学习失败的概率也会增加。
|
||||
学习率和步数的设置似乎很严格。请注意它们并自行承担使用它们的风险。
|
||||
-->
|
||||
|
||||
# 创建元数据文件
|
||||
|
||||
## 准备训练数据
|
||||
|
||||
如上所述准备好你要训练的图像数据,放在任意文件夹中。
|
||||
|
||||
例如,存储这样的图像:
|
||||
|
||||
|
||||
|
||||
## 自动captioning
|
||||
|
||||
如果您只想训练没有标题的标签,请跳过。
|
||||
|
||||
另外,手动准备caption时,请准备在与教师数据图像相同的目录下,文件名相同,扩展名.caption等。每个文件应该是只有一行的文本文件。
|
||||
### 使用 BLIP 添加caption
|
||||
|
||||
最新版本不再需要 BLIP 下载、权重下载和额外的虚拟环境。按原样工作。
|
||||
|
||||
运行 finetune 文件夹中的 make_captions.py。
|
||||
|
||||
```
|
||||
python finetune\make_captions.py --batch_size <バッチサイズ> <教師データフォルダ>
|
||||
```
|
||||
|
||||
如果batch size为8,训练数据放在父文件夹train_data中,则会如下所示
|
||||
```
|
||||
python finetune\make_captions.py --batch_size 8 ..\train_data
|
||||
```
|
||||
|
||||
caption文件创建在与教师数据图像相同的目录中,具有相同的文件名和扩展名.caption。
|
||||
|
||||
根据 GPU 的 VRAM 容量增加或减少 batch_size。越大越快(我认为 12GB 的 VRAM 可以多一点)。
|
||||
您可以使用 max_length 选项指定caption的最大长度。默认值为 75。如果使用 225 的令牌长度训练模型,它可能会更长。
|
||||
您可以使用 caption_extension 选项更改caption扩展名。默认为 .caption(.txt 与稍后描述的 DeepDanbooru 冲突)。
|
||||
如果有多个教师数据文件夹,则对每个文件夹执行。
|
||||
|
||||
请注意,推理是随机的,因此每次运行时结果都会发生变化。如果要修复它,请使用 --seed 选项指定一个随机数种子,例如 `--seed 42`。
|
||||
|
||||
其他的选项,请参考help with `--help`(好像没有文档说明参数的含义,得看源码)。
|
||||
|
||||
默认情况下,会生成扩展名为 .caption 的caption文件。
|
||||
|
||||
|
||||
|
||||
例如,标题如下:
|
||||
|
||||
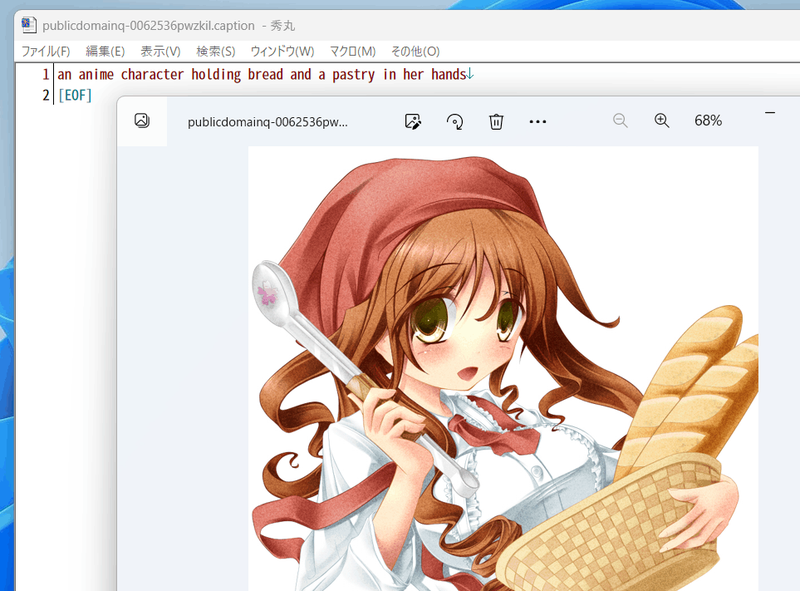
|
||||
|
||||
## 由 DeepDanbooru 标记
|
||||
|
||||
如果不想给danbooru标签本身打标签,请继续“标题和标签信息的预处理”。
|
||||
|
||||
标记是使用 DeepDanbooru 或 WD14Tagger 完成的。 WD14Tagger 似乎更准确。如果您想使用 WD14Tagger 进行标记,请跳至下一章。
|
||||
### 环境布置
|
||||
|
||||
将 DeepDanbooru https://github.com/KichangKim/DeepDanbooru 克隆到您的工作文件夹中,或下载并展开 zip。我解压缩了它。
|
||||
另外,从 DeepDanbooru 发布页面 https://github.com/KichangKim/DeepDanbooru/releases 上的“DeepDanbooru 预训练模型 v3-20211112-sgd-e28”的资产下载 deepdanbooru-v3-20211112-sgd-e28.zip 并解压到 DeepDanbooru 文件夹。
|
||||
|
||||
从下面下载。单击以打开资产并从那里下载。
|
||||
|
||||
|
||||
|
||||
做一个这样的目录结构
|
||||
|
||||
|
||||
为diffusers环境安装必要的库。进入 DeepDanbooru 文件夹并安装它(我认为它实际上只是添加了 tensorflow-io)。
|
||||
```
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
接下来,安装 DeepDanbooru 本身。
|
||||
|
||||
```
|
||||
pip install .
|
||||
```
|
||||
|
||||
这样就完成了标注环境的准备工作。
|
||||
|
||||
### 实施标记
|
||||
转到 DeepDanbooru 的文件夹并运行 deepdanbooru 进行标记。
|
||||
```
|
||||
deepdanbooru evaluate <教师资料夹> --project-path deepdanbooru-v3-20211112-sgd-e28 --allow-folder --save-txt
|
||||
```
|
||||
|
||||
如果将训练数据放在父文件夹train_data中,则如下所示。
|
||||
```
|
||||
deepdanbooru evaluate ../train_data --project-path deepdanbooru-v3-20211112-sgd-e28 --allow-folder --save-txt
|
||||
```
|
||||
|
||||
在与教师数据图像相同的目录中创建具有相同文件名和扩展名.txt 的标记文件。它很慢,因为它是一个接一个地处理的。
|
||||
|
||||
如果有多个教师数据文件夹,则对每个文件夹执行。
|
||||
|
||||
它生成如下。
|
||||
|
||||
|
||||
|
||||
它会被这样标记(信息量很大...)。
|
||||
|
||||
|
||||
|
||||
## WD14Tagger标记为
|
||||
|
||||
此过程使用 WD14Tagger 而不是 DeepDanbooru。
|
||||
|
||||
使用 Mr. Automatic1111 的 WebUI 中使用的标记器。我参考了这个 github 页面上的信息 (https://github.com/toriato/stable-diffusion-webui-wd14-tagger#mrsmilingwolfs-model-aka-waifu-diffusion-14-tagger)。
|
||||
|
||||
初始环境维护所需的模块已经安装。权重自动从 Hugging Face 下载。
|
||||
### 实施标记
|
||||
|
||||
运行脚本以进行标记。
|
||||
```
|
||||
python tag_images_by_wd14_tagger.py --batch_size <バッチサイズ> <教師データフォルダ>
|
||||
```
|
||||
|
||||
如果将训练数据放在父文件夹train_data中,则如下所示
|
||||
```
|
||||
python tag_images_by_wd14_tagger.py --batch_size 4 ..\train_data
|
||||
```
|
||||
|
||||
模型文件将在首次启动时自动下载到 wd14_tagger_model 文件夹(文件夹可以在选项中更改)。它将如下所示。
|
||||
|
||||
|
||||
在与教师数据图像相同的目录中创建具有相同文件名和扩展名.txt 的标记文件。
|
||||

|
||||
|
||||

|
||||
|
||||
使用 thresh 选项,您可以指定确定的标签的置信度数以附加标签。默认值为 0.35,与 WD14Tagger 示例相同。较低的值给出更多的标签,但准确性较低。
|
||||
|
||||
根据 GPU 的 VRAM 容量增加或减少 batch_size。越大越快(我认为 12GB 的 VRAM 可以多一点)。您可以使用 caption_extension 选项更改标记文件扩展名。默认为 .txt。
|
||||
|
||||
您可以使用 model_dir 选项指定保存模型的文件夹。
|
||||
|
||||
此外,如果指定 force_download 选项,即使有保存目标文件夹,也会重新下载模型。
|
||||
|
||||
如果有多个教师数据文件夹,则对每个文件夹执行。
|
||||
|
||||
## 预处理caption和标签信息
|
||||
|
||||
将caption和标签作为元数据合并到一个文件中,以便从脚本中轻松处理。
|
||||
### caption预处理
|
||||
|
||||
要将caption放入元数据,请在您的工作文件夹中运行以下命令(如果您不使用caption进行训练,则不需要运行它)(它实际上是一行,依此类推)。指定 `--full_path` 选项以将图像文件的完整路径存储在元数据中。如果省略此选项,则会记录相对路径,但 .toml 文件中需要单独的文件夹规范。
|
||||
```
|
||||
python merge_captions_to_metadata.py --full_path <教师资料夹>
|
||||
--in_json <要读取的元数据文件名> <元数据文件名>
|
||||
```
|
||||
|
||||
元数据文件名是任意名称。
|
||||
如果训练数据为train_data,没有读取元数据文件,元数据文件为meta_cap.json,则会如下。
|
||||
```
|
||||
python merge_captions_to_metadata.py --full_path train_data meta_cap.json
|
||||
```
|
||||
|
||||
您可以使用 caption_extension 选项指定标题扩展。
|
||||
|
||||
如果有多个教师数据文件夹,请指定 full_path 参数并为每个文件夹执行。
|
||||
```
|
||||
python merge_captions_to_metadata.py --full_path
|
||||
train_data1 meta_cap1.json
|
||||
python merge_captions_to_metadata.py --full_path --in_json meta_cap1.json
|
||||
train_data2 meta_cap2.json
|
||||
```
|
||||
如果省略in_json,如果有写入目标元数据文件,将从那里读取并覆盖。
|
||||
|
||||
__* 每次重写 in_json 选项和写入目标并写入单独的元数据文件是安全的。 __
|
||||
### 标签预处理
|
||||
|
||||
同样,标签也收集在元数据中(如果标签不用于训练,则无需这样做)。
|
||||
```
|
||||
python merge_dd_tags_to_metadata.py --full_path <教师资料夹>
|
||||
--in_json <要读取的元数据文件名> <要写入的元数据文件名>
|
||||
```
|
||||
|
||||
同样的目录结构,读取meta_cap.json和写入meta_cap_dd.json时,会是这样的。
|
||||
```
|
||||
python merge_dd_tags_to_metadata.py --full_path train_data --in_json meta_cap.json meta_cap_dd.json
|
||||
```
|
||||
|
||||
如果有多个教师数据文件夹,请指定 full_path 参数并为每个文件夹执行。
|
||||
|
||||
```
|
||||
python merge_dd_tags_to_metadata.py --full_path --in_json meta_cap2.json
|
||||
train_data1 meta_cap_dd1.json
|
||||
python merge_dd_tags_to_metadata.py --full_path --in_json meta_cap_dd1.json
|
||||
train_data2 meta_cap_dd2.json
|
||||
```
|
||||
|
||||
如果省略in_json,如果有写入目标元数据文件,将从那里读取并覆盖。
|
||||
__※ 通过每次重写 in_json 选项和写入目标,写入单独的元数据文件是安全的。 __
|
||||
### 标题和标签清理
|
||||
|
||||
到目前为止,标题和DeepDanbooru标签已经被整理到元数据文件中。然而,自动标题生成的标题存在表达差异等微妙问题(※),而标签中可能包含下划线和评级(DeepDanbooru的情况下)。因此,最好使用编辑器的替换功能清理标题和标签。
|
||||
|
||||
※例如,如果要学习动漫中的女孩,标题可能会包含girl/girls/woman/women等不同的表达方式。另外,将"anime girl"简单地替换为"girl"可能更合适。
|
||||
|
||||
我们提供了用于清理的脚本,请根据情况编辑脚本并使用它。
|
||||
|
||||
(不需要指定教师数据文件夹。将清理元数据中的所有数据。)
|
||||
|
||||
```
|
||||
python clean_captions_and_tags.py <要读取的元数据文件名> <要写入的元数据文件名>
|
||||
```
|
||||
|
||||
--in_json 请注意,不包括在内。例如:
|
||||
|
||||
```
|
||||
python clean_captions_and_tags.py meta_cap_dd.json meta_clean.json
|
||||
```
|
||||
|
||||
标题和标签的预处理现已完成。
|
||||
|
||||
## 预先获取 latents
|
||||
|
||||
※ 这一步骤并非必须。即使省略此步骤,也可以在训练过程中获取 latents。但是,如果在训练时执行 `random_crop` 或 `color_aug` 等操作,则无法预先获取 latents(因为每次图像都会改变)。如果不进行预先获取,则可以使用到目前为止的元数据进行训练。
|
||||
|
||||
提前获取图像的潜在表达并保存到磁盘上。这样可以加速训练过程。同时进行 bucketing(根据宽高比对训练数据进行分类)。
|
||||
|
||||
请在工作文件夹中输入以下内容。
|
||||
|
||||
```
|
||||
python prepare_buckets_latents.py --full_path <教师资料夹>
|
||||
<要读取的元数据文件名> <要写入的元数据文件名>
|
||||
<要微调的模型名称或检查点>
|
||||
--batch_size <批次大小>
|
||||
--max_resolution <分辨率宽、高>
|
||||
--mixed_precision <准确性>
|
||||
```
|
||||
|
||||
如果要从meta_clean.json中读取元数据,并将其写入meta_lat.json,使用模型model.ckpt,批处理大小为4,训练分辨率为512*512,精度为no(float32),则应如下所示。
|
||||
```
|
||||
python prepare_buckets_latents.py --full_path
|
||||
train_data meta_clean.json meta_lat.json model.ckpt
|
||||
--batch_size 4 --max_resolution 512,512 --mixed_precision no
|
||||
```
|
||||
|
||||
教师数据文件夹中,latents以numpy的npz格式保存。
|
||||
|
||||
您可以使用--min_bucket_reso选项指定最小分辨率大小,--max_bucket_reso指定最大大小。默认值分别为256和1024。例如,如果指定最小大小为384,则将不再使用分辨率为256 * 1024或320 * 768等。如果将分辨率增加到768 * 768等较大的值,则最好将最大大小指定为1280等。
|
||||
|
||||
如果指定--flip_aug选项,则进行左右翻转的数据增强。虽然这可以使数据量伪造一倍,但如果数据不是左右对称的(例如角色外观、发型等),则可能会导致训练不成功。
|
||||
|
||||
对于翻转的图像,也会获取latents,并保存名为\ *_flip.npz的文件,这是一个简单的实现。在fline_tune.py中不需要特定的选项。如果有带有\_flip的文件,则会随机加载带有和不带有flip的文件。
|
||||
|
||||
即使VRAM为12GB,批次大小也可以稍微增加。分辨率以“宽度,高度”的形式指定,必须是64的倍数。分辨率直接影响fine tuning时的内存大小。在12GB VRAM中,512,512似乎是极限(*)。如果有16GB,则可以将其提高到512,704或512,768。即使分辨率为256,256等,VRAM 8GB也很难承受(因为参数、优化器等与分辨率无关,需要一定的内存)。
|
||||
|
||||
*有报道称,在batch size为1的训练中,使用12GB VRAM和640,640的分辨率。
|
||||
|
||||
以下是bucketing结果的显示方式。
|
||||
|
||||
|
||||
|
||||
如果有多个教师数据文件夹,请指定 full_path 参数并为每个文件夹执行
|
||||
|
||||
```
|
||||
python prepare_buckets_latents.py --full_path
|
||||
train_data1 meta_clean.json meta_lat1.json model.ckpt
|
||||
--batch_size 4 --max_resolution 512,512 --mixed_precision no
|
||||
|
||||
python prepare_buckets_latents.py --full_path
|
||||
train_data2 meta_lat1.json meta_lat2.json model.ckpt
|
||||
--batch_size 4 --max_resolution 512,512 --mixed_precision no
|
||||
|
||||
```
|
||||
可以将读取源和写入目标设为相同,但分开设定更为安全。
|
||||
|
||||
__※建议每次更改参数并将其写入另一个元数据文件,以确保安全性。__
|
||||
84
docs/train_SDXL-en.md
Normal file
84
docs/train_SDXL-en.md
Normal file
@@ -0,0 +1,84 @@
|
||||
## SDXL training
|
||||
|
||||
The documentation will be moved to the training documentation in the future. The following is a brief explanation of the training scripts for SDXL.
|
||||
|
||||
### Training scripts for SDXL
|
||||
|
||||
- `sdxl_train.py` is a script for SDXL fine-tuning. The usage is almost the same as `fine_tune.py`, but it also supports DreamBooth dataset.
|
||||
- `--full_bf16` option is added. Thanks to KohakuBlueleaf!
|
||||
- This option enables the full bfloat16 training (includes gradients). This option is useful to reduce the GPU memory usage.
|
||||
- The full bfloat16 training might be unstable. Please use it at your own risk.
|
||||
- The different learning rates for each U-Net block are now supported in sdxl_train.py. Specify with `--block_lr` option. Specify 23 values separated by commas like `--block_lr 1e-3,1e-3 ... 1e-3`.
|
||||
- 23 values correspond to `0: time/label embed, 1-9: input blocks 0-8, 10-12: mid blocks 0-2, 13-21: output blocks 0-8, 22: out`.
|
||||
- `prepare_buckets_latents.py` now supports SDXL fine-tuning.
|
||||
|
||||
- `sdxl_train_network.py` is a script for LoRA training for SDXL. The usage is almost the same as `train_network.py`.
|
||||
|
||||
- Both scripts has following additional options:
|
||||
- `--cache_text_encoder_outputs` and `--cache_text_encoder_outputs_to_disk`: Cache the outputs of the text encoders. This option is useful to reduce the GPU memory usage. This option cannot be used with options for shuffling or dropping the captions.
|
||||
- `--no_half_vae`: Disable the half-precision (mixed-precision) VAE. VAE for SDXL seems to produce NaNs in some cases. This option is useful to avoid the NaNs.
|
||||
|
||||
- `--weighted_captions` option is not supported yet for both scripts.
|
||||
|
||||
- `sdxl_train_textual_inversion.py` is a script for Textual Inversion training for SDXL. The usage is almost the same as `train_textual_inversion.py`.
|
||||
- `--cache_text_encoder_outputs` is not supported.
|
||||
- There are two options for captions:
|
||||
1. Training with captions. All captions must include the token string. The token string is replaced with multiple tokens.
|
||||
2. Use `--use_object_template` or `--use_style_template` option. The captions are generated from the template. The existing captions are ignored.
|
||||
- See below for the format of the embeddings.
|
||||
|
||||
- `--min_timestep` and `--max_timestep` options are added to each training script. These options can be used to train U-Net with different timesteps. The default values are 0 and 1000.
|
||||
|
||||
### Utility scripts for SDXL
|
||||
|
||||
- `tools/cache_latents.py` is added. This script can be used to cache the latents to disk in advance.
|
||||
- The options are almost the same as `sdxl_train.py'. See the help message for the usage.
|
||||
- Please launch the script as follows:
|
||||
`accelerate launch --num_cpu_threads_per_process 1 tools/cache_latents.py ...`
|
||||
- This script should work with multi-GPU, but it is not tested in my environment.
|
||||
|
||||
- `tools/cache_text_encoder_outputs.py` is added. This script can be used to cache the text encoder outputs to disk in advance.
|
||||
- The options are almost the same as `cache_latents.py` and `sdxl_train.py`. See the help message for the usage.
|
||||
|
||||
- `sdxl_gen_img.py` is added. This script can be used to generate images with SDXL, including LoRA, Textual Inversion and ControlNet-LLLite. See the help message for the usage.
|
||||
|
||||
### Tips for SDXL training
|
||||
|
||||
- The default resolution of SDXL is 1024x1024.
|
||||
- The fine-tuning can be done with 24GB GPU memory with the batch size of 1. For 24GB GPU, the following options are recommended __for the fine-tuning with 24GB GPU memory__:
|
||||
- Train U-Net only.
|
||||
- Use gradient checkpointing.
|
||||
- Use `--cache_text_encoder_outputs` option and caching latents.
|
||||
- Use Adafactor optimizer. RMSprop 8bit or Adagrad 8bit may work. AdamW 8bit doesn't seem to work.
|
||||
- The LoRA training can be done with 8GB GPU memory (10GB recommended). For reducing the GPU memory usage, the following options are recommended:
|
||||
- Train U-Net only.
|
||||
- Use gradient checkpointing.
|
||||
- Use `--cache_text_encoder_outputs` option and caching latents.
|
||||
- Use one of 8bit optimizers or Adafactor optimizer.
|
||||
- Use lower dim (4 to 8 for 8GB GPU).
|
||||
- `--network_train_unet_only` option is highly recommended for SDXL LoRA. Because SDXL has two text encoders, the result of the training will be unexpected.
|
||||
- PyTorch 2 seems to use slightly less GPU memory than PyTorch 1.
|
||||
- `--bucket_reso_steps` can be set to 32 instead of the default value 64. Smaller values than 32 will not work for SDXL training.
|
||||
|
||||
Example of the optimizer settings for Adafactor with the fixed learning rate:
|
||||
```toml
|
||||
optimizer_type = "adafactor"
|
||||
optimizer_args = [ "scale_parameter=False", "relative_step=False", "warmup_init=False" ]
|
||||
lr_scheduler = "constant_with_warmup"
|
||||
lr_warmup_steps = 100
|
||||
learning_rate = 4e-7 # SDXL original learning rate
|
||||
```
|
||||
|
||||
### Format of Textual Inversion embeddings for SDXL
|
||||
|
||||
```python
|
||||
from safetensors.torch import save_file
|
||||
|
||||
state_dict = {"clip_g": embs_for_text_encoder_1280, "clip_l": embs_for_text_encoder_768}
|
||||
save_file(state_dict, file)
|
||||
```
|
||||
|
||||
### ControlNet-LLLite
|
||||
|
||||
ControlNet-LLLite, a novel method for ControlNet with SDXL, is added. See [documentation](./docs/train_lllite_README.md) for details.
|
||||
|
||||
162
docs/train_db_README-zh.md
Normal file
162
docs/train_db_README-zh.md
Normal file
@@ -0,0 +1,162 @@
|
||||
这是DreamBooth的指南。
|
||||
|
||||
请同时查看[关于学习的通用文档](./train_README-zh.md)。
|
||||
|
||||
# 概要
|
||||
|
||||
DreamBooth是一种将特定主题添加到图像生成模型中进行学习,并使用特定识别子生成它的技术。论文链接。
|
||||
|
||||
具体来说,它可以将角色和绘画风格等添加到Stable Diffusion模型中进行学习,并使用特定的单词(例如`shs`)来调用(呈现在生成的图像中)。
|
||||
|
||||
脚本基于Diffusers的DreamBooth,但添加了以下功能(一些功能已在原始脚本中得到支持)。
|
||||
|
||||
脚本的主要功能如下:
|
||||
|
||||
- 使用8位Adam优化器和潜在变量的缓存来节省内存(与Shivam Shrirao版相似)。
|
||||
- 使用xformers来节省内存。
|
||||
- 不仅支持512x512,还支持任意尺寸的训练。
|
||||
- 通过数据增强来提高质量。
|
||||
- 支持DreamBooth和Text Encoder + U-Net的微调。
|
||||
- 支持以Stable Diffusion格式读写模型。
|
||||
- 支持Aspect Ratio Bucketing。
|
||||
- 支持Stable Diffusion v2.0。
|
||||
|
||||
# 训练步骤
|
||||
|
||||
请先参阅此存储库的README以进行环境设置。
|
||||
|
||||
## 准备数据
|
||||
|
||||
请参阅[有关准备训练数据的说明](./train_README-zh.md)。
|
||||
|
||||
## 运行训练
|
||||
|
||||
运行脚本。以下是最大程度地节省内存的命令(实际上,这将在一行中输入)。请根据需要修改每行。它似乎需要约12GB的VRAM才能运行。
|
||||
```
|
||||
accelerate launch --num_cpu_threads_per_process 1 train_db.py
|
||||
--pretrained_model_name_or_path=<.ckpt或.safetensord或Diffusers版模型的目录>
|
||||
--dataset_config=<数据准备时创建的.toml文件>
|
||||
--output_dir=<训练模型的输出目录>
|
||||
--output_name=<训练模型输出时的文件名>
|
||||
--save_model_as=safetensors
|
||||
--prior_loss_weight=1.0
|
||||
--max_train_steps=1600
|
||||
--learning_rate=1e-6
|
||||
--optimizer_type="AdamW8bit"
|
||||
--xformers
|
||||
--mixed_precision="fp16"
|
||||
--cache_latents
|
||||
--gradient_checkpointing
|
||||
```
|
||||
`num_cpu_threads_per_process` 通常应该设置为1。
|
||||
|
||||
`pretrained_model_name_or_path` 指定要进行追加训练的基础模型。可以指定 Stable Diffusion 的 checkpoint 文件(.ckpt 或 .safetensors)、Diffusers 的本地模型目录或模型 ID(如 "stabilityai/stable-diffusion-2")。
|
||||
|
||||
`output_dir` 指定保存训练后模型的文件夹。在 `output_name` 中指定模型文件名,不包括扩展名。使用 `save_model_as` 指定以 safetensors 格式保存。
|
||||
|
||||
在 `dataset_config` 中指定 `.toml` 文件。初始批处理大小应为 `1`,以减少内存消耗。
|
||||
|
||||
`prior_loss_weight` 是正则化图像损失的权重。通常设为1.0。
|
||||
|
||||
将要训练的步数 `max_train_steps` 设置为1600。在这里,学习率 `learning_rate` 被设置为1e-6。
|
||||
|
||||
为了节省内存,设置 `mixed_precision="fp16"`(在 RTX30 系列及更高版本中也可以设置为 `bf16`)。同时指定 `gradient_checkpointing`。
|
||||
|
||||
为了使用内存消耗较少的 8bit AdamW 优化器(将模型优化为适合于训练数据的状态),指定 `optimizer_type="AdamW8bit"`。
|
||||
|
||||
指定 `xformers` 选项,并使用 xformers 的 CrossAttention。如果未安装 xformers 或出现错误(具体情况取决于环境,例如使用 `mixed_precision="no"`),则可以指定 `mem_eff_attn` 选项以使用省内存版的 CrossAttention(速度会变慢)。
|
||||
|
||||
为了节省内存,指定 `cache_latents` 选项以缓存 VAE 的输出。
|
||||
|
||||
如果有足够的内存,请编辑 `.toml` 文件将批处理大小增加到大约 `4`(可能会提高速度和精度)。此外,取消 `cache_latents` 选项可以进行数据增强。
|
||||
|
||||
### 常用选项
|
||||
|
||||
对于以下情况,请参阅“常用选项”部分。
|
||||
|
||||
- 学习 Stable Diffusion 2.x 或其衍生模型。
|
||||
- 学习基于 clip skip 大于等于2的模型。
|
||||
- 学习超过75个令牌的标题。
|
||||
|
||||
### 关于DreamBooth中的步数
|
||||
|
||||
为了实现省内存化,该脚本中每个步骤的学习次数减半(因为学习和正则化的图像在训练时被分为不同的批次)。
|
||||
|
||||
要进行与原始Diffusers版或XavierXiao的Stable Diffusion版几乎相同的学习,请将步骤数加倍。
|
||||
|
||||
(虽然在将学习图像和正则化图像整合后再打乱顺序,但我认为对学习没有太大影响。)
|
||||
|
||||
关于DreamBooth的批量大小
|
||||
|
||||
与像LoRA这样的学习相比,为了训练整个模型,内存消耗量会更大(与微调相同)。
|
||||
|
||||
关于学习率
|
||||
|
||||
在Diffusers版中,学习率为5e-6,而在Stable Diffusion版中为1e-6,因此在上面的示例中指定了1e-6。
|
||||
|
||||
当使用旧格式的数据集指定命令行时
|
||||
|
||||
使用选项指定分辨率和批量大小。命令行示例如下。
|
||||
```
|
||||
accelerate launch --num_cpu_threads_per_process 1 train_db.py
|
||||
--pretrained_model_name_or_path=<.ckpt或.safetensord或Diffusers版模型的目录>
|
||||
--train_data_dir=<训练数据的目录>
|
||||
--reg_data_dir=<正则化图像的目录>
|
||||
--output_dir=<训练后模型的输出目录>
|
||||
--output_name=<训练后模型输出文件的名称>
|
||||
--prior_loss_weight=1.0
|
||||
--resolution=512
|
||||
--train_batch_size=1
|
||||
--learning_rate=1e-6
|
||||
--max_train_steps=1600
|
||||
--use_8bit_adam
|
||||
--xformers
|
||||
--mixed_precision="bf16"
|
||||
--cache_latents
|
||||
--gradient_checkpointing
|
||||
```
|
||||
|
||||
## 使用训练好的模型生成图像
|
||||
|
||||
训练完成后,将在指定的文件夹中以指定的名称输出safetensors文件。
|
||||
|
||||
对于v1.4/1.5和其他派生模型,可以在此模型中使用Automatic1111先生的WebUI进行推断。请将其放置在models\Stable-diffusion文件夹中。
|
||||
|
||||
对于使用v2.x模型在WebUI中生成图像的情况,需要单独的.yaml文件来描述模型的规格。对于v2.x base,需要v2-inference.yaml,对于768/v,则需要v2-inference-v.yaml。请将它们放置在相同的文件夹中,并将文件扩展名之前的部分命名为与模型相同的名称。
|
||||

|
||||
|
||||
每个yaml文件都在[Stability AI的SD2.0存储库](https://github.com/Stability-AI/stablediffusion/tree/main/configs/stable-diffusion)……之中。
|
||||
|
||||
# DreamBooth的其他主要选项
|
||||
|
||||
有关所有选项的详细信息,请参阅另一份文档。
|
||||
|
||||
## 不在中途开始对文本编码器进行训练 --stop_text_encoder_training
|
||||
|
||||
如果在stop_text_encoder_training选项中指定一个数字,则在该步骤之后,将不再对文本编码器进行训练,只会对U-Net进行训练。在某些情况下,可能会期望提高精度。
|
||||
|
||||
(我们推测可能会有时候仅仅文本编码器会过度学习,而这样做可以避免这种情况,但详细影响尚不清楚。)
|
||||
|
||||
## 不进行分词器的填充 --no_token_padding
|
||||
|
||||
如果指定no_token_padding选项,则不会对分词器的输出进行填充(与Diffusers版本的旧DreamBooth相同)。
|
||||
|
||||
<!--
|
||||
如果使用分桶(bucketing)和数据增强(augmentation),则使用示例如下:
|
||||
```
|
||||
accelerate launch --num_cpu_threads_per_process 8 train_db.py
|
||||
--pretrained_model_name_or_path=<.ckpt或.safetensord或Diffusers版模型的目录>
|
||||
--train_data_dir=<训练数据的目录>
|
||||
--reg_data_dir=<正则化图像的目录>
|
||||
--output_dir=<训练后模型的输出目录>
|
||||
--resolution=768,512
|
||||
--train_batch_size=20 --learning_rate=5e-6 --max_train_steps=800
|
||||
--use_8bit_adam --xformers --mixed_precision="bf16"
|
||||
--save_every_n_epochs=1 --save_state --save_precision="bf16"
|
||||
--logging_dir=logs
|
||||
--enable_bucket --min_bucket_reso=384 --max_bucket_reso=1280
|
||||
--color_aug --flip_aug --gradient_checkpointing --seed 42
|
||||
```
|
||||
|
||||
|
||||
-->
|
||||
736
docs/train_leco.md
Normal file
736
docs/train_leco.md
Normal file
@@ -0,0 +1,736 @@
|
||||
# LECO Training Guide / LECO 学習ガイド
|
||||
|
||||
LECO (Low-rank adaptation for Erasing COncepts from diffusion models) is a technique for training LoRA models that modify or erase concepts from a diffusion model **without requiring any image dataset**. It works by training a LoRA against the model's own noise predictions using text prompts only.
|
||||
|
||||
This repository provides two LECO training scripts:
|
||||
|
||||
- `train_leco.py` for Stable Diffusion 1.x / 2.x
|
||||
- `sdxl_train_leco.py` for SDXL
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
LECO (Low-rank adaptation for Erasing COncepts from diffusion models) は、**画像データセットを一切必要とせず**、テキストプロンプトのみを使用してモデル自身のノイズ予測に対して LoRA を学習させる手法です。拡散モデルから概念を変更・消去する LoRA モデルを作成できます。
|
||||
|
||||
このリポジトリでは以下の2つの LECO 学習スクリプトを提供しています:
|
||||
|
||||
- `train_leco.py` : Stable Diffusion 1.x / 2.x 用
|
||||
- `sdxl_train_leco.py` : SDXL 用
|
||||
</details>
|
||||
|
||||
## 1. Overview / 概要
|
||||
|
||||
### What LECO Can Do / LECO でできること
|
||||
|
||||
LECO can be used for:
|
||||
|
||||
- **Concept erasing**: Remove a specific style or concept (e.g., erase "van gogh" style from generated images)
|
||||
- **Concept enhancing**: Strengthen a specific attribute (e.g., make "detailed" more pronounced)
|
||||
- **Slider LoRA**: Create a LoRA that controls an attribute bidirectionally (e.g., a slider between "short hair" and "long hair")
|
||||
|
||||
Unlike standard LoRA training, LECO does not use any training images. All training signals come from the difference between the model's own noise predictions on different text prompts.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
LECO は以下の用途に使用できます:
|
||||
|
||||
- **概念の消去**: 特定のスタイルや概念を除去する(例:生成画像から「van gogh」スタイルを消去)
|
||||
- **概念の強化**: 特定の属性を強化する(例:「detailed」をより顕著にする)
|
||||
- **スライダー LoRA**: 属性を双方向に制御する LoRA を作成する(例:「short hair」と「long hair」の間のスライダー)
|
||||
|
||||
通常の LoRA 学習とは異なり、LECO は学習画像を一切使用しません。学習のシグナルは全て、異なるテキストプロンプトに対するモデル自身のノイズ予測の差分から得られます。
|
||||
</details>
|
||||
|
||||
### Key Differences from Standard LoRA Training / 通常の LoRA 学習との違い
|
||||
|
||||
| | Standard LoRA | LECO |
|
||||
|---|---|---|
|
||||
| Training data | Image dataset required | **No images needed** |
|
||||
| Configuration | Dataset TOML | Prompt TOML |
|
||||
| Training target | U-Net and/or Text Encoder | **U-Net only** |
|
||||
| Training unit | Epochs and steps | **Steps only** |
|
||||
| Saving | Per-epoch or per-step | **Per-step only** (`--save_every_n_steps`) |
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
| | 通常の LoRA | LECO |
|
||||
|---|---|---|
|
||||
| 学習データ | 画像データセットが必要 | **画像不要** |
|
||||
| 設定ファイル | データセット TOML | プロンプト TOML |
|
||||
| 学習対象 | U-Net と Text Encoder | **U-Net のみ** |
|
||||
| 学習単位 | エポックとステップ | **ステップのみ** |
|
||||
| 保存 | エポック毎またはステップ毎 | **ステップ毎のみ** (`--save_every_n_steps`) |
|
||||
</details>
|
||||
|
||||
## 2. Prompt Configuration File / プロンプト設定ファイル
|
||||
|
||||
LECO uses a TOML file to define training prompts. Two formats are supported: the **original LECO format** and the **slider target format** (ai-toolkit style).
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
LECO は学習プロンプトの定義に TOML ファイルを使用します。**オリジナル LECO 形式**と**スライダーターゲット形式**(ai-toolkit スタイル)の2つの形式に対応しています。
|
||||
</details>
|
||||
|
||||
### 2.1. Original LECO Format / オリジナル LECO 形式
|
||||
|
||||
Use `[[prompts]]` sections to define prompt pairs directly. This gives you full control over each training pair.
|
||||
|
||||
```toml
|
||||
[[prompts]]
|
||||
target = "van gogh"
|
||||
positive = "van gogh"
|
||||
unconditional = ""
|
||||
neutral = ""
|
||||
action = "erase"
|
||||
guidance_scale = 1.0
|
||||
resolution = 512
|
||||
batch_size = 1
|
||||
multiplier = 1.0
|
||||
weight = 1.0
|
||||
```
|
||||
|
||||
Each `[[prompts]]` entry defines one training pair with the following fields:
|
||||
|
||||
| Field | Required | Default | Description |
|
||||
|-------|----------|---------|-------------|
|
||||
| `target` | Yes | - | The concept to be modified by the LoRA |
|
||||
| `positive` | No | same as `target` | The "positive direction" prompt for building the training target |
|
||||
| `unconditional` | No | `""` | The unconditional/negative prompt |
|
||||
| `neutral` | No | `""` | The neutral baseline prompt |
|
||||
| `action` | No | `"erase"` | `"erase"` to remove the concept, `"enhance"` to strengthen it |
|
||||
| `guidance_scale` | No | `1.0` | Scale factor for target construction (higher = stronger effect) |
|
||||
| `resolution` | No | `512` | Training resolution (int or `[height, width]`) |
|
||||
| `batch_size` | No | `1` | Number of latent samples per training step for this prompt |
|
||||
| `multiplier` | No | `1.0` | LoRA strength multiplier during training |
|
||||
| `weight` | No | `1.0` | Loss weight for this prompt pair |
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
`[[prompts]]` セクションを使用して、プロンプトペアを直接定義します。各学習ペアを細かく制御できます。
|
||||
|
||||
各 `[[prompts]]` エントリのフィールド:
|
||||
|
||||
| フィールド | 必須 | デフォルト | 説明 |
|
||||
|-----------|------|-----------|------|
|
||||
| `target` | はい | - | LoRA によって変更される概念 |
|
||||
| `positive` | いいえ | `target` と同じ | 学習ターゲット構築時の「正方向」プロンプト |
|
||||
| `unconditional` | いいえ | `""` | 無条件/ネガティブプロンプト |
|
||||
| `neutral` | いいえ | `""` | ニュートラルベースラインプロンプト |
|
||||
| `action` | いいえ | `"erase"` | `"erase"` で概念を除去、`"enhance"` で強化 |
|
||||
| `guidance_scale` | いいえ | `1.0` | ターゲット構築時のスケール係数(大きいほど効果が強い) |
|
||||
| `resolution` | いいえ | `512` | 学習解像度(整数または `[height, width]`) |
|
||||
| `batch_size` | いいえ | `1` | このプロンプトの学習ステップごとの latent サンプル数 |
|
||||
| `multiplier` | いいえ | `1.0` | 学習時の LoRA 強度乗数 |
|
||||
| `weight` | いいえ | `1.0` | このプロンプトペアの loss 重み |
|
||||
</details>
|
||||
|
||||
### 2.2. Slider Target Format / スライダーターゲット形式
|
||||
|
||||
Use `[[targets]]` sections to define slider-style LoRAs. Each target is automatically expanded into bidirectional training pairs (4 pairs when both `positive` and `negative` are provided, 2 pairs when only one is provided).
|
||||
|
||||
```toml
|
||||
guidance_scale = 1.0
|
||||
resolution = 1024
|
||||
neutral = ""
|
||||
|
||||
[[targets]]
|
||||
target_class = "1girl"
|
||||
positive = "1girl, long hair"
|
||||
negative = "1girl, short hair"
|
||||
multiplier = 1.0
|
||||
weight = 1.0
|
||||
```
|
||||
|
||||
Top-level fields (`guidance_scale`, `resolution`, `neutral`, `batch_size`, etc.) serve as defaults for all targets.
|
||||
|
||||
Each `[[targets]]` entry supports the following fields:
|
||||
|
||||
| Field | Required | Default | Description |
|
||||
|-------|----------|---------|-------------|
|
||||
| `target_class` | Yes | - | The base class/subject prompt |
|
||||
| `positive` | No* | `""` | Prompt for the positive direction of the slider |
|
||||
| `negative` | No* | `""` | Prompt for the negative direction of the slider |
|
||||
| `multiplier` | No | `1.0` | LoRA strength multiplier |
|
||||
| `weight` | No | `1.0` | Loss weight |
|
||||
|
||||
\* At least one of `positive` or `negative` must be provided.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
`[[targets]]` セクションを使用してスライダースタイルの LoRA を定義します。各ターゲットは自動的に双方向の学習ペアに展開されます(`positive` と `negative` の両方がある場合は4ペア、片方のみの場合は2ペア)。
|
||||
|
||||
トップレベルのフィールド(`guidance_scale`、`resolution`、`neutral`、`batch_size` など)は全ターゲットのデフォルト値として機能します。
|
||||
|
||||
各 `[[targets]]` エントリのフィールド:
|
||||
|
||||
| フィールド | 必須 | デフォルト | 説明 |
|
||||
|-----------|------|-----------|------|
|
||||
| `target_class` | はい | - | ベースとなるクラス/被写体プロンプト |
|
||||
| `positive` | いいえ* | `""` | スライダーの正方向プロンプト |
|
||||
| `negative` | いいえ* | `""` | スライダーの負方向プロンプト |
|
||||
| `multiplier` | いいえ | `1.0` | LoRA 強度乗数 |
|
||||
| `weight` | いいえ | `1.0` | loss 重み |
|
||||
|
||||
\* `positive` と `negative` のうち少なくとも一方を指定する必要があります。
|
||||
</details>
|
||||
|
||||
### 2.3. Multiple Neutral Prompts / 複数のニュートラルプロンプト
|
||||
|
||||
You can provide multiple neutral prompts for slider targets. Each neutral prompt generates a separate set of training pairs, which can improve generalization.
|
||||
|
||||
```toml
|
||||
guidance_scale = 1.5
|
||||
resolution = 1024
|
||||
neutrals = ["", "photo of a person", "cinematic portrait"]
|
||||
|
||||
[[targets]]
|
||||
target_class = "person"
|
||||
positive = "smiling person"
|
||||
negative = "expressionless person"
|
||||
```
|
||||
|
||||
You can also load neutral prompts from a text file (one prompt per line):
|
||||
|
||||
```toml
|
||||
neutral_prompt_file = "neutrals.txt"
|
||||
|
||||
[[targets]]
|
||||
target_class = ""
|
||||
positive = "high detail"
|
||||
negative = "low detail"
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
スライダーターゲットに対して複数のニュートラルプロンプトを指定できます。各ニュートラルプロンプトごとに個別の学習ペアが生成され、汎化性能の向上が期待できます。
|
||||
|
||||
ニュートラルプロンプトをテキストファイル(1行1プロンプト)から読み込むこともできます。
|
||||
</details>
|
||||
|
||||
### 2.4. Converting from ai-toolkit YAML / ai-toolkit の YAML からの変換
|
||||
|
||||
If you have an existing ai-toolkit style YAML config, convert it to TOML as follows:
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
既存の ai-toolkit スタイルの YAML 設定がある場合、以下のように TOML に変換してください。
|
||||
</details>
|
||||
|
||||
**YAML:**
|
||||
```yaml
|
||||
targets:
|
||||
- target_class: ""
|
||||
positive: "high detail"
|
||||
negative: "low detail"
|
||||
multiplier: 1.0
|
||||
guidance_scale: 1.0
|
||||
resolution: 512
|
||||
```
|
||||
|
||||
**TOML:**
|
||||
```toml
|
||||
guidance_scale = 1.0
|
||||
resolution = 512
|
||||
|
||||
[[targets]]
|
||||
target_class = ""
|
||||
positive = "high detail"
|
||||
negative = "low detail"
|
||||
multiplier = 1.0
|
||||
```
|
||||
|
||||
Key syntax differences:
|
||||
|
||||
- Use `=` instead of `:` for key-value pairs
|
||||
- Use `[[targets]]` header instead of `targets:` with `- ` list items
|
||||
- Arrays use `[brackets]` (e.g., `neutrals = ["a", "b"]`)
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
主な構文の違い:
|
||||
|
||||
- キーと値の区切りに `:` ではなく `=` を使用
|
||||
- `targets:` と `- ` のリスト記法ではなく `[[targets]]` ヘッダを使用
|
||||
- 配列は `[brackets]` で記述(例:`neutrals = ["a", "b"]`)
|
||||
</details>
|
||||
|
||||
## 3. Running the Training / 学習の実行
|
||||
|
||||
Training is started by executing the script from the terminal. Below are basic command-line examples.
|
||||
|
||||
In reality, you need to write the command in a single line, but it is shown with line breaks for readability. On Linux/Mac, add `\` at the end of each line; on Windows, add `^`.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
学習はターミナルからスクリプトを実行して開始します。以下に基本的なコマンドライン例を示します。
|
||||
|
||||
実際には1行で書く必要がありますが、見やすさのために改行しています。Linux/Mac では各行末に `\` を、Windows では `^` を追加してください。
|
||||
</details>
|
||||
|
||||
### SD 1.x / 2.x
|
||||
|
||||
```bash
|
||||
accelerate launch --mixed_precision bf16 train_leco.py
|
||||
--pretrained_model_name_or_path="model.safetensors"
|
||||
--prompts_file="prompts.toml"
|
||||
--output_dir="output"
|
||||
--output_name="my_leco"
|
||||
--network_dim=8
|
||||
--network_alpha=4
|
||||
--learning_rate=1e-4
|
||||
--optimizer_type="AdamW8bit"
|
||||
--max_train_steps=500
|
||||
--max_denoising_steps=40
|
||||
--mixed_precision=bf16
|
||||
--sdpa
|
||||
--gradient_checkpointing
|
||||
--save_every_n_steps=100
|
||||
```
|
||||
|
||||
### SDXL
|
||||
|
||||
```bash
|
||||
accelerate launch --mixed_precision bf16 sdxl_train_leco.py
|
||||
--pretrained_model_name_or_path="sdxl_model.safetensors"
|
||||
--prompts_file="slider.toml"
|
||||
--output_dir="output"
|
||||
--output_name="my_sdxl_slider"
|
||||
--network_dim=8
|
||||
--network_alpha=4
|
||||
--learning_rate=1e-4
|
||||
--optimizer_type="AdamW8bit"
|
||||
--max_train_steps=1000
|
||||
--max_denoising_steps=40
|
||||
--mixed_precision=bf16
|
||||
--sdpa
|
||||
--gradient_checkpointing
|
||||
--save_every_n_steps=200
|
||||
```
|
||||
|
||||
## 4. Command-Line Arguments / コマンドライン引数
|
||||
|
||||
### 4.1. LECO-Specific Arguments / LECO 固有の引数
|
||||
|
||||
These arguments are unique to LECO and not found in standard LoRA training scripts.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
以下の引数は LECO 固有のもので、通常の LoRA 学習スクリプトにはありません。
|
||||
</details>
|
||||
|
||||
* `--prompts_file="prompts.toml"` **[Required]**
|
||||
* Path to the LECO prompt configuration TOML file. See [Section 2](#2-prompt-configuration-file--プロンプト設定ファイル) for the file format.
|
||||
|
||||
* `--max_denoising_steps=40`
|
||||
* Number of partial denoising steps per training iteration. At each step, a random number of denoising steps (from 1 to this value) is performed. Default: `40`.
|
||||
|
||||
* `--leco_denoise_guidance_scale=3.0`
|
||||
* Guidance scale used during the partial denoising pass. This is separate from `guidance_scale` in the TOML file. Default: `3.0`.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
* `--prompts_file="prompts.toml"` **[必須]**
|
||||
* LECO プロンプト設定 TOML ファイルのパス。ファイル形式については[セクション2](#2-prompt-configuration-file--プロンプト設定ファイル)を参照してください。
|
||||
|
||||
* `--max_denoising_steps=40`
|
||||
* 各学習イテレーションでの部分デノイズステップ数。各ステップで1からこの値の間のランダムなステップ数でデノイズが行われます。デフォルト: `40`。
|
||||
|
||||
* `--leco_denoise_guidance_scale=3.0`
|
||||
* 部分デノイズ時の guidance scale。TOML ファイル内の `guidance_scale` とは別のパラメータです。デフォルト: `3.0`。
|
||||
</details>
|
||||
|
||||
#### Understanding the Two `guidance_scale` Parameters / 2つの `guidance_scale` の違い
|
||||
|
||||
There are two separate guidance scale parameters that control different aspects of LECO training:
|
||||
|
||||
1. **`--leco_denoise_guidance_scale` (command-line)**: Controls CFG strength during the partial denoising pass that generates intermediate latents. Higher values produce more prompt-adherent latents for the training signal.
|
||||
|
||||
2. **`guidance_scale` (in TOML file)**: Controls the magnitude of the concept offset when constructing the training target. Higher values produce a stronger erase/enhance effect. This can be set per-prompt or per-target.
|
||||
|
||||
If training results are too subtle, try increasing the TOML `guidance_scale` (e.g., `1.5` to `3.0`).
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
LECO の学習では、異なる役割を持つ2つの guidance scale パラメータがあります:
|
||||
|
||||
1. **`--leco_denoise_guidance_scale`(コマンドライン)**: 中間 latent を生成する部分デノイズパスの CFG 強度を制御します。大きな値にすると、プロンプトにより忠実な latent が学習シグナルとして生成されます。
|
||||
|
||||
2. **`guidance_scale`(TOML ファイル内)**: 学習ターゲット構築時の概念オフセットの大きさを制御します。大きな値にすると、消去/強化の効果が強くなります。プロンプトごと・ターゲットごとに設定可能です。
|
||||
|
||||
学習結果の効果が弱い場合は、TOML の `guidance_scale` を大きくしてみてください(例:`1.5` から `3.0`)。
|
||||
</details>
|
||||
|
||||
### 4.2. Model Arguments / モデル引数
|
||||
|
||||
* `--pretrained_model_name_or_path="model.safetensors"` **[Required]**
|
||||
* Path to the base Stable Diffusion model (`.ckpt`, `.safetensors`, Diffusers directory, or Hugging Face model ID).
|
||||
|
||||
* `--v2` (SD 1.x/2.x only)
|
||||
* Specify when using a Stable Diffusion v2.x model.
|
||||
|
||||
* `--v_parameterization` (SD 1.x/2.x only)
|
||||
* Specify when using a v-prediction model (e.g., SD 2.x 768px models).
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
* `--pretrained_model_name_or_path="model.safetensors"` **[必須]**
|
||||
* ベースとなる Stable Diffusion モデルのパス(`.ckpt`、`.safetensors`、Diffusers ディレクトリ、Hugging Face モデル ID)。
|
||||
|
||||
* `--v2`(SD 1.x/2.x のみ)
|
||||
* Stable Diffusion v2.x モデルを使用する場合に指定します。
|
||||
|
||||
* `--v_parameterization`(SD 1.x/2.x のみ)
|
||||
* v-prediction モデル(SD 2.x 768px モデルなど)を使用する場合に指定します。
|
||||
</details>
|
||||
|
||||
### 4.3. LoRA Network Arguments / LoRA ネットワーク引数
|
||||
|
||||
* `--network_module=networks.lora`
|
||||
* Network module to train. Default: `networks.lora`.
|
||||
|
||||
* `--network_dim=8`
|
||||
* LoRA rank (dimension). Higher values increase expressiveness but also file size. Typical values: `4` to `16`. Default: `4`.
|
||||
|
||||
* `--network_alpha=4`
|
||||
* LoRA alpha for learning rate scaling. A common choice is to set this to half of `network_dim`. Default: `1.0`.
|
||||
|
||||
* `--network_dropout=0.1`
|
||||
* Dropout rate for LoRA layers. Optional.
|
||||
|
||||
* `--network_args "key=value" ...`
|
||||
* Additional network-specific arguments. For example, `--network_args "conv_dim=4"` to enable Conv2d LoRA.
|
||||
|
||||
* `--network_weights="path/to/weights.safetensors"`
|
||||
* Load pretrained LoRA weights to continue training.
|
||||
|
||||
* `--dim_from_weights`
|
||||
* Infer `network_dim` from the weights specified by `--network_weights`. Requires `--network_weights`.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
* `--network_module=networks.lora`
|
||||
* 学習するネットワークモジュール。デフォルト: `networks.lora`。
|
||||
|
||||
* `--network_dim=8`
|
||||
* LoRA のランク(次元数)。大きいほど表現力が上がりますがファイルサイズも増加します。一般的な値: `4` から `16`。デフォルト: `4`。
|
||||
|
||||
* `--network_alpha=4`
|
||||
* 学習率スケーリング用の LoRA alpha。`network_dim` の半分程度に設定するのが一般的です。デフォルト: `1.0`。
|
||||
|
||||
* `--network_dropout=0.1`
|
||||
* LoRA レイヤーのドロップアウト率。省略可。
|
||||
|
||||
* `--network_args "key=value" ...`
|
||||
* ネットワーク固有の追加引数。例:`--network_args "conv_dim=4"` で Conv2d LoRA を有効にします。
|
||||
|
||||
* `--network_weights="path/to/weights.safetensors"`
|
||||
* 事前学習済み LoRA ウェイトを読み込んで学習を続行します。
|
||||
|
||||
* `--dim_from_weights`
|
||||
* `--network_weights` で指定したウェイトから `network_dim` を推定します。`--network_weights` の指定が必要です。
|
||||
</details>
|
||||
|
||||
### 4.4. Training Parameters / 学習パラメータ
|
||||
|
||||
* `--max_train_steps=500`
|
||||
* Total number of training steps. Default: `1600`. Typical range for LECO: `300` to `2000`.
|
||||
* Note: `--max_train_epochs` is **not supported** for LECO (the training loop is step-based only).
|
||||
|
||||
* `--learning_rate=1e-4`
|
||||
* Learning rate. Typical range for LECO: `1e-4` to `1e-3`.
|
||||
|
||||
* `--unet_lr=1e-4`
|
||||
* Separate learning rate for U-Net LoRA modules. If not specified, `--learning_rate` is used.
|
||||
|
||||
* `--optimizer_type="AdamW8bit"`
|
||||
* Optimizer type. Options include `AdamW8bit` (requires `bitsandbytes`), `AdamW`, `Lion`, `Adafactor`, etc.
|
||||
|
||||
* `--lr_scheduler="constant"`
|
||||
* Learning rate scheduler. Options: `constant`, `cosine`, `linear`, `constant_with_warmup`, etc.
|
||||
|
||||
* `--lr_warmup_steps=0`
|
||||
* Number of warmup steps for the learning rate scheduler.
|
||||
|
||||
* `--gradient_accumulation_steps=1`
|
||||
* Number of steps to accumulate gradients before updating. Effectively multiplies the batch size.
|
||||
|
||||
* `--max_grad_norm=1.0`
|
||||
* Maximum gradient norm for gradient clipping. Set to `0` to disable.
|
||||
|
||||
* `--min_snr_gamma=5.0`
|
||||
* Min-SNR weighting gamma. Applies SNR-based loss weighting. Optional.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
* `--max_train_steps=500`
|
||||
* 学習の総ステップ数。デフォルト: `1600`。LECO の一般的な範囲: `300` から `2000`。
|
||||
* 注意: `--max_train_epochs` は LECO では**サポートされていません**(学習ループはステップベースのみです)。
|
||||
|
||||
* `--learning_rate=1e-4`
|
||||
* 学習率。LECO の一般的な範囲: `1e-4` から `1e-3`。
|
||||
|
||||
* `--unet_lr=1e-4`
|
||||
* U-Net LoRA モジュール用の個別の学習率。指定しない場合は `--learning_rate` が使用されます。
|
||||
|
||||
* `--optimizer_type="AdamW8bit"`
|
||||
* オプティマイザの種類。`AdamW8bit`(要 `bitsandbytes`)、`AdamW`、`Lion`、`Adafactor` 等が選択可能です。
|
||||
|
||||
* `--lr_scheduler="constant"`
|
||||
* 学習率スケジューラ。`constant`、`cosine`、`linear`、`constant_with_warmup` 等が選択可能です。
|
||||
|
||||
* `--lr_warmup_steps=0`
|
||||
* 学習率スケジューラのウォームアップステップ数。
|
||||
|
||||
* `--gradient_accumulation_steps=1`
|
||||
* 勾配を累積するステップ数。実質的にバッチサイズを増加させます。
|
||||
|
||||
* `--max_grad_norm=1.0`
|
||||
* 勾配クリッピングの最大勾配ノルム。`0` で無効化。
|
||||
|
||||
* `--min_snr_gamma=5.0`
|
||||
* Min-SNR 重み付けのガンマ値。SNR ベースの loss 重み付けを適用します。省略可。
|
||||
</details>
|
||||
|
||||
### 4.5. Output and Save Arguments / 出力・保存引数
|
||||
|
||||
* `--output_dir="output"` **[Required]**
|
||||
* Directory for saving trained LoRA models and logs.
|
||||
|
||||
* `--output_name="my_leco"` **[Required]**
|
||||
* Base filename for the trained LoRA (without extension).
|
||||
|
||||
* `--save_model_as="safetensors"`
|
||||
* Model save format. Options: `safetensors` (default, recommended), `ckpt`, `pt`.
|
||||
|
||||
* `--save_every_n_steps=100`
|
||||
* Save an intermediate checkpoint every N steps. If not specified, only the final model is saved.
|
||||
* Note: `--save_every_n_epochs` is **not supported** for LECO.
|
||||
|
||||
* `--save_precision="fp16"`
|
||||
* Precision for saving the model. Options: `float`, `fp16`, `bf16`. If not specified, the training precision is used.
|
||||
|
||||
* `--no_metadata`
|
||||
* Do not write metadata into the saved model file.
|
||||
|
||||
* `--training_comment="my comment"`
|
||||
* A comment string stored in the model metadata.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
* `--output_dir="output"` **[必須]**
|
||||
* 学習済み LoRA モデルとログの保存先ディレクトリ。
|
||||
|
||||
* `--output_name="my_leco"` **[必須]**
|
||||
* 学習済み LoRA のベースファイル名(拡張子なし)。
|
||||
|
||||
* `--save_model_as="safetensors"`
|
||||
* モデルの保存形式。`safetensors`(デフォルト、推奨)、`ckpt`、`pt` から選択。
|
||||
|
||||
* `--save_every_n_steps=100`
|
||||
* N ステップごとに中間チェックポイントを保存。指定しない場合は最終モデルのみ保存されます。
|
||||
* 注意: `--save_every_n_epochs` は LECO では**サポートされていません**。
|
||||
|
||||
* `--save_precision="fp16"`
|
||||
* モデル保存時の精度。`float`、`fp16`、`bf16` から選択。省略時は学習時の精度が使用されます。
|
||||
|
||||
* `--no_metadata`
|
||||
* 保存するモデルファイルにメタデータを書き込みません。
|
||||
|
||||
* `--training_comment="my comment"`
|
||||
* モデルのメタデータに保存されるコメント文字列。
|
||||
</details>
|
||||
|
||||
### 4.6. Memory and Performance Arguments / メモリ・パフォーマンス引数
|
||||
|
||||
* `--mixed_precision="bf16"`
|
||||
* Mixed precision training. Options: `no`, `fp16`, `bf16`. Using `bf16` or `fp16` is recommended.
|
||||
|
||||
* `--full_fp16`
|
||||
* Train entirely in fp16 precision including gradients.
|
||||
|
||||
* `--full_bf16`
|
||||
* Train entirely in bf16 precision including gradients.
|
||||
|
||||
* `--gradient_checkpointing`
|
||||
* Enable gradient checkpointing to reduce VRAM usage at the cost of slightly slower training. **Recommended for LECO**, especially with larger models or higher resolutions.
|
||||
|
||||
* `--sdpa`
|
||||
* Use Scaled Dot-Product Attention. Reduces memory usage and can improve speed. Recommended.
|
||||
|
||||
* `--xformers`
|
||||
* Use xformers for memory-efficient attention (requires `xformers` package). Alternative to `--sdpa`.
|
||||
|
||||
* `--mem_eff_attn`
|
||||
* Use memory-efficient attention implementation. Another alternative to `--sdpa`.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
* `--mixed_precision="bf16"`
|
||||
* 混合精度学習。`no`、`fp16`、`bf16` から選択。`bf16` または `fp16` の使用を推奨します。
|
||||
|
||||
* `--full_fp16`
|
||||
* 勾配を含め全体を fp16 精度で学習します。
|
||||
|
||||
* `--full_bf16`
|
||||
* 勾配を含め全体を bf16 精度で学習します。
|
||||
|
||||
* `--gradient_checkpointing`
|
||||
* gradient checkpointing を有効にしてVRAM使用量を削減します(学習速度は若干低下)。特に大きなモデルや高解像度での LECO 学習時に**推奨**です。
|
||||
|
||||
* `--sdpa`
|
||||
* Scaled Dot-Product Attention を使用します。メモリ使用量を削減し速度向上が期待できます。推奨。
|
||||
|
||||
* `--xformers`
|
||||
* xformers を使用したメモリ効率の良い attention(`xformers` パッケージが必要)。`--sdpa` の代替。
|
||||
|
||||
* `--mem_eff_attn`
|
||||
* メモリ効率の良い attention 実装を使用。`--sdpa` の別の代替。
|
||||
</details>
|
||||
|
||||
### 4.7. Other Useful Arguments / その他の便利な引数
|
||||
|
||||
* `--seed=42`
|
||||
* Random seed for reproducibility. If not specified, a random seed is automatically generated.
|
||||
|
||||
* `--noise_offset=0.05`
|
||||
* Enable noise offset. Small values like `0.02` to `0.1` can help with training stability.
|
||||
|
||||
* `--zero_terminal_snr`
|
||||
* Fix noise scheduler betas to enforce zero terminal SNR.
|
||||
|
||||
* `--clip_skip=2` (SD 1.x/2.x only)
|
||||
* Use the output from the Nth-to-last layer of the text encoder. Common values: `1` (no skip) or `2`.
|
||||
|
||||
* `--logging_dir="logs"`
|
||||
* Directory for TensorBoard logs. Enables logging when specified.
|
||||
|
||||
* `--log_with="tensorboard"`
|
||||
* Logging tool. Options: `tensorboard`, `wandb`, `all`.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
* `--seed=42`
|
||||
* 再現性のための乱数シード。指定しない場合は自動生成されます。
|
||||
|
||||
* `--noise_offset=0.05`
|
||||
* ノイズオフセットを有効にします。`0.02` から `0.1` 程度の小さい値で学習の安定性が向上する場合があります。
|
||||
|
||||
* `--zero_terminal_snr`
|
||||
* noise scheduler の betas を修正してゼロ終端 SNR を強制します。
|
||||
|
||||
* `--clip_skip=2`(SD 1.x/2.x のみ)
|
||||
* text encoder の後ろから N 番目の層の出力を使用します。一般的な値: `1`(スキップなし)または `2`。
|
||||
|
||||
* `--logging_dir="logs"`
|
||||
* TensorBoard ログの出力ディレクトリ。指定時にログ出力が有効になります。
|
||||
|
||||
* `--log_with="tensorboard"`
|
||||
* ログツール。`tensorboard`、`wandb`、`all` から選択。
|
||||
</details>
|
||||
|
||||
## 5. Tips / ヒント
|
||||
|
||||
### Tuning the Effect Strength / 効果の強さの調整
|
||||
|
||||
If the trained LoRA has a weak or unnoticeable effect:
|
||||
|
||||
1. **Increase `guidance_scale` in TOML** (e.g., `1.5` to `3.0`). This is the most direct way to strengthen the effect.
|
||||
2. **Increase `multiplier` in TOML** (e.g., `1.5` to `2.0`).
|
||||
3. **Increase `--max_denoising_steps`** for more refined intermediate latents.
|
||||
4. **Increase `--max_train_steps`** to train longer.
|
||||
5. **Apply the LoRA with a higher weight** at inference time.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
学習した LoRA の効果が弱い、または認識できない場合:
|
||||
|
||||
1. **TOML の `guidance_scale` を上げる**(例:`1.5` から `3.0`)。効果を強める最も直接的な方法です。
|
||||
2. **TOML の `multiplier` を上げる**(例:`1.5` から `2.0`)。
|
||||
3. **`--max_denoising_steps` を増やす**。より精緻な中間 latent が生成されます。
|
||||
4. **`--max_train_steps` を増やして**、より長く学習する。
|
||||
5. **推論時に LoRA のウェイトを大きくして**適用する。
|
||||
</details>
|
||||
|
||||
### Recommended Starting Settings / 推奨の開始設定
|
||||
|
||||
| Parameter | SD 1.x/2.x | SDXL |
|
||||
|-----------|-------------|------|
|
||||
| `--network_dim` | `4`-`8` | `8`-`16` |
|
||||
| `--learning_rate` | `1e-4` | `1e-4` |
|
||||
| `--max_train_steps` | `300`-`1000` | `500`-`2000` |
|
||||
| `resolution` (in TOML) | `512` | `1024` |
|
||||
| `guidance_scale` (in TOML) | `1.0`-`2.0` | `1.0`-`3.0` |
|
||||
| `batch_size` (in TOML) | `1`-`4` | `1`-`4` |
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
| パラメータ | SD 1.x/2.x | SDXL |
|
||||
|-----------|-------------|------|
|
||||
| `--network_dim` | `4`-`8` | `8`-`16` |
|
||||
| `--learning_rate` | `1e-4` | `1e-4` |
|
||||
| `--max_train_steps` | `300`-`1000` | `500`-`2000` |
|
||||
| `resolution`(TOML内) | `512` | `1024` |
|
||||
| `guidance_scale`(TOML内) | `1.0`-`2.0` | `1.0`-`3.0` |
|
||||
| `batch_size`(TOML内) | `1`-`4` | `1`-`4` |
|
||||
</details>
|
||||
|
||||
### Dynamic Resolution and Crops (SDXL) / 動的解像度とクロップ(SDXL)
|
||||
|
||||
For SDXL slider targets, you can enable dynamic resolution and crops in the TOML file:
|
||||
|
||||
```toml
|
||||
resolution = 1024
|
||||
dynamic_resolution = true
|
||||
dynamic_crops = true
|
||||
|
||||
[[targets]]
|
||||
target_class = ""
|
||||
positive = "high detail"
|
||||
negative = "low detail"
|
||||
```
|
||||
|
||||
- `dynamic_resolution`: Randomly varies the training resolution around the base value using aspect ratio buckets.
|
||||
- `dynamic_crops`: Randomizes crop positions in the SDXL size conditioning embeddings.
|
||||
|
||||
These options can improve the LoRA's generalization across different aspect ratios.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
SDXL のスライダーターゲットでは、TOML ファイルで動的解像度とクロップを有効にできます。
|
||||
|
||||
- `dynamic_resolution`: アスペクト比バケツを使用して、ベース値の周囲で学習解像度をランダムに変化させます。
|
||||
- `dynamic_crops`: SDXL のサイズ条件付け埋め込みでクロップ位置をランダム化します。
|
||||
|
||||
これらのオプションにより、異なるアスペクト比に対する LoRA の汎化性能が向上する場合があります。
|
||||
</details>
|
||||
|
||||
## 6. Using the Trained Model / 学習済みモデルの利用
|
||||
|
||||
The trained LoRA file (`.safetensors`) is saved in the `--output_dir` directory. It can be used with GUI tools such as AUTOMATIC1111/stable-diffusion-webui, ComfyUI, etc.
|
||||
|
||||
For slider LoRAs, apply positive weights (e.g., `0.5` to `1.5`) to move in the positive direction, and negative weights (e.g., `-0.5` to `-1.5`) to move in the negative direction.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
学習済みの LoRA ファイル(`.safetensors`)は `--output_dir` ディレクトリに保存されます。AUTOMATIC1111/stable-diffusion-webui、ComfyUI 等の GUI ツールで使用できます。
|
||||
|
||||
スライダー LoRA の場合、正のウェイト(例:`0.5` から `1.5`)で正方向に、負のウェイト(例:`-0.5` から `-1.5`)で負方向に効果を適用できます。
|
||||
</details>
|
||||
218
docs/train_lllite_README-ja.md
Normal file
218
docs/train_lllite_README-ja.md
Normal file
@@ -0,0 +1,218 @@
|
||||
# ControlNet-LLLite について
|
||||
|
||||
__きわめて実験的な実装のため、将来的に大きく変更される可能性があります。__
|
||||
|
||||
## 概要
|
||||
ControlNet-LLLite は、[ControlNet](https://github.com/lllyasviel/ControlNet) の軽量版です。LoRA Like Lite という意味で、LoRAからインスピレーションを得た構造を持つ、軽量なControlNetです。現在はSDXLにのみ対応しています。
|
||||
|
||||
## サンプルの重みファイルと推論
|
||||
|
||||
こちらにあります: https://huggingface.co/kohya-ss/controlnet-lllite
|
||||
|
||||
ComfyUIのカスタムノードを用意しています。: https://github.com/kohya-ss/ControlNet-LLLite-ComfyUI
|
||||
|
||||
生成サンプルはこのページの末尾にあります。
|
||||
|
||||
## モデル構造
|
||||
ひとつのLLLiteモジュールは、制御用画像(以下conditioning image)を潜在空間に写像するconditioning image embeddingと、LoRAにちょっと似た構造を持つ小型のネットワークからなります。LLLiteモジュールを、LoRAと同様にU-NetのLinearやConvに追加します。詳しくはソースコードを参照してください。
|
||||
|
||||
推論環境の制限で、現在はCrossAttentionのみ(attn1のq/k/v、attn2のq)に追加されます。
|
||||
|
||||
## モデルの学習
|
||||
|
||||
### データセットの準備
|
||||
DreamBooth 方式の dataset で、`conditioning_data_dir` で指定したディレクトリにconditioning imageを格納してください。
|
||||
|
||||
(finetuning 方式の dataset はサポートしていません。)
|
||||
|
||||
conditioning imageは学習用画像と同じbasenameを持つ必要があります。また、conditioning imageは学習用画像と同じサイズに自動的にリサイズされます。conditioning imageにはキャプションファイルは不要です。
|
||||
|
||||
たとえば、キャプションにフォルダ名ではなくキャプションファイルを用いる場合の設定ファイルは以下のようになります。
|
||||
|
||||
```toml
|
||||
[[datasets.subsets]]
|
||||
image_dir = "path/to/image/dir"
|
||||
caption_extension = ".txt"
|
||||
conditioning_data_dir = "path/to/conditioning/image/dir"
|
||||
```
|
||||
|
||||
現時点の制約として、random_cropは使用できません。
|
||||
|
||||
学習データとしては、元のモデルで生成した画像を学習用画像として、そこから加工した画像をconditioning imageとした、合成によるデータセットを用いるのがもっとも簡単です(データセットの品質的には問題があるかもしれません)。具体的なデータセットの合成方法については後述します。
|
||||
|
||||
なお、元モデルと異なる画風の画像を学習用画像とすると、制御に加えて、その画風についても学ぶ必要が生じます。ControlNet-LLLiteは容量が少ないため、画風学習には不向きです。このような場合には、後述の次元数を多めにしてください。
|
||||
|
||||
### 学習
|
||||
スクリプトで生成する場合は、`sdxl_train_control_net_lllite.py` を実行してください。`--cond_emb_dim` でconditioning image embeddingの次元数を指定できます。`--network_dim` でLoRA的モジュールのrankを指定できます。その他のオプションは`sdxl_train_network.py`に準じますが、`--network_module`の指定は不要です。
|
||||
|
||||
学習時にはメモリを大量に使用しますので、キャッシュやgradient checkpointingなどの省メモリ化のオプションを有効にしてください。また`--full_bf16` オプションで、BFloat16を使用するのも有効です(RTX 30シリーズ以降のGPUが必要です)。24GB VRAMで動作確認しています。
|
||||
|
||||
conditioning image embeddingの次元数は、サンプルのCannyでは32を指定しています。LoRA的モジュールのrankは同じく64です。対象とするconditioning imageの特徴に合わせて調整してください。
|
||||
|
||||
(サンプルのCannyは恐らくかなり難しいと思われます。depthなどでは半分程度にしてもいいかもしれません。)
|
||||
|
||||
以下は .toml の設定例です。
|
||||
|
||||
```toml
|
||||
pretrained_model_name_or_path = "/path/to/model_trained_on.safetensors"
|
||||
max_train_epochs = 12
|
||||
max_data_loader_n_workers = 4
|
||||
persistent_data_loader_workers = true
|
||||
seed = 42
|
||||
gradient_checkpointing = true
|
||||
mixed_precision = "bf16"
|
||||
save_precision = "bf16"
|
||||
full_bf16 = true
|
||||
optimizer_type = "adamw8bit"
|
||||
learning_rate = 2e-4
|
||||
xformers = true
|
||||
output_dir = "/path/to/output/dir"
|
||||
output_name = "output_name"
|
||||
save_every_n_epochs = 1
|
||||
save_model_as = "safetensors"
|
||||
vae_batch_size = 4
|
||||
cache_latents = true
|
||||
cache_latents_to_disk = true
|
||||
cache_text_encoder_outputs = true
|
||||
cache_text_encoder_outputs_to_disk = true
|
||||
network_dim = 64
|
||||
cond_emb_dim = 32
|
||||
dataset_config = "/path/to/dataset.toml"
|
||||
```
|
||||
|
||||
### 推論
|
||||
|
||||
スクリプトで生成する場合は、`sdxl_gen_img.py` を実行してください。`--control_net_lllite_models` でLLLiteのモデルファイルを指定できます。次元数はモデルファイルから自動取得します。
|
||||
|
||||
`--guide_image_path`で推論に用いるconditioning imageを指定してください。なおpreprocessは行われないため、たとえばCannyならCanny処理を行った画像を指定してください(背景黒に白線)。`--control_net_preps`, `--control_net_weights`, `--control_net_ratios` には未対応です。
|
||||
|
||||
## データセットの合成方法
|
||||
|
||||
### 学習用画像の生成
|
||||
|
||||
学習のベースとなるモデルで画像生成を行います。Web UIやComfyUIなどで生成してください。画像サイズはモデルのデフォルトサイズで良いと思われます(1024x1024など)。bucketingを用いることもできます。その場合は適宜適切な解像度で生成してください。
|
||||
|
||||
生成時のキャプション等は、ControlNet-LLLiteの利用時に生成したい画像にあわせるのが良いと思われます。
|
||||
|
||||
生成した画像を任意のディレクトリに保存してください。このディレクトリをデータセットの設定ファイルで指定します。
|
||||
|
||||
当リポジトリ内の `sdxl_gen_img.py` でも生成できます。例えば以下のように実行します。
|
||||
|
||||
```dos
|
||||
python sdxl_gen_img.py --ckpt path/to/model.safetensors --n_iter 1 --scale 10 --steps 36 --outdir path/to/output/dir --xformers --W 1024 --H 1024 --original_width 2048 --original_height 2048 --bf16 --sampler ddim --batch_size 4 --vae_batch_size 2 --images_per_prompt 512 --max_embeddings_multiples 1 --prompt "{portrait|digital art|anime screen cap|detailed illustration} of 1girl, {standing|sitting|walking|running|dancing} on {classroom|street|town|beach|indoors|outdoors}, {looking at viewer|looking away|looking at another}, {in|wearing} {shirt and skirt|school uniform|casual wear} { |, dynamic pose}, (solo), teen age, {0-1$$smile,|blush,|kind smile,|expression less,|happy,|sadness,} {0-1$$upper body,|full body,|cowboy shot,|face focus,} trending on pixiv, {0-2$$depth of fields,|8k wallpaper,|highly detailed,|pov,} {0-1$$summer, |winter, |spring, |autumn, } beautiful face { |, from below|, from above|, from side|, from behind|, from back} --n nsfw, bad face, lowres, low quality, worst quality, low effort, watermark, signature, ugly, poorly drawn"
|
||||
```
|
||||
|
||||
VRAM 24GBの設定です。VRAMサイズにより`--batch_size` `--vae_batch_size`を調整してください。
|
||||
|
||||
`--prompt`でワイルドカードを利用してランダムに生成しています。適宜調整してください。
|
||||
|
||||
### 画像の加工
|
||||
|
||||
外部のプログラムを用いて、生成した画像を加工します。加工した画像を任意のディレクトリに保存してください。これらがconditioning imageになります。
|
||||
|
||||
加工にはたとえばCannyなら以下のようなスクリプトが使えます。
|
||||
|
||||
```python
|
||||
import glob
|
||||
import os
|
||||
import random
|
||||
import cv2
|
||||
import numpy as np
|
||||
|
||||
IMAGES_DIR = "path/to/generated/images"
|
||||
CANNY_DIR = "path/to/canny/images"
|
||||
|
||||
os.makedirs(CANNY_DIR, exist_ok=True)
|
||||
img_files = glob.glob(IMAGES_DIR + "/*.png")
|
||||
for img_file in img_files:
|
||||
can_file = CANNY_DIR + "/" + os.path.basename(img_file)
|
||||
if os.path.exists(can_file):
|
||||
print("Skip: " + img_file)
|
||||
continue
|
||||
|
||||
print(img_file)
|
||||
|
||||
img = cv2.imread(img_file)
|
||||
|
||||
# random threshold
|
||||
# while True:
|
||||
# threshold1 = random.randint(0, 127)
|
||||
# threshold2 = random.randint(128, 255)
|
||||
# if threshold2 - threshold1 > 80:
|
||||
# break
|
||||
|
||||
# fixed threshold
|
||||
threshold1 = 100
|
||||
threshold2 = 200
|
||||
|
||||
img = cv2.Canny(img, threshold1, threshold2)
|
||||
|
||||
cv2.imwrite(can_file, img)
|
||||
```
|
||||
|
||||
### キャプションファイルの作成
|
||||
|
||||
学習用画像のbasenameと同じ名前で、それぞれの画像に対応したキャプションファイルを作成してください。生成時のプロンプトをそのまま利用すれば良いと思われます。
|
||||
|
||||
`sdxl_gen_img.py` で生成した場合は、画像内のメタデータに生成時のプロンプトが記録されていますので、以下のようなスクリプトで学習用画像と同じディレクトリにキャプションファイルを作成できます(拡張子 `.txt`)。
|
||||
|
||||
```python
|
||||
import glob
|
||||
import os
|
||||
from PIL import Image
|
||||
|
||||
IMAGES_DIR = "path/to/generated/images"
|
||||
|
||||
img_files = glob.glob(IMAGES_DIR + "/*.png")
|
||||
for img_file in img_files:
|
||||
cap_file = img_file.replace(".png", ".txt")
|
||||
if os.path.exists(cap_file):
|
||||
print(f"Skip: {img_file}")
|
||||
continue
|
||||
print(img_file)
|
||||
|
||||
img = Image.open(img_file)
|
||||
prompt = img.text["prompt"] if "prompt" in img.text else ""
|
||||
if prompt == "":
|
||||
print(f"Prompt not found in {img_file}")
|
||||
|
||||
with open(cap_file, "w") as f:
|
||||
f.write(prompt + "\n")
|
||||
```
|
||||
|
||||
### データセットの設定ファイルの作成
|
||||
|
||||
コマンドラインオプションからの指定も可能ですが、`.toml`ファイルを作成する場合は `conditioning_data_dir` に加工した画像を保存したディレクトリを指定します。
|
||||
|
||||
以下は設定ファイルの例です。
|
||||
|
||||
```toml
|
||||
[general]
|
||||
flip_aug = false
|
||||
color_aug = false
|
||||
resolution = [1024,1024]
|
||||
|
||||
[[datasets]]
|
||||
batch_size = 8
|
||||
enable_bucket = false
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = "path/to/generated/image/dir"
|
||||
caption_extension = ".txt"
|
||||
conditioning_data_dir = "path/to/canny/image/dir"
|
||||
```
|
||||
|
||||
## 謝辞
|
||||
|
||||
ControlNetの作者である lllyasviel 氏、実装上のアドバイスとトラブル解決へのご尽力をいただいた furusu 氏、ControlNetデータセットを実装していただいた ddPn08 氏に感謝いたします。
|
||||
|
||||
## サンプル
|
||||
Canny
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
219
docs/train_lllite_README.md
Normal file
219
docs/train_lllite_README.md
Normal file
@@ -0,0 +1,219 @@
|
||||
# About ControlNet-LLLite
|
||||
|
||||
__This is an extremely experimental implementation and may change significantly in the future.__
|
||||
|
||||
日本語版は[こちら](./train_lllite_README-ja.md)
|
||||
|
||||
## Overview
|
||||
|
||||
ControlNet-LLLite is a lightweight version of [ControlNet](https://github.com/lllyasviel/ControlNet). It is a "LoRA Like Lite" that is inspired by LoRA and has a lightweight structure. Currently, only SDXL is supported.
|
||||
|
||||
## Sample weight file and inference
|
||||
|
||||
Sample weight file is available here: https://huggingface.co/kohya-ss/controlnet-lllite
|
||||
|
||||
A custom node for ComfyUI is available: https://github.com/kohya-ss/ControlNet-LLLite-ComfyUI
|
||||
|
||||
Sample images are at the end of this page.
|
||||
|
||||
## Model structure
|
||||
|
||||
A single LLLite module consists of a conditioning image embedding that maps a conditioning image to a latent space and a small network with a structure similar to LoRA. The LLLite module is added to U-Net's Linear and Conv in the same way as LoRA. Please refer to the source code for details.
|
||||
|
||||
Due to the limitations of the inference environment, only CrossAttention (attn1 q/k/v, attn2 q) is currently added.
|
||||
|
||||
## Model training
|
||||
|
||||
### Preparing the dataset
|
||||
|
||||
In addition to the normal DreamBooth method dataset, please store the conditioning image in the directory specified by `conditioning_data_dir`. The conditioning image must have the same basename as the training image. The conditioning image will be automatically resized to the same size as the training image. The conditioning image does not require a caption file.
|
||||
|
||||
(We do not support the finetuning method dataset.)
|
||||
|
||||
```toml
|
||||
[[datasets.subsets]]
|
||||
image_dir = "path/to/image/dir"
|
||||
caption_extension = ".txt"
|
||||
conditioning_data_dir = "path/to/conditioning/image/dir"
|
||||
```
|
||||
|
||||
At the moment, random_crop cannot be used.
|
||||
|
||||
For training data, it is easiest to use a synthetic dataset with the original model-generated images as training images and processed images as conditioning images (the quality of the dataset may be problematic). See below for specific methods of synthesizing datasets.
|
||||
|
||||
Note that if you use an image with a different art style than the original model as a training image, the model will have to learn not only the control but also the art style. ControlNet-LLLite has a small capacity, so it is not suitable for learning art styles. In such cases, increase the number of dimensions as described below.
|
||||
|
||||
### Training
|
||||
|
||||
Run `sdxl_train_control_net_lllite.py`. You can specify the dimension of the conditioning image embedding with `--cond_emb_dim`. You can specify the rank of the LoRA-like module with `--network_dim`. Other options are the same as `sdxl_train_network.py`, but `--network_module` is not required.
|
||||
|
||||
Since a large amount of memory is used during training, please enable memory-saving options such as cache and gradient checkpointing. It is also effective to use BFloat16 with the `--full_bf16` option (requires RTX 30 series or later GPU). It has been confirmed to work with 24GB VRAM.
|
||||
|
||||
For the sample Canny, the dimension of the conditioning image embedding is 32. The rank of the LoRA-like module is also 64. Adjust according to the features of the conditioning image you are targeting.
|
||||
|
||||
(The sample Canny is probably quite difficult. It may be better to reduce it to about half for depth, etc.)
|
||||
|
||||
The following is an example of a .toml configuration.
|
||||
|
||||
```toml
|
||||
pretrained_model_name_or_path = "/path/to/model_trained_on.safetensors"
|
||||
max_train_epochs = 12
|
||||
max_data_loader_n_workers = 4
|
||||
persistent_data_loader_workers = true
|
||||
seed = 42
|
||||
gradient_checkpointing = true
|
||||
mixed_precision = "bf16"
|
||||
save_precision = "bf16"
|
||||
full_bf16 = true
|
||||
optimizer_type = "adamw8bit"
|
||||
learning_rate = 2e-4
|
||||
xformers = true
|
||||
output_dir = "/path/to/output/dir"
|
||||
output_name = "output_name"
|
||||
save_every_n_epochs = 1
|
||||
save_model_as = "safetensors"
|
||||
vae_batch_size = 4
|
||||
cache_latents = true
|
||||
cache_latents_to_disk = true
|
||||
cache_text_encoder_outputs = true
|
||||
cache_text_encoder_outputs_to_disk = true
|
||||
network_dim = 64
|
||||
cond_emb_dim = 32
|
||||
dataset_config = "/path/to/dataset.toml"
|
||||
```
|
||||
|
||||
### Inference
|
||||
|
||||
If you want to generate images with a script, run `sdxl_gen_img.py`. You can specify the LLLite model file with `--control_net_lllite_models`. The dimension is automatically obtained from the model file.
|
||||
|
||||
Specify the conditioning image to be used for inference with `--guide_image_path`. Since preprocess is not performed, if it is Canny, specify an image processed with Canny (white line on black background). `--control_net_preps`, `--control_net_weights`, and `--control_net_ratios` are not supported.
|
||||
|
||||
## How to synthesize a dataset
|
||||
|
||||
### Generating training images
|
||||
|
||||
Generate images with the base model for training. Please generate them with Web UI or ComfyUI etc. The image size should be the default size of the model (1024x1024, etc.). You can also use bucketing. In that case, please generate it at an arbitrary resolution.
|
||||
|
||||
The captions and other settings when generating the images should be the same as when generating the images with the trained ControlNet-LLLite model.
|
||||
|
||||
Save the generated images in an arbitrary directory. Specify this directory in the dataset configuration file.
|
||||
|
||||
|
||||
You can also generate them with `sdxl_gen_img.py` in this repository. For example, run as follows:
|
||||
|
||||
```dos
|
||||
python sdxl_gen_img.py --ckpt path/to/model.safetensors --n_iter 1 --scale 10 --steps 36 --outdir path/to/output/dir --xformers --W 1024 --H 1024 --original_width 2048 --original_height 2048 --bf16 --sampler ddim --batch_size 4 --vae_batch_size 2 --images_per_prompt 512 --max_embeddings_multiples 1 --prompt "{portrait|digital art|anime screen cap|detailed illustration} of 1girl, {standing|sitting|walking|running|dancing} on {classroom|street|town|beach|indoors|outdoors}, {looking at viewer|looking away|looking at another}, {in|wearing} {shirt and skirt|school uniform|casual wear} { |, dynamic pose}, (solo), teen age, {0-1$$smile,|blush,|kind smile,|expression less,|happy,|sadness,} {0-1$$upper body,|full body,|cowboy shot,|face focus,} trending on pixiv, {0-2$$depth of fields,|8k wallpaper,|highly detailed,|pov,} {0-1$$summer, |winter, |spring, |autumn, } beautiful face { |, from below|, from above|, from side|, from behind|, from back} --n nsfw, bad face, lowres, low quality, worst quality, low effort, watermark, signature, ugly, poorly drawn"
|
||||
```
|
||||
|
||||
This is a setting for VRAM 24GB. Adjust `--batch_size` and `--vae_batch_size` according to the VRAM size.
|
||||
|
||||
The images are generated randomly using wildcards in `--prompt`. Adjust as necessary.
|
||||
|
||||
### Processing images
|
||||
|
||||
Use an external program to process the generated images. Save the processed images in an arbitrary directory. These will be the conditioning images.
|
||||
|
||||
For example, you can use the following script to process the images with Canny.
|
||||
|
||||
```python
|
||||
import glob
|
||||
import os
|
||||
import random
|
||||
import cv2
|
||||
import numpy as np
|
||||
|
||||
IMAGES_DIR = "path/to/generated/images"
|
||||
CANNY_DIR = "path/to/canny/images"
|
||||
|
||||
os.makedirs(CANNY_DIR, exist_ok=True)
|
||||
img_files = glob.glob(IMAGES_DIR + "/*.png")
|
||||
for img_file in img_files:
|
||||
can_file = CANNY_DIR + "/" + os.path.basename(img_file)
|
||||
if os.path.exists(can_file):
|
||||
print("Skip: " + img_file)
|
||||
continue
|
||||
|
||||
print(img_file)
|
||||
|
||||
img = cv2.imread(img_file)
|
||||
|
||||
# random threshold
|
||||
# while True:
|
||||
# threshold1 = random.randint(0, 127)
|
||||
# threshold2 = random.randint(128, 255)
|
||||
# if threshold2 - threshold1 > 80:
|
||||
# break
|
||||
|
||||
# fixed threshold
|
||||
threshold1 = 100
|
||||
threshold2 = 200
|
||||
|
||||
img = cv2.Canny(img, threshold1, threshold2)
|
||||
|
||||
cv2.imwrite(can_file, img)
|
||||
```
|
||||
|
||||
### Creating caption files
|
||||
|
||||
Create a caption file for each image with the same basename as the training image. It is fine to use the same caption as the one used when generating the image.
|
||||
|
||||
If you generated the images with `sdxl_gen_img.py`, you can use the following script to create the caption files (`*.txt`) from the metadata in the generated images.
|
||||
|
||||
```python
|
||||
import glob
|
||||
import os
|
||||
from PIL import Image
|
||||
|
||||
IMAGES_DIR = "path/to/generated/images"
|
||||
|
||||
img_files = glob.glob(IMAGES_DIR + "/*.png")
|
||||
for img_file in img_files:
|
||||
cap_file = img_file.replace(".png", ".txt")
|
||||
if os.path.exists(cap_file):
|
||||
print(f"Skip: {img_file}")
|
||||
continue
|
||||
print(img_file)
|
||||
|
||||
img = Image.open(img_file)
|
||||
prompt = img.text["prompt"] if "prompt" in img.text else ""
|
||||
if prompt == "":
|
||||
print(f"Prompt not found in {img_file}")
|
||||
|
||||
with open(cap_file, "w") as f:
|
||||
f.write(prompt + "\n")
|
||||
```
|
||||
|
||||
### Creating a dataset configuration file
|
||||
|
||||
You can use the command line argument `--conditioning_data_dir` of `sdxl_train_control_net_lllite.py` to specify the conditioning image directory. However, if you want to use a `.toml` file, specify the conditioning image directory in `conditioning_data_dir`.
|
||||
|
||||
```toml
|
||||
[general]
|
||||
flip_aug = false
|
||||
color_aug = false
|
||||
resolution = [1024,1024]
|
||||
|
||||
[[datasets]]
|
||||
batch_size = 8
|
||||
enable_bucket = false
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = "path/to/generated/image/dir"
|
||||
caption_extension = ".txt"
|
||||
conditioning_data_dir = "path/to/canny/image/dir"
|
||||
```
|
||||
|
||||
## Credit
|
||||
|
||||
I would like to thank lllyasviel, the author of ControlNet, furusu, who provided me with advice on implementation and helped me solve problems, and ddPn08, who implemented the ControlNet dataset.
|
||||
|
||||
## Sample
|
||||
|
||||
Canny
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
367
docs/train_network.md
Normal file
367
docs/train_network.md
Normal file
@@ -0,0 +1,367 @@
|
||||
# How to use the LoRA training script `train_network.py` / LoRA学習スクリプト `train_network.py` の使い方
|
||||
|
||||
This document explains the basic procedures for training LoRA (Low-Rank Adaptation) models using `train_network.py` included in the `sd-scripts` repository.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
このドキュメントでは、`sd-scripts` リポジトリに含まれる `train_network.py` を使用して LoRA (Low-Rank Adaptation) モデルを学習する基本的な手順について解説します。
|
||||
</details>
|
||||
|
||||
## 1. Introduction / はじめに
|
||||
|
||||
`train_network.py` is a script for training additional networks such as LoRA on Stable Diffusion models (v1.x, v2.x). It allows for additional training on the original model with a low computational cost, enabling the creation of models that reproduce specific characters or art styles.
|
||||
|
||||
This guide focuses on LoRA training and explains the basic configuration items.
|
||||
|
||||
**Prerequisites:**
|
||||
|
||||
* The `sd-scripts` repository has been cloned and the Python environment has been set up.
|
||||
* The training dataset has been prepared. (For dataset preparation, please refer to [this guide](link/to/dataset/doc))
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
`train_network.py` は、Stable Diffusion モデル(v1.x, v2.x)に対して、LoRA などの追加ネットワークを学習させるためのスクリプトです。少ない計算コストで元のモデルに追加学習を行い、特定のキャラクターや画風を再現するモデルを作成できます。
|
||||
|
||||
このガイドでは、LoRA 学習に焦点を当て、基本的な設定項目を中心に説明します。
|
||||
|
||||
**前提条件:**
|
||||
|
||||
* `sd-scripts` リポジトリのクローンと Python 環境のセットアップが完了していること。
|
||||
* 学習用データセットの準備が完了していること。(データセットの準備については[こちら](link/to/dataset/doc)を参照してください)
|
||||
</details>
|
||||
|
||||
## 2. Preparation / 準備
|
||||
|
||||
Before starting training, you will need the following files:
|
||||
|
||||
1. **Training script:** `train_network.py`
|
||||
2. **Dataset definition file (.toml):** A file in TOML format that describes the configuration of the training dataset.
|
||||
|
||||
### About the Dataset Definition File / データセット定義ファイルについて
|
||||
|
||||
The dataset definition file (`.toml`) contains detailed settings such as the directory of images to use, repetition count, caption settings, resolution buckets (optional), etc.
|
||||
|
||||
For more details on how to write the dataset definition file, please refer to the [Dataset Configuration Guide](./config_README-en.md).
|
||||
|
||||
In this guide, we will use a file named `my_dataset_config.toml` as an example.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
学習を開始する前に、以下のファイルが必要です。
|
||||
|
||||
1. **学習スクリプト:** `train_network.py`
|
||||
2. **データセット定義ファイル (.toml):** 学習データセットの設定を記述した TOML 形式のファイル。
|
||||
|
||||
**データセット定義ファイルについて**
|
||||
|
||||
データセット定義ファイル (`.toml`) には、使用する画像のディレクトリ、繰り返し回数、キャプションの設定、Aspect Ratio Bucketing(任意)などの詳細な設定を記述します。
|
||||
|
||||
データセット定義ファイルの詳しい書き方については、[データセット設定ガイド](./config_README-ja.md)を参照してください。
|
||||
|
||||
ここでは、例として `my_dataset_config.toml` という名前のファイルを使用することにします。
|
||||
</details>
|
||||
|
||||
## 3. Running the Training / 学習の実行
|
||||
|
||||
Training is started by executing `train_network.py` from the terminal. When executing, various training settings are specified as command-line arguments.
|
||||
|
||||
Below is a basic command-line execution example:
|
||||
|
||||
```bash
|
||||
accelerate launch --num_cpu_threads_per_process 1 train_network.py
|
||||
--pretrained_model_name_or_path="<path to Stable Diffusion model>"
|
||||
--dataset_config="my_dataset_config.toml"
|
||||
--output_dir="<output directory for training results>"
|
||||
--output_name="my_lora"
|
||||
--save_model_as=safetensors
|
||||
--network_module=networks.lora
|
||||
--network_dim=16
|
||||
--network_alpha=1
|
||||
--learning_rate=1e-4
|
||||
--optimizer_type="AdamW8bit"
|
||||
--lr_scheduler="constant"
|
||||
--sdpa
|
||||
--max_train_epochs=10
|
||||
--save_every_n_epochs=1
|
||||
--mixed_precision="fp16"
|
||||
--gradient_checkpointing
|
||||
```
|
||||
|
||||
In reality, you need to write this in a single line, but it's shown with line breaks for readability (on Linux or Mac, you can add `\` at the end of each line to break lines). For Windows, either write it in a single line without breaks or add `^` at the end of each line.
|
||||
|
||||
Next, we'll explain the main command-line arguments.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
学習は、ターミナルから `train_network.py` を実行することで開始します。実行時には、学習に関する様々な設定をコマンドライン引数として指定します。
|
||||
|
||||
以下に、基本的なコマンドライン実行例を示します。
|
||||
|
||||
実際には1行で書く必要がありますが、見やすさのために改行しています(Linux や Mac では `\` を行末に追加することで改行できます)。Windows の場合は、改行せずに1行で書くか、`^` を行末に追加してください。
|
||||
|
||||
次に、主要なコマンドライン引数について解説します。
|
||||
</details>
|
||||
|
||||
### 3.1. Main Command-Line Arguments / 主要なコマンドライン引数
|
||||
|
||||
#### Model Related / モデル関連
|
||||
|
||||
* `--pretrained_model_name_or_path="<path to model>"` **[Required]**
|
||||
* Specifies the Stable Diffusion model to be used as the base for training. You can specify the path to a local `.ckpt` or `.safetensors` file, or a directory containing a Diffusers format model. You can also specify a Hugging Face Hub model ID (e.g., `"stabilityai/stable-diffusion-2-1-base"`).
|
||||
* `--v2`
|
||||
* Specify this when the base model is Stable Diffusion v2.x.
|
||||
* `--v_parameterization`
|
||||
* Specify this when training with a v-prediction model (such as v2.x 768px models).
|
||||
|
||||
#### Dataset Related / データセット関連
|
||||
|
||||
* `--dataset_config="<path to configuration file>"`
|
||||
* Specifies the path to a `.toml` file describing the dataset configuration. (For details on dataset configuration, see [here](link/to/dataset/config/doc))
|
||||
* It's also possible to specify dataset settings from the command line, but using a `.toml` file is recommended as it becomes lengthy.
|
||||
|
||||
#### Output and Save Related / 出力・保存関連
|
||||
|
||||
* `--output_dir="<output directory>"` **[Required]**
|
||||
* Specifies the directory where trained LoRA models, sample images, logs, etc. will be output.
|
||||
* `--output_name="<output filename>"` **[Required]**
|
||||
* Specifies the filename of the trained LoRA model (excluding the extension).
|
||||
* `--save_model_as="safetensors"`
|
||||
* Specifies the format for saving the model. You can choose from `safetensors` (recommended), `ckpt`, or `pt`. The default is `safetensors`.
|
||||
* `--save_every_n_epochs=1`
|
||||
* Saves the model every specified number of epochs. If not specified, only the final model will be saved.
|
||||
* `--save_every_n_steps=1000`
|
||||
* Saves the model every specified number of steps. If both epoch and step saving are specified, both will be saved.
|
||||
|
||||
#### LoRA Parameters / LoRA パラメータ
|
||||
|
||||
* `--network_module=networks.lora` **[Required]**
|
||||
* Specifies the type of network to train. For LoRA, specify `networks.lora`.
|
||||
* `--network_dim=16` **[Required]**
|
||||
* Specifies the rank (dimension) of LoRA. Higher values increase expressiveness but also increase file size and computational cost. Values between 4 and 128 are commonly used. There is no default (module dependent).
|
||||
* `--network_alpha=1`
|
||||
* Specifies the alpha value for LoRA. This parameter is related to learning rate scaling. It is generally recommended to set it to about half the value of `network_dim`, but it can also be the same value as `network_dim`. The default is 1. Setting it to the same value as `network_dim` will result in behavior similar to older versions.
|
||||
* `--network_args`
|
||||
* Used to specify additional parameters specific to the LoRA module. For example, to use Conv2d (3x3) LoRA (LoRA-C3Lier), specify the following in `--network_args`. Use `conv_dim` to specify the rank for Conv2d (3x3) and `conv_alpha` for alpha.
|
||||
```
|
||||
--network_args "conv_dim=4" "conv_alpha=1"
|
||||
```
|
||||
|
||||
If alpha is omitted as shown below, it defaults to 1.
|
||||
```
|
||||
--network_args "conv_dim=4"
|
||||
```
|
||||
|
||||
#### Training Parameters / 学習パラメータ
|
||||
|
||||
* `--learning_rate=1e-4`
|
||||
* Specifies the learning rate. For LoRA training (when alpha value is 1), relatively higher values (e.g., from `1e-4` to `1e-3`) are often used.
|
||||
* `--unet_lr=1e-4`
|
||||
* Used to specify a separate learning rate for the LoRA modules in the U-Net part. If not specified, the value of `--learning_rate` is used.
|
||||
* `--text_encoder_lr=1e-5`
|
||||
* Used to specify a separate learning rate for the LoRA modules in the Text Encoder part. If not specified, the value of `--learning_rate` is used. A smaller value than that for U-Net is recommended.
|
||||
* `--optimizer_type="AdamW8bit"`
|
||||
* Specifies the optimizer to use for training. Options include `AdamW8bit` (requires `bitsandbytes`), `AdamW`, `Lion` (requires `lion-pytorch`), `DAdaptation` (requires `dadaptation`), and `Adafactor`. `AdamW8bit` is memory-efficient and widely used.
|
||||
* `--lr_scheduler="constant"`
|
||||
* Specifies the learning rate scheduler. This is the method for changing the learning rate as training progresses. Options include `constant` (no change), `cosine` (cosine curve), `linear` (linear decay), `constant_with_warmup` (constant with warmup), and `cosine_with_restarts`. `constant`, `cosine`, and `constant_with_warmup` are commonly used.
|
||||
* `--lr_warmup_steps=500`
|
||||
* Specifies the number of warmup steps for the learning rate scheduler. This is the period during which the learning rate gradually increases at the start of training. Valid when the `lr_scheduler` supports warmup.
|
||||
* `--max_train_steps=10000`
|
||||
* Specifies the total number of training steps. If `max_train_epochs` is specified, that takes precedence.
|
||||
* `--max_train_epochs=12`
|
||||
* Specifies the number of training epochs. If this is specified, `max_train_steps` is ignored.
|
||||
* `--sdpa`
|
||||
* Uses Scaled Dot-Product Attention. This can reduce memory usage and improve training speed for LoRA training.
|
||||
* `--mixed_precision="fp16"`
|
||||
* Specifies the mixed precision training setting. Options are `no` (disabled), `fp16` (half precision), and `bf16` (bfloat16). If your GPU supports it, specifying `fp16` or `bf16` can improve training speed and reduce memory usage.
|
||||
* `--gradient_accumulation_steps=1`
|
||||
* Specifies the number of steps to accumulate gradients. This effectively increases the batch size to `train_batch_size * gradient_accumulation_steps`. Set a larger value if GPU memory is insufficient. Usually `1` is fine.
|
||||
|
||||
#### Others / その他
|
||||
|
||||
* `--seed=42`
|
||||
* Specifies the random seed. Set this if you want to ensure reproducibility of the training.
|
||||
* `--logging_dir="<log directory>"`
|
||||
* Specifies the directory to output logs for TensorBoard, etc. If not specified, logs will not be output.
|
||||
* `--log_prefix="<prefix>"`
|
||||
* Specifies the prefix for the subdirectory name created within `logging_dir`.
|
||||
* `--gradient_checkpointing`
|
||||
* Enables Gradient Checkpointing. This can significantly reduce memory usage but slightly decreases training speed. Useful when memory is limited.
|
||||
* `--clip_skip=1`
|
||||
* Specifies how many layers to skip from the last layer of the Text Encoder. Specifying `2` will use the output from the second-to-last layer. `None` or `1` means no skip (uses the last layer). Check the recommended value for the model you are training.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
#### モデル関連
|
||||
|
||||
* `--pretrained_model_name_or_path="<モデルのパス>"` **[必須]**
|
||||
* 学習のベースとなる Stable Diffusion モデルを指定します。ローカルの `.ckpt` または `.safetensors` ファイルのパス、あるいは Diffusers 形式モデルのディレクトリを指定できます。Hugging Face Hub のモデル ID (例: `"stabilityai/stable-diffusion-2-1-base"`) も指定可能です。
|
||||
* `--v2`
|
||||
* ベースモデルが Stable Diffusion v2.x の場合に指定します。
|
||||
* `--v_parameterization`
|
||||
* v-prediction モデル(v2.x の 768px モデルなど)で学習する場合に指定します。
|
||||
|
||||
#### データセット関連
|
||||
|
||||
* `--dataset_config="<設定ファイルのパス>"`
|
||||
* データセット設定を記述した `.toml` ファイルのパスを指定します。(データセット設定の詳細は[こちら](link/to/dataset/config/doc))
|
||||
* コマンドラインからデータセット設定を指定することも可能ですが、長くなるため `.toml` ファイルを使用することを推奨します。
|
||||
|
||||
#### 出力・保存関連
|
||||
|
||||
* `--output_dir="<出力先ディレクトリ>"` **[必須]**
|
||||
* 学習済み LoRA モデルやサンプル画像、ログなどが出力されるディレクトリを指定します。
|
||||
* `--output_name="<出力ファイル名>"` **[必須]**
|
||||
* 学習済み LoRA モデルのファイル名(拡張子を除く)を指定します。
|
||||
* `--save_model_as="safetensors"`
|
||||
* モデルの保存形式を指定します。`safetensors` (推奨), `ckpt`, `pt` から選択できます。デフォルトは `safetensors` です。
|
||||
* `--save_every_n_epochs=1`
|
||||
* 指定したエポックごとにモデルを保存します。省略するとエポックごとの保存は行われません(最終モデルのみ保存)。
|
||||
* `--save_every_n_steps=1000`
|
||||
* 指定したステップごとにモデルを保存します。エポック指定 (`save_every_n_epochs`) と同時に指定された場合、両方とも保存されます。
|
||||
|
||||
#### LoRA パラメータ
|
||||
|
||||
* `--network_module=networks.lora` **[必須]**
|
||||
* 学習するネットワークの種別を指定します。LoRA の場合は `networks.lora` を指定します。
|
||||
* `--network_dim=16` **[必須]**
|
||||
* LoRA のランク (rank / 次元数) を指定します。値が大きいほど表現力は増しますが、ファイルサイズと計算コストが増加します。一般的には 4〜128 程度の値が使われます。デフォルトは指定されていません(モジュール依存)。
|
||||
* `--network_alpha=1`
|
||||
* LoRA のアルファ値 (alpha) を指定します。学習率のスケーリングに関係するパラメータで、一般的には `network_dim` の半分程度の値を指定することが推奨されますが、`network_dim` と同じ値を指定する場合もあります。デフォルトは 1 です。`network_dim` と同じ値に設定すると、旧バージョンと同様の挙動になります。
|
||||
|
||||
* `--network_args`
|
||||
* LoRA モジュールに特有の追加パラメータを指定するために使用します。例えば、Conv2d (3x3) の LoRA (LoRA-C3Lier) を使用する場合は`--network_args` に以下のように指定してください。`conv_dim` で Conv2d (3x3) の rank を、`conv_alpha` で alpha を指定します。
|
||||
```
|
||||
--network_args "conv_dim=4" "conv_alpha=1"
|
||||
```
|
||||
以下のように alpha を省略した時は1になります。
|
||||
```
|
||||
--network_args "conv_dim=4"
|
||||
```
|
||||
|
||||
#### 学習パラメータ
|
||||
|
||||
* `--learning_rate=1e-4`
|
||||
* 学習率を指定します。LoRA 学習では(アルファ値が1の場合)比較的高めの値(例: `1e-4`から`1e-3`)が使われることが多いです。
|
||||
* `--unet_lr=1e-4`
|
||||
* U-Net 部分の LoRA モジュールに対する学習率を個別に指定する場合に使用します。指定しない場合は `--learning_rate` の値が使用されます。
|
||||
* `--text_encoder_lr=1e-5`
|
||||
* Text Encoder 部分の LoRA モジュールに対する学習率を個別に指定する場合に使用します。指定しない場合は `--learning_rate` の値が使用されます。U-Net よりも小さめの値が推奨されます。
|
||||
* `--optimizer_type="AdamW8bit"`
|
||||
* 学習に使用するオプティマイザを指定します。`AdamW8bit` (要 `bitsandbytes`), `AdamW`, `Lion` (要 `lion-pytorch`), `DAdaptation` (要 `dadaptation`), `Adafactor` などが選択可能です。`AdamW8bit` はメモリ効率が良く、広く使われています。
|
||||
* `--lr_scheduler="constant"`
|
||||
* 学習率スケジューラを指定します。学習の進行に合わせて学習率を変化させる方法です。`constant` (変化なし), `cosine` (コサインカーブ), `linear` (線形減衰), `constant_with_warmup` (ウォームアップ付き定数), `cosine_with_restarts` などが選択可能です。`constant`や`cosine` 、 `constant_with_warmup` がよく使われます。
|
||||
* `--lr_warmup_steps=500`
|
||||
* 学習率スケジューラのウォームアップステップ数を指定します。学習開始時に学習率を徐々に上げていく期間です。`lr_scheduler` がウォームアップをサポートする場合に有効です。
|
||||
* `--max_train_steps=10000`
|
||||
* 学習の総ステップ数を指定します。`max_train_epochs` が指定されている場合はそちらが優先されます。
|
||||
* `--max_train_epochs=12`
|
||||
* 学習のエポック数を指定します。これを指定すると `max_train_steps` は無視されます。
|
||||
* `--sdpa`
|
||||
* Scaled Dot-Product Attention を使用します。LoRA の学習において、メモリ使用量を削減し、学習速度を向上させることができます。
|
||||
* `--mixed_precision="fp16"`
|
||||
* 混合精度学習の設定を指定します。`no` (無効), `fp16` (半精度), `bf16` (bfloat16) から選択できます。GPU が対応している場合は `fp16` または `bf16` を指定することで、学習速度の向上とメモリ使用量の削減が期待できます。
|
||||
* `--gradient_accumulation_steps=1`
|
||||
* 勾配を累積するステップ数を指定します。実質的なバッチサイズを `train_batch_size * gradient_accumulation_steps` に増やす効果があります。GPU メモリが足りない場合に大きな値を設定します。通常は `1` で問題ありません。
|
||||
|
||||
#### その他
|
||||
|
||||
* `--seed=42`
|
||||
* 乱数シードを指定します。学習の再現性を確保したい場合に設定します。
|
||||
* `--logging_dir="<ログディレクトリ>"`
|
||||
* TensorBoard などのログを出力するディレクトリを指定します。指定しない場合、ログは出力されません。
|
||||
* `--log_prefix="<プレフィックス>"`
|
||||
* `logging_dir` 内に作成されるサブディレクトリ名の接頭辞を指定します。
|
||||
* `--gradient_checkpointing`
|
||||
* Gradient Checkpointing を有効にします。メモリ使用量を大幅に削減できますが、学習速度は若干低下します。メモリが厳しい場合に有効です。
|
||||
* `--clip_skip=1`
|
||||
* Text Encoder の最後の層から数えて何層スキップするかを指定します。`2` を指定すると最後から 2 層目の出力を使用します。`None` または `1` はスキップなし(最後の層を使用)を意味します。学習対象のモデルの推奨する値を確認してください。
|
||||
</details>
|
||||
|
||||
### 3.2. Starting the Training / 学習の開始
|
||||
|
||||
After setting the necessary arguments and executing the command, training will begin. The progress of the training will be output to the console. If `logging_dir` is specified, you can visually check the training status (loss, learning rate, etc.) with TensorBoard.
|
||||
|
||||
```bash
|
||||
tensorboard --logdir <directory specified by logging_dir>
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
必要な引数を設定し、コマンドを実行すると学習が開始されます。学習の進行状況はコンソールに出力されます。`logging_dir` を指定した場合は、TensorBoard などで学習状況(損失や学習率など)を視覚的に確認できます。
|
||||
</details>
|
||||
|
||||
## 4. Using the Trained Model / 学習済みモデルの利用
|
||||
|
||||
Once training is complete, a LoRA model file (`.safetensors` or `.ckpt`) with the name specified by `output_name` will be saved in the directory specified by `output_dir`.
|
||||
|
||||
This file can be used with GUI tools such as AUTOMATIC1111/stable-diffusion-webui, ComfyUI, etc.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
学習が完了すると、`output_dir` で指定したディレクトリに、`output_name` で指定した名前の LoRA モデルファイル (`.safetensors` または `.ckpt`) が保存されます。
|
||||
|
||||
このファイルは、AUTOMATIC1111/stable-diffusion-webui 、ComfyUI などの GUI ツールで利用できます。
|
||||
</details>
|
||||
|
||||
## 5. Other Features / その他の機能
|
||||
|
||||
`train_network.py` has many other options not introduced here.
|
||||
|
||||
* Sample image generation (`--sample_prompts`, `--sample_every_n_steps`, etc.)
|
||||
* More detailed optimizer settings (`--optimizer_args`, etc.)
|
||||
* Caption preprocessing (`--shuffle_caption`, `--keep_tokens`, etc.)
|
||||
* Additional network settings (`--network_args`, etc.)
|
||||
|
||||
For these features, please refer to the script's help (`python train_network.py --help`) or other documents in the repository.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
`train_network.py` には、ここで紹介した以外にも多くのオプションがあります。
|
||||
|
||||
* サンプル画像の生成 (`--sample_prompts`, `--sample_every_n_steps` など)
|
||||
* より詳細なオプティマイザ設定 (`--optimizer_args` など)
|
||||
* キャプションの前処理 (`--shuffle_caption`, `--keep_tokens` など)
|
||||
* ネットワークの追加設定 (`--network_args` など)
|
||||
|
||||
これらの機能については、スクリプトのヘルプ (`python train_network.py --help`) やリポジトリ内の他のドキュメントを参照してください。
|
||||
</details>
|
||||
|
||||
## 6. Additional Information / 追加情報
|
||||
|
||||
### Naming of LoRA
|
||||
|
||||
The LoRA supported by `train_network.py` has been named to avoid confusion. The documentation has been updated. The following are the names of LoRA types in this repository.
|
||||
|
||||
1. __LoRA-LierLa__ : (LoRA for __Li__ n __e__ a __r__ __La__ yers)
|
||||
|
||||
LoRA for Linear layers and Conv2d layers with 1x1 kernel
|
||||
|
||||
2. __LoRA-C3Lier__ : (LoRA for __C__ olutional layers with __3__ x3 Kernel and __Li__ n __e__ a __r__ layers)
|
||||
|
||||
In addition to 1., LoRA for Conv2d layers with 3x3 kernel
|
||||
|
||||
LoRA-LierLa is the default LoRA type for `train_network.py` (without `conv_dim` network arg).
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
`train_network.py` がサポートするLoRAについて、混乱を避けるため名前を付けました。ドキュメントは更新済みです。以下は当リポジトリ内の独自の名称です。
|
||||
|
||||
1. __LoRA-LierLa__ : (LoRA for __Li__ n __e__ a __r__ __La__ yers、リエラと読みます)
|
||||
|
||||
Linear 層およびカーネルサイズ 1x1 の Conv2d 層に適用されるLoRA
|
||||
|
||||
2. __LoRA-C3Lier__ : (LoRA for __C__ olutional layers with __3__ x3 Kernel and __Li__ n __e__ a __r__ layers、セリアと読みます)
|
||||
|
||||
1.に加え、カーネルサイズ 3x3 の Conv2d 層に適用されるLoRA
|
||||
|
||||
デフォルトではLoRA-LierLaが使われます。LoRA-C3Lierを使う場合は `--network_args` に `conv_dim` を指定してください。
|
||||
|
||||
</details>
|
||||
@@ -102,6 +102,8 @@ accelerate launch --num_cpu_threads_per_process 1 train_network.py
|
||||
* Text Encoderに関連するLoRAモジュールに、通常の学習率(--learning_rateオプションで指定)とは異なる学習率を使う時に指定します。Text Encoderのほうを若干低めの学習率(5e-5など)にしたほうが良い、という話もあるようです。
|
||||
* `--network_args`
|
||||
* 複数の引数を指定できます。後述します。
|
||||
* `--alpha_mask`
|
||||
* 画像のアルファ値をマスクとして使用します。透過画像を学習する際に使用します。[PR #1223](https://github.com/kohya-ss/sd-scripts/pull/1223)
|
||||
|
||||
`--network_train_unet_only` と `--network_train_text_encoder_only` の両方とも未指定時(デフォルト)はText EncoderとU-Netの両方のLoRAモジュールを有効にします。
|
||||
|
||||
@@ -183,12 +185,14 @@ python networks\extract_lora_from_dylora.py --model "foldername/dylora-model.saf
|
||||
|
||||
フルモデルの25個のブロックの重みを指定できます。最初のブロックに該当するLoRAは存在しませんが、階層別LoRA適用等との互換性のために25個としています。またconv2d3x3に拡張しない場合も一部のブロックにはLoRAが存在しませんが、記述を統一するため常に25個の値を指定してください。
|
||||
|
||||
SDXL では down/up 9 個、middle 3 個の値を指定してください。
|
||||
|
||||
`--network_args` で以下の引数を指定してください。
|
||||
|
||||
- `down_lr_weight` : U-Netのdown blocksの学習率の重みを指定します。以下が指定可能です。
|
||||
- ブロックごとの重み : `"down_lr_weight=0,0,0,0,0,0,1,1,1,1,1,1"` のように12個の数値を指定します。
|
||||
- ブロックごとの重み : `"down_lr_weight=0,0,0,0,0,0,1,1,1,1,1,1"` のように12個(SDXL では 9 個)の数値を指定します。
|
||||
- プリセットからの指定 : `"down_lr_weight=sine"` のように指定します(サインカーブで重みを指定します)。sine, cosine, linear, reverse_linear, zeros が指定可能です。また `"down_lr_weight=cosine+.25"` のように `+数値` を追加すると、指定した数値を加算します(0.25~1.25になります)。
|
||||
- `mid_lr_weight` : U-Netのmid blockの学習率の重みを指定します。`"down_lr_weight=0.5"` のように数値を一つだけ指定します。
|
||||
- `mid_lr_weight` : U-Netのmid blockの学習率の重みを指定します。`"down_lr_weight=0.5"` のように数値を一つだけ指定します(SDXL の場合は 3 個)。
|
||||
- `up_lr_weight` : U-Netのup blocksの学習率の重みを指定します。down_lr_weightと同様です。
|
||||
- 指定を省略した部分は1.0として扱われます。また重みを0にするとそのブロックのLoRAモジュールは作成されません。
|
||||
- `block_lr_zero_threshold` : 重みがこの値以下の場合、LoRAモジュールを作成しません。デフォルトは0です。
|
||||
@@ -213,6 +217,9 @@ network_args = [ "block_lr_zero_threshold=0.1", "down_lr_weight=sine+.5", "mid_l
|
||||
|
||||
フルモデルの25個のブロックのdim (rank)を指定できます。階層別学習率と同様に一部のブロックにはLoRAが存在しない場合がありますが、常に25個の値を指定してください。
|
||||
|
||||
SDXL では 23 個の値を指定してください。一部のブロックにはLoRA が存在しませんが、`sdxl_train.py` の[階層別学習率](./train_SDXL-en.md) との互換性のためです。
|
||||
対応は、`0: time/label embed, 1-9: input blocks 0-8, 10-12: mid blocks 0-2, 13-21: output blocks 0-8, 22: out` です。
|
||||
|
||||
`--network_args` で以下の引数を指定してください。
|
||||
|
||||
- `block_dims` : 各ブロックのdim (rank)を指定します。`"block_dims=2,2,2,2,4,4,4,4,6,6,6,6,8,6,6,6,6,4,4,4,4,2,2,2,2"` のように25個の数値を指定します。
|
||||
@@ -246,6 +253,8 @@ network_args = [ "block_dims=2,4,4,4,8,8,8,8,12,12,12,12,16,12,12,12,12,8,8,8,8,
|
||||
|
||||
merge_lora.pyでStable DiffusionのモデルにLoRAの学習結果をマージしたり、複数のLoRAモデルをマージしたりできます。
|
||||
|
||||
SDXL向けにはsdxl_merge_lora.pyを用意しています。オプション等は同一ですので、以下のmerge_lora.pyを読み替えてください。
|
||||
|
||||
### Stable DiffusionのモデルにLoRAのモデルをマージする
|
||||
|
||||
マージ後のモデルは通常のStable Diffusionのckptと同様に扱えます。たとえば以下のようなコマンドラインになります。
|
||||
@@ -276,26 +285,28 @@ python networks\merge_lora.py --sd_model ..\model\model.ckpt
|
||||
|
||||
### 複数のLoRAのモデルをマージする
|
||||
|
||||
複数のLoRAモデルをひとつずつSDモデルに適用する場合と、複数のLoRAモデルをマージしてからSDモデルにマージする場合とは、計算順序の関連で微妙に異なる結果になります。
|
||||
--concatオプションを指定すると、複数のLoRAを単純に結合して新しいLoRAモデルを作成できます。ファイルサイズ(およびdim/rank)は指定したLoRAの合計サイズになります(マージ時にdim (rank)を変更する場合は `svd_merge_lora.py` を使用してください)。
|
||||
|
||||
たとえば以下のようなコマンドラインになります。
|
||||
|
||||
```
|
||||
python networks\merge_lora.py
|
||||
python networks\merge_lora.py --save_precision bf16
|
||||
--save_to ..\lora_train1\model-char1-style1-merged.safetensors
|
||||
--models ..\lora_train1\last.safetensors ..\lora_train2\last.safetensors --ratios 0.6 0.4
|
||||
--models ..\lora_train1\last.safetensors ..\lora_train2\last.safetensors
|
||||
--ratios 1.0 -1.0 --concat --shuffle
|
||||
```
|
||||
|
||||
--sd_modelオプションは指定不要です。
|
||||
--concatオプションを指定します。
|
||||
|
||||
また--shuffleオプションを追加し、重みをシャッフルします。シャッフルしないとマージ後のLoRAから元のLoRAを取り出せるため、コピー機学習などの場合には学習元データが明らかになります。ご注意ください。
|
||||
|
||||
--save_toオプションにマージ後のLoRAモデルの保存先を指定します(.ckptまたは.safetensors、拡張子で自動判定)。
|
||||
|
||||
--modelsに学習したLoRAのモデルファイルを指定します。三つ以上も指定可能です。
|
||||
|
||||
--ratiosにそれぞれのモデルの比率(どのくらい重みを元モデルに反映するか)を0~1.0の数値で指定します。二つのモデルを一対一でマージす場合は、「0.5 0.5」になります。「1.0 1.0」では合計の重みが大きくなりすぎて、恐らく結果はあまり望ましくないものになると思われます。
|
||||
|
||||
v1で学習したLoRAとv2で学習したLoRA、rank(次元数)や``alpha``の異なるLoRAはマージできません。U-NetだけのLoRAとU-Net+Text EncoderのLoRAはマージできるはずですが、結果は未知数です。
|
||||
--ratiosにそれぞれのモデルの比率(どのくらい重みを元モデルに反映するか)を0~1.0の数値で指定します。二つのモデルを一対一でマージする場合は、「0.5 0.5」になります。「1.0 1.0」では合計の重みが大きくなりすぎて、恐らく結果はあまり望ましくないものになると思われます。
|
||||
|
||||
v1で学習したLoRAとv2で学習したLoRA、rank(次元数)の異なるLoRAはマージできません。U-NetだけのLoRAとU-Net+Text EncoderのLoRAはマージできるはずですが、結果は未知数です。
|
||||
|
||||
### その他のオプション
|
||||
|
||||
@@ -304,6 +315,7 @@ v1で学習したLoRAとv2で学習したLoRA、rank(次元数)や``alpha``
|
||||
* save_precision
|
||||
* モデル保存時の精度をfloat、fp16、bf16から指定できます。省略時はprecisionと同じ精度になります。
|
||||
|
||||
他にもいくつかのオプションがありますので、--helpで確認してください。
|
||||
|
||||
## 複数のrankが異なるLoRAのモデルをマージする
|
||||
|
||||
468
docs/train_network_README-zh.md
Normal file
468
docs/train_network_README-zh.md
Normal file
@@ -0,0 +1,468 @@
|
||||
# 关于LoRA的学习。
|
||||
|
||||
[LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685)(arxiv)、[LoRA](https://github.com/microsoft/LoRA)(github)这是应用于Stable Diffusion“稳定扩散”的内容。
|
||||
|
||||
[cloneofsimo先生的代码仓库](https://github.com/cloneofsimo/lora) 我们非常感謝您提供的参考。非常感謝。
|
||||
|
||||
通常情況下,LoRA只适用于Linear和Kernel大小为1x1的Conv2d,但也可以將其擴展到Kernel大小为3x3的Conv2d。
|
||||
|
||||
Conv2d 3x3的扩展最初是由 [cloneofsimo先生的代码仓库](https://github.com/cloneofsimo/lora)
|
||||
而KohakuBlueleaf先生在[LoCon](https://github.com/KohakuBlueleaf/LoCon)中揭示了其有效性。我们深深地感谢KohakuBlueleaf先生。
|
||||
|
||||
看起来即使在8GB VRAM上也可以勉强运行。
|
||||
|
||||
请同时查看关于[学习的通用文档](./train_README-zh.md)。
|
||||
# 可学习的LoRA 类型
|
||||
|
||||
支持以下两种类型。以下是本仓库中自定义的名称。
|
||||
|
||||
1. __LoRA-LierLa__:(用于 __Li__ n __e__ a __r__ __La__ yers 的 LoRA,读作 "Liela")
|
||||
|
||||
适用于 Linear 和卷积层 Conv2d 的 1x1 Kernel 的 LoRA
|
||||
|
||||
2. __LoRA-C3Lier__:(用于具有 3x3 Kernel 的卷积层和 __Li__ n __e__ a __r__ 层的 LoRA,读作 "Seria")
|
||||
|
||||
除了第一种类型外,还适用于 3x3 Kernel 的 Conv2d 的 LoRA
|
||||
|
||||
与 LoRA-LierLa 相比,LoRA-C3Lier 可能会获得更高的准确性,因为它适用于更多的层。
|
||||
|
||||
在训练时,也可以使用 __DyLoRA__(将在后面介绍)。
|
||||
|
||||
## 请注意与所学模型相关的事项。
|
||||
|
||||
LoRA-LierLa可以用于AUTOMATIC1111先生的Web UI LoRA功能。
|
||||
|
||||
要使用LoRA-C3Liar并在Web UI中生成,请使用此处的[WebUI用extension](https://github.com/kohya-ss/sd-webui-additional-networks)。
|
||||
|
||||
在此存储库的脚本中,您还可以预先将经过训练的LoRA模型合并到Stable Diffusion模型中。
|
||||
|
||||
请注意,与cloneofsimo先生的存储库以及d8ahazard先生的[Stable-Diffusion-WebUI的Dreambooth扩展](https://github.com/d8ahazard/sd_dreambooth_extension)不兼容,因为它们进行了一些功能扩展(如下文所述)。
|
||||
|
||||
# 学习步骤
|
||||
|
||||
请先参考此存储库的README文件并进行环境设置。
|
||||
|
||||
## 准备数据
|
||||
|
||||
请参考 [关于准备学习数据](./train_README-zh.md)。
|
||||
|
||||
## 网络训练
|
||||
|
||||
使用`train_network.py`。
|
||||
|
||||
在`train_network.py`中,使用`--network_module`选项指定要训练的模块名称。对于LoRA模块,它应该是`network.lora`,请指定它。
|
||||
|
||||
请注意,学习率应该比通常的DreamBooth或fine tuning要高,建议指定为`1e-4`至`1e-3`左右。
|
||||
|
||||
以下是命令行示例。
|
||||
|
||||
```
|
||||
accelerate launch --num_cpu_threads_per_process 1 train_network.py
|
||||
--pretrained_model_name_or_path=<.ckpt或.safetensord或Diffusers版模型目录>
|
||||
--dataset_config=<数据集配置的.toml文件>
|
||||
--output_dir=<训练过程中的模型输出文件夹>
|
||||
--output_name=<训练模型输出时的文件名>
|
||||
--save_model_as=safetensors
|
||||
--prior_loss_weight=1.0
|
||||
--max_train_steps=400
|
||||
--learning_rate=1e-4
|
||||
--optimizer_type="AdamW8bit"
|
||||
--xformers
|
||||
--mixed_precision="fp16"
|
||||
--cache_latents
|
||||
--gradient_checkpointing
|
||||
--save_every_n_epochs=1
|
||||
--network_module=networks.lora
|
||||
```
|
||||
|
||||
在这个命令行中,LoRA-LierLa将会被训练。
|
||||
|
||||
LoRA的模型将会被保存在通过`--output_dir`选项指定的文件夹中。关于其他选项和优化器等,请参阅[学习的通用文档](./train_README-zh.md)中的“常用选项”。
|
||||
|
||||
此外,还可以指定以下选项:
|
||||
|
||||
* `--network_dim`
|
||||
* 指定LoRA的RANK(例如:`--network_dim=4`)。默认值为4。数值越大表示表现力越强,但需要更多的内存和时间来训练。而且不要盲目增加此数值。
|
||||
* `--network_alpha`
|
||||
* 指定用于防止下溢并稳定训练的alpha值。默认值为1。如果与`network_dim`指定相同的值,则将获得与以前版本相同的行为。
|
||||
* `--persistent_data_loader_workers`
|
||||
* 在Windows环境中指定可大幅缩短epoch之间的等待时间。
|
||||
* `--max_data_loader_n_workers`
|
||||
* 指定数据读取进程的数量。进程数越多,数据读取速度越快,可以更有效地利用GPU,但会占用主存。默认值为“`8`或`CPU同步执行线程数-1`的最小值”,因此如果主存不足或GPU使用率超过90%,则应将这些数字降低到约`2`或`1`。
|
||||
* `--network_weights`
|
||||
* 在训练之前读取预训练的LoRA权重,并在此基础上进行进一步的训练。
|
||||
* `--network_train_unet_only`
|
||||
* 仅启用与U-Net相关的LoRA模块。在类似fine tuning的学习中指定此选项可能会很有用。
|
||||
* `--network_train_text_encoder_only`
|
||||
* 仅启用与Text Encoder相关的LoRA模块。可能会期望Textual Inversion效果。
|
||||
* `--unet_lr`
|
||||
* 当在U-Net相关的LoRA模块中使用与常规学习率(由`--learning_rate`选项指定)不同的学习率时,应指定此选项。
|
||||
* `--text_encoder_lr`
|
||||
* 当在Text Encoder相关的LoRA模块中使用与常规学习率(由`--learning_rate`选项指定)不同的学习率时,应指定此选项。可能最好将Text Encoder的学习率稍微降低(例如5e-5)。
|
||||
* `--network_args`
|
||||
* 可以指定多个参数。将在下面详细说明。
|
||||
* `--alpha_mask`
|
||||
* 使用图像的 Alpha 值作为遮罩。这在学习透明图像时使用。[PR #1223](https://github.com/kohya-ss/sd-scripts/pull/1223)
|
||||
|
||||
当未指定`--network_train_unet_only`和`--network_train_text_encoder_only`时(默认情况),将启用Text Encoder和U-Net的两个LoRA模块。
|
||||
|
||||
# 其他的学习方法
|
||||
|
||||
## 学习 LoRA-C3Lier
|
||||
|
||||
请使用以下方式
|
||||
|
||||
```
|
||||
--network_args "conv_dim=4"
|
||||
```
|
||||
|
||||
DyLoRA是在这篇论文中提出的[DyLoRA: Parameter Efficient Tuning of Pre-trained Models using Dynamic Search-Free Low-Rank Adaptation](https://arxiv.org/abs/2210.07558),
|
||||
[其官方实现可在这里找到](https://github.com/huawei-noah/KD-NLP/tree/main/DyLoRA)。
|
||||
|
||||
根据论文,LoRA的rank并不是越高越好,而是需要根据模型、数据集、任务等因素来寻找合适的rank。使用DyLoRA,可以同时在指定的维度(rank)下学习多种rank的LoRA,从而省去了寻找最佳rank的麻烦。
|
||||
|
||||
本存储库的实现基于官方实现进行了自定义扩展(因此可能存在缺陷)。
|
||||
|
||||
### 本存储库DyLoRA的特点
|
||||
|
||||
DyLoRA训练后的模型文件与LoRA兼容。此外,可以从模型文件中提取多个低于指定维度(rank)的LoRA。
|
||||
|
||||
DyLoRA-LierLa和DyLoRA-C3Lier均可训练。
|
||||
|
||||
### 使用DyLoRA进行训练
|
||||
|
||||
请指定与DyLoRA相对应的`network.dylora`,例如 `--network_module=networks.dylora`。
|
||||
|
||||
此外,通过 `--network_args` 指定例如`--network_args "unit=4"`的参数。`unit`是划分rank的单位。例如,可以指定为`--network_dim=16 --network_args "unit=4"`。请将`unit`视为可以被`network_dim`整除的值(`network_dim`是`unit`的倍数)。
|
||||
|
||||
如果未指定`unit`,则默认为`unit=1`。
|
||||
|
||||
以下是示例说明。
|
||||
|
||||
```
|
||||
--network_module=networks.dylora --network_dim=16 --network_args "unit=4"
|
||||
|
||||
--network_module=networks.dylora --network_dim=32 --network_alpha=16 --network_args "unit=4"
|
||||
```
|
||||
|
||||
对于DyLoRA-C3Lier,需要在 `--network_args` 中指定 `conv_dim`,例如 `conv_dim=4`。与普通的LoRA不同,`conv_dim`必须与`network_dim`具有相同的值。以下是一个示例描述:
|
||||
|
||||
```
|
||||
--network_module=networks.dylora --network_dim=16 --network_args "conv_dim=16" "unit=4"
|
||||
|
||||
--network_module=networks.dylora --network_dim=32 --network_alpha=16 --network_args "conv_dim=32" "conv_alpha=16" "unit=8"
|
||||
```
|
||||
|
||||
例如,当使用dim=16、unit=4(如下所述)进行学习时,可以学习和提取4个rank的LoRA,即4、8、12和16。通过在每个提取的模型中生成图像并进行比较,可以选择最佳rank的LoRA。
|
||||
|
||||
其他选项与普通的LoRA相同。
|
||||
|
||||
*`unit`是本存储库的独有扩展,在DyLoRA中,由于预计相比同维度(rank)的普通LoRA,学习时间更长,因此将分割单位增加。
|
||||
|
||||
### 从DyLoRA模型中提取LoRA模型
|
||||
|
||||
请使用`networks`文件夹中的`extract_lora_from_dylora.py`。指定`unit`单位后,从DyLoRA模型中提取LoRA模型。
|
||||
|
||||
例如,命令行如下:
|
||||
|
||||
```powershell
|
||||
python networks\extract_lora_from_dylora.py --model "foldername/dylora-model.safetensors" --save_to "foldername/dylora-model-split.safetensors" --unit 4
|
||||
```
|
||||
|
||||
`--model` 参数用于指定DyLoRA模型文件。`--save_to` 参数用于指定要保存提取的模型的文件名(rank值将附加到文件名中)。`--unit` 参数用于指定DyLoRA训练时的`unit`。
|
||||
|
||||
## 分层学习率
|
||||
|
||||
请参阅PR#355了解详细信息。
|
||||
|
||||
您可以指定完整模型的25个块的权重。虽然第一个块没有对应的LoRA,但为了与分层LoRA应用等的兼容性,将其设为25个。此外,如果不扩展到conv2d3x3,则某些块中可能不存在LoRA,但为了统一描述,请始终指定25个值。
|
||||
|
||||
请在 `--network_args` 中指定以下参数。
|
||||
|
||||
- `down_lr_weight`:指定U-Net down blocks的学习率权重。可以指定以下内容:
|
||||
- 每个块的权重:指定12个数字,例如`"down_lr_weight=0,0,0,0,0,0,1,1,1,1,1,1"`
|
||||
- 从预设中指定:例如`"down_lr_weight=sine"`(使用正弦曲线指定权重)。可以指定sine、cosine、linear、reverse_linear、zeros。另外,添加 `+数字` 时,可以将指定的数字加上(变为0.25〜1.25)。
|
||||
- `mid_lr_weight`:指定U-Net mid block的学习率权重。只需指定一个数字,例如 `"mid_lr_weight=0.5"`。
|
||||
- `up_lr_weight`:指定U-Net up blocks的学习率权重。与down_lr_weight相同。
|
||||
- 省略指定的部分将被视为1.0。另外,如果将权重设为0,则不会创建该块的LoRA模块。
|
||||
- `block_lr_zero_threshold`:如果权重小于此值,则不会创建LoRA模块。默认值为0。
|
||||
|
||||
### 分层学习率命令行指定示例:
|
||||
|
||||
|
||||
```powershell
|
||||
--network_args "down_lr_weight=0.5,0.5,0.5,0.5,1.0,1.0,1.0,1.0,1.5,1.5,1.5,1.5" "mid_lr_weight=2.0" "up_lr_weight=1.5,1.5,1.5,1.5,1.0,1.0,1.0,1.0,0.5,0.5,0.5,0.5"
|
||||
|
||||
--network_args "block_lr_zero_threshold=0.1" "down_lr_weight=sine+.5" "mid_lr_weight=1.5" "up_lr_weight=cosine+.5"
|
||||
```
|
||||
|
||||
### Hierarchical Learning Rate指定的toml文件示例:
|
||||
|
||||
```toml
|
||||
network_args = [ "down_lr_weight=0.5,0.5,0.5,0.5,1.0,1.0,1.0,1.0,1.5,1.5,1.5,1.5", "mid_lr_weight=2.0", "up_lr_weight=1.5,1.5,1.5,1.5,1.0,1.0,1.0,1.0,0.5,0.5,0.5,0.5",]
|
||||
|
||||
network_args = [ "block_lr_zero_threshold=0.1", "down_lr_weight=sine+.5", "mid_lr_weight=1.5", "up_lr_weight=cosine+.5", ]
|
||||
```
|
||||
|
||||
## 层次结构维度(rank)
|
||||
|
||||
您可以指定完整模型的25个块的维度(rank)。与分层学习率一样,某些块可能不存在LoRA,但请始终指定25个值。
|
||||
|
||||
请在 `--network_args` 中指定以下参数:
|
||||
|
||||
- `block_dims`:指定每个块的维度(rank)。指定25个数字,例如 `"block_dims=2,2,2,2,4,4,4,4,6,6,6,6,8,6,6,6,6,4,4,4,4,2,2,2,2"`。
|
||||
- `block_alphas`:指定每个块的alpha。与block_dims一样,指定25个数字。如果省略,将使用network_alpha的值。
|
||||
- `conv_block_dims`:将LoRA扩展到Conv2d 3x3,并指定每个块的维度(rank)。
|
||||
- `conv_block_alphas`:在将LoRA扩展到Conv2d 3x3时指定每个块的alpha。如果省略,将使用conv_alpha的值。
|
||||
|
||||
### 层次结构维度(rank)命令行指定示例:
|
||||
|
||||
|
||||
```powershell
|
||||
--network_args "block_dims=2,4,4,4,8,8,8,8,12,12,12,12,16,12,12,12,12,8,8,8,8,4,4,4,2"
|
||||
|
||||
--network_args "block_dims=2,4,4,4,8,8,8,8,12,12,12,12,16,12,12,12,12,8,8,8,8,4,4,4,2" "conv_block_dims=2,2,2,2,4,4,4,4,6,6,6,6,8,6,6,6,6,4,4,4,4,2,2,2,2"
|
||||
|
||||
--network_args "block_dims=2,4,4,4,8,8,8,8,12,12,12,12,16,12,12,12,12,8,8,8,8,4,4,4,2" "block_alphas=2,2,2,2,4,4,4,4,6,6,6,6,8,6,6,6,6,4,4,4,4,2,2,2,2"
|
||||
```
|
||||
|
||||
### 层级别dim(rank) toml文件指定示例:
|
||||
|
||||
```toml
|
||||
network_args = [ "block_dims=2,4,4,4,8,8,8,8,12,12,12,12,16,12,12,12,12,8,8,8,8,4,4,4,2",]
|
||||
|
||||
network_args = [ "block_dims=2,4,4,4,8,8,8,8,12,12,12,12,16,12,12,12,12,8,8,8,8,4,4,4,2", "block_alphas=2,2,2,2,4,4,4,4,6,6,6,6,8,6,6,6,6,4,4,4,4,2,2,2,2",]
|
||||
```
|
||||
|
||||
# Other scripts
|
||||
这些是与LoRA相关的脚本,如合并脚本等。
|
||||
|
||||
关于合并脚本
|
||||
您可以使用merge_lora.py脚本将LoRA的训练结果合并到稳定扩散模型中,也可以将多个LoRA模型合并。
|
||||
|
||||
合并到稳定扩散模型中的LoRA模型
|
||||
合并后的模型可以像常规的稳定扩散ckpt一样使用。例如,以下是一个命令行示例:
|
||||
|
||||
```
|
||||
python networks\merge_lora.py --sd_model ..\model\model.ckpt
|
||||
--save_to ..\lora_train1\model-char1-merged.safetensors
|
||||
--models ..\lora_train1\last.safetensors --ratios 0.8
|
||||
```
|
||||
|
||||
请使用 Stable Diffusion v2.x 模型进行训练并进行合并时,需要指定--v2选项。
|
||||
|
||||
使用--sd_model选项指定要合并的 Stable Diffusion 模型文件(仅支持 .ckpt 或 .safetensors 格式,目前不支持 Diffusers)。
|
||||
|
||||
使用--save_to选项指定合并后模型的保存路径(根据扩展名自动判断为 .ckpt 或 .safetensors)。
|
||||
|
||||
使用--models选项指定已训练的 LoRA 模型文件,也可以指定多个,然后按顺序进行合并。
|
||||
|
||||
使用--ratios选项以0~1.0的数字指定每个模型的应用率(将多大比例的权重反映到原始模型中)。例如,在接近过度拟合的情况下,降低应用率可能会使结果更好。请指定与模型数量相同的比率。
|
||||
|
||||
当指定多个模型时,格式如下:
|
||||
|
||||
|
||||
```
|
||||
python networks\merge_lora.py --sd_model ..\model\model.ckpt
|
||||
--save_to ..\lora_train1\model-char1-merged.safetensors
|
||||
--models ..\lora_train1\last.safetensors ..\lora_train2\last.safetensors --ratios 0.8 0.5
|
||||
```
|
||||
|
||||
### 将多个LoRA模型合并
|
||||
|
||||
将多个LoRA模型逐个应用于SD模型与将多个LoRA模型合并后再应用于SD模型之间,由于计算顺序的不同,会得到微妙不同的结果。
|
||||
|
||||
例如,下面是一个命令行示例:
|
||||
|
||||
```
|
||||
python networks\merge_lora.py
|
||||
--save_to ..\lora_train1\model-char1-style1-merged.safetensors
|
||||
--models ..\lora_train1\last.safetensors ..\lora_train2\last.safetensors --ratios 0.6 0.4
|
||||
```
|
||||
|
||||
--sd_model选项不需要指定。
|
||||
|
||||
通过--save_to选项指定合并后的LoRA模型的保存位置(.ckpt或.safetensors,根据扩展名自动识别)。
|
||||
|
||||
通过--models选项指定学习的LoRA模型文件。可以指定三个或更多。
|
||||
|
||||
通过--ratios选项以0~1.0的数字指定每个模型的比率(反映多少权重来自原始模型)。如果将两个模型一对一合并,则比率将是“0.5 0.5”。如果比率为“1.0 1.0”,则总重量将过大,可能会产生不理想的结果。
|
||||
|
||||
在v1和v2中学习的LoRA,以及rank(维数)或“alpha”不同的LoRA不能合并。仅包含U-Net的LoRA和包含U-Net+文本编码器的LoRA可以合并,但结果未知。
|
||||
|
||||
### 其他选项
|
||||
|
||||
* 精度
|
||||
* 可以从float、fp16或bf16中选择合并计算时的精度。默认为float以保证精度。如果想减少内存使用量,请指定fp16/bf16。
|
||||
* save_precision
|
||||
* 可以从float、fp16或bf16中选择在保存模型时的精度。默认与精度相同。
|
||||
|
||||
## 合并多个维度不同的LoRA模型
|
||||
|
||||
将多个LoRA近似为一个LoRA(无法完全复制)。使用'svd_merge_lora.py'。例如,以下是命令行的示例。
|
||||
```
|
||||
python networks\svd_merge_lora.py
|
||||
--save_to ..\lora_train1\model-char1-style1-merged.safetensors
|
||||
--models ..\lora_train1\last.safetensors ..\lora_train2\last.safetensors
|
||||
--ratios 0.6 0.4 --new_rank 32 --device cuda
|
||||
```
|
||||
`merge_lora.py`和主要选项相同。以下选项已添加:
|
||||
|
||||
- `--new_rank`
|
||||
- 指定要创建的LoRA rank。
|
||||
- `--new_conv_rank`
|
||||
- 指定要创建的Conv2d 3x3 LoRA的rank。如果省略,则与`new_rank`相同。
|
||||
- `--device`
|
||||
- 如果指定为`--device cuda`,则在GPU上执行计算。处理速度将更快。
|
||||
|
||||
## 在此存储库中生成图像的脚本中
|
||||
|
||||
请在`gen_img_diffusers.py`中添加`--network_module`和`--network_weights`选项。其含义与训练时相同。
|
||||
|
||||
通过`--network_mul`选项,可以指定0~1.0的数字来改变LoRA的应用率。
|
||||
|
||||
## 请参考以下示例,在Diffusers的pipeline中生成。
|
||||
|
||||
所需文件仅为networks/lora.py。请注意,该示例只能在Diffusers版本0.10.2中正常运行。
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import StableDiffusionPipeline
|
||||
from networks.lora import LoRAModule, create_network_from_weights
|
||||
from safetensors.torch import load_file
|
||||
|
||||
# if the ckpt is CompVis based, convert it to Diffusers beforehand with tools/convert_diffusers20_original_sd.py. See --help for more details.
|
||||
|
||||
model_id_or_dir = r"model_id_on_hugging_face_or_dir"
|
||||
device = "cuda"
|
||||
|
||||
# create pipe
|
||||
print(f"creating pipe from {model_id_or_dir}...")
|
||||
pipe = StableDiffusionPipeline.from_pretrained(model_id_or_dir, revision="fp16", torch_dtype=torch.float16)
|
||||
pipe = pipe.to(device)
|
||||
vae = pipe.vae
|
||||
text_encoder = pipe.text_encoder
|
||||
unet = pipe.unet
|
||||
|
||||
# load lora networks
|
||||
print(f"loading lora networks...")
|
||||
|
||||
lora_path1 = r"lora1.safetensors"
|
||||
sd = load_file(lora_path1) # If the file is .ckpt, use torch.load instead.
|
||||
network1, sd = create_network_from_weights(0.5, None, vae, text_encoder,unet, sd)
|
||||
network1.apply_to(text_encoder, unet)
|
||||
network1.load_state_dict(sd)
|
||||
network1.to(device, dtype=torch.float16)
|
||||
|
||||
# # You can merge weights instead of apply_to+load_state_dict. network.set_multiplier does not work
|
||||
# network.merge_to(text_encoder, unet, sd)
|
||||
|
||||
lora_path2 = r"lora2.safetensors"
|
||||
sd = load_file(lora_path2)
|
||||
network2, sd = create_network_from_weights(0.7, None, vae, text_encoder,unet, sd)
|
||||
network2.apply_to(text_encoder, unet)
|
||||
network2.load_state_dict(sd)
|
||||
network2.to(device, dtype=torch.float16)
|
||||
|
||||
lora_path3 = r"lora3.safetensors"
|
||||
sd = load_file(lora_path3)
|
||||
network3, sd = create_network_from_weights(0.5, None, vae, text_encoder,unet, sd)
|
||||
network3.apply_to(text_encoder, unet)
|
||||
network3.load_state_dict(sd)
|
||||
network3.to(device, dtype=torch.float16)
|
||||
|
||||
# prompts
|
||||
prompt = "masterpiece, best quality, 1girl, in white shirt, looking at viewer"
|
||||
negative_prompt = "bad quality, worst quality, bad anatomy, bad hands"
|
||||
|
||||
# exec pipe
|
||||
print("generating image...")
|
||||
with torch.autocast("cuda"):
|
||||
image = pipe(prompt, guidance_scale=7.5, negative_prompt=negative_prompt).images[0]
|
||||
|
||||
# if not merged, you can use set_multiplier
|
||||
# network1.set_multiplier(0.8)
|
||||
# and generate image again...
|
||||
|
||||
# save image
|
||||
image.save(r"by_diffusers..png")
|
||||
```
|
||||
|
||||
## 从两个模型的差异中创建LoRA模型。
|
||||
|
||||
[参考讨论链接](https://github.com/cloneofsimo/lora/discussions/56)這是參考實現的結果。數學公式沒有改變(我並不完全理解,但似乎使用奇異值分解進行了近似)。
|
||||
|
||||
将两个模型(例如微调原始模型和微调后的模型)的差异近似为LoRA。
|
||||
|
||||
### 脚本执行方法
|
||||
|
||||
请按以下方式指定。
|
||||
|
||||
```
|
||||
python networks\extract_lora_from_models.py --model_org base-model.ckpt
|
||||
--model_tuned fine-tuned-model.ckpt
|
||||
--save_to lora-weights.safetensors --dim 4
|
||||
```
|
||||
|
||||
--model_org 选项指定原始的Stable Diffusion模型。如果要应用创建的LoRA模型,则需要指定该模型并将其应用。可以指定.ckpt或.safetensors文件。
|
||||
|
||||
--model_tuned 选项指定要提取差分的目标Stable Diffusion模型。例如,可以指定经过Fine Tuning或DreamBooth后的模型。可以指定.ckpt或.safetensors文件。
|
||||
|
||||
--save_to 指定LoRA模型的保存路径。--dim指定LoRA的维数。
|
||||
|
||||
生成的LoRA模型可以像已训练的LoRA模型一样使用。
|
||||
|
||||
当两个模型的文本编码器相同时,LoRA将成为仅包含U-Net的LoRA。
|
||||
|
||||
### 其他选项
|
||||
|
||||
- `--v2`
|
||||
- 如果使用v2.x的稳定扩散模型,请指定此选项。
|
||||
- `--device`
|
||||
- 指定为 ``--device cuda`` 可在GPU上执行计算。这会使处理速度更快(即使在CPU上也不会太慢,大约快几倍)。
|
||||
- `--save_precision`
|
||||
- 指定LoRA的保存格式为“float”、“fp16”、“bf16”。如果省略,将使用float。
|
||||
- `--conv_dim`
|
||||
- 指定后,将扩展LoRA的应用范围到Conv2d 3x3。指定Conv2d 3x3的rank。
|
||||
-
|
||||
## 图像大小调整脚本
|
||||
|
||||
(稍后将整理文件,但现在先在这里写下说明。)
|
||||
|
||||
在 Aspect Ratio Bucketing 的功能扩展中,现在可以将小图像直接用作教师数据,而无需进行放大。我收到了一个用于前处理的脚本,其中包括将原始教师图像缩小的图像添加到教师数据中可以提高准确性的报告。我整理了这个脚本并加入了感谢 bmaltais 先生。
|
||||
|
||||
### 执行脚本的方法如下。
|
||||
原始图像以及调整大小后的图像将保存到转换目标文件夹中。调整大小后的图像将在文件名中添加“+512x512”之类的调整后的分辨率(与图像大小不同)。小于调整大小后分辨率的图像将不会被放大。
|
||||
|
||||
```
|
||||
python tools\resize_images_to_resolution.py --max_resolution 512x512,384x384,256x256 --save_as_png
|
||||
--copy_associated_files 源图像文件夹目标文件夹
|
||||
```
|
||||
|
||||
在元画像文件夹中的图像文件将被调整大小以达到指定的分辨率(可以指定多个),并保存到目标文件夹中。除图像外的文件将被保留为原样。
|
||||
|
||||
请使用“--max_resolution”选项指定调整大小后的大小,使其达到指定的面积大小。如果指定多个,则会在每个分辨率上进行调整大小。例如,“512x512,384x384,256x256”将使目标文件夹中的图像变为原始大小和调整大小后的大小×3共计4张图像。
|
||||
|
||||
如果使用“--save_as_png”选项,则会以PNG格式保存。如果省略,则默认以JPEG格式(quality=100)保存。
|
||||
|
||||
如果使用“--copy_associated_files”选项,则会将与图像相同的文件名(例如标题等)的文件复制到调整大小后的图像文件的文件名相同的位置,但不包括扩展名。
|
||||
|
||||
### 其他选项
|
||||
|
||||
- divisible_by
|
||||
- 将图像中心裁剪到能够被该值整除的大小(分别是垂直和水平的大小),以便调整大小后的图像大小可以被该值整除。
|
||||
- interpolation
|
||||
- 指定缩小时的插值方法。可从``area、cubic、lanczos4``中选择,默认为``area``。
|
||||
|
||||
|
||||
# 追加信息
|
||||
|
||||
## 与cloneofsimo的代码库的区别
|
||||
|
||||
截至2022年12月25日,本代码库将LoRA应用扩展到了Text Encoder的MLP、U-Net的FFN以及Transformer的输入/输出投影中,从而增强了表现力。但是,内存使用量增加了,接近了8GB的限制。
|
||||
|
||||
此外,模块交换机制也完全不同。
|
||||
|
||||
## 关于未来的扩展
|
||||
|
||||
除了LoRA之外,我们还计划添加其他扩展,以支持更多的功能。
|
||||
561
docs/train_network_advanced.md
Normal file
561
docs/train_network_advanced.md
Normal file
@@ -0,0 +1,561 @@
|
||||
# Advanced Settings: Detailed Guide for SDXL LoRA Training Script `sdxl_train_network.py` / 高度な設定: SDXL LoRA学習スクリプト `sdxl_train_network.py` 詳細ガイド
|
||||
|
||||
This document describes the advanced options available when training LoRA models for SDXL (Stable Diffusion XL) with `sdxl_train_network.py` in the `sd-scripts` repository. For the basics, please read [How to Use the LoRA Training Script `train_network.py`](train_network.md) and [How to Use the SDXL LoRA Training Script `sdxl_train_network.py`](sdxl_train_network.md).
|
||||
|
||||
This guide targets experienced users who want to fine tune settings in detail.
|
||||
|
||||
**Prerequisites:**
|
||||
|
||||
* You have cloned the `sd-scripts` repository and prepared a Python environment.
|
||||
* A training dataset and its `.toml` configuration are ready (see the dataset configuration guide).
|
||||
* You are familiar with running basic LoRA training commands.
|
||||
|
||||
## 1. Command Line Options / コマンドライン引数 詳細解説
|
||||
|
||||
`sdxl_train_network.py` inherits the functionality of `train_network.py` and adds SDXL-specific features. Major options are grouped and explained below. For common arguments, see the other guides mentioned above.
|
||||
|
||||
### 1.1. Model Loading
|
||||
|
||||
* `--pretrained_model_name_or_path=\"<model path>\"` **[Required]**: specify the base SDXL model. Supports a Hugging Face model ID, a local Diffusers directory or a `.safetensors` file.
|
||||
* `--vae=\"<VAE path>\"`: optionally use a different VAE. Specify when using a VAE other than the one included in the SDXL model. Can specify `.ckpt` or `.safetensors` files.
|
||||
* `--no_half_vae`: keep the VAE in float32 even with fp16/bf16 training. The VAE for SDXL can become unstable with `float16`, so it is recommended to enable this when `fp16` is specified. Usually unnecessary for `bf16`.
|
||||
* `--fp8_base` / `--fp8_base_unet`: **Experimental**: load the base model (U-Net, Text Encoder) or just the U-Net in FP8 to reduce VRAM (requires PyTorch 2.1+). For details, refer to the relevant section in TODO add document later (this is an SD3 explanation but also applies to SDXL).
|
||||
|
||||
### 1.2. Dataset Settings
|
||||
|
||||
* `--dataset_config=\"<path to config>\"`: specify a `.toml` dataset config. High resolution data and aspect ratio buckets (specify `enable_bucket = true` in `.toml`) are common for SDXL. The resolution steps for aspect ratio buckets (`bucket_reso_steps`) must be multiples of 32 for SDXL. For details on writing `.toml` files, refer to the [Dataset Configuration Guide](link/to/dataset/config/doc).
|
||||
|
||||
### 1.3. Output and Saving
|
||||
|
||||
Options match `train_network.py`:
|
||||
|
||||
* `--output_dir`, `--output_name` (both required)
|
||||
* `--save_model_as` (recommended `safetensors`), `ckpt`, `pt`, `diffusers`, `diffusers_safetensors`
|
||||
* `--save_precision=\"fp16\"`, `\"bf16\"`, `\"float\"`: Specifies the precision for saving the model. If not specified, the model is saved with the training precision (`fp16`, `bf16`, etc.).
|
||||
* `--save_every_n_epochs=N`, `--save_every_n_steps=N`: Saves the model every N epochs/steps.
|
||||
* `--save_last_n_epochs=M`, `--save_last_n_steps=M`: When saving at every epoch/step, only the latest M files are kept, and older ones are deleted.
|
||||
* `--save_state`, `--save_state_on_train_end`: Saves the training state (`state`), including Optimizer status, etc., when saving the model or at the end of training. Required for resuming training with the `--resume` option.
|
||||
* `--save_last_n_epochs_state=M`, `--save_last_n_steps_state=M`: Limits the number of saved `state` files to M. Overrides the `--save_last_n_epochs/steps` specification.
|
||||
* `--no_metadata`: Does not save metadata to the output model.
|
||||
* `--save_state_to_huggingface` and related options (e.g., `--huggingface_repo_id`): Options related to uploading models and states to Hugging Face Hub. See TODO add document for details.
|
||||
|
||||
### 1.4. Network Parameters (LoRA)
|
||||
|
||||
* `--network_module=networks.lora` **[Required]**
|
||||
* `--network_dim=N` **[Required]**: Specifies the rank (dimensionality) of LoRA. For SDXL, values like 32 or 64 are often tried, but adjustment is necessary depending on the dataset and purpose.
|
||||
* `--network_alpha=M`: LoRA alpha value. Generally around half of `network_dim` or the same value as `network_dim`. Default is 1.
|
||||
* `--network_dropout=P`: Dropout rate (0.0-1.0) within LoRA modules. Can be effective in suppressing overfitting. Default is None (no dropout).
|
||||
* `--network_args ...`: Allows advanced settings by specifying additional arguments to the network module in `key=value` format. For LoRA, the following advanced settings are available:
|
||||
* **Block-wise dimensions/alphas:**
|
||||
* Allows specifying different `dim` and `alpha` for each block of the U-Net. This enables adjustments to strengthen or weaken the influence of specific layers.
|
||||
* `block_dims`: Comma-separated dims for Linear and Conv2d 1x1 layers in U-Net (23 values for SDXL).
|
||||
* `block_alphas`: Comma-separated alpha values corresponding to the above.
|
||||
* `conv_block_dims`: Comma-separated dims for Conv2d 3x3 layers in U-Net.
|
||||
* `conv_block_alphas`: Comma-separated alpha values corresponding to the above.
|
||||
* Blocks not specified will use values from `--network_dim`/`--network_alpha` or `--conv_dim`/`--conv_alpha` (if they exist).
|
||||
* For details, refer to [Block-wise learning rate for LoRA](train_network.md#lora-の階層別学習率) (in train_network.md, applicable to SDXL) and the implementation ([lora.py](lora.py)).
|
||||
* **LoRA+:**
|
||||
* `loraplus_lr_ratio=R`: Sets the learning rate of LoRA's upward weights (UP) to R times the learning rate of downward weights (DOWN). Expected to improve learning speed. Paper recommends 16.
|
||||
* `loraplus_unet_lr_ratio=RU`: Specifies the LoRA+ learning rate ratio for the U-Net part individually.
|
||||
* `loraplus_text_encoder_lr_ratio=RT`: Specifies the LoRA+ learning rate ratio for the Text Encoder part individually (multiplied by the learning rates specified with `--text_encoder_lr1`, `--text_encoder_lr2`).
|
||||
* For details, refer to [README](../README.md#jan-17-2025--2025-01-17-version-090) and the implementation ([lora.py](lora.py)).
|
||||
* `--network_train_unet_only`: Trains only the LoRA modules of the U-Net. Specify this if not training Text Encoders. Required when using `--cache_text_encoder_outputs`.
|
||||
* `--network_train_text_encoder_only`: Trains only the LoRA modules of the Text Encoders. Specify this if not training the U-Net.
|
||||
* `--network_weights=\"<weight file>\"`: Starts training by loading pre-trained LoRA weights. Used for fine-tuning or resuming training. The difference from `--resume` is that this option only loads LoRA module weights, while `--resume` also restores Optimizer state, step count, etc.
|
||||
* `--dim_from_weights`: Automatically reads the LoRA dimension (`dim`) from the weight file specified by `--network_weights`. Specification of `--network_dim` becomes unnecessary.
|
||||
|
||||
### 1.5. Training Parameters
|
||||
|
||||
* `--learning_rate=LR`: Sets the overall learning rate. This becomes the default value for each module (`unet_lr`, `text_encoder_lr1`, `text_encoder_lr2`). Values like `1e-3` or `1e-4` are often tried.
|
||||
* `--unet_lr=LR_U`: Learning rate for the LoRA module of the U-Net part.
|
||||
* `--text_encoder_lr1=LR_TE1`: Learning rate for the LoRA module of Text Encoder 1 (OpenCLIP ViT-G/14). Usually, a smaller value than U-Net (e.g., `1e-5`, `2e-5`) is recommended.
|
||||
* `--text_encoder_lr2=LR_TE2`: Learning rate for the LoRA module of Text Encoder 2 (CLIP ViT-L/14). Usually, a smaller value than U-Net (e.g., `1e-5`, `2e-5`) is recommended.
|
||||
* `--optimizer_type=\"...\"`: Specifies the optimizer to use. Options include `AdamW8bit` (memory-efficient, common), `Adafactor` (even more memory-efficient, proven in SDXL full model training), `Lion`, `DAdaptation`, `Prodigy`, etc. Each optimizer may require additional arguments (see `--optimizer_args`). `AdamW8bit` or `PagedAdamW8bit` (requires `bitsandbytes`) are common. `Adafactor` is memory-efficient but slightly complex to configure (relative step (`relative_step=True`) recommended, `adafactor` learning rate scheduler recommended). `DAdaptation`, `Prodigy` have automatic learning rate adjustment but cannot be used with LoRA+. Specify a learning rate around `1.0`. For details, see the `get_optimizer` function in [train_util.py](train_util.py).
|
||||
* `--optimizer_args ...`: Specifies additional arguments to the optimizer in `key=value` format (e.g., `\"weight_decay=0.01\"` `\"betas=0.9,0.999\"`).
|
||||
* `--lr_scheduler=\"...\"`: Specifies the learning rate scheduler. Options include `constant` (no change), `cosine` (cosine curve), `linear` (linear decay), `constant_with_warmup` (constant with warmup), `cosine_with_restarts`, etc. `constant`, `cosine`, and `constant_with_warmup` are commonly used. Some schedulers require additional arguments (see `--lr_scheduler_args`). If using optimizers with auto LR adjustment like `DAdaptation` or `Prodigy`, a scheduler is not needed (`constant` should be specified).
|
||||
* `--lr_warmup_steps=N`: Number of warmup steps for the learning rate scheduler. The learning rate gradually increases during this period at the start of training. If N < 1, it's interpreted as a fraction of total steps.
|
||||
* `--lr_scheduler_num_cycles=N` / `--lr_scheduler_power=P`: Parameters for specific schedulers (`cosine_with_restarts`, `polynomial`).
|
||||
* `--max_train_steps=N` / `--max_train_epochs=N`: Specifies the total number of training steps or epochs. Epoch specification takes precedence.
|
||||
* `--mixed_precision=\"bf16\"` / `\"fp16\"` / `\"no\"`: Mixed precision training settings. For SDXL, using `bf16` (if GPU supports it) or `fp16` is strongly recommended. Reduces VRAM usage and improves training speed.
|
||||
* `--full_fp16` / `--full_bf16`: Performs gradient calculations entirely in half-precision/bf16. Can further reduce VRAM usage but may affect training stability. Use if VRAM is critically low.
|
||||
* `--gradient_accumulation_steps=N`: Accumulates gradients for N steps before updating the optimizer. Effectively increases the batch size to `train_batch_size * N`, achieving the effect of a larger batch size with less VRAM. Default is 1.
|
||||
* `--max_grad_norm=N`: Gradient clipping threshold. Clips gradients if their norm exceeds N. Default is 1.0. `0` disables it.
|
||||
* `--gradient_checkpointing`: Significantly reduces memory usage but slightly decreases training speed. Recommended for SDXL due to high memory consumption.
|
||||
* `--fused_backward_pass`: **Experimental**: Fuses gradient calculation and optimizer steps to reduce VRAM usage. Available for SDXL. Currently only supports `Adafactor` optimizer. Cannot be used with Gradient Accumulation.
|
||||
* `--resume=\"<state directory>\"`: Resumes training from a saved state (saved with `--save_state`). Restores optimizer state, step count, etc.
|
||||
|
||||
### 1.6. Caching
|
||||
|
||||
Caching is effective for SDXL due to its high computational cost.
|
||||
|
||||
* `--cache_latents`: Caches VAE outputs (latents) in memory. Skips VAE computation, reducing VRAM usage and speeding up training. **Note:** Image augmentations (`color_aug`, `flip_aug`, `random_crop`, etc.) will be disabled.
|
||||
* `--cache_latents_to_disk`: Used with `--cache_latents` to cache to disk. Particularly effective for large datasets or multiple training runs. Caches are generated on disk during the first run and loaded from there on subsequent runs.
|
||||
* `--cache_text_encoder_outputs`: Caches Text Encoder outputs in memory. Skips Text Encoder computation, reducing VRAM usage and speeding up training. **Note:** Caption augmentations (`shuffle_caption`, `caption_dropout_rate`, etc.) will be disabled. **Also, when using this option, Text Encoder LoRA modules cannot be trained (requires `--network_train_unet_only`).**
|
||||
* `--cache_text_encoder_outputs_to_disk`: Used with `--cache_text_encoder_outputs` to cache to disk.
|
||||
* `--skip_cache_check`: Skips validation of cache file contents. File existence is checked, and if not found, caches are generated. Usually not needed unless intentionally re-caching for debugging, etc.
|
||||
|
||||
### 1.7. Sample Image Generation
|
||||
|
||||
Basic options are common with `train_network.py`.
|
||||
|
||||
* `--sample_every_n_steps=N` / `--sample_every_n_epochs=N`: Generates sample images every N steps/epochs.
|
||||
* `--sample_at_first`: Generates sample images before training starts.
|
||||
* `--sample_prompts=\"<prompt file>\"`: Specifies a file (`.txt`, `.toml`, `.json`) containing prompts for sample image generation.
|
||||
* `--sample_sampler=\"...\"`: Specifies the sampler (scheduler) for sample image generation. `euler_a`, `dpm++_2m_karras`, etc., are common. See `--help` for choices.
|
||||
|
||||
#### Format of Prompt File
|
||||
|
||||
A prompt file can contain multiple prompts with options, for example:
|
||||
|
||||
```
|
||||
# prompt 1
|
||||
masterpiece, best quality, (1girl), in white shirts, upper body, looking at viewer, simple background --n low quality, worst quality, bad anatomy,bad composition, poor, low effort --w 768 --h 768 --d 1 --l 7.5 --s 28
|
||||
|
||||
# prompt 2
|
||||
masterpiece, best quality, 1boy, in business suit, standing at street, looking back --n (low quality, worst quality), bad anatomy,bad composition, poor, low effort --w 576 --h 832 --d 2 --l 5.5 --s 40
|
||||
```
|
||||
|
||||
Lines beginning with `#` are comments. You can specify options for the generated image with options like `--n` after the prompt. The following can be used.
|
||||
|
||||
* `--n` Negative prompt up to the next option. Ignored when CFG scale is `1.0`.
|
||||
* `--w` Specifies the width of the generated image.
|
||||
* `--h` Specifies the height of the generated image.
|
||||
* `--d` Specifies the seed of the generated image.
|
||||
* `--l` Specifies the CFG scale of the generated image. For FLUX.1 models, the default is `1.0`, which means no CFG. For Chroma models, set to around `4.0` to enable CFG.
|
||||
* `--g` Specifies the embedded guidance scale for the models with embedded guidance (FLUX.1), the default is `3.5`. Set to `0.0` for Chroma models.
|
||||
* `--s` Specifies the number of steps in the generation.
|
||||
|
||||
The prompt weighting such as `( )` and `[ ]` are working for SD/SDXL models, not working for other models like FLUX.1.
|
||||
|
||||
### 1.8. Logging & Tracking
|
||||
|
||||
* `--logging_dir=\"<log directory>\"`: Specifies the directory for TensorBoard and other logs. If not specified, logs are not output.
|
||||
* `--log_with=\"tensorboard\"` / `\"wandb\"` / `\"all\"`: Specifies the logging tool to use. If using `wandb`, `pip install wandb` is required.
|
||||
* `--log_prefix=\"<prefix>\"`: Specifies the prefix for subdirectory names created within `logging_dir`.
|
||||
* `--wandb_api_key=\"<API key>\"` / `--wandb_run_name=\"<run name>\"`: Options for Weights & Biases (wandb).
|
||||
* `--log_tracker_name` / `--log_tracker_config`: Advanced tracker configuration options. Usually not needed.
|
||||
* `--log_config`: Logs the training configuration used (excluding some sensitive information) at the start of training. Helps ensure reproducibility.
|
||||
|
||||
### 1.9. Regularization and Advanced Techniques
|
||||
|
||||
* `--noise_offset=N`: Enables noise offset and specifies its value. Expected to improve bias in image brightness and contrast. Recommended to enable as SDXL base models are trained with this (e.g., 0.0357). Original technical explanation [here](https://www.crosslabs.org/blog/diffusion-with-offset-noise).
|
||||
* `--noise_offset_random_strength`: Randomly varies noise offset strength between 0 and the specified value.
|
||||
* `--adaptive_noise_scale=N`: Adjusts noise offset based on the mean absolute value of latents. Used with `--noise_offset`.
|
||||
* `--multires_noise_iterations=N` / `--multires_noise_discount=D`: Enables multi-resolution noise. Adding noise of different frequency components is expected to improve detail reproduction. Specify iteration count N (around 6-10) and discount rate D (around 0.3). Technical explanation [here](https://wandb.ai/johnowhitaker/multires_noise/reports/Multi-Resolution-Noise-for-Diffusion-Model-Training--VmlldzozNjYyOTU2).
|
||||
* `--ip_noise_gamma=G` / `--ip_noise_gamma_random_strength`: Enables Input Perturbation Noise. Adds small noise to input (latents) for regularization. Specify Gamma value (around 0.1). Strength can be randomized with `random_strength`.
|
||||
* `--min_snr_gamma=N`: Applies Min-SNR Weighting Strategy. Adjusts loss weights for timesteps with high noise in early training to stabilize learning. `N=5` etc. are used.
|
||||
* `--scale_v_pred_loss_like_noise_pred`: In v-prediction models, scales v-prediction loss similarly to noise prediction loss. **Not typically used for SDXL** as it's not a v-prediction model.
|
||||
* `--v_pred_like_loss=N`: Adds v-prediction-like loss to noise prediction models. `N` specifies its weight. **Not typically used for SDXL**.
|
||||
* `--debiased_estimation_loss`: Calculates loss using Debiased Estimation. Similar purpose to Min-SNR but a different approach.
|
||||
* `--loss_type=\"l1\"` / `\"l2\"` / `\"huber\"` / `\"smooth_l1\"`: Specifies the loss function. Default is `l2` (MSE). `huber` and `smooth_l1` are robust to outliers.
|
||||
* `--huber_schedule=\"constant\"` / `\"exponential\"` / `\"snr\"`: Scheduling method when using `huber` or `smooth_l1` loss. `snr` is recommended.
|
||||
* `--huber_c=C` / `--huber_scale=S`: Parameters for `huber` or `smooth_l1` loss.
|
||||
* `--masked_loss`: Limits loss calculation area based on a mask image. Requires specifying mask images (black and white) in `conditioning_data_dir` in dataset settings. See [About Masked Loss](masked_loss_README.md) for details.
|
||||
|
||||
### 1.10. Distributed Training and Other Training Related Options
|
||||
|
||||
* `--seed=N`: Specifies the random seed. Set this to ensure training reproducibility.
|
||||
* `--max_token_length=N` (`75`, `150`, `225`): Maximum token length processed by Text Encoders. For SDXL, typically `75` (default), `150`, or `225`. Longer lengths can handle more complex prompts but increase VRAM usage.
|
||||
* `--clip_skip=N`: Uses the output from N layers skipped from the final layer of Text Encoders. **Not typically used for SDXL**.
|
||||
* `--lowram` / `--highvram`: Options for memory usage optimization. `--lowram` is for environments like Colab where RAM < VRAM, `--highvram` is for environments with ample VRAM.
|
||||
* `--persistent_data_loader_workers` / `--max_data_loader_n_workers=N`: Settings for DataLoader worker processes. Affects wait time between epochs and memory usage.
|
||||
* `--config_file="<config file>"` / `--output_config`: Options to use/output a `.toml` file instead of command line arguments.
|
||||
* **Accelerate/DeepSpeed related:** (`--ddp_timeout`, `--ddp_gradient_as_bucket_view`, `--ddp_static_graph`): Detailed settings for distributed training. Accelerate settings (`accelerate config`) are usually sufficient. DeepSpeed requires separate configuration.
|
||||
* `--initial_epoch=<integer>` – Sets the initial epoch number. `1` means first epoch (same as not specifying). Note: `initial_epoch`/`initial_step` doesn't affect the lr scheduler, which means lr scheduler will start from 0 without `--resume`.
|
||||
* `--initial_step=<integer>` – Sets the initial step number including all epochs. `0` means first step (same as not specifying). Overwrites `initial_epoch`.
|
||||
* `--skip_until_initial_step` – Skips training until `initial_step` is reached.
|
||||
|
||||
### 1.11. Console and Logging / コンソールとログ
|
||||
|
||||
* `--console_log_level`: Sets the logging level for the console output. Choose from `DEBUG`, `INFO`, `WARNING`, `ERROR`, `CRITICAL`.
|
||||
* `--console_log_file`: Redirects console logs to a specified file.
|
||||
* `--console_log_simple`: Enables a simpler log format.
|
||||
|
||||
### 1.12. Hugging Face Hub Integration / Hugging Face Hub 連携
|
||||
|
||||
* `--huggingface_repo_id`: The repository name on Hugging Face Hub to upload the model to (e.g., `your-username/your-model`).
|
||||
* `--huggingface_repo_type`: The type of repository on Hugging Face Hub. Usually `model`.
|
||||
* `--huggingface_path_in_repo`: The path within the repository to upload files to.
|
||||
* `--huggingface_token`: Your Hugging Face Hub authentication token.
|
||||
* `--huggingface_repo_visibility`: Sets the visibility of the repository (`public` or `private`).
|
||||
* `--resume_from_huggingface`: Resumes training from a state saved on Hugging Face Hub.
|
||||
* `--async_upload`: Enables asynchronous uploading of models to the Hub, preventing it from blocking the training process.
|
||||
* `--save_n_epoch_ratio`: Saves the model at a certain ratio of total epochs. For example, `5` will save at least 5 checkpoints throughout the training.
|
||||
|
||||
### 1.13. Advanced Attention Settings / 高度なAttention設定
|
||||
|
||||
* `--mem_eff_attn`: Use memory-efficient attention mechanism. This is an older implementation and `sdpa` or `xformers` are generally recommended.
|
||||
* `--xformers`: Use xformers library for memory-efficient attention. Requires `pip install xformers`.
|
||||
|
||||
### 1.14. Advanced LR Scheduler Settings / 高度な学習率スケジューラ設定
|
||||
|
||||
* `--lr_scheduler_type`: Specifies a custom scheduler module.
|
||||
* `--lr_scheduler_args`: Provides additional arguments to the custom scheduler (e.g., `"T_max=100"`).
|
||||
* `--lr_decay_steps`: Sets the number of steps for the learning rate to decay.
|
||||
* `--lr_scheduler_timescale`: The timescale for the inverse square root scheduler.
|
||||
* `--lr_scheduler_min_lr_ratio`: Sets the minimum learning rate as a ratio of the initial learning rate for certain schedulers.
|
||||
|
||||
### 1.15. Differential Learning with LoRA / LoRAの差分学習
|
||||
|
||||
This technique involves merging a pre-trained LoRA into the base model before starting a new training session. This is useful for fine-tuning an existing LoRA or for learning the 'difference' from it.
|
||||
|
||||
* `--base_weights`: Path to one or more LoRA weight files to be merged into the base model before training begins.
|
||||
* `--base_weights_multiplier`: A multiplier for the weights of the LoRA specified by `--base_weights`. You can specify multiple values if you provide multiple weights.
|
||||
|
||||
### 1.16. Other Miscellaneous Options / その他のオプション
|
||||
|
||||
* `--tokenizer_cache_dir`: Specifies a directory to cache the tokenizer, which is useful for offline training.
|
||||
* `--scale_weight_norms`: Scales the weight norms of the LoRA modules. This can help prevent overfitting by controlling the magnitude of the weights. A value of `1.0` is a good starting point.
|
||||
* `--disable_mmap_load_safetensors`: Disables memory-mapped loading for `.safetensors` files. This can speed up model loading in some environments like WSL.
|
||||
|
||||
## 2. Other Tips / その他のTips
|
||||
|
||||
* **VRAM Usage:** SDXL LoRA training requires a lot of VRAM. Even with 24GB VRAM, you might run out of memory depending on settings. Reduce VRAM usage with these settings:
|
||||
* `--mixed_precision=\"bf16\"` or `\"fp16\"` (essential)
|
||||
* `--gradient_checkpointing` (strongly recommended)
|
||||
* `--cache_latents` / `--cache_text_encoder_outputs` (highly effective, with limitations)
|
||||
* `--optimizer_type=\"AdamW8bit\"` or `\"Adafactor\"`
|
||||
* Increase `--gradient_accumulation_steps` (reduce batch size)
|
||||
* `--full_fp16` / `--full_bf16` (be mindful of stability)
|
||||
* `--fp8_base` / `--fp8_base_unet` (experimental)
|
||||
* `--fused_backward_pass` (Adafactor only, experimental)
|
||||
* **Learning Rate:** Appropriate learning rates for SDXL LoRA depend on the dataset and `network_dim`/`alpha`. Starting around `1e-4` ~ `4e-5` (U-Net), `1e-5` ~ `2e-5` (Text Encoders) is common.
|
||||
* **Training Time:** Training takes time due to high-resolution data and the size of the SDXL model. Using caching features and appropriate hardware is important.
|
||||
* **Troubleshooting:**
|
||||
* **NaN Loss:** Learning rate might be too high, mixed precision settings incorrect (e.g., `--no_half_vae` not specified with `fp16`), or dataset issues.
|
||||
* **Out of Memory (OOM):** Try the VRAM reduction measures listed above.
|
||||
* **Training not progressing:** Learning rate might be too low, optimizer/scheduler settings incorrect, or dataset issues.
|
||||
|
||||
## 3. Conclusion / おわりに
|
||||
|
||||
`sdxl_train_network.py` offers many options to customize SDXL LoRA training. Refer to `--help`, other documents and the source code for further details.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
# 高度な設定: SDXL LoRA学習スクリプト `sdxl_train_network.py` 詳細ガイド
|
||||
|
||||
このドキュメントでは、`sd-scripts` リポジトリに含まれる `sdxl_train_network.py` を使用した、SDXL (Stable Diffusion XL) モデルに対する LoRA (Low-Rank Adaptation) モデル学習の高度な設定オプションについて解説します。
|
||||
|
||||
基本的な使い方については、以下のドキュメントを参照してください。
|
||||
|
||||
* [LoRA学習スクリプト `train_network.py` の使い方](train_network.md)
|
||||
* [SDXL LoRA学習スクリプト `sdxl_train_network.py` の使い方](sdxl_train_network.md)
|
||||
|
||||
このガイドは、基本的なLoRA学習の経験があり、より詳細な設定や高度な機能を試したい熟練した利用者を対象としています。
|
||||
|
||||
**前提条件:**
|
||||
|
||||
* `sd-scripts` リポジトリのクローンと Python 環境のセットアップが完了していること。
|
||||
* 学習用データセットの準備と設定(`.toml`ファイル)が完了していること。([データセット設定ガイド](link/to/dataset/config/doc)参照)
|
||||
* 基本的なLoRA学習のコマンドライン実行経験があること。
|
||||
|
||||
## 1. コマンドライン引数 詳細解説
|
||||
|
||||
`sdxl_train_network.py` は `train_network.py` の機能を継承しつつ、SDXL特有の機能を追加しています。ここでは、SDXL LoRA学習に関連する主要なコマンドライン引数について、機能別に分類して詳細に解説します。
|
||||
|
||||
基本的な引数については、[LoRA学習スクリプト `train_network.py` の使い方](train_network.md#31-主要なコマンドライン引数) および [SDXL LoRA学習スクリプト `sdxl_train_network.py` の使い方](sdxl_train_network.md#31-主要なコマンドライン引数(差分)) を参照してください。
|
||||
|
||||
### 1.1. モデル読み込み関連
|
||||
|
||||
* `--pretrained_model_name_or_path="<モデルパス>"` **[必須]**
|
||||
* 学習のベースとなる **SDXLモデル** を指定します。Hugging Face HubのモデルID、ローカルのDiffusers形式モデルディレクトリ、または`.safetensors`ファイルを指定できます。
|
||||
* 詳細は[基本ガイド](sdxl_train_network.md#モデル関連)を参照してください。
|
||||
* `--vae="<VAEパス>"`
|
||||
* オプションで、学習に使用するVAEを指定します。SDXLモデルに含まれるVAE以外を使用する場合に指定します。`.ckpt`または`.safetensors`ファイルを指定できます。
|
||||
* `--no_half_vae`
|
||||
* 混合精度(`fp16`/`bf16`)使用時でもVAEを`float32`で動作させます。SDXLのVAEは`float16`で不安定になることがあるため、`fp16`指定時には有効にすることが推奨されます。`bf16`では通常不要です。
|
||||
* `--fp8_base` / `--fp8_base_unet`
|
||||
* **実験的機能:** ベースモデル(U-Net, Text Encoder)またはU-NetのみをFP8で読み込み、VRAM使用量を削減します。PyTorch 2.1以上が必要です。詳細は TODO 後でドキュメントを追加 の関連セクションを参照してください (SD3の説明ですがSDXLにも適用されます)。
|
||||
|
||||
### 1.2. データセット設定関連
|
||||
|
||||
* `--dataset_config="<設定ファイルのパス>"`
|
||||
* データセットの設定を記述した`.toml`ファイルを指定します。SDXLでは高解像度データとバケツ機能(`.toml` で `enable_bucket = true` を指定)の利用が一般的です。
|
||||
* `.toml`ファイルの書き方の詳細は[データセット設定ガイド](link/to/dataset/config/doc)を参照してください。
|
||||
* アスペクト比バケツの解像度ステップ(`bucket_reso_steps`)は、SDXLでは32の倍数とする必要があります。
|
||||
|
||||
### 1.3. 出力・保存関連
|
||||
|
||||
基本的なオプションは `train_network.py` と共通です。
|
||||
|
||||
* `--output_dir="<出力先ディレクトリ>"` **[必須]**
|
||||
* `--output_name="<出力ファイル名>"` **[必須]**
|
||||
* `--save_model_as="safetensors"` (推奨), `ckpt`, `pt`, `diffusers`, `diffusers_safetensors`
|
||||
* `--save_precision="fp16"`, `"bf16"`, `"float"`
|
||||
* モデルの保存精度を指定します。未指定時は学習時の精度(`fp16`, `bf16`等)で保存されます。
|
||||
* `--save_every_n_epochs=N` / `--save_every_n_steps=N`
|
||||
* Nエポック/ステップごとにモデルを保存します。
|
||||
* `--save_last_n_epochs=M` / `--save_last_n_steps=M`
|
||||
* エポック/ステップごとに保存する際、最新のM個のみを保持し、古いものは削除します。
|
||||
* `--save_state` / `--save_state_on_train_end`
|
||||
* モデル保存時/学習終了時に、Optimizerの状態などを含む学習状態(`state`)を保存します。`--resume`オプションでの学習再開に必要です。
|
||||
* `--save_last_n_epochs_state=M` / `--save_last_n_steps_state=M`
|
||||
* `state`の保存数をM個に制限します。`--save_last_n_epochs/steps`の指定を上書きします。
|
||||
* `--no_metadata`
|
||||
* 出力モデルにメタデータを保存しません。
|
||||
* `--save_state_to_huggingface` / `--huggingface_repo_id` など
|
||||
* Hugging Face Hubへのモデルやstateのアップロード関連オプション。詳細は TODO ドキュメントを追加 を参照してください。
|
||||
|
||||
### 1.4. ネットワークパラメータ (LoRA)
|
||||
|
||||
基本的なオプションは `train_network.py` と共通です。
|
||||
|
||||
* `--network_module=networks.lora` **[必須]**
|
||||
* `--network_dim=N` **[必須]**
|
||||
* LoRAのランク (次元数) を指定します。SDXLでは32や64などが試されることが多いですが、データセットや目的に応じて調整が必要です。
|
||||
* `--network_alpha=M`
|
||||
* LoRAのアルファ値。`network_dim`の半分程度、または`network_dim`と同じ値などが一般的です。デフォルトは1。
|
||||
* `--network_dropout=P`
|
||||
* LoRAモジュール内のドロップアウト率 (0.0~1.0)。過学習抑制の効果が期待できます。デフォルトはNone (ドロップアウトなし)。
|
||||
* `--network_args ...`
|
||||
* ネットワークモジュールへの追加引数を `key=value` 形式で指定します。LoRAでは以下の高度な設定が可能です。
|
||||
* **階層別 (Block-wise) 次元数/アルファ:**
|
||||
* U-Netの各ブロックごとに異なる`dim`と`alpha`を指定できます。これにより、特定の層の影響を強めたり弱めたりする調整が可能です。
|
||||
* `block_dims`: U-NetのLinear層およびConv2d 1x1層に対するブロックごとのdimをカンマ区切りで指定します (SDXLでは23個の数値)。
|
||||
* `block_alphas`: 上記に対応するalpha値をカンマ区切りで指定します。
|
||||
* `conv_block_dims`: U-NetのConv2d 3x3層に対するブロックごとのdimをカンマ区切りで指定します。
|
||||
* `conv_block_alphas`: 上記に対応するalpha値をカンマ区切りで指定します。
|
||||
* 指定しないブロックは `--network_dim`/`--network_alpha` または `--conv_dim`/`--conv_alpha` (存在する場合) の値が使用されます。
|
||||
* 詳細は[LoRA の階層別学習率](train_network.md#lora-の階層別学習率) (train\_network.md内、SDXLでも同様に適用可能) や実装 ([lora.py](lora.py)) を参照してください。
|
||||
* **LoRA+:**
|
||||
* `loraplus_lr_ratio=R`: LoRAの上向き重み(UP)の学習率を、下向き重み(DOWN)の学習率のR倍にします。学習速度の向上が期待できます。論文推奨は16。
|
||||
* `loraplus_unet_lr_ratio=RU`: U-Net部分のLoRA+学習率比を個別に指定します。
|
||||
* `loraplus_text_encoder_lr_ratio=RT`: Text Encoder部分のLoRA+学習率比を個別に指定します。(`--text_encoder_lr1`, `--text_encoder_lr2`で指定した学習率に乗算されます)
|
||||
* 詳細は[README](../README.md#jan-17-2025--2025-01-17-version-090)や実装 ([lora.py](lora.py)) を参照してください。
|
||||
* `--network_train_unet_only`
|
||||
* U-NetのLoRAモジュールのみを学習します。Text Encoderの学習を行わない場合に指定します。`--cache_text_encoder_outputs` を使用する場合は必須です。
|
||||
* `--network_train_text_encoder_only`
|
||||
* Text EncoderのLoRAモジュールのみを学習します。U-Netの学習を行わない場合に指定します。
|
||||
* `--network_weights="<重みファイル>"`
|
||||
* 学習済みのLoRA重みを読み込んで学習を開始します。ファインチューニングや学習再開に使用します。`--resume` との違いは、このオプションはLoRAモジュールの重みのみを読み込み、`--resume` はOptimizerの状態や学習ステップ数なども復元します。
|
||||
* `--dim_from_weights`
|
||||
* `--network_weights` で指定した重みファイルからLoRAの次元数 (`dim`) を自動的に読み込みます。`--network_dim` の指定は不要になります。
|
||||
|
||||
### 1.5. 学習パラメータ
|
||||
|
||||
* `--learning_rate=LR`
|
||||
* 全体の学習率。各モジュール(`unet_lr`, `text_encoder_lr1`, `text_encoder_lr2`)のデフォルト値となります。`1e-3` や `1e-4` などが試されることが多いです。
|
||||
* `--unet_lr=LR_U`
|
||||
* U-Net部分のLoRAモジュールの学習率。
|
||||
* `--text_encoder_lr1=LR_TE1`
|
||||
* Text Encoder 1 (OpenCLIP ViT-G/14) のLoRAモジュールの学習率。通常、U-Netより小さい値 (例: `1e-5`, `2e-5`) が推奨されます。
|
||||
* `--text_encoder_lr2=LR_TE2`
|
||||
* Text Encoder 2 (CLIP ViT-L/14) のLoRAモジュールの学習率。通常、U-Netより小さい値 (例: `1e-5`, `2e-5`) が推奨されます。
|
||||
* `--optimizer_type="..."`
|
||||
* 使用するOptimizerを指定します。`AdamW8bit` (省メモリ、一般的), `Adafactor` (さらに省メモリ、SDXLフルモデル学習で実績あり), `Lion`, `DAdaptation`, `Prodigy`などが選択可能です。各Optimizerには追加の引数が必要な場合があります (`--optimizer_args`参照)。
|
||||
* `AdamW8bit` や `PagedAdamW8bit` (要 `bitsandbytes`) が一般的です。
|
||||
* `Adafactor` はメモリ効率が良いですが、設定がやや複雑です (相対ステップ(`relative_step=True`)推奨、学習率スケジューラは`adafactor`推奨)。
|
||||
* `DAdaptation`, `Prodigy` は学習率の自動調整機能がありますが、LoRA+との併用はできません。学習率は`1.0`程度を指定します。
|
||||
* 詳細は[train\_util.py](train_util.py)の`get_optimizer`関数を参照してください。
|
||||
* `--optimizer_args ...`
|
||||
* Optimizerへの追加引数を `key=value` 形式で指定します (例: `"weight_decay=0.01"` `"betas=0.9,0.999"`).
|
||||
* `--lr_scheduler="..."`
|
||||
* 学習率スケジューラを指定します。`constant` (変化なし), `cosine` (コサインカーブ), `linear` (線形減衰), `constant_with_warmup` (ウォームアップ付き定数), `cosine_with_restarts` など。`constant` や `cosine` 、 `constant_with_warmup` がよく使われます。
|
||||
* スケジューラによっては追加の引数が必要です (`--lr_scheduler_args`参照)。
|
||||
* `DAdaptation` や `Prodigy` などの自己学習率調整機能付きOptimizerを使用する場合、スケジューラは不要です (`constant` を指定)。
|
||||
* `--lr_warmup_steps=N`
|
||||
* 学習率スケジューラのウォームアップステップ数。学習開始時に学習率を徐々に上げていく期間です。N < 1 の場合は全ステップ数に対する割合と解釈されます。
|
||||
* `--lr_scheduler_num_cycles=N` / `--lr_scheduler_power=P`
|
||||
* 特定のスケジューラ (`cosine_with_restarts`, `polynomial`) のためのパラメータ。
|
||||
* `--max_train_steps=N` / `--max_train_epochs=N`
|
||||
* 学習の総ステップ数またはエポック数を指定します。エポック指定が優先されます。
|
||||
* `--mixed_precision="bf16"` / `"fp16"` / `"no"`
|
||||
* 混合精度学習の設定。SDXLでは `bf16` (対応GPUの場合) または `fp16` の使用が強く推奨されます。VRAM使用量を削減し、学習速度を向上させます。
|
||||
* `--full_fp16` / `--full_bf16`
|
||||
* 勾配計算も含めて完全に半精度/bf16で行います。VRAM使用量をさらに削減できますが、学習の安定性に影響する可能性があります。VRAMがどうしても足りない場合に使用します。
|
||||
* `--gradient_accumulation_steps=N`
|
||||
* 勾配をNステップ分蓄積してからOptimizerを更新します。実質的なバッチサイズを `train_batch_size * N` に増やし、少ないVRAMで大きなバッチサイズ相当の効果を得られます。デフォルトは1。
|
||||
* `--max_grad_norm=N`
|
||||
* 勾配クリッピングの閾値。勾配のノルムがNを超える場合にクリッピングします。デフォルトは1.0。`0`で無効。
|
||||
* `--gradient_checkpointing`
|
||||
* メモリ使用量を大幅に削減しますが、学習速度は若干低下します。SDXLではメモリ消費が大きいため、有効にすることが推奨されます。
|
||||
* `--fused_backward_pass`
|
||||
* **実験的機能:** 勾配計算とOptimizerのステップを融合し、VRAM使用量を削減します。SDXLで利用可能です。現在 `Adafactor` Optimizerのみ対応。Gradient Accumulationとは併用できません。
|
||||
* `--resume="<stateディレクトリ>"`
|
||||
* `--save_state`で保存された学習状態から学習を再開します。Optimizerの状態や学習ステップ数などが復元されます。
|
||||
|
||||
### 1.6. キャッシュ機能関連
|
||||
|
||||
SDXLは計算コストが高いため、キャッシュ機能が効果的です。
|
||||
|
||||
* `--cache_latents`
|
||||
* VAEの出力(Latent)をメモリにキャッシュします。VAEの計算を省略でき、VRAM使用量を削減し、学習を高速化します。**注意:** 画像に対するAugmentation (`color_aug`, `flip_aug`, `random_crop` 等) は無効になります。
|
||||
* `--cache_latents_to_disk`
|
||||
* `--cache_latents` と併用し、キャッシュ先をディスクにします。大量のデータセットや複数回の学習で特に有効です。初回実行時にディスクにキャッシュが生成され、2回目以降はそれを読み込みます。
|
||||
* `--cache_text_encoder_outputs`
|
||||
* Text Encoderの出力をメモリにキャッシュします。Text Encoderの計算を省略でき、VRAM使用量を削減し、学習を高速化します。**注意:** キャプションに対するAugmentation (`shuffle_caption`, `caption_dropout_rate` 等) は無効になります。**また、このオプションを使用する場合、Text EncoderのLoRAモジュールは学習できません (`--network_train_unet_only` の指定が必須です)。**
|
||||
* `--cache_text_encoder_outputs_to_disk`
|
||||
* `--cache_text_encoder_outputs` と併用し、キャッシュ先をディスクにします。
|
||||
* `--skip_cache_check`
|
||||
* キャッシュファイルの内容の検証をスキップします。ファイルの存在確認は行われ、存在しない場合はキャッシュが生成されます。デバッグ等で意図的に再キャッシュしたい場合を除き、通常は指定不要です。
|
||||
|
||||
### 1.7. サンプル画像生成関連
|
||||
|
||||
基本的なオプションは `train_network.py` と共通です。
|
||||
|
||||
* `--sample_every_n_steps=N` / `--sample_every_n_epochs=N`
|
||||
* Nステップ/エポックごとにサンプル画像を生成します。
|
||||
* `--sample_at_first`
|
||||
* 学習開始前にサンプル画像を生成します。
|
||||
* `--sample_prompts="<プロンプトファイル>"`
|
||||
* サンプル画像生成に使用するプロンプトを記述したファイル (`.txt`, `.toml`, `.json`) を指定します。
|
||||
* `--sample_sampler="..."`
|
||||
* サンプル画像生成時のサンプラー(スケジューラ)を指定します。`euler_a`, `dpm++_2m_karras` などが一般的です。選択肢は `--help` を参照してください。
|
||||
|
||||
#### プロンプトファイルの書式
|
||||
プロンプトファイルは複数のプロンプトとオプションを含めることができます。例えば:
|
||||
|
||||
```
|
||||
# prompt 1
|
||||
masterpiece, best quality, (1girl), in white shirts, upper body, looking at viewer, simple background --n low quality, worst quality, bad anatomy,bad composition, poor, low effort --w 768 --h 768 --d 1 --l 7.5 --s 28
|
||||
|
||||
# prompt 2
|
||||
masterpiece, best quality, 1boy, in business suit, standing at street, looking back --n (low quality, worst quality), bad anatomy,bad composition, poor, low effort --w 576 --h 832 --d 2 --l 5.5 --s 40
|
||||
```
|
||||
|
||||
`#`で始まる行はコメントです。生成画像のオプションはプロンプトの後に `--n` のように指定できます。以下のオプションが使用可能です。
|
||||
|
||||
* `--n` 次のオプションまでがネガティブプロンプトです。CFGスケールが `1.0` の場合は無視されます。
|
||||
* `--w` 生成画像の幅を指定します。
|
||||
* `--h` 生成画像の高さを指定します。
|
||||
* `--d` 生成画像のシード値を指定します。
|
||||
* `--l` 生成画像のCFGスケールを指定します。FLUX.1モデルでは、デフォルトは `1.0` でCFGなしを意味します。Chromaモデルでは、CFGを有効にするために `4.0` 程度に設定してください。
|
||||
* `--g` 埋め込みガイダンス付きモデル(FLUX.1)の埋め込みガイダンススケールを指定、デフォルトは `3.5`。Chromaモデルでは `0.0` に設定してください。
|
||||
* `--s` 生成時のステップ数を指定します。
|
||||
|
||||
プロンプトの重み付け `( )` や `[ ]` はSD/SDXLモデルで動作し、FLUX.1など他のモデルでは動作しません。
|
||||
|
||||
### 1.8. Logging & Tracking 関連
|
||||
|
||||
* `--logging_dir="<ログディレクトリ>"`
|
||||
* TensorBoardなどのログを出力するディレクトリを指定します。指定しない場合、ログは出力されません。
|
||||
* `--log_with="tensorboard"` / `"wandb"` / `"all"`
|
||||
* 使用するログツールを指定します。`wandb`を使用する場合、`pip install wandb`が必要です。
|
||||
* `--log_prefix="<プレフィックス>"`
|
||||
* `logging_dir` 内に作成されるサブディレクトリ名の接頭辞を指定します。
|
||||
* `--wandb_api_key="<APIキー>"` / `--wandb_run_name="<実行名>"`
|
||||
* Weights & Biases (wandb) 使用時のオプション。
|
||||
* `--log_tracker_name` / `--log_tracker_config`
|
||||
* 高度なトラッカー設定用オプション。通常は指定不要。
|
||||
* `--log_config`
|
||||
* 学習開始時に、使用された学習設定(一部の機密情報を除く)をログに出力します。再現性の確保に役立ちます。
|
||||
|
||||
### 1.9. 正則化・高度な学習テクニック関連
|
||||
|
||||
* `--noise_offset=N`
|
||||
* ノイズオフセットを有効にし、その値を指定します。画像の明るさやコントラストの偏りを改善する効果が期待できます。SDXLのベースモデルはこの値で学習されているため、有効にすることが推奨されます (例: 0.0357)。元々の技術解説は[こちら](https://www.crosslabs.org/blog/diffusion-with-offset-noise)。
|
||||
* `--noise_offset_random_strength`
|
||||
* ノイズオフセットの強度を0から指定値の間でランダムに変動させます。
|
||||
* `--adaptive_noise_scale=N`
|
||||
* Latentの平均絶対値に応じてノイズオフセットを調整します。`--noise_offset`と併用します。
|
||||
* `--multires_noise_iterations=N` / `--multires_noise_discount=D`
|
||||
* 複数解像度ノイズを有効にします。異なる周波数成分のノイズを加えることで、ディテールの再現性を向上させる効果が期待できます。イテレーション回数N (6-10程度) と割引率D (0.3程度) を指定します。技術解説は[こちら](https://wandb.ai/johnowhitaker/multires_noise/reports/Multi-Resolution-Noise-for-Diffusion-Model-Training--VmlldzozNjYyOTU2)。
|
||||
* `--ip_noise_gamma=G` / `--ip_noise_gamma_random_strength`
|
||||
* Input Perturbation Noiseを有効にします。入力(Latent)に微小なノイズを加えて正則化を行います。Gamma値 (0.1程度) を指定します。`random_strength`で強度をランダム化できます。
|
||||
* `--min_snr_gamma=N`
|
||||
* Min-SNR Weighting Strategy を適用します。学習初期のノイズが大きいタイムステップでのLossの重みを調整し、学習を安定させます。`N=5` などが使用されます。
|
||||
* `--scale_v_pred_loss_like_noise_pred`
|
||||
* v-predictionモデルにおいて、vの予測ロスをノイズ予測ロスと同様のスケールに調整します。SDXLはv-predictionではないため、**通常は使用しません**。
|
||||
* `--v_pred_like_loss=N`
|
||||
* ノイズ予測モデルにv予測ライクなロスを追加します。`N`でその重みを指定します。SDXLでは**通常は使用しません**。
|
||||
* `--debiased_estimation_loss`
|
||||
* Debiased EstimationによるLoss計算を行います。Min-SNRと類似の目的を持ちますが、異なるアプローチです。
|
||||
* `--loss_type="l1"` / `"l2"` / `"huber"` / `"smooth_l1"`
|
||||
* 損失関数を指定します。デフォルトは`l2` (MSE)。`huber`や`smooth_l1`は外れ値に頑健な損失関数です。
|
||||
* `--huber_schedule="constant"` / `"exponential"` / `"snr"`
|
||||
* `huber`または`smooth_l1`損失使用時のスケジューリング方法。`snr`が推奨されています。
|
||||
* `--huber_c=C` / `--huber_scale=S`
|
||||
* `huber`または`smooth_l1`損失のパラメータ。
|
||||
* `--masked_loss`
|
||||
* マスク画像に基づいてLoss計算領域を限定します。データセット設定で`conditioning_data_dir`にマスク画像(白黒)を指定する必要があります。詳細は[マスクロスについて](masked_loss_README.md)を参照してください。
|
||||
|
||||
### 1.10. 分散学習、その他学習関連
|
||||
|
||||
* `--seed=N`
|
||||
* 乱数シードを指定します。学習の再現性を確保したい場合に設定します。
|
||||
* `--max_token_length=N` (`75`, `150`, `225`)
|
||||
* Text Encoderが処理するトークンの最大長。SDXLでは通常`75` (デフォルト) または `150`, `225`。長くするとより複雑なプロンプトを扱えますが、VRAM使用量が増加します。
|
||||
* `--clip_skip=N`
|
||||
* Text Encoderの最終層からN層スキップした層の出力を使用します。SDXLでは**通常使用しません**。
|
||||
* `--lowram` / `--highvram`
|
||||
* メモリ使用量の最適化に関するオプション。`--lowram`はColabなどRAM < VRAM環境向け、`--highvram`はVRAM潤沢な環境向け。
|
||||
* `--persistent_data_loader_workers` / `--max_data_loader_n_workers=N`
|
||||
* DataLoaderのワーカプロセスに関する設定。エポック間の待ち時間やメモリ使用量に影響します。
|
||||
* `--config_file="<設定ファイル>"` / `--output_config`
|
||||
* コマンドライン引数の代わりに`.toml`ファイルを使用/出力するオプション。
|
||||
* **Accelerate/DeepSpeed関連:** (`--ddp_timeout`, `--ddp_gradient_as_bucket_view`, `--ddp_static_graph`)
|
||||
* 分散学習時の詳細設定。通常はAccelerateの設定 (`accelerate config`) で十分です。DeepSpeedを使用する場合は、別途設定が必要です。
|
||||
* `--initial_epoch=<integer>` – 開始エポック番号を設定します。`1`で最初のエポック(未指定時と同じ)。注意:`initial_epoch`/`initial_step`はlr schedulerに影響しないため、`--resume`しない場合はlr schedulerは0から始まります。
|
||||
* `--initial_step=<integer>` – 全エポックを含む開始ステップ番号を設定します。`0`で最初のステップ(未指定時と同じ)。`initial_epoch`を上書きします。
|
||||
* `--skip_until_initial_step` – `initial_step`に到達するまで学習をスキップします。
|
||||
|
||||
### 1.11. コンソールとログ
|
||||
|
||||
* `--console_log_level`: コンソール出力のログレベルを設定します。`DEBUG`, `INFO`, `WARNING`, `ERROR`, `CRITICAL`から選択します。
|
||||
* `--console_log_file`: コンソールのログを指定されたファイルに出力します。
|
||||
* `--console_log_simple`: よりシンプルなログフォーマットを有効にします。
|
||||
|
||||
### 1.12. Hugging Face Hub 連携
|
||||
|
||||
* `--huggingface_repo_id`: モデルをアップロードするHugging Face Hubのリポジトリ名 (例: `your-username/your-model`)。
|
||||
* `--huggingface_repo_type`: Hugging Face Hubのリポジトリの種類。通常は`model`です。
|
||||
* `--huggingface_path_in_repo`: リポジトリ内でファイルをアップロードするパス。
|
||||
* `--huggingface_token`: Hugging Face Hubの認証トークン。
|
||||
* `--huggingface_repo_visibility`: リポジトリの公開設定 (`public`または`private`)。
|
||||
* `--resume_from_huggingface`: Hugging Face Hubに保存された状態から学習を再開します。
|
||||
* `--async_upload`: Hubへのモデルの非同期アップロードを有効にし、学習プロセスをブロックしないようにします。
|
||||
* `--save_n_epoch_ratio`: 総エポック数に対する特定の比率でモデルを保存します。例えば`5`を指定すると、学習全体で少なくとも5つのチェックポイントが保存されます。
|
||||
|
||||
### 1.13. 高度なAttention設定
|
||||
|
||||
* `--mem_eff_attn`: メモリ効率の良いAttentionメカニズムを使用します。これは古い実装であり、一般的には`sdpa`や`xformers`の使用が推奨されます。
|
||||
* `--xformers`: メモリ効率の良いAttentionのためにxformersライブラリを使用します。`pip install xformers`が必要です。
|
||||
|
||||
### 1.14. 高度な学習率スケジューラ設定
|
||||
|
||||
* `--lr_scheduler_type`: カスタムスケジューラモジュールを指定します。
|
||||
* `--lr_scheduler_args`: カスタムスケジューラに追加の引数を渡します (例: `"T_max=100"`)。
|
||||
* `--lr_decay_steps`: 学習率が減衰するステップ数を設定します。
|
||||
* `--lr_scheduler_timescale`: 逆平方根スケジューラのタイムスケール。
|
||||
* `--lr_scheduler_min_lr_ratio`: 特定のスケジューラについて、初期学習率に対する最小学習率の比率を設定します。
|
||||
|
||||
### 1.15. LoRAの差分学習
|
||||
|
||||
既存の学習済みLoRAをベースモデルにマージしてから、新たな学習を開始する手法です。既存LoRAのファインチューニングや、差分を学習させたい場合に有効です。
|
||||
|
||||
* `--base_weights`: 学習開始前にベースモデルにマージするLoRAの重みファイルを1つ以上指定します。
|
||||
* `--base_weights_multiplier`: `--base_weights`で指定したLoRAの重みの倍率。複数指定も可能です。
|
||||
|
||||
### 1.16. その他のオプション
|
||||
|
||||
* `--tokenizer_cache_dir`: オフラインでの学習に便利なように、tokenizerをキャッシュするディレクトリを指定します。
|
||||
* `--scale_weight_norms`: LoRAモジュールの重みのノルムをスケーリングします。重みの大きさを制御することで過学習を防ぐ助けになります。`1.0`が良い出発点です。
|
||||
* `--disable_mmap_load_safetensors`: `.safetensors`ファイルのメモリマップドローディングを無効にします。WSLなどの一部環境でモデルの読み込みを高速化できます。
|
||||
|
||||
## 2. その他のTips
|
||||
|
||||
|
||||
* **VRAM使用量:** SDXL LoRA学習は多くのVRAMを必要とします。24GB VRAMでも設定によってはメモリ不足になることがあります。以下の設定でVRAM使用量を削減できます。
|
||||
* `--mixed_precision="bf16"` または `"fp16"` (必須級)
|
||||
* `--gradient_checkpointing` (強く推奨)
|
||||
* `--cache_latents` / `--cache_text_encoder_outputs` (効果大、制約あり)
|
||||
* `--optimizer_type="AdamW8bit"` または `"Adafactor"`
|
||||
* `--gradient_accumulation_steps` の値を増やす (バッチサイズを小さくする)
|
||||
* `--full_fp16` / `--full_bf16` (安定性に注意)
|
||||
* `--fp8_base` / `--fp8_base_unet` (実験的)
|
||||
* `--fused_backward_pass` (Adafactor限定、実験的)
|
||||
* **学習率:** SDXL LoRAの適切な学習率はデータセットや`network_dim`/`alpha`に依存します。`1e-4` ~ `4e-5` (U-Net), `1e-5` ~ `2e-5` (Text Encoders) あたりから試すのが一般的です。
|
||||
* **学習時間:** 高解像度データとSDXLモデルのサイズのため、学習には時間がかかります。キャッシュ機能や適切なハードウェアの利用が重要です。
|
||||
* **トラブルシューティング:**
|
||||
* **NaN Loss:** 学習率が高すぎる、混合精度の設定が不適切 (`fp16`時の`--no_half_vae`未指定など)、データセットの問題などが考えられます。
|
||||
* **VRAM不足 (OOM):** 上記のVRAM削減策を試してください。
|
||||
* **学習が進まない:** 学習率が低すぎる、Optimizer/Schedulerの設定が不適切、データセットの問題などが考えられます。
|
||||
|
||||
## 3. おわりに
|
||||
|
||||
`sdxl_train_network.py` は非常に多くのオプションを提供しており、SDXL LoRA学習の様々な側面をカスタマイズできます。このドキュメントが、より高度な設定やチューニングを行う際の助けとなれば幸いです。
|
||||
|
||||
不明な点や詳細については、各スクリプトの `--help` オプションや、リポジトリ内の他のドキュメント、実装コード自体を参照してください。
|
||||
|
||||
</details>
|
||||
291
docs/train_textual_inversion.md
Normal file
291
docs/train_textual_inversion.md
Normal file
@@ -0,0 +1,291 @@
|
||||
# How to use Textual Inversion training scripts / Textual Inversion学習スクリプトの使い方
|
||||
|
||||
This document explains how to train Textual Inversion embeddings using the `train_textual_inversion.py` and `sdxl_train_textual_inversion.py` scripts included in the `sd-scripts` repository.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
このドキュメントでは、`sd-scripts` リポジトリに含まれる `train_textual_inversion.py` および `sdxl_train_textual_inversion.py` を使用してTextual Inversionの埋め込みを学習する方法について解説します。
|
||||
</details>
|
||||
|
||||
## 1. Introduction / はじめに
|
||||
|
||||
[Textual Inversion](https://textual-inversion.github.io/) is a technique that teaches Stable Diffusion new concepts by learning new token embeddings. Instead of fine-tuning the entire model, it only optimizes the text encoder's token embeddings, making it a lightweight approach to teaching the model specific characters, objects, or artistic styles.
|
||||
|
||||
**Available Scripts:**
|
||||
- `train_textual_inversion.py`: For Stable Diffusion v1.x and v2.x models
|
||||
- `sdxl_train_textual_inversion.py`: For Stable Diffusion XL models
|
||||
|
||||
**Prerequisites:**
|
||||
* The `sd-scripts` repository has been cloned and the Python environment has been set up.
|
||||
* The training dataset has been prepared. For dataset preparation, please refer to the [Dataset Configuration Guide](config_README-en.md).
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
[Textual Inversion](https://textual-inversion.github.io/) は、新しいトークンの埋め込みを学習することで、Stable Diffusionに新しい概念を教える技術です。モデル全体をファインチューニングする代わりに、テキストエンコーダのトークン埋め込みのみを最適化するため、特定のキャラクター、オブジェクト、芸術的スタイルをモデルに教えるための軽量なアプローチです。
|
||||
|
||||
**利用可能なスクリプト:**
|
||||
- `train_textual_inversion.py`: Stable Diffusion v1.xおよびv2.xモデル用
|
||||
- `sdxl_train_textual_inversion.py`: Stable Diffusion XLモデル用
|
||||
|
||||
**前提条件:**
|
||||
* `sd-scripts` リポジトリのクローンとPython環境のセットアップが完了していること。
|
||||
* 学習用データセットの準備が完了していること。データセットの準備については[データセット設定ガイド](config_README-en.md)を参照してください。
|
||||
</details>
|
||||
|
||||
## 2. Basic Usage / 基本的な使用方法
|
||||
|
||||
### 2.1. For Stable Diffusion v1.x/v2.x Models / Stable Diffusion v1.x/v2.xモデル用
|
||||
|
||||
```bash
|
||||
accelerate launch --num_cpu_threads_per_process 1 train_textual_inversion.py \
|
||||
--pretrained_model_name_or_path="path/to/model.safetensors" \
|
||||
--dataset_config="dataset_config.toml" \
|
||||
--output_dir="output" \
|
||||
--output_name="my_textual_inversion" \
|
||||
--save_model_as="safetensors" \
|
||||
--token_string="mychar" \
|
||||
--init_word="girl" \
|
||||
--num_vectors_per_token=4 \
|
||||
--max_train_steps=1600 \
|
||||
--learning_rate=1e-6 \
|
||||
--optimizer_type="AdamW8bit" \
|
||||
--mixed_precision="fp16" \
|
||||
--cache_latents \
|
||||
--sdpa
|
||||
```
|
||||
|
||||
### 2.2. For SDXL Models / SDXLモデル用
|
||||
|
||||
```bash
|
||||
accelerate launch --num_cpu_threads_per_process 1 sdxl_train_textual_inversion.py \
|
||||
--pretrained_model_name_or_path="path/to/sdxl_model.safetensors" \
|
||||
--dataset_config="dataset_config.toml" \
|
||||
--output_dir="output" \
|
||||
--output_name="my_sdxl_textual_inversion" \
|
||||
--save_model_as="safetensors" \
|
||||
--token_string="mychar" \
|
||||
--init_word="girl" \
|
||||
--num_vectors_per_token=4 \
|
||||
--max_train_steps=1600 \
|
||||
--learning_rate=1e-6 \
|
||||
--optimizer_type="AdamW8bit" \
|
||||
--mixed_precision="fp16" \
|
||||
--cache_latents \
|
||||
--sdpa
|
||||
```
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
上記のコマンドは実際には1行で書く必要がありますが、見やすさのために改行しています(LinuxやMacでは行末に `\` を追加することで改行できます)。Windowsの場合は、改行せずに1行で書くか、`^` を行末に追加してください。
|
||||
</details>
|
||||
|
||||
## 3. Key Command-Line Arguments / 主要なコマンドライン引数
|
||||
|
||||
### 3.1. Textual Inversion Specific Arguments / Textual Inversion固有の引数
|
||||
|
||||
#### Core Parameters / コアパラメータ
|
||||
|
||||
* `--token_string="mychar"` **[Required]**
|
||||
* Specifies the token string used in training. This must not exist in the tokenizer's vocabulary. In your training prompts, include this token string (e.g., if token_string is "mychar", use prompts like "mychar 1girl").
|
||||
* 学習時に使用されるトークン文字列を指定します。tokenizerの語彙に存在しない文字である必要があります。学習時のプロンプトには、このトークン文字列を含める必要があります(例:token_stringが"mychar"なら、"mychar 1girl"のようなプロンプトを使用)。
|
||||
|
||||
* `--init_word="girl"`
|
||||
* Specifies the word to use for initializing the embedding vector. Choose a word that is conceptually close to what you want to teach. Must be a single token.
|
||||
* 埋め込みベクトルの初期化に使用する単語を指定します。教えたい概念に近い単語を選ぶとよいでしょう。単一のトークンである必要があります。
|
||||
|
||||
* `--num_vectors_per_token=4`
|
||||
* Specifies how many embedding vectors to use for this token. More vectors provide greater expressiveness but consume more tokens from the 77-token limit.
|
||||
* このトークンに使用する埋め込みベクトルの数を指定します。多いほど表現力が増しますが、77トークン制限からより多くのトークンを消費します。
|
||||
|
||||
* `--weights="path/to/existing_embedding.safetensors"`
|
||||
* Loads pre-trained embeddings to continue training from. Optional parameter for transfer learning.
|
||||
* 既存の埋め込みを読み込んで、そこから追加で学習します。転移学習のオプションパラメータです。
|
||||
|
||||
#### Template Options / テンプレートオプション
|
||||
|
||||
* `--use_object_template`
|
||||
* Ignores captions and uses predefined object templates (e.g., "a photo of a {}"). Same as the original implementation.
|
||||
* キャプションを無視して、事前定義された物体用テンプレート(例:"a photo of a {}")を使用します。公式実装と同じです。
|
||||
|
||||
* `--use_style_template`
|
||||
* Ignores captions and uses predefined style templates (e.g., "a painting in the style of {}"). Same as the original implementation.
|
||||
* キャプションを無視して、事前定義されたスタイル用テンプレート(例:"a painting in the style of {}")を使用します。公式実装と同じです。
|
||||
|
||||
### 3.2. Model and Dataset Arguments / モデル・データセット引数
|
||||
|
||||
For common model and dataset arguments, please refer to [LoRA Training Guide](train_network.md#31-main-command-line-arguments--主要なコマンドライン引数). The following arguments work the same way:
|
||||
|
||||
* `--pretrained_model_name_or_path`
|
||||
* `--dataset_config`
|
||||
* `--v2`, `--v_parameterization`
|
||||
* `--resolution`
|
||||
* `--cache_latents`, `--vae_batch_size`
|
||||
* `--enable_bucket`, `--min_bucket_reso`, `--max_bucket_reso`
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
一般的なモデル・データセット引数については、[LoRA学習ガイド](train_network.md#31-main-command-line-arguments--主要なコマンドライン引数)を参照してください。以下の引数は同様に動作します:
|
||||
|
||||
* `--pretrained_model_name_or_path`
|
||||
* `--dataset_config`
|
||||
* `--v2`, `--v_parameterization`
|
||||
* `--resolution`
|
||||
* `--cache_latents`, `--vae_batch_size`
|
||||
* `--enable_bucket`, `--min_bucket_reso`, `--max_bucket_reso`
|
||||
</details>
|
||||
|
||||
### 3.3. Training Parameters / 学習パラメータ
|
||||
|
||||
For training parameters, please refer to [LoRA Training Guide](train_network.md#31-main-command-line-arguments--主要なコマンドライン引数). Textual Inversion typically uses these settings:
|
||||
|
||||
* `--learning_rate=1e-6`: Lower learning rates are often used compared to LoRA training
|
||||
* `--max_train_steps=1600`: Fewer steps are usually sufficient
|
||||
* `--optimizer_type="AdamW8bit"`: Memory-efficient optimizer
|
||||
* `--mixed_precision="fp16"`: Reduces memory usage
|
||||
|
||||
**Note:** Textual Inversion has lower memory requirements compared to full model fine-tuning, so you can often use larger batch sizes.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
学習パラメータについては、[LoRA学習ガイド](train_network.md#31-main-command-line-arguments--主要なコマンドライン引数)を参照してください。Textual Inversionでは通常以下の設定を使用します:
|
||||
|
||||
* `--learning_rate=1e-6`: LoRA学習と比べて低い学習率がよく使用されます
|
||||
* `--max_train_steps=1600`: より少ないステップで十分な場合が多いです
|
||||
* `--optimizer_type="AdamW8bit"`: メモリ効率的なオプティマイザ
|
||||
* `--mixed_precision="fp16"`: メモリ使用量を削減
|
||||
|
||||
**注意:** Textual Inversionはモデル全体のファインチューニングと比べてメモリ要件が低いため、多くの場合、より大きなバッチサイズを使用できます。
|
||||
</details>
|
||||
|
||||
## 4. Dataset Preparation / データセット準備
|
||||
|
||||
### 4.1. Dataset Configuration / データセット設定
|
||||
|
||||
Create a TOML configuration file as described in the [Dataset Configuration Guide](config_README-en.md). Here's an example for Textual Inversion:
|
||||
|
||||
```toml
|
||||
[general]
|
||||
shuffle_caption = false
|
||||
caption_extension = ".txt"
|
||||
keep_tokens = 1
|
||||
|
||||
[[datasets]]
|
||||
resolution = 512 # 1024 for SDXL
|
||||
batch_size = 4 # Can use larger values than LoRA training
|
||||
enable_bucket = true
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = "path/to/images"
|
||||
caption_extension = ".txt"
|
||||
num_repeats = 10
|
||||
```
|
||||
|
||||
### 4.2. Caption Guidelines / キャプションガイドライン
|
||||
|
||||
**Important:** Your captions must include the token string you specified. For example:
|
||||
|
||||
* If `--token_string="mychar"`, captions should be like: "mychar, 1girl, blonde hair, blue eyes"
|
||||
* The token string can appear anywhere in the caption, but including it is essential
|
||||
|
||||
You can verify that your token string is being recognized by using `--debug_dataset`, which will show token IDs. Look for tokens with IDs ≥ 49408 (these are the new custom tokens).
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
**重要:** キャプションには指定したトークン文字列を含める必要があります。例:
|
||||
|
||||
* `--token_string="mychar"` の場合、キャプションは "mychar, 1girl, blonde hair, blue eyes" のようにします
|
||||
* トークン文字列はキャプション内のどこに配置しても構いませんが、含めることが必須です
|
||||
|
||||
`--debug_dataset` を使用してトークン文字列が認識されているかを確認できます。これによりトークンIDが表示されます。ID ≥ 49408 のトークン(これらは新しいカスタムトークン)を探してください。
|
||||
</details>
|
||||
|
||||
## 5. Advanced Configuration / 高度な設定
|
||||
|
||||
### 5.1. Multiple Token Vectors / 複数トークンベクトル
|
||||
|
||||
When using `--num_vectors_per_token` > 1, the system creates additional token variations:
|
||||
- `--token_string="mychar"` with `--num_vectors_per_token=4` creates: "mychar", "mychar1", "mychar2", "mychar3"
|
||||
|
||||
For generation, you can use either the base token or all tokens together.
|
||||
|
||||
### 5.2. Memory Optimization / メモリ最適化
|
||||
|
||||
* Use `--cache_latents` to cache VAE outputs and reduce VRAM usage
|
||||
* Use `--gradient_checkpointing` for additional memory savings
|
||||
* For SDXL, use `--cache_text_encoder_outputs` to cache text encoder outputs
|
||||
* Consider using `--mixed_precision="bf16"` on newer GPUs (RTX 30 series and later)
|
||||
|
||||
### 5.3. Training Tips / 学習のコツ
|
||||
|
||||
* **Learning Rate:** Start with 1e-6 and adjust based on results. Lower rates often work better than LoRA training.
|
||||
* **Steps:** 1000-2000 steps are usually sufficient, but this varies by dataset size and complexity.
|
||||
* **Batch Size:** Textual Inversion can handle larger batch sizes than full fine-tuning due to lower memory requirements.
|
||||
* **Templates:** Use `--use_object_template` for characters/objects, `--use_style_template` for artistic styles.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
* **学習率:** 1e-6から始めて、結果に基づいて調整してください。LoRA学習よりも低い率がよく機能します。
|
||||
* **ステップ数:** 通常1000-2000ステップで十分ですが、データセットのサイズと複雑さによって異なります。
|
||||
* **バッチサイズ:** メモリ要件が低いため、Textual Inversionは完全なファインチューニングよりも大きなバッチサイズを処理できます。
|
||||
* **テンプレート:** キャラクター/オブジェクトには `--use_object_template`、芸術的スタイルには `--use_style_template` を使用してください。
|
||||
</details>
|
||||
|
||||
## 6. Usage After Training / 学習後の使用方法
|
||||
|
||||
The trained Textual Inversion embeddings can be used in:
|
||||
|
||||
* **Automatic1111 WebUI:** Place the `.safetensors` file in the `embeddings` folder
|
||||
* **ComfyUI:** Use the embedding file with appropriate nodes
|
||||
* **Other Diffusers-based applications:** Load using the embedding path
|
||||
|
||||
In your prompts, simply use the token string you trained (e.g., "mychar") and the model will use the learned embedding.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
学習したTextual Inversionの埋め込みは以下で使用できます:
|
||||
|
||||
* **Automatic1111 WebUI:** `.safetensors` ファイルを `embeddings` フォルダに配置
|
||||
* **ComfyUI:** 適切なノードで埋め込みファイルを使用
|
||||
* **その他のDiffusersベースアプリケーション:** 埋め込みパスを使用して読み込み
|
||||
|
||||
プロンプトでは、学習したトークン文字列(例:"mychar")を単純に使用するだけで、モデルが学習した埋め込みを使用します。
|
||||
</details>
|
||||
|
||||
## 7. Troubleshooting / トラブルシューティング
|
||||
|
||||
### Common Issues / よくある問題
|
||||
|
||||
1. **Token string already exists in tokenizer**
|
||||
* Use a unique string that doesn't exist in the model's vocabulary
|
||||
* Try adding numbers or special characters (e.g., "mychar123")
|
||||
|
||||
2. **No improvement after training**
|
||||
* Ensure your captions include the token string
|
||||
* Try adjusting the learning rate (lower values like 5e-7)
|
||||
* Increase the number of training steps
|
||||
|
||||
* Use `--cache_latents`
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
1. **トークン文字列がtokenizerに既に存在する**
|
||||
* モデルの語彙に存在しない固有の文字列を使用してください
|
||||
* 数字や特殊文字を追加してみてください(例:"mychar123")
|
||||
|
||||
2. **学習後に改善が見られない**
|
||||
* キャプションにトークン文字列が含まれていることを確認してください
|
||||
* 学習率を調整してみてください(5e-7のような低い値)
|
||||
* 学習ステップ数を増やしてください
|
||||
|
||||
3. **メモリ不足エラー**
|
||||
* データセット設定でバッチサイズを減らしてください
|
||||
* `--gradient_checkpointing` を使用してください
|
||||
* `--cache_latents` を使用してください
|
||||
</details>
|
||||
|
||||
For additional training options and advanced configurations, please refer to the [LoRA Training Guide](train_network.md) as many parameters are shared between training methods.
|
||||
261
docs/validation.md
Normal file
261
docs/validation.md
Normal file
@@ -0,0 +1,261 @@
|
||||
# Validation Loss
|
||||
|
||||
Validation loss is a crucial metric for monitoring the training process of a model. It helps you assess how well your model is generalizing to data it hasn't seen during training, which is essential for preventing overfitting. By periodically evaluating the model on a separate validation dataset, you can gain insights into its performance and make more informed decisions about when to stop training or adjust hyperparameters.
|
||||
|
||||
This feature provides a stable and reliable validation loss metric by ensuring the validation process is deterministic.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
Validation loss(検証損失)は、モデルの学習過程を監視するための重要な指標です。モデルが学習中に見ていないデータに対してどの程度汎化できているかを評価するのに役立ち、過学習を防ぐために不可欠です。個別の検証データセットで定期的にモデルを評価することで、そのパフォーマンスに関する洞察を得て、学習をいつ停止するか、またはハイパーパラメータを調整するかについて、より多くの情報に基づいた決定を下すことができます。
|
||||
|
||||
この機能は、検証プロセスが決定論的であることを保証することにより、安定して信頼性の高い検証損失指標を提供します。
|
||||
|
||||
</details>
|
||||
|
||||
## How It Works
|
||||
|
||||
When validation is enabled, a portion of your dataset is set aside specifically for this purpose. The script then runs a validation step at regular intervals, calculating the loss on this validation data.
|
||||
|
||||
To ensure that the validation loss is a reliable indicator of model performance, the process is deterministic. This means that for every validation run, the same random seed is used for noise generation and timestep selection. This consistency ensures that any fluctuations in the validation loss are due to changes in the model's weights, not random variations in the validation process itself.
|
||||
|
||||
The average loss across all validation steps is then logged, providing a single, clear metric to track.
|
||||
|
||||
For more technical details, please refer to the original pull request: [PR #1903](https://github.com/kohya-ss/sd-scripts/pull/1903).
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
検証が有効になると、データセットの一部がこの目的のために特別に確保されます。スクリプトは定期的な間隔で検証ステップを実行し、この検証データに対する損失を計算します。
|
||||
|
||||
検証損失がモデルのパフォーマンスの信頼できる指標であることを保証するために、プロセスは決定論的です。つまり、すべての検証実行で、ノイズ生成とタイムステップ選択に同じランダムシードが使用されます。この一貫性により、検証損失の変動が、検証プロセス自体のランダムな変動ではなく、モデルの重みの変化によるものであることが保証されます。
|
||||
|
||||
すべての検証ステップにわたる平均損失がログに記録され、追跡するための単一の明確な指標が提供されます。
|
||||
|
||||
より技術的な詳細については、元のプルリクエストを参照してください: [PR #1903](https://github.com/kohya-ss/sd-scripts/pull/1903).
|
||||
|
||||
</details>
|
||||
|
||||
## How to Use
|
||||
|
||||
### Enabling Validation
|
||||
|
||||
There are two primary ways to enable validation:
|
||||
|
||||
1. **Using a Dataset Config File (Recommended)**: You can specify a validation set directly within your dataset `.toml` file. This method offers the most control, allowing you to designate entire directories as validation sets or split a percentage of a specific subset for validation.
|
||||
|
||||
To use a whole directory for validation, add a subset and set `validation_split = 1.0`.
|
||||
|
||||
**Example: Separate Validation Set**
|
||||
```toml
|
||||
[[datasets]]
|
||||
# ... training subset ...
|
||||
[[datasets.subsets]]
|
||||
image_dir = "path/to/train_images"
|
||||
# ... other settings ...
|
||||
|
||||
# Validation subset
|
||||
[[datasets.subsets]]
|
||||
image_dir = "path/to/validation_images"
|
||||
validation_split = 1.0 # Use this entire subset for validation
|
||||
```
|
||||
|
||||
To use a fraction of a subset for validation, set `validation_split` to a value between 0.0 and 1.0.
|
||||
|
||||
**Example: Splitting a Subset**
|
||||
```toml
|
||||
[[datasets]]
|
||||
# ... dataset settings ...
|
||||
[[datasets.subsets]]
|
||||
image_dir = "path/to/images"
|
||||
validation_split = 0.1 # Use 10% of this subset for validation
|
||||
```
|
||||
|
||||
2. **Using a Command-Line Argument**: For a simpler setup, you can use the `--validation_split` argument. This will take a random percentage of your *entire* training dataset for validation. This method is ignored if `validation_split` is defined in your dataset config file.
|
||||
|
||||
**Example Command:**
|
||||
```bash
|
||||
accelerate launch train_network.py ... --validation_split 0.1
|
||||
```
|
||||
This command will use 10% of the total training data for validation.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
### 検証を有効にする
|
||||
|
||||
検証を有効にする主な方法は2つあります。
|
||||
|
||||
1. **データセット設定ファイルを使用する(推奨)**: データセットの`.toml`ファイル内で直接検証セットを指定できます。この方法は最も制御性が高く、ディレクトリ全体を検証セットとして指定したり、特定のサブセットのパーセンテージを検証用に分割したりすることができます。
|
||||
|
||||
ディレクトリ全体を検証に使用するには、サブセットを追加して`validation_split = 1.0`と設定します。
|
||||
|
||||
**例:個別の検証セット**
|
||||
```toml
|
||||
[[datasets]]
|
||||
# ... training subset ...
|
||||
[[datasets.subsets]]
|
||||
image_dir = "path/to/train_images"
|
||||
# ... other settings ...
|
||||
|
||||
# Validation subset
|
||||
[[datasets.subsets]]
|
||||
image_dir = "path/to/validation_images"
|
||||
validation_split = 1.0 # このサブセット全体を検証に使用します
|
||||
```
|
||||
|
||||
サブセットの一部を検証に使用するには、`validation_split`を0.0から1.0の間の値に設定します。
|
||||
|
||||
**例:サブセットの分割**
|
||||
```toml
|
||||
[[datasets]]
|
||||
# ... dataset settings ...
|
||||
[[datasets.subsets]]
|
||||
image_dir = "path/to/images"
|
||||
validation_split = 0.1 # このサブセットの10%を検証に使用します
|
||||
```
|
||||
|
||||
2. **コマンドライン引数を使用する**: より簡単な設定のために、`--validation_split`引数を使用できます。これにより、*全*学習データセットのランダムなパーセンテージが検証に使用されます。この方法は、データセット設定ファイルで`validation_split`が定義されている場合は無視されます。
|
||||
|
||||
**コマンド例:**
|
||||
```bash
|
||||
accelerate launch train_network.py ... --validation_split 0.1
|
||||
```
|
||||
このコマンドは、全学習データの10%を検証に使用します。
|
||||
|
||||
</details>
|
||||
|
||||
### Configuration Options
|
||||
|
||||
| Argument | TOML Option | Description |
|
||||
| --------------------------- | ------------------- | -------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| `--validation_split` | `validation_split` | The fraction of the dataset to use for validation. The command-line argument applies globally, while the TOML option applies per-subset. The TOML setting takes precedence. |
|
||||
| `--validate_every_n_steps` | | Run validation every N steps. |
|
||||
| `--validate_every_n_epochs` | | Run validation every N epochs. If not specified, validation runs once per epoch by default. |
|
||||
| `--max_validation_steps` | | The maximum number of batches to use for a single validation run. If not set, the entire validation dataset is used. |
|
||||
| `--validation_seed` | `validation_seed` | A specific seed for the validation dataloader shuffling. If not set in the TOML file, the main training `--seed` is used. |
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
### 設定オプション
|
||||
|
||||
| 引数 | TOMLオプション | 説明 |
|
||||
| --------------------------- | ------------------- | -------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| `--validation_split` | `validation_split` | 検証に使用するデータセットの割合。コマンドライン引数は全体に適用され、TOMLオプションはサブセットごとに適用されます。TOML設定が優先されます。 |
|
||||
| `--validate_every_n_steps` | | Nステップごとに検証を実行します。 |
|
||||
| `--validate_every_n_epochs` | | Nエポックごとに検証を実行します。指定しない場合、デフォルトでエポックごとに1回検証が実行されます。 |
|
||||
| `--max_validation_steps` | | 1回の検証実行に使用するバッチの最大数。設定しない場合、検証データセット全体が使用されます。 |
|
||||
| `--validation_seed` | `validation_seed` | 検証データローダーのシャッフル用の特定のシード。TOMLファイルで設定されていない場合、メインの学習`--seed`が使用されます。 |
|
||||
|
||||
</details>
|
||||
|
||||
### Viewing the Results
|
||||
|
||||
The validation loss is logged to your tracking tool of choice (TensorBoard or Weights & Biases). Look for the metric `loss/validation` to monitor the performance.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
### 結果の表示
|
||||
|
||||
検証損失は、選択した追跡ツール(TensorBoardまたはWeights & Biases)に記録されます。パフォーマンスを監視するには、`loss/validation`という指標を探してください。
|
||||
|
||||
</details>
|
||||
|
||||
### Practical Example
|
||||
|
||||
Here is a complete example of how to run a LoRA training with validation enabled:
|
||||
|
||||
**1. Prepare your `dataset_config.toml`:**
|
||||
|
||||
```toml
|
||||
[general]
|
||||
shuffle_caption = true
|
||||
keep_tokens = 1
|
||||
|
||||
[[datasets]]
|
||||
resolution = "1024,1024"
|
||||
batch_size = 2
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'path/to/your_images'
|
||||
caption_extension = '.txt'
|
||||
num_repeats = 10
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'path/to/your_validation_images'
|
||||
caption_extension = '.txt'
|
||||
validation_split = 1.0 # Use this entire subset for validation
|
||||
```
|
||||
|
||||
**2. Run the training command:**
|
||||
|
||||
```bash
|
||||
accelerate launch sdxl_train_network.py \
|
||||
--pretrained_model_name_or_path="sd_xl_base_1.0.safetensors" \
|
||||
--dataset_config="dataset_config.toml" \
|
||||
--output_dir="output" \
|
||||
--output_name="my_lora" \
|
||||
--network_module=networks.lora \
|
||||
--network_dim=32 \
|
||||
--network_alpha=16 \
|
||||
--save_every_n_epochs=1 \
|
||||
--learning_rate=1e-4 \
|
||||
--optimizer_type="AdamW8bit" \
|
||||
--mixed_precision="bf16" \
|
||||
--logging_dir=logs
|
||||
```
|
||||
|
||||
The validation loss will be calculated once per epoch and saved to the `logs` directory, which you can view with TensorBoard.
|
||||
|
||||
<details>
|
||||
<summary>日本語</summary>
|
||||
|
||||
### 実践的な例
|
||||
|
||||
検証を有効にしてLoRAの学習を実行する完全な例を次に示します。
|
||||
|
||||
**1. `dataset_config.toml`を準備します:**
|
||||
|
||||
```toml
|
||||
[general]
|
||||
shuffle_caption = true
|
||||
keep_tokens = 1
|
||||
|
||||
[[datasets]]
|
||||
resolution = "1024,1024"
|
||||
batch_size = 2
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'path/to/your_images'
|
||||
caption_extension = '.txt'
|
||||
num_repeats = 10
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'path/to/your_validation_images'
|
||||
caption_extension = '.txt'
|
||||
validation_split = 1.0 # このサブセット全体を検証に使用します
|
||||
```
|
||||
|
||||
**2. 学習コマンドを実行します:**
|
||||
|
||||
```bash
|
||||
accelerate launch sdxl_train_network.py \
|
||||
--pretrained_model_name_or_path="sd_xl_base_1.0.safetensors" \
|
||||
--dataset_config="dataset_config.toml" \
|
||||
--output_dir="output" \
|
||||
--output_name="my_lora" \
|
||||
--network_module=networks.lora \
|
||||
--network_dim=32 \
|
||||
--network_alpha=16 \
|
||||
--save_every_n_epochs=1 \
|
||||
--learning_rate=1e-4 \
|
||||
--optimizer_type="AdamW8bit" \
|
||||
--mixed_precision="bf16" \
|
||||
--logging_dir=logs
|
||||
```
|
||||
|
||||
検証損失はエポックごとに1回計算され、`logs`ディレクトリに保存されます。これはTensorBoardで表示できます。
|
||||
|
||||
</details>
|
||||
92
docs/wd14_tagger_README-en.md
Normal file
92
docs/wd14_tagger_README-en.md
Normal file
@@ -0,0 +1,92 @@
|
||||
# Image Tagging using WD14Tagger
|
||||
|
||||
This document is based on the information from this github page (https://github.com/toriato/stable-diffusion-webui-wd14-tagger#mrsmilingwolfs-model-aka-waifu-diffusion-14-tagger).
|
||||
|
||||
Using onnx for inference is recommended. Please install onnx with the following command:
|
||||
|
||||
```powershell
|
||||
pip install onnx onnxruntime-gpu
|
||||
```
|
||||
|
||||
See [the official documentation](https://onnxruntime.ai/docs/install/#python-installs) for more details.
|
||||
|
||||
The model weights will be automatically downloaded from Hugging Face.
|
||||
|
||||
# Usage
|
||||
|
||||
Run the script to perform tagging.
|
||||
|
||||
```powershell
|
||||
python finetune/tag_images_by_wd14_tagger.py --onnx --repo_id <model repo id> --batch_size <batch size> <training data folder>
|
||||
```
|
||||
|
||||
For example, if using the repository `SmilingWolf/wd-swinv2-tagger-v3` with a batch size of 4, and the training data is located in the parent folder `train_data`, it would be:
|
||||
|
||||
```powershell
|
||||
python tag_images_by_wd14_tagger.py --onnx --repo_id SmilingWolf/wd-swinv2-tagger-v3 --batch_size 4 ..\train_data
|
||||
```
|
||||
|
||||
On the first run, the model files will be automatically downloaded to the `wd14_tagger_model` folder (the folder can be changed with an option).
|
||||
|
||||
Tag files will be created in the same directory as the training data images, with the same filename and a `.txt` extension.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
## Example
|
||||
|
||||
To output in the Animagine XL 3.1 format, it would be as follows (enter on a single line in practice):
|
||||
|
||||
```
|
||||
python tag_images_by_wd14_tagger.py --onnx --repo_id SmilingWolf/wd-swinv2-tagger-v3
|
||||
--batch_size 4 --remove_underscore --undesired_tags "PUT,YOUR,UNDESIRED,TAGS" --recursive
|
||||
--use_rating_tags_as_last_tag --character_tags_first --character_tag_expand
|
||||
--always_first_tags "1girl,1boy" ..\train_data
|
||||
```
|
||||
|
||||
## Available Repository IDs
|
||||
|
||||
[SmilingWolf's V2 and V3 models](https://huggingface.co/SmilingWolf) are available for use. Specify them in the format like `SmilingWolf/wd-vit-tagger-v3`. The default when omitted is `SmilingWolf/wd-v1-4-convnext-tagger-v2`.
|
||||
|
||||
# Options
|
||||
|
||||
All options can be checked with `python tag_images_by_wd14_tagger.py --help`.
|
||||
|
||||
## General Options
|
||||
|
||||
- `--onnx`: Use ONNX for inference. If not specified, TensorFlow will be used. If using TensorFlow, please install TensorFlow separately.
|
||||
- `--batch_size`: Number of images to process at once. Default is 1. Adjust according to VRAM capacity.
|
||||
- `--caption_extension`: File extension for caption files. Default is `.txt`.
|
||||
- `--max_data_loader_n_workers`: Maximum number of workers for DataLoader. Specifying a value of 1 or more will use DataLoader to speed up image loading. If unspecified, DataLoader will not be used.
|
||||
- `--thresh`: Confidence threshold for outputting tags. Default is 0.35. Lowering the value will assign more tags but accuracy will decrease.
|
||||
- `--general_threshold`: Confidence threshold for general tags. If omitted, same as `--thresh`.
|
||||
- `--character_threshold`: Confidence threshold for character tags. If omitted, same as `--thresh`.
|
||||
- `--recursive`: If specified, subfolders within the specified folder will also be processed recursively.
|
||||
- `--append_tags`: Append tags to existing tag files.
|
||||
- `--frequency_tags`: Output tag frequencies.
|
||||
- `--debug`: Debug mode. Outputs debug information if specified.
|
||||
|
||||
## Model Download
|
||||
|
||||
- `--model_dir`: Folder to save model files. Default is `wd14_tagger_model`.
|
||||
- `--force_download`: Re-download model files if specified.
|
||||
|
||||
## Tag Editing
|
||||
|
||||
- `--remove_underscore`: Remove underscores from output tags.
|
||||
- `--undesired_tags`: Specify tags not to output. Multiple tags can be specified, separated by commas. For example, `black eyes,black hair`.
|
||||
- `--use_rating_tags`: Output rating tags at the beginning of the tags.
|
||||
- `--use_rating_tags_as_last_tag`: Add rating tags at the end of the tags.
|
||||
- `--character_tags_first`: Output character tags first.
|
||||
- `--character_tag_expand`: Expand character tag series names. For example, split the tag `chara_name_(series)` into `chara_name, series`.
|
||||
- `--always_first_tags`: Specify tags to always output first when a certain tag appears in an image. Multiple tags can be specified, separated by commas. For example, `1girl,1boy`.
|
||||
- `--caption_separator`: Separate tags with this string in the output file. Default is `, `.
|
||||
- `--tag_replacement`: Perform tag replacement. Specify in the format `tag1,tag2;tag3,tag4`. If using `,` and `;`, escape them with `\`. \
|
||||
For example, specify `aira tsubase,aira tsubase (uniform)` (when you want to train a specific costume), `aira tsubase,aira tsubase\, heir of shadows` (when the series name is not included in the tag).
|
||||
|
||||
When using `tag_replacement`, it is applied after `character_tag_expand`.
|
||||
|
||||
When specifying `remove_underscore`, specify `undesired_tags`, `always_first_tags`, and `tag_replacement` without including underscores.
|
||||
|
||||
When specifying `caption_separator`, separate `undesired_tags` and `always_first_tags` with `caption_separator`. Always separate `tag_replacement` with `,`.
|
||||
92
docs/wd14_tagger_README-ja.md
Normal file
92
docs/wd14_tagger_README-ja.md
Normal file
@@ -0,0 +1,92 @@
|
||||
# WD14Taggerによるタグ付け
|
||||
|
||||
こちらのgithubページ(https://github.com/toriato/stable-diffusion-webui-wd14-tagger#mrsmilingwolfs-model-aka-waifu-diffusion-14-tagger )の情報を参考にさせていただきました。
|
||||
|
||||
onnx を用いた推論を推奨します。以下のコマンドで onnx をインストールしてください。
|
||||
|
||||
```powershell
|
||||
pip install onnx onnxruntime-gpu
|
||||
```
|
||||
|
||||
詳細は[公式ドキュメント](https://onnxruntime.ai/docs/install/#python-installs)をご覧ください。
|
||||
|
||||
モデルの重みはHugging Faceから自動的にダウンロードしてきます。
|
||||
|
||||
# 使い方
|
||||
|
||||
スクリプトを実行してタグ付けを行います。
|
||||
```
|
||||
python fintune/tag_images_by_wd14_tagger.py --onnx --repo_id <モデルのrepo id> --batch_size <バッチサイズ> <教師データフォルダ>
|
||||
```
|
||||
|
||||
レポジトリに `SmilingWolf/wd-swinv2-tagger-v3` を使用し、バッチサイズを4にして、教師データを親フォルダの `train_data`に置いた場合、以下のようになります。
|
||||
|
||||
```
|
||||
python tag_images_by_wd14_tagger.py --onnx --repo_id SmilingWolf/wd-swinv2-tagger-v3 --batch_size 4 ..\train_data
|
||||
```
|
||||
|
||||
初回起動時にはモデルファイルが `wd14_tagger_model` フォルダに自動的にダウンロードされます(フォルダはオプションで変えられます)。
|
||||
|
||||
タグファイルが教師データ画像と同じディレクトリに、同じファイル名、拡張子.txtで作成されます。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
## 記述例
|
||||
|
||||
Animagine XL 3.1 方式で出力する場合、以下のようになります(実際には 1 行で入力してください)。
|
||||
|
||||
```
|
||||
python tag_images_by_wd14_tagger.py --onnx --repo_id SmilingWolf/wd-swinv2-tagger-v3
|
||||
--batch_size 4 --remove_underscore --undesired_tags "PUT,YOUR,UNDESIRED,TAGS" --recursive
|
||||
--use_rating_tags_as_last_tag --character_tags_first --character_tag_expand
|
||||
--always_first_tags "1girl,1boy" ..\train_data
|
||||
```
|
||||
|
||||
## 使用可能なリポジトリID
|
||||
|
||||
[SmilingWolf 氏の V2、V3 のモデル](https://huggingface.co/SmilingWolf)が使用可能です。`SmilingWolf/wd-vit-tagger-v3` のように指定してください。省略時のデフォルトは `SmilingWolf/wd-v1-4-convnext-tagger-v2` です。
|
||||
|
||||
# オプション
|
||||
|
||||
全てオプションは `python tag_images_by_wd14_tagger.py --help` で確認できます。
|
||||
|
||||
## 一般オプション
|
||||
|
||||
- `--onnx` : ONNX を使用して推論します。指定しない場合は TensorFlow を使用します。TensorFlow 使用時は別途 TensorFlow をインストールしてください。
|
||||
- `--batch_size` : 一度に処理する画像の数。デフォルトは1です。VRAMの容量に応じて増減してください。
|
||||
- `--caption_extension` : キャプションファイルの拡張子。デフォルトは `.txt` です。
|
||||
- `--max_data_loader_n_workers` : DataLoader の最大ワーカー数です。このオプションに 1 以上の数値を指定すると、DataLoader を用いて画像読み込みを高速化します。未指定時は DataLoader を用いません。
|
||||
- `--thresh` : 出力するタグの信頼度の閾値。デフォルトは0.35です。値を下げるとより多くのタグが付与されますが、精度は下がります。
|
||||
- `--general_threshold` : 一般タグの信頼度の閾値。省略時は `--thresh` と同じです。
|
||||
- `--character_threshold` : キャラクタータグの信頼度の閾値。省略時は `--thresh` と同じです。
|
||||
- `--recursive` : 指定すると、指定したフォルダ内のサブフォルダも再帰的に処理します。
|
||||
- `--append_tags` : 既存のタグファイルにタグを追加します。
|
||||
- `--frequency_tags` : タグの頻度を出力します。
|
||||
- `--debug` : デバッグモード。指定するとデバッグ情報を出力します。
|
||||
|
||||
## モデルのダウンロード
|
||||
|
||||
- `--model_dir` : モデルファイルの保存先フォルダ。デフォルトは `wd14_tagger_model` です。
|
||||
- `--force_download` : 指定するとモデルファイルを再ダウンロードします。
|
||||
|
||||
## タグ編集関連
|
||||
|
||||
- `--remove_underscore` : 出力するタグからアンダースコアを削除します。
|
||||
- `--undesired_tags` : 出力しないタグを指定します。カンマ区切りで複数指定できます。たとえば `black eyes,black hair` のように指定します。
|
||||
- `--use_rating_tags` : タグの最初にレーティングタグを出力します。
|
||||
- `--use_rating_tags_as_last_tag` : タグの最後にレーティングタグを追加します。
|
||||
- `--character_tags_first` : キャラクタータグを最初に出力します。
|
||||
- `--character_tag_expand` : キャラクタータグのシリーズ名を展開します。たとえば `chara_name_(series)` のタグを `chara_name, series` に分割します。
|
||||
- `--always_first_tags` : あるタグが画像に出力されたとき、そのタグを最初に出力するタグを指定します。カンマ区切りで複数指定できます。たとえば `1girl,1boy` のように指定します。
|
||||
- `--caption_separator` : 出力するファイルでタグをこの文字列で区切ります。デフォルトは `, ` です。
|
||||
- `--tag_replacement` : タグの置換を行います。`tag1,tag2;tag3,tag4` のように指定します。`,` および `;` を使う場合は `\` でエスケープしてください。\
|
||||
たとえば `aira tsubase,aira tsubase (uniform)` (特定の衣装を学習させたいとき)、`aira tsubase,aira tsubase\, heir of shadows` (シリーズ名がタグに含まれないとき)のように指定します。
|
||||
|
||||
`tag_replacement` は `character_tag_expand` の後に適用されます。
|
||||
|
||||
`remove_underscore` 指定時は、`undesired_tags`、`always_first_tags`、`tag_replacement` はアンダースコアを含めずに指定してください。
|
||||
|
||||
`caption_separator` 指定時は、`undesired_tags`、`always_first_tags` は `caption_separator` で区切ってください。`tag_replacement` は必ず `,` で区切ってください。
|
||||
|
||||
402
fine_tune.py
402
fine_tune.py
@@ -2,77 +2,113 @@
|
||||
# XXX dropped option: hypernetwork training
|
||||
|
||||
import argparse
|
||||
import gc
|
||||
import math
|
||||
import os
|
||||
import toml
|
||||
from multiprocessing import Value
|
||||
import toml
|
||||
|
||||
from tqdm import tqdm
|
||||
|
||||
import torch
|
||||
from library import deepspeed_utils, strategy_base
|
||||
from library.device_utils import init_ipex, clean_memory_on_device
|
||||
|
||||
init_ipex()
|
||||
|
||||
from accelerate.utils import set_seed
|
||||
import diffusers
|
||||
from diffusers import DDPMScheduler
|
||||
|
||||
from library.utils import setup_logging, add_logging_arguments
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
import library.train_util as train_util
|
||||
import library.config_util as config_util
|
||||
import library.sai_model_spec as sai_model_spec
|
||||
from library.config_util import (
|
||||
ConfigSanitizer,
|
||||
BlueprintGenerator,
|
||||
)
|
||||
import library.custom_train_functions as custom_train_functions
|
||||
from library.custom_train_functions import apply_snr_weight, get_weighted_text_embeddings
|
||||
from library.custom_train_functions import (
|
||||
apply_snr_weight,
|
||||
get_weighted_text_embeddings,
|
||||
prepare_scheduler_for_custom_training,
|
||||
scale_v_prediction_loss_like_noise_prediction,
|
||||
apply_debiased_estimation,
|
||||
)
|
||||
import library.strategy_sd as strategy_sd
|
||||
|
||||
|
||||
def train(args):
|
||||
train_util.verify_training_args(args)
|
||||
train_util.prepare_dataset_args(args, True)
|
||||
deepspeed_utils.prepare_deepspeed_args(args)
|
||||
setup_logging(args, reset=True)
|
||||
|
||||
cache_latents = args.cache_latents
|
||||
|
||||
if args.seed is not None:
|
||||
set_seed(args.seed) # 乱数系列を初期化する
|
||||
|
||||
tokenizer = train_util.load_tokenizer(args)
|
||||
tokenize_strategy = strategy_sd.SdTokenizeStrategy(args.v2, args.max_token_length, args.tokenizer_cache_dir)
|
||||
strategy_base.TokenizeStrategy.set_strategy(tokenize_strategy)
|
||||
|
||||
blueprint_generator = BlueprintGenerator(ConfigSanitizer(False, True, True))
|
||||
if args.dataset_config is not None:
|
||||
print(f"Load dataset config from {args.dataset_config}")
|
||||
user_config = config_util.load_user_config(args.dataset_config)
|
||||
ignored = ["train_data_dir", "in_json"]
|
||||
if any(getattr(args, attr) is not None for attr in ignored):
|
||||
print(
|
||||
"ignore following options because config file is found: {0} / 設定ファイルが利用されるため以下のオプションは無視されます: {0}".format(
|
||||
", ".join(ignored)
|
||||
# prepare caching strategy: this must be set before preparing dataset. because dataset may use this strategy for initialization.
|
||||
if cache_latents:
|
||||
latents_caching_strategy = strategy_sd.SdSdxlLatentsCachingStrategy(
|
||||
False, args.cache_latents_to_disk, args.vae_batch_size, args.skip_cache_check
|
||||
)
|
||||
strategy_base.LatentsCachingStrategy.set_strategy(latents_caching_strategy)
|
||||
|
||||
# データセットを準備する
|
||||
if args.dataset_class is None:
|
||||
blueprint_generator = BlueprintGenerator(ConfigSanitizer(False, True, False, True))
|
||||
if args.dataset_config is not None:
|
||||
logger.info(f"Load dataset config from {args.dataset_config}")
|
||||
user_config = config_util.load_user_config(args.dataset_config)
|
||||
ignored = ["train_data_dir", "in_json"]
|
||||
if any(getattr(args, attr) is not None for attr in ignored):
|
||||
logger.warning(
|
||||
"ignore following options because config file is found: {0} / 設定ファイルが利用されるため以下のオプションは無視されます: {0}".format(
|
||||
", ".join(ignored)
|
||||
)
|
||||
)
|
||||
)
|
||||
else:
|
||||
user_config = {
|
||||
"datasets": [
|
||||
{
|
||||
"subsets": [
|
||||
{
|
||||
"image_dir": args.train_data_dir,
|
||||
"metadata_file": args.in_json,
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
else:
|
||||
user_config = {
|
||||
"datasets": [
|
||||
{
|
||||
"subsets": [
|
||||
{
|
||||
"image_dir": args.train_data_dir,
|
||||
"metadata_file": args.in_json,
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
blueprint = blueprint_generator.generate(user_config, args, tokenizer=tokenizer)
|
||||
train_dataset_group = config_util.generate_dataset_group_by_blueprint(blueprint.dataset_group)
|
||||
blueprint = blueprint_generator.generate(user_config, args)
|
||||
train_dataset_group, val_dataset_group = config_util.generate_dataset_group_by_blueprint(blueprint.dataset_group)
|
||||
else:
|
||||
train_dataset_group = train_util.load_arbitrary_dataset(args)
|
||||
val_dataset_group = None
|
||||
|
||||
current_epoch = Value("i", 0)
|
||||
current_step = Value("i", 0)
|
||||
ds_for_collater = train_dataset_group if args.max_data_loader_n_workers == 0 else None
|
||||
collater = train_util.collater_class(current_epoch, current_step, ds_for_collater)
|
||||
ds_for_collator = train_dataset_group if args.max_data_loader_n_workers == 0 else None
|
||||
collator = train_util.collator_class(current_epoch, current_step, ds_for_collator)
|
||||
|
||||
train_dataset_group.verify_bucket_reso_steps(64)
|
||||
|
||||
if args.debug_dataset:
|
||||
train_util.debug_dataset(train_dataset_group)
|
||||
return
|
||||
if len(train_dataset_group) == 0:
|
||||
print(
|
||||
logger.error(
|
||||
"No data found. Please verify the metadata file and train_data_dir option. / 画像がありません。メタデータおよびtrain_data_dirオプションを確認してください。"
|
||||
)
|
||||
return
|
||||
@@ -83,14 +119,15 @@ def train(args):
|
||||
), "when caching latents, either color_aug or random_crop cannot be used / latentをキャッシュするときはcolor_augとrandom_cropは使えません"
|
||||
|
||||
# acceleratorを準備する
|
||||
print("prepare accelerator")
|
||||
accelerator, unwrap_model = train_util.prepare_accelerator(args)
|
||||
logger.info("prepare accelerator")
|
||||
accelerator = train_util.prepare_accelerator(args)
|
||||
|
||||
# mixed precisionに対応した型を用意しておき適宜castする
|
||||
weight_dtype, save_dtype = train_util.prepare_dtype(args)
|
||||
vae_dtype = torch.float32 if args.no_half_vae else weight_dtype
|
||||
|
||||
# モデルを読み込む
|
||||
text_encoder, vae, unet, load_stable_diffusion_format = train_util.load_target_model(args, weight_dtype)
|
||||
text_encoder, vae, unet, load_stable_diffusion_format = train_util.load_target_model(args, weight_dtype, accelerator)
|
||||
|
||||
# verify load/save model formats
|
||||
if load_stable_diffusion_format:
|
||||
@@ -128,25 +165,24 @@ def train(args):
|
||||
|
||||
# モデルに xformers とか memory efficient attention を組み込む
|
||||
if args.diffusers_xformers:
|
||||
print("Use xformers by Diffusers")
|
||||
accelerator.print("Use xformers by Diffusers")
|
||||
set_diffusers_xformers_flag(unet, True)
|
||||
else:
|
||||
# Windows版のxformersはfloatで学習できないのでxformersを使わない設定も可能にしておく必要がある
|
||||
print("Disable Diffusers' xformers")
|
||||
accelerator.print("Disable Diffusers' xformers")
|
||||
set_diffusers_xformers_flag(unet, False)
|
||||
train_util.replace_unet_modules(unet, args.mem_eff_attn, args.xformers)
|
||||
train_util.replace_unet_modules(unet, args.mem_eff_attn, args.xformers, args.sdpa)
|
||||
|
||||
# 学習を準備する
|
||||
if cache_latents:
|
||||
vae.to(accelerator.device, dtype=weight_dtype)
|
||||
vae.to(accelerator.device, dtype=vae_dtype)
|
||||
vae.requires_grad_(False)
|
||||
vae.eval()
|
||||
with torch.no_grad():
|
||||
train_dataset_group.cache_latents(vae, args.vae_batch_size, args.cache_latents_to_disk, accelerator.is_main_process)
|
||||
|
||||
train_dataset_group.new_cache_latents(vae, accelerator)
|
||||
|
||||
vae.to("cpu")
|
||||
if torch.cuda.is_available():
|
||||
torch.cuda.empty_cache()
|
||||
gc.collect()
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
@@ -157,7 +193,7 @@ def train(args):
|
||||
training_models.append(unet)
|
||||
|
||||
if args.train_text_encoder:
|
||||
print("enable text encoder training")
|
||||
accelerator.print("enable text encoder training")
|
||||
if args.gradient_checkpointing:
|
||||
text_encoder.gradient_checkpointing_enable()
|
||||
training_models.append(text_encoder)
|
||||
@@ -170,30 +206,43 @@ def train(args):
|
||||
else:
|
||||
text_encoder.eval()
|
||||
|
||||
text_encoding_strategy = strategy_sd.SdTextEncodingStrategy(args.clip_skip)
|
||||
strategy_base.TextEncodingStrategy.set_strategy(text_encoding_strategy)
|
||||
|
||||
if not cache_latents:
|
||||
vae.requires_grad_(False)
|
||||
vae.eval()
|
||||
vae.to(accelerator.device, dtype=weight_dtype)
|
||||
vae.to(accelerator.device, dtype=vae_dtype)
|
||||
|
||||
for m in training_models:
|
||||
m.requires_grad_(True)
|
||||
params = []
|
||||
for m in training_models:
|
||||
params.extend(m.parameters())
|
||||
params_to_optimize = params
|
||||
|
||||
trainable_params = []
|
||||
if args.learning_rate_te is None or not args.train_text_encoder:
|
||||
for m in training_models:
|
||||
trainable_params.extend(m.parameters())
|
||||
else:
|
||||
trainable_params = [
|
||||
{"params": list(unet.parameters()), "lr": args.learning_rate},
|
||||
{"params": list(text_encoder.parameters()), "lr": args.learning_rate_te},
|
||||
]
|
||||
|
||||
# 学習に必要なクラスを準備する
|
||||
print("prepare optimizer, data loader etc.")
|
||||
_, _, optimizer = train_util.get_optimizer(args, trainable_params=params_to_optimize)
|
||||
accelerator.print("prepare optimizer, data loader etc.")
|
||||
_, _, optimizer = train_util.get_optimizer(args, trainable_params=trainable_params)
|
||||
|
||||
# dataloaderを準備する
|
||||
# DataLoaderのプロセス数:0はメインプロセスになる
|
||||
n_workers = min(args.max_data_loader_n_workers, os.cpu_count() - 1) # cpu_count-1 ただし最大で指定された数まで
|
||||
# prepare dataloader
|
||||
# strategies are set here because they cannot be referenced in another process. Copy them with the dataset
|
||||
# some strategies can be None
|
||||
train_dataset_group.set_current_strategies()
|
||||
|
||||
# DataLoaderのプロセス数:0 は persistent_workers が使えないので注意
|
||||
n_workers = min(args.max_data_loader_n_workers, os.cpu_count()) # cpu_count or max_data_loader_n_workers
|
||||
train_dataloader = torch.utils.data.DataLoader(
|
||||
train_dataset_group,
|
||||
batch_size=1,
|
||||
shuffle=True,
|
||||
collate_fn=collater,
|
||||
collate_fn=collator,
|
||||
num_workers=n_workers,
|
||||
persistent_workers=args.persistent_data_loader_workers,
|
||||
)
|
||||
@@ -203,7 +252,9 @@ def train(args):
|
||||
args.max_train_steps = args.max_train_epochs * math.ceil(
|
||||
len(train_dataloader) / accelerator.num_processes / args.gradient_accumulation_steps
|
||||
)
|
||||
print(f"override steps. steps for {args.max_train_epochs} epochs is / 指定エポックまでのステップ数: {args.max_train_steps}")
|
||||
accelerator.print(
|
||||
f"override steps. steps for {args.max_train_epochs} epochs is / 指定エポックまでのステップ数: {args.max_train_steps}"
|
||||
)
|
||||
|
||||
# データセット側にも学習ステップを送信
|
||||
train_dataset_group.set_max_train_steps(args.max_train_steps)
|
||||
@@ -216,17 +267,27 @@ def train(args):
|
||||
assert (
|
||||
args.mixed_precision == "fp16"
|
||||
), "full_fp16 requires mixed precision='fp16' / full_fp16を使う場合はmixed_precision='fp16'を指定してください。"
|
||||
print("enable full fp16 training.")
|
||||
accelerator.print("enable full fp16 training.")
|
||||
unet.to(weight_dtype)
|
||||
text_encoder.to(weight_dtype)
|
||||
|
||||
# acceleratorがなんかよろしくやってくれるらしい
|
||||
if args.train_text_encoder:
|
||||
unet, text_encoder, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
|
||||
unet, text_encoder, optimizer, train_dataloader, lr_scheduler
|
||||
if args.deepspeed:
|
||||
if args.train_text_encoder:
|
||||
ds_model = deepspeed_utils.prepare_deepspeed_model(args, unet=unet, text_encoder=text_encoder)
|
||||
else:
|
||||
ds_model = deepspeed_utils.prepare_deepspeed_model(args, unet=unet)
|
||||
ds_model, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
|
||||
ds_model, optimizer, train_dataloader, lr_scheduler
|
||||
)
|
||||
training_models = [ds_model]
|
||||
else:
|
||||
unet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(unet, optimizer, train_dataloader, lr_scheduler)
|
||||
# acceleratorがなんかよろしくやってくれるらしい
|
||||
if args.train_text_encoder:
|
||||
unet, text_encoder, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
|
||||
unet, text_encoder, optimizer, train_dataloader, lr_scheduler
|
||||
)
|
||||
else:
|
||||
unet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(unet, optimizer, train_dataloader, lr_scheduler)
|
||||
|
||||
# 実験的機能:勾配も含めたfp16学習を行う PyTorchにパッチを当ててfp16でのgrad scaleを有効にする
|
||||
if args.full_fp16:
|
||||
@@ -243,14 +304,16 @@ def train(args):
|
||||
|
||||
# 学習する
|
||||
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
|
||||
print("running training / 学習開始")
|
||||
print(f" num examples / サンプル数: {train_dataset_group.num_train_images}")
|
||||
print(f" num batches per epoch / 1epochのバッチ数: {len(train_dataloader)}")
|
||||
print(f" num epochs / epoch数: {num_train_epochs}")
|
||||
print(f" batch size per device / バッチサイズ: {args.train_batch_size}")
|
||||
print(f" total train batch size (with parallel & distributed & accumulation) / 総バッチサイズ(並列学習、勾配合計含む): {total_batch_size}")
|
||||
print(f" gradient accumulation steps / 勾配を合計するステップ数 = {args.gradient_accumulation_steps}")
|
||||
print(f" total optimization steps / 学習ステップ数: {args.max_train_steps}")
|
||||
accelerator.print("running training / 学習開始")
|
||||
accelerator.print(f" num examples / サンプル数: {train_dataset_group.num_train_images}")
|
||||
accelerator.print(f" num batches per epoch / 1epochのバッチ数: {len(train_dataloader)}")
|
||||
accelerator.print(f" num epochs / epoch数: {num_train_epochs}")
|
||||
accelerator.print(f" batch size per device / バッチサイズ: {args.train_batch_size}")
|
||||
accelerator.print(
|
||||
f" total train batch size (with parallel & distributed & accumulation) / 総バッチサイズ(並列学習、勾配合計含む): {total_batch_size}"
|
||||
)
|
||||
accelerator.print(f" gradient accumulation steps / 勾配を合計するステップ数 = {args.gradient_accumulation_steps}")
|
||||
accelerator.print(f" total optimization steps / 学習ステップ数: {args.max_train_steps}")
|
||||
|
||||
progress_bar = tqdm(range(args.max_train_steps), smoothing=0, disable=not accelerator.is_local_main_process, desc="steps")
|
||||
global_step = 0
|
||||
@@ -258,59 +321,68 @@ def train(args):
|
||||
noise_scheduler = DDPMScheduler(
|
||||
beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000, clip_sample=False
|
||||
)
|
||||
prepare_scheduler_for_custom_training(noise_scheduler, accelerator.device)
|
||||
if args.zero_terminal_snr:
|
||||
custom_train_functions.fix_noise_scheduler_betas_for_zero_terminal_snr(noise_scheduler)
|
||||
|
||||
if accelerator.is_main_process:
|
||||
accelerator.init_trackers("finetuning" if args.log_tracker_name is None else args.log_tracker_name)
|
||||
init_kwargs = {}
|
||||
if args.wandb_run_name:
|
||||
init_kwargs["wandb"] = {"name": args.wandb_run_name}
|
||||
if args.log_tracker_config is not None:
|
||||
init_kwargs = toml.load(args.log_tracker_config)
|
||||
accelerator.init_trackers(
|
||||
"finetuning" if args.log_tracker_name is None else args.log_tracker_name,
|
||||
config=train_util.get_sanitized_config_or_none(args),
|
||||
init_kwargs=init_kwargs,
|
||||
)
|
||||
|
||||
# For --sample_at_first
|
||||
train_util.sample_images(
|
||||
accelerator, args, 0, global_step, accelerator.device, vae, tokenize_strategy.tokenizer, text_encoder, unet
|
||||
)
|
||||
if len(accelerator.trackers) > 0:
|
||||
# log empty object to commit the sample images to wandb
|
||||
accelerator.log({}, step=0)
|
||||
|
||||
loss_recorder = train_util.LossRecorder()
|
||||
for epoch in range(num_train_epochs):
|
||||
print(f"epoch {epoch+1}/{num_train_epochs}")
|
||||
accelerator.print(f"\nepoch {epoch+1}/{num_train_epochs}")
|
||||
current_epoch.value = epoch + 1
|
||||
|
||||
for m in training_models:
|
||||
m.train()
|
||||
|
||||
loss_total = 0
|
||||
for step, batch in enumerate(train_dataloader):
|
||||
current_step.value = global_step
|
||||
with accelerator.accumulate(training_models[0]): # 複数モデルに対応していない模様だがとりあえずこうしておく
|
||||
with accelerator.accumulate(*training_models):
|
||||
with torch.no_grad():
|
||||
if "latents" in batch and batch["latents"] is not None:
|
||||
latents = batch["latents"].to(accelerator.device) # .to(dtype=weight_dtype)
|
||||
latents = batch["latents"].to(accelerator.device).to(dtype=weight_dtype)
|
||||
else:
|
||||
# latentに変換
|
||||
latents = vae.encode(batch["images"].to(dtype=weight_dtype)).latent_dist.sample()
|
||||
latents = vae.encode(batch["images"].to(dtype=vae_dtype)).latent_dist.sample().to(weight_dtype)
|
||||
latents = latents * 0.18215
|
||||
b_size = latents.shape[0]
|
||||
|
||||
with torch.set_grad_enabled(args.train_text_encoder):
|
||||
# Get the text embedding for conditioning
|
||||
if args.weighted_captions:
|
||||
encoder_hidden_states = get_weighted_text_embeddings(tokenizer,
|
||||
text_encoder,
|
||||
batch["captions"],
|
||||
accelerator.device,
|
||||
args.max_token_length // 75 if args.max_token_length else 1,
|
||||
clip_skip=args.clip_skip,
|
||||
)
|
||||
input_ids_list, weights_list = tokenize_strategy.tokenize_with_weights(batch["captions"])
|
||||
encoder_hidden_states = text_encoding_strategy.encode_tokens_with_weights(
|
||||
tokenize_strategy, [text_encoder], input_ids_list, weights_list
|
||||
)[0]
|
||||
else:
|
||||
input_ids = batch["input_ids"].to(accelerator.device)
|
||||
encoder_hidden_states = train_util.get_hidden_states(
|
||||
args, input_ids, tokenizer, text_encoder, None if not args.full_fp16 else weight_dtype
|
||||
)
|
||||
input_ids = batch["input_ids_list"][0].to(accelerator.device)
|
||||
encoder_hidden_states = text_encoding_strategy.encode_tokens(
|
||||
tokenize_strategy, [text_encoder], [input_ids]
|
||||
)[0]
|
||||
if args.full_fp16:
|
||||
encoder_hidden_states = encoder_hidden_states.to(weight_dtype)
|
||||
|
||||
# Sample noise that we'll add to the latents
|
||||
noise = torch.randn_like(latents, device=latents.device)
|
||||
if args.noise_offset:
|
||||
# https://www.crosslabs.org//blog/diffusion-with-offset-noise
|
||||
noise += args.noise_offset * torch.randn((latents.shape[0], latents.shape[1], 1, 1), device=latents.device)
|
||||
|
||||
# Sample a random timestep for each image
|
||||
timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (b_size,), device=latents.device)
|
||||
timesteps = timesteps.long()
|
||||
|
||||
# Add noise to the latents according to the noise magnitude at each timestep
|
||||
# (this is the forward diffusion process)
|
||||
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
|
||||
# Sample noise, sample a random timestep for each image, and add noise to the latents,
|
||||
# with noise offset and/or multires noise if specified
|
||||
noise, noisy_latents, timesteps = train_util.get_noise_noisy_latents_and_timesteps(args, noise_scheduler, latents)
|
||||
|
||||
# Predict the noise residual
|
||||
with accelerator.autocast():
|
||||
@@ -322,14 +394,22 @@ def train(args):
|
||||
else:
|
||||
target = noise
|
||||
|
||||
if args.min_snr_gamma:
|
||||
# do not mean over batch dimension for snr weight
|
||||
loss = torch.nn.functional.mse_loss(noise_pred.float(), target.float(), reduction="none")
|
||||
huber_c = train_util.get_huber_threshold_if_needed(args, timesteps, noise_scheduler)
|
||||
if args.min_snr_gamma or args.scale_v_pred_loss_like_noise_pred or args.debiased_estimation_loss:
|
||||
# do not mean over batch dimension for snr weight or scale v-pred loss
|
||||
loss = train_util.conditional_loss(noise_pred.float(), target.float(), args.loss_type, "none", huber_c)
|
||||
loss = loss.mean([1, 2, 3])
|
||||
loss = apply_snr_weight(loss, timesteps, noise_scheduler, args.min_snr_gamma)
|
||||
|
||||
if args.min_snr_gamma:
|
||||
loss = apply_snr_weight(loss, timesteps, noise_scheduler, args.min_snr_gamma, args.v_parameterization)
|
||||
if args.scale_v_pred_loss_like_noise_pred:
|
||||
loss = scale_v_prediction_loss_like_noise_prediction(loss, timesteps, noise_scheduler)
|
||||
if args.debiased_estimation_loss:
|
||||
loss = apply_debiased_estimation(loss, timesteps, noise_scheduler, args.v_parameterization)
|
||||
|
||||
loss = loss.mean() # mean over batch dimension
|
||||
else:
|
||||
loss = torch.nn.functional.mse_loss(noise_pred.float(), target.float(), reduction="mean")
|
||||
loss = train_util.conditional_loss(noise_pred.float(), target.float(), args.loss_type, "mean", huber_c)
|
||||
|
||||
accelerator.backward(loss)
|
||||
if accelerator.sync_gradients and args.max_grad_norm != 0.0:
|
||||
@@ -348,60 +428,81 @@ def train(args):
|
||||
global_step += 1
|
||||
|
||||
train_util.sample_images(
|
||||
accelerator, args, None, global_step, accelerator.device, vae, tokenizer, text_encoder, unet
|
||||
accelerator, args, None, global_step, accelerator.device, vae, tokenize_strategy.tokenizer, text_encoder, unet
|
||||
)
|
||||
|
||||
# 指定ステップごとにモデルを保存
|
||||
if args.save_every_n_steps is not None and global_step % args.save_every_n_steps == 0:
|
||||
accelerator.wait_for_everyone()
|
||||
if accelerator.is_main_process:
|
||||
src_path = src_stable_diffusion_ckpt if save_stable_diffusion_format else src_diffusers_model_path
|
||||
train_util.save_sd_model_on_epoch_end_or_stepwise(
|
||||
args,
|
||||
False,
|
||||
accelerator,
|
||||
src_path,
|
||||
save_stable_diffusion_format,
|
||||
use_safetensors,
|
||||
save_dtype,
|
||||
epoch,
|
||||
num_train_epochs,
|
||||
global_step,
|
||||
accelerator.unwrap_model(text_encoder),
|
||||
accelerator.unwrap_model(unet),
|
||||
vae,
|
||||
)
|
||||
|
||||
current_loss = loss.detach().item() # 平均なのでbatch sizeは関係ないはず
|
||||
if args.logging_dir is not None:
|
||||
logs = {"loss": current_loss, "lr": float(lr_scheduler.get_last_lr()[0])}
|
||||
if args.optimizer_type.lower() == "DAdaptation".lower(): # tracking d*lr value
|
||||
logs["lr/d*lr"] = (
|
||||
lr_scheduler.optimizers[0].param_groups[0]["d"] * lr_scheduler.optimizers[0].param_groups[0]["lr"]
|
||||
)
|
||||
if len(accelerator.trackers) > 0:
|
||||
logs = {"loss": current_loss}
|
||||
train_util.append_lr_to_logs(logs, lr_scheduler, args.optimizer_type, including_unet=True)
|
||||
accelerator.log(logs, step=global_step)
|
||||
|
||||
# TODO moving averageにする
|
||||
loss_total += current_loss
|
||||
avr_loss = loss_total / (step + 1)
|
||||
logs = {"loss": avr_loss} # , "lr": lr_scheduler.get_last_lr()[0]}
|
||||
loss_recorder.add(epoch=epoch, step=step, loss=current_loss)
|
||||
avr_loss: float = loss_recorder.moving_average
|
||||
logs = {"avr_loss": avr_loss} # , "lr": lr_scheduler.get_last_lr()[0]}
|
||||
progress_bar.set_postfix(**logs)
|
||||
|
||||
if global_step >= args.max_train_steps:
|
||||
break
|
||||
|
||||
if args.logging_dir is not None:
|
||||
logs = {"loss/epoch": loss_total / len(train_dataloader)}
|
||||
if len(accelerator.trackers) > 0:
|
||||
logs = {"loss/epoch": loss_recorder.moving_average}
|
||||
accelerator.log(logs, step=epoch + 1)
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
if args.save_every_n_epochs is not None:
|
||||
src_path = src_stable_diffusion_ckpt if save_stable_diffusion_format else src_diffusers_model_path
|
||||
train_util.save_sd_model_on_epoch_end(
|
||||
args,
|
||||
accelerator,
|
||||
src_path,
|
||||
save_stable_diffusion_format,
|
||||
use_safetensors,
|
||||
save_dtype,
|
||||
epoch,
|
||||
num_train_epochs,
|
||||
global_step,
|
||||
unwrap_model(text_encoder),
|
||||
unwrap_model(unet),
|
||||
vae,
|
||||
)
|
||||
if accelerator.is_main_process:
|
||||
src_path = src_stable_diffusion_ckpt if save_stable_diffusion_format else src_diffusers_model_path
|
||||
train_util.save_sd_model_on_epoch_end_or_stepwise(
|
||||
args,
|
||||
True,
|
||||
accelerator,
|
||||
src_path,
|
||||
save_stable_diffusion_format,
|
||||
use_safetensors,
|
||||
save_dtype,
|
||||
epoch,
|
||||
num_train_epochs,
|
||||
global_step,
|
||||
accelerator.unwrap_model(text_encoder),
|
||||
accelerator.unwrap_model(unet),
|
||||
vae,
|
||||
)
|
||||
|
||||
train_util.sample_images(accelerator, args, epoch + 1, global_step, accelerator.device, vae, tokenizer, text_encoder, unet)
|
||||
train_util.sample_images(
|
||||
accelerator, args, epoch + 1, global_step, accelerator.device, vae, tokenize_strategy.tokenizer, text_encoder, unet
|
||||
)
|
||||
|
||||
is_main_process = accelerator.is_main_process
|
||||
if is_main_process:
|
||||
unet = unwrap_model(unet)
|
||||
text_encoder = unwrap_model(text_encoder)
|
||||
unet = accelerator.unwrap_model(unet)
|
||||
text_encoder = accelerator.unwrap_model(text_encoder)
|
||||
|
||||
accelerator.end_training()
|
||||
|
||||
if args.save_state:
|
||||
if is_main_process and (args.save_state or args.save_state_on_train_end):
|
||||
train_util.save_state_on_train_end(args, accelerator)
|
||||
|
||||
del accelerator # この後メモリを使うのでこれは消す
|
||||
@@ -411,22 +512,38 @@ def train(args):
|
||||
train_util.save_sd_model_on_train_end(
|
||||
args, src_path, save_stable_diffusion_format, use_safetensors, save_dtype, epoch, global_step, text_encoder, unet, vae
|
||||
)
|
||||
print("model saved.")
|
||||
logger.info("model saved.")
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
add_logging_arguments(parser)
|
||||
train_util.add_sd_models_arguments(parser)
|
||||
sai_model_spec.add_model_spec_arguments(parser)
|
||||
train_util.add_dataset_arguments(parser, False, True, True)
|
||||
train_util.add_training_arguments(parser, False)
|
||||
deepspeed_utils.add_deepspeed_arguments(parser)
|
||||
train_util.add_sd_saving_arguments(parser)
|
||||
train_util.add_optimizer_arguments(parser)
|
||||
config_util.add_config_arguments(parser)
|
||||
custom_train_functions.add_custom_train_arguments(parser)
|
||||
|
||||
parser.add_argument("--diffusers_xformers", action="store_true", help="use xformers by diffusers / Diffusersでxformersを使用する")
|
||||
parser.add_argument(
|
||||
"--diffusers_xformers", action="store_true", help="use xformers by diffusers / Diffusersでxformersを使用する"
|
||||
)
|
||||
parser.add_argument("--train_text_encoder", action="store_true", help="train text encoder / text encoderも学習する")
|
||||
parser.add_argument(
|
||||
"--learning_rate_te",
|
||||
type=float,
|
||||
default=None,
|
||||
help="learning rate for text encoder, default is same as unet / Text Encoderの学習率、デフォルトはunetと同じ",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--no_half_vae",
|
||||
action="store_true",
|
||||
help="do not use fp16/bf16 VAE in mixed precision (use float VAE) / mixed precisionでも fp16/bf16 VAEを使わずfloat VAEを使う",
|
||||
)
|
||||
|
||||
return parser
|
||||
|
||||
@@ -435,6 +552,7 @@ if __name__ == "__main__":
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
train_util.verify_command_line_training_args(args)
|
||||
args = train_util.read_config_from_file(args, parser)
|
||||
|
||||
train(args)
|
||||
train(args)
|
||||
|
||||
@@ -21,6 +21,10 @@ import torch.nn.functional as F
|
||||
import os
|
||||
from urllib.parse import urlparse
|
||||
from timm.models.hub import download_cached_file
|
||||
from library.utils import setup_logging
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class BLIP_Base(nn.Module):
|
||||
def __init__(self,
|
||||
@@ -130,8 +134,9 @@ class BLIP_Decoder(nn.Module):
|
||||
def generate(self, image, sample=False, num_beams=3, max_length=30, min_length=10, top_p=0.9, repetition_penalty=1.0):
|
||||
image_embeds = self.visual_encoder(image)
|
||||
|
||||
if not sample:
|
||||
image_embeds = image_embeds.repeat_interleave(num_beams,dim=0)
|
||||
# recent version of transformers seems to do repeat_interleave automatically
|
||||
# if not sample:
|
||||
# image_embeds = image_embeds.repeat_interleave(num_beams,dim=0)
|
||||
|
||||
image_atts = torch.ones(image_embeds.size()[:-1],dtype=torch.long).to(image.device)
|
||||
model_kwargs = {"encoder_hidden_states": image_embeds, "encoder_attention_mask":image_atts}
|
||||
@@ -235,6 +240,6 @@ def load_checkpoint(model,url_or_filename):
|
||||
del state_dict[key]
|
||||
|
||||
msg = model.load_state_dict(state_dict,strict=False)
|
||||
print('load checkpoint from %s'%url_or_filename)
|
||||
logger.info('load checkpoint from %s'%url_or_filename)
|
||||
return model,msg
|
||||
|
||||
|
||||
@@ -8,6 +8,10 @@ import json
|
||||
import re
|
||||
|
||||
from tqdm import tqdm
|
||||
from library.utils import setup_logging
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
PATTERN_HAIR_LENGTH = re.compile(r', (long|short|medium) hair, ')
|
||||
PATTERN_HAIR_CUT = re.compile(r', (bob|hime) cut, ')
|
||||
@@ -36,13 +40,13 @@ def clean_tags(image_key, tags):
|
||||
tokens = tags.split(", rating")
|
||||
if len(tokens) == 1:
|
||||
# WD14 taggerのときはこちらになるのでメッセージは出さない
|
||||
# print("no rating:")
|
||||
# print(f"{image_key} {tags}")
|
||||
# logger.info("no rating:")
|
||||
# logger.info(f"{image_key} {tags}")
|
||||
pass
|
||||
else:
|
||||
if len(tokens) > 2:
|
||||
print("multiple ratings:")
|
||||
print(f"{image_key} {tags}")
|
||||
logger.info("multiple ratings:")
|
||||
logger.info(f"{image_key} {tags}")
|
||||
tags = tokens[0]
|
||||
|
||||
tags = ", " + tags.replace(", ", ", , ") + ", " # カンマ付きで検索をするための身も蓋もない対策
|
||||
@@ -124,43 +128,43 @@ def clean_caption(caption):
|
||||
|
||||
def main(args):
|
||||
if os.path.exists(args.in_json):
|
||||
print(f"loading existing metadata: {args.in_json}")
|
||||
logger.info(f"loading existing metadata: {args.in_json}")
|
||||
with open(args.in_json, "rt", encoding='utf-8') as f:
|
||||
metadata = json.load(f)
|
||||
else:
|
||||
print("no metadata / メタデータファイルがありません")
|
||||
logger.error("no metadata / メタデータファイルがありません")
|
||||
return
|
||||
|
||||
print("cleaning captions and tags.")
|
||||
logger.info("cleaning captions and tags.")
|
||||
image_keys = list(metadata.keys())
|
||||
for image_key in tqdm(image_keys):
|
||||
tags = metadata[image_key].get('tags')
|
||||
if tags is None:
|
||||
print(f"image does not have tags / メタデータにタグがありません: {image_key}")
|
||||
logger.error(f"image does not have tags / メタデータにタグがありません: {image_key}")
|
||||
else:
|
||||
org = tags
|
||||
tags = clean_tags(image_key, tags)
|
||||
metadata[image_key]['tags'] = tags
|
||||
if args.debug and org != tags:
|
||||
print("FROM: " + org)
|
||||
print("TO: " + tags)
|
||||
logger.info("FROM: " + org)
|
||||
logger.info("TO: " + tags)
|
||||
|
||||
caption = metadata[image_key].get('caption')
|
||||
if caption is None:
|
||||
print(f"image does not have caption / メタデータにキャプションがありません: {image_key}")
|
||||
logger.error(f"image does not have caption / メタデータにキャプションがありません: {image_key}")
|
||||
else:
|
||||
org = caption
|
||||
caption = clean_caption(caption)
|
||||
metadata[image_key]['caption'] = caption
|
||||
if args.debug and org != caption:
|
||||
print("FROM: " + org)
|
||||
print("TO: " + caption)
|
||||
logger.info("FROM: " + org)
|
||||
logger.info("TO: " + caption)
|
||||
|
||||
# metadataを書き出して終わり
|
||||
print(f"writing metadata: {args.out_json}")
|
||||
logger.info(f"writing metadata: {args.out_json}")
|
||||
with open(args.out_json, "wt", encoding='utf-8') as f:
|
||||
json.dump(metadata, f, indent=2)
|
||||
print("done!")
|
||||
logger.info("done!")
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
@@ -178,10 +182,10 @@ if __name__ == '__main__':
|
||||
|
||||
args, unknown = parser.parse_known_args()
|
||||
if len(unknown) == 1:
|
||||
print("WARNING: train_data_dir argument is removed. This script will not work with three arguments in future. Please specify two arguments: in_json and out_json.")
|
||||
print("All captions and tags in the metadata are processed.")
|
||||
print("警告: train_data_dir引数は不要になりました。将来的には三つの引数を指定すると動かなくなる予定です。読み込み元のメタデータと書き出し先の二つの引数だけ指定してください。")
|
||||
print("メタデータ内のすべてのキャプションとタグが処理されます。")
|
||||
logger.warning("WARNING: train_data_dir argument is removed. This script will not work with three arguments in future. Please specify two arguments: in_json and out_json.")
|
||||
logger.warning("All captions and tags in the metadata are processed.")
|
||||
logger.warning("警告: train_data_dir引数は不要になりました。将来的には三つの引数を指定すると動かなくなる予定です。読み込み元のメタデータと書き出し先の二つの引数だけ指定してください。")
|
||||
logger.warning("メタデータ内のすべてのキャプションとタグが処理されます。")
|
||||
args.in_json = args.out_json
|
||||
args.out_json = unknown[0]
|
||||
elif len(unknown) > 0:
|
||||
|
||||
@@ -3,18 +3,28 @@ import glob
|
||||
import os
|
||||
import json
|
||||
import random
|
||||
import sys
|
||||
|
||||
from pathlib import Path
|
||||
from PIL import Image
|
||||
from tqdm import tqdm
|
||||
import numpy as np
|
||||
|
||||
import torch
|
||||
from library.device_utils import init_ipex, get_preferred_device
|
||||
init_ipex()
|
||||
|
||||
from torchvision import transforms
|
||||
from torchvision.transforms.functional import InterpolationMode
|
||||
from blip.blip import blip_decoder
|
||||
sys.path.append(os.path.dirname(__file__))
|
||||
from blip.blip import blip_decoder, is_url
|
||||
import library.train_util as train_util
|
||||
from library.utils import setup_logging
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
||||
DEVICE = get_preferred_device()
|
||||
|
||||
|
||||
IMAGE_SIZE = 384
|
||||
@@ -45,7 +55,7 @@ class ImageLoadingTransformDataset(torch.utils.data.Dataset):
|
||||
# convert to tensor temporarily so dataloader will accept it
|
||||
tensor = IMAGE_TRANSFORM(image)
|
||||
except Exception as e:
|
||||
print(f"Could not load image path / 画像を読み込めません: {img_path}, error: {e}")
|
||||
logger.error(f"Could not load image path / 画像を読み込めません: {img_path}, error: {e}")
|
||||
return None
|
||||
|
||||
return (tensor, img_path)
|
||||
@@ -72,19 +82,21 @@ def main(args):
|
||||
args.train_data_dir = os.path.abspath(args.train_data_dir) # convert to absolute path
|
||||
|
||||
cwd = os.getcwd()
|
||||
print("Current Working Directory is: ", cwd)
|
||||
logger.info(f"Current Working Directory is: {cwd}")
|
||||
os.chdir("finetune")
|
||||
if not is_url(args.caption_weights) and not os.path.isfile(args.caption_weights):
|
||||
args.caption_weights = os.path.join("..", args.caption_weights)
|
||||
|
||||
print(f"load images from {args.train_data_dir}")
|
||||
logger.info(f"load images from {args.train_data_dir}")
|
||||
train_data_dir_path = Path(args.train_data_dir)
|
||||
image_paths = train_util.glob_images_pathlib(train_data_dir_path, args.recursive)
|
||||
print(f"found {len(image_paths)} images.")
|
||||
logger.info(f"found {len(image_paths)} images.")
|
||||
|
||||
print(f"loading BLIP caption: {args.caption_weights}")
|
||||
logger.info(f"loading BLIP caption: {args.caption_weights}")
|
||||
model = blip_decoder(pretrained=args.caption_weights, image_size=IMAGE_SIZE, vit="large", med_config="./blip/med_config.json")
|
||||
model.eval()
|
||||
model = model.to(DEVICE)
|
||||
print("BLIP loaded")
|
||||
logger.info("BLIP loaded")
|
||||
|
||||
# captioningする
|
||||
def run_batch(path_imgs):
|
||||
@@ -104,7 +116,7 @@ def main(args):
|
||||
with open(os.path.splitext(image_path)[0] + args.caption_extension, "wt", encoding="utf-8") as f:
|
||||
f.write(caption + "\n")
|
||||
if args.debug:
|
||||
print(image_path, caption)
|
||||
logger.info(f'{image_path} {caption}')
|
||||
|
||||
# 読み込みの高速化のためにDataLoaderを使うオプション
|
||||
if args.max_data_loader_n_workers is not None:
|
||||
@@ -134,7 +146,7 @@ def main(args):
|
||||
raw_image = raw_image.convert("RGB")
|
||||
img_tensor = IMAGE_TRANSFORM(raw_image)
|
||||
except Exception as e:
|
||||
print(f"Could not load image path / 画像を読み込めません: {image_path}, error: {e}")
|
||||
logger.error(f"Could not load image path / 画像を読み込めません: {image_path}, error: {e}")
|
||||
continue
|
||||
|
||||
b_imgs.append((image_path, img_tensor))
|
||||
@@ -144,7 +156,7 @@ def main(args):
|
||||
if len(b_imgs) > 0:
|
||||
run_batch(b_imgs)
|
||||
|
||||
print("done!")
|
||||
logger.info("done!")
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
|
||||
@@ -5,12 +5,19 @@ import re
|
||||
from pathlib import Path
|
||||
from PIL import Image
|
||||
from tqdm import tqdm
|
||||
|
||||
import torch
|
||||
from library.device_utils import init_ipex, get_preferred_device
|
||||
init_ipex()
|
||||
|
||||
from transformers import AutoProcessor, AutoModelForCausalLM
|
||||
from transformers.generation.utils import GenerationMixin
|
||||
|
||||
import library.train_util as train_util
|
||||
|
||||
from library.utils import setup_logging
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
||||
|
||||
@@ -35,8 +42,8 @@ def remove_words(captions, debug):
|
||||
for pat in PATTERN_REPLACE:
|
||||
cap = pat.sub("", cap)
|
||||
if debug and cap != caption:
|
||||
print(caption)
|
||||
print(cap)
|
||||
logger.info(caption)
|
||||
logger.info(cap)
|
||||
removed_caps.append(cap)
|
||||
return removed_caps
|
||||
|
||||
@@ -52,6 +59,9 @@ def collate_fn_remove_corrupted(batch):
|
||||
|
||||
|
||||
def main(args):
|
||||
r"""
|
||||
transformers 4.30.2で、バッチサイズ>1でも動くようになったので、以下コメントアウト
|
||||
|
||||
# GITにバッチサイズが1より大きくても動くようにパッチを当てる: transformers 4.26.0用
|
||||
org_prepare_input_ids_for_generation = GenerationMixin._prepare_input_ids_for_generation
|
||||
curr_batch_size = [args.batch_size] # ループの最後で件数がbatch_size未満になるので入れ替えられるように
|
||||
@@ -65,23 +75,24 @@ def main(args):
|
||||
return input_ids
|
||||
|
||||
GenerationMixin._prepare_input_ids_for_generation = _prepare_input_ids_for_generation_patch
|
||||
"""
|
||||
|
||||
print(f"load images from {args.train_data_dir}")
|
||||
logger.info(f"load images from {args.train_data_dir}")
|
||||
train_data_dir_path = Path(args.train_data_dir)
|
||||
image_paths = train_util.glob_images_pathlib(train_data_dir_path, args.recursive)
|
||||
print(f"found {len(image_paths)} images.")
|
||||
logger.info(f"found {len(image_paths)} images.")
|
||||
|
||||
# できればcacheに依存せず明示的にダウンロードしたい
|
||||
print(f"loading GIT: {args.model_id}")
|
||||
logger.info(f"loading GIT: {args.model_id}")
|
||||
git_processor = AutoProcessor.from_pretrained(args.model_id)
|
||||
git_model = AutoModelForCausalLM.from_pretrained(args.model_id).to(DEVICE)
|
||||
print("GIT loaded")
|
||||
logger.info("GIT loaded")
|
||||
|
||||
# captioningする
|
||||
def run_batch(path_imgs):
|
||||
imgs = [im for _, im in path_imgs]
|
||||
|
||||
curr_batch_size[0] = len(path_imgs)
|
||||
# curr_batch_size[0] = len(path_imgs)
|
||||
inputs = git_processor(images=imgs, return_tensors="pt").to(DEVICE) # 画像はpil形式
|
||||
generated_ids = git_model.generate(pixel_values=inputs.pixel_values, max_length=args.max_length)
|
||||
captions = git_processor.batch_decode(generated_ids, skip_special_tokens=True)
|
||||
@@ -93,7 +104,7 @@ def main(args):
|
||||
with open(os.path.splitext(image_path)[0] + args.caption_extension, "wt", encoding="utf-8") as f:
|
||||
f.write(caption + "\n")
|
||||
if args.debug:
|
||||
print(image_path, caption)
|
||||
logger.info(f"{image_path} {caption}")
|
||||
|
||||
# 読み込みの高速化のためにDataLoaderを使うオプション
|
||||
if args.max_data_loader_n_workers is not None:
|
||||
@@ -122,7 +133,7 @@ def main(args):
|
||||
if image.mode != "RGB":
|
||||
image = image.convert("RGB")
|
||||
except Exception as e:
|
||||
print(f"Could not load image path / 画像を読み込めません: {image_path}, error: {e}")
|
||||
logger.error(f"Could not load image path / 画像を読み込めません: {image_path}, error: {e}")
|
||||
continue
|
||||
|
||||
b_imgs.append((image_path, image))
|
||||
@@ -133,7 +144,7 @@ def main(args):
|
||||
if len(b_imgs) > 0:
|
||||
run_batch(b_imgs)
|
||||
|
||||
print("done!")
|
||||
logger.info("done!")
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
|
||||
@@ -5,72 +5,96 @@ from typing import List
|
||||
from tqdm import tqdm
|
||||
import library.train_util as train_util
|
||||
import os
|
||||
from library.utils import setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
def main(args):
|
||||
assert not args.recursive or (args.recursive and args.full_path), "recursive requires full_path / recursiveはfull_pathと同時に指定してください"
|
||||
assert not args.recursive or (
|
||||
args.recursive and args.full_path
|
||||
), "recursive requires full_path / recursiveはfull_pathと同時に指定してください"
|
||||
|
||||
train_data_dir_path = Path(args.train_data_dir)
|
||||
image_paths: List[Path] = train_util.glob_images_pathlib(train_data_dir_path, args.recursive)
|
||||
print(f"found {len(image_paths)} images.")
|
||||
train_data_dir_path = Path(args.train_data_dir)
|
||||
image_paths: List[Path] = train_util.glob_images_pathlib(train_data_dir_path, args.recursive)
|
||||
logger.info(f"found {len(image_paths)} images.")
|
||||
|
||||
if args.in_json is None and Path(args.out_json).is_file():
|
||||
args.in_json = args.out_json
|
||||
if args.in_json is None and Path(args.out_json).is_file():
|
||||
args.in_json = args.out_json
|
||||
|
||||
if args.in_json is not None:
|
||||
print(f"loading existing metadata: {args.in_json}")
|
||||
metadata = json.loads(Path(args.in_json).read_text(encoding='utf-8'))
|
||||
print("captions for existing images will be overwritten / 既存の画像のキャプションは上書きされます")
|
||||
else:
|
||||
print("new metadata will be created / 新しいメタデータファイルが作成されます")
|
||||
metadata = {}
|
||||
if args.in_json is not None:
|
||||
logger.info(f"loading existing metadata: {args.in_json}")
|
||||
metadata = json.loads(Path(args.in_json).read_text(encoding="utf-8"))
|
||||
logger.warning("captions for existing images will be overwritten / 既存の画像のキャプションは上書きされます")
|
||||
else:
|
||||
logger.info("new metadata will be created / 新しいメタデータファイルが作成されます")
|
||||
metadata = {}
|
||||
|
||||
print("merge caption texts to metadata json.")
|
||||
for image_path in tqdm(image_paths):
|
||||
caption_path = image_path.with_suffix(args.caption_extension)
|
||||
caption = caption_path.read_text(encoding='utf-8').strip()
|
||||
logger.info("merge caption texts to metadata json.")
|
||||
for image_path in tqdm(image_paths):
|
||||
caption_path = image_path.with_suffix(args.caption_extension)
|
||||
caption = caption_path.read_text(encoding="utf-8").strip()
|
||||
|
||||
if not os.path.exists(caption_path):
|
||||
caption_path = os.path.join(image_path, args.caption_extension)
|
||||
if not os.path.exists(caption_path):
|
||||
caption_path = os.path.join(image_path, args.caption_extension)
|
||||
|
||||
image_key = str(image_path) if args.full_path else image_path.stem
|
||||
if image_key not in metadata:
|
||||
metadata[image_key] = {}
|
||||
image_key = str(image_path) if args.full_path else image_path.stem
|
||||
if image_key not in metadata:
|
||||
metadata[image_key] = {}
|
||||
|
||||
metadata[image_key]['caption'] = caption
|
||||
if args.debug:
|
||||
print(image_key, caption)
|
||||
metadata[image_key]["caption"] = caption
|
||||
if args.debug:
|
||||
logger.info(f"{image_key} {caption}")
|
||||
|
||||
# metadataを書き出して終わり
|
||||
print(f"writing metadata: {args.out_json}")
|
||||
Path(args.out_json).write_text(json.dumps(metadata, indent=2), encoding='utf-8')
|
||||
print("done!")
|
||||
# metadataを書き出して終わり
|
||||
logger.info(f"writing metadata: {args.out_json}")
|
||||
Path(args.out_json).write_text(json.dumps(metadata, indent=2), encoding="utf-8")
|
||||
logger.info("done!")
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("train_data_dir", type=str, help="directory for train images / 学習画像データのディレクトリ")
|
||||
parser.add_argument("out_json", type=str, help="metadata file to output / メタデータファイル書き出し先")
|
||||
parser.add_argument("--in_json", type=str,
|
||||
help="metadata file to input (if omitted and out_json exists, existing out_json is read) / 読み込むメタデータファイル(省略時、out_jsonが存在すればそれを読み込む)")
|
||||
parser.add_argument("--caption_extention", type=str, default=None,
|
||||
help="extension of caption file (for backward compatibility) / 読み込むキャプションファイルの拡張子(スペルミスしていたのを残してあります)")
|
||||
parser.add_argument("--caption_extension", type=str, default=".caption", help="extension of caption file / 読み込むキャプションファイルの拡張子")
|
||||
parser.add_argument("--full_path", action="store_true",
|
||||
help="use full path as image-key in metadata (supports multiple directories) / メタデータで画像キーをフルパスにする(複数の学習画像ディレクトリに対応)")
|
||||
parser.add_argument("--recursive", action="store_true",
|
||||
help="recursively look for training tags in all child folders of train_data_dir / train_data_dirのすべての子フォルダにある学習タグを再帰的に探す")
|
||||
parser.add_argument("--debug", action="store_true", help="debug mode")
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("train_data_dir", type=str, help="directory for train images / 学習画像データのディレクトリ")
|
||||
parser.add_argument("out_json", type=str, help="metadata file to output / メタデータファイル書き出し先")
|
||||
parser.add_argument(
|
||||
"--in_json",
|
||||
type=str,
|
||||
help="metadata file to input (if omitted and out_json exists, existing out_json is read) / 読み込むメタデータファイル(省略時、out_jsonが存在すればそれを読み込む)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--caption_extention",
|
||||
type=str,
|
||||
default=None,
|
||||
help="extension of caption file (for backward compatibility) / 読み込むキャプションファイルの拡張子(スペルミスしていたのを残してあります)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--caption_extension", type=str, default=".caption", help="extension of caption file / 読み込むキャプションファイルの拡張子"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--full_path",
|
||||
action="store_true",
|
||||
help="use full path as image-key in metadata (supports multiple directories) / メタデータで画像キーをフルパスにする(複数の学習画像ディレクトリに対応)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--recursive",
|
||||
action="store_true",
|
||||
help="recursively look for training tags in all child folders of train_data_dir / train_data_dirのすべての子フォルダにある学習タグを再帰的に探す",
|
||||
)
|
||||
parser.add_argument("--debug", action="store_true", help="debug mode")
|
||||
|
||||
return parser
|
||||
return parser
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = setup_parser()
|
||||
if __name__ == "__main__":
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
args = parser.parse_args()
|
||||
|
||||
# スペルミスしていたオプションを復元する
|
||||
if args.caption_extention is not None:
|
||||
args.caption_extension = args.caption_extention
|
||||
# スペルミスしていたオプションを復元する
|
||||
if args.caption_extention is not None:
|
||||
args.caption_extension = args.caption_extention
|
||||
|
||||
main(args)
|
||||
main(args)
|
||||
|
||||
@@ -5,67 +5,89 @@ from typing import List
|
||||
from tqdm import tqdm
|
||||
import library.train_util as train_util
|
||||
import os
|
||||
from library.utils import setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
def main(args):
|
||||
assert not args.recursive or (args.recursive and args.full_path), "recursive requires full_path / recursiveはfull_pathと同時に指定してください"
|
||||
assert not args.recursive or (
|
||||
args.recursive and args.full_path
|
||||
), "recursive requires full_path / recursiveはfull_pathと同時に指定してください"
|
||||
|
||||
train_data_dir_path = Path(args.train_data_dir)
|
||||
image_paths: List[Path] = train_util.glob_images_pathlib(train_data_dir_path, args.recursive)
|
||||
print(f"found {len(image_paths)} images.")
|
||||
train_data_dir_path = Path(args.train_data_dir)
|
||||
image_paths: List[Path] = train_util.glob_images_pathlib(train_data_dir_path, args.recursive)
|
||||
logger.info(f"found {len(image_paths)} images.")
|
||||
|
||||
if args.in_json is None and Path(args.out_json).is_file():
|
||||
args.in_json = args.out_json
|
||||
if args.in_json is None and Path(args.out_json).is_file():
|
||||
args.in_json = args.out_json
|
||||
|
||||
if args.in_json is not None:
|
||||
print(f"loading existing metadata: {args.in_json}")
|
||||
metadata = json.loads(Path(args.in_json).read_text(encoding='utf-8'))
|
||||
print("tags data for existing images will be overwritten / 既存の画像のタグは上書きされます")
|
||||
else:
|
||||
print("new metadata will be created / 新しいメタデータファイルが作成されます")
|
||||
metadata = {}
|
||||
if args.in_json is not None:
|
||||
logger.info(f"loading existing metadata: {args.in_json}")
|
||||
metadata = json.loads(Path(args.in_json).read_text(encoding="utf-8"))
|
||||
logger.warning("tags data for existing images will be overwritten / 既存の画像のタグは上書きされます")
|
||||
else:
|
||||
logger.info("new metadata will be created / 新しいメタデータファイルが作成されます")
|
||||
metadata = {}
|
||||
|
||||
print("merge tags to metadata json.")
|
||||
for image_path in tqdm(image_paths):
|
||||
tags_path = image_path.with_suffix(args.caption_extension)
|
||||
tags = tags_path.read_text(encoding='utf-8').strip()
|
||||
logger.info("merge tags to metadata json.")
|
||||
for image_path in tqdm(image_paths):
|
||||
tags_path = image_path.with_suffix(args.caption_extension)
|
||||
tags = tags_path.read_text(encoding="utf-8").strip()
|
||||
|
||||
if not os.path.exists(tags_path):
|
||||
tags_path = os.path.join(image_path, args.caption_extension)
|
||||
if not os.path.exists(tags_path):
|
||||
tags_path = os.path.join(image_path, args.caption_extension)
|
||||
|
||||
image_key = str(image_path) if args.full_path else image_path.stem
|
||||
if image_key not in metadata:
|
||||
metadata[image_key] = {}
|
||||
image_key = str(image_path) if args.full_path else image_path.stem
|
||||
if image_key not in metadata:
|
||||
metadata[image_key] = {}
|
||||
|
||||
metadata[image_key]['tags'] = tags
|
||||
if args.debug:
|
||||
print(image_key, tags)
|
||||
metadata[image_key]["tags"] = tags
|
||||
if args.debug:
|
||||
logger.info(f"{image_key} {tags}")
|
||||
|
||||
# metadataを書き出して終わり
|
||||
print(f"writing metadata: {args.out_json}")
|
||||
Path(args.out_json).write_text(json.dumps(metadata, indent=2), encoding='utf-8')
|
||||
# metadataを書き出して終わり
|
||||
logger.info(f"writing metadata: {args.out_json}")
|
||||
Path(args.out_json).write_text(json.dumps(metadata, indent=2), encoding="utf-8")
|
||||
|
||||
print("done!")
|
||||
logger.info("done!")
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("train_data_dir", type=str, help="directory for train images / 学習画像データのディレクトリ")
|
||||
parser.add_argument("out_json", type=str, help="metadata file to output / メタデータファイル書き出し先")
|
||||
parser.add_argument("--in_json", type=str,
|
||||
help="metadata file to input (if omitted and out_json exists, existing out_json is read) / 読み込むメタデータファイル(省略時、out_jsonが存在すればそれを読み込む)")
|
||||
parser.add_argument("--full_path", action="store_true",
|
||||
help="use full path as image-key in metadata (supports multiple directories) / メタデータで画像キーをフルパスにする(複数の学習画像ディレクトリに対応)")
|
||||
parser.add_argument("--recursive", action="store_true",
|
||||
help="recursively look for training tags in all child folders of train_data_dir / train_data_dirのすべての子フォルダにある学習タグを再帰的に探す")
|
||||
parser.add_argument("--caption_extension", type=str, default=".txt",
|
||||
help="extension of caption (tag) file / 読み込むキャプション(タグ)ファイルの拡張子")
|
||||
parser.add_argument("--debug", action="store_true", help="debug mode, print tags")
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("train_data_dir", type=str, help="directory for train images / 学習画像データのディレクトリ")
|
||||
parser.add_argument("out_json", type=str, help="metadata file to output / メタデータファイル書き出し先")
|
||||
parser.add_argument(
|
||||
"--in_json",
|
||||
type=str,
|
||||
help="metadata file to input (if omitted and out_json exists, existing out_json is read) / 読み込むメタデータファイル(省略時、out_jsonが存在すればそれを読み込む)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--full_path",
|
||||
action="store_true",
|
||||
help="use full path as image-key in metadata (supports multiple directories) / メタデータで画像キーをフルパスにする(複数の学習画像ディレクトリに対応)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--recursive",
|
||||
action="store_true",
|
||||
help="recursively look for training tags in all child folders of train_data_dir / train_data_dirのすべての子フォルダにある学習タグを再帰的に探す",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--caption_extension",
|
||||
type=str,
|
||||
default=".txt",
|
||||
help="extension of caption (tag) file / 読み込むキャプション(タグ)ファイルの拡張子",
|
||||
)
|
||||
parser.add_argument("--debug", action="store_true", help="debug mode, print tags")
|
||||
|
||||
return parser
|
||||
return parser
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = setup_parser()
|
||||
if __name__ == "__main__":
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
main(args)
|
||||
args = parser.parse_args()
|
||||
main(args)
|
||||
|
||||
@@ -8,13 +8,24 @@ from tqdm import tqdm
|
||||
import numpy as np
|
||||
from PIL import Image
|
||||
import cv2
|
||||
|
||||
import torch
|
||||
from library.device_utils import init_ipex, get_preferred_device
|
||||
|
||||
init_ipex()
|
||||
|
||||
from torchvision import transforms
|
||||
|
||||
import library.model_util as model_util
|
||||
import library.train_util as train_util
|
||||
from library.utils import setup_logging
|
||||
|
||||
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
DEVICE = get_preferred_device()
|
||||
|
||||
IMAGE_TRANSFORMS = transforms.Compose(
|
||||
[
|
||||
@@ -34,16 +45,7 @@ def collate_fn_remove_corrupted(batch):
|
||||
return batch
|
||||
|
||||
|
||||
def get_latents(vae, images, weight_dtype):
|
||||
img_tensors = [IMAGE_TRANSFORMS(image) for image in images]
|
||||
img_tensors = torch.stack(img_tensors)
|
||||
img_tensors = img_tensors.to(DEVICE, weight_dtype)
|
||||
with torch.no_grad():
|
||||
latents = vae.encode(img_tensors).latent_dist.sample().float().to("cpu").numpy()
|
||||
return latents
|
||||
|
||||
|
||||
def get_npz_filename_wo_ext(data_dir, image_key, is_full_path, flip, recursive):
|
||||
def get_npz_filename(data_dir, image_key, is_full_path, recursive):
|
||||
if is_full_path:
|
||||
base_name = os.path.splitext(os.path.basename(image_key))[0]
|
||||
relative_path = os.path.relpath(os.path.dirname(image_key), data_dir)
|
||||
@@ -51,30 +53,31 @@ def get_npz_filename_wo_ext(data_dir, image_key, is_full_path, flip, recursive):
|
||||
base_name = image_key
|
||||
relative_path = ""
|
||||
|
||||
if flip:
|
||||
base_name += "_flip"
|
||||
|
||||
if recursive and relative_path:
|
||||
return os.path.join(data_dir, relative_path, base_name)
|
||||
return os.path.join(data_dir, relative_path, base_name) + ".npz"
|
||||
else:
|
||||
return os.path.join(data_dir, base_name)
|
||||
return os.path.join(data_dir, base_name) + ".npz"
|
||||
|
||||
|
||||
def main(args):
|
||||
# assert args.bucket_reso_steps % 8 == 0, f"bucket_reso_steps must be divisible by 8 / bucket_reso_stepは8で割り切れる必要があります"
|
||||
if args.bucket_reso_steps % 8 > 0:
|
||||
print(f"resolution of buckets in training time is a multiple of 8 / 学習時の各bucketの解像度は8単位になります")
|
||||
logger.warning(f"resolution of buckets in training time is a multiple of 8 / 学習時の各bucketの解像度は8単位になります")
|
||||
if args.bucket_reso_steps % 32 > 0:
|
||||
logger.warning(
|
||||
f"WARNING: bucket_reso_steps is not divisible by 32. It is not working with SDXL / bucket_reso_stepsが32で割り切れません。SDXLでは動作しません"
|
||||
)
|
||||
|
||||
train_data_dir_path = Path(args.train_data_dir)
|
||||
image_paths: List[str] = [str(p) for p in train_util.glob_images_pathlib(train_data_dir_path, args.recursive)]
|
||||
print(f"found {len(image_paths)} images.")
|
||||
logger.info(f"found {len(image_paths)} images.")
|
||||
|
||||
if os.path.exists(args.in_json):
|
||||
print(f"loading existing metadata: {args.in_json}")
|
||||
logger.info(f"loading existing metadata: {args.in_json}")
|
||||
with open(args.in_json, "rt", encoding="utf-8") as f:
|
||||
metadata = json.load(f)
|
||||
else:
|
||||
print(f"no metadata / メタデータファイルがありません: {args.in_json}")
|
||||
logger.error(f"no metadata / メタデータファイルがありません: {args.in_json}")
|
||||
return
|
||||
|
||||
weight_dtype = torch.float32
|
||||
@@ -89,7 +92,9 @@ def main(args):
|
||||
|
||||
# bucketのサイズを計算する
|
||||
max_reso = tuple([int(t) for t in args.max_resolution.split(",")])
|
||||
assert len(max_reso) == 2, f"illegal resolution (not 'width,height') / 画像サイズに誤りがあります。'幅,高さ'で指定してください: {args.max_resolution}"
|
||||
assert (
|
||||
len(max_reso) == 2
|
||||
), f"illegal resolution (not 'width,height') / 画像サイズに誤りがあります。'幅,高さ'で指定してください: {args.max_resolution}"
|
||||
|
||||
bucket_manager = train_util.BucketManager(
|
||||
args.bucket_no_upscale, max_reso, args.min_bucket_reso, args.max_bucket_reso, args.bucket_reso_steps
|
||||
@@ -97,7 +102,7 @@ def main(args):
|
||||
if not args.bucket_no_upscale:
|
||||
bucket_manager.make_buckets()
|
||||
else:
|
||||
print(
|
||||
logger.warning(
|
||||
"min_bucket_reso and max_bucket_reso are ignored if bucket_no_upscale is set, because bucket reso is defined by image size automatically / bucket_no_upscaleが指定された場合は、bucketの解像度は画像サイズから自動計算されるため、min_bucket_resoとmax_bucket_resoは無視されます"
|
||||
)
|
||||
|
||||
@@ -107,34 +112,7 @@ def main(args):
|
||||
def process_batch(is_last):
|
||||
for bucket in bucket_manager.buckets:
|
||||
if (is_last and len(bucket) > 0) or len(bucket) >= args.batch_size:
|
||||
latents = get_latents(vae, [img for _, img in bucket], weight_dtype)
|
||||
assert (
|
||||
latents.shape[2] == bucket[0][1].shape[0] // 8 and latents.shape[3] == bucket[0][1].shape[1] // 8
|
||||
), f"latent shape {latents.shape}, {bucket[0][1].shape}"
|
||||
|
||||
for (image_key, _), latent in zip(bucket, latents):
|
||||
npz_file_name = get_npz_filename_wo_ext(args.train_data_dir, image_key, args.full_path, False, args.recursive)
|
||||
np.savez(npz_file_name, latent)
|
||||
|
||||
# flip
|
||||
if args.flip_aug:
|
||||
latents = get_latents(vae, [img[:, ::-1].copy() for _, img in bucket], weight_dtype) # copyがないとTensor変換できない
|
||||
|
||||
for (image_key, _), latent in zip(bucket, latents):
|
||||
npz_file_name = get_npz_filename_wo_ext(
|
||||
args.train_data_dir, image_key, args.full_path, True, args.recursive
|
||||
)
|
||||
np.savez(npz_file_name, latent)
|
||||
else:
|
||||
# remove existing flipped npz
|
||||
for image_key, _ in bucket:
|
||||
npz_file_name = (
|
||||
get_npz_filename_wo_ext(args.train_data_dir, image_key, args.full_path, True, args.recursive) + ".npz"
|
||||
)
|
||||
if os.path.isfile(npz_file_name):
|
||||
print(f"remove existing flipped npz / 既存のflipされたnpzファイルを削除します: {npz_file_name}")
|
||||
os.remove(npz_file_name)
|
||||
|
||||
train_util.cache_batch_latents(vae, True, bucket, args.flip_aug, args.alpha_mask, False)
|
||||
bucket.clear()
|
||||
|
||||
# 読み込みの高速化のためにDataLoaderを使うオプション
|
||||
@@ -165,7 +143,7 @@ def main(args):
|
||||
if image.mode != "RGB":
|
||||
image = image.convert("RGB")
|
||||
except Exception as e:
|
||||
print(f"Could not load image path / 画像を読み込めません: {image_path}, error: {e}")
|
||||
logger.error(f"Could not load image path / 画像を読み込めません: {image_path}, error: {e}")
|
||||
continue
|
||||
|
||||
image_key = image_path if args.full_path else os.path.splitext(os.path.basename(image_path))[0]
|
||||
@@ -194,50 +172,19 @@ def main(args):
|
||||
resized_size[0] >= reso[0] and resized_size[1] >= reso[1]
|
||||
), f"internal error resized size is small: {resized_size}, {reso}"
|
||||
|
||||
# 既に存在するファイルがあればshapeを確認して同じならskipする
|
||||
# 既に存在するファイルがあればshape等を確認して同じならskipする
|
||||
npz_file_name = get_npz_filename(args.train_data_dir, image_key, args.full_path, args.recursive)
|
||||
if args.skip_existing:
|
||||
npz_files = [get_npz_filename_wo_ext(args.train_data_dir, image_key, args.full_path, False, args.recursive) + ".npz"]
|
||||
if args.flip_aug:
|
||||
npz_files.append(
|
||||
get_npz_filename_wo_ext(args.train_data_dir, image_key, args.full_path, True, args.recursive) + ".npz"
|
||||
)
|
||||
|
||||
found = True
|
||||
for npz_file in npz_files:
|
||||
if not os.path.exists(npz_file):
|
||||
found = False
|
||||
break
|
||||
|
||||
dat = np.load(npz_file)["arr_0"]
|
||||
if dat.shape[1] != reso[1] // 8 or dat.shape[2] != reso[0] // 8: # latentsのshapeを確認
|
||||
found = False
|
||||
break
|
||||
if found:
|
||||
if train_util.is_disk_cached_latents_is_expected(reso, npz_file_name, args.flip_aug):
|
||||
continue
|
||||
|
||||
# 画像をリサイズしてトリミングする
|
||||
# PILにinter_areaがないのでcv2で……
|
||||
image = np.array(image)
|
||||
if resized_size[0] != image.shape[1] or resized_size[1] != image.shape[0]: # リサイズ処理が必要?
|
||||
image = cv2.resize(image, resized_size, interpolation=cv2.INTER_AREA)
|
||||
|
||||
if resized_size[0] > reso[0]:
|
||||
trim_size = resized_size[0] - reso[0]
|
||||
image = image[:, trim_size // 2 : trim_size // 2 + reso[0]]
|
||||
|
||||
if resized_size[1] > reso[1]:
|
||||
trim_size = resized_size[1] - reso[1]
|
||||
image = image[trim_size // 2 : trim_size // 2 + reso[1]]
|
||||
|
||||
assert (
|
||||
image.shape[0] == reso[1] and image.shape[1] == reso[0]
|
||||
), f"internal error, illegal trimmed size: {image.shape}, {reso}"
|
||||
|
||||
# # debug
|
||||
# cv2.imwrite(f"r:\\test\\img_{len(img_ar_errors)}.jpg", image[:, :, ::-1])
|
||||
|
||||
# バッチへ追加
|
||||
bucket_manager.add_image(reso, (image_key, image))
|
||||
image_info = train_util.ImageInfo(image_key, 1, "", False, image_path)
|
||||
image_info.latents_npz = npz_file_name
|
||||
image_info.bucket_reso = reso
|
||||
image_info.resized_size = resized_size
|
||||
image_info.image = image
|
||||
bucket_manager.add_image(reso, image_info)
|
||||
|
||||
# バッチを推論するか判定して推論する
|
||||
process_batch(False)
|
||||
@@ -249,15 +196,15 @@ def main(args):
|
||||
for i, reso in enumerate(bucket_manager.resos):
|
||||
count = bucket_counts.get(reso, 0)
|
||||
if count > 0:
|
||||
print(f"bucket {i} {reso}: {count}")
|
||||
logger.info(f"bucket {i} {reso}: {count}")
|
||||
img_ar_errors = np.array(img_ar_errors)
|
||||
print(f"mean ar error: {np.mean(img_ar_errors)}")
|
||||
logger.info(f"mean ar error: {np.mean(img_ar_errors)}")
|
||||
|
||||
# metadataを書き出して終わり
|
||||
print(f"writing metadata: {args.out_json}")
|
||||
logger.info(f"writing metadata: {args.out_json}")
|
||||
with open(args.out_json, "wt", encoding="utf-8") as f:
|
||||
json.dump(metadata, f, indent=2)
|
||||
print("done!")
|
||||
logger.info("done!")
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
@@ -266,7 +213,9 @@ def setup_parser() -> argparse.ArgumentParser:
|
||||
parser.add_argument("in_json", type=str, help="metadata file to input / 読み込むメタデータファイル")
|
||||
parser.add_argument("out_json", type=str, help="metadata file to output / メタデータファイル書き出し先")
|
||||
parser.add_argument("model_name_or_path", type=str, help="model name or path to encode latents / latentを取得するためのモデル")
|
||||
parser.add_argument("--v2", action="store_true", help="not used (for backward compatibility) / 使用されません(互換性のため残してあります)")
|
||||
parser.add_argument(
|
||||
"--v2", action="store_true", help="not used (for backward compatibility) / 使用されません(互換性のため残してあります)"
|
||||
)
|
||||
parser.add_argument("--batch_size", type=int, default=1, help="batch size in inference / 推論時のバッチサイズ")
|
||||
parser.add_argument(
|
||||
"--max_data_loader_n_workers",
|
||||
@@ -281,7 +230,7 @@ def setup_parser() -> argparse.ArgumentParser:
|
||||
help="max resolution in fine tuning (width,height) / fine tuning時の最大画像サイズ 「幅,高さ」(使用メモリ量に関係します)",
|
||||
)
|
||||
parser.add_argument("--min_bucket_reso", type=int, default=256, help="minimum resolution for buckets / bucketの最小解像度")
|
||||
parser.add_argument("--max_bucket_reso", type=int, default=1024, help="maximum resolution for buckets / bucketの最小解像度")
|
||||
parser.add_argument("--max_bucket_reso", type=int, default=1024, help="maximum resolution for buckets / bucketの最大解像度")
|
||||
parser.add_argument(
|
||||
"--bucket_reso_steps",
|
||||
type=int,
|
||||
@@ -289,10 +238,16 @@ def setup_parser() -> argparse.ArgumentParser:
|
||||
help="steps of resolution for buckets, divisible by 8 is recommended / bucketの解像度の単位、8で割り切れる値を推奨します",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--bucket_no_upscale", action="store_true", help="make bucket for each image without upscaling / 画像を拡大せずbucketを作成します"
|
||||
"--bucket_no_upscale",
|
||||
action="store_true",
|
||||
help="make bucket for each image without upscaling / 画像を拡大せずbucketを作成します",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--mixed_precision", type=str, default="no", choices=["no", "fp16", "bf16"], help="use mixed precision / 混合精度を使う場合、その精度"
|
||||
"--mixed_precision",
|
||||
type=str,
|
||||
default="no",
|
||||
choices=["no", "fp16", "bf16"],
|
||||
help="use mixed precision / 混合精度を使う場合、その精度",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--full_path",
|
||||
@@ -300,7 +255,15 @@ def setup_parser() -> argparse.ArgumentParser:
|
||||
help="use full path as image-key in metadata (supports multiple directories) / メタデータで画像キーをフルパスにする(複数の学習画像ディレクトリに対応)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--flip_aug", action="store_true", help="flip augmentation, save latents for flipped images / 左右反転した画像もlatentを取得、保存する"
|
||||
"--flip_aug",
|
||||
action="store_true",
|
||||
help="flip augmentation, save latents for flipped images / 左右反転した画像もlatentを取得、保存する",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--alpha_mask",
|
||||
type=str,
|
||||
default="",
|
||||
help="save alpha mask for images for loss calculation / 損失計算用に画像のアルファマスクを保存する",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--skip_existing",
|
||||
|
||||
@@ -1,18 +1,24 @@
|
||||
import argparse
|
||||
import csv
|
||||
import glob
|
||||
import json
|
||||
import math
|
||||
import os
|
||||
|
||||
from PIL import Image
|
||||
import cv2
|
||||
from tqdm import tqdm
|
||||
import numpy as np
|
||||
from tensorflow.keras.models import load_model
|
||||
from huggingface_hub import hf_hub_download
|
||||
import torch
|
||||
from pathlib import Path
|
||||
from typing import Optional
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from huggingface_hub import hf_hub_download
|
||||
from PIL import Image
|
||||
from tqdm import tqdm
|
||||
|
||||
import library.train_util as train_util
|
||||
from library.utils import setup_logging, resize_image
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# from wd14 tagger
|
||||
IMAGE_SIZE = 448
|
||||
@@ -20,12 +26,27 @@ IMAGE_SIZE = 448
|
||||
# wd-v1-4-swinv2-tagger-v2 / wd-v1-4-vit-tagger / wd-v1-4-vit-tagger-v2/ wd-v1-4-convnext-tagger / wd-v1-4-convnext-tagger-v2
|
||||
DEFAULT_WD14_TAGGER_REPO = "SmilingWolf/wd-v1-4-convnext-tagger-v2"
|
||||
FILES = ["keras_metadata.pb", "saved_model.pb", "selected_tags.csv"]
|
||||
FILES_ONNX = ["model.onnx"]
|
||||
SUB_DIR = "variables"
|
||||
SUB_DIR_FILES = ["variables.data-00000-of-00001", "variables.index"]
|
||||
CSV_FILE = FILES[-1]
|
||||
|
||||
TAG_JSON_FILE = "tag_mapping.json"
|
||||
|
||||
|
||||
def preprocess_image(image: Image.Image) -> np.ndarray:
|
||||
# If image has transparency, convert to RGBA. If not, convert to RGB
|
||||
if image.mode in ("RGBA", "LA") or "transparency" in image.info:
|
||||
image = image.convert("RGBA")
|
||||
elif image.mode != "RGB":
|
||||
image = image.convert("RGB")
|
||||
|
||||
# If image is RGBA, combine with white background
|
||||
if image.mode == "RGBA":
|
||||
background = Image.new("RGB", image.size, (255, 255, 255))
|
||||
background.paste(image, mask=image.split()[3]) # Use alpha channel as mask
|
||||
image = background
|
||||
|
||||
def preprocess_image(image):
|
||||
image = np.array(image)
|
||||
image = image[:, :, ::-1] # RGB->BGR
|
||||
|
||||
@@ -37,194 +58,548 @@ def preprocess_image(image):
|
||||
pad_t = pad_y // 2
|
||||
image = np.pad(image, ((pad_t, pad_y - pad_t), (pad_l, pad_x - pad_l), (0, 0)), mode="constant", constant_values=255)
|
||||
|
||||
interp = cv2.INTER_AREA if size > IMAGE_SIZE else cv2.INTER_LANCZOS4
|
||||
image = cv2.resize(image, (IMAGE_SIZE, IMAGE_SIZE), interpolation=interp)
|
||||
image = resize_image(image, image.shape[0], image.shape[1], IMAGE_SIZE, IMAGE_SIZE)
|
||||
|
||||
image = image.astype(np.float32)
|
||||
return image
|
||||
|
||||
|
||||
class ImageLoadingPrepDataset(torch.utils.data.Dataset):
|
||||
def __init__(self, image_paths):
|
||||
self.images = image_paths
|
||||
def __init__(self, image_paths: list[str], batch_size: int):
|
||||
self.image_paths = image_paths
|
||||
self.batch_size = batch_size
|
||||
|
||||
def __len__(self):
|
||||
return len(self.images)
|
||||
return math.ceil(len(self.image_paths) / self.batch_size)
|
||||
|
||||
def __getitem__(self, idx):
|
||||
img_path = str(self.images[idx])
|
||||
def __getitem__(self, batch_index: int) -> tuple[str, np.ndarray, tuple[int, int]]:
|
||||
image_index_start = batch_index * self.batch_size
|
||||
image_index_end = min((batch_index + 1) * self.batch_size, len(self.image_paths))
|
||||
|
||||
try:
|
||||
image = Image.open(img_path).convert("RGB")
|
||||
image = preprocess_image(image)
|
||||
tensor = torch.tensor(image)
|
||||
except Exception as e:
|
||||
print(f"Could not load image path / 画像を読み込めません: {img_path}, error: {e}")
|
||||
return None
|
||||
batch_image_paths = []
|
||||
images = []
|
||||
image_sizes = []
|
||||
for idx in range(image_index_start, image_index_end):
|
||||
img_path = str(self.image_paths[idx])
|
||||
|
||||
return (tensor, img_path)
|
||||
try:
|
||||
image = Image.open(img_path)
|
||||
image_size = image.size
|
||||
image = preprocess_image(image)
|
||||
|
||||
batch_image_paths.append(img_path)
|
||||
images.append(image)
|
||||
image_sizes.append(image_size)
|
||||
except Exception as e:
|
||||
logger.error(f"Could not load image path / 画像を読み込めません: {img_path}, error: {e}")
|
||||
|
||||
images = np.stack(images) if len(images) > 0 else np.zeros((0, IMAGE_SIZE, IMAGE_SIZE, 3))
|
||||
return batch_image_paths, images, image_sizes
|
||||
|
||||
|
||||
def collate_fn_remove_corrupted(batch):
|
||||
"""Collate function that allows to remove corrupted examples in the
|
||||
dataloader. It expects that the dataloader returns 'None' when that occurs.
|
||||
The 'None's in the batch are removed.
|
||||
"""
|
||||
# Filter out all the Nones (corrupted examples)
|
||||
batch = list(filter(lambda x: x is not None, batch))
|
||||
def collate_fn_no_op(batch):
|
||||
"""Collate function that does nothing and returns the batch as is."""
|
||||
return batch
|
||||
|
||||
|
||||
def main(args):
|
||||
# hf_hub_downloadをそのまま使うとsymlink関係で問題があるらしいので、キャッシュディレクトリとforce_filenameを指定してなんとかする
|
||||
# depreacatedの警告が出るけどなくなったらその時
|
||||
# https://github.com/toriato/stable-diffusion-webui-wd14-tagger/issues/22
|
||||
if not os.path.exists(args.model_dir) or args.force_download:
|
||||
print(f"downloading wd14 tagger model from hf_hub. id: {args.repo_id}")
|
||||
for file in FILES:
|
||||
hf_hub_download(args.repo_id, file, cache_dir=args.model_dir, force_download=True, force_filename=file)
|
||||
for file in SUB_DIR_FILES:
|
||||
hf_hub_download(
|
||||
args.repo_id,
|
||||
file,
|
||||
subfolder=SUB_DIR,
|
||||
cache_dir=os.path.join(args.model_dir, SUB_DIR),
|
||||
force_download=True,
|
||||
force_filename=file,
|
||||
)
|
||||
# model location is model_dir + repo_id
|
||||
# given repo_id may be "namespace/repo_name" or "namespace/repo_name/subdir"
|
||||
# so we split it to "namespace/reponame" and "subdir"
|
||||
tokens = args.repo_id.split("/")
|
||||
|
||||
if len(tokens) > 2:
|
||||
repo_id = "/".join(tokens[:2])
|
||||
subdir = "/".join(tokens[2:])
|
||||
model_location = os.path.join(args.model_dir, repo_id.replace("/", "_"), subdir)
|
||||
onnx_model_name = "model_optimized.onnx"
|
||||
default_format = False
|
||||
else:
|
||||
print("using existing wd14 tagger model")
|
||||
repo_id = args.repo_id
|
||||
subdir = None
|
||||
model_location = os.path.join(args.model_dir, repo_id.replace("/", "_"))
|
||||
onnx_model_name = "model.onnx"
|
||||
default_format = True
|
||||
|
||||
# 画像を読み込む
|
||||
model = load_model(args.model_dir)
|
||||
# https://github.com/toriato/stable-diffusion-webui-wd14-tagger/issues/22
|
||||
|
||||
if not os.path.exists(model_location) or args.force_download:
|
||||
os.makedirs(args.model_dir, exist_ok=True)
|
||||
logger.info(f"downloading wd14 tagger model from hf_hub. id: {args.repo_id}")
|
||||
|
||||
if subdir is None:
|
||||
# SmilingWolf structure
|
||||
files = FILES
|
||||
if args.onnx:
|
||||
files = ["selected_tags.csv"]
|
||||
files += FILES_ONNX
|
||||
else:
|
||||
for file in SUB_DIR_FILES:
|
||||
hf_hub_download(
|
||||
repo_id=args.repo_id,
|
||||
filename=file,
|
||||
subfolder=SUB_DIR,
|
||||
local_dir=os.path.join(model_location, SUB_DIR),
|
||||
force_download=True,
|
||||
)
|
||||
|
||||
for file in files:
|
||||
hf_hub_download(
|
||||
repo_id=args.repo_id,
|
||||
filename=file,
|
||||
local_dir=model_location,
|
||||
force_download=True,
|
||||
)
|
||||
else:
|
||||
# another structure
|
||||
files = [onnx_model_name, "tag_mapping.json"]
|
||||
|
||||
for file in files:
|
||||
hf_hub_download(
|
||||
repo_id=repo_id,
|
||||
filename=file,
|
||||
subfolder=subdir,
|
||||
local_dir=os.path.join(args.model_dir, repo_id.replace("/", "_")), # because subdir is specified
|
||||
force_download=True,
|
||||
)
|
||||
else:
|
||||
logger.info("using existing wd14 tagger model")
|
||||
|
||||
# モデルを読み込む
|
||||
if args.onnx:
|
||||
import onnx
|
||||
import onnxruntime as ort
|
||||
|
||||
onnx_path = os.path.join(model_location, onnx_model_name)
|
||||
logger.info("Running wd14 tagger with onnx")
|
||||
logger.info(f"loading onnx model: {onnx_path}")
|
||||
|
||||
if not os.path.exists(onnx_path):
|
||||
raise Exception(
|
||||
f"onnx model not found: {onnx_path}, please redownload the model with --force_download"
|
||||
+ " / onnxモデルが見つかりませんでした。--force_downloadで再ダウンロードしてください"
|
||||
)
|
||||
|
||||
model = onnx.load(onnx_path)
|
||||
input_name = model.graph.input[0].name
|
||||
try:
|
||||
batch_size = model.graph.input[0].type.tensor_type.shape.dim[0].dim_value
|
||||
except Exception:
|
||||
batch_size = model.graph.input[0].type.tensor_type.shape.dim[0].dim_param
|
||||
|
||||
if args.batch_size != batch_size and not isinstance(batch_size, str) and batch_size > 0:
|
||||
# some rebatch model may use 'N' as dynamic axes
|
||||
logger.warning(
|
||||
f"Batch size {args.batch_size} doesn't match onnx model batch size {batch_size}, use model batch size {batch_size}"
|
||||
)
|
||||
args.batch_size = batch_size
|
||||
|
||||
del model
|
||||
|
||||
if "OpenVINOExecutionProvider" in ort.get_available_providers():
|
||||
# requires provider options for gpu support
|
||||
# fp16 causes nonsense outputs
|
||||
ort_sess = ort.InferenceSession(
|
||||
onnx_path,
|
||||
providers=(["OpenVINOExecutionProvider"]),
|
||||
provider_options=[{"device_type": "GPU", "precision": "FP32"}],
|
||||
)
|
||||
else:
|
||||
providers = (
|
||||
["CUDAExecutionProvider"]
|
||||
if "CUDAExecutionProvider" in ort.get_available_providers()
|
||||
else (
|
||||
["ROCMExecutionProvider"]
|
||||
if "ROCMExecutionProvider" in ort.get_available_providers()
|
||||
else ["CPUExecutionProvider"]
|
||||
)
|
||||
)
|
||||
logger.info(f"Using onnxruntime providers: {providers}")
|
||||
ort_sess = ort.InferenceSession(onnx_path, providers=providers)
|
||||
else:
|
||||
from tensorflow.keras.models import load_model
|
||||
|
||||
model = load_model(f"{model_location}")
|
||||
|
||||
# We read the CSV file manually to avoid adding dependencies.
|
||||
# label_names = pd.read_csv("2022_0000_0899_6549/selected_tags.csv")
|
||||
# 依存ライブラリを増やしたくないので自力で読むよ
|
||||
|
||||
with open(os.path.join(args.model_dir, CSV_FILE), "r", encoding="utf-8") as f:
|
||||
reader = csv.reader(f)
|
||||
l = [row for row in reader]
|
||||
header = l[0] # tag_id,name,category,count
|
||||
rows = l[1:]
|
||||
assert header[0] == "tag_id" and header[1] == "name" and header[2] == "category", f"unexpected csv format: {header}"
|
||||
def expand_character_tags(char_tags):
|
||||
for i, tag in enumerate(char_tags):
|
||||
if tag.endswith(")"):
|
||||
# chara_name_(series) -> chara_name, series
|
||||
# chara_name_(costume)_(series) -> chara_name_(costume), series
|
||||
tags = tag.split("(")
|
||||
character_tag = "(".join(tags[:-1])
|
||||
if character_tag.endswith("_"):
|
||||
character_tag = character_tag[:-1]
|
||||
series_tag = tags[-1].replace(")", "")
|
||||
char_tags[i] = character_tag + args.caption_separator + series_tag
|
||||
|
||||
general_tags = [row[1] for row in rows[1:] if row[2] == "0"]
|
||||
character_tags = [row[1] for row in rows[1:] if row[2] == "4"]
|
||||
def remove_underscore(tags):
|
||||
return [tag.replace("_", " ") if len(tag) > 3 else tag for tag in tags]
|
||||
|
||||
def process_tag_replacement(tags: list[str], tag_replacements_arg: str) -> list[str]:
|
||||
# escape , and ; in tag_replacement: wd14 tag names may contain , and ;,
|
||||
# so user must be specified them like `aa\,bb,AA\,BB;cc\;dd,CC\;DD` which means
|
||||
# `aa,bb` is replaced with `AA,BB` and `cc;dd` is replaced with `CC;DD`
|
||||
escaped_tag_replacements = tag_replacements_arg.replace("\\,", "@@@@").replace("\\;", "####")
|
||||
tag_replacements = escaped_tag_replacements.split(";")
|
||||
|
||||
for tag_replacements_arg in tag_replacements:
|
||||
tags = tag_replacements_arg.split(",") # source, target
|
||||
assert (
|
||||
len(tags) == 2
|
||||
), f"tag replacement must be in the format of `source,target` / タグの置換は `置換元,置換先` の形式で指定してください: {args.tag_replacement}"
|
||||
|
||||
source, target = [tag.replace("@@@@", ",").replace("####", ";") for tag in tags]
|
||||
logger.info(f"replacing tag: {source} -> {target}")
|
||||
|
||||
if source in tags:
|
||||
tags[tags.index(source)] = target
|
||||
|
||||
return tags
|
||||
|
||||
if default_format:
|
||||
with open(os.path.join(model_location, CSV_FILE), "r", encoding="utf-8") as f:
|
||||
reader = csv.reader(f)
|
||||
line = [row for row in reader]
|
||||
header = line[0] # tag_id,name,category,count
|
||||
rows = line[1:]
|
||||
assert header[0] == "tag_id" and header[1] == "name" and header[2] == "category", f"unexpected csv format: {header}"
|
||||
|
||||
rating_tags = [row[1] for row in rows[0:] if row[2] == "9"]
|
||||
general_tags = [row[1] for row in rows[0:] if row[2] == "0"]
|
||||
character_tags = [row[1] for row in rows[0:] if row[2] == "4"]
|
||||
|
||||
if args.character_tag_expand:
|
||||
expand_character_tags(character_tags)
|
||||
if args.remove_underscore:
|
||||
rating_tags = remove_underscore(rating_tags)
|
||||
character_tags = remove_underscore(character_tags)
|
||||
general_tags = remove_underscore(general_tags)
|
||||
if args.tag_replacement is not None:
|
||||
process_tag_replacement(rating_tags, args.tag_replacement)
|
||||
process_tag_replacement(general_tags, args.tag_replacement)
|
||||
process_tag_replacement(character_tags, args.tag_replacement)
|
||||
else:
|
||||
with open(os.path.join(model_location, TAG_JSON_FILE), "r", encoding="utf-8") as f:
|
||||
tag_mapping = json.load(f)
|
||||
|
||||
rating_tags = []
|
||||
general_tags = []
|
||||
character_tags = []
|
||||
|
||||
tag_id_to_tag_mapping = {}
|
||||
tag_id_to_category_mapping = {}
|
||||
for tag_id, tag_info in tag_mapping.items():
|
||||
tag = tag_info["tag"]
|
||||
category = tag_info["category"]
|
||||
assert category in [
|
||||
"Rating",
|
||||
"General",
|
||||
"Character",
|
||||
"Copyright",
|
||||
"Meta",
|
||||
"Model",
|
||||
"Quality",
|
||||
"Artist",
|
||||
], f"unexpected category: {category}"
|
||||
|
||||
if args.remove_underscore:
|
||||
tag = remove_underscore([tag])[0]
|
||||
if args.tag_replacement is not None:
|
||||
tag = process_tag_replacement([tag], args.tag_replacement)[0]
|
||||
if category == "Character" and args.character_tag_expand:
|
||||
tag_list = [tag]
|
||||
expand_character_tags(tag_list)
|
||||
tag = tag_list[0]
|
||||
|
||||
tag_id_to_tag_mapping[int(tag_id)] = tag
|
||||
tag_id_to_category_mapping[int(tag_id)] = category
|
||||
|
||||
# 画像を読み込む
|
||||
|
||||
train_data_dir_path = Path(args.train_data_dir)
|
||||
image_paths = train_util.glob_images_pathlib(train_data_dir_path, args.recursive)
|
||||
print(f"found {len(image_paths)} images.")
|
||||
logger.info(f"found {len(image_paths)} images.")
|
||||
image_paths = [str(ip) for ip in image_paths]
|
||||
|
||||
tag_freq = {}
|
||||
|
||||
undesired_tags = set(args.undesired_tags.split(","))
|
||||
caption_separator = args.caption_separator
|
||||
stripped_caption_separator = caption_separator.strip()
|
||||
undesired_tags = args.undesired_tags.split(stripped_caption_separator)
|
||||
undesired_tags = set([tag.strip() for tag in undesired_tags if tag.strip() != ""])
|
||||
|
||||
def run_batch(path_imgs):
|
||||
imgs = np.array([im for _, im in path_imgs])
|
||||
always_first_tags = None
|
||||
if args.always_first_tags is not None:
|
||||
always_first_tags = [tag for tag in args.always_first_tags.split(stripped_caption_separator) if tag.strip() != ""]
|
||||
|
||||
probs = model(imgs, training=False)
|
||||
probs = probs.numpy()
|
||||
def run_batch(path_imgs: tuple[list[str], np.ndarray, list[tuple[int, int]]]) -> Optional[dict[str, dict]]:
|
||||
nonlocal args, default_format, model, ort_sess, input_name, tag_freq
|
||||
|
||||
for (image_path, _), prob in zip(path_imgs, probs):
|
||||
# 最初の4つはratingなので無視する
|
||||
# # First 4 labels are actually ratings: pick one with argmax
|
||||
# ratings_names = label_names[:4]
|
||||
# rating_index = ratings_names["probs"].argmax()
|
||||
# found_rating = ratings_names[rating_index: rating_index + 1][["name", "probs"]]
|
||||
imgs = path_imgs[1]
|
||||
result = {}
|
||||
|
||||
# それ以降はタグなのでconfidenceがthresholdより高いものを追加する
|
||||
# Everything else is tags: pick any where prediction confidence > threshold
|
||||
if args.onnx:
|
||||
# if len(imgs) < args.batch_size:
|
||||
# imgs = np.concatenate([imgs, np.zeros((args.batch_size - len(imgs), IMAGE_SIZE, IMAGE_SIZE, 3))], axis=0)
|
||||
if not default_format:
|
||||
imgs = imgs.transpose(0, 3, 1, 2) # to NCHW
|
||||
imgs = imgs / 127.5 - 1.0
|
||||
probs = ort_sess.run(None, {input_name: imgs})[0] # onnx output numpy
|
||||
probs = probs[: len(imgs)] # remove padding
|
||||
else:
|
||||
probs = model(imgs, training=False)
|
||||
probs = probs.numpy()
|
||||
|
||||
for image_path, image_size, prob in zip(path_imgs[0], path_imgs[2], probs):
|
||||
combined_tags = []
|
||||
general_tag_text = ""
|
||||
rating_tag_text = ""
|
||||
character_tag_text = ""
|
||||
for i, p in enumerate(prob[4:]):
|
||||
if i < len(general_tags) and p >= args.general_threshold:
|
||||
tag_name = general_tags[i]
|
||||
if args.remove_underscore and len(tag_name) > 3: # ignore emoji tags like >_< and ^_^
|
||||
tag_name = tag_name.replace("_", " ")
|
||||
general_tag_text = ""
|
||||
other_tag_text = ""
|
||||
|
||||
if tag_name not in undesired_tags:
|
||||
tag_freq[tag_name] = tag_freq.get(tag_name, 0) + 1
|
||||
general_tag_text += ", " + tag_name
|
||||
combined_tags.append(tag_name)
|
||||
elif i >= len(general_tags) and p >= args.character_threshold:
|
||||
tag_name = character_tags[i - len(general_tags)]
|
||||
if args.remove_underscore and len(tag_name) > 3:
|
||||
tag_name = tag_name.replace("_", " ")
|
||||
if default_format:
|
||||
# 最初の4つ以降はタグなのでconfidenceがthreshold以上のものを追加する
|
||||
# First 4 labels are ratings, the rest are tags: pick any where prediction confidence >= threshold
|
||||
for i, p in enumerate(prob[4:]):
|
||||
if i < len(general_tags) and p >= args.general_threshold:
|
||||
tag_name = general_tags[i]
|
||||
|
||||
if tag_name not in undesired_tags:
|
||||
if tag_name not in undesired_tags:
|
||||
tag_freq[tag_name] = tag_freq.get(tag_name, 0) + 1
|
||||
general_tag_text += caption_separator + tag_name
|
||||
combined_tags.append(tag_name)
|
||||
elif i >= len(general_tags) and p >= args.character_threshold:
|
||||
tag_name = character_tags[i - len(general_tags)]
|
||||
|
||||
if tag_name not in undesired_tags:
|
||||
tag_freq[tag_name] = tag_freq.get(tag_name, 0) + 1
|
||||
character_tag_text += caption_separator + tag_name
|
||||
if args.character_tags_first: # insert to the beginning
|
||||
combined_tags.insert(0, tag_name)
|
||||
else:
|
||||
combined_tags.append(tag_name)
|
||||
|
||||
# 最初の4つはratingなのでargmaxで選ぶ
|
||||
# First 4 labels are actually ratings: pick one with argmax
|
||||
if args.use_rating_tags or args.use_rating_tags_as_last_tag:
|
||||
ratings_probs = prob[:4]
|
||||
rating_index = ratings_probs.argmax()
|
||||
found_rating = rating_tags[rating_index]
|
||||
|
||||
if found_rating not in undesired_tags:
|
||||
tag_freq[found_rating] = tag_freq.get(found_rating, 0) + 1
|
||||
rating_tag_text = found_rating
|
||||
if args.use_rating_tags:
|
||||
combined_tags.insert(0, found_rating) # insert to the beginning
|
||||
else:
|
||||
combined_tags.append(found_rating)
|
||||
else:
|
||||
# apply sigmoid to probabilities
|
||||
prob = 1 / (1 + np.exp(-prob))
|
||||
|
||||
rating_max_prob = -1
|
||||
rating_tag = None
|
||||
quality_max_prob = -1
|
||||
quality_tag = None
|
||||
img_character_tags = []
|
||||
|
||||
min_thres = min(
|
||||
args.thresh,
|
||||
args.general_threshold,
|
||||
args.character_threshold,
|
||||
args.copyright_threshold,
|
||||
args.meta_threshold,
|
||||
args.model_threshold,
|
||||
args.artist_threshold,
|
||||
)
|
||||
prob_indices = np.where(prob >= min_thres)[0]
|
||||
# for i, p in enumerate(prob):
|
||||
for i in prob_indices:
|
||||
if i not in tag_id_to_tag_mapping:
|
||||
continue
|
||||
p = prob[i]
|
||||
|
||||
tag_name = tag_id_to_tag_mapping[i]
|
||||
category = tag_id_to_category_mapping[i]
|
||||
if tag_name in undesired_tags:
|
||||
continue
|
||||
|
||||
if category == "Rating":
|
||||
if p > rating_max_prob:
|
||||
rating_max_prob = p
|
||||
rating_tag = tag_name
|
||||
rating_tag_text = tag_name
|
||||
continue
|
||||
elif category == "Quality":
|
||||
if p > quality_max_prob:
|
||||
quality_max_prob = p
|
||||
quality_tag = tag_name
|
||||
if args.use_quality_tags or args.use_quality_tags_as_last_tag:
|
||||
other_tag_text += caption_separator + tag_name
|
||||
continue
|
||||
|
||||
if category == "General" and p >= args.general_threshold:
|
||||
tag_freq[tag_name] = tag_freq.get(tag_name, 0) + 1
|
||||
character_tag_text += ", " + tag_name
|
||||
combined_tags.append(tag_name)
|
||||
general_tag_text += caption_separator + tag_name
|
||||
combined_tags.append((tag_name, p))
|
||||
elif category == "Character" and p >= args.character_threshold:
|
||||
tag_freq[tag_name] = tag_freq.get(tag_name, 0) + 1
|
||||
character_tag_text += caption_separator + tag_name
|
||||
if args.character_tags_first: # we separate character tags
|
||||
img_character_tags.append((tag_name, p))
|
||||
else:
|
||||
combined_tags.append((tag_name, p))
|
||||
elif (
|
||||
(category == "Copyright" and p >= args.copyright_threshold)
|
||||
or (category == "Meta" and p >= args.meta_threshold)
|
||||
or (category == "Model" and p >= args.model_threshold)
|
||||
or (category == "Artist" and p >= args.artist_threshold)
|
||||
):
|
||||
tag_freq[tag_name] = tag_freq.get(tag_name, 0) + 1
|
||||
other_tag_text += f"{caption_separator}{tag_name} ({category})"
|
||||
combined_tags.append((tag_name, p))
|
||||
|
||||
# sort by probability
|
||||
combined_tags.sort(key=lambda x: x[1], reverse=True)
|
||||
if img_character_tags:
|
||||
img_character_tags.sort(key=lambda x: x[1], reverse=True)
|
||||
combined_tags = img_character_tags + combined_tags
|
||||
combined_tags = [t[0] for t in combined_tags] # remove probability
|
||||
|
||||
if quality_tag is not None:
|
||||
if args.use_quality_tags_as_last_tag:
|
||||
combined_tags.append(quality_tag)
|
||||
elif args.use_quality_tags:
|
||||
combined_tags.insert(0, quality_tag)
|
||||
if rating_tag is not None:
|
||||
if args.use_rating_tags_as_last_tag:
|
||||
combined_tags.append(rating_tag)
|
||||
elif args.use_rating_tags:
|
||||
combined_tags.insert(0, rating_tag)
|
||||
|
||||
# 一番最初に置くタグを指定する
|
||||
# Always put some tags at the beginning
|
||||
if always_first_tags is not None:
|
||||
for tag in always_first_tags:
|
||||
if tag in combined_tags:
|
||||
combined_tags.remove(tag)
|
||||
combined_tags.insert(0, tag)
|
||||
|
||||
# 先頭のカンマを取る
|
||||
if len(general_tag_text) > 0:
|
||||
general_tag_text = general_tag_text[2:]
|
||||
general_tag_text = general_tag_text[len(caption_separator) :]
|
||||
if len(character_tag_text) > 0:
|
||||
character_tag_text = character_tag_text[2:]
|
||||
character_tag_text = character_tag_text[len(caption_separator) :]
|
||||
if len(other_tag_text) > 0:
|
||||
other_tag_text = other_tag_text[len(caption_separator) :]
|
||||
|
||||
tag_text = ", ".join(combined_tags)
|
||||
caption_file = os.path.splitext(image_path)[0] + args.caption_extension
|
||||
|
||||
with open(os.path.splitext(image_path)[0] + args.caption_extension, "wt", encoding="utf-8") as f:
|
||||
f.write(tag_text + "\n")
|
||||
if args.debug:
|
||||
print(f"\n{image_path}:\n Character tags: {character_tag_text}\n General tags: {general_tag_text}")
|
||||
tag_text = caption_separator.join(combined_tags)
|
||||
|
||||
if args.append_tags:
|
||||
# Check if file exists
|
||||
if os.path.exists(caption_file):
|
||||
with open(caption_file, "rt", encoding="utf-8") as f:
|
||||
# Read file and remove new lines
|
||||
existing_content = f.read().strip("\n") # Remove newlines
|
||||
|
||||
# Split the content into tags and store them in a list
|
||||
existing_tags = [tag.strip() for tag in existing_content.split(stripped_caption_separator) if tag.strip()]
|
||||
|
||||
# Check and remove repeating tags in tag_text
|
||||
new_tags = [tag for tag in combined_tags if tag not in existing_tags]
|
||||
|
||||
# Create new tag_text
|
||||
tag_text = caption_separator.join(existing_tags + new_tags)
|
||||
|
||||
if not args.output_path:
|
||||
with open(caption_file, "wt", encoding="utf-8") as f:
|
||||
f.write(tag_text + "\n")
|
||||
else:
|
||||
entry = {"tags": tag_text, "image_size": list(image_size)}
|
||||
result[image_path] = entry
|
||||
|
||||
if args.debug:
|
||||
logger.info("")
|
||||
logger.info(f"{image_path}:")
|
||||
logger.info(f"\tRating tags: {rating_tag_text}")
|
||||
logger.info(f"\tCharacter tags: {character_tag_text}")
|
||||
logger.info(f"\tGeneral tags: {general_tag_text}")
|
||||
if other_tag_text:
|
||||
logger.info(f"\tOther tags: {other_tag_text}")
|
||||
|
||||
return result
|
||||
|
||||
# 読み込みの高速化のためにDataLoaderを使うオプション
|
||||
if args.max_data_loader_n_workers is not None:
|
||||
dataset = ImageLoadingPrepDataset(image_paths)
|
||||
dataset = ImageLoadingPrepDataset(image_paths, args.batch_size)
|
||||
data = torch.utils.data.DataLoader(
|
||||
dataset,
|
||||
batch_size=args.batch_size,
|
||||
batch_size=1,
|
||||
shuffle=False,
|
||||
num_workers=args.max_data_loader_n_workers,
|
||||
collate_fn=collate_fn_remove_corrupted,
|
||||
collate_fn=collate_fn_no_op,
|
||||
drop_last=False,
|
||||
)
|
||||
else:
|
||||
data = [[(None, ip)] for ip in image_paths]
|
||||
# data = [[(ip, None, None)] for ip in image_paths]
|
||||
data = [[]]
|
||||
for ip in image_paths:
|
||||
if len(data[-1]) >= args.batch_size:
|
||||
data.append([])
|
||||
data[-1].append((ip, None, None))
|
||||
|
||||
b_imgs = []
|
||||
results = {}
|
||||
for data_entry in tqdm(data, smoothing=0.0):
|
||||
for data in data_entry:
|
||||
if data is None:
|
||||
continue
|
||||
if data_entry is None or len(data_entry) == 0:
|
||||
continue
|
||||
|
||||
image, image_path = data
|
||||
if image is not None:
|
||||
image = image.detach().numpy()
|
||||
else:
|
||||
try:
|
||||
image = Image.open(image_path)
|
||||
if image.mode != "RGB":
|
||||
image = image.convert("RGB")
|
||||
image = preprocess_image(image)
|
||||
except Exception as e:
|
||||
print(f"Could not load image path / 画像を読み込めません: {image_path}, error: {e}")
|
||||
continue
|
||||
b_imgs.append((image_path, image))
|
||||
if data_entry[0][1] is None:
|
||||
# No preloaded image, need to load
|
||||
images = []
|
||||
image_sizes = []
|
||||
for image_path, _, _ in data_entry:
|
||||
image = Image.open(image_path)
|
||||
image_size = image.size
|
||||
image = preprocess_image(image)
|
||||
images.append(image)
|
||||
image_sizes.append(image_size)
|
||||
b_imgs = ([ip for ip, _, _ in data_entry], np.stack(images), image_sizes)
|
||||
else:
|
||||
b_imgs = data_entry[0]
|
||||
|
||||
if len(b_imgs) >= args.batch_size:
|
||||
b_imgs = [(str(image_path), image) for image_path, image in b_imgs] # Convert image_path to string
|
||||
run_batch(b_imgs)
|
||||
b_imgs.clear()
|
||||
r = run_batch(b_imgs)
|
||||
if args.output_path and r is not None:
|
||||
results.update(r)
|
||||
|
||||
if len(b_imgs) > 0:
|
||||
b_imgs = [(str(image_path), image) for image_path, image in b_imgs] # Convert image_path to string
|
||||
run_batch(b_imgs)
|
||||
if args.output_path:
|
||||
if args.output_path.endswith(".jsonl"):
|
||||
# optional JSONL metadata
|
||||
with open(args.output_path, "wt", encoding="utf-8") as f:
|
||||
for image_path, entry in results.items():
|
||||
f.write(
|
||||
json.dumps({"image_path": image_path, "caption": entry["tags"], "image_size": entry["image_size"]}) + "\n"
|
||||
)
|
||||
else:
|
||||
# standard JSON metadata
|
||||
with open(args.output_path, "wt", encoding="utf-8") as f:
|
||||
json.dump(results, f, ensure_ascii=False, indent=4)
|
||||
logger.info(f"captions saved to {args.output_path}")
|
||||
|
||||
if args.frequency_tags:
|
||||
sorted_tags = sorted(tag_freq.items(), key=lambda x: x[1], reverse=True)
|
||||
print("\nTag frequencies:")
|
||||
print("Tag frequencies:")
|
||||
for tag, freq in sorted_tags:
|
||||
print(f"{tag}: {freq}")
|
||||
|
||||
print("done!")
|
||||
logger.info("done!")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("train_data_dir", type=str, help="directory for train images / 学習画像データのディレクトリ")
|
||||
parser.add_argument(
|
||||
@@ -240,7 +615,9 @@ if __name__ == "__main__":
|
||||
help="directory to store wd14 tagger model / wd14 taggerのモデルを格納するディレクトリ",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--force_download", action="store_true", help="force downloading wd14 tagger models / wd14 taggerのモデルを再ダウンロードします"
|
||||
"--force_download",
|
||||
action="store_true",
|
||||
help="force downloading wd14 tagger models / wd14 taggerのモデルを再ダウンロードします",
|
||||
)
|
||||
parser.add_argument("--batch_size", type=int, default=1, help="batch size in inference / 推論時のバッチサイズ")
|
||||
parser.add_argument(
|
||||
@@ -249,14 +626,24 @@ if __name__ == "__main__":
|
||||
default=None,
|
||||
help="enable image reading by DataLoader with this number of workers (faster) / DataLoaderによる画像読み込みを有効にしてこのワーカー数を適用する(読み込みを高速化)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--output_path",
|
||||
type=str,
|
||||
default=None,
|
||||
help="path for output captions (json format). if this is set, captions will be saved to this file / 出力キャプションのパス(json形式)。このオプションが設定されている場合、キャプションはこのファイルに保存されます",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--caption_extention",
|
||||
type=str,
|
||||
default=None,
|
||||
help="extension of caption file (for backward compatibility) / 出力されるキャプションファイルの拡張子(スペルミスしていたのを残してあります)",
|
||||
)
|
||||
parser.add_argument("--caption_extension", type=str, default=".txt", help="extension of caption file / 出力されるキャプションファイルの拡張子")
|
||||
parser.add_argument("--thresh", type=float, default=0.35, help="threshold of confidence to add a tag / タグを追加するか判定する閾値")
|
||||
parser.add_argument(
|
||||
"--caption_extension", type=str, default=".txt", help="extension of caption file / 出力されるキャプションファイルの拡張子"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--thresh", type=float, default=0.35, help="threshold of confidence to add a tag / タグを追加するか判定する閾値"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--general_threshold",
|
||||
type=float,
|
||||
@@ -267,9 +654,40 @@ if __name__ == "__main__":
|
||||
"--character_threshold",
|
||||
type=float,
|
||||
default=None,
|
||||
help="threshold of confidence to add a tag for character category, same as --thres if omitted / characterカテゴリのタグを追加するための確信度の閾値、省略時は --thresh と同じ",
|
||||
help="threshold of confidence to add a tag for character category, same as --thres if omitted. set above 1 to disable character tags"
|
||||
" / characterカテゴリのタグを追加するための確信度の閾値、省略時は --thresh と同じ。1以上にするとcharacterタグを無効化できる",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--meta_threshold",
|
||||
type=float,
|
||||
default=None,
|
||||
help="threshold of confidence to add a tag for meta category, same as --thresh if omitted. set above 1 to disable meta tags"
|
||||
" / metaカテゴリのタグを追加するための確信度の閾値、省略時は --thresh と同じ。1以上にするとmetaタグを無効化できる",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--model_threshold",
|
||||
type=float,
|
||||
default=None,
|
||||
help="threshold of confidence to add a tag for model category, same as --thresh if omitted. set above 1 to disable model tags"
|
||||
" / modelカテゴリのタグを追加するための確信度の閾値、省略時は --thresh と同じ。1以上にするとmodelタグを無効化できる",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--copyright_threshold",
|
||||
type=float,
|
||||
default=None,
|
||||
help="threshold of confidence to add a tag for copyright category, same as --thresh if omitted. set above 1 to disable copyright tags"
|
||||
" / copyrightカテゴリのタグを追加するための確信度の閾値、省略時は --thresh と同じ。1以上にするとcopyrightタグを無効化できる",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--artist_threshold",
|
||||
type=float,
|
||||
default=None,
|
||||
help="threshold of confidence to add a tag for artist category, same as --thresh if omitted. set above 1 to disable artist tags"
|
||||
" / artistカテゴリのタグを追加するための確信度の閾値、省略時は --thresh と同じ。1以上にするとartistタグを無効化できる",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--recursive", action="store_true", help="search for images in subfolders recursively / サブフォルダを再帰的に検索する"
|
||||
)
|
||||
parser.add_argument("--recursive", action="store_true", help="search for images in subfolders recursively / サブフォルダを再帰的に検索する")
|
||||
parser.add_argument(
|
||||
"--remove_underscore",
|
||||
action="store_true",
|
||||
@@ -282,7 +700,70 @@ if __name__ == "__main__":
|
||||
default="",
|
||||
help="comma-separated list of undesired tags to remove from the output / 出力から除外したいタグのカンマ区切りのリスト",
|
||||
)
|
||||
parser.add_argument("--frequency_tags", action="store_true", help="Show frequency of tags for images / 画像ごとのタグの出現頻度を表示する")
|
||||
parser.add_argument(
|
||||
"--frequency_tags", action="store_true", help="Show frequency of tags for images / タグの出現頻度を表示する"
|
||||
)
|
||||
parser.add_argument("--onnx", action="store_true", help="use onnx model for inference / onnxモデルを推論に使用する")
|
||||
parser.add_argument(
|
||||
"--append_tags", action="store_true", help="Append captions instead of overwriting / 上書きではなくキャプションを追記する"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--use_rating_tags",
|
||||
action="store_true",
|
||||
help="Adds rating tags as the first tag / レーティングタグを最初のタグとして追加する",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--use_rating_tags_as_last_tag",
|
||||
action="store_true",
|
||||
help="Adds rating tags as the last tag / レーティングタグを最後のタグとして追加する",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--use_quality_tags",
|
||||
action="store_true",
|
||||
help="Adds quality tags as the first tag / クオリティタグを最初のタグとして追加する",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--use_quality_tags_as_last_tag",
|
||||
action="store_true",
|
||||
help="Adds quality tags as the last tag / クオリティタグを最後のタグとして追加する",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--character_tags_first",
|
||||
action="store_true",
|
||||
help="Always inserts character tags before the general tags / characterタグを常にgeneralタグの前に出力する",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--always_first_tags",
|
||||
type=str,
|
||||
default=None,
|
||||
help="comma-separated list of tags to always put at the beginning, e.g. `1girl,1boy`"
|
||||
+ " / 必ず先頭に置くタグのカンマ区切りリスト、例 : `1girl,1boy`",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--caption_separator",
|
||||
type=str,
|
||||
default=", ",
|
||||
help="Separator for captions, include space if needed / キャプションの区切り文字、必要ならスペースを含めてください",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--tag_replacement",
|
||||
type=str,
|
||||
default=None,
|
||||
help="tag replacement in the format of `source1,target1;source2,target2; ...`. Escape `,` and `;` with `\`. e.g. `tag1,tag2;tag3,tag4`"
|
||||
+ " / タグの置換を `置換元1,置換先1;置換元2,置換先2; ...`で指定する。`\` で `,` と `;` をエスケープできる。例: `tag1,tag2;tag3,tag4`",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--character_tag_expand",
|
||||
action="store_true",
|
||||
help="expand tag tail parenthesis to another tag for character tags. `chara_name_(series)` becomes `chara_name, series`"
|
||||
+ " / キャラクタタグの末尾の括弧を別のタグに展開する。`chara_name_(series)` は `chara_name, series` になる",
|
||||
)
|
||||
|
||||
return parser
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
@@ -294,5 +775,13 @@ if __name__ == "__main__":
|
||||
args.general_threshold = args.thresh
|
||||
if args.character_threshold is None:
|
||||
args.character_threshold = args.thresh
|
||||
if args.meta_threshold is None:
|
||||
args.meta_threshold = args.thresh
|
||||
if args.model_threshold is None:
|
||||
args.model_threshold = args.thresh
|
||||
if args.copyright_threshold is None:
|
||||
args.copyright_threshold = args.thresh
|
||||
if args.artist_threshold is None:
|
||||
args.artist_threshold = args.thresh
|
||||
|
||||
main(args)
|
||||
|
||||
596
flux_minimal_inference.py
Normal file
596
flux_minimal_inference.py
Normal file
@@ -0,0 +1,596 @@
|
||||
# Minimum Inference Code for FLUX
|
||||
|
||||
import argparse
|
||||
import datetime
|
||||
import math
|
||||
import os
|
||||
import random
|
||||
from typing import Callable, List, Optional
|
||||
import einops
|
||||
import numpy as np
|
||||
|
||||
import torch
|
||||
from tqdm import tqdm
|
||||
from PIL import Image
|
||||
import accelerate
|
||||
from transformers import CLIPTextModel
|
||||
from safetensors.torch import load_file
|
||||
|
||||
from library import device_utils
|
||||
from library.device_utils import init_ipex, get_preferred_device
|
||||
from networks import oft_flux
|
||||
|
||||
init_ipex()
|
||||
|
||||
|
||||
from library.utils import setup_logging, str_to_dtype
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
import networks.lora_flux as lora_flux
|
||||
from library import flux_models, flux_utils, sd3_utils, strategy_flux
|
||||
|
||||
|
||||
def time_shift(mu: float, sigma: float, t: torch.Tensor):
|
||||
return math.exp(mu) / (math.exp(mu) + (1 / t - 1) ** sigma)
|
||||
|
||||
|
||||
def get_lin_function(x1: float = 256, y1: float = 0.5, x2: float = 4096, y2: float = 1.15) -> Callable[[float], float]:
|
||||
m = (y2 - y1) / (x2 - x1)
|
||||
b = y1 - m * x1
|
||||
return lambda x: m * x + b
|
||||
|
||||
|
||||
def get_schedule(
|
||||
num_steps: int,
|
||||
image_seq_len: int,
|
||||
base_shift: float = 0.5,
|
||||
max_shift: float = 1.15,
|
||||
shift: bool = True,
|
||||
) -> list[float]:
|
||||
# extra step for zero
|
||||
timesteps = torch.linspace(1, 0, num_steps + 1)
|
||||
|
||||
# shifting the schedule to favor high timesteps for higher signal images
|
||||
if shift:
|
||||
# eastimate mu based on linear estimation between two points
|
||||
mu = get_lin_function(y1=base_shift, y2=max_shift)(image_seq_len)
|
||||
timesteps = time_shift(mu, 1.0, timesteps)
|
||||
|
||||
return timesteps.tolist()
|
||||
|
||||
|
||||
def denoise(
|
||||
model: flux_models.Flux,
|
||||
img: torch.Tensor,
|
||||
img_ids: torch.Tensor,
|
||||
txt: torch.Tensor,
|
||||
txt_ids: torch.Tensor,
|
||||
vec: torch.Tensor,
|
||||
timesteps: list[float],
|
||||
guidance: float = 4.0,
|
||||
t5_attn_mask: Optional[torch.Tensor] = None,
|
||||
neg_txt: Optional[torch.Tensor] = None,
|
||||
neg_vec: Optional[torch.Tensor] = None,
|
||||
neg_t5_attn_mask: Optional[torch.Tensor] = None,
|
||||
cfg_scale: Optional[float] = None,
|
||||
):
|
||||
# prepare classifier free guidance
|
||||
logger.info(f"guidance: {guidance}, cfg_scale: {cfg_scale}")
|
||||
do_cfg = neg_txt is not None and (cfg_scale is not None and cfg_scale != 1.0)
|
||||
|
||||
# this is ignored for schnell
|
||||
guidance_vec = torch.full((img.shape[0] * (2 if do_cfg else 1),), guidance, device=img.device, dtype=img.dtype)
|
||||
|
||||
if do_cfg:
|
||||
print("Using classifier free guidance")
|
||||
b_img_ids = torch.cat([img_ids, img_ids], dim=0)
|
||||
b_txt_ids = torch.cat([txt_ids, txt_ids], dim=0)
|
||||
b_txt = torch.cat([neg_txt, txt], dim=0)
|
||||
b_vec = torch.cat([neg_vec, vec], dim=0) if neg_vec is not None else None
|
||||
if t5_attn_mask is not None and neg_t5_attn_mask is not None:
|
||||
b_t5_attn_mask = torch.cat([neg_t5_attn_mask, t5_attn_mask], dim=0)
|
||||
else:
|
||||
b_t5_attn_mask = None
|
||||
else:
|
||||
b_img_ids = img_ids
|
||||
b_txt_ids = txt_ids
|
||||
b_txt = txt
|
||||
b_vec = vec
|
||||
b_t5_attn_mask = t5_attn_mask
|
||||
|
||||
for t_curr, t_prev in zip(tqdm(timesteps[:-1]), timesteps[1:]):
|
||||
t_vec = torch.full((b_img_ids.shape[0],), t_curr, dtype=img.dtype, device=img.device)
|
||||
|
||||
# classifier free guidance
|
||||
if do_cfg:
|
||||
b_img = torch.cat([img, img], dim=0)
|
||||
else:
|
||||
b_img = img
|
||||
|
||||
y_input = b_vec
|
||||
|
||||
mod_vectors = model.get_mod_vectors(timesteps=t_vec, guidance=guidance_vec, batch_size=b_img.shape[0])
|
||||
|
||||
pred = model(
|
||||
img=b_img,
|
||||
img_ids=b_img_ids,
|
||||
txt=b_txt,
|
||||
txt_ids=b_txt_ids,
|
||||
y=y_input,
|
||||
timesteps=t_vec,
|
||||
guidance=guidance_vec,
|
||||
txt_attention_mask=b_t5_attn_mask,
|
||||
mod_vectors=mod_vectors,
|
||||
)
|
||||
|
||||
# classifier free guidance
|
||||
if do_cfg:
|
||||
pred_uncond, pred = torch.chunk(pred, 2, dim=0)
|
||||
pred = pred_uncond + cfg_scale * (pred - pred_uncond)
|
||||
|
||||
img = img + (t_prev - t_curr) * pred
|
||||
|
||||
return img
|
||||
|
||||
|
||||
def do_sample(
|
||||
accelerator: Optional[accelerate.Accelerator],
|
||||
model: flux_models.Flux,
|
||||
img: torch.Tensor,
|
||||
img_ids: torch.Tensor,
|
||||
l_pooled: Optional[torch.Tensor],
|
||||
t5_out: torch.Tensor,
|
||||
txt_ids: torch.Tensor,
|
||||
num_steps: int,
|
||||
guidance: float,
|
||||
t5_attn_mask: Optional[torch.Tensor],
|
||||
is_schnell: bool,
|
||||
device: torch.device,
|
||||
flux_dtype: torch.dtype,
|
||||
neg_l_pooled: Optional[torch.Tensor] = None,
|
||||
neg_t5_out: Optional[torch.Tensor] = None,
|
||||
neg_t5_attn_mask: Optional[torch.Tensor] = None,
|
||||
cfg_scale: Optional[float] = None,
|
||||
):
|
||||
logger.info(f"num_steps: {num_steps}")
|
||||
timesteps = get_schedule(num_steps, img.shape[1], shift=not is_schnell)
|
||||
|
||||
# denoise initial noise
|
||||
if accelerator:
|
||||
with accelerator.autocast(), torch.no_grad():
|
||||
x = denoise(
|
||||
model,
|
||||
img,
|
||||
img_ids,
|
||||
t5_out,
|
||||
txt_ids,
|
||||
l_pooled,
|
||||
timesteps,
|
||||
guidance,
|
||||
t5_attn_mask,
|
||||
neg_t5_out,
|
||||
neg_l_pooled,
|
||||
neg_t5_attn_mask,
|
||||
cfg_scale,
|
||||
)
|
||||
else:
|
||||
with torch.autocast(device_type=device.type, dtype=flux_dtype), torch.no_grad():
|
||||
x = denoise(
|
||||
model,
|
||||
img,
|
||||
img_ids,
|
||||
t5_out,
|
||||
txt_ids,
|
||||
l_pooled,
|
||||
timesteps,
|
||||
guidance,
|
||||
t5_attn_mask,
|
||||
neg_t5_out,
|
||||
neg_l_pooled,
|
||||
neg_t5_attn_mask,
|
||||
cfg_scale,
|
||||
)
|
||||
|
||||
return x
|
||||
|
||||
|
||||
def generate_image(
|
||||
model,
|
||||
clip_l: Optional[CLIPTextModel],
|
||||
t5xxl,
|
||||
ae,
|
||||
prompt: str,
|
||||
seed: Optional[int],
|
||||
image_width: int,
|
||||
image_height: int,
|
||||
steps: Optional[int],
|
||||
guidance: float,
|
||||
negative_prompt: Optional[str],
|
||||
cfg_scale: float,
|
||||
):
|
||||
seed = seed if seed is not None else random.randint(0, 2**32 - 1)
|
||||
logger.info(f"Seed: {seed}")
|
||||
|
||||
# make first noise with packed shape
|
||||
# original: b,16,2*h//16,2*w//16, packed: b,h//16*w//16,16*2*2
|
||||
packed_latent_height, packed_latent_width = math.ceil(image_height / 16), math.ceil(image_width / 16)
|
||||
noise_dtype = torch.float32 if is_fp8(dtype) else dtype
|
||||
noise = torch.randn(
|
||||
1,
|
||||
packed_latent_height * packed_latent_width,
|
||||
16 * 2 * 2,
|
||||
device=device,
|
||||
dtype=noise_dtype,
|
||||
generator=torch.Generator(device=device).manual_seed(seed),
|
||||
)
|
||||
|
||||
# prepare img and img ids
|
||||
|
||||
# this is needed only for img2img
|
||||
# img = rearrange(img, "b c (h ph) (w pw) -> b (h w) (c ph pw)", ph=2, pw=2)
|
||||
# if img.shape[0] == 1 and bs > 1:
|
||||
# img = repeat(img, "1 ... -> bs ...", bs=bs)
|
||||
|
||||
# txt2img only needs img_ids
|
||||
img_ids = flux_utils.prepare_img_ids(1, packed_latent_height, packed_latent_width)
|
||||
|
||||
# prepare fp8 models
|
||||
if clip_l is not None and is_fp8(clip_l_dtype) and (not hasattr(clip_l, "fp8_prepared") or not clip_l.fp8_prepared):
|
||||
logger.info(f"prepare CLIP-L for fp8: set to {clip_l_dtype}, set embeddings to {torch.bfloat16}")
|
||||
clip_l.to(clip_l_dtype) # fp8
|
||||
clip_l.text_model.embeddings.to(dtype=torch.bfloat16)
|
||||
clip_l.fp8_prepared = True
|
||||
|
||||
if is_fp8(t5xxl_dtype) and (not hasattr(t5xxl, "fp8_prepared") or not t5xxl.fp8_prepared):
|
||||
logger.info(f"prepare T5xxl for fp8: set to {t5xxl_dtype}")
|
||||
|
||||
def prepare_fp8(text_encoder, target_dtype):
|
||||
def forward_hook(module):
|
||||
def forward(hidden_states):
|
||||
hidden_gelu = module.act(module.wi_0(hidden_states))
|
||||
hidden_linear = module.wi_1(hidden_states)
|
||||
hidden_states = hidden_gelu * hidden_linear
|
||||
hidden_states = module.dropout(hidden_states)
|
||||
|
||||
hidden_states = module.wo(hidden_states)
|
||||
return hidden_states
|
||||
|
||||
return forward
|
||||
|
||||
for module in text_encoder.modules():
|
||||
if module.__class__.__name__ in ["T5LayerNorm", "Embedding"]:
|
||||
# print("set", module.__class__.__name__, "to", target_dtype)
|
||||
module.to(target_dtype)
|
||||
if module.__class__.__name__ in ["T5DenseGatedActDense"]:
|
||||
# print("set", module.__class__.__name__, "hooks")
|
||||
module.forward = forward_hook(module)
|
||||
|
||||
t5xxl.to(t5xxl_dtype)
|
||||
prepare_fp8(t5xxl.encoder, torch.bfloat16)
|
||||
t5xxl.fp8_prepared = True
|
||||
|
||||
# prepare embeddings
|
||||
logger.info("Encoding prompts...")
|
||||
if clip_l is not None:
|
||||
clip_l = clip_l.to(device)
|
||||
t5xxl = t5xxl.to(device)
|
||||
|
||||
def encode(prpt: str):
|
||||
tokens_and_masks = tokenize_strategy.tokenize(prpt)
|
||||
with torch.no_grad():
|
||||
if clip_l is not None:
|
||||
if is_fp8(clip_l_dtype):
|
||||
with accelerator.autocast():
|
||||
l_pooled, _, _, _ = encoding_strategy.encode_tokens(tokenize_strategy, [clip_l, None], tokens_and_masks)
|
||||
else:
|
||||
with torch.autocast(device_type=device.type, dtype=clip_l_dtype):
|
||||
l_pooled, _, _, _ = encoding_strategy.encode_tokens(tokenize_strategy, [clip_l, None], tokens_and_masks)
|
||||
else:
|
||||
l_pooled = None
|
||||
|
||||
if is_fp8(t5xxl_dtype):
|
||||
with accelerator.autocast():
|
||||
_, t5_out, txt_ids, t5_attn_mask = encoding_strategy.encode_tokens(
|
||||
tokenize_strategy, [clip_l, t5xxl], tokens_and_masks, args.apply_t5_attn_mask
|
||||
)
|
||||
else:
|
||||
with torch.autocast(device_type=device.type, dtype=t5xxl_dtype):
|
||||
_, t5_out, txt_ids, t5_attn_mask = encoding_strategy.encode_tokens(
|
||||
tokenize_strategy, [clip_l, t5xxl], tokens_and_masks, args.apply_t5_attn_mask
|
||||
)
|
||||
return l_pooled, t5_out, txt_ids, t5_attn_mask
|
||||
|
||||
l_pooled, t5_out, txt_ids, t5_attn_mask = encode(prompt)
|
||||
if negative_prompt:
|
||||
neg_l_pooled, neg_t5_out, _, neg_t5_attn_mask = encode(negative_prompt)
|
||||
else:
|
||||
neg_l_pooled, neg_t5_out, neg_t5_attn_mask = None, None, None
|
||||
|
||||
# NaN check
|
||||
if l_pooled is not None and torch.isnan(l_pooled).any():
|
||||
raise ValueError("NaN in l_pooled")
|
||||
if torch.isnan(t5_out).any():
|
||||
raise ValueError("NaN in t5_out")
|
||||
|
||||
if args.offload:
|
||||
if clip_l is not None:
|
||||
clip_l = clip_l.cpu()
|
||||
t5xxl = t5xxl.cpu()
|
||||
# del clip_l, t5xxl
|
||||
device_utils.clean_memory()
|
||||
|
||||
# generate image
|
||||
logger.info("Generating image...")
|
||||
model = model.to(device)
|
||||
if steps is None:
|
||||
steps = 4 if is_schnell else 50
|
||||
|
||||
img_ids = img_ids.to(device)
|
||||
t5_attn_mask = t5_attn_mask.to(device) if args.apply_t5_attn_mask else None
|
||||
neg_t5_attn_mask = neg_t5_attn_mask.to(device) if neg_t5_attn_mask is not None and args.apply_t5_attn_mask else None
|
||||
|
||||
x = do_sample(
|
||||
accelerator,
|
||||
model,
|
||||
noise,
|
||||
img_ids,
|
||||
l_pooled,
|
||||
t5_out,
|
||||
txt_ids,
|
||||
steps,
|
||||
guidance,
|
||||
t5_attn_mask,
|
||||
is_schnell,
|
||||
device,
|
||||
flux_dtype,
|
||||
neg_l_pooled,
|
||||
neg_t5_out,
|
||||
neg_t5_attn_mask,
|
||||
cfg_scale,
|
||||
)
|
||||
if args.offload:
|
||||
model = model.cpu()
|
||||
# del model
|
||||
device_utils.clean_memory()
|
||||
|
||||
# unpack
|
||||
x = x.float()
|
||||
x = einops.rearrange(x, "b (h w) (c ph pw) -> b c (h ph) (w pw)", h=packed_latent_height, w=packed_latent_width, ph=2, pw=2)
|
||||
|
||||
# decode
|
||||
logger.info("Decoding image...")
|
||||
ae = ae.to(device)
|
||||
with torch.no_grad():
|
||||
if is_fp8(ae_dtype):
|
||||
with accelerator.autocast():
|
||||
x = ae.decode(x)
|
||||
else:
|
||||
with torch.autocast(device_type=device.type, dtype=ae_dtype):
|
||||
x = ae.decode(x)
|
||||
if args.offload:
|
||||
ae = ae.cpu()
|
||||
|
||||
x = x.clamp(-1, 1)
|
||||
x = x.permute(0, 2, 3, 1)
|
||||
img = Image.fromarray((127.5 * (x + 1.0)).float().cpu().numpy().astype(np.uint8)[0])
|
||||
|
||||
# save image
|
||||
output_dir = args.output_dir
|
||||
os.makedirs(output_dir, exist_ok=True)
|
||||
output_path = os.path.join(output_dir, f"{datetime.datetime.now().strftime('%Y%m%d_%H%M%S')}.png")
|
||||
img.save(output_path)
|
||||
|
||||
logger.info(f"Saved image to {output_path}")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
target_height = 768 # 1024
|
||||
target_width = 1360 # 1024
|
||||
|
||||
# steps = 50 # 28 # 50
|
||||
# guidance_scale = 5
|
||||
# seed = 1 # None # 1
|
||||
|
||||
device = get_preferred_device()
|
||||
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--ckpt_path", type=str, required=True)
|
||||
parser.add_argument("--model_type", type=str, choices=["flux", "chroma"], default="flux", help="Model type to use")
|
||||
parser.add_argument("--clip_l", type=str, required=False)
|
||||
parser.add_argument("--t5xxl", type=str, required=False)
|
||||
parser.add_argument("--ae", type=str, required=False)
|
||||
parser.add_argument("--apply_t5_attn_mask", action="store_true")
|
||||
parser.add_argument("--prompt", type=str, default="A photo of a cat")
|
||||
parser.add_argument("--output_dir", type=str, default=".")
|
||||
parser.add_argument("--dtype", type=str, default="bfloat16", help="base dtype")
|
||||
parser.add_argument("--clip_l_dtype", type=str, default=None, help="dtype for clip_l")
|
||||
parser.add_argument("--ae_dtype", type=str, default=None, help="dtype for ae")
|
||||
parser.add_argument("--t5xxl_dtype", type=str, default=None, help="dtype for t5xxl")
|
||||
parser.add_argument("--flux_dtype", type=str, default=None, help="dtype for flux")
|
||||
parser.add_argument("--seed", type=int, default=None)
|
||||
parser.add_argument("--steps", type=int, default=None, help="Number of steps. Default is 4 for schnell, 50 for dev")
|
||||
parser.add_argument("--guidance", type=float, default=3.5)
|
||||
parser.add_argument("--negative_prompt", type=str, default=None)
|
||||
parser.add_argument("--cfg_scale", type=float, default=1.0)
|
||||
parser.add_argument("--offload", action="store_true", help="Offload to CPU")
|
||||
parser.add_argument(
|
||||
"--lora_weights",
|
||||
type=str,
|
||||
nargs="*",
|
||||
default=[],
|
||||
help="LoRA weights, only supports networks.lora_flux and lora_oft, each argument is a `path;multiplier` (semi-colon separated)",
|
||||
)
|
||||
parser.add_argument("--merge_lora_weights", action="store_true", help="Merge LoRA weights to model")
|
||||
parser.add_argument("--width", type=int, default=target_width)
|
||||
parser.add_argument("--height", type=int, default=target_height)
|
||||
parser.add_argument("--interactive", action="store_true")
|
||||
args = parser.parse_args()
|
||||
|
||||
seed = args.seed
|
||||
steps = args.steps
|
||||
guidance_scale = args.guidance
|
||||
|
||||
def is_fp8(dt):
|
||||
return dt in [torch.float8_e4m3fn, torch.float8_e4m3fnuz, torch.float8_e5m2, torch.float8_e5m2fnuz]
|
||||
|
||||
dtype = str_to_dtype(args.dtype)
|
||||
clip_l_dtype = str_to_dtype(args.clip_l_dtype, dtype)
|
||||
t5xxl_dtype = str_to_dtype(args.t5xxl_dtype, dtype)
|
||||
ae_dtype = str_to_dtype(args.ae_dtype, dtype)
|
||||
flux_dtype = str_to_dtype(args.flux_dtype, dtype)
|
||||
|
||||
logger.info(f"Dtypes for clip_l, t5xxl, ae, flux: {clip_l_dtype}, {t5xxl_dtype}, {ae_dtype}, {flux_dtype}")
|
||||
|
||||
loading_device = "cpu" if args.offload else device
|
||||
|
||||
use_fp8 = [is_fp8(d) for d in [dtype, clip_l_dtype, t5xxl_dtype, ae_dtype, flux_dtype]]
|
||||
if any(use_fp8):
|
||||
accelerator = accelerate.Accelerator(mixed_precision="bf16")
|
||||
else:
|
||||
accelerator = None
|
||||
|
||||
# load clip_l (skip for chroma model)
|
||||
if args.model_type == "flux":
|
||||
logger.info(f"Loading clip_l from {args.clip_l}...")
|
||||
clip_l = flux_utils.load_clip_l(args.clip_l, clip_l_dtype, loading_device, disable_mmap=True)
|
||||
clip_l.eval()
|
||||
else:
|
||||
clip_l = None
|
||||
|
||||
logger.info(f"Loading t5xxl from {args.t5xxl}...")
|
||||
t5xxl = flux_utils.load_t5xxl(args.t5xxl, t5xxl_dtype, loading_device, disable_mmap=True)
|
||||
t5xxl.eval()
|
||||
|
||||
# if is_fp8(clip_l_dtype):
|
||||
# clip_l = accelerator.prepare(clip_l)
|
||||
# if is_fp8(t5xxl_dtype):
|
||||
# t5xxl = accelerator.prepare(t5xxl)
|
||||
|
||||
# DiT
|
||||
is_schnell, model = flux_utils.load_flow_model(
|
||||
args.ckpt_path, None, loading_device, disable_mmap=True, model_type=args.model_type
|
||||
)
|
||||
model.eval()
|
||||
logger.info(f"Casting model to {flux_dtype}")
|
||||
model.to(flux_dtype) # make sure model is dtype
|
||||
# if is_fp8(flux_dtype):
|
||||
# model = accelerator.prepare(model)
|
||||
# if args.offload:
|
||||
# model = model.to("cpu")
|
||||
|
||||
t5xxl_max_length = 256 if is_schnell else 512
|
||||
tokenize_strategy = strategy_flux.FluxTokenizeStrategy(t5xxl_max_length)
|
||||
encoding_strategy = strategy_flux.FluxTextEncodingStrategy()
|
||||
|
||||
# AE
|
||||
ae = flux_utils.load_ae(args.ae, ae_dtype, loading_device)
|
||||
ae.eval()
|
||||
# if is_fp8(ae_dtype):
|
||||
# ae = accelerator.prepare(ae)
|
||||
|
||||
# LoRA
|
||||
lora_models: List[lora_flux.LoRANetwork] = []
|
||||
for weights_file in args.lora_weights:
|
||||
if ";" in weights_file:
|
||||
weights_file, multiplier = weights_file.split(";")
|
||||
multiplier = float(multiplier)
|
||||
else:
|
||||
multiplier = 1.0
|
||||
|
||||
weights_sd = load_file(weights_file)
|
||||
is_lora = is_oft = False
|
||||
for key in weights_sd.keys():
|
||||
if key.startswith("lora"):
|
||||
is_lora = True
|
||||
if key.startswith("oft"):
|
||||
is_oft = True
|
||||
if is_lora or is_oft:
|
||||
break
|
||||
|
||||
module = lora_flux if is_lora else oft_flux
|
||||
lora_model, _ = module.create_network_from_weights(multiplier, None, ae, [clip_l, t5xxl], model, weights_sd, True)
|
||||
|
||||
if args.merge_lora_weights:
|
||||
lora_model.merge_to([clip_l, t5xxl], model, weights_sd)
|
||||
else:
|
||||
lora_model.apply_to([clip_l, t5xxl], model)
|
||||
info = lora_model.load_state_dict(weights_sd, strict=True)
|
||||
logger.info(f"Loaded LoRA weights from {weights_file}: {info}")
|
||||
lora_model.eval()
|
||||
lora_model.to(device)
|
||||
|
||||
lora_models.append(lora_model)
|
||||
|
||||
if not args.interactive:
|
||||
generate_image(
|
||||
model,
|
||||
clip_l,
|
||||
t5xxl,
|
||||
ae,
|
||||
args.prompt,
|
||||
args.seed,
|
||||
args.width,
|
||||
args.height,
|
||||
args.steps,
|
||||
args.guidance,
|
||||
args.negative_prompt,
|
||||
args.cfg_scale,
|
||||
)
|
||||
else:
|
||||
# loop for interactive
|
||||
width = target_width
|
||||
height = target_height
|
||||
steps = None
|
||||
guidance = args.guidance
|
||||
cfg_scale = args.cfg_scale
|
||||
|
||||
while True:
|
||||
print(
|
||||
"Enter prompt (empty to exit). Options: --w <width> --h <height> --s <steps> --d <seed> --g <guidance> --m <multipliers for LoRA>"
|
||||
" --n <negative prompt>, `-` for empty negative prompt --c <cfg_scale>"
|
||||
)
|
||||
prompt = input()
|
||||
if prompt == "":
|
||||
break
|
||||
|
||||
# parse options
|
||||
options = prompt.split("--")
|
||||
prompt = options[0].strip()
|
||||
seed = None
|
||||
negative_prompt = None
|
||||
for opt in options[1:]:
|
||||
try:
|
||||
opt = opt.strip()
|
||||
if opt.startswith("w"):
|
||||
width = int(opt[1:].strip())
|
||||
elif opt.startswith("h"):
|
||||
height = int(opt[1:].strip())
|
||||
elif opt.startswith("s"):
|
||||
steps = int(opt[1:].strip())
|
||||
elif opt.startswith("d"):
|
||||
seed = int(opt[1:].strip())
|
||||
elif opt.startswith("g"):
|
||||
guidance = float(opt[1:].strip())
|
||||
elif opt.startswith("m"):
|
||||
mutipliers = opt[1:].strip().split(",")
|
||||
if len(mutipliers) != len(lora_models):
|
||||
logger.error(f"Invalid number of multipliers, expected {len(lora_models)}")
|
||||
continue
|
||||
for i, lora_model in enumerate(lora_models):
|
||||
lora_model.set_multiplier(float(mutipliers[i]))
|
||||
elif opt.startswith("n"):
|
||||
negative_prompt = opt[1:].strip()
|
||||
if negative_prompt == "-":
|
||||
negative_prompt = ""
|
||||
elif opt.startswith("c"):
|
||||
cfg_scale = float(opt[1:].strip())
|
||||
except ValueError as e:
|
||||
logger.error(f"Invalid option: {opt}, {e}")
|
||||
|
||||
generate_image(model, clip_l, t5xxl, ae, prompt, seed, width, height, steps, guidance, negative_prompt, cfg_scale)
|
||||
|
||||
logger.info("Done!")
|
||||
851
flux_train.py
Normal file
851
flux_train.py
Normal file
@@ -0,0 +1,851 @@
|
||||
# training with captions
|
||||
|
||||
# Swap blocks between CPU and GPU:
|
||||
# This implementation is inspired by and based on the work of 2kpr.
|
||||
# Many thanks to 2kpr for the original concept and implementation of memory-efficient offloading.
|
||||
# The original idea has been adapted and extended to fit the current project's needs.
|
||||
|
||||
# Key features:
|
||||
# - CPU offloading during forward and backward passes
|
||||
# - Use of fused optimizer and grad_hook for efficient gradient processing
|
||||
# - Per-block fused optimizer instances
|
||||
|
||||
import argparse
|
||||
from concurrent.futures import ThreadPoolExecutor
|
||||
import copy
|
||||
import math
|
||||
import os
|
||||
from multiprocessing import Value
|
||||
import time
|
||||
from typing import List, Optional, Tuple, Union
|
||||
import toml
|
||||
|
||||
from tqdm import tqdm
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from library import utils
|
||||
from library.device_utils import init_ipex, clean_memory_on_device
|
||||
|
||||
init_ipex()
|
||||
|
||||
from accelerate.utils import set_seed
|
||||
from library import deepspeed_utils, flux_train_utils, flux_utils, strategy_base, strategy_flux, sai_model_spec
|
||||
from library.sd3_train_utils import FlowMatchEulerDiscreteScheduler
|
||||
|
||||
import library.train_util as train_util
|
||||
|
||||
from library.utils import setup_logging, add_logging_arguments
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
import library.config_util as config_util
|
||||
|
||||
# import library.sdxl_train_util as sdxl_train_util
|
||||
from library.config_util import (
|
||||
ConfigSanitizer,
|
||||
BlueprintGenerator,
|
||||
)
|
||||
from library.custom_train_functions import apply_masked_loss, add_custom_train_arguments
|
||||
|
||||
|
||||
def train(args):
|
||||
train_util.verify_training_args(args)
|
||||
train_util.prepare_dataset_args(args, True)
|
||||
# sdxl_train_util.verify_sdxl_training_args(args)
|
||||
deepspeed_utils.prepare_deepspeed_args(args)
|
||||
setup_logging(args, reset=True)
|
||||
|
||||
# temporary: backward compatibility for deprecated options. remove in the future
|
||||
if not args.skip_cache_check:
|
||||
args.skip_cache_check = args.skip_latents_validity_check
|
||||
|
||||
# assert (
|
||||
# not args.weighted_captions
|
||||
# ), "weighted_captions is not supported currently / weighted_captionsは現在サポートされていません"
|
||||
if args.cache_text_encoder_outputs_to_disk and not args.cache_text_encoder_outputs:
|
||||
logger.warning(
|
||||
"cache_text_encoder_outputs_to_disk is enabled, so cache_text_encoder_outputs is also enabled / cache_text_encoder_outputs_to_diskが有効になっているため、cache_text_encoder_outputsも有効になります"
|
||||
)
|
||||
args.cache_text_encoder_outputs = True
|
||||
|
||||
if args.cpu_offload_checkpointing and not args.gradient_checkpointing:
|
||||
logger.warning(
|
||||
"cpu_offload_checkpointing is enabled, so gradient_checkpointing is also enabled / cpu_offload_checkpointingが有効になっているため、gradient_checkpointingも有効になります"
|
||||
)
|
||||
args.gradient_checkpointing = True
|
||||
|
||||
assert (
|
||||
args.blocks_to_swap is None or args.blocks_to_swap == 0
|
||||
) or not args.cpu_offload_checkpointing, (
|
||||
"blocks_to_swap is not supported with cpu_offload_checkpointing / blocks_to_swapはcpu_offload_checkpointingと併用できません"
|
||||
)
|
||||
|
||||
cache_latents = args.cache_latents
|
||||
use_dreambooth_method = args.in_json is None
|
||||
|
||||
if args.seed is not None:
|
||||
set_seed(args.seed) # 乱数系列を初期化する
|
||||
|
||||
# prepare caching strategy: this must be set before preparing dataset. because dataset may use this strategy for initialization.
|
||||
if args.cache_latents:
|
||||
latents_caching_strategy = strategy_flux.FluxLatentsCachingStrategy(
|
||||
args.cache_latents_to_disk, args.vae_batch_size, args.skip_cache_check
|
||||
)
|
||||
strategy_base.LatentsCachingStrategy.set_strategy(latents_caching_strategy)
|
||||
|
||||
# データセットを準備する
|
||||
if args.dataset_class is None:
|
||||
blueprint_generator = BlueprintGenerator(ConfigSanitizer(True, True, args.masked_loss, True))
|
||||
if args.dataset_config is not None:
|
||||
logger.info(f"Load dataset config from {args.dataset_config}")
|
||||
user_config = config_util.load_user_config(args.dataset_config)
|
||||
ignored = ["train_data_dir", "in_json"]
|
||||
if any(getattr(args, attr) is not None for attr in ignored):
|
||||
logger.warning(
|
||||
"ignore following options because config file is found: {0} / 設定ファイルが利用されるため以下のオプションは無視されます: {0}".format(
|
||||
", ".join(ignored)
|
||||
)
|
||||
)
|
||||
else:
|
||||
if use_dreambooth_method:
|
||||
logger.info("Using DreamBooth method.")
|
||||
user_config = {
|
||||
"datasets": [
|
||||
{
|
||||
"subsets": config_util.generate_dreambooth_subsets_config_by_subdirs(
|
||||
args.train_data_dir, args.reg_data_dir
|
||||
)
|
||||
}
|
||||
]
|
||||
}
|
||||
else:
|
||||
logger.info("Training with captions.")
|
||||
user_config = {
|
||||
"datasets": [
|
||||
{
|
||||
"subsets": [
|
||||
{
|
||||
"image_dir": args.train_data_dir,
|
||||
"metadata_file": args.in_json,
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
blueprint = blueprint_generator.generate(user_config, args)
|
||||
train_dataset_group, val_dataset_group = config_util.generate_dataset_group_by_blueprint(blueprint.dataset_group)
|
||||
else:
|
||||
train_dataset_group = train_util.load_arbitrary_dataset(args)
|
||||
val_dataset_group = None
|
||||
|
||||
current_epoch = Value("i", 0)
|
||||
current_step = Value("i", 0)
|
||||
ds_for_collator = train_dataset_group if args.max_data_loader_n_workers == 0 else None
|
||||
collator = train_util.collator_class(current_epoch, current_step, ds_for_collator)
|
||||
|
||||
train_dataset_group.verify_bucket_reso_steps(16) # TODO これでいいか確認
|
||||
|
||||
_, is_schnell, _, _ = flux_utils.analyze_checkpoint_state(args.pretrained_model_name_or_path)
|
||||
if args.debug_dataset:
|
||||
if args.cache_text_encoder_outputs:
|
||||
strategy_base.TextEncoderOutputsCachingStrategy.set_strategy(
|
||||
strategy_flux.FluxTextEncoderOutputsCachingStrategy(
|
||||
args.cache_text_encoder_outputs_to_disk, args.text_encoder_batch_size, args.skip_cache_check, False
|
||||
)
|
||||
)
|
||||
t5xxl_max_token_length = (
|
||||
args.t5xxl_max_token_length if args.t5xxl_max_token_length is not None else (256 if is_schnell else 512)
|
||||
)
|
||||
strategy_base.TokenizeStrategy.set_strategy(strategy_flux.FluxTokenizeStrategy(t5xxl_max_token_length))
|
||||
|
||||
train_dataset_group.set_current_strategies()
|
||||
train_util.debug_dataset(train_dataset_group, True)
|
||||
return
|
||||
if len(train_dataset_group) == 0:
|
||||
logger.error(
|
||||
"No data found. Please verify the metadata file and train_data_dir option. / 画像がありません。メタデータおよびtrain_data_dirオプションを確認してください。"
|
||||
)
|
||||
return
|
||||
|
||||
if cache_latents:
|
||||
assert (
|
||||
train_dataset_group.is_latent_cacheable()
|
||||
), "when caching latents, either color_aug or random_crop cannot be used / latentをキャッシュするときはcolor_augとrandom_cropは使えません"
|
||||
|
||||
if args.cache_text_encoder_outputs:
|
||||
assert (
|
||||
train_dataset_group.is_text_encoder_output_cacheable()
|
||||
), "when caching text encoder output, either caption_dropout_rate, shuffle_caption, token_warmup_step or caption_tag_dropout_rate cannot be used / text encoderの出力をキャッシュするときはcaption_dropout_rate, shuffle_caption, token_warmup_step, caption_tag_dropout_rateは使えません"
|
||||
|
||||
# acceleratorを準備する
|
||||
logger.info("prepare accelerator")
|
||||
accelerator = train_util.prepare_accelerator(args)
|
||||
|
||||
# mixed precisionに対応した型を用意しておき適宜castする
|
||||
weight_dtype, save_dtype = train_util.prepare_dtype(args)
|
||||
|
||||
# モデルを読み込む
|
||||
|
||||
# load VAE for caching latents
|
||||
ae = None
|
||||
if cache_latents:
|
||||
ae = flux_utils.load_ae(args.ae, weight_dtype, "cpu", args.disable_mmap_load_safetensors)
|
||||
ae.to(accelerator.device, dtype=weight_dtype)
|
||||
ae.requires_grad_(False)
|
||||
ae.eval()
|
||||
|
||||
train_dataset_group.new_cache_latents(ae, accelerator)
|
||||
|
||||
ae.to("cpu") # if no sampling, vae can be deleted
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
# prepare tokenize strategy
|
||||
if args.t5xxl_max_token_length is None:
|
||||
if is_schnell:
|
||||
t5xxl_max_token_length = 256
|
||||
else:
|
||||
t5xxl_max_token_length = 512
|
||||
else:
|
||||
t5xxl_max_token_length = args.t5xxl_max_token_length
|
||||
|
||||
flux_tokenize_strategy = strategy_flux.FluxTokenizeStrategy(t5xxl_max_token_length)
|
||||
strategy_base.TokenizeStrategy.set_strategy(flux_tokenize_strategy)
|
||||
|
||||
# load clip_l, t5xxl for caching text encoder outputs
|
||||
clip_l = flux_utils.load_clip_l(args.clip_l, weight_dtype, "cpu", args.disable_mmap_load_safetensors)
|
||||
t5xxl = flux_utils.load_t5xxl(args.t5xxl, weight_dtype, "cpu", args.disable_mmap_load_safetensors)
|
||||
clip_l.eval()
|
||||
t5xxl.eval()
|
||||
clip_l.requires_grad_(False)
|
||||
t5xxl.requires_grad_(False)
|
||||
|
||||
text_encoding_strategy = strategy_flux.FluxTextEncodingStrategy(args.apply_t5_attn_mask)
|
||||
strategy_base.TextEncodingStrategy.set_strategy(text_encoding_strategy)
|
||||
|
||||
# cache text encoder outputs
|
||||
sample_prompts_te_outputs = None
|
||||
if args.cache_text_encoder_outputs:
|
||||
# Text Encodes are eval and no grad here
|
||||
clip_l.to(accelerator.device)
|
||||
t5xxl.to(accelerator.device)
|
||||
|
||||
text_encoder_caching_strategy = strategy_flux.FluxTextEncoderOutputsCachingStrategy(
|
||||
args.cache_text_encoder_outputs_to_disk, args.text_encoder_batch_size, False, False, args.apply_t5_attn_mask
|
||||
)
|
||||
strategy_base.TextEncoderOutputsCachingStrategy.set_strategy(text_encoder_caching_strategy)
|
||||
|
||||
with accelerator.autocast():
|
||||
train_dataset_group.new_cache_text_encoder_outputs([clip_l, t5xxl], accelerator)
|
||||
|
||||
# cache sample prompt's embeddings to free text encoder's memory
|
||||
if args.sample_prompts is not None:
|
||||
logger.info(f"cache Text Encoder outputs for sample prompt: {args.sample_prompts}")
|
||||
|
||||
text_encoding_strategy: strategy_flux.FluxTextEncodingStrategy = strategy_base.TextEncodingStrategy.get_strategy()
|
||||
|
||||
prompts = train_util.load_prompts(args.sample_prompts)
|
||||
sample_prompts_te_outputs = {} # key: prompt, value: text encoder outputs
|
||||
with accelerator.autocast(), torch.no_grad():
|
||||
for prompt_dict in prompts:
|
||||
for p in [prompt_dict.get("prompt", ""), prompt_dict.get("negative_prompt", "")]:
|
||||
if p not in sample_prompts_te_outputs:
|
||||
logger.info(f"cache Text Encoder outputs for prompt: {p}")
|
||||
tokens_and_masks = flux_tokenize_strategy.tokenize(p)
|
||||
sample_prompts_te_outputs[p] = text_encoding_strategy.encode_tokens(
|
||||
flux_tokenize_strategy, [clip_l, t5xxl], tokens_and_masks, args.apply_t5_attn_mask
|
||||
)
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
# now we can delete Text Encoders to free memory
|
||||
clip_l = None
|
||||
t5xxl = None
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
# load FLUX
|
||||
_, flux = flux_utils.load_flow_model(
|
||||
args.pretrained_model_name_or_path, weight_dtype, "cpu", args.disable_mmap_load_safetensors, model_type="flux"
|
||||
)
|
||||
|
||||
if args.gradient_checkpointing:
|
||||
flux.enable_gradient_checkpointing(cpu_offload=args.cpu_offload_checkpointing)
|
||||
|
||||
flux.requires_grad_(True)
|
||||
|
||||
# block swap
|
||||
|
||||
# backward compatibility
|
||||
if args.blocks_to_swap is None:
|
||||
blocks_to_swap = args.double_blocks_to_swap or 0
|
||||
if args.single_blocks_to_swap is not None:
|
||||
blocks_to_swap += args.single_blocks_to_swap // 2
|
||||
if blocks_to_swap > 0:
|
||||
logger.warning(
|
||||
"double_blocks_to_swap and single_blocks_to_swap are deprecated. Use blocks_to_swap instead."
|
||||
" / double_blocks_to_swapとsingle_blocks_to_swapは非推奨です。blocks_to_swapを使ってください。"
|
||||
)
|
||||
logger.info(
|
||||
f"double_blocks_to_swap={args.double_blocks_to_swap} and single_blocks_to_swap={args.single_blocks_to_swap} are converted to blocks_to_swap={blocks_to_swap}."
|
||||
)
|
||||
args.blocks_to_swap = blocks_to_swap
|
||||
del blocks_to_swap
|
||||
|
||||
is_swapping_blocks = args.blocks_to_swap is not None and args.blocks_to_swap > 0
|
||||
if is_swapping_blocks:
|
||||
# Swap blocks between CPU and GPU to reduce memory usage, in forward and backward passes.
|
||||
# This idea is based on 2kpr's great work. Thank you!
|
||||
logger.info(f"enable block swap: blocks_to_swap={args.blocks_to_swap}")
|
||||
flux.enable_block_swap(args.blocks_to_swap, accelerator.device)
|
||||
|
||||
if not cache_latents:
|
||||
# load VAE here if not cached
|
||||
ae = flux_utils.load_ae(args.ae, weight_dtype, "cpu")
|
||||
ae.requires_grad_(False)
|
||||
ae.eval()
|
||||
ae.to(accelerator.device, dtype=weight_dtype)
|
||||
|
||||
training_models = []
|
||||
params_to_optimize = []
|
||||
training_models.append(flux)
|
||||
name_and_params = list(flux.named_parameters())
|
||||
# single param group for now
|
||||
params_to_optimize.append({"params": [p for _, p in name_and_params], "lr": args.learning_rate})
|
||||
param_names = [[n for n, _ in name_and_params]]
|
||||
|
||||
# calculate number of trainable parameters
|
||||
n_params = 0
|
||||
for group in params_to_optimize:
|
||||
for p in group["params"]:
|
||||
n_params += p.numel()
|
||||
|
||||
accelerator.print(f"number of trainable parameters: {n_params}")
|
||||
|
||||
# 学習に必要なクラスを準備する
|
||||
accelerator.print("prepare optimizer, data loader etc.")
|
||||
|
||||
if args.blockwise_fused_optimizers:
|
||||
# fused backward pass: https://pytorch.org/tutorials/intermediate/optimizer_step_in_backward_tutorial.html
|
||||
# Instead of creating an optimizer for all parameters as in the tutorial, we create an optimizer for each block of parameters.
|
||||
# This balances memory usage and management complexity.
|
||||
|
||||
# split params into groups. currently different learning rates are not supported
|
||||
grouped_params = []
|
||||
param_group = {}
|
||||
for group in params_to_optimize:
|
||||
named_parameters = list(flux.named_parameters())
|
||||
assert len(named_parameters) == len(group["params"]), "number of parameters does not match"
|
||||
for p, np in zip(group["params"], named_parameters):
|
||||
# determine target layer and block index for each parameter
|
||||
block_type = "other" # double, single or other
|
||||
if np[0].startswith("double_blocks"):
|
||||
block_index = int(np[0].split(".")[1])
|
||||
block_type = "double"
|
||||
elif np[0].startswith("single_blocks"):
|
||||
block_index = int(np[0].split(".")[1])
|
||||
block_type = "single"
|
||||
else:
|
||||
block_index = -1
|
||||
|
||||
param_group_key = (block_type, block_index)
|
||||
if param_group_key not in param_group:
|
||||
param_group[param_group_key] = []
|
||||
param_group[param_group_key].append(p)
|
||||
|
||||
block_types_and_indices = []
|
||||
for param_group_key, param_group in param_group.items():
|
||||
block_types_and_indices.append(param_group_key)
|
||||
grouped_params.append({"params": param_group, "lr": args.learning_rate})
|
||||
|
||||
num_params = 0
|
||||
for p in param_group:
|
||||
num_params += p.numel()
|
||||
accelerator.print(f"block {param_group_key}: {num_params} parameters")
|
||||
|
||||
# prepare optimizers for each group
|
||||
optimizers = []
|
||||
for group in grouped_params:
|
||||
_, _, optimizer = train_util.get_optimizer(args, trainable_params=[group])
|
||||
optimizers.append(optimizer)
|
||||
optimizer = optimizers[0] # avoid error in the following code
|
||||
|
||||
logger.info(f"using {len(optimizers)} optimizers for blockwise fused optimizers")
|
||||
|
||||
if train_util.is_schedulefree_optimizer(optimizers[0], args):
|
||||
raise ValueError("Schedule-free optimizer is not supported with blockwise fused optimizers")
|
||||
optimizer_train_fn = lambda: None # dummy function
|
||||
optimizer_eval_fn = lambda: None # dummy function
|
||||
else:
|
||||
_, _, optimizer = train_util.get_optimizer(args, trainable_params=params_to_optimize)
|
||||
optimizer_train_fn, optimizer_eval_fn = train_util.get_optimizer_train_eval_fn(optimizer, args)
|
||||
|
||||
# prepare dataloader
|
||||
# strategies are set here because they cannot be referenced in another process. Copy them with the dataset
|
||||
# some strategies can be None
|
||||
train_dataset_group.set_current_strategies()
|
||||
|
||||
# DataLoaderのプロセス数:0 は persistent_workers が使えないので注意
|
||||
n_workers = min(args.max_data_loader_n_workers, os.cpu_count()) # cpu_count or max_data_loader_n_workers
|
||||
train_dataloader = torch.utils.data.DataLoader(
|
||||
train_dataset_group,
|
||||
batch_size=1,
|
||||
shuffle=True,
|
||||
collate_fn=collator,
|
||||
num_workers=n_workers,
|
||||
persistent_workers=args.persistent_data_loader_workers,
|
||||
)
|
||||
|
||||
# 学習ステップ数を計算する
|
||||
if args.max_train_epochs is not None:
|
||||
args.max_train_steps = args.max_train_epochs * math.ceil(
|
||||
len(train_dataloader) / accelerator.num_processes / args.gradient_accumulation_steps
|
||||
)
|
||||
accelerator.print(
|
||||
f"override steps. steps for {args.max_train_epochs} epochs is / 指定エポックまでのステップ数: {args.max_train_steps}"
|
||||
)
|
||||
|
||||
# データセット側にも学習ステップを送信
|
||||
train_dataset_group.set_max_train_steps(args.max_train_steps)
|
||||
|
||||
# lr schedulerを用意する
|
||||
if args.blockwise_fused_optimizers:
|
||||
# prepare lr schedulers for each optimizer
|
||||
lr_schedulers = [train_util.get_scheduler_fix(args, optimizer, accelerator.num_processes) for optimizer in optimizers]
|
||||
lr_scheduler = lr_schedulers[0] # avoid error in the following code
|
||||
else:
|
||||
lr_scheduler = train_util.get_scheduler_fix(args, optimizer, accelerator.num_processes)
|
||||
|
||||
# 実験的機能:勾配も含めたfp16/bf16学習を行う モデル全体をfp16/bf16にする
|
||||
if args.full_fp16:
|
||||
assert (
|
||||
args.mixed_precision == "fp16"
|
||||
), "full_fp16 requires mixed precision='fp16' / full_fp16を使う場合はmixed_precision='fp16'を指定してください。"
|
||||
accelerator.print("enable full fp16 training.")
|
||||
flux.to(weight_dtype)
|
||||
if clip_l is not None:
|
||||
clip_l.to(weight_dtype)
|
||||
t5xxl.to(weight_dtype) # TODO check works with fp16 or not
|
||||
elif args.full_bf16:
|
||||
assert (
|
||||
args.mixed_precision == "bf16"
|
||||
), "full_bf16 requires mixed precision='bf16' / full_bf16を使う場合はmixed_precision='bf16'を指定してください。"
|
||||
accelerator.print("enable full bf16 training.")
|
||||
flux.to(weight_dtype)
|
||||
if clip_l is not None:
|
||||
clip_l.to(weight_dtype)
|
||||
t5xxl.to(weight_dtype)
|
||||
|
||||
# if we don't cache text encoder outputs, move them to device
|
||||
if not args.cache_text_encoder_outputs:
|
||||
clip_l.to(accelerator.device)
|
||||
t5xxl.to(accelerator.device)
|
||||
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
if args.deepspeed:
|
||||
ds_model = deepspeed_utils.prepare_deepspeed_model(args, mmdit=flux)
|
||||
# most of ZeRO stage uses optimizer partitioning, so we have to prepare optimizer and ds_model at the same time. # pull/1139#issuecomment-1986790007
|
||||
ds_model, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
|
||||
ds_model, optimizer, train_dataloader, lr_scheduler
|
||||
)
|
||||
training_models = [ds_model]
|
||||
|
||||
else:
|
||||
# accelerator does some magic
|
||||
# if we doesn't swap blocks, we can move the model to device
|
||||
flux = accelerator.prepare(flux, device_placement=[not is_swapping_blocks])
|
||||
if is_swapping_blocks:
|
||||
accelerator.unwrap_model(flux).move_to_device_except_swap_blocks(accelerator.device) # reduce peak memory usage
|
||||
optimizer, train_dataloader, lr_scheduler = accelerator.prepare(optimizer, train_dataloader, lr_scheduler)
|
||||
|
||||
# 実験的機能:勾配も含めたfp16学習を行う PyTorchにパッチを当ててfp16でのgrad scaleを有効にする
|
||||
if args.full_fp16:
|
||||
# During deepseed training, accelerate not handles fp16/bf16|mixed precision directly via scaler. Let deepspeed engine do.
|
||||
# -> But we think it's ok to patch accelerator even if deepspeed is enabled.
|
||||
train_util.patch_accelerator_for_fp16_training(accelerator)
|
||||
|
||||
# resumeする
|
||||
train_util.resume_from_local_or_hf_if_specified(accelerator, args)
|
||||
|
||||
if args.fused_backward_pass:
|
||||
# use fused optimizer for backward pass: other optimizers will be supported in the future
|
||||
import library.adafactor_fused
|
||||
|
||||
library.adafactor_fused.patch_adafactor_fused(optimizer)
|
||||
|
||||
for param_group, param_name_group in zip(optimizer.param_groups, param_names):
|
||||
for parameter, param_name in zip(param_group["params"], param_name_group):
|
||||
if parameter.requires_grad:
|
||||
|
||||
def create_grad_hook(p_name, p_group):
|
||||
def grad_hook(tensor: torch.Tensor):
|
||||
if accelerator.sync_gradients and args.max_grad_norm != 0.0:
|
||||
accelerator.clip_grad_norm_(tensor, args.max_grad_norm)
|
||||
optimizer.step_param(tensor, p_group)
|
||||
tensor.grad = None
|
||||
|
||||
return grad_hook
|
||||
|
||||
parameter.register_post_accumulate_grad_hook(create_grad_hook(param_name, param_group))
|
||||
|
||||
elif args.blockwise_fused_optimizers:
|
||||
# prepare for additional optimizers and lr schedulers
|
||||
for i in range(1, len(optimizers)):
|
||||
optimizers[i] = accelerator.prepare(optimizers[i])
|
||||
lr_schedulers[i] = accelerator.prepare(lr_schedulers[i])
|
||||
|
||||
# counters are used to determine when to step the optimizer
|
||||
global optimizer_hooked_count
|
||||
global num_parameters_per_group
|
||||
global parameter_optimizer_map
|
||||
|
||||
optimizer_hooked_count = {}
|
||||
num_parameters_per_group = [0] * len(optimizers)
|
||||
parameter_optimizer_map = {}
|
||||
|
||||
for opt_idx, optimizer in enumerate(optimizers):
|
||||
for param_group in optimizer.param_groups:
|
||||
for parameter in param_group["params"]:
|
||||
if parameter.requires_grad:
|
||||
|
||||
def grad_hook(parameter: torch.Tensor):
|
||||
if accelerator.sync_gradients and args.max_grad_norm != 0.0:
|
||||
accelerator.clip_grad_norm_(parameter, args.max_grad_norm)
|
||||
|
||||
i = parameter_optimizer_map[parameter]
|
||||
optimizer_hooked_count[i] += 1
|
||||
if optimizer_hooked_count[i] == num_parameters_per_group[i]:
|
||||
optimizers[i].step()
|
||||
optimizers[i].zero_grad(set_to_none=True)
|
||||
|
||||
parameter.register_post_accumulate_grad_hook(grad_hook)
|
||||
parameter_optimizer_map[parameter] = opt_idx
|
||||
num_parameters_per_group[opt_idx] += 1
|
||||
|
||||
# epoch数を計算する
|
||||
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
|
||||
num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
|
||||
if (args.save_n_epoch_ratio is not None) and (args.save_n_epoch_ratio > 0):
|
||||
args.save_every_n_epochs = math.floor(num_train_epochs / args.save_n_epoch_ratio) or 1
|
||||
|
||||
# 学習する
|
||||
# total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
|
||||
accelerator.print("running training / 学習開始")
|
||||
accelerator.print(f" num examples / サンプル数: {train_dataset_group.num_train_images}")
|
||||
accelerator.print(f" num batches per epoch / 1epochのバッチ数: {len(train_dataloader)}")
|
||||
accelerator.print(f" num epochs / epoch数: {num_train_epochs}")
|
||||
accelerator.print(
|
||||
f" batch size per device / バッチサイズ: {', '.join([str(d.batch_size) for d in train_dataset_group.datasets])}"
|
||||
)
|
||||
# accelerator.print(
|
||||
# f" total train batch size (with parallel & distributed & accumulation) / 総バッチサイズ(並列学習、勾配合計含む): {total_batch_size}"
|
||||
# )
|
||||
accelerator.print(f" gradient accumulation steps / 勾配を合計するステップ数 = {args.gradient_accumulation_steps}")
|
||||
accelerator.print(f" total optimization steps / 学習ステップ数: {args.max_train_steps}")
|
||||
|
||||
progress_bar = tqdm(range(args.max_train_steps), smoothing=0, disable=not accelerator.is_local_main_process, desc="steps")
|
||||
global_step = 0
|
||||
|
||||
noise_scheduler = FlowMatchEulerDiscreteScheduler(num_train_timesteps=1000, shift=args.discrete_flow_shift)
|
||||
noise_scheduler_copy = copy.deepcopy(noise_scheduler)
|
||||
|
||||
if accelerator.is_main_process:
|
||||
init_kwargs = {}
|
||||
if args.wandb_run_name:
|
||||
init_kwargs["wandb"] = {"name": args.wandb_run_name}
|
||||
if args.log_tracker_config is not None:
|
||||
init_kwargs = toml.load(args.log_tracker_config)
|
||||
accelerator.init_trackers(
|
||||
"finetuning" if args.log_tracker_name is None else args.log_tracker_name,
|
||||
config=train_util.get_sanitized_config_or_none(args),
|
||||
init_kwargs=init_kwargs,
|
||||
)
|
||||
|
||||
if is_swapping_blocks:
|
||||
accelerator.unwrap_model(flux).prepare_block_swap_before_forward()
|
||||
|
||||
# For --sample_at_first
|
||||
optimizer_eval_fn()
|
||||
flux_train_utils.sample_images(accelerator, args, 0, global_step, flux, ae, [clip_l, t5xxl], sample_prompts_te_outputs)
|
||||
optimizer_train_fn()
|
||||
if len(accelerator.trackers) > 0:
|
||||
# log empty object to commit the sample images to wandb
|
||||
accelerator.log({}, step=0)
|
||||
|
||||
loss_recorder = train_util.LossRecorder()
|
||||
epoch = 0 # avoid error when max_train_steps is 0
|
||||
for epoch in range(num_train_epochs):
|
||||
accelerator.print(f"\nepoch {epoch+1}/{num_train_epochs}")
|
||||
current_epoch.value = epoch + 1
|
||||
|
||||
for m in training_models:
|
||||
m.train()
|
||||
|
||||
for step, batch in enumerate(train_dataloader):
|
||||
current_step.value = global_step
|
||||
|
||||
if args.blockwise_fused_optimizers:
|
||||
optimizer_hooked_count = {i: 0 for i in range(len(optimizers))} # reset counter for each step
|
||||
|
||||
with accelerator.accumulate(*training_models):
|
||||
if "latents" in batch and batch["latents"] is not None:
|
||||
latents = batch["latents"].to(accelerator.device, dtype=weight_dtype)
|
||||
else:
|
||||
with torch.no_grad():
|
||||
# encode images to latents. images are [-1, 1]
|
||||
latents = ae.encode(batch["images"].to(ae.dtype)).to(accelerator.device, dtype=weight_dtype)
|
||||
|
||||
# NaNが含まれていれば警告を表示し0に置き換える
|
||||
if torch.any(torch.isnan(latents)):
|
||||
accelerator.print("NaN found in latents, replacing with zeros")
|
||||
latents = torch.nan_to_num(latents, 0, out=latents)
|
||||
|
||||
text_encoder_outputs_list = batch.get("text_encoder_outputs_list", None)
|
||||
if text_encoder_outputs_list is not None:
|
||||
text_encoder_conds = text_encoder_outputs_list
|
||||
else:
|
||||
# not cached or training, so get from text encoders
|
||||
tokens_and_masks = batch["input_ids_list"]
|
||||
with torch.no_grad():
|
||||
input_ids = [ids.to(accelerator.device) for ids in batch["input_ids_list"]]
|
||||
text_encoder_conds = text_encoding_strategy.encode_tokens(
|
||||
flux_tokenize_strategy, [clip_l, t5xxl], input_ids, args.apply_t5_attn_mask
|
||||
)
|
||||
if args.full_fp16:
|
||||
text_encoder_conds = [c.to(weight_dtype) for c in text_encoder_conds]
|
||||
|
||||
# TODO support some features for noise implemented in get_noise_noisy_latents_and_timesteps
|
||||
|
||||
# Sample noise that we'll add to the latents
|
||||
noise = torch.randn_like(latents)
|
||||
bsz = latents.shape[0]
|
||||
|
||||
# get noisy model input and timesteps
|
||||
noisy_model_input, timesteps, sigmas = flux_train_utils.get_noisy_model_input_and_timesteps(
|
||||
args, noise_scheduler_copy, latents, noise, accelerator.device, weight_dtype
|
||||
)
|
||||
|
||||
# pack latents and get img_ids
|
||||
packed_noisy_model_input = flux_utils.pack_latents(noisy_model_input) # b, c, h*2, w*2 -> b, h*w, c*4
|
||||
packed_latent_height, packed_latent_width = noisy_model_input.shape[2] // 2, noisy_model_input.shape[3] // 2
|
||||
img_ids = flux_utils.prepare_img_ids(bsz, packed_latent_height, packed_latent_width).to(device=accelerator.device)
|
||||
|
||||
# get guidance: ensure args.guidance_scale is float
|
||||
guidance_vec = torch.full((bsz,), float(args.guidance_scale), device=accelerator.device)
|
||||
|
||||
# call model
|
||||
l_pooled, t5_out, txt_ids, t5_attn_mask = text_encoder_conds
|
||||
if not args.apply_t5_attn_mask:
|
||||
t5_attn_mask = None
|
||||
|
||||
with accelerator.autocast():
|
||||
# YiYi notes: divide it by 1000 for now because we scale it by 1000 in the transformer model (we should not keep it but I want to keep the inputs same for the model for testing)
|
||||
model_pred = flux(
|
||||
img=packed_noisy_model_input,
|
||||
img_ids=img_ids,
|
||||
txt=t5_out,
|
||||
txt_ids=txt_ids,
|
||||
y=l_pooled,
|
||||
timesteps=timesteps / 1000,
|
||||
guidance=guidance_vec,
|
||||
txt_attention_mask=t5_attn_mask,
|
||||
)
|
||||
|
||||
# unpack latents
|
||||
model_pred = flux_utils.unpack_latents(model_pred, packed_latent_height, packed_latent_width)
|
||||
|
||||
# apply model prediction type
|
||||
model_pred, weighting = flux_train_utils.apply_model_prediction_type(args, model_pred, noisy_model_input, sigmas)
|
||||
|
||||
# flow matching loss: this is different from SD3
|
||||
target = noise - latents
|
||||
|
||||
# calculate loss
|
||||
huber_c = train_util.get_huber_threshold_if_needed(args, timesteps, noise_scheduler)
|
||||
loss = train_util.conditional_loss(model_pred.float(), target.float(), args.loss_type, "none", huber_c)
|
||||
if weighting is not None:
|
||||
loss = loss * weighting
|
||||
if args.masked_loss or ("alpha_masks" in batch and batch["alpha_masks"] is not None):
|
||||
loss = apply_masked_loss(loss, batch)
|
||||
loss = loss.mean([1, 2, 3])
|
||||
|
||||
loss_weights = batch["loss_weights"] # 各sampleごとのweight
|
||||
loss = loss * loss_weights
|
||||
loss = loss.mean()
|
||||
|
||||
# backward
|
||||
accelerator.backward(loss)
|
||||
|
||||
if not (args.fused_backward_pass or args.blockwise_fused_optimizers):
|
||||
if accelerator.sync_gradients and args.max_grad_norm != 0.0:
|
||||
params_to_clip = []
|
||||
for m in training_models:
|
||||
params_to_clip.extend(m.parameters())
|
||||
accelerator.clip_grad_norm_(params_to_clip, args.max_grad_norm)
|
||||
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
optimizer.zero_grad(set_to_none=True)
|
||||
else:
|
||||
# optimizer.step() and optimizer.zero_grad() are called in the optimizer hook
|
||||
lr_scheduler.step()
|
||||
if args.blockwise_fused_optimizers:
|
||||
for i in range(1, len(optimizers)):
|
||||
lr_schedulers[i].step()
|
||||
|
||||
# Checks if the accelerator has performed an optimization step behind the scenes
|
||||
if accelerator.sync_gradients:
|
||||
progress_bar.update(1)
|
||||
global_step += 1
|
||||
|
||||
optimizer_eval_fn()
|
||||
flux_train_utils.sample_images(
|
||||
accelerator, args, None, global_step, flux, ae, [clip_l, t5xxl], sample_prompts_te_outputs
|
||||
)
|
||||
|
||||
# 指定ステップごとにモデルを保存
|
||||
if args.save_every_n_steps is not None and global_step % args.save_every_n_steps == 0:
|
||||
accelerator.wait_for_everyone()
|
||||
if accelerator.is_main_process:
|
||||
flux_train_utils.save_flux_model_on_epoch_end_or_stepwise(
|
||||
args,
|
||||
False,
|
||||
accelerator,
|
||||
save_dtype,
|
||||
epoch,
|
||||
num_train_epochs,
|
||||
global_step,
|
||||
accelerator.unwrap_model(flux),
|
||||
)
|
||||
optimizer_train_fn()
|
||||
|
||||
current_loss = loss.detach().item() # 平均なのでbatch sizeは関係ないはず
|
||||
if len(accelerator.trackers) > 0:
|
||||
logs = {"loss": current_loss}
|
||||
train_util.append_lr_to_logs(logs, lr_scheduler, args.optimizer_type, including_unet=True)
|
||||
|
||||
accelerator.log(logs, step=global_step)
|
||||
|
||||
loss_recorder.add(epoch=epoch, step=step, loss=current_loss)
|
||||
avr_loss: float = loss_recorder.moving_average
|
||||
logs = {"avr_loss": avr_loss} # , "lr": lr_scheduler.get_last_lr()[0]}
|
||||
progress_bar.set_postfix(**logs)
|
||||
|
||||
if global_step >= args.max_train_steps:
|
||||
break
|
||||
|
||||
if len(accelerator.trackers) > 0:
|
||||
logs = {"loss/epoch": loss_recorder.moving_average}
|
||||
accelerator.log(logs, step=epoch + 1)
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
optimizer_eval_fn()
|
||||
if args.save_every_n_epochs is not None:
|
||||
if accelerator.is_main_process:
|
||||
flux_train_utils.save_flux_model_on_epoch_end_or_stepwise(
|
||||
args,
|
||||
True,
|
||||
accelerator,
|
||||
save_dtype,
|
||||
epoch,
|
||||
num_train_epochs,
|
||||
global_step,
|
||||
accelerator.unwrap_model(flux),
|
||||
)
|
||||
|
||||
flux_train_utils.sample_images(
|
||||
accelerator, args, epoch + 1, global_step, flux, ae, [clip_l, t5xxl], sample_prompts_te_outputs
|
||||
)
|
||||
optimizer_train_fn()
|
||||
|
||||
is_main_process = accelerator.is_main_process
|
||||
# if is_main_process:
|
||||
flux = accelerator.unwrap_model(flux)
|
||||
|
||||
accelerator.end_training()
|
||||
optimizer_eval_fn()
|
||||
|
||||
if args.save_state or args.save_state_on_train_end:
|
||||
train_util.save_state_on_train_end(args, accelerator)
|
||||
|
||||
del accelerator # この後メモリを使うのでこれは消す
|
||||
|
||||
if is_main_process:
|
||||
flux_train_utils.save_flux_model_on_train_end(args, save_dtype, epoch, global_step, flux)
|
||||
logger.info("model saved.")
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
add_logging_arguments(parser)
|
||||
train_util.add_sd_models_arguments(parser) # TODO split this
|
||||
sai_model_spec.add_model_spec_arguments(parser)
|
||||
train_util.add_dataset_arguments(parser, True, True, True)
|
||||
train_util.add_training_arguments(parser, False)
|
||||
train_util.add_masked_loss_arguments(parser)
|
||||
deepspeed_utils.add_deepspeed_arguments(parser)
|
||||
train_util.add_sd_saving_arguments(parser)
|
||||
train_util.add_optimizer_arguments(parser)
|
||||
config_util.add_config_arguments(parser)
|
||||
add_custom_train_arguments(parser) # TODO remove this from here
|
||||
train_util.add_dit_training_arguments(parser)
|
||||
flux_train_utils.add_flux_train_arguments(parser)
|
||||
|
||||
parser.add_argument(
|
||||
"--mem_eff_save",
|
||||
action="store_true",
|
||||
help="[EXPERIMENTAL] use memory efficient custom model saving method / メモリ効率の良い独自のモデル保存方法を使う",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--fused_optimizer_groups",
|
||||
type=int,
|
||||
default=None,
|
||||
help="**this option is not working** will be removed in the future / このオプションは動作しません。将来削除されます",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--blockwise_fused_optimizers",
|
||||
action="store_true",
|
||||
help="enable blockwise optimizers for fused backward pass and optimizer step / fused backward passとoptimizer step のためブロック単位のoptimizerを有効にする",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--skip_latents_validity_check",
|
||||
action="store_true",
|
||||
help="[Deprecated] use 'skip_cache_check' instead / 代わりに 'skip_cache_check' を使用してください",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--double_blocks_to_swap",
|
||||
type=int,
|
||||
default=None,
|
||||
help="[Deprecated] use 'blocks_to_swap' instead / 代わりに 'blocks_to_swap' を使用してください",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--single_blocks_to_swap",
|
||||
type=int,
|
||||
default=None,
|
||||
help="[Deprecated] use 'blocks_to_swap' instead / 代わりに 'blocks_to_swap' を使用してください",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--cpu_offload_checkpointing",
|
||||
action="store_true",
|
||||
help="[EXPERIMENTAL] enable offloading of tensors to CPU during checkpointing / チェックポイント時にテンソルをCPUにオフロードする",
|
||||
)
|
||||
return parser
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
train_util.verify_command_line_training_args(args)
|
||||
args = train_util.read_config_from_file(args, parser)
|
||||
|
||||
train(args)
|
||||
885
flux_train_control_net.py
Normal file
885
flux_train_control_net.py
Normal file
@@ -0,0 +1,885 @@
|
||||
# training with captions
|
||||
|
||||
# Swap blocks between CPU and GPU:
|
||||
# This implementation is inspired by and based on the work of 2kpr.
|
||||
# Many thanks to 2kpr for the original concept and implementation of memory-efficient offloading.
|
||||
# The original idea has been adapted and extended to fit the current project's needs.
|
||||
|
||||
# Key features:
|
||||
# - CPU offloading during forward and backward passes
|
||||
# - Use of fused optimizer and grad_hook for efficient gradient processing
|
||||
# - Per-block fused optimizer instances
|
||||
|
||||
import argparse
|
||||
import copy
|
||||
import math
|
||||
import os
|
||||
import time
|
||||
from concurrent.futures import ThreadPoolExecutor
|
||||
from multiprocessing import Value
|
||||
from typing import List, Optional, Tuple, Union
|
||||
|
||||
import toml
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from tqdm import tqdm
|
||||
|
||||
from library import utils
|
||||
from library.device_utils import clean_memory_on_device, init_ipex
|
||||
|
||||
init_ipex()
|
||||
|
||||
from accelerate.utils import set_seed
|
||||
|
||||
import library.train_util as train_util
|
||||
import library.sai_model_spec as sai_model_spec
|
||||
from library import (
|
||||
deepspeed_utils,
|
||||
flux_train_utils,
|
||||
flux_utils,
|
||||
strategy_base,
|
||||
strategy_flux,
|
||||
)
|
||||
from library.sd3_train_utils import FlowMatchEulerDiscreteScheduler
|
||||
from library.utils import add_logging_arguments, setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
import library.config_util as config_util
|
||||
|
||||
# import library.sdxl_train_util as sdxl_train_util
|
||||
from library.config_util import (
|
||||
BlueprintGenerator,
|
||||
ConfigSanitizer,
|
||||
)
|
||||
from library.custom_train_functions import add_custom_train_arguments, apply_masked_loss
|
||||
|
||||
|
||||
def train(args):
|
||||
train_util.verify_training_args(args)
|
||||
train_util.prepare_dataset_args(args, True)
|
||||
# sdxl_train_util.verify_sdxl_training_args(args)
|
||||
deepspeed_utils.prepare_deepspeed_args(args)
|
||||
setup_logging(args, reset=True)
|
||||
|
||||
# temporary: backward compatibility for deprecated options. remove in the future
|
||||
if not args.skip_cache_check:
|
||||
args.skip_cache_check = args.skip_latents_validity_check
|
||||
|
||||
if args.model_type != "flux":
|
||||
raise ValueError(
|
||||
f"FLUX.1 ControlNet training requires model_type='flux'. / FLUX.1 ControlNetの学習にはmodel_type='flux'を指定してください。"
|
||||
)
|
||||
|
||||
# assert (
|
||||
# not args.weighted_captions
|
||||
# ), "weighted_captions is not supported currently / weighted_captionsは現在サポートされていません"
|
||||
if args.cache_text_encoder_outputs_to_disk and not args.cache_text_encoder_outputs:
|
||||
logger.warning(
|
||||
"cache_text_encoder_outputs_to_disk is enabled, so cache_text_encoder_outputs is also enabled / cache_text_encoder_outputs_to_diskが有効になっているため、cache_text_encoder_outputsも有効になります"
|
||||
)
|
||||
args.cache_text_encoder_outputs = True
|
||||
|
||||
if args.cpu_offload_checkpointing and not args.gradient_checkpointing:
|
||||
logger.warning(
|
||||
"cpu_offload_checkpointing is enabled, so gradient_checkpointing is also enabled / cpu_offload_checkpointingが有効になっているため、gradient_checkpointingも有効になります"
|
||||
)
|
||||
args.gradient_checkpointing = True
|
||||
|
||||
assert (
|
||||
args.blocks_to_swap is None or args.blocks_to_swap == 0
|
||||
) or not args.cpu_offload_checkpointing, (
|
||||
"blocks_to_swap is not supported with cpu_offload_checkpointing / blocks_to_swapはcpu_offload_checkpointingと併用できません"
|
||||
)
|
||||
|
||||
cache_latents = args.cache_latents
|
||||
|
||||
if args.seed is not None:
|
||||
set_seed(args.seed) # 乱数系列を初期化する
|
||||
|
||||
# prepare caching strategy: this must be set before preparing dataset. because dataset may use this strategy for initialization.
|
||||
if args.cache_latents:
|
||||
latents_caching_strategy = strategy_flux.FluxLatentsCachingStrategy(
|
||||
args.cache_latents_to_disk, args.vae_batch_size, args.skip_cache_check
|
||||
)
|
||||
strategy_base.LatentsCachingStrategy.set_strategy(latents_caching_strategy)
|
||||
|
||||
# データセットを準備する
|
||||
if args.dataset_class is None:
|
||||
blueprint_generator = BlueprintGenerator(ConfigSanitizer(False, False, True, True))
|
||||
if args.dataset_config is not None:
|
||||
logger.info(f"Load dataset config from {args.dataset_config}")
|
||||
user_config = config_util.load_user_config(args.dataset_config)
|
||||
ignored = ["train_data_dir", "conditioning_data_dir"]
|
||||
if any(getattr(args, attr) is not None for attr in ignored):
|
||||
logger.warning(
|
||||
"ignore following options because config file is found: {0} / 設定ファイルが利用されるため以下のオプションは無視されます: {0}".format(
|
||||
", ".join(ignored)
|
||||
)
|
||||
)
|
||||
else:
|
||||
user_config = {
|
||||
"datasets": [
|
||||
{
|
||||
"subsets": config_util.generate_controlnet_subsets_config_by_subdirs(
|
||||
args.train_data_dir, args.conditioning_data_dir, args.caption_extension
|
||||
)
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
blueprint = blueprint_generator.generate(user_config, args)
|
||||
train_dataset_group, val_dataset_group = config_util.generate_dataset_group_by_blueprint(blueprint.dataset_group)
|
||||
else:
|
||||
train_dataset_group = train_util.load_arbitrary_dataset(args)
|
||||
val_dataset_group = None
|
||||
|
||||
current_epoch = Value("i", 0)
|
||||
current_step = Value("i", 0)
|
||||
ds_for_collator = train_dataset_group if args.max_data_loader_n_workers == 0 else None
|
||||
collator = train_util.collator_class(current_epoch, current_step, ds_for_collator)
|
||||
|
||||
train_dataset_group.verify_bucket_reso_steps(16) # TODO これでいいか確認
|
||||
|
||||
_, is_schnell, _, _ = flux_utils.analyze_checkpoint_state(args.pretrained_model_name_or_path)
|
||||
if args.debug_dataset:
|
||||
if args.cache_text_encoder_outputs:
|
||||
strategy_base.TextEncoderOutputsCachingStrategy.set_strategy(
|
||||
strategy_flux.FluxTextEncoderOutputsCachingStrategy(
|
||||
args.cache_text_encoder_outputs_to_disk, args.text_encoder_batch_size, args.skip_cache_check, False
|
||||
)
|
||||
)
|
||||
t5xxl_max_token_length = (
|
||||
args.t5xxl_max_token_length if args.t5xxl_max_token_length is not None else (256 if is_schnell else 512)
|
||||
)
|
||||
strategy_base.TokenizeStrategy.set_strategy(strategy_flux.FluxTokenizeStrategy(t5xxl_max_token_length))
|
||||
|
||||
train_dataset_group.set_current_strategies()
|
||||
train_util.debug_dataset(train_dataset_group, True)
|
||||
return
|
||||
if len(train_dataset_group) == 0:
|
||||
logger.error(
|
||||
"No data found. Please verify the metadata file and train_data_dir option. / 画像がありません。メタデータおよびtrain_data_dirオプションを確認してください。"
|
||||
)
|
||||
return
|
||||
|
||||
if cache_latents:
|
||||
assert (
|
||||
train_dataset_group.is_latent_cacheable()
|
||||
), "when caching latents, either color_aug or random_crop cannot be used / latentをキャッシュするときはcolor_augとrandom_cropは使えません"
|
||||
|
||||
if args.cache_text_encoder_outputs:
|
||||
assert (
|
||||
train_dataset_group.is_text_encoder_output_cacheable()
|
||||
), "when caching text encoder output, either caption_dropout_rate, shuffle_caption, token_warmup_step or caption_tag_dropout_rate cannot be used / text encoderの出力をキャッシュするときはcaption_dropout_rate, shuffle_caption, token_warmup_step, caption_tag_dropout_rateは使えません"
|
||||
|
||||
# acceleratorを準備する
|
||||
logger.info("prepare accelerator")
|
||||
accelerator = train_util.prepare_accelerator(args)
|
||||
|
||||
# mixed precisionに対応した型を用意しておき適宜castする
|
||||
weight_dtype, save_dtype = train_util.prepare_dtype(args)
|
||||
|
||||
# モデルを読み込む
|
||||
|
||||
# load VAE for caching latents
|
||||
ae = None
|
||||
if cache_latents:
|
||||
ae = flux_utils.load_ae(args.ae, weight_dtype, "cpu", args.disable_mmap_load_safetensors)
|
||||
ae.to(accelerator.device, dtype=weight_dtype)
|
||||
ae.requires_grad_(False)
|
||||
ae.eval()
|
||||
|
||||
train_dataset_group.new_cache_latents(ae, accelerator)
|
||||
|
||||
ae.to("cpu") # if no sampling, vae can be deleted
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
# prepare tokenize strategy
|
||||
if args.t5xxl_max_token_length is None:
|
||||
if is_schnell:
|
||||
t5xxl_max_token_length = 256
|
||||
else:
|
||||
t5xxl_max_token_length = 512
|
||||
else:
|
||||
t5xxl_max_token_length = args.t5xxl_max_token_length
|
||||
|
||||
flux_tokenize_strategy = strategy_flux.FluxTokenizeStrategy(t5xxl_max_token_length)
|
||||
strategy_base.TokenizeStrategy.set_strategy(flux_tokenize_strategy)
|
||||
|
||||
# load clip_l, t5xxl for caching text encoder outputs
|
||||
clip_l = flux_utils.load_clip_l(args.clip_l, weight_dtype, "cpu", args.disable_mmap_load_safetensors)
|
||||
t5xxl = flux_utils.load_t5xxl(args.t5xxl, weight_dtype, "cpu", args.disable_mmap_load_safetensors)
|
||||
clip_l.eval()
|
||||
t5xxl.eval()
|
||||
clip_l.requires_grad_(False)
|
||||
t5xxl.requires_grad_(False)
|
||||
|
||||
text_encoding_strategy = strategy_flux.FluxTextEncodingStrategy(args.apply_t5_attn_mask)
|
||||
strategy_base.TextEncodingStrategy.set_strategy(text_encoding_strategy)
|
||||
|
||||
# cache text encoder outputs
|
||||
sample_prompts_te_outputs = None
|
||||
if args.cache_text_encoder_outputs:
|
||||
# Text Encodes are eval and no grad here
|
||||
clip_l.to(accelerator.device)
|
||||
t5xxl.to(accelerator.device)
|
||||
|
||||
text_encoder_caching_strategy = strategy_flux.FluxTextEncoderOutputsCachingStrategy(
|
||||
args.cache_text_encoder_outputs_to_disk, args.text_encoder_batch_size, False, False, args.apply_t5_attn_mask
|
||||
)
|
||||
strategy_base.TextEncoderOutputsCachingStrategy.set_strategy(text_encoder_caching_strategy)
|
||||
|
||||
with accelerator.autocast():
|
||||
train_dataset_group.new_cache_text_encoder_outputs([clip_l, t5xxl], accelerator)
|
||||
|
||||
# cache sample prompt's embeddings to free text encoder's memory
|
||||
if args.sample_prompts is not None:
|
||||
logger.info(f"cache Text Encoder outputs for sample prompt: {args.sample_prompts}")
|
||||
|
||||
text_encoding_strategy: strategy_flux.FluxTextEncodingStrategy = strategy_base.TextEncodingStrategy.get_strategy()
|
||||
|
||||
prompts = train_util.load_prompts(args.sample_prompts)
|
||||
sample_prompts_te_outputs = {} # key: prompt, value: text encoder outputs
|
||||
with accelerator.autocast(), torch.no_grad():
|
||||
for prompt_dict in prompts:
|
||||
for p in [prompt_dict.get("prompt", ""), prompt_dict.get("negative_prompt", "")]:
|
||||
if p not in sample_prompts_te_outputs:
|
||||
logger.info(f"cache Text Encoder outputs for prompt: {p}")
|
||||
tokens_and_masks = flux_tokenize_strategy.tokenize(p)
|
||||
sample_prompts_te_outputs[p] = text_encoding_strategy.encode_tokens(
|
||||
flux_tokenize_strategy, [clip_l, t5xxl], tokens_and_masks, args.apply_t5_attn_mask
|
||||
)
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
# now we can delete Text Encoders to free memory
|
||||
clip_l = None
|
||||
t5xxl = None
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
# load FLUX
|
||||
is_schnell, flux = flux_utils.load_flow_model(
|
||||
args.pretrained_model_name_or_path, weight_dtype, "cpu", args.disable_mmap_load_safetensors, model_type="flux"
|
||||
)
|
||||
flux.requires_grad_(False)
|
||||
|
||||
# load controlnet
|
||||
controlnet_dtype = torch.float32 if args.deepspeed else weight_dtype
|
||||
controlnet = flux_utils.load_controlnet(
|
||||
args.controlnet_model_name_or_path, is_schnell, controlnet_dtype, accelerator.device, args.disable_mmap_load_safetensors
|
||||
)
|
||||
controlnet.train()
|
||||
|
||||
if args.gradient_checkpointing:
|
||||
if not args.deepspeed:
|
||||
flux.enable_gradient_checkpointing(cpu_offload=args.cpu_offload_checkpointing)
|
||||
controlnet.enable_gradient_checkpointing(cpu_offload=args.cpu_offload_checkpointing)
|
||||
|
||||
# block swap
|
||||
|
||||
# backward compatibility
|
||||
if args.blocks_to_swap is None:
|
||||
blocks_to_swap = args.double_blocks_to_swap or 0
|
||||
if args.single_blocks_to_swap is not None:
|
||||
blocks_to_swap += args.single_blocks_to_swap // 2
|
||||
if blocks_to_swap > 0:
|
||||
logger.warning(
|
||||
"double_blocks_to_swap and single_blocks_to_swap are deprecated. Use blocks_to_swap instead."
|
||||
" / double_blocks_to_swapとsingle_blocks_to_swapは非推奨です。blocks_to_swapを使ってください。"
|
||||
)
|
||||
logger.info(
|
||||
f"double_blocks_to_swap={args.double_blocks_to_swap} and single_blocks_to_swap={args.single_blocks_to_swap} are converted to blocks_to_swap={blocks_to_swap}."
|
||||
)
|
||||
args.blocks_to_swap = blocks_to_swap
|
||||
del blocks_to_swap
|
||||
|
||||
is_swapping_blocks = args.blocks_to_swap is not None and args.blocks_to_swap > 0
|
||||
if is_swapping_blocks:
|
||||
# Swap blocks between CPU and GPU to reduce memory usage, in forward and backward passes.
|
||||
# This idea is based on 2kpr's great work. Thank you!
|
||||
logger.info(f"enable block swap: blocks_to_swap={args.blocks_to_swap}")
|
||||
flux.enable_block_swap(args.blocks_to_swap, accelerator.device)
|
||||
flux.move_to_device_except_swap_blocks(accelerator.device) # reduce peak memory usage
|
||||
# ControlNet only has two blocks, so we can keep it on GPU
|
||||
# controlnet.enable_block_swap(args.blocks_to_swap, accelerator.device)
|
||||
else:
|
||||
flux.to(accelerator.device)
|
||||
|
||||
if not cache_latents:
|
||||
# load VAE here if not cached
|
||||
ae = flux_utils.load_ae(args.ae, weight_dtype, "cpu")
|
||||
ae.requires_grad_(False)
|
||||
ae.eval()
|
||||
ae.to(accelerator.device, dtype=weight_dtype)
|
||||
|
||||
training_models = []
|
||||
params_to_optimize = []
|
||||
training_models.append(controlnet)
|
||||
name_and_params = list(controlnet.named_parameters())
|
||||
# single param group for now
|
||||
params_to_optimize.append({"params": [p for _, p in name_and_params], "lr": args.learning_rate})
|
||||
param_names = [[n for n, _ in name_and_params]]
|
||||
|
||||
# calculate number of trainable parameters
|
||||
n_params = 0
|
||||
for group in params_to_optimize:
|
||||
for p in group["params"]:
|
||||
n_params += p.numel()
|
||||
|
||||
accelerator.print(f"number of trainable parameters: {n_params}")
|
||||
|
||||
# 学習に必要なクラスを準備する
|
||||
accelerator.print("prepare optimizer, data loader etc.")
|
||||
|
||||
if args.blockwise_fused_optimizers:
|
||||
# fused backward pass: https://pytorch.org/tutorials/intermediate/optimizer_step_in_backward_tutorial.html
|
||||
# Instead of creating an optimizer for all parameters as in the tutorial, we create an optimizer for each block of parameters.
|
||||
# This balances memory usage and management complexity.
|
||||
|
||||
# split params into groups. currently different learning rates are not supported
|
||||
grouped_params = []
|
||||
param_group = {}
|
||||
for group in params_to_optimize:
|
||||
named_parameters = list(controlnet.named_parameters())
|
||||
assert len(named_parameters) == len(group["params"]), "number of parameters does not match"
|
||||
for p, np in zip(group["params"], named_parameters):
|
||||
# determine target layer and block index for each parameter
|
||||
block_type = "other" # double, single or other
|
||||
if np[0].startswith("double_blocks"):
|
||||
block_index = int(np[0].split(".")[1])
|
||||
block_type = "double"
|
||||
elif np[0].startswith("single_blocks"):
|
||||
block_index = int(np[0].split(".")[1])
|
||||
block_type = "single"
|
||||
else:
|
||||
block_index = -1
|
||||
|
||||
param_group_key = (block_type, block_index)
|
||||
if param_group_key not in param_group:
|
||||
param_group[param_group_key] = []
|
||||
param_group[param_group_key].append(p)
|
||||
|
||||
block_types_and_indices = []
|
||||
for param_group_key, param_group in param_group.items():
|
||||
block_types_and_indices.append(param_group_key)
|
||||
grouped_params.append({"params": param_group, "lr": args.learning_rate})
|
||||
|
||||
num_params = 0
|
||||
for p in param_group:
|
||||
num_params += p.numel()
|
||||
accelerator.print(f"block {param_group_key}: {num_params} parameters")
|
||||
|
||||
# prepare optimizers for each group
|
||||
optimizers = []
|
||||
for group in grouped_params:
|
||||
_, _, optimizer = train_util.get_optimizer(args, trainable_params=[group])
|
||||
optimizers.append(optimizer)
|
||||
optimizer = optimizers[0] # avoid error in the following code
|
||||
|
||||
logger.info(f"using {len(optimizers)} optimizers for blockwise fused optimizers")
|
||||
|
||||
if train_util.is_schedulefree_optimizer(optimizers[0], args):
|
||||
raise ValueError("Schedule-free optimizer is not supported with blockwise fused optimizers")
|
||||
optimizer_train_fn = lambda: None # dummy function
|
||||
optimizer_eval_fn = lambda: None # dummy function
|
||||
else:
|
||||
_, _, optimizer = train_util.get_optimizer(args, trainable_params=params_to_optimize)
|
||||
optimizer_train_fn, optimizer_eval_fn = train_util.get_optimizer_train_eval_fn(optimizer, args)
|
||||
|
||||
# prepare dataloader
|
||||
# strategies are set here because they cannot be referenced in another process. Copy them with the dataset
|
||||
# some strategies can be None
|
||||
train_dataset_group.set_current_strategies()
|
||||
|
||||
# DataLoaderのプロセス数:0 は persistent_workers が使えないので注意
|
||||
n_workers = min(args.max_data_loader_n_workers, os.cpu_count()) # cpu_count or max_data_loader_n_workers
|
||||
train_dataloader = torch.utils.data.DataLoader(
|
||||
train_dataset_group,
|
||||
batch_size=1,
|
||||
shuffle=True,
|
||||
collate_fn=collator,
|
||||
num_workers=n_workers,
|
||||
persistent_workers=args.persistent_data_loader_workers,
|
||||
)
|
||||
|
||||
# 学習ステップ数を計算する
|
||||
if args.max_train_epochs is not None:
|
||||
args.max_train_steps = args.max_train_epochs * math.ceil(
|
||||
len(train_dataloader) / accelerator.num_processes / args.gradient_accumulation_steps
|
||||
)
|
||||
accelerator.print(
|
||||
f"override steps. steps for {args.max_train_epochs} epochs is / 指定エポックまでのステップ数: {args.max_train_steps}"
|
||||
)
|
||||
|
||||
# データセット側にも学習ステップを送信
|
||||
train_dataset_group.set_max_train_steps(args.max_train_steps)
|
||||
|
||||
# lr schedulerを用意する
|
||||
if args.blockwise_fused_optimizers:
|
||||
# prepare lr schedulers for each optimizer
|
||||
lr_schedulers = [train_util.get_scheduler_fix(args, optimizer, accelerator.num_processes) for optimizer in optimizers]
|
||||
lr_scheduler = lr_schedulers[0] # avoid error in the following code
|
||||
else:
|
||||
lr_scheduler = train_util.get_scheduler_fix(args, optimizer, accelerator.num_processes)
|
||||
|
||||
# 実験的機能:勾配も含めたfp16/bf16学習を行う モデル全体をfp16/bf16にする
|
||||
if args.full_fp16:
|
||||
assert (
|
||||
args.mixed_precision == "fp16"
|
||||
), "full_fp16 requires mixed precision='fp16' / full_fp16を使う場合はmixed_precision='fp16'を指定してください。"
|
||||
accelerator.print("enable full fp16 training.")
|
||||
flux.to(weight_dtype)
|
||||
controlnet.to(weight_dtype)
|
||||
if clip_l is not None:
|
||||
clip_l.to(weight_dtype)
|
||||
t5xxl.to(weight_dtype) # TODO check works with fp16 or not
|
||||
elif args.full_bf16:
|
||||
assert (
|
||||
args.mixed_precision == "bf16"
|
||||
), "full_bf16 requires mixed precision='bf16' / full_bf16を使う場合はmixed_precision='bf16'を指定してください。"
|
||||
accelerator.print("enable full bf16 training.")
|
||||
flux.to(weight_dtype)
|
||||
controlnet.to(weight_dtype)
|
||||
if clip_l is not None:
|
||||
clip_l.to(weight_dtype)
|
||||
t5xxl.to(weight_dtype)
|
||||
|
||||
# if we don't cache text encoder outputs, move them to device
|
||||
if not args.cache_text_encoder_outputs:
|
||||
clip_l.to(accelerator.device)
|
||||
t5xxl.to(accelerator.device)
|
||||
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
if args.deepspeed:
|
||||
ds_model = deepspeed_utils.prepare_deepspeed_model(args, mmdit=controlnet)
|
||||
# most of ZeRO stage uses optimizer partitioning, so we have to prepare optimizer and ds_model at the same time. # pull/1139#issuecomment-1986790007
|
||||
ds_model, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
|
||||
ds_model, optimizer, train_dataloader, lr_scheduler
|
||||
)
|
||||
training_models = [ds_model]
|
||||
|
||||
else:
|
||||
# accelerator does some magic
|
||||
# if we doesn't swap blocks, we can move the model to device
|
||||
controlnet = accelerator.prepare(controlnet) # , device_placement=[not is_swapping_blocks])
|
||||
optimizer, train_dataloader, lr_scheduler = accelerator.prepare(optimizer, train_dataloader, lr_scheduler)
|
||||
|
||||
# 実験的機能:勾配も含めたfp16学習を行う PyTorchにパッチを当ててfp16でのgrad scaleを有効にする
|
||||
if args.full_fp16:
|
||||
# During deepseed training, accelerate not handles fp16/bf16|mixed precision directly via scaler. Let deepspeed engine do.
|
||||
# -> But we think it's ok to patch accelerator even if deepspeed is enabled.
|
||||
train_util.patch_accelerator_for_fp16_training(accelerator)
|
||||
|
||||
# resumeする
|
||||
train_util.resume_from_local_or_hf_if_specified(accelerator, args)
|
||||
|
||||
if args.fused_backward_pass:
|
||||
# use fused optimizer for backward pass: other optimizers will be supported in the future
|
||||
import library.adafactor_fused
|
||||
|
||||
library.adafactor_fused.patch_adafactor_fused(optimizer)
|
||||
|
||||
for param_group, param_name_group in zip(optimizer.param_groups, param_names):
|
||||
for parameter, param_name in zip(param_group["params"], param_name_group):
|
||||
if parameter.requires_grad:
|
||||
|
||||
def create_grad_hook(p_name, p_group):
|
||||
def grad_hook(tensor: torch.Tensor):
|
||||
if accelerator.sync_gradients and args.max_grad_norm != 0.0:
|
||||
accelerator.clip_grad_norm_(tensor, args.max_grad_norm)
|
||||
optimizer.step_param(tensor, p_group)
|
||||
tensor.grad = None
|
||||
|
||||
return grad_hook
|
||||
|
||||
parameter.register_post_accumulate_grad_hook(create_grad_hook(param_name, param_group))
|
||||
|
||||
elif args.blockwise_fused_optimizers:
|
||||
# prepare for additional optimizers and lr schedulers
|
||||
for i in range(1, len(optimizers)):
|
||||
optimizers[i] = accelerator.prepare(optimizers[i])
|
||||
lr_schedulers[i] = accelerator.prepare(lr_schedulers[i])
|
||||
|
||||
# counters are used to determine when to step the optimizer
|
||||
global optimizer_hooked_count
|
||||
global num_parameters_per_group
|
||||
global parameter_optimizer_map
|
||||
|
||||
optimizer_hooked_count = {}
|
||||
num_parameters_per_group = [0] * len(optimizers)
|
||||
parameter_optimizer_map = {}
|
||||
|
||||
for opt_idx, optimizer in enumerate(optimizers):
|
||||
for param_group in optimizer.param_groups:
|
||||
for parameter in param_group["params"]:
|
||||
if parameter.requires_grad:
|
||||
|
||||
def grad_hook(parameter: torch.Tensor):
|
||||
if accelerator.sync_gradients and args.max_grad_norm != 0.0:
|
||||
accelerator.clip_grad_norm_(parameter, args.max_grad_norm)
|
||||
|
||||
i = parameter_optimizer_map[parameter]
|
||||
optimizer_hooked_count[i] += 1
|
||||
if optimizer_hooked_count[i] == num_parameters_per_group[i]:
|
||||
optimizers[i].step()
|
||||
optimizers[i].zero_grad(set_to_none=True)
|
||||
|
||||
parameter.register_post_accumulate_grad_hook(grad_hook)
|
||||
parameter_optimizer_map[parameter] = opt_idx
|
||||
num_parameters_per_group[opt_idx] += 1
|
||||
|
||||
# epoch数を計算する
|
||||
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
|
||||
num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
|
||||
if (args.save_n_epoch_ratio is not None) and (args.save_n_epoch_ratio > 0):
|
||||
args.save_every_n_epochs = math.floor(num_train_epochs / args.save_n_epoch_ratio) or 1
|
||||
|
||||
# 学習する
|
||||
# total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
|
||||
accelerator.print("running training / 学習開始")
|
||||
accelerator.print(f" num examples / サンプル数: {train_dataset_group.num_train_images}")
|
||||
accelerator.print(f" num batches per epoch / 1epochのバッチ数: {len(train_dataloader)}")
|
||||
accelerator.print(f" num epochs / epoch数: {num_train_epochs}")
|
||||
accelerator.print(
|
||||
f" batch size per device / バッチサイズ: {', '.join([str(d.batch_size) for d in train_dataset_group.datasets])}"
|
||||
)
|
||||
# accelerator.print(
|
||||
# f" total train batch size (with parallel & distributed & accumulation) / 総バッチサイズ(並列学習、勾配合計含む): {total_batch_size}"
|
||||
# )
|
||||
accelerator.print(f" gradient accumulation steps / 勾配を合計するステップ数 = {args.gradient_accumulation_steps}")
|
||||
accelerator.print(f" total optimization steps / 学習ステップ数: {args.max_train_steps}")
|
||||
|
||||
progress_bar = tqdm(range(args.max_train_steps), smoothing=0, disable=not accelerator.is_local_main_process, desc="steps")
|
||||
global_step = 0
|
||||
|
||||
noise_scheduler = FlowMatchEulerDiscreteScheduler(num_train_timesteps=1000, shift=args.discrete_flow_shift)
|
||||
noise_scheduler_copy = copy.deepcopy(noise_scheduler)
|
||||
|
||||
if accelerator.is_main_process:
|
||||
init_kwargs = {}
|
||||
if args.wandb_run_name:
|
||||
init_kwargs["wandb"] = {"name": args.wandb_run_name}
|
||||
if args.log_tracker_config is not None:
|
||||
init_kwargs = toml.load(args.log_tracker_config)
|
||||
accelerator.init_trackers(
|
||||
"finetuning" if args.log_tracker_name is None else args.log_tracker_name,
|
||||
config=train_util.get_sanitized_config_or_none(args),
|
||||
init_kwargs=init_kwargs,
|
||||
)
|
||||
|
||||
if is_swapping_blocks:
|
||||
flux.prepare_block_swap_before_forward()
|
||||
|
||||
# For --sample_at_first
|
||||
optimizer_eval_fn()
|
||||
flux_train_utils.sample_images(
|
||||
accelerator, args, 0, global_step, flux, ae, [clip_l, t5xxl], sample_prompts_te_outputs, controlnet=controlnet
|
||||
)
|
||||
optimizer_train_fn()
|
||||
if len(accelerator.trackers) > 0:
|
||||
# log empty object to commit the sample images to wandb
|
||||
accelerator.log({}, step=0)
|
||||
|
||||
loss_recorder = train_util.LossRecorder()
|
||||
epoch = 0 # avoid error when max_train_steps is 0
|
||||
for epoch in range(num_train_epochs):
|
||||
accelerator.print(f"\nepoch {epoch+1}/{num_train_epochs}")
|
||||
current_epoch.value = epoch + 1
|
||||
|
||||
for m in training_models:
|
||||
m.train()
|
||||
|
||||
for step, batch in enumerate(train_dataloader):
|
||||
current_step.value = global_step
|
||||
|
||||
if args.blockwise_fused_optimizers:
|
||||
optimizer_hooked_count = {i: 0 for i in range(len(optimizers))} # reset counter for each step
|
||||
|
||||
with accelerator.accumulate(*training_models):
|
||||
if "latents" in batch and batch["latents"] is not None:
|
||||
latents = batch["latents"].to(accelerator.device, dtype=weight_dtype)
|
||||
else:
|
||||
with torch.no_grad():
|
||||
# encode images to latents. images are [-1, 1]
|
||||
latents = ae.encode(batch["images"].to(ae.dtype)).to(accelerator.device, dtype=weight_dtype)
|
||||
|
||||
# NaNが含まれていれば警告を表示し0に置き換える
|
||||
if torch.any(torch.isnan(latents)):
|
||||
accelerator.print("NaN found in latents, replacing with zeros")
|
||||
latents = torch.nan_to_num(latents, 0, out=latents)
|
||||
|
||||
text_encoder_outputs_list = batch.get("text_encoder_outputs_list", None)
|
||||
if text_encoder_outputs_list is not None:
|
||||
text_encoder_conds = text_encoder_outputs_list
|
||||
else:
|
||||
# not cached or training, so get from text encoders
|
||||
tokens_and_masks = batch["input_ids_list"]
|
||||
with torch.no_grad():
|
||||
input_ids = [ids.to(accelerator.device) for ids in batch["input_ids_list"]]
|
||||
text_encoder_conds = text_encoding_strategy.encode_tokens(
|
||||
flux_tokenize_strategy, [clip_l, t5xxl], input_ids, args.apply_t5_attn_mask
|
||||
)
|
||||
text_encoder_conds = [c.to(weight_dtype) for c in text_encoder_conds]
|
||||
|
||||
# TODO support some features for noise implemented in get_noise_noisy_latents_and_timesteps
|
||||
|
||||
# Sample noise that we'll add to the latents
|
||||
noise = torch.randn_like(latents)
|
||||
bsz = latents.shape[0]
|
||||
|
||||
# get noisy model input and timesteps
|
||||
noisy_model_input, timesteps, sigmas = flux_train_utils.get_noisy_model_input_and_timesteps(
|
||||
args, noise_scheduler_copy, latents, noise, accelerator.device, weight_dtype
|
||||
)
|
||||
|
||||
# pack latents and get img_ids
|
||||
packed_noisy_model_input = flux_utils.pack_latents(noisy_model_input) # b, c, h*2, w*2 -> b, h*w, c*4
|
||||
packed_latent_height, packed_latent_width = noisy_model_input.shape[2] // 2, noisy_model_input.shape[3] // 2
|
||||
img_ids = (
|
||||
flux_utils.prepare_img_ids(bsz, packed_latent_height, packed_latent_width)
|
||||
.to(device=accelerator.device)
|
||||
.to(weight_dtype)
|
||||
)
|
||||
|
||||
# get guidance: ensure args.guidance_scale is float
|
||||
guidance_vec = torch.full((bsz,), float(args.guidance_scale), device=accelerator.device, dtype=weight_dtype)
|
||||
|
||||
# call model
|
||||
l_pooled, t5_out, txt_ids, t5_attn_mask = text_encoder_conds
|
||||
if not args.apply_t5_attn_mask:
|
||||
t5_attn_mask = None
|
||||
|
||||
with accelerator.autocast():
|
||||
block_samples, block_single_samples = controlnet(
|
||||
img=packed_noisy_model_input,
|
||||
img_ids=img_ids,
|
||||
controlnet_cond=batch["conditioning_images"].to(accelerator.device).to(weight_dtype),
|
||||
txt=t5_out,
|
||||
txt_ids=txt_ids,
|
||||
y=l_pooled,
|
||||
timesteps=timesteps / 1000,
|
||||
guidance=guidance_vec,
|
||||
txt_attention_mask=t5_attn_mask,
|
||||
)
|
||||
# YiYi notes: divide it by 1000 for now because we scale it by 1000 in the transformer model (we should not keep it but I want to keep the inputs same for the model for testing)
|
||||
model_pred = flux(
|
||||
img=packed_noisy_model_input,
|
||||
img_ids=img_ids,
|
||||
txt=t5_out,
|
||||
txt_ids=txt_ids,
|
||||
y=l_pooled,
|
||||
block_controlnet_hidden_states=block_samples,
|
||||
block_controlnet_single_hidden_states=block_single_samples,
|
||||
timesteps=timesteps / 1000,
|
||||
guidance=guidance_vec,
|
||||
txt_attention_mask=t5_attn_mask,
|
||||
)
|
||||
|
||||
# unpack latents
|
||||
model_pred = flux_utils.unpack_latents(model_pred, packed_latent_height, packed_latent_width)
|
||||
|
||||
# apply model prediction type
|
||||
model_pred, weighting = flux_train_utils.apply_model_prediction_type(args, model_pred, noisy_model_input, sigmas)
|
||||
|
||||
# flow matching loss: this is different from SD3
|
||||
target = noise - latents
|
||||
|
||||
# calculate loss
|
||||
loss = train_util.conditional_loss(
|
||||
model_pred.float(), target.float(), reduction="none", loss_type=args.loss_type, huber_c=None
|
||||
)
|
||||
if weighting is not None:
|
||||
loss = loss * weighting
|
||||
if args.masked_loss or ("alpha_masks" in batch and batch["alpha_masks"] is not None):
|
||||
loss = apply_masked_loss(loss, batch)
|
||||
loss = loss.mean([1, 2, 3])
|
||||
|
||||
loss_weights = batch["loss_weights"] # 各sampleごとのweight
|
||||
loss = loss * loss_weights
|
||||
loss = loss.mean()
|
||||
|
||||
# backward
|
||||
accelerator.backward(loss)
|
||||
|
||||
if not (args.fused_backward_pass or args.blockwise_fused_optimizers):
|
||||
if accelerator.sync_gradients and args.max_grad_norm != 0.0:
|
||||
params_to_clip = []
|
||||
for m in training_models:
|
||||
params_to_clip.extend(m.parameters())
|
||||
accelerator.clip_grad_norm_(params_to_clip, args.max_grad_norm)
|
||||
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
optimizer.zero_grad(set_to_none=True)
|
||||
else:
|
||||
# optimizer.step() and optimizer.zero_grad() are called in the optimizer hook
|
||||
lr_scheduler.step()
|
||||
if args.blockwise_fused_optimizers:
|
||||
for i in range(1, len(optimizers)):
|
||||
lr_schedulers[i].step()
|
||||
|
||||
# Checks if the accelerator has performed an optimization step behind the scenes
|
||||
if accelerator.sync_gradients:
|
||||
progress_bar.update(1)
|
||||
global_step += 1
|
||||
|
||||
optimizer_eval_fn()
|
||||
flux_train_utils.sample_images(
|
||||
accelerator,
|
||||
args,
|
||||
None,
|
||||
global_step,
|
||||
flux,
|
||||
ae,
|
||||
[clip_l, t5xxl],
|
||||
sample_prompts_te_outputs,
|
||||
controlnet=controlnet,
|
||||
)
|
||||
|
||||
# 指定ステップごとにモデルを保存
|
||||
if args.save_every_n_steps is not None and global_step % args.save_every_n_steps == 0:
|
||||
accelerator.wait_for_everyone()
|
||||
if accelerator.is_main_process:
|
||||
flux_train_utils.save_flux_model_on_epoch_end_or_stepwise(
|
||||
args,
|
||||
False,
|
||||
accelerator,
|
||||
save_dtype,
|
||||
epoch,
|
||||
num_train_epochs,
|
||||
global_step,
|
||||
accelerator.unwrap_model(controlnet),
|
||||
)
|
||||
optimizer_train_fn()
|
||||
|
||||
current_loss = loss.detach().item() # 平均なのでbatch sizeは関係ないはず
|
||||
if len(accelerator.trackers) > 0:
|
||||
logs = {"loss": current_loss}
|
||||
train_util.append_lr_to_logs(logs, lr_scheduler, args.optimizer_type, including_unet=True)
|
||||
|
||||
accelerator.log(logs, step=global_step)
|
||||
|
||||
loss_recorder.add(epoch=epoch, step=step, loss=current_loss)
|
||||
avr_loss: float = loss_recorder.moving_average
|
||||
logs = {"avr_loss": avr_loss} # , "lr": lr_scheduler.get_last_lr()[0]}
|
||||
progress_bar.set_postfix(**logs)
|
||||
|
||||
if global_step >= args.max_train_steps:
|
||||
break
|
||||
|
||||
if len(accelerator.trackers) > 0:
|
||||
logs = {"loss/epoch": loss_recorder.moving_average}
|
||||
accelerator.log(logs, step=epoch + 1)
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
optimizer_eval_fn()
|
||||
if args.save_every_n_epochs is not None:
|
||||
if accelerator.is_main_process:
|
||||
flux_train_utils.save_flux_model_on_epoch_end_or_stepwise(
|
||||
args,
|
||||
True,
|
||||
accelerator,
|
||||
save_dtype,
|
||||
epoch,
|
||||
num_train_epochs,
|
||||
global_step,
|
||||
accelerator.unwrap_model(controlnet),
|
||||
)
|
||||
|
||||
flux_train_utils.sample_images(
|
||||
accelerator, args, epoch + 1, global_step, flux, ae, [clip_l, t5xxl], sample_prompts_te_outputs, controlnet=controlnet
|
||||
)
|
||||
optimizer_train_fn()
|
||||
|
||||
is_main_process = accelerator.is_main_process
|
||||
# if is_main_process:
|
||||
controlnet = accelerator.unwrap_model(controlnet)
|
||||
|
||||
accelerator.end_training()
|
||||
optimizer_eval_fn()
|
||||
|
||||
if args.save_state or args.save_state_on_train_end:
|
||||
train_util.save_state_on_train_end(args, accelerator)
|
||||
|
||||
del accelerator # この後メモリを使うのでこれは消す
|
||||
|
||||
if is_main_process:
|
||||
flux_train_utils.save_flux_model_on_train_end(args, save_dtype, epoch, global_step, controlnet)
|
||||
logger.info("model saved.")
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
add_logging_arguments(parser)
|
||||
train_util.add_sd_models_arguments(parser) # TODO split this
|
||||
sai_model_spec.add_model_spec_arguments(parser)
|
||||
train_util.add_dataset_arguments(parser, False, True, True)
|
||||
train_util.add_training_arguments(parser, False)
|
||||
train_util.add_masked_loss_arguments(parser)
|
||||
deepspeed_utils.add_deepspeed_arguments(parser)
|
||||
train_util.add_sd_saving_arguments(parser)
|
||||
train_util.add_optimizer_arguments(parser)
|
||||
config_util.add_config_arguments(parser)
|
||||
add_custom_train_arguments(parser) # TODO remove this from here
|
||||
train_util.add_dit_training_arguments(parser)
|
||||
flux_train_utils.add_flux_train_arguments(parser)
|
||||
|
||||
parser.add_argument(
|
||||
"--mem_eff_save",
|
||||
action="store_true",
|
||||
help="[EXPERIMENTAL] use memory efficient custom model saving method / メモリ効率の良い独自のモデル保存方法を使う",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--fused_optimizer_groups",
|
||||
type=int,
|
||||
default=None,
|
||||
help="**this option is not working** will be removed in the future / このオプションは動作しません。将来削除されます",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--blockwise_fused_optimizers",
|
||||
action="store_true",
|
||||
help="enable blockwise optimizers for fused backward pass and optimizer step / fused backward passとoptimizer step のためブロック単位のoptimizerを有効にする",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--skip_latents_validity_check",
|
||||
action="store_true",
|
||||
help="[Deprecated] use 'skip_cache_check' instead / 代わりに 'skip_cache_check' を使用してください",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--double_blocks_to_swap",
|
||||
type=int,
|
||||
default=None,
|
||||
help="[Deprecated] use 'blocks_to_swap' instead / 代わりに 'blocks_to_swap' を使用してください",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--single_blocks_to_swap",
|
||||
type=int,
|
||||
default=None,
|
||||
help="[Deprecated] use 'blocks_to_swap' instead / 代わりに 'blocks_to_swap' を使用してください",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--cpu_offload_checkpointing",
|
||||
action="store_true",
|
||||
help="[EXPERIMENTAL] enable offloading of tensors to CPU during checkpointing / チェックポイント時にテンソルをCPUにオフロードする",
|
||||
)
|
||||
return parser
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
train_util.verify_command_line_training_args(args)
|
||||
args = train_util.read_config_from_file(args, parser)
|
||||
|
||||
train(args)
|
||||
547
flux_train_network.py
Normal file
547
flux_train_network.py
Normal file
@@ -0,0 +1,547 @@
|
||||
import argparse
|
||||
import copy
|
||||
import math
|
||||
import random
|
||||
from typing import Any, Optional, Union
|
||||
|
||||
import torch
|
||||
from accelerate import Accelerator
|
||||
|
||||
from library.device_utils import clean_memory_on_device, init_ipex
|
||||
|
||||
init_ipex()
|
||||
|
||||
import train_network
|
||||
from library import (
|
||||
flux_models,
|
||||
flux_train_utils,
|
||||
flux_utils,
|
||||
sd3_train_utils,
|
||||
strategy_base,
|
||||
strategy_flux,
|
||||
train_util,
|
||||
)
|
||||
from library.utils import setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
class FluxNetworkTrainer(train_network.NetworkTrainer):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.sample_prompts_te_outputs = None
|
||||
self.is_schnell: Optional[bool] = None
|
||||
self.is_swapping_blocks: bool = False
|
||||
self.model_type: Optional[str] = None
|
||||
|
||||
def assert_extra_args(
|
||||
self,
|
||||
args,
|
||||
train_dataset_group: Union[train_util.DatasetGroup, train_util.MinimalDataset],
|
||||
val_dataset_group: Optional[train_util.DatasetGroup],
|
||||
):
|
||||
super().assert_extra_args(args, train_dataset_group, val_dataset_group)
|
||||
# sdxl_train_util.verify_sdxl_training_args(args)
|
||||
|
||||
self.model_type = args.model_type # "flux" or "chroma"
|
||||
if self.model_type != "chroma":
|
||||
self.use_clip_l = True
|
||||
else:
|
||||
self.use_clip_l = False # Chroma does not use CLIP-L
|
||||
assert args.apply_t5_attn_mask, "apply_t5_attn_mask must be True for Chroma / Chromaではapply_t5_attn_maskを指定する必要があります"
|
||||
|
||||
if args.fp8_base_unet:
|
||||
args.fp8_base = True # if fp8_base_unet is enabled, fp8_base is also enabled for FLUX.1
|
||||
|
||||
if args.cache_text_encoder_outputs_to_disk and not args.cache_text_encoder_outputs:
|
||||
logger.warning(
|
||||
"cache_text_encoder_outputs_to_disk is enabled, so cache_text_encoder_outputs is also enabled / cache_text_encoder_outputs_to_diskが有効になっているため、cache_text_encoder_outputsも有効になります"
|
||||
)
|
||||
args.cache_text_encoder_outputs = True
|
||||
|
||||
if args.cache_text_encoder_outputs:
|
||||
assert (
|
||||
train_dataset_group.is_text_encoder_output_cacheable()
|
||||
), "when caching Text Encoder output, either caption_dropout_rate, shuffle_caption, token_warmup_step or caption_tag_dropout_rate cannot be used / Text Encoderの出力をキャッシュするときはcaption_dropout_rate, shuffle_caption, token_warmup_step, caption_tag_dropout_rateは使えません"
|
||||
|
||||
# prepare CLIP-L/T5XXL training flags
|
||||
self.train_clip_l = not args.network_train_unet_only and self.use_clip_l
|
||||
self.train_t5xxl = False # default is False even if args.network_train_unet_only is False
|
||||
|
||||
if args.max_token_length is not None:
|
||||
logger.warning("max_token_length is not used in Flux training / max_token_lengthはFluxのトレーニングでは使用されません")
|
||||
|
||||
assert (
|
||||
args.blocks_to_swap is None or args.blocks_to_swap == 0
|
||||
) or not args.cpu_offload_checkpointing, "blocks_to_swap is not supported with cpu_offload_checkpointing / blocks_to_swapはcpu_offload_checkpointingと併用できません"
|
||||
|
||||
# deprecated split_mode option
|
||||
if args.split_mode:
|
||||
if args.blocks_to_swap is not None:
|
||||
logger.warning(
|
||||
"split_mode is deprecated. Because `--blocks_to_swap` is set, `--split_mode` is ignored."
|
||||
" / split_modeは非推奨です。`--blocks_to_swap`が設定されているため、`--split_mode`は無視されます。"
|
||||
)
|
||||
else:
|
||||
logger.warning(
|
||||
"split_mode is deprecated. Please use `--blocks_to_swap` instead. `--blocks_to_swap 18` is automatically set."
|
||||
" / split_modeは非推奨です。代わりに`--blocks_to_swap`を使用してください。`--blocks_to_swap 18`が自動的に設定されました。"
|
||||
)
|
||||
args.blocks_to_swap = 18 # 18 is safe for most cases
|
||||
|
||||
train_dataset_group.verify_bucket_reso_steps(32) # TODO check this
|
||||
if val_dataset_group is not None:
|
||||
val_dataset_group.verify_bucket_reso_steps(32) # TODO check this
|
||||
|
||||
def load_target_model(self, args, weight_dtype, accelerator):
|
||||
# currently offload to cpu for some models
|
||||
|
||||
# if the file is fp8 and we are using fp8_base, we can load it as is (fp8)
|
||||
loading_dtype = None if args.fp8_base else weight_dtype
|
||||
|
||||
# if we load to cpu, flux.to(fp8) takes a long time, so we should load to gpu in future
|
||||
_, model = flux_utils.load_flow_model(
|
||||
args.pretrained_model_name_or_path,
|
||||
loading_dtype,
|
||||
"cpu",
|
||||
disable_mmap=args.disable_mmap_load_safetensors,
|
||||
model_type=self.model_type,
|
||||
)
|
||||
if args.fp8_base:
|
||||
# check dtype of model
|
||||
if model.dtype == torch.float8_e4m3fnuz or model.dtype == torch.float8_e5m2 or model.dtype == torch.float8_e5m2fnuz:
|
||||
raise ValueError(f"Unsupported fp8 model dtype: {model.dtype}")
|
||||
elif model.dtype == torch.float8_e4m3fn:
|
||||
logger.info("Loaded fp8 FLUX model")
|
||||
else:
|
||||
logger.info(
|
||||
"Cast FLUX model to fp8. This may take a while. You can reduce the time by using fp8 checkpoint."
|
||||
" / FLUXモデルをfp8に変換しています。これには時間がかかる場合があります。fp8チェックポイントを使用することで時間を短縮できます。"
|
||||
)
|
||||
model.to(torch.float8_e4m3fn)
|
||||
|
||||
# if args.split_mode:
|
||||
# model = self.prepare_split_model(model, weight_dtype, accelerator)
|
||||
|
||||
self.is_swapping_blocks = args.blocks_to_swap is not None and args.blocks_to_swap > 0
|
||||
if self.is_swapping_blocks:
|
||||
# Swap blocks between CPU and GPU to reduce memory usage, in forward and backward passes.
|
||||
logger.info(f"enable block swap: blocks_to_swap={args.blocks_to_swap}")
|
||||
model.enable_block_swap(args.blocks_to_swap, accelerator.device)
|
||||
|
||||
if self.use_clip_l:
|
||||
clip_l = flux_utils.load_clip_l(args.clip_l, weight_dtype, "cpu", disable_mmap=args.disable_mmap_load_safetensors)
|
||||
else:
|
||||
clip_l = flux_utils.dummy_clip_l() # dummy CLIP-L for Chroma, which does not use CLIP-L
|
||||
clip_l.eval()
|
||||
|
||||
# if the file is fp8 and we are using fp8_base (not unet), we can load it as is (fp8)
|
||||
if args.fp8_base and not args.fp8_base_unet:
|
||||
loading_dtype = None # as is
|
||||
else:
|
||||
loading_dtype = weight_dtype
|
||||
|
||||
# loading t5xxl to cpu takes a long time, so we should load to gpu in future
|
||||
t5xxl = flux_utils.load_t5xxl(args.t5xxl, loading_dtype, "cpu", disable_mmap=args.disable_mmap_load_safetensors)
|
||||
t5xxl.eval()
|
||||
if args.fp8_base and not args.fp8_base_unet:
|
||||
# check dtype of model
|
||||
if t5xxl.dtype == torch.float8_e4m3fnuz or t5xxl.dtype == torch.float8_e5m2 or t5xxl.dtype == torch.float8_e5m2fnuz:
|
||||
raise ValueError(f"Unsupported fp8 model dtype: {t5xxl.dtype}")
|
||||
elif t5xxl.dtype == torch.float8_e4m3fn:
|
||||
logger.info("Loaded fp8 T5XXL model")
|
||||
|
||||
ae = flux_utils.load_ae(args.ae, weight_dtype, "cpu", disable_mmap=args.disable_mmap_load_safetensors)
|
||||
|
||||
model_version = flux_utils.MODEL_VERSION_FLUX_V1 if self.model_type != "chroma" else flux_utils.MODEL_VERSION_CHROMA
|
||||
return model_version, [clip_l, t5xxl], ae, model
|
||||
|
||||
def get_tokenize_strategy(self, args):
|
||||
# This method is called before `assert_extra_args`, so we cannot use `self.is_schnell` here.
|
||||
# Instead, we analyze the checkpoint state to determine if it is schnell.
|
||||
if args.model_type != "chroma":
|
||||
_, is_schnell, _, _ = flux_utils.analyze_checkpoint_state(args.pretrained_model_name_or_path)
|
||||
else:
|
||||
is_schnell = False
|
||||
self.is_schnell = is_schnell
|
||||
|
||||
if args.t5xxl_max_token_length is None:
|
||||
if self.is_schnell:
|
||||
t5xxl_max_token_length = 256
|
||||
else:
|
||||
t5xxl_max_token_length = 512
|
||||
else:
|
||||
t5xxl_max_token_length = args.t5xxl_max_token_length
|
||||
|
||||
logger.info(f"t5xxl_max_token_length: {t5xxl_max_token_length}")
|
||||
return strategy_flux.FluxTokenizeStrategy(t5xxl_max_token_length, args.tokenizer_cache_dir)
|
||||
|
||||
def get_tokenizers(self, tokenize_strategy: strategy_flux.FluxTokenizeStrategy):
|
||||
return [tokenize_strategy.clip_l, tokenize_strategy.t5xxl]
|
||||
|
||||
def get_latents_caching_strategy(self, args):
|
||||
latents_caching_strategy = strategy_flux.FluxLatentsCachingStrategy(args.cache_latents_to_disk, args.vae_batch_size, False)
|
||||
return latents_caching_strategy
|
||||
|
||||
def get_text_encoding_strategy(self, args):
|
||||
return strategy_flux.FluxTextEncodingStrategy(apply_t5_attn_mask=args.apply_t5_attn_mask)
|
||||
|
||||
def post_process_network(self, args, accelerator, network, text_encoders, unet):
|
||||
# check t5xxl is trained or not
|
||||
self.train_t5xxl = network.train_t5xxl
|
||||
|
||||
if self.train_t5xxl and args.cache_text_encoder_outputs:
|
||||
raise ValueError(
|
||||
"T5XXL is trained, so cache_text_encoder_outputs cannot be used / T5XXL学習時はcache_text_encoder_outputsは使用できません"
|
||||
)
|
||||
|
||||
def get_models_for_text_encoding(self, args, accelerator, text_encoders):
|
||||
if args.cache_text_encoder_outputs:
|
||||
if self.train_clip_l and not self.train_t5xxl:
|
||||
return text_encoders[0:1] # only CLIP-L is needed for encoding because T5XXL is cached
|
||||
else:
|
||||
return None # no text encoders are needed for encoding because both are cached
|
||||
else:
|
||||
return text_encoders # both CLIP-L and T5XXL are needed for encoding
|
||||
|
||||
def get_text_encoders_train_flags(self, args, text_encoders):
|
||||
return [self.train_clip_l, self.train_t5xxl]
|
||||
|
||||
def get_text_encoder_outputs_caching_strategy(self, args):
|
||||
if args.cache_text_encoder_outputs:
|
||||
# if the text encoders is trained, we need tokenization, so is_partial is True
|
||||
return strategy_flux.FluxTextEncoderOutputsCachingStrategy(
|
||||
args.cache_text_encoder_outputs_to_disk,
|
||||
args.text_encoder_batch_size,
|
||||
args.skip_cache_check,
|
||||
is_partial=self.train_clip_l or self.train_t5xxl,
|
||||
apply_t5_attn_mask=args.apply_t5_attn_mask,
|
||||
)
|
||||
else:
|
||||
return None
|
||||
|
||||
def cache_text_encoder_outputs_if_needed(
|
||||
self, args, accelerator: Accelerator, unet, vae, text_encoders, dataset: train_util.DatasetGroup, weight_dtype
|
||||
):
|
||||
if args.cache_text_encoder_outputs:
|
||||
if not args.lowram:
|
||||
# メモリ消費を減らす
|
||||
logger.info("move vae and unet to cpu to save memory")
|
||||
org_vae_device = vae.device
|
||||
org_unet_device = unet.device
|
||||
vae.to("cpu")
|
||||
unet.to("cpu")
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
# When TE is not be trained, it will not be prepared so we need to use explicit autocast
|
||||
logger.info("move text encoders to gpu")
|
||||
text_encoders[0].to(accelerator.device, dtype=weight_dtype) # always not fp8
|
||||
text_encoders[1].to(accelerator.device)
|
||||
|
||||
if text_encoders[1].dtype == torch.float8_e4m3fn:
|
||||
# if we load fp8 weights, the model is already fp8, so we use it as is
|
||||
self.prepare_text_encoder_fp8(1, text_encoders[1], text_encoders[1].dtype, weight_dtype)
|
||||
else:
|
||||
# otherwise, we need to convert it to target dtype
|
||||
text_encoders[1].to(weight_dtype)
|
||||
|
||||
with accelerator.autocast():
|
||||
dataset.new_cache_text_encoder_outputs(text_encoders, accelerator)
|
||||
|
||||
# cache sample prompts
|
||||
if args.sample_prompts is not None:
|
||||
logger.info(f"cache Text Encoder outputs for sample prompt: {args.sample_prompts}")
|
||||
|
||||
tokenize_strategy: strategy_flux.FluxTokenizeStrategy = strategy_base.TokenizeStrategy.get_strategy()
|
||||
text_encoding_strategy: strategy_flux.FluxTextEncodingStrategy = strategy_base.TextEncodingStrategy.get_strategy()
|
||||
|
||||
prompts = train_util.load_prompts(args.sample_prompts)
|
||||
sample_prompts_te_outputs = {} # key: prompt, value: text encoder outputs
|
||||
with accelerator.autocast(), torch.no_grad():
|
||||
for prompt_dict in prompts:
|
||||
for p in [prompt_dict.get("prompt", ""), prompt_dict.get("negative_prompt", "")]:
|
||||
if p not in sample_prompts_te_outputs:
|
||||
logger.info(f"cache Text Encoder outputs for prompt: {p}")
|
||||
tokens_and_masks = tokenize_strategy.tokenize(p)
|
||||
sample_prompts_te_outputs[p] = text_encoding_strategy.encode_tokens(
|
||||
tokenize_strategy, text_encoders, tokens_and_masks, args.apply_t5_attn_mask
|
||||
)
|
||||
self.sample_prompts_te_outputs = sample_prompts_te_outputs
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
# move back to cpu
|
||||
if not self.is_train_text_encoder(args):
|
||||
logger.info("move CLIP-L back to cpu")
|
||||
text_encoders[0].to("cpu")
|
||||
logger.info("move t5XXL back to cpu")
|
||||
text_encoders[1].to("cpu")
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
if not args.lowram:
|
||||
logger.info("move vae and unet back to original device")
|
||||
vae.to(org_vae_device)
|
||||
unet.to(org_unet_device)
|
||||
else:
|
||||
# Text Encoderから毎回出力を取得するので、GPUに乗せておく
|
||||
text_encoders[0].to(accelerator.device, dtype=weight_dtype)
|
||||
text_encoders[1].to(accelerator.device)
|
||||
|
||||
def sample_images(self, accelerator, args, epoch, global_step, device, ae, tokenizer, text_encoder, flux):
|
||||
text_encoders = text_encoder # for compatibility
|
||||
text_encoders = self.get_models_for_text_encoding(args, accelerator, text_encoders)
|
||||
|
||||
flux_train_utils.sample_images(
|
||||
accelerator, args, epoch, global_step, flux, ae, text_encoders, self.sample_prompts_te_outputs
|
||||
)
|
||||
|
||||
def get_noise_scheduler(self, args: argparse.Namespace, device: torch.device) -> Any:
|
||||
noise_scheduler = sd3_train_utils.FlowMatchEulerDiscreteScheduler(num_train_timesteps=1000, shift=args.discrete_flow_shift)
|
||||
self.noise_scheduler_copy = copy.deepcopy(noise_scheduler)
|
||||
return noise_scheduler
|
||||
|
||||
def encode_images_to_latents(self, args, vae, images):
|
||||
return vae.encode(images)
|
||||
|
||||
def shift_scale_latents(self, args, latents):
|
||||
return latents
|
||||
|
||||
def get_noise_pred_and_target(
|
||||
self,
|
||||
args,
|
||||
accelerator,
|
||||
noise_scheduler,
|
||||
latents,
|
||||
batch,
|
||||
text_encoder_conds,
|
||||
unet: flux_models.Flux,
|
||||
network,
|
||||
weight_dtype,
|
||||
train_unet,
|
||||
is_train=True,
|
||||
):
|
||||
# Sample noise that we'll add to the latents
|
||||
noise = torch.randn_like(latents)
|
||||
bsz = latents.shape[0]
|
||||
|
||||
# get noisy model input and timesteps
|
||||
noisy_model_input, timesteps, sigmas = flux_train_utils.get_noisy_model_input_and_timesteps(
|
||||
args, noise_scheduler, latents, noise, accelerator.device, weight_dtype
|
||||
)
|
||||
|
||||
# pack latents and get img_ids
|
||||
packed_noisy_model_input = flux_utils.pack_latents(noisy_model_input) # b, c, h*2, w*2 -> b, h*w, c*4
|
||||
packed_latent_height, packed_latent_width = noisy_model_input.shape[2] // 2, noisy_model_input.shape[3] // 2
|
||||
img_ids = flux_utils.prepare_img_ids(bsz, packed_latent_height, packed_latent_width).to(device=accelerator.device)
|
||||
|
||||
# get guidance
|
||||
# ensure guidance_scale in args is float
|
||||
guidance_vec = torch.full((bsz,), float(args.guidance_scale), device=accelerator.device)
|
||||
|
||||
# get modulation vectors for Chroma
|
||||
with accelerator.autocast(), torch.no_grad():
|
||||
mod_vectors = unet.get_mod_vectors(timesteps=timesteps / 1000, guidance=guidance_vec, batch_size=bsz)
|
||||
|
||||
if args.gradient_checkpointing:
|
||||
noisy_model_input.requires_grad_(True)
|
||||
for t in text_encoder_conds:
|
||||
if t is not None and t.dtype.is_floating_point:
|
||||
t.requires_grad_(True)
|
||||
img_ids.requires_grad_(True)
|
||||
guidance_vec.requires_grad_(True)
|
||||
if mod_vectors is not None:
|
||||
mod_vectors.requires_grad_(True)
|
||||
|
||||
# Predict the noise residual
|
||||
l_pooled, t5_out, txt_ids, t5_attn_mask = text_encoder_conds
|
||||
if not args.apply_t5_attn_mask:
|
||||
t5_attn_mask = None
|
||||
|
||||
def call_dit(img, img_ids, t5_out, txt_ids, l_pooled, timesteps, guidance_vec, t5_attn_mask, mod_vectors):
|
||||
# grad is enabled even if unet is not in train mode, because Text Encoder is in train mode
|
||||
with torch.set_grad_enabled(is_train), accelerator.autocast():
|
||||
# YiYi notes: divide it by 1000 for now because we scale it by 1000 in the transformer model (we should not keep it but I want to keep the inputs same for the model for testing)
|
||||
model_pred = unet(
|
||||
img=img,
|
||||
img_ids=img_ids,
|
||||
txt=t5_out,
|
||||
txt_ids=txt_ids,
|
||||
y=l_pooled,
|
||||
timesteps=timesteps / 1000,
|
||||
guidance=guidance_vec,
|
||||
txt_attention_mask=t5_attn_mask,
|
||||
mod_vectors=mod_vectors,
|
||||
)
|
||||
return model_pred
|
||||
|
||||
model_pred = call_dit(
|
||||
img=packed_noisy_model_input,
|
||||
img_ids=img_ids,
|
||||
t5_out=t5_out,
|
||||
txt_ids=txt_ids,
|
||||
l_pooled=l_pooled,
|
||||
timesteps=timesteps,
|
||||
guidance_vec=guidance_vec,
|
||||
t5_attn_mask=t5_attn_mask,
|
||||
mod_vectors=mod_vectors,
|
||||
)
|
||||
|
||||
# unpack latents
|
||||
model_pred = flux_utils.unpack_latents(model_pred, packed_latent_height, packed_latent_width)
|
||||
|
||||
# apply model prediction type
|
||||
model_pred, weighting = flux_train_utils.apply_model_prediction_type(args, model_pred, noisy_model_input, sigmas)
|
||||
|
||||
# flow matching loss: this is different from SD3
|
||||
target = noise - latents
|
||||
|
||||
# differential output preservation
|
||||
if "custom_attributes" in batch:
|
||||
diff_output_pr_indices = []
|
||||
for i, custom_attributes in enumerate(batch["custom_attributes"]):
|
||||
if "diff_output_preservation" in custom_attributes and custom_attributes["diff_output_preservation"]:
|
||||
diff_output_pr_indices.append(i)
|
||||
|
||||
if len(diff_output_pr_indices) > 0:
|
||||
network.set_multiplier(0.0)
|
||||
unet.prepare_block_swap_before_forward()
|
||||
with torch.no_grad():
|
||||
model_pred_prior = call_dit(
|
||||
img=packed_noisy_model_input[diff_output_pr_indices],
|
||||
img_ids=img_ids[diff_output_pr_indices],
|
||||
t5_out=t5_out[diff_output_pr_indices],
|
||||
txt_ids=txt_ids[diff_output_pr_indices],
|
||||
l_pooled=l_pooled[diff_output_pr_indices],
|
||||
timesteps=timesteps[diff_output_pr_indices],
|
||||
guidance_vec=guidance_vec[diff_output_pr_indices] if guidance_vec is not None else None,
|
||||
t5_attn_mask=t5_attn_mask[diff_output_pr_indices] if t5_attn_mask is not None else None,
|
||||
mod_vectors=mod_vectors[diff_output_pr_indices] if mod_vectors is not None else None,
|
||||
)
|
||||
network.set_multiplier(1.0) # may be overwritten by "network_multipliers" in the next step
|
||||
|
||||
model_pred_prior = flux_utils.unpack_latents(model_pred_prior, packed_latent_height, packed_latent_width)
|
||||
model_pred_prior, _ = flux_train_utils.apply_model_prediction_type(
|
||||
args,
|
||||
model_pred_prior,
|
||||
noisy_model_input[diff_output_pr_indices],
|
||||
sigmas[diff_output_pr_indices] if sigmas is not None else None,
|
||||
)
|
||||
target[diff_output_pr_indices] = model_pred_prior.to(target.dtype)
|
||||
|
||||
return model_pred, target, timesteps, weighting
|
||||
|
||||
def post_process_loss(self, loss, args, timesteps, noise_scheduler):
|
||||
return loss
|
||||
|
||||
def get_sai_model_spec(self, args):
|
||||
if self.model_type != "chroma":
|
||||
model_description = "schnell" if self.is_schnell else "dev"
|
||||
else:
|
||||
model_description = "chroma"
|
||||
return train_util.get_sai_model_spec(None, args, False, True, False, flux=model_description)
|
||||
|
||||
def update_metadata(self, metadata, args):
|
||||
metadata["ss_model_type"] = args.model_type
|
||||
metadata["ss_apply_t5_attn_mask"] = args.apply_t5_attn_mask
|
||||
metadata["ss_weighting_scheme"] = args.weighting_scheme
|
||||
metadata["ss_logit_mean"] = args.logit_mean
|
||||
metadata["ss_logit_std"] = args.logit_std
|
||||
metadata["ss_mode_scale"] = args.mode_scale
|
||||
metadata["ss_guidance_scale"] = args.guidance_scale
|
||||
metadata["ss_timestep_sampling"] = args.timestep_sampling
|
||||
metadata["ss_sigmoid_scale"] = args.sigmoid_scale
|
||||
metadata["ss_model_prediction_type"] = args.model_prediction_type
|
||||
metadata["ss_discrete_flow_shift"] = args.discrete_flow_shift
|
||||
|
||||
def is_text_encoder_not_needed_for_training(self, args):
|
||||
return args.cache_text_encoder_outputs and not self.is_train_text_encoder(args)
|
||||
|
||||
def prepare_text_encoder_grad_ckpt_workaround(self, index, text_encoder):
|
||||
if index == 0: # CLIP-L
|
||||
return super().prepare_text_encoder_grad_ckpt_workaround(index, text_encoder)
|
||||
else: # T5XXL
|
||||
text_encoder.encoder.embed_tokens.requires_grad_(True)
|
||||
|
||||
def prepare_text_encoder_fp8(self, index, text_encoder, te_weight_dtype, weight_dtype):
|
||||
if index == 0: # CLIP-L
|
||||
logger.info(f"prepare CLIP-L for fp8: set to {te_weight_dtype}, set embeddings to {weight_dtype}")
|
||||
text_encoder.to(te_weight_dtype) # fp8
|
||||
text_encoder.text_model.embeddings.to(dtype=weight_dtype)
|
||||
else: # T5XXL
|
||||
|
||||
def prepare_fp8(text_encoder, target_dtype):
|
||||
def forward_hook(module):
|
||||
def forward(hidden_states):
|
||||
hidden_gelu = module.act(module.wi_0(hidden_states))
|
||||
hidden_linear = module.wi_1(hidden_states)
|
||||
hidden_states = hidden_gelu * hidden_linear
|
||||
hidden_states = module.dropout(hidden_states)
|
||||
|
||||
hidden_states = module.wo(hidden_states)
|
||||
return hidden_states
|
||||
|
||||
return forward
|
||||
|
||||
for module in text_encoder.modules():
|
||||
if module.__class__.__name__ in ["T5LayerNorm", "Embedding"]:
|
||||
# print("set", module.__class__.__name__, "to", target_dtype)
|
||||
module.to(target_dtype)
|
||||
if module.__class__.__name__ in ["T5DenseGatedActDense"]:
|
||||
# print("set", module.__class__.__name__, "hooks")
|
||||
module.forward = forward_hook(module)
|
||||
|
||||
if flux_utils.get_t5xxl_actual_dtype(text_encoder) == torch.float8_e4m3fn and text_encoder.dtype == weight_dtype:
|
||||
logger.info(f"T5XXL already prepared for fp8")
|
||||
else:
|
||||
logger.info(f"prepare T5XXL for fp8: set to {te_weight_dtype}, set embeddings to {weight_dtype}, add hooks")
|
||||
text_encoder.to(te_weight_dtype) # fp8
|
||||
prepare_fp8(text_encoder, weight_dtype)
|
||||
|
||||
def on_validation_step_end(self, args, accelerator, network, text_encoders, unet, batch, weight_dtype):
|
||||
if self.is_swapping_blocks:
|
||||
# prepare for next forward: because backward pass is not called, we need to prepare it here
|
||||
accelerator.unwrap_model(unet).prepare_block_swap_before_forward()
|
||||
|
||||
def prepare_unet_with_accelerator(
|
||||
self, args: argparse.Namespace, accelerator: Accelerator, unet: torch.nn.Module
|
||||
) -> torch.nn.Module:
|
||||
if not self.is_swapping_blocks:
|
||||
return super().prepare_unet_with_accelerator(args, accelerator, unet)
|
||||
|
||||
# if we doesn't swap blocks, we can move the model to device
|
||||
flux: flux_models.Flux = unet
|
||||
flux = accelerator.prepare(flux, device_placement=[not self.is_swapping_blocks])
|
||||
accelerator.unwrap_model(flux).move_to_device_except_swap_blocks(accelerator.device) # reduce peak memory usage
|
||||
accelerator.unwrap_model(flux).prepare_block_swap_before_forward()
|
||||
|
||||
return flux
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = train_network.setup_parser()
|
||||
train_util.add_dit_training_arguments(parser)
|
||||
flux_train_utils.add_flux_train_arguments(parser)
|
||||
|
||||
parser.add_argument(
|
||||
"--split_mode",
|
||||
action="store_true",
|
||||
# help="[EXPERIMENTAL] use split mode for Flux model, network arg `train_blocks=single` is required"
|
||||
# + "/[実験的] Fluxモデルの分割モードを使用する。ネットワーク引数`train_blocks=single`が必要",
|
||||
help="[Deprecated] This option is deprecated. Please use `--blocks_to_swap` instead."
|
||||
" / このオプションは非推奨です。代わりに`--blocks_to_swap`を使用してください。",
|
||||
)
|
||||
return parser
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
train_util.verify_command_line_training_args(args)
|
||||
args = train_util.read_config_from_file(args, parser)
|
||||
|
||||
trainer = FluxNetworkTrainer()
|
||||
trainer.train(args)
|
||||
3564
gen_img.py
Normal file
3564
gen_img.py
Normal file
File diff suppressed because it is too large
Load Diff
1471
gen_img_diffusers.py
1471
gen_img_diffusers.py
File diff suppressed because it is too large
Load Diff
1268
hunyuan_image_minimal_inference.py
Normal file
1268
hunyuan_image_minimal_inference.py
Normal file
File diff suppressed because it is too large
Load Diff
717
hunyuan_image_train_network.py
Normal file
717
hunyuan_image_train_network.py
Normal file
@@ -0,0 +1,717 @@
|
||||
import argparse
|
||||
import copy
|
||||
import gc
|
||||
from typing import Any, Optional, Union, cast
|
||||
import os
|
||||
import time
|
||||
from types import SimpleNamespace
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from PIL import Image
|
||||
from accelerate import Accelerator, PartialState
|
||||
|
||||
from library import flux_utils, hunyuan_image_models, hunyuan_image_vae, strategy_base, train_util
|
||||
from library.device_utils import clean_memory_on_device, init_ipex
|
||||
|
||||
init_ipex()
|
||||
|
||||
import train_network
|
||||
from library import (
|
||||
flux_train_utils,
|
||||
hunyuan_image_models,
|
||||
hunyuan_image_text_encoder,
|
||||
hunyuan_image_utils,
|
||||
hunyuan_image_vae,
|
||||
sd3_train_utils,
|
||||
strategy_base,
|
||||
strategy_hunyuan_image,
|
||||
train_util,
|
||||
)
|
||||
from library.utils import setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
# region sampling
|
||||
|
||||
|
||||
# TODO commonize with flux_utils
|
||||
def sample_images(
|
||||
accelerator: Accelerator,
|
||||
args: argparse.Namespace,
|
||||
epoch,
|
||||
steps,
|
||||
dit: hunyuan_image_models.HYImageDiffusionTransformer,
|
||||
vae,
|
||||
text_encoders,
|
||||
sample_prompts_te_outputs,
|
||||
prompt_replacement=None,
|
||||
):
|
||||
if steps == 0:
|
||||
if not args.sample_at_first:
|
||||
return
|
||||
else:
|
||||
if args.sample_every_n_steps is None and args.sample_every_n_epochs is None:
|
||||
return
|
||||
if args.sample_every_n_epochs is not None:
|
||||
# sample_every_n_steps は無視する
|
||||
if epoch is None or epoch % args.sample_every_n_epochs != 0:
|
||||
return
|
||||
else:
|
||||
if steps % args.sample_every_n_steps != 0 or epoch is not None: # steps is not divisible or end of epoch
|
||||
return
|
||||
|
||||
logger.info("")
|
||||
logger.info(f"generating sample images at step / サンプル画像生成 ステップ: {steps}")
|
||||
if not os.path.isfile(args.sample_prompts) and sample_prompts_te_outputs is None:
|
||||
logger.error(f"No prompt file / プロンプトファイルがありません: {args.sample_prompts}")
|
||||
return
|
||||
|
||||
distributed_state = PartialState() # for multi gpu distributed inference. this is a singleton, so it's safe to use it here
|
||||
|
||||
# unwrap unet and text_encoder(s)
|
||||
dit = accelerator.unwrap_model(dit)
|
||||
dit = cast(hunyuan_image_models.HYImageDiffusionTransformer, dit)
|
||||
dit.switch_block_swap_for_inference()
|
||||
if text_encoders is not None:
|
||||
text_encoders = [(accelerator.unwrap_model(te) if te is not None else None) for te in text_encoders]
|
||||
# print([(te.parameters().__next__().device if te is not None else None) for te in text_encoders])
|
||||
|
||||
prompts = train_util.load_prompts(args.sample_prompts)
|
||||
|
||||
save_dir = args.output_dir + "/sample"
|
||||
os.makedirs(save_dir, exist_ok=True)
|
||||
|
||||
# save random state to restore later
|
||||
rng_state = torch.get_rng_state()
|
||||
cuda_rng_state = None
|
||||
try:
|
||||
cuda_rng_state = torch.cuda.get_rng_state() if torch.cuda.is_available() else None
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
if distributed_state.num_processes <= 1:
|
||||
# If only one device is available, just use the original prompt list. We don't need to care about the distribution of prompts.
|
||||
with torch.no_grad(), accelerator.autocast():
|
||||
for prompt_dict in prompts:
|
||||
sample_image_inference(
|
||||
accelerator,
|
||||
args,
|
||||
dit,
|
||||
text_encoders,
|
||||
vae,
|
||||
save_dir,
|
||||
prompt_dict,
|
||||
epoch,
|
||||
steps,
|
||||
sample_prompts_te_outputs,
|
||||
prompt_replacement,
|
||||
)
|
||||
else:
|
||||
# Creating list with N elements, where each element is a list of prompt_dicts, and N is the number of processes available (number of devices available)
|
||||
# prompt_dicts are assigned to lists based on order of processes, to attempt to time the image creation time to match enum order. Probably only works when steps and sampler are identical.
|
||||
per_process_prompts = [] # list of lists
|
||||
for i in range(distributed_state.num_processes):
|
||||
per_process_prompts.append(prompts[i :: distributed_state.num_processes])
|
||||
|
||||
with torch.no_grad():
|
||||
with distributed_state.split_between_processes(per_process_prompts) as prompt_dict_lists:
|
||||
for prompt_dict in prompt_dict_lists[0]:
|
||||
sample_image_inference(
|
||||
accelerator,
|
||||
args,
|
||||
dit,
|
||||
text_encoders,
|
||||
vae,
|
||||
save_dir,
|
||||
prompt_dict,
|
||||
epoch,
|
||||
steps,
|
||||
sample_prompts_te_outputs,
|
||||
prompt_replacement,
|
||||
)
|
||||
|
||||
torch.set_rng_state(rng_state)
|
||||
if cuda_rng_state is not None:
|
||||
torch.cuda.set_rng_state(cuda_rng_state)
|
||||
|
||||
dit.switch_block_swap_for_training()
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
|
||||
def sample_image_inference(
|
||||
accelerator: Accelerator,
|
||||
args: argparse.Namespace,
|
||||
dit: hunyuan_image_models.HYImageDiffusionTransformer,
|
||||
text_encoders: Optional[list[nn.Module]],
|
||||
vae: hunyuan_image_vae.HunyuanVAE2D,
|
||||
save_dir,
|
||||
prompt_dict,
|
||||
epoch,
|
||||
steps,
|
||||
sample_prompts_te_outputs,
|
||||
prompt_replacement,
|
||||
):
|
||||
assert isinstance(prompt_dict, dict)
|
||||
negative_prompt = prompt_dict.get("negative_prompt")
|
||||
sample_steps = prompt_dict.get("sample_steps", 20)
|
||||
width = prompt_dict.get("width", 512)
|
||||
height = prompt_dict.get("height", 512)
|
||||
cfg_scale = prompt_dict.get("scale", 3.5)
|
||||
seed = prompt_dict.get("seed")
|
||||
prompt: str = prompt_dict.get("prompt", "")
|
||||
flow_shift: float = prompt_dict.get("flow_shift", 5.0)
|
||||
# sampler_name: str = prompt_dict.get("sample_sampler", args.sample_sampler)
|
||||
|
||||
if prompt_replacement is not None:
|
||||
prompt = prompt.replace(prompt_replacement[0], prompt_replacement[1])
|
||||
if negative_prompt is not None:
|
||||
negative_prompt = negative_prompt.replace(prompt_replacement[0], prompt_replacement[1])
|
||||
|
||||
if seed is not None:
|
||||
torch.manual_seed(seed)
|
||||
torch.cuda.manual_seed(seed)
|
||||
else:
|
||||
# True random sample image generation
|
||||
torch.seed()
|
||||
torch.cuda.seed()
|
||||
|
||||
if negative_prompt is None:
|
||||
negative_prompt = ""
|
||||
height = max(64, height - height % 16) # round to divisible by 16
|
||||
width = max(64, width - width % 16) # round to divisible by 16
|
||||
logger.info(f"prompt: {prompt}")
|
||||
if cfg_scale != 1.0:
|
||||
logger.info(f"negative_prompt: {negative_prompt}")
|
||||
elif negative_prompt != "":
|
||||
logger.info(f"negative prompt is ignored because scale is 1.0")
|
||||
logger.info(f"height: {height}")
|
||||
logger.info(f"width: {width}")
|
||||
logger.info(f"sample_steps: {sample_steps}")
|
||||
if cfg_scale != 1.0:
|
||||
logger.info(f"CFG scale: {cfg_scale}")
|
||||
logger.info(f"flow_shift: {flow_shift}")
|
||||
# logger.info(f"sample_sampler: {sampler_name}")
|
||||
if seed is not None:
|
||||
logger.info(f"seed: {seed}")
|
||||
|
||||
# encode prompts
|
||||
tokenize_strategy = strategy_base.TokenizeStrategy.get_strategy()
|
||||
encoding_strategy = strategy_base.TextEncodingStrategy.get_strategy()
|
||||
|
||||
def encode_prompt(prpt):
|
||||
text_encoder_conds = []
|
||||
if sample_prompts_te_outputs and prpt in sample_prompts_te_outputs:
|
||||
text_encoder_conds = sample_prompts_te_outputs[prpt]
|
||||
# print(f"Using cached text encoder outputs for prompt: {prpt}")
|
||||
if text_encoders is not None:
|
||||
# print(f"Encoding prompt: {prpt}")
|
||||
tokens_and_masks = tokenize_strategy.tokenize(prpt)
|
||||
encoded_text_encoder_conds = encoding_strategy.encode_tokens(tokenize_strategy, text_encoders, tokens_and_masks)
|
||||
|
||||
# if text_encoder_conds is not cached, use encoded_text_encoder_conds
|
||||
if len(text_encoder_conds) == 0:
|
||||
text_encoder_conds = encoded_text_encoder_conds
|
||||
else:
|
||||
# if encoded_text_encoder_conds is not None, update cached text_encoder_conds
|
||||
for i in range(len(encoded_text_encoder_conds)):
|
||||
if encoded_text_encoder_conds[i] is not None:
|
||||
text_encoder_conds[i] = encoded_text_encoder_conds[i]
|
||||
return text_encoder_conds
|
||||
|
||||
vl_embed, vl_mask, byt5_embed, byt5_mask, ocr_mask = encode_prompt(prompt)
|
||||
arg_c = {
|
||||
"embed": vl_embed,
|
||||
"mask": vl_mask,
|
||||
"embed_byt5": byt5_embed,
|
||||
"mask_byt5": byt5_mask,
|
||||
"ocr_mask": ocr_mask,
|
||||
"prompt": prompt,
|
||||
}
|
||||
|
||||
# encode negative prompts
|
||||
if cfg_scale != 1.0:
|
||||
neg_vl_embed, neg_vl_mask, neg_byt5_embed, neg_byt5_mask, neg_ocr_mask = encode_prompt(negative_prompt)
|
||||
arg_c_null = {
|
||||
"embed": neg_vl_embed,
|
||||
"mask": neg_vl_mask,
|
||||
"embed_byt5": neg_byt5_embed,
|
||||
"mask_byt5": neg_byt5_mask,
|
||||
"ocr_mask": neg_ocr_mask,
|
||||
"prompt": negative_prompt,
|
||||
}
|
||||
else:
|
||||
arg_c_null = None
|
||||
|
||||
gen_args = SimpleNamespace(
|
||||
image_size=(height, width),
|
||||
infer_steps=sample_steps,
|
||||
flow_shift=flow_shift,
|
||||
guidance_scale=cfg_scale,
|
||||
fp8=args.fp8_scaled,
|
||||
apg_start_step_ocr=38,
|
||||
apg_start_step_general=5,
|
||||
guidance_rescale=0.0,
|
||||
guidance_rescale_apg=0.0,
|
||||
)
|
||||
|
||||
from hunyuan_image_minimal_inference import generate_body # import here to avoid circular import
|
||||
|
||||
dit_is_training = dit.training
|
||||
dit.eval()
|
||||
x = generate_body(gen_args, dit, arg_c, arg_c_null, accelerator.device, seed)
|
||||
if dit_is_training:
|
||||
dit.train()
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
# latent to image
|
||||
org_vae_device = vae.device # will be on cpu
|
||||
vae.to(accelerator.device) # distributed_state.device is same as accelerator.device
|
||||
with torch.no_grad():
|
||||
x = x / vae.scaling_factor
|
||||
x = vae.decode(x.to(vae.device, dtype=vae.dtype))
|
||||
vae.to(org_vae_device)
|
||||
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
x = x.clamp(-1, 1)
|
||||
x = x.permute(0, 2, 3, 1)
|
||||
image = Image.fromarray((127.5 * (x + 1.0)).float().cpu().numpy().astype(np.uint8)[0])
|
||||
|
||||
# adding accelerator.wait_for_everyone() here should sync up and ensure that sample images are saved in the same order as the original prompt list
|
||||
# but adding 'enum' to the filename should be enough
|
||||
|
||||
ts_str = time.strftime("%Y%m%d%H%M%S", time.localtime())
|
||||
num_suffix = f"e{epoch:06d}" if epoch is not None else f"{steps:06d}"
|
||||
seed_suffix = "" if seed is None else f"_{seed}"
|
||||
i: int = prompt_dict["enum"]
|
||||
img_filename = f"{'' if args.output_name is None else args.output_name + '_'}{num_suffix}_{i:02d}_{ts_str}{seed_suffix}.png"
|
||||
image.save(os.path.join(save_dir, img_filename))
|
||||
|
||||
# send images to wandb if enabled
|
||||
if "wandb" in [tracker.name for tracker in accelerator.trackers]:
|
||||
wandb_tracker = accelerator.get_tracker("wandb")
|
||||
|
||||
import wandb
|
||||
|
||||
# not to commit images to avoid inconsistency between training and logging steps
|
||||
wandb_tracker.log({f"sample_{i}": wandb.Image(image, caption=prompt)}, commit=False) # positive prompt as a caption
|
||||
|
||||
|
||||
# endregion
|
||||
|
||||
|
||||
class HunyuanImageNetworkTrainer(train_network.NetworkTrainer):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.sample_prompts_te_outputs = None
|
||||
self.is_swapping_blocks: bool = False
|
||||
self.rotary_pos_emb_cache = {}
|
||||
|
||||
def assert_extra_args(
|
||||
self,
|
||||
args,
|
||||
train_dataset_group: Union[train_util.DatasetGroup, train_util.MinimalDataset],
|
||||
val_dataset_group: Optional[train_util.DatasetGroup],
|
||||
):
|
||||
super().assert_extra_args(args, train_dataset_group, val_dataset_group)
|
||||
# sdxl_train_util.verify_sdxl_training_args(args)
|
||||
|
||||
if args.mixed_precision == "fp16":
|
||||
logger.warning(
|
||||
"mixed_precision bf16 is recommended for HunyuanImage-2.1 / HunyuanImage-2.1ではmixed_precision bf16が推奨されます"
|
||||
)
|
||||
|
||||
if (args.fp8_base or args.fp8_base_unet) and not args.fp8_scaled:
|
||||
logger.warning(
|
||||
"fp8_base and fp8_base_unet are not supported. Use fp8_scaled instead / fp8_baseとfp8_base_unetはサポートされていません。代わりにfp8_scaledを使用してください"
|
||||
)
|
||||
if args.fp8_scaled and (args.fp8_base or args.fp8_base_unet):
|
||||
logger.info(
|
||||
"fp8_scaled is used, so fp8_base and fp8_base_unet are ignored / fp8_scaledが使われているので、fp8_baseとfp8_base_unetは無視されます"
|
||||
)
|
||||
args.fp8_base = False
|
||||
args.fp8_base_unet = False
|
||||
|
||||
if args.cache_text_encoder_outputs_to_disk and not args.cache_text_encoder_outputs:
|
||||
logger.warning(
|
||||
"cache_text_encoder_outputs_to_disk is enabled, so cache_text_encoder_outputs is also enabled / cache_text_encoder_outputs_to_diskが有効になっているため、cache_text_encoder_outputsも有効になります"
|
||||
)
|
||||
args.cache_text_encoder_outputs = True
|
||||
|
||||
if args.cache_text_encoder_outputs:
|
||||
assert (
|
||||
train_dataset_group.is_text_encoder_output_cacheable()
|
||||
), "when caching Text Encoder output, either caption_dropout_rate, shuffle_caption, token_warmup_step or caption_tag_dropout_rate cannot be used / Text Encoderの出力をキャッシュするときはcaption_dropout_rate, shuffle_caption, token_warmup_step, caption_tag_dropout_rateは使えません"
|
||||
|
||||
train_dataset_group.verify_bucket_reso_steps(32)
|
||||
if val_dataset_group is not None:
|
||||
val_dataset_group.verify_bucket_reso_steps(32)
|
||||
|
||||
def load_target_model(self, args, weight_dtype, accelerator):
|
||||
self.is_swapping_blocks = args.blocks_to_swap is not None and args.blocks_to_swap > 0
|
||||
|
||||
vl_dtype = torch.float8_e4m3fn if args.fp8_vl else torch.bfloat16
|
||||
vl_device = "cpu" # loading to cpu and move to gpu later in cache_text_encoder_outputs_if_needed
|
||||
_, text_encoder_vlm = hunyuan_image_text_encoder.load_qwen2_5_vl(
|
||||
args.text_encoder, dtype=vl_dtype, device=vl_device, disable_mmap=args.disable_mmap_load_safetensors
|
||||
)
|
||||
_, text_encoder_byt5 = hunyuan_image_text_encoder.load_byt5(
|
||||
args.byt5, dtype=torch.float16, device=vl_device, disable_mmap=args.disable_mmap_load_safetensors
|
||||
)
|
||||
|
||||
vae = hunyuan_image_vae.load_vae(
|
||||
args.vae, "cpu", disable_mmap=args.disable_mmap_load_safetensors, chunk_size=args.vae_chunk_size
|
||||
)
|
||||
vae.to(dtype=torch.float16) # VAE is always fp16
|
||||
vae.eval()
|
||||
|
||||
model_version = hunyuan_image_utils.MODEL_VERSION_2_1
|
||||
return model_version, [text_encoder_vlm, text_encoder_byt5], vae, None # unet will be loaded later
|
||||
|
||||
def load_unet_lazily(self, args, weight_dtype, accelerator, text_encoders) -> tuple[nn.Module, list[nn.Module]]:
|
||||
if args.cache_text_encoder_outputs:
|
||||
logger.info("Replace text encoders with dummy models to save memory")
|
||||
|
||||
# This doesn't free memory, so we move text encoders to meta device in cache_text_encoder_outputs_if_needed
|
||||
text_encoders = [flux_utils.dummy_clip_l() for _ in text_encoders]
|
||||
clean_memory_on_device(accelerator.device)
|
||||
gc.collect()
|
||||
|
||||
loading_dtype = None if args.fp8_scaled else weight_dtype
|
||||
loading_device = "cpu" if self.is_swapping_blocks else accelerator.device
|
||||
|
||||
attn_mode = "torch"
|
||||
if args.xformers:
|
||||
attn_mode = "xformers"
|
||||
if args.attn_mode is not None:
|
||||
attn_mode = args.attn_mode
|
||||
|
||||
logger.info(f"Loading DiT model with attn_mode: {attn_mode}, split_attn: {args.split_attn}, fp8_scaled: {args.fp8_scaled}")
|
||||
model = hunyuan_image_models.load_hunyuan_image_model(
|
||||
accelerator.device,
|
||||
args.pretrained_model_name_or_path,
|
||||
attn_mode,
|
||||
args.split_attn,
|
||||
loading_device,
|
||||
loading_dtype,
|
||||
args.fp8_scaled,
|
||||
)
|
||||
|
||||
if self.is_swapping_blocks:
|
||||
# Swap blocks between CPU and GPU to reduce memory usage, in forward and backward passes.
|
||||
logger.info(f"enable block swap: blocks_to_swap={args.blocks_to_swap}")
|
||||
model.enable_block_swap(args.blocks_to_swap, accelerator.device, supports_backward=True)
|
||||
|
||||
return model, text_encoders
|
||||
|
||||
def get_tokenize_strategy(self, args):
|
||||
return strategy_hunyuan_image.HunyuanImageTokenizeStrategy(args.tokenizer_cache_dir)
|
||||
|
||||
def get_tokenizers(self, tokenize_strategy: strategy_hunyuan_image.HunyuanImageTokenizeStrategy):
|
||||
return [tokenize_strategy.vlm_tokenizer, tokenize_strategy.byt5_tokenizer]
|
||||
|
||||
def get_latents_caching_strategy(self, args):
|
||||
return strategy_hunyuan_image.HunyuanImageLatentsCachingStrategy(args.cache_latents_to_disk, args.vae_batch_size, False)
|
||||
|
||||
def get_text_encoding_strategy(self, args):
|
||||
return strategy_hunyuan_image.HunyuanImageTextEncodingStrategy()
|
||||
|
||||
def post_process_network(self, args, accelerator, network, text_encoders, unet):
|
||||
pass
|
||||
|
||||
def get_models_for_text_encoding(self, args, accelerator, text_encoders):
|
||||
if args.cache_text_encoder_outputs:
|
||||
return None # no text encoders are needed for encoding because both are cached
|
||||
else:
|
||||
return text_encoders
|
||||
|
||||
def get_text_encoders_train_flags(self, args, text_encoders):
|
||||
# HunyuanImage-2.1 does not support training VLM or byT5
|
||||
return [False, False]
|
||||
|
||||
def get_text_encoder_outputs_caching_strategy(self, args):
|
||||
if args.cache_text_encoder_outputs:
|
||||
return strategy_hunyuan_image.HunyuanImageTextEncoderOutputsCachingStrategy(
|
||||
args.cache_text_encoder_outputs_to_disk, args.text_encoder_batch_size, args.skip_cache_check, False
|
||||
)
|
||||
else:
|
||||
return None
|
||||
|
||||
def cache_text_encoder_outputs_if_needed(
|
||||
self, args, accelerator: Accelerator, unet, vae, text_encoders, dataset: train_util.DatasetGroup, weight_dtype
|
||||
):
|
||||
vlm_device = "cpu" if args.text_encoder_cpu else accelerator.device
|
||||
if args.cache_text_encoder_outputs:
|
||||
if not args.lowram:
|
||||
# メモリ消費を減らす
|
||||
logger.info("move vae to cpu to save memory")
|
||||
org_vae_device = vae.device
|
||||
vae.to("cpu")
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
logger.info(f"move text encoders to {vlm_device} to encode and cache text encoder outputs")
|
||||
text_encoders[0].to(vlm_device)
|
||||
text_encoders[1].to(vlm_device)
|
||||
|
||||
# VLM (bf16) and byT5 (fp16) are used for encoding, so we cannot use autocast here
|
||||
dataset.new_cache_text_encoder_outputs(text_encoders, accelerator)
|
||||
|
||||
# cache sample prompts
|
||||
if args.sample_prompts is not None:
|
||||
logger.info(f"cache Text Encoder outputs for sample prompt: {args.sample_prompts}")
|
||||
|
||||
tokenize_strategy: strategy_hunyuan_image.HunyuanImageTokenizeStrategy = (
|
||||
strategy_base.TokenizeStrategy.get_strategy()
|
||||
)
|
||||
text_encoding_strategy: strategy_hunyuan_image.HunyuanImageTextEncodingStrategy = (
|
||||
strategy_base.TextEncodingStrategy.get_strategy()
|
||||
)
|
||||
|
||||
prompts = train_util.load_prompts(args.sample_prompts)
|
||||
sample_prompts_te_outputs = {} # key: prompt, value: text encoder outputs
|
||||
with accelerator.autocast(), torch.no_grad():
|
||||
for prompt_dict in prompts:
|
||||
for p in [prompt_dict.get("prompt", ""), prompt_dict.get("negative_prompt", "")]:
|
||||
if p not in sample_prompts_te_outputs:
|
||||
logger.info(f"cache Text Encoder outputs for prompt: {p}")
|
||||
tokens_and_masks = tokenize_strategy.tokenize(p)
|
||||
sample_prompts_te_outputs[p] = text_encoding_strategy.encode_tokens(
|
||||
tokenize_strategy, text_encoders, tokens_and_masks
|
||||
)
|
||||
self.sample_prompts_te_outputs = sample_prompts_te_outputs
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
# text encoders are not needed for training, so we move to meta device
|
||||
logger.info("move text encoders to meta device to save memory")
|
||||
text_encoders = [te.to("meta") for te in text_encoders]
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
if not args.lowram:
|
||||
logger.info("move vae back to original device")
|
||||
vae.to(org_vae_device)
|
||||
else:
|
||||
# Text Encoderから毎回出力を取得するので、GPUに乗せておく
|
||||
text_encoders[0].to(vlm_device)
|
||||
text_encoders[1].to(vlm_device)
|
||||
|
||||
def sample_images(self, accelerator, args, epoch, global_step, device, ae, tokenizer, text_encoder, flux):
|
||||
text_encoders = text_encoder # for compatibility
|
||||
text_encoders = self.get_models_for_text_encoding(args, accelerator, text_encoders)
|
||||
|
||||
sample_images(accelerator, args, epoch, global_step, flux, ae, text_encoders, self.sample_prompts_te_outputs)
|
||||
|
||||
def get_noise_scheduler(self, args: argparse.Namespace, device: torch.device) -> Any:
|
||||
noise_scheduler = sd3_train_utils.FlowMatchEulerDiscreteScheduler(num_train_timesteps=1000, shift=args.discrete_flow_shift)
|
||||
self.noise_scheduler_copy = copy.deepcopy(noise_scheduler)
|
||||
return noise_scheduler
|
||||
|
||||
def encode_images_to_latents(self, args, vae: hunyuan_image_vae.HunyuanVAE2D, images):
|
||||
return vae.encode(images).sample()
|
||||
|
||||
def shift_scale_latents(self, args, latents):
|
||||
# for encoding, we need to scale the latents
|
||||
return latents * hunyuan_image_vae.LATENT_SCALING_FACTOR
|
||||
|
||||
def get_noise_pred_and_target(
|
||||
self,
|
||||
args,
|
||||
accelerator,
|
||||
noise_scheduler,
|
||||
latents,
|
||||
batch,
|
||||
text_encoder_conds,
|
||||
unet: hunyuan_image_models.HYImageDiffusionTransformer,
|
||||
network,
|
||||
weight_dtype,
|
||||
train_unet,
|
||||
is_train=True,
|
||||
):
|
||||
# Sample noise that we'll add to the latents
|
||||
noise = torch.randn_like(latents)
|
||||
|
||||
# get noisy model input and timesteps
|
||||
noisy_model_input, _, sigmas = flux_train_utils.get_noisy_model_input_and_timesteps(
|
||||
args, noise_scheduler, latents, noise, accelerator.device, weight_dtype
|
||||
)
|
||||
# bfloat16 is too low precision for 0-1000 TODO fix get_noisy_model_input_and_timesteps
|
||||
timesteps = (sigmas[:, 0, 0, 0] * 1000).to(torch.int64)
|
||||
# print(
|
||||
# f"timestep: {timesteps}, noisy_model_input shape: {noisy_model_input.shape}, mean: {noisy_model_input.mean()}, std: {noisy_model_input.std()}"
|
||||
# )
|
||||
|
||||
if args.gradient_checkpointing:
|
||||
noisy_model_input.requires_grad_(True)
|
||||
for t in text_encoder_conds:
|
||||
if t is not None and t.dtype.is_floating_point:
|
||||
t.requires_grad_(True)
|
||||
|
||||
# Predict the noise residual
|
||||
# ocr_mask is for inference only, so it is not used here
|
||||
vlm_embed, vlm_mask, byt5_embed, byt5_mask, ocr_mask = text_encoder_conds
|
||||
|
||||
# print(f"embed shape: {vlm_embed.shape}, mean: {vlm_embed.mean()}, std: {vlm_embed.std()}")
|
||||
# print(f"embed_byt5 shape: {byt5_embed.shape}, mean: {byt5_embed.mean()}, std: {byt5_embed.std()}")
|
||||
# print(f"latents shape: {latents.shape}, mean: {latents.mean()}, std: {latents.std()}")
|
||||
# print(f"mask shape: {vlm_mask.shape}, sum: {vlm_mask.sum()}")
|
||||
# print(f"mask_byt5 shape: {byt5_mask.shape}, sum: {byt5_mask.sum()}")
|
||||
with torch.set_grad_enabled(is_train), accelerator.autocast():
|
||||
model_pred = unet(
|
||||
noisy_model_input, timesteps, vlm_embed, vlm_mask, byt5_embed, byt5_mask # , self.rotary_pos_emb_cache
|
||||
)
|
||||
|
||||
# apply model prediction type
|
||||
model_pred, weighting = flux_train_utils.apply_model_prediction_type(args, model_pred, noisy_model_input, sigmas)
|
||||
|
||||
# flow matching loss
|
||||
target = noise - latents
|
||||
|
||||
# differential output preservation is not used for HunyuanImage-2.1 currently
|
||||
|
||||
return model_pred, target, timesteps, weighting
|
||||
|
||||
def post_process_loss(self, loss, args, timesteps, noise_scheduler):
|
||||
return loss
|
||||
|
||||
def get_sai_model_spec(self, args):
|
||||
return train_util.get_sai_model_spec_dataclass(None, args, False, True, False, hunyuan_image="2.1").to_metadata_dict()
|
||||
|
||||
def update_metadata(self, metadata, args):
|
||||
metadata["ss_logit_mean"] = args.logit_mean
|
||||
metadata["ss_logit_std"] = args.logit_std
|
||||
metadata["ss_mode_scale"] = args.mode_scale
|
||||
metadata["ss_timestep_sampling"] = args.timestep_sampling
|
||||
metadata["ss_sigmoid_scale"] = args.sigmoid_scale
|
||||
metadata["ss_model_prediction_type"] = args.model_prediction_type
|
||||
metadata["ss_discrete_flow_shift"] = args.discrete_flow_shift
|
||||
|
||||
def is_text_encoder_not_needed_for_training(self, args):
|
||||
return args.cache_text_encoder_outputs and not self.is_train_text_encoder(args)
|
||||
|
||||
def prepare_text_encoder_grad_ckpt_workaround(self, index, text_encoder):
|
||||
# do not support text encoder training for HunyuanImage-2.1
|
||||
pass
|
||||
|
||||
def cast_text_encoder(self, args):
|
||||
return False # VLM is bf16, byT5 is fp16, so do not cast to other dtype
|
||||
|
||||
def cast_vae(self, args):
|
||||
return False # VAE is fp16, so do not cast to other dtype
|
||||
|
||||
def cast_unet(self, args):
|
||||
return not args.fp8_scaled # if fp8_scaled is used, do not cast to other dtype
|
||||
|
||||
def prepare_text_encoder_fp8(self, index, text_encoder, te_weight_dtype, weight_dtype):
|
||||
# fp8 text encoder for HunyuanImage-2.1 is not supported currently
|
||||
pass
|
||||
|
||||
def on_validation_step_end(self, args, accelerator, network, text_encoders, unet, batch, weight_dtype):
|
||||
if self.is_swapping_blocks:
|
||||
# prepare for next forward: because backward pass is not called, we need to prepare it here
|
||||
accelerator.unwrap_model(unet).prepare_block_swap_before_forward()
|
||||
|
||||
def prepare_unet_with_accelerator(
|
||||
self, args: argparse.Namespace, accelerator: Accelerator, unet: torch.nn.Module
|
||||
) -> torch.nn.Module:
|
||||
if not self.is_swapping_blocks:
|
||||
return super().prepare_unet_with_accelerator(args, accelerator, unet)
|
||||
|
||||
# if we doesn't swap blocks, we can move the model to device
|
||||
model: hunyuan_image_models.HYImageDiffusionTransformer = unet
|
||||
model = accelerator.prepare(model, device_placement=[not self.is_swapping_blocks])
|
||||
accelerator.unwrap_model(model).move_to_device_except_swap_blocks(accelerator.device) # reduce peak memory usage
|
||||
accelerator.unwrap_model(model).prepare_block_swap_before_forward()
|
||||
|
||||
return model
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = train_network.setup_parser()
|
||||
train_util.add_dit_training_arguments(parser)
|
||||
|
||||
parser.add_argument(
|
||||
"--text_encoder",
|
||||
type=str,
|
||||
help="path to Qwen2.5-VL (*.sft or *.safetensors), should be bfloat16 / Qwen2.5-VLのパス(*.sftまたは*.safetensors)、bfloat16が前提",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--byt5",
|
||||
type=str,
|
||||
help="path to byt5 (*.sft or *.safetensors), should be float16 / byt5のパス(*.sftまたは*.safetensors)、float16が前提",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--timestep_sampling",
|
||||
choices=["sigma", "uniform", "sigmoid", "shift", "flux_shift"],
|
||||
default="sigma",
|
||||
help="Method to sample timesteps: sigma-based, uniform random, sigmoid of random normal, shift of sigmoid and FLUX.1 shifting."
|
||||
" / タイムステップをサンプリングする方法:sigma、random uniform、random normalのsigmoid、sigmoidのシフト、FLUX.1のシフト。",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--sigmoid_scale",
|
||||
type=float,
|
||||
default=1.0,
|
||||
help='Scale factor for sigmoid timestep sampling (only used when timestep-sampling is "sigmoid"). / sigmoidタイムステップサンプリングの倍率(timestep-samplingが"sigmoid"の場合のみ有効)。',
|
||||
)
|
||||
parser.add_argument(
|
||||
"--model_prediction_type",
|
||||
choices=["raw", "additive", "sigma_scaled"],
|
||||
default="raw",
|
||||
help="How to interpret and process the model prediction: "
|
||||
"raw (use as is), additive (add to noisy input), sigma_scaled (apply sigma scaling). Default is raw unlike FLUX.1."
|
||||
" / モデル予測の解釈と処理方法:"
|
||||
"raw(そのまま使用)、additive(ノイズ入力に加算)、sigma_scaled(シグマスケーリングを適用)。デフォルトはFLUX.1とは異なりrawです。",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--discrete_flow_shift",
|
||||
type=float,
|
||||
default=5.0,
|
||||
help="Discrete flow shift for the Euler Discrete Scheduler, default is 5.0. / Euler Discrete Schedulerの離散フローシフト、デフォルトは5.0。",
|
||||
)
|
||||
parser.add_argument("--fp8_scaled", action="store_true", help="Use scaled fp8 for DiT / DiTにスケーリングされたfp8を使う")
|
||||
parser.add_argument("--fp8_vl", action="store_true", help="Use fp8 for VLM text encoder / VLMテキストエンコーダにfp8を使用する")
|
||||
parser.add_argument(
|
||||
"--text_encoder_cpu", action="store_true", help="Inference on CPU for Text Encoders / テキストエンコーダをCPUで推論する"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--vae_chunk_size",
|
||||
type=int,
|
||||
default=None, # default is None (no chunking)
|
||||
help="Chunk size for VAE decoding to reduce memory usage. Default is None (no chunking). 16 is recommended if enabled"
|
||||
" / メモリ使用量を減らすためのVAEデコードのチャンクサイズ。デフォルトはNone(チャンクなし)。有効にする場合は16程度を推奨。",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--attn_mode",
|
||||
choices=["torch", "xformers", "flash", "sageattn", "sdpa"], # "sdpa" is for backward compatibility
|
||||
default=None,
|
||||
help="Attention implementation to use. Default is None (torch). xformers requires --split_attn. sageattn does not support training (inference only). This option overrides --xformers or --sdpa."
|
||||
" / 使用するAttentionの実装。デフォルトはNone(torch)です。xformersは--split_attnの指定が必要です。sageattnはトレーニングをサポートしていません(推論のみ)。このオプションは--xformersまたは--sdpaを上書きします。",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--split_attn",
|
||||
action="store_true",
|
||||
help="split attention computation to reduce memory usage / メモリ使用量を減らすためにattention時にバッチを分割する",
|
||||
)
|
||||
|
||||
return parser
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
train_util.verify_command_line_training_args(args)
|
||||
args = train_util.read_config_from_file(args, parser)
|
||||
|
||||
if args.attn_mode == "sdpa":
|
||||
args.attn_mode = "torch" # backward compatibility
|
||||
|
||||
trainer = HunyuanImageNetworkTrainer()
|
||||
trainer.train(args)
|
||||
BIN
images/logo_aihub.png
Normal file
BIN
images/logo_aihub.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 6.9 KiB |
138
library/adafactor_fused.py
Normal file
138
library/adafactor_fused.py
Normal file
@@ -0,0 +1,138 @@
|
||||
import math
|
||||
import torch
|
||||
from transformers import Adafactor
|
||||
|
||||
# stochastic rounding for bfloat16
|
||||
# The implementation was provided by 2kpr. Thank you very much!
|
||||
|
||||
def copy_stochastic_(target: torch.Tensor, source: torch.Tensor):
|
||||
"""
|
||||
copies source into target using stochastic rounding
|
||||
|
||||
Args:
|
||||
target: the target tensor with dtype=bfloat16
|
||||
source: the target tensor with dtype=float32
|
||||
"""
|
||||
# create a random 16 bit integer
|
||||
result = torch.randint_like(source, dtype=torch.int32, low=0, high=(1 << 16))
|
||||
|
||||
# add the random number to the lower 16 bit of the mantissa
|
||||
result.add_(source.view(dtype=torch.int32))
|
||||
|
||||
# mask off the lower 16 bit of the mantissa
|
||||
result.bitwise_and_(-65536) # -65536 = FFFF0000 as a signed int32
|
||||
|
||||
# copy the higher 16 bit into the target tensor
|
||||
target.copy_(result.view(dtype=torch.float32))
|
||||
|
||||
del result
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def adafactor_step_param(self, p, group):
|
||||
if p.grad is None:
|
||||
return
|
||||
grad = p.grad
|
||||
if grad.dtype in {torch.float16, torch.bfloat16}:
|
||||
grad = grad.float()
|
||||
if grad.is_sparse:
|
||||
raise RuntimeError("Adafactor does not support sparse gradients.")
|
||||
|
||||
state = self.state[p]
|
||||
grad_shape = grad.shape
|
||||
|
||||
factored, use_first_moment = Adafactor._get_options(group, grad_shape)
|
||||
# State Initialization
|
||||
if len(state) == 0:
|
||||
state["step"] = 0
|
||||
|
||||
if use_first_moment:
|
||||
# Exponential moving average of gradient values
|
||||
state["exp_avg"] = torch.zeros_like(grad)
|
||||
if factored:
|
||||
state["exp_avg_sq_row"] = torch.zeros(grad_shape[:-1]).to(grad)
|
||||
state["exp_avg_sq_col"] = torch.zeros(grad_shape[:-2] + grad_shape[-1:]).to(grad)
|
||||
else:
|
||||
state["exp_avg_sq"] = torch.zeros_like(grad)
|
||||
|
||||
state["RMS"] = 0
|
||||
else:
|
||||
if use_first_moment:
|
||||
state["exp_avg"] = state["exp_avg"].to(grad)
|
||||
if factored:
|
||||
state["exp_avg_sq_row"] = state["exp_avg_sq_row"].to(grad)
|
||||
state["exp_avg_sq_col"] = state["exp_avg_sq_col"].to(grad)
|
||||
else:
|
||||
state["exp_avg_sq"] = state["exp_avg_sq"].to(grad)
|
||||
|
||||
p_data_fp32 = p
|
||||
if p.dtype in {torch.float16, torch.bfloat16}:
|
||||
p_data_fp32 = p_data_fp32.float()
|
||||
|
||||
state["step"] += 1
|
||||
state["RMS"] = Adafactor._rms(p_data_fp32)
|
||||
lr = Adafactor._get_lr(group, state)
|
||||
|
||||
beta2t = 1.0 - math.pow(state["step"], group["decay_rate"])
|
||||
update = (grad**2) + group["eps"][0]
|
||||
if factored:
|
||||
exp_avg_sq_row = state["exp_avg_sq_row"]
|
||||
exp_avg_sq_col = state["exp_avg_sq_col"]
|
||||
|
||||
exp_avg_sq_row.mul_(beta2t).add_(update.mean(dim=-1), alpha=(1.0 - beta2t))
|
||||
exp_avg_sq_col.mul_(beta2t).add_(update.mean(dim=-2), alpha=(1.0 - beta2t))
|
||||
|
||||
# Approximation of exponential moving average of square of gradient
|
||||
update = Adafactor._approx_sq_grad(exp_avg_sq_row, exp_avg_sq_col)
|
||||
update.mul_(grad)
|
||||
else:
|
||||
exp_avg_sq = state["exp_avg_sq"]
|
||||
|
||||
exp_avg_sq.mul_(beta2t).add_(update, alpha=(1.0 - beta2t))
|
||||
update = exp_avg_sq.rsqrt().mul_(grad)
|
||||
|
||||
update.div_((Adafactor._rms(update) / group["clip_threshold"]).clamp_(min=1.0))
|
||||
update.mul_(lr)
|
||||
|
||||
if use_first_moment:
|
||||
exp_avg = state["exp_avg"]
|
||||
exp_avg.mul_(group["beta1"]).add_(update, alpha=(1 - group["beta1"]))
|
||||
update = exp_avg
|
||||
|
||||
if group["weight_decay"] != 0:
|
||||
p_data_fp32.add_(p_data_fp32, alpha=(-group["weight_decay"] * lr))
|
||||
|
||||
p_data_fp32.add_(-update)
|
||||
|
||||
# if p.dtype in {torch.float16, torch.bfloat16}:
|
||||
# p.copy_(p_data_fp32)
|
||||
|
||||
if p.dtype == torch.bfloat16:
|
||||
copy_stochastic_(p, p_data_fp32)
|
||||
elif p.dtype == torch.float16:
|
||||
p.copy_(p_data_fp32)
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def adafactor_step(self, closure=None):
|
||||
"""
|
||||
Performs a single optimization step
|
||||
|
||||
Arguments:
|
||||
closure (callable, optional): A closure that reevaluates the model
|
||||
and returns the loss.
|
||||
"""
|
||||
loss = None
|
||||
if closure is not None:
|
||||
loss = closure()
|
||||
|
||||
for group in self.param_groups:
|
||||
for p in group["params"]:
|
||||
adafactor_step_param(self, p, group)
|
||||
|
||||
return loss
|
||||
|
||||
|
||||
def patch_adafactor_fused(optimizer: Adafactor):
|
||||
optimizer.step_param = adafactor_step_param.__get__(optimizer)
|
||||
optimizer.step = adafactor_step.__get__(optimizer)
|
||||
1671
library/anima_models.py
Normal file
1671
library/anima_models.py
Normal file
File diff suppressed because it is too large
Load Diff
615
library/anima_train_utils.py
Normal file
615
library/anima_train_utils.py
Normal file
@@ -0,0 +1,615 @@
|
||||
# Anima Training Utilities
|
||||
|
||||
import argparse
|
||||
import gc
|
||||
import math
|
||||
import os
|
||||
import time
|
||||
from typing import Optional
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from accelerate import Accelerator
|
||||
from tqdm import tqdm
|
||||
from PIL import Image
|
||||
|
||||
from library.device_utils import init_ipex, clean_memory_on_device, synchronize_device
|
||||
from library import anima_models, anima_utils, train_util, qwen_image_autoencoder_kl
|
||||
|
||||
init_ipex()
|
||||
|
||||
from .utils import setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
# Anima-specific training arguments
|
||||
|
||||
|
||||
def add_anima_training_arguments(parser: argparse.ArgumentParser):
|
||||
"""Add Anima-specific training arguments to the parser."""
|
||||
parser.add_argument(
|
||||
"--qwen3",
|
||||
type=str,
|
||||
default=None,
|
||||
help="Path to Qwen3-0.6B model (safetensors file or directory)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--llm_adapter_path",
|
||||
type=str,
|
||||
default=None,
|
||||
help="Path to separate LLM adapter weights. If None, adapter is loaded from DiT file if present",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--llm_adapter_lr",
|
||||
type=float,
|
||||
default=None,
|
||||
help="Learning rate for LLM adapter. None=same as base LR, 0=freeze adapter",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--self_attn_lr",
|
||||
type=float,
|
||||
default=None,
|
||||
help="Learning rate for self-attention layers. None=same as base LR, 0=freeze",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--cross_attn_lr",
|
||||
type=float,
|
||||
default=None,
|
||||
help="Learning rate for cross-attention layers. None=same as base LR, 0=freeze",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--mlp_lr",
|
||||
type=float,
|
||||
default=None,
|
||||
help="Learning rate for MLP layers. None=same as base LR, 0=freeze",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--mod_lr",
|
||||
type=float,
|
||||
default=None,
|
||||
help="Learning rate for AdaLN modulation layers. None=same as base LR, 0=freeze. Note: mod layers are not included in LoRA by default.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--t5_tokenizer_path",
|
||||
type=str,
|
||||
default=None,
|
||||
help="Path to T5 tokenizer directory. If None, uses default configs/t5_old/",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--qwen3_max_token_length",
|
||||
type=int,
|
||||
default=512,
|
||||
help="Maximum token length for Qwen3 tokenizer (default: 512)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--t5_max_token_length",
|
||||
type=int,
|
||||
default=512,
|
||||
help="Maximum token length for T5 tokenizer (default: 512)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--discrete_flow_shift",
|
||||
type=float,
|
||||
default=1.0,
|
||||
help="Timestep distribution shift for rectified flow training (default: 1.0)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--timestep_sampling",
|
||||
type=str,
|
||||
default="sigmoid",
|
||||
choices=["sigma", "uniform", "sigmoid", "shift", "flux_shift"],
|
||||
help="Timestep sampling method (default: sigmoid (logit normal))",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--sigmoid_scale",
|
||||
type=float,
|
||||
default=1.0,
|
||||
help="Scale factor for sigmoid (logit_normal) timestep sampling (default: 1.0)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--attn_mode",
|
||||
choices=["torch", "xformers", "flash", "sageattn", "sdpa"], # "sdpa" is for backward compatibility
|
||||
default=None,
|
||||
help="Attention implementation to use. Default is None (torch). xformers requires --split_attn. sageattn does not support training (inference only). This option overrides --xformers or --sdpa."
|
||||
" / 使用するAttentionの実装。デフォルトはNone(torch)です。xformersは--split_attnの指定が必要です。sageattnはトレーニングをサポートしていません(推論のみ)。このオプションは--xformersまたは--sdpaを上書きします。",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--split_attn",
|
||||
action="store_true",
|
||||
help="split attention computation to reduce memory usage / メモリ使用量を減らすためにattention時にバッチを分割する",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--vae_chunk_size",
|
||||
type=int,
|
||||
default=None,
|
||||
help="Spatial chunk size for VAE encoding/decoding to reduce memory usage. Must be even number. If not specified, chunking is disabled (official behavior)."
|
||||
+ " / メモリ使用量を減らすためのVAEエンコード/デコードの空間チャンクサイズ。偶数である必要があります。未指定の場合、チャンク処理は無効になります(公式の動作)。",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--vae_disable_cache",
|
||||
action="store_true",
|
||||
help="Disable internal VAE caching mechanism to reduce memory usage. Encoding / decoding will also be faster, but this differs from official behavior."
|
||||
+ " / VAEのメモリ使用量を減らすために内部のキャッシュ機構を無効にします。エンコード/デコードも速くなりますが、公式の動作とは異なります。",
|
||||
)
|
||||
|
||||
|
||||
# Loss weighting
|
||||
|
||||
|
||||
def compute_loss_weighting_for_anima(weighting_scheme: str, sigmas: torch.Tensor) -> torch.Tensor:
|
||||
"""Compute loss weighting for Anima training.
|
||||
|
||||
Same schemes as SD3 but can add Anima-specific ones if needed in future.
|
||||
"""
|
||||
if weighting_scheme == "sigma_sqrt":
|
||||
weighting = (sigmas**-2.0).float()
|
||||
elif weighting_scheme == "cosmap":
|
||||
bot = 1 - 2 * sigmas + 2 * sigmas**2
|
||||
weighting = 2 / (math.pi * bot)
|
||||
elif weighting_scheme == "none" or weighting_scheme is None:
|
||||
weighting = torch.ones_like(sigmas)
|
||||
else:
|
||||
weighting = torch.ones_like(sigmas)
|
||||
return weighting
|
||||
|
||||
|
||||
# Parameter groups (6 groups with separate LRs)
|
||||
def get_anima_param_groups(
|
||||
dit,
|
||||
base_lr: float,
|
||||
self_attn_lr: Optional[float] = None,
|
||||
cross_attn_lr: Optional[float] = None,
|
||||
mlp_lr: Optional[float] = None,
|
||||
mod_lr: Optional[float] = None,
|
||||
llm_adapter_lr: Optional[float] = None,
|
||||
):
|
||||
"""Create parameter groups for Anima training with separate learning rates.
|
||||
|
||||
Args:
|
||||
dit: Anima model
|
||||
base_lr: Base learning rate
|
||||
self_attn_lr: LR for self-attention layers (None = base_lr, 0 = freeze)
|
||||
cross_attn_lr: LR for cross-attention layers
|
||||
mlp_lr: LR for MLP layers
|
||||
mod_lr: LR for AdaLN modulation layers
|
||||
llm_adapter_lr: LR for LLM adapter
|
||||
|
||||
Returns:
|
||||
List of parameter group dicts for optimizer
|
||||
"""
|
||||
if self_attn_lr is None:
|
||||
self_attn_lr = base_lr
|
||||
if cross_attn_lr is None:
|
||||
cross_attn_lr = base_lr
|
||||
if mlp_lr is None:
|
||||
mlp_lr = base_lr
|
||||
if mod_lr is None:
|
||||
mod_lr = base_lr
|
||||
if llm_adapter_lr is None:
|
||||
llm_adapter_lr = base_lr
|
||||
|
||||
base_params = []
|
||||
self_attn_params = []
|
||||
cross_attn_params = []
|
||||
mlp_params = []
|
||||
mod_params = []
|
||||
llm_adapter_params = []
|
||||
|
||||
for name, p in dit.named_parameters():
|
||||
# Store original name for debugging
|
||||
p.original_name = name
|
||||
|
||||
if "llm_adapter" in name:
|
||||
llm_adapter_params.append(p)
|
||||
elif ".self_attn" in name:
|
||||
self_attn_params.append(p)
|
||||
elif ".cross_attn" in name:
|
||||
cross_attn_params.append(p)
|
||||
elif ".mlp" in name:
|
||||
mlp_params.append(p)
|
||||
elif ".adaln_modulation" in name:
|
||||
mod_params.append(p)
|
||||
else:
|
||||
base_params.append(p)
|
||||
|
||||
logger.info(f"Parameter groups:")
|
||||
logger.info(f" base_params: {len(base_params)} (lr={base_lr})")
|
||||
logger.info(f" self_attn_params: {len(self_attn_params)} (lr={self_attn_lr})")
|
||||
logger.info(f" cross_attn_params: {len(cross_attn_params)} (lr={cross_attn_lr})")
|
||||
logger.info(f" mlp_params: {len(mlp_params)} (lr={mlp_lr})")
|
||||
logger.info(f" mod_params: {len(mod_params)} (lr={mod_lr})")
|
||||
logger.info(f" llm_adapter_params: {len(llm_adapter_params)} (lr={llm_adapter_lr})")
|
||||
|
||||
param_groups = []
|
||||
for lr, params, name in [
|
||||
(base_lr, base_params, "base"),
|
||||
(self_attn_lr, self_attn_params, "self_attn"),
|
||||
(cross_attn_lr, cross_attn_params, "cross_attn"),
|
||||
(mlp_lr, mlp_params, "mlp"),
|
||||
(mod_lr, mod_params, "mod"),
|
||||
(llm_adapter_lr, llm_adapter_params, "llm_adapter"),
|
||||
]:
|
||||
if lr == 0:
|
||||
for p in params:
|
||||
p.requires_grad_(False)
|
||||
logger.info(f" Frozen {name} params ({len(params)} parameters)")
|
||||
elif len(params) > 0:
|
||||
param_groups.append({"params": params, "lr": lr})
|
||||
|
||||
total_trainable = sum(p.numel() for group in param_groups for p in group["params"] if p.requires_grad)
|
||||
logger.info(f"Total trainable parameters: {total_trainable:,}")
|
||||
|
||||
return param_groups
|
||||
|
||||
|
||||
# Save functions
|
||||
def save_anima_model_on_train_end(
|
||||
args: argparse.Namespace,
|
||||
save_dtype: torch.dtype,
|
||||
epoch: int,
|
||||
global_step: int,
|
||||
dit: anima_models.Anima,
|
||||
):
|
||||
"""Save Anima model at the end of training."""
|
||||
|
||||
def sd_saver(ckpt_file, epoch_no, global_step):
|
||||
sai_metadata = train_util.get_sai_model_spec_dataclass(
|
||||
None, args, False, False, False, is_stable_diffusion_ckpt=True, anima="preview"
|
||||
).to_metadata_dict()
|
||||
dit_sd = dit.state_dict()
|
||||
# Save with 'net.' prefix for ComfyUI compatibility
|
||||
anima_utils.save_anima_model(ckpt_file, dit_sd, sai_metadata, save_dtype)
|
||||
|
||||
train_util.save_sd_model_on_train_end_common(args, True, True, epoch, global_step, sd_saver, None)
|
||||
|
||||
|
||||
def save_anima_model_on_epoch_end_or_stepwise(
|
||||
args: argparse.Namespace,
|
||||
on_epoch_end: bool,
|
||||
accelerator: Accelerator,
|
||||
save_dtype: torch.dtype,
|
||||
epoch: int,
|
||||
num_train_epochs: int,
|
||||
global_step: int,
|
||||
dit: anima_models.Anima,
|
||||
):
|
||||
"""Save Anima model at epoch end or specific steps."""
|
||||
|
||||
def sd_saver(ckpt_file, epoch_no, global_step):
|
||||
sai_metadata = train_util.get_sai_model_spec_dataclass(
|
||||
None, args, False, False, False, is_stable_diffusion_ckpt=True, anima="preview"
|
||||
).to_metadata_dict()
|
||||
dit_sd = dit.state_dict()
|
||||
anima_utils.save_anima_model(ckpt_file, dit_sd, sai_metadata, save_dtype)
|
||||
|
||||
train_util.save_sd_model_on_epoch_end_or_stepwise_common(
|
||||
args,
|
||||
on_epoch_end,
|
||||
accelerator,
|
||||
True,
|
||||
True,
|
||||
epoch,
|
||||
num_train_epochs,
|
||||
global_step,
|
||||
sd_saver,
|
||||
None,
|
||||
)
|
||||
|
||||
|
||||
# Sampling (Euler discrete for rectified flow)
|
||||
def do_sample(
|
||||
height: int,
|
||||
width: int,
|
||||
seed: Optional[int],
|
||||
dit: anima_models.Anima,
|
||||
crossattn_emb: torch.Tensor,
|
||||
steps: int,
|
||||
dtype: torch.dtype,
|
||||
device: torch.device,
|
||||
guidance_scale: float = 1.0,
|
||||
flow_shift: float = 3.0,
|
||||
neg_crossattn_emb: Optional[torch.Tensor] = None,
|
||||
) -> torch.Tensor:
|
||||
"""Generate a sample using Euler discrete sampling for rectified flow.
|
||||
|
||||
Args:
|
||||
height, width: Output image dimensions
|
||||
seed: Random seed (None for random)
|
||||
dit: Anima model
|
||||
crossattn_emb: Cross-attention embeddings (B, N, D)
|
||||
steps: Number of sampling steps
|
||||
dtype: Compute dtype
|
||||
device: Compute device
|
||||
guidance_scale: CFG scale (1.0 = no guidance)
|
||||
flow_shift: Flow shift parameter for rectified flow
|
||||
neg_crossattn_emb: Negative cross-attention embeddings for CFG
|
||||
|
||||
Returns:
|
||||
Denoised latents
|
||||
"""
|
||||
# Latent shape: (1, 16, 1, H/8, W/8) for single image
|
||||
latent_h = height // 8
|
||||
latent_w = width // 8
|
||||
latent = torch.zeros(1, 16, 1, latent_h, latent_w, device=device, dtype=dtype)
|
||||
|
||||
# Generate noise
|
||||
if seed is not None:
|
||||
generator = torch.manual_seed(seed)
|
||||
else:
|
||||
generator = None
|
||||
noise = torch.randn(latent.size(), dtype=torch.float32, generator=generator, device="cpu").to(dtype).to(device)
|
||||
|
||||
# Timestep schedule: linear from 1.0 to 0.0
|
||||
sigmas = torch.linspace(1.0, 0.0, steps + 1, device=device, dtype=dtype)
|
||||
flow_shift = float(flow_shift)
|
||||
if flow_shift != 1.0:
|
||||
sigmas = (sigmas * flow_shift) / (1 + (flow_shift - 1) * sigmas)
|
||||
|
||||
# Start from pure noise
|
||||
x = noise.clone()
|
||||
|
||||
# Padding mask (zeros = no padding) — resized in prepare_embedded_sequence to match latent dims
|
||||
padding_mask = torch.zeros(1, 1, latent_h, latent_w, dtype=dtype, device=device)
|
||||
|
||||
use_cfg = guidance_scale > 1.0 and neg_crossattn_emb is not None
|
||||
|
||||
for i in tqdm(range(steps), desc="Sampling"):
|
||||
sigma = sigmas[i]
|
||||
t = sigma.unsqueeze(0) # (1,)
|
||||
|
||||
if use_cfg:
|
||||
# CFG: two separate passes to reduce memory usage
|
||||
pos_out = dit(x, t, crossattn_emb, padding_mask=padding_mask)
|
||||
pos_out = pos_out.float()
|
||||
neg_out = dit(x, t, neg_crossattn_emb, padding_mask=padding_mask)
|
||||
neg_out = neg_out.float()
|
||||
|
||||
model_output = neg_out + guidance_scale * (pos_out - neg_out)
|
||||
else:
|
||||
model_output = dit(x, t, crossattn_emb, padding_mask=padding_mask)
|
||||
model_output = model_output.float()
|
||||
|
||||
# Euler step: x_{t-1} = x_t - (sigma_t - sigma_{t-1}) * model_output
|
||||
dt = sigmas[i + 1] - sigma
|
||||
x = x + model_output * dt
|
||||
x = x.to(dtype)
|
||||
|
||||
return x
|
||||
|
||||
|
||||
def sample_images(
|
||||
accelerator: Accelerator,
|
||||
args: argparse.Namespace,
|
||||
epoch,
|
||||
steps,
|
||||
dit: anima_models.Anima,
|
||||
vae,
|
||||
text_encoder,
|
||||
tokenize_strategy,
|
||||
text_encoding_strategy,
|
||||
sample_prompts_te_outputs=None,
|
||||
prompt_replacement=None,
|
||||
):
|
||||
"""Generate sample images during training.
|
||||
|
||||
This is a simplified sampler for Anima - it generates images using the current model state.
|
||||
"""
|
||||
if steps == 0:
|
||||
if not args.sample_at_first:
|
||||
return
|
||||
else:
|
||||
if args.sample_every_n_steps is None and args.sample_every_n_epochs is None:
|
||||
return
|
||||
if args.sample_every_n_epochs is not None:
|
||||
if epoch is None or epoch % args.sample_every_n_epochs != 0:
|
||||
return
|
||||
else:
|
||||
if steps % args.sample_every_n_steps != 0 or epoch is not None:
|
||||
return
|
||||
|
||||
logger.info(f"Generating sample images at step {steps}")
|
||||
if not os.path.isfile(args.sample_prompts) and sample_prompts_te_outputs is None:
|
||||
logger.error(f"No prompt file: {args.sample_prompts}")
|
||||
return
|
||||
|
||||
# Unwrap models
|
||||
dit = accelerator.unwrap_model(dit)
|
||||
if text_encoder is not None:
|
||||
text_encoder = accelerator.unwrap_model(text_encoder)
|
||||
|
||||
dit.switch_block_swap_for_inference()
|
||||
|
||||
prompts = train_util.load_prompts(args.sample_prompts)
|
||||
save_dir = os.path.join(args.output_dir, "sample")
|
||||
os.makedirs(save_dir, exist_ok=True)
|
||||
|
||||
# Save RNG state
|
||||
rng_state = torch.get_rng_state()
|
||||
cuda_rng_state = None
|
||||
try:
|
||||
cuda_rng_state = torch.cuda.get_rng_state() if torch.cuda.is_available() else None
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
with torch.no_grad(), accelerator.autocast():
|
||||
for prompt_dict in prompts:
|
||||
dit.prepare_block_swap_before_forward()
|
||||
_sample_image_inference(
|
||||
accelerator,
|
||||
args,
|
||||
dit,
|
||||
text_encoder,
|
||||
vae,
|
||||
tokenize_strategy,
|
||||
text_encoding_strategy,
|
||||
save_dir,
|
||||
prompt_dict,
|
||||
epoch,
|
||||
steps,
|
||||
sample_prompts_te_outputs,
|
||||
prompt_replacement,
|
||||
)
|
||||
|
||||
# Restore RNG state
|
||||
torch.set_rng_state(rng_state)
|
||||
if cuda_rng_state is not None:
|
||||
torch.cuda.set_rng_state(cuda_rng_state)
|
||||
|
||||
dit.switch_block_swap_for_training()
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
|
||||
def _sample_image_inference(
|
||||
accelerator,
|
||||
args,
|
||||
dit,
|
||||
text_encoder,
|
||||
vae: qwen_image_autoencoder_kl.AutoencoderKLQwenImage,
|
||||
tokenize_strategy,
|
||||
text_encoding_strategy,
|
||||
save_dir,
|
||||
prompt_dict,
|
||||
epoch,
|
||||
steps,
|
||||
sample_prompts_te_outputs,
|
||||
prompt_replacement,
|
||||
):
|
||||
"""Generate a single sample image."""
|
||||
prompt = prompt_dict.get("prompt", "")
|
||||
negative_prompt = prompt_dict.get("negative_prompt", "")
|
||||
sample_steps = prompt_dict.get("sample_steps", 30)
|
||||
width = prompt_dict.get("width", 512)
|
||||
height = prompt_dict.get("height", 512)
|
||||
scale = prompt_dict.get("scale", 7.5)
|
||||
seed = prompt_dict.get("seed")
|
||||
flow_shift = prompt_dict.get("flow_shift", 3.0)
|
||||
|
||||
if prompt_replacement is not None:
|
||||
prompt = prompt.replace(prompt_replacement[0], prompt_replacement[1])
|
||||
if negative_prompt:
|
||||
negative_prompt = negative_prompt.replace(prompt_replacement[0], prompt_replacement[1])
|
||||
|
||||
if seed is not None:
|
||||
torch.manual_seed(seed)
|
||||
torch.cuda.manual_seed_all(seed) # seed all CUDA devices for multi-GPU
|
||||
|
||||
height = max(64, height - height % 16)
|
||||
width = max(64, width - width % 16)
|
||||
|
||||
logger.info(
|
||||
f" prompt: {prompt}, size: {width}x{height}, steps: {sample_steps}, scale: {scale}, flow_shift: {flow_shift}, seed: {seed}"
|
||||
)
|
||||
|
||||
# Encode prompt
|
||||
def encode_prompt(prpt):
|
||||
if sample_prompts_te_outputs and prpt in sample_prompts_te_outputs:
|
||||
return sample_prompts_te_outputs[prpt]
|
||||
if text_encoder is not None:
|
||||
tokens = tokenize_strategy.tokenize(prpt)
|
||||
encoded = text_encoding_strategy.encode_tokens(tokenize_strategy, [text_encoder], tokens)
|
||||
return encoded
|
||||
return None
|
||||
|
||||
encoded = encode_prompt(prompt)
|
||||
if encoded is None:
|
||||
logger.warning("Cannot encode prompt, skipping sample")
|
||||
return
|
||||
|
||||
prompt_embeds, attn_mask, t5_input_ids, t5_attn_mask = encoded
|
||||
|
||||
# Convert to tensors if numpy
|
||||
if isinstance(prompt_embeds, np.ndarray):
|
||||
prompt_embeds = torch.from_numpy(prompt_embeds).unsqueeze(0)
|
||||
attn_mask = torch.from_numpy(attn_mask).unsqueeze(0)
|
||||
t5_input_ids = torch.from_numpy(t5_input_ids).unsqueeze(0)
|
||||
t5_attn_mask = torch.from_numpy(t5_attn_mask).unsqueeze(0)
|
||||
|
||||
prompt_embeds = prompt_embeds.to(accelerator.device, dtype=dit.dtype)
|
||||
attn_mask = attn_mask.to(accelerator.device)
|
||||
t5_input_ids = t5_input_ids.to(accelerator.device, dtype=torch.long)
|
||||
t5_attn_mask = t5_attn_mask.to(accelerator.device)
|
||||
|
||||
# Process through LLM adapter if available
|
||||
if dit.use_llm_adapter:
|
||||
crossattn_emb = dit.llm_adapter(
|
||||
source_hidden_states=prompt_embeds,
|
||||
target_input_ids=t5_input_ids,
|
||||
target_attention_mask=t5_attn_mask,
|
||||
source_attention_mask=attn_mask,
|
||||
)
|
||||
crossattn_emb[~t5_attn_mask.bool()] = 0
|
||||
else:
|
||||
crossattn_emb = prompt_embeds
|
||||
|
||||
# Encode negative prompt for CFG
|
||||
neg_crossattn_emb = None
|
||||
if scale > 1.0 and negative_prompt is not None:
|
||||
neg_encoded = encode_prompt(negative_prompt)
|
||||
if neg_encoded is not None:
|
||||
neg_pe, neg_am, neg_t5_ids, neg_t5_am = neg_encoded
|
||||
if isinstance(neg_pe, np.ndarray):
|
||||
neg_pe = torch.from_numpy(neg_pe).unsqueeze(0)
|
||||
neg_am = torch.from_numpy(neg_am).unsqueeze(0)
|
||||
neg_t5_ids = torch.from_numpy(neg_t5_ids).unsqueeze(0)
|
||||
neg_t5_am = torch.from_numpy(neg_t5_am).unsqueeze(0)
|
||||
|
||||
neg_pe = neg_pe.to(accelerator.device, dtype=dit.dtype)
|
||||
neg_am = neg_am.to(accelerator.device)
|
||||
neg_t5_ids = neg_t5_ids.to(accelerator.device, dtype=torch.long)
|
||||
neg_t5_am = neg_t5_am.to(accelerator.device)
|
||||
|
||||
if dit.use_llm_adapter:
|
||||
neg_crossattn_emb = dit.llm_adapter(
|
||||
source_hidden_states=neg_pe,
|
||||
target_input_ids=neg_t5_ids,
|
||||
target_attention_mask=neg_t5_am,
|
||||
source_attention_mask=neg_am,
|
||||
)
|
||||
neg_crossattn_emb[~neg_t5_am.bool()] = 0
|
||||
else:
|
||||
neg_crossattn_emb = neg_pe
|
||||
|
||||
# Generate sample
|
||||
clean_memory_on_device(accelerator.device)
|
||||
latents = do_sample(
|
||||
height, width, seed, dit, crossattn_emb, sample_steps, dit.dtype, accelerator.device, scale, flow_shift, neg_crossattn_emb
|
||||
)
|
||||
|
||||
# Decode latents
|
||||
gc.collect()
|
||||
synchronize_device(accelerator.device)
|
||||
clean_memory_on_device(accelerator.device)
|
||||
org_vae_device = vae.device
|
||||
vae.to(accelerator.device)
|
||||
decoded = vae.decode_to_pixels(latents)
|
||||
vae.to(org_vae_device)
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
# Convert to image
|
||||
image = decoded.float()
|
||||
image = torch.clamp((image + 1.0) / 2.0, min=0.0, max=1.0)[0]
|
||||
# Remove temporal dim if present
|
||||
if image.ndim == 4:
|
||||
image = image[:, 0, :, :]
|
||||
decoded_np = 255.0 * np.moveaxis(image.cpu().numpy(), 0, 2)
|
||||
decoded_np = decoded_np.astype(np.uint8)
|
||||
|
||||
image = Image.fromarray(decoded_np)
|
||||
|
||||
ts_str = time.strftime("%Y%m%d%H%M%S", time.localtime())
|
||||
num_suffix = f"e{epoch:06d}" if epoch is not None else f"{steps:06d}"
|
||||
seed_suffix = "" if seed is None else f"_{seed}"
|
||||
i = prompt_dict.get("enum", 0)
|
||||
img_filename = f"{'' if args.output_name is None else args.output_name + '_'}{num_suffix}_{i:02d}_{ts_str}{seed_suffix}.png"
|
||||
image.save(os.path.join(save_dir, img_filename))
|
||||
|
||||
# Log to wandb if enabled
|
||||
if "wandb" in [tracker.name for tracker in accelerator.trackers]:
|
||||
wandb_tracker = accelerator.get_tracker("wandb")
|
||||
import wandb
|
||||
|
||||
wandb_tracker.log({f"sample_{i}": wandb.Image(image, caption=prompt)}, commit=False)
|
||||
309
library/anima_utils.py
Normal file
309
library/anima_utils.py
Normal file
@@ -0,0 +1,309 @@
|
||||
# Anima model loading/saving utilities
|
||||
|
||||
import os
|
||||
from typing import Dict, List, Optional, Union
|
||||
import torch
|
||||
from safetensors.torch import load_file, save_file
|
||||
from accelerate.utils import set_module_tensor_to_device # kept for potential future use
|
||||
from accelerate import init_empty_weights
|
||||
|
||||
from library.fp8_optimization_utils import apply_fp8_monkey_patch
|
||||
from library.lora_utils import load_safetensors_with_lora_and_fp8
|
||||
from library import anima_models
|
||||
from library.safetensors_utils import WeightTransformHooks
|
||||
from .utils import setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
# Original Anima high-precision keys. Kept for reference, but not used currently.
|
||||
# # Keys that should stay in high precision (float32/bfloat16, not quantized)
|
||||
# KEEP_IN_HIGH_PRECISION = ["x_embedder", "t_embedder", "t_embedding_norm", "final_layer"]
|
||||
|
||||
|
||||
FP8_OPTIMIZATION_TARGET_KEYS = ["blocks", ""]
|
||||
# ".embed." excludes Embedding in LLMAdapter
|
||||
FP8_OPTIMIZATION_EXCLUDE_KEYS = ["_embedder", "norm", "adaln", "final_layer", ".embed."]
|
||||
|
||||
|
||||
def load_anima_model(
|
||||
device: Union[str, torch.device],
|
||||
dit_path: str,
|
||||
attn_mode: str,
|
||||
split_attn: bool,
|
||||
loading_device: Union[str, torch.device],
|
||||
dit_weight_dtype: Optional[torch.dtype],
|
||||
fp8_scaled: bool = False,
|
||||
lora_weights_list: Optional[List[Dict[str, torch.Tensor]]] = None,
|
||||
lora_multipliers: Optional[list[float]] = None,
|
||||
) -> anima_models.Anima:
|
||||
"""
|
||||
Load Anima model from the specified checkpoint.
|
||||
|
||||
Args:
|
||||
device (Union[str, torch.device]): Device for optimization or merging
|
||||
dit_path (str): Path to the DiT model checkpoint.
|
||||
attn_mode (str): Attention mode to use, e.g., "torch", "flash", etc.
|
||||
split_attn (bool): Whether to use split attention.
|
||||
loading_device (Union[str, torch.device]): Device to load the model weights on.
|
||||
dit_weight_dtype (Optional[torch.dtype]): Data type of the DiT weights.
|
||||
If None, it will be loaded as is (same as the state_dict) or scaled for fp8. if not None, model weights will be casted to this dtype.
|
||||
fp8_scaled (bool): Whether to use fp8 scaling for the model weights.
|
||||
lora_weights_list (Optional[List[Dict[str, torch.Tensor]]]): LoRA weights to apply, if any.
|
||||
lora_multipliers (Optional[List[float]]): LoRA multipliers for the weights, if any.
|
||||
"""
|
||||
# dit_weight_dtype is None for fp8_scaled
|
||||
assert (
|
||||
not fp8_scaled and dit_weight_dtype is not None
|
||||
) or dit_weight_dtype is None, "dit_weight_dtype should be None when fp8_scaled is True"
|
||||
|
||||
device = torch.device(device)
|
||||
loading_device = torch.device(loading_device)
|
||||
|
||||
# We currently support fixed DiT config for Anima models
|
||||
dit_config = {
|
||||
"max_img_h": 512,
|
||||
"max_img_w": 512,
|
||||
"max_frames": 128,
|
||||
"in_channels": 16,
|
||||
"out_channels": 16,
|
||||
"patch_spatial": 2,
|
||||
"patch_temporal": 1,
|
||||
"model_channels": 2048,
|
||||
"concat_padding_mask": True,
|
||||
"crossattn_emb_channels": 1024,
|
||||
"pos_emb_cls": "rope3d",
|
||||
"pos_emb_learnable": True,
|
||||
"pos_emb_interpolation": "crop",
|
||||
"min_fps": 1,
|
||||
"max_fps": 30,
|
||||
"use_adaln_lora": True,
|
||||
"adaln_lora_dim": 256,
|
||||
"num_blocks": 28,
|
||||
"num_heads": 16,
|
||||
"extra_per_block_abs_pos_emb": False,
|
||||
"rope_h_extrapolation_ratio": 4.0,
|
||||
"rope_w_extrapolation_ratio": 4.0,
|
||||
"rope_t_extrapolation_ratio": 1.0,
|
||||
"extra_h_extrapolation_ratio": 1.0,
|
||||
"extra_w_extrapolation_ratio": 1.0,
|
||||
"extra_t_extrapolation_ratio": 1.0,
|
||||
"rope_enable_fps_modulation": False,
|
||||
"use_llm_adapter": True,
|
||||
"attn_mode": attn_mode,
|
||||
"split_attn": split_attn,
|
||||
}
|
||||
with init_empty_weights():
|
||||
model = anima_models.Anima(**dit_config)
|
||||
if dit_weight_dtype is not None:
|
||||
model.to(dit_weight_dtype)
|
||||
|
||||
# load model weights with dynamic fp8 optimization and LoRA merging if needed
|
||||
logger.info(f"Loading DiT model from {dit_path}, device={loading_device}")
|
||||
rename_hooks = WeightTransformHooks(rename_hook=lambda k: k[len("net.") :] if k.startswith("net.") else k)
|
||||
sd = load_safetensors_with_lora_and_fp8(
|
||||
model_files=dit_path,
|
||||
lora_weights_list=lora_weights_list,
|
||||
lora_multipliers=lora_multipliers,
|
||||
fp8_optimization=fp8_scaled,
|
||||
calc_device=device,
|
||||
move_to_device=(loading_device == device),
|
||||
dit_weight_dtype=dit_weight_dtype,
|
||||
target_keys=FP8_OPTIMIZATION_TARGET_KEYS,
|
||||
exclude_keys=FP8_OPTIMIZATION_EXCLUDE_KEYS,
|
||||
weight_transform_hooks=rename_hooks,
|
||||
)
|
||||
|
||||
if fp8_scaled:
|
||||
apply_fp8_monkey_patch(model, sd, use_scaled_mm=False)
|
||||
|
||||
if loading_device.type != "cpu":
|
||||
# make sure all the model weights are on the loading_device
|
||||
logger.info(f"Moving weights to {loading_device}")
|
||||
for key in sd.keys():
|
||||
sd[key] = sd[key].to(loading_device)
|
||||
|
||||
missing, unexpected = model.load_state_dict(sd, strict=False, assign=True)
|
||||
if missing:
|
||||
# Filter out expected missing buffers (initialized in __init__, not saved in checkpoint)
|
||||
unexpected_missing = [
|
||||
k
|
||||
for k in missing
|
||||
if not any(buf_name in k for buf_name in ("seq", "dim_spatial_range", "dim_temporal_range", "inv_freq"))
|
||||
]
|
||||
if unexpected_missing:
|
||||
# Raise error to avoid silent failures
|
||||
raise RuntimeError(
|
||||
f"Missing keys in checkpoint: {unexpected_missing[:10]}{'...' if len(unexpected_missing) > 10 else ''}"
|
||||
)
|
||||
missing = {} # all missing keys were expected
|
||||
if unexpected:
|
||||
# Raise error to avoid silent failures
|
||||
raise RuntimeError(f"Unexpected keys in checkpoint: {unexpected[:5]}{'...' if len(unexpected) > 5 else ''}")
|
||||
logger.info(f"Loaded DiT model from {dit_path}, unexpected missing keys: {len(missing)}, unexpected keys: {len(unexpected)}")
|
||||
|
||||
return model
|
||||
|
||||
|
||||
def load_qwen3_tokenizer(qwen3_path: str):
|
||||
"""Load Qwen3 tokenizer only (without the text encoder model).
|
||||
|
||||
Args:
|
||||
qwen3_path: Path to either a directory with model files or a safetensors file.
|
||||
If a directory, loads tokenizer from it directly.
|
||||
If a file, uses configs/qwen3_06b/ for tokenizer config.
|
||||
Returns:
|
||||
tokenizer
|
||||
"""
|
||||
from transformers import AutoTokenizer
|
||||
|
||||
if os.path.isdir(qwen3_path):
|
||||
tokenizer = AutoTokenizer.from_pretrained(qwen3_path, local_files_only=True)
|
||||
else:
|
||||
config_dir = os.path.join(os.path.dirname(os.path.dirname(__file__)), "configs", "qwen3_06b")
|
||||
if not os.path.exists(config_dir):
|
||||
raise FileNotFoundError(
|
||||
f"Qwen3 config directory not found at {config_dir}. "
|
||||
"Expected configs/qwen3_06b/ with config.json, tokenizer.json, etc. "
|
||||
"You can download these from the Qwen3-0.6B HuggingFace repository."
|
||||
)
|
||||
tokenizer = AutoTokenizer.from_pretrained(config_dir, local_files_only=True)
|
||||
|
||||
if tokenizer.pad_token is None:
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
|
||||
return tokenizer
|
||||
|
||||
|
||||
def load_qwen3_text_encoder(
|
||||
qwen3_path: str,
|
||||
dtype: torch.dtype = torch.bfloat16,
|
||||
device: str = "cpu",
|
||||
lora_weights: Optional[List[Dict[str, torch.Tensor]]] = None,
|
||||
lora_multipliers: Optional[List[float]] = None,
|
||||
):
|
||||
"""Load Qwen3-0.6B text encoder.
|
||||
|
||||
Args:
|
||||
qwen3_path: Path to either a directory with model files or a safetensors file
|
||||
dtype: Model dtype
|
||||
device: Device to load to
|
||||
|
||||
Returns:
|
||||
(text_encoder_model, tokenizer)
|
||||
"""
|
||||
import transformers
|
||||
from transformers import AutoTokenizer
|
||||
|
||||
logger.info(f"Loading Qwen3 text encoder from {qwen3_path}")
|
||||
|
||||
if os.path.isdir(qwen3_path):
|
||||
# Directory with full model
|
||||
tokenizer = AutoTokenizer.from_pretrained(qwen3_path, local_files_only=True)
|
||||
model = transformers.AutoModelForCausalLM.from_pretrained(qwen3_path, torch_dtype=dtype, local_files_only=True).model
|
||||
else:
|
||||
# Single safetensors file - use configs/qwen3_06b/ for config
|
||||
config_dir = os.path.join(os.path.dirname(os.path.dirname(__file__)), "configs", "qwen3_06b")
|
||||
if not os.path.exists(config_dir):
|
||||
raise FileNotFoundError(
|
||||
f"Qwen3 config directory not found at {config_dir}. "
|
||||
"Expected configs/qwen3_06b/ with config.json, tokenizer.json, etc. "
|
||||
"You can download these from the Qwen3-0.6B HuggingFace repository."
|
||||
)
|
||||
|
||||
tokenizer = AutoTokenizer.from_pretrained(config_dir, local_files_only=True)
|
||||
qwen3_config = transformers.Qwen3Config.from_pretrained(config_dir, local_files_only=True)
|
||||
model = transformers.Qwen3ForCausalLM(qwen3_config).model
|
||||
|
||||
# Load weights
|
||||
if qwen3_path.endswith(".safetensors"):
|
||||
if lora_weights is None:
|
||||
state_dict = load_file(qwen3_path, device="cpu")
|
||||
else:
|
||||
state_dict = load_safetensors_with_lora_and_fp8(
|
||||
model_files=qwen3_path,
|
||||
lora_weights_list=lora_weights,
|
||||
lora_multipliers=lora_multipliers,
|
||||
fp8_optimization=False,
|
||||
calc_device=device,
|
||||
move_to_device=True,
|
||||
dit_weight_dtype=None,
|
||||
)
|
||||
else:
|
||||
assert lora_weights is None, "LoRA weights merging is only supported for safetensors checkpoints"
|
||||
state_dict = torch.load(qwen3_path, map_location="cpu", weights_only=True)
|
||||
|
||||
# Remove 'model.' prefix if present
|
||||
new_sd = {}
|
||||
for k, v in state_dict.items():
|
||||
if k.startswith("model."):
|
||||
new_sd[k[len("model.") :]] = v
|
||||
else:
|
||||
new_sd[k] = v
|
||||
|
||||
info = model.load_state_dict(new_sd, strict=False)
|
||||
logger.info(f"Loaded Qwen3 state dict: {info}")
|
||||
|
||||
if tokenizer.pad_token is None:
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
|
||||
model.config.use_cache = False
|
||||
model = model.requires_grad_(False).to(device, dtype=dtype)
|
||||
|
||||
logger.info(f"Loaded Qwen3 text encoder. Parameters: {sum(p.numel() for p in model.parameters()):,}")
|
||||
return model, tokenizer
|
||||
|
||||
|
||||
def load_t5_tokenizer(t5_tokenizer_path: Optional[str] = None):
|
||||
"""Load T5 tokenizer for LLM Adapter target tokens.
|
||||
|
||||
Args:
|
||||
t5_tokenizer_path: Optional path to T5 tokenizer directory. If None, uses default configs.
|
||||
"""
|
||||
from transformers import T5TokenizerFast
|
||||
|
||||
if t5_tokenizer_path is not None:
|
||||
return T5TokenizerFast.from_pretrained(t5_tokenizer_path, local_files_only=True)
|
||||
|
||||
# Use bundled config
|
||||
config_dir = os.path.join(os.path.dirname(os.path.dirname(__file__)), "configs", "t5_old")
|
||||
if os.path.exists(config_dir):
|
||||
return T5TokenizerFast(
|
||||
vocab_file=os.path.join(config_dir, "spiece.model"),
|
||||
tokenizer_file=os.path.join(config_dir, "tokenizer.json"),
|
||||
)
|
||||
|
||||
raise FileNotFoundError(
|
||||
f"T5 tokenizer config directory not found at {config_dir}. "
|
||||
"Expected configs/t5_old/ with spiece.model and tokenizer.json. "
|
||||
"You can download these from the google/t5-v1_1-xxl HuggingFace repository."
|
||||
)
|
||||
|
||||
|
||||
def save_anima_model(
|
||||
save_path: str, dit_state_dict: Dict[str, torch.Tensor], metadata: Dict[str, any], dtype: Optional[torch.dtype] = None
|
||||
):
|
||||
"""Save Anima DiT model with 'net.' prefix for ComfyUI compatibility.
|
||||
|
||||
Args:
|
||||
save_path: Output path (.safetensors)
|
||||
dit_state_dict: State dict from dit.state_dict()
|
||||
metadata: Metadata dict to include in the safetensors file
|
||||
dtype: Optional dtype to cast to before saving
|
||||
"""
|
||||
prefixed_sd = {}
|
||||
for k, v in dit_state_dict.items():
|
||||
if dtype is not None:
|
||||
# v = v.to(dtype)
|
||||
v = v.detach().clone().to("cpu").to(dtype) # Reduce GPU memory usage during save
|
||||
prefixed_sd["net." + k] = v.contiguous()
|
||||
|
||||
if metadata is None:
|
||||
metadata = {}
|
||||
metadata["format"] = "pt" # For compatibility with the official .safetensors file
|
||||
|
||||
save_file(prefixed_sd, save_path, metadata=metadata) # safetensors.save_file cosumes a lot of memory, but Anima is small enough
|
||||
logger.info(f"Saved Anima model to {save_path}")
|
||||
268
library/attention.py
Normal file
268
library/attention.py
Normal file
@@ -0,0 +1,268 @@
|
||||
# Unified attention function supporting various implementations
|
||||
|
||||
from dataclasses import dataclass
|
||||
import torch
|
||||
from typing import Optional, Union
|
||||
|
||||
try:
|
||||
import flash_attn
|
||||
from flash_attn.flash_attn_interface import _flash_attn_forward
|
||||
from flash_attn.flash_attn_interface import flash_attn_varlen_func
|
||||
from flash_attn.flash_attn_interface import flash_attn_func
|
||||
except ImportError:
|
||||
flash_attn = None
|
||||
flash_attn_varlen_func = None
|
||||
_flash_attn_forward = None
|
||||
flash_attn_func = None
|
||||
|
||||
try:
|
||||
from sageattention import sageattn_varlen, sageattn
|
||||
except ImportError:
|
||||
sageattn_varlen = None
|
||||
sageattn = None
|
||||
|
||||
try:
|
||||
import xformers.ops as xops
|
||||
except ImportError:
|
||||
xops = None
|
||||
|
||||
|
||||
@dataclass
|
||||
class AttentionParams:
|
||||
attn_mode: Optional[str] = None
|
||||
split_attn: bool = False
|
||||
img_len: Optional[int] = None
|
||||
attention_mask: Optional[torch.Tensor] = None
|
||||
seqlens: Optional[torch.Tensor] = None
|
||||
cu_seqlens: Optional[torch.Tensor] = None
|
||||
max_seqlen: Optional[int] = None
|
||||
|
||||
@property
|
||||
def supports_fp32(self) -> bool:
|
||||
return self.attn_mode not in ["flash"]
|
||||
|
||||
@property
|
||||
def requires_same_dtype(self) -> bool:
|
||||
return self.attn_mode in ["xformers"]
|
||||
|
||||
@staticmethod
|
||||
def create_attention_params(attn_mode: Optional[str], split_attn: bool) -> "AttentionParams":
|
||||
return AttentionParams(attn_mode, split_attn)
|
||||
|
||||
@staticmethod
|
||||
def create_attention_params_from_mask(
|
||||
attn_mode: Optional[str], split_attn: bool, img_len: Optional[int], attention_mask: Optional[torch.Tensor]
|
||||
) -> "AttentionParams":
|
||||
if attention_mask is None:
|
||||
# No attention mask provided: assume all tokens are valid
|
||||
return AttentionParams(attn_mode, split_attn, None, None, None, None, None)
|
||||
else:
|
||||
# Note: attention_mask is only for text tokens, not including image tokens
|
||||
seqlens = attention_mask.sum(dim=1).to(torch.int32) + img_len # [B]
|
||||
max_seqlen = attention_mask.shape[1] + img_len
|
||||
|
||||
if split_attn:
|
||||
# cu_seqlens is not needed for split attention
|
||||
return AttentionParams(attn_mode, split_attn, img_len, attention_mask, seqlens, None, max_seqlen)
|
||||
|
||||
# Convert attention mask to cumulative sequence lengths for flash attention
|
||||
batch_size = attention_mask.shape[0]
|
||||
cu_seqlens = torch.zeros([2 * batch_size + 1], dtype=torch.int32, device=attention_mask.device)
|
||||
for i in range(batch_size):
|
||||
cu_seqlens[2 * i + 1] = i * max_seqlen + seqlens[i] # end of valid tokens for query
|
||||
cu_seqlens[2 * i + 2] = (i + 1) * max_seqlen # end of all tokens for query
|
||||
|
||||
# Expand attention mask to include image tokens
|
||||
attention_mask = torch.nn.functional.pad(attention_mask, (img_len, 0), value=1) # [B, img_len + L]
|
||||
|
||||
if attn_mode == "xformers":
|
||||
seqlens_list = seqlens.cpu().tolist()
|
||||
attention_mask = xops.fmha.attn_bias.BlockDiagonalMask.from_seqlens(
|
||||
seqlens_list, seqlens_list, device=attention_mask.device
|
||||
)
|
||||
elif attn_mode == "torch":
|
||||
attention_mask = attention_mask[:, None, None, :].to(torch.bool) # [B, 1, 1, img_len + L]
|
||||
|
||||
return AttentionParams(attn_mode, split_attn, img_len, attention_mask, seqlens, cu_seqlens, max_seqlen)
|
||||
|
||||
|
||||
def attention(
|
||||
qkv_or_q: Union[torch.Tensor, list],
|
||||
k: Optional[torch.Tensor] = None,
|
||||
v: Optional[torch.Tensor] = None,
|
||||
attn_params: Optional[AttentionParams] = None,
|
||||
drop_rate: float = 0.0,
|
||||
) -> torch.Tensor:
|
||||
"""
|
||||
Compute scaled dot-product attention with variable sequence lengths.
|
||||
|
||||
Handles batches with different sequence lengths by splitting and
|
||||
processing each sequence individually.
|
||||
|
||||
Args:
|
||||
qkv_or_q: Query tensor [B, L, H, D]. or list of such tensors.
|
||||
k: Key tensor [B, L, H, D].
|
||||
v: Value tensor [B, L, H, D].
|
||||
attn_params: Attention parameters including mask and sequence lengths.
|
||||
drop_rate: Attention dropout rate.
|
||||
|
||||
Returns:
|
||||
Attention output tensor [B, L, H*D].
|
||||
"""
|
||||
if isinstance(qkv_or_q, list):
|
||||
q, k, v = qkv_or_q
|
||||
q: torch.Tensor = q
|
||||
qkv_or_q.clear()
|
||||
del qkv_or_q
|
||||
else:
|
||||
q: torch.Tensor = qkv_or_q
|
||||
del qkv_or_q
|
||||
assert k is not None and v is not None, "k and v must be provided if qkv_or_q is a tensor"
|
||||
if attn_params is None:
|
||||
attn_params = AttentionParams.create_attention_params("torch", False)
|
||||
|
||||
# If split attn is False, attention mask is provided and all sequence lengths are same, we can trim the sequence
|
||||
seqlen_trimmed = False
|
||||
if not attn_params.split_attn and attn_params.attention_mask is not None and attn_params.seqlens is not None:
|
||||
if torch.all(attn_params.seqlens == attn_params.seqlens[0]):
|
||||
seqlen = attn_params.seqlens[0].item()
|
||||
q = q[:, :seqlen]
|
||||
k = k[:, :seqlen]
|
||||
v = v[:, :seqlen]
|
||||
max_seqlen = attn_params.max_seqlen
|
||||
attn_params = AttentionParams.create_attention_params(attn_params.attn_mode, False) # do not in-place modify
|
||||
attn_params.max_seqlen = max_seqlen # keep max_seqlen for padding
|
||||
seqlen_trimmed = True
|
||||
|
||||
# Determine tensor layout based on attention implementation
|
||||
if attn_params.attn_mode == "torch" or (
|
||||
attn_params.attn_mode == "sageattn" and (attn_params.split_attn or attn_params.cu_seqlens is None)
|
||||
):
|
||||
transpose_fn = lambda x: x.transpose(1, 2) # [B, H, L, D] for SDPA and sageattn with fixed length
|
||||
# pad on sequence length dimension
|
||||
pad_fn = lambda x, pad_to: torch.nn.functional.pad(x, (0, 0, 0, pad_to - x.shape[-2]), value=0)
|
||||
else:
|
||||
transpose_fn = lambda x: x # [B, L, H, D] for other implementations
|
||||
# pad on sequence length dimension
|
||||
pad_fn = lambda x, pad_to: torch.nn.functional.pad(x, (0, 0, 0, 0, 0, pad_to - x.shape[-3]), value=0)
|
||||
|
||||
# Process each batch element with its valid sequence lengths
|
||||
if attn_params.split_attn:
|
||||
if attn_params.seqlens is None:
|
||||
# If no seqlens provided, assume all tokens are valid
|
||||
attn_params = AttentionParams.create_attention_params(attn_params.attn_mode, True) # do not in-place modify
|
||||
attn_params.seqlens = torch.tensor([q.shape[1]] * q.shape[0], device=q.device)
|
||||
attn_params.max_seqlen = q.shape[1]
|
||||
q = [transpose_fn(q[i : i + 1, : attn_params.seqlens[i]]) for i in range(len(q))]
|
||||
k = [transpose_fn(k[i : i + 1, : attn_params.seqlens[i]]) for i in range(len(k))]
|
||||
v = [transpose_fn(v[i : i + 1, : attn_params.seqlens[i]]) for i in range(len(v))]
|
||||
else:
|
||||
q = transpose_fn(q)
|
||||
k = transpose_fn(k)
|
||||
v = transpose_fn(v)
|
||||
|
||||
if attn_params.attn_mode == "torch":
|
||||
if attn_params.split_attn:
|
||||
x = []
|
||||
for i in range(len(q)):
|
||||
x_i = torch.nn.functional.scaled_dot_product_attention(q[i], k[i], v[i], dropout_p=drop_rate)
|
||||
q[i] = None
|
||||
k[i] = None
|
||||
v[i] = None
|
||||
x.append(pad_fn(x_i, attn_params.max_seqlen)) # B, H, L, D
|
||||
x = torch.cat(x, dim=0)
|
||||
del q, k, v
|
||||
|
||||
else:
|
||||
x = torch.nn.functional.scaled_dot_product_attention(q, k, v, attn_mask=attn_params.attention_mask, dropout_p=drop_rate)
|
||||
del q, k, v
|
||||
|
||||
elif attn_params.attn_mode == "xformers":
|
||||
if attn_params.split_attn:
|
||||
x = []
|
||||
for i in range(len(q)):
|
||||
x_i = xops.memory_efficient_attention(q[i], k[i], v[i], p=drop_rate)
|
||||
q[i] = None
|
||||
k[i] = None
|
||||
v[i] = None
|
||||
x.append(pad_fn(x_i, attn_params.max_seqlen)) # B, L, H, D
|
||||
x = torch.cat(x, dim=0)
|
||||
del q, k, v
|
||||
|
||||
else:
|
||||
x = xops.memory_efficient_attention(q, k, v, attn_bias=attn_params.attention_mask, p=drop_rate)
|
||||
del q, k, v
|
||||
|
||||
elif attn_params.attn_mode == "sageattn":
|
||||
if attn_params.split_attn:
|
||||
x = []
|
||||
for i in range(len(q)):
|
||||
# HND seems to cause an error
|
||||
x_i = sageattn(q[i], k[i], v[i]) # B, H, L, D. No dropout support
|
||||
q[i] = None
|
||||
k[i] = None
|
||||
v[i] = None
|
||||
x.append(pad_fn(x_i, attn_params.max_seqlen)) # B, H, L, D
|
||||
x = torch.cat(x, dim=0)
|
||||
del q, k, v
|
||||
elif attn_params.cu_seqlens is None: # all tokens are valid
|
||||
x = sageattn(q, k, v) # B, L, H, D. No dropout support
|
||||
del q, k, v
|
||||
else:
|
||||
# Reshape to [(bxs), a, d]
|
||||
batch_size, seqlen = q.shape[0], q.shape[1]
|
||||
q = q.view(q.shape[0] * q.shape[1], *q.shape[2:]) # [B*L, H, D]
|
||||
k = k.view(k.shape[0] * k.shape[1], *k.shape[2:]) # [B*L, H, D]
|
||||
v = v.view(v.shape[0] * v.shape[1], *v.shape[2:]) # [B*L, H, D]
|
||||
|
||||
# Assume cu_seqlens_q == cu_seqlens_kv and max_seqlen_q == max_seqlen_kv. No dropout support
|
||||
x = sageattn_varlen(
|
||||
q, k, v, attn_params.cu_seqlens, attn_params.cu_seqlens, attn_params.max_seqlen, attn_params.max_seqlen
|
||||
)
|
||||
del q, k, v
|
||||
|
||||
# Reshape x with shape [(bxs), a, d] to [b, s, a, d]
|
||||
x = x.view(batch_size, seqlen, x.shape[-2], x.shape[-1]) # B, L, H, D
|
||||
|
||||
elif attn_params.attn_mode == "flash":
|
||||
if attn_params.split_attn:
|
||||
x = []
|
||||
for i in range(len(q)):
|
||||
# HND seems to cause an error
|
||||
x_i = flash_attn_func(q[i], k[i], v[i], drop_rate) # B, L, H, D
|
||||
q[i] = None
|
||||
k[i] = None
|
||||
v[i] = None
|
||||
x.append(pad_fn(x_i, attn_params.max_seqlen)) # B, L, H, D
|
||||
x = torch.cat(x, dim=0)
|
||||
del q, k, v
|
||||
elif attn_params.cu_seqlens is None: # all tokens are valid
|
||||
x = flash_attn_func(q, k, v, drop_rate) # B, L, H, D
|
||||
del q, k, v
|
||||
else:
|
||||
# Reshape to [(bxs), a, d]
|
||||
batch_size, seqlen = q.shape[0], q.shape[1]
|
||||
q = q.view(q.shape[0] * q.shape[1], *q.shape[2:]) # [B*L, H, D]
|
||||
k = k.view(k.shape[0] * k.shape[1], *k.shape[2:]) # [B*L, H, D]
|
||||
v = v.view(v.shape[0] * v.shape[1], *v.shape[2:]) # [B*L, H, D]
|
||||
|
||||
# Assume cu_seqlens_q == cu_seqlens_kv and max_seqlen_q == max_seqlen_kv
|
||||
x = flash_attn_varlen_func(
|
||||
q, k, v, attn_params.cu_seqlens, attn_params.cu_seqlens, attn_params.max_seqlen, attn_params.max_seqlen, drop_rate
|
||||
)
|
||||
del q, k, v
|
||||
|
||||
# Reshape x with shape [(bxs), a, d] to [b, s, a, d]
|
||||
x = x.view(batch_size, seqlen, x.shape[-2], x.shape[-1]) # B, L, H, D
|
||||
|
||||
else:
|
||||
# Currently only PyTorch SDPA and xformers are implemented
|
||||
raise ValueError(f"Unsupported attention mode: {attn_params.attn_mode}")
|
||||
|
||||
x = transpose_fn(x) # [B, L, H, D]
|
||||
x = x.reshape(x.shape[0], x.shape[1], -1) # [B, L, H*D]
|
||||
|
||||
if seqlen_trimmed:
|
||||
x = torch.nn.functional.pad(x, (0, 0, 0, attn_params.max_seqlen - x.shape[1]), value=0) # pad back to max_seqlen
|
||||
|
||||
return x
|
||||
227
library/attention_processors.py
Normal file
227
library/attention_processors.py
Normal file
@@ -0,0 +1,227 @@
|
||||
import math
|
||||
from typing import Any
|
||||
from einops import rearrange
|
||||
import torch
|
||||
from diffusers.models.attention_processor import Attention
|
||||
|
||||
|
||||
# flash attention forwards and backwards
|
||||
|
||||
# https://arxiv.org/abs/2205.14135
|
||||
|
||||
EPSILON = 1e-6
|
||||
|
||||
|
||||
class FlashAttentionFunction(torch.autograd.function.Function):
|
||||
@staticmethod
|
||||
@torch.no_grad()
|
||||
def forward(ctx, q, k, v, mask, causal, q_bucket_size, k_bucket_size):
|
||||
"""Algorithm 2 in the paper"""
|
||||
|
||||
device = q.device
|
||||
dtype = q.dtype
|
||||
max_neg_value = -torch.finfo(q.dtype).max
|
||||
qk_len_diff = max(k.shape[-2] - q.shape[-2], 0)
|
||||
|
||||
o = torch.zeros_like(q)
|
||||
all_row_sums = torch.zeros((*q.shape[:-1], 1), dtype=dtype, device=device)
|
||||
all_row_maxes = torch.full(
|
||||
(*q.shape[:-1], 1), max_neg_value, dtype=dtype, device=device
|
||||
)
|
||||
|
||||
scale = q.shape[-1] ** -0.5
|
||||
|
||||
if mask is None:
|
||||
mask = (None,) * math.ceil(q.shape[-2] / q_bucket_size)
|
||||
else:
|
||||
mask = rearrange(mask, "b n -> b 1 1 n")
|
||||
mask = mask.split(q_bucket_size, dim=-1)
|
||||
|
||||
row_splits = zip(
|
||||
q.split(q_bucket_size, dim=-2),
|
||||
o.split(q_bucket_size, dim=-2),
|
||||
mask,
|
||||
all_row_sums.split(q_bucket_size, dim=-2),
|
||||
all_row_maxes.split(q_bucket_size, dim=-2),
|
||||
)
|
||||
|
||||
for ind, (qc, oc, row_mask, row_sums, row_maxes) in enumerate(row_splits):
|
||||
q_start_index = ind * q_bucket_size - qk_len_diff
|
||||
|
||||
col_splits = zip(
|
||||
k.split(k_bucket_size, dim=-2),
|
||||
v.split(k_bucket_size, dim=-2),
|
||||
)
|
||||
|
||||
for k_ind, (kc, vc) in enumerate(col_splits):
|
||||
k_start_index = k_ind * k_bucket_size
|
||||
|
||||
attn_weights = (
|
||||
torch.einsum("... i d, ... j d -> ... i j", qc, kc) * scale
|
||||
)
|
||||
|
||||
if row_mask is not None:
|
||||
attn_weights.masked_fill_(~row_mask, max_neg_value)
|
||||
|
||||
if causal and q_start_index < (k_start_index + k_bucket_size - 1):
|
||||
causal_mask = torch.ones(
|
||||
(qc.shape[-2], kc.shape[-2]), dtype=torch.bool, device=device
|
||||
).triu(q_start_index - k_start_index + 1)
|
||||
attn_weights.masked_fill_(causal_mask, max_neg_value)
|
||||
|
||||
block_row_maxes = attn_weights.amax(dim=-1, keepdims=True)
|
||||
attn_weights -= block_row_maxes
|
||||
exp_weights = torch.exp(attn_weights)
|
||||
|
||||
if row_mask is not None:
|
||||
exp_weights.masked_fill_(~row_mask, 0.0)
|
||||
|
||||
block_row_sums = exp_weights.sum(dim=-1, keepdims=True).clamp(
|
||||
min=EPSILON
|
||||
)
|
||||
|
||||
new_row_maxes = torch.maximum(block_row_maxes, row_maxes)
|
||||
|
||||
exp_values = torch.einsum(
|
||||
"... i j, ... j d -> ... i d", exp_weights, vc
|
||||
)
|
||||
|
||||
exp_row_max_diff = torch.exp(row_maxes - new_row_maxes)
|
||||
exp_block_row_max_diff = torch.exp(block_row_maxes - new_row_maxes)
|
||||
|
||||
new_row_sums = (
|
||||
exp_row_max_diff * row_sums
|
||||
+ exp_block_row_max_diff * block_row_sums
|
||||
)
|
||||
|
||||
oc.mul_((row_sums / new_row_sums) * exp_row_max_diff).add_(
|
||||
(exp_block_row_max_diff / new_row_sums) * exp_values
|
||||
)
|
||||
|
||||
row_maxes.copy_(new_row_maxes)
|
||||
row_sums.copy_(new_row_sums)
|
||||
|
||||
ctx.args = (causal, scale, mask, q_bucket_size, k_bucket_size)
|
||||
ctx.save_for_backward(q, k, v, o, all_row_sums, all_row_maxes)
|
||||
|
||||
return o
|
||||
|
||||
@staticmethod
|
||||
@torch.no_grad()
|
||||
def backward(ctx, do):
|
||||
"""Algorithm 4 in the paper"""
|
||||
|
||||
causal, scale, mask, q_bucket_size, k_bucket_size = ctx.args
|
||||
q, k, v, o, l, m = ctx.saved_tensors
|
||||
|
||||
device = q.device
|
||||
|
||||
max_neg_value = -torch.finfo(q.dtype).max
|
||||
qk_len_diff = max(k.shape[-2] - q.shape[-2], 0)
|
||||
|
||||
dq = torch.zeros_like(q)
|
||||
dk = torch.zeros_like(k)
|
||||
dv = torch.zeros_like(v)
|
||||
|
||||
row_splits = zip(
|
||||
q.split(q_bucket_size, dim=-2),
|
||||
o.split(q_bucket_size, dim=-2),
|
||||
do.split(q_bucket_size, dim=-2),
|
||||
mask,
|
||||
l.split(q_bucket_size, dim=-2),
|
||||
m.split(q_bucket_size, dim=-2),
|
||||
dq.split(q_bucket_size, dim=-2),
|
||||
)
|
||||
|
||||
for ind, (qc, oc, doc, row_mask, lc, mc, dqc) in enumerate(row_splits):
|
||||
q_start_index = ind * q_bucket_size - qk_len_diff
|
||||
|
||||
col_splits = zip(
|
||||
k.split(k_bucket_size, dim=-2),
|
||||
v.split(k_bucket_size, dim=-2),
|
||||
dk.split(k_bucket_size, dim=-2),
|
||||
dv.split(k_bucket_size, dim=-2),
|
||||
)
|
||||
|
||||
for k_ind, (kc, vc, dkc, dvc) in enumerate(col_splits):
|
||||
k_start_index = k_ind * k_bucket_size
|
||||
|
||||
attn_weights = (
|
||||
torch.einsum("... i d, ... j d -> ... i j", qc, kc) * scale
|
||||
)
|
||||
|
||||
if causal and q_start_index < (k_start_index + k_bucket_size - 1):
|
||||
causal_mask = torch.ones(
|
||||
(qc.shape[-2], kc.shape[-2]), dtype=torch.bool, device=device
|
||||
).triu(q_start_index - k_start_index + 1)
|
||||
attn_weights.masked_fill_(causal_mask, max_neg_value)
|
||||
|
||||
exp_attn_weights = torch.exp(attn_weights - mc)
|
||||
|
||||
if row_mask is not None:
|
||||
exp_attn_weights.masked_fill_(~row_mask, 0.0)
|
||||
|
||||
p = exp_attn_weights / lc
|
||||
|
||||
dv_chunk = torch.einsum("... i j, ... i d -> ... j d", p, doc)
|
||||
dp = torch.einsum("... i d, ... j d -> ... i j", doc, vc)
|
||||
|
||||
D = (doc * oc).sum(dim=-1, keepdims=True)
|
||||
ds = p * scale * (dp - D)
|
||||
|
||||
dq_chunk = torch.einsum("... i j, ... j d -> ... i d", ds, kc)
|
||||
dk_chunk = torch.einsum("... i j, ... i d -> ... j d", ds, qc)
|
||||
|
||||
dqc.add_(dq_chunk)
|
||||
dkc.add_(dk_chunk)
|
||||
dvc.add_(dv_chunk)
|
||||
|
||||
return dq, dk, dv, None, None, None, None
|
||||
|
||||
|
||||
class FlashAttnProcessor:
|
||||
def __call__(
|
||||
self,
|
||||
attn: Attention,
|
||||
hidden_states,
|
||||
encoder_hidden_states=None,
|
||||
attention_mask=None,
|
||||
) -> Any:
|
||||
q_bucket_size = 512
|
||||
k_bucket_size = 1024
|
||||
|
||||
h = attn.heads
|
||||
q = attn.to_q(hidden_states)
|
||||
|
||||
encoder_hidden_states = (
|
||||
encoder_hidden_states
|
||||
if encoder_hidden_states is not None
|
||||
else hidden_states
|
||||
)
|
||||
encoder_hidden_states = encoder_hidden_states.to(hidden_states.dtype)
|
||||
|
||||
if hasattr(attn, "hypernetwork") and attn.hypernetwork is not None:
|
||||
context_k, context_v = attn.hypernetwork.forward(
|
||||
hidden_states, encoder_hidden_states
|
||||
)
|
||||
context_k = context_k.to(hidden_states.dtype)
|
||||
context_v = context_v.to(hidden_states.dtype)
|
||||
else:
|
||||
context_k = encoder_hidden_states
|
||||
context_v = encoder_hidden_states
|
||||
|
||||
k = attn.to_k(context_k)
|
||||
v = attn.to_v(context_v)
|
||||
del encoder_hidden_states, hidden_states
|
||||
|
||||
q, k, v = map(lambda t: rearrange(t, "b n (h d) -> b h n d", h=h), (q, k, v))
|
||||
|
||||
out = FlashAttentionFunction.apply(
|
||||
q, k, v, attention_mask, False, q_bucket_size, k_bucket_size
|
||||
)
|
||||
|
||||
out = rearrange(out, "b h n d -> b n (h d)")
|
||||
|
||||
out = attn.to_out[0](out)
|
||||
out = attn.to_out[1](out)
|
||||
return out
|
||||
744
library/chroma_models.py
Normal file
744
library/chroma_models.py
Normal file
@@ -0,0 +1,744 @@
|
||||
# copy from the official repo: https://github.com/lodestone-rock/flow/blob/master/src/models/chroma/model.py
|
||||
# and modified
|
||||
# licensed under Apache License 2.0
|
||||
|
||||
import math
|
||||
from dataclasses import dataclass
|
||||
|
||||
import torch
|
||||
from einops import rearrange
|
||||
from torch import Tensor, nn
|
||||
import torch.nn.functional as F
|
||||
import torch.utils.checkpoint as ckpt
|
||||
|
||||
from .flux_models import attention, rope, apply_rope, EmbedND, timestep_embedding, MLPEmbedder, RMSNorm, QKNorm, SelfAttention, Flux
|
||||
from . import custom_offloading_utils
|
||||
|
||||
|
||||
def distribute_modulations(tensor: torch.Tensor, depth_single_blocks, depth_double_blocks):
|
||||
"""
|
||||
Distributes slices of the tensor into the block_dict as ModulationOut objects.
|
||||
|
||||
Args:
|
||||
tensor (torch.Tensor): Input tensor with shape [batch_size, vectors, dim].
|
||||
"""
|
||||
batch_size, vectors, dim = tensor.shape
|
||||
|
||||
block_dict = {}
|
||||
|
||||
# HARD CODED VALUES! lookup table for the generated vectors
|
||||
# TODO: move this into chroma config!
|
||||
# Add 38 single mod blocks
|
||||
for i in range(depth_single_blocks):
|
||||
key = f"single_blocks.{i}.modulation.lin"
|
||||
block_dict[key] = None
|
||||
|
||||
# Add 19 image double blocks
|
||||
for i in range(depth_double_blocks):
|
||||
key = f"double_blocks.{i}.img_mod.lin"
|
||||
block_dict[key] = None
|
||||
|
||||
# Add 19 text double blocks
|
||||
for i in range(depth_double_blocks):
|
||||
key = f"double_blocks.{i}.txt_mod.lin"
|
||||
block_dict[key] = None
|
||||
|
||||
# Add the final layer
|
||||
block_dict["final_layer.adaLN_modulation.1"] = None
|
||||
# 6.2b version
|
||||
# block_dict["lite_double_blocks.4.img_mod.lin"] = None
|
||||
# block_dict["lite_double_blocks.4.txt_mod.lin"] = None
|
||||
|
||||
idx = 0 # Index to keep track of the vector slices
|
||||
|
||||
for key in block_dict.keys():
|
||||
if "single_blocks" in key:
|
||||
# Single block: 1 ModulationOut
|
||||
block_dict[key] = ModulationOut(
|
||||
shift=tensor[:, idx : idx + 1, :],
|
||||
scale=tensor[:, idx + 1 : idx + 2, :],
|
||||
gate=tensor[:, idx + 2 : idx + 3, :],
|
||||
)
|
||||
idx += 3 # Advance by 3 vectors
|
||||
|
||||
elif "img_mod" in key:
|
||||
# Double block: List of 2 ModulationOut
|
||||
double_block = []
|
||||
for _ in range(2): # Create 2 ModulationOut objects
|
||||
double_block.append(
|
||||
ModulationOut(
|
||||
shift=tensor[:, idx : idx + 1, :],
|
||||
scale=tensor[:, idx + 1 : idx + 2, :],
|
||||
gate=tensor[:, idx + 2 : idx + 3, :],
|
||||
)
|
||||
)
|
||||
idx += 3 # Advance by 3 vectors per ModulationOut
|
||||
block_dict[key] = double_block
|
||||
|
||||
elif "txt_mod" in key:
|
||||
# Double block: List of 2 ModulationOut
|
||||
double_block = []
|
||||
for _ in range(2): # Create 2 ModulationOut objects
|
||||
double_block.append(
|
||||
ModulationOut(
|
||||
shift=tensor[:, idx : idx + 1, :],
|
||||
scale=tensor[:, idx + 1 : idx + 2, :],
|
||||
gate=tensor[:, idx + 2 : idx + 3, :],
|
||||
)
|
||||
)
|
||||
idx += 3 # Advance by 3 vectors per ModulationOut
|
||||
block_dict[key] = double_block
|
||||
|
||||
elif "final_layer" in key:
|
||||
# Final layer: 1 ModulationOut
|
||||
block_dict[key] = [
|
||||
tensor[:, idx : idx + 1, :],
|
||||
tensor[:, idx + 1 : idx + 2, :],
|
||||
]
|
||||
idx += 2 # Advance by 3 vectors
|
||||
|
||||
return block_dict
|
||||
|
||||
|
||||
class Approximator(nn.Module):
|
||||
def __init__(self, in_dim: int, out_dim: int, hidden_dim: int, n_layers=4):
|
||||
super().__init__()
|
||||
self.in_proj = nn.Linear(in_dim, hidden_dim, bias=True)
|
||||
self.layers = nn.ModuleList([MLPEmbedder(hidden_dim, hidden_dim) for x in range(n_layers)])
|
||||
self.norms = nn.ModuleList([RMSNorm(hidden_dim) for x in range(n_layers)])
|
||||
self.out_proj = nn.Linear(hidden_dim, out_dim)
|
||||
|
||||
@property
|
||||
def device(self):
|
||||
# Get the device of the module (assumes all parameters are on the same device)
|
||||
return next(self.parameters()).device
|
||||
|
||||
def enable_gradient_checkpointing(self):
|
||||
for layer in self.layers:
|
||||
layer.enable_gradient_checkpointing()
|
||||
|
||||
def disable_gradient_checkpointing(self):
|
||||
for layer in self.layers:
|
||||
layer.disable_gradient_checkpointing()
|
||||
|
||||
def forward(self, x: Tensor) -> Tensor:
|
||||
x = self.in_proj(x)
|
||||
|
||||
for layer, norms in zip(self.layers, self.norms):
|
||||
x = x + layer(norms(x))
|
||||
|
||||
x = self.out_proj(x)
|
||||
|
||||
return x
|
||||
|
||||
|
||||
@dataclass
|
||||
class ModulationOut:
|
||||
shift: Tensor
|
||||
scale: Tensor
|
||||
gate: Tensor
|
||||
|
||||
|
||||
def _modulation_shift_scale_fn(x, scale, shift):
|
||||
return (1 + scale) * x + shift
|
||||
|
||||
|
||||
def _modulation_gate_fn(x, gate, gate_params):
|
||||
return x + gate * gate_params
|
||||
|
||||
|
||||
class DoubleStreamBlock(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: int,
|
||||
num_heads: int,
|
||||
mlp_ratio: float,
|
||||
qkv_bias: bool = False,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
mlp_hidden_dim = int(hidden_size * mlp_ratio)
|
||||
self.num_heads = num_heads
|
||||
self.hidden_size = hidden_size
|
||||
self.img_norm1 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
|
||||
self.img_attn = SelfAttention(
|
||||
dim=hidden_size,
|
||||
num_heads=num_heads,
|
||||
qkv_bias=qkv_bias,
|
||||
)
|
||||
|
||||
self.img_norm2 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
|
||||
self.img_mlp = nn.Sequential(
|
||||
nn.Linear(hidden_size, mlp_hidden_dim, bias=True),
|
||||
nn.GELU(approximate="tanh"),
|
||||
nn.Linear(mlp_hidden_dim, hidden_size, bias=True),
|
||||
)
|
||||
|
||||
self.txt_norm1 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
|
||||
self.txt_attn = SelfAttention(
|
||||
dim=hidden_size,
|
||||
num_heads=num_heads,
|
||||
qkv_bias=qkv_bias,
|
||||
)
|
||||
|
||||
self.txt_norm2 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
|
||||
self.txt_mlp = nn.Sequential(
|
||||
nn.Linear(hidden_size, mlp_hidden_dim, bias=True),
|
||||
nn.GELU(approximate="tanh"),
|
||||
nn.Linear(mlp_hidden_dim, hidden_size, bias=True),
|
||||
)
|
||||
|
||||
self.gradient_checkpointing = False
|
||||
|
||||
@property
|
||||
def device(self):
|
||||
# Get the device of the module (assumes all parameters are on the same device)
|
||||
return next(self.parameters()).device
|
||||
|
||||
def modulation_shift_scale_fn(self, x, scale, shift):
|
||||
return _modulation_shift_scale_fn(x, scale, shift)
|
||||
|
||||
def modulation_gate_fn(self, x, gate, gate_params):
|
||||
return _modulation_gate_fn(x, gate, gate_params)
|
||||
|
||||
def enable_gradient_checkpointing(self):
|
||||
self.gradient_checkpointing = True
|
||||
|
||||
def disable_gradient_checkpointing(self):
|
||||
self.gradient_checkpointing = False
|
||||
|
||||
def _forward(
|
||||
self,
|
||||
img: Tensor,
|
||||
txt: Tensor,
|
||||
pe: list[Tensor],
|
||||
distill_vec: list[ModulationOut],
|
||||
txt_seq_len: Tensor,
|
||||
) -> tuple[Tensor, Tensor]:
|
||||
(img_mod1, img_mod2), (txt_mod1, txt_mod2) = distill_vec
|
||||
|
||||
# prepare image for attention
|
||||
img_modulated = self.img_norm1(img)
|
||||
# replaced with compiled fn
|
||||
# img_modulated = (1 + img_mod1.scale) * img_modulated + img_mod1.shift
|
||||
img_modulated = self.modulation_shift_scale_fn(img_modulated, img_mod1.scale, img_mod1.shift)
|
||||
img_qkv = self.img_attn.qkv(img_modulated)
|
||||
del img_modulated
|
||||
|
||||
img_q, img_k, img_v = rearrange(img_qkv, "B L (K H D) -> K B H L D", K=3, H=self.num_heads)
|
||||
del img_qkv
|
||||
img_q, img_k = self.img_attn.norm(img_q, img_k, img_v)
|
||||
|
||||
# prepare txt for attention
|
||||
txt_modulated = self.txt_norm1(txt)
|
||||
# replaced with compiled fn
|
||||
# txt_modulated = (1 + txt_mod1.scale) * txt_modulated + txt_mod1.shift
|
||||
txt_modulated = self.modulation_shift_scale_fn(txt_modulated, txt_mod1.scale, txt_mod1.shift)
|
||||
txt_qkv = self.txt_attn.qkv(txt_modulated)
|
||||
del txt_modulated
|
||||
|
||||
txt_q, txt_k, txt_v = rearrange(txt_qkv, "B L (K H D) -> K B H L D", K=3, H=self.num_heads)
|
||||
del txt_qkv
|
||||
txt_q, txt_k = self.txt_attn.norm(txt_q, txt_k, txt_v)
|
||||
|
||||
# run actual attention: we split the batch into each element
|
||||
max_txt_len = torch.max(txt_seq_len).item()
|
||||
img_len = img_q.shape[-2] # max 64
|
||||
txt_q = list(torch.chunk(txt_q, txt_q.shape[0], dim=0)) # list of [B, H, L, D] tensors
|
||||
txt_k = list(torch.chunk(txt_k, txt_k.shape[0], dim=0))
|
||||
txt_v = list(torch.chunk(txt_v, txt_v.shape[0], dim=0))
|
||||
img_q = list(torch.chunk(img_q, img_q.shape[0], dim=0))
|
||||
img_k = list(torch.chunk(img_k, img_k.shape[0], dim=0))
|
||||
img_v = list(torch.chunk(img_v, img_v.shape[0], dim=0))
|
||||
txt_attn = []
|
||||
img_attn = []
|
||||
for i in range(txt.shape[0]):
|
||||
txt_q[i] = txt_q[i][:, :, : txt_seq_len[i]]
|
||||
q = torch.cat((img_q[i], txt_q[i]), dim=2)
|
||||
txt_q[i] = None
|
||||
img_q[i] = None
|
||||
|
||||
txt_k[i] = txt_k[i][:, :, : txt_seq_len[i]]
|
||||
k = torch.cat((img_k[i], txt_k[i]), dim=2)
|
||||
txt_k[i] = None
|
||||
img_k[i] = None
|
||||
|
||||
txt_v[i] = txt_v[i][:, :, : txt_seq_len[i]]
|
||||
v = torch.cat((img_v[i], txt_v[i]), dim=2)
|
||||
txt_v[i] = None
|
||||
img_v[i] = None
|
||||
|
||||
attn = attention(q, k, v, pe=pe[i : i + 1, :, : q.shape[2]], attn_mask=None) # attn = (1, L, D)
|
||||
del q, k, v
|
||||
img_attn_i = attn[:, :img_len, :]
|
||||
txt_attn_i = torch.zeros((1, max_txt_len, attn.shape[-1]), dtype=attn.dtype, device=self.device)
|
||||
txt_attn_i[:, : txt_seq_len[i], :] = attn[:, img_len:, :]
|
||||
del attn
|
||||
txt_attn.append(txt_attn_i)
|
||||
img_attn.append(img_attn_i)
|
||||
|
||||
txt_attn = torch.cat(txt_attn, dim=0)
|
||||
img_attn = torch.cat(img_attn, dim=0)
|
||||
|
||||
# q = torch.cat((txt_q, img_q), dim=2)
|
||||
# k = torch.cat((txt_k, img_k), dim=2)
|
||||
# v = torch.cat((txt_v, img_v), dim=2)
|
||||
|
||||
# attn = attention(q, k, v, pe=pe, attn_mask=mask)
|
||||
# txt_attn, img_attn = attn[:, : txt.shape[1]], attn[:, txt.shape[1] :]
|
||||
|
||||
# calculate the img blocks
|
||||
# replaced with compiled fn
|
||||
# img = img + img_mod1.gate * self.img_attn.proj(img_attn)
|
||||
# img = img + img_mod2.gate * self.img_mlp((1 + img_mod2.scale) * self.img_norm2(img) + img_mod2.shift)
|
||||
img = self.modulation_gate_fn(img, img_mod1.gate, self.img_attn.proj(img_attn))
|
||||
del img_attn, img_mod1
|
||||
img = self.modulation_gate_fn(
|
||||
img,
|
||||
img_mod2.gate,
|
||||
self.img_mlp(self.modulation_shift_scale_fn(self.img_norm2(img), img_mod2.scale, img_mod2.shift)),
|
||||
)
|
||||
del img_mod2
|
||||
|
||||
# calculate the txt blocks
|
||||
# replaced with compiled fn
|
||||
# txt = txt + txt_mod1.gate * self.txt_attn.proj(txt_attn)
|
||||
# txt = txt + txt_mod2.gate * self.txt_mlp((1 + txt_mod2.scale) * self.txt_norm2(txt) + txt_mod2.shift)
|
||||
txt = self.modulation_gate_fn(txt, txt_mod1.gate, self.txt_attn.proj(txt_attn))
|
||||
del txt_attn, txt_mod1
|
||||
txt = self.modulation_gate_fn(
|
||||
txt,
|
||||
txt_mod2.gate,
|
||||
self.txt_mlp(self.modulation_shift_scale_fn(self.txt_norm2(txt), txt_mod2.scale, txt_mod2.shift)),
|
||||
)
|
||||
del txt_mod2
|
||||
|
||||
return img, txt
|
||||
|
||||
def forward(
|
||||
self,
|
||||
img: Tensor,
|
||||
txt: Tensor,
|
||||
pe: Tensor,
|
||||
distill_vec: list[ModulationOut],
|
||||
txt_seq_len: Tensor,
|
||||
) -> tuple[Tensor, Tensor]:
|
||||
if self.training and self.gradient_checkpointing:
|
||||
return ckpt.checkpoint(self._forward, img, txt, pe, distill_vec, txt_seq_len, use_reentrant=False)
|
||||
else:
|
||||
return self._forward(img, txt, pe, distill_vec, txt_seq_len)
|
||||
|
||||
|
||||
class SingleStreamBlock(nn.Module):
|
||||
"""
|
||||
A DiT block with parallel linear layers as described in
|
||||
https://arxiv.org/abs/2302.05442 and adapted modulation interface.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: int,
|
||||
num_heads: int,
|
||||
mlp_ratio: float = 4.0,
|
||||
qk_scale: float | None = None,
|
||||
):
|
||||
super().__init__()
|
||||
self.hidden_dim = hidden_size
|
||||
self.num_heads = num_heads
|
||||
head_dim = hidden_size // num_heads
|
||||
self.scale = qk_scale or head_dim**-0.5
|
||||
|
||||
self.mlp_hidden_dim = int(hidden_size * mlp_ratio)
|
||||
# qkv and mlp_in
|
||||
self.linear1 = nn.Linear(hidden_size, hidden_size * 3 + self.mlp_hidden_dim)
|
||||
# proj and mlp_out
|
||||
self.linear2 = nn.Linear(hidden_size + self.mlp_hidden_dim, hidden_size)
|
||||
|
||||
self.norm = QKNorm(head_dim)
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
self.pre_norm = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
|
||||
|
||||
self.mlp_act = nn.GELU(approximate="tanh")
|
||||
|
||||
self.gradient_checkpointing = False
|
||||
|
||||
@property
|
||||
def device(self):
|
||||
# Get the device of the module (assumes all parameters are on the same device)
|
||||
return next(self.parameters()).device
|
||||
|
||||
def modulation_shift_scale_fn(self, x, scale, shift):
|
||||
return _modulation_shift_scale_fn(x, scale, shift)
|
||||
|
||||
def modulation_gate_fn(self, x, gate, gate_params):
|
||||
return _modulation_gate_fn(x, gate, gate_params)
|
||||
|
||||
def enable_gradient_checkpointing(self):
|
||||
self.gradient_checkpointing = True
|
||||
|
||||
def disable_gradient_checkpointing(self):
|
||||
self.gradient_checkpointing = False
|
||||
|
||||
def _forward(self, x: Tensor, pe: list[Tensor], distill_vec: list[ModulationOut], txt_seq_len: Tensor) -> Tensor:
|
||||
mod = distill_vec
|
||||
# replaced with compiled fn
|
||||
# x_mod = (1 + mod.scale) * self.pre_norm(x) + mod.shift
|
||||
x_mod = self.modulation_shift_scale_fn(self.pre_norm(x), mod.scale, mod.shift)
|
||||
qkv, mlp = torch.split(self.linear1(x_mod), [3 * self.hidden_size, self.mlp_hidden_dim], dim=-1)
|
||||
del x_mod
|
||||
|
||||
q, k, v = rearrange(qkv, "B L (K H D) -> K B H L D", K=3, H=self.num_heads)
|
||||
del qkv
|
||||
q, k = self.norm(q, k, v)
|
||||
|
||||
# # compute attention
|
||||
# attn = attention(q, k, v, pe=pe, attn_mask=mask)
|
||||
|
||||
# compute attention: we split the batch into each element
|
||||
max_txt_len = torch.max(txt_seq_len).item()
|
||||
img_len = q.shape[-2] - max_txt_len
|
||||
q = list(torch.chunk(q, q.shape[0], dim=0))
|
||||
k = list(torch.chunk(k, k.shape[0], dim=0))
|
||||
v = list(torch.chunk(v, v.shape[0], dim=0))
|
||||
attn = []
|
||||
for i in range(x.size(0)):
|
||||
q[i] = q[i][:, :, : img_len + txt_seq_len[i]]
|
||||
k[i] = k[i][:, :, : img_len + txt_seq_len[i]]
|
||||
v[i] = v[i][:, :, : img_len + txt_seq_len[i]]
|
||||
attn_trimmed = attention(q[i], k[i], v[i], pe=pe[i : i + 1, :, : img_len + txt_seq_len[i]], attn_mask=None)
|
||||
q[i] = None
|
||||
k[i] = None
|
||||
v[i] = None
|
||||
|
||||
attn_i = torch.zeros((1, x.shape[1], attn_trimmed.shape[-1]), dtype=attn_trimmed.dtype, device=self.device)
|
||||
attn_i[:, : img_len + txt_seq_len[i], :] = attn_trimmed
|
||||
del attn_trimmed
|
||||
attn.append(attn_i)
|
||||
|
||||
attn = torch.cat(attn, dim=0)
|
||||
|
||||
# compute activation in mlp stream, cat again and run second linear layer
|
||||
mlp = self.mlp_act(mlp)
|
||||
output = self.linear2(torch.cat((attn, mlp), 2))
|
||||
del attn, mlp
|
||||
# replaced with compiled fn
|
||||
# return x + mod.gate * output
|
||||
return self.modulation_gate_fn(x, mod.gate, output)
|
||||
|
||||
def forward(self, x: Tensor, pe: Tensor, distill_vec: list[ModulationOut], txt_seq_len: Tensor) -> Tensor:
|
||||
if self.training and self.gradient_checkpointing:
|
||||
return ckpt.checkpoint(self._forward, x, pe, distill_vec, txt_seq_len, use_reentrant=False)
|
||||
else:
|
||||
return self._forward(x, pe, distill_vec, txt_seq_len)
|
||||
|
||||
|
||||
class LastLayer(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: int,
|
||||
patch_size: int,
|
||||
out_channels: int,
|
||||
):
|
||||
super().__init__()
|
||||
self.norm_final = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
|
||||
self.linear = nn.Linear(hidden_size, patch_size * patch_size * out_channels, bias=True)
|
||||
|
||||
@property
|
||||
def device(self):
|
||||
# Get the device of the module (assumes all parameters are on the same device)
|
||||
return next(self.parameters()).device
|
||||
|
||||
def modulation_shift_scale_fn(self, x, scale, shift):
|
||||
return _modulation_shift_scale_fn(x, scale, shift)
|
||||
|
||||
def forward(self, x: Tensor, distill_vec: list[Tensor]) -> Tensor:
|
||||
shift, scale = distill_vec
|
||||
shift = shift.squeeze(1)
|
||||
scale = scale.squeeze(1)
|
||||
# replaced with compiled fn
|
||||
# x = (1 + scale[:, None, :]) * self.norm_final(x) + shift[:, None, :]
|
||||
x = self.modulation_shift_scale_fn(self.norm_final(x), scale[:, None, :], shift[:, None, :])
|
||||
x = self.linear(x)
|
||||
return x
|
||||
|
||||
|
||||
@dataclass
|
||||
class ChromaParams:
|
||||
in_channels: int
|
||||
context_in_dim: int
|
||||
hidden_size: int
|
||||
mlp_ratio: float
|
||||
num_heads: int
|
||||
depth: int
|
||||
depth_single_blocks: int
|
||||
axes_dim: list[int]
|
||||
theta: int
|
||||
qkv_bias: bool
|
||||
guidance_embed: bool
|
||||
approximator_in_dim: int
|
||||
approximator_depth: int
|
||||
approximator_hidden_size: int
|
||||
_use_compiled: bool
|
||||
|
||||
|
||||
chroma_params = ChromaParams(
|
||||
in_channels=64,
|
||||
context_in_dim=4096,
|
||||
hidden_size=3072,
|
||||
mlp_ratio=4.0,
|
||||
num_heads=24,
|
||||
depth=19,
|
||||
depth_single_blocks=38,
|
||||
axes_dim=[16, 56, 56],
|
||||
theta=10_000,
|
||||
qkv_bias=True,
|
||||
guidance_embed=True,
|
||||
approximator_in_dim=64,
|
||||
approximator_depth=5,
|
||||
approximator_hidden_size=5120,
|
||||
_use_compiled=False,
|
||||
)
|
||||
|
||||
|
||||
def modify_mask_to_attend_padding(mask, max_seq_length, num_extra_padding=8):
|
||||
"""
|
||||
Modifies attention mask to allow attention to a few extra padding tokens.
|
||||
|
||||
Args:
|
||||
mask: Original attention mask (1 for tokens to attend to, 0 for masked tokens)
|
||||
max_seq_length: Maximum sequence length of the model
|
||||
num_extra_padding: Number of padding tokens to unmask
|
||||
|
||||
Returns:
|
||||
Modified mask
|
||||
"""
|
||||
# Get the actual sequence length from the mask
|
||||
seq_length = mask.sum(dim=-1)
|
||||
batch_size = mask.shape[0]
|
||||
|
||||
modified_mask = mask.clone()
|
||||
|
||||
for i in range(batch_size):
|
||||
current_seq_len = int(seq_length[i].item())
|
||||
|
||||
# Only add extra padding tokens if there's room
|
||||
if current_seq_len < max_seq_length:
|
||||
# Calculate how many padding tokens we can unmask
|
||||
available_padding = max_seq_length - current_seq_len
|
||||
tokens_to_unmask = min(num_extra_padding, available_padding)
|
||||
|
||||
# Unmask the specified number of padding tokens right after the sequence
|
||||
modified_mask[i, current_seq_len : current_seq_len + tokens_to_unmask] = 1
|
||||
|
||||
return modified_mask
|
||||
|
||||
|
||||
class Chroma(Flux):
|
||||
"""
|
||||
Transformer model for flow matching on sequences.
|
||||
"""
|
||||
|
||||
def __init__(self, params: ChromaParams):
|
||||
nn.Module.__init__(self)
|
||||
self.params = params
|
||||
self.in_channels = params.in_channels
|
||||
self.out_channels = self.in_channels
|
||||
if params.hidden_size % params.num_heads != 0:
|
||||
raise ValueError(f"Hidden size {params.hidden_size} must be divisible by num_heads {params.num_heads}")
|
||||
pe_dim = params.hidden_size // params.num_heads
|
||||
if sum(params.axes_dim) != pe_dim:
|
||||
raise ValueError(f"Got {params.axes_dim} but expected positional dim {pe_dim}")
|
||||
self.hidden_size = params.hidden_size
|
||||
self.num_heads = params.num_heads
|
||||
self.pe_embedder = EmbedND(dim=pe_dim, theta=params.theta, axes_dim=params.axes_dim)
|
||||
self.img_in = nn.Linear(self.in_channels, self.hidden_size, bias=True)
|
||||
|
||||
# TODO: need proper mapping for this approximator output!
|
||||
# currently the mapping is hardcoded in distribute_modulations function
|
||||
self.distilled_guidance_layer = Approximator(
|
||||
params.approximator_in_dim,
|
||||
self.hidden_size,
|
||||
params.approximator_hidden_size,
|
||||
params.approximator_depth,
|
||||
)
|
||||
self.txt_in = nn.Linear(params.context_in_dim, self.hidden_size)
|
||||
|
||||
self.double_blocks = nn.ModuleList(
|
||||
[
|
||||
DoubleStreamBlock(
|
||||
self.hidden_size,
|
||||
self.num_heads,
|
||||
mlp_ratio=params.mlp_ratio,
|
||||
qkv_bias=params.qkv_bias,
|
||||
)
|
||||
for _ in range(params.depth)
|
||||
]
|
||||
)
|
||||
|
||||
self.single_blocks = nn.ModuleList(
|
||||
[
|
||||
SingleStreamBlock(
|
||||
self.hidden_size,
|
||||
self.num_heads,
|
||||
mlp_ratio=params.mlp_ratio,
|
||||
)
|
||||
for _ in range(params.depth_single_blocks)
|
||||
]
|
||||
)
|
||||
|
||||
self.final_layer = LastLayer(
|
||||
self.hidden_size,
|
||||
1,
|
||||
self.out_channels,
|
||||
)
|
||||
|
||||
# TODO: move this hardcoded value to config
|
||||
# single layer has 3 modulation vectors
|
||||
# double layer has 6 modulation vectors for each expert
|
||||
# final layer has 2 modulation vectors
|
||||
self.mod_index_length = 3 * params.depth_single_blocks + 2 * 6 * params.depth + 2
|
||||
self.depth_single_blocks = params.depth_single_blocks
|
||||
self.depth_double_blocks = params.depth
|
||||
# self.mod_index = torch.tensor(list(range(self.mod_index_length)), device=0)
|
||||
self.register_buffer(
|
||||
"mod_index",
|
||||
torch.tensor(list(range(self.mod_index_length)), device="cpu"),
|
||||
persistent=False,
|
||||
)
|
||||
self.approximator_in_dim = params.approximator_in_dim
|
||||
|
||||
self.blocks_to_swap = None
|
||||
self.offloader_double = None
|
||||
self.offloader_single = None
|
||||
self.num_double_blocks = len(self.double_blocks)
|
||||
self.num_single_blocks = len(self.single_blocks)
|
||||
|
||||
# Initialize properties required by Flux parent class
|
||||
self.gradient_checkpointing = False
|
||||
self.cpu_offload_checkpointing = False
|
||||
|
||||
def get_model_type(self) -> str:
|
||||
return "chroma"
|
||||
|
||||
def enable_gradient_checkpointing(self, cpu_offload: bool = False):
|
||||
self.gradient_checkpointing = True
|
||||
self.cpu_offload_checkpointing = cpu_offload
|
||||
|
||||
self.distilled_guidance_layer.enable_gradient_checkpointing()
|
||||
for block in self.double_blocks + self.single_blocks:
|
||||
block.enable_gradient_checkpointing()
|
||||
|
||||
print(f"Chroma: Gradient checkpointing enabled.")
|
||||
|
||||
def disable_gradient_checkpointing(self):
|
||||
self.gradient_checkpointing = False
|
||||
self.cpu_offload_checkpointing = False
|
||||
|
||||
self.distilled_guidance_layer.disable_gradient_checkpointing()
|
||||
for block in self.double_blocks + self.single_blocks:
|
||||
block.disable_gradient_checkpointing()
|
||||
|
||||
print("Chroma: Gradient checkpointing disabled.")
|
||||
|
||||
def get_mod_vectors(self, timesteps: Tensor, guidance: Tensor | None = None, batch_size: int | None = None) -> Tensor:
|
||||
# We extract this logic from forward to clarify the propagation of the gradients
|
||||
# original comment: https://github.com/lodestone-rock/flow/blob/c76f63058980d0488826936025889e256a2e0458/src/models/chroma/model.py#L195
|
||||
|
||||
# print(f"Chroma get_input_vec: timesteps {timesteps}, guidance: {guidance}, batch_size: {batch_size}")
|
||||
distill_timestep = timestep_embedding(timesteps, self.approximator_in_dim // 4)
|
||||
# TODO: need to add toggle to omit this from schnell but that's not a priority
|
||||
distil_guidance = timestep_embedding(guidance, self.approximator_in_dim // 4)
|
||||
# get all modulation index
|
||||
modulation_index = timestep_embedding(self.mod_index, self.approximator_in_dim // 2)
|
||||
# we need to broadcast the modulation index here so each batch has all of the index
|
||||
modulation_index = modulation_index.unsqueeze(0).repeat(batch_size, 1, 1)
|
||||
# and we need to broadcast timestep and guidance along too
|
||||
timestep_guidance = torch.cat([distill_timestep, distil_guidance], dim=1).unsqueeze(1).repeat(1, self.mod_index_length, 1)
|
||||
# then and only then we could concatenate it together
|
||||
input_vec = torch.cat([timestep_guidance, modulation_index], dim=-1)
|
||||
|
||||
mod_vectors = self.distilled_guidance_layer(input_vec)
|
||||
return mod_vectors
|
||||
|
||||
def forward(
|
||||
self,
|
||||
img: Tensor,
|
||||
img_ids: Tensor,
|
||||
txt: Tensor,
|
||||
txt_ids: Tensor,
|
||||
timesteps: Tensor,
|
||||
y: Tensor,
|
||||
block_controlnet_hidden_states=None,
|
||||
block_controlnet_single_hidden_states=None,
|
||||
guidance: Tensor | None = None,
|
||||
txt_attention_mask: Tensor | None = None,
|
||||
attn_padding: int = 1,
|
||||
mod_vectors: Tensor | None = None,
|
||||
) -> Tensor:
|
||||
# print(
|
||||
# f"Chroma forward: img shape {img.shape}, txt shape {txt.shape}, img_ids shape {img_ids.shape}, txt_ids shape {txt_ids.shape}"
|
||||
# )
|
||||
# print(f"input_vec shape: {input_vec.shape if input_vec is not None else 'None'}")
|
||||
# print(f"timesteps: {timesteps}, guidance: {guidance}")
|
||||
|
||||
if img.ndim != 3 or txt.ndim != 3:
|
||||
raise ValueError("Input img and txt tensors must have 3 dimensions.")
|
||||
|
||||
# running on sequences img
|
||||
img = self.img_in(img)
|
||||
txt = self.txt_in(txt)
|
||||
|
||||
if mod_vectors is None: # fallback to the original logic
|
||||
with torch.no_grad():
|
||||
mod_vectors = self.get_mod_vectors(timesteps, guidance, img.shape[0])
|
||||
mod_vectors_dict = distribute_modulations(mod_vectors, self.depth_single_blocks, self.depth_double_blocks)
|
||||
|
||||
# calculate text length for each batch instead of masking
|
||||
txt_emb_len = txt.shape[1]
|
||||
txt_seq_len = txt_attention_mask[:, :txt_emb_len].sum(dim=-1).to(torch.int64) # (batch_size, )
|
||||
txt_seq_len = torch.clip(txt_seq_len + attn_padding, 0, txt_emb_len)
|
||||
max_txt_len = torch.max(txt_seq_len).item() # max text length in the batch
|
||||
# print(f"max_txt_len: {max_txt_len}, txt_seq_len: {txt_seq_len}")
|
||||
|
||||
# trim txt embedding to the text length
|
||||
txt = txt[:, :max_txt_len, :]
|
||||
|
||||
# create positional encoding for the text and image
|
||||
ids = torch.cat((img_ids, txt_ids[:, :max_txt_len]), dim=1) # reverse order of ids for faster attention
|
||||
pe = self.pe_embedder(ids) # B, 1, seq_length, 64, 2, 2
|
||||
|
||||
for i, block in enumerate(self.double_blocks):
|
||||
if self.blocks_to_swap:
|
||||
self.offloader_double.wait_for_block(i)
|
||||
|
||||
# the guidance replaced by FFN output
|
||||
img_mod = mod_vectors_dict.pop(f"double_blocks.{i}.img_mod.lin")
|
||||
txt_mod = mod_vectors_dict.pop(f"double_blocks.{i}.txt_mod.lin")
|
||||
double_mod = [img_mod, txt_mod]
|
||||
del img_mod, txt_mod
|
||||
|
||||
img, txt = block(img=img, txt=txt, pe=pe, distill_vec=double_mod, txt_seq_len=txt_seq_len)
|
||||
del double_mod
|
||||
|
||||
if self.blocks_to_swap:
|
||||
self.offloader_double.submit_move_blocks(self.double_blocks, i)
|
||||
|
||||
img = torch.cat((img, txt), 1)
|
||||
del txt
|
||||
|
||||
for i, block in enumerate(self.single_blocks):
|
||||
if self.blocks_to_swap:
|
||||
self.offloader_single.wait_for_block(i)
|
||||
|
||||
single_mod = mod_vectors_dict.pop(f"single_blocks.{i}.modulation.lin")
|
||||
img = block(img, pe=pe, distill_vec=single_mod, txt_seq_len=txt_seq_len)
|
||||
del single_mod
|
||||
|
||||
if self.blocks_to_swap:
|
||||
self.offloader_single.submit_move_blocks(self.single_blocks, i)
|
||||
|
||||
img = img[:, :-max_txt_len, ...]
|
||||
final_mod = mod_vectors_dict["final_layer.adaLN_modulation.1"]
|
||||
img = self.final_layer(img, distill_vec=final_mod) # (N, T, patch_size ** 2 * out_channels)
|
||||
return img
|
||||
File diff suppressed because it is too large
Load Diff
345
library/custom_offloading_utils.py
Normal file
345
library/custom_offloading_utils.py
Normal file
@@ -0,0 +1,345 @@
|
||||
from concurrent.futures import ThreadPoolExecutor
|
||||
import gc
|
||||
import time
|
||||
from typing import Any, Optional, Union, Callable, Tuple
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
|
||||
# Keep these functions here for portability, and private to avoid confusion with the ones in device_utils.py
|
||||
def _clean_memory_on_device(device: torch.device):
|
||||
r"""
|
||||
Clean memory on the specified device, will be called from training scripts.
|
||||
"""
|
||||
gc.collect()
|
||||
|
||||
# device may "cuda" or "cuda:0", so we need to check the type of device
|
||||
if device.type == "cuda":
|
||||
torch.cuda.empty_cache()
|
||||
if device.type == "xpu":
|
||||
torch.xpu.empty_cache()
|
||||
if device.type == "mps":
|
||||
torch.mps.empty_cache()
|
||||
|
||||
|
||||
def _synchronize_device(device: torch.device):
|
||||
if device.type == "cuda":
|
||||
torch.cuda.synchronize()
|
||||
elif device.type == "xpu":
|
||||
torch.xpu.synchronize()
|
||||
elif device.type == "mps":
|
||||
torch.mps.synchronize()
|
||||
|
||||
|
||||
def swap_weight_devices_cuda(device: torch.device, layer_to_cpu: nn.Module, layer_to_cuda: nn.Module):
|
||||
assert layer_to_cpu.__class__ == layer_to_cuda.__class__
|
||||
|
||||
weight_swap_jobs: list[Tuple[nn.Module, nn.Module, torch.Tensor, torch.Tensor]] = []
|
||||
|
||||
# This is not working for all cases (e.g. SD3), so we need to find the corresponding modules
|
||||
# for module_to_cpu, module_to_cuda in zip(layer_to_cpu.modules(), layer_to_cuda.modules()):
|
||||
# print(module_to_cpu.__class__, module_to_cuda.__class__)
|
||||
# if hasattr(module_to_cpu, "weight") and module_to_cpu.weight is not None:
|
||||
# weight_swap_jobs.append((module_to_cpu, module_to_cuda, module_to_cpu.weight.data, module_to_cuda.weight.data))
|
||||
|
||||
modules_to_cpu = {k: v for k, v in layer_to_cpu.named_modules()}
|
||||
for module_to_cuda_name, module_to_cuda in layer_to_cuda.named_modules():
|
||||
if hasattr(module_to_cuda, "weight") and module_to_cuda.weight is not None:
|
||||
module_to_cpu = modules_to_cpu.get(module_to_cuda_name, None)
|
||||
if module_to_cpu is not None and module_to_cpu.weight.shape == module_to_cuda.weight.shape:
|
||||
weight_swap_jobs.append((module_to_cpu, module_to_cuda, module_to_cpu.weight.data, module_to_cuda.weight.data))
|
||||
else:
|
||||
if module_to_cuda.weight.data.device.type != device.type:
|
||||
# print(
|
||||
# f"Module {module_to_cuda_name} not found in CPU model or shape mismatch, so not swapping and moving to device"
|
||||
# )
|
||||
module_to_cuda.weight.data = module_to_cuda.weight.data.to(device)
|
||||
|
||||
torch.cuda.current_stream().synchronize() # this prevents the illegal loss value
|
||||
|
||||
stream = torch.Stream(device="cuda")
|
||||
with torch.cuda.stream(stream):
|
||||
# cuda to cpu
|
||||
for module_to_cpu, module_to_cuda, cuda_data_view, cpu_data_view in weight_swap_jobs:
|
||||
cuda_data_view.record_stream(stream)
|
||||
module_to_cpu.weight.data = cuda_data_view.data.to("cpu", non_blocking=True)
|
||||
|
||||
stream.synchronize()
|
||||
|
||||
# cpu to cuda
|
||||
for module_to_cpu, module_to_cuda, cuda_data_view, cpu_data_view in weight_swap_jobs:
|
||||
cuda_data_view.copy_(module_to_cuda.weight.data, non_blocking=True)
|
||||
module_to_cuda.weight.data = cuda_data_view
|
||||
|
||||
stream.synchronize()
|
||||
torch.cuda.current_stream().synchronize() # this prevents the illegal loss value
|
||||
|
||||
|
||||
def swap_weight_devices_no_cuda(device: torch.device, layer_to_cpu: nn.Module, layer_to_cuda: nn.Module):
|
||||
"""
|
||||
not tested
|
||||
"""
|
||||
assert layer_to_cpu.__class__ == layer_to_cuda.__class__
|
||||
|
||||
weight_swap_jobs: list[Tuple[nn.Module, nn.Module, torch.Tensor, torch.Tensor]] = []
|
||||
for module_to_cpu, module_to_cuda in zip(layer_to_cpu.modules(), layer_to_cuda.modules()):
|
||||
if hasattr(module_to_cpu, "weight") and module_to_cpu.weight is not None:
|
||||
weight_swap_jobs.append((module_to_cpu, module_to_cuda, module_to_cpu.weight.data, module_to_cuda.weight.data))
|
||||
|
||||
# device to cpu
|
||||
for module_to_cpu, module_to_cuda, cuda_data_view, cpu_data_view in weight_swap_jobs:
|
||||
module_to_cpu.weight.data = cuda_data_view.data.to("cpu", non_blocking=True)
|
||||
|
||||
_synchronize_device(device)
|
||||
|
||||
# cpu to device
|
||||
for module_to_cpu, module_to_cuda, cuda_data_view, cpu_data_view in weight_swap_jobs:
|
||||
cuda_data_view.copy_(module_to_cuda.weight.data, non_blocking=True)
|
||||
module_to_cuda.weight.data = cuda_data_view
|
||||
|
||||
_synchronize_device(device)
|
||||
|
||||
|
||||
def weighs_to_device(layer: nn.Module, device: torch.device):
|
||||
for module in layer.modules():
|
||||
if hasattr(module, "weight") and module.weight is not None:
|
||||
module.weight.data = module.weight.data.to(device, non_blocking=True)
|
||||
|
||||
|
||||
class Offloader:
|
||||
"""
|
||||
common offloading class
|
||||
"""
|
||||
|
||||
def __init__(self, num_blocks: int, blocks_to_swap: int, device: torch.device, debug: bool = False):
|
||||
self.num_blocks = num_blocks
|
||||
self.blocks_to_swap = blocks_to_swap
|
||||
self.device = device
|
||||
self.debug = debug
|
||||
|
||||
self.thread_pool = ThreadPoolExecutor(max_workers=1)
|
||||
self.futures = {}
|
||||
self.cuda_available = device.type == "cuda"
|
||||
|
||||
def swap_weight_devices(self, block_to_cpu: nn.Module, block_to_cuda: nn.Module):
|
||||
if self.cuda_available:
|
||||
swap_weight_devices_cuda(self.device, block_to_cpu, block_to_cuda)
|
||||
else:
|
||||
swap_weight_devices_no_cuda(self.device, block_to_cpu, block_to_cuda)
|
||||
|
||||
def _submit_move_blocks(self, blocks, block_idx_to_cpu, block_idx_to_cuda):
|
||||
def move_blocks(bidx_to_cpu, block_to_cpu, bidx_to_cuda, block_to_cuda):
|
||||
if self.debug:
|
||||
start_time = time.perf_counter()
|
||||
print(f"Move block {bidx_to_cpu} to CPU and block {bidx_to_cuda} to {'CUDA' if self.cuda_available else 'device'}")
|
||||
|
||||
self.swap_weight_devices(block_to_cpu, block_to_cuda)
|
||||
|
||||
if self.debug:
|
||||
print(f"Moved blocks {bidx_to_cpu} and {bidx_to_cuda} in {time.perf_counter() - start_time:.2f}s")
|
||||
return bidx_to_cpu, bidx_to_cuda # , event
|
||||
|
||||
block_to_cpu = blocks[block_idx_to_cpu]
|
||||
block_to_cuda = blocks[block_idx_to_cuda]
|
||||
|
||||
self.futures[block_idx_to_cuda] = self.thread_pool.submit(
|
||||
move_blocks, block_idx_to_cpu, block_to_cpu, block_idx_to_cuda, block_to_cuda
|
||||
)
|
||||
|
||||
def _wait_blocks_move(self, block_idx):
|
||||
if block_idx not in self.futures:
|
||||
return
|
||||
|
||||
if self.debug:
|
||||
print(f"Wait for block {block_idx}")
|
||||
start_time = time.perf_counter()
|
||||
|
||||
future = self.futures.pop(block_idx)
|
||||
_, bidx_to_cuda = future.result()
|
||||
|
||||
assert block_idx == bidx_to_cuda, f"Block index mismatch: {block_idx} != {bidx_to_cuda}"
|
||||
|
||||
if self.debug:
|
||||
print(f"Waited for block {block_idx}: {time.perf_counter() - start_time:.2f}s")
|
||||
|
||||
|
||||
# Gradient tensors
|
||||
_grad_t = Union[tuple[torch.Tensor, ...], torch.Tensor]
|
||||
|
||||
|
||||
class ModelOffloader(Offloader):
|
||||
"""
|
||||
supports forward offloading
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
blocks: Union[list[nn.Module], nn.ModuleList],
|
||||
blocks_to_swap: int,
|
||||
device: torch.device,
|
||||
supports_backward: bool = True,
|
||||
debug: bool = False,
|
||||
):
|
||||
super().__init__(len(blocks), blocks_to_swap, device, debug)
|
||||
|
||||
self.supports_backward = supports_backward
|
||||
self.forward_only = not supports_backward # forward only offloading: can be changed to True for inference
|
||||
|
||||
if self.supports_backward:
|
||||
# register backward hooks
|
||||
self.remove_handles = []
|
||||
for i, block in enumerate(blocks):
|
||||
hook = self.create_backward_hook(blocks, i)
|
||||
if hook is not None:
|
||||
handle = block.register_full_backward_hook(hook)
|
||||
self.remove_handles.append(handle)
|
||||
|
||||
def set_forward_only(self, forward_only: bool):
|
||||
# switching must wait for all pending transfers
|
||||
for block_idx in list(self.futures.keys()):
|
||||
self._wait_blocks_move(block_idx)
|
||||
self.forward_only = forward_only
|
||||
|
||||
def __del__(self):
|
||||
if self.supports_backward:
|
||||
for handle in self.remove_handles:
|
||||
handle.remove()
|
||||
|
||||
def create_backward_hook(
|
||||
self, blocks: Union[list[nn.Module], nn.ModuleList], block_index: int
|
||||
) -> Optional[Callable[[nn.Module, _grad_t, _grad_t], Union[None, _grad_t]]]:
|
||||
# -1 for 0-based index
|
||||
num_blocks_propagated = self.num_blocks - block_index - 1
|
||||
swapping = num_blocks_propagated > 0 and num_blocks_propagated <= self.blocks_to_swap
|
||||
waiting = block_index > 0 and block_index <= self.blocks_to_swap
|
||||
|
||||
if not swapping and not waiting:
|
||||
return None
|
||||
|
||||
# create hook
|
||||
block_idx_to_cpu = self.num_blocks - num_blocks_propagated
|
||||
block_idx_to_cuda = self.blocks_to_swap - num_blocks_propagated
|
||||
block_idx_to_wait = block_index - 1
|
||||
|
||||
def backward_hook(module: nn.Module, grad_input: _grad_t, grad_output: _grad_t):
|
||||
if self.debug:
|
||||
print(f"Backward hook for block {block_index}")
|
||||
|
||||
if swapping:
|
||||
self._submit_move_blocks(blocks, block_idx_to_cpu, block_idx_to_cuda)
|
||||
if waiting:
|
||||
self._wait_blocks_move(block_idx_to_wait)
|
||||
return None
|
||||
|
||||
return backward_hook
|
||||
|
||||
def prepare_block_devices_before_forward(self, blocks: Union[list[nn.Module], nn.ModuleList]):
|
||||
if self.blocks_to_swap is None or self.blocks_to_swap == 0:
|
||||
return
|
||||
|
||||
if self.debug:
|
||||
print(f"Prepare block devices before forward")
|
||||
|
||||
# wait for all pending transfers
|
||||
for block_idx in list(self.futures.keys()):
|
||||
self._wait_blocks_move(block_idx)
|
||||
|
||||
for b in blocks[0 : self.num_blocks - self.blocks_to_swap]:
|
||||
b.to(self.device)
|
||||
weighs_to_device(b, self.device) # make sure weights are on device
|
||||
|
||||
for b in blocks[self.num_blocks - self.blocks_to_swap :]:
|
||||
b.to(self.device) # move block to device first. this makes sure that buffers (non weights) are on the device
|
||||
weighs_to_device(b, torch.device("cpu")) # make sure weights are on cpu
|
||||
|
||||
_synchronize_device(self.device)
|
||||
_clean_memory_on_device(self.device)
|
||||
|
||||
def wait_for_block(self, block_idx: int):
|
||||
if self.blocks_to_swap is None or self.blocks_to_swap == 0:
|
||||
return
|
||||
self._wait_blocks_move(block_idx)
|
||||
|
||||
def submit_move_blocks(self, blocks: Union[list[nn.Module], nn.ModuleList], block_idx: int):
|
||||
# check if blocks_to_swap is enabled
|
||||
if self.blocks_to_swap is None or self.blocks_to_swap == 0:
|
||||
return
|
||||
|
||||
# if backward is enabled, we do not swap blocks in forward pass more than blocks_to_swap, because it should be on GPU
|
||||
if not self.forward_only and block_idx >= self.blocks_to_swap:
|
||||
return
|
||||
|
||||
block_idx_to_cpu = block_idx
|
||||
block_idx_to_cuda = self.num_blocks - self.blocks_to_swap + block_idx
|
||||
# this works for forward-only offloading. move upstream blocks to cuda
|
||||
block_idx_to_cuda = block_idx_to_cuda % self.num_blocks
|
||||
self._submit_move_blocks(blocks, block_idx_to_cpu, block_idx_to_cuda)
|
||||
|
||||
|
||||
# endregion
|
||||
|
||||
# region cpu offload utils
|
||||
|
||||
|
||||
def to_device(x: Any, device: torch.device) -> Any:
|
||||
if isinstance(x, torch.Tensor):
|
||||
return x.to(device)
|
||||
elif isinstance(x, list):
|
||||
return [to_device(elem, device) for elem in x]
|
||||
elif isinstance(x, tuple):
|
||||
return tuple(to_device(elem, device) for elem in x)
|
||||
elif isinstance(x, dict):
|
||||
return {k: to_device(v, device) for k, v in x.items()}
|
||||
else:
|
||||
return x
|
||||
|
||||
|
||||
def to_cpu(x: Any) -> Any:
|
||||
"""
|
||||
Recursively moves torch.Tensor objects (and containers thereof) to CPU.
|
||||
|
||||
Args:
|
||||
x: A torch.Tensor, or a (possibly nested) list, tuple, or dict containing tensors.
|
||||
|
||||
Returns:
|
||||
The same structure as x, with all torch.Tensor objects moved to CPU.
|
||||
Non-tensor objects are returned unchanged.
|
||||
"""
|
||||
if isinstance(x, torch.Tensor):
|
||||
return x.cpu()
|
||||
elif isinstance(x, list):
|
||||
return [to_cpu(elem) for elem in x]
|
||||
elif isinstance(x, tuple):
|
||||
return tuple(to_cpu(elem) for elem in x)
|
||||
elif isinstance(x, dict):
|
||||
return {k: to_cpu(v) for k, v in x.items()}
|
||||
else:
|
||||
return x
|
||||
|
||||
|
||||
def create_cpu_offloading_wrapper(func: Callable, device: torch.device) -> Callable:
|
||||
"""
|
||||
Create a wrapper function that offloads inputs to CPU before calling the original function
|
||||
and moves outputs back to the specified device.
|
||||
|
||||
Args:
|
||||
func: The original function to wrap.
|
||||
device: The device to move outputs back to.
|
||||
|
||||
Returns:
|
||||
A wrapped function that offloads inputs to CPU and moves outputs back to the specified device.
|
||||
"""
|
||||
|
||||
def wrapper(orig_func: Callable) -> Callable:
|
||||
def custom_forward(*inputs):
|
||||
nonlocal device, orig_func
|
||||
cuda_inputs = to_device(inputs, device)
|
||||
outputs = orig_func(*cuda_inputs)
|
||||
return to_cpu(outputs)
|
||||
|
||||
return custom_forward
|
||||
|
||||
return wrapper(func)
|
||||
|
||||
|
||||
# endregion
|
||||
@@ -1,23 +1,117 @@
|
||||
from diffusers.schedulers.scheduling_ddpm import DDPMScheduler
|
||||
import torch
|
||||
import argparse
|
||||
import random
|
||||
import re
|
||||
from torch.types import Number
|
||||
from typing import List, Optional, Union
|
||||
from .utils import setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
def apply_snr_weight(loss, timesteps, noise_scheduler, gamma):
|
||||
def prepare_scheduler_for_custom_training(noise_scheduler, device):
|
||||
if hasattr(noise_scheduler, "all_snr"):
|
||||
return
|
||||
|
||||
alphas_cumprod = noise_scheduler.alphas_cumprod
|
||||
sqrt_alphas_cumprod = torch.sqrt(alphas_cumprod)
|
||||
sqrt_one_minus_alphas_cumprod = torch.sqrt(1.0 - alphas_cumprod)
|
||||
alpha = sqrt_alphas_cumprod
|
||||
sigma = sqrt_one_minus_alphas_cumprod
|
||||
all_snr = (alpha / sigma) ** 2
|
||||
snr = torch.stack([all_snr[t] for t in timesteps])
|
||||
gamma_over_snr = torch.div(torch.ones_like(snr) * gamma, snr)
|
||||
snr_weight = torch.minimum(gamma_over_snr, torch.ones_like(gamma_over_snr)).float() # from paper
|
||||
|
||||
noise_scheduler.all_snr = all_snr.to(device)
|
||||
|
||||
|
||||
def fix_noise_scheduler_betas_for_zero_terminal_snr(noise_scheduler):
|
||||
# fix beta: zero terminal SNR
|
||||
logger.info(f"fix noise scheduler betas: https://arxiv.org/abs/2305.08891")
|
||||
|
||||
def enforce_zero_terminal_snr(betas):
|
||||
# Convert betas to alphas_bar_sqrt
|
||||
alphas = 1 - betas
|
||||
alphas_bar = alphas.cumprod(0)
|
||||
alphas_bar_sqrt = alphas_bar.sqrt()
|
||||
|
||||
# Store old values.
|
||||
alphas_bar_sqrt_0 = alphas_bar_sqrt[0].clone()
|
||||
alphas_bar_sqrt_T = alphas_bar_sqrt[-1].clone()
|
||||
# Shift so last timestep is zero.
|
||||
alphas_bar_sqrt -= alphas_bar_sqrt_T
|
||||
# Scale so first timestep is back to old value.
|
||||
alphas_bar_sqrt *= alphas_bar_sqrt_0 / (alphas_bar_sqrt_0 - alphas_bar_sqrt_T)
|
||||
|
||||
# Convert alphas_bar_sqrt to betas
|
||||
alphas_bar = alphas_bar_sqrt**2
|
||||
alphas = alphas_bar[1:] / alphas_bar[:-1]
|
||||
alphas = torch.cat([alphas_bar[0:1], alphas])
|
||||
betas = 1 - alphas
|
||||
return betas
|
||||
|
||||
betas = noise_scheduler.betas
|
||||
betas = enforce_zero_terminal_snr(betas)
|
||||
alphas = 1.0 - betas
|
||||
alphas_cumprod = torch.cumprod(alphas, dim=0)
|
||||
|
||||
# logger.info(f"original: {noise_scheduler.betas}")
|
||||
# logger.info(f"fixed: {betas}")
|
||||
|
||||
noise_scheduler.betas = betas
|
||||
noise_scheduler.alphas = alphas
|
||||
noise_scheduler.alphas_cumprod = alphas_cumprod
|
||||
|
||||
|
||||
def apply_snr_weight(loss: torch.Tensor, timesteps: torch.IntTensor, noise_scheduler: DDPMScheduler, gamma: Number, v_prediction=False):
|
||||
snr = torch.stack([noise_scheduler.all_snr[t] for t in timesteps])
|
||||
min_snr_gamma = torch.minimum(snr, torch.full_like(snr, gamma))
|
||||
if v_prediction:
|
||||
snr_weight = torch.div(min_snr_gamma, snr + 1).float().to(loss.device)
|
||||
else:
|
||||
snr_weight = torch.div(min_snr_gamma, snr).float().to(loss.device)
|
||||
loss = loss * snr_weight
|
||||
return loss
|
||||
|
||||
|
||||
def scale_v_prediction_loss_like_noise_prediction(loss: torch.Tensor, timesteps: torch.IntTensor, noise_scheduler: DDPMScheduler):
|
||||
scale = get_snr_scale(timesteps, noise_scheduler)
|
||||
loss = loss * scale
|
||||
return loss
|
||||
|
||||
|
||||
def get_snr_scale(timesteps: torch.IntTensor, noise_scheduler: DDPMScheduler):
|
||||
snr_t = torch.stack([noise_scheduler.all_snr[t] for t in timesteps]) # batch_size
|
||||
snr_t = torch.minimum(snr_t, torch.ones_like(snr_t) * 1000) # if timestep is 0, snr_t is inf, so limit it to 1000
|
||||
scale = snr_t / (snr_t + 1)
|
||||
# # show debug info
|
||||
# logger.info(f"timesteps: {timesteps}, snr_t: {snr_t}, scale: {scale}")
|
||||
return scale
|
||||
|
||||
|
||||
def add_v_prediction_like_loss(loss: torch.Tensor, timesteps: torch.IntTensor, noise_scheduler: DDPMScheduler, v_pred_like_loss: torch.Tensor):
|
||||
scale = get_snr_scale(timesteps, noise_scheduler)
|
||||
# logger.info(f"add v-prediction like loss: {v_pred_like_loss}, scale: {scale}, loss: {loss}, time: {timesteps}")
|
||||
loss = loss + loss / scale * v_pred_like_loss
|
||||
return loss
|
||||
|
||||
|
||||
def apply_debiased_estimation(loss: torch.Tensor, timesteps: torch.IntTensor, noise_scheduler: DDPMScheduler, v_prediction=False):
|
||||
snr_t = torch.stack([noise_scheduler.all_snr[t] for t in timesteps]) # batch_size
|
||||
snr_t = torch.minimum(snr_t, torch.ones_like(snr_t) * 1000) # if timestep is 0, snr_t is inf, so limit it to 1000
|
||||
if v_prediction:
|
||||
weight = 1 / (snr_t + 1)
|
||||
else:
|
||||
weight = 1 / torch.sqrt(snr_t)
|
||||
loss = weight * loss
|
||||
return loss
|
||||
|
||||
|
||||
# TODO train_utilと分散しているのでどちらかに寄せる
|
||||
|
||||
|
||||
def add_custom_train_arguments(parser: argparse.ArgumentParser, support_weighted_captions: bool = True):
|
||||
parser.add_argument(
|
||||
"--min_snr_gamma",
|
||||
@@ -25,6 +119,22 @@ def add_custom_train_arguments(parser: argparse.ArgumentParser, support_weighted
|
||||
default=None,
|
||||
help="gamma for reducing the weight of high loss timesteps. Lower numbers have stronger effect. 5 is recommended by paper. / 低いタイムステップでの高いlossに対して重みを減らすためのgamma値、低いほど効果が強く、論文では5が推奨",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--scale_v_pred_loss_like_noise_pred",
|
||||
action="store_true",
|
||||
help="scale v-prediction loss like noise prediction loss / v-prediction lossをnoise prediction lossと同じようにスケーリングする",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--v_pred_like_loss",
|
||||
type=float,
|
||||
default=None,
|
||||
help="add v-prediction like loss multiplied by this value / v-prediction lossをこの値をかけたものをlossに加算する",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--debiased_estimation_loss",
|
||||
action="store_true",
|
||||
help="debiased estimation loss / debiased estimation loss",
|
||||
)
|
||||
if support_weighted_captions:
|
||||
parser.add_argument(
|
||||
"--weighted_captions",
|
||||
@@ -171,7 +281,7 @@ def get_prompts_with_weights(tokenizer, prompt: List[str], max_length: int):
|
||||
tokens.append(text_token)
|
||||
weights.append(text_weight)
|
||||
if truncated:
|
||||
print("Prompt was truncated. Try to shorten the prompt or increase max_embeddings_multiples")
|
||||
logger.warning("Prompt was truncated. Try to shorten the prompt or increase max_embeddings_multiples")
|
||||
return tokens, weights
|
||||
|
||||
|
||||
@@ -239,11 +349,6 @@ def get_unweighted_text_embeddings(
|
||||
text_embedding = enc_out["hidden_states"][-clip_skip]
|
||||
text_embedding = text_encoder.text_model.final_layer_norm(text_embedding)
|
||||
|
||||
# cover the head and the tail by the starting and the ending tokens
|
||||
text_input_chunk[:, 0] = text_input[0, 0]
|
||||
text_input_chunk[:, -1] = text_input[0, -1]
|
||||
text_embedding = text_encoder(text_input_chunk, attention_mask=None)[0]
|
||||
|
||||
if no_boseos_middle:
|
||||
if i == 0:
|
||||
# discard the ending token
|
||||
@@ -258,7 +363,12 @@ def get_unweighted_text_embeddings(
|
||||
text_embeddings.append(text_embedding)
|
||||
text_embeddings = torch.concat(text_embeddings, axis=1)
|
||||
else:
|
||||
text_embeddings = text_encoder(text_input)[0]
|
||||
if clip_skip is None or clip_skip == 1:
|
||||
text_embeddings = text_encoder(text_input)[0]
|
||||
else:
|
||||
enc_out = text_encoder(text_input, output_hidden_states=True, return_dict=True)
|
||||
text_embeddings = enc_out["hidden_states"][-clip_skip]
|
||||
text_embeddings = text_encoder.text_model.final_layer_norm(text_embeddings)
|
||||
return text_embeddings
|
||||
|
||||
|
||||
@@ -342,3 +452,110 @@ def get_weighted_text_embeddings(
|
||||
text_embeddings = text_embeddings * (previous_mean / current_mean).unsqueeze(-1).unsqueeze(-1)
|
||||
|
||||
return text_embeddings
|
||||
|
||||
|
||||
# https://wandb.ai/johnowhitaker/multires_noise/reports/Multi-Resolution-Noise-for-Diffusion-Model-Training--VmlldzozNjYyOTU2
|
||||
def pyramid_noise_like(noise, device, iterations=6, discount=0.4) -> torch.FloatTensor:
|
||||
b, c, w, h = noise.shape # EDIT: w and h get over-written, rename for a different variant!
|
||||
u = torch.nn.Upsample(size=(w, h), mode="bilinear").to(device)
|
||||
for i in range(iterations):
|
||||
r = random.random() * 2 + 2 # Rather than always going 2x,
|
||||
wn, hn = max(1, int(w / (r**i))), max(1, int(h / (r**i)))
|
||||
noise += u(torch.randn(b, c, wn, hn).to(device)) * discount**i
|
||||
if wn == 1 or hn == 1:
|
||||
break # Lowest resolution is 1x1
|
||||
return noise / noise.std() # Scaled back to roughly unit variance
|
||||
|
||||
|
||||
# https://www.crosslabs.org//blog/diffusion-with-offset-noise
|
||||
def apply_noise_offset(latents, noise, noise_offset, adaptive_noise_scale) -> torch.FloatTensor:
|
||||
if noise_offset is None:
|
||||
return noise
|
||||
if adaptive_noise_scale is not None:
|
||||
# latent shape: (batch_size, channels, height, width)
|
||||
# abs mean value for each channel
|
||||
latent_mean = torch.abs(latents.mean(dim=(2, 3), keepdim=True))
|
||||
|
||||
# multiply adaptive noise scale to the mean value and add it to the noise offset
|
||||
noise_offset = noise_offset + adaptive_noise_scale * latent_mean
|
||||
noise_offset = torch.clamp(noise_offset, 0.0, None) # in case of adaptive noise scale is negative
|
||||
|
||||
noise = noise + noise_offset * torch.randn((latents.shape[0], latents.shape[1], 1, 1), device=latents.device)
|
||||
return noise
|
||||
|
||||
|
||||
def apply_masked_loss(loss, batch) -> torch.FloatTensor:
|
||||
if "conditioning_images" in batch:
|
||||
# conditioning image is -1 to 1. we need to convert it to 0 to 1
|
||||
mask_image = batch["conditioning_images"].to(dtype=loss.dtype)[:, 0].unsqueeze(1) # use R channel
|
||||
mask_image = mask_image / 2 + 0.5
|
||||
# print(f"conditioning_image: {mask_image.shape}")
|
||||
elif "alpha_masks" in batch and batch["alpha_masks"] is not None:
|
||||
# alpha mask is 0 to 1
|
||||
mask_image = batch["alpha_masks"].to(dtype=loss.dtype).unsqueeze(1) # add channel dimension
|
||||
# print(f"mask_image: {mask_image.shape}, {mask_image.mean()}")
|
||||
else:
|
||||
return loss
|
||||
|
||||
# resize to the same size as the loss
|
||||
mask_image = torch.nn.functional.interpolate(mask_image, size=loss.shape[2:], mode="area")
|
||||
loss = loss * mask_image
|
||||
return loss
|
||||
|
||||
|
||||
"""
|
||||
##########################################
|
||||
# Perlin Noise
|
||||
def rand_perlin_2d(device, shape, res, fade=lambda t: 6 * t**5 - 15 * t**4 + 10 * t**3):
|
||||
delta = (res[0] / shape[0], res[1] / shape[1])
|
||||
d = (shape[0] // res[0], shape[1] // res[1])
|
||||
|
||||
grid = (
|
||||
torch.stack(
|
||||
torch.meshgrid(torch.arange(0, res[0], delta[0], device=device), torch.arange(0, res[1], delta[1], device=device)),
|
||||
dim=-1,
|
||||
)
|
||||
% 1
|
||||
)
|
||||
angles = 2 * torch.pi * torch.rand(res[0] + 1, res[1] + 1, device=device)
|
||||
gradients = torch.stack((torch.cos(angles), torch.sin(angles)), dim=-1)
|
||||
|
||||
tile_grads = (
|
||||
lambda slice1, slice2: gradients[slice1[0] : slice1[1], slice2[0] : slice2[1]]
|
||||
.repeat_interleave(d[0], 0)
|
||||
.repeat_interleave(d[1], 1)
|
||||
)
|
||||
dot = lambda grad, shift: (
|
||||
torch.stack((grid[: shape[0], : shape[1], 0] + shift[0], grid[: shape[0], : shape[1], 1] + shift[1]), dim=-1)
|
||||
* grad[: shape[0], : shape[1]]
|
||||
).sum(dim=-1)
|
||||
|
||||
n00 = dot(tile_grads([0, -1], [0, -1]), [0, 0])
|
||||
n10 = dot(tile_grads([1, None], [0, -1]), [-1, 0])
|
||||
n01 = dot(tile_grads([0, -1], [1, None]), [0, -1])
|
||||
n11 = dot(tile_grads([1, None], [1, None]), [-1, -1])
|
||||
t = fade(grid[: shape[0], : shape[1]])
|
||||
return 1.414 * torch.lerp(torch.lerp(n00, n10, t[..., 0]), torch.lerp(n01, n11, t[..., 0]), t[..., 1])
|
||||
|
||||
|
||||
def rand_perlin_2d_octaves(device, shape, res, octaves=1, persistence=0.5):
|
||||
noise = torch.zeros(shape, device=device)
|
||||
frequency = 1
|
||||
amplitude = 1
|
||||
for _ in range(octaves):
|
||||
noise += amplitude * rand_perlin_2d(device, shape, (frequency * res[0], frequency * res[1]))
|
||||
frequency *= 2
|
||||
amplitude *= persistence
|
||||
return noise
|
||||
|
||||
|
||||
def perlin_noise(noise, device, octaves):
|
||||
_, c, w, h = noise.shape
|
||||
perlin = lambda: rand_perlin_2d_octaves(device, (w, h), (4, 4), octaves)
|
||||
noise_perlin = []
|
||||
for _ in range(c):
|
||||
noise_perlin.append(perlin())
|
||||
noise_perlin = torch.stack(noise_perlin).unsqueeze(0) # (1, c, w, h)
|
||||
noise += noise_perlin # broadcast for each batch
|
||||
return noise / noise.std() # Scaled back to roughly unit variance
|
||||
"""
|
||||
|
||||
179
library/deepspeed_utils.py
Normal file
179
library/deepspeed_utils.py
Normal file
@@ -0,0 +1,179 @@
|
||||
import os
|
||||
import argparse
|
||||
import torch
|
||||
from accelerate import DeepSpeedPlugin, Accelerator
|
||||
|
||||
from .utils import setup_logging
|
||||
|
||||
from .device_utils import get_preferred_device
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
def add_deepspeed_arguments(parser: argparse.ArgumentParser):
|
||||
# DeepSpeed Arguments. https://huggingface.co/docs/accelerate/usage_guides/deepspeed
|
||||
parser.add_argument("--deepspeed", action="store_true", help="enable deepspeed training")
|
||||
parser.add_argument("--zero_stage", type=int, default=2, choices=[0, 1, 2, 3], help="Possible options are 0,1,2,3.")
|
||||
parser.add_argument(
|
||||
"--offload_optimizer_device",
|
||||
type=str,
|
||||
default=None,
|
||||
choices=[None, "cpu", "nvme"],
|
||||
help="Possible options are none|cpu|nvme. Only applicable with ZeRO Stages 2 and 3.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--offload_optimizer_nvme_path",
|
||||
type=str,
|
||||
default=None,
|
||||
help="Possible options are /nvme|/local_nvme. Only applicable with ZeRO Stage 3.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--offload_param_device",
|
||||
type=str,
|
||||
default=None,
|
||||
choices=[None, "cpu", "nvme"],
|
||||
help="Possible options are none|cpu|nvme. Only applicable with ZeRO Stage 3.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--offload_param_nvme_path",
|
||||
type=str,
|
||||
default=None,
|
||||
help="Possible options are /nvme|/local_nvme. Only applicable with ZeRO Stage 3.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--zero3_init_flag",
|
||||
action="store_true",
|
||||
help="Flag to indicate whether to enable `deepspeed.zero.Init` for constructing massive models."
|
||||
"Only applicable with ZeRO Stage-3.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--zero3_save_16bit_model",
|
||||
action="store_true",
|
||||
help="Flag to indicate whether to save 16-bit model. Only applicable with ZeRO Stage-3.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--fp16_master_weights_and_gradients",
|
||||
action="store_true",
|
||||
help="fp16_master_and_gradients requires optimizer to support keeping fp16 master and gradients while keeping the optimizer states in fp32.",
|
||||
)
|
||||
|
||||
|
||||
def prepare_deepspeed_args(args: argparse.Namespace):
|
||||
if not args.deepspeed:
|
||||
return
|
||||
|
||||
# To avoid RuntimeError: DataLoader worker exited unexpectedly with exit code 1.
|
||||
args.max_data_loader_n_workers = 1
|
||||
|
||||
|
||||
def prepare_deepspeed_plugin(args: argparse.Namespace):
|
||||
if not args.deepspeed:
|
||||
return None
|
||||
|
||||
try:
|
||||
import deepspeed
|
||||
except ImportError as e:
|
||||
logger.error(
|
||||
"deepspeed is not installed. please install deepspeed in your environment with following command. DS_BUILD_OPS=0 pip install deepspeed"
|
||||
)
|
||||
exit(1)
|
||||
|
||||
deepspeed_plugin = DeepSpeedPlugin(
|
||||
zero_stage=args.zero_stage,
|
||||
gradient_accumulation_steps=args.gradient_accumulation_steps,
|
||||
gradient_clipping=args.max_grad_norm,
|
||||
offload_optimizer_device=args.offload_optimizer_device,
|
||||
offload_optimizer_nvme_path=args.offload_optimizer_nvme_path,
|
||||
offload_param_device=args.offload_param_device,
|
||||
offload_param_nvme_path=args.offload_param_nvme_path,
|
||||
zero3_init_flag=args.zero3_init_flag,
|
||||
zero3_save_16bit_model=args.zero3_save_16bit_model,
|
||||
)
|
||||
deepspeed_plugin.deepspeed_config["train_micro_batch_size_per_gpu"] = args.train_batch_size
|
||||
deepspeed_plugin.deepspeed_config["train_batch_size"] = (
|
||||
args.train_batch_size * args.gradient_accumulation_steps * int(os.environ["WORLD_SIZE"])
|
||||
)
|
||||
|
||||
deepspeed_plugin.set_mixed_precision(args.mixed_precision)
|
||||
if args.mixed_precision.lower() == "fp16":
|
||||
deepspeed_plugin.deepspeed_config["fp16"]["initial_scale_power"] = 0 # preventing overflow.
|
||||
if args.full_fp16 or args.fp16_master_weights_and_gradients:
|
||||
if args.offload_optimizer_device == "cpu" and args.zero_stage == 2:
|
||||
deepspeed_plugin.deepspeed_config["fp16"]["fp16_master_weights_and_grads"] = True
|
||||
logger.info("[DeepSpeed] full fp16 enable.")
|
||||
else:
|
||||
logger.info(
|
||||
"[DeepSpeed]full fp16, fp16_master_weights_and_grads currently only supported using ZeRO-Offload with DeepSpeedCPUAdam on ZeRO-2 stage."
|
||||
)
|
||||
|
||||
if args.offload_optimizer_device is not None:
|
||||
logger.info("[DeepSpeed] start to manually build cpu_adam.")
|
||||
deepspeed.ops.op_builder.CPUAdamBuilder().load()
|
||||
logger.info("[DeepSpeed] building cpu_adam done.")
|
||||
|
||||
return deepspeed_plugin
|
||||
|
||||
|
||||
# Accelerate library does not support multiple models for deepspeed. So, we need to wrap multiple models into a single model.
|
||||
def prepare_deepspeed_model(args: argparse.Namespace, **models):
|
||||
# remove None from models
|
||||
models = {k: v for k, v in models.items() if v is not None}
|
||||
|
||||
class DeepSpeedWrapper(torch.nn.Module):
|
||||
def __init__(self, **kw_models) -> None:
|
||||
super().__init__()
|
||||
|
||||
self.models = torch.nn.ModuleDict()
|
||||
|
||||
wrap_model_forward_with_torch_autocast = args.mixed_precision != "no"
|
||||
|
||||
for key, model in kw_models.items():
|
||||
if isinstance(model, list):
|
||||
model = torch.nn.ModuleList(model)
|
||||
|
||||
if wrap_model_forward_with_torch_autocast:
|
||||
model = self.__wrap_model_with_torch_autocast(model)
|
||||
|
||||
assert isinstance(
|
||||
model, torch.nn.Module
|
||||
), f"model must be an instance of torch.nn.Module, but got {key} is {type(model)}"
|
||||
|
||||
self.models.update(torch.nn.ModuleDict({key: model}))
|
||||
|
||||
def __wrap_model_with_torch_autocast(self, model):
|
||||
if isinstance(model, torch.nn.ModuleList):
|
||||
model = torch.nn.ModuleList([self.__wrap_model_forward_with_torch_autocast(m) for m in model])
|
||||
else:
|
||||
model = self.__wrap_model_forward_with_torch_autocast(model)
|
||||
return model
|
||||
|
||||
def __wrap_model_forward_with_torch_autocast(self, model):
|
||||
|
||||
assert hasattr(model, "forward"), f"model must have a forward method."
|
||||
|
||||
forward_fn = model.forward
|
||||
|
||||
def forward(*args, **kwargs):
|
||||
try:
|
||||
device_type = model.device.type
|
||||
except AttributeError:
|
||||
logger.warning(
|
||||
"[DeepSpeed] model.device is not available. Using get_preferred_device() "
|
||||
"to determine the device_type for torch.autocast()."
|
||||
)
|
||||
device_type = get_preferred_device().type
|
||||
|
||||
with torch.autocast(device_type=device_type):
|
||||
return forward_fn(*args, **kwargs)
|
||||
|
||||
model.forward = forward
|
||||
return model
|
||||
|
||||
def get_models(self):
|
||||
return self.models
|
||||
|
||||
ds_model = DeepSpeedWrapper(**models)
|
||||
return ds_model
|
||||
108
library/device_utils.py
Normal file
108
library/device_utils.py
Normal file
@@ -0,0 +1,108 @@
|
||||
import functools
|
||||
import gc
|
||||
from typing import Optional, Union
|
||||
|
||||
import torch
|
||||
|
||||
|
||||
try:
|
||||
# intel gpu support for pytorch older than 2.5
|
||||
# ipex is not needed after pytorch 2.5
|
||||
import intel_extension_for_pytorch as ipex # noqa
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
|
||||
try:
|
||||
HAS_CUDA = torch.cuda.is_available()
|
||||
except Exception:
|
||||
HAS_CUDA = False
|
||||
|
||||
try:
|
||||
HAS_MPS = torch.backends.mps.is_available()
|
||||
except Exception:
|
||||
HAS_MPS = False
|
||||
|
||||
try:
|
||||
HAS_XPU = torch.xpu.is_available()
|
||||
except Exception:
|
||||
HAS_XPU = False
|
||||
|
||||
|
||||
def clean_memory():
|
||||
gc.collect()
|
||||
if HAS_CUDA:
|
||||
torch.cuda.empty_cache()
|
||||
if HAS_XPU:
|
||||
torch.xpu.empty_cache()
|
||||
if HAS_MPS:
|
||||
torch.mps.empty_cache()
|
||||
|
||||
|
||||
def clean_memory_on_device(device: Optional[Union[str, torch.device]]):
|
||||
r"""
|
||||
Clean memory on the specified device, will be called from training scripts.
|
||||
"""
|
||||
gc.collect()
|
||||
if device is None:
|
||||
return
|
||||
if isinstance(device, str):
|
||||
device = torch.device(device)
|
||||
# device may "cuda" or "cuda:0", so we need to check the type of device
|
||||
if device.type == "cuda":
|
||||
torch.cuda.empty_cache()
|
||||
if device.type == "xpu":
|
||||
torch.xpu.empty_cache()
|
||||
if device.type == "mps":
|
||||
torch.mps.empty_cache()
|
||||
|
||||
|
||||
def synchronize_device(device: Optional[Union[str, torch.device]]):
|
||||
if device is None:
|
||||
return
|
||||
if isinstance(device, str):
|
||||
device = torch.device(device)
|
||||
if device.type == "cuda":
|
||||
torch.cuda.synchronize()
|
||||
elif device.type == "xpu":
|
||||
torch.xpu.synchronize()
|
||||
elif device.type == "mps":
|
||||
torch.mps.synchronize()
|
||||
|
||||
|
||||
@functools.lru_cache(maxsize=None)
|
||||
def get_preferred_device() -> torch.device:
|
||||
r"""
|
||||
Do not call this function from training scripts. Use accelerator.device instead.
|
||||
"""
|
||||
if HAS_CUDA:
|
||||
device = torch.device("cuda")
|
||||
elif HAS_XPU:
|
||||
device = torch.device("xpu")
|
||||
elif HAS_MPS:
|
||||
device = torch.device("mps")
|
||||
else:
|
||||
device = torch.device("cpu")
|
||||
print(f"get_preferred_device() -> {device}")
|
||||
return device
|
||||
|
||||
|
||||
def init_ipex():
|
||||
"""
|
||||
Apply IPEX to CUDA hijacks using `library.ipex.ipex_init`.
|
||||
|
||||
This function should run right after importing torch and before doing anything else.
|
||||
|
||||
If xpu is not available, this function does nothing.
|
||||
"""
|
||||
try:
|
||||
if HAS_XPU:
|
||||
from library.ipex import ipex_init
|
||||
|
||||
is_initialized, error_message = ipex_init()
|
||||
if not is_initialized:
|
||||
print("failed to initialize ipex:", error_message)
|
||||
else:
|
||||
return
|
||||
except Exception as e:
|
||||
print("failed to initialize ipex:", e)
|
||||
1329
library/flux_models.py
Normal file
1329
library/flux_models.py
Normal file
File diff suppressed because it is too large
Load Diff
690
library/flux_train_utils.py
Normal file
690
library/flux_train_utils.py
Normal file
@@ -0,0 +1,690 @@
|
||||
import argparse
|
||||
import math
|
||||
import os
|
||||
import numpy as np
|
||||
import toml
|
||||
import json
|
||||
import time
|
||||
from typing import Callable, Dict, List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
from accelerate import Accelerator, PartialState
|
||||
from transformers import CLIPTextModel
|
||||
from tqdm import tqdm
|
||||
from PIL import Image
|
||||
from safetensors.torch import save_file
|
||||
|
||||
from library import flux_models, flux_utils, strategy_base, train_util
|
||||
from library.device_utils import init_ipex, clean_memory_on_device
|
||||
from library.safetensors_utils import mem_eff_save_file
|
||||
|
||||
init_ipex()
|
||||
|
||||
from .utils import setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
# region sample images
|
||||
|
||||
|
||||
def sample_images(
|
||||
accelerator: Accelerator,
|
||||
args: argparse.Namespace,
|
||||
epoch,
|
||||
steps,
|
||||
flux,
|
||||
ae,
|
||||
text_encoders,
|
||||
sample_prompts_te_outputs,
|
||||
prompt_replacement=None,
|
||||
controlnet=None,
|
||||
):
|
||||
if steps == 0:
|
||||
if not args.sample_at_first:
|
||||
return
|
||||
else:
|
||||
if args.sample_every_n_steps is None and args.sample_every_n_epochs is None:
|
||||
return
|
||||
if args.sample_every_n_epochs is not None:
|
||||
# sample_every_n_steps は無視する
|
||||
if epoch is None or epoch % args.sample_every_n_epochs != 0:
|
||||
return
|
||||
else:
|
||||
if steps % args.sample_every_n_steps != 0 or epoch is not None: # steps is not divisible or end of epoch
|
||||
return
|
||||
|
||||
logger.info("")
|
||||
logger.info(f"generating sample images at step / サンプル画像生成 ステップ: {steps}")
|
||||
if not os.path.isfile(args.sample_prompts) and sample_prompts_te_outputs is None:
|
||||
logger.error(f"No prompt file / プロンプトファイルがありません: {args.sample_prompts}")
|
||||
return
|
||||
|
||||
distributed_state = PartialState() # for multi gpu distributed inference. this is a singleton, so it's safe to use it here
|
||||
|
||||
# unwrap unet and text_encoder(s)
|
||||
flux = accelerator.unwrap_model(flux)
|
||||
if text_encoders is not None:
|
||||
text_encoders = [(accelerator.unwrap_model(te) if te is not None else None) for te in text_encoders]
|
||||
if controlnet is not None:
|
||||
controlnet = accelerator.unwrap_model(controlnet)
|
||||
# print([(te.parameters().__next__().device if te is not None else None) for te in text_encoders])
|
||||
|
||||
prompts = train_util.load_prompts(args.sample_prompts)
|
||||
|
||||
save_dir = args.output_dir + "/sample"
|
||||
os.makedirs(save_dir, exist_ok=True)
|
||||
|
||||
# save random state to restore later
|
||||
rng_state = torch.get_rng_state()
|
||||
cuda_rng_state = None
|
||||
try:
|
||||
cuda_rng_state = torch.cuda.get_rng_state() if torch.cuda.is_available() else None
|
||||
except Exception:
|
||||
pass
|
||||
|
||||
if distributed_state.num_processes <= 1:
|
||||
# If only one device is available, just use the original prompt list. We don't need to care about the distribution of prompts.
|
||||
with torch.no_grad(), accelerator.autocast():
|
||||
for prompt_dict in prompts:
|
||||
sample_image_inference(
|
||||
accelerator,
|
||||
args,
|
||||
flux,
|
||||
text_encoders,
|
||||
ae,
|
||||
save_dir,
|
||||
prompt_dict,
|
||||
epoch,
|
||||
steps,
|
||||
sample_prompts_te_outputs,
|
||||
prompt_replacement,
|
||||
controlnet,
|
||||
)
|
||||
else:
|
||||
# Creating list with N elements, where each element is a list of prompt_dicts, and N is the number of processes available (number of devices available)
|
||||
# prompt_dicts are assigned to lists based on order of processes, to attempt to time the image creation time to match enum order. Probably only works when steps and sampler are identical.
|
||||
per_process_prompts = [] # list of lists
|
||||
for i in range(distributed_state.num_processes):
|
||||
per_process_prompts.append(prompts[i :: distributed_state.num_processes])
|
||||
|
||||
with torch.no_grad():
|
||||
with distributed_state.split_between_processes(per_process_prompts) as prompt_dict_lists:
|
||||
for prompt_dict in prompt_dict_lists[0]:
|
||||
sample_image_inference(
|
||||
accelerator,
|
||||
args,
|
||||
flux,
|
||||
text_encoders,
|
||||
ae,
|
||||
save_dir,
|
||||
prompt_dict,
|
||||
epoch,
|
||||
steps,
|
||||
sample_prompts_te_outputs,
|
||||
prompt_replacement,
|
||||
controlnet,
|
||||
)
|
||||
|
||||
torch.set_rng_state(rng_state)
|
||||
if cuda_rng_state is not None:
|
||||
torch.cuda.set_rng_state(cuda_rng_state)
|
||||
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
|
||||
def sample_image_inference(
|
||||
accelerator: Accelerator,
|
||||
args: argparse.Namespace,
|
||||
flux: flux_models.Flux,
|
||||
text_encoders: Optional[List[CLIPTextModel]],
|
||||
ae: flux_models.AutoEncoder,
|
||||
save_dir,
|
||||
prompt_dict,
|
||||
epoch,
|
||||
steps,
|
||||
sample_prompts_te_outputs,
|
||||
prompt_replacement,
|
||||
controlnet,
|
||||
):
|
||||
assert isinstance(prompt_dict, dict)
|
||||
negative_prompt = prompt_dict.get("negative_prompt")
|
||||
sample_steps = prompt_dict.get("sample_steps", 20)
|
||||
width = prompt_dict.get("width", 512)
|
||||
height = prompt_dict.get("height", 512)
|
||||
emb_guidance_scale = prompt_dict.get("guidance_scale", 3.5)
|
||||
cfg_scale = prompt_dict.get("scale", 1.0)
|
||||
seed = prompt_dict.get("seed")
|
||||
controlnet_image = prompt_dict.get("controlnet_image")
|
||||
prompt: str = prompt_dict.get("prompt", "")
|
||||
# sampler_name: str = prompt_dict.get("sample_sampler", args.sample_sampler)
|
||||
|
||||
if prompt_replacement is not None:
|
||||
prompt = prompt.replace(prompt_replacement[0], prompt_replacement[1])
|
||||
if negative_prompt is not None:
|
||||
negative_prompt = negative_prompt.replace(prompt_replacement[0], prompt_replacement[1])
|
||||
|
||||
if seed is not None:
|
||||
torch.manual_seed(seed)
|
||||
torch.cuda.manual_seed(seed)
|
||||
else:
|
||||
# True random sample image generation
|
||||
torch.seed()
|
||||
torch.cuda.seed()
|
||||
|
||||
if negative_prompt is None:
|
||||
negative_prompt = ""
|
||||
height = max(64, height - height % 16) # round to divisible by 16
|
||||
width = max(64, width - width % 16) # round to divisible by 16
|
||||
logger.info(f"prompt: {prompt}")
|
||||
if cfg_scale != 1.0:
|
||||
logger.info(f"negative_prompt: {negative_prompt}")
|
||||
elif negative_prompt != "":
|
||||
logger.info(f"negative prompt is ignored because scale is 1.0")
|
||||
logger.info(f"height: {height}")
|
||||
logger.info(f"width: {width}")
|
||||
logger.info(f"sample_steps: {sample_steps}")
|
||||
logger.info(f"embedded guidance scale: {emb_guidance_scale}")
|
||||
if cfg_scale != 1.0:
|
||||
logger.info(f"CFG scale: {cfg_scale}")
|
||||
# logger.info(f"sample_sampler: {sampler_name}")
|
||||
if seed is not None:
|
||||
logger.info(f"seed: {seed}")
|
||||
|
||||
# encode prompts
|
||||
tokenize_strategy = strategy_base.TokenizeStrategy.get_strategy()
|
||||
encoding_strategy = strategy_base.TextEncodingStrategy.get_strategy()
|
||||
|
||||
def encode_prompt(prpt):
|
||||
text_encoder_conds = []
|
||||
if sample_prompts_te_outputs and prpt in sample_prompts_te_outputs:
|
||||
text_encoder_conds = sample_prompts_te_outputs[prpt]
|
||||
print(f"Using cached text encoder outputs for prompt: {prpt}")
|
||||
if text_encoders is not None:
|
||||
print(f"Encoding prompt: {prpt}")
|
||||
tokens_and_masks = tokenize_strategy.tokenize(prpt)
|
||||
# strategy has apply_t5_attn_mask option
|
||||
encoded_text_encoder_conds = encoding_strategy.encode_tokens(tokenize_strategy, text_encoders, tokens_and_masks)
|
||||
|
||||
# if text_encoder_conds is not cached, use encoded_text_encoder_conds
|
||||
if len(text_encoder_conds) == 0:
|
||||
text_encoder_conds = encoded_text_encoder_conds
|
||||
else:
|
||||
# if encoded_text_encoder_conds is not None, update cached text_encoder_conds
|
||||
for i in range(len(encoded_text_encoder_conds)):
|
||||
if encoded_text_encoder_conds[i] is not None:
|
||||
text_encoder_conds[i] = encoded_text_encoder_conds[i]
|
||||
return text_encoder_conds
|
||||
|
||||
l_pooled, t5_out, txt_ids, t5_attn_mask = encode_prompt(prompt)
|
||||
# encode negative prompts
|
||||
if cfg_scale != 1.0:
|
||||
neg_l_pooled, neg_t5_out, _, neg_t5_attn_mask = encode_prompt(negative_prompt)
|
||||
neg_t5_attn_mask = (
|
||||
neg_t5_attn_mask.to(accelerator.device) if args.apply_t5_attn_mask and neg_t5_attn_mask is not None else None
|
||||
)
|
||||
neg_cond = (cfg_scale, neg_l_pooled, neg_t5_out, neg_t5_attn_mask)
|
||||
else:
|
||||
neg_cond = None
|
||||
|
||||
# sample image
|
||||
weight_dtype = ae.dtype # TOFO give dtype as argument
|
||||
packed_latent_height = height // 16
|
||||
packed_latent_width = width // 16
|
||||
noise = torch.randn(
|
||||
1,
|
||||
packed_latent_height * packed_latent_width,
|
||||
16 * 2 * 2,
|
||||
device=accelerator.device,
|
||||
dtype=weight_dtype,
|
||||
generator=torch.Generator(device=accelerator.device).manual_seed(seed) if seed is not None else None,
|
||||
)
|
||||
timesteps = get_schedule(sample_steps, noise.shape[1], shift=True) # Chroma can use shift=True
|
||||
img_ids = flux_utils.prepare_img_ids(1, packed_latent_height, packed_latent_width).to(accelerator.device, weight_dtype)
|
||||
t5_attn_mask = t5_attn_mask.to(accelerator.device) if args.apply_t5_attn_mask else None
|
||||
|
||||
if controlnet_image is not None:
|
||||
controlnet_image = Image.open(controlnet_image).convert("RGB")
|
||||
controlnet_image = controlnet_image.resize((width, height), Image.LANCZOS)
|
||||
controlnet_image = torch.from_numpy((np.array(controlnet_image) / 127.5) - 1)
|
||||
controlnet_image = controlnet_image.permute(2, 0, 1).unsqueeze(0).to(weight_dtype).to(accelerator.device)
|
||||
|
||||
with accelerator.autocast(), torch.no_grad():
|
||||
x = denoise(
|
||||
flux,
|
||||
noise,
|
||||
img_ids,
|
||||
t5_out,
|
||||
txt_ids,
|
||||
l_pooled,
|
||||
timesteps=timesteps,
|
||||
guidance=emb_guidance_scale,
|
||||
t5_attn_mask=t5_attn_mask,
|
||||
controlnet=controlnet,
|
||||
controlnet_img=controlnet_image,
|
||||
neg_cond=neg_cond,
|
||||
)
|
||||
|
||||
x = flux_utils.unpack_latents(x, packed_latent_height, packed_latent_width)
|
||||
|
||||
# latent to image
|
||||
clean_memory_on_device(accelerator.device)
|
||||
org_vae_device = ae.device # will be on cpu
|
||||
ae.to(accelerator.device) # distributed_state.device is same as accelerator.device
|
||||
with accelerator.autocast(), torch.no_grad():
|
||||
x = ae.decode(x)
|
||||
ae.to(org_vae_device)
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
x = x.clamp(-1, 1)
|
||||
x = x.permute(0, 2, 3, 1)
|
||||
image = Image.fromarray((127.5 * (x + 1.0)).float().cpu().numpy().astype(np.uint8)[0])
|
||||
|
||||
# adding accelerator.wait_for_everyone() here should sync up and ensure that sample images are saved in the same order as the original prompt list
|
||||
# but adding 'enum' to the filename should be enough
|
||||
|
||||
ts_str = time.strftime("%Y%m%d%H%M%S", time.localtime())
|
||||
num_suffix = f"e{epoch:06d}" if epoch is not None else f"{steps:06d}"
|
||||
seed_suffix = "" if seed is None else f"_{seed}"
|
||||
i: int = prompt_dict["enum"]
|
||||
img_filename = f"{'' if args.output_name is None else args.output_name + '_'}{num_suffix}_{i:02d}_{ts_str}{seed_suffix}.png"
|
||||
image.save(os.path.join(save_dir, img_filename))
|
||||
|
||||
# send images to wandb if enabled
|
||||
if "wandb" in [tracker.name for tracker in accelerator.trackers]:
|
||||
wandb_tracker = accelerator.get_tracker("wandb")
|
||||
|
||||
import wandb
|
||||
|
||||
# not to commit images to avoid inconsistency between training and logging steps
|
||||
wandb_tracker.log({f"sample_{i}": wandb.Image(image, caption=prompt)}, commit=False) # positive prompt as a caption
|
||||
|
||||
|
||||
def time_shift(mu: float, sigma: float, t: torch.Tensor):
|
||||
return math.exp(mu) / (math.exp(mu) + (1 / t - 1) ** sigma)
|
||||
|
||||
|
||||
def get_lin_function(x1: float = 256, y1: float = 0.5, x2: float = 4096, y2: float = 1.15) -> Callable[[float], float]:
|
||||
m = (y2 - y1) / (x2 - x1)
|
||||
b = y1 - m * x1
|
||||
return lambda x: m * x + b
|
||||
|
||||
|
||||
def get_schedule(
|
||||
num_steps: int,
|
||||
image_seq_len: int,
|
||||
base_shift: float = 0.5,
|
||||
max_shift: float = 1.15,
|
||||
shift: bool = True,
|
||||
) -> list[float]:
|
||||
# extra step for zero
|
||||
timesteps = torch.linspace(1, 0, num_steps + 1)
|
||||
|
||||
# shifting the schedule to favor high timesteps for higher signal images
|
||||
if shift:
|
||||
# eastimate mu based on linear estimation between two points
|
||||
mu = get_lin_function(y1=base_shift, y2=max_shift)(image_seq_len)
|
||||
timesteps = time_shift(mu, 1.0, timesteps)
|
||||
|
||||
return timesteps.tolist()
|
||||
|
||||
|
||||
def denoise(
|
||||
model: flux_models.Flux,
|
||||
img: torch.Tensor,
|
||||
img_ids: torch.Tensor,
|
||||
txt: torch.Tensor, # t5_out
|
||||
txt_ids: torch.Tensor,
|
||||
vec: torch.Tensor, # l_pooled
|
||||
timesteps: list[float],
|
||||
guidance: float = 4.0,
|
||||
t5_attn_mask: Optional[torch.Tensor] = None,
|
||||
controlnet: Optional[flux_models.ControlNetFlux] = None,
|
||||
controlnet_img: Optional[torch.Tensor] = None,
|
||||
neg_cond: Optional[Tuple[float, torch.Tensor, torch.Tensor, torch.Tensor]] = None,
|
||||
):
|
||||
# this is ignored for schnell
|
||||
guidance_vec = torch.full((img.shape[0],), guidance, device=img.device, dtype=img.dtype)
|
||||
do_cfg = neg_cond is not None
|
||||
|
||||
for t_curr, t_prev in zip(tqdm(timesteps[:-1]), timesteps[1:]):
|
||||
t_vec = torch.full((img.shape[0],), t_curr, dtype=img.dtype, device=img.device)
|
||||
model.prepare_block_swap_before_forward()
|
||||
|
||||
if controlnet is not None:
|
||||
block_samples, block_single_samples = controlnet(
|
||||
img=img,
|
||||
img_ids=img_ids,
|
||||
controlnet_cond=controlnet_img,
|
||||
txt=txt,
|
||||
txt_ids=txt_ids,
|
||||
y=vec,
|
||||
timesteps=t_vec,
|
||||
guidance=guidance_vec,
|
||||
txt_attention_mask=t5_attn_mask,
|
||||
)
|
||||
else:
|
||||
block_samples = None
|
||||
block_single_samples = None
|
||||
|
||||
if not do_cfg:
|
||||
pred = model(
|
||||
img=img,
|
||||
img_ids=img_ids,
|
||||
txt=txt,
|
||||
txt_ids=txt_ids,
|
||||
y=vec,
|
||||
block_controlnet_hidden_states=block_samples,
|
||||
block_controlnet_single_hidden_states=block_single_samples,
|
||||
timesteps=t_vec,
|
||||
guidance=guidance_vec,
|
||||
txt_attention_mask=t5_attn_mask,
|
||||
)
|
||||
|
||||
img = img + (t_prev - t_curr) * pred
|
||||
else:
|
||||
cfg_scale, neg_l_pooled, neg_t5_out, neg_t5_attn_mask = neg_cond
|
||||
nc_c_t5_attn_mask = None if t5_attn_mask is None else torch.cat([neg_t5_attn_mask, t5_attn_mask], dim=0)
|
||||
|
||||
# TODO is it ok to use the same block samples for both cond and uncond?
|
||||
block_samples = None if block_samples is None else torch.cat([block_samples, block_samples], dim=0)
|
||||
block_single_samples = (
|
||||
None if block_single_samples is None else torch.cat([block_single_samples, block_single_samples], dim=0)
|
||||
)
|
||||
|
||||
nc_c_pred = model(
|
||||
img=torch.cat([img, img], dim=0),
|
||||
img_ids=torch.cat([img_ids, img_ids], dim=0),
|
||||
txt=torch.cat([neg_t5_out, txt], dim=0),
|
||||
txt_ids=torch.cat([txt_ids, txt_ids], dim=0),
|
||||
y=torch.cat([neg_l_pooled, vec], dim=0),
|
||||
block_controlnet_hidden_states=block_samples,
|
||||
block_controlnet_single_hidden_states=block_single_samples,
|
||||
timesteps=t_vec.repeat(2),
|
||||
guidance=guidance_vec.repeat(2),
|
||||
txt_attention_mask=nc_c_t5_attn_mask,
|
||||
)
|
||||
neg_pred, pred = torch.chunk(nc_c_pred, 2, dim=0)
|
||||
pred = neg_pred + (pred - neg_pred) * cfg_scale
|
||||
|
||||
img = img + (t_prev - t_curr) * pred
|
||||
|
||||
model.prepare_block_swap_before_forward()
|
||||
return img
|
||||
|
||||
|
||||
# endregion
|
||||
|
||||
|
||||
# region train
|
||||
def get_sigmas(noise_scheduler, timesteps, device, n_dim=4, dtype=torch.float32):
|
||||
sigmas = noise_scheduler.sigmas.to(device=device, dtype=dtype)
|
||||
schedule_timesteps = noise_scheduler.timesteps.to(device)
|
||||
timesteps = timesteps.to(device)
|
||||
step_indices = [(schedule_timesteps == t).nonzero().item() for t in timesteps]
|
||||
|
||||
sigma = sigmas[step_indices].flatten()
|
||||
return sigma
|
||||
|
||||
|
||||
def compute_density_for_timestep_sampling(
|
||||
weighting_scheme: str, batch_size: int, logit_mean: float = None, logit_std: float = None, mode_scale: float = None
|
||||
):
|
||||
"""Compute the density for sampling the timesteps when doing SD3 training.
|
||||
|
||||
Courtesy: This was contributed by Rafie Walker in https://github.com/huggingface/diffusers/pull/8528.
|
||||
|
||||
SD3 paper reference: https://arxiv.org/abs/2403.03206v1.
|
||||
"""
|
||||
if weighting_scheme == "logit_normal":
|
||||
# See 3.1 in the SD3 paper ($rf/lognorm(0.00,1.00)$).
|
||||
u = torch.normal(mean=logit_mean, std=logit_std, size=(batch_size,), device="cpu")
|
||||
u = torch.nn.functional.sigmoid(u)
|
||||
elif weighting_scheme == "mode":
|
||||
u = torch.rand(size=(batch_size,), device="cpu")
|
||||
u = 1 - u - mode_scale * (torch.cos(math.pi * u / 2) ** 2 - 1 + u)
|
||||
else:
|
||||
u = torch.rand(size=(batch_size,), device="cpu")
|
||||
return u
|
||||
|
||||
|
||||
def compute_loss_weighting_for_sd3(weighting_scheme: str, sigmas=None):
|
||||
"""Computes loss weighting scheme for SD3 training.
|
||||
|
||||
Courtesy: This was contributed by Rafie Walker in https://github.com/huggingface/diffusers/pull/8528.
|
||||
|
||||
SD3 paper reference: https://arxiv.org/abs/2403.03206v1.
|
||||
"""
|
||||
if weighting_scheme == "sigma_sqrt":
|
||||
weighting = (sigmas**-2.0).float()
|
||||
elif weighting_scheme == "cosmap":
|
||||
bot = 1 - 2 * sigmas + 2 * sigmas**2
|
||||
weighting = 2 / (math.pi * bot)
|
||||
else:
|
||||
weighting = torch.ones_like(sigmas)
|
||||
return weighting
|
||||
|
||||
|
||||
def get_noisy_model_input_and_timesteps(
|
||||
args, noise_scheduler, latents: torch.Tensor, noise: torch.Tensor, device, dtype
|
||||
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
|
||||
bsz, h, w = latents.shape[0], latents.shape[-2], latents.shape[-1]
|
||||
assert bsz > 0, "Batch size not large enough"
|
||||
num_timesteps = noise_scheduler.config.num_train_timesteps
|
||||
if args.timestep_sampling == "uniform" or args.timestep_sampling == "sigmoid":
|
||||
# Simple random sigma-based noise sampling
|
||||
if args.timestep_sampling == "sigmoid":
|
||||
# https://github.com/XLabs-AI/x-flux/tree/main
|
||||
sigmas = torch.sigmoid(args.sigmoid_scale * torch.randn((bsz,), device=device))
|
||||
else:
|
||||
sigmas = torch.rand((bsz,), device=device)
|
||||
|
||||
timesteps = sigmas * num_timesteps
|
||||
elif args.timestep_sampling == "shift":
|
||||
shift = args.discrete_flow_shift
|
||||
sigmas = torch.randn(bsz, device=device)
|
||||
sigmas = sigmas * args.sigmoid_scale # larger scale for more uniform sampling
|
||||
sigmas = sigmas.sigmoid()
|
||||
sigmas = (sigmas * shift) / (1 + (shift - 1) * sigmas)
|
||||
timesteps = sigmas * num_timesteps
|
||||
elif args.timestep_sampling == "flux_shift":
|
||||
sigmas = torch.randn(bsz, device=device)
|
||||
sigmas = sigmas * args.sigmoid_scale # larger scale for more uniform sampling
|
||||
sigmas = sigmas.sigmoid()
|
||||
mu = get_lin_function(y1=0.5, y2=1.15)((h // 2) * (w // 2)) # we are pre-packed so must adjust for packed size
|
||||
sigmas = time_shift(mu, 1.0, sigmas)
|
||||
timesteps = sigmas * num_timesteps
|
||||
else:
|
||||
# Sample a random timestep for each image
|
||||
# for weighting schemes where we sample timesteps non-uniformly
|
||||
u = compute_density_for_timestep_sampling(
|
||||
weighting_scheme=args.weighting_scheme,
|
||||
batch_size=bsz,
|
||||
logit_mean=args.logit_mean,
|
||||
logit_std=args.logit_std,
|
||||
mode_scale=args.mode_scale,
|
||||
)
|
||||
indices = (u * num_timesteps).long()
|
||||
timesteps = noise_scheduler.timesteps[indices].to(device=device)
|
||||
sigmas = get_sigmas(noise_scheduler, timesteps, device, n_dim=latents.ndim, dtype=dtype)
|
||||
|
||||
# Broadcast sigmas to latent shape
|
||||
sigmas = sigmas.view(-1, 1, 1, 1) if latents.ndim == 4 else sigmas.view(-1, 1, 1, 1, 1)
|
||||
|
||||
# Add noise to the latents according to the noise magnitude at each timestep
|
||||
# (this is the forward diffusion process)
|
||||
if args.ip_noise_gamma:
|
||||
xi = torch.randn_like(latents, device=latents.device, dtype=dtype)
|
||||
if args.ip_noise_gamma_random_strength:
|
||||
ip_noise_gamma = torch.rand(1, device=latents.device, dtype=dtype) * args.ip_noise_gamma
|
||||
else:
|
||||
ip_noise_gamma = args.ip_noise_gamma
|
||||
noisy_model_input = (1.0 - sigmas) * latents + sigmas * (noise + ip_noise_gamma * xi)
|
||||
else:
|
||||
noisy_model_input = (1.0 - sigmas) * latents + sigmas * noise
|
||||
|
||||
return noisy_model_input.to(dtype), timesteps.to(dtype), sigmas
|
||||
|
||||
|
||||
def apply_model_prediction_type(args, model_pred, noisy_model_input, sigmas):
|
||||
weighting = None
|
||||
if args.model_prediction_type == "raw":
|
||||
pass
|
||||
elif args.model_prediction_type == "additive":
|
||||
# add the model_pred to the noisy_model_input
|
||||
model_pred = model_pred + noisy_model_input
|
||||
elif args.model_prediction_type == "sigma_scaled":
|
||||
# apply sigma scaling
|
||||
model_pred = model_pred * (-sigmas) + noisy_model_input
|
||||
|
||||
# these weighting schemes use a uniform timestep sampling
|
||||
# and instead post-weight the loss
|
||||
weighting = compute_loss_weighting_for_sd3(weighting_scheme=args.weighting_scheme, sigmas=sigmas)
|
||||
|
||||
return model_pred, weighting
|
||||
|
||||
|
||||
def save_models(
|
||||
ckpt_path: str,
|
||||
flux: flux_models.Flux,
|
||||
sai_metadata: Optional[dict],
|
||||
save_dtype: Optional[torch.dtype] = None,
|
||||
use_mem_eff_save: bool = False,
|
||||
):
|
||||
state_dict = {}
|
||||
|
||||
def update_sd(prefix, sd):
|
||||
for k, v in sd.items():
|
||||
key = prefix + k
|
||||
if save_dtype is not None and v.dtype != save_dtype:
|
||||
v = v.detach().clone().to("cpu").to(save_dtype)
|
||||
state_dict[key] = v
|
||||
|
||||
update_sd("", flux.state_dict())
|
||||
|
||||
if not use_mem_eff_save:
|
||||
save_file(state_dict, ckpt_path, metadata=sai_metadata)
|
||||
else:
|
||||
mem_eff_save_file(state_dict, ckpt_path, metadata=sai_metadata)
|
||||
|
||||
|
||||
def save_flux_model_on_train_end(
|
||||
args: argparse.Namespace, save_dtype: torch.dtype, epoch: int, global_step: int, flux: flux_models.Flux
|
||||
):
|
||||
def sd_saver(ckpt_file, epoch_no, global_step):
|
||||
sai_metadata = train_util.get_sai_model_spec(None, args, False, False, False, is_stable_diffusion_ckpt=True, flux="dev")
|
||||
save_models(ckpt_file, flux, sai_metadata, save_dtype, args.mem_eff_save)
|
||||
|
||||
train_util.save_sd_model_on_train_end_common(args, True, True, epoch, global_step, sd_saver, None)
|
||||
|
||||
|
||||
# epochとstepの保存、メタデータにepoch/stepが含まれ引数が同じになるため、統合している
|
||||
# on_epoch_end: Trueならepoch終了時、Falseならstep経過時
|
||||
def save_flux_model_on_epoch_end_or_stepwise(
|
||||
args: argparse.Namespace,
|
||||
on_epoch_end: bool,
|
||||
accelerator,
|
||||
save_dtype: torch.dtype,
|
||||
epoch: int,
|
||||
num_train_epochs: int,
|
||||
global_step: int,
|
||||
flux: flux_models.Flux,
|
||||
):
|
||||
def sd_saver(ckpt_file, epoch_no, global_step):
|
||||
sai_metadata = train_util.get_sai_model_spec(None, args, False, False, False, is_stable_diffusion_ckpt=True, flux="dev")
|
||||
save_models(ckpt_file, flux, sai_metadata, save_dtype, args.mem_eff_save)
|
||||
|
||||
train_util.save_sd_model_on_epoch_end_or_stepwise_common(
|
||||
args,
|
||||
on_epoch_end,
|
||||
accelerator,
|
||||
True,
|
||||
True,
|
||||
epoch,
|
||||
num_train_epochs,
|
||||
global_step,
|
||||
sd_saver,
|
||||
None,
|
||||
)
|
||||
|
||||
|
||||
# endregion
|
||||
|
||||
|
||||
def add_flux_train_arguments(parser: argparse.ArgumentParser):
|
||||
parser.add_argument(
|
||||
"--clip_l",
|
||||
type=str,
|
||||
help="path to clip_l (*.sft or *.safetensors), should be float16 / clip_lのパス(*.sftまたは*.safetensors)、float16が前提",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--t5xxl",
|
||||
type=str,
|
||||
help="path to t5xxl (*.sft or *.safetensors), should be float16 / t5xxlのパス(*.sftまたは*.safetensors)、float16が前提",
|
||||
)
|
||||
parser.add_argument("--ae", type=str, help="path to ae (*.sft or *.safetensors) / aeのパス(*.sftまたは*.safetensors)")
|
||||
parser.add_argument(
|
||||
"--controlnet_model_name_or_path",
|
||||
type=str,
|
||||
default=None,
|
||||
help="path to controlnet (*.sft or *.safetensors) / controlnetのパス(*.sftまたは*.safetensors)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--t5xxl_max_token_length",
|
||||
type=int,
|
||||
default=None,
|
||||
help="maximum token length for T5-XXL. if omitted, 256 for schnell and 512 for dev"
|
||||
" / T5-XXLの最大トークン長。省略された場合、schnellの場合は256、devの場合は512",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--apply_t5_attn_mask",
|
||||
action="store_true",
|
||||
help="apply attention mask to T5-XXL encode and FLUX double blocks / T5-XXLエンコードとFLUXダブルブロックにアテンションマスクを適用する",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--guidance_scale",
|
||||
type=float,
|
||||
default=3.5,
|
||||
help="the FLUX.1 dev variant is a guidance distilled model",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--timestep_sampling",
|
||||
choices=["sigma", "uniform", "sigmoid", "shift", "flux_shift"],
|
||||
default="sigma",
|
||||
help="Method to sample timesteps: sigma-based, uniform random, sigmoid of random normal, shift of sigmoid and FLUX.1 shifting."
|
||||
" / タイムステップをサンプリングする方法:sigma、random uniform、random normalのsigmoid、sigmoidのシフト、FLUX.1のシフト。",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--sigmoid_scale",
|
||||
type=float,
|
||||
default=1.0,
|
||||
help='Scale factor for sigmoid timestep sampling (only used when timestep-sampling is "sigmoid"). / sigmoidタイムステップサンプリングの倍率(timestep-samplingが"sigmoid"の場合のみ有効)。',
|
||||
)
|
||||
parser.add_argument(
|
||||
"--model_prediction_type",
|
||||
choices=["raw", "additive", "sigma_scaled"],
|
||||
default="sigma_scaled",
|
||||
help="How to interpret and process the model prediction: "
|
||||
"raw (use as is), additive (add to noisy input), sigma_scaled (apply sigma scaling)."
|
||||
" / モデル予測の解釈と処理方法:"
|
||||
"raw(そのまま使用)、additive(ノイズ入力に加算)、sigma_scaled(シグマスケーリングを適用)。",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--discrete_flow_shift",
|
||||
type=float,
|
||||
default=3.0,
|
||||
help="Discrete flow shift for the Euler Discrete Scheduler, default is 3.0. / Euler Discrete Schedulerの離散フローシフト、デフォルトは3.0。",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--model_type",
|
||||
type=str,
|
||||
choices=["flux", "chroma"],
|
||||
default="flux",
|
||||
help="Model type to use for training / トレーニングに使用するモデルタイプ:flux or chroma (default: flux)",
|
||||
)
|
||||
563
library/flux_utils.py
Normal file
563
library/flux_utils.py
Normal file
@@ -0,0 +1,563 @@
|
||||
import json
|
||||
import os
|
||||
from dataclasses import replace
|
||||
from typing import List, Optional, Tuple, Union
|
||||
|
||||
import einops
|
||||
import torch
|
||||
from accelerate import init_empty_weights
|
||||
from safetensors import safe_open
|
||||
from safetensors.torch import load_file
|
||||
from transformers import CLIPConfig, CLIPTextModel, T5Config, T5EncoderModel
|
||||
|
||||
from library.utils import setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
from library import flux_models
|
||||
from library.safetensors_utils import load_safetensors
|
||||
|
||||
MODEL_VERSION_FLUX_V1 = "flux1"
|
||||
MODEL_NAME_DEV = "dev"
|
||||
MODEL_NAME_SCHNELL = "schnell"
|
||||
MODEL_VERSION_CHROMA = "chroma"
|
||||
|
||||
|
||||
def analyze_checkpoint_state(ckpt_path: str) -> Tuple[bool, bool, Tuple[int, int], List[str]]:
|
||||
"""
|
||||
チェックポイントの状態を分析し、DiffusersかBFLか、devかschnellか、ブロック数を計算して返す。
|
||||
|
||||
Args:
|
||||
ckpt_path (str): チェックポイントファイルまたはディレクトリのパス。
|
||||
|
||||
Returns:
|
||||
Tuple[bool, bool, Tuple[int, int], List[str]]:
|
||||
- bool: Diffusersかどうかを示すフラグ。
|
||||
- bool: Schnellかどうかを示すフラグ。
|
||||
- Tuple[int, int]: ダブルブロックとシングルブロックの数。
|
||||
- List[str]: チェックポイントに含まれるキーのリスト。
|
||||
"""
|
||||
# check the state dict: Diffusers or BFL, dev or schnell, number of blocks
|
||||
logger.info(f"Checking the state dict: Diffusers or BFL, dev or schnell")
|
||||
|
||||
if os.path.isdir(ckpt_path): # if ckpt_path is a directory, it is Diffusers
|
||||
ckpt_path = os.path.join(ckpt_path, "transformer", "diffusion_pytorch_model-00001-of-00003.safetensors")
|
||||
if "00001-of-00003" in ckpt_path:
|
||||
ckpt_paths = [ckpt_path.replace("00001-of-00003", f"0000{i}-of-00003") for i in range(1, 4)]
|
||||
else:
|
||||
ckpt_paths = [ckpt_path]
|
||||
|
||||
keys = []
|
||||
for ckpt_path in ckpt_paths:
|
||||
with safe_open(ckpt_path, framework="pt") as f:
|
||||
keys.extend(f.keys())
|
||||
|
||||
# if the key has annoying prefix, remove it
|
||||
if keys[0].startswith("model.diffusion_model."):
|
||||
keys = [key.replace("model.diffusion_model.", "") for key in keys]
|
||||
|
||||
is_diffusers = "transformer_blocks.0.attn.add_k_proj.bias" in keys
|
||||
is_schnell = not ("guidance_in.in_layer.bias" in keys or "time_text_embed.guidance_embedder.linear_1.bias" in keys)
|
||||
|
||||
# check number of double and single blocks
|
||||
if not is_diffusers:
|
||||
max_double_block_index = max(
|
||||
[int(key.split(".")[1]) for key in keys if key.startswith("double_blocks.") and key.endswith(".img_attn.proj.bias")]
|
||||
)
|
||||
max_single_block_index = max(
|
||||
[int(key.split(".")[1]) for key in keys if key.startswith("single_blocks.") and key.endswith(".modulation.lin.bias")]
|
||||
)
|
||||
else:
|
||||
max_double_block_index = max(
|
||||
[
|
||||
int(key.split(".")[1])
|
||||
for key in keys
|
||||
if key.startswith("transformer_blocks.") and key.endswith(".attn.add_k_proj.bias")
|
||||
]
|
||||
)
|
||||
max_single_block_index = max(
|
||||
[
|
||||
int(key.split(".")[1])
|
||||
for key in keys
|
||||
if key.startswith("single_transformer_blocks.") and key.endswith(".attn.to_k.bias")
|
||||
]
|
||||
)
|
||||
|
||||
num_double_blocks = max_double_block_index + 1
|
||||
num_single_blocks = max_single_block_index + 1
|
||||
|
||||
return is_diffusers, is_schnell, (num_double_blocks, num_single_blocks), ckpt_paths
|
||||
|
||||
|
||||
def load_flow_model(
|
||||
ckpt_path: str,
|
||||
dtype: Optional[torch.dtype],
|
||||
device: Union[str, torch.device],
|
||||
disable_mmap: bool = False,
|
||||
model_type: str = "flux",
|
||||
) -> Tuple[bool, flux_models.Flux]:
|
||||
if model_type == "flux":
|
||||
is_diffusers, is_schnell, (num_double_blocks, num_single_blocks), ckpt_paths = analyze_checkpoint_state(ckpt_path)
|
||||
name = MODEL_NAME_DEV if not is_schnell else MODEL_NAME_SCHNELL
|
||||
|
||||
# build model
|
||||
logger.info(f"Building Flux model {name} from {'Diffusers' if is_diffusers else 'BFL'} checkpoint")
|
||||
with torch.device("meta"):
|
||||
params = flux_models.configs[name].params
|
||||
|
||||
# set the number of blocks
|
||||
if params.depth != num_double_blocks:
|
||||
logger.info(f"Setting the number of double blocks from {params.depth} to {num_double_blocks}")
|
||||
params = replace(params, depth=num_double_blocks)
|
||||
if params.depth_single_blocks != num_single_blocks:
|
||||
logger.info(f"Setting the number of single blocks from {params.depth_single_blocks} to {num_single_blocks}")
|
||||
params = replace(params, depth_single_blocks=num_single_blocks)
|
||||
|
||||
model = flux_models.Flux(params)
|
||||
if dtype is not None:
|
||||
model = model.to(dtype)
|
||||
|
||||
# load_sft doesn't support torch.device
|
||||
logger.info(f"Loading state dict from {ckpt_path}")
|
||||
sd = {}
|
||||
for ckpt_path in ckpt_paths:
|
||||
sd.update(load_safetensors(ckpt_path, device=device, disable_mmap=disable_mmap, dtype=dtype))
|
||||
|
||||
# convert Diffusers to BFL
|
||||
if is_diffusers:
|
||||
logger.info("Converting Diffusers to BFL")
|
||||
sd = convert_diffusers_sd_to_bfl(sd, num_double_blocks, num_single_blocks)
|
||||
logger.info("Converted Diffusers to BFL")
|
||||
|
||||
# if the key has annoying prefix, remove it
|
||||
for key in list(sd.keys()):
|
||||
new_key = key.replace("model.diffusion_model.", "")
|
||||
if new_key == key:
|
||||
break # the model doesn't have annoying prefix
|
||||
sd[new_key] = sd.pop(key)
|
||||
|
||||
info = model.load_state_dict(sd, strict=False, assign=True)
|
||||
logger.info(f"Loaded Flux: {info}")
|
||||
return is_schnell, model
|
||||
|
||||
elif model_type == "chroma":
|
||||
from . import chroma_models
|
||||
|
||||
# build model
|
||||
logger.info("Building Chroma model")
|
||||
with torch.device("meta"):
|
||||
model = chroma_models.Chroma(chroma_models.chroma_params)
|
||||
if dtype is not None:
|
||||
model = model.to(dtype)
|
||||
|
||||
# load_sft doesn't support torch.device
|
||||
logger.info(f"Loading state dict from {ckpt_path}")
|
||||
sd = load_safetensors(ckpt_path, device=str(device), disable_mmap=disable_mmap, dtype=dtype)
|
||||
|
||||
# if the key has annoying prefix, remove it
|
||||
for key in list(sd.keys()):
|
||||
new_key = key.replace("model.diffusion_model.", "")
|
||||
if new_key == key:
|
||||
break # the model doesn't have annoying prefix
|
||||
sd[new_key] = sd.pop(key)
|
||||
|
||||
info = model.load_state_dict(sd, strict=False, assign=True)
|
||||
logger.info(f"Loaded Chroma: {info}")
|
||||
is_schnell = False # Chroma is not schnell
|
||||
return is_schnell, model
|
||||
|
||||
else:
|
||||
raise ValueError(f"Unsupported model_type: {model_type}. Supported types are 'flux' and 'chroma'.")
|
||||
|
||||
|
||||
def load_ae(
|
||||
ckpt_path: str, dtype: torch.dtype, device: Union[str, torch.device], disable_mmap: bool = False
|
||||
) -> flux_models.AutoEncoder:
|
||||
logger.info("Building AutoEncoder")
|
||||
with torch.device("meta"):
|
||||
# dev and schnell have the same AE params
|
||||
ae = flux_models.AutoEncoder(flux_models.configs[MODEL_NAME_DEV].ae_params).to(dtype)
|
||||
|
||||
logger.info(f"Loading state dict from {ckpt_path}")
|
||||
sd = load_safetensors(ckpt_path, device=str(device), disable_mmap=disable_mmap, dtype=dtype)
|
||||
info = ae.load_state_dict(sd, strict=False, assign=True)
|
||||
logger.info(f"Loaded AE: {info}")
|
||||
return ae
|
||||
|
||||
|
||||
def load_controlnet(
|
||||
ckpt_path: Optional[str], is_schnell: bool, dtype: torch.dtype, device: Union[str, torch.device], disable_mmap: bool = False
|
||||
):
|
||||
logger.info("Building ControlNet")
|
||||
name = MODEL_NAME_DEV if not is_schnell else MODEL_NAME_SCHNELL
|
||||
with torch.device(device):
|
||||
controlnet = flux_models.ControlNetFlux(flux_models.configs[name].params).to(dtype)
|
||||
|
||||
if ckpt_path is not None:
|
||||
logger.info(f"Loading state dict from {ckpt_path}")
|
||||
sd = load_safetensors(ckpt_path, device=str(device), disable_mmap=disable_mmap, dtype=dtype)
|
||||
info = controlnet.load_state_dict(sd, strict=False, assign=True)
|
||||
logger.info(f"Loaded ControlNet: {info}")
|
||||
return controlnet
|
||||
|
||||
|
||||
def dummy_clip_l() -> torch.nn.Module:
|
||||
"""
|
||||
Returns a dummy CLIP-L model with the output shape of (N, 77, 768).
|
||||
"""
|
||||
return DummyCLIPL()
|
||||
|
||||
|
||||
class DummyTextModel(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.embeddings = torch.nn.Parameter(torch.zeros(1))
|
||||
|
||||
|
||||
class DummyCLIPL(torch.nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.output_shape = (77, 1) # Note: The original code had (77, 768), but we use (77, 1) for the dummy output
|
||||
|
||||
# dtype and device from these parameters. train_network.py accesses them
|
||||
self.dummy_param = torch.nn.Parameter(torch.zeros(1))
|
||||
self.dummy_param_2 = torch.nn.Parameter(torch.zeros(1))
|
||||
self.dummy_param_3 = torch.nn.Parameter(torch.zeros(1))
|
||||
self.text_model = DummyTextModel()
|
||||
|
||||
@property
|
||||
def device(self):
|
||||
return self.dummy_param.device
|
||||
|
||||
@property
|
||||
def dtype(self):
|
||||
return self.dummy_param.dtype
|
||||
|
||||
def forward(self, *args, **kwargs):
|
||||
"""
|
||||
Returns a dummy output with the shape of (N, 77, 768).
|
||||
"""
|
||||
batch_size = args[0].shape[0] if args else 1
|
||||
return {"pooler_output": torch.zeros(batch_size, *self.output_shape, device=self.device, dtype=self.dtype)}
|
||||
|
||||
|
||||
def load_clip_l(
|
||||
ckpt_path: Optional[str],
|
||||
dtype: torch.dtype,
|
||||
device: Union[str, torch.device],
|
||||
disable_mmap: bool = False,
|
||||
state_dict: Optional[dict] = None,
|
||||
) -> CLIPTextModel:
|
||||
logger.info("Building CLIP-L")
|
||||
CLIPL_CONFIG = {
|
||||
"_name_or_path": "clip-vit-large-patch14/",
|
||||
"architectures": ["CLIPModel"],
|
||||
"initializer_factor": 1.0,
|
||||
"logit_scale_init_value": 2.6592,
|
||||
"model_type": "clip",
|
||||
"projection_dim": 768,
|
||||
# "text_config": {
|
||||
"_name_or_path": "",
|
||||
"add_cross_attention": False,
|
||||
"architectures": None,
|
||||
"attention_dropout": 0.0,
|
||||
"bad_words_ids": None,
|
||||
"bos_token_id": 0,
|
||||
"chunk_size_feed_forward": 0,
|
||||
"cross_attention_hidden_size": None,
|
||||
"decoder_start_token_id": None,
|
||||
"diversity_penalty": 0.0,
|
||||
"do_sample": False,
|
||||
"dropout": 0.0,
|
||||
"early_stopping": False,
|
||||
"encoder_no_repeat_ngram_size": 0,
|
||||
"eos_token_id": 2,
|
||||
"finetuning_task": None,
|
||||
"forced_bos_token_id": None,
|
||||
"forced_eos_token_id": None,
|
||||
"hidden_act": "quick_gelu",
|
||||
"hidden_size": 768,
|
||||
"id2label": {"0": "LABEL_0", "1": "LABEL_1"},
|
||||
"initializer_factor": 1.0,
|
||||
"initializer_range": 0.02,
|
||||
"intermediate_size": 3072,
|
||||
"is_decoder": False,
|
||||
"is_encoder_decoder": False,
|
||||
"label2id": {"LABEL_0": 0, "LABEL_1": 1},
|
||||
"layer_norm_eps": 1e-05,
|
||||
"length_penalty": 1.0,
|
||||
"max_length": 20,
|
||||
"max_position_embeddings": 77,
|
||||
"min_length": 0,
|
||||
"model_type": "clip_text_model",
|
||||
"no_repeat_ngram_size": 0,
|
||||
"num_attention_heads": 12,
|
||||
"num_beam_groups": 1,
|
||||
"num_beams": 1,
|
||||
"num_hidden_layers": 12,
|
||||
"num_return_sequences": 1,
|
||||
"output_attentions": False,
|
||||
"output_hidden_states": False,
|
||||
"output_scores": False,
|
||||
"pad_token_id": 1,
|
||||
"prefix": None,
|
||||
"problem_type": None,
|
||||
"projection_dim": 768,
|
||||
"pruned_heads": {},
|
||||
"remove_invalid_values": False,
|
||||
"repetition_penalty": 1.0,
|
||||
"return_dict": True,
|
||||
"return_dict_in_generate": False,
|
||||
"sep_token_id": None,
|
||||
"task_specific_params": None,
|
||||
"temperature": 1.0,
|
||||
"tie_encoder_decoder": False,
|
||||
"tie_word_embeddings": True,
|
||||
"tokenizer_class": None,
|
||||
"top_k": 50,
|
||||
"top_p": 1.0,
|
||||
"torch_dtype": None,
|
||||
"torchscript": False,
|
||||
"transformers_version": "4.16.0.dev0",
|
||||
"use_bfloat16": False,
|
||||
"vocab_size": 49408,
|
||||
"hidden_act": "gelu",
|
||||
"hidden_size": 1280,
|
||||
"intermediate_size": 5120,
|
||||
"num_attention_heads": 20,
|
||||
"num_hidden_layers": 32,
|
||||
# },
|
||||
# "text_config_dict": {
|
||||
"hidden_size": 768,
|
||||
"intermediate_size": 3072,
|
||||
"num_attention_heads": 12,
|
||||
"num_hidden_layers": 12,
|
||||
"projection_dim": 768,
|
||||
# },
|
||||
# "torch_dtype": "float32",
|
||||
# "transformers_version": None,
|
||||
}
|
||||
config = CLIPConfig(**CLIPL_CONFIG)
|
||||
with init_empty_weights():
|
||||
clip = CLIPTextModel._from_config(config)
|
||||
|
||||
if state_dict is not None:
|
||||
sd = state_dict
|
||||
else:
|
||||
logger.info(f"Loading state dict from {ckpt_path}")
|
||||
sd = load_safetensors(ckpt_path, device=str(device), disable_mmap=disable_mmap, dtype=dtype)
|
||||
info = clip.load_state_dict(sd, strict=False, assign=True)
|
||||
logger.info(f"Loaded CLIP-L: {info}")
|
||||
return clip
|
||||
|
||||
|
||||
def load_t5xxl(
|
||||
ckpt_path: str,
|
||||
dtype: Optional[torch.dtype],
|
||||
device: Union[str, torch.device],
|
||||
disable_mmap: bool = False,
|
||||
state_dict: Optional[dict] = None,
|
||||
) -> T5EncoderModel:
|
||||
T5_CONFIG_JSON = """
|
||||
{
|
||||
"architectures": [
|
||||
"T5EncoderModel"
|
||||
],
|
||||
"classifier_dropout": 0.0,
|
||||
"d_ff": 10240,
|
||||
"d_kv": 64,
|
||||
"d_model": 4096,
|
||||
"decoder_start_token_id": 0,
|
||||
"dense_act_fn": "gelu_new",
|
||||
"dropout_rate": 0.1,
|
||||
"eos_token_id": 1,
|
||||
"feed_forward_proj": "gated-gelu",
|
||||
"initializer_factor": 1.0,
|
||||
"is_encoder_decoder": true,
|
||||
"is_gated_act": true,
|
||||
"layer_norm_epsilon": 1e-06,
|
||||
"model_type": "t5",
|
||||
"num_decoder_layers": 24,
|
||||
"num_heads": 64,
|
||||
"num_layers": 24,
|
||||
"output_past": true,
|
||||
"pad_token_id": 0,
|
||||
"relative_attention_max_distance": 128,
|
||||
"relative_attention_num_buckets": 32,
|
||||
"tie_word_embeddings": false,
|
||||
"torch_dtype": "float16",
|
||||
"transformers_version": "4.41.2",
|
||||
"use_cache": true,
|
||||
"vocab_size": 32128
|
||||
}
|
||||
"""
|
||||
config = json.loads(T5_CONFIG_JSON)
|
||||
config = T5Config(**config)
|
||||
with init_empty_weights():
|
||||
t5xxl = T5EncoderModel._from_config(config)
|
||||
|
||||
if state_dict is not None:
|
||||
sd = state_dict
|
||||
else:
|
||||
logger.info(f"Loading state dict from {ckpt_path}")
|
||||
sd = load_safetensors(ckpt_path, device=str(device), disable_mmap=disable_mmap, dtype=dtype)
|
||||
info = t5xxl.load_state_dict(sd, strict=False, assign=True)
|
||||
logger.info(f"Loaded T5xxl: {info}")
|
||||
return t5xxl
|
||||
|
||||
|
||||
def get_t5xxl_actual_dtype(t5xxl: T5EncoderModel) -> torch.dtype:
|
||||
# nn.Embedding is the first layer, but it could be casted to bfloat16 or float32
|
||||
return t5xxl.encoder.block[0].layer[0].SelfAttention.q.weight.dtype
|
||||
|
||||
|
||||
def prepare_img_ids(batch_size: int, packed_latent_height: int, packed_latent_width: int):
|
||||
img_ids = torch.zeros(packed_latent_height, packed_latent_width, 3)
|
||||
img_ids[..., 1] = img_ids[..., 1] + torch.arange(packed_latent_height)[:, None]
|
||||
img_ids[..., 2] = img_ids[..., 2] + torch.arange(packed_latent_width)[None, :]
|
||||
img_ids = einops.repeat(img_ids, "h w c -> b (h w) c", b=batch_size)
|
||||
return img_ids
|
||||
|
||||
|
||||
def unpack_latents(x: torch.Tensor, packed_latent_height: int, packed_latent_width: int) -> torch.Tensor:
|
||||
"""
|
||||
x: [b (h w) (c ph pw)] -> [b c (h ph) (w pw)], ph=2, pw=2
|
||||
"""
|
||||
x = einops.rearrange(x, "b (h w) (c ph pw) -> b c (h ph) (w pw)", h=packed_latent_height, w=packed_latent_width, ph=2, pw=2)
|
||||
return x
|
||||
|
||||
|
||||
def pack_latents(x: torch.Tensor) -> torch.Tensor:
|
||||
"""
|
||||
x: [b c (h ph) (w pw)] -> [b (h w) (c ph pw)], ph=2, pw=2
|
||||
"""
|
||||
x = einops.rearrange(x, "b c (h ph) (w pw) -> b (h w) (c ph pw)", ph=2, pw=2)
|
||||
return x
|
||||
|
||||
|
||||
# region Diffusers
|
||||
|
||||
NUM_DOUBLE_BLOCKS = 19
|
||||
NUM_SINGLE_BLOCKS = 38
|
||||
|
||||
BFL_TO_DIFFUSERS_MAP = {
|
||||
"time_in.in_layer.weight": ["time_text_embed.timestep_embedder.linear_1.weight"],
|
||||
"time_in.in_layer.bias": ["time_text_embed.timestep_embedder.linear_1.bias"],
|
||||
"time_in.out_layer.weight": ["time_text_embed.timestep_embedder.linear_2.weight"],
|
||||
"time_in.out_layer.bias": ["time_text_embed.timestep_embedder.linear_2.bias"],
|
||||
"vector_in.in_layer.weight": ["time_text_embed.text_embedder.linear_1.weight"],
|
||||
"vector_in.in_layer.bias": ["time_text_embed.text_embedder.linear_1.bias"],
|
||||
"vector_in.out_layer.weight": ["time_text_embed.text_embedder.linear_2.weight"],
|
||||
"vector_in.out_layer.bias": ["time_text_embed.text_embedder.linear_2.bias"],
|
||||
"guidance_in.in_layer.weight": ["time_text_embed.guidance_embedder.linear_1.weight"],
|
||||
"guidance_in.in_layer.bias": ["time_text_embed.guidance_embedder.linear_1.bias"],
|
||||
"guidance_in.out_layer.weight": ["time_text_embed.guidance_embedder.linear_2.weight"],
|
||||
"guidance_in.out_layer.bias": ["time_text_embed.guidance_embedder.linear_2.bias"],
|
||||
"txt_in.weight": ["context_embedder.weight"],
|
||||
"txt_in.bias": ["context_embedder.bias"],
|
||||
"img_in.weight": ["x_embedder.weight"],
|
||||
"img_in.bias": ["x_embedder.bias"],
|
||||
"double_blocks.().img_mod.lin.weight": ["norm1.linear.weight"],
|
||||
"double_blocks.().img_mod.lin.bias": ["norm1.linear.bias"],
|
||||
"double_blocks.().txt_mod.lin.weight": ["norm1_context.linear.weight"],
|
||||
"double_blocks.().txt_mod.lin.bias": ["norm1_context.linear.bias"],
|
||||
"double_blocks.().img_attn.qkv.weight": ["attn.to_q.weight", "attn.to_k.weight", "attn.to_v.weight"],
|
||||
"double_blocks.().img_attn.qkv.bias": ["attn.to_q.bias", "attn.to_k.bias", "attn.to_v.bias"],
|
||||
"double_blocks.().txt_attn.qkv.weight": ["attn.add_q_proj.weight", "attn.add_k_proj.weight", "attn.add_v_proj.weight"],
|
||||
"double_blocks.().txt_attn.qkv.bias": ["attn.add_q_proj.bias", "attn.add_k_proj.bias", "attn.add_v_proj.bias"],
|
||||
"double_blocks.().img_attn.norm.query_norm.scale": ["attn.norm_q.weight"],
|
||||
"double_blocks.().img_attn.norm.key_norm.scale": ["attn.norm_k.weight"],
|
||||
"double_blocks.().txt_attn.norm.query_norm.scale": ["attn.norm_added_q.weight"],
|
||||
"double_blocks.().txt_attn.norm.key_norm.scale": ["attn.norm_added_k.weight"],
|
||||
"double_blocks.().img_mlp.0.weight": ["ff.net.0.proj.weight"],
|
||||
"double_blocks.().img_mlp.0.bias": ["ff.net.0.proj.bias"],
|
||||
"double_blocks.().img_mlp.2.weight": ["ff.net.2.weight"],
|
||||
"double_blocks.().img_mlp.2.bias": ["ff.net.2.bias"],
|
||||
"double_blocks.().txt_mlp.0.weight": ["ff_context.net.0.proj.weight"],
|
||||
"double_blocks.().txt_mlp.0.bias": ["ff_context.net.0.proj.bias"],
|
||||
"double_blocks.().txt_mlp.2.weight": ["ff_context.net.2.weight"],
|
||||
"double_blocks.().txt_mlp.2.bias": ["ff_context.net.2.bias"],
|
||||
"double_blocks.().img_attn.proj.weight": ["attn.to_out.0.weight"],
|
||||
"double_blocks.().img_attn.proj.bias": ["attn.to_out.0.bias"],
|
||||
"double_blocks.().txt_attn.proj.weight": ["attn.to_add_out.weight"],
|
||||
"double_blocks.().txt_attn.proj.bias": ["attn.to_add_out.bias"],
|
||||
"single_blocks.().modulation.lin.weight": ["norm.linear.weight"],
|
||||
"single_blocks.().modulation.lin.bias": ["norm.linear.bias"],
|
||||
"single_blocks.().linear1.weight": ["attn.to_q.weight", "attn.to_k.weight", "attn.to_v.weight", "proj_mlp.weight"],
|
||||
"single_blocks.().linear1.bias": ["attn.to_q.bias", "attn.to_k.bias", "attn.to_v.bias", "proj_mlp.bias"],
|
||||
"single_blocks.().linear2.weight": ["proj_out.weight"],
|
||||
"single_blocks.().norm.query_norm.scale": ["attn.norm_q.weight"],
|
||||
"single_blocks.().norm.key_norm.scale": ["attn.norm_k.weight"],
|
||||
"single_blocks.().linear2.weight": ["proj_out.weight"],
|
||||
"single_blocks.().linear2.bias": ["proj_out.bias"],
|
||||
"final_layer.linear.weight": ["proj_out.weight"],
|
||||
"final_layer.linear.bias": ["proj_out.bias"],
|
||||
"final_layer.adaLN_modulation.1.weight": ["norm_out.linear.weight"],
|
||||
"final_layer.adaLN_modulation.1.bias": ["norm_out.linear.bias"],
|
||||
}
|
||||
|
||||
|
||||
def make_diffusers_to_bfl_map(num_double_blocks: int, num_single_blocks: int) -> dict[str, tuple[int, str]]:
|
||||
# make reverse map from diffusers map
|
||||
diffusers_to_bfl_map = {} # key: diffusers_key, value: (index, bfl_key)
|
||||
for b in range(num_double_blocks):
|
||||
for key, weights in BFL_TO_DIFFUSERS_MAP.items():
|
||||
if key.startswith("double_blocks."):
|
||||
block_prefix = f"transformer_blocks.{b}."
|
||||
for i, weight in enumerate(weights):
|
||||
diffusers_to_bfl_map[f"{block_prefix}{weight}"] = (i, key.replace("()", f"{b}"))
|
||||
for b in range(num_single_blocks):
|
||||
for key, weights in BFL_TO_DIFFUSERS_MAP.items():
|
||||
if key.startswith("single_blocks."):
|
||||
block_prefix = f"single_transformer_blocks.{b}."
|
||||
for i, weight in enumerate(weights):
|
||||
diffusers_to_bfl_map[f"{block_prefix}{weight}"] = (i, key.replace("()", f"{b}"))
|
||||
for key, weights in BFL_TO_DIFFUSERS_MAP.items():
|
||||
if not (key.startswith("double_blocks.") or key.startswith("single_blocks.")):
|
||||
for i, weight in enumerate(weights):
|
||||
diffusers_to_bfl_map[weight] = (i, key)
|
||||
return diffusers_to_bfl_map
|
||||
|
||||
|
||||
def convert_diffusers_sd_to_bfl(
|
||||
diffusers_sd: dict[str, torch.Tensor], num_double_blocks: int = NUM_DOUBLE_BLOCKS, num_single_blocks: int = NUM_SINGLE_BLOCKS
|
||||
) -> dict[str, torch.Tensor]:
|
||||
diffusers_to_bfl_map = make_diffusers_to_bfl_map(num_double_blocks, num_single_blocks)
|
||||
|
||||
# iterate over three safetensors files to reduce memory usage
|
||||
flux_sd = {}
|
||||
for diffusers_key, tensor in diffusers_sd.items():
|
||||
if diffusers_key in diffusers_to_bfl_map:
|
||||
index, bfl_key = diffusers_to_bfl_map[diffusers_key]
|
||||
if bfl_key not in flux_sd:
|
||||
flux_sd[bfl_key] = []
|
||||
flux_sd[bfl_key].append((index, tensor))
|
||||
else:
|
||||
logger.error(f"Error: Key not found in diffusers_to_bfl_map: {diffusers_key}")
|
||||
raise KeyError(f"Key not found in diffusers_to_bfl_map: {diffusers_key}")
|
||||
|
||||
# concat tensors if multiple tensors are mapped to a single key, sort by index
|
||||
for key, values in flux_sd.items():
|
||||
if len(values) == 1:
|
||||
flux_sd[key] = values[0][1]
|
||||
else:
|
||||
flux_sd[key] = torch.cat([value[1] for value in sorted(values, key=lambda x: x[0])])
|
||||
|
||||
# special case for final_layer.adaLN_modulation.1.weight and final_layer.adaLN_modulation.1.bias
|
||||
def swap_scale_shift(weight):
|
||||
shift, scale = weight.chunk(2, dim=0)
|
||||
new_weight = torch.cat([scale, shift], dim=0)
|
||||
return new_weight
|
||||
|
||||
if "final_layer.adaLN_modulation.1.weight" in flux_sd:
|
||||
flux_sd["final_layer.adaLN_modulation.1.weight"] = swap_scale_shift(flux_sd["final_layer.adaLN_modulation.1.weight"])
|
||||
if "final_layer.adaLN_modulation.1.bias" in flux_sd:
|
||||
flux_sd["final_layer.adaLN_modulation.1.bias"] = swap_scale_shift(flux_sd["final_layer.adaLN_modulation.1.bias"])
|
||||
|
||||
return flux_sd
|
||||
|
||||
|
||||
# endregion
|
||||
482
library/fp8_optimization_utils.py
Normal file
482
library/fp8_optimization_utils.py
Normal file
@@ -0,0 +1,482 @@
|
||||
import os
|
||||
from typing import List, Optional, Union
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
import logging
|
||||
|
||||
from tqdm import tqdm
|
||||
|
||||
from library.device_utils import clean_memory_on_device
|
||||
from library.safetensors_utils import MemoryEfficientSafeOpen, TensorWeightAdapter, WeightTransformHooks
|
||||
from library.utils import setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
def calculate_fp8_maxval(exp_bits=4, mantissa_bits=3, sign_bits=1):
|
||||
"""
|
||||
Calculate the maximum representable value in FP8 format.
|
||||
Default is E4M3 format (4-bit exponent, 3-bit mantissa, 1-bit sign). Only supports E4M3 and E5M2 with sign bit.
|
||||
|
||||
Args:
|
||||
exp_bits (int): Number of exponent bits
|
||||
mantissa_bits (int): Number of mantissa bits
|
||||
sign_bits (int): Number of sign bits (0 or 1)
|
||||
|
||||
Returns:
|
||||
float: Maximum value representable in FP8 format
|
||||
"""
|
||||
assert exp_bits + mantissa_bits + sign_bits == 8, "Total bits must be 8"
|
||||
if exp_bits == 4 and mantissa_bits == 3 and sign_bits == 1:
|
||||
return torch.finfo(torch.float8_e4m3fn).max
|
||||
elif exp_bits == 5 and mantissa_bits == 2 and sign_bits == 1:
|
||||
return torch.finfo(torch.float8_e5m2).max
|
||||
else:
|
||||
raise ValueError(f"Unsupported FP8 format: E{exp_bits}M{mantissa_bits} with sign_bits={sign_bits}")
|
||||
|
||||
|
||||
# The following is a manual calculation method (wrong implementation for E5M2), kept for reference.
|
||||
"""
|
||||
# Calculate exponent bias
|
||||
bias = 2 ** (exp_bits - 1) - 1
|
||||
|
||||
# Calculate maximum mantissa value
|
||||
mantissa_max = 1.0
|
||||
for i in range(mantissa_bits - 1):
|
||||
mantissa_max += 2 ** -(i + 1)
|
||||
|
||||
# Calculate maximum value
|
||||
max_value = mantissa_max * (2 ** (2**exp_bits - 1 - bias))
|
||||
|
||||
return max_value
|
||||
"""
|
||||
|
||||
|
||||
def quantize_fp8(tensor, scale, fp8_dtype, max_value, min_value):
|
||||
"""
|
||||
Quantize a tensor to FP8 format using PyTorch's native FP8 dtype support.
|
||||
|
||||
Args:
|
||||
tensor (torch.Tensor): Tensor to quantize
|
||||
scale (float or torch.Tensor): Scale factor
|
||||
fp8_dtype (torch.dtype): Target FP8 dtype (torch.float8_e4m3fn or torch.float8_e5m2)
|
||||
max_value (float): Maximum representable value in FP8
|
||||
min_value (float): Minimum representable value in FP8
|
||||
|
||||
Returns:
|
||||
torch.Tensor: Quantized tensor in FP8 format
|
||||
"""
|
||||
tensor = tensor.to(torch.float32) # ensure tensor is in float32 for division
|
||||
|
||||
# Create scaled tensor
|
||||
tensor = torch.div(tensor, scale).nan_to_num_(0.0) # handle NaN values, equivalent to nonzero_mask in previous function
|
||||
|
||||
# Clamp tensor to range
|
||||
tensor = tensor.clamp_(min=min_value, max=max_value)
|
||||
|
||||
# Convert to FP8 dtype
|
||||
tensor = tensor.to(fp8_dtype)
|
||||
|
||||
return tensor
|
||||
|
||||
|
||||
def optimize_state_dict_with_fp8(
|
||||
state_dict: dict,
|
||||
calc_device: Union[str, torch.device],
|
||||
target_layer_keys: Optional[list[str]] = None,
|
||||
exclude_layer_keys: Optional[list[str]] = None,
|
||||
exp_bits: int = 4,
|
||||
mantissa_bits: int = 3,
|
||||
move_to_device: bool = False,
|
||||
quantization_mode: str = "block",
|
||||
block_size: Optional[int] = 64,
|
||||
):
|
||||
"""
|
||||
Optimize Linear layer weights in a model's state dict to FP8 format. The state dict is modified in-place.
|
||||
This function is a static version of load_safetensors_with_fp8_optimization without loading from files.
|
||||
|
||||
Args:
|
||||
state_dict (dict): State dict to optimize, replaced in-place
|
||||
calc_device (str): Device to quantize tensors on
|
||||
target_layer_keys (list, optional): Layer key patterns to target (None for all Linear layers)
|
||||
exclude_layer_keys (list, optional): Layer key patterns to exclude
|
||||
exp_bits (int): Number of exponent bits
|
||||
mantissa_bits (int): Number of mantissa bits
|
||||
move_to_device (bool): Move optimized tensors to the calculating device
|
||||
|
||||
Returns:
|
||||
dict: FP8 optimized state dict
|
||||
"""
|
||||
if exp_bits == 4 and mantissa_bits == 3:
|
||||
fp8_dtype = torch.float8_e4m3fn
|
||||
elif exp_bits == 5 and mantissa_bits == 2:
|
||||
fp8_dtype = torch.float8_e5m2
|
||||
else:
|
||||
raise ValueError(f"Unsupported FP8 format: E{exp_bits}M{mantissa_bits}")
|
||||
|
||||
# Calculate FP8 max value
|
||||
max_value = calculate_fp8_maxval(exp_bits, mantissa_bits)
|
||||
min_value = -max_value # this function supports only signed FP8
|
||||
|
||||
# Create optimized state dict
|
||||
optimized_count = 0
|
||||
|
||||
# Enumerate tarket keys
|
||||
target_state_dict_keys = []
|
||||
for key in state_dict.keys():
|
||||
# Check if it's a weight key and matches target patterns
|
||||
is_target = (target_layer_keys is None or any(pattern in key for pattern in target_layer_keys)) and key.endswith(".weight")
|
||||
is_excluded = exclude_layer_keys is not None and any(pattern in key for pattern in exclude_layer_keys)
|
||||
is_target = is_target and not is_excluded
|
||||
|
||||
if is_target and isinstance(state_dict[key], torch.Tensor):
|
||||
target_state_dict_keys.append(key)
|
||||
|
||||
# Process each key
|
||||
for key in tqdm(target_state_dict_keys):
|
||||
value = state_dict[key]
|
||||
|
||||
# Save original device and dtype
|
||||
original_device = value.device
|
||||
original_dtype = value.dtype
|
||||
|
||||
# Move to calculation device
|
||||
if calc_device is not None:
|
||||
value = value.to(calc_device)
|
||||
|
||||
quantized_weight, scale_tensor = quantize_weight(key, value, fp8_dtype, max_value, min_value, quantization_mode, block_size)
|
||||
|
||||
# Add to state dict using original key for weight and new key for scale
|
||||
fp8_key = key # Maintain original key
|
||||
scale_key = key.replace(".weight", ".scale_weight")
|
||||
|
||||
if not move_to_device:
|
||||
quantized_weight = quantized_weight.to(original_device)
|
||||
|
||||
# keep scale shape: [1] or [out,1] or [out, num_blocks, 1]. We can determine the quantization mode from the shape of scale_weight in the patched model.
|
||||
scale_tensor = scale_tensor.to(dtype=original_dtype, device=quantized_weight.device)
|
||||
|
||||
state_dict[fp8_key] = quantized_weight
|
||||
state_dict[scale_key] = scale_tensor
|
||||
|
||||
optimized_count += 1
|
||||
|
||||
if calc_device is not None: # optimized_count % 10 == 0 and
|
||||
# free memory on calculation device
|
||||
clean_memory_on_device(calc_device)
|
||||
|
||||
logger.info(f"Number of optimized Linear layers: {optimized_count}")
|
||||
return state_dict
|
||||
|
||||
|
||||
def quantize_weight(
|
||||
key: str,
|
||||
tensor: torch.Tensor,
|
||||
fp8_dtype: torch.dtype,
|
||||
max_value: float,
|
||||
min_value: float,
|
||||
quantization_mode: str = "block",
|
||||
block_size: int = 64,
|
||||
):
|
||||
original_shape = tensor.shape
|
||||
|
||||
# Determine quantization mode
|
||||
if quantization_mode == "block":
|
||||
if tensor.ndim != 2:
|
||||
quantization_mode = "tensor" # fallback to per-tensor
|
||||
else:
|
||||
out_features, in_features = tensor.shape
|
||||
if in_features % block_size != 0:
|
||||
quantization_mode = "channel" # fallback to per-channel
|
||||
logger.warning(
|
||||
f"Layer {key} with shape {tensor.shape} is not divisible by block_size {block_size}, fallback to per-channel quantization."
|
||||
)
|
||||
else:
|
||||
num_blocks = in_features // block_size
|
||||
tensor = tensor.contiguous().view(out_features, num_blocks, block_size) # [out, num_blocks, block_size]
|
||||
elif quantization_mode == "channel":
|
||||
if tensor.ndim != 2:
|
||||
quantization_mode = "tensor" # fallback to per-tensor
|
||||
|
||||
# Calculate scale factor (per-tensor or per-output-channel with percentile or max)
|
||||
# value shape is expected to be [out_features, in_features] for Linear weights
|
||||
if quantization_mode == "channel" or quantization_mode == "block":
|
||||
# row-wise percentile to avoid being dominated by outliers
|
||||
# result shape: [out_features, 1] or [out_features, num_blocks, 1]
|
||||
scale_dim = 1 if quantization_mode == "channel" else 2
|
||||
abs_w = torch.abs(tensor)
|
||||
|
||||
# shape: [out_features, 1] or [out_features, num_blocks, 1]
|
||||
row_max = torch.max(abs_w, dim=scale_dim, keepdim=True).values
|
||||
scale = row_max / max_value
|
||||
|
||||
else:
|
||||
# per-tensor
|
||||
tensor_max = torch.max(torch.abs(tensor).view(-1))
|
||||
scale = tensor_max / max_value
|
||||
|
||||
# print(f"Optimizing {key} with scale: {scale}")
|
||||
|
||||
# numerical safety
|
||||
scale = torch.clamp(scale, min=1e-8)
|
||||
scale = scale.to(torch.float32) # ensure scale is in float32 for division
|
||||
|
||||
# Quantize weight to FP8 (scale can be scalar or [out,1], broadcasting works)
|
||||
quantized_weight = quantize_fp8(tensor, scale, fp8_dtype, max_value, min_value)
|
||||
|
||||
# If block-wise, restore original shape
|
||||
if quantization_mode == "block":
|
||||
quantized_weight = quantized_weight.view(original_shape) # restore to original shape [out, in]
|
||||
|
||||
return quantized_weight, scale
|
||||
|
||||
|
||||
def load_safetensors_with_fp8_optimization(
|
||||
model_files: List[str],
|
||||
calc_device: Union[str, torch.device],
|
||||
target_layer_keys=None,
|
||||
exclude_layer_keys=None,
|
||||
exp_bits=4,
|
||||
mantissa_bits=3,
|
||||
move_to_device=False,
|
||||
weight_hook=None,
|
||||
quantization_mode: str = "block",
|
||||
block_size: Optional[int] = 64,
|
||||
disable_numpy_memmap: bool = False,
|
||||
weight_transform_hooks: Optional[WeightTransformHooks] = None,
|
||||
) -> dict:
|
||||
"""
|
||||
Load weight tensors from safetensors files and merge LoRA weights into the state dict with explicit FP8 optimization.
|
||||
|
||||
Args:
|
||||
model_files (list[str]): List of model files to load
|
||||
calc_device (str or torch.device): Device to quantize tensors on
|
||||
target_layer_keys (list, optional): Layer key patterns to target for optimization (None for all Linear layers)
|
||||
exclude_layer_keys (list, optional): Layer key patterns to exclude from optimization
|
||||
exp_bits (int): Number of exponent bits
|
||||
mantissa_bits (int): Number of mantissa bits
|
||||
move_to_device (bool): Move optimized tensors to the calculating device
|
||||
weight_hook (callable, optional): Function to apply to each weight tensor before optimization
|
||||
quantization_mode (str): Quantization mode, "tensor", "channel", or "block"
|
||||
block_size (int, optional): Block size for block-wise quantization (used if quantization_mode is "block")
|
||||
disable_numpy_memmap (bool): Disable numpy memmap when loading safetensors
|
||||
weight_transform_hooks (WeightTransformHooks, optional): Hooks for weight transformation during loading
|
||||
|
||||
Returns:
|
||||
dict: FP8 optimized state dict
|
||||
"""
|
||||
if exp_bits == 4 and mantissa_bits == 3:
|
||||
fp8_dtype = torch.float8_e4m3fn
|
||||
elif exp_bits == 5 and mantissa_bits == 2:
|
||||
fp8_dtype = torch.float8_e5m2
|
||||
else:
|
||||
raise ValueError(f"Unsupported FP8 format: E{exp_bits}M{mantissa_bits}")
|
||||
|
||||
# Calculate FP8 max value
|
||||
max_value = calculate_fp8_maxval(exp_bits, mantissa_bits)
|
||||
min_value = -max_value # this function supports only signed FP8
|
||||
|
||||
# Define function to determine if a key is a target key. target means fp8 optimization, not for weight hook.
|
||||
def is_target_key(key):
|
||||
# Check if weight key matches target patterns and does not match exclude patterns
|
||||
is_target = (target_layer_keys is None or any(pattern in key for pattern in target_layer_keys)) and key.endswith(".weight")
|
||||
is_excluded = exclude_layer_keys is not None and any(pattern in key for pattern in exclude_layer_keys)
|
||||
return is_target and not is_excluded
|
||||
|
||||
# Create optimized state dict
|
||||
optimized_count = 0
|
||||
|
||||
# Process each file
|
||||
state_dict = {}
|
||||
for model_file in model_files:
|
||||
with MemoryEfficientSafeOpen(model_file, disable_numpy_memmap=disable_numpy_memmap) as original_f:
|
||||
f = TensorWeightAdapter(weight_transform_hooks, original_f) if weight_transform_hooks is not None else original_f
|
||||
|
||||
keys = f.keys()
|
||||
for key in tqdm(keys, desc=f"Loading {os.path.basename(model_file)}", unit="key"):
|
||||
value = f.get_tensor(key)
|
||||
|
||||
# Save original device
|
||||
original_device = value.device # usually cpu
|
||||
|
||||
if weight_hook is not None:
|
||||
# Apply weight hook if provided
|
||||
value = weight_hook(key, value, keep_on_calc_device=(calc_device is not None))
|
||||
|
||||
if not is_target_key(key):
|
||||
target_device = calc_device if (calc_device is not None and move_to_device) else original_device
|
||||
value = value.to(target_device)
|
||||
state_dict[key] = value
|
||||
continue
|
||||
|
||||
# Move to calculation device
|
||||
if calc_device is not None:
|
||||
value = value.to(calc_device)
|
||||
|
||||
original_dtype = value.dtype
|
||||
if original_dtype.itemsize == 1:
|
||||
raise ValueError(
|
||||
f"Layer {key} is already in {original_dtype} format. `--fp8_scaled` optimization should not be applied. Please use fp16/bf16/float32 model weights."
|
||||
+ f" / レイヤー {key} は既に{original_dtype}形式です。`--fp8_scaled` 最適化は適用できません。FP16/BF16/Float32のモデル重みを使用してください。"
|
||||
)
|
||||
quantized_weight, scale_tensor = quantize_weight(
|
||||
key, value, fp8_dtype, max_value, min_value, quantization_mode, block_size
|
||||
)
|
||||
|
||||
# Add to state dict using original key for weight and new key for scale
|
||||
fp8_key = key # Maintain original key
|
||||
scale_key = key.replace(".weight", ".scale_weight")
|
||||
assert fp8_key != scale_key, "FP8 key and scale key must be different"
|
||||
|
||||
if not move_to_device:
|
||||
quantized_weight = quantized_weight.to(original_device)
|
||||
|
||||
# keep scale shape: [1] or [out,1] or [out, num_blocks, 1]. We can determine the quantization mode from the shape of scale_weight in the patched model.
|
||||
scale_tensor = scale_tensor.to(dtype=original_dtype, device=quantized_weight.device)
|
||||
|
||||
state_dict[fp8_key] = quantized_weight
|
||||
state_dict[scale_key] = scale_tensor
|
||||
|
||||
optimized_count += 1
|
||||
|
||||
if calc_device is not None and optimized_count % 10 == 0:
|
||||
# free memory on calculation device
|
||||
clean_memory_on_device(calc_device)
|
||||
|
||||
logger.info(f"Number of optimized Linear layers: {optimized_count}")
|
||||
return state_dict
|
||||
|
||||
|
||||
def fp8_linear_forward_patch(self: nn.Linear, x, use_scaled_mm=False, max_value=None):
|
||||
"""
|
||||
Patched forward method for Linear layers with FP8 weights.
|
||||
|
||||
Args:
|
||||
self: Linear layer instance
|
||||
x (torch.Tensor): Input tensor
|
||||
use_scaled_mm (bool): Use scaled_mm for FP8 Linear layers, requires SM 8.9+ (RTX 40 series)
|
||||
max_value (float): Maximum value for FP8 quantization. If None, no quantization is applied for input tensor.
|
||||
|
||||
Returns:
|
||||
torch.Tensor: Result of linear transformation
|
||||
"""
|
||||
if use_scaled_mm:
|
||||
# **not tested**
|
||||
# _scaled_mm only works for per-tensor scale for now (per-channel scale does not work in certain cases)
|
||||
if self.scale_weight.ndim != 1:
|
||||
raise ValueError("scaled_mm only supports per-tensor scale_weight for now.")
|
||||
|
||||
input_dtype = x.dtype
|
||||
original_weight_dtype = self.scale_weight.dtype
|
||||
target_dtype = self.weight.dtype
|
||||
# assert x.ndim == 3, "Input tensor must be 3D (batch_size, seq_len, hidden_dim)"
|
||||
|
||||
if max_value is None:
|
||||
# no input quantization
|
||||
scale_x = torch.tensor(1.0, dtype=torch.float32, device=x.device)
|
||||
else:
|
||||
# calculate scale factor for input tensor
|
||||
scale_x = (torch.max(torch.abs(x.flatten())) / max_value).to(torch.float32)
|
||||
|
||||
# quantize input tensor to FP8: this seems to consume a lot of memory
|
||||
fp8_max_value = torch.finfo(target_dtype).max
|
||||
fp8_min_value = torch.finfo(target_dtype).min
|
||||
x = quantize_fp8(x, scale_x, target_dtype, fp8_max_value, fp8_min_value)
|
||||
|
||||
original_shape = x.shape
|
||||
x = x.reshape(-1, x.shape[-1]).to(target_dtype)
|
||||
|
||||
weight = self.weight.t()
|
||||
scale_weight = self.scale_weight.to(torch.float32)
|
||||
|
||||
if self.bias is not None:
|
||||
# float32 is not supported with bias in scaled_mm
|
||||
o = torch._scaled_mm(x, weight, out_dtype=original_weight_dtype, bias=self.bias, scale_a=scale_x, scale_b=scale_weight)
|
||||
else:
|
||||
o = torch._scaled_mm(x, weight, out_dtype=input_dtype, scale_a=scale_x, scale_b=scale_weight)
|
||||
|
||||
o = o.reshape(original_shape[0], original_shape[1], -1) if len(original_shape) == 3 else o.reshape(original_shape[0], -1)
|
||||
return o.to(input_dtype)
|
||||
|
||||
else:
|
||||
# Dequantize the weight
|
||||
original_dtype = self.scale_weight.dtype
|
||||
if self.scale_weight.ndim < 3:
|
||||
# per-tensor or per-channel quantization, we can broadcast
|
||||
dequantized_weight = self.weight.to(original_dtype) * self.scale_weight
|
||||
else:
|
||||
# block-wise quantization, need to reshape weight to match scale shape for broadcasting
|
||||
out_features, num_blocks, _ = self.scale_weight.shape
|
||||
dequantized_weight = self.weight.to(original_dtype).contiguous().view(out_features, num_blocks, -1)
|
||||
dequantized_weight = dequantized_weight * self.scale_weight
|
||||
dequantized_weight = dequantized_weight.view(self.weight.shape)
|
||||
|
||||
# Perform linear transformation
|
||||
if self.bias is not None:
|
||||
output = F.linear(x, dequantized_weight, self.bias)
|
||||
else:
|
||||
output = F.linear(x, dequantized_weight)
|
||||
|
||||
return output
|
||||
|
||||
|
||||
def apply_fp8_monkey_patch(model, optimized_state_dict, use_scaled_mm=False):
|
||||
"""
|
||||
Apply monkey patching to a model using FP8 optimized state dict.
|
||||
|
||||
Args:
|
||||
model (nn.Module): Model instance to patch
|
||||
optimized_state_dict (dict): FP8 optimized state dict
|
||||
use_scaled_mm (bool): Use scaled_mm for FP8 Linear layers, requires SM 8.9+ (RTX 40 series)
|
||||
|
||||
Returns:
|
||||
nn.Module: The patched model (same instance, modified in-place)
|
||||
"""
|
||||
# # Calculate FP8 float8_e5m2 max value
|
||||
# max_value = calculate_fp8_maxval(5, 2)
|
||||
max_value = None # do not quantize input tensor
|
||||
|
||||
# Find all scale keys to identify FP8-optimized layers
|
||||
scale_keys = [k for k in optimized_state_dict.keys() if k.endswith(".scale_weight")]
|
||||
|
||||
# Enumerate patched layers
|
||||
patched_module_paths = set()
|
||||
scale_shape_info = {}
|
||||
for scale_key in scale_keys:
|
||||
# Extract module path from scale key (remove .scale_weight)
|
||||
module_path = scale_key.rsplit(".scale_weight", 1)[0]
|
||||
patched_module_paths.add(module_path)
|
||||
|
||||
# Store scale shape information
|
||||
scale_shape_info[module_path] = optimized_state_dict[scale_key].shape
|
||||
|
||||
patched_count = 0
|
||||
|
||||
# Apply monkey patch to each layer with FP8 weights
|
||||
for name, module in model.named_modules():
|
||||
# Check if this module has a corresponding scale_weight
|
||||
has_scale = name in patched_module_paths
|
||||
|
||||
# Apply patch if it's a Linear layer with FP8 scale
|
||||
if isinstance(module, nn.Linear) and has_scale:
|
||||
# register the scale_weight as a buffer to load the state_dict
|
||||
# module.register_buffer("scale_weight", torch.tensor(1.0, dtype=module.weight.dtype))
|
||||
scale_shape = scale_shape_info[name]
|
||||
module.register_buffer("scale_weight", torch.ones(scale_shape, dtype=module.weight.dtype))
|
||||
|
||||
# Create a new forward method with the patched version.
|
||||
def new_forward(self, x):
|
||||
return fp8_linear_forward_patch(self, x, use_scaled_mm, max_value)
|
||||
|
||||
# Bind method to module
|
||||
module.forward = new_forward.__get__(module, type(module))
|
||||
|
||||
patched_count += 1
|
||||
|
||||
logger.info(f"Number of monkey-patched Linear layers: {patched_count}")
|
||||
return model
|
||||
@@ -1,15 +1,15 @@
|
||||
from typing import *
|
||||
from typing import Union, BinaryIO
|
||||
from huggingface_hub import HfApi
|
||||
from pathlib import Path
|
||||
import argparse
|
||||
import os
|
||||
|
||||
from library.utils import fire_in_thread
|
||||
from library.utils import setup_logging
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
def exists_repo(
|
||||
repo_id: str, repo_type: str, revision: str = "main", token: str = None
|
||||
):
|
||||
def exists_repo(repo_id: str, repo_type: str, revision: str = "main", token: str = None):
|
||||
api = HfApi(
|
||||
token=token,
|
||||
)
|
||||
@@ -29,31 +29,39 @@ def upload(
|
||||
repo_id = args.huggingface_repo_id
|
||||
repo_type = args.huggingface_repo_type
|
||||
token = args.huggingface_token
|
||||
path_in_repo = args.huggingface_path_in_repo + dest_suffix
|
||||
path_in_repo = args.huggingface_path_in_repo + dest_suffix if args.huggingface_path_in_repo is not None else None
|
||||
private = args.huggingface_repo_visibility is None or args.huggingface_repo_visibility != "public"
|
||||
api = HfApi(token=token)
|
||||
if not exists_repo(repo_id=repo_id, repo_type=repo_type, token=token):
|
||||
api.create_repo(repo_id=repo_id, repo_type=repo_type, private=private)
|
||||
try:
|
||||
api.create_repo(repo_id=repo_id, repo_type=repo_type, private=private)
|
||||
except Exception as e: # とりあえずRepositoryNotFoundErrorは確認したが他にあると困るので
|
||||
logger.error("===========================================")
|
||||
logger.error(f"failed to create HuggingFace repo / HuggingFaceのリポジトリの作成に失敗しました : {e}")
|
||||
logger.error("===========================================")
|
||||
|
||||
is_folder = (type(src) == str and os.path.isdir(src)) or (
|
||||
isinstance(src, Path) and src.is_dir()
|
||||
)
|
||||
is_folder = (type(src) == str and os.path.isdir(src)) or (isinstance(src, Path) and src.is_dir())
|
||||
|
||||
def uploader():
|
||||
if is_folder:
|
||||
api.upload_folder(
|
||||
repo_id=repo_id,
|
||||
repo_type=repo_type,
|
||||
folder_path=src,
|
||||
path_in_repo=path_in_repo,
|
||||
)
|
||||
else:
|
||||
api.upload_file(
|
||||
repo_id=repo_id,
|
||||
repo_type=repo_type,
|
||||
path_or_fileobj=src,
|
||||
path_in_repo=path_in_repo,
|
||||
)
|
||||
try:
|
||||
if is_folder:
|
||||
api.upload_folder(
|
||||
repo_id=repo_id,
|
||||
repo_type=repo_type,
|
||||
folder_path=src,
|
||||
path_in_repo=path_in_repo,
|
||||
)
|
||||
else:
|
||||
api.upload_file(
|
||||
repo_id=repo_id,
|
||||
repo_type=repo_type,
|
||||
path_or_fileobj=src,
|
||||
path_in_repo=path_in_repo,
|
||||
)
|
||||
except Exception as e: # RuntimeErrorを確認済みだが他にあると困るので
|
||||
logger.error("===========================================")
|
||||
logger.error(f"failed to upload to HuggingFace / HuggingFaceへのアップロードに失敗しました : {e}")
|
||||
logger.error("===========================================")
|
||||
|
||||
if args.async_upload and not force_sync_upload:
|
||||
fire_in_thread(uploader)
|
||||
@@ -72,7 +80,5 @@ def list_dir(
|
||||
token=token,
|
||||
)
|
||||
repo_info = api.repo_info(repo_id=repo_id, revision=revision, repo_type=repo_type)
|
||||
file_list = [
|
||||
file for file in repo_info.siblings if file.rfilename.startswith(subfolder)
|
||||
]
|
||||
file_list = [file for file in repo_info.siblings if file.rfilename.startswith(subfolder)]
|
||||
return file_list
|
||||
|
||||
489
library/hunyuan_image_models.py
Normal file
489
library/hunyuan_image_models.py
Normal file
@@ -0,0 +1,489 @@
|
||||
# Original work: https://github.com/Tencent-Hunyuan/HunyuanImage-2.1
|
||||
# Re-implemented for license compliance for sd-scripts.
|
||||
|
||||
from typing import Dict, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from accelerate import init_empty_weights
|
||||
|
||||
from library import custom_offloading_utils
|
||||
from library.attention import AttentionParams
|
||||
from library.fp8_optimization_utils import apply_fp8_monkey_patch
|
||||
from library.lora_utils import load_safetensors_with_lora_and_fp8
|
||||
from library.utils import setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
from library.hunyuan_image_modules import (
|
||||
SingleTokenRefiner,
|
||||
ByT5Mapper,
|
||||
PatchEmbed2D,
|
||||
TimestepEmbedder,
|
||||
MMDoubleStreamBlock,
|
||||
MMSingleStreamBlock,
|
||||
FinalLayer,
|
||||
)
|
||||
from library.hunyuan_image_utils import get_nd_rotary_pos_embed
|
||||
|
||||
FP8_OPTIMIZATION_TARGET_KEYS = ["double_blocks", "single_blocks"]
|
||||
# FP8_OPTIMIZATION_EXCLUDE_KEYS = ["norm", "_mod", "_emb"] # , "modulation"
|
||||
FP8_OPTIMIZATION_EXCLUDE_KEYS = ["norm", "_emb"] # , "modulation", "_mod"
|
||||
|
||||
# full exclude 24.2GB
|
||||
# norm and _emb 19.7GB
|
||||
# fp8 cast 19.7GB
|
||||
|
||||
|
||||
# region DiT Model
|
||||
class HYImageDiffusionTransformer(nn.Module):
|
||||
"""
|
||||
HunyuanImage-2.1 Diffusion Transformer.
|
||||
|
||||
A multimodal transformer for image generation with text conditioning,
|
||||
featuring separate double-stream and single-stream processing blocks.
|
||||
|
||||
Args:
|
||||
attn_mode: Attention implementation mode ("torch" or "sageattn").
|
||||
"""
|
||||
|
||||
def __init__(self, attn_mode: str = "torch", split_attn: bool = False):
|
||||
super().__init__()
|
||||
|
||||
# Fixed architecture parameters for HunyuanImage-2.1
|
||||
self.patch_size = [1, 1] # 1x1 patch size (no spatial downsampling)
|
||||
self.in_channels = 64 # Input latent channels
|
||||
self.out_channels = 64 # Output latent channels
|
||||
self.unpatchify_channels = self.out_channels
|
||||
self.guidance_embed = False # Guidance embedding disabled
|
||||
self.rope_dim_list = [64, 64] # RoPE dimensions for 2D positional encoding
|
||||
self.rope_theta = 256 # RoPE frequency scaling
|
||||
self.use_attention_mask = True
|
||||
self.text_projection = "single_refiner"
|
||||
self.hidden_size = 3584 # Model dimension
|
||||
self.heads_num = 28 # Number of attention heads
|
||||
|
||||
# Architecture configuration
|
||||
mm_double_blocks_depth = 20 # Double-stream transformer blocks
|
||||
mm_single_blocks_depth = 40 # Single-stream transformer blocks
|
||||
mlp_width_ratio = 4 # MLP expansion ratio
|
||||
text_states_dim = 3584 # Text encoder output dimension
|
||||
guidance_embed = False # No guidance embedding
|
||||
|
||||
# Layer configuration
|
||||
mlp_act_type: str = "gelu_tanh" # MLP activation function
|
||||
qkv_bias: bool = True # Use bias in QKV projections
|
||||
qk_norm: bool = True # Apply QK normalization
|
||||
qk_norm_type: str = "rms" # RMS normalization type
|
||||
|
||||
self.attn_mode = attn_mode
|
||||
self.split_attn = split_attn
|
||||
|
||||
# ByT5 character-level text encoder mapping
|
||||
self.byt5_in = ByT5Mapper(in_dim=1472, out_dim=2048, hidden_dim=2048, out_dim1=self.hidden_size, use_residual=False)
|
||||
|
||||
# Image latent patch embedding
|
||||
self.img_in = PatchEmbed2D(self.patch_size, self.in_channels, self.hidden_size)
|
||||
|
||||
# Text token refinement with cross-attention
|
||||
self.txt_in = SingleTokenRefiner(text_states_dim, self.hidden_size, self.heads_num, depth=2)
|
||||
|
||||
# Timestep embedding for diffusion process
|
||||
self.time_in = TimestepEmbedder(self.hidden_size, nn.SiLU)
|
||||
|
||||
# MeanFlow not supported in this implementation
|
||||
self.time_r_in = None
|
||||
|
||||
# Guidance embedding (disabled for non-distilled model)
|
||||
self.guidance_in = TimestepEmbedder(self.hidden_size, nn.SiLU) if guidance_embed else None
|
||||
|
||||
# Double-stream blocks: separate image and text processing
|
||||
self.double_blocks = nn.ModuleList(
|
||||
[
|
||||
MMDoubleStreamBlock(
|
||||
self.hidden_size,
|
||||
self.heads_num,
|
||||
mlp_width_ratio=mlp_width_ratio,
|
||||
mlp_act_type=mlp_act_type,
|
||||
qk_norm=qk_norm,
|
||||
qk_norm_type=qk_norm_type,
|
||||
qkv_bias=qkv_bias,
|
||||
)
|
||||
for _ in range(mm_double_blocks_depth)
|
||||
]
|
||||
)
|
||||
|
||||
# Single-stream blocks: joint processing of concatenated features
|
||||
self.single_blocks = nn.ModuleList(
|
||||
[
|
||||
MMSingleStreamBlock(
|
||||
self.hidden_size,
|
||||
self.heads_num,
|
||||
mlp_width_ratio=mlp_width_ratio,
|
||||
mlp_act_type=mlp_act_type,
|
||||
qk_norm=qk_norm,
|
||||
qk_norm_type=qk_norm_type,
|
||||
)
|
||||
for _ in range(mm_single_blocks_depth)
|
||||
]
|
||||
)
|
||||
|
||||
self.final_layer = FinalLayer(self.hidden_size, self.patch_size, self.out_channels, nn.SiLU)
|
||||
|
||||
self.gradient_checkpointing = False
|
||||
self.cpu_offload_checkpointing = False
|
||||
self.blocks_to_swap = None
|
||||
|
||||
self.offloader_double = None
|
||||
self.offloader_single = None
|
||||
self.num_double_blocks = len(self.double_blocks)
|
||||
self.num_single_blocks = len(self.single_blocks)
|
||||
|
||||
@property
|
||||
def device(self):
|
||||
return next(self.parameters()).device
|
||||
|
||||
@property
|
||||
def dtype(self):
|
||||
return next(self.parameters()).dtype
|
||||
|
||||
def enable_gradient_checkpointing(self, cpu_offload: bool = False):
|
||||
self.gradient_checkpointing = True
|
||||
self.cpu_offload_checkpointing = cpu_offload
|
||||
|
||||
for block in self.double_blocks + self.single_blocks:
|
||||
block.enable_gradient_checkpointing(cpu_offload=cpu_offload)
|
||||
|
||||
print(f"HunyuanImage-2.1: Gradient checkpointing enabled. CPU offload: {cpu_offload}")
|
||||
|
||||
def disable_gradient_checkpointing(self):
|
||||
self.gradient_checkpointing = False
|
||||
self.cpu_offload_checkpointing = False
|
||||
|
||||
for block in self.double_blocks + self.single_blocks:
|
||||
block.disable_gradient_checkpointing()
|
||||
|
||||
print("HunyuanImage-2.1: Gradient checkpointing disabled.")
|
||||
|
||||
def enable_block_swap(self, num_blocks: int, device: torch.device, supports_backward: bool = False):
|
||||
self.blocks_to_swap = num_blocks
|
||||
double_blocks_to_swap = num_blocks // 2
|
||||
single_blocks_to_swap = (num_blocks - double_blocks_to_swap) * 2
|
||||
|
||||
assert double_blocks_to_swap <= self.num_double_blocks - 2 and single_blocks_to_swap <= self.num_single_blocks - 2, (
|
||||
f"Cannot swap more than {self.num_double_blocks - 2} double blocks and {self.num_single_blocks - 2} single blocks. "
|
||||
f"Requested {double_blocks_to_swap} double blocks and {single_blocks_to_swap} single blocks."
|
||||
)
|
||||
|
||||
self.offloader_double = custom_offloading_utils.ModelOffloader(
|
||||
self.double_blocks, double_blocks_to_swap, device, supports_backward=supports_backward
|
||||
)
|
||||
self.offloader_single = custom_offloading_utils.ModelOffloader(
|
||||
self.single_blocks, single_blocks_to_swap, device, supports_backward=supports_backward
|
||||
)
|
||||
# , debug=True
|
||||
print(
|
||||
f"HunyuanImage-2.1: Block swap enabled. Swapping {num_blocks} blocks, double blocks: {double_blocks_to_swap}, single blocks: {single_blocks_to_swap}."
|
||||
)
|
||||
|
||||
def switch_block_swap_for_inference(self):
|
||||
if self.blocks_to_swap:
|
||||
self.offloader_double.set_forward_only(True)
|
||||
self.offloader_single.set_forward_only(True)
|
||||
self.prepare_block_swap_before_forward()
|
||||
print(f"HunyuanImage-2.1: Block swap set to forward only.")
|
||||
|
||||
def switch_block_swap_for_training(self):
|
||||
if self.blocks_to_swap:
|
||||
self.offloader_double.set_forward_only(False)
|
||||
self.offloader_single.set_forward_only(False)
|
||||
self.prepare_block_swap_before_forward()
|
||||
print(f"HunyuanImage-2.1: Block swap set to forward and backward.")
|
||||
|
||||
def move_to_device_except_swap_blocks(self, device: torch.device):
|
||||
# assume model is on cpu. do not move blocks to device to reduce temporary memory usage
|
||||
if self.blocks_to_swap:
|
||||
save_double_blocks = self.double_blocks
|
||||
save_single_blocks = self.single_blocks
|
||||
self.double_blocks = nn.ModuleList()
|
||||
self.single_blocks = nn.ModuleList()
|
||||
|
||||
self.to(device)
|
||||
|
||||
if self.blocks_to_swap:
|
||||
self.double_blocks = save_double_blocks
|
||||
self.single_blocks = save_single_blocks
|
||||
|
||||
def prepare_block_swap_before_forward(self):
|
||||
if self.blocks_to_swap is None or self.blocks_to_swap == 0:
|
||||
return
|
||||
self.offloader_double.prepare_block_devices_before_forward(self.double_blocks)
|
||||
self.offloader_single.prepare_block_devices_before_forward(self.single_blocks)
|
||||
|
||||
def get_rotary_pos_embed(self, rope_sizes):
|
||||
"""
|
||||
Generate 2D rotary position embeddings for image tokens.
|
||||
|
||||
Args:
|
||||
rope_sizes: Tuple of (height, width) for spatial dimensions.
|
||||
|
||||
Returns:
|
||||
Tuple of (freqs_cos, freqs_sin) tensors for rotary position encoding.
|
||||
"""
|
||||
freqs_cos, freqs_sin = get_nd_rotary_pos_embed(self.rope_dim_list, rope_sizes, theta=self.rope_theta)
|
||||
return freqs_cos, freqs_sin
|
||||
|
||||
def reorder_txt_token(
|
||||
self, byt5_txt: torch.Tensor, txt: torch.Tensor, byt5_text_mask: torch.Tensor, text_mask: torch.Tensor
|
||||
) -> Tuple[torch.Tensor, torch.Tensor, list[int]]:
|
||||
"""
|
||||
Combine and reorder ByT5 character-level and word-level text embeddings.
|
||||
|
||||
Concatenates valid tokens from both encoders and creates appropriate masks.
|
||||
|
||||
Args:
|
||||
byt5_txt: ByT5 character-level embeddings [B, L1, D].
|
||||
txt: Word-level text embeddings [B, L2, D].
|
||||
byt5_text_mask: Valid token mask for ByT5 [B, L1].
|
||||
text_mask: Valid token mask for word tokens [B, L2].
|
||||
|
||||
Returns:
|
||||
Tuple of (reordered_embeddings, combined_mask, sequence_lengths).
|
||||
"""
|
||||
# Process each batch element separately to handle variable sequence lengths
|
||||
|
||||
reorder_txt = []
|
||||
reorder_mask = []
|
||||
|
||||
txt_lens = []
|
||||
for i in range(text_mask.shape[0]):
|
||||
byt5_text_mask_i = byt5_text_mask[i].bool()
|
||||
text_mask_i = text_mask[i].bool()
|
||||
byt5_text_length = byt5_text_mask_i.sum()
|
||||
text_length = text_mask_i.sum()
|
||||
assert byt5_text_length == byt5_text_mask_i[:byt5_text_length].sum()
|
||||
assert text_length == text_mask_i[:text_length].sum()
|
||||
|
||||
byt5_txt_i = byt5_txt[i]
|
||||
txt_i = txt[i]
|
||||
reorder_txt_i = torch.cat(
|
||||
[byt5_txt_i[:byt5_text_length], txt_i[:text_length], byt5_txt_i[byt5_text_length:], txt_i[text_length:]], dim=0
|
||||
)
|
||||
|
||||
reorder_mask_i = torch.zeros(
|
||||
byt5_text_mask_i.shape[0] + text_mask_i.shape[0], dtype=torch.bool, device=byt5_text_mask_i.device
|
||||
)
|
||||
reorder_mask_i[: byt5_text_length + text_length] = True
|
||||
|
||||
reorder_txt.append(reorder_txt_i)
|
||||
reorder_mask.append(reorder_mask_i)
|
||||
txt_lens.append(byt5_text_length + text_length)
|
||||
|
||||
reorder_txt = torch.stack(reorder_txt)
|
||||
reorder_mask = torch.stack(reorder_mask).to(dtype=torch.int64)
|
||||
|
||||
return reorder_txt, reorder_mask, txt_lens
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
timestep: torch.LongTensor,
|
||||
text_states: torch.Tensor,
|
||||
encoder_attention_mask: torch.Tensor,
|
||||
byt5_text_states: Optional[torch.Tensor] = None,
|
||||
byt5_text_mask: Optional[torch.Tensor] = None,
|
||||
rotary_pos_emb_cache: Optional[Dict[Tuple[int, int], Tuple[torch.Tensor, torch.Tensor]]] = None,
|
||||
) -> torch.Tensor:
|
||||
"""
|
||||
Forward pass through the HunyuanImage diffusion transformer.
|
||||
|
||||
Args:
|
||||
hidden_states: Input image latents [B, C, H, W].
|
||||
timestep: Diffusion timestep [B].
|
||||
text_states: Word-level text embeddings [B, L, D].
|
||||
encoder_attention_mask: Text attention mask [B, L].
|
||||
byt5_text_states: ByT5 character-level embeddings [B, L_byt5, D_byt5].
|
||||
byt5_text_mask: ByT5 attention mask [B, L_byt5].
|
||||
|
||||
Returns:
|
||||
Tuple of (denoised_image, spatial_shape).
|
||||
"""
|
||||
img = x = hidden_states
|
||||
text_mask = encoder_attention_mask
|
||||
t = timestep
|
||||
txt = text_states
|
||||
|
||||
# Calculate spatial dimensions for rotary position embeddings
|
||||
_, _, oh, ow = x.shape
|
||||
th, tw = oh, ow # Height and width (patch_size=[1,1] means no spatial downsampling)
|
||||
if rotary_pos_emb_cache is not None:
|
||||
if (th, tw) in rotary_pos_emb_cache:
|
||||
freqs_cis = rotary_pos_emb_cache[(th, tw)]
|
||||
freqs_cis = (freqs_cis[0].to(img.device), freqs_cis[1].to(img.device))
|
||||
else:
|
||||
freqs_cis = self.get_rotary_pos_embed((th, tw))
|
||||
rotary_pos_emb_cache[(th, tw)] = (freqs_cis[0].cpu(), freqs_cis[1].cpu())
|
||||
else:
|
||||
freqs_cis = self.get_rotary_pos_embed((th, tw))
|
||||
|
||||
# Reshape image latents to sequence format: [B, C, H, W] -> [B, H*W, C]
|
||||
img = self.img_in(img)
|
||||
|
||||
# Generate timestep conditioning vector
|
||||
vec = self.time_in(t)
|
||||
|
||||
# MeanFlow and guidance embedding not used in this configuration
|
||||
|
||||
# Process text tokens through refinement layers
|
||||
txt_attn_params = AttentionParams.create_attention_params_from_mask(self.attn_mode, self.split_attn, 0, text_mask)
|
||||
txt = self.txt_in(txt, t, txt_attn_params)
|
||||
|
||||
# Integrate character-level ByT5 features with word-level tokens
|
||||
# Use variable length sequences with sequence lengths
|
||||
byt5_txt = self.byt5_in(byt5_text_states)
|
||||
txt, text_mask, txt_lens = self.reorder_txt_token(byt5_txt, txt, byt5_text_mask, text_mask)
|
||||
|
||||
# Trim sequences to maximum length in the batch
|
||||
img_seq_len = img.shape[1]
|
||||
max_txt_len = max(txt_lens)
|
||||
txt = txt[:, :max_txt_len, :]
|
||||
text_mask = text_mask[:, :max_txt_len]
|
||||
|
||||
attn_params = AttentionParams.create_attention_params_from_mask(self.attn_mode, self.split_attn, img_seq_len, text_mask)
|
||||
|
||||
input_device = img.device
|
||||
|
||||
# Process through double-stream blocks (separate image/text attention)
|
||||
for index, block in enumerate(self.double_blocks):
|
||||
if self.blocks_to_swap:
|
||||
self.offloader_double.wait_for_block(index)
|
||||
img, txt = block(img, txt, vec, freqs_cis, attn_params)
|
||||
if self.blocks_to_swap:
|
||||
self.offloader_double.submit_move_blocks(self.double_blocks, index)
|
||||
|
||||
# Concatenate image and text tokens for joint processing
|
||||
x = torch.cat((img, txt), 1)
|
||||
|
||||
# Process through single-stream blocks (joint attention)
|
||||
for index, block in enumerate(self.single_blocks):
|
||||
if self.blocks_to_swap:
|
||||
self.offloader_single.wait_for_block(index)
|
||||
x = block(x, vec, freqs_cis, attn_params)
|
||||
if self.blocks_to_swap:
|
||||
self.offloader_single.submit_move_blocks(self.single_blocks, index)
|
||||
|
||||
x = x.to(input_device)
|
||||
vec = vec.to(input_device)
|
||||
|
||||
img = x[:, :img_seq_len, ...]
|
||||
del x
|
||||
|
||||
# Apply final projection to output space
|
||||
img = self.final_layer(img, vec)
|
||||
del vec
|
||||
|
||||
# Reshape from sequence to spatial format: [B, L, C] -> [B, C, H, W]
|
||||
img = self.unpatchify_2d(img, th, tw)
|
||||
return img
|
||||
|
||||
def unpatchify_2d(self, x, h, w):
|
||||
"""
|
||||
Convert sequence format back to spatial image format.
|
||||
|
||||
Args:
|
||||
x: Input tensor [B, H*W, C].
|
||||
h: Height dimension.
|
||||
w: Width dimension.
|
||||
|
||||
Returns:
|
||||
Spatial tensor [B, C, H, W].
|
||||
"""
|
||||
c = self.unpatchify_channels
|
||||
|
||||
x = x.reshape(shape=(x.shape[0], h, w, c))
|
||||
imgs = x.permute(0, 3, 1, 2)
|
||||
return imgs
|
||||
|
||||
|
||||
# endregion
|
||||
|
||||
# region Model Utils
|
||||
|
||||
|
||||
def create_model(attn_mode: str, split_attn: bool, dtype: Optional[torch.dtype]) -> HYImageDiffusionTransformer:
|
||||
with init_empty_weights():
|
||||
model = HYImageDiffusionTransformer(attn_mode=attn_mode, split_attn=split_attn)
|
||||
if dtype is not None:
|
||||
model.to(dtype)
|
||||
return model
|
||||
|
||||
|
||||
def load_hunyuan_image_model(
|
||||
device: Union[str, torch.device],
|
||||
dit_path: str,
|
||||
attn_mode: str,
|
||||
split_attn: bool,
|
||||
loading_device: Union[str, torch.device],
|
||||
dit_weight_dtype: Optional[torch.dtype],
|
||||
fp8_scaled: bool = False,
|
||||
lora_weights_list: Optional[Dict[str, torch.Tensor]] = None,
|
||||
lora_multipliers: Optional[list[float]] = None,
|
||||
) -> HYImageDiffusionTransformer:
|
||||
"""
|
||||
Load a HunyuanImage model from the specified checkpoint.
|
||||
|
||||
Args:
|
||||
device (Union[str, torch.device]): Device for optimization or merging
|
||||
dit_path (str): Path to the DiT model checkpoint.
|
||||
attn_mode (str): Attention mode to use, e.g., "torch", "flash", etc.
|
||||
split_attn (bool): Whether to use split attention.
|
||||
loading_device (Union[str, torch.device]): Device to load the model weights on.
|
||||
dit_weight_dtype (Optional[torch.dtype]): Data type of the DiT weights.
|
||||
If None, it will be loaded as is (same as the state_dict) or scaled for fp8. if not None, model weights will be casted to this dtype.
|
||||
fp8_scaled (bool): Whether to use fp8 scaling for the model weights.
|
||||
lora_weights_list (Optional[Dict[str, torch.Tensor]]): LoRA weights to apply, if any.
|
||||
lora_multipliers (Optional[List[float]]): LoRA multipliers for the weights, if any.
|
||||
"""
|
||||
# dit_weight_dtype is None for fp8_scaled
|
||||
assert (not fp8_scaled and dit_weight_dtype is not None) or (fp8_scaled and dit_weight_dtype is None)
|
||||
|
||||
device = torch.device(device)
|
||||
loading_device = torch.device(loading_device)
|
||||
|
||||
model = create_model(attn_mode, split_attn, dit_weight_dtype)
|
||||
|
||||
# load model weights with dynamic fp8 optimization and LoRA merging if needed
|
||||
logger.info(f"Loading DiT model from {dit_path}, device={loading_device}")
|
||||
|
||||
sd = load_safetensors_with_lora_and_fp8(
|
||||
model_files=dit_path,
|
||||
lora_weights_list=lora_weights_list,
|
||||
lora_multipliers=lora_multipliers,
|
||||
fp8_optimization=fp8_scaled,
|
||||
calc_device=device,
|
||||
move_to_device=(loading_device == device),
|
||||
dit_weight_dtype=dit_weight_dtype,
|
||||
target_keys=FP8_OPTIMIZATION_TARGET_KEYS,
|
||||
exclude_keys=FP8_OPTIMIZATION_EXCLUDE_KEYS,
|
||||
)
|
||||
|
||||
if fp8_scaled:
|
||||
apply_fp8_monkey_patch(model, sd, use_scaled_mm=False)
|
||||
|
||||
if loading_device.type != "cpu":
|
||||
# make sure all the model weights are on the loading_device
|
||||
logger.info(f"Moving weights to {loading_device}")
|
||||
for key in sd.keys():
|
||||
sd[key] = sd[key].to(loading_device)
|
||||
|
||||
info = model.load_state_dict(sd, strict=True, assign=True)
|
||||
logger.info(f"Loaded DiT model from {dit_path}, info={info}")
|
||||
|
||||
return model
|
||||
|
||||
|
||||
# endregion
|
||||
863
library/hunyuan_image_modules.py
Normal file
863
library/hunyuan_image_modules.py
Normal file
@@ -0,0 +1,863 @@
|
||||
# Original work: https://github.com/Tencent-Hunyuan/HunyuanImage-2.1
|
||||
# Re-implemented for license compliance for sd-scripts.
|
||||
|
||||
from typing import Tuple, Callable
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from einops import rearrange
|
||||
|
||||
from library import custom_offloading_utils
|
||||
from library.attention import AttentionParams, attention
|
||||
from library.hunyuan_image_utils import timestep_embedding, apply_rotary_emb, _to_tuple, apply_gate, modulate
|
||||
from library.attention import attention
|
||||
|
||||
# region Modules
|
||||
|
||||
|
||||
class ByT5Mapper(nn.Module):
|
||||
"""
|
||||
Maps ByT5 character-level encoder outputs to transformer hidden space.
|
||||
|
||||
Applies layer normalization, two MLP layers with GELU activation,
|
||||
and optional residual connection.
|
||||
|
||||
Args:
|
||||
in_dim: Input dimension from ByT5 encoder (1472 for ByT5-large).
|
||||
out_dim: Intermediate dimension after first projection.
|
||||
hidden_dim: Hidden dimension for MLP layer.
|
||||
out_dim1: Final output dimension matching transformer hidden size.
|
||||
use_residual: Whether to add residual connection (requires in_dim == out_dim).
|
||||
"""
|
||||
|
||||
def __init__(self, in_dim, out_dim, hidden_dim, out_dim1, use_residual=True):
|
||||
super().__init__()
|
||||
if use_residual:
|
||||
assert in_dim == out_dim
|
||||
self.layernorm = nn.LayerNorm(in_dim)
|
||||
self.fc1 = nn.Linear(in_dim, hidden_dim)
|
||||
self.fc2 = nn.Linear(hidden_dim, out_dim)
|
||||
self.fc3 = nn.Linear(out_dim, out_dim1)
|
||||
self.use_residual = use_residual
|
||||
self.act_fn = nn.GELU()
|
||||
|
||||
def forward(self, x):
|
||||
"""
|
||||
Transform ByT5 embeddings to transformer space.
|
||||
|
||||
Args:
|
||||
x: Input ByT5 embeddings [..., in_dim].
|
||||
|
||||
Returns:
|
||||
Transformed embeddings [..., out_dim1].
|
||||
"""
|
||||
residual = x if self.use_residual else None
|
||||
x = self.layernorm(x)
|
||||
x = self.fc1(x)
|
||||
x = self.act_fn(x)
|
||||
x = self.fc2(x)
|
||||
x = self.act_fn(x)
|
||||
x = self.fc3(x)
|
||||
if self.use_residual:
|
||||
x = x + residual
|
||||
return x
|
||||
|
||||
|
||||
class PatchEmbed2D(nn.Module):
|
||||
"""
|
||||
2D patch embedding layer for converting image latents to transformer tokens.
|
||||
|
||||
Uses 2D convolution to project image patches to embedding space.
|
||||
For HunyuanImage-2.1, patch_size=[1,1] means no spatial downsampling.
|
||||
|
||||
Args:
|
||||
patch_size: Spatial size of patches (int or tuple).
|
||||
in_chans: Number of input channels.
|
||||
embed_dim: Output embedding dimension.
|
||||
"""
|
||||
|
||||
def __init__(self, patch_size=16, in_chans=3, embed_dim=768):
|
||||
super().__init__()
|
||||
self.patch_size = tuple(patch_size)
|
||||
|
||||
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=self.patch_size, stride=self.patch_size, bias=True)
|
||||
self.norm = nn.Identity() # No normalization layer used
|
||||
|
||||
def forward(self, x):
|
||||
x = self.proj(x)
|
||||
x = x.flatten(2).transpose(1, 2)
|
||||
x = self.norm(x)
|
||||
return x
|
||||
|
||||
|
||||
class TimestepEmbedder(nn.Module):
|
||||
"""
|
||||
Embeds scalar diffusion timesteps into vector representations.
|
||||
|
||||
Uses sinusoidal encoding followed by a two-layer MLP.
|
||||
|
||||
Args:
|
||||
hidden_size: Output embedding dimension.
|
||||
act_layer: Activation function class (e.g., nn.SiLU).
|
||||
frequency_embedding_size: Dimension of sinusoidal encoding.
|
||||
max_period: Maximum period for sinusoidal frequencies.
|
||||
out_size: Output dimension (defaults to hidden_size).
|
||||
"""
|
||||
|
||||
def __init__(self, hidden_size, act_layer, frequency_embedding_size=256, max_period=10000, out_size=None):
|
||||
super().__init__()
|
||||
self.frequency_embedding_size = frequency_embedding_size
|
||||
self.max_period = max_period
|
||||
if out_size is None:
|
||||
out_size = hidden_size
|
||||
|
||||
self.mlp = nn.Sequential(
|
||||
nn.Linear(frequency_embedding_size, hidden_size, bias=True), act_layer(), nn.Linear(hidden_size, out_size, bias=True)
|
||||
)
|
||||
|
||||
def forward(self, t):
|
||||
t_freq = timestep_embedding(t, self.frequency_embedding_size, self.max_period).type(self.mlp[0].weight.dtype)
|
||||
return self.mlp(t_freq)
|
||||
|
||||
|
||||
class TextProjection(nn.Module):
|
||||
"""
|
||||
Projects text embeddings through a two-layer MLP.
|
||||
|
||||
Used for context-aware representation computation in token refinement.
|
||||
|
||||
Args:
|
||||
in_channels: Input feature dimension.
|
||||
hidden_size: Hidden and output dimension.
|
||||
act_layer: Activation function class.
|
||||
"""
|
||||
|
||||
def __init__(self, in_channels, hidden_size, act_layer):
|
||||
super().__init__()
|
||||
self.linear_1 = nn.Linear(in_features=in_channels, out_features=hidden_size, bias=True)
|
||||
self.act_1 = act_layer()
|
||||
self.linear_2 = nn.Linear(in_features=hidden_size, out_features=hidden_size, bias=True)
|
||||
|
||||
def forward(self, caption):
|
||||
hidden_states = self.linear_1(caption)
|
||||
hidden_states = self.act_1(hidden_states)
|
||||
hidden_states = self.linear_2(hidden_states)
|
||||
return hidden_states
|
||||
|
||||
|
||||
class MLP(nn.Module):
|
||||
"""
|
||||
Multi-layer perceptron with configurable activation and normalization.
|
||||
|
||||
Standard two-layer MLP with optional dropout and intermediate normalization.
|
||||
|
||||
Args:
|
||||
in_channels: Input feature dimension.
|
||||
hidden_channels: Hidden layer dimension (defaults to in_channels).
|
||||
out_features: Output dimension (defaults to in_channels).
|
||||
act_layer: Activation function class.
|
||||
norm_layer: Optional normalization layer class.
|
||||
bias: Whether to use bias (can be bool or tuple for each layer).
|
||||
drop: Dropout rate (can be float or tuple for each layer).
|
||||
use_conv: Whether to use convolution instead of linear (not supported).
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
in_channels,
|
||||
hidden_channels=None,
|
||||
out_features=None,
|
||||
act_layer=nn.GELU,
|
||||
norm_layer=None,
|
||||
bias=True,
|
||||
drop=0.0,
|
||||
use_conv=False,
|
||||
):
|
||||
super().__init__()
|
||||
assert not use_conv, "Convolutional MLP not supported in this implementation."
|
||||
|
||||
out_features = out_features or in_channels
|
||||
hidden_channels = hidden_channels or in_channels
|
||||
bias = _to_tuple(bias, 2)
|
||||
drop_probs = _to_tuple(drop, 2)
|
||||
|
||||
self.fc1 = nn.Linear(in_channels, hidden_channels, bias=bias[0])
|
||||
self.act = act_layer()
|
||||
self.drop1 = nn.Dropout(drop_probs[0])
|
||||
self.norm = norm_layer(hidden_channels) if norm_layer is not None else nn.Identity()
|
||||
self.fc2 = nn.Linear(hidden_channels, out_features, bias=bias[1])
|
||||
self.drop2 = nn.Dropout(drop_probs[1])
|
||||
|
||||
def forward(self, x):
|
||||
x = self.fc1(x)
|
||||
x = self.act(x)
|
||||
x = self.drop1(x)
|
||||
x = self.norm(x)
|
||||
x = self.fc2(x)
|
||||
x = self.drop2(x)
|
||||
return x
|
||||
|
||||
|
||||
class IndividualTokenRefinerBlock(nn.Module):
|
||||
"""
|
||||
Single transformer block for individual token refinement.
|
||||
|
||||
Applies self-attention and MLP with adaptive layer normalization (AdaLN)
|
||||
conditioned on timestep and context information.
|
||||
|
||||
Args:
|
||||
hidden_size: Model dimension.
|
||||
heads_num: Number of attention heads.
|
||||
mlp_width_ratio: MLP expansion ratio.
|
||||
mlp_drop_rate: MLP dropout rate.
|
||||
act_type: Activation function (only "silu" supported).
|
||||
qk_norm: QK normalization flag (must be False).
|
||||
qk_norm_type: QK normalization type (only "layer" supported).
|
||||
qkv_bias: Use bias in QKV projections.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: int,
|
||||
heads_num: int,
|
||||
mlp_width_ratio: float = 4.0,
|
||||
mlp_drop_rate: float = 0.0,
|
||||
act_type: str = "silu",
|
||||
qk_norm: bool = False,
|
||||
qk_norm_type: str = "layer",
|
||||
qkv_bias: bool = True,
|
||||
):
|
||||
super().__init__()
|
||||
assert qk_norm_type == "layer", "Only layer normalization supported for QK norm."
|
||||
assert act_type == "silu", "Only SiLU activation supported."
|
||||
assert not qk_norm, "QK normalization must be disabled."
|
||||
|
||||
self.heads_num = heads_num
|
||||
mlp_hidden_dim = int(hidden_size * mlp_width_ratio)
|
||||
|
||||
self.norm1 = nn.LayerNorm(hidden_size, elementwise_affine=True, eps=1e-6)
|
||||
self.self_attn_qkv = nn.Linear(hidden_size, hidden_size * 3, bias=qkv_bias)
|
||||
|
||||
self.self_attn_q_norm = nn.Identity()
|
||||
self.self_attn_k_norm = nn.Identity()
|
||||
self.self_attn_proj = nn.Linear(hidden_size, hidden_size, bias=qkv_bias)
|
||||
|
||||
self.norm2 = nn.LayerNorm(hidden_size, elementwise_affine=True, eps=1e-6)
|
||||
self.mlp = MLP(in_channels=hidden_size, hidden_channels=mlp_hidden_dim, act_layer=nn.SiLU, drop=mlp_drop_rate)
|
||||
|
||||
self.adaLN_modulation = nn.Sequential(
|
||||
nn.SiLU(),
|
||||
nn.Linear(hidden_size, 2 * hidden_size, bias=True),
|
||||
)
|
||||
|
||||
def forward(self, x: torch.Tensor, c: torch.Tensor, attn_params: AttentionParams) -> torch.Tensor:
|
||||
"""
|
||||
Apply self-attention and MLP with adaptive conditioning.
|
||||
|
||||
Args:
|
||||
x: Input token embeddings [B, L, C].
|
||||
c: Combined conditioning vector [B, C].
|
||||
attn_params: Attention parameters including sequence lengths.
|
||||
|
||||
Returns:
|
||||
Refined token embeddings [B, L, C].
|
||||
"""
|
||||
gate_msa, gate_mlp = self.adaLN_modulation(c).chunk(2, dim=1)
|
||||
norm_x = self.norm1(x)
|
||||
qkv = self.self_attn_qkv(norm_x)
|
||||
del norm_x
|
||||
q, k, v = rearrange(qkv, "B L (K H D) -> K B L H D", K=3, H=self.heads_num)
|
||||
del qkv
|
||||
q = self.self_attn_q_norm(q).to(v)
|
||||
k = self.self_attn_k_norm(k).to(v)
|
||||
qkv = [q, k, v]
|
||||
del q, k, v
|
||||
attn = attention(qkv, attn_params=attn_params)
|
||||
|
||||
x = x + apply_gate(self.self_attn_proj(attn), gate_msa)
|
||||
x = x + apply_gate(self.mlp(self.norm2(x)), gate_mlp)
|
||||
return x
|
||||
|
||||
|
||||
class IndividualTokenRefiner(nn.Module):
|
||||
"""
|
||||
Stack of token refinement blocks with self-attention.
|
||||
|
||||
Processes tokens individually with adaptive layer normalization.
|
||||
|
||||
Args:
|
||||
hidden_size: Model dimension.
|
||||
heads_num: Number of attention heads.
|
||||
depth: Number of refinement blocks.
|
||||
mlp_width_ratio: MLP expansion ratio.
|
||||
mlp_drop_rate: MLP dropout rate.
|
||||
act_type: Activation function type.
|
||||
qk_norm: QK normalization flag.
|
||||
qk_norm_type: QK normalization type.
|
||||
qkv_bias: Use bias in QKV projections.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: int,
|
||||
heads_num: int,
|
||||
depth: int,
|
||||
mlp_width_ratio: float = 4.0,
|
||||
mlp_drop_rate: float = 0.0,
|
||||
act_type: str = "silu",
|
||||
qk_norm: bool = False,
|
||||
qk_norm_type: str = "layer",
|
||||
qkv_bias: bool = True,
|
||||
):
|
||||
super().__init__()
|
||||
self.blocks = nn.ModuleList(
|
||||
[
|
||||
IndividualTokenRefinerBlock(
|
||||
hidden_size=hidden_size,
|
||||
heads_num=heads_num,
|
||||
mlp_width_ratio=mlp_width_ratio,
|
||||
mlp_drop_rate=mlp_drop_rate,
|
||||
act_type=act_type,
|
||||
qk_norm=qk_norm,
|
||||
qk_norm_type=qk_norm_type,
|
||||
qkv_bias=qkv_bias,
|
||||
)
|
||||
for _ in range(depth)
|
||||
]
|
||||
)
|
||||
|
||||
def forward(self, x: torch.Tensor, c: torch.LongTensor, attn_params: AttentionParams) -> torch.Tensor:
|
||||
"""
|
||||
Apply sequential token refinement.
|
||||
|
||||
Args:
|
||||
x: Input token embeddings [B, L, C].
|
||||
c: Combined conditioning vector [B, C].
|
||||
attn_params: Attention parameters including sequence lengths.
|
||||
|
||||
Returns:
|
||||
Refined token embeddings [B, L, C].
|
||||
"""
|
||||
for block in self.blocks:
|
||||
x = block(x, c, attn_params)
|
||||
return x
|
||||
|
||||
|
||||
class SingleTokenRefiner(nn.Module):
|
||||
"""
|
||||
Text embedding refinement with timestep and context conditioning.
|
||||
|
||||
Projects input text embeddings and applies self-attention refinement
|
||||
conditioned on diffusion timestep and aggregate text context.
|
||||
|
||||
Args:
|
||||
in_channels: Input text embedding dimension.
|
||||
hidden_size: Transformer hidden dimension.
|
||||
heads_num: Number of attention heads.
|
||||
depth: Number of refinement blocks.
|
||||
"""
|
||||
|
||||
def __init__(self, in_channels: int, hidden_size: int, heads_num: int, depth: int):
|
||||
# Fixed architecture parameters for HunyuanImage-2.1
|
||||
mlp_drop_rate: float = 0.0 # No MLP dropout
|
||||
act_type: str = "silu" # SiLU activation
|
||||
mlp_width_ratio: float = 4.0 # 4x MLP expansion
|
||||
qk_norm: bool = False # No QK normalization
|
||||
qk_norm_type: str = "layer" # Layer norm type (unused)
|
||||
qkv_bias: bool = True # Use QKV bias
|
||||
|
||||
super().__init__()
|
||||
self.input_embedder = nn.Linear(in_channels, hidden_size, bias=True)
|
||||
act_layer = nn.SiLU
|
||||
self.t_embedder = TimestepEmbedder(hidden_size, act_layer)
|
||||
self.c_embedder = TextProjection(in_channels, hidden_size, act_layer)
|
||||
self.individual_token_refiner = IndividualTokenRefiner(
|
||||
hidden_size=hidden_size,
|
||||
heads_num=heads_num,
|
||||
depth=depth,
|
||||
mlp_width_ratio=mlp_width_ratio,
|
||||
mlp_drop_rate=mlp_drop_rate,
|
||||
act_type=act_type,
|
||||
qk_norm=qk_norm,
|
||||
qk_norm_type=qk_norm_type,
|
||||
qkv_bias=qkv_bias,
|
||||
)
|
||||
|
||||
def forward(self, x: torch.Tensor, t: torch.LongTensor, attn_params: AttentionParams) -> torch.Tensor:
|
||||
"""
|
||||
Refine text embeddings with timestep conditioning.
|
||||
|
||||
Args:
|
||||
x: Input text embeddings [B, L, in_channels].
|
||||
t: Diffusion timestep [B].
|
||||
attn_params: Attention parameters including sequence lengths.
|
||||
|
||||
Returns:
|
||||
Refined embeddings [B, L, hidden_size].
|
||||
"""
|
||||
timestep_aware_representations = self.t_embedder(t)
|
||||
|
||||
# Compute context-aware representations by averaging valid tokens
|
||||
txt_lens = attn_params.seqlens # img_len is not used for SingleTokenRefiner
|
||||
context_aware_representations = torch.stack([x[i, : txt_lens[i]].mean(dim=0) for i in range(x.shape[0])], dim=0) # [B, C]
|
||||
|
||||
context_aware_representations = self.c_embedder(context_aware_representations)
|
||||
c = timestep_aware_representations + context_aware_representations
|
||||
del timestep_aware_representations, context_aware_representations
|
||||
x = self.input_embedder(x)
|
||||
x = self.individual_token_refiner(x, c, attn_params)
|
||||
return x
|
||||
|
||||
|
||||
class FinalLayer(nn.Module):
|
||||
"""
|
||||
Final output projection layer with adaptive layer normalization.
|
||||
|
||||
Projects transformer hidden states to output patch space with
|
||||
timestep-conditioned modulation.
|
||||
|
||||
Args:
|
||||
hidden_size: Input hidden dimension.
|
||||
patch_size: Spatial patch size for output reshaping.
|
||||
out_channels: Number of output channels.
|
||||
act_layer: Activation function class.
|
||||
"""
|
||||
|
||||
def __init__(self, hidden_size, patch_size, out_channels, act_layer):
|
||||
super().__init__()
|
||||
|
||||
# Layer normalization without learnable parameters
|
||||
self.norm_final = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
|
||||
out_size = (patch_size[0] * patch_size[1]) * out_channels
|
||||
self.linear = nn.Linear(hidden_size, out_size, bias=True)
|
||||
|
||||
# Adaptive layer normalization modulation
|
||||
self.adaLN_modulation = nn.Sequential(
|
||||
act_layer(),
|
||||
nn.Linear(hidden_size, 2 * hidden_size, bias=True),
|
||||
)
|
||||
|
||||
def forward(self, x, c):
|
||||
shift, scale = self.adaLN_modulation(c).chunk(2, dim=1)
|
||||
x = modulate(self.norm_final(x), shift=shift, scale=scale)
|
||||
del shift, scale, c
|
||||
x = self.linear(x)
|
||||
return x
|
||||
|
||||
|
||||
class RMSNorm(nn.Module):
|
||||
"""
|
||||
Root Mean Square Layer Normalization.
|
||||
|
||||
Normalizes input using RMS and applies learnable scaling.
|
||||
More efficient than LayerNorm as it doesn't compute mean.
|
||||
|
||||
Args:
|
||||
dim: Input feature dimension.
|
||||
eps: Small value for numerical stability.
|
||||
"""
|
||||
|
||||
def __init__(self, dim: int, eps: float = 1e-6):
|
||||
super().__init__()
|
||||
self.eps = eps
|
||||
self.weight = nn.Parameter(torch.ones(dim))
|
||||
|
||||
def _norm(self, x):
|
||||
"""
|
||||
Apply RMS normalization.
|
||||
|
||||
Args:
|
||||
x: Input tensor.
|
||||
|
||||
Returns:
|
||||
RMS normalized tensor.
|
||||
"""
|
||||
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
|
||||
|
||||
def reset_parameters(self):
|
||||
self.weight.fill_(1)
|
||||
|
||||
def forward(self, x):
|
||||
"""
|
||||
Apply RMSNorm with learnable scaling.
|
||||
|
||||
Args:
|
||||
x: Input tensor.
|
||||
|
||||
Returns:
|
||||
Normalized and scaled tensor.
|
||||
"""
|
||||
output = self._norm(x.float()).type_as(x)
|
||||
del x
|
||||
# output = output * self.weight
|
||||
# fp8 support
|
||||
output = output * self.weight.to(output.dtype)
|
||||
return output
|
||||
|
||||
|
||||
# kept for reference, not used in current implementation
|
||||
# class LinearWarpforSingle(nn.Module):
|
||||
# """
|
||||
# Linear layer wrapper for concatenating and projecting two inputs.
|
||||
|
||||
# Used in single-stream blocks to combine attention output with MLP features.
|
||||
|
||||
# Args:
|
||||
# in_dim: Input dimension (sum of both input feature dimensions).
|
||||
# out_dim: Output dimension.
|
||||
# bias: Whether to use bias in linear projection.
|
||||
# """
|
||||
|
||||
# def __init__(self, in_dim: int, out_dim: int, bias=False):
|
||||
# super().__init__()
|
||||
# self.fc = nn.Linear(in_dim, out_dim, bias=bias)
|
||||
|
||||
# def forward(self, x, y):
|
||||
# """Concatenate inputs along feature dimension and project."""
|
||||
# x = torch.cat([x.contiguous(), y.contiguous()], dim=2).contiguous()
|
||||
# return self.fc(x)
|
||||
|
||||
|
||||
class ModulateDiT(nn.Module):
|
||||
"""
|
||||
Timestep conditioning modulation layer.
|
||||
|
||||
Projects timestep embeddings to multiple modulation parameters
|
||||
for adaptive layer normalization.
|
||||
|
||||
Args:
|
||||
hidden_size: Input conditioning dimension.
|
||||
factor: Number of modulation parameters to generate.
|
||||
act_layer: Activation function class.
|
||||
"""
|
||||
|
||||
def __init__(self, hidden_size: int, factor: int, act_layer: Callable):
|
||||
super().__init__()
|
||||
self.act = act_layer()
|
||||
self.linear = nn.Linear(hidden_size, factor * hidden_size, bias=True)
|
||||
|
||||
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
||||
return self.linear(self.act(x))
|
||||
|
||||
|
||||
class MMDoubleStreamBlock(nn.Module):
|
||||
"""
|
||||
Multimodal double-stream transformer block.
|
||||
|
||||
Processes image and text tokens separately with cross-modal attention.
|
||||
Each stream has its own normalization and MLP layers but shares
|
||||
attention computation for cross-modal interaction.
|
||||
|
||||
Args:
|
||||
hidden_size: Model dimension.
|
||||
heads_num: Number of attention heads.
|
||||
mlp_width_ratio: MLP expansion ratio.
|
||||
mlp_act_type: MLP activation function (only "gelu_tanh" supported).
|
||||
qk_norm: QK normalization flag (must be True).
|
||||
qk_norm_type: QK normalization type (only "rms" supported).
|
||||
qkv_bias: Use bias in QKV projections.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: int,
|
||||
heads_num: int,
|
||||
mlp_width_ratio: float,
|
||||
mlp_act_type: str = "gelu_tanh",
|
||||
qk_norm: bool = True,
|
||||
qk_norm_type: str = "rms",
|
||||
qkv_bias: bool = False,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
assert mlp_act_type == "gelu_tanh", "Only GELU-tanh activation supported."
|
||||
assert qk_norm_type == "rms", "Only RMS normalization supported."
|
||||
assert qk_norm, "QK normalization must be enabled."
|
||||
|
||||
self.heads_num = heads_num
|
||||
head_dim = hidden_size // heads_num
|
||||
mlp_hidden_dim = int(hidden_size * mlp_width_ratio)
|
||||
|
||||
# Image stream processing components
|
||||
self.img_mod = ModulateDiT(hidden_size, factor=6, act_layer=nn.SiLU)
|
||||
self.img_norm1 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
|
||||
|
||||
self.img_attn_qkv = nn.Linear(hidden_size, hidden_size * 3, bias=qkv_bias)
|
||||
|
||||
self.img_attn_q_norm = RMSNorm(head_dim, eps=1e-6)
|
||||
self.img_attn_k_norm = RMSNorm(head_dim, eps=1e-6)
|
||||
self.img_attn_proj = nn.Linear(hidden_size, hidden_size, bias=qkv_bias)
|
||||
|
||||
self.img_norm2 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
|
||||
self.img_mlp = MLP(hidden_size, mlp_hidden_dim, act_layer=lambda: nn.GELU(approximate="tanh"), bias=True)
|
||||
|
||||
# Text stream processing components
|
||||
self.txt_mod = ModulateDiT(hidden_size, factor=6, act_layer=nn.SiLU)
|
||||
self.txt_norm1 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
|
||||
|
||||
self.txt_attn_qkv = nn.Linear(hidden_size, hidden_size * 3, bias=qkv_bias)
|
||||
self.txt_attn_q_norm = RMSNorm(head_dim, eps=1e-6)
|
||||
self.txt_attn_k_norm = RMSNorm(head_dim, eps=1e-6)
|
||||
self.txt_attn_proj = nn.Linear(hidden_size, hidden_size, bias=qkv_bias)
|
||||
|
||||
self.txt_norm2 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
|
||||
self.txt_mlp = MLP(hidden_size, mlp_hidden_dim, act_layer=lambda: nn.GELU(approximate="tanh"), bias=True)
|
||||
|
||||
self.gradient_checkpointing = False
|
||||
self.cpu_offload_checkpointing = False
|
||||
|
||||
def enable_gradient_checkpointing(self, cpu_offload: bool = False):
|
||||
self.gradient_checkpointing = True
|
||||
self.cpu_offload_checkpointing = cpu_offload
|
||||
|
||||
def disable_gradient_checkpointing(self):
|
||||
self.gradient_checkpointing = False
|
||||
self.cpu_offload_checkpointing = False
|
||||
|
||||
def _forward(
|
||||
self, img: torch.Tensor, txt: torch.Tensor, vec: torch.Tensor, freqs_cis: tuple = None, attn_params: AttentionParams = None
|
||||
) -> Tuple[torch.Tensor, torch.Tensor]:
|
||||
# Extract modulation parameters for image and text streams
|
||||
(img_mod1_shift, img_mod1_scale, img_mod1_gate, img_mod2_shift, img_mod2_scale, img_mod2_gate) = self.img_mod(vec).chunk(
|
||||
6, dim=-1
|
||||
)
|
||||
(txt_mod1_shift, txt_mod1_scale, txt_mod1_gate, txt_mod2_shift, txt_mod2_scale, txt_mod2_gate) = self.txt_mod(vec).chunk(
|
||||
6, dim=-1
|
||||
)
|
||||
|
||||
# Process image stream for attention
|
||||
img_modulated = self.img_norm1(img)
|
||||
img_modulated = modulate(img_modulated, shift=img_mod1_shift, scale=img_mod1_scale)
|
||||
del img_mod1_shift, img_mod1_scale
|
||||
|
||||
img_qkv = self.img_attn_qkv(img_modulated)
|
||||
del img_modulated
|
||||
img_q, img_k, img_v = img_qkv.chunk(3, dim=-1)
|
||||
del img_qkv
|
||||
|
||||
img_q = rearrange(img_q, "B L (H D) -> B L H D", H=self.heads_num)
|
||||
img_k = rearrange(img_k, "B L (H D) -> B L H D", H=self.heads_num)
|
||||
img_v = rearrange(img_v, "B L (H D) -> B L H D", H=self.heads_num)
|
||||
|
||||
# Apply QK-Norm if enabled
|
||||
img_q = self.img_attn_q_norm(img_q).to(img_v)
|
||||
img_k = self.img_attn_k_norm(img_k).to(img_v)
|
||||
|
||||
# Apply rotary position embeddings to image tokens
|
||||
if freqs_cis is not None:
|
||||
img_q, img_k = apply_rotary_emb(img_q, img_k, freqs_cis, head_first=False)
|
||||
del freqs_cis
|
||||
|
||||
# Process text stream for attention
|
||||
txt_modulated = self.txt_norm1(txt)
|
||||
txt_modulated = modulate(txt_modulated, shift=txt_mod1_shift, scale=txt_mod1_scale)
|
||||
|
||||
txt_qkv = self.txt_attn_qkv(txt_modulated)
|
||||
del txt_modulated
|
||||
txt_q, txt_k, txt_v = txt_qkv.chunk(3, dim=-1)
|
||||
del txt_qkv
|
||||
|
||||
txt_q = rearrange(txt_q, "B L (H D) -> B L H D", H=self.heads_num)
|
||||
txt_k = rearrange(txt_k, "B L (H D) -> B L H D", H=self.heads_num)
|
||||
txt_v = rearrange(txt_v, "B L (H D) -> B L H D", H=self.heads_num)
|
||||
|
||||
# Apply QK-Norm if enabled
|
||||
txt_q = self.txt_attn_q_norm(txt_q).to(txt_v)
|
||||
txt_k = self.txt_attn_k_norm(txt_k).to(txt_v)
|
||||
|
||||
# Concatenate image and text tokens for joint attention
|
||||
img_seq_len = img.shape[1]
|
||||
q = torch.cat([img_q, txt_q], dim=1)
|
||||
del img_q, txt_q
|
||||
k = torch.cat([img_k, txt_k], dim=1)
|
||||
del img_k, txt_k
|
||||
v = torch.cat([img_v, txt_v], dim=1)
|
||||
del img_v, txt_v
|
||||
|
||||
qkv = [q, k, v]
|
||||
del q, k, v
|
||||
attn = attention(qkv, attn_params=attn_params)
|
||||
del qkv
|
||||
|
||||
# Split attention outputs back to separate streams
|
||||
img_attn, txt_attn = (attn[:, :img_seq_len].contiguous(), attn[:, img_seq_len:].contiguous())
|
||||
del attn
|
||||
|
||||
# Apply attention projection and residual connection for image stream
|
||||
img = img + apply_gate(self.img_attn_proj(img_attn), gate=img_mod1_gate)
|
||||
del img_attn, img_mod1_gate
|
||||
|
||||
# Apply MLP and residual connection for image stream
|
||||
img = img + apply_gate(
|
||||
self.img_mlp(modulate(self.img_norm2(img), shift=img_mod2_shift, scale=img_mod2_scale)),
|
||||
gate=img_mod2_gate,
|
||||
)
|
||||
del img_mod2_shift, img_mod2_scale, img_mod2_gate
|
||||
|
||||
# Apply attention projection and residual connection for text stream
|
||||
txt = txt + apply_gate(self.txt_attn_proj(txt_attn), gate=txt_mod1_gate)
|
||||
del txt_attn, txt_mod1_gate
|
||||
|
||||
# Apply MLP and residual connection for text stream
|
||||
txt = txt + apply_gate(
|
||||
self.txt_mlp(modulate(self.txt_norm2(txt), shift=txt_mod2_shift, scale=txt_mod2_scale)),
|
||||
gate=txt_mod2_gate,
|
||||
)
|
||||
del txt_mod2_shift, txt_mod2_scale, txt_mod2_gate
|
||||
|
||||
return img, txt
|
||||
|
||||
def forward(
|
||||
self, img: torch.Tensor, txt: torch.Tensor, vec: torch.Tensor, freqs_cis: tuple = None, attn_params: AttentionParams = None
|
||||
) -> Tuple[torch.Tensor, torch.Tensor]:
|
||||
if self.gradient_checkpointing and self.training:
|
||||
forward_fn = self._forward
|
||||
if self.cpu_offload_checkpointing:
|
||||
forward_fn = custom_offloading_utils.cpu_offload_wrapper(forward_fn, self.img_attn_qkv.weight.device)
|
||||
|
||||
return torch.utils.checkpoint.checkpoint(forward_fn, img, txt, vec, freqs_cis, attn_params, use_reentrant=False)
|
||||
else:
|
||||
return self._forward(img, txt, vec, freqs_cis, attn_params)
|
||||
|
||||
|
||||
class MMSingleStreamBlock(nn.Module):
|
||||
"""
|
||||
Multimodal single-stream transformer block.
|
||||
|
||||
Processes concatenated image and text tokens jointly with shared attention.
|
||||
Uses parallel linear layers for efficiency and applies RoPE only to image tokens.
|
||||
|
||||
Args:
|
||||
hidden_size: Model dimension.
|
||||
heads_num: Number of attention heads.
|
||||
mlp_width_ratio: MLP expansion ratio.
|
||||
mlp_act_type: MLP activation function (only "gelu_tanh" supported).
|
||||
qk_norm: QK normalization flag (must be True).
|
||||
qk_norm_type: QK normalization type (only "rms" supported).
|
||||
qk_scale: Attention scaling factor (computed automatically if None).
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: int,
|
||||
heads_num: int,
|
||||
mlp_width_ratio: float = 4.0,
|
||||
mlp_act_type: str = "gelu_tanh",
|
||||
qk_norm: bool = True,
|
||||
qk_norm_type: str = "rms",
|
||||
qk_scale: float = None,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
assert mlp_act_type == "gelu_tanh", "Only GELU-tanh activation supported."
|
||||
assert qk_norm_type == "rms", "Only RMS normalization supported."
|
||||
assert qk_norm, "QK normalization must be enabled."
|
||||
|
||||
self.hidden_size = hidden_size
|
||||
self.heads_num = heads_num
|
||||
head_dim = hidden_size // heads_num
|
||||
mlp_hidden_dim = int(hidden_size * mlp_width_ratio)
|
||||
self.mlp_hidden_dim = mlp_hidden_dim
|
||||
self.scale = qk_scale or head_dim**-0.5
|
||||
|
||||
# Parallel linear projections for efficiency
|
||||
self.linear1 = nn.Linear(hidden_size, hidden_size * 3 + mlp_hidden_dim)
|
||||
|
||||
# Combined output projection
|
||||
# self.linear2 = LinearWarpforSingle(hidden_size + mlp_hidden_dim, hidden_size, bias=True) # for reference
|
||||
self.linear2 = nn.Linear(hidden_size + mlp_hidden_dim, hidden_size, bias=True)
|
||||
|
||||
# QK normalization layers
|
||||
self.q_norm = RMSNorm(head_dim, eps=1e-6)
|
||||
self.k_norm = RMSNorm(head_dim, eps=1e-6)
|
||||
|
||||
self.pre_norm = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
|
||||
|
||||
self.mlp_act = nn.GELU(approximate="tanh")
|
||||
self.modulation = ModulateDiT(hidden_size, factor=3, act_layer=nn.SiLU)
|
||||
|
||||
self.gradient_checkpointing = False
|
||||
self.cpu_offload_checkpointing = False
|
||||
|
||||
def enable_gradient_checkpointing(self, cpu_offload: bool = False):
|
||||
self.gradient_checkpointing = True
|
||||
self.cpu_offload_checkpointing = cpu_offload
|
||||
|
||||
def disable_gradient_checkpointing(self):
|
||||
self.gradient_checkpointing = False
|
||||
self.cpu_offload_checkpointing = False
|
||||
|
||||
def _forward(
|
||||
self,
|
||||
x: torch.Tensor,
|
||||
vec: torch.Tensor,
|
||||
freqs_cis: Tuple[torch.Tensor, torch.Tensor] = None,
|
||||
attn_params: AttentionParams = None,
|
||||
) -> torch.Tensor:
|
||||
# Extract modulation parameters
|
||||
mod_shift, mod_scale, mod_gate = self.modulation(vec).chunk(3, dim=-1)
|
||||
x_mod = modulate(self.pre_norm(x), shift=mod_shift, scale=mod_scale)
|
||||
|
||||
# Compute Q, K, V, and MLP input
|
||||
qkv_mlp = self.linear1(x_mod)
|
||||
del x_mod
|
||||
q, k, v, mlp = qkv_mlp.split([self.hidden_size, self.hidden_size, self.hidden_size, self.mlp_hidden_dim], dim=-1)
|
||||
del qkv_mlp
|
||||
|
||||
q = rearrange(q, "B L (H D) -> B L H D", H=self.heads_num)
|
||||
k = rearrange(k, "B L (H D) -> B L H D", H=self.heads_num)
|
||||
v = rearrange(v, "B L (H D) -> B L H D", H=self.heads_num)
|
||||
|
||||
# Apply QK-Norm if enabled
|
||||
q = self.q_norm(q).to(v)
|
||||
k = self.k_norm(k).to(v)
|
||||
|
||||
# Separate image and text tokens
|
||||
img_q, txt_q = q[:, : attn_params.img_len, :, :], q[:, attn_params.img_len :, :, :]
|
||||
del q
|
||||
img_k, txt_k = k[:, : attn_params.img_len, :, :], k[:, attn_params.img_len :, :, :]
|
||||
del k
|
||||
|
||||
# Apply rotary position embeddings only to image tokens
|
||||
img_q, img_k = apply_rotary_emb(img_q, img_k, freqs_cis, head_first=False)
|
||||
del freqs_cis
|
||||
|
||||
# Recombine and compute joint attention
|
||||
q = torch.cat([img_q, txt_q], dim=1)
|
||||
del img_q, txt_q
|
||||
k = torch.cat([img_k, txt_k], dim=1)
|
||||
del img_k, txt_k
|
||||
# v = torch.cat([img_v, txt_v], dim=1)
|
||||
# del img_v, txt_v
|
||||
qkv = [q, k, v]
|
||||
del q, k, v
|
||||
attn = attention(qkv, attn_params=attn_params)
|
||||
del qkv
|
||||
|
||||
# Combine attention and MLP outputs, apply gating
|
||||
# output = self.linear2(attn, self.mlp_act(mlp))
|
||||
|
||||
mlp = self.mlp_act(mlp)
|
||||
output = torch.cat([attn, mlp], dim=2).contiguous()
|
||||
del attn, mlp
|
||||
output = self.linear2(output)
|
||||
|
||||
return x + apply_gate(output, gate=mod_gate)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
x: torch.Tensor,
|
||||
vec: torch.Tensor,
|
||||
freqs_cis: Tuple[torch.Tensor, torch.Tensor] = None,
|
||||
attn_params: AttentionParams = None,
|
||||
) -> torch.Tensor:
|
||||
if self.gradient_checkpointing and self.training:
|
||||
forward_fn = self._forward
|
||||
if self.cpu_offload_checkpointing:
|
||||
forward_fn = custom_offloading_utils.create_cpu_offloading_wrapper(forward_fn, self.linear1.weight.device)
|
||||
|
||||
return torch.utils.checkpoint.checkpoint(forward_fn, x, vec, freqs_cis, attn_params, use_reentrant=False)
|
||||
else:
|
||||
return self._forward(x, vec, freqs_cis, attn_params)
|
||||
|
||||
|
||||
# endregion
|
||||
661
library/hunyuan_image_text_encoder.py
Normal file
661
library/hunyuan_image_text_encoder.py
Normal file
@@ -0,0 +1,661 @@
|
||||
import json
|
||||
import re
|
||||
from typing import Tuple, Optional, Union
|
||||
import torch
|
||||
from transformers import (
|
||||
AutoTokenizer,
|
||||
Qwen2_5_VLConfig,
|
||||
Qwen2_5_VLForConditionalGeneration,
|
||||
Qwen2Tokenizer,
|
||||
T5ForConditionalGeneration,
|
||||
T5Config,
|
||||
T5Tokenizer,
|
||||
)
|
||||
from transformers.models.t5.modeling_t5 import T5Stack
|
||||
from accelerate import init_empty_weights
|
||||
|
||||
from library.safetensors_utils import load_safetensors
|
||||
from library.utils import setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
BYT5_TOKENIZER_PATH = "google/byt5-small"
|
||||
QWEN_2_5_VL_IMAGE_ID = "Qwen/Qwen2.5-VL-7B-Instruct"
|
||||
|
||||
|
||||
# Copy from Glyph-SDXL-V2
|
||||
|
||||
COLOR_IDX_JSON = """{"white": 0, "black": 1, "darkslategray": 2, "dimgray": 3, "darkolivegreen": 4, "midnightblue": 5, "saddlebrown": 6, "sienna": 7, "whitesmoke": 8, "darkslateblue": 9,
|
||||
"indianred": 10, "linen": 11, "maroon": 12, "khaki": 13, "sandybrown": 14, "gray": 15, "gainsboro": 16, "teal": 17, "peru": 18, "gold": 19,
|
||||
"snow": 20, "firebrick": 21, "crimson": 22, "chocolate": 23, "tomato": 24, "brown": 25, "goldenrod": 26, "antiquewhite": 27, "rosybrown": 28, "steelblue": 29,
|
||||
"floralwhite": 30, "seashell": 31, "darkgreen": 32, "oldlace": 33, "darkkhaki": 34, "burlywood": 35, "red": 36, "darkgray": 37, "orange": 38, "royalblue": 39,
|
||||
"seagreen": 40, "lightgray": 41, "tan": 42, "coral": 43, "beige": 44, "palevioletred": 45, "wheat": 46, "lavender": 47, "darkcyan": 48, "slateblue": 49,
|
||||
"slategray": 50, "orangered": 51, "silver": 52, "olivedrab": 53, "forestgreen": 54, "darkgoldenrod": 55, "ivory": 56, "darkorange": 57, "yellow": 58, "hotpink": 59,
|
||||
"ghostwhite": 60, "lightcoral": 61, "indigo": 62, "bisque": 63, "darkred": 64, "darksalmon": 65, "lightslategray": 66, "dodgerblue": 67, "lightpink": 68, "mistyrose": 69,
|
||||
"mediumvioletred": 70, "cadetblue": 71, "deeppink": 72, "salmon": 73, "palegoldenrod": 74, "blanchedalmond": 75, "lightseagreen": 76, "cornflowerblue": 77, "yellowgreen": 78, "greenyellow": 79,
|
||||
"navajowhite": 80, "papayawhip": 81, "mediumslateblue": 82, "purple": 83, "blueviolet": 84, "pink": 85, "cornsilk": 86, "lightsalmon": 87, "mediumpurple": 88, "moccasin": 89,
|
||||
"turquoise": 90, "mediumseagreen": 91, "lavenderblush": 92, "mediumblue": 93, "darkseagreen": 94, "mediumturquoise": 95, "paleturquoise": 96, "skyblue": 97, "lemonchiffon": 98, "olive": 99,
|
||||
"peachpuff": 100, "lightyellow": 101, "lightsteelblue": 102, "mediumorchid": 103, "plum": 104, "darkturquoise": 105, "aliceblue": 106, "mediumaquamarine": 107, "orchid": 108, "powderblue": 109,
|
||||
"blue": 110, "darkorchid": 111, "violet": 112, "lightskyblue": 113, "lightcyan": 114, "lightgoldenrodyellow": 115, "navy": 116, "thistle": 117, "honeydew": 118, "mintcream": 119,
|
||||
"lightblue": 120, "darkblue": 121, "darkmagenta": 122, "deepskyblue": 123, "magenta": 124, "limegreen": 125, "darkviolet": 126, "cyan": 127, "palegreen": 128, "aquamarine": 129,
|
||||
"lawngreen": 130, "lightgreen": 131, "azure": 132, "chartreuse": 133, "green": 134, "mediumspringgreen": 135, "lime": 136, "springgreen": 137}"""
|
||||
|
||||
MULTILINGUAL_10_LANG_IDX_JSON = """{"en-Montserrat-Regular": 0, "en-Poppins-Italic": 1, "en-GlacialIndifference-Regular": 2, "en-OpenSans-ExtraBoldItalic": 3, "en-Montserrat-Bold": 4, "en-Now-Regular": 5, "en-Garet-Regular": 6, "en-LeagueSpartan-Bold": 7, "en-DMSans-Regular": 8, "en-OpenSauceOne-Regular": 9,
|
||||
"en-OpenSans-ExtraBold": 10, "en-KGPrimaryPenmanship": 11, "en-Anton-Regular": 12, "en-Aileron-BlackItalic": 13, "en-Quicksand-Light": 14, "en-Roboto-BoldItalic": 15, "en-TheSeasons-It": 16, "en-Kollektif": 17, "en-Inter-BoldItalic": 18, "en-Poppins-Medium": 19,
|
||||
"en-Poppins-Light": 20, "en-RoxboroughCF-RegularItalic": 21, "en-PlayfairDisplay-SemiBold": 22, "en-Agrandir-Italic": 23, "en-Lato-Regular": 24, "en-MoreSugarRegular": 25, "en-CanvaSans-RegularItalic": 26, "en-PublicSans-Italic": 27, "en-CodePro-NormalLC": 28, "en-Belleza-Regular": 29,
|
||||
"en-JosefinSans-Bold": 30, "en-HKGrotesk-Bold": 31, "en-Telegraf-Medium": 32, "en-BrittanySignatureRegular": 33, "en-Raleway-ExtraBoldItalic": 34, "en-Mont-RegularItalic": 35, "en-Arimo-BoldItalic": 36, "en-Lora-Italic": 37, "en-ArchivoBlack-Regular": 38, "en-Poppins": 39,
|
||||
"en-Barlow-Black": 40, "en-CormorantGaramond-Bold": 41, "en-LibreBaskerville-Regular": 42, "en-CanvaSchoolFontRegular": 43, "en-BebasNeueBold": 44, "en-LazydogRegular": 45, "en-FredokaOne-Regular": 46, "en-Horizon-Bold": 47, "en-Nourd-Regular": 48, "en-Hatton-Regular": 49,
|
||||
"en-Nunito-ExtraBoldItalic": 50, "en-CerebriSans-Regular": 51, "en-Montserrat-Light": 52, "en-TenorSans": 53, "en-Norwester-Regular": 54, "en-ClearSans-Bold": 55, "en-Cardo-Regular": 56, "en-Alice-Regular": 57, "en-Oswald-Regular": 58, "en-Gaegu-Bold": 59,
|
||||
"en-Muli-Black": 60, "en-TAN-PEARL-Regular": 61, "en-CooperHewitt-Book": 62, "en-Agrandir-Grand": 63, "en-BlackMango-Thin": 64, "en-DMSerifDisplay-Regular": 65, "en-Antonio-Bold": 66, "en-Sniglet-Regular": 67, "en-BeVietnam-Regular": 68, "en-NunitoSans10pt-BlackItalic": 69,
|
||||
"en-AbhayaLibre-ExtraBold": 70, "en-Rubik-Regular": 71, "en-PPNeueMachina-Regular": 72, "en-TAN - MON CHERI-Regular": 73, "en-Jua-Regular": 74, "en-Playlist-Script": 75, "en-SourceSansPro-BoldItalic": 76, "en-MoonTime-Regular": 77, "en-Eczar-ExtraBold": 78, "en-Gatwick-Regular": 79,
|
||||
"en-MonumentExtended-Regular": 80, "en-BarlowSemiCondensed-Regular": 81, "en-BarlowCondensed-Regular": 82, "en-Alegreya-Regular": 83, "en-DreamAvenue": 84, "en-RobotoCondensed-Italic": 85, "en-BobbyJones-Regular": 86, "en-Garet-ExtraBold": 87, "en-YesevaOne-Regular": 88, "en-Dosis-ExtraBold": 89,
|
||||
"en-LeagueGothic-Regular": 90, "en-OpenSans-Italic": 91, "en-TANAEGEAN-Regular": 92, "en-Maharlika-Regular": 93, "en-MarykateRegular": 94, "en-Cinzel-Regular": 95, "en-Agrandir-Wide": 96, "en-Chewy-Regular": 97, "en-BodoniFLF-BoldItalic": 98, "en-Nunito-BlackItalic": 99,
|
||||
"en-LilitaOne": 100, "en-HandyCasualCondensed-Regular": 101, "en-Ovo": 102, "en-Livvic-Regular": 103, "en-Agrandir-Narrow": 104, "en-CrimsonPro-Italic": 105, "en-AnonymousPro-Bold": 106, "en-NF-OneLittleFont-Bold": 107, "en-RedHatDisplay-BoldItalic": 108, "en-CodecPro-Regular": 109,
|
||||
"en-HalimunRegular": 110, "en-LibreFranklin-Black": 111, "en-TeXGyreTermes-BoldItalic": 112, "en-Shrikhand-Regular": 113, "en-TTNormsPro-Italic": 114, "en-Gagalin-Regular": 115, "en-OpenSans-Bold": 116, "en-GreatVibes-Regular": 117, "en-Breathing": 118, "en-HeroLight-Regular": 119,
|
||||
"en-KGPrimaryDots": 120, "en-Quicksand-Bold": 121, "en-Brice-ExtraLightSemiExpanded": 122, "en-Lato-BoldItalic": 123, "en-Fraunces9pt-Italic": 124, "en-AbrilFatface-Regular": 125, "en-BerkshireSwash-Regular": 126, "en-Atma-Bold": 127, "en-HolidayRegular": 128, "en-BebasNeueCyrillic": 129,
|
||||
"en-IntroRust-Base": 130, "en-Gistesy": 131, "en-BDScript-Regular": 132, "en-ApricotsRegular": 133, "en-Prompt-Black": 134, "en-TAN MERINGUE": 135, "en-Sukar Regular": 136, "en-GentySans-Regular": 137, "en-NeueEinstellung-Normal": 138, "en-Garet-Bold": 139,
|
||||
"en-FiraSans-Black": 140, "en-BantayogLight": 141, "en-NotoSerifDisplay-Black": 142, "en-TTChocolates-Regular": 143, "en-Ubuntu-Regular": 144, "en-Assistant-Bold": 145, "en-ABeeZee-Regular": 146, "en-LexendDeca-Regular": 147, "en-KingredSerif": 148, "en-Radley-Regular": 149,
|
||||
"en-BrownSugar": 150, "en-MigraItalic-ExtraboldItalic": 151, "en-ChildosArabic-Regular": 152, "en-PeaceSans": 153, "en-LondrinaSolid-Black": 154, "en-SpaceMono-BoldItalic": 155, "en-RobotoMono-Light": 156, "en-CourierPrime-Regular": 157, "en-Alata-Regular": 158, "en-Amsterdam-One": 159,
|
||||
"en-IreneFlorentina-Regular": 160, "en-CatchyMager": 161, "en-Alta_regular": 162, "en-ArticulatCF-Regular": 163, "en-Raleway-Regular": 164, "en-BrasikaDisplay": 165, "en-TANAngleton-Italic": 166, "en-NotoSerifDisplay-ExtraCondensedItalic": 167, "en-Bryndan Write": 168, "en-TTCommonsPro-It": 169,
|
||||
"en-AlexBrush-Regular": 170, "en-Antic-Regular": 171, "en-TTHoves-Bold": 172, "en-DroidSerif": 173, "en-AblationRegular": 174, "en-Marcellus-Regular": 175, "en-Sanchez-Italic": 176, "en-JosefinSans": 177, "en-Afrah-Regular": 178, "en-PinyonScript": 179,
|
||||
"en-TTInterphases-BoldItalic": 180, "en-Yellowtail-Regular": 181, "en-Gliker-Regular": 182, "en-BobbyJonesSoft-Regular": 183, "en-IBMPlexSans": 184, "en-Amsterdam-Three": 185, "en-Amsterdam-FourSlant": 186, "en-TTFors-Regular": 187, "en-Quattrocento": 188, "en-Sifonn-Basic": 189,
|
||||
"en-AlegreyaSans-Black": 190, "en-Daydream": 191, "en-AristotelicaProTx-Rg": 192, "en-NotoSerif": 193, "en-EBGaramond-Italic": 194, "en-HammersmithOne-Regular": 195, "en-RobotoSlab-Regular": 196, "en-DO-Sans-Regular": 197, "en-KGPrimaryDotsLined": 198, "en-Blinker-Regular": 199,
|
||||
"en-TAN NIMBUS": 200, "en-Blueberry-Regular": 201, "en-Rosario-Regular": 202, "en-Forum": 203, "en-MistrullyRegular": 204, "en-SourceSerifPro-Regular": 205, "en-Bugaki-Regular": 206, "en-CMUSerif-Roman": 207, "en-GulfsDisplay-NormalItalic": 208, "en-PTSans-Bold": 209,
|
||||
"en-Sensei-Medium": 210, "en-SquadaOne-Regular": 211, "en-Arapey-Italic": 212, "en-Parisienne-Regular": 213, "en-Aleo-Italic": 214, "en-QuicheDisplay-Italic": 215, "en-RocaOne-It": 216, "en-Funtastic-Regular": 217, "en-PTSerif-BoldItalic": 218, "en-Muller-RegularItalic": 219,
|
||||
"en-ArgentCF-Regular": 220, "en-Brightwall-Italic": 221, "en-Knewave-Regular": 222, "en-TYSerif-D": 223, "en-Agrandir-Tight": 224, "en-AlfaSlabOne-Regular": 225, "en-TANTangkiwood-Display": 226, "en-Kief-Montaser-Regular": 227, "en-Gotham-Book": 228, "en-JuliusSansOne-Regular": 229,
|
||||
"en-CocoGothic-Italic": 230, "en-SairaCondensed-Regular": 231, "en-DellaRespira-Regular": 232, "en-Questrial-Regular": 233, "en-BukhariScript-Regular": 234, "en-HelveticaWorld-Bold": 235, "en-TANKINDRED-Display": 236, "en-CinzelDecorative-Regular": 237, "en-Vidaloka-Regular": 238, "en-AlegreyaSansSC-Black": 239,
|
||||
"en-FeelingPassionate-Regular": 240, "en-QuincyCF-Regular": 241, "en-FiraCode-Regular": 242, "en-Genty-Regular": 243, "en-Nickainley-Normal": 244, "en-RubikOne-Regular": 245, "en-Gidole-Regular": 246, "en-Borsok": 247, "en-Gordita-RegularItalic": 248, "en-Scripter-Regular": 249,
|
||||
"en-Buffalo-Regular": 250, "en-KleinText-Regular": 251, "en-Creepster-Regular": 252, "en-Arvo-Bold": 253, "en-GabrielSans-NormalItalic": 254, "en-Heebo-Black": 255, "en-LexendExa-Regular": 256, "en-BrixtonSansTC-Regular": 257, "en-GildaDisplay-Regular": 258, "en-ChunkFive-Roman": 259,
|
||||
"en-Amaranth-BoldItalic": 260, "en-BubbleboddyNeue-Regular": 261, "en-MavenPro-Bold": 262, "en-TTDrugs-Italic": 263, "en-CyGrotesk-KeyRegular": 264, "en-VarelaRound-Regular": 265, "en-Ruda-Black": 266, "en-SafiraMarch": 267, "en-BloggerSans": 268, "en-TANHEADLINE-Regular": 269,
|
||||
"en-SloopScriptPro-Regular": 270, "en-NeueMontreal-Regular": 271, "en-Schoolbell-Regular": 272, "en-SigherRegular": 273, "en-InriaSerif-Regular": 274, "en-JetBrainsMono-Regular": 275, "en-MADEEvolveSans": 276, "en-Dekko": 277, "en-Handyman-Regular": 278, "en-Aileron-BoldItalic": 279,
|
||||
"en-Bright-Italic": 280, "en-Solway-Regular": 281, "en-Higuen-Regular": 282, "en-WedgesItalic": 283, "en-TANASHFORD-BOLD": 284, "en-IBMPlexMono": 285, "en-RacingSansOne-Regular": 286, "en-RegularBrush": 287, "en-OpenSans-LightItalic": 288, "en-SpecialElite-Regular": 289,
|
||||
"en-FuturaLTPro-Medium": 290, "en-MaragsaDisplay": 291, "en-BigShouldersDisplay-Regular": 292, "en-BDSans-Regular": 293, "en-RasputinRegular": 294, "en-Yvesyvesdrawing-BoldItalic": 295, "en-Bitter-Regular": 296, "en-LuckiestGuy-Regular": 297, "en-CanvaSchoolFontDotted": 298, "en-TTFirsNeue-Italic": 299,
|
||||
"en-Sunday-Regular": 300, "en-HKGothic-MediumItalic": 301, "en-CaveatBrush-Regular": 302, "en-HeliosExt": 303, "en-ArchitectsDaughter-Regular": 304, "en-Angelina": 305, "en-Calistoga-Regular": 306, "en-ArchivoNarrow-Regular": 307, "en-ObjectSans-MediumSlanted": 308, "en-AyrLucidityCondensed-Regular": 309,
|
||||
"en-Nexa-RegularItalic": 310, "en-Lustria-Regular": 311, "en-Amsterdam-TwoSlant": 312, "en-Virtual-Regular": 313, "en-Brusher-Regular": 314, "en-NF-Lepetitcochon-Regular": 315, "en-TANTWINKLE": 316, "en-LeJour-Serif": 317, "en-Prata-Regular": 318, "en-PPWoodland-Regular": 319,
|
||||
"en-PlayfairDisplay-BoldItalic": 320, "en-AmaticSC-Regular": 321, "en-Cabin-Regular": 322, "en-Manjari-Bold": 323, "en-MrDafoe-Regular": 324, "en-TTRamillas-Italic": 325, "en-Luckybones-Bold": 326, "en-DarkerGrotesque-Light": 327, "en-BellabooRegular": 328, "en-CormorantSC-Bold": 329,
|
||||
"en-GochiHand-Regular": 330, "en-Atteron": 331, "en-RocaTwo-Lt": 332, "en-ZCOOLXiaoWei-Regular": 333, "en-TANSONGBIRD": 334, "en-HeadingNow-74Regular": 335, "en-Luthier-BoldItalic": 336, "en-Oregano-Regular": 337, "en-AyrTropikaIsland-Int": 338, "en-Mali-Regular": 339,
|
||||
"en-DidactGothic-Regular": 340, "en-Lovelace-Regular": 341, "en-BakerieSmooth-Regular": 342, "en-CarterOne": 343, "en-HussarBd": 344, "en-OldStandard-Italic": 345, "en-TAN-ASTORIA-Display": 346, "en-rugratssans-Regular": 347, "en-BMHANNA": 348, "en-BetterSaturday": 349,
|
||||
"en-AdigianaToybox": 350, "en-Sailors": 351, "en-PlayfairDisplaySC-Italic": 352, "en-Etna-Regular": 353, "en-Revive80Signature": 354, "en-CAGenerated": 355, "en-Poppins-Regular": 356, "en-Jonathan-Regular": 357, "en-Pacifico-Regular": 358, "en-Saira-Black": 359,
|
||||
"en-Loubag-Regular": 360, "en-Decalotype-Black": 361, "en-Mansalva-Regular": 362, "en-Allura-Regular": 363, "en-ProximaNova-Bold": 364, "en-TANMIGNON-DISPLAY": 365, "en-ArsenicaAntiqua-Regular": 366, "en-BreulGroteskA-RegularItalic": 367, "en-HKModular-Bold": 368, "en-TANNightingale-Regular": 369,
|
||||
"en-AristotelicaProCndTxt-Rg": 370, "en-Aprila-Regular": 371, "en-Tomorrow-Regular": 372, "en-AngellaWhite": 373, "en-KaushanScript-Regular": 374, "en-NotoSans": 375, "en-LeJour-Script": 376, "en-BrixtonTC-Regular": 377, "en-OleoScript-Regular": 378, "en-Cakerolli-Regular": 379,
|
||||
"en-Lobster-Regular": 380, "en-FrunchySerif-Regular": 381, "en-PorcelainRegular": 382, "en-AlojaExtended": 383, "en-SergioTrendy-Italic": 384, "en-LovelaceText-Bold": 385, "en-Anaktoria": 386, "en-JimmyScript-Light": 387, "en-IBMPlexSerif": 388, "en-Marta": 389,
|
||||
"en-Mango-Regular": 390, "en-Overpass-Italic": 391, "en-Hagrid-Regular": 392, "en-ElikaGorica": 393, "en-Amiko-Regular": 394, "en-EFCOBrookshire-Regular": 395, "en-Caladea-Regular": 396, "en-MoonlightBold": 397, "en-Staatliches-Regular": 398, "en-Helios-Bold": 399,
|
||||
"en-Satisfy-Regular": 400, "en-NexaScript-Regular": 401, "en-Trocchi-Regular": 402, "en-March": 403, "en-IbarraRealNova-Regular": 404, "en-Nectarine-Regular": 405, "en-Overpass-Light": 406, "en-TruetypewriterPolyglOTT": 407, "en-Bangers-Regular": 408, "en-Lazord-BoldExpandedItalic": 409,
|
||||
"en-Chloe-Regular": 410, "en-BaskervilleDisplayPT-Regular": 411, "en-Bright-Regular": 412, "en-Vollkorn-Regular": 413, "en-Harmattan": 414, "en-SortsMillGoudy-Regular": 415, "en-Biryani-Bold": 416, "en-SugoProDisplay-Italic": 417, "en-Lazord-BoldItalic": 418, "en-Alike-Regular": 419,
|
||||
"en-PermanentMarker-Regular": 420, "en-Sacramento-Regular": 421, "en-HKGroteskPro-Italic": 422, "en-Aleo-BoldItalic": 423, "en-Noot": 424, "en-TANGARLAND-Regular": 425, "en-Twister": 426, "en-Arsenal-Italic": 427, "en-Bogart-Italic": 428, "en-BethEllen-Regular": 429,
|
||||
"en-Caveat-Regular": 430, "en-BalsamiqSans-Bold": 431, "en-BreeSerif-Regular": 432, "en-CodecPro-ExtraBold": 433, "en-Pierson-Light": 434, "en-CyGrotesk-WideRegular": 435, "en-Lumios-Marker": 436, "en-Comfortaa-Bold": 437, "en-TraceFontRegular": 438, "en-RTL-AdamScript-Regular": 439,
|
||||
"en-EastmanGrotesque-Italic": 440, "en-Kalam-Bold": 441, "en-ChauPhilomeneOne-Regular": 442, "en-Coiny-Regular": 443, "en-Lovera": 444, "en-Gellatio": 445, "en-TitilliumWeb-Bold": 446, "en-OilvareBase-Italic": 447, "en-Catamaran-Black": 448, "en-Anteb-Italic": 449,
|
||||
"en-SueEllenFrancisco": 450, "en-SweetApricot": 451, "en-BrightSunshine": 452, "en-IM_FELL_Double_Pica_Italic": 453, "en-Granaina-limpia": 454, "en-TANPARFAIT": 455, "en-AcherusGrotesque-Regular": 456, "en-AwesomeLathusca-Italic": 457, "en-Signika-Bold": 458, "en-Andasia": 459,
|
||||
"en-DO-AllCaps-Slanted": 460, "en-Zenaida-Regular": 461, "en-Fahkwang-Regular": 462, "en-Play-Regular": 463, "en-BERNIERRegular-Regular": 464, "en-PlumaThin-Regular": 465, "en-SportsWorld": 466, "en-Garet-Black": 467, "en-CarolloPlayscript-BlackItalic": 468, "en-Cheque-Regular": 469,
|
||||
"en-SEGO": 470, "en-BobbyJones-Condensed": 471, "en-NexaSlab-RegularItalic": 472, "en-DancingScript-Regular": 473, "en-PaalalabasDisplayWideBETA": 474, "en-Magnolia-Script": 475, "en-OpunMai-400It": 476, "en-MadelynFill-Regular": 477, "en-ZingRust-Base": 478, "en-FingerPaint-Regular": 479,
|
||||
"en-BostonAngel-Light": 480, "en-Gliker-RegularExpanded": 481, "en-Ahsing": 482, "en-Engagement-Regular": 483, "en-EyesomeScript": 484, "en-LibraSerifModern-Regular": 485, "en-London-Regular": 486, "en-AtkinsonHyperlegible-Regular": 487, "en-StadioNow-TextItalic": 488, "en-Aniyah": 489,
|
||||
"en-ITCAvantGardePro-Bold": 490, "en-Comica-Regular": 491, "en-Coustard-Regular": 492, "en-Brice-BoldCondensed": 493, "en-TANNEWYORK-Bold": 494, "en-TANBUSTER-Bold": 495, "en-Alatsi-Regular": 496, "en-TYSerif-Book": 497, "en-Jingleberry": 498, "en-Rajdhani-Bold": 499,
|
||||
"en-LobsterTwo-BoldItalic": 500, "en-BestLight-Medium": 501, "en-Hitchcut-Regular": 502, "en-GermaniaOne-Regular": 503, "en-Emitha-Script": 504, "en-LemonTuesday": 505, "en-Cubao_Free_Regular": 506, "en-MonterchiSerif-Regular": 507, "en-AllertaStencil-Regular": 508, "en-RTL-Sondos-Regular": 509,
|
||||
"en-HomemadeApple-Regular": 510, "en-CosmicOcto-Medium": 511, "cn-HelloFont-FangHuaTi": 0, "cn-HelloFont-ID-DianFangSong-Bold": 1, "cn-HelloFont-ID-DianFangSong": 2, "cn-HelloFont-ID-DianHei-CEJ": 3, "cn-HelloFont-ID-DianHei-DEJ": 4, "cn-HelloFont-ID-DianHei-EEJ": 5, "cn-HelloFont-ID-DianHei-FEJ": 6, "cn-HelloFont-ID-DianHei-GEJ": 7, "cn-HelloFont-ID-DianKai-Bold": 8, "cn-HelloFont-ID-DianKai": 9,
|
||||
"cn-HelloFont-WenYiHei": 10, "cn-Hellofont-ID-ChenYanXingKai": 11, "cn-Hellofont-ID-DaZiBao": 12, "cn-Hellofont-ID-DaoCaoRen": 13, "cn-Hellofont-ID-JianSong": 14, "cn-Hellofont-ID-JiangHuZhaoPaiHei": 15, "cn-Hellofont-ID-KeSong": 16, "cn-Hellofont-ID-LeYuanTi": 17, "cn-Hellofont-ID-Pinocchio": 18, "cn-Hellofont-ID-QiMiaoTi": 19,
|
||||
"cn-Hellofont-ID-QingHuaKai": 20, "cn-Hellofont-ID-QingHuaXingKai": 21, "cn-Hellofont-ID-ShanShuiXingKai": 22, "cn-Hellofont-ID-ShouXieQiShu": 23, "cn-Hellofont-ID-ShouXieTongZhenTi": 24, "cn-Hellofont-ID-TengLingTi": 25, "cn-Hellofont-ID-XiaoLiShu": 26, "cn-Hellofont-ID-XuanZhenSong": 27, "cn-Hellofont-ID-ZhongLingXingKai": 28, "cn-HellofontIDJiaoTangTi": 29,
|
||||
"cn-HellofontIDJiuZhuTi": 30, "cn-HuXiaoBao-SaoBao": 31, "cn-HuXiaoBo-NanShen": 32, "cn-HuXiaoBo-ZhenShuai": 33, "cn-SourceHanSansSC-Bold": 34, "cn-SourceHanSansSC-ExtraLight": 35, "cn-SourceHanSansSC-Heavy": 36, "cn-SourceHanSansSC-Light": 37, "cn-SourceHanSansSC-Medium": 38, "cn-SourceHanSansSC-Normal": 39,
|
||||
"cn-SourceHanSansSC-Regular": 40, "cn-SourceHanSerifSC-Bold": 41, "cn-SourceHanSerifSC-ExtraLight": 42, "cn-SourceHanSerifSC-Heavy": 43, "cn-SourceHanSerifSC-Light": 44, "cn-SourceHanSerifSC-Medium": 45, "cn-SourceHanSerifSC-Regular": 46, "cn-SourceHanSerifSC-SemiBold": 47, "cn-xiaowei": 48, "cn-AaJianHaoTi": 49,
|
||||
"cn-AlibabaPuHuiTi-Bold": 50, "cn-AlibabaPuHuiTi-Heavy": 51, "cn-AlibabaPuHuiTi-Light": 52, "cn-AlibabaPuHuiTi-Medium": 53, "cn-AlibabaPuHuiTi-Regular": 54, "cn-CanvaAcidBoldSC": 55, "cn-CanvaBreezeCN": 56, "cn-CanvaBumperCropSC": 57, "cn-CanvaCakeShopCN": 58, "cn-CanvaEndeavorBlackSC": 59,
|
||||
"cn-CanvaJoyHeiCN": 60, "cn-CanvaLiCN": 61, "cn-CanvaOrientalBrushCN": 62, "cn-CanvaPoster": 63, "cn-CanvaQinfuCalligraphyCN": 64, "cn-CanvaSweetHeartCN": 65, "cn-CanvaSwordLikeDreamCN": 66, "cn-CanvaTangyuanHandwritingCN": 67, "cn-CanvaWanderWorldCN": 68, "cn-CanvaWenCN": 69,
|
||||
"cn-DianZiChunYi": 70, "cn-GenSekiGothicTW-H": 71, "cn-GenWanMinTW-L": 72, "cn-GenYoMinTW-B": 73, "cn-GenYoMinTW-EL": 74, "cn-GenYoMinTW-H": 75, "cn-GenYoMinTW-M": 76, "cn-GenYoMinTW-R": 77, "cn-GenYoMinTW-SB": 78, "cn-HYQiHei-AZEJ": 79,
|
||||
"cn-HYQiHei-EES": 80, "cn-HanaMinA": 81, "cn-HappyZcool-2016": 82, "cn-HelloFont ZJ KeKouKeAiTi": 83, "cn-HelloFont-ID-BoBoTi": 84, "cn-HelloFont-ID-FuGuHei-25": 85, "cn-HelloFont-ID-FuGuHei-35": 86, "cn-HelloFont-ID-FuGuHei-45": 87, "cn-HelloFont-ID-FuGuHei-55": 88, "cn-HelloFont-ID-FuGuHei-65": 89,
|
||||
"cn-HelloFont-ID-FuGuHei-75": 90, "cn-HelloFont-ID-FuGuHei-85": 91, "cn-HelloFont-ID-HeiKa": 92, "cn-HelloFont-ID-HeiTang": 93, "cn-HelloFont-ID-JianSong-95": 94, "cn-HelloFont-ID-JueJiangHei-50": 95, "cn-HelloFont-ID-JueJiangHei-55": 96, "cn-HelloFont-ID-JueJiangHei-60": 97, "cn-HelloFont-ID-JueJiangHei-65": 98, "cn-HelloFont-ID-JueJiangHei-70": 99,
|
||||
"cn-HelloFont-ID-JueJiangHei-75": 100, "cn-HelloFont-ID-JueJiangHei-80": 101, "cn-HelloFont-ID-KuHeiTi": 102, "cn-HelloFont-ID-LingDongTi": 103, "cn-HelloFont-ID-LingLiTi": 104, "cn-HelloFont-ID-MuFengTi": 105, "cn-HelloFont-ID-NaiNaiJiangTi": 106, "cn-HelloFont-ID-PangDu": 107, "cn-HelloFont-ID-ReLieTi": 108, "cn-HelloFont-ID-RouRun": 109,
|
||||
"cn-HelloFont-ID-SaShuangShouXieTi": 110, "cn-HelloFont-ID-WangZheFengFan": 111, "cn-HelloFont-ID-YouQiTi": 112, "cn-Hellofont-ID-XiaLeTi": 113, "cn-Hellofont-ID-XianXiaTi": 114, "cn-HuXiaoBoKuHei": 115, "cn-IDDanMoXingKai": 116, "cn-IDJueJiangHei": 117, "cn-IDMeiLingTi": 118, "cn-IDQQSugar": 119,
|
||||
"cn-LiuJianMaoCao-Regular": 120, "cn-LongCang-Regular": 121, "cn-MaShanZheng-Regular": 122, "cn-PangMenZhengDao-3": 123, "cn-PangMenZhengDao-Cu": 124, "cn-PangMenZhengDao": 125, "cn-SentyCaramel": 126, "cn-SourceHanSerifSC": 127, "cn-WenCang-Regular": 128, "cn-WenQuanYiMicroHei": 129,
|
||||
"cn-XianErTi": 130, "cn-YRDZSTJF": 131, "cn-YS-HelloFont-BangBangTi": 132, "cn-ZCOOLKuaiLe-Regular": 133, "cn-ZCOOLQingKeHuangYou-Regular": 134, "cn-ZCOOLXiaoWei-Regular": 135, "cn-ZCOOL_KuHei": 136, "cn-ZhiMangXing-Regular": 137, "cn-baotuxiaobaiti": 138, "cn-jiangxizhuokai-Regular": 139,
|
||||
"cn-zcool-gdh": 140, "cn-zcoolqingkehuangyouti-Regular": 141, "cn-zcoolwenyiti": 142, "jp-04KanjyukuGothic": 0, "jp-07LightNovelPOP": 1, "jp-07NikumaruFont": 2, "jp-07YasashisaAntique": 3, "jp-07YasashisaGothic": 4, "jp-BokutachinoGothic2Bold": 5, "jp-BokutachinoGothic2Regular": 6, "jp-CHI_SpeedyRight_full_211128-Regular": 7, "jp-CHI_SpeedyRight_italic_full_211127-Regular": 8, "jp-CP-Font": 9,
|
||||
"jp-Canva_CezanneProN-B": 10, "jp-Canva_CezanneProN-M": 11, "jp-Canva_ChiaroStd-B": 12, "jp-Canva_CometStd-B": 13, "jp-Canva_DotMincho16Std-M": 14, "jp-Canva_GrecoStd-B": 15, "jp-Canva_GrecoStd-M": 16, "jp-Canva_LyraStd-DB": 17, "jp-Canva_MatisseHatsuhiPro-B": 18, "jp-Canva_MatisseHatsuhiPro-M": 19,
|
||||
"jp-Canva_ModeMinAStd-B": 20, "jp-Canva_NewCezanneProN-B": 21, "jp-Canva_NewCezanneProN-M": 22, "jp-Canva_PearlStd-L": 23, "jp-Canva_RaglanStd-UB": 24, "jp-Canva_RailwayStd-B": 25, "jp-Canva_ReggaeStd-B": 26, "jp-Canva_RocknRollStd-DB": 27, "jp-Canva_RodinCattleyaPro-B": 28, "jp-Canva_RodinCattleyaPro-M": 29,
|
||||
"jp-Canva_RodinCattleyaPro-UB": 30, "jp-Canva_RodinHimawariPro-B": 31, "jp-Canva_RodinHimawariPro-M": 32, "jp-Canva_RodinMariaPro-B": 33, "jp-Canva_RodinMariaPro-DB": 34, "jp-Canva_RodinProN-M": 35, "jp-Canva_ShadowTLStd-B": 36, "jp-Canva_StickStd-B": 37, "jp-Canva_TsukuAOldMinPr6N-B": 38, "jp-Canva_TsukuAOldMinPr6N-R": 39,
|
||||
"jp-Canva_UtrilloPro-DB": 40, "jp-Canva_UtrilloPro-M": 41, "jp-Canva_YurukaStd-UB": 42, "jp-FGUIGEN": 43, "jp-GlowSansJ-Condensed-Heavy": 44, "jp-GlowSansJ-Condensed-Light": 45, "jp-GlowSansJ-Normal-Bold": 46, "jp-GlowSansJ-Normal-Light": 47, "jp-HannariMincho": 48, "jp-HarenosoraMincho": 49,
|
||||
"jp-Jiyucho": 50, "jp-Kaiso-Makina-B": 51, "jp-Kaisotai-Next-UP-B": 52, "jp-KokoroMinchoutai": 53, "jp-Mamelon-3-Hi-Regular": 54, "jp-MotoyaAnemoneStd-W1": 55, "jp-MotoyaAnemoneStd-W5": 56, "jp-MotoyaAnticPro-W3": 57, "jp-MotoyaCedarStd-W3": 58, "jp-MotoyaCedarStd-W5": 59,
|
||||
"jp-MotoyaGochikaStd-W4": 60, "jp-MotoyaGochikaStd-W8": 61, "jp-MotoyaGothicMiyabiStd-W6": 62, "jp-MotoyaGothicStd-W3": 63, "jp-MotoyaGothicStd-W5": 64, "jp-MotoyaKoinStd-W3": 65, "jp-MotoyaKyotaiStd-W2": 66, "jp-MotoyaKyotaiStd-W4": 67, "jp-MotoyaMaruStd-W3": 68, "jp-MotoyaMaruStd-W5": 69,
|
||||
"jp-MotoyaMinchoMiyabiStd-W4": 70, "jp-MotoyaMinchoMiyabiStd-W6": 71, "jp-MotoyaMinchoModernStd-W4": 72, "jp-MotoyaMinchoModernStd-W6": 73, "jp-MotoyaMinchoStd-W3": 74, "jp-MotoyaMinchoStd-W5": 75, "jp-MotoyaReisyoStd-W2": 76, "jp-MotoyaReisyoStd-W6": 77, "jp-MotoyaTohitsuStd-W4": 78, "jp-MotoyaTohitsuStd-W6": 79,
|
||||
"jp-MtySousyokuEmBcJis-W6": 80, "jp-MtySousyokuLiBcJis-W6": 81, "jp-Mushin": 82, "jp-NotoSansJP-Bold": 83, "jp-NotoSansJP-Regular": 84, "jp-NudMotoyaAporoStd-W3": 85, "jp-NudMotoyaAporoStd-W5": 86, "jp-NudMotoyaCedarStd-W3": 87, "jp-NudMotoyaCedarStd-W5": 88, "jp-NudMotoyaMaruStd-W3": 89,
|
||||
"jp-NudMotoyaMaruStd-W5": 90, "jp-NudMotoyaMinchoStd-W5": 91, "jp-Ounen-mouhitsu": 92, "jp-Ronde-B-Square": 93, "jp-SMotoyaGyosyoStd-W5": 94, "jp-SMotoyaSinkaiStd-W3": 95, "jp-SMotoyaSinkaiStd-W5": 96, "jp-SourceHanSansJP-Bold": 97, "jp-SourceHanSansJP-Regular": 98, "jp-SourceHanSerifJP-Bold": 99,
|
||||
"jp-SourceHanSerifJP-Regular": 100, "jp-TazuganeGothicStdN-Bold": 101, "jp-TazuganeGothicStdN-Regular": 102, "jp-TelopMinProN-B": 103, "jp-Togalite-Bold": 104, "jp-Togalite-Regular": 105, "jp-TsukuMinPr6N-E": 106, "jp-TsukuMinPr6N-M": 107, "jp-mikachan_o": 108, "jp-nagayama_kai": 109,
|
||||
"jp-07LogoTypeGothic7": 110, "jp-07TetsubinGothic": 111, "jp-851CHIKARA-DZUYOKU-KANA-A": 112, "jp-ARMinchoJIS-Light": 113, "jp-ARMinchoJIS-Ultra": 114, "jp-ARPCrystalMinchoJIS-Medium": 115, "jp-ARPCrystalRGothicJIS-Medium": 116, "jp-ARShounanShinpitsuGyosyoJIS-Medium": 117, "jp-AozoraMincho-bold": 118, "jp-AozoraMinchoRegular": 119,
|
||||
"jp-ArialUnicodeMS-Bold": 120, "jp-ArialUnicodeMS": 121, "jp-CanvaBreezeJP": 122, "jp-CanvaLiCN": 123, "jp-CanvaLiJP": 124, "jp-CanvaOrientalBrushCN": 125, "jp-CanvaQinfuCalligraphyJP": 126, "jp-CanvaSweetHeartJP": 127, "jp-CanvaWenJP": 128, "jp-Corporate-Logo-Bold": 129,
|
||||
"jp-DelaGothicOne-Regular": 130, "jp-GN-Kin-iro_SansSerif": 131, "jp-GN-Koharuiro_Sunray": 132, "jp-GenEiGothicM-B": 133, "jp-GenEiGothicM-R": 134, "jp-GenJyuuGothic-Bold": 135, "jp-GenRyuMinTW-B": 136, "jp-GenRyuMinTW-R": 137, "jp-GenSekiGothicTW-B": 138, "jp-GenSekiGothicTW-R": 139,
|
||||
"jp-GenSenRoundedTW-B": 140, "jp-GenSenRoundedTW-R": 141, "jp-GenShinGothic-Bold": 142, "jp-GenShinGothic-Normal": 143, "jp-GenWanMinTW-L": 144, "jp-GenYoGothicTW-B": 145, "jp-GenYoGothicTW-R": 146, "jp-GenYoMinTW-B": 147, "jp-GenYoMinTW-R": 148, "jp-HGBouquet": 149,
|
||||
"jp-HanaMinA": 150, "jp-HanazomeFont": 151, "jp-HinaMincho-Regular": 152, "jp-Honoka-Antique-Maru": 153, "jp-Honoka-Mincho": 154, "jp-HuiFontP": 155, "jp-IPAexMincho": 156, "jp-JK-Gothic-L": 157, "jp-JK-Gothic-M": 158, "jp-JackeyFont": 159,
|
||||
"jp-KaiseiTokumin-Bold": 160, "jp-KaiseiTokumin-Regular": 161, "jp-Keifont": 162, "jp-KiwiMaru-Regular": 163, "jp-Koku-Mincho-Regular": 164, "jp-MotoyaLMaru-W3-90ms-RKSJ-H": 165, "jp-NewTegomin-Regular": 166, "jp-NicoKaku": 167, "jp-NicoMoji+": 168, "jp-Otsutome_font-Bold": 169,
|
||||
"jp-PottaOne-Regular": 170, "jp-RampartOne-Regular": 171, "jp-Senobi-Gothic-Bold": 172, "jp-Senobi-Gothic-Regular": 173, "jp-SmartFontUI-Proportional": 174, "jp-SoukouMincho": 175, "jp-TEST_Klee-DB": 176, "jp-TEST_Klee-M": 177, "jp-TEST_UDMincho-B": 178, "jp-TEST_UDMincho-L": 179,
|
||||
"jp-TT_Akakane-EB": 180, "jp-Tanuki-Permanent-Marker": 181, "jp-TrainOne-Regular": 182, "jp-TsunagiGothic-Black": 183, "jp-Ume-Hy-Gothic": 184, "jp-Ume-P-Mincho": 185, "jp-WenQuanYiMicroHei": 186, "jp-XANO-mincho-U32": 187, "jp-YOzFontM90-Regular": 188, "jp-Yomogi-Regular": 189,
|
||||
"jp-YujiBoku-Regular": 190, "jp-YujiSyuku-Regular": 191, "jp-ZenKakuGothicNew-Bold": 192, "jp-ZenKakuGothicNew-Regular": 193, "jp-ZenKurenaido-Regular": 194, "jp-ZenMaruGothic-Bold": 195, "jp-ZenMaruGothic-Regular": 196, "jp-darts-font": 197, "jp-irohakakuC-Bold": 198, "jp-irohakakuC-Medium": 199,
|
||||
"jp-irohakakuC-Regular": 200, "jp-katyou": 201, "jp-mplus-1m-bold": 202, "jp-mplus-1m-regular": 203, "jp-mplus-1p-bold": 204, "jp-mplus-1p-regular": 205, "jp-rounded-mplus-1p-bold": 206, "jp-rounded-mplus-1p-regular": 207, "jp-timemachine-wa": 208, "jp-ttf-GenEiLateMin-Medium": 209,
|
||||
"jp-uzura_font": 210, "kr-Arita-buri-Bold_OTF": 0, "kr-Arita-buri-HairLine_OTF": 1, "kr-Arita-buri-Light_OTF": 2, "kr-Arita-buri-Medium_OTF": 3, "kr-Arita-buri-SemiBold_OTF": 4, "kr-Canva_YDSunshineL": 5, "kr-Canva_YDSunshineM": 6, "kr-Canva_YoonGulimPro710": 7, "kr-Canva_YoonGulimPro730": 8, "kr-Canva_YoonGulimPro740": 9,
|
||||
"kr-Canva_YoonGulimPro760": 10, "kr-Canva_YoonGulimPro770": 11, "kr-Canva_YoonGulimPro790": 12, "kr-CreHappB": 13, "kr-CreHappL": 14, "kr-CreHappM": 15, "kr-CreHappS": 16, "kr-OTAuroraB": 17, "kr-OTAuroraL": 18, "kr-OTAuroraR": 19,
|
||||
"kr-OTDoldamgilB": 20, "kr-OTDoldamgilL": 21, "kr-OTDoldamgilR": 22, "kr-OTHamsterB": 23, "kr-OTHamsterL": 24, "kr-OTHamsterR": 25, "kr-OTHapchangdanB": 26, "kr-OTHapchangdanL": 27, "kr-OTHapchangdanR": 28, "kr-OTSupersizeBkBOX": 29,
|
||||
"kr-SourceHanSansKR-Bold": 30, "kr-SourceHanSansKR-ExtraLight": 31, "kr-SourceHanSansKR-Heavy": 32, "kr-SourceHanSansKR-Light": 33, "kr-SourceHanSansKR-Medium": 34, "kr-SourceHanSansKR-Normal": 35, "kr-SourceHanSansKR-Regular": 36, "kr-SourceHanSansSC-Bold": 37, "kr-SourceHanSansSC-ExtraLight": 38, "kr-SourceHanSansSC-Heavy": 39,
|
||||
"kr-SourceHanSansSC-Light": 40, "kr-SourceHanSansSC-Medium": 41, "kr-SourceHanSansSC-Normal": 42, "kr-SourceHanSansSC-Regular": 43, "kr-SourceHanSerifSC-Bold": 44, "kr-SourceHanSerifSC-SemiBold": 45, "kr-TDTDBubbleBubbleOTF": 46, "kr-TDTDConfusionOTF": 47, "kr-TDTDCuteAndCuteOTF": 48, "kr-TDTDEggTakOTF": 49,
|
||||
"kr-TDTDEmotionalLetterOTF": 50, "kr-TDTDGalapagosOTF": 51, "kr-TDTDHappyHourOTF": 52, "kr-TDTDLatteOTF": 53, "kr-TDTDMoonLightOTF": 54, "kr-TDTDParkForestOTF": 55, "kr-TDTDPencilOTF": 56, "kr-TDTDSmileOTF": 57, "kr-TDTDSproutOTF": 58, "kr-TDTDSunshineOTF": 59,
|
||||
"kr-TDTDWaferOTF": 60, "kr-777Chyaochyureu": 61, "kr-ArialUnicodeMS-Bold": 62, "kr-ArialUnicodeMS": 63, "kr-BMHANNA": 64, "kr-Baekmuk-Dotum": 65, "kr-BagelFatOne-Regular": 66, "kr-CoreBandi": 67, "kr-CoreBandiFace": 68, "kr-CoreBori": 69,
|
||||
"kr-DoHyeon-Regular": 70, "kr-Dokdo-Regular": 71, "kr-Gaegu-Bold": 72, "kr-Gaegu-Light": 73, "kr-Gaegu-Regular": 74, "kr-GamjaFlower-Regular": 75, "kr-GasoekOne-Regular": 76, "kr-GothicA1-Black": 77, "kr-GothicA1-Bold": 78, "kr-GothicA1-ExtraBold": 79,
|
||||
"kr-GothicA1-ExtraLight": 80, "kr-GothicA1-Light": 81, "kr-GothicA1-Medium": 82, "kr-GothicA1-Regular": 83, "kr-GothicA1-SemiBold": 84, "kr-GothicA1-Thin": 85, "kr-Gugi-Regular": 86, "kr-HiMelody-Regular": 87, "kr-Jua-Regular": 88, "kr-KirangHaerang-Regular": 89,
|
||||
"kr-NanumBrush": 90, "kr-NanumPen": 91, "kr-NanumSquareRoundB": 92, "kr-NanumSquareRoundEB": 93, "kr-NanumSquareRoundL": 94, "kr-NanumSquareRoundR": 95, "kr-SeH-CB": 96, "kr-SeH-CBL": 97, "kr-SeH-CEB": 98, "kr-SeH-CL": 99,
|
||||
"kr-SeH-CM": 100, "kr-SeN-CB": 101, "kr-SeN-CBL": 102, "kr-SeN-CEB": 103, "kr-SeN-CL": 104, "kr-SeN-CM": 105, "kr-Sunflower-Bold": 106, "kr-Sunflower-Light": 107, "kr-Sunflower-Medium": 108, "kr-TTClaytoyR": 109,
|
||||
"kr-TTDalpangiR": 110, "kr-TTMamablockR": 111, "kr-TTNauidongmuR": 112, "kr-TTOktapbangR": 113, "kr-UhBeeMiMi": 114, "kr-UhBeeMiMiBold": 115, "kr-UhBeeSe_hyun": 116, "kr-UhBeeSe_hyunBold": 117, "kr-UhBeenamsoyoung": 118, "kr-UhBeenamsoyoungBold": 119,
|
||||
"kr-WenQuanYiMicroHei": 120, "kr-YeonSung-Regular": 121}"""
|
||||
|
||||
|
||||
def add_special_token(tokenizer: T5Tokenizer, text_encoder: T5Stack):
|
||||
"""
|
||||
Add special tokens for color and font to tokenizer and text encoder.
|
||||
|
||||
Args:
|
||||
tokenizer: Huggingface tokenizer.
|
||||
text_encoder: Huggingface T5 encoder.
|
||||
"""
|
||||
idx_font_dict = json.loads(MULTILINGUAL_10_LANG_IDX_JSON)
|
||||
idx_color_dict = json.loads(COLOR_IDX_JSON)
|
||||
|
||||
font_token = [f"<{font_code[:2]}-font-{idx_font_dict[font_code]}>" for font_code in idx_font_dict]
|
||||
color_token = [f"<color-{i}>" for i in range(len(idx_color_dict))]
|
||||
additional_special_tokens = []
|
||||
additional_special_tokens += color_token
|
||||
additional_special_tokens += font_token
|
||||
|
||||
tokenizer.add_tokens(additional_special_tokens, special_tokens=True)
|
||||
# Set mean_resizing=False to avoid PyTorch LAPACK dependency
|
||||
text_encoder.resize_token_embeddings(len(tokenizer), mean_resizing=False)
|
||||
|
||||
|
||||
def load_byt5(
|
||||
ckpt_path: str,
|
||||
dtype: Optional[torch.dtype],
|
||||
device: Union[str, torch.device],
|
||||
disable_mmap: bool = False,
|
||||
state_dict: Optional[dict] = None,
|
||||
) -> Tuple[T5Stack, T5Tokenizer]:
|
||||
BYT5_CONFIG_JSON = """
|
||||
{
|
||||
"_name_or_path": "/home/patrick/t5/byt5-small",
|
||||
"architectures": [
|
||||
"T5ForConditionalGeneration"
|
||||
],
|
||||
"d_ff": 3584,
|
||||
"d_kv": 64,
|
||||
"d_model": 1472,
|
||||
"decoder_start_token_id": 0,
|
||||
"dropout_rate": 0.1,
|
||||
"eos_token_id": 1,
|
||||
"feed_forward_proj": "gated-gelu",
|
||||
"gradient_checkpointing": false,
|
||||
"initializer_factor": 1.0,
|
||||
"is_encoder_decoder": true,
|
||||
"layer_norm_epsilon": 1e-06,
|
||||
"model_type": "t5",
|
||||
"num_decoder_layers": 4,
|
||||
"num_heads": 6,
|
||||
"num_layers": 12,
|
||||
"pad_token_id": 0,
|
||||
"relative_attention_num_buckets": 32,
|
||||
"tie_word_embeddings": false,
|
||||
"tokenizer_class": "ByT5Tokenizer",
|
||||
"transformers_version": "4.7.0.dev0",
|
||||
"use_cache": true,
|
||||
"vocab_size": 384
|
||||
}
|
||||
"""
|
||||
|
||||
logger.info(f"Loading BYT5 tokenizer from {BYT5_TOKENIZER_PATH}")
|
||||
byt5_tokenizer = AutoTokenizer.from_pretrained(BYT5_TOKENIZER_PATH)
|
||||
|
||||
logger.info("Initializing BYT5 text encoder")
|
||||
config = json.loads(BYT5_CONFIG_JSON)
|
||||
config = T5Config(**config)
|
||||
with init_empty_weights():
|
||||
byt5_text_encoder = T5ForConditionalGeneration._from_config(config).get_encoder()
|
||||
|
||||
add_special_token(byt5_tokenizer, byt5_text_encoder)
|
||||
|
||||
if state_dict is not None:
|
||||
sd = state_dict
|
||||
else:
|
||||
logger.info(f"Loading state dict from {ckpt_path}")
|
||||
sd = load_safetensors(ckpt_path, device, disable_mmap=disable_mmap, dtype=dtype)
|
||||
|
||||
# remove "encoder." prefix
|
||||
sd = {k[len("encoder.") :] if k.startswith("encoder.") else k: v for k, v in sd.items()}
|
||||
sd["embed_tokens.weight"] = sd.pop("shared.weight")
|
||||
|
||||
info = byt5_text_encoder.load_state_dict(sd, strict=True, assign=True)
|
||||
byt5_text_encoder.to(device)
|
||||
byt5_text_encoder.eval()
|
||||
logger.info(f"BYT5 text encoder loaded with info: {info}")
|
||||
|
||||
return byt5_tokenizer, byt5_text_encoder
|
||||
|
||||
|
||||
def load_qwen2_5_vl(
|
||||
ckpt_path: str,
|
||||
dtype: Optional[torch.dtype],
|
||||
device: Union[str, torch.device],
|
||||
disable_mmap: bool = False,
|
||||
state_dict: Optional[dict] = None,
|
||||
) -> tuple[Qwen2Tokenizer, Qwen2_5_VLForConditionalGeneration]:
|
||||
QWEN2_5_VL_CONFIG_JSON = """
|
||||
{
|
||||
"architectures": [
|
||||
"Qwen2_5_VLForConditionalGeneration"
|
||||
],
|
||||
"attention_dropout": 0.0,
|
||||
"bos_token_id": 151643,
|
||||
"eos_token_id": 151645,
|
||||
"hidden_act": "silu",
|
||||
"hidden_size": 3584,
|
||||
"image_token_id": 151655,
|
||||
"initializer_range": 0.02,
|
||||
"intermediate_size": 18944,
|
||||
"max_position_embeddings": 128000,
|
||||
"max_window_layers": 28,
|
||||
"model_type": "qwen2_5_vl",
|
||||
"num_attention_heads": 28,
|
||||
"num_hidden_layers": 28,
|
||||
"num_key_value_heads": 4,
|
||||
"rms_norm_eps": 1e-06,
|
||||
"rope_scaling": {
|
||||
"mrope_section": [
|
||||
16,
|
||||
24,
|
||||
24
|
||||
],
|
||||
"rope_type": "default",
|
||||
"type": "default"
|
||||
},
|
||||
"rope_theta": 1000000.0,
|
||||
"sliding_window": 32768,
|
||||
"text_config": {
|
||||
"architectures": [
|
||||
"Qwen2_5_VLForConditionalGeneration"
|
||||
],
|
||||
"attention_dropout": 0.0,
|
||||
"bos_token_id": 151643,
|
||||
"eos_token_id": 151645,
|
||||
"hidden_act": "silu",
|
||||
"hidden_size": 3584,
|
||||
"image_token_id": null,
|
||||
"initializer_range": 0.02,
|
||||
"intermediate_size": 18944,
|
||||
"layer_types": [
|
||||
"full_attention",
|
||||
"full_attention",
|
||||
"full_attention",
|
||||
"full_attention",
|
||||
"full_attention",
|
||||
"full_attention",
|
||||
"full_attention",
|
||||
"full_attention",
|
||||
"full_attention",
|
||||
"full_attention",
|
||||
"full_attention",
|
||||
"full_attention",
|
||||
"full_attention",
|
||||
"full_attention",
|
||||
"full_attention",
|
||||
"full_attention",
|
||||
"full_attention",
|
||||
"full_attention",
|
||||
"full_attention",
|
||||
"full_attention",
|
||||
"full_attention",
|
||||
"full_attention",
|
||||
"full_attention",
|
||||
"full_attention",
|
||||
"full_attention",
|
||||
"full_attention",
|
||||
"full_attention",
|
||||
"full_attention"
|
||||
],
|
||||
"max_position_embeddings": 128000,
|
||||
"max_window_layers": 28,
|
||||
"model_type": "qwen2_5_vl_text",
|
||||
"num_attention_heads": 28,
|
||||
"num_hidden_layers": 28,
|
||||
"num_key_value_heads": 4,
|
||||
"rms_norm_eps": 1e-06,
|
||||
"rope_scaling": {
|
||||
"mrope_section": [
|
||||
16,
|
||||
24,
|
||||
24
|
||||
],
|
||||
"rope_type": "default",
|
||||
"type": "default"
|
||||
},
|
||||
"rope_theta": 1000000.0,
|
||||
"sliding_window": null,
|
||||
"torch_dtype": "float32",
|
||||
"use_cache": true,
|
||||
"use_sliding_window": false,
|
||||
"video_token_id": null,
|
||||
"vision_end_token_id": 151653,
|
||||
"vision_start_token_id": 151652,
|
||||
"vision_token_id": 151654,
|
||||
"vocab_size": 152064
|
||||
},
|
||||
"tie_word_embeddings": false,
|
||||
"torch_dtype": "bfloat16",
|
||||
"transformers_version": "4.53.1",
|
||||
"use_cache": true,
|
||||
"use_sliding_window": false,
|
||||
"video_token_id": 151656,
|
||||
"vision_config": {
|
||||
"depth": 32,
|
||||
"fullatt_block_indexes": [
|
||||
7,
|
||||
15,
|
||||
23,
|
||||
31
|
||||
],
|
||||
"hidden_act": "silu",
|
||||
"hidden_size": 1280,
|
||||
"in_channels": 3,
|
||||
"in_chans": 3,
|
||||
"initializer_range": 0.02,
|
||||
"intermediate_size": 3420,
|
||||
"model_type": "qwen2_5_vl",
|
||||
"num_heads": 16,
|
||||
"out_hidden_size": 3584,
|
||||
"patch_size": 14,
|
||||
"spatial_merge_size": 2,
|
||||
"spatial_patch_size": 14,
|
||||
"temporal_patch_size": 2,
|
||||
"tokens_per_second": 2,
|
||||
"torch_dtype": "float32",
|
||||
"window_size": 112
|
||||
},
|
||||
"vision_end_token_id": 151653,
|
||||
"vision_start_token_id": 151652,
|
||||
"vision_token_id": 151654,
|
||||
"vocab_size": 152064
|
||||
}
|
||||
"""
|
||||
config = json.loads(QWEN2_5_VL_CONFIG_JSON)
|
||||
config = Qwen2_5_VLConfig(**config)
|
||||
with init_empty_weights():
|
||||
qwen2_5_vl = Qwen2_5_VLForConditionalGeneration._from_config(config)
|
||||
|
||||
if state_dict is not None:
|
||||
sd = state_dict
|
||||
else:
|
||||
logger.info(f"Loading state dict from {ckpt_path}")
|
||||
sd = load_safetensors(ckpt_path, device, disable_mmap=disable_mmap, dtype=dtype)
|
||||
|
||||
# convert prefixes
|
||||
for key in list(sd.keys()):
|
||||
if key.startswith("model."):
|
||||
new_key = key.replace("model.", "model.language_model.", 1)
|
||||
elif key.startswith("visual."):
|
||||
new_key = key.replace("visual.", "model.visual.", 1)
|
||||
else:
|
||||
continue
|
||||
if key not in sd:
|
||||
logger.warning(f"Key {key} not found in state dict, skipping.")
|
||||
continue
|
||||
sd[new_key] = sd.pop(key)
|
||||
|
||||
info = qwen2_5_vl.load_state_dict(sd, strict=True, assign=True)
|
||||
logger.info(f"Loaded Qwen2.5-VL: {info}")
|
||||
qwen2_5_vl.to(device)
|
||||
qwen2_5_vl.eval()
|
||||
|
||||
if dtype is not None:
|
||||
if dtype.itemsize == 1: # fp8
|
||||
org_dtype = torch.bfloat16 # model weight is fp8 in loading, but original dtype is bfloat16
|
||||
logger.info(f"prepare Qwen2.5-VL for fp8: set to {dtype} from {org_dtype}")
|
||||
qwen2_5_vl.to(dtype)
|
||||
|
||||
# prepare LLM for fp8
|
||||
def prepare_fp8(vl_model: Qwen2_5_VLForConditionalGeneration, target_dtype):
|
||||
def forward_hook(module):
|
||||
def forward(hidden_states):
|
||||
input_dtype = hidden_states.dtype
|
||||
hidden_states = hidden_states.to(torch.float32)
|
||||
variance = hidden_states.pow(2).mean(-1, keepdim=True)
|
||||
hidden_states = hidden_states * torch.rsqrt(variance + module.variance_epsilon)
|
||||
# return module.weight.to(input_dtype) * hidden_states.to(input_dtype)
|
||||
return (module.weight.to(torch.float32) * hidden_states.to(torch.float32)).to(input_dtype)
|
||||
|
||||
return forward
|
||||
|
||||
def decoder_forward_hook(module):
|
||||
def forward(
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
position_ids: Optional[torch.LongTensor] = None,
|
||||
past_key_value: Optional[tuple[torch.Tensor]] = None,
|
||||
output_attentions: Optional[bool] = False,
|
||||
use_cache: Optional[bool] = False,
|
||||
cache_position: Optional[torch.LongTensor] = None,
|
||||
position_embeddings: Optional[tuple[torch.Tensor, torch.Tensor]] = None, # necessary, but kept here for BC
|
||||
**kwargs,
|
||||
) -> tuple[torch.FloatTensor, Optional[tuple[torch.FloatTensor, torch.FloatTensor]]]:
|
||||
|
||||
residual = hidden_states
|
||||
|
||||
hidden_states = module.input_layernorm(hidden_states)
|
||||
|
||||
# Self Attention
|
||||
hidden_states, self_attn_weights = module.self_attn(
|
||||
hidden_states=hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
position_ids=position_ids,
|
||||
past_key_value=past_key_value,
|
||||
output_attentions=output_attentions,
|
||||
use_cache=use_cache,
|
||||
cache_position=cache_position,
|
||||
position_embeddings=position_embeddings,
|
||||
**kwargs,
|
||||
)
|
||||
input_dtype = hidden_states.dtype
|
||||
hidden_states = residual.to(torch.float32) + hidden_states.to(torch.float32)
|
||||
hidden_states = hidden_states.to(input_dtype)
|
||||
|
||||
# Fully Connected
|
||||
residual = hidden_states
|
||||
hidden_states = module.post_attention_layernorm(hidden_states)
|
||||
hidden_states = module.mlp(hidden_states)
|
||||
hidden_states = residual + hidden_states
|
||||
|
||||
outputs = (hidden_states,)
|
||||
|
||||
if output_attentions:
|
||||
outputs += (self_attn_weights,)
|
||||
|
||||
return outputs
|
||||
|
||||
return forward
|
||||
|
||||
for module in vl_model.modules():
|
||||
if module.__class__.__name__ in ["Embedding"]:
|
||||
# print("set", module.__class__.__name__, "to", target_dtype)
|
||||
module.to(target_dtype)
|
||||
if module.__class__.__name__ in ["Qwen2RMSNorm"]:
|
||||
# print("set", module.__class__.__name__, "hooks")
|
||||
module.forward = forward_hook(module)
|
||||
if module.__class__.__name__ in ["Qwen2_5_VLDecoderLayer"]:
|
||||
# print("set", module.__class__.__name__, "hooks")
|
||||
module.forward = decoder_forward_hook(module)
|
||||
if module.__class__.__name__ in ["Qwen2_5_VisionRotaryEmbedding"]:
|
||||
# print("set", module.__class__.__name__, "hooks")
|
||||
module.to(target_dtype)
|
||||
|
||||
prepare_fp8(qwen2_5_vl, org_dtype)
|
||||
|
||||
else:
|
||||
logger.info(f"Setting Qwen2.5-VL to dtype: {dtype}")
|
||||
qwen2_5_vl.to(dtype)
|
||||
|
||||
# Load tokenizer
|
||||
logger.info(f"Loading tokenizer from {QWEN_2_5_VL_IMAGE_ID}")
|
||||
tokenizer = Qwen2Tokenizer.from_pretrained(QWEN_2_5_VL_IMAGE_ID)
|
||||
return tokenizer, qwen2_5_vl
|
||||
|
||||
|
||||
TOKENIZER_MAX_LENGTH = 1024
|
||||
PROMPT_TEMPLATE_ENCODE_START_IDX = 34
|
||||
|
||||
|
||||
def get_qwen_prompt_embeds(
|
||||
tokenizer: Qwen2Tokenizer, vlm: Qwen2_5_VLForConditionalGeneration, prompt: Union[str, list[str]] = None
|
||||
) -> Tuple[torch.Tensor, torch.Tensor]:
|
||||
input_ids, mask = get_qwen_tokens(tokenizer, prompt)
|
||||
return get_qwen_prompt_embeds_from_tokens(vlm, input_ids, mask)
|
||||
|
||||
|
||||
def get_qwen_tokens(tokenizer: Qwen2Tokenizer, prompt: Union[str, list[str]] = None) -> Tuple[torch.Tensor, torch.Tensor]:
|
||||
tokenizer_max_length = TOKENIZER_MAX_LENGTH
|
||||
|
||||
# HunyuanImage-2.1 does not use "<|im_start|>assistant\n" in the prompt template
|
||||
prompt_template_encode = "<|im_start|>system\nDescribe the image by detailing the color, shape, size, texture, quantity, text, spatial relationships of the objects and background:<|im_end|>\n<|im_start|>user\n{}<|im_end|>"
|
||||
# \n<|im_start|>assistant\n"
|
||||
prompt_template_encode_start_idx = PROMPT_TEMPLATE_ENCODE_START_IDX
|
||||
# default_sample_size = 128
|
||||
|
||||
prompt = [prompt] if isinstance(prompt, str) else prompt
|
||||
|
||||
template = prompt_template_encode
|
||||
drop_idx = prompt_template_encode_start_idx
|
||||
txt = [template.format(e) for e in prompt]
|
||||
txt_tokens = tokenizer(txt, max_length=tokenizer_max_length + drop_idx, padding=True, truncation=True, return_tensors="pt")
|
||||
return txt_tokens.input_ids, txt_tokens.attention_mask
|
||||
|
||||
|
||||
def get_qwen_prompt_embeds_from_tokens(
|
||||
vlm: Qwen2_5_VLForConditionalGeneration, input_ids: torch.Tensor, attention_mask: torch.Tensor
|
||||
) -> Tuple[torch.Tensor, torch.Tensor]:
|
||||
tokenizer_max_length = TOKENIZER_MAX_LENGTH
|
||||
drop_idx = PROMPT_TEMPLATE_ENCODE_START_IDX
|
||||
|
||||
device = vlm.device
|
||||
dtype = vlm.dtype
|
||||
|
||||
input_ids = input_ids.to(device=device)
|
||||
attention_mask = attention_mask.to(device=device)
|
||||
|
||||
if dtype.itemsize == 1: # fp8
|
||||
with torch.no_grad(), torch.autocast(device_type=device.type, dtype=torch.bfloat16, enabled=True):
|
||||
encoder_hidden_states = vlm(input_ids=input_ids, attention_mask=attention_mask, output_hidden_states=True)
|
||||
else:
|
||||
with torch.no_grad(), torch.autocast(device_type=device.type, dtype=dtype, enabled=True):
|
||||
encoder_hidden_states = vlm(input_ids=input_ids, attention_mask=attention_mask, output_hidden_states=True)
|
||||
|
||||
hidden_states = encoder_hidden_states.hidden_states[-3] # use the 3rd last layer's hidden states for HunyuanImage-2.1
|
||||
if hidden_states.shape[1] > tokenizer_max_length + drop_idx:
|
||||
logger.warning(f"Hidden states shape {hidden_states.shape} exceeds max length {tokenizer_max_length + drop_idx}")
|
||||
|
||||
# --- Unnecessary complicated processing, keep for reference ---
|
||||
# split_hidden_states = extract_masked_hidden(hidden_states, txt_tokens.attention_mask)
|
||||
# split_hidden_states = [e[drop_idx:] for e in split_hidden_states]
|
||||
# attn_mask_list = [torch.ones(e.size(0), dtype=torch.long, device=e.device) for e in split_hidden_states]
|
||||
# max_seq_len = max([e.size(0) for e in split_hidden_states])
|
||||
# prompt_embeds = torch.stack([torch.cat([u, u.new_zeros(max_seq_len - u.size(0), u.size(1))]) for u in split_hidden_states])
|
||||
# encoder_attention_mask = torch.stack([torch.cat([u, u.new_zeros(max_seq_len - u.size(0))]) for u in attn_mask_list])
|
||||
# ----------------------------------------------------------
|
||||
|
||||
prompt_embeds = hidden_states[:, drop_idx:, :]
|
||||
encoder_attention_mask = attention_mask[:, drop_idx:]
|
||||
prompt_embeds = prompt_embeds.to(device=device)
|
||||
|
||||
return prompt_embeds, encoder_attention_mask
|
||||
|
||||
|
||||
def format_prompt(texts, styles):
|
||||
"""
|
||||
Text "{text}" in {color}, {type}.
|
||||
"""
|
||||
|
||||
prompt = ""
|
||||
for text, style in zip(texts, styles):
|
||||
# color and style are always None in official implementation, so we only use text
|
||||
text_prompt = f'Text "{text}"'
|
||||
text_prompt += ". "
|
||||
prompt = prompt + text_prompt
|
||||
return prompt
|
||||
|
||||
|
||||
BYT5_MAX_LENGTH = 128
|
||||
|
||||
|
||||
def get_glyph_prompt_embeds(
|
||||
tokenizer: T5Tokenizer, text_encoder: T5Stack, prompt: Optional[str] = None
|
||||
) -> Tuple[list[bool], torch.Tensor, torch.Tensor]:
|
||||
byt5_tokens, byt5_text_mask = get_byt5_text_tokens(tokenizer, prompt)
|
||||
return get_byt5_prompt_embeds_from_tokens(text_encoder, byt5_tokens, byt5_text_mask)
|
||||
|
||||
|
||||
def get_byt5_prompt_embeds_from_tokens(
|
||||
text_encoder: T5Stack, byt5_text_ids: Optional[torch.Tensor], byt5_text_mask: Optional[torch.Tensor]
|
||||
) -> Tuple[list[bool], torch.Tensor, torch.Tensor]:
|
||||
byt5_max_length = BYT5_MAX_LENGTH
|
||||
|
||||
if byt5_text_ids is None or byt5_text_mask is None or byt5_text_mask.sum() == 0:
|
||||
return (
|
||||
[False],
|
||||
torch.zeros((1, byt5_max_length, 1472), device=text_encoder.device),
|
||||
torch.zeros((1, byt5_max_length), device=text_encoder.device, dtype=torch.int64),
|
||||
)
|
||||
|
||||
byt5_text_ids = byt5_text_ids.to(device=text_encoder.device)
|
||||
byt5_text_mask = byt5_text_mask.to(device=text_encoder.device)
|
||||
|
||||
with torch.no_grad(), torch.autocast(device_type=text_encoder.device.type, dtype=text_encoder.dtype, enabled=True):
|
||||
byt5_prompt_embeds = text_encoder(byt5_text_ids, attention_mask=byt5_text_mask.float())
|
||||
byt5_emb = byt5_prompt_embeds[0]
|
||||
|
||||
return [True], byt5_emb, byt5_text_mask
|
||||
|
||||
|
||||
def get_byt5_text_tokens(tokenizer, prompt):
|
||||
if not prompt:
|
||||
return None, None
|
||||
|
||||
try:
|
||||
text_prompt_texts = []
|
||||
# pattern_quote_single = r"\'(.*?)\'"
|
||||
pattern_quote_double = r"\"(.*?)\""
|
||||
pattern_quote_chinese_single = r"‘(.*?)’"
|
||||
pattern_quote_chinese_double = r"“(.*?)”"
|
||||
|
||||
# matches_quote_single = re.findall(pattern_quote_single, prompt)
|
||||
matches_quote_double = re.findall(pattern_quote_double, prompt)
|
||||
matches_quote_chinese_single = re.findall(pattern_quote_chinese_single, prompt)
|
||||
matches_quote_chinese_double = re.findall(pattern_quote_chinese_double, prompt)
|
||||
|
||||
# text_prompt_texts.extend(matches_quote_single)
|
||||
text_prompt_texts.extend(matches_quote_double)
|
||||
text_prompt_texts.extend(matches_quote_chinese_single)
|
||||
text_prompt_texts.extend(matches_quote_chinese_double)
|
||||
|
||||
if not text_prompt_texts:
|
||||
return None, None
|
||||
|
||||
text_prompt_style_list = [{"color": None, "font-family": None} for _ in range(len(text_prompt_texts))]
|
||||
glyph_text_formatted = format_prompt(text_prompt_texts, text_prompt_style_list)
|
||||
logger.info(f"Glyph text formatted: {glyph_text_formatted}")
|
||||
|
||||
byt5_text_inputs = tokenizer(
|
||||
glyph_text_formatted,
|
||||
padding="max_length",
|
||||
max_length=BYT5_MAX_LENGTH,
|
||||
truncation=True,
|
||||
add_special_tokens=True,
|
||||
return_tensors="pt",
|
||||
)
|
||||
|
||||
byt5_text_ids = byt5_text_inputs.input_ids
|
||||
byt5_text_mask = byt5_text_inputs.attention_mask
|
||||
|
||||
return byt5_text_ids, byt5_text_mask
|
||||
|
||||
except Exception as e:
|
||||
logger.warning(f"Warning: Error in glyph encoding, using fallback: {e}")
|
||||
return None, None
|
||||
525
library/hunyuan_image_utils.py
Normal file
525
library/hunyuan_image_utils.py
Normal file
@@ -0,0 +1,525 @@
|
||||
# Original work: https://github.com/Tencent-Hunyuan/HunyuanImage-2.1
|
||||
# Re-implemented for license compliance for sd-scripts.
|
||||
|
||||
import math
|
||||
from typing import Tuple, Union, Optional
|
||||
import torch
|
||||
|
||||
from library.utils import setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
MODEL_VERSION_2_1 = "hunyuan-image-2.1"
|
||||
|
||||
# region model
|
||||
|
||||
|
||||
def _to_tuple(x, dim=2):
|
||||
"""
|
||||
Convert int or sequence to tuple of specified dimension.
|
||||
|
||||
Args:
|
||||
x: Int or sequence to convert.
|
||||
dim: Target dimension for tuple.
|
||||
|
||||
Returns:
|
||||
Tuple of length dim.
|
||||
"""
|
||||
if isinstance(x, int) or isinstance(x, float):
|
||||
return (x,) * dim
|
||||
elif len(x) == dim:
|
||||
return x
|
||||
else:
|
||||
raise ValueError(f"Expected length {dim} or int, but got {x}")
|
||||
|
||||
|
||||
def get_meshgrid_nd(start, dim=2):
|
||||
"""
|
||||
Generate n-dimensional coordinate meshgrid from 0 to grid_size.
|
||||
|
||||
Creates coordinate grids for each spatial dimension, useful for
|
||||
generating position embeddings.
|
||||
|
||||
Args:
|
||||
start: Grid size for each dimension (int or tuple).
|
||||
dim: Number of spatial dimensions.
|
||||
|
||||
Returns:
|
||||
Coordinate grid tensor [dim, *grid_size].
|
||||
"""
|
||||
# Convert start to grid sizes
|
||||
num = _to_tuple(start, dim=dim)
|
||||
start = (0,) * dim
|
||||
stop = num
|
||||
|
||||
# Generate coordinate arrays for each dimension
|
||||
axis_grid = []
|
||||
for i in range(dim):
|
||||
a, b, n = start[i], stop[i], num[i]
|
||||
g = torch.linspace(a, b, n + 1, dtype=torch.float32)[:n]
|
||||
axis_grid.append(g)
|
||||
grid = torch.meshgrid(*axis_grid, indexing="ij") # dim x [W, H, D]
|
||||
grid = torch.stack(grid, dim=0) # [dim, W, H, D]
|
||||
|
||||
return grid
|
||||
|
||||
|
||||
def get_nd_rotary_pos_embed(rope_dim_list, start, theta=10000.0):
|
||||
"""
|
||||
Generate n-dimensional rotary position embeddings for spatial tokens.
|
||||
|
||||
Creates RoPE embeddings for multi-dimensional positional encoding,
|
||||
distributing head dimensions across spatial dimensions.
|
||||
|
||||
Args:
|
||||
rope_dim_list: Dimensions allocated to each spatial axis (should sum to head_dim).
|
||||
start: Spatial grid size for each dimension.
|
||||
theta: Base frequency for RoPE computation.
|
||||
|
||||
Returns:
|
||||
Tuple of (cos_freqs, sin_freqs) for rotary embedding [H*W, D/2].
|
||||
"""
|
||||
|
||||
grid = get_meshgrid_nd(start, dim=len(rope_dim_list)) # [3, W, H, D] / [2, W, H]
|
||||
|
||||
# Generate RoPE embeddings for each spatial dimension
|
||||
embs = []
|
||||
for i in range(len(rope_dim_list)):
|
||||
emb = get_1d_rotary_pos_embed(rope_dim_list[i], grid[i].reshape(-1), theta) # 2 x [WHD, rope_dim_list[i]]
|
||||
embs.append(emb)
|
||||
|
||||
cos = torch.cat([emb[0] for emb in embs], dim=1) # (WHD, D/2)
|
||||
sin = torch.cat([emb[1] for emb in embs], dim=1) # (WHD, D/2)
|
||||
return cos, sin
|
||||
|
||||
|
||||
def get_1d_rotary_pos_embed(
|
||||
dim: int, pos: Union[torch.FloatTensor, int], theta: float = 10000.0
|
||||
) -> Tuple[torch.Tensor, torch.Tensor]:
|
||||
"""
|
||||
Generate 1D rotary position embeddings.
|
||||
|
||||
Args:
|
||||
dim: Embedding dimension (must be even).
|
||||
pos: Position indices [S] or scalar for sequence length.
|
||||
theta: Base frequency for sinusoidal encoding.
|
||||
|
||||
Returns:
|
||||
Tuple of (cos_freqs, sin_freqs) tensors [S, D].
|
||||
"""
|
||||
if isinstance(pos, int):
|
||||
pos = torch.arange(pos).float()
|
||||
|
||||
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim)) # [D/2]
|
||||
freqs = torch.outer(pos, freqs) # [S, D/2]
|
||||
freqs_cos = freqs.cos().repeat_interleave(2, dim=1) # [S, D]
|
||||
freqs_sin = freqs.sin().repeat_interleave(2, dim=1) # [S, D]
|
||||
return freqs_cos, freqs_sin
|
||||
|
||||
|
||||
def timestep_embedding(t, dim, max_period=10000):
|
||||
"""
|
||||
Create sinusoidal timestep embeddings for diffusion models.
|
||||
|
||||
Converts scalar timesteps to high-dimensional embeddings using
|
||||
sinusoidal encoding at different frequencies.
|
||||
|
||||
Args:
|
||||
t: Timestep tensor [N].
|
||||
dim: Output embedding dimension.
|
||||
max_period: Maximum period for frequency computation.
|
||||
|
||||
Returns:
|
||||
Timestep embeddings [N, dim].
|
||||
"""
|
||||
half = dim // 2
|
||||
freqs = torch.exp(-math.log(max_period) * torch.arange(start=0, end=half, dtype=torch.float32) / half).to(device=t.device)
|
||||
args = t[:, None].float() * freqs[None]
|
||||
embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1)
|
||||
if dim % 2:
|
||||
embedding = torch.cat([embedding, torch.zeros_like(embedding[:, :1])], dim=-1)
|
||||
return embedding
|
||||
|
||||
|
||||
def modulate(x, shift=None, scale=None):
|
||||
"""
|
||||
Apply adaptive layer normalization modulation.
|
||||
|
||||
Applies scale and shift transformations for conditioning
|
||||
in adaptive layer normalization.
|
||||
|
||||
Args:
|
||||
x: Input tensor to modulate.
|
||||
shift: Additive shift parameter (optional).
|
||||
scale: Multiplicative scale parameter (optional).
|
||||
|
||||
Returns:
|
||||
Modulated tensor x * (1 + scale) + shift.
|
||||
"""
|
||||
if scale is None and shift is None:
|
||||
return x
|
||||
elif shift is None:
|
||||
return x * (1 + scale.unsqueeze(1))
|
||||
elif scale is None:
|
||||
return x + shift.unsqueeze(1)
|
||||
else:
|
||||
return x * (1 + scale.unsqueeze(1)) + shift.unsqueeze(1)
|
||||
|
||||
|
||||
def apply_gate(x, gate=None, tanh=False):
|
||||
"""
|
||||
Apply gating mechanism to tensor.
|
||||
|
||||
Multiplies input by gate values, optionally applying tanh activation.
|
||||
Used in residual connections for adaptive control.
|
||||
|
||||
Args:
|
||||
x: Input tensor to gate.
|
||||
gate: Gating values (optional).
|
||||
tanh: Whether to apply tanh to gate values.
|
||||
|
||||
Returns:
|
||||
Gated tensor x * gate (with optional tanh).
|
||||
"""
|
||||
if gate is None:
|
||||
return x
|
||||
if tanh:
|
||||
return x * gate.unsqueeze(1).tanh()
|
||||
else:
|
||||
return x * gate.unsqueeze(1)
|
||||
|
||||
|
||||
def reshape_for_broadcast(
|
||||
freqs_cis: Tuple[torch.Tensor, torch.Tensor],
|
||||
x: torch.Tensor,
|
||||
head_first=False,
|
||||
):
|
||||
"""
|
||||
Reshape RoPE frequency tensors for broadcasting with attention tensors.
|
||||
|
||||
Args:
|
||||
freqs_cis: Tuple of (cos_freqs, sin_freqs) tensors.
|
||||
x: Target tensor for broadcasting compatibility.
|
||||
head_first: Must be False (only supported layout).
|
||||
|
||||
Returns:
|
||||
Reshaped (cos_freqs, sin_freqs) tensors ready for broadcasting.
|
||||
"""
|
||||
assert not head_first, "Only head_first=False layout supported."
|
||||
assert isinstance(freqs_cis, tuple), "Expected tuple of (cos, sin) frequency tensors."
|
||||
assert x.ndim > 1, f"x should have at least 2 dimensions, but got {x.ndim}"
|
||||
|
||||
# Validate frequency tensor dimensions match target tensor
|
||||
assert freqs_cis[0].shape == (
|
||||
x.shape[1],
|
||||
x.shape[-1],
|
||||
), f"Frequency tensor shape {freqs_cis[0].shape} incompatible with target shape {x.shape}"
|
||||
|
||||
shape = [d if i == 1 or i == x.ndim - 1 else 1 for i, d in enumerate(x.shape)]
|
||||
return freqs_cis[0].view(*shape), freqs_cis[1].view(*shape)
|
||||
|
||||
|
||||
def rotate_half(x):
|
||||
"""
|
||||
Rotate half the dimensions for RoPE computation.
|
||||
|
||||
Splits the last dimension in half and applies a 90-degree rotation
|
||||
by swapping and negating components.
|
||||
|
||||
Args:
|
||||
x: Input tensor [..., D] where D is even.
|
||||
|
||||
Returns:
|
||||
Rotated tensor with same shape as input.
|
||||
"""
|
||||
x_real, x_imag = x.float().reshape(*x.shape[:-1], -1, 2).unbind(-1) # [B, S, H, D//2]
|
||||
return torch.stack([-x_imag, x_real], dim=-1).flatten(3)
|
||||
|
||||
|
||||
def apply_rotary_emb(
|
||||
xq: torch.Tensor, xk: torch.Tensor, freqs_cis: Tuple[torch.Tensor, torch.Tensor], head_first: bool = False
|
||||
) -> Tuple[torch.Tensor, torch.Tensor]:
|
||||
"""
|
||||
Apply rotary position embeddings to query and key tensors.
|
||||
|
||||
Args:
|
||||
xq: Query tensor [B, S, H, D].
|
||||
xk: Key tensor [B, S, H, D].
|
||||
freqs_cis: Tuple of (cos_freqs, sin_freqs) for rotation.
|
||||
head_first: Whether head dimension precedes sequence dimension.
|
||||
|
||||
Returns:
|
||||
Tuple of rotated (query, key) tensors.
|
||||
"""
|
||||
device = xq.device
|
||||
dtype = xq.dtype
|
||||
|
||||
cos, sin = reshape_for_broadcast(freqs_cis, xq, head_first)
|
||||
cos, sin = cos.to(device), sin.to(device)
|
||||
|
||||
# Apply rotation: x' = x * cos + rotate_half(x) * sin
|
||||
xq_out = (xq.float() * cos + rotate_half(xq.float()) * sin).to(dtype)
|
||||
xk_out = (xk.float() * cos + rotate_half(xk.float()) * sin).to(dtype)
|
||||
|
||||
return xq_out, xk_out
|
||||
|
||||
|
||||
# endregion
|
||||
|
||||
# region inference
|
||||
|
||||
|
||||
def get_timesteps_sigmas(sampling_steps: int, shift: float, device: torch.device) -> Tuple[torch.Tensor, torch.Tensor]:
|
||||
"""
|
||||
Generate timesteps and sigmas for diffusion sampling.
|
||||
|
||||
Args:
|
||||
sampling_steps: Number of sampling steps.
|
||||
shift: Sigma shift parameter for schedule modification.
|
||||
device: Target device for tensors.
|
||||
|
||||
Returns:
|
||||
Tuple of (timesteps, sigmas) tensors.
|
||||
"""
|
||||
sigmas = torch.linspace(1, 0, sampling_steps + 1)
|
||||
sigmas = (shift * sigmas) / (1 + (shift - 1) * sigmas)
|
||||
sigmas = sigmas.to(torch.float32)
|
||||
timesteps = (sigmas[:-1] * 1000).to(dtype=torch.float32, device=device)
|
||||
return timesteps, sigmas
|
||||
|
||||
|
||||
def step(latents, noise_pred, sigmas, step_i):
|
||||
"""
|
||||
Perform a single diffusion sampling step.
|
||||
|
||||
Args:
|
||||
latents: Current latent state.
|
||||
noise_pred: Predicted noise.
|
||||
sigmas: Noise schedule sigmas.
|
||||
step_i: Current step index.
|
||||
|
||||
Returns:
|
||||
Updated latents after the step.
|
||||
"""
|
||||
return latents.float() - (sigmas[step_i] - sigmas[step_i + 1]) * noise_pred.float()
|
||||
|
||||
|
||||
# endregion
|
||||
|
||||
|
||||
# region AdaptiveProjectedGuidance
|
||||
|
||||
|
||||
class MomentumBuffer:
|
||||
"""
|
||||
Exponential moving average buffer for APG momentum.
|
||||
"""
|
||||
|
||||
def __init__(self, momentum: float):
|
||||
self.momentum = momentum
|
||||
self.running_average = 0
|
||||
|
||||
def update(self, update_value: torch.Tensor):
|
||||
new_average = self.momentum * self.running_average
|
||||
self.running_average = update_value + new_average
|
||||
|
||||
|
||||
def normalized_guidance_apg(
|
||||
pred_cond: torch.Tensor,
|
||||
pred_uncond: torch.Tensor,
|
||||
guidance_scale: float,
|
||||
momentum_buffer: Optional[MomentumBuffer] = None,
|
||||
eta: float = 1.0,
|
||||
norm_threshold: float = 0.0,
|
||||
use_original_formulation: bool = False,
|
||||
):
|
||||
"""
|
||||
Apply normalized adaptive projected guidance.
|
||||
|
||||
Projects the guidance vector to reduce over-saturation while maintaining
|
||||
directional control by decomposing into parallel and orthogonal components.
|
||||
|
||||
Args:
|
||||
pred_cond: Conditional prediction.
|
||||
pred_uncond: Unconditional prediction.
|
||||
guidance_scale: Guidance scale factor.
|
||||
momentum_buffer: Optional momentum buffer for temporal smoothing.
|
||||
eta: Scaling factor for parallel component.
|
||||
norm_threshold: Maximum norm for guidance vector clipping.
|
||||
use_original_formulation: Whether to use original APG formulation.
|
||||
|
||||
Returns:
|
||||
Guided prediction tensor.
|
||||
"""
|
||||
diff = pred_cond - pred_uncond
|
||||
dim = [-i for i in range(1, len(diff.shape))] # All dimensions except batch
|
||||
|
||||
# Apply momentum smoothing if available
|
||||
if momentum_buffer is not None:
|
||||
momentum_buffer.update(diff)
|
||||
diff = momentum_buffer.running_average
|
||||
|
||||
# Apply norm clipping if threshold is set
|
||||
if norm_threshold > 0:
|
||||
diff_norm = diff.norm(p=2, dim=dim, keepdim=True)
|
||||
scale_factor = torch.minimum(torch.ones_like(diff_norm), norm_threshold / diff_norm)
|
||||
diff = diff * scale_factor
|
||||
|
||||
# Project guidance vector into parallel and orthogonal components
|
||||
v0, v1 = diff.double(), pred_cond.double()
|
||||
v1 = torch.nn.functional.normalize(v1, dim=dim)
|
||||
v0_parallel = (v0 * v1).sum(dim=dim, keepdim=True) * v1
|
||||
v0_orthogonal = v0 - v0_parallel
|
||||
diff_parallel, diff_orthogonal = v0_parallel.type_as(diff), v0_orthogonal.type_as(diff)
|
||||
|
||||
# Combine components with different scaling
|
||||
normalized_update = diff_orthogonal + eta * diff_parallel
|
||||
pred = pred_cond if use_original_formulation else pred_uncond
|
||||
pred = pred + guidance_scale * normalized_update
|
||||
|
||||
return pred
|
||||
|
||||
|
||||
class AdaptiveProjectedGuidance:
|
||||
"""
|
||||
Adaptive Projected Guidance for classifier-free guidance.
|
||||
|
||||
Implements APG which projects the guidance vector to reduce over-saturation
|
||||
while maintaining directional control.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
guidance_scale: float = 7.5,
|
||||
adaptive_projected_guidance_momentum: Optional[float] = None,
|
||||
adaptive_projected_guidance_rescale: float = 15.0,
|
||||
eta: float = 0.0,
|
||||
guidance_rescale: float = 0.0,
|
||||
use_original_formulation: bool = False,
|
||||
):
|
||||
self.guidance_scale = guidance_scale
|
||||
self.adaptive_projected_guidance_momentum = adaptive_projected_guidance_momentum
|
||||
self.adaptive_projected_guidance_rescale = adaptive_projected_guidance_rescale
|
||||
self.eta = eta
|
||||
self.guidance_rescale = guidance_rescale
|
||||
self.use_original_formulation = use_original_formulation
|
||||
self.momentum_buffer = None
|
||||
|
||||
def __call__(self, pred_cond: torch.Tensor, pred_uncond: Optional[torch.Tensor] = None, step=None) -> torch.Tensor:
|
||||
if step == 0 and self.adaptive_projected_guidance_momentum is not None:
|
||||
self.momentum_buffer = MomentumBuffer(self.adaptive_projected_guidance_momentum)
|
||||
|
||||
pred = normalized_guidance_apg(
|
||||
pred_cond,
|
||||
pred_uncond,
|
||||
self.guidance_scale,
|
||||
self.momentum_buffer,
|
||||
self.eta,
|
||||
self.adaptive_projected_guidance_rescale,
|
||||
self.use_original_formulation,
|
||||
)
|
||||
|
||||
if self.guidance_rescale > 0.0:
|
||||
pred = rescale_noise_cfg(pred, pred_cond, self.guidance_rescale)
|
||||
|
||||
return pred
|
||||
|
||||
|
||||
def rescale_noise_cfg(guided_noise, conditional_noise, rescale_factor=0.0):
|
||||
"""
|
||||
Rescale guided noise prediction to prevent overexposure and improve image quality.
|
||||
|
||||
This implementation addresses the overexposure issue described in "Common Diffusion Noise
|
||||
Schedules and Sample Steps are Flawed" (https://arxiv.org/pdf/2305.08891.pdf) (Section 3.4).
|
||||
The rescaling preserves the statistical properties of the conditional prediction while reducing artifacts.
|
||||
|
||||
Args:
|
||||
guided_noise (torch.Tensor): Noise prediction from classifier-free guidance.
|
||||
conditional_noise (torch.Tensor): Noise prediction from conditional model.
|
||||
rescale_factor (float): Interpolation factor between original and rescaled predictions.
|
||||
0.0 = no rescaling, 1.0 = full rescaling.
|
||||
|
||||
Returns:
|
||||
torch.Tensor: Rescaled noise prediction with reduced overexposure.
|
||||
"""
|
||||
if rescale_factor == 0.0:
|
||||
return guided_noise
|
||||
|
||||
# Calculate standard deviation across spatial dimensions for both predictions
|
||||
spatial_dims = list(range(1, conditional_noise.ndim))
|
||||
conditional_std = conditional_noise.std(dim=spatial_dims, keepdim=True)
|
||||
guided_std = guided_noise.std(dim=spatial_dims, keepdim=True)
|
||||
|
||||
# Rescale guided noise to match conditional noise statistics
|
||||
std_ratio = conditional_std / guided_std
|
||||
rescaled_prediction = guided_noise * std_ratio
|
||||
|
||||
# Interpolate between original and rescaled predictions
|
||||
final_prediction = rescale_factor * rescaled_prediction + (1.0 - rescale_factor) * guided_noise
|
||||
|
||||
return final_prediction
|
||||
|
||||
|
||||
def apply_classifier_free_guidance(
|
||||
noise_pred_text: torch.Tensor,
|
||||
noise_pred_uncond: torch.Tensor,
|
||||
is_ocr: bool,
|
||||
guidance_scale: float,
|
||||
step: int,
|
||||
apg_start_step_ocr: int = 38,
|
||||
apg_start_step_general: int = 5,
|
||||
cfg_guider_ocr: AdaptiveProjectedGuidance = None,
|
||||
cfg_guider_general: AdaptiveProjectedGuidance = None,
|
||||
guidance_rescale: float = 0.0,
|
||||
):
|
||||
"""
|
||||
Apply classifier-free guidance with OCR-aware APG for batch_size=1.
|
||||
|
||||
Args:
|
||||
noise_pred_text: Conditional noise prediction tensor [1, ...].
|
||||
noise_pred_uncond: Unconditional noise prediction tensor [1, ...].
|
||||
is_ocr: Whether this sample requires OCR-specific guidance.
|
||||
guidance_scale: Guidance scale for CFG.
|
||||
step: Current diffusion step index.
|
||||
apg_start_step_ocr: Step to start APG for OCR regions.
|
||||
apg_start_step_general: Step to start APG for general regions.
|
||||
cfg_guider_ocr: APG guider for OCR regions.
|
||||
cfg_guider_general: APG guider for general regions.
|
||||
|
||||
Returns:
|
||||
Guided noise prediction tensor [1, ...].
|
||||
"""
|
||||
if guidance_scale == 1.0:
|
||||
return noise_pred_text
|
||||
|
||||
# Select appropriate guider and start step based on OCR requirement
|
||||
if is_ocr:
|
||||
cfg_guider = cfg_guider_ocr
|
||||
apg_start_step = apg_start_step_ocr
|
||||
else:
|
||||
cfg_guider = cfg_guider_general
|
||||
apg_start_step = apg_start_step_general
|
||||
|
||||
# Apply standard CFG or APG based on current step
|
||||
if step <= apg_start_step:
|
||||
# Standard classifier-free guidance
|
||||
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
|
||||
|
||||
if guidance_rescale > 0.0:
|
||||
# Based on 3.4. in https://arxiv.org/pdf/2305.08891.pdf
|
||||
noise_pred = rescale_noise_cfg(noise_pred, noise_pred_text, guidance_rescale)
|
||||
|
||||
# Initialize APG guider state
|
||||
_ = cfg_guider(noise_pred_text, noise_pred_uncond, step=step)
|
||||
else:
|
||||
# Use APG for guidance
|
||||
noise_pred = cfg_guider(noise_pred_text, noise_pred_uncond, step=step)
|
||||
|
||||
return noise_pred
|
||||
|
||||
|
||||
# endregion
|
||||
755
library/hunyuan_image_vae.py
Normal file
755
library/hunyuan_image_vae.py
Normal file
@@ -0,0 +1,755 @@
|
||||
from typing import Optional, Tuple
|
||||
|
||||
from einops import rearrange
|
||||
import numpy as np
|
||||
import torch
|
||||
from torch import Tensor, nn
|
||||
from torch.nn import Conv2d
|
||||
from diffusers.models.autoencoders.vae import DiagonalGaussianDistribution
|
||||
|
||||
from library.safetensors_utils import load_safetensors
|
||||
from library.utils import setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
VAE_SCALE_FACTOR = 32 # 32x spatial compression
|
||||
|
||||
LATENT_SCALING_FACTOR = 0.75289 # Latent scaling factor for Hunyuan Image-2.1
|
||||
|
||||
|
||||
def swish(x: Tensor) -> Tensor:
|
||||
"""Swish activation function: x * sigmoid(x)."""
|
||||
return x * torch.sigmoid(x)
|
||||
|
||||
|
||||
class AttnBlock(nn.Module):
|
||||
"""Self-attention block using scaled dot-product attention."""
|
||||
|
||||
def __init__(self, in_channels: int, chunk_size: Optional[int] = None):
|
||||
super().__init__()
|
||||
self.in_channels = in_channels
|
||||
self.norm = nn.GroupNorm(num_groups=32, num_channels=in_channels, eps=1e-6, affine=True)
|
||||
if chunk_size is None or chunk_size <= 0:
|
||||
self.q = Conv2d(in_channels, in_channels, kernel_size=1)
|
||||
self.k = Conv2d(in_channels, in_channels, kernel_size=1)
|
||||
self.v = Conv2d(in_channels, in_channels, kernel_size=1)
|
||||
self.proj_out = Conv2d(in_channels, in_channels, kernel_size=1)
|
||||
else:
|
||||
self.q = ChunkedConv2d(in_channels, in_channels, kernel_size=1, chunk_size=chunk_size)
|
||||
self.k = ChunkedConv2d(in_channels, in_channels, kernel_size=1, chunk_size=chunk_size)
|
||||
self.v = ChunkedConv2d(in_channels, in_channels, kernel_size=1, chunk_size=chunk_size)
|
||||
self.proj_out = ChunkedConv2d(in_channels, in_channels, kernel_size=1, chunk_size=chunk_size)
|
||||
|
||||
def attention(self, x: Tensor) -> Tensor:
|
||||
x = self.norm(x)
|
||||
q = self.q(x)
|
||||
k = self.k(x)
|
||||
v = self.v(x)
|
||||
|
||||
b, c, h, w = q.shape
|
||||
q = rearrange(q, "b c h w -> b (h w) c").contiguous()
|
||||
k = rearrange(k, "b c h w -> b (h w) c").contiguous()
|
||||
v = rearrange(v, "b c h w -> b (h w) c").contiguous()
|
||||
|
||||
x = nn.functional.scaled_dot_product_attention(q, k, v)
|
||||
return rearrange(x, "b (h w) c -> b c h w", h=h, w=w, c=c, b=b)
|
||||
|
||||
def forward(self, x: Tensor) -> Tensor:
|
||||
return x + self.proj_out(self.attention(x))
|
||||
|
||||
|
||||
class ChunkedConv2d(nn.Conv2d):
|
||||
"""
|
||||
Convolutional layer that processes input in chunks to reduce memory usage.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
chunk_size : int, optional
|
||||
Size of chunks to process at a time. Default is 64.
|
||||
"""
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
if "chunk_size" in kwargs:
|
||||
self.chunk_size = kwargs.pop("chunk_size", 64)
|
||||
super().__init__(*args, **kwargs)
|
||||
assert self.padding_mode == "zeros", "Only 'zeros' padding mode is supported."
|
||||
assert self.dilation == (1, 1) and self.stride == (1, 1), "Only dilation=1 and stride=1 are supported."
|
||||
assert self.groups == 1, "Only groups=1 is supported."
|
||||
assert self.kernel_size[0] == self.kernel_size[1], "Only square kernels are supported."
|
||||
assert (
|
||||
self.padding[0] == self.padding[1] and self.padding[0] == self.kernel_size[0] // 2
|
||||
), "Only kernel_size//2 padding is supported."
|
||||
self.original_padding = self.padding
|
||||
self.padding = (0, 0) # We handle padding manually in forward
|
||||
|
||||
def forward(self, x: Tensor) -> Tensor:
|
||||
# If chunking is not needed, process normally. We chunk only along height dimension.
|
||||
if self.chunk_size is None or x.shape[1] <= self.chunk_size:
|
||||
self.padding = self.original_padding
|
||||
x = super().forward(x)
|
||||
self.padding = (0, 0)
|
||||
if torch.cuda.is_available():
|
||||
torch.cuda.empty_cache()
|
||||
return x
|
||||
|
||||
# Process input in chunks to reduce memory usage
|
||||
org_shape = x.shape
|
||||
|
||||
# If kernel size is not 1, we need to use overlapping chunks
|
||||
overlap = self.kernel_size[0] // 2 # 1 for kernel size 3
|
||||
step = self.chunk_size - overlap
|
||||
y = torch.zeros((org_shape[0], self.out_channels, org_shape[2], org_shape[3]), dtype=x.dtype, device=x.device)
|
||||
yi = 0
|
||||
i = 0
|
||||
while i < org_shape[2]:
|
||||
si = i if i == 0 else i - overlap
|
||||
ei = i + self.chunk_size
|
||||
|
||||
# Check last chunk. If remaining part is small, include it in last chunk
|
||||
if ei > org_shape[2] or ei + step // 4 > org_shape[2]:
|
||||
ei = org_shape[2]
|
||||
|
||||
chunk = x[:, :, : ei - si, :]
|
||||
x = x[:, :, ei - si - overlap * 2 :, :]
|
||||
|
||||
# Pad chunk if needed: This is as the original Conv2d with padding
|
||||
if i == 0: # First chunk
|
||||
# Pad except bottom
|
||||
chunk = torch.nn.functional.pad(chunk, (overlap, overlap, overlap, 0), mode="constant", value=0)
|
||||
elif ei == org_shape[2]: # Last chunk
|
||||
# Pad except top
|
||||
chunk = torch.nn.functional.pad(chunk, (overlap, overlap, 0, overlap), mode="constant", value=0)
|
||||
else:
|
||||
# Pad left and right only
|
||||
chunk = torch.nn.functional.pad(chunk, (overlap, overlap), mode="constant", value=0)
|
||||
|
||||
chunk = super().forward(chunk)
|
||||
y[:, :, yi : yi + chunk.shape[2], :] = chunk
|
||||
yi += chunk.shape[2]
|
||||
del chunk
|
||||
|
||||
if ei == org_shape[2]:
|
||||
break
|
||||
i += step
|
||||
|
||||
assert yi == org_shape[2], f"yi={yi}, org_shape[2]={org_shape[2]}"
|
||||
|
||||
if torch.cuda.is_available():
|
||||
torch.cuda.empty_cache() # This helps reduce peak memory usage, but slows down a bit
|
||||
return y
|
||||
|
||||
|
||||
class ResnetBlock(nn.Module):
|
||||
"""
|
||||
Residual block with two convolutions, group normalization, and swish activation.
|
||||
Includes skip connection with optional channel dimension matching.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
in_channels : int
|
||||
Number of input channels.
|
||||
out_channels : int
|
||||
Number of output channels.
|
||||
"""
|
||||
|
||||
def __init__(self, in_channels: int, out_channels: int, chunk_size: Optional[int] = None):
|
||||
super().__init__()
|
||||
self.in_channels = in_channels
|
||||
self.out_channels = out_channels
|
||||
|
||||
self.norm1 = nn.GroupNorm(num_groups=32, num_channels=in_channels, eps=1e-6, affine=True)
|
||||
self.norm2 = nn.GroupNorm(num_groups=32, num_channels=out_channels, eps=1e-6, affine=True)
|
||||
if chunk_size is None or chunk_size <= 0:
|
||||
self.conv1 = Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
|
||||
self.conv2 = Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
|
||||
|
||||
# Skip connection projection for channel dimension mismatch
|
||||
if self.in_channels != self.out_channels:
|
||||
self.nin_shortcut = Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0)
|
||||
else:
|
||||
self.conv1 = ChunkedConv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1, chunk_size=chunk_size)
|
||||
self.conv2 = ChunkedConv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, chunk_size=chunk_size)
|
||||
|
||||
# Skip connection projection for channel dimension mismatch
|
||||
if self.in_channels != self.out_channels:
|
||||
self.nin_shortcut = ChunkedConv2d(
|
||||
in_channels, out_channels, kernel_size=1, stride=1, padding=0, chunk_size=chunk_size
|
||||
)
|
||||
|
||||
def forward(self, x: Tensor) -> Tensor:
|
||||
h = x
|
||||
# First convolution block
|
||||
h = self.norm1(h)
|
||||
h = swish(h)
|
||||
h = self.conv1(h)
|
||||
# Second convolution block
|
||||
h = self.norm2(h)
|
||||
h = swish(h)
|
||||
h = self.conv2(h)
|
||||
|
||||
# Apply skip connection with optional projection
|
||||
if self.in_channels != self.out_channels:
|
||||
x = self.nin_shortcut(x)
|
||||
return x + h
|
||||
|
||||
|
||||
class Downsample(nn.Module):
|
||||
"""
|
||||
Spatial downsampling block that reduces resolution by 2x using convolution followed by
|
||||
pixel rearrangement. Includes skip connection with grouped averaging.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
in_channels : int
|
||||
Number of input channels.
|
||||
out_channels : int
|
||||
Number of output channels (must be divisible by 4).
|
||||
"""
|
||||
|
||||
def __init__(self, in_channels: int, out_channels: int, chunk_size: Optional[int] = None):
|
||||
super().__init__()
|
||||
factor = 4 # 2x2 spatial reduction factor
|
||||
assert out_channels % factor == 0
|
||||
|
||||
if chunk_size is None or chunk_size <= 0:
|
||||
self.conv = Conv2d(in_channels, out_channels // factor, kernel_size=3, stride=1, padding=1)
|
||||
else:
|
||||
self.conv = ChunkedConv2d(
|
||||
in_channels, out_channels // factor, kernel_size=3, stride=1, padding=1, chunk_size=chunk_size
|
||||
)
|
||||
self.group_size = factor * in_channels // out_channels
|
||||
|
||||
def forward(self, x: Tensor) -> Tensor:
|
||||
# Apply convolution and rearrange pixels for 2x downsampling
|
||||
h = self.conv(x)
|
||||
h = rearrange(h, "b c (h r1) (w r2) -> b (r1 r2 c) h w", r1=2, r2=2)
|
||||
|
||||
# Create skip connection with pixel rearrangement
|
||||
shortcut = rearrange(x, "b c (h r1) (w r2) -> b (r1 r2 c) h w", r1=2, r2=2)
|
||||
B, C, H, W = shortcut.shape
|
||||
shortcut = shortcut.view(B, h.shape[1], self.group_size, H, W).mean(dim=2)
|
||||
|
||||
return h + shortcut
|
||||
|
||||
|
||||
class Upsample(nn.Module):
|
||||
"""
|
||||
Spatial upsampling block that increases resolution by 2x using convolution followed by
|
||||
pixel rearrangement. Includes skip connection with channel repetition.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
in_channels : int
|
||||
Number of input channels.
|
||||
out_channels : int
|
||||
Number of output channels.
|
||||
"""
|
||||
|
||||
def __init__(self, in_channels: int, out_channels: int, chunk_size: Optional[int] = None):
|
||||
super().__init__()
|
||||
factor = 4 # 2x2 spatial expansion factor
|
||||
|
||||
if chunk_size is None or chunk_size <= 0:
|
||||
self.conv = Conv2d(in_channels, out_channels * factor, kernel_size=3, stride=1, padding=1)
|
||||
else:
|
||||
self.conv = ChunkedConv2d(in_channels, out_channels * factor, kernel_size=3, stride=1, padding=1, chunk_size=chunk_size)
|
||||
|
||||
self.repeats = factor * out_channels // in_channels
|
||||
|
||||
def forward(self, x: Tensor) -> Tensor:
|
||||
# Apply convolution and rearrange pixels for 2x upsampling
|
||||
h = self.conv(x)
|
||||
h = rearrange(h, "b (r1 r2 c) h w -> b c (h r1) (w r2)", r1=2, r2=2)
|
||||
|
||||
# Create skip connection with channel repetition
|
||||
shortcut = x.repeat_interleave(repeats=self.repeats, dim=1)
|
||||
shortcut = rearrange(shortcut, "b (r1 r2 c) h w -> b c (h r1) (w r2)", r1=2, r2=2)
|
||||
|
||||
return h + shortcut
|
||||
|
||||
|
||||
class Encoder(nn.Module):
|
||||
"""
|
||||
VAE encoder that progressively downsamples input images to a latent representation.
|
||||
Uses residual blocks, attention, and spatial downsampling.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
in_channels : int
|
||||
Number of input image channels (e.g., 3 for RGB).
|
||||
z_channels : int
|
||||
Number of latent channels in the output.
|
||||
block_out_channels : Tuple[int, ...]
|
||||
Output channels for each downsampling block.
|
||||
num_res_blocks : int
|
||||
Number of residual blocks per downsampling stage.
|
||||
ffactor_spatial : int
|
||||
Total spatial downsampling factor (e.g., 32 for 32x compression).
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
in_channels: int,
|
||||
z_channels: int,
|
||||
block_out_channels: Tuple[int, ...],
|
||||
num_res_blocks: int,
|
||||
ffactor_spatial: int,
|
||||
chunk_size: Optional[int] = None,
|
||||
):
|
||||
super().__init__()
|
||||
assert block_out_channels[-1] % (2 * z_channels) == 0
|
||||
|
||||
self.z_channels = z_channels
|
||||
self.block_out_channels = block_out_channels
|
||||
self.num_res_blocks = num_res_blocks
|
||||
|
||||
if chunk_size is None or chunk_size <= 0:
|
||||
self.conv_in = Conv2d(in_channels, block_out_channels[0], kernel_size=3, stride=1, padding=1)
|
||||
else:
|
||||
self.conv_in = ChunkedConv2d(
|
||||
in_channels, block_out_channels[0], kernel_size=3, stride=1, padding=1, chunk_size=chunk_size
|
||||
)
|
||||
|
||||
self.down = nn.ModuleList()
|
||||
block_in = block_out_channels[0]
|
||||
|
||||
# Build downsampling blocks
|
||||
for i_level, ch in enumerate(block_out_channels):
|
||||
block = nn.ModuleList()
|
||||
block_out = ch
|
||||
|
||||
# Add residual blocks for this level
|
||||
for _ in range(self.num_res_blocks):
|
||||
block.append(ResnetBlock(in_channels=block_in, out_channels=block_out, chunk_size=chunk_size))
|
||||
block_in = block_out
|
||||
|
||||
down = nn.Module()
|
||||
down.block = block
|
||||
|
||||
# Add spatial downsampling if needed
|
||||
add_spatial_downsample = bool(i_level < np.log2(ffactor_spatial))
|
||||
if add_spatial_downsample:
|
||||
assert i_level < len(block_out_channels) - 1
|
||||
block_out = block_out_channels[i_level + 1]
|
||||
down.downsample = Downsample(block_in, block_out, chunk_size=chunk_size)
|
||||
block_in = block_out
|
||||
|
||||
self.down.append(down)
|
||||
|
||||
# Middle blocks with attention
|
||||
self.mid = nn.Module()
|
||||
self.mid.block_1 = ResnetBlock(in_channels=block_in, out_channels=block_in, chunk_size=chunk_size)
|
||||
self.mid.attn_1 = AttnBlock(block_in, chunk_size=chunk_size)
|
||||
self.mid.block_2 = ResnetBlock(in_channels=block_in, out_channels=block_in, chunk_size=chunk_size)
|
||||
|
||||
# Output layers
|
||||
self.norm_out = nn.GroupNorm(num_groups=32, num_channels=block_in, eps=1e-6, affine=True)
|
||||
if chunk_size is None or chunk_size <= 0:
|
||||
self.conv_out = Conv2d(block_in, 2 * z_channels, kernel_size=3, stride=1, padding=1)
|
||||
else:
|
||||
self.conv_out = ChunkedConv2d(block_in, 2 * z_channels, kernel_size=3, stride=1, padding=1, chunk_size=chunk_size)
|
||||
|
||||
def forward(self, x: Tensor) -> Tensor:
|
||||
# Initial convolution
|
||||
h = self.conv_in(x)
|
||||
|
||||
# Progressive downsampling through blocks
|
||||
for i_level in range(len(self.block_out_channels)):
|
||||
# Apply residual blocks at this level
|
||||
for i_block in range(self.num_res_blocks):
|
||||
h = self.down[i_level].block[i_block](h)
|
||||
# Apply spatial downsampling if available
|
||||
if hasattr(self.down[i_level], "downsample"):
|
||||
h = self.down[i_level].downsample(h)
|
||||
|
||||
# Middle processing with attention
|
||||
h = self.mid.block_1(h)
|
||||
h = self.mid.attn_1(h)
|
||||
h = self.mid.block_2(h)
|
||||
|
||||
# Final output layers with skip connection
|
||||
group_size = self.block_out_channels[-1] // (2 * self.z_channels)
|
||||
shortcut = rearrange(h, "b (c r) h w -> b c r h w", r=group_size).mean(dim=2)
|
||||
h = self.norm_out(h)
|
||||
h = swish(h)
|
||||
h = self.conv_out(h)
|
||||
h += shortcut
|
||||
return h
|
||||
|
||||
|
||||
class Decoder(nn.Module):
|
||||
"""
|
||||
VAE decoder that progressively upsamples latent representations back to images.
|
||||
Uses residual blocks, attention, and spatial upsampling.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
z_channels : int
|
||||
Number of latent channels in the input.
|
||||
out_channels : int
|
||||
Number of output image channels (e.g., 3 for RGB).
|
||||
block_out_channels : Tuple[int, ...]
|
||||
Output channels for each upsampling block.
|
||||
num_res_blocks : int
|
||||
Number of residual blocks per upsampling stage.
|
||||
ffactor_spatial : int
|
||||
Total spatial upsampling factor (e.g., 32 for 32x expansion).
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
z_channels: int,
|
||||
out_channels: int,
|
||||
block_out_channels: Tuple[int, ...],
|
||||
num_res_blocks: int,
|
||||
ffactor_spatial: int,
|
||||
chunk_size: Optional[int] = None,
|
||||
):
|
||||
super().__init__()
|
||||
assert block_out_channels[0] % z_channels == 0
|
||||
|
||||
self.z_channels = z_channels
|
||||
self.block_out_channels = block_out_channels
|
||||
self.num_res_blocks = num_res_blocks
|
||||
|
||||
block_in = block_out_channels[0]
|
||||
if chunk_size is None or chunk_size <= 0:
|
||||
self.conv_in = Conv2d(z_channels, block_in, kernel_size=3, stride=1, padding=1)
|
||||
else:
|
||||
self.conv_in = ChunkedConv2d(z_channels, block_in, kernel_size=3, stride=1, padding=1, chunk_size=chunk_size)
|
||||
|
||||
# Middle blocks with attention
|
||||
self.mid = nn.Module()
|
||||
self.mid.block_1 = ResnetBlock(in_channels=block_in, out_channels=block_in, chunk_size=chunk_size)
|
||||
self.mid.attn_1 = AttnBlock(block_in, chunk_size=chunk_size)
|
||||
self.mid.block_2 = ResnetBlock(in_channels=block_in, out_channels=block_in, chunk_size=chunk_size)
|
||||
|
||||
# Build upsampling blocks
|
||||
self.up = nn.ModuleList()
|
||||
for i_level, ch in enumerate(block_out_channels):
|
||||
block = nn.ModuleList()
|
||||
block_out = ch
|
||||
|
||||
# Add residual blocks for this level (extra block for decoder)
|
||||
for _ in range(self.num_res_blocks + 1):
|
||||
block.append(ResnetBlock(in_channels=block_in, out_channels=block_out, chunk_size=chunk_size))
|
||||
block_in = block_out
|
||||
|
||||
up = nn.Module()
|
||||
up.block = block
|
||||
|
||||
# Add spatial upsampling if needed
|
||||
add_spatial_upsample = bool(i_level < np.log2(ffactor_spatial))
|
||||
if add_spatial_upsample:
|
||||
assert i_level < len(block_out_channels) - 1
|
||||
block_out = block_out_channels[i_level + 1]
|
||||
up.upsample = Upsample(block_in, block_out, chunk_size=chunk_size)
|
||||
block_in = block_out
|
||||
|
||||
self.up.append(up)
|
||||
|
||||
# Output layers
|
||||
self.norm_out = nn.GroupNorm(num_groups=32, num_channels=block_in, eps=1e-6, affine=True)
|
||||
if chunk_size is None or chunk_size <= 0:
|
||||
self.conv_out = Conv2d(block_in, out_channels, kernel_size=3, stride=1, padding=1)
|
||||
else:
|
||||
self.conv_out = ChunkedConv2d(block_in, out_channels, kernel_size=3, stride=1, padding=1, chunk_size=chunk_size)
|
||||
|
||||
def forward(self, z: Tensor) -> Tensor:
|
||||
# Initial processing with skip connection
|
||||
repeats = self.block_out_channels[0] // self.z_channels
|
||||
h = self.conv_in(z) + z.repeat_interleave(repeats=repeats, dim=1)
|
||||
|
||||
# Middle processing with attention
|
||||
h = self.mid.block_1(h)
|
||||
h = self.mid.attn_1(h)
|
||||
h = self.mid.block_2(h)
|
||||
|
||||
# Progressive upsampling through blocks
|
||||
for i_level in range(len(self.block_out_channels)):
|
||||
# Apply residual blocks at this level
|
||||
for i_block in range(self.num_res_blocks + 1):
|
||||
h = self.up[i_level].block[i_block](h)
|
||||
# Apply spatial upsampling if available
|
||||
if hasattr(self.up[i_level], "upsample"):
|
||||
h = self.up[i_level].upsample(h)
|
||||
|
||||
# Final output layers
|
||||
h = self.norm_out(h)
|
||||
h = swish(h)
|
||||
h = self.conv_out(h)
|
||||
return h
|
||||
|
||||
|
||||
class HunyuanVAE2D(nn.Module):
|
||||
"""
|
||||
VAE model for Hunyuan Image-2.1 with spatial tiling support.
|
||||
|
||||
This VAE uses a fixed architecture optimized for the Hunyuan Image-2.1 model,
|
||||
with 32x spatial compression and optional memory-efficient tiling for large images.
|
||||
"""
|
||||
|
||||
def __init__(self, chunk_size: Optional[int] = None):
|
||||
super().__init__()
|
||||
|
||||
# Fixed configuration for Hunyuan Image-2.1
|
||||
block_out_channels = (128, 256, 512, 512, 1024, 1024)
|
||||
in_channels = 3 # RGB input
|
||||
out_channels = 3 # RGB output
|
||||
latent_channels = 64
|
||||
layers_per_block = 2
|
||||
ffactor_spatial = 32 # 32x spatial compression
|
||||
sample_size = 384 # Minimum sample size for tiling
|
||||
scaling_factor = LATENT_SCALING_FACTOR # 0.75289 # Latent scaling factor
|
||||
|
||||
self.ffactor_spatial = ffactor_spatial
|
||||
self.scaling_factor = scaling_factor
|
||||
|
||||
self.encoder = Encoder(
|
||||
in_channels=in_channels,
|
||||
z_channels=latent_channels,
|
||||
block_out_channels=block_out_channels,
|
||||
num_res_blocks=layers_per_block,
|
||||
ffactor_spatial=ffactor_spatial,
|
||||
chunk_size=chunk_size,
|
||||
)
|
||||
|
||||
self.decoder = Decoder(
|
||||
z_channels=latent_channels,
|
||||
out_channels=out_channels,
|
||||
block_out_channels=list(reversed(block_out_channels)),
|
||||
num_res_blocks=layers_per_block,
|
||||
ffactor_spatial=ffactor_spatial,
|
||||
chunk_size=chunk_size,
|
||||
)
|
||||
|
||||
# Spatial tiling configuration for memory efficiency
|
||||
self.use_spatial_tiling = False
|
||||
self.tile_sample_min_size = sample_size
|
||||
self.tile_latent_min_size = sample_size // ffactor_spatial
|
||||
self.tile_overlap_factor = 0.25 # 25% overlap between tiles
|
||||
|
||||
@property
|
||||
def dtype(self):
|
||||
"""Get the data type of the model parameters."""
|
||||
return next(self.encoder.parameters()).dtype
|
||||
|
||||
@property
|
||||
def device(self):
|
||||
"""Get the device of the model parameters."""
|
||||
return next(self.encoder.parameters()).device
|
||||
|
||||
def enable_spatial_tiling(self, use_tiling: bool = True):
|
||||
"""Enable or disable spatial tiling."""
|
||||
self.use_spatial_tiling = use_tiling
|
||||
|
||||
def disable_spatial_tiling(self):
|
||||
"""Disable spatial tiling."""
|
||||
self.use_spatial_tiling = False
|
||||
|
||||
def enable_tiling(self, use_tiling: bool = True):
|
||||
"""Enable or disable spatial tiling (alias for enable_spatial_tiling)."""
|
||||
self.enable_spatial_tiling(use_tiling)
|
||||
|
||||
def disable_tiling(self):
|
||||
"""Disable spatial tiling (alias for disable_spatial_tiling)."""
|
||||
self.disable_spatial_tiling()
|
||||
|
||||
def blend_h(self, a: torch.Tensor, b: torch.Tensor, blend_extent: int) -> torch.Tensor:
|
||||
"""
|
||||
Blend two tensors horizontally with smooth transition.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
a : torch.Tensor
|
||||
Left tensor.
|
||||
b : torch.Tensor
|
||||
Right tensor.
|
||||
blend_extent : int
|
||||
Number of columns to blend.
|
||||
"""
|
||||
blend_extent = min(a.shape[-1], b.shape[-1], blend_extent)
|
||||
for x in range(blend_extent):
|
||||
b[:, :, :, x] = a[:, :, :, -blend_extent + x] * (1 - x / blend_extent) + b[:, :, :, x] * (x / blend_extent)
|
||||
return b
|
||||
|
||||
def blend_v(self, a: torch.Tensor, b: torch.Tensor, blend_extent: int) -> torch.Tensor:
|
||||
"""
|
||||
Blend two tensors vertically with smooth transition.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
a : torch.Tensor
|
||||
Top tensor.
|
||||
b : torch.Tensor
|
||||
Bottom tensor.
|
||||
blend_extent : int
|
||||
Number of rows to blend.
|
||||
"""
|
||||
blend_extent = min(a.shape[-2], b.shape[-2], blend_extent)
|
||||
for y in range(blend_extent):
|
||||
b[:, :, y, :] = a[:, :, -blend_extent + y, :] * (1 - y / blend_extent) + b[:, :, y, :] * (y / blend_extent)
|
||||
return b
|
||||
|
||||
def spatial_tiled_encode(self, x: torch.Tensor) -> torch.Tensor:
|
||||
"""
|
||||
Encode large images using spatial tiling to reduce memory usage.
|
||||
Tiles are processed independently and blended at boundaries.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
x : torch.Tensor
|
||||
Input tensor of shape (B, C, T, H, W) or (B, C, H, W).
|
||||
"""
|
||||
# Handle 5D input (B, C, T, H, W) by removing time dimension
|
||||
original_ndim = x.ndim
|
||||
if original_ndim == 5:
|
||||
x = x.squeeze(2)
|
||||
|
||||
B, C, H, W = x.shape
|
||||
overlap_size = int(self.tile_sample_min_size * (1 - self.tile_overlap_factor))
|
||||
blend_extent = int(self.tile_latent_min_size * self.tile_overlap_factor)
|
||||
row_limit = self.tile_latent_min_size - blend_extent
|
||||
|
||||
rows = []
|
||||
for i in range(0, H, overlap_size):
|
||||
row = []
|
||||
for j in range(0, W, overlap_size):
|
||||
tile = x[:, :, i : i + self.tile_sample_min_size, j : j + self.tile_sample_min_size]
|
||||
tile = self.encoder(tile)
|
||||
row.append(tile)
|
||||
rows.append(row)
|
||||
|
||||
result_rows = []
|
||||
for i, row in enumerate(rows):
|
||||
result_row = []
|
||||
for j, tile in enumerate(row):
|
||||
if i > 0:
|
||||
tile = self.blend_v(rows[i - 1][j], tile, blend_extent)
|
||||
if j > 0:
|
||||
tile = self.blend_h(row[j - 1], tile, blend_extent)
|
||||
result_row.append(tile[:, :, :row_limit, :row_limit])
|
||||
result_rows.append(torch.cat(result_row, dim=-1))
|
||||
|
||||
moments = torch.cat(result_rows, dim=-2)
|
||||
return moments
|
||||
|
||||
def spatial_tiled_decode(self, z: torch.Tensor) -> torch.Tensor:
|
||||
"""
|
||||
Decode large latents using spatial tiling to reduce memory usage.
|
||||
Tiles are processed independently and blended at boundaries.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
z : torch.Tensor
|
||||
Latent tensor of shape (B, C, H, W).
|
||||
"""
|
||||
B, C, H, W = z.shape
|
||||
overlap_size = int(self.tile_latent_min_size * (1 - self.tile_overlap_factor))
|
||||
blend_extent = int(self.tile_sample_min_size * self.tile_overlap_factor)
|
||||
row_limit = self.tile_sample_min_size - blend_extent
|
||||
|
||||
rows = []
|
||||
for i in range(0, H, overlap_size):
|
||||
row = []
|
||||
for j in range(0, W, overlap_size):
|
||||
tile = z[:, :, :, i : i + self.tile_latent_min_size, j : j + self.tile_latent_min_size]
|
||||
decoded = self.decoder(tile)
|
||||
row.append(decoded)
|
||||
rows.append(row)
|
||||
|
||||
result_rows = []
|
||||
for i, row in enumerate(rows):
|
||||
result_row = []
|
||||
for j, tile in enumerate(row):
|
||||
if i > 0:
|
||||
tile = self.blend_v(rows[i - 1][j], tile, blend_extent)
|
||||
if j > 0:
|
||||
tile = self.blend_h(row[j - 1], tile, blend_extent)
|
||||
result_row.append(tile[:, :, :, :row_limit, :row_limit])
|
||||
result_rows.append(torch.cat(result_row, dim=-1))
|
||||
|
||||
dec = torch.cat(result_rows, dim=-2)
|
||||
return dec
|
||||
|
||||
def encode(self, x: Tensor) -> DiagonalGaussianDistribution:
|
||||
"""
|
||||
Encode input images to latent representation.
|
||||
Uses spatial tiling for large images if enabled.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
x : Tensor
|
||||
Input image tensor of shape (B, C, H, W) or (B, C, T, H, W).
|
||||
|
||||
Returns
|
||||
-------
|
||||
DiagonalGaussianDistribution
|
||||
Latent distribution with mean and logvar.
|
||||
"""
|
||||
# Handle 5D input (B, C, T, H, W) by removing time dimension
|
||||
original_ndim = x.ndim
|
||||
if original_ndim == 5:
|
||||
x = x.squeeze(2)
|
||||
|
||||
# Use tiling for large images to reduce memory usage
|
||||
if self.use_spatial_tiling and (x.shape[-1] > self.tile_sample_min_size or x.shape[-2] > self.tile_sample_min_size):
|
||||
h = self.spatial_tiled_encode(x)
|
||||
else:
|
||||
h = self.encoder(x)
|
||||
|
||||
# Restore time dimension if input was 5D
|
||||
if original_ndim == 5:
|
||||
h = h.unsqueeze(2)
|
||||
|
||||
posterior = DiagonalGaussianDistribution(h)
|
||||
return posterior
|
||||
|
||||
def decode(self, z: Tensor):
|
||||
"""
|
||||
Decode latent representation back to images.
|
||||
Uses spatial tiling for large latents if enabled.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
z : Tensor
|
||||
Latent tensor of shape (B, C, H, W) or (B, C, T, H, W).
|
||||
|
||||
Returns
|
||||
-------
|
||||
Tensor
|
||||
Decoded image tensor.
|
||||
"""
|
||||
# Handle 5D input (B, C, T, H, W) by removing time dimension
|
||||
original_ndim = z.ndim
|
||||
if original_ndim == 5:
|
||||
z = z.squeeze(2)
|
||||
|
||||
# Use tiling for large latents to reduce memory usage
|
||||
if self.use_spatial_tiling and (z.shape[-1] > self.tile_latent_min_size or z.shape[-2] > self.tile_latent_min_size):
|
||||
decoded = self.spatial_tiled_decode(z)
|
||||
else:
|
||||
decoded = self.decoder(z)
|
||||
|
||||
# Restore time dimension if input was 5D
|
||||
if original_ndim == 5:
|
||||
decoded = decoded.unsqueeze(2)
|
||||
|
||||
return decoded
|
||||
|
||||
|
||||
def load_vae(vae_path: str, device: torch.device, disable_mmap: bool = False, chunk_size: Optional[int] = None) -> HunyuanVAE2D:
|
||||
logger.info(f"Initializing VAE with chunk_size={chunk_size}")
|
||||
vae = HunyuanVAE2D(chunk_size=chunk_size)
|
||||
|
||||
logger.info(f"Loading VAE from {vae_path}")
|
||||
state_dict = load_safetensors(vae_path, device=device, disable_mmap=disable_mmap)
|
||||
info = vae.load_state_dict(state_dict, strict=True, assign=True)
|
||||
logger.info(f"Loaded VAE: {info}")
|
||||
|
||||
vae.to(device)
|
||||
return vae
|
||||
223
library/hypernetwork.py
Normal file
223
library/hypernetwork.py
Normal file
@@ -0,0 +1,223 @@
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
from diffusers.models.attention_processor import (
|
||||
Attention,
|
||||
AttnProcessor2_0,
|
||||
SlicedAttnProcessor,
|
||||
XFormersAttnProcessor
|
||||
)
|
||||
|
||||
try:
|
||||
import xformers.ops
|
||||
except:
|
||||
xformers = None
|
||||
|
||||
|
||||
loaded_networks = []
|
||||
|
||||
|
||||
def apply_single_hypernetwork(
|
||||
hypernetwork, hidden_states, encoder_hidden_states
|
||||
):
|
||||
context_k, context_v = hypernetwork.forward(hidden_states, encoder_hidden_states)
|
||||
return context_k, context_v
|
||||
|
||||
|
||||
def apply_hypernetworks(context_k, context_v, layer=None):
|
||||
if len(loaded_networks) == 0:
|
||||
return context_v, context_v
|
||||
for hypernetwork in loaded_networks:
|
||||
context_k, context_v = hypernetwork.forward(context_k, context_v)
|
||||
|
||||
context_k = context_k.to(dtype=context_k.dtype)
|
||||
context_v = context_v.to(dtype=context_k.dtype)
|
||||
|
||||
return context_k, context_v
|
||||
|
||||
|
||||
|
||||
def xformers_forward(
|
||||
self: XFormersAttnProcessor,
|
||||
attn: Attention,
|
||||
hidden_states: torch.Tensor,
|
||||
encoder_hidden_states: torch.Tensor = None,
|
||||
attention_mask: torch.Tensor = None,
|
||||
):
|
||||
batch_size, sequence_length, _ = (
|
||||
hidden_states.shape
|
||||
if encoder_hidden_states is None
|
||||
else encoder_hidden_states.shape
|
||||
)
|
||||
|
||||
attention_mask = attn.prepare_attention_mask(
|
||||
attention_mask, sequence_length, batch_size
|
||||
)
|
||||
|
||||
query = attn.to_q(hidden_states)
|
||||
|
||||
if encoder_hidden_states is None:
|
||||
encoder_hidden_states = hidden_states
|
||||
elif attn.norm_cross:
|
||||
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
||||
|
||||
context_k, context_v = apply_hypernetworks(hidden_states, encoder_hidden_states)
|
||||
|
||||
key = attn.to_k(context_k)
|
||||
value = attn.to_v(context_v)
|
||||
|
||||
query = attn.head_to_batch_dim(query).contiguous()
|
||||
key = attn.head_to_batch_dim(key).contiguous()
|
||||
value = attn.head_to_batch_dim(value).contiguous()
|
||||
|
||||
hidden_states = xformers.ops.memory_efficient_attention(
|
||||
query,
|
||||
key,
|
||||
value,
|
||||
attn_bias=attention_mask,
|
||||
op=self.attention_op,
|
||||
scale=attn.scale,
|
||||
)
|
||||
hidden_states = hidden_states.to(query.dtype)
|
||||
hidden_states = attn.batch_to_head_dim(hidden_states)
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states)
|
||||
# dropout
|
||||
hidden_states = attn.to_out[1](hidden_states)
|
||||
return hidden_states
|
||||
|
||||
|
||||
def sliced_attn_forward(
|
||||
self: SlicedAttnProcessor,
|
||||
attn: Attention,
|
||||
hidden_states: torch.Tensor,
|
||||
encoder_hidden_states: torch.Tensor = None,
|
||||
attention_mask: torch.Tensor = None,
|
||||
):
|
||||
batch_size, sequence_length, _ = (
|
||||
hidden_states.shape
|
||||
if encoder_hidden_states is None
|
||||
else encoder_hidden_states.shape
|
||||
)
|
||||
attention_mask = attn.prepare_attention_mask(
|
||||
attention_mask, sequence_length, batch_size
|
||||
)
|
||||
|
||||
query = attn.to_q(hidden_states)
|
||||
dim = query.shape[-1]
|
||||
query = attn.head_to_batch_dim(query)
|
||||
|
||||
if encoder_hidden_states is None:
|
||||
encoder_hidden_states = hidden_states
|
||||
elif attn.norm_cross:
|
||||
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
||||
|
||||
context_k, context_v = apply_hypernetworks(hidden_states, encoder_hidden_states)
|
||||
|
||||
key = attn.to_k(context_k)
|
||||
value = attn.to_v(context_v)
|
||||
key = attn.head_to_batch_dim(key)
|
||||
value = attn.head_to_batch_dim(value)
|
||||
|
||||
batch_size_attention, query_tokens, _ = query.shape
|
||||
hidden_states = torch.zeros(
|
||||
(batch_size_attention, query_tokens, dim // attn.heads),
|
||||
device=query.device,
|
||||
dtype=query.dtype,
|
||||
)
|
||||
|
||||
for i in range(batch_size_attention // self.slice_size):
|
||||
start_idx = i * self.slice_size
|
||||
end_idx = (i + 1) * self.slice_size
|
||||
|
||||
query_slice = query[start_idx:end_idx]
|
||||
key_slice = key[start_idx:end_idx]
|
||||
attn_mask_slice = (
|
||||
attention_mask[start_idx:end_idx] if attention_mask is not None else None
|
||||
)
|
||||
|
||||
attn_slice = attn.get_attention_scores(query_slice, key_slice, attn_mask_slice)
|
||||
|
||||
attn_slice = torch.bmm(attn_slice, value[start_idx:end_idx])
|
||||
|
||||
hidden_states[start_idx:end_idx] = attn_slice
|
||||
|
||||
hidden_states = attn.batch_to_head_dim(hidden_states)
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states)
|
||||
# dropout
|
||||
hidden_states = attn.to_out[1](hidden_states)
|
||||
|
||||
return hidden_states
|
||||
|
||||
|
||||
def v2_0_forward(
|
||||
self: AttnProcessor2_0,
|
||||
attn: Attention,
|
||||
hidden_states,
|
||||
encoder_hidden_states=None,
|
||||
attention_mask=None,
|
||||
):
|
||||
batch_size, sequence_length, _ = (
|
||||
hidden_states.shape
|
||||
if encoder_hidden_states is None
|
||||
else encoder_hidden_states.shape
|
||||
)
|
||||
inner_dim = hidden_states.shape[-1]
|
||||
|
||||
if attention_mask is not None:
|
||||
attention_mask = attn.prepare_attention_mask(
|
||||
attention_mask, sequence_length, batch_size
|
||||
)
|
||||
# scaled_dot_product_attention expects attention_mask shape to be
|
||||
# (batch, heads, source_length, target_length)
|
||||
attention_mask = attention_mask.view(
|
||||
batch_size, attn.heads, -1, attention_mask.shape[-1]
|
||||
)
|
||||
|
||||
query = attn.to_q(hidden_states)
|
||||
|
||||
if encoder_hidden_states is None:
|
||||
encoder_hidden_states = hidden_states
|
||||
elif attn.norm_cross:
|
||||
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
||||
|
||||
context_k, context_v = apply_hypernetworks(hidden_states, encoder_hidden_states)
|
||||
|
||||
key = attn.to_k(context_k)
|
||||
value = attn.to_v(context_v)
|
||||
|
||||
head_dim = inner_dim // attn.heads
|
||||
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
|
||||
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
||||
# TODO: add support for attn.scale when we move to Torch 2.1
|
||||
hidden_states = F.scaled_dot_product_attention(
|
||||
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
|
||||
)
|
||||
|
||||
hidden_states = hidden_states.transpose(1, 2).reshape(
|
||||
batch_size, -1, attn.heads * head_dim
|
||||
)
|
||||
hidden_states = hidden_states.to(query.dtype)
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states)
|
||||
# dropout
|
||||
hidden_states = attn.to_out[1](hidden_states)
|
||||
return hidden_states
|
||||
|
||||
|
||||
def replace_attentions_for_hypernetwork():
|
||||
import diffusers.models.attention_processor
|
||||
|
||||
diffusers.models.attention_processor.XFormersAttnProcessor.__call__ = (
|
||||
xformers_forward
|
||||
)
|
||||
diffusers.models.attention_processor.SlicedAttnProcessor.__call__ = (
|
||||
sliced_attn_forward
|
||||
)
|
||||
diffusers.models.attention_processor.AttnProcessor2_0.__call__ = v2_0_forward
|
||||
204
library/ipex/__init__.py
Normal file
204
library/ipex/__init__.py
Normal file
@@ -0,0 +1,204 @@
|
||||
import os
|
||||
import sys
|
||||
import torch
|
||||
try:
|
||||
import intel_extension_for_pytorch as ipex # pylint: disable=import-error, unused-import
|
||||
has_ipex = True
|
||||
except Exception:
|
||||
has_ipex = False
|
||||
from .hijacks import ipex_hijacks
|
||||
|
||||
torch_version = float(torch.__version__[:3])
|
||||
|
||||
# pylint: disable=protected-access, missing-function-docstring, line-too-long
|
||||
|
||||
def ipex_init(): # pylint: disable=too-many-statements
|
||||
try:
|
||||
if hasattr(torch, "cuda") and hasattr(torch.cuda, "is_xpu_hijacked") and torch.cuda.is_xpu_hijacked:
|
||||
return True, "Skipping IPEX hijack"
|
||||
else:
|
||||
try:
|
||||
# force xpu device on torch compile and triton
|
||||
# import inductor utils to get around lazy import
|
||||
from torch._inductor import utils as torch_inductor_utils # pylint: disable=import-error, unused-import # noqa: F401
|
||||
torch._inductor.utils.GPU_TYPES = ["xpu"]
|
||||
torch._inductor.utils.get_gpu_type = lambda *args, **kwargs: "xpu"
|
||||
from triton import backends as triton_backends # pylint: disable=import-error
|
||||
triton_backends.backends["nvidia"].driver.is_active = lambda *args, **kwargs: False
|
||||
except Exception:
|
||||
pass
|
||||
# Replace cuda with xpu:
|
||||
torch.cuda.current_device = torch.xpu.current_device
|
||||
torch.cuda.current_stream = torch.xpu.current_stream
|
||||
torch.cuda.device = torch.xpu.device
|
||||
torch.cuda.device_count = torch.xpu.device_count
|
||||
torch.cuda.device_of = torch.xpu.device_of
|
||||
torch.cuda.get_device_name = torch.xpu.get_device_name
|
||||
torch.cuda.get_device_properties = torch.xpu.get_device_properties
|
||||
torch.cuda.init = torch.xpu.init
|
||||
torch.cuda.is_available = torch.xpu.is_available
|
||||
torch.cuda.is_initialized = torch.xpu.is_initialized
|
||||
torch.cuda.is_current_stream_capturing = lambda: False
|
||||
torch.cuda.stream = torch.xpu.stream
|
||||
torch.cuda.Event = torch.xpu.Event
|
||||
torch.cuda.Stream = torch.xpu.Stream
|
||||
torch.Tensor.cuda = torch.Tensor.xpu
|
||||
torch.Tensor.is_cuda = torch.Tensor.is_xpu
|
||||
torch.nn.Module.cuda = torch.nn.Module.xpu
|
||||
torch.cuda.Optional = torch.xpu.Optional
|
||||
torch.cuda.__cached__ = torch.xpu.__cached__
|
||||
torch.cuda.__loader__ = torch.xpu.__loader__
|
||||
torch.cuda.streams = torch.xpu.streams
|
||||
torch.cuda.Any = torch.xpu.Any
|
||||
torch.cuda.__doc__ = torch.xpu.__doc__
|
||||
torch.cuda.default_generators = torch.xpu.default_generators
|
||||
torch.cuda._get_device_index = torch.xpu._get_device_index
|
||||
torch.cuda.__path__ = torch.xpu.__path__
|
||||
torch.cuda.set_stream = torch.xpu.set_stream
|
||||
torch.cuda.torch = torch.xpu.torch
|
||||
torch.cuda.Union = torch.xpu.Union
|
||||
torch.cuda.__annotations__ = torch.xpu.__annotations__
|
||||
torch.cuda.__package__ = torch.xpu.__package__
|
||||
torch.cuda.__builtins__ = torch.xpu.__builtins__
|
||||
torch.cuda._lazy_init = torch.xpu._lazy_init
|
||||
torch.cuda.StreamContext = torch.xpu.StreamContext
|
||||
torch.cuda._lazy_call = torch.xpu._lazy_call
|
||||
torch.cuda.random = torch.xpu.random
|
||||
torch.cuda._device = torch.xpu._device
|
||||
torch.cuda.__name__ = torch.xpu.__name__
|
||||
torch.cuda._device_t = torch.xpu._device_t
|
||||
torch.cuda.__spec__ = torch.xpu.__spec__
|
||||
torch.cuda.__file__ = torch.xpu.__file__
|
||||
# torch.cuda.is_current_stream_capturing = torch.xpu.is_current_stream_capturing
|
||||
|
||||
if torch_version < 2.3:
|
||||
torch.cuda._initialization_lock = torch.xpu.lazy_init._initialization_lock
|
||||
torch.cuda._initialized = torch.xpu.lazy_init._initialized
|
||||
torch.cuda._is_in_bad_fork = torch.xpu.lazy_init._is_in_bad_fork
|
||||
torch.cuda._lazy_seed_tracker = torch.xpu.lazy_init._lazy_seed_tracker
|
||||
torch.cuda._queued_calls = torch.xpu.lazy_init._queued_calls
|
||||
torch.cuda._tls = torch.xpu.lazy_init._tls
|
||||
torch.cuda.threading = torch.xpu.lazy_init.threading
|
||||
torch.cuda.traceback = torch.xpu.lazy_init.traceback
|
||||
torch.cuda._lazy_new = torch.xpu._lazy_new
|
||||
|
||||
torch.cuda.FloatTensor = torch.xpu.FloatTensor
|
||||
torch.cuda.FloatStorage = torch.xpu.FloatStorage
|
||||
torch.cuda.BFloat16Tensor = torch.xpu.BFloat16Tensor
|
||||
torch.cuda.BFloat16Storage = torch.xpu.BFloat16Storage
|
||||
torch.cuda.HalfTensor = torch.xpu.HalfTensor
|
||||
torch.cuda.HalfStorage = torch.xpu.HalfStorage
|
||||
torch.cuda.ByteTensor = torch.xpu.ByteTensor
|
||||
torch.cuda.ByteStorage = torch.xpu.ByteStorage
|
||||
torch.cuda.DoubleTensor = torch.xpu.DoubleTensor
|
||||
torch.cuda.DoubleStorage = torch.xpu.DoubleStorage
|
||||
torch.cuda.ShortTensor = torch.xpu.ShortTensor
|
||||
torch.cuda.ShortStorage = torch.xpu.ShortStorage
|
||||
torch.cuda.LongTensor = torch.xpu.LongTensor
|
||||
torch.cuda.LongStorage = torch.xpu.LongStorage
|
||||
torch.cuda.IntTensor = torch.xpu.IntTensor
|
||||
torch.cuda.IntStorage = torch.xpu.IntStorage
|
||||
torch.cuda.CharTensor = torch.xpu.CharTensor
|
||||
torch.cuda.CharStorage = torch.xpu.CharStorage
|
||||
torch.cuda.BoolTensor = torch.xpu.BoolTensor
|
||||
torch.cuda.BoolStorage = torch.xpu.BoolStorage
|
||||
torch.cuda.ComplexFloatStorage = torch.xpu.ComplexFloatStorage
|
||||
torch.cuda.ComplexDoubleStorage = torch.xpu.ComplexDoubleStorage
|
||||
else:
|
||||
torch.cuda._initialization_lock = torch.xpu._initialization_lock
|
||||
torch.cuda._initialized = torch.xpu._initialized
|
||||
torch.cuda._is_in_bad_fork = torch.xpu._is_in_bad_fork
|
||||
torch.cuda._lazy_seed_tracker = torch.xpu._lazy_seed_tracker
|
||||
torch.cuda._queued_calls = torch.xpu._queued_calls
|
||||
torch.cuda._tls = torch.xpu._tls
|
||||
torch.cuda.threading = torch.xpu.threading
|
||||
torch.cuda.traceback = torch.xpu.traceback
|
||||
|
||||
if torch_version < 2.5:
|
||||
torch.cuda.os = torch.xpu.os
|
||||
torch.cuda.Device = torch.xpu.Device
|
||||
torch.cuda.warnings = torch.xpu.warnings
|
||||
torch.cuda.classproperty = torch.xpu.classproperty
|
||||
torch.UntypedStorage.cuda = torch.UntypedStorage.xpu
|
||||
|
||||
if torch_version < 2.7:
|
||||
torch.cuda.Tuple = torch.xpu.Tuple
|
||||
torch.cuda.List = torch.xpu.List
|
||||
|
||||
|
||||
# Memory:
|
||||
if 'linux' in sys.platform and "WSL2" in os.popen("uname -a").read():
|
||||
torch.xpu.empty_cache = lambda: None
|
||||
torch.cuda.empty_cache = torch.xpu.empty_cache
|
||||
|
||||
if has_ipex:
|
||||
torch.cuda.memory_summary = torch.xpu.memory_summary
|
||||
torch.cuda.memory_snapshot = torch.xpu.memory_snapshot
|
||||
torch.cuda.memory = torch.xpu.memory
|
||||
torch.cuda.memory_stats = torch.xpu.memory_stats
|
||||
torch.cuda.memory_allocated = torch.xpu.memory_allocated
|
||||
torch.cuda.max_memory_allocated = torch.xpu.max_memory_allocated
|
||||
torch.cuda.memory_reserved = torch.xpu.memory_reserved
|
||||
torch.cuda.memory_cached = torch.xpu.memory_reserved
|
||||
torch.cuda.max_memory_reserved = torch.xpu.max_memory_reserved
|
||||
torch.cuda.max_memory_cached = torch.xpu.max_memory_reserved
|
||||
torch.cuda.reset_peak_memory_stats = torch.xpu.reset_peak_memory_stats
|
||||
torch.cuda.reset_max_memory_cached = torch.xpu.reset_peak_memory_stats
|
||||
torch.cuda.reset_max_memory_allocated = torch.xpu.reset_peak_memory_stats
|
||||
torch.cuda.memory_stats_as_nested_dict = torch.xpu.memory_stats_as_nested_dict
|
||||
torch.cuda.reset_accumulated_memory_stats = torch.xpu.reset_accumulated_memory_stats
|
||||
|
||||
# RNG:
|
||||
torch.cuda.get_rng_state = torch.xpu.get_rng_state
|
||||
torch.cuda.get_rng_state_all = torch.xpu.get_rng_state_all
|
||||
torch.cuda.set_rng_state = torch.xpu.set_rng_state
|
||||
torch.cuda.set_rng_state_all = torch.xpu.set_rng_state_all
|
||||
torch.cuda.manual_seed = torch.xpu.manual_seed
|
||||
torch.cuda.manual_seed_all = torch.xpu.manual_seed_all
|
||||
torch.cuda.seed = torch.xpu.seed
|
||||
torch.cuda.seed_all = torch.xpu.seed_all
|
||||
torch.cuda.initial_seed = torch.xpu.initial_seed
|
||||
|
||||
# C
|
||||
if torch_version < 2.3:
|
||||
torch._C._cuda_getCurrentRawStream = ipex._C._getCurrentRawStream
|
||||
ipex._C._DeviceProperties.multi_processor_count = ipex._C._DeviceProperties.gpu_subslice_count
|
||||
ipex._C._DeviceProperties.major = 12
|
||||
ipex._C._DeviceProperties.minor = 1
|
||||
ipex._C._DeviceProperties.L2_cache_size = 16*1024*1024 # A770 and A750
|
||||
else:
|
||||
torch._C._cuda_getCurrentRawStream = torch._C._xpu_getCurrentRawStream
|
||||
torch._C._XpuDeviceProperties.multi_processor_count = torch._C._XpuDeviceProperties.gpu_subslice_count
|
||||
torch._C._XpuDeviceProperties.major = 12
|
||||
torch._C._XpuDeviceProperties.minor = 1
|
||||
torch._C._XpuDeviceProperties.L2_cache_size = 16*1024*1024 # A770 and A750
|
||||
|
||||
# Fix functions with ipex:
|
||||
# torch.xpu.mem_get_info always returns the total memory as free memory
|
||||
torch.xpu.mem_get_info = lambda device=None: [(torch.xpu.get_device_properties(device).total_memory - torch.xpu.memory_reserved(device)), torch.xpu.get_device_properties(device).total_memory]
|
||||
torch.cuda.mem_get_info = torch.xpu.mem_get_info
|
||||
torch._utils._get_available_device_type = lambda: "xpu"
|
||||
torch.has_cuda = True
|
||||
torch.cuda.has_half = True
|
||||
torch.cuda.is_bf16_supported = getattr(torch.xpu, "is_bf16_supported", lambda *args, **kwargs: True)
|
||||
torch.cuda.is_fp16_supported = lambda *args, **kwargs: True
|
||||
torch.backends.cuda.is_built = lambda *args, **kwargs: True
|
||||
torch.version.cuda = "12.1"
|
||||
torch.cuda.get_arch_list = getattr(torch.xpu, "get_arch_list", lambda: ["pvc", "dg2", "ats-m150"])
|
||||
torch.cuda.get_device_capability = lambda *args, **kwargs: (12,1)
|
||||
torch.cuda.get_device_properties.major = 12
|
||||
torch.cuda.get_device_properties.minor = 1
|
||||
torch.cuda.get_device_properties.L2_cache_size = 16*1024*1024 # A770 and A750
|
||||
torch.cuda.ipc_collect = lambda *args, **kwargs: None
|
||||
torch.cuda.utilization = lambda *args, **kwargs: 0
|
||||
|
||||
device_supports_fp64 = ipex_hijacks()
|
||||
try:
|
||||
from .diffusers import ipex_diffusers
|
||||
ipex_diffusers(device_supports_fp64=device_supports_fp64)
|
||||
except Exception: # pylint: disable=broad-exception-caught
|
||||
pass
|
||||
torch.cuda.is_xpu_hijacked = True
|
||||
except Exception as e:
|
||||
return False, e
|
||||
return True, None
|
||||
119
library/ipex/attention.py
Normal file
119
library/ipex/attention.py
Normal file
@@ -0,0 +1,119 @@
|
||||
import os
|
||||
import torch
|
||||
from functools import cache, wraps
|
||||
|
||||
# pylint: disable=protected-access, missing-function-docstring, line-too-long
|
||||
|
||||
# ARC GPUs can't allocate more than 4GB to a single block so we slice the attention layers
|
||||
|
||||
sdpa_slice_trigger_rate = float(os.environ.get('IPEX_SDPA_SLICE_TRIGGER_RATE', 1))
|
||||
attention_slice_rate = float(os.environ.get('IPEX_ATTENTION_SLICE_RATE', 0.5))
|
||||
|
||||
# Find something divisible with the input_tokens
|
||||
@cache
|
||||
def find_split_size(original_size, slice_block_size, slice_rate=2):
|
||||
split_size = original_size
|
||||
while True:
|
||||
if (split_size * slice_block_size) <= slice_rate and original_size % split_size == 0:
|
||||
return split_size
|
||||
split_size = split_size - 1
|
||||
if split_size <= 1:
|
||||
return 1
|
||||
return split_size
|
||||
|
||||
|
||||
# Find slice sizes for SDPA
|
||||
@cache
|
||||
def find_sdpa_slice_sizes(query_shape, key_shape, query_element_size, slice_rate=2, trigger_rate=3):
|
||||
batch_size, attn_heads, query_len, _ = query_shape
|
||||
_, _, key_len, _ = key_shape
|
||||
|
||||
slice_batch_size = attn_heads * (query_len * key_len) * query_element_size / 1024 / 1024 / 1024
|
||||
|
||||
split_batch_size = batch_size
|
||||
split_head_size = attn_heads
|
||||
split_query_size = query_len
|
||||
|
||||
do_batch_split = False
|
||||
do_head_split = False
|
||||
do_query_split = False
|
||||
|
||||
if batch_size * slice_batch_size >= trigger_rate:
|
||||
do_batch_split = True
|
||||
split_batch_size = find_split_size(batch_size, slice_batch_size, slice_rate=slice_rate)
|
||||
|
||||
if split_batch_size * slice_batch_size > slice_rate:
|
||||
slice_head_size = split_batch_size * (query_len * key_len) * query_element_size / 1024 / 1024 / 1024
|
||||
do_head_split = True
|
||||
split_head_size = find_split_size(attn_heads, slice_head_size, slice_rate=slice_rate)
|
||||
|
||||
if split_head_size * slice_head_size > slice_rate:
|
||||
slice_query_size = split_batch_size * split_head_size * (key_len) * query_element_size / 1024 / 1024 / 1024
|
||||
do_query_split = True
|
||||
split_query_size = find_split_size(query_len, slice_query_size, slice_rate=slice_rate)
|
||||
|
||||
return do_batch_split, do_head_split, do_query_split, split_batch_size, split_head_size, split_query_size
|
||||
|
||||
|
||||
original_scaled_dot_product_attention = torch.nn.functional.scaled_dot_product_attention
|
||||
@wraps(torch.nn.functional.scaled_dot_product_attention)
|
||||
def dynamic_scaled_dot_product_attention(query, key, value, attn_mask=None, dropout_p=0.0, is_causal=False, **kwargs):
|
||||
if query.device.type != "xpu":
|
||||
return original_scaled_dot_product_attention(query, key, value, attn_mask=attn_mask, dropout_p=dropout_p, is_causal=is_causal, **kwargs)
|
||||
is_unsqueezed = False
|
||||
if query.dim() == 3:
|
||||
query = query.unsqueeze(0)
|
||||
is_unsqueezed = True
|
||||
if key.dim() == 3:
|
||||
key = key.unsqueeze(0)
|
||||
if value.dim() == 3:
|
||||
value = value.unsqueeze(0)
|
||||
do_batch_split, do_head_split, do_query_split, split_batch_size, split_head_size, split_query_size = find_sdpa_slice_sizes(query.shape, key.shape, query.element_size(), slice_rate=attention_slice_rate, trigger_rate=sdpa_slice_trigger_rate)
|
||||
|
||||
# Slice SDPA
|
||||
if do_batch_split:
|
||||
batch_size, attn_heads, query_len, _ = query.shape
|
||||
_, _, _, head_dim = value.shape
|
||||
hidden_states = torch.zeros((batch_size, attn_heads, query_len, head_dim), device=query.device, dtype=query.dtype)
|
||||
if attn_mask is not None:
|
||||
attn_mask = attn_mask.expand((query.shape[0], query.shape[1], query.shape[2], key.shape[-2]))
|
||||
for ib in range(batch_size // split_batch_size):
|
||||
start_idx = ib * split_batch_size
|
||||
end_idx = (ib + 1) * split_batch_size
|
||||
if do_head_split:
|
||||
for ih in range(attn_heads // split_head_size): # pylint: disable=invalid-name
|
||||
start_idx_h = ih * split_head_size
|
||||
end_idx_h = (ih + 1) * split_head_size
|
||||
if do_query_split:
|
||||
for iq in range(query_len // split_query_size): # pylint: disable=invalid-name
|
||||
start_idx_q = iq * split_query_size
|
||||
end_idx_q = (iq + 1) * split_query_size
|
||||
hidden_states[start_idx:end_idx, start_idx_h:end_idx_h, start_idx_q:end_idx_q, :] = original_scaled_dot_product_attention(
|
||||
query[start_idx:end_idx, start_idx_h:end_idx_h, start_idx_q:end_idx_q, :],
|
||||
key[start_idx:end_idx, start_idx_h:end_idx_h, :, :],
|
||||
value[start_idx:end_idx, start_idx_h:end_idx_h, :, :],
|
||||
attn_mask=attn_mask[start_idx:end_idx, start_idx_h:end_idx_h, start_idx_q:end_idx_q, :] if attn_mask is not None else attn_mask,
|
||||
dropout_p=dropout_p, is_causal=is_causal, **kwargs
|
||||
)
|
||||
else:
|
||||
hidden_states[start_idx:end_idx, start_idx_h:end_idx_h, :, :] = original_scaled_dot_product_attention(
|
||||
query[start_idx:end_idx, start_idx_h:end_idx_h, :, :],
|
||||
key[start_idx:end_idx, start_idx_h:end_idx_h, :, :],
|
||||
value[start_idx:end_idx, start_idx_h:end_idx_h, :, :],
|
||||
attn_mask=attn_mask[start_idx:end_idx, start_idx_h:end_idx_h, :, :] if attn_mask is not None else attn_mask,
|
||||
dropout_p=dropout_p, is_causal=is_causal, **kwargs
|
||||
)
|
||||
else:
|
||||
hidden_states[start_idx:end_idx, :, :, :] = original_scaled_dot_product_attention(
|
||||
query[start_idx:end_idx, :, :, :],
|
||||
key[start_idx:end_idx, :, :, :],
|
||||
value[start_idx:end_idx, :, :, :],
|
||||
attn_mask=attn_mask[start_idx:end_idx, :, :, :] if attn_mask is not None else attn_mask,
|
||||
dropout_p=dropout_p, is_causal=is_causal, **kwargs
|
||||
)
|
||||
torch.xpu.synchronize(query.device)
|
||||
else:
|
||||
hidden_states = original_scaled_dot_product_attention(query, key, value, attn_mask=attn_mask, dropout_p=dropout_p, is_causal=is_causal, **kwargs)
|
||||
if is_unsqueezed:
|
||||
hidden_states = hidden_states.squeeze(0)
|
||||
return hidden_states
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user