mirror of
https://github.com/kohya-ss/sd-scripts.git
synced 2026-04-06 21:52:27 +00:00
Compare commits
1013 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
8f4ee8fc34 | ||
|
|
367f348430 | ||
|
|
acdca2abb7 | ||
|
|
6e3c1d0b58 | ||
|
|
345daaa986 | ||
|
|
6adb69be63 | ||
|
|
e5ac095749 | ||
|
|
e070bd9973 | ||
|
|
ca44e3e447 | ||
|
|
900d551a6a | ||
|
|
56b4ea963e | ||
|
|
b1e6504007 | ||
|
|
b8ae745d0c | ||
|
|
c632af860e | ||
|
|
be14c06267 | ||
|
|
0e7c592933 | ||
|
|
e1b63c2249 | ||
|
|
8fc30f8205 | ||
|
|
012e7e63a5 | ||
|
|
1567549220 | ||
|
|
fe2aa32484 | ||
|
|
ce49ced699 | ||
|
|
a94bc84dec | ||
|
|
4296e286b8 | ||
|
|
bf91bea2e4 | ||
|
|
1beddd84e5 | ||
|
|
e74f58148c | ||
|
|
c1d16a76d6 | ||
|
|
ab7b231870 | ||
|
|
29177d2f03 | ||
|
|
e1f23af1bc | ||
|
|
0b7927e50b | ||
|
|
d7e14721e2 | ||
|
|
9c757c2fba | ||
|
|
e7040669bc | ||
|
|
93d9fbf607 | ||
|
|
43ad73860d | ||
|
|
b755ebd0a4 | ||
|
|
f4a0bea6dc | ||
|
|
734d2e5b2b | ||
|
|
9d2860760d | ||
|
|
3387dc7306 | ||
|
|
57ae44eb61 | ||
|
|
1d7118a622 | ||
|
|
c7c666b182 | ||
|
|
6dbfd47a59 | ||
|
|
fd68703f37 | ||
|
|
62ec3e6424 | ||
|
|
de25945a93 | ||
|
|
0005867ba5 | ||
|
|
16bb5699ac | ||
|
|
319e4d9831 | ||
|
|
1bcf8d600b | ||
|
|
f8f5b16958 | ||
|
|
826ab5ce2e | ||
|
|
3a6154b7b0 | ||
|
|
2a3aefb4e4 | ||
|
|
d5c076cf90 | ||
|
|
4ca29edbff | ||
|
|
1e8108fec9 | ||
|
|
afb971f9c3 | ||
|
|
74f91c2ff7 | ||
|
|
9ca7a5b6cc | ||
|
|
1f16b80e88 | ||
|
|
2e67978ee2 | ||
|
|
87526942a6 | ||
|
|
0b3e4f7ab6 | ||
|
|
9dd1ee458c | ||
|
|
25f961bc77 | ||
|
|
56bb81c9e6 | ||
|
|
22413a5247 | ||
|
|
18d7597b0b | ||
|
|
4a441889d4 | ||
|
|
3259928ce4 | ||
|
|
1a104dc75e | ||
|
|
58fb64819a | ||
|
|
5bfe5e411b | ||
|
|
4ecbac131a | ||
|
|
4dbcef429b | ||
|
|
321e24d83b | ||
|
|
e5bab69e3a | ||
|
|
3eb27ced52 | ||
|
|
b2363f1021 | ||
|
|
0d96e10b3e | ||
|
|
fc85496f7e | ||
|
|
2870be9b52 | ||
|
|
71ad3c0f45 | ||
|
|
ffce3b5098 | ||
|
|
a4c3155148 | ||
|
|
58cadf476b | ||
|
|
d50c1b3c5c | ||
|
|
e8cfd4ba1d | ||
|
|
fb12b6d8e5 | ||
|
|
00513b9b70 | ||
|
|
da6fea3d97 | ||
|
|
f2dd43e198 | ||
|
|
db6752901f | ||
|
|
febc5c59fa | ||
|
|
4c798129b0 | ||
|
|
38e4c602b1 | ||
|
|
e4d9e3c843 | ||
|
|
de0e0b9468 | ||
|
|
c68baae480 | ||
|
|
47187f7079 | ||
|
|
e3ddd1fbbe | ||
|
|
0640f017ab | ||
|
|
2f19175dfe | ||
|
|
146edce693 | ||
|
|
153764a687 | ||
|
|
589c2aa025 | ||
|
|
16677da0d9 | ||
|
|
a384bf2187 | ||
|
|
1c296f7229 | ||
|
|
e96a5217c3 | ||
|
|
39b82f26e5 | ||
|
|
3701507874 | ||
|
|
78020936d2 | ||
|
|
9ddb4d7a01 | ||
|
|
8d1b1acd33 | ||
|
|
02298e3c4a | ||
|
|
44190416c6 | ||
|
|
3c8193f642 | ||
|
|
c6a437054a | ||
|
|
1ffc0b330a | ||
|
|
e01e148705 | ||
|
|
e9f3a622f4 | ||
|
|
7983d3db5f | ||
|
|
bee8cee7e8 | ||
|
|
f3d2cf22ff | ||
|
|
6dbc23cf63 | ||
|
|
c1ba0b4356 | ||
|
|
607e041f3d | ||
|
|
793aeb94da | ||
|
|
b56d5f7801 | ||
|
|
017b82ebe3 | ||
|
|
2a359e0a41 | ||
|
|
3fd8cdc55d | ||
|
|
7fe81502d0 | ||
|
|
52e64c69cf | ||
|
|
58c2d856ae | ||
|
|
8db0cadcee | ||
|
|
dbb7bb288e | ||
|
|
969f82ab47 | ||
|
|
834445a1d6 | ||
|
|
fdbb03c360 | ||
|
|
040e26ff1d | ||
|
|
0540c33aca | ||
|
|
52652cba1a | ||
|
|
5cb145d13b | ||
|
|
b886d0a359 | ||
|
|
4477116a64 | ||
|
|
2c9db5d9f2 | ||
|
|
fc374375de | ||
|
|
feefcf256e | ||
|
|
64916a35b2 | ||
|
|
4f203ce40d | ||
|
|
68467bdf4d | ||
|
|
75833e84a1 | ||
|
|
71e2c91330 | ||
|
|
bfb352bc43 | ||
|
|
c973b29da4 | ||
|
|
683f3d6ab3 | ||
|
|
dfa30790a9 | ||
|
|
d30ebb205c | ||
|
|
90b18795fc | ||
|
|
089727b5ee | ||
|
|
921036dd91 | ||
|
|
cd587ce62c | ||
|
|
1933ab4b48 | ||
|
|
b748b48dbb | ||
|
|
c7691607ea | ||
|
|
f99fe281cb | ||
|
|
80e9f72234 | ||
|
|
2258a1b753 | ||
|
|
059ee047f3 | ||
|
|
2c2ca9d726 | ||
|
|
f5323e3c4b | ||
|
|
cae5aa0a56 | ||
|
|
6ba84288d9 | ||
|
|
434dc408f9 | ||
|
|
ae3f625739 | ||
|
|
f1f30ab418 | ||
|
|
bc586ce190 | ||
|
|
4012fd24f6 | ||
|
|
954731d564 | ||
|
|
dd9763be31 | ||
|
|
b86af6798d | ||
|
|
6f7e93d5cc | ||
|
|
6c08e97e1f | ||
|
|
78e0a7630c | ||
|
|
c86e356013 | ||
|
|
5a2afb3588 | ||
|
|
ab1e389347 | ||
|
|
ea05e3fd5b | ||
|
|
a2b8531627 | ||
|
|
c24422fb9d | ||
|
|
9c4492b58a | ||
|
|
9bbb28c361 | ||
|
|
1648ade6da | ||
|
|
993b2ab4c1 | ||
|
|
8d5858826f | ||
|
|
025347214d | ||
|
|
ae97c8bfd1 | ||
|
|
381c44955e | ||
|
|
ad97410ba5 | ||
|
|
691f04322a | ||
|
|
79d1c12ab0 | ||
|
|
0c7baea88c | ||
|
|
f4a4c11cd3 | ||
|
|
594c7f7050 | ||
|
|
d17c0f5084 | ||
|
|
a35e7bd595 | ||
|
|
d9456020d7 | ||
|
|
fbb98f144e | ||
|
|
9b6b39f204 | ||
|
|
855add067b | ||
|
|
bf6cd4b9da | ||
|
|
3b0db0f17f | ||
|
|
119cc99fb0 | ||
|
|
5f6196e4c7 | ||
|
|
46331a9e8e | ||
|
|
cf09c6aa9f | ||
|
|
80dbbf5e48 | ||
|
|
7da41be281 | ||
|
|
e281e867e6 | ||
|
|
6c51c971d1 | ||
|
|
a71c35ccd9 | ||
|
|
5410a8c79b | ||
|
|
a7dff592d3 | ||
|
|
f9317052ed | ||
|
|
86e40fabbc | ||
|
|
3419c3de0d | ||
|
|
7081a0cf0f | ||
|
|
0ef4fe70f0 | ||
|
|
443f02942c | ||
|
|
0a8ec5224e | ||
|
|
6b1520a46b | ||
|
|
f811b115ba | ||
|
|
53954a1e2e | ||
|
|
86399407b2 | ||
|
|
948029fe61 | ||
|
|
97524f1bda | ||
|
|
74c266a597 | ||
|
|
d282c45002 | ||
|
|
095b8035e6 | ||
|
|
124ec45876 | ||
|
|
14c9372a38 | ||
|
|
a9b64ffba8 | ||
|
|
e3ccf8fbf7 | ||
|
|
0e4a5738df | ||
|
|
eefb3cc1e7 | ||
|
|
074d32af20 | ||
|
|
2d7389185c | ||
|
|
4a5546d40e | ||
|
|
175193623b | ||
|
|
f2c727fc8c | ||
|
|
577e9913ca | ||
|
|
fccbee2727 | ||
|
|
e0acb10f31 | ||
|
|
5d5f39b6e6 | ||
|
|
e69d34103b | ||
|
|
a21218bdd5 | ||
|
|
81e8af6519 | ||
|
|
8b7c14246a | ||
|
|
52b3799989 | ||
|
|
738c397e1a | ||
|
|
0e703608f9 | ||
|
|
fb9110bac1 | ||
|
|
24092e6f21 | ||
|
|
f4132018c5 | ||
|
|
488d1870ab | ||
|
|
86279c8855 | ||
|
|
4d5186d1cf | ||
|
|
a6f1ed2e14 | ||
|
|
d1fb480887 | ||
|
|
75e4a951d0 | ||
|
|
42f3318e17 | ||
|
|
baa0e97ced | ||
|
|
71ebcc5e25 | ||
|
|
93bed60762 | ||
|
|
41d32c0be4 | ||
|
|
cbe9c5dc06 | ||
|
|
d3745db764 | ||
|
|
358ca205a3 | ||
|
|
c748719115 | ||
|
|
98f42d3a0b | ||
|
|
35c6053de3 | ||
|
|
20ae603221 | ||
|
|
672851e805 | ||
|
|
e579648ce9 | ||
|
|
e24d9606a2 | ||
|
|
75ecb047e2 | ||
|
|
f897d55781 | ||
|
|
7202596393 | ||
|
|
03f0816f86 | ||
|
|
5d9e2873f6 | ||
|
|
055f02e1e1 | ||
|
|
9b8ea12d34 | ||
|
|
74fe0453b2 | ||
|
|
a98fecaeb1 | ||
|
|
2445a5b74e | ||
|
|
62556619bd | ||
|
|
7d2a9268b9 | ||
|
|
3970bf4080 | ||
|
|
4295f91dcd | ||
|
|
2824312d5e | ||
|
|
64873c1b43 | ||
|
|
efd3b58973 | ||
|
|
6279b33736 | ||
|
|
5f6bf29e52 | ||
|
|
e793d7780d | ||
|
|
1492bcbfa2 | ||
|
|
bf2de5620c | ||
|
|
dfe08f395f | ||
|
|
6269682c56 | ||
|
|
2f9a344297 | ||
|
|
11aced3500 | ||
|
|
1567ce1e17 | ||
|
|
5cca1fdc40 | ||
|
|
9f0f0d573d | ||
|
|
716a92cbed | ||
|
|
a6a2b5a867 | ||
|
|
2ca4d0c831 | ||
|
|
7f948db158 | ||
|
|
9d7729c00d | ||
|
|
988dee02b9 | ||
|
|
d4b9568269 | ||
|
|
ccc3a481e7 | ||
|
|
8f6f734a6f | ||
|
|
cd19df49cd | ||
|
|
736365bdd5 | ||
|
|
6ceedb9448 | ||
|
|
930a3912a7 | ||
|
|
cf790d87c4 | ||
|
|
4e67fb8444 | ||
|
|
50f631c768 | ||
|
|
85bc371ebc | ||
|
|
322ee52c77 | ||
|
|
c576f80639 | ||
|
|
478156b4f7 | ||
|
|
afc38707d5 | ||
|
|
2e4bee6f24 | ||
|
|
d5ab97b69b | ||
|
|
7cb44e4502 | ||
|
|
7a20df5ad5 | ||
|
|
bea4362e21 | ||
|
|
6805cafa9b | ||
|
|
711b40ccda | ||
|
|
696dd7f668 | ||
|
|
e0a3c69223 | ||
|
|
c59249a664 | ||
|
|
fef172966f | ||
|
|
5a1ebc4c7c | ||
|
|
2a0f45aea9 | ||
|
|
1f77bb6e73 | ||
|
|
a7ef6422b6 | ||
|
|
9cfa68c92f | ||
|
|
6f3f701d3d | ||
|
|
d2a99a19d4 | ||
|
|
0395a35543 | ||
|
|
987d4a969d | ||
|
|
976d092c68 | ||
|
|
e6b15c7e4a | ||
|
|
ef50436464 | ||
|
|
26d35794e3 | ||
|
|
dcf0eeb5b6 | ||
|
|
32b759a328 | ||
|
|
09ef3ffa8b | ||
|
|
aab265e431 | ||
|
|
da9b34fa26 | ||
|
|
716bad188b | ||
|
|
4f93bf10f0 | ||
|
|
07bf2a21ac | ||
|
|
8ac2d2a92f | ||
|
|
76aee71257 | ||
|
|
1db5d790ed | ||
|
|
663b481029 | ||
|
|
1ab6493268 | ||
|
|
ab716302e4 | ||
|
|
b9d2181192 | ||
|
|
49148eb36e | ||
|
|
479bac447e | ||
|
|
15d5e78ac2 | ||
|
|
fd7f27f044 | ||
|
|
62e7516537 | ||
|
|
20296b4f0e | ||
|
|
5cae6db804 | ||
|
|
1a36f9dc65 | ||
|
|
c2497877ca | ||
|
|
3b5c1a1d4b | ||
|
|
9a2e385f12 | ||
|
|
7080e1a11c | ||
|
|
0a52b83c6a | ||
|
|
11ed8e2a6d | ||
|
|
bb20c09a9a | ||
|
|
04ef8d395f | ||
|
|
0676f1a86f | ||
|
|
6b7823df07 | ||
|
|
2186e417ba | ||
|
|
1519e3067c | ||
|
|
35e5424255 | ||
|
|
8c7d05afd2 | ||
|
|
f8360a4831 | ||
|
|
8556b9d7f5 | ||
|
|
3efd90b2ad | ||
|
|
7adcd9cd1a | ||
|
|
aff05e043f | ||
|
|
ff2c0c192e | ||
|
|
d309a27a51 | ||
|
|
471d274803 | ||
|
|
35f4c9b5c7 | ||
|
|
034a49c69d | ||
|
|
3b6825d7e2 | ||
|
|
bb5ae389f7 | ||
|
|
d61ecb26fd | ||
|
|
07ef03d340 | ||
|
|
9278031e60 | ||
|
|
4a2cef887c | ||
|
|
42750f7846 | ||
|
|
e8c3a02830 | ||
|
|
d31aa143f4 | ||
|
|
710e777a92 | ||
|
|
912dca8f65 | ||
|
|
db84530074 | ||
|
|
72bbaac96d | ||
|
|
5713d63dc5 | ||
|
|
d653e594c2 | ||
|
|
dd7bb33ab6 | ||
|
|
a9c6182b3f | ||
|
|
3d70137d31 | ||
|
|
bce9a081db | ||
|
|
46cf41cc93 | ||
|
|
81a440c8e8 | ||
|
|
f24a3b5282 | ||
|
|
383b4a2c3e | ||
|
|
df59822a27 | ||
|
|
0908c5414d | ||
|
|
ee46134fa7 | ||
|
|
7a4e50705c | ||
|
|
2952bca520 | ||
|
|
39bb319d4c | ||
|
|
29b6fa6212 | ||
|
|
1bdd83a85f | ||
|
|
1624c239c2 | ||
|
|
4a913ce61e | ||
|
|
2c50ea0403 | ||
|
|
298c6c2343 | ||
|
|
2897a89dfd | ||
|
|
764e333fa2 | ||
|
|
c61e3bf4c9 | ||
|
|
fc8649d80f | ||
|
|
0fb9ecf1f3 | ||
|
|
97958400fb | ||
|
|
610566fbb9 | ||
|
|
684954695d | ||
|
|
6d6d86260b | ||
|
|
c856ea4249 | ||
|
|
d0923d6710 | ||
|
|
f312522cef | ||
|
|
da5a144589 | ||
|
|
2c1e669bd8 | ||
|
|
e20e9f61ac | ||
|
|
6b3148fd3f | ||
|
|
95ae56bd22 | ||
|
|
990192d077 | ||
|
|
f3e69531c3 | ||
|
|
0cb3272bda | ||
|
|
6231aa91e2 | ||
|
|
489b728dbc | ||
|
|
583e2b2d01 | ||
|
|
5dc2a0d3fd | ||
|
|
2c731418ad | ||
|
|
5c150675bf | ||
|
|
fea810b437 | ||
|
|
96d877be90 | ||
|
|
40d917b0fe | ||
|
|
e72020ae01 | ||
|
|
01d929ee2a | ||
|
|
cf876fcdb4 | ||
|
|
291c29caaf | ||
|
|
01e00ac1b0 | ||
|
|
a9ed4ed8a8 | ||
|
|
9d6a5a0c79 | ||
|
|
fb97a7aab1 | ||
|
|
1cefb2a753 | ||
|
|
63992b81c8 | ||
|
|
d8f68674fb | ||
|
|
9d00c8eea2 | ||
|
|
0d21925bdf | ||
|
|
efef5c8ead | ||
|
|
3d2bb1a8f1 | ||
|
|
837a4dddb8 | ||
|
|
b2626bc7a9 | ||
|
|
202f2c3292 | ||
|
|
2a23713f71 | ||
|
|
681034d001 | ||
|
|
17813ff5b4 | ||
|
|
3e81bd6b67 | ||
|
|
23ae358e0f | ||
|
|
f611726364 | ||
|
|
33ee0acd35 | ||
|
|
8b79e3b06c | ||
|
|
cf49e912fc | ||
|
|
66741c035c | ||
|
|
406511c333 | ||
|
|
8a2d68d63e | ||
|
|
07d297fdbe | ||
|
|
0d4e8b50d0 | ||
|
|
1d7c5c2a98 | ||
|
|
0faa350175 | ||
|
|
8a7509db75 | ||
|
|
025368f51c | ||
|
|
5fe52ed322 | ||
|
|
8b247a330b | ||
|
|
d6f458fcb3 | ||
|
|
b8b84021e5 | ||
|
|
70fe7e18be | ||
|
|
9378da3c82 | ||
|
|
a4857fa764 | ||
|
|
592014923f | ||
|
|
6d06b215bf | ||
|
|
2d87bb648f | ||
|
|
56ebef35b0 | ||
|
|
13d8b22d25 | ||
|
|
27f9b6ffeb | ||
|
|
c8fcfd4581 | ||
|
|
49c24285c7 | ||
|
|
c918489259 | ||
|
|
93155242fa | ||
|
|
4cc919607a | ||
|
|
81419f7f32 | ||
|
|
6bd6cd9c51 | ||
|
|
35a1d68eb6 | ||
|
|
365a06bdb6 | ||
|
|
8e117f9f92 | ||
|
|
209eafb631 | ||
|
|
14aa2923cf | ||
|
|
1e395ed285 | ||
|
|
98615166b0 | ||
|
|
28272de97a | ||
|
|
7e736da30c | ||
|
|
20e929e27e | ||
|
|
477b5260aa | ||
|
|
d39f1a3427 | ||
|
|
3757855231 | ||
|
|
d846431015 | ||
|
|
624edf428f | ||
|
|
54500b861d | ||
|
|
f2491ee0ac | ||
|
|
1f169ee7fb | ||
|
|
66817992c1 | ||
|
|
8052bcd5cd | ||
|
|
55886a0116 | ||
|
|
33e90cc6a0 | ||
|
|
d5be8125b0 | ||
|
|
b99cd2a920 | ||
|
|
b64389c8a9 | ||
|
|
db7a28ac25 | ||
|
|
d337bbf8a0 | ||
|
|
90c47140b8 | ||
|
|
0ecfd91a20 | ||
|
|
a0e05fa291 | ||
|
|
e33c007cd0 | ||
|
|
80aca1ccc7 | ||
|
|
6b3a580ee5 | ||
|
|
207fc8b256 | ||
|
|
74561dbdac | ||
|
|
867e7d3238 | ||
|
|
5f08a21d12 | ||
|
|
95bc6e8749 | ||
|
|
4530b96c67 | ||
|
|
360af27749 | ||
|
|
0ee75fd75d | ||
|
|
2eae9b66d0 | ||
|
|
f6d417e26d | ||
|
|
903825af6f | ||
|
|
948cf17499 | ||
|
|
cd59003003 | ||
|
|
f19a48a28c | ||
|
|
4c6f3125fc | ||
|
|
497051c14b | ||
|
|
6400116715 | ||
|
|
f77bdf96d8 | ||
|
|
c06a86706a | ||
|
|
e0beb6a999 | ||
|
|
633bb8d339 | ||
|
|
7e850f3b7e | ||
|
|
59c9a8e7ae | ||
|
|
c2419ddabf | ||
|
|
2e0942d5c8 | ||
|
|
6155f9c171 | ||
|
|
f64c78b777 | ||
|
|
3d12cdc643 | ||
|
|
526488feaa | ||
|
|
5d88351bb5 | ||
|
|
a46a4781e8 | ||
|
|
b44644bcec | ||
|
|
1f4a495e16 | ||
|
|
d97a1638d3 | ||
|
|
ef28a919d2 | ||
|
|
71369ac98b | ||
|
|
85f1114c4a | ||
|
|
927c687628 | ||
|
|
6d5cffaee9 | ||
|
|
fbc550d02e | ||
|
|
014c4b47c9 | ||
|
|
9be19ad777 | ||
|
|
1161a5c6da | ||
|
|
9947197a84 | ||
|
|
50c6aaae62 | ||
|
|
edd314cc8a | ||
|
|
8b2a11fd5e | ||
|
|
15b463d18d | ||
|
|
0c1975501c | ||
|
|
98f8785a4f | ||
|
|
b74dfba215 | ||
|
|
bee5c3f1b8 | ||
|
|
e191892824 | ||
|
|
2841927dba | ||
|
|
0646112010 | ||
|
|
782b11b844 | ||
|
|
5a86bbc0a0 | ||
|
|
fef7eb73ad | ||
|
|
62fa4734fe | ||
|
|
b5db90c8a8 | ||
|
|
3e1591661e | ||
|
|
1e52fe6e09 | ||
|
|
809fca0be9 | ||
|
|
5fa473d5f3 | ||
|
|
784a90c3a6 | ||
|
|
6111151f50 | ||
|
|
afc03af3ca | ||
|
|
306ee24c90 | ||
|
|
3f7235c36f | ||
|
|
9d678a6f41 | ||
|
|
983698dd1b | ||
|
|
9a60b8a0ba | ||
|
|
adf99a332e | ||
|
|
d713e4c757 | ||
|
|
a90c9c2776 | ||
|
|
d43fcd638e | ||
|
|
e32e24adf5 | ||
|
|
e2c2689f5c | ||
|
|
8415014de6 | ||
|
|
3307ccb2dc | ||
|
|
6889ee2b85 | ||
|
|
bf31f18c46 | ||
|
|
e73d103eca | ||
|
|
12e58ab37f | ||
|
|
daad50e384 | ||
|
|
4e339bb101 | ||
|
|
b83ce0c352 | ||
|
|
6f80fe17fc | ||
|
|
7ea38f90d7 | ||
|
|
f4a2bc6cf8 | ||
|
|
78226f8574 | ||
|
|
04b1defaf9 | ||
|
|
3cdbbb43be | ||
|
|
92f41f1051 | ||
|
|
c142dadb46 | ||
|
|
cd54af019a | ||
|
|
e5f9772a35 | ||
|
|
a02056c566 | ||
|
|
2dfa26cca0 | ||
|
|
25d8cd473e | ||
|
|
f4935dd6be | ||
|
|
9d855091bf | ||
|
|
f3be995c28 | ||
|
|
9d7619d1eb | ||
|
|
c6d52fdea4 | ||
|
|
cf6832896f | ||
|
|
6b1cf6c4fd | ||
|
|
db80c5a2e7 | ||
|
|
89aae3e04f | ||
|
|
0636399c8c | ||
|
|
7e474d21ca | ||
|
|
f61996b425 | ||
|
|
496c3f2732 | ||
|
|
8856c19c76 | ||
|
|
0eacadfa99 | ||
|
|
2a4ae88f18 | ||
|
|
a296654c1b | ||
|
|
b62185b821 | ||
|
|
e6034b7eb6 | ||
|
|
54a4aa22ed | ||
|
|
9ec70252d0 | ||
|
|
e20b6acfe9 | ||
|
|
d9180c03f6 | ||
|
|
4072f723c1 | ||
|
|
cf8021020f | ||
|
|
fb1054b5e3 | ||
|
|
1e4512b2c8 | ||
|
|
3a7326ae46 | ||
|
|
38b59a93de | ||
|
|
1199eacb72 | ||
|
|
fdb58b0b62 | ||
|
|
315fbc11e5 | ||
|
|
4a1b92d309 | ||
|
|
272dd993e6 | ||
|
|
96a52d9810 | ||
|
|
50544b7805 | ||
|
|
b78c0e2a69 | ||
|
|
2b969e9c42 | ||
|
|
e83ee217d3 | ||
|
|
b1e44e96bc | ||
|
|
7ae0cde754 | ||
|
|
c1d5c24bc7 | ||
|
|
eec6aaddda | ||
|
|
bb167f94ca | ||
|
|
2e4783bcdf | ||
|
|
7b31c0830f | ||
|
|
8f645d354e | ||
|
|
7ec9a7af79 | ||
|
|
50b53e183e | ||
|
|
d131bde183 | ||
|
|
d1864e2430 | ||
|
|
8ba02ac829 | ||
|
|
73a08c0be0 | ||
|
|
c45d2f214b | ||
|
|
9a67e0df39 | ||
|
|
acf16c063a | ||
|
|
86a8cbd002 | ||
|
|
fc276a51fb | ||
|
|
771f33d17d | ||
|
|
e6d1f509a0 | ||
|
|
225e871819 | ||
|
|
7875ca8fb5 | ||
|
|
6d2d8dfd2f | ||
|
|
0ec7166098 | ||
|
|
3d66a234b0 | ||
|
|
8a073ee49f | ||
|
|
7e20c6d1a1 | ||
|
|
1d4672d747 | ||
|
|
39e62b948e | ||
|
|
41d195715d | ||
|
|
3db97f8897 | ||
|
|
516f64f4d9 | ||
|
|
62dd99bee5 | ||
|
|
94c151aea3 | ||
|
|
81fa54837f | ||
|
|
9de357e373 | ||
|
|
b4a3824ce4 | ||
|
|
3bb80ebf20 | ||
|
|
cdffd19f61 | ||
|
|
a7ce2633f3 | ||
|
|
8fa5fb2816 | ||
|
|
8df948565a | ||
|
|
3c67e595b8 | ||
|
|
814996b14f | ||
|
|
2e67d74df4 | ||
|
|
b841dd78fe | ||
|
|
68ca0ea995 | ||
|
|
f54b784d88 | ||
|
|
b6e328ea8f | ||
|
|
5c80117fbd | ||
|
|
c2ceb6de5f | ||
|
|
77ec70d145 | ||
|
|
a380502c01 | ||
|
|
0416f26a76 | ||
|
|
3579b4570f | ||
|
|
256ff5b56c | ||
|
|
7502f662ab | ||
|
|
d974959738 | ||
|
|
5f348579d1 | ||
|
|
8371a7a3aa | ||
|
|
1d25703ac3 | ||
|
|
fe7ede5af3 | ||
|
|
d599394f60 | ||
|
|
66c03be45f | ||
|
|
c1d62383c6 | ||
|
|
73ab110260 | ||
|
|
cc3d40ca44 | ||
|
|
288efddf2f | ||
|
|
4a34e5804e | ||
|
|
3d0375daa6 | ||
|
|
3060eb5baf | ||
|
|
ce46aa0c3b | ||
|
|
3b35547da0 | ||
|
|
6aa62b9b66 | ||
|
|
2febbfe4b0 | ||
|
|
ea182461d3 | ||
|
|
5863676ccb | ||
|
|
97611e89ca | ||
|
|
64cf922841 | ||
|
|
227a62e4c4 | ||
|
|
38e21f5c1a | ||
|
|
d395bc0647 | ||
|
|
afce13d101 | ||
|
|
8521ab7990 | ||
|
|
71a6d49d06 | ||
|
|
07d5c71090 | ||
|
|
a751dc25d6 | ||
|
|
753c63e11b | ||
|
|
b0dfbe7086 | ||
|
|
31018d57b6 | ||
|
|
9ebebb22db | ||
|
|
2c461e4ad3 | ||
|
|
56ca5dfa15 | ||
|
|
747af145ed | ||
|
|
7981ee186f | ||
|
|
9e9df2b501 | ||
|
|
f7f762c676 | ||
|
|
0b730d904f | ||
|
|
11e8c7d8ff | ||
|
|
663f953a78 | ||
|
|
bfd909ab79 | ||
|
|
0cfcb5a49c | ||
|
|
6a86de1927 | ||
|
|
5114e8daf1 | ||
|
|
1c09867b3e | ||
|
|
2b4229fa51 | ||
|
|
92e50133f8 | ||
|
|
c4269b5efa | ||
|
|
19dfa24abb | ||
|
|
c7fd336c5d | ||
|
|
ed30af8343 | ||
|
|
1e0b059982 | ||
|
|
038c09f552 | ||
|
|
5d1b54de45 | ||
|
|
18156bf2a1 | ||
|
|
5845de7d7c | ||
|
|
e97d67a681 | ||
|
|
f0bb3ae825 | ||
|
|
9806b00f74 | ||
|
|
f2989b36c2 | ||
|
|
624fbadea2 | ||
|
|
d4ba37f543 | ||
|
|
449ad7502c | ||
|
|
44404fcd6d | ||
|
|
1da6d43109 | ||
|
|
9aee793078 | ||
|
|
89c3033401 | ||
|
|
67f09b7d7e | ||
|
|
0dfffcd88a | ||
|
|
9e1683cf2b | ||
|
|
4d0c06e397 | ||
|
|
0315611b11 | ||
|
|
33a6234b52 | ||
|
|
4b7b3bc04a | ||
|
|
035dd3a900 | ||
|
|
4e25c8f78e | ||
|
|
7f6b581ef8 | ||
|
|
cc274fb7fb | ||
|
|
334d07bf96 | ||
|
|
6417f5d7c1 | ||
|
|
8088c04a71 | ||
|
|
f7b1911f1b | ||
|
|
045cd38b6e | ||
|
|
dccdb8771c | ||
|
|
d4b5cab7f7 | ||
|
|
363f1dfab9 | ||
|
|
4e24733f1c | ||
|
|
bb91a10b5f | ||
|
|
98635ebde2 | ||
|
|
24823b061d | ||
|
|
0fe1afd4ef | ||
|
|
c0a7df9ee1 | ||
|
|
5907bbd9de | ||
|
|
5db792b10b | ||
|
|
7c38c33ed6 | ||
|
|
5bec05e045 | ||
|
|
6084611508 | ||
|
|
71a7a27319 | ||
|
|
ec2efe52e4 | ||
|
|
0f0158ddaa | ||
|
|
dde7807b00 | ||
|
|
1e3daa247b | ||
|
|
3bd00b88c2 | ||
|
|
62d00b4520 | ||
|
|
4f8ce00477 | ||
|
|
1214f35985 | ||
|
|
e743ee5d5c | ||
|
|
23c4e5cb01 | ||
|
|
1f1cae6c5a | ||
|
|
c8d209d36c | ||
|
|
f8e8df5a04 | ||
|
|
f4c9276336 | ||
|
|
a5c38e5d5b | ||
|
|
9c7237157d | ||
|
|
5931948adb | ||
|
|
8a5e3904a0 | ||
|
|
d679dc4de1 | ||
|
|
a002d10a4d | ||
|
|
3a06968332 | ||
|
|
6fbd526931 | ||
|
|
c437dce056 | ||
|
|
fc00691898 | ||
|
|
990ceddd14 | ||
|
|
226db64736 | ||
|
|
2429ac73b2 | ||
|
|
dd8e17cb37 | ||
|
|
db756e9a34 | ||
|
|
16e5981d31 | ||
|
|
575c51fd3b | ||
|
|
5b2447f71d | ||
|
|
0ccb4d4a3a | ||
|
|
b5bb8bec67 | ||
|
|
5cdf4e34a1 | ||
|
|
061e157191 | ||
|
|
d859a3a925 | ||
|
|
5a1a14f9fc | ||
|
|
b6ba4cac83 | ||
|
|
99b607c60c | ||
|
|
289298b17d | ||
|
|
f7a1868fc2 | ||
|
|
02bb8e0ac3 | ||
|
|
bc909e8359 | ||
|
|
c971d9319c | ||
|
|
0c942106bf | ||
|
|
c0c4d4ddc6 | ||
|
|
c924c47f37 | ||
|
|
5b54086663 | ||
|
|
9e797cc151 | ||
|
|
cc10a62e16 | ||
|
|
7e5b6154d0 | ||
|
|
6d6df18387 | ||
|
|
ca36f47dfc | ||
|
|
45f9cc9e0e | ||
|
|
3699a90645 | ||
|
|
714846e1e1 | ||
|
|
08d85d4013 | ||
|
|
0ec7743436 | ||
|
|
a72d80aa85 | ||
|
|
b556fc43bc | ||
|
|
dbb9c19669 | ||
|
|
bca6a44974 | ||
|
|
8ab5c8cb28 | ||
|
|
774c4059fb | ||
|
|
5f1d07d62f | ||
|
|
cd984992cf | ||
|
|
99f4940eb7 | ||
|
|
41dd835a89 | ||
|
|
ee42c5cd42 | ||
|
|
47b6101465 | ||
|
|
7889a52f95 | ||
|
|
8d562ecf48 | ||
|
|
2767a0f9f2 | ||
|
|
af08c56ce0 | ||
|
|
dfc56e9227 | ||
|
|
84d157995e | ||
|
|
ed5bfda372 | ||
|
|
a59822540f | ||
|
|
968bbd2f47 | ||
|
|
1b4bdff331 | ||
|
|
678fe003e3 | ||
|
|
3b1af3f1a6 | ||
|
|
437501cde3 | ||
|
|
8bd2072e19 | ||
|
|
85df289190 | ||
|
|
8856496aac | ||
|
|
a7df7db464 | ||
|
|
59507c7c02 | ||
|
|
09c719c926 | ||
|
|
e54b6311ef | ||
|
|
fdbdb4748a | ||
|
|
76a2b14cdb | ||
|
|
b08154dc36 | ||
|
|
165fc43655 | ||
|
|
42cbf75cfa | ||
|
|
e6ad3cbc66 | ||
|
|
2127907dd3 | ||
|
|
164a1978de | ||
|
|
cb1076ed23 | ||
|
|
ad5f318d06 | ||
|
|
60bbe64489 | ||
|
|
b9085fc80a | ||
|
|
2fad5b88bc | ||
|
|
b271a6bd89 | ||
|
|
758a1e7f66 | ||
|
|
1cba447102 | ||
|
|
e25164cfed | ||
|
|
f6556f7972 | ||
|
|
69579668bb | ||
|
|
2e688b7cd3 | ||
|
|
2fcbfec178 | ||
|
|
e1143caf38 | ||
|
|
a7485e4d9e | ||
|
|
335b2f960e | ||
|
|
b18d099291 | ||
|
|
bc803e01c7 | ||
|
|
eaa2460701 | ||
|
|
c7dbcc6483 | ||
|
|
ad8a5934e1 | ||
|
|
7078e6477e | ||
|
|
69475f5bf1 | ||
|
|
ddeeb9428c | ||
|
|
780c60630c | ||
|
|
40c37b1219 | ||
|
|
c14b09376a | ||
|
|
fbcf56b2ba | ||
|
|
2d369b32f9 | ||
|
|
d52c524fc2 | ||
|
|
c2b51fbe98 | ||
|
|
7f2ac589f9 | ||
|
|
dff3872897 | ||
|
|
4f4b92da7d | ||
|
|
18f171d885 | ||
|
|
c72f8acea1 | ||
|
|
abedbc726f | ||
|
|
3e8d389e3e | ||
|
|
8810f8a728 | ||
|
|
5de91b9d81 | ||
|
|
57bc2abf41 | ||
|
|
dd50514d17 | ||
|
|
ac4935bf79 | ||
|
|
c817862cf7 | ||
|
|
c3768aaa46 | ||
|
|
a85fcfe05f | ||
|
|
1890535d1b | ||
|
|
9bb52acc14 | ||
|
|
551fdf32c3 | ||
|
|
74008ce487 | ||
|
|
852481e14d |
7
.github/dependabot.yml
vendored
Normal file
7
.github/dependabot.yml
vendored
Normal file
@@ -0,0 +1,7 @@
|
||||
---
|
||||
version: 2
|
||||
updates:
|
||||
- package-ecosystem: "github-actions"
|
||||
directory: "/"
|
||||
schedule:
|
||||
interval: "monthly"
|
||||
4
.github/workflows/typos.yml
vendored
4
.github/workflows/typos.yml
vendored
@@ -15,7 +15,7 @@ jobs:
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
- uses: actions/checkout@v4
|
||||
|
||||
- name: typos-action
|
||||
uses: crate-ci/typos@v1.13.10
|
||||
uses: crate-ci/typos@v1.24.3
|
||||
|
||||
114
README-ja.md
114
README-ja.md
@@ -3,26 +3,30 @@ Stable Diffusionの学習、画像生成、その他のスクリプトを入れ
|
||||
|
||||
[README in English](./README.md) ←更新情報はこちらにあります
|
||||
|
||||
開発中のバージョンはdevブランチにあります。最新の変更点はdevブランチをご確認ください。
|
||||
|
||||
FLUX.1およびSD3/SD3.5対応はsd3ブランチで行っています。それらの学習を行う場合はsd3ブランチをご利用ください。
|
||||
|
||||
GUIやPowerShellスクリプトなど、より使いやすくする機能が[bmaltais氏のリポジトリ](https://github.com/bmaltais/kohya_ss)で提供されています(英語です)のであわせてご覧ください。bmaltais氏に感謝します。
|
||||
|
||||
以下のスクリプトがあります。
|
||||
|
||||
* DreamBooth、U-NetおよびText Encoderの学習をサポート
|
||||
* fine-tuning、同上
|
||||
* LoRAの学習をサポート
|
||||
* 画像生成
|
||||
* モデル変換(Stable Diffision ckpt/safetensorsとDiffusersの相互変換)
|
||||
|
||||
## 使用法について
|
||||
|
||||
当リポジトリ内およびnote.comに記事がありますのでそちらをご覧ください(将来的にはすべてこちらへ移すかもしれません)。
|
||||
|
||||
* [学習について、共通編](./train_README-ja.md) : データ整備やオプションなど
|
||||
* [データセット設定](./config_README-ja.md)
|
||||
* [DreamBoothの学習について](./train_db_README-ja.md)
|
||||
* [fine-tuningのガイド](./fine_tune_README_ja.md):
|
||||
* [LoRAの学習について](./train_network_README-ja.md)
|
||||
* [Textual Inversionの学習について](./train_ti_README-ja.md)
|
||||
* note.com [画像生成スクリプト](https://note.com/kohya_ss/n/n2693183a798e)
|
||||
* [学習について、共通編](./docs/train_README-ja.md) : データ整備やオプションなど
|
||||
* [データセット設定](./docs/config_README-ja.md)
|
||||
* [SDXL学習](./docs/train_SDXL-en.md) (英語版)
|
||||
* [DreamBoothの学習について](./docs/train_db_README-ja.md)
|
||||
* [fine-tuningのガイド](./docs/fine_tune_README_ja.md):
|
||||
* [LoRAの学習について](./docs/train_network_README-ja.md)
|
||||
* [Textual Inversionの学習について](./docs/train_ti_README-ja.md)
|
||||
* [画像生成スクリプト](./docs/gen_img_README-ja.md)
|
||||
* note.com [モデル変換スクリプト](https://note.com/kohya_ss/n/n374f316fe4ad)
|
||||
|
||||
## Windowsでの動作に必要なプログラム
|
||||
@@ -32,6 +36,8 @@ Python 3.10.6およびGitが必要です。
|
||||
- Python 3.10.6: https://www.python.org/ftp/python/3.10.6/python-3.10.6-amd64.exe
|
||||
- git: https://git-scm.com/download/win
|
||||
|
||||
Python 3.10.x、3.11.x、3.12.xでも恐らく動作しますが、3.10.6でテストしています。
|
||||
|
||||
PowerShellを使う場合、venvを使えるようにするためには以下の手順でセキュリティ設定を変更してください。
|
||||
(venvに限らずスクリプトの実行が可能になりますので注意してください。)
|
||||
|
||||
@@ -41,11 +47,11 @@ PowerShellを使う場合、venvを使えるようにするためには以下の
|
||||
|
||||
## Windows環境でのインストール
|
||||
|
||||
以下の例ではPyTorchは1.12.1/CUDA 11.6版をインストールします。CUDA 11.3版やPyTorch 1.13を使う場合は適宜書き換えください。
|
||||
スクリプトはPyTorch 2.1.2でテストしています。PyTorch 2.2以降でも恐らく動作します。
|
||||
|
||||
(なお、python -m venv~の行で「python」とだけ表示された場合、py -m venv~のようにpythonをpyに変更してください。)
|
||||
|
||||
通常の(管理者ではない)PowerShellを開き以下を順に実行します。
|
||||
PowerShellを使う場合、通常の(管理者ではない)PowerShellを開き以下を順に実行します。
|
||||
|
||||
```powershell
|
||||
git clone https://github.com/kohya-ss/sd-scripts.git
|
||||
@@ -54,50 +60,23 @@ cd sd-scripts
|
||||
python -m venv venv
|
||||
.\venv\Scripts\activate
|
||||
|
||||
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
|
||||
pip install torch==2.1.2 torchvision==0.16.2 --index-url https://download.pytorch.org/whl/cu118
|
||||
pip install --upgrade -r requirements.txt
|
||||
pip install -U -I --no-deps https://github.com/C43H66N12O12S2/stable-diffusion-webui/releases/download/f/xformers-0.0.14.dev0-cp310-cp310-win_amd64.whl
|
||||
|
||||
cp .\bitsandbytes_windows\*.dll .\venv\Lib\site-packages\bitsandbytes\
|
||||
cp .\bitsandbytes_windows\cextension.py .\venv\Lib\site-packages\bitsandbytes\cextension.py
|
||||
cp .\bitsandbytes_windows\main.py .\venv\Lib\site-packages\bitsandbytes\cuda_setup\main.py
|
||||
pip install xformers==0.0.23.post1 --index-url https://download.pytorch.org/whl/cu118
|
||||
|
||||
accelerate config
|
||||
```
|
||||
|
||||
<!--
|
||||
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117
|
||||
pip install --use-pep517 --upgrade -r requirements.txt
|
||||
pip install -U -I --no-deps xformers==0.0.16
|
||||
-->
|
||||
コマンドプロンプトでも同一です。
|
||||
|
||||
コマンドプロンプトでは以下になります。
|
||||
注:`bitsandbytes==0.44.0`、`prodigyopt==1.0`、`lion-pytorch==0.0.6` は `requirements.txt` に含まれるようになりました。他のバージョンを使う場合は適宜インストールしてください。
|
||||
|
||||
この例では PyTorch および xfomers は2.1.2/CUDA 11.8版をインストールします。CUDA 12.1版やPyTorch 1.12.1を使う場合は適宜書き換えください。たとえば CUDA 12.1版の場合は `pip install torch==2.1.2 torchvision==0.16.2 --index-url https://download.pytorch.org/whl/cu121` および `pip install xformers==0.0.23.post1 --index-url https://download.pytorch.org/whl/cu121` としてください。
|
||||
|
||||
```bat
|
||||
git clone https://github.com/kohya-ss/sd-scripts.git
|
||||
cd sd-scripts
|
||||
|
||||
python -m venv venv
|
||||
.\venv\Scripts\activate
|
||||
|
||||
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
|
||||
pip install --upgrade -r requirements.txt
|
||||
pip install -U -I --no-deps https://github.com/C43H66N12O12S2/stable-diffusion-webui/releases/download/f/xformers-0.0.14.dev0-cp310-cp310-win_amd64.whl
|
||||
|
||||
copy /y .\bitsandbytes_windows\*.dll .\venv\Lib\site-packages\bitsandbytes\
|
||||
copy /y .\bitsandbytes_windows\cextension.py .\venv\Lib\site-packages\bitsandbytes\cextension.py
|
||||
copy /y .\bitsandbytes_windows\main.py .\venv\Lib\site-packages\bitsandbytes\cuda_setup\main.py
|
||||
|
||||
accelerate config
|
||||
```
|
||||
|
||||
(注:``python -m venv venv`` のほうが ``python -m venv --system-site-packages venv`` より安全そうなため書き換えました。globalなpythonにパッケージがインストールしてあると、後者だといろいろと問題が起きます。)
|
||||
PyTorch 2.2以降を用いる場合は、`torch==2.1.2` と `torchvision==0.16.2` 、および `xformers==0.0.23.post1` を適宜変更してください。
|
||||
|
||||
accelerate configの質問には以下のように答えてください。(bf16で学習する場合、最後の質問にはbf16と答えてください。)
|
||||
|
||||
※0.15.0から日本語環境では選択のためにカーソルキーを押すと落ちます(……)。数字キーの0、1、2……で選択できますので、そちらを使ってください。
|
||||
|
||||
```txt
|
||||
- This machine
|
||||
- No distributed training
|
||||
@@ -111,10 +90,6 @@ accelerate configの質問には以下のように答えてください。(bf1
|
||||
※場合によって ``ValueError: fp16 mixed precision requires a GPU`` というエラーが出ることがあるようです。この場合、6番目の質問(
|
||||
``What GPU(s) (by id) should be used for training on this machine as a comma-separated list? [all]:``)に「0」と答えてください。(id `0`のGPUが使われます。)
|
||||
|
||||
### PyTorchとxformersのバージョンについて
|
||||
|
||||
他のバージョンでは学習がうまくいかない場合があるようです。特に他の理由がなければ指定のバージョンをお使いください。
|
||||
|
||||
## アップグレード
|
||||
|
||||
新しいリリースがあった場合、以下のコマンドで更新できます。
|
||||
@@ -144,4 +119,47 @@ Conv2d 3x3への拡大は [cloneofsimo氏](https://github.com/cloneofsimo/lora)
|
||||
|
||||
[BLIP](https://github.com/salesforce/BLIP): BSD-3-Clause
|
||||
|
||||
## その他の情報
|
||||
|
||||
### LoRAの名称について
|
||||
|
||||
`train_network.py` がサポートするLoRAについて、混乱を避けるため名前を付けました。ドキュメントは更新済みです。以下は当リポジトリ内の独自の名称です。
|
||||
|
||||
1. __LoRA-LierLa__ : (LoRA for __Li__ n __e__ a __r__ __La__ yers、リエラと読みます)
|
||||
|
||||
Linear 層およびカーネルサイズ 1x1 の Conv2d 層に適用されるLoRA
|
||||
|
||||
2. __LoRA-C3Lier__ : (LoRA for __C__ olutional layers with __3__ x3 Kernel and __Li__ n __e__ a __r__ layers、セリアと読みます)
|
||||
|
||||
1.に加え、カーネルサイズ 3x3 の Conv2d 層に適用されるLoRA
|
||||
|
||||
デフォルトではLoRA-LierLaが使われます。LoRA-C3Lierを使う場合は `--network_args` に `conv_dim` を指定してください。
|
||||
|
||||
<!--
|
||||
LoRA-LierLa は[Web UI向け拡張](https://github.com/kohya-ss/sd-webui-additional-networks)、またはAUTOMATIC1111氏のWeb UIのLoRA機能で使用することができます。
|
||||
|
||||
LoRA-C3Lierを使いWeb UIで生成するには拡張を使用してください。
|
||||
-->
|
||||
|
||||
### 学習中のサンプル画像生成
|
||||
|
||||
プロンプトファイルは例えば以下のようになります。
|
||||
|
||||
```
|
||||
# prompt 1
|
||||
masterpiece, best quality, (1girl), in white shirts, upper body, looking at viewer, simple background --n low quality, worst quality, bad anatomy,bad composition, poor, low effort --w 768 --h 768 --d 1 --l 7.5 --s 28
|
||||
|
||||
# prompt 2
|
||||
masterpiece, best quality, 1boy, in business suit, standing at street, looking back --n (low quality, worst quality), bad anatomy,bad composition, poor, low effort --w 576 --h 832 --d 2 --l 5.5 --s 40
|
||||
```
|
||||
|
||||
`#` で始まる行はコメントになります。`--n` のように「ハイフン二個+英小文字」の形でオプションを指定できます。以下が使用可能できます。
|
||||
|
||||
* `--n` Negative prompt up to the next option.
|
||||
* `--w` Specifies the width of the generated image.
|
||||
* `--h` Specifies the height of the generated image.
|
||||
* `--d` Specifies the seed of the generated image.
|
||||
* `--l` Specifies the CFG scale of the generated image.
|
||||
* `--s` Specifies the number of steps in the generation.
|
||||
|
||||
`( )` や `[ ]` などの重みづけも動作します。
|
||||
|
||||
577
README.md
577
README.md
@@ -1,9 +1,16 @@
|
||||
This repository contains training, generation and utility scripts for Stable Diffusion.
|
||||
|
||||
[__Change History__](#change-history) is moved to the bottom of the page.
|
||||
[__Change History__](#change-history) is moved to the bottom of the page.
|
||||
更新履歴は[ページ末尾](#change-history)に移しました。
|
||||
|
||||
[日本語版README](./README-ja.md)
|
||||
Latest update: 2025-03-21 (Version 0.9.1)
|
||||
|
||||
[日本語版READMEはこちら](./README-ja.md)
|
||||
|
||||
The development version is in the `dev` branch. Please check the dev branch for the latest changes.
|
||||
|
||||
FLUX.1 and SD3/SD3.5 support is done in the `sd3` branch. If you want to train them, please use the sd3 branch.
|
||||
|
||||
|
||||
For easier use (GUI and PowerShell scripts etc...), please visit [the repository maintained by bmaltais](https://github.com/bmaltais/kohya_ss). Thanks to @bmaltais!
|
||||
|
||||
@@ -12,29 +19,32 @@ This repository contains the scripts for:
|
||||
* DreamBooth training, including U-Net and Text Encoder
|
||||
* Fine-tuning (native training), including U-Net and Text Encoder
|
||||
* LoRA training
|
||||
* Texutl Inversion training
|
||||
* Textual Inversion training
|
||||
* Image generation
|
||||
* Model conversion (supports 1.x and 2.x, Stable Diffision ckpt/safetensors and Diffusers)
|
||||
|
||||
__Stable Diffusion web UI now seems to support LoRA trained by ``sd-scripts``.__ (SD 1.x based only) Thank you for great work!!!
|
||||
|
||||
## About requirements.txt
|
||||
|
||||
These files do not contain requirements for PyTorch. Because the versions of them depend on your environment. Please install PyTorch at first (see installation guide below.)
|
||||
The file does not contain requirements for PyTorch. Because the version of PyTorch depends on the environment, it is not included in the file. Please install PyTorch first according to the environment. See installation instructions below.
|
||||
|
||||
The scripts are tested with PyTorch 1.12.1 and 1.13.0, Diffusers 0.10.2.
|
||||
The scripts are tested with Pytorch 2.1.2. PyTorch 2.2 or later will work. Please install the appropriate version of PyTorch and xformers.
|
||||
|
||||
## Links to how-to-use documents
|
||||
## Links to usage documentation
|
||||
|
||||
All documents are in Japanese currently.
|
||||
Most of the documents are written in Japanese.
|
||||
|
||||
* [Training guide - common](./train_README-ja.md) : data preparation, options etc...
|
||||
* [Dataset config](./config_README-ja.md)
|
||||
* [DreamBooth training guide](./train_db_README-ja.md)
|
||||
* [Step by Step fine-tuning guide](./fine_tune_README_ja.md):
|
||||
* [training LoRA](./train_network_README-ja.md)
|
||||
* [training Textual Inversion](./train_ti_README-ja.md)
|
||||
* note.com [Image generation](https://note.com/kohya_ss/n/n2693183a798e)
|
||||
[English translation by darkstorm2150 is here](https://github.com/darkstorm2150/sd-scripts#links-to-usage-documentation). Thanks to darkstorm2150!
|
||||
|
||||
* [Training guide - common](./docs/train_README-ja.md) : data preparation, options etc...
|
||||
* [Chinese version](./docs/train_README-zh.md)
|
||||
* [SDXL training](./docs/train_SDXL-en.md) (English version)
|
||||
* [Dataset config](./docs/config_README-ja.md)
|
||||
* [English version](./docs/config_README-en.md)
|
||||
* [DreamBooth training guide](./docs/train_db_README-ja.md)
|
||||
* [Step by Step fine-tuning guide](./docs/fine_tune_README_ja.md):
|
||||
* [Training LoRA](./docs/train_network_README-ja.md)
|
||||
* [Training Textual Inversion](./docs/train_ti_README-ja.md)
|
||||
* [Image generation](./docs/gen_img_README-ja.md)
|
||||
* note.com [Model conversion](https://note.com/kohya_ss/n/n374f316fe4ad)
|
||||
|
||||
## Windows Required Dependencies
|
||||
@@ -44,6 +54,8 @@ Python 3.10.6 and Git:
|
||||
- Python 3.10.6: https://www.python.org/ftp/python/3.10.6/python-3.10.6-amd64.exe
|
||||
- git: https://git-scm.com/download/win
|
||||
|
||||
Python 3.10.x, 3.11.x, and 3.12.x will work but not tested.
|
||||
|
||||
Give unrestricted script access to powershell so venv can work:
|
||||
|
||||
- Open an administrator powershell window
|
||||
@@ -61,19 +73,26 @@ cd sd-scripts
|
||||
python -m venv venv
|
||||
.\venv\Scripts\activate
|
||||
|
||||
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
|
||||
pip install torch==2.1.2 torchvision==0.16.2 --index-url https://download.pytorch.org/whl/cu118
|
||||
pip install --upgrade -r requirements.txt
|
||||
pip install -U -I --no-deps https://github.com/C43H66N12O12S2/stable-diffusion-webui/releases/download/f/xformers-0.0.14.dev0-cp310-cp310-win_amd64.whl
|
||||
|
||||
cp .\bitsandbytes_windows\*.dll .\venv\Lib\site-packages\bitsandbytes\
|
||||
cp .\bitsandbytes_windows\cextension.py .\venv\Lib\site-packages\bitsandbytes\cextension.py
|
||||
cp .\bitsandbytes_windows\main.py .\venv\Lib\site-packages\bitsandbytes\cuda_setup\main.py
|
||||
pip install xformers==0.0.23.post1 --index-url https://download.pytorch.org/whl/cu118
|
||||
|
||||
accelerate config
|
||||
```
|
||||
|
||||
update: ``python -m venv venv`` is seemed to be safer than ``python -m venv --system-site-packages venv`` (some user have packages in global python).
|
||||
If `python -m venv` shows only `python`, change `python` to `py`.
|
||||
|
||||
Note: Now `bitsandbytes==0.44.0`, `prodigyopt==1.0` and `lion-pytorch==0.0.6` are included in the requirements.txt. If you'd like to use the another version, please install it manually.
|
||||
|
||||
This installation is for CUDA 11.8. If you use a different version of CUDA, please install the appropriate version of PyTorch and xformers. For example, if you use CUDA 12, please install `pip install torch==2.1.2 torchvision==0.16.2 --index-url https://download.pytorch.org/whl/cu121` and `pip install xformers==0.0.23.post1 --index-url https://download.pytorch.org/whl/cu121`.
|
||||
|
||||
If you use PyTorch 2.2 or later, please change `torch==2.1.2` and `torchvision==0.16.2` and `xformers==0.0.23.post1` to the appropriate version.
|
||||
|
||||
<!--
|
||||
cp .\bitsandbytes_windows\*.dll .\venv\Lib\site-packages\bitsandbytes\
|
||||
cp .\bitsandbytes_windows\cextension.py .\venv\Lib\site-packages\bitsandbytes\cextension.py
|
||||
cp .\bitsandbytes_windows\main.py .\venv\Lib\site-packages\bitsandbytes\cuda_setup\main.py
|
||||
-->
|
||||
Answers to accelerate config:
|
||||
|
||||
```txt
|
||||
@@ -86,16 +105,13 @@ Answers to accelerate config:
|
||||
- fp16
|
||||
```
|
||||
|
||||
note: Some user reports ``ValueError: fp16 mixed precision requires a GPU`` is occurred in training. In this case, answer `0` for the 6th question:
|
||||
If you'd like to use bf16, please answer `bf16` to the last question.
|
||||
|
||||
Note: Some user reports ``ValueError: fp16 mixed precision requires a GPU`` is occurred in training. In this case, answer `0` for the 6th question:
|
||||
``What GPU(s) (by id) should be used for training on this machine as a comma-separated list? [all]:``
|
||||
|
||||
(Single GPU with id `0` will be used.)
|
||||
|
||||
### about PyTorch and xformers
|
||||
|
||||
Other versions of PyTorch and xformers seem to have problems with training.
|
||||
If there is no other reason, please install the specified version.
|
||||
|
||||
## Upgrade
|
||||
|
||||
When a new release comes out you can upgrade your repo with the following command:
|
||||
@@ -109,6 +125,10 @@ pip install --use-pep517 --upgrade -r requirements.txt
|
||||
|
||||
Once the commands have completed successfully you should be ready to use the new version.
|
||||
|
||||
### Upgrade PyTorch
|
||||
|
||||
If you want to upgrade PyTorch, you can upgrade it with `pip install` command in [Windows Installation](#windows-installation) section. `xformers` is also required to be upgraded when PyTorch is upgraded.
|
||||
|
||||
## Credits
|
||||
|
||||
The implementation for LoRA is based on [cloneofsimo's repo](https://github.com/cloneofsimo/lora). Thank you for great work!
|
||||
@@ -125,38 +145,414 @@ The majority of scripts is licensed under ASL 2.0 (including codes from Diffuser
|
||||
|
||||
[BLIP](https://github.com/salesforce/BLIP): BSD-3-Clause
|
||||
|
||||
|
||||
## Change History
|
||||
|
||||
### 23 Apr. 2023, 2023/4/23:
|
||||
### Mar 21, 2025 / 2025-03-21 Version 0.9.1
|
||||
|
||||
- Fixed to log to TensorBoard when `--logging_dir` is specified and `--log_with` is not specified.
|
||||
- `--logging_dir`を指定し`--log_with`を指定しない場合に、以前と同様にTensorBoardへログ出力するよう修正しました。
|
||||
- Fixed a bug where some of LoRA modules for CLIP Text Encoder were not trained. Thank you Nekotekina for PR [#1964](https://github.com/kohya-ss/sd-scripts/pull/1964)
|
||||
- The LoRA modules for CLIP Text Encoder are now 264 modules, which is the same as before. Only 88 modules were trained in the previous version.
|
||||
|
||||
### 22 Apr. 2023, 2023/4/22:
|
||||
### Jan 17, 2025 / 2025-01-17 Version 0.9.0
|
||||
|
||||
- Added support for logging to wandb. Please refer to [PR #428](https://github.com/kohya-ss/sd-scripts/pull/428). Thank you p1atdev!
|
||||
- `wandb` installation is required. Please install it with `pip install wandb`. Login to wandb with `wandb login` command, or set `--wandb_api_key` option for automatic login.
|
||||
- Please let me know if you find any bugs as the test is not complete.
|
||||
- You can automatically login to wandb by setting the `--wandb_api_key` option. Please be careful with the handling of API Key. [PR #435](https://github.com/kohya-ss/sd-scripts/pull/435) Thank you Linaqruf!
|
||||
- __important__ The dependent libraries are updated. Please see [Upgrade](#upgrade) and update the libraries.
|
||||
- bitsandbytes, transformers, accelerate and huggingface_hub are updated.
|
||||
- If you encounter any issues, please report them.
|
||||
|
||||
- Improved the behavior of `--debug_dataset` on non-Windows environments. [PR #429](https://github.com/kohya-ss/sd-scripts/pull/429) Thank you tsukimiya!
|
||||
- Fixed `--face_crop_aug` option not working in Fine tuning method.
|
||||
- Prepared code to use any upscaler in `gen_img_diffusers.py`.
|
||||
- The dev branch is merged into main. The documentation is delayed, and I apologize for that. I will gradually improve it.
|
||||
- The state just before the merge is released as Version 0.8.8, so please use it if you encounter any issues.
|
||||
- The following changes are included.
|
||||
|
||||
- wandbへのロギングをサポートしました。詳細は [PR #428](https://github.com/kohya-ss/sd-scripts/pull/428)をご覧ください。p1atdev氏に感謝します。
|
||||
- `wandb` のインストールが別途必要です。`pip install wandb` でインストールしてください。また `wandb login` でログインしてください(学習スクリプト内でログインする場合は `--wandb_api_key` オプションを設定してください)。
|
||||
- テスト未了のため不具合等ありましたらご連絡ください。
|
||||
- wandbへのロギング時に `--wandb_api_key` オプションを設定することで自動ログインできます。API Keyの扱いにご注意ください。 [PR #435](https://github.com/kohya-ss/sd-scripts/pull/435) Linaqruf氏に感謝します。
|
||||
#### Changes
|
||||
|
||||
- Windows以外の環境での`--debug_dataset` の動作を改善しました。[PR #429](https://github.com/kohya-ss/sd-scripts/pull/429) tsukimiya氏に感謝します。
|
||||
- `--face_crop_aug`オプションがFine tuning方式で動作しなかったのを修正しました。
|
||||
- `gen_img_diffusers.py`に任意のupscalerを利用するためのコード準備を行いました。
|
||||
|
||||
### 19 Apr. 2023, 2023/4/19:
|
||||
- Fixed `lora_interrogator.py` not working. Please refer to [PR #392](https://github.com/kohya-ss/sd-scripts/pull/392) for details. Thank you A2va and heyalexchoi!
|
||||
- Fixed the handling of tags containing `_` in `tag_images_by_wd14_tagger.py`.
|
||||
- `lora_interrogator.py`が動作しなくなっていたのを修正しました。詳細は [PR #392](https://github.com/kohya-ss/sd-scripts/pull/392) をご参照ください。A2va氏およびheyalexchoi氏に感謝します。
|
||||
- `tag_images_by_wd14_tagger.py`で`_`を含むタグの取り扱いを修正しました。
|
||||
- Fixed a bug where the loss weight was incorrect when `--debiased_estimation_loss` was specified with `--v_parameterization`. PR [#1715](https://github.com/kohya-ss/sd-scripts/pull/1715) Thanks to catboxanon! See [the PR](https://github.com/kohya-ss/sd-scripts/pull/1715) for details.
|
||||
- Removed the warning when `--v_parameterization` is specified in SDXL and SD1.5. PR [#1717](https://github.com/kohya-ss/sd-scripts/pull/1717)
|
||||
|
||||
- There was a bug where the min_bucket_reso/max_bucket_reso in the dataset configuration did not create the correct resolution bucket if it was not divisible by bucket_reso_steps. These values are now warned and automatically rounded to a divisible value. Thanks to Maru-mee for raising the issue. Related PR [#1632](https://github.com/kohya-ss/sd-scripts/pull/1632)
|
||||
|
||||
- `bitsandbytes` is updated to 0.44.0. Now you can use `AdEMAMix8bit` and `PagedAdEMAMix8bit` in the training script. PR [#1640](https://github.com/kohya-ss/sd-scripts/pull/1640) Thanks to sdbds!
|
||||
- There is no abbreviation, so please specify the full path like `--optimizer_type bitsandbytes.optim.AdEMAMix8bit` (not bnb but bitsandbytes).
|
||||
|
||||
- Fixed a bug in the cache of latents. When `flip_aug`, `alpha_mask`, and `random_crop` are different in multiple subsets in the dataset configuration file (.toml), the last subset is used instead of reflecting them correctly.
|
||||
|
||||
- Fixed an issue where the timesteps in the batch were the same when using Huber loss. PR [#1628](https://github.com/kohya-ss/sd-scripts/pull/1628) Thanks to recris!
|
||||
|
||||
- Improvements in OFT (Orthogonal Finetuning) Implementation
|
||||
1. Optimization of Calculation Order:
|
||||
- Changed the calculation order in the forward method from (Wx)R to W(xR).
|
||||
- This has improved computational efficiency and processing speed.
|
||||
2. Correction of Bias Application:
|
||||
- In the previous implementation, R was incorrectly applied to the bias.
|
||||
- The new implementation now correctly handles bias by using F.conv2d and F.linear.
|
||||
3. Efficiency Enhancement in Matrix Operations:
|
||||
- Introduced einsum in both the forward and merge_to methods.
|
||||
- This has optimized matrix operations, resulting in further speed improvements.
|
||||
4. Proper Handling of Data Types:
|
||||
- Improved to use torch.float32 during calculations and convert results back to the original data type.
|
||||
- This maintains precision while ensuring compatibility with the original model.
|
||||
5. Unified Processing for Conv2d and Linear Layers:
|
||||
- Implemented a consistent method for applying OFT to both layer types.
|
||||
- These changes have made the OFT implementation more efficient and accurate, potentially leading to improved model performance and training stability.
|
||||
|
||||
- Additional Information
|
||||
* Recommended α value for OFT constraint: We recommend using α values between 1e-4 and 1e-2. This differs slightly from the original implementation of "(α\*out_dim\*out_dim)". Our implementation uses "(α\*out_dim)", hence we recommend higher values than the 1e-5 suggested in the original implementation.
|
||||
|
||||
* Performance Improvement: Training speed has been improved by approximately 30%.
|
||||
|
||||
* Inference Environment: This implementation is compatible with and operates within Stable Diffusion web UI (SD1/2 and SDXL).
|
||||
|
||||
- The INVERSE_SQRT, COSINE_WITH_MIN_LR, and WARMUP_STABLE_DECAY learning rate schedules are now available in the transformers library. See PR [#1393](https://github.com/kohya-ss/sd-scripts/pull/1393) for details. Thanks to sdbds!
|
||||
- See the [transformers documentation](https://huggingface.co/docs/transformers/v4.44.2/en/main_classes/optimizer_schedules#schedules) for details on each scheduler.
|
||||
- `--lr_warmup_steps` and `--lr_decay_steps` can now be specified as a ratio of the number of training steps, not just the step value. Example: `--lr_warmup_steps=0.1` or `--lr_warmup_steps=10%`, etc.
|
||||
|
||||
- When enlarging images in the script (when the size of the training image is small and bucket_no_upscale is not specified), it has been changed to use Pillow's resize and LANCZOS interpolation instead of OpenCV2's resize and Lanczos4 interpolation. The quality of the image enlargement may be slightly improved. PR [#1426](https://github.com/kohya-ss/sd-scripts/pull/1426) Thanks to sdbds!
|
||||
|
||||
- Sample image generation during training now works on non-CUDA devices. PR [#1433](https://github.com/kohya-ss/sd-scripts/pull/1433) Thanks to millie-v!
|
||||
|
||||
- `--v_parameterization` is available in `sdxl_train.py`. The results are unpredictable, so use with caution. PR [#1505](https://github.com/kohya-ss/sd-scripts/pull/1505) Thanks to liesened!
|
||||
|
||||
- Fused optimizer is available for SDXL training. PR [#1259](https://github.com/kohya-ss/sd-scripts/pull/1259) Thanks to 2kpr!
|
||||
- The memory usage during training is significantly reduced by integrating the optimizer's backward pass with step. The training results are the same as before, but if you have plenty of memory, the speed will be slower.
|
||||
- Specify the `--fused_backward_pass` option in `sdxl_train.py`. At this time, only AdaFactor is supported. Gradient accumulation is not available.
|
||||
- Setting mixed precision to `no` seems to use less memory than `fp16` or `bf16`.
|
||||
- Training is possible with a memory usage of about 17GB with a batch size of 1 and fp32. If you specify the `--full_bf16` option, you can further reduce the memory usage (but the accuracy will be lower). With the same memory usage as before, you can increase the batch size.
|
||||
- PyTorch 2.1 or later is required because it uses the new API `Tensor.register_post_accumulate_grad_hook(hook)`.
|
||||
- Mechanism: Normally, backward -> step is performed for each parameter, so all gradients need to be temporarily stored in memory. "Fuse backward and step" reduces memory usage by performing backward/step for each parameter and reflecting the gradient immediately. The more parameters there are, the greater the effect, so it is not effective in other training scripts (LoRA, etc.) where the memory usage peak is elsewhere, and there are no plans to implement it in those training scripts.
|
||||
|
||||
- Optimizer groups feature is added to SDXL training. PR [#1319](https://github.com/kohya-ss/sd-scripts/pull/1319)
|
||||
- Memory usage is reduced by the same principle as Fused optimizer. The training results and speed are the same as Fused optimizer.
|
||||
- Specify the number of groups like `--fused_optimizer_groups 10` in `sdxl_train.py`. Increasing the number of groups reduces memory usage but slows down training. Since the effect is limited to a certain number, it is recommended to specify 4-10.
|
||||
- Any optimizer can be used, but optimizers that automatically calculate the learning rate (such as D-Adaptation and Prodigy) cannot be used. Gradient accumulation is not available.
|
||||
- `--fused_optimizer_groups` cannot be used with `--fused_backward_pass`. When using AdaFactor, the memory usage is slightly larger than with Fused optimizer. PyTorch 2.1 or later is required.
|
||||
- Mechanism: While Fused optimizer performs backward/step for individual parameters within the optimizer, optimizer groups reduce memory usage by grouping parameters and creating multiple optimizers to perform backward/step for each group. Fused optimizer requires implementation on the optimizer side, while optimizer groups are implemented only on the training script side.
|
||||
|
||||
- LoRA+ is supported. PR [#1233](https://github.com/kohya-ss/sd-scripts/pull/1233) Thanks to rockerBOO!
|
||||
- LoRA+ is a method to improve training speed by increasing the learning rate of the UP side (LoRA-B) of LoRA. Specify the multiple. The original paper recommends 16, but adjust as needed. Please see the PR for details.
|
||||
- Specify `loraplus_lr_ratio` with `--network_args`. Example: `--network_args "loraplus_lr_ratio=16"`
|
||||
- `loraplus_unet_lr_ratio` and `loraplus_lr_ratio` can be specified separately for U-Net and Text Encoder.
|
||||
- Example: `--network_args "loraplus_unet_lr_ratio=16" "loraplus_text_encoder_lr_ratio=4"` or `--network_args "loraplus_lr_ratio=16" "loraplus_text_encoder_lr_ratio=4"` etc.
|
||||
- `network_module` `networks.lora` and `networks.dylora` are available.
|
||||
|
||||
- The feature to use the transparency (alpha channel) of the image as a mask in the loss calculation has been added. PR [#1223](https://github.com/kohya-ss/sd-scripts/pull/1223) Thanks to u-haru!
|
||||
- The transparent part is ignored during training. Specify the `--alpha_mask` option in the training script or specify `alpha_mask = true` in the dataset configuration file.
|
||||
- See [About masked loss](./docs/masked_loss_README.md) for details.
|
||||
|
||||
- LoRA training in SDXL now supports block-wise learning rates and block-wise dim (rank). PR [#1331](https://github.com/kohya-ss/sd-scripts/pull/1331)
|
||||
- Specify the learning rate and dim (rank) for each block.
|
||||
- See [Block-wise learning rates in LoRA](./docs/train_network_README-ja.md#階層別学習率) for details (Japanese only).
|
||||
|
||||
- Negative learning rates can now be specified during SDXL model training. PR [#1277](https://github.com/kohya-ss/sd-scripts/pull/1277) Thanks to Cauldrath!
|
||||
- The model is trained to move away from the training images, so the model is easily collapsed. Use with caution. A value close to 0 is recommended.
|
||||
- When specifying from the command line, use `=` like `--learning_rate=-1e-7`.
|
||||
|
||||
- Training scripts can now output training settings to wandb or Tensor Board logs. Specify the `--log_config` option. PR [#1285](https://github.com/kohya-ss/sd-scripts/pull/1285) Thanks to ccharest93, plucked, rockerBOO, and VelocityRa!
|
||||
- Some settings, such as API keys and directory specifications, are not output due to security issues.
|
||||
|
||||
- The ControlNet training script `train_controlnet.py` for SD1.5/2.x was not working, but it has been fixed. PR [#1284](https://github.com/kohya-ss/sd-scripts/pull/1284) Thanks to sdbds!
|
||||
|
||||
- `train_network.py` and `sdxl_train_network.py` now restore the order/position of data loading from DataSet when resuming training. PR [#1353](https://github.com/kohya-ss/sd-scripts/pull/1353) [#1359](https://github.com/kohya-ss/sd-scripts/pull/1359) Thanks to KohakuBlueleaf!
|
||||
- This resolves the issue where the order of data loading from DataSet changes when resuming training.
|
||||
- Specify the `--skip_until_initial_step` option to skip data loading until the specified step. If not specified, data loading starts from the beginning of the DataSet (same as before).
|
||||
- If `--resume` is specified, the step saved in the state is used.
|
||||
- Specify the `--initial_step` or `--initial_epoch` option to skip data loading until the specified step or epoch. Use these options in conjunction with `--skip_until_initial_step`. These options can be used without `--resume` (use them when resuming training with `--network_weights`).
|
||||
|
||||
- An option `--disable_mmap_load_safetensors` is added to disable memory mapping when loading the model's .safetensors in SDXL. PR [#1266](https://github.com/kohya-ss/sd-scripts/pull/1266) Thanks to Zovjsra!
|
||||
- It seems that the model file loading is faster in the WSL environment etc.
|
||||
- Available in `sdxl_train.py`, `sdxl_train_network.py`, `sdxl_train_textual_inversion.py`, and `sdxl_train_control_net_lllite.py`.
|
||||
|
||||
- When there is an error in the cached latents file on disk, the file name is now displayed. PR [#1278](https://github.com/kohya-ss/sd-scripts/pull/1278) Thanks to Cauldrath!
|
||||
|
||||
- Fixed an error that occurs when specifying `--max_dataloader_n_workers` in `tag_images_by_wd14_tagger.py` when Onnx is not used. PR [#1291](
|
||||
https://github.com/kohya-ss/sd-scripts/pull/1291) issue [#1290](
|
||||
https://github.com/kohya-ss/sd-scripts/pull/1290) Thanks to frodo821!
|
||||
|
||||
- Fixed a bug that `caption_separator` cannot be specified in the subset in the dataset settings .toml file. [#1312](https://github.com/kohya-ss/sd-scripts/pull/1312) and [#1313](https://github.com/kohya-ss/sd-scripts/pull/1312) Thanks to rockerBOO!
|
||||
|
||||
- Fixed a potential bug in ControlNet-LLLite training. PR [#1322](https://github.com/kohya-ss/sd-scripts/pull/1322) Thanks to aria1th!
|
||||
|
||||
- Fixed some bugs when using DeepSpeed. Related [#1247](https://github.com/kohya-ss/sd-scripts/pull/1247)
|
||||
|
||||
- Added a prompt option `--f` to `gen_imgs.py` to specify the file name when saving. Also, Diffusers-based keys for LoRA weights are now supported.
|
||||
|
||||
#### 変更点
|
||||
|
||||
- devブランチがmainにマージされました。ドキュメントの整備が遅れており申し訳ありません。少しずつ整備していきます。
|
||||
- マージ直前の状態が Version 0.8.8 としてリリースされていますので、問題があればそちらをご利用ください。
|
||||
- 以下の変更が含まれます。
|
||||
|
||||
- SDXL の学習時に Fused optimizer が使えるようになりました。PR [#1259](https://github.com/kohya-ss/sd-scripts/pull/1259) 2kpr 氏に感謝します。
|
||||
- optimizer の backward pass に step を統合することで学習時のメモリ使用量を大きく削減します。学習結果は未適用時と同一ですが、メモリが潤沢にある場合は速度は遅くなります。
|
||||
- `sdxl_train.py` に `--fused_backward_pass` オプションを指定してください。現時点では optimizer は AdaFactor のみ対応しています。また gradient accumulation は使えません。
|
||||
- mixed precision は `no` のほうが `fp16` や `bf16` よりも使用メモリ量が少ないようです。
|
||||
- バッチサイズ 1、fp32 で 17GB 程度で学習可能なようです。`--full_bf16` オプションを指定するとさらに削減できます(精度は劣ります)。以前と同じメモリ使用量ではバッチサイズを増やせます。
|
||||
- PyTorch 2.1 以降の新 API `Tensor.register_post_accumulate_grad_hook(hook)` を使用しているため、PyTorch 2.1 以降が必要です。
|
||||
- 仕組み:通常は backward -> step の順で行うためすべての勾配を一時的にメモリに保持する必要があります。「backward と step の統合」はパラメータごとに backward/step を行って、勾配をすぐ反映することでメモリ使用量を削減します。パラメータ数が多いほど効果が大きいため、SDXL の学習以外(LoRA 等)ではほぼ効果がなく(メモリ使用量のピークが他の場所にあるため)、それらの学習スクリプトへの実装予定もありません。
|
||||
|
||||
- SDXL の学習時に optimizer group 機能を追加しました。PR [#1319](https://github.com/kohya-ss/sd-scripts/pull/1319)
|
||||
- Fused optimizer と同様の原理でメモリ使用量を削減します。学習結果や速度についても同様です。
|
||||
- `sdxl_train.py` に `--fused_optimizer_groups 10` のようにグループ数を指定してください。グループ数を増やすとメモリ使用量が削減されますが、速度は遅くなります。ある程度の数までしか効果がないため、4~10 程度を指定すると良いでしょう。
|
||||
- 任意の optimizer が使えますが、学習率を自動計算する optimizer (D-Adaptation や Prodigy など)は使えません。gradient accumulation は使えません。
|
||||
- `--fused_optimizer_groups` は `--fused_backward_pass` と併用できません。AdaFactor 使用時は Fused optimizer よりも若干メモリ使用量は大きくなります。PyTorch 2.1 以降が必要です。
|
||||
- 仕組み:Fused optimizer が optimizer 内で個別のパラメータについて backward/step を行っているのに対して、optimizer groups はパラメータをグループ化して複数の optimizer を作成し、それぞれ backward/step を行うことでメモリ使用量を削減します。Fused optimizer は optimizer 側の実装が必要ですが、optimizer groups は学習スクリプト側のみで実装されています。やはり SDXL の学習でのみ効果があります。
|
||||
|
||||
- LoRA+ がサポートされました。PR [#1233](https://github.com/kohya-ss/sd-scripts/pull/1233) rockerBOO 氏に感謝します。
|
||||
- LoRA の UP 側(LoRA-B)の学習率を上げることで学習速度の向上を図る手法です。倍数で指定します。元の論文では 16 が推奨されていますが、データセット等にもよりますので、適宜調整してください。PR もあわせてご覧ください。
|
||||
- `--network_args` で `loraplus_lr_ratio` を指定します。例:`--network_args "loraplus_lr_ratio=16"`
|
||||
- `loraplus_unet_lr_ratio` と `loraplus_lr_ratio` で、U-Net および Text Encoder に個別の値を指定することも可能です。
|
||||
- 例:`--network_args "loraplus_unet_lr_ratio=16" "loraplus_text_encoder_lr_ratio=4"` または `--network_args "loraplus_lr_ratio=16" "loraplus_text_encoder_lr_ratio=4"` など
|
||||
- `network_module` の `networks.lora` および `networks.dylora` で使用可能です。
|
||||
|
||||
- 画像の透明度(アルファチャネル)をロス計算時のマスクとして使用する機能が追加されました。PR [#1223](https://github.com/kohya-ss/sd-scripts/pull/1223) u-haru 氏に感謝します。
|
||||
- 透明部分が学習時に無視されるようになります。学習スクリプトに `--alpha_mask` オプションを指定するか、データセット設定ファイルに `alpha_mask = true` を指定してください。
|
||||
- 詳細は [マスクロスについて](./docs/masked_loss_README-ja.md) をご覧ください。
|
||||
|
||||
- SDXL の LoRA で階層別学習率、階層別 dim (rank) をサポートしました。PR [#1331](https://github.com/kohya-ss/sd-scripts/pull/1331)
|
||||
- ブロックごとに学習率および dim (rank) を指定することができます。
|
||||
- 詳細は [LoRA の階層別学習率](./docs/train_network_README-ja.md#階層別学習率) をご覧ください。
|
||||
|
||||
- `sdxl_train.py` での SDXL モデル学習時に負の学習率が指定できるようになりました。PR [#1277](https://github.com/kohya-ss/sd-scripts/pull/1277) Cauldrath 氏に感謝します。
|
||||
- 学習画像から離れるように学習するため、モデルは容易に崩壊します。注意して使用してください。0 に近い値を推奨します。
|
||||
- コマンドラインから指定する場合、`--learning_rate=-1e-7` のように`=` を使ってください。
|
||||
|
||||
- 各学習スクリプトで学習設定を wandb や Tensor Board などのログに出力できるようになりました。`--log_config` オプションを指定してください。PR [#1285](https://github.com/kohya-ss/sd-scripts/pull/1285) ccharest93 氏、plucked 氏、rockerBOO 氏および VelocityRa 氏に感謝します。
|
||||
- API キーや各種ディレクトリ指定など、一部の設定はセキュリティ上の問題があるため出力されません。
|
||||
|
||||
- SD1.5/2.x 用の ControlNet 学習スクリプト `train_controlnet.py` が動作しなくなっていたのが修正されました。PR [#1284](https://github.com/kohya-ss/sd-scripts/pull/1284) sdbds 氏に感謝します。
|
||||
|
||||
- `train_network.py` および `sdxl_train_network.py` で、学習再開時に DataSet の読み込み順についても復元できるようになりました。PR [#1353](https://github.com/kohya-ss/sd-scripts/pull/1353) [#1359](https://github.com/kohya-ss/sd-scripts/pull/1359) KohakuBlueleaf 氏に感謝します。
|
||||
- これにより、学習再開時に DataSet の読み込み順が変わってしまう問題が解消されます。
|
||||
- `--skip_until_initial_step` オプションを指定すると、指定したステップまで DataSet 読み込みをスキップします。指定しない場合の動作は変わりません(DataSet の最初から読み込みます)
|
||||
- `--resume` オプションを指定すると、state に保存されたステップ数が使用されます。
|
||||
- `--initial_step` または `--initial_epoch` オプションを指定すると、指定したステップまたはエポックまで DataSet 読み込みをスキップします。これらのオプションは `--skip_until_initial_step` と併用してください。またこれらのオプションは `--resume` と併用しなくても使えます(`--network_weights` を用いた学習再開時などにお使いください )。
|
||||
|
||||
- SDXL でモデルの .safetensors を読み込む際にメモリマッピングを無効化するオプション `--disable_mmap_load_safetensors` が追加されました。PR [#1266](https://github.com/kohya-ss/sd-scripts/pull/1266) Zovjsra 氏に感謝します。
|
||||
- WSL 環境等でモデルファイルの読み込みが高速化されるようです。
|
||||
- `sdxl_train.py`、`sdxl_train_network.py`、`sdxl_train_textual_inversion.py`、`sdxl_train_control_net_lllite.py` で使用可能です。
|
||||
|
||||
- ディスクにキャッシュされた latents ファイルに何らかのエラーがあったとき、そのファイル名が表示されるようになりました。 PR [#1278](https://github.com/kohya-ss/sd-scripts/pull/1278) Cauldrath 氏に感謝します。
|
||||
|
||||
- `tag_images_by_wd14_tagger.py` で Onnx 未使用時に `--max_dataloader_n_workers` を指定するとエラーになる不具合が修正されました。 PR [#1291](
|
||||
https://github.com/kohya-ss/sd-scripts/pull/1291) issue [#1290](
|
||||
https://github.com/kohya-ss/sd-scripts/pull/1290) frodo821 氏に感謝します。
|
||||
|
||||
- データセット設定の .toml ファイルで、`caption_separator` が subset に指定できない不具合が修正されました。 PR [#1312](https://github.com/kohya-ss/sd-scripts/pull/1312) および [#1313](https://github.com/kohya-ss/sd-scripts/pull/1313) rockerBOO 氏に感謝します。
|
||||
|
||||
- ControlNet-LLLite 学習時の潜在バグが修正されました。 PR [#1322](https://github.com/kohya-ss/sd-scripts/pull/1322) aria1th 氏に感謝します。
|
||||
|
||||
- DeepSpeed 使用時のいくつかのバグを修正しました。関連 [#1247](https://github.com/kohya-ss/sd-scripts/pull/1247)
|
||||
|
||||
- `gen_imgs.py` のプロンプトオプションに、保存時のファイル名を指定する `--f` オプションを追加しました。また同スクリプトで Diffusers ベースのキーを持つ LoRA の重みに対応しました。
|
||||
|
||||
|
||||
### Oct 27, 2024 / 2024-10-27:
|
||||
|
||||
- `svd_merge_lora.py` VRAM usage has been reduced. However, main memory usage will increase (32GB is sufficient).
|
||||
- This will be included in the next release.
|
||||
- `svd_merge_lora.py` のVRAM使用量を削減しました。ただし、メインメモリの使用量は増加します(32GBあれば十分です)。
|
||||
- これは次回リリースに含まれます。
|
||||
|
||||
### Oct 26, 2024 / 2024-10-26:
|
||||
|
||||
- Fixed a bug in `svd_merge_lora.py`, `sdxl_merge_lora.py`, and `resize_lora.py` where the hash value of LoRA metadata was not correctly calculated when the `save_precision` was different from the `precision` used in the calculation. See issue [#1722](https://github.com/kohya-ss/sd-scripts/pull/1722) for details. Thanks to JujoHotaru for raising the issue.
|
||||
- It will be included in the next release.
|
||||
|
||||
- `svd_merge_lora.py`、`sdxl_merge_lora.py`、`resize_lora.py`で、保存時の精度が計算時の精度と異なる場合、LoRAメタデータのハッシュ値が正しく計算されない不具合を修正しました。詳細は issue [#1722](https://github.com/kohya-ss/sd-scripts/pull/1722) をご覧ください。問題提起していただいた JujoHotaru 氏に感謝します。
|
||||
- 以上は次回リリースに含まれます。
|
||||
|
||||
### Sep 13, 2024 / 2024-09-13:
|
||||
|
||||
- `sdxl_merge_lora.py` now supports OFT. Thanks to Maru-mee for the PR [#1580](https://github.com/kohya-ss/sd-scripts/pull/1580).
|
||||
- `svd_merge_lora.py` now supports LBW. Thanks to terracottahaniwa. See PR [#1575](https://github.com/kohya-ss/sd-scripts/pull/1575) for details.
|
||||
- `sdxl_merge_lora.py` also supports LBW.
|
||||
- See [LoRA Block Weight](https://github.com/hako-mikan/sd-webui-lora-block-weight) by hako-mikan for details on LBW.
|
||||
- These will be included in the next release.
|
||||
|
||||
- `sdxl_merge_lora.py` が OFT をサポートされました。PR [#1580](https://github.com/kohya-ss/sd-scripts/pull/1580) Maru-mee 氏に感謝します。
|
||||
- `svd_merge_lora.py` で LBW がサポートされました。PR [#1575](https://github.com/kohya-ss/sd-scripts/pull/1575) terracottahaniwa 氏に感謝します。
|
||||
- `sdxl_merge_lora.py` でも LBW がサポートされました。
|
||||
- LBW の詳細は hako-mikan 氏の [LoRA Block Weight](https://github.com/hako-mikan/sd-webui-lora-block-weight) をご覧ください。
|
||||
- 以上は次回リリースに含まれます。
|
||||
|
||||
### Jun 23, 2024 / 2024-06-23:
|
||||
|
||||
- Fixed `cache_latents.py` and `cache_text_encoder_outputs.py` not working. (Will be included in the next release.)
|
||||
|
||||
- `cache_latents.py` および `cache_text_encoder_outputs.py` が動作しなくなっていたのを修正しました。(次回リリースに含まれます。)
|
||||
|
||||
### Apr 7, 2024 / 2024-04-07: v0.8.7
|
||||
|
||||
- The default value of `huber_schedule` in Scheduled Huber Loss is changed from `exponential` to `snr`, which is expected to give better results.
|
||||
|
||||
- Scheduled Huber Loss の `huber_schedule` のデフォルト値を `exponential` から、より良い結果が期待できる `snr` に変更しました。
|
||||
|
||||
### Apr 7, 2024 / 2024-04-07: v0.8.6
|
||||
|
||||
#### Highlights
|
||||
|
||||
- The dependent libraries are updated. Please see [Upgrade](#upgrade) and update the libraries.
|
||||
- Especially `imagesize` is newly added, so if you cannot update the libraries immediately, please install with `pip install imagesize==1.4.1` separately.
|
||||
- `bitsandbytes==0.43.0`, `prodigyopt==1.0`, `lion-pytorch==0.0.6` are included in the requirements.txt.
|
||||
- `bitsandbytes` no longer requires complex procedures as it now officially supports Windows.
|
||||
- Also, the PyTorch version is updated to 2.1.2 (PyTorch does not need to be updated immediately). In the upgrade procedure, PyTorch is not updated, so please manually install or update torch, torchvision, xformers if necessary (see [Upgrade PyTorch](#upgrade-pytorch)).
|
||||
- When logging to wandb is enabled, the entire command line is exposed. Therefore, it is recommended to write wandb API key and HuggingFace token in the configuration file (`.toml`). Thanks to bghira for raising the issue.
|
||||
- A warning is displayed at the start of training if such information is included in the command line.
|
||||
- Also, if there is an absolute path, the path may be exposed, so it is recommended to specify a relative path or write it in the configuration file. In such cases, an INFO log is displayed.
|
||||
- See [#1123](https://github.com/kohya-ss/sd-scripts/pull/1123) and PR [#1240](https://github.com/kohya-ss/sd-scripts/pull/1240) for details.
|
||||
- Colab seems to stop with log output. Try specifying `--console_log_simple` option in the training script to disable rich logging.
|
||||
- Other improvements include the addition of masked loss, scheduled Huber Loss, DeepSpeed support, dataset settings improvements, and image tagging improvements. See below for details.
|
||||
|
||||
#### Training scripts
|
||||
|
||||
- `train_network.py` and `sdxl_train_network.py` are modified to record some dataset settings in the metadata of the trained model (`caption_prefix`, `caption_suffix`, `keep_tokens_separator`, `secondary_separator`, `enable_wildcard`).
|
||||
- Fixed a bug that U-Net and Text Encoders are included in the state in `train_network.py` and `sdxl_train_network.py`. The saving and loading of the state are faster, the file size is smaller, and the memory usage when loading is reduced.
|
||||
- DeepSpeed is supported. PR [#1101](https://github.com/kohya-ss/sd-scripts/pull/1101) and [#1139](https://github.com/kohya-ss/sd-scripts/pull/1139) Thanks to BootsofLagrangian! See PR [#1101](https://github.com/kohya-ss/sd-scripts/pull/1101) for details.
|
||||
- The masked loss is supported in each training script. PR [#1207](https://github.com/kohya-ss/sd-scripts/pull/1207) See [Masked loss](#about-masked-loss) for details.
|
||||
- Scheduled Huber Loss has been introduced to each training scripts. PR [#1228](https://github.com/kohya-ss/sd-scripts/pull/1228/) Thanks to kabachuha for the PR and cheald, drhead, and others for the discussion! See the PR and [Scheduled Huber Loss](#about-scheduled-huber-loss) for details.
|
||||
- The options `--noise_offset_random_strength` and `--ip_noise_gamma_random_strength` are added to each training script. These options can be used to vary the noise offset and ip noise gamma in the range of 0 to the specified value. PR [#1177](https://github.com/kohya-ss/sd-scripts/pull/1177) Thanks to KohakuBlueleaf!
|
||||
- The options `--save_state_on_train_end` are added to each training script. PR [#1168](https://github.com/kohya-ss/sd-scripts/pull/1168) Thanks to gesen2egee!
|
||||
- The options `--sample_every_n_epochs` and `--sample_every_n_steps` in each training script now display a warning and ignore them when a number less than or equal to `0` is specified. Thanks to S-Del for raising the issue.
|
||||
|
||||
#### Dataset settings
|
||||
|
||||
- The [English version of the dataset settings documentation](./docs/config_README-en.md) is added. PR [#1175](https://github.com/kohya-ss/sd-scripts/pull/1175) Thanks to darkstorm2150!
|
||||
- The `.toml` file for the dataset config is now read in UTF-8 encoding. PR [#1167](https://github.com/kohya-ss/sd-scripts/pull/1167) Thanks to Horizon1704!
|
||||
- Fixed a bug that the last subset settings are applied to all images when multiple subsets of regularization images are specified in the dataset settings. The settings for each subset are correctly applied to each image. PR [#1205](https://github.com/kohya-ss/sd-scripts/pull/1205) Thanks to feffy380!
|
||||
- Some features are added to the dataset subset settings.
|
||||
- `secondary_separator` is added to specify the tag separator that is not the target of shuffling or dropping.
|
||||
- Specify `secondary_separator=";;;"`. When you specify `secondary_separator`, the part is not shuffled or dropped.
|
||||
- `enable_wildcard` is added. When set to `true`, the wildcard notation `{aaa|bbb|ccc}` can be used. The multi-line caption is also enabled.
|
||||
- `keep_tokens_separator` is updated to be used twice in the caption. When you specify `keep_tokens_separator="|||"`, the part divided by the second `|||` is not shuffled or dropped and remains at the end.
|
||||
- The existing features `caption_prefix` and `caption_suffix` can be used together. `caption_prefix` and `caption_suffix` are processed first, and then `enable_wildcard`, `keep_tokens_separator`, shuffling and dropping, and `secondary_separator` are processed in order.
|
||||
- See [Dataset config](./docs/config_README-en.md) for details.
|
||||
- The dataset with DreamBooth method supports caching image information (size, caption). PR [#1178](https://github.com/kohya-ss/sd-scripts/pull/1178) and [#1206](https://github.com/kohya-ss/sd-scripts/pull/1206) Thanks to KohakuBlueleaf! See [DreamBooth method specific options](./docs/config_README-en.md#dreambooth-specific-options) for details.
|
||||
|
||||
#### Image tagging
|
||||
|
||||
- The support for v3 repositories is added to `tag_image_by_wd14_tagger.py` (`--onnx` option only). PR [#1192](https://github.com/kohya-ss/sd-scripts/pull/1192) Thanks to sdbds!
|
||||
- Onnx may need to be updated. Onnx is not installed by default, so please install or update it with `pip install onnx==1.15.0 onnxruntime-gpu==1.17.1` etc. Please also check the comments in `requirements.txt`.
|
||||
- The model is now saved in the subdirectory as `--repo_id` in `tag_image_by_wd14_tagger.py` . This caches multiple repo_id models. Please delete unnecessary files under `--model_dir`.
|
||||
- Some options are added to `tag_image_by_wd14_tagger.py`.
|
||||
- Some are added in PR [#1216](https://github.com/kohya-ss/sd-scripts/pull/1216) Thanks to Disty0!
|
||||
- Output rating tags `--use_rating_tags` and `--use_rating_tags_as_last_tag`
|
||||
- Output character tags first `--character_tags_first`
|
||||
- Expand character tags and series `--character_tag_expand`
|
||||
- Specify tags to output first `--always_first_tags`
|
||||
- Replace tags `--tag_replacement`
|
||||
- See [Tagging documentation](./docs/wd14_tagger_README-en.md) for details.
|
||||
- Fixed an error when specifying `--beam_search` and a value of 2 or more for `--num_beams` in `make_captions.py`.
|
||||
|
||||
#### About Masked loss
|
||||
|
||||
The masked loss is supported in each training script. To enable the masked loss, specify the `--masked_loss` option.
|
||||
|
||||
The feature is not fully tested, so there may be bugs. If you find any issues, please open an Issue.
|
||||
|
||||
ControlNet dataset is used to specify the mask. The mask images should be the RGB images. The pixel value 255 in R channel is treated as the mask (the loss is calculated only for the pixels with the mask), and 0 is treated as the non-mask. The pixel values 0-255 are converted to 0-1 (i.e., the pixel value 128 is treated as the half weight of the loss). See details for the dataset specification in the [LLLite documentation](./docs/train_lllite_README.md#preparing-the-dataset).
|
||||
|
||||
#### About Scheduled Huber Loss
|
||||
|
||||
Scheduled Huber Loss has been introduced to each training scripts. This is a method to improve robustness against outliers or anomalies (data corruption) in the training data.
|
||||
|
||||
With the traditional MSE (L2) loss function, the impact of outliers could be significant, potentially leading to a degradation in the quality of generated images. On the other hand, while the Huber loss function can suppress the influence of outliers, it tends to compromise the reproduction of fine details in images.
|
||||
|
||||
To address this, the proposed method employs a clever application of the Huber loss function. By scheduling the use of Huber loss in the early stages of training (when noise is high) and MSE in the later stages, it strikes a balance between outlier robustness and fine detail reproduction.
|
||||
|
||||
Experimental results have confirmed that this method achieves higher accuracy on data containing outliers compared to pure Huber loss or MSE. The increase in computational cost is minimal.
|
||||
|
||||
The newly added arguments loss_type, huber_schedule, and huber_c allow for the selection of the loss function type (Huber, smooth L1, MSE), scheduling method (exponential, constant, SNR), and Huber's parameter. This enables optimization based on the characteristics of the dataset.
|
||||
|
||||
See PR [#1228](https://github.com/kohya-ss/sd-scripts/pull/1228/) for details.
|
||||
|
||||
- `loss_type`: Specify the loss function type. Choose `huber` for Huber loss, `smooth_l1` for smooth L1 loss, and `l2` for MSE loss. The default is `l2`, which is the same as before.
|
||||
- `huber_schedule`: Specify the scheduling method. Choose `exponential`, `constant`, or `snr`. The default is `snr`.
|
||||
- `huber_c`: Specify the Huber's parameter. The default is `0.1`.
|
||||
|
||||
Please read [Releases](https://github.com/kohya-ss/sd-scripts/releases) for recent updates.
|
||||
|
||||
#### 主要な変更点
|
||||
|
||||
- 依存ライブラリが更新されました。[アップグレード](./README-ja.md#アップグレード) を参照しライブラリを更新してください。
|
||||
- 特に `imagesize` が新しく追加されていますので、すぐにライブラリの更新ができない場合は `pip install imagesize==1.4.1` で個別にインストールしてください。
|
||||
- `bitsandbytes==0.43.0`、`prodigyopt==1.0`、`lion-pytorch==0.0.6` が requirements.txt に含まれるようになりました。
|
||||
- `bitsandbytes` が公式に Windows をサポートしたため複雑な手順が不要になりました。
|
||||
- また PyTorch のバージョンを 2.1.2 に更新しました。PyTorch はすぐに更新する必要はありません。更新時は、アップグレードの手順では PyTorch が更新されませんので、torch、torchvision、xformers を手動でインストールしてください。
|
||||
- wandb へのログ出力が有効の場合、コマンドライン全体が公開されます。そのため、コマンドラインに wandb の API キーや HuggingFace のトークンなどが含まれる場合、設定ファイル(`.toml`)への記載をお勧めします。問題提起していただいた bghira 氏に感謝します。
|
||||
- このような場合には学習開始時に警告が表示されます。
|
||||
- また絶対パスの指定がある場合、そのパスが公開される可能性がありますので、相対パスを指定するか設定ファイルに記載することをお勧めします。このような場合は INFO ログが表示されます。
|
||||
- 詳細は [#1123](https://github.com/kohya-ss/sd-scripts/pull/1123) および PR [#1240](https://github.com/kohya-ss/sd-scripts/pull/1240) をご覧ください。
|
||||
- Colab での動作時、ログ出力で停止してしまうようです。学習スクリプトに `--console_log_simple` オプションを指定し、rich のロギングを無効してお試しください。
|
||||
- その他、マスクロス追加、Scheduled Huber Loss 追加、DeepSpeed 対応、データセット設定の改善、画像タグ付けの改善などがあります。詳細は以下をご覧ください。
|
||||
|
||||
#### 学習スクリプト
|
||||
|
||||
- `train_network.py` および `sdxl_train_network.py` で、学習したモデルのメタデータに一部のデータセット設定が記録されるよう修正しました(`caption_prefix`、`caption_suffix`、`keep_tokens_separator`、`secondary_separator`、`enable_wildcard`)。
|
||||
- `train_network.py` および `sdxl_train_network.py` で、state に U-Net および Text Encoder が含まれる不具合を修正しました。state の保存、読み込みが高速化され、ファイルサイズも小さくなり、また読み込み時のメモリ使用量も削減されます。
|
||||
- DeepSpeed がサポートされました。PR [#1101](https://github.com/kohya-ss/sd-scripts/pull/1101) 、[#1139](https://github.com/kohya-ss/sd-scripts/pull/1139) BootsofLagrangian 氏に感謝します。詳細は PR [#1101](https://github.com/kohya-ss/sd-scripts/pull/1101) をご覧ください。
|
||||
- 各学習スクリプトでマスクロスをサポートしました。PR [#1207](https://github.com/kohya-ss/sd-scripts/pull/1207) 詳細は [マスクロスについて](#マスクロスについて) をご覧ください。
|
||||
- 各学習スクリプトに Scheduled Huber Loss を追加しました。PR [#1228](https://github.com/kohya-ss/sd-scripts/pull/1228/) ご提案いただいた kabachuha 氏、および議論を深めてくださった cheald 氏、drhead 氏を始めとする諸氏に感謝します。詳細は当該 PR および [Scheduled Huber Loss について](#scheduled-huber-loss-について) をご覧ください。
|
||||
- 各学習スクリプトに、noise offset、ip noise gammaを、それぞれ 0~指定した値の範囲で変動させるオプション `--noise_offset_random_strength` および `--ip_noise_gamma_random_strength` が追加されました。 PR [#1177](https://github.com/kohya-ss/sd-scripts/pull/1177) KohakuBlueleaf 氏に感謝します。
|
||||
- 各学習スクリプトに、学習終了時に state を保存する `--save_state_on_train_end` オプションが追加されました。 PR [#1168](https://github.com/kohya-ss/sd-scripts/pull/1168) gesen2egee 氏に感謝します。
|
||||
- 各学習スクリプトで `--sample_every_n_epochs` および `--sample_every_n_steps` オプションに `0` 以下の数値を指定した時、警告を表示するとともにそれらを無視するよう変更しました。問題提起していただいた S-Del 氏に感謝します。
|
||||
|
||||
#### データセット設定
|
||||
|
||||
- データセット設定の `.toml` ファイルが UTF-8 encoding で読み込まれるようになりました。PR [#1167](https://github.com/kohya-ss/sd-scripts/pull/1167) Horizon1704 氏に感謝します。
|
||||
- データセット設定で、正則化画像のサブセットを複数指定した時、最後のサブセットの各種設定がすべてのサブセットの画像に適用される不具合が修正されました。それぞれのサブセットの設定が、それぞれの画像に正しく適用されます。PR [#1205](https://github.com/kohya-ss/sd-scripts/pull/1205) feffy380 氏に感謝します。
|
||||
- データセットのサブセット設定にいくつかの機能を追加しました。
|
||||
- シャッフルの対象とならないタグ分割識別子の指定 `secondary_separator` を追加しました。`secondary_separator=";;;"` のように指定します。`secondary_separator` で区切ることで、その部分はシャッフル、drop 時にまとめて扱われます。
|
||||
- `enable_wildcard` を追加しました。`true` にするとワイルドカード記法 `{aaa|bbb|ccc}` が使えます。また複数行キャプションも有効になります。
|
||||
- `keep_tokens_separator` をキャプション内に 2 つ使えるようにしました。たとえば `keep_tokens_separator="|||"` と指定したとき、`1girl, hatsune miku, vocaloid ||| stage, mic ||| best quality, rating: general` とキャプションを指定すると、二番目の `|||` で分割された部分はシャッフル、drop されず末尾に残ります。
|
||||
- 既存の機能 `caption_prefix` と `caption_suffix` とあわせて使えます。`caption_prefix` と `caption_suffix` は一番最初に処理され、その後、ワイルドカード、`keep_tokens_separator`、シャッフルおよび drop、`secondary_separator` の順に処理されます。
|
||||
- 詳細は [データセット設定](./docs/config_README-ja.md) をご覧ください。
|
||||
- DreamBooth 方式の DataSet で画像情報(サイズ、キャプション)をキャッシュする機能が追加されました。PR [#1178](https://github.com/kohya-ss/sd-scripts/pull/1178)、[#1206](https://github.com/kohya-ss/sd-scripts/pull/1206) KohakuBlueleaf 氏に感謝します。詳細は [データセット設定](./docs/config_README-ja.md#dreambooth-方式専用のオプション) をご覧ください。
|
||||
- データセット設定の[英語版ドキュメント](./docs/config_README-en.md) が追加されました。PR [#1175](https://github.com/kohya-ss/sd-scripts/pull/1175) darkstorm2150 氏に感謝します。
|
||||
|
||||
#### 画像のタグ付け
|
||||
|
||||
- `tag_image_by_wd14_tagger.py` で v3 のリポジトリがサポートされました(`--onnx` 指定時のみ有効)。 PR [#1192](https://github.com/kohya-ss/sd-scripts/pull/1192) sdbds 氏に感謝します。
|
||||
- Onnx のバージョンアップが必要になるかもしれません。デフォルトでは Onnx はインストールされていませんので、`pip install onnx==1.15.0 onnxruntime-gpu==1.17.1` 等でインストール、アップデートしてください。`requirements.txt` のコメントもあわせてご確認ください。
|
||||
- `tag_image_by_wd14_tagger.py` で、モデルを`--repo_id` のサブディレクトリに保存するようにしました。これにより複数のモデルファイルがキャッシュされます。`--model_dir` 直下の不要なファイルは削除願います。
|
||||
- `tag_image_by_wd14_tagger.py` にいくつかのオプションを追加しました。
|
||||
- 一部は PR [#1216](https://github.com/kohya-ss/sd-scripts/pull/1216) で追加されました。Disty0 氏に感謝します。
|
||||
- レーティングタグを出力する `--use_rating_tags` および `--use_rating_tags_as_last_tag`
|
||||
- キャラクタタグを最初に出力する `--character_tags_first`
|
||||
- キャラクタタグとシリーズを展開する `--character_tag_expand`
|
||||
- 常に最初に出力するタグを指定する `--always_first_tags`
|
||||
- タグを置換する `--tag_replacement`
|
||||
- 詳細は [タグ付けに関するドキュメント](./docs/wd14_tagger_README-ja.md) をご覧ください。
|
||||
- `make_captions.py` で `--beam_search` を指定し `--num_beams` に2以上の値を指定した時のエラーを修正しました。
|
||||
|
||||
#### マスクロスについて
|
||||
|
||||
各学習スクリプトでマスクロスをサポートしました。マスクロスを有効にするには `--masked_loss` オプションを指定してください。
|
||||
|
||||
機能は完全にテストされていないため、不具合があるかもしれません。その場合は Issue を立てていただけると助かります。
|
||||
|
||||
マスクの指定には ControlNet データセットを使用します。マスク画像は RGB 画像である必要があります。R チャンネルのピクセル値 255 がロス計算対象、0 がロス計算対象外になります。0-255 の値は、0-1 の範囲に変換されます(つまりピクセル値 128 の部分はロスの重みが半分になります)。データセットの詳細は [LLLite ドキュメント](./docs/train_lllite_README-ja.md#データセットの準備) をご覧ください。
|
||||
|
||||
#### Scheduled Huber Loss について
|
||||
|
||||
各学習スクリプトに、学習データ中の異常値や外れ値(data corruption)への耐性を高めるための手法、Scheduled Huber Lossが導入されました。
|
||||
|
||||
従来のMSE(L2)損失関数では、異常値の影響を大きく受けてしまい、生成画像の品質低下を招く恐れがありました。一方、Huber損失関数は異常値の影響を抑えられますが、画像の細部再現性が損なわれがちでした。
|
||||
|
||||
この手法ではHuber損失関数の適用を工夫し、学習の初期段階(ノイズが大きい場合)ではHuber損失を、後期段階ではMSEを用いるようスケジューリングすることで、異常値耐性と細部再現性のバランスを取ります。
|
||||
|
||||
実験の結果では、この手法が純粋なHuber損失やMSEと比べ、異常値を含むデータでより高い精度を達成することが確認されています。また計算コストの増加はわずかです。
|
||||
|
||||
具体的には、新たに追加された引数loss_type、huber_schedule、huber_cで、損失関数の種類(Huber, smooth L1, MSE)とスケジューリング方法(exponential, constant, SNR)を選択できます。これによりデータセットに応じた最適化が可能になります。
|
||||
|
||||
詳細は PR [#1228](https://github.com/kohya-ss/sd-scripts/pull/1228/) をご覧ください。
|
||||
|
||||
- `loss_type` : 損失関数の種類を指定します。`huber` で Huber損失、`smooth_l1` で smooth L1 損失、`l2` で MSE 損失を選択します。デフォルトは `l2` で、従来と同様です。
|
||||
- `huber_schedule` : スケジューリング方法を指定します。`exponential` で指数関数的、`constant` で一定、`snr` で信号対雑音比に基づくスケジューリングを選択します。デフォルトは `snr` です。
|
||||
- `huber_c` : Huber損失のパラメータを指定します。デフォルトは `0.1` です。
|
||||
|
||||
PR 内でいくつかの比較が共有されています。この機能を試す場合、最初は `--loss_type smooth_l1 --huber_schedule snr --huber_c 0.1` などで試してみるとよいかもしれません。
|
||||
|
||||
最近の更新情報は [Release](https://github.com/kohya-ss/sd-scripts/releases) をご覧ください。
|
||||
|
||||
## Additional Information
|
||||
|
||||
### Naming of LoRA
|
||||
|
||||
@@ -170,52 +566,14 @@ The LoRA supported by `train_network.py` has been named to avoid confusion. The
|
||||
|
||||
In addition to 1., LoRA for Conv2d layers with 3x3 kernel
|
||||
|
||||
LoRA-LierLa is the default LoRA type for `train_network.py` (without `conv_dim` network arg). LoRA-LierLa can be used with [our extension](https://github.com/kohya-ss/sd-webui-additional-networks) for AUTOMATIC1111's Web UI, or with the built-in LoRA feature of the Web UI.
|
||||
LoRA-LierLa is the default LoRA type for `train_network.py` (without `conv_dim` network arg).
|
||||
<!--
|
||||
LoRA-LierLa can be used with [our extension](https://github.com/kohya-ss/sd-webui-additional-networks) for AUTOMATIC1111's Web UI, or with the built-in LoRA feature of the Web UI.
|
||||
|
||||
To use LoRA-C3Liar with Web UI, please use our extension.
|
||||
To use LoRA-C3Lier with Web UI, please use our extension.
|
||||
-->
|
||||
|
||||
### LoRAの名称について
|
||||
|
||||
`train_network.py` がサポートするLoRAについて、混乱を避けるため名前を付けました。ドキュメントは更新済みです。以下は当リポジトリ内の独自の名称です。
|
||||
|
||||
1. __LoRA-LierLa__ : (LoRA for __Li__ n __e__ a __r__ __La__ yers、リエラと読みます)
|
||||
|
||||
Linear 層およびカーネルサイズ 1x1 の Conv2d 層に適用されるLoRA
|
||||
|
||||
2. __LoRA-C3Lier__ : (LoRA for __C__ olutional layers with __3__ x3 Kernel and __Li__ n __e__ a __r__ layers、セリアと読みます)
|
||||
|
||||
1.に加え、カーネルサイズ 3x3 の Conv2d 層に適用されるLoRA
|
||||
|
||||
LoRA-LierLa は[Web UI向け拡張](https://github.com/kohya-ss/sd-webui-additional-networks)、またはAUTOMATIC1111氏のWeb UIのLoRA機能で使用することができます。
|
||||
|
||||
LoRA-C3Liarを使いWeb UIで生成するには拡張を使用してください。
|
||||
|
||||
### 17 Apr. 2023, 2023/4/17:
|
||||
|
||||
- Added the `--recursive` option to each script in the `finetune` folder to process folders recursively. Please refer to [PR #400](https://github.com/kohya-ss/sd-scripts/pull/400/) for details. Thanks to Linaqruf!
|
||||
- `finetune`フォルダ内の各スクリプトに再起的にフォルダを処理するオプション`--recursive`を追加しました。詳細は [PR #400](https://github.com/kohya-ss/sd-scripts/pull/400/) を参照してください。Linaqruf 氏に感謝します。
|
||||
|
||||
### 14 Apr. 2023, 2023/4/14:
|
||||
- Fixed a bug that caused an error when loading DyLoRA with the `--network_weight` option in `train_network.py`.
|
||||
- `train_network.py`で、DyLoRAを`--network_weight`オプションで読み込むとエラーになる不具合を修正しました。
|
||||
|
||||
### 13 Apr. 2023, 2023/4/13:
|
||||
|
||||
- Added support for DyLoRA in `train_network.py`. Please refer to [here](./train_network_README-ja.md#dylora) for details (currently only in Japanese).
|
||||
- Added support for caching latents to disk in each training script. Please specify __both__ `--cache_latents` and `--cache_latents_to_disk` options.
|
||||
- The files are saved in the same folder as the images with the extension `.npz`. If you specify the `--flip_aug` option, the files with `_flip.npz` will also be saved.
|
||||
- Multi-GPU training has not been tested.
|
||||
- This feature is not tested with all combinations of datasets and training scripts, so there may be bugs.
|
||||
- Added workaround for an error that occurs when training with `fp16` or `bf16` in `fine_tune.py`.
|
||||
|
||||
- `train_network.py`でDyLoRAをサポートしました。詳細は[こちら](./train_network_README-ja.md#dylora)をご覧ください。
|
||||
- 各学習スクリプトでlatentのディスクへのキャッシュをサポートしました。`--cache_latents`オプションに __加えて__、`--cache_latents_to_disk`オプションを指定してください。
|
||||
- 画像と同じフォルダに、拡張子 `.npz` で保存されます。`--flip_aug`オプションを指定した場合、`_flip.npz`が付いたファイルにも保存されます。
|
||||
- マルチGPUでの学習は未テストです。
|
||||
- すべてのDataset、学習スクリプトの組み合わせでテストしたわけではないため、不具合があるかもしれません。
|
||||
- `fine_tune.py`で、`fp16`および`bf16`の学習時にエラーが出る不具合に対して対策を行いました。
|
||||
|
||||
## Sample image generation during training
|
||||
### Sample image generation during training
|
||||
A prompt file might look like this, for example
|
||||
|
||||
```
|
||||
@@ -236,28 +594,3 @@ masterpiece, best quality, 1boy, in business suit, standing at street, looking b
|
||||
* `--s` Specifies the number of steps in the generation.
|
||||
|
||||
The prompt weighting such as `( )` and `[ ]` are working.
|
||||
|
||||
## サンプル画像生成
|
||||
プロンプトファイルは例えば以下のようになります。
|
||||
|
||||
```
|
||||
# prompt 1
|
||||
masterpiece, best quality, (1girl), in white shirts, upper body, looking at viewer, simple background --n low quality, worst quality, bad anatomy,bad composition, poor, low effort --w 768 --h 768 --d 1 --l 7.5 --s 28
|
||||
|
||||
# prompt 2
|
||||
masterpiece, best quality, 1boy, in business suit, standing at street, looking back --n (low quality, worst quality), bad anatomy,bad composition, poor, low effort --w 576 --h 832 --d 2 --l 5.5 --s 40
|
||||
```
|
||||
|
||||
`#` で始まる行はコメントになります。`--n` のように「ハイフン二個+英小文字」の形でオプションを指定できます。以下が使用可能できます。
|
||||
|
||||
* `--n` Negative prompt up to the next option.
|
||||
* `--w` Specifies the width of the generated image.
|
||||
* `--h` Specifies the height of the generated image.
|
||||
* `--d` Specifies the seed of the generated image.
|
||||
* `--l` Specifies the CFG scale of the generated image.
|
||||
* `--s` Specifies the number of steps in the generation.
|
||||
|
||||
`( )` や `[ ]` などの重みづけも動作します。
|
||||
|
||||
Please read [Releases](https://github.com/kohya-ss/sd-scripts/releases) for recent updates.
|
||||
最近の更新情報は [Release](https://github.com/kohya-ss/sd-scripts/releases) をご覧ください。
|
||||
|
||||
213
XTI_hijack.py
213
XTI_hijack.py
@@ -1,133 +1,127 @@
|
||||
import torch
|
||||
from library.device_utils import init_ipex
|
||||
init_ipex()
|
||||
|
||||
from typing import Union, List, Optional, Dict, Any, Tuple
|
||||
from diffusers.models.unet_2d_condition import UNet2DConditionOutput
|
||||
|
||||
def unet_forward_XTI(self,
|
||||
sample: torch.FloatTensor,
|
||||
timestep: Union[torch.Tensor, float, int],
|
||||
encoder_hidden_states: torch.Tensor,
|
||||
class_labels: Optional[torch.Tensor] = None,
|
||||
return_dict: bool = True,
|
||||
) -> Union[UNet2DConditionOutput, Tuple]:
|
||||
r"""
|
||||
Args:
|
||||
sample (`torch.FloatTensor`): (batch, channel, height, width) noisy inputs tensor
|
||||
timestep (`torch.FloatTensor` or `float` or `int`): (batch) timesteps
|
||||
encoder_hidden_states (`torch.FloatTensor`): (batch, sequence_length, feature_dim) encoder hidden states
|
||||
return_dict (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not to return a [`models.unet_2d_condition.UNet2DConditionOutput`] instead of a plain tuple.
|
||||
from library.original_unet import SampleOutput
|
||||
|
||||
Returns:
|
||||
[`~models.unet_2d_condition.UNet2DConditionOutput`] or `tuple`:
|
||||
[`~models.unet_2d_condition.UNet2DConditionOutput`] if `return_dict` is True, otherwise a `tuple`. When
|
||||
returning a tuple, the first element is the sample tensor.
|
||||
"""
|
||||
# By default samples have to be AT least a multiple of the overall upsampling factor.
|
||||
# The overall upsampling factor is equal to 2 ** (# num of upsampling layears).
|
||||
# However, the upsampling interpolation output size can be forced to fit any upsampling size
|
||||
# on the fly if necessary.
|
||||
default_overall_up_factor = 2**self.num_upsamplers
|
||||
|
||||
# upsample size should be forwarded when sample is not a multiple of `default_overall_up_factor`
|
||||
forward_upsample_size = False
|
||||
upsample_size = None
|
||||
def unet_forward_XTI(
|
||||
self,
|
||||
sample: torch.FloatTensor,
|
||||
timestep: Union[torch.Tensor, float, int],
|
||||
encoder_hidden_states: torch.Tensor,
|
||||
class_labels: Optional[torch.Tensor] = None,
|
||||
return_dict: bool = True,
|
||||
) -> Union[Dict, Tuple]:
|
||||
r"""
|
||||
Args:
|
||||
sample (`torch.FloatTensor`): (batch, channel, height, width) noisy inputs tensor
|
||||
timestep (`torch.FloatTensor` or `float` or `int`): (batch) timesteps
|
||||
encoder_hidden_states (`torch.FloatTensor`): (batch, sequence_length, feature_dim) encoder hidden states
|
||||
return_dict (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not to return a dict instead of a plain tuple.
|
||||
|
||||
if any(s % default_overall_up_factor != 0 for s in sample.shape[-2:]):
|
||||
logger.info("Forward upsample size to force interpolation output size.")
|
||||
forward_upsample_size = True
|
||||
Returns:
|
||||
`SampleOutput` or `tuple`:
|
||||
`SampleOutput` if `return_dict` is True, otherwise a `tuple`. When returning a tuple, the first element is the sample tensor.
|
||||
"""
|
||||
# By default samples have to be AT least a multiple of the overall upsampling factor.
|
||||
# The overall upsampling factor is equal to 2 ** (# num of upsampling layears).
|
||||
# However, the upsampling interpolation output size can be forced to fit any upsampling size
|
||||
# on the fly if necessary.
|
||||
# デフォルトではサンプルは「2^アップサンプルの数」、つまり64の倍数である必要がある
|
||||
# ただそれ以外のサイズにも対応できるように、必要ならアップサンプルのサイズを変更する
|
||||
# 多分画質が悪くなるので、64で割り切れるようにしておくのが良い
|
||||
default_overall_up_factor = 2**self.num_upsamplers
|
||||
|
||||
# 0. center input if necessary
|
||||
if self.config.center_input_sample:
|
||||
sample = 2 * sample - 1.0
|
||||
# upsample size should be forwarded when sample is not a multiple of `default_overall_up_factor`
|
||||
# 64で割り切れないときはupsamplerにサイズを伝える
|
||||
forward_upsample_size = False
|
||||
upsample_size = None
|
||||
|
||||
# 1. time
|
||||
timesteps = timestep
|
||||
if not torch.is_tensor(timesteps):
|
||||
# TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
|
||||
# This would be a good case for the `match` statement (Python 3.10+)
|
||||
is_mps = sample.device.type == "mps"
|
||||
if isinstance(timestep, float):
|
||||
dtype = torch.float32 if is_mps else torch.float64
|
||||
else:
|
||||
dtype = torch.int32 if is_mps else torch.int64
|
||||
timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
|
||||
elif len(timesteps.shape) == 0:
|
||||
timesteps = timesteps[None].to(sample.device)
|
||||
if any(s % default_overall_up_factor != 0 for s in sample.shape[-2:]):
|
||||
# logger.info("Forward upsample size to force interpolation output size.")
|
||||
forward_upsample_size = True
|
||||
|
||||
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
|
||||
timesteps = timesteps.expand(sample.shape[0])
|
||||
# 1. time
|
||||
timesteps = timestep
|
||||
timesteps = self.handle_unusual_timesteps(sample, timesteps) # 変な時だけ処理
|
||||
|
||||
t_emb = self.time_proj(timesteps)
|
||||
t_emb = self.time_proj(timesteps)
|
||||
|
||||
# timesteps does not contain any weights and will always return f32 tensors
|
||||
# but time_embedding might actually be running in fp16. so we need to cast here.
|
||||
# there might be better ways to encapsulate this.
|
||||
t_emb = t_emb.to(dtype=self.dtype)
|
||||
emb = self.time_embedding(t_emb)
|
||||
# timesteps does not contain any weights and will always return f32 tensors
|
||||
# but time_embedding might actually be running in fp16. so we need to cast here.
|
||||
# there might be better ways to encapsulate this.
|
||||
# timestepsは重みを含まないので常にfloat32のテンソルを返す
|
||||
# しかしtime_embeddingはfp16で動いているかもしれないので、ここでキャストする必要がある
|
||||
# time_projでキャストしておけばいいんじゃね?
|
||||
t_emb = t_emb.to(dtype=self.dtype)
|
||||
emb = self.time_embedding(t_emb)
|
||||
|
||||
if self.config.num_class_embeds is not None:
|
||||
if class_labels is None:
|
||||
raise ValueError("class_labels should be provided when num_class_embeds > 0")
|
||||
class_emb = self.class_embedding(class_labels).to(dtype=self.dtype)
|
||||
emb = emb + class_emb
|
||||
# 2. pre-process
|
||||
sample = self.conv_in(sample)
|
||||
|
||||
# 2. pre-process
|
||||
sample = self.conv_in(sample)
|
||||
# 3. down
|
||||
down_block_res_samples = (sample,)
|
||||
down_i = 0
|
||||
for downsample_block in self.down_blocks:
|
||||
# downblockはforwardで必ずencoder_hidden_statesを受け取るようにしても良さそうだけど、
|
||||
# まあこちらのほうがわかりやすいかもしれない
|
||||
if downsample_block.has_cross_attention:
|
||||
sample, res_samples = downsample_block(
|
||||
hidden_states=sample,
|
||||
temb=emb,
|
||||
encoder_hidden_states=encoder_hidden_states[down_i : down_i + 2],
|
||||
)
|
||||
down_i += 2
|
||||
else:
|
||||
sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
|
||||
|
||||
# 3. down
|
||||
down_block_res_samples = (sample,)
|
||||
down_i = 0
|
||||
for downsample_block in self.down_blocks:
|
||||
if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
|
||||
sample, res_samples = downsample_block(
|
||||
hidden_states=sample,
|
||||
temb=emb,
|
||||
encoder_hidden_states=encoder_hidden_states[down_i:down_i+2],
|
||||
)
|
||||
down_i += 2
|
||||
else:
|
||||
sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
|
||||
down_block_res_samples += res_samples
|
||||
|
||||
down_block_res_samples += res_samples
|
||||
# 4. mid
|
||||
sample = self.mid_block(sample, emb, encoder_hidden_states=encoder_hidden_states[6])
|
||||
|
||||
# 4. mid
|
||||
sample = self.mid_block(sample, emb, encoder_hidden_states=encoder_hidden_states[6])
|
||||
# 5. up
|
||||
up_i = 7
|
||||
for i, upsample_block in enumerate(self.up_blocks):
|
||||
is_final_block = i == len(self.up_blocks) - 1
|
||||
|
||||
# 5. up
|
||||
up_i = 7
|
||||
for i, upsample_block in enumerate(self.up_blocks):
|
||||
is_final_block = i == len(self.up_blocks) - 1
|
||||
res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
|
||||
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)] # skip connection
|
||||
|
||||
res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
|
||||
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
|
||||
# if we have not reached the final block and need to forward the upsample size, we do it here
|
||||
# 前述のように最後のブロック以外ではupsample_sizeを伝える
|
||||
if not is_final_block and forward_upsample_size:
|
||||
upsample_size = down_block_res_samples[-1].shape[2:]
|
||||
|
||||
# if we have not reached the final block and need to forward the
|
||||
# upsample size, we do it here
|
||||
if not is_final_block and forward_upsample_size:
|
||||
upsample_size = down_block_res_samples[-1].shape[2:]
|
||||
if upsample_block.has_cross_attention:
|
||||
sample = upsample_block(
|
||||
hidden_states=sample,
|
||||
temb=emb,
|
||||
res_hidden_states_tuple=res_samples,
|
||||
encoder_hidden_states=encoder_hidden_states[up_i : up_i + 3],
|
||||
upsample_size=upsample_size,
|
||||
)
|
||||
up_i += 3
|
||||
else:
|
||||
sample = upsample_block(
|
||||
hidden_states=sample, temb=emb, res_hidden_states_tuple=res_samples, upsample_size=upsample_size
|
||||
)
|
||||
|
||||
if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
|
||||
sample = upsample_block(
|
||||
hidden_states=sample,
|
||||
temb=emb,
|
||||
res_hidden_states_tuple=res_samples,
|
||||
encoder_hidden_states=encoder_hidden_states[up_i:up_i+3],
|
||||
upsample_size=upsample_size,
|
||||
)
|
||||
up_i += 3
|
||||
else:
|
||||
sample = upsample_block(
|
||||
hidden_states=sample, temb=emb, res_hidden_states_tuple=res_samples, upsample_size=upsample_size
|
||||
)
|
||||
# 6. post-process
|
||||
sample = self.conv_norm_out(sample)
|
||||
sample = self.conv_act(sample)
|
||||
sample = self.conv_out(sample)
|
||||
# 6. post-process
|
||||
sample = self.conv_norm_out(sample)
|
||||
sample = self.conv_act(sample)
|
||||
sample = self.conv_out(sample)
|
||||
|
||||
if not return_dict:
|
||||
return (sample,)
|
||||
if not return_dict:
|
||||
return (sample,)
|
||||
|
||||
return SampleOutput(sample=sample)
|
||||
|
||||
return UNet2DConditionOutput(sample=sample)
|
||||
|
||||
def downblock_forward_XTI(
|
||||
self, hidden_states, temb=None, encoder_hidden_states=None, attention_mask=None, cross_attention_kwargs=None
|
||||
@@ -166,6 +160,7 @@ def downblock_forward_XTI(
|
||||
|
||||
return hidden_states, output_states
|
||||
|
||||
|
||||
def upblock_forward_XTI(
|
||||
self,
|
||||
hidden_states,
|
||||
@@ -199,11 +194,11 @@ def upblock_forward_XTI(
|
||||
else:
|
||||
hidden_states = resnet(hidden_states, temb)
|
||||
hidden_states = attn(hidden_states, encoder_hidden_states=encoder_hidden_states[i]).sample
|
||||
|
||||
|
||||
i += 1
|
||||
|
||||
if self.upsamplers is not None:
|
||||
for upsampler in self.upsamplers:
|
||||
hidden_states = upsampler(hidden_states, upsample_size)
|
||||
|
||||
return hidden_states
|
||||
return hidden_states
|
||||
|
||||
22
_typos.toml
22
_typos.toml
@@ -2,6 +2,7 @@
|
||||
# Instruction: https://github.com/marketplace/actions/typos-action#getting-started
|
||||
|
||||
[default.extend-identifiers]
|
||||
ddPn08="ddPn08"
|
||||
|
||||
[default.extend-words]
|
||||
NIN="NIN"
|
||||
@@ -9,7 +10,26 @@ parms="parms"
|
||||
nin="nin"
|
||||
extention="extention" # Intentionally left
|
||||
nd="nd"
|
||||
shs="shs"
|
||||
sts="sts"
|
||||
scs="scs"
|
||||
cpc="cpc"
|
||||
coc="coc"
|
||||
cic="cic"
|
||||
msm="msm"
|
||||
usu="usu"
|
||||
ici="ici"
|
||||
lvl="lvl"
|
||||
dii="dii"
|
||||
muk="muk"
|
||||
ori="ori"
|
||||
hru="hru"
|
||||
rik="rik"
|
||||
koo="koo"
|
||||
yos="yos"
|
||||
wn="wn"
|
||||
hime="hime"
|
||||
|
||||
|
||||
[files]
|
||||
extend-exclude = ["_typos.toml"]
|
||||
extend-exclude = ["_typos.toml", "venv"]
|
||||
|
||||
BIN
bitsandbytes_windows/libbitsandbytes_cuda118.dll
Normal file
BIN
bitsandbytes_windows/libbitsandbytes_cuda118.dll
Normal file
Binary file not shown.
@@ -1,166 +1,166 @@
|
||||
"""
|
||||
extract factors the build is dependent on:
|
||||
[X] compute capability
|
||||
[ ] TODO: Q - What if we have multiple GPUs of different makes?
|
||||
- CUDA version
|
||||
- Software:
|
||||
- CPU-only: only CPU quantization functions (no optimizer, no matrix multiple)
|
||||
- CuBLAS-LT: full-build 8-bit optimizer
|
||||
- no CuBLAS-LT: no 8-bit matrix multiplication (`nomatmul`)
|
||||
|
||||
evaluation:
|
||||
- if paths faulty, return meaningful error
|
||||
- else:
|
||||
- determine CUDA version
|
||||
- determine capabilities
|
||||
- based on that set the default path
|
||||
"""
|
||||
|
||||
import ctypes
|
||||
|
||||
from .paths import determine_cuda_runtime_lib_path
|
||||
|
||||
|
||||
def check_cuda_result(cuda, result_val):
|
||||
# 3. Check for CUDA errors
|
||||
if result_val != 0:
|
||||
error_str = ctypes.c_char_p()
|
||||
cuda.cuGetErrorString(result_val, ctypes.byref(error_str))
|
||||
print(f"CUDA exception! Error code: {error_str.value.decode()}")
|
||||
|
||||
def get_cuda_version(cuda, cudart_path):
|
||||
# https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART____VERSION.html#group__CUDART____VERSION
|
||||
try:
|
||||
cudart = ctypes.CDLL(cudart_path)
|
||||
except OSError:
|
||||
# TODO: shouldn't we error or at least warn here?
|
||||
print(f'ERROR: libcudart.so could not be read from path: {cudart_path}!')
|
||||
return None
|
||||
|
||||
version = ctypes.c_int()
|
||||
check_cuda_result(cuda, cudart.cudaRuntimeGetVersion(ctypes.byref(version)))
|
||||
version = int(version.value)
|
||||
major = version//1000
|
||||
minor = (version-(major*1000))//10
|
||||
|
||||
if major < 11:
|
||||
print('CUDA SETUP: CUDA version lower than 11 are currently not supported for LLM.int8(). You will be only to use 8-bit optimizers and quantization routines!!')
|
||||
|
||||
return f'{major}{minor}'
|
||||
|
||||
|
||||
def get_cuda_lib_handle():
|
||||
# 1. find libcuda.so library (GPU driver) (/usr/lib)
|
||||
try:
|
||||
cuda = ctypes.CDLL("libcuda.so")
|
||||
except OSError:
|
||||
# TODO: shouldn't we error or at least warn here?
|
||||
print('CUDA SETUP: WARNING! libcuda.so not found! Do you have a CUDA driver installed? If you are on a cluster, make sure you are on a CUDA machine!')
|
||||
return None
|
||||
check_cuda_result(cuda, cuda.cuInit(0))
|
||||
|
||||
return cuda
|
||||
|
||||
|
||||
def get_compute_capabilities(cuda):
|
||||
"""
|
||||
1. find libcuda.so library (GPU driver) (/usr/lib)
|
||||
init_device -> init variables -> call function by reference
|
||||
2. call extern C function to determine CC
|
||||
(https://docs.nvidia.com/cuda/cuda-driver-api/group__CUDA__DEVICE__DEPRECATED.html)
|
||||
3. Check for CUDA errors
|
||||
https://stackoverflow.com/questions/14038589/what-is-the-canonical-way-to-check-for-errors-using-the-cuda-runtime-api
|
||||
# bits taken from https://gist.github.com/f0k/63a664160d016a491b2cbea15913d549
|
||||
"""
|
||||
|
||||
|
||||
nGpus = ctypes.c_int()
|
||||
cc_major = ctypes.c_int()
|
||||
cc_minor = ctypes.c_int()
|
||||
|
||||
device = ctypes.c_int()
|
||||
|
||||
check_cuda_result(cuda, cuda.cuDeviceGetCount(ctypes.byref(nGpus)))
|
||||
ccs = []
|
||||
for i in range(nGpus.value):
|
||||
check_cuda_result(cuda, cuda.cuDeviceGet(ctypes.byref(device), i))
|
||||
ref_major = ctypes.byref(cc_major)
|
||||
ref_minor = ctypes.byref(cc_minor)
|
||||
# 2. call extern C function to determine CC
|
||||
check_cuda_result(
|
||||
cuda, cuda.cuDeviceComputeCapability(ref_major, ref_minor, device)
|
||||
)
|
||||
ccs.append(f"{cc_major.value}.{cc_minor.value}")
|
||||
|
||||
return ccs
|
||||
|
||||
|
||||
# def get_compute_capability()-> Union[List[str, ...], None]: # FIXME: error
|
||||
def get_compute_capability(cuda):
|
||||
"""
|
||||
Extracts the highest compute capbility from all available GPUs, as compute
|
||||
capabilities are downwards compatible. If no GPUs are detected, it returns
|
||||
None.
|
||||
"""
|
||||
ccs = get_compute_capabilities(cuda)
|
||||
if ccs is not None:
|
||||
# TODO: handle different compute capabilities; for now, take the max
|
||||
return ccs[-1]
|
||||
return None
|
||||
|
||||
|
||||
def evaluate_cuda_setup():
|
||||
print('')
|
||||
print('='*35 + 'BUG REPORT' + '='*35)
|
||||
print('Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issues')
|
||||
print('For effortless bug reporting copy-paste your error into this form: https://docs.google.com/forms/d/e/1FAIpQLScPB8emS3Thkp66nvqwmjTEgxp8Y9ufuWTzFyr9kJ5AoI47dQ/viewform?usp=sf_link')
|
||||
print('='*80)
|
||||
return "libbitsandbytes_cuda116.dll" # $$$
|
||||
|
||||
binary_name = "libbitsandbytes_cpu.so"
|
||||
#if not torch.cuda.is_available():
|
||||
#print('No GPU detected. Loading CPU library...')
|
||||
#return binary_name
|
||||
|
||||
cudart_path = determine_cuda_runtime_lib_path()
|
||||
if cudart_path is None:
|
||||
print(
|
||||
"WARNING: No libcudart.so found! Install CUDA or the cudatoolkit package (anaconda)!"
|
||||
)
|
||||
return binary_name
|
||||
|
||||
print(f"CUDA SETUP: CUDA runtime path found: {cudart_path}")
|
||||
cuda = get_cuda_lib_handle()
|
||||
cc = get_compute_capability(cuda)
|
||||
print(f"CUDA SETUP: Highest compute capability among GPUs detected: {cc}")
|
||||
cuda_version_string = get_cuda_version(cuda, cudart_path)
|
||||
|
||||
|
||||
if cc == '':
|
||||
print(
|
||||
"WARNING: No GPU detected! Check your CUDA paths. Processing to load CPU-only library..."
|
||||
)
|
||||
return binary_name
|
||||
|
||||
# 7.5 is the minimum CC vor cublaslt
|
||||
has_cublaslt = cc in ["7.5", "8.0", "8.6"]
|
||||
|
||||
# TODO:
|
||||
# (1) CUDA missing cases (no CUDA installed by CUDA driver (nvidia-smi accessible)
|
||||
# (2) Multiple CUDA versions installed
|
||||
|
||||
# we use ls -l instead of nvcc to determine the cuda version
|
||||
# since most installations will have the libcudart.so installed, but not the compiler
|
||||
print(f'CUDA SETUP: Detected CUDA version {cuda_version_string}')
|
||||
|
||||
def get_binary_name():
|
||||
"if not has_cublaslt (CC < 7.5), then we have to choose _nocublaslt.so"
|
||||
bin_base_name = "libbitsandbytes_cuda"
|
||||
if has_cublaslt:
|
||||
return f"{bin_base_name}{cuda_version_string}.so"
|
||||
else:
|
||||
return f"{bin_base_name}{cuda_version_string}_nocublaslt.so"
|
||||
|
||||
binary_name = get_binary_name()
|
||||
|
||||
return binary_name
|
||||
"""
|
||||
extract factors the build is dependent on:
|
||||
[X] compute capability
|
||||
[ ] TODO: Q - What if we have multiple GPUs of different makes?
|
||||
- CUDA version
|
||||
- Software:
|
||||
- CPU-only: only CPU quantization functions (no optimizer, no matrix multiple)
|
||||
- CuBLAS-LT: full-build 8-bit optimizer
|
||||
- no CuBLAS-LT: no 8-bit matrix multiplication (`nomatmul`)
|
||||
|
||||
evaluation:
|
||||
- if paths faulty, return meaningful error
|
||||
- else:
|
||||
- determine CUDA version
|
||||
- determine capabilities
|
||||
- based on that set the default path
|
||||
"""
|
||||
|
||||
import ctypes
|
||||
|
||||
from .paths import determine_cuda_runtime_lib_path
|
||||
|
||||
|
||||
def check_cuda_result(cuda, result_val):
|
||||
# 3. Check for CUDA errors
|
||||
if result_val != 0:
|
||||
error_str = ctypes.c_char_p()
|
||||
cuda.cuGetErrorString(result_val, ctypes.byref(error_str))
|
||||
print(f"CUDA exception! Error code: {error_str.value.decode()}")
|
||||
|
||||
def get_cuda_version(cuda, cudart_path):
|
||||
# https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART____VERSION.html#group__CUDART____VERSION
|
||||
try:
|
||||
cudart = ctypes.CDLL(cudart_path)
|
||||
except OSError:
|
||||
# TODO: shouldn't we error or at least warn here?
|
||||
print(f'ERROR: libcudart.so could not be read from path: {cudart_path}!')
|
||||
return None
|
||||
|
||||
version = ctypes.c_int()
|
||||
check_cuda_result(cuda, cudart.cudaRuntimeGetVersion(ctypes.byref(version)))
|
||||
version = int(version.value)
|
||||
major = version//1000
|
||||
minor = (version-(major*1000))//10
|
||||
|
||||
if major < 11:
|
||||
print('CUDA SETUP: CUDA version lower than 11 are currently not supported for LLM.int8(). You will be only to use 8-bit optimizers and quantization routines!!')
|
||||
|
||||
return f'{major}{minor}'
|
||||
|
||||
|
||||
def get_cuda_lib_handle():
|
||||
# 1. find libcuda.so library (GPU driver) (/usr/lib)
|
||||
try:
|
||||
cuda = ctypes.CDLL("libcuda.so")
|
||||
except OSError:
|
||||
# TODO: shouldn't we error or at least warn here?
|
||||
print('CUDA SETUP: WARNING! libcuda.so not found! Do you have a CUDA driver installed? If you are on a cluster, make sure you are on a CUDA machine!')
|
||||
return None
|
||||
check_cuda_result(cuda, cuda.cuInit(0))
|
||||
|
||||
return cuda
|
||||
|
||||
|
||||
def get_compute_capabilities(cuda):
|
||||
"""
|
||||
1. find libcuda.so library (GPU driver) (/usr/lib)
|
||||
init_device -> init variables -> call function by reference
|
||||
2. call extern C function to determine CC
|
||||
(https://docs.nvidia.com/cuda/cuda-driver-api/group__CUDA__DEVICE__DEPRECATED.html)
|
||||
3. Check for CUDA errors
|
||||
https://stackoverflow.com/questions/14038589/what-is-the-canonical-way-to-check-for-errors-using-the-cuda-runtime-api
|
||||
# bits taken from https://gist.github.com/f0k/63a664160d016a491b2cbea15913d549
|
||||
"""
|
||||
|
||||
|
||||
nGpus = ctypes.c_int()
|
||||
cc_major = ctypes.c_int()
|
||||
cc_minor = ctypes.c_int()
|
||||
|
||||
device = ctypes.c_int()
|
||||
|
||||
check_cuda_result(cuda, cuda.cuDeviceGetCount(ctypes.byref(nGpus)))
|
||||
ccs = []
|
||||
for i in range(nGpus.value):
|
||||
check_cuda_result(cuda, cuda.cuDeviceGet(ctypes.byref(device), i))
|
||||
ref_major = ctypes.byref(cc_major)
|
||||
ref_minor = ctypes.byref(cc_minor)
|
||||
# 2. call extern C function to determine CC
|
||||
check_cuda_result(
|
||||
cuda, cuda.cuDeviceComputeCapability(ref_major, ref_minor, device)
|
||||
)
|
||||
ccs.append(f"{cc_major.value}.{cc_minor.value}")
|
||||
|
||||
return ccs
|
||||
|
||||
|
||||
# def get_compute_capability()-> Union[List[str, ...], None]: # FIXME: error
|
||||
def get_compute_capability(cuda):
|
||||
"""
|
||||
Extracts the highest compute capbility from all available GPUs, as compute
|
||||
capabilities are downwards compatible. If no GPUs are detected, it returns
|
||||
None.
|
||||
"""
|
||||
ccs = get_compute_capabilities(cuda)
|
||||
if ccs is not None:
|
||||
# TODO: handle different compute capabilities; for now, take the max
|
||||
return ccs[-1]
|
||||
return None
|
||||
|
||||
|
||||
def evaluate_cuda_setup():
|
||||
print('')
|
||||
print('='*35 + 'BUG REPORT' + '='*35)
|
||||
print('Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issues')
|
||||
print('For effortless bug reporting copy-paste your error into this form: https://docs.google.com/forms/d/e/1FAIpQLScPB8emS3Thkp66nvqwmjTEgxp8Y9ufuWTzFyr9kJ5AoI47dQ/viewform?usp=sf_link')
|
||||
print('='*80)
|
||||
return "libbitsandbytes_cuda116.dll" # $$$
|
||||
|
||||
binary_name = "libbitsandbytes_cpu.so"
|
||||
#if not torch.cuda.is_available():
|
||||
#print('No GPU detected. Loading CPU library...')
|
||||
#return binary_name
|
||||
|
||||
cudart_path = determine_cuda_runtime_lib_path()
|
||||
if cudart_path is None:
|
||||
print(
|
||||
"WARNING: No libcudart.so found! Install CUDA or the cudatoolkit package (anaconda)!"
|
||||
)
|
||||
return binary_name
|
||||
|
||||
print(f"CUDA SETUP: CUDA runtime path found: {cudart_path}")
|
||||
cuda = get_cuda_lib_handle()
|
||||
cc = get_compute_capability(cuda)
|
||||
print(f"CUDA SETUP: Highest compute capability among GPUs detected: {cc}")
|
||||
cuda_version_string = get_cuda_version(cuda, cudart_path)
|
||||
|
||||
|
||||
if cc == '':
|
||||
print(
|
||||
"WARNING: No GPU detected! Check your CUDA paths. Processing to load CPU-only library..."
|
||||
)
|
||||
return binary_name
|
||||
|
||||
# 7.5 is the minimum CC vor cublaslt
|
||||
has_cublaslt = cc in ["7.5", "8.0", "8.6"]
|
||||
|
||||
# TODO:
|
||||
# (1) CUDA missing cases (no CUDA installed by CUDA driver (nvidia-smi accessible)
|
||||
# (2) Multiple CUDA versions installed
|
||||
|
||||
# we use ls -l instead of nvcc to determine the cuda version
|
||||
# since most installations will have the libcudart.so installed, but not the compiler
|
||||
print(f'CUDA SETUP: Detected CUDA version {cuda_version_string}')
|
||||
|
||||
def get_binary_name():
|
||||
"if not has_cublaslt (CC < 7.5), then we have to choose _nocublaslt.so"
|
||||
bin_base_name = "libbitsandbytes_cuda"
|
||||
if has_cublaslt:
|
||||
return f"{bin_base_name}{cuda_version_string}.so"
|
||||
else:
|
||||
return f"{bin_base_name}{cuda_version_string}_nocublaslt.so"
|
||||
|
||||
binary_name = get_binary_name()
|
||||
|
||||
return binary_name
|
||||
|
||||
386
docs/config_README-en.md
Normal file
386
docs/config_README-en.md
Normal file
@@ -0,0 +1,386 @@
|
||||
Original Source by kohya-ss
|
||||
|
||||
First version:
|
||||
A.I Translation by Model: NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO, editing by Darkstorm2150
|
||||
|
||||
Some parts are manually added.
|
||||
|
||||
# Config Readme
|
||||
|
||||
This README is about the configuration files that can be passed with the `--dataset_config` option.
|
||||
|
||||
## Overview
|
||||
|
||||
By passing a configuration file, users can make detailed settings.
|
||||
|
||||
* Multiple datasets can be configured
|
||||
* For example, by setting `resolution` for each dataset, they can be mixed and trained.
|
||||
* In training methods that support both the DreamBooth approach and the fine-tuning approach, datasets of the DreamBooth method and the fine-tuning method can be mixed.
|
||||
* Settings can be changed for each subset
|
||||
* A subset is a partition of the dataset by image directory or metadata. Several subsets make up a dataset.
|
||||
* Options such as `keep_tokens` and `flip_aug` can be set for each subset. On the other hand, options such as `resolution` and `batch_size` can be set for each dataset, and their values are common among subsets belonging to the same dataset. More details will be provided later.
|
||||
|
||||
The configuration file format can be JSON or TOML. Considering the ease of writing, it is recommended to use [TOML](https://toml.io/ja/v1.0.0-rc.2). The following explanation assumes the use of TOML.
|
||||
|
||||
|
||||
Here is an example of a configuration file written in TOML.
|
||||
|
||||
```toml
|
||||
[general]
|
||||
shuffle_caption = true
|
||||
caption_extension = '.txt'
|
||||
keep_tokens = 1
|
||||
|
||||
# This is a DreamBooth-style dataset
|
||||
[[datasets]]
|
||||
resolution = 512
|
||||
batch_size = 4
|
||||
keep_tokens = 2
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\hoge'
|
||||
class_tokens = 'hoge girl'
|
||||
# This subset uses keep_tokens = 2 (the value of the parent datasets)
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\fuga'
|
||||
class_tokens = 'fuga boy'
|
||||
keep_tokens = 3
|
||||
|
||||
[[datasets.subsets]]
|
||||
is_reg = true
|
||||
image_dir = 'C:\reg'
|
||||
class_tokens = 'human'
|
||||
keep_tokens = 1
|
||||
|
||||
# This is a fine-tuning dataset
|
||||
[[datasets]]
|
||||
resolution = [768, 768]
|
||||
batch_size = 2
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\piyo'
|
||||
metadata_file = 'C:\piyo\piyo_md.json'
|
||||
# This subset uses keep_tokens = 1 (the value of [general])
|
||||
```
|
||||
|
||||
In this example, three directories are trained as a DreamBooth-style dataset at 512x512 (batch size 4), and one directory is trained as a fine-tuning dataset at 768x768 (batch size 2).
|
||||
|
||||
## Settings for datasets and subsets
|
||||
|
||||
Settings for datasets and subsets are divided into several registration locations.
|
||||
|
||||
* `[general]`
|
||||
* This is where options that apply to all datasets or all subsets are specified.
|
||||
* If there are options with the same name in the dataset-specific or subset-specific settings, the dataset-specific or subset-specific settings take precedence.
|
||||
* `[[datasets]]`
|
||||
* `datasets` is where settings for datasets are registered. This is where options that apply individually to each dataset are specified.
|
||||
* If there are subset-specific settings, the subset-specific settings take precedence.
|
||||
* `[[datasets.subsets]]`
|
||||
* `datasets.subsets` is where settings for subsets are registered. This is where options that apply individually to each subset are specified.
|
||||
|
||||
Here is an image showing the correspondence between image directories and registration locations in the previous example.
|
||||
|
||||
```
|
||||
C:\
|
||||
├─ hoge -> [[datasets.subsets]] No.1 ┐ ┐
|
||||
├─ fuga -> [[datasets.subsets]] No.2 |-> [[datasets]] No.1 |-> [general]
|
||||
├─ reg -> [[datasets.subsets]] No.3 ┘ |
|
||||
└─ piyo -> [[datasets.subsets]] No.4 --> [[datasets]] No.2 ┘
|
||||
```
|
||||
|
||||
The image directory corresponds to each `[[datasets.subsets]]`. Then, multiple `[[datasets.subsets]]` are combined to form one `[[datasets]]`. All `[[datasets]]` and `[[datasets.subsets]]` belong to `[general]`.
|
||||
|
||||
The available options for each registration location may differ, but if the same option is specified, the value in the lower registration location will take precedence. You can check how the `keep_tokens` option is handled in the previous example for better understanding.
|
||||
|
||||
Additionally, the available options may vary depending on the method that the learning approach supports.
|
||||
|
||||
* Options specific to the DreamBooth method
|
||||
* Options specific to the fine-tuning method
|
||||
* Options available when using the caption dropout technique
|
||||
|
||||
When using both the DreamBooth method and the fine-tuning method, they can be used together with a learning approach that supports both.
|
||||
When using them together, a point to note is that the method is determined based on the dataset, so it is not possible to mix DreamBooth method subsets and fine-tuning method subsets within the same dataset.
|
||||
In other words, if you want to use both methods together, you need to set up subsets of different methods belonging to different datasets.
|
||||
|
||||
In terms of program behavior, if the `metadata_file` option exists, it is determined to be a subset of fine-tuning. Therefore, for subsets belonging to the same dataset, as long as they are either "all have the `metadata_file` option" or "all have no `metadata_file` option," there is no problem.
|
||||
|
||||
Below, the available options will be explained. For options with the same name as the command-line argument, the explanation will be omitted in principle. Please refer to other READMEs.
|
||||
|
||||
### Common options for all learning methods
|
||||
|
||||
These are options that can be specified regardless of the learning method.
|
||||
|
||||
#### Data set specific options
|
||||
|
||||
These are options related to the configuration of the data set. They cannot be described in `datasets.subsets`.
|
||||
|
||||
|
||||
| Option Name | Example Setting | `[general]` | `[[datasets]]` |
|
||||
| ---- | ---- | ---- | ---- |
|
||||
| `batch_size` | `1` | o | o |
|
||||
| `bucket_no_upscale` | `true` | o | o |
|
||||
| `bucket_reso_steps` | `64` | o | o |
|
||||
| `enable_bucket` | `true` | o | o |
|
||||
| `max_bucket_reso` | `1024` | o | o |
|
||||
| `min_bucket_reso` | `128` | o | o |
|
||||
| `resolution` | `256`, `[512, 512]` | o | o |
|
||||
|
||||
* `batch_size`
|
||||
* This corresponds to the command-line argument `--train_batch_size`.
|
||||
* `max_bucket_reso`, `min_bucket_reso`
|
||||
* Specify the maximum and minimum resolutions of the bucket. It must be divisible by `bucket_reso_steps`.
|
||||
|
||||
These settings are fixed per dataset. That means that subsets belonging to the same dataset will share these settings. For example, if you want to prepare datasets with different resolutions, you can define them as separate datasets as shown in the example above, and set different resolutions for each.
|
||||
|
||||
#### Options for Subsets
|
||||
|
||||
These options are related to subset configuration.
|
||||
|
||||
| Option Name | Example | `[general]` | `[[datasets]]` | `[[dataset.subsets]]` |
|
||||
| ---- | ---- | ---- | ---- | ---- |
|
||||
| `color_aug` | `false` | o | o | o |
|
||||
| `face_crop_aug_range` | `[1.0, 3.0]` | o | o | o |
|
||||
| `flip_aug` | `true` | o | o | o |
|
||||
| `keep_tokens` | `2` | o | o | o |
|
||||
| `num_repeats` | `10` | o | o | o |
|
||||
| `random_crop` | `false` | o | o | o |
|
||||
| `shuffle_caption` | `true` | o | o | o |
|
||||
| `caption_prefix` | `"masterpiece, best quality, "` | o | o | o |
|
||||
| `caption_suffix` | `", from side"` | o | o | o |
|
||||
| `caption_separator` | (not specified) | o | o | o |
|
||||
| `keep_tokens_separator` | `“|||”` | o | o | o |
|
||||
| `secondary_separator` | `“;;;”` | o | o | o |
|
||||
| `enable_wildcard` | `true` | o | o | o |
|
||||
|
||||
* `num_repeats`
|
||||
* Specifies the number of repeats for images in a subset. This is equivalent to `--dataset_repeats` in fine-tuning but can be specified for any training method.
|
||||
* `caption_prefix`, `caption_suffix`
|
||||
* Specifies the prefix and suffix strings to be appended to the captions. Shuffling is performed with these strings included. Be cautious when using `keep_tokens`.
|
||||
* `caption_separator`
|
||||
* Specifies the string to separate the tags. The default is `,`. This option is usually not necessary to set.
|
||||
* `keep_tokens_separator`
|
||||
* Specifies the string to separate the parts to be fixed in the caption. For example, if you specify `aaa, bbb ||| ccc, ddd, eee, fff ||| ggg, hhh`, the parts `aaa, bbb` and `ggg, hhh` will remain, and the rest will be shuffled and dropped. The comma in between is not necessary. As a result, the prompt will be `aaa, bbb, eee, ccc, fff, ggg, hhh` or `aaa, bbb, fff, ccc, eee, ggg, hhh`, etc.
|
||||
* `secondary_separator`
|
||||
* Specifies an additional separator. The part separated by this separator is treated as one tag and is shuffled and dropped. It is then replaced by `caption_separator`. For example, if you specify `aaa;;;bbb;;;ccc`, it will be replaced by `aaa,bbb,ccc` or dropped together.
|
||||
* `enable_wildcard`
|
||||
* Enables wildcard notation. This will be explained later.
|
||||
|
||||
### DreamBooth-specific options
|
||||
|
||||
DreamBooth-specific options only exist as subsets-specific options.
|
||||
|
||||
#### Subset-specific options
|
||||
|
||||
Options related to the configuration of DreamBooth subsets.
|
||||
|
||||
| Option Name | Example Setting | `[general]` | `[[datasets]]` | `[[dataset.subsets]]` |
|
||||
| ---- | ---- | ---- | ---- | ---- |
|
||||
| `image_dir` | `'C:\hoge'` | - | - | o (required) |
|
||||
| `caption_extension` | `".txt"` | o | o | o |
|
||||
| `class_tokens` | `"sks girl"` | - | - | o |
|
||||
| `cache_info` | `false` | o | o | o |
|
||||
| `is_reg` | `false` | - | - | o |
|
||||
|
||||
Firstly, note that for `image_dir`, the path to the image files must be specified as being directly in the directory. Unlike the previous DreamBooth method, where images had to be placed in subdirectories, this is not compatible with that specification. Also, even if you name the folder something like "5_cat", the number of repeats of the image and the class name will not be reflected. If you want to set these individually, you will need to explicitly specify them using `num_repeats` and `class_tokens`.
|
||||
|
||||
* `image_dir`
|
||||
* Specifies the path to the image directory. This is a required option.
|
||||
* Images must be placed directly under the directory.
|
||||
* `class_tokens`
|
||||
* Sets the class tokens.
|
||||
* Only used during training when a corresponding caption file does not exist. The determination of whether or not to use it is made on a per-image basis. If `class_tokens` is not specified and a caption file is not found, an error will occur.
|
||||
* `cache_info`
|
||||
* Specifies whether to cache the image size and caption. If not specified, it is set to `false`. The cache is saved in `metadata_cache.json` in `image_dir`.
|
||||
* Caching speeds up the loading of the dataset after the first time. It is effective when dealing with thousands of images or more.
|
||||
* `is_reg`
|
||||
* Specifies whether the subset images are for normalization. If not specified, it is set to `false`, meaning that the images are not for normalization.
|
||||
|
||||
### Fine-tuning method specific options
|
||||
|
||||
The options for the fine-tuning method only exist for subset-specific options.
|
||||
|
||||
#### Subset-specific options
|
||||
|
||||
These options are related to the configuration of the fine-tuning method's subsets.
|
||||
|
||||
| Option name | Example setting | `[general]` | `[[datasets]]` | `[[dataset.subsets]]` |
|
||||
| ---- | ---- | ---- | ---- | ---- |
|
||||
| `image_dir` | `'C:\hoge'` | - | - | o |
|
||||
| `metadata_file` | `'C:\piyo\piyo_md.json'` | - | - | o (required) |
|
||||
|
||||
* `image_dir`
|
||||
* Specify the path to the image directory. Unlike the DreamBooth method, specifying it is not mandatory, but it is recommended to do so.
|
||||
* The case where it is not necessary to specify is when the `--full_path` is added to the command line when generating the metadata file.
|
||||
* The images must be placed directly under the directory.
|
||||
* `metadata_file`
|
||||
* Specify the path to the metadata file used for the subset. This is a required option.
|
||||
* It is equivalent to the command-line argument `--in_json`.
|
||||
* Due to the specification that a metadata file must be specified for each subset, it is recommended to avoid creating a metadata file with images from different directories as a single metadata file. It is strongly recommended to prepare a separate metadata file for each image directory and register them as separate subsets.
|
||||
|
||||
### Options available when caption dropout method can be used
|
||||
|
||||
The options available when the caption dropout method can be used exist only for subsets. Regardless of whether it's the DreamBooth method or fine-tuning method, if it supports caption dropout, it can be specified.
|
||||
|
||||
#### Subset-specific options
|
||||
|
||||
Options related to the setting of subsets that caption dropout can be used for.
|
||||
|
||||
| Option Name | `[general]` | `[[datasets]]` | `[[dataset.subsets]]` |
|
||||
| ---- | ---- | ---- | ---- |
|
||||
| `caption_dropout_every_n_epochs` | o | o | o |
|
||||
| `caption_dropout_rate` | o | o | o |
|
||||
| `caption_tag_dropout_rate` | o | o | o |
|
||||
|
||||
## Behavior when there are duplicate subsets
|
||||
|
||||
In the case of the DreamBooth dataset, if there are multiple `image_dir` directories with the same content, they are considered to be duplicate subsets. For the fine-tuning dataset, if there are multiple `metadata_file` files with the same content, they are considered to be duplicate subsets. If duplicate subsets exist in the dataset, subsequent subsets will be ignored.
|
||||
|
||||
However, if they belong to different datasets, they are not considered duplicates. For example, if you have subsets with the same `image_dir` in different datasets, they will not be considered duplicates. This is useful when you want to train with the same image but with different resolutions.
|
||||
|
||||
```toml
|
||||
# If data sets exist separately, they are not considered duplicates and are both used for training.
|
||||
|
||||
[[datasets]]
|
||||
resolution = 512
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\hoge'
|
||||
|
||||
[[datasets]]
|
||||
resolution = 768
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\hoge'
|
||||
```
|
||||
|
||||
## Command Line Argument and Configuration File
|
||||
|
||||
There are options in the configuration file that have overlapping roles with command line argument options.
|
||||
|
||||
The following command line argument options are ignored if a configuration file is passed:
|
||||
|
||||
* `--train_data_dir`
|
||||
* `--reg_data_dir`
|
||||
* `--in_json`
|
||||
|
||||
The following command line argument options are given priority over the configuration file options if both are specified simultaneously. In most cases, they have the same names as the corresponding options in the configuration file.
|
||||
|
||||
| Command Line Argument Option | Prioritized Configuration File Option |
|
||||
| ------------------------------- | ------------------------------------- |
|
||||
| `--bucket_no_upscale` | |
|
||||
| `--bucket_reso_steps` | |
|
||||
| `--caption_dropout_every_n_epochs` | |
|
||||
| `--caption_dropout_rate` | |
|
||||
| `--caption_extension` | |
|
||||
| `--caption_tag_dropout_rate` | |
|
||||
| `--color_aug` | |
|
||||
| `--dataset_repeats` | `num_repeats` |
|
||||
| `--enable_bucket` | |
|
||||
| `--face_crop_aug_range` | |
|
||||
| `--flip_aug` | |
|
||||
| `--keep_tokens` | |
|
||||
| `--min_bucket_reso` | |
|
||||
| `--random_crop` | |
|
||||
| `--resolution` | |
|
||||
| `--shuffle_caption` | |
|
||||
| `--train_batch_size` | `batch_size` |
|
||||
|
||||
## Error Guide
|
||||
|
||||
Currently, we are using an external library to check if the configuration file is written correctly, but the development has not been completed, and there is a problem that the error message is not clear. In the future, we plan to improve this problem.
|
||||
|
||||
As a temporary measure, we will list common errors and their solutions. If you encounter an error even though it should be correct or if the error content is not understandable, please contact us as it may be a bug.
|
||||
|
||||
* `voluptuous.error.MultipleInvalid: required key not provided @ ...`: This error occurs when a required option is not provided. It is highly likely that you forgot to specify the option or misspelled the option name.
|
||||
* The error location is indicated by `...` in the error message. For example, if you encounter an error like `voluptuous.error.MultipleInvalid: required key not provided @ data['datasets'][0]['subsets'][0]['image_dir']`, it means that the `image_dir` option does not exist in the 0th `subsets` of the 0th `datasets` setting.
|
||||
* `voluptuous.error.MultipleInvalid: expected int for dictionary value @ ...`: This error occurs when the specified value format is incorrect. It is highly likely that the value format is incorrect. The `int` part changes depending on the target option. The example configurations in this README may be helpful.
|
||||
* `voluptuous.error.MultipleInvalid: extra keys not allowed @ ...`: This error occurs when there is an option name that is not supported. It is highly likely that you misspelled the option name or mistakenly included it.
|
||||
|
||||
## Miscellaneous
|
||||
|
||||
### Multi-line captions
|
||||
|
||||
By setting `enable_wildcard = true`, multiple-line captions are also enabled. If the caption file consists of multiple lines, one line is randomly selected as the caption.
|
||||
|
||||
```txt
|
||||
1girl, hatsune miku, vocaloid, upper body, looking at viewer, microphone, stage
|
||||
a girl with a microphone standing on a stage
|
||||
detailed digital art of a girl with a microphone on a stage
|
||||
```
|
||||
|
||||
It can be combined with wildcard notation.
|
||||
|
||||
In metadata files, you can also specify multiple-line captions. In the `.json` metadata file, use `\n` to represent a line break. If the caption file consists of multiple lines, `merge_captions_to_metadata.py` will create a metadata file in this format.
|
||||
|
||||
The tags in the metadata (`tags`) are added to each line of the caption.
|
||||
|
||||
```json
|
||||
{
|
||||
"/path/to/image.png": {
|
||||
"caption": "a cartoon of a frog with the word frog on it\ntest multiline caption1\ntest multiline caption2",
|
||||
"tags": "open mouth, simple background, standing, no humans, animal, black background, frog, animal costume, animal focus"
|
||||
},
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
In this case, the actual caption will be `a cartoon of a frog with the word frog on it, open mouth, simple background ...`, `test multiline caption1, open mouth, simple background ...`, `test multiline caption2, open mouth, simple background ...`, etc.
|
||||
|
||||
### Example of configuration file : `secondary_separator`, wildcard notation, `keep_tokens_separator`, etc.
|
||||
|
||||
```toml
|
||||
[general]
|
||||
flip_aug = true
|
||||
color_aug = false
|
||||
resolution = [1024, 1024]
|
||||
|
||||
[[datasets]]
|
||||
batch_size = 6
|
||||
enable_bucket = true
|
||||
bucket_no_upscale = true
|
||||
caption_extension = ".txt"
|
||||
keep_tokens_separator= "|||"
|
||||
shuffle_caption = true
|
||||
caption_tag_dropout_rate = 0.1
|
||||
secondary_separator = ";;;" # subset 側に書くこともできます / can be written in the subset side
|
||||
enable_wildcard = true # 同上 / same as above
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = "/path/to/image_dir"
|
||||
num_repeats = 1
|
||||
|
||||
# ||| の前後はカンマは不要です(自動的に追加されます) / No comma is required before and after ||| (it is added automatically)
|
||||
caption_prefix = "1girl, hatsune miku, vocaloid |||"
|
||||
|
||||
# ||| の後はシャッフル、drop されず残ります / After |||, it is not shuffled or dropped and remains
|
||||
# 単純に文字列として連結されるので、カンマなどは自分で入れる必要があります / It is simply concatenated as a string, so you need to put commas yourself
|
||||
caption_suffix = ", anime screencap ||| masterpiece, rating: general"
|
||||
```
|
||||
|
||||
### Example of caption, secondary_separator notation: `secondary_separator = ";;;"`
|
||||
|
||||
```txt
|
||||
1girl, hatsune miku, vocaloid, upper body, looking at viewer, sky;;;cloud;;;day, outdoors
|
||||
```
|
||||
The part `sky;;;cloud;;;day` is replaced with `sky,cloud,day` without shuffling or dropping. When shuffling and dropping are enabled, it is processed as a whole (as one tag). For example, it becomes `vocaloid, 1girl, upper body, sky,cloud,day, outdoors, hatsune miku` (shuffled) or `vocaloid, 1girl, outdoors, looking at viewer, upper body, hatsune miku` (dropped).
|
||||
|
||||
### Example of caption, enable_wildcard notation: `enable_wildcard = true`
|
||||
|
||||
```txt
|
||||
1girl, hatsune miku, vocaloid, upper body, looking at viewer, {simple|white} background
|
||||
```
|
||||
`simple` or `white` is randomly selected, and it becomes `simple background` or `white background`.
|
||||
|
||||
```txt
|
||||
1girl, hatsune miku, vocaloid, {{retro style}}
|
||||
```
|
||||
If you want to include `{` or `}` in the tag string, double them like `{{` or `}}` (in this example, the actual caption used for training is `{retro style}`).
|
||||
|
||||
### Example of caption, `keep_tokens_separator` notation: `keep_tokens_separator = "|||"`
|
||||
|
||||
```txt
|
||||
1girl, hatsune miku, vocaloid ||| stage, microphone, white shirt, smile ||| best quality, rating: general
|
||||
```
|
||||
It becomes `1girl, hatsune miku, vocaloid, microphone, stage, white shirt, best quality, rating: general` or `1girl, hatsune miku, vocaloid, white shirt, smile, stage, microphone, best quality, rating: general` etc.
|
||||
|
||||
@@ -1,5 +1,3 @@
|
||||
For non-Japanese speakers: this README is provided only in Japanese in the current state. Sorry for inconvenience. We will provide English version in the near future.
|
||||
|
||||
`--dataset_config` で渡すことができる設定ファイルに関する説明です。
|
||||
|
||||
## 概要
|
||||
@@ -120,6 +118,8 @@ DreamBooth の手法と fine tuning の手法の両方とも利用可能な学
|
||||
|
||||
* `batch_size`
|
||||
* コマンドライン引数の `--train_batch_size` と同等です。
|
||||
* `max_bucket_reso`, `min_bucket_reso`
|
||||
* bucketの最大、最小解像度を指定します。`bucket_reso_steps` で割り切れる必要があります。
|
||||
|
||||
これらの設定はデータセットごとに固定です。
|
||||
つまり、データセットに所属するサブセットはこれらの設定を共有することになります。
|
||||
@@ -138,9 +138,29 @@ DreamBooth の手法と fine tuning の手法の両方とも利用可能な学
|
||||
| `num_repeats` | `10` | o | o | o |
|
||||
| `random_crop` | `false` | o | o | o |
|
||||
| `shuffle_caption` | `true` | o | o | o |
|
||||
| `caption_prefix` | `“masterpiece, best quality, ”` | o | o | o |
|
||||
| `caption_suffix` | `“, from side”` | o | o | o |
|
||||
| `caption_separator` | (通常は設定しません) | o | o | o |
|
||||
| `keep_tokens_separator` | `“|||”` | o | o | o |
|
||||
| `secondary_separator` | `“;;;”` | o | o | o |
|
||||
| `enable_wildcard` | `true` | o | o | o |
|
||||
|
||||
* `num_repeats`
|
||||
* サブセットの画像の繰り返し回数を指定します。fine tuning における `--dataset_repeats` に相当しますが、`num_repeats` はどの学習方法でも指定可能です。
|
||||
* `caption_prefix`, `caption_suffix`
|
||||
* キャプションの前、後に付与する文字列を指定します。シャッフルはこれらの文字列を含めた状態で行われます。`keep_tokens` を指定する場合には注意してください。
|
||||
|
||||
* `caption_separator`
|
||||
* タグを区切る文字列を指定します。デフォルトは `,` です。このオプションは通常は設定する必要はありません。
|
||||
|
||||
* `keep_tokens_separator`
|
||||
* キャプションで固定したい部分を区切る文字列を指定します。たとえば `aaa, bbb ||| ccc, ddd, eee, fff ||| ggg, hhh` のように指定すると、`aaa, bbb` と `ggg, hhh` の部分はシャッフル、drop されず残ります。間のカンマは不要です。結果としてプロンプトは `aaa, bbb, eee, ccc, fff, ggg, hhh` や `aaa, bbb, fff, ccc, eee, ggg, hhh` などになります。
|
||||
|
||||
* `secondary_separator`
|
||||
* 追加の区切り文字を指定します。この区切り文字で区切られた部分は一つのタグとして扱われ、シャッフル、drop されます。その後、`caption_separator` に置き換えられます。たとえば `aaa;;;bbb;;;ccc` のように指定すると、`aaa,bbb,ccc` に置き換えられるか、まとめて drop されます。
|
||||
|
||||
* `enable_wildcard`
|
||||
* ワイルドカード記法および複数行キャプションを有効にします。ワイルドカード記法、複数行キャプションについては後述します。
|
||||
|
||||
### DreamBooth 方式専用のオプション
|
||||
|
||||
@@ -155,6 +175,7 @@ DreamBooth 方式のサブセットの設定に関わるオプションです。
|
||||
| `image_dir` | `‘C:\hoge’` | - | - | o(必須) |
|
||||
| `caption_extension` | `".txt"` | o | o | o |
|
||||
| `class_tokens` | `“sks girl”` | - | - | o |
|
||||
| `cache_info` | `false` | o | o | o |
|
||||
| `is_reg` | `false` | - | - | o |
|
||||
|
||||
まず注意点として、 `image_dir` には画像ファイルが直下に置かれているパスを指定する必要があります。従来の DreamBooth の手法ではサブディレクトリに画像を置く必要がありましたが、そちらとは仕様に互換性がありません。また、`5_cat` のようなフォルダ名にしても、画像の繰り返し回数とクラス名は反映されません。これらを個別に設定したい場合、`num_repeats` と `class_tokens` で明示的に指定する必要があることに注意してください。
|
||||
@@ -165,6 +186,9 @@ DreamBooth 方式のサブセットの設定に関わるオプションです。
|
||||
* `class_tokens`
|
||||
* クラストークンを設定します。
|
||||
* 画像に対応する caption ファイルが存在しない場合にのみ学習時に利用されます。利用するかどうかの判定は画像ごとに行います。`class_tokens` を指定しなかった場合に caption ファイルも見つからなかった場合にはエラーになります。
|
||||
* `cache_info`
|
||||
* 画像サイズ、キャプションをキャッシュするかどうかを指定します。指定しなかった場合は `false` になります。キャッシュは `image_dir` に `metadata_cache.json` というファイル名で保存されます。
|
||||
* キャッシュを行うと、二回目以降のデータセット読み込みが高速化されます。数千枚以上の画像を扱う場合には有効です。
|
||||
* `is_reg`
|
||||
* サブセットの画像が正規化用かどうかを指定します。指定しなかった場合は `false` として、つまり正規化画像ではないとして扱います。
|
||||
|
||||
@@ -276,4 +300,89 @@ resolution = 768
|
||||
* `voluptuous.error.MultipleInvalid: expected int for dictionary value @ ...`: 指定する値の形式が不正というエラーです。値の形式が間違っている可能性が高いです。`int` の部分は対象となるオプションによって変わります。この README に載っているオプションの「設定例」が役立つかもしれません。
|
||||
* `voluptuous.error.MultipleInvalid: extra keys not allowed @ ...`: 対応していないオプション名が存在している場合に発生するエラーです。オプション名を間違って記述しているか、誤って紛れ込んでいる可能性が高いです。
|
||||
|
||||
## その他
|
||||
|
||||
### 複数行キャプション
|
||||
|
||||
`enable_wildcard = true` を設定することで、複数行キャプションも同時に有効になります。キャプションファイルが複数の行からなる場合、ランダムに一つの行が選ばれてキャプションとして利用されます。
|
||||
|
||||
```txt
|
||||
1girl, hatsune miku, vocaloid, upper body, looking at viewer, microphone, stage
|
||||
a girl with a microphone standing on a stage
|
||||
detailed digital art of a girl with a microphone on a stage
|
||||
```
|
||||
|
||||
ワイルドカード記法と組み合わせることも可能です。
|
||||
|
||||
メタデータファイルでも同様に複数行キャプションを指定することができます。メタデータの .json 内には、`\n` を使って改行を表現してください。キャプションファイルが複数行からなる場合、`merge_captions_to_metadata.py` を使うと、この形式でメタデータファイルが作成されます。
|
||||
|
||||
メタデータのタグ (`tags`) は、キャプションの各行に追加されます。
|
||||
|
||||
```json
|
||||
{
|
||||
"/path/to/image.png": {
|
||||
"caption": "a cartoon of a frog with the word frog on it\ntest multiline caption1\ntest multiline caption2",
|
||||
"tags": "open mouth, simple background, standing, no humans, animal, black background, frog, animal costume, animal focus"
|
||||
},
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
この場合、実際のキャプションは `a cartoon of a frog with the word frog on it, open mouth, simple background ...` または `test multiline caption1, open mouth, simple background ...`、 `test multiline caption2, open mouth, simple background ...` 等になります。
|
||||
|
||||
### 設定ファイルの記述例:追加の区切り文字、ワイルドカード記法、`keep_tokens_separator` 等
|
||||
|
||||
```toml
|
||||
[general]
|
||||
flip_aug = true
|
||||
color_aug = false
|
||||
resolution = [1024, 1024]
|
||||
|
||||
[[datasets]]
|
||||
batch_size = 6
|
||||
enable_bucket = true
|
||||
bucket_no_upscale = true
|
||||
caption_extension = ".txt"
|
||||
keep_tokens_separator= "|||"
|
||||
shuffle_caption = true
|
||||
caption_tag_dropout_rate = 0.1
|
||||
secondary_separator = ";;;" # subset 側に書くこともできます / can be written in the subset side
|
||||
enable_wildcard = true # 同上 / same as above
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = "/path/to/image_dir"
|
||||
num_repeats = 1
|
||||
|
||||
# ||| の前後はカンマは不要です(自動的に追加されます) / No comma is required before and after ||| (it is added automatically)
|
||||
caption_prefix = "1girl, hatsune miku, vocaloid |||"
|
||||
|
||||
# ||| の後はシャッフル、drop されず残ります / After |||, it is not shuffled or dropped and remains
|
||||
# 単純に文字列として連結されるので、カンマなどは自分で入れる必要があります / It is simply concatenated as a string, so you need to put commas yourself
|
||||
caption_suffix = ", anime screencap ||| masterpiece, rating: general"
|
||||
```
|
||||
|
||||
### キャプション記述例、secondary_separator 記法:`secondary_separator = ";;;"` の場合
|
||||
|
||||
```txt
|
||||
1girl, hatsune miku, vocaloid, upper body, looking at viewer, sky;;;cloud;;;day, outdoors
|
||||
```
|
||||
`sky;;;cloud;;;day` の部分はシャッフル、drop されず `sky,cloud,day` に置換されます。シャッフル、drop が有効な場合、まとめて(一つのタグとして)処理されます。つまり `vocaloid, 1girl, upper body, sky,cloud,day, outdoors, hatsune miku` (シャッフル)や `vocaloid, 1girl, outdoors, looking at viewer, upper body, hatsune miku` (drop されたケース)などになります。
|
||||
|
||||
### キャプション記述例、ワイルドカード記法: `enable_wildcard = true` の場合
|
||||
|
||||
```txt
|
||||
1girl, hatsune miku, vocaloid, upper body, looking at viewer, {simple|white} background
|
||||
```
|
||||
ランダムに `simple` または `white` が選ばれ、`simple background` または `white background` になります。
|
||||
|
||||
```txt
|
||||
1girl, hatsune miku, vocaloid, {{retro style}}
|
||||
```
|
||||
タグ文字列に `{` や `}` そのものを含めたい場合は `{{` や `}}` のように二つ重ねてください(この例では実際に学習に用いられるキャプションは `{retro style}` になります)。
|
||||
|
||||
### キャプション記述例、`keep_tokens_separator` 記法: `keep_tokens_separator = "|||"` の場合
|
||||
|
||||
```txt
|
||||
1girl, hatsune miku, vocaloid ||| stage, microphone, white shirt, smile ||| best quality, rating: general
|
||||
```
|
||||
`1girl, hatsune miku, vocaloid, microphone, stage, white shirt, best quality, rating: general` や `1girl, hatsune miku, vocaloid, white shirt, smile, stage, microphone, best quality, rating: general` などになります。
|
||||
487
docs/gen_img_README-ja.md
Normal file
487
docs/gen_img_README-ja.md
Normal file
@@ -0,0 +1,487 @@
|
||||
SD 1.xおよび2.xのモデル、当リポジトリで学習したLoRA、ControlNet(v1.0のみ動作確認)などに対応した、Diffusersベースの推論(画像生成)スクリプトです。コマンドラインから用います。
|
||||
|
||||
# 概要
|
||||
|
||||
* Diffusers (v0.10.2) ベースの推論(画像生成)スクリプト。
|
||||
* SD 1.xおよび2.x (base/v-parameterization)モデルに対応。
|
||||
* txt2img、img2img、inpaintingに対応。
|
||||
* 対話モード、およびファイルからのプロンプト読み込み、連続生成に対応。
|
||||
* プロンプト1行あたりの生成枚数を指定可能。
|
||||
* 全体の繰り返し回数を指定可能。
|
||||
* `fp16`だけでなく`bf16`にも対応。
|
||||
* xformersに対応し高速生成が可能。
|
||||
* xformersにより省メモリ生成を行いますが、Automatic 1111氏のWeb UIほど最適化していないため、512*512の画像生成でおおむね6GB程度のVRAMを使用します。
|
||||
* プロンプトの225トークンへの拡張。ネガティブプロンプト、重みづけに対応。
|
||||
* Diffusersの各種samplerに対応(Web UIよりもsampler数は少ないです)。
|
||||
* Text Encoderのclip skip(最後からn番目の層の出力を用いる)に対応。
|
||||
* VAEの別途読み込み。
|
||||
* CLIP Guided Stable Diffusion、VGG16 Guided Stable Diffusion、Highres. fix、upscale対応。
|
||||
* Highres. fixはWeb UIの実装を全く確認していない独自実装のため、出力結果は異なるかもしれません。
|
||||
* LoRA対応。適用率指定、複数LoRA同時利用、重みのマージに対応。
|
||||
* Text EncoderとU-Netで別の適用率を指定することはできません。
|
||||
* Attention Coupleに対応。
|
||||
* ControlNet v1.0に対応。
|
||||
* 途中でモデルを切り替えることはできませんが、バッチファイルを組むことで対応できます。
|
||||
* 個人的に欲しくなった機能をいろいろ追加。
|
||||
|
||||
機能追加時にすべてのテストを行っているわけではないため、以前の機能に影響が出て一部機能が動かない可能性があります。何か問題があればお知らせください。
|
||||
|
||||
# 基本的な使い方
|
||||
|
||||
## 対話モードでの画像生成
|
||||
|
||||
以下のように入力してください。
|
||||
|
||||
```batchfile
|
||||
python gen_img_diffusers.py --ckpt <モデル名> --outdir <画像出力先> --xformers --fp16 --interactive
|
||||
```
|
||||
|
||||
`--ckpt`オプションにモデル(Stable Diffusionのcheckpointファイル、またはDiffusersのモデルフォルダ)、`--outdir`オプションに画像の出力先フォルダを指定します。
|
||||
|
||||
`--xformers`オプションでxformersの使用を指定します(xformersを使わない場合は外してください)。`--fp16`オプションでfp16(単精度)での推論を行います。RTX 30系のGPUでは `--bf16`オプションでbf16(bfloat16)での推論を行うこともできます。
|
||||
|
||||
`--interactive`オプションで対話モードを指定しています。
|
||||
|
||||
Stable Diffusion 2.0(またはそこからの追加学習モデル)を使う場合は`--v2`オプションを追加してください。v-parameterizationを使うモデル(`768-v-ema.ckpt`およびそこからの追加学習モデル)を使う場合はさらに`--v_parameterization`を追加してください。
|
||||
|
||||
`--v2`の指定有無が間違っているとモデル読み込み時にエラーになります。`--v_parameterization`の指定有無が間違っていると茶色い画像が表示されます。
|
||||
|
||||
`Type prompt:`と表示されたらプロンプトを入力してください。
|
||||
|
||||

|
||||
|
||||
※画像が表示されずエラーになる場合、headless(画面表示機能なし)のOpenCVがインストールされているかもしれません。`pip install opencv-python`として通常のOpenCVを入れてください。または`--no_preview`オプションで画像表示を止めてください。
|
||||
|
||||
画像ウィンドウを選択してから何らかのキーを押すとウィンドウが閉じ、次のプロンプトが入力できます。プロンプトでCtrl+Z、エンターの順に打鍵するとスクリプトを閉じます。
|
||||
|
||||
## 単一のプロンプトで画像を一括生成
|
||||
|
||||
以下のように入力します(実際には1行で入力します)。
|
||||
|
||||
```batchfile
|
||||
python gen_img_diffusers.py --ckpt <モデル名> --outdir <画像出力先>
|
||||
--xformers --fp16 --images_per_prompt <生成枚数> --prompt "<プロンプト>"
|
||||
```
|
||||
|
||||
`--images_per_prompt`オプションで、プロンプト1件当たりの生成枚数を指定します。`--prompt`オプションでプロンプトを指定します。スペースを含む場合はダブルクォーテーションで囲んでください。
|
||||
|
||||
`--batch_size`オプションでバッチサイズを指定できます(後述)。
|
||||
|
||||
## ファイルからプロンプトを読み込み一括生成
|
||||
|
||||
以下のように入力します。
|
||||
|
||||
```batchfile
|
||||
python gen_img_diffusers.py --ckpt <モデル名> --outdir <画像出力先>
|
||||
--xformers --fp16 --from_file <プロンプトファイル名>
|
||||
```
|
||||
|
||||
`--from_file`オプションで、プロンプトが記述されたファイルを指定します。1行1プロンプトで記述してください。`--images_per_prompt`オプションを指定して1行あたり生成枚数を指定できます。
|
||||
|
||||
## ネガティブプロンプト、重みづけの使用
|
||||
|
||||
プロンプトオプション(プロンプト内で`--x`のように指定、後述)で`--n`を書くと、以降がネガティブプロンプトとなります。
|
||||
|
||||
またAUTOMATIC1111氏のWeb UIと同様の `()` や` []` 、`(xxx:1.3)` などによる重みづけが可能です(実装はDiffusersの[Long Prompt Weighting Stable Diffusion](https://github.com/huggingface/diffusers/blob/main/examples/community/README.md#long-prompt-weighting-stable-diffusion)からコピーしたものです)。
|
||||
|
||||
コマンドラインからのプロンプト指定、ファイルからのプロンプト読み込みでも同様に指定できます。
|
||||
|
||||

|
||||
|
||||
# 主なオプション
|
||||
|
||||
コマンドラインから指定してください。
|
||||
|
||||
## モデルの指定
|
||||
|
||||
- `--ckpt <モデル名>`:モデル名を指定します。`--ckpt`オプションは必須です。Stable Diffusionのcheckpointファイル、またはDiffusersのモデルフォルダ、Hugging FaceのモデルIDを指定できます。
|
||||
|
||||
- `--v2`:Stable Diffusion 2.x系のモデルを使う場合に指定します。1.x系の場合には指定不要です。
|
||||
|
||||
- `--v_parameterization`:v-parameterizationを使うモデルを使う場合に指定します(`768-v-ema.ckpt`およびそこからの追加学習モデル、Waifu Diffusion v1.5など)。
|
||||
|
||||
`--v2`の指定有無が間違っているとモデル読み込み時にエラーになります。`--v_parameterization`の指定有無が間違っていると茶色い画像が表示されます。
|
||||
|
||||
- `--vae`:使用するVAEを指定します。未指定時はモデル内のVAEを使用します。
|
||||
|
||||
## 画像生成と出力
|
||||
|
||||
- `--interactive`:インタラクティブモードで動作します。プロンプトを入力すると画像が生成されます。
|
||||
|
||||
- `--prompt <プロンプト>`:プロンプトを指定します。スペースを含む場合はダブルクォーテーションで囲んでください。
|
||||
|
||||
- `--from_file <プロンプトファイル名>`:プロンプトが記述されたファイルを指定します。1行1プロンプトで記述してください。なお画像サイズやguidance scaleはプロンプトオプション(後述)で指定できます。
|
||||
|
||||
- `--W <画像幅>`:画像の幅を指定します。デフォルトは`512`です。
|
||||
|
||||
- `--H <画像高さ>`:画像の高さを指定します。デフォルトは`512`です。
|
||||
|
||||
- `--steps <ステップ数>`:サンプリングステップ数を指定します。デフォルトは`50`です。
|
||||
|
||||
- `--scale <ガイダンススケール>`:unconditionalガイダンススケールを指定します。デフォルトは`7.5`です。
|
||||
|
||||
- `--sampler <サンプラー名>`:サンプラーを指定します。デフォルトは`ddim`です。Diffusersで提供されているddim、pndm、dpmsolver、dpmsolver+++、lms、euler、euler_a、が指定可能です(後ろの三つはk_lms、k_euler、k_euler_aでも指定できます)。
|
||||
|
||||
- `--outdir <画像出力先フォルダ>`:画像の出力先を指定します。
|
||||
|
||||
- `--images_per_prompt <生成枚数>`:プロンプト1件当たりの生成枚数を指定します。デフォルトは`1`です。
|
||||
|
||||
- `--clip_skip <スキップ数>`:CLIPの後ろから何番目の層を使うかを指定します。省略時は最後の層を使います。
|
||||
|
||||
- `--max_embeddings_multiples <倍数>`:CLIPの入出力長をデフォルト(75)の何倍にするかを指定します。未指定時は75のままです。たとえば3を指定すると入出力長が225になります。
|
||||
|
||||
- `--negative_scale` : uncoditioningのguidance scaleを個別に指定します。[gcem156氏のこちらの記事](https://note.com/gcem156/n/ne9a53e4a6f43)を参考に実装したものです。
|
||||
|
||||
## メモリ使用量や生成速度の調整
|
||||
|
||||
- `--batch_size <バッチサイズ>`:バッチサイズを指定します。デフォルトは`1`です。バッチサイズが大きいとメモリを多く消費しますが、生成速度が速くなります。
|
||||
|
||||
- `--vae_batch_size <VAEのバッチサイズ>`:VAEのバッチサイズを指定します。デフォルトはバッチサイズと同じです。
|
||||
VAEのほうがメモリを多く消費するため、デノイジング後(stepが100%になった後)でメモリ不足になる場合があります。このような場合にはVAEのバッチサイズを小さくしてください。
|
||||
|
||||
- `--xformers`:xformersを使う場合に指定します。
|
||||
|
||||
- `--fp16`:fp16(単精度)での推論を行います。`fp16`と`bf16`をどちらも指定しない場合はfp32(単精度)での推論を行います。
|
||||
|
||||
- `--bf16`:bf16(bfloat16)での推論を行います。RTX 30系のGPUでのみ指定可能です。`--bf16`オプションはRTX 30系以外のGPUではエラーになります。`fp16`よりも`bf16`のほうが推論結果がNaNになる(真っ黒の画像になる)可能性が低いようです。
|
||||
|
||||
## 追加ネットワーク(LoRA等)の使用
|
||||
|
||||
- `--network_module`:使用する追加ネットワークを指定します。LoRAの場合は`--network_module networks.lora`と指定します。複数のLoRAを使用する場合は`--network_module networks.lora networks.lora networks.lora`のように指定します。
|
||||
|
||||
- `--network_weights`:使用する追加ネットワークの重みファイルを指定します。`--network_weights model.safetensors`のように指定します。複数のLoRAを使用する場合は`--network_weights model1.safetensors model2.safetensors model3.safetensors`のように指定します。引数の数は`--network_module`で指定した数と同じにしてください。
|
||||
|
||||
- `--network_mul`:使用する追加ネットワークの重みを何倍にするかを指定します。デフォルトは`1`です。`--network_mul 0.8`のように指定します。複数のLoRAを使用する場合は`--network_mul 0.4 0.5 0.7`のように指定します。引数の数は`--network_module`で指定した数と同じにしてください。
|
||||
|
||||
- `--network_merge`:使用する追加ネットワークの重みを`--network_mul`に指定した重みであらかじめマージします。`--network_pre_calc` と同時に使用できません。プロンプトオプションの`--am`、およびRegional LoRAは使用できなくなりますが、LoRA未使用時と同じ程度まで生成が高速化されます。
|
||||
|
||||
- `--network_pre_calc`:使用する追加ネットワークの重みを生成ごとにあらかじめ計算します。プロンプトオプションの`--am`が使用できます。LoRA未使用時と同じ程度まで生成は高速化されますが、生成前に重みを計算する時間が必要で、またメモリ使用量も若干増加します。Regional LoRA使用時は無効になります 。
|
||||
|
||||
# 主なオプションの指定例
|
||||
|
||||
次は同一プロンプトで64枚をバッチサイズ4で一括生成する例です。
|
||||
|
||||
```batchfile
|
||||
python gen_img_diffusers.py --ckpt model.ckpt --outdir outputs
|
||||
--xformers --fp16 --W 512 --H 704 --scale 12.5 --sampler k_euler_a
|
||||
--steps 32 --batch_size 4 --images_per_prompt 64
|
||||
--prompt "beautiful flowers --n monochrome"
|
||||
```
|
||||
|
||||
次はファイルに書かれたプロンプトを、それぞれ10枚ずつ、バッチサイズ4で一括生成する例です。
|
||||
|
||||
```batchfile
|
||||
python gen_img_diffusers.py --ckpt model.ckpt --outdir outputs
|
||||
--xformers --fp16 --W 512 --H 704 --scale 12.5 --sampler k_euler_a
|
||||
--steps 32 --batch_size 4 --images_per_prompt 10
|
||||
--from_file prompts.txt
|
||||
```
|
||||
|
||||
Textual Inversion(後述)およびLoRAの使用例です。
|
||||
|
||||
```batchfile
|
||||
python gen_img_diffusers.py --ckpt model.safetensors
|
||||
--scale 8 --steps 48 --outdir txt2img --xformers
|
||||
--W 512 --H 768 --fp16 --sampler k_euler_a
|
||||
--textual_inversion_embeddings goodembed.safetensors negprompt.pt
|
||||
--network_module networks.lora networks.lora
|
||||
--network_weights model1.safetensors model2.safetensors
|
||||
--network_mul 0.4 0.8
|
||||
--clip_skip 2 --max_embeddings_multiples 1
|
||||
--batch_size 8 --images_per_prompt 1 --interactive
|
||||
```
|
||||
|
||||
# プロンプトオプション
|
||||
|
||||
プロンプト内で、`--n`のように「ハイフンふたつ+アルファベットn文字」でプロンプトから各種オプションの指定が可能です。対話モード、コマンドライン、ファイル、いずれからプロンプトを指定する場合でも有効です。
|
||||
|
||||
プロンプトのオプション指定`--n`の前後にはスペースを入れてください。
|
||||
|
||||
- `--n`:ネガティブプロンプトを指定します。
|
||||
|
||||
- `--w`:画像幅を指定します。コマンドラインからの指定を上書きします。
|
||||
|
||||
- `--h`:画像高さを指定します。コマンドラインからの指定を上書きします。
|
||||
|
||||
- `--s`:ステップ数を指定します。コマンドラインからの指定を上書きします。
|
||||
|
||||
- `--d`:この画像の乱数seedを指定します。`--images_per_prompt`を指定している場合は「--d 1,2,3,4」のようにカンマ区切りで複数指定してください。
|
||||
※様々な理由により、Web UIとは同じ乱数seedでも生成される画像が異なる場合があります。
|
||||
|
||||
- `--l`:guidance scaleを指定します。コマンドラインからの指定を上書きします。
|
||||
|
||||
- `--t`:img2img(後述)のstrengthを指定します。コマンドラインからの指定を上書きします。
|
||||
|
||||
- `--nl`:ネガティブプロンプトのguidance scaleを指定します(後述)。コマンドラインからの指定を上書きします。
|
||||
|
||||
- `--am`:追加ネットワークの重みを指定します。コマンドラインからの指定を上書きします。複数の追加ネットワークを使用する場合は`--am 0.8,0.5,0.3`のように __カンマ区切りで__ 指定します。
|
||||
|
||||
※これらのオプションを指定すると、バッチサイズよりも小さいサイズでバッチが実行される場合があります(これらの値が異なると一括生成できないため)。(あまり気にしなくて大丈夫ですが、ファイルからプロンプトを読み込み生成する場合は、これらの値が同一のプロンプトを並べておくと効率が良くなります。)
|
||||
|
||||
例:
|
||||
```
|
||||
(masterpiece, best quality), 1girl, in shirt and plated skirt, standing at street under cherry blossoms, upper body, [from below], kind smile, looking at another, [goodembed] --n realistic, real life, (negprompt), (lowres:1.1), (worst quality:1.2), (low quality:1.1), bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, normal quality, jpeg artifacts, signature, watermark, username, blurry --w 960 --h 640 --s 28 --d 1
|
||||
```
|
||||
|
||||

|
||||
|
||||
# img2img
|
||||
|
||||
## オプション
|
||||
|
||||
- `--image_path`:img2imgに利用する画像を指定します。`--image_path template.png`のように指定します。フォルダを指定すると、そのフォルダの画像を順次利用します。
|
||||
|
||||
- `--strength`:img2imgのstrengthを指定します。`--strength 0.8`のように指定します。デフォルトは`0.8`です。
|
||||
|
||||
- `--sequential_file_name`:ファイル名を連番にするかどうかを指定します。指定すると生成されるファイル名が`im_000001.png`からの連番になります。
|
||||
|
||||
- `--use_original_file_name`:指定すると生成ファイル名がオリジナルのファイル名と同じになります。
|
||||
|
||||
## コマンドラインからの実行例
|
||||
|
||||
```batchfile
|
||||
python gen_img_diffusers.py --ckpt trinart_characters_it4_v1_vae_merged.ckpt
|
||||
--outdir outputs --xformers --fp16 --scale 12.5 --sampler k_euler --steps 32
|
||||
--image_path template.png --strength 0.8
|
||||
--prompt "1girl, cowboy shot, brown hair, pony tail, brown eyes,
|
||||
sailor school uniform, outdoors
|
||||
--n lowres, bad anatomy, bad hands, error, missing fingers, cropped,
|
||||
worst quality, low quality, normal quality, jpeg artifacts, (blurry),
|
||||
hair ornament, glasses"
|
||||
--batch_size 8 --images_per_prompt 32
|
||||
```
|
||||
|
||||
`--image_path`オプションにフォルダを指定すると、そのフォルダの画像を順次読み込みます。生成される枚数は画像枚数ではなく、プロンプト数になりますので、`--images_per_promptPPオプションを指定してimg2imgする画像の枚数とプロンプト数を合わせてください。
|
||||
|
||||
ファイルはファイル名でソートして読み込みます。なおソート順は文字列順となりますので(`1.jpg→2.jpg→10.jpg`ではなく`1.jpg→10.jpg→2.jpg`の順)、頭を0埋めするなどしてご対応ください(`01.jpg→02.jpg→10.jpg`)。
|
||||
|
||||
## img2imgを利用したupscale
|
||||
|
||||
img2img時にコマンドラインオプションの`--W`と`--H`で生成画像サイズを指定すると、元画像をそのサイズにリサイズしてからimg2imgを行います。
|
||||
|
||||
またimg2imgの元画像がこのスクリプトで生成した画像の場合、プロンプトを省略すると、元画像のメタデータからプロンプトを取得しそのまま用います。これによりHighres. fixの2nd stageの動作だけを行うことができます。
|
||||
|
||||
## img2img時のinpainting
|
||||
|
||||
画像およびマスク画像を指定してinpaintingできます(inpaintingモデルには対応しておらず、単にマスク領域を対象にimg2imgするだけです)。
|
||||
|
||||
オプションは以下の通りです。
|
||||
|
||||
- `--mask_image`:マスク画像を指定します。`--img_path`と同様にフォルダを指定すると、そのフォルダの画像を順次利用します。
|
||||
|
||||
マスク画像はグレースケール画像で、白の部分がinpaintingされます。境界をグラデーションしておくとなんとなく滑らかになりますのでお勧めです。
|
||||
|
||||

|
||||
|
||||
# その他の機能
|
||||
|
||||
## Textual Inversion
|
||||
|
||||
`--textual_inversion_embeddings`オプションで使用するembeddingsを指定します(複数指定可)。拡張子を除いたファイル名をプロンプト内で使用することで、そのembeddingsを利用します(Web UIと同様の使用法です)。ネガティブプロンプト内でも使用できます。
|
||||
|
||||
モデルとして、当リポジトリで学習したTextual Inversionモデル、およびWeb UIで学習したTextual Inversionモデル(画像埋め込みは非対応)を利用できます
|
||||
|
||||
## Extended Textual Inversion
|
||||
|
||||
`--textual_inversion_embeddings`の代わりに`--XTI_embeddings`オプションを指定してください。使用法は`--textual_inversion_embeddings`と同じです。
|
||||
|
||||
## Highres. fix
|
||||
|
||||
AUTOMATIC1111氏のWeb UIにある機能の類似機能です(独自実装のためもしかしたらいろいろ異なるかもしれません)。最初に小さめの画像を生成し、その画像を元にimg2imgすることで、画像全体の破綻を防ぎつつ大きな解像度の画像を生成します。
|
||||
|
||||
2nd stageのstep数は`--steps` と`--strength`オプションの値から計算されます(`steps*strength`)。
|
||||
|
||||
img2imgと併用できません。
|
||||
|
||||
以下のオプションがあります。
|
||||
|
||||
- `--highres_fix_scale`:Highres. fixを有効にして、1st stageで生成する画像のサイズを、倍率で指定します。最終出力が1024x1024で、最初に512x512の画像を生成する場合は`--highres_fix_scale 0.5`のように指定します。Web UI出の指定の逆数になっていますのでご注意ください。
|
||||
|
||||
- `--highres_fix_steps`:1st stageの画像のステップ数を指定します。デフォルトは`28`です。
|
||||
|
||||
- `--highres_fix_save_1st`:1st stageの画像を保存するかどうかを指定します。
|
||||
|
||||
- `--highres_fix_latents_upscaling`:指定すると2nd stageの画像生成時に1st stageの画像をlatentベースでupscalingします(bilinearのみ対応)。未指定時は画像をLANCZOS4でupscalingします。
|
||||
|
||||
- `--highres_fix_upscaler`:2nd stageに任意のupscalerを利用します。現在は`--highres_fix_upscaler tools.latent_upscaler` のみ対応しています。
|
||||
|
||||
- `--highres_fix_upscaler_args`:`--highres_fix_upscaler`で指定したupscalerに渡す引数を指定します。
|
||||
`tools.latent_upscaler`の場合は、`--highres_fix_upscaler_args "weights=D:\Work\SD\Models\others\etc\upscaler-v1-e100-220.safetensors"`のように重みファイルを指定します。
|
||||
|
||||
コマンドラインの例です。
|
||||
|
||||
```batchfile
|
||||
python gen_img_diffusers.py --ckpt trinart_characters_it4_v1_vae_merged.ckpt
|
||||
--n_iter 1 --scale 7.5 --W 1024 --H 1024 --batch_size 1 --outdir ../txt2img
|
||||
--steps 48 --sampler ddim --fp16
|
||||
--xformers
|
||||
--images_per_prompt 1 --interactive
|
||||
--highres_fix_scale 0.5 --highres_fix_steps 28 --strength 0.5
|
||||
```
|
||||
|
||||
## ControlNet
|
||||
|
||||
現在はControlNet 1.0のみ動作確認しています。プリプロセスはCannyのみサポートしています。
|
||||
|
||||
以下のオプションがあります。
|
||||
|
||||
- `--control_net_models`:ControlNetのモデルファイルを指定します。
|
||||
複数指定すると、それらをstepごとに切り替えて利用します(Web UIのControlNet拡張の実装と異なります)。diffと通常の両方をサポートします。
|
||||
|
||||
- `--guide_image_path`:ControlNetに使うヒント画像を指定します。`--img_path`と同様にフォルダを指定すると、そのフォルダの画像を順次利用します。Canny以外のモデルの場合には、あらかじめプリプロセスを行っておいてください。
|
||||
|
||||
- `--control_net_preps`:ControlNetのプリプロセスを指定します。`--control_net_models`と同様に複数指定可能です。現在はcannyのみ対応しています。対象モデルでプリプロセスを使用しない場合は `none` を指定します。
|
||||
cannyの場合 `--control_net_preps canny_63_191`のように、閾値1と2を'_'で区切って指定できます。
|
||||
|
||||
- `--control_net_weights`:ControlNetの適用時の重みを指定します(`1.0`で通常、`0.5`なら半分の影響力で適用)。`--control_net_models`と同様に複数指定可能です。
|
||||
|
||||
- `--control_net_ratios`:ControlNetを適用するstepの範囲を指定します。`0.5`の場合は、step数の半分までControlNetを適用します。`--control_net_models`と同様に複数指定可能です。
|
||||
|
||||
コマンドラインの例です。
|
||||
|
||||
```batchfile
|
||||
python gen_img_diffusers.py --ckpt model_ckpt --scale 8 --steps 48 --outdir txt2img --xformers
|
||||
--W 512 --H 768 --bf16 --sampler k_euler_a
|
||||
--control_net_models diff_control_sd15_canny.safetensors --control_net_weights 1.0
|
||||
--guide_image_path guide.png --control_net_ratios 1.0 --interactive
|
||||
```
|
||||
|
||||
## Attention Couple + Reginal LoRA
|
||||
|
||||
プロンプトをいくつかの部分に分割し、それぞれのプロンプトを画像内のどの領域に適用するかを指定できる機能です。個別のオプションはありませんが、`mask_path`とプロンプトで指定します。
|
||||
|
||||
まず、プロンプトで` AND `を利用して、複数部分を定義します。最初の3つに対して領域指定ができ、以降の部分は画像全体へ適用されます。ネガティブプロンプトは画像全体に適用されます。
|
||||
|
||||
以下ではANDで3つの部分を定義しています。
|
||||
|
||||
```
|
||||
shs 2girls, looking at viewer, smile AND bsb 2girls, looking back AND 2girls --n bad quality, worst quality
|
||||
```
|
||||
|
||||
次にマスク画像を用意します。マスク画像はカラーの画像で、RGBの各チャネルがプロンプトのANDで区切られた部分に対応します。またあるチャネルの値がすべて0の場合、画像全体に適用されます。
|
||||
|
||||
上記の例では、Rチャネルが`shs 2girls, looking at viewer, smile`、Gチャネルが`bsb 2girls, looking back`に、Bチャネルが`2girls`に対応します。次のようなマスク画像を使用すると、Bチャネルに指定がありませんので、`2girls`は画像全体に適用されます。
|
||||
|
||||

|
||||
|
||||
マスク画像は`--mask_path`で指定します。現在は1枚のみ対応しています。指定した画像サイズに自動的にリサイズされ適用されます。
|
||||
|
||||
ControlNetと組み合わせることも可能です(細かい位置指定にはControlNetとの組み合わせを推奨します)。
|
||||
|
||||
LoRAを指定すると、`--network_weights`で指定した複数のLoRAがそれぞれANDの各部分に対応します。現在の制約として、LoRAの数はANDの部分の数と同じである必要があります。
|
||||
|
||||
## CLIP Guided Stable Diffusion
|
||||
|
||||
DiffusersのCommunity Examplesの[こちらのcustom pipeline](https://github.com/huggingface/diffusers/blob/main/examples/community/README.md#clip-guided-stable-diffusion)からソースをコピー、変更したものです。
|
||||
|
||||
通常のプロンプトによる生成指定に加えて、追加でより大規模のCLIPでプロンプトのテキストの特徴量を取得し、生成中の画像の特徴量がそのテキストの特徴量に近づくよう、生成される画像をコントロールします(私のざっくりとした理解です)。大きめのCLIPを使いますのでVRAM使用量はかなり増加し(VRAM 8GBでは512*512でも厳しいかもしれません)、生成時間も掛かります。
|
||||
|
||||
なお選択できるサンプラーはDDIM、PNDM、LMSのみとなります。
|
||||
|
||||
`--clip_guidance_scale`オプションにどの程度、CLIPの特徴量を反映するかを数値で指定します。先のサンプルでは100になっていますので、そのあたりから始めて増減すると良いようです。
|
||||
|
||||
デフォルトではプロンプトの先頭75トークン(重みづけの特殊文字を除く)がCLIPに渡されます。プロンプトの`--c`オプションで、通常のプロンプトではなく、CLIPに渡すテキストを別に指定できます(たとえばCLIPはDreamBoothのidentifier(識別子)や「1girl」などのモデル特有の単語は認識できないと思われますので、それらを省いたテキストが良いと思われます)。
|
||||
|
||||
コマンドラインの例です。
|
||||
|
||||
```batchfile
|
||||
python gen_img_diffusers.py --ckpt v1-5-pruned-emaonly.ckpt --n_iter 1
|
||||
--scale 2.5 --W 512 --H 512 --batch_size 1 --outdir ../txt2img --steps 36
|
||||
--sampler ddim --fp16 --opt_channels_last --xformers --images_per_prompt 1
|
||||
--interactive --clip_guidance_scale 100
|
||||
```
|
||||
|
||||
## CLIP Image Guided Stable Diffusion
|
||||
|
||||
テキストではなくCLIPに別の画像を渡し、その特徴量に近づくよう生成をコントロールする機能です。`--clip_image_guidance_scale`オプションで適用量の数値を、`--guide_image_path`オプションでguideに使用する画像(ファイルまたはフォルダ)を指定してください。
|
||||
|
||||
コマンドラインの例です。
|
||||
|
||||
```batchfile
|
||||
python gen_img_diffusers.py --ckpt trinart_characters_it4_v1_vae_merged.ckpt
|
||||
--n_iter 1 --scale 7.5 --W 512 --H 512 --batch_size 1 --outdir ../txt2img
|
||||
--steps 80 --sampler ddim --fp16 --opt_channels_last --xformers
|
||||
--images_per_prompt 1 --interactive --clip_image_guidance_scale 100
|
||||
--guide_image_path YUKA160113420I9A4104_TP_V.jpg
|
||||
```
|
||||
|
||||
### VGG16 Guided Stable Diffusion
|
||||
|
||||
指定した画像に近づくように画像生成する機能です。通常のプロンプトによる生成指定に加えて、追加でVGG16の特徴量を取得し、生成中の画像が指定したガイド画像に近づくよう、生成される画像をコントロールします。img2imgでの使用をお勧めします(通常の生成では画像がぼやけた感じになります)。CLIP Guided Stable Diffusionの仕組みを流用した独自の機能です。またアイデアはVGGを利用したスタイル変換から拝借しています。
|
||||
|
||||
なお選択できるサンプラーはDDIM、PNDM、LMSのみとなります。
|
||||
|
||||
`--vgg16_guidance_scale`オプションにどの程度、VGG16特徴量を反映するかを数値で指定します。試した感じでは100くらいから始めて増減すると良いようです。`--guide_image_path`オプションでguideに使用する画像(ファイルまたはフォルダ)を指定してください。
|
||||
|
||||
複数枚の画像を一括でimg2img変換し、元画像をガイド画像とする場合、`--guide_image_path`と`--image_path`に同じ値を指定すればOKです。
|
||||
|
||||
コマンドラインの例です。
|
||||
|
||||
```batchfile
|
||||
python gen_img_diffusers.py --ckpt wd-v1-3-full-pruned-half.ckpt
|
||||
--n_iter 1 --scale 5.5 --steps 60 --outdir ../txt2img
|
||||
--xformers --sampler ddim --fp16 --W 512 --H 704
|
||||
--batch_size 1 --images_per_prompt 1
|
||||
--prompt "picturesque, 1girl, solo, anime face, skirt, beautiful face
|
||||
--n lowres, bad anatomy, bad hands, error, missing fingers,
|
||||
cropped, worst quality, low quality, normal quality,
|
||||
jpeg artifacts, blurry, 3d, bad face, monochrome --d 1"
|
||||
--strength 0.8 --image_path ..\src_image
|
||||
--vgg16_guidance_scale 100 --guide_image_path ..\src_image
|
||||
```
|
||||
|
||||
`--vgg16_guidance_layerPで特徴量取得に使用するVGG16のレイヤー番号を指定できます(デフォルトは20でconv4-2のReLUです)。上の層ほど画風を表現し、下の層ほどコンテンツを表現するといわれています。
|
||||
|
||||

|
||||
|
||||
# その他のオプション
|
||||
|
||||
- `--no_preview` : 対話モードでプレビュー画像を表示しません。OpenCVがインストールされていない場合や、出力されたファイルを直接確認する場合に指定してください。
|
||||
|
||||
- `--n_iter` : 生成を繰り返す回数を指定します。デフォルトは1です。プロンプトをファイルから読み込むとき、複数回の生成を行いたい場合に指定します。
|
||||
|
||||
- `--tokenizer_cache_dir` : トークナイザーのキャッシュディレクトリを指定します。(作業中)
|
||||
|
||||
- `--seed` : 乱数seedを指定します。1枚生成時はその画像のseed、複数枚生成時は各画像のseedを生成するための乱数のseedになります(`--from_file`で複数画像生成するとき、`--seed`オプションを指定すると複数回実行したときに各画像が同じseedになります)。
|
||||
|
||||
- `--iter_same_seed` : プロンプトに乱数seedの指定がないとき、`--n_iter`の繰り返し内ではすべて同じseedを使います。`--from_file`で指定した複数のプロンプト間でseedを統一して比較するときに使います。
|
||||
|
||||
- `--diffusers_xformers` : Diffuserのxformersを使用します。
|
||||
|
||||
- `--opt_channels_last` : 推論時にテンソルのチャンネルを最後に配置します。場合によっては高速化されることがあります。
|
||||
|
||||
- `--network_show_meta` : 追加ネットワークのメタデータを表示します。
|
||||
|
||||
|
||||
---
|
||||
|
||||
# About Gradual Latent
|
||||
|
||||
Gradual Latent is a Hires fix that gradually increases the size of the latent. `gen_img.py`, `sdxl_gen_img.py`, and `gen_img_diffusers.py` have the following options.
|
||||
|
||||
- `--gradual_latent_timesteps`: Specifies the timestep to start increasing the size of the latent. The default is None, which means Gradual Latent is not used. Please try around 750 at first.
|
||||
- `--gradual_latent_ratio`: Specifies the initial size of the latent. The default is 0.5, which means it starts with half the default latent size.
|
||||
- `--gradual_latent_ratio_step`: Specifies the ratio to increase the size of the latent. The default is 0.125, which means the latent size is gradually increased to 0.625, 0.75, 0.875, 1.0.
|
||||
- `--gradual_latent_ratio_every_n_steps`: Specifies the interval to increase the size of the latent. The default is 3, which means the latent size is increased every 3 steps.
|
||||
|
||||
Each option can also be specified with prompt options, `--glt`, `--glr`, `--gls`, `--gle`.
|
||||
|
||||
__Please specify `euler_a` for the sampler.__ Because the source code of the sampler is modified. It will not work with other samplers.
|
||||
|
||||
It is more effective with SD 1.5. It is quite subtle with SDXL.
|
||||
|
||||
# Gradual Latent について
|
||||
|
||||
latentのサイズを徐々に大きくしていくHires fixです。`gen_img.py` 、``sdxl_gen_img.py` 、`gen_img_diffusers.py` に以下のオプションが追加されています。
|
||||
|
||||
- `--gradual_latent_timesteps` : latentのサイズを大きくし始めるタイムステップを指定します。デフォルトは None で、Gradual Latentを使用しません。750 くらいから始めてみてください。
|
||||
- `--gradual_latent_ratio` : latentの初期サイズを指定します。デフォルトは 0.5 で、デフォルトの latent サイズの半分のサイズから始めます。
|
||||
- `--gradual_latent_ratio_step`: latentのサイズを大きくする割合を指定します。デフォルトは 0.125 で、latentのサイズを 0.625, 0.75, 0.875, 1.0 と徐々に大きくします。
|
||||
- `--gradual_latent_ratio_every_n_steps`: latentのサイズを大きくする間隔を指定します。デフォルトは 3 で、3ステップごとに latent のサイズを大きくします。
|
||||
|
||||
それぞれのオプションは、プロンプトオプション、`--glt`、`--glr`、`--gls`、`--gle` でも指定できます。
|
||||
|
||||
サンプラーに手を加えているため、__サンプラーに `euler_a` を指定してください。__ 他のサンプラーでは動作しません。
|
||||
|
||||
SD 1.5 のほうが効果があります。SDXL ではかなり微妙です。
|
||||
|
||||
57
docs/masked_loss_README-ja.md
Normal file
57
docs/masked_loss_README-ja.md
Normal file
@@ -0,0 +1,57 @@
|
||||
## マスクロスについて
|
||||
|
||||
マスクロスは、入力画像のマスクで指定された部分だけ損失計算することで、画像の一部分だけを学習することができる機能です。
|
||||
たとえばキャラクタを学習したい場合、キャラクタ部分だけをマスクして学習することで、背景を無視して学習することができます。
|
||||
|
||||
マスクロスのマスクには、二種類の指定方法があります。
|
||||
|
||||
- マスク画像を用いる方法
|
||||
- 透明度(アルファチャネル)を使用する方法
|
||||
|
||||
なお、サンプルは [ずんずんPJイラスト/3Dデータ](https://zunko.jp/con_illust.html) の「AI画像モデル用学習データ」を使用しています。
|
||||
|
||||
### マスク画像を用いる方法
|
||||
|
||||
学習画像それぞれに対応するマスク画像を用意する方法です。学習画像と同じファイル名のマスク画像を用意し、それを学習画像と別のディレクトリに保存します。
|
||||
|
||||
- 学習画像
|
||||

|
||||
- マスク画像
|
||||

|
||||
|
||||
```.toml
|
||||
[[datasets.subsets]]
|
||||
image_dir = "/path/to/a_zundamon"
|
||||
caption_extension = ".txt"
|
||||
conditioning_data_dir = "/path/to/a_zundamon_mask"
|
||||
num_repeats = 8
|
||||
```
|
||||
|
||||
マスク画像は、学習画像と同じサイズで、学習する部分を白、無視する部分を黒で描画します。グレースケールにも対応しています(127 ならロス重みが 0.5 になります)。なお、正確にはマスク画像の R チャネルが用いられます。
|
||||
|
||||
DreamBooth 方式の dataset で、`conditioning_data_dir` で指定したディレクトリにマスク画像を保存してください。ControlNet のデータセットと同じですので、詳細は [ControlNet-LLLite](train_lllite_README-ja.md#データセットの準備) を参照してください。
|
||||
|
||||
### 透明度(アルファチャネル)を使用する方法
|
||||
|
||||
学習画像の透明度(アルファチャネル)がマスクとして使用されます。透明度が 0 の部分は無視され、255 の部分は学習されます。半透明の場合は、その透明度に応じてロス重みが変化します(127 ならおおむね 0.5)。
|
||||
|
||||

|
||||
|
||||
※それぞれの画像は透過PNG
|
||||
|
||||
学習時のスクリプトのオプションに `--alpha_mask` を指定するか、dataset の設定ファイルの subset で、`alpha_mask` を指定してください。たとえば、以下のようになります。
|
||||
|
||||
```toml
|
||||
[[datasets.subsets]]
|
||||
image_dir = "/path/to/image/dir"
|
||||
caption_extension = ".txt"
|
||||
num_repeats = 8
|
||||
alpha_mask = true
|
||||
```
|
||||
|
||||
## 学習時の注意事項
|
||||
|
||||
- 現時点では DreamBooth 方式の dataset のみ対応しています。
|
||||
- マスクは latents のサイズ、つまり 1/8 に縮小されてから適用されます。そのため、細かい部分(たとえばアホ毛やイヤリングなど)はうまく学習できない可能性があります。マスクをわずかに拡張するなどの工夫が必要かもしれません。
|
||||
- マスクロスを用いる場合、学習対象外の部分をキャプションに含める必要はないかもしれません。(要検証)
|
||||
- `alpha_mask` の場合、マスクの有無を切り替えると latents キャッシュが自動的に再生成されます。
|
||||
56
docs/masked_loss_README.md
Normal file
56
docs/masked_loss_README.md
Normal file
@@ -0,0 +1,56 @@
|
||||
## Masked Loss
|
||||
|
||||
Masked loss is a feature that allows you to train only part of an image by calculating the loss only for the part specified by the mask of the input image. For example, if you want to train a character, you can train only the character part by masking it, ignoring the background.
|
||||
|
||||
There are two ways to specify the mask for masked loss.
|
||||
|
||||
- Using a mask image
|
||||
- Using transparency (alpha channel) of the image
|
||||
|
||||
The sample uses the "AI image model training data" from [ZunZunPJ Illustration/3D Data](https://zunko.jp/con_illust.html).
|
||||
|
||||
### Using a mask image
|
||||
|
||||
This is a method of preparing a mask image corresponding to each training image. Prepare a mask image with the same file name as the training image and save it in a different directory from the training image.
|
||||
|
||||
- Training image
|
||||

|
||||
- Mask image
|
||||

|
||||
|
||||
```.toml
|
||||
[[datasets.subsets]]
|
||||
image_dir = "/path/to/a_zundamon"
|
||||
caption_extension = ".txt"
|
||||
conditioning_data_dir = "/path/to/a_zundamon_mask"
|
||||
num_repeats = 8
|
||||
```
|
||||
|
||||
The mask image is the same size as the training image, with the part to be trained drawn in white and the part to be ignored in black. It also supports grayscale (127 gives a loss weight of 0.5). The R channel of the mask image is used currently.
|
||||
|
||||
Use the dataset in the DreamBooth method, and save the mask image in the directory specified by `conditioning_data_dir`. It is the same as the ControlNet dataset, so please refer to [ControlNet-LLLite](train_lllite_README.md#Preparing-the-dataset) for details.
|
||||
|
||||
### Using transparency (alpha channel) of the image
|
||||
|
||||
The transparency (alpha channel) of the training image is used as a mask. The part with transparency 0 is ignored, the part with transparency 255 is trained. For semi-transparent parts, the loss weight changes according to the transparency (127 gives a weight of about 0.5).
|
||||
|
||||

|
||||
|
||||
※Each image is a transparent PNG
|
||||
|
||||
Specify `--alpha_mask` in the training script options or specify `alpha_mask` in the subset of the dataset configuration file. For example, it will look like this.
|
||||
|
||||
```toml
|
||||
[[datasets.subsets]]
|
||||
image_dir = "/path/to/image/dir"
|
||||
caption_extension = ".txt"
|
||||
num_repeats = 8
|
||||
alpha_mask = true
|
||||
```
|
||||
|
||||
## Notes on training
|
||||
|
||||
- At the moment, only the dataset in the DreamBooth method is supported.
|
||||
- The mask is applied after the size is reduced to 1/8, which is the size of the latents. Therefore, fine details (such as ahoge or earrings) may not be learned well. Some dilations of the mask may be necessary.
|
||||
- If using masked loss, it may not be necessary to include parts that are not to be trained in the caption. (To be verified)
|
||||
- In the case of `alpha_mask`, the latents cache is automatically regenerated when the enable/disable state of the mask is switched.
|
||||
@@ -295,7 +295,7 @@ Stable Diffusion のv1は512\*512で学習されていますが、それに加
|
||||
|
||||
また任意の解像度で学習するため、事前に画像データの縦横比を統一しておく必要がなくなります。
|
||||
|
||||
設定で有効、向こうが切り替えられますが、ここまでの設定ファイルの記述例では有効になっています(`true` が設定されています)。
|
||||
設定で有効、無効が切り替えられますが、ここまでの設定ファイルの記述例では有効になっています(`true` が設定されています)。
|
||||
|
||||
学習解像度はパラメータとして与えられた解像度の面積(=メモリ使用量)を超えない範囲で、64ピクセル単位(デフォルト、変更可)で縦横に調整、作成されます。
|
||||
|
||||
@@ -374,6 +374,10 @@ classがひとつで対象が複数の場合、正則化画像フォルダはひ
|
||||
|
||||
サンプル出力するステップ数またはエポック数を指定します。この数ごとにサンプル出力します。両方指定するとエポック数が優先されます。
|
||||
|
||||
- `--sample_at_first`
|
||||
|
||||
学習開始前にサンプル出力します。学習前との比較ができます。
|
||||
|
||||
- `--sample_prompts`
|
||||
|
||||
サンプル出力用プロンプトのファイルを指定します。
|
||||
@@ -463,27 +467,6 @@ masterpiece, best quality, 1boy, in business suit, standing at street, looking b
|
||||
|
||||
xformersオプションを指定するとxformersのCrossAttentionを用います。xformersをインストールしていない場合やエラーとなる場合(環境にもよりますが `mixed_precision="no"` の場合など)、代わりに `mem_eff_attn` オプションを指定すると省メモリ版CrossAttentionを使用します(xformersよりも速度は遅くなります)。
|
||||
|
||||
- `--save_precision`
|
||||
|
||||
保存時のデータ精度を指定します。save_precisionオプションにfloat、fp16、bf16のいずれかを指定すると、その形式でモデルを保存します(DreamBooth、fine tuningでDiffusers形式でモデルを保存する場合は無効です)。モデルのサイズを削減したい場合などにお使いください。
|
||||
|
||||
- `--save_every_n_epochs` / `--save_state` / `--resume`
|
||||
save_every_n_epochsオプションに数値を指定すると、そのエポックごとに学習途中のモデルを保存します。
|
||||
|
||||
save_stateオプションを同時に指定すると、optimizer等の状態も含めた学習状態を合わせて保存します(保存したモデルからも学習再開できますが、それに比べると精度の向上、学習時間の短縮が期待できます)。保存先はフォルダになります。
|
||||
|
||||
学習状態は保存先フォルダに `<output_name>-??????-state`(??????はエポック数)という名前のフォルダで出力されます。長時間にわたる学習時にご利用ください。
|
||||
|
||||
保存された学習状態から学習を再開するにはresumeオプションを使います。学習状態のフォルダ(`output_dir` ではなくその中のstateのフォルダ)を指定してください。
|
||||
|
||||
なおAcceleratorの仕様により、エポック数、global stepは保存されておらず、resumeしたときにも1からになりますがご容赦ください。
|
||||
|
||||
- `--save_model_as` (DreamBooth, fine tuning のみ)
|
||||
|
||||
モデルの保存形式を`ckpt, safetensors, diffusers, diffusers_safetensors` から選べます。
|
||||
|
||||
`--save_model_as=safetensors` のように指定します。Stable Diffusion形式(ckptまたはsafetensors)を読み込み、Diffusers形式で保存する場合、不足する情報はHugging Faceからv1.5またはv2.1の情報を落としてきて補完します。
|
||||
|
||||
- `--clip_skip`
|
||||
|
||||
`2` を指定すると、Text Encoder (CLIP) の後ろから二番目の層の出力を用います。1またはオプション省略時は最後の層を用います。
|
||||
@@ -502,6 +485,12 @@ masterpiece, best quality, 1boy, in business suit, standing at street, looking b
|
||||
|
||||
clip_skipと同様に、モデルの学習状態と異なる長さで学習するには、ある程度の教師データ枚数、長めの学習時間が必要になると思われます。
|
||||
|
||||
- `--weighted_captions`
|
||||
|
||||
指定するとAutomatic1111氏のWeb UIと同様の重み付きキャプションが有効になります。「Textual Inversion と XTI」以外の学習に使用できます。キャプションだけでなく DreamBooth 手法の token string でも有効です。
|
||||
|
||||
重みづけキャプションの記法はWeb UIとほぼ同じで、(abc)や[abc]、(abc:1.23)などが使用できます。入れ子も可能です。括弧内にカンマを含めるとプロンプトのshuffle/dropoutで括弧の対応付けがおかしくなるため、括弧内にはカンマを含めないでください。
|
||||
|
||||
- `--persistent_data_loader_workers`
|
||||
|
||||
Windows環境で指定するとエポック間の待ち時間が大幅に短縮されます。
|
||||
@@ -527,12 +516,28 @@ masterpiece, best quality, 1boy, in business suit, standing at street, looking b
|
||||
|
||||
その後ブラウザを開き、http://localhost:6006/ へアクセスすると表示されます。
|
||||
|
||||
- `--log_with` / `--log_tracker_name`
|
||||
|
||||
学習ログの保存に関するオプションです。`tensorboard` だけでなく `wandb`への保存が可能です。詳細は [PR#428](https://github.com/kohya-ss/sd-scripts/pull/428)をご覧ください。
|
||||
|
||||
- `--noise_offset`
|
||||
|
||||
こちらの記事の実装になります: https://www.crosslabs.org//blog/diffusion-with-offset-noise
|
||||
|
||||
全体的に暗い、明るい画像の生成結果が良くなる可能性があるようです。LoRA学習でも有効なようです。`0.1` 程度の値を指定するとよいようです。
|
||||
|
||||
- `--adaptive_noise_scale` (実験的オプション)
|
||||
|
||||
Noise offsetの値を、latentsの各チャネルの平均値の絶対値に応じて自動調整するオプションです。`--noise_offset` と同時に指定することで有効になります。Noise offsetの値は `noise_offset + abs(mean(latents, dim=(2,3))) * adaptive_noise_scale` で計算されます。latentは正規分布に近いためnoise_offsetの1/10~同程度の値を指定するとよいかもしれません。
|
||||
|
||||
負の値も指定でき、その場合はnoise offsetは0以上にclipされます。
|
||||
|
||||
- `--multires_noise_iterations` / `--multires_noise_discount`
|
||||
|
||||
Multi resolution noise (pyramid noise)の設定です。詳細は [PR#471](https://github.com/kohya-ss/sd-scripts/pull/471) およびこちらのページ [Multi-Resolution Noise for Diffusion Model Training](https://wandb.ai/johnowhitaker/multires_noise/reports/Multi-Resolution-Noise-for-Diffusion-Model-Training--VmlldzozNjYyOTU2) を参照してください。
|
||||
|
||||
`--multires_noise_iterations` に数値を指定すると有効になります。6~10程度の値が良いようです。`--multires_noise_discount` に0.1~0.3 程度の値(LoRA学習等比較的データセットが小さい場合のPR作者の推奨)、ないしは0.8程度の値(元記事の推奨)を指定してください(デフォルトは 0.3)。
|
||||
|
||||
- `--debug_dataset`
|
||||
|
||||
このオプションを付けることで学習を行う前に事前にどのような画像データ、キャプションで学習されるかを確認できます。Escキーを押すと終了してコマンドラインに戻ります。`S`キーで次のステップ(バッチ)、`E`キーで次のエポックに進みます。
|
||||
@@ -545,14 +550,62 @@ masterpiece, best quality, 1boy, in business suit, standing at street, looking b
|
||||
|
||||
DreamBoothおよびfine tuningでは、保存されるモデルはこのVAEを組み込んだものになります。
|
||||
|
||||
- `--cache_latents`
|
||||
- `--cache_latents` / `--cache_latents_to_disk`
|
||||
|
||||
使用VRAMを減らすためVAEの出力をメインメモリにキャッシュします。`flip_aug` 以外のaugmentationは使えなくなります。また全体の学習速度が若干速くなります。
|
||||
|
||||
cache_latents_to_diskを指定するとキャッシュをディスクに保存します。スクリプトを終了し、再度起動した場合もキャッシュが有効になります。
|
||||
|
||||
- `--min_snr_gamma`
|
||||
|
||||
Min-SNR Weighting strategyを指定します。詳細は[こちら](https://github.com/kohya-ss/sd-scripts/pull/308)を参照してください。論文では`5`が推奨されています。
|
||||
|
||||
## モデルの保存に関する設定
|
||||
|
||||
- `--save_precision`
|
||||
|
||||
保存時のデータ精度を指定します。save_precisionオプションにfloat、fp16、bf16のいずれかを指定すると、その形式でモデルを保存します(DreamBooth、fine tuningでDiffusers形式でモデルを保存する場合は無効です)。モデルのサイズを削減したい場合などにお使いください。
|
||||
|
||||
- `--save_every_n_epochs` / `--save_state` / `--resume`
|
||||
|
||||
save_every_n_epochsオプションに数値を指定すると、そのエポックごとに学習途中のモデルを保存します。
|
||||
|
||||
save_stateオプションを同時に指定すると、optimizer等の状態も含めた学習状態を合わせて保存します(保存したモデルからも学習再開できますが、それに比べると精度の向上、学習時間の短縮が期待できます)。保存先はフォルダになります。
|
||||
|
||||
学習状態は保存先フォルダに `<output_name>-??????-state`(??????はエポック数)という名前のフォルダで出力されます。長時間にわたる学習時にご利用ください。
|
||||
|
||||
保存された学習状態から学習を再開するにはresumeオプションを使います。学習状態のフォルダ(`output_dir` ではなくその中のstateのフォルダ)を指定してください。
|
||||
|
||||
なおAcceleratorの仕様により、エポック数、global stepは保存されておらず、resumeしたときにも1からになりますがご容赦ください。
|
||||
|
||||
- `--save_every_n_steps`
|
||||
|
||||
save_every_n_stepsオプションに数値を指定すると、そのステップごとに学習途中のモデルを保存します。save_every_n_epochsと同時に指定できます。
|
||||
|
||||
- `--save_model_as` (DreamBooth, fine tuning のみ)
|
||||
|
||||
モデルの保存形式を`ckpt, safetensors, diffusers, diffusers_safetensors` から選べます。
|
||||
|
||||
`--save_model_as=safetensors` のように指定します。Stable Diffusion形式(ckptまたはsafetensors)を読み込み、Diffusers形式で保存する場合、不足する情報はHugging Faceからv1.5またはv2.1の情報を落としてきて補完します。
|
||||
|
||||
- `--huggingface_repo_id` 等
|
||||
|
||||
huggingface_repo_idが指定されているとモデル保存時に同時にHuggingFaceにアップロードします。アクセストークンの取り扱いに注意してください(HuggingFaceのドキュメントを参照してください)。
|
||||
|
||||
他の引数をたとえば以下のように指定してください。
|
||||
|
||||
- `--huggingface_repo_id "your-hf-name/your-model" --huggingface_path_in_repo "path" --huggingface_repo_type model --huggingface_repo_visibility private --huggingface_token hf_YourAccessTokenHere`
|
||||
|
||||
huggingface_repo_visibilityに`public`を指定するとリポジトリが公開されます。省略時または`private`(などpublic以外)を指定すると非公開になります。
|
||||
|
||||
`--save_state`オプション指定時に`--save_state_to_huggingface`を指定するとstateもアップロードします。
|
||||
|
||||
`--resume`オプション指定時に`--resume_from_huggingface`を指定するとHuggingFaceからstateをダウンロードして再開します。その時の --resumeオプションは `--resume {repo_id}/{path_in_repo}:{revision}:{repo_type}`になります。
|
||||
|
||||
例: `--resume_from_huggingface --resume your-hf-name/your-model/path/test-000002-state:main:model`
|
||||
|
||||
`--async_upload`オプションを指定するとアップロードを非同期で行います。
|
||||
|
||||
## オプティマイザ関係
|
||||
|
||||
- `--optimizer_type`
|
||||
@@ -560,12 +613,22 @@ masterpiece, best quality, 1boy, in business suit, standing at street, looking b
|
||||
- AdamW : [torch.optim.AdamW](https://pytorch.org/docs/stable/generated/torch.optim.AdamW.html)
|
||||
- 過去のバージョンのオプション未指定時と同じ
|
||||
- AdamW8bit : 引数は同上
|
||||
- PagedAdamW8bit : 引数は同上
|
||||
- 過去のバージョンの--use_8bit_adam指定時と同じ
|
||||
- Lion : https://github.com/lucidrains/lion-pytorch
|
||||
- 過去のバージョンの--use_lion_optimizer指定時と同じ
|
||||
- Lion8bit : 引数は同上
|
||||
- PagedLion8bit : 引数は同上
|
||||
- SGDNesterov : [torch.optim.SGD](https://pytorch.org/docs/stable/generated/torch.optim.SGD.html), nesterov=True
|
||||
- SGDNesterov8bit : 引数は同上
|
||||
- DAdaptation : https://github.com/facebookresearch/dadaptation
|
||||
- DAdaptation(DAdaptAdamPreprint) : https://github.com/facebookresearch/dadaptation
|
||||
- DAdaptAdam : 引数は同上
|
||||
- DAdaptAdaGrad : 引数は同上
|
||||
- DAdaptAdan : 引数は同上
|
||||
- DAdaptAdanIP : 引数は同上
|
||||
- DAdaptLion : 引数は同上
|
||||
- DAdaptSGD : 引数は同上
|
||||
- Prodigy : https://github.com/konstmish/prodigy
|
||||
- AdaFactor : [Transformers AdaFactor](https://huggingface.co/docs/transformers/main_classes/optimizer_schedules)
|
||||
- 任意のオプティマイザ
|
||||
|
||||
@@ -585,7 +648,7 @@ masterpiece, best quality, 1boy, in business suit, standing at street, looking b
|
||||
|
||||
詳細については各自お調べください。
|
||||
|
||||
任意のスケジューラを使う場合、任意のオプティマイザと同様に、`--scheduler_args`でオプション引数を指定してください。
|
||||
任意のスケジューラを使う場合、任意のオプティマイザと同様に、`--lr_scheduler_args`でオプション引数を指定してください。
|
||||
|
||||
### オプティマイザの指定について
|
||||
|
||||
912
docs/train_README-zh.md
Normal file
912
docs/train_README-zh.md
Normal file
@@ -0,0 +1,912 @@
|
||||
__由于文档正在更新中,描述可能有错误。__
|
||||
|
||||
# 关于训练,通用描述
|
||||
本库支持模型微调(fine tuning)、DreamBooth、训练LoRA和文本反转(Textual Inversion)(包括[XTI:P+](https://github.com/kohya-ss/sd-scripts/pull/327)
|
||||
)
|
||||
本文档将说明它们通用的训练数据准备方法和选项等。
|
||||
|
||||
# 概要
|
||||
|
||||
请提前参考本仓库的README,准备好环境。
|
||||
|
||||
|
||||
以下本节说明。
|
||||
|
||||
1. 准备训练数据(使用设置文件的新格式)
|
||||
1. 训练中使用的术语的简要解释
|
||||
1. 先前的指定格式(不使用设置文件,而是从命令行指定)
|
||||
1. 生成训练过程中的示例图像
|
||||
1. 各脚本中常用的共同选项
|
||||
1. 准备 fine tuning 方法的元数据:如说明文字(打标签)等
|
||||
|
||||
|
||||
1. 如果只执行一次,训练就可以进行(相关内容,请参阅各个脚本的文档)。如果需要,以后可以随时参考。
|
||||
|
||||
|
||||
|
||||
# 关于准备训练数据
|
||||
|
||||
在任意文件夹(也可以是多个文件夹)中准备好训练数据的图像文件。支持 `.png`, `.jpg`, `.jpeg`, `.webp`, `.bmp` 格式的文件。通常不需要进行任何预处理,如调整大小等。
|
||||
|
||||
但是请勿使用极小的图像,若其尺寸比训练分辨率(稍后将提到)还小,建议事先使用超分辨率AI等进行放大。另外,请注意不要使用过大的图像(约为3000 x 3000像素以上),因为这可能会导致错误,建议事先缩小。
|
||||
|
||||
在训练时,需要整理要用于训练模型的图像数据,并将其指定给脚本。根据训练数据的数量、训练目标和说明(图像描述)是否可用等因素,可以使用几种方法指定训练数据。以下是其中的一些方法(每个名称都不是通用的,而是该存储库自定义的定义)。有关正则化图像的信息将在稍后提供。
|
||||
|
||||
1. DreamBooth、class + identifier方式(可使用正则化图像)
|
||||
|
||||
将训练目标与特定单词(identifier)相关联进行训练。无需准备说明。例如,当要学习特定角色时,由于无需准备说明,因此比较方便,但由于训练数据的所有元素都与identifier相关联,例如发型、服装、背景等,因此在生成时可能会出现无法更换服装的情况。
|
||||
|
||||
2. DreamBooth、说明方式(可使用正则化图像)
|
||||
|
||||
事先给每个图片写说明(caption),存放到文本文件中,然后进行训练。例如,通过将图像详细信息(如穿着白色衣服的角色A、穿着红色衣服的角色A等)记录在caption中,可以将角色和其他元素分离,并期望模型更准确地学习角色。
|
||||
|
||||
3. 微调方式(不可使用正则化图像)
|
||||
|
||||
先将说明收集到元数据文件中。支持分离标签和说明以及预先缓存latents等功能,以加速训练(这些将在另一篇文档中介绍)。(虽然名为fine tuning方式,但不仅限于fine tuning。)
|
||||
|
||||
训练对象和你可以使用的规范方法的组合如下。
|
||||
|
||||
| 训练对象或方法 | 脚本 | DB/class+identifier | DB/caption | fine tuning |
|
||||
|----------------| ----- | ----- | ----- | ----- |
|
||||
| fine tuning微调模型 | `fine_tune.py`| x | x | o |
|
||||
| DreamBooth训练模型 | `train_db.py`| o | o | x |
|
||||
| LoRA | `train_network.py`| o | o | o |
|
||||
| Textual Invesion | `train_textual_inversion.py`| o | o | o |
|
||||
|
||||
## 选择哪一个
|
||||
|
||||
如果您想要训练LoRA、Textual Inversion而不需要准备说明(caption)文件,则建议使用DreamBooth class+identifier。如果您能够准备caption文件,则DreamBooth Captions方法更好。如果您有大量的训练数据并且不使用正则化图像,则请考虑使用fine-tuning方法。
|
||||
|
||||
对于DreamBooth也是一样的,但不能使用fine-tuning方法。若要进行微调,只能使用fine-tuning方式。
|
||||
|
||||
# 每种方法的指定方式
|
||||
|
||||
在这里,我们只介绍每种指定方法的典型模式。有关更详细的指定方法,请参见[数据集设置](./config_README-ja.md)。
|
||||
|
||||
# DreamBooth,class+identifier方法(可使用正则化图像)
|
||||
|
||||
在该方法中,每个图像将被视为使用与 `class identifier` 相同的标题进行训练(例如 `shs dog`)。
|
||||
|
||||
这样一来,每张图片都相当于使用标题“分类标识”(例如“shs dog”)进行训练。
|
||||
|
||||
## step 1.确定identifier和class
|
||||
|
||||
要将训练的目标与identifier和属于该目标的class相关联。
|
||||
|
||||
(虽然有很多称呼,但暂时按照原始论文的说法。)
|
||||
|
||||
以下是简要说明(请查阅详细信息)。
|
||||
|
||||
class是训练目标的一般类别。例如,如果要学习特定品种的狗,则class将是“dog”。对于动漫角色,根据模型不同,可能是“boy”或“girl”,也可能是“1boy”或“1girl”。
|
||||
|
||||
identifier是用于识别训练目标并进行学习的单词。可以使用任何单词,但是根据原始论文,“Tokenizer生成的3个或更少字符的罕见单词”是最好的选择。
|
||||
|
||||
使用identifier和class,例如,“shs dog”可以将模型训练为从class中识别并学习所需的目标。
|
||||
|
||||
在图像生成时,使用“shs dog”将生成所学习狗种的图像。
|
||||
|
||||
(作为identifier,我最近使用的一些参考是“shs sts scs cpc coc cic msm usu ici lvl cic dii muk ori hru rik koo yos wny”等。最好是不包含在Danbooru标签中的单词。)
|
||||
|
||||
## step 2. 决定是否使用正则化图像,并在使用时生成正则化图像
|
||||
|
||||
正则化图像是为防止前面提到的语言漂移,即整个类别被拉扯成为训练目标而生成的图像。如果不使用正则化图像,例如在 `shs 1girl` 中学习特定角色时,即使在简单的 `1girl` 提示下生成,也会越来越像该角色。这是因为 `1girl` 在训练时的标题中包含了该角色的信息。
|
||||
|
||||
通过同时学习目标图像和正则化图像,类别仍然保持不变,仅在将标识符附加到提示中时才生成目标图像。
|
||||
|
||||
如果您只想在LoRA或DreamBooth中使用特定的角色,则可以不使用正则化图像。
|
||||
|
||||
在Textual Inversion中也不需要使用(如果要学习的token string不包含在标题中,则不会学习任何内容)。
|
||||
|
||||
一般情况下,使用在训练目标模型时只使用类别名称生成的图像作为正则化图像是常见的做法(例如 `1girl`)。但是,如果生成的图像质量不佳,可以尝试修改提示或使用从网络上另外下载的图像。
|
||||
|
||||
(由于正则化图像也被训练,因此其质量会影响模型。)
|
||||
|
||||
通常,准备数百张图像是理想的(图像数量太少会导致类别图像无法被归纳,特征也不会被学习)。
|
||||
|
||||
如果要使用生成的图像,生成图像的大小通常应与训练分辨率(更准确地说,是bucket的分辨率,见下文)相匹配。
|
||||
|
||||
|
||||
|
||||
## step 2. 设置文件的描述
|
||||
|
||||
创建一个文本文件,并将其扩展名更改为`.toml`。例如,您可以按以下方式进行描述:
|
||||
|
||||
(以`#`开头的部分是注释,因此您可以直接复制粘贴,或者将其删除。)
|
||||
|
||||
```toml
|
||||
[general]
|
||||
enable_bucket = true # 是否使用Aspect Ratio Bucketing
|
||||
|
||||
[[datasets]]
|
||||
resolution = 512 # 训练分辨率
|
||||
batch_size = 4 # 批次大小
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\hoge' # 指定包含训练图像的文件夹
|
||||
class_tokens = 'hoge girl' # 指定标识符类
|
||||
num_repeats = 10 # 训练图像的重复次数
|
||||
|
||||
# 以下仅在使用正则化图像时进行描述。不使用则删除
|
||||
[[datasets.subsets]]
|
||||
is_reg = true
|
||||
image_dir = 'C:\reg' # 指定包含正则化图像的文件夹
|
||||
class_tokens = 'girl' # 指定class
|
||||
num_repeats = 1 # 正则化图像的重复次数,基本上1就可以了
|
||||
```
|
||||
|
||||
基本上只需更改以下几个地方即可进行训练。
|
||||
|
||||
1. 训练分辨率
|
||||
|
||||
指定一个数字表示正方形(如果是 `512`,则为 512x512),如果使用方括号和逗号分隔的两个数字,则表示横向×纵向(如果是`[512,768]`,则为 512x768)。在SD1.x系列中,原始训练分辨率为512。指定较大的分辨率,如 `[512,768]` 可能会减少纵向和横向图像生成时的错误。在SD2.x 768系列中,分辨率为 `768`。
|
||||
|
||||
1. 批次大小
|
||||
|
||||
指定同时训练多少个数据。这取决于GPU的VRAM大小和训练分辨率。详细信息将在后面说明。此外,fine tuning/DreamBooth/LoRA等也会影响批次大小,请查看各个脚本的说明。
|
||||
|
||||
1. 文件夹指定
|
||||
|
||||
指定用于学习的图像和正则化图像(仅在使用时)的文件夹。指定包含图像数据的文件夹。
|
||||
|
||||
1. identifier 和 class 的指定
|
||||
|
||||
如前所述,与示例相同。
|
||||
|
||||
1. 重复次数
|
||||
|
||||
将在后面说明。
|
||||
|
||||
### 关于重复次数
|
||||
|
||||
重复次数用于调整正则化图像和训练用图像的数量。由于正则化图像的数量多于训练用图像,因此需要重复使用训练用图像来达到一对一的比例,从而实现训练。
|
||||
|
||||
请将重复次数指定为“ __训练用图像的重复次数×训练用图像的数量≥正则化图像的重复次数×正则化图像的数量__ ”。
|
||||
|
||||
(1个epoch(指训练数据过完一遍)的数据量为“训练用图像的重复次数×训练用图像的数量”。如果正则化图像的数量多于这个值,则剩余的正则化图像将不会被使用。)
|
||||
|
||||
## 步骤 3. 训练
|
||||
|
||||
详情请参考相关文档进行训练。
|
||||
|
||||
# DreamBooth,文本说明(caption)方式(可使用正则化图像)
|
||||
|
||||
在此方式中,每个图像都将通过caption进行训练。
|
||||
|
||||
## 步骤 1. 准备文本说明文件
|
||||
|
||||
请将与图像具有相同文件名且扩展名为 `.caption`(可以在设置中更改)的文件放置在用于训练图像的文件夹中。每个文件应该只有一行。编码为 `UTF-8`。
|
||||
|
||||
## 步骤 2. 决定是否使用正则化图像,并在使用时生成正则化图像
|
||||
|
||||
与class+identifier格式相同。可以在规范化图像上附加caption,但通常不需要。
|
||||
|
||||
## 步骤 2. 编写设置文件
|
||||
|
||||
创建一个文本文件并将扩展名更改为 `.toml`。例如,您可以按以下方式进行描述:
|
||||
|
||||
```toml
|
||||
[general]
|
||||
enable_bucket = true # 是否使用Aspect Ratio Bucketing
|
||||
|
||||
[[datasets]]
|
||||
resolution = 512 # 训练分辨率
|
||||
batch_size = 4 # 批次大小
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\hoge' # 指定包含训练图像的文件夹
|
||||
caption_extension = '.caption' # 若使用txt文件,更改此项
|
||||
num_repeats = 10 # 训练图像的重复次数
|
||||
|
||||
# 以下仅在使用正则化图像时进行描述。不使用则删除
|
||||
[[datasets.subsets]]
|
||||
is_reg = true
|
||||
image_dir = 'C:\reg' # 指定包含正则化图像的文件夹
|
||||
class_tokens = 'girl' # 指定class
|
||||
num_repeats = 1 # 正则化图像的重复次数,基本上1就可以了
|
||||
```
|
||||
|
||||
基本上只需更改以下几个地方来训练。除非另有说明,否则与class+identifier方法相同。
|
||||
|
||||
1. 训练分辨率
|
||||
2. 批次大小
|
||||
3. 文件夹指定
|
||||
4. caption文件的扩展名
|
||||
|
||||
可以指定任意的扩展名。
|
||||
5. 重复次数
|
||||
|
||||
## 步骤 3. 训练
|
||||
|
||||
详情请参考相关文档进行训练。
|
||||
|
||||
# 微调方法(fine tuning)
|
||||
|
||||
## 步骤 1. 准备元数据
|
||||
|
||||
将caption和标签整合到管理文件中称为元数据。它的扩展名为 `.json`,格式为json。由于创建方法较长,因此在本文档的末尾进行描述。
|
||||
|
||||
## 步骤 2. 编写设置文件
|
||||
|
||||
创建一个文本文件,将扩展名设置为 `.toml`。例如,可以按以下方式编写:
|
||||
```toml
|
||||
[general]
|
||||
shuffle_caption = true
|
||||
keep_tokens = 1
|
||||
|
||||
[[datasets]]
|
||||
resolution = 512 # 图像分辨率
|
||||
batch_size = 4 # 批次大小
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\piyo' # 指定包含训练图像的文件夹
|
||||
metadata_file = 'C:\piyo\piyo_md.json' # 元数据文件名
|
||||
```
|
||||
|
||||
基本上只需更改以下几个地方来训练。除非另有说明,否则与DreamBooth, class+identifier方法相同。
|
||||
|
||||
1. 训练分辨率
|
||||
2. 批次大小
|
||||
3. 指定文件夹
|
||||
4. 元数据文件名
|
||||
|
||||
指定使用后面所述方法创建的元数据文件。
|
||||
|
||||
|
||||
## 第三步:训练
|
||||
|
||||
详情请参考相关文档进行训练。
|
||||
|
||||
# 训练中使用的术语简单解释
|
||||
|
||||
由于省略了细节并且我自己也没有完全理解,因此请自行查阅详细信息。
|
||||
|
||||
## 微调(fine tuning)
|
||||
|
||||
指训练模型并微调其性能。具体含义因用法而异,但在 Stable Diffusion 中,狭义的微调是指使用图像和caption进行训练模型。DreamBooth 可视为狭义微调的一种特殊方法。广义的微调包括 LoRA、Textual Inversion、Hypernetworks 等,包括训练模型的所有内容。
|
||||
|
||||
## 步骤(step)
|
||||
|
||||
粗略地说,每次在训练数据上进行一次计算即为一步。具体来说,“将训练数据的caption传递给当前模型,将生成的图像与训练数据的图像进行比较,稍微更改模型,以使其更接近训练数据”即为一步。
|
||||
|
||||
## 批次大小(batch size)
|
||||
|
||||
批次大小指定每个步骤要计算多少数据。批次计算可以提高速度。一般来说,批次大小越大,精度也越高。
|
||||
|
||||
“批次大小×步数”是用于训练的数据数量。因此,建议减少步数以增加批次大小。
|
||||
|
||||
(但是,例如,“批次大小为 1,步数为 1600”和“批次大小为 4,步数为 400”将不会产生相同的结果。如果使用相同的学习速率,通常后者会导致模型欠拟合。请尝试增加学习率(例如 `2e-6`),将步数设置为 500 等。)
|
||||
|
||||
批次大小越大,GPU 内存消耗就越大。如果内存不足,将导致错误,或者在边缘时将导致训练速度降低。建议在任务管理器或 `nvidia-smi` 命令中检查使用的内存量进行调整。
|
||||
|
||||
注意,一个批次是指“一个数据单位”。
|
||||
|
||||
## 学习率
|
||||
|
||||
学习率指的是每个步骤中改变的程度。如果指定一个大的值,学习速度就会加快,但是可能会出现变化太大导致模型崩溃或无法达到最佳状态的情况。如果指定一个小的值,学习速度会变慢,同时可能无法达到最佳状态。
|
||||
|
||||
在fine tuning、DreamBooth、LoRA等过程中,学习率会有很大的差异,并且也会受到训练数据、所需训练的模型、批次大小和步骤数等因素的影响。建议从通常值开始,观察训练状态并逐渐调整。
|
||||
|
||||
默认情况下,整个训练过程中学习率是固定的。但是可以通过调度程序指定学习率如何变化,因此结果也会有所不同。
|
||||
|
||||
## Epoch
|
||||
|
||||
Epoch指的是训练数据被完整训练一遍(即数据已经迭代一轮)。如果指定了重复次数,则在重复后的数据迭代一轮后,为1个epoch。
|
||||
|
||||
1个epoch的步骤数通常为“数据量÷批次大小”,但如果使用Aspect Ratio Bucketing,则略微增加(由于不同bucket的数据不能在同一个批次中,因此步骤数会增加)。
|
||||
|
||||
## 长宽比分桶(Aspect Ratio Bucketing)
|
||||
|
||||
Stable Diffusion 的 v1 是以 512\*512 的分辨率进行训练的,但同时也可以在其他分辨率下进行训练,例如 256\*1024 和 384\*640。这样可以减少裁剪的部分,希望更准确地学习图像和标题之间的关系。
|
||||
|
||||
此外,由于可以在任意分辨率下进行训练,因此不再需要事先统一图像数据的长宽比。
|
||||
|
||||
此值可以被设定,其在此之前的配置文件示例中已被启用(设置为 `true`)。
|
||||
|
||||
只要不超过作为参数给出的分辨率区域(= 内存使用量),就可以按 64 像素的增量(默认值,可更改)在垂直和水平方向上调整和创建训练分辨率。
|
||||
|
||||
在机器学习中,通常需要将所有输入大小统一,但实际上只要在同一批次中统一即可。 NovelAI 所说的分桶(bucketing) 指的是,预先将训练数据按照长宽比分类到每个学习分辨率下,并通过使用每个 bucket 内的图像创建批次来统一批次图像大小。
|
||||
|
||||
# 以前的指定格式(不使用 .toml 文件,而是使用命令行选项指定)
|
||||
|
||||
这是一种通过命令行选项而不是指定 .toml 文件的方法。有 DreamBooth 类+标识符方法、DreamBooth caption方法、微调方法三种方式。
|
||||
|
||||
## DreamBooth、类+标识符方式
|
||||
|
||||
指定文件夹名称以指定迭代次数。还要使用 `train_data_dir` 和 `reg_data_dir` 选项。
|
||||
|
||||
### 第1步。准备用于训练的图像
|
||||
|
||||
创建一个用于存储训练图像的文件夹。__此外__,按以下名称创建目录。
|
||||
|
||||
```
|
||||
<迭代次数>_<标识符> <类别>
|
||||
```
|
||||
|
||||
不要忘记下划线``_``。
|
||||
|
||||
例如,如果在名为“sls frog”的提示下重复数据 20 次,则为“20_sls frog”。如下所示:
|
||||
|
||||

|
||||
|
||||
### 多个类别、多个标识符的训练
|
||||
|
||||
该方法很简单,在用于训练的图像文件夹中,需要准备多个文件夹,每个文件夹都是以“重复次数_<标识符> <类别>”命名的,同样,在正则化图像文件夹中,也需要准备多个文件夹,每个文件夹都是以“重复次数_<类别>”命名的。
|
||||
|
||||
例如,如果要同时训练“sls青蛙”和“cpc兔子”,则应按以下方式准备文件夹。
|
||||
|
||||
|
||||
|
||||
如果一个类别包含多个对象,可以只使用一个正则化图像文件夹。例如,如果在1girl类别中有角色A和角色B,则可以按照以下方式处理:
|
||||
|
||||
- train_girls
|
||||
- 10_sls 1girl
|
||||
- 10_cpc 1girl
|
||||
- reg_girls
|
||||
- 1_1girl
|
||||
|
||||
### step 2. 准备正规化图像
|
||||
|
||||
这是使用正则化图像时的过程。
|
||||
|
||||
创建一个文件夹来存储正则化的图像。 __此外,__ 创建一个名为``<repeat count>_<class>`` 的目录。
|
||||
|
||||
例如,使用提示“frog”并且不重复数据(仅一次):
|
||||
|
||||
|
||||
|
||||
步骤3. 执行训练
|
||||
|
||||
执行每个训练脚本。使用 `--train_data_dir` 选项指定包含训练数据文件夹的父文件夹(不是包含图像的文件夹),使用 `--reg_data_dir` 选项指定包含正则化图像的父文件夹(不是包含图像的文件夹)。
|
||||
|
||||
## DreamBooth,带文本说明(caption)的方式
|
||||
|
||||
在包含训练图像和正则化图像的文件夹中,将与图像具有相同文件名的文件.caption(可以使用选项进行更改)放置在该文件夹中,然后从该文件中加载caption所作为提示进行训练。
|
||||
|
||||
※文件夹名称(标识符类)不再用于这些图像的训练。
|
||||
|
||||
默认的caption文件扩展名为.caption。可以使用训练脚本的 `--caption_extension` 选项进行更改。 使用 `--shuffle_caption` 选项,同时对每个逗号分隔的部分进行训练时会对训练时的caption进行混洗。
|
||||
|
||||
## 微调方式
|
||||
|
||||
创建元数据的方式与使用配置文件相同。 使用 `in_json` 选项指定元数据文件。
|
||||
|
||||
# 训练过程中的样本输出
|
||||
|
||||
通过在训练中使用模型生成图像,可以检查训练进度。将以下选项指定为训练脚本。
|
||||
|
||||
- `--sample_every_n_steps` / `--sample_every_n_epochs`
|
||||
|
||||
指定要采样的步数或epoch数。为这些数字中的每一个输出样本。如果两者都指定,则 epoch 数优先。
|
||||
- `--sample_prompts`
|
||||
|
||||
指定示例输出的提示文件。
|
||||
|
||||
- `--sample_sampler`
|
||||
|
||||
指定用于采样输出的采样器。
|
||||
`'ddim', 'pndm', 'heun', 'dpmsolver', 'dpmsolver++', 'dpmsingle', 'k_lms', 'k_euler', 'k_euler_a', 'k_dpm_2', 'k_dpm_2_a'`が選べます。
|
||||
|
||||
要输出样本,您需要提前准备一个包含提示的文本文件。每行输入一个提示。
|
||||
|
||||
```txt
|
||||
# prompt 1
|
||||
masterpiece, best quality, 1girl, in white shirts, upper body, looking at viewer, simple background --n low quality, worst quality, bad anatomy,bad composition, poor, low effort --w 768 --h 768 --d 1 --l 7.5 --s 28
|
||||
|
||||
# prompt 2
|
||||
masterpiece, best quality, 1boy, in business suit, standing at street, looking back --n low quality, worst quality, bad anatomy,bad composition, poor, low effort --w 576 --h 832 --d 2 --l 5.5 --s 40
|
||||
```
|
||||
|
||||
以“#”开头的行是注释。您可以使用“`--` + 小写字母”为生成的图像指定选项,例如 `--n`。您可以使用:
|
||||
|
||||
- `--n` 否定提示到下一个选项。
|
||||
- `--w` 指定生成图像的宽度。
|
||||
- `--h` 指定生成图像的高度。
|
||||
- `--d` 指定生成图像的种子。
|
||||
- `--l` 指定生成图像的 CFG 比例。
|
||||
- `--s` 指定生成过程中的步骤数。
|
||||
|
||||
|
||||
# 每个脚本通用的常用选项
|
||||
|
||||
文档更新可能跟不上脚本更新。在这种情况下,请使用 `--help` 选项检查可用选项。
|
||||
## 学习模型规范
|
||||
|
||||
- `--v2` / `--v_parameterization`
|
||||
|
||||
如果使用 Hugging Face 的 stable-diffusion-2-base 或来自它的微调模型作为学习目标模型(对于在推理时指示使用 `v2-inference.yaml` 的模型),`- 当使用-v2` 选项与 stable-diffusion-2、768-v-ema.ckpt 及其微调模型(对于在推理过程中使用 `v2-inference-v.yaml` 的模型),`- 指定两个 -v2`和 `--v_parameterization` 选项。
|
||||
|
||||
以下几点在 Stable Diffusion 2.0 中发生了显着变化。
|
||||
|
||||
1. 使用分词器
|
||||
2. 使用哪个Text Encoder,使用哪个输出层(2.0使用倒数第二层)
|
||||
3. Text Encoder的输出维度(768->1024)
|
||||
4. U-Net的结构(CrossAttention的头数等)
|
||||
5. v-parameterization(采样方式好像变了)
|
||||
|
||||
其中base使用1-4,非base使用1-5(768-v)。使用 1-4 进行 v2 选择,使用 5 进行 v_parameterization 选择。
|
||||
- `--pretrained_model_name_or_path`
|
||||
|
||||
指定要从中执行额外训练的模型。您可以指定Stable Diffusion检查点文件(.ckpt 或 .safetensors)、diffusers本地磁盘上的模型目录或diffusers模型 ID(例如“stabilityai/stable-diffusion-2”)。
|
||||
## 训练设置
|
||||
|
||||
- `--output_dir`
|
||||
|
||||
指定训练后保存模型的文件夹。
|
||||
|
||||
- `--output_name`
|
||||
|
||||
指定不带扩展名的模型文件名。
|
||||
|
||||
- `--dataset_config`
|
||||
|
||||
指定描述数据集配置的 .toml 文件。
|
||||
|
||||
- `--max_train_steps` / `--max_train_epochs`
|
||||
|
||||
指定要训练的步数或epoch数。如果两者都指定,则 epoch 数优先。
|
||||
-
|
||||
- `--mixed_precision`
|
||||
|
||||
训练混合精度以节省内存。指定像`--mixed_precision = "fp16"`。与无混合精度(默认)相比,精度可能较低,但训练所需的 GPU 内存明显较少。
|
||||
|
||||
(在RTX30系列以后也可以指定`bf16`,请配合您在搭建环境时做的加速设置)。
|
||||
- `--gradient_checkpointing`
|
||||
|
||||
通过逐步计算权重而不是在训练期间一次计算所有权重来减少训练所需的 GPU 内存量。关闭它不会影响准确性,但打开它允许更大的批次大小,所以那里有影响。
|
||||
|
||||
另外,打开它通常会减慢速度,但可以增加批次大小,因此总的训练时间实际上可能会更快。
|
||||
|
||||
- `--xformers` / `--mem_eff_attn`
|
||||
|
||||
当指定 xformers 选项时,使用 xformers 的 CrossAttention。如果未安装 xformers 或发生错误(取决于环境,例如 `mixed_precision="no"`),请指定 `mem_eff_attn` 选项而不是使用 CrossAttention 的内存节省版本(xformers 比 慢)。
|
||||
- `--save_precision`
|
||||
|
||||
指定保存时的数据精度。为 save_precision 选项指定 float、fp16 或 bf16 将以该格式保存模型(在 DreamBooth 中保存 Diffusers 格式时无效,微调)。当您想缩小模型的尺寸时请使用它。
|
||||
- `--save_every_n_epochs` / `--save_state` / `--resume`
|
||||
为 save_every_n_epochs 选项指定一个数字可以在每个时期的训练期间保存模型。
|
||||
|
||||
如果同时指定save_state选项,训练状态包括优化器的状态等都会一起保存。。保存目的地将是一个文件夹。
|
||||
|
||||
训练状态输出到目标文件夹中名为“<output_name>-??????-state”(??????是epoch数)的文件夹中。长时间训练时请使用。
|
||||
|
||||
使用 resume 选项从保存的训练状态恢复训练。指定训练状态文件夹(其中的状态文件夹,而不是 `output_dir`)。
|
||||
|
||||
请注意,由于 Accelerator 规范,epoch 数和全局步数不会保存,即使恢复时它们也从 1 开始。
|
||||
- `--save_model_as` (DreamBooth, fine tuning 仅有的)
|
||||
|
||||
您可以从 `ckpt, safetensors, diffusers, diffusers_safetensors` 中选择模型保存格式。
|
||||
|
||||
- `--save_model_as=safetensors` 指定喜欢当读取Stable Diffusion格式(ckpt 或safetensors)并以diffusers格式保存时,缺少的信息通过从 Hugging Face 中删除 v1.5 或 v2.1 信息来补充。
|
||||
|
||||
- `--clip_skip`
|
||||
|
||||
`2` 如果指定,则使用文本编码器 (CLIP) 的倒数第二层的输出。如果省略 1 或选项,则使用最后一层。
|
||||
|
||||
*SD2.0默认使用倒数第二层,训练SD2.0时请不要指定。
|
||||
|
||||
如果被训练的模型最初被训练为使用第二层,则 2 是一个很好的值。
|
||||
|
||||
如果您使用的是最后一层,那么整个模型都会根据该假设进行训练。因此,如果再次使用第二层进行训练,可能需要一定数量的teacher数据和更长时间的训练才能得到想要的训练结果。
|
||||
- `--max_token_length`
|
||||
|
||||
默认值为 75。您可以通过指定“150”或“225”来扩展令牌长度来训练。使用长字幕训练时指定。
|
||||
|
||||
但由于训练时token展开的规范与Automatic1111的web UI(除法等规范)略有不同,如非必要建议用75训练。
|
||||
|
||||
与clip_skip一样,训练与模型训练状态不同的长度可能需要一定量的teacher数据和更长的学习时间。
|
||||
|
||||
- `--persistent_data_loader_workers`
|
||||
|
||||
在 Windows 环境中指定它可以显着减少时期之间的延迟。
|
||||
|
||||
- `--max_data_loader_n_workers`
|
||||
|
||||
指定数据加载的进程数。大量的进程会更快地加载数据并更有效地使用 GPU,但会消耗更多的主内存。默认是"`8`或者`CPU并发执行线程数 - 1`,取小者",所以如果主存没有空间或者GPU使用率大概在90%以上,就看那些数字和 `2` 或将其降低到大约 `1`。
|
||||
- `--logging_dir` / `--log_prefix`
|
||||
|
||||
保存训练日志的选项。在 logging_dir 选项中指定日志保存目标文件夹。以 TensorBoard 格式保存日志。
|
||||
|
||||
例如,如果您指定 --logging_dir=logs,将在您的工作文件夹中创建一个日志文件夹,并将日志保存在日期/时间文件夹中。
|
||||
此外,如果您指定 --log_prefix 选项,则指定的字符串将添加到日期和时间之前。使用“--logging_dir=logs --log_prefix=db_style1_”进行识别。
|
||||
|
||||
要检查 TensorBoard 中的日志,请打开另一个命令提示符并在您的工作文件夹中键入:
|
||||
```
|
||||
tensorboard --logdir=logs
|
||||
```
|
||||
|
||||
我觉得tensorboard会在环境搭建的时候安装,如果没有安装,请用`pip install tensorboard`安装。)
|
||||
|
||||
然后打开浏览器到http://localhost:6006/就可以看到了。
|
||||
- `--noise_offset`
|
||||
本文的实现:https://www.crosslabs.org//blog/diffusion-with-offset-noise
|
||||
|
||||
看起来它可能会为整体更暗和更亮的图像产生更好的结果。它似乎对 LoRA 训练也有效。指定一个大约 0.1 的值似乎很好。
|
||||
|
||||
- `--debug_dataset`
|
||||
|
||||
通过添加此选项,您可以在训练之前检查将训练什么样的图像数据和标题。按 Esc 退出并返回命令行。按 `S` 进入下一步(批次),按 `E` 进入下一个epoch。
|
||||
|
||||
*图片在 Linux 环境(包括 Colab)下不显示。
|
||||
|
||||
- `--vae`
|
||||
|
||||
如果您在 vae 选项中指定Stable Diffusion检查点、VAE 检查点文件、扩散模型或 VAE(两者都可以指定本地或拥抱面模型 ID),则该 VAE 用于训练(缓存时的潜伏)或在训练过程中获得潜伏)。
|
||||
|
||||
对于 DreamBooth 和微调,保存的模型将包含此 VAE
|
||||
|
||||
- `--cache_latents`
|
||||
|
||||
在主内存中缓存 VAE 输出以减少 VRAM 使用。除 flip_aug 之外的任何增强都将不可用。此外,整体训练速度略快。
|
||||
- `--min_snr_gamma`
|
||||
|
||||
指定最小 SNR 加权策略。细节是[这里](https://github.com/kohya-ss/sd-scripts/pull/308)请参阅。论文中推荐`5`。
|
||||
|
||||
## 优化器相关
|
||||
|
||||
- `--optimizer_type`
|
||||
-- 指定优化器类型。您可以指定
|
||||
- AdamW : [torch.optim.AdamW](https://pytorch.org/docs/stable/generated/torch.optim.AdamW.html)
|
||||
- 与过去版本中未指定选项时相同
|
||||
- AdamW8bit : 参数同上
|
||||
- PagedAdamW8bit : 参数同上
|
||||
- 与过去版本中指定的 --use_8bit_adam 相同
|
||||
- Lion : https://github.com/lucidrains/lion-pytorch
|
||||
- Lion8bit : 参数同上
|
||||
- PagedLion8bit : 参数同上
|
||||
- 与过去版本中指定的 --use_lion_optimizer 相同
|
||||
- SGDNesterov : [torch.optim.SGD](https://pytorch.org/docs/stable/generated/torch.optim.SGD.html), nesterov=True
|
||||
- SGDNesterov8bit : 参数同上
|
||||
- DAdaptation(DAdaptAdamPreprint) : https://github.com/facebookresearch/dadaptation
|
||||
- DAdaptAdam : 参数同上
|
||||
- DAdaptAdaGrad : 参数同上
|
||||
- DAdaptAdan : 参数同上
|
||||
- DAdaptAdanIP : 参数同上
|
||||
- DAdaptLion : 参数同上
|
||||
- DAdaptSGD : 参数同上
|
||||
- Prodigy : https://github.com/konstmish/prodigy
|
||||
- AdaFactor : [Transformers AdaFactor](https://huggingface.co/docs/transformers/main_classes/optimizer_schedules)
|
||||
- 任何优化器
|
||||
|
||||
- `--learning_rate`
|
||||
|
||||
指定学习率。合适的学习率取决于训练脚本,所以请参考每个解释。
|
||||
- `--lr_scheduler` / `--lr_warmup_steps` / `--lr_scheduler_num_cycles` / `--lr_scheduler_power`
|
||||
|
||||
学习率的调度程序相关规范。
|
||||
|
||||
使用 lr_scheduler 选项,您可以从线性、余弦、cosine_with_restarts、多项式、常数、constant_with_warmup 或任何调度程序中选择学习率调度程序。默认值是常量。
|
||||
|
||||
使用 lr_warmup_steps,您可以指定预热调度程序的步数(逐渐改变学习率)。
|
||||
|
||||
lr_scheduler_num_cycles 是 cosine with restarts 调度器中的重启次数,lr_scheduler_power 是多项式调度器中的多项式幂。
|
||||
|
||||
有关详细信息,请自行研究。
|
||||
|
||||
要使用任何调度程序,请像使用任何优化器一样使用“--lr_scheduler_args”指定可选参数。
|
||||
### 关于指定优化器
|
||||
|
||||
使用 --optimizer_args 选项指定优化器选项参数。可以以key=value的格式指定多个值。此外,您可以指定多个值,以逗号分隔。例如,要指定 AdamW 优化器的参数,``--optimizer_args weight_decay=0.01 betas=.9,.999``。
|
||||
|
||||
指定可选参数时,请检查每个优化器的规格。
|
||||
一些优化器有一个必需的参数,如果省略它会自动添加(例如 SGDNesterov 的动量)。检查控制台输出。
|
||||
|
||||
D-Adaptation 优化器自动调整学习率。学习率选项指定的值不是学习率本身,而是D-Adaptation决定的学习率的应用率,所以通常指定1.0。如果您希望 Text Encoder 的学习率是 U-Net 的一半,请指定 ``--text_encoder_lr=0.5 --unet_lr=1.0``。
|
||||
如果指定 relative_step=True,AdaFactor 优化器可以自动调整学习率(如果省略,将默认添加)。自动调整时,学习率调度器被迫使用 adafactor_scheduler。此外,指定 scale_parameter 和 warmup_init 似乎也不错。
|
||||
|
||||
自动调整的选项类似于``--optimizer_args "relative_step=True" "scale_parameter=True" "warmup_init=True"``。
|
||||
|
||||
如果您不想自动调整学习率,请添加可选参数 ``relative_step=False``。在那种情况下,似乎建议将 constant_with_warmup 用于学习率调度程序,而不要为梯度剪裁范数。所以参数就像``--optimizer_type=adafactor --optimizer_args "relative_step=False" --lr_scheduler="constant_with_warmup" --max_grad_norm=0.0``。
|
||||
|
||||
### 使用任何优化器
|
||||
|
||||
使用 ``torch.optim`` 优化器时,仅指定类名(例如 ``--optimizer_type=RMSprop``),使用其他模块的优化器时,指定“模块名.类名”。(例如``--optimizer_type=bitsandbytes.optim.lamb.LAMB``)。
|
||||
|
||||
(内部仅通过 importlib 未确认操作。如果需要,请安装包。)
|
||||
<!--
|
||||
## 使用任意大小的图像进行训练 --resolution
|
||||
你可以在广场外训练。请在分辨率中指定“宽度、高度”,如“448,640”。宽度和高度必须能被 64 整除。匹配训练图像和正则化图像的大小。
|
||||
|
||||
就我个人而言,我经常生成垂直长的图像,所以我有时会用“448、640”来训练。
|
||||
|
||||
## 纵横比分桶 --enable_bucket / --min_bucket_reso / --max_bucket_reso
|
||||
它通过指定 enable_bucket 选项来启用。 Stable Diffusion 在 512x512 分辨率下训练,但也在 256x768 和 384x640 等分辨率下训练。
|
||||
|
||||
如果指定此选项,则不需要将训练图像和正则化图像统一为特定分辨率。从多种分辨率(纵横比)中进行选择,并在该分辨率下训练。
|
||||
由于分辨率为 64 像素,纵横比可能与原始图像不完全相同。
|
||||
|
||||
您可以使用 min_bucket_reso 选项指定分辨率的最小大小,使用 max_bucket_reso 指定最大大小。默认值分别为 256 和 1024。
|
||||
例如,将最小尺寸指定为 384 将不会使用 256x1024 或 320x768 等分辨率。
|
||||
如果将分辨率增加到 768x768,您可能需要将 1280 指定为最大尺寸。
|
||||
|
||||
启用 Aspect Ratio Ratio Bucketing 时,最好准备具有与训练图像相似的各种分辨率的正则化图像。
|
||||
|
||||
(因为一批中的图像不偏向于训练图像和正则化图像。
|
||||
|
||||
## 扩充 --color_aug / --flip_aug
|
||||
增强是一种通过在训练过程中动态改变数据来提高模型性能的方法。在使用 color_aug 巧妙地改变色调并使用 flip_aug 左右翻转的同时训练。
|
||||
|
||||
由于数据是动态变化的,因此不能与 cache_latents 选项一起指定。
|
||||
|
||||
## 使用 fp16 梯度训练(实验特征)--full_fp16
|
||||
如果指定 full_fp16 选项,梯度从普通 float32 变为 float16 (fp16) 并训练(它似乎是 full fp16 训练而不是混合精度)。
|
||||
结果,似乎 SD1.x 512x512 大小可以在 VRAM 使用量小于 8GB 的情况下训练,而 SD2.x 512x512 大小可以在 VRAM 使用量小于 12GB 的情况下训练。
|
||||
|
||||
预先在加速配置中指定 fp16,并可选择设置 ``mixed_precision="fp16"``(bf16 不起作用)。
|
||||
|
||||
为了最大限度地减少内存使用,请使用 xformers、use_8bit_adam、cache_latents、gradient_checkpointing 选项并将 train_batch_size 设置为 1。
|
||||
|
||||
(如果你负担得起,逐步增加 train_batch_size 应该会提高一点精度。)
|
||||
|
||||
它是通过修补 PyTorch 源代码实现的(已通过 PyTorch 1.12.1 和 1.13.0 确认)。准确率会大幅下降,途中学习失败的概率也会增加。
|
||||
学习率和步数的设置似乎很严格。请注意它们并自行承担使用它们的风险。
|
||||
-->
|
||||
|
||||
# 创建元数据文件
|
||||
|
||||
## 准备训练数据
|
||||
|
||||
如上所述准备好你要训练的图像数据,放在任意文件夹中。
|
||||
|
||||
例如,存储这样的图像:
|
||||
|
||||
|
||||
|
||||
## 自动captioning
|
||||
|
||||
如果您只想训练没有标题的标签,请跳过。
|
||||
|
||||
另外,手动准备caption时,请准备在与教师数据图像相同的目录下,文件名相同,扩展名.caption等。每个文件应该是只有一行的文本文件。
|
||||
### 使用 BLIP 添加caption
|
||||
|
||||
最新版本不再需要 BLIP 下载、权重下载和额外的虚拟环境。按原样工作。
|
||||
|
||||
运行 finetune 文件夹中的 make_captions.py。
|
||||
|
||||
```
|
||||
python finetune\make_captions.py --batch_size <バッチサイズ> <教師データフォルダ>
|
||||
```
|
||||
|
||||
如果batch size为8,训练数据放在父文件夹train_data中,则会如下所示
|
||||
```
|
||||
python finetune\make_captions.py --batch_size 8 ..\train_data
|
||||
```
|
||||
|
||||
caption文件创建在与教师数据图像相同的目录中,具有相同的文件名和扩展名.caption。
|
||||
|
||||
根据 GPU 的 VRAM 容量增加或减少 batch_size。越大越快(我认为 12GB 的 VRAM 可以多一点)。
|
||||
您可以使用 max_length 选项指定caption的最大长度。默认值为 75。如果使用 225 的令牌长度训练模型,它可能会更长。
|
||||
您可以使用 caption_extension 选项更改caption扩展名。默认为 .caption(.txt 与稍后描述的 DeepDanbooru 冲突)。
|
||||
如果有多个教师数据文件夹,则对每个文件夹执行。
|
||||
|
||||
请注意,推理是随机的,因此每次运行时结果都会发生变化。如果要修复它,请使用 --seed 选项指定一个随机数种子,例如 `--seed 42`。
|
||||
|
||||
其他的选项,请参考help with `--help`(好像没有文档说明参数的含义,得看源码)。
|
||||
|
||||
默认情况下,会生成扩展名为 .caption 的caption文件。
|
||||
|
||||
|
||||
|
||||
例如,标题如下:
|
||||
|
||||
|
||||
|
||||
## 由 DeepDanbooru 标记
|
||||
|
||||
如果不想给danbooru标签本身打标签,请继续“标题和标签信息的预处理”。
|
||||
|
||||
标记是使用 DeepDanbooru 或 WD14Tagger 完成的。 WD14Tagger 似乎更准确。如果您想使用 WD14Tagger 进行标记,请跳至下一章。
|
||||
### 环境布置
|
||||
|
||||
将 DeepDanbooru https://github.com/KichangKim/DeepDanbooru 克隆到您的工作文件夹中,或下载并展开 zip。我解压缩了它。
|
||||
另外,从 DeepDanbooru 发布页面 https://github.com/KichangKim/DeepDanbooru/releases 上的“DeepDanbooru 预训练模型 v3-20211112-sgd-e28”的资产下载 deepdanbooru-v3-20211112-sgd-e28.zip 并解压到 DeepDanbooru 文件夹。
|
||||
|
||||
从下面下载。单击以打开资产并从那里下载。
|
||||
|
||||
|
||||
|
||||
做一个这样的目录结构
|
||||
|
||||
|
||||
为diffusers环境安装必要的库。进入 DeepDanbooru 文件夹并安装它(我认为它实际上只是添加了 tensorflow-io)。
|
||||
```
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
接下来,安装 DeepDanbooru 本身。
|
||||
|
||||
```
|
||||
pip install .
|
||||
```
|
||||
|
||||
这样就完成了标注环境的准备工作。
|
||||
|
||||
### 实施标记
|
||||
转到 DeepDanbooru 的文件夹并运行 deepdanbooru 进行标记。
|
||||
```
|
||||
deepdanbooru evaluate <教师资料夹> --project-path deepdanbooru-v3-20211112-sgd-e28 --allow-folder --save-txt
|
||||
```
|
||||
|
||||
如果将训练数据放在父文件夹train_data中,则如下所示。
|
||||
```
|
||||
deepdanbooru evaluate ../train_data --project-path deepdanbooru-v3-20211112-sgd-e28 --allow-folder --save-txt
|
||||
```
|
||||
|
||||
在与教师数据图像相同的目录中创建具有相同文件名和扩展名.txt 的标记文件。它很慢,因为它是一个接一个地处理的。
|
||||
|
||||
如果有多个教师数据文件夹,则对每个文件夹执行。
|
||||
|
||||
它生成如下。
|
||||
|
||||
|
||||
|
||||
它会被这样标记(信息量很大...)。
|
||||
|
||||
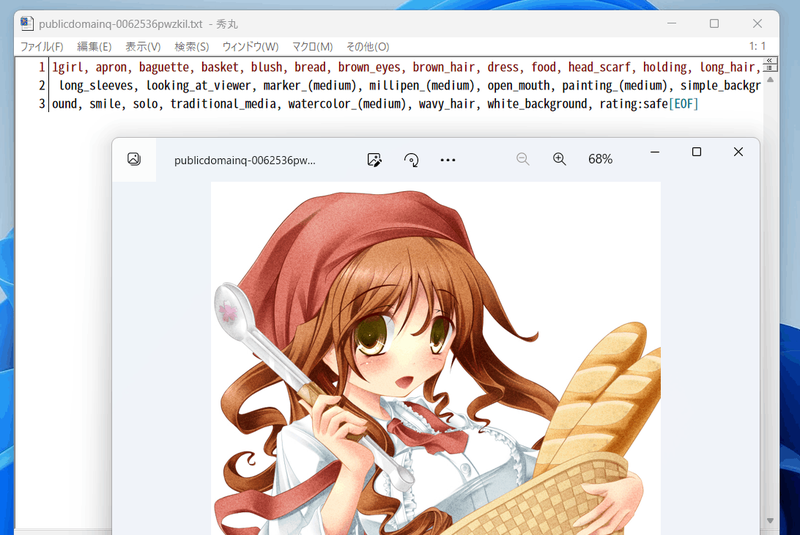
|
||||
|
||||
## WD14Tagger标记为
|
||||
|
||||
此过程使用 WD14Tagger 而不是 DeepDanbooru。
|
||||
|
||||
使用 Mr. Automatic1111 的 WebUI 中使用的标记器。我参考了这个 github 页面上的信息 (https://github.com/toriato/stable-diffusion-webui-wd14-tagger#mrsmilingwolfs-model-aka-waifu-diffusion-14-tagger)。
|
||||
|
||||
初始环境维护所需的模块已经安装。权重自动从 Hugging Face 下载。
|
||||
### 实施标记
|
||||
|
||||
运行脚本以进行标记。
|
||||
```
|
||||
python tag_images_by_wd14_tagger.py --batch_size <バッチサイズ> <教師データフォルダ>
|
||||
```
|
||||
|
||||
如果将训练数据放在父文件夹train_data中,则如下所示
|
||||
```
|
||||
python tag_images_by_wd14_tagger.py --batch_size 4 ..\train_data
|
||||
```
|
||||
|
||||
模型文件将在首次启动时自动下载到 wd14_tagger_model 文件夹(文件夹可以在选项中更改)。它将如下所示。
|
||||
|
||||
|
||||
在与教师数据图像相同的目录中创建具有相同文件名和扩展名.txt 的标记文件。
|
||||

|
||||
|
||||

|
||||
|
||||
使用 thresh 选项,您可以指定确定的标签的置信度数以附加标签。默认值为 0.35,与 WD14Tagger 示例相同。较低的值给出更多的标签,但准确性较低。
|
||||
|
||||
根据 GPU 的 VRAM 容量增加或减少 batch_size。越大越快(我认为 12GB 的 VRAM 可以多一点)。您可以使用 caption_extension 选项更改标记文件扩展名。默认为 .txt。
|
||||
|
||||
您可以使用 model_dir 选项指定保存模型的文件夹。
|
||||
|
||||
此外,如果指定 force_download 选项,即使有保存目标文件夹,也会重新下载模型。
|
||||
|
||||
如果有多个教师数据文件夹,则对每个文件夹执行。
|
||||
|
||||
## 预处理caption和标签信息
|
||||
|
||||
将caption和标签作为元数据合并到一个文件中,以便从脚本中轻松处理。
|
||||
### caption预处理
|
||||
|
||||
要将caption放入元数据,请在您的工作文件夹中运行以下命令(如果您不使用caption进行训练,则不需要运行它)(它实际上是一行,依此类推)。指定 `--full_path` 选项以将图像文件的完整路径存储在元数据中。如果省略此选项,则会记录相对路径,但 .toml 文件中需要单独的文件夹规范。
|
||||
```
|
||||
python merge_captions_to_metadata.py --full_path <教师资料夹>
|
||||
--in_json <要读取的元数据文件名> <元数据文件名>
|
||||
```
|
||||
|
||||
元数据文件名是任意名称。
|
||||
如果训练数据为train_data,没有读取元数据文件,元数据文件为meta_cap.json,则会如下。
|
||||
```
|
||||
python merge_captions_to_metadata.py --full_path train_data meta_cap.json
|
||||
```
|
||||
|
||||
您可以使用 caption_extension 选项指定标题扩展。
|
||||
|
||||
如果有多个教师数据文件夹,请指定 full_path 参数并为每个文件夹执行。
|
||||
```
|
||||
python merge_captions_to_metadata.py --full_path
|
||||
train_data1 meta_cap1.json
|
||||
python merge_captions_to_metadata.py --full_path --in_json meta_cap1.json
|
||||
train_data2 meta_cap2.json
|
||||
```
|
||||
如果省略in_json,如果有写入目标元数据文件,将从那里读取并覆盖。
|
||||
|
||||
__* 每次重写 in_json 选项和写入目标并写入单独的元数据文件是安全的。 __
|
||||
### 标签预处理
|
||||
|
||||
同样,标签也收集在元数据中(如果标签不用于训练,则无需这样做)。
|
||||
```
|
||||
python merge_dd_tags_to_metadata.py --full_path <教师资料夹>
|
||||
--in_json <要读取的元数据文件名> <要写入的元数据文件名>
|
||||
```
|
||||
|
||||
同样的目录结构,读取meta_cap.json和写入meta_cap_dd.json时,会是这样的。
|
||||
```
|
||||
python merge_dd_tags_to_metadata.py --full_path train_data --in_json meta_cap.json meta_cap_dd.json
|
||||
```
|
||||
|
||||
如果有多个教师数据文件夹,请指定 full_path 参数并为每个文件夹执行。
|
||||
|
||||
```
|
||||
python merge_dd_tags_to_metadata.py --full_path --in_json meta_cap2.json
|
||||
train_data1 meta_cap_dd1.json
|
||||
python merge_dd_tags_to_metadata.py --full_path --in_json meta_cap_dd1.json
|
||||
train_data2 meta_cap_dd2.json
|
||||
```
|
||||
|
||||
如果省略in_json,如果有写入目标元数据文件,将从那里读取并覆盖。
|
||||
__※ 通过每次重写 in_json 选项和写入目标,写入单独的元数据文件是安全的。 __
|
||||
### 标题和标签清理
|
||||
|
||||
到目前为止,标题和DeepDanbooru标签已经被整理到元数据文件中。然而,自动标题生成的标题存在表达差异等微妙问题(※),而标签中可能包含下划线和评级(DeepDanbooru的情况下)。因此,最好使用编辑器的替换功能清理标题和标签。
|
||||
|
||||
※例如,如果要学习动漫中的女孩,标题可能会包含girl/girls/woman/women等不同的表达方式。另外,将"anime girl"简单地替换为"girl"可能更合适。
|
||||
|
||||
我们提供了用于清理的脚本,请根据情况编辑脚本并使用它。
|
||||
|
||||
(不需要指定教师数据文件夹。将清理元数据中的所有数据。)
|
||||
|
||||
```
|
||||
python clean_captions_and_tags.py <要读取的元数据文件名> <要写入的元数据文件名>
|
||||
```
|
||||
|
||||
--in_json 请注意,不包括在内。例如:
|
||||
|
||||
```
|
||||
python clean_captions_and_tags.py meta_cap_dd.json meta_clean.json
|
||||
```
|
||||
|
||||
标题和标签的预处理现已完成。
|
||||
|
||||
## 预先获取 latents
|
||||
|
||||
※ 这一步骤并非必须。即使省略此步骤,也可以在训练过程中获取 latents。但是,如果在训练时执行 `random_crop` 或 `color_aug` 等操作,则无法预先获取 latents(因为每次图像都会改变)。如果不进行预先获取,则可以使用到目前为止的元数据进行训练。
|
||||
|
||||
提前获取图像的潜在表达并保存到磁盘上。这样可以加速训练过程。同时进行 bucketing(根据宽高比对训练数据进行分类)。
|
||||
|
||||
请在工作文件夹中输入以下内容。
|
||||
|
||||
```
|
||||
python prepare_buckets_latents.py --full_path <教师资料夹>
|
||||
<要读取的元数据文件名> <要写入的元数据文件名>
|
||||
<要微调的模型名称或检查点>
|
||||
--batch_size <批次大小>
|
||||
--max_resolution <分辨率宽、高>
|
||||
--mixed_precision <准确性>
|
||||
```
|
||||
|
||||
如果要从meta_clean.json中读取元数据,并将其写入meta_lat.json,使用模型model.ckpt,批处理大小为4,训练分辨率为512*512,精度为no(float32),则应如下所示。
|
||||
```
|
||||
python prepare_buckets_latents.py --full_path
|
||||
train_data meta_clean.json meta_lat.json model.ckpt
|
||||
--batch_size 4 --max_resolution 512,512 --mixed_precision no
|
||||
```
|
||||
|
||||
教师数据文件夹中,latents以numpy的npz格式保存。
|
||||
|
||||
您可以使用--min_bucket_reso选项指定最小分辨率大小,--max_bucket_reso指定最大大小。默认值分别为256和1024。例如,如果指定最小大小为384,则将不再使用分辨率为256 * 1024或320 * 768等。如果将分辨率增加到768 * 768等较大的值,则最好将最大大小指定为1280等。
|
||||
|
||||
如果指定--flip_aug选项,则进行左右翻转的数据增强。虽然这可以使数据量伪造一倍,但如果数据不是左右对称的(例如角色外观、发型等),则可能会导致训练不成功。
|
||||
|
||||
对于翻转的图像,也会获取latents,并保存名为\ *_flip.npz的文件,这是一个简单的实现。在fline_tune.py中不需要特定的选项。如果有带有\_flip的文件,则会随机加载带有和不带有flip的文件。
|
||||
|
||||
即使VRAM为12GB,批次大小也可以稍微增加。分辨率以“宽度,高度”的形式指定,必须是64的倍数。分辨率直接影响fine tuning时的内存大小。在12GB VRAM中,512,512似乎是极限(*)。如果有16GB,则可以将其提高到512,704或512,768。即使分辨率为256,256等,VRAM 8GB也很难承受(因为参数、优化器等与分辨率无关,需要一定的内存)。
|
||||
|
||||
*有报道称,在batch size为1的训练中,使用12GB VRAM和640,640的分辨率。
|
||||
|
||||
以下是bucketing结果的显示方式。
|
||||
|
||||
|
||||
|
||||
如果有多个教师数据文件夹,请指定 full_path 参数并为每个文件夹执行
|
||||
|
||||
```
|
||||
python prepare_buckets_latents.py --full_path
|
||||
train_data1 meta_clean.json meta_lat1.json model.ckpt
|
||||
--batch_size 4 --max_resolution 512,512 --mixed_precision no
|
||||
|
||||
python prepare_buckets_latents.py --full_path
|
||||
train_data2 meta_lat1.json meta_lat2.json model.ckpt
|
||||
--batch_size 4 --max_resolution 512,512 --mixed_precision no
|
||||
|
||||
```
|
||||
可以将读取源和写入目标设为相同,但分开设定更为安全。
|
||||
|
||||
__※建议每次更改参数并将其写入另一个元数据文件,以确保安全性。__
|
||||
84
docs/train_SDXL-en.md
Normal file
84
docs/train_SDXL-en.md
Normal file
@@ -0,0 +1,84 @@
|
||||
## SDXL training
|
||||
|
||||
The documentation will be moved to the training documentation in the future. The following is a brief explanation of the training scripts for SDXL.
|
||||
|
||||
### Training scripts for SDXL
|
||||
|
||||
- `sdxl_train.py` is a script for SDXL fine-tuning. The usage is almost the same as `fine_tune.py`, but it also supports DreamBooth dataset.
|
||||
- `--full_bf16` option is added. Thanks to KohakuBlueleaf!
|
||||
- This option enables the full bfloat16 training (includes gradients). This option is useful to reduce the GPU memory usage.
|
||||
- The full bfloat16 training might be unstable. Please use it at your own risk.
|
||||
- The different learning rates for each U-Net block are now supported in sdxl_train.py. Specify with `--block_lr` option. Specify 23 values separated by commas like `--block_lr 1e-3,1e-3 ... 1e-3`.
|
||||
- 23 values correspond to `0: time/label embed, 1-9: input blocks 0-8, 10-12: mid blocks 0-2, 13-21: output blocks 0-8, 22: out`.
|
||||
- `prepare_buckets_latents.py` now supports SDXL fine-tuning.
|
||||
|
||||
- `sdxl_train_network.py` is a script for LoRA training for SDXL. The usage is almost the same as `train_network.py`.
|
||||
|
||||
- Both scripts has following additional options:
|
||||
- `--cache_text_encoder_outputs` and `--cache_text_encoder_outputs_to_disk`: Cache the outputs of the text encoders. This option is useful to reduce the GPU memory usage. This option cannot be used with options for shuffling or dropping the captions.
|
||||
- `--no_half_vae`: Disable the half-precision (mixed-precision) VAE. VAE for SDXL seems to produce NaNs in some cases. This option is useful to avoid the NaNs.
|
||||
|
||||
- `--weighted_captions` option is not supported yet for both scripts.
|
||||
|
||||
- `sdxl_train_textual_inversion.py` is a script for Textual Inversion training for SDXL. The usage is almost the same as `train_textual_inversion.py`.
|
||||
- `--cache_text_encoder_outputs` is not supported.
|
||||
- There are two options for captions:
|
||||
1. Training with captions. All captions must include the token string. The token string is replaced with multiple tokens.
|
||||
2. Use `--use_object_template` or `--use_style_template` option. The captions are generated from the template. The existing captions are ignored.
|
||||
- See below for the format of the embeddings.
|
||||
|
||||
- `--min_timestep` and `--max_timestep` options are added to each training script. These options can be used to train U-Net with different timesteps. The default values are 0 and 1000.
|
||||
|
||||
### Utility scripts for SDXL
|
||||
|
||||
- `tools/cache_latents.py` is added. This script can be used to cache the latents to disk in advance.
|
||||
- The options are almost the same as `sdxl_train.py'. See the help message for the usage.
|
||||
- Please launch the script as follows:
|
||||
`accelerate launch --num_cpu_threads_per_process 1 tools/cache_latents.py ...`
|
||||
- This script should work with multi-GPU, but it is not tested in my environment.
|
||||
|
||||
- `tools/cache_text_encoder_outputs.py` is added. This script can be used to cache the text encoder outputs to disk in advance.
|
||||
- The options are almost the same as `cache_latents.py` and `sdxl_train.py`. See the help message for the usage.
|
||||
|
||||
- `sdxl_gen_img.py` is added. This script can be used to generate images with SDXL, including LoRA, Textual Inversion and ControlNet-LLLite. See the help message for the usage.
|
||||
|
||||
### Tips for SDXL training
|
||||
|
||||
- The default resolution of SDXL is 1024x1024.
|
||||
- The fine-tuning can be done with 24GB GPU memory with the batch size of 1. For 24GB GPU, the following options are recommended __for the fine-tuning with 24GB GPU memory__:
|
||||
- Train U-Net only.
|
||||
- Use gradient checkpointing.
|
||||
- Use `--cache_text_encoder_outputs` option and caching latents.
|
||||
- Use Adafactor optimizer. RMSprop 8bit or Adagrad 8bit may work. AdamW 8bit doesn't seem to work.
|
||||
- The LoRA training can be done with 8GB GPU memory (10GB recommended). For reducing the GPU memory usage, the following options are recommended:
|
||||
- Train U-Net only.
|
||||
- Use gradient checkpointing.
|
||||
- Use `--cache_text_encoder_outputs` option and caching latents.
|
||||
- Use one of 8bit optimizers or Adafactor optimizer.
|
||||
- Use lower dim (4 to 8 for 8GB GPU).
|
||||
- `--network_train_unet_only` option is highly recommended for SDXL LoRA. Because SDXL has two text encoders, the result of the training will be unexpected.
|
||||
- PyTorch 2 seems to use slightly less GPU memory than PyTorch 1.
|
||||
- `--bucket_reso_steps` can be set to 32 instead of the default value 64. Smaller values than 32 will not work for SDXL training.
|
||||
|
||||
Example of the optimizer settings for Adafactor with the fixed learning rate:
|
||||
```toml
|
||||
optimizer_type = "adafactor"
|
||||
optimizer_args = [ "scale_parameter=False", "relative_step=False", "warmup_init=False" ]
|
||||
lr_scheduler = "constant_with_warmup"
|
||||
lr_warmup_steps = 100
|
||||
learning_rate = 4e-7 # SDXL original learning rate
|
||||
```
|
||||
|
||||
### Format of Textual Inversion embeddings for SDXL
|
||||
|
||||
```python
|
||||
from safetensors.torch import save_file
|
||||
|
||||
state_dict = {"clip_g": embs_for_text_encoder_1280, "clip_l": embs_for_text_encoder_768}
|
||||
save_file(state_dict, file)
|
||||
```
|
||||
|
||||
### ControlNet-LLLite
|
||||
|
||||
ControlNet-LLLite, a novel method for ControlNet with SDXL, is added. See [documentation](./docs/train_lllite_README.md) for details.
|
||||
|
||||
162
docs/train_db_README-zh.md
Normal file
162
docs/train_db_README-zh.md
Normal file
@@ -0,0 +1,162 @@
|
||||
这是DreamBooth的指南。
|
||||
|
||||
请同时查看[关于学习的通用文档](./train_README-zh.md)。
|
||||
|
||||
# 概要
|
||||
|
||||
DreamBooth是一种将特定主题添加到图像生成模型中进行学习,并使用特定识别子生成它的技术。论文链接。
|
||||
|
||||
具体来说,它可以将角色和绘画风格等添加到Stable Diffusion模型中进行学习,并使用特定的单词(例如`shs`)来调用(呈现在生成的图像中)。
|
||||
|
||||
脚本基于Diffusers的DreamBooth,但添加了以下功能(一些功能已在原始脚本中得到支持)。
|
||||
|
||||
脚本的主要功能如下:
|
||||
|
||||
- 使用8位Adam优化器和潜在变量的缓存来节省内存(与Shivam Shrirao版相似)。
|
||||
- 使用xformers来节省内存。
|
||||
- 不仅支持512x512,还支持任意尺寸的训练。
|
||||
- 通过数据增强来提高质量。
|
||||
- 支持DreamBooth和Text Encoder + U-Net的微调。
|
||||
- 支持以Stable Diffusion格式读写模型。
|
||||
- 支持Aspect Ratio Bucketing。
|
||||
- 支持Stable Diffusion v2.0。
|
||||
|
||||
# 训练步骤
|
||||
|
||||
请先参阅此存储库的README以进行环境设置。
|
||||
|
||||
## 准备数据
|
||||
|
||||
请参阅[有关准备训练数据的说明](./train_README-zh.md)。
|
||||
|
||||
## 运行训练
|
||||
|
||||
运行脚本。以下是最大程度地节省内存的命令(实际上,这将在一行中输入)。请根据需要修改每行。它似乎需要约12GB的VRAM才能运行。
|
||||
```
|
||||
accelerate launch --num_cpu_threads_per_process 1 train_db.py
|
||||
--pretrained_model_name_or_path=<.ckpt或.safetensord或Diffusers版模型的目录>
|
||||
--dataset_config=<数据准备时创建的.toml文件>
|
||||
--output_dir=<训练模型的输出目录>
|
||||
--output_name=<训练模型输出时的文件名>
|
||||
--save_model_as=safetensors
|
||||
--prior_loss_weight=1.0
|
||||
--max_train_steps=1600
|
||||
--learning_rate=1e-6
|
||||
--optimizer_type="AdamW8bit"
|
||||
--xformers
|
||||
--mixed_precision="fp16"
|
||||
--cache_latents
|
||||
--gradient_checkpointing
|
||||
```
|
||||
`num_cpu_threads_per_process` 通常应该设置为1。
|
||||
|
||||
`pretrained_model_name_or_path` 指定要进行追加训练的基础模型。可以指定 Stable Diffusion 的 checkpoint 文件(.ckpt 或 .safetensors)、Diffusers 的本地模型目录或模型 ID(如 "stabilityai/stable-diffusion-2")。
|
||||
|
||||
`output_dir` 指定保存训练后模型的文件夹。在 `output_name` 中指定模型文件名,不包括扩展名。使用 `save_model_as` 指定以 safetensors 格式保存。
|
||||
|
||||
在 `dataset_config` 中指定 `.toml` 文件。初始批处理大小应为 `1`,以减少内存消耗。
|
||||
|
||||
`prior_loss_weight` 是正则化图像损失的权重。通常设为1.0。
|
||||
|
||||
将要训练的步数 `max_train_steps` 设置为1600。在这里,学习率 `learning_rate` 被设置为1e-6。
|
||||
|
||||
为了节省内存,设置 `mixed_precision="fp16"`(在 RTX30 系列及更高版本中也可以设置为 `bf16`)。同时指定 `gradient_checkpointing`。
|
||||
|
||||
为了使用内存消耗较少的 8bit AdamW 优化器(将模型优化为适合于训练数据的状态),指定 `optimizer_type="AdamW8bit"`。
|
||||
|
||||
指定 `xformers` 选项,并使用 xformers 的 CrossAttention。如果未安装 xformers 或出现错误(具体情况取决于环境,例如使用 `mixed_precision="no"`),则可以指定 `mem_eff_attn` 选项以使用省内存版的 CrossAttention(速度会变慢)。
|
||||
|
||||
为了节省内存,指定 `cache_latents` 选项以缓存 VAE 的输出。
|
||||
|
||||
如果有足够的内存,请编辑 `.toml` 文件将批处理大小增加到大约 `4`(可能会提高速度和精度)。此外,取消 `cache_latents` 选项可以进行数据增强。
|
||||
|
||||
### 常用选项
|
||||
|
||||
对于以下情况,请参阅“常用选项”部分。
|
||||
|
||||
- 学习 Stable Diffusion 2.x 或其衍生模型。
|
||||
- 学习基于 clip skip 大于等于2的模型。
|
||||
- 学习超过75个令牌的标题。
|
||||
|
||||
### 关于DreamBooth中的步数
|
||||
|
||||
为了实现省内存化,该脚本中每个步骤的学习次数减半(因为学习和正则化的图像在训练时被分为不同的批次)。
|
||||
|
||||
要进行与原始Diffusers版或XavierXiao的Stable Diffusion版几乎相同的学习,请将步骤数加倍。
|
||||
|
||||
(虽然在将学习图像和正则化图像整合后再打乱顺序,但我认为对学习没有太大影响。)
|
||||
|
||||
关于DreamBooth的批量大小
|
||||
|
||||
与像LoRA这样的学习相比,为了训练整个模型,内存消耗量会更大(与微调相同)。
|
||||
|
||||
关于学习率
|
||||
|
||||
在Diffusers版中,学习率为5e-6,而在Stable Diffusion版中为1e-6,因此在上面的示例中指定了1e-6。
|
||||
|
||||
当使用旧格式的数据集指定命令行时
|
||||
|
||||
使用选项指定分辨率和批量大小。命令行示例如下。
|
||||
```
|
||||
accelerate launch --num_cpu_threads_per_process 1 train_db.py
|
||||
--pretrained_model_name_or_path=<.ckpt或.safetensord或Diffusers版模型的目录>
|
||||
--train_data_dir=<训练数据的目录>
|
||||
--reg_data_dir=<正则化图像的目录>
|
||||
--output_dir=<训练后模型的输出目录>
|
||||
--output_name=<训练后模型输出文件的名称>
|
||||
--prior_loss_weight=1.0
|
||||
--resolution=512
|
||||
--train_batch_size=1
|
||||
--learning_rate=1e-6
|
||||
--max_train_steps=1600
|
||||
--use_8bit_adam
|
||||
--xformers
|
||||
--mixed_precision="bf16"
|
||||
--cache_latents
|
||||
--gradient_checkpointing
|
||||
```
|
||||
|
||||
## 使用训练好的模型生成图像
|
||||
|
||||
训练完成后,将在指定的文件夹中以指定的名称输出safetensors文件。
|
||||
|
||||
对于v1.4/1.5和其他派生模型,可以在此模型中使用Automatic1111先生的WebUI进行推断。请将其放置在models\Stable-diffusion文件夹中。
|
||||
|
||||
对于使用v2.x模型在WebUI中生成图像的情况,需要单独的.yaml文件来描述模型的规格。对于v2.x base,需要v2-inference.yaml,对于768/v,则需要v2-inference-v.yaml。请将它们放置在相同的文件夹中,并将文件扩展名之前的部分命名为与模型相同的名称。
|
||||

|
||||
|
||||
每个yaml文件都在[Stability AI的SD2.0存储库](https://github.com/Stability-AI/stablediffusion/tree/main/configs/stable-diffusion)……之中。
|
||||
|
||||
# DreamBooth的其他主要选项
|
||||
|
||||
有关所有选项的详细信息,请参阅另一份文档。
|
||||
|
||||
## 不在中途开始对文本编码器进行训练 --stop_text_encoder_training
|
||||
|
||||
如果在stop_text_encoder_training选项中指定一个数字,则在该步骤之后,将不再对文本编码器进行训练,只会对U-Net进行训练。在某些情况下,可能会期望提高精度。
|
||||
|
||||
(我们推测可能会有时候仅仅文本编码器会过度学习,而这样做可以避免这种情况,但详细影响尚不清楚。)
|
||||
|
||||
## 不进行分词器的填充 --no_token_padding
|
||||
|
||||
如果指定no_token_padding选项,则不会对分词器的输出进行填充(与Diffusers版本的旧DreamBooth相同)。
|
||||
|
||||
<!--
|
||||
如果使用分桶(bucketing)和数据增强(augmentation),则使用示例如下:
|
||||
```
|
||||
accelerate launch --num_cpu_threads_per_process 8 train_db.py
|
||||
--pretrained_model_name_or_path=<.ckpt或.safetensord或Diffusers版模型的目录>
|
||||
--train_data_dir=<训练数据的目录>
|
||||
--reg_data_dir=<正则化图像的目录>
|
||||
--output_dir=<训练后模型的输出目录>
|
||||
--resolution=768,512
|
||||
--train_batch_size=20 --learning_rate=5e-6 --max_train_steps=800
|
||||
--use_8bit_adam --xformers --mixed_precision="bf16"
|
||||
--save_every_n_epochs=1 --save_state --save_precision="bf16"
|
||||
--logging_dir=logs
|
||||
--enable_bucket --min_bucket_reso=384 --max_bucket_reso=1280
|
||||
--color_aug --flip_aug --gradient_checkpointing --seed 42
|
||||
```
|
||||
|
||||
|
||||
-->
|
||||
218
docs/train_lllite_README-ja.md
Normal file
218
docs/train_lllite_README-ja.md
Normal file
@@ -0,0 +1,218 @@
|
||||
# ControlNet-LLLite について
|
||||
|
||||
__きわめて実験的な実装のため、将来的に大きく変更される可能性があります。__
|
||||
|
||||
## 概要
|
||||
ControlNet-LLLite は、[ControlNet](https://github.com/lllyasviel/ControlNet) の軽量版です。LoRA Like Lite という意味で、LoRAからインスピレーションを得た構造を持つ、軽量なControlNetです。現在はSDXLにのみ対応しています。
|
||||
|
||||
## サンプルの重みファイルと推論
|
||||
|
||||
こちらにあります: https://huggingface.co/kohya-ss/controlnet-lllite
|
||||
|
||||
ComfyUIのカスタムノードを用意しています。: https://github.com/kohya-ss/ControlNet-LLLite-ComfyUI
|
||||
|
||||
生成サンプルはこのページの末尾にあります。
|
||||
|
||||
## モデル構造
|
||||
ひとつのLLLiteモジュールは、制御用画像(以下conditioning image)を潜在空間に写像するconditioning image embeddingと、LoRAにちょっと似た構造を持つ小型のネットワークからなります。LLLiteモジュールを、LoRAと同様にU-NetのLinearやConvに追加します。詳しくはソースコードを参照してください。
|
||||
|
||||
推論環境の制限で、現在はCrossAttentionのみ(attn1のq/k/v、attn2のq)に追加されます。
|
||||
|
||||
## モデルの学習
|
||||
|
||||
### データセットの準備
|
||||
DreamBooth 方式の dataset で、`conditioning_data_dir` で指定したディレクトリにconditioning imageを格納してください。
|
||||
|
||||
(finetuning 方式の dataset はサポートしていません。)
|
||||
|
||||
conditioning imageは学習用画像と同じbasenameを持つ必要があります。また、conditioning imageは学習用画像と同じサイズに自動的にリサイズされます。conditioning imageにはキャプションファイルは不要です。
|
||||
|
||||
たとえば、キャプションにフォルダ名ではなくキャプションファイルを用いる場合の設定ファイルは以下のようになります。
|
||||
|
||||
```toml
|
||||
[[datasets.subsets]]
|
||||
image_dir = "path/to/image/dir"
|
||||
caption_extension = ".txt"
|
||||
conditioning_data_dir = "path/to/conditioning/image/dir"
|
||||
```
|
||||
|
||||
現時点の制約として、random_cropは使用できません。
|
||||
|
||||
学習データとしては、元のモデルで生成した画像を学習用画像として、そこから加工した画像をconditioning imageとした、合成によるデータセットを用いるのがもっとも簡単です(データセットの品質的には問題があるかもしれません)。具体的なデータセットの合成方法については後述します。
|
||||
|
||||
なお、元モデルと異なる画風の画像を学習用画像とすると、制御に加えて、その画風についても学ぶ必要が生じます。ControlNet-LLLiteは容量が少ないため、画風学習には不向きです。このような場合には、後述の次元数を多めにしてください。
|
||||
|
||||
### 学習
|
||||
スクリプトで生成する場合は、`sdxl_train_control_net_lllite.py` を実行してください。`--cond_emb_dim` でconditioning image embeddingの次元数を指定できます。`--network_dim` でLoRA的モジュールのrankを指定できます。その他のオプションは`sdxl_train_network.py`に準じますが、`--network_module`の指定は不要です。
|
||||
|
||||
学習時にはメモリを大量に使用しますので、キャッシュやgradient checkpointingなどの省メモリ化のオプションを有効にしてください。また`--full_bf16` オプションで、BFloat16を使用するのも有効です(RTX 30シリーズ以降のGPUが必要です)。24GB VRAMで動作確認しています。
|
||||
|
||||
conditioning image embeddingの次元数は、サンプルのCannyでは32を指定しています。LoRA的モジュールのrankは同じく64です。対象とするconditioning imageの特徴に合わせて調整してください。
|
||||
|
||||
(サンプルのCannyは恐らくかなり難しいと思われます。depthなどでは半分程度にしてもいいかもしれません。)
|
||||
|
||||
以下は .toml の設定例です。
|
||||
|
||||
```toml
|
||||
pretrained_model_name_or_path = "/path/to/model_trained_on.safetensors"
|
||||
max_train_epochs = 12
|
||||
max_data_loader_n_workers = 4
|
||||
persistent_data_loader_workers = true
|
||||
seed = 42
|
||||
gradient_checkpointing = true
|
||||
mixed_precision = "bf16"
|
||||
save_precision = "bf16"
|
||||
full_bf16 = true
|
||||
optimizer_type = "adamw8bit"
|
||||
learning_rate = 2e-4
|
||||
xformers = true
|
||||
output_dir = "/path/to/output/dir"
|
||||
output_name = "output_name"
|
||||
save_every_n_epochs = 1
|
||||
save_model_as = "safetensors"
|
||||
vae_batch_size = 4
|
||||
cache_latents = true
|
||||
cache_latents_to_disk = true
|
||||
cache_text_encoder_outputs = true
|
||||
cache_text_encoder_outputs_to_disk = true
|
||||
network_dim = 64
|
||||
cond_emb_dim = 32
|
||||
dataset_config = "/path/to/dataset.toml"
|
||||
```
|
||||
|
||||
### 推論
|
||||
|
||||
スクリプトで生成する場合は、`sdxl_gen_img.py` を実行してください。`--control_net_lllite_models` でLLLiteのモデルファイルを指定できます。次元数はモデルファイルから自動取得します。
|
||||
|
||||
`--guide_image_path`で推論に用いるconditioning imageを指定してください。なおpreprocessは行われないため、たとえばCannyならCanny処理を行った画像を指定してください(背景黒に白線)。`--control_net_preps`, `--control_net_weights`, `--control_net_ratios` には未対応です。
|
||||
|
||||
## データセットの合成方法
|
||||
|
||||
### 学習用画像の生成
|
||||
|
||||
学習のベースとなるモデルで画像生成を行います。Web UIやComfyUIなどで生成してください。画像サイズはモデルのデフォルトサイズで良いと思われます(1024x1024など)。bucketingを用いることもできます。その場合は適宜適切な解像度で生成してください。
|
||||
|
||||
生成時のキャプション等は、ControlNet-LLLiteの利用時に生成したい画像にあわせるのが良いと思われます。
|
||||
|
||||
生成した画像を任意のディレクトリに保存してください。このディレクトリをデータセットの設定ファイルで指定します。
|
||||
|
||||
当リポジトリ内の `sdxl_gen_img.py` でも生成できます。例えば以下のように実行します。
|
||||
|
||||
```dos
|
||||
python sdxl_gen_img.py --ckpt path/to/model.safetensors --n_iter 1 --scale 10 --steps 36 --outdir path/to/output/dir --xformers --W 1024 --H 1024 --original_width 2048 --original_height 2048 --bf16 --sampler ddim --batch_size 4 --vae_batch_size 2 --images_per_prompt 512 --max_embeddings_multiples 1 --prompt "{portrait|digital art|anime screen cap|detailed illustration} of 1girl, {standing|sitting|walking|running|dancing} on {classroom|street|town|beach|indoors|outdoors}, {looking at viewer|looking away|looking at another}, {in|wearing} {shirt and skirt|school uniform|casual wear} { |, dynamic pose}, (solo), teen age, {0-1$$smile,|blush,|kind smile,|expression less,|happy,|sadness,} {0-1$$upper body,|full body,|cowboy shot,|face focus,} trending on pixiv, {0-2$$depth of fields,|8k wallpaper,|highly detailed,|pov,} {0-1$$summer, |winter, |spring, |autumn, } beautiful face { |, from below|, from above|, from side|, from behind|, from back} --n nsfw, bad face, lowres, low quality, worst quality, low effort, watermark, signature, ugly, poorly drawn"
|
||||
```
|
||||
|
||||
VRAM 24GBの設定です。VRAMサイズにより`--batch_size` `--vae_batch_size`を調整してください。
|
||||
|
||||
`--prompt`でワイルドカードを利用してランダムに生成しています。適宜調整してください。
|
||||
|
||||
### 画像の加工
|
||||
|
||||
外部のプログラムを用いて、生成した画像を加工します。加工した画像を任意のディレクトリに保存してください。これらがconditioning imageになります。
|
||||
|
||||
加工にはたとえばCannyなら以下のようなスクリプトが使えます。
|
||||
|
||||
```python
|
||||
import glob
|
||||
import os
|
||||
import random
|
||||
import cv2
|
||||
import numpy as np
|
||||
|
||||
IMAGES_DIR = "path/to/generated/images"
|
||||
CANNY_DIR = "path/to/canny/images"
|
||||
|
||||
os.makedirs(CANNY_DIR, exist_ok=True)
|
||||
img_files = glob.glob(IMAGES_DIR + "/*.png")
|
||||
for img_file in img_files:
|
||||
can_file = CANNY_DIR + "/" + os.path.basename(img_file)
|
||||
if os.path.exists(can_file):
|
||||
print("Skip: " + img_file)
|
||||
continue
|
||||
|
||||
print(img_file)
|
||||
|
||||
img = cv2.imread(img_file)
|
||||
|
||||
# random threshold
|
||||
# while True:
|
||||
# threshold1 = random.randint(0, 127)
|
||||
# threshold2 = random.randint(128, 255)
|
||||
# if threshold2 - threshold1 > 80:
|
||||
# break
|
||||
|
||||
# fixed threshold
|
||||
threshold1 = 100
|
||||
threshold2 = 200
|
||||
|
||||
img = cv2.Canny(img, threshold1, threshold2)
|
||||
|
||||
cv2.imwrite(can_file, img)
|
||||
```
|
||||
|
||||
### キャプションファイルの作成
|
||||
|
||||
学習用画像のbasenameと同じ名前で、それぞれの画像に対応したキャプションファイルを作成してください。生成時のプロンプトをそのまま利用すれば良いと思われます。
|
||||
|
||||
`sdxl_gen_img.py` で生成した場合は、画像内のメタデータに生成時のプロンプトが記録されていますので、以下のようなスクリプトで学習用画像と同じディレクトリにキャプションファイルを作成できます(拡張子 `.txt`)。
|
||||
|
||||
```python
|
||||
import glob
|
||||
import os
|
||||
from PIL import Image
|
||||
|
||||
IMAGES_DIR = "path/to/generated/images"
|
||||
|
||||
img_files = glob.glob(IMAGES_DIR + "/*.png")
|
||||
for img_file in img_files:
|
||||
cap_file = img_file.replace(".png", ".txt")
|
||||
if os.path.exists(cap_file):
|
||||
print(f"Skip: {img_file}")
|
||||
continue
|
||||
print(img_file)
|
||||
|
||||
img = Image.open(img_file)
|
||||
prompt = img.text["prompt"] if "prompt" in img.text else ""
|
||||
if prompt == "":
|
||||
print(f"Prompt not found in {img_file}")
|
||||
|
||||
with open(cap_file, "w") as f:
|
||||
f.write(prompt + "\n")
|
||||
```
|
||||
|
||||
### データセットの設定ファイルの作成
|
||||
|
||||
コマンドラインオプションからの指定も可能ですが、`.toml`ファイルを作成する場合は `conditioning_data_dir` に加工した画像を保存したディレクトリを指定します。
|
||||
|
||||
以下は設定ファイルの例です。
|
||||
|
||||
```toml
|
||||
[general]
|
||||
flip_aug = false
|
||||
color_aug = false
|
||||
resolution = [1024,1024]
|
||||
|
||||
[[datasets]]
|
||||
batch_size = 8
|
||||
enable_bucket = false
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = "path/to/generated/image/dir"
|
||||
caption_extension = ".txt"
|
||||
conditioning_data_dir = "path/to/canny/image/dir"
|
||||
```
|
||||
|
||||
## 謝辞
|
||||
|
||||
ControlNetの作者である lllyasviel 氏、実装上のアドバイスとトラブル解決へのご尽力をいただいた furusu 氏、ControlNetデータセットを実装していただいた ddPn08 氏に感謝いたします。
|
||||
|
||||
## サンプル
|
||||
Canny
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
219
docs/train_lllite_README.md
Normal file
219
docs/train_lllite_README.md
Normal file
@@ -0,0 +1,219 @@
|
||||
# About ControlNet-LLLite
|
||||
|
||||
__This is an extremely experimental implementation and may change significantly in the future.__
|
||||
|
||||
日本語版は[こちら](./train_lllite_README-ja.md)
|
||||
|
||||
## Overview
|
||||
|
||||
ControlNet-LLLite is a lightweight version of [ControlNet](https://github.com/lllyasviel/ControlNet). It is a "LoRA Like Lite" that is inspired by LoRA and has a lightweight structure. Currently, only SDXL is supported.
|
||||
|
||||
## Sample weight file and inference
|
||||
|
||||
Sample weight file is available here: https://huggingface.co/kohya-ss/controlnet-lllite
|
||||
|
||||
A custom node for ComfyUI is available: https://github.com/kohya-ss/ControlNet-LLLite-ComfyUI
|
||||
|
||||
Sample images are at the end of this page.
|
||||
|
||||
## Model structure
|
||||
|
||||
A single LLLite module consists of a conditioning image embedding that maps a conditioning image to a latent space and a small network with a structure similar to LoRA. The LLLite module is added to U-Net's Linear and Conv in the same way as LoRA. Please refer to the source code for details.
|
||||
|
||||
Due to the limitations of the inference environment, only CrossAttention (attn1 q/k/v, attn2 q) is currently added.
|
||||
|
||||
## Model training
|
||||
|
||||
### Preparing the dataset
|
||||
|
||||
In addition to the normal DreamBooth method dataset, please store the conditioning image in the directory specified by `conditioning_data_dir`. The conditioning image must have the same basename as the training image. The conditioning image will be automatically resized to the same size as the training image. The conditioning image does not require a caption file.
|
||||
|
||||
(We do not support the finetuning method dataset.)
|
||||
|
||||
```toml
|
||||
[[datasets.subsets]]
|
||||
image_dir = "path/to/image/dir"
|
||||
caption_extension = ".txt"
|
||||
conditioning_data_dir = "path/to/conditioning/image/dir"
|
||||
```
|
||||
|
||||
At the moment, random_crop cannot be used.
|
||||
|
||||
For training data, it is easiest to use a synthetic dataset with the original model-generated images as training images and processed images as conditioning images (the quality of the dataset may be problematic). See below for specific methods of synthesizing datasets.
|
||||
|
||||
Note that if you use an image with a different art style than the original model as a training image, the model will have to learn not only the control but also the art style. ControlNet-LLLite has a small capacity, so it is not suitable for learning art styles. In such cases, increase the number of dimensions as described below.
|
||||
|
||||
### Training
|
||||
|
||||
Run `sdxl_train_control_net_lllite.py`. You can specify the dimension of the conditioning image embedding with `--cond_emb_dim`. You can specify the rank of the LoRA-like module with `--network_dim`. Other options are the same as `sdxl_train_network.py`, but `--network_module` is not required.
|
||||
|
||||
Since a large amount of memory is used during training, please enable memory-saving options such as cache and gradient checkpointing. It is also effective to use BFloat16 with the `--full_bf16` option (requires RTX 30 series or later GPU). It has been confirmed to work with 24GB VRAM.
|
||||
|
||||
For the sample Canny, the dimension of the conditioning image embedding is 32. The rank of the LoRA-like module is also 64. Adjust according to the features of the conditioning image you are targeting.
|
||||
|
||||
(The sample Canny is probably quite difficult. It may be better to reduce it to about half for depth, etc.)
|
||||
|
||||
The following is an example of a .toml configuration.
|
||||
|
||||
```toml
|
||||
pretrained_model_name_or_path = "/path/to/model_trained_on.safetensors"
|
||||
max_train_epochs = 12
|
||||
max_data_loader_n_workers = 4
|
||||
persistent_data_loader_workers = true
|
||||
seed = 42
|
||||
gradient_checkpointing = true
|
||||
mixed_precision = "bf16"
|
||||
save_precision = "bf16"
|
||||
full_bf16 = true
|
||||
optimizer_type = "adamw8bit"
|
||||
learning_rate = 2e-4
|
||||
xformers = true
|
||||
output_dir = "/path/to/output/dir"
|
||||
output_name = "output_name"
|
||||
save_every_n_epochs = 1
|
||||
save_model_as = "safetensors"
|
||||
vae_batch_size = 4
|
||||
cache_latents = true
|
||||
cache_latents_to_disk = true
|
||||
cache_text_encoder_outputs = true
|
||||
cache_text_encoder_outputs_to_disk = true
|
||||
network_dim = 64
|
||||
cond_emb_dim = 32
|
||||
dataset_config = "/path/to/dataset.toml"
|
||||
```
|
||||
|
||||
### Inference
|
||||
|
||||
If you want to generate images with a script, run `sdxl_gen_img.py`. You can specify the LLLite model file with `--control_net_lllite_models`. The dimension is automatically obtained from the model file.
|
||||
|
||||
Specify the conditioning image to be used for inference with `--guide_image_path`. Since preprocess is not performed, if it is Canny, specify an image processed with Canny (white line on black background). `--control_net_preps`, `--control_net_weights`, and `--control_net_ratios` are not supported.
|
||||
|
||||
## How to synthesize a dataset
|
||||
|
||||
### Generating training images
|
||||
|
||||
Generate images with the base model for training. Please generate them with Web UI or ComfyUI etc. The image size should be the default size of the model (1024x1024, etc.). You can also use bucketing. In that case, please generate it at an arbitrary resolution.
|
||||
|
||||
The captions and other settings when generating the images should be the same as when generating the images with the trained ControlNet-LLLite model.
|
||||
|
||||
Save the generated images in an arbitrary directory. Specify this directory in the dataset configuration file.
|
||||
|
||||
|
||||
You can also generate them with `sdxl_gen_img.py` in this repository. For example, run as follows:
|
||||
|
||||
```dos
|
||||
python sdxl_gen_img.py --ckpt path/to/model.safetensors --n_iter 1 --scale 10 --steps 36 --outdir path/to/output/dir --xformers --W 1024 --H 1024 --original_width 2048 --original_height 2048 --bf16 --sampler ddim --batch_size 4 --vae_batch_size 2 --images_per_prompt 512 --max_embeddings_multiples 1 --prompt "{portrait|digital art|anime screen cap|detailed illustration} of 1girl, {standing|sitting|walking|running|dancing} on {classroom|street|town|beach|indoors|outdoors}, {looking at viewer|looking away|looking at another}, {in|wearing} {shirt and skirt|school uniform|casual wear} { |, dynamic pose}, (solo), teen age, {0-1$$smile,|blush,|kind smile,|expression less,|happy,|sadness,} {0-1$$upper body,|full body,|cowboy shot,|face focus,} trending on pixiv, {0-2$$depth of fields,|8k wallpaper,|highly detailed,|pov,} {0-1$$summer, |winter, |spring, |autumn, } beautiful face { |, from below|, from above|, from side|, from behind|, from back} --n nsfw, bad face, lowres, low quality, worst quality, low effort, watermark, signature, ugly, poorly drawn"
|
||||
```
|
||||
|
||||
This is a setting for VRAM 24GB. Adjust `--batch_size` and `--vae_batch_size` according to the VRAM size.
|
||||
|
||||
The images are generated randomly using wildcards in `--prompt`. Adjust as necessary.
|
||||
|
||||
### Processing images
|
||||
|
||||
Use an external program to process the generated images. Save the processed images in an arbitrary directory. These will be the conditioning images.
|
||||
|
||||
For example, you can use the following script to process the images with Canny.
|
||||
|
||||
```python
|
||||
import glob
|
||||
import os
|
||||
import random
|
||||
import cv2
|
||||
import numpy as np
|
||||
|
||||
IMAGES_DIR = "path/to/generated/images"
|
||||
CANNY_DIR = "path/to/canny/images"
|
||||
|
||||
os.makedirs(CANNY_DIR, exist_ok=True)
|
||||
img_files = glob.glob(IMAGES_DIR + "/*.png")
|
||||
for img_file in img_files:
|
||||
can_file = CANNY_DIR + "/" + os.path.basename(img_file)
|
||||
if os.path.exists(can_file):
|
||||
print("Skip: " + img_file)
|
||||
continue
|
||||
|
||||
print(img_file)
|
||||
|
||||
img = cv2.imread(img_file)
|
||||
|
||||
# random threshold
|
||||
# while True:
|
||||
# threshold1 = random.randint(0, 127)
|
||||
# threshold2 = random.randint(128, 255)
|
||||
# if threshold2 - threshold1 > 80:
|
||||
# break
|
||||
|
||||
# fixed threshold
|
||||
threshold1 = 100
|
||||
threshold2 = 200
|
||||
|
||||
img = cv2.Canny(img, threshold1, threshold2)
|
||||
|
||||
cv2.imwrite(can_file, img)
|
||||
```
|
||||
|
||||
### Creating caption files
|
||||
|
||||
Create a caption file for each image with the same basename as the training image. It is fine to use the same caption as the one used when generating the image.
|
||||
|
||||
If you generated the images with `sdxl_gen_img.py`, you can use the following script to create the caption files (`*.txt`) from the metadata in the generated images.
|
||||
|
||||
```python
|
||||
import glob
|
||||
import os
|
||||
from PIL import Image
|
||||
|
||||
IMAGES_DIR = "path/to/generated/images"
|
||||
|
||||
img_files = glob.glob(IMAGES_DIR + "/*.png")
|
||||
for img_file in img_files:
|
||||
cap_file = img_file.replace(".png", ".txt")
|
||||
if os.path.exists(cap_file):
|
||||
print(f"Skip: {img_file}")
|
||||
continue
|
||||
print(img_file)
|
||||
|
||||
img = Image.open(img_file)
|
||||
prompt = img.text["prompt"] if "prompt" in img.text else ""
|
||||
if prompt == "":
|
||||
print(f"Prompt not found in {img_file}")
|
||||
|
||||
with open(cap_file, "w") as f:
|
||||
f.write(prompt + "\n")
|
||||
```
|
||||
|
||||
### Creating a dataset configuration file
|
||||
|
||||
You can use the command line arguments of `sdxl_train_control_net_lllite.py` to specify the conditioning image directory. However, if you want to use a `.toml` file, specify the conditioning image directory in `conditioning_data_dir`.
|
||||
|
||||
```toml
|
||||
[general]
|
||||
flip_aug = false
|
||||
color_aug = false
|
||||
resolution = [1024,1024]
|
||||
|
||||
[[datasets]]
|
||||
batch_size = 8
|
||||
enable_bucket = false
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = "path/to/generated/image/dir"
|
||||
caption_extension = ".txt"
|
||||
conditioning_data_dir = "path/to/canny/image/dir"
|
||||
```
|
||||
|
||||
## Credit
|
||||
|
||||
I would like to thank lllyasviel, the author of ControlNet, furusu, who provided me with advice on implementation and helped me solve problems, and ddPn08, who implemented the ControlNet dataset.
|
||||
|
||||
## Sample
|
||||
|
||||
Canny
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
@@ -102,6 +102,8 @@ accelerate launch --num_cpu_threads_per_process 1 train_network.py
|
||||
* Text Encoderに関連するLoRAモジュールに、通常の学習率(--learning_rateオプションで指定)とは異なる学習率を使う時に指定します。Text Encoderのほうを若干低めの学習率(5e-5など)にしたほうが良い、という話もあるようです。
|
||||
* `--network_args`
|
||||
* 複数の引数を指定できます。後述します。
|
||||
* `--alpha_mask`
|
||||
* 画像のアルファ値をマスクとして使用します。透過画像を学習する際に使用します。[PR #1223](https://github.com/kohya-ss/sd-scripts/pull/1223)
|
||||
|
||||
`--network_train_unet_only` と `--network_train_text_encoder_only` の両方とも未指定時(デフォルト)はText EncoderとU-Netの両方のLoRAモジュールを有効にします。
|
||||
|
||||
@@ -183,12 +185,14 @@ python networks\extract_lora_from_dylora.py --model "foldername/dylora-model.saf
|
||||
|
||||
フルモデルの25個のブロックの重みを指定できます。最初のブロックに該当するLoRAは存在しませんが、階層別LoRA適用等との互換性のために25個としています。またconv2d3x3に拡張しない場合も一部のブロックにはLoRAが存在しませんが、記述を統一するため常に25個の値を指定してください。
|
||||
|
||||
SDXL では down/up 9 個、middle 3 個の値を指定してください。
|
||||
|
||||
`--network_args` で以下の引数を指定してください。
|
||||
|
||||
- `down_lr_weight` : U-Netのdown blocksの学習率の重みを指定します。以下が指定可能です。
|
||||
- ブロックごとの重み : `"down_lr_weight=0,0,0,0,0,0,1,1,1,1,1,1"` のように12個の数値を指定します。
|
||||
- ブロックごとの重み : `"down_lr_weight=0,0,0,0,0,0,1,1,1,1,1,1"` のように12個(SDXL では 9 個)の数値を指定します。
|
||||
- プリセットからの指定 : `"down_lr_weight=sine"` のように指定します(サインカーブで重みを指定します)。sine, cosine, linear, reverse_linear, zeros が指定可能です。また `"down_lr_weight=cosine+.25"` のように `+数値` を追加すると、指定した数値を加算します(0.25~1.25になります)。
|
||||
- `mid_lr_weight` : U-Netのmid blockの学習率の重みを指定します。`"down_lr_weight=0.5"` のように数値を一つだけ指定します。
|
||||
- `mid_lr_weight` : U-Netのmid blockの学習率の重みを指定します。`"down_lr_weight=0.5"` のように数値を一つだけ指定します(SDXL の場合は 3 個)。
|
||||
- `up_lr_weight` : U-Netのup blocksの学習率の重みを指定します。down_lr_weightと同様です。
|
||||
- 指定を省略した部分は1.0として扱われます。また重みを0にするとそのブロックのLoRAモジュールは作成されません。
|
||||
- `block_lr_zero_threshold` : 重みがこの値以下の場合、LoRAモジュールを作成しません。デフォルトは0です。
|
||||
@@ -213,6 +217,9 @@ network_args = [ "block_lr_zero_threshold=0.1", "down_lr_weight=sine+.5", "mid_l
|
||||
|
||||
フルモデルの25個のブロックのdim (rank)を指定できます。階層別学習率と同様に一部のブロックにはLoRAが存在しない場合がありますが、常に25個の値を指定してください。
|
||||
|
||||
SDXL では 23 個の値を指定してください。一部のブロックにはLoRA が存在しませんが、`sdxl_train.py` の[階層別学習率](./train_SDXL-en.md) との互換性のためです。
|
||||
対応は、`0: time/label embed, 1-9: input blocks 0-8, 10-12: mid blocks 0-2, 13-21: output blocks 0-8, 22: out` です。
|
||||
|
||||
`--network_args` で以下の引数を指定してください。
|
||||
|
||||
- `block_dims` : 各ブロックのdim (rank)を指定します。`"block_dims=2,2,2,2,4,4,4,4,6,6,6,6,8,6,6,6,6,4,4,4,4,2,2,2,2"` のように25個の数値を指定します。
|
||||
@@ -246,6 +253,8 @@ network_args = [ "block_dims=2,4,4,4,8,8,8,8,12,12,12,12,16,12,12,12,12,8,8,8,8,
|
||||
|
||||
merge_lora.pyでStable DiffusionのモデルにLoRAの学習結果をマージしたり、複数のLoRAモデルをマージしたりできます。
|
||||
|
||||
SDXL向けにはsdxl_merge_lora.pyを用意しています。オプション等は同一ですので、以下のmerge_lora.pyを読み替えてください。
|
||||
|
||||
### Stable DiffusionのモデルにLoRAのモデルをマージする
|
||||
|
||||
マージ後のモデルは通常のStable Diffusionのckptと同様に扱えます。たとえば以下のようなコマンドラインになります。
|
||||
@@ -276,26 +285,28 @@ python networks\merge_lora.py --sd_model ..\model\model.ckpt
|
||||
|
||||
### 複数のLoRAのモデルをマージする
|
||||
|
||||
複数のLoRAモデルをひとつずつSDモデルに適用する場合と、複数のLoRAモデルをマージしてからSDモデルにマージする場合とは、計算順序の関連で微妙に異なる結果になります。
|
||||
--concatオプションを指定すると、複数のLoRAを単純に結合して新しいLoRAモデルを作成できます。ファイルサイズ(およびdim/rank)は指定したLoRAの合計サイズになります(マージ時にdim (rank)を変更する場合は `svd_merge_lora.py` を使用してください)。
|
||||
|
||||
たとえば以下のようなコマンドラインになります。
|
||||
|
||||
```
|
||||
python networks\merge_lora.py
|
||||
python networks\merge_lora.py --save_precision bf16
|
||||
--save_to ..\lora_train1\model-char1-style1-merged.safetensors
|
||||
--models ..\lora_train1\last.safetensors ..\lora_train2\last.safetensors --ratios 0.6 0.4
|
||||
--models ..\lora_train1\last.safetensors ..\lora_train2\last.safetensors
|
||||
--ratios 1.0 -1.0 --concat --shuffle
|
||||
```
|
||||
|
||||
--sd_modelオプションは指定不要です。
|
||||
--concatオプションを指定します。
|
||||
|
||||
また--shuffleオプションを追加し、重みをシャッフルします。シャッフルしないとマージ後のLoRAから元のLoRAを取り出せるため、コピー機学習などの場合には学習元データが明らかになります。ご注意ください。
|
||||
|
||||
--save_toオプションにマージ後のLoRAモデルの保存先を指定します(.ckptまたは.safetensors、拡張子で自動判定)。
|
||||
|
||||
--modelsに学習したLoRAのモデルファイルを指定します。三つ以上も指定可能です。
|
||||
|
||||
--ratiosにそれぞれのモデルの比率(どのくらい重みを元モデルに反映するか)を0~1.0の数値で指定します。二つのモデルを一対一でマージす場合は、「0.5 0.5」になります。「1.0 1.0」では合計の重みが大きくなりすぎて、恐らく結果はあまり望ましくないものになると思われます。
|
||||
|
||||
v1で学習したLoRAとv2で学習したLoRA、rank(次元数)や``alpha``の異なるLoRAはマージできません。U-NetだけのLoRAとU-Net+Text EncoderのLoRAはマージできるはずですが、結果は未知数です。
|
||||
--ratiosにそれぞれのモデルの比率(どのくらい重みを元モデルに反映するか)を0~1.0の数値で指定します。二つのモデルを一対一でマージする場合は、「0.5 0.5」になります。「1.0 1.0」では合計の重みが大きくなりすぎて、恐らく結果はあまり望ましくないものになると思われます。
|
||||
|
||||
v1で学習したLoRAとv2で学習したLoRA、rank(次元数)の異なるLoRAはマージできません。U-NetだけのLoRAとU-Net+Text EncoderのLoRAはマージできるはずですが、結果は未知数です。
|
||||
|
||||
### その他のオプション
|
||||
|
||||
@@ -304,6 +315,7 @@ v1で学習したLoRAとv2で学習したLoRA、rank(次元数)や``alpha``
|
||||
* save_precision
|
||||
* モデル保存時の精度をfloat、fp16、bf16から指定できます。省略時はprecisionと同じ精度になります。
|
||||
|
||||
他にもいくつかのオプションがありますので、--helpで確認してください。
|
||||
|
||||
## 複数のrankが異なるLoRAのモデルをマージする
|
||||
|
||||
468
docs/train_network_README-zh.md
Normal file
468
docs/train_network_README-zh.md
Normal file
@@ -0,0 +1,468 @@
|
||||
# 关于LoRA的学习。
|
||||
|
||||
[LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685)(arxiv)、[LoRA](https://github.com/microsoft/LoRA)(github)这是应用于Stable Diffusion“稳定扩散”的内容。
|
||||
|
||||
[cloneofsimo先生的代码仓库](https://github.com/cloneofsimo/lora) 我们非常感謝您提供的参考。非常感謝。
|
||||
|
||||
通常情況下,LoRA只适用于Linear和Kernel大小为1x1的Conv2d,但也可以將其擴展到Kernel大小为3x3的Conv2d。
|
||||
|
||||
Conv2d 3x3的扩展最初是由 [cloneofsimo先生的代码仓库](https://github.com/cloneofsimo/lora)
|
||||
而KohakuBlueleaf先生在[LoCon](https://github.com/KohakuBlueleaf/LoCon)中揭示了其有效性。我们深深地感谢KohakuBlueleaf先生。
|
||||
|
||||
看起来即使在8GB VRAM上也可以勉强运行。
|
||||
|
||||
请同时查看关于[学习的通用文档](./train_README-zh.md)。
|
||||
# 可学习的LoRA 类型
|
||||
|
||||
支持以下两种类型。以下是本仓库中自定义的名称。
|
||||
|
||||
1. __LoRA-LierLa__:(用于 __Li__ n __e__ a __r__ __La__ yers 的 LoRA,读作 "Liela")
|
||||
|
||||
适用于 Linear 和卷积层 Conv2d 的 1x1 Kernel 的 LoRA
|
||||
|
||||
2. __LoRA-C3Lier__:(用于具有 3x3 Kernel 的卷积层和 __Li__ n __e__ a __r__ 层的 LoRA,读作 "Seria")
|
||||
|
||||
除了第一种类型外,还适用于 3x3 Kernel 的 Conv2d 的 LoRA
|
||||
|
||||
与 LoRA-LierLa 相比,LoRA-C3Lier 可能会获得更高的准确性,因为它适用于更多的层。
|
||||
|
||||
在训练时,也可以使用 __DyLoRA__(将在后面介绍)。
|
||||
|
||||
## 请注意与所学模型相关的事项。
|
||||
|
||||
LoRA-LierLa可以用于AUTOMATIC1111先生的Web UI LoRA功能。
|
||||
|
||||
要使用LoRA-C3Liar并在Web UI中生成,请使用此处的[WebUI用extension](https://github.com/kohya-ss/sd-webui-additional-networks)。
|
||||
|
||||
在此存储库的脚本中,您还可以预先将经过训练的LoRA模型合并到Stable Diffusion模型中。
|
||||
|
||||
请注意,与cloneofsimo先生的存储库以及d8ahazard先生的[Stable-Diffusion-WebUI的Dreambooth扩展](https://github.com/d8ahazard/sd_dreambooth_extension)不兼容,因为它们进行了一些功能扩展(如下文所述)。
|
||||
|
||||
# 学习步骤
|
||||
|
||||
请先参考此存储库的README文件并进行环境设置。
|
||||
|
||||
## 准备数据
|
||||
|
||||
请参考 [关于准备学习数据](./train_README-zh.md)。
|
||||
|
||||
## 网络训练
|
||||
|
||||
使用`train_network.py`。
|
||||
|
||||
在`train_network.py`中,使用`--network_module`选项指定要训练的模块名称。对于LoRA模块,它应该是`network.lora`,请指定它。
|
||||
|
||||
请注意,学习率应该比通常的DreamBooth或fine tuning要高,建议指定为`1e-4`至`1e-3`左右。
|
||||
|
||||
以下是命令行示例。
|
||||
|
||||
```
|
||||
accelerate launch --num_cpu_threads_per_process 1 train_network.py
|
||||
--pretrained_model_name_or_path=<.ckpt或.safetensord或Diffusers版模型目录>
|
||||
--dataset_config=<数据集配置的.toml文件>
|
||||
--output_dir=<训练过程中的模型输出文件夹>
|
||||
--output_name=<训练模型输出时的文件名>
|
||||
--save_model_as=safetensors
|
||||
--prior_loss_weight=1.0
|
||||
--max_train_steps=400
|
||||
--learning_rate=1e-4
|
||||
--optimizer_type="AdamW8bit"
|
||||
--xformers
|
||||
--mixed_precision="fp16"
|
||||
--cache_latents
|
||||
--gradient_checkpointing
|
||||
--save_every_n_epochs=1
|
||||
--network_module=networks.lora
|
||||
```
|
||||
|
||||
在这个命令行中,LoRA-LierLa将会被训练。
|
||||
|
||||
LoRA的模型将会被保存在通过`--output_dir`选项指定的文件夹中。关于其他选项和优化器等,请参阅[学习的通用文档](./train_README-zh.md)中的“常用选项”。
|
||||
|
||||
此外,还可以指定以下选项:
|
||||
|
||||
* `--network_dim`
|
||||
* 指定LoRA的RANK(例如:`--network_dim=4`)。默认值为4。数值越大表示表现力越强,但需要更多的内存和时间来训练。而且不要盲目增加此数值。
|
||||
* `--network_alpha`
|
||||
* 指定用于防止下溢并稳定训练的alpha值。默认值为1。如果与`network_dim`指定相同的值,则将获得与以前版本相同的行为。
|
||||
* `--persistent_data_loader_workers`
|
||||
* 在Windows环境中指定可大幅缩短epoch之间的等待时间。
|
||||
* `--max_data_loader_n_workers`
|
||||
* 指定数据读取进程的数量。进程数越多,数据读取速度越快,可以更有效地利用GPU,但会占用主存。默认值为“`8`或`CPU同步执行线程数-1`的最小值”,因此如果主存不足或GPU使用率超过90%,则应将这些数字降低到约`2`或`1`。
|
||||
* `--network_weights`
|
||||
* 在训练之前读取预训练的LoRA权重,并在此基础上进行进一步的训练。
|
||||
* `--network_train_unet_only`
|
||||
* 仅启用与U-Net相关的LoRA模块。在类似fine tuning的学习中指定此选项可能会很有用。
|
||||
* `--network_train_text_encoder_only`
|
||||
* 仅启用与Text Encoder相关的LoRA模块。可能会期望Textual Inversion效果。
|
||||
* `--unet_lr`
|
||||
* 当在U-Net相关的LoRA模块中使用与常规学习率(由`--learning_rate`选项指定)不同的学习率时,应指定此选项。
|
||||
* `--text_encoder_lr`
|
||||
* 当在Text Encoder相关的LoRA模块中使用与常规学习率(由`--learning_rate`选项指定)不同的学习率时,应指定此选项。可能最好将Text Encoder的学习率稍微降低(例如5e-5)。
|
||||
* `--network_args`
|
||||
* 可以指定多个参数。将在下面详细说明。
|
||||
* `--alpha_mask`
|
||||
* 使用图像的 Alpha 值作为遮罩。这在学习透明图像时使用。[PR #1223](https://github.com/kohya-ss/sd-scripts/pull/1223)
|
||||
|
||||
当未指定`--network_train_unet_only`和`--network_train_text_encoder_only`时(默认情况),将启用Text Encoder和U-Net的两个LoRA模块。
|
||||
|
||||
# 其他的学习方法
|
||||
|
||||
## 学习 LoRA-C3Lier
|
||||
|
||||
请使用以下方式
|
||||
|
||||
```
|
||||
--network_args "conv_dim=4"
|
||||
```
|
||||
|
||||
DyLoRA是在这篇论文中提出的[DyLoRA: Parameter Efficient Tuning of Pre-trained Models using Dynamic Search-Free Low-Rank Adaptation](https://arxiv.org/abs/2210.07558),
|
||||
[其官方实现可在这里找到](https://github.com/huawei-noah/KD-NLP/tree/main/DyLoRA)。
|
||||
|
||||
根据论文,LoRA的rank并不是越高越好,而是需要根据模型、数据集、任务等因素来寻找合适的rank。使用DyLoRA,可以同时在指定的维度(rank)下学习多种rank的LoRA,从而省去了寻找最佳rank的麻烦。
|
||||
|
||||
本存储库的实现基于官方实现进行了自定义扩展(因此可能存在缺陷)。
|
||||
|
||||
### 本存储库DyLoRA的特点
|
||||
|
||||
DyLoRA训练后的模型文件与LoRA兼容。此外,可以从模型文件中提取多个低于指定维度(rank)的LoRA。
|
||||
|
||||
DyLoRA-LierLa和DyLoRA-C3Lier均可训练。
|
||||
|
||||
### 使用DyLoRA进行训练
|
||||
|
||||
请指定与DyLoRA相对应的`network.dylora`,例如 `--network_module=networks.dylora`。
|
||||
|
||||
此外,通过 `--network_args` 指定例如`--network_args "unit=4"`的参数。`unit`是划分rank的单位。例如,可以指定为`--network_dim=16 --network_args "unit=4"`。请将`unit`视为可以被`network_dim`整除的值(`network_dim`是`unit`的倍数)。
|
||||
|
||||
如果未指定`unit`,则默认为`unit=1`。
|
||||
|
||||
以下是示例说明。
|
||||
|
||||
```
|
||||
--network_module=networks.dylora --network_dim=16 --network_args "unit=4"
|
||||
|
||||
--network_module=networks.dylora --network_dim=32 --network_alpha=16 --network_args "unit=4"
|
||||
```
|
||||
|
||||
对于DyLoRA-C3Lier,需要在 `--network_args` 中指定 `conv_dim`,例如 `conv_dim=4`。与普通的LoRA不同,`conv_dim`必须与`network_dim`具有相同的值。以下是一个示例描述:
|
||||
|
||||
```
|
||||
--network_module=networks.dylora --network_dim=16 --network_args "conv_dim=16" "unit=4"
|
||||
|
||||
--network_module=networks.dylora --network_dim=32 --network_alpha=16 --network_args "conv_dim=32" "conv_alpha=16" "unit=8"
|
||||
```
|
||||
|
||||
例如,当使用dim=16、unit=4(如下所述)进行学习时,可以学习和提取4个rank的LoRA,即4、8、12和16。通过在每个提取的模型中生成图像并进行比较,可以选择最佳rank的LoRA。
|
||||
|
||||
其他选项与普通的LoRA相同。
|
||||
|
||||
*`unit`是本存储库的独有扩展,在DyLoRA中,由于预计相比同维度(rank)的普通LoRA,学习时间更长,因此将分割单位增加。
|
||||
|
||||
### 从DyLoRA模型中提取LoRA模型
|
||||
|
||||
请使用`networks`文件夹中的`extract_lora_from_dylora.py`。指定`unit`单位后,从DyLoRA模型中提取LoRA模型。
|
||||
|
||||
例如,命令行如下:
|
||||
|
||||
```powershell
|
||||
python networks\extract_lora_from_dylora.py --model "foldername/dylora-model.safetensors" --save_to "foldername/dylora-model-split.safetensors" --unit 4
|
||||
```
|
||||
|
||||
`--model` 参数用于指定DyLoRA模型文件。`--save_to` 参数用于指定要保存提取的模型的文件名(rank值将附加到文件名中)。`--unit` 参数用于指定DyLoRA训练时的`unit`。
|
||||
|
||||
## 分层学习率
|
||||
|
||||
请参阅PR#355了解详细信息。
|
||||
|
||||
您可以指定完整模型的25个块的权重。虽然第一个块没有对应的LoRA,但为了与分层LoRA应用等的兼容性,将其设为25个。此外,如果不扩展到conv2d3x3,则某些块中可能不存在LoRA,但为了统一描述,请始终指定25个值。
|
||||
|
||||
请在 `--network_args` 中指定以下参数。
|
||||
|
||||
- `down_lr_weight`:指定U-Net down blocks的学习率权重。可以指定以下内容:
|
||||
- 每个块的权重:指定12个数字,例如`"down_lr_weight=0,0,0,0,0,0,1,1,1,1,1,1"`
|
||||
- 从预设中指定:例如`"down_lr_weight=sine"`(使用正弦曲线指定权重)。可以指定sine、cosine、linear、reverse_linear、zeros。另外,添加 `+数字` 时,可以将指定的数字加上(变为0.25〜1.25)。
|
||||
- `mid_lr_weight`:指定U-Net mid block的学习率权重。只需指定一个数字,例如 `"mid_lr_weight=0.5"`。
|
||||
- `up_lr_weight`:指定U-Net up blocks的学习率权重。与down_lr_weight相同。
|
||||
- 省略指定的部分将被视为1.0。另外,如果将权重设为0,则不会创建该块的LoRA模块。
|
||||
- `block_lr_zero_threshold`:如果权重小于此值,则不会创建LoRA模块。默认值为0。
|
||||
|
||||
### 分层学习率命令行指定示例:
|
||||
|
||||
|
||||
```powershell
|
||||
--network_args "down_lr_weight=0.5,0.5,0.5,0.5,1.0,1.0,1.0,1.0,1.5,1.5,1.5,1.5" "mid_lr_weight=2.0" "up_lr_weight=1.5,1.5,1.5,1.5,1.0,1.0,1.0,1.0,0.5,0.5,0.5,0.5"
|
||||
|
||||
--network_args "block_lr_zero_threshold=0.1" "down_lr_weight=sine+.5" "mid_lr_weight=1.5" "up_lr_weight=cosine+.5"
|
||||
```
|
||||
|
||||
### Hierarchical Learning Rate指定的toml文件示例:
|
||||
|
||||
```toml
|
||||
network_args = [ "down_lr_weight=0.5,0.5,0.5,0.5,1.0,1.0,1.0,1.0,1.5,1.5,1.5,1.5", "mid_lr_weight=2.0", "up_lr_weight=1.5,1.5,1.5,1.5,1.0,1.0,1.0,1.0,0.5,0.5,0.5,0.5",]
|
||||
|
||||
network_args = [ "block_lr_zero_threshold=0.1", "down_lr_weight=sine+.5", "mid_lr_weight=1.5", "up_lr_weight=cosine+.5", ]
|
||||
```
|
||||
|
||||
## 层次结构维度(rank)
|
||||
|
||||
您可以指定完整模型的25个块的维度(rank)。与分层学习率一样,某些块可能不存在LoRA,但请始终指定25个值。
|
||||
|
||||
请在 `--network_args` 中指定以下参数:
|
||||
|
||||
- `block_dims`:指定每个块的维度(rank)。指定25个数字,例如 `"block_dims=2,2,2,2,4,4,4,4,6,6,6,6,8,6,6,6,6,4,4,4,4,2,2,2,2"`。
|
||||
- `block_alphas`:指定每个块的alpha。与block_dims一样,指定25个数字。如果省略,将使用network_alpha的值。
|
||||
- `conv_block_dims`:将LoRA扩展到Conv2d 3x3,并指定每个块的维度(rank)。
|
||||
- `conv_block_alphas`:在将LoRA扩展到Conv2d 3x3时指定每个块的alpha。如果省略,将使用conv_alpha的值。
|
||||
|
||||
### 层次结构维度(rank)命令行指定示例:
|
||||
|
||||
|
||||
```powershell
|
||||
--network_args "block_dims=2,4,4,4,8,8,8,8,12,12,12,12,16,12,12,12,12,8,8,8,8,4,4,4,2"
|
||||
|
||||
--network_args "block_dims=2,4,4,4,8,8,8,8,12,12,12,12,16,12,12,12,12,8,8,8,8,4,4,4,2" "conv_block_dims=2,2,2,2,4,4,4,4,6,6,6,6,8,6,6,6,6,4,4,4,4,2,2,2,2"
|
||||
|
||||
--network_args "block_dims=2,4,4,4,8,8,8,8,12,12,12,12,16,12,12,12,12,8,8,8,8,4,4,4,2" "block_alphas=2,2,2,2,4,4,4,4,6,6,6,6,8,6,6,6,6,4,4,4,4,2,2,2,2"
|
||||
```
|
||||
|
||||
### 层级别dim(rank) toml文件指定示例:
|
||||
|
||||
```toml
|
||||
network_args = [ "block_dims=2,4,4,4,8,8,8,8,12,12,12,12,16,12,12,12,12,8,8,8,8,4,4,4,2",]
|
||||
|
||||
network_args = [ "block_dims=2,4,4,4,8,8,8,8,12,12,12,12,16,12,12,12,12,8,8,8,8,4,4,4,2", "block_alphas=2,2,2,2,4,4,4,4,6,6,6,6,8,6,6,6,6,4,4,4,4,2,2,2,2",]
|
||||
```
|
||||
|
||||
# Other scripts
|
||||
这些是与LoRA相关的脚本,如合并脚本等。
|
||||
|
||||
关于合并脚本
|
||||
您可以使用merge_lora.py脚本将LoRA的训练结果合并到稳定扩散模型中,也可以将多个LoRA模型合并。
|
||||
|
||||
合并到稳定扩散模型中的LoRA模型
|
||||
合并后的模型可以像常规的稳定扩散ckpt一样使用。例如,以下是一个命令行示例:
|
||||
|
||||
```
|
||||
python networks\merge_lora.py --sd_model ..\model\model.ckpt
|
||||
--save_to ..\lora_train1\model-char1-merged.safetensors
|
||||
--models ..\lora_train1\last.safetensors --ratios 0.8
|
||||
```
|
||||
|
||||
请使用 Stable Diffusion v2.x 模型进行训练并进行合并时,需要指定--v2选项。
|
||||
|
||||
使用--sd_model选项指定要合并的 Stable Diffusion 模型文件(仅支持 .ckpt 或 .safetensors 格式,目前不支持 Diffusers)。
|
||||
|
||||
使用--save_to选项指定合并后模型的保存路径(根据扩展名自动判断为 .ckpt 或 .safetensors)。
|
||||
|
||||
使用--models选项指定已训练的 LoRA 模型文件,也可以指定多个,然后按顺序进行合并。
|
||||
|
||||
使用--ratios选项以0~1.0的数字指定每个模型的应用率(将多大比例的权重反映到原始模型中)。例如,在接近过度拟合的情况下,降低应用率可能会使结果更好。请指定与模型数量相同的比率。
|
||||
|
||||
当指定多个模型时,格式如下:
|
||||
|
||||
|
||||
```
|
||||
python networks\merge_lora.py --sd_model ..\model\model.ckpt
|
||||
--save_to ..\lora_train1\model-char1-merged.safetensors
|
||||
--models ..\lora_train1\last.safetensors ..\lora_train2\last.safetensors --ratios 0.8 0.5
|
||||
```
|
||||
|
||||
### 将多个LoRA模型合并
|
||||
|
||||
将多个LoRA模型逐个应用于SD模型与将多个LoRA模型合并后再应用于SD模型之间,由于计算顺序的不同,会得到微妙不同的结果。
|
||||
|
||||
例如,下面是一个命令行示例:
|
||||
|
||||
```
|
||||
python networks\merge_lora.py
|
||||
--save_to ..\lora_train1\model-char1-style1-merged.safetensors
|
||||
--models ..\lora_train1\last.safetensors ..\lora_train2\last.safetensors --ratios 0.6 0.4
|
||||
```
|
||||
|
||||
--sd_model选项不需要指定。
|
||||
|
||||
通过--save_to选项指定合并后的LoRA模型的保存位置(.ckpt或.safetensors,根据扩展名自动识别)。
|
||||
|
||||
通过--models选项指定学习的LoRA模型文件。可以指定三个或更多。
|
||||
|
||||
通过--ratios选项以0~1.0的数字指定每个模型的比率(反映多少权重来自原始模型)。如果将两个模型一对一合并,则比率将是“0.5 0.5”。如果比率为“1.0 1.0”,则总重量将过大,可能会产生不理想的结果。
|
||||
|
||||
在v1和v2中学习的LoRA,以及rank(维数)或“alpha”不同的LoRA不能合并。仅包含U-Net的LoRA和包含U-Net+文本编码器的LoRA可以合并,但结果未知。
|
||||
|
||||
### 其他选项
|
||||
|
||||
* 精度
|
||||
* 可以从float、fp16或bf16中选择合并计算时的精度。默认为float以保证精度。如果想减少内存使用量,请指定fp16/bf16。
|
||||
* save_precision
|
||||
* 可以从float、fp16或bf16中选择在保存模型时的精度。默认与精度相同。
|
||||
|
||||
## 合并多个维度不同的LoRA模型
|
||||
|
||||
将多个LoRA近似为一个LoRA(无法完全复制)。使用'svd_merge_lora.py'。例如,以下是命令行的示例。
|
||||
```
|
||||
python networks\svd_merge_lora.py
|
||||
--save_to ..\lora_train1\model-char1-style1-merged.safetensors
|
||||
--models ..\lora_train1\last.safetensors ..\lora_train2\last.safetensors
|
||||
--ratios 0.6 0.4 --new_rank 32 --device cuda
|
||||
```
|
||||
`merge_lora.py`和主要选项相同。以下选项已添加:
|
||||
|
||||
- `--new_rank`
|
||||
- 指定要创建的LoRA rank。
|
||||
- `--new_conv_rank`
|
||||
- 指定要创建的Conv2d 3x3 LoRA的rank。如果省略,则与`new_rank`相同。
|
||||
- `--device`
|
||||
- 如果指定为`--device cuda`,则在GPU上执行计算。处理速度将更快。
|
||||
|
||||
## 在此存储库中生成图像的脚本中
|
||||
|
||||
请在`gen_img_diffusers.py`中添加`--network_module`和`--network_weights`选项。其含义与训练时相同。
|
||||
|
||||
通过`--network_mul`选项,可以指定0~1.0的数字来改变LoRA的应用率。
|
||||
|
||||
## 请参考以下示例,在Diffusers的pipeline中生成。
|
||||
|
||||
所需文件仅为networks/lora.py。请注意,该示例只能在Diffusers版本0.10.2中正常运行。
|
||||
|
||||
```python
|
||||
import torch
|
||||
from diffusers import StableDiffusionPipeline
|
||||
from networks.lora import LoRAModule, create_network_from_weights
|
||||
from safetensors.torch import load_file
|
||||
|
||||
# if the ckpt is CompVis based, convert it to Diffusers beforehand with tools/convert_diffusers20_original_sd.py. See --help for more details.
|
||||
|
||||
model_id_or_dir = r"model_id_on_hugging_face_or_dir"
|
||||
device = "cuda"
|
||||
|
||||
# create pipe
|
||||
print(f"creating pipe from {model_id_or_dir}...")
|
||||
pipe = StableDiffusionPipeline.from_pretrained(model_id_or_dir, revision="fp16", torch_dtype=torch.float16)
|
||||
pipe = pipe.to(device)
|
||||
vae = pipe.vae
|
||||
text_encoder = pipe.text_encoder
|
||||
unet = pipe.unet
|
||||
|
||||
# load lora networks
|
||||
print(f"loading lora networks...")
|
||||
|
||||
lora_path1 = r"lora1.safetensors"
|
||||
sd = load_file(lora_path1) # If the file is .ckpt, use torch.load instead.
|
||||
network1, sd = create_network_from_weights(0.5, None, vae, text_encoder,unet, sd)
|
||||
network1.apply_to(text_encoder, unet)
|
||||
network1.load_state_dict(sd)
|
||||
network1.to(device, dtype=torch.float16)
|
||||
|
||||
# # You can merge weights instead of apply_to+load_state_dict. network.set_multiplier does not work
|
||||
# network.merge_to(text_encoder, unet, sd)
|
||||
|
||||
lora_path2 = r"lora2.safetensors"
|
||||
sd = load_file(lora_path2)
|
||||
network2, sd = create_network_from_weights(0.7, None, vae, text_encoder,unet, sd)
|
||||
network2.apply_to(text_encoder, unet)
|
||||
network2.load_state_dict(sd)
|
||||
network2.to(device, dtype=torch.float16)
|
||||
|
||||
lora_path3 = r"lora3.safetensors"
|
||||
sd = load_file(lora_path3)
|
||||
network3, sd = create_network_from_weights(0.5, None, vae, text_encoder,unet, sd)
|
||||
network3.apply_to(text_encoder, unet)
|
||||
network3.load_state_dict(sd)
|
||||
network3.to(device, dtype=torch.float16)
|
||||
|
||||
# prompts
|
||||
prompt = "masterpiece, best quality, 1girl, in white shirt, looking at viewer"
|
||||
negative_prompt = "bad quality, worst quality, bad anatomy, bad hands"
|
||||
|
||||
# exec pipe
|
||||
print("generating image...")
|
||||
with torch.autocast("cuda"):
|
||||
image = pipe(prompt, guidance_scale=7.5, negative_prompt=negative_prompt).images[0]
|
||||
|
||||
# if not merged, you can use set_multiplier
|
||||
# network1.set_multiplier(0.8)
|
||||
# and generate image again...
|
||||
|
||||
# save image
|
||||
image.save(r"by_diffusers..png")
|
||||
```
|
||||
|
||||
## 从两个模型的差异中创建LoRA模型。
|
||||
|
||||
[参考讨论链接](https://github.com/cloneofsimo/lora/discussions/56)這是參考實現的結果。數學公式沒有改變(我並不完全理解,但似乎使用奇異值分解進行了近似)。
|
||||
|
||||
将两个模型(例如微调原始模型和微调后的模型)的差异近似为LoRA。
|
||||
|
||||
### 脚本执行方法
|
||||
|
||||
请按以下方式指定。
|
||||
|
||||
```
|
||||
python networks\extract_lora_from_models.py --model_org base-model.ckpt
|
||||
--model_tuned fine-tuned-model.ckpt
|
||||
--save_to lora-weights.safetensors --dim 4
|
||||
```
|
||||
|
||||
--model_org 选项指定原始的Stable Diffusion模型。如果要应用创建的LoRA模型,则需要指定该模型并将其应用。可以指定.ckpt或.safetensors文件。
|
||||
|
||||
--model_tuned 选项指定要提取差分的目标Stable Diffusion模型。例如,可以指定经过Fine Tuning或DreamBooth后的模型。可以指定.ckpt或.safetensors文件。
|
||||
|
||||
--save_to 指定LoRA模型的保存路径。--dim指定LoRA的维数。
|
||||
|
||||
生成的LoRA模型可以像已训练的LoRA模型一样使用。
|
||||
|
||||
当两个模型的文本编码器相同时,LoRA将成为仅包含U-Net的LoRA。
|
||||
|
||||
### 其他选项
|
||||
|
||||
- `--v2`
|
||||
- 如果使用v2.x的稳定扩散模型,请指定此选项。
|
||||
- `--device`
|
||||
- 指定为 ``--device cuda`` 可在GPU上执行计算。这会使处理速度更快(即使在CPU上也不会太慢,大约快几倍)。
|
||||
- `--save_precision`
|
||||
- 指定LoRA的保存格式为“float”、“fp16”、“bf16”。如果省略,将使用float。
|
||||
- `--conv_dim`
|
||||
- 指定后,将扩展LoRA的应用范围到Conv2d 3x3。指定Conv2d 3x3的rank。
|
||||
-
|
||||
## 图像大小调整脚本
|
||||
|
||||
(稍后将整理文件,但现在先在这里写下说明。)
|
||||
|
||||
在 Aspect Ratio Bucketing 的功能扩展中,现在可以将小图像直接用作教师数据,而无需进行放大。我收到了一个用于前处理的脚本,其中包括将原始教师图像缩小的图像添加到教师数据中可以提高准确性的报告。我整理了这个脚本并加入了感谢 bmaltais 先生。
|
||||
|
||||
### 执行脚本的方法如下。
|
||||
原始图像以及调整大小后的图像将保存到转换目标文件夹中。调整大小后的图像将在文件名中添加“+512x512”之类的调整后的分辨率(与图像大小不同)。小于调整大小后分辨率的图像将不会被放大。
|
||||
|
||||
```
|
||||
python tools\resize_images_to_resolution.py --max_resolution 512x512,384x384,256x256 --save_as_png
|
||||
--copy_associated_files 源图像文件夹目标文件夹
|
||||
```
|
||||
|
||||
在元画像文件夹中的图像文件将被调整大小以达到指定的分辨率(可以指定多个),并保存到目标文件夹中。除图像外的文件将被保留为原样。
|
||||
|
||||
请使用“--max_resolution”选项指定调整大小后的大小,使其达到指定的面积大小。如果指定多个,则会在每个分辨率上进行调整大小。例如,“512x512,384x384,256x256”将使目标文件夹中的图像变为原始大小和调整大小后的大小×3共计4张图像。
|
||||
|
||||
如果使用“--save_as_png”选项,则会以PNG格式保存。如果省略,则默认以JPEG格式(quality=100)保存。
|
||||
|
||||
如果使用“--copy_associated_files”选项,则会将与图像相同的文件名(例如标题等)的文件复制到调整大小后的图像文件的文件名相同的位置,但不包括扩展名。
|
||||
|
||||
### 其他选项
|
||||
|
||||
- divisible_by
|
||||
- 将图像中心裁剪到能够被该值整除的大小(分别是垂直和水平的大小),以便调整大小后的图像大小可以被该值整除。
|
||||
- interpolation
|
||||
- 指定缩小时的插值方法。可从``area、cubic、lanczos4``中选择,默认为``area``。
|
||||
|
||||
|
||||
# 追加信息
|
||||
|
||||
## 与cloneofsimo的代码库的区别
|
||||
|
||||
截至2022年12月25日,本代码库将LoRA应用扩展到了Text Encoder的MLP、U-Net的FFN以及Transformer的输入/输出投影中,从而增强了表现力。但是,内存使用量增加了,接近了8GB的限制。
|
||||
|
||||
此外,模块交换机制也完全不同。
|
||||
|
||||
## 关于未来的扩展
|
||||
|
||||
除了LoRA之外,我们还计划添加其他扩展,以支持更多的功能。
|
||||
88
docs/wd14_tagger_README-en.md
Normal file
88
docs/wd14_tagger_README-en.md
Normal file
@@ -0,0 +1,88 @@
|
||||
# Image Tagging using WD14Tagger
|
||||
|
||||
This document is based on the information from this github page (https://github.com/toriato/stable-diffusion-webui-wd14-tagger#mrsmilingwolfs-model-aka-waifu-diffusion-14-tagger).
|
||||
|
||||
Using onnx for inference is recommended. Please install onnx with the following command:
|
||||
|
||||
```powershell
|
||||
pip install onnx==1.15.0 onnxruntime-gpu==1.17.1
|
||||
```
|
||||
|
||||
The model weights will be automatically downloaded from Hugging Face.
|
||||
|
||||
# Usage
|
||||
|
||||
Run the script to perform tagging.
|
||||
|
||||
```powershell
|
||||
python finetune/tag_images_by_wd14_tagger.py --onnx --repo_id <model repo id> --batch_size <batch size> <training data folder>
|
||||
```
|
||||
|
||||
For example, if using the repository `SmilingWolf/wd-swinv2-tagger-v3` with a batch size of 4, and the training data is located in the parent folder `train_data`, it would be:
|
||||
|
||||
```powershell
|
||||
python tag_images_by_wd14_tagger.py --onnx --repo_id SmilingWolf/wd-swinv2-tagger-v3 --batch_size 4 ..\train_data
|
||||
```
|
||||
|
||||
On the first run, the model files will be automatically downloaded to the `wd14_tagger_model` folder (the folder can be changed with an option).
|
||||
|
||||
Tag files will be created in the same directory as the training data images, with the same filename and a `.txt` extension.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
## Example
|
||||
|
||||
To output in the Animagine XL 3.1 format, it would be as follows (enter on a single line in practice):
|
||||
|
||||
```
|
||||
python tag_images_by_wd14_tagger.py --onnx --repo_id SmilingWolf/wd-swinv2-tagger-v3
|
||||
--batch_size 4 --remove_underscore --undesired_tags "PUT,YOUR,UNDESIRED,TAGS" --recursive
|
||||
--use_rating_tags_as_last_tag --character_tags_first --character_tag_expand
|
||||
--always_first_tags "1girl,1boy" ..\train_data
|
||||
```
|
||||
|
||||
## Available Repository IDs
|
||||
|
||||
[SmilingWolf's V2 and V3 models](https://huggingface.co/SmilingWolf) are available for use. Specify them in the format like `SmilingWolf/wd-vit-tagger-v3`. The default when omitted is `SmilingWolf/wd-v1-4-convnext-tagger-v2`.
|
||||
|
||||
# Options
|
||||
|
||||
## General Options
|
||||
|
||||
- `--onnx`: Use ONNX for inference. If not specified, TensorFlow will be used. If using TensorFlow, please install TensorFlow separately.
|
||||
- `--batch_size`: Number of images to process at once. Default is 1. Adjust according to VRAM capacity.
|
||||
- `--caption_extension`: File extension for caption files. Default is `.txt`.
|
||||
- `--max_data_loader_n_workers`: Maximum number of workers for DataLoader. Specifying a value of 1 or more will use DataLoader to speed up image loading. If unspecified, DataLoader will not be used.
|
||||
- `--thresh`: Confidence threshold for outputting tags. Default is 0.35. Lowering the value will assign more tags but accuracy will decrease.
|
||||
- `--general_threshold`: Confidence threshold for general tags. If omitted, same as `--thresh`.
|
||||
- `--character_threshold`: Confidence threshold for character tags. If omitted, same as `--thresh`.
|
||||
- `--recursive`: If specified, subfolders within the specified folder will also be processed recursively.
|
||||
- `--append_tags`: Append tags to existing tag files.
|
||||
- `--frequency_tags`: Output tag frequencies.
|
||||
- `--debug`: Debug mode. Outputs debug information if specified.
|
||||
|
||||
## Model Download
|
||||
|
||||
- `--model_dir`: Folder to save model files. Default is `wd14_tagger_model`.
|
||||
- `--force_download`: Re-download model files if specified.
|
||||
|
||||
## Tag Editing
|
||||
|
||||
- `--remove_underscore`: Remove underscores from output tags.
|
||||
- `--undesired_tags`: Specify tags not to output. Multiple tags can be specified, separated by commas. For example, `black eyes,black hair`.
|
||||
- `--use_rating_tags`: Output rating tags at the beginning of the tags.
|
||||
- `--use_rating_tags_as_last_tag`: Add rating tags at the end of the tags.
|
||||
- `--character_tags_first`: Output character tags first.
|
||||
- `--character_tag_expand`: Expand character tag series names. For example, split the tag `chara_name_(series)` into `chara_name, series`.
|
||||
- `--always_first_tags`: Specify tags to always output first when a certain tag appears in an image. Multiple tags can be specified, separated by commas. For example, `1girl,1boy`.
|
||||
- `--caption_separator`: Separate tags with this string in the output file. Default is `, `.
|
||||
- `--tag_replacement`: Perform tag replacement. Specify in the format `tag1,tag2;tag3,tag4`. If using `,` and `;`, escape them with `\`. \
|
||||
For example, specify `aira tsubase,aira tsubase (uniform)` (when you want to train a specific costume), `aira tsubase,aira tsubase\, heir of shadows` (when the series name is not included in the tag).
|
||||
|
||||
When using `tag_replacement`, it is applied after `character_tag_expand`.
|
||||
|
||||
When specifying `remove_underscore`, specify `undesired_tags`, `always_first_tags`, and `tag_replacement` without including underscores.
|
||||
|
||||
When specifying `caption_separator`, separate `undesired_tags` and `always_first_tags` with `caption_separator`. Always separate `tag_replacement` with `,`.
|
||||
88
docs/wd14_tagger_README-ja.md
Normal file
88
docs/wd14_tagger_README-ja.md
Normal file
@@ -0,0 +1,88 @@
|
||||
# WD14Taggerによるタグ付け
|
||||
|
||||
こちらのgithubページ(https://github.com/toriato/stable-diffusion-webui-wd14-tagger#mrsmilingwolfs-model-aka-waifu-diffusion-14-tagger )の情報を参考にさせていただきました。
|
||||
|
||||
onnx を用いた推論を推奨します。以下のコマンドで onnx をインストールしてください。
|
||||
|
||||
```powershell
|
||||
pip install onnx==1.15.0 onnxruntime-gpu==1.17.1
|
||||
```
|
||||
|
||||
モデルの重みはHugging Faceから自動的にダウンロードしてきます。
|
||||
|
||||
# 使い方
|
||||
|
||||
スクリプトを実行してタグ付けを行います。
|
||||
```
|
||||
python fintune/tag_images_by_wd14_tagger.py --onnx --repo_id <モデルのrepo id> --batch_size <バッチサイズ> <教師データフォルダ>
|
||||
```
|
||||
|
||||
レポジトリに `SmilingWolf/wd-swinv2-tagger-v3` を使用し、バッチサイズを4にして、教師データを親フォルダの `train_data`に置いた場合、以下のようになります。
|
||||
|
||||
```
|
||||
python tag_images_by_wd14_tagger.py --onnx --repo_id SmilingWolf/wd-swinv2-tagger-v3 --batch_size 4 ..\train_data
|
||||
```
|
||||
|
||||
初回起動時にはモデルファイルが `wd14_tagger_model` フォルダに自動的にダウンロードされます(フォルダはオプションで変えられます)。
|
||||
|
||||
タグファイルが教師データ画像と同じディレクトリに、同じファイル名、拡張子.txtで作成されます。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
## 記述例
|
||||
|
||||
Animagine XL 3.1 方式で出力する場合、以下のようになります(実際には 1 行で入力してください)。
|
||||
|
||||
```
|
||||
python tag_images_by_wd14_tagger.py --onnx --repo_id SmilingWolf/wd-swinv2-tagger-v3
|
||||
--batch_size 4 --remove_underscore --undesired_tags "PUT,YOUR,UNDESIRED,TAGS" --recursive
|
||||
--use_rating_tags_as_last_tag --character_tags_first --character_tag_expand
|
||||
--always_first_tags "1girl,1boy" ..\train_data
|
||||
```
|
||||
|
||||
## 使用可能なリポジトリID
|
||||
|
||||
[SmilingWolf 氏の V2、V3 のモデル](https://huggingface.co/SmilingWolf)が使用可能です。`SmilingWolf/wd-vit-tagger-v3` のように指定してください。省略時のデフォルトは `SmilingWolf/wd-v1-4-convnext-tagger-v2` です。
|
||||
|
||||
# オプション
|
||||
|
||||
## 一般オプション
|
||||
|
||||
- `--onnx` : ONNX を使用して推論します。指定しない場合は TensorFlow を使用します。TensorFlow 使用時は別途 TensorFlow をインストールしてください。
|
||||
- `--batch_size` : 一度に処理する画像の数。デフォルトは1です。VRAMの容量に応じて増減してください。
|
||||
- `--caption_extension` : キャプションファイルの拡張子。デフォルトは `.txt` です。
|
||||
- `--max_data_loader_n_workers` : DataLoader の最大ワーカー数です。このオプションに 1 以上の数値を指定すると、DataLoader を用いて画像読み込みを高速化します。未指定時は DataLoader を用いません。
|
||||
- `--thresh` : 出力するタグの信頼度の閾値。デフォルトは0.35です。値を下げるとより多くのタグが付与されますが、精度は下がります。
|
||||
- `--general_threshold` : 一般タグの信頼度の閾値。省略時は `--thresh` と同じです。
|
||||
- `--character_threshold` : キャラクタータグの信頼度の閾値。省略時は `--thresh` と同じです。
|
||||
- `--recursive` : 指定すると、指定したフォルダ内のサブフォルダも再帰的に処理します。
|
||||
- `--append_tags` : 既存のタグファイルにタグを追加します。
|
||||
- `--frequency_tags` : タグの頻度を出力します。
|
||||
- `--debug` : デバッグモード。指定するとデバッグ情報を出力します。
|
||||
|
||||
## モデルのダウンロード
|
||||
|
||||
- `--model_dir` : モデルファイルの保存先フォルダ。デフォルトは `wd14_tagger_model` です。
|
||||
- `--force_download` : 指定するとモデルファイルを再ダウンロードします。
|
||||
|
||||
## タグ編集関連
|
||||
|
||||
- `--remove_underscore` : 出力するタグからアンダースコアを削除します。
|
||||
- `--undesired_tags` : 出力しないタグを指定します。カンマ区切りで複数指定できます。たとえば `black eyes,black hair` のように指定します。
|
||||
- `--use_rating_tags` : タグの最初にレーティングタグを出力します。
|
||||
- `--use_rating_tags_as_last_tag` : タグの最後にレーティングタグを追加します。
|
||||
- `--character_tags_first` : キャラクタータグを最初に出力します。
|
||||
- `--character_tag_expand` : キャラクタータグのシリーズ名を展開します。たとえば `chara_name_(series)` のタグを `chara_name, series` に分割します。
|
||||
- `--always_first_tags` : あるタグが画像に出力されたとき、そのタグを最初に出力するタグを指定します。カンマ区切りで複数指定できます。たとえば `1girl,1boy` のように指定します。
|
||||
- `--caption_separator` : 出力するファイルでタグをこの文字列で区切ります。デフォルトは `, ` です。
|
||||
- `--tag_replacement` : タグの置換を行います。`tag1,tag2;tag3,tag4` のように指定します。`,` および `;` を使う場合は `\` でエスケープしてください。\
|
||||
たとえば `aira tsubase,aira tsubase (uniform)` (特定の衣装を学習させたいとき)、`aira tsubase,aira tsubase\, heir of shadows` (シリーズ名がタグに含まれないとき)のように指定します。
|
||||
|
||||
`tag_replacement` は `character_tag_expand` の後に適用されます。
|
||||
|
||||
`remove_underscore` 指定時は、`undesired_tags`、`always_first_tags`、`tag_replacement` はアンダースコアを含めずに指定してください。
|
||||
|
||||
`caption_separator` 指定時は、`undesired_tags`、`always_first_tags` は `caption_separator` で区切ってください。`tag_replacement` は必ず `,` で区切ってください。
|
||||
|
||||
364
fine_tune.py
364
fine_tune.py
@@ -2,18 +2,29 @@
|
||||
# XXX dropped option: hypernetwork training
|
||||
|
||||
import argparse
|
||||
import gc
|
||||
import math
|
||||
import os
|
||||
import toml
|
||||
from multiprocessing import Value
|
||||
import toml
|
||||
|
||||
from tqdm import tqdm
|
||||
|
||||
import torch
|
||||
from library import deepspeed_utils
|
||||
from library.device_utils import init_ipex, clean_memory_on_device
|
||||
|
||||
init_ipex()
|
||||
|
||||
from accelerate.utils import set_seed
|
||||
import diffusers
|
||||
from diffusers import DDPMScheduler
|
||||
|
||||
from library.utils import setup_logging, add_logging_arguments
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
import library.train_util as train_util
|
||||
import library.config_util as config_util
|
||||
from library.config_util import (
|
||||
@@ -21,12 +32,20 @@ from library.config_util import (
|
||||
BlueprintGenerator,
|
||||
)
|
||||
import library.custom_train_functions as custom_train_functions
|
||||
from library.custom_train_functions import apply_snr_weight, get_weighted_text_embeddings
|
||||
from library.custom_train_functions import (
|
||||
apply_snr_weight,
|
||||
get_weighted_text_embeddings,
|
||||
prepare_scheduler_for_custom_training,
|
||||
scale_v_prediction_loss_like_noise_prediction,
|
||||
apply_debiased_estimation,
|
||||
)
|
||||
|
||||
|
||||
def train(args):
|
||||
train_util.verify_training_args(args)
|
||||
train_util.prepare_dataset_args(args, True)
|
||||
deepspeed_utils.prepare_deepspeed_args(args)
|
||||
setup_logging(args, reset=True)
|
||||
|
||||
cache_latents = args.cache_latents
|
||||
|
||||
@@ -35,44 +54,50 @@ def train(args):
|
||||
|
||||
tokenizer = train_util.load_tokenizer(args)
|
||||
|
||||
blueprint_generator = BlueprintGenerator(ConfigSanitizer(False, True, True))
|
||||
if args.dataset_config is not None:
|
||||
print(f"Load dataset config from {args.dataset_config}")
|
||||
user_config = config_util.load_user_config(args.dataset_config)
|
||||
ignored = ["train_data_dir", "in_json"]
|
||||
if any(getattr(args, attr) is not None for attr in ignored):
|
||||
print(
|
||||
"ignore following options because config file is found: {0} / 設定ファイルが利用されるため以下のオプションは無視されます: {0}".format(
|
||||
", ".join(ignored)
|
||||
# データセットを準備する
|
||||
if args.dataset_class is None:
|
||||
blueprint_generator = BlueprintGenerator(ConfigSanitizer(False, True, False, True))
|
||||
if args.dataset_config is not None:
|
||||
logger.info(f"Load dataset config from {args.dataset_config}")
|
||||
user_config = config_util.load_user_config(args.dataset_config)
|
||||
ignored = ["train_data_dir", "in_json"]
|
||||
if any(getattr(args, attr) is not None for attr in ignored):
|
||||
logger.warning(
|
||||
"ignore following options because config file is found: {0} / 設定ファイルが利用されるため以下のオプションは無視されます: {0}".format(
|
||||
", ".join(ignored)
|
||||
)
|
||||
)
|
||||
)
|
||||
else:
|
||||
user_config = {
|
||||
"datasets": [
|
||||
{
|
||||
"subsets": [
|
||||
{
|
||||
"image_dir": args.train_data_dir,
|
||||
"metadata_file": args.in_json,
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
else:
|
||||
user_config = {
|
||||
"datasets": [
|
||||
{
|
||||
"subsets": [
|
||||
{
|
||||
"image_dir": args.train_data_dir,
|
||||
"metadata_file": args.in_json,
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
blueprint = blueprint_generator.generate(user_config, args, tokenizer=tokenizer)
|
||||
train_dataset_group = config_util.generate_dataset_group_by_blueprint(blueprint.dataset_group)
|
||||
blueprint = blueprint_generator.generate(user_config, args, tokenizer=tokenizer)
|
||||
train_dataset_group = config_util.generate_dataset_group_by_blueprint(blueprint.dataset_group)
|
||||
else:
|
||||
train_dataset_group = train_util.load_arbitrary_dataset(args, tokenizer)
|
||||
|
||||
current_epoch = Value("i", 0)
|
||||
current_step = Value("i", 0)
|
||||
ds_for_collater = train_dataset_group if args.max_data_loader_n_workers == 0 else None
|
||||
collater = train_util.collater_class(current_epoch, current_step, ds_for_collater)
|
||||
ds_for_collator = train_dataset_group if args.max_data_loader_n_workers == 0 else None
|
||||
collator = train_util.collator_class(current_epoch, current_step, ds_for_collator)
|
||||
|
||||
train_dataset_group.verify_bucket_reso_steps(64)
|
||||
|
||||
if args.debug_dataset:
|
||||
train_util.debug_dataset(train_dataset_group)
|
||||
return
|
||||
if len(train_dataset_group) == 0:
|
||||
print(
|
||||
logger.error(
|
||||
"No data found. Please verify the metadata file and train_data_dir option. / 画像がありません。メタデータおよびtrain_data_dirオプションを確認してください。"
|
||||
)
|
||||
return
|
||||
@@ -83,14 +108,15 @@ def train(args):
|
||||
), "when caching latents, either color_aug or random_crop cannot be used / latentをキャッシュするときはcolor_augとrandom_cropは使えません"
|
||||
|
||||
# acceleratorを準備する
|
||||
print("prepare accelerator")
|
||||
accelerator, unwrap_model = train_util.prepare_accelerator(args)
|
||||
logger.info("prepare accelerator")
|
||||
accelerator = train_util.prepare_accelerator(args)
|
||||
|
||||
# mixed precisionに対応した型を用意しておき適宜castする
|
||||
weight_dtype, save_dtype = train_util.prepare_dtype(args)
|
||||
vae_dtype = torch.float32 if args.no_half_vae else weight_dtype
|
||||
|
||||
# モデルを読み込む
|
||||
text_encoder, vae, unet, load_stable_diffusion_format = train_util.load_target_model(args, weight_dtype)
|
||||
text_encoder, vae, unet, load_stable_diffusion_format = train_util.load_target_model(args, weight_dtype, accelerator)
|
||||
|
||||
# verify load/save model formats
|
||||
if load_stable_diffusion_format:
|
||||
@@ -128,25 +154,23 @@ def train(args):
|
||||
|
||||
# モデルに xformers とか memory efficient attention を組み込む
|
||||
if args.diffusers_xformers:
|
||||
print("Use xformers by Diffusers")
|
||||
accelerator.print("Use xformers by Diffusers")
|
||||
set_diffusers_xformers_flag(unet, True)
|
||||
else:
|
||||
# Windows版のxformersはfloatで学習できないのでxformersを使わない設定も可能にしておく必要がある
|
||||
print("Disable Diffusers' xformers")
|
||||
accelerator.print("Disable Diffusers' xformers")
|
||||
set_diffusers_xformers_flag(unet, False)
|
||||
train_util.replace_unet_modules(unet, args.mem_eff_attn, args.xformers)
|
||||
train_util.replace_unet_modules(unet, args.mem_eff_attn, args.xformers, args.sdpa)
|
||||
|
||||
# 学習を準備する
|
||||
if cache_latents:
|
||||
vae.to(accelerator.device, dtype=weight_dtype)
|
||||
vae.to(accelerator.device, dtype=vae_dtype)
|
||||
vae.requires_grad_(False)
|
||||
vae.eval()
|
||||
with torch.no_grad():
|
||||
train_dataset_group.cache_latents(vae, args.vae_batch_size, args.cache_latents_to_disk, accelerator.is_main_process)
|
||||
vae.to("cpu")
|
||||
if torch.cuda.is_available():
|
||||
torch.cuda.empty_cache()
|
||||
gc.collect()
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
@@ -157,7 +181,7 @@ def train(args):
|
||||
training_models.append(unet)
|
||||
|
||||
if args.train_text_encoder:
|
||||
print("enable text encoder training")
|
||||
accelerator.print("enable text encoder training")
|
||||
if args.gradient_checkpointing:
|
||||
text_encoder.gradient_checkpointing_enable()
|
||||
training_models.append(text_encoder)
|
||||
@@ -173,27 +197,33 @@ def train(args):
|
||||
if not cache_latents:
|
||||
vae.requires_grad_(False)
|
||||
vae.eval()
|
||||
vae.to(accelerator.device, dtype=weight_dtype)
|
||||
vae.to(accelerator.device, dtype=vae_dtype)
|
||||
|
||||
for m in training_models:
|
||||
m.requires_grad_(True)
|
||||
params = []
|
||||
for m in training_models:
|
||||
params.extend(m.parameters())
|
||||
params_to_optimize = params
|
||||
|
||||
trainable_params = []
|
||||
if args.learning_rate_te is None or not args.train_text_encoder:
|
||||
for m in training_models:
|
||||
trainable_params.extend(m.parameters())
|
||||
else:
|
||||
trainable_params = [
|
||||
{"params": list(unet.parameters()), "lr": args.learning_rate},
|
||||
{"params": list(text_encoder.parameters()), "lr": args.learning_rate_te},
|
||||
]
|
||||
|
||||
# 学習に必要なクラスを準備する
|
||||
print("prepare optimizer, data loader etc.")
|
||||
_, _, optimizer = train_util.get_optimizer(args, trainable_params=params_to_optimize)
|
||||
accelerator.print("prepare optimizer, data loader etc.")
|
||||
_, _, optimizer = train_util.get_optimizer(args, trainable_params=trainable_params)
|
||||
|
||||
# dataloaderを準備する
|
||||
# DataLoaderのプロセス数:0はメインプロセスになる
|
||||
n_workers = min(args.max_data_loader_n_workers, os.cpu_count() - 1) # cpu_count-1 ただし最大で指定された数まで
|
||||
# DataLoaderのプロセス数:0 は persistent_workers が使えないので注意
|
||||
n_workers = min(args.max_data_loader_n_workers, os.cpu_count()) # cpu_count or max_data_loader_n_workers
|
||||
train_dataloader = torch.utils.data.DataLoader(
|
||||
train_dataset_group,
|
||||
batch_size=1,
|
||||
shuffle=True,
|
||||
collate_fn=collater,
|
||||
collate_fn=collator,
|
||||
num_workers=n_workers,
|
||||
persistent_workers=args.persistent_data_loader_workers,
|
||||
)
|
||||
@@ -203,7 +233,9 @@ def train(args):
|
||||
args.max_train_steps = args.max_train_epochs * math.ceil(
|
||||
len(train_dataloader) / accelerator.num_processes / args.gradient_accumulation_steps
|
||||
)
|
||||
print(f"override steps. steps for {args.max_train_epochs} epochs is / 指定エポックまでのステップ数: {args.max_train_steps}")
|
||||
accelerator.print(
|
||||
f"override steps. steps for {args.max_train_epochs} epochs is / 指定エポックまでのステップ数: {args.max_train_steps}"
|
||||
)
|
||||
|
||||
# データセット側にも学習ステップを送信
|
||||
train_dataset_group.set_max_train_steps(args.max_train_steps)
|
||||
@@ -216,17 +248,27 @@ def train(args):
|
||||
assert (
|
||||
args.mixed_precision == "fp16"
|
||||
), "full_fp16 requires mixed precision='fp16' / full_fp16を使う場合はmixed_precision='fp16'を指定してください。"
|
||||
print("enable full fp16 training.")
|
||||
accelerator.print("enable full fp16 training.")
|
||||
unet.to(weight_dtype)
|
||||
text_encoder.to(weight_dtype)
|
||||
|
||||
# acceleratorがなんかよろしくやってくれるらしい
|
||||
if args.train_text_encoder:
|
||||
unet, text_encoder, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
|
||||
unet, text_encoder, optimizer, train_dataloader, lr_scheduler
|
||||
if args.deepspeed:
|
||||
if args.train_text_encoder:
|
||||
ds_model = deepspeed_utils.prepare_deepspeed_model(args, unet=unet, text_encoder=text_encoder)
|
||||
else:
|
||||
ds_model = deepspeed_utils.prepare_deepspeed_model(args, unet=unet)
|
||||
ds_model, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
|
||||
ds_model, optimizer, train_dataloader, lr_scheduler
|
||||
)
|
||||
training_models = [ds_model]
|
||||
else:
|
||||
unet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(unet, optimizer, train_dataloader, lr_scheduler)
|
||||
# acceleratorがなんかよろしくやってくれるらしい
|
||||
if args.train_text_encoder:
|
||||
unet, text_encoder, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
|
||||
unet, text_encoder, optimizer, train_dataloader, lr_scheduler
|
||||
)
|
||||
else:
|
||||
unet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(unet, optimizer, train_dataloader, lr_scheduler)
|
||||
|
||||
# 実験的機能:勾配も含めたfp16学習を行う PyTorchにパッチを当ててfp16でのgrad scaleを有効にする
|
||||
if args.full_fp16:
|
||||
@@ -243,14 +285,16 @@ def train(args):
|
||||
|
||||
# 学習する
|
||||
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
|
||||
print("running training / 学習開始")
|
||||
print(f" num examples / サンプル数: {train_dataset_group.num_train_images}")
|
||||
print(f" num batches per epoch / 1epochのバッチ数: {len(train_dataloader)}")
|
||||
print(f" num epochs / epoch数: {num_train_epochs}")
|
||||
print(f" batch size per device / バッチサイズ: {args.train_batch_size}")
|
||||
print(f" total train batch size (with parallel & distributed & accumulation) / 総バッチサイズ(並列学習、勾配合計含む): {total_batch_size}")
|
||||
print(f" gradient accumulation steps / 勾配を合計するステップ数 = {args.gradient_accumulation_steps}")
|
||||
print(f" total optimization steps / 学習ステップ数: {args.max_train_steps}")
|
||||
accelerator.print("running training / 学習開始")
|
||||
accelerator.print(f" num examples / サンプル数: {train_dataset_group.num_train_images}")
|
||||
accelerator.print(f" num batches per epoch / 1epochのバッチ数: {len(train_dataloader)}")
|
||||
accelerator.print(f" num epochs / epoch数: {num_train_epochs}")
|
||||
accelerator.print(f" batch size per device / バッチサイズ: {args.train_batch_size}")
|
||||
accelerator.print(
|
||||
f" total train batch size (with parallel & distributed & accumulation) / 総バッチサイズ(並列学習、勾配合計含む): {total_batch_size}"
|
||||
)
|
||||
accelerator.print(f" gradient accumulation steps / 勾配を合計するステップ数 = {args.gradient_accumulation_steps}")
|
||||
accelerator.print(f" total optimization steps / 学習ステップ数: {args.max_train_steps}")
|
||||
|
||||
progress_bar = tqdm(range(args.max_train_steps), smoothing=0, disable=not accelerator.is_local_main_process, desc="steps")
|
||||
global_step = 0
|
||||
@@ -258,59 +302,67 @@ def train(args):
|
||||
noise_scheduler = DDPMScheduler(
|
||||
beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000, clip_sample=False
|
||||
)
|
||||
prepare_scheduler_for_custom_training(noise_scheduler, accelerator.device)
|
||||
if args.zero_terminal_snr:
|
||||
custom_train_functions.fix_noise_scheduler_betas_for_zero_terminal_snr(noise_scheduler)
|
||||
|
||||
if accelerator.is_main_process:
|
||||
accelerator.init_trackers("finetuning" if args.log_tracker_name is None else args.log_tracker_name)
|
||||
init_kwargs = {}
|
||||
if args.wandb_run_name:
|
||||
init_kwargs["wandb"] = {"name": args.wandb_run_name}
|
||||
if args.log_tracker_config is not None:
|
||||
init_kwargs = toml.load(args.log_tracker_config)
|
||||
accelerator.init_trackers(
|
||||
"finetuning" if args.log_tracker_name is None else args.log_tracker_name,
|
||||
config=train_util.get_sanitized_config_or_none(args),
|
||||
init_kwargs=init_kwargs,
|
||||
)
|
||||
|
||||
# For --sample_at_first
|
||||
train_util.sample_images(accelerator, args, 0, global_step, accelerator.device, vae, tokenizer, text_encoder, unet)
|
||||
|
||||
loss_recorder = train_util.LossRecorder()
|
||||
for epoch in range(num_train_epochs):
|
||||
print(f"epoch {epoch+1}/{num_train_epochs}")
|
||||
accelerator.print(f"\nepoch {epoch+1}/{num_train_epochs}")
|
||||
current_epoch.value = epoch + 1
|
||||
|
||||
for m in training_models:
|
||||
m.train()
|
||||
|
||||
loss_total = 0
|
||||
for step, batch in enumerate(train_dataloader):
|
||||
current_step.value = global_step
|
||||
with accelerator.accumulate(training_models[0]): # 複数モデルに対応していない模様だがとりあえずこうしておく
|
||||
with accelerator.accumulate(*training_models):
|
||||
with torch.no_grad():
|
||||
if "latents" in batch and batch["latents"] is not None:
|
||||
latents = batch["latents"].to(accelerator.device) # .to(dtype=weight_dtype)
|
||||
latents = batch["latents"].to(accelerator.device).to(dtype=weight_dtype)
|
||||
else:
|
||||
# latentに変換
|
||||
latents = vae.encode(batch["images"].to(dtype=weight_dtype)).latent_dist.sample()
|
||||
latents = vae.encode(batch["images"].to(dtype=vae_dtype)).latent_dist.sample().to(weight_dtype)
|
||||
latents = latents * 0.18215
|
||||
b_size = latents.shape[0]
|
||||
|
||||
with torch.set_grad_enabled(args.train_text_encoder):
|
||||
# Get the text embedding for conditioning
|
||||
if args.weighted_captions:
|
||||
encoder_hidden_states = get_weighted_text_embeddings(tokenizer,
|
||||
text_encoder,
|
||||
batch["captions"],
|
||||
accelerator.device,
|
||||
args.max_token_length // 75 if args.max_token_length else 1,
|
||||
clip_skip=args.clip_skip,
|
||||
encoder_hidden_states = get_weighted_text_embeddings(
|
||||
tokenizer,
|
||||
text_encoder,
|
||||
batch["captions"],
|
||||
accelerator.device,
|
||||
args.max_token_length // 75 if args.max_token_length else 1,
|
||||
clip_skip=args.clip_skip,
|
||||
)
|
||||
else:
|
||||
input_ids = batch["input_ids"].to(accelerator.device)
|
||||
encoder_hidden_states = train_util.get_hidden_states(
|
||||
args, input_ids, tokenizer, text_encoder, None if not args.full_fp16 else weight_dtype
|
||||
)
|
||||
input_ids = batch["input_ids"].to(accelerator.device)
|
||||
encoder_hidden_states = train_util.get_hidden_states(
|
||||
args, input_ids, tokenizer, text_encoder, None if not args.full_fp16 else weight_dtype
|
||||
)
|
||||
|
||||
# Sample noise that we'll add to the latents
|
||||
noise = torch.randn_like(latents, device=latents.device)
|
||||
if args.noise_offset:
|
||||
# https://www.crosslabs.org//blog/diffusion-with-offset-noise
|
||||
noise += args.noise_offset * torch.randn((latents.shape[0], latents.shape[1], 1, 1), device=latents.device)
|
||||
|
||||
# Sample a random timestep for each image
|
||||
timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (b_size,), device=latents.device)
|
||||
timesteps = timesteps.long()
|
||||
|
||||
# Add noise to the latents according to the noise magnitude at each timestep
|
||||
# (this is the forward diffusion process)
|
||||
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
|
||||
# Sample noise, sample a random timestep for each image, and add noise to the latents,
|
||||
# with noise offset and/or multires noise if specified
|
||||
noise, noisy_latents, timesteps, huber_c = train_util.get_noise_noisy_latents_and_timesteps(
|
||||
args, noise_scheduler, latents
|
||||
)
|
||||
|
||||
# Predict the noise residual
|
||||
with accelerator.autocast():
|
||||
@@ -322,14 +374,25 @@ def train(args):
|
||||
else:
|
||||
target = noise
|
||||
|
||||
if args.min_snr_gamma:
|
||||
# do not mean over batch dimension for snr weight
|
||||
loss = torch.nn.functional.mse_loss(noise_pred.float(), target.float(), reduction="none")
|
||||
if args.min_snr_gamma or args.scale_v_pred_loss_like_noise_pred or args.debiased_estimation_loss:
|
||||
# do not mean over batch dimension for snr weight or scale v-pred loss
|
||||
loss = train_util.conditional_loss(
|
||||
noise_pred.float(), target.float(), reduction="none", loss_type=args.loss_type, huber_c=huber_c
|
||||
)
|
||||
loss = loss.mean([1, 2, 3])
|
||||
loss = apply_snr_weight(loss, timesteps, noise_scheduler, args.min_snr_gamma)
|
||||
|
||||
if args.min_snr_gamma:
|
||||
loss = apply_snr_weight(loss, timesteps, noise_scheduler, args.min_snr_gamma, args.v_parameterization)
|
||||
if args.scale_v_pred_loss_like_noise_pred:
|
||||
loss = scale_v_prediction_loss_like_noise_prediction(loss, timesteps, noise_scheduler)
|
||||
if args.debiased_estimation_loss:
|
||||
loss = apply_debiased_estimation(loss, timesteps, noise_scheduler, args.v_parameterization)
|
||||
|
||||
loss = loss.mean() # mean over batch dimension
|
||||
else:
|
||||
loss = torch.nn.functional.mse_loss(noise_pred.float(), target.float(), reduction="mean")
|
||||
loss = train_util.conditional_loss(
|
||||
noise_pred.float(), target.float(), reduction="mean", loss_type=args.loss_type, huber_c=huber_c
|
||||
)
|
||||
|
||||
accelerator.backward(loss)
|
||||
if accelerator.sync_gradients and args.max_grad_norm != 0.0:
|
||||
@@ -351,57 +414,76 @@ def train(args):
|
||||
accelerator, args, None, global_step, accelerator.device, vae, tokenizer, text_encoder, unet
|
||||
)
|
||||
|
||||
# 指定ステップごとにモデルを保存
|
||||
if args.save_every_n_steps is not None and global_step % args.save_every_n_steps == 0:
|
||||
accelerator.wait_for_everyone()
|
||||
if accelerator.is_main_process:
|
||||
src_path = src_stable_diffusion_ckpt if save_stable_diffusion_format else src_diffusers_model_path
|
||||
train_util.save_sd_model_on_epoch_end_or_stepwise(
|
||||
args,
|
||||
False,
|
||||
accelerator,
|
||||
src_path,
|
||||
save_stable_diffusion_format,
|
||||
use_safetensors,
|
||||
save_dtype,
|
||||
epoch,
|
||||
num_train_epochs,
|
||||
global_step,
|
||||
accelerator.unwrap_model(text_encoder),
|
||||
accelerator.unwrap_model(unet),
|
||||
vae,
|
||||
)
|
||||
|
||||
current_loss = loss.detach().item() # 平均なのでbatch sizeは関係ないはず
|
||||
if args.logging_dir is not None:
|
||||
logs = {"loss": current_loss, "lr": float(lr_scheduler.get_last_lr()[0])}
|
||||
if args.optimizer_type.lower() == "DAdaptation".lower(): # tracking d*lr value
|
||||
logs["lr/d*lr"] = (
|
||||
lr_scheduler.optimizers[0].param_groups[0]["d"] * lr_scheduler.optimizers[0].param_groups[0]["lr"]
|
||||
)
|
||||
logs = {"loss": current_loss}
|
||||
train_util.append_lr_to_logs(logs, lr_scheduler, args.optimizer_type, including_unet=True)
|
||||
accelerator.log(logs, step=global_step)
|
||||
|
||||
# TODO moving averageにする
|
||||
loss_total += current_loss
|
||||
avr_loss = loss_total / (step + 1)
|
||||
logs = {"loss": avr_loss} # , "lr": lr_scheduler.get_last_lr()[0]}
|
||||
loss_recorder.add(epoch=epoch, step=step, loss=current_loss)
|
||||
avr_loss: float = loss_recorder.moving_average
|
||||
logs = {"avr_loss": avr_loss} # , "lr": lr_scheduler.get_last_lr()[0]}
|
||||
progress_bar.set_postfix(**logs)
|
||||
|
||||
if global_step >= args.max_train_steps:
|
||||
break
|
||||
|
||||
if args.logging_dir is not None:
|
||||
logs = {"loss/epoch": loss_total / len(train_dataloader)}
|
||||
logs = {"loss/epoch": loss_recorder.moving_average}
|
||||
accelerator.log(logs, step=epoch + 1)
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
if args.save_every_n_epochs is not None:
|
||||
src_path = src_stable_diffusion_ckpt if save_stable_diffusion_format else src_diffusers_model_path
|
||||
train_util.save_sd_model_on_epoch_end(
|
||||
args,
|
||||
accelerator,
|
||||
src_path,
|
||||
save_stable_diffusion_format,
|
||||
use_safetensors,
|
||||
save_dtype,
|
||||
epoch,
|
||||
num_train_epochs,
|
||||
global_step,
|
||||
unwrap_model(text_encoder),
|
||||
unwrap_model(unet),
|
||||
vae,
|
||||
)
|
||||
if accelerator.is_main_process:
|
||||
src_path = src_stable_diffusion_ckpt if save_stable_diffusion_format else src_diffusers_model_path
|
||||
train_util.save_sd_model_on_epoch_end_or_stepwise(
|
||||
args,
|
||||
True,
|
||||
accelerator,
|
||||
src_path,
|
||||
save_stable_diffusion_format,
|
||||
use_safetensors,
|
||||
save_dtype,
|
||||
epoch,
|
||||
num_train_epochs,
|
||||
global_step,
|
||||
accelerator.unwrap_model(text_encoder),
|
||||
accelerator.unwrap_model(unet),
|
||||
vae,
|
||||
)
|
||||
|
||||
train_util.sample_images(accelerator, args, epoch + 1, global_step, accelerator.device, vae, tokenizer, text_encoder, unet)
|
||||
|
||||
is_main_process = accelerator.is_main_process
|
||||
if is_main_process:
|
||||
unet = unwrap_model(unet)
|
||||
text_encoder = unwrap_model(text_encoder)
|
||||
unet = accelerator.unwrap_model(unet)
|
||||
text_encoder = accelerator.unwrap_model(text_encoder)
|
||||
|
||||
accelerator.end_training()
|
||||
|
||||
if args.save_state:
|
||||
if is_main_process and (args.save_state or args.save_state_on_train_end):
|
||||
train_util.save_state_on_train_end(args, accelerator)
|
||||
|
||||
del accelerator # この後メモリを使うのでこれは消す
|
||||
@@ -411,22 +493,37 @@ def train(args):
|
||||
train_util.save_sd_model_on_train_end(
|
||||
args, src_path, save_stable_diffusion_format, use_safetensors, save_dtype, epoch, global_step, text_encoder, unet, vae
|
||||
)
|
||||
print("model saved.")
|
||||
logger.info("model saved.")
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
add_logging_arguments(parser)
|
||||
train_util.add_sd_models_arguments(parser)
|
||||
train_util.add_dataset_arguments(parser, False, True, True)
|
||||
train_util.add_training_arguments(parser, False)
|
||||
deepspeed_utils.add_deepspeed_arguments(parser)
|
||||
train_util.add_sd_saving_arguments(parser)
|
||||
train_util.add_optimizer_arguments(parser)
|
||||
config_util.add_config_arguments(parser)
|
||||
custom_train_functions.add_custom_train_arguments(parser)
|
||||
|
||||
parser.add_argument("--diffusers_xformers", action="store_true", help="use xformers by diffusers / Diffusersでxformersを使用する")
|
||||
parser.add_argument(
|
||||
"--diffusers_xformers", action="store_true", help="use xformers by diffusers / Diffusersでxformersを使用する"
|
||||
)
|
||||
parser.add_argument("--train_text_encoder", action="store_true", help="train text encoder / text encoderも学習する")
|
||||
parser.add_argument(
|
||||
"--learning_rate_te",
|
||||
type=float,
|
||||
default=None,
|
||||
help="learning rate for text encoder, default is same as unet / Text Encoderの学習率、デフォルトはunetと同じ",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--no_half_vae",
|
||||
action="store_true",
|
||||
help="do not use fp16/bf16 VAE in mixed precision (use float VAE) / mixed precisionでも fp16/bf16 VAEを使わずfloat VAEを使う",
|
||||
)
|
||||
|
||||
return parser
|
||||
|
||||
@@ -435,6 +532,7 @@ if __name__ == "__main__":
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
train_util.verify_command_line_training_args(args)
|
||||
args = train_util.read_config_from_file(args, parser)
|
||||
|
||||
train(args)
|
||||
train(args)
|
||||
|
||||
@@ -21,6 +21,10 @@ import torch.nn.functional as F
|
||||
import os
|
||||
from urllib.parse import urlparse
|
||||
from timm.models.hub import download_cached_file
|
||||
from library.utils import setup_logging
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class BLIP_Base(nn.Module):
|
||||
def __init__(self,
|
||||
@@ -130,8 +134,9 @@ class BLIP_Decoder(nn.Module):
|
||||
def generate(self, image, sample=False, num_beams=3, max_length=30, min_length=10, top_p=0.9, repetition_penalty=1.0):
|
||||
image_embeds = self.visual_encoder(image)
|
||||
|
||||
if not sample:
|
||||
image_embeds = image_embeds.repeat_interleave(num_beams,dim=0)
|
||||
# recent version of transformers seems to do repeat_interleave automatically
|
||||
# if not sample:
|
||||
# image_embeds = image_embeds.repeat_interleave(num_beams,dim=0)
|
||||
|
||||
image_atts = torch.ones(image_embeds.size()[:-1],dtype=torch.long).to(image.device)
|
||||
model_kwargs = {"encoder_hidden_states": image_embeds, "encoder_attention_mask":image_atts}
|
||||
@@ -235,6 +240,6 @@ def load_checkpoint(model,url_or_filename):
|
||||
del state_dict[key]
|
||||
|
||||
msg = model.load_state_dict(state_dict,strict=False)
|
||||
print('load checkpoint from %s'%url_or_filename)
|
||||
logger.info('load checkpoint from %s'%url_or_filename)
|
||||
return model,msg
|
||||
|
||||
|
||||
@@ -8,6 +8,10 @@ import json
|
||||
import re
|
||||
|
||||
from tqdm import tqdm
|
||||
from library.utils import setup_logging
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
PATTERN_HAIR_LENGTH = re.compile(r', (long|short|medium) hair, ')
|
||||
PATTERN_HAIR_CUT = re.compile(r', (bob|hime) cut, ')
|
||||
@@ -36,13 +40,13 @@ def clean_tags(image_key, tags):
|
||||
tokens = tags.split(", rating")
|
||||
if len(tokens) == 1:
|
||||
# WD14 taggerのときはこちらになるのでメッセージは出さない
|
||||
# print("no rating:")
|
||||
# print(f"{image_key} {tags}")
|
||||
# logger.info("no rating:")
|
||||
# logger.info(f"{image_key} {tags}")
|
||||
pass
|
||||
else:
|
||||
if len(tokens) > 2:
|
||||
print("multiple ratings:")
|
||||
print(f"{image_key} {tags}")
|
||||
logger.info("multiple ratings:")
|
||||
logger.info(f"{image_key} {tags}")
|
||||
tags = tokens[0]
|
||||
|
||||
tags = ", " + tags.replace(", ", ", , ") + ", " # カンマ付きで検索をするための身も蓋もない対策
|
||||
@@ -124,43 +128,43 @@ def clean_caption(caption):
|
||||
|
||||
def main(args):
|
||||
if os.path.exists(args.in_json):
|
||||
print(f"loading existing metadata: {args.in_json}")
|
||||
logger.info(f"loading existing metadata: {args.in_json}")
|
||||
with open(args.in_json, "rt", encoding='utf-8') as f:
|
||||
metadata = json.load(f)
|
||||
else:
|
||||
print("no metadata / メタデータファイルがありません")
|
||||
logger.error("no metadata / メタデータファイルがありません")
|
||||
return
|
||||
|
||||
print("cleaning captions and tags.")
|
||||
logger.info("cleaning captions and tags.")
|
||||
image_keys = list(metadata.keys())
|
||||
for image_key in tqdm(image_keys):
|
||||
tags = metadata[image_key].get('tags')
|
||||
if tags is None:
|
||||
print(f"image does not have tags / メタデータにタグがありません: {image_key}")
|
||||
logger.error(f"image does not have tags / メタデータにタグがありません: {image_key}")
|
||||
else:
|
||||
org = tags
|
||||
tags = clean_tags(image_key, tags)
|
||||
metadata[image_key]['tags'] = tags
|
||||
if args.debug and org != tags:
|
||||
print("FROM: " + org)
|
||||
print("TO: " + tags)
|
||||
logger.info("FROM: " + org)
|
||||
logger.info("TO: " + tags)
|
||||
|
||||
caption = metadata[image_key].get('caption')
|
||||
if caption is None:
|
||||
print(f"image does not have caption / メタデータにキャプションがありません: {image_key}")
|
||||
logger.error(f"image does not have caption / メタデータにキャプションがありません: {image_key}")
|
||||
else:
|
||||
org = caption
|
||||
caption = clean_caption(caption)
|
||||
metadata[image_key]['caption'] = caption
|
||||
if args.debug and org != caption:
|
||||
print("FROM: " + org)
|
||||
print("TO: " + caption)
|
||||
logger.info("FROM: " + org)
|
||||
logger.info("TO: " + caption)
|
||||
|
||||
# metadataを書き出して終わり
|
||||
print(f"writing metadata: {args.out_json}")
|
||||
logger.info(f"writing metadata: {args.out_json}")
|
||||
with open(args.out_json, "wt", encoding='utf-8') as f:
|
||||
json.dump(metadata, f, indent=2)
|
||||
print("done!")
|
||||
logger.info("done!")
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
@@ -178,10 +182,10 @@ if __name__ == '__main__':
|
||||
|
||||
args, unknown = parser.parse_known_args()
|
||||
if len(unknown) == 1:
|
||||
print("WARNING: train_data_dir argument is removed. This script will not work with three arguments in future. Please specify two arguments: in_json and out_json.")
|
||||
print("All captions and tags in the metadata are processed.")
|
||||
print("警告: train_data_dir引数は不要になりました。将来的には三つの引数を指定すると動かなくなる予定です。読み込み元のメタデータと書き出し先の二つの引数だけ指定してください。")
|
||||
print("メタデータ内のすべてのキャプションとタグが処理されます。")
|
||||
logger.warning("WARNING: train_data_dir argument is removed. This script will not work with three arguments in future. Please specify two arguments: in_json and out_json.")
|
||||
logger.warning("All captions and tags in the metadata are processed.")
|
||||
logger.warning("警告: train_data_dir引数は不要になりました。将来的には三つの引数を指定すると動かなくなる予定です。読み込み元のメタデータと書き出し先の二つの引数だけ指定してください。")
|
||||
logger.warning("メタデータ内のすべてのキャプションとタグが処理されます。")
|
||||
args.in_json = args.out_json
|
||||
args.out_json = unknown[0]
|
||||
elif len(unknown) > 0:
|
||||
|
||||
@@ -3,18 +3,28 @@ import glob
|
||||
import os
|
||||
import json
|
||||
import random
|
||||
import sys
|
||||
|
||||
from pathlib import Path
|
||||
from PIL import Image
|
||||
from tqdm import tqdm
|
||||
import numpy as np
|
||||
|
||||
import torch
|
||||
from library.device_utils import init_ipex, get_preferred_device
|
||||
init_ipex()
|
||||
|
||||
from torchvision import transforms
|
||||
from torchvision.transforms.functional import InterpolationMode
|
||||
from blip.blip import blip_decoder
|
||||
sys.path.append(os.path.dirname(__file__))
|
||||
from blip.blip import blip_decoder, is_url
|
||||
import library.train_util as train_util
|
||||
from library.utils import setup_logging
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
||||
DEVICE = get_preferred_device()
|
||||
|
||||
|
||||
IMAGE_SIZE = 384
|
||||
@@ -45,7 +55,7 @@ class ImageLoadingTransformDataset(torch.utils.data.Dataset):
|
||||
# convert to tensor temporarily so dataloader will accept it
|
||||
tensor = IMAGE_TRANSFORM(image)
|
||||
except Exception as e:
|
||||
print(f"Could not load image path / 画像を読み込めません: {img_path}, error: {e}")
|
||||
logger.error(f"Could not load image path / 画像を読み込めません: {img_path}, error: {e}")
|
||||
return None
|
||||
|
||||
return (tensor, img_path)
|
||||
@@ -72,19 +82,21 @@ def main(args):
|
||||
args.train_data_dir = os.path.abspath(args.train_data_dir) # convert to absolute path
|
||||
|
||||
cwd = os.getcwd()
|
||||
print("Current Working Directory is: ", cwd)
|
||||
logger.info(f"Current Working Directory is: {cwd}")
|
||||
os.chdir("finetune")
|
||||
if not is_url(args.caption_weights) and not os.path.isfile(args.caption_weights):
|
||||
args.caption_weights = os.path.join("..", args.caption_weights)
|
||||
|
||||
print(f"load images from {args.train_data_dir}")
|
||||
logger.info(f"load images from {args.train_data_dir}")
|
||||
train_data_dir_path = Path(args.train_data_dir)
|
||||
image_paths = train_util.glob_images_pathlib(train_data_dir_path, args.recursive)
|
||||
print(f"found {len(image_paths)} images.")
|
||||
logger.info(f"found {len(image_paths)} images.")
|
||||
|
||||
print(f"loading BLIP caption: {args.caption_weights}")
|
||||
logger.info(f"loading BLIP caption: {args.caption_weights}")
|
||||
model = blip_decoder(pretrained=args.caption_weights, image_size=IMAGE_SIZE, vit="large", med_config="./blip/med_config.json")
|
||||
model.eval()
|
||||
model = model.to(DEVICE)
|
||||
print("BLIP loaded")
|
||||
logger.info("BLIP loaded")
|
||||
|
||||
# captioningする
|
||||
def run_batch(path_imgs):
|
||||
@@ -104,7 +116,7 @@ def main(args):
|
||||
with open(os.path.splitext(image_path)[0] + args.caption_extension, "wt", encoding="utf-8") as f:
|
||||
f.write(caption + "\n")
|
||||
if args.debug:
|
||||
print(image_path, caption)
|
||||
logger.info(f'{image_path} {caption}')
|
||||
|
||||
# 読み込みの高速化のためにDataLoaderを使うオプション
|
||||
if args.max_data_loader_n_workers is not None:
|
||||
@@ -134,7 +146,7 @@ def main(args):
|
||||
raw_image = raw_image.convert("RGB")
|
||||
img_tensor = IMAGE_TRANSFORM(raw_image)
|
||||
except Exception as e:
|
||||
print(f"Could not load image path / 画像を読み込めません: {image_path}, error: {e}")
|
||||
logger.error(f"Could not load image path / 画像を読み込めません: {image_path}, error: {e}")
|
||||
continue
|
||||
|
||||
b_imgs.append((image_path, img_tensor))
|
||||
@@ -144,7 +156,7 @@ def main(args):
|
||||
if len(b_imgs) > 0:
|
||||
run_batch(b_imgs)
|
||||
|
||||
print("done!")
|
||||
logger.info("done!")
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
|
||||
@@ -5,12 +5,19 @@ import re
|
||||
from pathlib import Path
|
||||
from PIL import Image
|
||||
from tqdm import tqdm
|
||||
|
||||
import torch
|
||||
from library.device_utils import init_ipex, get_preferred_device
|
||||
init_ipex()
|
||||
|
||||
from transformers import AutoProcessor, AutoModelForCausalLM
|
||||
from transformers.generation.utils import GenerationMixin
|
||||
|
||||
import library.train_util as train_util
|
||||
|
||||
from library.utils import setup_logging
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
||||
|
||||
@@ -35,8 +42,8 @@ def remove_words(captions, debug):
|
||||
for pat in PATTERN_REPLACE:
|
||||
cap = pat.sub("", cap)
|
||||
if debug and cap != caption:
|
||||
print(caption)
|
||||
print(cap)
|
||||
logger.info(caption)
|
||||
logger.info(cap)
|
||||
removed_caps.append(cap)
|
||||
return removed_caps
|
||||
|
||||
@@ -52,6 +59,9 @@ def collate_fn_remove_corrupted(batch):
|
||||
|
||||
|
||||
def main(args):
|
||||
r"""
|
||||
transformers 4.30.2で、バッチサイズ>1でも動くようになったので、以下コメントアウト
|
||||
|
||||
# GITにバッチサイズが1より大きくても動くようにパッチを当てる: transformers 4.26.0用
|
||||
org_prepare_input_ids_for_generation = GenerationMixin._prepare_input_ids_for_generation
|
||||
curr_batch_size = [args.batch_size] # ループの最後で件数がbatch_size未満になるので入れ替えられるように
|
||||
@@ -65,23 +75,24 @@ def main(args):
|
||||
return input_ids
|
||||
|
||||
GenerationMixin._prepare_input_ids_for_generation = _prepare_input_ids_for_generation_patch
|
||||
"""
|
||||
|
||||
print(f"load images from {args.train_data_dir}")
|
||||
logger.info(f"load images from {args.train_data_dir}")
|
||||
train_data_dir_path = Path(args.train_data_dir)
|
||||
image_paths = train_util.glob_images_pathlib(train_data_dir_path, args.recursive)
|
||||
print(f"found {len(image_paths)} images.")
|
||||
logger.info(f"found {len(image_paths)} images.")
|
||||
|
||||
# できればcacheに依存せず明示的にダウンロードしたい
|
||||
print(f"loading GIT: {args.model_id}")
|
||||
logger.info(f"loading GIT: {args.model_id}")
|
||||
git_processor = AutoProcessor.from_pretrained(args.model_id)
|
||||
git_model = AutoModelForCausalLM.from_pretrained(args.model_id).to(DEVICE)
|
||||
print("GIT loaded")
|
||||
logger.info("GIT loaded")
|
||||
|
||||
# captioningする
|
||||
def run_batch(path_imgs):
|
||||
imgs = [im for _, im in path_imgs]
|
||||
|
||||
curr_batch_size[0] = len(path_imgs)
|
||||
# curr_batch_size[0] = len(path_imgs)
|
||||
inputs = git_processor(images=imgs, return_tensors="pt").to(DEVICE) # 画像はpil形式
|
||||
generated_ids = git_model.generate(pixel_values=inputs.pixel_values, max_length=args.max_length)
|
||||
captions = git_processor.batch_decode(generated_ids, skip_special_tokens=True)
|
||||
@@ -93,7 +104,7 @@ def main(args):
|
||||
with open(os.path.splitext(image_path)[0] + args.caption_extension, "wt", encoding="utf-8") as f:
|
||||
f.write(caption + "\n")
|
||||
if args.debug:
|
||||
print(image_path, caption)
|
||||
logger.info(f"{image_path} {caption}")
|
||||
|
||||
# 読み込みの高速化のためにDataLoaderを使うオプション
|
||||
if args.max_data_loader_n_workers is not None:
|
||||
@@ -122,7 +133,7 @@ def main(args):
|
||||
if image.mode != "RGB":
|
||||
image = image.convert("RGB")
|
||||
except Exception as e:
|
||||
print(f"Could not load image path / 画像を読み込めません: {image_path}, error: {e}")
|
||||
logger.error(f"Could not load image path / 画像を読み込めません: {image_path}, error: {e}")
|
||||
continue
|
||||
|
||||
b_imgs.append((image_path, image))
|
||||
@@ -133,7 +144,7 @@ def main(args):
|
||||
if len(b_imgs) > 0:
|
||||
run_batch(b_imgs)
|
||||
|
||||
print("done!")
|
||||
logger.info("done!")
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
|
||||
@@ -5,72 +5,96 @@ from typing import List
|
||||
from tqdm import tqdm
|
||||
import library.train_util as train_util
|
||||
import os
|
||||
from library.utils import setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
def main(args):
|
||||
assert not args.recursive or (args.recursive and args.full_path), "recursive requires full_path / recursiveはfull_pathと同時に指定してください"
|
||||
assert not args.recursive or (
|
||||
args.recursive and args.full_path
|
||||
), "recursive requires full_path / recursiveはfull_pathと同時に指定してください"
|
||||
|
||||
train_data_dir_path = Path(args.train_data_dir)
|
||||
image_paths: List[Path] = train_util.glob_images_pathlib(train_data_dir_path, args.recursive)
|
||||
print(f"found {len(image_paths)} images.")
|
||||
train_data_dir_path = Path(args.train_data_dir)
|
||||
image_paths: List[Path] = train_util.glob_images_pathlib(train_data_dir_path, args.recursive)
|
||||
logger.info(f"found {len(image_paths)} images.")
|
||||
|
||||
if args.in_json is None and Path(args.out_json).is_file():
|
||||
args.in_json = args.out_json
|
||||
if args.in_json is None and Path(args.out_json).is_file():
|
||||
args.in_json = args.out_json
|
||||
|
||||
if args.in_json is not None:
|
||||
print(f"loading existing metadata: {args.in_json}")
|
||||
metadata = json.loads(Path(args.in_json).read_text(encoding='utf-8'))
|
||||
print("captions for existing images will be overwritten / 既存の画像のキャプションは上書きされます")
|
||||
else:
|
||||
print("new metadata will be created / 新しいメタデータファイルが作成されます")
|
||||
metadata = {}
|
||||
if args.in_json is not None:
|
||||
logger.info(f"loading existing metadata: {args.in_json}")
|
||||
metadata = json.loads(Path(args.in_json).read_text(encoding="utf-8"))
|
||||
logger.warning("captions for existing images will be overwritten / 既存の画像のキャプションは上書きされます")
|
||||
else:
|
||||
logger.info("new metadata will be created / 新しいメタデータファイルが作成されます")
|
||||
metadata = {}
|
||||
|
||||
print("merge caption texts to metadata json.")
|
||||
for image_path in tqdm(image_paths):
|
||||
caption_path = image_path.with_suffix(args.caption_extension)
|
||||
caption = caption_path.read_text(encoding='utf-8').strip()
|
||||
logger.info("merge caption texts to metadata json.")
|
||||
for image_path in tqdm(image_paths):
|
||||
caption_path = image_path.with_suffix(args.caption_extension)
|
||||
caption = caption_path.read_text(encoding="utf-8").strip()
|
||||
|
||||
if not os.path.exists(caption_path):
|
||||
caption_path = os.path.join(image_path, args.caption_extension)
|
||||
if not os.path.exists(caption_path):
|
||||
caption_path = os.path.join(image_path, args.caption_extension)
|
||||
|
||||
image_key = str(image_path) if args.full_path else image_path.stem
|
||||
if image_key not in metadata:
|
||||
metadata[image_key] = {}
|
||||
image_key = str(image_path) if args.full_path else image_path.stem
|
||||
if image_key not in metadata:
|
||||
metadata[image_key] = {}
|
||||
|
||||
metadata[image_key]['caption'] = caption
|
||||
if args.debug:
|
||||
print(image_key, caption)
|
||||
metadata[image_key]["caption"] = caption
|
||||
if args.debug:
|
||||
logger.info(f"{image_key} {caption}")
|
||||
|
||||
# metadataを書き出して終わり
|
||||
print(f"writing metadata: {args.out_json}")
|
||||
Path(args.out_json).write_text(json.dumps(metadata, indent=2), encoding='utf-8')
|
||||
print("done!")
|
||||
# metadataを書き出して終わり
|
||||
logger.info(f"writing metadata: {args.out_json}")
|
||||
Path(args.out_json).write_text(json.dumps(metadata, indent=2), encoding="utf-8")
|
||||
logger.info("done!")
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("train_data_dir", type=str, help="directory for train images / 学習画像データのディレクトリ")
|
||||
parser.add_argument("out_json", type=str, help="metadata file to output / メタデータファイル書き出し先")
|
||||
parser.add_argument("--in_json", type=str,
|
||||
help="metadata file to input (if omitted and out_json exists, existing out_json is read) / 読み込むメタデータファイル(省略時、out_jsonが存在すればそれを読み込む)")
|
||||
parser.add_argument("--caption_extention", type=str, default=None,
|
||||
help="extension of caption file (for backward compatibility) / 読み込むキャプションファイルの拡張子(スペルミスしていたのを残してあります)")
|
||||
parser.add_argument("--caption_extension", type=str, default=".caption", help="extension of caption file / 読み込むキャプションファイルの拡張子")
|
||||
parser.add_argument("--full_path", action="store_true",
|
||||
help="use full path as image-key in metadata (supports multiple directories) / メタデータで画像キーをフルパスにする(複数の学習画像ディレクトリに対応)")
|
||||
parser.add_argument("--recursive", action="store_true",
|
||||
help="recursively look for training tags in all child folders of train_data_dir / train_data_dirのすべての子フォルダにある学習タグを再帰的に探す")
|
||||
parser.add_argument("--debug", action="store_true", help="debug mode")
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("train_data_dir", type=str, help="directory for train images / 学習画像データのディレクトリ")
|
||||
parser.add_argument("out_json", type=str, help="metadata file to output / メタデータファイル書き出し先")
|
||||
parser.add_argument(
|
||||
"--in_json",
|
||||
type=str,
|
||||
help="metadata file to input (if omitted and out_json exists, existing out_json is read) / 読み込むメタデータファイル(省略時、out_jsonが存在すればそれを読み込む)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--caption_extention",
|
||||
type=str,
|
||||
default=None,
|
||||
help="extension of caption file (for backward compatibility) / 読み込むキャプションファイルの拡張子(スペルミスしていたのを残してあります)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--caption_extension", type=str, default=".caption", help="extension of caption file / 読み込むキャプションファイルの拡張子"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--full_path",
|
||||
action="store_true",
|
||||
help="use full path as image-key in metadata (supports multiple directories) / メタデータで画像キーをフルパスにする(複数の学習画像ディレクトリに対応)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--recursive",
|
||||
action="store_true",
|
||||
help="recursively look for training tags in all child folders of train_data_dir / train_data_dirのすべての子フォルダにある学習タグを再帰的に探す",
|
||||
)
|
||||
parser.add_argument("--debug", action="store_true", help="debug mode")
|
||||
|
||||
return parser
|
||||
return parser
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = setup_parser()
|
||||
if __name__ == "__main__":
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
args = parser.parse_args()
|
||||
|
||||
# スペルミスしていたオプションを復元する
|
||||
if args.caption_extention is not None:
|
||||
args.caption_extension = args.caption_extention
|
||||
# スペルミスしていたオプションを復元する
|
||||
if args.caption_extention is not None:
|
||||
args.caption_extension = args.caption_extention
|
||||
|
||||
main(args)
|
||||
main(args)
|
||||
|
||||
@@ -5,67 +5,89 @@ from typing import List
|
||||
from tqdm import tqdm
|
||||
import library.train_util as train_util
|
||||
import os
|
||||
from library.utils import setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
def main(args):
|
||||
assert not args.recursive or (args.recursive and args.full_path), "recursive requires full_path / recursiveはfull_pathと同時に指定してください"
|
||||
assert not args.recursive or (
|
||||
args.recursive and args.full_path
|
||||
), "recursive requires full_path / recursiveはfull_pathと同時に指定してください"
|
||||
|
||||
train_data_dir_path = Path(args.train_data_dir)
|
||||
image_paths: List[Path] = train_util.glob_images_pathlib(train_data_dir_path, args.recursive)
|
||||
print(f"found {len(image_paths)} images.")
|
||||
train_data_dir_path = Path(args.train_data_dir)
|
||||
image_paths: List[Path] = train_util.glob_images_pathlib(train_data_dir_path, args.recursive)
|
||||
logger.info(f"found {len(image_paths)} images.")
|
||||
|
||||
if args.in_json is None and Path(args.out_json).is_file():
|
||||
args.in_json = args.out_json
|
||||
if args.in_json is None and Path(args.out_json).is_file():
|
||||
args.in_json = args.out_json
|
||||
|
||||
if args.in_json is not None:
|
||||
print(f"loading existing metadata: {args.in_json}")
|
||||
metadata = json.loads(Path(args.in_json).read_text(encoding='utf-8'))
|
||||
print("tags data for existing images will be overwritten / 既存の画像のタグは上書きされます")
|
||||
else:
|
||||
print("new metadata will be created / 新しいメタデータファイルが作成されます")
|
||||
metadata = {}
|
||||
if args.in_json is not None:
|
||||
logger.info(f"loading existing metadata: {args.in_json}")
|
||||
metadata = json.loads(Path(args.in_json).read_text(encoding="utf-8"))
|
||||
logger.warning("tags data for existing images will be overwritten / 既存の画像のタグは上書きされます")
|
||||
else:
|
||||
logger.info("new metadata will be created / 新しいメタデータファイルが作成されます")
|
||||
metadata = {}
|
||||
|
||||
print("merge tags to metadata json.")
|
||||
for image_path in tqdm(image_paths):
|
||||
tags_path = image_path.with_suffix(args.caption_extension)
|
||||
tags = tags_path.read_text(encoding='utf-8').strip()
|
||||
logger.info("merge tags to metadata json.")
|
||||
for image_path in tqdm(image_paths):
|
||||
tags_path = image_path.with_suffix(args.caption_extension)
|
||||
tags = tags_path.read_text(encoding="utf-8").strip()
|
||||
|
||||
if not os.path.exists(tags_path):
|
||||
tags_path = os.path.join(image_path, args.caption_extension)
|
||||
if not os.path.exists(tags_path):
|
||||
tags_path = os.path.join(image_path, args.caption_extension)
|
||||
|
||||
image_key = str(image_path) if args.full_path else image_path.stem
|
||||
if image_key not in metadata:
|
||||
metadata[image_key] = {}
|
||||
image_key = str(image_path) if args.full_path else image_path.stem
|
||||
if image_key not in metadata:
|
||||
metadata[image_key] = {}
|
||||
|
||||
metadata[image_key]['tags'] = tags
|
||||
if args.debug:
|
||||
print(image_key, tags)
|
||||
metadata[image_key]["tags"] = tags
|
||||
if args.debug:
|
||||
logger.info(f"{image_key} {tags}")
|
||||
|
||||
# metadataを書き出して終わり
|
||||
print(f"writing metadata: {args.out_json}")
|
||||
Path(args.out_json).write_text(json.dumps(metadata, indent=2), encoding='utf-8')
|
||||
# metadataを書き出して終わり
|
||||
logger.info(f"writing metadata: {args.out_json}")
|
||||
Path(args.out_json).write_text(json.dumps(metadata, indent=2), encoding="utf-8")
|
||||
|
||||
print("done!")
|
||||
logger.info("done!")
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("train_data_dir", type=str, help="directory for train images / 学習画像データのディレクトリ")
|
||||
parser.add_argument("out_json", type=str, help="metadata file to output / メタデータファイル書き出し先")
|
||||
parser.add_argument("--in_json", type=str,
|
||||
help="metadata file to input (if omitted and out_json exists, existing out_json is read) / 読み込むメタデータファイル(省略時、out_jsonが存在すればそれを読み込む)")
|
||||
parser.add_argument("--full_path", action="store_true",
|
||||
help="use full path as image-key in metadata (supports multiple directories) / メタデータで画像キーをフルパスにする(複数の学習画像ディレクトリに対応)")
|
||||
parser.add_argument("--recursive", action="store_true",
|
||||
help="recursively look for training tags in all child folders of train_data_dir / train_data_dirのすべての子フォルダにある学習タグを再帰的に探す")
|
||||
parser.add_argument("--caption_extension", type=str, default=".txt",
|
||||
help="extension of caption (tag) file / 読み込むキャプション(タグ)ファイルの拡張子")
|
||||
parser.add_argument("--debug", action="store_true", help="debug mode, print tags")
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("train_data_dir", type=str, help="directory for train images / 学習画像データのディレクトリ")
|
||||
parser.add_argument("out_json", type=str, help="metadata file to output / メタデータファイル書き出し先")
|
||||
parser.add_argument(
|
||||
"--in_json",
|
||||
type=str,
|
||||
help="metadata file to input (if omitted and out_json exists, existing out_json is read) / 読み込むメタデータファイル(省略時、out_jsonが存在すればそれを読み込む)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--full_path",
|
||||
action="store_true",
|
||||
help="use full path as image-key in metadata (supports multiple directories) / メタデータで画像キーをフルパスにする(複数の学習画像ディレクトリに対応)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--recursive",
|
||||
action="store_true",
|
||||
help="recursively look for training tags in all child folders of train_data_dir / train_data_dirのすべての子フォルダにある学習タグを再帰的に探す",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--caption_extension",
|
||||
type=str,
|
||||
default=".txt",
|
||||
help="extension of caption (tag) file / 読み込むキャプション(タグ)ファイルの拡張子",
|
||||
)
|
||||
parser.add_argument("--debug", action="store_true", help="debug mode, print tags")
|
||||
|
||||
return parser
|
||||
return parser
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = setup_parser()
|
||||
if __name__ == "__main__":
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
main(args)
|
||||
args = parser.parse_args()
|
||||
main(args)
|
||||
|
||||
@@ -8,13 +8,24 @@ from tqdm import tqdm
|
||||
import numpy as np
|
||||
from PIL import Image
|
||||
import cv2
|
||||
|
||||
import torch
|
||||
from library.device_utils import init_ipex, get_preferred_device
|
||||
|
||||
init_ipex()
|
||||
|
||||
from torchvision import transforms
|
||||
|
||||
import library.model_util as model_util
|
||||
import library.train_util as train_util
|
||||
from library.utils import setup_logging
|
||||
|
||||
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
DEVICE = get_preferred_device()
|
||||
|
||||
IMAGE_TRANSFORMS = transforms.Compose(
|
||||
[
|
||||
@@ -34,16 +45,7 @@ def collate_fn_remove_corrupted(batch):
|
||||
return batch
|
||||
|
||||
|
||||
def get_latents(vae, images, weight_dtype):
|
||||
img_tensors = [IMAGE_TRANSFORMS(image) for image in images]
|
||||
img_tensors = torch.stack(img_tensors)
|
||||
img_tensors = img_tensors.to(DEVICE, weight_dtype)
|
||||
with torch.no_grad():
|
||||
latents = vae.encode(img_tensors).latent_dist.sample().float().to("cpu").numpy()
|
||||
return latents
|
||||
|
||||
|
||||
def get_npz_filename_wo_ext(data_dir, image_key, is_full_path, flip, recursive):
|
||||
def get_npz_filename(data_dir, image_key, is_full_path, recursive):
|
||||
if is_full_path:
|
||||
base_name = os.path.splitext(os.path.basename(image_key))[0]
|
||||
relative_path = os.path.relpath(os.path.dirname(image_key), data_dir)
|
||||
@@ -51,30 +53,31 @@ def get_npz_filename_wo_ext(data_dir, image_key, is_full_path, flip, recursive):
|
||||
base_name = image_key
|
||||
relative_path = ""
|
||||
|
||||
if flip:
|
||||
base_name += "_flip"
|
||||
|
||||
if recursive and relative_path:
|
||||
return os.path.join(data_dir, relative_path, base_name)
|
||||
return os.path.join(data_dir, relative_path, base_name) + ".npz"
|
||||
else:
|
||||
return os.path.join(data_dir, base_name)
|
||||
return os.path.join(data_dir, base_name) + ".npz"
|
||||
|
||||
|
||||
def main(args):
|
||||
# assert args.bucket_reso_steps % 8 == 0, f"bucket_reso_steps must be divisible by 8 / bucket_reso_stepは8で割り切れる必要があります"
|
||||
if args.bucket_reso_steps % 8 > 0:
|
||||
print(f"resolution of buckets in training time is a multiple of 8 / 学習時の各bucketの解像度は8単位になります")
|
||||
logger.warning(f"resolution of buckets in training time is a multiple of 8 / 学習時の各bucketの解像度は8単位になります")
|
||||
if args.bucket_reso_steps % 32 > 0:
|
||||
logger.warning(
|
||||
f"WARNING: bucket_reso_steps is not divisible by 32. It is not working with SDXL / bucket_reso_stepsが32で割り切れません。SDXLでは動作しません"
|
||||
)
|
||||
|
||||
train_data_dir_path = Path(args.train_data_dir)
|
||||
image_paths: List[str] = [str(p) for p in train_util.glob_images_pathlib(train_data_dir_path, args.recursive)]
|
||||
print(f"found {len(image_paths)} images.")
|
||||
logger.info(f"found {len(image_paths)} images.")
|
||||
|
||||
if os.path.exists(args.in_json):
|
||||
print(f"loading existing metadata: {args.in_json}")
|
||||
logger.info(f"loading existing metadata: {args.in_json}")
|
||||
with open(args.in_json, "rt", encoding="utf-8") as f:
|
||||
metadata = json.load(f)
|
||||
else:
|
||||
print(f"no metadata / メタデータファイルがありません: {args.in_json}")
|
||||
logger.error(f"no metadata / メタデータファイルがありません: {args.in_json}")
|
||||
return
|
||||
|
||||
weight_dtype = torch.float32
|
||||
@@ -89,7 +92,9 @@ def main(args):
|
||||
|
||||
# bucketのサイズを計算する
|
||||
max_reso = tuple([int(t) for t in args.max_resolution.split(",")])
|
||||
assert len(max_reso) == 2, f"illegal resolution (not 'width,height') / 画像サイズに誤りがあります。'幅,高さ'で指定してください: {args.max_resolution}"
|
||||
assert (
|
||||
len(max_reso) == 2
|
||||
), f"illegal resolution (not 'width,height') / 画像サイズに誤りがあります。'幅,高さ'で指定してください: {args.max_resolution}"
|
||||
|
||||
bucket_manager = train_util.BucketManager(
|
||||
args.bucket_no_upscale, max_reso, args.min_bucket_reso, args.max_bucket_reso, args.bucket_reso_steps
|
||||
@@ -97,7 +102,7 @@ def main(args):
|
||||
if not args.bucket_no_upscale:
|
||||
bucket_manager.make_buckets()
|
||||
else:
|
||||
print(
|
||||
logger.warning(
|
||||
"min_bucket_reso and max_bucket_reso are ignored if bucket_no_upscale is set, because bucket reso is defined by image size automatically / bucket_no_upscaleが指定された場合は、bucketの解像度は画像サイズから自動計算されるため、min_bucket_resoとmax_bucket_resoは無視されます"
|
||||
)
|
||||
|
||||
@@ -107,34 +112,7 @@ def main(args):
|
||||
def process_batch(is_last):
|
||||
for bucket in bucket_manager.buckets:
|
||||
if (is_last and len(bucket) > 0) or len(bucket) >= args.batch_size:
|
||||
latents = get_latents(vae, [img for _, img in bucket], weight_dtype)
|
||||
assert (
|
||||
latents.shape[2] == bucket[0][1].shape[0] // 8 and latents.shape[3] == bucket[0][1].shape[1] // 8
|
||||
), f"latent shape {latents.shape}, {bucket[0][1].shape}"
|
||||
|
||||
for (image_key, _), latent in zip(bucket, latents):
|
||||
npz_file_name = get_npz_filename_wo_ext(args.train_data_dir, image_key, args.full_path, False, args.recursive)
|
||||
np.savez(npz_file_name, latent)
|
||||
|
||||
# flip
|
||||
if args.flip_aug:
|
||||
latents = get_latents(vae, [img[:, ::-1].copy() for _, img in bucket], weight_dtype) # copyがないとTensor変換できない
|
||||
|
||||
for (image_key, _), latent in zip(bucket, latents):
|
||||
npz_file_name = get_npz_filename_wo_ext(
|
||||
args.train_data_dir, image_key, args.full_path, True, args.recursive
|
||||
)
|
||||
np.savez(npz_file_name, latent)
|
||||
else:
|
||||
# remove existing flipped npz
|
||||
for image_key, _ in bucket:
|
||||
npz_file_name = (
|
||||
get_npz_filename_wo_ext(args.train_data_dir, image_key, args.full_path, True, args.recursive) + ".npz"
|
||||
)
|
||||
if os.path.isfile(npz_file_name):
|
||||
print(f"remove existing flipped npz / 既存のflipされたnpzファイルを削除します: {npz_file_name}")
|
||||
os.remove(npz_file_name)
|
||||
|
||||
train_util.cache_batch_latents(vae, True, bucket, args.flip_aug, args.alpha_mask, False)
|
||||
bucket.clear()
|
||||
|
||||
# 読み込みの高速化のためにDataLoaderを使うオプション
|
||||
@@ -165,7 +143,7 @@ def main(args):
|
||||
if image.mode != "RGB":
|
||||
image = image.convert("RGB")
|
||||
except Exception as e:
|
||||
print(f"Could not load image path / 画像を読み込めません: {image_path}, error: {e}")
|
||||
logger.error(f"Could not load image path / 画像を読み込めません: {image_path}, error: {e}")
|
||||
continue
|
||||
|
||||
image_key = image_path if args.full_path else os.path.splitext(os.path.basename(image_path))[0]
|
||||
@@ -194,50 +172,19 @@ def main(args):
|
||||
resized_size[0] >= reso[0] and resized_size[1] >= reso[1]
|
||||
), f"internal error resized size is small: {resized_size}, {reso}"
|
||||
|
||||
# 既に存在するファイルがあればshapeを確認して同じならskipする
|
||||
# 既に存在するファイルがあればshape等を確認して同じならskipする
|
||||
npz_file_name = get_npz_filename(args.train_data_dir, image_key, args.full_path, args.recursive)
|
||||
if args.skip_existing:
|
||||
npz_files = [get_npz_filename_wo_ext(args.train_data_dir, image_key, args.full_path, False, args.recursive) + ".npz"]
|
||||
if args.flip_aug:
|
||||
npz_files.append(
|
||||
get_npz_filename_wo_ext(args.train_data_dir, image_key, args.full_path, True, args.recursive) + ".npz"
|
||||
)
|
||||
|
||||
found = True
|
||||
for npz_file in npz_files:
|
||||
if not os.path.exists(npz_file):
|
||||
found = False
|
||||
break
|
||||
|
||||
dat = np.load(npz_file)["arr_0"]
|
||||
if dat.shape[1] != reso[1] // 8 or dat.shape[2] != reso[0] // 8: # latentsのshapeを確認
|
||||
found = False
|
||||
break
|
||||
if found:
|
||||
if train_util.is_disk_cached_latents_is_expected(reso, npz_file_name, args.flip_aug):
|
||||
continue
|
||||
|
||||
# 画像をリサイズしてトリミングする
|
||||
# PILにinter_areaがないのでcv2で……
|
||||
image = np.array(image)
|
||||
if resized_size[0] != image.shape[1] or resized_size[1] != image.shape[0]: # リサイズ処理が必要?
|
||||
image = cv2.resize(image, resized_size, interpolation=cv2.INTER_AREA)
|
||||
|
||||
if resized_size[0] > reso[0]:
|
||||
trim_size = resized_size[0] - reso[0]
|
||||
image = image[:, trim_size // 2 : trim_size // 2 + reso[0]]
|
||||
|
||||
if resized_size[1] > reso[1]:
|
||||
trim_size = resized_size[1] - reso[1]
|
||||
image = image[trim_size // 2 : trim_size // 2 + reso[1]]
|
||||
|
||||
assert (
|
||||
image.shape[0] == reso[1] and image.shape[1] == reso[0]
|
||||
), f"internal error, illegal trimmed size: {image.shape}, {reso}"
|
||||
|
||||
# # debug
|
||||
# cv2.imwrite(f"r:\\test\\img_{len(img_ar_errors)}.jpg", image[:, :, ::-1])
|
||||
|
||||
# バッチへ追加
|
||||
bucket_manager.add_image(reso, (image_key, image))
|
||||
image_info = train_util.ImageInfo(image_key, 1, "", False, image_path)
|
||||
image_info.latents_npz = npz_file_name
|
||||
image_info.bucket_reso = reso
|
||||
image_info.resized_size = resized_size
|
||||
image_info.image = image
|
||||
bucket_manager.add_image(reso, image_info)
|
||||
|
||||
# バッチを推論するか判定して推論する
|
||||
process_batch(False)
|
||||
@@ -249,15 +196,15 @@ def main(args):
|
||||
for i, reso in enumerate(bucket_manager.resos):
|
||||
count = bucket_counts.get(reso, 0)
|
||||
if count > 0:
|
||||
print(f"bucket {i} {reso}: {count}")
|
||||
logger.info(f"bucket {i} {reso}: {count}")
|
||||
img_ar_errors = np.array(img_ar_errors)
|
||||
print(f"mean ar error: {np.mean(img_ar_errors)}")
|
||||
logger.info(f"mean ar error: {np.mean(img_ar_errors)}")
|
||||
|
||||
# metadataを書き出して終わり
|
||||
print(f"writing metadata: {args.out_json}")
|
||||
logger.info(f"writing metadata: {args.out_json}")
|
||||
with open(args.out_json, "wt", encoding="utf-8") as f:
|
||||
json.dump(metadata, f, indent=2)
|
||||
print("done!")
|
||||
logger.info("done!")
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
@@ -266,7 +213,9 @@ def setup_parser() -> argparse.ArgumentParser:
|
||||
parser.add_argument("in_json", type=str, help="metadata file to input / 読み込むメタデータファイル")
|
||||
parser.add_argument("out_json", type=str, help="metadata file to output / メタデータファイル書き出し先")
|
||||
parser.add_argument("model_name_or_path", type=str, help="model name or path to encode latents / latentを取得するためのモデル")
|
||||
parser.add_argument("--v2", action="store_true", help="not used (for backward compatibility) / 使用されません(互換性のため残してあります)")
|
||||
parser.add_argument(
|
||||
"--v2", action="store_true", help="not used (for backward compatibility) / 使用されません(互換性のため残してあります)"
|
||||
)
|
||||
parser.add_argument("--batch_size", type=int, default=1, help="batch size in inference / 推論時のバッチサイズ")
|
||||
parser.add_argument(
|
||||
"--max_data_loader_n_workers",
|
||||
@@ -281,7 +230,7 @@ def setup_parser() -> argparse.ArgumentParser:
|
||||
help="max resolution in fine tuning (width,height) / fine tuning時の最大画像サイズ 「幅,高さ」(使用メモリ量に関係します)",
|
||||
)
|
||||
parser.add_argument("--min_bucket_reso", type=int, default=256, help="minimum resolution for buckets / bucketの最小解像度")
|
||||
parser.add_argument("--max_bucket_reso", type=int, default=1024, help="maximum resolution for buckets / bucketの最小解像度")
|
||||
parser.add_argument("--max_bucket_reso", type=int, default=1024, help="maximum resolution for buckets / bucketの最大解像度")
|
||||
parser.add_argument(
|
||||
"--bucket_reso_steps",
|
||||
type=int,
|
||||
@@ -289,10 +238,16 @@ def setup_parser() -> argparse.ArgumentParser:
|
||||
help="steps of resolution for buckets, divisible by 8 is recommended / bucketの解像度の単位、8で割り切れる値を推奨します",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--bucket_no_upscale", action="store_true", help="make bucket for each image without upscaling / 画像を拡大せずbucketを作成します"
|
||||
"--bucket_no_upscale",
|
||||
action="store_true",
|
||||
help="make bucket for each image without upscaling / 画像を拡大せずbucketを作成します",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--mixed_precision", type=str, default="no", choices=["no", "fp16", "bf16"], help="use mixed precision / 混合精度を使う場合、その精度"
|
||||
"--mixed_precision",
|
||||
type=str,
|
||||
default="no",
|
||||
choices=["no", "fp16", "bf16"],
|
||||
help="use mixed precision / 混合精度を使う場合、その精度",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--full_path",
|
||||
@@ -300,7 +255,15 @@ def setup_parser() -> argparse.ArgumentParser:
|
||||
help="use full path as image-key in metadata (supports multiple directories) / メタデータで画像キーをフルパスにする(複数の学習画像ディレクトリに対応)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--flip_aug", action="store_true", help="flip augmentation, save latents for flipped images / 左右反転した画像もlatentを取得、保存する"
|
||||
"--flip_aug",
|
||||
action="store_true",
|
||||
help="flip augmentation, save latents for flipped images / 左右反転した画像もlatentを取得、保存する",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--alpha_mask",
|
||||
type=str,
|
||||
default="",
|
||||
help="save alpha mask for images for loss calculation / 損失計算用に画像のアルファマスクを保存する",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--skip_existing",
|
||||
|
||||
@@ -1,18 +1,22 @@
|
||||
import argparse
|
||||
import csv
|
||||
import glob
|
||||
import os
|
||||
|
||||
from PIL import Image
|
||||
import cv2
|
||||
from tqdm import tqdm
|
||||
import numpy as np
|
||||
from tensorflow.keras.models import load_model
|
||||
from huggingface_hub import hf_hub_download
|
||||
import torch
|
||||
from pathlib import Path
|
||||
|
||||
import cv2
|
||||
import numpy as np
|
||||
import torch
|
||||
from huggingface_hub import hf_hub_download
|
||||
from PIL import Image
|
||||
from tqdm import tqdm
|
||||
|
||||
import library.train_util as train_util
|
||||
from library.utils import setup_logging, pil_resize
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# from wd14 tagger
|
||||
IMAGE_SIZE = 448
|
||||
@@ -20,6 +24,7 @@ IMAGE_SIZE = 448
|
||||
# wd-v1-4-swinv2-tagger-v2 / wd-v1-4-vit-tagger / wd-v1-4-vit-tagger-v2/ wd-v1-4-convnext-tagger / wd-v1-4-convnext-tagger-v2
|
||||
DEFAULT_WD14_TAGGER_REPO = "SmilingWolf/wd-v1-4-convnext-tagger-v2"
|
||||
FILES = ["keras_metadata.pb", "saved_model.pb", "selected_tags.csv"]
|
||||
FILES_ONNX = ["model.onnx"]
|
||||
SUB_DIR = "variables"
|
||||
SUB_DIR_FILES = ["variables.data-00000-of-00001", "variables.index"]
|
||||
CSV_FILE = FILES[-1]
|
||||
@@ -37,8 +42,10 @@ def preprocess_image(image):
|
||||
pad_t = pad_y // 2
|
||||
image = np.pad(image, ((pad_t, pad_y - pad_t), (pad_l, pad_x - pad_l), (0, 0)), mode="constant", constant_values=255)
|
||||
|
||||
interp = cv2.INTER_AREA if size > IMAGE_SIZE else cv2.INTER_LANCZOS4
|
||||
image = cv2.resize(image, (IMAGE_SIZE, IMAGE_SIZE), interpolation=interp)
|
||||
if size > IMAGE_SIZE:
|
||||
image = cv2.resize(image, (IMAGE_SIZE, IMAGE_SIZE), cv2.INTER_AREA)
|
||||
else:
|
||||
image = pil_resize(image, (IMAGE_SIZE, IMAGE_SIZE))
|
||||
|
||||
image = image.astype(np.float32)
|
||||
return image
|
||||
@@ -57,12 +64,12 @@ class ImageLoadingPrepDataset(torch.utils.data.Dataset):
|
||||
try:
|
||||
image = Image.open(img_path).convert("RGB")
|
||||
image = preprocess_image(image)
|
||||
tensor = torch.tensor(image)
|
||||
# tensor = torch.tensor(image) # これ Tensor に変換する必要ないな……(;・∀・)
|
||||
except Exception as e:
|
||||
print(f"Could not load image path / 画像を読み込めません: {img_path}, error: {e}")
|
||||
logger.error(f"Could not load image path / 画像を読み込めません: {img_path}, error: {e}")
|
||||
return None
|
||||
|
||||
return (tensor, img_path)
|
||||
return (image, img_path)
|
||||
|
||||
|
||||
def collate_fn_remove_corrupted(batch):
|
||||
@@ -76,101 +83,250 @@ def collate_fn_remove_corrupted(batch):
|
||||
|
||||
|
||||
def main(args):
|
||||
# model location is model_dir + repo_id
|
||||
# repo id may be like "user/repo" or "user/repo/branch", so we need to remove slash
|
||||
model_location = os.path.join(args.model_dir, args.repo_id.replace("/", "_"))
|
||||
|
||||
# hf_hub_downloadをそのまま使うとsymlink関係で問題があるらしいので、キャッシュディレクトリとforce_filenameを指定してなんとかする
|
||||
# depreacatedの警告が出るけどなくなったらその時
|
||||
# https://github.com/toriato/stable-diffusion-webui-wd14-tagger/issues/22
|
||||
if not os.path.exists(args.model_dir) or args.force_download:
|
||||
print(f"downloading wd14 tagger model from hf_hub. id: {args.repo_id}")
|
||||
for file in FILES:
|
||||
hf_hub_download(args.repo_id, file, cache_dir=args.model_dir, force_download=True, force_filename=file)
|
||||
for file in SUB_DIR_FILES:
|
||||
hf_hub_download(
|
||||
args.repo_id,
|
||||
file,
|
||||
subfolder=SUB_DIR,
|
||||
cache_dir=os.path.join(args.model_dir, SUB_DIR),
|
||||
force_download=True,
|
||||
force_filename=file,
|
||||
if not os.path.exists(model_location) or args.force_download:
|
||||
os.makedirs(args.model_dir, exist_ok=True)
|
||||
logger.info(f"downloading wd14 tagger model from hf_hub. id: {args.repo_id}")
|
||||
files = FILES
|
||||
if args.onnx:
|
||||
files = ["selected_tags.csv"]
|
||||
files += FILES_ONNX
|
||||
else:
|
||||
for file in SUB_DIR_FILES:
|
||||
hf_hub_download(
|
||||
args.repo_id,
|
||||
file,
|
||||
subfolder=SUB_DIR,
|
||||
cache_dir=os.path.join(model_location, SUB_DIR),
|
||||
force_download=True,
|
||||
force_filename=file,
|
||||
)
|
||||
for file in files:
|
||||
hf_hub_download(args.repo_id, file, cache_dir=model_location, force_download=True, force_filename=file)
|
||||
else:
|
||||
logger.info("using existing wd14 tagger model")
|
||||
|
||||
# モデルを読み込む
|
||||
if args.onnx:
|
||||
import onnx
|
||||
import onnxruntime as ort
|
||||
|
||||
onnx_path = f"{model_location}/model.onnx"
|
||||
logger.info("Running wd14 tagger with onnx")
|
||||
logger.info(f"loading onnx model: {onnx_path}")
|
||||
|
||||
if not os.path.exists(onnx_path):
|
||||
raise Exception(
|
||||
f"onnx model not found: {onnx_path}, please redownload the model with --force_download"
|
||||
+ " / onnxモデルが見つかりませんでした。--force_downloadで再ダウンロードしてください"
|
||||
)
|
||||
|
||||
model = onnx.load(onnx_path)
|
||||
input_name = model.graph.input[0].name
|
||||
try:
|
||||
batch_size = model.graph.input[0].type.tensor_type.shape.dim[0].dim_value
|
||||
except Exception:
|
||||
batch_size = model.graph.input[0].type.tensor_type.shape.dim[0].dim_param
|
||||
|
||||
if args.batch_size != batch_size and not isinstance(batch_size, str) and batch_size > 0:
|
||||
# some rebatch model may use 'N' as dynamic axes
|
||||
logger.warning(
|
||||
f"Batch size {args.batch_size} doesn't match onnx model batch size {batch_size}, use model batch size {batch_size}"
|
||||
)
|
||||
args.batch_size = batch_size
|
||||
|
||||
del model
|
||||
|
||||
if "OpenVINOExecutionProvider" in ort.get_available_providers():
|
||||
# requires provider options for gpu support
|
||||
# fp16 causes nonsense outputs
|
||||
ort_sess = ort.InferenceSession(
|
||||
onnx_path,
|
||||
providers=(["OpenVINOExecutionProvider"]),
|
||||
provider_options=[{'device_type' : "GPU_FP32"}],
|
||||
)
|
||||
else:
|
||||
ort_sess = ort.InferenceSession(
|
||||
onnx_path,
|
||||
providers=(
|
||||
["CUDAExecutionProvider"] if "CUDAExecutionProvider" in ort.get_available_providers() else
|
||||
["ROCMExecutionProvider"] if "ROCMExecutionProvider" in ort.get_available_providers() else
|
||||
["CPUExecutionProvider"]
|
||||
),
|
||||
)
|
||||
else:
|
||||
print("using existing wd14 tagger model")
|
||||
from tensorflow.keras.models import load_model
|
||||
|
||||
# 画像を読み込む
|
||||
model = load_model(args.model_dir)
|
||||
model = load_model(f"{model_location}")
|
||||
|
||||
# label_names = pd.read_csv("2022_0000_0899_6549/selected_tags.csv")
|
||||
# 依存ライブラリを増やしたくないので自力で読むよ
|
||||
|
||||
with open(os.path.join(args.model_dir, CSV_FILE), "r", encoding="utf-8") as f:
|
||||
with open(os.path.join(model_location, CSV_FILE), "r", encoding="utf-8") as f:
|
||||
reader = csv.reader(f)
|
||||
l = [row for row in reader]
|
||||
header = l[0] # tag_id,name,category,count
|
||||
rows = l[1:]
|
||||
line = [row for row in reader]
|
||||
header = line[0] # tag_id,name,category,count
|
||||
rows = line[1:]
|
||||
assert header[0] == "tag_id" and header[1] == "name" and header[2] == "category", f"unexpected csv format: {header}"
|
||||
|
||||
general_tags = [row[1] for row in rows[1:] if row[2] == "0"]
|
||||
character_tags = [row[1] for row in rows[1:] if row[2] == "4"]
|
||||
rating_tags = [row[1] for row in rows[0:] if row[2] == "9"]
|
||||
general_tags = [row[1] for row in rows[0:] if row[2] == "0"]
|
||||
character_tags = [row[1] for row in rows[0:] if row[2] == "4"]
|
||||
|
||||
# preprocess tags in advance
|
||||
if args.character_tag_expand:
|
||||
for i, tag in enumerate(character_tags):
|
||||
if tag.endswith(")"):
|
||||
# chara_name_(series) -> chara_name, series
|
||||
# chara_name_(costume)_(series) -> chara_name_(costume), series
|
||||
tags = tag.split("(")
|
||||
character_tag = "(".join(tags[:-1])
|
||||
if character_tag.endswith("_"):
|
||||
character_tag = character_tag[:-1]
|
||||
series_tag = tags[-1].replace(")", "")
|
||||
character_tags[i] = character_tag + args.caption_separator + series_tag
|
||||
|
||||
if args.remove_underscore:
|
||||
rating_tags = [tag.replace("_", " ") if len(tag) > 3 else tag for tag in rating_tags]
|
||||
general_tags = [tag.replace("_", " ") if len(tag) > 3 else tag for tag in general_tags]
|
||||
character_tags = [tag.replace("_", " ") if len(tag) > 3 else tag for tag in character_tags]
|
||||
|
||||
if args.tag_replacement is not None:
|
||||
# escape , and ; in tag_replacement: wd14 tag names may contain , and ;
|
||||
escaped_tag_replacements = args.tag_replacement.replace("\\,", "@@@@").replace("\\;", "####")
|
||||
tag_replacements = escaped_tag_replacements.split(";")
|
||||
for tag_replacement in tag_replacements:
|
||||
tags = tag_replacement.split(",") # source, target
|
||||
assert len(tags) == 2, f"tag replacement must be in the format of `source,target` / タグの置換は `置換元,置換先` の形式で指定してください: {args.tag_replacement}"
|
||||
|
||||
source, target = [tag.replace("@@@@", ",").replace("####", ";") for tag in tags]
|
||||
logger.info(f"replacing tag: {source} -> {target}")
|
||||
|
||||
if source in general_tags:
|
||||
general_tags[general_tags.index(source)] = target
|
||||
elif source in character_tags:
|
||||
character_tags[character_tags.index(source)] = target
|
||||
elif source in rating_tags:
|
||||
rating_tags[rating_tags.index(source)] = target
|
||||
|
||||
# 画像を読み込む
|
||||
|
||||
train_data_dir_path = Path(args.train_data_dir)
|
||||
image_paths = train_util.glob_images_pathlib(train_data_dir_path, args.recursive)
|
||||
print(f"found {len(image_paths)} images.")
|
||||
logger.info(f"found {len(image_paths)} images.")
|
||||
|
||||
tag_freq = {}
|
||||
|
||||
undesired_tags = set(args.undesired_tags.split(","))
|
||||
caption_separator = args.caption_separator
|
||||
stripped_caption_separator = caption_separator.strip()
|
||||
undesired_tags = args.undesired_tags.split(stripped_caption_separator)
|
||||
undesired_tags = set([tag.strip() for tag in undesired_tags if tag.strip() != ""])
|
||||
|
||||
always_first_tags = None
|
||||
if args.always_first_tags is not None:
|
||||
always_first_tags = [tag for tag in args.always_first_tags.split(stripped_caption_separator) if tag.strip() != ""]
|
||||
|
||||
def run_batch(path_imgs):
|
||||
imgs = np.array([im for _, im in path_imgs])
|
||||
|
||||
probs = model(imgs, training=False)
|
||||
probs = probs.numpy()
|
||||
if args.onnx:
|
||||
# if len(imgs) < args.batch_size:
|
||||
# imgs = np.concatenate([imgs, np.zeros((args.batch_size - len(imgs), IMAGE_SIZE, IMAGE_SIZE, 3))], axis=0)
|
||||
probs = ort_sess.run(None, {input_name: imgs})[0] # onnx output numpy
|
||||
probs = probs[: len(path_imgs)]
|
||||
else:
|
||||
probs = model(imgs, training=False)
|
||||
probs = probs.numpy()
|
||||
|
||||
for (image_path, _), prob in zip(path_imgs, probs):
|
||||
# 最初の4つはratingなので無視する
|
||||
# # First 4 labels are actually ratings: pick one with argmax
|
||||
# ratings_names = label_names[:4]
|
||||
# rating_index = ratings_names["probs"].argmax()
|
||||
# found_rating = ratings_names[rating_index: rating_index + 1][["name", "probs"]]
|
||||
|
||||
# それ以降はタグなのでconfidenceがthresholdより高いものを追加する
|
||||
# Everything else is tags: pick any where prediction confidence > threshold
|
||||
combined_tags = []
|
||||
general_tag_text = ""
|
||||
rating_tag_text = ""
|
||||
character_tag_text = ""
|
||||
general_tag_text = ""
|
||||
|
||||
# 最初の4つ以降はタグなのでconfidenceがthreshold以上のものを追加する
|
||||
# First 4 labels are ratings, the rest are tags: pick any where prediction confidence >= threshold
|
||||
for i, p in enumerate(prob[4:]):
|
||||
if i < len(general_tags) and p >= args.general_threshold:
|
||||
tag_name = general_tags[i]
|
||||
if args.remove_underscore and len(tag_name) > 3: # ignore emoji tags like >_< and ^_^
|
||||
tag_name = tag_name.replace("_", " ")
|
||||
|
||||
if tag_name not in undesired_tags:
|
||||
tag_freq[tag_name] = tag_freq.get(tag_name, 0) + 1
|
||||
general_tag_text += ", " + tag_name
|
||||
general_tag_text += caption_separator + tag_name
|
||||
combined_tags.append(tag_name)
|
||||
elif i >= len(general_tags) and p >= args.character_threshold:
|
||||
tag_name = character_tags[i - len(general_tags)]
|
||||
if args.remove_underscore and len(tag_name) > 3:
|
||||
tag_name = tag_name.replace("_", " ")
|
||||
|
||||
if tag_name not in undesired_tags:
|
||||
tag_freq[tag_name] = tag_freq.get(tag_name, 0) + 1
|
||||
character_tag_text += ", " + tag_name
|
||||
combined_tags.append(tag_name)
|
||||
character_tag_text += caption_separator + tag_name
|
||||
if args.character_tags_first: # insert to the beginning
|
||||
combined_tags.insert(0, tag_name)
|
||||
else:
|
||||
combined_tags.append(tag_name)
|
||||
|
||||
# 最初の4つはratingなのでargmaxで選ぶ
|
||||
# First 4 labels are actually ratings: pick one with argmax
|
||||
if args.use_rating_tags or args.use_rating_tags_as_last_tag:
|
||||
ratings_probs = prob[:4]
|
||||
rating_index = ratings_probs.argmax()
|
||||
found_rating = rating_tags[rating_index]
|
||||
|
||||
if found_rating not in undesired_tags:
|
||||
tag_freq[found_rating] = tag_freq.get(found_rating, 0) + 1
|
||||
rating_tag_text = found_rating
|
||||
if args.use_rating_tags:
|
||||
combined_tags.insert(0, found_rating) # insert to the beginning
|
||||
else:
|
||||
combined_tags.append(found_rating)
|
||||
|
||||
# 一番最初に置くタグを指定する
|
||||
# Always put some tags at the beginning
|
||||
if always_first_tags is not None:
|
||||
for tag in always_first_tags:
|
||||
if tag in combined_tags:
|
||||
combined_tags.remove(tag)
|
||||
combined_tags.insert(0, tag)
|
||||
|
||||
# 先頭のカンマを取る
|
||||
if len(general_tag_text) > 0:
|
||||
general_tag_text = general_tag_text[2:]
|
||||
general_tag_text = general_tag_text[len(caption_separator) :]
|
||||
if len(character_tag_text) > 0:
|
||||
character_tag_text = character_tag_text[2:]
|
||||
character_tag_text = character_tag_text[len(caption_separator) :]
|
||||
|
||||
tag_text = ", ".join(combined_tags)
|
||||
caption_file = os.path.splitext(image_path)[0] + args.caption_extension
|
||||
|
||||
with open(os.path.splitext(image_path)[0] + args.caption_extension, "wt", encoding="utf-8") as f:
|
||||
tag_text = caption_separator.join(combined_tags)
|
||||
|
||||
if args.append_tags:
|
||||
# Check if file exists
|
||||
if os.path.exists(caption_file):
|
||||
with open(caption_file, "rt", encoding="utf-8") as f:
|
||||
# Read file and remove new lines
|
||||
existing_content = f.read().strip("\n") # Remove newlines
|
||||
|
||||
# Split the content into tags and store them in a list
|
||||
existing_tags = [tag.strip() for tag in existing_content.split(stripped_caption_separator) if tag.strip()]
|
||||
|
||||
# Check and remove repeating tags in tag_text
|
||||
new_tags = [tag for tag in combined_tags if tag not in existing_tags]
|
||||
|
||||
# Create new tag_text
|
||||
tag_text = caption_separator.join(existing_tags + new_tags)
|
||||
|
||||
with open(caption_file, "wt", encoding="utf-8") as f:
|
||||
f.write(tag_text + "\n")
|
||||
if args.debug:
|
||||
print(f"\n{image_path}:\n Character tags: {character_tag_text}\n General tags: {general_tag_text}")
|
||||
logger.info("")
|
||||
logger.info(f"{image_path}:")
|
||||
logger.info(f"\tRating tags: {rating_tag_text}")
|
||||
logger.info(f"\tCharacter tags: {character_tag_text}")
|
||||
logger.info(f"\tGeneral tags: {general_tag_text}")
|
||||
|
||||
# 読み込みの高速化のためにDataLoaderを使うオプション
|
||||
if args.max_data_loader_n_workers is not None:
|
||||
@@ -193,16 +349,14 @@ def main(args):
|
||||
continue
|
||||
|
||||
image, image_path = data
|
||||
if image is not None:
|
||||
image = image.detach().numpy()
|
||||
else:
|
||||
if image is None:
|
||||
try:
|
||||
image = Image.open(image_path)
|
||||
if image.mode != "RGB":
|
||||
image = image.convert("RGB")
|
||||
image = preprocess_image(image)
|
||||
except Exception as e:
|
||||
print(f"Could not load image path / 画像を読み込めません: {image_path}, error: {e}")
|
||||
logger.error(f"Could not load image path / 画像を読み込めません: {image_path}, error: {e}")
|
||||
continue
|
||||
b_imgs.append((image_path, image))
|
||||
|
||||
@@ -217,16 +371,18 @@ def main(args):
|
||||
|
||||
if args.frequency_tags:
|
||||
sorted_tags = sorted(tag_freq.items(), key=lambda x: x[1], reverse=True)
|
||||
print("\nTag frequencies:")
|
||||
print("Tag frequencies:")
|
||||
for tag, freq in sorted_tags:
|
||||
print(f"{tag}: {freq}")
|
||||
|
||||
print("done!")
|
||||
logger.info("done!")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("train_data_dir", type=str, help="directory for train images / 学習画像データのディレクトリ")
|
||||
parser.add_argument(
|
||||
"train_data_dir", type=str, help="directory for train images / 学習画像データのディレクトリ"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--repo_id",
|
||||
type=str,
|
||||
@@ -240,9 +396,13 @@ if __name__ == "__main__":
|
||||
help="directory to store wd14 tagger model / wd14 taggerのモデルを格納するディレクトリ",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--force_download", action="store_true", help="force downloading wd14 tagger models / wd14 taggerのモデルを再ダウンロードします"
|
||||
"--force_download",
|
||||
action="store_true",
|
||||
help="force downloading wd14 tagger models / wd14 taggerのモデルを再ダウンロードします",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--batch_size", type=int, default=1, help="batch size in inference / 推論時のバッチサイズ"
|
||||
)
|
||||
parser.add_argument("--batch_size", type=int, default=1, help="batch size in inference / 推論時のバッチサイズ")
|
||||
parser.add_argument(
|
||||
"--max_data_loader_n_workers",
|
||||
type=int,
|
||||
@@ -255,8 +415,12 @@ if __name__ == "__main__":
|
||||
default=None,
|
||||
help="extension of caption file (for backward compatibility) / 出力されるキャプションファイルの拡張子(スペルミスしていたのを残してあります)",
|
||||
)
|
||||
parser.add_argument("--caption_extension", type=str, default=".txt", help="extension of caption file / 出力されるキャプションファイルの拡張子")
|
||||
parser.add_argument("--thresh", type=float, default=0.35, help="threshold of confidence to add a tag / タグを追加するか判定する閾値")
|
||||
parser.add_argument(
|
||||
"--caption_extension", type=str, default=".txt", help="extension of caption file / 出力されるキャプションファイルの拡張子"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--thresh", type=float, default=0.35, help="threshold of confidence to add a tag / タグを追加するか判定する閾値"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--general_threshold",
|
||||
type=float,
|
||||
@@ -269,20 +433,73 @@ if __name__ == "__main__":
|
||||
default=None,
|
||||
help="threshold of confidence to add a tag for character category, same as --thres if omitted / characterカテゴリのタグを追加するための確信度の閾値、省略時は --thresh と同じ",
|
||||
)
|
||||
parser.add_argument("--recursive", action="store_true", help="search for images in subfolders recursively / サブフォルダを再帰的に検索する")
|
||||
parser.add_argument(
|
||||
"--recursive", action="store_true", help="search for images in subfolders recursively / サブフォルダを再帰的に検索する"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--remove_underscore",
|
||||
action="store_true",
|
||||
help="replace underscores with spaces in the output tags / 出力されるタグのアンダースコアをスペースに置き換える",
|
||||
)
|
||||
parser.add_argument("--debug", action="store_true", help="debug mode")
|
||||
parser.add_argument(
|
||||
"--debug", action="store_true", help="debug mode"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--undesired_tags",
|
||||
type=str,
|
||||
default="",
|
||||
help="comma-separated list of undesired tags to remove from the output / 出力から除外したいタグのカンマ区切りのリスト",
|
||||
)
|
||||
parser.add_argument("--frequency_tags", action="store_true", help="Show frequency of tags for images / 画像ごとのタグの出現頻度を表示する")
|
||||
parser.add_argument(
|
||||
"--frequency_tags", action="store_true", help="Show frequency of tags for images / タグの出現頻度を表示する"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--onnx", action="store_true", help="use onnx model for inference / onnxモデルを推論に使用する"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--append_tags", action="store_true", help="Append captions instead of overwriting / 上書きではなくキャプションを追記する"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--use_rating_tags", action="store_true", help="Adds rating tags as the first tag / レーティングタグを最初のタグとして追加する",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--use_rating_tags_as_last_tag", action="store_true", help="Adds rating tags as the last tag / レーティングタグを最後のタグとして追加する",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--character_tags_first", action="store_true", help="Always inserts character tags before the general tags / characterタグを常にgeneralタグの前に出力する",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--always_first_tags",
|
||||
type=str,
|
||||
default=None,
|
||||
help="comma-separated list of tags to always put at the beginning, e.g. `1girl,1boy`"
|
||||
+ " / 必ず先頭に置くタグのカンマ区切りリスト、例 : `1girl,1boy`",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--caption_separator",
|
||||
type=str,
|
||||
default=", ",
|
||||
help="Separator for captions, include space if needed / キャプションの区切り文字、必要ならスペースを含めてください",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--tag_replacement",
|
||||
type=str,
|
||||
default=None,
|
||||
help="tag replacement in the format of `source1,target1;source2,target2; ...`. Escape `,` and `;` with `\`. e.g. `tag1,tag2;tag3,tag4`"
|
||||
+ " / タグの置換を `置換元1,置換先1;置換元2,置換先2; ...`で指定する。`\` で `,` と `;` をエスケープできる。例: `tag1,tag2;tag3,tag4`",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--character_tag_expand",
|
||||
action="store_true",
|
||||
help="expand tag tail parenthesis to another tag for character tags. `chara_name_(series)` becomes `chara_name, series`"
|
||||
+ " / キャラクタタグの末尾の括弧を別のタグに展開する。`chara_name_(series)` は `chara_name, series` になる",
|
||||
)
|
||||
|
||||
return parser
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
|
||||
3358
gen_img.py
Normal file
3358
gen_img.py
Normal file
File diff suppressed because it is too large
Load Diff
1471
gen_img_diffusers.py
1471
gen_img_diffusers.py
File diff suppressed because it is too large
Load Diff
106
library/adafactor_fused.py
Normal file
106
library/adafactor_fused.py
Normal file
@@ -0,0 +1,106 @@
|
||||
import math
|
||||
import torch
|
||||
from transformers import Adafactor
|
||||
|
||||
@torch.no_grad()
|
||||
def adafactor_step_param(self, p, group):
|
||||
if p.grad is None:
|
||||
return
|
||||
grad = p.grad
|
||||
if grad.dtype in {torch.float16, torch.bfloat16}:
|
||||
grad = grad.float()
|
||||
if grad.is_sparse:
|
||||
raise RuntimeError("Adafactor does not support sparse gradients.")
|
||||
|
||||
state = self.state[p]
|
||||
grad_shape = grad.shape
|
||||
|
||||
factored, use_first_moment = Adafactor._get_options(group, grad_shape)
|
||||
# State Initialization
|
||||
if len(state) == 0:
|
||||
state["step"] = 0
|
||||
|
||||
if use_first_moment:
|
||||
# Exponential moving average of gradient values
|
||||
state["exp_avg"] = torch.zeros_like(grad)
|
||||
if factored:
|
||||
state["exp_avg_sq_row"] = torch.zeros(grad_shape[:-1]).to(grad)
|
||||
state["exp_avg_sq_col"] = torch.zeros(grad_shape[:-2] + grad_shape[-1:]).to(grad)
|
||||
else:
|
||||
state["exp_avg_sq"] = torch.zeros_like(grad)
|
||||
|
||||
state["RMS"] = 0
|
||||
else:
|
||||
if use_first_moment:
|
||||
state["exp_avg"] = state["exp_avg"].to(grad)
|
||||
if factored:
|
||||
state["exp_avg_sq_row"] = state["exp_avg_sq_row"].to(grad)
|
||||
state["exp_avg_sq_col"] = state["exp_avg_sq_col"].to(grad)
|
||||
else:
|
||||
state["exp_avg_sq"] = state["exp_avg_sq"].to(grad)
|
||||
|
||||
p_data_fp32 = p
|
||||
if p.dtype in {torch.float16, torch.bfloat16}:
|
||||
p_data_fp32 = p_data_fp32.float()
|
||||
|
||||
state["step"] += 1
|
||||
state["RMS"] = Adafactor._rms(p_data_fp32)
|
||||
lr = Adafactor._get_lr(group, state)
|
||||
|
||||
beta2t = 1.0 - math.pow(state["step"], group["decay_rate"])
|
||||
update = (grad ** 2) + group["eps"][0]
|
||||
if factored:
|
||||
exp_avg_sq_row = state["exp_avg_sq_row"]
|
||||
exp_avg_sq_col = state["exp_avg_sq_col"]
|
||||
|
||||
exp_avg_sq_row.mul_(beta2t).add_(update.mean(dim=-1), alpha=(1.0 - beta2t))
|
||||
exp_avg_sq_col.mul_(beta2t).add_(update.mean(dim=-2), alpha=(1.0 - beta2t))
|
||||
|
||||
# Approximation of exponential moving average of square of gradient
|
||||
update = Adafactor._approx_sq_grad(exp_avg_sq_row, exp_avg_sq_col)
|
||||
update.mul_(grad)
|
||||
else:
|
||||
exp_avg_sq = state["exp_avg_sq"]
|
||||
|
||||
exp_avg_sq.mul_(beta2t).add_(update, alpha=(1.0 - beta2t))
|
||||
update = exp_avg_sq.rsqrt().mul_(grad)
|
||||
|
||||
update.div_((Adafactor._rms(update) / group["clip_threshold"]).clamp_(min=1.0))
|
||||
update.mul_(lr)
|
||||
|
||||
if use_first_moment:
|
||||
exp_avg = state["exp_avg"]
|
||||
exp_avg.mul_(group["beta1"]).add_(update, alpha=(1 - group["beta1"]))
|
||||
update = exp_avg
|
||||
|
||||
if group["weight_decay"] != 0:
|
||||
p_data_fp32.add_(p_data_fp32, alpha=(-group["weight_decay"] * lr))
|
||||
|
||||
p_data_fp32.add_(-update)
|
||||
|
||||
if p.dtype in {torch.float16, torch.bfloat16}:
|
||||
p.copy_(p_data_fp32)
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def adafactor_step(self, closure=None):
|
||||
"""
|
||||
Performs a single optimization step
|
||||
|
||||
Arguments:
|
||||
closure (callable, optional): A closure that reevaluates the model
|
||||
and returns the loss.
|
||||
"""
|
||||
loss = None
|
||||
if closure is not None:
|
||||
loss = closure()
|
||||
|
||||
for group in self.param_groups:
|
||||
for p in group["params"]:
|
||||
adafactor_step_param(self, p, group)
|
||||
|
||||
return loss
|
||||
|
||||
def patch_adafactor_fused(optimizer: Adafactor):
|
||||
optimizer.step_param = adafactor_step_param.__get__(optimizer)
|
||||
optimizer.step = adafactor_step.__get__(optimizer)
|
||||
227
library/attention_processors.py
Normal file
227
library/attention_processors.py
Normal file
@@ -0,0 +1,227 @@
|
||||
import math
|
||||
from typing import Any
|
||||
from einops import rearrange
|
||||
import torch
|
||||
from diffusers.models.attention_processor import Attention
|
||||
|
||||
|
||||
# flash attention forwards and backwards
|
||||
|
||||
# https://arxiv.org/abs/2205.14135
|
||||
|
||||
EPSILON = 1e-6
|
||||
|
||||
|
||||
class FlashAttentionFunction(torch.autograd.function.Function):
|
||||
@staticmethod
|
||||
@torch.no_grad()
|
||||
def forward(ctx, q, k, v, mask, causal, q_bucket_size, k_bucket_size):
|
||||
"""Algorithm 2 in the paper"""
|
||||
|
||||
device = q.device
|
||||
dtype = q.dtype
|
||||
max_neg_value = -torch.finfo(q.dtype).max
|
||||
qk_len_diff = max(k.shape[-2] - q.shape[-2], 0)
|
||||
|
||||
o = torch.zeros_like(q)
|
||||
all_row_sums = torch.zeros((*q.shape[:-1], 1), dtype=dtype, device=device)
|
||||
all_row_maxes = torch.full(
|
||||
(*q.shape[:-1], 1), max_neg_value, dtype=dtype, device=device
|
||||
)
|
||||
|
||||
scale = q.shape[-1] ** -0.5
|
||||
|
||||
if mask is None:
|
||||
mask = (None,) * math.ceil(q.shape[-2] / q_bucket_size)
|
||||
else:
|
||||
mask = rearrange(mask, "b n -> b 1 1 n")
|
||||
mask = mask.split(q_bucket_size, dim=-1)
|
||||
|
||||
row_splits = zip(
|
||||
q.split(q_bucket_size, dim=-2),
|
||||
o.split(q_bucket_size, dim=-2),
|
||||
mask,
|
||||
all_row_sums.split(q_bucket_size, dim=-2),
|
||||
all_row_maxes.split(q_bucket_size, dim=-2),
|
||||
)
|
||||
|
||||
for ind, (qc, oc, row_mask, row_sums, row_maxes) in enumerate(row_splits):
|
||||
q_start_index = ind * q_bucket_size - qk_len_diff
|
||||
|
||||
col_splits = zip(
|
||||
k.split(k_bucket_size, dim=-2),
|
||||
v.split(k_bucket_size, dim=-2),
|
||||
)
|
||||
|
||||
for k_ind, (kc, vc) in enumerate(col_splits):
|
||||
k_start_index = k_ind * k_bucket_size
|
||||
|
||||
attn_weights = (
|
||||
torch.einsum("... i d, ... j d -> ... i j", qc, kc) * scale
|
||||
)
|
||||
|
||||
if row_mask is not None:
|
||||
attn_weights.masked_fill_(~row_mask, max_neg_value)
|
||||
|
||||
if causal and q_start_index < (k_start_index + k_bucket_size - 1):
|
||||
causal_mask = torch.ones(
|
||||
(qc.shape[-2], kc.shape[-2]), dtype=torch.bool, device=device
|
||||
).triu(q_start_index - k_start_index + 1)
|
||||
attn_weights.masked_fill_(causal_mask, max_neg_value)
|
||||
|
||||
block_row_maxes = attn_weights.amax(dim=-1, keepdims=True)
|
||||
attn_weights -= block_row_maxes
|
||||
exp_weights = torch.exp(attn_weights)
|
||||
|
||||
if row_mask is not None:
|
||||
exp_weights.masked_fill_(~row_mask, 0.0)
|
||||
|
||||
block_row_sums = exp_weights.sum(dim=-1, keepdims=True).clamp(
|
||||
min=EPSILON
|
||||
)
|
||||
|
||||
new_row_maxes = torch.maximum(block_row_maxes, row_maxes)
|
||||
|
||||
exp_values = torch.einsum(
|
||||
"... i j, ... j d -> ... i d", exp_weights, vc
|
||||
)
|
||||
|
||||
exp_row_max_diff = torch.exp(row_maxes - new_row_maxes)
|
||||
exp_block_row_max_diff = torch.exp(block_row_maxes - new_row_maxes)
|
||||
|
||||
new_row_sums = (
|
||||
exp_row_max_diff * row_sums
|
||||
+ exp_block_row_max_diff * block_row_sums
|
||||
)
|
||||
|
||||
oc.mul_((row_sums / new_row_sums) * exp_row_max_diff).add_(
|
||||
(exp_block_row_max_diff / new_row_sums) * exp_values
|
||||
)
|
||||
|
||||
row_maxes.copy_(new_row_maxes)
|
||||
row_sums.copy_(new_row_sums)
|
||||
|
||||
ctx.args = (causal, scale, mask, q_bucket_size, k_bucket_size)
|
||||
ctx.save_for_backward(q, k, v, o, all_row_sums, all_row_maxes)
|
||||
|
||||
return o
|
||||
|
||||
@staticmethod
|
||||
@torch.no_grad()
|
||||
def backward(ctx, do):
|
||||
"""Algorithm 4 in the paper"""
|
||||
|
||||
causal, scale, mask, q_bucket_size, k_bucket_size = ctx.args
|
||||
q, k, v, o, l, m = ctx.saved_tensors
|
||||
|
||||
device = q.device
|
||||
|
||||
max_neg_value = -torch.finfo(q.dtype).max
|
||||
qk_len_diff = max(k.shape[-2] - q.shape[-2], 0)
|
||||
|
||||
dq = torch.zeros_like(q)
|
||||
dk = torch.zeros_like(k)
|
||||
dv = torch.zeros_like(v)
|
||||
|
||||
row_splits = zip(
|
||||
q.split(q_bucket_size, dim=-2),
|
||||
o.split(q_bucket_size, dim=-2),
|
||||
do.split(q_bucket_size, dim=-2),
|
||||
mask,
|
||||
l.split(q_bucket_size, dim=-2),
|
||||
m.split(q_bucket_size, dim=-2),
|
||||
dq.split(q_bucket_size, dim=-2),
|
||||
)
|
||||
|
||||
for ind, (qc, oc, doc, row_mask, lc, mc, dqc) in enumerate(row_splits):
|
||||
q_start_index = ind * q_bucket_size - qk_len_diff
|
||||
|
||||
col_splits = zip(
|
||||
k.split(k_bucket_size, dim=-2),
|
||||
v.split(k_bucket_size, dim=-2),
|
||||
dk.split(k_bucket_size, dim=-2),
|
||||
dv.split(k_bucket_size, dim=-2),
|
||||
)
|
||||
|
||||
for k_ind, (kc, vc, dkc, dvc) in enumerate(col_splits):
|
||||
k_start_index = k_ind * k_bucket_size
|
||||
|
||||
attn_weights = (
|
||||
torch.einsum("... i d, ... j d -> ... i j", qc, kc) * scale
|
||||
)
|
||||
|
||||
if causal and q_start_index < (k_start_index + k_bucket_size - 1):
|
||||
causal_mask = torch.ones(
|
||||
(qc.shape[-2], kc.shape[-2]), dtype=torch.bool, device=device
|
||||
).triu(q_start_index - k_start_index + 1)
|
||||
attn_weights.masked_fill_(causal_mask, max_neg_value)
|
||||
|
||||
exp_attn_weights = torch.exp(attn_weights - mc)
|
||||
|
||||
if row_mask is not None:
|
||||
exp_attn_weights.masked_fill_(~row_mask, 0.0)
|
||||
|
||||
p = exp_attn_weights / lc
|
||||
|
||||
dv_chunk = torch.einsum("... i j, ... i d -> ... j d", p, doc)
|
||||
dp = torch.einsum("... i d, ... j d -> ... i j", doc, vc)
|
||||
|
||||
D = (doc * oc).sum(dim=-1, keepdims=True)
|
||||
ds = p * scale * (dp - D)
|
||||
|
||||
dq_chunk = torch.einsum("... i j, ... j d -> ... i d", ds, kc)
|
||||
dk_chunk = torch.einsum("... i j, ... i d -> ... j d", ds, qc)
|
||||
|
||||
dqc.add_(dq_chunk)
|
||||
dkc.add_(dk_chunk)
|
||||
dvc.add_(dv_chunk)
|
||||
|
||||
return dq, dk, dv, None, None, None, None
|
||||
|
||||
|
||||
class FlashAttnProcessor:
|
||||
def __call__(
|
||||
self,
|
||||
attn: Attention,
|
||||
hidden_states,
|
||||
encoder_hidden_states=None,
|
||||
attention_mask=None,
|
||||
) -> Any:
|
||||
q_bucket_size = 512
|
||||
k_bucket_size = 1024
|
||||
|
||||
h = attn.heads
|
||||
q = attn.to_q(hidden_states)
|
||||
|
||||
encoder_hidden_states = (
|
||||
encoder_hidden_states
|
||||
if encoder_hidden_states is not None
|
||||
else hidden_states
|
||||
)
|
||||
encoder_hidden_states = encoder_hidden_states.to(hidden_states.dtype)
|
||||
|
||||
if hasattr(attn, "hypernetwork") and attn.hypernetwork is not None:
|
||||
context_k, context_v = attn.hypernetwork.forward(
|
||||
hidden_states, encoder_hidden_states
|
||||
)
|
||||
context_k = context_k.to(hidden_states.dtype)
|
||||
context_v = context_v.to(hidden_states.dtype)
|
||||
else:
|
||||
context_k = encoder_hidden_states
|
||||
context_v = encoder_hidden_states
|
||||
|
||||
k = attn.to_k(context_k)
|
||||
v = attn.to_v(context_v)
|
||||
del encoder_hidden_states, hidden_states
|
||||
|
||||
q, k, v = map(lambda t: rearrange(t, "b n (h d) -> b h n d", h=h), (q, k, v))
|
||||
|
||||
out = FlashAttentionFunction.apply(
|
||||
q, k, v, attention_mask, False, q_bucket_size, k_bucket_size
|
||||
)
|
||||
|
||||
out = rearrange(out, "b h n d -> b n (h d)")
|
||||
|
||||
out = attn.to_out[0](out)
|
||||
out = attn.to_out[1](out)
|
||||
return out
|
||||
File diff suppressed because it is too large
Load Diff
@@ -1,23 +1,115 @@
|
||||
import torch
|
||||
import argparse
|
||||
import random
|
||||
import re
|
||||
from typing import List, Optional, Union
|
||||
from .utils import setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
def apply_snr_weight(loss, timesteps, noise_scheduler, gamma):
|
||||
def prepare_scheduler_for_custom_training(noise_scheduler, device):
|
||||
if hasattr(noise_scheduler, "all_snr"):
|
||||
return
|
||||
|
||||
alphas_cumprod = noise_scheduler.alphas_cumprod
|
||||
sqrt_alphas_cumprod = torch.sqrt(alphas_cumprod)
|
||||
sqrt_one_minus_alphas_cumprod = torch.sqrt(1.0 - alphas_cumprod)
|
||||
alpha = sqrt_alphas_cumprod
|
||||
sigma = sqrt_one_minus_alphas_cumprod
|
||||
all_snr = (alpha / sigma) ** 2
|
||||
snr = torch.stack([all_snr[t] for t in timesteps])
|
||||
gamma_over_snr = torch.div(torch.ones_like(snr) * gamma, snr)
|
||||
snr_weight = torch.minimum(gamma_over_snr, torch.ones_like(gamma_over_snr)).float() # from paper
|
||||
|
||||
noise_scheduler.all_snr = all_snr.to(device)
|
||||
|
||||
|
||||
def fix_noise_scheduler_betas_for_zero_terminal_snr(noise_scheduler):
|
||||
# fix beta: zero terminal SNR
|
||||
logger.info(f"fix noise scheduler betas: https://arxiv.org/abs/2305.08891")
|
||||
|
||||
def enforce_zero_terminal_snr(betas):
|
||||
# Convert betas to alphas_bar_sqrt
|
||||
alphas = 1 - betas
|
||||
alphas_bar = alphas.cumprod(0)
|
||||
alphas_bar_sqrt = alphas_bar.sqrt()
|
||||
|
||||
# Store old values.
|
||||
alphas_bar_sqrt_0 = alphas_bar_sqrt[0].clone()
|
||||
alphas_bar_sqrt_T = alphas_bar_sqrt[-1].clone()
|
||||
# Shift so last timestep is zero.
|
||||
alphas_bar_sqrt -= alphas_bar_sqrt_T
|
||||
# Scale so first timestep is back to old value.
|
||||
alphas_bar_sqrt *= alphas_bar_sqrt_0 / (alphas_bar_sqrt_0 - alphas_bar_sqrt_T)
|
||||
|
||||
# Convert alphas_bar_sqrt to betas
|
||||
alphas_bar = alphas_bar_sqrt**2
|
||||
alphas = alphas_bar[1:] / alphas_bar[:-1]
|
||||
alphas = torch.cat([alphas_bar[0:1], alphas])
|
||||
betas = 1 - alphas
|
||||
return betas
|
||||
|
||||
betas = noise_scheduler.betas
|
||||
betas = enforce_zero_terminal_snr(betas)
|
||||
alphas = 1.0 - betas
|
||||
alphas_cumprod = torch.cumprod(alphas, dim=0)
|
||||
|
||||
# logger.info(f"original: {noise_scheduler.betas}")
|
||||
# logger.info(f"fixed: {betas}")
|
||||
|
||||
noise_scheduler.betas = betas
|
||||
noise_scheduler.alphas = alphas
|
||||
noise_scheduler.alphas_cumprod = alphas_cumprod
|
||||
|
||||
|
||||
def apply_snr_weight(loss, timesteps, noise_scheduler, gamma, v_prediction=False):
|
||||
snr = torch.stack([noise_scheduler.all_snr[t] for t in timesteps])
|
||||
min_snr_gamma = torch.minimum(snr, torch.full_like(snr, gamma))
|
||||
if v_prediction:
|
||||
snr_weight = torch.div(min_snr_gamma, snr + 1).float().to(loss.device)
|
||||
else:
|
||||
snr_weight = torch.div(min_snr_gamma, snr).float().to(loss.device)
|
||||
loss = loss * snr_weight
|
||||
return loss
|
||||
|
||||
|
||||
def scale_v_prediction_loss_like_noise_prediction(loss, timesteps, noise_scheduler):
|
||||
scale = get_snr_scale(timesteps, noise_scheduler)
|
||||
loss = loss * scale
|
||||
return loss
|
||||
|
||||
|
||||
def get_snr_scale(timesteps, noise_scheduler):
|
||||
snr_t = torch.stack([noise_scheduler.all_snr[t] for t in timesteps]) # batch_size
|
||||
snr_t = torch.minimum(snr_t, torch.ones_like(snr_t) * 1000) # if timestep is 0, snr_t is inf, so limit it to 1000
|
||||
scale = snr_t / (snr_t + 1)
|
||||
# # show debug info
|
||||
# logger.info(f"timesteps: {timesteps}, snr_t: {snr_t}, scale: {scale}")
|
||||
return scale
|
||||
|
||||
|
||||
def add_v_prediction_like_loss(loss, timesteps, noise_scheduler, v_pred_like_loss):
|
||||
scale = get_snr_scale(timesteps, noise_scheduler)
|
||||
# logger.info(f"add v-prediction like loss: {v_pred_like_loss}, scale: {scale}, loss: {loss}, time: {timesteps}")
|
||||
loss = loss + loss / scale * v_pred_like_loss
|
||||
return loss
|
||||
|
||||
|
||||
def apply_debiased_estimation(loss, timesteps, noise_scheduler, v_prediction=False):
|
||||
snr_t = torch.stack([noise_scheduler.all_snr[t] for t in timesteps]) # batch_size
|
||||
snr_t = torch.minimum(snr_t, torch.ones_like(snr_t) * 1000) # if timestep is 0, snr_t is inf, so limit it to 1000
|
||||
if v_prediction:
|
||||
weight = 1 / (snr_t + 1)
|
||||
else:
|
||||
weight = 1 / torch.sqrt(snr_t)
|
||||
loss = weight * loss
|
||||
return loss
|
||||
|
||||
|
||||
# TODO train_utilと分散しているのでどちらかに寄せる
|
||||
|
||||
|
||||
def add_custom_train_arguments(parser: argparse.ArgumentParser, support_weighted_captions: bool = True):
|
||||
parser.add_argument(
|
||||
"--min_snr_gamma",
|
||||
@@ -25,6 +117,22 @@ def add_custom_train_arguments(parser: argparse.ArgumentParser, support_weighted
|
||||
default=None,
|
||||
help="gamma for reducing the weight of high loss timesteps. Lower numbers have stronger effect. 5 is recommended by paper. / 低いタイムステップでの高いlossに対して重みを減らすためのgamma値、低いほど効果が強く、論文では5が推奨",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--scale_v_pred_loss_like_noise_pred",
|
||||
action="store_true",
|
||||
help="scale v-prediction loss like noise prediction loss / v-prediction lossをnoise prediction lossと同じようにスケーリングする",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--v_pred_like_loss",
|
||||
type=float,
|
||||
default=None,
|
||||
help="add v-prediction like loss multiplied by this value / v-prediction lossをこの値をかけたものをlossに加算する",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--debiased_estimation_loss",
|
||||
action="store_true",
|
||||
help="debiased estimation loss / debiased estimation loss",
|
||||
)
|
||||
if support_weighted_captions:
|
||||
parser.add_argument(
|
||||
"--weighted_captions",
|
||||
@@ -171,7 +279,7 @@ def get_prompts_with_weights(tokenizer, prompt: List[str], max_length: int):
|
||||
tokens.append(text_token)
|
||||
weights.append(text_weight)
|
||||
if truncated:
|
||||
print("Prompt was truncated. Try to shorten the prompt or increase max_embeddings_multiples")
|
||||
logger.warning("Prompt was truncated. Try to shorten the prompt or increase max_embeddings_multiples")
|
||||
return tokens, weights
|
||||
|
||||
|
||||
@@ -239,11 +347,6 @@ def get_unweighted_text_embeddings(
|
||||
text_embedding = enc_out["hidden_states"][-clip_skip]
|
||||
text_embedding = text_encoder.text_model.final_layer_norm(text_embedding)
|
||||
|
||||
# cover the head and the tail by the starting and the ending tokens
|
||||
text_input_chunk[:, 0] = text_input[0, 0]
|
||||
text_input_chunk[:, -1] = text_input[0, -1]
|
||||
text_embedding = text_encoder(text_input_chunk, attention_mask=None)[0]
|
||||
|
||||
if no_boseos_middle:
|
||||
if i == 0:
|
||||
# discard the ending token
|
||||
@@ -258,7 +361,12 @@ def get_unweighted_text_embeddings(
|
||||
text_embeddings.append(text_embedding)
|
||||
text_embeddings = torch.concat(text_embeddings, axis=1)
|
||||
else:
|
||||
text_embeddings = text_encoder(text_input)[0]
|
||||
if clip_skip is None or clip_skip == 1:
|
||||
text_embeddings = text_encoder(text_input)[0]
|
||||
else:
|
||||
enc_out = text_encoder(text_input, output_hidden_states=True, return_dict=True)
|
||||
text_embeddings = enc_out["hidden_states"][-clip_skip]
|
||||
text_embeddings = text_encoder.text_model.final_layer_norm(text_embeddings)
|
||||
return text_embeddings
|
||||
|
||||
|
||||
@@ -342,3 +450,110 @@ def get_weighted_text_embeddings(
|
||||
text_embeddings = text_embeddings * (previous_mean / current_mean).unsqueeze(-1).unsqueeze(-1)
|
||||
|
||||
return text_embeddings
|
||||
|
||||
|
||||
# https://wandb.ai/johnowhitaker/multires_noise/reports/Multi-Resolution-Noise-for-Diffusion-Model-Training--VmlldzozNjYyOTU2
|
||||
def pyramid_noise_like(noise, device, iterations=6, discount=0.4):
|
||||
b, c, w, h = noise.shape # EDIT: w and h get over-written, rename for a different variant!
|
||||
u = torch.nn.Upsample(size=(w, h), mode="bilinear").to(device)
|
||||
for i in range(iterations):
|
||||
r = random.random() * 2 + 2 # Rather than always going 2x,
|
||||
wn, hn = max(1, int(w / (r**i))), max(1, int(h / (r**i)))
|
||||
noise += u(torch.randn(b, c, wn, hn).to(device)) * discount**i
|
||||
if wn == 1 or hn == 1:
|
||||
break # Lowest resolution is 1x1
|
||||
return noise / noise.std() # Scaled back to roughly unit variance
|
||||
|
||||
|
||||
# https://www.crosslabs.org//blog/diffusion-with-offset-noise
|
||||
def apply_noise_offset(latents, noise, noise_offset, adaptive_noise_scale):
|
||||
if noise_offset is None:
|
||||
return noise
|
||||
if adaptive_noise_scale is not None:
|
||||
# latent shape: (batch_size, channels, height, width)
|
||||
# abs mean value for each channel
|
||||
latent_mean = torch.abs(latents.mean(dim=(2, 3), keepdim=True))
|
||||
|
||||
# multiply adaptive noise scale to the mean value and add it to the noise offset
|
||||
noise_offset = noise_offset + adaptive_noise_scale * latent_mean
|
||||
noise_offset = torch.clamp(noise_offset, 0.0, None) # in case of adaptive noise scale is negative
|
||||
|
||||
noise = noise + noise_offset * torch.randn((latents.shape[0], latents.shape[1], 1, 1), device=latents.device)
|
||||
return noise
|
||||
|
||||
|
||||
def apply_masked_loss(loss, batch):
|
||||
if "conditioning_images" in batch:
|
||||
# conditioning image is -1 to 1. we need to convert it to 0 to 1
|
||||
mask_image = batch["conditioning_images"].to(dtype=loss.dtype)[:, 0].unsqueeze(1) # use R channel
|
||||
mask_image = mask_image / 2 + 0.5
|
||||
# print(f"conditioning_image: {mask_image.shape}")
|
||||
elif "alpha_masks" in batch and batch["alpha_masks"] is not None:
|
||||
# alpha mask is 0 to 1
|
||||
mask_image = batch["alpha_masks"].to(dtype=loss.dtype).unsqueeze(1) # add channel dimension
|
||||
# print(f"mask_image: {mask_image.shape}, {mask_image.mean()}")
|
||||
else:
|
||||
return loss
|
||||
|
||||
# resize to the same size as the loss
|
||||
mask_image = torch.nn.functional.interpolate(mask_image, size=loss.shape[2:], mode="area")
|
||||
loss = loss * mask_image
|
||||
return loss
|
||||
|
||||
|
||||
"""
|
||||
##########################################
|
||||
# Perlin Noise
|
||||
def rand_perlin_2d(device, shape, res, fade=lambda t: 6 * t**5 - 15 * t**4 + 10 * t**3):
|
||||
delta = (res[0] / shape[0], res[1] / shape[1])
|
||||
d = (shape[0] // res[0], shape[1] // res[1])
|
||||
|
||||
grid = (
|
||||
torch.stack(
|
||||
torch.meshgrid(torch.arange(0, res[0], delta[0], device=device), torch.arange(0, res[1], delta[1], device=device)),
|
||||
dim=-1,
|
||||
)
|
||||
% 1
|
||||
)
|
||||
angles = 2 * torch.pi * torch.rand(res[0] + 1, res[1] + 1, device=device)
|
||||
gradients = torch.stack((torch.cos(angles), torch.sin(angles)), dim=-1)
|
||||
|
||||
tile_grads = (
|
||||
lambda slice1, slice2: gradients[slice1[0] : slice1[1], slice2[0] : slice2[1]]
|
||||
.repeat_interleave(d[0], 0)
|
||||
.repeat_interleave(d[1], 1)
|
||||
)
|
||||
dot = lambda grad, shift: (
|
||||
torch.stack((grid[: shape[0], : shape[1], 0] + shift[0], grid[: shape[0], : shape[1], 1] + shift[1]), dim=-1)
|
||||
* grad[: shape[0], : shape[1]]
|
||||
).sum(dim=-1)
|
||||
|
||||
n00 = dot(tile_grads([0, -1], [0, -1]), [0, 0])
|
||||
n10 = dot(tile_grads([1, None], [0, -1]), [-1, 0])
|
||||
n01 = dot(tile_grads([0, -1], [1, None]), [0, -1])
|
||||
n11 = dot(tile_grads([1, None], [1, None]), [-1, -1])
|
||||
t = fade(grid[: shape[0], : shape[1]])
|
||||
return 1.414 * torch.lerp(torch.lerp(n00, n10, t[..., 0]), torch.lerp(n01, n11, t[..., 0]), t[..., 1])
|
||||
|
||||
|
||||
def rand_perlin_2d_octaves(device, shape, res, octaves=1, persistence=0.5):
|
||||
noise = torch.zeros(shape, device=device)
|
||||
frequency = 1
|
||||
amplitude = 1
|
||||
for _ in range(octaves):
|
||||
noise += amplitude * rand_perlin_2d(device, shape, (frequency * res[0], frequency * res[1]))
|
||||
frequency *= 2
|
||||
amplitude *= persistence
|
||||
return noise
|
||||
|
||||
|
||||
def perlin_noise(noise, device, octaves):
|
||||
_, c, w, h = noise.shape
|
||||
perlin = lambda: rand_perlin_2d_octaves(device, (w, h), (4, 4), octaves)
|
||||
noise_perlin = []
|
||||
for _ in range(c):
|
||||
noise_perlin.append(perlin())
|
||||
noise_perlin = torch.stack(noise_perlin).unsqueeze(0) # (1, c, w, h)
|
||||
noise += noise_perlin # broadcast for each batch
|
||||
return noise / noise.std() # Scaled back to roughly unit variance
|
||||
"""
|
||||
|
||||
139
library/deepspeed_utils.py
Normal file
139
library/deepspeed_utils.py
Normal file
@@ -0,0 +1,139 @@
|
||||
import os
|
||||
import argparse
|
||||
import torch
|
||||
from accelerate import DeepSpeedPlugin, Accelerator
|
||||
|
||||
from .utils import setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
def add_deepspeed_arguments(parser: argparse.ArgumentParser):
|
||||
# DeepSpeed Arguments. https://huggingface.co/docs/accelerate/usage_guides/deepspeed
|
||||
parser.add_argument("--deepspeed", action="store_true", help="enable deepspeed training")
|
||||
parser.add_argument("--zero_stage", type=int, default=2, choices=[0, 1, 2, 3], help="Possible options are 0,1,2,3.")
|
||||
parser.add_argument(
|
||||
"--offload_optimizer_device",
|
||||
type=str,
|
||||
default=None,
|
||||
choices=[None, "cpu", "nvme"],
|
||||
help="Possible options are none|cpu|nvme. Only applicable with ZeRO Stages 2 and 3.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--offload_optimizer_nvme_path",
|
||||
type=str,
|
||||
default=None,
|
||||
help="Possible options are /nvme|/local_nvme. Only applicable with ZeRO Stage 3.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--offload_param_device",
|
||||
type=str,
|
||||
default=None,
|
||||
choices=[None, "cpu", "nvme"],
|
||||
help="Possible options are none|cpu|nvme. Only applicable with ZeRO Stage 3.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--offload_param_nvme_path",
|
||||
type=str,
|
||||
default=None,
|
||||
help="Possible options are /nvme|/local_nvme. Only applicable with ZeRO Stage 3.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--zero3_init_flag",
|
||||
action="store_true",
|
||||
help="Flag to indicate whether to enable `deepspeed.zero.Init` for constructing massive models."
|
||||
"Only applicable with ZeRO Stage-3.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--zero3_save_16bit_model",
|
||||
action="store_true",
|
||||
help="Flag to indicate whether to save 16-bit model. Only applicable with ZeRO Stage-3.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--fp16_master_weights_and_gradients",
|
||||
action="store_true",
|
||||
help="fp16_master_and_gradients requires optimizer to support keeping fp16 master and gradients while keeping the optimizer states in fp32.",
|
||||
)
|
||||
|
||||
|
||||
def prepare_deepspeed_args(args: argparse.Namespace):
|
||||
if not args.deepspeed:
|
||||
return
|
||||
|
||||
# To avoid RuntimeError: DataLoader worker exited unexpectedly with exit code 1.
|
||||
args.max_data_loader_n_workers = 1
|
||||
|
||||
|
||||
def prepare_deepspeed_plugin(args: argparse.Namespace):
|
||||
if not args.deepspeed:
|
||||
return None
|
||||
|
||||
try:
|
||||
import deepspeed
|
||||
except ImportError as e:
|
||||
logger.error(
|
||||
"deepspeed is not installed. please install deepspeed in your environment with following command. DS_BUILD_OPS=0 pip install deepspeed"
|
||||
)
|
||||
exit(1)
|
||||
|
||||
deepspeed_plugin = DeepSpeedPlugin(
|
||||
zero_stage=args.zero_stage,
|
||||
gradient_accumulation_steps=args.gradient_accumulation_steps,
|
||||
gradient_clipping=args.max_grad_norm,
|
||||
offload_optimizer_device=args.offload_optimizer_device,
|
||||
offload_optimizer_nvme_path=args.offload_optimizer_nvme_path,
|
||||
offload_param_device=args.offload_param_device,
|
||||
offload_param_nvme_path=args.offload_param_nvme_path,
|
||||
zero3_init_flag=args.zero3_init_flag,
|
||||
zero3_save_16bit_model=args.zero3_save_16bit_model,
|
||||
)
|
||||
deepspeed_plugin.deepspeed_config["train_micro_batch_size_per_gpu"] = args.train_batch_size
|
||||
deepspeed_plugin.deepspeed_config["train_batch_size"] = (
|
||||
args.train_batch_size * args.gradient_accumulation_steps * int(os.environ["WORLD_SIZE"])
|
||||
)
|
||||
deepspeed_plugin.set_mixed_precision(args.mixed_precision)
|
||||
if args.mixed_precision.lower() == "fp16":
|
||||
deepspeed_plugin.deepspeed_config["fp16"]["initial_scale_power"] = 0 # preventing overflow.
|
||||
if args.full_fp16 or args.fp16_master_weights_and_gradients:
|
||||
if args.offload_optimizer_device == "cpu" and args.zero_stage == 2:
|
||||
deepspeed_plugin.deepspeed_config["fp16"]["fp16_master_weights_and_grads"] = True
|
||||
logger.info("[DeepSpeed] full fp16 enable.")
|
||||
else:
|
||||
logger.info(
|
||||
"[DeepSpeed]full fp16, fp16_master_weights_and_grads currently only supported using ZeRO-Offload with DeepSpeedCPUAdam on ZeRO-2 stage."
|
||||
)
|
||||
|
||||
if args.offload_optimizer_device is not None:
|
||||
logger.info("[DeepSpeed] start to manually build cpu_adam.")
|
||||
deepspeed.ops.op_builder.CPUAdamBuilder().load()
|
||||
logger.info("[DeepSpeed] building cpu_adam done.")
|
||||
|
||||
return deepspeed_plugin
|
||||
|
||||
|
||||
# Accelerate library does not support multiple models for deepspeed. So, we need to wrap multiple models into a single model.
|
||||
def prepare_deepspeed_model(args: argparse.Namespace, **models):
|
||||
# remove None from models
|
||||
models = {k: v for k, v in models.items() if v is not None}
|
||||
|
||||
class DeepSpeedWrapper(torch.nn.Module):
|
||||
def __init__(self, **kw_models) -> None:
|
||||
super().__init__()
|
||||
self.models = torch.nn.ModuleDict()
|
||||
|
||||
for key, model in kw_models.items():
|
||||
if isinstance(model, list):
|
||||
model = torch.nn.ModuleList(model)
|
||||
assert isinstance(
|
||||
model, torch.nn.Module
|
||||
), f"model must be an instance of torch.nn.Module, but got {key} is {type(model)}"
|
||||
self.models.update(torch.nn.ModuleDict({key: model}))
|
||||
|
||||
def get_models(self):
|
||||
return self.models
|
||||
|
||||
ds_model = DeepSpeedWrapper(**models)
|
||||
return ds_model
|
||||
84
library/device_utils.py
Normal file
84
library/device_utils.py
Normal file
@@ -0,0 +1,84 @@
|
||||
import functools
|
||||
import gc
|
||||
|
||||
import torch
|
||||
|
||||
try:
|
||||
HAS_CUDA = torch.cuda.is_available()
|
||||
except Exception:
|
||||
HAS_CUDA = False
|
||||
|
||||
try:
|
||||
HAS_MPS = torch.backends.mps.is_available()
|
||||
except Exception:
|
||||
HAS_MPS = False
|
||||
|
||||
try:
|
||||
import intel_extension_for_pytorch as ipex # noqa
|
||||
|
||||
HAS_XPU = torch.xpu.is_available()
|
||||
except Exception:
|
||||
HAS_XPU = False
|
||||
|
||||
|
||||
def clean_memory():
|
||||
gc.collect()
|
||||
if HAS_CUDA:
|
||||
torch.cuda.empty_cache()
|
||||
if HAS_XPU:
|
||||
torch.xpu.empty_cache()
|
||||
if HAS_MPS:
|
||||
torch.mps.empty_cache()
|
||||
|
||||
|
||||
def clean_memory_on_device(device: torch.device):
|
||||
r"""
|
||||
Clean memory on the specified device, will be called from training scripts.
|
||||
"""
|
||||
gc.collect()
|
||||
|
||||
# device may "cuda" or "cuda:0", so we need to check the type of device
|
||||
if device.type == "cuda":
|
||||
torch.cuda.empty_cache()
|
||||
if device.type == "xpu":
|
||||
torch.xpu.empty_cache()
|
||||
if device.type == "mps":
|
||||
torch.mps.empty_cache()
|
||||
|
||||
|
||||
@functools.lru_cache(maxsize=None)
|
||||
def get_preferred_device() -> torch.device:
|
||||
r"""
|
||||
Do not call this function from training scripts. Use accelerator.device instead.
|
||||
"""
|
||||
if HAS_CUDA:
|
||||
device = torch.device("cuda")
|
||||
elif HAS_XPU:
|
||||
device = torch.device("xpu")
|
||||
elif HAS_MPS:
|
||||
device = torch.device("mps")
|
||||
else:
|
||||
device = torch.device("cpu")
|
||||
print(f"get_preferred_device() -> {device}")
|
||||
return device
|
||||
|
||||
|
||||
def init_ipex():
|
||||
"""
|
||||
Apply IPEX to CUDA hijacks using `library.ipex.ipex_init`.
|
||||
|
||||
This function should run right after importing torch and before doing anything else.
|
||||
|
||||
If IPEX is not available, this function does nothing.
|
||||
"""
|
||||
try:
|
||||
if HAS_XPU:
|
||||
from library.ipex import ipex_init
|
||||
|
||||
is_initialized, error_message = ipex_init()
|
||||
if not is_initialized:
|
||||
print("failed to initialize ipex:", error_message)
|
||||
else:
|
||||
return
|
||||
except Exception as e:
|
||||
print("failed to initialize ipex:", e)
|
||||
@@ -1,15 +1,15 @@
|
||||
from typing import *
|
||||
from typing import Union, BinaryIO
|
||||
from huggingface_hub import HfApi
|
||||
from pathlib import Path
|
||||
import argparse
|
||||
import os
|
||||
|
||||
from library.utils import fire_in_thread
|
||||
from library.utils import setup_logging
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
def exists_repo(
|
||||
repo_id: str, repo_type: str, revision: str = "main", token: str = None
|
||||
):
|
||||
def exists_repo(repo_id: str, repo_type: str, revision: str = "main", token: str = None):
|
||||
api = HfApi(
|
||||
token=token,
|
||||
)
|
||||
@@ -29,31 +29,39 @@ def upload(
|
||||
repo_id = args.huggingface_repo_id
|
||||
repo_type = args.huggingface_repo_type
|
||||
token = args.huggingface_token
|
||||
path_in_repo = args.huggingface_path_in_repo + dest_suffix
|
||||
path_in_repo = args.huggingface_path_in_repo + dest_suffix if args.huggingface_path_in_repo is not None else None
|
||||
private = args.huggingface_repo_visibility is None or args.huggingface_repo_visibility != "public"
|
||||
api = HfApi(token=token)
|
||||
if not exists_repo(repo_id=repo_id, repo_type=repo_type, token=token):
|
||||
api.create_repo(repo_id=repo_id, repo_type=repo_type, private=private)
|
||||
try:
|
||||
api.create_repo(repo_id=repo_id, repo_type=repo_type, private=private)
|
||||
except Exception as e: # とりあえずRepositoryNotFoundErrorは確認したが他にあると困るので
|
||||
logger.error("===========================================")
|
||||
logger.error(f"failed to create HuggingFace repo / HuggingFaceのリポジトリの作成に失敗しました : {e}")
|
||||
logger.error("===========================================")
|
||||
|
||||
is_folder = (type(src) == str and os.path.isdir(src)) or (
|
||||
isinstance(src, Path) and src.is_dir()
|
||||
)
|
||||
is_folder = (type(src) == str and os.path.isdir(src)) or (isinstance(src, Path) and src.is_dir())
|
||||
|
||||
def uploader():
|
||||
if is_folder:
|
||||
api.upload_folder(
|
||||
repo_id=repo_id,
|
||||
repo_type=repo_type,
|
||||
folder_path=src,
|
||||
path_in_repo=path_in_repo,
|
||||
)
|
||||
else:
|
||||
api.upload_file(
|
||||
repo_id=repo_id,
|
||||
repo_type=repo_type,
|
||||
path_or_fileobj=src,
|
||||
path_in_repo=path_in_repo,
|
||||
)
|
||||
try:
|
||||
if is_folder:
|
||||
api.upload_folder(
|
||||
repo_id=repo_id,
|
||||
repo_type=repo_type,
|
||||
folder_path=src,
|
||||
path_in_repo=path_in_repo,
|
||||
)
|
||||
else:
|
||||
api.upload_file(
|
||||
repo_id=repo_id,
|
||||
repo_type=repo_type,
|
||||
path_or_fileobj=src,
|
||||
path_in_repo=path_in_repo,
|
||||
)
|
||||
except Exception as e: # RuntimeErrorを確認済みだが他にあると困るので
|
||||
logger.error("===========================================")
|
||||
logger.error(f"failed to upload to HuggingFace / HuggingFaceへのアップロードに失敗しました : {e}")
|
||||
logger.error("===========================================")
|
||||
|
||||
if args.async_upload and not force_sync_upload:
|
||||
fire_in_thread(uploader)
|
||||
@@ -72,7 +80,5 @@ def list_dir(
|
||||
token=token,
|
||||
)
|
||||
repo_info = api.repo_info(repo_id=repo_id, revision=revision, repo_type=repo_type)
|
||||
file_list = [
|
||||
file for file in repo_info.siblings if file.rfilename.startswith(subfolder)
|
||||
]
|
||||
file_list = [file for file in repo_info.siblings if file.rfilename.startswith(subfolder)]
|
||||
return file_list
|
||||
|
||||
223
library/hypernetwork.py
Normal file
223
library/hypernetwork.py
Normal file
@@ -0,0 +1,223 @@
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
from diffusers.models.attention_processor import (
|
||||
Attention,
|
||||
AttnProcessor2_0,
|
||||
SlicedAttnProcessor,
|
||||
XFormersAttnProcessor
|
||||
)
|
||||
|
||||
try:
|
||||
import xformers.ops
|
||||
except:
|
||||
xformers = None
|
||||
|
||||
|
||||
loaded_networks = []
|
||||
|
||||
|
||||
def apply_single_hypernetwork(
|
||||
hypernetwork, hidden_states, encoder_hidden_states
|
||||
):
|
||||
context_k, context_v = hypernetwork.forward(hidden_states, encoder_hidden_states)
|
||||
return context_k, context_v
|
||||
|
||||
|
||||
def apply_hypernetworks(context_k, context_v, layer=None):
|
||||
if len(loaded_networks) == 0:
|
||||
return context_v, context_v
|
||||
for hypernetwork in loaded_networks:
|
||||
context_k, context_v = hypernetwork.forward(context_k, context_v)
|
||||
|
||||
context_k = context_k.to(dtype=context_k.dtype)
|
||||
context_v = context_v.to(dtype=context_k.dtype)
|
||||
|
||||
return context_k, context_v
|
||||
|
||||
|
||||
|
||||
def xformers_forward(
|
||||
self: XFormersAttnProcessor,
|
||||
attn: Attention,
|
||||
hidden_states: torch.Tensor,
|
||||
encoder_hidden_states: torch.Tensor = None,
|
||||
attention_mask: torch.Tensor = None,
|
||||
):
|
||||
batch_size, sequence_length, _ = (
|
||||
hidden_states.shape
|
||||
if encoder_hidden_states is None
|
||||
else encoder_hidden_states.shape
|
||||
)
|
||||
|
||||
attention_mask = attn.prepare_attention_mask(
|
||||
attention_mask, sequence_length, batch_size
|
||||
)
|
||||
|
||||
query = attn.to_q(hidden_states)
|
||||
|
||||
if encoder_hidden_states is None:
|
||||
encoder_hidden_states = hidden_states
|
||||
elif attn.norm_cross:
|
||||
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
||||
|
||||
context_k, context_v = apply_hypernetworks(hidden_states, encoder_hidden_states)
|
||||
|
||||
key = attn.to_k(context_k)
|
||||
value = attn.to_v(context_v)
|
||||
|
||||
query = attn.head_to_batch_dim(query).contiguous()
|
||||
key = attn.head_to_batch_dim(key).contiguous()
|
||||
value = attn.head_to_batch_dim(value).contiguous()
|
||||
|
||||
hidden_states = xformers.ops.memory_efficient_attention(
|
||||
query,
|
||||
key,
|
||||
value,
|
||||
attn_bias=attention_mask,
|
||||
op=self.attention_op,
|
||||
scale=attn.scale,
|
||||
)
|
||||
hidden_states = hidden_states.to(query.dtype)
|
||||
hidden_states = attn.batch_to_head_dim(hidden_states)
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states)
|
||||
# dropout
|
||||
hidden_states = attn.to_out[1](hidden_states)
|
||||
return hidden_states
|
||||
|
||||
|
||||
def sliced_attn_forward(
|
||||
self: SlicedAttnProcessor,
|
||||
attn: Attention,
|
||||
hidden_states: torch.Tensor,
|
||||
encoder_hidden_states: torch.Tensor = None,
|
||||
attention_mask: torch.Tensor = None,
|
||||
):
|
||||
batch_size, sequence_length, _ = (
|
||||
hidden_states.shape
|
||||
if encoder_hidden_states is None
|
||||
else encoder_hidden_states.shape
|
||||
)
|
||||
attention_mask = attn.prepare_attention_mask(
|
||||
attention_mask, sequence_length, batch_size
|
||||
)
|
||||
|
||||
query = attn.to_q(hidden_states)
|
||||
dim = query.shape[-1]
|
||||
query = attn.head_to_batch_dim(query)
|
||||
|
||||
if encoder_hidden_states is None:
|
||||
encoder_hidden_states = hidden_states
|
||||
elif attn.norm_cross:
|
||||
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
||||
|
||||
context_k, context_v = apply_hypernetworks(hidden_states, encoder_hidden_states)
|
||||
|
||||
key = attn.to_k(context_k)
|
||||
value = attn.to_v(context_v)
|
||||
key = attn.head_to_batch_dim(key)
|
||||
value = attn.head_to_batch_dim(value)
|
||||
|
||||
batch_size_attention, query_tokens, _ = query.shape
|
||||
hidden_states = torch.zeros(
|
||||
(batch_size_attention, query_tokens, dim // attn.heads),
|
||||
device=query.device,
|
||||
dtype=query.dtype,
|
||||
)
|
||||
|
||||
for i in range(batch_size_attention // self.slice_size):
|
||||
start_idx = i * self.slice_size
|
||||
end_idx = (i + 1) * self.slice_size
|
||||
|
||||
query_slice = query[start_idx:end_idx]
|
||||
key_slice = key[start_idx:end_idx]
|
||||
attn_mask_slice = (
|
||||
attention_mask[start_idx:end_idx] if attention_mask is not None else None
|
||||
)
|
||||
|
||||
attn_slice = attn.get_attention_scores(query_slice, key_slice, attn_mask_slice)
|
||||
|
||||
attn_slice = torch.bmm(attn_slice, value[start_idx:end_idx])
|
||||
|
||||
hidden_states[start_idx:end_idx] = attn_slice
|
||||
|
||||
hidden_states = attn.batch_to_head_dim(hidden_states)
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states)
|
||||
# dropout
|
||||
hidden_states = attn.to_out[1](hidden_states)
|
||||
|
||||
return hidden_states
|
||||
|
||||
|
||||
def v2_0_forward(
|
||||
self: AttnProcessor2_0,
|
||||
attn: Attention,
|
||||
hidden_states,
|
||||
encoder_hidden_states=None,
|
||||
attention_mask=None,
|
||||
):
|
||||
batch_size, sequence_length, _ = (
|
||||
hidden_states.shape
|
||||
if encoder_hidden_states is None
|
||||
else encoder_hidden_states.shape
|
||||
)
|
||||
inner_dim = hidden_states.shape[-1]
|
||||
|
||||
if attention_mask is not None:
|
||||
attention_mask = attn.prepare_attention_mask(
|
||||
attention_mask, sequence_length, batch_size
|
||||
)
|
||||
# scaled_dot_product_attention expects attention_mask shape to be
|
||||
# (batch, heads, source_length, target_length)
|
||||
attention_mask = attention_mask.view(
|
||||
batch_size, attn.heads, -1, attention_mask.shape[-1]
|
||||
)
|
||||
|
||||
query = attn.to_q(hidden_states)
|
||||
|
||||
if encoder_hidden_states is None:
|
||||
encoder_hidden_states = hidden_states
|
||||
elif attn.norm_cross:
|
||||
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
||||
|
||||
context_k, context_v = apply_hypernetworks(hidden_states, encoder_hidden_states)
|
||||
|
||||
key = attn.to_k(context_k)
|
||||
value = attn.to_v(context_v)
|
||||
|
||||
head_dim = inner_dim // attn.heads
|
||||
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
||||
|
||||
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
||||
# TODO: add support for attn.scale when we move to Torch 2.1
|
||||
hidden_states = F.scaled_dot_product_attention(
|
||||
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
|
||||
)
|
||||
|
||||
hidden_states = hidden_states.transpose(1, 2).reshape(
|
||||
batch_size, -1, attn.heads * head_dim
|
||||
)
|
||||
hidden_states = hidden_states.to(query.dtype)
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states)
|
||||
# dropout
|
||||
hidden_states = attn.to_out[1](hidden_states)
|
||||
return hidden_states
|
||||
|
||||
|
||||
def replace_attentions_for_hypernetwork():
|
||||
import diffusers.models.attention_processor
|
||||
|
||||
diffusers.models.attention_processor.XFormersAttnProcessor.__call__ = (
|
||||
xformers_forward
|
||||
)
|
||||
diffusers.models.attention_processor.SlicedAttnProcessor.__call__ = (
|
||||
sliced_attn_forward
|
||||
)
|
||||
diffusers.models.attention_processor.AttnProcessor2_0.__call__ = v2_0_forward
|
||||
180
library/ipex/__init__.py
Normal file
180
library/ipex/__init__.py
Normal file
@@ -0,0 +1,180 @@
|
||||
import os
|
||||
import sys
|
||||
import contextlib
|
||||
import torch
|
||||
import intel_extension_for_pytorch as ipex # pylint: disable=import-error, unused-import
|
||||
from .hijacks import ipex_hijacks
|
||||
|
||||
# pylint: disable=protected-access, missing-function-docstring, line-too-long
|
||||
|
||||
def ipex_init(): # pylint: disable=too-many-statements
|
||||
try:
|
||||
if hasattr(torch, "cuda") and hasattr(torch.cuda, "is_xpu_hijacked") and torch.cuda.is_xpu_hijacked:
|
||||
return True, "Skipping IPEX hijack"
|
||||
else:
|
||||
# Replace cuda with xpu:
|
||||
torch.cuda.current_device = torch.xpu.current_device
|
||||
torch.cuda.current_stream = torch.xpu.current_stream
|
||||
torch.cuda.device = torch.xpu.device
|
||||
torch.cuda.device_count = torch.xpu.device_count
|
||||
torch.cuda.device_of = torch.xpu.device_of
|
||||
torch.cuda.get_device_name = torch.xpu.get_device_name
|
||||
torch.cuda.get_device_properties = torch.xpu.get_device_properties
|
||||
torch.cuda.init = torch.xpu.init
|
||||
torch.cuda.is_available = torch.xpu.is_available
|
||||
torch.cuda.is_initialized = torch.xpu.is_initialized
|
||||
torch.cuda.is_current_stream_capturing = lambda: False
|
||||
torch.cuda.set_device = torch.xpu.set_device
|
||||
torch.cuda.stream = torch.xpu.stream
|
||||
torch.cuda.synchronize = torch.xpu.synchronize
|
||||
torch.cuda.Event = torch.xpu.Event
|
||||
torch.cuda.Stream = torch.xpu.Stream
|
||||
torch.cuda.FloatTensor = torch.xpu.FloatTensor
|
||||
torch.Tensor.cuda = torch.Tensor.xpu
|
||||
torch.Tensor.is_cuda = torch.Tensor.is_xpu
|
||||
torch.nn.Module.cuda = torch.nn.Module.xpu
|
||||
torch.UntypedStorage.cuda = torch.UntypedStorage.xpu
|
||||
torch.cuda._initialization_lock = torch.xpu.lazy_init._initialization_lock
|
||||
torch.cuda._initialized = torch.xpu.lazy_init._initialized
|
||||
torch.cuda._lazy_seed_tracker = torch.xpu.lazy_init._lazy_seed_tracker
|
||||
torch.cuda._queued_calls = torch.xpu.lazy_init._queued_calls
|
||||
torch.cuda._tls = torch.xpu.lazy_init._tls
|
||||
torch.cuda.threading = torch.xpu.lazy_init.threading
|
||||
torch.cuda.traceback = torch.xpu.lazy_init.traceback
|
||||
torch.cuda.Optional = torch.xpu.Optional
|
||||
torch.cuda.__cached__ = torch.xpu.__cached__
|
||||
torch.cuda.__loader__ = torch.xpu.__loader__
|
||||
torch.cuda.ComplexFloatStorage = torch.xpu.ComplexFloatStorage
|
||||
torch.cuda.Tuple = torch.xpu.Tuple
|
||||
torch.cuda.streams = torch.xpu.streams
|
||||
torch.cuda._lazy_new = torch.xpu._lazy_new
|
||||
torch.cuda.FloatStorage = torch.xpu.FloatStorage
|
||||
torch.cuda.Any = torch.xpu.Any
|
||||
torch.cuda.__doc__ = torch.xpu.__doc__
|
||||
torch.cuda.default_generators = torch.xpu.default_generators
|
||||
torch.cuda.HalfTensor = torch.xpu.HalfTensor
|
||||
torch.cuda._get_device_index = torch.xpu._get_device_index
|
||||
torch.cuda.__path__ = torch.xpu.__path__
|
||||
torch.cuda.Device = torch.xpu.Device
|
||||
torch.cuda.IntTensor = torch.xpu.IntTensor
|
||||
torch.cuda.ByteStorage = torch.xpu.ByteStorage
|
||||
torch.cuda.set_stream = torch.xpu.set_stream
|
||||
torch.cuda.BoolStorage = torch.xpu.BoolStorage
|
||||
torch.cuda.os = torch.xpu.os
|
||||
torch.cuda.torch = torch.xpu.torch
|
||||
torch.cuda.BFloat16Storage = torch.xpu.BFloat16Storage
|
||||
torch.cuda.Union = torch.xpu.Union
|
||||
torch.cuda.DoubleTensor = torch.xpu.DoubleTensor
|
||||
torch.cuda.ShortTensor = torch.xpu.ShortTensor
|
||||
torch.cuda.LongTensor = torch.xpu.LongTensor
|
||||
torch.cuda.IntStorage = torch.xpu.IntStorage
|
||||
torch.cuda.LongStorage = torch.xpu.LongStorage
|
||||
torch.cuda.__annotations__ = torch.xpu.__annotations__
|
||||
torch.cuda.__package__ = torch.xpu.__package__
|
||||
torch.cuda.__builtins__ = torch.xpu.__builtins__
|
||||
torch.cuda.CharTensor = torch.xpu.CharTensor
|
||||
torch.cuda.List = torch.xpu.List
|
||||
torch.cuda._lazy_init = torch.xpu._lazy_init
|
||||
torch.cuda.BFloat16Tensor = torch.xpu.BFloat16Tensor
|
||||
torch.cuda.DoubleStorage = torch.xpu.DoubleStorage
|
||||
torch.cuda.ByteTensor = torch.xpu.ByteTensor
|
||||
torch.cuda.StreamContext = torch.xpu.StreamContext
|
||||
torch.cuda.ComplexDoubleStorage = torch.xpu.ComplexDoubleStorage
|
||||
torch.cuda.ShortStorage = torch.xpu.ShortStorage
|
||||
torch.cuda._lazy_call = torch.xpu._lazy_call
|
||||
torch.cuda.HalfStorage = torch.xpu.HalfStorage
|
||||
torch.cuda.random = torch.xpu.random
|
||||
torch.cuda._device = torch.xpu._device
|
||||
torch.cuda.classproperty = torch.xpu.classproperty
|
||||
torch.cuda.__name__ = torch.xpu.__name__
|
||||
torch.cuda._device_t = torch.xpu._device_t
|
||||
torch.cuda.warnings = torch.xpu.warnings
|
||||
torch.cuda.__spec__ = torch.xpu.__spec__
|
||||
torch.cuda.BoolTensor = torch.xpu.BoolTensor
|
||||
torch.cuda.CharStorage = torch.xpu.CharStorage
|
||||
torch.cuda.__file__ = torch.xpu.__file__
|
||||
torch.cuda._is_in_bad_fork = torch.xpu.lazy_init._is_in_bad_fork
|
||||
# torch.cuda.is_current_stream_capturing = torch.xpu.is_current_stream_capturing
|
||||
|
||||
# Memory:
|
||||
torch.cuda.memory = torch.xpu.memory
|
||||
if 'linux' in sys.platform and "WSL2" in os.popen("uname -a").read():
|
||||
torch.xpu.empty_cache = lambda: None
|
||||
torch.cuda.empty_cache = torch.xpu.empty_cache
|
||||
torch.cuda.memory_stats = torch.xpu.memory_stats
|
||||
torch.cuda.memory_summary = torch.xpu.memory_summary
|
||||
torch.cuda.memory_snapshot = torch.xpu.memory_snapshot
|
||||
torch.cuda.memory_allocated = torch.xpu.memory_allocated
|
||||
torch.cuda.max_memory_allocated = torch.xpu.max_memory_allocated
|
||||
torch.cuda.memory_reserved = torch.xpu.memory_reserved
|
||||
torch.cuda.memory_cached = torch.xpu.memory_reserved
|
||||
torch.cuda.max_memory_reserved = torch.xpu.max_memory_reserved
|
||||
torch.cuda.max_memory_cached = torch.xpu.max_memory_reserved
|
||||
torch.cuda.reset_peak_memory_stats = torch.xpu.reset_peak_memory_stats
|
||||
torch.cuda.reset_max_memory_cached = torch.xpu.reset_peak_memory_stats
|
||||
torch.cuda.reset_max_memory_allocated = torch.xpu.reset_peak_memory_stats
|
||||
torch.cuda.memory_stats_as_nested_dict = torch.xpu.memory_stats_as_nested_dict
|
||||
torch.cuda.reset_accumulated_memory_stats = torch.xpu.reset_accumulated_memory_stats
|
||||
|
||||
# RNG:
|
||||
torch.cuda.get_rng_state = torch.xpu.get_rng_state
|
||||
torch.cuda.get_rng_state_all = torch.xpu.get_rng_state_all
|
||||
torch.cuda.set_rng_state = torch.xpu.set_rng_state
|
||||
torch.cuda.set_rng_state_all = torch.xpu.set_rng_state_all
|
||||
torch.cuda.manual_seed = torch.xpu.manual_seed
|
||||
torch.cuda.manual_seed_all = torch.xpu.manual_seed_all
|
||||
torch.cuda.seed = torch.xpu.seed
|
||||
torch.cuda.seed_all = torch.xpu.seed_all
|
||||
torch.cuda.initial_seed = torch.xpu.initial_seed
|
||||
|
||||
# AMP:
|
||||
torch.cuda.amp = torch.xpu.amp
|
||||
torch.is_autocast_enabled = torch.xpu.is_autocast_xpu_enabled
|
||||
torch.get_autocast_gpu_dtype = torch.xpu.get_autocast_xpu_dtype
|
||||
|
||||
if not hasattr(torch.cuda.amp, "common"):
|
||||
torch.cuda.amp.common = contextlib.nullcontext()
|
||||
torch.cuda.amp.common.amp_definitely_not_available = lambda: False
|
||||
|
||||
try:
|
||||
torch.cuda.amp.GradScaler = torch.xpu.amp.GradScaler
|
||||
except Exception: # pylint: disable=broad-exception-caught
|
||||
try:
|
||||
from .gradscaler import gradscaler_init # pylint: disable=import-outside-toplevel, import-error
|
||||
gradscaler_init()
|
||||
torch.cuda.amp.GradScaler = torch.xpu.amp.GradScaler
|
||||
except Exception: # pylint: disable=broad-exception-caught
|
||||
torch.cuda.amp.GradScaler = ipex.cpu.autocast._grad_scaler.GradScaler
|
||||
|
||||
# C
|
||||
torch._C._cuda_getCurrentRawStream = ipex._C._getCurrentStream
|
||||
ipex._C._DeviceProperties.multi_processor_count = ipex._C._DeviceProperties.gpu_subslice_count
|
||||
ipex._C._DeviceProperties.major = 2024
|
||||
ipex._C._DeviceProperties.minor = 0
|
||||
|
||||
# Fix functions with ipex:
|
||||
torch.cuda.mem_get_info = lambda device=None: [(torch.xpu.get_device_properties(device).total_memory - torch.xpu.memory_reserved(device)), torch.xpu.get_device_properties(device).total_memory]
|
||||
torch._utils._get_available_device_type = lambda: "xpu"
|
||||
torch.has_cuda = True
|
||||
torch.cuda.has_half = True
|
||||
torch.cuda.is_bf16_supported = lambda *args, **kwargs: True
|
||||
torch.cuda.is_fp16_supported = lambda *args, **kwargs: True
|
||||
torch.backends.cuda.is_built = lambda *args, **kwargs: True
|
||||
torch.version.cuda = "12.1"
|
||||
torch.cuda.get_device_capability = lambda *args, **kwargs: [12,1]
|
||||
torch.cuda.get_device_properties.major = 12
|
||||
torch.cuda.get_device_properties.minor = 1
|
||||
torch.cuda.ipc_collect = lambda *args, **kwargs: None
|
||||
torch.cuda.utilization = lambda *args, **kwargs: 0
|
||||
|
||||
ipex_hijacks()
|
||||
if not torch.xpu.has_fp64_dtype() or os.environ.get('IPEX_FORCE_ATTENTION_SLICE', None) is not None:
|
||||
try:
|
||||
from .diffusers import ipex_diffusers
|
||||
ipex_diffusers()
|
||||
except Exception: # pylint: disable=broad-exception-caught
|
||||
pass
|
||||
torch.cuda.is_xpu_hijacked = True
|
||||
except Exception as e:
|
||||
return False, e
|
||||
return True, None
|
||||
177
library/ipex/attention.py
Normal file
177
library/ipex/attention.py
Normal file
@@ -0,0 +1,177 @@
|
||||
import os
|
||||
import torch
|
||||
import intel_extension_for_pytorch as ipex # pylint: disable=import-error, unused-import
|
||||
from functools import cache
|
||||
|
||||
# pylint: disable=protected-access, missing-function-docstring, line-too-long
|
||||
|
||||
# ARC GPUs can't allocate more than 4GB to a single block so we slice the attention layers
|
||||
|
||||
sdpa_slice_trigger_rate = float(os.environ.get('IPEX_SDPA_SLICE_TRIGGER_RATE', 4))
|
||||
attention_slice_rate = float(os.environ.get('IPEX_ATTENTION_SLICE_RATE', 4))
|
||||
|
||||
# Find something divisible with the input_tokens
|
||||
@cache
|
||||
def find_slice_size(slice_size, slice_block_size):
|
||||
while (slice_size * slice_block_size) > attention_slice_rate:
|
||||
slice_size = slice_size // 2
|
||||
if slice_size <= 1:
|
||||
slice_size = 1
|
||||
break
|
||||
return slice_size
|
||||
|
||||
# Find slice sizes for SDPA
|
||||
@cache
|
||||
def find_sdpa_slice_sizes(query_shape, query_element_size):
|
||||
if len(query_shape) == 3:
|
||||
batch_size_attention, query_tokens, shape_three = query_shape
|
||||
shape_four = 1
|
||||
else:
|
||||
batch_size_attention, query_tokens, shape_three, shape_four = query_shape
|
||||
|
||||
slice_block_size = query_tokens * shape_three * shape_four / 1024 / 1024 * query_element_size
|
||||
block_size = batch_size_attention * slice_block_size
|
||||
|
||||
split_slice_size = batch_size_attention
|
||||
split_2_slice_size = query_tokens
|
||||
split_3_slice_size = shape_three
|
||||
|
||||
do_split = False
|
||||
do_split_2 = False
|
||||
do_split_3 = False
|
||||
|
||||
if block_size > sdpa_slice_trigger_rate:
|
||||
do_split = True
|
||||
split_slice_size = find_slice_size(split_slice_size, slice_block_size)
|
||||
if split_slice_size * slice_block_size > attention_slice_rate:
|
||||
slice_2_block_size = split_slice_size * shape_three * shape_four / 1024 / 1024 * query_element_size
|
||||
do_split_2 = True
|
||||
split_2_slice_size = find_slice_size(split_2_slice_size, slice_2_block_size)
|
||||
if split_2_slice_size * slice_2_block_size > attention_slice_rate:
|
||||
slice_3_block_size = split_slice_size * split_2_slice_size * shape_four / 1024 / 1024 * query_element_size
|
||||
do_split_3 = True
|
||||
split_3_slice_size = find_slice_size(split_3_slice_size, slice_3_block_size)
|
||||
|
||||
return do_split, do_split_2, do_split_3, split_slice_size, split_2_slice_size, split_3_slice_size
|
||||
|
||||
# Find slice sizes for BMM
|
||||
@cache
|
||||
def find_bmm_slice_sizes(input_shape, input_element_size, mat2_shape):
|
||||
batch_size_attention, input_tokens, mat2_atten_shape = input_shape[0], input_shape[1], mat2_shape[2]
|
||||
slice_block_size = input_tokens * mat2_atten_shape / 1024 / 1024 * input_element_size
|
||||
block_size = batch_size_attention * slice_block_size
|
||||
|
||||
split_slice_size = batch_size_attention
|
||||
split_2_slice_size = input_tokens
|
||||
split_3_slice_size = mat2_atten_shape
|
||||
|
||||
do_split = False
|
||||
do_split_2 = False
|
||||
do_split_3 = False
|
||||
|
||||
if block_size > attention_slice_rate:
|
||||
do_split = True
|
||||
split_slice_size = find_slice_size(split_slice_size, slice_block_size)
|
||||
if split_slice_size * slice_block_size > attention_slice_rate:
|
||||
slice_2_block_size = split_slice_size * mat2_atten_shape / 1024 / 1024 * input_element_size
|
||||
do_split_2 = True
|
||||
split_2_slice_size = find_slice_size(split_2_slice_size, slice_2_block_size)
|
||||
if split_2_slice_size * slice_2_block_size > attention_slice_rate:
|
||||
slice_3_block_size = split_slice_size * split_2_slice_size / 1024 / 1024 * input_element_size
|
||||
do_split_3 = True
|
||||
split_3_slice_size = find_slice_size(split_3_slice_size, slice_3_block_size)
|
||||
|
||||
return do_split, do_split_2, do_split_3, split_slice_size, split_2_slice_size, split_3_slice_size
|
||||
|
||||
|
||||
original_torch_bmm = torch.bmm
|
||||
def torch_bmm_32_bit(input, mat2, *, out=None):
|
||||
if input.device.type != "xpu":
|
||||
return original_torch_bmm(input, mat2, out=out)
|
||||
do_split, do_split_2, do_split_3, split_slice_size, split_2_slice_size, split_3_slice_size = find_bmm_slice_sizes(input.shape, input.element_size(), mat2.shape)
|
||||
|
||||
# Slice BMM
|
||||
if do_split:
|
||||
batch_size_attention, input_tokens, mat2_atten_shape = input.shape[0], input.shape[1], mat2.shape[2]
|
||||
hidden_states = torch.zeros(input.shape[0], input.shape[1], mat2.shape[2], device=input.device, dtype=input.dtype)
|
||||
for i in range(batch_size_attention // split_slice_size):
|
||||
start_idx = i * split_slice_size
|
||||
end_idx = (i + 1) * split_slice_size
|
||||
if do_split_2:
|
||||
for i2 in range(input_tokens // split_2_slice_size): # pylint: disable=invalid-name
|
||||
start_idx_2 = i2 * split_2_slice_size
|
||||
end_idx_2 = (i2 + 1) * split_2_slice_size
|
||||
if do_split_3:
|
||||
for i3 in range(mat2_atten_shape // split_3_slice_size): # pylint: disable=invalid-name
|
||||
start_idx_3 = i3 * split_3_slice_size
|
||||
end_idx_3 = (i3 + 1) * split_3_slice_size
|
||||
hidden_states[start_idx:end_idx, start_idx_2:end_idx_2, start_idx_3:end_idx_3] = original_torch_bmm(
|
||||
input[start_idx:end_idx, start_idx_2:end_idx_2, start_idx_3:end_idx_3],
|
||||
mat2[start_idx:end_idx, start_idx_2:end_idx_2, start_idx_3:end_idx_3],
|
||||
out=out
|
||||
)
|
||||
else:
|
||||
hidden_states[start_idx:end_idx, start_idx_2:end_idx_2] = original_torch_bmm(
|
||||
input[start_idx:end_idx, start_idx_2:end_idx_2],
|
||||
mat2[start_idx:end_idx, start_idx_2:end_idx_2],
|
||||
out=out
|
||||
)
|
||||
else:
|
||||
hidden_states[start_idx:end_idx] = original_torch_bmm(
|
||||
input[start_idx:end_idx],
|
||||
mat2[start_idx:end_idx],
|
||||
out=out
|
||||
)
|
||||
torch.xpu.synchronize(input.device)
|
||||
else:
|
||||
return original_torch_bmm(input, mat2, out=out)
|
||||
return hidden_states
|
||||
|
||||
original_scaled_dot_product_attention = torch.nn.functional.scaled_dot_product_attention
|
||||
def scaled_dot_product_attention_32_bit(query, key, value, attn_mask=None, dropout_p=0.0, is_causal=False, **kwargs):
|
||||
if query.device.type != "xpu":
|
||||
return original_scaled_dot_product_attention(query, key, value, attn_mask=attn_mask, dropout_p=dropout_p, is_causal=is_causal, **kwargs)
|
||||
do_split, do_split_2, do_split_3, split_slice_size, split_2_slice_size, split_3_slice_size = find_sdpa_slice_sizes(query.shape, query.element_size())
|
||||
|
||||
# Slice SDPA
|
||||
if do_split:
|
||||
batch_size_attention, query_tokens, shape_three = query.shape[0], query.shape[1], query.shape[2]
|
||||
hidden_states = torch.zeros(query.shape, device=query.device, dtype=query.dtype)
|
||||
for i in range(batch_size_attention // split_slice_size):
|
||||
start_idx = i * split_slice_size
|
||||
end_idx = (i + 1) * split_slice_size
|
||||
if do_split_2:
|
||||
for i2 in range(query_tokens // split_2_slice_size): # pylint: disable=invalid-name
|
||||
start_idx_2 = i2 * split_2_slice_size
|
||||
end_idx_2 = (i2 + 1) * split_2_slice_size
|
||||
if do_split_3:
|
||||
for i3 in range(shape_three // split_3_slice_size): # pylint: disable=invalid-name
|
||||
start_idx_3 = i3 * split_3_slice_size
|
||||
end_idx_3 = (i3 + 1) * split_3_slice_size
|
||||
hidden_states[start_idx:end_idx, start_idx_2:end_idx_2, start_idx_3:end_idx_3] = original_scaled_dot_product_attention(
|
||||
query[start_idx:end_idx, start_idx_2:end_idx_2, start_idx_3:end_idx_3],
|
||||
key[start_idx:end_idx, start_idx_2:end_idx_2, start_idx_3:end_idx_3],
|
||||
value[start_idx:end_idx, start_idx_2:end_idx_2, start_idx_3:end_idx_3],
|
||||
attn_mask=attn_mask[start_idx:end_idx, start_idx_2:end_idx_2, start_idx_3:end_idx_3] if attn_mask is not None else attn_mask,
|
||||
dropout_p=dropout_p, is_causal=is_causal, **kwargs
|
||||
)
|
||||
else:
|
||||
hidden_states[start_idx:end_idx, start_idx_2:end_idx_2] = original_scaled_dot_product_attention(
|
||||
query[start_idx:end_idx, start_idx_2:end_idx_2],
|
||||
key[start_idx:end_idx, start_idx_2:end_idx_2],
|
||||
value[start_idx:end_idx, start_idx_2:end_idx_2],
|
||||
attn_mask=attn_mask[start_idx:end_idx, start_idx_2:end_idx_2] if attn_mask is not None else attn_mask,
|
||||
dropout_p=dropout_p, is_causal=is_causal, **kwargs
|
||||
)
|
||||
else:
|
||||
hidden_states[start_idx:end_idx] = original_scaled_dot_product_attention(
|
||||
query[start_idx:end_idx],
|
||||
key[start_idx:end_idx],
|
||||
value[start_idx:end_idx],
|
||||
attn_mask=attn_mask[start_idx:end_idx] if attn_mask is not None else attn_mask,
|
||||
dropout_p=dropout_p, is_causal=is_causal, **kwargs
|
||||
)
|
||||
torch.xpu.synchronize(query.device)
|
||||
else:
|
||||
return original_scaled_dot_product_attention(query, key, value, attn_mask=attn_mask, dropout_p=dropout_p, is_causal=is_causal, **kwargs)
|
||||
return hidden_states
|
||||
312
library/ipex/diffusers.py
Normal file
312
library/ipex/diffusers.py
Normal file
@@ -0,0 +1,312 @@
|
||||
import os
|
||||
import torch
|
||||
import intel_extension_for_pytorch as ipex # pylint: disable=import-error, unused-import
|
||||
import diffusers #0.24.0 # pylint: disable=import-error
|
||||
from diffusers.models.attention_processor import Attention
|
||||
from diffusers.utils import USE_PEFT_BACKEND
|
||||
from functools import cache
|
||||
|
||||
# pylint: disable=protected-access, missing-function-docstring, line-too-long
|
||||
|
||||
attention_slice_rate = float(os.environ.get('IPEX_ATTENTION_SLICE_RATE', 4))
|
||||
|
||||
@cache
|
||||
def find_slice_size(slice_size, slice_block_size):
|
||||
while (slice_size * slice_block_size) > attention_slice_rate:
|
||||
slice_size = slice_size // 2
|
||||
if slice_size <= 1:
|
||||
slice_size = 1
|
||||
break
|
||||
return slice_size
|
||||
|
||||
@cache
|
||||
def find_attention_slice_sizes(query_shape, query_element_size, query_device_type, slice_size=None):
|
||||
if len(query_shape) == 3:
|
||||
batch_size_attention, query_tokens, shape_three = query_shape
|
||||
shape_four = 1
|
||||
else:
|
||||
batch_size_attention, query_tokens, shape_three, shape_four = query_shape
|
||||
if slice_size is not None:
|
||||
batch_size_attention = slice_size
|
||||
|
||||
slice_block_size = query_tokens * shape_three * shape_four / 1024 / 1024 * query_element_size
|
||||
block_size = batch_size_attention * slice_block_size
|
||||
|
||||
split_slice_size = batch_size_attention
|
||||
split_2_slice_size = query_tokens
|
||||
split_3_slice_size = shape_three
|
||||
|
||||
do_split = False
|
||||
do_split_2 = False
|
||||
do_split_3 = False
|
||||
|
||||
if query_device_type != "xpu":
|
||||
return do_split, do_split_2, do_split_3, split_slice_size, split_2_slice_size, split_3_slice_size
|
||||
|
||||
if block_size > attention_slice_rate:
|
||||
do_split = True
|
||||
split_slice_size = find_slice_size(split_slice_size, slice_block_size)
|
||||
if split_slice_size * slice_block_size > attention_slice_rate:
|
||||
slice_2_block_size = split_slice_size * shape_three * shape_four / 1024 / 1024 * query_element_size
|
||||
do_split_2 = True
|
||||
split_2_slice_size = find_slice_size(split_2_slice_size, slice_2_block_size)
|
||||
if split_2_slice_size * slice_2_block_size > attention_slice_rate:
|
||||
slice_3_block_size = split_slice_size * split_2_slice_size * shape_four / 1024 / 1024 * query_element_size
|
||||
do_split_3 = True
|
||||
split_3_slice_size = find_slice_size(split_3_slice_size, slice_3_block_size)
|
||||
|
||||
return do_split, do_split_2, do_split_3, split_slice_size, split_2_slice_size, split_3_slice_size
|
||||
|
||||
class SlicedAttnProcessor: # pylint: disable=too-few-public-methods
|
||||
r"""
|
||||
Processor for implementing sliced attention.
|
||||
|
||||
Args:
|
||||
slice_size (`int`, *optional*):
|
||||
The number of steps to compute attention. Uses as many slices as `attention_head_dim // slice_size`, and
|
||||
`attention_head_dim` must be a multiple of the `slice_size`.
|
||||
"""
|
||||
|
||||
def __init__(self, slice_size):
|
||||
self.slice_size = slice_size
|
||||
|
||||
def __call__(self, attn: Attention, hidden_states: torch.FloatTensor,
|
||||
encoder_hidden_states=None, attention_mask=None) -> torch.FloatTensor: # pylint: disable=too-many-statements, too-many-locals, too-many-branches
|
||||
|
||||
residual = hidden_states
|
||||
|
||||
input_ndim = hidden_states.ndim
|
||||
|
||||
if input_ndim == 4:
|
||||
batch_size, channel, height, width = hidden_states.shape
|
||||
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
||||
|
||||
batch_size, sequence_length, _ = (
|
||||
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
||||
)
|
||||
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
||||
|
||||
if attn.group_norm is not None:
|
||||
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
||||
|
||||
query = attn.to_q(hidden_states)
|
||||
dim = query.shape[-1]
|
||||
query = attn.head_to_batch_dim(query)
|
||||
|
||||
if encoder_hidden_states is None:
|
||||
encoder_hidden_states = hidden_states
|
||||
elif attn.norm_cross:
|
||||
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
||||
|
||||
key = attn.to_k(encoder_hidden_states)
|
||||
value = attn.to_v(encoder_hidden_states)
|
||||
key = attn.head_to_batch_dim(key)
|
||||
value = attn.head_to_batch_dim(value)
|
||||
|
||||
batch_size_attention, query_tokens, shape_three = query.shape
|
||||
hidden_states = torch.zeros(
|
||||
(batch_size_attention, query_tokens, dim // attn.heads), device=query.device, dtype=query.dtype
|
||||
)
|
||||
|
||||
####################################################################
|
||||
# ARC GPUs can't allocate more than 4GB to a single block, Slice it:
|
||||
_, do_split_2, do_split_3, split_slice_size, split_2_slice_size, split_3_slice_size = find_attention_slice_sizes(query.shape, query.element_size(), query.device.type, slice_size=self.slice_size)
|
||||
|
||||
for i in range(batch_size_attention // split_slice_size):
|
||||
start_idx = i * split_slice_size
|
||||
end_idx = (i + 1) * split_slice_size
|
||||
if do_split_2:
|
||||
for i2 in range(query_tokens // split_2_slice_size): # pylint: disable=invalid-name
|
||||
start_idx_2 = i2 * split_2_slice_size
|
||||
end_idx_2 = (i2 + 1) * split_2_slice_size
|
||||
if do_split_3:
|
||||
for i3 in range(shape_three // split_3_slice_size): # pylint: disable=invalid-name
|
||||
start_idx_3 = i3 * split_3_slice_size
|
||||
end_idx_3 = (i3 + 1) * split_3_slice_size
|
||||
|
||||
query_slice = query[start_idx:end_idx, start_idx_2:end_idx_2, start_idx_3:end_idx_3]
|
||||
key_slice = key[start_idx:end_idx, start_idx_2:end_idx_2, start_idx_3:end_idx_3]
|
||||
attn_mask_slice = attention_mask[start_idx:end_idx, start_idx_2:end_idx_2, start_idx_3:end_idx_3] if attention_mask is not None else None
|
||||
|
||||
attn_slice = attn.get_attention_scores(query_slice, key_slice, attn_mask_slice)
|
||||
del query_slice
|
||||
del key_slice
|
||||
del attn_mask_slice
|
||||
attn_slice = torch.bmm(attn_slice, value[start_idx:end_idx, start_idx_2:end_idx_2, start_idx_3:end_idx_3])
|
||||
|
||||
hidden_states[start_idx:end_idx, start_idx_2:end_idx_2, start_idx_3:end_idx_3] = attn_slice
|
||||
del attn_slice
|
||||
else:
|
||||
query_slice = query[start_idx:end_idx, start_idx_2:end_idx_2]
|
||||
key_slice = key[start_idx:end_idx, start_idx_2:end_idx_2]
|
||||
attn_mask_slice = attention_mask[start_idx:end_idx, start_idx_2:end_idx_2] if attention_mask is not None else None
|
||||
|
||||
attn_slice = attn.get_attention_scores(query_slice, key_slice, attn_mask_slice)
|
||||
del query_slice
|
||||
del key_slice
|
||||
del attn_mask_slice
|
||||
attn_slice = torch.bmm(attn_slice, value[start_idx:end_idx, start_idx_2:end_idx_2])
|
||||
|
||||
hidden_states[start_idx:end_idx, start_idx_2:end_idx_2] = attn_slice
|
||||
del attn_slice
|
||||
torch.xpu.synchronize(query.device)
|
||||
else:
|
||||
query_slice = query[start_idx:end_idx]
|
||||
key_slice = key[start_idx:end_idx]
|
||||
attn_mask_slice = attention_mask[start_idx:end_idx] if attention_mask is not None else None
|
||||
|
||||
attn_slice = attn.get_attention_scores(query_slice, key_slice, attn_mask_slice)
|
||||
del query_slice
|
||||
del key_slice
|
||||
del attn_mask_slice
|
||||
attn_slice = torch.bmm(attn_slice, value[start_idx:end_idx])
|
||||
|
||||
hidden_states[start_idx:end_idx] = attn_slice
|
||||
del attn_slice
|
||||
####################################################################
|
||||
|
||||
hidden_states = attn.batch_to_head_dim(hidden_states)
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states)
|
||||
# dropout
|
||||
hidden_states = attn.to_out[1](hidden_states)
|
||||
|
||||
if input_ndim == 4:
|
||||
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
||||
|
||||
if attn.residual_connection:
|
||||
hidden_states = hidden_states + residual
|
||||
|
||||
hidden_states = hidden_states / attn.rescale_output_factor
|
||||
|
||||
return hidden_states
|
||||
|
||||
|
||||
class AttnProcessor:
|
||||
r"""
|
||||
Default processor for performing attention-related computations.
|
||||
"""
|
||||
|
||||
def __call__(self, attn: Attention, hidden_states: torch.FloatTensor,
|
||||
encoder_hidden_states=None, attention_mask=None,
|
||||
temb=None, scale: float = 1.0) -> torch.Tensor: # pylint: disable=too-many-statements, too-many-locals, too-many-branches
|
||||
|
||||
residual = hidden_states
|
||||
|
||||
args = () if USE_PEFT_BACKEND else (scale,)
|
||||
|
||||
if attn.spatial_norm is not None:
|
||||
hidden_states = attn.spatial_norm(hidden_states, temb)
|
||||
|
||||
input_ndim = hidden_states.ndim
|
||||
|
||||
if input_ndim == 4:
|
||||
batch_size, channel, height, width = hidden_states.shape
|
||||
hidden_states = hidden_states.view(batch_size, channel, height * width).transpose(1, 2)
|
||||
|
||||
batch_size, sequence_length, _ = (
|
||||
hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
|
||||
)
|
||||
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
|
||||
|
||||
if attn.group_norm is not None:
|
||||
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(1, 2)
|
||||
|
||||
query = attn.to_q(hidden_states, *args)
|
||||
|
||||
if encoder_hidden_states is None:
|
||||
encoder_hidden_states = hidden_states
|
||||
elif attn.norm_cross:
|
||||
encoder_hidden_states = attn.norm_encoder_hidden_states(encoder_hidden_states)
|
||||
|
||||
key = attn.to_k(encoder_hidden_states, *args)
|
||||
value = attn.to_v(encoder_hidden_states, *args)
|
||||
|
||||
query = attn.head_to_batch_dim(query)
|
||||
key = attn.head_to_batch_dim(key)
|
||||
value = attn.head_to_batch_dim(value)
|
||||
|
||||
####################################################################
|
||||
# ARC GPUs can't allocate more than 4GB to a single block, Slice it:
|
||||
batch_size_attention, query_tokens, shape_three = query.shape[0], query.shape[1], query.shape[2]
|
||||
hidden_states = torch.zeros(query.shape, device=query.device, dtype=query.dtype)
|
||||
do_split, do_split_2, do_split_3, split_slice_size, split_2_slice_size, split_3_slice_size = find_attention_slice_sizes(query.shape, query.element_size(), query.device.type)
|
||||
|
||||
if do_split:
|
||||
for i in range(batch_size_attention // split_slice_size):
|
||||
start_idx = i * split_slice_size
|
||||
end_idx = (i + 1) * split_slice_size
|
||||
if do_split_2:
|
||||
for i2 in range(query_tokens // split_2_slice_size): # pylint: disable=invalid-name
|
||||
start_idx_2 = i2 * split_2_slice_size
|
||||
end_idx_2 = (i2 + 1) * split_2_slice_size
|
||||
if do_split_3:
|
||||
for i3 in range(shape_three // split_3_slice_size): # pylint: disable=invalid-name
|
||||
start_idx_3 = i3 * split_3_slice_size
|
||||
end_idx_3 = (i3 + 1) * split_3_slice_size
|
||||
|
||||
query_slice = query[start_idx:end_idx, start_idx_2:end_idx_2, start_idx_3:end_idx_3]
|
||||
key_slice = key[start_idx:end_idx, start_idx_2:end_idx_2, start_idx_3:end_idx_3]
|
||||
attn_mask_slice = attention_mask[start_idx:end_idx, start_idx_2:end_idx_2, start_idx_3:end_idx_3] if attention_mask is not None else None
|
||||
|
||||
attn_slice = attn.get_attention_scores(query_slice, key_slice, attn_mask_slice)
|
||||
del query_slice
|
||||
del key_slice
|
||||
del attn_mask_slice
|
||||
attn_slice = torch.bmm(attn_slice, value[start_idx:end_idx, start_idx_2:end_idx_2, start_idx_3:end_idx_3])
|
||||
|
||||
hidden_states[start_idx:end_idx, start_idx_2:end_idx_2, start_idx_3:end_idx_3] = attn_slice
|
||||
del attn_slice
|
||||
else:
|
||||
query_slice = query[start_idx:end_idx, start_idx_2:end_idx_2]
|
||||
key_slice = key[start_idx:end_idx, start_idx_2:end_idx_2]
|
||||
attn_mask_slice = attention_mask[start_idx:end_idx, start_idx_2:end_idx_2] if attention_mask is not None else None
|
||||
|
||||
attn_slice = attn.get_attention_scores(query_slice, key_slice, attn_mask_slice)
|
||||
del query_slice
|
||||
del key_slice
|
||||
del attn_mask_slice
|
||||
attn_slice = torch.bmm(attn_slice, value[start_idx:end_idx, start_idx_2:end_idx_2])
|
||||
|
||||
hidden_states[start_idx:end_idx, start_idx_2:end_idx_2] = attn_slice
|
||||
del attn_slice
|
||||
else:
|
||||
query_slice = query[start_idx:end_idx]
|
||||
key_slice = key[start_idx:end_idx]
|
||||
attn_mask_slice = attention_mask[start_idx:end_idx] if attention_mask is not None else None
|
||||
|
||||
attn_slice = attn.get_attention_scores(query_slice, key_slice, attn_mask_slice)
|
||||
del query_slice
|
||||
del key_slice
|
||||
del attn_mask_slice
|
||||
attn_slice = torch.bmm(attn_slice, value[start_idx:end_idx])
|
||||
|
||||
hidden_states[start_idx:end_idx] = attn_slice
|
||||
del attn_slice
|
||||
torch.xpu.synchronize(query.device)
|
||||
else:
|
||||
attention_probs = attn.get_attention_scores(query, key, attention_mask)
|
||||
hidden_states = torch.bmm(attention_probs, value)
|
||||
####################################################################
|
||||
hidden_states = attn.batch_to_head_dim(hidden_states)
|
||||
|
||||
# linear proj
|
||||
hidden_states = attn.to_out[0](hidden_states, *args)
|
||||
# dropout
|
||||
hidden_states = attn.to_out[1](hidden_states)
|
||||
|
||||
if input_ndim == 4:
|
||||
hidden_states = hidden_states.transpose(-1, -2).reshape(batch_size, channel, height, width)
|
||||
|
||||
if attn.residual_connection:
|
||||
hidden_states = hidden_states + residual
|
||||
|
||||
hidden_states = hidden_states / attn.rescale_output_factor
|
||||
|
||||
return hidden_states
|
||||
|
||||
def ipex_diffusers():
|
||||
#ARC GPUs can't allocate more than 4GB to a single block:
|
||||
diffusers.models.attention_processor.SlicedAttnProcessor = SlicedAttnProcessor
|
||||
diffusers.models.attention_processor.AttnProcessor = AttnProcessor
|
||||
183
library/ipex/gradscaler.py
Normal file
183
library/ipex/gradscaler.py
Normal file
@@ -0,0 +1,183 @@
|
||||
from collections import defaultdict
|
||||
import torch
|
||||
import intel_extension_for_pytorch as ipex # pylint: disable=import-error, unused-import
|
||||
import intel_extension_for_pytorch._C as core # pylint: disable=import-error, unused-import
|
||||
|
||||
# pylint: disable=protected-access, missing-function-docstring, line-too-long
|
||||
|
||||
device_supports_fp64 = torch.xpu.has_fp64_dtype()
|
||||
OptState = ipex.cpu.autocast._grad_scaler.OptState
|
||||
_MultiDeviceReplicator = ipex.cpu.autocast._grad_scaler._MultiDeviceReplicator
|
||||
_refresh_per_optimizer_state = ipex.cpu.autocast._grad_scaler._refresh_per_optimizer_state
|
||||
|
||||
def _unscale_grads_(self, optimizer, inv_scale, found_inf, allow_fp16): # pylint: disable=unused-argument
|
||||
per_device_inv_scale = _MultiDeviceReplicator(inv_scale)
|
||||
per_device_found_inf = _MultiDeviceReplicator(found_inf)
|
||||
|
||||
# To set up _amp_foreach_non_finite_check_and_unscale_, split grads by device and dtype.
|
||||
# There could be hundreds of grads, so we'd like to iterate through them just once.
|
||||
# However, we don't know their devices or dtypes in advance.
|
||||
|
||||
# https://stackoverflow.com/questions/5029934/defaultdict-of-defaultdict
|
||||
# Google says mypy struggles with defaultdicts type annotations.
|
||||
per_device_and_dtype_grads = defaultdict(lambda: defaultdict(list)) # type: ignore[var-annotated]
|
||||
# sync grad to master weight
|
||||
if hasattr(optimizer, "sync_grad"):
|
||||
optimizer.sync_grad()
|
||||
with torch.no_grad():
|
||||
for group in optimizer.param_groups:
|
||||
for param in group["params"]:
|
||||
if param.grad is None:
|
||||
continue
|
||||
if (not allow_fp16) and param.grad.dtype == torch.float16:
|
||||
raise ValueError("Attempting to unscale FP16 gradients.")
|
||||
if param.grad.is_sparse:
|
||||
# is_coalesced() == False means the sparse grad has values with duplicate indices.
|
||||
# coalesce() deduplicates indices and adds all values that have the same index.
|
||||
# For scaled fp16 values, there's a good chance coalescing will cause overflow,
|
||||
# so we should check the coalesced _values().
|
||||
if param.grad.dtype is torch.float16:
|
||||
param.grad = param.grad.coalesce()
|
||||
to_unscale = param.grad._values()
|
||||
else:
|
||||
to_unscale = param.grad
|
||||
|
||||
# -: is there a way to split by device and dtype without appending in the inner loop?
|
||||
to_unscale = to_unscale.to("cpu")
|
||||
per_device_and_dtype_grads[to_unscale.device][
|
||||
to_unscale.dtype
|
||||
].append(to_unscale)
|
||||
|
||||
for _, per_dtype_grads in per_device_and_dtype_grads.items():
|
||||
for grads in per_dtype_grads.values():
|
||||
core._amp_foreach_non_finite_check_and_unscale_(
|
||||
grads,
|
||||
per_device_found_inf.get("cpu"),
|
||||
per_device_inv_scale.get("cpu"),
|
||||
)
|
||||
|
||||
return per_device_found_inf._per_device_tensors
|
||||
|
||||
def unscale_(self, optimizer):
|
||||
"""
|
||||
Divides ("unscales") the optimizer's gradient tensors by the scale factor.
|
||||
:meth:`unscale_` is optional, serving cases where you need to
|
||||
:ref:`modify or inspect gradients<working-with-unscaled-gradients>`
|
||||
between the backward pass(es) and :meth:`step`.
|
||||
If :meth:`unscale_` is not called explicitly, gradients will be unscaled automatically during :meth:`step`.
|
||||
Simple example, using :meth:`unscale_` to enable clipping of unscaled gradients::
|
||||
...
|
||||
scaler.scale(loss).backward()
|
||||
scaler.unscale_(optimizer)
|
||||
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
|
||||
scaler.step(optimizer)
|
||||
scaler.update()
|
||||
Args:
|
||||
optimizer (torch.optim.Optimizer): Optimizer that owns the gradients to be unscaled.
|
||||
.. warning::
|
||||
:meth:`unscale_` should only be called once per optimizer per :meth:`step` call,
|
||||
and only after all gradients for that optimizer's assigned parameters have been accumulated.
|
||||
Calling :meth:`unscale_` twice for a given optimizer between each :meth:`step` triggers a RuntimeError.
|
||||
.. warning::
|
||||
:meth:`unscale_` may unscale sparse gradients out of place, replacing the ``.grad`` attribute.
|
||||
"""
|
||||
if not self._enabled:
|
||||
return
|
||||
|
||||
self._check_scale_growth_tracker("unscale_")
|
||||
|
||||
optimizer_state = self._per_optimizer_states[id(optimizer)]
|
||||
|
||||
if optimizer_state["stage"] is OptState.UNSCALED: # pylint: disable=no-else-raise
|
||||
raise RuntimeError(
|
||||
"unscale_() has already been called on this optimizer since the last update()."
|
||||
)
|
||||
elif optimizer_state["stage"] is OptState.STEPPED:
|
||||
raise RuntimeError("unscale_() is being called after step().")
|
||||
|
||||
# FP32 division can be imprecise for certain compile options, so we carry out the reciprocal in FP64.
|
||||
assert self._scale is not None
|
||||
if device_supports_fp64:
|
||||
inv_scale = self._scale.double().reciprocal().float()
|
||||
else:
|
||||
inv_scale = self._scale.to("cpu").double().reciprocal().float().to(self._scale.device)
|
||||
found_inf = torch.full(
|
||||
(1,), 0.0, dtype=torch.float32, device=self._scale.device
|
||||
)
|
||||
|
||||
optimizer_state["found_inf_per_device"] = self._unscale_grads_(
|
||||
optimizer, inv_scale, found_inf, False
|
||||
)
|
||||
optimizer_state["stage"] = OptState.UNSCALED
|
||||
|
||||
def update(self, new_scale=None):
|
||||
"""
|
||||
Updates the scale factor.
|
||||
If any optimizer steps were skipped the scale is multiplied by ``backoff_factor``
|
||||
to reduce it. If ``growth_interval`` unskipped iterations occurred consecutively,
|
||||
the scale is multiplied by ``growth_factor`` to increase it.
|
||||
Passing ``new_scale`` sets the new scale value manually. (``new_scale`` is not
|
||||
used directly, it's used to fill GradScaler's internal scale tensor. So if
|
||||
``new_scale`` was a tensor, later in-place changes to that tensor will not further
|
||||
affect the scale GradScaler uses internally.)
|
||||
Args:
|
||||
new_scale (float or :class:`torch.FloatTensor`, optional, default=None): New scale factor.
|
||||
.. warning::
|
||||
:meth:`update` should only be called at the end of the iteration, after ``scaler.step(optimizer)`` has
|
||||
been invoked for all optimizers used this iteration.
|
||||
"""
|
||||
if not self._enabled:
|
||||
return
|
||||
|
||||
_scale, _growth_tracker = self._check_scale_growth_tracker("update")
|
||||
|
||||
if new_scale is not None:
|
||||
# Accept a new user-defined scale.
|
||||
if isinstance(new_scale, float):
|
||||
self._scale.fill_(new_scale) # type: ignore[union-attr]
|
||||
else:
|
||||
reason = "new_scale should be a float or a 1-element torch.FloatTensor with requires_grad=False."
|
||||
assert isinstance(new_scale, torch.FloatTensor), reason # type: ignore[attr-defined]
|
||||
assert new_scale.numel() == 1, reason
|
||||
assert new_scale.requires_grad is False, reason
|
||||
self._scale.copy_(new_scale) # type: ignore[union-attr]
|
||||
else:
|
||||
# Consume shared inf/nan data collected from optimizers to update the scale.
|
||||
# If all found_inf tensors are on the same device as self._scale, this operation is asynchronous.
|
||||
found_infs = [
|
||||
found_inf.to(device="cpu", non_blocking=True)
|
||||
for state in self._per_optimizer_states.values()
|
||||
for found_inf in state["found_inf_per_device"].values()
|
||||
]
|
||||
|
||||
assert len(found_infs) > 0, "No inf checks were recorded prior to update."
|
||||
|
||||
found_inf_combined = found_infs[0]
|
||||
if len(found_infs) > 1:
|
||||
for i in range(1, len(found_infs)):
|
||||
found_inf_combined += found_infs[i]
|
||||
|
||||
to_device = _scale.device
|
||||
_scale = _scale.to("cpu")
|
||||
_growth_tracker = _growth_tracker.to("cpu")
|
||||
|
||||
core._amp_update_scale_(
|
||||
_scale,
|
||||
_growth_tracker,
|
||||
found_inf_combined,
|
||||
self._growth_factor,
|
||||
self._backoff_factor,
|
||||
self._growth_interval,
|
||||
)
|
||||
|
||||
_scale = _scale.to(to_device)
|
||||
_growth_tracker = _growth_tracker.to(to_device)
|
||||
# To prepare for next iteration, clear the data collected from optimizers this iteration.
|
||||
self._per_optimizer_states = defaultdict(_refresh_per_optimizer_state)
|
||||
|
||||
def gradscaler_init():
|
||||
torch.xpu.amp.GradScaler = ipex.cpu.autocast._grad_scaler.GradScaler
|
||||
torch.xpu.amp.GradScaler._unscale_grads_ = _unscale_grads_
|
||||
torch.xpu.amp.GradScaler.unscale_ = unscale_
|
||||
torch.xpu.amp.GradScaler.update = update
|
||||
return torch.xpu.amp.GradScaler
|
||||
313
library/ipex/hijacks.py
Normal file
313
library/ipex/hijacks.py
Normal file
@@ -0,0 +1,313 @@
|
||||
import os
|
||||
from functools import wraps
|
||||
from contextlib import nullcontext
|
||||
import torch
|
||||
import intel_extension_for_pytorch as ipex # pylint: disable=import-error, unused-import
|
||||
import numpy as np
|
||||
|
||||
device_supports_fp64 = torch.xpu.has_fp64_dtype()
|
||||
|
||||
# pylint: disable=protected-access, missing-function-docstring, line-too-long, unnecessary-lambda, no-else-return
|
||||
|
||||
class DummyDataParallel(torch.nn.Module): # pylint: disable=missing-class-docstring, unused-argument, too-few-public-methods
|
||||
def __new__(cls, module, device_ids=None, output_device=None, dim=0): # pylint: disable=unused-argument
|
||||
if isinstance(device_ids, list) and len(device_ids) > 1:
|
||||
print("IPEX backend doesn't support DataParallel on multiple XPU devices")
|
||||
return module.to("xpu")
|
||||
|
||||
def return_null_context(*args, **kwargs): # pylint: disable=unused-argument
|
||||
return nullcontext()
|
||||
|
||||
@property
|
||||
def is_cuda(self):
|
||||
return self.device.type == 'xpu' or self.device.type == 'cuda'
|
||||
|
||||
def check_device(device):
|
||||
return bool((isinstance(device, torch.device) and device.type == "cuda") or (isinstance(device, str) and "cuda" in device) or isinstance(device, int))
|
||||
|
||||
def return_xpu(device):
|
||||
return f"xpu:{device.split(':')[-1]}" if isinstance(device, str) and ":" in device else f"xpu:{device}" if isinstance(device, int) else torch.device("xpu") if isinstance(device, torch.device) else "xpu"
|
||||
|
||||
|
||||
# Autocast
|
||||
original_autocast_init = torch.amp.autocast_mode.autocast.__init__
|
||||
@wraps(torch.amp.autocast_mode.autocast.__init__)
|
||||
def autocast_init(self, device_type, dtype=None, enabled=True, cache_enabled=None):
|
||||
if device_type == "cuda":
|
||||
return original_autocast_init(self, device_type="xpu", dtype=dtype, enabled=enabled, cache_enabled=cache_enabled)
|
||||
else:
|
||||
return original_autocast_init(self, device_type=device_type, dtype=dtype, enabled=enabled, cache_enabled=cache_enabled)
|
||||
|
||||
# Latent Antialias CPU Offload:
|
||||
original_interpolate = torch.nn.functional.interpolate
|
||||
@wraps(torch.nn.functional.interpolate)
|
||||
def interpolate(tensor, size=None, scale_factor=None, mode='nearest', align_corners=None, recompute_scale_factor=None, antialias=False): # pylint: disable=too-many-arguments
|
||||
if antialias or align_corners is not None or mode == 'bicubic':
|
||||
return_device = tensor.device
|
||||
return_dtype = tensor.dtype
|
||||
return original_interpolate(tensor.to("cpu", dtype=torch.float32), size=size, scale_factor=scale_factor, mode=mode,
|
||||
align_corners=align_corners, recompute_scale_factor=recompute_scale_factor, antialias=antialias).to(return_device, dtype=return_dtype)
|
||||
else:
|
||||
return original_interpolate(tensor, size=size, scale_factor=scale_factor, mode=mode,
|
||||
align_corners=align_corners, recompute_scale_factor=recompute_scale_factor, antialias=antialias)
|
||||
|
||||
|
||||
# Diffusers Float64 (Alchemist GPUs doesn't support 64 bit):
|
||||
original_from_numpy = torch.from_numpy
|
||||
@wraps(torch.from_numpy)
|
||||
def from_numpy(ndarray):
|
||||
if ndarray.dtype == float:
|
||||
return original_from_numpy(ndarray.astype('float32'))
|
||||
else:
|
||||
return original_from_numpy(ndarray)
|
||||
|
||||
original_as_tensor = torch.as_tensor
|
||||
@wraps(torch.as_tensor)
|
||||
def as_tensor(data, dtype=None, device=None):
|
||||
if check_device(device):
|
||||
device = return_xpu(device)
|
||||
if isinstance(data, np.ndarray) and data.dtype == float and not (
|
||||
(isinstance(device, torch.device) and device.type == "cpu") or (isinstance(device, str) and "cpu" in device)):
|
||||
return original_as_tensor(data, dtype=torch.float32, device=device)
|
||||
else:
|
||||
return original_as_tensor(data, dtype=dtype, device=device)
|
||||
|
||||
|
||||
if device_supports_fp64 and os.environ.get('IPEX_FORCE_ATTENTION_SLICE', None) is None:
|
||||
original_torch_bmm = torch.bmm
|
||||
original_scaled_dot_product_attention = torch.nn.functional.scaled_dot_product_attention
|
||||
else:
|
||||
# 32 bit attention workarounds for Alchemist:
|
||||
try:
|
||||
from .attention import torch_bmm_32_bit as original_torch_bmm
|
||||
from .attention import scaled_dot_product_attention_32_bit as original_scaled_dot_product_attention
|
||||
except Exception: # pylint: disable=broad-exception-caught
|
||||
original_torch_bmm = torch.bmm
|
||||
original_scaled_dot_product_attention = torch.nn.functional.scaled_dot_product_attention
|
||||
|
||||
|
||||
# Data Type Errors:
|
||||
@wraps(torch.bmm)
|
||||
def torch_bmm(input, mat2, *, out=None):
|
||||
if input.dtype != mat2.dtype:
|
||||
mat2 = mat2.to(input.dtype)
|
||||
return original_torch_bmm(input, mat2, out=out)
|
||||
|
||||
@wraps(torch.nn.functional.scaled_dot_product_attention)
|
||||
def scaled_dot_product_attention(query, key, value, attn_mask=None, dropout_p=0.0, is_causal=False):
|
||||
if query.dtype != key.dtype:
|
||||
key = key.to(dtype=query.dtype)
|
||||
if query.dtype != value.dtype:
|
||||
value = value.to(dtype=query.dtype)
|
||||
if attn_mask is not None and query.dtype != attn_mask.dtype:
|
||||
attn_mask = attn_mask.to(dtype=query.dtype)
|
||||
return original_scaled_dot_product_attention(query, key, value, attn_mask=attn_mask, dropout_p=dropout_p, is_causal=is_causal)
|
||||
|
||||
# A1111 FP16
|
||||
original_functional_group_norm = torch.nn.functional.group_norm
|
||||
@wraps(torch.nn.functional.group_norm)
|
||||
def functional_group_norm(input, num_groups, weight=None, bias=None, eps=1e-05):
|
||||
if weight is not None and input.dtype != weight.data.dtype:
|
||||
input = input.to(dtype=weight.data.dtype)
|
||||
if bias is not None and weight is not None and bias.data.dtype != weight.data.dtype:
|
||||
bias.data = bias.data.to(dtype=weight.data.dtype)
|
||||
return original_functional_group_norm(input, num_groups, weight=weight, bias=bias, eps=eps)
|
||||
|
||||
# A1111 BF16
|
||||
original_functional_layer_norm = torch.nn.functional.layer_norm
|
||||
@wraps(torch.nn.functional.layer_norm)
|
||||
def functional_layer_norm(input, normalized_shape, weight=None, bias=None, eps=1e-05):
|
||||
if weight is not None and input.dtype != weight.data.dtype:
|
||||
input = input.to(dtype=weight.data.dtype)
|
||||
if bias is not None and weight is not None and bias.data.dtype != weight.data.dtype:
|
||||
bias.data = bias.data.to(dtype=weight.data.dtype)
|
||||
return original_functional_layer_norm(input, normalized_shape, weight=weight, bias=bias, eps=eps)
|
||||
|
||||
# Training
|
||||
original_functional_linear = torch.nn.functional.linear
|
||||
@wraps(torch.nn.functional.linear)
|
||||
def functional_linear(input, weight, bias=None):
|
||||
if input.dtype != weight.data.dtype:
|
||||
input = input.to(dtype=weight.data.dtype)
|
||||
if bias is not None and bias.data.dtype != weight.data.dtype:
|
||||
bias.data = bias.data.to(dtype=weight.data.dtype)
|
||||
return original_functional_linear(input, weight, bias=bias)
|
||||
|
||||
original_functional_conv2d = torch.nn.functional.conv2d
|
||||
@wraps(torch.nn.functional.conv2d)
|
||||
def functional_conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1):
|
||||
if input.dtype != weight.data.dtype:
|
||||
input = input.to(dtype=weight.data.dtype)
|
||||
if bias is not None and bias.data.dtype != weight.data.dtype:
|
||||
bias.data = bias.data.to(dtype=weight.data.dtype)
|
||||
return original_functional_conv2d(input, weight, bias=bias, stride=stride, padding=padding, dilation=dilation, groups=groups)
|
||||
|
||||
# A1111 Embedding BF16
|
||||
original_torch_cat = torch.cat
|
||||
@wraps(torch.cat)
|
||||
def torch_cat(tensor, *args, **kwargs):
|
||||
if len(tensor) == 3 and (tensor[0].dtype != tensor[1].dtype or tensor[2].dtype != tensor[1].dtype):
|
||||
return original_torch_cat([tensor[0].to(tensor[1].dtype), tensor[1], tensor[2].to(tensor[1].dtype)], *args, **kwargs)
|
||||
else:
|
||||
return original_torch_cat(tensor, *args, **kwargs)
|
||||
|
||||
# SwinIR BF16:
|
||||
original_functional_pad = torch.nn.functional.pad
|
||||
@wraps(torch.nn.functional.pad)
|
||||
def functional_pad(input, pad, mode='constant', value=None):
|
||||
if mode == 'reflect' and input.dtype == torch.bfloat16:
|
||||
return original_functional_pad(input.to(torch.float32), pad, mode=mode, value=value).to(dtype=torch.bfloat16)
|
||||
else:
|
||||
return original_functional_pad(input, pad, mode=mode, value=value)
|
||||
|
||||
|
||||
original_torch_tensor = torch.tensor
|
||||
@wraps(torch.tensor)
|
||||
def torch_tensor(data, *args, dtype=None, device=None, **kwargs):
|
||||
if check_device(device):
|
||||
device = return_xpu(device)
|
||||
if not device_supports_fp64:
|
||||
if (isinstance(device, torch.device) and device.type == "xpu") or (isinstance(device, str) and "xpu" in device):
|
||||
if dtype == torch.float64:
|
||||
dtype = torch.float32
|
||||
elif dtype is None and (hasattr(data, "dtype") and (data.dtype == torch.float64 or data.dtype == float)):
|
||||
dtype = torch.float32
|
||||
return original_torch_tensor(data, *args, dtype=dtype, device=device, **kwargs)
|
||||
|
||||
original_Tensor_to = torch.Tensor.to
|
||||
@wraps(torch.Tensor.to)
|
||||
def Tensor_to(self, device=None, *args, **kwargs):
|
||||
if check_device(device):
|
||||
return original_Tensor_to(self, return_xpu(device), *args, **kwargs)
|
||||
else:
|
||||
return original_Tensor_to(self, device, *args, **kwargs)
|
||||
|
||||
original_Tensor_cuda = torch.Tensor.cuda
|
||||
@wraps(torch.Tensor.cuda)
|
||||
def Tensor_cuda(self, device=None, *args, **kwargs):
|
||||
if check_device(device):
|
||||
return original_Tensor_cuda(self, return_xpu(device), *args, **kwargs)
|
||||
else:
|
||||
return original_Tensor_cuda(self, device, *args, **kwargs)
|
||||
|
||||
original_Tensor_pin_memory = torch.Tensor.pin_memory
|
||||
@wraps(torch.Tensor.pin_memory)
|
||||
def Tensor_pin_memory(self, device=None, *args, **kwargs):
|
||||
if device is None:
|
||||
device = "xpu"
|
||||
if check_device(device):
|
||||
return original_Tensor_pin_memory(self, return_xpu(device), *args, **kwargs)
|
||||
else:
|
||||
return original_Tensor_pin_memory(self, device, *args, **kwargs)
|
||||
|
||||
original_UntypedStorage_init = torch.UntypedStorage.__init__
|
||||
@wraps(torch.UntypedStorage.__init__)
|
||||
def UntypedStorage_init(*args, device=None, **kwargs):
|
||||
if check_device(device):
|
||||
return original_UntypedStorage_init(*args, device=return_xpu(device), **kwargs)
|
||||
else:
|
||||
return original_UntypedStorage_init(*args, device=device, **kwargs)
|
||||
|
||||
original_UntypedStorage_cuda = torch.UntypedStorage.cuda
|
||||
@wraps(torch.UntypedStorage.cuda)
|
||||
def UntypedStorage_cuda(self, device=None, *args, **kwargs):
|
||||
if check_device(device):
|
||||
return original_UntypedStorage_cuda(self, return_xpu(device), *args, **kwargs)
|
||||
else:
|
||||
return original_UntypedStorage_cuda(self, device, *args, **kwargs)
|
||||
|
||||
original_torch_empty = torch.empty
|
||||
@wraps(torch.empty)
|
||||
def torch_empty(*args, device=None, **kwargs):
|
||||
if check_device(device):
|
||||
return original_torch_empty(*args, device=return_xpu(device), **kwargs)
|
||||
else:
|
||||
return original_torch_empty(*args, device=device, **kwargs)
|
||||
|
||||
original_torch_randn = torch.randn
|
||||
@wraps(torch.randn)
|
||||
def torch_randn(*args, device=None, dtype=None, **kwargs):
|
||||
if dtype == bytes:
|
||||
dtype = None
|
||||
if check_device(device):
|
||||
return original_torch_randn(*args, device=return_xpu(device), **kwargs)
|
||||
else:
|
||||
return original_torch_randn(*args, device=device, **kwargs)
|
||||
|
||||
original_torch_ones = torch.ones
|
||||
@wraps(torch.ones)
|
||||
def torch_ones(*args, device=None, **kwargs):
|
||||
if check_device(device):
|
||||
return original_torch_ones(*args, device=return_xpu(device), **kwargs)
|
||||
else:
|
||||
return original_torch_ones(*args, device=device, **kwargs)
|
||||
|
||||
original_torch_zeros = torch.zeros
|
||||
@wraps(torch.zeros)
|
||||
def torch_zeros(*args, device=None, **kwargs):
|
||||
if check_device(device):
|
||||
return original_torch_zeros(*args, device=return_xpu(device), **kwargs)
|
||||
else:
|
||||
return original_torch_zeros(*args, device=device, **kwargs)
|
||||
|
||||
original_torch_linspace = torch.linspace
|
||||
@wraps(torch.linspace)
|
||||
def torch_linspace(*args, device=None, **kwargs):
|
||||
if check_device(device):
|
||||
return original_torch_linspace(*args, device=return_xpu(device), **kwargs)
|
||||
else:
|
||||
return original_torch_linspace(*args, device=device, **kwargs)
|
||||
|
||||
original_torch_Generator = torch.Generator
|
||||
@wraps(torch.Generator)
|
||||
def torch_Generator(device=None):
|
||||
if check_device(device):
|
||||
return original_torch_Generator(return_xpu(device))
|
||||
else:
|
||||
return original_torch_Generator(device)
|
||||
|
||||
original_torch_load = torch.load
|
||||
@wraps(torch.load)
|
||||
def torch_load(f, map_location=None, *args, **kwargs):
|
||||
if map_location is None:
|
||||
map_location = "xpu"
|
||||
if check_device(map_location):
|
||||
return original_torch_load(f, *args, map_location=return_xpu(map_location), **kwargs)
|
||||
else:
|
||||
return original_torch_load(f, *args, map_location=map_location, **kwargs)
|
||||
|
||||
|
||||
# Hijack Functions:
|
||||
def ipex_hijacks():
|
||||
torch.tensor = torch_tensor
|
||||
torch.Tensor.to = Tensor_to
|
||||
torch.Tensor.cuda = Tensor_cuda
|
||||
torch.Tensor.pin_memory = Tensor_pin_memory
|
||||
torch.UntypedStorage.__init__ = UntypedStorage_init
|
||||
torch.UntypedStorage.cuda = UntypedStorage_cuda
|
||||
torch.empty = torch_empty
|
||||
torch.randn = torch_randn
|
||||
torch.ones = torch_ones
|
||||
torch.zeros = torch_zeros
|
||||
torch.linspace = torch_linspace
|
||||
torch.Generator = torch_Generator
|
||||
torch.load = torch_load
|
||||
|
||||
torch.backends.cuda.sdp_kernel = return_null_context
|
||||
torch.nn.DataParallel = DummyDataParallel
|
||||
torch.UntypedStorage.is_cuda = is_cuda
|
||||
torch.amp.autocast_mode.autocast.__init__ = autocast_init
|
||||
|
||||
torch.nn.functional.scaled_dot_product_attention = scaled_dot_product_attention
|
||||
torch.nn.functional.group_norm = functional_group_norm
|
||||
torch.nn.functional.layer_norm = functional_layer_norm
|
||||
torch.nn.functional.linear = functional_linear
|
||||
torch.nn.functional.conv2d = functional_conv2d
|
||||
torch.nn.functional.interpolate = interpolate
|
||||
torch.nn.functional.pad = functional_pad
|
||||
|
||||
torch.bmm = torch_bmm
|
||||
torch.cat = torch_cat
|
||||
if not device_supports_fp64:
|
||||
torch.from_numpy = from_numpy
|
||||
torch.as_tensor = as_tensor
|
||||
@@ -6,10 +6,10 @@ import re
|
||||
from typing import Callable, List, Optional, Union
|
||||
|
||||
import numpy as np
|
||||
import PIL
|
||||
import PIL.Image
|
||||
import torch
|
||||
from packaging import version
|
||||
from transformers import CLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer
|
||||
from transformers import CLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer, CLIPVisionModelWithProjection
|
||||
|
||||
import diffusers
|
||||
from diffusers import SchedulerMixin, StableDiffusionPipeline
|
||||
@@ -17,7 +17,6 @@ from diffusers.models import AutoencoderKL, UNet2DConditionModel
|
||||
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput, StableDiffusionSafetyChecker
|
||||
from diffusers.utils import logging
|
||||
|
||||
|
||||
try:
|
||||
from diffusers.utils import PIL_INTERPOLATION
|
||||
except ImportError:
|
||||
@@ -245,11 +244,6 @@ def get_unweighted_text_embeddings(
|
||||
text_embedding = enc_out["hidden_states"][-clip_skip]
|
||||
text_embedding = pipe.text_encoder.text_model.final_layer_norm(text_embedding)
|
||||
|
||||
# cover the head and the tail by the starting and the ending tokens
|
||||
text_input_chunk[:, 0] = text_input[0, 0]
|
||||
text_input_chunk[:, -1] = text_input[0, -1]
|
||||
text_embedding = pipe.text_encoder(text_input_chunk, attention_mask=None)[0]
|
||||
|
||||
if no_boseos_middle:
|
||||
if i == 0:
|
||||
# discard the ending token
|
||||
@@ -264,7 +258,12 @@ def get_unweighted_text_embeddings(
|
||||
text_embeddings.append(text_embedding)
|
||||
text_embeddings = torch.concat(text_embeddings, axis=1)
|
||||
else:
|
||||
text_embeddings = pipe.text_encoder(text_input)[0]
|
||||
if clip_skip is None or clip_skip == 1:
|
||||
text_embeddings = pipe.text_encoder(text_input)[0]
|
||||
else:
|
||||
enc_out = pipe.text_encoder(text_input, output_hidden_states=True, return_dict=True)
|
||||
text_embeddings = enc_out["hidden_states"][-clip_skip]
|
||||
text_embeddings = pipe.text_encoder.text_model.final_layer_norm(text_embeddings)
|
||||
return text_embeddings
|
||||
|
||||
|
||||
@@ -426,6 +425,58 @@ def preprocess_mask(mask, scale_factor=8):
|
||||
return mask
|
||||
|
||||
|
||||
def prepare_controlnet_image(
|
||||
image: PIL.Image.Image,
|
||||
width: int,
|
||||
height: int,
|
||||
batch_size: int,
|
||||
num_images_per_prompt: int,
|
||||
device: torch.device,
|
||||
dtype: torch.dtype,
|
||||
do_classifier_free_guidance: bool = False,
|
||||
guess_mode: bool = False,
|
||||
):
|
||||
if not isinstance(image, torch.Tensor):
|
||||
if isinstance(image, PIL.Image.Image):
|
||||
image = [image]
|
||||
|
||||
if isinstance(image[0], PIL.Image.Image):
|
||||
images = []
|
||||
|
||||
for image_ in image:
|
||||
image_ = image_.convert("RGB")
|
||||
image_ = image_.resize((width, height), resample=PIL_INTERPOLATION["lanczos"])
|
||||
image_ = np.array(image_)
|
||||
image_ = image_[None, :]
|
||||
images.append(image_)
|
||||
|
||||
image = images
|
||||
|
||||
image = np.concatenate(image, axis=0)
|
||||
image = np.array(image).astype(np.float32) / 255.0
|
||||
image = image.transpose(0, 3, 1, 2)
|
||||
image = torch.from_numpy(image)
|
||||
elif isinstance(image[0], torch.Tensor):
|
||||
image = torch.cat(image, dim=0)
|
||||
|
||||
image_batch_size = image.shape[0]
|
||||
|
||||
if image_batch_size == 1:
|
||||
repeat_by = batch_size
|
||||
else:
|
||||
# image batch size is the same as prompt batch size
|
||||
repeat_by = num_images_per_prompt
|
||||
|
||||
image = image.repeat_interleave(repeat_by, dim=0)
|
||||
|
||||
image = image.to(device=device, dtype=dtype)
|
||||
|
||||
if do_classifier_free_guidance and not guess_mode:
|
||||
image = torch.cat([image] * 2)
|
||||
|
||||
return image
|
||||
|
||||
|
||||
class StableDiffusionLongPromptWeightingPipeline(StableDiffusionPipeline):
|
||||
r"""
|
||||
Pipeline for text-to-image generation using Stable Diffusion without tokens length limit, and support parsing
|
||||
@@ -464,10 +515,12 @@ class StableDiffusionLongPromptWeightingPipeline(StableDiffusionPipeline):
|
||||
tokenizer: CLIPTokenizer,
|
||||
unet: UNet2DConditionModel,
|
||||
scheduler: SchedulerMixin,
|
||||
clip_skip: int,
|
||||
# clip_skip: int,
|
||||
safety_checker: StableDiffusionSafetyChecker,
|
||||
feature_extractor: CLIPFeatureExtractor,
|
||||
requires_safety_checker: bool = True,
|
||||
image_encoder: CLIPVisionModelWithProjection = None,
|
||||
clip_skip: int = 1,
|
||||
):
|
||||
super().__init__(
|
||||
vae=vae,
|
||||
@@ -478,32 +531,11 @@ class StableDiffusionLongPromptWeightingPipeline(StableDiffusionPipeline):
|
||||
safety_checker=safety_checker,
|
||||
feature_extractor=feature_extractor,
|
||||
requires_safety_checker=requires_safety_checker,
|
||||
image_encoder=image_encoder,
|
||||
)
|
||||
self.clip_skip = clip_skip
|
||||
self.custom_clip_skip = clip_skip
|
||||
self.__init__additional__()
|
||||
|
||||
# else:
|
||||
# def __init__(
|
||||
# self,
|
||||
# vae: AutoencoderKL,
|
||||
# text_encoder: CLIPTextModel,
|
||||
# tokenizer: CLIPTokenizer,
|
||||
# unet: UNet2DConditionModel,
|
||||
# scheduler: SchedulerMixin,
|
||||
# safety_checker: StableDiffusionSafetyChecker,
|
||||
# feature_extractor: CLIPFeatureExtractor,
|
||||
# ):
|
||||
# super().__init__(
|
||||
# vae=vae,
|
||||
# text_encoder=text_encoder,
|
||||
# tokenizer=tokenizer,
|
||||
# unet=unet,
|
||||
# scheduler=scheduler,
|
||||
# safety_checker=safety_checker,
|
||||
# feature_extractor=feature_extractor,
|
||||
# )
|
||||
# self.__init__additional__()
|
||||
|
||||
def __init__additional__(self):
|
||||
if not hasattr(self, "vae_scale_factor"):
|
||||
setattr(self, "vae_scale_factor", 2 ** (len(self.vae.config.block_out_channels) - 1))
|
||||
@@ -571,7 +603,7 @@ class StableDiffusionLongPromptWeightingPipeline(StableDiffusionPipeline):
|
||||
prompt=prompt,
|
||||
uncond_prompt=negative_prompt if do_classifier_free_guidance else None,
|
||||
max_embeddings_multiples=max_embeddings_multiples,
|
||||
clip_skip=self.clip_skip,
|
||||
clip_skip=self.custom_clip_skip,
|
||||
)
|
||||
bs_embed, seq_len, _ = text_embeddings.shape
|
||||
text_embeddings = text_embeddings.repeat(1, num_images_per_prompt, 1)
|
||||
@@ -593,7 +625,7 @@ class StableDiffusionLongPromptWeightingPipeline(StableDiffusionPipeline):
|
||||
raise ValueError(f"The value of strength should in [0.0, 1.0] but is {strength}")
|
||||
|
||||
if height % 8 != 0 or width % 8 != 0:
|
||||
print(height, width)
|
||||
logger.info(f'{height} {width}')
|
||||
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
|
||||
|
||||
if (callback_steps is None) or (
|
||||
@@ -707,6 +739,8 @@ class StableDiffusionLongPromptWeightingPipeline(StableDiffusionPipeline):
|
||||
max_embeddings_multiples: Optional[int] = 3,
|
||||
output_type: Optional[str] = "pil",
|
||||
return_dict: bool = True,
|
||||
controlnet=None,
|
||||
controlnet_image=None,
|
||||
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
|
||||
is_cancelled_callback: Optional[Callable[[], bool]] = None,
|
||||
callback_steps: int = 1,
|
||||
@@ -767,6 +801,11 @@ class StableDiffusionLongPromptWeightingPipeline(StableDiffusionPipeline):
|
||||
return_dict (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
|
||||
plain tuple.
|
||||
controlnet (`diffusers.ControlNetModel`, *optional*):
|
||||
A controlnet model to be used for the inference. If not provided, controlnet will be disabled.
|
||||
controlnet_image (`torch.FloatTensor` or `PIL.Image.Image`, *optional*):
|
||||
`Image`, or tensor representing an image batch, to be used as the starting point for the controlnet
|
||||
inference.
|
||||
callback (`Callable`, *optional*):
|
||||
A function that will be called every `callback_steps` steps during inference. The function will be
|
||||
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
|
||||
@@ -785,6 +824,9 @@ class StableDiffusionLongPromptWeightingPipeline(StableDiffusionPipeline):
|
||||
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
|
||||
(nsfw) content, according to the `safety_checker`.
|
||||
"""
|
||||
if controlnet is not None and controlnet_image is None:
|
||||
raise ValueError("controlnet_image must be provided if controlnet is not None.")
|
||||
|
||||
# 0. Default height and width to unet
|
||||
height = height or self.unet.config.sample_size * self.vae_scale_factor
|
||||
width = width or self.unet.config.sample_size * self.vae_scale_factor
|
||||
@@ -824,6 +866,11 @@ class StableDiffusionLongPromptWeightingPipeline(StableDiffusionPipeline):
|
||||
else:
|
||||
mask = None
|
||||
|
||||
if controlnet_image is not None:
|
||||
controlnet_image = prepare_controlnet_image(
|
||||
controlnet_image, width, height, batch_size, 1, self.device, controlnet.dtype, do_classifier_free_guidance, False
|
||||
)
|
||||
|
||||
# 5. set timesteps
|
||||
self.scheduler.set_timesteps(num_inference_steps, device=device)
|
||||
timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength, device, image is None)
|
||||
@@ -851,8 +898,22 @@ class StableDiffusionLongPromptWeightingPipeline(StableDiffusionPipeline):
|
||||
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
|
||||
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
|
||||
|
||||
unet_additional_args = {}
|
||||
if controlnet is not None:
|
||||
down_block_res_samples, mid_block_res_sample = controlnet(
|
||||
latent_model_input,
|
||||
t,
|
||||
encoder_hidden_states=text_embeddings,
|
||||
controlnet_cond=controlnet_image,
|
||||
conditioning_scale=1.0,
|
||||
guess_mode=False,
|
||||
return_dict=False,
|
||||
)
|
||||
unet_additional_args["down_block_additional_residuals"] = down_block_res_samples
|
||||
unet_additional_args["mid_block_additional_residual"] = mid_block_res_sample
|
||||
|
||||
# predict the noise residual
|
||||
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
|
||||
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings, **unet_additional_args).sample
|
||||
|
||||
# perform guidance
|
||||
if do_classifier_free_guidance:
|
||||
@@ -874,20 +935,13 @@ class StableDiffusionLongPromptWeightingPipeline(StableDiffusionPipeline):
|
||||
if is_cancelled_callback is not None and is_cancelled_callback():
|
||||
return None
|
||||
|
||||
return latents
|
||||
|
||||
def latents_to_image(self, latents):
|
||||
# 9. Post-processing
|
||||
image = self.decode_latents(latents)
|
||||
|
||||
# 10. Run safety checker
|
||||
image, has_nsfw_concept = self.run_safety_checker(image, device, text_embeddings.dtype)
|
||||
|
||||
# 11. Convert to PIL
|
||||
if output_type == "pil":
|
||||
image = self.numpy_to_pil(image)
|
||||
|
||||
if not return_dict:
|
||||
return image, has_nsfw_concept
|
||||
|
||||
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
|
||||
image = self.decode_latents(latents.to(self.vae.dtype))
|
||||
image = self.numpy_to_pil(image)
|
||||
return image
|
||||
|
||||
def text2img(
|
||||
self,
|
||||
|
||||
@@ -3,10 +3,20 @@
|
||||
|
||||
import math
|
||||
import os
|
||||
|
||||
import torch
|
||||
from library.device_utils import init_ipex
|
||||
init_ipex()
|
||||
|
||||
import diffusers
|
||||
from transformers import CLIPTextModel, CLIPTokenizer, CLIPTextConfig, logging
|
||||
from diffusers import AutoencoderKL, DDIMScheduler, StableDiffusionPipeline, UNet2DConditionModel
|
||||
from diffusers import AutoencoderKL, DDIMScheduler, StableDiffusionPipeline # , UNet2DConditionModel
|
||||
from safetensors.torch import load_file, save_file
|
||||
from library.original_unet import UNet2DConditionModel
|
||||
from library.utils import setup_logging
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# DiffUsers版StableDiffusionのモデルパラメータ
|
||||
NUM_TRAIN_TIMESTEPS = 1000
|
||||
@@ -22,6 +32,7 @@ UNET_PARAMS_OUT_CHANNELS = 4
|
||||
UNET_PARAMS_NUM_RES_BLOCKS = 2
|
||||
UNET_PARAMS_CONTEXT_DIM = 768
|
||||
UNET_PARAMS_NUM_HEADS = 8
|
||||
# UNET_PARAMS_USE_LINEAR_PROJECTION = False
|
||||
|
||||
VAE_PARAMS_Z_CHANNELS = 4
|
||||
VAE_PARAMS_RESOLUTION = 256
|
||||
@@ -34,6 +45,7 @@ VAE_PARAMS_NUM_RES_BLOCKS = 2
|
||||
# V2
|
||||
V2_UNET_PARAMS_ATTENTION_HEAD_DIM = [5, 10, 20, 20]
|
||||
V2_UNET_PARAMS_CONTEXT_DIM = 1024
|
||||
# V2_UNET_PARAMS_USE_LINEAR_PROJECTION = True
|
||||
|
||||
# Diffusersの設定を読み込むための参照モデル
|
||||
DIFFUSERS_REF_MODEL_ID_V1 = "runwayml/stable-diffusion-v1-5"
|
||||
@@ -124,17 +136,30 @@ def renew_vae_attention_paths(old_list, n_shave_prefix_segments=0):
|
||||
new_item = new_item.replace("norm.weight", "group_norm.weight")
|
||||
new_item = new_item.replace("norm.bias", "group_norm.bias")
|
||||
|
||||
new_item = new_item.replace("q.weight", "query.weight")
|
||||
new_item = new_item.replace("q.bias", "query.bias")
|
||||
if diffusers.__version__ < "0.17.0":
|
||||
new_item = new_item.replace("q.weight", "query.weight")
|
||||
new_item = new_item.replace("q.bias", "query.bias")
|
||||
|
||||
new_item = new_item.replace("k.weight", "key.weight")
|
||||
new_item = new_item.replace("k.bias", "key.bias")
|
||||
new_item = new_item.replace("k.weight", "key.weight")
|
||||
new_item = new_item.replace("k.bias", "key.bias")
|
||||
|
||||
new_item = new_item.replace("v.weight", "value.weight")
|
||||
new_item = new_item.replace("v.bias", "value.bias")
|
||||
new_item = new_item.replace("v.weight", "value.weight")
|
||||
new_item = new_item.replace("v.bias", "value.bias")
|
||||
|
||||
new_item = new_item.replace("proj_out.weight", "proj_attn.weight")
|
||||
new_item = new_item.replace("proj_out.bias", "proj_attn.bias")
|
||||
new_item = new_item.replace("proj_out.weight", "proj_attn.weight")
|
||||
new_item = new_item.replace("proj_out.bias", "proj_attn.bias")
|
||||
else:
|
||||
new_item = new_item.replace("q.weight", "to_q.weight")
|
||||
new_item = new_item.replace("q.bias", "to_q.bias")
|
||||
|
||||
new_item = new_item.replace("k.weight", "to_k.weight")
|
||||
new_item = new_item.replace("k.bias", "to_k.bias")
|
||||
|
||||
new_item = new_item.replace("v.weight", "to_v.weight")
|
||||
new_item = new_item.replace("v.bias", "to_v.bias")
|
||||
|
||||
new_item = new_item.replace("proj_out.weight", "to_out.0.weight")
|
||||
new_item = new_item.replace("proj_out.bias", "to_out.0.bias")
|
||||
|
||||
new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
|
||||
|
||||
@@ -189,8 +214,16 @@ def assign_to_checkpoint(
|
||||
new_path = new_path.replace(replacement["old"], replacement["new"])
|
||||
|
||||
# proj_attn.weight has to be converted from conv 1D to linear
|
||||
if "proj_attn.weight" in new_path:
|
||||
checkpoint[new_path] = old_checkpoint[path["old"]][:, :, 0]
|
||||
reshaping = False
|
||||
if diffusers.__version__ < "0.17.0":
|
||||
if "proj_attn.weight" in new_path:
|
||||
reshaping = True
|
||||
else:
|
||||
if ".attentions." in new_path and ".0.to_" in new_path and old_checkpoint[path["old"]].ndim > 2:
|
||||
reshaping = True
|
||||
|
||||
if reshaping:
|
||||
checkpoint[new_path] = old_checkpoint[path["old"]][:, :, 0, 0]
|
||||
else:
|
||||
checkpoint[new_path] = old_checkpoint[path["old"]]
|
||||
|
||||
@@ -357,8 +390,9 @@ def convert_ldm_unet_checkpoint(v2, checkpoint, config):
|
||||
|
||||
new_checkpoint[new_path] = unet_state_dict[old_path]
|
||||
|
||||
# SDのv2では1*1のconv2dがlinearに変わっているので、linear->convに変換する
|
||||
if v2:
|
||||
# SDのv2では1*1のconv2dがlinearに変わっている
|
||||
# 誤って Diffusers 側を conv2d のままにしてしまったので、変換必要
|
||||
if v2 and not config.get("use_linear_projection", False):
|
||||
linear_transformer_to_conv(new_checkpoint)
|
||||
|
||||
return new_checkpoint
|
||||
@@ -468,7 +502,7 @@ def convert_ldm_vae_checkpoint(checkpoint, config):
|
||||
return new_checkpoint
|
||||
|
||||
|
||||
def create_unet_diffusers_config(v2):
|
||||
def create_unet_diffusers_config(v2, use_linear_projection_in_v2=False):
|
||||
"""
|
||||
Creates a config for the diffusers based on the config of the LDM model.
|
||||
"""
|
||||
@@ -500,7 +534,10 @@ def create_unet_diffusers_config(v2):
|
||||
layers_per_block=UNET_PARAMS_NUM_RES_BLOCKS,
|
||||
cross_attention_dim=UNET_PARAMS_CONTEXT_DIM if not v2 else V2_UNET_PARAMS_CONTEXT_DIM,
|
||||
attention_head_dim=UNET_PARAMS_NUM_HEADS if not v2 else V2_UNET_PARAMS_ATTENTION_HEAD_DIM,
|
||||
# use_linear_projection=UNET_PARAMS_USE_LINEAR_PROJECTION if not v2 else V2_UNET_PARAMS_USE_LINEAR_PROJECTION,
|
||||
)
|
||||
if v2 and use_linear_projection_in_v2:
|
||||
config["use_linear_projection"] = True
|
||||
|
||||
return config
|
||||
|
||||
@@ -534,6 +571,11 @@ def convert_ldm_clip_checkpoint_v1(checkpoint):
|
||||
for key in keys:
|
||||
if key.startswith("cond_stage_model.transformer"):
|
||||
text_model_dict[key[len("cond_stage_model.transformer.") :]] = checkpoint[key]
|
||||
|
||||
# remove position_ids for newer transformer, which causes error :(
|
||||
if "text_model.embeddings.position_ids" in text_model_dict:
|
||||
text_model_dict.pop("text_model.embeddings.position_ids")
|
||||
|
||||
return text_model_dict
|
||||
|
||||
|
||||
@@ -726,6 +768,105 @@ def convert_unet_state_dict_to_sd(v2, unet_state_dict):
|
||||
return new_state_dict
|
||||
|
||||
|
||||
def controlnet_conversion_map():
|
||||
unet_conversion_map = [
|
||||
("time_embed.0.weight", "time_embedding.linear_1.weight"),
|
||||
("time_embed.0.bias", "time_embedding.linear_1.bias"),
|
||||
("time_embed.2.weight", "time_embedding.linear_2.weight"),
|
||||
("time_embed.2.bias", "time_embedding.linear_2.bias"),
|
||||
("input_blocks.0.0.weight", "conv_in.weight"),
|
||||
("input_blocks.0.0.bias", "conv_in.bias"),
|
||||
("middle_block_out.0.weight", "controlnet_mid_block.weight"),
|
||||
("middle_block_out.0.bias", "controlnet_mid_block.bias"),
|
||||
]
|
||||
|
||||
unet_conversion_map_resnet = [
|
||||
("in_layers.0", "norm1"),
|
||||
("in_layers.2", "conv1"),
|
||||
("out_layers.0", "norm2"),
|
||||
("out_layers.3", "conv2"),
|
||||
("emb_layers.1", "time_emb_proj"),
|
||||
("skip_connection", "conv_shortcut"),
|
||||
]
|
||||
|
||||
unet_conversion_map_layer = []
|
||||
for i in range(4):
|
||||
for j in range(2):
|
||||
hf_down_res_prefix = f"down_blocks.{i}.resnets.{j}."
|
||||
sd_down_res_prefix = f"input_blocks.{3*i + j + 1}.0."
|
||||
unet_conversion_map_layer.append((sd_down_res_prefix, hf_down_res_prefix))
|
||||
|
||||
if i < 3:
|
||||
hf_down_atn_prefix = f"down_blocks.{i}.attentions.{j}."
|
||||
sd_down_atn_prefix = f"input_blocks.{3*i + j + 1}.1."
|
||||
unet_conversion_map_layer.append((sd_down_atn_prefix, hf_down_atn_prefix))
|
||||
|
||||
if i < 3:
|
||||
hf_downsample_prefix = f"down_blocks.{i}.downsamplers.0.conv."
|
||||
sd_downsample_prefix = f"input_blocks.{3*(i+1)}.0.op."
|
||||
unet_conversion_map_layer.append((sd_downsample_prefix, hf_downsample_prefix))
|
||||
|
||||
hf_mid_atn_prefix = "mid_block.attentions.0."
|
||||
sd_mid_atn_prefix = "middle_block.1."
|
||||
unet_conversion_map_layer.append((sd_mid_atn_prefix, hf_mid_atn_prefix))
|
||||
|
||||
for j in range(2):
|
||||
hf_mid_res_prefix = f"mid_block.resnets.{j}."
|
||||
sd_mid_res_prefix = f"middle_block.{2*j}."
|
||||
unet_conversion_map_layer.append((sd_mid_res_prefix, hf_mid_res_prefix))
|
||||
|
||||
controlnet_cond_embedding_names = ["conv_in"] + [f"blocks.{i}" for i in range(6)] + ["conv_out"]
|
||||
for i, hf_prefix in enumerate(controlnet_cond_embedding_names):
|
||||
hf_prefix = f"controlnet_cond_embedding.{hf_prefix}."
|
||||
sd_prefix = f"input_hint_block.{i*2}."
|
||||
unet_conversion_map_layer.append((sd_prefix, hf_prefix))
|
||||
|
||||
for i in range(12):
|
||||
hf_prefix = f"controlnet_down_blocks.{i}."
|
||||
sd_prefix = f"zero_convs.{i}.0."
|
||||
unet_conversion_map_layer.append((sd_prefix, hf_prefix))
|
||||
|
||||
return unet_conversion_map, unet_conversion_map_resnet, unet_conversion_map_layer
|
||||
|
||||
|
||||
def convert_controlnet_state_dict_to_sd(controlnet_state_dict):
|
||||
unet_conversion_map, unet_conversion_map_resnet, unet_conversion_map_layer = controlnet_conversion_map()
|
||||
|
||||
mapping = {k: k for k in controlnet_state_dict.keys()}
|
||||
for sd_name, diffusers_name in unet_conversion_map:
|
||||
mapping[diffusers_name] = sd_name
|
||||
for k, v in mapping.items():
|
||||
if "resnets" in k:
|
||||
for sd_part, diffusers_part in unet_conversion_map_resnet:
|
||||
v = v.replace(diffusers_part, sd_part)
|
||||
mapping[k] = v
|
||||
for k, v in mapping.items():
|
||||
for sd_part, diffusers_part in unet_conversion_map_layer:
|
||||
v = v.replace(diffusers_part, sd_part)
|
||||
mapping[k] = v
|
||||
new_state_dict = {v: controlnet_state_dict[k] for k, v in mapping.items()}
|
||||
return new_state_dict
|
||||
|
||||
|
||||
def convert_controlnet_state_dict_to_diffusers(controlnet_state_dict):
|
||||
unet_conversion_map, unet_conversion_map_resnet, unet_conversion_map_layer = controlnet_conversion_map()
|
||||
|
||||
mapping = {k: k for k in controlnet_state_dict.keys()}
|
||||
for sd_name, diffusers_name in unet_conversion_map:
|
||||
mapping[sd_name] = diffusers_name
|
||||
for k, v in mapping.items():
|
||||
for sd_part, diffusers_part in unet_conversion_map_layer:
|
||||
v = v.replace(sd_part, diffusers_part)
|
||||
mapping[k] = v
|
||||
for k, v in mapping.items():
|
||||
if "resnets" in v:
|
||||
for sd_part, diffusers_part in unet_conversion_map_resnet:
|
||||
v = v.replace(sd_part, diffusers_part)
|
||||
mapping[k] = v
|
||||
new_state_dict = {v: controlnet_state_dict[k] for k, v in mapping.items()}
|
||||
return new_state_dict
|
||||
|
||||
|
||||
# ================#
|
||||
# VAE Conversion #
|
||||
# ================#
|
||||
@@ -773,14 +914,24 @@ def convert_vae_state_dict(vae_state_dict):
|
||||
sd_mid_res_prefix = f"mid.block_{i+1}."
|
||||
vae_conversion_map.append((sd_mid_res_prefix, hf_mid_res_prefix))
|
||||
|
||||
vae_conversion_map_attn = [
|
||||
# (stable-diffusion, HF Diffusers)
|
||||
("norm.", "group_norm."),
|
||||
("q.", "query."),
|
||||
("k.", "key."),
|
||||
("v.", "value."),
|
||||
("proj_out.", "proj_attn."),
|
||||
]
|
||||
if diffusers.__version__ < "0.17.0":
|
||||
vae_conversion_map_attn = [
|
||||
# (stable-diffusion, HF Diffusers)
|
||||
("norm.", "group_norm."),
|
||||
("q.", "query."),
|
||||
("k.", "key."),
|
||||
("v.", "value."),
|
||||
("proj_out.", "proj_attn."),
|
||||
]
|
||||
else:
|
||||
vae_conversion_map_attn = [
|
||||
# (stable-diffusion, HF Diffusers)
|
||||
("norm.", "group_norm."),
|
||||
("q.", "to_q."),
|
||||
("k.", "to_k."),
|
||||
("v.", "to_v."),
|
||||
("proj_out.", "to_out.0."),
|
||||
]
|
||||
|
||||
mapping = {k: k for k in vae_state_dict.keys()}
|
||||
for k, v in mapping.items():
|
||||
@@ -797,7 +948,7 @@ def convert_vae_state_dict(vae_state_dict):
|
||||
for k, v in new_state_dict.items():
|
||||
for weight_name in weights_to_convert:
|
||||
if f"mid.attn_1.{weight_name}.weight" in k:
|
||||
# print(f"Reshaping {k} for SD format")
|
||||
# logger.info(f"Reshaping {k} for SD format: shape {v.shape} -> {v.shape} x 1 x 1")
|
||||
new_state_dict[k] = reshape_weight_for_sd(v)
|
||||
|
||||
return new_state_dict
|
||||
@@ -846,16 +997,16 @@ def load_checkpoint_with_text_encoder_conversion(ckpt_path, device="cpu"):
|
||||
|
||||
|
||||
# TODO dtype指定の動作が怪しいので確認する text_encoderを指定形式で作れるか未確認
|
||||
def load_models_from_stable_diffusion_checkpoint(v2, ckpt_path, device="cpu", dtype=None):
|
||||
def load_models_from_stable_diffusion_checkpoint(v2, ckpt_path, device="cpu", dtype=None, unet_use_linear_projection_in_v2=True):
|
||||
_, state_dict = load_checkpoint_with_text_encoder_conversion(ckpt_path, device)
|
||||
|
||||
# Convert the UNet2DConditionModel model.
|
||||
unet_config = create_unet_diffusers_config(v2)
|
||||
unet_config = create_unet_diffusers_config(v2, unet_use_linear_projection_in_v2)
|
||||
converted_unet_checkpoint = convert_ldm_unet_checkpoint(v2, state_dict, unet_config)
|
||||
|
||||
unet = UNet2DConditionModel(**unet_config).to(device)
|
||||
info = unet.load_state_dict(converted_unet_checkpoint)
|
||||
print("loading u-net:", info)
|
||||
logger.info(f"loading u-net: {info}")
|
||||
|
||||
# Convert the VAE model.
|
||||
vae_config = create_vae_diffusers_config()
|
||||
@@ -863,7 +1014,7 @@ def load_models_from_stable_diffusion_checkpoint(v2, ckpt_path, device="cpu", dt
|
||||
|
||||
vae = AutoencoderKL(**vae_config).to(device)
|
||||
info = vae.load_state_dict(converted_vae_checkpoint)
|
||||
print("loading vae:", info)
|
||||
logger.info(f"loading vae: {info}")
|
||||
|
||||
# convert text_model
|
||||
if v2:
|
||||
@@ -894,16 +1045,49 @@ def load_models_from_stable_diffusion_checkpoint(v2, ckpt_path, device="cpu", dt
|
||||
else:
|
||||
converted_text_encoder_checkpoint = convert_ldm_clip_checkpoint_v1(state_dict)
|
||||
|
||||
logging.set_verbosity_error() # don't show annoying warning
|
||||
text_model = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14").to(device)
|
||||
logging.set_verbosity_warning()
|
||||
|
||||
# logging.set_verbosity_error() # don't show annoying warning
|
||||
# text_model = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14").to(device)
|
||||
# logging.set_verbosity_warning()
|
||||
# logger.info(f"config: {text_model.config}")
|
||||
cfg = CLIPTextConfig(
|
||||
vocab_size=49408,
|
||||
hidden_size=768,
|
||||
intermediate_size=3072,
|
||||
num_hidden_layers=12,
|
||||
num_attention_heads=12,
|
||||
max_position_embeddings=77,
|
||||
hidden_act="quick_gelu",
|
||||
layer_norm_eps=1e-05,
|
||||
dropout=0.0,
|
||||
attention_dropout=0.0,
|
||||
initializer_range=0.02,
|
||||
initializer_factor=1.0,
|
||||
pad_token_id=1,
|
||||
bos_token_id=0,
|
||||
eos_token_id=2,
|
||||
model_type="clip_text_model",
|
||||
projection_dim=768,
|
||||
torch_dtype="float32",
|
||||
)
|
||||
text_model = CLIPTextModel._from_config(cfg)
|
||||
info = text_model.load_state_dict(converted_text_encoder_checkpoint)
|
||||
print("loading text encoder:", info)
|
||||
logger.info(f"loading text encoder: {info}")
|
||||
|
||||
return text_model, vae, unet
|
||||
|
||||
|
||||
def get_model_version_str_for_sd1_sd2(v2, v_parameterization):
|
||||
# only for reference
|
||||
version_str = "sd"
|
||||
if v2:
|
||||
version_str += "_v2"
|
||||
else:
|
||||
version_str += "_v1"
|
||||
if v_parameterization:
|
||||
version_str += "_v"
|
||||
return version_str
|
||||
|
||||
|
||||
def convert_text_encoder_state_dict_to_sd_v2(checkpoint, make_dummy_weights=False):
|
||||
def convert_key(key):
|
||||
# position_idsの除去
|
||||
@@ -962,7 +1146,7 @@ def convert_text_encoder_state_dict_to_sd_v2(checkpoint, make_dummy_weights=Fals
|
||||
|
||||
# 最後の層などを捏造するか
|
||||
if make_dummy_weights:
|
||||
print("make dummy weights for resblock.23, text_projection and logit scale.")
|
||||
logger.info("make dummy weights for resblock.23, text_projection and logit scale.")
|
||||
keys = list(new_sd.keys())
|
||||
for key in keys:
|
||||
if key.startswith("transformer.resblocks.22."):
|
||||
@@ -975,7 +1159,9 @@ def convert_text_encoder_state_dict_to_sd_v2(checkpoint, make_dummy_weights=Fals
|
||||
return new_sd
|
||||
|
||||
|
||||
def save_stable_diffusion_checkpoint(v2, output_file, text_encoder, unet, ckpt_path, epochs, steps, save_dtype=None, vae=None):
|
||||
def save_stable_diffusion_checkpoint(
|
||||
v2, output_file, text_encoder, unet, ckpt_path, epochs, steps, metadata, save_dtype=None, vae=None
|
||||
):
|
||||
if ckpt_path is not None:
|
||||
# epoch/stepを参照する。またVAEがメモリ上にないときなど、もう一度VAEを含めて読み込む
|
||||
checkpoint, state_dict = load_checkpoint_with_text_encoder_conversion(ckpt_path)
|
||||
@@ -1037,7 +1223,7 @@ def save_stable_diffusion_checkpoint(v2, output_file, text_encoder, unet, ckpt_p
|
||||
|
||||
if is_safetensors(output_file):
|
||||
# TODO Tensor以外のdictの値を削除したほうがいいか
|
||||
save_file(state_dict, output_file)
|
||||
save_file(state_dict, output_file, metadata)
|
||||
else:
|
||||
torch.save(new_ckpt, output_file)
|
||||
|
||||
@@ -1057,8 +1243,13 @@ def save_diffusers_checkpoint(v2, output_dir, text_encoder, unet, pretrained_mod
|
||||
if vae is None:
|
||||
vae = AutoencoderKL.from_pretrained(pretrained_model_name_or_path, subfolder="vae")
|
||||
|
||||
# original U-Net cannot be saved, so we need to convert it to the Diffusers version
|
||||
# TODO this consumes a lot of memory
|
||||
diffusers_unet = diffusers.UNet2DConditionModel.from_pretrained(pretrained_model_name_or_path, subfolder="unet")
|
||||
diffusers_unet.load_state_dict(unet.state_dict())
|
||||
|
||||
pipeline = StableDiffusionPipeline(
|
||||
unet=unet,
|
||||
unet=diffusers_unet,
|
||||
text_encoder=text_encoder,
|
||||
vae=vae,
|
||||
scheduler=scheduler,
|
||||
@@ -1074,14 +1265,14 @@ VAE_PREFIX = "first_stage_model."
|
||||
|
||||
|
||||
def load_vae(vae_id, dtype):
|
||||
print(f"load VAE: {vae_id}")
|
||||
logger.info(f"load VAE: {vae_id}")
|
||||
if os.path.isdir(vae_id) or not os.path.isfile(vae_id):
|
||||
# Diffusers local/remote
|
||||
try:
|
||||
vae = AutoencoderKL.from_pretrained(vae_id, subfolder=None, torch_dtype=dtype)
|
||||
except EnvironmentError as e:
|
||||
print(f"exception occurs in loading vae: {e}")
|
||||
print("retry with subfolder='vae'")
|
||||
logger.error(f"exception occurs in loading vae: {e}")
|
||||
logger.error("retry with subfolder='vae'")
|
||||
vae = AutoencoderKL.from_pretrained(vae_id, subfolder="vae", torch_dtype=dtype)
|
||||
return vae
|
||||
|
||||
@@ -1122,19 +1313,19 @@ def load_vae(vae_id, dtype):
|
||||
|
||||
def make_bucket_resolutions(max_reso, min_size=256, max_size=1024, divisible=64):
|
||||
max_width, max_height = max_reso
|
||||
max_area = (max_width // divisible) * (max_height // divisible)
|
||||
max_area = max_width * max_height
|
||||
|
||||
resos = set()
|
||||
|
||||
size = int(math.sqrt(max_area)) * divisible
|
||||
resos.add((size, size))
|
||||
width = int(math.sqrt(max_area) // divisible) * divisible
|
||||
resos.add((width, width))
|
||||
|
||||
size = min_size
|
||||
while size <= max_size:
|
||||
width = size
|
||||
height = min(max_size, (max_area // (width // divisible)) * divisible)
|
||||
resos.add((width, height))
|
||||
resos.add((height, width))
|
||||
width = min_size
|
||||
while width <= max_size:
|
||||
height = min(max_size, int((max_area // width) // divisible) * divisible)
|
||||
if height >= min_size:
|
||||
resos.add((width, height))
|
||||
resos.add((height, width))
|
||||
|
||||
# # make additional resos
|
||||
# if width >= height and width - divisible >= min_size:
|
||||
@@ -1144,7 +1335,7 @@ def make_bucket_resolutions(max_reso, min_size=256, max_size=1024, divisible=64)
|
||||
# resos.add((width, height - divisible))
|
||||
# resos.add((height - divisible, width))
|
||||
|
||||
size += divisible
|
||||
width += divisible
|
||||
|
||||
resos = list(resos)
|
||||
resos.sort()
|
||||
@@ -1153,13 +1344,13 @@ def make_bucket_resolutions(max_reso, min_size=256, max_size=1024, divisible=64)
|
||||
|
||||
if __name__ == "__main__":
|
||||
resos = make_bucket_resolutions((512, 768))
|
||||
print(len(resos))
|
||||
print(resos)
|
||||
logger.info(f"{len(resos)}")
|
||||
logger.info(f"{resos}")
|
||||
aspect_ratios = [w / h for w, h in resos]
|
||||
print(aspect_ratios)
|
||||
logger.info(f"{aspect_ratios}")
|
||||
|
||||
ars = set()
|
||||
for ar in aspect_ratios:
|
||||
if ar in ars:
|
||||
print("error! duplicate ar:", ar)
|
||||
logger.error(f"error! duplicate ar: {ar}")
|
||||
ars.add(ar)
|
||||
|
||||
1919
library/original_unet.py
Normal file
1919
library/original_unet.py
Normal file
File diff suppressed because it is too large
Load Diff
309
library/sai_model_spec.py
Normal file
309
library/sai_model_spec.py
Normal file
@@ -0,0 +1,309 @@
|
||||
# based on https://github.com/Stability-AI/ModelSpec
|
||||
import datetime
|
||||
import hashlib
|
||||
from io import BytesIO
|
||||
import os
|
||||
from typing import List, Optional, Tuple, Union
|
||||
import safetensors
|
||||
from library.utils import setup_logging
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
r"""
|
||||
# Metadata Example
|
||||
metadata = {
|
||||
# === Must ===
|
||||
"modelspec.sai_model_spec": "1.0.0", # Required version ID for the spec
|
||||
"modelspec.architecture": "stable-diffusion-xl-v1-base", # Architecture, reference the ID of the original model of the arch to match the ID
|
||||
"modelspec.implementation": "sgm",
|
||||
"modelspec.title": "Example Model Version 1.0", # Clean, human-readable title. May use your own phrasing/language/etc
|
||||
# === Should ===
|
||||
"modelspec.author": "Example Corp", # Your name or company name
|
||||
"modelspec.description": "This is my example model to show you how to do it!", # Describe the model in your own words/language/etc. Focus on what users need to know
|
||||
"modelspec.date": "2023-07-20", # ISO-8601 compliant date of when the model was created
|
||||
# === Can ===
|
||||
"modelspec.license": "ExampleLicense-1.0", # eg CreativeML Open RAIL, etc.
|
||||
"modelspec.usage_hint": "Use keyword 'example'" # In your own language, very short hints about how the user should use the model
|
||||
}
|
||||
"""
|
||||
|
||||
BASE_METADATA = {
|
||||
# === Must ===
|
||||
"modelspec.sai_model_spec": "1.0.0", # Required version ID for the spec
|
||||
"modelspec.architecture": None,
|
||||
"modelspec.implementation": None,
|
||||
"modelspec.title": None,
|
||||
"modelspec.resolution": None,
|
||||
# === Should ===
|
||||
"modelspec.description": None,
|
||||
"modelspec.author": None,
|
||||
"modelspec.date": None,
|
||||
# === Can ===
|
||||
"modelspec.license": None,
|
||||
"modelspec.tags": None,
|
||||
"modelspec.merged_from": None,
|
||||
"modelspec.prediction_type": None,
|
||||
"modelspec.timestep_range": None,
|
||||
"modelspec.encoder_layer": None,
|
||||
}
|
||||
|
||||
# 別に使うやつだけ定義
|
||||
MODELSPEC_TITLE = "modelspec.title"
|
||||
|
||||
ARCH_SD_V1 = "stable-diffusion-v1"
|
||||
ARCH_SD_V2_512 = "stable-diffusion-v2-512"
|
||||
ARCH_SD_V2_768_V = "stable-diffusion-v2-768-v"
|
||||
ARCH_SD_XL_V1_BASE = "stable-diffusion-xl-v1-base"
|
||||
|
||||
ADAPTER_LORA = "lora"
|
||||
ADAPTER_TEXTUAL_INVERSION = "textual-inversion"
|
||||
|
||||
IMPL_STABILITY_AI = "https://github.com/Stability-AI/generative-models"
|
||||
IMPL_DIFFUSERS = "diffusers"
|
||||
|
||||
PRED_TYPE_EPSILON = "epsilon"
|
||||
PRED_TYPE_V = "v"
|
||||
|
||||
|
||||
def load_bytes_in_safetensors(tensors):
|
||||
bytes = safetensors.torch.save(tensors)
|
||||
b = BytesIO(bytes)
|
||||
|
||||
b.seek(0)
|
||||
header = b.read(8)
|
||||
n = int.from_bytes(header, "little")
|
||||
|
||||
offset = n + 8
|
||||
b.seek(offset)
|
||||
|
||||
return b.read()
|
||||
|
||||
|
||||
def precalculate_safetensors_hashes(state_dict):
|
||||
# calculate each tensor one by one to reduce memory usage
|
||||
hash_sha256 = hashlib.sha256()
|
||||
for tensor in state_dict.values():
|
||||
single_tensor_sd = {"tensor": tensor}
|
||||
bytes_for_tensor = load_bytes_in_safetensors(single_tensor_sd)
|
||||
hash_sha256.update(bytes_for_tensor)
|
||||
|
||||
return f"0x{hash_sha256.hexdigest()}"
|
||||
|
||||
|
||||
def update_hash_sha256(metadata: dict, state_dict: dict):
|
||||
raise NotImplementedError
|
||||
|
||||
|
||||
def build_metadata(
|
||||
state_dict: Optional[dict],
|
||||
v2: bool,
|
||||
v_parameterization: bool,
|
||||
sdxl: bool,
|
||||
lora: bool,
|
||||
textual_inversion: bool,
|
||||
timestamp: float,
|
||||
title: Optional[str] = None,
|
||||
reso: Optional[Union[int, Tuple[int, int]]] = None,
|
||||
is_stable_diffusion_ckpt: Optional[bool] = None,
|
||||
author: Optional[str] = None,
|
||||
description: Optional[str] = None,
|
||||
license: Optional[str] = None,
|
||||
tags: Optional[str] = None,
|
||||
merged_from: Optional[str] = None,
|
||||
timesteps: Optional[Tuple[int, int]] = None,
|
||||
clip_skip: Optional[int] = None,
|
||||
):
|
||||
# if state_dict is None, hash is not calculated
|
||||
|
||||
metadata = {}
|
||||
metadata.update(BASE_METADATA)
|
||||
|
||||
# TODO メモリを消費せずかつ正しいハッシュ計算の方法がわかったら実装する
|
||||
# if state_dict is not None:
|
||||
# hash = precalculate_safetensors_hashes(state_dict)
|
||||
# metadata["modelspec.hash_sha256"] = hash
|
||||
|
||||
if sdxl:
|
||||
arch = ARCH_SD_XL_V1_BASE
|
||||
elif v2:
|
||||
if v_parameterization:
|
||||
arch = ARCH_SD_V2_768_V
|
||||
else:
|
||||
arch = ARCH_SD_V2_512
|
||||
else:
|
||||
arch = ARCH_SD_V1
|
||||
|
||||
if lora:
|
||||
arch += f"/{ADAPTER_LORA}"
|
||||
elif textual_inversion:
|
||||
arch += f"/{ADAPTER_TEXTUAL_INVERSION}"
|
||||
|
||||
metadata["modelspec.architecture"] = arch
|
||||
|
||||
if not lora and not textual_inversion and is_stable_diffusion_ckpt is None:
|
||||
is_stable_diffusion_ckpt = True # default is stable diffusion ckpt if not lora and not textual_inversion
|
||||
|
||||
if (lora and sdxl) or textual_inversion or is_stable_diffusion_ckpt:
|
||||
# Stable Diffusion ckpt, TI, SDXL LoRA
|
||||
impl = IMPL_STABILITY_AI
|
||||
else:
|
||||
# v1/v2 LoRA or Diffusers
|
||||
impl = IMPL_DIFFUSERS
|
||||
metadata["modelspec.implementation"] = impl
|
||||
|
||||
if title is None:
|
||||
if lora:
|
||||
title = "LoRA"
|
||||
elif textual_inversion:
|
||||
title = "TextualInversion"
|
||||
else:
|
||||
title = "Checkpoint"
|
||||
title += f"@{timestamp}"
|
||||
metadata[MODELSPEC_TITLE] = title
|
||||
|
||||
if author is not None:
|
||||
metadata["modelspec.author"] = author
|
||||
else:
|
||||
del metadata["modelspec.author"]
|
||||
|
||||
if description is not None:
|
||||
metadata["modelspec.description"] = description
|
||||
else:
|
||||
del metadata["modelspec.description"]
|
||||
|
||||
if merged_from is not None:
|
||||
metadata["modelspec.merged_from"] = merged_from
|
||||
else:
|
||||
del metadata["modelspec.merged_from"]
|
||||
|
||||
if license is not None:
|
||||
metadata["modelspec.license"] = license
|
||||
else:
|
||||
del metadata["modelspec.license"]
|
||||
|
||||
if tags is not None:
|
||||
metadata["modelspec.tags"] = tags
|
||||
else:
|
||||
del metadata["modelspec.tags"]
|
||||
|
||||
# remove microsecond from time
|
||||
int_ts = int(timestamp)
|
||||
|
||||
# time to iso-8601 compliant date
|
||||
date = datetime.datetime.fromtimestamp(int_ts).isoformat()
|
||||
metadata["modelspec.date"] = date
|
||||
|
||||
if reso is not None:
|
||||
# comma separated to tuple
|
||||
if isinstance(reso, str):
|
||||
reso = tuple(map(int, reso.split(",")))
|
||||
if len(reso) == 1:
|
||||
reso = (reso[0], reso[0])
|
||||
else:
|
||||
# resolution is defined in dataset, so use default
|
||||
if sdxl:
|
||||
reso = 1024
|
||||
elif v2 and v_parameterization:
|
||||
reso = 768
|
||||
else:
|
||||
reso = 512
|
||||
if isinstance(reso, int):
|
||||
reso = (reso, reso)
|
||||
|
||||
metadata["modelspec.resolution"] = f"{reso[0]}x{reso[1]}"
|
||||
|
||||
if v_parameterization:
|
||||
metadata["modelspec.prediction_type"] = PRED_TYPE_V
|
||||
else:
|
||||
metadata["modelspec.prediction_type"] = PRED_TYPE_EPSILON
|
||||
|
||||
if timesteps is not None:
|
||||
if isinstance(timesteps, str) or isinstance(timesteps, int):
|
||||
timesteps = (timesteps, timesteps)
|
||||
if len(timesteps) == 1:
|
||||
timesteps = (timesteps[0], timesteps[0])
|
||||
metadata["modelspec.timestep_range"] = f"{timesteps[0]},{timesteps[1]}"
|
||||
else:
|
||||
del metadata["modelspec.timestep_range"]
|
||||
|
||||
if clip_skip is not None:
|
||||
metadata["modelspec.encoder_layer"] = f"{clip_skip}"
|
||||
else:
|
||||
del metadata["modelspec.encoder_layer"]
|
||||
|
||||
# # assert all values are filled
|
||||
# assert all([v is not None for v in metadata.values()]), metadata
|
||||
if not all([v is not None for v in metadata.values()]):
|
||||
logger.error(f"Internal error: some metadata values are None: {metadata}")
|
||||
|
||||
return metadata
|
||||
|
||||
|
||||
# region utils
|
||||
|
||||
|
||||
def get_title(metadata: dict) -> Optional[str]:
|
||||
return metadata.get(MODELSPEC_TITLE, None)
|
||||
|
||||
|
||||
def load_metadata_from_safetensors(model: str) -> dict:
|
||||
if not model.endswith(".safetensors"):
|
||||
return {}
|
||||
|
||||
with safetensors.safe_open(model, framework="pt") as f:
|
||||
metadata = f.metadata()
|
||||
if metadata is None:
|
||||
metadata = {}
|
||||
return metadata
|
||||
|
||||
|
||||
def build_merged_from(models: List[str]) -> str:
|
||||
def get_title(model: str):
|
||||
metadata = load_metadata_from_safetensors(model)
|
||||
title = metadata.get(MODELSPEC_TITLE, None)
|
||||
if title is None:
|
||||
title = os.path.splitext(os.path.basename(model))[0] # use filename
|
||||
return title
|
||||
|
||||
titles = [get_title(model) for model in models]
|
||||
return ", ".join(titles)
|
||||
|
||||
|
||||
# endregion
|
||||
|
||||
|
||||
r"""
|
||||
if __name__ == "__main__":
|
||||
import argparse
|
||||
import torch
|
||||
from safetensors.torch import load_file
|
||||
from library import train_util
|
||||
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--ckpt", type=str, required=True)
|
||||
args = parser.parse_args()
|
||||
|
||||
print(f"Loading {args.ckpt}")
|
||||
state_dict = load_file(args.ckpt)
|
||||
|
||||
print(f"Calculating metadata")
|
||||
metadata = get(state_dict, False, False, False, False, "sgm", False, False, "title", "date", 256, 1000, 0)
|
||||
print(metadata)
|
||||
del state_dict
|
||||
|
||||
# by reference implementation
|
||||
with open(args.ckpt, mode="rb") as file_data:
|
||||
file_hash = hashlib.sha256()
|
||||
head_len = struct.unpack("Q", file_data.read(8)) # int64 header length prefix
|
||||
header = json.loads(file_data.read(head_len[0])) # header itself, json string
|
||||
content = (
|
||||
file_data.read()
|
||||
) # All other content is tightly packed tensors. Copy to RAM for simplicity, but you can avoid this read with a more careful FS-dependent impl.
|
||||
file_hash.update(content)
|
||||
# ===== Update the hash for modelspec =====
|
||||
by_ref = f"0x{file_hash.hexdigest()}"
|
||||
print(by_ref)
|
||||
print("is same?", by_ref == metadata["modelspec.hash_sha256"])
|
||||
|
||||
"""
|
||||
1347
library/sdxl_lpw_stable_diffusion.py
Normal file
1347
library/sdxl_lpw_stable_diffusion.py
Normal file
File diff suppressed because it is too large
Load Diff
583
library/sdxl_model_util.py
Normal file
583
library/sdxl_model_util.py
Normal file
@@ -0,0 +1,583 @@
|
||||
import torch
|
||||
import safetensors
|
||||
from accelerate import init_empty_weights
|
||||
from accelerate.utils.modeling import set_module_tensor_to_device
|
||||
from safetensors.torch import load_file, save_file
|
||||
from transformers import CLIPTextModel, CLIPTextConfig, CLIPTextModelWithProjection, CLIPTokenizer
|
||||
from typing import List
|
||||
from diffusers import AutoencoderKL, EulerDiscreteScheduler, UNet2DConditionModel
|
||||
from library import model_util
|
||||
from library import sdxl_original_unet
|
||||
from .utils import setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
VAE_SCALE_FACTOR = 0.13025
|
||||
MODEL_VERSION_SDXL_BASE_V1_0 = "sdxl_base_v1-0"
|
||||
|
||||
# Diffusersの設定を読み込むための参照モデル
|
||||
DIFFUSERS_REF_MODEL_ID_SDXL = "stabilityai/stable-diffusion-xl-base-1.0"
|
||||
|
||||
DIFFUSERS_SDXL_UNET_CONFIG = {
|
||||
"act_fn": "silu",
|
||||
"addition_embed_type": "text_time",
|
||||
"addition_embed_type_num_heads": 64,
|
||||
"addition_time_embed_dim": 256,
|
||||
"attention_head_dim": [5, 10, 20],
|
||||
"block_out_channels": [320, 640, 1280],
|
||||
"center_input_sample": False,
|
||||
"class_embed_type": None,
|
||||
"class_embeddings_concat": False,
|
||||
"conv_in_kernel": 3,
|
||||
"conv_out_kernel": 3,
|
||||
"cross_attention_dim": 2048,
|
||||
"cross_attention_norm": None,
|
||||
"down_block_types": ["DownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D"],
|
||||
"downsample_padding": 1,
|
||||
"dual_cross_attention": False,
|
||||
"encoder_hid_dim": None,
|
||||
"encoder_hid_dim_type": None,
|
||||
"flip_sin_to_cos": True,
|
||||
"freq_shift": 0,
|
||||
"in_channels": 4,
|
||||
"layers_per_block": 2,
|
||||
"mid_block_only_cross_attention": None,
|
||||
"mid_block_scale_factor": 1,
|
||||
"mid_block_type": "UNetMidBlock2DCrossAttn",
|
||||
"norm_eps": 1e-05,
|
||||
"norm_num_groups": 32,
|
||||
"num_attention_heads": None,
|
||||
"num_class_embeds": None,
|
||||
"only_cross_attention": False,
|
||||
"out_channels": 4,
|
||||
"projection_class_embeddings_input_dim": 2816,
|
||||
"resnet_out_scale_factor": 1.0,
|
||||
"resnet_skip_time_act": False,
|
||||
"resnet_time_scale_shift": "default",
|
||||
"sample_size": 128,
|
||||
"time_cond_proj_dim": None,
|
||||
"time_embedding_act_fn": None,
|
||||
"time_embedding_dim": None,
|
||||
"time_embedding_type": "positional",
|
||||
"timestep_post_act": None,
|
||||
"transformer_layers_per_block": [1, 2, 10],
|
||||
"up_block_types": ["CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "UpBlock2D"],
|
||||
"upcast_attention": False,
|
||||
"use_linear_projection": True,
|
||||
}
|
||||
|
||||
|
||||
def convert_sdxl_text_encoder_2_checkpoint(checkpoint, max_length):
|
||||
SDXL_KEY_PREFIX = "conditioner.embedders.1.model."
|
||||
|
||||
# SD2のと、基本的には同じ。logit_scaleを後で使うので、それを追加で返す
|
||||
# logit_scaleはcheckpointの保存時に使用する
|
||||
def convert_key(key):
|
||||
# common conversion
|
||||
key = key.replace(SDXL_KEY_PREFIX + "transformer.", "text_model.encoder.")
|
||||
key = key.replace(SDXL_KEY_PREFIX, "text_model.")
|
||||
|
||||
if "resblocks" in key:
|
||||
# resblocks conversion
|
||||
key = key.replace(".resblocks.", ".layers.")
|
||||
if ".ln_" in key:
|
||||
key = key.replace(".ln_", ".layer_norm")
|
||||
elif ".mlp." in key:
|
||||
key = key.replace(".c_fc.", ".fc1.")
|
||||
key = key.replace(".c_proj.", ".fc2.")
|
||||
elif ".attn.out_proj" in key:
|
||||
key = key.replace(".attn.out_proj.", ".self_attn.out_proj.")
|
||||
elif ".attn.in_proj" in key:
|
||||
key = None # 特殊なので後で処理する
|
||||
else:
|
||||
raise ValueError(f"unexpected key in SD: {key}")
|
||||
elif ".positional_embedding" in key:
|
||||
key = key.replace(".positional_embedding", ".embeddings.position_embedding.weight")
|
||||
elif ".text_projection" in key:
|
||||
key = key.replace("text_model.text_projection", "text_projection.weight")
|
||||
elif ".logit_scale" in key:
|
||||
key = None # 後で処理する
|
||||
elif ".token_embedding" in key:
|
||||
key = key.replace(".token_embedding.weight", ".embeddings.token_embedding.weight")
|
||||
elif ".ln_final" in key:
|
||||
key = key.replace(".ln_final", ".final_layer_norm")
|
||||
# ckpt from comfy has this key: text_model.encoder.text_model.embeddings.position_ids
|
||||
elif ".embeddings.position_ids" in key:
|
||||
key = None # remove this key: position_ids is not used in newer transformers
|
||||
return key
|
||||
|
||||
keys = list(checkpoint.keys())
|
||||
new_sd = {}
|
||||
for key in keys:
|
||||
new_key = convert_key(key)
|
||||
if new_key is None:
|
||||
continue
|
||||
new_sd[new_key] = checkpoint[key]
|
||||
|
||||
# attnの変換
|
||||
for key in keys:
|
||||
if ".resblocks" in key and ".attn.in_proj_" in key:
|
||||
# 三つに分割
|
||||
values = torch.chunk(checkpoint[key], 3)
|
||||
|
||||
key_suffix = ".weight" if "weight" in key else ".bias"
|
||||
key_pfx = key.replace(SDXL_KEY_PREFIX + "transformer.resblocks.", "text_model.encoder.layers.")
|
||||
key_pfx = key_pfx.replace("_weight", "")
|
||||
key_pfx = key_pfx.replace("_bias", "")
|
||||
key_pfx = key_pfx.replace(".attn.in_proj", ".self_attn.")
|
||||
new_sd[key_pfx + "q_proj" + key_suffix] = values[0]
|
||||
new_sd[key_pfx + "k_proj" + key_suffix] = values[1]
|
||||
new_sd[key_pfx + "v_proj" + key_suffix] = values[2]
|
||||
|
||||
# logit_scale はDiffusersには含まれないが、保存時に戻したいので別途返す
|
||||
logit_scale = checkpoint.get(SDXL_KEY_PREFIX + "logit_scale", None)
|
||||
|
||||
# temporary workaround for text_projection.weight.weight for Playground-v2
|
||||
if "text_projection.weight.weight" in new_sd:
|
||||
logger.info("convert_sdxl_text_encoder_2_checkpoint: convert text_projection.weight.weight to text_projection.weight")
|
||||
new_sd["text_projection.weight"] = new_sd["text_projection.weight.weight"]
|
||||
del new_sd["text_projection.weight.weight"]
|
||||
|
||||
return new_sd, logit_scale
|
||||
|
||||
|
||||
# load state_dict without allocating new tensors
|
||||
def _load_state_dict_on_device(model, state_dict, device, dtype=None):
|
||||
# dtype will use fp32 as default
|
||||
missing_keys = list(model.state_dict().keys() - state_dict.keys())
|
||||
unexpected_keys = list(state_dict.keys() - model.state_dict().keys())
|
||||
|
||||
# similar to model.load_state_dict()
|
||||
if not missing_keys and not unexpected_keys:
|
||||
for k in list(state_dict.keys()):
|
||||
set_module_tensor_to_device(model, k, device, value=state_dict.pop(k), dtype=dtype)
|
||||
return "<All keys matched successfully>"
|
||||
|
||||
# error_msgs
|
||||
error_msgs: List[str] = []
|
||||
if missing_keys:
|
||||
error_msgs.insert(0, "Missing key(s) in state_dict: {}. ".format(", ".join('"{}"'.format(k) for k in missing_keys)))
|
||||
if unexpected_keys:
|
||||
error_msgs.insert(0, "Unexpected key(s) in state_dict: {}. ".format(", ".join('"{}"'.format(k) for k in unexpected_keys)))
|
||||
|
||||
raise RuntimeError("Error(s) in loading state_dict for {}:\n\t{}".format(model.__class__.__name__, "\n\t".join(error_msgs)))
|
||||
|
||||
|
||||
def load_models_from_sdxl_checkpoint(model_version, ckpt_path, map_location, dtype=None, disable_mmap=False):
|
||||
# model_version is reserved for future use
|
||||
# dtype is used for full_fp16/bf16 integration. Text Encoder will remain fp32, because it runs on CPU when caching
|
||||
|
||||
# Load the state dict
|
||||
if model_util.is_safetensors(ckpt_path):
|
||||
checkpoint = None
|
||||
if disable_mmap:
|
||||
state_dict = safetensors.torch.load(open(ckpt_path, "rb").read())
|
||||
else:
|
||||
try:
|
||||
state_dict = load_file(ckpt_path, device=map_location)
|
||||
except:
|
||||
state_dict = load_file(ckpt_path) # prevent device invalid Error
|
||||
epoch = None
|
||||
global_step = None
|
||||
else:
|
||||
checkpoint = torch.load(ckpt_path, map_location=map_location)
|
||||
if "state_dict" in checkpoint:
|
||||
state_dict = checkpoint["state_dict"]
|
||||
epoch = checkpoint.get("epoch", 0)
|
||||
global_step = checkpoint.get("global_step", 0)
|
||||
else:
|
||||
state_dict = checkpoint
|
||||
epoch = 0
|
||||
global_step = 0
|
||||
checkpoint = None
|
||||
|
||||
# U-Net
|
||||
logger.info("building U-Net")
|
||||
with init_empty_weights():
|
||||
unet = sdxl_original_unet.SdxlUNet2DConditionModel()
|
||||
|
||||
logger.info("loading U-Net from checkpoint")
|
||||
unet_sd = {}
|
||||
for k in list(state_dict.keys()):
|
||||
if k.startswith("model.diffusion_model."):
|
||||
unet_sd[k.replace("model.diffusion_model.", "")] = state_dict.pop(k)
|
||||
info = _load_state_dict_on_device(unet, unet_sd, device=map_location, dtype=dtype)
|
||||
logger.info(f"U-Net: {info}")
|
||||
|
||||
# Text Encoders
|
||||
logger.info("building text encoders")
|
||||
|
||||
# Text Encoder 1 is same to Stability AI's SDXL
|
||||
text_model1_cfg = CLIPTextConfig(
|
||||
vocab_size=49408,
|
||||
hidden_size=768,
|
||||
intermediate_size=3072,
|
||||
num_hidden_layers=12,
|
||||
num_attention_heads=12,
|
||||
max_position_embeddings=77,
|
||||
hidden_act="quick_gelu",
|
||||
layer_norm_eps=1e-05,
|
||||
dropout=0.0,
|
||||
attention_dropout=0.0,
|
||||
initializer_range=0.02,
|
||||
initializer_factor=1.0,
|
||||
pad_token_id=1,
|
||||
bos_token_id=0,
|
||||
eos_token_id=2,
|
||||
model_type="clip_text_model",
|
||||
projection_dim=768,
|
||||
# torch_dtype="float32",
|
||||
# transformers_version="4.25.0.dev0",
|
||||
)
|
||||
with init_empty_weights():
|
||||
text_model1 = CLIPTextModel._from_config(text_model1_cfg)
|
||||
|
||||
# Text Encoder 2 is different from Stability AI's SDXL. SDXL uses open clip, but we use the model from HuggingFace.
|
||||
# Note: Tokenizer from HuggingFace is different from SDXL. We must use open clip's tokenizer.
|
||||
text_model2_cfg = CLIPTextConfig(
|
||||
vocab_size=49408,
|
||||
hidden_size=1280,
|
||||
intermediate_size=5120,
|
||||
num_hidden_layers=32,
|
||||
num_attention_heads=20,
|
||||
max_position_embeddings=77,
|
||||
hidden_act="gelu",
|
||||
layer_norm_eps=1e-05,
|
||||
dropout=0.0,
|
||||
attention_dropout=0.0,
|
||||
initializer_range=0.02,
|
||||
initializer_factor=1.0,
|
||||
pad_token_id=1,
|
||||
bos_token_id=0,
|
||||
eos_token_id=2,
|
||||
model_type="clip_text_model",
|
||||
projection_dim=1280,
|
||||
# torch_dtype="float32",
|
||||
# transformers_version="4.25.0.dev0",
|
||||
)
|
||||
with init_empty_weights():
|
||||
text_model2 = CLIPTextModelWithProjection(text_model2_cfg)
|
||||
|
||||
logger.info("loading text encoders from checkpoint")
|
||||
te1_sd = {}
|
||||
te2_sd = {}
|
||||
for k in list(state_dict.keys()):
|
||||
if k.startswith("conditioner.embedders.0.transformer."):
|
||||
te1_sd[k.replace("conditioner.embedders.0.transformer.", "")] = state_dict.pop(k)
|
||||
elif k.startswith("conditioner.embedders.1.model."):
|
||||
te2_sd[k] = state_dict.pop(k)
|
||||
|
||||
# 最新の transformers では position_ids を含むとエラーになるので削除 / remove position_ids for latest transformers
|
||||
if "text_model.embeddings.position_ids" in te1_sd:
|
||||
te1_sd.pop("text_model.embeddings.position_ids")
|
||||
|
||||
info1 = _load_state_dict_on_device(text_model1, te1_sd, device=map_location) # remain fp32
|
||||
logger.info(f"text encoder 1: {info1}")
|
||||
|
||||
converted_sd, logit_scale = convert_sdxl_text_encoder_2_checkpoint(te2_sd, max_length=77)
|
||||
info2 = _load_state_dict_on_device(text_model2, converted_sd, device=map_location) # remain fp32
|
||||
logger.info(f"text encoder 2: {info2}")
|
||||
|
||||
# prepare vae
|
||||
logger.info("building VAE")
|
||||
vae_config = model_util.create_vae_diffusers_config()
|
||||
with init_empty_weights():
|
||||
vae = AutoencoderKL(**vae_config)
|
||||
|
||||
logger.info("loading VAE from checkpoint")
|
||||
converted_vae_checkpoint = model_util.convert_ldm_vae_checkpoint(state_dict, vae_config)
|
||||
info = _load_state_dict_on_device(vae, converted_vae_checkpoint, device=map_location, dtype=dtype)
|
||||
logger.info(f"VAE: {info}")
|
||||
|
||||
ckpt_info = (epoch, global_step) if epoch is not None else None
|
||||
return text_model1, text_model2, vae, unet, logit_scale, ckpt_info
|
||||
|
||||
|
||||
def make_unet_conversion_map():
|
||||
unet_conversion_map_layer = []
|
||||
|
||||
for i in range(3): # num_blocks is 3 in sdxl
|
||||
# loop over downblocks/upblocks
|
||||
for j in range(2):
|
||||
# loop over resnets/attentions for downblocks
|
||||
hf_down_res_prefix = f"down_blocks.{i}.resnets.{j}."
|
||||
sd_down_res_prefix = f"input_blocks.{3*i + j + 1}.0."
|
||||
unet_conversion_map_layer.append((sd_down_res_prefix, hf_down_res_prefix))
|
||||
|
||||
if i < 3:
|
||||
# no attention layers in down_blocks.3
|
||||
hf_down_atn_prefix = f"down_blocks.{i}.attentions.{j}."
|
||||
sd_down_atn_prefix = f"input_blocks.{3*i + j + 1}.1."
|
||||
unet_conversion_map_layer.append((sd_down_atn_prefix, hf_down_atn_prefix))
|
||||
|
||||
for j in range(3):
|
||||
# loop over resnets/attentions for upblocks
|
||||
hf_up_res_prefix = f"up_blocks.{i}.resnets.{j}."
|
||||
sd_up_res_prefix = f"output_blocks.{3*i + j}.0."
|
||||
unet_conversion_map_layer.append((sd_up_res_prefix, hf_up_res_prefix))
|
||||
|
||||
# if i > 0: commentout for sdxl
|
||||
# no attention layers in up_blocks.0
|
||||
hf_up_atn_prefix = f"up_blocks.{i}.attentions.{j}."
|
||||
sd_up_atn_prefix = f"output_blocks.{3*i + j}.1."
|
||||
unet_conversion_map_layer.append((sd_up_atn_prefix, hf_up_atn_prefix))
|
||||
|
||||
if i < 3:
|
||||
# no downsample in down_blocks.3
|
||||
hf_downsample_prefix = f"down_blocks.{i}.downsamplers.0.conv."
|
||||
sd_downsample_prefix = f"input_blocks.{3*(i+1)}.0.op."
|
||||
unet_conversion_map_layer.append((sd_downsample_prefix, hf_downsample_prefix))
|
||||
|
||||
# no upsample in up_blocks.3
|
||||
hf_upsample_prefix = f"up_blocks.{i}.upsamplers.0."
|
||||
sd_upsample_prefix = f"output_blocks.{3*i + 2}.{2}." # change for sdxl
|
||||
unet_conversion_map_layer.append((sd_upsample_prefix, hf_upsample_prefix))
|
||||
|
||||
hf_mid_atn_prefix = "mid_block.attentions.0."
|
||||
sd_mid_atn_prefix = "middle_block.1."
|
||||
unet_conversion_map_layer.append((sd_mid_atn_prefix, hf_mid_atn_prefix))
|
||||
|
||||
for j in range(2):
|
||||
hf_mid_res_prefix = f"mid_block.resnets.{j}."
|
||||
sd_mid_res_prefix = f"middle_block.{2*j}."
|
||||
unet_conversion_map_layer.append((sd_mid_res_prefix, hf_mid_res_prefix))
|
||||
|
||||
unet_conversion_map_resnet = [
|
||||
# (stable-diffusion, HF Diffusers)
|
||||
("in_layers.0.", "norm1."),
|
||||
("in_layers.2.", "conv1."),
|
||||
("out_layers.0.", "norm2."),
|
||||
("out_layers.3.", "conv2."),
|
||||
("emb_layers.1.", "time_emb_proj."),
|
||||
("skip_connection.", "conv_shortcut."),
|
||||
]
|
||||
|
||||
unet_conversion_map = []
|
||||
for sd, hf in unet_conversion_map_layer:
|
||||
if "resnets" in hf:
|
||||
for sd_res, hf_res in unet_conversion_map_resnet:
|
||||
unet_conversion_map.append((sd + sd_res, hf + hf_res))
|
||||
else:
|
||||
unet_conversion_map.append((sd, hf))
|
||||
|
||||
for j in range(2):
|
||||
hf_time_embed_prefix = f"time_embedding.linear_{j+1}."
|
||||
sd_time_embed_prefix = f"time_embed.{j*2}."
|
||||
unet_conversion_map.append((sd_time_embed_prefix, hf_time_embed_prefix))
|
||||
|
||||
for j in range(2):
|
||||
hf_label_embed_prefix = f"add_embedding.linear_{j+1}."
|
||||
sd_label_embed_prefix = f"label_emb.0.{j*2}."
|
||||
unet_conversion_map.append((sd_label_embed_prefix, hf_label_embed_prefix))
|
||||
|
||||
unet_conversion_map.append(("input_blocks.0.0.", "conv_in."))
|
||||
unet_conversion_map.append(("out.0.", "conv_norm_out."))
|
||||
unet_conversion_map.append(("out.2.", "conv_out."))
|
||||
|
||||
return unet_conversion_map
|
||||
|
||||
|
||||
def convert_diffusers_unet_state_dict_to_sdxl(du_sd):
|
||||
unet_conversion_map = make_unet_conversion_map()
|
||||
|
||||
conversion_map = {hf: sd for sd, hf in unet_conversion_map}
|
||||
return convert_unet_state_dict(du_sd, conversion_map)
|
||||
|
||||
|
||||
def convert_unet_state_dict(src_sd, conversion_map):
|
||||
converted_sd = {}
|
||||
for src_key, value in src_sd.items():
|
||||
# さすがに全部回すのは時間がかかるので右から要素を削りつつprefixを探す
|
||||
src_key_fragments = src_key.split(".")[:-1] # remove weight/bias
|
||||
while len(src_key_fragments) > 0:
|
||||
src_key_prefix = ".".join(src_key_fragments) + "."
|
||||
if src_key_prefix in conversion_map:
|
||||
converted_prefix = conversion_map[src_key_prefix]
|
||||
converted_key = converted_prefix + src_key[len(src_key_prefix) :]
|
||||
converted_sd[converted_key] = value
|
||||
break
|
||||
src_key_fragments.pop(-1)
|
||||
assert len(src_key_fragments) > 0, f"key {src_key} not found in conversion map"
|
||||
|
||||
return converted_sd
|
||||
|
||||
|
||||
def convert_sdxl_unet_state_dict_to_diffusers(sd):
|
||||
unet_conversion_map = make_unet_conversion_map()
|
||||
|
||||
conversion_dict = {sd: hf for sd, hf in unet_conversion_map}
|
||||
return convert_unet_state_dict(sd, conversion_dict)
|
||||
|
||||
|
||||
def convert_text_encoder_2_state_dict_to_sdxl(checkpoint, logit_scale):
|
||||
def convert_key(key):
|
||||
# position_idsの除去
|
||||
if ".position_ids" in key:
|
||||
return None
|
||||
|
||||
# common
|
||||
key = key.replace("text_model.encoder.", "transformer.")
|
||||
key = key.replace("text_model.", "")
|
||||
if "layers" in key:
|
||||
# resblocks conversion
|
||||
key = key.replace(".layers.", ".resblocks.")
|
||||
if ".layer_norm" in key:
|
||||
key = key.replace(".layer_norm", ".ln_")
|
||||
elif ".mlp." in key:
|
||||
key = key.replace(".fc1.", ".c_fc.")
|
||||
key = key.replace(".fc2.", ".c_proj.")
|
||||
elif ".self_attn.out_proj" in key:
|
||||
key = key.replace(".self_attn.out_proj.", ".attn.out_proj.")
|
||||
elif ".self_attn." in key:
|
||||
key = None # 特殊なので後で処理する
|
||||
else:
|
||||
raise ValueError(f"unexpected key in DiffUsers model: {key}")
|
||||
elif ".position_embedding" in key:
|
||||
key = key.replace("embeddings.position_embedding.weight", "positional_embedding")
|
||||
elif ".token_embedding" in key:
|
||||
key = key.replace("embeddings.token_embedding.weight", "token_embedding.weight")
|
||||
elif "text_projection" in key: # no dot in key
|
||||
key = key.replace("text_projection.weight", "text_projection")
|
||||
elif "final_layer_norm" in key:
|
||||
key = key.replace("final_layer_norm", "ln_final")
|
||||
return key
|
||||
|
||||
keys = list(checkpoint.keys())
|
||||
new_sd = {}
|
||||
for key in keys:
|
||||
new_key = convert_key(key)
|
||||
if new_key is None:
|
||||
continue
|
||||
new_sd[new_key] = checkpoint[key]
|
||||
|
||||
# attnの変換
|
||||
for key in keys:
|
||||
if "layers" in key and "q_proj" in key:
|
||||
# 三つを結合
|
||||
key_q = key
|
||||
key_k = key.replace("q_proj", "k_proj")
|
||||
key_v = key.replace("q_proj", "v_proj")
|
||||
|
||||
value_q = checkpoint[key_q]
|
||||
value_k = checkpoint[key_k]
|
||||
value_v = checkpoint[key_v]
|
||||
value = torch.cat([value_q, value_k, value_v])
|
||||
|
||||
new_key = key.replace("text_model.encoder.layers.", "transformer.resblocks.")
|
||||
new_key = new_key.replace(".self_attn.q_proj.", ".attn.in_proj_")
|
||||
new_sd[new_key] = value
|
||||
|
||||
if logit_scale is not None:
|
||||
new_sd["logit_scale"] = logit_scale
|
||||
|
||||
return new_sd
|
||||
|
||||
|
||||
def save_stable_diffusion_checkpoint(
|
||||
output_file,
|
||||
text_encoder1,
|
||||
text_encoder2,
|
||||
unet,
|
||||
epochs,
|
||||
steps,
|
||||
ckpt_info,
|
||||
vae,
|
||||
logit_scale,
|
||||
metadata,
|
||||
save_dtype=None,
|
||||
):
|
||||
state_dict = {}
|
||||
|
||||
def update_sd(prefix, sd):
|
||||
for k, v in sd.items():
|
||||
key = prefix + k
|
||||
if save_dtype is not None:
|
||||
v = v.detach().clone().to("cpu").to(save_dtype)
|
||||
state_dict[key] = v
|
||||
|
||||
# Convert the UNet model
|
||||
update_sd("model.diffusion_model.", unet.state_dict())
|
||||
|
||||
# Convert the text encoders
|
||||
update_sd("conditioner.embedders.0.transformer.", text_encoder1.state_dict())
|
||||
|
||||
text_enc2_dict = convert_text_encoder_2_state_dict_to_sdxl(text_encoder2.state_dict(), logit_scale)
|
||||
update_sd("conditioner.embedders.1.model.", text_enc2_dict)
|
||||
|
||||
# Convert the VAE
|
||||
vae_dict = model_util.convert_vae_state_dict(vae.state_dict())
|
||||
update_sd("first_stage_model.", vae_dict)
|
||||
|
||||
# Put together new checkpoint
|
||||
key_count = len(state_dict.keys())
|
||||
new_ckpt = {"state_dict": state_dict}
|
||||
|
||||
# epoch and global_step are sometimes not int
|
||||
if ckpt_info is not None:
|
||||
epochs += ckpt_info[0]
|
||||
steps += ckpt_info[1]
|
||||
|
||||
new_ckpt["epoch"] = epochs
|
||||
new_ckpt["global_step"] = steps
|
||||
|
||||
if model_util.is_safetensors(output_file):
|
||||
save_file(state_dict, output_file, metadata)
|
||||
else:
|
||||
torch.save(new_ckpt, output_file)
|
||||
|
||||
return key_count
|
||||
|
||||
|
||||
def save_diffusers_checkpoint(
|
||||
output_dir, text_encoder1, text_encoder2, unet, pretrained_model_name_or_path, vae=None, use_safetensors=False, save_dtype=None
|
||||
):
|
||||
from diffusers import StableDiffusionXLPipeline
|
||||
|
||||
# convert U-Net
|
||||
unet_sd = unet.state_dict()
|
||||
du_unet_sd = convert_sdxl_unet_state_dict_to_diffusers(unet_sd)
|
||||
|
||||
diffusers_unet = UNet2DConditionModel(**DIFFUSERS_SDXL_UNET_CONFIG)
|
||||
if save_dtype is not None:
|
||||
diffusers_unet.to(save_dtype)
|
||||
diffusers_unet.load_state_dict(du_unet_sd)
|
||||
|
||||
# create pipeline to save
|
||||
if pretrained_model_name_or_path is None:
|
||||
pretrained_model_name_or_path = DIFFUSERS_REF_MODEL_ID_SDXL
|
||||
|
||||
scheduler = EulerDiscreteScheduler.from_pretrained(pretrained_model_name_or_path, subfolder="scheduler")
|
||||
tokenizer1 = CLIPTokenizer.from_pretrained(pretrained_model_name_or_path, subfolder="tokenizer")
|
||||
tokenizer2 = CLIPTokenizer.from_pretrained(pretrained_model_name_or_path, subfolder="tokenizer_2")
|
||||
if vae is None:
|
||||
vae = AutoencoderKL.from_pretrained(pretrained_model_name_or_path, subfolder="vae")
|
||||
|
||||
# prevent local path from being saved
|
||||
def remove_name_or_path(model):
|
||||
if hasattr(model, "config"):
|
||||
model.config._name_or_path = None
|
||||
model.config._name_or_path = None
|
||||
|
||||
remove_name_or_path(diffusers_unet)
|
||||
remove_name_or_path(text_encoder1)
|
||||
remove_name_or_path(text_encoder2)
|
||||
remove_name_or_path(scheduler)
|
||||
remove_name_or_path(tokenizer1)
|
||||
remove_name_or_path(tokenizer2)
|
||||
remove_name_or_path(vae)
|
||||
|
||||
pipeline = StableDiffusionXLPipeline(
|
||||
unet=diffusers_unet,
|
||||
text_encoder=text_encoder1,
|
||||
text_encoder_2=text_encoder2,
|
||||
vae=vae,
|
||||
scheduler=scheduler,
|
||||
tokenizer=tokenizer1,
|
||||
tokenizer_2=tokenizer2,
|
||||
)
|
||||
if save_dtype is not None:
|
||||
pipeline.to(None, save_dtype)
|
||||
pipeline.save_pretrained(output_dir, safe_serialization=use_safetensors)
|
||||
1286
library/sdxl_original_unet.py
Normal file
1286
library/sdxl_original_unet.py
Normal file
File diff suppressed because it is too large
Load Diff
381
library/sdxl_train_util.py
Normal file
381
library/sdxl_train_util.py
Normal file
@@ -0,0 +1,381 @@
|
||||
import argparse
|
||||
import math
|
||||
import os
|
||||
from typing import Optional
|
||||
|
||||
import torch
|
||||
from library.device_utils import init_ipex, clean_memory_on_device
|
||||
|
||||
init_ipex()
|
||||
|
||||
from accelerate import init_empty_weights
|
||||
from tqdm import tqdm
|
||||
from transformers import CLIPTokenizer
|
||||
from library import model_util, sdxl_model_util, train_util, sdxl_original_unet
|
||||
from library.sdxl_lpw_stable_diffusion import SdxlStableDiffusionLongPromptWeightingPipeline
|
||||
from .utils import setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
TOKENIZER1_PATH = "openai/clip-vit-large-patch14"
|
||||
TOKENIZER2_PATH = "laion/CLIP-ViT-bigG-14-laion2B-39B-b160k"
|
||||
|
||||
# DEFAULT_NOISE_OFFSET = 0.0357
|
||||
|
||||
|
||||
def load_target_model(args, accelerator, model_version: str, weight_dtype):
|
||||
model_dtype = match_mixed_precision(args, weight_dtype) # prepare fp16/bf16
|
||||
for pi in range(accelerator.state.num_processes):
|
||||
if pi == accelerator.state.local_process_index:
|
||||
logger.info(f"loading model for process {accelerator.state.local_process_index}/{accelerator.state.num_processes}")
|
||||
|
||||
(
|
||||
load_stable_diffusion_format,
|
||||
text_encoder1,
|
||||
text_encoder2,
|
||||
vae,
|
||||
unet,
|
||||
logit_scale,
|
||||
ckpt_info,
|
||||
) = _load_target_model(
|
||||
args.pretrained_model_name_or_path,
|
||||
args.vae,
|
||||
model_version,
|
||||
weight_dtype,
|
||||
accelerator.device if args.lowram else "cpu",
|
||||
model_dtype,
|
||||
args.disable_mmap_load_safetensors,
|
||||
)
|
||||
|
||||
# work on low-ram device
|
||||
if args.lowram:
|
||||
text_encoder1.to(accelerator.device)
|
||||
text_encoder2.to(accelerator.device)
|
||||
unet.to(accelerator.device)
|
||||
vae.to(accelerator.device)
|
||||
|
||||
clean_memory_on_device(accelerator.device)
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
return load_stable_diffusion_format, text_encoder1, text_encoder2, vae, unet, logit_scale, ckpt_info
|
||||
|
||||
|
||||
def _load_target_model(
|
||||
name_or_path: str, vae_path: Optional[str], model_version: str, weight_dtype, device="cpu", model_dtype=None, disable_mmap=False
|
||||
):
|
||||
# model_dtype only work with full fp16/bf16
|
||||
name_or_path = os.readlink(name_or_path) if os.path.islink(name_or_path) else name_or_path
|
||||
load_stable_diffusion_format = os.path.isfile(name_or_path) # determine SD or Diffusers
|
||||
|
||||
if load_stable_diffusion_format:
|
||||
logger.info(f"load StableDiffusion checkpoint: {name_or_path}")
|
||||
(
|
||||
text_encoder1,
|
||||
text_encoder2,
|
||||
vae,
|
||||
unet,
|
||||
logit_scale,
|
||||
ckpt_info,
|
||||
) = sdxl_model_util.load_models_from_sdxl_checkpoint(model_version, name_or_path, device, model_dtype, disable_mmap)
|
||||
else:
|
||||
# Diffusers model is loaded to CPU
|
||||
from diffusers import StableDiffusionXLPipeline
|
||||
|
||||
variant = "fp16" if weight_dtype == torch.float16 else None
|
||||
logger.info(f"load Diffusers pretrained models: {name_or_path}, variant={variant}")
|
||||
try:
|
||||
try:
|
||||
pipe = StableDiffusionXLPipeline.from_pretrained(
|
||||
name_or_path, torch_dtype=model_dtype, variant=variant, tokenizer=None
|
||||
)
|
||||
except EnvironmentError as ex:
|
||||
if variant is not None:
|
||||
logger.info("try to load fp32 model")
|
||||
pipe = StableDiffusionXLPipeline.from_pretrained(name_or_path, variant=None, tokenizer=None)
|
||||
else:
|
||||
raise ex
|
||||
except EnvironmentError as ex:
|
||||
logger.error(
|
||||
f"model is not found as a file or in Hugging Face, perhaps file name is wrong? / 指定したモデル名のファイル、またはHugging Faceのモデルが見つかりません。ファイル名が誤っているかもしれません: {name_or_path}"
|
||||
)
|
||||
raise ex
|
||||
|
||||
text_encoder1 = pipe.text_encoder
|
||||
text_encoder2 = pipe.text_encoder_2
|
||||
|
||||
# convert to fp32 for cache text_encoders outputs
|
||||
if text_encoder1.dtype != torch.float32:
|
||||
text_encoder1 = text_encoder1.to(dtype=torch.float32)
|
||||
if text_encoder2.dtype != torch.float32:
|
||||
text_encoder2 = text_encoder2.to(dtype=torch.float32)
|
||||
|
||||
vae = pipe.vae
|
||||
unet = pipe.unet
|
||||
del pipe
|
||||
|
||||
# Diffusers U-Net to original U-Net
|
||||
state_dict = sdxl_model_util.convert_diffusers_unet_state_dict_to_sdxl(unet.state_dict())
|
||||
with init_empty_weights():
|
||||
unet = sdxl_original_unet.SdxlUNet2DConditionModel() # overwrite unet
|
||||
sdxl_model_util._load_state_dict_on_device(unet, state_dict, device=device, dtype=model_dtype)
|
||||
logger.info("U-Net converted to original U-Net")
|
||||
|
||||
logit_scale = None
|
||||
ckpt_info = None
|
||||
|
||||
# VAEを読み込む
|
||||
if vae_path is not None:
|
||||
vae = model_util.load_vae(vae_path, weight_dtype)
|
||||
logger.info("additional VAE loaded")
|
||||
|
||||
return load_stable_diffusion_format, text_encoder1, text_encoder2, vae, unet, logit_scale, ckpt_info
|
||||
|
||||
|
||||
def load_tokenizers(args: argparse.Namespace):
|
||||
logger.info("prepare tokenizers")
|
||||
|
||||
original_paths = [TOKENIZER1_PATH, TOKENIZER2_PATH]
|
||||
tokeniers = []
|
||||
for i, original_path in enumerate(original_paths):
|
||||
tokenizer: CLIPTokenizer = None
|
||||
if args.tokenizer_cache_dir:
|
||||
local_tokenizer_path = os.path.join(args.tokenizer_cache_dir, original_path.replace("/", "_"))
|
||||
if os.path.exists(local_tokenizer_path):
|
||||
logger.info(f"load tokenizer from cache: {local_tokenizer_path}")
|
||||
tokenizer = CLIPTokenizer.from_pretrained(local_tokenizer_path)
|
||||
|
||||
if tokenizer is None:
|
||||
tokenizer = CLIPTokenizer.from_pretrained(original_path)
|
||||
|
||||
if args.tokenizer_cache_dir and not os.path.exists(local_tokenizer_path):
|
||||
logger.info(f"save Tokenizer to cache: {local_tokenizer_path}")
|
||||
tokenizer.save_pretrained(local_tokenizer_path)
|
||||
|
||||
if i == 1:
|
||||
tokenizer.pad_token_id = 0 # fix pad token id to make same as open clip tokenizer
|
||||
|
||||
tokeniers.append(tokenizer)
|
||||
|
||||
if hasattr(args, "max_token_length") and args.max_token_length is not None:
|
||||
logger.info(f"update token length: {args.max_token_length}")
|
||||
|
||||
return tokeniers
|
||||
|
||||
|
||||
def match_mixed_precision(args, weight_dtype):
|
||||
if args.full_fp16:
|
||||
assert (
|
||||
weight_dtype == torch.float16
|
||||
), "full_fp16 requires mixed precision='fp16' / full_fp16を使う場合はmixed_precision='fp16'を指定してください。"
|
||||
return weight_dtype
|
||||
elif args.full_bf16:
|
||||
assert (
|
||||
weight_dtype == torch.bfloat16
|
||||
), "full_bf16 requires mixed precision='bf16' / full_bf16を使う場合はmixed_precision='bf16'を指定してください。"
|
||||
return weight_dtype
|
||||
else:
|
||||
return None
|
||||
|
||||
|
||||
def timestep_embedding(timesteps, dim, max_period=10000):
|
||||
"""
|
||||
Create sinusoidal timestep embeddings.
|
||||
:param timesteps: a 1-D Tensor of N indices, one per batch element.
|
||||
These may be fractional.
|
||||
:param dim: the dimension of the output.
|
||||
:param max_period: controls the minimum frequency of the embeddings.
|
||||
:return: an [N x dim] Tensor of positional embeddings.
|
||||
"""
|
||||
half = dim // 2
|
||||
freqs = torch.exp(-math.log(max_period) * torch.arange(start=0, end=half, dtype=torch.float32) / half).to(
|
||||
device=timesteps.device
|
||||
)
|
||||
args = timesteps[:, None].float() * freqs[None]
|
||||
embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1)
|
||||
if dim % 2:
|
||||
embedding = torch.cat([embedding, torch.zeros_like(embedding[:, :1])], dim=-1)
|
||||
return embedding
|
||||
|
||||
|
||||
def get_timestep_embedding(x, outdim):
|
||||
assert len(x.shape) == 2
|
||||
b, dims = x.shape[0], x.shape[1]
|
||||
x = torch.flatten(x)
|
||||
emb = timestep_embedding(x, outdim)
|
||||
emb = torch.reshape(emb, (b, dims * outdim))
|
||||
return emb
|
||||
|
||||
|
||||
def get_size_embeddings(orig_size, crop_size, target_size, device):
|
||||
emb1 = get_timestep_embedding(orig_size, 256)
|
||||
emb2 = get_timestep_embedding(crop_size, 256)
|
||||
emb3 = get_timestep_embedding(target_size, 256)
|
||||
vector = torch.cat([emb1, emb2, emb3], dim=1).to(device)
|
||||
return vector
|
||||
|
||||
|
||||
def save_sd_model_on_train_end(
|
||||
args: argparse.Namespace,
|
||||
src_path: str,
|
||||
save_stable_diffusion_format: bool,
|
||||
use_safetensors: bool,
|
||||
save_dtype: torch.dtype,
|
||||
epoch: int,
|
||||
global_step: int,
|
||||
text_encoder1,
|
||||
text_encoder2,
|
||||
unet,
|
||||
vae,
|
||||
logit_scale,
|
||||
ckpt_info,
|
||||
):
|
||||
def sd_saver(ckpt_file, epoch_no, global_step):
|
||||
sai_metadata = train_util.get_sai_model_spec(None, args, True, False, False, is_stable_diffusion_ckpt=True)
|
||||
sdxl_model_util.save_stable_diffusion_checkpoint(
|
||||
ckpt_file,
|
||||
text_encoder1,
|
||||
text_encoder2,
|
||||
unet,
|
||||
epoch_no,
|
||||
global_step,
|
||||
ckpt_info,
|
||||
vae,
|
||||
logit_scale,
|
||||
sai_metadata,
|
||||
save_dtype,
|
||||
)
|
||||
|
||||
def diffusers_saver(out_dir):
|
||||
sdxl_model_util.save_diffusers_checkpoint(
|
||||
out_dir,
|
||||
text_encoder1,
|
||||
text_encoder2,
|
||||
unet,
|
||||
src_path,
|
||||
vae,
|
||||
use_safetensors=use_safetensors,
|
||||
save_dtype=save_dtype,
|
||||
)
|
||||
|
||||
train_util.save_sd_model_on_train_end_common(
|
||||
args, save_stable_diffusion_format, use_safetensors, epoch, global_step, sd_saver, diffusers_saver
|
||||
)
|
||||
|
||||
|
||||
# epochとstepの保存、メタデータにepoch/stepが含まれ引数が同じになるため、統合している
|
||||
# on_epoch_end: Trueならepoch終了時、Falseならstep経過時
|
||||
def save_sd_model_on_epoch_end_or_stepwise(
|
||||
args: argparse.Namespace,
|
||||
on_epoch_end: bool,
|
||||
accelerator,
|
||||
src_path,
|
||||
save_stable_diffusion_format: bool,
|
||||
use_safetensors: bool,
|
||||
save_dtype: torch.dtype,
|
||||
epoch: int,
|
||||
num_train_epochs: int,
|
||||
global_step: int,
|
||||
text_encoder1,
|
||||
text_encoder2,
|
||||
unet,
|
||||
vae,
|
||||
logit_scale,
|
||||
ckpt_info,
|
||||
):
|
||||
def sd_saver(ckpt_file, epoch_no, global_step):
|
||||
sai_metadata = train_util.get_sai_model_spec(None, args, True, False, False, is_stable_diffusion_ckpt=True)
|
||||
sdxl_model_util.save_stable_diffusion_checkpoint(
|
||||
ckpt_file,
|
||||
text_encoder1,
|
||||
text_encoder2,
|
||||
unet,
|
||||
epoch_no,
|
||||
global_step,
|
||||
ckpt_info,
|
||||
vae,
|
||||
logit_scale,
|
||||
sai_metadata,
|
||||
save_dtype,
|
||||
)
|
||||
|
||||
def diffusers_saver(out_dir):
|
||||
sdxl_model_util.save_diffusers_checkpoint(
|
||||
out_dir,
|
||||
text_encoder1,
|
||||
text_encoder2,
|
||||
unet,
|
||||
src_path,
|
||||
vae,
|
||||
use_safetensors=use_safetensors,
|
||||
save_dtype=save_dtype,
|
||||
)
|
||||
|
||||
train_util.save_sd_model_on_epoch_end_or_stepwise_common(
|
||||
args,
|
||||
on_epoch_end,
|
||||
accelerator,
|
||||
save_stable_diffusion_format,
|
||||
use_safetensors,
|
||||
epoch,
|
||||
num_train_epochs,
|
||||
global_step,
|
||||
sd_saver,
|
||||
diffusers_saver,
|
||||
)
|
||||
|
||||
|
||||
def add_sdxl_training_arguments(parser: argparse.ArgumentParser):
|
||||
parser.add_argument(
|
||||
"--cache_text_encoder_outputs", action="store_true", help="cache text encoder outputs / text encoderの出力をキャッシュする"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--cache_text_encoder_outputs_to_disk",
|
||||
action="store_true",
|
||||
help="cache text encoder outputs to disk / text encoderの出力をディスクにキャッシュする",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--disable_mmap_load_safetensors",
|
||||
action="store_true",
|
||||
help="disable mmap load for safetensors. Speed up model loading in WSL environment / safetensorsのmmapロードを無効にする。WSL環境等でモデル読み込みを高速化できる",
|
||||
)
|
||||
|
||||
|
||||
def verify_sdxl_training_args(args: argparse.Namespace, supportTextEncoderCaching: bool = True):
|
||||
assert not args.v2, "v2 cannot be enabled in SDXL training / SDXL学習ではv2を有効にすることはできません"
|
||||
if args.v_parameterization:
|
||||
logger.warning("v_parameterization will be unexpected / SDXL学習ではv_parameterizationは想定外の動作になります")
|
||||
|
||||
if args.clip_skip is not None:
|
||||
logger.warning("clip_skip will be unexpected / SDXL学習ではclip_skipは動作しません")
|
||||
|
||||
# if args.multires_noise_iterations:
|
||||
# logger.info(
|
||||
# f"Warning: SDXL has been trained with noise_offset={DEFAULT_NOISE_OFFSET}, but noise_offset is disabled due to multires_noise_iterations / SDXLはnoise_offset={DEFAULT_NOISE_OFFSET}で学習されていますが、multires_noise_iterationsが有効になっているためnoise_offsetは無効になります"
|
||||
# )
|
||||
# else:
|
||||
# if args.noise_offset is None:
|
||||
# args.noise_offset = DEFAULT_NOISE_OFFSET
|
||||
# elif args.noise_offset != DEFAULT_NOISE_OFFSET:
|
||||
# logger.info(
|
||||
# f"Warning: SDXL has been trained with noise_offset={DEFAULT_NOISE_OFFSET} / SDXLはnoise_offset={DEFAULT_NOISE_OFFSET}で学習されています"
|
||||
# )
|
||||
# logger.info(f"noise_offset is set to {args.noise_offset} / noise_offsetが{args.noise_offset}に設定されました")
|
||||
|
||||
assert (
|
||||
not hasattr(args, "weighted_captions") or not args.weighted_captions
|
||||
), "weighted_captions cannot be enabled in SDXL training currently / SDXL学習では今のところweighted_captionsを有効にすることはできません"
|
||||
|
||||
if supportTextEncoderCaching:
|
||||
if args.cache_text_encoder_outputs_to_disk and not args.cache_text_encoder_outputs:
|
||||
args.cache_text_encoder_outputs = True
|
||||
logger.warning(
|
||||
"cache_text_encoder_outputs is enabled because cache_text_encoder_outputs_to_disk is enabled / "
|
||||
+ "cache_text_encoder_outputs_to_diskが有効になっているためcache_text_encoder_outputsが有効になりました"
|
||||
)
|
||||
|
||||
|
||||
def sample_images(*args, **kwargs):
|
||||
return train_util.sample_images_common(SdxlStableDiffusionLongPromptWeightingPipeline, *args, **kwargs)
|
||||
682
library/slicing_vae.py
Normal file
682
library/slicing_vae.py
Normal file
@@ -0,0 +1,682 @@
|
||||
# Modified from Diffusers to reduce VRAM usage
|
||||
|
||||
# Copyright 2022 The HuggingFace Team. All rights reserved.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
from dataclasses import dataclass
|
||||
from typing import Optional, Tuple, Union
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
|
||||
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
||||
from diffusers.models.modeling_utils import ModelMixin
|
||||
from diffusers.models.unet_2d_blocks import UNetMidBlock2D, get_down_block, get_up_block
|
||||
from diffusers.models.vae import DecoderOutput, DiagonalGaussianDistribution
|
||||
from diffusers.models.autoencoder_kl import AutoencoderKLOutput
|
||||
from .utils import setup_logging
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
def slice_h(x, num_slices):
|
||||
# slice with pad 1 both sides: to eliminate side effect of padding of conv2d
|
||||
# Conv2dのpaddingの副作用を排除するために、両側にpad 1しながらHをスライスする
|
||||
# NCHWでもNHWCでもどちらでも動く
|
||||
size = (x.shape[2] + num_slices - 1) // num_slices
|
||||
sliced = []
|
||||
for i in range(num_slices):
|
||||
if i == 0:
|
||||
sliced.append(x[:, :, : size + 1, :])
|
||||
else:
|
||||
end = size * (i + 1) + 1
|
||||
if x.shape[2] - end < 3: # if the last slice is too small, use the rest of the tensor 最後が細すぎるとconv2dできないので全部使う
|
||||
end = x.shape[2]
|
||||
sliced.append(x[:, :, size * i - 1 : end, :])
|
||||
if end >= x.shape[2]:
|
||||
break
|
||||
return sliced
|
||||
|
||||
|
||||
def cat_h(sliced):
|
||||
# padding分を除いて結合する
|
||||
cat = []
|
||||
for i, x in enumerate(sliced):
|
||||
if i == 0:
|
||||
cat.append(x[:, :, :-1, :])
|
||||
elif i == len(sliced) - 1:
|
||||
cat.append(x[:, :, 1:, :])
|
||||
else:
|
||||
cat.append(x[:, :, 1:-1, :])
|
||||
del x
|
||||
x = torch.cat(cat, dim=2)
|
||||
return x
|
||||
|
||||
|
||||
def resblock_forward(_self, num_slices, input_tensor, temb, **kwargs):
|
||||
assert _self.upsample is None and _self.downsample is None
|
||||
assert _self.norm1.num_groups == _self.norm2.num_groups
|
||||
assert temb is None
|
||||
|
||||
# make sure norms are on cpu
|
||||
org_device = input_tensor.device
|
||||
cpu_device = torch.device("cpu")
|
||||
_self.norm1.to(cpu_device)
|
||||
_self.norm2.to(cpu_device)
|
||||
|
||||
# GroupNormがCPUでfp16で動かない対策
|
||||
org_dtype = input_tensor.dtype
|
||||
if org_dtype == torch.float16:
|
||||
_self.norm1.to(torch.float32)
|
||||
_self.norm2.to(torch.float32)
|
||||
|
||||
# すべてのテンソルをCPUに移動する
|
||||
input_tensor = input_tensor.to(cpu_device)
|
||||
hidden_states = input_tensor
|
||||
|
||||
# どうもこれは結果が異なるようだ……
|
||||
# def sliced_norm1(norm, x):
|
||||
# num_div = 4 if up_block_idx <= 2 else x.shape[1] // norm.num_groups
|
||||
# sliced_tensor = torch.chunk(x, num_div, dim=1)
|
||||
# sliced_weight = torch.chunk(norm.weight, num_div, dim=0)
|
||||
# sliced_bias = torch.chunk(norm.bias, num_div, dim=0)
|
||||
# logger.info(sliced_tensor[0].shape, num_div, sliced_weight[0].shape, sliced_bias[0].shape)
|
||||
# normed_tensor = []
|
||||
# for i in range(num_div):
|
||||
# n = torch.group_norm(sliced_tensor[i], norm.num_groups, sliced_weight[i], sliced_bias[i], norm.eps)
|
||||
# normed_tensor.append(n)
|
||||
# del n
|
||||
# x = torch.cat(normed_tensor, dim=1)
|
||||
# return num_div, x
|
||||
|
||||
# normを分割すると結果が変わるので、ここだけは分割しない。GPUで計算するとVRAMが足りなくなるので、CPUで計算する。幸いCPUでもそこまで遅くない
|
||||
if org_dtype == torch.float16:
|
||||
hidden_states = hidden_states.to(torch.float32)
|
||||
hidden_states = _self.norm1(hidden_states) # run on cpu
|
||||
if org_dtype == torch.float16:
|
||||
hidden_states = hidden_states.to(torch.float16)
|
||||
|
||||
sliced = slice_h(hidden_states, num_slices)
|
||||
del hidden_states
|
||||
|
||||
for i in range(len(sliced)):
|
||||
x = sliced[i]
|
||||
sliced[i] = None
|
||||
|
||||
# 計算する部分だけGPUに移動する、以下同様
|
||||
x = x.to(org_device)
|
||||
x = _self.nonlinearity(x)
|
||||
x = _self.conv1(x)
|
||||
x = x.to(cpu_device)
|
||||
sliced[i] = x
|
||||
del x
|
||||
|
||||
hidden_states = cat_h(sliced)
|
||||
del sliced
|
||||
|
||||
if org_dtype == torch.float16:
|
||||
hidden_states = hidden_states.to(torch.float32)
|
||||
hidden_states = _self.norm2(hidden_states) # run on cpu
|
||||
if org_dtype == torch.float16:
|
||||
hidden_states = hidden_states.to(torch.float16)
|
||||
|
||||
sliced = slice_h(hidden_states, num_slices)
|
||||
del hidden_states
|
||||
|
||||
for i in range(len(sliced)):
|
||||
x = sliced[i]
|
||||
sliced[i] = None
|
||||
|
||||
x = x.to(org_device)
|
||||
x = _self.nonlinearity(x)
|
||||
x = _self.dropout(x)
|
||||
x = _self.conv2(x)
|
||||
x = x.to(cpu_device)
|
||||
sliced[i] = x
|
||||
del x
|
||||
|
||||
hidden_states = cat_h(sliced)
|
||||
del sliced
|
||||
|
||||
# make shortcut
|
||||
if _self.conv_shortcut is not None:
|
||||
sliced = list(torch.chunk(input_tensor, num_slices, dim=2)) # no padding in conv_shortcut パディングがないので普通にスライスする
|
||||
del input_tensor
|
||||
|
||||
for i in range(len(sliced)):
|
||||
x = sliced[i]
|
||||
sliced[i] = None
|
||||
|
||||
x = x.to(org_device)
|
||||
x = _self.conv_shortcut(x)
|
||||
x = x.to(cpu_device)
|
||||
sliced[i] = x
|
||||
del x
|
||||
|
||||
input_tensor = torch.cat(sliced, dim=2)
|
||||
del sliced
|
||||
|
||||
output_tensor = (input_tensor + hidden_states) / _self.output_scale_factor
|
||||
|
||||
output_tensor = output_tensor.to(org_device) # 次のレイヤーがGPUで計算する
|
||||
return output_tensor
|
||||
|
||||
|
||||
class SlicingEncoder(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
in_channels=3,
|
||||
out_channels=3,
|
||||
down_block_types=("DownEncoderBlock2D",),
|
||||
block_out_channels=(64,),
|
||||
layers_per_block=2,
|
||||
norm_num_groups=32,
|
||||
act_fn="silu",
|
||||
double_z=True,
|
||||
num_slices=2,
|
||||
):
|
||||
super().__init__()
|
||||
self.layers_per_block = layers_per_block
|
||||
|
||||
self.conv_in = torch.nn.Conv2d(in_channels, block_out_channels[0], kernel_size=3, stride=1, padding=1)
|
||||
|
||||
self.mid_block = None
|
||||
self.down_blocks = nn.ModuleList([])
|
||||
|
||||
# down
|
||||
output_channel = block_out_channels[0]
|
||||
for i, down_block_type in enumerate(down_block_types):
|
||||
input_channel = output_channel
|
||||
output_channel = block_out_channels[i]
|
||||
is_final_block = i == len(block_out_channels) - 1
|
||||
|
||||
down_block = get_down_block(
|
||||
down_block_type,
|
||||
num_layers=self.layers_per_block,
|
||||
in_channels=input_channel,
|
||||
out_channels=output_channel,
|
||||
add_downsample=not is_final_block,
|
||||
resnet_eps=1e-6,
|
||||
downsample_padding=0,
|
||||
resnet_act_fn=act_fn,
|
||||
resnet_groups=norm_num_groups,
|
||||
attention_head_dim=output_channel,
|
||||
temb_channels=None,
|
||||
)
|
||||
self.down_blocks.append(down_block)
|
||||
|
||||
# mid
|
||||
self.mid_block = UNetMidBlock2D(
|
||||
in_channels=block_out_channels[-1],
|
||||
resnet_eps=1e-6,
|
||||
resnet_act_fn=act_fn,
|
||||
output_scale_factor=1,
|
||||
resnet_time_scale_shift="default",
|
||||
attention_head_dim=block_out_channels[-1],
|
||||
resnet_groups=norm_num_groups,
|
||||
temb_channels=None,
|
||||
)
|
||||
self.mid_block.attentions[0].set_use_memory_efficient_attention_xformers(True) # とりあえずDiffusersのxformersを使う
|
||||
|
||||
# out
|
||||
self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[-1], num_groups=norm_num_groups, eps=1e-6)
|
||||
self.conv_act = nn.SiLU()
|
||||
|
||||
conv_out_channels = 2 * out_channels if double_z else out_channels
|
||||
self.conv_out = nn.Conv2d(block_out_channels[-1], conv_out_channels, 3, padding=1)
|
||||
|
||||
# replace forward of ResBlocks
|
||||
def wrapper(func, module, num_slices):
|
||||
def forward(*args, **kwargs):
|
||||
return func(module, num_slices, *args, **kwargs)
|
||||
|
||||
return forward
|
||||
|
||||
self.num_slices = num_slices
|
||||
div = num_slices / (2 ** (len(self.down_blocks) - 1)) # 深い層はそこまで分割しなくていいので適宜減らす
|
||||
# logger.info(f"initial divisor: {div}")
|
||||
if div >= 2:
|
||||
div = int(div)
|
||||
for resnet in self.mid_block.resnets:
|
||||
resnet.forward = wrapper(resblock_forward, resnet, div)
|
||||
# midblock doesn't have downsample
|
||||
|
||||
for i, down_block in enumerate(self.down_blocks[::-1]):
|
||||
if div >= 2:
|
||||
div = int(div)
|
||||
# logger.info(f"down block: {i} divisor: {div}")
|
||||
for resnet in down_block.resnets:
|
||||
resnet.forward = wrapper(resblock_forward, resnet, div)
|
||||
if down_block.downsamplers is not None:
|
||||
# logger.info("has downsample")
|
||||
for downsample in down_block.downsamplers:
|
||||
downsample.forward = wrapper(self.downsample_forward, downsample, div * 2)
|
||||
div *= 2
|
||||
|
||||
def forward(self, x):
|
||||
sample = x
|
||||
del x
|
||||
|
||||
org_device = sample.device
|
||||
cpu_device = torch.device("cpu")
|
||||
|
||||
# sample = self.conv_in(sample)
|
||||
sample = sample.to(cpu_device)
|
||||
sliced = slice_h(sample, self.num_slices)
|
||||
del sample
|
||||
|
||||
for i in range(len(sliced)):
|
||||
x = sliced[i]
|
||||
sliced[i] = None
|
||||
|
||||
x = x.to(org_device)
|
||||
x = self.conv_in(x)
|
||||
x = x.to(cpu_device)
|
||||
sliced[i] = x
|
||||
del x
|
||||
|
||||
sample = cat_h(sliced)
|
||||
del sliced
|
||||
|
||||
sample = sample.to(org_device)
|
||||
|
||||
# down
|
||||
for down_block in self.down_blocks:
|
||||
sample = down_block(sample)
|
||||
|
||||
# middle
|
||||
sample = self.mid_block(sample)
|
||||
|
||||
# post-process
|
||||
# ここも省メモリ化したいが、恐らくそこまでメモリを食わないので省略
|
||||
sample = self.conv_norm_out(sample)
|
||||
sample = self.conv_act(sample)
|
||||
sample = self.conv_out(sample)
|
||||
|
||||
return sample
|
||||
|
||||
def downsample_forward(self, _self, num_slices, hidden_states):
|
||||
assert hidden_states.shape[1] == _self.channels
|
||||
assert _self.use_conv and _self.padding == 0
|
||||
logger.info(f"downsample forward {num_slices} {hidden_states.shape}")
|
||||
|
||||
org_device = hidden_states.device
|
||||
cpu_device = torch.device("cpu")
|
||||
|
||||
hidden_states = hidden_states.to(cpu_device)
|
||||
pad = (0, 1, 0, 1)
|
||||
hidden_states = torch.nn.functional.pad(hidden_states, pad, mode="constant", value=0)
|
||||
|
||||
# slice with even number because of stride 2
|
||||
# strideが2なので偶数でスライスする
|
||||
# slice with pad 1 both sides: to eliminate side effect of padding of conv2d
|
||||
size = (hidden_states.shape[2] + num_slices - 1) // num_slices
|
||||
size = size + 1 if size % 2 == 1 else size
|
||||
|
||||
sliced = []
|
||||
for i in range(num_slices):
|
||||
if i == 0:
|
||||
sliced.append(hidden_states[:, :, : size + 1, :])
|
||||
else:
|
||||
end = size * (i + 1) + 1
|
||||
if hidden_states.shape[2] - end < 4: # if the last slice is too small, use the rest of the tensor
|
||||
end = hidden_states.shape[2]
|
||||
sliced.append(hidden_states[:, :, size * i - 1 : end, :])
|
||||
if end >= hidden_states.shape[2]:
|
||||
break
|
||||
del hidden_states
|
||||
|
||||
for i in range(len(sliced)):
|
||||
x = sliced[i]
|
||||
sliced[i] = None
|
||||
|
||||
x = x.to(org_device)
|
||||
x = _self.conv(x)
|
||||
x = x.to(cpu_device)
|
||||
|
||||
# ここだけ雰囲気が違うのはCopilotのせい
|
||||
if i == 0:
|
||||
hidden_states = x
|
||||
else:
|
||||
hidden_states = torch.cat([hidden_states, x], dim=2)
|
||||
|
||||
hidden_states = hidden_states.to(org_device)
|
||||
# logger.info(f"downsample forward done {hidden_states.shape}")
|
||||
return hidden_states
|
||||
|
||||
|
||||
class SlicingDecoder(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
in_channels=3,
|
||||
out_channels=3,
|
||||
up_block_types=("UpDecoderBlock2D",),
|
||||
block_out_channels=(64,),
|
||||
layers_per_block=2,
|
||||
norm_num_groups=32,
|
||||
act_fn="silu",
|
||||
num_slices=2,
|
||||
):
|
||||
super().__init__()
|
||||
self.layers_per_block = layers_per_block
|
||||
|
||||
self.conv_in = nn.Conv2d(in_channels, block_out_channels[-1], kernel_size=3, stride=1, padding=1)
|
||||
|
||||
self.mid_block = None
|
||||
self.up_blocks = nn.ModuleList([])
|
||||
|
||||
# mid
|
||||
self.mid_block = UNetMidBlock2D(
|
||||
in_channels=block_out_channels[-1],
|
||||
resnet_eps=1e-6,
|
||||
resnet_act_fn=act_fn,
|
||||
output_scale_factor=1,
|
||||
resnet_time_scale_shift="default",
|
||||
attention_head_dim=block_out_channels[-1],
|
||||
resnet_groups=norm_num_groups,
|
||||
temb_channels=None,
|
||||
)
|
||||
self.mid_block.attentions[0].set_use_memory_efficient_attention_xformers(True) # とりあえずDiffusersのxformersを使う
|
||||
|
||||
# up
|
||||
reversed_block_out_channels = list(reversed(block_out_channels))
|
||||
output_channel = reversed_block_out_channels[0]
|
||||
for i, up_block_type in enumerate(up_block_types):
|
||||
prev_output_channel = output_channel
|
||||
output_channel = reversed_block_out_channels[i]
|
||||
|
||||
is_final_block = i == len(block_out_channels) - 1
|
||||
|
||||
up_block = get_up_block(
|
||||
up_block_type,
|
||||
num_layers=self.layers_per_block + 1,
|
||||
in_channels=prev_output_channel,
|
||||
out_channels=output_channel,
|
||||
prev_output_channel=None,
|
||||
add_upsample=not is_final_block,
|
||||
resnet_eps=1e-6,
|
||||
resnet_act_fn=act_fn,
|
||||
resnet_groups=norm_num_groups,
|
||||
attention_head_dim=output_channel,
|
||||
temb_channels=None,
|
||||
)
|
||||
self.up_blocks.append(up_block)
|
||||
prev_output_channel = output_channel
|
||||
|
||||
# out
|
||||
self.conv_norm_out = nn.GroupNorm(num_channels=block_out_channels[0], num_groups=norm_num_groups, eps=1e-6)
|
||||
self.conv_act = nn.SiLU()
|
||||
self.conv_out = nn.Conv2d(block_out_channels[0], out_channels, 3, padding=1)
|
||||
|
||||
# replace forward of ResBlocks
|
||||
def wrapper(func, module, num_slices):
|
||||
def forward(*args, **kwargs):
|
||||
return func(module, num_slices, *args, **kwargs)
|
||||
|
||||
return forward
|
||||
|
||||
self.num_slices = num_slices
|
||||
div = num_slices / (2 ** (len(self.up_blocks) - 1))
|
||||
logger.info(f"initial divisor: {div}")
|
||||
if div >= 2:
|
||||
div = int(div)
|
||||
for resnet in self.mid_block.resnets:
|
||||
resnet.forward = wrapper(resblock_forward, resnet, div)
|
||||
# midblock doesn't have upsample
|
||||
|
||||
for i, up_block in enumerate(self.up_blocks):
|
||||
if div >= 2:
|
||||
div = int(div)
|
||||
# logger.info(f"up block: {i} divisor: {div}")
|
||||
for resnet in up_block.resnets:
|
||||
resnet.forward = wrapper(resblock_forward, resnet, div)
|
||||
if up_block.upsamplers is not None:
|
||||
# logger.info("has upsample")
|
||||
for upsample in up_block.upsamplers:
|
||||
upsample.forward = wrapper(self.upsample_forward, upsample, div * 2)
|
||||
div *= 2
|
||||
|
||||
def forward(self, z):
|
||||
sample = z
|
||||
del z
|
||||
sample = self.conv_in(sample)
|
||||
|
||||
# middle
|
||||
sample = self.mid_block(sample)
|
||||
|
||||
# up
|
||||
for i, up_block in enumerate(self.up_blocks):
|
||||
sample = up_block(sample)
|
||||
|
||||
# post-process
|
||||
sample = self.conv_norm_out(sample)
|
||||
sample = self.conv_act(sample)
|
||||
|
||||
# conv_out with slicing because of VRAM usage
|
||||
# conv_outはとてもVRAM使うのでスライスして対応
|
||||
org_device = sample.device
|
||||
cpu_device = torch.device("cpu")
|
||||
sample = sample.to(cpu_device)
|
||||
|
||||
sliced = slice_h(sample, self.num_slices)
|
||||
del sample
|
||||
for i in range(len(sliced)):
|
||||
x = sliced[i]
|
||||
sliced[i] = None
|
||||
|
||||
x = x.to(org_device)
|
||||
x = self.conv_out(x)
|
||||
x = x.to(cpu_device)
|
||||
sliced[i] = x
|
||||
sample = cat_h(sliced)
|
||||
del sliced
|
||||
|
||||
sample = sample.to(org_device)
|
||||
return sample
|
||||
|
||||
def upsample_forward(self, _self, num_slices, hidden_states, output_size=None):
|
||||
assert hidden_states.shape[1] == _self.channels
|
||||
assert _self.use_conv_transpose == False and _self.use_conv
|
||||
|
||||
org_dtype = hidden_states.dtype
|
||||
org_device = hidden_states.device
|
||||
cpu_device = torch.device("cpu")
|
||||
|
||||
hidden_states = hidden_states.to(cpu_device)
|
||||
sliced = slice_h(hidden_states, num_slices)
|
||||
del hidden_states
|
||||
|
||||
for i in range(len(sliced)):
|
||||
x = sliced[i]
|
||||
sliced[i] = None
|
||||
|
||||
x = x.to(org_device)
|
||||
|
||||
# Cast to float32 to as 'upsample_nearest2d_out_frame' op does not support bfloat16
|
||||
# TODO(Suraj): Remove this cast once the issue is fixed in PyTorch
|
||||
# https://github.com/pytorch/pytorch/issues/86679
|
||||
# PyTorch 2で直らないかね……
|
||||
if org_dtype == torch.bfloat16:
|
||||
x = x.to(torch.float32)
|
||||
|
||||
x = torch.nn.functional.interpolate(x, scale_factor=2.0, mode="nearest")
|
||||
|
||||
if org_dtype == torch.bfloat16:
|
||||
x = x.to(org_dtype)
|
||||
|
||||
x = _self.conv(x)
|
||||
|
||||
# upsampleされてるのでpadは2になる
|
||||
if i == 0:
|
||||
x = x[:, :, :-2, :]
|
||||
elif i == num_slices - 1:
|
||||
x = x[:, :, 2:, :]
|
||||
else:
|
||||
x = x[:, :, 2:-2, :]
|
||||
|
||||
x = x.to(cpu_device)
|
||||
sliced[i] = x
|
||||
del x
|
||||
|
||||
hidden_states = torch.cat(sliced, dim=2)
|
||||
# logger.info(f"us hidden_states {hidden_states.shape}")
|
||||
del sliced
|
||||
|
||||
hidden_states = hidden_states.to(org_device)
|
||||
return hidden_states
|
||||
|
||||
|
||||
class SlicingAutoencoderKL(ModelMixin, ConfigMixin):
|
||||
r"""Variational Autoencoder (VAE) model with KL loss from the paper Auto-Encoding Variational Bayes by Diederik P. Kingma
|
||||
and Max Welling.
|
||||
|
||||
This model inherits from [`ModelMixin`]. Check the superclass documentation for the generic methods the library
|
||||
implements for all the model (such as downloading or saving, etc.)
|
||||
|
||||
Parameters:
|
||||
in_channels (int, *optional*, defaults to 3): Number of channels in the input image.
|
||||
out_channels (int, *optional*, defaults to 3): Number of channels in the output.
|
||||
down_block_types (`Tuple[str]`, *optional*, defaults to :
|
||||
obj:`("DownEncoderBlock2D",)`): Tuple of downsample block types.
|
||||
up_block_types (`Tuple[str]`, *optional*, defaults to :
|
||||
obj:`("UpDecoderBlock2D",)`): Tuple of upsample block types.
|
||||
block_out_channels (`Tuple[int]`, *optional*, defaults to :
|
||||
obj:`(64,)`): Tuple of block output channels.
|
||||
act_fn (`str`, *optional*, defaults to `"silu"`): The activation function to use.
|
||||
latent_channels (`int`, *optional*, defaults to `4`): Number of channels in the latent space.
|
||||
sample_size (`int`, *optional*, defaults to `32`): TODO
|
||||
"""
|
||||
|
||||
@register_to_config
|
||||
def __init__(
|
||||
self,
|
||||
in_channels: int = 3,
|
||||
out_channels: int = 3,
|
||||
down_block_types: Tuple[str] = ("DownEncoderBlock2D",),
|
||||
up_block_types: Tuple[str] = ("UpDecoderBlock2D",),
|
||||
block_out_channels: Tuple[int] = (64,),
|
||||
layers_per_block: int = 1,
|
||||
act_fn: str = "silu",
|
||||
latent_channels: int = 4,
|
||||
norm_num_groups: int = 32,
|
||||
sample_size: int = 32,
|
||||
num_slices: int = 16,
|
||||
):
|
||||
super().__init__()
|
||||
|
||||
# pass init params to Encoder
|
||||
self.encoder = SlicingEncoder(
|
||||
in_channels=in_channels,
|
||||
out_channels=latent_channels,
|
||||
down_block_types=down_block_types,
|
||||
block_out_channels=block_out_channels,
|
||||
layers_per_block=layers_per_block,
|
||||
act_fn=act_fn,
|
||||
norm_num_groups=norm_num_groups,
|
||||
double_z=True,
|
||||
num_slices=num_slices,
|
||||
)
|
||||
|
||||
# pass init params to Decoder
|
||||
self.decoder = SlicingDecoder(
|
||||
in_channels=latent_channels,
|
||||
out_channels=out_channels,
|
||||
up_block_types=up_block_types,
|
||||
block_out_channels=block_out_channels,
|
||||
layers_per_block=layers_per_block,
|
||||
norm_num_groups=norm_num_groups,
|
||||
act_fn=act_fn,
|
||||
num_slices=num_slices,
|
||||
)
|
||||
|
||||
self.quant_conv = torch.nn.Conv2d(2 * latent_channels, 2 * latent_channels, 1)
|
||||
self.post_quant_conv = torch.nn.Conv2d(latent_channels, latent_channels, 1)
|
||||
self.use_slicing = False
|
||||
|
||||
def encode(self, x: torch.FloatTensor, return_dict: bool = True) -> AutoencoderKLOutput:
|
||||
h = self.encoder(x)
|
||||
moments = self.quant_conv(h)
|
||||
posterior = DiagonalGaussianDistribution(moments)
|
||||
|
||||
if not return_dict:
|
||||
return (posterior,)
|
||||
|
||||
return AutoencoderKLOutput(latent_dist=posterior)
|
||||
|
||||
def _decode(self, z: torch.FloatTensor, return_dict: bool = True) -> Union[DecoderOutput, torch.FloatTensor]:
|
||||
z = self.post_quant_conv(z)
|
||||
dec = self.decoder(z)
|
||||
|
||||
if not return_dict:
|
||||
return (dec,)
|
||||
|
||||
return DecoderOutput(sample=dec)
|
||||
|
||||
# これはバッチ方向のスライシング 紛らわしい
|
||||
def enable_slicing(self):
|
||||
r"""
|
||||
Enable sliced VAE decoding.
|
||||
|
||||
When this option is enabled, the VAE will split the input tensor in slices to compute decoding in several
|
||||
steps. This is useful to save some memory and allow larger batch sizes.
|
||||
"""
|
||||
self.use_slicing = True
|
||||
|
||||
def disable_slicing(self):
|
||||
r"""
|
||||
Disable sliced VAE decoding. If `enable_slicing` was previously invoked, this method will go back to computing
|
||||
decoding in one step.
|
||||
"""
|
||||
self.use_slicing = False
|
||||
|
||||
def decode(self, z: torch.FloatTensor, return_dict: bool = True) -> Union[DecoderOutput, torch.FloatTensor]:
|
||||
if self.use_slicing and z.shape[0] > 1:
|
||||
decoded_slices = [self._decode(z_slice).sample for z_slice in z.split(1)]
|
||||
decoded = torch.cat(decoded_slices)
|
||||
else:
|
||||
decoded = self._decode(z).sample
|
||||
|
||||
if not return_dict:
|
||||
return (decoded,)
|
||||
|
||||
return DecoderOutput(sample=decoded)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
sample: torch.FloatTensor,
|
||||
sample_posterior: bool = False,
|
||||
return_dict: bool = True,
|
||||
generator: Optional[torch.Generator] = None,
|
||||
) -> Union[DecoderOutput, torch.FloatTensor]:
|
||||
r"""
|
||||
Args:
|
||||
sample (`torch.FloatTensor`): Input sample.
|
||||
sample_posterior (`bool`, *optional*, defaults to `False`):
|
||||
Whether to sample from the posterior.
|
||||
return_dict (`bool`, *optional*, defaults to `True`):
|
||||
Whether or not to return a [`DecoderOutput`] instead of a plain tuple.
|
||||
"""
|
||||
x = sample
|
||||
posterior = self.encode(x).latent_dist
|
||||
if sample_posterior:
|
||||
z = posterior.sample(generator=generator)
|
||||
else:
|
||||
z = posterior.mode()
|
||||
dec = self.decode(z).sample
|
||||
|
||||
if not return_dict:
|
||||
return (dec,)
|
||||
|
||||
return DecoderOutput(sample=dec)
|
||||
File diff suppressed because it is too large
Load Diff
283
library/utils.py
283
library/utils.py
@@ -1,6 +1,287 @@
|
||||
import logging
|
||||
import sys
|
||||
import threading
|
||||
import torch
|
||||
from torchvision import transforms
|
||||
from typing import *
|
||||
from diffusers import EulerAncestralDiscreteScheduler
|
||||
import diffusers.schedulers.scheduling_euler_ancestral_discrete
|
||||
from diffusers.schedulers.scheduling_euler_ancestral_discrete import EulerAncestralDiscreteSchedulerOutput
|
||||
import cv2
|
||||
from PIL import Image
|
||||
import numpy as np
|
||||
|
||||
|
||||
def fire_in_thread(f, *args, **kwargs):
|
||||
threading.Thread(target=f, args=args, kwargs=kwargs).start()
|
||||
threading.Thread(target=f, args=args, kwargs=kwargs).start()
|
||||
|
||||
|
||||
def add_logging_arguments(parser):
|
||||
parser.add_argument(
|
||||
"--console_log_level",
|
||||
type=str,
|
||||
default=None,
|
||||
choices=["DEBUG", "INFO", "WARNING", "ERROR", "CRITICAL"],
|
||||
help="Set the logging level, default is INFO / ログレベルを設定する。デフォルトはINFO",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--console_log_file",
|
||||
type=str,
|
||||
default=None,
|
||||
help="Log to a file instead of stderr / 標準エラー出力ではなくファイルにログを出力する",
|
||||
)
|
||||
parser.add_argument("--console_log_simple", action="store_true", help="Simple log output / シンプルなログ出力")
|
||||
|
||||
|
||||
def setup_logging(args=None, log_level=None, reset=False):
|
||||
if logging.root.handlers:
|
||||
if reset:
|
||||
# remove all handlers
|
||||
for handler in logging.root.handlers[:]:
|
||||
logging.root.removeHandler(handler)
|
||||
else:
|
||||
return
|
||||
|
||||
# log_level can be set by the caller or by the args, the caller has priority. If not set, use INFO
|
||||
if log_level is None and args is not None:
|
||||
log_level = args.console_log_level
|
||||
if log_level is None:
|
||||
log_level = "INFO"
|
||||
log_level = getattr(logging, log_level)
|
||||
|
||||
msg_init = None
|
||||
if args is not None and args.console_log_file:
|
||||
handler = logging.FileHandler(args.console_log_file, mode="w")
|
||||
else:
|
||||
handler = None
|
||||
if not args or not args.console_log_simple:
|
||||
try:
|
||||
from rich.logging import RichHandler
|
||||
from rich.console import Console
|
||||
from rich.logging import RichHandler
|
||||
|
||||
handler = RichHandler(console=Console(stderr=True))
|
||||
except ImportError:
|
||||
# print("rich is not installed, using basic logging")
|
||||
msg_init = "rich is not installed, using basic logging"
|
||||
|
||||
if handler is None:
|
||||
handler = logging.StreamHandler(sys.stdout) # same as print
|
||||
handler.propagate = False
|
||||
|
||||
formatter = logging.Formatter(
|
||||
fmt="%(message)s",
|
||||
datefmt="%Y-%m-%d %H:%M:%S",
|
||||
)
|
||||
handler.setFormatter(formatter)
|
||||
logging.root.setLevel(log_level)
|
||||
logging.root.addHandler(handler)
|
||||
|
||||
if msg_init is not None:
|
||||
logger = logging.getLogger(__name__)
|
||||
logger.info(msg_init)
|
||||
|
||||
|
||||
def pil_resize(image, size, interpolation=Image.LANCZOS):
|
||||
has_alpha = image.shape[2] == 4 if len(image.shape) == 3 else False
|
||||
|
||||
if has_alpha:
|
||||
pil_image = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGRA2RGBA))
|
||||
else:
|
||||
pil_image = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
|
||||
|
||||
resized_pil = pil_image.resize(size, interpolation)
|
||||
|
||||
# Convert back to cv2 format
|
||||
if has_alpha:
|
||||
resized_cv2 = cv2.cvtColor(np.array(resized_pil), cv2.COLOR_RGBA2BGRA)
|
||||
else:
|
||||
resized_cv2 = cv2.cvtColor(np.array(resized_pil), cv2.COLOR_RGB2BGR)
|
||||
|
||||
return resized_cv2
|
||||
|
||||
|
||||
# TODO make inf_utils.py
|
||||
|
||||
|
||||
# region Gradual Latent hires fix
|
||||
|
||||
|
||||
class GradualLatent:
|
||||
def __init__(
|
||||
self,
|
||||
ratio,
|
||||
start_timesteps,
|
||||
every_n_steps,
|
||||
ratio_step,
|
||||
s_noise=1.0,
|
||||
gaussian_blur_ksize=None,
|
||||
gaussian_blur_sigma=0.5,
|
||||
gaussian_blur_strength=0.5,
|
||||
unsharp_target_x=True,
|
||||
):
|
||||
self.ratio = ratio
|
||||
self.start_timesteps = start_timesteps
|
||||
self.every_n_steps = every_n_steps
|
||||
self.ratio_step = ratio_step
|
||||
self.s_noise = s_noise
|
||||
self.gaussian_blur_ksize = gaussian_blur_ksize
|
||||
self.gaussian_blur_sigma = gaussian_blur_sigma
|
||||
self.gaussian_blur_strength = gaussian_blur_strength
|
||||
self.unsharp_target_x = unsharp_target_x
|
||||
|
||||
def __str__(self) -> str:
|
||||
return (
|
||||
f"GradualLatent(ratio={self.ratio}, start_timesteps={self.start_timesteps}, "
|
||||
+ f"every_n_steps={self.every_n_steps}, ratio_step={self.ratio_step}, s_noise={self.s_noise}, "
|
||||
+ f"gaussian_blur_ksize={self.gaussian_blur_ksize}, gaussian_blur_sigma={self.gaussian_blur_sigma}, gaussian_blur_strength={self.gaussian_blur_strength}, "
|
||||
+ f"unsharp_target_x={self.unsharp_target_x})"
|
||||
)
|
||||
|
||||
def apply_unshark_mask(self, x: torch.Tensor):
|
||||
if self.gaussian_blur_ksize is None:
|
||||
return x
|
||||
blurred = transforms.functional.gaussian_blur(x, self.gaussian_blur_ksize, self.gaussian_blur_sigma)
|
||||
# mask = torch.sigmoid((x - blurred) * self.gaussian_blur_strength)
|
||||
mask = (x - blurred) * self.gaussian_blur_strength
|
||||
sharpened = x + mask
|
||||
return sharpened
|
||||
|
||||
def interpolate(self, x: torch.Tensor, resized_size, unsharp=True):
|
||||
org_dtype = x.dtype
|
||||
if org_dtype == torch.bfloat16:
|
||||
x = x.float()
|
||||
|
||||
x = torch.nn.functional.interpolate(x, size=resized_size, mode="bicubic", align_corners=False).to(dtype=org_dtype)
|
||||
|
||||
# apply unsharp mask / アンシャープマスクを適用する
|
||||
if unsharp and self.gaussian_blur_ksize:
|
||||
x = self.apply_unshark_mask(x)
|
||||
|
||||
return x
|
||||
|
||||
|
||||
class EulerAncestralDiscreteSchedulerGL(EulerAncestralDiscreteScheduler):
|
||||
def __init__(self, *args, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
self.resized_size = None
|
||||
self.gradual_latent = None
|
||||
|
||||
def set_gradual_latent_params(self, size, gradual_latent: GradualLatent):
|
||||
self.resized_size = size
|
||||
self.gradual_latent = gradual_latent
|
||||
|
||||
def step(
|
||||
self,
|
||||
model_output: torch.FloatTensor,
|
||||
timestep: Union[float, torch.FloatTensor],
|
||||
sample: torch.FloatTensor,
|
||||
generator: Optional[torch.Generator] = None,
|
||||
return_dict: bool = True,
|
||||
) -> Union[EulerAncestralDiscreteSchedulerOutput, Tuple]:
|
||||
"""
|
||||
Predict the sample from the previous timestep by reversing the SDE. This function propagates the diffusion
|
||||
process from the learned model outputs (most often the predicted noise).
|
||||
|
||||
Args:
|
||||
model_output (`torch.FloatTensor`):
|
||||
The direct output from learned diffusion model.
|
||||
timestep (`float`):
|
||||
The current discrete timestep in the diffusion chain.
|
||||
sample (`torch.FloatTensor`):
|
||||
A current instance of a sample created by the diffusion process.
|
||||
generator (`torch.Generator`, *optional*):
|
||||
A random number generator.
|
||||
return_dict (`bool`):
|
||||
Whether or not to return a
|
||||
[`~schedulers.scheduling_euler_ancestral_discrete.EulerAncestralDiscreteSchedulerOutput`] or tuple.
|
||||
|
||||
Returns:
|
||||
[`~schedulers.scheduling_euler_ancestral_discrete.EulerAncestralDiscreteSchedulerOutput`] or `tuple`:
|
||||
If return_dict is `True`,
|
||||
[`~schedulers.scheduling_euler_ancestral_discrete.EulerAncestralDiscreteSchedulerOutput`] is returned,
|
||||
otherwise a tuple is returned where the first element is the sample tensor.
|
||||
|
||||
"""
|
||||
|
||||
if isinstance(timestep, int) or isinstance(timestep, torch.IntTensor) or isinstance(timestep, torch.LongTensor):
|
||||
raise ValueError(
|
||||
(
|
||||
"Passing integer indices (e.g. from `enumerate(timesteps)`) as timesteps to"
|
||||
" `EulerDiscreteScheduler.step()` is not supported. Make sure to pass"
|
||||
" one of the `scheduler.timesteps` as a timestep."
|
||||
),
|
||||
)
|
||||
|
||||
if not self.is_scale_input_called:
|
||||
# logger.warning(
|
||||
print(
|
||||
"The `scale_model_input` function should be called before `step` to ensure correct denoising. "
|
||||
"See `StableDiffusionPipeline` for a usage example."
|
||||
)
|
||||
|
||||
if self.step_index is None:
|
||||
self._init_step_index(timestep)
|
||||
|
||||
sigma = self.sigmas[self.step_index]
|
||||
|
||||
# 1. compute predicted original sample (x_0) from sigma-scaled predicted noise
|
||||
if self.config.prediction_type == "epsilon":
|
||||
pred_original_sample = sample - sigma * model_output
|
||||
elif self.config.prediction_type == "v_prediction":
|
||||
# * c_out + input * c_skip
|
||||
pred_original_sample = model_output * (-sigma / (sigma**2 + 1) ** 0.5) + (sample / (sigma**2 + 1))
|
||||
elif self.config.prediction_type == "sample":
|
||||
raise NotImplementedError("prediction_type not implemented yet: sample")
|
||||
else:
|
||||
raise ValueError(f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, or `v_prediction`")
|
||||
|
||||
sigma_from = self.sigmas[self.step_index]
|
||||
sigma_to = self.sigmas[self.step_index + 1]
|
||||
sigma_up = (sigma_to**2 * (sigma_from**2 - sigma_to**2) / sigma_from**2) ** 0.5
|
||||
sigma_down = (sigma_to**2 - sigma_up**2) ** 0.5
|
||||
|
||||
# 2. Convert to an ODE derivative
|
||||
derivative = (sample - pred_original_sample) / sigma
|
||||
|
||||
dt = sigma_down - sigma
|
||||
|
||||
device = model_output.device
|
||||
if self.resized_size is None:
|
||||
prev_sample = sample + derivative * dt
|
||||
|
||||
noise = diffusers.schedulers.scheduling_euler_ancestral_discrete.randn_tensor(
|
||||
model_output.shape, dtype=model_output.dtype, device=device, generator=generator
|
||||
)
|
||||
s_noise = 1.0
|
||||
else:
|
||||
print("resized_size", self.resized_size, "model_output.shape", model_output.shape, "sample.shape", sample.shape)
|
||||
s_noise = self.gradual_latent.s_noise
|
||||
|
||||
if self.gradual_latent.unsharp_target_x:
|
||||
prev_sample = sample + derivative * dt
|
||||
prev_sample = self.gradual_latent.interpolate(prev_sample, self.resized_size)
|
||||
else:
|
||||
sample = self.gradual_latent.interpolate(sample, self.resized_size)
|
||||
derivative = self.gradual_latent.interpolate(derivative, self.resized_size, unsharp=False)
|
||||
prev_sample = sample + derivative * dt
|
||||
|
||||
noise = diffusers.schedulers.scheduling_euler_ancestral_discrete.randn_tensor(
|
||||
(model_output.shape[0], model_output.shape[1], self.resized_size[0], self.resized_size[1]),
|
||||
dtype=model_output.dtype,
|
||||
device=device,
|
||||
generator=generator,
|
||||
)
|
||||
|
||||
prev_sample = prev_sample + noise * sigma_up * s_noise
|
||||
|
||||
# upon completion increase step index by one
|
||||
self._step_index += 1
|
||||
|
||||
if not return_dict:
|
||||
return (prev_sample,)
|
||||
|
||||
return EulerAncestralDiscreteSchedulerOutput(prev_sample=prev_sample, pred_original_sample=pred_original_sample)
|
||||
|
||||
|
||||
# endregion
|
||||
|
||||
@@ -2,38 +2,47 @@ import argparse
|
||||
import os
|
||||
import torch
|
||||
from safetensors.torch import load_file
|
||||
|
||||
from library.utils import setup_logging
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
def main(file):
|
||||
print(f"loading: {file}")
|
||||
if os.path.splitext(file)[1] == '.safetensors':
|
||||
sd = load_file(file)
|
||||
else:
|
||||
sd = torch.load(file, map_location='cpu')
|
||||
logger.info(f"loading: {file}")
|
||||
if os.path.splitext(file)[1] == ".safetensors":
|
||||
sd = load_file(file)
|
||||
else:
|
||||
sd = torch.load(file, map_location="cpu")
|
||||
|
||||
values = []
|
||||
values = []
|
||||
|
||||
keys = list(sd.keys())
|
||||
for key in keys:
|
||||
if 'lora_up' in key or 'lora_down' in key:
|
||||
values.append((key, sd[key]))
|
||||
print(f"number of LoRA modules: {len(values)}")
|
||||
keys = list(sd.keys())
|
||||
for key in keys:
|
||||
if "lora_up" in key or "lora_down" in key or "lora_A" in key or "lora_B" in key or "oft_" in key:
|
||||
values.append((key, sd[key]))
|
||||
print(f"number of LoRA modules: {len(values)}")
|
||||
|
||||
for key, value in values:
|
||||
value = value.to(torch.float32)
|
||||
print(f"{key},{str(tuple(value.size())).replace(', ', '-')},{torch.mean(torch.abs(value))},{torch.min(torch.abs(value))}")
|
||||
if args.show_all_keys:
|
||||
for key in [k for k in keys if k not in values]:
|
||||
values.append((key, sd[key]))
|
||||
print(f"number of all modules: {len(values)}")
|
||||
|
||||
for key, value in values:
|
||||
value = value.to(torch.float32)
|
||||
print(f"{key},{str(tuple(value.size())).replace(', ', '-')},{torch.mean(torch.abs(value))},{torch.min(torch.abs(value))}")
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("file", type=str, help="model file to check / 重みを確認するモデルファイル")
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("file", type=str, help="model file to check / 重みを確認するモデルファイル")
|
||||
parser.add_argument("-s", "--show_all_keys", action="store_true", help="show all keys / 全てのキーを表示する")
|
||||
|
||||
return parser
|
||||
return parser
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = setup_parser()
|
||||
if __name__ == "__main__":
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
args = parser.parse_args()
|
||||
|
||||
main(args.file)
|
||||
main(args.file)
|
||||
|
||||
449
networks/control_net_lllite.py
Normal file
449
networks/control_net_lllite.py
Normal file
@@ -0,0 +1,449 @@
|
||||
import os
|
||||
from typing import Optional, List, Type
|
||||
import torch
|
||||
from library import sdxl_original_unet
|
||||
from library.utils import setup_logging
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# input_blocksに適用するかどうか / if True, input_blocks are not applied
|
||||
SKIP_INPUT_BLOCKS = False
|
||||
|
||||
# output_blocksに適用するかどうか / if True, output_blocks are not applied
|
||||
SKIP_OUTPUT_BLOCKS = True
|
||||
|
||||
# conv2dに適用するかどうか / if True, conv2d are not applied
|
||||
SKIP_CONV2D = False
|
||||
|
||||
# transformer_blocksのみに適用するかどうか。Trueの場合、ResBlockには適用されない
|
||||
# if True, only transformer_blocks are applied, and ResBlocks are not applied
|
||||
TRANSFORMER_ONLY = True # if True, SKIP_CONV2D is ignored because conv2d is not used in transformer_blocks
|
||||
|
||||
# Trueならattn1とattn2にのみ適用し、ffなどには適用しない / if True, apply only to attn1 and attn2, not to ff etc.
|
||||
ATTN1_2_ONLY = True
|
||||
|
||||
# Trueならattn1のQKV、attn2のQにのみ適用する、ATTN1_2_ONLY指定時のみ有効 / if True, apply only to attn1 QKV and attn2 Q, only valid when ATTN1_2_ONLY is specified
|
||||
ATTN_QKV_ONLY = True
|
||||
|
||||
# Trueならattn1やffなどにのみ適用し、attn2などには適用しない / if True, apply only to attn1 and ff, not to attn2
|
||||
# ATTN1_2_ONLYと同時にTrueにできない / cannot be True at the same time as ATTN1_2_ONLY
|
||||
ATTN1_ETC_ONLY = False # True
|
||||
|
||||
# transformer_blocksの最大インデックス。Noneなら全てのtransformer_blocksに適用
|
||||
# max index of transformer_blocks. if None, apply to all transformer_blocks
|
||||
TRANSFORMER_MAX_BLOCK_INDEX = None
|
||||
|
||||
|
||||
class LLLiteModule(torch.nn.Module):
|
||||
def __init__(self, depth, cond_emb_dim, name, org_module, mlp_dim, dropout=None, multiplier=1.0):
|
||||
super().__init__()
|
||||
|
||||
self.is_conv2d = org_module.__class__.__name__ == "Conv2d"
|
||||
self.lllite_name = name
|
||||
self.cond_emb_dim = cond_emb_dim
|
||||
self.org_module = [org_module]
|
||||
self.dropout = dropout
|
||||
self.multiplier = multiplier
|
||||
|
||||
if self.is_conv2d:
|
||||
in_dim = org_module.in_channels
|
||||
else:
|
||||
in_dim = org_module.in_features
|
||||
|
||||
# conditioning1はconditioning imageを embedding する。timestepごとに呼ばれない
|
||||
# conditioning1 embeds conditioning image. it is not called for each timestep
|
||||
modules = []
|
||||
modules.append(torch.nn.Conv2d(3, cond_emb_dim // 2, kernel_size=4, stride=4, padding=0)) # to latent (from VAE) size
|
||||
if depth == 1:
|
||||
modules.append(torch.nn.ReLU(inplace=True))
|
||||
modules.append(torch.nn.Conv2d(cond_emb_dim // 2, cond_emb_dim, kernel_size=2, stride=2, padding=0))
|
||||
elif depth == 2:
|
||||
modules.append(torch.nn.ReLU(inplace=True))
|
||||
modules.append(torch.nn.Conv2d(cond_emb_dim // 2, cond_emb_dim, kernel_size=4, stride=4, padding=0))
|
||||
elif depth == 3:
|
||||
# kernel size 8は大きすぎるので、4にする / kernel size 8 is too large, so set it to 4
|
||||
modules.append(torch.nn.ReLU(inplace=True))
|
||||
modules.append(torch.nn.Conv2d(cond_emb_dim // 2, cond_emb_dim // 2, kernel_size=4, stride=4, padding=0))
|
||||
modules.append(torch.nn.ReLU(inplace=True))
|
||||
modules.append(torch.nn.Conv2d(cond_emb_dim // 2, cond_emb_dim, kernel_size=2, stride=2, padding=0))
|
||||
|
||||
self.conditioning1 = torch.nn.Sequential(*modules)
|
||||
|
||||
# downで入力の次元数を削減する。LoRAにヒントを得ていることにする
|
||||
# midでconditioning image embeddingと入力を結合する
|
||||
# upで元の次元数に戻す
|
||||
# これらはtimestepごとに呼ばれる
|
||||
# reduce the number of input dimensions with down. inspired by LoRA
|
||||
# combine conditioning image embedding and input with mid
|
||||
# restore to the original dimension with up
|
||||
# these are called for each timestep
|
||||
|
||||
if self.is_conv2d:
|
||||
self.down = torch.nn.Sequential(
|
||||
torch.nn.Conv2d(in_dim, mlp_dim, kernel_size=1, stride=1, padding=0),
|
||||
torch.nn.ReLU(inplace=True),
|
||||
)
|
||||
self.mid = torch.nn.Sequential(
|
||||
torch.nn.Conv2d(mlp_dim + cond_emb_dim, mlp_dim, kernel_size=1, stride=1, padding=0),
|
||||
torch.nn.ReLU(inplace=True),
|
||||
)
|
||||
self.up = torch.nn.Sequential(
|
||||
torch.nn.Conv2d(mlp_dim, in_dim, kernel_size=1, stride=1, padding=0),
|
||||
)
|
||||
else:
|
||||
# midの前にconditioningをreshapeすること / reshape conditioning before mid
|
||||
self.down = torch.nn.Sequential(
|
||||
torch.nn.Linear(in_dim, mlp_dim),
|
||||
torch.nn.ReLU(inplace=True),
|
||||
)
|
||||
self.mid = torch.nn.Sequential(
|
||||
torch.nn.Linear(mlp_dim + cond_emb_dim, mlp_dim),
|
||||
torch.nn.ReLU(inplace=True),
|
||||
)
|
||||
self.up = torch.nn.Sequential(
|
||||
torch.nn.Linear(mlp_dim, in_dim),
|
||||
)
|
||||
|
||||
# Zero-Convにする / set to Zero-Conv
|
||||
torch.nn.init.zeros_(self.up[0].weight) # zero conv
|
||||
|
||||
self.depth = depth # 1~3
|
||||
self.cond_emb = None
|
||||
self.batch_cond_only = False # Trueなら推論時のcondにのみ適用する / if True, apply only to cond at inference
|
||||
self.use_zeros_for_batch_uncond = False # Trueならuncondのconditioningを0にする / if True, set uncond conditioning to 0
|
||||
|
||||
# batch_cond_onlyとuse_zeros_for_batch_uncondはどちらも適用すると生成画像の色味がおかしくなるので実際には使えそうにない
|
||||
# Controlの種類によっては使えるかも
|
||||
# both batch_cond_only and use_zeros_for_batch_uncond make the color of the generated image strange, so it doesn't seem to be usable in practice
|
||||
# it may be available depending on the type of Control
|
||||
|
||||
def set_cond_image(self, cond_image):
|
||||
r"""
|
||||
中でモデルを呼び出すので必要ならwith torch.no_grad()で囲む
|
||||
/ call the model inside, so if necessary, surround it with torch.no_grad()
|
||||
"""
|
||||
if cond_image is None:
|
||||
self.cond_emb = None
|
||||
return
|
||||
|
||||
# timestepごとに呼ばれないので、あらかじめ計算しておく / it is not called for each timestep, so calculate it in advance
|
||||
# logger.info(f"C {self.lllite_name}, cond_image.shape={cond_image.shape}")
|
||||
cx = self.conditioning1(cond_image)
|
||||
if not self.is_conv2d:
|
||||
# reshape / b,c,h,w -> b,h*w,c
|
||||
n, c, h, w = cx.shape
|
||||
cx = cx.view(n, c, h * w).permute(0, 2, 1)
|
||||
self.cond_emb = cx
|
||||
|
||||
def set_batch_cond_only(self, cond_only, zeros):
|
||||
self.batch_cond_only = cond_only
|
||||
self.use_zeros_for_batch_uncond = zeros
|
||||
|
||||
def apply_to(self):
|
||||
self.org_forward = self.org_module[0].forward
|
||||
self.org_module[0].forward = self.forward
|
||||
|
||||
def forward(self, x):
|
||||
r"""
|
||||
学習用の便利forward。元のモジュールのforwardを呼び出す
|
||||
/ convenient forward for training. call the forward of the original module
|
||||
"""
|
||||
if self.multiplier == 0.0 or self.cond_emb is None:
|
||||
return self.org_forward(x)
|
||||
|
||||
cx = self.cond_emb
|
||||
|
||||
if not self.batch_cond_only and x.shape[0] // 2 == cx.shape[0]: # inference only
|
||||
cx = cx.repeat(2, 1, 1, 1) if self.is_conv2d else cx.repeat(2, 1, 1)
|
||||
if self.use_zeros_for_batch_uncond:
|
||||
cx[0::2] = 0.0 # uncond is zero
|
||||
# logger.info(f"C {self.lllite_name}, x.shape={x.shape}, cx.shape={cx.shape}")
|
||||
|
||||
# downで入力の次元数を削減し、conditioning image embeddingと結合する
|
||||
# 加算ではなくchannel方向に結合することで、うまいこと混ぜてくれることを期待している
|
||||
# down reduces the number of input dimensions and combines it with conditioning image embedding
|
||||
# we expect that it will mix well by combining in the channel direction instead of adding
|
||||
|
||||
cx = torch.cat([cx, self.down(x if not self.batch_cond_only else x[1::2])], dim=1 if self.is_conv2d else 2)
|
||||
cx = self.mid(cx)
|
||||
|
||||
if self.dropout is not None and self.training:
|
||||
cx = torch.nn.functional.dropout(cx, p=self.dropout)
|
||||
|
||||
cx = self.up(cx) * self.multiplier
|
||||
|
||||
# residual (x) を加算して元のforwardを呼び出す / add residual (x) and call the original forward
|
||||
if self.batch_cond_only:
|
||||
zx = torch.zeros_like(x)
|
||||
zx[1::2] += cx
|
||||
cx = zx
|
||||
|
||||
x = self.org_forward(x + cx) # ここで元のモジュールを呼び出す / call the original module here
|
||||
return x
|
||||
|
||||
|
||||
class ControlNetLLLite(torch.nn.Module):
|
||||
UNET_TARGET_REPLACE_MODULE = ["Transformer2DModel"]
|
||||
UNET_TARGET_REPLACE_MODULE_CONV2D_3X3 = ["ResnetBlock2D", "Downsample2D", "Upsample2D"]
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
unet: sdxl_original_unet.SdxlUNet2DConditionModel,
|
||||
cond_emb_dim: int = 16,
|
||||
mlp_dim: int = 16,
|
||||
dropout: Optional[float] = None,
|
||||
varbose: Optional[bool] = False,
|
||||
multiplier: Optional[float] = 1.0,
|
||||
) -> None:
|
||||
super().__init__()
|
||||
# self.unets = [unet]
|
||||
|
||||
def create_modules(
|
||||
root_module: torch.nn.Module,
|
||||
target_replace_modules: List[torch.nn.Module],
|
||||
module_class: Type[object],
|
||||
) -> List[torch.nn.Module]:
|
||||
prefix = "lllite_unet"
|
||||
|
||||
modules = []
|
||||
for name, module in root_module.named_modules():
|
||||
if module.__class__.__name__ in target_replace_modules:
|
||||
for child_name, child_module in module.named_modules():
|
||||
is_linear = child_module.__class__.__name__ == "Linear"
|
||||
is_conv2d = child_module.__class__.__name__ == "Conv2d"
|
||||
|
||||
if is_linear or (is_conv2d and not SKIP_CONV2D):
|
||||
# block indexからdepthを計算: depthはconditioningのサイズやチャネルを計算するのに使う
|
||||
# block index to depth: depth is using to calculate conditioning size and channels
|
||||
block_name, index1, index2 = (name + "." + child_name).split(".")[:3]
|
||||
index1 = int(index1)
|
||||
if block_name == "input_blocks":
|
||||
if SKIP_INPUT_BLOCKS:
|
||||
continue
|
||||
depth = 1 if index1 <= 2 else (2 if index1 <= 5 else 3)
|
||||
elif block_name == "middle_block":
|
||||
depth = 3
|
||||
elif block_name == "output_blocks":
|
||||
if SKIP_OUTPUT_BLOCKS:
|
||||
continue
|
||||
depth = 3 if index1 <= 2 else (2 if index1 <= 5 else 1)
|
||||
if int(index2) >= 2:
|
||||
depth -= 1
|
||||
else:
|
||||
raise NotImplementedError()
|
||||
|
||||
lllite_name = prefix + "." + name + "." + child_name
|
||||
lllite_name = lllite_name.replace(".", "_")
|
||||
|
||||
if TRANSFORMER_MAX_BLOCK_INDEX is not None:
|
||||
p = lllite_name.find("transformer_blocks")
|
||||
if p >= 0:
|
||||
tf_index = int(lllite_name[p:].split("_")[2])
|
||||
if tf_index > TRANSFORMER_MAX_BLOCK_INDEX:
|
||||
continue
|
||||
|
||||
# time embは適用外とする
|
||||
# attn2のconditioning (CLIPからの入力) はshapeが違うので適用できない
|
||||
# time emb is not applied
|
||||
# attn2 conditioning (input from CLIP) cannot be applied because the shape is different
|
||||
if "emb_layers" in lllite_name or (
|
||||
"attn2" in lllite_name and ("to_k" in lllite_name or "to_v" in lllite_name)
|
||||
):
|
||||
continue
|
||||
|
||||
if ATTN1_2_ONLY:
|
||||
if not ("attn1" in lllite_name or "attn2" in lllite_name):
|
||||
continue
|
||||
if ATTN_QKV_ONLY:
|
||||
if "to_out" in lllite_name:
|
||||
continue
|
||||
|
||||
if ATTN1_ETC_ONLY:
|
||||
if "proj_out" in lllite_name:
|
||||
pass
|
||||
elif "attn1" in lllite_name and (
|
||||
"to_k" in lllite_name or "to_v" in lllite_name or "to_out" in lllite_name
|
||||
):
|
||||
pass
|
||||
elif "ff_net_2" in lllite_name:
|
||||
pass
|
||||
else:
|
||||
continue
|
||||
|
||||
module = module_class(
|
||||
depth,
|
||||
cond_emb_dim,
|
||||
lllite_name,
|
||||
child_module,
|
||||
mlp_dim,
|
||||
dropout=dropout,
|
||||
multiplier=multiplier,
|
||||
)
|
||||
modules.append(module)
|
||||
return modules
|
||||
|
||||
target_modules = ControlNetLLLite.UNET_TARGET_REPLACE_MODULE
|
||||
if not TRANSFORMER_ONLY:
|
||||
target_modules = target_modules + ControlNetLLLite.UNET_TARGET_REPLACE_MODULE_CONV2D_3X3
|
||||
|
||||
# create module instances
|
||||
self.unet_modules: List[LLLiteModule] = create_modules(unet, target_modules, LLLiteModule)
|
||||
logger.info(f"create ControlNet LLLite for U-Net: {len(self.unet_modules)} modules.")
|
||||
|
||||
def forward(self, x):
|
||||
return x # dummy
|
||||
|
||||
def set_cond_image(self, cond_image):
|
||||
r"""
|
||||
中でモデルを呼び出すので必要ならwith torch.no_grad()で囲む
|
||||
/ call the model inside, so if necessary, surround it with torch.no_grad()
|
||||
"""
|
||||
for module in self.unet_modules:
|
||||
module.set_cond_image(cond_image)
|
||||
|
||||
def set_batch_cond_only(self, cond_only, zeros):
|
||||
for module in self.unet_modules:
|
||||
module.set_batch_cond_only(cond_only, zeros)
|
||||
|
||||
def set_multiplier(self, multiplier):
|
||||
for module in self.unet_modules:
|
||||
module.multiplier = multiplier
|
||||
|
||||
def load_weights(self, file):
|
||||
if os.path.splitext(file)[1] == ".safetensors":
|
||||
from safetensors.torch import load_file
|
||||
|
||||
weights_sd = load_file(file)
|
||||
else:
|
||||
weights_sd = torch.load(file, map_location="cpu")
|
||||
|
||||
info = self.load_state_dict(weights_sd, False)
|
||||
return info
|
||||
|
||||
def apply_to(self):
|
||||
logger.info("applying LLLite for U-Net...")
|
||||
for module in self.unet_modules:
|
||||
module.apply_to()
|
||||
self.add_module(module.lllite_name, module)
|
||||
|
||||
# マージできるかどうかを返す
|
||||
def is_mergeable(self):
|
||||
return False
|
||||
|
||||
def merge_to(self, text_encoder, unet, weights_sd, dtype, device):
|
||||
raise NotImplementedError()
|
||||
|
||||
def enable_gradient_checkpointing(self):
|
||||
# not supported
|
||||
pass
|
||||
|
||||
def prepare_optimizer_params(self):
|
||||
self.requires_grad_(True)
|
||||
return self.parameters()
|
||||
|
||||
def prepare_grad_etc(self):
|
||||
self.requires_grad_(True)
|
||||
|
||||
def on_epoch_start(self):
|
||||
self.train()
|
||||
|
||||
def get_trainable_params(self):
|
||||
return self.parameters()
|
||||
|
||||
def save_weights(self, file, dtype, metadata):
|
||||
if metadata is not None and len(metadata) == 0:
|
||||
metadata = None
|
||||
|
||||
state_dict = self.state_dict()
|
||||
|
||||
if dtype is not None:
|
||||
for key in list(state_dict.keys()):
|
||||
v = state_dict[key]
|
||||
v = v.detach().clone().to("cpu").to(dtype)
|
||||
state_dict[key] = v
|
||||
|
||||
if os.path.splitext(file)[1] == ".safetensors":
|
||||
from safetensors.torch import save_file
|
||||
|
||||
save_file(state_dict, file, metadata)
|
||||
else:
|
||||
torch.save(state_dict, file)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# デバッグ用 / for debug
|
||||
|
||||
# sdxl_original_unet.USE_REENTRANT = False
|
||||
|
||||
# test shape etc
|
||||
logger.info("create unet")
|
||||
unet = sdxl_original_unet.SdxlUNet2DConditionModel()
|
||||
unet.to("cuda").to(torch.float16)
|
||||
|
||||
logger.info("create ControlNet-LLLite")
|
||||
control_net = ControlNetLLLite(unet, 32, 64)
|
||||
control_net.apply_to()
|
||||
control_net.to("cuda")
|
||||
|
||||
logger.info(control_net)
|
||||
|
||||
# logger.info number of parameters
|
||||
logger.info(f"number of parameters {sum(p.numel() for p in control_net.parameters() if p.requires_grad)}")
|
||||
|
||||
input()
|
||||
|
||||
unet.set_use_memory_efficient_attention(True, False)
|
||||
unet.set_gradient_checkpointing(True)
|
||||
unet.train() # for gradient checkpointing
|
||||
|
||||
control_net.train()
|
||||
|
||||
# # visualize
|
||||
# import torchviz
|
||||
# logger.info("run visualize")
|
||||
# controlnet.set_control(conditioning_image)
|
||||
# output = unet(x, t, ctx, y)
|
||||
# logger.info("make_dot")
|
||||
# image = torchviz.make_dot(output, params=dict(controlnet.named_parameters()))
|
||||
# logger.info("render")
|
||||
# image.format = "svg" # "png"
|
||||
# image.render("NeuralNet") # すごく時間がかかるので注意 / be careful because it takes a long time
|
||||
# input()
|
||||
|
||||
import bitsandbytes
|
||||
|
||||
optimizer = bitsandbytes.adam.Adam8bit(control_net.prepare_optimizer_params(), 1e-3)
|
||||
|
||||
scaler = torch.cuda.amp.GradScaler(enabled=True)
|
||||
|
||||
logger.info("start training")
|
||||
steps = 10
|
||||
|
||||
sample_param = [p for p in control_net.named_parameters() if "up" in p[0]][0]
|
||||
for step in range(steps):
|
||||
logger.info(f"step {step}")
|
||||
|
||||
batch_size = 1
|
||||
conditioning_image = torch.rand(batch_size, 3, 1024, 1024).cuda() * 2.0 - 1.0
|
||||
x = torch.randn(batch_size, 4, 128, 128).cuda()
|
||||
t = torch.randint(low=0, high=10, size=(batch_size,)).cuda()
|
||||
ctx = torch.randn(batch_size, 77, 2048).cuda()
|
||||
y = torch.randn(batch_size, sdxl_original_unet.ADM_IN_CHANNELS).cuda()
|
||||
|
||||
with torch.cuda.amp.autocast(enabled=True):
|
||||
control_net.set_cond_image(conditioning_image)
|
||||
|
||||
output = unet(x, t, ctx, y)
|
||||
target = torch.randn_like(output)
|
||||
loss = torch.nn.functional.mse_loss(output, target)
|
||||
|
||||
scaler.scale(loss).backward()
|
||||
scaler.step(optimizer)
|
||||
scaler.update()
|
||||
optimizer.zero_grad(set_to_none=True)
|
||||
logger.info(f"{sample_param}")
|
||||
|
||||
# from safetensors.torch import save_file
|
||||
|
||||
# save_file(control_net.state_dict(), "logs/control_net.safetensors")
|
||||
501
networks/control_net_lllite_for_train.py
Normal file
501
networks/control_net_lllite_for_train.py
Normal file
@@ -0,0 +1,501 @@
|
||||
# cond_imageをU-Netのforwardで渡すバージョンのControlNet-LLLite検証用実装
|
||||
# ControlNet-LLLite implementation for verification with cond_image passed in U-Net's forward
|
||||
|
||||
import os
|
||||
import re
|
||||
from typing import Optional, List, Type
|
||||
import torch
|
||||
from library import sdxl_original_unet
|
||||
from library.utils import setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# input_blocksに適用するかどうか / if True, input_blocks are not applied
|
||||
SKIP_INPUT_BLOCKS = False
|
||||
|
||||
# output_blocksに適用するかどうか / if True, output_blocks are not applied
|
||||
SKIP_OUTPUT_BLOCKS = True
|
||||
|
||||
# conv2dに適用するかどうか / if True, conv2d are not applied
|
||||
SKIP_CONV2D = False
|
||||
|
||||
# transformer_blocksのみに適用するかどうか。Trueの場合、ResBlockには適用されない
|
||||
# if True, only transformer_blocks are applied, and ResBlocks are not applied
|
||||
TRANSFORMER_ONLY = True # if True, SKIP_CONV2D is ignored because conv2d is not used in transformer_blocks
|
||||
|
||||
# Trueならattn1とattn2にのみ適用し、ffなどには適用しない / if True, apply only to attn1 and attn2, not to ff etc.
|
||||
ATTN1_2_ONLY = True
|
||||
|
||||
# Trueならattn1のQKV、attn2のQにのみ適用する、ATTN1_2_ONLY指定時のみ有効 / if True, apply only to attn1 QKV and attn2 Q, only valid when ATTN1_2_ONLY is specified
|
||||
ATTN_QKV_ONLY = True
|
||||
|
||||
# Trueならattn1やffなどにのみ適用し、attn2などには適用しない / if True, apply only to attn1 and ff, not to attn2
|
||||
# ATTN1_2_ONLYと同時にTrueにできない / cannot be True at the same time as ATTN1_2_ONLY
|
||||
ATTN1_ETC_ONLY = False # True
|
||||
|
||||
# transformer_blocksの最大インデックス。Noneなら全てのtransformer_blocksに適用
|
||||
# max index of transformer_blocks. if None, apply to all transformer_blocks
|
||||
TRANSFORMER_MAX_BLOCK_INDEX = None
|
||||
|
||||
ORIGINAL_LINEAR = torch.nn.Linear
|
||||
ORIGINAL_CONV2D = torch.nn.Conv2d
|
||||
|
||||
|
||||
def add_lllite_modules(module: torch.nn.Module, in_dim: int, depth, cond_emb_dim, mlp_dim) -> None:
|
||||
# conditioning1はconditioning imageを embedding する。timestepごとに呼ばれない
|
||||
# conditioning1 embeds conditioning image. it is not called for each timestep
|
||||
modules = []
|
||||
modules.append(ORIGINAL_CONV2D(3, cond_emb_dim // 2, kernel_size=4, stride=4, padding=0)) # to latent (from VAE) size
|
||||
if depth == 1:
|
||||
modules.append(torch.nn.ReLU(inplace=True))
|
||||
modules.append(ORIGINAL_CONV2D(cond_emb_dim // 2, cond_emb_dim, kernel_size=2, stride=2, padding=0))
|
||||
elif depth == 2:
|
||||
modules.append(torch.nn.ReLU(inplace=True))
|
||||
modules.append(ORIGINAL_CONV2D(cond_emb_dim // 2, cond_emb_dim, kernel_size=4, stride=4, padding=0))
|
||||
elif depth == 3:
|
||||
# kernel size 8は大きすぎるので、4にする / kernel size 8 is too large, so set it to 4
|
||||
modules.append(torch.nn.ReLU(inplace=True))
|
||||
modules.append(ORIGINAL_CONV2D(cond_emb_dim // 2, cond_emb_dim // 2, kernel_size=4, stride=4, padding=0))
|
||||
modules.append(torch.nn.ReLU(inplace=True))
|
||||
modules.append(ORIGINAL_CONV2D(cond_emb_dim // 2, cond_emb_dim, kernel_size=2, stride=2, padding=0))
|
||||
|
||||
module.lllite_conditioning1 = torch.nn.Sequential(*modules)
|
||||
|
||||
# downで入力の次元数を削減する。LoRAにヒントを得ていることにする
|
||||
# midでconditioning image embeddingと入力を結合する
|
||||
# upで元の次元数に戻す
|
||||
# これらはtimestepごとに呼ばれる
|
||||
# reduce the number of input dimensions with down. inspired by LoRA
|
||||
# combine conditioning image embedding and input with mid
|
||||
# restore to the original dimension with up
|
||||
# these are called for each timestep
|
||||
|
||||
module.lllite_down = torch.nn.Sequential(
|
||||
ORIGINAL_LINEAR(in_dim, mlp_dim),
|
||||
torch.nn.ReLU(inplace=True),
|
||||
)
|
||||
module.lllite_mid = torch.nn.Sequential(
|
||||
ORIGINAL_LINEAR(mlp_dim + cond_emb_dim, mlp_dim),
|
||||
torch.nn.ReLU(inplace=True),
|
||||
)
|
||||
module.lllite_up = torch.nn.Sequential(
|
||||
ORIGINAL_LINEAR(mlp_dim, in_dim),
|
||||
)
|
||||
|
||||
# Zero-Convにする / set to Zero-Conv
|
||||
torch.nn.init.zeros_(module.lllite_up[0].weight) # zero conv
|
||||
|
||||
|
||||
class LLLiteLinear(ORIGINAL_LINEAR):
|
||||
def __init__(self, in_features: int, out_features: int, **kwargs):
|
||||
super().__init__(in_features, out_features, **kwargs)
|
||||
self.enabled = False
|
||||
|
||||
def set_lllite(self, depth, cond_emb_dim, name, mlp_dim, dropout=None, multiplier=1.0):
|
||||
self.enabled = True
|
||||
self.lllite_name = name
|
||||
self.cond_emb_dim = cond_emb_dim
|
||||
self.dropout = dropout
|
||||
self.multiplier = multiplier # ignored
|
||||
|
||||
in_dim = self.in_features
|
||||
add_lllite_modules(self, in_dim, depth, cond_emb_dim, mlp_dim)
|
||||
|
||||
self.cond_image = None
|
||||
|
||||
def set_cond_image(self, cond_image):
|
||||
self.cond_image = cond_image
|
||||
|
||||
def forward(self, x):
|
||||
if not self.enabled:
|
||||
return super().forward(x)
|
||||
|
||||
cx = self.lllite_conditioning1(self.cond_image) # make forward and backward compatible
|
||||
|
||||
# reshape / b,c,h,w -> b,h*w,c
|
||||
n, c, h, w = cx.shape
|
||||
cx = cx.view(n, c, h * w).permute(0, 2, 1)
|
||||
|
||||
cx = torch.cat([cx, self.lllite_down(x)], dim=2)
|
||||
cx = self.lllite_mid(cx)
|
||||
|
||||
if self.dropout is not None and self.training:
|
||||
cx = torch.nn.functional.dropout(cx, p=self.dropout)
|
||||
|
||||
cx = self.lllite_up(cx) * self.multiplier
|
||||
|
||||
x = super().forward(x + cx) # ここで元のモジュールを呼び出す / call the original module here
|
||||
return x
|
||||
|
||||
|
||||
class LLLiteConv2d(ORIGINAL_CONV2D):
|
||||
def __init__(self, in_channels: int, out_channels: int, kernel_size, **kwargs):
|
||||
super().__init__(in_channels, out_channels, kernel_size, **kwargs)
|
||||
self.enabled = False
|
||||
|
||||
def set_lllite(self, depth, cond_emb_dim, name, mlp_dim, dropout=None, multiplier=1.0):
|
||||
self.enabled = True
|
||||
self.lllite_name = name
|
||||
self.cond_emb_dim = cond_emb_dim
|
||||
self.dropout = dropout
|
||||
self.multiplier = multiplier # ignored
|
||||
|
||||
in_dim = self.in_channels
|
||||
add_lllite_modules(self, in_dim, depth, cond_emb_dim, mlp_dim)
|
||||
|
||||
self.cond_image = None
|
||||
self.cond_emb = None
|
||||
|
||||
def set_cond_image(self, cond_image):
|
||||
self.cond_image = cond_image
|
||||
self.cond_emb = None
|
||||
|
||||
def forward(self, x): # , cond_image=None):
|
||||
if not self.enabled:
|
||||
return super().forward(x)
|
||||
|
||||
cx = self.lllite_conditioning1(self.cond_image)
|
||||
|
||||
cx = torch.cat([cx, self.down(x)], dim=1)
|
||||
cx = self.mid(cx)
|
||||
|
||||
if self.dropout is not None and self.training:
|
||||
cx = torch.nn.functional.dropout(cx, p=self.dropout)
|
||||
|
||||
cx = self.up(cx) * self.multiplier
|
||||
|
||||
x = super().forward(x + cx) # ここで元のモジュールを呼び出す / call the original module here
|
||||
return x
|
||||
|
||||
|
||||
class SdxlUNet2DConditionModelControlNetLLLite(sdxl_original_unet.SdxlUNet2DConditionModel):
|
||||
UNET_TARGET_REPLACE_MODULE = ["Transformer2DModel"]
|
||||
UNET_TARGET_REPLACE_MODULE_CONV2D_3X3 = ["ResnetBlock2D", "Downsample2D", "Upsample2D"]
|
||||
LLLITE_PREFIX = "lllite_unet"
|
||||
|
||||
def __init__(self, **kwargs):
|
||||
super().__init__(**kwargs)
|
||||
|
||||
def apply_lllite(
|
||||
self,
|
||||
cond_emb_dim: int = 16,
|
||||
mlp_dim: int = 16,
|
||||
dropout: Optional[float] = None,
|
||||
varbose: Optional[bool] = False,
|
||||
multiplier: Optional[float] = 1.0,
|
||||
) -> None:
|
||||
def apply_to_modules(
|
||||
root_module: torch.nn.Module,
|
||||
target_replace_modules: List[torch.nn.Module],
|
||||
) -> List[torch.nn.Module]:
|
||||
prefix = "lllite_unet"
|
||||
|
||||
modules = []
|
||||
for name, module in root_module.named_modules():
|
||||
if module.__class__.__name__ in target_replace_modules:
|
||||
for child_name, child_module in module.named_modules():
|
||||
is_linear = child_module.__class__.__name__ == "LLLiteLinear"
|
||||
is_conv2d = child_module.__class__.__name__ == "LLLiteConv2d"
|
||||
|
||||
if is_linear or (is_conv2d and not SKIP_CONV2D):
|
||||
# block indexからdepthを計算: depthはconditioningのサイズやチャネルを計算するのに使う
|
||||
# block index to depth: depth is using to calculate conditioning size and channels
|
||||
block_name, index1, index2 = (name + "." + child_name).split(".")[:3]
|
||||
index1 = int(index1)
|
||||
if block_name == "input_blocks":
|
||||
if SKIP_INPUT_BLOCKS:
|
||||
continue
|
||||
depth = 1 if index1 <= 2 else (2 if index1 <= 5 else 3)
|
||||
elif block_name == "middle_block":
|
||||
depth = 3
|
||||
elif block_name == "output_blocks":
|
||||
if SKIP_OUTPUT_BLOCKS:
|
||||
continue
|
||||
depth = 3 if index1 <= 2 else (2 if index1 <= 5 else 1)
|
||||
if int(index2) >= 2:
|
||||
depth -= 1
|
||||
else:
|
||||
raise NotImplementedError()
|
||||
|
||||
lllite_name = prefix + "." + name + "." + child_name
|
||||
lllite_name = lllite_name.replace(".", "_")
|
||||
|
||||
if TRANSFORMER_MAX_BLOCK_INDEX is not None:
|
||||
p = lllite_name.find("transformer_blocks")
|
||||
if p >= 0:
|
||||
tf_index = int(lllite_name[p:].split("_")[2])
|
||||
if tf_index > TRANSFORMER_MAX_BLOCK_INDEX:
|
||||
continue
|
||||
|
||||
# time embは適用外とする
|
||||
# attn2のconditioning (CLIPからの入力) はshapeが違うので適用できない
|
||||
# time emb is not applied
|
||||
# attn2 conditioning (input from CLIP) cannot be applied because the shape is different
|
||||
if "emb_layers" in lllite_name or (
|
||||
"attn2" in lllite_name and ("to_k" in lllite_name or "to_v" in lllite_name)
|
||||
):
|
||||
continue
|
||||
|
||||
if ATTN1_2_ONLY:
|
||||
if not ("attn1" in lllite_name or "attn2" in lllite_name):
|
||||
continue
|
||||
if ATTN_QKV_ONLY:
|
||||
if "to_out" in lllite_name:
|
||||
continue
|
||||
|
||||
if ATTN1_ETC_ONLY:
|
||||
if "proj_out" in lllite_name:
|
||||
pass
|
||||
elif "attn1" in lllite_name and (
|
||||
"to_k" in lllite_name or "to_v" in lllite_name or "to_out" in lllite_name
|
||||
):
|
||||
pass
|
||||
elif "ff_net_2" in lllite_name:
|
||||
pass
|
||||
else:
|
||||
continue
|
||||
|
||||
child_module.set_lllite(depth, cond_emb_dim, lllite_name, mlp_dim, dropout, multiplier)
|
||||
modules.append(child_module)
|
||||
|
||||
return modules
|
||||
|
||||
target_modules = SdxlUNet2DConditionModelControlNetLLLite.UNET_TARGET_REPLACE_MODULE
|
||||
if not TRANSFORMER_ONLY:
|
||||
target_modules = target_modules + SdxlUNet2DConditionModelControlNetLLLite.UNET_TARGET_REPLACE_MODULE_CONV2D_3X3
|
||||
|
||||
# create module instances
|
||||
self.lllite_modules = apply_to_modules(self, target_modules)
|
||||
logger.info(f"enable ControlNet LLLite for U-Net: {len(self.lllite_modules)} modules.")
|
||||
|
||||
# def prepare_optimizer_params(self):
|
||||
def prepare_params(self):
|
||||
train_params = []
|
||||
non_train_params = []
|
||||
for name, p in self.named_parameters():
|
||||
if "lllite" in name:
|
||||
train_params.append(p)
|
||||
else:
|
||||
non_train_params.append(p)
|
||||
logger.info(f"count of trainable parameters: {len(train_params)}")
|
||||
logger.info(f"count of non-trainable parameters: {len(non_train_params)}")
|
||||
|
||||
for p in non_train_params:
|
||||
p.requires_grad_(False)
|
||||
|
||||
# without this, an error occurs in the optimizer
|
||||
# RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
|
||||
non_train_params[0].requires_grad_(True)
|
||||
|
||||
for p in train_params:
|
||||
p.requires_grad_(True)
|
||||
|
||||
return train_params
|
||||
|
||||
# def prepare_grad_etc(self):
|
||||
# self.requires_grad_(True)
|
||||
|
||||
# def on_epoch_start(self):
|
||||
# self.train()
|
||||
|
||||
def get_trainable_params(self):
|
||||
return [p[1] for p in self.named_parameters() if "lllite" in p[0]]
|
||||
|
||||
def save_lllite_weights(self, file, dtype, metadata):
|
||||
if metadata is not None and len(metadata) == 0:
|
||||
metadata = None
|
||||
|
||||
org_state_dict = self.state_dict()
|
||||
|
||||
# copy LLLite keys from org_state_dict to state_dict with key conversion
|
||||
state_dict = {}
|
||||
for key in org_state_dict.keys():
|
||||
# split with ".lllite"
|
||||
pos = key.find(".lllite")
|
||||
if pos < 0:
|
||||
continue
|
||||
lllite_key = SdxlUNet2DConditionModelControlNetLLLite.LLLITE_PREFIX + "." + key[:pos]
|
||||
lllite_key = lllite_key.replace(".", "_") + key[pos:]
|
||||
lllite_key = lllite_key.replace(".lllite_", ".")
|
||||
state_dict[lllite_key] = org_state_dict[key]
|
||||
|
||||
if dtype is not None:
|
||||
for key in list(state_dict.keys()):
|
||||
v = state_dict[key]
|
||||
v = v.detach().clone().to("cpu").to(dtype)
|
||||
state_dict[key] = v
|
||||
|
||||
if os.path.splitext(file)[1] == ".safetensors":
|
||||
from safetensors.torch import save_file
|
||||
|
||||
save_file(state_dict, file, metadata)
|
||||
else:
|
||||
torch.save(state_dict, file)
|
||||
|
||||
def load_lllite_weights(self, file, non_lllite_unet_sd=None):
|
||||
r"""
|
||||
LLLiteの重みを読み込まない(initされた値を使う)場合はfileにNoneを指定する。
|
||||
この場合、non_lllite_unet_sdにはU-Netのstate_dictを指定する。
|
||||
|
||||
If you do not want to load LLLite weights (use initialized values), specify None for file.
|
||||
In this case, specify the state_dict of U-Net for non_lllite_unet_sd.
|
||||
"""
|
||||
if not file:
|
||||
state_dict = self.state_dict()
|
||||
for key in non_lllite_unet_sd:
|
||||
if key in state_dict:
|
||||
state_dict[key] = non_lllite_unet_sd[key]
|
||||
info = self.load_state_dict(state_dict, False)
|
||||
return info
|
||||
|
||||
if os.path.splitext(file)[1] == ".safetensors":
|
||||
from safetensors.torch import load_file
|
||||
|
||||
weights_sd = load_file(file)
|
||||
else:
|
||||
weights_sd = torch.load(file, map_location="cpu")
|
||||
|
||||
# module_name = module_name.replace("_block", "@blocks")
|
||||
# module_name = module_name.replace("_layer", "@layer")
|
||||
# module_name = module_name.replace("to_", "to@")
|
||||
# module_name = module_name.replace("time_embed", "time@embed")
|
||||
# module_name = module_name.replace("label_emb", "label@emb")
|
||||
# module_name = module_name.replace("skip_connection", "skip@connection")
|
||||
# module_name = module_name.replace("proj_in", "proj@in")
|
||||
# module_name = module_name.replace("proj_out", "proj@out")
|
||||
pattern = re.compile(r"(_block|_layer|to_|time_embed|label_emb|skip_connection|proj_in|proj_out)")
|
||||
|
||||
# convert to lllite with U-Net state dict
|
||||
state_dict = non_lllite_unet_sd.copy() if non_lllite_unet_sd is not None else {}
|
||||
for key in weights_sd.keys():
|
||||
# split with "."
|
||||
pos = key.find(".")
|
||||
if pos < 0:
|
||||
continue
|
||||
|
||||
module_name = key[:pos]
|
||||
weight_name = key[pos + 1 :] # exclude "."
|
||||
module_name = module_name.replace(SdxlUNet2DConditionModelControlNetLLLite.LLLITE_PREFIX + "_", "")
|
||||
|
||||
# これはうまくいかない。逆変換を考えなかった設計が悪い / this does not work well. bad design because I didn't think about inverse conversion
|
||||
# module_name = module_name.replace("_", ".")
|
||||
|
||||
# ださいけどSDXLのU-Netの "_" を "@" に変換する / ugly but convert "_" of SDXL U-Net to "@"
|
||||
matches = pattern.findall(module_name)
|
||||
if matches is not None:
|
||||
for m in matches:
|
||||
logger.info(f"{module_name} {m}")
|
||||
module_name = module_name.replace(m, m.replace("_", "@"))
|
||||
module_name = module_name.replace("_", ".")
|
||||
module_name = module_name.replace("@", "_")
|
||||
|
||||
lllite_key = module_name + ".lllite_" + weight_name
|
||||
|
||||
state_dict[lllite_key] = weights_sd[key]
|
||||
|
||||
info = self.load_state_dict(state_dict, False)
|
||||
return info
|
||||
|
||||
def forward(self, x, timesteps=None, context=None, y=None, cond_image=None, **kwargs):
|
||||
for m in self.lllite_modules:
|
||||
m.set_cond_image(cond_image)
|
||||
return super().forward(x, timesteps, context, y, **kwargs)
|
||||
|
||||
|
||||
def replace_unet_linear_and_conv2d():
|
||||
logger.info("replace torch.nn.Linear and torch.nn.Conv2d to LLLiteLinear and LLLiteConv2d in U-Net")
|
||||
sdxl_original_unet.torch.nn.Linear = LLLiteLinear
|
||||
sdxl_original_unet.torch.nn.Conv2d = LLLiteConv2d
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# デバッグ用 / for debug
|
||||
|
||||
# sdxl_original_unet.USE_REENTRANT = False
|
||||
replace_unet_linear_and_conv2d()
|
||||
|
||||
# test shape etc
|
||||
logger.info("create unet")
|
||||
unet = SdxlUNet2DConditionModelControlNetLLLite()
|
||||
|
||||
logger.info("enable ControlNet-LLLite")
|
||||
unet.apply_lllite(32, 64, None, False, 1.0)
|
||||
unet.to("cuda") # .to(torch.float16)
|
||||
|
||||
# from safetensors.torch import load_file
|
||||
|
||||
# model_sd = load_file(r"E:\Work\SD\Models\sdxl\sd_xl_base_1.0_0.9vae.safetensors")
|
||||
# unet_sd = {}
|
||||
|
||||
# # copy U-Net keys from unet_state_dict to state_dict
|
||||
# prefix = "model.diffusion_model."
|
||||
# for key in model_sd.keys():
|
||||
# if key.startswith(prefix):
|
||||
# converted_key = key[len(prefix) :]
|
||||
# unet_sd[converted_key] = model_sd[key]
|
||||
|
||||
# info = unet.load_lllite_weights("r:/lllite_from_unet.safetensors", unet_sd)
|
||||
# logger.info(info)
|
||||
|
||||
# logger.info(unet)
|
||||
|
||||
# logger.info number of parameters
|
||||
params = unet.prepare_params()
|
||||
logger.info(f"number of parameters {sum(p.numel() for p in params)}")
|
||||
# logger.info("type any key to continue")
|
||||
# input()
|
||||
|
||||
unet.set_use_memory_efficient_attention(True, False)
|
||||
unet.set_gradient_checkpointing(True)
|
||||
unet.train() # for gradient checkpointing
|
||||
|
||||
# # visualize
|
||||
# import torchviz
|
||||
# logger.info("run visualize")
|
||||
# controlnet.set_control(conditioning_image)
|
||||
# output = unet(x, t, ctx, y)
|
||||
# logger.info("make_dot")
|
||||
# image = torchviz.make_dot(output, params=dict(controlnet.named_parameters()))
|
||||
# logger.info("render")
|
||||
# image.format = "svg" # "png"
|
||||
# image.render("NeuralNet") # すごく時間がかかるので注意 / be careful because it takes a long time
|
||||
# input()
|
||||
|
||||
import bitsandbytes
|
||||
|
||||
optimizer = bitsandbytes.adam.Adam8bit(params, 1e-3)
|
||||
|
||||
scaler = torch.cuda.amp.GradScaler(enabled=True)
|
||||
|
||||
logger.info("start training")
|
||||
steps = 10
|
||||
batch_size = 1
|
||||
|
||||
sample_param = [p for p in unet.named_parameters() if ".lllite_up." in p[0]][0]
|
||||
for step in range(steps):
|
||||
logger.info(f"step {step}")
|
||||
|
||||
conditioning_image = torch.rand(batch_size, 3, 1024, 1024).cuda() * 2.0 - 1.0
|
||||
x = torch.randn(batch_size, 4, 128, 128).cuda()
|
||||
t = torch.randint(low=0, high=10, size=(batch_size,)).cuda()
|
||||
ctx = torch.randn(batch_size, 77, 2048).cuda()
|
||||
y = torch.randn(batch_size, sdxl_original_unet.ADM_IN_CHANNELS).cuda()
|
||||
|
||||
with torch.cuda.amp.autocast(enabled=True, dtype=torch.bfloat16):
|
||||
output = unet(x, t, ctx, y, conditioning_image)
|
||||
target = torch.randn_like(output)
|
||||
loss = torch.nn.functional.mse_loss(output, target)
|
||||
|
||||
scaler.scale(loss).backward()
|
||||
scaler.step(optimizer)
|
||||
scaler.update()
|
||||
optimizer.zero_grad(set_to_none=True)
|
||||
logger.info(sample_param)
|
||||
|
||||
# from safetensors.torch import save_file
|
||||
|
||||
# logger.info("save weights")
|
||||
# unet.save_lllite_weights("r:/lllite_from_unet.safetensors", torch.float16, None)
|
||||
@@ -12,9 +12,17 @@
|
||||
import math
|
||||
import os
|
||||
import random
|
||||
from typing import List, Tuple, Union
|
||||
from typing import Dict, List, Optional, Tuple, Type, Union
|
||||
from diffusers import AutoencoderKL
|
||||
from transformers import CLIPTextModel
|
||||
import torch
|
||||
from torch import nn
|
||||
from library.utils import setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
class DyLoRAModule(torch.nn.Module):
|
||||
@@ -165,7 +173,15 @@ class DyLoRAModule(torch.nn.Module):
|
||||
super()._load_from_state_dict(state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs)
|
||||
|
||||
|
||||
def create_network(multiplier, network_dim, network_alpha, vae, text_encoder, unet, **kwargs):
|
||||
def create_network(
|
||||
multiplier: float,
|
||||
network_dim: Optional[int],
|
||||
network_alpha: Optional[float],
|
||||
vae: AutoencoderKL,
|
||||
text_encoder: Union[CLIPTextModel, List[CLIPTextModel]],
|
||||
unet,
|
||||
**kwargs,
|
||||
):
|
||||
if network_dim is None:
|
||||
network_dim = 4 # default
|
||||
if network_alpha is None:
|
||||
@@ -182,6 +198,7 @@ def create_network(multiplier, network_dim, network_alpha, vae, text_encoder, un
|
||||
conv_alpha = 1.0
|
||||
else:
|
||||
conv_alpha = float(conv_alpha)
|
||||
|
||||
if unit is not None:
|
||||
unit = int(unit)
|
||||
else:
|
||||
@@ -197,6 +214,16 @@ def create_network(multiplier, network_dim, network_alpha, vae, text_encoder, un
|
||||
unit=unit,
|
||||
varbose=True,
|
||||
)
|
||||
|
||||
loraplus_lr_ratio = kwargs.get("loraplus_lr_ratio", None)
|
||||
loraplus_unet_lr_ratio = kwargs.get("loraplus_unet_lr_ratio", None)
|
||||
loraplus_text_encoder_lr_ratio = kwargs.get("loraplus_text_encoder_lr_ratio", None)
|
||||
loraplus_lr_ratio = float(loraplus_lr_ratio) if loraplus_lr_ratio is not None else None
|
||||
loraplus_unet_lr_ratio = float(loraplus_unet_lr_ratio) if loraplus_unet_lr_ratio is not None else None
|
||||
loraplus_text_encoder_lr_ratio = float(loraplus_text_encoder_lr_ratio) if loraplus_text_encoder_lr_ratio is not None else None
|
||||
if loraplus_lr_ratio is not None or loraplus_unet_lr_ratio is not None or loraplus_text_encoder_lr_ratio is not None:
|
||||
network.set_loraplus_lr_ratio(loraplus_lr_ratio, loraplus_unet_lr_ratio, loraplus_text_encoder_lr_ratio)
|
||||
|
||||
return network
|
||||
|
||||
|
||||
@@ -223,7 +250,7 @@ def create_network_from_weights(multiplier, file, vae, text_encoder, unet, weigh
|
||||
elif "lora_down" in key:
|
||||
dim = value.size()[0]
|
||||
modules_dim[lora_name] = dim
|
||||
# print(lora_name, value.size(), dim)
|
||||
# logger.info(f"{lora_name} {value.size()} {dim}")
|
||||
|
||||
# support old LoRA without alpha
|
||||
for key in modules_dim.keys():
|
||||
@@ -239,9 +266,9 @@ def create_network_from_weights(multiplier, file, vae, text_encoder, unet, weigh
|
||||
|
||||
|
||||
class DyLoRANetwork(torch.nn.Module):
|
||||
UNET_TARGET_REPLACE_MODULE = ["Transformer2DModel", "Attention"]
|
||||
UNET_TARGET_REPLACE_MODULE = ["Transformer2DModel"]
|
||||
UNET_TARGET_REPLACE_MODULE_CONV2D_3X3 = ["ResnetBlock2D", "Downsample2D", "Upsample2D"]
|
||||
TEXT_ENCODER_TARGET_REPLACE_MODULE = ["CLIPAttention", "CLIPMLP"]
|
||||
TEXT_ENCODER_TARGET_REPLACE_MODULE = ["CLIPAttention", "CLIPSdpaAttention", "CLIPMLP"]
|
||||
LORA_PREFIX_UNET = "lora_unet"
|
||||
LORA_PREFIX_TEXT_ENCODER = "lora_te"
|
||||
|
||||
@@ -266,12 +293,16 @@ class DyLoRANetwork(torch.nn.Module):
|
||||
self.alpha = alpha
|
||||
self.apply_to_conv = apply_to_conv
|
||||
|
||||
self.loraplus_lr_ratio = None
|
||||
self.loraplus_unet_lr_ratio = None
|
||||
self.loraplus_text_encoder_lr_ratio = None
|
||||
|
||||
if modules_dim is not None:
|
||||
print(f"create LoRA network from weights")
|
||||
logger.info("create LoRA network from weights")
|
||||
else:
|
||||
print(f"create LoRA network. base dim (rank): {lora_dim}, alpha: {alpha}, unit: {unit}")
|
||||
logger.info(f"create LoRA network. base dim (rank): {lora_dim}, alpha: {alpha}, unit: {unit}")
|
||||
if self.apply_to_conv:
|
||||
print(f"apply LoRA to Conv2d with kernel size (3,3).")
|
||||
logger.info("apply LoRA to Conv2d with kernel size (3,3).")
|
||||
|
||||
# create module instances
|
||||
def create_modules(is_unet, root_module: torch.nn.Module, target_replace_modules) -> List[DyLoRAModule]:
|
||||
@@ -307,8 +338,22 @@ class DyLoRANetwork(torch.nn.Module):
|
||||
loras.append(lora)
|
||||
return loras
|
||||
|
||||
self.text_encoder_loras = create_modules(False, text_encoder, DyLoRANetwork.TEXT_ENCODER_TARGET_REPLACE_MODULE)
|
||||
print(f"create LoRA for Text Encoder: {len(self.text_encoder_loras)} modules.")
|
||||
text_encoders = text_encoder if type(text_encoder) == list else [text_encoder]
|
||||
|
||||
self.text_encoder_loras = []
|
||||
for i, text_encoder in enumerate(text_encoders):
|
||||
if len(text_encoders) > 1:
|
||||
index = i + 1
|
||||
logger.info(f"create LoRA for Text Encoder {index}")
|
||||
else:
|
||||
index = None
|
||||
logger.info("create LoRA for Text Encoder")
|
||||
|
||||
text_encoder_loras = create_modules(False, text_encoder, DyLoRANetwork.TEXT_ENCODER_TARGET_REPLACE_MODULE)
|
||||
self.text_encoder_loras.extend(text_encoder_loras)
|
||||
|
||||
# self.text_encoder_loras = create_modules(False, text_encoder, DyLoRANetwork.TEXT_ENCODER_TARGET_REPLACE_MODULE)
|
||||
logger.info(f"create LoRA for Text Encoder: {len(self.text_encoder_loras)} modules.")
|
||||
|
||||
# extend U-Net target modules if conv2d 3x3 is enabled, or load from weights
|
||||
target_modules = DyLoRANetwork.UNET_TARGET_REPLACE_MODULE
|
||||
@@ -316,7 +361,15 @@ class DyLoRANetwork(torch.nn.Module):
|
||||
target_modules += DyLoRANetwork.UNET_TARGET_REPLACE_MODULE_CONV2D_3X3
|
||||
|
||||
self.unet_loras = create_modules(True, unet, target_modules)
|
||||
print(f"create LoRA for U-Net: {len(self.unet_loras)} modules.")
|
||||
logger.info(f"create LoRA for U-Net: {len(self.unet_loras)} modules.")
|
||||
|
||||
def set_loraplus_lr_ratio(self, loraplus_lr_ratio, loraplus_unet_lr_ratio, loraplus_text_encoder_lr_ratio):
|
||||
self.loraplus_lr_ratio = loraplus_lr_ratio
|
||||
self.loraplus_unet_lr_ratio = loraplus_unet_lr_ratio
|
||||
self.loraplus_text_encoder_lr_ratio = loraplus_text_encoder_lr_ratio
|
||||
|
||||
logger.info(f"LoRA+ UNet LR Ratio: {self.loraplus_unet_lr_ratio or self.loraplus_lr_ratio}")
|
||||
logger.info(f"LoRA+ Text Encoder LR Ratio: {self.loraplus_text_encoder_lr_ratio or self.loraplus_lr_ratio}")
|
||||
|
||||
def set_multiplier(self, multiplier):
|
||||
self.multiplier = multiplier
|
||||
@@ -336,12 +389,12 @@ class DyLoRANetwork(torch.nn.Module):
|
||||
|
||||
def apply_to(self, text_encoder, unet, apply_text_encoder=True, apply_unet=True):
|
||||
if apply_text_encoder:
|
||||
print("enable LoRA for text encoder")
|
||||
logger.info("enable LoRA for text encoder")
|
||||
else:
|
||||
self.text_encoder_loras = []
|
||||
|
||||
if apply_unet:
|
||||
print("enable LoRA for U-Net")
|
||||
logger.info("enable LoRA for U-Net")
|
||||
else:
|
||||
self.unet_loras = []
|
||||
|
||||
@@ -359,12 +412,12 @@ class DyLoRANetwork(torch.nn.Module):
|
||||
apply_unet = True
|
||||
|
||||
if apply_text_encoder:
|
||||
print("enable LoRA for text encoder")
|
||||
logger.info("enable LoRA for text encoder")
|
||||
else:
|
||||
self.text_encoder_loras = []
|
||||
|
||||
if apply_unet:
|
||||
print("enable LoRA for U-Net")
|
||||
logger.info("enable LoRA for U-Net")
|
||||
else:
|
||||
self.unet_loras = []
|
||||
|
||||
@@ -375,30 +428,56 @@ class DyLoRANetwork(torch.nn.Module):
|
||||
sd_for_lora[key[len(lora.lora_name) + 1 :]] = weights_sd[key]
|
||||
lora.merge_to(sd_for_lora, dtype, device)
|
||||
|
||||
print(f"weights are merged")
|
||||
logger.info(f"weights are merged")
|
||||
"""
|
||||
|
||||
# 二つのText Encoderに別々の学習率を設定できるようにするといいかも
|
||||
def prepare_optimizer_params(self, text_encoder_lr, unet_lr, default_lr):
|
||||
self.requires_grad_(True)
|
||||
all_params = []
|
||||
|
||||
def enumerate_params(loras):
|
||||
params = []
|
||||
def assemble_params(loras, lr, ratio):
|
||||
param_groups = {"lora": {}, "plus": {}}
|
||||
for lora in loras:
|
||||
params.extend(lora.parameters())
|
||||
for name, param in lora.named_parameters():
|
||||
if ratio is not None and "lora_B" in name:
|
||||
param_groups["plus"][f"{lora.lora_name}.{name}"] = param
|
||||
else:
|
||||
param_groups["lora"][f"{lora.lora_name}.{name}"] = param
|
||||
|
||||
params = []
|
||||
for key in param_groups.keys():
|
||||
param_data = {"params": param_groups[key].values()}
|
||||
|
||||
if len(param_data["params"]) == 0:
|
||||
continue
|
||||
|
||||
if lr is not None:
|
||||
if key == "plus":
|
||||
param_data["lr"] = lr * ratio
|
||||
else:
|
||||
param_data["lr"] = lr
|
||||
|
||||
if param_data.get("lr", None) == 0 or param_data.get("lr", None) is None:
|
||||
continue
|
||||
|
||||
params.append(param_data)
|
||||
|
||||
return params
|
||||
|
||||
if self.text_encoder_loras:
|
||||
param_data = {"params": enumerate_params(self.text_encoder_loras)}
|
||||
if text_encoder_lr is not None:
|
||||
param_data["lr"] = text_encoder_lr
|
||||
all_params.append(param_data)
|
||||
params = assemble_params(
|
||||
self.text_encoder_loras,
|
||||
text_encoder_lr if text_encoder_lr is not None else default_lr,
|
||||
self.loraplus_text_encoder_lr_ratio or self.loraplus_lr_ratio,
|
||||
)
|
||||
all_params.extend(params)
|
||||
|
||||
if self.unet_loras:
|
||||
param_data = {"params": enumerate_params(self.unet_loras)}
|
||||
if unet_lr is not None:
|
||||
param_data["lr"] = unet_lr
|
||||
all_params.append(param_data)
|
||||
params = assemble_params(
|
||||
self.unet_loras, default_lr if unet_lr is None else unet_lr, self.loraplus_unet_lr_ratio or self.loraplus_lr_ratio
|
||||
)
|
||||
all_params.extend(params)
|
||||
|
||||
return all_params
|
||||
|
||||
|
||||
@@ -10,7 +10,10 @@ from safetensors.torch import load_file, save_file, safe_open
|
||||
from tqdm import tqdm
|
||||
from library import train_util, model_util
|
||||
import numpy as np
|
||||
|
||||
from library.utils import setup_logging
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
def load_state_dict(file_name):
|
||||
if model_util.is_safetensors(file_name):
|
||||
@@ -40,13 +43,13 @@ def split_lora_model(lora_sd, unit):
|
||||
rank = value.size()[0]
|
||||
if rank > max_rank:
|
||||
max_rank = rank
|
||||
print(f"Max rank: {max_rank}")
|
||||
logger.info(f"Max rank: {max_rank}")
|
||||
|
||||
rank = unit
|
||||
split_models = []
|
||||
new_alpha = None
|
||||
while rank < max_rank:
|
||||
print(f"Splitting rank {rank}")
|
||||
logger.info(f"Splitting rank {rank}")
|
||||
new_sd = {}
|
||||
for key, value in lora_sd.items():
|
||||
if "lora_down" in key:
|
||||
@@ -57,7 +60,7 @@ def split_lora_model(lora_sd, unit):
|
||||
# なぜかscaleするとおかしくなる……
|
||||
# this_rank = lora_sd[key.replace("alpha", "lora_down.weight")].size()[0]
|
||||
# scale = math.sqrt(this_rank / rank) # rank is > unit
|
||||
# print(key, value.size(), this_rank, rank, value, scale)
|
||||
# logger.info(key, value.size(), this_rank, rank, value, scale)
|
||||
# new_alpha = value * scale # always same
|
||||
# new_sd[key] = new_alpha
|
||||
new_sd[key] = value
|
||||
@@ -69,10 +72,10 @@ def split_lora_model(lora_sd, unit):
|
||||
|
||||
|
||||
def split(args):
|
||||
print("loading Model...")
|
||||
logger.info("loading Model...")
|
||||
lora_sd, metadata = load_state_dict(args.model)
|
||||
|
||||
print("Splitting Model...")
|
||||
logger.info("Splitting Model...")
|
||||
original_rank, split_models = split_lora_model(lora_sd, args.unit)
|
||||
|
||||
comment = metadata.get("ss_training_comment", "")
|
||||
@@ -94,7 +97,7 @@ def split(args):
|
||||
filename, ext = os.path.splitext(args.save_to)
|
||||
model_file_name = filename + f"-{new_rank:04d}{ext}"
|
||||
|
||||
print(f"saving model to: {model_file_name}")
|
||||
logger.info(f"saving model to: {model_file_name}")
|
||||
save_to_file(model_file_name, state_dict, new_metadata)
|
||||
|
||||
|
||||
|
||||
@@ -3,187 +3,358 @@
|
||||
# Thanks to cloneofsimo!
|
||||
|
||||
import argparse
|
||||
import json
|
||||
import os
|
||||
import time
|
||||
import torch
|
||||
from safetensors.torch import load_file, save_file
|
||||
from tqdm import tqdm
|
||||
import library.model_util as model_util
|
||||
from library import sai_model_spec, model_util, sdxl_model_util
|
||||
import lora
|
||||
from library.utils import setup_logging
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
CLAMP_QUANTILE = 0.99
|
||||
MIN_DIFF = 1e-6
|
||||
# CLAMP_QUANTILE = 0.99
|
||||
# MIN_DIFF = 1e-1
|
||||
|
||||
|
||||
def save_to_file(file_name, model, state_dict, dtype):
|
||||
if dtype is not None:
|
||||
for key in list(state_dict.keys()):
|
||||
if type(state_dict[key]) == torch.Tensor:
|
||||
state_dict[key] = state_dict[key].to(dtype)
|
||||
if dtype is not None:
|
||||
for key in list(state_dict.keys()):
|
||||
if type(state_dict[key]) == torch.Tensor:
|
||||
state_dict[key] = state_dict[key].to(dtype)
|
||||
|
||||
if os.path.splitext(file_name)[1] == '.safetensors':
|
||||
save_file(model, file_name)
|
||||
else:
|
||||
torch.save(model, file_name)
|
||||
if os.path.splitext(file_name)[1] == ".safetensors":
|
||||
save_file(model, file_name)
|
||||
else:
|
||||
torch.save(model, file_name)
|
||||
|
||||
|
||||
def svd(args):
|
||||
def str_to_dtype(p):
|
||||
if p == 'float':
|
||||
return torch.float
|
||||
if p == 'fp16':
|
||||
return torch.float16
|
||||
if p == 'bf16':
|
||||
return torch.bfloat16
|
||||
return None
|
||||
def svd(
|
||||
model_org=None,
|
||||
model_tuned=None,
|
||||
save_to=None,
|
||||
dim=4,
|
||||
v2=None,
|
||||
sdxl=None,
|
||||
conv_dim=None,
|
||||
v_parameterization=None,
|
||||
device=None,
|
||||
save_precision=None,
|
||||
clamp_quantile=0.99,
|
||||
min_diff=0.01,
|
||||
no_metadata=False,
|
||||
load_precision=None,
|
||||
load_original_model_to=None,
|
||||
load_tuned_model_to=None,
|
||||
):
|
||||
def str_to_dtype(p):
|
||||
if p == "float":
|
||||
return torch.float
|
||||
if p == "fp16":
|
||||
return torch.float16
|
||||
if p == "bf16":
|
||||
return torch.bfloat16
|
||||
return None
|
||||
|
||||
save_dtype = str_to_dtype(args.save_precision)
|
||||
assert v2 != sdxl or (not v2 and not sdxl), "v2 and sdxl cannot be specified at the same time / v2とsdxlは同時に指定できません"
|
||||
if v_parameterization is None:
|
||||
v_parameterization = v2
|
||||
|
||||
print(f"loading SD model : {args.model_org}")
|
||||
text_encoder_o, _, unet_o = model_util.load_models_from_stable_diffusion_checkpoint(args.v2, args.model_org)
|
||||
print(f"loading SD model : {args.model_tuned}")
|
||||
text_encoder_t, _, unet_t = model_util.load_models_from_stable_diffusion_checkpoint(args.v2, args.model_tuned)
|
||||
load_dtype = str_to_dtype(load_precision) if load_precision else None
|
||||
save_dtype = str_to_dtype(save_precision)
|
||||
work_device = "cpu"
|
||||
|
||||
# create LoRA network to extract weights: Use dim (rank) as alpha
|
||||
if args.conv_dim is None:
|
||||
kwargs = {}
|
||||
else:
|
||||
kwargs = {"conv_dim": args.conv_dim, "conv_alpha": args.conv_dim}
|
||||
# load models
|
||||
if not sdxl:
|
||||
logger.info(f"loading original SD model : {model_org}")
|
||||
text_encoder_o, _, unet_o = model_util.load_models_from_stable_diffusion_checkpoint(v2, model_org)
|
||||
text_encoders_o = [text_encoder_o]
|
||||
if load_dtype is not None:
|
||||
text_encoder_o = text_encoder_o.to(load_dtype)
|
||||
unet_o = unet_o.to(load_dtype)
|
||||
|
||||
lora_network_o = lora.create_network(1.0, args.dim, args.dim, None, text_encoder_o, unet_o, **kwargs)
|
||||
lora_network_t = lora.create_network(1.0, args.dim, args.dim, None, text_encoder_t, unet_t, **kwargs)
|
||||
assert len(lora_network_o.text_encoder_loras) == len(
|
||||
lora_network_t.text_encoder_loras), f"model version is different (SD1.x vs SD2.x) / それぞれのモデルのバージョンが違います(SD1.xベースとSD2.xベース) "
|
||||
logger.info(f"loading tuned SD model : {model_tuned}")
|
||||
text_encoder_t, _, unet_t = model_util.load_models_from_stable_diffusion_checkpoint(v2, model_tuned)
|
||||
text_encoders_t = [text_encoder_t]
|
||||
if load_dtype is not None:
|
||||
text_encoder_t = text_encoder_t.to(load_dtype)
|
||||
unet_t = unet_t.to(load_dtype)
|
||||
|
||||
# get diffs
|
||||
diffs = {}
|
||||
text_encoder_different = False
|
||||
for i, (lora_o, lora_t) in enumerate(zip(lora_network_o.text_encoder_loras, lora_network_t.text_encoder_loras)):
|
||||
lora_name = lora_o.lora_name
|
||||
module_o = lora_o.org_module
|
||||
module_t = lora_t.org_module
|
||||
diff = module_t.weight - module_o.weight
|
||||
model_version = model_util.get_model_version_str_for_sd1_sd2(v2, v_parameterization)
|
||||
else:
|
||||
device_org = load_original_model_to if load_original_model_to else "cpu"
|
||||
device_tuned = load_tuned_model_to if load_tuned_model_to else "cpu"
|
||||
|
||||
# Text Encoder might be same
|
||||
if torch.max(torch.abs(diff)) > MIN_DIFF:
|
||||
text_encoder_different = True
|
||||
logger.info(f"loading original SDXL model : {model_org}")
|
||||
text_encoder_o1, text_encoder_o2, _, unet_o, _, _ = sdxl_model_util.load_models_from_sdxl_checkpoint(
|
||||
sdxl_model_util.MODEL_VERSION_SDXL_BASE_V1_0, model_org, device_org
|
||||
)
|
||||
text_encoders_o = [text_encoder_o1, text_encoder_o2]
|
||||
if load_dtype is not None:
|
||||
text_encoder_o1 = text_encoder_o1.to(load_dtype)
|
||||
text_encoder_o2 = text_encoder_o2.to(load_dtype)
|
||||
unet_o = unet_o.to(load_dtype)
|
||||
|
||||
diff = diff.float()
|
||||
diffs[lora_name] = diff
|
||||
logger.info(f"loading original SDXL model : {model_tuned}")
|
||||
text_encoder_t1, text_encoder_t2, _, unet_t, _, _ = sdxl_model_util.load_models_from_sdxl_checkpoint(
|
||||
sdxl_model_util.MODEL_VERSION_SDXL_BASE_V1_0, model_tuned, device_tuned
|
||||
)
|
||||
text_encoders_t = [text_encoder_t1, text_encoder_t2]
|
||||
if load_dtype is not None:
|
||||
text_encoder_t1 = text_encoder_t1.to(load_dtype)
|
||||
text_encoder_t2 = text_encoder_t2.to(load_dtype)
|
||||
unet_t = unet_t.to(load_dtype)
|
||||
|
||||
if not text_encoder_different:
|
||||
print("Text encoder is same. Extract U-Net only.")
|
||||
lora_network_o.text_encoder_loras = []
|
||||
model_version = sdxl_model_util.MODEL_VERSION_SDXL_BASE_V1_0
|
||||
|
||||
# create LoRA network to extract weights: Use dim (rank) as alpha
|
||||
if conv_dim is None:
|
||||
kwargs = {}
|
||||
else:
|
||||
kwargs = {"conv_dim": conv_dim, "conv_alpha": conv_dim}
|
||||
|
||||
lora_network_o = lora.create_network(1.0, dim, dim, None, text_encoders_o, unet_o, **kwargs)
|
||||
lora_network_t = lora.create_network(1.0, dim, dim, None, text_encoders_t, unet_t, **kwargs)
|
||||
assert len(lora_network_o.text_encoder_loras) == len(
|
||||
lora_network_t.text_encoder_loras
|
||||
), f"model version is different (SD1.x vs SD2.x) / それぞれのモデルのバージョンが違います(SD1.xベースとSD2.xベース) "
|
||||
|
||||
# get diffs
|
||||
diffs = {}
|
||||
text_encoder_different = False
|
||||
for i, (lora_o, lora_t) in enumerate(zip(lora_network_o.text_encoder_loras, lora_network_t.text_encoder_loras)):
|
||||
lora_name = lora_o.lora_name
|
||||
module_o = lora_o.org_module
|
||||
module_t = lora_t.org_module
|
||||
diff = module_t.weight.to(work_device) - module_o.weight.to(work_device)
|
||||
|
||||
for i, (lora_o, lora_t) in enumerate(zip(lora_network_o.unet_loras, lora_network_t.unet_loras)):
|
||||
lora_name = lora_o.lora_name
|
||||
module_o = lora_o.org_module
|
||||
module_t = lora_t.org_module
|
||||
diff = module_t.weight - module_o.weight
|
||||
diff = diff.float()
|
||||
# clear weight to save memory
|
||||
module_o.weight = None
|
||||
module_t.weight = None
|
||||
|
||||
if args.device:
|
||||
diff = diff.to(args.device)
|
||||
# Text Encoder might be same
|
||||
if not text_encoder_different and torch.max(torch.abs(diff)) > min_diff:
|
||||
text_encoder_different = True
|
||||
logger.info(f"Text encoder is different. {torch.max(torch.abs(diff))} > {min_diff}")
|
||||
|
||||
diffs[lora_name] = diff
|
||||
diffs[lora_name] = diff
|
||||
|
||||
# make LoRA with svd
|
||||
print("calculating by svd")
|
||||
lora_weights = {}
|
||||
with torch.no_grad():
|
||||
for lora_name, mat in tqdm(list(diffs.items())):
|
||||
# if args.conv_dim is None, diffs do not include LoRAs for conv2d-3x3
|
||||
conv2d = (len(mat.size()) == 4)
|
||||
kernel_size = None if not conv2d else mat.size()[2:4]
|
||||
conv2d_3x3 = conv2d and kernel_size != (1, 1)
|
||||
# clear target Text Encoder to save memory
|
||||
for text_encoder in text_encoders_t:
|
||||
del text_encoder
|
||||
|
||||
rank = args.dim if not conv2d_3x3 or args.conv_dim is None else args.conv_dim
|
||||
out_dim, in_dim = mat.size()[0:2]
|
||||
if not text_encoder_different:
|
||||
logger.warning("Text encoder is same. Extract U-Net only.")
|
||||
lora_network_o.text_encoder_loras = []
|
||||
diffs = {} # clear diffs
|
||||
|
||||
if args.device:
|
||||
mat = mat.to(args.device)
|
||||
for i, (lora_o, lora_t) in enumerate(zip(lora_network_o.unet_loras, lora_network_t.unet_loras)):
|
||||
lora_name = lora_o.lora_name
|
||||
module_o = lora_o.org_module
|
||||
module_t = lora_t.org_module
|
||||
diff = module_t.weight.to(work_device) - module_o.weight.to(work_device)
|
||||
|
||||
# print(lora_name, mat.size(), mat.device, rank, in_dim, out_dim)
|
||||
rank = min(rank, in_dim, out_dim) # LoRA rank cannot exceed the original dim
|
||||
# clear weight to save memory
|
||||
module_o.weight = None
|
||||
module_t.weight = None
|
||||
|
||||
if conv2d:
|
||||
if conv2d_3x3:
|
||||
mat = mat.flatten(start_dim=1)
|
||||
else:
|
||||
mat = mat.squeeze()
|
||||
diffs[lora_name] = diff
|
||||
|
||||
U, S, Vh = torch.linalg.svd(mat)
|
||||
# clear LoRA network, target U-Net to save memory
|
||||
del lora_network_o
|
||||
del lora_network_t
|
||||
del unet_t
|
||||
|
||||
U = U[:, :rank]
|
||||
S = S[:rank]
|
||||
U = U @ torch.diag(S)
|
||||
# make LoRA with svd
|
||||
logger.info("calculating by svd")
|
||||
lora_weights = {}
|
||||
with torch.no_grad():
|
||||
for lora_name, mat in tqdm(list(diffs.items())):
|
||||
if args.device:
|
||||
mat = mat.to(args.device)
|
||||
mat = mat.to(torch.float) # calc by float
|
||||
|
||||
Vh = Vh[:rank, :]
|
||||
# if conv_dim is None, diffs do not include LoRAs for conv2d-3x3
|
||||
conv2d = len(mat.size()) == 4
|
||||
kernel_size = None if not conv2d else mat.size()[2:4]
|
||||
conv2d_3x3 = conv2d and kernel_size != (1, 1)
|
||||
|
||||
dist = torch.cat([U.flatten(), Vh.flatten()])
|
||||
hi_val = torch.quantile(dist, CLAMP_QUANTILE)
|
||||
low_val = -hi_val
|
||||
rank = dim if not conv2d_3x3 or conv_dim is None else conv_dim
|
||||
out_dim, in_dim = mat.size()[0:2]
|
||||
|
||||
U = U.clamp(low_val, hi_val)
|
||||
Vh = Vh.clamp(low_val, hi_val)
|
||||
if device:
|
||||
mat = mat.to(device)
|
||||
|
||||
if conv2d:
|
||||
U = U.reshape(out_dim, rank, 1, 1)
|
||||
Vh = Vh.reshape(rank, in_dim, kernel_size[0], kernel_size[1])
|
||||
# logger.info(lora_name, mat.size(), mat.device, rank, in_dim, out_dim)
|
||||
rank = min(rank, in_dim, out_dim) # LoRA rank cannot exceed the original dim
|
||||
|
||||
U = U.to("cpu").contiguous()
|
||||
Vh = Vh.to("cpu").contiguous()
|
||||
if conv2d:
|
||||
if conv2d_3x3:
|
||||
mat = mat.flatten(start_dim=1)
|
||||
else:
|
||||
mat = mat.squeeze()
|
||||
|
||||
lora_weights[lora_name] = (U, Vh)
|
||||
U, S, Vh = torch.linalg.svd(mat)
|
||||
|
||||
# make state dict for LoRA
|
||||
lora_sd = {}
|
||||
for lora_name, (up_weight, down_weight) in lora_weights.items():
|
||||
lora_sd[lora_name + '.lora_up.weight'] = up_weight
|
||||
lora_sd[lora_name + '.lora_down.weight'] = down_weight
|
||||
lora_sd[lora_name + '.alpha'] = torch.tensor(down_weight.size()[0])
|
||||
U = U[:, :rank]
|
||||
S = S[:rank]
|
||||
U = U @ torch.diag(S)
|
||||
|
||||
# load state dict to LoRA and save it
|
||||
lora_network_save, lora_sd = lora.create_network_from_weights(1.0, None, None, text_encoder_o, unet_o, weights_sd=lora_sd)
|
||||
lora_network_save.apply_to(text_encoder_o, unet_o) # create internal module references for state_dict
|
||||
Vh = Vh[:rank, :]
|
||||
|
||||
info = lora_network_save.load_state_dict(lora_sd)
|
||||
print(f"Loading extracted LoRA weights: {info}")
|
||||
dist = torch.cat([U.flatten(), Vh.flatten()])
|
||||
hi_val = torch.quantile(dist, clamp_quantile)
|
||||
low_val = -hi_val
|
||||
|
||||
dir_name = os.path.dirname(args.save_to)
|
||||
if dir_name and not os.path.exists(dir_name):
|
||||
os.makedirs(dir_name, exist_ok=True)
|
||||
U = U.clamp(low_val, hi_val)
|
||||
Vh = Vh.clamp(low_val, hi_val)
|
||||
|
||||
# minimum metadata
|
||||
metadata = {"ss_network_module": "networks.lora", "ss_network_dim": str(args.dim), "ss_network_alpha": str(args.dim)}
|
||||
if conv2d:
|
||||
U = U.reshape(out_dim, rank, 1, 1)
|
||||
Vh = Vh.reshape(rank, in_dim, kernel_size[0], kernel_size[1])
|
||||
|
||||
lora_network_save.save_weights(args.save_to, save_dtype, metadata)
|
||||
print(f"LoRA weights are saved to: {args.save_to}")
|
||||
U = U.to(work_device, dtype=save_dtype).contiguous()
|
||||
Vh = Vh.to(work_device, dtype=save_dtype).contiguous()
|
||||
|
||||
lora_weights[lora_name] = (U, Vh)
|
||||
|
||||
# make state dict for LoRA
|
||||
lora_sd = {}
|
||||
for lora_name, (up_weight, down_weight) in lora_weights.items():
|
||||
lora_sd[lora_name + ".lora_up.weight"] = up_weight
|
||||
lora_sd[lora_name + ".lora_down.weight"] = down_weight
|
||||
lora_sd[lora_name + ".alpha"] = torch.tensor(down_weight.size()[0])
|
||||
|
||||
# load state dict to LoRA and save it
|
||||
lora_network_save, lora_sd = lora.create_network_from_weights(1.0, None, None, text_encoders_o, unet_o, weights_sd=lora_sd)
|
||||
lora_network_save.apply_to(text_encoders_o, unet_o) # create internal module references for state_dict
|
||||
|
||||
info = lora_network_save.load_state_dict(lora_sd)
|
||||
logger.info(f"Loading extracted LoRA weights: {info}")
|
||||
|
||||
dir_name = os.path.dirname(save_to)
|
||||
if dir_name and not os.path.exists(dir_name):
|
||||
os.makedirs(dir_name, exist_ok=True)
|
||||
|
||||
# minimum metadata
|
||||
net_kwargs = {}
|
||||
if conv_dim is not None:
|
||||
net_kwargs["conv_dim"] = str(conv_dim)
|
||||
net_kwargs["conv_alpha"] = str(float(conv_dim))
|
||||
|
||||
metadata = {
|
||||
"ss_v2": str(v2),
|
||||
"ss_base_model_version": model_version,
|
||||
"ss_network_module": "networks.lora",
|
||||
"ss_network_dim": str(dim),
|
||||
"ss_network_alpha": str(float(dim)),
|
||||
"ss_network_args": json.dumps(net_kwargs),
|
||||
}
|
||||
|
||||
if not no_metadata:
|
||||
title = os.path.splitext(os.path.basename(save_to))[0]
|
||||
sai_metadata = sai_model_spec.build_metadata(None, v2, v_parameterization, sdxl, True, False, time.time(), title=title)
|
||||
metadata.update(sai_metadata)
|
||||
|
||||
lora_network_save.save_weights(save_to, save_dtype, metadata)
|
||||
logger.info(f"LoRA weights are saved to: {save_to}")
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--v2", action='store_true',
|
||||
help='load Stable Diffusion v2.x model / Stable Diffusion 2.xのモデルを読み込む')
|
||||
parser.add_argument("--save_precision", type=str, default=None,
|
||||
choices=[None, "float", "fp16", "bf16"], help="precision in saving, same to merging if omitted / 保存時に精度を変更して保存する、省略時はfloat")
|
||||
parser.add_argument("--model_org", type=str, default=None,
|
||||
help="Stable Diffusion original model: ckpt or safetensors file / 元モデル、ckptまたはsafetensors")
|
||||
parser.add_argument("--model_tuned", type=str, default=None,
|
||||
help="Stable Diffusion tuned model, LoRA is difference of `original to tuned`: ckpt or safetensors file / 派生モデル(生成されるLoRAは元→派生の差分になります)、ckptまたはsafetensors")
|
||||
parser.add_argument("--save_to", type=str, default=None,
|
||||
help="destination file name: ckpt or safetensors file / 保存先のファイル名、ckptまたはsafetensors")
|
||||
parser.add_argument("--dim", type=int, default=4, help="dimension (rank) of LoRA (default 4) / LoRAの次元数(rank)(デフォルト4)")
|
||||
parser.add_argument("--conv_dim", type=int, default=None,
|
||||
help="dimension (rank) of LoRA for Conv2d-3x3 (default None, disabled) / LoRAのConv2d-3x3の次元数(rank)(デフォルトNone、適用なし)")
|
||||
parser.add_argument("--device", type=str, default=None, help="device to use, cuda for GPU / 計算を行うデバイス、cuda でGPUを使う")
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--v2", action="store_true", help="load Stable Diffusion v2.x model / Stable Diffusion 2.xのモデルを読み込む")
|
||||
parser.add_argument(
|
||||
"--v_parameterization",
|
||||
action="store_true",
|
||||
default=None,
|
||||
help="make LoRA metadata for v-parameterization (default is same to v2) / 作成するLoRAのメタデータにv-parameterization用と設定する(省略時はv2と同じ)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--sdxl", action="store_true", help="load Stable Diffusion SDXL base model / Stable Diffusion SDXL baseのモデルを読み込む"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--load_precision",
|
||||
type=str,
|
||||
default=None,
|
||||
choices=[None, "float", "fp16", "bf16"],
|
||||
help="precision in loading, model default if omitted / 読み込み時に精度を変更して読み込む、省略時はモデルファイルによる"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--save_precision",
|
||||
type=str,
|
||||
default=None,
|
||||
choices=[None, "float", "fp16", "bf16"],
|
||||
help="precision in saving, same to merging if omitted / 保存時に精度を変更して保存する、省略時はfloat",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--model_org",
|
||||
type=str,
|
||||
default=None,
|
||||
required=True,
|
||||
help="Stable Diffusion original model: ckpt or safetensors file / 元モデル、ckptまたはsafetensors",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--model_tuned",
|
||||
type=str,
|
||||
default=None,
|
||||
required=True,
|
||||
help="Stable Diffusion tuned model, LoRA is difference of `original to tuned`: ckpt or safetensors file / 派生モデル(生成されるLoRAは元→派生の差分になります)、ckptまたはsafetensors",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--save_to",
|
||||
type=str,
|
||||
default=None,
|
||||
required=True,
|
||||
help="destination file name: ckpt or safetensors file / 保存先のファイル名、ckptまたはsafetensors",
|
||||
)
|
||||
parser.add_argument("--dim", type=int, default=4, help="dimension (rank) of LoRA (default 4) / LoRAの次元数(rank)(デフォルト4)")
|
||||
parser.add_argument(
|
||||
"--conv_dim",
|
||||
type=int,
|
||||
default=None,
|
||||
help="dimension (rank) of LoRA for Conv2d-3x3 (default None, disabled) / LoRAのConv2d-3x3の次元数(rank)(デフォルトNone、適用なし)",
|
||||
)
|
||||
parser.add_argument("--device", type=str, default=None, help="device to use, cuda for GPU / 計算を行うデバイス、cuda でGPUを使う")
|
||||
parser.add_argument(
|
||||
"--clamp_quantile",
|
||||
type=float,
|
||||
default=0.99,
|
||||
help="Quantile clamping value, float, (0-1). Default = 0.99 / 値をクランプするための分位点、float、(0-1)。デフォルトは0.99",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--min_diff",
|
||||
type=float,
|
||||
default=0.01,
|
||||
help="Minimum difference between finetuned model and base to consider them different enough to extract, float, (0-1). Default = 0.01 /"
|
||||
+ "LoRAを抽出するために元モデルと派生モデルの差分の最小値、float、(0-1)。デフォルトは0.01",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--no_metadata",
|
||||
action="store_true",
|
||||
help="do not save sai modelspec metadata (minimum ss_metadata for LoRA is saved) / "
|
||||
+ "sai modelspecのメタデータを保存しない(LoRAの最低限のss_metadataは保存される)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--load_original_model_to",
|
||||
type=str,
|
||||
default=None,
|
||||
help="location to load original model, cpu or cuda, cuda:0, etc, default is cpu, only for SDXL / 元モデル読み込み先、cpuまたはcuda、cuda:0など、省略時はcpu、SDXLのみ有効",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--load_tuned_model_to",
|
||||
type=str,
|
||||
default=None,
|
||||
help="location to load tuned model, cpu or cuda, cuda:0, etc, default is cpu, only for SDXL / 派生モデル読み込み先、cpuまたはcuda、cuda:0など、省略時はcpu、SDXLのみ有効",
|
||||
)
|
||||
|
||||
return parser
|
||||
return parser
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = setup_parser()
|
||||
if __name__ == "__main__":
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
svd(args)
|
||||
args = parser.parse_args()
|
||||
svd(**vars(args))
|
||||
|
||||
949
networks/lora.py
949
networks/lora.py
File diff suppressed because it is too large
Load Diff
616
networks/lora_diffusers.py
Normal file
616
networks/lora_diffusers.py
Normal file
@@ -0,0 +1,616 @@
|
||||
# Diffusersで動くLoRA。このファイル単独で完結する。
|
||||
# LoRA module for Diffusers. This file works independently.
|
||||
|
||||
import bisect
|
||||
import math
|
||||
import random
|
||||
from typing import Any, Dict, List, Mapping, Optional, Union
|
||||
from diffusers import UNet2DConditionModel
|
||||
import numpy as np
|
||||
from tqdm import tqdm
|
||||
from transformers import CLIPTextModel
|
||||
|
||||
import torch
|
||||
from library.device_utils import init_ipex, get_preferred_device
|
||||
init_ipex()
|
||||
|
||||
from library.utils import setup_logging
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
def make_unet_conversion_map() -> Dict[str, str]:
|
||||
unet_conversion_map_layer = []
|
||||
|
||||
for i in range(3): # num_blocks is 3 in sdxl
|
||||
# loop over downblocks/upblocks
|
||||
for j in range(2):
|
||||
# loop over resnets/attentions for downblocks
|
||||
hf_down_res_prefix = f"down_blocks.{i}.resnets.{j}."
|
||||
sd_down_res_prefix = f"input_blocks.{3*i + j + 1}.0."
|
||||
unet_conversion_map_layer.append((sd_down_res_prefix, hf_down_res_prefix))
|
||||
|
||||
if i < 3:
|
||||
# no attention layers in down_blocks.3
|
||||
hf_down_atn_prefix = f"down_blocks.{i}.attentions.{j}."
|
||||
sd_down_atn_prefix = f"input_blocks.{3*i + j + 1}.1."
|
||||
unet_conversion_map_layer.append((sd_down_atn_prefix, hf_down_atn_prefix))
|
||||
|
||||
for j in range(3):
|
||||
# loop over resnets/attentions for upblocks
|
||||
hf_up_res_prefix = f"up_blocks.{i}.resnets.{j}."
|
||||
sd_up_res_prefix = f"output_blocks.{3*i + j}.0."
|
||||
unet_conversion_map_layer.append((sd_up_res_prefix, hf_up_res_prefix))
|
||||
|
||||
# if i > 0: commentout for sdxl
|
||||
# no attention layers in up_blocks.0
|
||||
hf_up_atn_prefix = f"up_blocks.{i}.attentions.{j}."
|
||||
sd_up_atn_prefix = f"output_blocks.{3*i + j}.1."
|
||||
unet_conversion_map_layer.append((sd_up_atn_prefix, hf_up_atn_prefix))
|
||||
|
||||
if i < 3:
|
||||
# no downsample in down_blocks.3
|
||||
hf_downsample_prefix = f"down_blocks.{i}.downsamplers.0.conv."
|
||||
sd_downsample_prefix = f"input_blocks.{3*(i+1)}.0.op."
|
||||
unet_conversion_map_layer.append((sd_downsample_prefix, hf_downsample_prefix))
|
||||
|
||||
# no upsample in up_blocks.3
|
||||
hf_upsample_prefix = f"up_blocks.{i}.upsamplers.0."
|
||||
sd_upsample_prefix = f"output_blocks.{3*i + 2}.{2}." # change for sdxl
|
||||
unet_conversion_map_layer.append((sd_upsample_prefix, hf_upsample_prefix))
|
||||
|
||||
hf_mid_atn_prefix = "mid_block.attentions.0."
|
||||
sd_mid_atn_prefix = "middle_block.1."
|
||||
unet_conversion_map_layer.append((sd_mid_atn_prefix, hf_mid_atn_prefix))
|
||||
|
||||
for j in range(2):
|
||||
hf_mid_res_prefix = f"mid_block.resnets.{j}."
|
||||
sd_mid_res_prefix = f"middle_block.{2*j}."
|
||||
unet_conversion_map_layer.append((sd_mid_res_prefix, hf_mid_res_prefix))
|
||||
|
||||
unet_conversion_map_resnet = [
|
||||
# (stable-diffusion, HF Diffusers)
|
||||
("in_layers.0.", "norm1."),
|
||||
("in_layers.2.", "conv1."),
|
||||
("out_layers.0.", "norm2."),
|
||||
("out_layers.3.", "conv2."),
|
||||
("emb_layers.1.", "time_emb_proj."),
|
||||
("skip_connection.", "conv_shortcut."),
|
||||
]
|
||||
|
||||
unet_conversion_map = []
|
||||
for sd, hf in unet_conversion_map_layer:
|
||||
if "resnets" in hf:
|
||||
for sd_res, hf_res in unet_conversion_map_resnet:
|
||||
unet_conversion_map.append((sd + sd_res, hf + hf_res))
|
||||
else:
|
||||
unet_conversion_map.append((sd, hf))
|
||||
|
||||
for j in range(2):
|
||||
hf_time_embed_prefix = f"time_embedding.linear_{j+1}."
|
||||
sd_time_embed_prefix = f"time_embed.{j*2}."
|
||||
unet_conversion_map.append((sd_time_embed_prefix, hf_time_embed_prefix))
|
||||
|
||||
for j in range(2):
|
||||
hf_label_embed_prefix = f"add_embedding.linear_{j+1}."
|
||||
sd_label_embed_prefix = f"label_emb.0.{j*2}."
|
||||
unet_conversion_map.append((sd_label_embed_prefix, hf_label_embed_prefix))
|
||||
|
||||
unet_conversion_map.append(("input_blocks.0.0.", "conv_in."))
|
||||
unet_conversion_map.append(("out.0.", "conv_norm_out."))
|
||||
unet_conversion_map.append(("out.2.", "conv_out."))
|
||||
|
||||
sd_hf_conversion_map = {sd.replace(".", "_")[:-1]: hf.replace(".", "_")[:-1] for sd, hf in unet_conversion_map}
|
||||
return sd_hf_conversion_map
|
||||
|
||||
|
||||
UNET_CONVERSION_MAP = make_unet_conversion_map()
|
||||
|
||||
|
||||
class LoRAModule(torch.nn.Module):
|
||||
"""
|
||||
replaces forward method of the original Linear, instead of replacing the original Linear module.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
lora_name,
|
||||
org_module: torch.nn.Module,
|
||||
multiplier=1.0,
|
||||
lora_dim=4,
|
||||
alpha=1,
|
||||
):
|
||||
"""if alpha == 0 or None, alpha is rank (no scaling)."""
|
||||
super().__init__()
|
||||
self.lora_name = lora_name
|
||||
|
||||
if org_module.__class__.__name__ == "Conv2d" or org_module.__class__.__name__ == "LoRACompatibleConv":
|
||||
in_dim = org_module.in_channels
|
||||
out_dim = org_module.out_channels
|
||||
else:
|
||||
in_dim = org_module.in_features
|
||||
out_dim = org_module.out_features
|
||||
|
||||
self.lora_dim = lora_dim
|
||||
|
||||
if org_module.__class__.__name__ == "Conv2d" or org_module.__class__.__name__ == "LoRACompatibleConv":
|
||||
kernel_size = org_module.kernel_size
|
||||
stride = org_module.stride
|
||||
padding = org_module.padding
|
||||
self.lora_down = torch.nn.Conv2d(in_dim, self.lora_dim, kernel_size, stride, padding, bias=False)
|
||||
self.lora_up = torch.nn.Conv2d(self.lora_dim, out_dim, (1, 1), (1, 1), bias=False)
|
||||
else:
|
||||
self.lora_down = torch.nn.Linear(in_dim, self.lora_dim, bias=False)
|
||||
self.lora_up = torch.nn.Linear(self.lora_dim, out_dim, bias=False)
|
||||
|
||||
if type(alpha) == torch.Tensor:
|
||||
alpha = alpha.detach().float().numpy() # without casting, bf16 causes error
|
||||
alpha = self.lora_dim if alpha is None or alpha == 0 else alpha
|
||||
self.scale = alpha / self.lora_dim
|
||||
self.register_buffer("alpha", torch.tensor(alpha)) # 勾配計算に含めない / not included in gradient calculation
|
||||
|
||||
# same as microsoft's
|
||||
torch.nn.init.kaiming_uniform_(self.lora_down.weight, a=math.sqrt(5))
|
||||
torch.nn.init.zeros_(self.lora_up.weight)
|
||||
|
||||
self.multiplier = multiplier
|
||||
self.org_module = [org_module]
|
||||
self.enabled = True
|
||||
self.network: LoRANetwork = None
|
||||
self.org_forward = None
|
||||
|
||||
# override org_module's forward method
|
||||
def apply_to(self, multiplier=None):
|
||||
if multiplier is not None:
|
||||
self.multiplier = multiplier
|
||||
if self.org_forward is None:
|
||||
self.org_forward = self.org_module[0].forward
|
||||
self.org_module[0].forward = self.forward
|
||||
|
||||
# restore org_module's forward method
|
||||
def unapply_to(self):
|
||||
if self.org_forward is not None:
|
||||
self.org_module[0].forward = self.org_forward
|
||||
|
||||
# forward with lora
|
||||
# scale is used LoRACompatibleConv, but we ignore it because we have multiplier
|
||||
def forward(self, x, scale=1.0):
|
||||
if not self.enabled:
|
||||
return self.org_forward(x)
|
||||
return self.org_forward(x) + self.lora_up(self.lora_down(x)) * self.multiplier * self.scale
|
||||
|
||||
def set_network(self, network):
|
||||
self.network = network
|
||||
|
||||
# merge lora weight to org weight
|
||||
def merge_to(self, multiplier=1.0):
|
||||
# get lora weight
|
||||
lora_weight = self.get_weight(multiplier)
|
||||
|
||||
# get org weight
|
||||
org_sd = self.org_module[0].state_dict()
|
||||
org_weight = org_sd["weight"]
|
||||
weight = org_weight + lora_weight.to(org_weight.device, dtype=org_weight.dtype)
|
||||
|
||||
# set weight to org_module
|
||||
org_sd["weight"] = weight
|
||||
self.org_module[0].load_state_dict(org_sd)
|
||||
|
||||
# restore org weight from lora weight
|
||||
def restore_from(self, multiplier=1.0):
|
||||
# get lora weight
|
||||
lora_weight = self.get_weight(multiplier)
|
||||
|
||||
# get org weight
|
||||
org_sd = self.org_module[0].state_dict()
|
||||
org_weight = org_sd["weight"]
|
||||
weight = org_weight - lora_weight.to(org_weight.device, dtype=org_weight.dtype)
|
||||
|
||||
# set weight to org_module
|
||||
org_sd["weight"] = weight
|
||||
self.org_module[0].load_state_dict(org_sd)
|
||||
|
||||
# return lora weight
|
||||
def get_weight(self, multiplier=None):
|
||||
if multiplier is None:
|
||||
multiplier = self.multiplier
|
||||
|
||||
# get up/down weight from module
|
||||
up_weight = self.lora_up.weight.to(torch.float)
|
||||
down_weight = self.lora_down.weight.to(torch.float)
|
||||
|
||||
# pre-calculated weight
|
||||
if len(down_weight.size()) == 2:
|
||||
# linear
|
||||
weight = self.multiplier * (up_weight @ down_weight) * self.scale
|
||||
elif down_weight.size()[2:4] == (1, 1):
|
||||
# conv2d 1x1
|
||||
weight = (
|
||||
self.multiplier
|
||||
* (up_weight.squeeze(3).squeeze(2) @ down_weight.squeeze(3).squeeze(2)).unsqueeze(2).unsqueeze(3)
|
||||
* self.scale
|
||||
)
|
||||
else:
|
||||
# conv2d 3x3
|
||||
conved = torch.nn.functional.conv2d(down_weight.permute(1, 0, 2, 3), up_weight).permute(1, 0, 2, 3)
|
||||
weight = self.multiplier * conved * self.scale
|
||||
|
||||
return weight
|
||||
|
||||
|
||||
# Create network from weights for inference, weights are not loaded here
|
||||
def create_network_from_weights(
|
||||
text_encoder: Union[CLIPTextModel, List[CLIPTextModel]], unet: UNet2DConditionModel, weights_sd: Dict, multiplier: float = 1.0
|
||||
):
|
||||
# get dim/alpha mapping
|
||||
modules_dim = {}
|
||||
modules_alpha = {}
|
||||
for key, value in weights_sd.items():
|
||||
if "." not in key:
|
||||
continue
|
||||
|
||||
lora_name = key.split(".")[0]
|
||||
if "alpha" in key:
|
||||
modules_alpha[lora_name] = value
|
||||
elif "lora_down" in key:
|
||||
dim = value.size()[0]
|
||||
modules_dim[lora_name] = dim
|
||||
# logger.info(f"{lora_name} {value.size()} {dim}")
|
||||
|
||||
# support old LoRA without alpha
|
||||
for key in modules_dim.keys():
|
||||
if key not in modules_alpha:
|
||||
modules_alpha[key] = modules_dim[key]
|
||||
|
||||
return LoRANetwork(text_encoder, unet, multiplier=multiplier, modules_dim=modules_dim, modules_alpha=modules_alpha)
|
||||
|
||||
|
||||
def merge_lora_weights(pipe, weights_sd: Dict, multiplier: float = 1.0):
|
||||
text_encoders = [pipe.text_encoder, pipe.text_encoder_2] if hasattr(pipe, "text_encoder_2") else [pipe.text_encoder]
|
||||
unet = pipe.unet
|
||||
|
||||
lora_network = create_network_from_weights(text_encoders, unet, weights_sd, multiplier=multiplier)
|
||||
lora_network.load_state_dict(weights_sd)
|
||||
lora_network.merge_to(multiplier=multiplier)
|
||||
|
||||
|
||||
# block weightや学習に対応しない簡易版 / simple version without block weight and training
|
||||
class LoRANetwork(torch.nn.Module):
|
||||
UNET_TARGET_REPLACE_MODULE = ["Transformer2DModel"]
|
||||
UNET_TARGET_REPLACE_MODULE_CONV2D_3X3 = ["ResnetBlock2D", "Downsample2D", "Upsample2D"]
|
||||
TEXT_ENCODER_TARGET_REPLACE_MODULE = ["CLIPAttention", "CLIPSdpaAttention", "CLIPMLP"]
|
||||
LORA_PREFIX_UNET = "lora_unet"
|
||||
LORA_PREFIX_TEXT_ENCODER = "lora_te"
|
||||
|
||||
# SDXL: must starts with LORA_PREFIX_TEXT_ENCODER
|
||||
LORA_PREFIX_TEXT_ENCODER1 = "lora_te1"
|
||||
LORA_PREFIX_TEXT_ENCODER2 = "lora_te2"
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
text_encoder: Union[List[CLIPTextModel], CLIPTextModel],
|
||||
unet: UNet2DConditionModel,
|
||||
multiplier: float = 1.0,
|
||||
modules_dim: Optional[Dict[str, int]] = None,
|
||||
modules_alpha: Optional[Dict[str, int]] = None,
|
||||
varbose: Optional[bool] = False,
|
||||
) -> None:
|
||||
super().__init__()
|
||||
self.multiplier = multiplier
|
||||
|
||||
logger.info("create LoRA network from weights")
|
||||
|
||||
# convert SDXL Stability AI's U-Net modules to Diffusers
|
||||
converted = self.convert_unet_modules(modules_dim, modules_alpha)
|
||||
if converted:
|
||||
logger.info(f"converted {converted} Stability AI's U-Net LoRA modules to Diffusers (SDXL)")
|
||||
|
||||
# create module instances
|
||||
def create_modules(
|
||||
is_unet: bool,
|
||||
text_encoder_idx: Optional[int], # None, 1, 2
|
||||
root_module: torch.nn.Module,
|
||||
target_replace_modules: List[torch.nn.Module],
|
||||
) -> List[LoRAModule]:
|
||||
prefix = (
|
||||
self.LORA_PREFIX_UNET
|
||||
if is_unet
|
||||
else (
|
||||
self.LORA_PREFIX_TEXT_ENCODER
|
||||
if text_encoder_idx is None
|
||||
else (self.LORA_PREFIX_TEXT_ENCODER1 if text_encoder_idx == 1 else self.LORA_PREFIX_TEXT_ENCODER2)
|
||||
)
|
||||
)
|
||||
loras = []
|
||||
skipped = []
|
||||
for name, module in root_module.named_modules():
|
||||
if module.__class__.__name__ in target_replace_modules:
|
||||
for child_name, child_module in module.named_modules():
|
||||
is_linear = (
|
||||
child_module.__class__.__name__ == "Linear" or child_module.__class__.__name__ == "LoRACompatibleLinear"
|
||||
)
|
||||
is_conv2d = (
|
||||
child_module.__class__.__name__ == "Conv2d" or child_module.__class__.__name__ == "LoRACompatibleConv"
|
||||
)
|
||||
|
||||
if is_linear or is_conv2d:
|
||||
lora_name = prefix + "." + name + "." + child_name
|
||||
lora_name = lora_name.replace(".", "_")
|
||||
|
||||
if lora_name not in modules_dim:
|
||||
# logger.info(f"skipped {lora_name} (not found in modules_dim)")
|
||||
skipped.append(lora_name)
|
||||
continue
|
||||
|
||||
dim = modules_dim[lora_name]
|
||||
alpha = modules_alpha[lora_name]
|
||||
lora = LoRAModule(
|
||||
lora_name,
|
||||
child_module,
|
||||
self.multiplier,
|
||||
dim,
|
||||
alpha,
|
||||
)
|
||||
loras.append(lora)
|
||||
return loras, skipped
|
||||
|
||||
text_encoders = text_encoder if type(text_encoder) == list else [text_encoder]
|
||||
|
||||
# create LoRA for text encoder
|
||||
# 毎回すべてのモジュールを作るのは無駄なので要検討 / it is wasteful to create all modules every time, need to consider
|
||||
self.text_encoder_loras: List[LoRAModule] = []
|
||||
skipped_te = []
|
||||
for i, text_encoder in enumerate(text_encoders):
|
||||
if len(text_encoders) > 1:
|
||||
index = i + 1
|
||||
else:
|
||||
index = None
|
||||
|
||||
text_encoder_loras, skipped = create_modules(False, index, text_encoder, LoRANetwork.TEXT_ENCODER_TARGET_REPLACE_MODULE)
|
||||
self.text_encoder_loras.extend(text_encoder_loras)
|
||||
skipped_te += skipped
|
||||
logger.info(f"create LoRA for Text Encoder: {len(self.text_encoder_loras)} modules.")
|
||||
if len(skipped_te) > 0:
|
||||
logger.warning(f"skipped {len(skipped_te)} modules because of missing weight for text encoder.")
|
||||
|
||||
# extend U-Net target modules to include Conv2d 3x3
|
||||
target_modules = LoRANetwork.UNET_TARGET_REPLACE_MODULE + LoRANetwork.UNET_TARGET_REPLACE_MODULE_CONV2D_3X3
|
||||
|
||||
self.unet_loras: List[LoRAModule]
|
||||
self.unet_loras, skipped_un = create_modules(True, None, unet, target_modules)
|
||||
logger.info(f"create LoRA for U-Net: {len(self.unet_loras)} modules.")
|
||||
if len(skipped_un) > 0:
|
||||
logger.warning(f"skipped {len(skipped_un)} modules because of missing weight for U-Net.")
|
||||
|
||||
# assertion
|
||||
names = set()
|
||||
for lora in self.text_encoder_loras + self.unet_loras:
|
||||
names.add(lora.lora_name)
|
||||
for lora_name in modules_dim.keys():
|
||||
assert lora_name in names, f"{lora_name} is not found in created LoRA modules."
|
||||
|
||||
# make to work load_state_dict
|
||||
for lora in self.text_encoder_loras + self.unet_loras:
|
||||
self.add_module(lora.lora_name, lora)
|
||||
|
||||
# SDXL: convert SDXL Stability AI's U-Net modules to Diffusers
|
||||
def convert_unet_modules(self, modules_dim, modules_alpha):
|
||||
converted_count = 0
|
||||
not_converted_count = 0
|
||||
|
||||
map_keys = list(UNET_CONVERSION_MAP.keys())
|
||||
map_keys.sort()
|
||||
|
||||
for key in list(modules_dim.keys()):
|
||||
if key.startswith(LoRANetwork.LORA_PREFIX_UNET + "_"):
|
||||
search_key = key.replace(LoRANetwork.LORA_PREFIX_UNET + "_", "")
|
||||
position = bisect.bisect_right(map_keys, search_key)
|
||||
map_key = map_keys[position - 1]
|
||||
if search_key.startswith(map_key):
|
||||
new_key = key.replace(map_key, UNET_CONVERSION_MAP[map_key])
|
||||
modules_dim[new_key] = modules_dim[key]
|
||||
modules_alpha[new_key] = modules_alpha[key]
|
||||
del modules_dim[key]
|
||||
del modules_alpha[key]
|
||||
converted_count += 1
|
||||
else:
|
||||
not_converted_count += 1
|
||||
assert (
|
||||
converted_count == 0 or not_converted_count == 0
|
||||
), f"some modules are not converted: {converted_count} converted, {not_converted_count} not converted"
|
||||
return converted_count
|
||||
|
||||
def set_multiplier(self, multiplier):
|
||||
self.multiplier = multiplier
|
||||
for lora in self.text_encoder_loras + self.unet_loras:
|
||||
lora.multiplier = self.multiplier
|
||||
|
||||
def apply_to(self, multiplier=1.0, apply_text_encoder=True, apply_unet=True):
|
||||
if apply_text_encoder:
|
||||
logger.info("enable LoRA for text encoder")
|
||||
for lora in self.text_encoder_loras:
|
||||
lora.apply_to(multiplier)
|
||||
if apply_unet:
|
||||
logger.info("enable LoRA for U-Net")
|
||||
for lora in self.unet_loras:
|
||||
lora.apply_to(multiplier)
|
||||
|
||||
def unapply_to(self):
|
||||
for lora in self.text_encoder_loras + self.unet_loras:
|
||||
lora.unapply_to()
|
||||
|
||||
def merge_to(self, multiplier=1.0):
|
||||
logger.info("merge LoRA weights to original weights")
|
||||
for lora in tqdm(self.text_encoder_loras + self.unet_loras):
|
||||
lora.merge_to(multiplier)
|
||||
logger.info(f"weights are merged")
|
||||
|
||||
def restore_from(self, multiplier=1.0):
|
||||
logger.info("restore LoRA weights from original weights")
|
||||
for lora in tqdm(self.text_encoder_loras + self.unet_loras):
|
||||
lora.restore_from(multiplier)
|
||||
logger.info(f"weights are restored")
|
||||
|
||||
def load_state_dict(self, state_dict: Mapping[str, Any], strict: bool = True):
|
||||
# convert SDXL Stability AI's state dict to Diffusers' based state dict
|
||||
map_keys = list(UNET_CONVERSION_MAP.keys()) # prefix of U-Net modules
|
||||
map_keys.sort()
|
||||
for key in list(state_dict.keys()):
|
||||
if key.startswith(LoRANetwork.LORA_PREFIX_UNET + "_"):
|
||||
search_key = key.replace(LoRANetwork.LORA_PREFIX_UNET + "_", "")
|
||||
position = bisect.bisect_right(map_keys, search_key)
|
||||
map_key = map_keys[position - 1]
|
||||
if search_key.startswith(map_key):
|
||||
new_key = key.replace(map_key, UNET_CONVERSION_MAP[map_key])
|
||||
state_dict[new_key] = state_dict[key]
|
||||
del state_dict[key]
|
||||
|
||||
# in case of V2, some weights have different shape, so we need to convert them
|
||||
# because V2 LoRA is based on U-Net created by use_linear_projection=False
|
||||
my_state_dict = self.state_dict()
|
||||
for key in state_dict.keys():
|
||||
if state_dict[key].size() != my_state_dict[key].size():
|
||||
# logger.info(f"convert {key} from {state_dict[key].size()} to {my_state_dict[key].size()}")
|
||||
state_dict[key] = state_dict[key].view(my_state_dict[key].size())
|
||||
|
||||
return super().load_state_dict(state_dict, strict)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# sample code to use LoRANetwork
|
||||
import os
|
||||
import argparse
|
||||
from diffusers import StableDiffusionPipeline, StableDiffusionXLPipeline
|
||||
import torch
|
||||
|
||||
device = get_preferred_device()
|
||||
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--model_id", type=str, default=None, help="model id for huggingface")
|
||||
parser.add_argument("--lora_weights", type=str, default=None, help="path to LoRA weights")
|
||||
parser.add_argument("--sdxl", action="store_true", help="use SDXL model")
|
||||
parser.add_argument("--prompt", type=str, default="A photo of cat", help="prompt text")
|
||||
parser.add_argument("--negative_prompt", type=str, default="", help="negative prompt text")
|
||||
parser.add_argument("--seed", type=int, default=0, help="random seed")
|
||||
args = parser.parse_args()
|
||||
|
||||
image_prefix = args.model_id.replace("/", "_") + "_"
|
||||
|
||||
# load Diffusers model
|
||||
logger.info(f"load model from {args.model_id}")
|
||||
pipe: Union[StableDiffusionPipeline, StableDiffusionXLPipeline]
|
||||
if args.sdxl:
|
||||
# use_safetensors=True does not work with 0.18.2
|
||||
pipe = StableDiffusionXLPipeline.from_pretrained(args.model_id, variant="fp16", torch_dtype=torch.float16)
|
||||
else:
|
||||
pipe = StableDiffusionPipeline.from_pretrained(args.model_id, variant="fp16", torch_dtype=torch.float16)
|
||||
pipe.to(device)
|
||||
pipe.set_use_memory_efficient_attention_xformers(True)
|
||||
|
||||
text_encoders = [pipe.text_encoder, pipe.text_encoder_2] if args.sdxl else [pipe.text_encoder]
|
||||
|
||||
# load LoRA weights
|
||||
logger.info(f"load LoRA weights from {args.lora_weights}")
|
||||
if os.path.splitext(args.lora_weights)[1] == ".safetensors":
|
||||
from safetensors.torch import load_file
|
||||
|
||||
lora_sd = load_file(args.lora_weights)
|
||||
else:
|
||||
lora_sd = torch.load(args.lora_weights)
|
||||
|
||||
# create by LoRA weights and load weights
|
||||
logger.info(f"create LoRA network")
|
||||
lora_network: LoRANetwork = create_network_from_weights(text_encoders, pipe.unet, lora_sd, multiplier=1.0)
|
||||
|
||||
logger.info(f"load LoRA network weights")
|
||||
lora_network.load_state_dict(lora_sd)
|
||||
|
||||
lora_network.to(device, dtype=pipe.unet.dtype) # required to apply_to. merge_to works without this
|
||||
|
||||
# 必要があれば、元のモデルの重みをバックアップしておく
|
||||
# back-up unet/text encoder weights if necessary
|
||||
def detach_and_move_to_cpu(state_dict):
|
||||
for k, v in state_dict.items():
|
||||
state_dict[k] = v.detach().cpu()
|
||||
return state_dict
|
||||
|
||||
org_unet_sd = pipe.unet.state_dict()
|
||||
detach_and_move_to_cpu(org_unet_sd)
|
||||
|
||||
org_text_encoder_sd = pipe.text_encoder.state_dict()
|
||||
detach_and_move_to_cpu(org_text_encoder_sd)
|
||||
|
||||
if args.sdxl:
|
||||
org_text_encoder_2_sd = pipe.text_encoder_2.state_dict()
|
||||
detach_and_move_to_cpu(org_text_encoder_2_sd)
|
||||
|
||||
def seed_everything(seed):
|
||||
torch.manual_seed(seed)
|
||||
torch.cuda.manual_seed_all(seed)
|
||||
np.random.seed(seed)
|
||||
random.seed(seed)
|
||||
|
||||
# create image with original weights
|
||||
logger.info(f"create image with original weights")
|
||||
seed_everything(args.seed)
|
||||
image = pipe(args.prompt, negative_prompt=args.negative_prompt).images[0]
|
||||
image.save(image_prefix + "original.png")
|
||||
|
||||
# apply LoRA network to the model: slower than merge_to, but can be reverted easily
|
||||
logger.info(f"apply LoRA network to the model")
|
||||
lora_network.apply_to(multiplier=1.0)
|
||||
|
||||
logger.info(f"create image with applied LoRA")
|
||||
seed_everything(args.seed)
|
||||
image = pipe(args.prompt, negative_prompt=args.negative_prompt).images[0]
|
||||
image.save(image_prefix + "applied_lora.png")
|
||||
|
||||
# unapply LoRA network to the model
|
||||
logger.info(f"unapply LoRA network to the model")
|
||||
lora_network.unapply_to()
|
||||
|
||||
logger.info(f"create image with unapplied LoRA")
|
||||
seed_everything(args.seed)
|
||||
image = pipe(args.prompt, negative_prompt=args.negative_prompt).images[0]
|
||||
image.save(image_prefix + "unapplied_lora.png")
|
||||
|
||||
# merge LoRA network to the model: faster than apply_to, but requires back-up of original weights (or unmerge_to)
|
||||
logger.info(f"merge LoRA network to the model")
|
||||
lora_network.merge_to(multiplier=1.0)
|
||||
|
||||
logger.info(f"create image with LoRA")
|
||||
seed_everything(args.seed)
|
||||
image = pipe(args.prompt, negative_prompt=args.negative_prompt).images[0]
|
||||
image.save(image_prefix + "merged_lora.png")
|
||||
|
||||
# restore (unmerge) LoRA weights: numerically unstable
|
||||
# マージされた重みを元に戻す。計算誤差のため、元の重みと完全に一致しないことがあるかもしれない
|
||||
# 保存したstate_dictから元の重みを復元するのが確実
|
||||
logger.info(f"restore (unmerge) LoRA weights")
|
||||
lora_network.restore_from(multiplier=1.0)
|
||||
|
||||
logger.info(f"create image without LoRA")
|
||||
seed_everything(args.seed)
|
||||
image = pipe(args.prompt, negative_prompt=args.negative_prompt).images[0]
|
||||
image.save(image_prefix + "unmerged_lora.png")
|
||||
|
||||
# restore original weights
|
||||
logger.info(f"restore original weights")
|
||||
pipe.unet.load_state_dict(org_unet_sd)
|
||||
pipe.text_encoder.load_state_dict(org_text_encoder_sd)
|
||||
if args.sdxl:
|
||||
pipe.text_encoder_2.load_state_dict(org_text_encoder_2_sd)
|
||||
|
||||
logger.info(f"create image with restored original weights")
|
||||
seed_everything(args.seed)
|
||||
image = pipe(args.prompt, negative_prompt=args.negative_prompt).images[0]
|
||||
image.save(image_prefix + "restore_original.png")
|
||||
|
||||
# use convenience function to merge LoRA weights
|
||||
logger.info(f"merge LoRA weights with convenience function")
|
||||
merge_lora_weights(pipe, lora_sd, multiplier=1.0)
|
||||
|
||||
logger.info(f"create image with merged LoRA weights")
|
||||
seed_everything(args.seed)
|
||||
image = pipe(args.prompt, negative_prompt=args.negative_prompt).images[0]
|
||||
image.save(image_prefix + "convenience_merged_lora.png")
|
||||
1244
networks/lora_fa.py
Normal file
1244
networks/lora_fa.py
Normal file
File diff suppressed because it is too large
Load Diff
@@ -5,27 +5,34 @@ from library import model_util
|
||||
import library.train_util as train_util
|
||||
import argparse
|
||||
from transformers import CLIPTokenizer
|
||||
|
||||
import torch
|
||||
from library.device_utils import init_ipex, get_preferred_device
|
||||
init_ipex()
|
||||
|
||||
import library.model_util as model_util
|
||||
import lora
|
||||
from library.utils import setup_logging
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
TOKENIZER_PATH = "openai/clip-vit-large-patch14"
|
||||
V2_STABLE_DIFFUSION_PATH = "stabilityai/stable-diffusion-2" # ここからtokenizerだけ使う
|
||||
|
||||
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
||||
DEVICE = get_preferred_device()
|
||||
|
||||
|
||||
def interrogate(args):
|
||||
weights_dtype = torch.float16
|
||||
|
||||
# いろいろ準備する
|
||||
print(f"loading SD model: {args.sd_model}")
|
||||
logger.info(f"loading SD model: {args.sd_model}")
|
||||
args.pretrained_model_name_or_path = args.sd_model
|
||||
args.vae = None
|
||||
text_encoder, vae, unet, _ = train_util.load_target_model(args,weights_dtype, DEVICE)
|
||||
text_encoder, vae, unet, _ = train_util._load_target_model(args,weights_dtype, DEVICE)
|
||||
|
||||
print(f"loading LoRA: {args.model}")
|
||||
logger.info(f"loading LoRA: {args.model}")
|
||||
network, weights_sd = lora.create_network_from_weights(1.0, args.model, vae, text_encoder, unet)
|
||||
|
||||
# text encoder向けの重みがあるかチェックする:本当はlora側でやるのがいい
|
||||
@@ -35,11 +42,11 @@ def interrogate(args):
|
||||
has_te_weight = True
|
||||
break
|
||||
if not has_te_weight:
|
||||
print("This LoRA does not have modules for Text Encoder, cannot interrogate / このLoRAはText Encoder向けのモジュールがないため調査できません")
|
||||
logger.error("This LoRA does not have modules for Text Encoder, cannot interrogate / このLoRAはText Encoder向けのモジュールがないため調査できません")
|
||||
return
|
||||
del vae
|
||||
|
||||
print("loading tokenizer")
|
||||
logger.info("loading tokenizer")
|
||||
if args.v2:
|
||||
tokenizer: CLIPTokenizer = CLIPTokenizer.from_pretrained(V2_STABLE_DIFFUSION_PATH, subfolder="tokenizer")
|
||||
else:
|
||||
@@ -53,7 +60,7 @@ def interrogate(args):
|
||||
# トークンをひとつひとつ当たっていく
|
||||
token_id_start = 0
|
||||
token_id_end = max(tokenizer.all_special_ids)
|
||||
print(f"interrogate tokens are: {token_id_start} to {token_id_end}")
|
||||
logger.info(f"interrogate tokens are: {token_id_start} to {token_id_end}")
|
||||
|
||||
def get_all_embeddings(text_encoder):
|
||||
embs = []
|
||||
@@ -79,24 +86,24 @@ def interrogate(args):
|
||||
embs.extend(encoder_hidden_states)
|
||||
return torch.stack(embs)
|
||||
|
||||
print("get original text encoder embeddings.")
|
||||
logger.info("get original text encoder embeddings.")
|
||||
orig_embs = get_all_embeddings(text_encoder)
|
||||
|
||||
network.apply_to(text_encoder, unet, True, len(network.unet_loras) > 0)
|
||||
info = network.load_state_dict(weights_sd, strict=False)
|
||||
print(f"Loading LoRA weights: {info}")
|
||||
logger.info(f"Loading LoRA weights: {info}")
|
||||
|
||||
network.to(DEVICE, dtype=weights_dtype)
|
||||
network.eval()
|
||||
|
||||
del unet
|
||||
|
||||
print("You can ignore warning messages start with '_IncompatibleKeys' (LoRA model does not have alpha because trained by older script) / '_IncompatibleKeys'の警告は無視して構いません(以前のスクリプトで学習されたLoRAモデルのためalphaの定義がありません)")
|
||||
print("get text encoder embeddings with lora.")
|
||||
logger.info("You can ignore warning messages start with '_IncompatibleKeys' (LoRA model does not have alpha because trained by older script) / '_IncompatibleKeys'の警告は無視して構いません(以前のスクリプトで学習されたLoRAモデルのためalphaの定義がありません)")
|
||||
logger.info("get text encoder embeddings with lora.")
|
||||
lora_embs = get_all_embeddings(text_encoder)
|
||||
|
||||
# 比べる:とりあえず単純に差分の絶対値で
|
||||
print("comparing...")
|
||||
logger.info("comparing...")
|
||||
diffs = {}
|
||||
for i, (orig_emb, lora_emb) in enumerate(zip(orig_embs, tqdm(lora_embs))):
|
||||
diff = torch.mean(torch.abs(orig_emb - lora_emb))
|
||||
|
||||
@@ -1,31 +1,40 @@
|
||||
import math
|
||||
import argparse
|
||||
import os
|
||||
import time
|
||||
import torch
|
||||
from safetensors.torch import load_file, save_file
|
||||
from library import sai_model_spec, train_util
|
||||
import library.model_util as model_util
|
||||
import lora
|
||||
|
||||
from library.utils import setup_logging
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
def load_state_dict(file_name, dtype):
|
||||
if os.path.splitext(file_name)[1] == ".safetensors":
|
||||
sd = load_file(file_name)
|
||||
metadata = train_util.load_metadata_from_safetensors(file_name)
|
||||
else:
|
||||
sd = torch.load(file_name, map_location="cpu")
|
||||
metadata = {}
|
||||
|
||||
for key in list(sd.keys()):
|
||||
if type(sd[key]) == torch.Tensor:
|
||||
sd[key] = sd[key].to(dtype)
|
||||
return sd
|
||||
|
||||
return sd, metadata
|
||||
|
||||
|
||||
def save_to_file(file_name, model, state_dict, dtype):
|
||||
def save_to_file(file_name, model, state_dict, dtype, metadata):
|
||||
if dtype is not None:
|
||||
for key in list(state_dict.keys()):
|
||||
if type(state_dict[key]) == torch.Tensor:
|
||||
state_dict[key] = state_dict[key].to(dtype)
|
||||
|
||||
if os.path.splitext(file_name)[1] == ".safetensors":
|
||||
save_file(model, file_name)
|
||||
save_file(model, file_name, metadata=metadata)
|
||||
else:
|
||||
torch.save(model, file_name)
|
||||
|
||||
@@ -55,10 +64,10 @@ def merge_to_sd_model(text_encoder, unet, models, ratios, merge_dtype):
|
||||
name_to_module[lora_name] = child_module
|
||||
|
||||
for model, ratio in zip(models, ratios):
|
||||
print(f"loading: {model}")
|
||||
lora_sd = load_state_dict(model, merge_dtype)
|
||||
logger.info(f"loading: {model}")
|
||||
lora_sd, _ = load_state_dict(model, merge_dtype)
|
||||
|
||||
print(f"merging...")
|
||||
logger.info(f"merging...")
|
||||
for key in lora_sd.keys():
|
||||
if "lora_down" in key:
|
||||
up_key = key.replace("lora_down", "lora_up")
|
||||
@@ -67,10 +76,10 @@ def merge_to_sd_model(text_encoder, unet, models, ratios, merge_dtype):
|
||||
# find original module for this lora
|
||||
module_name = ".".join(key.split(".")[:-2]) # remove trailing ".lora_down.weight"
|
||||
if module_name not in name_to_module:
|
||||
print(f"no module found for LoRA weight: {key}")
|
||||
logger.info(f"no module found for LoRA weight: {key}")
|
||||
continue
|
||||
module = name_to_module[module_name]
|
||||
# print(f"apply {key} to {module}")
|
||||
# logger.info(f"apply {key} to {module}")
|
||||
|
||||
down_weight = lora_sd[key]
|
||||
up_weight = lora_sd[up_key]
|
||||
@@ -81,9 +90,11 @@ def merge_to_sd_model(text_encoder, unet, models, ratios, merge_dtype):
|
||||
|
||||
# W <- W + U * D
|
||||
weight = module.weight
|
||||
# print(module_name, down_weight.size(), up_weight.size())
|
||||
if len(weight.size()) == 2:
|
||||
# linear
|
||||
if len(up_weight.size()) == 4: # use linear projection mismatch
|
||||
up_weight = up_weight.squeeze(3).squeeze(2)
|
||||
down_weight = down_weight.squeeze(3).squeeze(2)
|
||||
weight = weight + ratio * (up_weight @ down_weight) * scale
|
||||
elif down_weight.size()[2:4] == (1, 1):
|
||||
# conv2d 1x1
|
||||
@@ -96,20 +107,28 @@ def merge_to_sd_model(text_encoder, unet, models, ratios, merge_dtype):
|
||||
else:
|
||||
# conv2d 3x3
|
||||
conved = torch.nn.functional.conv2d(down_weight.permute(1, 0, 2, 3), up_weight).permute(1, 0, 2, 3)
|
||||
# print(conved.size(), weight.size(), module.stride, module.padding)
|
||||
# logger.info(conved.size(), weight.size(), module.stride, module.padding)
|
||||
weight = weight + ratio * conved * scale
|
||||
|
||||
module.weight = torch.nn.Parameter(weight)
|
||||
|
||||
|
||||
def merge_lora_models(models, ratios, merge_dtype):
|
||||
def merge_lora_models(models, ratios, merge_dtype, concat=False, shuffle=False):
|
||||
base_alphas = {} # alpha for merged model
|
||||
base_dims = {}
|
||||
|
||||
merged_sd = {}
|
||||
v2 = None
|
||||
base_model = None
|
||||
for model, ratio in zip(models, ratios):
|
||||
print(f"loading: {model}")
|
||||
lora_sd = load_state_dict(model, merge_dtype)
|
||||
logger.info(f"loading: {model}")
|
||||
lora_sd, lora_metadata = load_state_dict(model, merge_dtype)
|
||||
|
||||
if lora_metadata is not None:
|
||||
if v2 is None:
|
||||
v2 = lora_metadata.get(train_util.SS_METADATA_KEY_V2, None) # return string
|
||||
if base_model is None:
|
||||
base_model = lora_metadata.get(train_util.SS_METADATA_KEY_BASE_MODEL_VERSION, None)
|
||||
|
||||
# get alpha and dim
|
||||
alphas = {} # alpha for current model
|
||||
@@ -135,13 +154,19 @@ def merge_lora_models(models, ratios, merge_dtype):
|
||||
if lora_module_name not in base_alphas:
|
||||
base_alphas[lora_module_name] = alpha
|
||||
|
||||
print(f"dim: {list(set(dims.values()))}, alpha: {list(set(alphas.values()))}")
|
||||
logger.info(f"dim: {list(set(dims.values()))}, alpha: {list(set(alphas.values()))}")
|
||||
|
||||
# merge
|
||||
print(f"merging...")
|
||||
logger.info(f"merging...")
|
||||
for key in lora_sd.keys():
|
||||
if "alpha" in key:
|
||||
continue
|
||||
if "lora_up" in key and concat:
|
||||
concat_dim = 1
|
||||
elif "lora_down" in key and concat:
|
||||
concat_dim = 0
|
||||
else:
|
||||
concat_dim = None
|
||||
|
||||
lora_module_name = key[: key.rfind(".lora_")]
|
||||
|
||||
@@ -149,12 +174,16 @@ def merge_lora_models(models, ratios, merge_dtype):
|
||||
alpha = alphas[lora_module_name]
|
||||
|
||||
scale = math.sqrt(alpha / base_alpha) * ratio
|
||||
scale = abs(scale) if "lora_up" in key else scale # マイナスの重みに対応する。
|
||||
|
||||
if key in merged_sd:
|
||||
assert (
|
||||
merged_sd[key].size() == lora_sd[key].size()
|
||||
merged_sd[key].size() == lora_sd[key].size() or concat_dim is not None
|
||||
), f"weights shape mismatch merging v1 and v2, different dims? / 重みのサイズが合いません。v1とv2、または次元数の異なるモデルはマージできません"
|
||||
merged_sd[key] = merged_sd[key] + lora_sd[key] * scale
|
||||
if concat_dim is not None:
|
||||
merged_sd[key] = torch.cat([merged_sd[key], lora_sd[key] * scale], dim=concat_dim)
|
||||
else:
|
||||
merged_sd[key] = merged_sd[key] + lora_sd[key] * scale
|
||||
else:
|
||||
merged_sd[key] = lora_sd[key] * scale
|
||||
|
||||
@@ -162,11 +191,37 @@ def merge_lora_models(models, ratios, merge_dtype):
|
||||
for lora_module_name, alpha in base_alphas.items():
|
||||
key = lora_module_name + ".alpha"
|
||||
merged_sd[key] = torch.tensor(alpha)
|
||||
if shuffle:
|
||||
key_down = lora_module_name + ".lora_down.weight"
|
||||
key_up = lora_module_name + ".lora_up.weight"
|
||||
dim = merged_sd[key_down].shape[0]
|
||||
perm = torch.randperm(dim)
|
||||
merged_sd[key_down] = merged_sd[key_down][perm]
|
||||
merged_sd[key_up] = merged_sd[key_up][:,perm]
|
||||
|
||||
print("merged model")
|
||||
print(f"dim: {list(set(base_dims.values()))}, alpha: {list(set(base_alphas.values()))}")
|
||||
logger.info("merged model")
|
||||
logger.info(f"dim: {list(set(base_dims.values()))}, alpha: {list(set(base_alphas.values()))}")
|
||||
|
||||
return merged_sd
|
||||
# check all dims are same
|
||||
dims_list = list(set(base_dims.values()))
|
||||
alphas_list = list(set(base_alphas.values()))
|
||||
all_same_dims = True
|
||||
all_same_alphas = True
|
||||
for dims in dims_list:
|
||||
if dims != dims_list[0]:
|
||||
all_same_dims = False
|
||||
break
|
||||
for alphas in alphas_list:
|
||||
if alphas != alphas_list[0]:
|
||||
all_same_alphas = False
|
||||
break
|
||||
|
||||
# build minimum metadata
|
||||
dims = f"{dims_list[0]}" if all_same_dims else "Dynamic"
|
||||
alphas = f"{alphas_list[0]}" if all_same_alphas else "Dynamic"
|
||||
metadata = train_util.build_minimum_network_metadata(v2, base_model, "networks.lora", dims, alphas, None)
|
||||
|
||||
return merged_sd, metadata, v2 == "True"
|
||||
|
||||
|
||||
def merge(args):
|
||||
@@ -187,19 +242,63 @@ def merge(args):
|
||||
save_dtype = merge_dtype
|
||||
|
||||
if args.sd_model is not None:
|
||||
print(f"loading SD model: {args.sd_model}")
|
||||
logger.info(f"loading SD model: {args.sd_model}")
|
||||
|
||||
text_encoder, vae, unet = model_util.load_models_from_stable_diffusion_checkpoint(args.v2, args.sd_model)
|
||||
|
||||
merge_to_sd_model(text_encoder, unet, args.models, args.ratios, merge_dtype)
|
||||
|
||||
print(f"saving SD model to: {args.save_to}")
|
||||
model_util.save_stable_diffusion_checkpoint(args.v2, args.save_to, text_encoder, unet, args.sd_model, 0, 0, save_dtype, vae)
|
||||
else:
|
||||
state_dict = merge_lora_models(args.models, args.ratios, merge_dtype)
|
||||
if args.no_metadata:
|
||||
sai_metadata = None
|
||||
else:
|
||||
merged_from = sai_model_spec.build_merged_from([args.sd_model] + args.models)
|
||||
title = os.path.splitext(os.path.basename(args.save_to))[0]
|
||||
sai_metadata = sai_model_spec.build_metadata(
|
||||
None,
|
||||
args.v2,
|
||||
args.v2,
|
||||
False,
|
||||
False,
|
||||
False,
|
||||
time.time(),
|
||||
title=title,
|
||||
merged_from=merged_from,
|
||||
is_stable_diffusion_ckpt=True,
|
||||
)
|
||||
if args.v2:
|
||||
# TODO read sai modelspec
|
||||
logger.warning(
|
||||
"Cannot determine if model is for v-prediction, so save metadata as v-prediction / modelがv-prediction用か否か不明なため、仮にv-prediction用としてmetadataを保存します"
|
||||
)
|
||||
|
||||
print(f"saving model to: {args.save_to}")
|
||||
save_to_file(args.save_to, state_dict, state_dict, save_dtype)
|
||||
logger.info(f"saving SD model to: {args.save_to}")
|
||||
model_util.save_stable_diffusion_checkpoint(
|
||||
args.v2, args.save_to, text_encoder, unet, args.sd_model, 0, 0, sai_metadata, save_dtype, vae
|
||||
)
|
||||
else:
|
||||
state_dict, metadata, v2 = merge_lora_models(args.models, args.ratios, merge_dtype, args.concat, args.shuffle)
|
||||
|
||||
logger.info(f"calculating hashes and creating metadata...")
|
||||
|
||||
model_hash, legacy_hash = train_util.precalculate_safetensors_hashes(state_dict, metadata)
|
||||
metadata["sshs_model_hash"] = model_hash
|
||||
metadata["sshs_legacy_hash"] = legacy_hash
|
||||
|
||||
if not args.no_metadata:
|
||||
merged_from = sai_model_spec.build_merged_from(args.models)
|
||||
title = os.path.splitext(os.path.basename(args.save_to))[0]
|
||||
sai_metadata = sai_model_spec.build_metadata(
|
||||
state_dict, v2, v2, False, True, False, time.time(), title=title, merged_from=merged_from
|
||||
)
|
||||
if v2:
|
||||
# TODO read sai modelspec
|
||||
logger.warning(
|
||||
"Cannot determine if LoRA is for v-prediction, so save metadata as v-prediction / LoRAがv-prediction用か否か不明なため、仮にv-prediction用としてmetadataを保存します"
|
||||
)
|
||||
metadata.update(sai_metadata)
|
||||
|
||||
logger.info(f"saving model to: {args.save_to}")
|
||||
save_to_file(args.save_to, state_dict, state_dict, save_dtype, metadata)
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
@@ -232,7 +331,25 @@ def setup_parser() -> argparse.ArgumentParser:
|
||||
"--models", type=str, nargs="*", help="LoRA models to merge: ckpt or safetensors file / マージするLoRAモデル、ckptまたはsafetensors"
|
||||
)
|
||||
parser.add_argument("--ratios", type=float, nargs="*", help="ratios for each model / それぞれのLoRAモデルの比率")
|
||||
|
||||
parser.add_argument(
|
||||
"--no_metadata",
|
||||
action="store_true",
|
||||
help="do not save sai modelspec metadata (minimum ss_metadata for LoRA is saved) / "
|
||||
+ "sai modelspecのメタデータを保存しない(LoRAの最低限のss_metadataは保存される)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--concat",
|
||||
action="store_true",
|
||||
help="concat lora instead of merge (The dim(rank) of the output LoRA is the sum of the input dims) / "
|
||||
+ "マージの代わりに結合する(LoRAのdim(rank)は入力dimの合計になる)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--shuffle",
|
||||
action="store_true",
|
||||
help="shuffle lora weight./ "
|
||||
+ "LoRAの重みをシャッフルする",
|
||||
)
|
||||
|
||||
return parser
|
||||
|
||||
|
||||
|
||||
@@ -6,7 +6,10 @@ import torch
|
||||
from safetensors.torch import load_file, save_file
|
||||
import library.model_util as model_util
|
||||
import lora
|
||||
|
||||
from library.utils import setup_logging
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
def load_state_dict(file_name, dtype):
|
||||
if os.path.splitext(file_name)[1] == '.safetensors':
|
||||
@@ -54,10 +57,10 @@ def merge_to_sd_model(text_encoder, unet, models, ratios, merge_dtype):
|
||||
name_to_module[lora_name] = child_module
|
||||
|
||||
for model, ratio in zip(models, ratios):
|
||||
print(f"loading: {model}")
|
||||
logger.info(f"loading: {model}")
|
||||
lora_sd = load_state_dict(model, merge_dtype)
|
||||
|
||||
print(f"merging...")
|
||||
logger.info(f"merging...")
|
||||
for key in lora_sd.keys():
|
||||
if "lora_down" in key:
|
||||
up_key = key.replace("lora_down", "lora_up")
|
||||
@@ -66,10 +69,10 @@ def merge_to_sd_model(text_encoder, unet, models, ratios, merge_dtype):
|
||||
# find original module for this lora
|
||||
module_name = '.'.join(key.split('.')[:-2]) # remove trailing ".lora_down.weight"
|
||||
if module_name not in name_to_module:
|
||||
print(f"no module found for LoRA weight: {key}")
|
||||
logger.info(f"no module found for LoRA weight: {key}")
|
||||
continue
|
||||
module = name_to_module[module_name]
|
||||
# print(f"apply {key} to {module}")
|
||||
# logger.info(f"apply {key} to {module}")
|
||||
|
||||
down_weight = lora_sd[key]
|
||||
up_weight = lora_sd[up_key]
|
||||
@@ -96,10 +99,10 @@ def merge_lora_models(models, ratios, merge_dtype):
|
||||
alpha = None
|
||||
dim = None
|
||||
for model, ratio in zip(models, ratios):
|
||||
print(f"loading: {model}")
|
||||
logger.info(f"loading: {model}")
|
||||
lora_sd = load_state_dict(model, merge_dtype)
|
||||
|
||||
print(f"merging...")
|
||||
logger.info(f"merging...")
|
||||
for key in lora_sd.keys():
|
||||
if 'alpha' in key:
|
||||
if key in merged_sd:
|
||||
@@ -117,7 +120,7 @@ def merge_lora_models(models, ratios, merge_dtype):
|
||||
dim = lora_sd[key].size()[0]
|
||||
merged_sd[key] = lora_sd[key] * ratio
|
||||
|
||||
print(f"dim (rank): {dim}, alpha: {alpha}")
|
||||
logger.info(f"dim (rank): {dim}, alpha: {alpha}")
|
||||
if alpha is None:
|
||||
alpha = dim
|
||||
|
||||
@@ -142,19 +145,21 @@ def merge(args):
|
||||
save_dtype = merge_dtype
|
||||
|
||||
if args.sd_model is not None:
|
||||
print(f"loading SD model: {args.sd_model}")
|
||||
logger.info(f"loading SD model: {args.sd_model}")
|
||||
|
||||
text_encoder, vae, unet = model_util.load_models_from_stable_diffusion_checkpoint(args.v2, args.sd_model)
|
||||
|
||||
merge_to_sd_model(text_encoder, unet, args.models, args.ratios, merge_dtype)
|
||||
|
||||
print(f"saving SD model to: {args.save_to}")
|
||||
logger.info("")
|
||||
logger.info(f"saving SD model to: {args.save_to}")
|
||||
model_util.save_stable_diffusion_checkpoint(args.v2, args.save_to, text_encoder, unet,
|
||||
args.sd_model, 0, 0, save_dtype, vae)
|
||||
else:
|
||||
state_dict, _, _ = merge_lora_models(args.models, args.ratios, merge_dtype)
|
||||
|
||||
print(f"saving model to: {args.save_to}")
|
||||
logger.info(f"")
|
||||
logger.info(f"saving model to: {args.save_to}")
|
||||
save_to_file(args.save_to, state_dict, state_dict, save_dtype)
|
||||
|
||||
|
||||
|
||||
459
networks/oft.py
Normal file
459
networks/oft.py
Normal file
@@ -0,0 +1,459 @@
|
||||
# OFT network module
|
||||
|
||||
import math
|
||||
import os
|
||||
from typing import Dict, List, Optional, Tuple, Type, Union
|
||||
from diffusers import AutoencoderKL
|
||||
import einops
|
||||
from transformers import CLIPTextModel
|
||||
import numpy as np
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
import re
|
||||
from library.utils import setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
RE_UPDOWN = re.compile(r"(up|down)_blocks_(\d+)_(resnets|upsamplers|downsamplers|attentions)_(\d+)_")
|
||||
|
||||
|
||||
class OFTModule(torch.nn.Module):
|
||||
"""
|
||||
replaces forward method of the original Linear, instead of replacing the original Linear module.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
oft_name,
|
||||
org_module: torch.nn.Module,
|
||||
multiplier=1.0,
|
||||
dim=4,
|
||||
alpha=1,
|
||||
):
|
||||
"""
|
||||
dim -> num blocks
|
||||
alpha -> constraint
|
||||
"""
|
||||
super().__init__()
|
||||
self.oft_name = oft_name
|
||||
|
||||
self.num_blocks = dim
|
||||
|
||||
if "Linear" in org_module.__class__.__name__:
|
||||
out_dim = org_module.out_features
|
||||
elif "Conv" in org_module.__class__.__name__:
|
||||
out_dim = org_module.out_channels
|
||||
|
||||
if type(alpha) == torch.Tensor:
|
||||
alpha = alpha.detach().numpy()
|
||||
|
||||
# constraint in original paper is alpha * out_dim * out_dim, but we use alpha * out_dim for backward compatibility
|
||||
# original alpha is 1e-6, so we use 1e-3 or 1e-4 for alpha
|
||||
self.constraint = alpha * out_dim
|
||||
|
||||
self.register_buffer("alpha", torch.tensor(alpha))
|
||||
|
||||
self.block_size = out_dim // self.num_blocks
|
||||
self.oft_blocks = torch.nn.Parameter(torch.zeros(self.num_blocks, self.block_size, self.block_size))
|
||||
self.I = torch.eye(self.block_size).unsqueeze(0).repeat(self.num_blocks, 1, 1) # cpu
|
||||
|
||||
self.out_dim = out_dim
|
||||
self.shape = org_module.weight.shape
|
||||
|
||||
self.multiplier = multiplier
|
||||
self.org_module = [org_module] # moduleにならないようにlistに入れる
|
||||
|
||||
def apply_to(self):
|
||||
self.org_forward = self.org_module[0].forward
|
||||
self.org_module[0].forward = self.forward
|
||||
|
||||
def get_weight(self, multiplier=None):
|
||||
if multiplier is None:
|
||||
multiplier = self.multiplier
|
||||
|
||||
block_Q = self.oft_blocks - self.oft_blocks.transpose(1, 2)
|
||||
norm_Q = torch.norm(block_Q.flatten())
|
||||
new_norm_Q = torch.clamp(norm_Q, max=self.constraint)
|
||||
block_Q = block_Q * ((new_norm_Q + 1e-8) / (norm_Q + 1e-8))
|
||||
|
||||
if self.I.device != block_Q.device:
|
||||
self.I = self.I.to(block_Q.device)
|
||||
I = self.I
|
||||
block_R = torch.matmul(I + block_Q, (I - block_Q).float().inverse())
|
||||
block_R_weighted = self.multiplier * (block_R - I) + I
|
||||
return block_R_weighted
|
||||
|
||||
def forward(self, x, scale=None):
|
||||
if self.multiplier == 0.0:
|
||||
return self.org_forward(x)
|
||||
org_module = self.org_module[0]
|
||||
org_dtype = x.dtype
|
||||
|
||||
R = self.get_weight().to(torch.float32)
|
||||
W = org_module.weight.to(torch.float32)
|
||||
|
||||
if len(W.shape) == 4: # Conv2d
|
||||
W_reshaped = einops.rearrange(W, "(k n) ... -> k n ...", k=self.num_blocks, n=self.block_size)
|
||||
RW = torch.einsum("k n m, k n ... -> k m ...", R, W_reshaped)
|
||||
RW = einops.rearrange(RW, "k m ... -> (k m) ...")
|
||||
result = F.conv2d(
|
||||
x, RW.to(org_dtype), org_module.bias, org_module.stride, org_module.padding, org_module.dilation, org_module.groups
|
||||
)
|
||||
else: # Linear
|
||||
W_reshaped = einops.rearrange(W, "(k n) m -> k n m", k=self.num_blocks, n=self.block_size)
|
||||
RW = torch.einsum("k n m, k n p -> k m p", R, W_reshaped)
|
||||
RW = einops.rearrange(RW, "k m p -> (k m) p")
|
||||
result = F.linear(x, RW.to(org_dtype), org_module.bias)
|
||||
return result
|
||||
|
||||
|
||||
class OFTInfModule(OFTModule):
|
||||
def __init__(
|
||||
self,
|
||||
oft_name,
|
||||
org_module: torch.nn.Module,
|
||||
multiplier=1.0,
|
||||
dim=4,
|
||||
alpha=1,
|
||||
**kwargs,
|
||||
):
|
||||
# no dropout for inference
|
||||
super().__init__(oft_name, org_module, multiplier, dim, alpha)
|
||||
self.enabled = True
|
||||
self.network: OFTNetwork = None
|
||||
|
||||
def set_network(self, network):
|
||||
self.network = network
|
||||
|
||||
def forward(self, x, scale=None):
|
||||
if not self.enabled:
|
||||
return self.org_forward(x)
|
||||
return super().forward(x, scale)
|
||||
|
||||
def merge_to(self, multiplier=None):
|
||||
# get org weight
|
||||
org_sd = self.org_module[0].state_dict()
|
||||
org_weight = org_sd["weight"].to(torch.float32)
|
||||
|
||||
R = self.get_weight(multiplier).to(torch.float32)
|
||||
|
||||
weight = org_weight.reshape(self.num_blocks, self.block_size, -1)
|
||||
weight = torch.einsum("k n m, k n ... -> k m ...", R, weight)
|
||||
weight = weight.reshape(org_weight.shape)
|
||||
|
||||
# convert back to original dtype
|
||||
weight = weight.to(org_sd["weight"].dtype)
|
||||
|
||||
# set weight to org_module
|
||||
org_sd["weight"] = weight
|
||||
self.org_module[0].load_state_dict(org_sd)
|
||||
|
||||
|
||||
def create_network(
|
||||
multiplier: float,
|
||||
network_dim: Optional[int],
|
||||
network_alpha: Optional[float],
|
||||
vae: AutoencoderKL,
|
||||
text_encoder: Union[CLIPTextModel, List[CLIPTextModel]],
|
||||
unet,
|
||||
neuron_dropout: Optional[float] = None,
|
||||
**kwargs,
|
||||
):
|
||||
if network_dim is None:
|
||||
network_dim = 4 # default
|
||||
if network_alpha is None: # should be set
|
||||
logger.info(
|
||||
"network_alpha is not set, use default value 1e-3 / network_alphaが設定されていないのでデフォルト値 1e-3 を使用します"
|
||||
)
|
||||
network_alpha = 1e-3
|
||||
elif network_alpha >= 1:
|
||||
logger.warning(
|
||||
"network_alpha is too large (>=1, maybe default value is too large), please consider to set smaller value like 1e-3"
|
||||
" / network_alphaが大きすぎるようです(>=1, デフォルト値が大きすぎる可能性があります)。1e-3のような小さな値を推奨"
|
||||
)
|
||||
|
||||
enable_all_linear = kwargs.get("enable_all_linear", None)
|
||||
enable_conv = kwargs.get("enable_conv", None)
|
||||
if enable_all_linear is not None:
|
||||
enable_all_linear = bool(enable_all_linear)
|
||||
if enable_conv is not None:
|
||||
enable_conv = bool(enable_conv)
|
||||
|
||||
network = OFTNetwork(
|
||||
text_encoder,
|
||||
unet,
|
||||
multiplier=multiplier,
|
||||
dim=network_dim,
|
||||
alpha=network_alpha,
|
||||
enable_all_linear=enable_all_linear,
|
||||
enable_conv=enable_conv,
|
||||
varbose=True,
|
||||
)
|
||||
return network
|
||||
|
||||
|
||||
# Create network from weights for inference, weights are not loaded here (because can be merged)
|
||||
def create_network_from_weights(multiplier, file, vae, text_encoder, unet, weights_sd=None, for_inference=False, **kwargs):
|
||||
if weights_sd is None:
|
||||
if os.path.splitext(file)[1] == ".safetensors":
|
||||
from safetensors.torch import load_file, safe_open
|
||||
|
||||
weights_sd = load_file(file)
|
||||
else:
|
||||
weights_sd = torch.load(file, map_location="cpu")
|
||||
|
||||
# check dim, alpha and if weights have for conv2d
|
||||
dim = None
|
||||
alpha = None
|
||||
has_conv2d = None
|
||||
all_linear = None
|
||||
for name, param in weights_sd.items():
|
||||
if name.endswith(".alpha"):
|
||||
if alpha is None:
|
||||
alpha = param.item()
|
||||
else:
|
||||
if dim is None:
|
||||
dim = param.size()[0]
|
||||
if has_conv2d is None and "in_layers_2" in name:
|
||||
has_conv2d = True
|
||||
if all_linear is None and "_ff_" in name:
|
||||
all_linear = True
|
||||
if dim is not None and alpha is not None and has_conv2d is not None and all_linear is not None:
|
||||
break
|
||||
if has_conv2d is None:
|
||||
has_conv2d = False
|
||||
if all_linear is None:
|
||||
all_linear = False
|
||||
|
||||
module_class = OFTInfModule if for_inference else OFTModule
|
||||
network = OFTNetwork(
|
||||
text_encoder,
|
||||
unet,
|
||||
multiplier=multiplier,
|
||||
dim=dim,
|
||||
alpha=alpha,
|
||||
enable_all_linear=all_linear,
|
||||
enable_conv=has_conv2d,
|
||||
module_class=module_class,
|
||||
)
|
||||
return network, weights_sd
|
||||
|
||||
|
||||
class OFTNetwork(torch.nn.Module):
|
||||
UNET_TARGET_REPLACE_MODULE_ATTN_ONLY = ["CrossAttention"]
|
||||
UNET_TARGET_REPLACE_MODULE_ALL_LINEAR = ["Transformer2DModel"]
|
||||
UNET_TARGET_REPLACE_MODULE_CONV2D_3X3 = ["ResnetBlock2D", "Downsample2D", "Upsample2D"]
|
||||
OFT_PREFIX_UNET = "oft_unet" # これ変えないほうがいいかな
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
text_encoder: Union[List[CLIPTextModel], CLIPTextModel],
|
||||
unet,
|
||||
multiplier: float = 1.0,
|
||||
dim: int = 4,
|
||||
alpha: float = 1,
|
||||
enable_all_linear: Optional[bool] = False,
|
||||
enable_conv: Optional[bool] = False,
|
||||
module_class: Type[object] = OFTModule,
|
||||
varbose: Optional[bool] = False,
|
||||
) -> None:
|
||||
super().__init__()
|
||||
self.multiplier = multiplier
|
||||
|
||||
self.dim = dim
|
||||
self.alpha = alpha
|
||||
|
||||
logger.info(
|
||||
f"create OFT network. num blocks: {self.dim}, constraint: {self.alpha}, multiplier: {self.multiplier}, enable_conv: {enable_conv}, enable_all_linear: {enable_all_linear}"
|
||||
)
|
||||
|
||||
# create module instances
|
||||
def create_modules(
|
||||
root_module: torch.nn.Module,
|
||||
target_replace_modules: List[torch.nn.Module],
|
||||
) -> List[OFTModule]:
|
||||
prefix = self.OFT_PREFIX_UNET
|
||||
ofts = []
|
||||
for name, module in root_module.named_modules():
|
||||
if module.__class__.__name__ in target_replace_modules:
|
||||
for child_name, child_module in module.named_modules():
|
||||
is_linear = "Linear" in child_module.__class__.__name__
|
||||
is_conv2d = "Conv2d" in child_module.__class__.__name__
|
||||
is_conv2d_1x1 = is_conv2d and child_module.kernel_size == (1, 1)
|
||||
|
||||
if is_linear or is_conv2d_1x1 or (is_conv2d and enable_conv):
|
||||
oft_name = prefix + "." + name + "." + child_name
|
||||
oft_name = oft_name.replace(".", "_")
|
||||
# logger.info(oft_name)
|
||||
|
||||
oft = module_class(
|
||||
oft_name,
|
||||
child_module,
|
||||
self.multiplier,
|
||||
dim,
|
||||
alpha,
|
||||
)
|
||||
ofts.append(oft)
|
||||
return ofts
|
||||
|
||||
# extend U-Net target modules if conv2d 3x3 is enabled, or load from weights
|
||||
if enable_all_linear:
|
||||
target_modules = OFTNetwork.UNET_TARGET_REPLACE_MODULE_ALL_LINEAR
|
||||
else:
|
||||
target_modules = OFTNetwork.UNET_TARGET_REPLACE_MODULE_ATTN_ONLY
|
||||
if enable_conv:
|
||||
target_modules += OFTNetwork.UNET_TARGET_REPLACE_MODULE_CONV2D_3X3
|
||||
|
||||
self.unet_ofts: List[OFTModule] = create_modules(unet, target_modules)
|
||||
logger.info(f"create OFT for U-Net: {len(self.unet_ofts)} modules.")
|
||||
|
||||
# assertion
|
||||
names = set()
|
||||
for oft in self.unet_ofts:
|
||||
assert oft.oft_name not in names, f"duplicated oft name: {oft.oft_name}"
|
||||
names.add(oft.oft_name)
|
||||
|
||||
def set_multiplier(self, multiplier):
|
||||
self.multiplier = multiplier
|
||||
for oft in self.unet_ofts:
|
||||
oft.multiplier = self.multiplier
|
||||
|
||||
def load_weights(self, file):
|
||||
if os.path.splitext(file)[1] == ".safetensors":
|
||||
from safetensors.torch import load_file
|
||||
|
||||
weights_sd = load_file(file)
|
||||
else:
|
||||
weights_sd = torch.load(file, map_location="cpu")
|
||||
|
||||
info = self.load_state_dict(weights_sd, False)
|
||||
return info
|
||||
|
||||
def apply_to(self, text_encoder, unet, apply_text_encoder=True, apply_unet=True):
|
||||
assert apply_unet, "apply_unet must be True"
|
||||
|
||||
for oft in self.unet_ofts:
|
||||
oft.apply_to()
|
||||
self.add_module(oft.oft_name, oft)
|
||||
|
||||
# マージできるかどうかを返す
|
||||
def is_mergeable(self):
|
||||
return True
|
||||
|
||||
# TODO refactor to common function with apply_to
|
||||
def merge_to(self, text_encoder, unet, weights_sd, dtype, device):
|
||||
logger.info("enable OFT for U-Net")
|
||||
|
||||
for oft in self.unet_ofts:
|
||||
sd_for_lora = {}
|
||||
for key in weights_sd.keys():
|
||||
if key.startswith(oft.oft_name):
|
||||
sd_for_lora[key[len(oft.oft_name) + 1 :]] = weights_sd[key]
|
||||
oft.load_state_dict(sd_for_lora, False)
|
||||
oft.merge_to()
|
||||
|
||||
logger.info(f"weights are merged")
|
||||
|
||||
# 二つのText Encoderに別々の学習率を設定できるようにするといいかも
|
||||
def prepare_optimizer_params(self, text_encoder_lr, unet_lr, default_lr):
|
||||
self.requires_grad_(True)
|
||||
all_params = []
|
||||
|
||||
def enumerate_params(ofts):
|
||||
params = []
|
||||
for oft in ofts:
|
||||
params.extend(oft.parameters())
|
||||
|
||||
# logger.info num of params
|
||||
num_params = 0
|
||||
for p in params:
|
||||
num_params += p.numel()
|
||||
logger.info(f"OFT params: {num_params}")
|
||||
return params
|
||||
|
||||
param_data = {"params": enumerate_params(self.unet_ofts)}
|
||||
if unet_lr is not None:
|
||||
param_data["lr"] = unet_lr
|
||||
all_params.append(param_data)
|
||||
|
||||
return all_params
|
||||
|
||||
def enable_gradient_checkpointing(self):
|
||||
# not supported
|
||||
pass
|
||||
|
||||
def prepare_grad_etc(self, text_encoder, unet):
|
||||
self.requires_grad_(True)
|
||||
|
||||
def on_epoch_start(self, text_encoder, unet):
|
||||
self.train()
|
||||
|
||||
def get_trainable_params(self):
|
||||
return self.parameters()
|
||||
|
||||
def save_weights(self, file, dtype, metadata):
|
||||
if metadata is not None and len(metadata) == 0:
|
||||
metadata = None
|
||||
|
||||
state_dict = self.state_dict()
|
||||
|
||||
if dtype is not None:
|
||||
for key in list(state_dict.keys()):
|
||||
v = state_dict[key]
|
||||
v = v.detach().clone().to("cpu").to(dtype)
|
||||
state_dict[key] = v
|
||||
|
||||
if os.path.splitext(file)[1] == ".safetensors":
|
||||
from safetensors.torch import save_file
|
||||
from library import train_util
|
||||
|
||||
# Precalculate model hashes to save time on indexing
|
||||
if metadata is None:
|
||||
metadata = {}
|
||||
model_hash, legacy_hash = train_util.precalculate_safetensors_hashes(state_dict, metadata)
|
||||
metadata["sshs_model_hash"] = model_hash
|
||||
metadata["sshs_legacy_hash"] = legacy_hash
|
||||
|
||||
save_file(state_dict, file, metadata)
|
||||
else:
|
||||
torch.save(state_dict, file)
|
||||
|
||||
def backup_weights(self):
|
||||
# 重みのバックアップを行う
|
||||
ofts: List[OFTInfModule] = self.unet_ofts
|
||||
for oft in ofts:
|
||||
org_module = oft.org_module[0]
|
||||
if not hasattr(org_module, "_lora_org_weight"):
|
||||
sd = org_module.state_dict()
|
||||
org_module._lora_org_weight = sd["weight"].detach().clone()
|
||||
org_module._lora_restored = True
|
||||
|
||||
def restore_weights(self):
|
||||
# 重みのリストアを行う
|
||||
ofts: List[OFTInfModule] = self.unet_ofts
|
||||
for oft in ofts:
|
||||
org_module = oft.org_module[0]
|
||||
if not org_module._lora_restored:
|
||||
sd = org_module.state_dict()
|
||||
sd["weight"] = org_module._lora_org_weight
|
||||
org_module.load_state_dict(sd)
|
||||
org_module._lora_restored = True
|
||||
|
||||
def pre_calculation(self):
|
||||
# 事前計算を行う
|
||||
ofts: List[OFTInfModule] = self.unet_ofts
|
||||
for oft in ofts:
|
||||
org_module = oft.org_module[0]
|
||||
oft.merge_to()
|
||||
# sd = org_module.state_dict()
|
||||
# org_weight = sd["weight"]
|
||||
# lora_weight = oft.get_weight().to(org_weight.device, dtype=org_weight.dtype)
|
||||
# sd["weight"] = org_weight + lora_weight
|
||||
# assert sd["weight"].shape == org_weight.shape
|
||||
# org_module.load_state_dict(sd)
|
||||
|
||||
org_module._lora_restored = False
|
||||
oft.enabled = False
|
||||
@@ -2,80 +2,86 @@
|
||||
# This code is based off the extract_lora_from_models.py file which is based on https://github.com/cloneofsimo/lora/blob/develop/lora_diffusion/cli_svd.py
|
||||
# Thanks to cloneofsimo
|
||||
|
||||
import os
|
||||
import argparse
|
||||
import torch
|
||||
from safetensors.torch import load_file, save_file, safe_open
|
||||
from tqdm import tqdm
|
||||
from library import train_util, model_util
|
||||
import numpy as np
|
||||
|
||||
from library import train_util
|
||||
from library import model_util
|
||||
from library.utils import setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
MIN_SV = 1e-6
|
||||
|
||||
# Model save and load functions
|
||||
|
||||
|
||||
def load_state_dict(file_name, dtype):
|
||||
if model_util.is_safetensors(file_name):
|
||||
sd = load_file(file_name)
|
||||
with safe_open(file_name, framework="pt") as f:
|
||||
metadata = f.metadata()
|
||||
else:
|
||||
sd = torch.load(file_name, map_location='cpu')
|
||||
metadata = None
|
||||
if model_util.is_safetensors(file_name):
|
||||
sd = load_file(file_name)
|
||||
with safe_open(file_name, framework="pt") as f:
|
||||
metadata = f.metadata()
|
||||
else:
|
||||
sd = torch.load(file_name, map_location="cpu")
|
||||
metadata = None
|
||||
|
||||
for key in list(sd.keys()):
|
||||
if type(sd[key]) == torch.Tensor:
|
||||
sd[key] = sd[key].to(dtype)
|
||||
for key in list(sd.keys()):
|
||||
if type(sd[key]) == torch.Tensor:
|
||||
sd[key] = sd[key].to(dtype)
|
||||
|
||||
return sd, metadata
|
||||
return sd, metadata
|
||||
|
||||
|
||||
def save_to_file(file_name, model, state_dict, dtype, metadata):
|
||||
if dtype is not None:
|
||||
for key in list(state_dict.keys()):
|
||||
if type(state_dict[key]) == torch.Tensor:
|
||||
state_dict[key] = state_dict[key].to(dtype)
|
||||
|
||||
if model_util.is_safetensors(file_name):
|
||||
save_file(model, file_name, metadata)
|
||||
else:
|
||||
torch.save(model, file_name)
|
||||
def save_to_file(file_name, state_dict, metadata):
|
||||
if model_util.is_safetensors(file_name):
|
||||
save_file(state_dict, file_name, metadata)
|
||||
else:
|
||||
torch.save(state_dict, file_name)
|
||||
|
||||
|
||||
# Indexing functions
|
||||
|
||||
def index_sv_cumulative(S, target):
|
||||
original_sum = float(torch.sum(S))
|
||||
cumulative_sums = torch.cumsum(S, dim=0)/original_sum
|
||||
index = int(torch.searchsorted(cumulative_sums, target)) + 1
|
||||
index = max(1, min(index, len(S)-1))
|
||||
|
||||
return index
|
||||
def index_sv_cumulative(S, target):
|
||||
original_sum = float(torch.sum(S))
|
||||
cumulative_sums = torch.cumsum(S, dim=0) / original_sum
|
||||
index = int(torch.searchsorted(cumulative_sums, target)) + 1
|
||||
index = max(1, min(index, len(S) - 1))
|
||||
|
||||
return index
|
||||
|
||||
|
||||
def index_sv_fro(S, target):
|
||||
S_squared = S.pow(2)
|
||||
s_fro_sq = float(torch.sum(S_squared))
|
||||
sum_S_squared = torch.cumsum(S_squared, dim=0)/s_fro_sq
|
||||
index = int(torch.searchsorted(sum_S_squared, target**2)) + 1
|
||||
index = max(1, min(index, len(S)-1))
|
||||
S_squared = S.pow(2)
|
||||
S_fro_sq = float(torch.sum(S_squared))
|
||||
sum_S_squared = torch.cumsum(S_squared, dim=0) / S_fro_sq
|
||||
index = int(torch.searchsorted(sum_S_squared, target**2)) + 1
|
||||
index = max(1, min(index, len(S) - 1))
|
||||
|
||||
return index
|
||||
return index
|
||||
|
||||
|
||||
def index_sv_ratio(S, target):
|
||||
max_sv = S[0]
|
||||
min_sv = max_sv/target
|
||||
index = int(torch.sum(S > min_sv).item())
|
||||
index = max(1, min(index, len(S)-1))
|
||||
max_sv = S[0]
|
||||
min_sv = max_sv / target
|
||||
index = int(torch.sum(S > min_sv).item())
|
||||
index = max(1, min(index, len(S) - 1))
|
||||
|
||||
return index
|
||||
return index
|
||||
|
||||
|
||||
# Modified from Kohaku-blueleaf's extract/merge functions
|
||||
def extract_conv(weight, lora_rank, dynamic_method, dynamic_param, device, scale=1):
|
||||
out_size, in_size, kernel_size, _ = weight.size()
|
||||
U, S, Vh = torch.linalg.svd(weight.reshape(out_size, -1).to(device))
|
||||
|
||||
|
||||
param_dict = rank_resize(S, lora_rank, dynamic_method, dynamic_param, scale)
|
||||
lora_rank = param_dict["new_rank"]
|
||||
|
||||
@@ -92,17 +98,17 @@ def extract_conv(weight, lora_rank, dynamic_method, dynamic_param, device, scale
|
||||
|
||||
def extract_linear(weight, lora_rank, dynamic_method, dynamic_param, device, scale=1):
|
||||
out_size, in_size = weight.size()
|
||||
|
||||
|
||||
U, S, Vh = torch.linalg.svd(weight.to(device))
|
||||
|
||||
|
||||
param_dict = rank_resize(S, lora_rank, dynamic_method, dynamic_param, scale)
|
||||
lora_rank = param_dict["new_rank"]
|
||||
|
||||
|
||||
U = U[:, :lora_rank]
|
||||
S = S[:lora_rank]
|
||||
U = U @ torch.diag(S)
|
||||
Vh = Vh[:lora_rank, :]
|
||||
|
||||
|
||||
param_dict["lora_down"] = Vh.reshape(lora_rank, in_size).cpu()
|
||||
param_dict["lora_up"] = U.reshape(out_size, lora_rank).cpu()
|
||||
del U, S, Vh, weight
|
||||
@@ -113,7 +119,7 @@ def merge_conv(lora_down, lora_up, device):
|
||||
in_rank, in_size, kernel_size, k_ = lora_down.shape
|
||||
out_size, out_rank, _, _ = lora_up.shape
|
||||
assert in_rank == out_rank and kernel_size == k_, f"rank {in_rank} {out_rank} or kernel {kernel_size} {k_} mismatch"
|
||||
|
||||
|
||||
lora_down = lora_down.to(device)
|
||||
lora_up = lora_up.to(device)
|
||||
|
||||
@@ -127,233 +133,280 @@ def merge_linear(lora_down, lora_up, device):
|
||||
in_rank, in_size = lora_down.shape
|
||||
out_size, out_rank = lora_up.shape
|
||||
assert in_rank == out_rank, f"rank {in_rank} {out_rank} mismatch"
|
||||
|
||||
|
||||
lora_down = lora_down.to(device)
|
||||
lora_up = lora_up.to(device)
|
||||
|
||||
|
||||
weight = lora_up @ lora_down
|
||||
del lora_up, lora_down
|
||||
return weight
|
||||
|
||||
|
||||
|
||||
# Calculate new rank
|
||||
|
||||
|
||||
def rank_resize(S, rank, dynamic_method, dynamic_param, scale=1):
|
||||
param_dict = {}
|
||||
|
||||
if dynamic_method=="sv_ratio":
|
||||
if dynamic_method == "sv_ratio":
|
||||
# Calculate new dim and alpha based off ratio
|
||||
new_rank = index_sv_ratio(S, dynamic_param) + 1
|
||||
new_alpha = float(scale*new_rank)
|
||||
new_alpha = float(scale * new_rank)
|
||||
|
||||
elif dynamic_method=="sv_cumulative":
|
||||
elif dynamic_method == "sv_cumulative":
|
||||
# Calculate new dim and alpha based off cumulative sum
|
||||
new_rank = index_sv_cumulative(S, dynamic_param) + 1
|
||||
new_alpha = float(scale*new_rank)
|
||||
new_alpha = float(scale * new_rank)
|
||||
|
||||
elif dynamic_method=="sv_fro":
|
||||
elif dynamic_method == "sv_fro":
|
||||
# Calculate new dim and alpha based off sqrt sum of squares
|
||||
new_rank = index_sv_fro(S, dynamic_param) + 1
|
||||
new_alpha = float(scale*new_rank)
|
||||
new_alpha = float(scale * new_rank)
|
||||
else:
|
||||
new_rank = rank
|
||||
new_alpha = float(scale*new_rank)
|
||||
new_alpha = float(scale * new_rank)
|
||||
|
||||
|
||||
if S[0] <= MIN_SV: # Zero matrix, set dim to 1
|
||||
if S[0] <= MIN_SV: # Zero matrix, set dim to 1
|
||||
new_rank = 1
|
||||
new_alpha = float(scale*new_rank)
|
||||
elif new_rank > rank: # cap max rank at rank
|
||||
new_alpha = float(scale * new_rank)
|
||||
elif new_rank > rank: # cap max rank at rank
|
||||
new_rank = rank
|
||||
new_alpha = float(scale*new_rank)
|
||||
|
||||
new_alpha = float(scale * new_rank)
|
||||
|
||||
# Calculate resize info
|
||||
s_sum = torch.sum(torch.abs(S))
|
||||
s_rank = torch.sum(torch.abs(S[:new_rank]))
|
||||
|
||||
|
||||
S_squared = S.pow(2)
|
||||
s_fro = torch.sqrt(torch.sum(S_squared))
|
||||
s_red_fro = torch.sqrt(torch.sum(S_squared[:new_rank]))
|
||||
fro_percent = float(s_red_fro/s_fro)
|
||||
fro_percent = float(s_red_fro / s_fro)
|
||||
|
||||
param_dict["new_rank"] = new_rank
|
||||
param_dict["new_alpha"] = new_alpha
|
||||
param_dict["sum_retained"] = (s_rank)/s_sum
|
||||
param_dict["sum_retained"] = (s_rank) / s_sum
|
||||
param_dict["fro_retained"] = fro_percent
|
||||
param_dict["max_ratio"] = S[0]/S[new_rank - 1]
|
||||
param_dict["max_ratio"] = S[0] / S[new_rank - 1]
|
||||
|
||||
return param_dict
|
||||
|
||||
|
||||
def resize_lora_model(lora_sd, new_rank, save_dtype, device, dynamic_method, dynamic_param, verbose):
|
||||
network_alpha = None
|
||||
network_dim = None
|
||||
verbose_str = "\n"
|
||||
fro_list = []
|
||||
def resize_lora_model(lora_sd, new_rank, new_conv_rank, save_dtype, device, dynamic_method, dynamic_param, verbose):
|
||||
network_alpha = None
|
||||
network_dim = None
|
||||
verbose_str = "\n"
|
||||
fro_list = []
|
||||
|
||||
# Extract loaded lora dim and alpha
|
||||
for key, value in lora_sd.items():
|
||||
if network_alpha is None and 'alpha' in key:
|
||||
network_alpha = value
|
||||
if network_dim is None and 'lora_down' in key and len(value.size()) == 2:
|
||||
network_dim = value.size()[0]
|
||||
if network_alpha is not None and network_dim is not None:
|
||||
break
|
||||
if network_alpha is None:
|
||||
network_alpha = network_dim
|
||||
# Extract loaded lora dim and alpha
|
||||
for key, value in lora_sd.items():
|
||||
if network_alpha is None and "alpha" in key:
|
||||
network_alpha = value
|
||||
if network_dim is None and "lora_down" in key and len(value.size()) == 2:
|
||||
network_dim = value.size()[0]
|
||||
if network_alpha is not None and network_dim is not None:
|
||||
break
|
||||
if network_alpha is None:
|
||||
network_alpha = network_dim
|
||||
|
||||
scale = network_alpha/network_dim
|
||||
scale = network_alpha / network_dim
|
||||
|
||||
if dynamic_method:
|
||||
print(f"Dynamically determining new alphas and dims based off {dynamic_method}: {dynamic_param}, max rank is {new_rank}")
|
||||
if dynamic_method:
|
||||
logger.info(
|
||||
f"Dynamically determining new alphas and dims based off {dynamic_method}: {dynamic_param}, max rank is {new_rank}"
|
||||
)
|
||||
|
||||
lora_down_weight = None
|
||||
lora_up_weight = None
|
||||
lora_down_weight = None
|
||||
lora_up_weight = None
|
||||
|
||||
o_lora_sd = lora_sd.copy()
|
||||
block_down_name = None
|
||||
block_up_name = None
|
||||
o_lora_sd = lora_sd.copy()
|
||||
block_down_name = None
|
||||
block_up_name = None
|
||||
|
||||
with torch.no_grad():
|
||||
for key, value in tqdm(lora_sd.items()):
|
||||
weight_name = None
|
||||
if 'lora_down' in key:
|
||||
block_down_name = key.split(".")[0]
|
||||
weight_name = key.split(".")[-1]
|
||||
lora_down_weight = value
|
||||
else:
|
||||
continue
|
||||
with torch.no_grad():
|
||||
for key, value in tqdm(lora_sd.items()):
|
||||
weight_name = None
|
||||
if "lora_down" in key:
|
||||
block_down_name = key.rsplit(".lora_down", 1)[0]
|
||||
weight_name = key.rsplit(".", 1)[-1]
|
||||
lora_down_weight = value
|
||||
else:
|
||||
continue
|
||||
|
||||
# find corresponding lora_up and alpha
|
||||
block_up_name = block_down_name
|
||||
lora_up_weight = lora_sd.get(block_up_name + '.lora_up.' + weight_name, None)
|
||||
lora_alpha = lora_sd.get(block_down_name + '.alpha', None)
|
||||
# find corresponding lora_up and alpha
|
||||
block_up_name = block_down_name
|
||||
lora_up_weight = lora_sd.get(block_up_name + ".lora_up." + weight_name, None)
|
||||
lora_alpha = lora_sd.get(block_down_name + ".alpha", None)
|
||||
|
||||
weights_loaded = (lora_down_weight is not None and lora_up_weight is not None)
|
||||
weights_loaded = lora_down_weight is not None and lora_up_weight is not None
|
||||
|
||||
if weights_loaded:
|
||||
if weights_loaded:
|
||||
|
||||
conv2d = (len(lora_down_weight.size()) == 4)
|
||||
if lora_alpha is None:
|
||||
scale = 1.0
|
||||
else:
|
||||
scale = lora_alpha/lora_down_weight.size()[0]
|
||||
conv2d = len(lora_down_weight.size()) == 4
|
||||
if lora_alpha is None:
|
||||
scale = 1.0
|
||||
else:
|
||||
scale = lora_alpha / lora_down_weight.size()[0]
|
||||
|
||||
if conv2d:
|
||||
full_weight_matrix = merge_conv(lora_down_weight, lora_up_weight, device)
|
||||
param_dict = extract_conv(full_weight_matrix, new_rank, dynamic_method, dynamic_param, device, scale)
|
||||
else:
|
||||
full_weight_matrix = merge_linear(lora_down_weight, lora_up_weight, device)
|
||||
param_dict = extract_linear(full_weight_matrix, new_rank, dynamic_method, dynamic_param, device, scale)
|
||||
if conv2d:
|
||||
full_weight_matrix = merge_conv(lora_down_weight, lora_up_weight, device)
|
||||
param_dict = extract_conv(full_weight_matrix, new_conv_rank, dynamic_method, dynamic_param, device, scale)
|
||||
else:
|
||||
full_weight_matrix = merge_linear(lora_down_weight, lora_up_weight, device)
|
||||
param_dict = extract_linear(full_weight_matrix, new_rank, dynamic_method, dynamic_param, device, scale)
|
||||
|
||||
if verbose:
|
||||
max_ratio = param_dict['max_ratio']
|
||||
sum_retained = param_dict['sum_retained']
|
||||
fro_retained = param_dict['fro_retained']
|
||||
if not np.isnan(fro_retained):
|
||||
fro_list.append(float(fro_retained))
|
||||
if verbose:
|
||||
max_ratio = param_dict["max_ratio"]
|
||||
sum_retained = param_dict["sum_retained"]
|
||||
fro_retained = param_dict["fro_retained"]
|
||||
if not np.isnan(fro_retained):
|
||||
fro_list.append(float(fro_retained))
|
||||
|
||||
verbose_str+=f"{block_down_name:75} | "
|
||||
verbose_str+=f"sum(S) retained: {sum_retained:.1%}, fro retained: {fro_retained:.1%}, max(S) ratio: {max_ratio:0.1f}"
|
||||
verbose_str += f"{block_down_name:75} | "
|
||||
verbose_str += (
|
||||
f"sum(S) retained: {sum_retained:.1%}, fro retained: {fro_retained:.1%}, max(S) ratio: {max_ratio:0.1f}"
|
||||
)
|
||||
|
||||
if verbose and dynamic_method:
|
||||
verbose_str+=f", dynamic | dim: {param_dict['new_rank']}, alpha: {param_dict['new_alpha']}\n"
|
||||
else:
|
||||
verbose_str+=f"\n"
|
||||
if verbose and dynamic_method:
|
||||
verbose_str += f", dynamic | dim: {param_dict['new_rank']}, alpha: {param_dict['new_alpha']}\n"
|
||||
else:
|
||||
verbose_str += "\n"
|
||||
|
||||
new_alpha = param_dict['new_alpha']
|
||||
o_lora_sd[block_down_name + "." + "lora_down.weight"] = param_dict["lora_down"].to(save_dtype).contiguous()
|
||||
o_lora_sd[block_up_name + "." + "lora_up.weight"] = param_dict["lora_up"].to(save_dtype).contiguous()
|
||||
o_lora_sd[block_up_name + "." "alpha"] = torch.tensor(param_dict['new_alpha']).to(save_dtype)
|
||||
new_alpha = param_dict["new_alpha"]
|
||||
o_lora_sd[block_down_name + "." + "lora_down.weight"] = param_dict["lora_down"].to(save_dtype).contiguous()
|
||||
o_lora_sd[block_up_name + "." + "lora_up.weight"] = param_dict["lora_up"].to(save_dtype).contiguous()
|
||||
o_lora_sd[block_up_name + "." "alpha"] = torch.tensor(param_dict["new_alpha"]).to(save_dtype)
|
||||
|
||||
block_down_name = None
|
||||
block_up_name = None
|
||||
lora_down_weight = None
|
||||
lora_up_weight = None
|
||||
weights_loaded = False
|
||||
del param_dict
|
||||
block_down_name = None
|
||||
block_up_name = None
|
||||
lora_down_weight = None
|
||||
lora_up_weight = None
|
||||
weights_loaded = False
|
||||
del param_dict
|
||||
|
||||
if verbose:
|
||||
print(verbose_str)
|
||||
|
||||
print(f"Average Frobenius norm retention: {np.mean(fro_list):.2%} | std: {np.std(fro_list):0.3f}")
|
||||
print("resizing complete")
|
||||
return o_lora_sd, network_dim, new_alpha
|
||||
if verbose:
|
||||
print(verbose_str)
|
||||
print(f"Average Frobenius norm retention: {np.mean(fro_list):.2%} | std: {np.std(fro_list):0.3f}")
|
||||
logger.info("resizing complete")
|
||||
return o_lora_sd, network_dim, new_alpha
|
||||
|
||||
|
||||
def resize(args):
|
||||
if args.save_to is None or not (
|
||||
args.save_to.endswith(".ckpt")
|
||||
or args.save_to.endswith(".pt")
|
||||
or args.save_to.endswith(".pth")
|
||||
or args.save_to.endswith(".safetensors")
|
||||
):
|
||||
raise Exception("The --save_to argument must be specified and must be a .ckpt , .pt, .pth or .safetensors file.")
|
||||
|
||||
def str_to_dtype(p):
|
||||
if p == 'float':
|
||||
return torch.float
|
||||
if p == 'fp16':
|
||||
return torch.float16
|
||||
if p == 'bf16':
|
||||
return torch.bfloat16
|
||||
return None
|
||||
args.new_conv_rank = args.new_conv_rank if args.new_conv_rank is not None else args.new_rank
|
||||
|
||||
if args.dynamic_method and not args.dynamic_param:
|
||||
raise Exception("If using dynamic_method, then dynamic_param is required")
|
||||
def str_to_dtype(p):
|
||||
if p == "float":
|
||||
return torch.float
|
||||
if p == "fp16":
|
||||
return torch.float16
|
||||
if p == "bf16":
|
||||
return torch.bfloat16
|
||||
return None
|
||||
|
||||
merge_dtype = str_to_dtype('float') # matmul method above only seems to work in float32
|
||||
save_dtype = str_to_dtype(args.save_precision)
|
||||
if save_dtype is None:
|
||||
save_dtype = merge_dtype
|
||||
if args.dynamic_method and not args.dynamic_param:
|
||||
raise Exception("If using dynamic_method, then dynamic_param is required")
|
||||
|
||||
print("loading Model...")
|
||||
lora_sd, metadata = load_state_dict(args.model, merge_dtype)
|
||||
merge_dtype = str_to_dtype("float") # matmul method above only seems to work in float32
|
||||
save_dtype = str_to_dtype(args.save_precision)
|
||||
if save_dtype is None:
|
||||
save_dtype = merge_dtype
|
||||
|
||||
print("Resizing Lora...")
|
||||
state_dict, old_dim, new_alpha = resize_lora_model(lora_sd, args.new_rank, save_dtype, args.device, args.dynamic_method, args.dynamic_param, args.verbose)
|
||||
logger.info("loading Model...")
|
||||
lora_sd, metadata = load_state_dict(args.model, merge_dtype)
|
||||
|
||||
# update metadata
|
||||
if metadata is None:
|
||||
metadata = {}
|
||||
logger.info("Resizing Lora...")
|
||||
state_dict, old_dim, new_alpha = resize_lora_model(
|
||||
lora_sd, args.new_rank, args.new_conv_rank, save_dtype, args.device, args.dynamic_method, args.dynamic_param, args.verbose
|
||||
)
|
||||
|
||||
comment = metadata.get("ss_training_comment", "")
|
||||
# update metadata
|
||||
if metadata is None:
|
||||
metadata = {}
|
||||
|
||||
if not args.dynamic_method:
|
||||
metadata["ss_training_comment"] = f"dimension is resized from {old_dim} to {args.new_rank}; {comment}"
|
||||
metadata["ss_network_dim"] = str(args.new_rank)
|
||||
metadata["ss_network_alpha"] = str(new_alpha)
|
||||
else:
|
||||
metadata["ss_training_comment"] = f"Dynamic resize with {args.dynamic_method}: {args.dynamic_param} from {old_dim}; {comment}"
|
||||
metadata["ss_network_dim"] = 'Dynamic'
|
||||
metadata["ss_network_alpha"] = 'Dynamic'
|
||||
comment = metadata.get("ss_training_comment", "")
|
||||
|
||||
model_hash, legacy_hash = train_util.precalculate_safetensors_hashes(state_dict, metadata)
|
||||
metadata["sshs_model_hash"] = model_hash
|
||||
metadata["sshs_legacy_hash"] = legacy_hash
|
||||
if not args.dynamic_method:
|
||||
conv_desc = "" if args.new_rank == args.new_conv_rank else f" (conv: {args.new_conv_rank})"
|
||||
metadata["ss_training_comment"] = f"dimension is resized from {old_dim} to {args.new_rank}{conv_desc}; {comment}"
|
||||
metadata["ss_network_dim"] = str(args.new_rank)
|
||||
metadata["ss_network_alpha"] = str(new_alpha)
|
||||
else:
|
||||
metadata["ss_training_comment"] = (
|
||||
f"Dynamic resize with {args.dynamic_method}: {args.dynamic_param} from {old_dim}; {comment}"
|
||||
)
|
||||
metadata["ss_network_dim"] = "Dynamic"
|
||||
metadata["ss_network_alpha"] = "Dynamic"
|
||||
|
||||
print(f"saving model to: {args.save_to}")
|
||||
save_to_file(args.save_to, state_dict, state_dict, save_dtype, metadata)
|
||||
# cast to save_dtype before calculating hashes
|
||||
for key in list(state_dict.keys()):
|
||||
value = state_dict[key]
|
||||
if type(value) == torch.Tensor and value.dtype.is_floating_point and value.dtype != save_dtype:
|
||||
state_dict[key] = value.to(save_dtype)
|
||||
|
||||
model_hash, legacy_hash = train_util.precalculate_safetensors_hashes(state_dict, metadata)
|
||||
metadata["sshs_model_hash"] = model_hash
|
||||
metadata["sshs_legacy_hash"] = legacy_hash
|
||||
|
||||
logger.info(f"saving model to: {args.save_to}")
|
||||
save_to_file(args.save_to, state_dict, metadata)
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = argparse.ArgumentParser()
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
parser.add_argument("--save_precision", type=str, default=None,
|
||||
choices=[None, "float", "fp16", "bf16"], help="precision in saving, float if omitted / 保存時の精度、未指定時はfloat")
|
||||
parser.add_argument("--new_rank", type=int, default=4,
|
||||
help="Specify rank of output LoRA / 出力するLoRAのrank (dim)")
|
||||
parser.add_argument("--save_to", type=str, default=None,
|
||||
help="destination file name: ckpt or safetensors file / 保存先のファイル名、ckptまたはsafetensors")
|
||||
parser.add_argument("--model", type=str, default=None,
|
||||
help="LoRA model to resize at to new rank: ckpt or safetensors file / 読み込むLoRAモデル、ckptまたはsafetensors")
|
||||
parser.add_argument("--device", type=str, default=None, help="device to use, cuda for GPU / 計算を行うデバイス、cuda でGPUを使う")
|
||||
parser.add_argument("--verbose", action="store_true",
|
||||
help="Display verbose resizing information / rank変更時の詳細情報を出力する")
|
||||
parser.add_argument("--dynamic_method", type=str, default=None, choices=[None, "sv_ratio", "sv_fro", "sv_cumulative"],
|
||||
help="Specify dynamic resizing method, --new_rank is used as a hard limit for max rank")
|
||||
parser.add_argument("--dynamic_param", type=float, default=None,
|
||||
help="Specify target for dynamic reduction")
|
||||
|
||||
return parser
|
||||
parser.add_argument(
|
||||
"--save_precision",
|
||||
type=str,
|
||||
default=None,
|
||||
choices=[None, "float", "fp16", "bf16"],
|
||||
help="precision in saving, float if omitted / 保存時の精度、未指定時はfloat",
|
||||
)
|
||||
parser.add_argument("--new_rank", type=int, default=4, help="Specify rank of output LoRA / 出力するLoRAのrank (dim)")
|
||||
parser.add_argument(
|
||||
"--new_conv_rank",
|
||||
type=int,
|
||||
default=None,
|
||||
help="Specify rank of output LoRA for Conv2d 3x3, None for same as new_rank / 出力するConv2D 3x3 LoRAのrank (dim)、Noneでnew_rankと同じ",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--save_to",
|
||||
type=str,
|
||||
default=None,
|
||||
help="destination file name: ckpt or safetensors file / 保存先のファイル名、ckptまたはsafetensors",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--model",
|
||||
type=str,
|
||||
default=None,
|
||||
help="LoRA model to resize at to new rank: ckpt or safetensors file / 読み込むLoRAモデル、ckptまたはsafetensors",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--device", type=str, default=None, help="device to use, cuda for GPU / 計算を行うデバイス、cuda でGPUを使う"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--verbose", action="store_true", help="Display verbose resizing information / rank変更時の詳細情報を出力する"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--dynamic_method",
|
||||
type=str,
|
||||
default=None,
|
||||
choices=[None, "sv_ratio", "sv_fro", "sv_cumulative"],
|
||||
help="Specify dynamic resizing method, --new_rank is used as a hard limit for max rank",
|
||||
)
|
||||
parser.add_argument("--dynamic_param", type=float, default=None, help="Specify target for dynamic reduction")
|
||||
|
||||
return parser
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = setup_parser()
|
||||
if __name__ == "__main__":
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
resize(args)
|
||||
args = parser.parse_args()
|
||||
resize(args)
|
||||
|
||||
513
networks/sdxl_merge_lora.py
Normal file
513
networks/sdxl_merge_lora.py
Normal file
@@ -0,0 +1,513 @@
|
||||
import itertools
|
||||
import math
|
||||
import argparse
|
||||
import os
|
||||
import time
|
||||
import concurrent.futures
|
||||
import torch
|
||||
from safetensors.torch import load_file, save_file
|
||||
from tqdm import tqdm
|
||||
from library import sai_model_spec, sdxl_model_util, train_util
|
||||
import library.model_util as model_util
|
||||
import lora
|
||||
import oft
|
||||
from svd_merge_lora import format_lbws, get_lbw_block_index, LAYER26
|
||||
from library.utils import setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
def load_state_dict(file_name, dtype):
|
||||
if os.path.splitext(file_name)[1] == ".safetensors":
|
||||
sd = load_file(file_name)
|
||||
metadata = train_util.load_metadata_from_safetensors(file_name)
|
||||
else:
|
||||
sd = torch.load(file_name, map_location="cpu")
|
||||
metadata = {}
|
||||
|
||||
for key in list(sd.keys()):
|
||||
if type(sd[key]) == torch.Tensor:
|
||||
sd[key] = sd[key].to(dtype)
|
||||
|
||||
return sd, metadata
|
||||
|
||||
|
||||
def save_to_file(file_name, model, metadata):
|
||||
if os.path.splitext(file_name)[1] == ".safetensors":
|
||||
save_file(model, file_name, metadata=metadata)
|
||||
else:
|
||||
torch.save(model, file_name)
|
||||
|
||||
|
||||
def detect_method_from_training_model(models, dtype):
|
||||
for model in models:
|
||||
# TODO It is better to use key names to detect the method
|
||||
lora_sd, _ = load_state_dict(model, dtype)
|
||||
for key in tqdm(lora_sd.keys()):
|
||||
if "lora_up" in key or "lora_down" in key:
|
||||
return "LoRA"
|
||||
elif "oft_blocks" in key:
|
||||
return "OFT"
|
||||
|
||||
|
||||
def merge_to_sd_model(text_encoder1, text_encoder2, unet, models, ratios, lbws, merge_dtype):
|
||||
text_encoder1.to(merge_dtype)
|
||||
text_encoder2.to(merge_dtype)
|
||||
unet.to(merge_dtype)
|
||||
|
||||
# detect the method: OFT or LoRA_module
|
||||
method = detect_method_from_training_model(models, merge_dtype)
|
||||
logger.info(f"method:{method}")
|
||||
|
||||
if lbws:
|
||||
lbws, _, LBW_TARGET_IDX = format_lbws(lbws)
|
||||
else:
|
||||
LBW_TARGET_IDX = []
|
||||
|
||||
# create module map
|
||||
name_to_module = {}
|
||||
for i, root_module in enumerate([text_encoder1, text_encoder2, unet]):
|
||||
if method == "LoRA":
|
||||
if i <= 1:
|
||||
if i == 0:
|
||||
prefix = lora.LoRANetwork.LORA_PREFIX_TEXT_ENCODER1
|
||||
else:
|
||||
prefix = lora.LoRANetwork.LORA_PREFIX_TEXT_ENCODER2
|
||||
target_replace_modules = lora.LoRANetwork.TEXT_ENCODER_TARGET_REPLACE_MODULE
|
||||
else:
|
||||
prefix = lora.LoRANetwork.LORA_PREFIX_UNET
|
||||
target_replace_modules = (
|
||||
lora.LoRANetwork.UNET_TARGET_REPLACE_MODULE + lora.LoRANetwork.UNET_TARGET_REPLACE_MODULE_CONV2D_3X3
|
||||
)
|
||||
elif method == "OFT":
|
||||
prefix = oft.OFTNetwork.OFT_PREFIX_UNET
|
||||
# ALL_LINEAR includes ATTN_ONLY, so we don't need to specify ATTN_ONLY
|
||||
target_replace_modules = (
|
||||
oft.OFTNetwork.UNET_TARGET_REPLACE_MODULE_ALL_LINEAR + oft.OFTNetwork.UNET_TARGET_REPLACE_MODULE_CONV2D_3X3
|
||||
)
|
||||
|
||||
for name, module in root_module.named_modules():
|
||||
if module.__class__.__name__ in target_replace_modules:
|
||||
for child_name, child_module in module.named_modules():
|
||||
if child_module.__class__.__name__ == "Linear" or child_module.__class__.__name__ == "Conv2d":
|
||||
lora_name = prefix + "." + name + "." + child_name
|
||||
lora_name = lora_name.replace(".", "_")
|
||||
name_to_module[lora_name] = child_module
|
||||
|
||||
for model, ratio, lbw in itertools.zip_longest(models, ratios, lbws):
|
||||
logger.info(f"loading: {model}")
|
||||
lora_sd, _ = load_state_dict(model, merge_dtype)
|
||||
|
||||
logger.info(f"merging...")
|
||||
|
||||
if lbw:
|
||||
lbw_weights = [1] * 26
|
||||
for index, value in zip(LBW_TARGET_IDX, lbw):
|
||||
lbw_weights[index] = value
|
||||
logger.info(f"lbw: {dict(zip(LAYER26.keys(), lbw_weights))}")
|
||||
|
||||
if method == "LoRA":
|
||||
for key in tqdm(lora_sd.keys()):
|
||||
if "lora_down" in key:
|
||||
up_key = key.replace("lora_down", "lora_up")
|
||||
alpha_key = key[: key.index("lora_down")] + "alpha"
|
||||
|
||||
# find original module for this lora
|
||||
module_name = ".".join(key.split(".")[:-2]) # remove trailing ".lora_down.weight"
|
||||
if module_name not in name_to_module:
|
||||
logger.info(f"no module found for LoRA weight: {key}")
|
||||
continue
|
||||
module = name_to_module[module_name]
|
||||
# logger.info(f"apply {key} to {module}")
|
||||
|
||||
down_weight = lora_sd[key]
|
||||
up_weight = lora_sd[up_key]
|
||||
|
||||
dim = down_weight.size()[0]
|
||||
alpha = lora_sd.get(alpha_key, dim)
|
||||
scale = alpha / dim
|
||||
|
||||
if lbw:
|
||||
index = get_lbw_block_index(key, True)
|
||||
is_lbw_target = index in LBW_TARGET_IDX
|
||||
if is_lbw_target:
|
||||
scale *= lbw_weights[index] # keyがlbwの対象であれば、lbwの重みを掛ける
|
||||
|
||||
# W <- W + U * D
|
||||
weight = module.weight
|
||||
# logger.info(module_name, down_weight.size(), up_weight.size())
|
||||
if len(weight.size()) == 2:
|
||||
# linear
|
||||
weight = weight + ratio * (up_weight @ down_weight) * scale
|
||||
elif down_weight.size()[2:4] == (1, 1):
|
||||
# conv2d 1x1
|
||||
weight = (
|
||||
weight
|
||||
+ ratio
|
||||
* (up_weight.squeeze(3).squeeze(2) @ down_weight.squeeze(3).squeeze(2)).unsqueeze(2).unsqueeze(3)
|
||||
* scale
|
||||
)
|
||||
else:
|
||||
# conv2d 3x3
|
||||
conved = torch.nn.functional.conv2d(down_weight.permute(1, 0, 2, 3), up_weight).permute(1, 0, 2, 3)
|
||||
# logger.info(conved.size(), weight.size(), module.stride, module.padding)
|
||||
weight = weight + ratio * conved * scale
|
||||
|
||||
module.weight = torch.nn.Parameter(weight)
|
||||
|
||||
elif method == "OFT":
|
||||
|
||||
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
||||
|
||||
for key in tqdm(lora_sd.keys()):
|
||||
if "oft_blocks" in key:
|
||||
oft_blocks = lora_sd[key]
|
||||
dim = oft_blocks.shape[0]
|
||||
break
|
||||
for key in tqdm(lora_sd.keys()):
|
||||
if "alpha" in key:
|
||||
oft_blocks = lora_sd[key]
|
||||
alpha = oft_blocks.item()
|
||||
break
|
||||
|
||||
def merge_to(key):
|
||||
if "alpha" in key:
|
||||
return
|
||||
|
||||
# find original module for this OFT
|
||||
module_name = ".".join(key.split(".")[:-1])
|
||||
if module_name not in name_to_module:
|
||||
logger.info(f"no module found for OFT weight: {key}")
|
||||
return
|
||||
module = name_to_module[module_name]
|
||||
|
||||
# logger.info(f"apply {key} to {module}")
|
||||
|
||||
oft_blocks = lora_sd[key]
|
||||
|
||||
if isinstance(module, torch.nn.Linear):
|
||||
out_dim = module.out_features
|
||||
elif isinstance(module, torch.nn.Conv2d):
|
||||
out_dim = module.out_channels
|
||||
|
||||
num_blocks = dim
|
||||
block_size = out_dim // dim
|
||||
constraint = (0 if alpha is None else alpha) * out_dim
|
||||
|
||||
multiplier = 1
|
||||
if lbw:
|
||||
index = get_lbw_block_index(key, False)
|
||||
is_lbw_target = index in LBW_TARGET_IDX
|
||||
if is_lbw_target:
|
||||
multiplier *= lbw_weights[index]
|
||||
|
||||
block_Q = oft_blocks - oft_blocks.transpose(1, 2)
|
||||
norm_Q = torch.norm(block_Q.flatten())
|
||||
new_norm_Q = torch.clamp(norm_Q, max=constraint)
|
||||
block_Q = block_Q * ((new_norm_Q + 1e-8) / (norm_Q + 1e-8))
|
||||
I = torch.eye(block_size, device=oft_blocks.device).unsqueeze(0).repeat(num_blocks, 1, 1)
|
||||
block_R = torch.matmul(I + block_Q, (I - block_Q).inverse())
|
||||
block_R_weighted = multiplier * block_R + (1 - multiplier) * I
|
||||
R = torch.block_diag(*block_R_weighted)
|
||||
|
||||
# get org weight
|
||||
org_sd = module.state_dict()
|
||||
org_weight = org_sd["weight"].to(device)
|
||||
|
||||
R = R.to(org_weight.device, dtype=org_weight.dtype)
|
||||
|
||||
if org_weight.dim() == 4:
|
||||
weight = torch.einsum("oihw, op -> pihw", org_weight, R)
|
||||
else:
|
||||
weight = torch.einsum("oi, op -> pi", org_weight, R)
|
||||
|
||||
weight = weight.contiguous() # Make Tensor contiguous; required due to ThreadPoolExecutor
|
||||
|
||||
module.weight = torch.nn.Parameter(weight)
|
||||
|
||||
# TODO multi-threading may cause OOM on CPU if cpu_count is too high and RAM is not enough
|
||||
max_workers = 1 if device.type != "cpu" else None # avoid OOM on GPU
|
||||
with concurrent.futures.ThreadPoolExecutor(max_workers=max_workers) as executor:
|
||||
list(tqdm(executor.map(merge_to, lora_sd.keys()), total=len(lora_sd.keys())))
|
||||
|
||||
|
||||
def merge_lora_models(models, ratios, lbws, merge_dtype, concat=False, shuffle=False):
|
||||
base_alphas = {} # alpha for merged model
|
||||
base_dims = {}
|
||||
|
||||
# detect the method: OFT or LoRA_module
|
||||
method = detect_method_from_training_model(models, merge_dtype)
|
||||
if method == "OFT":
|
||||
raise ValueError(
|
||||
"OFT model is not supported for merging OFT models. / OFTモデルはOFTモデル同士のマージには対応していません"
|
||||
)
|
||||
|
||||
if lbws:
|
||||
lbws, _, LBW_TARGET_IDX = format_lbws(lbws)
|
||||
else:
|
||||
LBW_TARGET_IDX = []
|
||||
|
||||
merged_sd = {}
|
||||
v2 = None
|
||||
base_model = None
|
||||
for model, ratio, lbw in itertools.zip_longest(models, ratios, lbws):
|
||||
logger.info(f"loading: {model}")
|
||||
lora_sd, lora_metadata = load_state_dict(model, merge_dtype)
|
||||
|
||||
if lbw:
|
||||
lbw_weights = [1] * 26
|
||||
for index, value in zip(LBW_TARGET_IDX, lbw):
|
||||
lbw_weights[index] = value
|
||||
logger.info(f"lbw: {dict(zip(LAYER26.keys(), lbw_weights))}")
|
||||
|
||||
if lora_metadata is not None:
|
||||
if v2 is None:
|
||||
v2 = lora_metadata.get(train_util.SS_METADATA_KEY_V2, None) # returns string, SDXLはv2がないのでFalseのはず
|
||||
if base_model is None:
|
||||
base_model = lora_metadata.get(train_util.SS_METADATA_KEY_BASE_MODEL_VERSION, None)
|
||||
|
||||
# get alpha and dim
|
||||
alphas = {} # alpha for current model
|
||||
dims = {} # dims for current model
|
||||
for key in lora_sd.keys():
|
||||
if "alpha" in key:
|
||||
lora_module_name = key[: key.rfind(".alpha")]
|
||||
alpha = float(lora_sd[key].detach().numpy())
|
||||
alphas[lora_module_name] = alpha
|
||||
if lora_module_name not in base_alphas:
|
||||
base_alphas[lora_module_name] = alpha
|
||||
elif "lora_down" in key:
|
||||
lora_module_name = key[: key.rfind(".lora_down")]
|
||||
dim = lora_sd[key].size()[0]
|
||||
dims[lora_module_name] = dim
|
||||
if lora_module_name not in base_dims:
|
||||
base_dims[lora_module_name] = dim
|
||||
|
||||
for lora_module_name in dims.keys():
|
||||
if lora_module_name not in alphas:
|
||||
alpha = dims[lora_module_name]
|
||||
alphas[lora_module_name] = alpha
|
||||
if lora_module_name not in base_alphas:
|
||||
base_alphas[lora_module_name] = alpha
|
||||
|
||||
logger.info(f"dim: {list(set(dims.values()))}, alpha: {list(set(alphas.values()))}")
|
||||
|
||||
# merge
|
||||
logger.info(f"merging...")
|
||||
for key in tqdm(lora_sd.keys()):
|
||||
if "alpha" in key:
|
||||
continue
|
||||
|
||||
if "lora_up" in key and concat:
|
||||
concat_dim = 1
|
||||
elif "lora_down" in key and concat:
|
||||
concat_dim = 0
|
||||
else:
|
||||
concat_dim = None
|
||||
|
||||
lora_module_name = key[: key.rfind(".lora_")]
|
||||
|
||||
base_alpha = base_alphas[lora_module_name]
|
||||
alpha = alphas[lora_module_name]
|
||||
|
||||
scale = math.sqrt(alpha / base_alpha) * ratio
|
||||
scale = abs(scale) if "lora_up" in key else scale # マイナスの重みに対応する。
|
||||
|
||||
if lbw:
|
||||
index = get_lbw_block_index(key, True)
|
||||
is_lbw_target = index in LBW_TARGET_IDX
|
||||
if is_lbw_target:
|
||||
scale *= lbw_weights[index] # keyがlbwの対象であれば、lbwの重みを掛ける
|
||||
|
||||
if key in merged_sd:
|
||||
assert (
|
||||
merged_sd[key].size() == lora_sd[key].size() or concat_dim is not None
|
||||
), f"weights shape mismatch merging v1 and v2, different dims? / 重みのサイズが合いません。v1とv2、または次元数の異なるモデルはマージできません"
|
||||
if concat_dim is not None:
|
||||
merged_sd[key] = torch.cat([merged_sd[key], lora_sd[key] * scale], dim=concat_dim)
|
||||
else:
|
||||
merged_sd[key] = merged_sd[key] + lora_sd[key] * scale
|
||||
else:
|
||||
merged_sd[key] = lora_sd[key] * scale
|
||||
|
||||
# set alpha to sd
|
||||
for lora_module_name, alpha in base_alphas.items():
|
||||
key = lora_module_name + ".alpha"
|
||||
merged_sd[key] = torch.tensor(alpha)
|
||||
if shuffle:
|
||||
key_down = lora_module_name + ".lora_down.weight"
|
||||
key_up = lora_module_name + ".lora_up.weight"
|
||||
dim = merged_sd[key_down].shape[0]
|
||||
perm = torch.randperm(dim)
|
||||
merged_sd[key_down] = merged_sd[key_down][perm]
|
||||
merged_sd[key_up] = merged_sd[key_up][:, perm]
|
||||
|
||||
logger.info("merged model")
|
||||
logger.info(f"dim: {list(set(base_dims.values()))}, alpha: {list(set(base_alphas.values()))}")
|
||||
|
||||
# check all dims are same
|
||||
dims_list = list(set(base_dims.values()))
|
||||
alphas_list = list(set(base_alphas.values()))
|
||||
all_same_dims = True
|
||||
all_same_alphas = True
|
||||
for dims in dims_list:
|
||||
if dims != dims_list[0]:
|
||||
all_same_dims = False
|
||||
break
|
||||
for alphas in alphas_list:
|
||||
if alphas != alphas_list[0]:
|
||||
all_same_alphas = False
|
||||
break
|
||||
|
||||
# build minimum metadata
|
||||
dims = f"{dims_list[0]}" if all_same_dims else "Dynamic"
|
||||
alphas = f"{alphas_list[0]}" if all_same_alphas else "Dynamic"
|
||||
metadata = train_util.build_minimum_network_metadata(v2, base_model, "networks.lora", dims, alphas, None)
|
||||
|
||||
return merged_sd, metadata
|
||||
|
||||
|
||||
def merge(args):
|
||||
assert len(args.models) == len(
|
||||
args.ratios
|
||||
), f"number of models must be equal to number of ratios / モデルの数と重みの数は合わせてください"
|
||||
if args.lbws:
|
||||
assert len(args.models) == len(
|
||||
args.lbws
|
||||
), f"number of models must be equal to number of ratios / モデルの数と層別適用率の数は合わせてください"
|
||||
else:
|
||||
args.lbws = [] # zip_longestで扱えるようにlbws未使用時には空のリストにしておく
|
||||
|
||||
def str_to_dtype(p):
|
||||
if p == "float":
|
||||
return torch.float
|
||||
if p == "fp16":
|
||||
return torch.float16
|
||||
if p == "bf16":
|
||||
return torch.bfloat16
|
||||
return None
|
||||
|
||||
merge_dtype = str_to_dtype(args.precision)
|
||||
save_dtype = str_to_dtype(args.save_precision)
|
||||
if save_dtype is None:
|
||||
save_dtype = merge_dtype
|
||||
|
||||
if args.sd_model is not None:
|
||||
logger.info(f"loading SD model: {args.sd_model}")
|
||||
|
||||
(
|
||||
text_model1,
|
||||
text_model2,
|
||||
vae,
|
||||
unet,
|
||||
logit_scale,
|
||||
ckpt_info,
|
||||
) = sdxl_model_util.load_models_from_sdxl_checkpoint(sdxl_model_util.MODEL_VERSION_SDXL_BASE_V1_0, args.sd_model, "cpu")
|
||||
|
||||
merge_to_sd_model(text_model1, text_model2, unet, args.models, args.ratios, args.lbws, merge_dtype)
|
||||
|
||||
if args.no_metadata:
|
||||
sai_metadata = None
|
||||
else:
|
||||
merged_from = sai_model_spec.build_merged_from([args.sd_model] + args.models)
|
||||
title = os.path.splitext(os.path.basename(args.save_to))[0]
|
||||
sai_metadata = sai_model_spec.build_metadata(
|
||||
None, False, False, True, False, False, time.time(), title=title, merged_from=merged_from
|
||||
)
|
||||
|
||||
logger.info(f"saving SD model to: {args.save_to}")
|
||||
sdxl_model_util.save_stable_diffusion_checkpoint(
|
||||
args.save_to, text_model1, text_model2, unet, 0, 0, ckpt_info, vae, logit_scale, sai_metadata, save_dtype
|
||||
)
|
||||
else:
|
||||
state_dict, metadata = merge_lora_models(args.models, args.ratios, args.lbws, merge_dtype, args.concat, args.shuffle)
|
||||
|
||||
# cast to save_dtype before calculating hashes
|
||||
for key in list(state_dict.keys()):
|
||||
value = state_dict[key]
|
||||
if type(value) == torch.Tensor and value.dtype.is_floating_point and value.dtype != save_dtype:
|
||||
state_dict[key] = value.to(save_dtype)
|
||||
|
||||
logger.info(f"calculating hashes and creating metadata...")
|
||||
|
||||
model_hash, legacy_hash = train_util.precalculate_safetensors_hashes(state_dict, metadata)
|
||||
metadata["sshs_model_hash"] = model_hash
|
||||
metadata["sshs_legacy_hash"] = legacy_hash
|
||||
|
||||
if not args.no_metadata:
|
||||
merged_from = sai_model_spec.build_merged_from(args.models)
|
||||
title = os.path.splitext(os.path.basename(args.save_to))[0]
|
||||
sai_metadata = sai_model_spec.build_metadata(
|
||||
state_dict, False, False, True, True, False, time.time(), title=title, merged_from=merged_from
|
||||
)
|
||||
metadata.update(sai_metadata)
|
||||
|
||||
logger.info(f"saving model to: {args.save_to}")
|
||||
save_to_file(args.save_to, state_dict, metadata)
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument(
|
||||
"--save_precision",
|
||||
type=str,
|
||||
default=None,
|
||||
choices=[None, "float", "fp16", "bf16"],
|
||||
help="precision in saving, same to merging if omitted / 保存時に精度を変更して保存する、省略時はマージ時の精度と同じ",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--precision",
|
||||
type=str,
|
||||
default="float",
|
||||
choices=["float", "fp16", "bf16"],
|
||||
help="precision in merging (float is recommended) / マージの計算時の精度(floatを推奨)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--sd_model",
|
||||
type=str,
|
||||
default=None,
|
||||
help="Stable Diffusion model to load: ckpt or safetensors file, merge LoRA models if omitted / 読み込むモデル、ckptまたはsafetensors。省略時はLoRAモデル同士をマージする",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--save_to",
|
||||
type=str,
|
||||
default=None,
|
||||
help="destination file name: ckpt or safetensors file / 保存先のファイル名、ckptまたはsafetensors",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--models",
|
||||
type=str,
|
||||
nargs="*",
|
||||
help="LoRA models to merge: ckpt or safetensors file / マージするLoRAモデル、ckptまたはsafetensors",
|
||||
)
|
||||
parser.add_argument("--ratios", type=float, nargs="*", help="ratios for each model / それぞれのLoRAモデルの比率")
|
||||
parser.add_argument("--lbws", type=str, nargs="*", help="lbw for each model / それぞれのLoRAモデルの層別適用率")
|
||||
parser.add_argument(
|
||||
"--no_metadata",
|
||||
action="store_true",
|
||||
help="do not save sai modelspec metadata (minimum ss_metadata for LoRA is saved) / "
|
||||
+ "sai modelspecのメタデータを保存しない(LoRAの最低限のss_metadataは保存される)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--concat",
|
||||
action="store_true",
|
||||
help="concat lora instead of merge (The dim(rank) of the output LoRA is the sum of the input dims) / "
|
||||
+ "マージの代わりに結合する(LoRAのdim(rank)は入力dimの合計になる)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--shuffle",
|
||||
action="store_true",
|
||||
help="shuffle lora weight./ " + "LoRAの重みをシャッフルする",
|
||||
)
|
||||
|
||||
return parser
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
merge(args)
|
||||
@@ -1,192 +1,515 @@
|
||||
|
||||
import math
|
||||
import argparse
|
||||
import itertools
|
||||
import json
|
||||
import os
|
||||
import re
|
||||
import time
|
||||
import torch
|
||||
from safetensors.torch import load_file, save_file
|
||||
from tqdm import tqdm
|
||||
from library import sai_model_spec, train_util
|
||||
import library.model_util as model_util
|
||||
import lora
|
||||
from library.utils import setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
CLAMP_QUANTILE = 0.99
|
||||
|
||||
ACCEPTABLE = [12, 17, 20, 26]
|
||||
SDXL_LAYER_NUM = [12, 20]
|
||||
|
||||
LAYER12 = {
|
||||
"BASE": True,
|
||||
"IN00": False,
|
||||
"IN01": False,
|
||||
"IN02": False,
|
||||
"IN03": False,
|
||||
"IN04": True,
|
||||
"IN05": True,
|
||||
"IN06": False,
|
||||
"IN07": True,
|
||||
"IN08": True,
|
||||
"IN09": False,
|
||||
"IN10": False,
|
||||
"IN11": False,
|
||||
"MID": True,
|
||||
"OUT00": True,
|
||||
"OUT01": True,
|
||||
"OUT02": True,
|
||||
"OUT03": True,
|
||||
"OUT04": True,
|
||||
"OUT05": True,
|
||||
"OUT06": False,
|
||||
"OUT07": False,
|
||||
"OUT08": False,
|
||||
"OUT09": False,
|
||||
"OUT10": False,
|
||||
"OUT11": False,
|
||||
}
|
||||
|
||||
LAYER17 = {
|
||||
"BASE": True,
|
||||
"IN00": False,
|
||||
"IN01": True,
|
||||
"IN02": True,
|
||||
"IN03": False,
|
||||
"IN04": True,
|
||||
"IN05": True,
|
||||
"IN06": False,
|
||||
"IN07": True,
|
||||
"IN08": True,
|
||||
"IN09": False,
|
||||
"IN10": False,
|
||||
"IN11": False,
|
||||
"MID": True,
|
||||
"OUT00": False,
|
||||
"OUT01": False,
|
||||
"OUT02": False,
|
||||
"OUT03": True,
|
||||
"OUT04": True,
|
||||
"OUT05": True,
|
||||
"OUT06": True,
|
||||
"OUT07": True,
|
||||
"OUT08": True,
|
||||
"OUT09": True,
|
||||
"OUT10": True,
|
||||
"OUT11": True,
|
||||
}
|
||||
|
||||
LAYER20 = {
|
||||
"BASE": True,
|
||||
"IN00": True,
|
||||
"IN01": True,
|
||||
"IN02": True,
|
||||
"IN03": True,
|
||||
"IN04": True,
|
||||
"IN05": True,
|
||||
"IN06": True,
|
||||
"IN07": True,
|
||||
"IN08": True,
|
||||
"IN09": False,
|
||||
"IN10": False,
|
||||
"IN11": False,
|
||||
"MID": True,
|
||||
"OUT00": True,
|
||||
"OUT01": True,
|
||||
"OUT02": True,
|
||||
"OUT03": True,
|
||||
"OUT04": True,
|
||||
"OUT05": True,
|
||||
"OUT06": True,
|
||||
"OUT07": True,
|
||||
"OUT08": True,
|
||||
"OUT09": False,
|
||||
"OUT10": False,
|
||||
"OUT11": False,
|
||||
}
|
||||
|
||||
LAYER26 = {
|
||||
"BASE": True,
|
||||
"IN00": True,
|
||||
"IN01": True,
|
||||
"IN02": True,
|
||||
"IN03": True,
|
||||
"IN04": True,
|
||||
"IN05": True,
|
||||
"IN06": True,
|
||||
"IN07": True,
|
||||
"IN08": True,
|
||||
"IN09": True,
|
||||
"IN10": True,
|
||||
"IN11": True,
|
||||
"MID": True,
|
||||
"OUT00": True,
|
||||
"OUT01": True,
|
||||
"OUT02": True,
|
||||
"OUT03": True,
|
||||
"OUT04": True,
|
||||
"OUT05": True,
|
||||
"OUT06": True,
|
||||
"OUT07": True,
|
||||
"OUT08": True,
|
||||
"OUT09": True,
|
||||
"OUT10": True,
|
||||
"OUT11": True,
|
||||
}
|
||||
|
||||
assert len([v for v in LAYER12.values() if v]) == 12
|
||||
assert len([v for v in LAYER17.values() if v]) == 17
|
||||
assert len([v for v in LAYER20.values() if v]) == 20
|
||||
assert len([v for v in LAYER26.values() if v]) == 26
|
||||
|
||||
RE_UPDOWN = re.compile(r"(up|down)_blocks_(\d+)_(resnets|upsamplers|downsamplers|attentions)_(\d+)_")
|
||||
|
||||
|
||||
def get_lbw_block_index(lora_name: str, is_sdxl: bool = False) -> int:
|
||||
# lbw block index is 0-based, but 0 for text encoder, so we return 0 for text encoder
|
||||
if "text_model_encoder_" in lora_name: # LoRA for text encoder
|
||||
return 0
|
||||
|
||||
# lbw block index is 1-based for U-Net, and no "input_blocks.0" in CompVis SD, so "input_blocks.1" have index 2
|
||||
block_idx = -1 # invalid lora name
|
||||
if not is_sdxl:
|
||||
NUM_OF_BLOCKS = 12 # up/down blocks
|
||||
m = RE_UPDOWN.search(lora_name)
|
||||
if m:
|
||||
g = m.groups()
|
||||
up_down = g[0]
|
||||
i = int(g[1])
|
||||
j = int(g[3])
|
||||
if up_down == "down":
|
||||
if g[2] == "resnets" or g[2] == "attentions":
|
||||
idx = 3 * i + j + 1
|
||||
elif g[2] == "downsamplers":
|
||||
idx = 3 * (i + 1)
|
||||
else:
|
||||
return block_idx # invalid lora name
|
||||
elif up_down == "up":
|
||||
if g[2] == "resnets" or g[2] == "attentions":
|
||||
idx = 3 * i + j
|
||||
elif g[2] == "upsamplers":
|
||||
idx = 3 * i + 2
|
||||
else:
|
||||
return block_idx # invalid lora name
|
||||
|
||||
if g[0] == "down":
|
||||
block_idx = 1 + idx # 1-based index, down block index
|
||||
elif g[0] == "up":
|
||||
block_idx = 1 + NUM_OF_BLOCKS + 1 + idx # 1-based index, num blocks, mid block, up block index
|
||||
|
||||
elif "mid_block_" in lora_name:
|
||||
block_idx = 1 + NUM_OF_BLOCKS # 1-based index, num blocks, mid block
|
||||
else:
|
||||
# SDXL: some numbers are skipped
|
||||
if lora_name.startswith("lora_unet_"):
|
||||
name = lora_name[len("lora_unet_") :]
|
||||
if name.startswith("time_embed_") or name.startswith("label_emb_"): # 1, No LoRA in sd-scripts
|
||||
block_idx = 1
|
||||
elif name.startswith("input_blocks_"): # 1-8 to 2-9
|
||||
block_idx = 1 + int(name.split("_")[2])
|
||||
elif name.startswith("middle_block_"): # 13
|
||||
block_idx = 13
|
||||
elif name.startswith("output_blocks_"): # 0-8 to 14-22
|
||||
block_idx = 14 + int(name.split("_")[2])
|
||||
elif name.startswith("out_"): # 23, No LoRA in sd-scripts
|
||||
block_idx = 23
|
||||
|
||||
return block_idx
|
||||
|
||||
|
||||
def load_state_dict(file_name, dtype):
|
||||
if os.path.splitext(file_name)[1] == '.safetensors':
|
||||
sd = load_file(file_name)
|
||||
else:
|
||||
sd = torch.load(file_name, map_location='cpu')
|
||||
for key in list(sd.keys()):
|
||||
if type(sd[key]) == torch.Tensor:
|
||||
sd[key] = sd[key].to(dtype)
|
||||
return sd
|
||||
if os.path.splitext(file_name)[1] == ".safetensors":
|
||||
sd = load_file(file_name)
|
||||
metadata = train_util.load_metadata_from_safetensors(file_name)
|
||||
else:
|
||||
sd = torch.load(file_name, map_location="cpu")
|
||||
metadata = {}
|
||||
|
||||
for key in list(sd.keys()):
|
||||
if type(sd[key]) == torch.Tensor:
|
||||
sd[key] = sd[key].to(dtype)
|
||||
|
||||
return sd, metadata
|
||||
|
||||
|
||||
def save_to_file(file_name, state_dict, dtype):
|
||||
if dtype is not None:
|
||||
for key in list(state_dict.keys()):
|
||||
if type(state_dict[key]) == torch.Tensor:
|
||||
state_dict[key] = state_dict[key].to(dtype)
|
||||
|
||||
if os.path.splitext(file_name)[1] == '.safetensors':
|
||||
save_file(state_dict, file_name)
|
||||
else:
|
||||
torch.save(state_dict, file_name)
|
||||
def save_to_file(file_name, state_dict, metadata):
|
||||
if os.path.splitext(file_name)[1] == ".safetensors":
|
||||
save_file(state_dict, file_name, metadata=metadata)
|
||||
else:
|
||||
torch.save(state_dict, file_name)
|
||||
|
||||
|
||||
def merge_lora_models(models, ratios, new_rank, new_conv_rank, device, merge_dtype):
|
||||
print(f"new rank: {new_rank}, new conv rank: {new_conv_rank}")
|
||||
merged_sd = {}
|
||||
for model, ratio in zip(models, ratios):
|
||||
print(f"loading: {model}")
|
||||
lora_sd = load_state_dict(model, merge_dtype)
|
||||
def format_lbws(lbws):
|
||||
try:
|
||||
# lbwは"[1,1,1,1,1,1,1,1,1,1,1,1]"のような文字列で与えられることを期待している
|
||||
lbws = [json.loads(lbw) for lbw in lbws]
|
||||
except Exception:
|
||||
raise ValueError(f"format of lbws are must be json / 層別適用率はJSON形式で書いてください")
|
||||
assert all(isinstance(lbw, list) for lbw in lbws), f"lbws are must be list / 層別適用率はリストにしてください"
|
||||
assert len(set(len(lbw) for lbw in lbws)) == 1, "all lbws should have the same length / 層別適用率は同じ長さにしてください"
|
||||
assert all(
|
||||
len(lbw) in ACCEPTABLE for lbw in lbws
|
||||
), f"length of lbw are must be in {ACCEPTABLE} / 層別適用率の長さは{ACCEPTABLE}のいずれかにしてください"
|
||||
assert all(
|
||||
all(isinstance(weight, (int, float)) for weight in lbw) for lbw in lbws
|
||||
), f"values of lbs are must be numbers / 層別適用率の値はすべて数値にしてください"
|
||||
|
||||
# merge
|
||||
print(f"merging...")
|
||||
for key in tqdm(list(lora_sd.keys())):
|
||||
if 'lora_down' not in key:
|
||||
continue
|
||||
layer_num = len(lbws[0])
|
||||
is_sdxl = True if layer_num in SDXL_LAYER_NUM else False
|
||||
FLAGS = {
|
||||
"12": LAYER12.values(),
|
||||
"17": LAYER17.values(),
|
||||
"20": LAYER20.values(),
|
||||
"26": LAYER26.values(),
|
||||
}[str(layer_num)]
|
||||
LBW_TARGET_IDX = [i for i, flag in enumerate(FLAGS) if flag]
|
||||
return lbws, is_sdxl, LBW_TARGET_IDX
|
||||
|
||||
lora_module_name = key[:key.rfind(".lora_down")]
|
||||
|
||||
down_weight = lora_sd[key]
|
||||
network_dim = down_weight.size()[0]
|
||||
def merge_lora_models(models, ratios, lbws, new_rank, new_conv_rank, device, merge_dtype):
|
||||
logger.info(f"new rank: {new_rank}, new conv rank: {new_conv_rank}")
|
||||
merged_sd = {}
|
||||
v2 = None # This is meaning LoRA Metadata v2, Not meaning SD2
|
||||
base_model = None
|
||||
|
||||
up_weight = lora_sd[lora_module_name + '.lora_up.weight']
|
||||
alpha = lora_sd.get(lora_module_name + '.alpha', network_dim)
|
||||
if lbws:
|
||||
lbws, is_sdxl, LBW_TARGET_IDX = format_lbws(lbws)
|
||||
else:
|
||||
is_sdxl = False
|
||||
LBW_TARGET_IDX = []
|
||||
|
||||
in_dim = down_weight.size()[1]
|
||||
out_dim = up_weight.size()[0]
|
||||
conv2d = len(down_weight.size()) == 4
|
||||
kernel_size = None if not conv2d else down_weight.size()[2:4]
|
||||
# print(lora_module_name, network_dim, alpha, in_dim, out_dim, kernel_size)
|
||||
for model, ratio, lbw in itertools.zip_longest(models, ratios, lbws):
|
||||
logger.info(f"loading: {model}")
|
||||
lora_sd, lora_metadata = load_state_dict(model, merge_dtype)
|
||||
|
||||
# make original weight if not exist
|
||||
if lora_module_name not in merged_sd:
|
||||
weight = torch.zeros((out_dim, in_dim, *kernel_size) if conv2d else (out_dim, in_dim), dtype=merge_dtype)
|
||||
if device:
|
||||
weight = weight.to(device)
|
||||
else:
|
||||
weight = merged_sd[lora_module_name]
|
||||
if lora_metadata is not None:
|
||||
if v2 is None:
|
||||
v2 = lora_metadata.get(train_util.SS_METADATA_KEY_V2, None) # return string
|
||||
if base_model is None:
|
||||
base_model = lora_metadata.get(train_util.SS_METADATA_KEY_BASE_MODEL_VERSION, None)
|
||||
|
||||
# merge to weight
|
||||
if device:
|
||||
up_weight = up_weight.to(device)
|
||||
down_weight = down_weight.to(device)
|
||||
if lbw:
|
||||
lbw_weights = [1] * 26
|
||||
for index, value in zip(LBW_TARGET_IDX, lbw):
|
||||
lbw_weights[index] = value
|
||||
logger.info(f"lbw: {dict(zip(LAYER26.keys(), lbw_weights))}")
|
||||
|
||||
# W <- W + U * D
|
||||
scale = (alpha / network_dim)
|
||||
# merge
|
||||
logger.info(f"merging...")
|
||||
for key in tqdm(list(lora_sd.keys())):
|
||||
if "lora_down" not in key:
|
||||
continue
|
||||
|
||||
if device: # and isinstance(scale, torch.Tensor):
|
||||
scale = scale.to(device)
|
||||
lora_module_name = key[: key.rfind(".lora_down")]
|
||||
|
||||
if not conv2d: # linear
|
||||
weight = weight + ratio * (up_weight @ down_weight) * scale
|
||||
elif kernel_size == (1, 1):
|
||||
weight = weight + ratio * (up_weight.squeeze(3).squeeze(2) @ down_weight.squeeze(3).squeeze(2)
|
||||
).unsqueeze(2).unsqueeze(3) * scale
|
||||
else:
|
||||
conved = torch.nn.functional.conv2d(down_weight.permute(1, 0, 2, 3), up_weight).permute(1, 0, 2, 3)
|
||||
weight = weight + ratio * conved * scale
|
||||
down_weight = lora_sd[key]
|
||||
network_dim = down_weight.size()[0]
|
||||
|
||||
merged_sd[lora_module_name] = weight
|
||||
up_weight = lora_sd[lora_module_name + ".lora_up.weight"]
|
||||
alpha = lora_sd.get(lora_module_name + ".alpha", network_dim)
|
||||
|
||||
# extract from merged weights
|
||||
print("extract new lora...")
|
||||
merged_lora_sd = {}
|
||||
with torch.no_grad():
|
||||
for lora_module_name, mat in tqdm(list(merged_sd.items())):
|
||||
conv2d = (len(mat.size()) == 4)
|
||||
kernel_size = None if not conv2d else mat.size()[2:4]
|
||||
conv2d_3x3 = conv2d and kernel_size != (1, 1)
|
||||
out_dim, in_dim = mat.size()[0:2]
|
||||
in_dim = down_weight.size()[1]
|
||||
out_dim = up_weight.size()[0]
|
||||
conv2d = len(down_weight.size()) == 4
|
||||
kernel_size = None if not conv2d else down_weight.size()[2:4]
|
||||
# logger.info(lora_module_name, network_dim, alpha, in_dim, out_dim, kernel_size)
|
||||
|
||||
if conv2d:
|
||||
if conv2d_3x3:
|
||||
mat = mat.flatten(start_dim=1)
|
||||
else:
|
||||
mat = mat.squeeze()
|
||||
# make original weight if not exist
|
||||
if lora_module_name not in merged_sd:
|
||||
weight = torch.zeros((out_dim, in_dim, *kernel_size) if conv2d else (out_dim, in_dim), dtype=merge_dtype)
|
||||
else:
|
||||
weight = merged_sd[lora_module_name]
|
||||
if device:
|
||||
weight = weight.to(device)
|
||||
|
||||
module_new_rank = new_conv_rank if conv2d_3x3 else new_rank
|
||||
module_new_rank = min(module_new_rank, in_dim, out_dim) # LoRA rank cannot exceed the original dim
|
||||
# merge to weight
|
||||
if device:
|
||||
up_weight = up_weight.to(device)
|
||||
down_weight = down_weight.to(device)
|
||||
|
||||
U, S, Vh = torch.linalg.svd(mat)
|
||||
# W <- W + U * D
|
||||
scale = alpha / network_dim
|
||||
|
||||
U = U[:, :module_new_rank]
|
||||
S = S[:module_new_rank]
|
||||
U = U @ torch.diag(S)
|
||||
if lbw:
|
||||
index = get_lbw_block_index(key, is_sdxl)
|
||||
is_lbw_target = index in LBW_TARGET_IDX
|
||||
if is_lbw_target:
|
||||
scale *= lbw_weights[index] # keyがlbwの対象であれば、lbwの重みを掛ける
|
||||
|
||||
Vh = Vh[:module_new_rank, :]
|
||||
if device: # and isinstance(scale, torch.Tensor):
|
||||
scale = scale.to(device)
|
||||
|
||||
dist = torch.cat([U.flatten(), Vh.flatten()])
|
||||
hi_val = torch.quantile(dist, CLAMP_QUANTILE)
|
||||
low_val = -hi_val
|
||||
if not conv2d: # linear
|
||||
weight = weight + ratio * (up_weight @ down_weight) * scale
|
||||
elif kernel_size == (1, 1):
|
||||
weight = (
|
||||
weight
|
||||
+ ratio
|
||||
* (up_weight.squeeze(3).squeeze(2) @ down_weight.squeeze(3).squeeze(2)).unsqueeze(2).unsqueeze(3)
|
||||
* scale
|
||||
)
|
||||
else:
|
||||
conved = torch.nn.functional.conv2d(down_weight.permute(1, 0, 2, 3), up_weight).permute(1, 0, 2, 3)
|
||||
weight = weight + ratio * conved * scale
|
||||
|
||||
U = U.clamp(low_val, hi_val)
|
||||
Vh = Vh.clamp(low_val, hi_val)
|
||||
merged_sd[lora_module_name] = weight.to("cpu")
|
||||
|
||||
if conv2d:
|
||||
U = U.reshape(out_dim, module_new_rank, 1, 1)
|
||||
Vh = Vh.reshape(module_new_rank, in_dim, kernel_size[0], kernel_size[1])
|
||||
# extract from merged weights
|
||||
logger.info("extract new lora...")
|
||||
merged_lora_sd = {}
|
||||
with torch.no_grad():
|
||||
for lora_module_name, mat in tqdm(list(merged_sd.items())):
|
||||
if device:
|
||||
mat = mat.to(device)
|
||||
|
||||
up_weight = U
|
||||
down_weight = Vh
|
||||
conv2d = len(mat.size()) == 4
|
||||
kernel_size = None if not conv2d else mat.size()[2:4]
|
||||
conv2d_3x3 = conv2d and kernel_size != (1, 1)
|
||||
out_dim, in_dim = mat.size()[0:2]
|
||||
|
||||
merged_lora_sd[lora_module_name + '.lora_up.weight'] = up_weight.to("cpu").contiguous()
|
||||
merged_lora_sd[lora_module_name + '.lora_down.weight'] = down_weight.to("cpu").contiguous()
|
||||
merged_lora_sd[lora_module_name + '.alpha'] = torch.tensor(module_new_rank)
|
||||
if conv2d:
|
||||
if conv2d_3x3:
|
||||
mat = mat.flatten(start_dim=1)
|
||||
else:
|
||||
mat = mat.squeeze()
|
||||
|
||||
return merged_lora_sd
|
||||
module_new_rank = new_conv_rank if conv2d_3x3 else new_rank
|
||||
module_new_rank = min(module_new_rank, in_dim, out_dim) # LoRA rank cannot exceed the original dim
|
||||
|
||||
U, S, Vh = torch.linalg.svd(mat)
|
||||
|
||||
U = U[:, :module_new_rank]
|
||||
S = S[:module_new_rank]
|
||||
U = U @ torch.diag(S)
|
||||
|
||||
Vh = Vh[:module_new_rank, :]
|
||||
|
||||
dist = torch.cat([U.flatten(), Vh.flatten()])
|
||||
hi_val = torch.quantile(dist, CLAMP_QUANTILE)
|
||||
low_val = -hi_val
|
||||
|
||||
U = U.clamp(low_val, hi_val)
|
||||
Vh = Vh.clamp(low_val, hi_val)
|
||||
|
||||
if conv2d:
|
||||
U = U.reshape(out_dim, module_new_rank, 1, 1)
|
||||
Vh = Vh.reshape(module_new_rank, in_dim, kernel_size[0], kernel_size[1])
|
||||
|
||||
up_weight = U
|
||||
down_weight = Vh
|
||||
|
||||
merged_lora_sd[lora_module_name + ".lora_up.weight"] = up_weight.to("cpu").contiguous()
|
||||
merged_lora_sd[lora_module_name + ".lora_down.weight"] = down_weight.to("cpu").contiguous()
|
||||
merged_lora_sd[lora_module_name + ".alpha"] = torch.tensor(module_new_rank, device="cpu")
|
||||
|
||||
# build minimum metadata
|
||||
dims = f"{new_rank}"
|
||||
alphas = f"{new_rank}"
|
||||
if new_conv_rank is not None:
|
||||
network_args = {"conv_dim": new_conv_rank, "conv_alpha": new_conv_rank}
|
||||
else:
|
||||
network_args = None
|
||||
metadata = train_util.build_minimum_network_metadata(v2, base_model, "networks.lora", dims, alphas, network_args)
|
||||
|
||||
return merged_lora_sd, metadata, v2 == "True", base_model
|
||||
|
||||
|
||||
def merge(args):
|
||||
assert len(args.models) == len(args.ratios), f"number of models must be equal to number of ratios / モデルの数と重みの数は合わせてください"
|
||||
assert len(args.models) == len(
|
||||
args.ratios
|
||||
), f"number of models must be equal to number of ratios / モデルの数と重みの数は合わせてください"
|
||||
if args.lbws:
|
||||
assert len(args.models) == len(
|
||||
args.lbws
|
||||
), f"number of models must be equal to number of ratios / モデルの数と層別適用率の数は合わせてください"
|
||||
else:
|
||||
args.lbws = [] # zip_longestで扱えるようにlbws未使用時には空のリストにしておく
|
||||
|
||||
def str_to_dtype(p):
|
||||
if p == 'float':
|
||||
return torch.float
|
||||
if p == 'fp16':
|
||||
return torch.float16
|
||||
if p == 'bf16':
|
||||
return torch.bfloat16
|
||||
return None
|
||||
def str_to_dtype(p):
|
||||
if p == "float":
|
||||
return torch.float
|
||||
if p == "fp16":
|
||||
return torch.float16
|
||||
if p == "bf16":
|
||||
return torch.bfloat16
|
||||
return None
|
||||
|
||||
merge_dtype = str_to_dtype(args.precision)
|
||||
save_dtype = str_to_dtype(args.save_precision)
|
||||
if save_dtype is None:
|
||||
save_dtype = merge_dtype
|
||||
merge_dtype = str_to_dtype(args.precision)
|
||||
save_dtype = str_to_dtype(args.save_precision)
|
||||
if save_dtype is None:
|
||||
save_dtype = merge_dtype
|
||||
|
||||
new_conv_rank = args.new_conv_rank if args.new_conv_rank is not None else args.new_rank
|
||||
state_dict = merge_lora_models(args.models, args.ratios, args.new_rank, new_conv_rank, args.device, merge_dtype)
|
||||
new_conv_rank = args.new_conv_rank if args.new_conv_rank is not None else args.new_rank
|
||||
state_dict, metadata, v2, base_model = merge_lora_models(
|
||||
args.models, args.ratios, args.lbws, args.new_rank, new_conv_rank, args.device, merge_dtype
|
||||
)
|
||||
|
||||
print(f"saving model to: {args.save_to}")
|
||||
save_to_file(args.save_to, state_dict, save_dtype)
|
||||
# cast to save_dtype before calculating hashes
|
||||
for key in list(state_dict.keys()):
|
||||
value = state_dict[key]
|
||||
if type(value) == torch.Tensor and value.dtype.is_floating_point and value.dtype != save_dtype:
|
||||
state_dict[key] = value.to(save_dtype)
|
||||
|
||||
logger.info(f"calculating hashes and creating metadata...")
|
||||
|
||||
model_hash, legacy_hash = train_util.precalculate_safetensors_hashes(state_dict, metadata)
|
||||
metadata["sshs_model_hash"] = model_hash
|
||||
metadata["sshs_legacy_hash"] = legacy_hash
|
||||
|
||||
if not args.no_metadata:
|
||||
is_sdxl = base_model is not None and base_model.lower().startswith("sdxl")
|
||||
merged_from = sai_model_spec.build_merged_from(args.models)
|
||||
title = os.path.splitext(os.path.basename(args.save_to))[0]
|
||||
sai_metadata = sai_model_spec.build_metadata(
|
||||
state_dict, v2, v2, is_sdxl, True, False, time.time(), title=title, merged_from=merged_from
|
||||
)
|
||||
if v2:
|
||||
# TODO read sai modelspec
|
||||
logger.warning(
|
||||
"Cannot determine if LoRA is for v-prediction, so save metadata as v-prediction / LoRAがv-prediction用か否か不明なため、仮にv-prediction用としてmetadataを保存します"
|
||||
)
|
||||
metadata.update(sai_metadata)
|
||||
|
||||
logger.info(f"saving model to: {args.save_to}")
|
||||
save_to_file(args.save_to, state_dict, metadata)
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--save_precision", type=str, default=None,
|
||||
choices=[None, "float", "fp16", "bf16"], help="precision in saving, same to merging if omitted / 保存時に精度を変更して保存する、省略時はマージ時の精度と同じ")
|
||||
parser.add_argument("--precision", type=str, default="float",
|
||||
choices=["float", "fp16", "bf16"], help="precision in merging (float is recommended) / マージの計算時の精度(floatを推奨)")
|
||||
parser.add_argument("--save_to", type=str, default=None,
|
||||
help="destination file name: ckpt or safetensors file / 保存先のファイル名、ckptまたはsafetensors")
|
||||
parser.add_argument("--models", type=str, nargs='*',
|
||||
help="LoRA models to merge: ckpt or safetensors file / マージするLoRAモデル、ckptまたはsafetensors")
|
||||
parser.add_argument("--ratios", type=float, nargs='*',
|
||||
help="ratios for each model / それぞれのLoRAモデルの比率")
|
||||
parser.add_argument("--new_rank", type=int, default=4,
|
||||
help="Specify rank of output LoRA / 出力するLoRAのrank (dim)")
|
||||
parser.add_argument("--new_conv_rank", type=int, default=None,
|
||||
help="Specify rank of output LoRA for Conv2d 3x3, None for same as new_rank / 出力するConv2D 3x3 LoRAのrank (dim)、Noneでnew_rankと同じ")
|
||||
parser.add_argument("--device", type=str, default=None, help="device to use, cuda for GPU / 計算を行うデバイス、cuda でGPUを使う")
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument(
|
||||
"--save_precision",
|
||||
type=str,
|
||||
default=None,
|
||||
choices=[None, "float", "fp16", "bf16"],
|
||||
help="precision in saving, same to merging if omitted / 保存時に精度を変更して保存する、省略時はマージ時の精度と同じ",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--precision",
|
||||
type=str,
|
||||
default="float",
|
||||
choices=["float", "fp16", "bf16"],
|
||||
help="precision in merging (float is recommended) / マージの計算時の精度(floatを推奨)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--save_to",
|
||||
type=str,
|
||||
default=None,
|
||||
help="destination file name: ckpt or safetensors file / 保存先のファイル名、ckptまたはsafetensors",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--models",
|
||||
type=str,
|
||||
nargs="*",
|
||||
help="LoRA models to merge: ckpt or safetensors file / マージするLoRAモデル、ckptまたはsafetensors",
|
||||
)
|
||||
parser.add_argument("--ratios", type=float, nargs="*", help="ratios for each model / それぞれのLoRAモデルの比率")
|
||||
parser.add_argument("--lbws", type=str, nargs="*", help="lbw for each model / それぞれのLoRAモデルの層別適用率")
|
||||
parser.add_argument("--new_rank", type=int, default=4, help="Specify rank of output LoRA / 出力するLoRAのrank (dim)")
|
||||
parser.add_argument(
|
||||
"--new_conv_rank",
|
||||
type=int,
|
||||
default=None,
|
||||
help="Specify rank of output LoRA for Conv2d 3x3, None for same as new_rank / 出力するConv2D 3x3 LoRAのrank (dim)、Noneでnew_rankと同じ",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--device", type=str, default=None, help="device to use, cuda for GPU / 計算を行うデバイス、cuda でGPUを使う"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--no_metadata",
|
||||
action="store_true",
|
||||
help="do not save sai modelspec metadata (minimum ss_metadata for LoRA is saved) / "
|
||||
+ "sai modelspecのメタデータを保存しない(LoRAの最低限のss_metadataは保存される)",
|
||||
)
|
||||
|
||||
return parser
|
||||
return parser
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = setup_parser()
|
||||
if __name__ == "__main__":
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
merge(args)
|
||||
args = parser.parse_args()
|
||||
merge(args)
|
||||
|
||||
@@ -1,26 +1,42 @@
|
||||
accelerate==0.15.0
|
||||
transformers==4.26.0
|
||||
accelerate==0.30.0
|
||||
transformers==4.44.0
|
||||
diffusers[torch]==0.25.0
|
||||
ftfy==6.1.1
|
||||
albumentations==1.3.0
|
||||
opencv-python==4.7.0.68
|
||||
einops==0.6.0
|
||||
diffusers[torch]==0.10.2
|
||||
# albumentations==1.3.0
|
||||
opencv-python==4.8.1.78
|
||||
einops==0.7.0
|
||||
pytorch-lightning==1.9.0
|
||||
bitsandbytes==0.35.0
|
||||
tensorboard==2.10.1
|
||||
safetensors==0.2.6
|
||||
gradio==3.16.2
|
||||
bitsandbytes==0.44.0
|
||||
prodigyopt==1.0
|
||||
lion-pytorch==0.0.6
|
||||
tensorboard
|
||||
safetensors==0.4.2
|
||||
# gradio==3.16.2
|
||||
altair==4.2.2
|
||||
easygui==0.98.3
|
||||
toml==0.10.2
|
||||
voluptuous==0.13.1
|
||||
huggingface-hub==0.24.5
|
||||
# for Image utils
|
||||
imagesize==1.4.1
|
||||
# for BLIP captioning
|
||||
requests==2.28.2
|
||||
timm==0.6.12
|
||||
fairscale==0.4.13
|
||||
# for WD14 captioning
|
||||
# tensorflow<2.11
|
||||
tensorflow==2.10.1
|
||||
huggingface-hub==0.13.3
|
||||
# requests==2.28.2
|
||||
# timm==0.6.12
|
||||
# fairscale==0.4.13
|
||||
# for WD14 captioning (tensorflow)
|
||||
# tensorflow==2.10.1
|
||||
# for WD14 captioning (onnx)
|
||||
# onnx==1.15.0
|
||||
# onnxruntime-gpu==1.17.1
|
||||
# onnxruntime==1.17.1
|
||||
# for cuda 12.1(default 11.8)
|
||||
# onnxruntime-gpu --extra-index-url https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/onnxruntime-cuda-12/pypi/simple/
|
||||
|
||||
# this is for onnx:
|
||||
# protobuf==3.20.3
|
||||
# open clip for SDXL
|
||||
# open-clip-torch==2.20.0
|
||||
# For logging
|
||||
rich==13.7.0
|
||||
# for kohya_ss library
|
||||
.
|
||||
-e .
|
||||
|
||||
3210
sdxl_gen_img.py
Executable file
3210
sdxl_gen_img.py
Executable file
File diff suppressed because it is too large
Load Diff
345
sdxl_minimal_inference.py
Normal file
345
sdxl_minimal_inference.py
Normal file
@@ -0,0 +1,345 @@
|
||||
# 手元で推論を行うための最低限のコード。HuggingFace/DiffusersのCLIP、schedulerとVAEを使う
|
||||
# Minimal code for performing inference at local. Use HuggingFace/Diffusers CLIP, scheduler and VAE
|
||||
|
||||
import argparse
|
||||
import datetime
|
||||
import math
|
||||
import os
|
||||
import random
|
||||
from einops import repeat
|
||||
import numpy as np
|
||||
|
||||
import torch
|
||||
from library.device_utils import init_ipex, get_preferred_device
|
||||
|
||||
init_ipex()
|
||||
|
||||
from tqdm import tqdm
|
||||
from transformers import CLIPTokenizer
|
||||
from diffusers import EulerDiscreteScheduler
|
||||
from PIL import Image
|
||||
|
||||
# import open_clip
|
||||
from safetensors.torch import load_file
|
||||
|
||||
from library import model_util, sdxl_model_util
|
||||
import networks.lora as lora
|
||||
from library.utils import setup_logging
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# scheduler: このあたりの設定はSD1/2と同じでいいらしい
|
||||
# scheduler: The settings around here seem to be the same as SD1/2
|
||||
SCHEDULER_LINEAR_START = 0.00085
|
||||
SCHEDULER_LINEAR_END = 0.0120
|
||||
SCHEDULER_TIMESTEPS = 1000
|
||||
SCHEDLER_SCHEDULE = "scaled_linear"
|
||||
|
||||
|
||||
# Time EmbeddingはDiffusersからのコピー
|
||||
# Time Embedding is copied from Diffusers
|
||||
|
||||
|
||||
def timestep_embedding(timesteps, dim, max_period=10000, repeat_only=False):
|
||||
"""
|
||||
Create sinusoidal timestep embeddings.
|
||||
:param timesteps: a 1-D Tensor of N indices, one per batch element.
|
||||
These may be fractional.
|
||||
:param dim: the dimension of the output.
|
||||
:param max_period: controls the minimum frequency of the embeddings.
|
||||
:return: an [N x dim] Tensor of positional embeddings.
|
||||
"""
|
||||
if not repeat_only:
|
||||
half = dim // 2
|
||||
freqs = torch.exp(-math.log(max_period) * torch.arange(start=0, end=half, dtype=torch.float32) / half).to(
|
||||
device=timesteps.device
|
||||
)
|
||||
args = timesteps[:, None].float() * freqs[None]
|
||||
embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1)
|
||||
if dim % 2:
|
||||
embedding = torch.cat([embedding, torch.zeros_like(embedding[:, :1])], dim=-1)
|
||||
else:
|
||||
embedding = repeat(timesteps, "b -> b d", d=dim)
|
||||
return embedding
|
||||
|
||||
|
||||
def get_timestep_embedding(x, outdim):
|
||||
assert len(x.shape) == 2
|
||||
b, dims = x.shape[0], x.shape[1]
|
||||
# x = rearrange(x, "b d -> (b d)")
|
||||
x = torch.flatten(x)
|
||||
emb = timestep_embedding(x, outdim)
|
||||
# emb = rearrange(emb, "(b d) d2 -> b (d d2)", b=b, d=dims, d2=outdim)
|
||||
emb = torch.reshape(emb, (b, dims * outdim))
|
||||
return emb
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# 画像生成条件を変更する場合はここを変更 / change here to change image generation conditions
|
||||
|
||||
# SDXLの追加のvector embeddingへ渡す値 / Values to pass to additional vector embedding of SDXL
|
||||
target_height = 1024
|
||||
target_width = 1024
|
||||
original_height = target_height
|
||||
original_width = target_width
|
||||
crop_top = 0
|
||||
crop_left = 0
|
||||
|
||||
steps = 50
|
||||
guidance_scale = 7
|
||||
seed = None # 1
|
||||
|
||||
DEVICE = get_preferred_device()
|
||||
DTYPE = torch.float16 # bfloat16 may work
|
||||
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--ckpt_path", type=str, required=True)
|
||||
parser.add_argument("--prompt", type=str, default="A photo of a cat")
|
||||
parser.add_argument("--prompt2", type=str, default=None)
|
||||
parser.add_argument("--negative_prompt", type=str, default="")
|
||||
parser.add_argument("--output_dir", type=str, default=".")
|
||||
parser.add_argument(
|
||||
"--lora_weights",
|
||||
type=str,
|
||||
nargs="*",
|
||||
default=[],
|
||||
help="LoRA weights, only supports networks.lora, each argument is a `path;multiplier` (semi-colon separated)",
|
||||
)
|
||||
parser.add_argument("--interactive", action="store_true")
|
||||
args = parser.parse_args()
|
||||
|
||||
if args.prompt2 is None:
|
||||
args.prompt2 = args.prompt
|
||||
|
||||
# HuggingFaceのmodel id
|
||||
text_encoder_1_name = "openai/clip-vit-large-patch14"
|
||||
text_encoder_2_name = "laion/CLIP-ViT-bigG-14-laion2B-39B-b160k"
|
||||
|
||||
# checkpointを読み込む。モデル変換についてはそちらの関数を参照
|
||||
# Load checkpoint. For model conversion, see this function
|
||||
|
||||
# 本体RAMが少ない場合はGPUにロードするといいかも
|
||||
# If the main RAM is small, it may be better to load it on the GPU
|
||||
text_model1, text_model2, vae, unet, _, _ = sdxl_model_util.load_models_from_sdxl_checkpoint(
|
||||
sdxl_model_util.MODEL_VERSION_SDXL_BASE_V1_0, args.ckpt_path, "cpu"
|
||||
)
|
||||
|
||||
# Text Encoder 1はSDXL本体でもHuggingFaceのものを使っている
|
||||
# In SDXL, Text Encoder 1 is also using HuggingFace's
|
||||
|
||||
# Text Encoder 2はSDXL本体ではopen_clipを使っている
|
||||
# それを使ってもいいが、SD2のDiffusers版に合わせる形で、HuggingFaceのものを使う
|
||||
# 重みの変換コードはSD2とほぼ同じ
|
||||
# In SDXL, Text Encoder 2 is using open_clip
|
||||
# It's okay to use it, but to match the Diffusers version of SD2, use HuggingFace's
|
||||
# The weight conversion code is almost the same as SD2
|
||||
|
||||
# VAEの構造はSDXLもSD1/2と同じだが、重みは異なるようだ。何より謎のscale値が違う
|
||||
# fp16でNaNが出やすいようだ
|
||||
# The structure of VAE is the same as SD1/2, but the weights seem to be different. Above all, the mysterious scale value is different.
|
||||
# NaN seems to be more likely to occur in fp16
|
||||
|
||||
unet.to(DEVICE, dtype=DTYPE)
|
||||
unet.eval()
|
||||
|
||||
vae_dtype = DTYPE
|
||||
if DTYPE == torch.float16:
|
||||
logger.info("use float32 for vae")
|
||||
vae_dtype = torch.float32
|
||||
vae.to(DEVICE, dtype=vae_dtype)
|
||||
vae.eval()
|
||||
|
||||
text_model1.to(DEVICE, dtype=DTYPE)
|
||||
text_model1.eval()
|
||||
text_model2.to(DEVICE, dtype=DTYPE)
|
||||
text_model2.eval()
|
||||
|
||||
unet.set_use_memory_efficient_attention(True, False)
|
||||
if torch.__version__ >= "2.0.0": # PyTorch 2.0.0 以上対応のxformersなら以下が使える
|
||||
vae.set_use_memory_efficient_attention_xformers(True)
|
||||
|
||||
# Tokenizers
|
||||
tokenizer1 = CLIPTokenizer.from_pretrained(text_encoder_1_name)
|
||||
# tokenizer2 = lambda x: open_clip.tokenize(x, context_length=77)
|
||||
tokenizer2 = CLIPTokenizer.from_pretrained(text_encoder_2_name)
|
||||
|
||||
# LoRA
|
||||
for weights_file in args.lora_weights:
|
||||
if ";" in weights_file:
|
||||
weights_file, multiplier = weights_file.split(";")
|
||||
multiplier = float(multiplier)
|
||||
else:
|
||||
multiplier = 1.0
|
||||
|
||||
lora_model, weights_sd = lora.create_network_from_weights(
|
||||
multiplier, weights_file, vae, [text_model1, text_model2], unet, None, True
|
||||
)
|
||||
lora_model.merge_to([text_model1, text_model2], unet, weights_sd, DTYPE, DEVICE)
|
||||
|
||||
# scheduler
|
||||
scheduler = EulerDiscreteScheduler(
|
||||
num_train_timesteps=SCHEDULER_TIMESTEPS,
|
||||
beta_start=SCHEDULER_LINEAR_START,
|
||||
beta_end=SCHEDULER_LINEAR_END,
|
||||
beta_schedule=SCHEDLER_SCHEDULE,
|
||||
)
|
||||
|
||||
def generate_image(prompt, prompt2, negative_prompt, seed=None):
|
||||
# 将来的にサイズ情報も変えられるようにする / Make it possible to change the size information in the future
|
||||
# prepare embedding
|
||||
with torch.no_grad():
|
||||
# vector
|
||||
emb1 = get_timestep_embedding(torch.FloatTensor([original_height, original_width]).unsqueeze(0), 256)
|
||||
emb2 = get_timestep_embedding(torch.FloatTensor([crop_top, crop_left]).unsqueeze(0), 256)
|
||||
emb3 = get_timestep_embedding(torch.FloatTensor([target_height, target_width]).unsqueeze(0), 256)
|
||||
# logger.info("emb1", emb1.shape)
|
||||
c_vector = torch.cat([emb1, emb2, emb3], dim=1).to(DEVICE, dtype=DTYPE)
|
||||
uc_vector = c_vector.clone().to(
|
||||
DEVICE, dtype=DTYPE
|
||||
) # ちょっとここ正しいかどうかわからない I'm not sure if this is right
|
||||
|
||||
# crossattn
|
||||
|
||||
# Text Encoderを二つ呼ぶ関数 Function to call two Text Encoders
|
||||
def call_text_encoder(text, text2):
|
||||
# text encoder 1
|
||||
batch_encoding = tokenizer1(
|
||||
text,
|
||||
truncation=True,
|
||||
return_length=True,
|
||||
return_overflowing_tokens=False,
|
||||
padding="max_length",
|
||||
return_tensors="pt",
|
||||
)
|
||||
tokens = batch_encoding["input_ids"].to(DEVICE)
|
||||
|
||||
with torch.no_grad():
|
||||
enc_out = text_model1(tokens, output_hidden_states=True, return_dict=True)
|
||||
text_embedding1 = enc_out["hidden_states"][11]
|
||||
# text_embedding = pipe.text_encoder.text_model.final_layer_norm(text_embedding) # layer normは通さないらしい
|
||||
|
||||
# text encoder 2
|
||||
# tokens = tokenizer2(text2).to(DEVICE)
|
||||
tokens = tokenizer2(
|
||||
text,
|
||||
truncation=True,
|
||||
return_length=True,
|
||||
return_overflowing_tokens=False,
|
||||
padding="max_length",
|
||||
return_tensors="pt",
|
||||
)
|
||||
tokens = batch_encoding["input_ids"].to(DEVICE)
|
||||
|
||||
with torch.no_grad():
|
||||
enc_out = text_model2(tokens, output_hidden_states=True, return_dict=True)
|
||||
text_embedding2_penu = enc_out["hidden_states"][-2]
|
||||
# logger.info("hidden_states2", text_embedding2_penu.shape)
|
||||
text_embedding2_pool = enc_out["text_embeds"] # do not support Textual Inversion
|
||||
|
||||
# 連結して終了 concat and finish
|
||||
text_embedding = torch.cat([text_embedding1, text_embedding2_penu], dim=2)
|
||||
return text_embedding, text_embedding2_pool
|
||||
|
||||
# cond
|
||||
c_ctx, c_ctx_pool = call_text_encoder(prompt, prompt2)
|
||||
# logger.info(c_ctx.shape, c_ctx_p.shape, c_vector.shape)
|
||||
c_vector = torch.cat([c_ctx_pool, c_vector], dim=1)
|
||||
|
||||
# uncond
|
||||
uc_ctx, uc_ctx_pool = call_text_encoder(negative_prompt, negative_prompt)
|
||||
uc_vector = torch.cat([uc_ctx_pool, uc_vector], dim=1)
|
||||
|
||||
text_embeddings = torch.cat([uc_ctx, c_ctx])
|
||||
vector_embeddings = torch.cat([uc_vector, c_vector])
|
||||
|
||||
# メモリ使用量を減らすにはここでText Encoderを削除するかCPUへ移動する
|
||||
|
||||
if seed is not None:
|
||||
random.seed(seed)
|
||||
np.random.seed(seed)
|
||||
torch.manual_seed(seed)
|
||||
torch.cuda.manual_seed_all(seed)
|
||||
|
||||
# # random generator for initial noise
|
||||
# generator = torch.Generator(device="cuda").manual_seed(seed)
|
||||
generator = None
|
||||
else:
|
||||
generator = None
|
||||
|
||||
# get the initial random noise unless the user supplied it
|
||||
# SDXLはCPUでlatentsを作成しているので一応合わせておく、Diffusersはtarget deviceでlatentsを作成している
|
||||
# SDXL creates latents in CPU, Diffusers creates latents in target device
|
||||
latents_shape = (1, 4, target_height // 8, target_width // 8)
|
||||
latents = torch.randn(
|
||||
latents_shape,
|
||||
generator=generator,
|
||||
device="cpu",
|
||||
dtype=torch.float32,
|
||||
).to(DEVICE, dtype=DTYPE)
|
||||
|
||||
# scale the initial noise by the standard deviation required by the scheduler
|
||||
latents = latents * scheduler.init_noise_sigma
|
||||
|
||||
# set timesteps
|
||||
scheduler.set_timesteps(steps, DEVICE)
|
||||
|
||||
# このへんはDiffusersからのコピペ
|
||||
# Copy from Diffusers
|
||||
timesteps = scheduler.timesteps.to(DEVICE) # .to(DTYPE)
|
||||
num_latent_input = 2
|
||||
with torch.no_grad():
|
||||
for i, t in enumerate(tqdm(timesteps)):
|
||||
# expand the latents if we are doing classifier free guidance
|
||||
latent_model_input = latents.repeat((num_latent_input, 1, 1, 1))
|
||||
latent_model_input = scheduler.scale_model_input(latent_model_input, t)
|
||||
|
||||
noise_pred = unet(latent_model_input, t, text_embeddings, vector_embeddings)
|
||||
|
||||
noise_pred_uncond, noise_pred_text = noise_pred.chunk(num_latent_input) # uncond by negative prompt
|
||||
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
|
||||
|
||||
# compute the previous noisy sample x_t -> x_t-1
|
||||
# latents = scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
|
||||
latents = scheduler.step(noise_pred, t, latents).prev_sample
|
||||
|
||||
# latents = 1 / 0.18215 * latents
|
||||
latents = 1 / sdxl_model_util.VAE_SCALE_FACTOR * latents
|
||||
latents = latents.to(vae_dtype)
|
||||
image = vae.decode(latents).sample
|
||||
image = (image / 2 + 0.5).clamp(0, 1)
|
||||
|
||||
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloa16
|
||||
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
|
||||
|
||||
# image = self.numpy_to_pil(image)
|
||||
image = (image * 255).round().astype("uint8")
|
||||
image = [Image.fromarray(im) for im in image]
|
||||
|
||||
# 保存して終了 save and finish
|
||||
timestamp = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
|
||||
for i, img in enumerate(image):
|
||||
img.save(os.path.join(args.output_dir, f"image_{timestamp}_{i:03d}.png"))
|
||||
|
||||
if not args.interactive:
|
||||
generate_image(args.prompt, args.prompt2, args.negative_prompt, seed)
|
||||
else:
|
||||
# loop for interactive
|
||||
while True:
|
||||
prompt = input("prompt: ")
|
||||
if prompt == "":
|
||||
break
|
||||
prompt2 = input("prompt2: ")
|
||||
if prompt2 == "":
|
||||
prompt2 = prompt
|
||||
negative_prompt = input("negative prompt: ")
|
||||
seed = input("seed: ")
|
||||
if seed == "":
|
||||
seed = None
|
||||
else:
|
||||
seed = int(seed)
|
||||
generate_image(prompt, prompt2, negative_prompt, seed)
|
||||
|
||||
logger.info("Done!")
|
||||
952
sdxl_train.py
Normal file
952
sdxl_train.py
Normal file
@@ -0,0 +1,952 @@
|
||||
# training with captions
|
||||
|
||||
import argparse
|
||||
import math
|
||||
import os
|
||||
from multiprocessing import Value
|
||||
from typing import List
|
||||
import toml
|
||||
|
||||
from tqdm import tqdm
|
||||
|
||||
import torch
|
||||
from library.device_utils import init_ipex, clean_memory_on_device
|
||||
|
||||
|
||||
init_ipex()
|
||||
|
||||
from accelerate.utils import set_seed
|
||||
from diffusers import DDPMScheduler
|
||||
from library import deepspeed_utils, sdxl_model_util
|
||||
|
||||
import library.train_util as train_util
|
||||
|
||||
from library.utils import setup_logging, add_logging_arguments
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
import library.config_util as config_util
|
||||
import library.sdxl_train_util as sdxl_train_util
|
||||
from library.config_util import (
|
||||
ConfigSanitizer,
|
||||
BlueprintGenerator,
|
||||
)
|
||||
import library.custom_train_functions as custom_train_functions
|
||||
from library.custom_train_functions import (
|
||||
apply_snr_weight,
|
||||
prepare_scheduler_for_custom_training,
|
||||
scale_v_prediction_loss_like_noise_prediction,
|
||||
add_v_prediction_like_loss,
|
||||
apply_debiased_estimation,
|
||||
apply_masked_loss,
|
||||
)
|
||||
from library.sdxl_original_unet import SdxlUNet2DConditionModel
|
||||
|
||||
|
||||
UNET_NUM_BLOCKS_FOR_BLOCK_LR = 23
|
||||
|
||||
|
||||
def get_block_params_to_optimize(unet: SdxlUNet2DConditionModel, block_lrs: List[float]) -> List[dict]:
|
||||
block_params = [[] for _ in range(len(block_lrs))]
|
||||
|
||||
for i, (name, param) in enumerate(unet.named_parameters()):
|
||||
if name.startswith("time_embed.") or name.startswith("label_emb."):
|
||||
block_index = 0 # 0
|
||||
elif name.startswith("input_blocks."): # 1-9
|
||||
block_index = 1 + int(name.split(".")[1])
|
||||
elif name.startswith("middle_block."): # 10-12
|
||||
block_index = 10 + int(name.split(".")[1])
|
||||
elif name.startswith("output_blocks."): # 13-21
|
||||
block_index = 13 + int(name.split(".")[1])
|
||||
elif name.startswith("out."): # 22
|
||||
block_index = 22
|
||||
else:
|
||||
raise ValueError(f"unexpected parameter name: {name}")
|
||||
|
||||
block_params[block_index].append(param)
|
||||
|
||||
params_to_optimize = []
|
||||
for i, params in enumerate(block_params):
|
||||
if block_lrs[i] == 0: # 0のときは学習しない do not optimize when lr is 0
|
||||
continue
|
||||
params_to_optimize.append({"params": params, "lr": block_lrs[i]})
|
||||
|
||||
return params_to_optimize
|
||||
|
||||
|
||||
def append_block_lr_to_logs(block_lrs, logs, lr_scheduler, optimizer_type):
|
||||
names = []
|
||||
block_index = 0
|
||||
while block_index < UNET_NUM_BLOCKS_FOR_BLOCK_LR + 2:
|
||||
if block_index < UNET_NUM_BLOCKS_FOR_BLOCK_LR:
|
||||
if block_lrs[block_index] == 0:
|
||||
block_index += 1
|
||||
continue
|
||||
names.append(f"block{block_index}")
|
||||
elif block_index == UNET_NUM_BLOCKS_FOR_BLOCK_LR:
|
||||
names.append("text_encoder1")
|
||||
elif block_index == UNET_NUM_BLOCKS_FOR_BLOCK_LR + 1:
|
||||
names.append("text_encoder2")
|
||||
|
||||
block_index += 1
|
||||
|
||||
train_util.append_lr_to_logs_with_names(logs, lr_scheduler, optimizer_type, names)
|
||||
|
||||
|
||||
def train(args):
|
||||
train_util.verify_training_args(args)
|
||||
train_util.prepare_dataset_args(args, True)
|
||||
sdxl_train_util.verify_sdxl_training_args(args)
|
||||
deepspeed_utils.prepare_deepspeed_args(args)
|
||||
setup_logging(args, reset=True)
|
||||
|
||||
assert (
|
||||
not args.weighted_captions
|
||||
), "weighted_captions is not supported currently / weighted_captionsは現在サポートされていません"
|
||||
assert (
|
||||
not args.train_text_encoder or not args.cache_text_encoder_outputs
|
||||
), "cache_text_encoder_outputs is not supported when training text encoder / text encoderを学習するときはcache_text_encoder_outputsはサポートされていません"
|
||||
|
||||
if args.block_lr:
|
||||
block_lrs = [float(lr) for lr in args.block_lr.split(",")]
|
||||
assert (
|
||||
len(block_lrs) == UNET_NUM_BLOCKS_FOR_BLOCK_LR
|
||||
), f"block_lr must have {UNET_NUM_BLOCKS_FOR_BLOCK_LR} values / block_lrは{UNET_NUM_BLOCKS_FOR_BLOCK_LR}個の値を指定してください"
|
||||
else:
|
||||
block_lrs = None
|
||||
|
||||
cache_latents = args.cache_latents
|
||||
use_dreambooth_method = args.in_json is None
|
||||
|
||||
if args.seed is not None:
|
||||
set_seed(args.seed) # 乱数系列を初期化する
|
||||
|
||||
tokenizer1, tokenizer2 = sdxl_train_util.load_tokenizers(args)
|
||||
|
||||
# データセットを準備する
|
||||
if args.dataset_class is None:
|
||||
blueprint_generator = BlueprintGenerator(ConfigSanitizer(True, True, args.masked_loss, True))
|
||||
if args.dataset_config is not None:
|
||||
logger.info(f"Load dataset config from {args.dataset_config}")
|
||||
user_config = config_util.load_user_config(args.dataset_config)
|
||||
ignored = ["train_data_dir", "in_json"]
|
||||
if any(getattr(args, attr) is not None for attr in ignored):
|
||||
logger.warning(
|
||||
"ignore following options because config file is found: {0} / 設定ファイルが利用されるため以下のオプションは無視されます: {0}".format(
|
||||
", ".join(ignored)
|
||||
)
|
||||
)
|
||||
else:
|
||||
if use_dreambooth_method:
|
||||
logger.info("Using DreamBooth method.")
|
||||
user_config = {
|
||||
"datasets": [
|
||||
{
|
||||
"subsets": config_util.generate_dreambooth_subsets_config_by_subdirs(
|
||||
args.train_data_dir, args.reg_data_dir
|
||||
)
|
||||
}
|
||||
]
|
||||
}
|
||||
else:
|
||||
logger.info("Training with captions.")
|
||||
user_config = {
|
||||
"datasets": [
|
||||
{
|
||||
"subsets": [
|
||||
{
|
||||
"image_dir": args.train_data_dir,
|
||||
"metadata_file": args.in_json,
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
blueprint = blueprint_generator.generate(user_config, args, tokenizer=[tokenizer1, tokenizer2])
|
||||
train_dataset_group = config_util.generate_dataset_group_by_blueprint(blueprint.dataset_group)
|
||||
else:
|
||||
train_dataset_group = train_util.load_arbitrary_dataset(args, [tokenizer1, tokenizer2])
|
||||
|
||||
current_epoch = Value("i", 0)
|
||||
current_step = Value("i", 0)
|
||||
ds_for_collator = train_dataset_group if args.max_data_loader_n_workers == 0 else None
|
||||
collator = train_util.collator_class(current_epoch, current_step, ds_for_collator)
|
||||
|
||||
train_dataset_group.verify_bucket_reso_steps(32)
|
||||
|
||||
if args.debug_dataset:
|
||||
train_util.debug_dataset(train_dataset_group, True)
|
||||
return
|
||||
if len(train_dataset_group) == 0:
|
||||
logger.error(
|
||||
"No data found. Please verify the metadata file and train_data_dir option. / 画像がありません。メタデータおよびtrain_data_dirオプションを確認してください。"
|
||||
)
|
||||
return
|
||||
|
||||
if cache_latents:
|
||||
assert (
|
||||
train_dataset_group.is_latent_cacheable()
|
||||
), "when caching latents, either color_aug or random_crop cannot be used / latentをキャッシュするときはcolor_augとrandom_cropは使えません"
|
||||
|
||||
if args.cache_text_encoder_outputs:
|
||||
assert (
|
||||
train_dataset_group.is_text_encoder_output_cacheable()
|
||||
), "when caching text encoder output, either caption_dropout_rate, shuffle_caption, token_warmup_step or caption_tag_dropout_rate cannot be used / text encoderの出力をキャッシュするときはcaption_dropout_rate, shuffle_caption, token_warmup_step, caption_tag_dropout_rateは使えません"
|
||||
|
||||
# acceleratorを準備する
|
||||
logger.info("prepare accelerator")
|
||||
accelerator = train_util.prepare_accelerator(args)
|
||||
|
||||
# mixed precisionに対応した型を用意しておき適宜castする
|
||||
weight_dtype, save_dtype = train_util.prepare_dtype(args)
|
||||
vae_dtype = torch.float32 if args.no_half_vae else weight_dtype
|
||||
|
||||
# モデルを読み込む
|
||||
(
|
||||
load_stable_diffusion_format,
|
||||
text_encoder1,
|
||||
text_encoder2,
|
||||
vae,
|
||||
unet,
|
||||
logit_scale,
|
||||
ckpt_info,
|
||||
) = sdxl_train_util.load_target_model(args, accelerator, "sdxl", weight_dtype)
|
||||
# logit_scale = logit_scale.to(accelerator.device, dtype=weight_dtype)
|
||||
|
||||
# verify load/save model formats
|
||||
if load_stable_diffusion_format:
|
||||
src_stable_diffusion_ckpt = args.pretrained_model_name_or_path
|
||||
src_diffusers_model_path = None
|
||||
else:
|
||||
src_stable_diffusion_ckpt = None
|
||||
src_diffusers_model_path = args.pretrained_model_name_or_path
|
||||
|
||||
if args.save_model_as is None:
|
||||
save_stable_diffusion_format = load_stable_diffusion_format
|
||||
use_safetensors = args.use_safetensors
|
||||
else:
|
||||
save_stable_diffusion_format = args.save_model_as.lower() == "ckpt" or args.save_model_as.lower() == "safetensors"
|
||||
use_safetensors = args.use_safetensors or ("safetensors" in args.save_model_as.lower())
|
||||
# assert save_stable_diffusion_format, "save_model_as must be ckpt or safetensors / save_model_asはckptかsafetensorsである必要があります"
|
||||
|
||||
# Diffusers版のxformers使用フラグを設定する関数
|
||||
def set_diffusers_xformers_flag(model, valid):
|
||||
def fn_recursive_set_mem_eff(module: torch.nn.Module):
|
||||
if hasattr(module, "set_use_memory_efficient_attention_xformers"):
|
||||
module.set_use_memory_efficient_attention_xformers(valid)
|
||||
|
||||
for child in module.children():
|
||||
fn_recursive_set_mem_eff(child)
|
||||
|
||||
fn_recursive_set_mem_eff(model)
|
||||
|
||||
# モデルに xformers とか memory efficient attention を組み込む
|
||||
if args.diffusers_xformers:
|
||||
# もうU-Netを独自にしたので動かないけどVAEのxformersは動くはず
|
||||
accelerator.print("Use xformers by Diffusers")
|
||||
# set_diffusers_xformers_flag(unet, True)
|
||||
set_diffusers_xformers_flag(vae, True)
|
||||
else:
|
||||
# Windows版のxformersはfloatで学習できなかったりするのでxformersを使わない設定も可能にしておく必要がある
|
||||
accelerator.print("Disable Diffusers' xformers")
|
||||
train_util.replace_unet_modules(unet, args.mem_eff_attn, args.xformers, args.sdpa)
|
||||
if torch.__version__ >= "2.0.0": # PyTorch 2.0.0 以上対応のxformersなら以下が使える
|
||||
vae.set_use_memory_efficient_attention_xformers(args.xformers)
|
||||
|
||||
# 学習を準備する
|
||||
if cache_latents:
|
||||
vae.to(accelerator.device, dtype=vae_dtype)
|
||||
vae.requires_grad_(False)
|
||||
vae.eval()
|
||||
with torch.no_grad():
|
||||
train_dataset_group.cache_latents(vae, args.vae_batch_size, args.cache_latents_to_disk, accelerator.is_main_process)
|
||||
vae.to("cpu")
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
# 学習を準備する:モデルを適切な状態にする
|
||||
if args.gradient_checkpointing:
|
||||
unet.enable_gradient_checkpointing()
|
||||
train_unet = args.learning_rate != 0
|
||||
train_text_encoder1 = False
|
||||
train_text_encoder2 = False
|
||||
|
||||
if args.train_text_encoder:
|
||||
# TODO each option for two text encoders?
|
||||
accelerator.print("enable text encoder training")
|
||||
if args.gradient_checkpointing:
|
||||
text_encoder1.gradient_checkpointing_enable()
|
||||
text_encoder2.gradient_checkpointing_enable()
|
||||
lr_te1 = args.learning_rate_te1 if args.learning_rate_te1 is not None else args.learning_rate # 0 means not train
|
||||
lr_te2 = args.learning_rate_te2 if args.learning_rate_te2 is not None else args.learning_rate # 0 means not train
|
||||
train_text_encoder1 = lr_te1 != 0
|
||||
train_text_encoder2 = lr_te2 != 0
|
||||
|
||||
# caching one text encoder output is not supported
|
||||
if not train_text_encoder1:
|
||||
text_encoder1.to(weight_dtype)
|
||||
if not train_text_encoder2:
|
||||
text_encoder2.to(weight_dtype)
|
||||
text_encoder1.requires_grad_(train_text_encoder1)
|
||||
text_encoder2.requires_grad_(train_text_encoder2)
|
||||
text_encoder1.train(train_text_encoder1)
|
||||
text_encoder2.train(train_text_encoder2)
|
||||
else:
|
||||
text_encoder1.to(weight_dtype)
|
||||
text_encoder2.to(weight_dtype)
|
||||
text_encoder1.requires_grad_(False)
|
||||
text_encoder2.requires_grad_(False)
|
||||
text_encoder1.eval()
|
||||
text_encoder2.eval()
|
||||
|
||||
# TextEncoderの出力をキャッシュする
|
||||
if args.cache_text_encoder_outputs:
|
||||
# Text Encodes are eval and no grad
|
||||
with torch.no_grad(), accelerator.autocast():
|
||||
train_dataset_group.cache_text_encoder_outputs(
|
||||
(tokenizer1, tokenizer2),
|
||||
(text_encoder1, text_encoder2),
|
||||
accelerator.device,
|
||||
None,
|
||||
args.cache_text_encoder_outputs_to_disk,
|
||||
accelerator.is_main_process,
|
||||
)
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
if not cache_latents:
|
||||
vae.requires_grad_(False)
|
||||
vae.eval()
|
||||
vae.to(accelerator.device, dtype=vae_dtype)
|
||||
|
||||
unet.requires_grad_(train_unet)
|
||||
if not train_unet:
|
||||
unet.to(accelerator.device, dtype=weight_dtype) # because of unet is not prepared
|
||||
|
||||
training_models = []
|
||||
params_to_optimize = []
|
||||
if train_unet:
|
||||
training_models.append(unet)
|
||||
if block_lrs is None:
|
||||
params_to_optimize.append({"params": list(unet.parameters()), "lr": args.learning_rate})
|
||||
else:
|
||||
params_to_optimize.extend(get_block_params_to_optimize(unet, block_lrs))
|
||||
|
||||
if train_text_encoder1:
|
||||
training_models.append(text_encoder1)
|
||||
params_to_optimize.append({"params": list(text_encoder1.parameters()), "lr": args.learning_rate_te1 or args.learning_rate})
|
||||
if train_text_encoder2:
|
||||
training_models.append(text_encoder2)
|
||||
params_to_optimize.append({"params": list(text_encoder2.parameters()), "lr": args.learning_rate_te2 or args.learning_rate})
|
||||
|
||||
# calculate number of trainable parameters
|
||||
n_params = 0
|
||||
for group in params_to_optimize:
|
||||
for p in group["params"]:
|
||||
n_params += p.numel()
|
||||
|
||||
accelerator.print(f"train unet: {train_unet}, text_encoder1: {train_text_encoder1}, text_encoder2: {train_text_encoder2}")
|
||||
accelerator.print(f"number of models: {len(training_models)}")
|
||||
accelerator.print(f"number of trainable parameters: {n_params}")
|
||||
|
||||
# 学習に必要なクラスを準備する
|
||||
accelerator.print("prepare optimizer, data loader etc.")
|
||||
|
||||
if args.fused_optimizer_groups:
|
||||
# fused backward pass: https://pytorch.org/tutorials/intermediate/optimizer_step_in_backward_tutorial.html
|
||||
# Instead of creating an optimizer for all parameters as in the tutorial, we create an optimizer for each group of parameters.
|
||||
# This balances memory usage and management complexity.
|
||||
|
||||
# calculate total number of parameters
|
||||
n_total_params = sum(len(params["params"]) for params in params_to_optimize)
|
||||
params_per_group = math.ceil(n_total_params / args.fused_optimizer_groups)
|
||||
|
||||
# split params into groups, keeping the learning rate the same for all params in a group
|
||||
# this will increase the number of groups if the learning rate is different for different params (e.g. U-Net and text encoders)
|
||||
grouped_params = []
|
||||
param_group = []
|
||||
param_group_lr = -1
|
||||
for group in params_to_optimize:
|
||||
lr = group["lr"]
|
||||
for p in group["params"]:
|
||||
# if the learning rate is different for different params, start a new group
|
||||
if lr != param_group_lr:
|
||||
if param_group:
|
||||
grouped_params.append({"params": param_group, "lr": param_group_lr})
|
||||
param_group = []
|
||||
param_group_lr = lr
|
||||
|
||||
param_group.append(p)
|
||||
|
||||
# if the group has enough parameters, start a new group
|
||||
if len(param_group) == params_per_group:
|
||||
grouped_params.append({"params": param_group, "lr": param_group_lr})
|
||||
param_group = []
|
||||
param_group_lr = -1
|
||||
|
||||
if param_group:
|
||||
grouped_params.append({"params": param_group, "lr": param_group_lr})
|
||||
|
||||
# prepare optimizers for each group
|
||||
optimizers = []
|
||||
for group in grouped_params:
|
||||
_, _, optimizer = train_util.get_optimizer(args, trainable_params=[group])
|
||||
optimizers.append(optimizer)
|
||||
optimizer = optimizers[0] # avoid error in the following code
|
||||
|
||||
logger.info(f"using {len(optimizers)} optimizers for fused optimizer groups")
|
||||
|
||||
else:
|
||||
_, _, optimizer = train_util.get_optimizer(args, trainable_params=params_to_optimize)
|
||||
|
||||
# dataloaderを準備する
|
||||
# DataLoaderのプロセス数:0 は persistent_workers が使えないので注意
|
||||
n_workers = min(args.max_data_loader_n_workers, os.cpu_count()) # cpu_count or max_data_loader_n_workers
|
||||
train_dataloader = torch.utils.data.DataLoader(
|
||||
train_dataset_group,
|
||||
batch_size=1,
|
||||
shuffle=True,
|
||||
collate_fn=collator,
|
||||
num_workers=n_workers,
|
||||
persistent_workers=args.persistent_data_loader_workers,
|
||||
)
|
||||
|
||||
# 学習ステップ数を計算する
|
||||
if args.max_train_epochs is not None:
|
||||
args.max_train_steps = args.max_train_epochs * math.ceil(
|
||||
len(train_dataloader) / accelerator.num_processes / args.gradient_accumulation_steps
|
||||
)
|
||||
accelerator.print(
|
||||
f"override steps. steps for {args.max_train_epochs} epochs is / 指定エポックまでのステップ数: {args.max_train_steps}"
|
||||
)
|
||||
|
||||
# データセット側にも学習ステップを送信
|
||||
train_dataset_group.set_max_train_steps(args.max_train_steps)
|
||||
|
||||
# lr schedulerを用意する
|
||||
if args.fused_optimizer_groups:
|
||||
# prepare lr schedulers for each optimizer
|
||||
lr_schedulers = [train_util.get_scheduler_fix(args, optimizer, accelerator.num_processes) for optimizer in optimizers]
|
||||
lr_scheduler = lr_schedulers[0] # avoid error in the following code
|
||||
else:
|
||||
lr_scheduler = train_util.get_scheduler_fix(args, optimizer, accelerator.num_processes)
|
||||
|
||||
# 実験的機能:勾配も含めたfp16/bf16学習を行う モデル全体をfp16/bf16にする
|
||||
if args.full_fp16:
|
||||
assert (
|
||||
args.mixed_precision == "fp16"
|
||||
), "full_fp16 requires mixed precision='fp16' / full_fp16を使う場合はmixed_precision='fp16'を指定してください。"
|
||||
accelerator.print("enable full fp16 training.")
|
||||
unet.to(weight_dtype)
|
||||
text_encoder1.to(weight_dtype)
|
||||
text_encoder2.to(weight_dtype)
|
||||
elif args.full_bf16:
|
||||
assert (
|
||||
args.mixed_precision == "bf16"
|
||||
), "full_bf16 requires mixed precision='bf16' / full_bf16を使う場合はmixed_precision='bf16'を指定してください。"
|
||||
accelerator.print("enable full bf16 training.")
|
||||
unet.to(weight_dtype)
|
||||
text_encoder1.to(weight_dtype)
|
||||
text_encoder2.to(weight_dtype)
|
||||
|
||||
# freeze last layer and final_layer_norm in te1 since we use the output of the penultimate layer
|
||||
if train_text_encoder1:
|
||||
text_encoder1.text_model.encoder.layers[-1].requires_grad_(False)
|
||||
text_encoder1.text_model.final_layer_norm.requires_grad_(False)
|
||||
|
||||
if args.deepspeed:
|
||||
ds_model = deepspeed_utils.prepare_deepspeed_model(
|
||||
args,
|
||||
unet=unet if train_unet else None,
|
||||
text_encoder1=text_encoder1 if train_text_encoder1 else None,
|
||||
text_encoder2=text_encoder2 if train_text_encoder2 else None,
|
||||
)
|
||||
# most of ZeRO stage uses optimizer partitioning, so we have to prepare optimizer and ds_model at the same time. # pull/1139#issuecomment-1986790007
|
||||
ds_model, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
|
||||
ds_model, optimizer, train_dataloader, lr_scheduler
|
||||
)
|
||||
training_models = [ds_model]
|
||||
|
||||
else:
|
||||
# acceleratorがなんかよろしくやってくれるらしい
|
||||
if train_unet:
|
||||
unet = accelerator.prepare(unet)
|
||||
if train_text_encoder1:
|
||||
text_encoder1 = accelerator.prepare(text_encoder1)
|
||||
if train_text_encoder2:
|
||||
text_encoder2 = accelerator.prepare(text_encoder2)
|
||||
optimizer, train_dataloader, lr_scheduler = accelerator.prepare(optimizer, train_dataloader, lr_scheduler)
|
||||
|
||||
# TextEncoderの出力をキャッシュするときにはCPUへ移動する
|
||||
if args.cache_text_encoder_outputs:
|
||||
# move Text Encoders for sampling images. Text Encoder doesn't work on CPU with fp16
|
||||
text_encoder1.to("cpu", dtype=torch.float32)
|
||||
text_encoder2.to("cpu", dtype=torch.float32)
|
||||
clean_memory_on_device(accelerator.device)
|
||||
else:
|
||||
# make sure Text Encoders are on GPU
|
||||
text_encoder1.to(accelerator.device)
|
||||
text_encoder2.to(accelerator.device)
|
||||
|
||||
# 実験的機能:勾配も含めたfp16学習を行う PyTorchにパッチを当ててfp16でのgrad scaleを有効にする
|
||||
if args.full_fp16:
|
||||
# During deepseed training, accelerate not handles fp16/bf16|mixed precision directly via scaler. Let deepspeed engine do.
|
||||
# -> But we think it's ok to patch accelerator even if deepspeed is enabled.
|
||||
train_util.patch_accelerator_for_fp16_training(accelerator)
|
||||
|
||||
# resumeする
|
||||
train_util.resume_from_local_or_hf_if_specified(accelerator, args)
|
||||
|
||||
if args.fused_backward_pass:
|
||||
# use fused optimizer for backward pass: other optimizers will be supported in the future
|
||||
import library.adafactor_fused
|
||||
|
||||
library.adafactor_fused.patch_adafactor_fused(optimizer)
|
||||
for param_group in optimizer.param_groups:
|
||||
for parameter in param_group["params"]:
|
||||
if parameter.requires_grad:
|
||||
|
||||
def __grad_hook(tensor: torch.Tensor, param_group=param_group):
|
||||
if accelerator.sync_gradients and args.max_grad_norm != 0.0:
|
||||
accelerator.clip_grad_norm_(tensor, args.max_grad_norm)
|
||||
optimizer.step_param(tensor, param_group)
|
||||
tensor.grad = None
|
||||
|
||||
parameter.register_post_accumulate_grad_hook(__grad_hook)
|
||||
|
||||
elif args.fused_optimizer_groups:
|
||||
# prepare for additional optimizers and lr schedulers
|
||||
for i in range(1, len(optimizers)):
|
||||
optimizers[i] = accelerator.prepare(optimizers[i])
|
||||
lr_schedulers[i] = accelerator.prepare(lr_schedulers[i])
|
||||
|
||||
# counters are used to determine when to step the optimizer
|
||||
global optimizer_hooked_count
|
||||
global num_parameters_per_group
|
||||
global parameter_optimizer_map
|
||||
|
||||
optimizer_hooked_count = {}
|
||||
num_parameters_per_group = [0] * len(optimizers)
|
||||
parameter_optimizer_map = {}
|
||||
|
||||
for opt_idx, optimizer in enumerate(optimizers):
|
||||
for param_group in optimizer.param_groups:
|
||||
for parameter in param_group["params"]:
|
||||
if parameter.requires_grad:
|
||||
|
||||
def optimizer_hook(parameter: torch.Tensor):
|
||||
if accelerator.sync_gradients and args.max_grad_norm != 0.0:
|
||||
accelerator.clip_grad_norm_(parameter, args.max_grad_norm)
|
||||
|
||||
i = parameter_optimizer_map[parameter]
|
||||
optimizer_hooked_count[i] += 1
|
||||
if optimizer_hooked_count[i] == num_parameters_per_group[i]:
|
||||
optimizers[i].step()
|
||||
optimizers[i].zero_grad(set_to_none=True)
|
||||
|
||||
parameter.register_post_accumulate_grad_hook(optimizer_hook)
|
||||
parameter_optimizer_map[parameter] = opt_idx
|
||||
num_parameters_per_group[opt_idx] += 1
|
||||
|
||||
# epoch数を計算する
|
||||
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
|
||||
num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
|
||||
if (args.save_n_epoch_ratio is not None) and (args.save_n_epoch_ratio > 0):
|
||||
args.save_every_n_epochs = math.floor(num_train_epochs / args.save_n_epoch_ratio) or 1
|
||||
|
||||
# 学習する
|
||||
# total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
|
||||
accelerator.print("running training / 学習開始")
|
||||
accelerator.print(f" num examples / サンプル数: {train_dataset_group.num_train_images}")
|
||||
accelerator.print(f" num batches per epoch / 1epochのバッチ数: {len(train_dataloader)}")
|
||||
accelerator.print(f" num epochs / epoch数: {num_train_epochs}")
|
||||
accelerator.print(
|
||||
f" batch size per device / バッチサイズ: {', '.join([str(d.batch_size) for d in train_dataset_group.datasets])}"
|
||||
)
|
||||
# accelerator.print(
|
||||
# f" total train batch size (with parallel & distributed & accumulation) / 総バッチサイズ(並列学習、勾配合計含む): {total_batch_size}"
|
||||
# )
|
||||
accelerator.print(f" gradient accumulation steps / 勾配を合計するステップ数 = {args.gradient_accumulation_steps}")
|
||||
accelerator.print(f" total optimization steps / 学習ステップ数: {args.max_train_steps}")
|
||||
|
||||
progress_bar = tqdm(range(args.max_train_steps), smoothing=0, disable=not accelerator.is_local_main_process, desc="steps")
|
||||
global_step = 0
|
||||
|
||||
noise_scheduler = DDPMScheduler(
|
||||
beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000, clip_sample=False
|
||||
)
|
||||
prepare_scheduler_for_custom_training(noise_scheduler, accelerator.device)
|
||||
if args.zero_terminal_snr:
|
||||
custom_train_functions.fix_noise_scheduler_betas_for_zero_terminal_snr(noise_scheduler)
|
||||
|
||||
if accelerator.is_main_process:
|
||||
init_kwargs = {}
|
||||
if args.wandb_run_name:
|
||||
init_kwargs["wandb"] = {"name": args.wandb_run_name}
|
||||
if args.log_tracker_config is not None:
|
||||
init_kwargs = toml.load(args.log_tracker_config)
|
||||
accelerator.init_trackers(
|
||||
"finetuning" if args.log_tracker_name is None else args.log_tracker_name,
|
||||
config=train_util.get_sanitized_config_or_none(args),
|
||||
init_kwargs=init_kwargs,
|
||||
)
|
||||
|
||||
# For --sample_at_first
|
||||
sdxl_train_util.sample_images(
|
||||
accelerator, args, 0, global_step, accelerator.device, vae, [tokenizer1, tokenizer2], [text_encoder1, text_encoder2], unet
|
||||
)
|
||||
|
||||
loss_recorder = train_util.LossRecorder()
|
||||
for epoch in range(num_train_epochs):
|
||||
accelerator.print(f"\nepoch {epoch+1}/{num_train_epochs}")
|
||||
current_epoch.value = epoch + 1
|
||||
|
||||
for m in training_models:
|
||||
m.train()
|
||||
|
||||
for step, batch in enumerate(train_dataloader):
|
||||
current_step.value = global_step
|
||||
|
||||
if args.fused_optimizer_groups:
|
||||
optimizer_hooked_count = {i: 0 for i in range(len(optimizers))} # reset counter for each step
|
||||
|
||||
with accelerator.accumulate(*training_models):
|
||||
if "latents" in batch and batch["latents"] is not None:
|
||||
latents = batch["latents"].to(accelerator.device).to(dtype=weight_dtype)
|
||||
else:
|
||||
with torch.no_grad():
|
||||
# latentに変換
|
||||
latents = vae.encode(batch["images"].to(vae_dtype)).latent_dist.sample().to(weight_dtype)
|
||||
|
||||
# NaNが含まれていれば警告を表示し0に置き換える
|
||||
if torch.any(torch.isnan(latents)):
|
||||
accelerator.print("NaN found in latents, replacing with zeros")
|
||||
latents = torch.nan_to_num(latents, 0, out=latents)
|
||||
latents = latents * sdxl_model_util.VAE_SCALE_FACTOR
|
||||
|
||||
if "text_encoder_outputs1_list" not in batch or batch["text_encoder_outputs1_list"] is None:
|
||||
input_ids1 = batch["input_ids"]
|
||||
input_ids2 = batch["input_ids2"]
|
||||
with torch.set_grad_enabled(args.train_text_encoder):
|
||||
# Get the text embedding for conditioning
|
||||
# TODO support weighted captions
|
||||
# if args.weighted_captions:
|
||||
# encoder_hidden_states = get_weighted_text_embeddings(
|
||||
# tokenizer,
|
||||
# text_encoder,
|
||||
# batch["captions"],
|
||||
# accelerator.device,
|
||||
# args.max_token_length // 75 if args.max_token_length else 1,
|
||||
# clip_skip=args.clip_skip,
|
||||
# )
|
||||
# else:
|
||||
input_ids1 = input_ids1.to(accelerator.device)
|
||||
input_ids2 = input_ids2.to(accelerator.device)
|
||||
# unwrap_model is fine for models not wrapped by accelerator
|
||||
encoder_hidden_states1, encoder_hidden_states2, pool2 = train_util.get_hidden_states_sdxl(
|
||||
args.max_token_length,
|
||||
input_ids1,
|
||||
input_ids2,
|
||||
tokenizer1,
|
||||
tokenizer2,
|
||||
text_encoder1,
|
||||
text_encoder2,
|
||||
None if not args.full_fp16 else weight_dtype,
|
||||
accelerator=accelerator,
|
||||
)
|
||||
else:
|
||||
encoder_hidden_states1 = batch["text_encoder_outputs1_list"].to(accelerator.device).to(weight_dtype)
|
||||
encoder_hidden_states2 = batch["text_encoder_outputs2_list"].to(accelerator.device).to(weight_dtype)
|
||||
pool2 = batch["text_encoder_pool2_list"].to(accelerator.device).to(weight_dtype)
|
||||
|
||||
# # verify that the text encoder outputs are correct
|
||||
# ehs1, ehs2, p2 = train_util.get_hidden_states_sdxl(
|
||||
# args.max_token_length,
|
||||
# batch["input_ids"].to(text_encoder1.device),
|
||||
# batch["input_ids2"].to(text_encoder1.device),
|
||||
# tokenizer1,
|
||||
# tokenizer2,
|
||||
# text_encoder1,
|
||||
# text_encoder2,
|
||||
# None if not args.full_fp16 else weight_dtype,
|
||||
# )
|
||||
# b_size = encoder_hidden_states1.shape[0]
|
||||
# assert ((encoder_hidden_states1.to("cpu") - ehs1.to(dtype=weight_dtype)).abs().max() > 1e-2).sum() <= b_size * 2
|
||||
# assert ((encoder_hidden_states2.to("cpu") - ehs2.to(dtype=weight_dtype)).abs().max() > 1e-2).sum() <= b_size * 2
|
||||
# assert ((pool2.to("cpu") - p2.to(dtype=weight_dtype)).abs().max() > 1e-2).sum() <= b_size * 2
|
||||
# logger.info("text encoder outputs verified")
|
||||
|
||||
# get size embeddings
|
||||
orig_size = batch["original_sizes_hw"]
|
||||
crop_size = batch["crop_top_lefts"]
|
||||
target_size = batch["target_sizes_hw"]
|
||||
embs = sdxl_train_util.get_size_embeddings(orig_size, crop_size, target_size, accelerator.device).to(weight_dtype)
|
||||
|
||||
# concat embeddings
|
||||
vector_embedding = torch.cat([pool2, embs], dim=1).to(weight_dtype)
|
||||
text_embedding = torch.cat([encoder_hidden_states1, encoder_hidden_states2], dim=2).to(weight_dtype)
|
||||
|
||||
# Sample noise, sample a random timestep for each image, and add noise to the latents,
|
||||
# with noise offset and/or multires noise if specified
|
||||
noise, noisy_latents, timesteps, huber_c = train_util.get_noise_noisy_latents_and_timesteps(
|
||||
args, noise_scheduler, latents
|
||||
)
|
||||
|
||||
noisy_latents = noisy_latents.to(weight_dtype) # TODO check why noisy_latents is not weight_dtype
|
||||
|
||||
# Predict the noise residual
|
||||
with accelerator.autocast():
|
||||
noise_pred = unet(noisy_latents, timesteps, text_embedding, vector_embedding)
|
||||
|
||||
if args.v_parameterization:
|
||||
# v-parameterization training
|
||||
target = noise_scheduler.get_velocity(latents, noise, timesteps)
|
||||
else:
|
||||
target = noise
|
||||
|
||||
if (
|
||||
args.min_snr_gamma
|
||||
or args.scale_v_pred_loss_like_noise_pred
|
||||
or args.v_pred_like_loss
|
||||
or args.debiased_estimation_loss
|
||||
or args.masked_loss
|
||||
):
|
||||
# do not mean over batch dimension for snr weight or scale v-pred loss
|
||||
loss = train_util.conditional_loss(
|
||||
noise_pred.float(), target.float(), reduction="none", loss_type=args.loss_type, huber_c=huber_c
|
||||
)
|
||||
if args.masked_loss or ("alpha_masks" in batch and batch["alpha_masks"] is not None):
|
||||
loss = apply_masked_loss(loss, batch)
|
||||
loss = loss.mean([1, 2, 3])
|
||||
|
||||
if args.min_snr_gamma:
|
||||
loss = apply_snr_weight(loss, timesteps, noise_scheduler, args.min_snr_gamma, args.v_parameterization)
|
||||
if args.scale_v_pred_loss_like_noise_pred:
|
||||
loss = scale_v_prediction_loss_like_noise_prediction(loss, timesteps, noise_scheduler)
|
||||
if args.v_pred_like_loss:
|
||||
loss = add_v_prediction_like_loss(loss, timesteps, noise_scheduler, args.v_pred_like_loss)
|
||||
if args.debiased_estimation_loss:
|
||||
loss = apply_debiased_estimation(loss, timesteps, noise_scheduler, args.v_parameterization)
|
||||
|
||||
loss = loss.mean() # mean over batch dimension
|
||||
else:
|
||||
loss = train_util.conditional_loss(
|
||||
noise_pred.float(), target.float(), reduction="mean", loss_type=args.loss_type, huber_c=huber_c
|
||||
)
|
||||
|
||||
accelerator.backward(loss)
|
||||
|
||||
if not (args.fused_backward_pass or args.fused_optimizer_groups):
|
||||
if accelerator.sync_gradients and args.max_grad_norm != 0.0:
|
||||
params_to_clip = []
|
||||
for m in training_models:
|
||||
params_to_clip.extend(m.parameters())
|
||||
accelerator.clip_grad_norm_(params_to_clip, args.max_grad_norm)
|
||||
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
optimizer.zero_grad(set_to_none=True)
|
||||
else:
|
||||
# optimizer.step() and optimizer.zero_grad() are called in the optimizer hook
|
||||
lr_scheduler.step()
|
||||
if args.fused_optimizer_groups:
|
||||
for i in range(1, len(optimizers)):
|
||||
lr_schedulers[i].step()
|
||||
|
||||
# Checks if the accelerator has performed an optimization step behind the scenes
|
||||
if accelerator.sync_gradients:
|
||||
progress_bar.update(1)
|
||||
global_step += 1
|
||||
|
||||
sdxl_train_util.sample_images(
|
||||
accelerator,
|
||||
args,
|
||||
None,
|
||||
global_step,
|
||||
accelerator.device,
|
||||
vae,
|
||||
[tokenizer1, tokenizer2],
|
||||
[text_encoder1, text_encoder2],
|
||||
unet,
|
||||
)
|
||||
|
||||
# 指定ステップごとにモデルを保存
|
||||
if args.save_every_n_steps is not None and global_step % args.save_every_n_steps == 0:
|
||||
accelerator.wait_for_everyone()
|
||||
if accelerator.is_main_process:
|
||||
src_path = src_stable_diffusion_ckpt if save_stable_diffusion_format else src_diffusers_model_path
|
||||
sdxl_train_util.save_sd_model_on_epoch_end_or_stepwise(
|
||||
args,
|
||||
False,
|
||||
accelerator,
|
||||
src_path,
|
||||
save_stable_diffusion_format,
|
||||
use_safetensors,
|
||||
save_dtype,
|
||||
epoch,
|
||||
num_train_epochs,
|
||||
global_step,
|
||||
accelerator.unwrap_model(text_encoder1),
|
||||
accelerator.unwrap_model(text_encoder2),
|
||||
accelerator.unwrap_model(unet),
|
||||
vae,
|
||||
logit_scale,
|
||||
ckpt_info,
|
||||
)
|
||||
|
||||
current_loss = loss.detach().item() # 平均なのでbatch sizeは関係ないはず
|
||||
if args.logging_dir is not None:
|
||||
logs = {"loss": current_loss}
|
||||
if block_lrs is None:
|
||||
train_util.append_lr_to_logs(logs, lr_scheduler, args.optimizer_type, including_unet=train_unet)
|
||||
else:
|
||||
append_block_lr_to_logs(block_lrs, logs, lr_scheduler, args.optimizer_type) # U-Net is included in block_lrs
|
||||
|
||||
accelerator.log(logs, step=global_step)
|
||||
|
||||
loss_recorder.add(epoch=epoch, step=step, loss=current_loss)
|
||||
avr_loss: float = loss_recorder.moving_average
|
||||
logs = {"avr_loss": avr_loss} # , "lr": lr_scheduler.get_last_lr()[0]}
|
||||
progress_bar.set_postfix(**logs)
|
||||
|
||||
if global_step >= args.max_train_steps:
|
||||
break
|
||||
|
||||
if args.logging_dir is not None:
|
||||
logs = {"loss/epoch": loss_recorder.moving_average}
|
||||
accelerator.log(logs, step=epoch + 1)
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
if args.save_every_n_epochs is not None:
|
||||
if accelerator.is_main_process:
|
||||
src_path = src_stable_diffusion_ckpt if save_stable_diffusion_format else src_diffusers_model_path
|
||||
sdxl_train_util.save_sd_model_on_epoch_end_or_stepwise(
|
||||
args,
|
||||
True,
|
||||
accelerator,
|
||||
src_path,
|
||||
save_stable_diffusion_format,
|
||||
use_safetensors,
|
||||
save_dtype,
|
||||
epoch,
|
||||
num_train_epochs,
|
||||
global_step,
|
||||
accelerator.unwrap_model(text_encoder1),
|
||||
accelerator.unwrap_model(text_encoder2),
|
||||
accelerator.unwrap_model(unet),
|
||||
vae,
|
||||
logit_scale,
|
||||
ckpt_info,
|
||||
)
|
||||
|
||||
sdxl_train_util.sample_images(
|
||||
accelerator,
|
||||
args,
|
||||
epoch + 1,
|
||||
global_step,
|
||||
accelerator.device,
|
||||
vae,
|
||||
[tokenizer1, tokenizer2],
|
||||
[text_encoder1, text_encoder2],
|
||||
unet,
|
||||
)
|
||||
|
||||
is_main_process = accelerator.is_main_process
|
||||
# if is_main_process:
|
||||
unet = accelerator.unwrap_model(unet)
|
||||
text_encoder1 = accelerator.unwrap_model(text_encoder1)
|
||||
text_encoder2 = accelerator.unwrap_model(text_encoder2)
|
||||
|
||||
accelerator.end_training()
|
||||
|
||||
if args.save_state or args.save_state_on_train_end:
|
||||
train_util.save_state_on_train_end(args, accelerator)
|
||||
|
||||
del accelerator # この後メモリを使うのでこれは消す
|
||||
|
||||
if is_main_process:
|
||||
src_path = src_stable_diffusion_ckpt if save_stable_diffusion_format else src_diffusers_model_path
|
||||
sdxl_train_util.save_sd_model_on_train_end(
|
||||
args,
|
||||
src_path,
|
||||
save_stable_diffusion_format,
|
||||
use_safetensors,
|
||||
save_dtype,
|
||||
epoch,
|
||||
global_step,
|
||||
text_encoder1,
|
||||
text_encoder2,
|
||||
unet,
|
||||
vae,
|
||||
logit_scale,
|
||||
ckpt_info,
|
||||
)
|
||||
logger.info("model saved.")
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
add_logging_arguments(parser)
|
||||
train_util.add_sd_models_arguments(parser)
|
||||
train_util.add_dataset_arguments(parser, True, True, True)
|
||||
train_util.add_training_arguments(parser, False)
|
||||
train_util.add_masked_loss_arguments(parser)
|
||||
deepspeed_utils.add_deepspeed_arguments(parser)
|
||||
train_util.add_sd_saving_arguments(parser)
|
||||
train_util.add_optimizer_arguments(parser)
|
||||
config_util.add_config_arguments(parser)
|
||||
custom_train_functions.add_custom_train_arguments(parser)
|
||||
sdxl_train_util.add_sdxl_training_arguments(parser)
|
||||
|
||||
parser.add_argument(
|
||||
"--learning_rate_te1",
|
||||
type=float,
|
||||
default=None,
|
||||
help="learning rate for text encoder 1 (ViT-L) / text encoder 1 (ViT-L)の学習率",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--learning_rate_te2",
|
||||
type=float,
|
||||
default=None,
|
||||
help="learning rate for text encoder 2 (BiG-G) / text encoder 2 (BiG-G)の学習率",
|
||||
)
|
||||
|
||||
parser.add_argument(
|
||||
"--diffusers_xformers", action="store_true", help="use xformers by diffusers / Diffusersでxformersを使用する"
|
||||
)
|
||||
parser.add_argument("--train_text_encoder", action="store_true", help="train text encoder / text encoderも学習する")
|
||||
parser.add_argument(
|
||||
"--no_half_vae",
|
||||
action="store_true",
|
||||
help="do not use fp16/bf16 VAE in mixed precision (use float VAE) / mixed precisionでも fp16/bf16 VAEを使わずfloat VAEを使う",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--block_lr",
|
||||
type=str,
|
||||
default=None,
|
||||
help=f"learning rates for each block of U-Net, comma-separated, {UNET_NUM_BLOCKS_FOR_BLOCK_LR} values / "
|
||||
+ f"U-Netの各ブロックの学習率、カンマ区切り、{UNET_NUM_BLOCKS_FOR_BLOCK_LR}個の値",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--fused_optimizer_groups",
|
||||
type=int,
|
||||
default=None,
|
||||
help="number of optimizers for fused backward pass and optimizer step / fused backward passとoptimizer stepのためのoptimizer数",
|
||||
)
|
||||
return parser
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
train_util.verify_command_line_training_args(args)
|
||||
args = train_util.read_config_from_file(args, parser)
|
||||
|
||||
train(args)
|
||||
626
sdxl_train_control_net_lllite.py
Normal file
626
sdxl_train_control_net_lllite.py
Normal file
@@ -0,0 +1,626 @@
|
||||
# cond_imageをU-Netのforwardで渡すバージョンのControlNet-LLLite検証用学習コード
|
||||
# training code for ControlNet-LLLite with passing cond_image to U-Net's forward
|
||||
|
||||
import argparse
|
||||
import json
|
||||
import math
|
||||
import os
|
||||
import random
|
||||
import time
|
||||
from multiprocessing import Value
|
||||
from types import SimpleNamespace
|
||||
import toml
|
||||
|
||||
from tqdm import tqdm
|
||||
|
||||
import torch
|
||||
from library.device_utils import init_ipex, clean_memory_on_device
|
||||
|
||||
init_ipex()
|
||||
|
||||
from torch.nn.parallel import DistributedDataParallel as DDP
|
||||
from accelerate.utils import set_seed
|
||||
import accelerate
|
||||
from diffusers import DDPMScheduler, ControlNetModel
|
||||
from safetensors.torch import load_file
|
||||
from library import deepspeed_utils, sai_model_spec, sdxl_model_util, sdxl_original_unet, sdxl_train_util
|
||||
|
||||
import library.model_util as model_util
|
||||
import library.train_util as train_util
|
||||
import library.config_util as config_util
|
||||
from library.config_util import (
|
||||
ConfigSanitizer,
|
||||
BlueprintGenerator,
|
||||
)
|
||||
import library.huggingface_util as huggingface_util
|
||||
import library.custom_train_functions as custom_train_functions
|
||||
from library.custom_train_functions import (
|
||||
add_v_prediction_like_loss,
|
||||
apply_snr_weight,
|
||||
prepare_scheduler_for_custom_training,
|
||||
pyramid_noise_like,
|
||||
apply_noise_offset,
|
||||
scale_v_prediction_loss_like_noise_prediction,
|
||||
apply_debiased_estimation,
|
||||
)
|
||||
import networks.control_net_lllite_for_train as control_net_lllite_for_train
|
||||
from library.utils import setup_logging, add_logging_arguments
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
# TODO 他のスクリプトと共通化する
|
||||
def generate_step_logs(args: argparse.Namespace, current_loss, avr_loss, lr_scheduler):
|
||||
logs = {
|
||||
"loss/current": current_loss,
|
||||
"loss/average": avr_loss,
|
||||
"lr": lr_scheduler.get_last_lr()[0],
|
||||
}
|
||||
|
||||
if args.optimizer_type.lower().startswith("DAdapt".lower()):
|
||||
logs["lr/d*lr"] = lr_scheduler.optimizers[-1].param_groups[0]["d"] * lr_scheduler.optimizers[-1].param_groups[0]["lr"]
|
||||
|
||||
return logs
|
||||
|
||||
|
||||
def train(args):
|
||||
train_util.verify_training_args(args)
|
||||
train_util.prepare_dataset_args(args, True)
|
||||
sdxl_train_util.verify_sdxl_training_args(args)
|
||||
setup_logging(args, reset=True)
|
||||
|
||||
cache_latents = args.cache_latents
|
||||
use_user_config = args.dataset_config is not None
|
||||
|
||||
if args.seed is None:
|
||||
args.seed = random.randint(0, 2**32)
|
||||
set_seed(args.seed)
|
||||
|
||||
tokenizer1, tokenizer2 = sdxl_train_util.load_tokenizers(args)
|
||||
|
||||
# データセットを準備する
|
||||
blueprint_generator = BlueprintGenerator(ConfigSanitizer(False, False, True, True))
|
||||
if use_user_config:
|
||||
logger.info(f"Load dataset config from {args.dataset_config}")
|
||||
user_config = config_util.load_user_config(args.dataset_config)
|
||||
ignored = ["train_data_dir", "conditioning_data_dir"]
|
||||
if any(getattr(args, attr) is not None for attr in ignored):
|
||||
logger.warning(
|
||||
"ignore following options because config file is found: {0} / 設定ファイルが利用されるため以下のオプションは無視されます: {0}".format(
|
||||
", ".join(ignored)
|
||||
)
|
||||
)
|
||||
else:
|
||||
user_config = {
|
||||
"datasets": [
|
||||
{
|
||||
"subsets": config_util.generate_controlnet_subsets_config_by_subdirs(
|
||||
args.train_data_dir,
|
||||
args.conditioning_data_dir,
|
||||
args.caption_extension,
|
||||
)
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
blueprint = blueprint_generator.generate(user_config, args, tokenizer=[tokenizer1, tokenizer2])
|
||||
train_dataset_group = config_util.generate_dataset_group_by_blueprint(blueprint.dataset_group)
|
||||
|
||||
current_epoch = Value("i", 0)
|
||||
current_step = Value("i", 0)
|
||||
ds_for_collator = train_dataset_group if args.max_data_loader_n_workers == 0 else None
|
||||
collator = train_util.collator_class(current_epoch, current_step, ds_for_collator)
|
||||
|
||||
train_dataset_group.verify_bucket_reso_steps(32)
|
||||
|
||||
if args.debug_dataset:
|
||||
train_util.debug_dataset(train_dataset_group)
|
||||
return
|
||||
if len(train_dataset_group) == 0:
|
||||
logger.error(
|
||||
"No data found. Please verify arguments (train_data_dir must be the parent of folders with images) / 画像がありません。引数指定を確認してください(train_data_dirには画像があるフォルダではなく、画像があるフォルダの親フォルダを指定する必要があります)"
|
||||
)
|
||||
return
|
||||
|
||||
if cache_latents:
|
||||
assert (
|
||||
train_dataset_group.is_latent_cacheable()
|
||||
), "when caching latents, either color_aug or random_crop cannot be used / latentをキャッシュするときはcolor_augとrandom_cropは使えません"
|
||||
else:
|
||||
logger.warning(
|
||||
"WARNING: random_crop is not supported yet for ControlNet training / ControlNetの学習ではrandom_cropはまだサポートされていません"
|
||||
)
|
||||
|
||||
if args.cache_text_encoder_outputs:
|
||||
assert (
|
||||
train_dataset_group.is_text_encoder_output_cacheable()
|
||||
), "when caching Text Encoder output, either caption_dropout_rate, shuffle_caption, token_warmup_step or caption_tag_dropout_rate cannot be used / Text Encoderの出力をキャッシュするときはcaption_dropout_rate, shuffle_caption, token_warmup_step, caption_tag_dropout_rateは使えません"
|
||||
|
||||
# acceleratorを準備する
|
||||
logger.info("prepare accelerator")
|
||||
accelerator = train_util.prepare_accelerator(args)
|
||||
is_main_process = accelerator.is_main_process
|
||||
|
||||
# mixed precisionに対応した型を用意しておき適宜castする
|
||||
weight_dtype, save_dtype = train_util.prepare_dtype(args)
|
||||
vae_dtype = torch.float32 if args.no_half_vae else weight_dtype
|
||||
|
||||
# モデルを読み込む
|
||||
(
|
||||
load_stable_diffusion_format,
|
||||
text_encoder1,
|
||||
text_encoder2,
|
||||
vae,
|
||||
unet,
|
||||
logit_scale,
|
||||
ckpt_info,
|
||||
) = sdxl_train_util.load_target_model(args, accelerator, sdxl_model_util.MODEL_VERSION_SDXL_BASE_V1_0, weight_dtype)
|
||||
|
||||
# 学習を準備する
|
||||
if cache_latents:
|
||||
vae.to(accelerator.device, dtype=vae_dtype)
|
||||
vae.requires_grad_(False)
|
||||
vae.eval()
|
||||
with torch.no_grad():
|
||||
train_dataset_group.cache_latents(
|
||||
vae,
|
||||
args.vae_batch_size,
|
||||
args.cache_latents_to_disk,
|
||||
accelerator.is_main_process,
|
||||
)
|
||||
vae.to("cpu")
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
# TextEncoderの出力をキャッシュする
|
||||
if args.cache_text_encoder_outputs:
|
||||
# Text Encodes are eval and no grad
|
||||
with torch.no_grad():
|
||||
train_dataset_group.cache_text_encoder_outputs(
|
||||
(tokenizer1, tokenizer2),
|
||||
(text_encoder1, text_encoder2),
|
||||
accelerator.device,
|
||||
None,
|
||||
args.cache_text_encoder_outputs_to_disk,
|
||||
accelerator.is_main_process,
|
||||
)
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
# prepare ControlNet-LLLite
|
||||
control_net_lllite_for_train.replace_unet_linear_and_conv2d()
|
||||
|
||||
if args.network_weights is not None:
|
||||
accelerator.print(f"initialize U-Net with ControlNet-LLLite")
|
||||
with accelerate.init_empty_weights():
|
||||
unet_lllite = control_net_lllite_for_train.SdxlUNet2DConditionModelControlNetLLLite()
|
||||
unet_lllite.to(accelerator.device, dtype=weight_dtype)
|
||||
|
||||
unet_sd = unet.state_dict()
|
||||
info = unet_lllite.load_lllite_weights(args.network_weights, unet_sd)
|
||||
accelerator.print(f"load ControlNet-LLLite weights from {args.network_weights}: {info}")
|
||||
else:
|
||||
# cosumes large memory, so send to GPU before creating the LLLite model
|
||||
accelerator.print("sending U-Net to GPU")
|
||||
unet.to(accelerator.device, dtype=weight_dtype)
|
||||
unet_sd = unet.state_dict()
|
||||
|
||||
# init LLLite weights
|
||||
accelerator.print(f"initialize U-Net with ControlNet-LLLite")
|
||||
|
||||
if args.lowram:
|
||||
with accelerate.init_on_device(accelerator.device):
|
||||
unet_lllite = control_net_lllite_for_train.SdxlUNet2DConditionModelControlNetLLLite()
|
||||
else:
|
||||
unet_lllite = control_net_lllite_for_train.SdxlUNet2DConditionModelControlNetLLLite()
|
||||
unet_lllite.to(weight_dtype)
|
||||
|
||||
info = unet_lllite.load_lllite_weights(None, unet_sd)
|
||||
accelerator.print(f"init U-Net with ControlNet-LLLite weights: {info}")
|
||||
del unet_sd, unet
|
||||
|
||||
unet: control_net_lllite_for_train.SdxlUNet2DConditionModelControlNetLLLite = unet_lllite
|
||||
del unet_lllite
|
||||
|
||||
unet.apply_lllite(args.cond_emb_dim, args.network_dim, args.network_dropout)
|
||||
|
||||
# モデルに xformers とか memory efficient attention を組み込む
|
||||
train_util.replace_unet_modules(unet, args.mem_eff_attn, args.xformers, args.sdpa)
|
||||
|
||||
if args.gradient_checkpointing:
|
||||
unet.enable_gradient_checkpointing()
|
||||
|
||||
# 学習に必要なクラスを準備する
|
||||
accelerator.print("prepare optimizer, data loader etc.")
|
||||
|
||||
trainable_params = list(unet.prepare_params())
|
||||
logger.info(f"trainable params count: {len(trainable_params)}")
|
||||
logger.info(f"number of trainable parameters: {sum(p.numel() for p in trainable_params if p.requires_grad)}")
|
||||
|
||||
_, _, optimizer = train_util.get_optimizer(args, trainable_params)
|
||||
|
||||
# dataloaderを準備する
|
||||
# DataLoaderのプロセス数:0 は persistent_workers が使えないので注意
|
||||
n_workers = min(args.max_data_loader_n_workers, os.cpu_count()) # cpu_count or max_data_loader_n_workers
|
||||
|
||||
train_dataloader = torch.utils.data.DataLoader(
|
||||
train_dataset_group,
|
||||
batch_size=1,
|
||||
shuffle=True,
|
||||
collate_fn=collator,
|
||||
num_workers=n_workers,
|
||||
persistent_workers=args.persistent_data_loader_workers,
|
||||
)
|
||||
|
||||
# 学習ステップ数を計算する
|
||||
if args.max_train_epochs is not None:
|
||||
args.max_train_steps = args.max_train_epochs * math.ceil(
|
||||
len(train_dataloader) / accelerator.num_processes / args.gradient_accumulation_steps
|
||||
)
|
||||
accelerator.print(
|
||||
f"override steps. steps for {args.max_train_epochs} epochs is / 指定エポックまでのステップ数: {args.max_train_steps}"
|
||||
)
|
||||
|
||||
# データセット側にも学習ステップを送信
|
||||
train_dataset_group.set_max_train_steps(args.max_train_steps)
|
||||
|
||||
# lr schedulerを用意する
|
||||
lr_scheduler = train_util.get_scheduler_fix(args, optimizer, accelerator.num_processes)
|
||||
|
||||
# 実験的機能:勾配も含めたfp16/bf16学習を行う モデル全体をfp16/bf16にする
|
||||
# if args.full_fp16:
|
||||
# assert (
|
||||
# args.mixed_precision == "fp16"
|
||||
# ), "full_fp16 requires mixed precision='fp16' / full_fp16を使う場合はmixed_precision='fp16'を指定してください。"
|
||||
# accelerator.print("enable full fp16 training.")
|
||||
# unet.to(weight_dtype)
|
||||
# elif args.full_bf16:
|
||||
# assert (
|
||||
# args.mixed_precision == "bf16"
|
||||
# ), "full_bf16 requires mixed precision='bf16' / full_bf16を使う場合はmixed_precision='bf16'を指定してください。"
|
||||
# accelerator.print("enable full bf16 training.")
|
||||
# unet.to(weight_dtype)
|
||||
|
||||
unet.to(weight_dtype)
|
||||
|
||||
# acceleratorがなんかよろしくやってくれるらしい
|
||||
unet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(unet, optimizer, train_dataloader, lr_scheduler)
|
||||
|
||||
if isinstance(unet, DDP):
|
||||
unet._set_static_graph() # avoid error for multiple use of the parameter
|
||||
|
||||
if args.gradient_checkpointing:
|
||||
unet.train() # according to TI example in Diffusers, train is required -> これオリジナルのU-Netしたので本当は外せる
|
||||
else:
|
||||
unet.eval()
|
||||
|
||||
# TextEncoderの出力をキャッシュするときにはCPUへ移動する
|
||||
if args.cache_text_encoder_outputs:
|
||||
# move Text Encoders for sampling images. Text Encoder doesn't work on CPU with fp16
|
||||
text_encoder1.to("cpu", dtype=torch.float32)
|
||||
text_encoder2.to("cpu", dtype=torch.float32)
|
||||
clean_memory_on_device(accelerator.device)
|
||||
else:
|
||||
# make sure Text Encoders are on GPU
|
||||
text_encoder1.to(accelerator.device)
|
||||
text_encoder2.to(accelerator.device)
|
||||
|
||||
if not cache_latents:
|
||||
vae.requires_grad_(False)
|
||||
vae.eval()
|
||||
vae.to(accelerator.device, dtype=vae_dtype)
|
||||
|
||||
# 実験的機能:勾配も含めたfp16学習を行う PyTorchにパッチを当ててfp16でのgrad scaleを有効にする
|
||||
if args.full_fp16:
|
||||
train_util.patch_accelerator_for_fp16_training(accelerator)
|
||||
|
||||
# resumeする
|
||||
train_util.resume_from_local_or_hf_if_specified(accelerator, args)
|
||||
|
||||
# epoch数を計算する
|
||||
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
|
||||
num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
|
||||
if (args.save_n_epoch_ratio is not None) and (args.save_n_epoch_ratio > 0):
|
||||
args.save_every_n_epochs = math.floor(num_train_epochs / args.save_n_epoch_ratio) or 1
|
||||
|
||||
# 学習する
|
||||
# TODO: find a way to handle total batch size when there are multiple datasets
|
||||
accelerator.print("running training / 学習開始")
|
||||
accelerator.print(f" num train images * repeats / 学習画像の数×繰り返し回数: {train_dataset_group.num_train_images}")
|
||||
accelerator.print(f" num reg images / 正則化画像の数: {train_dataset_group.num_reg_images}")
|
||||
accelerator.print(f" num batches per epoch / 1epochのバッチ数: {len(train_dataloader)}")
|
||||
accelerator.print(f" num epochs / epoch数: {num_train_epochs}")
|
||||
accelerator.print(
|
||||
f" batch size per device / バッチサイズ: {', '.join([str(d.batch_size) for d in train_dataset_group.datasets])}"
|
||||
)
|
||||
# logger.info(f" total train batch size (with parallel & distributed & accumulation) / 総バッチサイズ(並列学習、勾配合計含む): {total_batch_size}")
|
||||
accelerator.print(f" gradient accumulation steps / 勾配を合計するステップ数 = {args.gradient_accumulation_steps}")
|
||||
accelerator.print(f" total optimization steps / 学習ステップ数: {args.max_train_steps}")
|
||||
|
||||
progress_bar = tqdm(range(args.max_train_steps), smoothing=0, disable=not accelerator.is_local_main_process, desc="steps")
|
||||
global_step = 0
|
||||
|
||||
noise_scheduler = DDPMScheduler(
|
||||
beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000, clip_sample=False
|
||||
)
|
||||
prepare_scheduler_for_custom_training(noise_scheduler, accelerator.device)
|
||||
if args.zero_terminal_snr:
|
||||
custom_train_functions.fix_noise_scheduler_betas_for_zero_terminal_snr(noise_scheduler)
|
||||
|
||||
if accelerator.is_main_process:
|
||||
init_kwargs = {}
|
||||
if args.wandb_run_name:
|
||||
init_kwargs["wandb"] = {"name": args.wandb_run_name}
|
||||
if args.log_tracker_config is not None:
|
||||
init_kwargs = toml.load(args.log_tracker_config)
|
||||
accelerator.init_trackers(
|
||||
"lllite_control_net_train" if args.log_tracker_name is None else args.log_tracker_name, config=train_util.get_sanitized_config_or_none(args), init_kwargs=init_kwargs
|
||||
)
|
||||
|
||||
loss_recorder = train_util.LossRecorder()
|
||||
del train_dataset_group
|
||||
|
||||
# function for saving/removing
|
||||
def save_model(
|
||||
ckpt_name,
|
||||
unwrapped_nw: control_net_lllite_for_train.SdxlUNet2DConditionModelControlNetLLLite,
|
||||
steps,
|
||||
epoch_no,
|
||||
force_sync_upload=False,
|
||||
):
|
||||
os.makedirs(args.output_dir, exist_ok=True)
|
||||
ckpt_file = os.path.join(args.output_dir, ckpt_name)
|
||||
|
||||
accelerator.print(f"\nsaving checkpoint: {ckpt_file}")
|
||||
sai_metadata = train_util.get_sai_model_spec(None, args, True, True, False)
|
||||
sai_metadata["modelspec.architecture"] = sai_model_spec.ARCH_SD_XL_V1_BASE + "/control-net-lllite"
|
||||
|
||||
unwrapped_nw.save_lllite_weights(ckpt_file, save_dtype, sai_metadata)
|
||||
if args.huggingface_repo_id is not None:
|
||||
huggingface_util.upload(args, ckpt_file, "/" + ckpt_name, force_sync_upload=force_sync_upload)
|
||||
|
||||
def remove_model(old_ckpt_name):
|
||||
old_ckpt_file = os.path.join(args.output_dir, old_ckpt_name)
|
||||
if os.path.exists(old_ckpt_file):
|
||||
accelerator.print(f"removing old checkpoint: {old_ckpt_file}")
|
||||
os.remove(old_ckpt_file)
|
||||
|
||||
# training loop
|
||||
for epoch in range(num_train_epochs):
|
||||
accelerator.print(f"\nepoch {epoch+1}/{num_train_epochs}")
|
||||
current_epoch.value = epoch + 1
|
||||
|
||||
for step, batch in enumerate(train_dataloader):
|
||||
current_step.value = global_step
|
||||
with accelerator.accumulate(unet):
|
||||
with torch.no_grad():
|
||||
if "latents" in batch and batch["latents"] is not None:
|
||||
latents = batch["latents"].to(accelerator.device).to(dtype=weight_dtype)
|
||||
else:
|
||||
# latentに変換
|
||||
latents = vae.encode(batch["images"].to(dtype=vae_dtype)).latent_dist.sample().to(dtype=weight_dtype)
|
||||
|
||||
# NaNが含まれていれば警告を表示し0に置き換える
|
||||
if torch.any(torch.isnan(latents)):
|
||||
accelerator.print("NaN found in latents, replacing with zeros")
|
||||
latents = torch.nan_to_num(latents, 0, out=latents)
|
||||
latents = latents * sdxl_model_util.VAE_SCALE_FACTOR
|
||||
|
||||
if "text_encoder_outputs1_list" not in batch or batch["text_encoder_outputs1_list"] is None:
|
||||
input_ids1 = batch["input_ids"]
|
||||
input_ids2 = batch["input_ids2"]
|
||||
with torch.no_grad():
|
||||
# Get the text embedding for conditioning
|
||||
input_ids1 = input_ids1.to(accelerator.device)
|
||||
input_ids2 = input_ids2.to(accelerator.device)
|
||||
encoder_hidden_states1, encoder_hidden_states2, pool2 = train_util.get_hidden_states_sdxl(
|
||||
args.max_token_length,
|
||||
input_ids1,
|
||||
input_ids2,
|
||||
tokenizer1,
|
||||
tokenizer2,
|
||||
text_encoder1,
|
||||
text_encoder2,
|
||||
None if not args.full_fp16 else weight_dtype,
|
||||
)
|
||||
else:
|
||||
encoder_hidden_states1 = batch["text_encoder_outputs1_list"].to(accelerator.device).to(weight_dtype)
|
||||
encoder_hidden_states2 = batch["text_encoder_outputs2_list"].to(accelerator.device).to(weight_dtype)
|
||||
pool2 = batch["text_encoder_pool2_list"].to(accelerator.device).to(weight_dtype)
|
||||
|
||||
# get size embeddings
|
||||
orig_size = batch["original_sizes_hw"]
|
||||
crop_size = batch["crop_top_lefts"]
|
||||
target_size = batch["target_sizes_hw"]
|
||||
embs = sdxl_train_util.get_size_embeddings(orig_size, crop_size, target_size, accelerator.device).to(weight_dtype)
|
||||
|
||||
# concat embeddings
|
||||
vector_embedding = torch.cat([pool2, embs], dim=1).to(weight_dtype)
|
||||
text_embedding = torch.cat([encoder_hidden_states1, encoder_hidden_states2], dim=2).to(weight_dtype)
|
||||
|
||||
# Sample noise, sample a random timestep for each image, and add noise to the latents,
|
||||
# with noise offset and/or multires noise if specified
|
||||
noise, noisy_latents, timesteps, huber_c = train_util.get_noise_noisy_latents_and_timesteps(
|
||||
args, noise_scheduler, latents
|
||||
)
|
||||
|
||||
noisy_latents = noisy_latents.to(weight_dtype) # TODO check why noisy_latents is not weight_dtype
|
||||
|
||||
controlnet_image = batch["conditioning_images"].to(dtype=weight_dtype)
|
||||
|
||||
with accelerator.autocast():
|
||||
# conditioning imageをControlNetに渡す / pass conditioning image to ControlNet
|
||||
# 内部でcond_embに変換される / it will be converted to cond_emb inside
|
||||
|
||||
# それらの値を使いつつ、U-Netでノイズを予測する / predict noise with U-Net using those values
|
||||
noise_pred = unet(noisy_latents, timesteps, text_embedding, vector_embedding, controlnet_image)
|
||||
|
||||
if args.v_parameterization:
|
||||
# v-parameterization training
|
||||
target = noise_scheduler.get_velocity(latents, noise, timesteps)
|
||||
else:
|
||||
target = noise
|
||||
|
||||
loss = train_util.conditional_loss(
|
||||
noise_pred.float(), target.float(), reduction="none", loss_type=args.loss_type, huber_c=huber_c
|
||||
)
|
||||
loss = loss.mean([1, 2, 3])
|
||||
|
||||
loss_weights = batch["loss_weights"] # 各sampleごとのweight
|
||||
loss = loss * loss_weights
|
||||
|
||||
if args.min_snr_gamma:
|
||||
loss = apply_snr_weight(loss, timesteps, noise_scheduler, args.min_snr_gamma, args.v_parameterization)
|
||||
if args.scale_v_pred_loss_like_noise_pred:
|
||||
loss = scale_v_prediction_loss_like_noise_prediction(loss, timesteps, noise_scheduler)
|
||||
if args.v_pred_like_loss:
|
||||
loss = add_v_prediction_like_loss(loss, timesteps, noise_scheduler, args.v_pred_like_loss)
|
||||
if args.debiased_estimation_loss:
|
||||
loss = apply_debiased_estimation(loss, timesteps, noise_scheduler, args.v_parameterization)
|
||||
|
||||
loss = loss.mean() # 平均なのでbatch_sizeで割る必要なし
|
||||
|
||||
accelerator.backward(loss)
|
||||
if accelerator.sync_gradients and args.max_grad_norm != 0.0:
|
||||
params_to_clip = accelerator.unwrap_model(unet).get_trainable_params()
|
||||
accelerator.clip_grad_norm_(params_to_clip, args.max_grad_norm)
|
||||
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
optimizer.zero_grad(set_to_none=True)
|
||||
|
||||
# Checks if the accelerator has performed an optimization step behind the scenes
|
||||
if accelerator.sync_gradients:
|
||||
progress_bar.update(1)
|
||||
global_step += 1
|
||||
|
||||
# sdxl_train_util.sample_images(accelerator, args, None, global_step, accelerator.device, vae, tokenizer, text_encoder, unet)
|
||||
|
||||
# 指定ステップごとにモデルを保存
|
||||
if args.save_every_n_steps is not None and global_step % args.save_every_n_steps == 0:
|
||||
accelerator.wait_for_everyone()
|
||||
if accelerator.is_main_process:
|
||||
ckpt_name = train_util.get_step_ckpt_name(args, "." + args.save_model_as, global_step)
|
||||
save_model(ckpt_name, accelerator.unwrap_model(unet), global_step, epoch)
|
||||
|
||||
if args.save_state:
|
||||
train_util.save_and_remove_state_stepwise(args, accelerator, global_step)
|
||||
|
||||
remove_step_no = train_util.get_remove_step_no(args, global_step)
|
||||
if remove_step_no is not None:
|
||||
remove_ckpt_name = train_util.get_step_ckpt_name(args, "." + args.save_model_as, remove_step_no)
|
||||
remove_model(remove_ckpt_name)
|
||||
|
||||
current_loss = loss.detach().item()
|
||||
loss_recorder.add(epoch=epoch, step=step, loss=current_loss)
|
||||
avr_loss: float = loss_recorder.moving_average
|
||||
logs = {"avr_loss": avr_loss} # , "lr": lr_scheduler.get_last_lr()[0]}
|
||||
progress_bar.set_postfix(**logs)
|
||||
|
||||
if args.logging_dir is not None:
|
||||
logs = generate_step_logs(args, current_loss, avr_loss, lr_scheduler)
|
||||
accelerator.log(logs, step=global_step)
|
||||
|
||||
if global_step >= args.max_train_steps:
|
||||
break
|
||||
|
||||
if args.logging_dir is not None:
|
||||
logs = {"loss/epoch": loss_recorder.moving_average}
|
||||
accelerator.log(logs, step=epoch + 1)
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
# 指定エポックごとにモデルを保存
|
||||
if args.save_every_n_epochs is not None:
|
||||
saving = (epoch + 1) % args.save_every_n_epochs == 0 and (epoch + 1) < num_train_epochs
|
||||
if is_main_process and saving:
|
||||
ckpt_name = train_util.get_epoch_ckpt_name(args, "." + args.save_model_as, epoch + 1)
|
||||
save_model(ckpt_name, accelerator.unwrap_model(unet), global_step, epoch + 1)
|
||||
|
||||
remove_epoch_no = train_util.get_remove_epoch_no(args, epoch + 1)
|
||||
if remove_epoch_no is not None:
|
||||
remove_ckpt_name = train_util.get_epoch_ckpt_name(args, "." + args.save_model_as, remove_epoch_no)
|
||||
remove_model(remove_ckpt_name)
|
||||
|
||||
if args.save_state:
|
||||
train_util.save_and_remove_state_on_epoch_end(args, accelerator, epoch + 1)
|
||||
|
||||
# self.sample_images(accelerator, args, epoch + 1, global_step, accelerator.device, vae, tokenizer, text_encoder, unet)
|
||||
|
||||
# end of epoch
|
||||
|
||||
if is_main_process:
|
||||
unet = accelerator.unwrap_model(unet)
|
||||
|
||||
accelerator.end_training()
|
||||
|
||||
if is_main_process and (args.save_state or args.save_state_on_train_end):
|
||||
train_util.save_state_on_train_end(args, accelerator)
|
||||
|
||||
if is_main_process:
|
||||
ckpt_name = train_util.get_last_ckpt_name(args, "." + args.save_model_as)
|
||||
save_model(ckpt_name, unet, global_step, num_train_epochs, force_sync_upload=True)
|
||||
|
||||
logger.info("model saved.")
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
add_logging_arguments(parser)
|
||||
train_util.add_sd_models_arguments(parser)
|
||||
train_util.add_dataset_arguments(parser, False, True, True)
|
||||
train_util.add_training_arguments(parser, False)
|
||||
deepspeed_utils.add_deepspeed_arguments(parser)
|
||||
train_util.add_optimizer_arguments(parser)
|
||||
config_util.add_config_arguments(parser)
|
||||
custom_train_functions.add_custom_train_arguments(parser)
|
||||
sdxl_train_util.add_sdxl_training_arguments(parser)
|
||||
|
||||
parser.add_argument(
|
||||
"--save_model_as",
|
||||
type=str,
|
||||
default="safetensors",
|
||||
choices=[None, "ckpt", "pt", "safetensors"],
|
||||
help="format to save the model (default is .safetensors) / モデル保存時の形式(デフォルトはsafetensors)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--cond_emb_dim", type=int, default=None, help="conditioning embedding dimension / 条件付け埋め込みの次元数"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--network_weights", type=str, default=None, help="pretrained weights for network / 学習するネットワークの初期重み"
|
||||
)
|
||||
parser.add_argument("--network_dim", type=int, default=None, help="network dimensions (rank) / モジュールの次元数")
|
||||
parser.add_argument(
|
||||
"--network_dropout",
|
||||
type=float,
|
||||
default=None,
|
||||
help="Drops neurons out of training every step (0 or None is default behavior (no dropout), 1 would drop all neurons) / 訓練時に毎ステップでニューロンをdropする(0またはNoneはdropoutなし、1は全ニューロンをdropout)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--conditioning_data_dir",
|
||||
type=str,
|
||||
default=None,
|
||||
help="conditioning data directory / 条件付けデータのディレクトリ",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--no_half_vae",
|
||||
action="store_true",
|
||||
help="do not use fp16/bf16 VAE in mixed precision (use float VAE) / mixed precisionでも fp16/bf16 VAEを使わずfloat VAEを使う",
|
||||
)
|
||||
return parser
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# sdxl_original_unet.USE_REENTRANT = False
|
||||
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
train_util.verify_command_line_training_args(args)
|
||||
args = train_util.read_config_from_file(args, parser)
|
||||
|
||||
train(args)
|
||||
586
sdxl_train_control_net_lllite_old.py
Normal file
586
sdxl_train_control_net_lllite_old.py
Normal file
@@ -0,0 +1,586 @@
|
||||
import argparse
|
||||
import json
|
||||
import math
|
||||
import os
|
||||
import random
|
||||
import time
|
||||
from multiprocessing import Value
|
||||
from types import SimpleNamespace
|
||||
import toml
|
||||
|
||||
from tqdm import tqdm
|
||||
|
||||
import torch
|
||||
from library.device_utils import init_ipex, clean_memory_on_device
|
||||
init_ipex()
|
||||
|
||||
from torch.nn.parallel import DistributedDataParallel as DDP
|
||||
from accelerate.utils import set_seed
|
||||
from diffusers import DDPMScheduler, ControlNetModel
|
||||
from safetensors.torch import load_file
|
||||
from library import deepspeed_utils, sai_model_spec, sdxl_model_util, sdxl_original_unet, sdxl_train_util
|
||||
|
||||
import library.model_util as model_util
|
||||
import library.train_util as train_util
|
||||
import library.config_util as config_util
|
||||
from library.config_util import (
|
||||
ConfigSanitizer,
|
||||
BlueprintGenerator,
|
||||
)
|
||||
import library.huggingface_util as huggingface_util
|
||||
import library.custom_train_functions as custom_train_functions
|
||||
from library.custom_train_functions import (
|
||||
add_v_prediction_like_loss,
|
||||
apply_snr_weight,
|
||||
prepare_scheduler_for_custom_training,
|
||||
pyramid_noise_like,
|
||||
apply_noise_offset,
|
||||
scale_v_prediction_loss_like_noise_prediction,
|
||||
apply_debiased_estimation,
|
||||
)
|
||||
import networks.control_net_lllite as control_net_lllite
|
||||
from library.utils import setup_logging, add_logging_arguments
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
# TODO 他のスクリプトと共通化する
|
||||
def generate_step_logs(args: argparse.Namespace, current_loss, avr_loss, lr_scheduler):
|
||||
logs = {
|
||||
"loss/current": current_loss,
|
||||
"loss/average": avr_loss,
|
||||
"lr": lr_scheduler.get_last_lr()[0],
|
||||
}
|
||||
|
||||
if args.optimizer_type.lower().startswith("DAdapt".lower()):
|
||||
logs["lr/d*lr"] = lr_scheduler.optimizers[-1].param_groups[0]["d"] * lr_scheduler.optimizers[-1].param_groups[0]["lr"]
|
||||
|
||||
return logs
|
||||
|
||||
|
||||
def train(args):
|
||||
train_util.verify_training_args(args)
|
||||
train_util.prepare_dataset_args(args, True)
|
||||
sdxl_train_util.verify_sdxl_training_args(args)
|
||||
setup_logging(args, reset=True)
|
||||
|
||||
cache_latents = args.cache_latents
|
||||
use_user_config = args.dataset_config is not None
|
||||
|
||||
if args.seed is None:
|
||||
args.seed = random.randint(0, 2**32)
|
||||
set_seed(args.seed)
|
||||
|
||||
tokenizer1, tokenizer2 = sdxl_train_util.load_tokenizers(args)
|
||||
|
||||
# データセットを準備する
|
||||
blueprint_generator = BlueprintGenerator(ConfigSanitizer(False, False, True, True))
|
||||
if use_user_config:
|
||||
logger.info(f"Load dataset config from {args.dataset_config}")
|
||||
user_config = config_util.load_user_config(args.dataset_config)
|
||||
ignored = ["train_data_dir", "conditioning_data_dir"]
|
||||
if any(getattr(args, attr) is not None for attr in ignored):
|
||||
logger.warning(
|
||||
"ignore following options because config file is found: {0} / 設定ファイルが利用されるため以下のオプションは無視されます: {0}".format(
|
||||
", ".join(ignored)
|
||||
)
|
||||
)
|
||||
else:
|
||||
user_config = {
|
||||
"datasets": [
|
||||
{
|
||||
"subsets": config_util.generate_controlnet_subsets_config_by_subdirs(
|
||||
args.train_data_dir,
|
||||
args.conditioning_data_dir,
|
||||
args.caption_extension,
|
||||
)
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
blueprint = blueprint_generator.generate(user_config, args, tokenizer=[tokenizer1, tokenizer2])
|
||||
train_dataset_group = config_util.generate_dataset_group_by_blueprint(blueprint.dataset_group)
|
||||
|
||||
current_epoch = Value("i", 0)
|
||||
current_step = Value("i", 0)
|
||||
ds_for_collator = train_dataset_group if args.max_data_loader_n_workers == 0 else None
|
||||
collator = train_util.collator_class(current_epoch, current_step, ds_for_collator)
|
||||
|
||||
train_dataset_group.verify_bucket_reso_steps(32)
|
||||
|
||||
if args.debug_dataset:
|
||||
train_util.debug_dataset(train_dataset_group)
|
||||
return
|
||||
if len(train_dataset_group) == 0:
|
||||
logger.error(
|
||||
"No data found. Please verify arguments (train_data_dir must be the parent of folders with images) / 画像がありません。引数指定を確認してください(train_data_dirには画像があるフォルダではなく、画像があるフォルダの親フォルダを指定する必要があります)"
|
||||
)
|
||||
return
|
||||
|
||||
if cache_latents:
|
||||
assert (
|
||||
train_dataset_group.is_latent_cacheable()
|
||||
), "when caching latents, either color_aug or random_crop cannot be used / latentをキャッシュするときはcolor_augとrandom_cropは使えません"
|
||||
else:
|
||||
logger.warning(
|
||||
"WARNING: random_crop is not supported yet for ControlNet training / ControlNetの学習ではrandom_cropはまだサポートされていません"
|
||||
)
|
||||
|
||||
if args.cache_text_encoder_outputs:
|
||||
assert (
|
||||
train_dataset_group.is_text_encoder_output_cacheable()
|
||||
), "when caching Text Encoder output, either caption_dropout_rate, shuffle_caption, token_warmup_step or caption_tag_dropout_rate cannot be used / Text Encoderの出力をキャッシュするときはcaption_dropout_rate, shuffle_caption, token_warmup_step, caption_tag_dropout_rateは使えません"
|
||||
|
||||
# acceleratorを準備する
|
||||
logger.info("prepare accelerator")
|
||||
accelerator = train_util.prepare_accelerator(args)
|
||||
is_main_process = accelerator.is_main_process
|
||||
|
||||
# mixed precisionに対応した型を用意しておき適宜castする
|
||||
weight_dtype, save_dtype = train_util.prepare_dtype(args)
|
||||
vae_dtype = torch.float32 if args.no_half_vae else weight_dtype
|
||||
|
||||
# モデルを読み込む
|
||||
(
|
||||
load_stable_diffusion_format,
|
||||
text_encoder1,
|
||||
text_encoder2,
|
||||
vae,
|
||||
unet,
|
||||
logit_scale,
|
||||
ckpt_info,
|
||||
) = sdxl_train_util.load_target_model(args, accelerator, sdxl_model_util.MODEL_VERSION_SDXL_BASE_V1_0, weight_dtype)
|
||||
|
||||
# モデルに xformers とか memory efficient attention を組み込む
|
||||
train_util.replace_unet_modules(unet, args.mem_eff_attn, args.xformers, args.sdpa)
|
||||
|
||||
# 学習を準備する
|
||||
if cache_latents:
|
||||
vae.to(accelerator.device, dtype=vae_dtype)
|
||||
vae.requires_grad_(False)
|
||||
vae.eval()
|
||||
with torch.no_grad():
|
||||
train_dataset_group.cache_latents(
|
||||
vae,
|
||||
args.vae_batch_size,
|
||||
args.cache_latents_to_disk,
|
||||
accelerator.is_main_process,
|
||||
)
|
||||
vae.to("cpu")
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
# TextEncoderの出力をキャッシュする
|
||||
if args.cache_text_encoder_outputs:
|
||||
# Text Encodes are eval and no grad
|
||||
with torch.no_grad():
|
||||
train_dataset_group.cache_text_encoder_outputs(
|
||||
(tokenizer1, tokenizer2),
|
||||
(text_encoder1, text_encoder2),
|
||||
accelerator.device,
|
||||
None,
|
||||
args.cache_text_encoder_outputs_to_disk,
|
||||
accelerator.is_main_process,
|
||||
)
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
# prepare ControlNet
|
||||
network = control_net_lllite.ControlNetLLLite(unet, args.cond_emb_dim, args.network_dim, args.network_dropout)
|
||||
network.apply_to()
|
||||
|
||||
if args.network_weights is not None:
|
||||
info = network.load_weights(args.network_weights)
|
||||
accelerator.print(f"load ControlNet weights from {args.network_weights}: {info}")
|
||||
|
||||
if args.gradient_checkpointing:
|
||||
unet.enable_gradient_checkpointing()
|
||||
network.enable_gradient_checkpointing() # may have no effect
|
||||
|
||||
# 学習に必要なクラスを準備する
|
||||
accelerator.print("prepare optimizer, data loader etc.")
|
||||
|
||||
trainable_params = list(network.prepare_optimizer_params())
|
||||
logger.info(f"trainable params count: {len(trainable_params)}")
|
||||
logger.info(f"number of trainable parameters: {sum(p.numel() for p in trainable_params if p.requires_grad)}")
|
||||
|
||||
_, _, optimizer = train_util.get_optimizer(args, trainable_params)
|
||||
|
||||
# dataloaderを準備する
|
||||
# DataLoaderのプロセス数:0 は persistent_workers が使えないので注意
|
||||
n_workers = min(args.max_data_loader_n_workers, os.cpu_count()) # cpu_count or max_data_loader_n_workers
|
||||
|
||||
train_dataloader = torch.utils.data.DataLoader(
|
||||
train_dataset_group,
|
||||
batch_size=1,
|
||||
shuffle=True,
|
||||
collate_fn=collator,
|
||||
num_workers=n_workers,
|
||||
persistent_workers=args.persistent_data_loader_workers,
|
||||
)
|
||||
|
||||
# 学習ステップ数を計算する
|
||||
if args.max_train_epochs is not None:
|
||||
args.max_train_steps = args.max_train_epochs * math.ceil(
|
||||
len(train_dataloader) / accelerator.num_processes / args.gradient_accumulation_steps
|
||||
)
|
||||
accelerator.print(
|
||||
f"override steps. steps for {args.max_train_epochs} epochs is / 指定エポックまでのステップ数: {args.max_train_steps}"
|
||||
)
|
||||
|
||||
# データセット側にも学習ステップを送信
|
||||
train_dataset_group.set_max_train_steps(args.max_train_steps)
|
||||
|
||||
# lr schedulerを用意する
|
||||
lr_scheduler = train_util.get_scheduler_fix(args, optimizer, accelerator.num_processes)
|
||||
|
||||
# 実験的機能:勾配も含めたfp16/bf16学習を行う モデル全体をfp16/bf16にする
|
||||
if args.full_fp16:
|
||||
assert (
|
||||
args.mixed_precision == "fp16"
|
||||
), "full_fp16 requires mixed precision='fp16' / full_fp16を使う場合はmixed_precision='fp16'を指定してください。"
|
||||
accelerator.print("enable full fp16 training.")
|
||||
unet.to(weight_dtype)
|
||||
network.to(weight_dtype)
|
||||
elif args.full_bf16:
|
||||
assert (
|
||||
args.mixed_precision == "bf16"
|
||||
), "full_bf16 requires mixed precision='bf16' / full_bf16を使う場合はmixed_precision='bf16'を指定してください。"
|
||||
accelerator.print("enable full bf16 training.")
|
||||
unet.to(weight_dtype)
|
||||
network.to(weight_dtype)
|
||||
|
||||
# acceleratorがなんかよろしくやってくれるらしい
|
||||
unet, network, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
|
||||
unet, network, optimizer, train_dataloader, lr_scheduler
|
||||
)
|
||||
network: control_net_lllite.ControlNetLLLite
|
||||
|
||||
if args.gradient_checkpointing:
|
||||
unet.train() # according to TI example in Diffusers, train is required -> これオリジナルのU-Netしたので本当は外せる
|
||||
else:
|
||||
unet.eval()
|
||||
|
||||
network.prepare_grad_etc()
|
||||
|
||||
# TextEncoderの出力をキャッシュするときにはCPUへ移動する
|
||||
if args.cache_text_encoder_outputs:
|
||||
# move Text Encoders for sampling images. Text Encoder doesn't work on CPU with fp16
|
||||
text_encoder1.to("cpu", dtype=torch.float32)
|
||||
text_encoder2.to("cpu", dtype=torch.float32)
|
||||
clean_memory_on_device(accelerator.device)
|
||||
else:
|
||||
# make sure Text Encoders are on GPU
|
||||
text_encoder1.to(accelerator.device)
|
||||
text_encoder2.to(accelerator.device)
|
||||
|
||||
if not cache_latents:
|
||||
vae.requires_grad_(False)
|
||||
vae.eval()
|
||||
vae.to(accelerator.device, dtype=vae_dtype)
|
||||
|
||||
# 実験的機能:勾配も含めたfp16学習を行う PyTorchにパッチを当ててfp16でのgrad scaleを有効にする
|
||||
if args.full_fp16:
|
||||
train_util.patch_accelerator_for_fp16_training(accelerator)
|
||||
|
||||
# resumeする
|
||||
train_util.resume_from_local_or_hf_if_specified(accelerator, args)
|
||||
|
||||
# epoch数を計算する
|
||||
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
|
||||
num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
|
||||
if (args.save_n_epoch_ratio is not None) and (args.save_n_epoch_ratio > 0):
|
||||
args.save_every_n_epochs = math.floor(num_train_epochs / args.save_n_epoch_ratio) or 1
|
||||
|
||||
# 学習する
|
||||
# TODO: find a way to handle total batch size when there are multiple datasets
|
||||
accelerator.print("running training / 学習開始")
|
||||
accelerator.print(f" num train images * repeats / 学習画像の数×繰り返し回数: {train_dataset_group.num_train_images}")
|
||||
accelerator.print(f" num reg images / 正則化画像の数: {train_dataset_group.num_reg_images}")
|
||||
accelerator.print(f" num batches per epoch / 1epochのバッチ数: {len(train_dataloader)}")
|
||||
accelerator.print(f" num epochs / epoch数: {num_train_epochs}")
|
||||
accelerator.print(
|
||||
f" batch size per device / バッチサイズ: {', '.join([str(d.batch_size) for d in train_dataset_group.datasets])}"
|
||||
)
|
||||
# logger.info(f" total train batch size (with parallel & distributed & accumulation) / 総バッチサイズ(並列学習、勾配合計含む): {total_batch_size}")
|
||||
accelerator.print(f" gradient accumulation steps / 勾配を合計するステップ数 = {args.gradient_accumulation_steps}")
|
||||
accelerator.print(f" total optimization steps / 学習ステップ数: {args.max_train_steps}")
|
||||
|
||||
progress_bar = tqdm(range(args.max_train_steps), smoothing=0, disable=not accelerator.is_local_main_process, desc="steps")
|
||||
global_step = 0
|
||||
|
||||
noise_scheduler = DDPMScheduler(
|
||||
beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000, clip_sample=False
|
||||
)
|
||||
prepare_scheduler_for_custom_training(noise_scheduler, accelerator.device)
|
||||
if args.zero_terminal_snr:
|
||||
custom_train_functions.fix_noise_scheduler_betas_for_zero_terminal_snr(noise_scheduler)
|
||||
|
||||
if accelerator.is_main_process:
|
||||
init_kwargs = {}
|
||||
if args.log_tracker_config is not None:
|
||||
init_kwargs = toml.load(args.log_tracker_config)
|
||||
accelerator.init_trackers(
|
||||
"lllite_control_net_train" if args.log_tracker_name is None else args.log_tracker_name, config=train_util.get_sanitized_config_or_none(args), init_kwargs=init_kwargs
|
||||
)
|
||||
|
||||
loss_recorder = train_util.LossRecorder()
|
||||
del train_dataset_group
|
||||
|
||||
# function for saving/removing
|
||||
def save_model(ckpt_name, unwrapped_nw, steps, epoch_no, force_sync_upload=False):
|
||||
os.makedirs(args.output_dir, exist_ok=True)
|
||||
ckpt_file = os.path.join(args.output_dir, ckpt_name)
|
||||
|
||||
accelerator.print(f"\nsaving checkpoint: {ckpt_file}")
|
||||
sai_metadata = train_util.get_sai_model_spec(None, args, True, True, False)
|
||||
sai_metadata["modelspec.architecture"] = sai_model_spec.ARCH_SD_XL_V1_BASE + "/control-net-lllite"
|
||||
|
||||
unwrapped_nw.save_weights(ckpt_file, save_dtype, sai_metadata)
|
||||
if args.huggingface_repo_id is not None:
|
||||
huggingface_util.upload(args, ckpt_file, "/" + ckpt_name, force_sync_upload=force_sync_upload)
|
||||
|
||||
def remove_model(old_ckpt_name):
|
||||
old_ckpt_file = os.path.join(args.output_dir, old_ckpt_name)
|
||||
if os.path.exists(old_ckpt_file):
|
||||
accelerator.print(f"removing old checkpoint: {old_ckpt_file}")
|
||||
os.remove(old_ckpt_file)
|
||||
|
||||
# training loop
|
||||
for epoch in range(num_train_epochs):
|
||||
accelerator.print(f"\nepoch {epoch+1}/{num_train_epochs}")
|
||||
current_epoch.value = epoch + 1
|
||||
|
||||
network.on_epoch_start() # train()
|
||||
|
||||
for step, batch in enumerate(train_dataloader):
|
||||
current_step.value = global_step
|
||||
with accelerator.accumulate(network):
|
||||
with torch.no_grad():
|
||||
if "latents" in batch and batch["latents"] is not None:
|
||||
latents = batch["latents"].to(accelerator.device).to(dtype=weight_dtype)
|
||||
else:
|
||||
# latentに変換
|
||||
latents = vae.encode(batch["images"].to(dtype=vae_dtype)).latent_dist.sample().to(dtype=weight_dtype)
|
||||
|
||||
# NaNが含まれていれば警告を表示し0に置き換える
|
||||
if torch.any(torch.isnan(latents)):
|
||||
accelerator.print("NaN found in latents, replacing with zeros")
|
||||
latents = torch.nan_to_num(latents, 0, out=latents)
|
||||
latents = latents * sdxl_model_util.VAE_SCALE_FACTOR
|
||||
|
||||
if "text_encoder_outputs1_list" not in batch or batch["text_encoder_outputs1_list"] is None:
|
||||
input_ids1 = batch["input_ids"]
|
||||
input_ids2 = batch["input_ids2"]
|
||||
with torch.no_grad():
|
||||
# Get the text embedding for conditioning
|
||||
input_ids1 = input_ids1.to(accelerator.device)
|
||||
input_ids2 = input_ids2.to(accelerator.device)
|
||||
encoder_hidden_states1, encoder_hidden_states2, pool2 = train_util.get_hidden_states_sdxl(
|
||||
args.max_token_length,
|
||||
input_ids1,
|
||||
input_ids2,
|
||||
tokenizer1,
|
||||
tokenizer2,
|
||||
text_encoder1,
|
||||
text_encoder2,
|
||||
None if not args.full_fp16 else weight_dtype,
|
||||
)
|
||||
else:
|
||||
encoder_hidden_states1 = batch["text_encoder_outputs1_list"].to(accelerator.device).to(weight_dtype)
|
||||
encoder_hidden_states2 = batch["text_encoder_outputs2_list"].to(accelerator.device).to(weight_dtype)
|
||||
pool2 = batch["text_encoder_pool2_list"].to(accelerator.device).to(weight_dtype)
|
||||
|
||||
# get size embeddings
|
||||
orig_size = batch["original_sizes_hw"]
|
||||
crop_size = batch["crop_top_lefts"]
|
||||
target_size = batch["target_sizes_hw"]
|
||||
embs = sdxl_train_util.get_size_embeddings(orig_size, crop_size, target_size, accelerator.device).to(weight_dtype)
|
||||
|
||||
# concat embeddings
|
||||
vector_embedding = torch.cat([pool2, embs], dim=1).to(weight_dtype)
|
||||
text_embedding = torch.cat([encoder_hidden_states1, encoder_hidden_states2], dim=2).to(weight_dtype)
|
||||
|
||||
# Sample noise, sample a random timestep for each image, and add noise to the latents,
|
||||
# with noise offset and/or multires noise if specified
|
||||
noise, noisy_latents, timesteps, huber_c = train_util.get_noise_noisy_latents_and_timesteps(args, noise_scheduler, latents)
|
||||
|
||||
noisy_latents = noisy_latents.to(weight_dtype) # TODO check why noisy_latents is not weight_dtype
|
||||
|
||||
controlnet_image = batch["conditioning_images"].to(dtype=weight_dtype)
|
||||
|
||||
with accelerator.autocast():
|
||||
# conditioning imageをControlNetに渡す / pass conditioning image to ControlNet
|
||||
# 内部でcond_embに変換される / it will be converted to cond_emb inside
|
||||
network.set_cond_image(controlnet_image)
|
||||
|
||||
# それらの値を使いつつ、U-Netでノイズを予測する / predict noise with U-Net using those values
|
||||
noise_pred = unet(noisy_latents, timesteps, text_embedding, vector_embedding)
|
||||
|
||||
if args.v_parameterization:
|
||||
# v-parameterization training
|
||||
target = noise_scheduler.get_velocity(latents, noise, timesteps)
|
||||
else:
|
||||
target = noise
|
||||
|
||||
loss = train_util.conditional_loss(noise_pred.float(), target.float(), reduction="none", loss_type=args.loss_type, huber_c=huber_c)
|
||||
loss = loss.mean([1, 2, 3])
|
||||
|
||||
loss_weights = batch["loss_weights"] # 各sampleごとのweight
|
||||
loss = loss * loss_weights
|
||||
|
||||
if args.min_snr_gamma:
|
||||
loss = apply_snr_weight(loss, timesteps, noise_scheduler, args.min_snr_gamma, args.v_parameterization)
|
||||
if args.scale_v_pred_loss_like_noise_pred:
|
||||
loss = scale_v_prediction_loss_like_noise_prediction(loss, timesteps, noise_scheduler)
|
||||
if args.v_pred_like_loss:
|
||||
loss = add_v_prediction_like_loss(loss, timesteps, noise_scheduler, args.v_pred_like_loss)
|
||||
if args.debiased_estimation_loss:
|
||||
loss = apply_debiased_estimation(loss, timesteps, noise_scheduler, args.v_parameterization)
|
||||
|
||||
loss = loss.mean() # 平均なのでbatch_sizeで割る必要なし
|
||||
|
||||
accelerator.backward(loss)
|
||||
if accelerator.sync_gradients and args.max_grad_norm != 0.0:
|
||||
params_to_clip = network.get_trainable_params()
|
||||
accelerator.clip_grad_norm_(params_to_clip, args.max_grad_norm)
|
||||
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
optimizer.zero_grad(set_to_none=True)
|
||||
|
||||
# Checks if the accelerator has performed an optimization step behind the scenes
|
||||
if accelerator.sync_gradients:
|
||||
progress_bar.update(1)
|
||||
global_step += 1
|
||||
|
||||
# sdxl_train_util.sample_images(accelerator, args, None, global_step, accelerator.device, vae, tokenizer, text_encoder, unet)
|
||||
|
||||
# 指定ステップごとにモデルを保存
|
||||
if args.save_every_n_steps is not None and global_step % args.save_every_n_steps == 0:
|
||||
accelerator.wait_for_everyone()
|
||||
if accelerator.is_main_process:
|
||||
ckpt_name = train_util.get_step_ckpt_name(args, "." + args.save_model_as, global_step)
|
||||
save_model(ckpt_name, accelerator.unwrap_model(network), global_step, epoch)
|
||||
|
||||
if args.save_state:
|
||||
train_util.save_and_remove_state_stepwise(args, accelerator, global_step)
|
||||
|
||||
remove_step_no = train_util.get_remove_step_no(args, global_step)
|
||||
if remove_step_no is not None:
|
||||
remove_ckpt_name = train_util.get_step_ckpt_name(args, "." + args.save_model_as, remove_step_no)
|
||||
remove_model(remove_ckpt_name)
|
||||
|
||||
current_loss = loss.detach().item()
|
||||
loss_recorder.add(epoch=epoch, step=step, loss=current_loss)
|
||||
avr_loss: float = loss_recorder.moving_average
|
||||
logs = {"avr_loss": avr_loss} # , "lr": lr_scheduler.get_last_lr()[0]}
|
||||
progress_bar.set_postfix(**logs)
|
||||
|
||||
if args.logging_dir is not None:
|
||||
logs = generate_step_logs(args, current_loss, avr_loss, lr_scheduler)
|
||||
accelerator.log(logs, step=global_step)
|
||||
|
||||
if global_step >= args.max_train_steps:
|
||||
break
|
||||
|
||||
if args.logging_dir is not None:
|
||||
logs = {"loss/epoch": loss_recorder.moving_average}
|
||||
accelerator.log(logs, step=epoch + 1)
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
# 指定エポックごとにモデルを保存
|
||||
if args.save_every_n_epochs is not None:
|
||||
saving = (epoch + 1) % args.save_every_n_epochs == 0 and (epoch + 1) < num_train_epochs
|
||||
if is_main_process and saving:
|
||||
ckpt_name = train_util.get_epoch_ckpt_name(args, "." + args.save_model_as, epoch + 1)
|
||||
save_model(ckpt_name, accelerator.unwrap_model(network), global_step, epoch + 1)
|
||||
|
||||
remove_epoch_no = train_util.get_remove_epoch_no(args, epoch + 1)
|
||||
if remove_epoch_no is not None:
|
||||
remove_ckpt_name = train_util.get_epoch_ckpt_name(args, "." + args.save_model_as, remove_epoch_no)
|
||||
remove_model(remove_ckpt_name)
|
||||
|
||||
if args.save_state:
|
||||
train_util.save_and_remove_state_on_epoch_end(args, accelerator, epoch + 1)
|
||||
|
||||
# self.sample_images(accelerator, args, epoch + 1, global_step, accelerator.device, vae, tokenizer, text_encoder, unet)
|
||||
|
||||
# end of epoch
|
||||
|
||||
if is_main_process:
|
||||
network = accelerator.unwrap_model(network)
|
||||
|
||||
accelerator.end_training()
|
||||
|
||||
if is_main_process and args.save_state:
|
||||
train_util.save_state_on_train_end(args, accelerator)
|
||||
|
||||
if is_main_process:
|
||||
ckpt_name = train_util.get_last_ckpt_name(args, "." + args.save_model_as)
|
||||
save_model(ckpt_name, network, global_step, num_train_epochs, force_sync_upload=True)
|
||||
|
||||
logger.info("model saved.")
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
add_logging_arguments(parser)
|
||||
train_util.add_sd_models_arguments(parser)
|
||||
train_util.add_dataset_arguments(parser, False, True, True)
|
||||
train_util.add_training_arguments(parser, False)
|
||||
deepspeed_utils.add_deepspeed_arguments(parser)
|
||||
train_util.add_optimizer_arguments(parser)
|
||||
config_util.add_config_arguments(parser)
|
||||
custom_train_functions.add_custom_train_arguments(parser)
|
||||
sdxl_train_util.add_sdxl_training_arguments(parser)
|
||||
|
||||
parser.add_argument(
|
||||
"--save_model_as",
|
||||
type=str,
|
||||
default="safetensors",
|
||||
choices=[None, "ckpt", "pt", "safetensors"],
|
||||
help="format to save the model (default is .safetensors) / モデル保存時の形式(デフォルトはsafetensors)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--cond_emb_dim", type=int, default=None, help="conditioning embedding dimension / 条件付け埋め込みの次元数"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--network_weights", type=str, default=None, help="pretrained weights for network / 学習するネットワークの初期重み"
|
||||
)
|
||||
parser.add_argument("--network_dim", type=int, default=None, help="network dimensions (rank) / モジュールの次元数")
|
||||
parser.add_argument(
|
||||
"--network_dropout",
|
||||
type=float,
|
||||
default=None,
|
||||
help="Drops neurons out of training every step (0 or None is default behavior (no dropout), 1 would drop all neurons) / 訓練時に毎ステップでニューロンをdropする(0またはNoneはdropoutなし、1は全ニューロンをdropout)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--conditioning_data_dir",
|
||||
type=str,
|
||||
default=None,
|
||||
help="conditioning data directory / 条件付けデータのディレクトリ",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--no_half_vae",
|
||||
action="store_true",
|
||||
help="do not use fp16/bf16 VAE in mixed precision (use float VAE) / mixed precisionでも fp16/bf16 VAEを使わずfloat VAEを使う",
|
||||
)
|
||||
return parser
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# sdxl_original_unet.USE_REENTRANT = False
|
||||
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
train_util.verify_command_line_training_args(args)
|
||||
args = train_util.read_config_from_file(args, parser)
|
||||
|
||||
train(args)
|
||||
185
sdxl_train_network.py
Normal file
185
sdxl_train_network.py
Normal file
@@ -0,0 +1,185 @@
|
||||
import argparse
|
||||
|
||||
import torch
|
||||
from library.device_utils import init_ipex, clean_memory_on_device
|
||||
init_ipex()
|
||||
|
||||
from library import sdxl_model_util, sdxl_train_util, train_util
|
||||
import train_network
|
||||
from library.utils import setup_logging
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class SdxlNetworkTrainer(train_network.NetworkTrainer):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.vae_scale_factor = sdxl_model_util.VAE_SCALE_FACTOR
|
||||
self.is_sdxl = True
|
||||
|
||||
def assert_extra_args(self, args, train_dataset_group):
|
||||
super().assert_extra_args(args, train_dataset_group)
|
||||
sdxl_train_util.verify_sdxl_training_args(args)
|
||||
|
||||
if args.cache_text_encoder_outputs:
|
||||
assert (
|
||||
train_dataset_group.is_text_encoder_output_cacheable()
|
||||
), "when caching Text Encoder output, either caption_dropout_rate, shuffle_caption, token_warmup_step or caption_tag_dropout_rate cannot be used / Text Encoderの出力をキャッシュするときはcaption_dropout_rate, shuffle_caption, token_warmup_step, caption_tag_dropout_rateは使えません"
|
||||
|
||||
assert (
|
||||
args.network_train_unet_only or not args.cache_text_encoder_outputs
|
||||
), "network for Text Encoder cannot be trained with caching Text Encoder outputs / Text Encoderの出力をキャッシュしながらText Encoderのネットワークを学習することはできません"
|
||||
|
||||
train_dataset_group.verify_bucket_reso_steps(32)
|
||||
|
||||
def load_target_model(self, args, weight_dtype, accelerator):
|
||||
(
|
||||
load_stable_diffusion_format,
|
||||
text_encoder1,
|
||||
text_encoder2,
|
||||
vae,
|
||||
unet,
|
||||
logit_scale,
|
||||
ckpt_info,
|
||||
) = sdxl_train_util.load_target_model(args, accelerator, sdxl_model_util.MODEL_VERSION_SDXL_BASE_V1_0, weight_dtype)
|
||||
|
||||
self.load_stable_diffusion_format = load_stable_diffusion_format
|
||||
self.logit_scale = logit_scale
|
||||
self.ckpt_info = ckpt_info
|
||||
|
||||
return sdxl_model_util.MODEL_VERSION_SDXL_BASE_V1_0, [text_encoder1, text_encoder2], vae, unet
|
||||
|
||||
def load_tokenizer(self, args):
|
||||
tokenizer = sdxl_train_util.load_tokenizers(args)
|
||||
return tokenizer
|
||||
|
||||
def is_text_encoder_outputs_cached(self, args):
|
||||
return args.cache_text_encoder_outputs
|
||||
|
||||
def cache_text_encoder_outputs_if_needed(
|
||||
self, args, accelerator, unet, vae, tokenizers, text_encoders, dataset: train_util.DatasetGroup, weight_dtype
|
||||
):
|
||||
if args.cache_text_encoder_outputs:
|
||||
if not args.lowram:
|
||||
# メモリ消費を減らす
|
||||
logger.info("move vae and unet to cpu to save memory")
|
||||
org_vae_device = vae.device
|
||||
org_unet_device = unet.device
|
||||
vae.to("cpu")
|
||||
unet.to("cpu")
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
# When TE is not be trained, it will not be prepared so we need to use explicit autocast
|
||||
with accelerator.autocast():
|
||||
dataset.cache_text_encoder_outputs(
|
||||
tokenizers,
|
||||
text_encoders,
|
||||
accelerator.device,
|
||||
weight_dtype,
|
||||
args.cache_text_encoder_outputs_to_disk,
|
||||
accelerator.is_main_process,
|
||||
)
|
||||
|
||||
text_encoders[0].to("cpu", dtype=torch.float32) # Text Encoder doesn't work with fp16 on CPU
|
||||
text_encoders[1].to("cpu", dtype=torch.float32)
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
if not args.lowram:
|
||||
logger.info("move vae and unet back to original device")
|
||||
vae.to(org_vae_device)
|
||||
unet.to(org_unet_device)
|
||||
else:
|
||||
# Text Encoderから毎回出力を取得するので、GPUに乗せておく
|
||||
text_encoders[0].to(accelerator.device, dtype=weight_dtype)
|
||||
text_encoders[1].to(accelerator.device, dtype=weight_dtype)
|
||||
|
||||
def get_text_cond(self, args, accelerator, batch, tokenizers, text_encoders, weight_dtype):
|
||||
if "text_encoder_outputs1_list" not in batch or batch["text_encoder_outputs1_list"] is None:
|
||||
input_ids1 = batch["input_ids"]
|
||||
input_ids2 = batch["input_ids2"]
|
||||
with torch.enable_grad():
|
||||
# Get the text embedding for conditioning
|
||||
# TODO support weighted captions
|
||||
# if args.weighted_captions:
|
||||
# encoder_hidden_states = get_weighted_text_embeddings(
|
||||
# tokenizer,
|
||||
# text_encoder,
|
||||
# batch["captions"],
|
||||
# accelerator.device,
|
||||
# args.max_token_length // 75 if args.max_token_length else 1,
|
||||
# clip_skip=args.clip_skip,
|
||||
# )
|
||||
# else:
|
||||
input_ids1 = input_ids1.to(accelerator.device)
|
||||
input_ids2 = input_ids2.to(accelerator.device)
|
||||
encoder_hidden_states1, encoder_hidden_states2, pool2 = train_util.get_hidden_states_sdxl(
|
||||
args.max_token_length,
|
||||
input_ids1,
|
||||
input_ids2,
|
||||
tokenizers[0],
|
||||
tokenizers[1],
|
||||
text_encoders[0],
|
||||
text_encoders[1],
|
||||
None if not args.full_fp16 else weight_dtype,
|
||||
accelerator=accelerator,
|
||||
)
|
||||
else:
|
||||
encoder_hidden_states1 = batch["text_encoder_outputs1_list"].to(accelerator.device).to(weight_dtype)
|
||||
encoder_hidden_states2 = batch["text_encoder_outputs2_list"].to(accelerator.device).to(weight_dtype)
|
||||
pool2 = batch["text_encoder_pool2_list"].to(accelerator.device).to(weight_dtype)
|
||||
|
||||
# # verify that the text encoder outputs are correct
|
||||
# ehs1, ehs2, p2 = train_util.get_hidden_states_sdxl(
|
||||
# args.max_token_length,
|
||||
# batch["input_ids"].to(text_encoders[0].device),
|
||||
# batch["input_ids2"].to(text_encoders[0].device),
|
||||
# tokenizers[0],
|
||||
# tokenizers[1],
|
||||
# text_encoders[0],
|
||||
# text_encoders[1],
|
||||
# None if not args.full_fp16 else weight_dtype,
|
||||
# )
|
||||
# b_size = encoder_hidden_states1.shape[0]
|
||||
# assert ((encoder_hidden_states1.to("cpu") - ehs1.to(dtype=weight_dtype)).abs().max() > 1e-2).sum() <= b_size * 2
|
||||
# assert ((encoder_hidden_states2.to("cpu") - ehs2.to(dtype=weight_dtype)).abs().max() > 1e-2).sum() <= b_size * 2
|
||||
# assert ((pool2.to("cpu") - p2.to(dtype=weight_dtype)).abs().max() > 1e-2).sum() <= b_size * 2
|
||||
# logger.info("text encoder outputs verified")
|
||||
|
||||
return encoder_hidden_states1, encoder_hidden_states2, pool2
|
||||
|
||||
def call_unet(self, args, accelerator, unet, noisy_latents, timesteps, text_conds, batch, weight_dtype):
|
||||
noisy_latents = noisy_latents.to(weight_dtype) # TODO check why noisy_latents is not weight_dtype
|
||||
|
||||
# get size embeddings
|
||||
orig_size = batch["original_sizes_hw"]
|
||||
crop_size = batch["crop_top_lefts"]
|
||||
target_size = batch["target_sizes_hw"]
|
||||
embs = sdxl_train_util.get_size_embeddings(orig_size, crop_size, target_size, accelerator.device).to(weight_dtype)
|
||||
|
||||
# concat embeddings
|
||||
encoder_hidden_states1, encoder_hidden_states2, pool2 = text_conds
|
||||
vector_embedding = torch.cat([pool2, embs], dim=1).to(weight_dtype)
|
||||
text_embedding = torch.cat([encoder_hidden_states1, encoder_hidden_states2], dim=2).to(weight_dtype)
|
||||
|
||||
noise_pred = unet(noisy_latents, timesteps, text_embedding, vector_embedding)
|
||||
return noise_pred
|
||||
|
||||
def sample_images(self, accelerator, args, epoch, global_step, device, vae, tokenizer, text_encoder, unet):
|
||||
sdxl_train_util.sample_images(accelerator, args, epoch, global_step, device, vae, tokenizer, text_encoder, unet)
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = train_network.setup_parser()
|
||||
sdxl_train_util.add_sdxl_training_arguments(parser)
|
||||
return parser
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
train_util.verify_command_line_training_args(args)
|
||||
args = train_util.read_config_from_file(args, parser)
|
||||
|
||||
trainer = SdxlNetworkTrainer()
|
||||
trainer.train(args)
|
||||
138
sdxl_train_textual_inversion.py
Normal file
138
sdxl_train_textual_inversion.py
Normal file
@@ -0,0 +1,138 @@
|
||||
import argparse
|
||||
import os
|
||||
|
||||
import regex
|
||||
|
||||
import torch
|
||||
from library.device_utils import init_ipex
|
||||
init_ipex()
|
||||
|
||||
from library import sdxl_model_util, sdxl_train_util, train_util
|
||||
|
||||
import train_textual_inversion
|
||||
|
||||
|
||||
class SdxlTextualInversionTrainer(train_textual_inversion.TextualInversionTrainer):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.vae_scale_factor = sdxl_model_util.VAE_SCALE_FACTOR
|
||||
self.is_sdxl = True
|
||||
|
||||
def assert_extra_args(self, args, train_dataset_group):
|
||||
super().assert_extra_args(args, train_dataset_group)
|
||||
sdxl_train_util.verify_sdxl_training_args(args, supportTextEncoderCaching=False)
|
||||
|
||||
train_dataset_group.verify_bucket_reso_steps(32)
|
||||
|
||||
def load_target_model(self, args, weight_dtype, accelerator):
|
||||
(
|
||||
load_stable_diffusion_format,
|
||||
text_encoder1,
|
||||
text_encoder2,
|
||||
vae,
|
||||
unet,
|
||||
logit_scale,
|
||||
ckpt_info,
|
||||
) = sdxl_train_util.load_target_model(args, accelerator, sdxl_model_util.MODEL_VERSION_SDXL_BASE_V1_0, weight_dtype)
|
||||
|
||||
self.load_stable_diffusion_format = load_stable_diffusion_format
|
||||
self.logit_scale = logit_scale
|
||||
self.ckpt_info = ckpt_info
|
||||
|
||||
return sdxl_model_util.MODEL_VERSION_SDXL_BASE_V1_0, [text_encoder1, text_encoder2], vae, unet
|
||||
|
||||
def load_tokenizer(self, args):
|
||||
tokenizer = sdxl_train_util.load_tokenizers(args)
|
||||
return tokenizer
|
||||
|
||||
def get_text_cond(self, args, accelerator, batch, tokenizers, text_encoders, weight_dtype):
|
||||
input_ids1 = batch["input_ids"]
|
||||
input_ids2 = batch["input_ids2"]
|
||||
with torch.enable_grad():
|
||||
input_ids1 = input_ids1.to(accelerator.device)
|
||||
input_ids2 = input_ids2.to(accelerator.device)
|
||||
encoder_hidden_states1, encoder_hidden_states2, pool2 = train_util.get_hidden_states_sdxl(
|
||||
args.max_token_length,
|
||||
input_ids1,
|
||||
input_ids2,
|
||||
tokenizers[0],
|
||||
tokenizers[1],
|
||||
text_encoders[0],
|
||||
text_encoders[1],
|
||||
None if not args.full_fp16 else weight_dtype,
|
||||
accelerator=accelerator,
|
||||
)
|
||||
return encoder_hidden_states1, encoder_hidden_states2, pool2
|
||||
|
||||
def call_unet(self, args, accelerator, unet, noisy_latents, timesteps, text_conds, batch, weight_dtype):
|
||||
noisy_latents = noisy_latents.to(weight_dtype) # TODO check why noisy_latents is not weight_dtype
|
||||
|
||||
# get size embeddings
|
||||
orig_size = batch["original_sizes_hw"]
|
||||
crop_size = batch["crop_top_lefts"]
|
||||
target_size = batch["target_sizes_hw"]
|
||||
embs = sdxl_train_util.get_size_embeddings(orig_size, crop_size, target_size, accelerator.device).to(weight_dtype)
|
||||
|
||||
# concat embeddings
|
||||
encoder_hidden_states1, encoder_hidden_states2, pool2 = text_conds
|
||||
vector_embedding = torch.cat([pool2, embs], dim=1).to(weight_dtype)
|
||||
text_embedding = torch.cat([encoder_hidden_states1, encoder_hidden_states2], dim=2).to(weight_dtype)
|
||||
|
||||
noise_pred = unet(noisy_latents, timesteps, text_embedding, vector_embedding)
|
||||
return noise_pred
|
||||
|
||||
def sample_images(self, accelerator, args, epoch, global_step, device, vae, tokenizer, text_encoder, unet, prompt_replacement):
|
||||
sdxl_train_util.sample_images(
|
||||
accelerator, args, epoch, global_step, device, vae, tokenizer, text_encoder, unet, prompt_replacement
|
||||
)
|
||||
|
||||
def save_weights(self, file, updated_embs, save_dtype, metadata):
|
||||
state_dict = {"clip_l": updated_embs[0], "clip_g": updated_embs[1]}
|
||||
|
||||
if save_dtype is not None:
|
||||
for key in list(state_dict.keys()):
|
||||
v = state_dict[key]
|
||||
v = v.detach().clone().to("cpu").to(save_dtype)
|
||||
state_dict[key] = v
|
||||
|
||||
if os.path.splitext(file)[1] == ".safetensors":
|
||||
from safetensors.torch import save_file
|
||||
|
||||
save_file(state_dict, file, metadata)
|
||||
else:
|
||||
torch.save(state_dict, file)
|
||||
|
||||
def load_weights(self, file):
|
||||
if os.path.splitext(file)[1] == ".safetensors":
|
||||
from safetensors.torch import load_file
|
||||
|
||||
data = load_file(file)
|
||||
else:
|
||||
data = torch.load(file, map_location="cpu")
|
||||
|
||||
emb_l = data.get("clip_l", None) # ViT-L text encoder 1
|
||||
emb_g = data.get("clip_g", None) # BiG-G text encoder 2
|
||||
|
||||
assert (
|
||||
emb_l is not None or emb_g is not None
|
||||
), f"weight file does not contains weights for text encoder 1 or 2 / 重みファイルにテキストエンコーダー1または2の重みが含まれていません: {file}"
|
||||
|
||||
return [emb_l, emb_g]
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = train_textual_inversion.setup_parser()
|
||||
# don't add sdxl_train_util.add_sdxl_training_arguments(parser): because it only adds text encoder caching
|
||||
# sdxl_train_util.add_sdxl_training_arguments(parser)
|
||||
return parser
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
train_util.verify_command_line_training_args(args)
|
||||
args = train_util.read_config_from_file(args, parser)
|
||||
|
||||
trainer = SdxlTextualInversionTrainer()
|
||||
trainer.train(args)
|
||||
205
tools/cache_latents.py
Normal file
205
tools/cache_latents.py
Normal file
@@ -0,0 +1,205 @@
|
||||
# latentsのdiskへの事前キャッシュを行う / cache latents to disk
|
||||
|
||||
import argparse
|
||||
import math
|
||||
from multiprocessing import Value
|
||||
import os
|
||||
|
||||
from accelerate.utils import set_seed
|
||||
import torch
|
||||
from tqdm import tqdm
|
||||
|
||||
from library import config_util
|
||||
from library import train_util
|
||||
from library import sdxl_train_util
|
||||
from library.config_util import (
|
||||
ConfigSanitizer,
|
||||
BlueprintGenerator,
|
||||
)
|
||||
from library.utils import setup_logging, add_logging_arguments
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
def cache_to_disk(args: argparse.Namespace) -> None:
|
||||
setup_logging(args, reset=True)
|
||||
train_util.prepare_dataset_args(args, True)
|
||||
|
||||
# check cache latents arg
|
||||
assert args.cache_latents_to_disk, "cache_latents_to_disk must be True / cache_latents_to_diskはTrueである必要があります"
|
||||
|
||||
use_dreambooth_method = args.in_json is None
|
||||
|
||||
if args.seed is not None:
|
||||
set_seed(args.seed) # 乱数系列を初期化する
|
||||
|
||||
# tokenizerを準備する:datasetを動かすために必要
|
||||
if args.sdxl:
|
||||
tokenizer1, tokenizer2 = sdxl_train_util.load_tokenizers(args)
|
||||
tokenizers = [tokenizer1, tokenizer2]
|
||||
else:
|
||||
tokenizer = train_util.load_tokenizer(args)
|
||||
tokenizers = [tokenizer]
|
||||
|
||||
# データセットを準備する
|
||||
if args.dataset_class is None:
|
||||
blueprint_generator = BlueprintGenerator(ConfigSanitizer(True, True, False, True))
|
||||
if args.dataset_config is not None:
|
||||
logger.info(f"Load dataset config from {args.dataset_config}")
|
||||
user_config = config_util.load_user_config(args.dataset_config)
|
||||
ignored = ["train_data_dir", "in_json"]
|
||||
if any(getattr(args, attr) is not None for attr in ignored):
|
||||
logger.warning(
|
||||
"ignore following options because config file is found: {0} / 設定ファイルが利用されるため以下のオプションは無視されます: {0}".format(
|
||||
", ".join(ignored)
|
||||
)
|
||||
)
|
||||
else:
|
||||
if use_dreambooth_method:
|
||||
logger.info("Using DreamBooth method.")
|
||||
user_config = {
|
||||
"datasets": [
|
||||
{
|
||||
"subsets": config_util.generate_dreambooth_subsets_config_by_subdirs(
|
||||
args.train_data_dir, args.reg_data_dir
|
||||
)
|
||||
}
|
||||
]
|
||||
}
|
||||
else:
|
||||
logger.info("Training with captions.")
|
||||
user_config = {
|
||||
"datasets": [
|
||||
{
|
||||
"subsets": [
|
||||
{
|
||||
"image_dir": args.train_data_dir,
|
||||
"metadata_file": args.in_json,
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
blueprint = blueprint_generator.generate(user_config, args, tokenizer=tokenizers)
|
||||
train_dataset_group = config_util.generate_dataset_group_by_blueprint(blueprint.dataset_group)
|
||||
else:
|
||||
train_dataset_group = train_util.load_arbitrary_dataset(args, tokenizers)
|
||||
|
||||
# datasetのcache_latentsを呼ばなければ、生の画像が返る
|
||||
|
||||
current_epoch = Value("i", 0)
|
||||
current_step = Value("i", 0)
|
||||
ds_for_collator = train_dataset_group if args.max_data_loader_n_workers == 0 else None
|
||||
collator = train_util.collator_class(current_epoch, current_step, ds_for_collator)
|
||||
|
||||
# acceleratorを準備する
|
||||
logger.info("prepare accelerator")
|
||||
args.deepspeed = False
|
||||
accelerator = train_util.prepare_accelerator(args)
|
||||
|
||||
# mixed precisionに対応した型を用意しておき適宜castする
|
||||
weight_dtype, _ = train_util.prepare_dtype(args)
|
||||
vae_dtype = torch.float32 if args.no_half_vae else weight_dtype
|
||||
|
||||
# モデルを読み込む
|
||||
logger.info("load model")
|
||||
if args.sdxl:
|
||||
(_, _, _, vae, _, _, _) = sdxl_train_util.load_target_model(args, accelerator, "sdxl", weight_dtype)
|
||||
else:
|
||||
_, vae, _, _ = train_util.load_target_model(args, weight_dtype, accelerator)
|
||||
|
||||
if torch.__version__ >= "2.0.0": # PyTorch 2.0.0 以上対応のxformersなら以下が使える
|
||||
vae.set_use_memory_efficient_attention_xformers(args.xformers)
|
||||
vae.to(accelerator.device, dtype=vae_dtype)
|
||||
vae.requires_grad_(False)
|
||||
vae.eval()
|
||||
|
||||
# dataloaderを準備する
|
||||
train_dataset_group.set_caching_mode("latents")
|
||||
|
||||
# DataLoaderのプロセス数:0 は persistent_workers が使えないので注意
|
||||
n_workers = min(args.max_data_loader_n_workers, os.cpu_count()) # cpu_count or max_data_loader_n_workers
|
||||
|
||||
train_dataloader = torch.utils.data.DataLoader(
|
||||
train_dataset_group,
|
||||
batch_size=1,
|
||||
shuffle=True,
|
||||
collate_fn=collator,
|
||||
num_workers=n_workers,
|
||||
persistent_workers=args.persistent_data_loader_workers,
|
||||
)
|
||||
|
||||
# acceleratorを使ってモデルを準備する:マルチGPUで使えるようになるはず
|
||||
train_dataloader = accelerator.prepare(train_dataloader)
|
||||
|
||||
# データ取得のためのループ
|
||||
for batch in tqdm(train_dataloader):
|
||||
b_size = len(batch["images"])
|
||||
vae_batch_size = b_size if args.vae_batch_size is None else args.vae_batch_size
|
||||
flip_aug = batch["flip_aug"]
|
||||
alpha_mask = batch["alpha_mask"]
|
||||
random_crop = batch["random_crop"]
|
||||
bucket_reso = batch["bucket_reso"]
|
||||
|
||||
# バッチを分割して処理する
|
||||
for i in range(0, b_size, vae_batch_size):
|
||||
images = batch["images"][i : i + vae_batch_size]
|
||||
absolute_paths = batch["absolute_paths"][i : i + vae_batch_size]
|
||||
resized_sizes = batch["resized_sizes"][i : i + vae_batch_size]
|
||||
|
||||
image_infos = []
|
||||
for i, (image, absolute_path, resized_size) in enumerate(zip(images, absolute_paths, resized_sizes)):
|
||||
image_info = train_util.ImageInfo(absolute_path, 1, "dummy", False, absolute_path)
|
||||
image_info.image = image
|
||||
image_info.bucket_reso = bucket_reso
|
||||
image_info.resized_size = resized_size
|
||||
image_info.latents_npz = os.path.splitext(absolute_path)[0] + ".npz"
|
||||
|
||||
if args.skip_existing:
|
||||
if train_util.is_disk_cached_latents_is_expected(
|
||||
image_info.bucket_reso, image_info.latents_npz, flip_aug, alpha_mask
|
||||
):
|
||||
logger.warning(f"Skipping {image_info.latents_npz} because it already exists.")
|
||||
continue
|
||||
|
||||
image_infos.append(image_info)
|
||||
|
||||
if len(image_infos) > 0:
|
||||
train_util.cache_batch_latents(vae, True, image_infos, flip_aug, alpha_mask, random_crop)
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
accelerator.print(f"Finished caching latents for {len(train_dataset_group)} batches.")
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
add_logging_arguments(parser)
|
||||
train_util.add_sd_models_arguments(parser)
|
||||
train_util.add_training_arguments(parser, True)
|
||||
train_util.add_dataset_arguments(parser, True, True, True)
|
||||
config_util.add_config_arguments(parser)
|
||||
parser.add_argument("--sdxl", action="store_true", help="Use SDXL model / SDXLモデルを使用する")
|
||||
parser.add_argument(
|
||||
"--no_half_vae",
|
||||
action="store_true",
|
||||
help="do not use fp16/bf16 VAE in mixed precision (use float VAE) / mixed precisionでも fp16/bf16 VAEを使わずfloat VAEを使う",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--skip_existing",
|
||||
action="store_true",
|
||||
help="skip images if npz already exists (both normal and flipped exists if flip_aug is enabled) / npzが既に存在する画像をスキップする(flip_aug有効時は通常、反転の両方が存在する画像をスキップ)",
|
||||
)
|
||||
return parser
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
args = train_util.read_config_from_file(args, parser)
|
||||
|
||||
cache_to_disk(args)
|
||||
197
tools/cache_text_encoder_outputs.py
Normal file
197
tools/cache_text_encoder_outputs.py
Normal file
@@ -0,0 +1,197 @@
|
||||
# text encoder出力のdiskへの事前キャッシュを行う / cache text encoder outputs to disk in advance
|
||||
|
||||
import argparse
|
||||
import math
|
||||
from multiprocessing import Value
|
||||
import os
|
||||
|
||||
from accelerate.utils import set_seed
|
||||
import torch
|
||||
from tqdm import tqdm
|
||||
|
||||
from library import config_util
|
||||
from library import train_util
|
||||
from library import sdxl_train_util
|
||||
from library.config_util import (
|
||||
ConfigSanitizer,
|
||||
BlueprintGenerator,
|
||||
)
|
||||
from library.utils import setup_logging, add_logging_arguments
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
def cache_to_disk(args: argparse.Namespace) -> None:
|
||||
setup_logging(args, reset=True)
|
||||
train_util.prepare_dataset_args(args, True)
|
||||
|
||||
# check cache arg
|
||||
assert (
|
||||
args.cache_text_encoder_outputs_to_disk
|
||||
), "cache_text_encoder_outputs_to_disk must be True / cache_text_encoder_outputs_to_diskはTrueである必要があります"
|
||||
|
||||
# できるだけ準備はしておくが今のところSDXLのみしか動かない
|
||||
assert (
|
||||
args.sdxl
|
||||
), "cache_text_encoder_outputs_to_disk is only available for SDXL / cache_text_encoder_outputs_to_diskはSDXLのみ利用可能です"
|
||||
|
||||
use_dreambooth_method = args.in_json is None
|
||||
|
||||
if args.seed is not None:
|
||||
set_seed(args.seed) # 乱数系列を初期化する
|
||||
|
||||
# tokenizerを準備する:datasetを動かすために必要
|
||||
if args.sdxl:
|
||||
tokenizer1, tokenizer2 = sdxl_train_util.load_tokenizers(args)
|
||||
tokenizers = [tokenizer1, tokenizer2]
|
||||
else:
|
||||
tokenizer = train_util.load_tokenizer(args)
|
||||
tokenizers = [tokenizer]
|
||||
|
||||
# データセットを準備する
|
||||
if args.dataset_class is None:
|
||||
blueprint_generator = BlueprintGenerator(ConfigSanitizer(True, True, False, True))
|
||||
if args.dataset_config is not None:
|
||||
logger.info(f"Load dataset config from {args.dataset_config}")
|
||||
user_config = config_util.load_user_config(args.dataset_config)
|
||||
ignored = ["train_data_dir", "in_json"]
|
||||
if any(getattr(args, attr) is not None for attr in ignored):
|
||||
logger.warning(
|
||||
"ignore following options because config file is found: {0} / 設定ファイルが利用されるため以下のオプションは無視されます: {0}".format(
|
||||
", ".join(ignored)
|
||||
)
|
||||
)
|
||||
else:
|
||||
if use_dreambooth_method:
|
||||
logger.info("Using DreamBooth method.")
|
||||
user_config = {
|
||||
"datasets": [
|
||||
{
|
||||
"subsets": config_util.generate_dreambooth_subsets_config_by_subdirs(
|
||||
args.train_data_dir, args.reg_data_dir
|
||||
)
|
||||
}
|
||||
]
|
||||
}
|
||||
else:
|
||||
logger.info("Training with captions.")
|
||||
user_config = {
|
||||
"datasets": [
|
||||
{
|
||||
"subsets": [
|
||||
{
|
||||
"image_dir": args.train_data_dir,
|
||||
"metadata_file": args.in_json,
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
blueprint = blueprint_generator.generate(user_config, args, tokenizer=tokenizers)
|
||||
train_dataset_group = config_util.generate_dataset_group_by_blueprint(blueprint.dataset_group)
|
||||
else:
|
||||
train_dataset_group = train_util.load_arbitrary_dataset(args, tokenizers)
|
||||
|
||||
current_epoch = Value("i", 0)
|
||||
current_step = Value("i", 0)
|
||||
ds_for_collator = train_dataset_group if args.max_data_loader_n_workers == 0 else None
|
||||
collator = train_util.collator_class(current_epoch, current_step, ds_for_collator)
|
||||
|
||||
# acceleratorを準備する
|
||||
logger.info("prepare accelerator")
|
||||
args.deepspeed = False
|
||||
accelerator = train_util.prepare_accelerator(args)
|
||||
|
||||
# mixed precisionに対応した型を用意しておき適宜castする
|
||||
weight_dtype, _ = train_util.prepare_dtype(args)
|
||||
|
||||
# モデルを読み込む
|
||||
logger.info("load model")
|
||||
if args.sdxl:
|
||||
(_, text_encoder1, text_encoder2, _, _, _, _) = sdxl_train_util.load_target_model(args, accelerator, "sdxl", weight_dtype)
|
||||
text_encoders = [text_encoder1, text_encoder2]
|
||||
else:
|
||||
text_encoder1, _, _, _ = train_util.load_target_model(args, weight_dtype, accelerator)
|
||||
text_encoders = [text_encoder1]
|
||||
|
||||
for text_encoder in text_encoders:
|
||||
text_encoder.to(accelerator.device, dtype=weight_dtype)
|
||||
text_encoder.requires_grad_(False)
|
||||
text_encoder.eval()
|
||||
|
||||
# dataloaderを準備する
|
||||
train_dataset_group.set_caching_mode("text")
|
||||
|
||||
# DataLoaderのプロセス数:0 は persistent_workers が使えないので注意
|
||||
n_workers = min(args.max_data_loader_n_workers, os.cpu_count()) # cpu_count or max_data_loader_n_workers
|
||||
|
||||
train_dataloader = torch.utils.data.DataLoader(
|
||||
train_dataset_group,
|
||||
batch_size=1,
|
||||
shuffle=True,
|
||||
collate_fn=collator,
|
||||
num_workers=n_workers,
|
||||
persistent_workers=args.persistent_data_loader_workers,
|
||||
)
|
||||
|
||||
# acceleratorを使ってモデルを準備する:マルチGPUで使えるようになるはず
|
||||
train_dataloader = accelerator.prepare(train_dataloader)
|
||||
|
||||
# データ取得のためのループ
|
||||
for batch in tqdm(train_dataloader):
|
||||
absolute_paths = batch["absolute_paths"]
|
||||
input_ids1_list = batch["input_ids1_list"]
|
||||
input_ids2_list = batch["input_ids2_list"]
|
||||
|
||||
image_infos = []
|
||||
for absolute_path, input_ids1, input_ids2 in zip(absolute_paths, input_ids1_list, input_ids2_list):
|
||||
image_info = train_util.ImageInfo(absolute_path, 1, "dummy", False, absolute_path)
|
||||
image_info.text_encoder_outputs_npz = os.path.splitext(absolute_path)[0] + train_util.TEXT_ENCODER_OUTPUTS_CACHE_SUFFIX
|
||||
image_info
|
||||
|
||||
if args.skip_existing:
|
||||
if os.path.exists(image_info.text_encoder_outputs_npz):
|
||||
logger.warning(f"Skipping {image_info.text_encoder_outputs_npz} because it already exists.")
|
||||
continue
|
||||
|
||||
image_info.input_ids1 = input_ids1
|
||||
image_info.input_ids2 = input_ids2
|
||||
image_infos.append(image_info)
|
||||
|
||||
if len(image_infos) > 0:
|
||||
b_input_ids1 = torch.stack([image_info.input_ids1 for image_info in image_infos])
|
||||
b_input_ids2 = torch.stack([image_info.input_ids2 for image_info in image_infos])
|
||||
train_util.cache_batch_text_encoder_outputs(
|
||||
image_infos, tokenizers, text_encoders, args.max_token_length, True, b_input_ids1, b_input_ids2, weight_dtype
|
||||
)
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
accelerator.print(f"Finished caching latents for {len(train_dataset_group)} batches.")
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
add_logging_arguments(parser)
|
||||
train_util.add_sd_models_arguments(parser)
|
||||
train_util.add_training_arguments(parser, True)
|
||||
train_util.add_dataset_arguments(parser, True, True, True)
|
||||
config_util.add_config_arguments(parser)
|
||||
sdxl_train_util.add_sdxl_training_arguments(parser)
|
||||
parser.add_argument("--sdxl", action="store_true", help="Use SDXL model / SDXLモデルを使用する")
|
||||
parser.add_argument(
|
||||
"--skip_existing",
|
||||
action="store_true",
|
||||
help="skip images if npz already exists (both normal and flipped exists if flip_aug is enabled) / npzが既に存在する画像をスキップする(flip_aug有効時は通常、反転の両方が存在する画像をスキップ)",
|
||||
)
|
||||
return parser
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
args = train_util.read_config_from_file(args, parser)
|
||||
|
||||
cache_to_disk(args)
|
||||
@@ -1,6 +1,10 @@
|
||||
import argparse
|
||||
import cv2
|
||||
|
||||
import logging
|
||||
from library.utils import setup_logging
|
||||
setup_logging()
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
def canny(args):
|
||||
img = cv2.imread(args.input)
|
||||
@@ -10,7 +14,7 @@ def canny(args):
|
||||
# canny_img = 255 - canny_img
|
||||
|
||||
cv2.imwrite(args.output, canny_img)
|
||||
print("done!")
|
||||
logger.info("done!")
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
|
||||
@@ -6,7 +6,10 @@ import torch
|
||||
from diffusers import StableDiffusionPipeline
|
||||
|
||||
import library.model_util as model_util
|
||||
|
||||
from library.utils import setup_logging
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
def convert(args):
|
||||
# 引数を確認する
|
||||
@@ -23,21 +26,23 @@ def convert(args):
|
||||
is_load_ckpt = os.path.isfile(args.model_to_load)
|
||||
is_save_ckpt = len(os.path.splitext(args.model_to_save)[1]) > 0
|
||||
|
||||
assert not is_load_ckpt or args.v1 != args.v2, f"v1 or v2 is required to load checkpoint / checkpointの読み込みにはv1/v2指定が必要です"
|
||||
assert (
|
||||
is_save_ckpt or args.reference_model is not None
|
||||
), f"reference model is required to save as Diffusers / Diffusers形式での保存には参照モデルが必要です"
|
||||
assert not is_load_ckpt or args.v1 != args.v2, "v1 or v2 is required to load checkpoint / checkpointの読み込みにはv1/v2指定が必要です"
|
||||
# assert (
|
||||
# is_save_ckpt or args.reference_model is not None
|
||||
# ), f"reference model is required to save as Diffusers / Diffusers形式での保存には参照モデルが必要です"
|
||||
|
||||
# モデルを読み込む
|
||||
msg = "checkpoint" if is_load_ckpt else ("Diffusers" + (" as fp16" if args.fp16 else ""))
|
||||
print(f"loading {msg}: {args.model_to_load}")
|
||||
logger.info(f"loading {msg}: {args.model_to_load}")
|
||||
|
||||
if is_load_ckpt:
|
||||
v2_model = args.v2
|
||||
text_encoder, vae, unet = model_util.load_models_from_stable_diffusion_checkpoint(v2_model, args.model_to_load)
|
||||
text_encoder, vae, unet = model_util.load_models_from_stable_diffusion_checkpoint(
|
||||
v2_model, args.model_to_load, unet_use_linear_projection_in_v2=args.unet_use_linear_projection
|
||||
)
|
||||
else:
|
||||
pipe = StableDiffusionPipeline.from_pretrained(
|
||||
args.model_to_load, torch_dtype=load_dtype, tokenizer=None, safety_checker=None
|
||||
args.model_to_load, torch_dtype=load_dtype, tokenizer=None, safety_checker=None, variant=args.variant
|
||||
)
|
||||
text_encoder = pipe.text_encoder
|
||||
vae = pipe.vae
|
||||
@@ -46,26 +51,37 @@ def convert(args):
|
||||
if args.v1 == args.v2:
|
||||
# 自動判定する
|
||||
v2_model = unet.config.cross_attention_dim == 1024
|
||||
print("checking model version: model is " + ("v2" if v2_model else "v1"))
|
||||
logger.info("checking model version: model is " + ("v2" if v2_model else "v1"))
|
||||
else:
|
||||
v2_model = not args.v1
|
||||
|
||||
# 変換して保存する
|
||||
msg = ("checkpoint" + ("" if save_dtype is None else f" in {save_dtype}")) if is_save_ckpt else "Diffusers"
|
||||
print(f"converting and saving as {msg}: {args.model_to_save}")
|
||||
logger.info(f"converting and saving as {msg}: {args.model_to_save}")
|
||||
|
||||
if is_save_ckpt:
|
||||
original_model = args.model_to_load if is_load_ckpt else None
|
||||
key_count = model_util.save_stable_diffusion_checkpoint(
|
||||
v2_model, args.model_to_save, text_encoder, unet, original_model, args.epoch, args.global_step, save_dtype, vae
|
||||
v2_model,
|
||||
args.model_to_save,
|
||||
text_encoder,
|
||||
unet,
|
||||
original_model,
|
||||
args.epoch,
|
||||
args.global_step,
|
||||
None if args.metadata is None else eval(args.metadata),
|
||||
save_dtype=save_dtype,
|
||||
vae=vae,
|
||||
)
|
||||
print(f"model saved. total converted state_dict keys: {key_count}")
|
||||
logger.info(f"model saved. total converted state_dict keys: {key_count}")
|
||||
else:
|
||||
print(f"copy scheduler/tokenizer config from: {args.reference_model}")
|
||||
logger.info(
|
||||
f"copy scheduler/tokenizer config from: {args.reference_model if args.reference_model is not None else 'default model'}"
|
||||
)
|
||||
model_util.save_diffusers_checkpoint(
|
||||
v2_model, args.model_to_save, text_encoder, unet, args.reference_model, vae, args.use_safetensors
|
||||
)
|
||||
print(f"model saved.")
|
||||
logger.info("model saved.")
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
@@ -76,6 +92,11 @@ def setup_parser() -> argparse.ArgumentParser:
|
||||
parser.add_argument(
|
||||
"--v2", action="store_true", help="load v2.0 model (v1 or v2 is required to load checkpoint) / 2.0のモデルを読み込む"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--unet_use_linear_projection",
|
||||
action="store_true",
|
||||
help="When saving v2 model as Diffusers, set U-Net config to `use_linear_projection=true` (to match stabilityai's model) / Diffusers形式でv2モデルを保存するときにU-Netの設定を`use_linear_projection=true`にする(stabilityaiのモデルと合わせる)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--fp16",
|
||||
action="store_true",
|
||||
@@ -96,11 +117,23 @@ def setup_parser() -> argparse.ArgumentParser:
|
||||
parser.add_argument(
|
||||
"--global_step", type=int, default=0, help="global_step to write to checkpoint / checkpointに記録するglobal_stepの値"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--metadata",
|
||||
type=str,
|
||||
default=None,
|
||||
help='モデルに保存されるメタデータ、Pythonの辞書形式で指定 / metadata: metadata written in to the model in Python Dictionary. Example metadata: \'{"name": "model_name", "resolution": "512x512"}\'',
|
||||
)
|
||||
parser.add_argument(
|
||||
"--variant",
|
||||
type=str,
|
||||
default=None,
|
||||
help="読む込むDiffusersのvariantを指定する、例: fp16 / variant: Diffusers variant to load. Example: fp16",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--reference_model",
|
||||
type=str,
|
||||
default=None,
|
||||
help="reference model for schduler/tokenizer, required in saving Diffusers, copy schduler/tokenizer from this / scheduler/tokenizerのコピー元のDiffusersモデル、Diffusers形式で保存するときに必要",
|
||||
help="scheduler/tokenizerのコピー元Diffusersモデル、Diffusers形式で保存するときに使用される、省略時は`runwayml/stable-diffusion-v1-5` または `stabilityai/stable-diffusion-2-1` / reference Diffusers model to copy scheduler/tokenizer config from, used when saving as Diffusers format, default is `runwayml/stable-diffusion-v1-5` or `stabilityai/stable-diffusion-2-1`",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--use_safetensors",
|
||||
|
||||
@@ -15,6 +15,10 @@ import os
|
||||
from anime_face_detector import create_detector
|
||||
from tqdm import tqdm
|
||||
import numpy as np
|
||||
from library.utils import setup_logging, pil_resize
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
KP_REYE = 11
|
||||
KP_LEYE = 19
|
||||
@@ -24,7 +28,7 @@ SCORE_THRES = 0.90
|
||||
|
||||
def detect_faces(detector, image, min_size):
|
||||
preds = detector(image) # bgr
|
||||
# print(len(preds))
|
||||
# logger.info(len(preds))
|
||||
|
||||
faces = []
|
||||
for pred in preds:
|
||||
@@ -78,7 +82,7 @@ def process(args):
|
||||
assert args.crop_ratio is None or args.resize_face_size is None, f"crop_ratio指定時はresize_face_sizeは指定できません"
|
||||
|
||||
# アニメ顔検出モデルを読み込む
|
||||
print("loading face detector.")
|
||||
logger.info("loading face detector.")
|
||||
detector = create_detector('yolov3')
|
||||
|
||||
# cropの引数を解析する
|
||||
@@ -97,7 +101,7 @@ def process(args):
|
||||
crop_h_ratio, crop_v_ratio = [float(t) for t in tokens]
|
||||
|
||||
# 画像を処理する
|
||||
print("processing.")
|
||||
logger.info("processing.")
|
||||
output_extension = ".png"
|
||||
|
||||
os.makedirs(args.dst_dir, exist_ok=True)
|
||||
@@ -111,7 +115,7 @@ def process(args):
|
||||
if len(image.shape) == 2:
|
||||
image = cv2.cvtColor(image, cv2.COLOR_GRAY2BGR)
|
||||
if image.shape[2] == 4:
|
||||
print(f"image has alpha. ignore / 画像の透明度が設定されているため無視します: {path}")
|
||||
logger.warning(f"image has alpha. ignore / 画像の透明度が設定されているため無視します: {path}")
|
||||
image = image[:, :, :3].copy() # copyをしないと内部的に透明度情報が付いたままになるらしい
|
||||
|
||||
h, w = image.shape[:2]
|
||||
@@ -144,11 +148,11 @@ def process(args):
|
||||
# 顔サイズを基準にリサイズする
|
||||
scale = args.resize_face_size / face_size
|
||||
if scale < cur_crop_width / w:
|
||||
print(
|
||||
logger.warning(
|
||||
f"image width too small in face size based resizing / 顔を基準にリサイズすると画像の幅がcrop sizeより小さい(顔が相対的に大きすぎる)ので顔サイズが変わります: {path}")
|
||||
scale = cur_crop_width / w
|
||||
if scale < cur_crop_height / h:
|
||||
print(
|
||||
logger.warning(
|
||||
f"image height too small in face size based resizing / 顔を基準にリサイズすると画像の高さがcrop sizeより小さい(顔が相対的に大きすぎる)ので顔サイズが変わります: {path}")
|
||||
scale = cur_crop_height / h
|
||||
elif crop_h_ratio is not None:
|
||||
@@ -157,10 +161,10 @@ def process(args):
|
||||
else:
|
||||
# 切り出しサイズ指定あり
|
||||
if w < cur_crop_width:
|
||||
print(f"image width too small/ 画像の幅がcrop sizeより小さいので画質が劣化します: {path}")
|
||||
logger.warning(f"image width too small/ 画像の幅がcrop sizeより小さいので画質が劣化します: {path}")
|
||||
scale = cur_crop_width / w
|
||||
if h < cur_crop_height:
|
||||
print(f"image height too small/ 画像の高さがcrop sizeより小さいので画質が劣化します: {path}")
|
||||
logger.warning(f"image height too small/ 画像の高さがcrop sizeより小さいので画質が劣化します: {path}")
|
||||
scale = cur_crop_height / h
|
||||
if args.resize_fit:
|
||||
scale = max(cur_crop_width / w, cur_crop_height / h)
|
||||
@@ -168,7 +172,10 @@ def process(args):
|
||||
if scale != 1.0:
|
||||
w = int(w * scale + .5)
|
||||
h = int(h * scale + .5)
|
||||
face_img = cv2.resize(face_img, (w, h), interpolation=cv2.INTER_AREA if scale < 1.0 else cv2.INTER_LANCZOS4)
|
||||
if scale < 1.0:
|
||||
face_img = cv2.resize(face_img, (w, h), interpolation=cv2.INTER_AREA)
|
||||
else:
|
||||
face_img = pil_resize(face_img, (w, h))
|
||||
cx = int(cx * scale + .5)
|
||||
cy = int(cy * scale + .5)
|
||||
fw = int(fw * scale + .5)
|
||||
@@ -198,7 +205,7 @@ def process(args):
|
||||
face_img = face_img[y:y + cur_crop_height]
|
||||
|
||||
# # debug
|
||||
# print(path, cx, cy, angle)
|
||||
# logger.info(path, cx, cy, angle)
|
||||
# crp = cv2.resize(image, (image.shape[1]//8, image.shape[0]//8))
|
||||
# cv2.imshow("image", crp)
|
||||
# if cv2.waitKey() == 27:
|
||||
|
||||
@@ -11,10 +11,16 @@ from typing import Dict, List
|
||||
import numpy as np
|
||||
|
||||
import torch
|
||||
from library.device_utils import init_ipex, get_preferred_device
|
||||
init_ipex()
|
||||
|
||||
from torch import nn
|
||||
from tqdm import tqdm
|
||||
from PIL import Image
|
||||
|
||||
from library.utils import setup_logging
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class ResidualBlock(nn.Module):
|
||||
def __init__(self, in_channels, out_channels=None, kernel_size=3, stride=1, padding=1):
|
||||
@@ -216,7 +222,7 @@ class Upscaler(nn.Module):
|
||||
upsampled_images = upsampled_images / 127.5 - 1.0
|
||||
|
||||
# convert upsample images to latents with batch size
|
||||
# print("Encoding upsampled (LANCZOS4) images...")
|
||||
# logger.info("Encoding upsampled (LANCZOS4) images...")
|
||||
upsampled_latents = []
|
||||
for i in tqdm(range(0, upsampled_images.shape[0], vae_batch_size)):
|
||||
batch = upsampled_images[i : i + vae_batch_size].to(vae.device)
|
||||
@@ -227,7 +233,7 @@ class Upscaler(nn.Module):
|
||||
upsampled_latents = torch.cat(upsampled_latents, dim=0)
|
||||
|
||||
# upscale (refine) latents with this model with batch size
|
||||
print("Upscaling latents...")
|
||||
logger.info("Upscaling latents...")
|
||||
upscaled_latents = []
|
||||
for i in range(0, upsampled_latents.shape[0], batch_size):
|
||||
with torch.no_grad():
|
||||
@@ -242,27 +248,33 @@ def create_upscaler(**kwargs):
|
||||
weights = kwargs["weights"]
|
||||
model = Upscaler()
|
||||
|
||||
print(f"Loading weights from {weights}...")
|
||||
model.load_state_dict(torch.load(weights, map_location=torch.device("cpu")))
|
||||
logger.info(f"Loading weights from {weights}...")
|
||||
if os.path.splitext(weights)[1] == ".safetensors":
|
||||
from safetensors.torch import load_file
|
||||
|
||||
sd = load_file(weights)
|
||||
else:
|
||||
sd = torch.load(weights, map_location=torch.device("cpu"))
|
||||
model.load_state_dict(sd)
|
||||
return model
|
||||
|
||||
|
||||
# another interface: upscale images with a model for given images from command line
|
||||
def upscale_images(args: argparse.Namespace):
|
||||
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
||||
DEVICE = get_preferred_device()
|
||||
us_dtype = torch.float16 # TODO: support fp32/bf16
|
||||
os.makedirs(args.output_dir, exist_ok=True)
|
||||
|
||||
# load VAE with Diffusers
|
||||
assert args.vae_path is not None, "VAE path is required"
|
||||
print(f"Loading VAE from {args.vae_path}...")
|
||||
logger.info(f"Loading VAE from {args.vae_path}...")
|
||||
vae = AutoencoderKL.from_pretrained(args.vae_path, subfolder="vae")
|
||||
vae.to(DEVICE, dtype=us_dtype)
|
||||
|
||||
# prepare model
|
||||
print("Preparing model...")
|
||||
logger.info("Preparing model...")
|
||||
upscaler: Upscaler = create_upscaler(weights=args.weights)
|
||||
# print("Loading weights from", args.weights)
|
||||
# logger.info("Loading weights from", args.weights)
|
||||
# upscaler.load_state_dict(torch.load(args.weights))
|
||||
upscaler.eval()
|
||||
upscaler.to(DEVICE, dtype=us_dtype)
|
||||
@@ -297,14 +309,14 @@ def upscale_images(args: argparse.Namespace):
|
||||
image_debug.save(dest_file_name)
|
||||
|
||||
# upscale
|
||||
print("Upscaling...")
|
||||
logger.info("Upscaling...")
|
||||
upscaled_latents = upscaler.upscale(
|
||||
vae, images, None, us_dtype, width * 2, height * 2, batch_size=args.batch_size, vae_batch_size=args.vae_batch_size
|
||||
)
|
||||
upscaled_latents /= 0.18215
|
||||
|
||||
# decode with batch
|
||||
print("Decoding...")
|
||||
logger.info("Decoding...")
|
||||
upscaled_images = []
|
||||
for i in tqdm(range(0, upscaled_latents.shape[0], args.vae_batch_size)):
|
||||
with torch.no_grad():
|
||||
|
||||
171
tools/merge_models.py
Normal file
171
tools/merge_models.py
Normal file
@@ -0,0 +1,171 @@
|
||||
import argparse
|
||||
import os
|
||||
|
||||
import torch
|
||||
from safetensors import safe_open
|
||||
from safetensors.torch import load_file, save_file
|
||||
from tqdm import tqdm
|
||||
from library.utils import setup_logging
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
def is_unet_key(key):
|
||||
# VAE or TextEncoder, the last one is for SDXL
|
||||
return not ("first_stage_model" in key or "cond_stage_model" in key or "conditioner." in key)
|
||||
|
||||
|
||||
TEXT_ENCODER_KEY_REPLACEMENTS = [
|
||||
("cond_stage_model.transformer.embeddings.", "cond_stage_model.transformer.text_model.embeddings."),
|
||||
("cond_stage_model.transformer.encoder.", "cond_stage_model.transformer.text_model.encoder."),
|
||||
("cond_stage_model.transformer.final_layer_norm.", "cond_stage_model.transformer.text_model.final_layer_norm."),
|
||||
]
|
||||
|
||||
|
||||
# support for models with different text encoder keys
|
||||
def replace_text_encoder_key(key):
|
||||
for rep_from, rep_to in TEXT_ENCODER_KEY_REPLACEMENTS:
|
||||
if key.startswith(rep_from):
|
||||
return True, rep_to + key[len(rep_from) :]
|
||||
return False, key
|
||||
|
||||
|
||||
def merge(args):
|
||||
if args.precision == "fp16":
|
||||
dtype = torch.float16
|
||||
elif args.precision == "bf16":
|
||||
dtype = torch.bfloat16
|
||||
else:
|
||||
dtype = torch.float
|
||||
|
||||
if args.saving_precision == "fp16":
|
||||
save_dtype = torch.float16
|
||||
elif args.saving_precision == "bf16":
|
||||
save_dtype = torch.bfloat16
|
||||
else:
|
||||
save_dtype = torch.float
|
||||
|
||||
# check if all models are safetensors
|
||||
for model in args.models:
|
||||
if not model.endswith("safetensors"):
|
||||
logger.info(f"Model {model} is not a safetensors model")
|
||||
exit()
|
||||
if not os.path.isfile(model):
|
||||
logger.info(f"Model {model} does not exist")
|
||||
exit()
|
||||
|
||||
assert args.ratios is None or len(args.models) == len(args.ratios), "ratios must be the same length as models"
|
||||
|
||||
# load and merge
|
||||
ratio = 1.0 / len(args.models) # default
|
||||
supplementary_key_ratios = {} # [key] = ratio, for keys not in all models, add later
|
||||
|
||||
merged_sd = None
|
||||
first_model_keys = set() # check missing keys in other models
|
||||
for i, model in enumerate(args.models):
|
||||
if args.ratios is not None:
|
||||
ratio = args.ratios[i]
|
||||
|
||||
if merged_sd is None:
|
||||
# load first model
|
||||
logger.info(f"Loading model {model}, ratio = {ratio}...")
|
||||
merged_sd = {}
|
||||
with safe_open(model, framework="pt", device=args.device) as f:
|
||||
for key in tqdm(f.keys()):
|
||||
value = f.get_tensor(key)
|
||||
_, key = replace_text_encoder_key(key)
|
||||
|
||||
first_model_keys.add(key)
|
||||
|
||||
if not is_unet_key(key) and args.unet_only:
|
||||
supplementary_key_ratios[key] = 1.0 # use first model's value for VAE or TextEncoder
|
||||
continue
|
||||
|
||||
value = ratio * value.to(dtype) # first model's value * ratio
|
||||
merged_sd[key] = value
|
||||
|
||||
logger.info(f"Model has {len(merged_sd)} keys " + ("(UNet only)" if args.unet_only else ""))
|
||||
continue
|
||||
|
||||
# load other models
|
||||
logger.info(f"Loading model {model}, ratio = {ratio}...")
|
||||
|
||||
with safe_open(model, framework="pt", device=args.device) as f:
|
||||
model_keys = f.keys()
|
||||
for key in tqdm(model_keys):
|
||||
_, new_key = replace_text_encoder_key(key)
|
||||
if new_key not in merged_sd:
|
||||
if args.show_skipped and new_key not in first_model_keys:
|
||||
logger.info(f"Skip: {new_key}")
|
||||
continue
|
||||
|
||||
value = f.get_tensor(key)
|
||||
merged_sd[new_key] = merged_sd[new_key] + ratio * value.to(dtype)
|
||||
|
||||
# enumerate keys not in this model
|
||||
model_keys = set(model_keys)
|
||||
for key in merged_sd.keys():
|
||||
if key in model_keys:
|
||||
continue
|
||||
logger.warning(f"Key {key} not in model {model}, use first model's value")
|
||||
if key in supplementary_key_ratios:
|
||||
supplementary_key_ratios[key] += ratio
|
||||
else:
|
||||
supplementary_key_ratios[key] = ratio
|
||||
|
||||
# add supplementary keys' value (including VAE and TextEncoder)
|
||||
if len(supplementary_key_ratios) > 0:
|
||||
logger.info("add first model's value")
|
||||
with safe_open(args.models[0], framework="pt", device=args.device) as f:
|
||||
for key in tqdm(f.keys()):
|
||||
_, new_key = replace_text_encoder_key(key)
|
||||
if new_key not in supplementary_key_ratios:
|
||||
continue
|
||||
|
||||
if is_unet_key(new_key): # not VAE or TextEncoder
|
||||
logger.warning(f"Key {new_key} not in all models, ratio = {supplementary_key_ratios[new_key]}")
|
||||
|
||||
value = f.get_tensor(key) # original key
|
||||
|
||||
if new_key not in merged_sd:
|
||||
merged_sd[new_key] = supplementary_key_ratios[new_key] * value.to(dtype)
|
||||
else:
|
||||
merged_sd[new_key] = merged_sd[new_key] + supplementary_key_ratios[new_key] * value.to(dtype)
|
||||
|
||||
# save
|
||||
output_file = args.output
|
||||
if not output_file.endswith(".safetensors"):
|
||||
output_file = output_file + ".safetensors"
|
||||
|
||||
logger.info(f"Saving to {output_file}...")
|
||||
|
||||
# convert to save_dtype
|
||||
for k in merged_sd.keys():
|
||||
merged_sd[k] = merged_sd[k].to(save_dtype)
|
||||
|
||||
save_file(merged_sd, output_file)
|
||||
|
||||
logger.info("Done!")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser(description="Merge models")
|
||||
parser.add_argument("--models", nargs="+", type=str, help="Models to merge")
|
||||
parser.add_argument("--output", type=str, help="Output model")
|
||||
parser.add_argument("--ratios", nargs="+", type=float, help="Ratios of models, default is equal, total = 1.0")
|
||||
parser.add_argument("--unet_only", action="store_true", help="Only merge unet")
|
||||
parser.add_argument("--device", type=str, default="cpu", help="Device to use, default is cpu")
|
||||
parser.add_argument(
|
||||
"--precision", type=str, default="float", choices=["float", "fp16", "bf16"], help="Calculation precision, default is float"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--saving_precision",
|
||||
type=str,
|
||||
default="float",
|
||||
choices=["float", "fp16", "bf16"],
|
||||
help="Saving precision, default is float",
|
||||
)
|
||||
parser.add_argument("--show_skipped", action="store_true", help="Show skipped keys (keys not in first model)")
|
||||
|
||||
args = parser.parse_args()
|
||||
merge(args)
|
||||
@@ -4,175 +4,203 @@ import cv2
|
||||
import torch
|
||||
from safetensors.torch import load_file
|
||||
|
||||
from diffusers import UNet2DConditionModel
|
||||
from diffusers.models.unet_2d_condition import UNet2DConditionOutput
|
||||
from library.original_unet import UNet2DConditionModel, SampleOutput
|
||||
|
||||
import library.model_util as model_util
|
||||
|
||||
from library.utils import setup_logging
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
class ControlNetInfo(NamedTuple):
|
||||
unet: Any
|
||||
net: Any
|
||||
prep: Any
|
||||
weight: float
|
||||
ratio: float
|
||||
unet: Any
|
||||
net: Any
|
||||
prep: Any
|
||||
weight: float
|
||||
ratio: float
|
||||
|
||||
|
||||
class ControlNet(torch.nn.Module):
|
||||
def __init__(self) -> None:
|
||||
super().__init__()
|
||||
def __init__(self) -> None:
|
||||
super().__init__()
|
||||
|
||||
# make control model
|
||||
self.control_model = torch.nn.Module()
|
||||
# make control model
|
||||
self.control_model = torch.nn.Module()
|
||||
|
||||
dims = [320, 320, 320, 320, 640, 640, 640, 1280, 1280, 1280, 1280, 1280]
|
||||
zero_convs = torch.nn.ModuleList()
|
||||
for i, dim in enumerate(dims):
|
||||
sub_list = torch.nn.ModuleList([torch.nn.Conv2d(dim, dim, 1)])
|
||||
zero_convs.append(sub_list)
|
||||
self.control_model.add_module("zero_convs", zero_convs)
|
||||
dims = [320, 320, 320, 320, 640, 640, 640, 1280, 1280, 1280, 1280, 1280]
|
||||
zero_convs = torch.nn.ModuleList()
|
||||
for i, dim in enumerate(dims):
|
||||
sub_list = torch.nn.ModuleList([torch.nn.Conv2d(dim, dim, 1)])
|
||||
zero_convs.append(sub_list)
|
||||
self.control_model.add_module("zero_convs", zero_convs)
|
||||
|
||||
middle_block_out = torch.nn.Conv2d(1280, 1280, 1)
|
||||
self.control_model.add_module("middle_block_out", torch.nn.ModuleList([middle_block_out]))
|
||||
middle_block_out = torch.nn.Conv2d(1280, 1280, 1)
|
||||
self.control_model.add_module("middle_block_out", torch.nn.ModuleList([middle_block_out]))
|
||||
|
||||
dims = [16, 16, 32, 32, 96, 96, 256, 320]
|
||||
strides = [1, 1, 2, 1, 2, 1, 2, 1]
|
||||
prev_dim = 3
|
||||
input_hint_block = torch.nn.Sequential()
|
||||
for i, (dim, stride) in enumerate(zip(dims, strides)):
|
||||
input_hint_block.append(torch.nn.Conv2d(prev_dim, dim, 3, stride, 1))
|
||||
if i < len(dims) - 1:
|
||||
input_hint_block.append(torch.nn.SiLU())
|
||||
prev_dim = dim
|
||||
self.control_model.add_module("input_hint_block", input_hint_block)
|
||||
dims = [16, 16, 32, 32, 96, 96, 256, 320]
|
||||
strides = [1, 1, 2, 1, 2, 1, 2, 1]
|
||||
prev_dim = 3
|
||||
input_hint_block = torch.nn.Sequential()
|
||||
for i, (dim, stride) in enumerate(zip(dims, strides)):
|
||||
input_hint_block.append(torch.nn.Conv2d(prev_dim, dim, 3, stride, 1))
|
||||
if i < len(dims) - 1:
|
||||
input_hint_block.append(torch.nn.SiLU())
|
||||
prev_dim = dim
|
||||
self.control_model.add_module("input_hint_block", input_hint_block)
|
||||
|
||||
|
||||
def load_control_net(v2, unet, model):
|
||||
device = unet.device
|
||||
device = unet.device
|
||||
|
||||
# control sdからキー変換しつつU-Netに対応する部分のみ取り出し、DiffusersのU-Netに読み込む
|
||||
# state dictを読み込む
|
||||
print(f"ControlNet: loading control SD model : {model}")
|
||||
# control sdからキー変換しつつU-Netに対応する部分のみ取り出し、DiffusersのU-Netに読み込む
|
||||
# state dictを読み込む
|
||||
logger.info(f"ControlNet: loading control SD model : {model}")
|
||||
|
||||
if model_util.is_safetensors(model):
|
||||
ctrl_sd_sd = load_file(model)
|
||||
else:
|
||||
ctrl_sd_sd = torch.load(model, map_location='cpu')
|
||||
ctrl_sd_sd = ctrl_sd_sd.pop("state_dict", ctrl_sd_sd)
|
||||
if model_util.is_safetensors(model):
|
||||
ctrl_sd_sd = load_file(model)
|
||||
else:
|
||||
ctrl_sd_sd = torch.load(model, map_location="cpu")
|
||||
ctrl_sd_sd = ctrl_sd_sd.pop("state_dict", ctrl_sd_sd)
|
||||
|
||||
# 重みをU-Netに読み込めるようにする。ControlNetはSD版のstate dictなので、それを読み込む
|
||||
is_difference = "difference" in ctrl_sd_sd
|
||||
print("ControlNet: loading difference")
|
||||
# 重みをU-Netに読み込めるようにする。ControlNetはSD版のstate dictなので、それを読み込む
|
||||
is_difference = "difference" in ctrl_sd_sd
|
||||
logger.info(f"ControlNet: loading difference: {is_difference}")
|
||||
|
||||
# ControlNetには存在しないキーがあるので、まず現在のU-NetでSD版の全keyを作っておく
|
||||
# またTransfer Controlの元weightとなる
|
||||
ctrl_unet_sd_sd = model_util.convert_unet_state_dict_to_sd(v2, unet.state_dict())
|
||||
# ControlNetには存在しないキーがあるので、まず現在のU-NetでSD版の全keyを作っておく
|
||||
# またTransfer Controlの元weightとなる
|
||||
ctrl_unet_sd_sd = model_util.convert_unet_state_dict_to_sd(v2, unet.state_dict())
|
||||
|
||||
# 元のU-Netに影響しないようにコピーする。またprefixが付いていないので付ける
|
||||
for key in list(ctrl_unet_sd_sd.keys()):
|
||||
ctrl_unet_sd_sd["model.diffusion_model." + key] = ctrl_unet_sd_sd.pop(key).clone()
|
||||
# 元のU-Netに影響しないようにコピーする。またprefixが付いていないので付ける
|
||||
for key in list(ctrl_unet_sd_sd.keys()):
|
||||
ctrl_unet_sd_sd["model.diffusion_model." + key] = ctrl_unet_sd_sd.pop(key).clone()
|
||||
|
||||
zero_conv_sd = {}
|
||||
for key in list(ctrl_sd_sd.keys()):
|
||||
if key.startswith("control_"):
|
||||
unet_key = "model.diffusion_" + key[len("control_"):]
|
||||
if unet_key not in ctrl_unet_sd_sd: # zero conv
|
||||
zero_conv_sd[key] = ctrl_sd_sd[key]
|
||||
continue
|
||||
if is_difference: # Transfer Control
|
||||
ctrl_unet_sd_sd[unet_key] += ctrl_sd_sd[key].to(device, dtype=unet.dtype)
|
||||
else:
|
||||
ctrl_unet_sd_sd[unet_key] = ctrl_sd_sd[key].to(device, dtype=unet.dtype)
|
||||
zero_conv_sd = {}
|
||||
for key in list(ctrl_sd_sd.keys()):
|
||||
if key.startswith("control_"):
|
||||
unet_key = "model.diffusion_" + key[len("control_") :]
|
||||
if unet_key not in ctrl_unet_sd_sd: # zero conv
|
||||
zero_conv_sd[key] = ctrl_sd_sd[key]
|
||||
continue
|
||||
if is_difference: # Transfer Control
|
||||
ctrl_unet_sd_sd[unet_key] += ctrl_sd_sd[key].to(device, dtype=unet.dtype)
|
||||
else:
|
||||
ctrl_unet_sd_sd[unet_key] = ctrl_sd_sd[key].to(device, dtype=unet.dtype)
|
||||
|
||||
unet_config = model_util.create_unet_diffusers_config(v2)
|
||||
ctrl_unet_du_sd = model_util.convert_ldm_unet_checkpoint(v2, ctrl_unet_sd_sd, unet_config) # DiffUsers版ControlNetのstate dict
|
||||
unet_config = model_util.create_unet_diffusers_config(v2)
|
||||
ctrl_unet_du_sd = model_util.convert_ldm_unet_checkpoint(v2, ctrl_unet_sd_sd, unet_config) # DiffUsers版ControlNetのstate dict
|
||||
|
||||
# ControlNetのU-Netを作成する
|
||||
ctrl_unet = UNet2DConditionModel(**unet_config)
|
||||
info = ctrl_unet.load_state_dict(ctrl_unet_du_sd)
|
||||
print("ControlNet: loading Control U-Net:", info)
|
||||
# ControlNetのU-Netを作成する
|
||||
ctrl_unet = UNet2DConditionModel(**unet_config)
|
||||
info = ctrl_unet.load_state_dict(ctrl_unet_du_sd)
|
||||
logger.info(f"ControlNet: loading Control U-Net: {info}")
|
||||
|
||||
# U-Net以外のControlNetを作成する
|
||||
# TODO support middle only
|
||||
ctrl_net = ControlNet()
|
||||
info = ctrl_net.load_state_dict(zero_conv_sd)
|
||||
print("ControlNet: loading ControlNet:", info)
|
||||
# U-Net以外のControlNetを作成する
|
||||
# TODO support middle only
|
||||
ctrl_net = ControlNet()
|
||||
info = ctrl_net.load_state_dict(zero_conv_sd)
|
||||
logger.info("ControlNet: loading ControlNet: {info}")
|
||||
|
||||
ctrl_unet.to(unet.device, dtype=unet.dtype)
|
||||
ctrl_net.to(unet.device, dtype=unet.dtype)
|
||||
return ctrl_unet, ctrl_net
|
||||
ctrl_unet.to(unet.device, dtype=unet.dtype)
|
||||
ctrl_net.to(unet.device, dtype=unet.dtype)
|
||||
return ctrl_unet, ctrl_net
|
||||
|
||||
|
||||
def load_preprocess(prep_type: str):
|
||||
if prep_type is None or prep_type.lower() == "none":
|
||||
if prep_type is None or prep_type.lower() == "none":
|
||||
return None
|
||||
|
||||
if prep_type.startswith("canny"):
|
||||
args = prep_type.split("_")
|
||||
th1 = int(args[1]) if len(args) >= 2 else 63
|
||||
th2 = int(args[2]) if len(args) >= 3 else 191
|
||||
|
||||
def canny(img):
|
||||
img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
|
||||
return cv2.Canny(img, th1, th2)
|
||||
|
||||
return canny
|
||||
|
||||
logger.info(f"Unsupported prep type: {prep_type}")
|
||||
return None
|
||||
|
||||
if prep_type.startswith("canny"):
|
||||
args = prep_type.split("_")
|
||||
th1 = int(args[1]) if len(args) >= 2 else 63
|
||||
th2 = int(args[2]) if len(args) >= 3 else 191
|
||||
|
||||
def canny(img):
|
||||
img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
|
||||
return cv2.Canny(img, th1, th2)
|
||||
return canny
|
||||
|
||||
print("Unsupported prep type:", prep_type)
|
||||
return None
|
||||
|
||||
|
||||
def preprocess_ctrl_net_hint_image(image):
|
||||
image = np.array(image).astype(np.float32) / 255.0
|
||||
image = image[:, :, ::-1].copy() # rgb to bgr
|
||||
image = image[None].transpose(0, 3, 1, 2) # nchw
|
||||
image = torch.from_numpy(image)
|
||||
return image # 0 to 1
|
||||
image = np.array(image).astype(np.float32) / 255.0
|
||||
# ControlNetのサンプルはcv2を使っているが、読み込みはGradioなので実はRGBになっている
|
||||
# image = image[:, :, ::-1].copy() # rgb to bgr
|
||||
image = image[None].transpose(0, 3, 1, 2) # nchw
|
||||
image = torch.from_numpy(image)
|
||||
return image # 0 to 1
|
||||
|
||||
|
||||
def get_guided_hints(control_nets: List[ControlNetInfo], num_latent_input, b_size, hints):
|
||||
guided_hints = []
|
||||
for i, cnet_info in enumerate(control_nets):
|
||||
# hintは 1枚目の画像のcnet1, 1枚目の画像のcnet2, 1枚目の画像のcnet3, 2枚目の画像のcnet1, 2枚目の画像のcnet2 ... と並んでいること
|
||||
b_hints = []
|
||||
if len(hints) == 1: # すべて同じ画像をhintとして使う
|
||||
hint = hints[0]
|
||||
if cnet_info.prep is not None:
|
||||
hint = cnet_info.prep(hint)
|
||||
hint = preprocess_ctrl_net_hint_image(hint)
|
||||
b_hints = [hint for _ in range(b_size)]
|
||||
else:
|
||||
for bi in range(b_size):
|
||||
hint = hints[(bi * len(control_nets) + i) % len(hints)]
|
||||
if cnet_info.prep is not None:
|
||||
hint = cnet_info.prep(hint)
|
||||
hint = preprocess_ctrl_net_hint_image(hint)
|
||||
b_hints.append(hint)
|
||||
b_hints = torch.cat(b_hints, dim=0)
|
||||
b_hints = b_hints.to(cnet_info.unet.device, dtype=cnet_info.unet.dtype)
|
||||
guided_hints = []
|
||||
for i, cnet_info in enumerate(control_nets):
|
||||
# hintは 1枚目の画像のcnet1, 1枚目の画像のcnet2, 1枚目の画像のcnet3, 2枚目の画像のcnet1, 2枚目の画像のcnet2 ... と並んでいること
|
||||
b_hints = []
|
||||
if len(hints) == 1: # すべて同じ画像をhintとして使う
|
||||
hint = hints[0]
|
||||
if cnet_info.prep is not None:
|
||||
hint = cnet_info.prep(hint)
|
||||
hint = preprocess_ctrl_net_hint_image(hint)
|
||||
b_hints = [hint for _ in range(b_size)]
|
||||
else:
|
||||
for bi in range(b_size):
|
||||
hint = hints[(bi * len(control_nets) + i) % len(hints)]
|
||||
if cnet_info.prep is not None:
|
||||
hint = cnet_info.prep(hint)
|
||||
hint = preprocess_ctrl_net_hint_image(hint)
|
||||
b_hints.append(hint)
|
||||
b_hints = torch.cat(b_hints, dim=0)
|
||||
b_hints = b_hints.to(cnet_info.unet.device, dtype=cnet_info.unet.dtype)
|
||||
|
||||
guided_hint = cnet_info.net.control_model.input_hint_block(b_hints)
|
||||
guided_hints.append(guided_hint)
|
||||
return guided_hints
|
||||
guided_hint = cnet_info.net.control_model.input_hint_block(b_hints)
|
||||
guided_hints.append(guided_hint)
|
||||
return guided_hints
|
||||
|
||||
|
||||
def call_unet_and_control_net(step, num_latent_input, original_unet, control_nets: List[ControlNetInfo], guided_hints, current_ratio, sample, timestep, encoder_hidden_states):
|
||||
# ControlNet
|
||||
# 複数のControlNetの場合は、出力をマージするのではなく交互に適用する
|
||||
cnet_cnt = len(control_nets)
|
||||
cnet_idx = step % cnet_cnt
|
||||
cnet_info = control_nets[cnet_idx]
|
||||
def call_unet_and_control_net(
|
||||
step,
|
||||
num_latent_input,
|
||||
original_unet,
|
||||
control_nets: List[ControlNetInfo],
|
||||
guided_hints,
|
||||
current_ratio,
|
||||
sample,
|
||||
timestep,
|
||||
encoder_hidden_states,
|
||||
encoder_hidden_states_for_control_net,
|
||||
):
|
||||
# ControlNet
|
||||
# 複数のControlNetの場合は、出力をマージするのではなく交互に適用する
|
||||
cnet_cnt = len(control_nets)
|
||||
cnet_idx = step % cnet_cnt
|
||||
cnet_info = control_nets[cnet_idx]
|
||||
|
||||
# print(current_ratio, cnet_info.prep, cnet_info.weight, cnet_info.ratio)
|
||||
if cnet_info.ratio < current_ratio:
|
||||
return original_unet(sample, timestep, encoder_hidden_states)
|
||||
# logger.info(current_ratio, cnet_info.prep, cnet_info.weight, cnet_info.ratio)
|
||||
if cnet_info.ratio < current_ratio:
|
||||
return original_unet(sample, timestep, encoder_hidden_states)
|
||||
|
||||
guided_hint = guided_hints[cnet_idx]
|
||||
guided_hint = guided_hint.repeat((num_latent_input, 1, 1, 1))
|
||||
outs = unet_forward(True, cnet_info.net, cnet_info.unet, guided_hint, None, sample, timestep, encoder_hidden_states)
|
||||
outs = [o * cnet_info.weight for o in outs]
|
||||
guided_hint = guided_hints[cnet_idx]
|
||||
|
||||
# U-Net
|
||||
return unet_forward(False, cnet_info.net, original_unet, None, outs, sample, timestep, encoder_hidden_states)
|
||||
# gradual latent support: match the size of guided_hint to the size of sample
|
||||
if guided_hint.shape[-2:] != sample.shape[-2:]:
|
||||
# print(f"guided_hint.shape={guided_hint.shape}, sample.shape={sample.shape}")
|
||||
org_dtype = guided_hint.dtype
|
||||
if org_dtype == torch.bfloat16:
|
||||
guided_hint = guided_hint.to(torch.float32)
|
||||
guided_hint = torch.nn.functional.interpolate(guided_hint, size=sample.shape[-2:], mode="bicubic")
|
||||
if org_dtype == torch.bfloat16:
|
||||
guided_hint = guided_hint.to(org_dtype)
|
||||
|
||||
guided_hint = guided_hint.repeat((num_latent_input, 1, 1, 1))
|
||||
outs = unet_forward(
|
||||
True, cnet_info.net, cnet_info.unet, guided_hint, None, sample, timestep, encoder_hidden_states_for_control_net
|
||||
)
|
||||
outs = [o * cnet_info.weight for o in outs]
|
||||
|
||||
# U-Net
|
||||
return unet_forward(False, cnet_info.net, original_unet, None, outs, sample, timestep, encoder_hidden_states)
|
||||
|
||||
|
||||
"""
|
||||
@@ -180,7 +208,7 @@ def call_unet_and_control_net(step, num_latent_input, original_unet, control_net
|
||||
# ControlNet
|
||||
cnet_outs_list = []
|
||||
for i, cnet_info in enumerate(control_nets):
|
||||
# print(current_ratio, cnet_info.prep, cnet_info.weight, cnet_info.ratio)
|
||||
# logger.info(current_ratio, cnet_info.prep, cnet_info.weight, cnet_info.ratio)
|
||||
if cnet_info.ratio < current_ratio:
|
||||
continue
|
||||
guided_hint = guided_hints[i]
|
||||
@@ -203,118 +231,123 @@ def call_unet_and_control_net(step, num_latent_input, original_unet, control_net
|
||||
"""
|
||||
|
||||
|
||||
def unet_forward(is_control_net, control_net: ControlNet, unet: UNet2DConditionModel, guided_hint, ctrl_outs, sample, timestep, encoder_hidden_states):
|
||||
# copy from UNet2DConditionModel
|
||||
default_overall_up_factor = 2**unet.num_upsamplers
|
||||
def unet_forward(
|
||||
is_control_net,
|
||||
control_net: ControlNet,
|
||||
unet: UNet2DConditionModel,
|
||||
guided_hint,
|
||||
ctrl_outs,
|
||||
sample,
|
||||
timestep,
|
||||
encoder_hidden_states,
|
||||
):
|
||||
# copy from UNet2DConditionModel
|
||||
default_overall_up_factor = 2**unet.num_upsamplers
|
||||
|
||||
forward_upsample_size = False
|
||||
upsample_size = None
|
||||
forward_upsample_size = False
|
||||
upsample_size = None
|
||||
|
||||
if any(s % default_overall_up_factor != 0 for s in sample.shape[-2:]):
|
||||
print("Forward upsample size to force interpolation output size.")
|
||||
forward_upsample_size = True
|
||||
if any(s % default_overall_up_factor != 0 for s in sample.shape[-2:]):
|
||||
logger.info("Forward upsample size to force interpolation output size.")
|
||||
forward_upsample_size = True
|
||||
|
||||
# 0. center input if necessary
|
||||
if unet.config.center_input_sample:
|
||||
sample = 2 * sample - 1.0
|
||||
# 1. time
|
||||
timesteps = timestep
|
||||
if not torch.is_tensor(timesteps):
|
||||
# TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
|
||||
# This would be a good case for the `match` statement (Python 3.10+)
|
||||
is_mps = sample.device.type == "mps"
|
||||
if isinstance(timestep, float):
|
||||
dtype = torch.float32 if is_mps else torch.float64
|
||||
else:
|
||||
dtype = torch.int32 if is_mps else torch.int64
|
||||
timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
|
||||
elif len(timesteps.shape) == 0:
|
||||
timesteps = timesteps[None].to(sample.device)
|
||||
|
||||
# 1. time
|
||||
timesteps = timestep
|
||||
if not torch.is_tensor(timesteps):
|
||||
# TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
|
||||
# This would be a good case for the `match` statement (Python 3.10+)
|
||||
is_mps = sample.device.type == "mps"
|
||||
if isinstance(timestep, float):
|
||||
dtype = torch.float32 if is_mps else torch.float64
|
||||
else:
|
||||
dtype = torch.int32 if is_mps else torch.int64
|
||||
timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
|
||||
elif len(timesteps.shape) == 0:
|
||||
timesteps = timesteps[None].to(sample.device)
|
||||
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
|
||||
timesteps = timesteps.expand(sample.shape[0])
|
||||
|
||||
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
|
||||
timesteps = timesteps.expand(sample.shape[0])
|
||||
t_emb = unet.time_proj(timesteps)
|
||||
|
||||
t_emb = unet.time_proj(timesteps)
|
||||
# timesteps does not contain any weights and will always return f32 tensors
|
||||
# but time_embedding might actually be running in fp16. so we need to cast here.
|
||||
# there might be better ways to encapsulate this.
|
||||
t_emb = t_emb.to(dtype=unet.dtype)
|
||||
emb = unet.time_embedding(t_emb)
|
||||
|
||||
# timesteps does not contain any weights and will always return f32 tensors
|
||||
# but time_embedding might actually be running in fp16. so we need to cast here.
|
||||
# there might be better ways to encapsulate this.
|
||||
t_emb = t_emb.to(dtype=unet.dtype)
|
||||
emb = unet.time_embedding(t_emb)
|
||||
outs = [] # output of ControlNet
|
||||
zc_idx = 0
|
||||
|
||||
outs = [] # output of ControlNet
|
||||
zc_idx = 0
|
||||
|
||||
# 2. pre-process
|
||||
sample = unet.conv_in(sample)
|
||||
if is_control_net:
|
||||
sample += guided_hint
|
||||
outs.append(control_net.control_model.zero_convs[zc_idx][0](sample)) # , emb, encoder_hidden_states))
|
||||
zc_idx += 1
|
||||
|
||||
# 3. down
|
||||
down_block_res_samples = (sample,)
|
||||
for downsample_block in unet.down_blocks:
|
||||
if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
|
||||
sample, res_samples = downsample_block(
|
||||
hidden_states=sample,
|
||||
temb=emb,
|
||||
encoder_hidden_states=encoder_hidden_states,
|
||||
)
|
||||
else:
|
||||
sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
|
||||
# 2. pre-process
|
||||
sample = unet.conv_in(sample)
|
||||
if is_control_net:
|
||||
for rs in res_samples:
|
||||
outs.append(control_net.control_model.zero_convs[zc_idx][0](rs)) # , emb, encoder_hidden_states))
|
||||
sample += guided_hint
|
||||
outs.append(control_net.control_model.zero_convs[zc_idx][0](sample)) # , emb, encoder_hidden_states))
|
||||
zc_idx += 1
|
||||
|
||||
down_block_res_samples += res_samples
|
||||
# 3. down
|
||||
down_block_res_samples = (sample,)
|
||||
for downsample_block in unet.down_blocks:
|
||||
if downsample_block.has_cross_attention:
|
||||
sample, res_samples = downsample_block(
|
||||
hidden_states=sample,
|
||||
temb=emb,
|
||||
encoder_hidden_states=encoder_hidden_states,
|
||||
)
|
||||
else:
|
||||
sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
|
||||
if is_control_net:
|
||||
for rs in res_samples:
|
||||
outs.append(control_net.control_model.zero_convs[zc_idx][0](rs)) # , emb, encoder_hidden_states))
|
||||
zc_idx += 1
|
||||
|
||||
# 4. mid
|
||||
sample = unet.mid_block(sample, emb, encoder_hidden_states=encoder_hidden_states)
|
||||
if is_control_net:
|
||||
outs.append(control_net.control_model.middle_block_out[0](sample))
|
||||
return outs
|
||||
down_block_res_samples += res_samples
|
||||
|
||||
if not is_control_net:
|
||||
sample += ctrl_outs.pop()
|
||||
# 4. mid
|
||||
sample = unet.mid_block(sample, emb, encoder_hidden_states=encoder_hidden_states)
|
||||
if is_control_net:
|
||||
outs.append(control_net.control_model.middle_block_out[0](sample))
|
||||
return outs
|
||||
|
||||
# 5. up
|
||||
for i, upsample_block in enumerate(unet.up_blocks):
|
||||
is_final_block = i == len(unet.up_blocks) - 1
|
||||
if not is_control_net:
|
||||
sample += ctrl_outs.pop()
|
||||
|
||||
res_samples = down_block_res_samples[-len(upsample_block.resnets):]
|
||||
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
|
||||
# 5. up
|
||||
for i, upsample_block in enumerate(unet.up_blocks):
|
||||
is_final_block = i == len(unet.up_blocks) - 1
|
||||
|
||||
if not is_control_net and len(ctrl_outs) > 0:
|
||||
res_samples = list(res_samples)
|
||||
apply_ctrl_outs = ctrl_outs[-len(res_samples):]
|
||||
ctrl_outs = ctrl_outs[:-len(res_samples)]
|
||||
for j in range(len(res_samples)):
|
||||
res_samples[j] = res_samples[j] + apply_ctrl_outs[j]
|
||||
res_samples = tuple(res_samples)
|
||||
res_samples = down_block_res_samples[-len(upsample_block.resnets) :]
|
||||
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
|
||||
|
||||
# if we have not reached the final block and need to forward the
|
||||
# upsample size, we do it here
|
||||
if not is_final_block and forward_upsample_size:
|
||||
upsample_size = down_block_res_samples[-1].shape[2:]
|
||||
if not is_control_net and len(ctrl_outs) > 0:
|
||||
res_samples = list(res_samples)
|
||||
apply_ctrl_outs = ctrl_outs[-len(res_samples) :]
|
||||
ctrl_outs = ctrl_outs[: -len(res_samples)]
|
||||
for j in range(len(res_samples)):
|
||||
res_samples[j] = res_samples[j] + apply_ctrl_outs[j]
|
||||
res_samples = tuple(res_samples)
|
||||
|
||||
if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
|
||||
sample = upsample_block(
|
||||
hidden_states=sample,
|
||||
temb=emb,
|
||||
res_hidden_states_tuple=res_samples,
|
||||
encoder_hidden_states=encoder_hidden_states,
|
||||
upsample_size=upsample_size,
|
||||
)
|
||||
else:
|
||||
sample = upsample_block(
|
||||
hidden_states=sample, temb=emb, res_hidden_states_tuple=res_samples, upsample_size=upsample_size
|
||||
)
|
||||
# 6. post-process
|
||||
sample = unet.conv_norm_out(sample)
|
||||
sample = unet.conv_act(sample)
|
||||
sample = unet.conv_out(sample)
|
||||
# if we have not reached the final block and need to forward the
|
||||
# upsample size, we do it here
|
||||
if not is_final_block and forward_upsample_size:
|
||||
upsample_size = down_block_res_samples[-1].shape[2:]
|
||||
|
||||
return UNet2DConditionOutput(sample=sample)
|
||||
if upsample_block.has_cross_attention:
|
||||
sample = upsample_block(
|
||||
hidden_states=sample,
|
||||
temb=emb,
|
||||
res_hidden_states_tuple=res_samples,
|
||||
encoder_hidden_states=encoder_hidden_states,
|
||||
upsample_size=upsample_size,
|
||||
)
|
||||
else:
|
||||
sample = upsample_block(
|
||||
hidden_states=sample, temb=emb, res_hidden_states_tuple=res_samples, upsample_size=upsample_size
|
||||
)
|
||||
# 6. post-process
|
||||
sample = unet.conv_norm_out(sample)
|
||||
sample = unet.conv_act(sample)
|
||||
sample = unet.conv_out(sample)
|
||||
|
||||
return SampleOutput(sample=sample)
|
||||
|
||||
@@ -6,7 +6,10 @@ import shutil
|
||||
import math
|
||||
from PIL import Image
|
||||
import numpy as np
|
||||
|
||||
from library.utils import setup_logging, pil_resize
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
def resize_images(src_img_folder, dst_img_folder, max_resolution="512x512", divisible_by=2, interpolation=None, save_as_png=False, copy_associated_files=False):
|
||||
# Split the max_resolution string by "," and strip any whitespaces
|
||||
@@ -21,9 +24,9 @@ def resize_images(src_img_folder, dst_img_folder, max_resolution="512x512", divi
|
||||
|
||||
# Select interpolation method
|
||||
if interpolation == 'lanczos4':
|
||||
cv2_interpolation = cv2.INTER_LANCZOS4
|
||||
pil_interpolation = Image.LANCZOS
|
||||
elif interpolation == 'cubic':
|
||||
cv2_interpolation = cv2.INTER_CUBIC
|
||||
pil_interpolation = Image.BICUBIC
|
||||
else:
|
||||
cv2_interpolation = cv2.INTER_AREA
|
||||
|
||||
@@ -61,7 +64,10 @@ def resize_images(src_img_folder, dst_img_folder, max_resolution="512x512", divi
|
||||
new_width = int(img.shape[1] * math.sqrt(scale_factor))
|
||||
|
||||
# Resize image
|
||||
img = cv2.resize(img, (new_width, new_height), interpolation=cv2_interpolation)
|
||||
if cv2_interpolation:
|
||||
img = cv2.resize(img, (new_width, new_height), interpolation=cv2_interpolation)
|
||||
else:
|
||||
img = pil_resize(img, (new_width, new_height), interpolation=pil_interpolation)
|
||||
else:
|
||||
new_height, new_width = img.shape[0:2]
|
||||
|
||||
@@ -83,7 +89,7 @@ def resize_images(src_img_folder, dst_img_folder, max_resolution="512x512", divi
|
||||
image.save(os.path.join(dst_img_folder, new_filename), quality=100)
|
||||
|
||||
proc = "Resized" if current_pixels > max_pixels else "Saved"
|
||||
print(f"{proc} image: {filename} with size {img.shape[0]}x{img.shape[1]} as {new_filename}")
|
||||
logger.info(f"{proc} image: {filename} with size {img.shape[0]}x{img.shape[1]} as {new_filename}")
|
||||
|
||||
# If other files with same basename, copy them with resolution suffix
|
||||
if copy_associated_files:
|
||||
@@ -94,7 +100,7 @@ def resize_images(src_img_folder, dst_img_folder, max_resolution="512x512", divi
|
||||
continue
|
||||
for max_resolution in max_resolutions:
|
||||
new_asoc_file = base + '+' + max_resolution + ext
|
||||
print(f"Copy {asoc_file} as {new_asoc_file}")
|
||||
logger.info(f"Copy {asoc_file} as {new_asoc_file}")
|
||||
shutil.copy(os.path.join(src_img_folder, asoc_file), os.path.join(dst_img_folder, new_asoc_file))
|
||||
|
||||
|
||||
|
||||
23
tools/show_metadata.py
Normal file
23
tools/show_metadata.py
Normal file
@@ -0,0 +1,23 @@
|
||||
import json
|
||||
import argparse
|
||||
from safetensors import safe_open
|
||||
from library.utils import setup_logging
|
||||
setup_logging()
|
||||
import logging
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--model", type=str, required=True)
|
||||
args = parser.parse_args()
|
||||
|
||||
with safe_open(args.model, framework="pt") as f:
|
||||
metadata = f.metadata()
|
||||
|
||||
if metadata is None:
|
||||
logger.error("No metadata found")
|
||||
else:
|
||||
# metadata is json dict, but not pretty printed
|
||||
# sort by key and pretty print
|
||||
print(json.dumps(metadata, indent=4, sort_keys=True))
|
||||
|
||||
|
||||
648
train_controlnet.py
Normal file
648
train_controlnet.py
Normal file
@@ -0,0 +1,648 @@
|
||||
import argparse
|
||||
import json
|
||||
import math
|
||||
import os
|
||||
import random
|
||||
import time
|
||||
from multiprocessing import Value
|
||||
|
||||
# from omegaconf import OmegaConf
|
||||
import toml
|
||||
|
||||
from tqdm import tqdm
|
||||
|
||||
import torch
|
||||
from library import deepspeed_utils
|
||||
from library.device_utils import init_ipex, clean_memory_on_device
|
||||
|
||||
init_ipex()
|
||||
|
||||
from torch.nn.parallel import DistributedDataParallel as DDP
|
||||
from accelerate.utils import set_seed
|
||||
from diffusers import DDPMScheduler, ControlNetModel
|
||||
from safetensors.torch import load_file
|
||||
|
||||
import library.model_util as model_util
|
||||
import library.train_util as train_util
|
||||
import library.config_util as config_util
|
||||
from library.config_util import (
|
||||
ConfigSanitizer,
|
||||
BlueprintGenerator,
|
||||
)
|
||||
import library.huggingface_util as huggingface_util
|
||||
import library.custom_train_functions as custom_train_functions
|
||||
from library.custom_train_functions import (
|
||||
apply_snr_weight,
|
||||
pyramid_noise_like,
|
||||
apply_noise_offset,
|
||||
)
|
||||
from library.utils import setup_logging, add_logging_arguments
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
|
||||
# TODO 他のスクリプトと共通化する
|
||||
def generate_step_logs(args: argparse.Namespace, current_loss, avr_loss, lr_scheduler):
|
||||
logs = {
|
||||
"loss/current": current_loss,
|
||||
"loss/average": avr_loss,
|
||||
"lr": lr_scheduler.get_last_lr()[0],
|
||||
}
|
||||
|
||||
if args.optimizer_type.lower().startswith("DAdapt".lower()):
|
||||
logs["lr/d*lr"] = lr_scheduler.optimizers[-1].param_groups[0]["d"] * lr_scheduler.optimizers[-1].param_groups[0]["lr"]
|
||||
|
||||
return logs
|
||||
|
||||
|
||||
def train(args):
|
||||
# session_id = random.randint(0, 2**32)
|
||||
# training_started_at = time.time()
|
||||
train_util.verify_training_args(args)
|
||||
train_util.prepare_dataset_args(args, True)
|
||||
setup_logging(args, reset=True)
|
||||
|
||||
cache_latents = args.cache_latents
|
||||
use_user_config = args.dataset_config is not None
|
||||
|
||||
if args.seed is None:
|
||||
args.seed = random.randint(0, 2**32)
|
||||
set_seed(args.seed)
|
||||
|
||||
tokenizer = train_util.load_tokenizer(args)
|
||||
|
||||
# データセットを準備する
|
||||
blueprint_generator = BlueprintGenerator(ConfigSanitizer(False, False, True, True))
|
||||
if use_user_config:
|
||||
logger.info(f"Load dataset config from {args.dataset_config}")
|
||||
user_config = config_util.load_user_config(args.dataset_config)
|
||||
ignored = ["train_data_dir", "conditioning_data_dir"]
|
||||
if any(getattr(args, attr) is not None for attr in ignored):
|
||||
logger.warning(
|
||||
"ignore following options because config file is found: {0} / 設定ファイルが利用されるため以下のオプションは無視されます: {0}".format(
|
||||
", ".join(ignored)
|
||||
)
|
||||
)
|
||||
else:
|
||||
user_config = {
|
||||
"datasets": [
|
||||
{
|
||||
"subsets": config_util.generate_controlnet_subsets_config_by_subdirs(
|
||||
args.train_data_dir,
|
||||
args.conditioning_data_dir,
|
||||
args.caption_extension,
|
||||
)
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
blueprint = blueprint_generator.generate(user_config, args, tokenizer=tokenizer)
|
||||
train_dataset_group = config_util.generate_dataset_group_by_blueprint(blueprint.dataset_group)
|
||||
|
||||
current_epoch = Value("i", 0)
|
||||
current_step = Value("i", 0)
|
||||
ds_for_collator = train_dataset_group if args.max_data_loader_n_workers == 0 else None
|
||||
collator = train_util.collator_class(current_epoch, current_step, ds_for_collator)
|
||||
|
||||
train_dataset_group.verify_bucket_reso_steps(64)
|
||||
|
||||
if args.debug_dataset:
|
||||
train_util.debug_dataset(train_dataset_group)
|
||||
return
|
||||
if len(train_dataset_group) == 0:
|
||||
logger.error(
|
||||
"No data found. Please verify arguments (train_data_dir must be the parent of folders with images) / 画像がありません。引数指定を確認してください(train_data_dirには画像があるフォルダではなく、画像があるフォルダの親フォルダを指定する必要があります)"
|
||||
)
|
||||
return
|
||||
|
||||
if cache_latents:
|
||||
assert (
|
||||
train_dataset_group.is_latent_cacheable()
|
||||
), "when caching latents, either color_aug or random_crop cannot be used / latentをキャッシュするときはcolor_augとrandom_cropは使えません"
|
||||
|
||||
# acceleratorを準備する
|
||||
logger.info("prepare accelerator")
|
||||
accelerator = train_util.prepare_accelerator(args)
|
||||
is_main_process = accelerator.is_main_process
|
||||
|
||||
# mixed precisionに対応した型を用意しておき適宜castする
|
||||
weight_dtype, save_dtype = train_util.prepare_dtype(args)
|
||||
|
||||
# モデルを読み込む
|
||||
text_encoder, vae, unet, _ = train_util.load_target_model(
|
||||
args, weight_dtype, accelerator, unet_use_linear_projection_in_v2=True
|
||||
)
|
||||
|
||||
# DiffusersのControlNetが使用するデータを準備する
|
||||
if args.v2:
|
||||
unet.config = {
|
||||
"act_fn": "silu",
|
||||
"attention_head_dim": [5, 10, 20, 20],
|
||||
"block_out_channels": [320, 640, 1280, 1280],
|
||||
"center_input_sample": False,
|
||||
"cross_attention_dim": 1024,
|
||||
"down_block_types": ["CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "DownBlock2D"],
|
||||
"downsample_padding": 1,
|
||||
"dual_cross_attention": False,
|
||||
"flip_sin_to_cos": True,
|
||||
"freq_shift": 0,
|
||||
"in_channels": 4,
|
||||
"layers_per_block": 2,
|
||||
"mid_block_scale_factor": 1,
|
||||
"mid_block_type": "UNetMidBlock2DCrossAttn",
|
||||
"norm_eps": 1e-05,
|
||||
"norm_num_groups": 32,
|
||||
"num_attention_heads": [5, 10, 20, 20],
|
||||
"num_class_embeds": None,
|
||||
"only_cross_attention": False,
|
||||
"out_channels": 4,
|
||||
"sample_size": 96,
|
||||
"up_block_types": ["UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D"],
|
||||
"use_linear_projection": True,
|
||||
"upcast_attention": True,
|
||||
"only_cross_attention": False,
|
||||
"downsample_padding": 1,
|
||||
"use_linear_projection": True,
|
||||
"class_embed_type": None,
|
||||
"num_class_embeds": None,
|
||||
"resnet_time_scale_shift": "default",
|
||||
"projection_class_embeddings_input_dim": None,
|
||||
}
|
||||
else:
|
||||
unet.config = {
|
||||
"act_fn": "silu",
|
||||
"attention_head_dim": 8,
|
||||
"block_out_channels": [320, 640, 1280, 1280],
|
||||
"center_input_sample": False,
|
||||
"cross_attention_dim": 768,
|
||||
"down_block_types": ["CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "CrossAttnDownBlock2D", "DownBlock2D"],
|
||||
"downsample_padding": 1,
|
||||
"flip_sin_to_cos": True,
|
||||
"freq_shift": 0,
|
||||
"in_channels": 4,
|
||||
"layers_per_block": 2,
|
||||
"mid_block_scale_factor": 1,
|
||||
"mid_block_type": "UNetMidBlock2DCrossAttn",
|
||||
"norm_eps": 1e-05,
|
||||
"norm_num_groups": 32,
|
||||
"num_attention_heads": 8,
|
||||
"out_channels": 4,
|
||||
"sample_size": 64,
|
||||
"up_block_types": ["UpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D", "CrossAttnUpBlock2D"],
|
||||
"only_cross_attention": False,
|
||||
"downsample_padding": 1,
|
||||
"use_linear_projection": False,
|
||||
"class_embed_type": None,
|
||||
"num_class_embeds": None,
|
||||
"upcast_attention": False,
|
||||
"resnet_time_scale_shift": "default",
|
||||
"projection_class_embeddings_input_dim": None,
|
||||
}
|
||||
# unet.config = OmegaConf.create(unet.config)
|
||||
|
||||
# make unet.config iterable and accessible by attribute
|
||||
class CustomConfig:
|
||||
def __init__(self, **kwargs):
|
||||
self.__dict__.update(kwargs)
|
||||
|
||||
def __getattr__(self, name):
|
||||
if name in self.__dict__:
|
||||
return self.__dict__[name]
|
||||
else:
|
||||
raise AttributeError(f"'{self.__class__.__name__}' object has no attribute '{name}'")
|
||||
|
||||
def __contains__(self, name):
|
||||
return name in self.__dict__
|
||||
|
||||
unet.config = CustomConfig(**unet.config)
|
||||
|
||||
controlnet = ControlNetModel.from_unet(unet)
|
||||
|
||||
if args.controlnet_model_name_or_path:
|
||||
filename = args.controlnet_model_name_or_path
|
||||
if os.path.isfile(filename):
|
||||
if os.path.splitext(filename)[1] == ".safetensors":
|
||||
state_dict = load_file(filename)
|
||||
else:
|
||||
state_dict = torch.load(filename)
|
||||
state_dict = model_util.convert_controlnet_state_dict_to_diffusers(state_dict)
|
||||
controlnet.load_state_dict(state_dict)
|
||||
elif os.path.isdir(filename):
|
||||
controlnet = ControlNetModel.from_pretrained(filename)
|
||||
|
||||
# モデルに xformers とか memory efficient attention を組み込む
|
||||
train_util.replace_unet_modules(unet, args.mem_eff_attn, args.xformers, args.sdpa)
|
||||
|
||||
# 学習を準備する
|
||||
if cache_latents:
|
||||
vae.to(accelerator.device, dtype=weight_dtype)
|
||||
vae.requires_grad_(False)
|
||||
vae.eval()
|
||||
with torch.no_grad():
|
||||
train_dataset_group.cache_latents(
|
||||
vae,
|
||||
args.vae_batch_size,
|
||||
args.cache_latents_to_disk,
|
||||
accelerator.is_main_process,
|
||||
)
|
||||
vae.to("cpu")
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
if args.gradient_checkpointing:
|
||||
controlnet.enable_gradient_checkpointing()
|
||||
|
||||
# 学習に必要なクラスを準備する
|
||||
accelerator.print("prepare optimizer, data loader etc.")
|
||||
|
||||
trainable_params = list(controlnet.parameters())
|
||||
|
||||
_, _, optimizer = train_util.get_optimizer(args, trainable_params)
|
||||
|
||||
# dataloaderを準備する
|
||||
# DataLoaderのプロセス数:0 は persistent_workers が使えないので注意
|
||||
n_workers = min(args.max_data_loader_n_workers, os.cpu_count()) # cpu_count or max_data_loader_n_workers
|
||||
|
||||
train_dataloader = torch.utils.data.DataLoader(
|
||||
train_dataset_group,
|
||||
batch_size=1,
|
||||
shuffle=True,
|
||||
collate_fn=collator,
|
||||
num_workers=n_workers,
|
||||
persistent_workers=args.persistent_data_loader_workers,
|
||||
)
|
||||
|
||||
# 学習ステップ数を計算する
|
||||
if args.max_train_epochs is not None:
|
||||
args.max_train_steps = args.max_train_epochs * math.ceil(
|
||||
len(train_dataloader) / accelerator.num_processes / args.gradient_accumulation_steps
|
||||
)
|
||||
accelerator.print(
|
||||
f"override steps. steps for {args.max_train_epochs} epochs is / 指定エポックまでのステップ数: {args.max_train_steps}"
|
||||
)
|
||||
|
||||
# データセット側にも学習ステップを送信
|
||||
train_dataset_group.set_max_train_steps(args.max_train_steps)
|
||||
|
||||
# lr schedulerを用意する
|
||||
lr_scheduler = train_util.get_scheduler_fix(args, optimizer, accelerator.num_processes)
|
||||
|
||||
# 実験的機能:勾配も含めたfp16学習を行う モデル全体をfp16にする
|
||||
if args.full_fp16:
|
||||
assert (
|
||||
args.mixed_precision == "fp16"
|
||||
), "full_fp16 requires mixed precision='fp16' / full_fp16を使う場合はmixed_precision='fp16'を指定してください。"
|
||||
accelerator.print("enable full fp16 training.")
|
||||
controlnet.to(weight_dtype)
|
||||
|
||||
# acceleratorがなんかよろしくやってくれるらしい
|
||||
controlnet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
|
||||
controlnet, optimizer, train_dataloader, lr_scheduler
|
||||
)
|
||||
|
||||
unet.requires_grad_(False)
|
||||
text_encoder.requires_grad_(False)
|
||||
unet.to(accelerator.device)
|
||||
text_encoder.to(accelerator.device)
|
||||
|
||||
# transform DDP after prepare
|
||||
controlnet = controlnet.module if isinstance(controlnet, DDP) else controlnet
|
||||
|
||||
controlnet.train()
|
||||
|
||||
if not cache_latents:
|
||||
vae.requires_grad_(False)
|
||||
vae.eval()
|
||||
vae.to(accelerator.device, dtype=weight_dtype)
|
||||
|
||||
# 実験的機能:勾配も含めたfp16学習を行う PyTorchにパッチを当ててfp16でのgrad scaleを有効にする
|
||||
if args.full_fp16:
|
||||
train_util.patch_accelerator_for_fp16_training(accelerator)
|
||||
|
||||
# resumeする
|
||||
train_util.resume_from_local_or_hf_if_specified(accelerator, args)
|
||||
|
||||
# epoch数を計算する
|
||||
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
|
||||
num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
|
||||
if (args.save_n_epoch_ratio is not None) and (args.save_n_epoch_ratio > 0):
|
||||
args.save_every_n_epochs = math.floor(num_train_epochs / args.save_n_epoch_ratio) or 1
|
||||
|
||||
# 学習する
|
||||
# TODO: find a way to handle total batch size when there are multiple datasets
|
||||
accelerator.print("running training / 学習開始")
|
||||
accelerator.print(f" num train images * repeats / 学習画像の数×繰り返し回数: {train_dataset_group.num_train_images}")
|
||||
accelerator.print(f" num reg images / 正則化画像の数: {train_dataset_group.num_reg_images}")
|
||||
accelerator.print(f" num batches per epoch / 1epochのバッチ数: {len(train_dataloader)}")
|
||||
accelerator.print(f" num epochs / epoch数: {num_train_epochs}")
|
||||
accelerator.print(
|
||||
f" batch size per device / バッチサイズ: {', '.join([str(d.batch_size) for d in train_dataset_group.datasets])}"
|
||||
)
|
||||
# logger.info(f" total train batch size (with parallel & distributed & accumulation) / 総バッチサイズ(並列学習、勾配合計含む): {total_batch_size}")
|
||||
accelerator.print(f" gradient accumulation steps / 勾配を合計するステップ数 = {args.gradient_accumulation_steps}")
|
||||
accelerator.print(f" total optimization steps / 学習ステップ数: {args.max_train_steps}")
|
||||
|
||||
progress_bar = tqdm(
|
||||
range(args.max_train_steps),
|
||||
smoothing=0,
|
||||
disable=not accelerator.is_local_main_process,
|
||||
desc="steps",
|
||||
)
|
||||
global_step = 0
|
||||
|
||||
noise_scheduler = DDPMScheduler(
|
||||
beta_start=0.00085,
|
||||
beta_end=0.012,
|
||||
beta_schedule="scaled_linear",
|
||||
num_train_timesteps=1000,
|
||||
clip_sample=False,
|
||||
)
|
||||
if accelerator.is_main_process:
|
||||
init_kwargs = {}
|
||||
if args.wandb_run_name:
|
||||
init_kwargs["wandb"] = {"name": args.wandb_run_name}
|
||||
if args.log_tracker_config is not None:
|
||||
init_kwargs = toml.load(args.log_tracker_config)
|
||||
accelerator.init_trackers(
|
||||
"controlnet_train" if args.log_tracker_name is None else args.log_tracker_name,
|
||||
config=train_util.get_sanitized_config_or_none(args),
|
||||
init_kwargs=init_kwargs,
|
||||
)
|
||||
|
||||
loss_recorder = train_util.LossRecorder()
|
||||
del train_dataset_group
|
||||
|
||||
# function for saving/removing
|
||||
def save_model(ckpt_name, model, force_sync_upload=False):
|
||||
os.makedirs(args.output_dir, exist_ok=True)
|
||||
ckpt_file = os.path.join(args.output_dir, ckpt_name)
|
||||
|
||||
accelerator.print(f"\nsaving checkpoint: {ckpt_file}")
|
||||
|
||||
state_dict = model_util.convert_controlnet_state_dict_to_sd(model.state_dict())
|
||||
|
||||
if save_dtype is not None:
|
||||
for key in list(state_dict.keys()):
|
||||
v = state_dict[key]
|
||||
v = v.detach().clone().to("cpu").to(save_dtype)
|
||||
state_dict[key] = v
|
||||
|
||||
if os.path.splitext(ckpt_file)[1] == ".safetensors":
|
||||
from safetensors.torch import save_file
|
||||
|
||||
save_file(state_dict, ckpt_file)
|
||||
else:
|
||||
torch.save(state_dict, ckpt_file)
|
||||
|
||||
if args.huggingface_repo_id is not None:
|
||||
huggingface_util.upload(args, ckpt_file, "/" + ckpt_name, force_sync_upload=force_sync_upload)
|
||||
|
||||
def remove_model(old_ckpt_name):
|
||||
old_ckpt_file = os.path.join(args.output_dir, old_ckpt_name)
|
||||
if os.path.exists(old_ckpt_file):
|
||||
accelerator.print(f"removing old checkpoint: {old_ckpt_file}")
|
||||
os.remove(old_ckpt_file)
|
||||
|
||||
# For --sample_at_first
|
||||
train_util.sample_images(
|
||||
accelerator, args, 0, global_step, accelerator.device, vae, tokenizer, text_encoder, unet, controlnet=controlnet
|
||||
)
|
||||
|
||||
# training loop
|
||||
for epoch in range(num_train_epochs):
|
||||
if is_main_process:
|
||||
accelerator.print(f"\nepoch {epoch+1}/{num_train_epochs}")
|
||||
current_epoch.value = epoch + 1
|
||||
|
||||
for step, batch in enumerate(train_dataloader):
|
||||
current_step.value = global_step
|
||||
with accelerator.accumulate(controlnet):
|
||||
with torch.no_grad():
|
||||
if "latents" in batch and batch["latents"] is not None:
|
||||
latents = batch["latents"].to(accelerator.device).to(dtype=weight_dtype)
|
||||
else:
|
||||
# latentに変換
|
||||
latents = vae.encode(batch["images"].to(dtype=weight_dtype)).latent_dist.sample()
|
||||
latents = latents * 0.18215
|
||||
b_size = latents.shape[0]
|
||||
|
||||
input_ids = batch["input_ids"].to(accelerator.device)
|
||||
encoder_hidden_states = train_util.get_hidden_states(args, input_ids, tokenizer, text_encoder, weight_dtype)
|
||||
|
||||
# Sample noise that we'll add to the latents
|
||||
noise = torch.randn_like(latents, device=latents.device)
|
||||
if args.noise_offset:
|
||||
noise = apply_noise_offset(latents, noise, args.noise_offset, args.adaptive_noise_scale)
|
||||
elif args.multires_noise_iterations:
|
||||
noise = pyramid_noise_like(
|
||||
noise,
|
||||
latents.device,
|
||||
args.multires_noise_iterations,
|
||||
args.multires_noise_discount,
|
||||
)
|
||||
|
||||
# Sample a random timestep for each image
|
||||
timesteps, huber_c = train_util.get_timesteps_and_huber_c(
|
||||
args, 0, noise_scheduler.config.num_train_timesteps, noise_scheduler, b_size, latents.device
|
||||
)
|
||||
|
||||
# Add noise to the latents according to the noise magnitude at each timestep
|
||||
# (this is the forward diffusion process)
|
||||
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
|
||||
|
||||
controlnet_image = batch["conditioning_images"].to(dtype=weight_dtype)
|
||||
|
||||
with accelerator.autocast():
|
||||
down_block_res_samples, mid_block_res_sample = controlnet(
|
||||
noisy_latents,
|
||||
timesteps,
|
||||
encoder_hidden_states=encoder_hidden_states,
|
||||
controlnet_cond=controlnet_image,
|
||||
return_dict=False,
|
||||
)
|
||||
|
||||
# Predict the noise residual
|
||||
noise_pred = unet(
|
||||
noisy_latents,
|
||||
timesteps,
|
||||
encoder_hidden_states,
|
||||
down_block_additional_residuals=[sample.to(dtype=weight_dtype) for sample in down_block_res_samples],
|
||||
mid_block_additional_residual=mid_block_res_sample.to(dtype=weight_dtype),
|
||||
).sample
|
||||
|
||||
if args.v_parameterization:
|
||||
# v-parameterization training
|
||||
target = noise_scheduler.get_velocity(latents, noise, timesteps)
|
||||
else:
|
||||
target = noise
|
||||
|
||||
loss = train_util.conditional_loss(
|
||||
noise_pred.float(), target.float(), reduction="none", loss_type=args.loss_type, huber_c=huber_c
|
||||
)
|
||||
loss = loss.mean([1, 2, 3])
|
||||
|
||||
loss_weights = batch["loss_weights"] # 各sampleごとのweight
|
||||
loss = loss * loss_weights
|
||||
|
||||
if args.min_snr_gamma:
|
||||
loss = apply_snr_weight(loss, timesteps, noise_scheduler, args.min_snr_gamma, args.v_parameterization)
|
||||
|
||||
loss = loss.mean() # 平均なのでbatch_sizeで割る必要なし
|
||||
|
||||
accelerator.backward(loss)
|
||||
if accelerator.sync_gradients and args.max_grad_norm != 0.0:
|
||||
params_to_clip = controlnet.parameters()
|
||||
accelerator.clip_grad_norm_(params_to_clip, args.max_grad_norm)
|
||||
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
optimizer.zero_grad(set_to_none=True)
|
||||
|
||||
# Checks if the accelerator has performed an optimization step behind the scenes
|
||||
if accelerator.sync_gradients:
|
||||
progress_bar.update(1)
|
||||
global_step += 1
|
||||
|
||||
train_util.sample_images(
|
||||
accelerator,
|
||||
args,
|
||||
None,
|
||||
global_step,
|
||||
accelerator.device,
|
||||
vae,
|
||||
tokenizer,
|
||||
text_encoder,
|
||||
unet,
|
||||
controlnet=controlnet,
|
||||
)
|
||||
|
||||
# 指定ステップごとにモデルを保存
|
||||
if args.save_every_n_steps is not None and global_step % args.save_every_n_steps == 0:
|
||||
accelerator.wait_for_everyone()
|
||||
if accelerator.is_main_process:
|
||||
ckpt_name = train_util.get_step_ckpt_name(args, "." + args.save_model_as, global_step)
|
||||
save_model(
|
||||
ckpt_name,
|
||||
accelerator.unwrap_model(controlnet),
|
||||
)
|
||||
|
||||
if args.save_state:
|
||||
train_util.save_and_remove_state_stepwise(args, accelerator, global_step)
|
||||
|
||||
remove_step_no = train_util.get_remove_step_no(args, global_step)
|
||||
if remove_step_no is not None:
|
||||
remove_ckpt_name = train_util.get_step_ckpt_name(args, "." + args.save_model_as, remove_step_no)
|
||||
remove_model(remove_ckpt_name)
|
||||
|
||||
current_loss = loss.detach().item()
|
||||
loss_recorder.add(epoch=epoch, step=step, loss=current_loss)
|
||||
avr_loss: float = loss_recorder.moving_average
|
||||
logs = {"avr_loss": avr_loss} # , "lr": lr_scheduler.get_last_lr()[0]}
|
||||
progress_bar.set_postfix(**logs)
|
||||
|
||||
if args.logging_dir is not None:
|
||||
logs = generate_step_logs(args, current_loss, avr_loss, lr_scheduler)
|
||||
accelerator.log(logs, step=global_step)
|
||||
|
||||
if global_step >= args.max_train_steps:
|
||||
break
|
||||
|
||||
if args.logging_dir is not None:
|
||||
logs = {"loss/epoch": loss_recorder.moving_average}
|
||||
accelerator.log(logs, step=epoch + 1)
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
# 指定エポックごとにモデルを保存
|
||||
if args.save_every_n_epochs is not None:
|
||||
saving = (epoch + 1) % args.save_every_n_epochs == 0 and (epoch + 1) < num_train_epochs
|
||||
if is_main_process and saving:
|
||||
ckpt_name = train_util.get_epoch_ckpt_name(args, "." + args.save_model_as, epoch + 1)
|
||||
save_model(ckpt_name, accelerator.unwrap_model(controlnet))
|
||||
|
||||
remove_epoch_no = train_util.get_remove_epoch_no(args, epoch + 1)
|
||||
if remove_epoch_no is not None:
|
||||
remove_ckpt_name = train_util.get_epoch_ckpt_name(args, "." + args.save_model_as, remove_epoch_no)
|
||||
remove_model(remove_ckpt_name)
|
||||
|
||||
if args.save_state:
|
||||
train_util.save_and_remove_state_on_epoch_end(args, accelerator, epoch + 1)
|
||||
|
||||
train_util.sample_images(
|
||||
accelerator,
|
||||
args,
|
||||
epoch + 1,
|
||||
global_step,
|
||||
accelerator.device,
|
||||
vae,
|
||||
tokenizer,
|
||||
text_encoder,
|
||||
unet,
|
||||
controlnet=controlnet,
|
||||
)
|
||||
|
||||
# end of epoch
|
||||
if is_main_process:
|
||||
controlnet = accelerator.unwrap_model(controlnet)
|
||||
|
||||
accelerator.end_training()
|
||||
|
||||
if is_main_process and (args.save_state or args.save_state_on_train_end):
|
||||
train_util.save_state_on_train_end(args, accelerator)
|
||||
|
||||
# del accelerator # この後メモリを使うのでこれは消す→printで使うので消さずにおく
|
||||
|
||||
if is_main_process:
|
||||
ckpt_name = train_util.get_last_ckpt_name(args, "." + args.save_model_as)
|
||||
save_model(ckpt_name, controlnet, force_sync_upload=True)
|
||||
|
||||
logger.info("model saved.")
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
add_logging_arguments(parser)
|
||||
train_util.add_sd_models_arguments(parser)
|
||||
train_util.add_dataset_arguments(parser, False, True, True)
|
||||
train_util.add_training_arguments(parser, False)
|
||||
deepspeed_utils.add_deepspeed_arguments(parser)
|
||||
train_util.add_optimizer_arguments(parser)
|
||||
config_util.add_config_arguments(parser)
|
||||
custom_train_functions.add_custom_train_arguments(parser)
|
||||
|
||||
parser.add_argument(
|
||||
"--save_model_as",
|
||||
type=str,
|
||||
default="safetensors",
|
||||
choices=[None, "ckpt", "pt", "safetensors"],
|
||||
help="format to save the model (default is .safetensors) / モデル保存時の形式(デフォルトはsafetensors)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--controlnet_model_name_or_path",
|
||||
type=str,
|
||||
default=None,
|
||||
help="controlnet model name or path / controlnetのモデル名またはパス",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--conditioning_data_dir",
|
||||
type=str,
|
||||
default=None,
|
||||
help="conditioning data directory / 条件付けデータのディレクトリ",
|
||||
)
|
||||
|
||||
return parser
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
train_util.verify_command_line_training_args(args)
|
||||
args = train_util.read_config_from_file(args, parser)
|
||||
|
||||
train(args)
|
||||
340
train_db.py
340
train_db.py
@@ -1,19 +1,23 @@
|
||||
# DreamBooth training
|
||||
# XXX dropped option: fine_tune
|
||||
|
||||
import gc
|
||||
import time
|
||||
import argparse
|
||||
import itertools
|
||||
import math
|
||||
import os
|
||||
import toml
|
||||
from multiprocessing import Value
|
||||
import toml
|
||||
|
||||
from tqdm import tqdm
|
||||
|
||||
import torch
|
||||
from library import deepspeed_utils
|
||||
from library.device_utils import init_ipex, clean_memory_on_device
|
||||
|
||||
|
||||
init_ipex()
|
||||
|
||||
from accelerate.utils import set_seed
|
||||
import diffusers
|
||||
from diffusers import DDPMScheduler
|
||||
|
||||
import library.train_util as train_util
|
||||
@@ -23,11 +27,31 @@ from library.config_util import (
|
||||
BlueprintGenerator,
|
||||
)
|
||||
import library.custom_train_functions as custom_train_functions
|
||||
from library.custom_train_functions import apply_snr_weight, get_weighted_text_embeddings
|
||||
from library.custom_train_functions import (
|
||||
apply_snr_weight,
|
||||
get_weighted_text_embeddings,
|
||||
prepare_scheduler_for_custom_training,
|
||||
pyramid_noise_like,
|
||||
apply_noise_offset,
|
||||
scale_v_prediction_loss_like_noise_prediction,
|
||||
apply_debiased_estimation,
|
||||
apply_masked_loss,
|
||||
)
|
||||
from library.utils import setup_logging, add_logging_arguments
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
# perlin_noise,
|
||||
|
||||
|
||||
def train(args):
|
||||
train_util.verify_training_args(args)
|
||||
train_util.prepare_dataset_args(args, False)
|
||||
deepspeed_utils.prepare_deepspeed_args(args)
|
||||
setup_logging(args, reset=True)
|
||||
|
||||
cache_latents = args.cache_latents
|
||||
|
||||
@@ -36,35 +60,41 @@ def train(args):
|
||||
|
||||
tokenizer = train_util.load_tokenizer(args)
|
||||
|
||||
blueprint_generator = BlueprintGenerator(ConfigSanitizer(True, False, True))
|
||||
if args.dataset_config is not None:
|
||||
print(f"Load dataset config from {args.dataset_config}")
|
||||
user_config = config_util.load_user_config(args.dataset_config)
|
||||
ignored = ["train_data_dir", "reg_data_dir"]
|
||||
if any(getattr(args, attr) is not None for attr in ignored):
|
||||
print(
|
||||
"ignore following options because config file is found: {0} / 設定ファイルが利用されるため以下のオプションは無視されます: {0}".format(
|
||||
", ".join(ignored)
|
||||
# データセットを準備する
|
||||
if args.dataset_class is None:
|
||||
blueprint_generator = BlueprintGenerator(ConfigSanitizer(True, False, args.masked_loss, True))
|
||||
if args.dataset_config is not None:
|
||||
logger.info(f"Load dataset config from {args.dataset_config}")
|
||||
user_config = config_util.load_user_config(args.dataset_config)
|
||||
ignored = ["train_data_dir", "reg_data_dir"]
|
||||
if any(getattr(args, attr) is not None for attr in ignored):
|
||||
logger.warning(
|
||||
"ignore following options because config file is found: {0} / 設定ファイルが利用されるため以下のオプションは無視されます: {0}".format(
|
||||
", ".join(ignored)
|
||||
)
|
||||
)
|
||||
)
|
||||
else:
|
||||
user_config = {
|
||||
"datasets": [
|
||||
{"subsets": config_util.generate_dreambooth_subsets_config_by_subdirs(args.train_data_dir, args.reg_data_dir)}
|
||||
]
|
||||
}
|
||||
else:
|
||||
user_config = {
|
||||
"datasets": [
|
||||
{"subsets": config_util.generate_dreambooth_subsets_config_by_subdirs(args.train_data_dir, args.reg_data_dir)}
|
||||
]
|
||||
}
|
||||
|
||||
blueprint = blueprint_generator.generate(user_config, args, tokenizer=tokenizer)
|
||||
train_dataset_group = config_util.generate_dataset_group_by_blueprint(blueprint.dataset_group)
|
||||
blueprint = blueprint_generator.generate(user_config, args, tokenizer=tokenizer)
|
||||
train_dataset_group = config_util.generate_dataset_group_by_blueprint(blueprint.dataset_group)
|
||||
else:
|
||||
train_dataset_group = train_util.load_arbitrary_dataset(args, tokenizer)
|
||||
|
||||
current_epoch = Value("i", 0)
|
||||
current_step = Value("i", 0)
|
||||
ds_for_collater = train_dataset_group if args.max_data_loader_n_workers == 0 else None
|
||||
collater = train_util.collater_class(current_epoch, current_step, ds_for_collater)
|
||||
ds_for_collator = train_dataset_group if args.max_data_loader_n_workers == 0 else None
|
||||
collator = train_util.collator_class(current_epoch, current_step, ds_for_collator)
|
||||
|
||||
if args.no_token_padding:
|
||||
train_dataset_group.disable_token_padding()
|
||||
|
||||
train_dataset_group.verify_bucket_reso_steps(64)
|
||||
|
||||
if args.debug_dataset:
|
||||
train_util.debug_dataset(train_dataset_group)
|
||||
return
|
||||
@@ -75,23 +105,24 @@ def train(args):
|
||||
), "when caching latents, either color_aug or random_crop cannot be used / latentをキャッシュするときはcolor_augとrandom_cropは使えません"
|
||||
|
||||
# acceleratorを準備する
|
||||
print("prepare accelerator")
|
||||
logger.info("prepare accelerator")
|
||||
|
||||
if args.gradient_accumulation_steps > 1:
|
||||
print(
|
||||
logger.warning(
|
||||
f"gradient_accumulation_steps is {args.gradient_accumulation_steps}. accelerate does not support gradient_accumulation_steps when training multiple models (U-Net and Text Encoder), so something might be wrong"
|
||||
)
|
||||
print(
|
||||
logger.warning(
|
||||
f"gradient_accumulation_stepsが{args.gradient_accumulation_steps}に設定されています。accelerateは複数モデル(U-NetおよびText Encoder)の学習時にgradient_accumulation_stepsをサポートしていないため結果は未知数です"
|
||||
)
|
||||
|
||||
accelerator, unwrap_model = train_util.prepare_accelerator(args)
|
||||
accelerator = train_util.prepare_accelerator(args)
|
||||
|
||||
# mixed precisionに対応した型を用意しておき適宜castする
|
||||
weight_dtype, save_dtype = train_util.prepare_dtype(args)
|
||||
vae_dtype = torch.float32 if args.no_half_vae else weight_dtype
|
||||
|
||||
# モデルを読み込む
|
||||
text_encoder, vae, unet, load_stable_diffusion_format = train_util.load_target_model(args, weight_dtype)
|
||||
text_encoder, vae, unet, load_stable_diffusion_format = train_util.load_target_model(args, weight_dtype, accelerator)
|
||||
|
||||
# verify load/save model formats
|
||||
if load_stable_diffusion_format:
|
||||
@@ -109,19 +140,17 @@ def train(args):
|
||||
use_safetensors = args.use_safetensors or ("safetensors" in args.save_model_as.lower())
|
||||
|
||||
# モデルに xformers とか memory efficient attention を組み込む
|
||||
train_util.replace_unet_modules(unet, args.mem_eff_attn, args.xformers)
|
||||
train_util.replace_unet_modules(unet, args.mem_eff_attn, args.xformers, args.sdpa)
|
||||
|
||||
# 学習を準備する
|
||||
if cache_latents:
|
||||
vae.to(accelerator.device, dtype=weight_dtype)
|
||||
vae.to(accelerator.device, dtype=vae_dtype)
|
||||
vae.requires_grad_(False)
|
||||
vae.eval()
|
||||
with torch.no_grad():
|
||||
train_dataset_group.cache_latents(vae, args.vae_batch_size, args.cache_latents_to_disk, accelerator.is_main_process)
|
||||
vae.to("cpu")
|
||||
if torch.cuda.is_available():
|
||||
torch.cuda.empty_cache()
|
||||
gc.collect()
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
@@ -130,7 +159,7 @@ def train(args):
|
||||
unet.requires_grad_(True) # 念のため追加
|
||||
text_encoder.requires_grad_(train_text_encoder)
|
||||
if not train_text_encoder:
|
||||
print("Text Encoder is not trained.")
|
||||
accelerator.print("Text Encoder is not trained.")
|
||||
|
||||
if args.gradient_checkpointing:
|
||||
unet.enable_gradient_checkpointing()
|
||||
@@ -142,22 +171,29 @@ def train(args):
|
||||
vae.to(accelerator.device, dtype=weight_dtype)
|
||||
|
||||
# 学習に必要なクラスを準備する
|
||||
print("prepare optimizer, data loader etc.")
|
||||
accelerator.print("prepare optimizer, data loader etc.")
|
||||
if train_text_encoder:
|
||||
trainable_params = itertools.chain(unet.parameters(), text_encoder.parameters())
|
||||
if args.learning_rate_te is None:
|
||||
# wightout list, adamw8bit is crashed
|
||||
trainable_params = list(itertools.chain(unet.parameters(), text_encoder.parameters()))
|
||||
else:
|
||||
trainable_params = [
|
||||
{"params": list(unet.parameters()), "lr": args.learning_rate},
|
||||
{"params": list(text_encoder.parameters()), "lr": args.learning_rate_te},
|
||||
]
|
||||
else:
|
||||
trainable_params = unet.parameters()
|
||||
|
||||
_, _, optimizer = train_util.get_optimizer(args, trainable_params)
|
||||
|
||||
# dataloaderを準備する
|
||||
# DataLoaderのプロセス数:0はメインプロセスになる
|
||||
n_workers = min(args.max_data_loader_n_workers, os.cpu_count() - 1) # cpu_count-1 ただし最大で指定された数まで
|
||||
# DataLoaderのプロセス数:0 は persistent_workers が使えないので注意
|
||||
n_workers = min(args.max_data_loader_n_workers, os.cpu_count()) # cpu_count or max_data_loader_n_workers
|
||||
train_dataloader = torch.utils.data.DataLoader(
|
||||
train_dataset_group,
|
||||
batch_size=1,
|
||||
shuffle=True,
|
||||
collate_fn=collater,
|
||||
collate_fn=collator,
|
||||
num_workers=n_workers,
|
||||
persistent_workers=args.persistent_data_loader_workers,
|
||||
)
|
||||
@@ -167,7 +203,9 @@ def train(args):
|
||||
args.max_train_steps = args.max_train_epochs * math.ceil(
|
||||
len(train_dataloader) / accelerator.num_processes / args.gradient_accumulation_steps
|
||||
)
|
||||
print(f"override steps. steps for {args.max_train_epochs} epochs is / 指定エポックまでのステップ数: {args.max_train_steps}")
|
||||
accelerator.print(
|
||||
f"override steps. steps for {args.max_train_epochs} epochs is / 指定エポックまでのステップ数: {args.max_train_steps}"
|
||||
)
|
||||
|
||||
# データセット側にも学習ステップを送信
|
||||
train_dataset_group.set_max_train_steps(args.max_train_steps)
|
||||
@@ -183,17 +221,30 @@ def train(args):
|
||||
assert (
|
||||
args.mixed_precision == "fp16"
|
||||
), "full_fp16 requires mixed precision='fp16' / full_fp16を使う場合はmixed_precision='fp16'を指定してください。"
|
||||
print("enable full fp16 training.")
|
||||
accelerator.print("enable full fp16 training.")
|
||||
unet.to(weight_dtype)
|
||||
text_encoder.to(weight_dtype)
|
||||
|
||||
# acceleratorがなんかよろしくやってくれるらしい
|
||||
if train_text_encoder:
|
||||
unet, text_encoder, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
|
||||
unet, text_encoder, optimizer, train_dataloader, lr_scheduler
|
||||
if args.deepspeed:
|
||||
if args.train_text_encoder:
|
||||
ds_model = deepspeed_utils.prepare_deepspeed_model(args, unet=unet, text_encoder=text_encoder)
|
||||
else:
|
||||
ds_model = deepspeed_utils.prepare_deepspeed_model(args, unet=unet)
|
||||
ds_model, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
|
||||
ds_model, optimizer, train_dataloader, lr_scheduler
|
||||
)
|
||||
training_models = [ds_model]
|
||||
|
||||
else:
|
||||
unet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(unet, optimizer, train_dataloader, lr_scheduler)
|
||||
if train_text_encoder:
|
||||
unet, text_encoder, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
|
||||
unet, text_encoder, optimizer, train_dataloader, lr_scheduler
|
||||
)
|
||||
training_models = [unet, text_encoder]
|
||||
else:
|
||||
unet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(unet, optimizer, train_dataloader, lr_scheduler)
|
||||
training_models = [unet]
|
||||
|
||||
if not train_text_encoder:
|
||||
text_encoder.to(accelerator.device, dtype=weight_dtype) # to avoid 'cpu' vs 'cuda' error
|
||||
@@ -213,15 +264,17 @@ def train(args):
|
||||
|
||||
# 学習する
|
||||
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
|
||||
print("running training / 学習開始")
|
||||
print(f" num train images * repeats / 学習画像の数×繰り返し回数: {train_dataset_group.num_train_images}")
|
||||
print(f" num reg images / 正則化画像の数: {train_dataset_group.num_reg_images}")
|
||||
print(f" num batches per epoch / 1epochのバッチ数: {len(train_dataloader)}")
|
||||
print(f" num epochs / epoch数: {num_train_epochs}")
|
||||
print(f" batch size per device / バッチサイズ: {args.train_batch_size}")
|
||||
print(f" total train batch size (with parallel & distributed & accumulation) / 総バッチサイズ(並列学習、勾配合計含む): {total_batch_size}")
|
||||
print(f" gradient ccumulation steps / 勾配を合計するステップ数 = {args.gradient_accumulation_steps}")
|
||||
print(f" total optimization steps / 学習ステップ数: {args.max_train_steps}")
|
||||
accelerator.print("running training / 学習開始")
|
||||
accelerator.print(f" num train images * repeats / 学習画像の数×繰り返し回数: {train_dataset_group.num_train_images}")
|
||||
accelerator.print(f" num reg images / 正則化画像の数: {train_dataset_group.num_reg_images}")
|
||||
accelerator.print(f" num batches per epoch / 1epochのバッチ数: {len(train_dataloader)}")
|
||||
accelerator.print(f" num epochs / epoch数: {num_train_epochs}")
|
||||
accelerator.print(f" batch size per device / バッチサイズ: {args.train_batch_size}")
|
||||
accelerator.print(
|
||||
f" total train batch size (with parallel & distributed & accumulation) / 総バッチサイズ(並列学習、勾配合計含む): {total_batch_size}"
|
||||
)
|
||||
accelerator.print(f" gradient ccumulation steps / 勾配を合計するステップ数 = {args.gradient_accumulation_steps}")
|
||||
accelerator.print(f" total optimization steps / 学習ステップ数: {args.max_train_steps}")
|
||||
|
||||
progress_bar = tqdm(range(args.max_train_steps), smoothing=0, disable=not accelerator.is_local_main_process, desc="steps")
|
||||
global_step = 0
|
||||
@@ -229,14 +282,24 @@ def train(args):
|
||||
noise_scheduler = DDPMScheduler(
|
||||
beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000, clip_sample=False
|
||||
)
|
||||
prepare_scheduler_for_custom_training(noise_scheduler, accelerator.device)
|
||||
if args.zero_terminal_snr:
|
||||
custom_train_functions.fix_noise_scheduler_betas_for_zero_terminal_snr(noise_scheduler)
|
||||
|
||||
if accelerator.is_main_process:
|
||||
accelerator.init_trackers("dreambooth" if args.log_tracker_name is None else args.log_tracker_name)
|
||||
init_kwargs = {}
|
||||
if args.wandb_run_name:
|
||||
init_kwargs["wandb"] = {"name": args.wandb_run_name}
|
||||
if args.log_tracker_config is not None:
|
||||
init_kwargs = toml.load(args.log_tracker_config)
|
||||
accelerator.init_trackers("dreambooth" if args.log_tracker_name is None else args.log_tracker_name, config=train_util.get_sanitized_config_or_none(args), init_kwargs=init_kwargs)
|
||||
|
||||
loss_list = []
|
||||
loss_total = 0.0
|
||||
# For --sample_at_first
|
||||
train_util.sample_images(accelerator, args, 0, global_step, accelerator.device, vae, tokenizer, text_encoder, unet)
|
||||
|
||||
loss_recorder = train_util.LossRecorder()
|
||||
for epoch in range(num_train_epochs):
|
||||
print(f"epoch {epoch+1}/{num_train_epochs}")
|
||||
accelerator.print(f"\nepoch {epoch+1}/{num_train_epochs}")
|
||||
current_epoch.value = epoch + 1
|
||||
|
||||
# 指定したステップ数までText Encoderを学習する:epoch最初の状態
|
||||
@@ -249,53 +312,47 @@ def train(args):
|
||||
current_step.value = global_step
|
||||
# 指定したステップ数でText Encoderの学習を止める
|
||||
if global_step == args.stop_text_encoder_training:
|
||||
print(f"stop text encoder training at step {global_step}")
|
||||
accelerator.print(f"stop text encoder training at step {global_step}")
|
||||
if not args.gradient_checkpointing:
|
||||
text_encoder.train(False)
|
||||
text_encoder.requires_grad_(False)
|
||||
if len(training_models) == 2:
|
||||
training_models = training_models[0] # remove text_encoder from training_models
|
||||
|
||||
with accelerator.accumulate(unet):
|
||||
with accelerator.accumulate(*training_models):
|
||||
with torch.no_grad():
|
||||
# latentに変換
|
||||
if cache_latents:
|
||||
latents = batch["latents"].to(accelerator.device)
|
||||
latents = batch["latents"].to(accelerator.device).to(dtype=weight_dtype)
|
||||
else:
|
||||
latents = vae.encode(batch["images"].to(dtype=weight_dtype)).latent_dist.sample()
|
||||
latents = latents * 0.18215
|
||||
b_size = latents.shape[0]
|
||||
|
||||
# Sample noise that we'll add to the latents
|
||||
noise = torch.randn_like(latents, device=latents.device)
|
||||
if args.noise_offset:
|
||||
# https://www.crosslabs.org//blog/diffusion-with-offset-noise
|
||||
noise += args.noise_offset * torch.randn((latents.shape[0], latents.shape[1], 1, 1), device=latents.device)
|
||||
|
||||
# Get the text embedding for conditioning
|
||||
with torch.set_grad_enabled(global_step < args.stop_text_encoder_training):
|
||||
if args.weighted_captions:
|
||||
encoder_hidden_states = get_weighted_text_embeddings(tokenizer,
|
||||
text_encoder,
|
||||
batch["captions"],
|
||||
accelerator.device,
|
||||
args.max_token_length // 75 if args.max_token_length else 1,
|
||||
clip_skip=args.clip_skip,
|
||||
encoder_hidden_states = get_weighted_text_embeddings(
|
||||
tokenizer,
|
||||
text_encoder,
|
||||
batch["captions"],
|
||||
accelerator.device,
|
||||
args.max_token_length // 75 if args.max_token_length else 1,
|
||||
clip_skip=args.clip_skip,
|
||||
)
|
||||
else:
|
||||
input_ids = batch["input_ids"].to(accelerator.device)
|
||||
encoder_hidden_states = train_util.get_hidden_states(
|
||||
args, input_ids, tokenizer, text_encoder, None if not args.full_fp16 else weight_dtype
|
||||
)
|
||||
input_ids = batch["input_ids"].to(accelerator.device)
|
||||
encoder_hidden_states = train_util.get_hidden_states(
|
||||
args, input_ids, tokenizer, text_encoder, None if not args.full_fp16 else weight_dtype
|
||||
)
|
||||
|
||||
# Sample a random timestep for each image
|
||||
timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (b_size,), device=latents.device)
|
||||
timesteps = timesteps.long()
|
||||
|
||||
# Add noise to the latents according to the noise magnitude at each timestep
|
||||
# (this is the forward diffusion process)
|
||||
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
|
||||
# Sample noise, sample a random timestep for each image, and add noise to the latents,
|
||||
# with noise offset and/or multires noise if specified
|
||||
noise, noisy_latents, timesteps, huber_c = train_util.get_noise_noisy_latents_and_timesteps(args, noise_scheduler, latents)
|
||||
|
||||
# Predict the noise residual
|
||||
noise_pred = unet(noisy_latents, timesteps, encoder_hidden_states).sample
|
||||
with accelerator.autocast():
|
||||
noise_pred = unet(noisy_latents, timesteps, encoder_hidden_states).sample
|
||||
|
||||
if args.v_parameterization:
|
||||
# v-parameterization training
|
||||
@@ -303,14 +360,20 @@ def train(args):
|
||||
else:
|
||||
target = noise
|
||||
|
||||
loss = torch.nn.functional.mse_loss(noise_pred.float(), target.float(), reduction="none")
|
||||
loss = train_util.conditional_loss(noise_pred.float(), target.float(), reduction="none", loss_type=args.loss_type, huber_c=huber_c)
|
||||
if args.masked_loss or ("alpha_masks" in batch and batch["alpha_masks"] is not None):
|
||||
loss = apply_masked_loss(loss, batch)
|
||||
loss = loss.mean([1, 2, 3])
|
||||
|
||||
loss_weights = batch["loss_weights"] # 各sampleごとのweight
|
||||
loss = loss * loss_weights
|
||||
|
||||
if args.min_snr_gamma:
|
||||
loss = apply_snr_weight(loss, timesteps, noise_scheduler, args.min_snr_gamma)
|
||||
loss = apply_snr_weight(loss, timesteps, noise_scheduler, args.min_snr_gamma, args.v_parameterization)
|
||||
if args.scale_v_pred_loss_like_noise_pred:
|
||||
loss = scale_v_prediction_loss_like_noise_prediction(loss, timesteps, noise_scheduler)
|
||||
if args.debiased_estimation_loss:
|
||||
loss = apply_debiased_estimation(loss, timesteps, noise_scheduler, args.v_parameterization)
|
||||
|
||||
loss = loss.mean() # 平均なのでbatch_sizeで割る必要なし
|
||||
|
||||
@@ -335,61 +398,77 @@ def train(args):
|
||||
accelerator, args, None, global_step, accelerator.device, vae, tokenizer, text_encoder, unet
|
||||
)
|
||||
|
||||
# 指定ステップごとにモデルを保存
|
||||
if args.save_every_n_steps is not None and global_step % args.save_every_n_steps == 0:
|
||||
accelerator.wait_for_everyone()
|
||||
if accelerator.is_main_process:
|
||||
src_path = src_stable_diffusion_ckpt if save_stable_diffusion_format else src_diffusers_model_path
|
||||
train_util.save_sd_model_on_epoch_end_or_stepwise(
|
||||
args,
|
||||
False,
|
||||
accelerator,
|
||||
src_path,
|
||||
save_stable_diffusion_format,
|
||||
use_safetensors,
|
||||
save_dtype,
|
||||
epoch,
|
||||
num_train_epochs,
|
||||
global_step,
|
||||
accelerator.unwrap_model(text_encoder),
|
||||
accelerator.unwrap_model(unet),
|
||||
vae,
|
||||
)
|
||||
|
||||
current_loss = loss.detach().item()
|
||||
if args.logging_dir is not None:
|
||||
logs = {"loss": current_loss, "lr": float(lr_scheduler.get_last_lr()[0])}
|
||||
if args.optimizer_type.lower() == "DAdaptation".lower(): # tracking d*lr value
|
||||
logs["lr/d*lr"] = (
|
||||
lr_scheduler.optimizers[0].param_groups[0]["d"] * lr_scheduler.optimizers[0].param_groups[0]["lr"]
|
||||
)
|
||||
logs = {"loss": current_loss}
|
||||
train_util.append_lr_to_logs(logs, lr_scheduler, args.optimizer_type, including_unet=True)
|
||||
accelerator.log(logs, step=global_step)
|
||||
|
||||
if epoch == 0:
|
||||
loss_list.append(current_loss)
|
||||
else:
|
||||
loss_total -= loss_list[step]
|
||||
loss_list[step] = current_loss
|
||||
loss_total += current_loss
|
||||
avr_loss = loss_total / len(loss_list)
|
||||
logs = {"loss": avr_loss} # , "lr": lr_scheduler.get_last_lr()[0]}
|
||||
loss_recorder.add(epoch=epoch, step=step, loss=current_loss)
|
||||
avr_loss: float = loss_recorder.moving_average
|
||||
logs = {"avr_loss": avr_loss} # , "lr": lr_scheduler.get_last_lr()[0]}
|
||||
progress_bar.set_postfix(**logs)
|
||||
|
||||
if global_step >= args.max_train_steps:
|
||||
break
|
||||
|
||||
if args.logging_dir is not None:
|
||||
logs = {"loss/epoch": loss_total / len(loss_list)}
|
||||
logs = {"loss/epoch": loss_recorder.moving_average}
|
||||
accelerator.log(logs, step=epoch + 1)
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
if args.save_every_n_epochs is not None:
|
||||
src_path = src_stable_diffusion_ckpt if save_stable_diffusion_format else src_diffusers_model_path
|
||||
train_util.save_sd_model_on_epoch_end(
|
||||
args,
|
||||
accelerator,
|
||||
src_path,
|
||||
save_stable_diffusion_format,
|
||||
use_safetensors,
|
||||
save_dtype,
|
||||
epoch,
|
||||
num_train_epochs,
|
||||
global_step,
|
||||
unwrap_model(text_encoder),
|
||||
unwrap_model(unet),
|
||||
vae,
|
||||
)
|
||||
if accelerator.is_main_process:
|
||||
# checking for saving is in util
|
||||
src_path = src_stable_diffusion_ckpt if save_stable_diffusion_format else src_diffusers_model_path
|
||||
train_util.save_sd_model_on_epoch_end_or_stepwise(
|
||||
args,
|
||||
True,
|
||||
accelerator,
|
||||
src_path,
|
||||
save_stable_diffusion_format,
|
||||
use_safetensors,
|
||||
save_dtype,
|
||||
epoch,
|
||||
num_train_epochs,
|
||||
global_step,
|
||||
accelerator.unwrap_model(text_encoder),
|
||||
accelerator.unwrap_model(unet),
|
||||
vae,
|
||||
)
|
||||
|
||||
train_util.sample_images(accelerator, args, epoch + 1, global_step, accelerator.device, vae, tokenizer, text_encoder, unet)
|
||||
|
||||
is_main_process = accelerator.is_main_process
|
||||
if is_main_process:
|
||||
unet = unwrap_model(unet)
|
||||
text_encoder = unwrap_model(text_encoder)
|
||||
unet = accelerator.unwrap_model(unet)
|
||||
text_encoder = accelerator.unwrap_model(text_encoder)
|
||||
|
||||
accelerator.end_training()
|
||||
|
||||
if args.save_state:
|
||||
if is_main_process and (args.save_state or args.save_state_on_train_end):
|
||||
train_util.save_state_on_train_end(args, accelerator)
|
||||
|
||||
del accelerator # この後メモリを使うのでこれは消す
|
||||
@@ -399,20 +478,29 @@ def train(args):
|
||||
train_util.save_sd_model_on_train_end(
|
||||
args, src_path, save_stable_diffusion_format, use_safetensors, save_dtype, epoch, global_step, text_encoder, unet, vae
|
||||
)
|
||||
print("model saved.")
|
||||
logger.info("model saved.")
|
||||
|
||||
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
add_logging_arguments(parser)
|
||||
train_util.add_sd_models_arguments(parser)
|
||||
train_util.add_dataset_arguments(parser, True, False, True)
|
||||
train_util.add_training_arguments(parser, True)
|
||||
train_util.add_masked_loss_arguments(parser)
|
||||
deepspeed_utils.add_deepspeed_arguments(parser)
|
||||
train_util.add_sd_saving_arguments(parser)
|
||||
train_util.add_optimizer_arguments(parser)
|
||||
config_util.add_config_arguments(parser)
|
||||
custom_train_functions.add_custom_train_arguments(parser)
|
||||
|
||||
parser.add_argument(
|
||||
"--learning_rate_te",
|
||||
type=float,
|
||||
default=None,
|
||||
help="learning rate for text encoder, default is same as unet / Text Encoderの学習率、デフォルトはunetと同じ",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--no_token_padding",
|
||||
action="store_true",
|
||||
@@ -424,6 +512,11 @@ def setup_parser() -> argparse.ArgumentParser:
|
||||
default=None,
|
||||
help="steps to stop text encoder training, -1 for no training / Text Encoderの学習を止めるステップ数、-1で最初から学習しない",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--no_half_vae",
|
||||
action="store_true",
|
||||
help="do not use fp16/bf16 VAE in mixed precision (use float VAE) / mixed precisionでも fp16/bf16 VAEを使わずfloat VAEを使う",
|
||||
)
|
||||
|
||||
return parser
|
||||
|
||||
@@ -432,6 +525,7 @@ if __name__ == "__main__":
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
train_util.verify_command_line_training_args(args)
|
||||
args = train_util.read_config_from_file(args, parser)
|
||||
|
||||
train(args)
|
||||
train(args)
|
||||
|
||||
1779
train_network.py
1779
train_network.py
File diff suppressed because it is too large
Load Diff
File diff suppressed because it is too large
Load Diff
@@ -1,16 +1,22 @@
|
||||
import importlib
|
||||
import argparse
|
||||
import gc
|
||||
import math
|
||||
import os
|
||||
import toml
|
||||
from multiprocessing import Value
|
||||
|
||||
from tqdm import tqdm
|
||||
|
||||
import torch
|
||||
from library import deepspeed_utils
|
||||
from library.device_utils import init_ipex, clean_memory_on_device
|
||||
|
||||
init_ipex()
|
||||
|
||||
from accelerate.utils import set_seed
|
||||
import diffusers
|
||||
from diffusers import DDPMScheduler
|
||||
import library
|
||||
|
||||
import library.train_util as train_util
|
||||
import library.huggingface_util as huggingface_util
|
||||
@@ -20,8 +26,23 @@ from library.config_util import (
|
||||
BlueprintGenerator,
|
||||
)
|
||||
import library.custom_train_functions as custom_train_functions
|
||||
from library.custom_train_functions import apply_snr_weight
|
||||
from library.custom_train_functions import (
|
||||
apply_snr_weight,
|
||||
prepare_scheduler_for_custom_training,
|
||||
pyramid_noise_like,
|
||||
apply_noise_offset,
|
||||
scale_v_prediction_loss_like_noise_prediction,
|
||||
apply_debiased_estimation,
|
||||
apply_masked_loss,
|
||||
)
|
||||
import library.original_unet as original_unet
|
||||
from XTI_hijack import unet_forward_XTI, downblock_forward_XTI, upblock_forward_XTI
|
||||
from library.utils import setup_logging, add_logging_arguments
|
||||
|
||||
setup_logging()
|
||||
import logging
|
||||
|
||||
logger = logging.getLogger(__name__)
|
||||
|
||||
imagenet_templates_small = [
|
||||
"a photo of a {}",
|
||||
@@ -80,14 +101,18 @@ def train(args):
|
||||
if args.output_name is None:
|
||||
args.output_name = args.token_string
|
||||
use_template = args.use_object_template or args.use_style_template
|
||||
setup_logging(args, reset=True)
|
||||
|
||||
train_util.verify_training_args(args)
|
||||
train_util.prepare_dataset_args(args, True)
|
||||
|
||||
if args.sample_every_n_steps is not None or args.sample_every_n_epochs is not None:
|
||||
print(
|
||||
logger.warning(
|
||||
"sample_every_n_steps and sample_every_n_epochs are not supported in this script currently / sample_every_n_stepsとsample_every_n_epochsは現在このスクリプトではサポートされていません"
|
||||
)
|
||||
assert (
|
||||
args.dataset_class is None
|
||||
), "dataset_class is not supported in this script currently / dataset_classは現在このスクリプトではサポートされていません"
|
||||
|
||||
cache_latents = args.cache_latents
|
||||
|
||||
@@ -97,20 +122,20 @@ def train(args):
|
||||
tokenizer = train_util.load_tokenizer(args)
|
||||
|
||||
# acceleratorを準備する
|
||||
print("prepare accelerator")
|
||||
accelerator, unwrap_model = train_util.prepare_accelerator(args)
|
||||
logger.info("prepare accelerator")
|
||||
accelerator = train_util.prepare_accelerator(args)
|
||||
|
||||
# mixed precisionに対応した型を用意しておき適宜castする
|
||||
weight_dtype, save_dtype = train_util.prepare_dtype(args)
|
||||
|
||||
# モデルを読み込む
|
||||
text_encoder, vae, unet, _ = train_util.load_target_model(args, weight_dtype)
|
||||
text_encoder, vae, unet, _ = train_util.load_target_model(args, weight_dtype, accelerator)
|
||||
|
||||
# Convert the init_word to token_id
|
||||
if args.init_word is not None:
|
||||
init_token_ids = tokenizer.encode(args.init_word, add_special_tokens=False)
|
||||
if len(init_token_ids) > 1 and len(init_token_ids) != args.num_vectors_per_token:
|
||||
print(
|
||||
logger.warning(
|
||||
f"token length for init words is not same to num_vectors_per_token, init words is repeated or truncated / 初期化単語のトークン長がnum_vectors_per_tokenと合わないため、繰り返しまたは切り捨てが発生します: length {len(init_token_ids)}"
|
||||
)
|
||||
else:
|
||||
@@ -124,7 +149,7 @@ def train(args):
|
||||
), f"tokenizer has same word to token string. please use another one / 指定したargs.token_stringは既に存在します。別の単語を使ってください: {args.token_string}"
|
||||
|
||||
token_ids = tokenizer.convert_tokens_to_ids(token_strings)
|
||||
print(f"tokens are added: {token_ids}")
|
||||
logger.info(f"tokens are added: {token_ids}")
|
||||
assert min(token_ids) == token_ids[0] and token_ids[-1] == token_ids[0] + len(token_ids) - 1, f"token ids is not ordered"
|
||||
assert len(tokenizer) - 1 == token_ids[-1], f"token ids is not end of tokenize: {len(tokenizer)}"
|
||||
|
||||
@@ -152,7 +177,7 @@ def train(args):
|
||||
|
||||
tokenizer.add_tokens(token_strings_XTI)
|
||||
token_ids_XTI = tokenizer.convert_tokens_to_ids(token_strings_XTI)
|
||||
print(f"tokens are added (XTI): {token_ids_XTI}")
|
||||
logger.info(f"tokens are added (XTI): {token_ids_XTI}")
|
||||
# Resize the token embeddings as we are adding new special tokens to the tokenizer
|
||||
text_encoder.resize_token_embeddings(len(tokenizer))
|
||||
|
||||
@@ -161,7 +186,7 @@ def train(args):
|
||||
if init_token_ids is not None:
|
||||
for i, token_id in enumerate(token_ids_XTI):
|
||||
token_embeds[token_id] = token_embeds[init_token_ids[(i // 16) % len(init_token_ids)]]
|
||||
# print(token_id, token_embeds[token_id].mean(), token_embeds[token_id].min())
|
||||
# logger.info(token_id, token_embeds[token_id].mean(), token_embeds[token_id].min())
|
||||
|
||||
# load weights
|
||||
if args.weights is not None:
|
||||
@@ -169,22 +194,22 @@ def train(args):
|
||||
assert len(token_ids) == len(
|
||||
embeddings
|
||||
), f"num_vectors_per_token is mismatch for weights / 指定した重みとnum_vectors_per_tokenの値が異なります: {len(embeddings)}"
|
||||
# print(token_ids, embeddings.size())
|
||||
# logger.info(token_ids, embeddings.size())
|
||||
for token_id, embedding in zip(token_ids_XTI, embeddings):
|
||||
token_embeds[token_id] = embedding
|
||||
# print(token_id, token_embeds[token_id].mean(), token_embeds[token_id].min())
|
||||
print(f"weighs loaded")
|
||||
# logger.info(token_id, token_embeds[token_id].mean(), token_embeds[token_id].min())
|
||||
logger.info(f"weighs loaded")
|
||||
|
||||
print(f"create embeddings for {args.num_vectors_per_token} tokens, for {args.token_string}")
|
||||
logger.info(f"create embeddings for {args.num_vectors_per_token} tokens, for {args.token_string}")
|
||||
|
||||
# データセットを準備する
|
||||
blueprint_generator = BlueprintGenerator(ConfigSanitizer(True, True, False))
|
||||
blueprint_generator = BlueprintGenerator(ConfigSanitizer(True, True, args.masked_loss, False))
|
||||
if args.dataset_config is not None:
|
||||
print(f"Load dataset config from {args.dataset_config}")
|
||||
logger.info(f"Load dataset config from {args.dataset_config}")
|
||||
user_config = config_util.load_user_config(args.dataset_config)
|
||||
ignored = ["train_data_dir", "reg_data_dir", "in_json"]
|
||||
if any(getattr(args, attr) is not None for attr in ignored):
|
||||
print(
|
||||
logger.info(
|
||||
"ignore following options because config file is found: {0} / 設定ファイルが利用されるため以下のオプションは無視されます: {0}".format(
|
||||
", ".join(ignored)
|
||||
)
|
||||
@@ -192,14 +217,14 @@ def train(args):
|
||||
else:
|
||||
use_dreambooth_method = args.in_json is None
|
||||
if use_dreambooth_method:
|
||||
print("Use DreamBooth method.")
|
||||
logger.info("Use DreamBooth method.")
|
||||
user_config = {
|
||||
"datasets": [
|
||||
{"subsets": config_util.generate_dreambooth_subsets_config_by_subdirs(args.train_data_dir, args.reg_data_dir)}
|
||||
]
|
||||
}
|
||||
else:
|
||||
print("Train with captions.")
|
||||
logger.info("Train with captions.")
|
||||
user_config = {
|
||||
"datasets": [
|
||||
{
|
||||
@@ -218,12 +243,12 @@ def train(args):
|
||||
train_dataset_group.enable_XTI(XTI_layers, token_strings=token_strings)
|
||||
current_epoch = Value("i", 0)
|
||||
current_step = Value("i", 0)
|
||||
ds_for_collater = train_dataset_group if args.max_data_loader_n_workers == 0 else None
|
||||
collater = train_util.collater_class(current_epoch, current_step, ds_for_collater)
|
||||
ds_for_collator = train_dataset_group if args.max_data_loader_n_workers == 0 else None
|
||||
collator = train_util.collator_class(current_epoch, current_step, ds_for_collator)
|
||||
|
||||
# make captions: tokenstring tokenstring1 tokenstring2 ...tokenstringn という文字列に書き換える超乱暴な実装
|
||||
if use_template:
|
||||
print("use template for training captions. is object: {args.use_object_template}")
|
||||
logger.info(f"use template for training captions. is object: {args.use_object_template}")
|
||||
templates = imagenet_templates_small if args.use_object_template else imagenet_style_templates_small
|
||||
replace_to = " ".join(token_strings)
|
||||
captions = []
|
||||
@@ -247,7 +272,7 @@ def train(args):
|
||||
train_util.debug_dataset(train_dataset_group, show_input_ids=True)
|
||||
return
|
||||
if len(train_dataset_group) == 0:
|
||||
print("No data found. Please verify arguments / 画像がありません。引数指定を確認してください")
|
||||
logger.error("No data found. Please verify arguments / 画像がありません。引数指定を確認してください")
|
||||
return
|
||||
|
||||
if cache_latents:
|
||||
@@ -256,10 +281,10 @@ def train(args):
|
||||
), "when caching latents, either color_aug or random_crop cannot be used / latentをキャッシュするときはcolor_augとrandom_cropは使えません"
|
||||
|
||||
# モデルに xformers とか memory efficient attention を組み込む
|
||||
train_util.replace_unet_modules(unet, args.mem_eff_attn, args.xformers)
|
||||
diffusers.models.UNet2DConditionModel.forward = unet_forward_XTI
|
||||
diffusers.models.unet_2d_blocks.CrossAttnDownBlock2D.forward = downblock_forward_XTI
|
||||
diffusers.models.unet_2d_blocks.CrossAttnUpBlock2D.forward = upblock_forward_XTI
|
||||
train_util.replace_unet_modules(unet, args.mem_eff_attn, args.xformers, args.sdpa)
|
||||
original_unet.UNet2DConditionModel.forward = unet_forward_XTI
|
||||
original_unet.CrossAttnDownBlock2D.forward = downblock_forward_XTI
|
||||
original_unet.CrossAttnUpBlock2D.forward = upblock_forward_XTI
|
||||
|
||||
# 学習を準備する
|
||||
if cache_latents:
|
||||
@@ -269,9 +294,7 @@ def train(args):
|
||||
with torch.no_grad():
|
||||
train_dataset_group.cache_latents(vae, args.vae_batch_size, args.cache_latents_to_disk, accelerator.is_main_process)
|
||||
vae.to("cpu")
|
||||
if torch.cuda.is_available():
|
||||
torch.cuda.empty_cache()
|
||||
gc.collect()
|
||||
clean_memory_on_device(accelerator.device)
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
@@ -280,18 +303,18 @@ def train(args):
|
||||
text_encoder.gradient_checkpointing_enable()
|
||||
|
||||
# 学習に必要なクラスを準備する
|
||||
print("prepare optimizer, data loader etc.")
|
||||
logger.info("prepare optimizer, data loader etc.")
|
||||
trainable_params = text_encoder.get_input_embeddings().parameters()
|
||||
_, _, optimizer = train_util.get_optimizer(args, trainable_params)
|
||||
|
||||
# dataloaderを準備する
|
||||
# DataLoaderのプロセス数:0はメインプロセスになる
|
||||
n_workers = min(args.max_data_loader_n_workers, os.cpu_count() - 1) # cpu_count-1 ただし最大で指定された数まで
|
||||
# DataLoaderのプロセス数:0 は persistent_workers が使えないので注意
|
||||
n_workers = min(args.max_data_loader_n_workers, os.cpu_count()) # cpu_count or max_data_loader_n_workers
|
||||
train_dataloader = torch.utils.data.DataLoader(
|
||||
train_dataset_group,
|
||||
batch_size=1,
|
||||
shuffle=True,
|
||||
collate_fn=collater,
|
||||
collate_fn=collator,
|
||||
num_workers=n_workers,
|
||||
persistent_workers=args.persistent_data_loader_workers,
|
||||
)
|
||||
@@ -301,7 +324,9 @@ def train(args):
|
||||
args.max_train_steps = args.max_train_epochs * math.ceil(
|
||||
len(train_dataloader) / accelerator.num_processes / args.gradient_accumulation_steps
|
||||
)
|
||||
print(f"override steps. steps for {args.max_train_epochs} epochs is / 指定エポックまでのステップ数: {args.max_train_steps}")
|
||||
logger.info(
|
||||
f"override steps. steps for {args.max_train_epochs} epochs is / 指定エポックまでのステップ数: {args.max_train_steps}"
|
||||
)
|
||||
|
||||
# データセット側にも学習ステップを送信
|
||||
train_dataset_group.set_max_train_steps(args.max_train_steps)
|
||||
@@ -315,8 +340,8 @@ def train(args):
|
||||
)
|
||||
|
||||
index_no_updates = torch.arange(len(tokenizer)) < token_ids_XTI[0]
|
||||
# print(len(index_no_updates), torch.sum(index_no_updates))
|
||||
orig_embeds_params = unwrap_model(text_encoder).get_input_embeddings().weight.data.detach().clone()
|
||||
# logger.info(len(index_no_updates), torch.sum(index_no_updates))
|
||||
orig_embeds_params = accelerator.unwrap_model(text_encoder).get_input_embeddings().weight.data.detach().clone()
|
||||
|
||||
# Freeze all parameters except for the token embeddings in text encoder
|
||||
text_encoder.requires_grad_(True)
|
||||
@@ -353,15 +378,17 @@ def train(args):
|
||||
|
||||
# 学習する
|
||||
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
|
||||
print("running training / 学習開始")
|
||||
print(f" num train images * repeats / 学習画像の数×繰り返し回数: {train_dataset_group.num_train_images}")
|
||||
print(f" num reg images / 正則化画像の数: {train_dataset_group.num_reg_images}")
|
||||
print(f" num batches per epoch / 1epochのバッチ数: {len(train_dataloader)}")
|
||||
print(f" num epochs / epoch数: {num_train_epochs}")
|
||||
print(f" batch size per device / バッチサイズ: {args.train_batch_size}")
|
||||
print(f" total train batch size (with parallel & distributed & accumulation) / 総バッチサイズ(並列学習、勾配合計含む): {total_batch_size}")
|
||||
print(f" gradient ccumulation steps / 勾配を合計するステップ数 = {args.gradient_accumulation_steps}")
|
||||
print(f" total optimization steps / 学習ステップ数: {args.max_train_steps}")
|
||||
logger.info("running training / 学習開始")
|
||||
logger.info(f" num train images * repeats / 学習画像の数×繰り返し回数: {train_dataset_group.num_train_images}")
|
||||
logger.info(f" num reg images / 正則化画像の数: {train_dataset_group.num_reg_images}")
|
||||
logger.info(f" num batches per epoch / 1epochのバッチ数: {len(train_dataloader)}")
|
||||
logger.info(f" num epochs / epoch数: {num_train_epochs}")
|
||||
logger.info(f" batch size per device / バッチサイズ: {args.train_batch_size}")
|
||||
logger.info(
|
||||
f" total train batch size (with parallel & distributed & accumulation) / 総バッチサイズ(並列学習、勾配合計含む): {total_batch_size}"
|
||||
)
|
||||
logger.info(f" gradient ccumulation steps / 勾配を合計するステップ数 = {args.gradient_accumulation_steps}")
|
||||
logger.info(f" total optimization steps / 学習ステップ数: {args.max_train_steps}")
|
||||
|
||||
progress_bar = tqdm(range(args.max_train_steps), smoothing=0, disable=not accelerator.is_local_main_process, desc="steps")
|
||||
global_step = 0
|
||||
@@ -369,12 +396,41 @@ def train(args):
|
||||
noise_scheduler = DDPMScheduler(
|
||||
beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000, clip_sample=False
|
||||
)
|
||||
prepare_scheduler_for_custom_training(noise_scheduler, accelerator.device)
|
||||
if args.zero_terminal_snr:
|
||||
custom_train_functions.fix_noise_scheduler_betas_for_zero_terminal_snr(noise_scheduler)
|
||||
|
||||
if accelerator.is_main_process:
|
||||
accelerator.init_trackers("textual_inversion" if args.log_tracker_name is None else args.log_tracker_name)
|
||||
init_kwargs = {}
|
||||
if args.wandb_run_name:
|
||||
init_kwargs["wandb"] = {"name": args.wandb_run_name}
|
||||
if args.log_tracker_config is not None:
|
||||
init_kwargs = toml.load(args.log_tracker_config)
|
||||
accelerator.init_trackers(
|
||||
"textual_inversion" if args.log_tracker_name is None else args.log_tracker_name, config=train_util.get_sanitized_config_or_none(args), init_kwargs=init_kwargs
|
||||
)
|
||||
|
||||
# function for saving/removing
|
||||
def save_model(ckpt_name, embs, steps, epoch_no, force_sync_upload=False):
|
||||
os.makedirs(args.output_dir, exist_ok=True)
|
||||
ckpt_file = os.path.join(args.output_dir, ckpt_name)
|
||||
|
||||
logger.info("")
|
||||
logger.info(f"saving checkpoint: {ckpt_file}")
|
||||
save_weights(ckpt_file, embs, save_dtype)
|
||||
if args.huggingface_repo_id is not None:
|
||||
huggingface_util.upload(args, ckpt_file, "/" + ckpt_name, force_sync_upload=force_sync_upload)
|
||||
|
||||
def remove_model(old_ckpt_name):
|
||||
old_ckpt_file = os.path.join(args.output_dir, old_ckpt_name)
|
||||
if os.path.exists(old_ckpt_file):
|
||||
logger.info(f"removing old checkpoint: {old_ckpt_file}")
|
||||
os.remove(old_ckpt_file)
|
||||
|
||||
# training loop
|
||||
for epoch in range(num_train_epochs):
|
||||
print(f"epoch {epoch+1}/{num_train_epochs}")
|
||||
logger.info("")
|
||||
logger.info(f"epoch {epoch+1}/{num_train_epochs}")
|
||||
current_epoch.value = epoch + 1
|
||||
|
||||
text_encoder.train()
|
||||
@@ -386,7 +442,7 @@ def train(args):
|
||||
with accelerator.accumulate(text_encoder):
|
||||
with torch.no_grad():
|
||||
if "latents" in batch and batch["latents"] is not None:
|
||||
latents = batch["latents"].to(accelerator.device)
|
||||
latents = batch["latents"].to(accelerator.device).to(dtype=weight_dtype)
|
||||
else:
|
||||
# latentに変換
|
||||
latents = vae.encode(batch["images"].to(dtype=weight_dtype)).latent_dist.sample()
|
||||
@@ -403,19 +459,9 @@ def train(args):
|
||||
]
|
||||
)
|
||||
|
||||
# Sample noise that we'll add to the latents
|
||||
noise = torch.randn_like(latents, device=latents.device)
|
||||
if args.noise_offset:
|
||||
# https://www.crosslabs.org//blog/diffusion-with-offset-noise
|
||||
noise += args.noise_offset * torch.randn((latents.shape[0], latents.shape[1], 1, 1), device=latents.device)
|
||||
|
||||
# Sample a random timestep for each image
|
||||
timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (b_size,), device=latents.device)
|
||||
timesteps = timesteps.long()
|
||||
|
||||
# Add noise to the latents according to the noise magnitude at each timestep
|
||||
# (this is the forward diffusion process)
|
||||
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
|
||||
# Sample noise, sample a random timestep for each image, and add noise to the latents,
|
||||
# with noise offset and/or multires noise if specified
|
||||
noise, noisy_latents, timesteps, huber_c = train_util.get_noise_noisy_latents_and_timesteps(args, noise_scheduler, latents)
|
||||
|
||||
# Predict the noise residual
|
||||
with accelerator.autocast():
|
||||
@@ -427,14 +473,20 @@ def train(args):
|
||||
else:
|
||||
target = noise
|
||||
|
||||
loss = torch.nn.functional.mse_loss(noise_pred.float(), target.float(), reduction="none")
|
||||
loss = train_util.conditional_loss(noise_pred.float(), target.float(), reduction="none", loss_type=args.loss_type, huber_c=huber_c)
|
||||
if args.masked_loss or ("alpha_masks" in batch and batch["alpha_masks"] is not None):
|
||||
loss = apply_masked_loss(loss, batch)
|
||||
loss = loss.mean([1, 2, 3])
|
||||
|
||||
if args.min_snr_gamma:
|
||||
loss = apply_snr_weight(loss, timesteps, noise_scheduler, args.min_snr_gamma)
|
||||
|
||||
loss_weights = batch["loss_weights"] # 各sampleごとのweight
|
||||
|
||||
loss = loss * loss_weights
|
||||
if args.min_snr_gamma:
|
||||
loss = apply_snr_weight(loss, timesteps, noise_scheduler, args.min_snr_gamma, args.v_parameterization)
|
||||
if args.scale_v_pred_loss_like_noise_pred:
|
||||
loss = scale_v_prediction_loss_like_noise_prediction(loss, timesteps, noise_scheduler)
|
||||
if args.debiased_estimation_loss:
|
||||
loss = apply_debiased_estimation(loss, timesteps, noise_scheduler, args.v_parameterization)
|
||||
|
||||
loss = loss.mean() # 平均なのでbatch_sizeで割る必要なし
|
||||
|
||||
@@ -449,7 +501,7 @@ def train(args):
|
||||
|
||||
# Let's make sure we don't update any embedding weights besides the newly added token
|
||||
with torch.no_grad():
|
||||
unwrap_model(text_encoder).get_input_embeddings().weight[index_no_updates] = orig_embeds_params[
|
||||
accelerator.unwrap_model(text_encoder).get_input_embeddings().weight[index_no_updates] = orig_embeds_params[
|
||||
index_no_updates
|
||||
]
|
||||
|
||||
@@ -462,10 +514,35 @@ def train(args):
|
||||
# accelerator, args, None, global_step, accelerator.device, vae, tokenizer, text_encoder, unet, prompt_replacement
|
||||
# )
|
||||
|
||||
# 指定ステップごとにモデルを保存
|
||||
if args.save_every_n_steps is not None and global_step % args.save_every_n_steps == 0:
|
||||
accelerator.wait_for_everyone()
|
||||
if accelerator.is_main_process:
|
||||
updated_embs = (
|
||||
accelerator.unwrap_model(text_encoder)
|
||||
.get_input_embeddings()
|
||||
.weight[token_ids_XTI]
|
||||
.data.detach()
|
||||
.clone()
|
||||
)
|
||||
|
||||
ckpt_name = train_util.get_step_ckpt_name(args, "." + args.save_model_as, global_step)
|
||||
save_model(ckpt_name, updated_embs, global_step, epoch)
|
||||
|
||||
if args.save_state:
|
||||
train_util.save_and_remove_state_stepwise(args, accelerator, global_step)
|
||||
|
||||
remove_step_no = train_util.get_remove_step_no(args, global_step)
|
||||
if remove_step_no is not None:
|
||||
remove_ckpt_name = train_util.get_step_ckpt_name(args, "." + args.save_model_as, remove_step_no)
|
||||
remove_model(remove_ckpt_name)
|
||||
|
||||
current_loss = loss.detach().item()
|
||||
if args.logging_dir is not None:
|
||||
logs = {"loss": current_loss, "lr": float(lr_scheduler.get_last_lr()[0])}
|
||||
if args.optimizer_type.lower() == "DAdaptation".lower(): # tracking d*lr value
|
||||
if (
|
||||
args.optimizer_type.lower().startswith("DAdapt".lower()) or args.optimizer_type.lower() == "Prodigy".lower()
|
||||
): # tracking d*lr value
|
||||
logs["lr/d*lr"] = (
|
||||
lr_scheduler.optimizers[0].param_groups[0]["d"] * lr_scheduler.optimizers[0].param_groups[0]["lr"]
|
||||
)
|
||||
@@ -485,29 +562,21 @@ def train(args):
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
updated_embs = unwrap_model(text_encoder).get_input_embeddings().weight[token_ids_XTI].data.detach().clone()
|
||||
updated_embs = accelerator.unwrap_model(text_encoder).get_input_embeddings().weight[token_ids_XTI].data.detach().clone()
|
||||
|
||||
if args.save_every_n_epochs is not None:
|
||||
model_name = train_util.DEFAULT_EPOCH_NAME if args.output_name is None else args.output_name
|
||||
saving = (epoch + 1) % args.save_every_n_epochs == 0 and (epoch + 1) < num_train_epochs
|
||||
if accelerator.is_main_process and saving:
|
||||
ckpt_name = train_util.get_epoch_ckpt_name(args, "." + args.save_model_as, epoch + 1)
|
||||
save_model(ckpt_name, updated_embs, epoch + 1, global_step)
|
||||
|
||||
def save_func():
|
||||
ckpt_name = train_util.EPOCH_FILE_NAME.format(model_name, epoch + 1) + "." + args.save_model_as
|
||||
ckpt_file = os.path.join(args.output_dir, ckpt_name)
|
||||
print(f"saving checkpoint: {ckpt_file}")
|
||||
save_weights(ckpt_file, updated_embs, save_dtype)
|
||||
if args.huggingface_repo_id is not None:
|
||||
huggingface_util.upload(args, ckpt_file, "/" + ckpt_name)
|
||||
remove_epoch_no = train_util.get_remove_epoch_no(args, epoch + 1)
|
||||
if remove_epoch_no is not None:
|
||||
remove_ckpt_name = train_util.get_epoch_ckpt_name(args, "." + args.save_model_as, remove_epoch_no)
|
||||
remove_model(remove_ckpt_name)
|
||||
|
||||
def remove_old_func(old_epoch_no):
|
||||
old_ckpt_name = train_util.EPOCH_FILE_NAME.format(model_name, old_epoch_no) + "." + args.save_model_as
|
||||
old_ckpt_file = os.path.join(args.output_dir, old_ckpt_name)
|
||||
if os.path.exists(old_ckpt_file):
|
||||
print(f"removing old checkpoint: {old_ckpt_file}")
|
||||
os.remove(old_ckpt_file)
|
||||
|
||||
saving = train_util.save_on_epoch_end(args, save_func, remove_old_func, epoch + 1, num_train_epochs)
|
||||
if saving and args.save_state:
|
||||
train_util.save_state_on_epoch_end(args, accelerator, model_name, epoch + 1)
|
||||
if args.save_state:
|
||||
train_util.save_and_remove_state_on_epoch_end(args, accelerator, epoch + 1)
|
||||
|
||||
# TODO: fix sample_images
|
||||
# train_util.sample_images(
|
||||
@@ -518,11 +587,11 @@ def train(args):
|
||||
|
||||
is_main_process = accelerator.is_main_process
|
||||
if is_main_process:
|
||||
text_encoder = unwrap_model(text_encoder)
|
||||
text_encoder = accelerator.unwrap_model(text_encoder)
|
||||
|
||||
accelerator.end_training()
|
||||
|
||||
if args.save_state:
|
||||
if is_main_process and (args.save_state or args.save_state_on_train_end):
|
||||
train_util.save_state_on_train_end(args, accelerator)
|
||||
|
||||
updated_embs = text_encoder.get_input_embeddings().weight[token_ids_XTI].data.detach().clone()
|
||||
@@ -530,17 +599,10 @@ def train(args):
|
||||
del accelerator # この後メモリを使うのでこれは消す
|
||||
|
||||
if is_main_process:
|
||||
os.makedirs(args.output_dir, exist_ok=True)
|
||||
ckpt_name = train_util.get_last_ckpt_name(args, "." + args.save_model_as)
|
||||
save_model(ckpt_name, updated_embs, global_step, num_train_epochs, force_sync_upload=True)
|
||||
|
||||
model_name = train_util.DEFAULT_LAST_OUTPUT_NAME if args.output_name is None else args.output_name
|
||||
ckpt_name = model_name + "." + args.save_model_as
|
||||
ckpt_file = os.path.join(args.output_dir, ckpt_name)
|
||||
|
||||
print(f"save trained model to {ckpt_file}")
|
||||
save_weights(ckpt_file, updated_embs, save_dtype)
|
||||
if args.huggingface_repo_id is not None:
|
||||
huggingface_util.upload(args, ckpt_file, "/" + ckpt_name, force_sync_upload=True)
|
||||
print("model saved.")
|
||||
logger.info("model saved.")
|
||||
|
||||
|
||||
def save_weights(file, updated_embs, save_dtype):
|
||||
@@ -601,9 +663,12 @@ def load_weights(file):
|
||||
def setup_parser() -> argparse.ArgumentParser:
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
add_logging_arguments(parser)
|
||||
train_util.add_sd_models_arguments(parser)
|
||||
train_util.add_dataset_arguments(parser, True, True, False)
|
||||
train_util.add_training_arguments(parser, True)
|
||||
train_util.add_masked_loss_arguments(parser)
|
||||
deepspeed_utils.add_deepspeed_arguments(parser)
|
||||
train_util.add_optimizer_arguments(parser)
|
||||
config_util.add_config_arguments(parser)
|
||||
custom_train_functions.add_custom_train_arguments(parser, False)
|
||||
@@ -616,7 +681,9 @@ def setup_parser() -> argparse.ArgumentParser:
|
||||
help="format to save the model (default is .pt) / モデル保存時の形式(デフォルトはpt)",
|
||||
)
|
||||
|
||||
parser.add_argument("--weights", type=str, default=None, help="embedding weights to initialize / 学習するネットワークの初期重み")
|
||||
parser.add_argument(
|
||||
"--weights", type=str, default=None, help="embedding weights to initialize / 学習するネットワークの初期重み"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--num_vectors_per_token", type=int, default=1, help="number of vectors per token / トークンに割り当てるembeddingsの要素数"
|
||||
)
|
||||
@@ -626,7 +693,9 @@ def setup_parser() -> argparse.ArgumentParser:
|
||||
default=None,
|
||||
help="token string used in training, must not exist in tokenizer / 学習時に使用されるトークン文字列、tokenizerに存在しない文字であること",
|
||||
)
|
||||
parser.add_argument("--init_word", type=str, default=None, help="words to initialize vector / ベクトルを初期化に使用する単語、複数可")
|
||||
parser.add_argument(
|
||||
"--init_word", type=str, default=None, help="words to initialize vector / ベクトルを初期化に使用する単語、複数可"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--use_object_template",
|
||||
action="store_true",
|
||||
@@ -645,6 +714,7 @@ if __name__ == "__main__":
|
||||
parser = setup_parser()
|
||||
|
||||
args = parser.parse_args()
|
||||
train_util.verify_command_line_training_args(args)
|
||||
args = train_util.read_config_from_file(args, parser)
|
||||
|
||||
train(args)
|
||||
|
||||
Reference in New Issue
Block a user