mirror of
https://github.com/kohya-ss/sd-scripts.git
synced 2026-04-06 21:52:27 +00:00
Compare commits
380 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
b80431de30 | ||
|
|
b177460807 | ||
|
|
c78c51c78f | ||
|
|
2652c9a66c | ||
|
|
618592c52b | ||
|
|
75d1883da6 | ||
|
|
4ad8e75291 | ||
|
|
e355b5e1d3 | ||
|
|
68cd874bb6 | ||
|
|
00a9d734d9 | ||
|
|
458173da5e | ||
|
|
1932c31c66 | ||
|
|
dd05d99efd | ||
|
|
cf2bc437ec | ||
|
|
aa317d4f57 | ||
|
|
51249b1ba0 | ||
|
|
e7051d427c | ||
|
|
b885c6f9d2 | ||
|
|
ad443e172a | ||
|
|
c4b4d1cb40 | ||
|
|
82aac26469 | ||
|
|
3ce846525b | ||
|
|
8929bf31d9 | ||
|
|
87846c043f | ||
|
|
7b0af4f382 | ||
|
|
225c533279 | ||
|
|
8d5ba29363 | ||
|
|
19386df6e9 | ||
|
|
5bb571ccc0 | ||
|
|
0cacefc749 | ||
|
|
573aa8b5e7 | ||
|
|
c2a8290965 | ||
|
|
772ee52ef2 | ||
|
|
46aee85d2a | ||
|
|
2ae33db83f | ||
|
|
1c00764d01 | ||
|
|
2ba6d74af8 | ||
|
|
dd39e5d944 | ||
|
|
db8c79c463 | ||
|
|
2b6e9d83fa | ||
|
|
4d9292e50a | ||
|
|
4a4450d6b6 | ||
|
|
fe4f4446f1 | ||
|
|
214ed092f2 | ||
|
|
4396350271 | ||
|
|
80be6fa130 | ||
|
|
45945f698a | ||
|
|
08fcc7b31c | ||
|
|
74f317abf8 | ||
|
|
5602e0e5fc | ||
|
|
2d2407410e | ||
|
|
09f575fd4d | ||
|
|
859f8361bb | ||
|
|
c3024be8bf | ||
|
|
7e1aa5f4d6 | ||
|
|
83bfb54f20 | ||
|
|
52ca6c515c | ||
|
|
e9f37c4049 | ||
|
|
c95943b663 | ||
|
|
04af36e7e2 | ||
|
|
d1d7d432e9 | ||
|
|
089a63c573 | ||
|
|
ed19a92bbe | ||
|
|
8abb8645ae | ||
|
|
efe4c98341 | ||
|
|
82707654ad | ||
|
|
57c565c402 | ||
|
|
dd523c94ff | ||
|
|
a28f9ae7a3 | ||
|
|
9993792656 | ||
|
|
f0ae7eea95 | ||
|
|
b22b0a5c75 | ||
|
|
c7a13c89c7 | ||
|
|
39a70f10bd | ||
|
|
a3c0e4cf44 | ||
|
|
9b13444b9c | ||
|
|
0eb01dea55 | ||
|
|
a3aa3b1712 | ||
|
|
95b5aed41b | ||
|
|
d9184ab21c | ||
|
|
e7dd77836d | ||
|
|
4c5c486d28 | ||
|
|
f403ac6132 | ||
|
|
b39cf6e2c0 | ||
|
|
71b728d5fc | ||
|
|
f0ef81f865 | ||
|
|
f68a48b354 | ||
|
|
7a0d2a2d45 | ||
|
|
e13e503cbc | ||
|
|
125039f491 | ||
|
|
f2b300a221 | ||
|
|
9ab964d0b8 | ||
|
|
663aad2b0d | ||
|
|
12d30afb39 | ||
|
|
107fa754e5 | ||
|
|
a17d1180cb | ||
|
|
014fd3d037 | ||
|
|
b29c5a750c | ||
|
|
b612d0b091 | ||
|
|
d94c0d70fe | ||
|
|
045a3dbe48 | ||
|
|
08ae46b163 | ||
|
|
4e5db58a71 | ||
|
|
e45e272e9d | ||
|
|
a9d29ac78c | ||
|
|
5c065eee79 | ||
|
|
048e7cd428 | ||
|
|
a76ad2d1d5 | ||
|
|
9d0f9736bf | ||
|
|
00bb8a65a6 | ||
|
|
dac2bd163a | ||
|
|
78d1fb5ce6 | ||
|
|
14d7b24619 | ||
|
|
3bc0d83769 | ||
|
|
ffdfd5f615 | ||
|
|
d01d953262 | ||
|
|
914d1505df | ||
|
|
8590d5dbca | ||
|
|
496c8cdc09 | ||
|
|
39aa390d2b | ||
|
|
82713e9aa6 | ||
|
|
e067d64b53 | ||
|
|
3d400667d2 | ||
|
|
2aef2872fb | ||
|
|
43c0a69843 | ||
|
|
8aed5125de | ||
|
|
e0f007f2a9 | ||
|
|
3c29784825 | ||
|
|
8f1e930bf4 | ||
|
|
f771396e90 | ||
|
|
f67b3f4452 | ||
|
|
21f5b618c3 | ||
|
|
64bffe5238 | ||
|
|
cebee02698 | ||
|
|
5471b0deb0 | ||
|
|
bc9fc4ccee | ||
|
|
2b1a3080e7 | ||
|
|
92a1af8024 | ||
|
|
b35b053b8d | ||
|
|
55521eece0 | ||
|
|
b32abdd327 | ||
|
|
d1ecfde487 | ||
|
|
04ad46a9a7 | ||
|
|
4c561411aa | ||
|
|
43a41c6c43 | ||
|
|
5367daa210 | ||
|
|
b825e4602c | ||
|
|
188e54b760 | ||
|
|
2c5f5c324a | ||
|
|
5777be5208 | ||
|
|
e727a0d222 | ||
|
|
cdd8882a01 | ||
|
|
3f3502fb57 | ||
|
|
20c00603a8 | ||
|
|
9239fefa52 | ||
|
|
53d60543e5 | ||
|
|
22e3aca89c | ||
|
|
8d86f58174 | ||
|
|
e5cc64a563 | ||
|
|
c7406d6b27 | ||
|
|
d2da3c4236 | ||
|
|
2bad87f2f6 | ||
|
|
ed62e566bb | ||
|
|
51b3dc2c11 | ||
|
|
74f4a8fab9 | ||
|
|
a75baf9143 | ||
|
|
b03721b4d9 | ||
|
|
6b790bace6 | ||
|
|
dcaecfd20b | ||
|
|
553ac4aa1b | ||
|
|
f0c8c95871 | ||
|
|
c2e1d4b71b | ||
|
|
3a72e6f003 | ||
|
|
f7b5abb595 | ||
|
|
b8ad17902f | ||
|
|
9a9ac79edf | ||
|
|
6473aa1dd7 | ||
|
|
b599adc938 | ||
|
|
5e96e1369d | ||
|
|
c0be52a773 | ||
|
|
fb312acb7f | ||
|
|
938bd71844 | ||
|
|
b3020db63f | ||
|
|
e42b2f7aa9 | ||
|
|
f9478f0d47 | ||
|
|
4fc9f1f8c5 | ||
|
|
5a3d1a57b6 | ||
|
|
7db98baa86 | ||
|
|
d591891048 | ||
|
|
3a93d18bb5 | ||
|
|
7511674333 | ||
|
|
883bd1269c | ||
|
|
2aa27b7a4b | ||
|
|
5ea5fefcd2 | ||
|
|
6a79ac6a03 | ||
|
|
ea2dfd09ef | ||
|
|
7380801dfc | ||
|
|
ae33d72479 | ||
|
|
19c2752e87 | ||
|
|
d80af9c17b | ||
|
|
fb230aff1b | ||
|
|
8cbd3f4fca | ||
|
|
b18db9fbbd | ||
|
|
b1635f4bf6 | ||
|
|
44013fe0ef | ||
|
|
9fd7fb813d | ||
|
|
89a9d3a92c | ||
|
|
9682772b09 | ||
|
|
b18a09edb5 | ||
|
|
c086e85d17 | ||
|
|
26efa88908 | ||
|
|
1bec2bfe07 | ||
|
|
76f53429be | ||
|
|
73d612ff9c | ||
|
|
58a809eaff | ||
|
|
93134cdd15 | ||
|
|
b7e7ee387a | ||
|
|
57d8483eaf | ||
|
|
949ee6fcc9 | ||
|
|
26a81d075c | ||
|
|
8c3a52ecc9 | ||
|
|
86f4e20337 | ||
|
|
9abbee0632 | ||
|
|
74eba06d13 | ||
|
|
4e1acc62f9 | ||
|
|
c20745b6e8 | ||
|
|
4cabb37977 | ||
|
|
86eba1d2cf | ||
|
|
05940940c0 | ||
|
|
6bbb4d426e | ||
|
|
7817e95a86 | ||
|
|
443ce7a30b | ||
|
|
ed2e431950 | ||
|
|
0fef7b4684 | ||
|
|
67e698af67 | ||
|
|
7c35aee042 | ||
|
|
481823796e | ||
|
|
835b0d54cd | ||
|
|
505768ea86 | ||
|
|
1614d30d1b | ||
|
|
25566182a8 | ||
|
|
6dffc88b44 | ||
|
|
64d5ceda71 | ||
|
|
e8806f29dc | ||
|
|
2ce9ad235c | ||
|
|
3fb12e41b7 | ||
|
|
591e3c1813 | ||
|
|
b5ba463512 | ||
|
|
e0d7f1d99d | ||
|
|
a68501bede | ||
|
|
c425afb08b | ||
|
|
46029b2707 | ||
|
|
02acae8e1d | ||
|
|
91a50ea637 | ||
|
|
9f644d8dc3 | ||
|
|
36dc97c841 | ||
|
|
e6bad080cb | ||
|
|
7f17237ada | ||
|
|
ebd3ea380c | ||
|
|
bf3a13bb4e | ||
|
|
1a170c4762 | ||
|
|
552cdbd6d8 | ||
|
|
a86514f1ad | ||
|
|
2e8a3d20dd | ||
|
|
66051883fb | ||
|
|
f7fbdc4b2a | ||
|
|
00f1296537 | ||
|
|
ebdb624d29 | ||
|
|
93df55d597 | ||
|
|
56bc806d52 | ||
|
|
25f8ac731f | ||
|
|
4ba1667978 | ||
|
|
0ca064287e | ||
|
|
a3171714ce | ||
|
|
4a1668fe37 | ||
|
|
4eb356f165 | ||
|
|
a7218574f2 | ||
|
|
ddfe94b33b | ||
|
|
8746188ed7 | ||
|
|
1bfcf164f1 | ||
|
|
d3bc5a1413 | ||
|
|
6e279730cf | ||
|
|
5e817e4343 | ||
|
|
b4636d4185 | ||
|
|
22ee0ac467 | ||
|
|
17089b1287 | ||
|
|
7ee808d5d7 | ||
|
|
9ff26af68b | ||
|
|
7dbcef745a | ||
|
|
cae42728ab | ||
|
|
50f65d683d | ||
|
|
0fc1cc8076 | ||
|
|
943eae1211 | ||
|
|
4c928c8d12 | ||
|
|
687044519b | ||
|
|
758323532b | ||
|
|
8bd844cdc1 | ||
|
|
4d4ebf600e | ||
|
|
e6a8c9d269 | ||
|
|
da48f74e7b | ||
|
|
e5d9f483f0 | ||
|
|
303c3410e2 | ||
|
|
de1dde1a06 | ||
|
|
3eb8fb1875 | ||
|
|
fda66db0d8 | ||
|
|
3815b82bef | ||
|
|
37fbefb3cd | ||
|
|
c6e28faa57 | ||
|
|
a888223869 | ||
|
|
d30ea7966d | ||
|
|
df9cb2f11c | ||
|
|
8544e219b0 | ||
|
|
186a2665ad | ||
|
|
f2f2ce0d7d | ||
|
|
c9fda104b4 | ||
|
|
aa40cb9345 | ||
|
|
b8734405c6 | ||
|
|
c2c1261b43 | ||
|
|
48110bcb23 | ||
|
|
60e5793d5e | ||
|
|
98b0cf0b3d | ||
|
|
88515c2985 | ||
|
|
89f5b3b8e6 | ||
|
|
61ec60a893 | ||
|
|
199a3cbae4 | ||
|
|
74eb43190e | ||
|
|
5851b2b773 | ||
|
|
e4695e9359 | ||
|
|
dfeadf9e52 | ||
|
|
b3d3f0c8ac | ||
|
|
4fe1dd6a1c | ||
|
|
95ee349e2a | ||
|
|
a75fd3964a | ||
|
|
29c9008e07 | ||
|
|
bf691aef69 | ||
|
|
807bdf9cc9 | ||
|
|
eba142ccb2 | ||
|
|
c1b14fcdd6 | ||
|
|
9fd91d26a3 | ||
|
|
9622082eb8 | ||
|
|
e4f9b2b715 | ||
|
|
895a599d34 | ||
|
|
58d24ba254 | ||
|
|
974674242e | ||
|
|
de37fd9906 | ||
|
|
0c4423d9dc | ||
|
|
2e4ce0fdff | ||
|
|
f981dfd38a | ||
|
|
a84ca297bd | ||
|
|
673f9ced47 | ||
|
|
c5aae65003 | ||
|
|
d8da85b38b | ||
|
|
c4bc435bc4 | ||
|
|
4a7b814700 | ||
|
|
223640e1ae | ||
|
|
fbaf373c8a | ||
|
|
6b62c44022 | ||
|
|
1945fa186d | ||
|
|
82e585cf01 | ||
|
|
80af4c0c42 | ||
|
|
9f1d3aca24 | ||
|
|
2efced0a9a | ||
|
|
40d1bf3809 | ||
|
|
4735b21318 | ||
|
|
fac1813ac0 | ||
|
|
cbfe8126d6 | ||
|
|
54928fac7b | ||
|
|
39a0293800 | ||
|
|
4dd22f4dc8 | ||
|
|
1b222dbf9b | ||
|
|
d62725b644 | ||
|
|
dcd101b3d5 | ||
|
|
f56988b252 | ||
|
|
6d10233a53 | ||
|
|
4c35006731 | ||
|
|
e31177adf3 | ||
|
|
6b522b34c1 | ||
|
|
305bda2928 | ||
|
|
85d8b49129 | ||
|
|
61a61c51ee |
21
.github/workflows/typos.yml
vendored
Normal file
21
.github/workflows/typos.yml
vendored
Normal file
@@ -0,0 +1,21 @@
|
||||
---
|
||||
# yamllint disable rule:line-length
|
||||
name: Typos
|
||||
|
||||
on: # yamllint disable-line rule:truthy
|
||||
push:
|
||||
pull_request:
|
||||
types:
|
||||
- opened
|
||||
- synchronize
|
||||
- reopened
|
||||
|
||||
jobs:
|
||||
build:
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v3
|
||||
|
||||
- name: typos-action
|
||||
uses: crate-ci/typos@v1.13.10
|
||||
3
.gitignore
vendored
3
.gitignore
vendored
@@ -3,4 +3,5 @@ __pycache__
|
||||
wd14_tagger_model
|
||||
venv
|
||||
*.egg-info
|
||||
build
|
||||
build
|
||||
.vscode
|
||||
46
README-ja.md
46
README-ja.md
@@ -1,7 +1,7 @@
|
||||
## リポジトリについて
|
||||
Stable Diffusionの学習、画像生成、その他のスクリプトを入れたリポジトリです。
|
||||
|
||||
[README in English](./README.md)
|
||||
[README in English](./README.md) ←更新情報はこちらにあります
|
||||
|
||||
GUIやPowerShellスクリプトなど、より使いやすくする機能が[bmaltais氏のリポジトリ](https://github.com/bmaltais/kohya_ss)で提供されています(英語です)のであわせてご覧ください。bmaltais氏に感謝します。
|
||||
|
||||
@@ -16,9 +16,12 @@ GUIやPowerShellスクリプトなど、より使いやすくする機能が[bma
|
||||
|
||||
当リポジトリ内およびnote.comに記事がありますのでそちらをご覧ください(将来的にはすべてこちらへ移すかもしれません)。
|
||||
|
||||
* note.com [環境整備とDreamBooth学習スクリプトについて](https://note.com/kohya_ss/n/nba4eceaa4594)
|
||||
* [学習について、共通編](./train_README-ja.md) : データ整備やオプションなど
|
||||
* [データセット設定](./config_README-ja.md)
|
||||
* [DreamBoothの学習について](./train_db_README-ja.md)
|
||||
* [fine-tuningのガイド](./fine_tune_README_ja.md):
|
||||
BLIPによるキャプショニングと、DeepDanbooruまたはWD14 taggerによるタグ付けを含みます
|
||||
* [LoRAの学習について](./train_network_README-ja.md)
|
||||
* [Textual Inversionの学習について](./train_ti_README-ja.md)
|
||||
* note.com [画像生成スクリプト](https://note.com/kohya_ss/n/n2693183a798e)
|
||||
* note.com [モデル変換スクリプト](https://note.com/kohya_ss/n/n374f316fe4ad)
|
||||
|
||||
@@ -44,12 +47,11 @@ PowerShellを使う場合、venvを使えるようにするためには以下の
|
||||
|
||||
通常の(管理者ではない)PowerShellを開き以下を順に実行します。
|
||||
|
||||
|
||||
```powershell
|
||||
git clone https://github.com/kohya-ss/sd-scripts.git
|
||||
cd sd-scripts
|
||||
|
||||
python -m venv --system-site-packages venv
|
||||
python -m venv venv
|
||||
.\venv\Scripts\activate
|
||||
|
||||
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
|
||||
@@ -63,6 +65,12 @@ cp .\bitsandbytes_windows\main.py .\venv\Lib\site-packages\bitsandbytes\cuda_set
|
||||
accelerate config
|
||||
```
|
||||
|
||||
<!--
|
||||
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117
|
||||
pip install --use-pep517 --upgrade -r requirements.txt
|
||||
pip install -U -I --no-deps xformers==0.0.16
|
||||
-->
|
||||
|
||||
コマンドプロンプトでは以下になります。
|
||||
|
||||
|
||||
@@ -70,7 +78,7 @@ accelerate config
|
||||
git clone https://github.com/kohya-ss/sd-scripts.git
|
||||
cd sd-scripts
|
||||
|
||||
python -m venv --system-site-packages venv
|
||||
python -m venv venv
|
||||
.\venv\Scripts\activate
|
||||
|
||||
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
|
||||
@@ -84,19 +92,29 @@ copy /y .\bitsandbytes_windows\main.py .\venv\Lib\site-packages\bitsandbytes\cud
|
||||
accelerate config
|
||||
```
|
||||
|
||||
(注:``python -m venv venv`` のほうが ``python -m venv --system-site-packages venv`` より安全そうなため書き換えました。globalなpythonにパッケージがインストールしてあると、後者だといろいろと問題が起きます。)
|
||||
|
||||
accelerate configの質問には以下のように答えてください。(bf16で学習する場合、最後の質問にはbf16と答えてください。)
|
||||
|
||||
※0.15.0から日本語環境では選択のためにカーソルキーを押すと落ちます(……)。数字キーの0、1、2……で選択できますので、そちらを使ってください。
|
||||
|
||||
```txt
|
||||
- 0
|
||||
- 0
|
||||
- This machine
|
||||
- No distributed training
|
||||
- NO
|
||||
- NO
|
||||
- All
|
||||
- NO
|
||||
- all
|
||||
- fp16
|
||||
```
|
||||
|
||||
※場合によって ``ValueError: fp16 mixed precision requires a GPU`` というエラーが出ることがあるようです。この場合、6番目の質問(
|
||||
``What GPU(s) (by id) should be used for training on this machine as a comma-separated list? [all]:``)に「0」と答えてください。(id `0`のGPUが使われます。)
|
||||
|
||||
### PyTorchとxformersのバージョンについて
|
||||
|
||||
他のバージョンでは学習がうまくいかない場合があるようです。特に他の理由がなければ指定のバージョンをお使いください。
|
||||
|
||||
## アップグレード
|
||||
|
||||
新しいリリースがあった場合、以下のコマンドで更新できます。
|
||||
@@ -105,14 +123,20 @@ accelerate configの質問には以下のように答えてください。(bf1
|
||||
cd sd-scripts
|
||||
git pull
|
||||
.\venv\Scripts\activate
|
||||
pip install --upgrade -r <requirement file name>
|
||||
pip install --use-pep517 --upgrade -r requirements.txt
|
||||
```
|
||||
|
||||
コマンドが成功すれば新しいバージョンが使用できます。
|
||||
|
||||
## 謝意
|
||||
|
||||
LoRAの実装は[cloneofsimo氏のリポジトリ](https://github.com/cloneofsimo/lora)を基にしたものです。感謝申し上げます。
|
||||
|
||||
Conv2d 3x3への拡大は [cloneofsimo氏](https://github.com/cloneofsimo/lora) が最初にリリースし、KohakuBlueleaf氏が [LoCon](https://github.com/KohakuBlueleaf/LoCon) でその有効性を明らかにしたものです。KohakuBlueleaf氏に深く感謝します。
|
||||
|
||||
## ライセンス
|
||||
|
||||
スクリプトのライセンスはASL 2.0ですが、一部他のライセンスのコードを含みます。
|
||||
スクリプトのライセンスはASL 2.0ですが(Diffusersおよびcloneofsimo氏のリポジトリ由来のものも同様)、一部他のライセンスのコードを含みます。
|
||||
|
||||
[Memory Efficient Attention Pytorch](https://github.com/lucidrains/memory-efficient-attention-pytorch): MIT
|
||||
|
||||
|
||||
153
README.md
153
README.md
@@ -1,5 +1,8 @@
|
||||
This repository contains training, generation and utility scripts for Stable Diffusion.
|
||||
|
||||
[__Change History__](#change-history) is moved to the bottom of the page.
|
||||
更新履歴は[ページ末尾](#change-history)に移しました。
|
||||
|
||||
[日本語版README](./README-ja.md)
|
||||
|
||||
For easier use (GUI and PowerShell scripts etc...), please visit [the repository maintained by bmaltais](https://github.com/bmaltais/kohya_ss). Thanks to @bmaltais!
|
||||
@@ -7,9 +10,13 @@ For easier use (GUI and PowerShell scripts etc...), please visit [the repository
|
||||
This repository contains the scripts for:
|
||||
|
||||
* DreamBooth training, including U-Net and Text Encoder
|
||||
* fine-tuning (native training), including U-Net and Text Encoder
|
||||
* image generation
|
||||
* model conversion (supports 1.x and 2.x, Stable Diffision ckpt/safetensors and Diffusers)
|
||||
* Fine-tuning (native training), including U-Net and Text Encoder
|
||||
* LoRA training
|
||||
* Texutl Inversion training
|
||||
* Image generation
|
||||
* Model conversion (supports 1.x and 2.x, Stable Diffision ckpt/safetensors and Diffusers)
|
||||
|
||||
__Stable Diffusion web UI now seems to support LoRA trained by ``sd-scripts``.__ (SD 1.x based only) Thank you for great work!!!
|
||||
|
||||
## About requirements.txt
|
||||
|
||||
@@ -19,12 +26,14 @@ The scripts are tested with PyTorch 1.12.1 and 1.13.0, Diffusers 0.10.2.
|
||||
|
||||
## Links to how-to-use documents
|
||||
|
||||
All documents are in Japanese currently, and CUI based.
|
||||
All documents are in Japanese currently.
|
||||
|
||||
* note.com [Environment setup and DreamBooth training guide](https://note.com/kohya_ss/n/nba4eceaa4594)
|
||||
* [Training guide - common](./train_README-ja.md) : data preparation, options etc...
|
||||
* [Dataset config](./config_README-ja.md)
|
||||
* [DreamBooth training guide](./train_db_README-ja.md)
|
||||
* [Step by Step fine-tuning guide](./fine_tune_README_ja.md):
|
||||
Including BLIP captioning and tagging by DeepDanbooru or WD14 tagger
|
||||
* [training LoRA](./train_network_README-ja.md)
|
||||
* [training Textual Inversion](./train_ti_README-ja.md)
|
||||
* note.com [Image generation](https://note.com/kohya_ss/n/n2693183a798e)
|
||||
* note.com [Model conversion](https://note.com/kohya_ss/n/n374f316fe4ad)
|
||||
|
||||
@@ -49,7 +58,7 @@ Open a regular Powershell terminal and type the following inside:
|
||||
git clone https://github.com/kohya-ss/sd-scripts.git
|
||||
cd sd-scripts
|
||||
|
||||
python -m venv --system-site-packages venv
|
||||
python -m venv venv
|
||||
.\venv\Scripts\activate
|
||||
|
||||
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
|
||||
@@ -61,20 +70,32 @@ cp .\bitsandbytes_windows\cextension.py .\venv\Lib\site-packages\bitsandbytes\ce
|
||||
cp .\bitsandbytes_windows\main.py .\venv\Lib\site-packages\bitsandbytes\cuda_setup\main.py
|
||||
|
||||
accelerate config
|
||||
|
||||
```
|
||||
|
||||
update: ``python -m venv venv`` is seemed to be safer than ``python -m venv --system-site-packages venv`` (some user have packages in global python).
|
||||
|
||||
Answers to accelerate config:
|
||||
|
||||
```txt
|
||||
- 0
|
||||
- 0
|
||||
- This machine
|
||||
- No distributed training
|
||||
- NO
|
||||
- NO
|
||||
- All
|
||||
- NO
|
||||
- all
|
||||
- fp16
|
||||
```
|
||||
|
||||
note: Some user reports ``ValueError: fp16 mixed precision requires a GPU`` is occurred in training. In this case, answer `0` for the 6th question:
|
||||
``What GPU(s) (by id) should be used for training on this machine as a comma-separated list? [all]:``
|
||||
|
||||
(Single GPU with id `0` will be used.)
|
||||
|
||||
### about PyTorch and xformers
|
||||
|
||||
Other versions of PyTorch and xformers seem to have problems with training.
|
||||
If there is no other reason, please install the specified version.
|
||||
|
||||
## Upgrade
|
||||
|
||||
When a new release comes out you can upgrade your repo with the following command:
|
||||
@@ -83,14 +104,20 @@ When a new release comes out you can upgrade your repo with the following comman
|
||||
cd sd-scripts
|
||||
git pull
|
||||
.\venv\Scripts\activate
|
||||
pip install --upgrade -r requirements.txt
|
||||
pip install --use-pep517 --upgrade -r requirements.txt
|
||||
```
|
||||
|
||||
Once the commands have completed successfully you should be ready to use the new version.
|
||||
|
||||
## Credits
|
||||
|
||||
The implementation for LoRA is based on [cloneofsimo's repo](https://github.com/cloneofsimo/lora). Thank you for great work!
|
||||
|
||||
The LoRA expansion to Conv2d 3x3 was initially released by cloneofsimo and its effectiveness was demonstrated at [LoCon](https://github.com/KohakuBlueleaf/LoCon) by KohakuBlueleaf. Thank you so much KohakuBlueleaf!
|
||||
|
||||
## License
|
||||
|
||||
The majority of scripts is licensed under ASL 2.0 (including codes from Diffusers), however portions of the project are available under separate license terms:
|
||||
The majority of scripts is licensed under ASL 2.0 (including codes from Diffusers, cloneofsimo's and LoCon), however portions of the project are available under separate license terms:
|
||||
|
||||
[Memory Efficient Attention Pytorch](https://github.com/lucidrains/memory-efficient-attention-pytorch): MIT
|
||||
|
||||
@@ -98,3 +125,103 @@ The majority of scripts is licensed under ASL 2.0 (including codes from Diffuser
|
||||
|
||||
[BLIP](https://github.com/salesforce/BLIP): BSD-3-Clause
|
||||
|
||||
## Change History
|
||||
|
||||
- 10 Mar. 2023, 2023/3/10: release v0.5.1
|
||||
- Fix to LoRA modules in the model are same to the previous (before 0.5.0) if Conv2d-3x3 is disabled (no `conv_dim` arg, default).
|
||||
- Conv2D with kernel size 1x1 in ResNet modules were accidentally included in v0.5.0.
|
||||
- Trained models with v0.5.0 will work with Web UI's built-in LoRA and Additional Networks extension.
|
||||
- Fix an issue that dim (rank) of LoRA module is limited to the in/out dimensions of the target Linear/Conv2d (in case of the dim > 320).
|
||||
- `resize_lora.py` now have a feature to `dynamic resizing` which means each LoRA module can have different ranks (dims). Thanks to mgz-dev for this great work!
|
||||
- The appropriate rank is selected based on the complexity of each module with an algorithm specified in the command line arguments. For details: https://github.com/kohya-ss/sd-scripts/pull/243
|
||||
- Multiple GPUs training is finally supported in `train_network.py`. Thanks to ddPn08 to solve this long running issue!
|
||||
- Dataset with fine-tuning method (with metadata json) now works without images if `.npz` files exist. Thanks to rvhfxb!
|
||||
- `train_network.py` can work if the current directory is not the directory where the script is in. Thanks to mio2333!
|
||||
- Fix `extract_lora_from_models.py` and `svd_merge_lora.py` doesn't work with higher rank (>320).
|
||||
|
||||
- LoRAのConv2d-3x3拡張を行わない場合(`conv_dim` を指定しない場合)、以前(v0.5.0)と同じ構成になるよう修正しました。
|
||||
- ResNetのカーネルサイズ1x1のConv2dが誤って対象になっていました。
|
||||
- ただv0.5.0で学習したモデルは Additional Networks 拡張、およびWeb UIのLoRA機能で問題なく使えると思われます。
|
||||
- LoRAモジュールの dim (rank) が、対象モジュールの次元数以下に制限される不具合を修正しました(320より大きい dim を指定した場合)。
|
||||
- `resize_lora.py` に `dynamic resizing` (リサイズ後の各LoRAモジュールが異なるrank (dim) を持てる機能)を追加しました。mgz-dev 氏の貢献に感謝します。
|
||||
- 適切なランクがコマンドライン引数で指定したアルゴリズムにより自動的に選択されます。詳細はこちらをご覧ください: https://github.com/kohya-ss/sd-scripts/pull/243
|
||||
- `train_network.py` でマルチGPU学習をサポートしました。長年の懸案を解決された ddPn08 氏に感謝します。
|
||||
- fine-tuning方式のデータセット(メタデータ.jsonファイルを使うデータセット)で `.npz` が存在するときには画像がなくても動作するようになりました。rvhfxb 氏に感謝します。
|
||||
- 他のディレクトリから `train_network.py` を呼び出しても動作するよう変更しました。 mio2333 氏に感謝します。
|
||||
- `extract_lora_from_models.py` および `svd_merge_lora.py` が320より大きいrankを指定すると動かない不具合を修正しました。
|
||||
|
||||
- 9 Mar. 2023, 2023/3/9: release v0.5.0
|
||||
- There may be problems due to major changes. If you cannot revert back to the previous version when problems occur, please do not update for a while.
|
||||
- Minimum metadata (module name, dim, alpha and network_args) is recorded even with `--no_metadata`, issue https://github.com/kohya-ss/sd-scripts/issues/254
|
||||
- `train_network.py` supports LoRA for Conv2d-3x3 (extended to conv2d with a kernel size not 1x1).
|
||||
- Same as a current version of [LoCon](https://github.com/KohakuBlueleaf/LoCon). __Thank you very much KohakuBlueleaf for your help!__
|
||||
- LoCon will be enhanced in the future. Compatibility for future versions is not guaranteed.
|
||||
- Specify `--network_args` option like: `--network_args "conv_dim=4" "conv_alpha=1"`
|
||||
- [Additional Networks extension](https://github.com/kohya-ss/sd-webui-additional-networks) version 0.5.0 or later is required to use 'LoRA for Conv2d-3x3' in Stable Diffusion web UI.
|
||||
- __Stable Diffusion web UI built-in LoRA does not support 'LoRA for Conv2d-3x3' now. Consider carefully whether or not to use it.__
|
||||
- Merging/extracting scripts also support LoRA for Conv2d-3x3.
|
||||
- Free CUDA memory after sample generation to reduce VRAM usage, issue https://github.com/kohya-ss/sd-scripts/issues/260
|
||||
- Empty caption doesn't cause error now, issue https://github.com/kohya-ss/sd-scripts/issues/258
|
||||
- Fix sample generation is crashing in Textual Inversion training when using templates, or if height/width is not divisible by 8.
|
||||
- Update documents (Japanese only).
|
||||
|
||||
- 大きく変更したため不具合があるかもしれません。問題が起きた時にスクリプトを前のバージョンに戻せない場合は、しばらく更新を控えてください。
|
||||
- 最低限のメタデータ(module name, dim, alpha および network_args)が `--no_metadata` オプション指定時にも記録されます。issue https://github.com/kohya-ss/sd-scripts/issues/254
|
||||
- `train_network.py` で LoRAの Conv2d-3x3 拡張に対応しました(カーネルサイズ1x1以外のConv2dにも対象範囲を拡大します)。
|
||||
- 現在のバージョンの [LoCon](https://github.com/KohakuBlueleaf/LoCon) と同一の仕様です。__KohakuBlueleaf氏のご支援に深く感謝します。__
|
||||
- LoCon が将来的に拡張された場合、それらのバージョンでの互換性は保証できません。
|
||||
- `--network_args` オプションを `--network_args "conv_dim=4" "conv_alpha=1"` のように指定してください。
|
||||
- Stable Diffusion web UI での使用には [Additional Networks extension](https://github.com/kohya-ss/sd-webui-additional-networks) のversion 0.5.0 以降が必要です。
|
||||
- __Stable Diffusion web UI の LoRA 機能は LoRAの Conv2d-3x3 拡張に対応していないようです。使用するか否か慎重にご検討ください。__
|
||||
- マージ、抽出のスクリプトについても LoRA の Conv2d-3x3 拡張に対応しました.
|
||||
- サンプル画像生成後にCUDAメモリを解放しVRAM使用量を削減しました。 issue https://github.com/kohya-ss/sd-scripts/issues/260
|
||||
- 空のキャプションが使えるようになりました。 issue https://github.com/kohya-ss/sd-scripts/issues/258
|
||||
- Textual Inversion 学習でテンプレートを使ったとき、height/width が 8 で割り切れなかったときにサンプル画像生成がクラッシュするのを修正しました。
|
||||
- ドキュメント類を更新しました。
|
||||
|
||||
- Sample image generation:
|
||||
A prompt file might look like this, for example
|
||||
|
||||
```
|
||||
# prompt 1
|
||||
masterpiece, best quality, 1girl, in white shirts, upper body, looking at viewer, simple background --n low quality, worst quality, bad anatomy,bad composition, poor, low effort --w 768 --h 768 --d 1 --l 7.5 --s 28
|
||||
|
||||
# prompt 2
|
||||
masterpiece, best quality, 1boy, in business suit, standing at street, looking back --n low quality, worst quality, bad anatomy,bad composition, poor, low effort --w 576 --h 832 --d 2 --l 5.5 --s 40
|
||||
```
|
||||
|
||||
Lines beginning with `#` are comments. You can specify options for the generated image with options like `--n` after the prompt. The following can be used.
|
||||
|
||||
* `--n` Negative prompt up to the next option.
|
||||
* `--w` Specifies the width of the generated image.
|
||||
* `--h` Specifies the height of the generated image.
|
||||
* `--d` Specifies the seed of the generated image.
|
||||
* `--l` Specifies the CFG scale of the generated image.
|
||||
* `--s` Specifies the number of steps in the generation.
|
||||
|
||||
The prompt weighting such as `( )` and `[ ]` are not working.
|
||||
|
||||
- サンプル画像生成:
|
||||
プロンプトファイルは例えば以下のようになります。
|
||||
|
||||
```
|
||||
# prompt 1
|
||||
masterpiece, best quality, 1girl, in white shirts, upper body, looking at viewer, simple background --n low quality, worst quality, bad anatomy,bad composition, poor, low effort --w 768 --h 768 --d 1 --l 7.5 --s 28
|
||||
|
||||
# prompt 2
|
||||
masterpiece, best quality, 1boy, in business suit, standing at street, looking back --n low quality, worst quality, bad anatomy,bad composition, poor, low effort --w 576 --h 832 --d 2 --l 5.5 --s 40
|
||||
```
|
||||
|
||||
`#` で始まる行はコメントになります。`--n` のように「ハイフン二個+英小文字」の形でオプションを指定できます。以下が使用可能できます。
|
||||
|
||||
* `--n` Negative prompt up to the next option.
|
||||
* `--w` Specifies the width of the generated image.
|
||||
* `--h` Specifies the height of the generated image.
|
||||
* `--d` Specifies the seed of the generated image.
|
||||
* `--l` Specifies the CFG scale of the generated image.
|
||||
* `--s` Specifies the number of steps in the generation.
|
||||
|
||||
`( )` や `[ ]` などの重みづけは動作しません。
|
||||
|
||||
Please read [Releases](https://github.com/kohya-ss/sd-scripts/releases) for recent updates.
|
||||
最近の更新情報は [Release](https://github.com/kohya-ss/sd-scripts/releases) をご覧ください。
|
||||
|
||||
15
_typos.toml
Normal file
15
_typos.toml
Normal file
@@ -0,0 +1,15 @@
|
||||
# Files for typos
|
||||
# Instruction: https://github.com/marketplace/actions/typos-action#getting-started
|
||||
|
||||
[default.extend-identifiers]
|
||||
|
||||
[default.extend-words]
|
||||
NIN="NIN"
|
||||
parms="parms"
|
||||
nin="nin"
|
||||
extention="extention" # Intentionally left
|
||||
nd="nd"
|
||||
|
||||
|
||||
[files]
|
||||
extend-exclude = ["_typos.toml"]
|
||||
279
config_README-ja.md
Normal file
279
config_README-ja.md
Normal file
@@ -0,0 +1,279 @@
|
||||
For non-Japanese speakers: this README is provided only in Japanese in the current state. Sorry for inconvenience. We will provide English version in the near future.
|
||||
|
||||
`--dataset_config` で渡すことができる設定ファイルに関する説明です。
|
||||
|
||||
## 概要
|
||||
|
||||
設定ファイルを渡すことにより、ユーザが細かい設定を行えるようにします。
|
||||
|
||||
* 複数のデータセットが設定可能になります
|
||||
* 例えば `resolution` をデータセットごとに設定して、それらを混合して学習できます。
|
||||
* DreamBooth の手法と fine tuning の手法の両方に対応している学習方法では、DreamBooth 方式と fine tuning 方式のデータセットを混合することが可能です。
|
||||
* サブセットごとに設定を変更することが可能になります
|
||||
* データセットを画像ディレクトリ別またはメタデータ別に分割したものがサブセットです。いくつかのサブセットが集まってデータセットを構成します。
|
||||
* `keep_tokens` や `flip_aug` 等のオプションはサブセットごとに設定可能です。一方、`resolution` や `batch_size` といったオプションはデータセットごとに設定可能で、同じデータセットに属するサブセットでは値が共通になります。詳しくは後述します。
|
||||
|
||||
設定ファイルの形式は JSON か TOML を利用できます。記述のしやすさを考えると [TOML](https://toml.io/ja/v1.0.0-rc.2) を利用するのがオススメです。以下、TOML の利用を前提に説明します。
|
||||
|
||||
TOML で記述した設定ファイルの例です。
|
||||
|
||||
```toml
|
||||
[general]
|
||||
shuffle_caption = true
|
||||
caption_extension = '.txt'
|
||||
keep_tokens = 1
|
||||
|
||||
# これは DreamBooth 方式のデータセット
|
||||
[[datasets]]
|
||||
resolution = 512
|
||||
batch_size = 4
|
||||
keep_tokens = 2
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\hoge'
|
||||
class_tokens = 'hoge girl'
|
||||
# このサブセットは keep_tokens = 2 (所属する datasets の値が使われる)
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\fuga'
|
||||
class_tokens = 'fuga boy'
|
||||
keep_tokens = 3
|
||||
|
||||
[[datasets.subsets]]
|
||||
is_reg = true
|
||||
image_dir = 'C:\reg'
|
||||
class_tokens = 'human'
|
||||
keep_tokens = 1
|
||||
|
||||
# これは fine tuning 方式のデータセット
|
||||
[[datasets]]
|
||||
resolution = [768, 768]
|
||||
batch_size = 2
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\piyo'
|
||||
metadata_file = 'C:\piyo\piyo_md.json'
|
||||
# このサブセットは keep_tokens = 1 (general の値が使われる)
|
||||
```
|
||||
|
||||
この例では、3 つのディレクトリを DreamBooth 方式のデータセットとして 512x512 (batch size 4) で学習させ、1 つのディレクトリを fine tuning 方式のデータセットとして 768x768 (batch size 2) で学習させることになります。
|
||||
|
||||
## データセット・サブセットに関する設定
|
||||
|
||||
データセット・サブセットに関する設定は、登録可能な箇所がいくつかに分かれています。
|
||||
|
||||
* `[general]`
|
||||
* 全データセットまたは全サブセットに適用されるオプションを指定する箇所です。
|
||||
* データセットごとの設定及びサブセットごとの設定に同名のオプションが存在していた場合には、データセット・サブセットごとの設定が優先されます。
|
||||
* `[[datasets]]`
|
||||
* `datasets` はデータセットに関する設定の登録箇所になります。各データセットに個別に適用されるオプションを指定する箇所です。
|
||||
* サブセットごとの設定が存在していた場合には、サブセットごとの設定が優先されます。
|
||||
* `[[datasets.subsets]]`
|
||||
* `datasets.subsets` はサブセットに関する設定の登録箇所になります。各サブセットに個別に適用されるオプションを指定する箇所です。
|
||||
|
||||
先程の例における、画像ディレクトリと登録箇所の対応に関するイメージ図です。
|
||||
|
||||
```
|
||||
C:\
|
||||
├─ hoge -> [[datasets.subsets]] No.1 ┐ ┐
|
||||
├─ fuga -> [[datasets.subsets]] No.2 |-> [[datasets]] No.1 |-> [general]
|
||||
├─ reg -> [[datasets.subsets]] No.3 ┘ |
|
||||
└─ piyo -> [[datasets.subsets]] No.4 --> [[datasets]] No.2 ┘
|
||||
```
|
||||
|
||||
画像ディレクトリがそれぞれ1つの `[[datasets.subsets]]` に対応しています。そして `[[datasets.subsets]]` が1つ以上組み合わさって1つの `[[datasets]]` を構成します。`[general]` には全ての `[[datasets]]`, `[[datasets.subsets]]` が属します。
|
||||
|
||||
登録箇所ごとに指定可能なオプションは異なりますが、同名のオプションが指定された場合は下位の登録箇所にある値が優先されます。先程の例の `keep_tokens` オプションの扱われ方を確認してもらうと理解しやすいかと思います。
|
||||
|
||||
加えて、学習方法が対応している手法によっても指定可能なオプションが変化します。
|
||||
|
||||
* DreamBooth 方式専用のオプション
|
||||
* fine tuning 方式専用のオプション
|
||||
* caption dropout の手法が使える場合のオプション
|
||||
|
||||
DreamBooth の手法と fine tuning の手法の両方とも利用可能な学習方法では、両者を併用することができます。
|
||||
併用する際の注意点として、DreamBooth 方式なのか fine tuning 方式なのかはデータセット単位で判別を行っているため、同じデータセット中に DreamBooth 方式のサブセットと fine tuning 方式のサブセットを混在させることはできません。
|
||||
つまり、これらを併用したい場合には異なる方式のサブセットが異なるデータセットに所属するように設定する必要があります。
|
||||
|
||||
プログラムの挙動としては、後述する `metadata_file` オプションが存在していたら fine tuning 方式のサブセットだと判断します。
|
||||
そのため、同一のデータセットに所属するサブセットについて言うと、「全てが `metadata_file` オプションを持つ」か「全てが `metadata_file` オプションを持たない」かのどちらかになっていれば問題ありません。
|
||||
|
||||
以下、利用可能なオプションを説明します。コマンドライン引数と名称が同一のオプションについては、基本的に説明を割愛します。他の README を参照してください。
|
||||
|
||||
### 全学習方法で共通のオプション
|
||||
|
||||
学習方法によらずに指定可能なオプションです。
|
||||
|
||||
#### データセット向けオプション
|
||||
|
||||
データセットの設定に関わるオプションです。`datasets.subsets` には記述できません。
|
||||
|
||||
| オプション名 | 設定例 | `[general]` | `[[datasets]]` |
|
||||
| ---- | ---- | ---- | ---- |
|
||||
| `batch_size` | `1` | o | o |
|
||||
| `bucket_no_upscale` | `true` | o | o |
|
||||
| `bucket_reso_steps` | `64` | o | o |
|
||||
| `enable_bucket` | `true` | o | o |
|
||||
| `max_bucket_reso` | `1024` | o | o |
|
||||
| `min_bucket_reso` | `128` | o | o |
|
||||
| `resolution` | `256`, `[512, 512]` | o | o |
|
||||
|
||||
* `batch_size`
|
||||
* コマンドライン引数の `--train_batch_size` と同等です。
|
||||
|
||||
これらの設定はデータセットごとに固定です。
|
||||
つまり、データセットに所属するサブセットはこれらの設定を共有することになります。
|
||||
例えば解像度が異なるデータセットを用意したい場合は、上に挙げた例のように別々のデータセットとして定義すれば別々の解像度を設定可能です。
|
||||
|
||||
#### サブセット向けオプション
|
||||
|
||||
サブセットの設定に関わるオプションです。
|
||||
|
||||
| オプション名 | 設定例 | `[general]` | `[[datasets]]` | `[[dataset.subsets]]` |
|
||||
| ---- | ---- | ---- | ---- | ---- |
|
||||
| `color_aug` | `false` | o | o | o |
|
||||
| `face_crop_aug_range` | `[1.0, 3.0]` | o | o | o |
|
||||
| `flip_aug` | `true` | o | o | o |
|
||||
| `keep_tokens` | `2` | o | o | o |
|
||||
| `num_repeats` | `10` | o | o | o |
|
||||
| `random_crop` | `false` | o | o | o |
|
||||
| `shuffle_caption` | `true` | o | o | o |
|
||||
|
||||
* `num_repeats`
|
||||
* サブセットの画像の繰り返し回数を指定します。fine tuning における `--dataset_repeats` に相当しますが、`num_repeats` はどの学習方法でも指定可能です。
|
||||
|
||||
### DreamBooth 方式専用のオプション
|
||||
|
||||
DreamBooth 方式のオプションは、サブセット向けオプションのみ存在します。
|
||||
|
||||
#### サブセット向けオプション
|
||||
|
||||
DreamBooth 方式のサブセットの設定に関わるオプションです。
|
||||
|
||||
| オプション名 | 設定例 | `[general]` | `[[datasets]]` | `[[dataset.subsets]]` |
|
||||
| ---- | ---- | ---- | ---- | ---- |
|
||||
| `image_dir` | `‘C:\hoge’` | - | - | o(必須) |
|
||||
| `caption_extension` | `".txt"` | o | o | o |
|
||||
| `class_tokens` | `“sks girl”` | - | - | o |
|
||||
| `is_reg` | `false` | - | - | o |
|
||||
|
||||
まず注意点として、 `image_dir` には画像ファイルが直下に置かれているパスを指定する必要があります。従来の DreamBooth の手法ではサブディレクトリに画像を置く必要がありましたが、そちらとは仕様に互換性がありません。また、`5_cat` のようなフォルダ名にしても、画像の繰り返し回数とクラス名は反映されません。これらを個別に設定したい場合、`num_repeats` と `class_tokens` で明示的に指定する必要があることに注意してください。
|
||||
|
||||
* `image_dir`
|
||||
* 画像ディレクトリのパスを指定します。指定必須オプションです。
|
||||
* 画像はディレクトリ直下に置かれている必要があります。
|
||||
* `class_tokens`
|
||||
* クラストークンを設定します。
|
||||
* 画像に対応する caption ファイルが存在しない場合にのみ学習時に利用されます。利用するかどうかの判定は画像ごとに行います。`class_tokens` を指定しなかった場合に caption ファイルも見つからなかった場合にはエラーになります。
|
||||
* `is_reg`
|
||||
* サブセットの画像が正規化用かどうかを指定します。指定しなかった場合は `false` として、つまり正規化画像ではないとして扱います。
|
||||
|
||||
### fine tuning 方式専用のオプション
|
||||
|
||||
fine tuning 方式のオプションは、サブセット向けオプションのみ存在します。
|
||||
|
||||
#### サブセット向けオプション
|
||||
|
||||
fine tuning 方式のサブセットの設定に関わるオプションです。
|
||||
|
||||
| オプション名 | 設定例 | `[general]` | `[[datasets]]` | `[[dataset.subsets]]` |
|
||||
| ---- | ---- | ---- | ---- | ---- |
|
||||
| `image_dir` | `‘C:\hoge’` | - | - | o |
|
||||
| `metadata_file` | `'C:\piyo\piyo_md.json'` | - | - | o(必須) |
|
||||
|
||||
* `image_dir`
|
||||
* 画像ディレクトリのパスを指定します。DreamBooth の手法の方とは異なり指定は必須ではありませんが、設定することを推奨します。
|
||||
* 指定する必要がない状況としては、メタデータファイルの生成時に `--full_path` を付与して実行していた場合です。
|
||||
* 画像はディレクトリ直下に置かれている必要があります。
|
||||
* `metadata_file`
|
||||
* サブセットで利用されるメタデータファイルのパスを指定します。指定必須オプションです。
|
||||
* コマンドライン引数の `--in_json` と同等です。
|
||||
* サブセットごとにメタデータファイルを指定する必要がある仕様上、ディレクトリを跨いだメタデータを1つのメタデータファイルとして作成することは避けた方が良いでしょう。画像ディレクトリごとにメタデータファイルを用意し、それらを別々のサブセットとして登録することを強く推奨します。
|
||||
|
||||
### caption dropout の手法が使える場合に指定可能なオプション
|
||||
|
||||
caption dropout の手法が使える場合のオプションは、サブセット向けオプションのみ存在します。
|
||||
DreamBooth 方式か fine tuning 方式かに関わらず、caption dropout に対応している学習方法であれば指定可能です。
|
||||
|
||||
#### サブセット向けオプション
|
||||
|
||||
caption dropout が使えるサブセットの設定に関わるオプションです。
|
||||
|
||||
| オプション名 | `[general]` | `[[datasets]]` | `[[dataset.subsets]]` |
|
||||
| ---- | ---- | ---- | ---- |
|
||||
| `caption_dropout_every_n_epochs` | o | o | o |
|
||||
| `caption_dropout_rate` | o | o | o |
|
||||
| `caption_tag_dropout_rate` | o | o | o |
|
||||
|
||||
## 重複したサブセットが存在する時の挙動
|
||||
|
||||
DreamBooth 方式のデータセットの場合、その中にある `image_dir` が同一のサブセットは重複していると見なされます。
|
||||
fine tuning 方式のデータセットの場合は、その中にある `metadata_file` が同一のサブセットは重複していると見なされます。
|
||||
データセット中に重複したサブセットが存在する場合、2個目以降は無視されます。
|
||||
|
||||
一方、異なるデータセットに所属している場合は、重複しているとは見なされません。
|
||||
例えば、以下のように同一の `image_dir` を持つサブセットを別々のデータセットに入れた場合には、重複していないと見なします。
|
||||
これは、同じ画像でも異なる解像度で学習したい場合に役立ちます。
|
||||
|
||||
```toml
|
||||
# 別々のデータセットに存在している場合は重複とは見なされず、両方とも学習に使われる
|
||||
|
||||
[[datasets]]
|
||||
resolution = 512
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\hoge'
|
||||
|
||||
[[datasets]]
|
||||
resolution = 768
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\hoge'
|
||||
```
|
||||
|
||||
## コマンドライン引数との併用
|
||||
|
||||
設定ファイルのオプションの中には、コマンドライン引数のオプションと役割が重複しているものがあります。
|
||||
|
||||
以下に挙げるコマンドライン引数のオプションは、設定ファイルを渡した場合には無視されます。
|
||||
|
||||
* `--train_data_dir`
|
||||
* `--reg_data_dir`
|
||||
* `--in_json`
|
||||
|
||||
以下に挙げるコマンドライン引数のオプションは、コマンドライン引数と設定ファイルで同時に指定された場合、コマンドライン引数の値よりも設定ファイルの値が優先されます。特に断りがなければ同名のオプションとなります。
|
||||
|
||||
| コマンドライン引数のオプション | 優先される設定ファイルのオプション |
|
||||
| ---------------------------------- | ---------------------------------- |
|
||||
| `--bucket_no_upscale` | |
|
||||
| `--bucket_reso_steps` | |
|
||||
| `--caption_dropout_every_n_epochs` | |
|
||||
| `--caption_dropout_rate` | |
|
||||
| `--caption_extension` | |
|
||||
| `--caption_tag_dropout_rate` | |
|
||||
| `--color_aug` | |
|
||||
| `--dataset_repeats` | `num_repeats` |
|
||||
| `--enable_bucket` | |
|
||||
| `--face_crop_aug_range` | |
|
||||
| `--flip_aug` | |
|
||||
| `--keep_tokens` | |
|
||||
| `--min_bucket_reso` | |
|
||||
| `--random_crop` | |
|
||||
| `--resolution` | |
|
||||
| `--shuffle_caption` | |
|
||||
| `--train_batch_size` | `batch_size` |
|
||||
|
||||
## エラーの手引き
|
||||
|
||||
現在、外部ライブラリを利用して設定ファイルの記述が正しいかどうかをチェックしているのですが、整備が行き届いておらずエラーメッセージがわかりづらいという問題があります。
|
||||
将来的にはこの問題の改善に取り組む予定です。
|
||||
|
||||
次善策として、頻出のエラーとその対処法について載せておきます。
|
||||
正しいはずなのにエラーが出る場合、エラー内容がどうしても分からない場合は、バグかもしれないのでご連絡ください。
|
||||
|
||||
* `voluptuous.error.MultipleInvalid: required key not provided @ ...`: 指定必須のオプションが指定されていないというエラーです。指定を忘れているか、オプション名を間違って記述している可能性が高いです。
|
||||
* `...` の箇所にはエラーが発生した場所が載っています。例えば `voluptuous.error.MultipleInvalid: required key not provided @ data['datasets'][0]['subsets'][0]['image_dir']` のようなエラーが出たら、0 番目の `datasets` 中の 0 番目の `subsets` の設定に `image_dir` が存在しないということになります。
|
||||
* `voluptuous.error.MultipleInvalid: expected int for dictionary value @ ...`: 指定する値の形式が不正というエラーです。値の形式が間違っている可能性が高いです。`int` の部分は対象となるオプションによって変わります。この README に載っているオプションの「設定例」が役立つかもしれません。
|
||||
* `voluptuous.error.MultipleInvalid: extra keys not allowed @ ...`: 対応していないオプション名が存在している場合に発生するエラーです。オプション名を間違って記述しているか、誤って紛れ込んでいる可能性が高いです。
|
||||
|
||||
|
||||
1008
fine_tune.py
1008
fine_tune.py
File diff suppressed because it is too large
Load Diff
@@ -1,6 +1,9 @@
|
||||
NovelAIの提案した学習手法、自動キャプションニング、タグ付け、Windows+VRAM 12GB(v1.4/1.5の場合)環境等に対応したfine tuningです。
|
||||
NovelAIの提案した学習手法、自動キャプションニング、タグ付け、Windows+VRAM 12GB(SD v1.xの場合)環境等に対応したfine tuningです。ここでfine tuningとは、モデルを画像とキャプションで学習することを指します(LoRAやTextual Inversion、Hypernetworksは含みません)
|
||||
|
||||
[学習についての共通ドキュメント](./train_README-ja.md) もあわせてご覧ください。
|
||||
|
||||
# 概要
|
||||
|
||||
## 概要
|
||||
Diffusersを用いてStable DiffusionのU-Netのfine tuningを行います。NovelAIの記事にある以下の改善に対応しています(Aspect Ratio BucketingについてはNovelAIのコードを参考にしましたが、最終的なコードはすべてオリジナルです)。
|
||||
|
||||
* CLIP(Text Encoder)の最後の層ではなく最後から二番目の層の出力を用いる。
|
||||
@@ -13,19 +16,24 @@ Diffusersを用いてStable DiffusionのU-Netのfine tuningを行います。Nov
|
||||
|
||||
デフォルトではText Encoderの学習は行いません。モデル全体のfine tuningではU-Netだけを学習するのが一般的なようです(NovelAIもそのようです)。オプション指定でText Encoderも学習対象とできます。
|
||||
|
||||
## 追加機能について
|
||||
### CLIPの出力の変更
|
||||
# 追加機能について
|
||||
|
||||
## CLIPの出力の変更
|
||||
|
||||
プロンプトを画像に反映するため、テキストの特徴量への変換を行うのがCLIP(Text Encoder)です。Stable DiffusionではCLIPの最後の層の出力を用いていますが、それを最後から二番目の層の出力を用いるよう変更できます。NovelAIによると、これによりより正確にプロンプトが反映されるようになるとのことです。
|
||||
元のまま、最後の層の出力を用いることも可能です。
|
||||
|
||||
※Stable Diffusion 2.0では最後から二番目の層をデフォルトで使います。clip_skipオプションを指定しないでください。
|
||||
|
||||
### 正方形以外の解像度での学習
|
||||
## 正方形以外の解像度での学習
|
||||
|
||||
Stable Diffusionは512\*512で学習されていますが、それに加えて256\*1024や384\*640といった解像度でも学習します。これによりトリミングされる部分が減り、より正しくプロンプトと画像の関係が学習されることが期待されます。
|
||||
学習解像度はパラメータとして与えられた解像度の面積(=メモリ使用量)を超えない範囲で、64ピクセル単位で縦横に調整、作成されます。
|
||||
|
||||
機械学習では入力サイズをすべて統一するのが一般的ですが、特に制約があるわけではなく、実際は同一のバッチ内で統一されていれば大丈夫です。NovelAIの言うbucketingは、あらかじめ教師データを、アスペクト比に応じた学習解像度ごとに分類しておくことを指しているようです。そしてバッチを各bucket内の画像で作成することで、バッチの画像サイズを統一します。
|
||||
|
||||
### トークン長の75から225への拡張
|
||||
## トークン長の75から225への拡張
|
||||
|
||||
Stable Diffusionでは最大75トークン(開始・終了を含むと77トークン)ですが、それを225トークンまで拡張します。
|
||||
ただしCLIPが受け付ける最大長は75トークンですので、225トークンの場合、単純に三分割してCLIPを呼び出してから結果を連結しています。
|
||||
|
||||
@@ -33,298 +41,69 @@ Stable Diffusionでは最大75トークン(開始・終了を含むと77トー
|
||||
|
||||
※Automatic1111氏のWeb UIではカンマを意識して分割、といったこともしているようですが、私の場合はそこまでしておらず単純な分割です。
|
||||
|
||||
## 環境整備
|
||||
# 学習の手順
|
||||
|
||||
このリポジトリの[README](./README-ja.md)を参照してください。
|
||||
あらかじめこのリポジトリのREADMEを参照し、環境整備を行ってください。
|
||||
|
||||
## 教師データの用意
|
||||
|
||||
学習させたい画像データを用意し、任意のフォルダに入れてください。リサイズ等の事前の準備は必要ありません。
|
||||
ただし学習解像度よりもサイズが小さい画像については、超解像などで品質を保ったまま拡大しておくことをお勧めします。
|
||||
|
||||
複数の教師データフォルダにも対応しています。前処理をそれぞれのフォルダに対して実行する形となります。
|
||||
|
||||
たとえば以下のように画像を格納します。
|
||||
|
||||
|
||||
|
||||
## 自動キャプショニング
|
||||
キャプションを使わずタグだけで学習する場合はスキップしてください。
|
||||
|
||||
また手動でキャプションを用意する場合、キャプションは教師データ画像と同じディレクトリに、同じファイル名、拡張子.caption等で用意してください。各ファイルは1行のみのテキストファイルとします。
|
||||
|
||||
### BLIPによるキャプショニング
|
||||
|
||||
最新版ではBLIPのダウンロード、重みのダウンロード、仮想環境の追加は不要になりました。そのままで動作します。
|
||||
|
||||
finetuneフォルダ内のmake_captions.pyを実行します。
|
||||
|
||||
```
|
||||
python finetune\make_captions.py --batch_size <バッチサイズ> <教師データフォルダ>
|
||||
```
|
||||
|
||||
バッチサイズ8、教師データを親フォルダのtrain_dataに置いた場合、以下のようになります。
|
||||
|
||||
```
|
||||
python finetune\make_captions.py --batch_size 8 ..\train_data
|
||||
```
|
||||
|
||||
キャプションファイルが教師データ画像と同じディレクトリに、同じファイル名、拡張子.captionで作成されます。
|
||||
|
||||
batch_sizeはGPUのVRAM容量に応じて増減してください。大きいほうが速くなります(VRAM 12GBでももう少し増やせると思います)。
|
||||
max_lengthオプションでキャプションの最大長を指定できます。デフォルトは75です。モデルをトークン長225で学習する場合には長くしても良いかもしれません。
|
||||
caption_extensionオプションでキャプションの拡張子を変更できます。デフォルトは.captionです(.txtにすると後述のDeepDanbooruと競合します)。
|
||||
|
||||
複数の教師データフォルダがある場合には、それぞれのフォルダに対して実行してください。
|
||||
|
||||
なお、推論にランダム性があるため、実行するたびに結果が変わります。固定する場合には--seedオプションで「--seed 42」のように乱数seedを指定してください。
|
||||
|
||||
その他のオプションは--helpでヘルプをご参照ください(パラメータの意味についてはドキュメントがまとまっていないようで、ソースを見るしかないようです)。
|
||||
|
||||
デフォルトでは拡張子.captionでキャプションファイルが生成されます。
|
||||
|
||||
|
||||
|
||||
たとえば以下のようなキャプションが付きます。
|
||||
|
||||
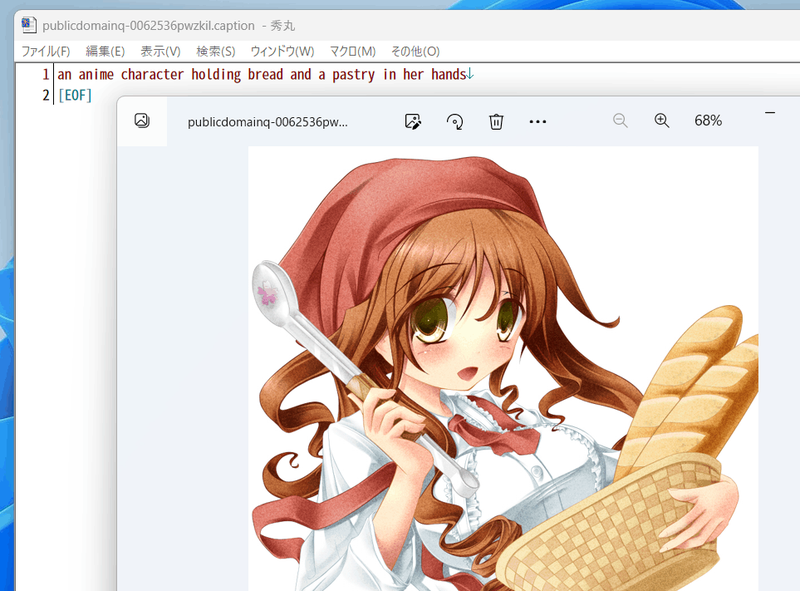
|
||||
|
||||
## DeepDanbooruによるタグ付け
|
||||
danbooruタグのタグ付け自体を行わない場合は「キャプションとタグ情報の前処理」に進んでください。
|
||||
|
||||
タグ付けはDeepDanbooruまたはWD14Taggerで行います。WD14Taggerのほうが精度が良いようです。WD14Taggerでタグ付けする場合は、次の章へ進んでください。
|
||||
|
||||
### 環境整備
|
||||
DeepDanbooru https://github.com/KichangKim/DeepDanbooru を作業フォルダにcloneしてくるか、zipをダウンロードして展開します。私はzipで展開しました。
|
||||
またDeepDanbooruのReleasesのページ https://github.com/KichangKim/DeepDanbooru/releases の「DeepDanbooru Pretrained Model v3-20211112-sgd-e28」のAssetsから、deepdanbooru-v3-20211112-sgd-e28.zipをダウンロードしてきてDeepDanbooruのフォルダに展開します。
|
||||
|
||||
以下からダウンロードします。Assetsをクリックして開き、そこからダウンロードします。
|
||||
|
||||
|
||||
|
||||
以下のようなこういうディレクトリ構造にしてください
|
||||
|
||||
|
||||
|
||||
Diffusersの環境に必要なライブラリをインストールします。DeepDanbooruのフォルダに移動してインストールします(実質的にはtensorflow-ioが追加されるだけだと思います)。
|
||||
|
||||
```
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
続いてDeepDanbooru自体をインストールします。
|
||||
|
||||
```
|
||||
pip install .
|
||||
```
|
||||
|
||||
以上でタグ付けの環境整備は完了です。
|
||||
|
||||
### タグ付けの実施
|
||||
DeepDanbooruのフォルダに移動し、deepdanbooruを実行してタグ付けを行います。
|
||||
|
||||
```
|
||||
deepdanbooru evaluate <教師データフォルダ> --project-path deepdanbooru-v3-20211112-sgd-e28 --allow-folder --save-txt
|
||||
```
|
||||
|
||||
教師データを親フォルダのtrain_dataに置いた場合、以下のようになります。
|
||||
|
||||
```
|
||||
deepdanbooru evaluate ../train_data --project-path deepdanbooru-v3-20211112-sgd-e28 --allow-folder --save-txt
|
||||
```
|
||||
|
||||
タグファイルが教師データ画像と同じディレクトリに、同じファイル名、拡張子.txtで作成されます。1件ずつ処理されるためわりと遅いです。
|
||||
|
||||
複数の教師データフォルダがある場合には、それぞれのフォルダに対して実行してください。
|
||||
|
||||
以下のように生成されます。
|
||||
|
||||
|
||||
|
||||
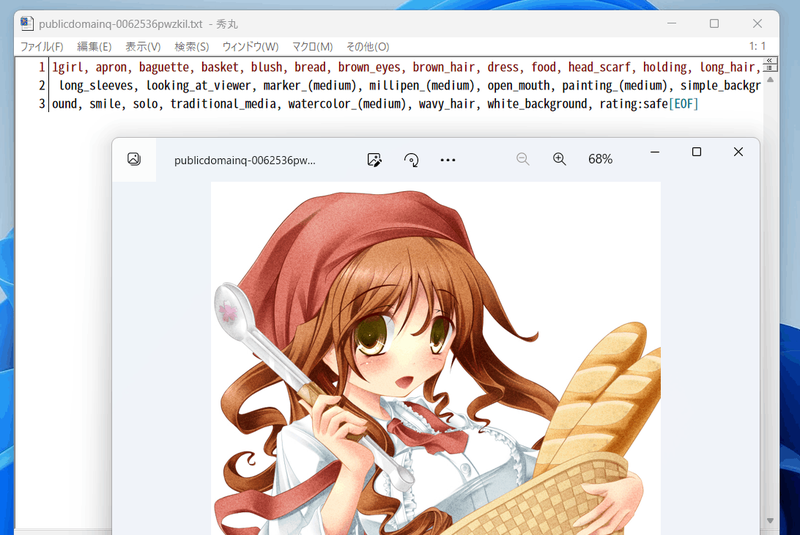
こんな感じにタグが付きます(すごい情報量……)。
|
||||
|
||||
|
||||
|
||||
## WD14Taggerによるタグ付け
|
||||
DeepDanbooruの代わりにWD14Taggerを用いる手順です。
|
||||
|
||||
Automatic1111氏のWebUIで使用しているtaggerを利用します。こちらのgithubページ(https://github.com/toriato/stable-diffusion-webui-wd14-tagger#mrsmilingwolfs-model-aka-waifu-diffusion-14-tagger )の情報を参考にさせていただきました。
|
||||
|
||||
最初の環境整備で必要なモジュールはインストール済みです。また重みはHugging Faceから自動的にダウンロードしてきます。
|
||||
|
||||
### タグ付けの実施
|
||||
スクリプトを実行してタグ付けを行います。
|
||||
```
|
||||
python tag_images_by_wd14_tagger.py --batch_size <バッチサイズ> <教師データフォルダ>
|
||||
```
|
||||
|
||||
教師データを親フォルダのtrain_dataに置いた場合、以下のようになります。
|
||||
```
|
||||
python tag_images_by_wd14_tagger.py --batch_size 4 ..\train_data
|
||||
```
|
||||
|
||||
初回起動時にはモデルファイルがwd14_tagger_modelフォルダに自動的にダウンロードされます(フォルダはオプションで変えられます)。以下のようになります。
|
||||
|
||||
|
||||
|
||||
タグファイルが教師データ画像と同じディレクトリに、同じファイル名、拡張子.txtで作成されます。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
threshオプションで、判定されたタグのconfidence(確信度)がいくつ以上でタグをつけるかが指定できます。デフォルトはWD14Taggerのサンプルと同じ0.35です。値を下げるとより多くのタグが付与されますが、精度は下がります。
|
||||
batch_sizeはGPUのVRAM容量に応じて増減してください。大きいほうが速くなります(VRAM 12GBでももう少し増やせると思います)。caption_extensionオプションでタグファイルの拡張子を変更できます。デフォルトは.txtです。
|
||||
model_dirオプションでモデルの保存先フォルダを指定できます。
|
||||
またforce_downloadオプションを指定すると保存先フォルダがあってもモデルを再ダウンロードします。
|
||||
|
||||
複数の教師データフォルダがある場合には、それぞれのフォルダに対して実行してください。
|
||||
|
||||
## キャプションとタグ情報の前処理
|
||||
|
||||
スクリプトから処理しやすいようにキャプションとタグをメタデータとしてひとつのファイルにまとめます。
|
||||
|
||||
### キャプションの前処理
|
||||
|
||||
キャプションをメタデータに入れるには、作業フォルダ内で以下を実行してください(キャプションを学習に使わない場合は実行不要です)(実際は1行で記述します、以下同様)。
|
||||
|
||||
```
|
||||
python merge_captions_to_metadata.py <教師データフォルダ>
|
||||
--in_json <読み込むメタデータファイル名>
|
||||
<メタデータファイル名>
|
||||
```
|
||||
|
||||
メタデータファイル名は任意の名前です。
|
||||
教師データがtrain_data、読み込むメタデータファイルなし、メタデータファイルがmeta_cap.jsonの場合、以下のようになります。
|
||||
|
||||
```
|
||||
python merge_captions_to_metadata.py train_data meta_cap.json
|
||||
```
|
||||
|
||||
caption_extensionオプションでキャプションの拡張子を指定できます。
|
||||
|
||||
複数の教師データフォルダがある場合には、full_path引数を指定してください(メタデータにフルパスで情報を持つようになります)。そして、それぞれのフォルダに対して実行してください。
|
||||
|
||||
```
|
||||
python merge_captions_to_metadata.py --full_path
|
||||
train_data1 meta_cap1.json
|
||||
python merge_captions_to_metadata.py --full_path --in_json meta_cap1.json
|
||||
train_data2 meta_cap2.json
|
||||
```
|
||||
|
||||
in_jsonを省略すると書き込み先メタデータファイルがあるとそこから読み込み、そこに上書きします。
|
||||
|
||||
__※in_jsonオプションと書き込み先を都度書き換えて、別のメタデータファイルへ書き出すようにすると安全です。__
|
||||
|
||||
### タグの前処理
|
||||
|
||||
同様にタグもメタデータにまとめます(タグを学習に使わない場合は実行不要です)。
|
||||
```
|
||||
python merge_dd_tags_to_metadata.py <教師データフォルダ>
|
||||
--in_json <読み込むメタデータファイル名>
|
||||
<書き込むメタデータファイル名>
|
||||
```
|
||||
|
||||
先と同じディレクトリ構成で、meta_cap.jsonを読み、meta_cap_dd.jsonに書きだす場合、以下となります。
|
||||
```
|
||||
python merge_dd_tags_to_metadata.py train_data --in_json meta_cap.json meta_cap_dd.json
|
||||
```
|
||||
|
||||
複数の教師データフォルダがある場合には、full_path引数を指定してください。そして、それぞれのフォルダに対して実行してください。
|
||||
|
||||
```
|
||||
python merge_dd_tags_to_metadata.py --full_path --in_json meta_cap2.json
|
||||
train_data1 meta_cap_dd1.json
|
||||
python merge_dd_tags_to_metadata.py --full_path --in_json meta_cap_dd1.json
|
||||
train_data2 meta_cap_dd2.json
|
||||
```
|
||||
|
||||
in_jsonを省略すると書き込み先メタデータファイルがあるとそこから読み込み、そこに上書きします。
|
||||
|
||||
__※in_jsonオプションと書き込み先を都度書き換えて、別のメタデータファイルへ書き出すようにすると安全です。__
|
||||
|
||||
### キャプションとタグのクリーニング
|
||||
ここまででメタデータファイルにキャプションとDeepDanbooruのタグがまとめられています。ただ自動キャプショニングにしたキャプションは表記ゆれなどがあり微妙(※)ですし、タグにはアンダースコアが含まれていたりratingが付いていたりしますので(DeepDanbooruの場合)、エディタの置換機能などを用いてキャプションとタグのクリーニングをしたほうがいいでしょう。
|
||||
|
||||
※たとえばアニメ絵の少女を学習する場合、キャプションにはgirl/girls/woman/womenなどのばらつきがあります。また「anime girl」なども単に「girl」としたほうが適切かもしれません。
|
||||
|
||||
クリーニング用のスクリプトが用意してありますので、スクリプトの内容を状況に応じて編集してお使いください。
|
||||
|
||||
(教師データフォルダの指定は不要になりました。メタデータ内の全データをクリーニングします。)
|
||||
|
||||
```
|
||||
python clean_captions_and_tags.py <読み込むメタデータファイル名> <書き込むメタデータファイル名>
|
||||
```
|
||||
|
||||
--in_jsonは付きませんのでご注意ください。たとえば次のようになります。
|
||||
|
||||
```
|
||||
python clean_captions_and_tags.py meta_cap_dd.json meta_clean.json
|
||||
```
|
||||
|
||||
以上でキャプションとタグの前処理は完了です。
|
||||
|
||||
## latentsの事前取得
|
||||
|
||||
学習を高速に進めるためあらかじめ画像の潜在表現を取得しディスクに保存しておきます。あわせてbucketing(教師データをアスペクト比に応じて分類する)を行います。
|
||||
|
||||
作業フォルダで以下のように入力してください。
|
||||
```
|
||||
python prepare_buckets_latents.py <教師データフォルダ>
|
||||
<読み込むメタデータファイル名> <書き込むメタデータファイル名>
|
||||
<fine tuningするモデル名またはcheckpoint>
|
||||
--batch_size <バッチサイズ>
|
||||
--max_resolution <解像度 幅,高さ>
|
||||
--mixed_precision <精度>
|
||||
```
|
||||
|
||||
モデルがmodel.ckpt、バッチサイズ4、学習解像度は512\*512、精度no(float32)で、meta_clean.jsonからメタデータを読み込み、meta_lat.jsonに書き込む場合、以下のようになります。
|
||||
|
||||
```
|
||||
python prepare_buckets_latents.py
|
||||
train_data meta_clean.json meta_lat.json model.ckpt
|
||||
--batch_size 4 --max_resolution 512,512 --mixed_precision no
|
||||
```
|
||||
|
||||
教師データフォルダにnumpyのnpz形式でlatentsが保存されます。
|
||||
|
||||
Stable Diffusion 2.0のモデルを読み込む場合は--v2オプションを指定してください(--v_parameterizationは不要です)。
|
||||
|
||||
解像度の最小サイズを--min_bucket_resoオプションで、最大サイズを--max_bucket_resoで指定できます。デフォルトはそれぞれ256、1024です。たとえば最小サイズに384を指定すると、256\*1024や320\*768などの解像度は使わなくなります。
|
||||
解像度を768\*768のように大きくした場合、最大サイズに1280などを指定すると良いでしょう。
|
||||
|
||||
--flip_augオプションを指定すると左右反転のaugmentation(データ拡張)を行います。疑似的にデータ量を二倍に増やすことができますが、データが左右対称でない場合に指定すると(例えばキャラクタの外見、髪型など)学習がうまく行かなくなります。
|
||||
(反転した画像についてもlatentsを取得し、\*\_flip.npzファイルを保存する単純な実装です。fline_tune.pyには特にオプション指定は必要ありません。\_flip付きのファイルがある場合、flip付き・なしのファイルを、ランダムに読み込みます。)
|
||||
|
||||
バッチサイズはVRAM 12GBでももう少し増やせるかもしれません。
|
||||
解像度は64で割り切れる数字で、"幅,高さ"で指定します。解像度はfine tuning時のメモリサイズに直結します。VRAM 12GBでは512,512が限界と思われます(※)。16GBなら512,704や512,768まで上げられるかもしれません。なお256,256等にしてもVRAM 8GBでは厳しいようです(パラメータやoptimizerなどは解像度に関係せず一定のメモリが必要なため)。
|
||||
|
||||
※batch size 1の学習で12GB VRAM、640,640で動いたとの報告もありました。
|
||||
|
||||
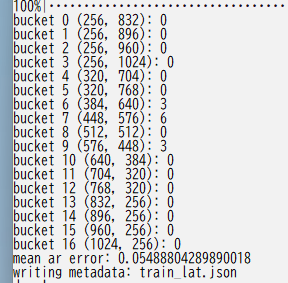
以下のようにbucketingの結果が表示されます。
|
||||
|
||||
|
||||
|
||||
複数の教師データフォルダがある場合には、full_path引数を指定してください。そして、それぞれのフォルダに対して実行してください。
|
||||
```
|
||||
python prepare_buckets_latents.py --full_path
|
||||
train_data1 meta_clean.json meta_lat1.json model.ckpt
|
||||
--batch_size 4 --max_resolution 512,512 --mixed_precision no
|
||||
|
||||
python prepare_buckets_latents.py --full_path
|
||||
train_data2 meta_lat1.json meta_lat2.json model.ckpt
|
||||
--batch_size 4 --max_resolution 512,512 --mixed_precision no
|
||||
|
||||
```
|
||||
読み込み元と書き込み先を同じにすることも可能ですが別々の方が安全です。
|
||||
|
||||
__※引数を都度書き換えて、別のメタデータファイルに書き込むと安全です。__
|
||||
## データの準備
|
||||
|
||||
[学習データの準備について](./train_README-ja.md) を参照してください。fine tuningではメタデータを用いるfine tuning方式のみ対応しています。
|
||||
|
||||
## 学習の実行
|
||||
たとえば以下のように実行します。以下は省メモリ化のための設定です。
|
||||
たとえば以下のように実行します。以下は省メモリ化のための設定です。それぞれの行を必要に応じて書き換えてください。
|
||||
|
||||
```
|
||||
accelerate launch --num_cpu_threads_per_process 8 fine_tune.py
|
||||
accelerate launch --num_cpu_threads_per_process 1 fine_tune.py
|
||||
--pretrained_model_name_or_path=<.ckptまたは.safetensordまたはDiffusers版モデルのディレクトリ>
|
||||
--output_dir=<学習したモデルの出力先フォルダ>
|
||||
--output_name=<学習したモデル出力時のファイル名>
|
||||
--dataset_config=<データ準備で作成した.tomlファイル>
|
||||
--save_model_as=safetensors
|
||||
--learning_rate=5e-6 --max_train_steps=10000
|
||||
--use_8bit_adam --xformers --gradient_checkpointing
|
||||
--mixed_precision=fp16
|
||||
```
|
||||
|
||||
`num_cpu_threads_per_process` には通常は1を指定するとよいようです。
|
||||
|
||||
`pretrained_model_name_or_path` に追加学習を行う元となるモデルを指定します。Stable Diffusionのcheckpointファイル(.ckptまたは.safetensors)、Diffusersのローカルディスクにあるモデルディレクトリ、DiffusersのモデルID("stabilityai/stable-diffusion-2"など)が指定できます。
|
||||
|
||||
`output_dir` に学習後のモデルを保存するフォルダを指定します。`output_name` にモデルのファイル名を拡張子を除いて指定します。`save_model_as` でsafetensors形式での保存を指定しています。
|
||||
|
||||
`dataset_config` に `.toml` ファイルを指定します。ファイル内でのバッチサイズ指定は、当初はメモリ消費を抑えるために `1` としてください。
|
||||
|
||||
学習させるステップ数 `max_train_steps` を10000とします。学習率 `learning_rate` はここでは5e-6を指定しています。
|
||||
|
||||
省メモリ化のため `mixed_precision="fp16"` を指定します(RTX30 シリーズ以降では `bf16` も指定できます。環境整備時にaccelerateに行った設定と合わせてください)。また `gradient_checkpointing` を指定します。
|
||||
|
||||
オプティマイザ(モデルを学習データにあうように最適化=学習させるクラス)にメモリ消費の少ない 8bit AdamW を使うため、 `optimizer_type="AdamW8bit"` を指定します。
|
||||
|
||||
`xformers` オプションを指定し、xformersのCrossAttentionを用います。xformersをインストールしていない場合やエラーとなる場合(環境にもよりますが `mixed_precision="no"` の場合など)、代わりに `mem_eff_attn` オプションを指定すると省メモリ版CrossAttentionを使用します(速度は遅くなります)。
|
||||
|
||||
ある程度メモリがある場合は、`.toml` ファイルを編集してバッチサイズをたとえば `4` くらいに増やしてください(高速化と精度向上の可能性があります)。
|
||||
|
||||
### よく使われるオプションについて
|
||||
|
||||
以下の場合にはオプションに関するドキュメントを参照してください。
|
||||
|
||||
- Stable Diffusion 2.xまたはそこからの派生モデルを学習する
|
||||
- clip skipを2以上を前提としたモデルを学習する
|
||||
- 75トークンを超えたキャプションで学習する
|
||||
|
||||
### バッチサイズについて
|
||||
|
||||
モデル全体を学習するためLoRA等の学習に比べるとメモリ消費量は多くなります(DreamBoothと同じ)。
|
||||
|
||||
### 学習率について
|
||||
|
||||
1e-6から5e-6程度が一般的なようです。他のfine tuningの例なども参照してみてください。
|
||||
|
||||
### 以前の形式のデータセット指定をした場合のコマンドライン
|
||||
|
||||
解像度やバッチサイズをオプションで指定します。コマンドラインの例は以下の通りです。
|
||||
|
||||
```
|
||||
accelerate launch --num_cpu_threads_per_process 1 fine_tune.py
|
||||
--pretrained_model_name_or_path=model.ckpt
|
||||
--in_json meta_lat.json
|
||||
--train_data_dir=train_data
|
||||
@@ -336,76 +115,7 @@ accelerate launch --num_cpu_threads_per_process 8 fine_tune.py
|
||||
--save_every_n_epochs=4
|
||||
```
|
||||
|
||||
accelerateのnum_cpu_threads_per_processにはCPUのコア数を指定するとよいようです。
|
||||
|
||||
pretrained_model_name_or_pathに学習対象のモデルを指定します(Stable DiffusionのcheckpointかDiffusersのモデル)。Stable Diffusionのcheckpointは.ckptと.safetensorsに対応しています(拡張子で自動判定)。
|
||||
|
||||
in_jsonにlatentをキャッシュしたときのメタデータファイルを指定します。
|
||||
|
||||
train_data_dirに教師データのフォルダを、output_dirに学習後のモデルの出力先フォルダを指定します。
|
||||
|
||||
shuffle_captionを指定すると、キャプション、タグをカンマ区切りされた単位でシャッフルして学習します(Waifu Diffusion v1.3で行っている手法です)。
|
||||
(先頭のトークンのいくつかをシャッフルせずに固定できます。その他のオプションのkeep_tokensをご覧ください。)
|
||||
|
||||
train_batch_sizeにバッチサイズを指定します。VRAM 12GBでは1か2程度を指定してください。解像度によっても指定可能な数は変わってきます。
|
||||
学習に使用される実際のデータ量は「バッチサイズ×ステップ数」です。バッチサイズを増やした時には、それに応じてステップ数を下げることが可能です。
|
||||
|
||||
learning_rateに学習率を指定します。たとえばWaifu Diffusion v1.3は5e-6のようです。
|
||||
max_train_stepsにステップ数を指定します。
|
||||
|
||||
use_8bit_adamを指定すると8-bit Adam Optimizerを使用します。省メモリ化、高速化されますが精度は下がる可能性があります。
|
||||
|
||||
xformersを指定するとCrossAttentionを置換して省メモリ化、高速化します。
|
||||
※11/9時点ではfloat32の学習ではxformersがエラーになるため、bf16/fp16を使うか、代わりにmem_eff_attnを指定して省メモリ版CrossAttentionを使ってください(速度はxformersに劣ります)。
|
||||
|
||||
gradient_checkpointingで勾配の途中保存を有効にします。速度は遅くなりますが使用メモリ量が減ります。
|
||||
|
||||
mixed_precisionで混合精度を使うか否かを指定します。"fp16"または"bf16"を指定すると省メモリになりますが精度は劣ります。
|
||||
"fp16"と"bf16"は使用メモリ量はほぼ同じで、bf16の方が学習結果は良くなるとの話もあります(試した範囲ではあまり違いは感じられませんでした)。
|
||||
"no"を指定すると使用しません(float32になります)。
|
||||
|
||||
※bf16で学習したcheckpointをAUTOMATIC1111氏のWeb UIで読み込むとエラーになるようです。これはデータ型のbfloat16がWeb UIのモデルsafety checkerでエラーとなるためのようです。save_precisionオプションを指定してfp16またはfloat32形式で保存してください。またはsafetensors形式で保管しても良さそうです。
|
||||
|
||||
save_every_n_epochsを指定するとそのエポックだけ経過するたびに学習中のモデルを保存します。
|
||||
|
||||
### Stable Diffusion 2.0対応
|
||||
Hugging Faceのstable-diffusion-2-baseを使う場合は--v2オプションを、stable-diffusion-2または768-v-ema.ckptを使う場合は--v2と--v_parameterizationの両方のオプションを指定してください。
|
||||
|
||||
### メモリに余裕がある場合に精度や速度を上げる
|
||||
まずgradient_checkpointingを外すと速度が上がります。ただし設定できるバッチサイズが減りますので、精度と速度のバランスを見ながら設定してください。
|
||||
|
||||
バッチサイズを増やすと速度、精度が上がります。メモリが足りる範囲で、1データ当たりの速度を確認しながら増やしてください(メモリがぎりぎりになるとかえって速度が落ちることがあります)。
|
||||
|
||||
### 使用するCLIP出力の変更
|
||||
clip_skipオプションに2を指定すると、後ろから二番目の層の出力を用います。1またはオプション省略時は最後の層を用います。
|
||||
学習したモデルはAutomatic1111氏のWeb UIで推論できるはずです。
|
||||
|
||||
※SD2.0はデフォルトで後ろから二番目の層を使うため、SD2.0の学習では指定しないでください。
|
||||
|
||||
学習対象のモデルがもともと二番目の層を使うように学習されている場合は、2を指定するとよいでしょう。
|
||||
|
||||
そうではなく最後の層を使用していた場合はモデル全体がそれを前提に学習されています。そのため改めて二番目の層を使用して学習すると、望ましい学習結果を得るにはある程度の枚数の教師データ、長めの学習が必要になるかもしれません。
|
||||
|
||||
### トークン長の拡張
|
||||
max_token_lengthに150または225を指定することでトークン長を拡張して学習できます。
|
||||
学習したモデルはAutomatic1111氏のWeb UIで推論できるはずです。
|
||||
|
||||
clip_skipと同様に、モデルの学習状態と異なる長さで学習するには、ある程度の教師データ枚数、長めの学習時間が必要になると思われます。
|
||||
|
||||
### 学習ログの保存
|
||||
logging_dirオプションにログ保存先フォルダを指定してください。TensorBoard形式のログが保存されます。
|
||||
|
||||
たとえば--logging_dir=logsと指定すると、作業フォルダにlogsフォルダが作成され、その中の日時フォルダにログが保存されます。
|
||||
また--log_prefixオプションを指定すると、日時の前に指定した文字列が追加されます。「--logging_dir=logs --log_prefix=fine_tune_style1」などとして識別用にお使いください。
|
||||
|
||||
TensorBoardでログを確認するには、別のコマンドプロンプトを開き、作業フォルダで以下のように入力します(tensorboardはDiffusersのインストール時にあわせてインストールされると思いますが、もし入っていないならpip install tensorboardで入れてください)。
|
||||
```
|
||||
tensorboard --logdir=logs
|
||||
```
|
||||
|
||||
### Hypernetworkの学習
|
||||
別の記事で解説予定です。
|
||||
|
||||
<!--
|
||||
### 勾配をfp16とした学習(実験的機能)
|
||||
full_fp16オプションを指定すると勾配を通常のfloat32からfloat16(fp16)に変更して学習します(mixed precisionではなく完全なfp16学習になるようです)。これによりSD1.xの512*512サイズでは8GB未満、SD2.xの512*512サイズで12GB未満のVRAM使用量で学習できるようです。
|
||||
|
||||
@@ -415,51 +125,16 @@ full_fp16オプションを指定すると勾配を通常のfloat32からfloat16
|
||||
(余裕があるようならtrain_batch_sizeを段階的に増やすと若干精度が上がるはずです。)
|
||||
|
||||
PyTorchのソースにパッチを当てて無理やり実現しています(PyTorch 1.12.1と1.13.0で確認)。精度はかなり落ちますし、途中で学習失敗する確率も高くなります。学習率やステップ数の設定もシビアなようです。それらを認識したうえで自己責任でお使いください。
|
||||
-->
|
||||
|
||||
### その他のオプション
|
||||
# fine tuning特有のその他の主なオプション
|
||||
|
||||
#### keep_tokens
|
||||
数値を指定するとキャプションの先頭から、指定した数だけのトークン(カンマ区切りの文字列)をシャッフルせず固定します。
|
||||
すべてのオプションについては別文書を参照してください。
|
||||
|
||||
キャプションとタグが両方ある場合、学習時のプロンプトは「キャプション,タグ1,タグ2……」のように連結されますので、「--keep_tokens=1」とすれば、学習時にキャプションが必ず先頭に来るようになります。
|
||||
|
||||
#### dataset_repeats
|
||||
データセットの枚数が極端に少ない場合、epochがすぐに終わってしまうため(epochの区切りで少し時間が掛かります)、数値を指定してデータを何倍かしてepochを長めにしてください。
|
||||
|
||||
#### train_text_encoder
|
||||
## `train_text_encoder`
|
||||
Text Encoderも学習対象とします。メモリ使用量が若干増加します。
|
||||
|
||||
通常のfine tuningではText Encoderは学習対象としませんが(恐らくText Encoderの出力に従うようにU-Netを学習するため)、学習データ数が少ない場合には、DreamBoothのようにText Encoder側に学習させるのも有効的なようです。
|
||||
|
||||
#### save_precision
|
||||
checkpoint保存時のデータ形式をfloat、fp16、bf16から指定できます(未指定時は学習中のデータ形式と同じ)。ディスク容量が節約できますがモデルによる生成結果は変わってきます。またfloatやfp16を指定すると、1111氏のWeb UIでも読めるようになるはずです。
|
||||
|
||||
※VAEについては元のcheckpointのデータ形式のままになりますので、fp16でもモデルサイズが2GB強まで小さくならない場合があります。
|
||||
|
||||
#### save_model_as
|
||||
モデルの保存形式を指定します。ckpt、safetensors、diffusers、diffusers_safetensorsのいずれかを指定してください。
|
||||
|
||||
Stable Diffusion形式(ckptまたはsafetensors)を読み込み、Diffusers形式で保存する場合、不足する情報はHugging Faceからv1.5またはv2.1の情報を落としてきて補完します。
|
||||
|
||||
#### use_safetensors
|
||||
このオプションを指定するとsafetensors形式でcheckpointを保存します。保存形式はデフォルト(読み込んだ形式と同じ)になります。
|
||||
|
||||
#### save_stateとresume
|
||||
save_stateオプションで、途中保存時および最終保存時に、checkpointに加えてoptimizer等の学習状態をフォルダに保存します。これにより中断してから学習再開したときの精度低下が避けられます(optimizerは状態を持ちながら最適化をしていくため、その状態がリセットされると再び初期状態から最適化を行わなくてはなりません)。なお、Accelerateの仕様でステップ数は保存されません。
|
||||
|
||||
スクリプト起動時、resumeオプションで状態の保存されたフォルダを指定すると再開できます。
|
||||
|
||||
学習状態は一回の保存あたり5GB程度になりますのでディスク容量にご注意ください。
|
||||
|
||||
#### gradient_accumulation_steps
|
||||
指定したステップ数だけまとめて勾配を更新します。バッチサイズを増やすのと同様の効果がありますが、メモリを若干消費します。
|
||||
|
||||
※Accelerateの仕様で学習モデルが複数の場合には対応していないとのことですので、Text Encoderを学習対象にして、このオプションに2以上の値を指定するとエラーになるかもしれません。
|
||||
|
||||
#### lr_scheduler / lr_warmup_steps
|
||||
lr_schedulerオプションで学習率のスケジューラをlinear, cosine, cosine_with_restarts, polynomial, constant, constant_with_warmupから選べます。デフォルトはconstantです。
|
||||
|
||||
lr_warmup_stepsでスケジューラのウォームアップ(だんだん学習率を変えていく)ステップ数を指定できます。詳細については各自お調べください。
|
||||
|
||||
#### diffusers_xformers
|
||||
## `diffusers_xformers`
|
||||
スクリプト独自のxformers置換機能ではなくDiffusersのxformers機能を利用します。Hypernetworkの学習はできなくなります。
|
||||
|
||||
@@ -5,13 +5,32 @@ import argparse
|
||||
import glob
|
||||
import os
|
||||
import json
|
||||
import re
|
||||
|
||||
from tqdm import tqdm
|
||||
|
||||
PATTERN_HAIR_LENGTH = re.compile(r', (long|short|medium) hair, ')
|
||||
PATTERN_HAIR_CUT = re.compile(r', (bob|hime) cut, ')
|
||||
PATTERN_HAIR = re.compile(r', ([\w\-]+) hair, ')
|
||||
PATTERN_WORD = re.compile(r', ([\w\-]+|hair ornament), ')
|
||||
|
||||
# 複数人がいるとき、複数の髪色や目の色が定義されていれば削除する
|
||||
PATTERNS_REMOVE_IN_MULTI = [
|
||||
PATTERN_HAIR_LENGTH,
|
||||
PATTERN_HAIR_CUT,
|
||||
re.compile(r', [\w\-]+ eyes, '),
|
||||
re.compile(r', ([\w\-]+ sleeves|sleeveless), '),
|
||||
# 複数の髪型定義がある場合は削除する
|
||||
re.compile(
|
||||
r', (ponytail|braid|ahoge|twintails|[\w\-]+ bun|single hair bun|single side bun|two side up|two tails|[\w\-]+ braid|sidelocks), '),
|
||||
]
|
||||
|
||||
|
||||
def clean_tags(image_key, tags):
|
||||
# replace '_' to ' '
|
||||
tags = tags.replace('^_^', '^@@@^')
|
||||
tags = tags.replace('_', ' ')
|
||||
tags = tags.replace('^@@@^', '^_^')
|
||||
|
||||
# remove rating: deepdanbooruのみ
|
||||
tokens = tags.split(", rating")
|
||||
@@ -26,6 +45,37 @@ def clean_tags(image_key, tags):
|
||||
print(f"{image_key} {tags}")
|
||||
tags = tokens[0]
|
||||
|
||||
tags = ", " + tags.replace(", ", ", , ") + ", " # カンマ付きで検索をするための身も蓋もない対策
|
||||
|
||||
# 複数の人物がいる場合は髪色等のタグを削除する
|
||||
if 'girls' in tags or 'boys' in tags:
|
||||
for pat in PATTERNS_REMOVE_IN_MULTI:
|
||||
found = pat.findall(tags)
|
||||
if len(found) > 1: # 二つ以上、タグがある
|
||||
tags = pat.sub("", tags)
|
||||
|
||||
# 髪の特殊対応
|
||||
srch_hair_len = PATTERN_HAIR_LENGTH.search(tags) # 髪の長さタグは例外なので避けておく(全員が同じ髪の長さの場合)
|
||||
if srch_hair_len:
|
||||
org = srch_hair_len.group()
|
||||
tags = PATTERN_HAIR_LENGTH.sub(", @@@, ", tags)
|
||||
|
||||
found = PATTERN_HAIR.findall(tags)
|
||||
if len(found) > 1:
|
||||
tags = PATTERN_HAIR.sub("", tags)
|
||||
|
||||
if srch_hair_len:
|
||||
tags = tags.replace(", @@@, ", org) # 戻す
|
||||
|
||||
# white shirtとshirtみたいな重複タグの削除
|
||||
found = PATTERN_WORD.findall(tags)
|
||||
for word in found:
|
||||
if re.search(f", ((\w+) )+{word}, ", tags):
|
||||
tags = tags.replace(f", {word}, ", "")
|
||||
|
||||
tags = tags.replace(", , ", ", ")
|
||||
assert tags.startswith(", ") and tags.endswith(", ")
|
||||
tags = tags[2:-2]
|
||||
return tags
|
||||
|
||||
|
||||
@@ -88,13 +138,23 @@ def main(args):
|
||||
if tags is None:
|
||||
print(f"image does not have tags / メタデータにタグがありません: {image_key}")
|
||||
else:
|
||||
metadata[image_key]['tags'] = clean_tags(image_key, tags)
|
||||
org = tags
|
||||
tags = clean_tags(image_key, tags)
|
||||
metadata[image_key]['tags'] = tags
|
||||
if args.debug and org != tags:
|
||||
print("FROM: " + org)
|
||||
print("TO: " + tags)
|
||||
|
||||
caption = metadata[image_key].get('caption')
|
||||
if caption is None:
|
||||
print(f"image does not have caption / メタデータにキャプションがありません: {image_key}")
|
||||
else:
|
||||
metadata[image_key]['caption'] = clean_caption(caption)
|
||||
org = caption
|
||||
caption = clean_caption(caption)
|
||||
metadata[image_key]['caption'] = caption
|
||||
if args.debug and org != caption:
|
||||
print("FROM: " + org)
|
||||
print("TO: " + caption)
|
||||
|
||||
# metadataを書き出して終わり
|
||||
print(f"writing metadata: {args.out_json}")
|
||||
@@ -108,6 +168,7 @@ if __name__ == '__main__':
|
||||
# parser.add_argument("train_data_dir", type=str, help="directory for train images / 学習画像データのディレクトリ")
|
||||
parser.add_argument("in_json", type=str, help="metadata file to input / 読み込むメタデータファイル")
|
||||
parser.add_argument("out_json", type=str, help="metadata file to output / メタデータファイル書き出し先")
|
||||
parser.add_argument("--debug", action="store_true", help="debug mode")
|
||||
|
||||
args, unknown = parser.parse_known_args()
|
||||
if len(unknown) == 1:
|
||||
|
||||
@@ -11,18 +11,59 @@ import torch
|
||||
from torchvision import transforms
|
||||
from torchvision.transforms.functional import InterpolationMode
|
||||
from blip.blip import blip_decoder
|
||||
# from Salesforce_BLIP.models.blip import blip_decoder
|
||||
import library.train_util as train_util
|
||||
|
||||
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
||||
|
||||
|
||||
IMAGE_SIZE = 384
|
||||
|
||||
# 正方形でいいのか? という気がするがソースがそうなので
|
||||
IMAGE_TRANSFORM = transforms.Compose([
|
||||
transforms.Resize((IMAGE_SIZE, IMAGE_SIZE), interpolation=InterpolationMode.BICUBIC),
|
||||
transforms.ToTensor(),
|
||||
transforms.Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711))
|
||||
])
|
||||
|
||||
# 共通化したいが微妙に処理が異なる……
|
||||
class ImageLoadingTransformDataset(torch.utils.data.Dataset):
|
||||
def __init__(self, image_paths):
|
||||
self.images = image_paths
|
||||
|
||||
def __len__(self):
|
||||
return len(self.images)
|
||||
|
||||
def __getitem__(self, idx):
|
||||
img_path = self.images[idx]
|
||||
|
||||
try:
|
||||
image = Image.open(img_path).convert("RGB")
|
||||
# convert to tensor temporarily so dataloader will accept it
|
||||
tensor = IMAGE_TRANSFORM(image)
|
||||
except Exception as e:
|
||||
print(f"Could not load image path / 画像を読み込めません: {img_path}, error: {e}")
|
||||
return None
|
||||
|
||||
return (tensor, img_path)
|
||||
|
||||
|
||||
def collate_fn_remove_corrupted(batch):
|
||||
"""Collate function that allows to remove corrupted examples in the
|
||||
dataloader. It expects that the dataloader returns 'None' when that occurs.
|
||||
The 'None's in the batch are removed.
|
||||
"""
|
||||
# Filter out all the Nones (corrupted examples)
|
||||
batch = list(filter(lambda x: x is not None, batch))
|
||||
return batch
|
||||
|
||||
|
||||
def main(args):
|
||||
# fix the seed for reproducibility
|
||||
seed = args.seed # + utils.get_rank()
|
||||
seed = args.seed # + utils.get_rank()
|
||||
torch.manual_seed(seed)
|
||||
np.random.seed(seed)
|
||||
random.seed(seed)
|
||||
|
||||
|
||||
if not os.path.exists("blip"):
|
||||
args.train_data_dir = os.path.abspath(args.train_data_dir) # convert to absolute path
|
||||
|
||||
@@ -31,24 +72,15 @@ def main(args):
|
||||
os.chdir('finetune')
|
||||
|
||||
print(f"load images from {args.train_data_dir}")
|
||||
image_paths = glob.glob(os.path.join(args.train_data_dir, "*.jpg")) + \
|
||||
glob.glob(os.path.join(args.train_data_dir, "*.png")) + glob.glob(os.path.join(args.train_data_dir, "*.webp"))
|
||||
image_paths = train_util.glob_images(args.train_data_dir)
|
||||
print(f"found {len(image_paths)} images.")
|
||||
|
||||
print(f"loading BLIP caption: {args.caption_weights}")
|
||||
image_size = 384
|
||||
model = blip_decoder(pretrained=args.caption_weights, image_size=image_size, vit='large', med_config="./blip/med_config.json")
|
||||
model = blip_decoder(pretrained=args.caption_weights, image_size=IMAGE_SIZE, vit='large', med_config="./blip/med_config.json")
|
||||
model.eval()
|
||||
model = model.to(DEVICE)
|
||||
print("BLIP loaded")
|
||||
|
||||
# 正方形でいいのか? という気がするがソースがそうなので
|
||||
transform = transforms.Compose([
|
||||
transforms.Resize((image_size, image_size), interpolation=InterpolationMode.BICUBIC),
|
||||
transforms.ToTensor(),
|
||||
transforms.Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711))
|
||||
])
|
||||
|
||||
# captioningする
|
||||
def run_batch(path_imgs):
|
||||
imgs = torch.stack([im for _, im in path_imgs]).to(DEVICE)
|
||||
@@ -66,18 +98,35 @@ def main(args):
|
||||
if args.debug:
|
||||
print(image_path, caption)
|
||||
|
||||
b_imgs = []
|
||||
for image_path in tqdm(image_paths, smoothing=0.0):
|
||||
raw_image = Image.open(image_path)
|
||||
if raw_image.mode != "RGB":
|
||||
print(f"convert image mode {raw_image.mode} to RGB: {image_path}")
|
||||
raw_image = raw_image.convert("RGB")
|
||||
# 読み込みの高速化のためにDataLoaderを使うオプション
|
||||
if args.max_data_loader_n_workers is not None:
|
||||
dataset = ImageLoadingTransformDataset(image_paths)
|
||||
data = torch.utils.data.DataLoader(dataset, batch_size=args.batch_size, shuffle=False,
|
||||
num_workers=args.max_data_loader_n_workers, collate_fn=collate_fn_remove_corrupted, drop_last=False)
|
||||
else:
|
||||
data = [[(None, ip)] for ip in image_paths]
|
||||
|
||||
image = transform(raw_image)
|
||||
b_imgs.append((image_path, image))
|
||||
if len(b_imgs) >= args.batch_size:
|
||||
run_batch(b_imgs)
|
||||
b_imgs.clear()
|
||||
b_imgs = []
|
||||
for data_entry in tqdm(data, smoothing=0.0):
|
||||
for data in data_entry:
|
||||
if data is None:
|
||||
continue
|
||||
|
||||
img_tensor, image_path = data
|
||||
if img_tensor is None:
|
||||
try:
|
||||
raw_image = Image.open(image_path)
|
||||
if raw_image.mode != 'RGB':
|
||||
raw_image = raw_image.convert("RGB")
|
||||
img_tensor = IMAGE_TRANSFORM(raw_image)
|
||||
except Exception as e:
|
||||
print(f"Could not load image path / 画像を読み込めません: {image_path}, error: {e}")
|
||||
continue
|
||||
|
||||
b_imgs.append((image_path, img_tensor))
|
||||
if len(b_imgs) >= args.batch_size:
|
||||
run_batch(b_imgs)
|
||||
b_imgs.clear()
|
||||
if len(b_imgs) > 0:
|
||||
run_batch(b_imgs)
|
||||
|
||||
@@ -95,6 +144,8 @@ if __name__ == '__main__':
|
||||
parser.add_argument("--beam_search", action="store_true",
|
||||
help="use beam search (default Nucleus sampling) / beam searchを使う(このオプション未指定時はNucleus sampling)")
|
||||
parser.add_argument("--batch_size", type=int, default=1, help="batch size in inference / 推論時のバッチサイズ")
|
||||
parser.add_argument("--max_data_loader_n_workers", type=int, default=None,
|
||||
help="enable image reading by DataLoader with this number of workers (faster) / DataLoaderによる画像読み込みを有効にしてこのワーカー数を適用する(読み込みを高速化)")
|
||||
parser.add_argument("--num_beams", type=int, default=1, help="num of beams in beam search /beam search時のビーム数(多いと精度が上がるが時間がかかる)")
|
||||
parser.add_argument("--top_p", type=float, default=0.9, help="top_p in Nucleus sampling / Nucleus sampling時のtop_p")
|
||||
parser.add_argument("--max_length", type=int, default=75, help="max length of caption / captionの最大長")
|
||||
|
||||
145
finetune/make_captions_by_git.py
Normal file
145
finetune/make_captions_by_git.py
Normal file
@@ -0,0 +1,145 @@
|
||||
import argparse
|
||||
import os
|
||||
import re
|
||||
|
||||
from PIL import Image
|
||||
from tqdm import tqdm
|
||||
import torch
|
||||
from transformers import AutoProcessor, AutoModelForCausalLM
|
||||
from transformers.generation.utils import GenerationMixin
|
||||
|
||||
import library.train_util as train_util
|
||||
|
||||
|
||||
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
||||
|
||||
PATTERN_REPLACE = [
|
||||
re.compile(r'(has|with|and) the (words?|letters?|name) (" ?[^"]*"|\w+)( ?(is )?(on|in) (the |her |their |him )?\w+)?'),
|
||||
re.compile(r'(with a sign )?that says ?(" ?[^"]*"|\w+)( ?on it)?'),
|
||||
re.compile(r"(with a sign )?that says ?(' ?(i'm)?[^']*'|\w+)( ?on it)?"),
|
||||
re.compile(r'with the number \d+ on (it|\w+ \w+)'),
|
||||
re.compile(r'with the words "'),
|
||||
re.compile(r'word \w+ on it'),
|
||||
re.compile(r'that says the word \w+ on it'),
|
||||
re.compile('that says\'the word "( on it)?'),
|
||||
]
|
||||
|
||||
# 誤検知しまくりの with the word xxxx を消す
|
||||
|
||||
|
||||
def remove_words(captions, debug):
|
||||
removed_caps = []
|
||||
for caption in captions:
|
||||
cap = caption
|
||||
for pat in PATTERN_REPLACE:
|
||||
cap = pat.sub("", cap)
|
||||
if debug and cap != caption:
|
||||
print(caption)
|
||||
print(cap)
|
||||
removed_caps.append(cap)
|
||||
return removed_caps
|
||||
|
||||
|
||||
def collate_fn_remove_corrupted(batch):
|
||||
"""Collate function that allows to remove corrupted examples in the
|
||||
dataloader. It expects that the dataloader returns 'None' when that occurs.
|
||||
The 'None's in the batch are removed.
|
||||
"""
|
||||
# Filter out all the Nones (corrupted examples)
|
||||
batch = list(filter(lambda x: x is not None, batch))
|
||||
return batch
|
||||
|
||||
|
||||
def main(args):
|
||||
# GITにバッチサイズが1より大きくても動くようにパッチを当てる: transformers 4.26.0用
|
||||
org_prepare_input_ids_for_generation = GenerationMixin._prepare_input_ids_for_generation
|
||||
curr_batch_size = [args.batch_size] # ループの最後で件数がbatch_size未満になるので入れ替えられるように
|
||||
|
||||
# input_idsがバッチサイズと同じ件数である必要がある:バッチサイズはこの関数から参照できないので外から渡す
|
||||
# ここより上で置き換えようとするとすごく大変
|
||||
def _prepare_input_ids_for_generation_patch(self, bos_token_id, encoder_outputs):
|
||||
input_ids = org_prepare_input_ids_for_generation(self, bos_token_id, encoder_outputs)
|
||||
if input_ids.size()[0] != curr_batch_size[0]:
|
||||
input_ids = input_ids.repeat(curr_batch_size[0], 1)
|
||||
return input_ids
|
||||
GenerationMixin._prepare_input_ids_for_generation = _prepare_input_ids_for_generation_patch
|
||||
|
||||
print(f"load images from {args.train_data_dir}")
|
||||
image_paths = train_util.glob_images(args.train_data_dir)
|
||||
print(f"found {len(image_paths)} images.")
|
||||
|
||||
# できればcacheに依存せず明示的にダウンロードしたい
|
||||
print(f"loading GIT: {args.model_id}")
|
||||
git_processor = AutoProcessor.from_pretrained(args.model_id)
|
||||
git_model = AutoModelForCausalLM.from_pretrained(args.model_id).to(DEVICE)
|
||||
print("GIT loaded")
|
||||
|
||||
# captioningする
|
||||
def run_batch(path_imgs):
|
||||
imgs = [im for _, im in path_imgs]
|
||||
|
||||
curr_batch_size[0] = len(path_imgs)
|
||||
inputs = git_processor(images=imgs, return_tensors="pt").to(DEVICE) # 画像はpil形式
|
||||
generated_ids = git_model.generate(pixel_values=inputs.pixel_values, max_length=args.max_length)
|
||||
captions = git_processor.batch_decode(generated_ids, skip_special_tokens=True)
|
||||
|
||||
if args.remove_words:
|
||||
captions = remove_words(captions, args.debug)
|
||||
|
||||
for (image_path, _), caption in zip(path_imgs, captions):
|
||||
with open(os.path.splitext(image_path)[0] + args.caption_extension, "wt", encoding='utf-8') as f:
|
||||
f.write(caption + "\n")
|
||||
if args.debug:
|
||||
print(image_path, caption)
|
||||
|
||||
# 読み込みの高速化のためにDataLoaderを使うオプション
|
||||
if args.max_data_loader_n_workers is not None:
|
||||
dataset = train_util.ImageLoadingDataset(image_paths)
|
||||
data = torch.utils.data.DataLoader(dataset, batch_size=args.batch_size, shuffle=False,
|
||||
num_workers=args.max_data_loader_n_workers, collate_fn=collate_fn_remove_corrupted, drop_last=False)
|
||||
else:
|
||||
data = [[(None, ip)] for ip in image_paths]
|
||||
|
||||
b_imgs = []
|
||||
for data_entry in tqdm(data, smoothing=0.0):
|
||||
for data in data_entry:
|
||||
if data is None:
|
||||
continue
|
||||
|
||||
image, image_path = data
|
||||
if image is None:
|
||||
try:
|
||||
image = Image.open(image_path)
|
||||
if image.mode != 'RGB':
|
||||
image = image.convert("RGB")
|
||||
except Exception as e:
|
||||
print(f"Could not load image path / 画像を読み込めません: {image_path}, error: {e}")
|
||||
continue
|
||||
|
||||
b_imgs.append((image_path, image))
|
||||
if len(b_imgs) >= args.batch_size:
|
||||
run_batch(b_imgs)
|
||||
b_imgs.clear()
|
||||
|
||||
if len(b_imgs) > 0:
|
||||
run_batch(b_imgs)
|
||||
|
||||
print("done!")
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("train_data_dir", type=str, help="directory for train images / 学習画像データのディレクトリ")
|
||||
parser.add_argument("--caption_extension", type=str, default=".caption", help="extension of caption file / 出力されるキャプションファイルの拡張子")
|
||||
parser.add_argument("--model_id", type=str, default="microsoft/git-large-textcaps",
|
||||
help="model id for GIT in Hugging Face / 使用するGITのHugging FaceのモデルID")
|
||||
parser.add_argument("--batch_size", type=int, default=1, help="batch size in inference / 推論時のバッチサイズ")
|
||||
parser.add_argument("--max_data_loader_n_workers", type=int, default=None,
|
||||
help="enable image reading by DataLoader with this number of workers (faster) / DataLoaderによる画像読み込みを有効にしてこのワーカー数を適用する(読み込みを高速化)")
|
||||
parser.add_argument("--max_length", type=int, default=50, help="max length of caption / captionの最大長")
|
||||
parser.add_argument("--remove_words", action="store_true",
|
||||
help="remove like `with the words xxx` from caption / `with the words xxx`のような部分をキャプションから削除する")
|
||||
parser.add_argument("--debug", action="store_true", help="debug mode")
|
||||
|
||||
args = parser.parse_args()
|
||||
main(args)
|
||||
@@ -1,26 +1,24 @@
|
||||
# このスクリプトのライセンスは、Apache License 2.0とします
|
||||
# (c) 2022 Kohya S. @kohya_ss
|
||||
|
||||
import argparse
|
||||
import glob
|
||||
import os
|
||||
import json
|
||||
|
||||
from pathlib import Path
|
||||
from typing import List
|
||||
from tqdm import tqdm
|
||||
import library.train_util as train_util
|
||||
|
||||
|
||||
def main(args):
|
||||
image_paths = glob.glob(os.path.join(args.train_data_dir, "*.jpg")) + \
|
||||
glob.glob(os.path.join(args.train_data_dir, "*.png")) + glob.glob(os.path.join(args.train_data_dir, "*.webp"))
|
||||
assert not args.recursive or (args.recursive and args.full_path), "recursive requires full_path / recursiveはfull_pathと同時に指定してください"
|
||||
|
||||
train_data_dir_path = Path(args.train_data_dir)
|
||||
image_paths: List[Path] = train_util.glob_images_pathlib(train_data_dir_path, args.recursive)
|
||||
print(f"found {len(image_paths)} images.")
|
||||
|
||||
if args.in_json is None and os.path.isfile(args.out_json):
|
||||
if args.in_json is None and Path(args.out_json).is_file():
|
||||
args.in_json = args.out_json
|
||||
|
||||
if args.in_json is not None:
|
||||
print(f"loading existing metadata: {args.in_json}")
|
||||
with open(args.in_json, "rt", encoding='utf-8') as f:
|
||||
metadata = json.load(f)
|
||||
metadata = json.loads(Path(args.in_json).read_text(encoding='utf-8'))
|
||||
print("captions for existing images will be overwritten / 既存の画像のキャプションは上書きされます")
|
||||
else:
|
||||
print("new metadata will be created / 新しいメタデータファイルが作成されます")
|
||||
@@ -28,11 +26,10 @@ def main(args):
|
||||
|
||||
print("merge caption texts to metadata json.")
|
||||
for image_path in tqdm(image_paths):
|
||||
caption_path = os.path.splitext(image_path)[0] + args.caption_extension
|
||||
with open(caption_path, "rt", encoding='utf-8') as f:
|
||||
caption = f.readlines()[0].strip()
|
||||
caption_path = image_path.with_suffix(args.caption_extension)
|
||||
caption = caption_path.read_text(encoding='utf-8').strip()
|
||||
|
||||
image_key = image_path if args.full_path else os.path.splitext(os.path.basename(image_path))[0]
|
||||
image_key = str(image_path) if args.full_path else image_path.stem
|
||||
if image_key not in metadata:
|
||||
metadata[image_key] = {}
|
||||
|
||||
@@ -42,8 +39,7 @@ def main(args):
|
||||
|
||||
# metadataを書き出して終わり
|
||||
print(f"writing metadata: {args.out_json}")
|
||||
with open(args.out_json, "wt", encoding='utf-8') as f:
|
||||
json.dump(metadata, f, indent=2)
|
||||
Path(args.out_json).write_text(json.dumps(metadata, indent=2), encoding='utf-8')
|
||||
print("done!")
|
||||
|
||||
|
||||
@@ -51,12 +47,15 @@ if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("train_data_dir", type=str, help="directory for train images / 学習画像データのディレクトリ")
|
||||
parser.add_argument("out_json", type=str, help="metadata file to output / メタデータファイル書き出し先")
|
||||
parser.add_argument("--in_json", type=str, help="metadata file to input (if omitted and out_json exists, existing out_json is read) / 読み込むメタデータファイル(省略時、out_jsonが存在すればそれを読み込む)")
|
||||
parser.add_argument("--in_json", type=str,
|
||||
help="metadata file to input (if omitted and out_json exists, existing out_json is read) / 読み込むメタデータファイル(省略時、out_jsonが存在すればそれを読み込む)")
|
||||
parser.add_argument("--caption_extention", type=str, default=None,
|
||||
help="extension of caption file (for backward compatibility) / 読み込むキャプションファイルの拡張子(スペルミスしていたのを残してあります)")
|
||||
parser.add_argument("--caption_extension", type=str, default=".caption", help="extension of caption file / 読み込むキャプションファイルの拡張子")
|
||||
parser.add_argument("--full_path", action="store_true",
|
||||
help="use full path as image-key in metadata (supports multiple directories) / メタデータで画像キーをフルパスにする(複数の学習画像ディレクトリに対応)")
|
||||
parser.add_argument("--recursive", action="store_true",
|
||||
help="recursively look for training tags in all child folders of train_data_dir / train_data_dirのすべての子フォルダにある学習タグを再帰的に探す")
|
||||
parser.add_argument("--debug", action="store_true", help="debug mode")
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
@@ -1,26 +1,24 @@
|
||||
# このスクリプトのライセンスは、Apache License 2.0とします
|
||||
# (c) 2022 Kohya S. @kohya_ss
|
||||
|
||||
import argparse
|
||||
import glob
|
||||
import os
|
||||
import json
|
||||
|
||||
from pathlib import Path
|
||||
from typing import List
|
||||
from tqdm import tqdm
|
||||
import library.train_util as train_util
|
||||
|
||||
|
||||
def main(args):
|
||||
image_paths = glob.glob(os.path.join(args.train_data_dir, "*.jpg")) + \
|
||||
glob.glob(os.path.join(args.train_data_dir, "*.png")) + glob.glob(os.path.join(args.train_data_dir, "*.webp"))
|
||||
assert not args.recursive or (args.recursive and args.full_path), "recursive requires full_path / recursiveはfull_pathと同時に指定してください"
|
||||
|
||||
train_data_dir_path = Path(args.train_data_dir)
|
||||
image_paths: List[Path] = train_util.glob_images_pathlib(train_data_dir_path, args.recursive)
|
||||
print(f"found {len(image_paths)} images.")
|
||||
|
||||
if args.in_json is None and os.path.isfile(args.out_json):
|
||||
if args.in_json is None and Path(args.out_json).is_file():
|
||||
args.in_json = args.out_json
|
||||
|
||||
if args.in_json is not None:
|
||||
print(f"loading existing metadata: {args.in_json}")
|
||||
with open(args.in_json, "rt", encoding='utf-8') as f:
|
||||
metadata = json.load(f)
|
||||
metadata = json.loads(Path(args.in_json).read_text(encoding='utf-8'))
|
||||
print("tags data for existing images will be overwritten / 既存の画像のタグは上書きされます")
|
||||
else:
|
||||
print("new metadata will be created / 新しいメタデータファイルが作成されます")
|
||||
@@ -28,11 +26,10 @@ def main(args):
|
||||
|
||||
print("merge tags to metadata json.")
|
||||
for image_path in tqdm(image_paths):
|
||||
tags_path = os.path.splitext(image_path)[0] + '.txt'
|
||||
with open(tags_path, "rt", encoding='utf-8') as f:
|
||||
tags = f.readlines()[0].strip()
|
||||
tags_path = image_path.with_suffix(args.caption_extension)
|
||||
tags = tags_path.read_text(encoding='utf-8').strip()
|
||||
|
||||
image_key = image_path if args.full_path else os.path.splitext(os.path.basename(image_path))[0]
|
||||
image_key = str(image_path) if args.full_path else image_path.stem
|
||||
if image_key not in metadata:
|
||||
metadata[image_key] = {}
|
||||
|
||||
@@ -42,8 +39,8 @@ def main(args):
|
||||
|
||||
# metadataを書き出して終わり
|
||||
print(f"writing metadata: {args.out_json}")
|
||||
with open(args.out_json, "wt", encoding='utf-8') as f:
|
||||
json.dump(metadata, f, indent=2)
|
||||
Path(args.out_json).write_text(json.dumps(metadata, indent=2), encoding='utf-8')
|
||||
|
||||
print("done!")
|
||||
|
||||
|
||||
@@ -51,9 +48,14 @@ if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("train_data_dir", type=str, help="directory for train images / 学習画像データのディレクトリ")
|
||||
parser.add_argument("out_json", type=str, help="metadata file to output / メタデータファイル書き出し先")
|
||||
parser.add_argument("--in_json", type=str, help="metadata file to input (if omitted and out_json exists, existing out_json is read) / 読み込むメタデータファイル(省略時、out_jsonが存在すればそれを読み込む)")
|
||||
parser.add_argument("--in_json", type=str,
|
||||
help="metadata file to input (if omitted and out_json exists, existing out_json is read) / 読み込むメタデータファイル(省略時、out_jsonが存在すればそれを読み込む)")
|
||||
parser.add_argument("--full_path", action="store_true",
|
||||
help="use full path as image-key in metadata (supports multiple directories) / メタデータで画像キーをフルパスにする(複数の学習画像ディレクトリに対応)")
|
||||
parser.add_argument("--recursive", action="store_true",
|
||||
help="recursively look for training tags in all child folders of train_data_dir / train_data_dirのすべての子フォルダにある学習タグを再帰的に探す")
|
||||
parser.add_argument("--caption_extension", type=str, default=".txt",
|
||||
help="extension of caption (tag) file / 読み込むキャプション(タグ)ファイルの拡張子")
|
||||
parser.add_argument("--debug", action="store_true", help="debug mode, print tags")
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
@@ -1,20 +1,16 @@
|
||||
# このスクリプトのライセンスは、Apache License 2.0とします
|
||||
# (c) 2022 Kohya S. @kohya_ss
|
||||
|
||||
import argparse
|
||||
import glob
|
||||
import os
|
||||
import json
|
||||
|
||||
from tqdm import tqdm
|
||||
import numpy as np
|
||||
from diffusers import AutoencoderKL
|
||||
from PIL import Image
|
||||
import cv2
|
||||
import torch
|
||||
from torchvision import transforms
|
||||
|
||||
import library.model_util as model_util
|
||||
import library.train_util as train_util
|
||||
|
||||
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
||||
|
||||
@@ -26,6 +22,16 @@ IMAGE_TRANSFORMS = transforms.Compose(
|
||||
)
|
||||
|
||||
|
||||
def collate_fn_remove_corrupted(batch):
|
||||
"""Collate function that allows to remove corrupted examples in the
|
||||
dataloader. It expects that the dataloader returns 'None' when that occurs.
|
||||
The 'None's in the batch are removed.
|
||||
"""
|
||||
# Filter out all the Nones (corrupted examples)
|
||||
batch = list(filter(lambda x: x is not None, batch))
|
||||
return batch
|
||||
|
||||
|
||||
def get_latents(vae, images, weight_dtype):
|
||||
img_tensors = [IMAGE_TRANSFORMS(image) for image in images]
|
||||
img_tensors = torch.stack(img_tensors)
|
||||
@@ -35,9 +41,22 @@ def get_latents(vae, images, weight_dtype):
|
||||
return latents
|
||||
|
||||
|
||||
def get_npz_filename_wo_ext(data_dir, image_key, is_full_path, flip):
|
||||
if is_full_path:
|
||||
base_name = os.path.splitext(os.path.basename(image_key))[0]
|
||||
else:
|
||||
base_name = image_key
|
||||
if flip:
|
||||
base_name += '_flip'
|
||||
return os.path.join(data_dir, base_name)
|
||||
|
||||
|
||||
def main(args):
|
||||
image_paths = glob.glob(os.path.join(args.train_data_dir, "*.jpg")) + \
|
||||
glob.glob(os.path.join(args.train_data_dir, "*.png")) + glob.glob(os.path.join(args.train_data_dir, "*.webp"))
|
||||
# assert args.bucket_reso_steps % 8 == 0, f"bucket_reso_steps must be divisible by 8 / bucket_reso_stepは8で割り切れる必要があります"
|
||||
if args.bucket_reso_steps % 8 > 0:
|
||||
print(f"resolution of buckets in training time is a multiple of 8 / 学習時の各bucketの解像度は8単位になります")
|
||||
|
||||
image_paths = train_util.glob_images(args.train_data_dir)
|
||||
print(f"found {len(image_paths)} images.")
|
||||
|
||||
if os.path.exists(args.in_json):
|
||||
@@ -62,89 +81,144 @@ def main(args):
|
||||
max_reso = tuple([int(t) for t in args.max_resolution.split(',')])
|
||||
assert len(max_reso) == 2, f"illegal resolution (not 'width,height') / 画像サイズに誤りがあります。'幅,高さ'で指定してください: {args.max_resolution}"
|
||||
|
||||
bucket_resos, bucket_aspect_ratios = model_util.make_bucket_resolutions(
|
||||
max_reso, args.min_bucket_reso, args.max_bucket_reso)
|
||||
bucket_manager = train_util.BucketManager(args.bucket_no_upscale, max_reso,
|
||||
args.min_bucket_reso, args.max_bucket_reso, args.bucket_reso_steps)
|
||||
if not args.bucket_no_upscale:
|
||||
bucket_manager.make_buckets()
|
||||
else:
|
||||
print("min_bucket_reso and max_bucket_reso are ignored if bucket_no_upscale is set, because bucket reso is defined by image size automatically / bucket_no_upscaleが指定された場合は、bucketの解像度は画像サイズから自動計算されるため、min_bucket_resoとmax_bucket_resoは無視されます")
|
||||
|
||||
# 画像をひとつずつ適切なbucketに割り当てながらlatentを計算する
|
||||
bucket_aspect_ratios = np.array(bucket_aspect_ratios)
|
||||
buckets_imgs = [[] for _ in range(len(bucket_resos))]
|
||||
bucket_counts = [0 for _ in range(len(bucket_resos))]
|
||||
img_ar_errors = []
|
||||
for i, image_path in enumerate(tqdm(image_paths, smoothing=0.0)):
|
||||
|
||||
def process_batch(is_last):
|
||||
for bucket in bucket_manager.buckets:
|
||||
if (is_last and len(bucket) > 0) or len(bucket) >= args.batch_size:
|
||||
latents = get_latents(vae, [img for _, img in bucket], weight_dtype)
|
||||
assert latents.shape[2] == bucket[0][1].shape[0] // 8 and latents.shape[3] == bucket[0][1].shape[1] // 8, \
|
||||
f"latent shape {latents.shape}, {bucket[0][1].shape}"
|
||||
|
||||
for (image_key, _), latent in zip(bucket, latents):
|
||||
npz_file_name = get_npz_filename_wo_ext(args.train_data_dir, image_key, args.full_path, False)
|
||||
np.savez(npz_file_name, latent)
|
||||
|
||||
# flip
|
||||
if args.flip_aug:
|
||||
latents = get_latents(vae, [img[:, ::-1].copy() for _, img in bucket], weight_dtype) # copyがないとTensor変換できない
|
||||
|
||||
for (image_key, _), latent in zip(bucket, latents):
|
||||
npz_file_name = get_npz_filename_wo_ext(args.train_data_dir, image_key, args.full_path, True)
|
||||
np.savez(npz_file_name, latent)
|
||||
else:
|
||||
# remove existing flipped npz
|
||||
for image_key, _ in bucket:
|
||||
npz_file_name = get_npz_filename_wo_ext(args.train_data_dir, image_key, args.full_path, True) + ".npz"
|
||||
if os.path.isfile(npz_file_name):
|
||||
print(f"remove existing flipped npz / 既存のflipされたnpzファイルを削除します: {npz_file_name}")
|
||||
os.remove(npz_file_name)
|
||||
|
||||
bucket.clear()
|
||||
|
||||
# 読み込みの高速化のためにDataLoaderを使うオプション
|
||||
if args.max_data_loader_n_workers is not None:
|
||||
dataset = train_util.ImageLoadingDataset(image_paths)
|
||||
data = torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False,
|
||||
num_workers=args.max_data_loader_n_workers, collate_fn=collate_fn_remove_corrupted, drop_last=False)
|
||||
else:
|
||||
data = [[(None, ip)] for ip in image_paths]
|
||||
|
||||
bucket_counts = {}
|
||||
for data_entry in tqdm(data, smoothing=0.0):
|
||||
if data_entry[0] is None:
|
||||
continue
|
||||
|
||||
img_tensor, image_path = data_entry[0]
|
||||
if img_tensor is not None:
|
||||
image = transforms.functional.to_pil_image(img_tensor)
|
||||
else:
|
||||
try:
|
||||
image = Image.open(image_path)
|
||||
if image.mode != 'RGB':
|
||||
image = image.convert("RGB")
|
||||
except Exception as e:
|
||||
print(f"Could not load image path / 画像を読み込めません: {image_path}, error: {e}")
|
||||
continue
|
||||
|
||||
image_key = image_path if args.full_path else os.path.splitext(os.path.basename(image_path))[0]
|
||||
if image_key not in metadata:
|
||||
metadata[image_key] = {}
|
||||
|
||||
image = Image.open(image_path)
|
||||
if image.mode != 'RGB':
|
||||
image = image.convert("RGB")
|
||||
# 本当はこのあとの部分もDataSetに持っていけば高速化できるがいろいろ大変
|
||||
|
||||
aspect_ratio = image.width / image.height
|
||||
ar_errors = bucket_aspect_ratios - aspect_ratio
|
||||
bucket_id = np.abs(ar_errors).argmin()
|
||||
reso = bucket_resos[bucket_id]
|
||||
ar_error = ar_errors[bucket_id]
|
||||
reso, resized_size, ar_error = bucket_manager.select_bucket(image.width, image.height)
|
||||
img_ar_errors.append(abs(ar_error))
|
||||
bucket_counts[reso] = bucket_counts.get(reso, 0) + 1
|
||||
|
||||
# どのサイズにリサイズするか→トリミングする方向で
|
||||
if ar_error <= 0: # 横が長い→縦を合わせる
|
||||
scale = reso[1] / image.height
|
||||
else:
|
||||
scale = reso[0] / image.width
|
||||
# メタデータに記録する解像度はlatent単位とするので、8単位で切り捨て
|
||||
metadata[image_key]['train_resolution'] = (reso[0] - reso[0] % 8, reso[1] - reso[1] % 8)
|
||||
|
||||
resized_size = (int(image.width * scale + .5), int(image.height * scale + .5))
|
||||
if not args.bucket_no_upscale:
|
||||
# upscaleを行わないときには、resize後のサイズは、bucketのサイズと、縦横どちらかが同じであることを確認する
|
||||
assert resized_size[0] == reso[0] or resized_size[1] == reso[
|
||||
1], f"internal error, resized size not match: {reso}, {resized_size}, {image.width}, {image.height}"
|
||||
assert resized_size[0] >= reso[0] and resized_size[1] >= reso[
|
||||
1], f"internal error, resized size too small: {reso}, {resized_size}, {image.width}, {image.height}"
|
||||
|
||||
# print(image.width, image.height, bucket_id, bucket_resos[bucket_id], ar_errors[bucket_id], resized_size,
|
||||
# bucket_resos[bucket_id][0] - resized_size[0], bucket_resos[bucket_id][1] - resized_size[1])
|
||||
|
||||
assert resized_size[0] == reso[0] or resized_size[1] == reso[
|
||||
1], f"internal error, resized size not match: {reso}, {resized_size}, {image.width}, {image.height}"
|
||||
assert resized_size[0] >= reso[0] and resized_size[1] >= reso[
|
||||
1], f"internal error, resized size too small: {reso}, {resized_size}, {image.width}, {image.height}"
|
||||
1], f"internal error resized size is small: {resized_size}, {reso}"
|
||||
|
||||
# 既に存在するファイルがあればshapeを確認して同じならskipする
|
||||
if args.skip_existing:
|
||||
npz_files = [get_npz_filename_wo_ext(args.train_data_dir, image_key, args.full_path, False) + ".npz"]
|
||||
if args.flip_aug:
|
||||
npz_files.append(get_npz_filename_wo_ext(args.train_data_dir, image_key, args.full_path, True) + ".npz")
|
||||
|
||||
found = True
|
||||
for npz_file in npz_files:
|
||||
if not os.path.exists(npz_file):
|
||||
found = False
|
||||
break
|
||||
|
||||
dat = np.load(npz_file)['arr_0']
|
||||
if dat.shape[1] != reso[1] // 8 or dat.shape[2] != reso[0] // 8: # latentsのshapeを確認
|
||||
found = False
|
||||
break
|
||||
if found:
|
||||
continue
|
||||
|
||||
# 画像をリサイズしてトリミングする
|
||||
# PILにinter_areaがないのでcv2で……
|
||||
image = np.array(image)
|
||||
image = cv2.resize(image, resized_size, interpolation=cv2.INTER_AREA)
|
||||
if resized_size[0] != image.shape[1] or resized_size[1] != image.shape[0]: # リサイズ処理が必要?
|
||||
image = cv2.resize(image, resized_size, interpolation=cv2.INTER_AREA)
|
||||
|
||||
if resized_size[0] > reso[0]:
|
||||
trim_size = resized_size[0] - reso[0]
|
||||
image = image[:, trim_size//2:trim_size//2 + reso[0]]
|
||||
elif resized_size[1] > reso[1]:
|
||||
|
||||
if resized_size[1] > reso[1]:
|
||||
trim_size = resized_size[1] - reso[1]
|
||||
image = image[trim_size//2:trim_size//2 + reso[1]]
|
||||
|
||||
assert image.shape[0] == reso[1] and image.shape[1] == reso[0], f"internal error, illegal trimmed size: {image.shape}, {reso}"
|
||||
|
||||
# # debug
|
||||
# cv2.imwrite(f"r:\\test\\img_{i:05d}.jpg", image[:, :, ::-1])
|
||||
# cv2.imwrite(f"r:\\test\\img_{len(img_ar_errors)}.jpg", image[:, :, ::-1])
|
||||
|
||||
# バッチへ追加
|
||||
buckets_imgs[bucket_id].append((image_key, reso, image))
|
||||
bucket_counts[bucket_id] += 1
|
||||
metadata[image_key]['train_resolution'] = reso
|
||||
bucket_manager.add_image(reso, (image_key, image))
|
||||
|
||||
# バッチを推論するか判定して推論する
|
||||
is_last = i == len(image_paths) - 1
|
||||
for j in range(len(buckets_imgs)):
|
||||
bucket = buckets_imgs[j]
|
||||
if (is_last and len(bucket) > 0) or len(bucket) >= args.batch_size:
|
||||
latents = get_latents(vae, [img for _, _, img in bucket], weight_dtype)
|
||||
process_batch(False)
|
||||
|
||||
for (image_key, reso, _), latent in zip(bucket, latents):
|
||||
npz_file_name = os.path.splitext(os.path.basename(image_key))[0] if args.full_path else image_key
|
||||
np.savez(os.path.join(args.train_data_dir, npz_file_name), latent)
|
||||
# 残りを処理する
|
||||
process_batch(True)
|
||||
|
||||
# flip
|
||||
if args.flip_aug:
|
||||
latents = get_latents(vae, [img[:, ::-1].copy() for _, _, img in bucket], weight_dtype) # copyがないとTensor変換できない
|
||||
|
||||
for (image_key, reso, _), latent in zip(bucket, latents):
|
||||
npz_file_name = os.path.splitext(os.path.basename(image_key))[0] if args.full_path else image_key
|
||||
np.savez(os.path.join(args.train_data_dir, npz_file_name + '_flip'), latent)
|
||||
|
||||
bucket.clear()
|
||||
|
||||
for i, (reso, count) in enumerate(zip(bucket_resos, bucket_counts)):
|
||||
print(f"bucket {i} {reso}: {count}")
|
||||
bucket_manager.sort()
|
||||
for i, reso in enumerate(bucket_manager.resos):
|
||||
count = bucket_counts.get(reso, 0)
|
||||
if count > 0:
|
||||
print(f"bucket {i} {reso}: {count}")
|
||||
img_ar_errors = np.array(img_ar_errors)
|
||||
print(f"mean ar error: {np.mean(img_ar_errors)}")
|
||||
|
||||
@@ -162,18 +236,26 @@ if __name__ == '__main__':
|
||||
parser.add_argument("out_json", type=str, help="metadata file to output / メタデータファイル書き出し先")
|
||||
parser.add_argument("model_name_or_path", type=str, help="model name or path to encode latents / latentを取得するためのモデル")
|
||||
parser.add_argument("--v2", action='store_true',
|
||||
help='load Stable Diffusion v2.0 model / Stable Diffusion 2.0のモデルを読み込む')
|
||||
help='not used (for backward compatibility) / 使用されません(互換性のため残してあります)')
|
||||
parser.add_argument("--batch_size", type=int, default=1, help="batch size in inference / 推論時のバッチサイズ")
|
||||
parser.add_argument("--max_data_loader_n_workers", type=int, default=None,
|
||||
help="enable image reading by DataLoader with this number of workers (faster) / DataLoaderによる画像読み込みを有効にしてこのワーカー数を適用する(読み込みを高速化)")
|
||||
parser.add_argument("--max_resolution", type=str, default="512,512",
|
||||
help="max resolution in fine tuning (width,height) / fine tuning時の最大画像サイズ 「幅,高さ」(使用メモリ量に関係します)")
|
||||
parser.add_argument("--min_bucket_reso", type=int, default=256, help="minimum resolution for buckets / bucketの最小解像度")
|
||||
parser.add_argument("--max_bucket_reso", type=int, default=1024, help="maximum resolution for buckets / bucketの最小解像度")
|
||||
parser.add_argument("--bucket_reso_steps", type=int, default=64,
|
||||
help="steps of resolution for buckets, divisible by 8 is recommended / bucketの解像度の単位、8で割り切れる値を推奨します")
|
||||
parser.add_argument("--bucket_no_upscale", action="store_true",
|
||||
help="make bucket for each image without upscaling / 画像を拡大せずbucketを作成します")
|
||||
parser.add_argument("--mixed_precision", type=str, default="no",
|
||||
choices=["no", "fp16", "bf16"], help="use mixed precision / 混合精度を使う場合、その精度")
|
||||
parser.add_argument("--full_path", action="store_true",
|
||||
help="use full path as image-key in metadata (supports multiple directories) / メタデータで画像キーをフルパスにする(複数の学習画像ディレクトリに対応)")
|
||||
parser.add_argument("--flip_aug", action="store_true",
|
||||
help="flip augmentation, save latents for flipped images / 左右反転した画像もlatentを取得、保存する")
|
||||
parser.add_argument("--skip_existing", action="store_true",
|
||||
help="skip images if npz already exists (both normal and flipped exists if flip_aug is enabled) / npzが既に存在する画像をスキップする(flip_aug有効時は通常、反転の両方が存在する画像をスキップ)")
|
||||
|
||||
args = parser.parse_args()
|
||||
main(args)
|
||||
|
||||
@@ -1,6 +1,3 @@
|
||||
# このスクリプトのライセンスは、Apache License 2.0とします
|
||||
# (c) 2022 Kohya S. @kohya_ss
|
||||
|
||||
import argparse
|
||||
import csv
|
||||
import glob
|
||||
@@ -12,32 +9,87 @@ from tqdm import tqdm
|
||||
import numpy as np
|
||||
from tensorflow.keras.models import load_model
|
||||
from huggingface_hub import hf_hub_download
|
||||
import torch
|
||||
|
||||
import library.train_util as train_util
|
||||
|
||||
# from wd14 tagger
|
||||
IMAGE_SIZE = 448
|
||||
|
||||
WD14_TAGGER_REPO = 'SmilingWolf/wd-v1-4-vit-tagger'
|
||||
# wd-v1-4-swinv2-tagger-v2 / wd-v1-4-vit-tagger / wd-v1-4-vit-tagger-v2/ wd-v1-4-convnext-tagger / wd-v1-4-convnext-tagger-v2
|
||||
DEFAULT_WD14_TAGGER_REPO = 'SmilingWolf/wd-v1-4-convnext-tagger-v2'
|
||||
FILES = ["keras_metadata.pb", "saved_model.pb", "selected_tags.csv"]
|
||||
SUB_DIR = "variables"
|
||||
SUB_DIR_FILES = ["variables.data-00000-of-00001", "variables.index"]
|
||||
CSV_FILE = FILES[-1]
|
||||
|
||||
|
||||
def preprocess_image(image):
|
||||
image = np.array(image)
|
||||
image = image[:, :, ::-1] # RGB->BGR
|
||||
|
||||
# pad to square
|
||||
size = max(image.shape[0:2])
|
||||
pad_x = size - image.shape[1]
|
||||
pad_y = size - image.shape[0]
|
||||
pad_l = pad_x // 2
|
||||
pad_t = pad_y // 2
|
||||
image = np.pad(image, ((pad_t, pad_y - pad_t), (pad_l, pad_x - pad_l), (0, 0)), mode='constant', constant_values=255)
|
||||
|
||||
interp = cv2.INTER_AREA if size > IMAGE_SIZE else cv2.INTER_LANCZOS4
|
||||
image = cv2.resize(image, (IMAGE_SIZE, IMAGE_SIZE), interpolation=interp)
|
||||
|
||||
image = image.astype(np.float32)
|
||||
return image
|
||||
|
||||
|
||||
class ImageLoadingPrepDataset(torch.utils.data.Dataset):
|
||||
def __init__(self, image_paths):
|
||||
self.images = image_paths
|
||||
|
||||
def __len__(self):
|
||||
return len(self.images)
|
||||
|
||||
def __getitem__(self, idx):
|
||||
img_path = self.images[idx]
|
||||
|
||||
try:
|
||||
image = Image.open(img_path).convert("RGB")
|
||||
image = preprocess_image(image)
|
||||
tensor = torch.tensor(image)
|
||||
except Exception as e:
|
||||
print(f"Could not load image path / 画像を読み込めません: {img_path}, error: {e}")
|
||||
return None
|
||||
|
||||
return (tensor, img_path)
|
||||
|
||||
|
||||
def collate_fn_remove_corrupted(batch):
|
||||
"""Collate function that allows to remove corrupted examples in the
|
||||
dataloader. It expects that the dataloader returns 'None' when that occurs.
|
||||
The 'None's in the batch are removed.
|
||||
"""
|
||||
# Filter out all the Nones (corrupted examples)
|
||||
batch = list(filter(lambda x: x is not None, batch))
|
||||
return batch
|
||||
|
||||
|
||||
def main(args):
|
||||
# hf_hub_downloadをそのまま使うとsymlink関係で問題があるらしいので、キャッシュディレクトリとforce_filenameを指定してなんとかする
|
||||
# depreacatedの警告が出るけどなくなったらその時
|
||||
# https://github.com/toriato/stable-diffusion-webui-wd14-tagger/issues/22
|
||||
if not os.path.exists(args.model_dir) or args.force_download:
|
||||
print("downloading wd14 tagger model from hf_hub")
|
||||
print(f"downloading wd14 tagger model from hf_hub. id: {args.repo_id}")
|
||||
for file in FILES:
|
||||
hf_hub_download(args.repo_id, file, cache_dir=args.model_dir, force_download=True, force_filename=file)
|
||||
for file in SUB_DIR_FILES:
|
||||
hf_hub_download(args.repo_id, file, subfolder=SUB_DIR, cache_dir=os.path.join(
|
||||
args.model_dir, SUB_DIR), force_download=True, force_filename=file)
|
||||
else:
|
||||
print("using existing wd14 tagger model")
|
||||
|
||||
# 画像を読み込む
|
||||
image_paths = glob.glob(os.path.join(args.train_data_dir, "*.jpg")) + \
|
||||
glob.glob(os.path.join(args.train_data_dir, "*.png")) + glob.glob(os.path.join(args.train_data_dir, "*.webp"))
|
||||
image_paths = train_util.glob_images(args.train_data_dir)
|
||||
print(f"found {len(image_paths)} images.")
|
||||
|
||||
print("loading model and labels")
|
||||
@@ -72,7 +124,7 @@ def main(args):
|
||||
# Everything else is tags: pick any where prediction confidence > threshold
|
||||
tag_text = ""
|
||||
for i, p in enumerate(prob[4:]): # numpyとか使うのが良いけど、まあそれほど数も多くないのでループで
|
||||
if p >= args.thresh:
|
||||
if p >= args.thresh and i < len(tags):
|
||||
tag_text += ", " + tags[i]
|
||||
|
||||
if len(tag_text) > 0:
|
||||
@@ -83,34 +135,37 @@ def main(args):
|
||||
if args.debug:
|
||||
print(image_path, tag_text)
|
||||
|
||||
# 読み込みの高速化のためにDataLoaderを使うオプション
|
||||
if args.max_data_loader_n_workers is not None:
|
||||
dataset = ImageLoadingPrepDataset(image_paths)
|
||||
data = torch.utils.data.DataLoader(dataset, batch_size=args.batch_size, shuffle=False,
|
||||
num_workers=args.max_data_loader_n_workers, collate_fn=collate_fn_remove_corrupted, drop_last=False)
|
||||
else:
|
||||
data = [[(None, ip)] for ip in image_paths]
|
||||
|
||||
b_imgs = []
|
||||
for image_path in tqdm(image_paths, smoothing=0.0):
|
||||
img = Image.open(image_path) # cv2は日本語ファイル名で死ぬのとモード変換したいのでpillowで開く
|
||||
if img.mode != 'RGB':
|
||||
img = img.convert("RGB")
|
||||
img = np.array(img)
|
||||
img = img[:, :, ::-1] # RGB->BGR
|
||||
for data_entry in tqdm(data, smoothing=0.0):
|
||||
for data in data_entry:
|
||||
if data is None:
|
||||
continue
|
||||
|
||||
# pad to square
|
||||
size = max(img.shape[0:2])
|
||||
pad_x = size - img.shape[1]
|
||||
pad_y = size - img.shape[0]
|
||||
pad_l = pad_x // 2
|
||||
pad_t = pad_y // 2
|
||||
img = np.pad(img, ((pad_t, pad_y - pad_t), (pad_l, pad_x - pad_l), (0, 0)), mode='constant', constant_values=255)
|
||||
image, image_path = data
|
||||
if image is not None:
|
||||
image = image.detach().numpy()
|
||||
else:
|
||||
try:
|
||||
image = Image.open(image_path)
|
||||
if image.mode != 'RGB':
|
||||
image = image.convert("RGB")
|
||||
image = preprocess_image(image)
|
||||
except Exception as e:
|
||||
print(f"Could not load image path / 画像を読み込めません: {image_path}, error: {e}")
|
||||
continue
|
||||
b_imgs.append((image_path, image))
|
||||
|
||||
interp = cv2.INTER_AREA if size > IMAGE_SIZE else cv2.INTER_LANCZOS4
|
||||
img = cv2.resize(img, (IMAGE_SIZE, IMAGE_SIZE), interpolation=interp)
|
||||
# cv2.imshow("img", img)
|
||||
# cv2.waitKey()
|
||||
# cv2.destroyAllWindows()
|
||||
|
||||
img = img.astype(np.float32)
|
||||
b_imgs.append((image_path, img))
|
||||
|
||||
if len(b_imgs) >= args.batch_size:
|
||||
run_batch(b_imgs)
|
||||
b_imgs.clear()
|
||||
if len(b_imgs) >= args.batch_size:
|
||||
run_batch(b_imgs)
|
||||
b_imgs.clear()
|
||||
|
||||
if len(b_imgs) > 0:
|
||||
run_batch(b_imgs)
|
||||
@@ -121,7 +176,7 @@ def main(args):
|
||||
if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("train_data_dir", type=str, help="directory for train images / 学習画像データのディレクトリ")
|
||||
parser.add_argument("--repo_id", type=str, default=WD14_TAGGER_REPO,
|
||||
parser.add_argument("--repo_id", type=str, default=DEFAULT_WD14_TAGGER_REPO,
|
||||
help="repo id for wd14 tagger on Hugging Face / Hugging Faceのwd14 taggerのリポジトリID")
|
||||
parser.add_argument("--model_dir", type=str, default="wd14_tagger_model",
|
||||
help="directory to store wd14 tagger model / wd14 taggerのモデルを格納するディレクトリ")
|
||||
@@ -129,6 +184,8 @@ if __name__ == '__main__':
|
||||
help="force downloading wd14 tagger models / wd14 taggerのモデルを再ダウンロードします")
|
||||
parser.add_argument("--thresh", type=float, default=0.35, help="threshold of confidence to add a tag / タグを追加するか判定する閾値")
|
||||
parser.add_argument("--batch_size", type=int, default=1, help="batch size in inference / 推論時のバッチサイズ")
|
||||
parser.add_argument("--max_data_loader_n_workers", type=int, default=None,
|
||||
help="enable image reading by DataLoader with this number of workers (faster) / DataLoaderによる画像読み込みを有効にしてこのワーカー数を適用する(読み込みを高速化)")
|
||||
parser.add_argument("--caption_extention", type=str, default=None,
|
||||
help="extension of caption file (for backward compatibility) / 出力されるキャプションファイルの拡張子(スペルミスしていたのを残してあります)")
|
||||
parser.add_argument("--caption_extension", type=str, default=".txt", help="extension of caption file / 出力されるキャプションファイルの拡張子")
|
||||
|
||||
@@ -1,38 +1,3 @@
|
||||
# txt2img with Diffusers: supports SD checkpoints, EulerScheduler, clip-skip, 225 tokens, Hypernetwork etc...
|
||||
|
||||
# v2: CLIP guided Stable Diffusion, Image guided Stable Diffusion, highres. fix
|
||||
# v3: Add dpmsolver/dpmsolver++, add VAE loading, add upscale, add 'bf16', fix the issue network_mul is not working
|
||||
# v4: SD2.0 support (new U-Net/text encoder/tokenizer), simplify by DiffUsers 0.9.0, no_preview in interactive mode
|
||||
# v5: fix clip_sample=True for scheduler, add VGG guidance
|
||||
# v6: refactor to use model util, load VAE without vae folder, support safe tensors
|
||||
# v7: add use_original_file_name and iter_same_seed option, change vgg16 guide input image size,
|
||||
# Diffusers 0.10.0 (support new schedulers (dpm_2, dpm_2_a, heun, dpmsingle), supports all scheduler in v-prediction)
|
||||
# v8: accept wildcard for ckpt name (when only one file is matched), fix a bug app crushes because PIL image doesn't have filename attr sometimes,
|
||||
# v9: sort file names, fix an issue in img2img when prompt from metadata with images_per_prompt>1
|
||||
# v10: fix app crashes when different image size in prompts
|
||||
|
||||
# Copyright 2022 kohya_ss @kohya_ss
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
# license of included scripts:
|
||||
|
||||
# FlashAttention: based on https://github.com/lucidrains/memory-efficient-attention-pytorch/blob/main/memory_efficient_attention_pytorch/flash_attention.py
|
||||
# MIT https://github.com/lucidrains/memory-efficient-attention-pytorch/blob/main/LICENSE
|
||||
|
||||
# Diffusers (model conversion, CLIP guided stable diffusion, schedulers etc.):
|
||||
# ASL 2.0 https://github.com/huggingface/diffusers/blob/main/LICENSE
|
||||
|
||||
"""
|
||||
VGG(
|
||||
(features): Sequential(
|
||||
@@ -81,11 +46,13 @@ VGG(
|
||||
)
|
||||
"""
|
||||
|
||||
from typing import List, Optional, Union
|
||||
import json
|
||||
from typing import Any, List, NamedTuple, Optional, Tuple, Union, Callable
|
||||
import glob
|
||||
import importlib
|
||||
import inspect
|
||||
import time
|
||||
import zipfile
|
||||
from diffusers.utils import deprecate
|
||||
from diffusers.configuration_utils import FrozenDict
|
||||
import argparse
|
||||
@@ -93,7 +60,6 @@ import math
|
||||
import os
|
||||
import random
|
||||
import re
|
||||
from typing import Any, Callable, List, Optional, Union
|
||||
|
||||
import diffusers
|
||||
import numpy as np
|
||||
@@ -114,6 +80,9 @@ from PIL import Image
|
||||
from PIL.PngImagePlugin import PngInfo
|
||||
|
||||
import library.model_util as model_util
|
||||
import library.train_util as train_util
|
||||
import tools.original_control_net as original_control_net
|
||||
from tools.original_control_net import ControlNetInfo
|
||||
|
||||
# Tokenizer: checkpointから読み込むのではなくあらかじめ提供されているものを使う
|
||||
TOKENIZER_PATH = "openai/clip-vit-large-patch14"
|
||||
@@ -503,6 +472,9 @@ class PipelineLike():
|
||||
self.scheduler = scheduler
|
||||
self.safety_checker = None
|
||||
|
||||
# Textual Inversion
|
||||
self.token_replacements = {}
|
||||
|
||||
# CLIP guidance
|
||||
self.clip_guidance_scale = clip_guidance_scale
|
||||
self.clip_image_guidance_scale = clip_image_guidance_scale
|
||||
@@ -517,7 +489,27 @@ class PipelineLike():
|
||||
self.vgg16_feat_model = torchvision.models._utils.IntermediateLayerGetter(vgg16_model.features, return_layers=return_layers)
|
||||
self.vgg16_normalize = transforms.Normalize(mean=VGG16_IMAGE_MEAN, std=VGG16_IMAGE_STD)
|
||||
|
||||
# region xformersとか使う部分:独自に書き換えるので関係なし
|
||||
# ControlNet
|
||||
self.control_nets: List[ControlNetInfo] = []
|
||||
|
||||
# Textual Inversion
|
||||
def add_token_replacement(self, target_token_id, rep_token_ids):
|
||||
self.token_replacements[target_token_id] = rep_token_ids
|
||||
|
||||
def replace_token(self, tokens):
|
||||
new_tokens = []
|
||||
for token in tokens:
|
||||
if token in self.token_replacements:
|
||||
new_tokens.extend(self.token_replacements[token])
|
||||
else:
|
||||
new_tokens.append(token)
|
||||
return new_tokens
|
||||
|
||||
def set_control_nets(self, ctrl_nets):
|
||||
self.control_nets = ctrl_nets
|
||||
|
||||
# region xformersとか使う部分:独自に書き換えるので関係なし
|
||||
|
||||
def enable_xformers_memory_efficient_attention(self):
|
||||
r"""
|
||||
Enable memory efficient attention as implemented in xformers.
|
||||
@@ -590,6 +582,7 @@ class PipelineLike():
|
||||
width: int = 512,
|
||||
num_inference_steps: int = 50,
|
||||
guidance_scale: float = 7.5,
|
||||
negative_scale: float = None,
|
||||
strength: float = 0.8,
|
||||
# num_images_per_prompt: Optional[int] = 1,
|
||||
eta: float = 0.0,
|
||||
@@ -597,6 +590,8 @@ class PipelineLike():
|
||||
latents: Optional[torch.FloatTensor] = None,
|
||||
max_embeddings_multiples: Optional[int] = 3,
|
||||
output_type: Optional[str] = "pil",
|
||||
vae_batch_size: float = None,
|
||||
return_latents: bool = False,
|
||||
# return_dict: bool = True,
|
||||
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
|
||||
is_cancelled_callback: Optional[Callable[[], bool]] = None,
|
||||
@@ -688,6 +683,9 @@ class PipelineLike():
|
||||
else:
|
||||
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
|
||||
|
||||
vae_batch_size = batch_size if vae_batch_size is None else (
|
||||
int(vae_batch_size) if vae_batch_size >= 1 else max(1, int(batch_size * vae_batch_size)))
|
||||
|
||||
if strength < 0 or strength > 1:
|
||||
raise ValueError(f"The value of strength should in [0.0, 1.0] but is {strength}")
|
||||
|
||||
@@ -708,6 +706,11 @@ class PipelineLike():
|
||||
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
|
||||
# corresponds to doing no classifier free guidance.
|
||||
do_classifier_free_guidance = guidance_scale > 1.0
|
||||
|
||||
if not do_classifier_free_guidance and negative_scale is not None:
|
||||
print(f"negative_scale is ignored if guidance scalle <= 1.0")
|
||||
negative_scale = None
|
||||
|
||||
# get unconditional embeddings for classifier free guidance
|
||||
if negative_prompt is None:
|
||||
negative_prompt = [""] * batch_size
|
||||
@@ -729,8 +732,21 @@ class PipelineLike():
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
if negative_scale is not None:
|
||||
_, real_uncond_embeddings, _ = get_weighted_text_embeddings(
|
||||
pipe=self,
|
||||
prompt=prompt, # こちらのトークン長に合わせてuncondを作るので75トークン超で必須
|
||||
uncond_prompt=[""]*batch_size,
|
||||
max_embeddings_multiples=max_embeddings_multiples,
|
||||
clip_skip=self.clip_skip,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
|
||||
if negative_scale is None:
|
||||
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
|
||||
else:
|
||||
text_embeddings = torch.cat([uncond_embeddings, text_embeddings, real_uncond_embeddings])
|
||||
|
||||
# CLIP guidanceで使用するembeddingsを取得する
|
||||
if self.clip_guidance_scale > 0:
|
||||
@@ -750,7 +766,7 @@ class PipelineLike():
|
||||
text_embeddings_clip = self.clip_model.get_text_features(clip_text_input)
|
||||
text_embeddings_clip = text_embeddings_clip / text_embeddings_clip.norm(p=2, dim=-1, keepdim=True) # prompt複数件でもOK
|
||||
|
||||
if self.clip_image_guidance_scale > 0 or self.vgg16_guidance_scale > 0 and clip_guide_images is not None:
|
||||
if self.clip_image_guidance_scale > 0 or self.vgg16_guidance_scale > 0 and clip_guide_images is not None or self.control_nets:
|
||||
if isinstance(clip_guide_images, PIL.Image.Image):
|
||||
clip_guide_images = [clip_guide_images]
|
||||
|
||||
@@ -763,7 +779,7 @@ class PipelineLike():
|
||||
image_embeddings_clip = image_embeddings_clip / image_embeddings_clip.norm(p=2, dim=-1, keepdim=True)
|
||||
if len(image_embeddings_clip) == 1:
|
||||
image_embeddings_clip = image_embeddings_clip.repeat((batch_size, 1, 1, 1))
|
||||
else:
|
||||
elif self.vgg16_guidance_scale > 0:
|
||||
size = (width // VGG16_INPUT_RESIZE_DIV, height // VGG16_INPUT_RESIZE_DIV) # とりあえず1/4に(小さいか?)
|
||||
clip_guide_images = [preprocess_vgg16_guide_image(im, size) for im in clip_guide_images]
|
||||
clip_guide_images = torch.cat(clip_guide_images, dim=0)
|
||||
@@ -772,6 +788,10 @@ class PipelineLike():
|
||||
image_embeddings_vgg16 = self.vgg16_feat_model(clip_guide_images)['feat']
|
||||
if len(image_embeddings_vgg16) == 1:
|
||||
image_embeddings_vgg16 = image_embeddings_vgg16.repeat((batch_size, 1, 1, 1))
|
||||
else:
|
||||
# ControlNetのhintにguide imageを流用する
|
||||
# 前処理はControlNet側で行う
|
||||
pass
|
||||
|
||||
# set timesteps
|
||||
self.scheduler.set_timesteps(num_inference_steps, self.device)
|
||||
@@ -779,7 +799,6 @@ class PipelineLike():
|
||||
latents_dtype = text_embeddings.dtype
|
||||
init_latents_orig = None
|
||||
mask = None
|
||||
noise = None
|
||||
|
||||
if init_image is None:
|
||||
# get the initial random noise unless the user supplied it
|
||||
@@ -811,6 +830,8 @@ class PipelineLike():
|
||||
if isinstance(init_image[0], PIL.Image.Image):
|
||||
init_image = [preprocess_image(im) for im in init_image]
|
||||
init_image = torch.cat(init_image)
|
||||
if isinstance(init_image, list):
|
||||
init_image = torch.stack(init_image)
|
||||
|
||||
# mask image to tensor
|
||||
if mask_image is not None:
|
||||
@@ -821,9 +842,24 @@ class PipelineLike():
|
||||
|
||||
# encode the init image into latents and scale the latents
|
||||
init_image = init_image.to(device=self.device, dtype=latents_dtype)
|
||||
init_latent_dist = self.vae.encode(init_image).latent_dist
|
||||
init_latents = init_latent_dist.sample(generator=generator)
|
||||
init_latents = 0.18215 * init_latents
|
||||
if init_image.size()[2:] == (height // 8, width // 8):
|
||||
init_latents = init_image
|
||||
else:
|
||||
if vae_batch_size >= batch_size:
|
||||
init_latent_dist = self.vae.encode(init_image).latent_dist
|
||||
init_latents = init_latent_dist.sample(generator=generator)
|
||||
else:
|
||||
if torch.cuda.is_available():
|
||||
torch.cuda.empty_cache()
|
||||
init_latents = []
|
||||
for i in tqdm(range(0, batch_size, vae_batch_size)):
|
||||
init_latent_dist = self.vae.encode(init_image[i:i + vae_batch_size]
|
||||
if vae_batch_size > 1 else init_image[i].unsqueeze(0)).latent_dist
|
||||
init_latents.append(init_latent_dist.sample(generator=generator))
|
||||
init_latents = torch.cat(init_latents)
|
||||
|
||||
init_latents = 0.18215 * init_latents
|
||||
|
||||
if len(init_latents) == 1:
|
||||
init_latents = init_latents.repeat((batch_size, 1, 1, 1))
|
||||
init_latents_orig = init_latents
|
||||
@@ -861,22 +897,37 @@ class PipelineLike():
|
||||
if accepts_eta:
|
||||
extra_step_kwargs["eta"] = eta
|
||||
|
||||
num_latent_input = (3 if negative_scale is not None else 2) if do_classifier_free_guidance else 1
|
||||
|
||||
if self.control_nets:
|
||||
guided_hints = original_control_net.get_guided_hints(self.control_nets, num_latent_input, batch_size, clip_guide_images)
|
||||
|
||||
for i, t in enumerate(tqdm(timesteps)):
|
||||
# expand the latents if we are doing classifier free guidance
|
||||
latent_model_input = latents.repeat((2, 1, 1, 1)) if do_classifier_free_guidance else latents
|
||||
latent_model_input = latents.repeat((num_latent_input, 1, 1, 1))
|
||||
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
|
||||
|
||||
# predict the noise residual
|
||||
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
|
||||
if self.control_nets:
|
||||
noise_pred = original_control_net.call_unet_and_control_net(
|
||||
i, num_latent_input, self.unet, self.control_nets, guided_hints, i / len(timesteps), latent_model_input, t, text_embeddings).sample
|
||||
else:
|
||||
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
|
||||
|
||||
# perform guidance
|
||||
if do_classifier_free_guidance:
|
||||
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
|
||||
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
|
||||
if negative_scale is None:
|
||||
noise_pred_uncond, noise_pred_text = noise_pred.chunk(num_latent_input) # uncond by negative prompt
|
||||
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
|
||||
else:
|
||||
noise_pred_negative, noise_pred_text, noise_pred_uncond = noise_pred.chunk(num_latent_input) # uncond is real uncond
|
||||
noise_pred = noise_pred_uncond + guidance_scale * \
|
||||
(noise_pred_text - noise_pred_uncond) - negative_scale * (noise_pred_negative - noise_pred_uncond)
|
||||
|
||||
# perform clip guidance
|
||||
if self.clip_guidance_scale > 0 or self.clip_image_guidance_scale > 0 or self.vgg16_guidance_scale > 0:
|
||||
text_embeddings_for_guidance = (text_embeddings.chunk(2)[1] if do_classifier_free_guidance else text_embeddings)
|
||||
text_embeddings_for_guidance = (text_embeddings.chunk(num_latent_input)[
|
||||
1] if do_classifier_free_guidance else text_embeddings)
|
||||
|
||||
if self.clip_guidance_scale > 0:
|
||||
noise_pred, latents = self.cond_fn(latents, t, i, text_embeddings_for_guidance, noise_pred,
|
||||
@@ -903,8 +954,19 @@ class PipelineLike():
|
||||
if is_cancelled_callback is not None and is_cancelled_callback():
|
||||
return None
|
||||
|
||||
if return_latents:
|
||||
return (latents, False)
|
||||
|
||||
latents = 1 / 0.18215 * latents
|
||||
image = self.vae.decode(latents).sample
|
||||
if vae_batch_size >= batch_size:
|
||||
image = self.vae.decode(latents).sample
|
||||
else:
|
||||
if torch.cuda.is_available():
|
||||
torch.cuda.empty_cache()
|
||||
images = []
|
||||
for i in tqdm(range(0, batch_size, vae_batch_size)):
|
||||
images.append(self.vae.decode(latents[i:i + vae_batch_size] if vae_batch_size > 1 else latents[i].unsqueeze(0)).sample)
|
||||
image = torch.cat(images)
|
||||
|
||||
image = (image / 2 + 0.5).clamp(0, 1)
|
||||
|
||||
@@ -1515,6 +1577,9 @@ def get_prompts_with_weights(pipe: PipelineLike, prompt: List[str], max_length:
|
||||
for word, weight in texts_and_weights:
|
||||
# tokenize and discard the starting and the ending token
|
||||
token = pipe.tokenizer(word).input_ids[1:-1]
|
||||
|
||||
token = pipe.replace_token(token)
|
||||
|
||||
text_token += token
|
||||
# copy the weight by length of token
|
||||
text_weight += [weight] * len(token)
|
||||
@@ -1584,10 +1649,11 @@ def get_unweighted_text_embeddings(
|
||||
if pad == eos: # v1
|
||||
text_input_chunk[:, -1] = text_input[0, -1]
|
||||
else: # v2
|
||||
if text_input_chunk[:, -1] != eos and text_input_chunk[:, -1] != pad: # 最後に普通の文字がある
|
||||
text_input_chunk[:, -1] = eos
|
||||
if text_input_chunk[:, 1] == pad: # BOSだけであとはPAD
|
||||
text_input_chunk[:, 1] = eos
|
||||
for j in range(len(text_input_chunk)):
|
||||
if text_input_chunk[j, -1] != eos and text_input_chunk[j, -1] != pad: # 最後に普通の文字がある
|
||||
text_input_chunk[j, -1] = eos
|
||||
if text_input_chunk[j, 1] == pad: # BOSだけであとはPAD
|
||||
text_input_chunk[j, 1] = eos
|
||||
|
||||
if clip_skip is None or clip_skip == 1:
|
||||
text_embedding = pipe.text_encoder(text_input_chunk)[0]
|
||||
@@ -1788,7 +1854,7 @@ def preprocess_mask(mask):
|
||||
mask = mask.convert("L")
|
||||
w, h = mask.size
|
||||
w, h = map(lambda x: x - x % 32, (w, h)) # resize to integer multiple of 32
|
||||
mask = mask.resize((w // 8, h // 8), resample=PIL.Image.LANCZOS)
|
||||
mask = mask.resize((w // 8, h // 8), resample=PIL.Image.BILINEAR) # LANCZOS)
|
||||
mask = np.array(mask).astype(np.float32) / 255.0
|
||||
mask = np.tile(mask, (4, 1, 1))
|
||||
mask = mask[None].transpose(0, 1, 2, 3) # what does this step do?
|
||||
@@ -1806,6 +1872,35 @@ def preprocess_mask(mask):
|
||||
# return text_encoder
|
||||
|
||||
|
||||
class BatchDataBase(NamedTuple):
|
||||
# バッチ分割が必要ないデータ
|
||||
step: int
|
||||
prompt: str
|
||||
negative_prompt: str
|
||||
seed: int
|
||||
init_image: Any
|
||||
mask_image: Any
|
||||
clip_prompt: str
|
||||
guide_image: Any
|
||||
|
||||
|
||||
class BatchDataExt(NamedTuple):
|
||||
# バッチ分割が必要なデータ
|
||||
width: int
|
||||
height: int
|
||||
steps: int
|
||||
scale: float
|
||||
negative_scale: float
|
||||
strength: float
|
||||
network_muls: Tuple[float]
|
||||
|
||||
|
||||
class BatchData(NamedTuple):
|
||||
return_latents: bool
|
||||
base: BatchDataBase
|
||||
ext: BatchDataExt
|
||||
|
||||
|
||||
def main(args):
|
||||
if args.fp16:
|
||||
dtype = torch.float16
|
||||
@@ -1834,12 +1929,12 @@ def main(args):
|
||||
text_encoder, vae, unet = model_util.load_models_from_stable_diffusion_checkpoint(args.v2, args.ckpt)
|
||||
else:
|
||||
print("load Diffusers pretrained models")
|
||||
pipe = StableDiffusionPipeline.from_pretrained(args.ckpt, safety_checker=None, torch_dtype=dtype)
|
||||
text_encoder = pipe.text_encoder
|
||||
vae = pipe.vae
|
||||
unet = pipe.unet
|
||||
tokenizer = pipe.tokenizer
|
||||
del pipe
|
||||
loading_pipe = StableDiffusionPipeline.from_pretrained(args.ckpt, safety_checker=None, torch_dtype=dtype)
|
||||
text_encoder = loading_pipe.text_encoder
|
||||
vae = loading_pipe.vae
|
||||
unet = loading_pipe.unet
|
||||
tokenizer = loading_pipe.tokenizer
|
||||
del loading_pipe
|
||||
|
||||
# VAEを読み込む
|
||||
if args.vae is not None:
|
||||
@@ -1870,10 +1965,7 @@ def main(args):
|
||||
# tokenizerを読み込む
|
||||
print("loading tokenizer")
|
||||
if use_stable_diffusion_format:
|
||||
if args.v2:
|
||||
tokenizer = CLIPTokenizer.from_pretrained(V2_STABLE_DIFFUSION_PATH, subfolder="tokenizer")
|
||||
else:
|
||||
tokenizer = CLIPTokenizer.from_pretrained(TOKENIZER_PATH) # , model_max_length=max_token_length + 2)
|
||||
tokenizer = train_util.load_tokenizer(args)
|
||||
|
||||
# schedulerを用意する
|
||||
sched_init_args = {}
|
||||
@@ -1982,26 +2074,63 @@ def main(args):
|
||||
vgg16_model.to(dtype).to(device)
|
||||
|
||||
# networkを組み込む
|
||||
if args.network_module is not None:
|
||||
# assert not args.diffusers_xformers, "cannot use network with diffusers_xformers / diffusers_xformers指定時はnetworkは利用できません"
|
||||
if args.network_module:
|
||||
networks = []
|
||||
network_default_muls = []
|
||||
for i, network_module in enumerate(args.network_module):
|
||||
print("import network module:", network_module)
|
||||
imported_module = importlib.import_module(network_module)
|
||||
|
||||
print("import network module:", args.network_module)
|
||||
network_module = importlib.import_module(args.network_module)
|
||||
network_mul = 1.0 if args.network_mul is None or len(args.network_mul) <= i else args.network_mul[i]
|
||||
network_default_muls.append(network_mul)
|
||||
|
||||
network = network_module.create_network(args.network_mul, args.network_dim, vae,text_encoder, unet) # , **net_kwargs)
|
||||
if network is None:
|
||||
return
|
||||
net_kwargs = {}
|
||||
if args.network_args and i < len(args.network_args):
|
||||
network_args = args.network_args[i]
|
||||
# TODO escape special chars
|
||||
network_args = network_args.split(";")
|
||||
for net_arg in network_args:
|
||||
key, value = net_arg.split("=")
|
||||
net_kwargs[key] = value
|
||||
|
||||
print("load network weights from:", args.network_weights)
|
||||
network.load_weights(args.network_weights)
|
||||
if args.network_weights and i < len(args.network_weights):
|
||||
network_weight = args.network_weights[i]
|
||||
print("load network weights from:", network_weight)
|
||||
|
||||
network.apply_to(text_encoder, unet)
|
||||
if model_util.is_safetensors(network_weight) and args.network_show_meta:
|
||||
from safetensors.torch import safe_open
|
||||
with safe_open(network_weight, framework="pt") as f:
|
||||
metadata = f.metadata()
|
||||
if metadata is not None:
|
||||
print(f"metadata for: {network_weight}: {metadata}")
|
||||
|
||||
if args.opt_channels_last:
|
||||
network.to(memory_format=torch.channels_last)
|
||||
network.to(dtype).to(device)
|
||||
network = imported_module.create_network_from_weights(network_mul, network_weight, vae, text_encoder, unet, **net_kwargs)
|
||||
else:
|
||||
raise ValueError("No weight. Weight is required.")
|
||||
if network is None:
|
||||
return
|
||||
|
||||
network.apply_to(text_encoder, unet)
|
||||
|
||||
if args.opt_channels_last:
|
||||
network.to(memory_format=torch.channels_last)
|
||||
network.to(dtype).to(device)
|
||||
|
||||
networks.append(network)
|
||||
else:
|
||||
network = None
|
||||
networks = []
|
||||
|
||||
# ControlNetの処理
|
||||
control_nets: List[ControlNetInfo] = []
|
||||
if args.control_net_models:
|
||||
for i, model in enumerate(args.control_net_models):
|
||||
prep_type = None if not args.control_net_preps or len(args.control_net_preps) <= i else args.control_net_preps[i]
|
||||
weight = 1.0 if not args.control_net_weights or len(args.control_net_weights) <= i else args.control_net_weights[i]
|
||||
ratio = 1.0 if not args.control_net_ratios or len(args.control_net_ratios) <= i else args.control_net_ratios[i]
|
||||
|
||||
ctrl_unet, ctrl_net = original_control_net.load_control_net(args.v2, unet, model)
|
||||
prep = original_control_net.load_preprocess(prep_type)
|
||||
control_nets.append(ControlNetInfo(ctrl_unet, ctrl_net, prep, weight, ratio))
|
||||
|
||||
if args.opt_channels_last:
|
||||
print(f"set optimizing: channels last")
|
||||
@@ -2010,19 +2139,63 @@ def main(args):
|
||||
unet.to(memory_format=torch.channels_last)
|
||||
if clip_model is not None:
|
||||
clip_model.to(memory_format=torch.channels_last)
|
||||
if network is not None:
|
||||
network.to(memory_format=torch.channels_last)
|
||||
if networks:
|
||||
for network in networks:
|
||||
network.to(memory_format=torch.channels_last)
|
||||
if vgg16_model is not None:
|
||||
vgg16_model.to(memory_format=torch.channels_last)
|
||||
|
||||
for cn in control_nets:
|
||||
cn.unet.to(memory_format=torch.channels_last)
|
||||
cn.net.to(memory_format=torch.channels_last)
|
||||
|
||||
pipe = PipelineLike(device, vae, text_encoder, tokenizer, unet, scheduler, args.clip_skip,
|
||||
clip_model, args.clip_guidance_scale, args.clip_image_guidance_scale,
|
||||
vgg16_model, args.vgg16_guidance_scale, args.vgg16_guidance_layer)
|
||||
pipe.set_control_nets(control_nets)
|
||||
print("pipeline is ready.")
|
||||
|
||||
if args.diffusers_xformers:
|
||||
pipe.enable_xformers_memory_efficient_attention()
|
||||
|
||||
# Textual Inversionを処理する
|
||||
if args.textual_inversion_embeddings:
|
||||
token_ids_embeds = []
|
||||
for embeds_file in args.textual_inversion_embeddings:
|
||||
if model_util.is_safetensors(embeds_file):
|
||||
from safetensors.torch import load_file
|
||||
data = load_file(embeds_file)
|
||||
else:
|
||||
data = torch.load(embeds_file, map_location="cpu")
|
||||
|
||||
embeds = next(iter(data.values()))
|
||||
if type(embeds) != torch.Tensor:
|
||||
raise ValueError(f"weight file does not contains Tensor / 重みファイルのデータがTensorではありません: {embeds_file}")
|
||||
|
||||
num_vectors_per_token = embeds.size()[0]
|
||||
token_string = os.path.splitext(os.path.basename(embeds_file))[0]
|
||||
token_strings = [token_string] + [f"{token_string}{i+1}" for i in range(num_vectors_per_token - 1)]
|
||||
|
||||
# add new word to tokenizer, count is num_vectors_per_token
|
||||
num_added_tokens = tokenizer.add_tokens(token_strings)
|
||||
assert num_added_tokens == num_vectors_per_token, f"tokenizer has same word to token string (filename). please rename the file / 指定した名前(ファイル名)のトークンが既に存在します。ファイルをリネームしてください: {embeds_file}"
|
||||
|
||||
token_ids = tokenizer.convert_tokens_to_ids(token_strings)
|
||||
print(f"Textual Inversion embeddings `{token_string}` loaded. Tokens are added: {token_ids}")
|
||||
assert min(token_ids) == token_ids[0] and token_ids[-1] == token_ids[0] + len(token_ids) - 1, f"token ids is not ordered"
|
||||
assert len(tokenizer) - 1 == token_ids[-1], f"token ids is not end of tokenize: {len(tokenizer)}"
|
||||
|
||||
if num_vectors_per_token > 1:
|
||||
pipe.add_token_replacement(token_ids[0], token_ids)
|
||||
|
||||
token_ids_embeds.append((token_ids, embeds))
|
||||
|
||||
text_encoder.resize_token_embeddings(len(tokenizer))
|
||||
token_embeds = text_encoder.get_input_embeddings().weight.data
|
||||
for token_ids, embeds in token_ids_embeds:
|
||||
for token_id, embed in zip(token_ids, embeds):
|
||||
token_embeds[token_id] = embed
|
||||
|
||||
# promptを取得する
|
||||
if args.from_file is not None:
|
||||
print(f"reading prompts from {args.from_file}")
|
||||
@@ -2053,7 +2226,7 @@ def main(args):
|
||||
print(f"convert image to RGB from {image.mode}: {p}")
|
||||
image = image.convert("RGB")
|
||||
images.append(image)
|
||||
|
||||
|
||||
return images
|
||||
|
||||
def resize_images(imgs, size):
|
||||
@@ -2104,18 +2277,34 @@ def main(args):
|
||||
mask_images = l
|
||||
|
||||
# 画像サイズにオプション指定があるときはリサイズする
|
||||
if init_images is not None and args.W is not None and args.H is not None:
|
||||
print(f"resize img2img source images to {args.W}*{args.H}")
|
||||
init_images = resize_images(init_images, (args.W, args.H))
|
||||
if args.W is not None and args.H is not None:
|
||||
if init_images is not None:
|
||||
print(f"resize img2img source images to {args.W}*{args.H}")
|
||||
init_images = resize_images(init_images, (args.W, args.H))
|
||||
if mask_images is not None:
|
||||
print(f"resize img2img mask images to {args.W}*{args.H}")
|
||||
mask_images = resize_images(mask_images, (args.W, args.H))
|
||||
|
||||
if networks and mask_images:
|
||||
# mask を領域情報として流用する、現在は1枚だけ対応
|
||||
# TODO 複数のnetwork classの混在時の考慮
|
||||
print("use mask as region")
|
||||
# import cv2
|
||||
# for i in range(3):
|
||||
# cv2.imshow("msk", np.array(mask_images[0])[:,:,i])
|
||||
# cv2.waitKey()
|
||||
# cv2.destroyAllWindows()
|
||||
networks[0].__class__.set_regions(networks, np.array(mask_images[0]))
|
||||
mask_images = None
|
||||
|
||||
prev_image = None # for VGG16 guided
|
||||
if args.guide_image_path is not None:
|
||||
print(f"load image for CLIP/VGG16 guidance: {args.guide_image_path}")
|
||||
guide_images = load_images(args.guide_image_path)
|
||||
print(f"loaded {len(guide_images)} guide images for CLIP/VGG16 guidance")
|
||||
print(f"load image for CLIP/VGG16/ControlNet guidance: {args.guide_image_path}")
|
||||
guide_images = []
|
||||
for p in args.guide_image_path:
|
||||
guide_images.extend(load_images(p))
|
||||
|
||||
print(f"loaded {len(guide_images)} guide images for guidance")
|
||||
if len(guide_images) == 0:
|
||||
print(f"No guide image, use previous generated image. / ガイド画像がありません。直前に生成した画像を使います: {args.image_path}")
|
||||
guide_images = None
|
||||
@@ -2141,37 +2330,51 @@ def main(args):
|
||||
os.makedirs(args.outdir, exist_ok=True)
|
||||
max_embeddings_multiples = 1 if args.max_embeddings_multiples is None else args.max_embeddings_multiples
|
||||
|
||||
for iter in range(args.n_iter):
|
||||
print(f"iteration {iter+1}/{args.n_iter}")
|
||||
for gen_iter in range(args.n_iter):
|
||||
print(f"iteration {gen_iter+1}/{args.n_iter}")
|
||||
iter_seed = random.randint(0, 0x7fffffff)
|
||||
|
||||
# バッチ処理の関数
|
||||
def process_batch(batch, highres_fix, highres_1st=False):
|
||||
def process_batch(batch: List[BatchData], highres_fix, highres_1st=False):
|
||||
batch_size = len(batch)
|
||||
|
||||
# highres_fixの処理
|
||||
if highres_fix and not highres_1st:
|
||||
# 1st stageのバッチを作成して呼び出す
|
||||
print("process 1st stage1")
|
||||
# 1st stageのバッチを作成して呼び出す:サイズを小さくして呼び出す
|
||||
print("process 1st stage")
|
||||
batch_1st = []
|
||||
for params1, (width, height, steps, scale, strength) in batch:
|
||||
width_1st = int(width * args.highres_fix_scale + .5)
|
||||
height_1st = int(height * args.highres_fix_scale + .5)
|
||||
for _, base, ext in batch:
|
||||
width_1st = int(ext.width * args.highres_fix_scale + .5)
|
||||
height_1st = int(ext.height * args.highres_fix_scale + .5)
|
||||
width_1st = width_1st - width_1st % 32
|
||||
height_1st = height_1st - height_1st % 32
|
||||
batch_1st.append((params1, (width_1st, height_1st, args.highres_fix_steps, scale, strength)))
|
||||
|
||||
ext_1st = BatchDataExt(width_1st, height_1st, args.highres_fix_steps, ext.scale,
|
||||
ext.negative_scale, ext.strength, ext.network_muls)
|
||||
batch_1st.append(BatchData(args.highres_fix_latents_upscaling, base, ext_1st))
|
||||
images_1st = process_batch(batch_1st, True, True)
|
||||
|
||||
# 2nd stageのバッチを作成して以下処理する
|
||||
print("process 2nd stage1")
|
||||
print("process 2nd stage")
|
||||
if args.highres_fix_latents_upscaling:
|
||||
org_dtype = images_1st.dtype
|
||||
if images_1st.dtype == torch.bfloat16:
|
||||
images_1st = images_1st.to(torch.float) # interpolateがbf16をサポートしていない
|
||||
images_1st = torch.nn.functional.interpolate(
|
||||
images_1st, (batch[0].ext.height // 8, batch[0].ext.width // 8), mode='bilinear') # , antialias=True)
|
||||
images_1st = images_1st.to(org_dtype)
|
||||
|
||||
batch_2nd = []
|
||||
for i, (b1, image) in enumerate(zip(batch, images_1st)):
|
||||
image = image.resize((width, height), resample=PIL.Image.LANCZOS)
|
||||
(step, prompt, negative_prompt, seed, _, _, clip_prompt, guide_image), params2 = b1
|
||||
batch_2nd.append(((step, prompt, negative_prompt, seed+1, image, None, clip_prompt, guide_image), params2))
|
||||
for i, (bd, image) in enumerate(zip(batch, images_1st)):
|
||||
if not args.highres_fix_latents_upscaling:
|
||||
image = image.resize((bd.ext.width, bd.ext.height), resample=PIL.Image.LANCZOS) # img2imgとして設定
|
||||
bd_2nd = BatchData(False, BatchDataBase(*bd.base[0:3], bd.base.seed+1, image, None, *bd.base[6:]), bd.ext)
|
||||
batch_2nd.append(bd_2nd)
|
||||
batch = batch_2nd
|
||||
|
||||
(step_first, _, _, _, init_image, mask_image, _, guide_image), (width, height, steps, scale, strength) = batch[0]
|
||||
# このバッチの情報を取り出す
|
||||
return_latents, (step_first, _, _, _, init_image, mask_image, _, guide_image), \
|
||||
(width, height, steps, scale, negative_scale, strength, network_muls) = batch[0]
|
||||
noise_shape = (LATENT_CHANNELS, height // DOWNSAMPLING_FACTOR, width // DOWNSAMPLING_FACTOR)
|
||||
|
||||
prompts = []
|
||||
@@ -2204,7 +2407,7 @@ def main(args):
|
||||
all_images_are_same = True
|
||||
all_masks_are_same = True
|
||||
all_guide_images_are_same = True
|
||||
for i, ((_, prompt, negative_prompt, seed, init_image, mask_image, clip_prompt, guide_image), _) in enumerate(batch):
|
||||
for i, (_, (_, prompt, negative_prompt, seed, init_image, mask_image, clip_prompt, guide_image), _) in enumerate(batch):
|
||||
prompts.append(prompt)
|
||||
negative_prompts.append(negative_prompt)
|
||||
seeds.append(seed)
|
||||
@@ -2221,9 +2424,13 @@ def main(args):
|
||||
all_masks_are_same = mask_images[-2] is mask_image
|
||||
|
||||
if guide_image is not None:
|
||||
guide_images.append(guide_image)
|
||||
if i > 0 and all_guide_images_are_same:
|
||||
all_guide_images_are_same = guide_images[-2] is guide_image
|
||||
if type(guide_image) is list:
|
||||
guide_images.extend(guide_image)
|
||||
all_guide_images_are_same = False
|
||||
else:
|
||||
guide_images.append(guide_image)
|
||||
if i > 0 and all_guide_images_are_same:
|
||||
all_guide_images_are_same = guide_images[-2] is guide_image
|
||||
|
||||
# make start code
|
||||
torch.manual_seed(seed)
|
||||
@@ -2246,10 +2453,24 @@ def main(args):
|
||||
if guide_images is not None and all_guide_images_are_same:
|
||||
guide_images = guide_images[0]
|
||||
|
||||
# ControlNet使用時はguide imageをリサイズする
|
||||
if control_nets:
|
||||
# TODO resampleのメソッド
|
||||
guide_images = guide_images if type(guide_images) == list else [guide_images]
|
||||
guide_images = [i.resize((width, height), resample=PIL.Image.LANCZOS) for i in guide_images]
|
||||
if len(guide_images) == 1:
|
||||
guide_images = guide_images[0]
|
||||
|
||||
# generate
|
||||
images = pipe(prompts, negative_prompts, init_images, mask_images, height, width, steps, scale, strength, latents=start_code,
|
||||
output_type='pil', max_embeddings_multiples=max_embeddings_multiples, img2img_noise=i2i_noises, clip_prompts=clip_prompts, clip_guide_images=guide_images)[0]
|
||||
if highres_1st and not args.highres_fix_save_1st:
|
||||
if networks:
|
||||
for n, m in zip(networks, network_muls if network_muls else network_default_muls):
|
||||
n.set_multiplier(m)
|
||||
|
||||
images = pipe(prompts, negative_prompts, init_images, mask_images, height, width, steps, scale, negative_scale, strength, latents=start_code,
|
||||
output_type='pil', max_embeddings_multiples=max_embeddings_multiples, img2img_noise=i2i_noises,
|
||||
vae_batch_size=args.vae_batch_size, return_latents=return_latents,
|
||||
clip_prompts=clip_prompts, clip_guide_images=guide_images)[0]
|
||||
if highres_1st and not args.highres_fix_save_1st: # return images or latents
|
||||
return images
|
||||
|
||||
# save image
|
||||
@@ -2264,6 +2485,8 @@ def main(args):
|
||||
metadata.add_text("scale", str(scale))
|
||||
if negative_prompt is not None:
|
||||
metadata.add_text("negative-prompt", negative_prompt)
|
||||
if negative_scale is not None:
|
||||
metadata.add_text("negative-scale", str(negative_scale))
|
||||
if clip_prompt is not None:
|
||||
metadata.add_text("clip-prompt", clip_prompt)
|
||||
|
||||
@@ -2316,11 +2539,13 @@ def main(args):
|
||||
width = args.W
|
||||
height = args.H
|
||||
scale = args.scale
|
||||
negative_scale = args.negative_scale
|
||||
steps = args.steps
|
||||
seeds = None
|
||||
strength = 0.8 if args.strength is None else args.strength
|
||||
negative_prompt = ""
|
||||
clip_prompt = None
|
||||
network_muls = None
|
||||
|
||||
prompt_args = prompt.strip().split(' --')
|
||||
prompt = prompt_args[0]
|
||||
@@ -2358,6 +2583,15 @@ def main(args):
|
||||
print(f"scale: {scale}")
|
||||
continue
|
||||
|
||||
m = re.match(r'nl ([\d\.]+|none|None)', parg, re.IGNORECASE)
|
||||
if m: # negative scale
|
||||
if m.group(1).lower() == 'none':
|
||||
negative_scale = None
|
||||
else:
|
||||
negative_scale = float(m.group(1))
|
||||
print(f"negative scale: {negative_scale}")
|
||||
continue
|
||||
|
||||
m = re.match(r't ([\d\.]+)', parg, re.IGNORECASE)
|
||||
if m: # strength
|
||||
strength = float(m.group(1))
|
||||
@@ -2375,6 +2609,15 @@ def main(args):
|
||||
clip_prompt = m.group(1)
|
||||
print(f"clip prompt: {clip_prompt}")
|
||||
continue
|
||||
|
||||
m = re.match(r'am ([\d\.\-,]+)', parg, re.IGNORECASE)
|
||||
if m: # network multiplies
|
||||
network_muls = [float(v) for v in m.group(1).split(",")]
|
||||
while len(network_muls) < len(networks):
|
||||
network_muls.append(network_muls[-1])
|
||||
print(f"network mul: {network_muls}")
|
||||
continue
|
||||
|
||||
except ValueError as ex:
|
||||
print(f"Exception in parsing / 解析エラー: {parg}")
|
||||
print(ex)
|
||||
@@ -2412,7 +2655,12 @@ def main(args):
|
||||
mask_image = mask_images[global_step % len(mask_images)]
|
||||
|
||||
if guide_images is not None:
|
||||
guide_image = guide_images[global_step % len(guide_images)]
|
||||
if control_nets: # 複数件の場合あり
|
||||
c = len(control_nets)
|
||||
p = global_step % (len(guide_images) // c)
|
||||
guide_image = guide_images[p * c:p * c + c]
|
||||
else:
|
||||
guide_image = guide_images[global_step % len(guide_images)]
|
||||
elif args.clip_image_guidance_scale > 0 or args.vgg16_guidance_scale > 0:
|
||||
if prev_image is None:
|
||||
print("Generate 1st image without guide image.")
|
||||
@@ -2420,9 +2668,9 @@ def main(args):
|
||||
print("Use previous image as guide image.")
|
||||
guide_image = prev_image
|
||||
|
||||
b1 = ((global_step, prompt, negative_prompt, seed, init_image, mask_image, clip_prompt, guide_image),
|
||||
(width, height, steps, scale, strength))
|
||||
if len(batch_data) > 0 and batch_data[-1][1] != b1[1]: # バッチ分割必要?
|
||||
b1 = BatchData(False, BatchDataBase(global_step, prompt, negative_prompt, seed, init_image, mask_image, clip_prompt, guide_image),
|
||||
BatchDataExt(width, height, steps, scale, negative_scale, strength, tuple(network_muls) if network_muls else None))
|
||||
if len(batch_data) > 0 and batch_data[-1].ext != b1.ext: # バッチ分割必要?
|
||||
process_batch(batch_data, highres_fix)
|
||||
batch_data.clear()
|
||||
|
||||
@@ -2466,6 +2714,8 @@ if __name__ == '__main__':
|
||||
parser.add_argument("--H", type=int, default=None, help="image height, in pixel space / 生成画像高さ")
|
||||
parser.add_argument("--W", type=int, default=None, help="image width, in pixel space / 生成画像幅")
|
||||
parser.add_argument("--batch_size", type=int, default=1, help="batch size / バッチサイズ")
|
||||
parser.add_argument("--vae_batch_size", type=float, default=None,
|
||||
help="batch size for VAE, < 1.0 for ratio / VAE処理時のバッチサイズ、1未満の値の場合は通常バッチサイズの比率")
|
||||
parser.add_argument("--steps", type=int, default=50, help="number of ddim sampling steps / サンプリングステップ数")
|
||||
parser.add_argument('--sampler', type=str, default='ddim',
|
||||
choices=['ddim', 'pndm', 'lms', 'euler', 'euler_a', 'heun', 'dpm_2', 'dpm_2_a', 'dpmsolver',
|
||||
@@ -2477,11 +2727,14 @@ if __name__ == '__main__':
|
||||
parser.add_argument("--ckpt", type=str, default=None, help="path to checkpoint of model / モデルのcheckpointファイルまたはディレクトリ")
|
||||
parser.add_argument("--vae", type=str, default=None,
|
||||
help="path to checkpoint of vae to replace / VAEを入れ替える場合、VAEのcheckpointファイルまたはディレクトリ")
|
||||
parser.add_argument("--tokenizer_cache_dir", type=str, default=None,
|
||||
help="directory for caching Tokenizer (for offline training) / Tokenizerをキャッシュするディレクトリ(ネット接続なしでの学習のため)")
|
||||
# parser.add_argument("--replace_clip_l14_336", action='store_true',
|
||||
# help="Replace CLIP (Text Encoder) to l/14@336 / CLIP(Text Encoder)をl/14@336に入れ替える")
|
||||
parser.add_argument("--seed", type=int, default=None,
|
||||
help="seed, or seed of seeds in multiple generation / 1枚生成時のseed、または複数枚生成時の乱数seedを決めるためのseed")
|
||||
parser.add_argument("--iter_same_seed", action='store_true', help='use same seed for all prompts in iteration if no seed specified / 乱数seedの指定がないとき繰り返し内はすべて同じseedを使う(プロンプト間の差異の比較用)')
|
||||
parser.add_argument("--iter_same_seed", action='store_true',
|
||||
help='use same seed for all prompts in iteration if no seed specified / 乱数seedの指定がないとき繰り返し内はすべて同じseedを使う(プロンプト間の差異の比較用)')
|
||||
parser.add_argument("--fp16", action='store_true', help='use fp16 / fp16を指定し省メモリ化する')
|
||||
parser.add_argument("--bf16", action='store_true', help='use bfloat16 / bfloat16を指定し省メモリ化する')
|
||||
parser.add_argument("--xformers", action='store_true', help='use xformers / xformersを使用し高速化する')
|
||||
@@ -2489,11 +2742,18 @@ if __name__ == '__main__':
|
||||
help='use xformers by diffusers (Hypernetworks doesn\'t work) / Diffusersでxformersを使用する(Hypernetwork利用不可)')
|
||||
parser.add_argument("--opt_channels_last", action='store_true',
|
||||
help='set channels last option to model / モデルにchannels lastを指定し最適化する')
|
||||
parser.add_argument("--network_module", type=str, default=None, help='Hypernetwork module to use / Hypernetworkを使う時そのモジュール名')
|
||||
parser.add_argument("--network_weights", type=str, default=None, help='Hypernetwork weights to load / Hypernetworkの重み')
|
||||
parser.add_argument("--network_mul", type=float, default=1.0, help='Hypernetwork multiplier / Hypernetworkの効果の倍率')
|
||||
parser.add_argument("--network_dim", type=int, default=None,
|
||||
help='network dimensions (depends on each network) / モジュールの次元数(ネットワークにより定義は異なります)')
|
||||
parser.add_argument("--network_module", type=str, default=None, nargs='*',
|
||||
help='additional network module to use / 追加ネットワークを使う時そのモジュール名')
|
||||
parser.add_argument("--network_weights", type=str, default=None, nargs='*',
|
||||
help='additional network weights to load / 追加ネットワークの重み')
|
||||
parser.add_argument("--network_mul", type=float, default=None, nargs='*',
|
||||
help='additional network multiplier / 追加ネットワークの効果の倍率')
|
||||
parser.add_argument("--network_args", type=str, default=None, nargs='*',
|
||||
help='additional argmuments for network (key=value) / ネットワークへの追加の引数')
|
||||
parser.add_argument("--network_show_meta", action='store_true',
|
||||
help='show metadata of network model / ネットワークモデルのメタデータを表示する')
|
||||
parser.add_argument("--textual_inversion_embeddings", type=str, default=None, nargs='*',
|
||||
help='Embeddings files of Textual Inversion / Textual Inversionのembeddings')
|
||||
parser.add_argument("--clip_skip", type=int, default=None, help='layer number from bottom to use in CLIP / CLIPの後ろからn層目の出力を使う')
|
||||
parser.add_argument("--max_embeddings_multiples", type=int, default=None,
|
||||
help='max embeding multiples, max token length is 75 * multiples / トークン長をデフォルトの何倍とするか 75*この値 がトークン長となる')
|
||||
@@ -2505,13 +2765,26 @@ if __name__ == '__main__':
|
||||
help='enable VGG16 guided SD by image, scale for guidance / 画像によるVGG16 guided SDを有効にしてこのscaleを適用する')
|
||||
parser.add_argument("--vgg16_guidance_layer", type=int, default=20,
|
||||
help='layer of VGG16 to calculate contents guide (1~30, 20 for conv4_2) / VGG16のcontents guideに使うレイヤー番号 (1~30、20はconv4_2)')
|
||||
parser.add_argument("--guide_image_path", type=str, default=None, help="image to CLIP guidance / CLIP guided SDでガイドに使う画像")
|
||||
parser.add_argument("--guide_image_path", type=str, default=None, nargs="*",
|
||||
help="image to CLIP guidance / CLIP guided SDでガイドに使う画像")
|
||||
parser.add_argument("--highres_fix_scale", type=float, default=None,
|
||||
help="enable highres fix, reso scale for 1st stage / highres fixを有効にして最初の解像度をこのscaleにする")
|
||||
parser.add_argument("--highres_fix_steps", type=int, default=28,
|
||||
help="1st stage steps for highres fix / highres fixの最初のステージのステップ数")
|
||||
parser.add_argument("--highres_fix_save_1st", action='store_true',
|
||||
help="save 1st stage images for highres fix / highres fixの最初のステージの画像を保存する")
|
||||
parser.add_argument("--highres_fix_latents_upscaling", action='store_true',
|
||||
help="use latents upscaling for highres fix / highres fixでlatentで拡大する")
|
||||
parser.add_argument("--negative_scale", type=float, default=None,
|
||||
help="set another guidance scale for negative prompt / ネガティブプロンプトのscaleを指定する")
|
||||
|
||||
parser.add_argument("--control_net_models", type=str, default=None, nargs='*',
|
||||
help='ControlNet models to use / 使用するControlNetのモデル名')
|
||||
parser.add_argument("--control_net_preps", type=str, default=None, nargs='*',
|
||||
help='ControlNet preprocess to use / 使用するControlNetのプリプロセス名')
|
||||
parser.add_argument("--control_net_weights", type=float, default=None, nargs='*', help='ControlNet weights / ControlNetの重み')
|
||||
parser.add_argument("--control_net_ratios", type=float, default=None, nargs='*',
|
||||
help='ControlNet guidance ratio for steps / ControlNetでガイドするステップ比率')
|
||||
|
||||
args = parser.parse_args()
|
||||
main(args)
|
||||
|
||||
527
library/config_util.py
Normal file
527
library/config_util.py
Normal file
@@ -0,0 +1,527 @@
|
||||
import argparse
|
||||
from dataclasses import (
|
||||
asdict,
|
||||
dataclass,
|
||||
)
|
||||
import functools
|
||||
from textwrap import dedent, indent
|
||||
import json
|
||||
from pathlib import Path
|
||||
# from toolz import curry
|
||||
from typing import (
|
||||
List,
|
||||
Optional,
|
||||
Sequence,
|
||||
Tuple,
|
||||
Union,
|
||||
)
|
||||
|
||||
import toml
|
||||
import voluptuous
|
||||
from voluptuous import (
|
||||
Any,
|
||||
ExactSequence,
|
||||
MultipleInvalid,
|
||||
Object,
|
||||
Required,
|
||||
Schema,
|
||||
)
|
||||
from transformers import CLIPTokenizer
|
||||
|
||||
from . import train_util
|
||||
from .train_util import (
|
||||
DreamBoothSubset,
|
||||
FineTuningSubset,
|
||||
DreamBoothDataset,
|
||||
FineTuningDataset,
|
||||
DatasetGroup,
|
||||
)
|
||||
|
||||
|
||||
def add_config_arguments(parser: argparse.ArgumentParser):
|
||||
parser.add_argument("--dataset_config", type=Path, default=None, help="config file for detail settings / 詳細な設定用の設定ファイル")
|
||||
|
||||
# TODO: inherit Params class in Subset, Dataset
|
||||
|
||||
@dataclass
|
||||
class BaseSubsetParams:
|
||||
image_dir: Optional[str] = None
|
||||
num_repeats: int = 1
|
||||
shuffle_caption: bool = False
|
||||
keep_tokens: int = 0
|
||||
color_aug: bool = False
|
||||
flip_aug: bool = False
|
||||
face_crop_aug_range: Optional[Tuple[float, float]] = None
|
||||
random_crop: bool = False
|
||||
caption_dropout_rate: float = 0.0
|
||||
caption_dropout_every_n_epochs: int = 0
|
||||
caption_tag_dropout_rate: float = 0.0
|
||||
|
||||
@dataclass
|
||||
class DreamBoothSubsetParams(BaseSubsetParams):
|
||||
is_reg: bool = False
|
||||
class_tokens: Optional[str] = None
|
||||
caption_extension: str = ".caption"
|
||||
|
||||
@dataclass
|
||||
class FineTuningSubsetParams(BaseSubsetParams):
|
||||
metadata_file: Optional[str] = None
|
||||
|
||||
@dataclass
|
||||
class BaseDatasetParams:
|
||||
tokenizer: CLIPTokenizer = None
|
||||
max_token_length: int = None
|
||||
resolution: Optional[Tuple[int, int]] = None
|
||||
debug_dataset: bool = False
|
||||
|
||||
@dataclass
|
||||
class DreamBoothDatasetParams(BaseDatasetParams):
|
||||
batch_size: int = 1
|
||||
enable_bucket: bool = False
|
||||
min_bucket_reso: int = 256
|
||||
max_bucket_reso: int = 1024
|
||||
bucket_reso_steps: int = 64
|
||||
bucket_no_upscale: bool = False
|
||||
prior_loss_weight: float = 1.0
|
||||
|
||||
@dataclass
|
||||
class FineTuningDatasetParams(BaseDatasetParams):
|
||||
batch_size: int = 1
|
||||
enable_bucket: bool = False
|
||||
min_bucket_reso: int = 256
|
||||
max_bucket_reso: int = 1024
|
||||
bucket_reso_steps: int = 64
|
||||
bucket_no_upscale: bool = False
|
||||
|
||||
@dataclass
|
||||
class SubsetBlueprint:
|
||||
params: Union[DreamBoothSubsetParams, FineTuningSubsetParams]
|
||||
|
||||
@dataclass
|
||||
class DatasetBlueprint:
|
||||
is_dreambooth: bool
|
||||
params: Union[DreamBoothDatasetParams, FineTuningDatasetParams]
|
||||
subsets: Sequence[SubsetBlueprint]
|
||||
|
||||
@dataclass
|
||||
class DatasetGroupBlueprint:
|
||||
datasets: Sequence[DatasetBlueprint]
|
||||
@dataclass
|
||||
class Blueprint:
|
||||
dataset_group: DatasetGroupBlueprint
|
||||
|
||||
|
||||
class ConfigSanitizer:
|
||||
# @curry
|
||||
@staticmethod
|
||||
def __validate_and_convert_twodim(klass, value: Sequence) -> Tuple:
|
||||
Schema(ExactSequence([klass, klass]))(value)
|
||||
return tuple(value)
|
||||
|
||||
# @curry
|
||||
@staticmethod
|
||||
def __validate_and_convert_scalar_or_twodim(klass, value: Union[float, Sequence]) -> Tuple:
|
||||
Schema(Any(klass, ExactSequence([klass, klass])))(value)
|
||||
try:
|
||||
Schema(klass)(value)
|
||||
return (value, value)
|
||||
except:
|
||||
return ConfigSanitizer.__validate_and_convert_twodim(klass, value)
|
||||
|
||||
# subset schema
|
||||
SUBSET_ASCENDABLE_SCHEMA = {
|
||||
"color_aug": bool,
|
||||
"face_crop_aug_range": functools.partial(__validate_and_convert_twodim.__func__, float),
|
||||
"flip_aug": bool,
|
||||
"num_repeats": int,
|
||||
"random_crop": bool,
|
||||
"shuffle_caption": bool,
|
||||
"keep_tokens": int,
|
||||
}
|
||||
# DO means DropOut
|
||||
DO_SUBSET_ASCENDABLE_SCHEMA = {
|
||||
"caption_dropout_every_n_epochs": int,
|
||||
"caption_dropout_rate": Any(float, int),
|
||||
"caption_tag_dropout_rate": Any(float, int),
|
||||
}
|
||||
# DB means DreamBooth
|
||||
DB_SUBSET_ASCENDABLE_SCHEMA = {
|
||||
"caption_extension": str,
|
||||
"class_tokens": str,
|
||||
}
|
||||
DB_SUBSET_DISTINCT_SCHEMA = {
|
||||
Required("image_dir"): str,
|
||||
"is_reg": bool,
|
||||
}
|
||||
# FT means FineTuning
|
||||
FT_SUBSET_DISTINCT_SCHEMA = {
|
||||
Required("metadata_file"): str,
|
||||
"image_dir": str,
|
||||
}
|
||||
|
||||
# datasets schema
|
||||
DATASET_ASCENDABLE_SCHEMA = {
|
||||
"batch_size": int,
|
||||
"bucket_no_upscale": bool,
|
||||
"bucket_reso_steps": int,
|
||||
"enable_bucket": bool,
|
||||
"max_bucket_reso": int,
|
||||
"min_bucket_reso": int,
|
||||
"resolution": functools.partial(__validate_and_convert_scalar_or_twodim.__func__, int),
|
||||
}
|
||||
|
||||
# options handled by argparse but not handled by user config
|
||||
ARGPARSE_SPECIFIC_SCHEMA = {
|
||||
"debug_dataset": bool,
|
||||
"max_token_length": Any(None, int),
|
||||
"prior_loss_weight": Any(float, int),
|
||||
}
|
||||
# for handling default None value of argparse
|
||||
ARGPARSE_NULLABLE_OPTNAMES = [
|
||||
"face_crop_aug_range",
|
||||
"resolution",
|
||||
]
|
||||
# prepare map because option name may differ among argparse and user config
|
||||
ARGPARSE_OPTNAME_TO_CONFIG_OPTNAME = {
|
||||
"train_batch_size": "batch_size",
|
||||
"dataset_repeats": "num_repeats",
|
||||
}
|
||||
|
||||
def __init__(self, support_dreambooth: bool, support_finetuning: bool, support_dropout: bool) -> None:
|
||||
assert support_dreambooth or support_finetuning, "Neither DreamBooth mode nor fine tuning mode specified. Please specify one mode or more. / DreamBooth モードか fine tuning モードのどちらも指定されていません。1つ以上指定してください。"
|
||||
|
||||
self.db_subset_schema = self.__merge_dict(
|
||||
self.SUBSET_ASCENDABLE_SCHEMA,
|
||||
self.DB_SUBSET_DISTINCT_SCHEMA,
|
||||
self.DB_SUBSET_ASCENDABLE_SCHEMA,
|
||||
self.DO_SUBSET_ASCENDABLE_SCHEMA if support_dropout else {},
|
||||
)
|
||||
|
||||
self.ft_subset_schema = self.__merge_dict(
|
||||
self.SUBSET_ASCENDABLE_SCHEMA,
|
||||
self.FT_SUBSET_DISTINCT_SCHEMA,
|
||||
self.DO_SUBSET_ASCENDABLE_SCHEMA if support_dropout else {},
|
||||
)
|
||||
|
||||
self.db_dataset_schema = self.__merge_dict(
|
||||
self.DATASET_ASCENDABLE_SCHEMA,
|
||||
self.SUBSET_ASCENDABLE_SCHEMA,
|
||||
self.DB_SUBSET_ASCENDABLE_SCHEMA,
|
||||
self.DO_SUBSET_ASCENDABLE_SCHEMA if support_dropout else {},
|
||||
{"subsets": [self.db_subset_schema]},
|
||||
)
|
||||
|
||||
self.ft_dataset_schema = self.__merge_dict(
|
||||
self.DATASET_ASCENDABLE_SCHEMA,
|
||||
self.SUBSET_ASCENDABLE_SCHEMA,
|
||||
self.DO_SUBSET_ASCENDABLE_SCHEMA if support_dropout else {},
|
||||
{"subsets": [self.ft_subset_schema]},
|
||||
)
|
||||
|
||||
if support_dreambooth and support_finetuning:
|
||||
def validate_flex_dataset(dataset_config: dict):
|
||||
subsets_config = dataset_config.get("subsets", [])
|
||||
|
||||
# check dataset meets FT style
|
||||
# NOTE: all FT subsets should have "metadata_file"
|
||||
if all(["metadata_file" in subset for subset in subsets_config]):
|
||||
return Schema(self.ft_dataset_schema)(dataset_config)
|
||||
# check dataset meets DB style
|
||||
# NOTE: all DB subsets should have no "metadata_file"
|
||||
elif all(["metadata_file" not in subset for subset in subsets_config]):
|
||||
return Schema(self.db_dataset_schema)(dataset_config)
|
||||
else:
|
||||
raise voluptuous.Invalid("DreamBooth subset and fine tuning subset cannot be mixed in the same dataset. Please split them into separate datasets. / DreamBoothのサブセットとfine tuninのサブセットを同一のデータセットに混在させることはできません。別々のデータセットに分割してください。")
|
||||
|
||||
self.dataset_schema = validate_flex_dataset
|
||||
elif support_dreambooth:
|
||||
self.dataset_schema = self.db_dataset_schema
|
||||
else:
|
||||
self.dataset_schema = self.ft_dataset_schema
|
||||
|
||||
self.general_schema = self.__merge_dict(
|
||||
self.DATASET_ASCENDABLE_SCHEMA,
|
||||
self.SUBSET_ASCENDABLE_SCHEMA,
|
||||
self.DB_SUBSET_ASCENDABLE_SCHEMA if support_dreambooth else {},
|
||||
self.DO_SUBSET_ASCENDABLE_SCHEMA if support_dropout else {},
|
||||
)
|
||||
|
||||
self.user_config_validator = Schema({
|
||||
"general": self.general_schema,
|
||||
"datasets": [self.dataset_schema],
|
||||
})
|
||||
|
||||
self.argparse_schema = self.__merge_dict(
|
||||
self.general_schema,
|
||||
self.ARGPARSE_SPECIFIC_SCHEMA,
|
||||
{optname: Any(None, self.general_schema[optname]) for optname in self.ARGPARSE_NULLABLE_OPTNAMES},
|
||||
{a_name: self.general_schema[c_name] for a_name, c_name in self.ARGPARSE_OPTNAME_TO_CONFIG_OPTNAME.items()},
|
||||
)
|
||||
|
||||
self.argparse_config_validator = Schema(Object(self.argparse_schema), extra=voluptuous.ALLOW_EXTRA)
|
||||
|
||||
def sanitize_user_config(self, user_config: dict) -> dict:
|
||||
try:
|
||||
return self.user_config_validator(user_config)
|
||||
except MultipleInvalid:
|
||||
# TODO: エラー発生時のメッセージをわかりやすくする
|
||||
print("Invalid user config / ユーザ設定の形式が正しくないようです")
|
||||
raise
|
||||
|
||||
# NOTE: In nature, argument parser result is not needed to be sanitize
|
||||
# However this will help us to detect program bug
|
||||
def sanitize_argparse_namespace(self, argparse_namespace: argparse.Namespace) -> argparse.Namespace:
|
||||
try:
|
||||
return self.argparse_config_validator(argparse_namespace)
|
||||
except MultipleInvalid:
|
||||
# XXX: this should be a bug
|
||||
print("Invalid cmdline parsed arguments. This should be a bug. / コマンドラインのパース結果が正しくないようです。プログラムのバグの可能性が高いです。")
|
||||
raise
|
||||
|
||||
# NOTE: value would be overwritten by latter dict if there is already the same key
|
||||
@staticmethod
|
||||
def __merge_dict(*dict_list: dict) -> dict:
|
||||
merged = {}
|
||||
for schema in dict_list:
|
||||
# merged |= schema
|
||||
for k, v in schema.items():
|
||||
merged[k] = v
|
||||
return merged
|
||||
|
||||
|
||||
class BlueprintGenerator:
|
||||
BLUEPRINT_PARAM_NAME_TO_CONFIG_OPTNAME = {
|
||||
}
|
||||
|
||||
def __init__(self, sanitizer: ConfigSanitizer):
|
||||
self.sanitizer = sanitizer
|
||||
|
||||
# runtime_params is for parameters which is only configurable on runtime, such as tokenizer
|
||||
def generate(self, user_config: dict, argparse_namespace: argparse.Namespace, **runtime_params) -> Blueprint:
|
||||
sanitized_user_config = self.sanitizer.sanitize_user_config(user_config)
|
||||
sanitized_argparse_namespace = self.sanitizer.sanitize_argparse_namespace(argparse_namespace)
|
||||
|
||||
# convert argparse namespace to dict like config
|
||||
# NOTE: it is ok to have extra entries in dict
|
||||
optname_map = self.sanitizer.ARGPARSE_OPTNAME_TO_CONFIG_OPTNAME
|
||||
argparse_config = {optname_map.get(optname, optname): value for optname, value in vars(sanitized_argparse_namespace).items()}
|
||||
|
||||
general_config = sanitized_user_config.get("general", {})
|
||||
|
||||
dataset_blueprints = []
|
||||
for dataset_config in sanitized_user_config.get("datasets", []):
|
||||
# NOTE: if subsets have no "metadata_file", these are DreamBooth datasets/subsets
|
||||
subsets = dataset_config.get("subsets", [])
|
||||
is_dreambooth = all(["metadata_file" not in subset for subset in subsets])
|
||||
if is_dreambooth:
|
||||
subset_params_klass = DreamBoothSubsetParams
|
||||
dataset_params_klass = DreamBoothDatasetParams
|
||||
else:
|
||||
subset_params_klass = FineTuningSubsetParams
|
||||
dataset_params_klass = FineTuningDatasetParams
|
||||
|
||||
subset_blueprints = []
|
||||
for subset_config in subsets:
|
||||
params = self.generate_params_by_fallbacks(subset_params_klass,
|
||||
[subset_config, dataset_config, general_config, argparse_config, runtime_params])
|
||||
subset_blueprints.append(SubsetBlueprint(params))
|
||||
|
||||
params = self.generate_params_by_fallbacks(dataset_params_klass,
|
||||
[dataset_config, general_config, argparse_config, runtime_params])
|
||||
dataset_blueprints.append(DatasetBlueprint(is_dreambooth, params, subset_blueprints))
|
||||
|
||||
dataset_group_blueprint = DatasetGroupBlueprint(dataset_blueprints)
|
||||
|
||||
return Blueprint(dataset_group_blueprint)
|
||||
|
||||
@staticmethod
|
||||
def generate_params_by_fallbacks(param_klass, fallbacks: Sequence[dict]):
|
||||
name_map = BlueprintGenerator.BLUEPRINT_PARAM_NAME_TO_CONFIG_OPTNAME
|
||||
search_value = BlueprintGenerator.search_value
|
||||
default_params = asdict(param_klass())
|
||||
param_names = default_params.keys()
|
||||
|
||||
params = {name: search_value(name_map.get(name, name), fallbacks, default_params.get(name)) for name in param_names}
|
||||
|
||||
return param_klass(**params)
|
||||
|
||||
@staticmethod
|
||||
def search_value(key: str, fallbacks: Sequence[dict], default_value = None):
|
||||
for cand in fallbacks:
|
||||
value = cand.get(key)
|
||||
if value is not None:
|
||||
return value
|
||||
|
||||
return default_value
|
||||
|
||||
|
||||
def generate_dataset_group_by_blueprint(dataset_group_blueprint: DatasetGroupBlueprint):
|
||||
datasets: List[Union[DreamBoothDataset, FineTuningDataset]] = []
|
||||
|
||||
for dataset_blueprint in dataset_group_blueprint.datasets:
|
||||
if dataset_blueprint.is_dreambooth:
|
||||
subset_klass = DreamBoothSubset
|
||||
dataset_klass = DreamBoothDataset
|
||||
else:
|
||||
subset_klass = FineTuningSubset
|
||||
dataset_klass = FineTuningDataset
|
||||
|
||||
subsets = [subset_klass(**asdict(subset_blueprint.params)) for subset_blueprint in dataset_blueprint.subsets]
|
||||
dataset = dataset_klass(subsets=subsets, **asdict(dataset_blueprint.params))
|
||||
datasets.append(dataset)
|
||||
|
||||
# print info
|
||||
info = ""
|
||||
for i, dataset in enumerate(datasets):
|
||||
is_dreambooth = isinstance(dataset, DreamBoothDataset)
|
||||
info += dedent(f"""\
|
||||
[Dataset {i}]
|
||||
batch_size: {dataset.batch_size}
|
||||
resolution: {(dataset.width, dataset.height)}
|
||||
enable_bucket: {dataset.enable_bucket}
|
||||
""")
|
||||
|
||||
if dataset.enable_bucket:
|
||||
info += indent(dedent(f"""\
|
||||
min_bucket_reso: {dataset.min_bucket_reso}
|
||||
max_bucket_reso: {dataset.max_bucket_reso}
|
||||
bucket_reso_steps: {dataset.bucket_reso_steps}
|
||||
bucket_no_upscale: {dataset.bucket_no_upscale}
|
||||
\n"""), " ")
|
||||
else:
|
||||
info += "\n"
|
||||
|
||||
for j, subset in enumerate(dataset.subsets):
|
||||
info += indent(dedent(f"""\
|
||||
[Subset {j} of Dataset {i}]
|
||||
image_dir: "{subset.image_dir}"
|
||||
image_count: {subset.img_count}
|
||||
num_repeats: {subset.num_repeats}
|
||||
shuffle_caption: {subset.shuffle_caption}
|
||||
keep_tokens: {subset.keep_tokens}
|
||||
caption_dropout_rate: {subset.caption_dropout_rate}
|
||||
caption_dropout_every_n_epoches: {subset.caption_dropout_every_n_epochs}
|
||||
caption_tag_dropout_rate: {subset.caption_tag_dropout_rate}
|
||||
color_aug: {subset.color_aug}
|
||||
flip_aug: {subset.flip_aug}
|
||||
face_crop_aug_range: {subset.face_crop_aug_range}
|
||||
random_crop: {subset.random_crop}
|
||||
"""), " ")
|
||||
|
||||
if is_dreambooth:
|
||||
info += indent(dedent(f"""\
|
||||
is_reg: {subset.is_reg}
|
||||
class_tokens: {subset.class_tokens}
|
||||
caption_extension: {subset.caption_extension}
|
||||
\n"""), " ")
|
||||
else:
|
||||
info += indent(dedent(f"""\
|
||||
metadata_file: {subset.metadata_file}
|
||||
\n"""), " ")
|
||||
|
||||
print(info)
|
||||
|
||||
# make buckets first because it determines the length of dataset
|
||||
for i, dataset in enumerate(datasets):
|
||||
print(f"[Dataset {i}]")
|
||||
dataset.make_buckets()
|
||||
|
||||
return DatasetGroup(datasets)
|
||||
|
||||
|
||||
def generate_dreambooth_subsets_config_by_subdirs(train_data_dir: Optional[str] = None, reg_data_dir: Optional[str] = None):
|
||||
def extract_dreambooth_params(name: str) -> Tuple[int, str]:
|
||||
tokens = name.split('_')
|
||||
try:
|
||||
n_repeats = int(tokens[0])
|
||||
except ValueError as e:
|
||||
print(f"ignore directory without repeats / 繰り返し回数のないディレクトリを無視します: {dir}")
|
||||
return 0, ""
|
||||
caption_by_folder = '_'.join(tokens[1:])
|
||||
return n_repeats, caption_by_folder
|
||||
|
||||
def generate(base_dir: Optional[str], is_reg: bool):
|
||||
if base_dir is None:
|
||||
return []
|
||||
|
||||
base_dir: Path = Path(base_dir)
|
||||
if not base_dir.is_dir():
|
||||
return []
|
||||
|
||||
subsets_config = []
|
||||
for subdir in base_dir.iterdir():
|
||||
if not subdir.is_dir():
|
||||
continue
|
||||
|
||||
num_repeats, class_tokens = extract_dreambooth_params(subdir.name)
|
||||
if num_repeats < 1:
|
||||
continue
|
||||
|
||||
subset_config = {"image_dir": str(subdir), "num_repeats": num_repeats, "is_reg": is_reg, "class_tokens": class_tokens}
|
||||
subsets_config.append(subset_config)
|
||||
|
||||
return subsets_config
|
||||
|
||||
subsets_config = []
|
||||
subsets_config += generate(train_data_dir, False)
|
||||
subsets_config += generate(reg_data_dir, True)
|
||||
|
||||
return subsets_config
|
||||
|
||||
|
||||
def load_user_config(file: str) -> dict:
|
||||
file: Path = Path(file)
|
||||
if not file.is_file():
|
||||
raise ValueError(f"file not found / ファイルが見つかりません: {file}")
|
||||
|
||||
if file.name.lower().endswith('.json'):
|
||||
try:
|
||||
config = json.load(file)
|
||||
except Exception:
|
||||
print(f"Error on parsing JSON config file. Please check the format. / JSON 形式の設定ファイルの読み込みに失敗しました。文法が正しいか確認してください。: {file}")
|
||||
raise
|
||||
elif file.name.lower().endswith('.toml'):
|
||||
try:
|
||||
config = toml.load(file)
|
||||
except Exception:
|
||||
print(f"Error on parsing TOML config file. Please check the format. / TOML 形式の設定ファイルの読み込みに失敗しました。文法が正しいか確認してください。: {file}")
|
||||
raise
|
||||
else:
|
||||
raise ValueError(f"not supported config file format / 対応していない設定ファイルの形式です: {file}")
|
||||
|
||||
return config
|
||||
|
||||
|
||||
# for config test
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--support_dreambooth", action="store_true")
|
||||
parser.add_argument("--support_finetuning", action="store_true")
|
||||
parser.add_argument("--support_dropout", action="store_true")
|
||||
parser.add_argument("dataset_config")
|
||||
config_args, remain = parser.parse_known_args()
|
||||
|
||||
parser = argparse.ArgumentParser()
|
||||
train_util.add_dataset_arguments(parser, config_args.support_dreambooth, config_args.support_finetuning, config_args.support_dropout)
|
||||
train_util.add_training_arguments(parser, config_args.support_dreambooth)
|
||||
argparse_namespace = parser.parse_args(remain)
|
||||
train_util.prepare_dataset_args(argparse_namespace, config_args.support_finetuning)
|
||||
|
||||
print("[argparse_namespace]")
|
||||
print(vars(argparse_namespace))
|
||||
|
||||
user_config = load_user_config(config_args.dataset_config)
|
||||
|
||||
print("\n[user_config]")
|
||||
print(user_config)
|
||||
|
||||
sanitizer = ConfigSanitizer(config_args.support_dreambooth, config_args.support_finetuning, config_args.support_dropout)
|
||||
sanitized_user_config = sanitizer.sanitize_user_config(user_config)
|
||||
|
||||
print("\n[sanitized_user_config]")
|
||||
print(sanitized_user_config)
|
||||
|
||||
blueprint = BlueprintGenerator(sanitizer).generate(user_config, argparse_namespace)
|
||||
|
||||
print("\n[blueprint]")
|
||||
print(blueprint)
|
||||
@@ -4,7 +4,7 @@
|
||||
import math
|
||||
import os
|
||||
import torch
|
||||
from transformers import CLIPTextModel, CLIPTokenizer, CLIPTextConfig
|
||||
from transformers import CLIPTextModel, CLIPTokenizer, CLIPTextConfig, logging
|
||||
from diffusers import AutoencoderKL, DDIMScheduler, StableDiffusionPipeline, UNet2DConditionModel
|
||||
from safetensors.torch import load_file, save_file
|
||||
|
||||
@@ -16,7 +16,7 @@ BETA_END = 0.0120
|
||||
UNET_PARAMS_MODEL_CHANNELS = 320
|
||||
UNET_PARAMS_CHANNEL_MULT = [1, 2, 4, 4]
|
||||
UNET_PARAMS_ATTENTION_RESOLUTIONS = [4, 2, 1]
|
||||
UNET_PARAMS_IMAGE_SIZE = 32 # unused
|
||||
UNET_PARAMS_IMAGE_SIZE = 64 # fixed from old invalid value `32`
|
||||
UNET_PARAMS_IN_CHANNELS = 4
|
||||
UNET_PARAMS_OUT_CHANNELS = 4
|
||||
UNET_PARAMS_NUM_RES_BLOCKS = 2
|
||||
@@ -632,7 +632,7 @@ def convert_ldm_clip_checkpoint_v2(checkpoint, max_length):
|
||||
del new_sd[ANOTHER_POSITION_IDS_KEY]
|
||||
else:
|
||||
position_ids = torch.Tensor([list(range(max_length))]).to(torch.int64)
|
||||
|
||||
|
||||
new_sd["text_model.embeddings.position_ids"] = position_ids
|
||||
return new_sd
|
||||
|
||||
@@ -886,7 +886,7 @@ def load_models_from_stable_diffusion_checkpoint(v2, ckpt_path, dtype=None):
|
||||
|
||||
vae = AutoencoderKL(**vae_config)
|
||||
info = vae.load_state_dict(converted_vae_checkpoint)
|
||||
print("loadint vae:", info)
|
||||
print("loading vae:", info)
|
||||
|
||||
# convert text_model
|
||||
if v2:
|
||||
@@ -916,7 +916,11 @@ def load_models_from_stable_diffusion_checkpoint(v2, ckpt_path, dtype=None):
|
||||
info = text_model.load_state_dict(converted_text_encoder_checkpoint)
|
||||
else:
|
||||
converted_text_encoder_checkpoint = convert_ldm_clip_checkpoint_v1(state_dict)
|
||||
|
||||
logging.set_verbosity_error() # don't show annoying warning
|
||||
text_model = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14")
|
||||
logging.set_verbosity_warning()
|
||||
|
||||
info = text_model.load_state_dict(converted_text_encoder_checkpoint)
|
||||
print("loading text encoder:", info)
|
||||
|
||||
@@ -1105,12 +1109,12 @@ def load_vae(vae_id, dtype):
|
||||
|
||||
if vae_id.endswith(".bin"):
|
||||
# SD 1.5 VAE on Huggingface
|
||||
vae_sd = torch.load(vae_id, map_location="cpu")
|
||||
converted_vae_checkpoint = vae_sd
|
||||
converted_vae_checkpoint = torch.load(vae_id, map_location="cpu")
|
||||
else:
|
||||
# StableDiffusion
|
||||
vae_model = torch.load(vae_id, map_location="cpu")
|
||||
vae_sd = vae_model['state_dict']
|
||||
vae_model = (load_file(vae_id, "cpu") if is_safetensors(vae_id)
|
||||
else torch.load(vae_id, map_location="cpu"))
|
||||
vae_sd = vae_model['state_dict'] if 'state_dict' in vae_model else vae_model
|
||||
|
||||
# vae only or full model
|
||||
full_model = False
|
||||
@@ -1132,15 +1136,6 @@ def load_vae(vae_id, dtype):
|
||||
vae.load_state_dict(converted_vae_checkpoint)
|
||||
return vae
|
||||
|
||||
|
||||
def get_epoch_ckpt_name(use_safetensors, epoch):
|
||||
return f"epoch-{epoch:06d}" + (".safetensors" if use_safetensors else ".ckpt")
|
||||
|
||||
|
||||
def get_last_ckpt_name(use_safetensors):
|
||||
return f"last" + (".safetensors" if use_safetensors else ".ckpt")
|
||||
|
||||
|
||||
# endregion
|
||||
|
||||
|
||||
@@ -1172,15 +1167,14 @@ def make_bucket_resolutions(max_reso, min_size=256, max_size=1024, divisible=64)
|
||||
|
||||
resos = list(resos)
|
||||
resos.sort()
|
||||
|
||||
aspect_ratios = [w / h for w, h in resos]
|
||||
return resos, aspect_ratios
|
||||
return resos
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
resos, aspect_ratios = make_bucket_resolutions((512, 768))
|
||||
resos = make_bucket_resolutions((512, 768))
|
||||
print(len(resos))
|
||||
print(resos)
|
||||
aspect_ratios = [w / h for w, h in resos]
|
||||
print(aspect_ratios)
|
||||
|
||||
ars = set()
|
||||
|
||||
2420
library/train_util.py
Normal file
2420
library/train_util.py
Normal file
File diff suppressed because it is too large
Load Diff
32
networks/check_lora_weights.py
Normal file
32
networks/check_lora_weights.py
Normal file
@@ -0,0 +1,32 @@
|
||||
import argparse
|
||||
import os
|
||||
import torch
|
||||
from safetensors.torch import load_file
|
||||
|
||||
|
||||
def main(file):
|
||||
print(f"loading: {file}")
|
||||
if os.path.splitext(file)[1] == '.safetensors':
|
||||
sd = load_file(file)
|
||||
else:
|
||||
sd = torch.load(file, map_location='cpu')
|
||||
|
||||
values = []
|
||||
|
||||
keys = list(sd.keys())
|
||||
for key in keys:
|
||||
if 'lora_up' in key or 'lora_down' in key:
|
||||
values.append((key, sd[key]))
|
||||
print(f"number of LoRA modules: {len(values)}")
|
||||
|
||||
for key, value in values:
|
||||
value = value.to(torch.float32)
|
||||
print(f"{key},{str(tuple(value.size())).replace(', ', '-')},{torch.mean(torch.abs(value))},{torch.min(torch.abs(value))}")
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("file", type=str, help="model file to check / 重みを確認するモデルファイル")
|
||||
args = parser.parse_args()
|
||||
|
||||
main(args.file)
|
||||
183
networks/extract_lora_from_models.py
Normal file
183
networks/extract_lora_from_models.py
Normal file
@@ -0,0 +1,183 @@
|
||||
# extract approximating LoRA by svd from two SD models
|
||||
# The code is based on https://github.com/cloneofsimo/lora/blob/develop/lora_diffusion/cli_svd.py
|
||||
# Thanks to cloneofsimo!
|
||||
|
||||
import argparse
|
||||
import os
|
||||
import torch
|
||||
from safetensors.torch import load_file, save_file
|
||||
from tqdm import tqdm
|
||||
import library.model_util as model_util
|
||||
import lora
|
||||
|
||||
|
||||
CLAMP_QUANTILE = 0.99
|
||||
MIN_DIFF = 1e-6
|
||||
|
||||
|
||||
def save_to_file(file_name, model, state_dict, dtype):
|
||||
if dtype is not None:
|
||||
for key in list(state_dict.keys()):
|
||||
if type(state_dict[key]) == torch.Tensor:
|
||||
state_dict[key] = state_dict[key].to(dtype)
|
||||
|
||||
if os.path.splitext(file_name)[1] == '.safetensors':
|
||||
save_file(model, file_name)
|
||||
else:
|
||||
torch.save(model, file_name)
|
||||
|
||||
|
||||
def svd(args):
|
||||
def str_to_dtype(p):
|
||||
if p == 'float':
|
||||
return torch.float
|
||||
if p == 'fp16':
|
||||
return torch.float16
|
||||
if p == 'bf16':
|
||||
return torch.bfloat16
|
||||
return None
|
||||
|
||||
save_dtype = str_to_dtype(args.save_precision)
|
||||
|
||||
print(f"loading SD model : {args.model_org}")
|
||||
text_encoder_o, _, unet_o = model_util.load_models_from_stable_diffusion_checkpoint(args.v2, args.model_org)
|
||||
print(f"loading SD model : {args.model_tuned}")
|
||||
text_encoder_t, _, unet_t = model_util.load_models_from_stable_diffusion_checkpoint(args.v2, args.model_tuned)
|
||||
|
||||
# create LoRA network to extract weights: Use dim (rank) as alpha
|
||||
if args.conv_dim is None:
|
||||
kwargs = {}
|
||||
else:
|
||||
kwargs = {"conv_dim": args.conv_dim, "conv_alpha": args.conv_dim}
|
||||
|
||||
lora_network_o = lora.create_network(1.0, args.dim, args.dim, None, text_encoder_o, unet_o, **kwargs)
|
||||
lora_network_t = lora.create_network(1.0, args.dim, args.dim, None, text_encoder_t, unet_t, **kwargs)
|
||||
assert len(lora_network_o.text_encoder_loras) == len(
|
||||
lora_network_t.text_encoder_loras), f"model version is different (SD1.x vs SD2.x) / それぞれのモデルのバージョンが違います(SD1.xベースとSD2.xベース) "
|
||||
|
||||
# get diffs
|
||||
diffs = {}
|
||||
text_encoder_different = False
|
||||
for i, (lora_o, lora_t) in enumerate(zip(lora_network_o.text_encoder_loras, lora_network_t.text_encoder_loras)):
|
||||
lora_name = lora_o.lora_name
|
||||
module_o = lora_o.org_module
|
||||
module_t = lora_t.org_module
|
||||
diff = module_t.weight - module_o.weight
|
||||
|
||||
# Text Encoder might be same
|
||||
if torch.max(torch.abs(diff)) > MIN_DIFF:
|
||||
text_encoder_different = True
|
||||
|
||||
diff = diff.float()
|
||||
diffs[lora_name] = diff
|
||||
|
||||
if not text_encoder_different:
|
||||
print("Text encoder is same. Extract U-Net only.")
|
||||
lora_network_o.text_encoder_loras = []
|
||||
diffs = {}
|
||||
|
||||
for i, (lora_o, lora_t) in enumerate(zip(lora_network_o.unet_loras, lora_network_t.unet_loras)):
|
||||
lora_name = lora_o.lora_name
|
||||
module_o = lora_o.org_module
|
||||
module_t = lora_t.org_module
|
||||
diff = module_t.weight - module_o.weight
|
||||
diff = diff.float()
|
||||
|
||||
if args.device:
|
||||
diff = diff.to(args.device)
|
||||
|
||||
diffs[lora_name] = diff
|
||||
|
||||
# make LoRA with svd
|
||||
print("calculating by svd")
|
||||
lora_weights = {}
|
||||
with torch.no_grad():
|
||||
for lora_name, mat in tqdm(list(diffs.items())):
|
||||
# if args.conv_dim is None, diffs do not include LoRAs for conv2d-3x3
|
||||
conv2d = (len(mat.size()) == 4)
|
||||
kernel_size = None if not conv2d else mat.size()[2:4]
|
||||
conv2d_3x3 = conv2d and kernel_size != (1, 1)
|
||||
|
||||
rank = args.dim if not conv2d_3x3 or args.conv_dim is None else args.conv_dim
|
||||
out_dim, in_dim = mat.size()[0:2]
|
||||
|
||||
if args.device:
|
||||
mat = mat.to(args.device)
|
||||
|
||||
# print(lora_name, mat.size(), mat.device, rank, in_dim, out_dim)
|
||||
rank = min(rank, in_dim, out_dim) # LoRA rank cannot exceed the original dim
|
||||
|
||||
if conv2d:
|
||||
if conv2d_3x3:
|
||||
mat = mat.flatten(start_dim=1)
|
||||
else:
|
||||
mat = mat.squeeze()
|
||||
|
||||
U, S, Vh = torch.linalg.svd(mat)
|
||||
|
||||
U = U[:, :rank]
|
||||
S = S[:rank]
|
||||
U = U @ torch.diag(S)
|
||||
|
||||
Vh = Vh[:rank, :]
|
||||
|
||||
dist = torch.cat([U.flatten(), Vh.flatten()])
|
||||
hi_val = torch.quantile(dist, CLAMP_QUANTILE)
|
||||
low_val = -hi_val
|
||||
|
||||
U = U.clamp(low_val, hi_val)
|
||||
Vh = Vh.clamp(low_val, hi_val)
|
||||
|
||||
if conv2d:
|
||||
U = U.reshape(out_dim, rank, 1, 1)
|
||||
Vh = Vh.reshape(rank, in_dim, kernel_size[0], kernel_size[1])
|
||||
|
||||
U = U.to("cpu").contiguous()
|
||||
Vh = Vh.to("cpu").contiguous()
|
||||
|
||||
lora_weights[lora_name] = (U, Vh)
|
||||
|
||||
# make state dict for LoRA
|
||||
lora_sd = {}
|
||||
for lora_name, (up_weight, down_weight) in lora_weights.items():
|
||||
lora_sd[lora_name + '.lora_up.weight'] = up_weight
|
||||
lora_sd[lora_name + '.lora_down.weight'] = down_weight
|
||||
lora_sd[lora_name + '.alpha'] = torch.tensor(down_weight.size()[0])
|
||||
|
||||
# load state dict to LoRA and save it
|
||||
lora_network_save = lora.create_network_from_weights(1.0, None, None, text_encoder_o, unet_o, weights_sd=lora_sd)
|
||||
lora_network_save.apply_to(text_encoder_o, unet_o) # create internal module references for state_dict
|
||||
|
||||
info = lora_network_save.load_state_dict(lora_sd)
|
||||
print(f"Loading extracted LoRA weights: {info}")
|
||||
|
||||
dir_name = os.path.dirname(args.save_to)
|
||||
if dir_name and not os.path.exists(dir_name):
|
||||
os.makedirs(dir_name, exist_ok=True)
|
||||
|
||||
# minimum metadata
|
||||
metadata = {"ss_network_module": "networks.lora", "ss_network_dim": str(args.dim), "ss_network_alpha": str(args.dim)}
|
||||
|
||||
lora_network_save.save_weights(args.save_to, save_dtype, metadata)
|
||||
print(f"LoRA weights are saved to: {args.save_to}")
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--v2", action='store_true',
|
||||
help='load Stable Diffusion v2.x model / Stable Diffusion 2.xのモデルを読み込む')
|
||||
parser.add_argument("--save_precision", type=str, default=None,
|
||||
choices=[None, "float", "fp16", "bf16"], help="precision in saving, same to merging if omitted / 保存時に精度を変更して保存する、省略時はfloat")
|
||||
parser.add_argument("--model_org", type=str, default=None,
|
||||
help="Stable Diffusion original model: ckpt or safetensors file / 元モデル、ckptまたはsafetensors")
|
||||
parser.add_argument("--model_tuned", type=str, default=None,
|
||||
help="Stable Diffusion tuned model, LoRA is difference of `original to tuned`: ckpt or safetensors file / 派生モデル(生成されるLoRAは元→派生の差分になります)、ckptまたはsafetensors")
|
||||
parser.add_argument("--save_to", type=str, default=None,
|
||||
help="destination file name: ckpt or safetensors file / 保存先のファイル名、ckptまたはsafetensors")
|
||||
parser.add_argument("--dim", type=int, default=4, help="dimension (rank) of LoRA (default 4) / LoRAの次元数(rank)(デフォルト4)")
|
||||
parser.add_argument("--conv_dim", type=int, default=None,
|
||||
help="dimension (rank) of LoRA for Conv2d-3x3 (default None, disabled) / LoRAのConv2d-3x3の次元数(rank)(デフォルトNone、適用なし)")
|
||||
parser.add_argument("--device", type=str, default=None, help="device to use, cuda for GPU / 計算を行うデバイス、cuda でGPUを使う")
|
||||
|
||||
args = parser.parse_args()
|
||||
svd(args)
|
||||
248
networks/lora.py
248
networks/lora.py
@@ -5,28 +5,52 @@
|
||||
|
||||
import math
|
||||
import os
|
||||
from typing import List
|
||||
import numpy as np
|
||||
import torch
|
||||
|
||||
from library import train_util
|
||||
|
||||
|
||||
class LoRAModule(torch.nn.Module):
|
||||
"""
|
||||
replaces forward method of the original Linear, instead of replacing the original Linear module.
|
||||
"""
|
||||
|
||||
def __init__(self, lora_name, org_module: torch.nn.Module, multiplier=1.0, lora_dim=4):
|
||||
def __init__(self, lora_name, org_module: torch.nn.Module, multiplier=1.0, lora_dim=4, alpha=1):
|
||||
""" if alpha == 0 or None, alpha is rank (no scaling). """
|
||||
super().__init__()
|
||||
self.lora_name = lora_name
|
||||
|
||||
if org_module.__class__.__name__ == 'Conv2d':
|
||||
in_dim = org_module.in_channels
|
||||
out_dim = org_module.out_channels
|
||||
self.lora_down = torch.nn.Conv2d(in_dim, lora_dim, (1, 1), bias=False)
|
||||
self.lora_up = torch.nn.Conv2d(lora_dim, out_dim, (1, 1), bias=False)
|
||||
else:
|
||||
in_dim = org_module.in_features
|
||||
out_dim = org_module.out_features
|
||||
self.lora_down = torch.nn.Linear(in_dim, lora_dim, bias=False)
|
||||
self.lora_up = torch.nn.Linear(lora_dim, out_dim, bias=False)
|
||||
|
||||
# if limit_rank:
|
||||
# self.lora_dim = min(lora_dim, in_dim, out_dim)
|
||||
# if self.lora_dim != lora_dim:
|
||||
# print(f"{lora_name} dim (rank) is changed to: {self.lora_dim}")
|
||||
# else:
|
||||
self.lora_dim = lora_dim
|
||||
|
||||
if org_module.__class__.__name__ == 'Conv2d':
|
||||
kernel_size = org_module.kernel_size
|
||||
stride = org_module.stride
|
||||
padding = org_module.padding
|
||||
self.lora_down = torch.nn.Conv2d(in_dim, self.lora_dim, kernel_size, stride, padding, bias=False)
|
||||
self.lora_up = torch.nn.Conv2d(self.lora_dim, out_dim, (1, 1), (1, 1), bias=False)
|
||||
else:
|
||||
self.lora_down = torch.nn.Linear(in_dim, self.lora_dim, bias=False)
|
||||
self.lora_up = torch.nn.Linear(self.lora_dim, out_dim, bias=False)
|
||||
|
||||
if type(alpha) == torch.Tensor:
|
||||
alpha = alpha.detach().float().numpy() # without casting, bf16 causes error
|
||||
alpha = self.lora_dim if alpha is None or alpha == 0 else alpha
|
||||
self.scale = alpha / self.lora_dim
|
||||
self.register_buffer('alpha', torch.tensor(alpha)) # 定数として扱える
|
||||
|
||||
# same as microsoft's
|
||||
torch.nn.init.kaiming_uniform_(self.lora_down.weight, a=math.sqrt(5))
|
||||
@@ -34,44 +58,192 @@ class LoRAModule(torch.nn.Module):
|
||||
|
||||
self.multiplier = multiplier
|
||||
self.org_module = org_module # remove in applying
|
||||
self.region = None
|
||||
self.region_mask = None
|
||||
|
||||
def apply_to(self):
|
||||
self.org_forward = self.org_module.forward
|
||||
self.org_module.forward = self.forward
|
||||
del self.org_module
|
||||
|
||||
def set_region(self, region):
|
||||
self.region = region
|
||||
self.region_mask = None
|
||||
|
||||
def forward(self, x):
|
||||
return self.org_forward(x) + self.lora_up(self.lora_down(x)) * self.multiplier
|
||||
if self.region is None:
|
||||
return self.org_forward(x) + self.lora_up(self.lora_down(x)) * self.multiplier * self.scale
|
||||
|
||||
# regional LoRA FIXME same as additional-network extension
|
||||
if x.size()[1] % 77 == 0:
|
||||
# print(f"LoRA for context: {self.lora_name}")
|
||||
self.region = None
|
||||
return self.org_forward(x) + self.lora_up(self.lora_down(x)) * self.multiplier * self.scale
|
||||
|
||||
# calculate region mask first time
|
||||
if self.region_mask is None:
|
||||
if len(x.size()) == 4:
|
||||
h, w = x.size()[2:4]
|
||||
else:
|
||||
seq_len = x.size()[1]
|
||||
ratio = math.sqrt((self.region.size()[0] * self.region.size()[1]) / seq_len)
|
||||
h = int(self.region.size()[0] / ratio + .5)
|
||||
w = seq_len // h
|
||||
|
||||
r = self.region.to(x.device)
|
||||
if r.dtype == torch.bfloat16:
|
||||
r = r.to(torch.float)
|
||||
r = r.unsqueeze(0).unsqueeze(1)
|
||||
# print(self.lora_name, self.region.size(), x.size(), r.size(), h, w)
|
||||
r = torch.nn.functional.interpolate(r, (h, w), mode='bilinear')
|
||||
r = r.to(x.dtype)
|
||||
|
||||
if len(x.size()) == 3:
|
||||
r = torch.reshape(r, (1, x.size()[1], -1))
|
||||
|
||||
self.region_mask = r
|
||||
|
||||
return self.org_forward(x) + self.lora_up(self.lora_down(x)) * self.multiplier * self.scale * self.region_mask
|
||||
|
||||
|
||||
def create_network(multiplier, network_dim, vae, text_encoder, unet, **kwargs):
|
||||
def create_network(multiplier, network_dim, network_alpha, vae, text_encoder, unet, **kwargs):
|
||||
if network_dim is None:
|
||||
network_dim = 4 # default
|
||||
network = LoRANetwork(text_encoder, unet, multiplier=multiplier, lora_dim=network_dim)
|
||||
|
||||
# extract dim/alpha for conv2d, and block dim
|
||||
conv_dim = kwargs.get('conv_dim', None)
|
||||
conv_alpha = kwargs.get('conv_alpha', None)
|
||||
if conv_dim is not None:
|
||||
conv_dim = int(conv_dim)
|
||||
if conv_alpha is None:
|
||||
conv_alpha = 1.0
|
||||
else:
|
||||
conv_alpha = float(conv_alpha)
|
||||
|
||||
"""
|
||||
block_dims = kwargs.get("block_dims")
|
||||
block_alphas = None
|
||||
|
||||
if block_dims is not None:
|
||||
block_dims = [int(d) for d in block_dims.split(',')]
|
||||
assert len(block_dims) == NUM_BLOCKS, f"Number of block dimensions is not same to {NUM_BLOCKS}"
|
||||
block_alphas = kwargs.get("block_alphas")
|
||||
if block_alphas is None:
|
||||
block_alphas = [1] * len(block_dims)
|
||||
else:
|
||||
block_alphas = [int(a) for a in block_alphas(',')]
|
||||
assert len(block_alphas) == NUM_BLOCKS, f"Number of block alphas is not same to {NUM_BLOCKS}"
|
||||
|
||||
conv_block_dims = kwargs.get("conv_block_dims")
|
||||
conv_block_alphas = None
|
||||
|
||||
if conv_block_dims is not None:
|
||||
conv_block_dims = [int(d) for d in conv_block_dims.split(',')]
|
||||
assert len(conv_block_dims) == NUM_BLOCKS, f"Number of block dimensions is not same to {NUM_BLOCKS}"
|
||||
conv_block_alphas = kwargs.get("conv_block_alphas")
|
||||
if conv_block_alphas is None:
|
||||
conv_block_alphas = [1] * len(conv_block_dims)
|
||||
else:
|
||||
conv_block_alphas = [int(a) for a in conv_block_alphas(',')]
|
||||
assert len(conv_block_alphas) == NUM_BLOCKS, f"Number of block alphas is not same to {NUM_BLOCKS}"
|
||||
"""
|
||||
|
||||
network = LoRANetwork(text_encoder, unet, multiplier=multiplier, lora_dim=network_dim,
|
||||
alpha=network_alpha, conv_lora_dim=conv_dim, conv_alpha=conv_alpha)
|
||||
return network
|
||||
|
||||
|
||||
def create_network_from_weights(multiplier, file, vae, text_encoder, unet, weights_sd=None, **kwargs):
|
||||
if weights_sd is None:
|
||||
if os.path.splitext(file)[1] == '.safetensors':
|
||||
from safetensors.torch import load_file, safe_open
|
||||
weights_sd = load_file(file)
|
||||
else:
|
||||
weights_sd = torch.load(file, map_location='cpu')
|
||||
|
||||
# get dim/alpha mapping
|
||||
modules_dim = {}
|
||||
modules_alpha = {}
|
||||
for key, value in weights_sd.items():
|
||||
if '.' not in key:
|
||||
continue
|
||||
|
||||
lora_name = key.split('.')[0]
|
||||
if 'alpha' in key:
|
||||
modules_alpha[lora_name] = value
|
||||
elif 'lora_down' in key:
|
||||
dim = value.size()[0]
|
||||
modules_dim[lora_name] = dim
|
||||
# print(lora_name, value.size(), dim)
|
||||
|
||||
# support old LoRA without alpha
|
||||
for key in modules_dim.keys():
|
||||
if key not in modules_alpha:
|
||||
modules_alpha = modules_dim[key]
|
||||
|
||||
network = LoRANetwork(text_encoder, unet, multiplier=multiplier, modules_dim=modules_dim, modules_alpha=modules_alpha)
|
||||
network.weights_sd = weights_sd
|
||||
return network
|
||||
|
||||
|
||||
class LoRANetwork(torch.nn.Module):
|
||||
# is it possible to apply conv_in and conv_out?
|
||||
UNET_TARGET_REPLACE_MODULE = ["Transformer2DModel", "Attention"]
|
||||
UNET_TARGET_REPLACE_MODULE_CONV2D_3X3 = ["ResnetBlock2D", "Downsample2D", "Upsample2D"]
|
||||
TEXT_ENCODER_TARGET_REPLACE_MODULE = ["CLIPAttention", "CLIPMLP"]
|
||||
LORA_PREFIX_UNET = 'lora_unet'
|
||||
LORA_PREFIX_TEXT_ENCODER = 'lora_te'
|
||||
|
||||
def __init__(self, text_encoder, unet, multiplier=1.0, lora_dim=4) -> None:
|
||||
def __init__(self, text_encoder, unet, multiplier=1.0, lora_dim=4, alpha=1, conv_lora_dim=None, conv_alpha=None, modules_dim=None, modules_alpha=None) -> None:
|
||||
super().__init__()
|
||||
self.multiplier = multiplier
|
||||
|
||||
self.lora_dim = lora_dim
|
||||
self.alpha = alpha
|
||||
self.conv_lora_dim = conv_lora_dim
|
||||
self.conv_alpha = conv_alpha
|
||||
|
||||
if modules_dim is not None:
|
||||
print(f"create LoRA network from weights")
|
||||
else:
|
||||
print(f"create LoRA network. base dim (rank): {lora_dim}, alpha: {alpha}")
|
||||
|
||||
self.apply_to_conv2d_3x3 = self.conv_lora_dim is not None
|
||||
if self.apply_to_conv2d_3x3:
|
||||
if self.conv_alpha is None:
|
||||
self.conv_alpha = self.alpha
|
||||
print(f"apply LoRA to Conv2d with kernel size (3,3). dim (rank): {self.conv_lora_dim}, alpha: {self.conv_alpha}")
|
||||
|
||||
# create module instances
|
||||
def create_modules(prefix, root_module: torch.nn.Module, target_replace_modules) -> list[LoRAModule]:
|
||||
def create_modules(prefix, root_module: torch.nn.Module, target_replace_modules) -> List[LoRAModule]:
|
||||
loras = []
|
||||
for name, module in root_module.named_modules():
|
||||
if module.__class__.__name__ in target_replace_modules:
|
||||
# TODO get block index here
|
||||
for child_name, child_module in module.named_modules():
|
||||
if child_module.__class__.__name__ == "Linear" or (child_module.__class__.__name__ == "Conv2d" and child_module.kernel_size == (1, 1)):
|
||||
is_linear = child_module.__class__.__name__ == "Linear"
|
||||
is_conv2d = child_module.__class__.__name__ == "Conv2d"
|
||||
is_conv2d_1x1 = is_conv2d and child_module.kernel_size == (1, 1)
|
||||
if is_linear or is_conv2d:
|
||||
lora_name = prefix + '.' + name + '.' + child_name
|
||||
lora_name = lora_name.replace('.', '_')
|
||||
lora = LoRAModule(lora_name, child_module, self.multiplier, self.lora_dim)
|
||||
|
||||
if modules_dim is not None:
|
||||
if lora_name not in modules_dim:
|
||||
continue # no LoRA module in this weights file
|
||||
dim = modules_dim[lora_name]
|
||||
alpha = modules_alpha[lora_name]
|
||||
else:
|
||||
if is_linear or is_conv2d_1x1:
|
||||
dim = self.lora_dim
|
||||
alpha = self.alpha
|
||||
elif self.apply_to_conv2d_3x3:
|
||||
dim = self.conv_lora_dim
|
||||
alpha = self.conv_alpha
|
||||
else:
|
||||
continue
|
||||
|
||||
lora = LoRAModule(lora_name, child_module, self.multiplier, dim, alpha)
|
||||
loras.append(lora)
|
||||
return loras
|
||||
|
||||
@@ -79,7 +251,12 @@ class LoRANetwork(torch.nn.Module):
|
||||
text_encoder, LoRANetwork.TEXT_ENCODER_TARGET_REPLACE_MODULE)
|
||||
print(f"create LoRA for Text Encoder: {len(self.text_encoder_loras)} modules.")
|
||||
|
||||
self.unet_loras = create_modules(LoRANetwork.LORA_PREFIX_UNET, unet, LoRANetwork.UNET_TARGET_REPLACE_MODULE)
|
||||
# extend U-Net target modules if conv2d 3x3 is enabled, or load from weights
|
||||
target_modules = LoRANetwork.UNET_TARGET_REPLACE_MODULE
|
||||
if modules_dim is not None or self.conv_lora_dim is not None:
|
||||
target_modules += LoRANetwork.UNET_TARGET_REPLACE_MODULE_CONV2D_3X3
|
||||
|
||||
self.unet_loras = create_modules(LoRANetwork.LORA_PREFIX_UNET, unet, target_modules)
|
||||
print(f"create LoRA for U-Net: {len(self.unet_loras)} modules.")
|
||||
|
||||
self.weights_sd = None
|
||||
@@ -90,9 +267,14 @@ class LoRANetwork(torch.nn.Module):
|
||||
assert lora.lora_name not in names, f"duplicated lora name: {lora.lora_name}"
|
||||
names.add(lora.lora_name)
|
||||
|
||||
def set_multiplier(self, multiplier):
|
||||
self.multiplier = multiplier
|
||||
for lora in self.text_encoder_loras + self.unet_loras:
|
||||
lora.multiplier = self.multiplier
|
||||
|
||||
def load_weights(self, file):
|
||||
if os.path.splitext(file)[1] == '.safetensors':
|
||||
from safetensors.torch import load_file
|
||||
from safetensors.torch import load_file, safe_open
|
||||
self.weights_sd = load_file(file)
|
||||
else:
|
||||
self.weights_sd = torch.load(file, map_location='cpu')
|
||||
@@ -149,21 +331,21 @@ class LoRANetwork(torch.nn.Module):
|
||||
return params
|
||||
|
||||
self.requires_grad_(True)
|
||||
params = []
|
||||
all_params = []
|
||||
|
||||
if self.text_encoder_loras:
|
||||
param_data = {'params': enumerate_params(self.text_encoder_loras)}
|
||||
if text_encoder_lr is not None:
|
||||
param_data['lr'] = text_encoder_lr
|
||||
params.append(param_data)
|
||||
all_params.append(param_data)
|
||||
|
||||
if self.unet_loras:
|
||||
param_data = {'params': enumerate_params(self.unet_loras)}
|
||||
if unet_lr is not None:
|
||||
param_data['lr'] = unet_lr
|
||||
params.append(param_data)
|
||||
all_params.append(param_data)
|
||||
|
||||
return params
|
||||
return all_params
|
||||
|
||||
def prepare_grad_etc(self, text_encoder, unet):
|
||||
self.requires_grad_(True)
|
||||
@@ -174,7 +356,10 @@ class LoRANetwork(torch.nn.Module):
|
||||
def get_trainable_params(self):
|
||||
return self.parameters()
|
||||
|
||||
def save_weights(self, file, dtype):
|
||||
def save_weights(self, file, dtype, metadata):
|
||||
if metadata is not None and len(metadata) == 0:
|
||||
metadata = None
|
||||
|
||||
state_dict = self.state_dict()
|
||||
|
||||
if dtype is not None:
|
||||
@@ -185,6 +370,29 @@ class LoRANetwork(torch.nn.Module):
|
||||
|
||||
if os.path.splitext(file)[1] == '.safetensors':
|
||||
from safetensors.torch import save_file
|
||||
save_file(state_dict, file)
|
||||
|
||||
# Precalculate model hashes to save time on indexing
|
||||
if metadata is None:
|
||||
metadata = {}
|
||||
model_hash, legacy_hash = train_util.precalculate_safetensors_hashes(state_dict, metadata)
|
||||
metadata["sshs_model_hash"] = model_hash
|
||||
metadata["sshs_legacy_hash"] = legacy_hash
|
||||
|
||||
save_file(state_dict, file, metadata)
|
||||
else:
|
||||
torch.save(state_dict, file)
|
||||
|
||||
@ staticmethod
|
||||
def set_regions(networks, image):
|
||||
image = image.astype(np.float32) / 255.0
|
||||
for i, network in enumerate(networks[:3]):
|
||||
# NOTE: consider averaging overwrapping area
|
||||
region = image[:, :, i]
|
||||
if region.max() == 0:
|
||||
continue
|
||||
region = torch.tensor(region)
|
||||
network.set_region(region)
|
||||
|
||||
def set_region(self, region):
|
||||
for lora in self.unet_loras:
|
||||
lora.set_region(region)
|
||||
|
||||
122
networks/lora_interrogator.py
Normal file
122
networks/lora_interrogator.py
Normal file
@@ -0,0 +1,122 @@
|
||||
|
||||
|
||||
from tqdm import tqdm
|
||||
from library import model_util
|
||||
import argparse
|
||||
from transformers import CLIPTokenizer
|
||||
import torch
|
||||
|
||||
import library.model_util as model_util
|
||||
import lora
|
||||
|
||||
TOKENIZER_PATH = "openai/clip-vit-large-patch14"
|
||||
V2_STABLE_DIFFUSION_PATH = "stabilityai/stable-diffusion-2" # ここからtokenizerだけ使う
|
||||
|
||||
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
||||
|
||||
|
||||
def interrogate(args):
|
||||
# いろいろ準備する
|
||||
print(f"loading SD model: {args.sd_model}")
|
||||
text_encoder, vae, unet = model_util.load_models_from_stable_diffusion_checkpoint(args.v2, args.sd_model)
|
||||
|
||||
print(f"loading LoRA: {args.model}")
|
||||
network = lora.create_network_from_weights(1.0, args.model, vae, text_encoder, unet)
|
||||
|
||||
# text encoder向けの重みがあるかチェックする:本当はlora側でやるのがいい
|
||||
has_te_weight = False
|
||||
for key in network.weights_sd.keys():
|
||||
if 'lora_te' in key:
|
||||
has_te_weight = True
|
||||
break
|
||||
if not has_te_weight:
|
||||
print("This LoRA does not have modules for Text Encoder, cannot interrogate / このLoRAはText Encoder向けのモジュールがないため調査できません")
|
||||
return
|
||||
del vae
|
||||
|
||||
print("loading tokenizer")
|
||||
if args.v2:
|
||||
tokenizer: CLIPTokenizer = CLIPTokenizer.from_pretrained(V2_STABLE_DIFFUSION_PATH, subfolder="tokenizer")
|
||||
else:
|
||||
tokenizer: CLIPTokenizer = CLIPTokenizer.from_pretrained(TOKENIZER_PATH) # , model_max_length=max_token_length + 2)
|
||||
|
||||
text_encoder.to(DEVICE)
|
||||
text_encoder.eval()
|
||||
unet.to(DEVICE)
|
||||
unet.eval() # U-Netは呼び出さないので不要だけど
|
||||
|
||||
# トークンをひとつひとつ当たっていく
|
||||
token_id_start = 0
|
||||
token_id_end = max(tokenizer.all_special_ids)
|
||||
print(f"interrogate tokens are: {token_id_start} to {token_id_end}")
|
||||
|
||||
def get_all_embeddings(text_encoder):
|
||||
embs = []
|
||||
with torch.no_grad():
|
||||
for token_id in tqdm(range(token_id_start, token_id_end + 1, args.batch_size)):
|
||||
batch = []
|
||||
for tid in range(token_id, min(token_id_end + 1, token_id + args.batch_size)):
|
||||
tokens = [tokenizer.bos_token_id, tid, tokenizer.eos_token_id]
|
||||
# tokens = [tid] # こちらは結果がいまひとつ
|
||||
batch.append(tokens)
|
||||
|
||||
# batch_embs = text_encoder(torch.tensor(batch).to(DEVICE))[0].to("cpu") # bos/eosも含めたほうが差が出るようだ [:, 1]
|
||||
# clip skip対応
|
||||
batch = torch.tensor(batch).to(DEVICE)
|
||||
if args.clip_skip is None:
|
||||
encoder_hidden_states = text_encoder(batch)[0]
|
||||
else:
|
||||
enc_out = text_encoder(batch, output_hidden_states=True, return_dict=True)
|
||||
encoder_hidden_states = enc_out['hidden_states'][-args.clip_skip]
|
||||
encoder_hidden_states = text_encoder.text_model.final_layer_norm(encoder_hidden_states)
|
||||
encoder_hidden_states = encoder_hidden_states.to("cpu")
|
||||
|
||||
embs.extend(encoder_hidden_states)
|
||||
return torch.stack(embs)
|
||||
|
||||
print("get original text encoder embeddings.")
|
||||
orig_embs = get_all_embeddings(text_encoder)
|
||||
|
||||
network.apply_to(text_encoder, unet, True, len(network.unet_loras) > 0)
|
||||
network.to(DEVICE)
|
||||
network.eval()
|
||||
|
||||
print("You can ignore warning messages start with '_IncompatibleKeys' (LoRA model does not have alpha because trained by older script) / '_IncompatibleKeys'の警告は無視して構いません(以前のスクリプトで学習されたLoRAモデルのためalphaの定義がありません)")
|
||||
print("get text encoder embeddings with lora.")
|
||||
lora_embs = get_all_embeddings(text_encoder)
|
||||
|
||||
# 比べる:とりあえず単純に差分の絶対値で
|
||||
print("comparing...")
|
||||
diffs = {}
|
||||
for i, (orig_emb, lora_emb) in enumerate(zip(orig_embs, tqdm(lora_embs))):
|
||||
diff = torch.mean(torch.abs(orig_emb - lora_emb))
|
||||
# diff = torch.mean(torch.cosine_similarity(orig_emb, lora_emb, dim=1)) # うまく検出できない
|
||||
diff = float(diff.detach().to('cpu').numpy())
|
||||
diffs[token_id_start + i] = diff
|
||||
|
||||
diffs_sorted = sorted(diffs.items(), key=lambda x: -x[1])
|
||||
|
||||
# 結果を表示する
|
||||
print("top 100:")
|
||||
for i, (token, diff) in enumerate(diffs_sorted[:100]):
|
||||
# if diff < 1e-6:
|
||||
# break
|
||||
string = tokenizer.convert_tokens_to_string(tokenizer.convert_ids_to_tokens([token]))
|
||||
print(f"[{i:3d}]: {token:5d} {string:<20s}: {diff:.5f}")
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--v2", action='store_true',
|
||||
help='load Stable Diffusion v2.x model / Stable Diffusion 2.xのモデルを読み込む')
|
||||
parser.add_argument("--sd_model", type=str, default=None,
|
||||
help="Stable Diffusion model to load: ckpt or safetensors file / 読み込むSDのモデル、ckptまたはsafetensors")
|
||||
parser.add_argument("--model", type=str, default=None,
|
||||
help="LoRA model to interrogate: ckpt or safetensors file / 調査するLoRAモデル、ckptまたはsafetensors")
|
||||
parser.add_argument("--batch_size", type=int, default=16,
|
||||
help="batch size for processing with Text Encoder / Text Encoderで処理するときのバッチサイズ")
|
||||
parser.add_argument("--clip_skip", type=int, default=None,
|
||||
help="use output of nth layer from back of text encoder (n>=1) / text encoderの後ろからn番目の層の出力を用いる(nは1以上)")
|
||||
|
||||
args = parser.parse_args()
|
||||
interrogate(args)
|
||||
@@ -1,5 +1,5 @@
|
||||
|
||||
|
||||
import math
|
||||
import argparse
|
||||
import os
|
||||
import torch
|
||||
@@ -48,7 +48,7 @@ def merge_to_sd_model(text_encoder, unet, models, ratios, merge_dtype):
|
||||
for name, module in root_module.named_modules():
|
||||
if module.__class__.__name__ in target_replace_modules:
|
||||
for child_name, child_module in module.named_modules():
|
||||
if child_module.__class__.__name__ == "Linear" or (child_module.__class__.__name__ == "Conv2d" and child_module.kernel_size == (1, 1)):
|
||||
if child_module.__class__.__name__ == "Linear" or child_module.__class__.__name__ == "Conv2d":
|
||||
lora_name = prefix + '.' + name + '.' + child_name
|
||||
lora_name = lora_name.replace('.', '_')
|
||||
name_to_module[lora_name] = child_module
|
||||
@@ -61,6 +61,7 @@ def merge_to_sd_model(text_encoder, unet, models, ratios, merge_dtype):
|
||||
for key in lora_sd.keys():
|
||||
if "lora_down" in key:
|
||||
up_key = key.replace("lora_down", "lora_up")
|
||||
alpha_key = key[:key.index("lora_down")] + 'alpha'
|
||||
|
||||
# find original module for this lora
|
||||
module_name = '.'.join(key.split('.')[:-2]) # remove trailing ".lora_down.weight"
|
||||
@@ -73,33 +74,91 @@ def merge_to_sd_model(text_encoder, unet, models, ratios, merge_dtype):
|
||||
down_weight = lora_sd[key]
|
||||
up_weight = lora_sd[up_key]
|
||||
|
||||
dim = down_weight.size()[0]
|
||||
alpha = lora_sd.get(alpha_key, dim)
|
||||
scale = alpha / dim
|
||||
|
||||
# W <- W + U * D
|
||||
weight = module.weight
|
||||
# print(module_name, down_weight.size(), up_weight.size())
|
||||
if len(weight.size()) == 2:
|
||||
# linear
|
||||
weight = weight + ratio * (up_weight @ down_weight)
|
||||
weight = weight + ratio * (up_weight @ down_weight) * scale
|
||||
elif down_weight.size()[2:4] == (1, 1):
|
||||
# conv2d 1x1
|
||||
weight = weight + ratio * (up_weight.squeeze(3).squeeze(2) @ down_weight.squeeze(3).squeeze(2)
|
||||
).unsqueeze(2).unsqueeze(3) * scale
|
||||
else:
|
||||
# conv2d
|
||||
weight = weight + ratio * (up_weight.squeeze(3).squeeze(2) @ down_weight.squeeze(3).squeeze(2)).unsqueeze(2).unsqueeze(3)
|
||||
# conv2d 3x3
|
||||
conved = torch.nn.functional.conv2d(down_weight.permute(1, 0, 2, 3), up_weight).permute(1, 0, 2, 3)
|
||||
# print(conved.size(), weight.size(), module.stride, module.padding)
|
||||
weight = weight + ratio * conved * scale
|
||||
|
||||
module.weight = torch.nn.Parameter(weight)
|
||||
|
||||
|
||||
def merge_lora_models(models, ratios, merge_dtype):
|
||||
merged_sd = {}
|
||||
base_alphas = {} # alpha for merged model
|
||||
base_dims = {}
|
||||
|
||||
merged_sd = {}
|
||||
for model, ratio in zip(models, ratios):
|
||||
print(f"loading: {model}")
|
||||
lora_sd = load_state_dict(model, merge_dtype)
|
||||
|
||||
# get alpha and dim
|
||||
alphas = {} # alpha for current model
|
||||
dims = {} # dims for current model
|
||||
for key in lora_sd.keys():
|
||||
if 'alpha' in key:
|
||||
lora_module_name = key[:key.rfind(".alpha")]
|
||||
alpha = float(lora_sd[key].detach().numpy())
|
||||
alphas[lora_module_name] = alpha
|
||||
if lora_module_name not in base_alphas:
|
||||
base_alphas[lora_module_name] = alpha
|
||||
elif "lora_down" in key:
|
||||
lora_module_name = key[:key.rfind(".lora_down")]
|
||||
dim = lora_sd[key].size()[0]
|
||||
dims[lora_module_name] = dim
|
||||
if lora_module_name not in base_dims:
|
||||
base_dims[lora_module_name] = dim
|
||||
|
||||
for lora_module_name in dims.keys():
|
||||
if lora_module_name not in alphas:
|
||||
alpha = dims[lora_module_name]
|
||||
alphas[lora_module_name] = alpha
|
||||
if lora_module_name not in base_alphas:
|
||||
base_alphas[lora_module_name] = alpha
|
||||
|
||||
print(f"dim: {list(set(dims.values()))}, alpha: {list(set(alphas.values()))}")
|
||||
|
||||
# merge
|
||||
print(f"merging...")
|
||||
for key in lora_sd.keys():
|
||||
if 'alpha' in key:
|
||||
continue
|
||||
|
||||
lora_module_name = key[:key.rfind(".lora_")]
|
||||
|
||||
base_alpha = base_alphas[lora_module_name]
|
||||
alpha = alphas[lora_module_name]
|
||||
|
||||
scale = math.sqrt(alpha / base_alpha) * ratio
|
||||
|
||||
if key in merged_sd:
|
||||
assert merged_sd[key].size() == lora_sd[key].size(
|
||||
), f"weights shape mismatch merging v1 and v2, different dims? / 重みのサイズが合いません。v1とv2、または次元数の異なるモデルはマージできません"
|
||||
merged_sd[key] = merged_sd[key] + lora_sd[key] * ratio
|
||||
merged_sd[key] = merged_sd[key] + lora_sd[key] * scale
|
||||
else:
|
||||
merged_sd[key] = lora_sd[key] * ratio
|
||||
merged_sd[key] = lora_sd[key] * scale
|
||||
|
||||
# set alpha to sd
|
||||
for lora_module_name, alpha in base_alphas.items():
|
||||
key = lora_module_name + ".alpha"
|
||||
merged_sd[key] = torch.tensor(alpha)
|
||||
|
||||
print("merged model")
|
||||
print(f"dim: {list(set(base_dims.values()))}, alpha: {list(set(base_alphas.values()))}")
|
||||
|
||||
return merged_sd
|
||||
|
||||
@@ -145,7 +204,7 @@ if __name__ == '__main__':
|
||||
parser.add_argument("--save_precision", type=str, default=None,
|
||||
choices=[None, "float", "fp16", "bf16"], help="precision in saving, same to merging if omitted / 保存時に精度を変更して保存する、省略時はマージ時の精度と同じ")
|
||||
parser.add_argument("--precision", type=str, default="float",
|
||||
choices=["float", "fp16", "bf16"], help="precision in merging / マージの計算時の精度")
|
||||
choices=["float", "fp16", "bf16"], help="precision in merging (float is recommended) / マージの計算時の精度(floatを推奨)")
|
||||
parser.add_argument("--sd_model", type=str, default=None,
|
||||
help="Stable Diffusion model to load: ckpt or safetensors file, merge LoRA models if omitted / 読み込むモデル、ckptまたはsafetensors。省略時はLoRAモデル同士をマージする")
|
||||
parser.add_argument("--save_to", type=str, default=None,
|
||||
|
||||
179
networks/merge_lora_old.py
Normal file
179
networks/merge_lora_old.py
Normal file
@@ -0,0 +1,179 @@
|
||||
|
||||
|
||||
import argparse
|
||||
import os
|
||||
import torch
|
||||
from safetensors.torch import load_file, save_file
|
||||
import library.model_util as model_util
|
||||
import lora
|
||||
|
||||
|
||||
def load_state_dict(file_name, dtype):
|
||||
if os.path.splitext(file_name)[1] == '.safetensors':
|
||||
sd = load_file(file_name)
|
||||
else:
|
||||
sd = torch.load(file_name, map_location='cpu')
|
||||
for key in list(sd.keys()):
|
||||
if type(sd[key]) == torch.Tensor:
|
||||
sd[key] = sd[key].to(dtype)
|
||||
return sd
|
||||
|
||||
|
||||
def save_to_file(file_name, model, state_dict, dtype):
|
||||
if dtype is not None:
|
||||
for key in list(state_dict.keys()):
|
||||
if type(state_dict[key]) == torch.Tensor:
|
||||
state_dict[key] = state_dict[key].to(dtype)
|
||||
|
||||
if os.path.splitext(file_name)[1] == '.safetensors':
|
||||
save_file(model, file_name)
|
||||
else:
|
||||
torch.save(model, file_name)
|
||||
|
||||
|
||||
def merge_to_sd_model(text_encoder, unet, models, ratios, merge_dtype):
|
||||
text_encoder.to(merge_dtype)
|
||||
unet.to(merge_dtype)
|
||||
|
||||
# create module map
|
||||
name_to_module = {}
|
||||
for i, root_module in enumerate([text_encoder, unet]):
|
||||
if i == 0:
|
||||
prefix = lora.LoRANetwork.LORA_PREFIX_TEXT_ENCODER
|
||||
target_replace_modules = lora.LoRANetwork.TEXT_ENCODER_TARGET_REPLACE_MODULE
|
||||
else:
|
||||
prefix = lora.LoRANetwork.LORA_PREFIX_UNET
|
||||
target_replace_modules = lora.LoRANetwork.UNET_TARGET_REPLACE_MODULE
|
||||
|
||||
for name, module in root_module.named_modules():
|
||||
if module.__class__.__name__ in target_replace_modules:
|
||||
for child_name, child_module in module.named_modules():
|
||||
if child_module.__class__.__name__ == "Linear" or (child_module.__class__.__name__ == "Conv2d" and child_module.kernel_size == (1, 1)):
|
||||
lora_name = prefix + '.' + name + '.' + child_name
|
||||
lora_name = lora_name.replace('.', '_')
|
||||
name_to_module[lora_name] = child_module
|
||||
|
||||
for model, ratio in zip(models, ratios):
|
||||
print(f"loading: {model}")
|
||||
lora_sd = load_state_dict(model, merge_dtype)
|
||||
|
||||
print(f"merging...")
|
||||
for key in lora_sd.keys():
|
||||
if "lora_down" in key:
|
||||
up_key = key.replace("lora_down", "lora_up")
|
||||
alpha_key = key[:key.index("lora_down")] + 'alpha'
|
||||
|
||||
# find original module for this lora
|
||||
module_name = '.'.join(key.split('.')[:-2]) # remove trailing ".lora_down.weight"
|
||||
if module_name not in name_to_module:
|
||||
print(f"no module found for LoRA weight: {key}")
|
||||
continue
|
||||
module = name_to_module[module_name]
|
||||
# print(f"apply {key} to {module}")
|
||||
|
||||
down_weight = lora_sd[key]
|
||||
up_weight = lora_sd[up_key]
|
||||
|
||||
dim = down_weight.size()[0]
|
||||
alpha = lora_sd.get(alpha_key, dim)
|
||||
scale = alpha / dim
|
||||
|
||||
# W <- W + U * D
|
||||
weight = module.weight
|
||||
if len(weight.size()) == 2:
|
||||
# linear
|
||||
weight = weight + ratio * (up_weight @ down_weight) * scale
|
||||
else:
|
||||
# conv2d
|
||||
weight = weight + ratio * (up_weight.squeeze(3).squeeze(2) @ down_weight.squeeze(3).squeeze(2)).unsqueeze(2).unsqueeze(3) * scale
|
||||
|
||||
module.weight = torch.nn.Parameter(weight)
|
||||
|
||||
|
||||
def merge_lora_models(models, ratios, merge_dtype):
|
||||
merged_sd = {}
|
||||
|
||||
alpha = None
|
||||
dim = None
|
||||
for model, ratio in zip(models, ratios):
|
||||
print(f"loading: {model}")
|
||||
lora_sd = load_state_dict(model, merge_dtype)
|
||||
|
||||
print(f"merging...")
|
||||
for key in lora_sd.keys():
|
||||
if 'alpha' in key:
|
||||
if key in merged_sd:
|
||||
assert merged_sd[key] == lora_sd[key], f"alpha mismatch / alphaが異なる場合、現時点ではマージできません"
|
||||
else:
|
||||
alpha = lora_sd[key].detach().numpy()
|
||||
merged_sd[key] = lora_sd[key]
|
||||
else:
|
||||
if key in merged_sd:
|
||||
assert merged_sd[key].size() == lora_sd[key].size(
|
||||
), f"weights shape mismatch merging v1 and v2, different dims? / 重みのサイズが合いません。v1とv2、または次元数の異なるモデルはマージできません"
|
||||
merged_sd[key] = merged_sd[key] + lora_sd[key] * ratio
|
||||
else:
|
||||
if "lora_down" in key:
|
||||
dim = lora_sd[key].size()[0]
|
||||
merged_sd[key] = lora_sd[key] * ratio
|
||||
|
||||
print(f"dim (rank): {dim}, alpha: {alpha}")
|
||||
if alpha is None:
|
||||
alpha = dim
|
||||
|
||||
return merged_sd, dim, alpha
|
||||
|
||||
|
||||
def merge(args):
|
||||
assert len(args.models) == len(args.ratios), f"number of models must be equal to number of ratios / モデルの数と重みの数は合わせてください"
|
||||
|
||||
def str_to_dtype(p):
|
||||
if p == 'float':
|
||||
return torch.float
|
||||
if p == 'fp16':
|
||||
return torch.float16
|
||||
if p == 'bf16':
|
||||
return torch.bfloat16
|
||||
return None
|
||||
|
||||
merge_dtype = str_to_dtype(args.precision)
|
||||
save_dtype = str_to_dtype(args.save_precision)
|
||||
if save_dtype is None:
|
||||
save_dtype = merge_dtype
|
||||
|
||||
if args.sd_model is not None:
|
||||
print(f"loading SD model: {args.sd_model}")
|
||||
|
||||
text_encoder, vae, unet = model_util.load_models_from_stable_diffusion_checkpoint(args.v2, args.sd_model)
|
||||
|
||||
merge_to_sd_model(text_encoder, unet, args.models, args.ratios, merge_dtype)
|
||||
|
||||
print(f"saving SD model to: {args.save_to}")
|
||||
model_util.save_stable_diffusion_checkpoint(args.v2, args.save_to, text_encoder, unet,
|
||||
args.sd_model, 0, 0, save_dtype, vae)
|
||||
else:
|
||||
state_dict, _, _ = merge_lora_models(args.models, args.ratios, merge_dtype)
|
||||
|
||||
print(f"saving model to: {args.save_to}")
|
||||
save_to_file(args.save_to, state_dict, state_dict, save_dtype)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--v2", action='store_true',
|
||||
help='load Stable Diffusion v2.x model / Stable Diffusion 2.xのモデルを読み込む')
|
||||
parser.add_argument("--save_precision", type=str, default=None,
|
||||
choices=[None, "float", "fp16", "bf16"], help="precision in saving, same to merging if omitted / 保存時に精度を変更して保存する、省略時はマージ時の精度と同じ")
|
||||
parser.add_argument("--precision", type=str, default="float",
|
||||
choices=["float", "fp16", "bf16"], help="precision in merging (float is recommended) / マージの計算時の精度(floatを推奨)")
|
||||
parser.add_argument("--sd_model", type=str, default=None,
|
||||
help="Stable Diffusion model to load: ckpt or safetensors file, merge LoRA models if omitted / 読み込むモデル、ckptまたはsafetensors。省略時はLoRAモデル同士をマージする")
|
||||
parser.add_argument("--save_to", type=str, default=None,
|
||||
help="destination file name: ckpt or safetensors file / 保存先のファイル名、ckptまたはsafetensors")
|
||||
parser.add_argument("--models", type=str, nargs='*',
|
||||
help="LoRA models to merge: ckpt or safetensors file / マージするLoRAモデル、ckptまたはsafetensors")
|
||||
parser.add_argument("--ratios", type=float, nargs='*',
|
||||
help="ratios for each model / それぞれのLoRAモデルの比率")
|
||||
|
||||
args = parser.parse_args()
|
||||
merge(args)
|
||||
335
networks/resize_lora.py
Normal file
335
networks/resize_lora.py
Normal file
@@ -0,0 +1,335 @@
|
||||
# Convert LoRA to different rank approximation (should only be used to go to lower rank)
|
||||
# This code is based off the extract_lora_from_models.py file which is based on https://github.com/cloneofsimo/lora/blob/develop/lora_diffusion/cli_svd.py
|
||||
# Thanks to cloneofsimo
|
||||
|
||||
import argparse
|
||||
import torch
|
||||
from safetensors.torch import load_file, save_file, safe_open
|
||||
from tqdm import tqdm
|
||||
from library import train_util, model_util
|
||||
import numpy as np
|
||||
|
||||
MIN_SV = 1e-6
|
||||
|
||||
def load_state_dict(file_name, dtype):
|
||||
if model_util.is_safetensors(file_name):
|
||||
sd = load_file(file_name)
|
||||
with safe_open(file_name, framework="pt") as f:
|
||||
metadata = f.metadata()
|
||||
else:
|
||||
sd = torch.load(file_name, map_location='cpu')
|
||||
metadata = None
|
||||
|
||||
for key in list(sd.keys()):
|
||||
if type(sd[key]) == torch.Tensor:
|
||||
sd[key] = sd[key].to(dtype)
|
||||
|
||||
return sd, metadata
|
||||
|
||||
|
||||
def save_to_file(file_name, model, state_dict, dtype, metadata):
|
||||
if dtype is not None:
|
||||
for key in list(state_dict.keys()):
|
||||
if type(state_dict[key]) == torch.Tensor:
|
||||
state_dict[key] = state_dict[key].to(dtype)
|
||||
|
||||
if model_util.is_safetensors(file_name):
|
||||
save_file(model, file_name, metadata)
|
||||
else:
|
||||
torch.save(model, file_name)
|
||||
|
||||
|
||||
def index_sv_cumulative(S, target):
|
||||
original_sum = float(torch.sum(S))
|
||||
cumulative_sums = torch.cumsum(S, dim=0)/original_sum
|
||||
index = int(torch.searchsorted(cumulative_sums, target)) + 1
|
||||
if index >= len(S):
|
||||
index = len(S) - 1
|
||||
|
||||
return index
|
||||
|
||||
|
||||
def index_sv_fro(S, target):
|
||||
S_squared = S.pow(2)
|
||||
s_fro_sq = float(torch.sum(S_squared))
|
||||
sum_S_squared = torch.cumsum(S_squared, dim=0)/s_fro_sq
|
||||
index = int(torch.searchsorted(sum_S_squared, target**2)) + 1
|
||||
if index >= len(S):
|
||||
index = len(S) - 1
|
||||
|
||||
return index
|
||||
|
||||
|
||||
# Modified from Kohaku-blueleaf's extract/merge functions
|
||||
def extract_conv(weight, lora_rank, dynamic_method, dynamic_param, device, scale=1):
|
||||
out_size, in_size, kernel_size, _ = weight.size()
|
||||
U, S, Vh = torch.linalg.svd(weight.reshape(out_size, -1).to(device))
|
||||
|
||||
param_dict = rank_resize(S, lora_rank, dynamic_method, dynamic_param, scale)
|
||||
lora_rank = param_dict["new_rank"]
|
||||
|
||||
U = U[:, :lora_rank]
|
||||
S = S[:lora_rank]
|
||||
U = U @ torch.diag(S)
|
||||
Vh = Vh[:lora_rank, :]
|
||||
|
||||
param_dict["lora_down"] = Vh.reshape(lora_rank, in_size, kernel_size, kernel_size).cpu()
|
||||
param_dict["lora_up"] = U.reshape(out_size, lora_rank, 1, 1).cpu()
|
||||
del U, S, Vh, weight
|
||||
return param_dict
|
||||
|
||||
|
||||
def extract_linear(weight, lora_rank, dynamic_method, dynamic_param, device, scale=1):
|
||||
out_size, in_size = weight.size()
|
||||
|
||||
U, S, Vh = torch.linalg.svd(weight.to(device))
|
||||
|
||||
param_dict = rank_resize(S, lora_rank, dynamic_method, dynamic_param, scale)
|
||||
lora_rank = param_dict["new_rank"]
|
||||
|
||||
U = U[:, :lora_rank]
|
||||
S = S[:lora_rank]
|
||||
U = U @ torch.diag(S)
|
||||
Vh = Vh[:lora_rank, :]
|
||||
|
||||
param_dict["lora_down"] = Vh.reshape(lora_rank, in_size).cpu()
|
||||
param_dict["lora_up"] = U.reshape(out_size, lora_rank).cpu()
|
||||
del U, S, Vh, weight
|
||||
return param_dict
|
||||
|
||||
|
||||
def merge_conv(lora_down, lora_up, device):
|
||||
in_rank, in_size, kernel_size, k_ = lora_down.shape
|
||||
out_size, out_rank, _, _ = lora_up.shape
|
||||
assert in_rank == out_rank and kernel_size == k_, f"rank {in_rank} {out_rank} or kernel {kernel_size} {k_} mismatch"
|
||||
|
||||
lora_down = lora_down.to(device)
|
||||
lora_up = lora_up.to(device)
|
||||
|
||||
merged = lora_up.reshape(out_size, -1) @ lora_down.reshape(in_rank, -1)
|
||||
weight = merged.reshape(out_size, in_size, kernel_size, kernel_size)
|
||||
del lora_up, lora_down
|
||||
return weight
|
||||
|
||||
|
||||
def merge_linear(lora_down, lora_up, device):
|
||||
in_rank, in_size = lora_down.shape
|
||||
out_size, out_rank = lora_up.shape
|
||||
assert in_rank == out_rank, f"rank {in_rank} {out_rank} mismatch"
|
||||
|
||||
lora_down = lora_down.to(device)
|
||||
lora_up = lora_up.to(device)
|
||||
|
||||
weight = lora_up @ lora_down
|
||||
del lora_up, lora_down
|
||||
return weight
|
||||
|
||||
|
||||
def rank_resize(S, rank, dynamic_method, dynamic_param, scale=1):
|
||||
param_dict = {}
|
||||
|
||||
if dynamic_method=="sv_ratio":
|
||||
# Calculate new dim and alpha based off ratio
|
||||
max_sv = S[0]
|
||||
min_sv = max_sv/dynamic_param
|
||||
new_rank = max(torch.sum(S > min_sv).item(),1)
|
||||
new_alpha = float(scale*new_rank)
|
||||
|
||||
elif dynamic_method=="sv_cumulative":
|
||||
# Calculate new dim and alpha based off cumulative sum
|
||||
new_rank = index_sv_cumulative(S, dynamic_param)
|
||||
new_rank = max(new_rank, 1)
|
||||
new_alpha = float(scale*new_rank)
|
||||
|
||||
elif dynamic_method=="sv_fro":
|
||||
# Calculate new dim and alpha based off sqrt sum of squares
|
||||
new_rank = index_sv_fro(S, dynamic_param)
|
||||
new_rank = min(max(new_rank, 1), len(S)-1)
|
||||
new_alpha = float(scale*new_rank)
|
||||
else:
|
||||
new_rank = rank
|
||||
new_alpha = float(scale*new_rank)
|
||||
|
||||
|
||||
if S[0] <= MIN_SV: # Zero matrix, set dim to 1
|
||||
new_rank = 1
|
||||
new_alpha = float(scale*new_rank)
|
||||
elif new_rank > rank: # cap max rank at rank
|
||||
new_rank = rank
|
||||
new_alpha = float(scale*new_rank)
|
||||
|
||||
|
||||
# Calculate resize info
|
||||
s_sum = torch.sum(torch.abs(S))
|
||||
s_rank = torch.sum(torch.abs(S[:new_rank]))
|
||||
|
||||
S_squared = S.pow(2)
|
||||
s_fro = torch.sqrt(torch.sum(S_squared))
|
||||
s_red_fro = torch.sqrt(torch.sum(S_squared[:new_rank]))
|
||||
fro_percent = float(s_red_fro/s_fro)
|
||||
|
||||
param_dict["new_rank"] = new_rank
|
||||
param_dict["new_alpha"] = new_alpha
|
||||
param_dict["sum_retained"] = (s_rank)/s_sum
|
||||
param_dict["fro_retained"] = fro_percent
|
||||
param_dict["max_ratio"] = S[0]/S[new_rank]
|
||||
|
||||
return param_dict
|
||||
|
||||
|
||||
def resize_lora_model(lora_sd, new_rank, save_dtype, device, dynamic_method, dynamic_param, verbose):
|
||||
network_alpha = None
|
||||
network_dim = None
|
||||
verbose_str = "\n"
|
||||
fro_list = []
|
||||
|
||||
# Extract loaded lora dim and alpha
|
||||
for key, value in lora_sd.items():
|
||||
if network_alpha is None and 'alpha' in key:
|
||||
network_alpha = value
|
||||
if network_dim is None and 'lora_down' in key and len(value.size()) == 2:
|
||||
network_dim = value.size()[0]
|
||||
if network_alpha is not None and network_dim is not None:
|
||||
break
|
||||
if network_alpha is None:
|
||||
network_alpha = network_dim
|
||||
|
||||
scale = network_alpha/network_dim
|
||||
|
||||
if dynamic_method:
|
||||
print(f"Dynamically determining new alphas and dims based off {dynamic_method}: {dynamic_param}, max rank is {new_rank}")
|
||||
|
||||
lora_down_weight = None
|
||||
lora_up_weight = None
|
||||
|
||||
o_lora_sd = lora_sd.copy()
|
||||
block_down_name = None
|
||||
block_up_name = None
|
||||
|
||||
with torch.no_grad():
|
||||
for key, value in tqdm(lora_sd.items()):
|
||||
if 'lora_down' in key:
|
||||
block_down_name = key.split(".")[0]
|
||||
lora_down_weight = value
|
||||
if 'lora_up' in key:
|
||||
block_up_name = key.split(".")[0]
|
||||
lora_up_weight = value
|
||||
|
||||
weights_loaded = (lora_down_weight is not None and lora_up_weight is not None)
|
||||
|
||||
if (block_down_name == block_up_name) and weights_loaded:
|
||||
|
||||
conv2d = (len(lora_down_weight.size()) == 4)
|
||||
|
||||
if conv2d:
|
||||
full_weight_matrix = merge_conv(lora_down_weight, lora_up_weight, device)
|
||||
param_dict = extract_conv(full_weight_matrix, new_rank, dynamic_method, dynamic_param, device, scale)
|
||||
else:
|
||||
full_weight_matrix = merge_linear(lora_down_weight, lora_up_weight, device)
|
||||
param_dict = extract_linear(full_weight_matrix, new_rank, dynamic_method, dynamic_param, device, scale)
|
||||
|
||||
if verbose:
|
||||
max_ratio = param_dict['max_ratio']
|
||||
sum_retained = param_dict['sum_retained']
|
||||
fro_retained = param_dict['fro_retained']
|
||||
if not np.isnan(fro_retained):
|
||||
fro_list.append(float(fro_retained))
|
||||
|
||||
verbose_str+=f"{block_down_name:75} | "
|
||||
verbose_str+=f"sum(S) retained: {sum_retained:.1%}, fro retained: {fro_retained:.1%}, max(S) ratio: {max_ratio:0.1f}"
|
||||
|
||||
if verbose and dynamic_method:
|
||||
verbose_str+=f", dynamic | dim: {param_dict['new_rank']}, alpha: {param_dict['new_alpha']}\n"
|
||||
else:
|
||||
verbose_str+=f"\n"
|
||||
|
||||
new_alpha = param_dict['new_alpha']
|
||||
o_lora_sd[block_down_name + "." + "lora_down.weight"] = param_dict["lora_down"].to(save_dtype).contiguous()
|
||||
o_lora_sd[block_up_name + "." + "lora_up.weight"] = param_dict["lora_up"].to(save_dtype).contiguous()
|
||||
o_lora_sd[block_up_name + "." "alpha"] = torch.tensor(param_dict['new_alpha']).to(save_dtype)
|
||||
|
||||
block_down_name = None
|
||||
block_up_name = None
|
||||
lora_down_weight = None
|
||||
lora_up_weight = None
|
||||
weights_loaded = False
|
||||
del param_dict
|
||||
|
||||
if verbose:
|
||||
print(verbose_str)
|
||||
|
||||
print(f"Average Frobenius norm retention: {np.mean(fro_list):.2%} | std: {np.std(fro_list):0.3f}")
|
||||
print("resizing complete")
|
||||
return o_lora_sd, network_dim, new_alpha
|
||||
|
||||
|
||||
def resize(args):
|
||||
|
||||
def str_to_dtype(p):
|
||||
if p == 'float':
|
||||
return torch.float
|
||||
if p == 'fp16':
|
||||
return torch.float16
|
||||
if p == 'bf16':
|
||||
return torch.bfloat16
|
||||
return None
|
||||
|
||||
if args.dynamic_method and not args.dynamic_param:
|
||||
raise Exception("If using dynamic_method, then dynamic_param is required")
|
||||
|
||||
merge_dtype = str_to_dtype('float') # matmul method above only seems to work in float32
|
||||
save_dtype = str_to_dtype(args.save_precision)
|
||||
if save_dtype is None:
|
||||
save_dtype = merge_dtype
|
||||
|
||||
print("loading Model...")
|
||||
lora_sd, metadata = load_state_dict(args.model, merge_dtype)
|
||||
|
||||
print("Resizing Lora...")
|
||||
state_dict, old_dim, new_alpha = resize_lora_model(lora_sd, args.new_rank, save_dtype, args.device, args.dynamic_method, args.dynamic_param, args.verbose)
|
||||
|
||||
# update metadata
|
||||
if metadata is None:
|
||||
metadata = {}
|
||||
|
||||
comment = metadata.get("ss_training_comment", "")
|
||||
|
||||
if not args.dynamic_method:
|
||||
metadata["ss_training_comment"] = f"dimension is resized from {old_dim} to {args.new_rank}; {comment}"
|
||||
metadata["ss_network_dim"] = str(args.new_rank)
|
||||
metadata["ss_network_alpha"] = str(new_alpha)
|
||||
else:
|
||||
metadata["ss_training_comment"] = f"Dynamic resize with {args.dynamic_method}: {args.dynamic_param} from {old_dim}; {comment}"
|
||||
metadata["ss_network_dim"] = 'Dynamic'
|
||||
metadata["ss_network_alpha"] = 'Dynamic'
|
||||
|
||||
model_hash, legacy_hash = train_util.precalculate_safetensors_hashes(state_dict, metadata)
|
||||
metadata["sshs_model_hash"] = model_hash
|
||||
metadata["sshs_legacy_hash"] = legacy_hash
|
||||
|
||||
print(f"saving model to: {args.save_to}")
|
||||
save_to_file(args.save_to, state_dict, state_dict, save_dtype, metadata)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
parser.add_argument("--save_precision", type=str, default=None,
|
||||
choices=[None, "float", "fp16", "bf16"], help="precision in saving, float if omitted / 保存時の精度、未指定時はfloat")
|
||||
parser.add_argument("--new_rank", type=int, default=4,
|
||||
help="Specify rank of output LoRA / 出力するLoRAのrank (dim)")
|
||||
parser.add_argument("--save_to", type=str, default=None,
|
||||
help="destination file name: ckpt or safetensors file / 保存先のファイル名、ckptまたはsafetensors")
|
||||
parser.add_argument("--model", type=str, default=None,
|
||||
help="LoRA model to resize at to new rank: ckpt or safetensors file / 読み込むLoRAモデル、ckptまたはsafetensors")
|
||||
parser.add_argument("--device", type=str, default=None, help="device to use, cuda for GPU / 計算を行うデバイス、cuda でGPUを使う")
|
||||
parser.add_argument("--verbose", action="store_true",
|
||||
help="Display verbose resizing information / rank変更時の詳細情報を出力する")
|
||||
parser.add_argument("--dynamic_method", type=str, default=None, choices=[None, "sv_ratio", "sv_fro", "sv_cumulative"],
|
||||
help="Specify dynamic resizing method, --new_rank is used as a hard limit for max rank")
|
||||
parser.add_argument("--dynamic_param", type=float, default=None,
|
||||
help="Specify target for dynamic reduction")
|
||||
|
||||
|
||||
args = parser.parse_args()
|
||||
resize(args)
|
||||
182
networks/svd_merge_lora.py
Normal file
182
networks/svd_merge_lora.py
Normal file
@@ -0,0 +1,182 @@
|
||||
|
||||
import math
|
||||
import argparse
|
||||
import os
|
||||
import torch
|
||||
from safetensors.torch import load_file, save_file
|
||||
from tqdm import tqdm
|
||||
import library.model_util as model_util
|
||||
import lora
|
||||
|
||||
|
||||
CLAMP_QUANTILE = 0.99
|
||||
|
||||
|
||||
def load_state_dict(file_name, dtype):
|
||||
if os.path.splitext(file_name)[1] == '.safetensors':
|
||||
sd = load_file(file_name)
|
||||
else:
|
||||
sd = torch.load(file_name, map_location='cpu')
|
||||
for key in list(sd.keys()):
|
||||
if type(sd[key]) == torch.Tensor:
|
||||
sd[key] = sd[key].to(dtype)
|
||||
return sd
|
||||
|
||||
|
||||
def save_to_file(file_name, state_dict, dtype):
|
||||
if dtype is not None:
|
||||
for key in list(state_dict.keys()):
|
||||
if type(state_dict[key]) == torch.Tensor:
|
||||
state_dict[key] = state_dict[key].to(dtype)
|
||||
|
||||
if os.path.splitext(file_name)[1] == '.safetensors':
|
||||
save_file(state_dict, file_name)
|
||||
else:
|
||||
torch.save(state_dict, file_name)
|
||||
|
||||
|
||||
def merge_lora_models(models, ratios, new_rank, new_conv_rank, device, merge_dtype):
|
||||
print(f"new rank: {new_rank}, new conv rank: {new_conv_rank}")
|
||||
merged_sd = {}
|
||||
for model, ratio in zip(models, ratios):
|
||||
print(f"loading: {model}")
|
||||
lora_sd = load_state_dict(model, merge_dtype)
|
||||
|
||||
# merge
|
||||
print(f"merging...")
|
||||
for key in tqdm(list(lora_sd.keys())):
|
||||
if 'lora_down' not in key:
|
||||
continue
|
||||
|
||||
lora_module_name = key[:key.rfind(".lora_down")]
|
||||
|
||||
down_weight = lora_sd[key]
|
||||
network_dim = down_weight.size()[0]
|
||||
|
||||
up_weight = lora_sd[lora_module_name + '.lora_up.weight']
|
||||
alpha = lora_sd.get(lora_module_name + '.alpha', network_dim)
|
||||
|
||||
in_dim = down_weight.size()[1]
|
||||
out_dim = up_weight.size()[0]
|
||||
conv2d = len(down_weight.size()) == 4
|
||||
kernel_size = None if not conv2d else down_weight.size()[2:4]
|
||||
# print(lora_module_name, network_dim, alpha, in_dim, out_dim, kernel_size)
|
||||
|
||||
# make original weight if not exist
|
||||
if lora_module_name not in merged_sd:
|
||||
weight = torch.zeros((out_dim, in_dim, *kernel_size) if conv2d else (out_dim, in_dim), dtype=merge_dtype)
|
||||
if device:
|
||||
weight = weight.to(device)
|
||||
else:
|
||||
weight = merged_sd[lora_module_name]
|
||||
|
||||
# merge to weight
|
||||
if device:
|
||||
up_weight = up_weight.to(device)
|
||||
down_weight = down_weight.to(device)
|
||||
|
||||
# W <- W + U * D
|
||||
scale = (alpha / network_dim)
|
||||
if not conv2d: # linear
|
||||
weight = weight + ratio * (up_weight @ down_weight) * scale
|
||||
elif kernel_size == (1, 1):
|
||||
weight = weight + ratio * (up_weight.squeeze(3).squeeze(2) @ down_weight.squeeze(3).squeeze(2)
|
||||
).unsqueeze(2).unsqueeze(3) * scale
|
||||
else:
|
||||
conved = torch.nn.functional.conv2d(down_weight.permute(1, 0, 2, 3), up_weight).permute(1, 0, 2, 3)
|
||||
weight = weight + ratio * conved * scale
|
||||
|
||||
merged_sd[lora_module_name] = weight
|
||||
|
||||
# extract from merged weights
|
||||
print("extract new lora...")
|
||||
merged_lora_sd = {}
|
||||
with torch.no_grad():
|
||||
for lora_module_name, mat in tqdm(list(merged_sd.items())):
|
||||
conv2d = (len(mat.size()) == 4)
|
||||
kernel_size = None if not conv2d else mat.size()[2:4]
|
||||
conv2d_3x3 = conv2d and kernel_size != (1, 1)
|
||||
out_dim, in_dim = mat.size()[0:2]
|
||||
|
||||
if conv2d:
|
||||
if conv2d_3x3:
|
||||
mat = mat.flatten(start_dim=1)
|
||||
else:
|
||||
mat = mat.squeeze()
|
||||
|
||||
module_new_rank = new_conv_rank if conv2d_3x3 else new_rank
|
||||
module_new_rank = min(module_new_rank, in_dim, out_dim) # LoRA rank cannot exceed the original dim
|
||||
|
||||
U, S, Vh = torch.linalg.svd(mat)
|
||||
|
||||
U = U[:, :module_new_rank]
|
||||
S = S[:module_new_rank]
|
||||
U = U @ torch.diag(S)
|
||||
|
||||
Vh = Vh[:module_new_rank, :]
|
||||
|
||||
dist = torch.cat([U.flatten(), Vh.flatten()])
|
||||
hi_val = torch.quantile(dist, CLAMP_QUANTILE)
|
||||
low_val = -hi_val
|
||||
|
||||
U = U.clamp(low_val, hi_val)
|
||||
Vh = Vh.clamp(low_val, hi_val)
|
||||
|
||||
if conv2d:
|
||||
U = U.reshape(out_dim, module_new_rank, 1, 1)
|
||||
Vh = Vh.reshape(module_new_rank, in_dim, kernel_size[0], kernel_size[1])
|
||||
|
||||
up_weight = U
|
||||
down_weight = Vh
|
||||
|
||||
merged_lora_sd[lora_module_name + '.lora_up.weight'] = up_weight.to("cpu").contiguous()
|
||||
merged_lora_sd[lora_module_name + '.lora_down.weight'] = down_weight.to("cpu").contiguous()
|
||||
merged_lora_sd[lora_module_name + '.alpha'] = torch.tensor(module_new_rank)
|
||||
|
||||
return merged_lora_sd
|
||||
|
||||
|
||||
def merge(args):
|
||||
assert len(args.models) == len(args.ratios), f"number of models must be equal to number of ratios / モデルの数と重みの数は合わせてください"
|
||||
|
||||
def str_to_dtype(p):
|
||||
if p == 'float':
|
||||
return torch.float
|
||||
if p == 'fp16':
|
||||
return torch.float16
|
||||
if p == 'bf16':
|
||||
return torch.bfloat16
|
||||
return None
|
||||
|
||||
merge_dtype = str_to_dtype(args.precision)
|
||||
save_dtype = str_to_dtype(args.save_precision)
|
||||
if save_dtype is None:
|
||||
save_dtype = merge_dtype
|
||||
|
||||
new_conv_rank = args.new_conv_rank if args.new_conv_rank is not None else args.new_rank
|
||||
state_dict = merge_lora_models(args.models, args.ratios, args.new_rank, new_conv_rank, args.device, merge_dtype)
|
||||
|
||||
print(f"saving model to: {args.save_to}")
|
||||
save_to_file(args.save_to, state_dict, save_dtype)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--save_precision", type=str, default=None,
|
||||
choices=[None, "float", "fp16", "bf16"], help="precision in saving, same to merging if omitted / 保存時に精度を変更して保存する、省略時はマージ時の精度と同じ")
|
||||
parser.add_argument("--precision", type=str, default="float",
|
||||
choices=["float", "fp16", "bf16"], help="precision in merging (float is recommended) / マージの計算時の精度(floatを推奨)")
|
||||
parser.add_argument("--save_to", type=str, default=None,
|
||||
help="destination file name: ckpt or safetensors file / 保存先のファイル名、ckptまたはsafetensors")
|
||||
parser.add_argument("--models", type=str, nargs='*',
|
||||
help="LoRA models to merge: ckpt or safetensors file / マージするLoRAモデル、ckptまたはsafetensors")
|
||||
parser.add_argument("--ratios", type=float, nargs='*',
|
||||
help="ratios for each model / それぞれのLoRAモデルの比率")
|
||||
parser.add_argument("--new_rank", type=int, default=4,
|
||||
help="Specify rank of output LoRA / 出力するLoRAのrank (dim)")
|
||||
parser.add_argument("--new_conv_rank", type=int, default=None,
|
||||
help="Specify rank of output LoRA for Conv2d 3x3, None for same as new_rank / 出力するConv2D 3x3 LoRAのrank (dim)、Noneでnew_rankと同じ")
|
||||
parser.add_argument("--device", type=str, default=None, help="device to use, cuda for GPU / 計算を行うデバイス、cuda でGPUを使う")
|
||||
|
||||
args = parser.parse_args()
|
||||
merge(args)
|
||||
@@ -1,23 +1,26 @@
|
||||
accelerate==0.15.0
|
||||
transformers==4.25.1
|
||||
ftfy
|
||||
albumentations
|
||||
opencv-python
|
||||
einops
|
||||
transformers==4.26.0
|
||||
ftfy==6.1.1
|
||||
albumentations==1.3.0
|
||||
opencv-python==4.7.0.68
|
||||
einops==0.6.0
|
||||
diffusers[torch]==0.10.2
|
||||
pytorch_lightning
|
||||
pytorch-lightning==1.9.0
|
||||
bitsandbytes==0.35.0
|
||||
tensorboard
|
||||
tensorboard==2.10.1
|
||||
safetensors==0.2.6
|
||||
gradio
|
||||
altair
|
||||
easygui
|
||||
gradio==3.16.2
|
||||
altair==4.2.2
|
||||
easygui==0.98.3
|
||||
toml==0.10.2
|
||||
voluptuous==0.13.1
|
||||
# for BLIP captioning
|
||||
requests
|
||||
timm==0.4.12
|
||||
fairscale==0.4.4
|
||||
requests==2.28.2
|
||||
timm==0.6.12
|
||||
fairscale==0.4.13
|
||||
# for WD14 captioning
|
||||
tensorflow<2.11
|
||||
huggingface-hub
|
||||
# tensorflow<2.11
|
||||
tensorflow==2.10.1
|
||||
huggingface-hub==0.12.0
|
||||
# for kohya_ss library
|
||||
.
|
||||
.
|
||||
|
||||
24
tools/canny.py
Normal file
24
tools/canny.py
Normal file
@@ -0,0 +1,24 @@
|
||||
import argparse
|
||||
import cv2
|
||||
|
||||
|
||||
def canny(args):
|
||||
img = cv2.imread(args.input)
|
||||
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
|
||||
|
||||
canny_img = cv2.Canny(img, args.thres1, args.thres2)
|
||||
# canny_img = 255 - canny_img
|
||||
|
||||
cv2.imwrite(args.output, canny_img)
|
||||
print("done!")
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--input", type=str, default=None, help="input path")
|
||||
parser.add_argument("--output", type=str, default=None, help="output path")
|
||||
parser.add_argument("--thres1", type=int, default=32, help="thres1")
|
||||
parser.add_argument("--thres2", type=int, default=224, help="thres2")
|
||||
|
||||
args = parser.parse_args()
|
||||
canny(args)
|
||||
@@ -1,8 +1,4 @@
|
||||
# convert Diffusers v1.x/v2.0 model to original Stable Diffusion
|
||||
# v1: initial version
|
||||
# v2: support safetensors
|
||||
# v3: fix to support another format
|
||||
# v4: support safetensors in Diffusers
|
||||
|
||||
import argparse
|
||||
import os
|
||||
|
||||
320
tools/original_control_net.py
Normal file
320
tools/original_control_net.py
Normal file
@@ -0,0 +1,320 @@
|
||||
from typing import List, NamedTuple, Any
|
||||
import numpy as np
|
||||
import cv2
|
||||
import torch
|
||||
from safetensors.torch import load_file
|
||||
|
||||
from diffusers import UNet2DConditionModel
|
||||
from diffusers.models.unet_2d_condition import UNet2DConditionOutput
|
||||
|
||||
import library.model_util as model_util
|
||||
|
||||
|
||||
class ControlNetInfo(NamedTuple):
|
||||
unet: Any
|
||||
net: Any
|
||||
prep: Any
|
||||
weight: float
|
||||
ratio: float
|
||||
|
||||
|
||||
class ControlNet(torch.nn.Module):
|
||||
def __init__(self) -> None:
|
||||
super().__init__()
|
||||
|
||||
# make control model
|
||||
self.control_model = torch.nn.Module()
|
||||
|
||||
dims = [320, 320, 320, 320, 640, 640, 640, 1280, 1280, 1280, 1280, 1280]
|
||||
zero_convs = torch.nn.ModuleList()
|
||||
for i, dim in enumerate(dims):
|
||||
sub_list = torch.nn.ModuleList([torch.nn.Conv2d(dim, dim, 1)])
|
||||
zero_convs.append(sub_list)
|
||||
self.control_model.add_module("zero_convs", zero_convs)
|
||||
|
||||
middle_block_out = torch.nn.Conv2d(1280, 1280, 1)
|
||||
self.control_model.add_module("middle_block_out", torch.nn.ModuleList([middle_block_out]))
|
||||
|
||||
dims = [16, 16, 32, 32, 96, 96, 256, 320]
|
||||
strides = [1, 1, 2, 1, 2, 1, 2, 1]
|
||||
prev_dim = 3
|
||||
input_hint_block = torch.nn.Sequential()
|
||||
for i, (dim, stride) in enumerate(zip(dims, strides)):
|
||||
input_hint_block.append(torch.nn.Conv2d(prev_dim, dim, 3, stride, 1))
|
||||
if i < len(dims) - 1:
|
||||
input_hint_block.append(torch.nn.SiLU())
|
||||
prev_dim = dim
|
||||
self.control_model.add_module("input_hint_block", input_hint_block)
|
||||
|
||||
|
||||
def load_control_net(v2, unet, model):
|
||||
device = unet.device
|
||||
|
||||
# control sdからキー変換しつつU-Netに対応する部分のみ取り出し、DiffusersのU-Netに読み込む
|
||||
# state dictを読み込む
|
||||
print(f"ControlNet: loading control SD model : {model}")
|
||||
|
||||
if model_util.is_safetensors(model):
|
||||
ctrl_sd_sd = load_file(model)
|
||||
else:
|
||||
ctrl_sd_sd = torch.load(model, map_location='cpu')
|
||||
ctrl_sd_sd = ctrl_sd_sd.pop("state_dict", ctrl_sd_sd)
|
||||
|
||||
# 重みをU-Netに読み込めるようにする。ControlNetはSD版のstate dictなので、それを読み込む
|
||||
is_difference = "difference" in ctrl_sd_sd
|
||||
print("ControlNet: loading difference")
|
||||
|
||||
# ControlNetには存在しないキーがあるので、まず現在のU-NetでSD版の全keyを作っておく
|
||||
# またTransfer Controlの元weightとなる
|
||||
ctrl_unet_sd_sd = model_util.convert_unet_state_dict_to_sd(v2, unet.state_dict())
|
||||
|
||||
# 元のU-Netに影響しないようにコピーする。またprefixが付いていないので付ける
|
||||
for key in list(ctrl_unet_sd_sd.keys()):
|
||||
ctrl_unet_sd_sd["model.diffusion_model." + key] = ctrl_unet_sd_sd.pop(key).clone()
|
||||
|
||||
zero_conv_sd = {}
|
||||
for key in list(ctrl_sd_sd.keys()):
|
||||
if key.startswith("control_"):
|
||||
unet_key = "model.diffusion_" + key[len("control_"):]
|
||||
if unet_key not in ctrl_unet_sd_sd: # zero conv
|
||||
zero_conv_sd[key] = ctrl_sd_sd[key]
|
||||
continue
|
||||
if is_difference: # Transfer Control
|
||||
ctrl_unet_sd_sd[unet_key] += ctrl_sd_sd[key].to(device, dtype=unet.dtype)
|
||||
else:
|
||||
ctrl_unet_sd_sd[unet_key] = ctrl_sd_sd[key].to(device, dtype=unet.dtype)
|
||||
|
||||
unet_config = model_util.create_unet_diffusers_config(v2)
|
||||
ctrl_unet_du_sd = model_util.convert_ldm_unet_checkpoint(v2, ctrl_unet_sd_sd, unet_config) # DiffUsers版ControlNetのstate dict
|
||||
|
||||
# ControlNetのU-Netを作成する
|
||||
ctrl_unet = UNet2DConditionModel(**unet_config)
|
||||
info = ctrl_unet.load_state_dict(ctrl_unet_du_sd)
|
||||
print("ControlNet: loading Control U-Net:", info)
|
||||
|
||||
# U-Net以外のControlNetを作成する
|
||||
# TODO support middle only
|
||||
ctrl_net = ControlNet()
|
||||
info = ctrl_net.load_state_dict(zero_conv_sd)
|
||||
print("ControlNet: loading ControlNet:", info)
|
||||
|
||||
ctrl_unet.to(unet.device, dtype=unet.dtype)
|
||||
ctrl_net.to(unet.device, dtype=unet.dtype)
|
||||
return ctrl_unet, ctrl_net
|
||||
|
||||
|
||||
def load_preprocess(prep_type: str):
|
||||
if prep_type is None or prep_type.lower() == "none":
|
||||
return None
|
||||
|
||||
if prep_type.startswith("canny"):
|
||||
args = prep_type.split("_")
|
||||
th1 = int(args[1]) if len(args) >= 2 else 63
|
||||
th2 = int(args[2]) if len(args) >= 3 else 191
|
||||
|
||||
def canny(img):
|
||||
img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
|
||||
return cv2.Canny(img, th1, th2)
|
||||
return canny
|
||||
|
||||
print("Unsupported prep type:", prep_type)
|
||||
return None
|
||||
|
||||
|
||||
def preprocess_ctrl_net_hint_image(image):
|
||||
image = np.array(image).astype(np.float32) / 255.0
|
||||
image = image[:, :, ::-1].copy() # rgb to bgr
|
||||
image = image[None].transpose(0, 3, 1, 2) # nchw
|
||||
image = torch.from_numpy(image)
|
||||
return image # 0 to 1
|
||||
|
||||
|
||||
def get_guided_hints(control_nets: List[ControlNetInfo], num_latent_input, b_size, hints):
|
||||
guided_hints = []
|
||||
for i, cnet_info in enumerate(control_nets):
|
||||
# hintは 1枚目の画像のcnet1, 1枚目の画像のcnet2, 1枚目の画像のcnet3, 2枚目の画像のcnet1, 2枚目の画像のcnet2 ... と並んでいること
|
||||
b_hints = []
|
||||
if len(hints) == 1: # すべて同じ画像をhintとして使う
|
||||
hint = hints[0]
|
||||
if cnet_info.prep is not None:
|
||||
hint = cnet_info.prep(hint)
|
||||
hint = preprocess_ctrl_net_hint_image(hint)
|
||||
b_hints = [hint for _ in range(b_size)]
|
||||
else:
|
||||
for bi in range(b_size):
|
||||
hint = hints[(bi * len(control_nets) + i) % len(hints)]
|
||||
if cnet_info.prep is not None:
|
||||
hint = cnet_info.prep(hint)
|
||||
hint = preprocess_ctrl_net_hint_image(hint)
|
||||
b_hints.append(hint)
|
||||
b_hints = torch.cat(b_hints, dim=0)
|
||||
b_hints = b_hints.to(cnet_info.unet.device, dtype=cnet_info.unet.dtype)
|
||||
|
||||
guided_hint = cnet_info.net.control_model.input_hint_block(b_hints)
|
||||
guided_hints.append(guided_hint)
|
||||
return guided_hints
|
||||
|
||||
|
||||
def call_unet_and_control_net(step, num_latent_input, original_unet, control_nets: List[ControlNetInfo], guided_hints, current_ratio, sample, timestep, encoder_hidden_states):
|
||||
# ControlNet
|
||||
# 複数のControlNetの場合は、出力をマージするのではなく交互に適用する
|
||||
cnet_cnt = len(control_nets)
|
||||
cnet_idx = step % cnet_cnt
|
||||
cnet_info = control_nets[cnet_idx]
|
||||
|
||||
# print(current_ratio, cnet_info.prep, cnet_info.weight, cnet_info.ratio)
|
||||
if cnet_info.ratio < current_ratio:
|
||||
return original_unet(sample, timestep, encoder_hidden_states)
|
||||
|
||||
guided_hint = guided_hints[cnet_idx]
|
||||
guided_hint = guided_hint.repeat((num_latent_input, 1, 1, 1))
|
||||
outs = unet_forward(True, cnet_info.net, cnet_info.unet, guided_hint, None, sample, timestep, encoder_hidden_states)
|
||||
outs = [o * cnet_info.weight for o in outs]
|
||||
|
||||
# U-Net
|
||||
return unet_forward(False, cnet_info.net, original_unet, None, outs, sample, timestep, encoder_hidden_states)
|
||||
|
||||
|
||||
"""
|
||||
# これはmergeのバージョン
|
||||
# ControlNet
|
||||
cnet_outs_list = []
|
||||
for i, cnet_info in enumerate(control_nets):
|
||||
# print(current_ratio, cnet_info.prep, cnet_info.weight, cnet_info.ratio)
|
||||
if cnet_info.ratio < current_ratio:
|
||||
continue
|
||||
guided_hint = guided_hints[i]
|
||||
outs = unet_forward(True, cnet_info.net, cnet_info.unet, guided_hint, None, sample, timestep, encoder_hidden_states)
|
||||
for i in range(len(outs)):
|
||||
outs[i] *= cnet_info.weight
|
||||
|
||||
cnet_outs_list.append(outs)
|
||||
|
||||
count = len(cnet_outs_list)
|
||||
if count == 0:
|
||||
return original_unet(sample, timestep, encoder_hidden_states)
|
||||
|
||||
# sum of controlnets
|
||||
for i in range(1, count):
|
||||
cnet_outs_list[0] += cnet_outs_list[i]
|
||||
|
||||
# U-Net
|
||||
return unet_forward(False, cnet_info.net, original_unet, None, cnet_outs_list[0], sample, timestep, encoder_hidden_states)
|
||||
"""
|
||||
|
||||
|
||||
def unet_forward(is_control_net, control_net: ControlNet, unet: UNet2DConditionModel, guided_hint, ctrl_outs, sample, timestep, encoder_hidden_states):
|
||||
# copy from UNet2DConditionModel
|
||||
default_overall_up_factor = 2**unet.num_upsamplers
|
||||
|
||||
forward_upsample_size = False
|
||||
upsample_size = None
|
||||
|
||||
if any(s % default_overall_up_factor != 0 for s in sample.shape[-2:]):
|
||||
print("Forward upsample size to force interpolation output size.")
|
||||
forward_upsample_size = True
|
||||
|
||||
# 0. center input if necessary
|
||||
if unet.config.center_input_sample:
|
||||
sample = 2 * sample - 1.0
|
||||
|
||||
# 1. time
|
||||
timesteps = timestep
|
||||
if not torch.is_tensor(timesteps):
|
||||
# TODO: this requires sync between CPU and GPU. So try to pass timesteps as tensors if you can
|
||||
# This would be a good case for the `match` statement (Python 3.10+)
|
||||
is_mps = sample.device.type == "mps"
|
||||
if isinstance(timestep, float):
|
||||
dtype = torch.float32 if is_mps else torch.float64
|
||||
else:
|
||||
dtype = torch.int32 if is_mps else torch.int64
|
||||
timesteps = torch.tensor([timesteps], dtype=dtype, device=sample.device)
|
||||
elif len(timesteps.shape) == 0:
|
||||
timesteps = timesteps[None].to(sample.device)
|
||||
|
||||
# broadcast to batch dimension in a way that's compatible with ONNX/Core ML
|
||||
timesteps = timesteps.expand(sample.shape[0])
|
||||
|
||||
t_emb = unet.time_proj(timesteps)
|
||||
|
||||
# timesteps does not contain any weights and will always return f32 tensors
|
||||
# but time_embedding might actually be running in fp16. so we need to cast here.
|
||||
# there might be better ways to encapsulate this.
|
||||
t_emb = t_emb.to(dtype=unet.dtype)
|
||||
emb = unet.time_embedding(t_emb)
|
||||
|
||||
outs = [] # output of ControlNet
|
||||
zc_idx = 0
|
||||
|
||||
# 2. pre-process
|
||||
sample = unet.conv_in(sample)
|
||||
if is_control_net:
|
||||
sample += guided_hint
|
||||
outs.append(control_net.control_model.zero_convs[zc_idx][0](sample)) # , emb, encoder_hidden_states))
|
||||
zc_idx += 1
|
||||
|
||||
# 3. down
|
||||
down_block_res_samples = (sample,)
|
||||
for downsample_block in unet.down_blocks:
|
||||
if hasattr(downsample_block, "has_cross_attention") and downsample_block.has_cross_attention:
|
||||
sample, res_samples = downsample_block(
|
||||
hidden_states=sample,
|
||||
temb=emb,
|
||||
encoder_hidden_states=encoder_hidden_states,
|
||||
)
|
||||
else:
|
||||
sample, res_samples = downsample_block(hidden_states=sample, temb=emb)
|
||||
if is_control_net:
|
||||
for rs in res_samples:
|
||||
outs.append(control_net.control_model.zero_convs[zc_idx][0](rs)) # , emb, encoder_hidden_states))
|
||||
zc_idx += 1
|
||||
|
||||
down_block_res_samples += res_samples
|
||||
|
||||
# 4. mid
|
||||
sample = unet.mid_block(sample, emb, encoder_hidden_states=encoder_hidden_states)
|
||||
if is_control_net:
|
||||
outs.append(control_net.control_model.middle_block_out[0](sample))
|
||||
return outs
|
||||
|
||||
if not is_control_net:
|
||||
sample += ctrl_outs.pop()
|
||||
|
||||
# 5. up
|
||||
for i, upsample_block in enumerate(unet.up_blocks):
|
||||
is_final_block = i == len(unet.up_blocks) - 1
|
||||
|
||||
res_samples = down_block_res_samples[-len(upsample_block.resnets):]
|
||||
down_block_res_samples = down_block_res_samples[: -len(upsample_block.resnets)]
|
||||
|
||||
if not is_control_net and len(ctrl_outs) > 0:
|
||||
res_samples = list(res_samples)
|
||||
apply_ctrl_outs = ctrl_outs[-len(res_samples):]
|
||||
ctrl_outs = ctrl_outs[:-len(res_samples)]
|
||||
for j in range(len(res_samples)):
|
||||
res_samples[j] = res_samples[j] + apply_ctrl_outs[j]
|
||||
res_samples = tuple(res_samples)
|
||||
|
||||
# if we have not reached the final block and need to forward the
|
||||
# upsample size, we do it here
|
||||
if not is_final_block and forward_upsample_size:
|
||||
upsample_size = down_block_res_samples[-1].shape[2:]
|
||||
|
||||
if hasattr(upsample_block, "has_cross_attention") and upsample_block.has_cross_attention:
|
||||
sample = upsample_block(
|
||||
hidden_states=sample,
|
||||
temb=emb,
|
||||
res_hidden_states_tuple=res_samples,
|
||||
encoder_hidden_states=encoder_hidden_states,
|
||||
upsample_size=upsample_size,
|
||||
)
|
||||
else:
|
||||
sample = upsample_block(
|
||||
hidden_states=sample, temb=emb, res_hidden_states_tuple=res_samples, upsample_size=upsample_size
|
||||
)
|
||||
# 6. post-process
|
||||
sample = unet.conv_norm_out(sample)
|
||||
sample = unet.conv_act(sample)
|
||||
sample = unet.conv_out(sample)
|
||||
|
||||
return UNet2DConditionOutput(sample=sample)
|
||||
122
tools/resize_images_to_resolution.py
Normal file
122
tools/resize_images_to_resolution.py
Normal file
@@ -0,0 +1,122 @@
|
||||
import glob
|
||||
import os
|
||||
import cv2
|
||||
import argparse
|
||||
import shutil
|
||||
import math
|
||||
from PIL import Image
|
||||
import numpy as np
|
||||
|
||||
|
||||
def resize_images(src_img_folder, dst_img_folder, max_resolution="512x512", divisible_by=2, interpolation=None, save_as_png=False, copy_associated_files=False):
|
||||
# Split the max_resolution string by "," and strip any whitespaces
|
||||
max_resolutions = [res.strip() for res in max_resolution.split(',')]
|
||||
|
||||
# # Calculate max_pixels from max_resolution string
|
||||
# max_pixels = int(max_resolution.split("x")[0]) * int(max_resolution.split("x")[1])
|
||||
|
||||
# Create destination folder if it does not exist
|
||||
if not os.path.exists(dst_img_folder):
|
||||
os.makedirs(dst_img_folder)
|
||||
|
||||
# Select interpolation method
|
||||
if interpolation == 'lanczos4':
|
||||
cv2_interpolation = cv2.INTER_LANCZOS4
|
||||
elif interpolation == 'cubic':
|
||||
cv2_interpolation = cv2.INTER_CUBIC
|
||||
else:
|
||||
cv2_interpolation = cv2.INTER_AREA
|
||||
|
||||
# Iterate through all files in src_img_folder
|
||||
img_exts = (".png", ".jpg", ".jpeg", ".webp", ".bmp") # copy from train_util.py
|
||||
for filename in os.listdir(src_img_folder):
|
||||
# Check if the image is png, jpg or webp etc...
|
||||
if not filename.endswith(img_exts):
|
||||
# Copy the file to the destination folder if not png, jpg or webp etc (.txt or .caption or etc.)
|
||||
shutil.copy(os.path.join(src_img_folder, filename), os.path.join(dst_img_folder, filename))
|
||||
continue
|
||||
|
||||
# Load image
|
||||
# img = cv2.imread(os.path.join(src_img_folder, filename))
|
||||
image = Image.open(os.path.join(src_img_folder, filename))
|
||||
if not image.mode == "RGB":
|
||||
image = image.convert("RGB")
|
||||
img = np.array(image, np.uint8)
|
||||
|
||||
base, _ = os.path.splitext(filename)
|
||||
for max_resolution in max_resolutions:
|
||||
# Calculate max_pixels from max_resolution string
|
||||
max_pixels = int(max_resolution.split("x")[0]) * int(max_resolution.split("x")[1])
|
||||
|
||||
# Calculate current number of pixels
|
||||
current_pixels = img.shape[0] * img.shape[1]
|
||||
|
||||
# Check if the image needs resizing
|
||||
if current_pixels > max_pixels:
|
||||
# Calculate scaling factor
|
||||
scale_factor = max_pixels / current_pixels
|
||||
|
||||
# Calculate new dimensions
|
||||
new_height = int(img.shape[0] * math.sqrt(scale_factor))
|
||||
new_width = int(img.shape[1] * math.sqrt(scale_factor))
|
||||
|
||||
# Resize image
|
||||
img = cv2.resize(img, (new_width, new_height), interpolation=cv2_interpolation)
|
||||
else:
|
||||
new_height, new_width = img.shape[0:2]
|
||||
|
||||
# Calculate the new height and width that are divisible by divisible_by (with/without resizing)
|
||||
new_height = new_height if new_height % divisible_by == 0 else new_height - new_height % divisible_by
|
||||
new_width = new_width if new_width % divisible_by == 0 else new_width - new_width % divisible_by
|
||||
|
||||
# Center crop the image to the calculated dimensions
|
||||
y = int((img.shape[0] - new_height) / 2)
|
||||
x = int((img.shape[1] - new_width) / 2)
|
||||
img = img[y:y + new_height, x:x + new_width]
|
||||
|
||||
# Split filename into base and extension
|
||||
new_filename = base + '+' + max_resolution + ('.png' if save_as_png else '.jpg')
|
||||
|
||||
# Save resized image in dst_img_folder
|
||||
# cv2.imwrite(os.path.join(dst_img_folder, new_filename), img, [cv2.IMWRITE_JPEG_QUALITY, 100])
|
||||
image = Image.fromarray(img)
|
||||
image.save(os.path.join(dst_img_folder, new_filename), quality=100)
|
||||
|
||||
proc = "Resized" if current_pixels > max_pixels else "Saved"
|
||||
print(f"{proc} image: {filename} with size {img.shape[0]}x{img.shape[1]} as {new_filename}")
|
||||
|
||||
# If other files with same basename, copy them with resolution suffix
|
||||
if copy_associated_files:
|
||||
asoc_files = glob.glob(os.path.join(src_img_folder, base + ".*"))
|
||||
for asoc_file in asoc_files:
|
||||
ext = os.path.splitext(asoc_file)[1]
|
||||
if ext in img_exts:
|
||||
continue
|
||||
for max_resolution in max_resolutions:
|
||||
new_asoc_file = base + '+' + max_resolution + ext
|
||||
print(f"Copy {asoc_file} as {new_asoc_file}")
|
||||
shutil.copy(os.path.join(src_img_folder, asoc_file), os.path.join(dst_img_folder, new_asoc_file))
|
||||
|
||||
|
||||
def main():
|
||||
parser = argparse.ArgumentParser(
|
||||
description='Resize images in a folder to a specified max resolution(s) / 指定されたフォルダ内の画像を指定した最大画像サイズ(面積)以下にアスペクト比を維持したままリサイズします')
|
||||
parser.add_argument('src_img_folder', type=str, help='Source folder containing the images / 元画像のフォルダ')
|
||||
parser.add_argument('dst_img_folder', type=str, help='Destination folder to save the resized images / リサイズ後の画像を保存するフォルダ')
|
||||
parser.add_argument('--max_resolution', type=str,
|
||||
help='Maximum resolution(s) in the format "512x512,384x384, etc, etc" / 最大画像サイズをカンマ区切りで指定 ("512x512,384x384, etc, etc" など)', default="512x512,384x384,256x256,128x128")
|
||||
parser.add_argument('--divisible_by', type=int,
|
||||
help='Ensure new dimensions are divisible by this value / リサイズ後の画像のサイズをこの値で割り切れるようにします', default=1)
|
||||
parser.add_argument('--interpolation', type=str, choices=['area', 'cubic', 'lanczos4'],
|
||||
default='area', help='Interpolation method for resizing / リサイズ時の補完方法')
|
||||
parser.add_argument('--save_as_png', action='store_true', help='Save as png format / png形式で保存')
|
||||
parser.add_argument('--copy_associated_files', action='store_true',
|
||||
help='Copy files with same base name to images (captions etc) / 画像と同じファイル名(拡張子を除く)のファイルもコピーする')
|
||||
|
||||
args = parser.parse_args()
|
||||
resize_images(args.src_img_folder, args.dst_img_folder, args.max_resolution,
|
||||
args.divisible_by, args.interpolation, args.save_as_png, args.copy_associated_files)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
936
train_README-ja.md
Normal file
936
train_README-ja.md
Normal file
@@ -0,0 +1,936 @@
|
||||
__ドキュメント更新中のため記述に誤りがあるかもしれません。__
|
||||
|
||||
# 学習について、共通編
|
||||
|
||||
当リポジトリではモデルのfine tuning、DreamBooth、およびLoRAとTextual Inversionの学習をサポートします。この文書ではそれらに共通する、学習データの準備方法やオプション等について説明します。
|
||||
|
||||
# 概要
|
||||
|
||||
あらかじめこのリポジトリのREADMEを参照し、環境整備を行ってください。
|
||||
|
||||
|
||||
以下について説明します。
|
||||
|
||||
1. 学習データの準備について(設定ファイルを用いる新形式)
|
||||
1. 学習で使われる用語のごく簡単な解説
|
||||
1. 以前の指定形式(設定ファイルを用いずコマンドラインから指定)
|
||||
1. 学習途中のサンプル画像生成
|
||||
1. 各スクリプトで共通の、よく使われるオプション
|
||||
1. fine tuning 方式のメタデータ準備:キャプションニングなど
|
||||
|
||||
1.だけ実行すればとりあえず学習は可能です(学習については各スクリプトのドキュメントを参照)。2.以降は必要に応じて参照してください。
|
||||
|
||||
|
||||
# 学習データの準備について
|
||||
|
||||
任意のフォルダ(複数でも可)に学習データの画像ファイルを用意しておきます。`.png`, `.jpg`, `.jpeg`, `.webp`, `.bmp` をサポートします。リサイズなどの前処理は基本的に必要ありません。
|
||||
|
||||
ただし学習解像度(後述)よりも極端に小さい画像は使わないか、あらかじめ超解像AIなどで拡大しておくことをお勧めします。また極端に大きな画像(3000x3000ピクセル程度?)よりも大きな画像はエラーになる場合があるようですので事前に縮小してください。
|
||||
|
||||
学習時には、モデルに学ばせる画像データを整理し、スクリプトに対して指定する必要があります。学習データの数、学習対象、キャプション(画像の説明)が用意できるか否かなどにより、いくつかの方法で学習データを指定できます。以下の方式があります(それぞれの名前は一般的なものではなく、当リポジトリ独自の定義です)。正則化画像については後述します。
|
||||
|
||||
1. DreamBooth、class+identifier方式(正則化画像使用可)
|
||||
|
||||
特定の単語 (identifier) に学習対象を紐づけるように学習します。キャプションを用意する必要はありません。たとえば特定のキャラを学ばせる場合に使うとキャプションを用意する必要がない分、手軽ですが、髪型や服装、背景など学習データの全要素が identifier に紐づけられて学習されるため、生成時のプロンプトで服が変えられない、といった事態も起こりえます。
|
||||
|
||||
1. DreamBooth、キャプション方式(正則化画像使用可)
|
||||
|
||||
画像ごとにキャプションが記録されたテキストファイルを用意して学習します。たとえば特定のキャラを学ばせると、画像の詳細をキャプションに記述することで(白い服を着たキャラA、赤い服を着たキャラA、など)キャラとそれ以外の要素が分離され、より厳密にモデルがキャラだけを学ぶことが期待できます。
|
||||
|
||||
1. fine tuning方式(正則化画像使用不可)
|
||||
|
||||
あらかじめキャプションをメタデータファイルにまとめます。タグとキャプションを分けて管理したり、学習を高速化するためlatentsを事前キャッシュしたりなどの機能をサポートします(いずれも別文書で説明しています)。(fine tuning方式という名前ですが fine tuning 以外でも使えます。)
|
||||
|
||||
学習したいものと使用できる指定方法の組み合わせは以下の通りです。
|
||||
|
||||
| 学習対象または方法 | スクリプト | DB / class+identifier | DB / キャプション | fine tuning |
|
||||
| ----- | ----- | ----- | ----- | ----- |
|
||||
| モデルをfine tuning | `fine_tune.py`| x | x | o |
|
||||
| モデルをDreamBooth | `train_db.py`| o | o | x |
|
||||
| LoRA | `train_network.py`| o | o | o |
|
||||
| Textual Invesion | `train_textual_inversion.py`| o | o | o |
|
||||
|
||||
## どれを選ぶか
|
||||
|
||||
LoRA、Textual Inversionについては、手軽にキャプションファイルを用意せずに学習したい場合はDreamBooth class+identifier、用意できるならDreamBooth キャプション方式がよいでしょう。学習データの枚数が多く、かつ正則化画像を使用しない場合はfine tuning方式も検討してください。
|
||||
|
||||
DreamBoothについても同様ですが、fine tuning方式は使えません。fine tuningの場合はfine tuning方式のみです。
|
||||
|
||||
# 各方式の指定方法について
|
||||
|
||||
ここではそれぞれの指定方法で典型的なパターンについてだけ説明します。より詳細な指定方法については [データセット設定](./config_README-ja.md) をご覧ください。
|
||||
|
||||
# DreamBooth、class+identifier方式(正則化画像使用可)
|
||||
|
||||
この方式では、各画像は `class identifier` というキャプションで学習されたのと同じことになります(`shs dog` など)。
|
||||
|
||||
## step 1. identifierとclassを決める
|
||||
|
||||
学ばせたい対象を結びつける単語identifierと、対象の属するclassを決めます。
|
||||
|
||||
(instanceなどいろいろな呼び方がありますが、とりあえず元の論文に合わせます。)
|
||||
|
||||
以下ごく簡単に説明します(詳しくは調べてください)。
|
||||
|
||||
classは学習対象の一般的な種別です。たとえば特定の犬種を学ばせる場合には、classはdogになります。アニメキャラならモデルによりboyやgirl、1boyや1girlになるでしょう。
|
||||
|
||||
identifierは学習対象を識別して学習するためのものです。任意の単語で構いませんが、元論文によると「tokinizerで1トークンになる3文字以下でレアな単語」が良いとのことです。
|
||||
|
||||
identifierとclassを使い、たとえば「shs dog」などでモデルを学習することで、学習させたい対象をclassから識別して学習できます。
|
||||
|
||||
画像生成時には「shs dog」とすれば学ばせた犬種の画像が生成されます。
|
||||
|
||||
(identifierとして私が最近使っているものを参考までに挙げると、``shs sts scs cpc coc cic msm usu ici lvl cic dii muk ori hru rik koo yos wny`` などです。本当は Danbooru Tag に含まれないやつがより望ましいです。)
|
||||
|
||||
## step 2. 正則化画像を使うか否かを決め、使う場合には正則化画像を生成する
|
||||
|
||||
正則化画像とは、前述のclass全体が、学習対象に引っ張られることを防ぐための画像です(language drift)。正則化画像を使わないと、たとえば `shs 1girl` で特定のキャラクタを学ばせると、単なる `1girl` というプロンプトで生成してもそのキャラに似てきます。これは `1girl` が学習時のキャプションに含まれているためです。
|
||||
|
||||
学習対象の画像と正則化画像を同時に学ばせることで、class は class のままで留まり、identifier をプロンプトにつけた時だけ学習対象が生成されるようになります。
|
||||
|
||||
LoRAやDreamBoothで特定のキャラだけ出てくればよい場合は、正則化画像を用いなくても良いといえます。
|
||||
|
||||
Textual Inversionでは用いなくてよいでしょう(学ばせる token string がキャプションに含まれない場合はなにも学習されないため)。
|
||||
|
||||
正則化画像としては、学習対象のモデルで、class 名だけで生成した画像を用いるのが一般的です(たとえば `1girl`)。ただし生成画像の品質が悪い場合には、プロンプトを工夫したり、ネットから別途ダウンロードした画像を用いることもできます。
|
||||
|
||||
(正則化画像も学習されるため、その品質はモデルに影響します。)
|
||||
|
||||
一般的には数百枚程度、用意するのが望ましいようです(枚数が少ないと class 画像が一般化されずそれらの特徴を学んでしまいます)。
|
||||
|
||||
生成画像を使う場合、通常、生成画像のサイズは学習解像度(より正確にはbucketの解像度、後述)にあわせてください。
|
||||
|
||||
## step 2. 設定ファイルの記述
|
||||
|
||||
テキストファイルを作成し、拡張子を `.toml` にします。たとえば以下のように記述します。
|
||||
|
||||
(`#` で始まっている部分はコメントですので、このままコピペしてそのままでもよいですし、削除しても問題ありません。)
|
||||
|
||||
```toml
|
||||
[general]
|
||||
enable_bucket = true # Aspect Ratio Bucketingを使うか否か
|
||||
|
||||
[[datasets]]
|
||||
resolution = 512 # 学習解像度
|
||||
batch_size = 4 # バッチサイズ
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\hoge' # 学習用画像を入れたフォルダを指定
|
||||
class_tokens = 'hoge girl' # identifier class を指定
|
||||
num_repeats = 10 # 学習用画像の繰り返し回数
|
||||
|
||||
# 以下は正則化画像を用いる場合のみ記述する。用いない場合は削除する
|
||||
[[datasets.subsets]]
|
||||
is_reg = true
|
||||
image_dir = 'C:\reg' # 正則化画像を入れたフォルダを指定
|
||||
class_tokens = 'girl' # class を指定
|
||||
num_repeats = 1 # 正則化画像の繰り返し回数、基本的には1でよい
|
||||
```
|
||||
|
||||
基本的には以下の場所のみ書き換えれば学習できます。
|
||||
|
||||
1. 学習解像度
|
||||
|
||||
数値1つを指定すると正方形(`512`なら512x512)、鍵カッコカンマ区切りで2つ指定すると横×縦(`[512,768]`なら512x768)になります。SD1.x系ではもともとの学習解像度は512です。`[512,768]` 等の大きめの解像度を指定すると縦長、横長画像生成時の破綻を小さくできるかもしれません。SD2.x 768系では `768` です。
|
||||
|
||||
1. バッチサイズ
|
||||
|
||||
同時に何件のデータを学習するかを指定します。GPUのVRAMサイズ、学習解像度によって変わってきます。詳しくは後述します。またfine tuning/DreamBooth/LoRA等でも変わってきますので各スクリプトの説明もご覧ください。
|
||||
|
||||
1. フォルダ指定
|
||||
|
||||
学習用画像、正則化画像(使用する場合のみ)のフォルダを指定します。画像データが含まれているフォルダそのものを指定します。
|
||||
|
||||
1. identifier と class の指定
|
||||
|
||||
前述のサンプルの通りです。
|
||||
|
||||
1. 繰り返し回数
|
||||
|
||||
後述します。
|
||||
|
||||
### 繰り返し回数について
|
||||
|
||||
繰り返し回数は、正則化画像の枚数と学習用画像の枚数を調整するために用いられます。正則化画像の枚数は学習用画像よりも多いため、学習用画像を繰り返して枚数を合わせ、1対1の比率で学習できるようにします。
|
||||
|
||||
繰り返し回数は「 __学習用画像の繰り返し回数×学習用画像の枚数≧正則化画像の繰り返し回数×正則化画像の枚数__ 」となるように指定してください。
|
||||
|
||||
(1 epoch(データが一周すると1 epoch)のデータ数が「学習用画像の繰り返し回数×学習用画像の枚数」となります。正則化画像の枚数がそれより多いと、余った部分の正則化画像は使用されません。)
|
||||
|
||||
## step 3. 学習
|
||||
|
||||
それぞれのドキュメントを参考に学習を行ってください。
|
||||
|
||||
# DreamBooth、キャプション方式(正則化画像使用可)
|
||||
|
||||
この方式では各画像はキャプションで学習されます。
|
||||
|
||||
## step 1. キャプションファイルを準備する
|
||||
|
||||
学習用画像のフォルダに、画像と同じファイル名で、拡張子 `.caption`(設定で変えられます)のファイルを置いてください。それぞれのファイルは1行のみとしてください。エンコーディングは `UTF-8` です。
|
||||
|
||||
## step 2. 正則化画像を使うか否かを決め、使う場合には正則化画像を生成する
|
||||
|
||||
class+identifier形式と同様です。なお正則化画像にもキャプションを付けることができますが、通常は不要でしょう。
|
||||
|
||||
## step 2. 設定ファイルの記述
|
||||
|
||||
テキストファイルを作成し、拡張子を `.toml` にします。たとえば以下のように記述します。
|
||||
|
||||
```toml
|
||||
[general]
|
||||
enable_bucket = true # Aspect Ratio Bucketingを使うか否か
|
||||
|
||||
[[datasets]]
|
||||
resolution = 512 # 学習解像度
|
||||
batch_size = 4 # バッチサイズ
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\hoge' # 学習用画像を入れたフォルダを指定
|
||||
caption_extension = '.caption' # キャプションファイルの拡張子 .txt を使う場合には書き換える
|
||||
num_repeats = 10 # 学習用画像の繰り返し回数
|
||||
|
||||
# 以下は正則化画像を用いる場合のみ記述する。用いない場合は削除する
|
||||
[[datasets.subsets]]
|
||||
is_reg = true
|
||||
image_dir = 'C:\reg' # 正則化画像を入れたフォルダを指定
|
||||
class_tokens = 'girl' # class を指定
|
||||
num_repeats = 1 # 正則化画像の繰り返し回数、基本的には1でよい
|
||||
```
|
||||
|
||||
基本的には以下を場所のみ書き換えれば学習できます。特に記述がない部分は class+identifier 方式と同じです。
|
||||
|
||||
1. 学習解像度
|
||||
1. バッチサイズ
|
||||
1. フォルダ指定
|
||||
1. キャプションファイルの拡張子
|
||||
|
||||
任意の拡張子を指定できます。
|
||||
1. 繰り返し回数
|
||||
|
||||
## step 3. 学習
|
||||
|
||||
それぞれのドキュメントを参考に学習を行ってください。
|
||||
|
||||
# fine tuning 方式
|
||||
|
||||
## step 1. メタデータを準備する
|
||||
|
||||
キャプションやタグをまとめた管理用ファイルをメタデータと呼びます。json形式で拡張子は `.json`
|
||||
です。作成方法は長くなりますのでこの文書の末尾に書きました。
|
||||
|
||||
## step 2. 設定ファイルの記述
|
||||
|
||||
テキストファイルを作成し、拡張子を `.toml` にします。たとえば以下のように記述します。
|
||||
|
||||
```toml
|
||||
[general]
|
||||
shuffle_caption = true
|
||||
keep_tokens = 1
|
||||
|
||||
[[datasets]]
|
||||
resolution = 512 # 学習解像度
|
||||
batch_size = 4 # バッチサイズ
|
||||
|
||||
[[datasets.subsets]]
|
||||
image_dir = 'C:\piyo' # 学習用画像を入れたフォルダを指定
|
||||
metadata_file = 'C:\piyo\piyo_md.json' # メタデータファイル名
|
||||
```
|
||||
|
||||
基本的には以下を場所のみ書き換えれば学習できます。特に記述がない部分は DreamBooth, class+identifier 方式と同じです。
|
||||
|
||||
1. 学習解像度
|
||||
1. バッチサイズ
|
||||
1. フォルダ指定
|
||||
1. メタデータファイル名
|
||||
|
||||
後述の方法で作成したメタデータファイルを指定します。
|
||||
|
||||
|
||||
## step 3. 学習
|
||||
|
||||
それぞれのドキュメントを参考に学習を行ってください。
|
||||
|
||||
# 学習で使われる用語のごく簡単な解説
|
||||
|
||||
細かいことは省略していますし私も完全には理解していないため、詳しくは各自お調べください。
|
||||
|
||||
## fine tuning(ファインチューニング)
|
||||
|
||||
モデルを学習して微調整することを指します。使われ方によって意味が異なってきますが、狭義のfine tuningはStable Diffusionの場合、モデルを画像とキャプションで学習することです。DreamBoothは狭義のfine tuningのひとつの特殊なやり方と言えます。広義のfine tuningは、LoRAやTextual Inversion、Hypernetworksなどを含み、モデルを学習することすべてを含みます。
|
||||
|
||||
## ステップ
|
||||
|
||||
ざっくりいうと学習データで1回計算すると1ステップです。「学習データのキャプションを今のモデルに流してみて、出てくる画像を学習データの画像と比較し、学習データに近づくようにモデルをわずかに変更する」のが1ステップです。
|
||||
|
||||
## バッチサイズ
|
||||
|
||||
バッチサイズは1ステップで何件のデータをまとめて計算するかを指定する値です。まとめて計算するため速度は相対的に向上します。また一般的には精度も高くなるといわれています。
|
||||
|
||||
`バッチサイズ×ステップ数` が学習に使われるデータの件数になります。そのため、バッチサイズを増やした分だけステップ数を減らすとよいでしょう。
|
||||
|
||||
(ただし、たとえば「バッチサイズ1で1600ステップ」と「バッチサイズ4で400ステップ」は同じ結果にはなりません。同じ学習率の場合、一般的には後者のほうが学習不足になります。学習率を多少大きくするか(たとえば `2e-6` など)、ステップ数をたとえば500ステップにするなどして工夫してください。)
|
||||
|
||||
バッチサイズを大きくするとその分だけGPUメモリを消費します。メモリが足りなくなるとエラーになりますし、エラーにならないギリギリでは学習速度が低下します。タスクマネージャーや `nvidia-smi` コマンドで使用メモリ量を確認しながら調整するとよいでしょう。
|
||||
|
||||
なお、バッチは「一塊のデータ」位の意味です。
|
||||
|
||||
## 学習率
|
||||
|
||||
ざっくりいうと1ステップごとにどのくらい変化させるかを表します。大きな値を指定するとそれだけ速く学習が進みますが、変化しすぎてモデルが壊れたり、最適な状態にまで至れない場合があります。小さい値を指定すると学習速度は遅くなり、また最適な状態にやはり至れない場合があります。
|
||||
|
||||
fine tuning、DreamBoooth、LoRAそれぞれで大きく異なり、また学習データや学習させたいモデル、バッチサイズやステップ数によっても変わってきます。一般的な値から初めて学習状態を見ながら増減してください。
|
||||
|
||||
デフォルトでは学習全体を通して学習率は固定です。スケジューラの指定で学習率をどう変化させるか決められますので、それらによっても結果は変わってきます。
|
||||
|
||||
## エポック(epoch)
|
||||
|
||||
学習データが一通り学習されると(データが一周すると)1 epochです。繰り返し回数を指定した場合は、その繰り返し後のデータが一周すると1 epochです。
|
||||
|
||||
1 epochのステップ数は、基本的には `データ件数÷バッチサイズ` ですが、Aspect Ratio Bucketing を使うと微妙に増えます(異なるbucketのデータは同じバッチにできないため、ステップ数が増えます)。
|
||||
|
||||
## Aspect Ratio Bucketing
|
||||
|
||||
Stable Diffusion のv1は512\*512で学習されていますが、それに加えて256\*1024や384\*640といった解像度でも学習します。これによりトリミングされる部分が減り、より正しくキャプションと画像の関係が学習されることが期待されます。
|
||||
|
||||
また任意の解像度で学習するため、事前に画像データの縦横比を統一しておく必要がなくなります。
|
||||
|
||||
設定で有効、向こうが切り替えられますが、ここまでの設定ファイルの記述例では有効になっています(`true` が設定されています)。
|
||||
|
||||
学習解像度はパラメータとして与えられた解像度の面積(=メモリ使用量)を超えない範囲で、64ピクセル単位(デフォルト、変更可)で縦横に調整、作成されます。
|
||||
|
||||
機械学習では入力サイズをすべて統一するのが一般的ですが、特に制約があるわけではなく、実際は同一のバッチ内で統一されていれば大丈夫です。NovelAIの言うbucketingは、あらかじめ教師データを、アスペクト比に応じた学習解像度ごとに分類しておくことを指しているようです。そしてバッチを各bucket内の画像で作成することで、バッチの画像サイズを統一します。
|
||||
|
||||
# 以前の指定形式(設定ファイルを用いずコマンドラインから指定)
|
||||
|
||||
`.toml` ファイルを指定せずコマンドラインオプションで指定する方法です。DreamBooth class+identifier方式、DreamBooth キャプション方式、fine tuning方式があります。
|
||||
|
||||
## DreamBooth、class+identifier方式
|
||||
|
||||
フォルダ名で繰り返し回数を指定します。また `train_data_dir` オプションと `reg_data_dir` オプションを用います。
|
||||
|
||||
### step 1. 学習用画像の準備
|
||||
|
||||
学習用画像を格納するフォルダを作成します。 __さらにその中に__ 、以下の名前でディレクトリを作成します。
|
||||
|
||||
```
|
||||
<繰り返し回数>_<identifier> <class>
|
||||
```
|
||||
|
||||
間の``_``を忘れないでください。
|
||||
|
||||
たとえば「sls frog」というプロンプトで、データを20回繰り返す場合、「20_sls frog」となります。以下のようになります。
|
||||
|
||||

|
||||
|
||||
### 複数class、複数対象(identifier)の学習
|
||||
|
||||
方法は単純で、学習用画像のフォルダ内に ``繰り返し回数_<identifier> <class>`` のフォルダを複数、正則化画像フォルダにも同様に ``繰り返し回数_<class>`` のフォルダを複数、用意してください。
|
||||
|
||||
たとえば「sls frog」と「cpc rabbit」を同時に学習する場合、以下のようになります。
|
||||
|
||||
|
||||
|
||||
classがひとつで対象が複数の場合、正則化画像フォルダはひとつで構いません。たとえば1girlにキャラAとキャラBがいる場合は次のようにします。
|
||||
|
||||
- train_girls
|
||||
- 10_sls 1girl
|
||||
- 10_cpc 1girl
|
||||
- reg_girls
|
||||
- 1_1girl
|
||||
|
||||
### step 2. 正則化画像の準備
|
||||
|
||||
正則化画像を使う場合の手順です。
|
||||
|
||||
正則化画像を格納するフォルダを作成します。 __さらにその中に__ ``<繰り返し回数>_<class>`` という名前でディレクトリを作成します。
|
||||
|
||||
たとえば「frog」というプロンプトで、データを繰り返さない(1回だけ)場合、以下のようになります。
|
||||
|
||||
|
||||
|
||||
|
||||
### step 3. 学習の実行
|
||||
|
||||
各学習スクリプトを実行します。 `--train_data_dir` オプションで前述の学習用データのフォルダを(__画像を含むフォルダではなく、その親フォルダ__)、`--reg_data_dir` オプションで正則化画像のフォルダ(__画像を含むフォルダではなく、その親フォルダ__)を指定してください。
|
||||
|
||||
## DreamBooth、キャプション方式
|
||||
|
||||
学習用画像、正則化画像のフォルダに、画像と同じファイル名で、拡張子.caption(オプションで変えられます)のファイルを置くと、そのファイルからキャプションを読み込みプロンプトとして学習します。
|
||||
|
||||
※それらの画像の学習に、フォルダ名(identifier class)は使用されなくなります。
|
||||
|
||||
キャプションファイルの拡張子はデフォルトで.captionです。学習スクリプトの `--caption_extension` オプションで変更できます。`--shuffle_caption` オプションで学習時のキャプションについて、カンマ区切りの各部分をシャッフルしながら学習します。
|
||||
|
||||
## fine tuning 方式
|
||||
|
||||
メタデータを作るところまでは設定ファイルを使う場合と同様です。`in_json` オプションでメタデータファイルを指定します。
|
||||
|
||||
# 学習途中でのサンプル出力
|
||||
|
||||
学習中のモデルで試しに画像生成することで学習の進み方を確認できます。学習スクリプトに以下のオプションを指定します。
|
||||
|
||||
- `--sample_every_n_steps` / `--sample_every_n_epochs`
|
||||
|
||||
サンプル出力するステップ数またはエポック数を指定します。この数ごとにサンプル出力します。両方指定するとエポック数が優先されます。
|
||||
|
||||
- `--sample_prompts`
|
||||
|
||||
サンプル出力用プロンプトのファイルを指定します。
|
||||
|
||||
- `--sample_sampler`
|
||||
|
||||
サンプル出力に使うサンプラーを指定します。
|
||||
`'ddim', 'pndm', 'heun', 'dpmsolver', 'dpmsolver++', 'dpmsingle', 'k_lms', 'k_euler', 'k_euler_a', 'k_dpm_2', 'k_dpm_2_a'`が選べます。
|
||||
|
||||
サンプル出力を行うにはあらかじめプロンプトを記述したテキストファイルを用意しておく必要があります。1行につき1プロンプトで記述します。
|
||||
|
||||
たとえば以下のようになります。
|
||||
|
||||
```txt
|
||||
# prompt 1
|
||||
masterpiece, best quality, 1girl, in white shirts, upper body, looking at viewer, simple background --n low quality, worst quality, bad anatomy,bad composition, poor, low effort --w 768 --h 768 --d 1 --l 7.5 --s 28
|
||||
|
||||
# prompt 2
|
||||
masterpiece, best quality, 1boy, in business suit, standing at street, looking back --n low quality, worst quality, bad anatomy,bad composition, poor, low effort --w 576 --h 832 --d 2 --l 5.5 --s 40
|
||||
```
|
||||
|
||||
先頭が `#` の行はコメントになります。`--n` のように 「`--` + 英小文字」で生成画像へのオプションを指定できます。以下が使えます。
|
||||
|
||||
- `--n` 次のオプションまでをネガティブプロンプトとします。
|
||||
- `--w` 生成画像の横幅を指定します。
|
||||
- `--h` 生成画像の高さを指定します。
|
||||
- `--d` 生成画像のseedを指定します。
|
||||
- `--l` 生成画像のCFG scaleを指定します。
|
||||
- `--s` 生成時のステップ数を指定します。
|
||||
|
||||
|
||||
# 各スクリプトで共通の、よく使われるオプション
|
||||
|
||||
スクリプトの更新後、ドキュメントの更新が追い付いていない場合があります。その場合は `--help` オプションで使用できるオプションを確認してください。
|
||||
|
||||
## 学習に使うモデル指定
|
||||
|
||||
- `--v2` / `--v_parameterization`
|
||||
|
||||
学習対象モデルとしてHugging Faceのstable-diffusion-2-base、またはそこからのfine tuningモデルを使う場合(推論時に `v2-inference.yaml` を使うように指示されているモデルの場合)は `--v2` オプションを、stable-diffusion-2や768-v-ema.ckpt、およびそれらのfine tuningモデルを使う場合(推論時に `v2-inference-v.yaml` を使うモデルの場合)は `--v2` と `--v_parameterization` の両方のオプションを指定してください。
|
||||
|
||||
Stable Diffusion 2.0では大きく以下の点が変わっています。
|
||||
|
||||
1. 使用するTokenizer
|
||||
2. 使用するText Encoderおよび使用する出力層(2.0は最後から二番目の層を使う)
|
||||
3. Text Encoderの出力次元数(768->1024)
|
||||
4. U-Netの構造(CrossAttentionのhead数など)
|
||||
5. v-parameterization(サンプリング方法が変更されているらしい)
|
||||
|
||||
このうちbaseでは1~4が、baseのつかない方(768-v)では1~5が採用されています。1~4を有効にするのがv2オプション、5を有効にするのがv_parameterizationオプションです。
|
||||
|
||||
- `--pretrained_model_name_or_path`
|
||||
|
||||
追加学習を行う元となるモデルを指定します。Stable Diffusionのcheckpointファイル(.ckptまたは.safetensors)、Diffusersのローカルディスクにあるモデルディレクトリ、DiffusersのモデルID("stabilityai/stable-diffusion-2"など)が指定できます。
|
||||
|
||||
## 学習に関する設定
|
||||
|
||||
- `--output_dir`
|
||||
|
||||
学習後のモデルを保存するフォルダを指定します。
|
||||
|
||||
- `--output_name`
|
||||
|
||||
モデルのファイル名を拡張子を除いて指定します。
|
||||
|
||||
- `--dataset_config`
|
||||
|
||||
データセットの設定を記述した `.toml` ファイルを指定します。
|
||||
|
||||
- `--max_train_steps` / `--max_train_epochs`
|
||||
|
||||
学習するステップ数やエポック数を指定します。両方指定するとエポック数のほうが優先されます。
|
||||
|
||||
- `--mixed_precision`
|
||||
|
||||
省メモリ化のため mixed precision (混合精度)で学習します。`--mixed_precision="fp16"` のように指定します。mixed precision なし(デフォルト)と比べて精度が低くなる可能性がありますが、学習に必要なGPUメモリ量が大きく減ります。
|
||||
|
||||
(RTX30 シリーズ以降では `bf16` も指定できます。環境整備時にaccelerateに行った設定と合わせてください)。
|
||||
|
||||
- `--gradient_checkpointing`
|
||||
|
||||
学習時の重みの計算をまとめて行うのではなく少しずつ行うことで、学習に必要なGPUメモリ量を減らします。オンオフは精度には影響しませんが、オンにするとバッチサイズを大きくできるため、そちらでの影響はあります。
|
||||
|
||||
また一般的にはオンにすると速度は低下しますが、バッチサイズを大きくできるので、トータルでの学習時間はむしろ速くなるかもしれません。
|
||||
|
||||
- `--xformers` / `--mem_eff_attn`
|
||||
|
||||
xformersオプションを指定するとxformersのCrossAttentionを用います。xformersをインストールしていない場合やエラーとなる場合(環境にもよりますが `mixed_precision="no"` の場合など)、代わりに `mem_eff_attn` オプションを指定すると省メモリ版CrossAttentionを使用します(xformersよりも速度は遅くなります)。
|
||||
|
||||
- `--save_precision`
|
||||
|
||||
保存時のデータ精度を指定します。save_precisionオプションにfloat、fp16、bf16のいずれかを指定すると、その形式でモデルを保存します(DreamBooth、fine tuningでDiffusers形式でモデルを保存する場合は無効です)。モデルのサイズを削減したい場合などにお使いください。
|
||||
|
||||
- `--save_every_n_epochs` / `--save_state` / `--resume`
|
||||
save_every_n_epochsオプションに数値を指定すると、そのエポックごとに学習途中のモデルを保存します。
|
||||
|
||||
save_stateオプションを同時に指定すると、optimizer等の状態も含めた学習状態を合わせて保存します(保存したモデルからも学習再開できますが、それに比べると精度の向上、学習時間の短縮が期待できます)。保存先はフォルダになります。
|
||||
|
||||
学習状態は保存先フォルダに `<output_name>-??????-state`(??????はエポック数)という名前のフォルダで出力されます。長時間にわたる学習時にご利用ください。
|
||||
|
||||
保存された学習状態から学習を再開するにはresumeオプションを使います。学習状態のフォルダ(`output_dir` ではなくその中のstateのフォルダ)を指定してください。
|
||||
|
||||
なおAcceleratorの仕様により、エポック数、global stepは保存されておらず、resumeしたときにも1からになりますがご容赦ください。
|
||||
|
||||
- `--save_model_as` (DreamBooth, fine tuning のみ)
|
||||
|
||||
モデルの保存形式を`ckpt, safetensors, diffusers, diffusers_safetensors` から選べます。
|
||||
|
||||
`--save_model_as=safetensors` のように指定します。Stable Diffusion形式(ckptまたはsafetensors)を読み込み、Diffusers形式で保存する場合、不足する情報はHugging Faceからv1.5またはv2.1の情報を落としてきて補完します。
|
||||
|
||||
- `--clip_skip`
|
||||
|
||||
`2` を指定すると、Text Encoder (CLIP) の後ろから二番目の層の出力を用います。1またはオプション省略時は最後の層を用います。
|
||||
|
||||
※SD2.0はデフォルトで後ろから二番目の層を使うため、SD2.0の学習では指定しないでください。
|
||||
|
||||
学習対象のモデルがもともと二番目の層を使うように学習されている場合は、2を指定するとよいでしょう。
|
||||
|
||||
そうではなく最後の層を使用していた場合はモデル全体がそれを前提に学習されています。そのため改めて二番目の層を使用して学習すると、望ましい学習結果を得るにはある程度の枚数の教師データ、長めの学習が必要になるかもしれません。
|
||||
|
||||
- `--max_token_length`
|
||||
|
||||
デフォルトは75です。`150` または `225` を指定することでトークン長を拡張して学習できます。長いキャプションで学習する場合に指定してください。
|
||||
|
||||
ただし学習時のトークン拡張の仕様は Automatic1111 氏のWeb UIとは微妙に異なるため(分割の仕様など)、必要なければ75で学習することをお勧めします。
|
||||
|
||||
clip_skipと同様に、モデルの学習状態と異なる長さで学習するには、ある程度の教師データ枚数、長めの学習時間が必要になると思われます。
|
||||
|
||||
- `--persistent_data_loader_workers`
|
||||
|
||||
Windows環境で指定するとエポック間の待ち時間が大幅に短縮されます。
|
||||
|
||||
- `--max_data_loader_n_workers`
|
||||
|
||||
データ読み込みのプロセス数を指定します。プロセス数が多いとデータ読み込みが速くなりGPUを効率的に利用できますが、メインメモリを消費します。デフォルトは「`8` または `CPU同時実行スレッド数-1` の小さいほう」なので、メインメモリに余裕がない場合や、GPU使用率が90%程度以上なら、それらの数値を見ながら `2` または `1` 程度まで下げてください。
|
||||
|
||||
- `--logging_dir` / `--log_prefix`
|
||||
|
||||
学習ログの保存に関するオプションです。logging_dirオプションにログ保存先フォルダを指定してください。TensorBoard形式のログが保存されます。
|
||||
|
||||
たとえば--logging_dir=logsと指定すると、作業フォルダにlogsフォルダが作成され、その中の日時フォルダにログが保存されます。
|
||||
また--log_prefixオプションを指定すると、日時の前に指定した文字列が追加されます。「--logging_dir=logs --log_prefix=db_style1_」などとして識別用にお使いください。
|
||||
|
||||
TensorBoardでログを確認するには、別のコマンドプロンプトを開き、作業フォルダで以下のように入力します。
|
||||
|
||||
```
|
||||
tensorboard --logdir=logs
|
||||
```
|
||||
|
||||
(tensorboardは環境整備時にあわせてインストールされると思いますが、もし入っていないなら `pip install tensorboard` で入れてください。)
|
||||
|
||||
その後ブラウザを開き、http://localhost:6006/ へアクセスすると表示されます。
|
||||
|
||||
- `--noise_offset`
|
||||
|
||||
こちらの記事の実装になります: https://www.crosslabs.org//blog/diffusion-with-offset-noise
|
||||
|
||||
全体的に暗い、明るい画像の生成結果が良くなる可能性があるようです。LoRA学習でも有効なようです。`0.1` 程度の値を指定するとよいようです。
|
||||
|
||||
- `--debug_dataset`
|
||||
|
||||
このオプションを付けることで学習を行う前に事前にどのような画像データ、キャプションで学習されるかを確認できます。Escキーを押すと終了してコマンドラインに戻ります。
|
||||
|
||||
※Linux環境(Colabを含む)では画像は表示されません。
|
||||
|
||||
- `--vae`
|
||||
|
||||
vaeオプションにStable Diffusionのcheckpoint、VAEのcheckpointファイル、DiffusesのモデルまたはVAE(ともにローカルまたはHugging FaceのモデルIDが指定できます)のいずれかを指定すると、そのVAEを使って学習します(latentsのキャッシュ時または学習中のlatents取得時)。
|
||||
|
||||
DreamBoothおよびfine tuningでは、保存されるモデルはこのVAEを組み込んだものになります。
|
||||
|
||||
|
||||
## オプティマイザ関係
|
||||
|
||||
- `--optimizer_type`
|
||||
--オプティマイザの種類を指定します。以下が指定できます。
|
||||
- AdamW : [torch.optim.AdamW](https://pytorch.org/docs/stable/generated/torch.optim.AdamW.html)
|
||||
- 過去のバージョンのオプション未指定時と同じ
|
||||
- AdamW8bit : 引数は同上
|
||||
- 過去のバージョンの--use_8bit_adam指定時と同じ
|
||||
- Lion : https://github.com/lucidrains/lion-pytorch
|
||||
- 過去のバージョンの--use_lion_optimizer指定時と同じ
|
||||
- SGDNesterov : [torch.optim.SGD](https://pytorch.org/docs/stable/generated/torch.optim.SGD.html), nesterov=True
|
||||
- SGDNesterov8bit : 引数は同上
|
||||
- DAdaptation : https://github.com/facebookresearch/dadaptation
|
||||
- AdaFactor : [Transformers AdaFactor](https://huggingface.co/docs/transformers/main_classes/optimizer_schedules)
|
||||
- 任意のオプティマイザ
|
||||
|
||||
- `--learning_rate`
|
||||
|
||||
学習率を指定します。適切な学習率は学習スクリプトにより異なりますので、それぞれの説明を参照してください。
|
||||
|
||||
- `--lr_scheduler` / `--lr_warmup_steps` / `--lr_scheduler_num_cycles` / `--lr_scheduler_power`
|
||||
|
||||
学習率のスケジューラ関連の指定です。
|
||||
|
||||
lr_schedulerオプションで学習率のスケジューラをlinear, cosine, cosine_with_restarts, polynomial, constant, constant_with_warmupから選べます。デフォルトはconstantです。
|
||||
|
||||
lr_warmup_stepsでスケジューラのウォームアップ(だんだん学習率を変えていく)ステップ数を指定できます。
|
||||
|
||||
lr_scheduler_num_cycles は cosine with restartsスケジューラでのリスタート回数、lr_scheduler_power は polynomialスケジューラでのpolynomial power です。
|
||||
|
||||
詳細については各自お調べください。
|
||||
|
||||
### オプティマイザの指定について
|
||||
|
||||
オプティマイザのオプション引数は--optimizer_argsオプションで指定してください。key=valueの形式で、複数の値が指定できます。また、valueはカンマ区切りで複数の値が指定できます。たとえばAdamWオプティマイザに引数を指定する場合は、``--optimizer_args weight_decay=0.01 betas=.9,.999``のようになります。
|
||||
|
||||
オプション引数を指定する場合は、それぞれのオプティマイザの仕様をご確認ください。
|
||||
|
||||
一部のオプティマイザでは必須の引数があり、省略すると自動的に追加されます(SGDNesterovのmomentumなど)。コンソールの出力を確認してください。
|
||||
|
||||
D-Adaptationオプティマイザは学習率を自動調整します。学習率のオプションに指定した値は学習率そのものではなくD-Adaptationが決定した学習率の適用率になりますので、通常は1.0を指定してください。Text EncoderにU-Netの半分の学習率を指定したい場合は、``--text_encoder_lr=0.5 --unet_lr=1.0``と指定します。
|
||||
|
||||
AdaFactorオプティマイザはrelative_step=Trueを指定すると学習率を自動調整できます(省略時はデフォルトで追加されます)。自動調整する場合は学習率のスケジューラにはadafactor_schedulerが強制的に使用されます。またscale_parameterとwarmup_initを指定するとよいようです。
|
||||
|
||||
自動調整する場合のオプション指定はたとえば ``--optimizer_args "relative_step=True" "scale_parameter=True" "warmup_init=True"`` のようになります。
|
||||
|
||||
学習率を自動調整しない場合はオプション引数 ``relative_step=False`` を追加してください。その場合、学習率のスケジューラにはconstant_with_warmupが、また勾配のclip normをしないことが推奨されているようです。そのため引数は ``--optimizer_type=adafactor --optimizer_args "relative_step=False" --lr_scheduler="constant_with_warmup" --max_grad_norm=0.0`` のようになります。
|
||||
|
||||
### 任意のオプティマイザを使う
|
||||
|
||||
``torch.optim`` のオプティマイザを使う場合にはクラス名のみを(``--optimizer_type=RMSprop``など)、他のモジュールのオプティマイザを使う時は「モジュール名.クラス名」を指定してください(``--optimizer_type=bitsandbytes.optim.lamb.LAMB``など)。
|
||||
|
||||
(内部でimportlibしているだけで動作は未確認です。必要ならパッケージをインストールしてください。)
|
||||
|
||||
|
||||
<!--
|
||||
## 任意サイズの画像での学習 --resolution
|
||||
正方形以外で学習できます。resolutionに「448,640」のように「幅,高さ」で指定してください。幅と高さは64で割り切れる必要があります。学習用画像、正則化画像のサイズを合わせてください。
|
||||
|
||||
個人的には縦長の画像を生成することが多いため「448,640」などで学習することもあります。
|
||||
|
||||
## Aspect Ratio Bucketing --enable_bucket / --min_bucket_reso / --max_bucket_reso
|
||||
enable_bucketオプションを指定すると有効になります。Stable Diffusionは512x512で学習されていますが、それに加えて256x768や384x640といった解像度でも学習します。
|
||||
|
||||
このオプションを指定した場合は、学習用画像、正則化画像を特定の解像度に統一する必要はありません。いくつかの解像度(アスペクト比)から最適なものを選び、その解像度で学習します。
|
||||
解像度は64ピクセル単位のため、元画像とアスペクト比が完全に一致しない場合がありますが、その場合は、はみ出した部分がわずかにトリミングされます。
|
||||
|
||||
解像度の最小サイズをmin_bucket_resoオプションで、最大サイズをmax_bucket_resoで指定できます。デフォルトはそれぞれ256、1024です。
|
||||
たとえば最小サイズに384を指定すると、256x1024や320x768などの解像度は使わなくなります。
|
||||
解像度を768x768のように大きくした場合、最大サイズに1280などを指定しても良いかもしれません。
|
||||
|
||||
なおAspect Ratio Bucketingを有効にするときには、正則化画像についても、学習用画像と似た傾向の様々な解像度を用意した方がいいかもしれません。
|
||||
|
||||
(ひとつのバッチ内の画像が学習用画像、正則化画像に偏らなくなるため。そこまで大きな影響はないと思いますが……。)
|
||||
|
||||
## augmentation --color_aug / --flip_aug
|
||||
augmentationは学習時に動的にデータを変化させることで、モデルの性能を上げる手法です。color_augで色合いを微妙に変えつつ、flip_augで左右反転をしつつ、学習します。
|
||||
|
||||
動的にデータを変化させるため、cache_latentsオプションと同時に指定できません。
|
||||
|
||||
|
||||
## 勾配をfp16とした学習(実験的機能) --full_fp16
|
||||
full_fp16オプションを指定すると勾配を通常のfloat32からfloat16(fp16)に変更して学習します(mixed precisionではなく完全なfp16学習になるようです)。
|
||||
これによりSD1.xの512x512サイズでは8GB未満、SD2.xの512x512サイズで12GB未満のVRAM使用量で学習できるようです。
|
||||
|
||||
あらかじめaccelerate configでfp16を指定し、オプションで ``mixed_precision="fp16"`` としてください(bf16では動作しません)。
|
||||
|
||||
メモリ使用量を最小化するためには、xformers、use_8bit_adam、cache_latents、gradient_checkpointingの各オプションを指定し、train_batch_sizeを1としてください。
|
||||
|
||||
(余裕があるようならtrain_batch_sizeを段階的に増やすと若干精度が上がるはずです。)
|
||||
|
||||
PyTorchのソースにパッチを当てて無理やり実現しています(PyTorch 1.12.1と1.13.0で確認)。精度はかなり落ちますし、途中で学習失敗する確率も高くなります。
|
||||
学習率やステップ数の設定もシビアなようです。それらを認識したうえで自己責任でお使いください。
|
||||
|
||||
-->
|
||||
|
||||
# メタデータファイルの作成
|
||||
|
||||
## 教師データの用意
|
||||
|
||||
前述のように学習させたい画像データを用意し、任意のフォルダに入れてください。
|
||||
|
||||
たとえば以下のように画像を格納します。
|
||||
|
||||

|
||||
|
||||
## 自動キャプショニング
|
||||
|
||||
キャプションを使わずタグだけで学習する場合はスキップしてください。
|
||||
|
||||
また手動でキャプションを用意する場合、キャプションは教師データ画像と同じディレクトリに、同じファイル名、拡張子.caption等で用意してください。各ファイルは1行のみのテキストファイルとします。
|
||||
|
||||
### BLIPによるキャプショニング
|
||||
|
||||
最新版ではBLIPのダウンロード、重みのダウンロード、仮想環境の追加は不要になりました。そのままで動作します。
|
||||
|
||||
finetuneフォルダ内のmake_captions.pyを実行します。
|
||||
|
||||
```
|
||||
python finetune\make_captions.py --batch_size <バッチサイズ> <教師データフォルダ>
|
||||
```
|
||||
|
||||
バッチサイズ8、教師データを親フォルダのtrain_dataに置いた場合、以下のようになります。
|
||||
|
||||
```
|
||||
python finetune\make_captions.py --batch_size 8 ..\train_data
|
||||
```
|
||||
|
||||
キャプションファイルが教師データ画像と同じディレクトリに、同じファイル名、拡張子.captionで作成されます。
|
||||
|
||||
batch_sizeはGPUのVRAM容量に応じて増減してください。大きいほうが速くなります(VRAM 12GBでももう少し増やせると思います)。
|
||||
max_lengthオプションでキャプションの最大長を指定できます。デフォルトは75です。モデルをトークン長225で学習する場合には長くしても良いかもしれません。
|
||||
caption_extensionオプションでキャプションの拡張子を変更できます。デフォルトは.captionです(.txtにすると後述のDeepDanbooruと競合します)。
|
||||
|
||||
複数の教師データフォルダがある場合には、それぞれのフォルダに対して実行してください。
|
||||
|
||||
なお、推論にランダム性があるため、実行するたびに結果が変わります。固定する場合には--seedオプションで `--seed 42` のように乱数seedを指定してください。
|
||||
|
||||
その他のオプションは `--help` でヘルプをご参照ください(パラメータの意味についてはドキュメントがまとまっていないようで、ソースを見るしかないようです)。
|
||||
|
||||
デフォルトでは拡張子.captionでキャプションファイルが生成されます。
|
||||
|
||||

|
||||
|
||||
たとえば以下のようなキャプションが付きます。
|
||||
|
||||

|
||||
|
||||
## DeepDanbooruによるタグ付け
|
||||
|
||||
danbooruタグのタグ付け自体を行わない場合は「キャプションとタグ情報の前処理」に進んでください。
|
||||
|
||||
タグ付けはDeepDanbooruまたはWD14Taggerで行います。WD14Taggerのほうが精度が良いようです。WD14Taggerでタグ付けする場合は、次の章へ進んでください。
|
||||
|
||||
### 環境整備
|
||||
|
||||
DeepDanbooru https://github.com/KichangKim/DeepDanbooru を作業フォルダにcloneしてくるか、zipをダウンロードして展開します。私はzipで展開しました。
|
||||
またDeepDanbooruのReleasesのページ https://github.com/KichangKim/DeepDanbooru/releases の「DeepDanbooru Pretrained Model v3-20211112-sgd-e28」のAssetsから、deepdanbooru-v3-20211112-sgd-e28.zipをダウンロードしてきてDeepDanbooruのフォルダに展開します。
|
||||
|
||||
以下からダウンロードします。Assetsをクリックして開き、そこからダウンロードします。
|
||||
|
||||

|
||||
|
||||
以下のようなこういうディレクトリ構造にしてください
|
||||
|
||||

|
||||
|
||||
Diffusersの環境に必要なライブラリをインストールします。DeepDanbooruのフォルダに移動してインストールします(実質的にはtensorflow-ioが追加されるだけだと思います)。
|
||||
|
||||
```
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
続いてDeepDanbooru自体をインストールします。
|
||||
|
||||
```
|
||||
pip install .
|
||||
```
|
||||
|
||||
以上でタグ付けの環境整備は完了です。
|
||||
|
||||
### タグ付けの実施
|
||||
DeepDanbooruのフォルダに移動し、deepdanbooruを実行してタグ付けを行います。
|
||||
|
||||
```
|
||||
deepdanbooru evaluate <教師データフォルダ> --project-path deepdanbooru-v3-20211112-sgd-e28 --allow-folder --save-txt
|
||||
```
|
||||
|
||||
教師データを親フォルダのtrain_dataに置いた場合、以下のようになります。
|
||||
|
||||
```
|
||||
deepdanbooru evaluate ../train_data --project-path deepdanbooru-v3-20211112-sgd-e28 --allow-folder --save-txt
|
||||
```
|
||||
|
||||
タグファイルが教師データ画像と同じディレクトリに、同じファイル名、拡張子.txtで作成されます。1件ずつ処理されるためわりと遅いです。
|
||||
|
||||
複数の教師データフォルダがある場合には、それぞれのフォルダに対して実行してください。
|
||||
|
||||
以下のように生成されます。
|
||||
|
||||

|
||||
|
||||
こんな感じにタグが付きます(すごい情報量……)。
|
||||
|
||||

|
||||
|
||||
## WD14Taggerによるタグ付け
|
||||
|
||||
DeepDanbooruの代わりにWD14Taggerを用いる手順です。
|
||||
|
||||
Automatic1111氏のWebUIで使用しているtaggerを利用します。こちらのgithubページ(https://github.com/toriato/stable-diffusion-webui-wd14-tagger#mrsmilingwolfs-model-aka-waifu-diffusion-14-tagger )の情報を参考にさせていただきました。
|
||||
|
||||
最初の環境整備で必要なモジュールはインストール済みです。また重みはHugging Faceから自動的にダウンロードしてきます。
|
||||
|
||||
### タグ付けの実施
|
||||
|
||||
スクリプトを実行してタグ付けを行います。
|
||||
```
|
||||
python tag_images_by_wd14_tagger.py --batch_size <バッチサイズ> <教師データフォルダ>
|
||||
```
|
||||
|
||||
教師データを親フォルダのtrain_dataに置いた場合、以下のようになります。
|
||||
```
|
||||
python tag_images_by_wd14_tagger.py --batch_size 4 ..\train_data
|
||||
```
|
||||
|
||||
初回起動時にはモデルファイルがwd14_tagger_modelフォルダに自動的にダウンロードされます(フォルダはオプションで変えられます)。以下のようになります。
|
||||
|
||||

|
||||
|
||||
タグファイルが教師データ画像と同じディレクトリに、同じファイル名、拡張子.txtで作成されます。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
threshオプションで、判定されたタグのconfidence(確信度)がいくつ以上でタグをつけるかが指定できます。デフォルトはWD14Taggerのサンプルと同じ0.35です。値を下げるとより多くのタグが付与されますが、精度は下がります。
|
||||
|
||||
batch_sizeはGPUのVRAM容量に応じて増減してください。大きいほうが速くなります(VRAM 12GBでももう少し増やせると思います)。caption_extensionオプションでタグファイルの拡張子を変更できます。デフォルトは.txtです。
|
||||
|
||||
model_dirオプションでモデルの保存先フォルダを指定できます。
|
||||
|
||||
またforce_downloadオプションを指定すると保存先フォルダがあってもモデルを再ダウンロードします。
|
||||
|
||||
複数の教師データフォルダがある場合には、それぞれのフォルダに対して実行してください。
|
||||
|
||||
## キャプションとタグ情報の前処理
|
||||
|
||||
スクリプトから処理しやすいようにキャプションとタグをメタデータとしてひとつのファイルにまとめます。
|
||||
|
||||
### キャプションの前処理
|
||||
|
||||
キャプションをメタデータに入れるには、作業フォルダ内で以下を実行してください(キャプションを学習に使わない場合は実行不要です)(実際は1行で記述します、以下同様)。`--full_path` オプションを指定してメタデータに画像ファイルの場所をフルパスで格納します。このオプションを省略すると相対パスで記録されますが、フォルダ指定が `.toml` ファイル内で別途必要になります。
|
||||
|
||||
```
|
||||
python merge_captions_to_metadata.py --full_apth <教師データフォルダ>
|
||||
--in_json <読み込むメタデータファイル名> <メタデータファイル名>
|
||||
```
|
||||
|
||||
メタデータファイル名は任意の名前です。
|
||||
教師データがtrain_data、読み込むメタデータファイルなし、メタデータファイルがmeta_cap.jsonの場合、以下のようになります。
|
||||
|
||||
```
|
||||
python merge_captions_to_metadata.py --full_path train_data meta_cap.json
|
||||
```
|
||||
|
||||
caption_extensionオプションでキャプションの拡張子を指定できます。
|
||||
|
||||
複数の教師データフォルダがある場合には、full_path引数を指定しつつ、それぞれのフォルダに対して実行してください。
|
||||
|
||||
```
|
||||
python merge_captions_to_metadata.py --full_path
|
||||
train_data1 meta_cap1.json
|
||||
python merge_captions_to_metadata.py --full_path --in_json meta_cap1.json
|
||||
train_data2 meta_cap2.json
|
||||
```
|
||||
|
||||
in_jsonを省略すると書き込み先メタデータファイルがあるとそこから読み込み、そこに上書きします。
|
||||
|
||||
__※in_jsonオプションと書き込み先を都度書き換えて、別のメタデータファイルへ書き出すようにすると安全です。__
|
||||
|
||||
### タグの前処理
|
||||
|
||||
同様にタグもメタデータにまとめます(タグを学習に使わない場合は実行不要です)。
|
||||
```
|
||||
python merge_dd_tags_to_metadata.py --full_path <教師データフォルダ>
|
||||
--in_json <読み込むメタデータファイル名> <書き込むメタデータファイル名>
|
||||
```
|
||||
|
||||
先と同じディレクトリ構成で、meta_cap.jsonを読み、meta_cap_dd.jsonに書きだす場合、以下となります。
|
||||
```
|
||||
python merge_dd_tags_to_metadata.py --full_path train_data --in_json meta_cap.json meta_cap_dd.json
|
||||
```
|
||||
|
||||
複数の教師データフォルダがある場合には、full_path引数を指定しつつ、それぞれのフォルダに対して実行してください。
|
||||
|
||||
```
|
||||
python merge_dd_tags_to_metadata.py --full_path --in_json meta_cap2.json
|
||||
train_data1 meta_cap_dd1.json
|
||||
python merge_dd_tags_to_metadata.py --full_path --in_json meta_cap_dd1.json
|
||||
train_data2 meta_cap_dd2.json
|
||||
```
|
||||
|
||||
in_jsonを省略すると書き込み先メタデータファイルがあるとそこから読み込み、そこに上書きします。
|
||||
|
||||
__※in_jsonオプションと書き込み先を都度書き換えて、別のメタデータファイルへ書き出すようにすると安全です。__
|
||||
|
||||
### キャプションとタグのクリーニング
|
||||
|
||||
ここまででメタデータファイルにキャプションとDeepDanbooruのタグがまとめられています。ただ自動キャプショニングにしたキャプションは表記ゆれなどがあり微妙(※)ですし、タグにはアンダースコアが含まれていたりratingが付いていたりしますので(DeepDanbooruの場合)、エディタの置換機能などを用いてキャプションとタグのクリーニングをしたほうがいいでしょう。
|
||||
|
||||
※たとえばアニメ絵の少女を学習する場合、キャプションにはgirl/girls/woman/womenなどのばらつきがあります。また「anime girl」なども単に「girl」としたほうが適切かもしれません。
|
||||
|
||||
クリーニング用のスクリプトが用意してありますので、スクリプトの内容を状況に応じて編集してお使いください。
|
||||
|
||||
(教師データフォルダの指定は不要になりました。メタデータ内の全データをクリーニングします。)
|
||||
|
||||
```
|
||||
python clean_captions_and_tags.py <読み込むメタデータファイル名> <書き込むメタデータファイル名>
|
||||
```
|
||||
|
||||
--in_jsonは付きませんのでご注意ください。たとえば次のようになります。
|
||||
|
||||
```
|
||||
python clean_captions_and_tags.py meta_cap_dd.json meta_clean.json
|
||||
```
|
||||
|
||||
以上でキャプションとタグの前処理は完了です。
|
||||
|
||||
## latentsの事前取得
|
||||
|
||||
※ このステップは必須ではありません。省略しても学習時にlatentsを取得しながら学習できます。
|
||||
また学習時に `random_crop` や `color_aug` などを行う場合にはlatentsの事前取得はできません(画像を毎回変えながら学習するため)。事前取得をしない場合、ここまでのメタデータで学習できます。
|
||||
|
||||
あらかじめ画像の潜在表現を取得しディスクに保存しておきます。それにより、学習を高速に進めることができます。あわせてbucketing(教師データをアスペクト比に応じて分類する)を行います。
|
||||
|
||||
作業フォルダで以下のように入力してください。
|
||||
```
|
||||
python prepare_buckets_latents.py --full_path <教師データフォルダ>
|
||||
<読み込むメタデータファイル名> <書き込むメタデータファイル名>
|
||||
<fine tuningするモデル名またはcheckpoint>
|
||||
--batch_size <バッチサイズ>
|
||||
--max_resolution <解像度 幅,高さ>
|
||||
--mixed_precision <精度>
|
||||
```
|
||||
|
||||
モデルがmodel.ckpt、バッチサイズ4、学習解像度は512\*512、精度no(float32)で、meta_clean.jsonからメタデータを読み込み、meta_lat.jsonに書き込む場合、以下のようになります。
|
||||
|
||||
```
|
||||
python prepare_buckets_latents.py --full_path
|
||||
train_data meta_clean.json meta_lat.json model.ckpt
|
||||
--batch_size 4 --max_resolution 512,512 --mixed_precision no
|
||||
```
|
||||
|
||||
教師データフォルダにnumpyのnpz形式でlatentsが保存されます。
|
||||
|
||||
解像度の最小サイズを--min_bucket_resoオプションで、最大サイズを--max_bucket_resoで指定できます。デフォルトはそれぞれ256、1024です。たとえば最小サイズに384を指定すると、256\*1024や320\*768などの解像度は使わなくなります。
|
||||
解像度を768\*768のように大きくした場合、最大サイズに1280などを指定すると良いでしょう。
|
||||
|
||||
--flip_augオプションを指定すると左右反転のaugmentation(データ拡張)を行います。疑似的にデータ量を二倍に増やすことができますが、データが左右対称でない場合に指定すると(例えばキャラクタの外見、髪型など)学習がうまく行かなくなります。
|
||||
|
||||
|
||||
(反転した画像についてもlatentsを取得し、\*\_flip.npzファイルを保存する単純な実装です。fline_tune.pyには特にオプション指定は必要ありません。\_flip付きのファイルがある場合、flip付き・なしのファイルを、ランダムに読み込みます。)
|
||||
|
||||
バッチサイズはVRAM 12GBでももう少し増やせるかもしれません。
|
||||
解像度は64で割り切れる数字で、"幅,高さ"で指定します。解像度はfine tuning時のメモリサイズに直結します。VRAM 12GBでは512,512が限界と思われます(※)。16GBなら512,704や512,768まで上げられるかもしれません。なお256,256等にしてもVRAM 8GBでは厳しいようです(パラメータやoptimizerなどは解像度に関係せず一定のメモリが必要なため)。
|
||||
|
||||
※batch size 1の学習で12GB VRAM、640,640で動いたとの報告もありました。
|
||||
|
||||
以下のようにbucketingの結果が表示されます。
|
||||
|
||||

|
||||
|
||||
複数の教師データフォルダがある場合には、full_path引数を指定しつつ、それぞれのフォルダに対して実行してください。
|
||||
```
|
||||
python prepare_buckets_latents.py --full_path
|
||||
train_data1 meta_clean.json meta_lat1.json model.ckpt
|
||||
--batch_size 4 --max_resolution 512,512 --mixed_precision no
|
||||
|
||||
python prepare_buckets_latents.py --full_path
|
||||
train_data2 meta_lat1.json meta_lat2.json model.ckpt
|
||||
--batch_size 4 --max_resolution 512,512 --mixed_precision no
|
||||
|
||||
```
|
||||
読み込み元と書き込み先を同じにすることも可能ですが別々の方が安全です。
|
||||
|
||||
__※引数を都度書き換えて、別のメタデータファイルに書き込むと安全です。__
|
||||
|
||||
1181
train_db.py
1181
train_db.py
File diff suppressed because it is too large
Load Diff
167
train_db_README-ja.md
Normal file
167
train_db_README-ja.md
Normal file
@@ -0,0 +1,167 @@
|
||||
DreamBoothのガイドです。
|
||||
|
||||
[学習についての共通ドキュメント](./train_README-ja.md) もあわせてご覧ください。
|
||||
|
||||
# 概要
|
||||
|
||||
DreamBoothとは、画像生成モデルに特定の主題を追加学習し、それを特定の識別子で生成する技術です。[論文はこちら](https://arxiv.org/abs/2208.12242)。
|
||||
|
||||
具体的には、Stable Diffusionのモデルにキャラや画風などを学ばせ、それを `shs` のような特定の単語で呼び出せる(生成画像に出現させる)ことができます。
|
||||
|
||||
スクリプトは[DiffusersのDreamBooth](https://github.com/huggingface/diffusers/tree/main/examples/dreambooth)を元にしていますが、以下のような機能追加を行っています(いくつかの機能は元のスクリプト側もその後対応しています)。
|
||||
|
||||
スクリプトの主な機能は以下の通りです。
|
||||
|
||||
- 8bit Adam optimizerおよびlatentのキャッシュによる省メモリ化([Shivam Shrirao氏版](https://github.com/ShivamShrirao/diffusers/tree/main/examples/dreambooth)と同様)。
|
||||
- xformersによる省メモリ化。
|
||||
- 512x512だけではなく任意サイズでの学習。
|
||||
- augmentationによる品質の向上。
|
||||
- DreamBoothだけではなくText Encoder+U-Netのfine tuningに対応。
|
||||
- Stable Diffusion形式でのモデルの読み書き。
|
||||
- Aspect Ratio Bucketing。
|
||||
- Stable Diffusion v2.0対応。
|
||||
|
||||
# 学習の手順
|
||||
|
||||
あらかじめこのリポジトリのREADMEを参照し、環境整備を行ってください。
|
||||
|
||||
## データの準備
|
||||
|
||||
[学習データの準備について](./train_README-ja.md) を参照してください。
|
||||
|
||||
## 学習の実行
|
||||
|
||||
スクリプトを実行します。最大限、メモリを節約したコマンドは以下のようになります(実際には1行で入力します)。それぞれの行を必要に応じて書き換えてください。12GB程度のVRAMで動作するようです。
|
||||
|
||||
```
|
||||
accelerate launch --num_cpu_threads_per_process 1 train_db.py
|
||||
--pretrained_model_name_or_path=<.ckptまたは.safetensordまたはDiffusers版モデルのディレクトリ>
|
||||
--dataset_config=<データ準備で作成した.tomlファイル>
|
||||
--output_dir=<学習したモデルの出力先フォルダ>
|
||||
--output_name=<学習したモデル出力時のファイル名>
|
||||
--save_model_as=safetensors
|
||||
--prior_loss_weight=1.0
|
||||
--max_train_steps=1600
|
||||
--learning_rate=1e-6
|
||||
--optimizer_type="AdamW8bit"
|
||||
--xformers
|
||||
--mixed_precision="fp16"
|
||||
--cache_latents
|
||||
--gradient_checkpointing
|
||||
```
|
||||
|
||||
`num_cpu_threads_per_process` には通常は1を指定するとよいようです。
|
||||
|
||||
`pretrained_model_name_or_path` に追加学習を行う元となるモデルを指定します。Stable Diffusionのcheckpointファイル(.ckptまたは.safetensors)、Diffusersのローカルディスクにあるモデルディレクトリ、DiffusersのモデルID("stabilityai/stable-diffusion-2"など)が指定できます。
|
||||
|
||||
`output_dir` に学習後のモデルを保存するフォルダを指定します。`output_name` にモデルのファイル名を拡張子を除いて指定します。`save_model_as` でsafetensors形式での保存を指定しています。
|
||||
|
||||
`dataset_config` に `.toml` ファイルを指定します。ファイル内でのバッチサイズ指定は、当初はメモリ消費を抑えるために `1` としてください。
|
||||
|
||||
`prior_loss_weight` は正則化画像のlossの重みです。通常は1.0を指定します。
|
||||
|
||||
学習させるステップ数 `max_train_steps` を1600とします。学習率 `learning_rate` はここでは1e-6を指定しています。
|
||||
|
||||
省メモリ化のため `mixed_precision="fp16"` を指定します(RTX30 シリーズ以降では `bf16` も指定できます。環境整備時にaccelerateに行った設定と合わせてください)。また `gradient_checkpointing` を指定します。
|
||||
|
||||
オプティマイザ(モデルを学習データにあうように最適化=学習させるクラス)にメモリ消費の少ない 8bit AdamW を使うため、 `optimizer_type="AdamW8bit"` を指定します。
|
||||
|
||||
`xformers` オプションを指定し、xformersのCrossAttentionを用います。xformersをインストールしていない場合やエラーとなる場合(環境にもよりますが `mixed_precision="no"` の場合など)、代わりに `mem_eff_attn` オプションを指定すると省メモリ版CrossAttentionを使用します(速度は遅くなります)。
|
||||
|
||||
省メモリ化のため `cache_latents` オプションを指定してVAEの出力をキャッシュします。
|
||||
|
||||
ある程度メモリがある場合は、`.toml` ファイルを編集してバッチサイズをたとえば `4` くらいに増やしてください(高速化と精度向上の可能性があります)。また `cache_latents` を外すことで augmentation が可能になります。
|
||||
|
||||
### よく使われるオプションについて
|
||||
|
||||
以下の場合には [学習の共通ドキュメント](./train_README-ja.md) の「よく使われるオプション」を参照してください。
|
||||
|
||||
- Stable Diffusion 2.xまたはそこからの派生モデルを学習する
|
||||
- clip skipを2以上を前提としたモデルを学習する
|
||||
- 75トークンを超えたキャプションで学習する
|
||||
|
||||
### DreamBoothでのステップ数について
|
||||
|
||||
当スクリプトでは省メモリ化のため、ステップ当たりの学習回数が元のスクリプトの半分になっています(対象の画像と正則化画像を同一のバッチではなく別のバッチに分割して学習するため)。
|
||||
|
||||
元のDiffusers版やXavierXiao氏のStable Diffusion版とほぼ同じ学習を行うには、ステップ数を倍にしてください。
|
||||
|
||||
(学習画像と正則化画像をまとめてから shuffle するため厳密にはデータの順番が変わってしまいますが、学習には大きな影響はないと思います。)
|
||||
|
||||
### DreamBoothでのバッチサイズについて
|
||||
|
||||
モデル全体を学習するためLoRA等の学習に比べるとメモリ消費量は多くなります(fine tuningと同じ)。
|
||||
|
||||
### 学習率について
|
||||
|
||||
Diffusers版では5e-6ですがStable Diffusion版は1e-6ですので、上のサンプルでは1e-6を指定しています。
|
||||
|
||||
### 以前の形式のデータセット指定をした場合のコマンドライン
|
||||
|
||||
解像度やバッチサイズをオプションで指定します。コマンドラインの例は以下の通りです。
|
||||
|
||||
```
|
||||
accelerate launch --num_cpu_threads_per_process 1 train_db.py
|
||||
--pretrained_model_name_or_path=<.ckptまたは.safetensordまたはDiffusers版モデルのディレクトリ>
|
||||
--train_data_dir=<学習用データのディレクトリ>
|
||||
--reg_data_dir=<正則化画像のディレクトリ>
|
||||
--output_dir=<学習したモデルの出力先ディレクトリ>
|
||||
--output_name=<学習したモデル出力時のファイル名>
|
||||
--prior_loss_weight=1.0
|
||||
--resolution=512
|
||||
--train_batch_size=1
|
||||
--learning_rate=1e-6
|
||||
--max_train_steps=1600
|
||||
--use_8bit_adam
|
||||
--xformers
|
||||
--mixed_precision="bf16"
|
||||
--cache_latents
|
||||
--gradient_checkpointing
|
||||
```
|
||||
|
||||
## 学習したモデルで画像生成する
|
||||
|
||||
学習が終わると指定したフォルダに指定した名前でsafetensorsファイルが出力されます。
|
||||
|
||||
v1.4/1.5およびその他の派生モデルの場合、このモデルでAutomatic1111氏のWebUIなどで推論できます。models\Stable-diffusionフォルダに置いてください。
|
||||
|
||||
v2.xモデルでWebUIで画像生成する場合、モデルの仕様が記述された.yamlファイルが別途必要になります。v2.x baseの場合はv2-inference.yamlを、768/vの場合はv2-inference-v.yamlを、同じフォルダに置き、拡張子の前の部分をモデルと同じ名前にしてください。
|
||||
|
||||

|
||||
|
||||
各yamlファイルは[Stability AIのSD2.0のリポジトリ](https://github.com/Stability-AI/stablediffusion/tree/main/configs/stable-diffusion)にあります。
|
||||
|
||||
# DreamBooth特有のその他の主なオプション
|
||||
|
||||
すべてのオプションについては別文書を参照してください。
|
||||
|
||||
## Text Encoderの学習を途中から行わない --stop_text_encoder_training
|
||||
|
||||
stop_text_encoder_trainingオプションに数値を指定すると、そのステップ数以降はText Encoderの学習を行わずU-Netだけ学習します。場合によっては精度の向上が期待できるかもしれません。
|
||||
|
||||
(恐らくText Encoderだけ先に過学習することがあり、それを防げるのではないかと推測していますが、詳細な影響は不明です。)
|
||||
|
||||
## Tokenizerのパディングをしない --no_token_padding
|
||||
no_token_paddingオプションを指定するとTokenizerの出力をpaddingしません(Diffusers版の旧DreamBoothと同じ動きになります)。
|
||||
|
||||
|
||||
<!--
|
||||
bucketing(後述)を利用しかつaugmentation(後述)を使う場合の例は以下のようになります。
|
||||
|
||||
```
|
||||
accelerate launch --num_cpu_threads_per_process 8 train_db.py
|
||||
--pretrained_model_name_or_path=<.ckptまたは.safetensordまたはDiffusers版モデルのディレクトリ>
|
||||
--train_data_dir=<学習用データのディレクトリ>
|
||||
--reg_data_dir=<正則化画像のディレクトリ>
|
||||
--output_dir=<学習したモデルの出力先ディレクトリ>
|
||||
--resolution=768,512
|
||||
--train_batch_size=20 --learning_rate=5e-6 --max_train_steps=800
|
||||
--use_8bit_adam --xformers --mixed_precision="bf16"
|
||||
--save_every_n_epochs=1 --save_state --save_precision="bf16"
|
||||
--logging_dir=logs
|
||||
--enable_bucket --min_bucket_reso=384 --max_bucket_reso=1280
|
||||
--color_aug --flip_aug --gradient_checkpointing --seed 42
|
||||
```
|
||||
|
||||
|
||||
-->
|
||||
1618
train_network.py
1618
train_network.py
File diff suppressed because it is too large
Load Diff
@@ -1,80 +1,103 @@
|
||||
## LoRAの学習について
|
||||
# LoRAの学習について
|
||||
|
||||
[LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685)(arxiv)、[LoRA](https://github.com/microsoft/LoRA)(github)をStable Diffusionに適用したものです。
|
||||
|
||||
[cloneofsimo氏のリポジトリ](https://github.com/cloneofsimo/lora)を大いに参考にさせていただきました。ありがとうございます。
|
||||
|
||||
通常のLoRAは Linear およぴカーネルサイズ 1x1 の Conv2d にのみ適用されますが、カーネルサイズ 3x3 のConv2dに適用を拡大することもできます。
|
||||
|
||||
Conv2d 3x3への拡大は [cloneofsimo氏](https://github.com/cloneofsimo/lora) が最初にリリースし、KohakuBlueleaf氏が [LoCon](https://github.com/KohakuBlueleaf/LoCon) でその有効性を明らかにしたものです。KohakuBlueleaf氏に深く感謝します。
|
||||
|
||||
8GB VRAMでもぎりぎり動作するようです。
|
||||
|
||||
[学習についての共通ドキュメント](./train_README-ja.md) もあわせてご覧ください。
|
||||
|
||||
## 学習したモデルに関する注意
|
||||
|
||||
cloneofsimo氏のリポジトリ、およびd8ahazard氏の[Dreambooth Extension for Stable-Diffusion-WebUI](https://github.com/d8ahazard/sd_dreambooth_extension)とは、現時点では互換性がありません。いくつかの機能拡張を行っているためです(後述)。
|
||||
|
||||
WebUI等で画像生成する場合には、学習したLoRAのモデルを学習元のStable Diffusionのモデルに、このリポジトリ内のスクリプトであらかじめマージしておく必要があります。マージ後のモデルファイルはLoRAの学習結果が反映されたものになります。
|
||||
WebUI等で画像生成する場合には、学習したLoRAのモデルを学習元のStable Diffusionのモデルにこのリポジトリ内のスクリプトであらかじめマージしておくか、こちらの[WebUI用extension](https://github.com/kohya-ss/sd-webui-additional-networks)を使ってください。
|
||||
|
||||
なお当リポジトリ内の画像生成スクリプトで生成する場合はマージ不要です。
|
||||
# 学習の手順
|
||||
|
||||
## 学習方法
|
||||
あらかじめこのリポジトリのREADMEを参照し、環境整備を行ってください。
|
||||
|
||||
train_network.pyを用います。
|
||||
## データの準備
|
||||
|
||||
DreamBoothの手法(identifier(sksなど)とclass、オプションで正則化画像を用いる)と、キャプションを用いるfine tuningの手法の両方で学習できます。
|
||||
[学習データの準備について](./train_README-ja.md) を参照してください。
|
||||
|
||||
どちらの方法も既存のスクリプトとほぼ同じ方法で学習できます。異なる点については後述します。
|
||||
|
||||
### DreamBoothの手法を用いる場合
|
||||
## 学習の実行
|
||||
|
||||
note.com [環境整備とDreamBooth学習スクリプトについて](https://note.com/kohya_ss/n/nba4eceaa4594) を参照してデータを用意してください。
|
||||
`train_network.py`を用います。
|
||||
|
||||
学習するとき、train_db.pyの代わりにtrain_network.pyを指定してください。
|
||||
|
||||
ほぼすべてのオプション(Stable Diffusionのモデル保存関係を除く)が使えますが、stop_text_encoder_trainingはサポートしていません。
|
||||
|
||||
### キャプションを用いる場合
|
||||
|
||||
[fine-tuningのガイド](./fine_tune_README_ja.md) を参照し、各手順を実行してください。
|
||||
|
||||
学習するとき、fine_tune.pyの代わりにtrain_network.pyを指定してください。ほぼすべてのオプション(モデル保存関係を除く)がそのまま使えます。
|
||||
|
||||
なお「latentsの事前取得」は行わなくても動作します。VAEから学習時(またはキャッシュ時)にlatentを取得するため学習速度は遅くなりますが、代わりにcolor_augが使えるようになります。
|
||||
|
||||
### LoRAの学習のためのオプション
|
||||
|
||||
train_network.pyでは--network_moduleオプションに、学習対象のモジュール名を指定します。LoRAに対応するのはnetwork.loraとなりますので、それを指定してください。
|
||||
`train_network.py`では `--network_module` オプションに、学習対象のモジュール名を指定します。LoRAに対応するのはnetwork.loraとなりますので、それを指定してください。
|
||||
|
||||
なお学習率は通常のDreamBoothやfine tuningよりも高めの、1e-4程度を指定するとよいようです。
|
||||
|
||||
以下はコマンドラインの例です(DreamBooth手法)。
|
||||
以下はコマンドラインの例です。
|
||||
|
||||
```
|
||||
accelerate launch --num_cpu_threads_per_process 12 train_network.py
|
||||
--pretrained_model_name_or_path=..\models\model.ckpt
|
||||
--train_data_dir=..\data\db\char1 --output_dir=..\lora_train1
|
||||
--reg_data_dir=..\data\db\reg1 --prior_loss_weight=1.0
|
||||
--resolution=448,640 --train_batch_size=1 --learning_rate=1e-4
|
||||
--max_train_steps=400 --use_8bit_adam --xformers --mixed_precision=fp16
|
||||
--save_every_n_epochs=1 --save_model_as=safetensors --clip_skip=2 --seed=42 --color_aug
|
||||
accelerate launch --num_cpu_threads_per_process 1 train_network.py
|
||||
--pretrained_model_name_or_path=<.ckptまたは.safetensordまたはDiffusers版モデルのディレクトリ>
|
||||
--dataset_config=<データ準備で作成した.tomlファイル>
|
||||
--output_dir=<学習したモデルの出力先フォルダ>
|
||||
--output_name=<学習したモデル出力時のファイル名>
|
||||
--save_model_as=safetensors
|
||||
--prior_loss_weight=1.0
|
||||
--max_train_steps=400
|
||||
--learning_rate=1e-4
|
||||
--optimizer_type="AdamW8bit"
|
||||
--xformers
|
||||
--mixed_precision="fp16"
|
||||
--cache_latents
|
||||
--gradient_checkpointing
|
||||
--save_every_n_epochs=1
|
||||
--network_module=networks.lora
|
||||
```
|
||||
|
||||
--output_dirオプションで指定したディレクトリに、LoRAのモデルが保存されます。
|
||||
`--output_dir` オプションで指定したフォルダに、LoRAのモデルが保存されます。他のオプション、オプティマイザ等については [学習の共通ドキュメント](./train_README-ja.md) の「よく使われるオプション」も参照してください。
|
||||
|
||||
その他、以下のオプションが指定できます。
|
||||
|
||||
* --network_dim
|
||||
* LoRAの次元数を指定します(``--networkdim=4``など)。省略時は4になります。数が多いほど表現力は増しますが、学習に必要なメモリ、時間は増えます。また闇雲に増やしても良くないようです。
|
||||
* --network_weights
|
||||
* `--network_dim`
|
||||
* LoRAのRANKを指定します(``--networkdim=4``など)。省略時は4になります。数が多いほど表現力は増しますが、学習に必要なメモリ、時間は増えます。また闇雲に増やしても良くないようです。
|
||||
* `--network_alpha`
|
||||
* アンダーフローを防ぎ安定して学習するための ``alpha`` 値を指定します。デフォルトは1です。``network_dim``と同じ値を指定すると以前のバージョンと同じ動作になります。
|
||||
* `--persistent_data_loader_workers`
|
||||
* Windows環境で指定するとエポック間の待ち時間が大幅に短縮されます。
|
||||
* `--max_data_loader_n_workers`
|
||||
* データ読み込みのプロセス数を指定します。プロセス数が多いとデータ読み込みが速くなりGPUを効率的に利用できますが、メインメモリを消費します。デフォルトは「`8` または `CPU同時実行スレッド数-1` の小さいほう」なので、メインメモリに余裕がない場合や、GPU使用率が90%程度以上なら、それらの数値を見ながら `2` または `1` 程度まで下げてください。
|
||||
* `--network_weights`
|
||||
* 学習前に学習済みのLoRAの重みを読み込み、そこから追加で学習します。
|
||||
* --network_train_unet_only
|
||||
* `--network_train_unet_only`
|
||||
* U-Netに関連するLoRAモジュールのみ有効とします。fine tuning的な学習で指定するとよいかもしれません。
|
||||
* --network_train_text_encoder_only
|
||||
* `--network_train_text_encoder_only`
|
||||
* Text Encoderに関連するLoRAモジュールのみ有効とします。Textual Inversion的な効果が期待できるかもしれません。
|
||||
* --unet_lr
|
||||
* `--unet_lr`
|
||||
* U-Netに関連するLoRAモジュールに、通常の学習率(--learning_rateオプションで指定)とは異なる学習率を使う時に指定します。
|
||||
* --text_encoder_lr
|
||||
* `--text_encoder_lr`
|
||||
* Text Encoderに関連するLoRAモジュールに、通常の学習率(--learning_rateオプションで指定)とは異なる学習率を使う時に指定します。Text Encoderのほうを若干低めの学習率(5e-5など)にしたほうが良い、という話もあるようです。
|
||||
* `--network_args`
|
||||
* 複数の引数を指定できます。後述します。
|
||||
|
||||
--network_train_unet_onlyと--network_train_text_encoder_onlyの両方とも未指定時(デフォルト)はText EncoderとU-Netの両方のLoRAモジュールを有効にします。
|
||||
`--network_train_unet_only` と `--network_train_text_encoder_only` の両方とも未指定時(デフォルト)はText EncoderとU-Netの両方のLoRAモジュールを有効にします。
|
||||
|
||||
## LoRA を Conv2d に拡大して適用する
|
||||
|
||||
通常のLoRAは Linear およぴカーネルサイズ 1x1 の Conv2d にのみ適用されますが、カーネルサイズ 3x3 のConv2dに適用を拡大することもできます。
|
||||
|
||||
`--network_args` に以下のように指定してください。`conv_dim` で Conv2d (3x3) の rank を、`conv_alpha` で alpha を指定してください。
|
||||
|
||||
```
|
||||
--network_args "conv_dim=1" "conv_alpha=1"
|
||||
```
|
||||
|
||||
以下のように alpha 省略時は1になります。
|
||||
|
||||
```
|
||||
--network_args "conv_dim=1"
|
||||
```
|
||||
|
||||
## マージスクリプトについて
|
||||
|
||||
@@ -110,7 +133,7 @@ python networks\merge_lora.py --sd_model ..\model\model.ckpt
|
||||
|
||||
### 複数のLoRAのモデルをマージする
|
||||
|
||||
結局のところSDモデルにマージしないと推論できないのであまり使い道はないかもしれません。ただ、複数のLoRAモデルをひとつずつSDモデルにマージしていく場合と、複数のLoRAモデルをマージしてからSDモデルにマージする場合とは、計算順序の関連で微妙に異なる結果になります。
|
||||
複数のLoRAモデルをひとつずつSDモデルに適用する場合と、複数のLoRAモデルをマージしてからSDモデルにマージする場合とは、計算順序の関連で微妙に異なる結果になります。
|
||||
|
||||
たとえば以下のようなコマンドラインになります。
|
||||
|
||||
@@ -128,7 +151,7 @@ python networks\merge_lora.py
|
||||
|
||||
--ratiosにそれぞれのモデルの比率(どのくらい重みを元モデルに反映するか)を0~1.0の数値で指定します。二つのモデルを一対一でマージす場合は、「0.5 0.5」になります。「1.0 1.0」では合計の重みが大きくなりすぎて、恐らく結果はあまり望ましくないものになると思われます。
|
||||
|
||||
v1で学習したLoRAとv2で学習したLoRA、次元数の異なるLoRAはマージできません。U-NetだけのLoRAとU-Net+Text EncoderのLoRAはマージできるはずですが、結果は未知数です。
|
||||
v1で学習したLoRAとv2で学習したLoRA、rank(次元数)や``alpha``の異なるLoRAはマージできません。U-NetだけのLoRAとU-Net+Text EncoderのLoRAはマージできるはずですが、結果は未知数です。
|
||||
|
||||
|
||||
### その他のオプション
|
||||
@@ -138,17 +161,106 @@ v1で学習したLoRAとv2で学習したLoRA、次元数の異なるLoRAはマ
|
||||
* save_precision
|
||||
* モデル保存時の精度をfloat、fp16、bf16から指定できます。省略時はprecisionと同じ精度になります。
|
||||
|
||||
|
||||
## 複数のrankが異なるLoRAのモデルをマージする
|
||||
|
||||
複数のLoRAをひとつのLoRAで近似します(完全な再現はできません)。`svd_merge_lora.py`を用います。たとえば以下のようなコマンドラインになります。
|
||||
|
||||
```
|
||||
python networks\svd_merge_lora.py
|
||||
--save_to ..\lora_train1\model-char1-style1-merged.safetensors
|
||||
--models ..\lora_train1\last.safetensors ..\lora_train2\last.safetensors
|
||||
--ratios 0.6 0.4 --new_rank 32 --device cuda
|
||||
```
|
||||
|
||||
`merge_lora.py` と主なオプションは同一です。以下のオプションが追加されています。
|
||||
|
||||
- `--new_rank`
|
||||
- 作成するLoRAのrankを指定します。
|
||||
- `--new_conv_rank`
|
||||
- 作成する Conv2d 3x3 LoRA の rank を指定します。省略時は `new_rank` と同じになります。
|
||||
- `--device`
|
||||
- `--device cuda`としてcudaを指定すると計算をGPU上で行います。処理が速くなります。
|
||||
|
||||
## 当リポジトリ内の画像生成スクリプトで生成する
|
||||
|
||||
gen_img_diffusers.pyに、--network_module、--network_weights、--network_dim(省略可)の各オプションを追加してください。意味は学習時と同様です。
|
||||
gen_img_diffusers.pyに、--network_module、--network_weightsの各オプションを追加してください。意味は学習時と同様です。
|
||||
|
||||
--network_mulオプションで0~1.0の数値を指定すると、LoRAの適用率を変えられます。
|
||||
|
||||
## 二つのモデルの差分からLoRAモデルを作成する
|
||||
|
||||
[こちらのディスカッション](https://github.com/cloneofsimo/lora/discussions/56)を参考に実装したものです。数式はそのまま使わせていただきました(よく理解していませんが近似には特異値分解を用いるようです)。
|
||||
|
||||
二つのモデル(たとえばfine tuningの元モデルとfine tuning後のモデル)の差分を、LoRAで近似します。
|
||||
|
||||
### スクリプトの実行方法
|
||||
|
||||
以下のように指定してください。
|
||||
```
|
||||
python networks\extract_lora_from_models.py --model_org base-model.ckpt
|
||||
--model_tuned fine-tuned-model.ckpt
|
||||
--save_to lora-weights.safetensors --dim 4
|
||||
```
|
||||
|
||||
--model_orgオプションに元のStable Diffusionモデルを指定します。作成したLoRAモデルを適用する場合は、このモデルを指定して適用することになります。.ckptまたは.safetensorsが指定できます。
|
||||
|
||||
--model_tunedオプションに差分を抽出する対象のStable Diffusionモデルを指定します。たとえばfine tuningやDreamBooth後のモデルを指定します。.ckptまたは.safetensorsが指定できます。
|
||||
|
||||
--save_toにLoRAモデルの保存先を指定します。--dimにLoRAの次元数を指定します。
|
||||
|
||||
生成されたLoRAモデルは、学習したLoRAモデルと同様に使用できます。
|
||||
|
||||
Text Encoderが二つのモデルで同じ場合にはLoRAはU-NetのみのLoRAとなります。
|
||||
|
||||
### その他のオプション
|
||||
|
||||
- `--v2`
|
||||
- v2.xのStable Diffusionモデルを使う場合に指定してください。
|
||||
- `--device`
|
||||
- ``--device cuda``としてcudaを指定すると計算をGPU上で行います。処理が速くなります(CPUでもそこまで遅くないため、せいぜい倍~数倍程度のようです)。
|
||||
- `--save_precision`
|
||||
- LoRAの保存形式を"float", "fp16", "bf16"から指定します。省略時はfloatになります。
|
||||
- `--conv_dim`
|
||||
- 指定するとLoRAの適用範囲を Conv2d 3x3 へ拡大します。Conv2d 3x3 の rank を指定します。
|
||||
|
||||
## 画像リサイズスクリプト
|
||||
|
||||
(のちほどドキュメントを整理しますがとりあえずここに説明を書いておきます。)
|
||||
|
||||
Aspect Ratio Bucketingの機能拡張で、小さな画像については拡大しないでそのまま教師データとすることが可能になりました。元の教師画像を縮小した画像を、教師データに加えると精度が向上したという報告とともに前処理用のスクリプトをいただきましたので整備して追加しました。bmaltais氏に感謝します。
|
||||
|
||||
### スクリプトの実行方法
|
||||
|
||||
以下のように指定してください。元の画像そのまま、およびリサイズ後の画像が変換先フォルダに保存されます。リサイズ後の画像には、ファイル名に ``+512x512`` のようにリサイズ先の解像度が付け加えられます(画像サイズとは異なります)。リサイズ先の解像度より小さい画像は拡大されることはありません。
|
||||
|
||||
```
|
||||
python tools\resize_images_to_resolution.py --max_resolution 512x512,384x384,256x256 --save_as_png
|
||||
--copy_associated_files 元画像フォルダ 変換先フォルダ
|
||||
```
|
||||
|
||||
元画像フォルダ内の画像ファイルが、指定した解像度(複数指定可)と同じ面積になるようにリサイズされ、変換先フォルダに保存されます。画像以外のファイルはそのままコピーされます。
|
||||
|
||||
``--max_resolution`` オプションにリサイズ先のサイズを例のように指定してください。面積がそのサイズになるようにリサイズします。複数指定すると、それぞれの解像度でリサイズされます。``512x512,384x384,256x256``なら、変換先フォルダの画像は、元サイズとリサイズ後サイズ×3の計4枚になります。
|
||||
|
||||
``--save_as_png`` オプションを指定するとpng形式で保存します。省略するとjpeg形式(quality=100)で保存されます。
|
||||
|
||||
``--copy_associated_files`` オプションを指定すると、拡張子を除き画像と同じファイル名(たとえばキャプションなど)のファイルが、リサイズ後の画像のファイル名と同じ名前でコピーされます。
|
||||
|
||||
|
||||
### その他のオプション
|
||||
|
||||
- divisible_by
|
||||
- リサイズ後の画像のサイズ(縦、横のそれぞれ)がこの値で割り切れるように、画像中心を切り出します。
|
||||
- interpolation
|
||||
- 縮小時の補完方法を指定します。``area, cubic, lanczos4``から選択可能で、デフォルトは``area``です。
|
||||
|
||||
|
||||
## 追加情報
|
||||
|
||||
### cloneofsimo氏のリポジトリとの違い
|
||||
|
||||
12/25時点では、当リポジトリはLoRAの適用個所をText EncoderのMLP、U-NetのFFN、Transformerのin/out projectionに拡大し、表現力が増しています。ただその代わりメモリ使用量は増え、8GBぎりぎりになりました。
|
||||
2022/12/25時点では、当リポジトリはLoRAの適用個所をText EncoderのMLP、U-NetのFFN、Transformerのin/out projectionに拡大し、表現力が増しています。ただその代わりメモリ使用量は増え、8GBぎりぎりになりました。
|
||||
|
||||
またモジュール入れ替え機構は全く異なります。
|
||||
|
||||
|
||||
526
train_textual_inversion.py
Normal file
526
train_textual_inversion.py
Normal file
@@ -0,0 +1,526 @@
|
||||
import importlib
|
||||
import argparse
|
||||
import gc
|
||||
import math
|
||||
import os
|
||||
|
||||
from tqdm import tqdm
|
||||
import torch
|
||||
from accelerate.utils import set_seed
|
||||
import diffusers
|
||||
from diffusers import DDPMScheduler
|
||||
|
||||
import library.train_util as train_util
|
||||
import library.config_util as config_util
|
||||
from library.config_util import (
|
||||
ConfigSanitizer,
|
||||
BlueprintGenerator,
|
||||
)
|
||||
|
||||
imagenet_templates_small = [
|
||||
"a photo of a {}",
|
||||
"a rendering of a {}",
|
||||
"a cropped photo of the {}",
|
||||
"the photo of a {}",
|
||||
"a photo of a clean {}",
|
||||
"a photo of a dirty {}",
|
||||
"a dark photo of the {}",
|
||||
"a photo of my {}",
|
||||
"a photo of the cool {}",
|
||||
"a close-up photo of a {}",
|
||||
"a bright photo of the {}",
|
||||
"a cropped photo of a {}",
|
||||
"a photo of the {}",
|
||||
"a good photo of the {}",
|
||||
"a photo of one {}",
|
||||
"a close-up photo of the {}",
|
||||
"a rendition of the {}",
|
||||
"a photo of the clean {}",
|
||||
"a rendition of a {}",
|
||||
"a photo of a nice {}",
|
||||
"a good photo of a {}",
|
||||
"a photo of the nice {}",
|
||||
"a photo of the small {}",
|
||||
"a photo of the weird {}",
|
||||
"a photo of the large {}",
|
||||
"a photo of a cool {}",
|
||||
"a photo of a small {}",
|
||||
]
|
||||
|
||||
imagenet_style_templates_small = [
|
||||
"a painting in the style of {}",
|
||||
"a rendering in the style of {}",
|
||||
"a cropped painting in the style of {}",
|
||||
"the painting in the style of {}",
|
||||
"a clean painting in the style of {}",
|
||||
"a dirty painting in the style of {}",
|
||||
"a dark painting in the style of {}",
|
||||
"a picture in the style of {}",
|
||||
"a cool painting in the style of {}",
|
||||
"a close-up painting in the style of {}",
|
||||
"a bright painting in the style of {}",
|
||||
"a cropped painting in the style of {}",
|
||||
"a good painting in the style of {}",
|
||||
"a close-up painting in the style of {}",
|
||||
"a rendition in the style of {}",
|
||||
"a nice painting in the style of {}",
|
||||
"a small painting in the style of {}",
|
||||
"a weird painting in the style of {}",
|
||||
"a large painting in the style of {}",
|
||||
]
|
||||
|
||||
|
||||
def collate_fn(examples):
|
||||
return examples[0]
|
||||
|
||||
|
||||
def train(args):
|
||||
if args.output_name is None:
|
||||
args.output_name = args.token_string
|
||||
use_template = args.use_object_template or args.use_style_template
|
||||
|
||||
train_util.verify_training_args(args)
|
||||
train_util.prepare_dataset_args(args, True)
|
||||
|
||||
cache_latents = args.cache_latents
|
||||
|
||||
if args.seed is not None:
|
||||
set_seed(args.seed)
|
||||
|
||||
tokenizer = train_util.load_tokenizer(args)
|
||||
|
||||
# acceleratorを準備する
|
||||
print("prepare accelerator")
|
||||
accelerator, unwrap_model = train_util.prepare_accelerator(args)
|
||||
|
||||
# mixed precisionに対応した型を用意しておき適宜castする
|
||||
weight_dtype, save_dtype = train_util.prepare_dtype(args)
|
||||
|
||||
# モデルを読み込む
|
||||
text_encoder, vae, unet, _ = train_util.load_target_model(args, weight_dtype)
|
||||
|
||||
# Convert the init_word to token_id
|
||||
if args.init_word is not None:
|
||||
init_token_ids = tokenizer.encode(args.init_word, add_special_tokens=False)
|
||||
if len(init_token_ids) > 1 and len(init_token_ids) != args.num_vectors_per_token:
|
||||
print(
|
||||
f"token length for init words is not same to num_vectors_per_token, init words is repeated or truncated / 初期化単語のトークン長がnum_vectors_per_tokenと合わないため、繰り返しまたは切り捨てが発生します: length {len(init_token_ids)}")
|
||||
else:
|
||||
init_token_ids = None
|
||||
|
||||
# add new word to tokenizer, count is num_vectors_per_token
|
||||
token_strings = [args.token_string] + [f"{args.token_string}{i+1}" for i in range(args.num_vectors_per_token - 1)]
|
||||
num_added_tokens = tokenizer.add_tokens(token_strings)
|
||||
assert num_added_tokens == args.num_vectors_per_token, f"tokenizer has same word to token string. please use another one / 指定したargs.token_stringは既に存在します。別の単語を使ってください: {args.token_string}"
|
||||
|
||||
token_ids = tokenizer.convert_tokens_to_ids(token_strings)
|
||||
print(f"tokens are added: {token_ids}")
|
||||
assert min(token_ids) == token_ids[0] and token_ids[-1] == token_ids[0] + len(token_ids) - 1, f"token ids is not ordered"
|
||||
assert len(tokenizer) - 1 == token_ids[-1], f"token ids is not end of tokenize: {len(tokenizer)}"
|
||||
|
||||
# Resize the token embeddings as we are adding new special tokens to the tokenizer
|
||||
text_encoder.resize_token_embeddings(len(tokenizer))
|
||||
|
||||
# Initialise the newly added placeholder token with the embeddings of the initializer token
|
||||
token_embeds = text_encoder.get_input_embeddings().weight.data
|
||||
if init_token_ids is not None:
|
||||
for i, token_id in enumerate(token_ids):
|
||||
token_embeds[token_id] = token_embeds[init_token_ids[i % len(init_token_ids)]]
|
||||
# print(token_id, token_embeds[token_id].mean(), token_embeds[token_id].min())
|
||||
|
||||
# load weights
|
||||
if args.weights is not None:
|
||||
embeddings = load_weights(args.weights)
|
||||
assert len(token_ids) == len(
|
||||
embeddings), f"num_vectors_per_token is mismatch for weights / 指定した重みとnum_vectors_per_tokenの値が異なります: {len(embeddings)}"
|
||||
# print(token_ids, embeddings.size())
|
||||
for token_id, embedding in zip(token_ids, embeddings):
|
||||
token_embeds[token_id] = embedding
|
||||
# print(token_id, token_embeds[token_id].mean(), token_embeds[token_id].min())
|
||||
print(f"weighs loaded")
|
||||
|
||||
print(f"create embeddings for {args.num_vectors_per_token} tokens, for {args.token_string}")
|
||||
|
||||
# データセットを準備する
|
||||
blueprint_generator = BlueprintGenerator(ConfigSanitizer(True, True, False))
|
||||
if args.dataset_config is not None:
|
||||
print(f"Load dataset config from {args.dataset_config}")
|
||||
user_config = config_util.load_user_config(args.dataset_config)
|
||||
ignored = ["train_data_dir", "reg_data_dir", "in_json"]
|
||||
if any(getattr(args, attr) is not None for attr in ignored):
|
||||
print("ignore following options because config file is found: {0} / 設定ファイルが利用されるため以下のオプションは無視されます: {0}".format(', '.join(ignored)))
|
||||
else:
|
||||
use_dreambooth_method = args.in_json is None
|
||||
if use_dreambooth_method:
|
||||
print("Use DreamBooth method.")
|
||||
user_config = {
|
||||
"datasets": [{
|
||||
"subsets": config_util.generate_dreambooth_subsets_config_by_subdirs(args.train_data_dir, args.reg_data_dir)
|
||||
}]
|
||||
}
|
||||
else:
|
||||
print("Train with captions.")
|
||||
user_config = {
|
||||
"datasets": [{
|
||||
"subsets": [{
|
||||
"image_dir": args.train_data_dir,
|
||||
"metadata_file": args.in_json,
|
||||
}]
|
||||
}]
|
||||
}
|
||||
|
||||
blueprint = blueprint_generator.generate(user_config, args, tokenizer=tokenizer)
|
||||
train_dataset_group = config_util.generate_dataset_group_by_blueprint(blueprint.dataset_group)
|
||||
|
||||
# make captions: tokenstring tokenstring1 tokenstring2 ...tokenstringn という文字列に書き換える超乱暴な実装
|
||||
if use_template:
|
||||
print("use template for training captions. is object: {args.use_object_template}")
|
||||
templates = imagenet_templates_small if args.use_object_template else imagenet_style_templates_small
|
||||
replace_to = " ".join(token_strings)
|
||||
captions = []
|
||||
for tmpl in templates:
|
||||
captions.append(tmpl.format(replace_to))
|
||||
train_dataset_group.add_replacement("", captions)
|
||||
|
||||
if args.num_vectors_per_token > 1:
|
||||
prompt_replacement = (args.token_string, replace_to)
|
||||
else:
|
||||
prompt_replacement = None
|
||||
else:
|
||||
if args.num_vectors_per_token > 1:
|
||||
replace_to = " ".join(token_strings)
|
||||
train_dataset_group.add_replacement(args.token_string, replace_to)
|
||||
prompt_replacement = (args.token_string, replace_to)
|
||||
else:
|
||||
prompt_replacement = None
|
||||
|
||||
if args.debug_dataset:
|
||||
train_util.debug_dataset(train_dataset_group, show_input_ids=True)
|
||||
return
|
||||
if len(train_dataset_group) == 0:
|
||||
print("No data found. Please verify arguments / 画像がありません。引数指定を確認してください")
|
||||
return
|
||||
|
||||
if cache_latents:
|
||||
assert train_dataset_group.is_latent_cacheable(), "when caching latents, either color_aug or random_crop cannot be used / latentをキャッシュするときはcolor_augとrandom_cropは使えません"
|
||||
|
||||
# モデルに xformers とか memory efficient attention を組み込む
|
||||
train_util.replace_unet_modules(unet, args.mem_eff_attn, args.xformers)
|
||||
|
||||
# 学習を準備する
|
||||
if cache_latents:
|
||||
vae.to(accelerator.device, dtype=weight_dtype)
|
||||
vae.requires_grad_(False)
|
||||
vae.eval()
|
||||
with torch.no_grad():
|
||||
train_dataset_group.cache_latents(vae)
|
||||
vae.to("cpu")
|
||||
if torch.cuda.is_available():
|
||||
torch.cuda.empty_cache()
|
||||
gc.collect()
|
||||
|
||||
if args.gradient_checkpointing:
|
||||
unet.enable_gradient_checkpointing()
|
||||
text_encoder.gradient_checkpointing_enable()
|
||||
|
||||
# 学習に必要なクラスを準備する
|
||||
print("prepare optimizer, data loader etc.")
|
||||
trainable_params = text_encoder.get_input_embeddings().parameters()
|
||||
_, _, optimizer = train_util.get_optimizer(args, trainable_params)
|
||||
|
||||
# dataloaderを準備する
|
||||
# DataLoaderのプロセス数:0はメインプロセスになる
|
||||
n_workers = min(args.max_data_loader_n_workers, os.cpu_count() - 1) # cpu_count-1 ただし最大で指定された数まで
|
||||
train_dataloader = torch.utils.data.DataLoader(
|
||||
train_dataset_group, batch_size=1, shuffle=True, collate_fn=collate_fn, num_workers=n_workers, persistent_workers=args.persistent_data_loader_workers)
|
||||
|
||||
# 学習ステップ数を計算する
|
||||
if args.max_train_epochs is not None:
|
||||
args.max_train_steps = args.max_train_epochs * len(train_dataloader)
|
||||
print(f"override steps. steps for {args.max_train_epochs} epochs is / 指定エポックまでのステップ数: {args.max_train_steps}")
|
||||
|
||||
# lr schedulerを用意する
|
||||
lr_scheduler = train_util.get_scheduler_fix(args.lr_scheduler, optimizer, num_warmup_steps=args.lr_warmup_steps,
|
||||
num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
|
||||
num_cycles=args.lr_scheduler_num_cycles, power=args.lr_scheduler_power)
|
||||
|
||||
# acceleratorがなんかよろしくやってくれるらしい
|
||||
text_encoder, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
|
||||
text_encoder, optimizer, train_dataloader, lr_scheduler)
|
||||
|
||||
index_no_updates = torch.arange(len(tokenizer)) < token_ids[0]
|
||||
# print(len(index_no_updates), torch.sum(index_no_updates))
|
||||
orig_embeds_params = unwrap_model(text_encoder).get_input_embeddings().weight.data.detach().clone()
|
||||
|
||||
# Freeze all parameters except for the token embeddings in text encoder
|
||||
text_encoder.requires_grad_(True)
|
||||
text_encoder.text_model.encoder.requires_grad_(False)
|
||||
text_encoder.text_model.final_layer_norm.requires_grad_(False)
|
||||
text_encoder.text_model.embeddings.position_embedding.requires_grad_(False)
|
||||
# text_encoder.text_model.embeddings.token_embedding.requires_grad_(True)
|
||||
|
||||
unet.requires_grad_(False)
|
||||
unet.to(accelerator.device, dtype=weight_dtype)
|
||||
if args.gradient_checkpointing: # according to TI example in Diffusers, train is required
|
||||
unet.train()
|
||||
else:
|
||||
unet.eval()
|
||||
|
||||
if not cache_latents:
|
||||
vae.requires_grad_(False)
|
||||
vae.eval()
|
||||
vae.to(accelerator.device, dtype=weight_dtype)
|
||||
|
||||
# 実験的機能:勾配も含めたfp16学習を行う PyTorchにパッチを当ててfp16でのgrad scaleを有効にする
|
||||
if args.full_fp16:
|
||||
train_util.patch_accelerator_for_fp16_training(accelerator)
|
||||
text_encoder.to(weight_dtype)
|
||||
|
||||
# resumeする
|
||||
if args.resume is not None:
|
||||
print(f"resume training from state: {args.resume}")
|
||||
accelerator.load_state(args.resume)
|
||||
|
||||
# epoch数を計算する
|
||||
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
|
||||
num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
|
||||
if (args.save_n_epoch_ratio is not None) and (args.save_n_epoch_ratio > 0):
|
||||
args.save_every_n_epochs = math.floor(num_train_epochs / args.save_n_epoch_ratio) or 1
|
||||
|
||||
# 学習する
|
||||
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
|
||||
print("running training / 学習開始")
|
||||
print(f" num train images * repeats / 学習画像の数×繰り返し回数: {train_dataset_group.num_train_images}")
|
||||
print(f" num reg images / 正則化画像の数: {train_dataset_group.num_reg_images}")
|
||||
print(f" num batches per epoch / 1epochのバッチ数: {len(train_dataloader)}")
|
||||
print(f" num epochs / epoch数: {num_train_epochs}")
|
||||
print(f" batch size per device / バッチサイズ: {args.train_batch_size}")
|
||||
print(f" total train batch size (with parallel & distributed & accumulation) / 総バッチサイズ(並列学習、勾配合計含む): {total_batch_size}")
|
||||
print(f" gradient ccumulation steps / 勾配を合計するステップ数 = {args.gradient_accumulation_steps}")
|
||||
print(f" total optimization steps / 学習ステップ数: {args.max_train_steps}")
|
||||
|
||||
progress_bar = tqdm(range(args.max_train_steps), smoothing=0, disable=not accelerator.is_local_main_process, desc="steps")
|
||||
global_step = 0
|
||||
|
||||
noise_scheduler = DDPMScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear",
|
||||
num_train_timesteps=1000, clip_sample=False)
|
||||
|
||||
if accelerator.is_main_process:
|
||||
accelerator.init_trackers("textual_inversion")
|
||||
|
||||
for epoch in range(num_train_epochs):
|
||||
print(f"epoch {epoch+1}/{num_train_epochs}")
|
||||
train_dataset_group.set_current_epoch(epoch + 1)
|
||||
|
||||
text_encoder.train()
|
||||
|
||||
loss_total = 0
|
||||
for step, batch in enumerate(train_dataloader):
|
||||
with accelerator.accumulate(text_encoder):
|
||||
with torch.no_grad():
|
||||
if "latents" in batch and batch["latents"] is not None:
|
||||
latents = batch["latents"].to(accelerator.device)
|
||||
else:
|
||||
# latentに変換
|
||||
latents = vae.encode(batch["images"].to(dtype=weight_dtype)).latent_dist.sample()
|
||||
latents = latents * 0.18215
|
||||
b_size = latents.shape[0]
|
||||
|
||||
# Get the text embedding for conditioning
|
||||
input_ids = batch["input_ids"].to(accelerator.device)
|
||||
# weight_dtype) use float instead of fp16/bf16 because text encoder is float
|
||||
encoder_hidden_states = train_util.get_hidden_states(args, input_ids, tokenizer, text_encoder, torch.float)
|
||||
|
||||
# Sample noise that we'll add to the latents
|
||||
noise = torch.randn_like(latents, device=latents.device)
|
||||
if args.noise_offset:
|
||||
# https://www.crosslabs.org//blog/diffusion-with-offset-noise
|
||||
noise += args.noise_offset * torch.randn((latents.shape[0], latents.shape[1], 1, 1), device=latents.device)
|
||||
|
||||
# Sample a random timestep for each image
|
||||
timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (b_size,), device=latents.device)
|
||||
timesteps = timesteps.long()
|
||||
|
||||
# Add noise to the latents according to the noise magnitude at each timestep
|
||||
# (this is the forward diffusion process)
|
||||
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
|
||||
|
||||
# Predict the noise residual
|
||||
noise_pred = unet(noisy_latents, timesteps, encoder_hidden_states).sample
|
||||
|
||||
if args.v_parameterization:
|
||||
# v-parameterization training
|
||||
target = noise_scheduler.get_velocity(latents, noise, timesteps)
|
||||
else:
|
||||
target = noise
|
||||
|
||||
loss = torch.nn.functional.mse_loss(noise_pred.float(), target.float(), reduction="none")
|
||||
loss = loss.mean([1, 2, 3])
|
||||
|
||||
loss_weights = batch["loss_weights"] # 各sampleごとのweight
|
||||
loss = loss * loss_weights
|
||||
|
||||
loss = loss.mean() # 平均なのでbatch_sizeで割る必要なし
|
||||
|
||||
accelerator.backward(loss)
|
||||
if accelerator.sync_gradients and args.max_grad_norm != 0.0:
|
||||
params_to_clip = text_encoder.get_input_embeddings().parameters()
|
||||
accelerator.clip_grad_norm_(params_to_clip, args.max_grad_norm)
|
||||
|
||||
optimizer.step()
|
||||
lr_scheduler.step()
|
||||
optimizer.zero_grad(set_to_none=True)
|
||||
|
||||
# Let's make sure we don't update any embedding weights besides the newly added token
|
||||
with torch.no_grad():
|
||||
unwrap_model(text_encoder).get_input_embeddings().weight[index_no_updates] = orig_embeds_params[index_no_updates]
|
||||
|
||||
# Checks if the accelerator has performed an optimization step behind the scenes
|
||||
if accelerator.sync_gradients:
|
||||
progress_bar.update(1)
|
||||
global_step += 1
|
||||
|
||||
train_util.sample_images(accelerator, args, None, global_step, accelerator.device,
|
||||
vae, tokenizer, text_encoder, unet, prompt_replacement)
|
||||
|
||||
current_loss = loss.detach().item()
|
||||
if args.logging_dir is not None:
|
||||
logs = {"loss": current_loss, "lr": float(lr_scheduler.get_last_lr()[0])}
|
||||
if args.optimizer_type.lower() == "DAdaptation".lower(): # tracking d*lr value
|
||||
logs["lr/d*lr"] = lr_scheduler.optimizers[0].param_groups[0]['d']*lr_scheduler.optimizers[0].param_groups[0]['lr']
|
||||
accelerator.log(logs, step=global_step)
|
||||
|
||||
loss_total += current_loss
|
||||
avr_loss = loss_total / (step+1)
|
||||
logs = {"loss": avr_loss} # , "lr": lr_scheduler.get_last_lr()[0]}
|
||||
progress_bar.set_postfix(**logs)
|
||||
|
||||
if global_step >= args.max_train_steps:
|
||||
break
|
||||
|
||||
if args.logging_dir is not None:
|
||||
logs = {"loss/epoch": loss_total / len(train_dataloader)}
|
||||
accelerator.log(logs, step=epoch+1)
|
||||
|
||||
accelerator.wait_for_everyone()
|
||||
|
||||
updated_embs = unwrap_model(text_encoder).get_input_embeddings().weight[token_ids].data.detach().clone()
|
||||
|
||||
if args.save_every_n_epochs is not None:
|
||||
model_name = train_util.DEFAULT_EPOCH_NAME if args.output_name is None else args.output_name
|
||||
|
||||
def save_func():
|
||||
ckpt_name = train_util.EPOCH_FILE_NAME.format(model_name, epoch + 1) + '.' + args.save_model_as
|
||||
ckpt_file = os.path.join(args.output_dir, ckpt_name)
|
||||
print(f"saving checkpoint: {ckpt_file}")
|
||||
save_weights(ckpt_file, updated_embs, save_dtype)
|
||||
|
||||
def remove_old_func(old_epoch_no):
|
||||
old_ckpt_name = train_util.EPOCH_FILE_NAME.format(model_name, old_epoch_no) + '.' + args.save_model_as
|
||||
old_ckpt_file = os.path.join(args.output_dir, old_ckpt_name)
|
||||
if os.path.exists(old_ckpt_file):
|
||||
print(f"removing old checkpoint: {old_ckpt_file}")
|
||||
os.remove(old_ckpt_file)
|
||||
|
||||
saving = train_util.save_on_epoch_end(args, save_func, remove_old_func, epoch + 1, num_train_epochs)
|
||||
if saving and args.save_state:
|
||||
train_util.save_state_on_epoch_end(args, accelerator, model_name, epoch + 1)
|
||||
|
||||
train_util.sample_images(accelerator, args, epoch + 1, global_step, accelerator.device,
|
||||
vae, tokenizer, text_encoder, unet, prompt_replacement)
|
||||
|
||||
# end of epoch
|
||||
|
||||
is_main_process = accelerator.is_main_process
|
||||
if is_main_process:
|
||||
text_encoder = unwrap_model(text_encoder)
|
||||
|
||||
accelerator.end_training()
|
||||
|
||||
if args.save_state:
|
||||
train_util.save_state_on_train_end(args, accelerator)
|
||||
|
||||
updated_embs = text_encoder.get_input_embeddings().weight[token_ids].data.detach().clone()
|
||||
|
||||
del accelerator # この後メモリを使うのでこれは消す
|
||||
|
||||
if is_main_process:
|
||||
os.makedirs(args.output_dir, exist_ok=True)
|
||||
|
||||
model_name = train_util.DEFAULT_LAST_OUTPUT_NAME if args.output_name is None else args.output_name
|
||||
ckpt_name = model_name + '.' + args.save_model_as
|
||||
ckpt_file = os.path.join(args.output_dir, ckpt_name)
|
||||
|
||||
print(f"save trained model to {ckpt_file}")
|
||||
save_weights(ckpt_file, updated_embs, save_dtype)
|
||||
print("model saved.")
|
||||
|
||||
|
||||
def save_weights(file, updated_embs, save_dtype):
|
||||
state_dict = {"emb_params": updated_embs}
|
||||
|
||||
if save_dtype is not None:
|
||||
for key in list(state_dict.keys()):
|
||||
v = state_dict[key]
|
||||
v = v.detach().clone().to("cpu").to(save_dtype)
|
||||
state_dict[key] = v
|
||||
|
||||
if os.path.splitext(file)[1] == '.safetensors':
|
||||
from safetensors.torch import save_file
|
||||
save_file(state_dict, file)
|
||||
else:
|
||||
torch.save(state_dict, file) # can be loaded in Web UI
|
||||
|
||||
|
||||
def load_weights(file):
|
||||
if os.path.splitext(file)[1] == '.safetensors':
|
||||
from safetensors.torch import load_file
|
||||
data = load_file(file)
|
||||
else:
|
||||
# compatible to Web UI's file format
|
||||
data = torch.load(file, map_location='cpu')
|
||||
if type(data) != dict:
|
||||
raise ValueError(f"weight file is not dict / 重みファイルがdict形式ではありません: {file}")
|
||||
|
||||
if 'string_to_param' in data: # textual inversion embeddings
|
||||
data = data['string_to_param']
|
||||
if hasattr(data, '_parameters'): # support old PyTorch?
|
||||
data = getattr(data, '_parameters')
|
||||
|
||||
emb = next(iter(data.values()))
|
||||
if type(emb) != torch.Tensor:
|
||||
raise ValueError(f"weight file does not contains Tensor / 重みファイルのデータがTensorではありません: {file}")
|
||||
|
||||
if len(emb.size()) == 1:
|
||||
emb = emb.unsqueeze(0)
|
||||
|
||||
return emb
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
parser = argparse.ArgumentParser()
|
||||
|
||||
train_util.add_sd_models_arguments(parser)
|
||||
train_util.add_dataset_arguments(parser, True, True, False)
|
||||
train_util.add_training_arguments(parser, True)
|
||||
train_util.add_optimizer_arguments(parser)
|
||||
config_util.add_config_arguments(parser)
|
||||
|
||||
parser.add_argument("--save_model_as", type=str, default="pt", choices=[None, "ckpt", "pt", "safetensors"],
|
||||
help="format to save the model (default is .pt) / モデル保存時の形式(デフォルトはpt)")
|
||||
|
||||
parser.add_argument("--weights", type=str, default=None,
|
||||
help="embedding weights to initialize / 学習するネットワークの初期重み")
|
||||
parser.add_argument("--num_vectors_per_token", type=int, default=1,
|
||||
help='number of vectors per token / トークンに割り当てるembeddingsの要素数')
|
||||
parser.add_argument("--token_string", type=str, default=None,
|
||||
help="token string used in training, must not exist in tokenizer / 学習時に使用されるトークン文字列、tokenizerに存在しない文字であること")
|
||||
parser.add_argument("--init_word", type=str, default=None,
|
||||
help="words to initialize vector / ベクトルを初期化に使用する単語、複数可")
|
||||
parser.add_argument("--use_object_template", action='store_true',
|
||||
help="ignore caption and use default templates for object / キャプションは使わずデフォルトの物体用テンプレートで学習する")
|
||||
parser.add_argument("--use_style_template", action='store_true',
|
||||
help="ignore caption and use default templates for stype / キャプションは使わずデフォルトのスタイル用テンプレートで学習する")
|
||||
|
||||
args = parser.parse_args()
|
||||
train(args)
|
||||
105
train_ti_README-ja.md
Normal file
105
train_ti_README-ja.md
Normal file
@@ -0,0 +1,105 @@
|
||||
[Textual Inversion](https://textual-inversion.github.io/) の学習についての説明です。
|
||||
|
||||
[学習についての共通ドキュメント](./train_README-ja.md) もあわせてご覧ください。
|
||||
|
||||
実装に当たっては https://github.com/huggingface/diffusers/tree/main/examples/textual_inversion を大いに参考にしました。
|
||||
|
||||
学習したモデルはWeb UIでもそのまま使えます。なお恐らくSD2.xにも対応していますが現時点では未テストです。
|
||||
|
||||
# 学習の手順
|
||||
|
||||
あらかじめこのリポジトリのREADMEを参照し、環境整備を行ってください。
|
||||
|
||||
## データの準備
|
||||
|
||||
[学習データの準備について](./train_README-ja.md) を参照してください。
|
||||
|
||||
## 学習の実行
|
||||
|
||||
``train_textual_inversion.py`` を用います。以下はコマンドラインの例です(DreamBooth手法)。
|
||||
|
||||
```
|
||||
accelerate launch --num_cpu_threads_per_process 1 train_textual_inversion.py
|
||||
--dataset_config=<データ準備で作成した.tomlファイル>
|
||||
--output_dir=<学習したモデルの出力先フォルダ>
|
||||
--output_name=<学習したモデル出力時のファイル名>
|
||||
--save_model_as=safetensors
|
||||
--prior_loss_weight=1.0
|
||||
--max_train_steps=1600
|
||||
--learning_rate=1e-6
|
||||
--optimizer_type="AdamW8bit"
|
||||
--xformers
|
||||
--mixed_precision="fp16"
|
||||
--cache_latents
|
||||
--gradient_checkpointing
|
||||
--token_string=mychar4 --init_word=cute --num_vectors_per_token=4
|
||||
```
|
||||
|
||||
``--token_string`` に学習時のトークン文字列を指定します。__学習時のプロンプトは、この文字列を含むようにしてください(token_stringがmychar4なら、``mychar4 1girl`` など)__。プロンプトのこの文字列の部分が、Textual Inversionの新しいtokenに置換されて学習されます。DreamBooth, class+identifier形式のデータセットとして、`token_string` をトークン文字列にするのが最も簡単で確実です。
|
||||
|
||||
プロンプトにトークン文字列が含まれているかどうかは、``--debug_dataset`` で置換後のtoken idが表示されますので、以下のように ``49408`` 以降のtokenが存在するかどうかで確認できます。
|
||||
|
||||
```
|
||||
input ids: tensor([[49406, 49408, 49409, 49410, 49411, 49412, 49413, 49414, 49415, 49407,
|
||||
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
|
||||
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
|
||||
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
|
||||
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
|
||||
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
|
||||
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
|
||||
49407, 49407, 49407, 49407, 49407, 49407, 49407]])
|
||||
```
|
||||
|
||||
tokenizerがすでに持っている単語(一般的な単語)は使用できません。
|
||||
|
||||
``--init_word`` にembeddingsを初期化するときのコピー元トークンの文字列を指定します。学ばせたい概念が近いものを選ぶとよいようです。二つ以上のトークンになる文字列は指定できません。
|
||||
|
||||
``--num_vectors_per_token`` にいくつのトークンをこの学習で使うかを指定します。多いほうが表現力が増しますが、その分多くのトークンを消費します。たとえばnum_vectors_per_token=8の場合、指定したトークン文字列は(一般的なプロンプトの77トークン制限のうち)8トークンを消費します。
|
||||
|
||||
以上がTextual Inversionのための主なオプションです。以降は他の学習スクリプトと同様です。
|
||||
|
||||
`num_cpu_threads_per_process` には通常は1を指定するとよいようです。
|
||||
|
||||
`pretrained_model_name_or_path` に追加学習を行う元となるモデルを指定します。Stable Diffusionのcheckpointファイル(.ckptまたは.safetensors)、Diffusersのローカルディスクにあるモデルディレクトリ、DiffusersのモデルID("stabilityai/stable-diffusion-2"など)が指定できます。
|
||||
|
||||
`output_dir` に学習後のモデルを保存するフォルダを指定します。`output_name` にモデルのファイル名を拡張子を除いて指定します。`save_model_as` でsafetensors形式での保存を指定しています。
|
||||
|
||||
`dataset_config` に `.toml` ファイルを指定します。ファイル内でのバッチサイズ指定は、当初はメモリ消費を抑えるために `1` としてください。
|
||||
|
||||
学習させるステップ数 `max_train_steps` を10000とします。学習率 `learning_rate` はここでは5e-6を指定しています。
|
||||
|
||||
省メモリ化のため `mixed_precision="fp16"` を指定します(RTX30 シリーズ以降では `bf16` も指定できます。環境整備時にaccelerateに行った設定と合わせてください)。また `gradient_checkpointing` を指定します。
|
||||
|
||||
オプティマイザ(モデルを学習データにあうように最適化=学習させるクラス)にメモリ消費の少ない 8bit AdamW を使うため、 `optimizer_type="AdamW8bit"` を指定します。
|
||||
|
||||
`xformers` オプションを指定し、xformersのCrossAttentionを用います。xformersをインストールしていない場合やエラーとなる場合(環境にもよりますが `mixed_precision="no"` の場合など)、代わりに `mem_eff_attn` オプションを指定すると省メモリ版CrossAttentionを使用します(速度は遅くなります)。
|
||||
|
||||
ある程度メモリがある場合は、`.toml` ファイルを編集してバッチサイズをたとえば `8` くらいに増やしてください(高速化と精度向上の可能性があります)。
|
||||
|
||||
### よく使われるオプションについて
|
||||
|
||||
以下の場合にはオプションに関するドキュメントを参照してください。
|
||||
|
||||
- Stable Diffusion 2.xまたはそこからの派生モデルを学習する
|
||||
- clip skipを2以上を前提としたモデルを学習する
|
||||
- 75トークンを超えたキャプションで学習する
|
||||
|
||||
### Textual Inversionでのバッチサイズについて
|
||||
|
||||
モデル全体を学習するDreamBoothやfine tuningに比べてメモリ使用量が少ないため、バッチサイズは大きめにできます。
|
||||
|
||||
# Textual Inversionのその他の主なオプション
|
||||
|
||||
すべてのオプションについては別文書を参照してください。
|
||||
|
||||
* `--weights`
|
||||
* 学習前に学習済みのembeddingsを読み込み、そこから追加で学習します。
|
||||
* `--use_object_template`
|
||||
* キャプションではなく既定の物体用テンプレート文字列(``a photo of a {}``など)で学習します。公式実装と同じになります。キャプションは無視されます。
|
||||
* `--use_style_template`
|
||||
* キャプションではなく既定のスタイル用テンプレート文字列で学習します(``a painting in the style of {}``など)。公式実装と同じになります。キャプションは無視されます。
|
||||
|
||||
## 当リポジトリ内の画像生成スクリプトで生成する
|
||||
|
||||
gen_img_diffusers.pyに、``--textual_inversion_embeddings`` オプションで学習したembeddingsファイルを指定してください(複数可)。プロンプトでembeddingsファイルのファイル名(拡張子を除く)を使うと、そのembeddingsが適用されます。
|
||||
|
||||
Reference in New Issue
Block a user