mirror of
https://github.com/kohya-ss/sd-scripts.git
synced 2026-04-18 17:35:47 +00:00
Merge branch 'kohya-ss:dev' into dev
This commit is contained in:
14
README.md
14
README.md
@@ -22,11 +22,21 @@ __Stable Diffusion web UI now seems to support LoRA trained by ``sd-scripts``.__
|
||||
|
||||
The feature of SDXL training is now available in sdxl branch as an experimental feature.
|
||||
|
||||
Aug 13, 2023: The feature will be merged into the main branch soon. Following are the changes from the previous version.
|
||||
Sep 3, 2023: The feature will be merged into the main branch soon. Following are the changes from the previous version.
|
||||
|
||||
- ControlNet-LLLite is added. See [documentation](./docs/train_lllite_README.md) for details.
|
||||
- JPEG XL is supported. [#786](https://github.com/kohya-ss/sd-scripts/pull/786)
|
||||
- Peak memory usage is reduced. [#791](https://github.com/kohya-ss/sd-scripts/pull/791)
|
||||
- Input perturbation noise is added. See [#798](https://github.com/kohya-ss/sd-scripts/pull/798) for details.
|
||||
- Dataset subset now has `caption_prefix` and `caption_suffix` options. The strings are added to the beginning and the end of the captions before shuffling. You can specify the options in `.toml`.
|
||||
- Other minor changes.
|
||||
- Thanks for contributions from Isotr0py, vvern999, lansing and others!
|
||||
|
||||
Aug 13, 2023:
|
||||
|
||||
- LoRA-FA is added experimentally. Specify `--network_module networks.lora_fa` option instead of `--network_module networks.lora`. The trained model can be used as a normal LoRA model.
|
||||
|
||||
Aug 12, 2023: Following are the changes from the previous version.
|
||||
Aug 12, 2023:
|
||||
|
||||
- The default value of noise offset when omitted has been changed to 0 from 0.0357.
|
||||
- The different learning rates for each U-Net block are now supported. Specify with `--block_lr` option. Specify 23 values separated by commas like `--block_lr 1e-3,1e-3 ... 1e-3`.
|
||||
|
||||
@@ -138,9 +138,13 @@ DreamBooth の手法と fine tuning の手法の両方とも利用可能な学
|
||||
| `num_repeats` | `10` | o | o | o |
|
||||
| `random_crop` | `false` | o | o | o |
|
||||
| `shuffle_caption` | `true` | o | o | o |
|
||||
| `caption_prefix` | `“masterpiece, best quality, ”` | o | o | o |
|
||||
| `caption_suffix` | `“, from side”` | o | o | o |
|
||||
|
||||
* `num_repeats`
|
||||
* サブセットの画像の繰り返し回数を指定します。fine tuning における `--dataset_repeats` に相当しますが、`num_repeats` はどの学習方法でも指定可能です。
|
||||
* `caption_prefix`, `caption_suffix`
|
||||
* キャプションの前、後に付与する文字列を指定します。シャッフルはこれらの文字列を含めた状態で行われます。`keep_tokens` を指定する場合には注意してください。
|
||||
|
||||
### DreamBooth 方式専用のオプション
|
||||
|
||||
|
||||
@@ -1,9 +1,9 @@
|
||||
__由于文档正在更新中,描述可能有错误。__
|
||||
|
||||
# 关于本学习文档,通用描述
|
||||
# 关于训练,通用描述
|
||||
本库支持模型微调(fine tuning)、DreamBooth、训练LoRA和文本反转(Textual Inversion)(包括[XTI:P+](https://github.com/kohya-ss/sd-scripts/pull/327)
|
||||
)
|
||||
本文档将说明它们通用的学习数据准备方法和选项等。
|
||||
本文档将说明它们通用的训练数据准备方法和选项等。
|
||||
|
||||
# 概要
|
||||
|
||||
@@ -12,15 +12,15 @@ __由于文档正在更新中,描述可能有错误。__
|
||||
|
||||
以下本节说明。
|
||||
|
||||
1. 关于准备学习数据的新形式(使用设置文件)
|
||||
1. 对于在学习中使用的术语的简要解释
|
||||
1. 准备训练数据(使用设置文件的新格式)
|
||||
1. 训练中使用的术语的简要解释
|
||||
1. 先前的指定格式(不使用设置文件,而是从命令行指定)
|
||||
1. 生成学习过程中的示例图像
|
||||
1. 生成训练过程中的示例图像
|
||||
1. 各脚本中常用的共同选项
|
||||
1. 准备 fine tuning 方法的元数据:如说明文字(打标签)等
|
||||
|
||||
|
||||
1. 如果只执行一次,学习就可以进行(相关内容,请参阅各个脚本的文档)。如果需要,以后可以随时参考。
|
||||
1. 如果只执行一次,训练就可以进行(相关内容,请参阅各个脚本的文档)。如果需要,以后可以随时参考。
|
||||
|
||||
|
||||
|
||||
@@ -34,18 +34,19 @@ __由于文档正在更新中,描述可能有错误。__
|
||||
|
||||
1. DreamBooth、class + identifier方式(可使用正则化图像)
|
||||
|
||||
将训练目标与特定单词(identifier)相关联进行训练。无需准备说明。例如,当要学习特定角色时,由于无需准备说明,因此比较方便,但由于学习数据的所有元素都与identifier相关联,例如发型、服装、背景等,因此在生成时可能会出现无法更换服装的情况。
|
||||
将训练目标与特定单词(identifier)相关联进行训练。无需准备说明。例如,当要学习特定角色时,由于无需准备说明,因此比较方便,但由于训练数据的所有元素都与identifier相关联,例如发型、服装、背景等,因此在生成时可能会出现无法更换服装的情况。
|
||||
|
||||
2. DreamBooth、说明方式(可使用正则化图像)
|
||||
|
||||
准备记录每个图像说明的文本文件进行训练。例如,通过将图像详细信息(如穿着白色衣服的角色A、穿着红色衣服的角色A等)记录在说明中,可以将角色和其他元素分离,并期望模型更准确地学习角色。
|
||||
事先给每个图片写说明(caption),存放到文本文件中,然后进行训练。例如,通过将图像详细信息(如穿着白色衣服的角色A、穿着红色衣服的角色A等)记录在caption中,可以将角色和其他元素分离,并期望模型更准确地学习角色。
|
||||
|
||||
3. 微调方式(不可使用正则化图像)
|
||||
|
||||
先将说明收集到元数据文件中。支持分离标签和说明以及预先缓存latents等功能,以加速训练(这些将在另一篇文档中介绍)。(虽然名为fine tuning方式,但不仅限于fine tuning。)
|
||||
你要学的东西和你可以使用的规范方法的组合如下。
|
||||
|
||||
训练对象和你可以使用的规范方法的组合如下。
|
||||
|
||||
| 学习对象或方法 | 脚本 | DB/class+identifier | DB/caption | fine tuning |
|
||||
| 训练对象或方法 | 脚本 | DB/class+identifier | DB/caption | fine tuning |
|
||||
|----------------| ----- | ----- | ----- | ----- |
|
||||
| fine tuning微调模型 | `fine_tune.py`| x | x | o |
|
||||
| DreamBooth训练模型 | `train_db.py`| o | o | x |
|
||||
@@ -54,7 +55,7 @@ __由于文档正在更新中,描述可能有错误。__
|
||||
|
||||
## 选择哪一个
|
||||
|
||||
如果您想要学习LoRA、Textual Inversion而不需要准备标题文件,则建议使用DreamBooth class+identifier。如果您能够准备标题文件,则DreamBooth Captions方法更好。如果您有大量的训练数据并且不使用规则化图像,则请考虑使用fine-tuning方法。
|
||||
如果您想要训练LoRA、Textual Inversion而不需要准备说明(caption)文件,则建议使用DreamBooth class+identifier。如果您能够准备caption文件,则DreamBooth Captions方法更好。如果您有大量的训练数据并且不使用正则化图像,则请考虑使用fine-tuning方法。
|
||||
|
||||
对于DreamBooth也是一样的,但不能使用fine-tuning方法。若要进行微调,只能使用fine-tuning方式。
|
||||
|
||||
@@ -62,7 +63,7 @@ __由于文档正在更新中,描述可能有错误。__
|
||||
|
||||
在这里,我们只介绍每种指定方法的典型模式。有关更详细的指定方法,请参见[数据集设置](./config_README-ja.md)。
|
||||
|
||||
# DreamBooth,class+identifier方法(可使用规则化图像)
|
||||
# DreamBooth,class+identifier方法(可使用正则化图像)
|
||||
|
||||
在该方法中,每个图像将被视为使用与 `class identifier` 相同的标题进行训练(例如 `shs dog`)。
|
||||
|
||||
@@ -70,15 +71,15 @@ __由于文档正在更新中,描述可能有错误。__
|
||||
|
||||
## step 1.确定identifier和class
|
||||
|
||||
要将学习的目标与identifier和属于该目标的class相关联。
|
||||
要将训练的目标与identifier和属于该目标的class相关联。
|
||||
|
||||
(虽然有很多称呼,但暂时按照原始论文的说法。)
|
||||
|
||||
以下是简要说明(请查阅详细信息)。
|
||||
|
||||
class是学习目标的一般类别。例如,如果要学习特定品种的狗,则class将是“dog”。对于动漫角色,根据模型不同,可能是“boy”或“girl”,也可能是“1boy”或“1girl”。
|
||||
class是训练目标的一般类别。例如,如果要学习特定品种的狗,则class将是“dog”。对于动漫角色,根据模型不同,可能是“boy”或“girl”,也可能是“1boy”或“1girl”。
|
||||
|
||||
identifier是用于识别学习目标并进行学习的单词。可以使用任何单词,但是根据原始论文,“Tokenizer生成的3个或更少字符的罕见单词”是最好的选择。
|
||||
identifier是用于识别训练目标并进行学习的单词。可以使用任何单词,但是根据原始论文,“Tokenizer生成的3个或更少字符的罕见单词”是最好的选择。
|
||||
|
||||
使用identifier和class,例如,“shs dog”可以将模型训练为从class中识别并学习所需的目标。
|
||||
|
||||
@@ -88,7 +89,7 @@ identifier是用于识别学习目标并进行学习的单词。可以使用任
|
||||
|
||||
## step 2. 决定是否使用正则化图像,并在使用时生成正则化图像
|
||||
|
||||
正则化图像是为防止前面提到的语言漂移,即整个类别被拉扯成为学习目标而生成的图像。如果不使用正则化图像,例如在 `shs 1girl` 中学习特定角色时,即使在简单的 `1girl` 提示下生成,也会越来越像该角色。这是因为 `1girl` 在训练时的标题中包含了该角色的信息。
|
||||
正则化图像是为防止前面提到的语言漂移,即整个类别被拉扯成为训练目标而生成的图像。如果不使用正则化图像,例如在 `shs 1girl` 中学习特定角色时,即使在简单的 `1girl` 提示下生成,也会越来越像该角色。这是因为 `1girl` 在训练时的标题中包含了该角色的信息。
|
||||
|
||||
通过同时学习目标图像和正则化图像,类别仍然保持不变,仅在将标识符附加到提示中时才生成目标图像。
|
||||
|
||||
@@ -117,7 +118,7 @@ identifier是用于识别学习目标并进行学习的单词。可以使用任
|
||||
enable_bucket = true # 是否使用Aspect Ratio Bucketing
|
||||
|
||||
[[datasets]]
|
||||
resolution = 512 # 学习分辨率
|
||||
resolution = 512 # 训练分辨率
|
||||
batch_size = 4 # 批次大小
|
||||
|
||||
[[datasets.subsets]]
|
||||
@@ -133,15 +134,15 @@ batch_size = 4 # 批次大小
|
||||
num_repeats = 1 # 正则化图像的重复次数,基本上1就可以了
|
||||
```
|
||||
|
||||
基本上只需更改以下几个地方即可进行学习。
|
||||
基本上只需更改以下几个地方即可进行训练。
|
||||
|
||||
1. 学习分辨率
|
||||
1. 训练分辨率
|
||||
|
||||
指定一个数字表示正方形(如果是 `512`,则为 512x512),如果使用方括号和逗号分隔的两个数字,则表示横向×纵向(如果是`[512,768]`,则为 512x768)。在SD1.x系列中,原始学习分辨率为512。指定较大的分辨率,如 `[512,768]` 可能会减少纵向和横向图像生成时的错误。在SD2.x 768系列中,分辨率为 `768`。
|
||||
指定一个数字表示正方形(如果是 `512`,则为 512x512),如果使用方括号和逗号分隔的两个数字,则表示横向×纵向(如果是`[512,768]`,则为 512x768)。在SD1.x系列中,原始训练分辨率为512。指定较大的分辨率,如 `[512,768]` 可能会减少纵向和横向图像生成时的错误。在SD2.x 768系列中,分辨率为 `768`。
|
||||
|
||||
1. 批次大小
|
||||
|
||||
指定同时学习多少个数据。这取决于GPU的VRAM大小和学习分辨率。详细信息将在后面说明。此外,fine tuning/DreamBooth/LoRA等也会影响批次大小,请查看各个脚本的说明。
|
||||
指定同时训练多少个数据。这取决于GPU的VRAM大小和训练分辨率。详细信息将在后面说明。此外,fine tuning/DreamBooth/LoRA等也会影响批次大小,请查看各个脚本的说明。
|
||||
|
||||
1. 文件夹指定
|
||||
|
||||
@@ -161,23 +162,23 @@ batch_size = 4 # 批次大小
|
||||
|
||||
请将重复次数指定为“ __训练用图像的重复次数×训练用图像的数量≥正则化图像的重复次数×正则化图像的数量__ ”。
|
||||
|
||||
(1个epoch(数据一周一次)的数据量为“训练用图像的重复次数×训练用图像的数量”。如果正则化图像的数量多于这个值,则剩余的正则化图像将不会被使用。)
|
||||
(1个epoch(指训练数据过完一遍)的数据量为“训练用图像的重复次数×训练用图像的数量”。如果正则化图像的数量多于这个值,则剩余的正则化图像将不会被使用。)
|
||||
|
||||
## 步骤 3. 学习
|
||||
## 步骤 3. 训练
|
||||
|
||||
详情请参考相关文档进行学习。
|
||||
详情请参考相关文档进行训练。
|
||||
|
||||
# DreamBooth,标题方式(可使用正则化图像)
|
||||
# DreamBooth,文本说明(caption)方式(可使用正则化图像)
|
||||
|
||||
在此方式中,每个图像都将通过标题进行学习。
|
||||
在此方式中,每个图像都将通过caption进行训练。
|
||||
|
||||
## 步骤 1. 准备标题文件
|
||||
## 步骤 1. 准备文本说明文件
|
||||
|
||||
请将与图像具有相同文件名且扩展名为 `.caption`(可以在设置中更改)的文件放置在用于训练图像的文件夹中。每个文件应该只有一行。编码为 `UTF-8`。
|
||||
|
||||
## 步骤 2. 决定是否使用正则化图像,并在使用时生成正则化图像
|
||||
|
||||
与class+identifier格式相同。可以在规范化图像上附加标题,但通常不需要。
|
||||
与class+identifier格式相同。可以在规范化图像上附加caption,但通常不需要。
|
||||
|
||||
## 步骤 2. 编写设置文件
|
||||
|
||||
@@ -188,7 +189,7 @@ batch_size = 4 # 批次大小
|
||||
enable_bucket = true # 是否使用Aspect Ratio Bucketing
|
||||
|
||||
[[datasets]]
|
||||
resolution = 512 # 学习分辨率
|
||||
resolution = 512 # 训练分辨率
|
||||
batch_size = 4 # 批次大小
|
||||
|
||||
[[datasets.subsets]]
|
||||
@@ -204,25 +205,25 @@ batch_size = 4 # 批次大小
|
||||
num_repeats = 1 # 正则化图像的重复次数,基本上1就可以了
|
||||
```
|
||||
|
||||
基本上只需更改以下几个地方来学习。除非另有说明,否则与class+identifier方法相同。
|
||||
基本上只需更改以下几个地方来训练。除非另有说明,否则与class+identifier方法相同。
|
||||
|
||||
1. 学习分辨率
|
||||
1. 训练分辨率
|
||||
2. 批次大小
|
||||
3. 文件夹指定
|
||||
4. 标题文件的扩展名
|
||||
4. caption文件的扩展名
|
||||
|
||||
可以指定任意的扩展名。
|
||||
5. 重复次数
|
||||
|
||||
## 步骤 3. 学习
|
||||
## 步骤 3. 训练
|
||||
|
||||
详情请参考相关文档进行学习。
|
||||
详情请参考相关文档进行训练。
|
||||
|
||||
# 微调方法(fine tuning)
|
||||
|
||||
## 步骤 1. 准备元数据
|
||||
|
||||
将标题和标签整合到管理文件中称为元数据。它的扩展名为 `.json`,格式为json。由于创建方法较长,因此在本文档的末尾进行描述。
|
||||
将caption和标签整合到管理文件中称为元数据。它的扩展名为 `.json`,格式为json。由于创建方法较长,因此在本文档的末尾进行描述。
|
||||
|
||||
## 步骤 2. 编写设置文件
|
||||
|
||||
@@ -241,9 +242,9 @@ batch_size = 4 # 批次大小
|
||||
metadata_file = 'C:\piyo\piyo_md.json' # 元数据文件名
|
||||
```
|
||||
|
||||
基本上只需更改以下几个地方来学习。除非另有说明,否则与DreamBooth, class+identifier方法相同。
|
||||
基本上只需更改以下几个地方来训练。除非另有说明,否则与DreamBooth, class+identifier方法相同。
|
||||
|
||||
1. 学习分辨率
|
||||
1. 训练分辨率
|
||||
2. 批次大小
|
||||
3. 指定文件夹
|
||||
4. 元数据文件名
|
||||
@@ -251,21 +252,21 @@ batch_size = 4 # 批次大小
|
||||
指定使用后面所述方法创建的元数据文件。
|
||||
|
||||
|
||||
## 第三步:学习
|
||||
## 第三步:训练
|
||||
|
||||
详情请参考相关文档进行学习。
|
||||
详情请参考相关文档进行训练。
|
||||
|
||||
# 学习中使用的术语简单解释
|
||||
# 训练中使用的术语简单解释
|
||||
|
||||
由于省略了细节并且我自己也没有完全理解,因此请自行查阅详细信息。
|
||||
|
||||
## 微调(fine tuning)
|
||||
|
||||
指训练模型并微调其性能。具体含义因用法而异,但在 Stable Diffusion 中,狭义的微调是指使用图像和标题进行训练模型。DreamBooth 可视为狭义微调的一种特殊方法。广义的微调包括 LoRA、Textual Inversion、Hypernetworks 等,包括训练模型的所有内容。
|
||||
指训练模型并微调其性能。具体含义因用法而异,但在 Stable Diffusion 中,狭义的微调是指使用图像和caption进行训练模型。DreamBooth 可视为狭义微调的一种特殊方法。广义的微调包括 LoRA、Textual Inversion、Hypernetworks 等,包括训练模型的所有内容。
|
||||
|
||||
## 步骤(step)
|
||||
|
||||
粗略地说,每次在训练数据上进行一次计算即为一步。具体来说,“将训练数据的标题传递给当前模型,将生成的图像与训练数据的图像进行比较,稍微更改模型,以使其更接近训练数据”即为一步。
|
||||
粗略地说,每次在训练数据上进行一次计算即为一步。具体来说,“将训练数据的caption传递给当前模型,将生成的图像与训练数据的图像进行比较,稍微更改模型,以使其更接近训练数据”即为一步。
|
||||
|
||||
## 批次大小(batch size)
|
||||
|
||||
@@ -287,7 +288,7 @@ batch_size = 4 # 批次大小
|
||||
|
||||
默认情况下,整个训练过程中学习率是固定的。但是可以通过调度程序指定学习率如何变化,因此结果也会有所不同。
|
||||
|
||||
## 时期(epoch)
|
||||
## Epoch
|
||||
|
||||
Epoch指的是训练数据被完整训练一遍(即数据已经迭代一轮)。如果指定了重复次数,则在重复后的数据迭代一轮后,为1个epoch。
|
||||
|
||||
@@ -307,7 +308,7 @@ Stable Diffusion 的 v1 是以 512\*512 的分辨率进行训练的,但同时
|
||||
|
||||
# 以前的指定格式(不使用 .toml 文件,而是使用命令行选项指定)
|
||||
|
||||
这是一种通过命令行选项而不是指定 .toml 文件的方法。有 DreamBooth 类+标识符方法、DreamBooth 标题方法、微调方法三种方式。
|
||||
这是一种通过命令行选项而不是指定 .toml 文件的方法。有 DreamBooth 类+标识符方法、DreamBooth caption方法、微调方法三种方式。
|
||||
|
||||
## DreamBooth、类+标识符方式
|
||||
|
||||
@@ -327,7 +328,7 @@ Stable Diffusion 的 v1 是以 512\*512 的分辨率进行训练的,但同时
|
||||
|
||||

|
||||
|
||||
### 多个类别、多个标识符的学习
|
||||
### 多个类别、多个标识符的训练
|
||||
|
||||
该方法很简单,在用于训练的图像文件夹中,需要准备多个文件夹,每个文件夹都是以“重复次数_<标识符> <类别>”命名的,同样,在正则化图像文件夹中,也需要准备多个文件夹,每个文件夹都是以“重复次数_<类别>”命名的。
|
||||
|
||||
@@ -345,37 +346,37 @@ Stable Diffusion 的 v1 是以 512\*512 的分辨率进行训练的,但同时
|
||||
|
||||
### step 2. 准备正规化图像
|
||||
|
||||
这是使用规则化图像时的过程。
|
||||
这是使用正则化图像时的过程。
|
||||
|
||||
创建一个文件夹来存储规则化的图像。 __此外,__ 创建一个名为``<repeat count>_<class>`` 的目录。
|
||||
创建一个文件夹来存储正则化的图像。 __此外,__ 创建一个名为``<repeat count>_<class>`` 的目录。
|
||||
|
||||
例如,使用提示“frog”并且不重复数据(仅一次):
|
||||
|
||||
|
||||
|
||||
步骤3. 执行学习
|
||||
步骤3. 执行训练
|
||||
|
||||
执行每个学习脚本。使用 `--train_data_dir` 选项指定包含训练数据文件夹的父文件夹(不是包含图像的文件夹),使用 `--reg_data_dir` 选项指定包含正则化图像的父文件夹(不是包含图像的文件夹)。
|
||||
执行每个训练脚本。使用 `--train_data_dir` 选项指定包含训练数据文件夹的父文件夹(不是包含图像的文件夹),使用 `--reg_data_dir` 选项指定包含正则化图像的父文件夹(不是包含图像的文件夹)。
|
||||
|
||||
## DreamBooth,带标题方式
|
||||
## DreamBooth,带文本说明(caption)的方式
|
||||
|
||||
在包含训练图像和正则化图像的文件夹中,将与图像具有相同文件名的文件.caption(可以使用选项进行更改)放置在该文件夹中,然后从该文件中加载标题作为提示进行学习。
|
||||
在包含训练图像和正则化图像的文件夹中,将与图像具有相同文件名的文件.caption(可以使用选项进行更改)放置在该文件夹中,然后从该文件中加载caption所作为提示进行训练。
|
||||
|
||||
※文件夹名称(标识符类)不再用于这些图像的训练。
|
||||
|
||||
默认的标题文件扩展名为.caption。可以使用学习脚本的 `--caption_extension` 选项进行更改。 使用 `--shuffle_caption` 选项,同时对每个逗号分隔的部分进行学习时会对学习时的标题进行混洗。
|
||||
默认的caption文件扩展名为.caption。可以使用训练脚本的 `--caption_extension` 选项进行更改。 使用 `--shuffle_caption` 选项,同时对每个逗号分隔的部分进行训练时会对训练时的caption进行混洗。
|
||||
|
||||
## 微调方式
|
||||
|
||||
创建元数据的方式与使用配置文件相同。 使用 `in_json` 选项指定元数据文件。
|
||||
|
||||
# 学习过程中的样本输出
|
||||
# 训练过程中的样本输出
|
||||
|
||||
通过在训练中使用模型生成图像,可以检查学习进度。将以下选项指定为学习脚本。
|
||||
通过在训练中使用模型生成图像,可以检查训练进度。将以下选项指定为训练脚本。
|
||||
|
||||
- `--sample_every_n_steps` / `--sample_every_n_epochs`
|
||||
|
||||
指定要采样的步数或纪元数。为这些数字中的每一个输出样本。如果两者都指定,则 epoch 数优先。
|
||||
指定要采样的步数或epoch数。为这些数字中的每一个输出样本。如果两者都指定,则 epoch 数优先。
|
||||
- `--sample_prompts`
|
||||
|
||||
指定示例输出的提示文件。
|
||||
@@ -422,11 +423,11 @@ masterpiece, best quality, 1boy, in business suit, standing at street, looking b
|
||||
4. U-Net的结构(CrossAttention的头数等)
|
||||
5. v-parameterization(采样方式好像变了)
|
||||
|
||||
其中碱基使用1-4个,非碱基使用1-5个(768-v)。使用 1-4 进行 v2 选择,使用 5 进行 v_parameterization 选择。
|
||||
-`--pretrained_model_name_or_path`
|
||||
其中base使用1-4,非base使用1-5(768-v)。使用 1-4 进行 v2 选择,使用 5 进行 v_parameterization 选择。
|
||||
- `--pretrained_model_name_or_path`
|
||||
|
||||
指定要从中执行额外训练的模型。您可以指定稳定扩散检查点文件(.ckpt 或 .safetensors)、扩散器本地磁盘上的模型目录或扩散器模型 ID(例如“stabilityai/stable-diffusion-2”)。
|
||||
## 学习设置
|
||||
指定要从中执行额外训练的模型。您可以指定Stable Diffusion检查点文件(.ckpt 或 .safetensors)、diffusers本地磁盘上的模型目录或diffusers模型 ID(例如“stabilityai/stable-diffusion-2”)。
|
||||
## 训练设置
|
||||
|
||||
- `--output_dir`
|
||||
|
||||
@@ -442,7 +443,7 @@ masterpiece, best quality, 1boy, in business suit, standing at street, looking b
|
||||
|
||||
- `--max_train_steps` / `--max_train_epochs`
|
||||
|
||||
指定要学习的步数或纪元数。如果两者都指定,则 epoch 数优先。
|
||||
指定要训练的步数或epoch数。如果两者都指定,则 epoch 数优先。
|
||||
-
|
||||
- `--mixed_precision`
|
||||
|
||||
@@ -453,7 +454,7 @@ masterpiece, best quality, 1boy, in business suit, standing at street, looking b
|
||||
|
||||
通过逐步计算权重而不是在训练期间一次计算所有权重来减少训练所需的 GPU 内存量。关闭它不会影响准确性,但打开它允许更大的批次大小,所以那里有影响。
|
||||
|
||||
另外,打开它通常会减慢速度,但可以增加批次大小,因此总的学习时间实际上可能会更快。
|
||||
另外,打开它通常会减慢速度,但可以增加批次大小,因此总的训练时间实际上可能会更快。
|
||||
|
||||
- `--xformers` / `--mem_eff_attn`
|
||||
|
||||
@@ -464,35 +465,35 @@ masterpiece, best quality, 1boy, in business suit, standing at street, looking b
|
||||
- `--save_every_n_epochs` / `--save_state` / `--resume`
|
||||
为 save_every_n_epochs 选项指定一个数字可以在每个时期的训练期间保存模型。
|
||||
|
||||
如果同时指定save_state选项,学习状态包括优化器的状态等都会一起保存。。保存目的地将是一个文件夹。
|
||||
如果同时指定save_state选项,训练状态包括优化器的状态等都会一起保存。。保存目的地将是一个文件夹。
|
||||
|
||||
学习状态输出到目标文件夹中名为“<output_name>-??????-state”(??????是纪元数)的文件夹中。长时间学习时请使用。
|
||||
训练状态输出到目标文件夹中名为“<output_name>-??????-state”(??????是epoch数)的文件夹中。长时间训练时请使用。
|
||||
|
||||
使用 resume 选项从保存的训练状态恢复训练。指定学习状态文件夹(其中的状态文件夹,而不是 `output_dir`)。
|
||||
使用 resume 选项从保存的训练状态恢复训练。指定训练状态文件夹(其中的状态文件夹,而不是 `output_dir`)。
|
||||
|
||||
请注意,由于 Accelerator 规范,epoch 数和全局步数不会保存,即使恢复时它们也从 1 开始。
|
||||
- `--save_model_as` (DreamBooth, fine tuning 仅有的)
|
||||
|
||||
您可以从 `ckpt, safetensors, diffusers, diffusers_safetensors` 中选择模型保存格式。
|
||||
|
||||
- `--save_model_as=safetensors` 指定喜欢当读取稳定扩散格式(ckpt 或安全张量)并以扩散器格式保存时,缺少的信息通过从 Hugging Face 中删除 v1.5 或 v2.1 信息来补充。
|
||||
- `--save_model_as=safetensors` 指定喜欢当读取Stable Diffusion格式(ckpt 或safetensors)并以diffusers格式保存时,缺少的信息通过从 Hugging Face 中删除 v1.5 或 v2.1 信息来补充。
|
||||
|
||||
- `--clip_skip`
|
||||
|
||||
`2` 如果指定,则使用文本编码器 (CLIP) 的倒数第二层的输出。如果省略 1 或选项,则使用最后一层。
|
||||
|
||||
*SD2.0默认使用倒数第二层,学习SD2.0时请不要指定。
|
||||
*SD2.0默认使用倒数第二层,训练SD2.0时请不要指定。
|
||||
|
||||
如果被训练的模型最初被训练为使用第二层,则 2 是一个很好的值。
|
||||
|
||||
如果您使用的是最后一层,那么整个模型都会根据该假设进行训练。因此,如果再次使用第二层进行训练,可能需要一定数量的teacher数据和更长时间的学习才能得到想要的学习结果。
|
||||
如果您使用的是最后一层,那么整个模型都会根据该假设进行训练。因此,如果再次使用第二层进行训练,可能需要一定数量的teacher数据和更长时间的训练才能得到想要的训练结果。
|
||||
- `--max_token_length`
|
||||
|
||||
默认值为 75。您可以通过指定“150”或“225”来扩展令牌长度来学习。使用长字幕学习时指定。
|
||||
默认值为 75。您可以通过指定“150”或“225”来扩展令牌长度来训练。使用长字幕训练时指定。
|
||||
|
||||
但由于学习时token展开的规范与Automatic1111的web UI(除法等规范)略有不同,如非必要建议用75学习。
|
||||
但由于训练时token展开的规范与Automatic1111的web UI(除法等规范)略有不同,如非必要建议用75训练。
|
||||
|
||||
与clip_skip一样,学习与模型学习状态不同的长度可能需要一定量的teacher数据和更长的学习时间。
|
||||
与clip_skip一样,训练与模型训练状态不同的长度可能需要一定量的teacher数据和更长的学习时间。
|
||||
|
||||
- `--persistent_data_loader_workers`
|
||||
|
||||
@@ -503,7 +504,7 @@ masterpiece, best quality, 1boy, in business suit, standing at street, looking b
|
||||
指定数据加载的进程数。大量的进程会更快地加载数据并更有效地使用 GPU,但会消耗更多的主内存。默认是"`8`或者`CPU并发执行线程数 - 1`,取小者",所以如果主存没有空间或者GPU使用率大概在90%以上,就看那些数字和 `2` 或将其降低到大约 `1`。
|
||||
- `--logging_dir` / `--log_prefix`
|
||||
|
||||
保存学习日志的选项。在 logging_dir 选项中指定日志保存目标文件夹。以 TensorBoard 格式保存日志。
|
||||
保存训练日志的选项。在 logging_dir 选项中指定日志保存目标文件夹。以 TensorBoard 格式保存日志。
|
||||
|
||||
例如,如果您指定 --logging_dir=logs,将在您的工作文件夹中创建一个日志文件夹,并将日志保存在日期/时间文件夹中。
|
||||
此外,如果您指定 --log_prefix 选项,则指定的字符串将添加到日期和时间之前。使用“--logging_dir=logs --log_prefix=db_style1_”进行识别。
|
||||
@@ -519,23 +520,23 @@ masterpiece, best quality, 1boy, in business suit, standing at street, looking b
|
||||
- `--noise_offset`
|
||||
本文的实现:https://www.crosslabs.org//blog/diffusion-with-offset-noise
|
||||
|
||||
看起来它可能会为整体更暗和更亮的图像产生更好的结果。它似乎对 LoRA 学习也有效。指定一个大约 0.1 的值似乎很好。
|
||||
看起来它可能会为整体更暗和更亮的图像产生更好的结果。它似乎对 LoRA 训练也有效。指定一个大约 0.1 的值似乎很好。
|
||||
|
||||
- `--debug_dataset`
|
||||
|
||||
通过添加此选项,您可以在学习之前检查将学习什么样的图像数据和标题。按 Esc 退出并返回命令行。按 `S` 进入下一步(批次),按 `E` 进入下一个纪元。
|
||||
通过添加此选项,您可以在训练之前检查将训练什么样的图像数据和标题。按 Esc 退出并返回命令行。按 `S` 进入下一步(批次),按 `E` 进入下一个epoch。
|
||||
|
||||
*图片在 Linux 环境(包括 Colab)下不显示。
|
||||
|
||||
- `--vae`
|
||||
|
||||
如果您在 vae 选项中指定稳定扩散检查点、VAE 检查点文件、扩散模型或 VAE(两者都可以指定本地或拥抱面模型 ID),则该 VAE 用于学习(缓存时的潜伏)或在学习过程中获得潜伏)。
|
||||
如果您在 vae 选项中指定Stable Diffusion检查点、VAE 检查点文件、扩散模型或 VAE(两者都可以指定本地或拥抱面模型 ID),则该 VAE 用于训练(缓存时的潜伏)或在训练过程中获得潜伏)。
|
||||
|
||||
对于 DreamBooth 和微调,保存的模型将包含此 VAE
|
||||
|
||||
- `--cache_latents`
|
||||
|
||||
在主内存中缓存 VAE 输出以减少 VRAM 使用。除 flip_aug 之外的任何增强都将不可用。此外,整体学习速度略快。
|
||||
在主内存中缓存 VAE 输出以减少 VRAM 使用。除 flip_aug 之外的任何增强都将不可用。此外,整体训练速度略快。
|
||||
- `--min_snr_gamma`
|
||||
|
||||
指定最小 SNR 加权策略。细节是[这里](https://github.com/kohya-ss/sd-scripts/pull/308)请参阅。论文中推荐`5`。
|
||||
@@ -568,7 +569,7 @@ masterpiece, best quality, 1boy, in business suit, standing at street, looking b
|
||||
|
||||
- `--learning_rate`
|
||||
|
||||
指定学习率。合适的学习率取决于学习脚本,所以请参考每个解释。
|
||||
指定学习率。合适的学习率取决于训练脚本,所以请参考每个解释。
|
||||
- `--lr_scheduler` / `--lr_warmup_steps` / `--lr_scheduler_num_cycles` / `--lr_scheduler_power`
|
||||
|
||||
学习率的调度程序相关规范。
|
||||
@@ -603,14 +604,14 @@ D-Adaptation 优化器自动调整学习率。学习率选项指定的值不是
|
||||
(内部仅通过 importlib 未确认操作。如果需要,请安装包。)
|
||||
<!--
|
||||
## 使用任意大小的图像进行训练 --resolution
|
||||
你可以在广场外学习。请在分辨率中指定“宽度、高度”,如“448,640”。宽度和高度必须能被 64 整除。匹配训练图像和正则化图像的大小。
|
||||
你可以在广场外训练。请在分辨率中指定“宽度、高度”,如“448,640”。宽度和高度必须能被 64 整除。匹配训练图像和正则化图像的大小。
|
||||
|
||||
就我个人而言,我经常生成垂直长的图像,所以我有时会用“448、640”来学习。
|
||||
就我个人而言,我经常生成垂直长的图像,所以我有时会用“448、640”来训练。
|
||||
|
||||
## 纵横比分桶 --enable_bucket / --min_bucket_reso / --max_bucket_reso
|
||||
它通过指定 enable_bucket 选项来启用。 Stable Diffusion 在 512x512 分辨率下训练,但也在 256x768 和 384x640 等分辨率下训练。
|
||||
|
||||
如果指定此选项,则不需要将训练图像和正则化图像统一为特定分辨率。从多种分辨率(纵横比)中进行选择,并在该分辨率下学习。
|
||||
如果指定此选项,则不需要将训练图像和正则化图像统一为特定分辨率。从多种分辨率(纵横比)中进行选择,并在该分辨率下训练。
|
||||
由于分辨率为 64 像素,纵横比可能与原始图像不完全相同。
|
||||
|
||||
您可以使用 min_bucket_reso 选项指定分辨率的最小大小,使用 max_bucket_reso 指定最大大小。默认值分别为 256 和 1024。
|
||||
@@ -622,13 +623,13 @@ D-Adaptation 优化器自动调整学习率。学习率选项指定的值不是
|
||||
(因为一批中的图像不偏向于训练图像和正则化图像。
|
||||
|
||||
## 扩充 --color_aug / --flip_aug
|
||||
增强是一种通过在学习过程中动态改变数据来提高模型性能的方法。在使用 color_aug 巧妙地改变色调并使用 flip_aug 左右翻转的同时学习。
|
||||
增强是一种通过在训练过程中动态改变数据来提高模型性能的方法。在使用 color_aug 巧妙地改变色调并使用 flip_aug 左右翻转的同时训练。
|
||||
|
||||
由于数据是动态变化的,因此不能与 cache_latents 选项一起指定。
|
||||
|
||||
## 使用 fp16 梯度训练(实验特征)--full_fp16
|
||||
如果指定 full_fp16 选项,梯度从普通 float32 变为 float16 (fp16) 并学习(它似乎是 full fp16 学习而不是混合精度)。
|
||||
结果,似乎 SD1.x 512x512 大小可以在 VRAM 使用量小于 8GB 的情况下学习,而 SD2.x 512x512 大小可以在 VRAM 使用量小于 12GB 的情况下学习。
|
||||
如果指定 full_fp16 选项,梯度从普通 float32 变为 float16 (fp16) 并训练(它似乎是 full fp16 训练而不是混合精度)。
|
||||
结果,似乎 SD1.x 512x512 大小可以在 VRAM 使用量小于 8GB 的情况下训练,而 SD2.x 512x512 大小可以在 VRAM 使用量小于 12GB 的情况下训练。
|
||||
|
||||
预先在加速配置中指定 fp16,并可选择设置 ``mixed_precision="fp16"``(bf16 不起作用)。
|
||||
|
||||
@@ -642,20 +643,20 @@ D-Adaptation 优化器自动调整学习率。学习率选项指定的值不是
|
||||
|
||||
# 创建元数据文件
|
||||
|
||||
## 准备教师资料
|
||||
## 准备训练数据
|
||||
|
||||
如上所述准备好你要学习的图像数据,放在任意文件夹中。
|
||||
如上所述准备好你要训练的图像数据,放在任意文件夹中。
|
||||
|
||||
例如,存储这样的图像:
|
||||
|
||||
|
||||
|
||||
## 自动字幕
|
||||
## 自动captioning
|
||||
|
||||
如果您只想学习没有标题的标签,请跳过。
|
||||
如果您只想训练没有标题的标签,请跳过。
|
||||
|
||||
另外,手动准备字幕时,请准备在与教师数据图像相同的目录下,文件名相同,扩展名.caption等。每个文件应该是只有一行的文本文件。
|
||||
### 使用 BLIP 添加字幕
|
||||
另外,手动准备caption时,请准备在与教师数据图像相同的目录下,文件名相同,扩展名.caption等。每个文件应该是只有一行的文本文件。
|
||||
### 使用 BLIP 添加caption
|
||||
|
||||
最新版本不再需要 BLIP 下载、权重下载和额外的虚拟环境。按原样工作。
|
||||
|
||||
@@ -670,24 +671,24 @@ python finetune\make_captions.py --batch_size <バッチサイズ> <教師デー
|
||||
python finetune\make_captions.py --batch_size 8 ..\train_data
|
||||
```
|
||||
|
||||
字幕文件创建在与教师数据图像相同的目录中,具有相同的文件名和扩展名.caption。
|
||||
caption文件创建在与教师数据图像相同的目录中,具有相同的文件名和扩展名.caption。
|
||||
|
||||
根据 GPU 的 VRAM 容量增加或减少 batch_size。越大越快(我认为 12GB 的 VRAM 可以多一点)。
|
||||
您可以使用 max_length 选项指定标题的最大长度。默认值为 75。如果使用 225 的令牌长度训练模型,它可能会更长。
|
||||
您可以使用 caption_extension 选项更改标题扩展名。默认为 .caption(.txt 与稍后描述的 DeepDanbooru 冲突)。
|
||||
您可以使用 max_length 选项指定caption的最大长度。默认值为 75。如果使用 225 的令牌长度训练模型,它可能会更长。
|
||||
您可以使用 caption_extension 选项更改caption扩展名。默认为 .caption(.txt 与稍后描述的 DeepDanbooru 冲突)。
|
||||
如果有多个教师数据文件夹,则对每个文件夹执行。
|
||||
|
||||
请注意,推理是随机的,因此每次运行时结果都会发生变化。如果要修复它,请使用 --seed 选项指定一个随机数种子,例如 `--seed 42`。
|
||||
|
||||
其他的选项,请参考help with `--help`(好像没有文档说明参数的含义,得看源码)。
|
||||
|
||||
默认情况下,会生成扩展名为 .caption 的字幕文件。
|
||||
默认情况下,会生成扩展名为 .caption 的caption文件。
|
||||
|
||||
|
||||
|
||||
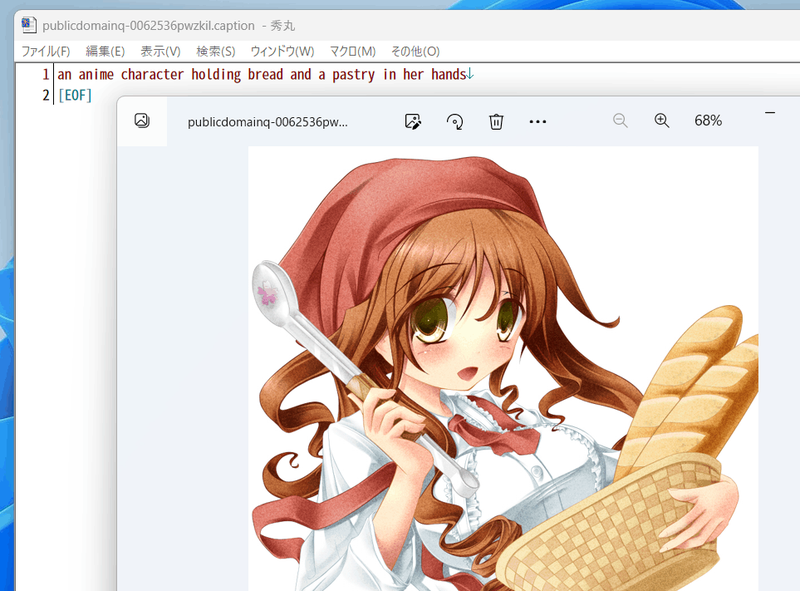
例如,标题如下:
|
||||
|
||||
|
||||

|
||||
|
||||
## 由 DeepDanbooru 标记
|
||||
|
||||
@@ -706,7 +707,7 @@ python finetune\make_captions.py --batch_size 8 ..\train_data
|
||||
做一个这样的目录结构
|
||||
|
||||
|
||||
为扩散器环境安装必要的库。进入 DeepDanbooru 文件夹并安装它(我认为它实际上只是添加了 tensorflow-io)。
|
||||
为diffusers环境安装必要的库。进入 DeepDanbooru 文件夹并安装它(我认为它实际上只是添加了 tensorflow-io)。
|
||||
```
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
@@ -779,12 +780,12 @@ python tag_images_by_wd14_tagger.py --batch_size 4 ..\train_data
|
||||
|
||||
如果有多个教师数据文件夹,则对每个文件夹执行。
|
||||
|
||||
## 预处理字幕和标签信息
|
||||
## 预处理caption和标签信息
|
||||
|
||||
将字幕和标签作为元数据合并到一个文件中,以便从脚本中轻松处理。
|
||||
### 字幕预处理
|
||||
将caption和标签作为元数据合并到一个文件中,以便从脚本中轻松处理。
|
||||
### caption预处理
|
||||
|
||||
要将字幕放入元数据,请在您的工作文件夹中运行以下命令(如果您不使用字幕进行学习,则不需要运行它)(它实际上是一行,依此类推)。指定 `--full_path` 选项以将图像文件的完整路径存储在元数据中。如果省略此选项,则会记录相对路径,但 .toml 文件中需要单独的文件夹规范。
|
||||
要将caption放入元数据,请在您的工作文件夹中运行以下命令(如果您不使用caption进行训练,则不需要运行它)(它实际上是一行,依此类推)。指定 `--full_path` 选项以将图像文件的完整路径存储在元数据中。如果省略此选项,则会记录相对路径,但 .toml 文件中需要单独的文件夹规范。
|
||||
```
|
||||
python merge_captions_to_metadata.py --full_path <教师资料夹>
|
||||
--in_json <要读取的元数据文件名> <元数据文件名>
|
||||
@@ -810,7 +811,7 @@ python merge_captions_to_metadata.py --full_path --in_json meta_cap1.json
|
||||
__* 每次重写 in_json 选项和写入目标并写入单独的元数据文件是安全的。 __
|
||||
### 标签预处理
|
||||
|
||||
同样,标签也收集在元数据中(如果标签不用于学习,则无需这样做)。
|
||||
同样,标签也收集在元数据中(如果标签不用于训练,则无需这样做)。
|
||||
```
|
||||
python merge_dd_tags_to_metadata.py --full_path <教师资料夹>
|
||||
--in_json <要读取的元数据文件名> <要写入的元数据文件名>
|
||||
|
||||
@@ -56,6 +56,8 @@ class BaseSubsetParams:
|
||||
flip_aug: bool = False
|
||||
face_crop_aug_range: Optional[Tuple[float, float]] = None
|
||||
random_crop: bool = False
|
||||
caption_prefix: Optional[str] = None
|
||||
caption_suffix: Optional[str] = None
|
||||
caption_dropout_rate: float = 0.0
|
||||
caption_dropout_every_n_epochs: int = 0
|
||||
caption_tag_dropout_rate: float = 0.0
|
||||
@@ -159,6 +161,8 @@ class ConfigSanitizer:
|
||||
"keep_tokens": int,
|
||||
"token_warmup_min": int,
|
||||
"token_warmup_step": Any(float,int),
|
||||
"caption_prefix": str,
|
||||
"caption_suffix": str,
|
||||
}
|
||||
# DO means DropOut
|
||||
DO_SUBSET_ASCENDABLE_SCHEMA = {
|
||||
@@ -459,6 +463,8 @@ def generate_dataset_group_by_blueprint(dataset_group_blueprint: DatasetGroupBlu
|
||||
caption_dropout_rate: {subset.caption_dropout_rate}
|
||||
caption_dropout_every_n_epoches: {subset.caption_dropout_every_n_epochs}
|
||||
caption_tag_dropout_rate: {subset.caption_tag_dropout_rate}
|
||||
caption_prefix: {subset.caption_prefix}
|
||||
caption_suffix: {subset.caption_suffix}
|
||||
color_aug: {subset.color_aug}
|
||||
flip_aug: {subset.flip_aug}
|
||||
face_crop_aug_range: {subset.face_crop_aug_range}
|
||||
|
||||
@@ -160,7 +160,7 @@ def _load_state_dict_on_device(model, state_dict, device, dtype=None):
|
||||
|
||||
def load_models_from_sdxl_checkpoint(model_version, ckpt_path, map_location, dtype=None):
|
||||
# model_version is reserved for future use
|
||||
# dtype is reserved for full_fp16/bf16 integration. Text Encoder will remain fp32, because it runs on CPU when caching
|
||||
# dtype is used for full_fp16/bf16 integration. Text Encoder will remain fp32, because it runs on CPU when caching
|
||||
|
||||
# Load the state dict
|
||||
if model_util.is_safetensors(ckpt_path):
|
||||
@@ -193,7 +193,7 @@ def load_models_from_sdxl_checkpoint(model_version, ckpt_path, map_location, dty
|
||||
for k in list(state_dict.keys()):
|
||||
if k.startswith("model.diffusion_model."):
|
||||
unet_sd[k.replace("model.diffusion_model.", "")] = state_dict.pop(k)
|
||||
info = _load_state_dict_on_device(unet, unet_sd, device=map_location)
|
||||
info = _load_state_dict_on_device(unet, unet_sd, device=map_location, dtype=dtype)
|
||||
print("U-Net: ", info)
|
||||
|
||||
# Text Encoders
|
||||
@@ -221,7 +221,8 @@ def load_models_from_sdxl_checkpoint(model_version, ckpt_path, map_location, dty
|
||||
# torch_dtype="float32",
|
||||
# transformers_version="4.25.0.dev0",
|
||||
)
|
||||
text_model1 = CLIPTextModel._from_config(text_model1_cfg)
|
||||
with init_empty_weights():
|
||||
text_model1 = CLIPTextModel._from_config(text_model1_cfg)
|
||||
|
||||
# Text Encoder 2 is different from Stability AI's SDXL. SDXL uses open clip, but we use the model from HuggingFace.
|
||||
# Note: Tokenizer from HuggingFace is different from SDXL. We must use open clip's tokenizer.
|
||||
@@ -246,7 +247,8 @@ def load_models_from_sdxl_checkpoint(model_version, ckpt_path, map_location, dty
|
||||
# torch_dtype="float32",
|
||||
# transformers_version="4.25.0.dev0",
|
||||
)
|
||||
text_model2 = CLIPTextModelWithProjection(text_model2_cfg)
|
||||
with init_empty_weights():
|
||||
text_model2 = CLIPTextModelWithProjection(text_model2_cfg)
|
||||
|
||||
print("loading text encoders from checkpoint")
|
||||
te1_sd = {}
|
||||
@@ -257,21 +259,22 @@ def load_models_from_sdxl_checkpoint(model_version, ckpt_path, map_location, dty
|
||||
elif k.startswith("conditioner.embedders.1.model."):
|
||||
te2_sd[k] = state_dict.pop(k)
|
||||
|
||||
info1 = text_model1.load_state_dict(te1_sd)
|
||||
info1 = _load_state_dict_on_device(text_model1, te1_sd, device=map_location) # remain fp32
|
||||
print("text encoder 1:", info1)
|
||||
|
||||
converted_sd, logit_scale = convert_sdxl_text_encoder_2_checkpoint(te2_sd, max_length=77)
|
||||
info2 = text_model2.load_state_dict(converted_sd)
|
||||
info2 = _load_state_dict_on_device(text_model2, converted_sd, device=map_location) # remain fp32
|
||||
print("text encoder 2:", info2)
|
||||
|
||||
# prepare vae
|
||||
print("building VAE")
|
||||
vae_config = model_util.create_vae_diffusers_config()
|
||||
vae = AutoencoderKL(**vae_config) # .to(device)
|
||||
with init_empty_weights():
|
||||
vae = AutoencoderKL(**vae_config)
|
||||
|
||||
print("loading VAE from checkpoint")
|
||||
converted_vae_checkpoint = model_util.convert_ldm_vae_checkpoint(state_dict, vae_config)
|
||||
info = vae.load_state_dict(converted_vae_checkpoint)
|
||||
info = _load_state_dict_on_device(vae, converted_vae_checkpoint, device=map_location, dtype=dtype)
|
||||
print("VAE:", info)
|
||||
|
||||
ckpt_info = (epoch, global_step) if epoch is not None else None
|
||||
|
||||
@@ -18,6 +18,7 @@ TOKENIZER2_PATH = "laion/CLIP-ViT-bigG-14-laion2B-39B-b160k"
|
||||
|
||||
def load_target_model(args, accelerator, model_version: str, weight_dtype):
|
||||
# load models for each process
|
||||
model_dtype = match_mixed_precision(args, weight_dtype) # prepare fp16/bf16
|
||||
for pi in range(accelerator.state.num_processes):
|
||||
if pi == accelerator.state.local_process_index:
|
||||
print(f"loading model for process {accelerator.state.local_process_index}/{accelerator.state.num_processes}")
|
||||
@@ -36,6 +37,7 @@ def load_target_model(args, accelerator, model_version: str, weight_dtype):
|
||||
model_version,
|
||||
weight_dtype,
|
||||
accelerator.device if args.lowram else "cpu",
|
||||
model_dtype,
|
||||
)
|
||||
|
||||
# work on low-ram device
|
||||
@@ -54,7 +56,10 @@ def load_target_model(args, accelerator, model_version: str, weight_dtype):
|
||||
return load_stable_diffusion_format, text_encoder1, text_encoder2, vae, unet, logit_scale, ckpt_info
|
||||
|
||||
|
||||
def _load_target_model(name_or_path: str, vae_path: Optional[str], model_version: str, weight_dtype, device="cpu"):
|
||||
def _load_target_model(
|
||||
name_or_path: str, vae_path: Optional[str], model_version: str, weight_dtype, device="cpu", model_dtype=None
|
||||
):
|
||||
# model_dtype only work with full fp16/bf16
|
||||
name_or_path = os.readlink(name_or_path) if os.path.islink(name_or_path) else name_or_path
|
||||
load_stable_diffusion_format = os.path.isfile(name_or_path) # determine SD or Diffusers
|
||||
|
||||
@@ -67,7 +72,7 @@ def _load_target_model(name_or_path: str, vae_path: Optional[str], model_version
|
||||
unet,
|
||||
logit_scale,
|
||||
ckpt_info,
|
||||
) = sdxl_model_util.load_models_from_sdxl_checkpoint(model_version, name_or_path, device, weight_dtype)
|
||||
) = sdxl_model_util.load_models_from_sdxl_checkpoint(model_version, name_or_path, device, model_dtype)
|
||||
else:
|
||||
# Diffusers model is loaded to CPU
|
||||
from diffusers import StableDiffusionXLPipeline
|
||||
@@ -77,7 +82,7 @@ def _load_target_model(name_or_path: str, vae_path: Optional[str], model_version
|
||||
try:
|
||||
try:
|
||||
pipe = StableDiffusionXLPipeline.from_pretrained(
|
||||
name_or_path, torch_dtype=weight_dtype, variant=variant, tokenizer=None
|
||||
name_or_path, torch_dtype=model_dtype, variant=variant, tokenizer=None
|
||||
)
|
||||
except EnvironmentError as ex:
|
||||
if variant is not None:
|
||||
@@ -93,6 +98,13 @@ def _load_target_model(name_or_path: str, vae_path: Optional[str], model_version
|
||||
|
||||
text_encoder1 = pipe.text_encoder
|
||||
text_encoder2 = pipe.text_encoder_2
|
||||
|
||||
# convert to fp32 for cache text_encoders outputs
|
||||
if text_encoder1.dtype != torch.float32:
|
||||
text_encoder1 = text_encoder1.to(dtype=torch.float32)
|
||||
if text_encoder2.dtype != torch.float32:
|
||||
text_encoder2 = text_encoder2.to(dtype=torch.float32)
|
||||
|
||||
vae = pipe.vae
|
||||
unet = pipe.unet
|
||||
del pipe
|
||||
@@ -101,7 +113,7 @@ def _load_target_model(name_or_path: str, vae_path: Optional[str], model_version
|
||||
state_dict = sdxl_model_util.convert_diffusers_unet_state_dict_to_sdxl(unet.state_dict())
|
||||
with init_empty_weights():
|
||||
unet = sdxl_original_unet.SdxlUNet2DConditionModel() # overwrite unet
|
||||
sdxl_model_util._load_state_dict_on_device(unet, state_dict, device=device)
|
||||
sdxl_model_util._load_state_dict_on_device(unet, state_dict, device=device, dtype=model_dtype)
|
||||
print("U-Net converted to original U-Net")
|
||||
|
||||
logit_scale = None
|
||||
@@ -146,6 +158,21 @@ def load_tokenizers(args: argparse.Namespace):
|
||||
return tokeniers
|
||||
|
||||
|
||||
def match_mixed_precision(args, weight_dtype):
|
||||
if args.full_fp16:
|
||||
assert (
|
||||
weight_dtype == torch.float16
|
||||
), "full_fp16 requires mixed precision='fp16' / full_fp16を使う場合はmixed_precision='fp16'を指定してください。"
|
||||
return weight_dtype
|
||||
elif args.full_bf16:
|
||||
assert (
|
||||
weight_dtype == torch.bfloat16
|
||||
), "full_bf16 requires mixed precision='bf16' / full_bf16を使う場合はmixed_precision='bf16'を指定してください。"
|
||||
return weight_dtype
|
||||
else:
|
||||
return None
|
||||
|
||||
|
||||
def timestep_embedding(timesteps, dim, max_period=10000):
|
||||
"""
|
||||
Create sinusoidal timestep embeddings.
|
||||
|
||||
@@ -22,10 +22,10 @@ import torch.nn as nn
|
||||
|
||||
|
||||
from diffusers.configuration_utils import ConfigMixin, register_to_config
|
||||
from diffusers.modeling_utils import ModelMixin
|
||||
from diffusers.utils import BaseOutput
|
||||
from diffusers.models.unet_2d_blocks import UNetMidBlock2D, get_down_block, get_up_block, ResnetBlock2D
|
||||
from diffusers.models.vae import DecoderOutput, Encoder, AutoencoderKLOutput, DiagonalGaussianDistribution
|
||||
from diffusers.models.modeling_utils import ModelMixin
|
||||
from diffusers.models.unet_2d_blocks import UNetMidBlock2D, get_down_block, get_up_block
|
||||
from diffusers.models.vae import DecoderOutput, DiagonalGaussianDistribution
|
||||
from diffusers.models.autoencoder_kl import AutoencoderKLOutput
|
||||
|
||||
|
||||
def slice_h(x, num_slices):
|
||||
@@ -209,7 +209,7 @@ class SlicingEncoder(nn.Module):
|
||||
downsample_padding=0,
|
||||
resnet_act_fn=act_fn,
|
||||
resnet_groups=norm_num_groups,
|
||||
attn_num_head_channels=None,
|
||||
attention_head_dim=output_channel,
|
||||
temb_channels=None,
|
||||
)
|
||||
self.down_blocks.append(down_block)
|
||||
@@ -221,7 +221,7 @@ class SlicingEncoder(nn.Module):
|
||||
resnet_act_fn=act_fn,
|
||||
output_scale_factor=1,
|
||||
resnet_time_scale_shift="default",
|
||||
attn_num_head_channels=None,
|
||||
attention_head_dim=block_out_channels[-1],
|
||||
resnet_groups=norm_num_groups,
|
||||
temb_channels=None,
|
||||
)
|
||||
@@ -381,7 +381,7 @@ class SlicingDecoder(nn.Module):
|
||||
resnet_act_fn=act_fn,
|
||||
output_scale_factor=1,
|
||||
resnet_time_scale_shift="default",
|
||||
attn_num_head_channels=None,
|
||||
attention_head_dim=block_out_channels[-1],
|
||||
resnet_groups=norm_num_groups,
|
||||
temb_channels=None,
|
||||
)
|
||||
@@ -406,7 +406,7 @@ class SlicingDecoder(nn.Module):
|
||||
resnet_eps=1e-6,
|
||||
resnet_act_fn=act_fn,
|
||||
resnet_groups=norm_num_groups,
|
||||
attn_num_head_channels=None,
|
||||
attention_head_dim=output_channel,
|
||||
temb_channels=None,
|
||||
)
|
||||
self.up_blocks.append(up_block)
|
||||
|
||||
@@ -96,6 +96,13 @@ try:
|
||||
except:
|
||||
pass
|
||||
|
||||
try:
|
||||
from jxlpy import JXLImagePlugin
|
||||
|
||||
IMAGE_EXTENSIONS.extend([".jxl", ".JXL"])
|
||||
except:
|
||||
pass
|
||||
|
||||
IMAGE_TRANSFORMS = transforms.Compose(
|
||||
[
|
||||
transforms.ToTensor(),
|
||||
@@ -333,6 +340,8 @@ class BaseSubset:
|
||||
caption_dropout_rate: float,
|
||||
caption_dropout_every_n_epochs: int,
|
||||
caption_tag_dropout_rate: float,
|
||||
caption_prefix: Optional[str],
|
||||
caption_suffix: Optional[str],
|
||||
token_warmup_min: int,
|
||||
token_warmup_step: Union[float, int],
|
||||
) -> None:
|
||||
@@ -347,6 +356,8 @@ class BaseSubset:
|
||||
self.caption_dropout_rate = caption_dropout_rate
|
||||
self.caption_dropout_every_n_epochs = caption_dropout_every_n_epochs
|
||||
self.caption_tag_dropout_rate = caption_tag_dropout_rate
|
||||
self.caption_prefix = caption_prefix
|
||||
self.caption_suffix = caption_suffix
|
||||
|
||||
self.token_warmup_min = token_warmup_min # step=0におけるタグの数
|
||||
self.token_warmup_step = token_warmup_step # N(N<1ならN*max_train_steps)ステップ目でタグの数が最大になる
|
||||
@@ -371,6 +382,8 @@ class DreamBoothSubset(BaseSubset):
|
||||
caption_dropout_rate,
|
||||
caption_dropout_every_n_epochs,
|
||||
caption_tag_dropout_rate,
|
||||
caption_prefix,
|
||||
caption_suffix,
|
||||
token_warmup_min,
|
||||
token_warmup_step,
|
||||
) -> None:
|
||||
@@ -388,6 +401,8 @@ class DreamBoothSubset(BaseSubset):
|
||||
caption_dropout_rate,
|
||||
caption_dropout_every_n_epochs,
|
||||
caption_tag_dropout_rate,
|
||||
caption_prefix,
|
||||
caption_suffix,
|
||||
token_warmup_min,
|
||||
token_warmup_step,
|
||||
)
|
||||
@@ -419,6 +434,8 @@ class FineTuningSubset(BaseSubset):
|
||||
caption_dropout_rate,
|
||||
caption_dropout_every_n_epochs,
|
||||
caption_tag_dropout_rate,
|
||||
caption_prefix,
|
||||
caption_suffix,
|
||||
token_warmup_min,
|
||||
token_warmup_step,
|
||||
) -> None:
|
||||
@@ -436,6 +453,8 @@ class FineTuningSubset(BaseSubset):
|
||||
caption_dropout_rate,
|
||||
caption_dropout_every_n_epochs,
|
||||
caption_tag_dropout_rate,
|
||||
caption_prefix,
|
||||
caption_suffix,
|
||||
token_warmup_min,
|
||||
token_warmup_step,
|
||||
)
|
||||
@@ -464,6 +483,8 @@ class ControlNetSubset(BaseSubset):
|
||||
caption_dropout_rate,
|
||||
caption_dropout_every_n_epochs,
|
||||
caption_tag_dropout_rate,
|
||||
caption_prefix,
|
||||
caption_suffix,
|
||||
token_warmup_min,
|
||||
token_warmup_step,
|
||||
) -> None:
|
||||
@@ -481,6 +502,8 @@ class ControlNetSubset(BaseSubset):
|
||||
caption_dropout_rate,
|
||||
caption_dropout_every_n_epochs,
|
||||
caption_tag_dropout_rate,
|
||||
caption_prefix,
|
||||
caption_suffix,
|
||||
token_warmup_min,
|
||||
token_warmup_step,
|
||||
)
|
||||
@@ -588,6 +611,12 @@ class BaseDataset(torch.utils.data.Dataset):
|
||||
self.replacements[str_from] = str_to
|
||||
|
||||
def process_caption(self, subset: BaseSubset, caption):
|
||||
# caption に prefix/suffix を付ける
|
||||
if subset.caption_prefix:
|
||||
caption = subset.caption_prefix + " " + caption
|
||||
if subset.caption_suffix:
|
||||
caption = caption + " " + subset.caption_suffix
|
||||
|
||||
# dropoutの決定:tag dropがこのメソッド内にあるのでここで行うのが良い
|
||||
is_drop_out = subset.caption_dropout_rate > 0 and random.random() < subset.caption_dropout_rate
|
||||
is_drop_out = (
|
||||
@@ -1676,6 +1705,8 @@ class ControlNetDataset(BaseDataset):
|
||||
subset.caption_dropout_rate,
|
||||
subset.caption_dropout_every_n_epochs,
|
||||
subset.caption_tag_dropout_rate,
|
||||
subset.caption_prefix,
|
||||
subset.caption_suffix,
|
||||
subset.token_warmup_min,
|
||||
subset.token_warmup_step,
|
||||
)
|
||||
@@ -2865,6 +2896,13 @@ def add_training_arguments(parser: argparse.ArgumentParser, support_dreambooth:
|
||||
default=None,
|
||||
help="enable multires noise with this number of iterations (if enabled, around 6-10 is recommended) / Multires noiseを有効にしてこのイテレーション数を設定する(有効にする場合は6-10程度を推奨)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--ip_noise_gamma",
|
||||
type=float,
|
||||
default=None,
|
||||
help="enable input perturbation noise. used for regularization. recommended value: around 0.1 (from arxiv.org/abs/2301.11706) "
|
||||
+ "/ input perturbation noiseを有効にする。正則化に使用される。推奨値: 0.1程度 (arxiv.org/abs/2301.11706 より)",
|
||||
)
|
||||
# parser.add_argument(
|
||||
# "--perlin_noise",
|
||||
# type=int,
|
||||
@@ -3061,6 +3099,18 @@ def add_dataset_arguments(
|
||||
default=0,
|
||||
help="keep heading N tokens when shuffling caption tokens (token means comma separated strings) / captionのシャッフル時に、先頭からこの個数のトークンをシャッフルしないで残す(トークンはカンマ区切りの各部分を意味する)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--caption_prefix",
|
||||
type=str,
|
||||
default=None,
|
||||
help="prefix for caption text / captionのテキストの先頭に付ける文字列",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--caption_suffix",
|
||||
type=str,
|
||||
default=None,
|
||||
help="suffix for caption text / captionのテキストの末尾に付ける文字列",
|
||||
)
|
||||
parser.add_argument("--color_aug", action="store_true", help="enable weak color augmentation / 学習時に色合いのaugmentationを有効にする")
|
||||
parser.add_argument("--flip_aug", action="store_true", help="enable horizontal flip augmentation / 学習時に左右反転のaugmentationを有効にする")
|
||||
parser.add_argument(
|
||||
@@ -4308,7 +4358,10 @@ def get_noise_noisy_latents_and_timesteps(args, noise_scheduler, latents):
|
||||
|
||||
# Add noise to the latents according to the noise magnitude at each timestep
|
||||
# (this is the forward diffusion process)
|
||||
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
|
||||
if args.ip_noise_gamma:
|
||||
noisy_latents = noise_scheduler.add_noise(latents, noise + args.ip_noise_gamma * torch.randn_like(latents), timesteps)
|
||||
else:
|
||||
noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
|
||||
|
||||
return noise, noisy_latents, timesteps
|
||||
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
# cond_imageをU-Netのforardで渡すバージョンのControlNet-LLLite検証用実装
|
||||
# cond_imageをU-Netのforwardで渡すバージョンのControlNet-LLLite検証用実装
|
||||
# ControlNet-LLLite implementation for verification with cond_image passed in U-Net's forward
|
||||
|
||||
import os
|
||||
|
||||
@@ -241,9 +241,13 @@ class LoRAInfModule(LoRAModule):
|
||||
else:
|
||||
area = x.size()[1]
|
||||
|
||||
mask = self.network.mask_dic[area]
|
||||
mask = self.network.mask_dic.get(area, None)
|
||||
if mask is None:
|
||||
raise ValueError(f"mask is None for resolution {area}")
|
||||
# raise ValueError(f"mask is None for resolution {area}")
|
||||
# emb_layers in SDXL doesn't have mask
|
||||
# print(f"mask is None for resolution {area}, {x.size()}")
|
||||
mask_size = (1, x.size()[1]) if len(x.size()) == 2 else (1, *x.size()[1:-1], 1)
|
||||
return torch.ones(mask_size, dtype=x.dtype, device=x.device) / self.network.num_sub_prompts
|
||||
if len(x.size()) != 4:
|
||||
mask = torch.reshape(mask, (1, -1, 1))
|
||||
return mask
|
||||
@@ -348,9 +352,10 @@ class LoRAInfModule(LoRAModule):
|
||||
out[-self.network.batch_size :] = x[-self.network.batch_size :] # real_uncond
|
||||
|
||||
# print("to_out_forward", self.lora_name, self.network.sub_prompt_index, self.network.num_sub_prompts)
|
||||
# for i in range(len(masks)):
|
||||
# if masks[i] is None:
|
||||
# masks[i] = torch.zeros_like(masks[-1])
|
||||
# if num_sub_prompts > num of LoRAs, fill with zero
|
||||
for i in range(len(masks)):
|
||||
if masks[i] is None:
|
||||
masks[i] = torch.zeros_like(masks[0])
|
||||
|
||||
mask = torch.cat(masks)
|
||||
mask_sum = torch.sum(mask, dim=0) + 1e-4
|
||||
|
||||
11
sdxl_gen_img.py
Normal file → Executable file
11
sdxl_gen_img.py
Normal file → Executable file
@@ -451,10 +451,11 @@ class PipelineLike:
|
||||
tes_text_embs = []
|
||||
tes_uncond_embs = []
|
||||
tes_real_uncond_embs = []
|
||||
# use last pool
|
||||
|
||||
for tokenizer, text_encoder in zip(self.tokenizers, self.text_encoders):
|
||||
token_replacer = self.get_token_replacer(tokenizer)
|
||||
|
||||
# use last text_pool, because it is from text encoder 2
|
||||
text_embeddings, text_pool, uncond_embeddings, uncond_pool, _ = get_weighted_text_embeddings(
|
||||
tokenizer,
|
||||
text_encoder,
|
||||
@@ -529,6 +530,11 @@ class PipelineLike:
|
||||
c_vector = torch.cat([emb1, emb2, emb3], dim=1).to(self.device, dtype=text_embeddings.dtype).repeat(batch_size, 1)
|
||||
uc_vector = torch.cat([uc_emb1, emb2, emb3], dim=1).to(self.device, dtype=text_embeddings.dtype).repeat(batch_size, 1)
|
||||
|
||||
if reginonal_network:
|
||||
# use last pool for conditioning
|
||||
num_sub_prompts = len(text_pool) // batch_size
|
||||
text_pool = text_pool[num_sub_prompts - 1 :: num_sub_prompts] # last subprompt
|
||||
|
||||
c_vector = torch.cat([text_pool, c_vector], dim=1)
|
||||
uc_vector = torch.cat([uncond_pool, uc_vector], dim=1)
|
||||
|
||||
@@ -761,6 +767,9 @@ class PipelineLike:
|
||||
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloa16
|
||||
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
|
||||
|
||||
if torch.cuda.is_available():
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
if output_type == "pil":
|
||||
# image = self.numpy_to_pil(image)
|
||||
image = (image * 255).round().astype("uint8")
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
# cond_imageをU-Netのforardで渡すバージョンのControlNet-LLLite検証用学習コード
|
||||
# cond_imageをU-Netのforwardで渡すバージョンのControlNet-LLLite検証用学習コード
|
||||
# training code for ControlNet-LLLite with passing cond_image to U-Net's forward
|
||||
|
||||
import argparse
|
||||
|
||||
Reference in New Issue
Block a user